Molecular Sequence Annotation
Mjukvara
Användare-datorgränssnitt
Bioinformatik
Sekvensinpassning
Databasadministrativa system
Molekylsekvensdata
DNA-sekvensanalys
Internet
Algoritmer
Dokumentation
Protein-sekvensanalys
Databaser, protein
Databaser, nukleinsyror
Informationslagring och -återvinning
Bayes teorem
Genuppsättning
Bassekvens
Uttryckta genmarkörer
Modeller, genetiska
Faktadatabaser
Proteiner
Sannolikhetsfunktioner
Markov-kedja
Fossiler
Sekvensanalys
RNA, ribosomalt, 18S
Biological Evolution
Aminosyrasekvens
Monte Carlo-metod
Vokabulär, kontrollerad
Mitokondrie-DNA
Datorsimulering
Ribosom-DNA
Genuttrycksmönster
Processering av naturligt språk
Data Mining
Terminologi, principer
DNA-mikromatrisanalys
Genom, humant
Proteom
Klusteranalys
Gene Ontology
RNA-sekvensanalys
Programmeringsspråk
Artificiell intelligens
Proteomik
High-Throughput Nucleotide Sequencing
Kartläggning av proteininteraktion
Transcriptome
Kunskapsdatabaser
Search Engine
Mönsterigenkännande, automatiserat
Semantik
Open Reading Frames
Gener
Abstrahering och indexering, principer
PubMed
Genbibliotek
Config-mappning
Enzymer
Metabola nätverk och banor
Pseudogener
Multigenfamilj
Bevarad sekvens
Automatisering
Resultats reproducerbarhet
Biologiska processer
Oryza sativa
UTRs
Sjukdom
Genom, mask
Prokaryotiska celler
Datatolkning, statistisk
MEDLINE
Ordbehandling
Synteni
Crowdsourcing
Regulatoriska gennätverk
Structural Homology, Protein
DNA, komplementärt
Hypermedia
Genom, insekt
Metagenomics
Alternativ splitsning
Biological Ontologies
Online-system
Workflow
Proteinstruktur, tertiär
Protein Interaction Maps
Klassificering
Artsspecificitet
RNA, Untranslated
'Molecular Sequence Annotation' refererar till processen att identifiera och kategorisera funktionella element i en molekylär sekvens, som är en serie av nukleotider (i DNA- eller RNA-sekvenser) eller aminosyror (i proteinsekvenser). Detta inkluderar identifikation av gener, regulatoriska regioner, repetitiva element, kodande sekvenser och deras funktionella domäner, signalpeptider, intron-exonstrukturen med mera. Denna information används för att förstå struktur, funktion och evolution av genetiska element och är viktig för att tolka data från genomik-, transkriptomik- och proteomikstudier.
'Mjukvara' (svenska) eller 'software' (engelska) är en samling instruktioner som tellas en dator att följa för att utföra specifika uppgifter. Det kan vara allt från operativsystem som styr datorn till programvaror som används för att skapa dokument, spela spel eller navigera på internet. Mjukvaran är inte en fysisk entitet utan snarare en samling data och information som lagras i minnet och på hårddisken i datorn.
Medicinsk definition av "Användare-datorgränssnitt" (User-Computer Interface) är inte vanligt förekommande, eftersom detta oftast faller under området datavetenskap och ingenjörsvetenskap. Men alltså, ett användar-datorgränssnitt (UI) är den plats där människa och dator möts, vilket innebär det visuella designade miljö där en användare kan interagera med en dator, webbplats, program eller applikation via hårdvara och/eller mjukvara.
UI:s är viktiga för att underlätta och förbättra användarupplevelsen (UX) genom att skapa enkelhet, tydlighet och tillgänglighet i interaktionen mellan människa och dator. Detta kan inkludera allt från grafiska användarmiljöer (GUI), kommandoradsgränssnitt (CLI) eller virtuella realitetsmiljöer (VR).
Inom medicinsk kontext kan ett användar-datorgränssnitt vara till exempel en webbplats där patienter kan boka termin, ett program för att övervaka vitala tecken eller en applikation för att skriva och spara elektroniska journalposter.
"Fylogenetik" (förekommande stavning inom biologi på engelska: 'phylogenetics') är ett område inom biologin som handlar om att studera evolutionära relationer mellan olika arter eller andra taxonomiska grupper. Genom att jämföra morfologiska, genetiska och/eller fossila data kan forskare konstruera ett fylogenetiskt träd som visar hur olika arter tros ha utvecklats från gemensamma förfäder över tid.
Termen "fylogen" (på engelska: 'phylogeny') refererar till den evolutionära historien och relationerna mellan olika taxa, det vill säga en grupp organismer som är relaterade genom gemensam härstamning. En fylogeni kan representeras av ett diagramatiskt träd där varje gren representerar en klad, det vill säga en monofyletisk grupp med alla dess ättlingar inkluderat och utan inslag av äldre gemensamma förfäder.
I medicinsk kontext kan fylogenetiska analyser användas för att studera evolutionära relationer mellan patogena mikroorganismer, vilket kan vara viktigt för att förstå hur sjukdomar sprids och utvecklas, och hur vacciner och andra behandlingsmetoder kan utformas.
Bioinformatik är en multidisciplinär forskningsgren som kombinerar biologi, datavetenskap och teknologi för att analysera och tolka stor datamängd biologisk information, särskilt inom genetik och genomik. Det inkluderar utvecklingen och användningen av databaser, algoritmer, statistiska metoder och artificiell intelligens för att lösa biologiska problem, såsom att förstå genstruktur och funktion, proteinstruktur och -funktion, genuttryck och reglering, evolutionära relationer mellan organismer och systembiologi.
"Genetic databases" er en samling av data relatert til gener og arvemasse. Disse databasene kan inneholde informasjon om forskjellige typer genetisk materiale, som kan være brukt i forskning, medisinsk behandling eller annen type av anvendelser.
Det kan eksempelvis være databaser som inneholder sekvensdata for gener og andre dele av DNA, strukturdata for proteiner, informasjon om varianter i genetisk materiale som er relatert til bestemte sykdommer eller egenskaper, familjehistorikk og annen slags klinisk informasjon.
Genetic databases kan være offentlige eller private, og de kan være tilgjengelige for forskere, medisinske fagpersoner, industri og andre interessenter. Anvendelsen av genetiske databaser er omstridt på grunn av etiske, lovmessige og privatsspersmal, derfor er det viktig å ha god kjennskap til reglene og retningslinjene for bruk av slike databaser.
'Sequencing' är ett begrepp inom genetiken som refererar till metoder för bestämandet av raka rader (sekvenser) av nukleotider, de grundläggande byggstenarna i DNA och RNA. 'Sequencing' används ofta för att undersöka gener och andra delar av DNA för att få information om deras struktur, funktion och evolutionära utveckling.
'Sekvensinpassning' (engelska: sequence alignment) är en metod inom bioinformatiken som används för att jämföra två eller flera DNA- eller proteinsekvenser för att hitta likheter och skillnader mellan dem. Genom att jämföra sekvenser kan forskare identifiera konserverade regioner, mutationer, evolutionära relationer och möjliga funktionella roller.
Sekvensinpassning kan användas för att undersöka olika aspekter av DNA- eller proteinsekvenser, till exempel struktur, funktion, evolutionärt ursprung och släktskap. Det är en viktig metod inom komparativ genetik, molekylär evolution och strukturell biologi.
I sekvensinpassning jämförs två eller flera sekvenser med varandra genom att lägga till luckor (gaps) i sekvenserna för att matcha upp dem så bra som möjligt. Det finns två huvudtyper av sekvensinpassning: global och lokal. Global inpassning jämför hela sekvenserna med varandra, medan lokal inpassning endast jämför delar av sekvenserna där likheter finns.
Sekvensinpassning kan användas för att hitta homologa sekvenser (sekvenser som har gemensam evolutionärt ursprung), identifiera mutationer och andra variationer, och studera evolutionära relationer mellan olika arter eller populationer. Det kan även användas för att förutsäga struktur och funktion hos okända sekvenser genom att jämföra dem med kända sekvenser med liknande egenskaper.
A medicinsk databasadministrativt system (ofta kortat till "databasadministration" eller "DBA") är ett system som används för att hantera, underhålla och skydda databaser inom en medicinsk kontext. Databasadministrativa system står för administrationen av databaser och säkerställer att de fungerar korrekt, effektivt och säkert.
I en medicinsk kontext kan ett databasadministrativt system användas för att hantera patientdata, såsom personliga information, diagnoser, behandlingsplaner och laboratorieresultat. Systemet kan också användas för att säkerställa att data är tillgängliga när de behövs, att datainsamlingen och -lagringen följer lagliga regler och etiska riktlinjer, samt att data skyddas mot olaglig åtkomst och andra säkerhetsrisker.
Exempel på uppgifter som kan ingå i databasadministration inom en medicinsk kontext är:
* Skapa och ta bort databaser
* Hantera användare och deras behörigheter
* Säkerställa dataintegritet och datakonsistens
* Optimeringsfrågor för prestanda
* Skydda mot dataintrång och andra säkerhetsrisker
* Säkerställa att systemet backas upp regelbundet och att data kan återställas om något går fel.
Molekylsekvensdata (molecular sequencing data) refererer til de resultater som bliver genereret når man secvenserer DNA, RNA eller proteiner i molekylærbiologien. Det innebærer typisk en række af nukleotider (i DNA- og RNA-sekvensering) eller aminosyrer (i proteinsekvensering), der repræsenterer den specifikke sekvens af gener, genetiske varianter eller andre molekyler i et biologisk prøve.
DNA-sekvensdata kan f.eks. anvendes til at identificere genetiske varianter, undersøge evolutionæ forhold og designe PCR-primerer. RNA-sekvensdata kan bruges til at studere genudtryk, splicevarianter og andre transkriptionelle reguleringsmekanismer. Proteinsekvensdata er vigtige for at forstå proteinstruktur, funktion og interaktioner.
Molekylsekvensdata kan genereres ved hjælp af forskellige metoder, herunder Sanger-sekvensering, pyrosekvensering (454), ion torrent-teknikker, single molecule real-time (SMRT) sekvensering og nanopore-sekvensering. Hver metode har sine styrker og svagheder, og valget af metode afhænger ofte af forskningens specifikke behov og ønskede udbytte.
DNA-sekvensanalys är en metod inom genetiken och bioinformatiken som används för att bestämma den exakta ordningsföljden (sekvensen) av nukleotider (baser) i en DNA-molekyl. Genom att undersöka och jämföra dessa sekvenser kan man få information om individens genetiska make-up, evolutionära härstamning och samband med olika arvsbundna sjukdomar eller andra genetiska egenskaper. DNA-sekvensanalys används också för att identifiera mikroorganismer såsom bakterier och virus genom att jämföra deras genetiska sekvenser med kända exemplar i databaser.
Det finns ingen officiell medicinsk definition av "Internet", eftersom det är ett allmänt begrepp som inte är specifikt relaterat till medicinen. Men för att ge dig en bred förståelse av vad Internet är:
Internet är ett globalt nätverk av datorer och andra enheter, som är sammanlänkade för att möjliggöra kommunikation och informationsutbyte mellan dem. Det bygger på standardiserade protokoll och består av en rad olika tjänster och tekniker, såsom webb, e-post, filuppladdning/-nedladdning, chatt, videokonferenser och sociala medier. Internet ger användarna möjlighet att snabbt och enkelt komma i kontakt med information, kunskaper och andra människor över hela världen.
En algoritm är en serie steg eller instruktioner som tas för att lösa ett problem eller utföra en viss uppgift inom medicinen, liksom i andra sammanhang. Algoritmer används ofta inom klinisk praxis för att standardisera vården och förbättra patientresultaten.
Exempel på algoritmer inom medicin kan vara:
* En algoritm för att diagnostisera och behandla en specifik sjukdom, till exempel en algoritm för att hantera sepsis eller akut koronarsyndrom.
* En algoritm för att utvärdera och hantera smärta, som innehåller steg för att bedöma smärtintensiteten, identifiera orsaken till smärtan och välja lämplig behandling.
* En algoritm för att besluta om en patient ska opereras eller inte, som tar hänsyn till faktorer som allvarligheten av sjukdomen, patientens preferenser och komorbiditeter.
Algoritmer kan variera i komplexitet från enkla listor över steg att följa till mer sofistikerade system som innehåller avancerad matematik och artificiell intelligens. Viktigt är att algoritmer utformas med omsorg och testas noggrant för att säkerställa att de ger korrekta och säkra resultat i alla tillämpningar.
'Dokumentation' betyder på dansk 'dokumentation' og er en central del af sundhedsvæsenets arbejde. Det handler om at systematisk indsamle, dokumentere og bevare oplysninger om en patients sygdomshistorie, behandling, forløb og resultater.
Dokumentationen skal være klar, nøjagtig, relevant, tilgængelig og beskyttet mod uautoriseret adgang, så patientens personlige oplysninger forbliver konfidensielle. Den anvendes af forskellige sundhedsfaglige faggrupper til at koordinere, planlægge og evaluere patients behandling, sikre kontinuitet i omsorgen og understøtte klinisk beslutningstagen.
Der findes forskellige former for dokumentation som patientjournaler, elektroniske sundhedsjournaler, medicinske noter, lægebreve, undersøgelses- og behandlingsrapporter samt laboratorie- og billedresultater. Al dokumentation skal overholde de lovmæssige krav og retningslinjer for patientdokumentation i det pågældende land.
Protein-sekvensanalys är en metod inom bioinformatik och proteomik som används för att undersöka, jämföra och analysera sekvenser av aminosyror i proteinmolekyler. Denna analys kan ge information om proteins struktur, funktion, evolutionärt ursprung och relaterade egenskaper. Metoden bygger ofta på databas-sökningar, flera-krångling (multiple sequence alignment) och prediktion av strukturella domäner och funktionella motiver i proteinsekvenserna.
A protein database is a type of biological database that contains information about proteins and their structures, functions, sequences, and interactions with other molecules. These databases can include experimentally determined data, such as protein sequences derived from DNA sequencing or mass spectrometry, as well as predicted data based on computational methods.
Some examples of protein databases include:
1. UniProtKB: a comprehensive protein database that provides information about protein sequences, functions, and structures, as well as links to other related resources.
2. PDB (Protein Data Bank): a database of three-dimensional structural data for proteins and nucleic acids, obtained through experimental methods such as X-ray crystallography and nuclear magnetic resonance (NMR) spectroscopy.
3. Pfam: a protein family database that provides information about the evolutionary relationships between different protein sequences and domains.
4. InterPro: a database of protein families, domains, and functional sites, which integrates data from multiple sources, including Pfam, PROSITE, and HAMAP.
5. MINT, IntAct, and STRING: databases that provide information about protein-protein interactions, based on experimental data or computational predictions.
Protein databases are essential tools for researchers in fields such as structural biology, proteomics, systems biology, and drug discovery. They enable scientists to analyze and compare protein sequences and structures, identify functional domains and motifs, predict protein-protein interactions, and design experiments to study protein function and regulation.
Molekylær evolution refererer til studiet af de molekylære mekanismer og processer som driver ændringer i DNA-sequencer over tid, hvilket resulterer i den biologiske evolution. Dette inkluderer studiet af mutationer, genetisk drift, genflow og naturlig selektion på molekylær niveau. Molekylær evolution anvender ofte sekvensdata fra DNA, RNA eller protein for at konstruere filogenetiske træer, der viser de evolutionære forhold mellem organismer.
'Genomik' (eller 'genomics' på engelska) är ett område inom molekylärbiologi och genetik som handlar om studiet av organismers genom, dvs. deras fullständiga arvsmassa. Genomen innehåller all information som behövs för att bygga och underhålla en levande organism, inklusive gener, regulatoriska sekvenser, icke-kodande DNA och andra strukturella element.
Genomik kan delas upp i flera underområden, såsom komparativ genomik (jämförande studier av genomer mellan olika arter), funktionell genomik (studier av geners funktioner och interaktioner) och strukturell genomik (bestämning av DNA-sekvenser och deras tredimensionella struktur). Genomik använder sig ofta av högthroughput-tekniker, såsom nästgenerationssekvensering och DNA-mikroarrayer, för att samla in stora mängder data om genomer. Dessa data kan sedan analyseras med hjälp av bioinformatiska metoder för att besvara biologiska frågor och få insikt i hur levande organismar fungerar på molekylär nivå.
En nucleotidbas är en typ av databas som primärt innehåller information om nucleotidsekvenser i DNA och RNA. Dessa databaser används ofta inom bioinformatik, genetik och genomforskning för att lagra, söka, analysera och jämföra information om olika organismer på molekylär nivå. Exempel på välkända nucleotidbaser är GenBank, ENA och DDBJ.
'Informationslagring och -återvinning' refererar till processen att ta emot, behandla, lagra och sedan återvinna information för framtida användning. Denna term används ofta inom områden som medicinsk IT, datalagring och datorsäkerhet.
I en medicinsk kontext kan informationslagring och -återvinning handla om att samla in patientdata från olika källor, till exempel elektroniska journaler, bildstudier och laboratorieresultat, och lagra dem på ett säkert sätt. Sedan kan informationen behandlas och analyseras för att stödja kliniska beslut, forskning eller övervakning av patientens hälsostatus.
Återvinningen av information innebär att informationen görs tillgänglig och användbar på ett effektivt sätt när den behövs. Det kan ske genom att söka efter specifika uppgifter i databasen, visualisera data i grafer eller diagram, eller använda artificiell intelligens för att hitta mönster och insikter i de lagrade data.
I allmänhet handlar informationslagring och -återvinning om att hantera, tolka och använda information på ett sätt som är säkert, effektivt och användarvänligt. Det är en viktig del av modern medicinsk vård och forskning, eftersom det möjliggör att samla in, analysera och dela upp stor mängder data för att stödja bättre beslut och patientresultat.
Bayes' teorem är en matematisk sats inom sannolikhetslära som beskriver hur man kan uppdatera sin förväntning om sannolikheten för en given hypotes, efter att ha mottagit ny information. Teoremet är uppkallat efter Thomas Bayes, en brittisk statistiker och präst.
Bayes' teorem kan formuleras som följer:
P(A|B) = [P(B|A) * P(A)] / P(B)
där:
- P(A|B) är sannolikheten för att hypotes A är sann, givet att B har inträffat.
- P(B|A) är sannolikheten för att B har inträffat, givet att A är sann.
- P(A) är a priori sannolikheten för hypotes A (dvs. sannolikheten för A före insamlandet av någon ny information).
- P(B) är marginal sannolikheten för B (dvs. summan av sannolikheterna för alla möjliga värden på A, multiplicerat med sannolikheten för B givet det specifika värdet på A).
Teoremet kan användas inom medicinsk diagnostik för att uppdatera sannolikheten för en given diagnos, baserat på resultaten av olika tester eller symtom. Det är även viktigt inom maskininlärning och konstgjord intelligens.
"Genuppsättning" är en ortopedisk term som används för att beskriva en abnormalitet i knäts benställning. Det exakta definitierandet av genuppsättning kan variera, men det vanligaste sättet att definiera den är när knäets rotationsaxel inte går genom den mellersta delen av knäskålens yta. I stället pekar axeln inåt (varusuppsättning) eller utåt (valgusuppsättning). Denna abnormalitet kan vara medfött eller aquired, och kan vara mild, moderat eller allvarlig. Genuppsättning kan orsaka smärta, ledbelastning och ökad risken för artros i knäet. Behandlingen kan innebära observation, fysioterapi, ortoser, skena eller kirurgi beroende på allvarlighetsgraden och symtomen.
"Bassekvens" er en medisinsk betegnelse for en abnorm, gentagen sekvens eller mønster i et individ's DNA-sekvens. Disse baseparsekvenser består typisk av fire nukleotider: adenin (A), timin (T), guanin (G) og cytosin (C). En bassekvens kan være arvelig eller opstå som en mutation under individets liv.
En abnormal bassekvens kan føre til genetiske sygdomme, fejlutviklinger eller forhøjet risiko for bestemte sykdommer. For eksempel kan en bassekvens, der koder for en defekt protein, føre til en arvelig sykdom som cystisk fibrose eller muskeldystrofi.
Det er viktig å understreke at en abnormal bassekvens ikke alltid vil resultere i en sykdom eller fejlutvikling. I mange tilfeller kan individet være asymptomatisk og leve et normalt liv.
Uttryckta genmarkörer, även kallade reportergener, är sekvenser av DNA som har införts in i ett genetiskt konstrukt för att fungera som indikatorer på genuttryck. De ger information om när och var en viss gen verkligen aktiveras och producirar ett protein. Genmarkörerna kan vara olika slags sekvenser, till exempel en enhållare för en specifik transkriptionfaktor eller en sekvens som kodar för en fluorescerande protein som kan ses under mikroskopi. När genen aktiveras och börjar producera protein kommer också reportergenen att uttryckas, vilket gör att man kan se var och när genen är aktiv.
Genetic models är matematiska eller konceptuella representationer av genetiska system, processer eller fenomen. De används för att simulera och förutsäga hur gener och arvsbetingade egenskaper fungerar och interagerar på molekylär, cellulär och organismnivå. Genetic models kan hjälpa forskare att förstå genetisk variation, arvsregler, evolution, sjukdomsgenetik och andra aspekter av genetiken.
Det finns olika typer av genetic models, beroende på vilka egenskaper de beskriver och hur de representerar informationen. Några exempel är:
1. Populationsgenetiska modeller: används för att studera genetisk variation och selektion i populationer. Dessa modeller kan vara statistiska, simuleringsbaserade eller matematiska.
2. Quantitativ genetiska modeller: används för att undersöka kontinuerliga fenotypiska drag som påverkas av flera gener och miljöfaktorer. Dessa modeller kan vara polynomiella, strukturella ekvationer eller multivariata.
3. Molekylära genetiska modeller: används för att studera interaktioner mellan DNA, RNA och protein i celler. Dessa modeller kan vara strukturella, funktionella eller systembiologiska.
4. Systemgenetiska modeller: använder sig av data från höghtrognhetsgenomik och andra tekniker för att bygga nätverk av gen-gen-interaktioner och -reguleringar i celler. Dessa modeller kan vara grafbaserade, matematiska eller simuleringsbaserade.
Genetic models är viktiga verktyg inom genetisk forskning, eftersom de möjliggör systematiskt studium av komplexa genetiska system och hjälper till att generera hypoteser som kan testas experimentellt.
Computer graphics, eller datorgrafik, är en gren inom datavetenskap där man använder datorer för att skapa, manipulera och visuaellt presentera information. Detta kan omfatta allt från stilla bilder till rörliga animationer och interaktiva 3D-miljöer.
Computer graphics kan delas in i två huvudkategorier: rastergrafik och vektorgrafik. Rastergrafik består av en samling pixel (bildpunkter) med olika färger och genomskinlighet, medan vektorgrafik bygger på geometriska former som linjer, kurvor och fyllningar.
Inom computer graphics används diverse tekniker och algoritmer för att skapa realistiska och övertygande visuella effekter, till exempel belysnings- och skuggeffekter, texturering, antialiasing och kompositing. Dessa tekniker används inom en rad olika applikationer, från datorspel och film till vetenskapliga visualiseringar och tekniska illustrationer.
En faktadatabas (ofte skrevet fact database) er en databas som inneholder fakta og informasjon som ikke endres ofte eller overordnet sett er upåvirkelig for ytre faktorer. Disse databasene brukes ofte i medisinske sammenhenger for å lagre og gi tilgang til informasjon som er relevant for klients or patienters behandling, diagnose eller forståelse av sykdommer og helseforhold.
Faktadatabaser kan inneholde informasjon som er almenlertidig og gjelder for alle mennesker, som f.eksso generell informasjon om kroppens anatomoi, fysiologi og vanlige sykdommer. De kan også inneholde mer spesifikk informasjon som er relatert til enklere medisinske forhold, som f.eksso informasjon om medisinske behandlinger, medisinske begreper og terminologi, eller informasjon om medisinske studier og forskning.
I tillegg kan faktadatabaser også inneholde informasjon som er relatert til enklere pasienter, som f.eksso allergi, medisinsk historie og laboratoriestudier. Disse opplysningene kan være viktige for å sikre at pasienten mottar riktig behandling og for å unngå unødvendige komplikasjoner.
I allianse med andre kilder som f.eksso lærebøker, videnskapelige artikler og eksperter i feltet, kan faktadatabaser være en viktig ressurs for medisinske fagpersoner og andre som jobber med helse og sykdom.
Proteiner (eller proteinmolekyler) är stora, komplexa molekyler som består av aminosyror som kedjas samman i en specifik sekvens. Proteiner bygger upp och utgör en väsentlig del av alla levande cellers struktur och funktion. De utför viktiga funktioner såsom att underlätta kroppens tillväxt och reparation, reglera processer i cellen, skydda organismen från främmande ämnen som t.ex. virus och bakterier samt hjälpa till vid transport av andra molekyler inom kroppen. Proteiner kan ha en mycket varierad struktur och form beroende på deras funktion, och de kan indelas i olika klasser baserat på deras specifika egenskaper och roller inom cellen.
I medicinen, sannolikhetsfunktioner (eller cumulative distribution functions, CDP) används inom statistisk analys för att beskriva sannolikheten för att en stokastisk variabel X kommer att vara mindre än eller lika med en viss värdesgräns. Sannolikhetsfunktionen representerar sålunda den kumulativa summan av sannolikheterna för alla värden som är mindre än eller lika med det specificerade värdet.
Formellt kan en sannolikhetsfunktion definieras som:
F(x) = P(X ≤ x)
där F(x) är sannolikhetsfunktionen för stokastisk variabel X, och P(X ≤ x) betecknar sannolikheten för att stokastisk variabel X antar ett värde som är mindre än eller lika med x.
Sannolikhetsfunktioner används ofta inom epidemiologi, klinisk forskning och biostatistik för att analysera data och dra slutsatser om samband mellan variabler och hälsoresultat. De är viktiga vid konstruktion av konfidensintervall, hypotesprövning och bedömning av risker och associationer i epidemiologiska studier.
En Markov-kedja är ett slags stokastiskt process där framtida tillstånd beror endast av det aktuella tillståndet och inte på hur den kom dit. Det innebär att sannolikheten för en viss händelse är oberoende av tidigare händelser, förutsatt att nuvarande tillstånd är känt. Denna egenskap kallas Markovegenskap och gör att man kan förutsäga sannolikheten för framtida tillstånd genom att bara ta hänsyn till nuvarande tillstånd istället för alla tidigare tillstånd.
Markov-kedjor är uppkallade efter den ryske matematikern Andrey Markov, som introducerade konceptet under tidigt 1900-tal. De har många tillämpningar inom olika områden, såsom ekonomi, fysik, datavetenskap och biologi.
'Fossil' er en medicinsk term som primært brukes innenom palynologi, et grensefag mellom geologi og biologi. Fossile betegner rester eller spor etfer organismer som har levd i fortid og som er bevart i jordens skal eller i andre geologiske lag over en periode på millioner av år. Disse fossile restene kan inneholde informasjon om slagsen til den utdøde organismen, dens fysiologi, og dens plassert i det tidlige livets historie.
I palynologi brukes termen 'fossil' spesielt til å referere til mikroskopiske rester av planter som pollen, sporer og kutikuler (et ytre lag på planters celler). Disse fossile partiklene kan være vitale for å forstå historien om planetens klima og økosystemer over tid.
Sekvensanalys är en metod inom bioinformatik och molekylärbiologi som används för att undersöka, jämföra och analysera DNA- eller proteinsekvenser. Denna teknik bygger på att bestämma den exakta ordningsföljden av nukleotider (i fallet med DNA-sekvenser) eller aminosyror (i fallet med proteinsekvenser).
Sekvensanalys kan användas för att:
1. Identifiera och klassificera gener och de proteiner de kodar för.
2. Jämföra sekvenser mellan olika organismer för att fastställa evolutionära relationer och gemensam härstamning.
3. Förutsäga struktur, funktion och interaktion av proteinerna baserat på deras aminosyrasekvenser.
4. Upptäcka genetiska variationer, mutationer och polymorfismer som kan vara associerade med sjukdomar eller andra fenotypiska drag.
5. Utforma molekylära diagnos- och screeningverktyg för att identifiera patogener och övervaka resistensutveckling mot läkemedel.
Sekvensanalys använder sig av olika bioinformatiska verktyg, databaser och algoritmer för att bearbeta och analysera sekvenserna. Exempel på dessa verktyg inkluderar BLAST (Basic Local Alignment Search Tool), Clustal Omega, Multiple Sequence Alignment (MSA) och PROSITE.
RNA står för Ribonukleinsyra och är ett molekylärt ämne som liknar DNA men har några viktiga skillnader i sin kemiska struktur. Det finns olika typer av RNA, inklusive ribosomalt RNA (rRNA).
Ribosomer är komplexa maskinerier som består av proteiner och RNA-molekyler och spelar en viktig roll i syntesen av protein. De två huvuddelarna av ett ribosom kallas för stora och små subenheter. I den stora subenheten finns det tre stycken rRNA-molekyler: 5S, 5.8S och 28S. I den lilla subenheten finns det en rRNA-molekyl som kallas 18S rRNA.
18S rRNA är en strukturell komponent i den lilla ribosomala subenheten och hjälper till att bilda den aktiva plats där aminosyror kopplas samman för att bilda proteiner under processen kallad translation. 18S rRNA är en viktig molekyl i cellens proteinproduktion och finns i alla levande celler.
Medical definition of "Biological Evolution" is:
The process of gradual change and development in the characteristics of living organisms over generations through natural selection, genetic variation, and genetic drift. This can lead to the emergence of new species and the extinction of others. It is a fundamental concept in the field of biology and is supported by extensive scientific evidence from various fields such as genetics, paleontology, and comparative anatomy.
En aminosyrasekvens är en rad av sammanfogade aminosyror som bildar ett protein. Varje protein har sin unika aminosyrasekvens, som bestäms av genetisk information i DNA-molekylen. Den genetiska koden specificerar exakt vilka aminosyror som ska ingå i sekvensen och i vilken ordning de ska vara placerade.
Aminosyrorna i en sekvens är sammanbundna med peptidbindningar, vilket bildar en polymer som kallas ett peptid. När antalet aminosyror i en peptid överstiger cirka 50-100 talar man istället om ett protein.
Aminosyrasekvensen innehåller information om proteinet och dess funktion, eftersom den bestämmer proteins tertiärstruktur (hur aminosyrorna är hopfogade i rymden) och kvartärstruktur (hur olika peptidkedjor är sammansatta till ett komplext protein). Dessa strukturer påverkar proteinet funktion, eftersom de avgör hur proteinet interagerar med andra molekyler i cellen.
Monte Carlo-metoden är ett statistiskt sannolikhetsmetod som används för att simulera slumpmässiga händelser och beräkna numeriska approximationsvärden av komplexa problem. Den bygger på principen om att generera slumptal och använda dem för att simulera ett stort antal scenarier eller utfall, vilka sedan kan analyseras statistiskt för att uppskatta sannolikheter eller andra egenskaper hos det ursprungliga problemet. Metoden är uppkallad efter den berömda kasinot i Monaco, där slumpmässiga händelser används för att ge spelarna chansen att vinna pengar. I medicinska sammanhang kan Monte Carlo-metoden användas för att simulera olika sjukdomsförlopp, behandlingsalternativ eller andra komplexa processer där det är svårt att finna exakta analytiska lösningar.
Den medicinska termen "kontrollerad vokabulär" används ofta inom området medicinsk terminologi och kodning. Det refererar till en uppsättning av termer eller begrepp som har specificerats och standardiserats för att användas inom ett visst sammanhang, såsom inom en viss medicinsk specialitet eller i samband med en viss diagnos eller behandling.
Den kontrollerade vokabulären garanterar att alla som använder sig av terminologin talar samma språk och förstår varandra korrekt, vilket underlättar kommunikationen mellan olika sjukvårdsfunktioner, som exempelvis läkare, sjuksköterskor, specialister och administratörer. Det underlättar även datainsamling, analys och jämförelser inom forskning och kvalitetsförbättring.
Ett exempel på en kontrollerad vokabulär är Systematized Nomenclature of Medicine (SNOMED), som används globalt för att koda diagnoser, undersökningar, behandlingar och andra medicinska händelser.
MITOKONDRIE-DNA (mtDNA) refererer til DNA-molekyler, der findes i mitokondrierne, som er små cellulære organeller i vores celler. Mitokondrierne har en vigtig rolle i cellens energiproduktion gennem et process kaldet cellet respiration.
Mitokondrie-DNA består af cirkulært DNA, der er meget mindre end det menneskelige kromosomale DNA i cellekernen. Mennesket har typisk 2-10 kopier af mtDNA i hver mitokondrie, og hvert individ har typisk flere hundrede til tusinder af mitokondrier i hver celle.
MtDNA indeholder gener, der koder for en del af de proteiner, der er involveret i cellet respiration, samt RNA-molekyler, der er nødvendige for syntesen af disse proteiner. MtDNA adskiller sig fra det kromosomale DNA ved at have en høj mutationsrate og en ikke-random matning (eller assortativ mating) mønster, hvilket betyder at der kan forekomme specifikke mtDNA profiler inden for familier eller populationer.
Mutationer i mitokondrie-DNA kan være forbundet med en række sygdomme, herunder neurologiske og muskuløse lidelser, som ofte viser sig i barndommen eller tidlig ungdom. Disse sygdomme skyldes oftest mutationer i gener, der koder for proteiner involveret i cellet respiration.
"Datorsimulering" er en betegnelse for en metode der bruger en dators model for å afterbere, forutsi eller illustrere forløp og adferd hos et fysisk eller biologisk system, en samling av regler, en proces eller en enhet. Dette gjøres ved å lage en matematisk modell som beskriver systemet, og deretter kjøre denne modellen i en simuleringsmotor som kan beregne hvordan systemet vil oppfører seg under forskjellige tilstande og betingelser.
I medisinsk sammenhengg kan datorsimulering brukes på mange ulike områder, for eksempel:
* Fysiologisk simulering: Her brukes datorsimulering til å forstå og forutsi hvordan forskjellige fysiologiske systemer i kroppen fungerer, som for eksempel hjertets slag, lungens veksling av luft eller nyrefunksjonen.
* Farmakologisk simulering: Her brukes datorsimulering til å forstå og forutsi hvordan legemer reagerer på forskjellige lægemidler, slik at man kan optimere dosering og forebygge bivirkninger.
* Kirurgisk simulering: Her brukes datorsimulering til å planlegge og forberede kirurgiske ingreper, slik at kirurgen kan få en bedre forståelse av hvordan operasjonen vil gå, og eventuelt praktisere den første gang.
* Medicinsk undervisning: Datorsimuleringer kan også brukes som en del av medicinsk utdanning, slik at studenter kan lære om forskjellige sykdommer og behandlingsmuligheter ved å interagere med virtuelle pasienter.
Dette er bare noen eksempler på hvordan datorsimuleringer kan brukes innenfor medicinen, men det finnes mange andre muligheter også.
Ribosom-DNA (rDNA) refererar till de specifika sekvenserna av DNA som kodar för ribosomalt RNA (rRNA), ett viktigt komponent i ribosomer, de subcellulära partiklar där protein syntesis sker i cellen. Ribosomer är nödvändiga för att bygga upp proteiner genom att översätta informationen från mRNA till aminosyror som bildar en polypeptidkedja.
I eukaryota celler, som exempelvis djur- och växtceller, finns rDNA-sekvenserna i kromosomernas nucleolus, ett område inne i cellkärnan där ribosomer tillverkas. Prokaryota celler, såsom bakterier, har också rDNA-sekvenser som ofta finns i plasmider eller andra extrakromosomala DNA-molekyler.
rRNA utgör en stor del av ribosomen och är känd för sin strukturella stabilitet och höga konservation mellan olika arter. Dessa egenskaper gör rDNA till ett användbart verktyg inom molekylärbiologi, exempelvis vid fylogenetisk analys och identifiering av okända organismer genom sekvensering av rDNA-sekvenser.
"Genetiskt uttrycks mönster" refererar till hur och när gener i ett individuellt genomi expressar sig, det vill säga hur de producerar specifika proteiner eller RNA-molekyler. Detta kan variera mellan olika celltyper, till exempel leverceller jämfört med hjärnceller, och under olika livscykel-faserna, som fostertillstånd jämfört med vuxen ålder. Genuttrycksmönster kan påverkas av både genetiska och miljömässiga faktorer.
Det är värt att notera att termen 'genetiskt uttrycks mönster' ofta används i samband med studier av epigenetik, som undersöker hur miljöfaktorer kan påverka genuttryck genom mekanismer som DNA-metylering och histonmodifiering. Dessa förändringar kan vara reversibla och är ofta specifika för en viss celltyp eller tillstånd, vilket leder till unika genuttrycks mönster.
'Bakteriellt genomi' refererar till det kompletta satta av genetisk information som finns hos en specifik bakterieart. Det består av DNA-molekyler som innehåller all information som behövs för att producera de proteiner och RNA-molekyler som är nödvändiga för bakteriens överlevnad, tillväxt och reproduktion.
Ett bakteriellt genomi kan vara linjärt eller cirkulärt och kan innehålla tusentals gener som kodar för tusentals olika proteiner. Genomet kan också innehålla icke-kodande DNA som har regulatoriska funktioner, till exempel kontrollerar när och hur mycket av varje gen ska uttryckas.
Genomstudier av bakterier kan ge oss information om deras evolutionära historia, deras patogenicitet, deras resistens mot antibiotika och möjligheter att utveckla nya behandlingsmetoder. Genomsekvensering har blivit en viktig metod inom bakteriell forskning och kan användas för att identifiera och klassificera nya bakteriearter, undersöka deras evolutionära släktskap och utveckla nya vacciner och behandlingsmetoder.
Processering av naturligt språk (NLP) är ett grenområde inom artificiell intelligens och datavetenskap som fokuserar på att utveckla tekniker för att analysera, tolka och generera mänskligt språk i sin naturliga form. Detta innefattar allt från att analysera text- eller talbaserad information för att extrahera mening, känslor, intentioner och fakta till att automatiskt översätta språk, summera dokument och generera naturligt klingande dialog. NLP används i en mängd olika tillämpningar, såsom sökmotorer, chattbottar, röstassistenter, språkinlärningsverktyg och medicinsk teknik.
"Data Mining" er en begrepsdefinisjon som oftest brukes innen området for datavitenskap og statistikk. Det kan definieres som:
"Den procesen av utokting og automatisering av skjult, nyttig og tidligere ukjent mønster, kausalitet eller struktur i store datasett, ved bruk av metoder fra maskinlæring, statistikk og systemteori."
Data Mining kan også være definert som en slags "kunnskapsutvinning" fra data, der man søker etter mønster, forstår relasjoner og foretar generell analyse av store datamengder for å støtte beslutningstaking i forretnings- eller medisinske sammenhenger.
'Terminologi, principer' refererer til de grundlæggende regler og retningslinjer, der anvendes ved udviklingen, valget og brug af fagterminologi inden for et bestemt medicinsk område. Disse principper søger at sikre en konsistent, præcis og klar brug af termer for at forebygge misforståelser og fejl i kommunikationen mellem sundhedsfaglige fagpersoner, patienter og andre relevante parter.
Nogle vigtige principer inden for medicinsk terminologi omfatter:
1. Præcision: Anvendelse af klare, uambigüe termer for at beskrive specifikke koncepter, processer eller tilstande.
2. Konsistens: Brug af ensartede termer inden for et given medicinsk område for at undgå forvirring og forbedre kommunikationen.
3. Multilingualitet: Udvikling af standardiserede ækvivalenter for fagterminologi i flere sprog for at understøtte international samarbejde og patientpleje.
4. Struktur: Anvendelse af en hierarkisk struktur for at organisere termer efter deres semantiske relationer, hvilket letter søgning og klassificering.
5. Kontinuerlig opdatering: Passe terminologien på aktuel viden og forskning for at sikre at den repræsenterer de mest relevante og præcise koncepter inden for et medicinsk område.
6. Unikke identifikatorer: Tildeling af unikke identifikatorer til hver terminologi for at lette referencer og integration med andre systemer.
7. Kontrol af autoritet: Fastlæggelse af en autoritet eller en organisation, der har ansvaret for at oprette, vedligeholde og udgive den kontrolleret terminologi.
8. Transparens: Dokumentation af metoder og processer, der anvendes til at udvikle og understøtte terminologien for at fremme tillid og accept blandt brugere.
DNA-mikroarrayanalyser, även känd som DNA-chip eller genexpressionsprofilering, är en teknik inom genomik och proteomik som används för att simultant undersöka aktiviteten hos tusentals gener i ett enda experiment. Denna metod bygger på hybridisering av fluorescentmärkta DNA-prover till komplementära DNA-prober som är fysiskt fäst på en glasslid eller en silikonplatta.
I en DNA-mikroarrayanalys används ofta prover från två olika biologiska tillstånd, exempelvis frisk och sjuk, för att jämföra deras genuttrycksmönster. Genom att mäta intensiteten av fluorescensen på varje punkt i arrayet kan forskaren fastställa relativa nivåer av genaktivitet för varje gener i de två proverna. Detta kan hjälpa till att identifiera olikheter i genuttryck som kan vara associerade med en viss sjukdom eller biologisk process.
DNA-mikroarrayanalys är ett kraftfullt verktyg inom forskning och har använts för att studera allt från cancer till neurovetenskap, immunologi och utvecklingsbiologi. Den kan också användas för att undersöka genuttrycket hos patogener såsom bakterier och virus, vilket kan hjälpa till att identifiera nya mål för läkemedelutveckling.
"Genom" refererar till den totala uppsättningen av gener som finns inneboende i varje cell hos en organism. Det är det genetiska materialet som består av DNA-molekyler och som innehåller all information som behövs för att utveckla och maintenira de specifika egenskaperna hos en individ och art.
I växter, såsom i andra levande organismer, är genomet uppbyggt av kromosomer som innehåller tusentals gener vardera. Växters genomer kan variera mycket i storlek, från några hundra megabaser till flera tusen megabaser. De flesta växter har en diploid genomuppsättning, vilket innebär att de har två kopior av varje kromosom, en från vardera föräldern.
Det finns också växter som har ett polyploid genomi, där det finns fler än två kopior av varje kromosom. Polyploidi kan uppstå genom reproduktiva fel, såsom non-disjunction under celldelning eller genom hybridisering mellan olika arter. Polyploidi är vanligt förekommande inom växtriket och kan leda till nya arter med förändrade egenskaper jämfört med sina förfäder.
Genomet i växter innehåller information om allt från grundläggande celldelning och cellväxt till mer komplexa processer som fotosyntes, sekundär metabolism och respons på abiotiska och biotiska stressorer. Genomstudier av växter har ökat vår förståelse av deras evolutionära historia, genetiska variation och användningsområden inom jordbruket och medicinen.
'Human genome' refererer til det totale sæt af genetisk information, der er indeholdt i hvert menneskes celler. Det består af DNA-molekyler, der indeholder næsten 20.000 gener og andre sekvenssekvenser, der koder for proteiner og regulerer cellernes funktioner.
Den Humane Genome Project (HGP) var en internationalt samarbejde, der blev iværksat i 1990 med det formål at bestemme den komplette sekvens af det humane genom. I 2003 blev det offentliggjort, at HGP havde fuldført sit mål, og at de fleste menneskelige gener var identificeret og sekventeret.
Kendskabet til den humane genome har haft en stor betydning for vores forståelse af menneskelig genetisk variation, arvelige sygdomme, evolution, og potentialet for personlig medicin og genteknologi.
Proteom refererar till den totala uppsättningen proteiner som produceras eller finns i ett levande cellsystem, såsom en celldel, cell, vävnad eller organism, under specifika förhållanden och tidpunkter. Proteomet består av alla de olika typerna av proteiner som uttrycks av generna i genomet, deras interaktioner med varandra och andra molekyler, och hur de är modifierade och regleras under olika fysiologiska tillstånd eller sjukdomszustånd. Studiet av proteom innefattar identifiering och karakterisering av proteiner, deras funktioner, interaktioner och roll i cellulära processer och sjukdomar. Proteomstudier kan användas för att förstå hur proteiner arbetar tillsammans för att utföra specifika uppgifter inne i cellen, och hur dessa processer störs vid sjukdom.
'Klusteranalys' är en typ av statistisk analys som används för att identifiera grupper (kluster) med hög similaritet inom en datauppsättning. Syftet är att hitta naturliga grupperingar eller mönster i data utan att ha några förutfattade idéer om vilka de skulle vara. Varje grupp består av observationer som är mer lika varandra än de är till observationer i andra grupper.
I en medicinsk kontext kan klusteranalys användas för att undersöka olika typer av data, såsom demografiska data, kliniska data eller genetiska data. Exempel på användningsområden inom medicinen är:
1. Identifiering av subtyper av en sjukdom baserat på symptom, genetisk information eller andra relevanta variabler.
2. Studier av epidemiologi och spridning av infektionssjukdomar genom att klustra tillsammans fall med liknande spridningsmönster.
3. Utveckling av personligat vård baserat på individuella patientegenskaper och behandlingsrespons.
4. Farmakogenetik, för att undersöka genetiska variationer som kan påverka effekten eller biverkningarna av läkemedel.
5. Utveckling av riskmodeller för att förutse sjukdomsutveckling, respons på behandling eller andra relevanta utfall.
I allmänhet är klusteranalys ett kraftfullt verktyg inom medicinsk forskning och praktisk vård, då det möjliggör en djupare förståelse av komplexa mönster och relationer i stora datamängder.
Gene Ontology (GO) är ett kontrollerat språk och en databas för att beskriva biologisk funktion på gennivå inom tre kategorier: molekylär funktion, cellulär komponent och biologisk process. Det används globalt inom genetik och bioinformatik för att organizera, integrera och analysera data från genomstudier. GO-terminer är standardiserade beskrivningar av olika aspekter av geners funktion, som till exempel enzymatisk aktivitet, subcellulär lokalisation eller inblandning i en viss biologisk process. Genom att kategorisera gener på detta sätt kan forskare jämföra och kontrastera geners funktioner mellan olika arter, celltyper eller tillstånd, vilket kan hjälpa till att förbättra vår förståelse av biologiska system och deras respons på olika stimuli eller sjukdomar.
RNA-sekvensanalys är en metod inom bioinformatik och genetisk forskning som innebär att analysera sekvensen av ribonukleinsyra (RNA) molekyler. RNA är ett biologiskt makromolekyl som spelar en viktig roll i cellens proteinsyntes och genuttryck.
RNA-sekvensanalys kan inkludera att undersöka sekvensen hos en specifik RNA-molekyl för att fastställa dess identitet, struktur och funktion. Detta kan göras genom jämförelser med kända RNA-sekvenser i databaser som GenBank och RefSeq.
RNA-sekvensanalys kan också användas för att undersöka variationer i RNA-sekvenser mellan olika individer eller populationer, vilket kan ge information om genetisk diversitet och evolutionära relationer. Dessutom kan metoden användas för att identifiera potentiala regulatoriska element i RNA-sekvenser, såsom miRNA-bindningsställen och riboswitche, som kan ha betydelse för genreglering och cellfunktion.
Till slut kan RNA-sekvensanalys användas för att undersöka differential expressionsnitten av olika gener i olika celltyper, tillstånd eller behandlingar, vilket kan ge information om molekylära mekanismer bakom sjukdomar och terapeutiska mål.
"Genkartläggning" är ett begrepp inom medicinen som refererar till den process där man fastställer en individs genetiska make upp. Detta kan involvera att analysera och identifiera specifika gener, kromosomer eller genetiska variationer hos en person. Genkartläggning kan användas för att ställa diagnoser av genetiska sjukdomar, för att fastställa ärftlighet av vissa sjukdomar eller egenskaper, och för att planera och utvärdera medicinska behandlingar. Genkartläggning kan också användas inom forskning för att undersöka genetiska associationer med olika sjukdomar och hälsotillstånd.
'Programmeringsspråk' är ett formellt språk som används för att skriva datorprogram. Det består av en uppsättning syntaxregler och semantik som specificerar hur programinstruktioner ska skrivas och tolkas av en dator. Programmeringsspråket översätts sedan till maskinkod som kan köras direkt på datorns processor.
Det finns många olika typer av programmeringsspråk, såsom imperativa språk (till exempel C, Java), deklarativa språk (till exempel SQL, Prolog), funktionella språk (till exempel Haskell, Lisp) och objektorienterade språk (till exempel C++, Python). Varje språk har sina egna unika egenskaper och användningsområden.
Programmeringsspråken är designade för att underlätta kommunikationen mellan människor och datorer, och de gör det möjligt för oss att skapa komplexa system som kan lösa olika typer av problem.
Artificiell intelligens (AI) definieras vanligtvis som förmågan för en dator eller ett datorprogram att simulera mänsklig intelligens i olika grader. Detta kan innebära att programmet har kapaciteten att lära sig från erfarenheter, anpassa sitt beteende baserat på omgivningen och göra beslut som en människa skulle göra i samma situation. AI-system kan vara specialdesignade för att lösa specifika problem eller ha generell intelligens som är mer lik mänsklig intelligens.
En annan definition av AI är "en dator eller ett datorprogrammedvetande som har förmågan att förstå, lära sig och använda kunskap i sitt arbete, såsom att tolka data från sin omgivning, lösa problem och göra beslut."
Det är värt att notera att det inte finns en allmänt accepterad definition av AI, och olika experter kan ha olika uppfattningar om vad som innefattas i begreppet.
Proteomik är ett forskningsområde inom biomedicin som handlar om studiet av proteomer, det vill säga den totala mängden proteiner och deras interaktioner i ett levande system, till exempel en cell, ett vävnadsprov eller en organism. Proteomiken innefattar identifiering och karakterisering av olika proteiner, deras funktioner, interaktioner med varandra och förändringar i uttryck under olika fysiologiska och patologiska tillstånd.
Proteomik använder sig ofta av högthroughput-tekniker som tvådimensionell gelélektrofores, masspektrometri och proteinkromatografi för att separera och identifiera proteiner. Dessa metoder kombineras ofta med bioinformatiska verktyg för att tolka de genererade data och hitta samband mellan olika proteiner och deras funktioner.
Proteomik har potentialen att ge insikt i komplexa sjukdomar som cancer, neurodegenerativa sjukdomar och infektionssjukdomar, genom att undersöka förändringar i proteomet och hitta nya mål för terapiutveckling.
'High-Throughput Nucleotide Sequencing' (HTS), också känt som nästa generation séquensiering (NGS), är en grupp av tekniker för sekvensering av DNA och RNA på hög genomförandhastighet och med låg kostnad per baskelv. Denna metod gör det möjligt att sekvensera stora mängder av nukleotidsekvenser samtidigt, vilket ger en mycket högre upplösning jämfört med traditionella sekvenseringsmetoder. HTS används ofta inom forskning och klinisk praktik för att studera genomet, transkriptomet och epigenomen hos levande organismer, vilket kan ge information om genetisk variation, genuttryck, mutationer och epigenetiska förändringar.
Proteininteraktionskartläggning (PPI, Protein-Protein Interaction mapping) är ett samlingsbegrepp för de metoder och tekniker som används för att undersöka och beskriva hur proteiner interagerar med varandra i cellulära system. Detta är en viktig del av molekylärbiologi och cellulär biokemi, eftersom proteininteraktioner spelar en central roll i nästan alla cellulära processer, inklusive signaltransduktion, reglering av genuttryck, DNA-replikering, och cellcykelkontroll.
Genom att kartlägga dessa interaktioner kan forskare få en bättre förståelse för hur proteiner fungerar tillsammans i nätverk och hur de styr cellulära processer. Detta kan hjälpa till att identifiera potentiala terapeutiska mål och utveckla nyare och effektivare behandlingsmetoder för sjukdomar som cancer, neurodegenerativa sjukdomar och infektionssjukdomar.
Det finns olika tekniker och metoder för att kartlägga proteininteraktioner, inklusive two-hybrid screening, affinitetschromatografi, masspektrometri, fluorescensresonansenergitransfer (FRET), bioluminiscensresonansenergiöverföring (BRET) och krosskärmstekniker. Varje metod har sina egna fördelar och begränsningar, och ofta används flera tekniker i kombination för att verifiera och validera resultaten.
"Svampgensom" refererer til det totale sæt af genetisk information, der er inkluderet i et svampes cellegennem. Svampe er en heterogen gruppe organismer, der inkluderer både encelleteknisk simple arter som gær og flercelletekniske arter som skinneklæder og skimmelsvampe.
Svampgensommet består af DNA-molekyler, der er fordelt i lineære eller cirkulære kromosomer. Disse kromosomer indeholder gener, der er delelementer af arvematerialet, som bestemmer de karakteristika og funktioner hos svampen.
Svampgensommet kan variere meget mellem forskellige svampearter, men det inkluderer typisk gener, der er involveret i celledeling, stofskifte, næringsupptagelse, seksuel og asexuel formering, og produktion af sekundære metabolitter som antibiotika og mycotoxiner.
Undersøgelse af svampgensommet kan give vigtig indsigt i svampens evolutionæ historie, fysiologi, patogenese, og muligheder for bioteknologisk anvendelse.
Transcriptom är ett samlingsbegrepp för alla RNA-molekyler som transkriberats, eller kopierats, från DNA:t i en cell vid en given tidpunkt. Det inkluderar både protein kodande RNA (mRNA) och icke-proteinkodande RNA (till exempel rRNA, tRNA, miRNA med mera). Transkriptomet ger därför information om vilka gener som är aktiva i en cell och hur mycket av varje gen som produceras. Genom att analysera transkriptomet kan forskare få insikt i celldifferentiering, cellcykler, respons på stimuli och sjukdomar.
Kunskapsdatabas (engelska: Knowledge base) är inom medicinen en databas som innehåller systematiskt sammanställda och strukturerade informationer om olika medicinska ämnen, till exempel sjukdomar, diagnoser, behandlingar, läkemedel och forskningsresultat. Denna typ av databaser används ofta som ett hjälpmedel inom klinisk praktik och forskning för att underlätta beslut om patientvård, undervisning och utveckling av nya behandlingsmetoder.
Exempel på vanliga kunskapsdatabaser inom medicinen är:
1. UpToDate: En evidensbaserad klinisk kunskapsresurs som ger läkare, sjuksköterskor och andra hälso- och sjukvårdspersonal stöd för att tillhandahålla den bästa möjliga vården.
2. DynaMed: En evidensbaserad klinisk kunskapsresurs som ger snabb, tillförlitlig och relevant information för beslut om patientvård.
3. MedlinePlus: En webbplats som erbjuder information om sjukdomar, diagnoser, behandlingar, läkemedel och kliniska prövningar för allmänheten på ett lättförståeligt sätt.
4. Cochrane Library: En samling av systematiska översikter, primärforskningsrapporter, forskningsöverblickar och andra typer av information som är relaterad till hälso- och sjukvården.
Dessa kunskapsdatabaser underhålls ofta av experter inom respektive område och uppdateras regelbundet för att säkerställa att informationen är aktuell och relevant.
'Search engine' er en betegnelse for et computerprogram eller en webtjeneste, der bruges til at søge efter og finde information på internettet. En search engine indeholder en database med webadresser (URL'er) og anden metadata om de websteder, som den har fundet under sit 'crawling' af World Wide Web. Brugerne kan skrive et søgeord eller en sætning ind i søgefeltet på search engine-siden, hvorefter search engine-algoritmen vil analysere brugerens input og sammenligne det med den information, der er gemt i databasen. Search engine-algoritmen rangerer derefter de relevante resultater efter deres anslåede relevans for søgeopgaven, således at de mest relevante resultater vises øverst på siden.
Search engines er blevet en vigtig del af vores hverdag og hjælper os med at finde information hurtigt og effektivt. De mest kendte search engines inkluderer Google, Bing, Yahoo!, og DuckDuckGo. Det er værd at notere, at nogle search engines kan have forskellige politikker omkring datainsamling, profilering, og annoncering, så det er altid en god ide at læse op om disse politikker, hvis du har bekymringer om din privatliv.
Medicinskt sett betyder "mönsterigenkännande, automatiserat" att ett datorbaserat system har kapaciteten att urskilja mönster i stor volym av medicinska data, som exempelvis elektroniska hälsorapporter eller bilddiagnostiska data, och att göra detta utan direkt användarinteraktion. Genom att träna på stora mängder data kan djupinlärningsalgoritmer automatisera mönsterigenkännandet och hjälpa till med att ställa diagnoser, förutsäga sjukdomsförlopp eller rekommendera behandlingar. Detta kan underlätta för vården och göra den mer effektiv, men det är också viktigt att vara medveten om möjliga begränsningar och risker, såsom bias i data eller algoritmer som kan påverka kliniska beslut.
"Arkeogenomik" är ett begrepp inom genetisk forskning och arkeologi som refererar till studiet av DNA-sekvenser från antika organismer, såsom fossil, mumifierade kroppar eller subfossila lämningar. Arkeogenomik använder sig av molekylärgenetiska metoder för att rekonstruera och analysera det genetiska materialet hos utdöda arter, populationer eller historiska individer. Detta kan ge viktig information om deras evolutionära historia, levnadssätt, migrationer och släktskap. Arkeogenomik har potentialen att förändra vårt förstånd av människans ursprung och utveckling, liksom andra djurarters.
I medically related context, "semantics" refererer til studiet af betydning og forståelse af sprog i kommunikation, særligt indenfor lægevidenskab og andre sundhedsfaglige områder. Det inkluderer forståelsen af patienters beskrivelser af deres symptomer, sygdomme og tilstande, samt effektiv kommunikation mellem sundhedspersonale og patienter.
Semantik i denne kontekst handler om at sikre at alle parter har en fælles forståelse af de begreber, ord og udtryk, der bruges i sundhedsrelaterede sammenhænge, såsom diagnoser, behandlinger, medicinske procedurer og andre relevante emner. Dette er særligt vigtigt for at undgå misforståelser, fejlbeskeder eller dårlig lægepatient-kommunikation, der kan føre til uhensigtsmæssige behandlinger, forværret sundhed og patientskade.
En bedre semantisk forståelse hjælper også med at styrke den empatiske forbindelse mellem læger og patienter, hvilket kan føre til en mere effektiv behandlingsproces og bedre sundhedsresultater.
'Open Reading Frames' (ORF) refererar till genetiska sekvenssegment som har potentialen att koda för proteiner. De definieras vanligtvis som en sekvens av minst 300 nukleotider som börjar med en startkod (ATG) och fortsätter till en stoppkod (TAA, TAG eller TGA). ORF:er hittas ofta i delar av DNA eller RNA som kallas icke-kodande, eftersom de inte direkt koder för proteiner. Genom att identifiera ORF:er kan forskare förutsäga potentiala proteinsekvenser och undersöka deras funktioner. Det är värt att notera att inte alla ORF:er leder till produktion av ett fullständigt protein, eftersom det finns olika mekanismer som kan påverka den genetiska informationens överföring från DNA till protein.
In medical terms, "gener" är inte en etablerad term. Det kan ha varit meningen att stava "genetisk", som refererar till arvsanlag eller egenskaper som är ärftliga och bestäms av gener, de grundläggande enheterna i arvsmassan.
En gen är en sekvens av DNA-nukleotider som innehåller information om hur att bygga ett protein eller reglera en biokemisk process. Genetisk information kan påverka många aspekter av individens hälsa och sjukdom, inklusive risken för ärftliga sjukdomar, svar på miljöfaktorer och läkemedelsrespons.
"Abstraktion och indexering är två viktiga processer inom informationshantering och sökteknik som används för att organisera och kategorisera information i medicinska dokument, såsom vetenskapliga artiklar och rapporter.
Abstraktion innebär att skapa en kort sammanfattning av ett dokument, ofta på några hundra ord eller mindre, som beskriver dess viktigaste aspekter och resultat. Abstrakten ger läsaren en snabb överblick över dokumentets innehåll och hjälper dem att avgöra om det är relevant för deras forskningsintresse eller behov. En god abstrakt ska vara objektiv, koncis och informativ, och innehålla de viktigaste nyckelorden och fraserna som beskriver dokumentets tema och resultat.
Indexering är en process där man tilldelar metadata till ett dokument för att underlätta sökning och rekvisition av relevant information. Detta görs genom att identifiera och kategorisera de viktigaste begreppen, nyckelorden och fraserna i dokumentet, och koppla dem till motsvarande termer i en kontrollerad terminologi, såsom MeSH (Medical Subject Headings) inom medicin. Indexeringen gör det möjligt att söka efter specifika begrepp, teman eller resultat över en stor mängd dokument, och hjälper användaren att hitta relevant information snabbt och effektivt.
Sammantaget är abstraktion och indexering viktiga verktyg för att underlätta sökning, hantering och delning av medicinsk information, och de bidrar till att öka den vetenskapliga kommunikationens kvalitet, effektivitet och åtkomlighet."
Mjukvarudesign (software design) är ett samlingsbegrepp för de aktiviteter och processer som utförs för att specificera och skapa en mjukvarulösning. Det inkluderar att definiera systemets arkitektur, gränssnitt, algoritmer och data strukturer. Mjukvarudesignen är ett viktigt steg i mjukvaruutvecklingsprocessen efter kravspecifikationen och före implementeringen. Syftet med mjukvarudesignen är att skapa en klar, fullständig och konsistent beskrivning av systemet som kan användas som grund för implementation, testning och underhåll.
PubMed är en kostnadsfri databas som tillhandahåller information om biomedicinsk forskning. Den innehåller referenser och sammanfattningar (abstracts) av artiklar från över 30 000 medicinska tidskrifter, såväl som böcker, teoretiska rapporter och kliniska studier. PubMed är en tjänst som drivs av National Center for Biotechnology Information (NCBI) vid National Library of Medicine (NLM) i USA.
PubMed innehåller också länkar till fulltextartiklar, både kostnadsfria och betalda, och har en funktion som heter "My NCBI" där användare kan spara sina sökningar, skapa alerta när nya artiklar publiceras inom ett specifikt område och dela resultat med andra.
PubMed är en värdefull resurs för forskare, läkare, studenter och alla andra som är intresserade av att hålla sig uppdaterade om den senaste forskningen inom sitt område.
'Genbibliotek' (engelska: genomic library) är ett sätt att lagra och organisera DNA-sekvenser från ett eller flera organizmer i form av kloner i värdarceller, ofta bakterier eller jäst. Genombiblioteken innehåller kompletta uppsättningar av genomet organismens DNA-fragment, vilket gör det möjligt att studera och analysera dessa sekvenser på ett systematiskt sätt. Denna teknik används ofta för att identifiera specifika gener eller andra intressanta DNA-sekvenser inom ett helt genome. Genombiblioteken kan också vara värdefulla resurser för att studera evolutionära relationer mellan olika arter och för att utveckla nya molekylära biologiska verktyg och metoder.
I'm sorry for any confusion, but "Config-mappning" is not a medical term that I am familiar with. It appears to be a term used in the field of technology and software development, referring to the process of mapping configuration settings between different systems or applications. If you have a term related to medicine or healthcare that you would like me to define, please let me know!
Enzymer är definierade inom medicin och biokemi som proteiner som accelererar kemiska reaktioner i levande organismers celler. De gör detta genom att sänka aktiveringsenergien för en viss kemisk reaktion, vilket resulterar i en ökad hastighet av produktbildning. Varje enzym är specialiserat för att katalysera en specifik reaktion eller en grupp närbesläktade reaktioner. Enzymer kan också regleras genom aktivering och inhibitering, vilket möjliggör kontroll av cellens metabolism och homeostas.
Metaboliska nätverk och banor refererar till de komplexa interaktionerna mellan olika kemiska reaktioner i levande celler som leder till nedbrytning (katabolism) och syntes (anabolism) av molekyler. Dessa processer är nödvändiga för att celler ska kunna fungera, växa och reproduceras.
Ett metaboliskt nätverk består av en mängd olika enzymatiska reaktioner som är sammankopplade genom gemensamma substrat och produkter. Varje reaktion katalyseras av ett specifikt enzym och kräver ofta energibärare som ATP, NADH eller FADH2 för att kunna ske. Genom att kombinera flera olika reaktioner kan cellen producera komplexa molekyler från enklare prekursorer eller bryta ner komplexa molekyler till enklare byggstenar.
Metaboliska banor är specifika vägar genom metaboliska nätverk som leder till syntesen eller nedbrytningen av specifika klasser av molekyler, såsom kolhydrater, lipider, aminosyror och nukleotider. Varje bana består av en serie sammankopplade reaktioner som katalyseras av olika enzymer och regleras av specifika signalsubstanser och mekanismer.
Metaboliska nätverk och banor är mycket dynamiska och kan variera beroende på cellens behov och den miljö den befinner sig i. De kan också vara störda av genetiska mutationer, toxiner, infektioner eller andra stressfaktorer, vilket kan leda till sjukdomar och patologiska tillstånd.
'Pseudogen' är ett begrepp inom genetiken och refererar till en sekvens i DNA som liknar en fungerande gen, men saknar förmågan att producera ett funktionellt protein. Det kan bero på att pseudogenen innehåller mutationer som förhindrar transkription eller translation av genen, eller att den saknar nödvändiga regulatoriska sekvenser. Pseudogener anses vara rester av evolutionära händelser, där genduplikering eller retrotransposition har skett och resulterat i en kopia av genen som senare blivit inaktiverad. De flesta pseudogener är ofunktionella, men vissa kan ha andra funktioner än att producera protein, till exempel kan de ha reguljära funktioner i cellen eller vara involverade i evolutionära processer.
I medicinsk kontext, betyder "multigen familj" en familj där flera personer över två generationer har diagnostiserats med samma ärftlig sjukdom. Detta kan inkludera till exempel en mor och hennes barn, deras far/morfar och eventuellt även syskon eller kusiner till barnen.
Multigen familjer är viktiga att identifiera eftersom det kan indikera ett större risk för släktingar att utveckla samma sjukdom. Genetisk rådgivning och screening kan då erbjudas för att tidigt upptäcka och möjligen behandla sjukdomen innan allvarliga symptom uppstår.
'Genom' refererar till det totala arvsmassan hos en organism, vilket består av DNA-sekvenser som innehåller all information kodad i gener som styr organismens utveckling och funktion.
'Protozoiskt' är ett adjektiv som används för att beskriva någonting relaterat till protozoer, en grupp encelliga eukaryota organismer som lever fritt i vatten eller som parasiter inom andra levande varelsers kroppar.
En medicinsk definition av 'genom, protozoiskt' skulle därför vara den totala arvsmassan hos en protozoisk organism, vilket inkluderar all DNA-sekvens som kodar för dess gener och styr dess utveckling och funktion.
"Bevarad sekvens" är ett begrepp inom genetik och molekylärbiologi som refererar till en del av DNA- eller RNA-molekylen som inte har genomgått någon form av mutation eller genetisk ändring. Den bevarade sekvensen är därför identisk med den ursprungliga sekvensen i det aktuella genomet.
I en medicinsk kontext kan begreppet användas för att beskriva en situation där en viss gen, kromosom eller DNA-sekvens har bevarats hos en individ, till exempel när man undersöker ärftliga sjukdomar eller genetiska markörer. En bevarad sekvens kan vara av intresse för forskare och kliniker eftersom den kan ge information om risken för att utveckla en viss sjukdom, svaret på en viss behandling eller andra medicinska aspekter.
"Automation" in a medical context refers to the use of technology and machinery to automatically perform tasks or processes that would otherwise be done by humans. This can include various types of equipment, such as laboratory analyzers, imaging machines, and robotic surgical systems. The goal of automation in healthcare is to improve efficiency, accuracy, and safety while reducing costs and the potential for human error. It can also help to free up healthcare professionals' time so that they can focus on more complex tasks and patient care.
"Resultatens reproducerbarhet" är ett begrepp inom forskning och medicin som refererar till förmågan att upprepa en experimentell studie eller ett försök och få liknande eller identiska resultat. Detta är viktigt eftersom det stärker den vetenskapliga evidensen för ett visst fynd eller en viss slutsats.
En studie som har hög reproducerbarhet innebär att andra forskare kan upprepa experimentet och få samma resultat, även om de använder olika metoder eller prover. Detta är ett fundamentalt koncept inom vetenskapen eftersom det understryker vikten av objektivitet och pålitlighet i forskningsprocessen.
I medicinsk forskning kan reproducerbarhet vara särskilt viktig när det gäller studier som undersöker effekterna av olika behandlingsmetoder eller läkemedel. Om en studie inte har hög reproducerbarhet, kan det ifrågasättas hur tillförlitliga dess resultat är och om de verkligen kan appliceras i klinisk praktik.
Biologiska processer är en samling komplexa system av interagerande molekyler, celldelar och vävnader som utgör basen för livets funktioner. Dessa processer inkluderar, men är inte begränsade till, cellers respiration, replikation och transkription av DNA, protein syntes, celldelning, signaltransduktion, immunförsvar och homeostas. Biologiska processer styr allt ifrån enstaka cellers funktion till hela organismers livscykel, inklusive födelsen, tillväxten, reproduktionen och döden.
'Växtgener' är ett begrepp inom genetiken och molekylärbiologin som refererar till den totala uppsättningen genetisk information hos växter. Genomer består av DNA-molekyler som innehåller tusentals gener, regulatoriska sekvenser och icke kodande regioner. Växters genomer varierar i storlek och komplexitet mellan olika arter. Exempel på växtgener inkluderar risgenomet (cirka 460 miljoner baspar), majsgenomet (cirka 2,3 miljarder baspar) och människans genomet (cirka 3 miljarder baspar). Studiet av växtgener har potentialen att förbättra jordbrukets produktivitet, föda världens växande befolkning och skydda mot skadegörare och klimatförändringar.
'Oryza sativa' er ein medisinsk betegnelse for ris, som er en viktig grønnsak og kreftfare i mange dele av verden. Ris er en art av graset (Poaceae) og er ei av de eldste og mest opplevande matproduktene i menneskelig historie. Det er rikt på kostromkjemikaliene kostfiber, protein, jern, magnesium, vitamin B6 og folat. Ris kan være en viktig kilde til næring for mange mennesker, særleg i deler av verden der det er ein grunnleggjande matprodukt. Der er flere typer ris, inkludert hvit ris, brun ris og integralt ris, som har ulika smak, konsistens og ernæringsvilkår.
UTR står för "untranslated region" och refererar till sektioner av eukaryot RNA (inklusive mRNA) som inte kodar för proteiner. Det finns två typer av UTR:er - 5'-UTR, som ligger upstream av startkodonen, och 3'-UTR, som ligger downstream av stoppkodonen. Dessa regioner innehåller signalsystem som reglerar stabiliteten, lokaliseringsmönstret och översättningen av mRNA till protein. De kan också innehålla bindningsställen för reguljära och icke-kodande RNA, såsom miRNA, som kan påverka översättningen och nedbrytningen av mRNA.
Sjukdom (eller illness) är en beteckning på ett tillstånd av nedsatt hälsa eller funktion hos en individ, orsakad av en skada, en infektion, en genetisk defekt eller ett störande fysiologiskt tillstånd. En sjukdom kan vara kortvarig (akut) eller varaktig (kronisk), och den kan variera i allvarlighetsgrad från milda symptom till livshotande tillstånd. Sjukdomar kan klassificeras på olika sätt, beroende på orsaken, lokalisationen i kroppen eller typen av symptom. Exempel på olika typer av sjukdomar inkluderar infektionssjukdomar, cancer, neurologiska sjukdomar, hjärtsjukdomar och lungsjukdomar.
"Genom" refererer til det totale sæt af genetisk information, der er inkluderet i alle kromosomer hos et levende væsen. Det består af DNA-molekyler, der indeholder alle de gener, som instruerer cellerne om at producere de proteiner, der udgør en organismes struktur og regulerer dens funktioner.
En "mask" er ikke en medicinsk eller biologisk term, så jeg antager, at du måske mener "maske", som er et redskab, der bruges til at filtrere luften, der indåses gennem næsen og munden.
Derfor kan jeg ikke give en medicinsk definition af 'Genom, mask', da det ikke er en gyldig kombination af begreber inden for medicin eller biologi.
Prokaryota är ett samlingsnamn för encelliga organismer som saknar cellkärna och andra membranbundna organeller. De två största grupperna inom Prokaryota är bakterier och archaea. Dessa celler har en enkel struktur jämförd med eukaryotiska celler, det vill säga celler hos djur, växter, svampar och protister.
Prokaryotiska celler består av:
1. En cellyta (cytoplasma) innehållande DNA, RNA och proteiner.
2. Ett enda cirkulärt kromosomalt DNA-molekyl som inte är omgivet av en membranös kärnhinna.
3. Ribosomer, där proteinsyntesen sker.
4. En celldelande mekanism som innebär att DNA replikeras och delas upp mellan två identiska dotterceller under celldelningen (mitos).
5. Vissa prokaryoter kan ha yttre strukturer såsom flageller, pili eller kapslar.
Det är värt att notera att archaea ofta har molekylära mekanismer och vävnader som liknar eukaryota celler, men de saknar ändå en tydlig cellyta och cellkärna.
"Data interpretation, statistical" refererer til procesen av att tolka och giva mening aan data med hjälp av statistiska metoder. Det innebär att analysera, summera och tolka data för att utvärdera hypoteser, identifiera mönster, korrelationer och kausalitet, samt dra slutsatser baserat på de statistiska resultaten.
Den statistiska datatolkningen inkluderar ofta metoder som deskriptiv statistik (som medelvärde, median, modus, standardavvikelse och procent), inferensstatistik (som t-test, chi i test, analys av variance (ANOVA) och regressionsanalys), multivariat analys och sannolikhetslära.
Syftet med statistisk datatolkning är att försöka extrahera mening och insikt från data, vilket kan användas för att stödja beslutsfattande, forskning, utveckling och kvalitetssäkring inom olika områden som medicin, teknik, ekonomi, samhällsvetenskap med mera.
Medline är en av världens största databaser för biomedicinsk litteratur, innehållande referenser till artiklar från över 5200 medicinska tidskrifter publicerade globalt. Databasen underhålls av National Library of Medicine (NLM) i USA och inkluderar artiklar främst inom områdena medicin, hälsovetenskap, veterinärmedicin och ämnen relaterade till biomedicinsk forskning. Medline är en del av NLMs sammanlagda system, PubMed, som ger tillgång till fulltextversioner av artiklar när de är tillgängliga.
I medicinsk kontext, betyder "ordbehandling" ofta användandet av psykoterapi eller andra former av samtalsterapi för att behandla psykiska problem eller störningar. Det innebär att en terapeut eller läkare har samtal med patienten för att hjälpa denne att hantera sina känslor, tankar och beteenden på ett konstruktivt sätt.
Det finns många olika typer av ordbehandling, inklusive kognitiv beteendeterapi (KBT), psykodynamisk terapi, familjeterapi och gruppterapi. Varje typ av terapi har sina egna unika tekniker och metoder för att hjälpa patienten att uppnå sina mål.
Exempel på problem som kan behandlas med ordbehandling inkluderar depression, ångest, trauman, personskapsproblem, relationsproblem och missbruksproblem. Genom att arbeta tillsammans med en terapeut kan patienten lära sig att hantera sina problem på ett effektivt sätt och uppnå en bättre livskvalitet.
"Synteni" er et begreb innen genetikk som refererer til situasjonen hvor to eller flere gener ligger på samme kromosom i samme rekkefølge hos to forskjellige organismer. Dette kan være anvendelig for å undersøke evolutionæ forhold mellom forskjellige arter, fordi forekomsten av synteni kan indikere en felles opprinnelse og eventuelle generelle skjeve endringer i kromosomstrukturen.
Det er viktig å nevne at synteni ikke betyr at generene er identiske mellom de to arter, men bare at de ligger på samme sted på kromosomet og kan ha like funksjon eller være involvert i like biologiske prosesser.
Crowdsourcing in a medicinsk kontext kan definieras som den processen där en grupp individer eller experter i ett medicinskt område samarbetar och delar med sig av kunskap, kompetens och idéer för att lösa ett medicinskt problem, utveckla nya terapeutiska metoder eller förbättra vården. Detta kan ske genom olika digitala plattformar, till exempel sociala medier, webbforum, speciella crowdsourcing-webbplatser eller andra samarbetsverktyg. Crowdsourcing kan vara användbart inom forskning, utveckling av läkemedel, diagnostisering, behandlingsplanering och patientengagemang.
Regulatoriska genetiska nätverk (RGN) är inom genetiken och systembiologin de interaktioner som sker mellan olika gener på ett sådant sätt att de reglerar varandras uttryck och funktion. Detta kan ske genom att en gen kodar för ett protein som binder till DNA-sequensen hos en annan gen och påverkar dess transkription, eller genom att en gen påverkar den signalsubstans som styr en annan genes aktivitet.
RGN inkluderar ofta flera olika typer av regulatoriska mekanismer, till exempel transkriptionsfaktorer, miRNA, epigenetiska modifieringar och andra signalsubstanser som påverkar genuttryck. Dessa nätverk är viktiga för att koordinera cellulära processer såsom celldifferentiering, cellcykelkontroll, apoptos och responser på stress- och signalsubstanser.
Förändringar i regulatoriska genetiska nätverk kan leda till olika sjukdomszustånd, inklusive cancer, neurodegenerativa sjukdomar och kardiovaskulära sjukdomar. Därför är studiet av RGN viktigt för att förstå sjukdomsprocesser och utveckla nya terapeutiska strategier.
Structural homology in the context of proteins refers to the similarity in the three-dimensional structure of proteins that are not necessarily related by sequence. This means that two or more proteins may have a similar overall fold or specific structural motifs despite having low sequence identity. Structural homology can arise due to convergent evolution, where unrelated proteins evolve similar structures to perform similar functions, or divergent evolution, where related proteins evolve different functions while maintaining a similar structure. The study of structural homology is important in understanding protein function and evolution, as well as in the design of drugs and other therapeutic interventions.
"Complementary DNA" (cDNA) är en syntetisk enkelsträngad DNA-molekyl som skapas genom att transkribera en messenger RNA (mRNA)-molekyl med hjälp av en revers transkriptas. cDNA används ofta i molekylärbiologiska experiment, till exempel för att klona specifika gener eller studera genuttryck.
Den komplementära naturen av cDNA och den ursprungliga mRNA-molekylen gör det möjligt att använda cDNA som en representation av den ursprungliga genen, eftersom basparningen mellan DNA och RNA följer komplementära regler (A parar sig med T respektive G parar sig med C). Detta gör cDNA till ett värdefullt verktyg inom molekylärbiologi, eftersom det ofta är lättare att arbeta med DNA än RNA.
I'm sorry for any confusion, but the term "Hypermedia" is typically not used in a medical context. It is a term that originates from the field of computer science and telecommunications, where it refers to a non-linear medium of information that includes hypertext and graphics, video, audio, and other multimedia elements. Hypermedia allows users to navigate through information in a flexible and non-sequential manner by clicking on links or using other forms of navigation.
In a medical context, terms such as "hypermedia" are not commonly used to describe medical concepts or conditions. Instead, medical terminology is typically used to describe specific diseases, symptoms, treatments, and other aspects of medical care. If you have any questions about a specific medical concept or condition, I would be happy to try to help you clarify it using appropriate medical terminology.
"Genom" refererer til det totale sæt af genetisk information, der er indeholdt i et organisme. Det består af DNA-molekyler, der indeholder alle de gener, som styrer organismens arvelige egenskaber og funktioner.
"Insekt" defineres som en gruppe af hvirvelløse, koldblodede dyr med et ydre skelet (ekskutter), der oftest har to par vinger og ben. De fleste insekter har også store øjne og antenner. Insekter udgør den største gruppe af alle levende organismer på jorden, med mere end en million kendte arter.
Så en medicinsk definition af "insektgenom" vil være det totale sæt af genetisk information, der er indeholdt i et insekt. Det omfatter alle de gener, som styrer insektsarten's arvelige egenskaber og funktioner.
'Metagenomics' definieras som ett område inom genomik som handlar om att studera genomet från samhällen av mikroorganismer i en specifik miljö, utan att kultivera dem individuellt först. Det innebär att man analyserar DNA-sekvenser direkt hämtade från ett miljöprover, till exempel jord, vatten eller tarmflora, för att få information om de olika mikroorganismernas arter, funktioner och interaktioner. Detta möjliggör en bredare och mer detaljerad undersökning av mikrobiotan i en viss miljö än vad som är möjligt med traditionell kultivationsbaserad metodik.
"Alternativ splitsning" (alternative splicing) är ett biologiskt fenomen där flera olika proteiner kan produceras från en och samma gen genom att olika delar av den genetiska informationen i RNA-molekylen exciseras och de kvarvarande delarna (exonerna) sedan sammanfogas på olika sätt. Detta medför att ett stort antal olika proteiner kan produceras från en enda gen, vilket ökar den genetiska variationsmöjligheten och komplexiteten hos levande organismer.
'Biological ontologies' are formal representations of knowledge in the form of standardized vocabularies and models that describe biological systems and their properties. They provide a way to represent, organize, and share data and information about biological entities such as genes, proteins, cells, tissues, organisms, and processes. Biological ontologies aim to capture the relationships and hierarchies between different concepts in a consistent and computable manner, enabling more effective integration, analysis, and interpretation of large-scale biological data. Examples of widely used biological ontologies include the Gene Ontology (GO), the Cell Ontology (CL), and the Chemical Entities of Biological Interest Ontology (ChEBI).
I'm happy to help! However, I believe there may be a typo in your question and you are asking for a medical definition of "Online system." It is important to note that the term "online system" is not a medical term per se, but it can refer to various systems used in the field of medicine that involve digital technology and internet connectivity. Here's a possible definition:
An online system in a medical context refers to a networked computer-based system that enables the electronic exchange and processing of healthcare information through the internet or other digital communication channels. Online systems can support various functions, such as remote patient monitoring, telemedicine consultations, electronic health records (EHRs), clinical decision support tools, and medication management systems. These systems aim to improve the efficiency, quality, and safety of healthcare delivery by facilitating real-time access to relevant patient data, reducing medical errors, and enhancing communication between healthcare providers and patients.
'Workflow' är ett begrepp inom hälso- och sjukvården som refererar till den sekvens av steg och aktiviteter som utförs för att hantera en specifik process eller uppgift. Det kan omfatta allt från registrering av patienter, genomförande av undersökningar och behandlingar, till dokumentation och follow-up.
En medicinsk workflow kan inkludera:
1. Inmatning av patientinformation: Den första stegen i en workflow är ofta att samla in och dokumentera patientens personliga information, anamnes och symptom.
2. Diagnostisk utvärdering: Workflows kan innehålla steg som hjälper läkare att fastställa en diagnos, såsom att beställa laboratorietester, bildstudier eller andra undersökningar.
3. Behandlingsplanering: När en diagnos har ställts, kan workflows innehålla steg för att utforma och dokumentera en behandlingsplan som är specifik för patienten.
4. Behandling: Workflows kan omfatta steg som hjälper läkare att leverera vården, såsom att skriva recept, planera operationer eller andra procedurer.
5. Uppföljning och dokumentation: Efter behandlingen, kan workflows innehålla steg för att övervaka patientens tillfrisknande, justera behandlingsplanen om det behövs och dokumentera allt i patientens medicinska journal.
Workflows är viktiga för att garantera att vården levereras på ett säkert, effektivt och kvalitetsgaranterat sätt. Genom att standardisera processer och uppgifter kan workflows hjälpa till att minska risken för misstag, förbättra kommunikationen mellan vårdpersonal och patienter, och underlätta övervakning och utvärdering av vården.
Tertiär proteinstruktur refererar till den tresdimensionella formen och flexibiliteten hos ett proteinmolekyl som resulterar från de specifika interaktionerna mellan dess sekundära strukturelement, såsom alfa-helixar och beta-flakor. Den tertiära strukturen av ett protein bestäms av den sekvensordningen (primär struktur) av aminosyror som utgör proteinet och de krafter som verkar mellan dem, såsom vätebindningar, dispersion-krafter och elektrostatiska attraktioner. Den tertiära strukturen är viktig för ett proteins funktionella aktivitet och kan vara stabil eller dynamisk beroende på proteinets roll i cellen.
Protein Interaction Maps, också kända som Protein-Protein Interaction Networks (PPIN), är grafiska representationer av proteiner och deras interaktioner med varandra. De visar hur proteiner i en viss cellulär miljö eller organism binds till varandra och formar komplexa nätverk som reglerar cellulära processer som signaltransduktion, DNA-replikation, transkription och homeostas.
I en Protein Interaction Map representeras proteiner som noder eller hörn i grafen, medan interaktionerna mellan dem visas som kantar eller linjer som förbinder noderna. Varje interaktion kan vara reversibel eller irreversibel och kan ha en viss styrka eller affinitet.
Protein Interaction Maps kan användas för att studera cellulära processer på systemnivå, för att identifiera nyckelproteiner i dessa processer och för att förstå hur störningar i proteininteraktionerna kan leda till sjukdomar. De kan också användas för att utveckla nya terapeutiska strategier som riktar sig mot specifika proteiner eller deras interaktioner.
'Klassificering' er et begreb som oftest bruges inden for medicin og biomediske sammenhænge for at organisere, gruppere eller kategorisere sygdomme, tilstande, lægemidler eller andre sundhedsrelaterede variable baseret på fælles karakteristika, egenskaber eller adfærd. Denne proces gør det muligt at forstå og analysere sygdomme og behandlinger bedre, hvilket kan føre til bedre diagnoser, prognoser og terapier. Der findes mange forskellige klassifikationssystemer alt efter konteksten, men nogle af de mest kendte er ICD (International Classification of Diseases) for sygdomme og DSM (Diagnostic and Statistical Manual of Mental Disorders) for psykiske lidelser.
"Arts specificity" är inte en etablerad medicinsk term, men inom konstterapi och relaterade områden kan det referera till användandet av specifika konstnärliga uttrycksformer, tekniker eller processer som har visat sig vara särskilt effektiva för att uppnå vissa terapeutiska mål.
Exempelvis kan "arts specificity" innebära användandet av musikterapi med specifika tonarter, rytmer eller melodier för att påverka patientens humör och emotionella tillstånd. I dansterapi kan det innebära användandet av specifika rörelsemönster eller koreografier för att främja självkännedom, kommunikation och social interaktion.
Det är värt att notera att termen "arts specificity" inte är allmänt accepterad inom alla konstterapeutiska sammanhang och kan variera beroende på teoretisk och praktisk inriktning.
"Untranslated RNA" refererer til de dele af et RNA-molekyle, som ikke oversættes til protein. Disse områder findes i både messenger RNA (mRNA) og ribosomalt RNA (rRNA). I mRNA kan der være en utranslateret region foran (5'-ende) og/eller efter (3'-ende) den del af molekylet, som kodes for et protein. Disse regioner kaldes henholdsvis 5'-utranslated region (5'-UTR) og 3'-utranslated region (3'-UTR). De utranslaterede regioner indeholder ofte sekvenser, som regulerer stabiliteten af mRNA, transporten af mRNA ud af nucleus og effektiviteten af proteintranslationen.
 Mycobacterium tuberculosis - Wikipedia
Mycobacterium tuberculosis - Wikipedia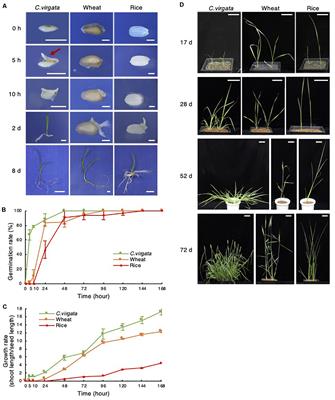










![Niche distribution and influence of environmental parameters in marine microbial communities: a systematic review [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2015/1008/1/fig-1-1x.jpg)