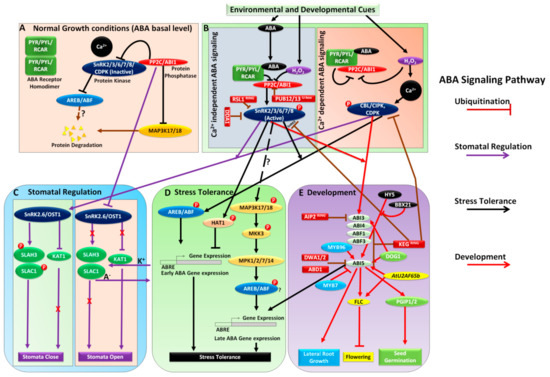
Transcriptional Activation
Transcription Factors
Transcription, Genetic
Promoter Regions, Genetic
DNA-Binding Proteins
Molecular Sequence Data
Base Sequence
Trans-Activators
Nuclear Proteins
Binding Sites
Gene Expression Regulation
Transfection
Protein Binding
Genes, Reporter
Amino Acid Sequence
Recombinant Fusion Proteins
Repressor Proteins
RNA, Messenger
Herpes Simplex Virus Protein Vmw65
Response Elements
DNA
HeLa Cells
Cell Nucleus
Histone Acetyltransferases
Luciferases
Saccharomyces cerevisiae Proteins
Mutation
Signal Transduction
Enhancer Elements, Genetic
Sp1 Transcription Factor
Chromatin
Saccharomyces cerevisiae
Tumor Cells, Cultured
Plasmids
p300-CBP Transcription Factors
CREB-Binding Protein
Protein Structure, Tertiary
Histones
Chloramphenicol O-Acetyltransferase
Gene Expression Regulation, Fungal
COS Cells
Regulatory Sequences, Nucleic Acid
3T3 Cells
TATA Box
Proto-Oncogene Proteins c-jun
Cells, Cultured
DNA Primers
Transcription Factor TFIID
Cloning, Molecular
Phosphorylation
Mutagenesis, Site-Directed
Zinc Fingers
Chromatin Immunoprecipitation
Cyclic AMP Response Element-Binding Protein
Homeodomain Proteins
Proto-Oncogene Proteins
NF-kappa B
Acetyltransferases
Gene Expression Regulation, Enzymologic
Transcription Factor AP-1
DNA Footprinting
TATA-Box Binding Protein
Electrophoretic Mobility Shift Assay
Tumor Suppressor Protein p53
Adenovirus E1A Proteins
Sequence Homology, Amino Acid
CCAAT-Enhancer-Binding Proteins
E1A-Associated p300 Protein
Proto-Oncogene Proteins c-fos
Nucleosomes
Gene Expression Regulation, Viral
Receptors, Retinoic Acid
Mutagenesis
Consensus Sequence
Oncogene Proteins v-myb
Gene Expression Regulation, Bacterial
Leucine Zippers
Two-Hybrid System Techniques
RNA Polymerase II
Helix-Loop-Helix Motifs
Receptors, Cytoplasmic and Nuclear
Blotting, Western
Oligodeoxyribonucleotides
Mediator Complex
Gene Expression Regulation, Neoplastic
Nuclear Receptor Coactivator 1
beta-Galactosidase
Precipitin Tests
Gene Expression Regulation, Developmental
Nuclear Receptor Coactivator 2
Immediate-Early Proteins
Dimerization
Cercopithecus aethiops
Drosophila Proteins
Genes, fos
Gene Expression
Carrier Proteins
Reverse Transcriptase Polymerase Chain Reaction
TATA-Binding Protein Associated Factors
Structure-Activity Relationship
Conserved Sequence
Basic-Leucine Zipper Transcription Factors
Histone Deacetylases
Receptors, Thyroid Hormone
Drosophila
Receptors, Glucocorticoid
Host Cell Factor C1
Cell Cycle Proteins
Up-Regulation
Proto-Oncogene Proteins c-myb
Transcription Factor TFIIB
Deoxyribonuclease I
CCAAT-Binding Factor
Basic Helix-Loop-Helix Leucine Zipper Transcription Factors
Cell Differentiation
Retinoid X Receptors
Genes, Regulator
Blotting, Northern
Upstream Stimulatory Factors
Glutathione Transferase
Early Growth Response Protein 1
Restriction Mapping
Models, Genetic
Methylation
Models, Biological
Sequence Homology, Nucleic Acid
Chromatin Assembly and Disassembly
Sequence Alignment
Proto-Oncogene Proteins c-myc
Gene Deletion
NFATC Transcription Factors
Mitogen-Activated Protein Kinases
DNA, Complementary
Point Mutation
Protein-Serine-Threonine Kinases
Receptors, Steroid
ets-Domain Protein Elk-1
Octamer Transcription Factor-1
Basic Helix-Loop-Helix Transcription Factors
Oligonucleotide Probes
Jurkat Cells
Yeasts
Activating Transcription Factor 2
Smad4 Protein
Proto-Oncogene Proteins c-ets
NIH 3T3 Cells
TCF Transcription Factors
Transcription Factors, TFII
beta Catenin
Serine
Active Transport, Cell Nucleus
NFI Transcription Factors
Transcription Factor RelA
Receptors, Estrogen
Fibroblasts
Amino Acid Motifs
Activating Transcription Factor 1
Serum Response Factor
Smad3 Protein
Macromolecular Substances
Phosphoproteins
Kruppel-Like Transcription Factors
Lymphoid Enhancer-Binding Factor 1
Cyclins
Estrogen Receptor alpha
Ligands
RNA, Small Interfering
Neoplasm Proteins
Genes, jun
Heat-Shock Proteins
Protein-Arginine N-Methyltransferases
Intracellular Signaling Peptides and Proteins
Retroviridae Proteins, Oncogenic
Polymerase Chain Reaction
HIV Long Terminal Repeat
Cell Cycle
Gene Products, tax
Transcription Factor TFIIA
Tetradecanoylphorbol Acetate
Enzyme Inhibitors
Transforming Growth Factor beta
Cyclin-Dependent Kinase Inhibitor p21
Escherichia coli
Cell Division
Sp3 Transcription Factor
Proteins
E2F1 Transcription Factor
Protein Isoforms
Tretinoin
Requirement of a novel gene, Xin, in cardiac morphogenesis. (1/18446)
A novel gene, Xin, from chick (cXin) and mouse (mXin) embryonic hearts, may be required for cardiac morphogenesis and looping. Both cloned cDNAs have a single open reading frame, encoding proteins with 2,562 and 1,677 amino acids for cXin and mXin, respectively. The derived amino acid sequences share 46% similarity. The overall domain structures of the predicted cXin and mXin proteins, including proline-rich regions, 16 amino acid repeats, DNA-binding domains, SH3-binding motifs and nuclear localization signals, are highly conserved. Northern blot analyses detect a single message of 8.9 and 5.8 kilo base (kb) from both cardiac and skeletal muscle of chick and mouse, respectively. In situ hybridization reveals that the cXin gene is specifically expressed in cardiac progenitor cells of chick embryos as early as stage 8, prior to heart tube formation. cXin continues to be expressed in the myocardium of developing hearts. By stage 15, cXin expression is also detected in the myotomes of developing somites. Immunofluorescence microscopy reveals that the mXin protein is colocalized with N-cadherin and connexin-43 in the intercalated discs of adult mouse hearts. Incubation of stage 6 chick embryos with cXin antisense oligonucleotides results in abnormal cardiac morphogenesis and an alteration of cardiac looping. The myocardium of the affected hearts becomes thickened and tends to form multiple invaginations into the heart cavity. This abnormal cellular process may account in part for the abnormal looping. cXin expression can be induced by bone morphogenetic protein (BMP) in explants of anterior medial mesoendoderm from stage 6 chick embryos, a tissue that is normally non-cardiogenic. This induction occurs following the BMP-mediated induction of two cardiac-restricted transcription factors, Nkx2.5 and MEF2C. Furthermore, either MEF2C or Nkx2.5 can transactivate a luciferase reporter driven by the mXin promoter in mouse fibroblasts. These results suggest that Xin may participate in a BMP-Nkx2.5-MEF2C pathway to control cardiac morphogenesis and looping. (+info)Cancer genetics: tumor suppressor meets oncogene. (2/18446)
The adenomatous polyposis coli (APC) tumor suppressor protein is inactivated by mutations in the majority of colorectal cancers. A recent study has revealed that alterations in the APC signaling pathway can result in the transcriptional activation of the c-MYC gene. (+info)Bcl-2 and Bcl-XL serve an anti-inflammatory function in endothelial cells through inhibition of NF-kappaB. (3/18446)
To maintain the integrity of the vascular barrier, endothelial cells (EC) are resistant to cell death. The molecular basis of this resistance may be explained by the function of antiapoptotic genes such as bcl family members. Overexpression of Bcl-2 or Bcl-XL protects EC from tumor necrosis factor (TNF)-mediated apoptosis. In addition, Bcl-2 or Bcl-XL inhibits activation of NF-kappaB and thus upregulation of proinflammatory genes. Bcl-2-mediated inhibition of NF-kappaB in EC occurs upstream of IkappaBalpha degradation without affecting p65-mediated transactivation. Overexpression of bcl genes in EC does not affect other transcription factors. Using deletion mutants of Bcl-2, the NF-kappaB inhibitory function of Bcl-2 was mapped to bcl homology domains BH2 and BH4, whereas all BH domains were required for the antiapoptotic function. These data suggest that Bcl-2 and Bcl-XL belong to a cytoprotective response that counteracts proapoptotic and proinflammatory insults and restores the physiological anti-inflammatory phenotype to the EC. By inhibiting NF-kappaB without sensitizing the cells (as with IkappaBalpha) to TNF-mediated apoptosis, Bcl-2 and Bcl-XL are prime candidates for genetic engineering of EC in pathological conditions where EC loss and unfettered activation are undesirable. (+info)B-MYB transactivates its own promoter through SP1-binding sites. (4/18446)
B-MYB is an ubiquitous protein required for mammalian cell growth. In this report we show that B-MYB transactivates its own promoter through a 120 bp segment proximal to the transcription start site. The B-MYB-responsive element does not contain myb-binding sites and gel-shift analysis shows that SP1, but not B-MYB, protein contained in SAOS2 cell extracts binds to the 120 bp B-myb promoter fragment. B-MYB-dependent transactivation is cooperatively increased in the presence of SP1, but not SP3 overexpression. When the SP1 elements of the B-myb promoter are transferred in front of a heterologous promoter, an increased response to B-MYB results. In contrast, c-MYB, the prototype member of the Myb family, is not able to activate the luciferase construct containing the SP1 elements. With the use of an SP1-GAL4 fusion protein, we have determined that the cooperative activation occurs through the domain A of SP1. These observations suggest that B-MYB functions as a coactivator of SP1, and that diverse combinations of myb and SP1 sites may dictate the responsiveness of myb-target genes to the various members of the myb family. (+info)Deletion of a region that is a candidate for the difference between the deletion forms of hereditary persistence of fetal hemoglobin and deltabeta-thalassemia affects beta- but not gamma-globin gene expression. (5/18446)
The analysis of a number of cases of beta-globin thalassemia and hereditary persistence of fetal hemoglobin (HPFH) due to large deletions in the beta-globin locus has led to the identification of several DNA elements that have been implicated in the switch from human fetal gamma- to adult beta-globin gene expression. We have tested this hypothesis for an element that covers the minimal distance between the thalassemia and HPFH deletions and is thought to be responsible for the difference between a deletion HPFH and deltabeta-thalassemia, located 5' of the delta-globin gene. This element has been deleted from a yeast artificial chromosome (YAC) containing the complete human beta-globin locus. Analysis of this modified YAC in transgenic mice shows that early embryonic expression is unaffected, but in the fetal liver it is subject to position effects. In addition, the efficiency of transcription of the beta-globin gene is decreased, but the developmental silencing of the gamma-globin genes is unaffected by the deletion. These results show that the deleted element is involved in the activation of the beta-globin gene perhaps through the loss of a structural function required for gene activation by long-range interactions. (+info)Assembly requirements of PU.1-Pip (IRF-4) activator complexes: inhibiting function in vivo using fused dimers. (6/18446)
Gene expression in higher eukaryotes appears to be regulated by specific combinations of transcription factors binding to regulatory sequences. The Ets factor PU.1 and the IRF protein Pip (IRF-4) represent a pair of interacting transcription factors implicated in regulating B cell-specific gene expression. Pip is recruited to its binding site on DNA by phosphorylated PU.1. PU.1-Pip interaction is shown to be template directed and involves two distinct protein-protein interaction surfaces: (i) the ets and IRF DNA-binding domains; and (ii) the phosphorylated PEST region of PU.1 and a lysine-requiring putative alpha-helix in Pip. Thus, a coordinated set of protein-protein and protein-DNA contacts are essential for PU.1-Pip ternary complex assembly. To analyze the function of these factors in vivo, we engineered chimeric repressors containing the ets and IRF DNA-binding domains connected by a flexible POU domain linker. When stably expressed, the wild-type fused dimer strongly repressed the expression of a rearranged immunoglobulin lambda gene, thereby establishing the functional importance of PU.1-Pip complexes in B cell gene expression. Comparative analysis of the wild-type dimer with a series of mutant dimers distinguished a gene regulated by PU.1 and Pip from one regulated by PU.1 alone. This strategy should prove generally useful in analyzing the function of interacting transcription factors in vivo, and for identifying novel genes regulated by such complexes. (+info)The amino-terminal C/H1 domain of CREB binding protein mediates zta transcriptional activation of latent Epstein-Barr virus. (7/18446)
Latent Epstein-Barr virus (EBV) is maintained as a nucleosome-covered episome that can be transcriptionally activated by overexpression of the viral immediate-early protein, Zta. We show here that reactivation of latent EBV by Zta can be significantly enhanced by coexpression of the cellular coactivators CREB binding protein (CBP) and p300. A stable complex containing both Zta and CBP could be isolated from lytically stimulated, but not latently infected RAJI nuclear extracts. Zta-mediated viral reactivation and transcriptional activation were both significantly inhibited by coexpression of the E1A 12S protein but not by an N-terminal deletion mutation of E1A (E1ADelta2-36), which fails to bind CBP. Zta bound directly to two related cysteine- and histidine-rich domains of CBP, referred to as C/H1 and C/H3. These domains both interacted specifically with the transcriptional activation domain of Zta in an electrophoretic mobility shift assay. Interestingly, we found that the C/H3 domain was a potent dominant negative inhibitor of Zta transcriptional activation function. In contrast, an amino-terminal fragment containing the C/H1 domain was sufficient for coactivation of Zta transcription and viral reactivation function. Thus, CBP can stimulate the transcription of latent EBV in a histone acetyltransferase-independent manner mediated by the CBP amino-terminal C/H1-containing domain. We propose that CBP may regulate aspects of EBV latency and reactivation by integrating cellular signals mediated by competitive interactions between C/H1, C/H3, and the Zta activation domain. (+info)Smad3-Smad4 and AP-1 complexes synergize in transcriptional activation of the c-Jun promoter by transforming growth factor beta. (8/18446)
Transcriptional regulation by transforming growth factor beta (TGF-beta) is a complex process which is likely to involve cross talk between different DNA responsive elements and transcription factors to achieve maximal promoter activation and specificity. Here, we describe a concurrent requirement for two discrete responsive elements in the regulation of the c-Jun promoter, one a binding site for a Smad3-Smad4 complex and the other an AP-1 binding site. The two elements are located 120 bp apart in the proximal c-Jun promoter, and each was able to independently bind its corresponding transcription factor complex. The effects of independently mutating each of these elements were nonadditive; disruption of either sequence resulted in complete or severe reductions in TGF-beta responsiveness. This simultaneous requirement for two distinct and independent DNA binding elements suggests that Smad and AP-1 complexes function synergistically to mediate TGF-beta-induced transcriptional activation of the c-Jun promoter. (+info)Transcriptional activation is the process by which a cell increases the rate of transcription of specific genes from DNA to RNA. This process is tightly regulated and plays a crucial role in various biological processes, including development, differentiation, and response to environmental stimuli.
Transcriptional activation occurs when transcription factors (proteins that bind to specific DNA sequences) interact with the promoter region of a gene and recruit co-activator proteins. These co-activators help to remodel the chromatin structure around the gene, making it more accessible for the transcription machinery to bind and initiate transcription.
Transcriptional activation can be regulated at multiple levels, including the availability and activity of transcription factors, the modification of histone proteins, and the recruitment of co-activators or co-repressors. Dysregulation of transcriptional activation has been implicated in various diseases, including cancer and genetic disorders.
Transcription factors are proteins that play a crucial role in regulating gene expression by controlling the transcription of DNA to messenger RNA (mRNA). They function by binding to specific DNA sequences, known as response elements, located in the promoter region or enhancer regions of target genes. This binding can either activate or repress the initiation of transcription, depending on the properties and interactions of the particular transcription factor. Transcription factors often act as part of a complex network of regulatory proteins that determine the precise spatiotemporal patterns of gene expression during development, differentiation, and homeostasis in an organism.
Genetic transcription is the process by which the information in a strand of DNA is used to create a complementary RNA molecule. This process is the first step in gene expression, where the genetic code in DNA is converted into a form that can be used to produce proteins or functional RNAs.
During transcription, an enzyme called RNA polymerase binds to the DNA template strand and reads the sequence of nucleotide bases. As it moves along the template, it adds complementary RNA nucleotides to the growing RNA chain, creating a single-stranded RNA molecule that is complementary to the DNA template strand. Once transcription is complete, the RNA molecule may undergo further processing before it can be translated into protein or perform its functional role in the cell.
Transcription can be either "constitutive" or "regulated." Constitutive transcription occurs at a relatively constant rate and produces essential proteins that are required for basic cellular functions. Regulated transcription, on the other hand, is subject to control by various intracellular and extracellular signals, allowing cells to respond to changing environmental conditions or developmental cues.
Promoter regions in genetics refer to specific DNA sequences located near the transcription start site of a gene. They serve as binding sites for RNA polymerase and various transcription factors that regulate the initiation of gene transcription. These regulatory elements help control the rate of transcription and, therefore, the level of gene expression. Promoter regions can be composed of different types of sequences, such as the TATA box and CAAT box, and their organization and composition can vary between different genes and species.
DNA-binding proteins are a type of protein that have the ability to bind to DNA (deoxyribonucleic acid), the genetic material of organisms. These proteins play crucial roles in various biological processes, such as regulation of gene expression, DNA replication, repair and recombination.
The binding of DNA-binding proteins to specific DNA sequences is mediated by non-covalent interactions, including electrostatic, hydrogen bonding, and van der Waals forces. The specificity of binding is determined by the recognition of particular nucleotide sequences or structural features of the DNA molecule.
DNA-binding proteins can be classified into several categories based on their structure and function, such as transcription factors, histones, and restriction enzymes. Transcription factors are a major class of DNA-binding proteins that regulate gene expression by binding to specific DNA sequences in the promoter region of genes and recruiting other proteins to modulate transcription. Histones are DNA-binding proteins that package DNA into nucleosomes, the basic unit of chromatin structure. Restriction enzymes are DNA-binding proteins that recognize and cleave specific DNA sequences, and are widely used in molecular biology research and biotechnology applications.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
Trans-activators are proteins that increase the transcriptional activity of a gene or a set of genes. They do this by binding to specific DNA sequences and interacting with the transcription machinery, thereby enhancing the recruitment and assembly of the complexes needed for transcription. In some cases, trans-activators can also modulate the chromatin structure to make the template more accessible to the transcription machinery.
In the context of HIV (Human Immunodeficiency Virus) infection, the term "trans-activator" is often used specifically to refer to the Tat protein. The Tat protein is a viral regulatory protein that plays a critical role in the replication of HIV by activating the transcription of the viral genome. It does this by binding to a specific RNA structure called the Trans-Activation Response Element (TAR) located at the 5' end of all nascent HIV transcripts, and recruiting cellular cofactors that enhance the processivity and efficiency of RNA polymerase II, leading to increased viral gene expression.
Nuclear proteins are a category of proteins that are primarily found in the nucleus of a eukaryotic cell. They play crucial roles in various nuclear functions, such as DNA replication, transcription, repair, and RNA processing. This group includes structural proteins like lamins, which form the nuclear lamina, and regulatory proteins, such as histones and transcription factors, that are involved in gene expression. Nuclear localization signals (NLS) often help target these proteins to the nucleus by interacting with importin proteins during active transport across the nuclear membrane.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
'Gene expression regulation' refers to the processes that control whether, when, and where a particular gene is expressed, meaning the production of a specific protein or functional RNA encoded by that gene. This complex mechanism can be influenced by various factors such as transcription factors, chromatin remodeling, DNA methylation, non-coding RNAs, and post-transcriptional modifications, among others. Proper regulation of gene expression is crucial for normal cellular function, development, and maintaining homeostasis in living organisms. Dysregulation of gene expression can lead to various diseases, including cancer and genetic disorders.
A cell line is a culture of cells that are grown in a laboratory for use in research. These cells are usually taken from a single cell or group of cells, and they are able to divide and grow continuously in the lab. Cell lines can come from many different sources, including animals, plants, and humans. They are often used in scientific research to study cellular processes, disease mechanisms, and to test new drugs or treatments. Some common types of human cell lines include HeLa cells (which come from a cancer patient named Henrietta Lacks), HEK293 cells (which come from embryonic kidney cells), and HUVEC cells (which come from umbilical vein endothelial cells). It is important to note that cell lines are not the same as primary cells, which are cells that are taken directly from a living organism and have not been grown in the lab.
Transfection is a term used in molecular biology that refers to the process of deliberately introducing foreign genetic material (DNA, RNA or artificial gene constructs) into cells. This is typically done using chemical or physical methods, such as lipofection or electroporation. Transfection is widely used in research and medical settings for various purposes, including studying gene function, producing proteins, developing gene therapies, and creating genetically modified organisms. It's important to note that transfection is different from transduction, which is the process of introducing genetic material into cells using viruses as vectors.
Protein binding, in the context of medical and biological sciences, refers to the interaction between a protein and another molecule (known as the ligand) that results in a stable complex. This process is often reversible and can be influenced by various factors such as pH, temperature, and concentration of the involved molecules.
In clinical chemistry, protein binding is particularly important when it comes to drugs, as many of them bind to proteins (especially albumin) in the bloodstream. The degree of protein binding can affect a drug's distribution, metabolism, and excretion, which in turn influence its therapeutic effectiveness and potential side effects.
Protein-bound drugs may be less available for interaction with their target tissues, as only the unbound or "free" fraction of the drug is active. Therefore, understanding protein binding can help optimize dosing regimens and minimize adverse reactions.
A "reporter gene" is a type of gene that is linked to a gene of interest in order to make the expression or activity of that gene detectable. The reporter gene encodes for a protein that can be easily measured and serves as an indicator of the presence and activity of the gene of interest. Commonly used reporter genes include those that encode for fluorescent proteins, enzymes that catalyze colorimetric reactions, or proteins that bind to specific molecules.
In the context of genetics and genomics research, a reporter gene is often used in studies involving gene expression, regulation, and function. By introducing the reporter gene into an organism or cell, researchers can monitor the activity of the gene of interest in real-time or after various experimental treatments. The information obtained from these studies can help elucidate the role of specific genes in biological processes and diseases, providing valuable insights for basic research and therapeutic development.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
Recombinant fusion proteins are artificially created biomolecules that combine the functional domains or properties of two or more different proteins into a single protein entity. They are generated through recombinant DNA technology, where the genes encoding the desired protein domains are linked together and expressed as a single, chimeric gene in a host organism, such as bacteria, yeast, or mammalian cells.
The resulting fusion protein retains the functional properties of its individual constituent proteins, allowing for novel applications in research, diagnostics, and therapeutics. For instance, recombinant fusion proteins can be designed to enhance protein stability, solubility, or immunogenicity, making them valuable tools for studying protein-protein interactions, developing targeted therapies, or generating vaccines against infectious diseases or cancer.
Examples of recombinant fusion proteins include:
1. Etaglunatide (ABT-523): A soluble Fc fusion protein that combines the heavy chain fragment crystallizable region (Fc) of an immunoglobulin with the extracellular domain of the human interleukin-6 receptor (IL-6R). This fusion protein functions as a decoy receptor, neutralizing IL-6 and its downstream signaling pathways in rheumatoid arthritis.
2. Etanercept (Enbrel): A soluble TNF receptor p75 Fc fusion protein that binds to tumor necrosis factor-alpha (TNF-α) and inhibits its proinflammatory activity, making it a valuable therapeutic option for treating autoimmune diseases like rheumatoid arthritis, ankylosing spondylitis, and psoriasis.
3. Abatacept (Orencia): A fusion protein consisting of the extracellular domain of cytotoxic T-lymphocyte antigen 4 (CTLA-4) linked to the Fc region of an immunoglobulin, which downregulates T-cell activation and proliferation in autoimmune diseases like rheumatoid arthritis.
4. Belimumab (Benlysta): A monoclonal antibody that targets B-lymphocyte stimulator (BLyS) protein, preventing its interaction with the B-cell surface receptor and inhibiting B-cell activation in systemic lupus erythematosus (SLE).
5. Romiplostim (Nplate): A fusion protein consisting of a thrombopoietin receptor agonist peptide linked to an immunoglobulin Fc region, which stimulates platelet production in patients with chronic immune thrombocytopenia (ITP).
6. Darbepoetin alfa (Aranesp): A hyperglycosylated erythropoiesis-stimulating protein that functions as a longer-acting form of recombinant human erythropoietin, used to treat anemia in patients with chronic kidney disease or cancer.
7. Palivizumab (Synagis): A monoclonal antibody directed against the F protein of respiratory syncytial virus (RSV), which prevents RSV infection and is administered prophylactically to high-risk infants during the RSV season.
8. Ranibizumab (Lucentis): A recombinant humanized monoclonal antibody fragment that binds and inhibits vascular endothelial growth factor A (VEGF-A), used in the treatment of age-related macular degeneration, diabetic retinopathy, and other ocular disorders.
9. Cetuximab (Erbitux): A chimeric monoclonal antibody that binds to epidermal growth factor receptor (EGFR), used in the treatment of colorectal cancer and head and neck squamous cell carcinoma.
10. Adalimumab (Humira): A fully humanized monoclonal antibody that targets tumor necrosis factor-alpha (TNF-α), used in the treatment of various inflammatory diseases, including rheumatoid arthritis, psoriasis, and Crohn's disease.
11. Bevacizumab (Avastin): A recombinant humanized monoclonal antibody that binds to VEGF-A, used in the treatment of various cancers, including colorectal, lung, breast, and kidney cancer.
12. Trastuzumab (Herceptin): A humanized monoclonal antibody that targets HER2/neu receptor, used in the treatment of breast cancer.
13. Rituximab (Rituxan): A chimeric monoclonal antibody that binds to CD20 antigen on B cells, used in the treatment of non-Hodgkin's lymphoma and rheumatoid arthritis.
14. Palivizumab (Synagis): A humanized monoclonal antibody that binds to the F protein of respiratory syncytial virus, used in the prevention of respiratory syncytial virus infection in high-risk infants.
15. Infliximab (Remicade): A chimeric monoclonal antibody that targets TNF-α, used in the treatment of various inflammatory diseases, including Crohn's disease, ulcerative colitis, rheumatoid arthritis, and ankylosing spondylitis.
16. Natalizumab (Tysabri): A humanized monoclonal antibody that binds to α4β1 integrin, used in the treatment of multiple sclerosis and Crohn's disease.
17. Adalimumab (Humira): A fully human monoclonal antibody that targets TNF-α, used in the treatment of various inflammatory diseases, including rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, Crohn's disease, and ulcerative colitis.
18. Golimumab (Simponi): A fully human monoclonal antibody that targets TNF-α, used in the treatment of rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, and ulcerative colitis.
19. Certolizumab pegol (Cimzia): A PEGylated Fab' fragment of a humanized monoclonal antibody that targets TNF-α, used in the treatment of rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, and Crohn's disease.
20. Ustekinumab (Stelara): A fully human monoclonal antibody that targets IL-12 and IL-23, used in the treatment of psoriasis, psoriatic arthritis, and Crohn's disease.
21. Secukinumab (Cosentyx): A fully human monoclonal antibody that targets IL-17A, used in the treatment of psoriasis, psoriatic arthritis, and ankylosing spondylitis.
22. Ixekizumab (Taltz): A fully human monoclonal antibody that targets IL-17A, used in the treatment of psoriasis and psoriatic arthritis.
23. Brodalumab (Siliq): A fully human monoclonal antibody that targets IL-17 receptor A, used in the treatment of psoriasis.
24. Sarilumab (Kevzara): A fully human monoclonal antibody that targets the IL-6 receptor, used in the treatment of rheumatoid arthritis.
25. Tocilizumab (Actemra): A humanized monoclonal antibody that targets the IL-6 receptor, used in the treatment of rheumatoid arthritis, systemic juvenile idiopathic arthritis, polyarticular juvenile idiopathic arthritis, giant cell arteritis, and chimeric antigen receptor T-cell-induced cytokine release syndrome.
26. Siltuximab (Sylvant): A chimeric monoclonal antibody that targets IL-6, used in the treatment of multicentric Castleman disease.
27. Satralizumab (Enspryng): A humanized monoclonal antibody that targets IL-6 receptor alpha, used in the treatment of neuromyelitis optica spectrum disorder.
28. Sirukumab (Plivensia): A human monoclonal antibody that targets IL-6, used in the treatment
Repressor proteins are a type of regulatory protein in molecular biology that suppress the transcription of specific genes into messenger RNA (mRNA) by binding to DNA. They function as part of gene regulation processes, often working in conjunction with an operator region and a promoter region within the DNA molecule. Repressor proteins can be activated or deactivated by various signals, allowing for precise control over gene expression in response to changing cellular conditions.
There are two main types of repressor proteins:
1. DNA-binding repressors: These directly bind to specific DNA sequences (operator regions) near the target gene and prevent RNA polymerase from transcribing the gene into mRNA.
2. Allosteric repressors: These bind to effector molecules, which then cause a conformational change in the repressor protein, enabling it to bind to DNA and inhibit transcription.
Repressor proteins play crucial roles in various biological processes, such as development, metabolism, and stress response, by controlling gene expression patterns in cells.
Messenger RNA (mRNA) is a type of RNA (ribonucleic acid) that carries genetic information copied from DNA in the form of a series of three-base code "words," each of which specifies a particular amino acid. This information is used by the cell's machinery to construct proteins, a process known as translation. After being transcribed from DNA, mRNA travels out of the nucleus to the ribosomes in the cytoplasm where protein synthesis occurs. Once the protein has been synthesized, the mRNA may be degraded and recycled. Post-transcriptional modifications can also occur to mRNA, such as alternative splicing and addition of a 5' cap and a poly(A) tail, which can affect its stability, localization, and translation efficiency.
Herpes Simplex Virus Protein Vmw65, also known as Infected Cell Protein 0 (ICP0), is a crucial regulatory protein of the Herpes Simplex Virus (HSV). It is a viral early protein, which means it becomes active during the initial stages of viral replication.
Vmw65 plays a significant role in the virus's ability to evade the host's immune response and promote viral replication. It functions as a transcriptional regulator, affecting the expression of various genes involved in the host's antiviral defense mechanisms. Vmw65 can induce the degradation of certain cellular proteins that inhibit viral replication and also enhance viral gene expression by promoting viral DNA synthesis.
The protein's name, Vmw65, is derived from its molecular weight (65 kilodaltons) and its initial discovery as a virus-induced membrane protein. However, it's now more commonly referred to as ICP0 due to its role as an immediate-early viral gene product that functions as a transcriptional regulatory protein.
"Response elements" is a term used in molecular biology, particularly in the study of gene regulation. Response elements are specific DNA sequences that can bind to transcription factors, which are proteins that regulate gene expression. When a transcription factor binds to a response element, it can either activate or repress the transcription of the nearby gene.
Response elements are often found in the promoter region of genes and are typically short, conserved sequences that can be recognized by specific transcription factors. The binding of a transcription factor to a response element can lead to changes in chromatin structure, recruitment of co-activators or co-repressors, and ultimately, the regulation of gene expression.
Response elements are important for many biological processes, including development, differentiation, and response to environmental stimuli such as hormones, growth factors, and stress. The specificity of transcription factor binding to response elements allows for precise control of gene expression in response to changing conditions within the cell or organism.
Deoxyribonucleic acid (DNA) is the genetic material present in the cells of organisms where it is responsible for the storage and transmission of hereditary information. DNA is a long molecule that consists of two strands coiled together to form a double helix. Each strand is made up of a series of four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - that are linked together by phosphate and sugar groups. The sequence of these bases along the length of the molecule encodes genetic information, with A always pairing with T and C always pairing with G. This base-pairing allows for the replication and transcription of DNA, which are essential processes in the functioning and reproduction of all living organisms.
HeLa cells are a type of immortalized cell line used in scientific research. They are derived from a cancer that developed in the cervical tissue of Henrietta Lacks, an African-American woman, in 1951. After her death, cells taken from her tumor were found to be capable of continuous division and growth in a laboratory setting, making them an invaluable resource for medical research.
HeLa cells have been used in a wide range of scientific studies, including research on cancer, viruses, genetics, and drug development. They were the first human cell line to be successfully cloned and are able to grow rapidly in culture, doubling their population every 20-24 hours. This has made them an essential tool for many areas of biomedical research.
It is important to note that while HeLa cells have been instrumental in numerous scientific breakthroughs, the story of their origin raises ethical questions about informed consent and the use of human tissue in research.
The cell nucleus is a membrane-bound organelle found in the eukaryotic cells (cells with a true nucleus). It contains most of the cell's genetic material, organized as DNA molecules in complex with proteins, RNA molecules, and histones to form chromosomes.
The primary function of the cell nucleus is to regulate and control the activities of the cell, including growth, metabolism, protein synthesis, and reproduction. It also plays a crucial role in the process of mitosis (cell division) by separating and protecting the genetic material during this process. The nuclear membrane, or nuclear envelope, surrounding the nucleus is composed of two lipid bilayers with numerous pores that allow for the selective transport of molecules between the nucleoplasm (nucleus interior) and the cytoplasm (cell exterior).
The cell nucleus is a vital structure in eukaryotic cells, and its dysfunction can lead to various diseases, including cancer and genetic disorders.
Histone Acetyltransferases (HATs) are a group of enzymes that play a crucial role in the regulation of gene expression. They function by adding acetyl groups to specific lysine residues on the N-terminal tails of histone proteins, which make up the structural core of nucleosomes - the fundamental units of chromatin.
The process of histone acetylation neutralizes the positive charge of lysine residues, reducing their attraction to the negatively charged DNA backbone. This leads to a more open and relaxed chromatin structure, facilitating the access of transcription factors and other regulatory proteins to the DNA, thereby promoting gene transcription.
HATs are classified into two main categories: type A HATs, which are primarily found in the nucleus and associated with transcriptional activation, and type B HATs, which are located in the cytoplasm and participate in chromatin assembly during DNA replication and repair. Dysregulation of HAT activity has been implicated in various human diseases, including cancer, neurodevelopmental disorders, and cardiovascular diseases.
Luciferases are a class of enzymes that catalyze the oxidation of their substrates, leading to the emission of light. This bioluminescent process is often associated with certain species of bacteria, insects, and fish. The term "luciferase" comes from the Latin word "lucifer," which means "light bearer."
The most well-known example of luciferase is probably that found in fireflies, where the enzyme reacts with a compound called luciferin to produce light. This reaction requires the presence of oxygen and ATP (adenosine triphosphate), which provides the energy needed for the reaction to occur.
Luciferases have important applications in scientific research, particularly in the development of sensitive assays for detecting gene expression and protein-protein interactions. By labeling a protein or gene of interest with luciferase, researchers can measure its activity by detecting the light emitted during the enzymatic reaction. This allows for highly sensitive and specific measurements, making luciferases valuable tools in molecular biology and biochemistry.
Saccharomyces cerevisiae proteins are the proteins that are produced by the budding yeast, Saccharomyces cerevisiae. This organism is a single-celled eukaryote that has been widely used as a model organism in scientific research for many years due to its relatively simple genetic makeup and its similarity to higher eukaryotic cells.
The genome of Saccharomyces cerevisiae has been fully sequenced, and it is estimated to contain approximately 6,000 genes that encode proteins. These proteins play a wide variety of roles in the cell, including catalyzing metabolic reactions, regulating gene expression, maintaining the structure of the cell, and responding to environmental stimuli.
Many Saccharomyces cerevisiae proteins have human homologs and are involved in similar biological processes, making this organism a valuable tool for studying human disease. For example, many of the proteins involved in DNA replication, repair, and recombination in yeast have human counterparts that are associated with cancer and other diseases. By studying these proteins in yeast, researchers can gain insights into their function and regulation in humans, which may lead to new treatments for disease.
A mutation is a permanent change in the DNA sequence of an organism's genome. Mutations can occur spontaneously or be caused by environmental factors such as exposure to radiation, chemicals, or viruses. They may have various effects on the organism, ranging from benign to harmful, depending on where they occur and whether they alter the function of essential proteins. In some cases, mutations can increase an individual's susceptibility to certain diseases or disorders, while in others, they may confer a survival advantage. Mutations are the driving force behind evolution, as they introduce new genetic variability into populations, which can then be acted upon by natural selection.
Signal transduction is the process by which a cell converts an extracellular signal, such as a hormone or neurotransmitter, into an intracellular response. This involves a series of molecular events that transmit the signal from the cell surface to the interior of the cell, ultimately resulting in changes in gene expression, protein activity, or metabolism.
The process typically begins with the binding of the extracellular signal to a receptor located on the cell membrane. This binding event activates the receptor, which then triggers a cascade of intracellular signaling molecules, such as second messengers, protein kinases, and ion channels. These molecules amplify and propagate the signal, ultimately leading to the activation or inhibition of specific cellular responses.
Signal transduction pathways are highly regulated and can be modulated by various factors, including other signaling molecules, post-translational modifications, and feedback mechanisms. Dysregulation of these pathways has been implicated in a variety of diseases, including cancer, diabetes, and neurological disorders.
Genetic enhancer elements are DNA sequences that increase the transcription of specific genes. They work by binding to regulatory proteins called transcription factors, which in turn recruit RNA polymerase II, the enzyme responsible for transcribing DNA into messenger RNA (mRNA). This results in the activation of gene transcription and increased production of the protein encoded by that gene.
Enhancer elements can be located upstream, downstream, or even within introns of the genes they regulate, and they can act over long distances along the DNA molecule. They are an important mechanism for controlling gene expression in a tissue-specific and developmental stage-specific manner, allowing for the precise regulation of gene activity during embryonic development and throughout adult life.
It's worth noting that genetic enhancer elements are often referred to simply as "enhancers," and they are distinct from other types of regulatory DNA sequences such as promoters, silencers, and insulators.
Sp1 (Specificity Protein 1) transcription factor is a protein that binds to specific DNA sequences, known as GC boxes, in the promoter regions of many genes. It plays a crucial role in the regulation of gene expression by controlling the initiation of transcription. Sp1 recognizes and binds to the consensus sequence of GGGCGG upstream of the transcription start site, thereby recruiting other co-activators or co-repressors to modulate the rate of transcription. Sp1 is involved in various cellular processes, including cell growth, differentiation, and apoptosis, and its dysregulation has been implicated in several human diseases, such as cancer.
Fungal proteins are a type of protein that is specifically produced and present in fungi, which are a group of eukaryotic organisms that include microorganisms such as yeasts and molds. These proteins play various roles in the growth, development, and survival of fungi. They can be involved in the structure and function of fungal cells, metabolism, pathogenesis, and other cellular processes. Some fungal proteins can also have important implications for human health, both in terms of their potential use as therapeutic targets and as allergens or toxins that can cause disease.
Fungal proteins can be classified into different categories based on their functions, such as enzymes, structural proteins, signaling proteins, and toxins. Enzymes are proteins that catalyze chemical reactions in fungal cells, while structural proteins provide support and protection for the cell. Signaling proteins are involved in communication between cells and regulation of various cellular processes, and toxins are proteins that can cause harm to other organisms, including humans.
Understanding the structure and function of fungal proteins is important for developing new treatments for fungal infections, as well as for understanding the basic biology of fungi. Research on fungal proteins has led to the development of several antifungal drugs that target specific fungal enzymes or other proteins, providing effective treatment options for a range of fungal diseases. Additionally, further study of fungal proteins may reveal new targets for drug development and help improve our ability to diagnose and treat fungal infections.
Chromatin is the complex of DNA, RNA, and proteins that make up the chromosomes in the nucleus of a cell. It is responsible for packaging the long DNA molecules into a more compact form that fits within the nucleus. Chromatin is made up of repeating units called nucleosomes, which consist of a histone protein octamer wrapped tightly by DNA. The structure of chromatin can be altered through chemical modifications to the histone proteins and DNA, which can influence gene expression and other cellular processes.
"Saccharomyces cerevisiae" is not typically considered a medical term, but it is a scientific name used in the field of microbiology. It refers to a species of yeast that is commonly used in various industrial processes, such as baking and brewing. It's also widely used in scientific research due to its genetic tractability and eukaryotic cellular organization.
However, it does have some relevance to medical fields like medicine and nutrition. For example, certain strains of S. cerevisiae are used as probiotics, which can provide health benefits when consumed. They may help support gut health, enhance the immune system, and even assist in the digestion of certain nutrients.
In summary, "Saccharomyces cerevisiae" is a species of yeast with various industrial and potential medical applications.
'Tumor cells, cultured' refers to the process of removing cancerous cells from a tumor and growing them in controlled laboratory conditions. This is typically done by isolating the tumor cells from a patient's tissue sample, then placing them in a nutrient-rich environment that promotes their growth and multiplication.
The resulting cultured tumor cells can be used for various research purposes, including the study of cancer biology, drug development, and toxicity testing. They provide a valuable tool for researchers to better understand the behavior and characteristics of cancer cells outside of the human body, which can lead to the development of more effective cancer treatments.
It is important to note that cultured tumor cells may not always behave exactly the same way as they do in the human body, so findings from cell culture studies must be validated through further research, such as animal models or clinical trials.
A plasmid is a small, circular, double-stranded DNA molecule that is separate from the chromosomal DNA of a bacterium or other organism. Plasmids are typically not essential for the survival of the organism, but they can confer beneficial traits such as antibiotic resistance or the ability to degrade certain types of pollutants.
Plasmids are capable of replicating independently of the chromosomal DNA and can be transferred between bacteria through a process called conjugation. They often contain genes that provide resistance to antibiotics, heavy metals, and other environmental stressors. Plasmids have also been engineered for use in molecular biology as cloning vectors, allowing scientists to replicate and manipulate specific DNA sequences.
Plasmids are important tools in genetic engineering and biotechnology because they can be easily manipulated and transferred between organisms. They have been used to produce vaccines, diagnostic tests, and genetically modified organisms (GMOs) for various applications, including agriculture, medicine, and industry.
P300 and CREB binding protein (CBP) are both transcriptional coactivators that play crucial roles in regulating gene expression. They function by binding to various transcription factors and modifying the chromatin structure to allow for the recruitment of the transcriptional machinery. The P300-CBP complex is essential for many cellular processes, including development, differentiation, and oncogenesis.
P300-CBP transcription factors refer to a family of proteins that include both p300 and CBP, as well as their various isoforms and splice variants. These proteins share structural and functional similarities and are often referred to together due to their overlapping roles in transcriptional regulation.
The P300-CBP complex plays a key role in the P300-CBP-mediated signal integration, which allows for the coordinated regulation of gene expression in response to various signals and stimuli. Dysregulation of P300-CBP transcription factors has been implicated in several diseases, including cancer, neurodevelopmental disorders, and inflammatory diseases.
In summary, P300-CBP transcription factors are a family of proteins that play crucial roles in regulating gene expression through their ability to bind to various transcription factors and modify the chromatin structure. Dysregulation of these proteins has been implicated in several diseases, making them important targets for therapeutic intervention.
CREB-binding protein (CBP) is a transcription coactivator that plays a crucial role in regulating gene expression. It is called a "coactivator" because it works together with other proteins, such as transcription factors, to enhance the process of gene transcription. CBP is so named because it can bind to the cAMP response element-binding (CREB) protein, which is a transcription factor that regulates the expression of various genes in response to different signals within cells.
CBP has intrinsic histone acetyltransferase (HAT) activity, which means it can add acetyl groups to histone proteins around which DNA is wound. This modification loosens the chromatin structure, making it more accessible for transcription factors and other proteins involved in gene expression. As a result, CBP acts as a global regulator of gene expression, influencing various cellular processes such as development, differentiation, and homeostasis.
Mutations in the CBP gene have been associated with several human diseases, including Rubinstein-Taybi syndrome, a rare genetic disorder characterized by growth retardation, mental deficiency, and distinct facial features. Additionally, CBP has been implicated in cancer, as its dysregulation can lead to uncontrolled cell growth and malignant transformation.
Tertiary protein structure refers to the three-dimensional arrangement of all the elements (polypeptide chains) of a single protein molecule. It is the highest level of structural organization and results from interactions between various side chains (R groups) of the amino acids that make up the protein. These interactions, which include hydrogen bonds, ionic bonds, van der Waals forces, and disulfide bridges, give the protein its unique shape and stability, which in turn determines its function. The tertiary structure of a protein can be stabilized by various factors such as temperature, pH, and the presence of certain ions. Any changes in these factors can lead to denaturation, where the protein loses its tertiary structure and thus its function.
Histones are highly alkaline proteins found in the chromatin of eukaryotic cells. They are rich in basic amino acid residues, such as arginine and lysine, which give them their positive charge. Histones play a crucial role in packaging DNA into a more compact structure within the nucleus by forming a complex with it called a nucleosome. Each nucleosome contains about 146 base pairs of DNA wrapped around an octamer of eight histone proteins (two each of H2A, H2B, H3, and H4). The N-terminal tails of these histones are subject to various post-translational modifications, such as methylation, acetylation, and phosphorylation, which can influence chromatin structure and gene expression. Histone variants also exist, which can contribute to the regulation of specific genes and other nuclear processes.
Chloramphenicol O-acetyltransferase is an enzyme that is encoded by the cat gene in certain bacteria. This enzyme is responsible for adding acetyl groups to chloramphenicol, which is an antibiotic that inhibits bacterial protein synthesis. When chloramphenicol is acetylated by this enzyme, it becomes inactivated and can no longer bind to the ribosome and prevent bacterial protein synthesis.
Bacteria that are resistant to chloramphenicol often have a plasmid-borne cat gene, which encodes for the production of Chloramphenicol O-acetyltransferase. This enzyme allows the bacteria to survive in the presence of chloramphenicol by rendering it ineffective. The transfer of this plasmid between bacteria can also confer resistance to other susceptible strains.
In summary, Chloramphenicol O-acetyltransferase is an enzyme that inactivates chloramphenicol by adding acetyl groups to it, making it an essential factor in bacterial resistance to this antibiotic.
Gene expression regulation in fungi refers to the complex cellular processes that control the production of proteins and other functional gene products in response to various internal and external stimuli. This regulation is crucial for normal growth, development, and adaptation of fungal cells to changing environmental conditions.
In fungi, gene expression is regulated at multiple levels, including transcriptional, post-transcriptional, translational, and post-translational modifications. Key regulatory mechanisms include:
1. Transcription factors (TFs): These proteins bind to specific DNA sequences in the promoter regions of target genes and either activate or repress their transcription. Fungi have a diverse array of TFs that respond to various signals, such as nutrient availability, stress, developmental cues, and quorum sensing.
2. Chromatin remodeling: The organization and compaction of DNA into chromatin can influence gene expression. Fungi utilize ATP-dependent chromatin remodeling complexes and histone modifying enzymes to alter chromatin structure, thereby facilitating or inhibiting the access of transcriptional machinery to genes.
3. Non-coding RNAs: Small non-coding RNAs (sncRNAs) play a role in post-transcriptional regulation of gene expression in fungi. These sncRNAs can guide RNA-induced transcriptional silencing (RITS) complexes to specific target loci, leading to the repression of gene expression through histone modifications and DNA methylation.
4. Alternative splicing: Fungi employ alternative splicing mechanisms to generate multiple mRNA isoforms from a single gene, thereby increasing proteome diversity. This process can be regulated by RNA-binding proteins that recognize specific sequence motifs in pre-mRNAs and promote or inhibit splicing events.
5. Protein stability and activity: Post-translational modifications (PTMs) of proteins, such as phosphorylation, ubiquitination, and sumoylation, can influence their stability, localization, and activity. These PTMs play a crucial role in regulating various cellular processes, including signal transduction, stress response, and cell cycle progression.
Understanding the complex interplay between these regulatory mechanisms is essential for elucidating the molecular basis of fungal development, pathogenesis, and drug resistance. This knowledge can be harnessed to develop novel strategies for combating fungal infections and improving agricultural productivity.
Acetylation is a chemical process that involves the addition of an acetyl group (-COCH3) to a molecule. In the context of medical biochemistry, acetylation often refers to the post-translational modification of proteins, where an acetyl group is added to the amino group of a lysine residue in a protein by an enzyme called acetyltransferase. This modification can alter the function or stability of the protein and plays a crucial role in regulating various cellular processes such as gene expression, DNA repair, and cell signaling. Acetylation can also occur on other types of molecules, including lipids and carbohydrates, and has important implications for drug metabolism and toxicity.
COS cells are a type of cell line that are commonly used in molecular biology and genetic research. The name "COS" is an acronym for "CV-1 in Origin," as these cells were originally derived from the African green monkey kidney cell line CV-1. COS cells have been modified through genetic engineering to express high levels of a protein called SV40 large T antigen, which allows them to efficiently take up and replicate exogenous DNA.
There are several different types of COS cells that are commonly used in research, including COS-1, COS-3, and COS-7 cells. These cells are widely used for the production of recombinant proteins, as well as for studies of gene expression, protein localization, and signal transduction.
It is important to note that while COS cells have been a valuable tool in scientific research, they are not without their limitations. For example, because they are derived from monkey kidney cells, there may be differences in the way that human genes are expressed or regulated in these cells compared to human cells. Additionally, because COS cells express SV40 large T antigen, they may have altered cell cycle regulation and other phenotypic changes that could affect experimental results. Therefore, it is important to carefully consider the choice of cell line when designing experiments and interpreting results.
A sequence deletion in a genetic context refers to the removal or absence of one or more nucleotides (the building blocks of DNA or RNA) from a specific region in a DNA or RNA molecule. This type of mutation can lead to the loss of genetic information, potentially resulting in changes in the function or expression of a gene. If the deletion involves a critical portion of the gene, it can cause diseases, depending on the role of that gene in the body. The size of the deleted sequence can vary, ranging from a single nucleotide to a large segment of DNA.
Regulatory sequences in nucleic acid refer to specific DNA or RNA segments that control the spatial and temporal expression of genes without encoding proteins. They are crucial for the proper functioning of cells as they regulate various cellular processes such as transcription, translation, mRNA stability, and localization. Regulatory sequences can be found in both coding and non-coding regions of DNA or RNA.
Some common types of regulatory sequences in nucleic acid include:
1. Promoters: DNA sequences typically located upstream of the gene that provide a binding site for RNA polymerase and transcription factors to initiate transcription.
2. Enhancers: DNA sequences, often located at a distance from the gene, that enhance transcription by binding to specific transcription factors and increasing the recruitment of RNA polymerase.
3. Silencers: DNA sequences that repress transcription by binding to specific proteins that inhibit the recruitment of RNA polymerase or promote chromatin compaction.
4. Intron splice sites: Specific nucleotide sequences within introns (non-coding regions) that mark the boundaries between exons (coding regions) and are essential for correct splicing of pre-mRNA.
5. 5' untranslated regions (UTRs): Regions located at the 5' end of an mRNA molecule that contain regulatory elements affecting translation efficiency, stability, and localization.
6. 3' untranslated regions (UTRs): Regions located at the 3' end of an mRNA molecule that contain regulatory elements influencing translation termination, stability, and localization.
7. miRNA target sites: Specific sequences in mRNAs that bind to microRNAs (miRNAs) leading to translational repression or degradation of the target mRNA.
3T3 cells are a type of cell line that is commonly used in scientific research. The name "3T3" is derived from the fact that these cells were developed by treating mouse embryo cells with a chemical called trypsin and then culturing them in a flask at a temperature of 37 degrees Celsius.
Specifically, 3T3 cells are a type of fibroblast, which is a type of cell that is responsible for producing connective tissue in the body. They are often used in studies involving cell growth and proliferation, as well as in toxicity tests and drug screening assays.
One particularly well-known use of 3T3 cells is in the 3T3-L1 cell line, which is a subtype of 3T3 cells that can be differentiated into adipocytes (fat cells) under certain conditions. These cells are often used in studies of adipose tissue biology and obesity.
It's important to note that because 3T3 cells are a type of immortalized cell line, they do not always behave exactly the same way as primary cells (cells that are taken directly from a living organism). As such, researchers must be careful when interpreting results obtained using 3T3 cells and consider any potential limitations or artifacts that may arise due to their use.
I'm sorry for any confusion, but "TATA box" is actually a term used in molecular biology, specifically in the field of genetics and gene regulation. It does not have a direct medical definition.
The TATA box is a DNA sequence located in the promoter region of many genes, which serves as a binding site for certain proteins involved in the initiation of transcription. Transcription is the first step in gene expression, where the information in a gene is used to create a corresponding protein or RNA molecule.
The TATA box is typically found about 25-30 base pairs upstream of the transcription start site and has the consensus sequence "TATAAA". It is recognized by the TATA-binding protein (TBP), which is a component of the transcription factor II D (TFIIB) complex. The binding of TBP to the TATA box helps to position the RNA polymerase enzyme properly for the initiation of transcription.
While not a medical term per se, understanding the function of the TATA box and other cis-acting elements in gene regulation is important for understanding how genes are turned on and off in various cellular processes and how this can go awry in certain diseases.
Proto-oncogene proteins, such as c-Jun, are normal cellular proteins that play crucial roles in various cellular processes including cell growth, differentiation, and apoptosis (programmed cell death). When proto-oncogenes undergo mutations or are overexpressed, they can become oncogenes, promoting uncontrolled cell growth and leading to cancer.
The c-Jun protein is a component of the AP-1 transcription factor complex, which regulates gene expression by binding to specific DNA sequences. It is involved in various cellular responses such as proliferation, differentiation, and survival. Dysregulation of c-Jun has been implicated in several types of cancer, including lung, breast, and colon cancers.
"Cells, cultured" is a medical term that refers to cells that have been removed from an organism and grown in controlled laboratory conditions outside of the body. This process is called cell culture and it allows scientists to study cells in a more controlled and accessible environment than they would have inside the body. Cultured cells can be derived from a variety of sources, including tissues, organs, or fluids from humans, animals, or cell lines that have been previously established in the laboratory.
Cell culture involves several steps, including isolation of the cells from the tissue, purification and characterization of the cells, and maintenance of the cells in appropriate growth conditions. The cells are typically grown in specialized media that contain nutrients, growth factors, and other components necessary for their survival and proliferation. Cultured cells can be used for a variety of purposes, including basic research, drug development and testing, and production of biological products such as vaccines and gene therapies.
It is important to note that cultured cells may behave differently than they do in the body, and results obtained from cell culture studies may not always translate directly to human physiology or disease. Therefore, it is essential to validate findings from cell culture experiments using additional models and ultimately in clinical trials involving human subjects.
DNA primers are short single-stranded DNA molecules that serve as a starting point for DNA synthesis. They are typically used in laboratory techniques such as the polymerase chain reaction (PCR) and DNA sequencing. The primer binds to a complementary sequence on the DNA template through base pairing, providing a free 3'-hydroxyl group for the DNA polymerase enzyme to add nucleotides and synthesize a new strand of DNA. This allows for specific and targeted amplification or analysis of a particular region of interest within a larger DNA molecule.
Transcription Factor TFIID is a multi-subunit protein complex that plays a crucial role in the process of transcription, which is the first step in gene expression. In eukaryotic cells, TFIID is responsible for recognizing and binding to the promoter region of genes, specifically to the TATA box, a sequence found in many promoters that acts as a binding site for the general transcription factors.
TFIID is composed of the TATA-box binding protein (TBP) and several TBP-associated factors (TAFs). The TBP subunit initially recognizes and binds to the TATA box, followed by the recruitment of other general transcription factors and RNA polymerase II to form a preinitiation complex. This complex then initiates the transcription of DNA into messenger RNA (mRNA), allowing for the production of proteins and the regulation of gene expression.
Transcription Factor TFIID is essential for accurate and efficient transcription, and its dysfunction can lead to various developmental and physiological abnormalities, including diseases such as cancer.
Molecular cloning is a laboratory technique used to create multiple copies of a specific DNA sequence. This process involves several steps:
1. Isolation: The first step in molecular cloning is to isolate the DNA sequence of interest from the rest of the genomic DNA. This can be done using various methods such as PCR (polymerase chain reaction), restriction enzymes, or hybridization.
2. Vector construction: Once the DNA sequence of interest has been isolated, it must be inserted into a vector, which is a small circular DNA molecule that can replicate independently in a host cell. Common vectors used in molecular cloning include plasmids and phages.
3. Transformation: The constructed vector is then introduced into a host cell, usually a bacterial or yeast cell, through a process called transformation. This can be done using various methods such as electroporation or chemical transformation.
4. Selection: After transformation, the host cells are grown in selective media that allow only those cells containing the vector to grow. This ensures that the DNA sequence of interest has been successfully cloned into the vector.
5. Amplification: Once the host cells have been selected, they can be grown in large quantities to amplify the number of copies of the cloned DNA sequence.
Molecular cloning is a powerful tool in molecular biology and has numerous applications, including the production of recombinant proteins, gene therapy, functional analysis of genes, and genetic engineering.
Phosphorylation is the process of adding a phosphate group (a molecule consisting of one phosphorus atom and four oxygen atoms) to a protein or other organic molecule, which is usually done by enzymes called kinases. This post-translational modification can change the function, localization, or activity of the target molecule, playing a crucial role in various cellular processes such as signal transduction, metabolism, and regulation of gene expression. Phosphorylation is reversible, and the removal of the phosphate group is facilitated by enzymes called phosphatases.
Site-directed mutagenesis is a molecular biology technique used to introduce specific and targeted changes to a specific DNA sequence. This process involves creating a new variant of a gene or a specific region of interest within a DNA molecule by introducing a planned, deliberate change, or mutation, at a predetermined site within the DNA sequence.
The methodology typically involves the use of molecular tools such as PCR (polymerase chain reaction), restriction enzymes, and/or ligases to introduce the desired mutation(s) into a plasmid or other vector containing the target DNA sequence. The resulting modified DNA molecule can then be used to transform host cells, allowing for the production of large quantities of the mutated gene or protein for further study.
Site-directed mutagenesis is a valuable tool in basic research, drug discovery, and biotechnology applications where specific changes to a DNA sequence are required to understand gene function, investigate protein structure/function relationships, or engineer novel biological properties into existing genes or proteins.
Zinc fingers are a type of protein structural motif involved in specific DNA binding and, by extension, in the regulation of gene expression. They are so named because of their characteristic "finger-like" shape that is formed when a zinc ion binds to the amino acids within the protein. This structure allows the protein to interact with and recognize specific DNA sequences, thereby playing a crucial role in various biological processes such as transcription, repair, and recombination of genetic material.
Chromatin Immunoprecipitation (ChIP) is a molecular biology technique used to analyze the interaction between proteins and DNA in the cell. It is a powerful tool for studying protein-DNA binding, such as transcription factor binding to specific DNA sequences, histone modification, and chromatin structure.
In ChIP assays, cells are first crosslinked with formaldehyde to preserve protein-DNA interactions. The chromatin is then fragmented into small pieces using sonication or other methods. Specific antibodies against the protein of interest are added to precipitate the protein-DNA complexes. After reversing the crosslinking, the DNA associated with the protein is purified and analyzed using PCR, sequencing, or microarray technologies.
ChIP assays can provide valuable information about the regulation of gene expression, epigenetic modifications, and chromatin structure in various biological processes and diseases, including cancer, development, and differentiation.
CREB (Cyclic AMP Response Element-Binding Protein) is a transcription factor that plays a crucial role in regulating gene expression in response to various cellular signals. CREB binds to the cAMP response element (CRE) sequence in the promoter region of target genes and regulates their transcription.
When activated, CREB undergoes phosphorylation at a specific serine residue (Ser-133), which leads to its binding to the coactivator protein CBP/p300 and recruitment of additional transcriptional machinery to the promoter region. This results in the activation of target gene transcription.
CREB is involved in various cellular processes, including metabolism, differentiation, survival, and memory formation. Dysregulation of CREB has been implicated in several diseases, such as cancer, neurodegenerative disorders, and mood disorders.
Homeodomain proteins are a group of transcription factors that play crucial roles in the development and differentiation of cells in animals and plants. They are characterized by the presence of a highly conserved DNA-binding domain called the homeodomain, which is typically about 60 amino acids long. The homeodomain consists of three helices, with the third helix responsible for recognizing and binding to specific DNA sequences.
Homeodomain proteins are involved in regulating gene expression during embryonic development, tissue maintenance, and organismal growth. They can act as activators or repressors of transcription, depending on the context and the presence of cofactors. Mutations in homeodomain proteins have been associated with various human diseases, including cancer, congenital abnormalities, and neurological disorders.
Some examples of homeodomain proteins include PAX6, which is essential for eye development, HOX genes, which are involved in body patterning, and NANOG, which plays a role in maintaining pluripotency in stem cells.
Proto-oncogene proteins are normal cellular proteins that play crucial roles in various cellular processes, such as signal transduction, cell cycle regulation, and apoptosis (programmed cell death). They are involved in the regulation of cell growth, differentiation, and survival under physiological conditions.
When proto-oncogene proteins undergo mutations or aberrations in their expression levels, they can transform into oncogenic forms, leading to uncontrolled cell growth and division. These altered proteins are then referred to as oncogene products or oncoproteins. Oncogenic mutations can occur due to various factors, including genetic predisposition, environmental exposures, and aging.
Examples of proto-oncogene proteins include:
1. Ras proteins: Involved in signal transduction pathways that regulate cell growth and differentiation. Activating mutations in Ras genes are found in various human cancers.
2. Myc proteins: Regulate gene expression related to cell cycle progression, apoptosis, and metabolism. Overexpression of Myc proteins is associated with several types of cancer.
3. EGFR (Epidermal Growth Factor Receptor): A transmembrane receptor tyrosine kinase that regulates cell proliferation, survival, and differentiation. Mutations or overexpression of EGFR are linked to various malignancies, such as lung cancer and glioblastoma.
4. Src family kinases: Intracellular tyrosine kinases that regulate signal transduction pathways involved in cell proliferation, survival, and migration. Dysregulation of Src family kinases is implicated in several types of cancer.
5. Abl kinases: Cytoplasmic tyrosine kinases that regulate various cellular processes, including cell growth, differentiation, and stress responses. Aberrant activation of Abl kinases, as seen in chronic myelogenous leukemia (CML), leads to uncontrolled cell proliferation.
Understanding the roles of proto-oncogene proteins and their dysregulation in cancer development is essential for developing targeted cancer therapies that aim to inhibit or modulate these aberrant signaling pathways.
Recombinant proteins are artificially created proteins produced through the use of recombinant DNA technology. This process involves combining DNA molecules from different sources to create a new set of genes that encode for a specific protein. The resulting recombinant protein can then be expressed, purified, and used for various applications in research, medicine, and industry.
Recombinant proteins are widely used in biomedical research to study protein function, structure, and interactions. They are also used in the development of diagnostic tests, vaccines, and therapeutic drugs. For example, recombinant insulin is a common treatment for diabetes, while recombinant human growth hormone is used to treat growth disorders.
The production of recombinant proteins typically involves the use of host cells, such as bacteria, yeast, or mammalian cells, which are engineered to express the desired protein. The host cells are transformed with a plasmid vector containing the gene of interest, along with regulatory elements that control its expression. Once the host cells are cultured and the protein is expressed, it can be purified using various chromatography techniques.
Overall, recombinant proteins have revolutionized many areas of biology and medicine, enabling researchers to study and manipulate proteins in ways that were previously impossible.
NF-κB (Nuclear Factor kappa-light-chain-enhancer of activated B cells) is a protein complex that plays a crucial role in regulating the immune response to infection and inflammation, as well as in cell survival, differentiation, and proliferation. It is composed of several subunits, including p50, p52, p65 (RelA), c-Rel, and RelB, which can form homodimers or heterodimers that bind to specific DNA sequences called κB sites in the promoter regions of target genes.
Under normal conditions, NF-κB is sequestered in the cytoplasm by inhibitory proteins known as IκBs (inhibitors of κB). However, upon stimulation by various signals such as cytokines, bacterial or viral products, and stress, IκBs are phosphorylated, ubiquitinated, and degraded, leading to the release and activation of NF-κB. Activated NF-κB then translocates to the nucleus, where it binds to κB sites and regulates the expression of target genes involved in inflammation, immunity, cell survival, and proliferation.
Dysregulation of NF-κB signaling has been implicated in various pathological conditions such as cancer, chronic inflammation, autoimmune diseases, and neurodegenerative disorders. Therefore, targeting NF-κB signaling has emerged as a potential therapeutic strategy for the treatment of these diseases.
Acetyltransferases are a type of enzyme that facilitates the transfer of an acetyl group (a chemical group consisting of an acetyl molecule, which is made up of carbon, hydrogen, and oxygen atoms) from a donor molecule to a recipient molecule. This transfer of an acetyl group can modify the function or activity of the recipient molecule.
In the context of biology and medicine, acetyltransferases are important for various cellular processes, including gene expression, DNA replication, and protein function. For example, histone acetyltransferases (HATs) are a type of acetyltransferase that add an acetyl group to the histone proteins around which DNA is wound. This modification can alter the structure of the chromatin, making certain genes more or less accessible for transcription, and thereby influencing gene expression.
Abnormal regulation of acetyltransferases has been implicated in various diseases, including cancer, neurodegenerative disorders, and infectious diseases. Therefore, understanding the function and regulation of these enzymes is an important area of research in biomedicine.
Gene expression regulation, enzymologic refers to the biochemical processes and mechanisms that control the transcription and translation of specific genes into functional proteins or enzymes. This regulation is achieved through various enzymatic activities that can either activate or repress gene expression at different levels, such as chromatin remodeling, transcription factor activation, mRNA processing, and protein degradation.
Enzymologic regulation of gene expression involves the action of specific enzymes that catalyze chemical reactions involved in these processes. For example, histone-modifying enzymes can alter the structure of chromatin to make genes more or less accessible for transcription, while RNA polymerase and its associated factors are responsible for transcribing DNA into mRNA. Additionally, various enzymes are involved in post-transcriptional modifications of mRNA, such as splicing, capping, and tailing, which can affect the stability and translation of the transcript.
Overall, the enzymologic regulation of gene expression is a complex and dynamic process that allows cells to respond to changes in their environment and maintain proper physiological function.
Transcription Factor AP-1 (Activator Protein 1) is a heterodimeric transcription factor that belongs to the bZIP (basic region-leucine zipper) family. It is formed by the dimerization of Jun (c-Jun, JunB, JunD) and Fos (c-Fos, FosB, Fra1, Fra2) protein families, or alternatively by homodimers of Jun proteins. AP-1 plays a crucial role in regulating gene expression in various cellular processes such as proliferation, differentiation, and apoptosis. Its activity is tightly controlled through various signaling pathways, including the MAPK (mitogen-activated protein kinase) cascades, which lead to phosphorylation and activation of its components. Once activated, AP-1 binds to specific DNA sequences called TPA response elements (TREs) or AP-1 sites, thereby modulating the transcription of target genes involved in various cellular responses, such as inflammation, immune response, stress response, and oncogenic transformation.
DNA footprinting is a laboratory technique used to identify specific DNA-protein interactions and map the binding sites of proteins on a DNA molecule. This technique involves the use of enzymes or chemicals that can cleave the DNA strand, but are prevented from doing so when a protein is bound to the DNA. By comparing the pattern of cuts in the presence and absence of the protein, researchers can identify the regions of the DNA where the protein binds.
The process typically involves treating the DNA-protein complex with a chemical or enzymatic agent that cleaves the DNA at specific sequences or sites. After the reaction is stopped, the DNA is separated into single strands and analyzed using techniques such as gel electrophoresis to visualize the pattern of cuts. The regions of the DNA where protein binding has occurred are protected from cleavage and appear as gaps or "footprints" in the pattern of cuts.
DNA footprinting is a valuable tool for studying gene regulation, as it can provide insights into how proteins interact with specific DNA sequences to control gene expression. It can also be used to study protein-DNA interactions involved in processes such as DNA replication, repair, and recombination.
The TATA-box binding protein (TBP) is a general transcription factor that plays a crucial role in the initiation of transcription of protein-coding genes in archaea and eukaryotes. It is named after its ability to bind to the TATA box, a conserved DNA sequence found in the promoter regions of many genes.
TBP is a key component of the transcription preinitiation complex (PIC), which also includes other general transcription factors and RNA polymerase II in eukaryotes. The TBP protein has a unique structure, characterized by a saddle-shaped DNA-binding domain that allows it to recognize and bind to the TATA box in a sequence-specific manner.
By binding to the TATA box, TBP helps to position the RNA polymerase II complex at the start site of transcription, allowing for the initiation of RNA synthesis. TBP also plays a role in regulating gene expression by interacting with various coactivators and corepressors that modulate its activity.
Mutations in the TBP gene have been associated with several human diseases, including some forms of cancer and neurodevelopmental disorders.
An Electrophoretic Mobility Shift Assay (EMSA) is a laboratory technique used to detect and analyze protein-DNA interactions. In this assay, a mixture of proteins and fluorescently or radioactively labeled DNA probes are loaded onto a native polyacrylamide gel matrix and subjected to an electric field. The negatively charged DNA probe migrates towards the positive electrode, and the rate of migration (mobility) is dependent on the size and charge of the molecule. When a protein binds to the DNA probe, it forms a complex that has a different size and/or charge than the unbound probe, resulting in a shift in its mobility on the gel.
The EMSA can be used to identify specific protein-DNA interactions, determine the binding affinity of proteins for specific DNA sequences, and investigate the effects of mutations or post-translational modifications on protein-DNA interactions. The technique is widely used in molecular biology research, including studies of gene regulation, DNA damage repair, and epigenetic modifications.
In summary, Electrophoretic Mobility Shift Assay (EMSA) is a laboratory technique that detects and analyzes protein-DNA interactions by subjecting a mixture of proteins and labeled DNA probes to an electric field in a native polyacrylamide gel matrix. The binding of proteins to the DNA probe results in a shift in its mobility on the gel, allowing for the detection and analysis of specific protein-DNA interactions.
Tumor suppressor protein p53, also known as p53 or tumor protein p53, is a nuclear phosphoprotein that plays a crucial role in preventing cancer development and maintaining genomic stability. It does so by regulating the cell cycle and acting as a transcription factor for various genes involved in apoptosis (programmed cell death), DNA repair, and cell senescence (permanent cell growth arrest).
In response to cellular stress, such as DNA damage or oncogene activation, p53 becomes activated and accumulates in the nucleus. Activated p53 can then bind to specific DNA sequences and promote the transcription of target genes that help prevent the proliferation of potentially cancerous cells. These targets include genes involved in cell cycle arrest (e.g., CDKN1A/p21), apoptosis (e.g., BAX, PUMA), and DNA repair (e.g., GADD45).
Mutations in the TP53 gene, which encodes p53, are among the most common genetic alterations found in human cancers. These mutations often lead to a loss or reduction of p53's tumor suppressive functions, allowing cancer cells to proliferate uncontrollably and evade apoptosis. As a result, p53 has been referred to as "the guardian of the genome" due to its essential role in preventing tumorigenesis.
Adenovirus E1A proteins are the early region 1A proteins encoded by adenoviruses, a group of viruses that commonly cause respiratory infections in humans. The E1A proteins play a crucial role in the regulation of the viral life cycle and host cell response. They function as transcriptional regulators, interacting with various cellular proteins to modulate gene expression and promote viral replication.
There are two major E1A protein isoforms, 289R and 243R, which differ in their amino-terminal regions due to alternative splicing of the E1A mRNA. The 289R isoform contains an additional 46 amino acids at its N-terminus compared to the 243R isoform. Both isoforms share conserved regions, including a strong transcriptional activation domain and a binding domain for cellular proteins involved in transcriptional regulation, such as retinoblastoma protein (pRb) and p300/CBP.
The interaction between E1A proteins and pRb is particularly important because it leads to the release of E2F transcription factors, which are essential for the initiation of viral DNA replication. By binding and inactivating pRb, E1A proteins promote the expression of cell cycle-regulated genes that facilitate viral replication in dividing cells.
In summary, adenovirus E1A proteins are multifunctional regulatory proteins involved in the control of viral gene expression and host cell response during adenovirus infection. They manipulate cellular transcription factors and pathways to create a favorable environment for viral replication.
Sequence homology, amino acid, refers to the similarity in the order of amino acids in a protein or a portion of a protein between two or more species. This similarity can be used to infer evolutionary relationships and functional similarities between proteins. The higher the degree of sequence homology, the more likely it is that the proteins are related and have similar functions. Sequence homology can be determined through various methods such as pairwise alignment or multiple sequence alignment, which compare the sequences and calculate a score based on the number and type of matching amino acids.
CCAAT-Enhancer-Binding Proteins (C/EBPs) are a family of transcription factors that play crucial roles in the regulation of various biological processes, including cell growth, development, and differentiation. They bind to specific DNA sequences called CCAAT boxes, which are found in the promoter or enhancer regions of many genes.
The C/EBP family consists of several members, including C/EBPα, C/EBPβ, C/EBPγ, C/EBPδ, and C/EBPε. These proteins share a highly conserved basic region-leucine zipper (bZIP) domain, which is responsible for their DNA-binding and dimerization activities.
C/EBPs can form homodimers or heterodimers with other bZIP proteins, allowing them to regulate gene expression in a combinatorial manner. They are involved in the regulation of various physiological processes, such as inflammation, immune response, metabolism, and cell cycle control. Dysregulation of C/EBP function has been implicated in several diseases, including cancer, diabetes, and inflammatory disorders.
A cell line that is derived from tumor cells and has been adapted to grow in culture. These cell lines are often used in research to study the characteristics of cancer cells, including their growth patterns, genetic changes, and responses to various treatments. They can be established from many different types of tumors, such as carcinomas, sarcomas, and leukemias. Once established, these cell lines can be grown and maintained indefinitely in the laboratory, allowing researchers to conduct experiments and studies that would not be feasible using primary tumor cells. It is important to note that tumor cell lines may not always accurately represent the behavior of the original tumor, as they can undergo genetic changes during their time in culture.
E1A-associated protein, also known as p300, is a transcriptional coactivator that plays a crucial role in the regulation of gene expression. It was initially identified as a protein that interacts with the E1A protein of adenovirus.
The p300 protein contains several functional domains, including a histone acetyltransferase (HAT) domain, which can modify histone proteins and alter chromatin structure to promote gene transcription. It also has a bromodomain that recognizes acetylated lysine residues on histones and other proteins, further enhancing its ability to regulate gene expression.
In addition to its role in transcriptional regulation, p300 is involved in various cellular processes such as DNA repair, differentiation, and apoptosis. Dysregulation of p300 function has been implicated in several human diseases, including cancer, neurodevelopmental disorders, and cardiovascular disease.
Proto-oncogene proteins, such as c-Fos, are normal cellular proteins that play crucial roles in various biological processes including cell growth, differentiation, and survival. They can be activated or overexpressed due to genetic alterations, leading to the formation of cancerous cells. The c-Fos protein is a nuclear phosphoprotein involved in signal transduction pathways and forms a heterodimer with c-Jun to create the activator protein-1 (AP-1) transcription factor complex. This complex binds to specific DNA sequences, thereby regulating the expression of target genes that contribute to various cellular responses, including proliferation, differentiation, and apoptosis. Dysregulation of c-Fos can result in uncontrolled cell growth and malignant transformation, contributing to tumor development and progression.
A nucleosome is a basic unit of DNA packaging in eukaryotic cells, consisting of a segment of DNA coiled around an octamer of histone proteins. This structure forms a repeating pattern along the length of the DNA molecule, with each nucleosome resembling a "bead on a string" when viewed under an electron microscope. The histone octamer is composed of two each of the histones H2A, H2B, H3, and H4, and the DNA wraps around it approximately 1.65 times. Nucleosomes play a crucial role in compacting the large DNA molecule within the nucleus and regulating access to the DNA for processes such as transcription, replication, and repair.
Gene expression regulation, viral, refers to the processes that control the production of viral gene products, such as proteins and nucleic acids, during the viral life cycle. This can involve both viral and host cell factors that regulate transcription, RNA processing, translation, and post-translational modifications of viral genes.
Viral gene expression regulation is critical for the virus to replicate and produce progeny virions. Different types of viruses have evolved diverse mechanisms to regulate their gene expression, including the use of promoters, enhancers, transcription factors, RNA silencing, and epigenetic modifications. Understanding these regulatory processes can provide insights into viral pathogenesis and help in the development of antiviral therapies.
Retinoic acid receptors (RARs) are a type of nuclear receptor proteins that play crucial roles in the regulation of gene transcription. They are activated by retinoic acid, which is a metabolite of vitamin A. There are three subtypes of RARs, namely RARα, RARβ, and RARγ, each encoded by different genes.
Once retinoic acid binds to RARs, they form heterodimers with another type of nuclear receptor called retinoid X receptors (RXRs). The RAR-RXR complex then binds to specific DNA sequences called retinoic acid response elements (RAREs) in the promoter regions of target genes. This binding event leads to the recruitment of coactivator proteins and the modification of chromatin structure, ultimately resulting in the activation or repression of gene transcription.
Retinoic acid and its receptors play essential roles in various biological processes, including embryonic development, cell differentiation, apoptosis, and immune function. In addition, RARs have been implicated in several diseases, such as cancer, where they can act as tumor suppressors or oncogenes depending on the context. Therefore, understanding the mechanisms of RAR signaling has important implications for the development of novel therapeutic strategies for various diseases.
Mutagenesis is the process by which the genetic material (DNA or RNA) of an organism is changed in a way that can alter its phenotype, or observable traits. These changes, known as mutations, can be caused by various factors such as chemicals, radiation, or viruses. Some mutations may have no effect on the organism, while others can cause harm, including diseases and cancer. Mutagenesis is a crucial area of study in genetics and molecular biology, with implications for understanding evolution, genetic disorders, and the development of new medical treatments.
A consensus sequence in genetics refers to the most common nucleotide (DNA or RNA) or amino acid at each position in a multiple sequence alignment. It is derived by comparing and analyzing several sequences of the same gene or protein from different individuals or organisms. The consensus sequence provides a general pattern or motif that is shared among these sequences and can be useful in identifying functional regions, conserved domains, or evolutionary relationships. However, it's important to note that not every sequence will exactly match the consensus sequence, as variations can occur naturally due to mutations or genetic differences among individuals.
v-Myb, also known as v-mybl2, is a retroviral oncogene that was originally isolated from the avian myeloblastosis virus (AMV). The protein product of this oncogene shares significant sequence homology with the human c-Myb protein, which is a member of the Myb family of transcription factors.
The c-Myb protein is involved in the regulation of gene expression during normal cell growth, differentiation, and development. However, when its function is deregulated or its expression is altered, it can contribute to tumorigenesis by promoting cell proliferation and inhibiting apoptosis (programmed cell death).
The v-Myb oncogene protein has a higher transforming potential than the c-Myb protein due to the presence of additional sequences that enhance its activity. These sequences allow v-Myb to bind to DNA more strongly, interact with other proteins more efficiently, and promote the expression of target genes involved in cell growth and survival.
Overexpression or mutation of c-Myb has been implicated in various human cancers, including leukemia, lymphoma, and carcinomas of the breast, colon, and prostate. Therefore, understanding the function and regulation of Myb proteins is important for developing new strategies to prevent and treat cancer.
Gene expression regulation in bacteria refers to the complex cellular processes that control the production of proteins from specific genes. This regulation allows bacteria to adapt to changing environmental conditions and ensure the appropriate amount of protein is produced at the right time.
Bacteria have a variety of mechanisms for regulating gene expression, including:
1. Operon structure: Many bacterial genes are organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule. The expression of these genes can be coordinately regulated by controlling the transcription of the entire operon.
2. Promoter regulation: Transcription is initiated at promoter regions upstream of the gene or operon. Bacteria have regulatory proteins called sigma factors that bind to the promoter and recruit RNA polymerase, the enzyme responsible for transcribing DNA into RNA. The binding of sigma factors can be influenced by environmental signals, allowing for regulation of transcription.
3. Attenuation: Some operons have regulatory regions called attenuators that control transcription termination. These regions contain hairpin structures that can form in the mRNA and cause transcription to stop prematurely. The formation of these hairpins is influenced by the concentration of specific metabolites, allowing for regulation of gene expression based on the availability of those metabolites.
4. Riboswitches: Some bacterial mRNAs contain regulatory elements called riboswitches that bind small molecules directly. When a small molecule binds to the riboswitch, it changes conformation and affects transcription or translation of the associated gene.
5. CRISPR-Cas systems: Bacteria use CRISPR-Cas systems for adaptive immunity against viruses and plasmids. These systems incorporate short sequences from foreign DNA into their own genome, which can then be used to recognize and cleave similar sequences in invading genetic elements.
Overall, gene expression regulation in bacteria is a complex process that allows them to respond quickly and efficiently to changing environmental conditions. Understanding these regulatory mechanisms can provide insights into bacterial physiology and help inform strategies for controlling bacterial growth and behavior.
I'm sorry for any confusion, but the term "Leucine Zippers" is not a medical term or concept. It is a term used in molecular biology to describe a specific structural motif found in some proteins. Leucine zippers are amino acid sequences that contain regularly spaced leucine residues and form coiled-coil structures, which play a role in protein-protein interactions, particularly in DNA binding transcription factors.
If you have any questions related to medical terminology or concepts, I would be happy to help!
Bacterial proteins are a type of protein that are produced by bacteria as part of their structural or functional components. These proteins can be involved in various cellular processes, such as metabolism, DNA replication, transcription, and translation. They can also play a role in bacterial pathogenesis, helping the bacteria to evade the host's immune system, acquire nutrients, and multiply within the host.
Bacterial proteins can be classified into different categories based on their function, such as:
1. Enzymes: Proteins that catalyze chemical reactions in the bacterial cell.
2. Structural proteins: Proteins that provide structural support and maintain the shape of the bacterial cell.
3. Signaling proteins: Proteins that help bacteria to communicate with each other and coordinate their behavior.
4. Transport proteins: Proteins that facilitate the movement of molecules across the bacterial cell membrane.
5. Toxins: Proteins that are produced by pathogenic bacteria to damage host cells and promote infection.
6. Surface proteins: Proteins that are located on the surface of the bacterial cell and interact with the environment or host cells.
Understanding the structure and function of bacterial proteins is important for developing new antibiotics, vaccines, and other therapeutic strategies to combat bacterial infections.
A two-hybrid system technique is a type of genetic screening method used in molecular biology to identify protein-protein interactions within an organism, most commonly baker's yeast (Saccharomyces cerevisiae) or Escherichia coli. The name "two-hybrid" refers to the fact that two separate proteins are being examined for their ability to interact with each other.
The technique is based on the modular nature of transcription factors, which typically consist of two distinct domains: a DNA-binding domain (DBD) and an activation domain (AD). In a two-hybrid system, one protein of interest is fused to the DBD, while the second protein of interest is fused to the AD. If the two proteins interact, the DBD and AD are brought in close proximity, allowing for transcriptional activation of a reporter gene that is linked to a specific promoter sequence recognized by the DBD.
The main components of a two-hybrid system include:
1. Bait protein (fused to the DNA-binding domain)
2. Prey protein (fused to the activation domain)
3. Reporter gene (transcribed upon interaction between bait and prey proteins)
4. Promoter sequence (recognized by the DBD when brought in proximity due to interaction)
The two-hybrid system technique has several advantages, including:
1. Ability to screen large libraries of potential interacting partners
2. High sensitivity for detecting weak or transient interactions
3. Applicability to various organisms and protein types
4. Potential for high-throughput analysis
However, there are also limitations to the technique, such as false positives (interactions that do not occur in vivo) and false negatives (lack of detection of true interactions). Additionally, the fusion proteins may not always fold or localize correctly, leading to potential artifacts. Despite these limitations, two-hybrid system techniques remain a valuable tool for studying protein-protein interactions and have contributed significantly to our understanding of various cellular processes.
RNA Polymerase II is a type of enzyme responsible for transcribing DNA into RNA in eukaryotic cells. It plays a crucial role in the process of gene expression, where the information stored in DNA is used to create proteins. Specifically, RNA Polymerase II transcribes protein-coding genes to produce precursor messenger RNA (pre-mRNA), which is then processed into mature mRNA. This mature mRNA serves as a template for protein synthesis during translation.
RNA Polymerase II has a complex structure, consisting of multiple subunits, and it requires the assistance of various transcription factors and coactivators to initiate and regulate transcription. The enzyme recognizes specific promoter sequences in DNA, unwinds the double-stranded DNA, and synthesizes a complementary RNA strand using one of the unwound DNA strands as a template. This process results in the formation of a nascent RNA molecule that is further processed into mature mRNA for protein synthesis or other functional RNAs involved in gene regulation.
Helix-loop-helix (HLH) motifs are structural domains found in certain proteins, particularly transcription factors, that play a crucial role in DNA binding and protein-protein interactions. These motifs consist of two amphipathic α-helices connected by a loop region. The first helix is known as the "helix-1" or "recognition helix," while the second one is called the "helix-2" or "dimerization helix."
In many HLH proteins, the helices come together to form a dimer through interactions between their hydrophobic residues located in the core of the helix-2. This dimerization enables DNA binding by positioning the recognition helices in close proximity to each other and allowing them to interact with specific DNA sequences, often referred to as E-box motifs (CANNTG).
HLH motifs can be further classified into basic HLH (bHLH) proteins and HLH-only proteins. bHLH proteins contain a basic region adjacent to the N-terminal end of the first helix, which facilitates DNA binding. In contrast, HLH-only proteins lack this basic region and primarily function as dimerization partners for bHLH proteins or participate in other protein-protein interactions.
These motifs are involved in various cellular processes, including cell fate determination, differentiation, proliferation, and apoptosis. Dysregulation of HLH proteins has been implicated in several diseases, such as cancer and neurodevelopmental disorders.
Cytoplasmic receptors and nuclear receptors are two types of intracellular receptors that play crucial roles in signal transduction pathways and regulation of gene expression. They are classified based on their location within the cell. Here are the medical definitions for each:
1. Cytoplasmic Receptors: These are a group of intracellular receptors primarily found in the cytoplasm of cells, which bind to specific hormones, growth factors, or other signaling molecules. Upon binding, these receptors undergo conformational changes that allow them to interact with various partners, such as adapter proteins and enzymes, leading to activation of downstream signaling cascades. These pathways ultimately result in modulation of cellular processes like proliferation, differentiation, and apoptosis. Examples of cytoplasmic receptors include receptor tyrosine kinases (RTKs), serine/threonine kinase receptors, and cytokine receptors.
2. Nuclear Receptors: These are a distinct class of intracellular receptors that reside primarily in the nucleus of cells. They bind to specific ligands, such as steroid hormones, thyroid hormones, vitamin D, retinoic acid, and various other lipophilic molecules. Upon binding, nuclear receptors undergo conformational changes that facilitate their interaction with co-regulatory proteins and the DNA. This interaction results in the modulation of gene transcription, ultimately leading to alterations in protein expression and cellular responses. Examples of nuclear receptors include estrogen receptor (ER), androgen receptor (AR), glucocorticoid receptor (GR), thyroid hormone receptor (TR), vitamin D receptor (VDR), and peroxisome proliferator-activated receptors (PPARs).
Both cytoplasmic and nuclear receptors are essential components of cellular communication networks, allowing cells to respond appropriately to extracellular signals and maintain homeostasis. Dysregulation of these receptors has been implicated in various diseases, including cancer, diabetes, and autoimmune disorders.
Western blotting is a laboratory technique used in molecular biology to detect and quantify specific proteins in a mixture of many different proteins. This technique is commonly used to confirm the expression of a protein of interest, determine its size, and investigate its post-translational modifications. The name "Western" blotting distinguishes this technique from Southern blotting (for DNA) and Northern blotting (for RNA).
The Western blotting procedure involves several steps:
1. Protein extraction: The sample containing the proteins of interest is first extracted, often by breaking open cells or tissues and using a buffer to extract the proteins.
2. Separation of proteins by electrophoresis: The extracted proteins are then separated based on their size by loading them onto a polyacrylamide gel and running an electric current through the gel (a process called sodium dodecyl sulfate-polyacrylamide gel electrophoresis or SDS-PAGE). This separates the proteins according to their molecular weight, with smaller proteins migrating faster than larger ones.
3. Transfer of proteins to a membrane: After separation, the proteins are transferred from the gel onto a nitrocellulose or polyvinylidene fluoride (PVDF) membrane using an electric current in a process called blotting. This creates a replica of the protein pattern on the gel but now immobilized on the membrane for further analysis.
4. Blocking: The membrane is then blocked with a blocking agent, such as non-fat dry milk or bovine serum albumin (BSA), to prevent non-specific binding of antibodies in subsequent steps.
5. Primary antibody incubation: A primary antibody that specifically recognizes the protein of interest is added and allowed to bind to its target protein on the membrane. This step may be performed at room temperature or 4°C overnight, depending on the antibody's properties.
6. Washing: The membrane is washed with a buffer to remove unbound primary antibodies.
7. Secondary antibody incubation: A secondary antibody that recognizes the primary antibody (often coupled to an enzyme or fluorophore) is added and allowed to bind to the primary antibody. This step may involve using a horseradish peroxidase (HRP)-conjugated or alkaline phosphatase (AP)-conjugated secondary antibody, depending on the detection method used later.
8. Washing: The membrane is washed again to remove unbound secondary antibodies.
9. Detection: A detection reagent is added to visualize the protein of interest by detecting the signal generated from the enzyme-conjugated or fluorophore-conjugated secondary antibody. This can be done using chemiluminescent, colorimetric, or fluorescent methods.
10. Analysis: The resulting image is analyzed to determine the presence and quantity of the protein of interest in the sample.
Western blotting is a powerful technique for identifying and quantifying specific proteins within complex mixtures. It can be used to study protein expression, post-translational modifications, protein-protein interactions, and more. However, it requires careful optimization and validation to ensure accurate and reproducible results.
Oligodeoxyribonucleotides (ODNs) are relatively short, synthetic single-stranded DNA molecules. They typically contain 15 to 30 nucleotides, but can range from 2 to several hundred nucleotides in length. ODNs are often used as tools in molecular biology research for various applications such as:
1. Nucleic acid detection and quantification (e.g., real-time PCR)
2. Gene regulation (antisense, RNA interference)
3. Gene editing (CRISPR-Cas systems)
4. Vaccine development
5. Diagnostic purposes
Due to their specificity and affinity towards complementary DNA or RNA sequences, ODNs can be designed to target a particular gene or sequence of interest. This makes them valuable tools in understanding gene function, regulation, and interaction with other molecules within the cell.
DNA Mutational Analysis is a laboratory test used to identify genetic variations or changes (mutations) in the DNA sequence of a gene. This type of analysis can be used to diagnose genetic disorders, predict the risk of developing certain diseases, determine the most effective treatment for cancer, or assess the likelihood of passing on an inherited condition to offspring.
The test involves extracting DNA from a patient's sample (such as blood, saliva, or tissue), amplifying specific regions of interest using polymerase chain reaction (PCR), and then sequencing those regions to determine the precise order of nucleotide bases in the DNA molecule. The resulting sequence is then compared to reference sequences to identify any variations or mutations that may be present.
DNA Mutational Analysis can detect a wide range of genetic changes, including single-nucleotide polymorphisms (SNPs), insertions, deletions, duplications, and rearrangements. The test is often used in conjunction with other diagnostic tests and clinical evaluations to provide a comprehensive assessment of a patient's genetic profile.
It is important to note that not all mutations are pathogenic or associated with disease, and the interpretation of DNA Mutational Analysis results requires careful consideration of the patient's medical history, family history, and other relevant factors.
The Mediator complex is a multi-subunit protein structure that acts as a bridge in the communication between regulatory elements, such as transcription factors, and the RNA polymerase II enzyme. It plays a crucial role in the regulation of gene expression by modulating the initiation and rate of transcription.
The Mediator complex is composed of approximately 30 subunits that are highly conserved across eukaryotes. The complex can be divided into four modules: the head, middle, tail, and kinase modules. Each module has a unique set of functions in regulating gene expression. For example, the tail module interacts with transcription factors to receive signals about which genes should be activated or repressed, while the kinase module phosphorylates the carboxy-terminal domain (CTD) of RNA polymerase II to promote its recruitment and activation at gene promoters.
Overall, the Mediator complex is an essential component of the eukaryotic transcriptional machinery, playing a critical role in regulating various cellular processes such as development, differentiation, and metabolism. Dysregulation of the Mediator complex has been implicated in several human diseases, including cancer and neurological disorders.
Neoplastic gene expression regulation refers to the processes that control the production of proteins and other molecules from genes in neoplastic cells, or cells that are part of a tumor or cancer. In a normal cell, gene expression is tightly regulated to ensure that the right genes are turned on or off at the right time. However, in cancer cells, this regulation can be disrupted, leading to the overexpression or underexpression of certain genes.
Neoplastic gene expression regulation can be affected by a variety of factors, including genetic mutations, epigenetic changes, and signals from the tumor microenvironment. These changes can lead to the activation of oncogenes (genes that promote cancer growth and development) or the inactivation of tumor suppressor genes (genes that prevent cancer).
Understanding neoplastic gene expression regulation is important for developing new therapies for cancer, as targeting specific genes or pathways involved in this process can help to inhibit cancer growth and progression.
Nuclear Receptor Coactivator 1 (NCOA1), also known as Steroid Receptor Coactivator-1 (SRC-1), is a protein that functions as a transcriptional coactivator. It plays an essential role in the regulation of gene expression by interacting with various nuclear receptors, such as estrogen receptor, androgen receptor, glucocorticoid receptor, and thyroid hormone receptor. NCOA1 contains several functional domains that enable it to bind to these nuclear receptors and recruit other coregulatory proteins, including histone modifiers and chromatin remodeling factors, to form a large transcriptional activation complex. This results in the modification of chromatin structure and the recruitment of RNA polymerase II, leading to the initiation of transcription of target genes. NCOA1 has been implicated in various physiological processes, including development, differentiation, metabolism, and reproduction, as well as in several pathological conditions, such as cancer and metabolic disorders.
Beta-galactosidase is an enzyme that catalyzes the hydrolysis of beta-galactosides into monosaccharides. It is found in various organisms, including bacteria, yeast, and mammals. In humans, it plays a role in the breakdown and absorption of certain complex carbohydrates, such as lactose, in the small intestine. Deficiency of this enzyme in humans can lead to a disorder called lactose intolerance. In scientific research, beta-galactosidase is often used as a marker for gene expression and protein localization studies.
A precipitin test is a type of immunodiagnostic test used to detect and measure the presence of specific antibodies or antigens in a patient's serum. The test is based on the principle of antigen-antibody interaction, where the addition of an antigen to a solution containing its corresponding antibody results in the formation of an insoluble immune complex known as a precipitin.
In this test, a small amount of the patient's serum is added to a solution containing a known antigen or antibody. If the patient has antibodies or antigens that correspond to the added reagent, they will bind and form a visible precipitate. The size and density of the precipitate can be used to quantify the amount of antibody or antigen present in the sample.
Precipitin tests are commonly used in the diagnosis of various infectious diseases, autoimmune disorders, and allergies. They can also be used in forensic science to identify biological samples. However, they have largely been replaced by more modern immunological techniques such as enzyme-linked immunosorbent assays (ELISAs) and radioimmunoassays (RIAs).
Developmental gene expression regulation refers to the processes that control the activation or repression of specific genes during embryonic and fetal development. These regulatory mechanisms ensure that genes are expressed at the right time, in the right cells, and at appropriate levels to guide proper growth, differentiation, and morphogenesis of an organism.
Developmental gene expression regulation is a complex and dynamic process involving various molecular players, such as transcription factors, chromatin modifiers, non-coding RNAs, and signaling molecules. These regulators can interact with cis-regulatory elements, like enhancers and promoters, to fine-tune the spatiotemporal patterns of gene expression during development.
Dysregulation of developmental gene expression can lead to various congenital disorders and developmental abnormalities. Therefore, understanding the principles and mechanisms governing developmental gene expression regulation is crucial for uncovering the etiology of developmental diseases and devising potential therapeutic strategies.
Nuclear Receptor Coactivator 2 (NCoA-2, also known as SRC-2 or TIF2) is a protein that functions as a transcriptional coactivator. It plays an essential role in the regulation of gene expression by interacting with nuclear receptors, which are transcription factors that bind to specific DNA sequences and control the expression of target genes.
NCoA-2 contains several functional domains, including an intrinsic histone acetyltransferase (HAT) domain, which can acetylate histone proteins and modify chromatin structure, leading to the activation of gene transcription. NCoA-2 also has a bromodomain, which recognizes and binds to acetylated lysine residues on histones, further contributing to its ability to modulate chromatin structure and function.
NCoA-2 interacts with various nuclear receptors, such as the estrogen receptor (ER), glucocorticoid receptor (GR), progesterone receptor (PR), and androgen receptor (AR). By binding to these receptors, NCoA-2 enhances their transcriptional activity, ultimately influencing various physiological processes, including cell growth, differentiation, and metabolism.
Dysregulation of NCoA-2 has been implicated in several diseases, such as cancer, where its overexpression can contribute to tumor progression and hormone resistance. Therefore, understanding the molecular mechanisms underlying NCoA-2 function is crucial for developing novel therapeutic strategies targeting nuclear receptor signaling pathways.
Immediate-early proteins (IEPs) are a class of regulatory proteins that play a crucial role in the early stages of gene expression in viral infection and cellular stress responses. These proteins are synthesized rapidly, without the need for new protein synthesis, after the induction of immediate-early genes (IEGs).
In the context of viral infection, IEPs are often the first proteins produced by the virus upon entry into the host cell. They function as transcription factors that bind to specific DNA sequences and regulate the expression of early and late viral genes required for replication and packaging of the viral genome.
IEPs can also be involved in modulating host cell signaling pathways, altering cell cycle progression, and inducing apoptosis (programmed cell death). Dysregulation of IEPs has been implicated in various diseases, including cancer and neurological disorders.
It is important to note that the term "immediate-early proteins" is primarily used in the context of viral infection, while in other contexts such as cellular stress responses or oncogene activation, these proteins may be referred to by different names, such as "early response genes" or "transcription factors."
Dimerization is a process in which two molecules, usually proteins or similar structures, bind together to form a larger complex. This can occur through various mechanisms, such as the formation of disulfide bonds, hydrogen bonding, or other non-covalent interactions. Dimerization can play important roles in cell signaling, enzyme function, and the regulation of gene expression.
In the context of medical research and therapy, dimerization is often studied in relation to specific proteins that are involved in diseases such as cancer. For example, some drugs have been developed to target and inhibit the dimerization of certain proteins, with the goal of disrupting their function and slowing or stopping the progression of the disease.
'Cercopithecus aethiops' is the scientific name for the monkey species more commonly known as the green monkey. It belongs to the family Cercopithecidae and is native to western Africa. The green monkey is omnivorous, with a diet that includes fruits, nuts, seeds, insects, and small vertebrates. They are known for their distinctive greenish-brown fur and long tail. Green monkeys are also important animal models in biomedical research due to their susceptibility to certain diseases, such as SIV (simian immunodeficiency virus), which is closely related to HIV.
'Drosophila proteins' refer to the proteins that are expressed in the fruit fly, Drosophila melanogaster. This organism is a widely used model system in genetics, developmental biology, and molecular biology research. The study of Drosophila proteins has contributed significantly to our understanding of various biological processes, including gene regulation, cell signaling, development, and aging.
Some examples of well-studied Drosophila proteins include:
1. HSP70 (Heat Shock Protein 70): A chaperone protein involved in protein folding and protection from stress conditions.
2. TUBULIN: A structural protein that forms microtubules, important for cell division and intracellular transport.
3. ACTIN: A cytoskeletal protein involved in muscle contraction, cell motility, and maintenance of cell shape.
4. BETA-GALACTOSIDASE (LACZ): A reporter protein often used to monitor gene expression patterns in transgenic flies.
5. ENDOGLIN: A protein involved in the development of blood vessels during embryogenesis.
6. P53: A tumor suppressor protein that plays a crucial role in preventing cancer by regulating cell growth and division.
7. JUN-KINASE (JNK): A signaling protein involved in stress response, apoptosis, and developmental processes.
8. DECAPENTAPLEGIC (DPP): A member of the TGF-β (Transforming Growth Factor Beta) superfamily, playing essential roles in embryonic development and tissue homeostasis.
These proteins are often studied using various techniques such as biochemistry, genetics, molecular biology, and structural biology to understand their functions, interactions, and regulation within the cell.
I'm happy to help! However, I believe there might be a slight error in your question. The correct term is "FOS" (for immediate-early gene Fos), not "fos genes." Here's the definition of the FOS protein and its associated gene:
FOS is a transcription factor that forms a complex with proteins JUN and JUND, forming the AP-1 (Activator Protein 1) transcription factor complex. The FOS protein plays a crucial role in regulating cell growth, differentiation, and transformation. It binds to specific DNA sequences in the promoter regions of target genes and modulates their expression.
The FOS gene is located on human chromosome 14 (14q21-31) and encodes the FOS protein. The FOS gene belongs to a family of immediate-early genes, which are rapidly activated in response to various extracellular signals such as growth factors, cytokines, and stress. Once activated, these genes regulate the expression of downstream target genes involved in various cellular processes, including proliferation, differentiation, and survival.
I hope this clarifies your question! If you have any more questions or need further information, please don't hesitate to ask.
Gene expression is the process by which the information encoded in a gene is used to synthesize a functional gene product, such as a protein or RNA molecule. This process involves several steps: transcription, RNA processing, and translation. During transcription, the genetic information in DNA is copied into a complementary RNA molecule, known as messenger RNA (mRNA). The mRNA then undergoes RNA processing, which includes adding a cap and tail to the mRNA and splicing out non-coding regions called introns. The resulting mature mRNA is then translated into a protein on ribosomes in the cytoplasm through the process of translation.
The regulation of gene expression is a complex and highly controlled process that allows cells to respond to changes in their environment, such as growth factors, hormones, and stress signals. This regulation can occur at various stages of gene expression, including transcriptional activation or repression, RNA processing, mRNA stability, and translation. Dysregulation of gene expression has been implicated in many diseases, including cancer, genetic disorders, and neurological conditions.
Carrier proteins, also known as transport proteins, are a type of protein that facilitates the movement of molecules across cell membranes. They are responsible for the selective and active transport of ions, sugars, amino acids, and other molecules from one side of the membrane to the other, against their concentration gradient. This process requires energy, usually in the form of ATP (adenosine triphosphate).
Carrier proteins have a specific binding site for the molecule they transport, and undergo conformational changes upon binding, which allows them to move the molecule across the membrane. Once the molecule has been transported, the carrier protein returns to its original conformation, ready to bind and transport another molecule.
Carrier proteins play a crucial role in maintaining the balance of ions and other molecules inside and outside of cells, and are essential for many physiological processes, including nerve impulse transmission, muscle contraction, and nutrient uptake.
Reverse Transcriptase Polymerase Chain Reaction (RT-PCR) is a laboratory technique used in molecular biology to amplify and detect specific DNA sequences. This technique is particularly useful for the detection and quantification of RNA viruses, as well as for the analysis of gene expression.
The process involves two main steps: reverse transcription and polymerase chain reaction (PCR). In the first step, reverse transcriptase enzyme is used to convert RNA into complementary DNA (cDNA) by reading the template provided by the RNA molecule. This cDNA then serves as a template for the PCR amplification step.
In the second step, the PCR reaction uses two primers that flank the target DNA sequence and a thermostable polymerase enzyme to repeatedly copy the targeted cDNA sequence. The reaction mixture is heated and cooled in cycles, allowing the primers to anneal to the template, and the polymerase to extend the new strand. This results in exponential amplification of the target DNA sequence, making it possible to detect even small amounts of RNA or cDNA.
RT-PCR is a sensitive and specific technique that has many applications in medical research and diagnostics, including the detection of viruses such as HIV, hepatitis C virus, and SARS-CoV-2 (the virus that causes COVID-19). It can also be used to study gene expression, identify genetic mutations, and diagnose genetic disorders.
TATA-binding protein associated factors (TAFs) are a group of proteins that associate with the TATA-binding protein (TBP) to form the basal transcription complex, which is involved in the initiation of gene transcription. In eukaryotes, TBP is a general transcription factor that recognizes and binds to the TATA box, a conserved DNA sequence found in the promoter regions of many genes. TAFs interact with TBP and other proteins to form the multi-subunit complex known as TFIID (transcription factor II D).
TAFs can be classified into two categories: TAF1 subunits and TAF2 subunits. The TAF1 subunits are characterized by a conserved histone fold motif, which is also found in the core histones of nucleosomes. These TAF1 subunits play a role in stabilizing the interaction between TBP and DNA, as well as recruiting additional transcription factors to the promoter. The TAF2 subunits, on the other hand, do not contain the histone fold motif and are involved in mediating interactions with other proteins and regulatory elements.
Together, TBP and TAFs help to position the RNA polymerase II enzyme at the start site of transcription and facilitate the assembly of the pre-initiation complex (PIC), which includes additional general transcription factors and mediator proteins. The PIC then initiates the synthesis of mRNA, allowing for the expression of specific genes.
In summary, TATA-binding protein associated factors are a group of proteins that associate with TBP to form the basal transcription complex, which plays a crucial role in the initiation of gene transcription by recruiting RNA polymerase II and other general transcription factors to the promoter region.
A Structure-Activity Relationship (SAR) in the context of medicinal chemistry and pharmacology refers to the relationship between the chemical structure of a drug or molecule and its biological activity or effect on a target protein, cell, or organism. SAR studies aim to identify patterns and correlations between structural features of a compound and its ability to interact with a specific biological target, leading to a desired therapeutic response or undesired side effects.
By analyzing the SAR, researchers can optimize the chemical structure of lead compounds to enhance their potency, selectivity, safety, and pharmacokinetic properties, ultimately guiding the design and development of novel drugs with improved efficacy and reduced toxicity.
A conserved sequence in the context of molecular biology refers to a pattern of nucleotides (in DNA or RNA) or amino acids (in proteins) that has remained relatively unchanged over evolutionary time. These sequences are often functionally important and are highly conserved across different species, indicating strong selection pressure against changes in these regions.
In the case of protein-coding genes, the corresponding amino acid sequence is deduced from the DNA sequence through the genetic code. Conserved sequences in proteins may indicate structurally or functionally important regions, such as active sites or binding sites, that are critical for the protein's activity. Similarly, conserved non-coding sequences in DNA may represent regulatory elements that control gene expression.
Identifying conserved sequences can be useful for inferring evolutionary relationships between species and for predicting the function of unknown genes or proteins.
Basic-leucine zipper (bZIP) transcription factors are a family of transcriptional regulatory proteins characterized by the presence of a basic region and a leucine zipper motif. The basic region, which is rich in basic amino acids such as lysine and arginine, is responsible for DNA binding, while the leucine zipper motif mediates protein-protein interactions and dimerization.
BZIP transcription factors play important roles in various cellular processes, including gene expression regulation, cell growth, differentiation, and stress response. They bind to specific DNA sequences called AP-1 sites, which are often found in the promoter regions of target genes. BZIP transcription factors can form homodimers or heterodimers with other bZIP proteins, allowing for combinatorial control of gene expression.
Examples of bZIP transcription factors include c-Jun, c-Fos, ATF (activating transcription factor), and CREB (cAMP response element-binding protein). Dysregulation of bZIP transcription factors has been implicated in various diseases, including cancer, inflammation, and neurodegenerative disorders.
Histone deacetylases (HDACs) are a group of enzymes that play a crucial role in the regulation of gene expression. They work by removing acetyl groups from histone proteins, which are the structural components around which DNA is wound to form chromatin, the material that makes up chromosomes.
Histone acetylation is a modification that generally results in an "open" chromatin structure, allowing for the transcription of genes into proteins. When HDACs remove these acetyl groups, the chromatin becomes more compact and gene expression is reduced or silenced.
HDACs are involved in various cellular processes, including development, differentiation, and survival. Dysregulation of HDAC activity has been implicated in several diseases, such as cancer, neurodegenerative disorders, and cardiovascular diseases. As a result, HDAC inhibitors have emerged as promising therapeutic agents for these conditions.
Thyroid hormone receptors (THRs) are nuclear receptor proteins that bind to thyroid hormones, triiodothyronine (T3) and thyroxine (T4), and regulate gene transcription in target cells. These receptors play a crucial role in the development, growth, and metabolism of an organism by mediating the actions of thyroid hormones. THRs are encoded by genes THRA and THRB, which give rise to two major isoforms: TRα1 and TRβ1. Additionally, alternative splicing results in other isoforms with distinct tissue distributions and functions. THRs function as heterodimers with retinoid X receptors (RXRs) and bind to thyroid hormone response elements (TREs) in the regulatory regions of target genes. The binding of T3 or T4 to THRs triggers a conformational change, which leads to recruitment of coactivators or corepressors, ultimately resulting in activation or repression of gene transcription.
"Drosophila" is a genus of small flies, also known as fruit flies. The most common species used in scientific research is "Drosophila melanogaster," which has been a valuable model organism for many areas of biological and medical research, including genetics, developmental biology, neurobiology, and aging.
The use of Drosophila as a model organism has led to numerous important discoveries in genetics and molecular biology, such as the identification of genes that are associated with human diseases like cancer, Parkinson's disease, and obesity. The short reproductive cycle, large number of offspring, and ease of genetic manipulation make Drosophila a powerful tool for studying complex biological processes.
Glucocorticoid receptors (GRs) are a type of nuclear receptor proteins found inside cells that bind to glucocorticoids, a class of steroid hormones. These receptors play an essential role in the regulation of various physiological processes, including metabolism, immune response, and stress response.
When a glucocorticoid hormone such as cortisol binds to the GR, it undergoes a conformational change that allows it to translocate into the nucleus of the cell. Once inside the nucleus, the GR acts as a transcription factor, binding to specific DNA sequences called glucocorticoid response elements (GREs) located in the promoter regions of target genes. The binding of the GR to the GRE can either activate or repress gene transcription, depending on the context and the presence of co-regulatory proteins.
Glucocorticoids have diverse effects on the body, including anti-inflammatory and immunosuppressive actions. They are commonly used in clinical settings to treat a variety of conditions such as asthma, rheumatoid arthritis, and inflammatory bowel disease. However, long-term use of glucocorticoids can lead to several side effects, including osteoporosis, weight gain, and increased risk of infections, due to the widespread effects of these hormones on multiple organ systems.
Host Cell Factor C1 (HCF-1) is a large cellular protein that plays a crucial role in the regulation of gene expression and chromatin dynamics within the host cell. It acts as a scaffold or docking platform, interacting with various transcription factors, coactivators, and histone modifying enzymes to form complex regulatory networks involved in different cellular processes such as development, differentiation, and metabolism. HCF-1 is particularly important for the regulation of viral gene expression during infection by certain DNA viruses, including Herpes simplex virus (HSV) and Human cytomegalovirus (HCMV). Mutations in the HCF-1 gene have been associated with neurodevelopmental disorders, highlighting its essential role in normal cellular functioning.
Cell cycle proteins are a group of regulatory proteins that control the progression of the cell cycle, which is the series of events that take place in a eukaryotic cell leading to its division and duplication. These proteins can be classified into several categories based on their functions during different stages of the cell cycle.
The major groups of cell cycle proteins include:
1. Cyclin-dependent kinases (CDKs): CDKs are serine/threonine protein kinases that regulate key transitions in the cell cycle. They require binding to a regulatory subunit called cyclin to become active. Different CDK-cyclin complexes are activated at different stages of the cell cycle.
2. Cyclins: Cyclins are a family of regulatory proteins that bind and activate CDKs. Their levels fluctuate throughout the cell cycle, with specific cyclins expressed during particular phases. For example, cyclin D is important for the G1 to S phase transition, while cyclin B is required for the G2 to M phase transition.
3. CDK inhibitors (CKIs): CKIs are regulatory proteins that bind to and inhibit CDKs, thereby preventing their activation. CKIs can be divided into two main families: the INK4 family and the Cip/Kip family. INK4 family members specifically inhibit CDK4 and CDK6, while Cip/Kip family members inhibit a broader range of CDKs.
4. Anaphase-promoting complex/cyclosome (APC/C): APC/C is an E3 ubiquitin ligase that targets specific proteins for degradation by the 26S proteasome. During the cell cycle, APC/C regulates the metaphase to anaphase transition and the exit from mitosis by targeting securin and cyclin B for degradation.
5. Other regulatory proteins: Several other proteins play crucial roles in regulating the cell cycle, such as p53, a transcription factor that responds to DNA damage and arrests the cell cycle, and the polo-like kinases (PLKs), which are involved in various aspects of mitosis.
Overall, cell cycle proteins work together to ensure the proper progression of the cell cycle, maintain genomic stability, and prevent uncontrolled cell growth, which can lead to cancer.
Up-regulation is a term used in molecular biology and medicine to describe an increase in the expression or activity of a gene, protein, or receptor in response to a stimulus. This can occur through various mechanisms such as increased transcription, translation, or reduced degradation of the molecule. Up-regulation can have important functional consequences, for example, enhancing the sensitivity or response of a cell to a hormone, neurotransmitter, or drug. It is a normal physiological process that can also be induced by disease or pharmacological interventions.
Proto-oncogene proteins c-Myb, also known as MYB proteins, are transcription factors that play crucial roles in the regulation of gene expression during normal cell growth, differentiation, and development. They are named after the avian myeloblastosis virus, which contains an oncogenic version of the c-myb gene.
The human c-Myb protein is encoded by the MYB gene located on chromosome 6 (6q22-q23). This protein contains a highly conserved N-terminal DNA-binding domain, followed by a transcription activation domain and a C-terminal negative regulatory domain. The DNA-binding domain recognizes specific DNA sequences in the promoter regions of target genes, allowing c-Myb to regulate their expression.
Inappropriate activation or overexpression of c-Myb can contribute to oncogenesis, leading to the development of various types of cancer, such as leukemia and lymphoma. This occurs due to uncontrolled cell growth and proliferation, impaired differentiation, and increased resistance to apoptosis (programmed cell death).
Regulation of c-Myb activity is tightly controlled in normal cells through various mechanisms, including post-translational modifications, protein-protein interactions, and degradation. Dysregulation of these control mechanisms can result in the aberrant activation of c-Myb, contributing to oncogenesis.
Transcription Factor IIB (TFIIB) is a general transcription factor that plays an essential role in the initiation of gene transcription by RNA polymerase II in eukaryotic cells. It is a small protein consisting of approximately 350 amino acids and has several functional domains, including a zinc-binding domain, a helix-turn-helix motif, and a cyclin-like fold.
TFIIB acts as a bridge between the RNA polymerase II complex and the promoter DNA, recognizing and binding to specific sequences in the promoter region known as the B recognition element (BRE) and the TATA box. By interacting with other transcription factors, such as TFIIF and TFIIH, TFIIB helps to position RNA polymerase II correctly on the promoter DNA and to unwind the double helix, allowing for the initiation of transcription.
TFIIB is a highly conserved protein across eukaryotes, and mutations in the gene encoding TFIIB have been associated with several human diseases, including developmental disorders and cancer.
Deoxyribonuclease I (DNase I) is an enzyme that cleaves the phosphodiester bonds in the DNA molecule, breaking it down into smaller pieces. It is also known as DNase A or bovine pancreatic deoxyribonuclease. This enzyme specifically hydrolyzes the internucleotide linkages of DNA by cleaving the phosphodiester bond between the 3'-hydroxyl group of one deoxyribose sugar and the phosphate group of another, leaving 3'-phosphomononucleotides as products.
DNase I plays a crucial role in various biological processes, including DNA degradation during apoptosis (programmed cell death), DNA repair, and host defense against pathogens by breaking down extracellular DNA from invading microorganisms or damaged cells. It is widely used in molecular biology research for applications such as DNA isolation, removing contaminating DNA from RNA samples, and generating defined DNA fragments for cloning purposes. DNase I can be found in various sources, including bovine pancreas, human tears, and bacterial cultures.
CCAAT-binding factor (CBF) is a transcription factor that binds to the CCAAT box, a specific DNA sequence found in the promoter regions of many genes. The CBF complex is composed of three subunits, NF-YA, NF-YB, and NF-YC, which are required for its DNA binding activity. The CBF complex plays important roles in various biological processes, including cell cycle regulation, differentiation, and stress response.
Basic Helix-Loop-Helix (bHLH) Leucine Zipper Transcription Factors are a type of transcription factors that share a common structural feature consisting of two amphipathic α-helices connected by a loop. The bHLH domain is involved in DNA binding and dimerization, while the leucine zipper motif mediates further stabilization of the dimer. These transcription factors play crucial roles in various biological processes such as cell fate determination, proliferation, differentiation, and apoptosis. They bind to specific DNA sequences called E-box motifs, which are CANNTG nucleotide sequences, often found in the promoter or enhancer regions of their target genes.
Cell differentiation is the process by which a less specialized cell, or stem cell, becomes a more specialized cell type with specific functions and structures. This process involves changes in gene expression, which are regulated by various intracellular signaling pathways and transcription factors. Differentiation results in the development of distinct cell types that make up tissues and organs in multicellular organisms. It is a crucial aspect of embryonic development, tissue repair, and maintenance of homeostasis in the body.
Retinoid X receptors (RXRs) are a subfamily of nuclear receptor proteins that function as transcription factors, playing crucial roles in the regulation of gene expression. They are activated by binding to retinoids, which are derivatives of vitamin A. RXRs can form heterodimers with other nuclear receptors, such as peroxisome proliferator-activated receptors (PPARs), liver X receptors (LXRs), farnesoid X receptors (FXRs), and thyroid hormone receptors (THRs). Upon activation by their respective ligands, these heterodimers bind to specific DNA sequences called response elements in the promoter regions of target genes, leading to modulation of transcription. RXRs are involved in various biological processes, including cell differentiation, development, metabolism, and homeostasis. Dysregulation of RXR-mediated signaling pathways has been implicated in several diseases, such as cancer, diabetes, and inflammatory disorders.
Regulator genes are a type of gene that regulates the activity of other genes in an organism. They do not code for a specific protein product but instead control the expression of other genes by producing regulatory proteins such as transcription factors, repressors, or enhancers. These regulatory proteins bind to specific DNA sequences near the target genes and either promote or inhibit their transcription into mRNA. This allows regulator genes to play a crucial role in coordinating complex biological processes, including development, differentiation, metabolism, and response to environmental stimuli.
There are several types of regulator genes, including:
1. Constitutive regulators: These genes are always active and produce regulatory proteins that control the expression of other genes in a consistent manner.
2. Inducible regulators: These genes respond to specific signals or environmental stimuli by producing regulatory proteins that modulate the expression of target genes.
3. Negative regulators: These genes produce repressor proteins that bind to DNA and inhibit the transcription of target genes, thereby reducing their expression.
4. Positive regulators: These genes produce activator proteins that bind to DNA and promote the transcription of target genes, thereby increasing their expression.
5. Master regulators: These genes control the expression of multiple downstream target genes involved in specific biological processes or developmental pathways.
Regulator genes are essential for maintaining proper gene expression patterns and ensuring normal cellular function. Mutations in regulator genes can lead to various diseases, including cancer, developmental disorders, and metabolic dysfunctions.
Northern blotting is a laboratory technique used in molecular biology to detect and analyze specific RNA molecules (such as mRNA) in a mixture of total RNA extracted from cells or tissues. This technique is called "Northern" blotting because it is analogous to the Southern blotting method, which is used for DNA detection.
The Northern blotting procedure involves several steps:
1. Electrophoresis: The total RNA mixture is first separated based on size by running it through an agarose gel using electrical current. This separates the RNA molecules according to their length, with smaller RNA fragments migrating faster than larger ones.
2. Transfer: After electrophoresis, the RNA bands are denatured (made single-stranded) and transferred from the gel onto a nitrocellulose or nylon membrane using a technique called capillary transfer or vacuum blotting. This step ensures that the order and relative positions of the RNA fragments are preserved on the membrane, similar to how they appear in the gel.
3. Cross-linking: The RNA is then chemically cross-linked to the membrane using UV light or heat treatment, which helps to immobilize the RNA onto the membrane and prevent it from washing off during subsequent steps.
4. Prehybridization: Before adding the labeled probe, the membrane is prehybridized in a solution containing blocking agents (such as salmon sperm DNA or yeast tRNA) to minimize non-specific binding of the probe to the membrane.
5. Hybridization: A labeled nucleic acid probe, specific to the RNA of interest, is added to the prehybridization solution and allowed to hybridize (form base pairs) with its complementary RNA sequence on the membrane. The probe can be either a DNA or an RNA molecule, and it is typically labeled with a radioactive isotope (such as ³²P) or a non-radioactive label (such as digoxigenin).
6. Washing: After hybridization, the membrane is washed to remove unbound probe and reduce background noise. The washing conditions (temperature, salt concentration, and detergent concentration) are optimized based on the stringency required for specific hybridization.
7. Detection: The presence of the labeled probe is then detected using an appropriate method, depending on the type of label used. For radioactive probes, this typically involves exposing the membrane to X-ray film or a phosphorimager screen and analyzing the resulting image. For non-radioactive probes, detection can be performed using colorimetric, chemiluminescent, or fluorescent methods.
8. Data analysis: The intensity of the signal is quantified and compared to controls (such as housekeeping genes) to determine the relative expression level of the RNA of interest. This information can be used for various purposes, such as identifying differentially expressed genes in response to a specific treatment or comparing gene expression levels across different samples or conditions.
Upstream stimulatory factors (USF) are a group of transcription factors that bind to the promoter or enhancer regions of genes and regulate their expression. They are called "upstream" because they bind to the DNA upstream of the gene's transcription start site. USFs are widely expressed in many tissues and play important roles in various cellular processes, including cell growth, differentiation, and metabolism.
There are two main members of the USF family, USF-1 and USF-2, which are encoded by separate genes but share a high degree of sequence similarity. Both USF proteins contain a conserved basic helix-loop-helix (bHLH) domain that mediates DNA binding and a conserved adjacent leucine zipper motif that facilitates protein dimerization. USFs can form homodimers or heterodimers with each other, as well as with other bHLH proteins, to regulate gene expression.
USFs have been shown to bind to and activate the transcription of a wide range of genes involved in various cellular processes, such as glycolysis, gluconeogenesis, lipid metabolism, and DNA repair. Dysregulation of USF activity has been implicated in several human diseases, including cancer, diabetes, and neurodegenerative disorders. Therefore, understanding the mechanisms of USF-mediated gene regulation may provide insights into the pathophysiology of these diseases and lead to the development of novel therapeutic strategies.
Glutathione transferases (GSTs) are a group of enzymes involved in the detoxification of xenobiotics and endogenous compounds. They facilitate the conjugation of these compounds with glutathione, a tripeptide consisting of cysteine, glutamic acid, and glycine, which results in more water-soluble products that can be easily excreted from the body.
GSTs play a crucial role in protecting cells against oxidative stress and chemical injury by neutralizing reactive electrophilic species and peroxides. They are found in various tissues, including the liver, kidneys, lungs, and intestines, and are classified into several families based on their structure and function.
Abnormalities in GST activity have been associated with increased susceptibility to certain diseases, such as cancer, neurological disorders, and respiratory diseases. Therefore, GSTs have become a subject of interest in toxicology, pharmacology, and clinical research.
Early Growth Response Protein 1 (EGR1) is a transcription factor that belongs to the EGR family of proteins, which are also known as zinc finger transcription factors. EGR1 plays crucial roles in various biological processes, including cell proliferation, differentiation, and apoptosis. It regulates gene expression by binding to specific DNA sequences in the promoter regions of target genes.
EGR1 is rapidly induced in response to a variety of stimuli, such as growth factors, neurotransmitters, and stress signals. Once induced, EGR1 modulates the transcription of downstream target genes involved in different signaling pathways, such as mitogen-activated protein kinase (MAPK), phosphatidylinositol 3-kinase (PI3K), and nuclear factor kappa B (NF-κB) pathways.
EGR1 has been implicated in several physiological and pathological processes, including development, learning and memory, neurodegeneration, and cancer. In the context of cancer, EGR1 can act as a tumor suppressor or an oncogene, depending on the cellular context and the specific target genes it regulates.
Restriction mapping is a technique used in molecular biology to identify the location and arrangement of specific restriction endonuclease recognition sites within a DNA molecule. Restriction endonucleases are enzymes that cut double-stranded DNA at specific sequences, producing fragments of various lengths. By digesting the DNA with different combinations of these enzymes and analyzing the resulting fragment sizes through techniques such as agarose gel electrophoresis, researchers can generate a restriction map - a visual representation of the locations and distances between recognition sites on the DNA molecule. This information is crucial for various applications, including cloning, genome analysis, and genetic engineering.
Genetic models are theoretical frameworks used in genetics to describe and explain the inheritance patterns and genetic architecture of traits, diseases, or phenomena. These models are based on mathematical equations and statistical methods that incorporate information about gene frequencies, modes of inheritance, and the effects of environmental factors. They can be used to predict the probability of certain genetic outcomes, to understand the genetic basis of complex traits, and to inform medical management and treatment decisions.
There are several types of genetic models, including:
1. Mendelian models: These models describe the inheritance patterns of simple genetic traits that follow Mendel's laws of segregation and independent assortment. Examples include autosomal dominant, autosomal recessive, and X-linked inheritance.
2. Complex trait models: These models describe the inheritance patterns of complex traits that are influenced by multiple genes and environmental factors. Examples include heart disease, diabetes, and cancer.
3. Population genetics models: These models describe the distribution and frequency of genetic variants within populations over time. They can be used to study evolutionary processes, such as natural selection and genetic drift.
4. Quantitative genetics models: These models describe the relationship between genetic variation and phenotypic variation in continuous traits, such as height or IQ. They can be used to estimate heritability and to identify quantitative trait loci (QTLs) that contribute to trait variation.
5. Statistical genetics models: These models use statistical methods to analyze genetic data and infer the presence of genetic associations or linkage. They can be used to identify genetic risk factors for diseases or traits.
Overall, genetic models are essential tools in genetics research and medical genetics, as they allow researchers to make predictions about genetic outcomes, test hypotheses about the genetic basis of traits and diseases, and develop strategies for prevention, diagnosis, and treatment.
Methylation, in the context of genetics and epigenetics, refers to the addition of a methyl group (CH3) to a molecule, usually to the nitrogenous base of DNA or to the side chain of amino acids in proteins. In DNA methylation, this process typically occurs at the 5-carbon position of cytosine residues that precede guanine residues (CpG sites) and is catalyzed by enzymes called DNA methyltransferases (DNMTs).
DNA methylation plays a crucial role in regulating gene expression, genomic imprinting, X-chromosome inactivation, and suppression of repetitive elements. Hypermethylation or hypomethylation of specific genes can lead to altered gene expression patterns, which have been associated with various human diseases, including cancer.
In summary, methylation is a fundamental epigenetic modification that influences genomic stability, gene regulation, and cellular function by introducing methyl groups to DNA or proteins.
Biological models, also known as physiological models or organismal models, are simplified representations of biological systems, processes, or mechanisms that are used to understand and explain the underlying principles and relationships. These models can be theoretical (conceptual or mathematical) or physical (such as anatomical models, cell cultures, or animal models). They are widely used in biomedical research to study various phenomena, including disease pathophysiology, drug action, and therapeutic interventions.
Examples of biological models include:
1. Mathematical models: These use mathematical equations and formulas to describe complex biological systems or processes, such as population dynamics, metabolic pathways, or gene regulation networks. They can help predict the behavior of these systems under different conditions and test hypotheses about their underlying mechanisms.
2. Cell cultures: These are collections of cells grown in a controlled environment, typically in a laboratory dish or flask. They can be used to study cellular processes, such as signal transduction, gene expression, or metabolism, and to test the effects of drugs or other treatments on these processes.
3. Animal models: These are living organisms, usually vertebrates like mice, rats, or non-human primates, that are used to study various aspects of human biology and disease. They can provide valuable insights into the pathophysiology of diseases, the mechanisms of drug action, and the safety and efficacy of new therapies.
4. Anatomical models: These are physical representations of biological structures or systems, such as plastic models of organs or tissues, that can be used for educational purposes or to plan surgical procedures. They can also serve as a basis for developing more sophisticated models, such as computer simulations or 3D-printed replicas.
Overall, biological models play a crucial role in advancing our understanding of biology and medicine, helping to identify new targets for therapeutic intervention, develop novel drugs and treatments, and improve human health.
Sequence homology in nucleic acids refers to the similarity or identity between the nucleotide sequences of two or more DNA or RNA molecules. It is often used as a measure of biological relationship between genes, organisms, or populations. High sequence homology suggests a recent common ancestry or functional constraint, while low sequence homology may indicate a more distant relationship or different functions.
Nucleic acid sequence homology can be determined by various methods such as pairwise alignment, multiple sequence alignment, and statistical analysis. The degree of homology is typically expressed as a percentage of identical or similar nucleotides in a given window of comparison.
It's important to note that the interpretation of sequence homology depends on the biological context and the evolutionary distance between the sequences compared. Therefore, functional and experimental validation is often necessary to confirm the significance of sequence homology.
Chromatin assembly and disassembly refer to the processes by which chromatin, the complex of DNA, histone proteins, and other molecules that make up chromosomes, is organized within the nucleus of a eukaryotic cell.
Chromatin assembly refers to the process by which DNA wraps around histone proteins to form nucleosomes, which are then packed together to form higher-order structures. This process is essential for compacting the vast amount of genetic material contained within the cell nucleus and for regulating gene expression. Chromatin assembly is mediated by a variety of protein complexes, including the histone chaperones and ATP-dependent chromatin remodeling enzymes.
Chromatin disassembly, on the other hand, refers to the process by which these higher-order structures are disassembled during cell division, allowing for the equal distribution of genetic material to daughter cells. This process is mediated by phosphorylation of histone proteins by kinases, which leads to the dissociation of nucleosomes and the decondensation of chromatin.
Both Chromatin assembly and disassembly are dynamic and highly regulated processes that play crucial roles in the maintenance of genome stability and the regulation of gene expression.
In genetics, sequence alignment is the process of arranging two or more DNA, RNA, or protein sequences to identify regions of similarity or homology between them. This is often done using computational methods to compare the nucleotide or amino acid sequences and identify matching patterns, which can provide insight into evolutionary relationships, functional domains, or potential genetic disorders. The alignment process typically involves adjusting gaps and mismatches in the sequences to maximize the similarity between them, resulting in an aligned sequence that can be visually represented and analyzed.
Proto-oncogene proteins, such as c-Myc, are crucial regulators of normal cell growth, differentiation, and apoptosis (programmed cell death). When proto-oncogenes undergo mutations or alterations in their regulation, they can become overactive or overexpressed, leading to the formation of oncogenes. Oncogenic forms of c-Myc contribute to uncontrolled cell growth and division, which can ultimately result in cancer development.
The c-Myc protein is a transcription factor that binds to specific DNA sequences, influencing the expression of target genes involved in various cellular processes, such as:
1. Cell cycle progression: c-Myc promotes the expression of genes required for the G1 to S phase transition, driving cells into the DNA synthesis and division phase.
2. Metabolism: c-Myc regulates genes associated with glucose metabolism, glycolysis, and mitochondrial function, enhancing energy production in rapidly dividing cells.
3. Apoptosis: c-Myc can either promote or inhibit apoptosis, depending on the cellular context and the presence of other regulatory factors.
4. Differentiation: c-Myc generally inhibits differentiation by repressing genes that are necessary for specialized cell functions.
5. Angiogenesis: c-Myc can induce the expression of pro-angiogenic factors, promoting the formation of new blood vessels to support tumor growth.
Dysregulation of c-Myc is frequently observed in various types of cancer, making it an important therapeutic target for cancer treatment.
Gene deletion is a type of mutation where a segment of DNA, containing one or more genes, is permanently lost or removed from a chromosome. This can occur due to various genetic mechanisms such as homologous recombination, non-homologous end joining, or other types of genomic rearrangements.
The deletion of a gene can have varying effects on the organism, depending on the function of the deleted gene and its importance for normal physiological processes. If the deleted gene is essential for survival, the deletion may result in embryonic lethality or developmental abnormalities. However, if the gene is non-essential or has redundant functions, the deletion may not have any noticeable effects on the organism's phenotype.
Gene deletions can also be used as a tool in genetic research to study the function of specific genes and their role in various biological processes. For example, researchers may use gene deletion techniques to create genetically modified animal models to investigate the impact of gene deletion on disease progression or development.
Nuclear factor of activated T-cells (NFAT) transcription factors are a group of proteins that play a crucial role in the regulation of gene transcription in various cells, including immune cells. They are involved in the activation of genes responsible for immune responses, cell survival, differentiation, and development.
NFAT transcription factors can be divided into five main members: NFATC1 (also known as NFAT2 or NFATp), NFATC2 (or NFAT1), NFATC3 (or NFATc), NFATC4 (or NFAT3), and NFAT5 (or TonEBP). These proteins share a highly conserved DNA-binding domain, known as the Rel homology region, which allows them to bind to specific sequences in the promoter or enhancer regions of target genes.
NFATC transcription factors are primarily located in the cytoplasm in their inactive form, bound to inhibitory proteins. Upon stimulation of the cell, typically through calcium-dependent signaling pathways, NFAT proteins get dephosphorylated by calcineurin phosphatase, leading to their nuclear translocation and activation. Once in the nucleus, NFATC transcription factors can form homodimers or heterodimers with other transcription factors, such as AP-1, to regulate gene expression.
In summary, NFATC transcription factors are a family of proteins involved in the regulation of gene transcription, primarily in immune cells, and play critical roles in various cellular processes, including immune responses, differentiation, and development.
Mitogen-Activated Protein Kinases (MAPKs) are a family of serine/threonine protein kinases that play crucial roles in various cellular processes, including proliferation, differentiation, transformation, and apoptosis, in response to diverse stimuli such as mitogens, growth factors, hormones, cytokines, and environmental stresses. They are highly conserved across eukaryotes and consist of a three-tiered kinase module composed of MAPK kinase kinases (MAP3Ks), MAPK kinases (MKKs or MAP2Ks), and MAPKs.
Activation of MAPKs occurs through a sequential phosphorylation and activation cascade, where MAP3Ks phosphorylate and activate MKKs, which in turn phosphorylate and activate MAPKs at specific residues (Thr-X-Tyr or Ser-Pro motifs). Once activated, MAPKs can further phosphorylate and regulate various downstream targets, including transcription factors and other protein kinases.
There are four major groups of MAPKs in mammals: extracellular signal-regulated kinases (ERK1/2), c-Jun N-terminal kinases (JNK1/2/3), p38 MAPKs (p38α/β/γ/δ), and ERK5/BMK1. Each group of MAPKs has distinct upstream activators, downstream targets, and cellular functions, allowing for a high degree of specificity in signal transduction and cellular responses. Dysregulation of MAPK signaling pathways has been implicated in various human diseases, including cancer, diabetes, neurodegenerative disorders, and inflammatory diseases.
Complementary DNA (cDNA) is a type of DNA that is synthesized from a single-stranded RNA molecule through the process of reverse transcription. In this process, the enzyme reverse transcriptase uses an RNA molecule as a template to synthesize a complementary DNA strand. The resulting cDNA is therefore complementary to the original RNA molecule and is a copy of its coding sequence, but it does not contain non-coding regions such as introns that are present in genomic DNA.
Complementary DNA is often used in molecular biology research to study gene expression, protein function, and other genetic phenomena. For example, cDNA can be used to create cDNA libraries, which are collections of cloned cDNA fragments that represent the expressed genes in a particular cell type or tissue. These libraries can then be screened for specific genes or gene products of interest. Additionally, cDNA can be used to produce recombinant proteins in heterologous expression systems, allowing researchers to study the structure and function of proteins that may be difficult to express or purify from their native sources.
A point mutation is a type of genetic mutation where a single nucleotide base (A, T, C, or G) in DNA is altered, deleted, or substituted with another nucleotide. Point mutations can have various effects on the organism, depending on the location of the mutation and whether it affects the function of any genes. Some point mutations may not have any noticeable effect, while others might lead to changes in the amino acids that make up proteins, potentially causing diseases or altering traits. Point mutations can occur spontaneously due to errors during DNA replication or be inherited from parents.
Protein-Serine-Threonine Kinases (PSTKs) are a type of protein kinase that catalyzes the transfer of a phosphate group from ATP to the hydroxyl side chains of serine or threonine residues on target proteins. This phosphorylation process plays a crucial role in various cellular signaling pathways, including regulation of metabolism, gene expression, cell cycle progression, and apoptosis. PSTKs are involved in many physiological and pathological processes, and their dysregulation has been implicated in several diseases, such as cancer, diabetes, and neurodegenerative disorders.
Steroid receptors are a type of nuclear receptor protein that are activated by the binding of steroid hormones or related molecules. These receptors play crucial roles in various physiological processes, including development, homeostasis, and metabolism. Steroid receptors function as transcription factors, regulating gene expression when activated by their respective ligands.
There are several subtypes of steroid receptors, classified based on the specific steroid hormones they bind to:
1. Glucocorticoid receptor (GR): Binds to glucocorticoids, which regulate metabolism, immune response, and stress response.
2. Mineralocorticoid receptor (MR): Binds to mineralocorticoids, which regulate electrolyte and fluid balance.
3. Androgen receptor (AR): Binds to androgens, which are male sex hormones that play a role in the development and maintenance of male sexual characteristics.
4. Estrogen receptor (ER): Binds to estrogens, which are female sex hormones that play a role in the development and maintenance of female sexual characteristics.
5. Progesterone receptor (PR): Binds to progesterone, which is a female sex hormone involved in the menstrual cycle and pregnancy.
6. Vitamin D receptor (VDR): Binds to vitamin D, which plays a role in calcium homeostasis and bone metabolism.
Upon ligand binding, steroid receptors undergo conformational changes that allow them to dimerize, interact with co-regulatory proteins, and bind to specific DNA sequences called hormone response elements (HREs) in the promoter regions of target genes. This interaction leads to the recruitment of transcriptional machinery, ultimately resulting in the modulation of gene expression. Dysregulation of steroid receptor signaling has been implicated in various diseases, including cancer, metabolic disorders, and inflammatory conditions.
ELK-1 is a transcription factor that belongs to the ETS domain protein family. Transcription factors are proteins that regulate gene expression by binding to specific DNA sequences, thereby controlling the rate of transcription of genetic information from DNA to RNA. The ETS domain is a conserved DNA-binding domain found in many transcription factors and is named after the E26 transformation-specific sequence, which was first identified in avian erythroblastosis virus.
ELK-1 is specifically involved in the regulation of genes that are responsible for cell growth, differentiation, and survival. It is activated by various signaling pathways, including the mitogen-activated protein kinase (MAPK) pathway, which is critical for relaying signals from the cell surface to the nucleus in response to growth factors, hormones, and other extracellular stimuli. Once activated, ELK-1 translocates to the nucleus, where it binds to specific DNA sequences called ETS-binding sites and recruits other proteins to modulate the transcription of target genes.
Dysregulation of ELK-1 has been implicated in several human diseases, including cancer, cardiovascular disease, and neurological disorders. For example, aberrant activation of ELK-1 has been observed in various types of cancer, such as lung, breast, and prostate cancer, and is often associated with poor clinical outcomes. Therefore, understanding the molecular mechanisms that regulate ELK-1 activity and function is crucial for developing novel therapeutic strategies to treat these diseases.
Octamer Transcription Factor-1 (OTF-1 or Oct-1) is a protein that, in humans, is encoded by the OCT1 gene. It belongs to the class of transcription factors known as POU domain proteins, which are characterized by a highly conserved DNA-binding domain called the POU domain.
Oct-1 binds to the octamer motif (ATGCAAAT) in the regulatory regions of many genes and plays a crucial role in regulating their expression. It can act as both an activator and repressor of transcription, depending on the context and the interactions with other proteins. Oct-1 is widely expressed in various tissues and is involved in several cellular processes, including cell cycle regulation, differentiation, and DNA damage response.
Fungal genes refer to the genetic material present in fungi, which are eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. The genetic material of fungi is composed of DNA, just like in other eukaryotes, and is organized into chromosomes located in the nucleus of the cell.
Fungal genes are segments of DNA that contain the information necessary to produce proteins and RNA molecules required for various cellular functions. These genes are transcribed into messenger RNA (mRNA) molecules, which are then translated into proteins by ribosomes in the cytoplasm.
Fungal genomes have been sequenced for many species, revealing a diverse range of genes that encode proteins involved in various cellular processes such as metabolism, signaling, and regulation. Comparative genomic analyses have also provided insights into the evolutionary relationships among different fungal lineages and have helped to identify unique genetic features that distinguish fungi from other eukaryotes.
Understanding fungal genes and their functions is essential for advancing our knowledge of fungal biology, as well as for developing new strategies to control fungal pathogens that can cause diseases in humans, animals, and plants.
Basic Helix-Loop-Helix (bHLH) transcription factors are a type of proteins that regulate gene expression through binding to specific DNA sequences. They play crucial roles in various biological processes, including cell growth, differentiation, and apoptosis. The bHLH domain is composed of two amphipathic α-helices separated by a loop region. This structure allows the formation of homodimers or heterodimers, which then bind to the E-box DNA motif (5'-CANNTG-3') to regulate transcription.
The bHLH family can be further divided into several subfamilies based on their sequence similarities and functional characteristics. Some members of this family are involved in the development and function of the nervous system, while others play critical roles in the development of muscle and bone. Dysregulation of bHLH transcription factors has been implicated in various human diseases, including cancer and neurodevelopmental disorders.
An oligonucleotide probe is a short, single-stranded DNA or RNA molecule that contains a specific sequence of nucleotides designed to hybridize with a complementary sequence in a target nucleic acid (DNA or RNA). These probes are typically 15-50 nucleotides long and are used in various molecular biology techniques, such as polymerase chain reaction (PCR), DNA sequencing, microarray analysis, and blotting methods.
Oligonucleotide probes can be labeled with various reporter molecules, like fluorescent dyes or radioactive isotopes, to enable the detection of hybridized targets. The high specificity of oligonucleotide probes allows for the precise identification and quantification of target nucleic acids in complex biological samples, making them valuable tools in diagnostic, research, and forensic applications.
Jurkat cells are a type of human immortalized T lymphocyte (a type of white blood cell) cell line that is commonly used in scientific research. They were originally isolated from the peripheral blood of a patient with acute T-cell leukemia. Jurkat cells are widely used as a model system to study T-cell activation, signal transduction, and apoptosis (programmed cell death). They are also used in the study of HIV infection and replication, as they can be infected with the virus and used to investigate viral replication and host cell responses.
Yeasts are single-celled microorganisms that belong to the fungus kingdom. They are characterized by their ability to reproduce asexually through budding or fission, and they obtain nutrients by fermenting sugars and other organic compounds. Some species of yeast can cause infections in humans, known as candidiasis or "yeast infections." These infections can occur in various parts of the body, including the skin, mouth, genitals, and internal organs. Common symptoms of a yeast infection may include itching, redness, irritation, and discharge. Yeast infections are typically treated with antifungal medications.
Activating Transcription Factor 2 (ATF-2) is a protein that belongs to the family of leucine zipper transcription factors. It plays a crucial role in regulating gene expression in response to various cellular stress signals, such as inflammation, DNA damage, and oxidative stress. ATF-2 can bind to specific DNA sequences called cis-acting elements, located within the promoter regions of target genes, and activate their transcription.
ATF-2 forms homodimers or heterodimers with other proteins, such as c-Jun, to regulate gene expression. The activity of ATF-2 is tightly controlled through various post-translational modifications, including phosphorylation, which can modulate its DNA binding and transactivation properties.
ATF-2 has been implicated in several biological processes, such as cell growth, differentiation, and apoptosis, and its dysregulation has been associated with various diseases, including cancer, neurodegenerative disorders, and cardiovascular diseases.
Smad4 protein is a transcription factor that plays a crucial role in the signaling pathways of transforming growth factor-beta (TGF-β), bone morphogenetic proteins (BMPs), and activins. These signaling pathways are involved in various cellular processes, including cell proliferation, differentiation, apoptosis, and migration.
Smad4 is the common mediator of these pathways and forms a complex with Smad2 or Smad3 upon TGF-β/activin stimulation or with Smad1, Smad5, or Smad8 upon BMP stimulation. The resulting complex then translocates to the nucleus, where it regulates gene expression by binding to specific DNA sequences and interacting with other transcription factors.
Smad4 also plays a role in negative feedback regulation of TGF-β signaling by promoting the expression of inhibitory Smads (Smad6 and Smad7), which compete for receptor binding and prevent further signal transduction. Mutations in the Smad4 gene have been associated with various human diseases, including cancer and vascular disorders.
Proto-oncogene proteins c-ets are a family of transcription factors that play crucial roles in regulating various cellular processes, including cell growth, differentiation, and apoptosis. These proteins contain a highly conserved DNA-binding domain known as the ETS domain, which recognizes and binds to specific DNA sequences in the promoter regions of target genes.
The c-ets proto-oncogenes encode for these transcription factors, and they can become oncogenic when they are abnormally activated or overexpressed due to genetic alterations such as chromosomal translocations, gene amplifications, or point mutations. Once activated, c-ets proteins can dysregulate the expression of genes involved in cell cycle control, survival, and angiogenesis, leading to tumor development and progression.
Abnormal activation of c-ets proto-oncogene proteins has been implicated in various types of cancer, including leukemia, lymphoma, breast, prostate, and lung cancer. Therefore, understanding the function and regulation of c-ets proto-oncogene proteins is essential for developing novel therapeutic strategies to treat cancer.
NIH 3T3 cells are a type of mouse fibroblast cell line that was developed by the National Institutes of Health (NIH). The "3T3" designation refers to the fact that these cells were derived from embryonic Swiss mouse tissue and were able to be passaged (i.e., subcultured) more than three times in tissue culture.
NIH 3T3 cells are widely used in scientific research, particularly in studies involving cell growth and differentiation, signal transduction, and gene expression. They have also been used as a model system for studying the effects of various chemicals and drugs on cell behavior. NIH 3T3 cells are known to be relatively easy to culture and maintain, and they have a stable, flat morphology that makes them well-suited for use in microscopy studies.
It is important to note that, as with any cell line, it is essential to verify the identity and authenticity of NIH 3T3 cells before using them in research, as contamination or misidentification can lead to erroneous results.
TCF (T-cell factor) transcription factors are a family of proteins that play a crucial role in the Wnt signaling pathway, which is involved in various biological processes such as cell proliferation, differentiation, and migration. TCF transcription factors bind to specific DNA sequences in the promoter region of target genes and regulate their transcription.
In the absence of Wnt signaling, TCF proteins form a complex with transcriptional repressors, which inhibits gene transcription. When Wnt ligands bind to their receptors, they initiate a cascade of intracellular signals that result in the accumulation and nuclear localization of β-catenin, a key player in the Wnt signaling pathway.
In the nucleus, β-catenin interacts with TCF proteins, displacing the transcriptional repressors and converting TCF into an activator of gene transcription. This leads to the expression of target genes that are involved in various cellular processes, including cell cycle regulation, stem cell maintenance, and tumorigenesis.
Mutations in TCF transcription factors or components of the Wnt signaling pathway have been implicated in several human diseases, including cancer, developmental disorders, and degenerative diseases.
Transcription factors (TFs) are proteins that regulate the transcription of genetic information from DNA to RNA by binding to specific DNA sequences. They play a crucial role in controlling gene expression, which is the process by which information in genes is converted into a functional product, such as a protein.
TFII, on the other hand, refers to a general class of transcription factors that are involved in the initiation of RNA polymerase II-dependent transcription. These proteins are often referred to as "general transcription factors" because they are required for the transcription of most protein-coding genes in eukaryotic cells.
TFII factors help to assemble the preinitiation complex (PIC) at the promoter region of a gene, which is a group of proteins that includes RNA polymerase II and other cofactors necessary for transcription. Once the PIC is assembled, TFII factors help to recruit RNA polymerase II to the promoter and initiate transcription.
Some examples of TFII factors include TFIIA, TFIIB, TFIID, TFIIE, TFIIF, and TFIIH. Each of these factors plays a specific role in the initiation of transcription, such as recognizing and binding to specific DNA sequences or modifying the chromatin structure around the promoter to make it more accessible to RNA polymerase II.
Beta-catenin is a protein that plays a crucial role in gene transcription and cell-cell adhesion. It is a key component of the Wnt signaling pathway, which regulates various processes such as cell proliferation, differentiation, and migration during embryonic development and tissue homeostasis in adults.
In the absence of Wnt signals, beta-catenin forms a complex with other proteins, including adenomatous polyposis coli (APC) and axin, which targets it for degradation by the proteasome. When Wnt ligands bind to their receptors, this complex is disrupted, allowing beta-catenin to accumulate in the cytoplasm and translocate to the nucleus. In the nucleus, beta-catenin interacts with T cell factor/lymphoid enhancer-binding factor (TCF/LEF) transcription factors to activate the transcription of target genes involved in cell fate determination, survival, and proliferation.
Mutations in the genes encoding components of the Wnt signaling pathway, including beta-catenin, have been implicated in various human diseases, such as cancer, developmental disorders, and degenerative conditions.
Serine is an amino acid, which is a building block of proteins. More specifically, it is a non-essential amino acid, meaning that the body can produce it from other compounds, and it does not need to be obtained through diet. Serine plays important roles in the body, such as contributing to the formation of the protective covering of nerve fibers (myelin sheath), helping to synthesize another amino acid called tryptophan, and taking part in the metabolism of fatty acids. It is also involved in the production of muscle tissues, the immune system, and the forming of cell structures. Serine can be found in various foods such as soy, eggs, cheese, meat, peanuts, lentils, and many others.
I'm sorry for any confusion, but "Active Transport, Cell Nucleus" is not a widely recognized or established medical term. Active transport typically refers to the energy-dependent process by which cells move molecules across their membranes against their concentration gradient. This process is facilitated by transport proteins and requires ATP as an energy source. However, this process primarily occurs in the cell membrane and not in the cell nucleus.
The cell nucleus, on the other hand, contains genetic material (DNA) and is responsible for controlling various cellular activities such as gene expression, replication, and repair. While there are transport processes that occur within the nucleus, they do not typically involve active transport in the same way that it occurs at the cell membrane.
Therefore, a medical definition of "Active Transport, Cell Nucleus" would not be applicable or informative in this context.
Nuclear Factor I (NFI) transcription factors are a family of transcriptional regulatory proteins that bind to specific DNA sequences and play crucial roles in the regulation of gene expression. They are involved in various biological processes, including cell growth, differentiation, and development. NFI transcription factors recognize and bind to the consensus sequence TTGGC(N)5GCCAA, where N represents any nucleotide. In humans, there are four known members of the NFI family (NFIA, NFIB, NFIC, and NFIX), each with distinct expression patterns and functions. These factors can act as both activators and repressors of transcription, depending on the context and interacting proteins.
Transcription Factor RelA, also known as NF-kB (nuclear factor kappa-light-chain-enhancer of activated B cells) p65, is a protein complex that plays a crucial role in regulating the immune response to infection and inflammation, as well as cell survival, differentiation, and proliferation.
RelA is one of the five subunits that make up the NF-kB protein complex, and it is responsible for the transcriptional activation of target genes. In response to various stimuli such as cytokines, bacterial or viral antigens, and stress signals, RelA can be activated by phosphorylation and then translocate into the nucleus where it binds to specific DNA sequences called kB sites in the promoter regions of target genes. This binding leads to the recruitment of coactivators and the initiation of transcription.
RelA has been implicated in a wide range of biological processes, including inflammation, immunity, cell growth, and apoptosis. Dysregulation of NF-kB signaling and RelA activity has been associated with various diseases, such as cancer, autoimmune disorders, and neurodegenerative diseases.
Estrogen receptors (ERs) are a type of nuclear receptor protein that are expressed in various tissues and cells throughout the body. They play a critical role in the regulation of gene expression and cellular responses to the hormone estrogen. There are two main subtypes of ERs, ERα and ERβ, which have distinct molecular structures, expression patterns, and functions.
ERs function as transcription factors that bind to specific DNA sequences called estrogen response elements (EREs) in the promoter regions of target genes. When estrogen binds to the ER, it causes a conformational change in the receptor that allows it to recruit co-activator proteins and initiate transcription of the target gene. This process can lead to a variety of cellular responses, including changes in cell growth, differentiation, and metabolism.
Estrogen receptors are involved in a wide range of physiological processes, including the development and maintenance of female reproductive tissues, bone homeostasis, cardiovascular function, and cognitive function. They have also been implicated in various pathological conditions, such as breast cancer, endometrial cancer, and osteoporosis. As a result, ERs are an important target for therapeutic interventions in these diseases.
Fibroblasts are specialized cells that play a critical role in the body's immune response and wound healing process. They are responsible for producing and maintaining the extracellular matrix (ECM), which is the non-cellular component present within all tissues and organs, providing structural support and biochemical signals for surrounding cells.
Fibroblasts produce various ECM proteins such as collagens, elastin, fibronectin, and laminins, forming a complex network of fibers that give tissues their strength and flexibility. They also help in the regulation of tissue homeostasis by controlling the turnover of ECM components through the process of remodeling.
In response to injury or infection, fibroblasts become activated and start to proliferate rapidly, migrating towards the site of damage. Here, they participate in the inflammatory response, releasing cytokines and chemokines that attract immune cells to the area. Additionally, they deposit new ECM components to help repair the damaged tissue and restore its functionality.
Dysregulation of fibroblast activity has been implicated in several pathological conditions, including fibrosis (excessive scarring), cancer (where they can contribute to tumor growth and progression), and autoimmune diseases (such as rheumatoid arthritis).
Amino acid motifs are recurring patterns or sequences of amino acids in a protein molecule. These motifs can be identified through various sequence analysis techniques and often have functional or structural significance. They can be as short as two amino acids in length, but typically contain at least three to five residues.
Some common examples of amino acid motifs include:
1. Active site motifs: These are specific sequences of amino acids that form the active site of an enzyme and participate in catalyzing chemical reactions. For example, the catalytic triad in serine proteases consists of three residues (serine, histidine, and aspartate) that work together to hydrolyze peptide bonds.
2. Signal peptide motifs: These are sequences of amino acids that target proteins for secretion or localization to specific organelles within the cell. For example, a typical signal peptide consists of a positively charged n-region, a hydrophobic h-region, and a polar c-region that directs the protein to the endoplasmic reticulum membrane for translocation.
3. Zinc finger motifs: These are structural domains that contain conserved sequences of amino acids that bind zinc ions and play important roles in DNA recognition and regulation of gene expression.
4. Transmembrane motifs: These are sequences of hydrophobic amino acids that span the lipid bilayer of cell membranes and anchor transmembrane proteins in place.
5. Phosphorylation sites: These are specific serine, threonine, or tyrosine residues that can be phosphorylated by protein kinases to regulate protein function.
Understanding amino acid motifs is important for predicting protein structure and function, as well as for identifying potential drug targets in disease-associated proteins.
Activating Transcription Factor 1 (ATF-1) is a protein that belongs to the family of leucine zipper transcription factors. It plays a crucial role in regulating gene expression by binding to specific DNA sequences, known as cAMP response elements (CREs), and activating the transcription of target genes.
ATF-1 forms homodimers or heterodimers with other members of the CREB/ATF family and binds to the CRE sites in the promoter regions of target genes. The activity of ATF-1 is regulated by various signaling pathways, including the cAMP-PKA pathway, which can modulate its transcriptional activity by phosphorylation.
ATF-1 has been implicated in several biological processes, such as cell growth, differentiation, and stress response. Dysregulation of ATF-1 has been associated with various diseases, including cancer, where it can act as a tumor suppressor or an oncogene depending on the context.
In the context of medicine and pharmacology, "kinetics" refers to the study of how a drug moves throughout the body, including its absorption, distribution, metabolism, and excretion (often abbreviated as ADME). This field is called "pharmacokinetics."
1. Absorption: This is the process of a drug moving from its site of administration into the bloodstream. Factors such as the route of administration (e.g., oral, intravenous, etc.), formulation, and individual physiological differences can affect absorption.
2. Distribution: Once a drug is in the bloodstream, it gets distributed throughout the body to various tissues and organs. This process is influenced by factors like blood flow, protein binding, and lipid solubility of the drug.
3. Metabolism: Drugs are often chemically modified in the body, typically in the liver, through processes known as metabolism. These changes can lead to the formation of active or inactive metabolites, which may then be further distributed, excreted, or undergo additional metabolic transformations.
4. Excretion: This is the process by which drugs and their metabolites are eliminated from the body, primarily through the kidneys (urine) and the liver (bile).
Understanding the kinetics of a drug is crucial for determining its optimal dosing regimen, potential interactions with other medications or foods, and any necessary adjustments for special populations like pediatric or geriatric patients, or those with impaired renal or hepatic function.
Serum Response Factor (SRF) is a transcription factor that binds to the serum response element (SRE) in the promoter region of many immediate early genes and some cell type-specific genes. SRF plays a crucial role in regulating various cellular processes, including gene expression related to differentiation, proliferation, and survival of cells. It is activated by various signals such as growth factors, cytokines, and mechanical stress, which leads to changes in the actin cytoskeleton and gene transcription. SRF also interacts with other cofactors to modulate its transcriptional activity, contributing to the specificity of gene regulation in different cell types.
Smad3 protein is a transcription factor that plays a crucial role in the TGF-β (transforming growth factor-beta) signaling pathway. When TGF-β binds to its receptor, it activates Smad3 through phosphorylation. Activated Smad3 then forms a complex with other Smad proteins and translocates into the nucleus where it regulates the transcription of target genes involved in various cellular processes such as proliferation, differentiation, apoptosis, and migration.
Mutations in the SMAD3 gene or dysregulation of the TGF-β/Smad3 signaling pathway have been implicated in several human diseases, including fibrotic disorders, cancer, and Marfan syndrome. Therefore, Smad3 protein is an important target for therapeutic interventions in these conditions.
Macromolecular substances, also known as macromolecules, are large, complex molecules made up of repeating subunits called monomers. These substances are formed through polymerization, a process in which many small molecules combine to form a larger one. Macromolecular substances can be naturally occurring, such as proteins, DNA, and carbohydrates, or synthetic, such as plastics and synthetic fibers.
In the context of medicine, macromolecular substances are often used in the development of drugs and medical devices. For example, some drugs are designed to bind to specific macromolecules in the body, such as proteins or DNA, in order to alter their function and produce a therapeutic effect. Additionally, macromolecular substances may be used in the creation of medical implants, such as artificial joints and heart valves, due to their strength and durability.
It is important for healthcare professionals to have an understanding of macromolecular substances and how they function in the body, as this knowledge can inform the development and use of medical treatments.
Phosphoproteins are proteins that have been post-translationally modified by the addition of a phosphate group (-PO3H2) onto specific amino acid residues, most commonly serine, threonine, or tyrosine. This process is known as phosphorylation and is mediated by enzymes called kinases. Phosphoproteins play crucial roles in various cellular processes such as signal transduction, cell cycle regulation, metabolism, and gene expression. The addition or removal of a phosphate group can activate or inhibit the function of a protein, thereby serving as a switch to control its activity. Phosphoproteins can be detected and quantified using techniques such as Western blotting, mass spectrometry, and immunofluorescence.
Fungal DNA refers to the genetic material present in fungi, which are a group of eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. The DNA of fungi, like that of all living organisms, is made up of nucleotides that are arranged in a double helix structure.
Fungal DNA contains the genetic information necessary for the growth, development, and reproduction of fungi. This includes the instructions for making proteins, which are essential for the structure and function of cells, as well as other important molecules such as enzymes and nucleic acids.
Studying fungal DNA can provide valuable insights into the biology and evolution of fungi, as well as their potential uses in medicine, agriculture, and industry. For example, researchers have used genetic engineering techniques to modify the DNA of fungi to produce drugs, biofuels, and other useful products. Additionally, understanding the genetic makeup of pathogenic fungi can help scientists develop new strategies for preventing and treating fungal infections.
Kruppel-like transcription factors (KLFs) are a family of transcription factors that are characterized by their highly conserved DNA-binding domain, known as the Kruppel-like zinc finger domain. This domain consists of approximately 30 amino acids and is responsible for binding to specific DNA sequences, thereby regulating gene expression.
KLFs play important roles in various biological processes, including cell proliferation, differentiation, apoptosis, and inflammation. They are involved in the development and function of many tissues and organs, such as the hematopoietic system, cardiovascular system, nervous system, and gastrointestinal tract.
There are 17 known members of the KLF family in humans, each with distinct functions and expression patterns. Some KLFs act as transcriptional activators, while others function as repressors. Dysregulation of KLFs has been implicated in various diseases, including cancer, cardiovascular disease, and diabetes.
Overall, Kruppel-like transcription factors are crucial regulators of gene expression that play important roles in normal development and physiology, as well as in the pathogenesis of various diseases.
Lymphoid Enhancer-Binding Factor 1 (LEF1) is a protein that functions as a transcription factor, playing a crucial role in the Wnt signaling pathway. It is involved in the regulation of gene expression, particularly during embryonic development and immune system function. LEF1 helps control the differentiation and proliferation of certain cells, including B and T lymphocytes, which are essential for adaptive immunity. Mutations in the LEF1 gene have been associated with various human diseases, such as cancer and immunodeficiency disorders.
Cyclins are a family of regulatory proteins that play a crucial role in the cell cycle, which is the series of events that take place as a cell grows, divides, and produces two daughter cells. They are called cyclins because their levels fluctuate or cycle during the different stages of the cell cycle.
Cyclins function as subunits of serine/threonine protein kinase complexes, forming an active enzyme that adds phosphate groups to other proteins, thereby modifying their activity. This post-translational modification is a critical mechanism for controlling various cellular processes, including the regulation of the cell cycle.
There are several types of cyclins (A, B, D, and E), each of which is active during specific phases of the cell cycle:
1. Cyclin D: Expressed in the G1 phase, it helps to initiate the cell cycle by activating cyclin-dependent kinases (CDKs) that promote progression through the G1 restriction point.
2. Cyclin E: Active during late G1 and early S phases, it forms a complex with CDK2 to regulate the transition from G1 to S phase, where DNA replication occurs.
3. Cyclin A: Expressed in the S and G2 phases, it associates with both CDK2 and CDK1 to control the progression through the S and G2 phases and entry into mitosis (M phase).
4. Cyclin B: Active during late G2 and M phases, it partners with CDK1 to regulate the onset of mitosis by controlling the breakdown of the nuclear envelope, chromosome condensation, and spindle formation.
The activity of cyclins is tightly controlled through several mechanisms, including transcriptional regulation, protein degradation, and phosphorylation/dephosphorylation events. Dysregulation of cyclin expression or function can lead to uncontrolled cell growth and proliferation, which are hallmarks of cancer.
Estrogen Receptor alpha (ERα) is a type of nuclear receptor protein that is activated by the hormone estrogen. It is encoded by the gene ESR1 and is primarily expressed in the cells of the reproductive system, breast, bone, liver, heart, and brain tissue.
When estrogen binds to ERα, it causes a conformational change in the receptor, which allows it to dimerize and translocate to the nucleus. Once in the nucleus, ERα functions as a transcription factor, binding to specific DNA sequences called estrogen response elements (EREs) and regulating the expression of target genes.
ERα plays important roles in various physiological processes, including the development and maintenance of female reproductive organs, bone homeostasis, and lipid metabolism. It is also a critical factor in the growth and progression of certain types of breast cancer, making ERα status an important consideration in the diagnosis and treatment of this disease.
A ligand, in the context of biochemistry and medicine, is a molecule that binds to a specific site on a protein or a larger biomolecule, such as an enzyme or a receptor. This binding interaction can modify the function or activity of the target protein, either activating it or inhibiting it. Ligands can be small molecules, like hormones or neurotransmitters, or larger structures, like antibodies. The study of ligand-protein interactions is crucial for understanding cellular processes and developing drugs, as many therapeutic compounds function by binding to specific targets within the body.
Small interfering RNA (siRNA) is a type of short, double-stranded RNA molecule that plays a role in the RNA interference (RNAi) pathway. The RNAi pathway is a natural cellular process that regulates gene expression by targeting and destroying specific messenger RNA (mRNA) molecules, thereby preventing the translation of those mRNAs into proteins.
SiRNAs are typically 20-25 base pairs in length and are generated from longer double-stranded RNA precursors called hairpin RNAs or dsRNAs by an enzyme called Dicer. Once generated, siRNAs associate with a protein complex called the RNA-induced silencing complex (RISC), which uses one strand of the siRNA (the guide strand) to recognize and bind to complementary sequences in the target mRNA. The RISC then cleaves the target mRNA, leading to its degradation and the inhibition of protein synthesis.
SiRNAs have emerged as a powerful tool for studying gene function and have shown promise as therapeutic agents for a variety of diseases, including viral infections, cancer, and genetic disorders. However, their use as therapeutics is still in the early stages of development, and there are challenges associated with delivering siRNAs to specific cells and tissues in the body.
A neoplasm is a tumor or growth that is formed by an abnormal and excessive proliferation of cells, which can be benign or malignant. Neoplasm proteins are therefore any proteins that are expressed or produced in these neoplastic cells. These proteins can play various roles in the development, progression, and maintenance of neoplasms.
Some neoplasm proteins may contribute to the uncontrolled cell growth and division seen in cancer, such as oncogenic proteins that promote cell cycle progression or inhibit apoptosis (programmed cell death). Others may help the neoplastic cells evade the immune system, allowing them to proliferate undetected. Still others may be involved in angiogenesis, the formation of new blood vessels that supply the tumor with nutrients and oxygen.
Neoplasm proteins can also serve as biomarkers for cancer diagnosis, prognosis, or treatment response. For example, the presence or level of certain neoplasm proteins in biological samples such as blood or tissue may indicate the presence of a specific type of cancer, help predict the likelihood of cancer recurrence, or suggest whether a particular therapy will be effective.
Overall, understanding the roles and behaviors of neoplasm proteins can provide valuable insights into the biology of cancer and inform the development of new diagnostic and therapeutic strategies.
I'm sorry for any confusion, but the term "genes, jun" does not appear to be a recognized or established medical term or concept in genetics or molecular biology. It is possible that there may be some misunderstanding or typo in the phrase. If you have any specific questions about genes or genetics, I would be happy to try and help clarify those for you.
In general, a gene is a segment of DNA that contains the instructions for making a particular protein or performing a specific function in the body. Genes are passed down from parents to offspring and can vary between individuals, leading to differences in traits and characteristics.
Heat-shock proteins (HSPs) are a group of conserved proteins that are produced by cells in response to stressful conditions, such as increased temperature, exposure to toxins, or infection. They play an essential role in protecting cells and promoting their survival under stressful conditions by assisting in the proper folding and assembly of other proteins, preventing protein aggregation, and helping to refold or degrade damaged proteins. HSPs are named according to their molecular weight, for example, HSP70 and HSP90. They are found in all living organisms, from bacteria to humans, indicating their fundamental importance in cellular function and survival.
Protein-Arginine N-Methyltransferases (PRMTs) are a group of enzymes that catalyze the transfer of methyl groups from S-adenosylmethionine to specific arginine residues in proteins, leading to the formation of N-methylarginines. This post-translational modification plays a crucial role in various cellular processes such as signal transduction, DNA repair, and RNA processing. There are nine known PRMTs in humans, which can be classified into three types based on the type of methylarginine produced: Type I (PRMT1, 2, 3, 4, 6, and 8) produce asymmetric dimethylarginines, Type II (PRMT5 and 9) produce symmetric dimethylarginines, and Type III (PRMT7) produces monomethylarginine. Aberrant PRMT activity has been implicated in several diseases, including cancer and neurological disorders.
Intracellular signaling peptides and proteins are molecules that play a crucial role in transmitting signals within cells, which ultimately lead to changes in cell behavior or function. These signals can originate from outside the cell (extracellular) or within the cell itself. Intracellular signaling molecules include various types of peptides and proteins, such as:
1. G-protein coupled receptors (GPCRs): These are seven-transmembrane domain receptors that bind to extracellular signaling molecules like hormones, neurotransmitters, or chemokines. Upon activation, they initiate a cascade of intracellular signals through G proteins and secondary messengers.
2. Receptor tyrosine kinases (RTKs): These are transmembrane receptors that bind to growth factors, cytokines, or hormones. Activation of RTKs leads to autophosphorylation of specific tyrosine residues, creating binding sites for intracellular signaling proteins such as adapter proteins, phosphatases, and enzymes like Ras, PI3K, and Src family kinases.
3. Second messenger systems: Intracellular second messengers are small molecules that amplify and propagate signals within the cell. Examples include cyclic adenosine monophosphate (cAMP), cyclic guanosine monophosphate (cGMP), diacylglycerol (DAG), inositol triphosphate (IP3), calcium ions (Ca2+), and nitric oxide (NO). These second messengers activate or inhibit various downstream effectors, leading to changes in cellular responses.
4. Signal transduction cascades: Intracellular signaling proteins often form complex networks of interacting molecules that relay signals from the plasma membrane to the nucleus. These cascades involve kinases (protein kinases A, B, C, etc.), phosphatases, and adapter proteins, which ultimately regulate gene expression, cell cycle progression, metabolism, and other cellular processes.
5. Ubiquitination and proteasome degradation: Intracellular signaling pathways can also control protein stability by modulating ubiquitin-proteasome degradation. E3 ubiquitin ligases recognize specific substrates and conjugate them with ubiquitin molecules, targeting them for proteasomal degradation. This process regulates the abundance of key signaling proteins and contributes to signal termination or amplification.
In summary, intracellular signaling pathways involve a complex network of interacting proteins that relay signals from the plasma membrane to various cellular compartments, ultimately regulating gene expression, metabolism, and other cellular processes. Dysregulation of these pathways can contribute to disease development and progression, making them attractive targets for therapeutic intervention.
Retroviridae proteins, oncogenic, refer to the proteins expressed by retroviruses that have the ability to transform normal cells into cancerous ones. These oncogenic proteins are typically encoded by viral genes known as "oncogenes," which are acquired through the process of transduction from the host cell's DNA during retroviral replication.
The most well-known example of an oncogenic retrovirus is the Human T-cell Leukemia Virus Type 1 (HTLV-1), which encodes the Tax and HBZ oncoproteins. These proteins manipulate various cellular signaling pathways, leading to uncontrolled cell growth and malignant transformation.
It is important to note that not all retroviruses are oncogenic, and only a small subset of them have been associated with cancer development in humans or animals.
Polymerase Chain Reaction (PCR) is a laboratory technique used to amplify specific regions of DNA. It enables the production of thousands to millions of copies of a particular DNA sequence in a rapid and efficient manner, making it an essential tool in various fields such as molecular biology, medical diagnostics, forensic science, and research.
The PCR process involves repeated cycles of heating and cooling to separate the DNA strands, allow primers (short sequences of single-stranded DNA) to attach to the target regions, and extend these primers using an enzyme called Taq polymerase, resulting in the exponential amplification of the desired DNA segment.
In a medical context, PCR is often used for detecting and quantifying specific pathogens (viruses, bacteria, fungi, or parasites) in clinical samples, identifying genetic mutations or polymorphisms associated with diseases, monitoring disease progression, and evaluating treatment effectiveness.
The HIV Long Terminal Repeat (LTR) is a regulatory region of the human immunodeficiency virus (HIV) genome that contains important sequences necessary for the transcription and replication of the virus. The LTR is divided into several functional regions, including the U3, R, and U5 regions.
The U3 region contains various transcription factor binding sites that regulate the initiation of viral transcription. The R region contains a promoter element that helps to recruit the enzyme RNA polymerase II for the transcription process. The U5 region contains signals required for the proper processing and termination of viral RNA transcription.
The LTR plays a crucial role in the life cycle of HIV, as it is involved in the integration of the viral genome into the host cell's DNA, allowing the virus to persist and replicate within the infected cell. Understanding the function and regulation of the HIV LTR has been an important area of research in the development of HIV therapies and potential vaccines.
The cell cycle is a series of events that take place in a cell leading to its division and duplication. It consists of four main phases: G1 phase, S phase, G2 phase, and M phase.
During the G1 phase, the cell grows in size and synthesizes mRNA and proteins in preparation for DNA replication. In the S phase, the cell's DNA is copied, resulting in two complete sets of chromosomes. During the G2 phase, the cell continues to grow and produces more proteins and organelles necessary for cell division.
The M phase is the final stage of the cell cycle and consists of mitosis (nuclear division) and cytokinesis (cytoplasmic division). Mitosis results in two genetically identical daughter nuclei, while cytokinesis divides the cytoplasm and creates two separate daughter cells.
The cell cycle is regulated by various checkpoints that ensure the proper completion of each phase before progressing to the next. These checkpoints help prevent errors in DNA replication and division, which can lead to mutations and cancer.
A gene product is the biochemical material, such as a protein or RNA, that is produced by the expression of a gene. Gene products are the result of the translation and transcription of genetic information encoded in DNA or RNA.
In the context of "tax," this term is not typically used in a medical definition of gene products. However, it may refer to the concept of taxing or regulating gene products in the context of genetic engineering or synthetic biology. This could involve imposing fees or restrictions on the production, use, or sale of certain gene products, particularly those that are genetically modified or engineered. The regulation of gene products is an important aspect of ensuring their safe and effective use in various applications, including medical treatments, agricultural production, and industrial processes.
Transcription Factor TFIIA is not a specific transcription factor itself, but rather a general term that refers to one of the several protein complexes that make up the larger Preinitiation Complex (PIC) in eukaryotic transcription. The PIC is responsible for the accurate initiation of transcription by RNA polymerase II, which transcribes most protein-coding genes in eukaryotes.
TFIIA is a heterotrimeric complex composed of three subunits: TAF1 (also known as TCP14/TCP22), TAF2 (also known as TCP80), and TAF3 (also known as GTF2A1). It plays a crucial role in the early stages of transcription initiation by helping to stabilize the binding of RNA polymerase II to the promoter region of the gene, as well as facilitating the correct positioning of other general transcription factors.
In addition to its role in the PIC, TFIIA has also been shown to have a function in regulating chromatin structure and accessibility, which can impact gene expression. Overall, Transcription Factor TFIIA is an essential component of the eukaryotic transcription machinery that helps ensure accurate and efficient initiation of gene transcription.
Tetradecanoylphorbol acetate (TPA) is defined as a pharmacological agent that is a derivative of the phorbol ester family. It is a potent tumor promoter and activator of protein kinase C (PKC), a group of enzymes that play a role in various cellular processes such as signal transduction, proliferation, and differentiation. TPA has been widely used in research to study PKC-mediated signaling pathways and its role in cancer development and progression. It is also used in topical treatments for skin conditions such as psoriasis.
Enzyme inhibitors are substances that bind to an enzyme and decrease its activity, preventing it from catalyzing a chemical reaction in the body. They can work by several mechanisms, including blocking the active site where the substrate binds, or binding to another site on the enzyme to change its shape and prevent substrate binding. Enzyme inhibitors are often used as drugs to treat various medical conditions, such as high blood pressure, abnormal heart rhythms, and bacterial infections. They can also be found naturally in some foods and plants, and can be used in research to understand enzyme function and regulation.
Transforming Growth Factor-beta (TGF-β) is a type of cytokine, which is a cell signaling protein involved in the regulation of various cellular processes, including cell growth, differentiation, and apoptosis (programmed cell death). TGF-β plays a critical role in embryonic development, tissue homeostasis, and wound healing. It also has been implicated in several pathological conditions such as fibrosis, cancer, and autoimmune diseases.
TGF-β exists in multiple isoforms (TGF-β1, TGF-β2, and TGF-β3) that are produced by many different cell types, including immune cells, epithelial cells, and fibroblasts. The protein is synthesized as a precursor molecule, which is cleaved to release the active TGF-β peptide. Once activated, TGF-β binds to its receptors on the cell surface, leading to the activation of intracellular signaling pathways that regulate gene expression and cell behavior.
In summary, Transforming Growth Factor-beta (TGF-β) is a multifunctional cytokine involved in various cellular processes, including cell growth, differentiation, apoptosis, embryonic development, tissue homeostasis, and wound healing. It has been implicated in several pathological conditions such as fibrosis, cancer, and autoimmune diseases.
Cyclin-dependent kinase inhibitor p21, also known as CDKN1A or p21/WAF1/CIP1, is a protein that regulates the cell cycle. It inhibits the activity of cyclin-dependent kinases (CDKs), which are enzymes that play crucial roles in controlling the progression of the cell cycle.
The binding of p21 to CDKs prevents the phosphorylation and activation of downstream targets, leading to cell cycle arrest. This protein is transcriptionally activated by tumor suppressor protein p53 in response to DNA damage or other stress signals, and it functions as an important mediator of p53-dependent growth arrest.
By inhibiting CDKs, p21 helps to ensure that cells do not proceed through the cell cycle until damaged DNA has been repaired, thereby preventing the propagation of potentially harmful mutations. Additionally, p21 has been implicated in other cellular processes such as apoptosis, differentiation, and senescence. Dysregulation of p21 has been associated with various human diseases, including cancer.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
Cell division is the process by which a single eukaryotic cell (a cell with a true nucleus) divides into two identical daughter cells. This complex process involves several stages, including replication of DNA, separation of chromosomes, and division of the cytoplasm. There are two main types of cell division: mitosis and meiosis.
Mitosis is the type of cell division that results in two genetically identical daughter cells. It is a fundamental process for growth, development, and tissue repair in multicellular organisms. The stages of mitosis include prophase, prometaphase, metaphase, anaphase, and telophase, followed by cytokinesis, which divides the cytoplasm.
Meiosis, on the other hand, is a type of cell division that occurs in the gonads (ovaries and testes) during the production of gametes (sex cells). Meiosis results in four genetically unique daughter cells, each with half the number of chromosomes as the parent cell. This process is essential for sexual reproduction and genetic diversity. The stages of meiosis include meiosis I and meiosis II, which are further divided into prophase, prometaphase, metaphase, anaphase, and telophase.
In summary, cell division is the process by which a single cell divides into two daughter cells, either through mitosis or meiosis. This process is critical for growth, development, tissue repair, and sexual reproduction in multicellular organisms.
I'm sorry for any confusion, but "Sp3 Transcription Factor" is not a recognized medical term. However, I can provide you with a scientific explanation:
Sp3 is a type of transcription factor that binds to specific DNA sequences and helps regulate gene expression in cells. Sp3 stands for Specificity Protein 3, which belongs to the Sp (Specificity protein) family of transcription factors. These proteins play crucial roles during development and differentiation of various tissues.
Transcription factors like Sp3 have modular structures, consisting of several functional domains that enable them to perform their regulatory functions:
1. DNA-binding domain (DBD): This region recognizes and binds to specific DNA sequences, usually located in the promoter or enhancer regions of target genes. The DBD of Sp3 proteins is a zinc finger domain, which contains multiple tandem repeats that fold into a structure that interacts with the DNA.
2. Transcriptional regulatory domain (TRD): This region can either activate or repress gene transcription depending on the context and interacting partners. The TRD of Sp3 proteins has an inhibitory effect on transcription, but it can be overcome by other activating co-factors.
3. Nuclear localization signal (NLS): This domain targets the protein to the nucleus, where it can perform its regulatory functions.
4. Protein-protein interaction domains: These regions allow Sp3 proteins to interact with other transcription factors and co-regulators, forming complexes that modulate gene expression.
In summary, Sp3 is a transcription factor that binds to specific DNA sequences and regulates the expression of target genes by either activating or repressing their transcription. It plays essential roles in various cellular processes during development and tissue differentiation.
Lysine is an essential amino acid, which means that it cannot be synthesized by the human body and must be obtained through the diet. Its chemical formula is (2S)-2,6-diaminohexanoic acid. Lysine is necessary for the growth and maintenance of tissues in the body, and it plays a crucial role in the production of enzymes, hormones, and antibodies. It is also essential for the absorption of calcium and the formation of collagen, which is an important component of bones and connective tissue. Foods that are good sources of lysine include meat, poultry, fish, eggs, and dairy products.
Proteins are complex, large molecules that play critical roles in the body's functions. They are made up of amino acids, which are organic compounds that are the building blocks of proteins. Proteins are required for the structure, function, and regulation of the body's tissues and organs. They are essential for the growth, repair, and maintenance of body tissues, and they play a crucial role in many biological processes, including metabolism, immune response, and cellular signaling. Proteins can be classified into different types based on their structure and function, such as enzymes, hormones, antibodies, and structural proteins. They are found in various foods, especially animal-derived products like meat, dairy, and eggs, as well as plant-based sources like beans, nuts, and grains.
E2F1 is a member of the E2F family of transcription factors, which are involved in the regulation of cell cycle progression and apoptosis (programmed cell death). Specifically, E2F1 plays a role as a transcriptional activator, binding to specific DNA sequences and promoting the expression of genes required for the G1/S transition of the cell cycle.
In more detail, E2F1 forms a complex with a retinoblastoma protein (pRb) in the G0 and early G1 phases of the cell cycle. When pRb is phosphorylated by cyclin-dependent kinases during the late G1 phase, E2F1 is released and can then bind to its target DNA sequences and activate transcription of genes involved in DNA replication and cell cycle progression.
However, if E2F1 is overexpressed or activated inappropriately, it can also promote apoptosis, making it a key player in both cell proliferation and cell death pathways. Dysregulation of E2F1 has been implicated in the development of various human cancers, including breast, lung, and prostate cancer.
Protein isoforms are different forms or variants of a protein that are produced from a single gene through the process of alternative splicing, where different exons (or parts of exons) are included in the mature mRNA molecule. This results in the production of multiple, slightly different proteins that share a common core structure but have distinct sequences and functions. Protein isoforms can also arise from genetic variations such as single nucleotide polymorphisms or mutations that alter the protein-coding sequence of a gene. These differences in protein sequence can affect the stability, localization, activity, or interaction partners of the protein isoform, leading to functional diversity and specialization within cells and organisms.
Tretinoin is a form of vitamin A that is used in the treatment of acne vulgaris, fine wrinkles, and dark spots caused by aging or sun damage. It works by increasing the turnover of skin cells, helping to unclog pores and promote the growth of new skin cells. Tretinoin is available as a cream, gel, or liquid, and is usually applied to the affected area once a day in the evening. Common side effects include redness, dryness, and peeling of the skin. It is important to avoid sunlight and use sunscreen while using tretinoin, as it can make the skin more sensitive to the sun.
Hydroxamic acids are organic compounds containing the functional group -CONHOH. They are derivatives of hydroxylamine, where the hydroxyl group is bound to a carbonyl (C=O) carbon atom. Hydroxamic acids can be found in various natural and synthetic sources and play significant roles in different biological processes.
In medicine and biochemistry, hydroxamic acids are often used as metal-chelating agents or siderophore mimics to treat iron overload disorders like hemochromatosis. They form stable complexes with iron ions, preventing them from participating in harmful reactions that can damage cells and tissues.
Furthermore, hydroxamic acids are also known for their ability to inhibit histone deacetylases (HDACs), enzymes involved in the regulation of gene expression. This property has been exploited in the development of anti-cancer drugs, as HDAC inhibition can lead to cell cycle arrest and apoptosis in cancer cells.
Some examples of hydroxamic acid-based drugs include:
1. Deferasirox (Exjade, Jadenu) - an iron chelator used to treat chronic iron overload in patients with blood disorders like thalassemia and sickle cell disease.
2. Panobinostat (Farydak) - an HDAC inhibitor approved for the treatment of multiple myeloma, a type of blood cancer.
3. Vorinostat (Zolinza) - another HDAC inhibitor used in the treatment of cutaneous T-cell lymphoma, a rare form of skin cancer.
Enzyme activation refers to the process by which an enzyme becomes biologically active and capable of carrying out its specific chemical or biological reaction. This is often achieved through various post-translational modifications, such as proteolytic cleavage, phosphorylation, or addition of cofactors or prosthetic groups to the enzyme molecule. These modifications can change the conformation or structure of the enzyme, exposing or creating a binding site for the substrate and allowing the enzymatic reaction to occur.
For example, in the case of proteolytic cleavage, an inactive precursor enzyme, known as a zymogen, is cleaved into its active form by a specific protease. This is seen in enzymes such as trypsin and chymotrypsin, which are initially produced in the pancreas as inactive precursors called trypsinogen and chymotrypsinogen, respectively. Once they reach the small intestine, they are activated by enteropeptidase, a protease that cleaves a specific peptide bond, releasing the active enzyme.
Phosphorylation is another common mechanism of enzyme activation, where a phosphate group is added to a specific serine, threonine, or tyrosine residue on the enzyme by a protein kinase. This modification can alter the conformation of the enzyme and create a binding site for the substrate, allowing the enzymatic reaction to occur.
Enzyme activation is a crucial process in many biological pathways, as it allows for precise control over when and where specific reactions take place. It also provides a mechanism for regulating enzyme activity in response to various signals and stimuli, such as hormones, neurotransmitters, or changes in the intracellular environment.
Neoplastic cell transformation is a process in which a normal cell undergoes genetic alterations that cause it to become cancerous or malignant. This process involves changes in the cell's DNA that result in uncontrolled cell growth and division, loss of contact inhibition, and the ability to invade surrounding tissues and metastasize (spread) to other parts of the body.
Neoplastic transformation can occur as a result of various factors, including genetic mutations, exposure to carcinogens, viral infections, chronic inflammation, and aging. These changes can lead to the activation of oncogenes or the inactivation of tumor suppressor genes, which regulate cell growth and division.
The transformation of normal cells into cancerous cells is a complex and multi-step process that involves multiple genetic and epigenetic alterations. It is characterized by several hallmarks, including sustained proliferative signaling, evasion of growth suppressors, resistance to cell death, enabling replicative immortality, induction of angiogenesis, activation of invasion and metastasis, reprogramming of energy metabolism, and evading immune destruction.
Neoplastic cell transformation is a fundamental concept in cancer biology and is critical for understanding the molecular mechanisms underlying cancer development and progression. It also has important implications for cancer diagnosis, prognosis, and treatment, as identifying the specific genetic alterations that underlie neoplastic transformation can help guide targeted therapies and personalized medicine approaches.
High mobility group proteins (HMG proteins) are a family of nuclear proteins that are characterized by their ability to bind to DNA and influence its structure and function. They are named "high mobility" because of their rapid movement in gel electrophoresis. HMG proteins are involved in various nuclear processes, including chromatin remodeling, transcription regulation, and DNA repair.
There are three main classes of HMG proteins: HMGA, HMGB, and HMGN. Each class has distinct structural features and functions. For example, HMGA proteins have a unique "AT-hook" domain that allows them to bind to the minor groove of AT-rich DNA sequences, while HMGB proteins have two "HMG-box" domains that enable them to bend and unwind DNA.
HMG proteins play important roles in many physiological and pathological processes, such as embryonic development, inflammation, and cancer. Dysregulation of HMG protein function has been implicated in various diseases, including neurodegenerative disorders, diabetes, and cancer. Therefore, understanding the structure, function, and regulation of HMG proteins is crucial for developing new therapeutic strategies for these diseases.
A "5' flanking region" in genetics refers to the DNA sequence that is located upstream (towards the 5' end) of a gene's transcription start site. This region contains various regulatory elements, such as promoters and enhancers, that control the initiation and rate of transcription of the gene. The 5' flanking region is important for the proper regulation of gene expression and can be influenced by genetic variations or mutations, which may lead to changes in gene function and contribute to disease susceptibility.
A "gene product" is the biochemical material that results from the expression of a gene. This can include both RNA and protein molecules. In the case of the tat (transactivator of transcription) gene in human immunodeficiency virus (HIV), the gene product is a regulatory protein that plays a crucial role in the viral replication cycle.
The tat protein is a viral transactivator, which means it increases the transcription of HIV genes by interacting with various components of the host cell's transcription machinery. Specifically, tat binds to a complex called TAR (transactivation response element), which is located in the 5' untranslated region of all nascent HIV mRNAs. By binding to TAR, tat recruits and activates positive transcription elongation factor b (P-TEFb), which then phosphorylates the carboxy-terminal domain of RNA polymerase II, leading to efficient elongation of HIV transcripts.
The tat protein is essential for HIV replication, as it enhances viral gene expression and promotes the production of new virus particles. Inhibiting tat function has been a target for developing antiretroviral therapies against HIV infection.
Protein Inhibitors of Activated STAT (PIAS) are a family of proteins that regulate the activity of signal transducer and activator of transcription (STAT) proteins, which are involved in various cellular processes such as differentiation, proliferation, and apoptosis. PIAS proteins function as E3 ubiquitin ligases and SUMO (small ubiquitin-like modifier) ligases, modifying STAT proteins and other transcription factors by adding SUMO molecules to them. This modification can alter the activity, localization, or stability of the target protein, thereby regulating its function in the cell. PIAS proteins have been shown to play a role in various physiological and pathological processes, including inflammation, cancer, and neurodegenerative diseases. Inhibiting PIAS proteins has emerged as a potential therapeutic strategy for the treatment of certain diseases associated with aberrant STAT activation.
Immunoglobulin J (JOINING) recombination signal sequence-binding protein, also known as RAG1 or RAG-1, is a protein that plays a critical role in the adaptive immune system. It is a component of the RAG complex, which also includes RAG2 and several other proteins.
The RAG complex is responsible for initiating the V(D)J recombination process, during which the variable regions of immunoglobulin (antibody) genes and T-cell receptor genes are assembled from gene segments called variable (V), diversity (D), and joining (J) segments. This process generates a diverse repertoire of antigen receptors that enable the immune system to recognize and respond to a wide range of pathogens.
RAG1 is an endonuclease that recognizes and cleaves specific sequences in the DNA called recombination signal sequences (RSSs) that flank the V, D, and J segments. Cleavage of these RSSs by RAG1 and RAG2 creates double-stranded breaks in the DNA, which are then processed by other proteins to form functional antigen receptor genes through a process called non-homologous end joining (NHEJ).
Therefore, Immunoglobulin J recombination signal sequence-binding protein is a crucial player in the adaptive immune system's ability to generate a diverse repertoire of antigen receptors and respond effectively to pathogens.
Artificial gene fusion refers to the creation of a new gene by joining together parts or whole sequences from two or more different genes. This is achieved through genetic engineering techniques, where the DNA segments are cut and pasted using enzymes called restriction endonucleases and ligases. The resulting artificial gene may encode for a novel protein with unique functions that neither of the parental genes possess. This approach has been widely used in biomedical research to study gene function, create new diagnostic tools, and develop gene therapies.
Proto-oncogene proteins, such as c-REL, are normal cellular proteins that play crucial roles in various cellular processes including regulation of gene expression, cell growth, and differentiation. Proto-oncogenes can become oncogenes when they undergo genetic alterations, such as mutations or chromosomal translocations, leading to their overexpression or hyperactivation. This, in turn, can contribute to uncontrolled cell growth and division, which may result in the development of cancer.
The c-REL protein is a member of the NF-κB (Nuclear Factor kappa-light-chain-enhancer of activated B cells) family of transcription factors. These proteins regulate the expression of various genes involved in immune responses, inflammation, cell survival, and proliferation. The c-REL protein forms homodimers or heterodimers with other NF-κB family members and binds to specific DNA sequences in the promoter regions of target genes to modulate their transcription. In normal cells, NF-κB signaling is tightly regulated and kept in check by inhibitory proteins called IκBs. However, deregulation of NF-κB signaling due to genetic alterations or other factors can lead to the overactivation of c-REL and other NF-κB family members, contributing to oncogenesis.
Hypoxia-Inducible Factor 1 (HIF-1) is a transcription factor that plays a crucial role in the body's response to low oxygen levels, also known as hypoxia. HIF-1 is a heterodimeric protein composed of two subunits: an alpha subunit (HIF-1α) and a beta subunit (HIF-1β).
The alpha subunit, HIF-1α, is the regulatory subunit that is subject to oxygen-dependent degradation. Under normal oxygen conditions (normoxia), HIF-1α is constantly produced in the cell but is rapidly degraded by proteasomes due to hydroxylation of specific proline residues by prolyl hydroxylase domain-containing proteins (PHDs). This hydroxylation reaction requires oxygen as a substrate, and under hypoxic conditions, the activity of PHDs is inhibited, leading to the stabilization and accumulation of HIF-1α.
Once stabilized, HIF-1α translocates to the nucleus, where it heterodimerizes with HIF-1β and binds to hypoxia-responsive elements (HREs) in the promoter regions of target genes. This binding results in the activation of gene transcription programs that promote cellular adaptation to low oxygen levels. These adaptive responses include increased erythropoiesis, angiogenesis, glucose metabolism, and pH regulation, among others.
Therefore, HIF-1α is a critical regulator of the body's response to hypoxia, and its dysregulation has been implicated in various pathological conditions, including cancer, cardiovascular disease, and neurodegenerative disorders.
Immunoblotting, also known as western blotting, is a laboratory technique used in molecular biology and immunogenetics to detect and quantify specific proteins in a complex mixture. This technique combines the electrophoretic separation of proteins by gel electrophoresis with their detection using antibodies that recognize specific epitopes (protein fragments) on the target protein.
The process involves several steps: first, the protein sample is separated based on size through sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE). Next, the separated proteins are transferred onto a nitrocellulose or polyvinylidene fluoride (PVDF) membrane using an electric field. The membrane is then blocked with a blocking agent to prevent non-specific binding of antibodies.
After blocking, the membrane is incubated with a primary antibody that specifically recognizes the target protein. Following this, the membrane is washed to remove unbound primary antibodies and then incubated with a secondary antibody conjugated to an enzyme such as horseradish peroxidase (HRP) or alkaline phosphatase (AP). The enzyme catalyzes a colorimetric or chemiluminescent reaction that allows for the detection of the target protein.
Immunoblotting is widely used in research and clinical settings to study protein expression, post-translational modifications, protein-protein interactions, and disease biomarkers. It provides high specificity and sensitivity, making it a valuable tool for identifying and quantifying proteins in various biological samples.
Gene silencing is a process by which the expression of a gene is blocked or inhibited, preventing the production of its corresponding protein. This can occur naturally through various mechanisms such as RNA interference (RNAi), where small RNAs bind to and degrade specific mRNAs, or DNA methylation, where methyl groups are added to the DNA molecule, preventing transcription. Gene silencing can also be induced artificially using techniques such as RNAi-based therapies, antisense oligonucleotides, or CRISPR-Cas9 systems, which allow for targeted suppression of gene expression in research and therapeutic applications.
Transcription Factor AP-2 is a specific protein involved in the process of gene transcription. It belongs to a family of transcription factors known as Activating Enhancer-Binding Proteins (AP-2). These proteins regulate gene expression by binding to specific DNA sequences called enhancers, which are located near the genes they control.
AP-2 is composed of four subunits that form a homo- or heterodimer, which then binds to the consensus sequence 5'-GCCNNNGGC-3'. This sequence is typically found in the promoter regions of target genes. Once bound, AP-2 can either activate or repress gene transcription, depending on the context and the presence of cofactors.
AP-2 plays crucial roles during embryonic development, particularly in the formation of the nervous system, limbs, and face. It is also involved in cell cycle regulation, differentiation, and apoptosis (programmed cell death). Dysregulation of AP-2 has been implicated in several diseases, including various types of cancer.
Apoptosis is a programmed and controlled cell death process that occurs in multicellular organisms. It is a natural process that helps maintain tissue homeostasis by eliminating damaged, infected, or unwanted cells. During apoptosis, the cell undergoes a series of morphological changes, including cell shrinkage, chromatin condensation, and fragmentation into membrane-bound vesicles called apoptotic bodies. These bodies are then recognized and engulfed by neighboring cells or phagocytic cells, preventing an inflammatory response. Apoptosis is regulated by a complex network of intracellular signaling pathways that involve proteins such as caspases, Bcl-2 family members, and inhibitors of apoptosis (IAPs).
Membrane proteins are a type of protein that are embedded in the lipid bilayer of biological membranes, such as the plasma membrane of cells or the inner membrane of mitochondria. These proteins play crucial roles in various cellular processes, including:
1. Cell-cell recognition and signaling
2. Transport of molecules across the membrane (selective permeability)
3. Enzymatic reactions at the membrane surface
4. Energy transduction and conversion
5. Mechanosensation and signal transduction
Membrane proteins can be classified into two main categories: integral membrane proteins, which are permanently associated with the lipid bilayer, and peripheral membrane proteins, which are temporarily or loosely attached to the membrane surface. Integral membrane proteins can further be divided into three subcategories based on their topology:
1. Transmembrane proteins, which span the entire width of the lipid bilayer with one or more alpha-helices or beta-barrels.
2. Lipid-anchored proteins, which are covalently attached to lipids in the membrane via a glycosylphosphatidylinositol (GPI) anchor or other lipid modifications.
3. Monotopic proteins, which are partially embedded in the membrane and have one or more domains exposed to either side of the bilayer.
Membrane proteins are essential for maintaining cellular homeostasis and are targets for various therapeutic interventions, including drug development and gene therapy. However, their structural complexity and hydrophobicity make them challenging to study using traditional biochemical methods, requiring specialized techniques such as X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and single-particle cryo-electron microscopy (cryo-EM).
Protein kinases are a group of enzymes that play a crucial role in many cellular processes by adding phosphate groups to other proteins, a process known as phosphorylation. This modification can activate or deactivate the target protein's function, thereby regulating various signaling pathways within the cell. Protein kinases are essential for numerous biological functions, including metabolism, signal transduction, cell cycle progression, and apoptosis (programmed cell death). Abnormal regulation of protein kinases has been implicated in several diseases, such as cancer, diabetes, and neurological disorders.
Myogenic regulatory factors (MRFs) are a group of transcription factors that play crucial roles in the development, growth, and maintenance of skeletal muscle cells. They are essential for the determination and differentiation of myoblasts into multinucleated myotubes and ultimately mature muscle fibers. The MRF family includes four key members: MyoD, Myf5, Mrf4 (also known as Myf6), and myogenin. These factors work together to regulate the expression of genes involved in various aspects of skeletal muscle formation and function.
1. MyoD: This MRF is a critical regulator of muscle cell differentiation and can induce non-muscle cells to adopt a muscle-like fate. It binds to specific DNA sequences, known as E-boxes, within the regulatory regions of target genes to activate or repress their transcription.
2. Myf5: Similar to MyoD, Myf5 is involved in the early determination and differentiation of myoblasts. However, it has a more restricted expression pattern during development compared to MyoD.
3. Mrf4 (Myf6): This MRF plays a role in both muscle cell differentiation and maintenance. It is expressed later than MyoD and Myf5 during development and helps regulate the terminal differentiation of myotubes into mature muscle fibers.
4. Myogenin: Among all MRFs, myogenin has the most specific function in muscle cell differentiation. It is required for the fusion of myoblasts to form multinucleated myotubes and is essential for the maturation and maintenance of skeletal muscle fibers.
In summary, Myogenic Regulatory Factors are a group of transcription factors that regulate skeletal muscle development, growth, and maintenance by controlling the expression of genes involved in various aspects of muscle cell differentiation and function.
Signal Transducer and Activator of Transcription 1 (STAT1) is a transcription factor that plays a crucial role in the regulation of gene expression in response to cytokines and interferons. It is activated through phosphorylation by Janus kinases (JAKs) upon binding of cytokines to their respective receptors. Once activated, STAT1 forms homodimers or heterodimers with other STAT family members, translocates to the nucleus, and binds to specific DNA sequences called gamma-activated sites (GAS) in the promoter regions of target genes. This results in the modulation of gene expression involved in various cellular processes such as immune responses, differentiation, apoptosis, and cell cycle control. STAT1 also plays a critical role in the antiviral response by mediating the transcription of interferon-stimulated genes (ISGs).
Immunoprecipitation (IP) is a research technique used in molecular biology and immunology to isolate specific antigens or antibodies from a mixture. It involves the use of an antibody that recognizes and binds to a specific antigen, which is then precipitated out of solution using various methods, such as centrifugation or chemical cross-linking.
In this technique, an antibody is first incubated with a sample containing the antigen of interest. The antibody specifically binds to the antigen, forming an immune complex. This complex can then be captured by adding protein A or G agarose beads, which bind to the constant region of the antibody. The beads are then washed to remove any unbound proteins, leaving behind the precipitated antigen-antibody complex.
Immunoprecipitation is a powerful tool for studying protein-protein interactions, post-translational modifications, and signal transduction pathways. It can also be used to detect and quantify specific proteins in biological samples, such as cells or tissues, and to identify potential biomarkers of disease.
RNA interference (RNAi) is a biological process in which RNA molecules inhibit the expression of specific genes. This process is mediated by small RNA molecules, including microRNAs (miRNAs) and small interfering RNAs (siRNAs), that bind to complementary sequences on messenger RNA (mRNA) molecules, leading to their degradation or translation inhibition.
RNAi plays a crucial role in regulating gene expression and defending against foreign genetic elements, such as viruses and transposons. It has also emerged as an important tool for studying gene function and developing therapeutic strategies for various diseases, including cancer and viral infections.
Viral proteins are the proteins that are encoded by the viral genome and are essential for the viral life cycle. These proteins can be structural or non-structural and play various roles in the virus's replication, infection, and assembly process. Structural proteins make up the physical structure of the virus, including the capsid (the protein shell that surrounds the viral genome) and any envelope proteins (that may be present on enveloped viruses). Non-structural proteins are involved in the replication of the viral genome and modulation of the host cell environment to favor viral replication. Overall, a thorough understanding of viral proteins is crucial for developing antiviral therapies and vaccines.
Hypoxia-Inducible Factor 1 (HIF-1) is a transcription factor that plays a crucial role in the cellular response to low oxygen levels, also known as hypoxia. It is a heterodimeric protein composed of two subunits: HIF-1α and HIF-1β.
Under normoxic conditions (adequate oxygen supply), HIF-1α is constantly produced but rapidly degraded by proteasomes due to the action of prolyl hydroxylases, which mark it for destruction in the presence of oxygen. However, under hypoxic conditions, the activity of prolyl hydroxylases is inhibited, leading to the stabilization and accumulation of HIF-1α.
Once stabilized, HIF-1α translocates to the nucleus and forms a complex with HIF-1β. This complex then binds to hypoxia-responsive elements (HREs) in the promoter regions of various genes involved in angiogenesis, glucose metabolism, erythropoiesis, cell survival, and other processes that help cells adapt to low oxygen levels.
By activating these target genes, HIF-1 plays a critical role in regulating the body's response to hypoxia, including promoting the formation of new blood vessels (angiogenesis), enhancing anaerobic metabolism, and inhibiting cell proliferation and apoptosis under low oxygen conditions. Dysregulation of HIF-1 has been implicated in several diseases, such as cancer, cardiovascular disease, and ischemic disorders.
MEF2 (Myocyte Enhancer Factor-2) transcription factors are a family of proteins that regulate the transcription of genes, particularly in muscle cells. They play crucial roles in the development, growth, and maintenance of skeletal, cardiac, and smooth muscles. MEF2 transcription factors bind to specific DNA sequences, known as MEF2 response elements (MREs), in the promoter regions of target genes. This binding can either activate or repress gene transcription, depending on the context and interacting proteins. MEF2 transcription factors are involved in various cellular processes, such as muscle differentiation, metabolism, and stress responses. Dysregulation of MEF2 transcription factors has been implicated in several diseases, including muscular dystrophies, cardiovascular disorders, and neurodegenerative conditions.
DNA-directed RNA polymerases are enzymes that synthesize RNA molecules using a DNA template in a process called transcription. These enzymes read the sequence of nucleotides in a DNA molecule and use it as a blueprint to construct a complementary RNA strand.
The RNA polymerase moves along the DNA template, adding ribonucleotides one by one to the growing RNA chain. The synthesis is directional, starting at the promoter region of the DNA and moving towards the terminator region.
In bacteria, there is a single type of RNA polymerase that is responsible for transcribing all types of RNA (mRNA, tRNA, and rRNA). In eukaryotic cells, however, there are three different types of RNA polymerases: RNA polymerase I, II, and III. Each type is responsible for transcribing specific types of RNA.
RNA polymerases play a crucial role in gene expression, as they link the genetic information encoded in DNA to the production of functional proteins. Inhibition or mutation of these enzymes can have significant consequences for cellular function and survival.
E2F transcription factors are a family of proteins that play crucial roles in the regulation of the cell cycle, DNA repair, and apoptosis (programmed cell death). These factors bind to specific DNA sequences called E2F responsive elements, located in the promoter regions of target genes. They can act as either transcriptional activators or repressors, depending on which E2F family member is involved, the presence of co-factors, and the phase of the cell cycle.
The E2F family consists of eight members, divided into two groups based on their functions: activator E2Fs (E2F1, E2F2, and E2F3a) and repressor E2Fs (E2F3b, E2F4, E2F5, E2F6, and E2F7). Activator E2Fs promote the expression of genes required for cell cycle progression, DNA replication, and repair. Repressor E2Fs, on the other hand, inhibit the transcription of these same genes as well as genes involved in differentiation and apoptosis.
Dysregulation of E2F transcription factors has been implicated in various human diseases, including cancer. Overexpression or hyperactivation of activator E2Fs can lead to uncontrolled cell proliferation and tumorigenesis, while loss of function or inhibition of repressor E2Fs can result in impaired differentiation and increased susceptibility to malignancies. Therefore, understanding the roles and regulation of E2F transcription factors is essential for developing novel therapeutic strategies against cancer and other diseases associated with cell cycle dysregulation.
Nuclear Receptor Coactivator 3 (NCOA3), also known as AIB1 (Amplified in Breast Cancer 1), is a protein that functions as a coactivator for several nuclear receptors. Nuclear receptors are transcription factors that regulate gene expression in response to various signals, such as hormones and vitamins.
NCOA3/AIB1 contains several functional domains, including an N-terminal basic helix-loop-helix Per-Arnt-Sim (bHLH-PAS) domain, two nuclear receptor interaction motifs, and a C-terminal activation domain. These domains enable NCOA3/AIB1 to interact with various nuclear receptors, recruit additional coactivators, and stimulate transcription of target genes.
NCOA3/AIB1 has been implicated in the development and progression of several types of cancer, including breast, prostate, and ovarian cancers. Amplification or overexpression of NCOA3/AIB1 has been observed in these cancers, leading to increased cell growth, survival, and metastasis. Additionally, NCOA3/AIB1 has been linked to endocrine resistance in breast cancer, making it a potential target for therapeutic intervention.
Aryl hydrocarbon receptors (AhRs) are a type of intracellular receptor that play a crucial role in the response to environmental contaminants and other xenobiotic compounds. They are primarily found in the cytoplasm of cells, where they bind to aromatic hydrocarbons, including polycyclic aromatic hydrocarbons (PAHs) and polychlorinated biphenyls (PCBs), which are common environmental pollutants.
Once activated by ligand binding, AhRs translocate to the nucleus, where they dimerize with the AhR nuclear translocator (ARNT) protein and bind to specific DNA sequences called xenobiotic response elements (XREs). This complex then regulates the expression of a variety of genes involved in xenobiotic metabolism, including those encoding cytochrome P450 enzymes.
In addition to their role in xenobiotic metabolism, AhRs have been implicated in various physiological processes, such as immune response, cell differentiation, and development. Dysregulation of AhR signaling has been associated with the pathogenesis of several diseases, including cancer, autoimmune disorders, and neurodevelopmental disorders.
Therefore, understanding the mechanisms of AhR activation and regulation is essential for developing strategies to prevent or treat environmental toxicant-induced diseases and other conditions linked to AhR dysfunction.
Smad proteins are a family of intracellular signaling molecules that play a crucial role in the transmission of signals from the cell surface to the nucleus in response to transforming growth factor β (TGF-β) superfamily ligands. These ligands include TGF-βs, bone morphogenetic proteins (BMPs), activins, and inhibins.
There are eight mammalian Smad proteins, which are categorized into three classes based on their function: receptor-regulated Smads (R-Smads), common mediator Smads (Co-Smads), and inhibitory Smads (I-Smads). R-Smads include Smad1, Smad2, Smad3, Smad5, and Smad8/9, while Smad4 is the only Co-Smad. The I-Smads consist of Smad6 and Smad7.
Upon TGF-β superfamily ligand binding to their transmembrane serine/threonine kinase receptors, R-Smads are phosphorylated and form complexes with Co-Smad4. These complexes then translocate into the nucleus, where they regulate the transcription of target genes involved in various cellular processes, such as proliferation, differentiation, apoptosis, migration, and extracellular matrix production. I-Smads act as negative regulators of TGF-β signaling by competing with R-Smads for receptor binding or promoting the degradation of receptors and R-Smads.
Dysregulation of Smad protein function has been implicated in various human diseases, including fibrosis, cancer, and developmental disorders.
A Serum Response Element (SRE) is a specific sequence in the DNA that can bind to certain transcription factors and regulate gene expression. It is named "serum response" because it was initially discovered to be activated by serum factors present in the blood, such as growth factors and cytokines.
The SRE is typically bound by the transcription factor complex made up of serum response factor (SRF) and ternary complex factors (TCFs), which include Elk-1, Sap-1, and Net. When activated by signals such as mitogens or growth factors, these transcription factors can bind to the SRE and induce the expression of target genes involved in various cellular processes, including proliferation, differentiation, and survival.
The SRE is a crucial regulatory element in many physiological and pathological processes, such as cardiovascular development, muscle differentiation, cancer, and inflammation.
Adaptor proteins are a type of protein that play a crucial role in intracellular signaling pathways by serving as a link between different components of the signaling complex. Specifically, "signal transducing adaptor proteins" refer to those adaptor proteins that are involved in signal transduction processes, where they help to transmit signals from the cell surface receptors to various intracellular effectors. These proteins typically contain modular domains that allow them to interact with multiple partners, thereby facilitating the formation of large signaling complexes and enabling the integration of signals from different pathways.
Signal transducing adaptor proteins can be classified into several families based on their structural features, including the Src homology 2 (SH2) domain, the Src homology 3 (SH3) domain, and the phosphotyrosine-binding (PTB) domain. These domains enable the adaptor proteins to recognize and bind to specific motifs on other signaling molecules, such as receptor tyrosine kinases, G protein-coupled receptors, and cytokine receptors.
One well-known example of a signal transducing adaptor protein is the growth factor receptor-bound protein 2 (Grb2), which contains an SH2 domain that binds to phosphotyrosine residues on activated receptor tyrosine kinases. Grb2 also contains an SH3 domain that interacts with proline-rich motifs on other signaling proteins, such as the guanine nucleotide exchange factor SOS. This interaction facilitates the activation of the Ras small GTPase and downstream signaling pathways involved in cell growth, differentiation, and survival.
Overall, signal transducing adaptor proteins play a critical role in regulating various cellular processes by modulating intracellular signaling pathways in response to extracellular stimuli. Dysregulation of these proteins has been implicated in various diseases, including cancer and inflammatory disorders.
Enzyme induction is a process by which the activity or expression of an enzyme is increased in response to some stimulus, such as a drug, hormone, or other environmental factor. This can occur through several mechanisms, including increasing the transcription of the enzyme's gene, stabilizing the mRNA that encodes the enzyme, or increasing the translation of the mRNA into protein.
In some cases, enzyme induction can be a beneficial process, such as when it helps the body to metabolize and clear drugs more quickly. However, in other cases, enzyme induction can have negative consequences, such as when it leads to the increased metabolism of important endogenous compounds or the activation of harmful procarcinogens.
Enzyme induction is an important concept in pharmacology and toxicology, as it can affect the efficacy and safety of drugs and other xenobiotics. It is also relevant to the study of drug interactions, as the induction of one enzyme by a drug can lead to altered metabolism and effects of another drug that is metabolized by the same enzyme.
HEK293 cells, also known as human embryonic kidney 293 cells, are a line of cells used in scientific research. They were originally derived from human embryonic kidney cells and have been adapted to grow in a lab setting. HEK293 cells are widely used in molecular biology and biochemistry because they can be easily transfected (a process by which DNA is introduced into cells) and highly express foreign genes. As a result, they are often used to produce proteins for structural and functional studies. It's important to note that while HEK293 cells are derived from human tissue, they have been grown in the lab for many generations and do not retain the characteristics of the original embryonic kidney cells.
A phenotype is the physical or biochemical expression of an organism's genes, or the observable traits and characteristics resulting from the interaction of its genetic constitution (genotype) with environmental factors. These characteristics can include appearance, development, behavior, and resistance to disease, among others. Phenotypes can vary widely, even among individuals with identical genotypes, due to differences in environmental influences, gene expression, and genetic interactions.
Proto-oncogene protein c-ets-1 is a transcription factor that regulates gene expression in various cellular processes, including cell growth, differentiation, and apoptosis. It belongs to the ETS family of transcription factors, which are characterized by a highly conserved DNA-binding domain known as the ETS domain. The c-ets-1 protein is encoded by the ETS1 gene located on chromosome 11 in humans.
In normal cells, c-ets-1 plays critical roles in development, tissue repair, and immune function. However, when its expression or activity is dysregulated, it can contribute to tumorigenesis and cancer progression. In particular, c-ets-1 has been implicated in the development of various types of leukemia and solid tumors, such as breast, prostate, and lung cancer.
The activation of c-ets-1 can occur through various mechanisms, including gene amplification, chromosomal translocation, or point mutations. Once activated, c-ets-1 can promote cell proliferation, survival, and migration, while also inhibiting apoptosis. These oncogenic properties make c-ets-1 a potential target for cancer therapy.
Tumor suppressor proteins are a type of regulatory protein that helps control the cell cycle and prevent cells from dividing and growing in an uncontrolled manner. They work to inhibit tumor growth by preventing the formation of tumors or slowing down their progression. These proteins can repair damaged DNA, regulate gene expression, and initiate programmed cell death (apoptosis) if the damage is too severe for repair.
Mutations in tumor suppressor genes, which provide the code for these proteins, can lead to a decrease or loss of function in the resulting protein. This can result in uncontrolled cell growth and division, leading to the formation of tumors and cancer. Examples of tumor suppressor proteins include p53, Rb (retinoblastoma), and BRCA1/2.
Repetitive sequences in nucleic acid refer to repeated stretches of DNA or RNA nucleotide bases that are present in a genome. These sequences can vary in length and can be arranged in different patterns such as direct repeats, inverted repeats, or tandem repeats. In some cases, these repetitive sequences do not code for proteins and are often found in non-coding regions of the genome. They can play a role in genetic instability, regulation of gene expression, and evolutionary processes. However, certain types of repeat expansions have been associated with various neurodegenerative disorders and other human diseases.
Post-translational protein processing refers to the modifications and changes that proteins undergo after their synthesis on ribosomes, which are complex molecular machines responsible for protein synthesis. These modifications occur through various biochemical processes and play a crucial role in determining the final structure, function, and stability of the protein.
The process begins with the translation of messenger RNA (mRNA) into a linear polypeptide chain, which is then subjected to several post-translational modifications. These modifications can include:
1. Proteolytic cleavage: The removal of specific segments or domains from the polypeptide chain by proteases, resulting in the formation of mature, functional protein subunits.
2. Chemical modifications: Addition or modification of chemical groups to the side chains of amino acids, such as phosphorylation (addition of a phosphate group), glycosylation (addition of sugar moieties), methylation (addition of a methyl group), acetylation (addition of an acetyl group), and ubiquitination (addition of a ubiquitin protein).
3. Disulfide bond formation: The oxidation of specific cysteine residues within the polypeptide chain, leading to the formation of disulfide bonds between them. This process helps stabilize the three-dimensional structure of proteins, particularly in extracellular environments.
4. Folding and assembly: The acquisition of a specific three-dimensional conformation by the polypeptide chain, which is essential for its function. Chaperone proteins assist in this process to ensure proper folding and prevent aggregation.
5. Protein targeting: The directed transport of proteins to their appropriate cellular locations, such as the nucleus, mitochondria, endoplasmic reticulum, or plasma membrane. This is often facilitated by specific signal sequences within the protein that are recognized and bound by transport machinery.
Collectively, these post-translational modifications contribute to the functional diversity of proteins in living organisms, allowing them to perform a wide range of cellular processes, including signaling, catalysis, regulation, and structural support.
Cycloheximide is an antibiotic that is primarily used in laboratory settings to inhibit protein synthesis in eukaryotic cells. It is derived from the actinobacteria species Streptomyces griseus. In medical terms, it is not used as a therapeutic drug in humans due to its significant side effects, including liver toxicity and potential neurotoxicity. However, it remains a valuable tool in research for studying protein function and cellular processes.
The antibiotic works by binding to the 60S subunit of the ribosome, thereby preventing the transfer RNA (tRNA) from delivering amino acids to the growing polypeptide chain during translation. This inhibition of protein synthesis can be lethal to cells, making cycloheximide a useful tool in studying cellular responses to protein depletion or misregulation.
In summary, while cycloheximide has significant research applications due to its ability to inhibit protein synthesis in eukaryotic cells, it is not used as a therapeutic drug in humans because of its toxic side effects.
Allantoin is a naturally occurring substance that is found in some plants and animals, including humans. It is a white, crystalline powder that is only slightly soluble in water and more soluble in alcohol and ether. In the medical field, allantoin is often used as an ingredient in topical creams, ointments, and other products due to its ability to promote wound healing, skin soothing, and softening. It can also help to increase the water content of the extracellular matrix, which can be beneficial for dry or damaged skin. Allantoin has been shown to have anti-inflammatory properties, making it useful in the treatment of various skin conditions such as eczema, dermatitis, and sunburn. It is considered safe and non-irritating, making it a popular ingredient in many cosmetic and personal care products.
Calcium-calmodulin-dependent protein kinases (CAMKs) are a family of enzymes that play a crucial role in intracellular signaling pathways. They are activated by the binding of calcium ions and calmodulin, a ubiquitous calcium-binding protein, to their regulatory domain.
Once activated, CAMKs phosphorylate specific serine or threonine residues on target proteins, thereby modulating their activity, localization, or stability. This post-translational modification is essential for various cellular processes, including synaptic plasticity, gene expression, metabolism, and cell cycle regulation.
There are several subfamilies of CAMKs, including CaMKI, CaMKII, CaMKIII (also known as CaMKIV), and CaMK kinase (CaMKK). Each subfamily has distinct structural features, substrate specificity, and regulatory mechanisms. Dysregulation of CAMK signaling has been implicated in various pathological conditions, such as neurodegenerative diseases, cancer, and cardiovascular disorders.
Dexamethasone is a type of corticosteroid medication, which is a synthetic version of a natural hormone produced by the adrenal glands. It is often used to reduce inflammation and suppress the immune system in a variety of medical conditions, including allergies, asthma, rheumatoid arthritis, and certain skin conditions.
Dexamethasone works by binding to specific receptors in cells, which triggers a range of anti-inflammatory effects. These include reducing the production of chemicals that cause inflammation, suppressing the activity of immune cells, and stabilizing cell membranes.
In addition to its anti-inflammatory effects, dexamethasone can also be used to treat other medical conditions, such as certain types of cancer, brain swelling, and adrenal insufficiency. It is available in a variety of forms, including tablets, liquids, creams, and injectable solutions.
Like all medications, dexamethasone can have side effects, particularly if used for long periods of time or at high doses. These may include mood changes, increased appetite, weight gain, acne, thinning skin, easy bruising, and an increased risk of infections. It is important to follow the instructions of a healthcare provider when taking dexamethasone to minimize the risk of side effects.
Interferon Regulatory Factor-1 (IRF-1) is a protein that belongs to the Interferon Regulatory Factor family. It functions as a transcription factor, which means it regulates the expression of specific genes. IRF-1 plays a crucial role in regulating the immune response and inflammation.
More specifically, IRF-1 is involved in the signaling pathways that are activated by interferons (IFNs), which are proteins released by cells in response to viral or bacterial infections. Once activated, IRF-1 binds to specific DNA sequences in the promoter regions of target genes and activates their transcription.
IRF-1 regulates the expression of a variety of genes involved in the immune response, including those that encode cytokines, chemokines, and major histocompatibility complex (MHC) molecules. It also plays a role in the regulation of cell growth, differentiation, and apoptosis (programmed cell death).
Mutations or dysregulation of IRF-1 have been implicated in various diseases, including cancer, autoimmune disorders, and viral infections.
Smad2 protein is a transcription factor that plays a critical role in the TGF-β (transforming growth factor-beta) signaling pathway, which regulates various cellular processes such as proliferation, differentiation, and apoptosis. Smad2 is primarily localized in the cytoplasm and becomes phosphorylated upon TGF-β receptor activation. Once phosphorylated, it forms a complex with Smad4 and translocates to the nucleus where it regulates the transcription of target genes. Mutations in the Smad2 gene have been associated with various human diseases, including cancer and fibrotic disorders.
Down-regulation is a process that occurs in response to various stimuli, where the number or sensitivity of cell surface receptors or the expression of specific genes is decreased. This process helps maintain homeostasis within cells and tissues by reducing the ability of cells to respond to certain signals or molecules.
In the context of cell surface receptors, down-regulation can occur through several mechanisms:
1. Receptor internalization: After binding to their ligands, receptors can be internalized into the cell through endocytosis. Once inside the cell, these receptors may be degraded or recycled back to the cell surface in smaller numbers.
2. Reduced receptor synthesis: Down-regulation can also occur at the transcriptional level, where the expression of genes encoding for specific receptors is decreased, leading to fewer receptors being produced.
3. Receptor desensitization: Prolonged exposure to a ligand can lead to a decrease in receptor sensitivity or affinity, making it more difficult for the cell to respond to the signal.
In the context of gene expression, down-regulation refers to the decreased transcription and/or stability of specific mRNAs, leading to reduced protein levels. This process can be induced by various factors, including microRNA (miRNA)-mediated regulation, histone modification, or DNA methylation.
Down-regulation is an essential mechanism in many physiological processes and can also contribute to the development of several diseases, such as cancer and neurodegenerative disorders.
Histone-Lysine N-Methyltransferase is a type of enzyme that transfers methyl groups to specific lysine residues on histone proteins. These histone proteins are the main protein components of chromatin, which is the complex of DNA and proteins that make up chromosomes.
Histone-Lysine N-Methyltransferases play a crucial role in the regulation of gene expression by modifying the structure of chromatin. The addition of methyl groups to histones can result in either the activation or repression of gene transcription, depending on the specific location and number of methyl groups added.
These enzymes are important targets for drug development, as their dysregulation has been implicated in various diseases, including cancer. Inhibitors of Histone-Lysine N-Methyltransferases have shown promise in preclinical studies for the treatment of certain types of cancer.
Immediate-early genes (IEGs) are a class of genes that respond rapidly to various extracellular signals and stimuli, including growth factors, hormones, neurotransmitters, and environmental stressors. In the context of genetics and molecular biology, IEGs do not directly code for proteins but instead encode regulatory transcription factors that control the expression of downstream genes involved in specific cellular processes such as proliferation, differentiation, survival, and apoptosis.
In the case of genes related to genetic material, 'Immediate-early' refers to a group of genes that are activated early in response to a stimulus, often within minutes, and before the activation of other genes known as delayed-early or late-response genes. These IEGs play crucial roles in initiating and coordinating complex cellular responses, including those related to development, learning, memory, and various disease states such as cancer and neurological disorders.
Examples of IEGs include the c-fos, c-jun, and egr-1 genes, which are widely studied in molecular biology and neuroscience research due to their rapid and transient response to stimuli and their involvement in various cellular processes.
Protein conformation refers to the specific three-dimensional shape that a protein molecule assumes due to the spatial arrangement of its constituent amino acid residues and their associated chemical groups. This complex structure is determined by several factors, including covalent bonds (disulfide bridges), hydrogen bonds, van der Waals forces, and ionic bonds, which help stabilize the protein's unique conformation.
Protein conformations can be broadly classified into two categories: primary, secondary, tertiary, and quaternary structures. The primary structure represents the linear sequence of amino acids in a polypeptide chain. The secondary structure arises from local interactions between adjacent amino acid residues, leading to the formation of recurring motifs such as α-helices and β-sheets. Tertiary structure refers to the overall three-dimensional folding pattern of a single polypeptide chain, while quaternary structure describes the spatial arrangement of multiple folded polypeptide chains (subunits) that interact to form a functional protein complex.
Understanding protein conformation is crucial for elucidating protein function, as the specific three-dimensional shape of a protein directly influences its ability to interact with other molecules, such as ligands, nucleic acids, or other proteins. Any alterations in protein conformation due to genetic mutations, environmental factors, or chemical modifications can lead to loss of function, misfolding, aggregation, and disease states like neurodegenerative disorders and cancer.
Androgen receptors (ARs) are a type of nuclear receptor protein that are expressed in various tissues throughout the body. They play a critical role in the development and maintenance of male sexual characteristics and reproductive function. ARs are activated by binding to androgens, which are steroid hormones such as testosterone and dihydrotestosterone (DHT). Once activated, ARs function as transcription factors that regulate gene expression, ultimately leading to various cellular responses.
In the context of medical definitions, androgen receptors can be defined as follows:
Androgen receptors are a type of nuclear receptor protein that bind to androgens, such as testosterone and dihydrotestosterone, and mediate their effects on gene expression in various tissues. They play critical roles in the development and maintenance of male sexual characteristics and reproductive function, and are involved in the pathogenesis of several medical conditions, including prostate cancer, benign prostatic hyperplasia, and androgen deficiency syndromes.
Gene expression regulation in plants refers to the processes that control the production of proteins and RNA from the genes present in the plant's DNA. This regulation is crucial for normal growth, development, and response to environmental stimuli in plants. It can occur at various levels, including transcription (the first step in gene expression, where the DNA sequence is copied into RNA), RNA processing (such as alternative splicing, which generates different mRNA molecules from a single gene), translation (where the information in the mRNA is used to produce a protein), and post-translational modification (where proteins are chemically modified after they have been synthesized).
In plants, gene expression regulation can be influenced by various factors such as hormones, light, temperature, and stress. Plants use complex networks of transcription factors, chromatin remodeling complexes, and small RNAs to regulate gene expression in response to these signals. Understanding the mechanisms of gene expression regulation in plants is important for basic research, as well as for developing crops with improved traits such as increased yield, stress tolerance, and disease resistance.
Proto-oncogenes are normal genes that are present in all cells and play crucial roles in regulating cell growth, division, and death. They code for proteins that are involved in signal transduction pathways that control various cellular processes such as proliferation, differentiation, and survival. When these genes undergo mutations or are activated abnormally, they can become oncogenes, which have the potential to cause uncontrolled cell growth and lead to cancer. Oncogenes can contribute to tumor formation through various mechanisms, including promoting cell division, inhibiting programmed cell death (apoptosis), and stimulating blood vessel growth (angiogenesis).
Nuclear Receptor Subfamily 4, Group A, Member 1 (NR4A1) is a protein that in humans is encoded by the NR4A1 gene. NR4A1 is a member of the nuclear receptor superfamily, which are transcription factors that regulate gene expression in response to hormonal and other signals.
NR4A1 is also known as Nur77, TR3, or NGFI-B and it plays important roles in various biological processes such as cell proliferation, differentiation, apoptosis, and inflammation. It can be activated by a variety of stimuli including stress, hormones, and growth factors. Once activated, NR4A1 translocates to the nucleus where it binds to specific DNA sequences and regulates the expression of target genes.
Mutations in the NR4A1 gene have been associated with several diseases, including cancer, inflammatory bowel disease, and rheumatoid arthritis. Therefore, NR4A1 is a potential therapeutic target for these conditions.
In the field of medicine, "time factors" refer to the duration of symptoms or time elapsed since the onset of a medical condition, which can have significant implications for diagnosis and treatment. Understanding time factors is crucial in determining the progression of a disease, evaluating the effectiveness of treatments, and making critical decisions regarding patient care.
For example, in stroke management, "time is brain," meaning that rapid intervention within a specific time frame (usually within 4.5 hours) is essential to administering tissue plasminogen activator (tPA), a clot-busting drug that can minimize brain damage and improve patient outcomes. Similarly, in trauma care, the "golden hour" concept emphasizes the importance of providing definitive care within the first 60 minutes after injury to increase survival rates and reduce morbidity.
Time factors also play a role in monitoring the progression of chronic conditions like diabetes or heart disease, where regular follow-ups and assessments help determine appropriate treatment adjustments and prevent complications. In infectious diseases, time factors are crucial for initiating antibiotic therapy and identifying potential outbreaks to control their spread.
Overall, "time factors" encompass the significance of recognizing and acting promptly in various medical scenarios to optimize patient outcomes and provide effective care.
The "tat" gene in the Human Immunodeficiency Virus (HIV) produces the Tat protein, which is a regulatory protein that plays a crucial role in the replication of the virus. The Tat protein functions by enhancing the transcription of the viral genome, increasing the production of viral RNA and ultimately leading to an increase in the production of new virus particles. This protein is essential for the efficient replication of HIV and is a target for potential antiretroviral therapies.
MyoD protein is a member of the family of muscle regulatory factors (MRFs) that play crucial roles in the development and regulation of skeletal muscle. MyoD is a transcription factor, which means it binds to specific DNA sequences and helps control the transcription of nearby genes into messenger RNA (mRNA).
MyoD protein is encoded by the MYOD1 gene and is primarily expressed in skeletal muscle cells, where it functions as a master regulator of muscle differentiation. During myogenesis, MyoD is activated and initiates the expression of various genes involved in muscle-specific functions, such as contractile proteins and ion channels.
MyoD protein can also induce cell cycle arrest and promote the differentiation of non-muscle cells into muscle cells, a process known as transdifferentiation. This property has been explored in regenerative medicine for potential therapeutic applications.
In summary, MyoD protein is a key regulator of skeletal muscle development, differentiation, and maintenance, and it plays essential roles in the regulation of gene expression during myogenesis.
Oncogene proteins, viral, are cancer-causing proteins that are encoded by the genetic material (DNA or RNA) of certain viruses. These viral oncogenes can be acquired through infection with retroviruses, such as human immunodeficiency virus (HIV), human T-cell leukemia virus (HTLV), and certain types of papillomaviruses and polyomaviruses.
When these viruses infect host cells, they can integrate their genetic material into the host cell's genome, leading to the expression of viral oncogenes. These oncogenes may then cause uncontrolled cell growth and division, ultimately resulting in the formation of tumors or cancers. The process by which viruses contribute to cancer development is complex and involves multiple steps, including the alteration of signaling pathways that regulate cell proliferation, differentiation, and survival.
Examples of viral oncogenes include the v-src gene found in the Rous sarcoma virus (RSV), which causes chicken sarcoma, and the E6 and E7 genes found in human papillomaviruses (HPVs), which are associated with cervical cancer and other anogenital cancers. Understanding viral oncogenes and their mechanisms of action is crucial for developing effective strategies to prevent and treat virus-associated cancers.
SUMO-1 (Small Ubiquitin-like Modifier 1) protein is a member of the SUMO family of post-translational modifiers, which are involved in the regulation of various cellular processes such as nuclear-cytoplasmic transport, transcriptional regulation, and DNA repair. The SUMO-1 protein is covalently attached to specific lysine residues on target proteins through a process called sumoylation, which can alter the activity, localization, or stability of the modified protein. Sumoylation plays a crucial role in maintaining cellular homeostasis and has been implicated in several human diseases, including cancer and neurodegenerative disorders.
Chromosomal proteins, non-histone, are a diverse group of proteins that are associated with chromatin, the complex of DNA and histone proteins, but do not have the characteristic structure of histones. These proteins play important roles in various nuclear processes such as DNA replication, transcription, repair, recombination, and chromosome condensation and segregation during cell division. They can be broadly classified into several categories based on their functions, including architectural proteins, enzymes, transcription factors, and structural proteins. Examples of non-histone chromosomal proteins include high mobility group (HMG) proteins, poly(ADP-ribose) polymerases (PARPs), and condensins.
A "cell line, transformed" is a type of cell culture that has undergone a stable genetic alteration, which confers the ability to grow indefinitely in vitro, outside of the organism from which it was derived. These cells have typically been immortalized through exposure to chemical or viral carcinogens, or by introducing specific oncogenes that disrupt normal cell growth regulation pathways.
Transformed cell lines are widely used in scientific research because they offer a consistent and renewable source of biological material for experimentation. They can be used to study various aspects of cell biology, including signal transduction, gene expression, drug discovery, and toxicity testing. However, it is important to note that transformed cells may not always behave identically to their normal counterparts, and results obtained using these cells should be validated in more physiologically relevant systems when possible.
"Competitive binding" is a term used in pharmacology and biochemistry to describe the behavior of two or more molecules (ligands) competing for the same binding site on a target protein or receptor. In this context, "binding" refers to the physical interaction between a ligand and its target.
When a ligand binds to a receptor, it can alter the receptor's function, either activating or inhibiting it. If multiple ligands compete for the same binding site, they will compete to bind to the receptor. The ability of each ligand to bind to the receptor is influenced by its affinity for the receptor, which is a measure of how strongly and specifically the ligand binds to the receptor.
In competitive binding, if one ligand is present in high concentrations, it can prevent other ligands with lower affinity from binding to the receptor. This is because the higher-affinity ligand will have a greater probability of occupying the binding site and blocking access to the other ligands. The competition between ligands can be described mathematically using equations such as the Langmuir isotherm, which describes the relationship between the concentration of ligand and the fraction of receptors that are occupied by the ligand.
Competitive binding is an important concept in drug development, as it can be used to predict how different drugs will interact with their targets and how they may affect each other's activity. By understanding the competitive binding properties of a drug, researchers can optimize its dosage and delivery to maximize its therapeutic effect while minimizing unwanted side effects.
RNA (Ribonucleic Acid) is a single-stranded, linear polymer of ribonucleotides. It is a nucleic acid present in the cells of all living organisms and some viruses. RNAs play crucial roles in various biological processes such as protein synthesis, gene regulation, and cellular signaling. There are several types of RNA including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), small nuclear RNA (snRNA), microRNA (miRNA), and long non-coding RNA (lncRNA). These RNAs differ in their structure, function, and location within the cell.
An operon is a genetic unit in prokaryotic organisms (like bacteria) consisting of a cluster of genes that are transcribed together as a single mRNA molecule, which then undergoes translation to produce multiple proteins. This genetic organization allows for the coordinated regulation of genes that are involved in the same metabolic pathway or functional process. The unit typically includes promoter and operator regions that control the transcription of the operon, as well as structural genes encoding the proteins. Operons were first discovered in bacteria, but similar genetic organizations have been found in some eukaryotic organisms, such as yeast.
Y-box-binding protein 1 (YB-1) is a multifunctional protein that belongs to the family of cold shock proteins. It binds to the Y-box DNA sequence, which is a cis-acting element found in the promoter regions of various genes. YB-1 plays a crucial role in several cellular processes such as transcription, translation, DNA repair, and nucleocytoplasmic shuttling.
YB-1 has been implicated in the regulation of gene expression in response to different stimuli, including stress, growth factors, and differentiation signals. It can function both as a transcriptional activator and repressor, depending on the cellular context and interacting partners. YB-1 is also involved in the regulation of mRNA stability, translation, and localization.
In addition to its role in normal cellular processes, YB-1 has been implicated in various pathological conditions, including cancer, neurodegenerative diseases, and viral infections. For instance, elevated levels of YB-1 have been found in several types of cancer, where it can promote tumor growth, invasion, and drug resistance.
Overall, YB-1 is a versatile protein that plays a critical role in the regulation of gene expression at multiple levels, and its dysregulation has been associated with various diseases.
Oncogene proteins are derived from oncogenes, which are genes that have the potential to cause cancer. Normally, these genes help regulate cell growth and division, but when they become altered or mutated, they can become overactive and lead to uncontrolled cell growth and division, which is a hallmark of cancer. Oncogene proteins can contribute to tumor formation and progression by promoting processes such as cell proliferation, survival, angiogenesis, and metastasis. Examples of oncogene proteins include HER2/neu, EGFR, and BCR-ABL.
Bovine papillomavirus 1 (BPV-1) is a species of papillomavirus that primarily infects cattle, causing benign warts or papillomas in the skin and mucous membranes. It is not known to infect humans or cause disease in humans. BPV-1 is closely related to other papillomaviruses that can cause cancer in animals, but its role in human cancer is unclear.
BPV-1 is a double-stranded DNA virus that replicates in the nucleus of infected cells. It encodes several early and late proteins that are involved in viral replication and the transformation of host cells. BPV-1 has been extensively studied as a model system for understanding the molecular mechanisms of papillomavirus infection and oncogenesis.
In addition to its role in animal health, BPV-1 has also been used as a tool in biomedical research. For example, it can be used to transform cells in culture, providing a valuable resource for studying the properties of cancer cells and testing potential therapies. However, it is important to note that BPV-1 is not known to cause human disease and should not be used in any therapeutic context involving humans.
STAT3 (Signal Transducer and Activator of Transcription 3) is a transcription factor protein that plays a crucial role in signal transduction and gene regulation. It is activated through phosphorylation by various cytokines and growth factors, which leads to its dimerization, nuclear translocation, and binding to specific DNA sequences. Once bound to the DNA, STAT3 regulates the expression of target genes involved in various cellular processes such as proliferation, differentiation, survival, and angiogenesis. Dysregulation of STAT3 has been implicated in several diseases, including cancer, autoimmune disorders, and inflammatory conditions.
Adenovirus early proteins refer to the viral proteins that are expressed by adenoviruses during the early phase of their replication cycle. Adenoviruses are a group of viruses that can cause various symptoms, such as respiratory illness, conjunctivitis, and gastroenteritis.
The adenovirus replication cycle is divided into two phases: the early phase and the late phase. During the early phase, which occurs shortly after the virus infects a host cell, the viral genome is transcribed and translated into early proteins that help to prepare the host cell for viral replication. These early proteins play various roles in regulating the host cell's transcription, translation, and DNA replication machinery, as well as inhibiting the host cell's antiviral response.
There are several different adenovirus early proteins that have been identified, each with its own specific function. For example, E1A is an early protein that acts as a transcriptional activator and helps to activate the expression of other viral genes. E1B is another early protein that functions as a DNA-binding protein and inhibits the host cell's apoptosis (programmed cell death) response.
Overall, adenovirus early proteins are critical for the efficient replication of the virus within host cells, and understanding their functions can provide valuable insights into the mechanisms of viral infection and pathogenesis.
Histone Deacetylase Inhibitors (HDACIs) are a class of pharmaceutical compounds that inhibit the function of histone deacetylases (HDACs), enzymes that remove acetyl groups from histone proteins. Histones are alkaline proteins around which DNA is wound to form chromatin, the structure of which can be modified by the addition or removal of acetyl groups.
Histone acetylation generally results in a more "open" chromatin structure, making genes more accessible for transcription and leading to increased gene expression. Conversely, histone deacetylation typically results in a more "closed" chromatin structure, which can suppress gene expression. HDACIs block the activity of HDACs, resulting in an accumulation of acetylated histones and other proteins, and ultimately leading to changes in gene expression profiles.
HDACIs have been shown to exhibit anticancer properties by modulating the expression of genes involved in cell cycle regulation, apoptosis, and angiogenesis. As a result, HDACIs are being investigated as potential therapeutic agents for various types of cancer, including hematological malignancies and solid tumors. Some HDACIs have already been approved by regulatory authorities for the treatment of specific cancers, while others are still in clinical trials or preclinical development.
Transgenic mice are genetically modified rodents that have incorporated foreign DNA (exogenous DNA) into their own genome. This is typically done through the use of recombinant DNA technology, where a specific gene or genetic sequence of interest is isolated and then introduced into the mouse embryo. The resulting transgenic mice can then express the protein encoded by the foreign gene, allowing researchers to study its function in a living organism.
The process of creating transgenic mice usually involves microinjecting the exogenous DNA into the pronucleus of a fertilized egg, which is then implanted into a surrogate mother. The offspring that result from this procedure are screened for the presence of the foreign DNA, and those that carry the desired genetic modification are used to establish a transgenic mouse line.
Transgenic mice have been widely used in biomedical research to model human diseases, study gene function, and test new therapies. They provide a valuable tool for understanding complex biological processes and developing new treatments for a variety of medical conditions.
Histone Deacetylase 1 (HDAC1) is a type of enzyme that plays a role in the regulation of gene expression. It works by removing acetyl groups from histone proteins, which are part of the chromatin structure in the cell's nucleus. This changes the chromatin structure and makes it more difficult for transcription factors to access DNA, thereby repressing gene transcription.
HDAC1 is a member of the class I HDAC family and is widely expressed in various tissues. It is involved in many cellular processes, including cell cycle progression, differentiation, and survival. Dysregulation of HDAC1 has been implicated in several diseases, such as cancer, neurodegenerative disorders, and heart disease. As a result, HDAC1 is a potential target for therapeutic intervention in these conditions.
An oncogene protein fusion is a result of a genetic alteration in which parts of two different genes combine to create a hybrid gene that can contribute to the development of cancer. This fusion can lead to the production of an abnormal protein that promotes uncontrolled cell growth and division, ultimately resulting in a malignant tumor. Oncogene protein fusions are often caused by chromosomal rearrangements such as translocations, inversions, or deletions and are commonly found in various types of cancer, including leukemia and sarcoma. These genetic alterations can serve as potential targets for cancer diagnosis and therapy.
Cytochrome P-450 CYP1A1 is an enzyme that is part of the cytochrome P450 family, which are a group of enzymes involved in the metabolism of drugs and other xenobiotics (foreign substances) in the body. Specifically, CYP1A1 is found primarily in the liver and lungs and plays a role in the metabolism of polycyclic aromatic hydrocarbons (PAHs), which are chemicals found in tobacco smoke and are produced by the burning of fossil fuels and other organic materials.
CYP1A1 also has the ability to activate certain procarcinogens, which are substances that can be converted into cancer-causing agents (carcinogens) within the body. Therefore, variations in the CYP1A1 gene may influence an individual's susceptibility to cancer and other diseases.
The term "P-450" refers to the fact that these enzymes absorb light at a wavelength of 450 nanometers when they are combined with carbon monoxide, giving them a characteristic pink color. The "CYP" stands for "cytochrome P," and the number and letter designations (e.g., 1A1) indicate the specific enzyme within the family.
Aspartate-ammonia ligase, also known as aspartate transcarbamylase or ATC, is an enzyme that catalyzes the first reaction in the synthesis of pyrimidines, which are essential components of nucleotides and nucleic acids. The reaction catalyzed by aspartate-ammonia ligase is the condensation of aspartate and ammonia to form N-carbamoyl-L-aspartate and releases ADP and Pi. This enzyme plays a crucial role in the regulation of pyrimidine biosynthesis, and its activity is tightly regulated in response to changes in cellular demand for nucleotides. Defects in aspartate-ammonia ligase have been implicated in several genetic disorders, including ornithine transcarbamylase deficiency and citrullinemia.
Erythroid-specific DNA-binding factors are transcription factors that bind to specific sequences of DNA and help regulate the expression of genes that are involved in the development and differentiation of erythroid cells, which are cells that mature to become red blood cells. These transcription factors play a crucial role in the production of hemoglobin, the protein in red blood cells that carries oxygen throughout the body. Examples of erythroid-specific DNA-binding factors include GATA-1 and KLF1.
Protein biosynthesis is the process by which cells generate new proteins. It involves two major steps: transcription and translation. Transcription is the process of creating a complementary RNA copy of a sequence of DNA. This RNA copy, or messenger RNA (mRNA), carries the genetic information to the site of protein synthesis, the ribosome. During translation, the mRNA is read by transfer RNA (tRNA) molecules, which bring specific amino acids to the ribosome based on the sequence of nucleotides in the mRNA. The ribosome then links these amino acids together in the correct order to form a polypeptide chain, which may then fold into a functional protein. Protein biosynthesis is essential for the growth and maintenance of all living organisms.
A multigene family is a group of genetically related genes that share a common ancestry and have similar sequences or structures. These genes are arranged in clusters on a chromosome and often encode proteins with similar functions. They can arise through various mechanisms, including gene duplication, recombination, and transposition. Multigene families play crucial roles in many biological processes, such as development, immunity, and metabolism. Examples of multigene families include the globin genes involved in oxygen transport, the immune system's major histocompatibility complex (MHC) genes, and the cytochrome P450 genes associated with drug metabolism.
RNA polymerase sigma 54 (σ^54) is not a medical term, but rather a molecular biology concept. It's a type of sigma factor that associates with the core RNA polymerase to form the holoenzyme in bacteria. Sigma factors are subunits of RNA polymerase that recognize and bind to specific promoter sequences on DNA, thereby initiating transcription of genes into messenger RNA (mRNA).
σ^54 is unique because it requires additional energy to melt the DNA strands at the promoter site for transcription initiation. This energy comes from ATP hydrolysis, which is facilitated by a group of proteins called bacterial enhancer-binding proteins (bEBPs). The σ^54-dependent promoters typically contain two conserved sequence elements: an upstream activating sequence (UAS) and a downstream core promoter element (DPE).
In summary, RNA polymerase sigma 54 is a type of sigma factor that plays a crucial role in the initiation of transcription in bacteria. It specifically recognizes and binds to certain promoter sequences on DNA, and its activity requires ATP hydrolysis facilitated by bEBPs.
Activating Transcription Factor 4 (ATF4) is a protein that plays a crucial role in the regulation of gene expression, particularly during times of cellular stress. It belongs to the family of basic leucine zipper (bZIP) transcription factors and is involved in various biological processes such as endoplasmic reticulum (ER) stress response, amino acid metabolism, and protein synthesis.
ATF4 is encoded by the ATF4 gene, located on human chromosome 22q13.1. The protein contains several functional domains, including a bZIP domain that facilitates its dimerization with other bZIP proteins and binding to specific DNA sequences called ER stress response elements (ERSE) or amino acid response elements (AARE).
Under normal conditions, ATF4 levels are relatively low in cells. However, during periods of cellular stress, such as nutrient deprivation, hypoxia, or ER stress, the translation of ATF4 mRNA is selectively enhanced, leading to increased ATF4 protein levels. This upregulation of ATF4 triggers the expression of various target genes involved in adapting to stress conditions, promoting cell survival, or initiating programmed cell death (apoptosis) if the stress cannot be resolved.
In summary, Activating Transcription Factor 4 is a crucial protein that helps regulate gene expression during cellular stress, playing essential roles in maintaining cellular homeostasis and responding to various environmental challenges.
Cricetinae is a subfamily of rodents that includes hamsters, gerbils, and relatives. These small mammals are characterized by having short limbs, compact bodies, and cheek pouches for storing food. They are native to various parts of the world, particularly in Europe, Asia, and Africa. Some species are popular pets due to their small size, easy care, and friendly nature. In a medical context, understanding the biology and behavior of Cricetinae species can be important for individuals who keep them as pets or for researchers studying their physiology.
Cyclic AMP Response Element Modulator (CREM) is a protein that functions as a transcription factor, which binds to specific DNA sequences called cis-acting elements in the promoter region of target genes and regulates their expression. The CREM protein is activated by cyclic AMP (cAMP), a second messenger molecule involved in various cellular signaling pathways.
The CREM protein contains several functional domains, including a DNA-binding domain that recognizes the cAMP response element (CRE) sequence, and a transactivation domain that interacts with other proteins to activate or repress gene transcription. The CREM protein can exist in multiple forms, including activated and repressed isoforms, which are generated by alternative splicing of its pre-mRNA.
The CREM protein plays important roles in various biological processes, such as neuronal development, circadian rhythm regulation, and immune response. Dysregulation of CREM has been implicated in several diseases, including cancer, neurodegenerative disorders, and metabolic disorders.
Gene knockdown techniques are methods used to reduce the expression or function of specific genes in order to study their role in biological processes. These techniques typically involve the use of small RNA molecules, such as siRNAs (small interfering RNAs) or shRNAs (short hairpin RNAs), which bind to and promote the degradation of complementary mRNA transcripts. This results in a decrease in the production of the protein encoded by the targeted gene.
Gene knockdown techniques are often used as an alternative to traditional gene knockout methods, which involve completely removing or disrupting the function of a gene. Knockdown techniques allow for more subtle and reversible manipulation of gene expression, making them useful for studying genes that are essential for cell survival or have redundant functions.
These techniques are widely used in molecular biology research to investigate gene function, genetic interactions, and disease mechanisms. However, it is important to note that gene knockdown can have off-target effects and may not completely eliminate the expression of the targeted gene, so results should be interpreted with caution.
C57BL/6 (C57 Black 6) is an inbred strain of laboratory mouse that is widely used in biomedical research. The term "inbred" refers to a strain of animals where matings have been carried out between siblings or other closely related individuals for many generations, resulting in a population that is highly homozygous at most genetic loci.
The C57BL/6 strain was established in 1920 by crossing a female mouse from the dilute brown (DBA) strain with a male mouse from the black strain. The resulting offspring were then interbred for many generations to create the inbred C57BL/6 strain.
C57BL/6 mice are known for their robust health, longevity, and ease of handling, making them a popular choice for researchers. They have been used in a wide range of biomedical research areas, including studies of cancer, immunology, neuroscience, cardiovascular disease, and metabolism.
One of the most notable features of the C57BL/6 strain is its sensitivity to certain genetic modifications, such as the introduction of mutations that lead to obesity or impaired glucose tolerance. This has made it a valuable tool for studying the genetic basis of complex diseases and traits.
Overall, the C57BL/6 inbred mouse strain is an important model organism in biomedical research, providing a valuable resource for understanding the genetic and molecular mechanisms underlying human health and disease.
Oncogenes are genes that have the potential to cause cancer. They can do this by promoting cell growth and division (cellular proliferation), preventing cell death (apoptosis), or enabling cells to invade surrounding tissue and spread to other parts of the body (metastasis). Oncogenes can be formed when normal genes, called proto-oncogenes, are mutated or altered in some way. This can happen as a result of exposure to certain chemicals or radiation, or through inherited genetic mutations. When activated, oncogenes can contribute to the development of cancer by causing cells to divide and grow in an uncontrolled manner.
An "HIV enhancer" is not a widely recognized or used term in the field of medicine or virology. However, I can provide some context that might help you understand where this term could be coming from.
In the genome of HIV (the Human Immunodeficiency Virus), there are regulatory regions called enhancers that play a crucial role in controlling the transcription of the viral genes. These enhancers are DNA sequences that serve as binding sites for various proteins, including transcription factors, which regulate the initiation and efficiency of gene transcription.
In some cases, researchers might refer to an "HIV enhancer" when discussing specific regulatory elements within the HIV genome that enhance (up-regulate) viral replication or transcription. One well-known example is the long terminal repeat (LTR) region of HIV, which contains enhancers and promoters that are critical for viral gene expression.
However, it's essential to clarify the context in which the term "HIV enhancer" is being used, as it may not be universally understood without additional information. I would recommend consulting the source or author for a more precise definition if you encounter this term in a specific scientific context.
The liver is a large, solid organ located in the upper right portion of the abdomen, beneath the diaphragm and above the stomach. It plays a vital role in several bodily functions, including:
1. Metabolism: The liver helps to metabolize carbohydrates, fats, and proteins from the food we eat into energy and nutrients that our bodies can use.
2. Detoxification: The liver detoxifies harmful substances in the body by breaking them down into less toxic forms or excreting them through bile.
3. Synthesis: The liver synthesizes important proteins, such as albumin and clotting factors, that are necessary for proper bodily function.
4. Storage: The liver stores glucose, vitamins, and minerals that can be released when the body needs them.
5. Bile production: The liver produces bile, a digestive juice that helps to break down fats in the small intestine.
6. Immune function: The liver plays a role in the immune system by filtering out bacteria and other harmful substances from the blood.
Overall, the liver is an essential organ that plays a critical role in maintaining overall health and well-being.
'Drosophila melanogaster' is the scientific name for a species of fruit fly that is commonly used as a model organism in various fields of biological research, including genetics, developmental biology, and evolutionary biology. Its small size, short generation time, large number of offspring, and ease of cultivation make it an ideal subject for laboratory studies. The fruit fly's genome has been fully sequenced, and many of its genes have counterparts in the human genome, which facilitates the understanding of genetic mechanisms and their role in human health and disease.
Here is a brief medical definition:
Drosophila melanogaster (droh-suh-fih-luh meh-lon-guh-ster): A species of fruit fly used extensively as a model organism in genetic, developmental, and evolutionary research. Its genome has been sequenced, revealing many genes with human counterparts, making it valuable for understanding genetic mechanisms and their role in human health and disease.
Proline is an organic compound that is classified as a non-essential amino acid, meaning it can be produced by the human body and does not need to be obtained through the diet. It is encoded in the genetic code as the codon CCU, CCC, CCA, or CCG. Proline is a cyclic amino acid, containing an unusual secondary amine group, which forms a ring structure with its carboxyl group.
In proteins, proline acts as a structural helix breaker, disrupting the alpha-helix structure and leading to the formation of turns and bends in the protein chain. This property is important for the proper folding and function of many proteins. Proline also plays a role in the stability of collagen, a major structural protein found in connective tissues such as tendons, ligaments, and skin.
In addition to its role in protein structure, proline has been implicated in various cellular processes, including signal transduction, apoptosis, and oxidative stress response. It is also a precursor for the synthesis of other biologically important compounds such as hydroxyproline, which is found in collagen and elastin, and glutamate, an excitatory neurotransmitter in the brain.
HSP70 heat-shock proteins are a family of highly conserved molecular chaperones that play a crucial role in protein folding and protection against stress-induced damage. They are named after the fact that they were first discovered in response to heat shock, but they are now known to be produced in response to various stressors, such as oxidative stress, inflammation, and exposure to toxins.
HSP70 proteins bind to exposed hydrophobic regions of unfolded or misfolded proteins, preventing their aggregation and assisting in their proper folding. They also help target irreversibly damaged proteins for degradation by the proteasome. In addition to their role in protein homeostasis, HSP70 proteins have been shown to have anti-inflammatory and immunomodulatory effects, making them a subject of interest in various therapeutic contexts.
Gene expression profiling is a laboratory technique used to measure the activity (expression) of thousands of genes at once. This technique allows researchers and clinicians to identify which genes are turned on or off in a particular cell, tissue, or organism under specific conditions, such as during health, disease, development, or in response to various treatments.
The process typically involves isolating RNA from the cells or tissues of interest, converting it into complementary DNA (cDNA), and then using microarray or high-throughput sequencing technologies to determine which genes are expressed and at what levels. The resulting data can be used to identify patterns of gene expression that are associated with specific biological states or processes, providing valuable insights into the underlying molecular mechanisms of diseases and potential targets for therapeutic intervention.
In recent years, gene expression profiling has become an essential tool in various fields, including cancer research, drug discovery, and personalized medicine, where it is used to identify biomarkers of disease, predict patient outcomes, and guide treatment decisions.
JNK (c-Jun N-terminal kinase) Mitogen-Activated Protein Kinases are a subgroup of the Ser/Thr protein kinases that are activated by stress stimuli and play important roles in various cellular processes, including inflammation, apoptosis, and differentiation. They are involved in the regulation of gene expression through phosphorylation of transcription factors such as c-Jun. JNKs are activated by a variety of upstream kinases, including MAP2Ks (MKK4/SEK1 and MKK7), which are in turn activated by MAP3Ks (such as ASK1, MEKK1, MLKs, and TAK1). JNK signaling pathways have been implicated in various diseases, including cancer, neurodegenerative disorders, and inflammatory diseases.
A bacterial gene is a segment of DNA (or RNA in some viruses) that contains the genetic information necessary for the synthesis of a functional bacterial protein or RNA molecule. These genes are responsible for encoding various characteristics and functions of bacteria such as metabolism, reproduction, and resistance to antibiotics. They can be transmitted between bacteria through horizontal gene transfer mechanisms like conjugation, transformation, and transduction. Bacterial genes are often organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule.
It's important to note that the term "bacterial gene" is used to describe genetic elements found in bacteria, but not all genetic elements in bacteria are considered genes. For example, some DNA sequences may not encode functional products and are therefore not considered genes. Additionally, some bacterial genes may be plasmid-borne or phage-borne, rather than being located on the bacterial chromosome.
Proto-oncogene proteins, such as c-MDM2, are normal cellular proteins that play crucial roles in regulating various cellular processes, including cell growth, differentiation, and apoptosis (programmed cell death). When these genes undergo mutations or are overexpressed, they can become oncogenes, which contribute to the development of cancer.
The c-MDM2 protein is a key regulator of the cell cycle and is involved in the negative regulation of the tumor suppressor protein p53. Under normal conditions, p53 helps prevent the formation of tumors by inducing cell cycle arrest or apoptosis in response to DNA damage or other stress signals. However, when c-MDM2 is overexpressed or mutated, it can bind and inhibit p53, leading to uncontrolled cell growth and increased risk of cancer development.
In summary, proto-oncogene proteins like c-MDM2 are important regulators of normal cellular processes, but when they become dysregulated through mutations or overexpression, they can contribute to the formation of tumors and cancer progression.
Wnt proteins are a family of secreted signaling molecules that play crucial roles in the regulation of fundamental biological processes, including cell proliferation, differentiation, migration, and survival. They were first discovered in 1982 through genetic studies in Drosophila melanogaster (fruit flies) and have since been found to be highly conserved across various species, from invertebrates to humans.
Wnt proteins exert their effects by binding to specific receptors on the target cell surface, leading to the activation of several intracellular signaling pathways:
1. Canonical Wnt/β-catenin pathway: In the absence of Wnt ligands, β-catenin is continuously degraded by a destruction complex consisting of Axin, APC (Adenomatous polyposis coli), and GSK3β (Glycogen synthase kinase 3 beta). When Wnt proteins bind to their receptors Frizzled and LRP5/6, the formation of a "signalosome" complex leads to the inhibition of the destruction complex, allowing β-catenin to accumulate in the cytoplasm and translocate into the nucleus. Here, it interacts with TCF/LEF (T-cell factor/lymphoid enhancer-binding factor) transcription factors to regulate the expression of target genes involved in cell proliferation, differentiation, and survival.
2. Non-canonical Wnt pathways: These include the Wnt/Ca^2+^ pathway and the planar cell polarity (PCP) pathway. In the Wnt/Ca^2+^ pathway, Wnt ligands bind to Frizzled receptors and activate heterotrimeric G proteins, leading to an increase in intracellular Ca^2+^ levels and activation of downstream targets such as protein kinase C (PKC) and calcium/calmodulin-dependent protein kinase II (CAMKII). These signaling events ultimately regulate cell movement, adhesion, and gene expression. In the PCP pathway, Wnt ligands bind to Frizzled receptors and coreceptor complexes containing Ror2 or Ryk, leading to activation of small GTPases such as RhoA and Rac1, which control cytoskeletal organization and cell polarity.
Dysregulation of Wnt signaling has been implicated in various human diseases, including cancer, developmental disorders, and degenerative conditions. In cancer, aberrant activation of the canonical Wnt/β-catenin pathway contributes to tumor initiation, progression, and metastasis by promoting cell proliferation, survival, and epithelial-mesenchymal transition (EMT). Inhibitors targeting different components of the Wnt signaling pathway are currently being developed as potential therapeutic strategies for cancer treatment.
Oligonucleotide Array Sequence Analysis is a type of microarray analysis that allows for the simultaneous measurement of the expression levels of thousands of genes in a single sample. In this technique, oligonucleotides (short DNA sequences) are attached to a solid support, such as a glass slide, in a specific pattern. These oligonucleotides are designed to be complementary to specific target mRNA sequences from the sample being analyzed.
During the analysis, labeled RNA or cDNA from the sample is hybridized to the oligonucleotide array. The level of hybridization is then measured and used to determine the relative abundance of each target sequence in the sample. This information can be used to identify differences in gene expression between samples, which can help researchers understand the underlying biological processes involved in various diseases or developmental stages.
It's important to note that this technique requires specialized equipment and bioinformatics tools for data analysis, as well as careful experimental design and validation to ensure accurate and reproducible results.
I-kappa B (IκB) proteins are a family of inhibitory proteins that play a crucial role in regulating the activity of nuclear factor kappa B (NF-κB), a key transcription factor involved in inflammation, immune response, and cell survival. In resting cells, NF-κB is sequestered in the cytoplasm by binding to IκB proteins, which prevents NF-κB from translocating into the nucleus and activating its target genes.
Upon stimulation of various signaling pathways, such as those triggered by proinflammatory cytokines, bacterial or viral components, and stress signals, IκB proteins become phosphorylated, ubiquitinated, and subsequently degraded by the 26S proteasome. This process allows NF-κB to dissociate from IκB, translocate into the nucleus, and bind to specific DNA sequences, leading to the expression of various genes involved in immune response, inflammation, cell growth, differentiation, and survival.
There are several members of the IκB protein family, including IκBα, IκBβ, IκBε, IκBγ, and Bcl-3. Each member has distinct functions and regulatory mechanisms in controlling NF-κB activity. Dysregulation of IκB proteins and NF-κB signaling has been implicated in various pathological conditions, such as chronic inflammation, autoimmune diseases, and cancer.
Human T-lymphotropic virus 1 (HTLV-1) is a complex retrovirus that infects CD4+ T lymphocytes and can cause adult T-cell leukemia/lymphoma (ATLL) and HTLV-1-associated myelopathy/tropical spastic paraparesis (HAM/TSP). The virus is primarily transmitted through breastfeeding, sexual contact, or contaminated blood products. After infection, the virus integrates into the host's genome and can remain latent for years or even decades before leading to disease. HTLV-1 is endemic in certain regions of the world, including Japan, the Caribbean, Central and South America, and parts of Africa.
I'm sorry for any confusion, but "Insect Proteins" is not a recognized medical term. However, I can provide some information about insect protein from a nutritional and food science perspective.
Insect proteins refer to the proteins that are obtained from insects. Insects are a rich source of protein, and their protein content varies by species. For example, mealworms and crickets have been found to contain approximately 47-63% and 60-72% protein by dry weight, respectively.
In recent years, insect proteins have gained attention as a potential sustainable source of nutrition due to their high protein content, low environmental impact, and the ability to convert feed into protein more efficiently compared to traditional livestock. Insect proteins can be used in various applications such as food and feed additives, nutritional supplements, and even cosmetics.
However, it's important to note that the use of insect proteins in human food is not widely accepted in many Western countries due to cultural and regulatory barriers. Nonetheless, research and development efforts continue to explore the potential benefits and applications of insect proteins in the global food system.
Nuclear factor erythroid-derived 2-like 2 (NFE2L2), also known as NF-E2-related factor 2 (NRF2), is a protein that plays a crucial role in the regulation of cellular responses to oxidative stress and electrophilic substances. It is a transcription factor that binds to the antioxidant response element (ARE) in the promoter region of various genes, inducing their expression and promoting cellular defense against harmful stimuli.
Under normal conditions, NRF2 is bound to its inhibitor, Kelch-like ECH-associated protein 1 (KEAP1), in the cytoplasm, where it is targeted for degradation by the proteasome. However, upon exposure to oxidative stress or electrophilic substances, KEAP1 undergoes conformational changes, leading to the release and stabilization of NRF2. Subsequently, NRF2 translocates to the nucleus, forms a complex with small Maf proteins, and binds to AREs, inducing the expression of genes involved in antioxidant response, detoxification, and cellular protection.
Genetic variations or dysregulation of the NFE2L2/KEAP1 pathway have been implicated in several diseases, including cancer, neurodegenerative disorders, and pulmonary fibrosis, highlighting its importance in maintaining cellular homeostasis and preventing disease progression.
Octamer Transcription Factor-2 (OCT-2, also known as OTF-2 or POU2F2) is a protein that, in humans, is encoded by the POU2F2 gene. It belongs to the class II family of POU domain transcription factors, which are characterized by a highly conserved DNA-binding domain called the POU domain.
The OCT-2 protein plays crucial roles in the development and function of the nervous system, particularly in the differentiation and maintenance of neurons. It is involved in regulating the expression of various genes that are essential for neural functions, such as neurotransmitter synthesis, synaptic plasticity, and neuronal survival.
OCT-2 forms homodimers or heterodimers with other transcription factors to bind to specific DNA sequences called octamer motifs, which typically have the consensus sequence ATGCAAAT. The binding of OCT-2 to these motifs influences the transcriptional activity of the target genes, either activating or repressing their expression.
Dysregulation of OCT-2 has been implicated in several neurological disorders and cancers, making it a potential therapeutic target for these conditions.
Hepatocyte Nuclear Factor 4 (HNF4) is a type of transcription factor that plays a crucial role in the development and function of the liver. It belongs to the nuclear receptor superfamily and is specifically involved in the regulation of genes that are essential for glucose, lipid, and drug metabolism, as well as bile acid synthesis and transport.
HNF4 exists in two major isoforms, HNF4α and HNF4γ, which are encoded by separate genes but share a high degree of sequence similarity. Both isoforms are expressed in the liver, as well as in other tissues such as the kidney, pancreas, and intestine.
HNF4α is considered to be the predominant isoform in the liver, where it helps regulate the expression of genes involved in hepatocyte differentiation, function, and survival. Mutations in the HNF4α gene have been associated with various forms of diabetes and liver disease, highlighting its importance in maintaining normal metabolic homeostasis.
In summary, Hepatocyte Nuclear Factor 4 is a key transcriptional regulator involved in the development, function, and maintenance of the liver and other tissues, with specific roles in glucose and lipid metabolism, bile acid synthesis, and drug detoxification.
Tetrachlorodibenzodioxin (TCDD) is not a common medical term, but it is known in toxicology and environmental health. TCDD is the most toxic and studied compound among a group of chemicals known as dioxins.
Medical-related definition:
Tetrachlorodibenzodioxin (TCDD) is an unintended byproduct of various industrial processes, including waste incineration, chemical manufacturing, and pulp and paper bleaching. It is a highly persistent environmental pollutant that accumulates in the food chain, primarily in animal fat. Human exposure to TCDD mainly occurs through consumption of contaminated food, such as meat, dairy products, and fish. TCDD is a potent toxicant with various health effects, including immunotoxicity, reproductive and developmental toxicity, and carcinogenicity. The severity of these effects depends on the level and duration of exposure.
p38 Mitogen-Activated Protein Kinases (p38 MAPKs) are a family of conserved serine-threonine protein kinases that play crucial roles in various cellular processes, including inflammation, immune response, differentiation, apoptosis, and stress responses. They are activated by diverse stimuli such as cytokines, ultraviolet radiation, heat shock, osmotic stress, and lipopolysaccharides (LPS).
Once activated, p38 MAPKs phosphorylate and regulate several downstream targets, including transcription factors and other protein kinases. This regulation leads to the expression of genes involved in inflammation, cell cycle arrest, and apoptosis. Dysregulation of p38 MAPK signaling has been implicated in various diseases, such as cancer, neurodegenerative disorders, and autoimmune diseases. Therefore, p38 MAPKs are considered promising targets for developing new therapeutic strategies to treat these conditions.
Cell proliferation is the process by which cells increase in number, typically through the process of cell division. In the context of biology and medicine, it refers to the reproduction of cells that makes up living tissue, allowing growth, maintenance, and repair. It involves several stages including the transition from a phase of quiescence (G0 phase) to an active phase (G1 phase), DNA replication in the S phase, and mitosis or M phase, where the cell divides into two daughter cells.
Abnormal or uncontrolled cell proliferation is a characteristic feature of many diseases, including cancer, where deregulated cell cycle control leads to excessive and unregulated growth of cells, forming tumors that can invade surrounding tissues and metastasize to distant sites in the body.
Organ specificity, in the context of immunology and toxicology, refers to the phenomenon where a substance (such as a drug or toxin) or an immune response primarily affects certain organs or tissues in the body. This can occur due to various reasons such as:
1. The presence of specific targets (like antigens in the case of an immune response or receptors in the case of drugs) that are more abundant in these organs.
2. The unique properties of certain cells or tissues that make them more susceptible to damage.
3. The way a substance is metabolized or cleared from the body, which can concentrate it in specific organs.
For example, in autoimmune diseases, organ specificity describes immune responses that are directed against antigens found only in certain organs, such as the thyroid gland in Hashimoto's disease. Similarly, some toxins or drugs may have a particular affinity for liver cells, leading to liver damage or specific drug interactions.
The Aryl Hydrocarbon Receptor Nuclear Translocator (ARNT) is a protein that plays a crucial role in the functioning of the aryl hydrocarbon receptor (AhR) signaling pathway. The AhR signaling pathway is involved in various biological processes, including the regulation of xenobiotic metabolism and cellular responses to environmental contaminants such as polycyclic aromatic hydrocarbons (PAHs) and dioxins.
The ARNT protein forms a heterodimer with the AhR protein upon ligand binding, which then translocates into the nucleus. Once in the nucleus, this complex binds to specific DNA sequences called xenobiotic response elements (XREs), leading to the activation or repression of target genes involved in various cellular processes such as detoxification, cell cycle regulation, and immune responses.
Therefore, the ARNT protein is an essential component of the AhR signaling pathway, and its dysregulation has been implicated in several diseases, including cancer, autoimmune disorders, and neurodevelopmental disorders.
Cytoplasm is the material within a eukaryotic cell (a cell with a true nucleus) that lies between the nuclear membrane and the cell membrane. It is composed of an aqueous solution called cytosol, in which various organelles such as mitochondria, ribosomes, endoplasmic reticulum, Golgi apparatus, lysosomes, and vacuoles are suspended. Cytoplasm also contains a variety of dissolved nutrients, metabolites, ions, and enzymes that are involved in various cellular processes such as metabolism, signaling, and transport. It is where most of the cell's metabolic activities take place, and it plays a crucial role in maintaining the structure and function of the cell.
The proteasome endopeptidase complex is a large protein complex found in the cells of eukaryotic organisms, as well as in archaea and some bacteria. It plays a crucial role in the degradation of damaged or unneeded proteins through a process called proteolysis. The proteasome complex contains multiple subunits, including both regulatory and catalytic particles.
The catalytic core of the proteasome is composed of four stacked rings, each containing seven subunits, forming a structure known as the 20S core particle. Three of these rings are made up of beta-subunits that contain the proteolytic active sites, while the fourth ring consists of alpha-subunits that control access to the interior of the complex.
The regulatory particles, called 19S or 11S regulators, cap the ends of the 20S core particle and are responsible for recognizing, unfolding, and translocating targeted proteins into the catalytic chamber. The proteasome endopeptidase complex can cleave peptide bonds in various ways, including hydrolysis of ubiquitinated proteins, which is an essential mechanism for maintaining protein quality control and regulating numerous cellular processes, such as cell cycle progression, signal transduction, and stress response.
In summary, the proteasome endopeptidase complex is a crucial intracellular machinery responsible for targeted protein degradation through proteolysis, contributing to various essential regulatory functions in cells.
Protein Kinase C (PKC) is a family of serine-threonine kinases that play crucial roles in various cellular signaling pathways. These enzymes are activated by second messengers such as diacylglycerol (DAG) and calcium ions (Ca2+), which result from the activation of cell surface receptors like G protein-coupled receptors (GPCRs) and receptor tyrosine kinases (RTKs).
Once activated, PKC proteins phosphorylate downstream target proteins, thereby modulating their activities. This regulation is involved in numerous cellular processes, including cell growth, differentiation, apoptosis, and membrane trafficking. There are at least 10 isoforms of PKC, classified into three subfamilies based on their second messenger requirements and structural features: conventional (cPKC; α, βI, βII, and γ), novel (nPKC; δ, ε, η, and θ), and atypical (aPKC; ζ and ι/λ). Dysregulation of PKC signaling has been implicated in several diseases, such as cancer, diabetes, and neurological disorders.
Mitogen-activated protein kinase (MAPK) signaling system is a crucial pathway for the transmission and regulation of various cellular responses in eukaryotic cells. It plays a significant role in several biological processes, including proliferation, differentiation, apoptosis, inflammation, and stress response. The MAPK cascade consists of three main components: MAP kinase kinase kinase (MAP3K or MEKK), MAP kinase kinase (MAP2K or MEK), and MAP kinase (MAPK).
The signaling system is activated by various extracellular stimuli, such as growth factors, cytokines, hormones, and stress signals. These stimuli initiate a phosphorylation cascade that ultimately leads to the activation of MAPKs. The activated MAPKs then translocate into the nucleus and regulate gene expression by phosphorylating various transcription factors and other regulatory proteins.
There are four major MAPK families: extracellular signal-regulated kinases (ERK1/2), c-Jun N-terminal kinases (JNK1/2/3), p38 MAPKs (p38α/β/γ/δ), and ERK5. Each family has distinct functions, substrates, and upstream activators. Dysregulation of the MAPK signaling system can lead to various diseases, including cancer, diabetes, cardiovascular diseases, and neurological disorders. Therefore, understanding the molecular mechanisms underlying this pathway is crucial for developing novel therapeutic strategies.
A DNA probe is a single-stranded DNA molecule that contains a specific sequence of nucleotides, and is labeled with a detectable marker such as a radioisotope or a fluorescent dye. It is used in molecular biology to identify and locate a complementary sequence within a sample of DNA. The probe hybridizes (forms a stable double-stranded structure) with its complementary sequence through base pairing, allowing for the detection and analysis of the target DNA. This technique is widely used in various applications such as genetic testing, diagnosis of infectious diseases, and forensic science.
Teratocarcinoma is a rare type of cancer that contains both malignant germ cells (cells that give rise to sperm or eggs) and various types of benign, or noncancerous, tissue such as muscle, bone, and nerve tissue. It most commonly occurs in the ovaries or testicles but can also develop in other areas of the body, such as the mediastinum (the area between the lungs), retroperitoneum (the area behind the abdominal lining), and pineal gland (a small endocrine gland in the brain).
Teratocarcinomas are aggressive tumors that can spread quickly to other parts of the body if not treated promptly. They typically affect young adults, with a median age at diagnosis of around 20 years old. Treatment usually involves surgical removal of the tumor, followed by chemotherapy and/or radiation therapy to kill any remaining cancer cells.
It's important to note that Teratocarcinoma is different from Teratoma which is a type of germ cell tumor that can contain various types of tissue but it does not have malignant component.
A dose-response relationship in the context of drugs refers to the changes in the effects or symptoms that occur as the dose of a drug is increased or decreased. Generally, as the dose of a drug is increased, the severity or intensity of its effects also increases. Conversely, as the dose is decreased, the effects of the drug become less severe or may disappear altogether.
The dose-response relationship is an important concept in pharmacology and toxicology because it helps to establish the safe and effective dosage range for a drug. By understanding how changes in the dose of a drug affect its therapeutic and adverse effects, healthcare providers can optimize treatment plans for their patients while minimizing the risk of harm.
The dose-response relationship is typically depicted as a curve that shows the relationship between the dose of a drug and its effect. The shape of the curve may vary depending on the drug and the specific effect being measured. Some drugs may have a steep dose-response curve, meaning that small changes in the dose can result in large differences in the effect. Other drugs may have a more gradual dose-response curve, where larger changes in the dose are needed to produce significant effects.
In addition to helping establish safe and effective dosages, the dose-response relationship is also used to evaluate the potential therapeutic benefits and risks of new drugs during clinical trials. By systematically testing different doses of a drug in controlled studies, researchers can identify the optimal dosage range for the drug and assess its safety and efficacy.
Genetic suppression is a concept in genetics that refers to the phenomenon where the expression or function of one gene is reduced or silenced by another gene. This can occur through various mechanisms such as:
* Allelic exclusion: When only one allele (version) of a gene is expressed, while the other is suppressed.
* Epigenetic modifications: Chemical changes to the DNA or histone proteins that package DNA can result in the suppression of gene expression.
* RNA interference: Small RNAs can bind to and degrade specific mRNAs (messenger RNAs), preventing their translation into proteins.
* Transcriptional repression: Proteins called transcription factors can bind to DNA and prevent the recruitment of RNA polymerase, which is necessary for gene transcription.
Genetic suppression plays a crucial role in regulating gene expression and maintaining proper cellular function. It can also contribute to diseases such as cancer when genes that suppress tumor growth are suppressed themselves.
A GA-binding protein (GABP) transcription factor is a type of protein complex that regulates gene expression by binding to specific DNA sequences known as GATA motifs. These motifs contain the consensus sequence (T/A)GAT(A/G)(A/T). GABP is composed of two subunits, GABPα and GABPβ, which form a heterodimer that recognizes and binds to the GATA motif.
GABP plays a crucial role in various biological processes, including cell proliferation, differentiation, and survival. It is involved in the regulation of genes that are important for the function of the cardiovascular, respiratory, and immune systems. Mutations in the genes encoding GABP subunits have been associated with several human diseases, such as congenital heart defects, pulmonary hypertension, and immunodeficiency disorders.
Overall, GABP transcription factors are essential regulators of gene expression that play a critical role in maintaining normal physiological functions and homeostasis in the body.
Transcription factor DP1 (TFDP1) is not a specific medical term, but it is a term used in molecular biology and genetics. TFDP1 is a protein that functions as a transcription factor, which means it helps regulate the expression of genes by binding to specific DNA sequences and controlling the rate of transcription of those genes into messenger RNA (mRNA).
TFDP1 typically forms a complex with another transcription factor called E2F, and this complex plays a critical role in regulating the cell cycle and promoting cell division. TFDP1 can act as both a transcriptional activator and repressor, depending on which E2F family member it binds to and the specific context of the cell.
Mutations or dysregulation of TFDP1 have been implicated in various human diseases, including cancer. For example, overexpression of TFDP1 has been observed in several types of cancer, such as breast, lung, and prostate cancer, and is often associated with poor clinical outcomes. Therefore, understanding the role of TFDP1 in gene regulation and cellular processes may provide insights into the development of new therapeutic strategies for treating human diseases.
Activating transcription factors (ATFs) are a family of proteins that regulate gene expression by binding to specific DNA sequences and promoting the initiation of transcription. They play crucial roles in various cellular processes, including development, differentiation, and stress response. ATFs can form homodimers or heterodimers with other transcription factors, such as cAMP response element-binding protein (CREB), and bind to the consensus sequence called the cyclic AMP response element (CRE) in the promoter region of target genes. The activation of ATFs can be regulated through various post-translational modifications, such as phosphorylation, which can alter their DNA-binding ability and transcriptional activity.
An amino acid substitution is a type of mutation in which one amino acid in a protein is replaced by another. This occurs when there is a change in the DNA sequence that codes for a particular amino acid in a protein. The genetic code is redundant, meaning that most amino acids are encoded by more than one codon (a sequence of three nucleotides). As a result, a single base pair change in the DNA sequence may not necessarily lead to an amino acid substitution. However, if a change does occur, it can have a variety of effects on the protein's structure and function, depending on the nature of the substituted amino acids. Some substitutions may be harmless, while others may alter the protein's activity or stability, leading to disease.
Tumor Necrosis Factor-alpha (TNF-α) is a cytokine, a type of small signaling protein involved in immune response and inflammation. It is primarily produced by activated macrophages, although other cell types such as T-cells, natural killer cells, and mast cells can also produce it.
TNF-α plays a crucial role in the body's defense against infection and tissue injury by mediating inflammatory responses, activating immune cells, and inducing apoptosis (programmed cell death) in certain types of cells. It does this by binding to its receptors, TNFR1 and TNFR2, which are found on the surface of many cell types.
In addition to its role in the immune response, TNF-α has been implicated in the pathogenesis of several diseases, including autoimmune disorders such as rheumatoid arthritis, inflammatory bowel disease, and psoriasis, as well as cancer, where it can promote tumor growth and metastasis.
Therapeutic agents that target TNF-α, such as infliximab, adalimumab, and etanercept, have been developed to treat these conditions. However, these drugs can also increase the risk of infections and other side effects, so their use must be carefully monitored.
MADS domain proteins are a family of transcription factors that play crucial roles in various developmental processes in plants, including flower development and organ formation. The name "MADS" is an acronym derived from the initial letters of four founding members: MCM1 from Saccharomyces cerevisiae, AGAMOUS from Arabidopsis thaliana, DEFICIENS from Antirrhinum majus, and SRF from Homo sapiens.
These proteins share a highly conserved DNA-binding domain called the MADS-box, which binds to specific sequences in the promoter regions of their target genes. The MADS domain proteins often form higher-order complexes through protein-protein interactions, leading to the regulation of gene expression involved in developmental transitions and cell fate determination. In plants, MADS domain proteins have been implicated in various aspects of reproductive development, such as floral meristem identity, floral organ specification, and ovule development.
Estrogens are a group of steroid hormones that are primarily responsible for the development and regulation of female sexual characteristics and reproductive functions. They are also present in lower levels in males. The main estrogen hormone is estradiol, which plays a key role in promoting the growth and development of the female reproductive system, including the uterus, fallopian tubes, and breasts. Estrogens also help regulate the menstrual cycle, maintain bone density, and have important effects on the cardiovascular system, skin, hair, and cognitive function.
Estrogens are produced primarily by the ovaries in women, but they can also be produced in smaller amounts by the adrenal glands and fat cells. In men, estrogens are produced from the conversion of testosterone, the primary male sex hormone, through a process called aromatization.
Estrogen levels vary throughout a woman's life, with higher levels during reproductive years and lower levels after menopause. Estrogen therapy is sometimes used to treat symptoms of menopause, such as hot flashes and vaginal dryness, or to prevent osteoporosis in postmenopausal women. However, estrogen therapy also carries risks, including an increased risk of certain cancers, blood clots, and stroke, so it is typically recommended only for women who have a high risk of these conditions.
A mammalian embryo is the developing offspring of a mammal, from the time of implantation of the fertilized egg (blastocyst) in the uterus until the end of the eighth week of gestation. During this period, the embryo undergoes rapid cell division and organ differentiation to form a complex structure with all the major organs and systems in place. This stage is followed by fetal development, which continues until birth. The study of mammalian embryos is important for understanding human development, evolution, and reproductive biology.
Protein interaction mapping is a research approach used to identify and characterize the physical interactions between different proteins within a cell or organism. This process often involves the use of high-throughput experimental techniques, such as yeast two-hybrid screening, mass spectrometry-based approaches, or protein fragment complementation assays, to detect and quantify the binding affinities of protein pairs. The resulting data is then used to construct a protein interaction network, which can provide insights into functional relationships between proteins, help elucidate cellular pathways, and inform our understanding of biological processes in health and disease.
Transcription Factor CHOP, also known as DNA Binding Protein C/EBP Homologous Protein or GADD153 (Growth Arrest and DNA Damage-inducible protein 153), is a transcription factor that is involved in the regulation of gene expression in response to various stress stimuli, such as endoplasmic reticulum (ER) stress, hypoxia, and DNA damage.
CHOP is a member of the C/EBP (CCAAT/enhancer-binding protein) family of transcription factors, which bind to specific DNA sequences called cis-acting elements in the promoter regions of target genes. CHOP can form heterodimers with other C/EBP family members and bind to their target DNA sequences, thereby regulating gene expression.
Under normal physiological conditions, CHOP is expressed at low levels. However, under stress conditions, such as ER stress, the expression of CHOP is upregulated through the activation of the unfolded protein response (UPR) signaling pathways. Once activated, CHOP can induce the transcription of genes involved in apoptosis, cell cycle arrest, and oxidative stress response, leading to programmed cell death or survival, depending on the severity and duration of the stress signal.
Therefore, CHOP plays a critical role in maintaining cellular homeostasis by regulating gene expression in response to various stress stimuli, and its dysregulation has been implicated in several pathological conditions, including neurodegenerative diseases, cancer, and metabolic disorders.
DNA replication is the biological process by which DNA makes an identical copy of itself during cell division. It is a fundamental mechanism that allows genetic information to be passed down from one generation of cells to the next. During DNA replication, each strand of the double helix serves as a template for the synthesis of a new complementary strand. This results in the creation of two identical DNA molecules. The enzymes responsible for DNA replication include helicase, which unwinds the double helix, and polymerase, which adds nucleotides to the growing strands.
DNA damage refers to any alteration in the structure or composition of deoxyribonucleic acid (DNA), which is the genetic material present in cells. DNA damage can result from various internal and external factors, including environmental exposures such as ultraviolet radiation, tobacco smoke, and certain chemicals, as well as normal cellular processes such as replication and oxidative metabolism.
Examples of DNA damage include base modifications, base deletions or insertions, single-strand breaks, double-strand breaks, and crosslinks between the two strands of the DNA helix. These types of damage can lead to mutations, genomic instability, and chromosomal aberrations, which can contribute to the development of diseases such as cancer, neurodegenerative disorders, and aging-related conditions.
The body has several mechanisms for repairing DNA damage, including base excision repair, nucleotide excision repair, mismatch repair, and double-strand break repair. However, if the damage is too extensive or the repair mechanisms are impaired, the cell may undergo apoptosis (programmed cell death) to prevent the propagation of potentially harmful mutations.
Bacterial DNA refers to the genetic material found in bacteria. It is composed of a double-stranded helix containing four nucleotide bases - adenine (A), thymine (T), guanine (G), and cytosine (C) - that are linked together by phosphodiester bonds. The sequence of these bases in the DNA molecule carries the genetic information necessary for the growth, development, and reproduction of bacteria.
Bacterial DNA is circular in most bacterial species, although some have linear chromosomes. In addition to the main chromosome, many bacteria also contain small circular pieces of DNA called plasmids that can carry additional genes and provide resistance to antibiotics or other environmental stressors.
Unlike eukaryotic cells, which have their DNA enclosed within a nucleus, bacterial DNA is present in the cytoplasm of the cell, where it is in direct contact with the cell's metabolic machinery. This allows for rapid gene expression and regulation in response to changing environmental conditions.
A "knockout" mouse is a genetically engineered mouse in which one or more genes have been deleted or "knocked out" using molecular biology techniques. This allows researchers to study the function of specific genes and their role in various biological processes, as well as potential associations with human diseases. The mice are generated by introducing targeted DNA modifications into embryonic stem cells, which are then used to create a live animal. Knockout mice have been widely used in biomedical research to investigate gene function, disease mechanisms, and potential therapeutic targets.
Protein-Tyrosine Kinases (PTKs) are a type of enzyme that plays a crucial role in various cellular functions, including signal transduction, cell growth, differentiation, and metabolism. They catalyze the transfer of a phosphate group from ATP to the tyrosine residues of proteins, thereby modifying their activity, localization, or interaction with other molecules.
PTKs can be divided into two main categories: receptor tyrosine kinases (RTKs) and non-receptor tyrosine kinases (NRTKs). RTKs are transmembrane proteins that become activated upon binding to specific ligands, such as growth factors or hormones. NRTKs, on the other hand, are intracellular enzymes that can be activated by various signals, including receptor-mediated signaling and intracellular messengers.
Dysregulation of PTK activity has been implicated in several diseases, such as cancer, diabetes, and inflammatory disorders. Therefore, PTKs are important targets for drug development and therapy.
Estradiol is a type of estrogen, which is a female sex hormone. It is the most potent and dominant form of estrogen in humans. Estradiol plays a crucial role in the development and maintenance of secondary sexual characteristics in women, such as breast development and regulation of the menstrual cycle. It also helps maintain bone density, protect the lining of the uterus, and is involved in cognition and mood regulation.
Estradiol is produced primarily by the ovaries, but it can also be synthesized in smaller amounts by the adrenal glands and fat cells. In men, estradiol is produced from testosterone through a process called aromatization. Abnormal levels of estradiol can contribute to various health issues, such as hormonal imbalances, infertility, osteoporosis, and certain types of cancer.
"Plant proteins" refer to the proteins that are derived from plant sources. These can include proteins from legumes such as beans, lentils, and peas, as well as proteins from grains like wheat, rice, and corn. Other sources of plant proteins include nuts, seeds, and vegetables.
Plant proteins are made up of individual amino acids, which are the building blocks of protein. While animal-based proteins typically contain all of the essential amino acids that the body needs to function properly, many plant-based proteins may be lacking in one or more of these essential amino acids. However, by consuming a variety of plant-based foods throughout the day, it is possible to get all of the essential amino acids that the body needs from plant sources alone.
Plant proteins are often lower in calories and saturated fat than animal proteins, making them a popular choice for those following a vegetarian or vegan diet, as well as those looking to maintain a healthy weight or reduce their risk of chronic diseases such as heart disease and cancer. Additionally, plant proteins have been shown to have a number of health benefits, including improving gut health, reducing inflammation, and supporting muscle growth and repair.
Dominant genes refer to the alleles (versions of a gene) that are fully expressed in an individual's phenotype, even if only one copy of the gene is present. In dominant inheritance patterns, an individual needs only to receive one dominant allele from either parent to express the associated trait. This is in contrast to recessive genes, where both copies of the gene must be the recessive allele for the trait to be expressed. Dominant genes are represented by uppercase letters (e.g., 'A') and recessive genes by lowercase letters (e.g., 'a'). If an individual inherits one dominant allele (A) from either parent, they will express the dominant trait (A).
Notch receptors are a type of transmembrane receptor proteins that play crucial roles in cell-cell communication and regulation of various biological processes, including cell fate determination, differentiation, proliferation, and apoptosis. These receptors are highly conserved across species and are essential for normal development and tissue homeostasis.
The Notch signaling pathway is initiated when the extracellular domain of a Notch receptor on one cell interacts with its ligand (such as Delta or Jagged) on an adjacent cell. This interaction triggers a series of proteolytic cleavage events that release the intracellular domain of the Notch receptor, which then translocates to the nucleus and regulates gene expression by interacting with transcription factors like CSL (CBF1/RBP-Jκ/Su(H)/Lag-1).
There are four known Notch receptors in humans (Notch1-4) that share a similar structure, consisting of an extracellular domain containing multiple epidermal growth factor (EGF)-like repeats, a transmembrane domain, and an intracellular domain. Mutations or dysregulation of the Notch signaling pathway have been implicated in various human diseases, including cancer, cardiovascular disorders, and developmental abnormalities.
Cytoskeletal proteins are a type of structural proteins that form the cytoskeleton, which is the internal framework of cells. The cytoskeleton provides shape, support, and structure to the cell, and plays important roles in cell division, intracellular transport, and maintenance of cell shape and integrity.
There are three main types of cytoskeletal proteins: actin filaments, intermediate filaments, and microtubules. Actin filaments are thin, rod-like structures that are involved in muscle contraction, cell motility, and cell division. Intermediate filaments are thicker than actin filaments and provide structural support to the cell. Microtubules are hollow tubes that are involved in intracellular transport, cell division, and maintenance of cell shape.
Cytoskeletal proteins are composed of different subunits that polymerize to form filamentous structures. These proteins can be dynamically assembled and disassembled, allowing cells to change their shape and move. Mutations in cytoskeletal proteins have been linked to various human diseases, including cancer, neurological disorders, and muscular dystrophies.
"Xenopus proteins" refer to the proteins that are expressed or isolated from the Xenopus species, which are primarily used as model organisms in biological and biomedical research. The most commonly used Xenopus species for research are the African clawed frogs, Xenopus laevis and Xenopus tropicalis. These proteins play crucial roles in various cellular processes and functions, and they serve as valuable tools to study different aspects of molecular biology, developmental biology, genetics, and biochemistry.
Some examples of Xenopus proteins that are widely studied include:
1. Xenopus Histones: These are the proteins that package DNA into nucleosomes, which are the fundamental units of chromatin in eukaryotic cells. They play a significant role in gene regulation and epigenetic modifications.
2. Xenopus Cyclins and Cyclin-dependent kinases (CDKs): These proteins regulate the cell cycle and control cell division, differentiation, and apoptosis.
3. Xenopus Transcription factors: These proteins bind to specific DNA sequences and regulate gene expression during development and in response to various stimuli.
4. Xenopus Signaling molecules: These proteins are involved in intracellular signaling pathways that control various cellular processes, such as cell growth, differentiation, migration, and survival.
5. Xenopus Cytoskeletal proteins: These proteins provide structural support to the cells and regulate their shape, motility, and organization.
6. Xenopus Enzymes: These proteins catalyze various biochemical reactions in the cell, such as metabolic pathways, DNA replication, transcription, and translation.
Overall, Xenopus proteins are essential tools for understanding fundamental biological processes and have contributed significantly to our current knowledge of molecular biology, genetics, and developmental biology.
I'm sorry for any confusion, but "G-Box Binding Factors" is not a widely recognized or established term in medical or molecular biology literature. The "G-box" is a specific sequence of DNA that can be found in the promoter regions of many genes and serves as a binding site for various transcription factors. Transcription factors are proteins that regulate gene expression by binding to specific DNA sequences and either promoting or inhibiting the initiation of transcription.
However, "G-Box Binding Factors" is too broad since multiple transcription factors can bind to the G-box sequence. Some examples of transcription factors known to bind to the G-box include proteins like GBF (G-box binding factor), HSF (heat shock transcription factor), and bZIP (basic region/leucine zipper) proteins, among others.
If you have a more specific context or reference related to "G-Box Binding Factors," I would be happy to help provide further information based on that context.
Alternative splicing is a process in molecular biology that occurs during the post-transcriptional modification of pre-messenger RNA (pre-mRNA) molecules. It involves the removal of non-coding sequences, known as introns, and the joining together of coding sequences, or exons, to form a mature messenger RNA (mRNA) molecule that can be translated into a protein.
In alternative splicing, different combinations of exons are selected and joined together to create multiple distinct mRNA transcripts from a single pre-mRNA template. This process increases the diversity of proteins that can be produced from a limited number of genes, allowing for greater functional complexity in organisms.
Alternative splicing is regulated by various cis-acting elements and trans-acting factors that bind to specific sequences in the pre-mRNA molecule and influence which exons are included or excluded during splicing. Abnormal alternative splicing has been implicated in several human diseases, including cancer, neurological disorders, and cardiovascular disease.
The G1 phase, or Gap 1 phase, is the first phase of the cell cycle, during which the cell grows in size and synthesizes mRNA and proteins in preparation for subsequent steps leading to mitosis. During this phase, the cell also checks its growth and makes sure that it is large enough to proceed through the cell cycle. If the cell is not large enough, it will arrest in the G1 phase until it has grown sufficiently. The G1 phase is followed by the S phase, during which DNA replication occurs.
The YY1 transcription factor, also known as Yin Yang 1, is a protein that plays a crucial role in the regulation of gene expression. It functions as a transcriptional repressor or activator, depending on the context and target gene. YY1 can bind to DNA at specific sites, known as YY1-binding sites, and it interacts with various other proteins to form complexes that modulate the activity of RNA polymerase II, which is responsible for transcribing protein-coding genes.
YY1 has been implicated in a wide range of biological processes, including embryonic development, cell growth, differentiation, and DNA damage response. Mutations or dysregulation of YY1 have been associated with various human diseases, such as cancer, neurodevelopmental disorders, and heart disease.
Proto-oncogene protein c-Fli-1 is a transcription factor that belongs to the ETS family and plays crucial roles in hematopoiesis, vascular development, and cell proliferation. The gene encoding this protein, called c-Fli-1, can be mutated or its expression can be dysregulated, leading to the formation of a proto-oncogene. When this happens, the protein can contribute to the development of various types of cancer, such as Ewing's sarcoma and acute myeloid leukemia. In these cases, the protein promotes cell growth and division, inhibits apoptosis (programmed cell death), and increases angiogenesis (the formation of new blood vessels). Overall, c-Fli-1 is an important regulator of normal cellular processes, but when its activity is deregulated, it can contribute to the development of cancer.
A genetic complementation test is a laboratory procedure used in molecular genetics to determine whether two mutated genes can complement each other's function, indicating that they are located at different loci and represent separate alleles. This test involves introducing a normal or wild-type copy of one gene into a cell containing a mutant version of the same gene, and then observing whether the presence of the normal gene restores the normal function of the mutated gene. If the introduction of the normal gene results in the restoration of the normal phenotype, it suggests that the two genes are located at different loci and can complement each other's function. However, if the introduction of the normal gene does not restore the normal phenotype, it suggests that the two genes are located at the same locus and represent different alleles of the same gene. This test is commonly used to map genes and identify genetic interactions in a variety of organisms, including bacteria, yeast, and animals.
Hepatocyte Nuclear Factor 1-alpha (HNF1A) is a transcription factor that plays a crucial role in the development and function of the liver. It belongs to the family of winged helix transcription factors and is primarily expressed in the hepatocytes, which are the major cell type in the liver.
HNF1A regulates the expression of various genes involved in glucose and lipid metabolism, bile acid synthesis, and drug metabolism. Mutations in the HNF1A gene have been associated with maturity-onset diabetes of the young (MODY), a form of diabetes that is typically inherited in an autosomal dominant manner and often diagnosed in early adulthood. These mutations can lead to impaired insulin secretion and decreased glucose tolerance, resulting in the development of diabetes.
In addition to its role in diabetes, HNF1A has also been implicated in liver diseases such as nonalcoholic fatty liver disease (NAFLD) and alcoholic liver disease (ALD). Dysregulation of HNF1A has been shown to contribute to the development and progression of these conditions by altering the expression of genes involved in lipid metabolism, inflammation, and fibrosis.
DNA Sequence Analysis is the systematic determination of the order of nucleotides in a DNA molecule. It is a critical component of modern molecular biology, genetics, and genetic engineering. The process involves determining the exact order of the four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - in a DNA molecule or fragment. This information is used in various applications such as identifying gene mutations, studying evolutionary relationships, developing molecular markers for breeding, and diagnosing genetic diseases.
The process of DNA Sequence Analysis typically involves several steps, including DNA extraction, PCR amplification (if necessary), purification, sequencing reaction, and electrophoresis. The resulting data is then analyzed using specialized software to determine the exact sequence of nucleotides.
In recent years, high-throughput DNA sequencing technologies have revolutionized the field of genomics, enabling the rapid and cost-effective sequencing of entire genomes. This has led to an explosion of genomic data and new insights into the genetic basis of many diseases and traits.
I'm sorry for any confusion, but "Genes, myc" is not a recognized medical term or abbreviation. It seems like there might be a misunderstanding or a missing word in the request. "Myc" could refer to the Myc family of transcription factors that are involved in cell growth and division, and are often deregulated in cancer. However, without more context, it's difficult to provide an accurate definition. If you could provide more information or clarify your question, I would be happy to help further!
Protein transport, in the context of cellular biology, refers to the process by which proteins are actively moved from one location to another within or between cells. This is a crucial mechanism for maintaining proper cell function and regulation.
Intracellular protein transport involves the movement of proteins within a single cell. Proteins can be transported across membranes (such as the nuclear envelope, endoplasmic reticulum, Golgi apparatus, or plasma membrane) via specialized transport systems like vesicles and transport channels.
Intercellular protein transport refers to the movement of proteins from one cell to another, often facilitated by exocytosis (release of proteins in vesicles) and endocytosis (uptake of extracellular substances via membrane-bound vesicles). This is essential for communication between cells, immune response, and other physiological processes.
It's important to note that any disruption in protein transport can lead to various diseases, including neurological disorders, cancer, and metabolic conditions.
Smad1 is a protein that belongs to the Smad family, which are intracellular signaling proteins that play a critical role in the transforming growth factor-beta (TGF-β) signaling pathway. Smad1 is primarily involved in the bone morphogenetic protein (BMP) branch of the TGF-β superfamily.
When BMPs bind to their receptors on the cell surface, they initiate a signaling cascade that leads to the phosphorylation and activation of Smad1. Once activated, Smad1 forms a complex with other Smad proteins, known as a Smad complex, which then translocates into the nucleus. In the nucleus, the Smad complex interacts with various DNA-binding proteins and transcription factors to regulate gene expression.
Smad1 plays crucial roles in several biological processes, including embryonic development, cell differentiation, and tissue homeostasis. Dysregulation of Smad1 signaling has been implicated in a variety of human diseases, such as cancer, fibrosis, and skeletal disorders.
Introns are non-coding sequences of DNA that are present within the genes of eukaryotic organisms, including plants, animals, and humans. Introns are removed during the process of RNA splicing, in which the initial RNA transcript is cut and reconnected to form a mature, functional RNA molecule.
After the intron sequences are removed, the remaining coding sequences, known as exons, are joined together to create a continuous stretch of genetic information that can be translated into a protein or used to produce non-coding RNAs with specific functions. The removal of introns allows for greater flexibility in gene expression and regulation, enabling the generation of multiple proteins from a single gene through alternative splicing.
In summary, introns are non-coding DNA sequences within genes that are removed during RNA processing to create functional RNA molecules or proteins.
Metallothioneins (MTs) are a group of small, cysteine-rich, metal-binding proteins found in the cells of many organisms, including humans. They play important roles in various biological processes such as:
1. Metal homeostasis and detoxification: MTs can bind to various heavy metals like zinc, copper, cadmium, and mercury with high affinity. This binding helps regulate the concentration of these metals within cells and protects against metal toxicity.
2. Oxidative stress protection: Due to their high cysteine content, MTs act as antioxidants by scavenging reactive oxygen species (ROS) and free radicals, thus protecting cells from oxidative damage.
3. Immune response regulation: MTs are involved in the modulation of immune cell function and inflammatory responses. They can influence the activation and proliferation of immune cells, as well as the production of cytokines and chemokines.
4. Development and differentiation: MTs have been implicated in cell growth, differentiation, and embryonic development, particularly in tissues with high rates of metal turnover, such as the liver and kidneys.
5. Neuroprotection: In the brain, MTs play a role in protecting neurons from oxidative stress, excitotoxicity, and heavy metal toxicity. They have been implicated in various neurodegenerative disorders, including Alzheimer's and Parkinson's diseases.
There are four main isoforms of metallothioneins (MT-1, MT-2, MT-3, and MT-4) in humans, each with distinct tissue expression patterns and functions.
A gene is a specific sequence of nucleotides in DNA that carries genetic information. Genes are the fundamental units of heredity and are responsible for the development and function of all living organisms. They code for proteins or RNA molecules, which carry out various functions within cells and are essential for the structure, function, and regulation of the body's tissues and organs.
Each gene has a specific location on a chromosome, and each person inherits two copies of every gene, one from each parent. Variations in the sequence of nucleotides in a gene can lead to differences in traits between individuals, including physical characteristics, susceptibility to disease, and responses to environmental factors.
Medical genetics is the study of genes and their role in health and disease. It involves understanding how genes contribute to the development and progression of various medical conditions, as well as identifying genetic risk factors and developing strategies for prevention, diagnosis, and treatment.
Epigenetics is the study of heritable changes in gene function that occur without a change in the underlying DNA sequence. These changes can be caused by various mechanisms such as DNA methylation, histone modification, and non-coding RNA molecules. Epigenetic changes can be influenced by various factors including age, environment, lifestyle, and disease state.
Genetic epigenesis specifically refers to the study of how genetic factors influence these epigenetic modifications. Genetic variations between individuals can lead to differences in epigenetic patterns, which in turn can contribute to phenotypic variation and susceptibility to diseases. For example, certain genetic variants may predispose an individual to develop cancer, and environmental factors such as smoking or exposure to chemicals can interact with these genetic variants to trigger epigenetic changes that promote tumor growth.
Overall, the field of genetic epigenesis aims to understand how genetic and environmental factors interact to regulate gene expression and contribute to disease susceptibility.
A genetic vector is a vehicle, often a plasmid or a virus, that is used to introduce foreign DNA into a host cell as part of genetic engineering or gene therapy techniques. The vector contains the desired gene or genes, along with regulatory elements such as promoters and enhancers, which are needed for the expression of the gene in the target cells.
The choice of vector depends on several factors, including the size of the DNA to be inserted, the type of cell to be targeted, and the efficiency of uptake and expression required. Commonly used vectors include plasmids, adenoviruses, retroviruses, and lentiviruses.
Plasmids are small circular DNA molecules that can replicate independently in bacteria. They are often used as cloning vectors to amplify and manipulate DNA fragments. Adenoviruses are double-stranded DNA viruses that infect a wide range of host cells, including human cells. They are commonly used as gene therapy vectors because they can efficiently transfer genes into both dividing and non-dividing cells.
Retroviruses and lentiviruses are RNA viruses that integrate their genetic material into the host cell's genome. This allows for stable expression of the transgene over time. Lentiviruses, a subclass of retroviruses, have the advantage of being able to infect non-dividing cells, making them useful for gene therapy applications in post-mitotic tissues such as neurons and muscle cells.
Overall, genetic vectors play a crucial role in modern molecular biology and medicine, enabling researchers to study gene function, develop new therapies, and modify organisms for various purposes.
Oligonucleotides are short sequences of nucleotides, the building blocks of DNA and RNA. They typically contain fewer than 100 nucleotides, and can be synthesized chemically to have specific sequences. Oligonucleotides are used in a variety of applications in molecular biology, including as probes for detecting specific DNA or RNA sequences, as inhibitors of gene expression, and as components of diagnostic tests and therapies. They can also be used in the study of protein-nucleic acid interactions and in the development of new drugs.
Viral DNA refers to the genetic material present in viruses that consist of DNA as their core component. Deoxyribonucleic acid (DNA) is one of the two types of nucleic acids that are responsible for storing and transmitting genetic information in living organisms. Viruses are infectious agents much smaller than bacteria that can only replicate inside the cells of other organisms, called hosts.
Viral DNA can be double-stranded (dsDNA) or single-stranded (ssDNA), depending on the type of virus. Double-stranded DNA viruses have a genome made up of two complementary strands of DNA, while single-stranded DNA viruses contain only one strand of DNA.
Examples of dsDNA viruses include Adenoviruses, Herpesviruses, and Poxviruses, while ssDNA viruses include Parvoviruses and Circoviruses. Viral DNA plays a crucial role in the replication cycle of the virus, encoding for various proteins necessary for its multiplication and survival within the host cell.
Mitogen-Activated Protein Kinase Kinases (MAP2K or MEK) are a group of protein kinases that play a crucial role in intracellular signal transduction pathways. They are so named because they are activated by mitogens, which are substances that stimulate cell division, and other extracellular signals.
MAP2Ks are positioned upstream of the Mitogen-Activated Protein Kinases (MAPK) in a three-tiered kinase cascade. Once activated, MAP2Ks phosphorylate and activate MAPKs, which then go on to regulate various cellular processes such as proliferation, differentiation, survival, and apoptosis.
There are several subfamilies of MAP2Ks, including MEK1/2, MEK3/6 (also known as MKK3/6), MEK4/7 (also known as MKK4/7), and MEK5. Each MAP2K is specific to activating a particular MAPK, and they are activated by different MAP3Ks (MAP kinase kinase kinases) in response to various extracellular signals.
Dysregulation of the MAPK/MAP2K signaling pathways has been implicated in numerous diseases, including cancer, cardiovascular disease, and neurological disorders. Therefore, targeting these pathways with therapeutic agents has emerged as a promising strategy for treating various diseases.
Cell hypoxia, also known as cellular hypoxia or tissue hypoxia, refers to a condition in which the cells or tissues in the body do not receive an adequate supply of oxygen. Oxygen is essential for the production of energy in the form of ATP (adenosine triphosphate) through a process called oxidative phosphorylation. When the cells are deprived of oxygen, they switch to anaerobic metabolism, which produces lactic acid as a byproduct and can lead to acidosis.
Cell hypoxia can result from various conditions, including:
1. Low oxygen levels in the blood (hypoxemia) due to lung diseases such as chronic obstructive pulmonary disease (COPD), pneumonia, or high altitude.
2. Reduced blood flow to tissues due to cardiovascular diseases such as heart failure, peripheral artery disease, or shock.
3. Anemia, which reduces the oxygen-carrying capacity of the blood.
4. Carbon monoxide poisoning, which binds to hemoglobin and prevents it from carrying oxygen.
5. Inadequate ventilation due to trauma, drug overdose, or other causes that can lead to respiratory failure.
Cell hypoxia can cause cell damage, tissue injury, and organ dysfunction, leading to various clinical manifestations depending on the severity and duration of hypoxia. Treatment aims to correct the underlying cause and improve oxygen delivery to the tissues.
Fushi Tarazu (FTZ) transcription factors are a family of proteins that regulate gene expression during development in various organisms, including insects and mammals. The name "Fushi Tarazu" comes from the phenotype observed in Drosophila melanogaster (fruit fly) mutants, which have segmentation defects resembling a "broken rosary bead" or "incomplete abdomen."
FTZ transcription factors contain a zinc finger DNA-binding domain and are involved in the regulation of homeotic genes, which control body pattern formation during development. They play crucial roles in establishing and maintaining proper segmentation and regional identity along the anterior-posterior axis of the organism. In mammals, FTZ transcription factors have been implicated in various processes, including neurogenesis, adipogenesis, and energy metabolism.
Beta-Naphthoflavone is a type of compound known as an aromatic hydrocarbon receptor (AHR) agonist. It is often used in research to study the effects of AHR activation on various biological processes, including the regulation of gene expression and the development of certain diseases such as cancer.
In the medical field, beta-Naphthoflavone may be used in experimental settings to investigate its potential as a therapeutic agent or as a tool for understanding the mechanisms underlying AHR-mediated diseases. However, it is not currently approved for use as a medication in humans.
Medical Definition of "Multiprotein Complexes" :
Multiprotein complexes are large molecular assemblies composed of two or more proteins that interact with each other to carry out specific cellular functions. These complexes can range from relatively simple dimers or trimers to massive structures containing hundreds of individual protein subunits. They are formed through a process known as protein-protein interaction, which is mediated by specialized regions on the protein surface called domains or motifs.
Multiprotein complexes play critical roles in many cellular processes, including signal transduction, gene regulation, DNA replication and repair, protein folding and degradation, and intracellular transport. The formation of these complexes is often dynamic and regulated in response to various stimuli, allowing for precise control of their function.
Disruption of multiprotein complexes can lead to a variety of diseases, including cancer, neurodegenerative disorders, and infectious diseases. Therefore, understanding the structure, composition, and regulation of these complexes is an important area of research in molecular biology and medicine.
Hepatocyte Nuclear Factor 1 (HNF-1) is a transcription factor that plays a crucial role in the development and function of the liver. It is composed of two subunits, HNF-1α and HNF-1β, which heterodimerize to form the functional transcription factor.
HNF-1 is involved in the regulation of genes that are essential for glucose and lipid metabolism, bile acid synthesis, and transport processes in the liver. Mutations in the genes encoding HNF-1α or HNF-1β can lead to various monogenic forms of diabetes, such as MODY (Maturity Onset Diabetes of the Young), and other liver diseases.
HNF-1α is primarily expressed in the liver, kidney, and pancreas, while HNF-1β is expressed in a wider range of tissues, including the liver, kidney, pancreas, intestine, and genitourinary tract. Both subunits recognize and bind to specific DNA sequences, known as HNF-1 binding sites, to regulate the transcription of their target genes.
Globins are a group of proteins that contain a heme prosthetic group, which binds and transports oxygen in the blood. The most well-known globin is hemoglobin, which is found in red blood cells and is responsible for carrying oxygen from the lungs to the body's tissues. Other members of the globin family include myoglobin, which is found in muscle tissue and stores oxygen, and neuroglobin and cytoglobin, which are found in the brain and other organs and may have roles in protecting against oxidative stress and hypoxia (low oxygen levels). Globins share a similar structure, with a folded protein surrounding a central heme group. Mutations in globin genes can lead to various diseases, such as sickle cell anemia and thalassemia.
Green Fluorescent Protein (GFP) is not a medical term per se, but a scientific term used in the field of molecular biology. GFP is a protein that exhibits bright green fluorescence when exposed to light, particularly blue or ultraviolet light. It was originally discovered in the jellyfish Aequorea victoria.
In medical and biological research, scientists often use recombinant DNA technology to introduce the gene for GFP into other organisms, including bacteria, plants, and animals, including humans. This allows them to track the expression and localization of specific genes or proteins of interest in living cells, tissues, or even whole organisms.
The ability to visualize specific cellular structures or processes in real-time has proven invaluable for a wide range of research areas, from studying the development and function of organs and organ systems to understanding the mechanisms of diseases and the effects of therapeutic interventions.
I'm happy to help! However, I believe there might be a slight confusion in your question. "Oncogene proteins v-rel" is not a standard medical term. Instead, it seems like you are referring to the "v-rel" oncogene protein. Here's a definition:
The v-rel oncogene protein is a viral transcription factor initially discovered in the reticuloendotheliosis virus (REV), which causes avian lymphoma. The v-rel gene shares homology with the cellular c-rel gene, which encodes a member of the NF-κB (nuclear factor kappa-light-chain-enhancer of activated B cells) family of transcription factors.
The v-rel protein is capable of transforming cells and contributing to tumorigenesis due to its ability to constitutively activate gene expression, particularly through the NF-κB signaling pathway. This aberrant activation can lead to uncontrolled cell growth, inhibition of apoptosis (programmed cell death), and ultimately cancer development.
The v-rel protein is an example of a viral oncogene, which are genes that have been acquired by a virus from the host organism and contribute to tumor formation when expressed in the host. Viral oncogenes can provide valuable insights into the mechanisms of cancer development and potential therapeutic targets.
RNA-binding proteins (RBPs) are a class of proteins that selectively interact with RNA molecules to form ribonucleoprotein complexes. These proteins play crucial roles in the post-transcriptional regulation of gene expression, including pre-mRNA processing, mRNA stability, transport, localization, and translation. RBPs recognize specific RNA sequences or structures through their modular RNA-binding domains, which can be highly degenerate and allow for the recognition of a wide range of RNA targets. The interaction between RBPs and RNA is often dynamic and can be regulated by various post-translational modifications of the proteins or by environmental stimuli, allowing for fine-tuning of gene expression in response to changing cellular needs. Dysregulation of RBP function has been implicated in various human diseases, including neurological disorders and cancer.
'Escherichia coli (E. coli) proteins' refer to the various types of proteins that are produced and expressed by the bacterium Escherichia coli. These proteins play a critical role in the growth, development, and survival of the organism. They are involved in various cellular processes such as metabolism, DNA replication, transcription, translation, repair, and regulation.
E. coli is a gram-negative, facultative anaerobe that is commonly found in the intestines of warm-blooded organisms. It is widely used as a model organism in scientific research due to its well-studied genetics, rapid growth, and ability to be easily manipulated in the laboratory. As a result, many E. coli proteins have been identified, characterized, and studied in great detail.
Some examples of E. coli proteins include enzymes involved in carbohydrate metabolism such as lactase, sucrase, and maltose; proteins involved in DNA replication such as the polymerases, single-stranded binding proteins, and helicases; proteins involved in transcription such as RNA polymerase and sigma factors; proteins involved in translation such as ribosomal proteins, tRNAs, and aminoacyl-tRNA synthetases; and regulatory proteins such as global regulators, two-component systems, and transcription factors.
Understanding the structure, function, and regulation of E. coli proteins is essential for understanding the basic biology of this important organism, as well as for developing new strategies for combating bacterial infections and improving industrial processes involving bacteria.
Isoenzymes, also known as isoforms, are multiple forms of an enzyme that catalyze the same chemical reaction but differ in their amino acid sequence, structure, and/or kinetic properties. They are encoded by different genes or alternative splicing of the same gene. Isoenzymes can be found in various tissues and organs, and they play a crucial role in biological processes such as metabolism, detoxification, and cell signaling. Measurement of isoenzyme levels in body fluids (such as blood) can provide valuable diagnostic information for certain medical conditions, including tissue damage, inflammation, and various diseases.
"Chickens" is a common term used to refer to the domesticated bird, Gallus gallus domesticus, which is widely raised for its eggs and meat. However, in medical terms, "chickens" is not a standard term with a specific definition. If you have any specific medical concern or question related to chickens, such as food safety or allergies, please provide more details so I can give a more accurate answer.
Retinoblastoma-Binding Protein 1 (RBP1) is not a medical term itself, but it is a protein that has been studied in the context of cancer research, including retinoblastoma. According to scientific and medical literature, RBP1 is a protein that binds to the retinoblastoma protein (pRb), which is a tumor suppressor protein. The binding of RBP1 to pRb can influence the activity of this tumor suppressor and contribute to the regulation of the cell cycle and cell growth.
In the case of retinoblastoma, mutations in the RB1 gene, which encodes for the pRb protein, have been identified as a cause of this rare eye cancer in children. However, the role of RBP1 in retinoblastoma or other cancers is not well-defined and requires further research to fully understand its implications in disease development and potential therapeutic targets.
Terminal repeat sequences (TRS) are repetitive DNA sequences that are located at the termini or ends of chromosomes, plasmids, and viral genomes. They play a significant role in various biological processes such as genome replication, packaging, and integration. In eukaryotic cells, telomeres are the most well-known TRS, which protect the chromosome ends from degradation, fusion, and other forms of DNA damage.
Telomeres consist of repetitive DNA sequences (5'-TTAGGG-3' in vertebrates) that are several kilobases long, associated with a set of shelterin proteins that protect them from being recognized as double-strand breaks by the DNA repair machinery. With each cell division, telomeres progressively shorten due to the end replication problem, which can ultimately lead to cellular senescence or apoptosis.
In contrast, prokaryotic TRS are often found at the ends of plasmids and phages and are involved in DNA replication, packaging, and integration into host genomes. For example, the attP and attB sites in bacteriophage lambda are TRS that facilitate site-specific recombination during integration and excision from the host genome.
Overall, terminal repeat sequences are essential for maintaining genome stability and integrity in various organisms, and their dysfunction can lead to genomic instability, disease, and aging.
Insertional mutagenesis is a process of introducing new genetic material into an organism's genome at a specific location, which can result in a change or disruption of the function of the gene at that site. This technique is often used in molecular biology research to study gene function and regulation. The introduction of the foreign DNA is typically accomplished through the use of mobile genetic elements, such as transposons or viruses, which are capable of inserting themselves into the genome.
The insertion of the new genetic material can lead to a loss or gain of function in the affected gene, resulting in a mutation. This type of mutagenesis is called "insertional" because the mutation is caused by the insertion of foreign DNA into the genome. The effects of insertional mutagenesis can range from subtle changes in gene expression to the complete inactivation of a gene.
This technique has been widely used in genetic research, including the study of developmental biology, cancer, and genetic diseases. It is also used in the development of genetically modified organisms (GMOs) for agricultural and industrial applications.
CHO cells, or Chinese Hamster Ovary cells, are a type of immortalized cell line that are commonly used in scientific research and biotechnology. They were originally derived from the ovaries of a female Chinese hamster (Cricetulus griseus) in the 1950s.
CHO cells have several characteristics that make them useful for laboratory experiments. They can grow and divide indefinitely under appropriate conditions, which allows researchers to culture large quantities of them for study. Additionally, CHO cells are capable of expressing high levels of recombinant proteins, making them a popular choice for the production of therapeutic drugs, vaccines, and other biologics.
In particular, CHO cells have become a workhorse in the field of biotherapeutics, with many approved monoclonal antibody-based therapies being produced using these cells. The ability to genetically modify CHO cells through various methods has further expanded their utility in research and industrial applications.
It is important to note that while CHO cells are widely used in scientific research, they may not always accurately represent human cell behavior or respond to drugs and other compounds in the same way as human cells do. Therefore, results obtained using CHO cells should be validated in more relevant systems when possible.
Epstein-Barr virus nuclear antigens (EBV NA) are proteins found inside the nucleus of cells that have been infected with the Epstein-Barr virus (EBV). EBV is a type of herpesvirus that is best known as the cause of infectious mononucleosis (also known as "mono" or "the kissing disease").
There are two main types of EBV NA: EBNA-1 and EBNA-2. These proteins play a role in the replication and survival of the virus within infected cells. They can be detected using laboratory tests, such as immunofluorescence assays or Western blotting, to help diagnose EBV infection or detect the presence of EBV-associated diseases, such as certain types of lymphoma and nasopharyngeal carcinoma.
EBNA-1 is essential for the maintenance and replication of the EBV genome within infected cells, while EBNA-2 activates viral gene expression and modulates the host cell's immune response to promote virus survival. Both proteins are considered potential targets for the development of antiviral therapies and vaccines against EBV infection.
B-lymphocytes, also known as B-cells, are a type of white blood cell that plays a key role in the immune system's response to infection. They are responsible for producing antibodies, which are proteins that help to neutralize or destroy pathogens such as bacteria and viruses.
When a B-lymphocyte encounters a pathogen, it becomes activated and begins to divide and differentiate into plasma cells, which produce and secrete large amounts of antibodies specific to the antigens on the surface of the pathogen. These antibodies bind to the pathogen, marking it for destruction by other immune cells such as neutrophils and macrophages.
B-lymphocytes also have a role in presenting antigens to T-lymphocytes, another type of white blood cell involved in the immune response. This helps to stimulate the activation and proliferation of T-lymphocytes, which can then go on to destroy infected cells or help to coordinate the overall immune response.
Overall, B-lymphocytes are an essential part of the adaptive immune system, providing long-lasting immunity to previously encountered pathogens and helping to protect against future infections.
According to the medical definition, ultraviolet (UV) rays are invisible radiations that fall in the range of the electromagnetic spectrum between 100-400 nanometers. UV rays are further divided into three categories: UVA (320-400 nm), UVB (280-320 nm), and UVC (100-280 nm).
UV rays have various sources, including the sun and artificial sources like tanning beds. Prolonged exposure to UV rays can cause damage to the skin, leading to premature aging, eye damage, and an increased risk of skin cancer. UVA rays penetrate deeper into the skin and are associated with skin aging, while UVB rays primarily affect the outer layer of the skin and are linked to sunburns and skin cancer. UVC rays are the most harmful but fortunately, they are absorbed by the Earth's atmosphere and do not reach the surface.
Healthcare professionals recommend limiting exposure to UV rays, wearing protective clothing, using broad-spectrum sunscreen with an SPF of at least 30, and avoiding tanning beds to reduce the risk of UV-related health problems.
FOS-related antigen-2 (FRA-2) is a protein that is encoded by the FRA2 gene in humans. It belongs to the FOS family of transcription factors, which form heterodimers with proteins of the JUN family to form the activator protein-1 (AP-1) transcription complex. AP-1 regulates gene expression in response to various stimuli such as cytokines, growth factors, and stress. FRA-2 has been implicated in several cellular processes including proliferation, differentiation, and transformation. Mutations in the FRA2 gene have been associated with certain types of cancer.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
CCAAT-Enhancer-Binding Protein-beta (CEBPB) is a transcription factor that plays a crucial role in the regulation of gene expression. It binds to the CCAAT box, a specific DNA sequence found in the promoter or enhancer regions of many genes. CEBPB is involved in various biological processes such as cell growth, development, and immune response. Dysregulation of CEBPB has been implicated in several diseases, including cancer and inflammatory disorders.
Mammals are a group of warm-blooded vertebrates constituting the class Mammalia, characterized by the presence of mammary glands (which produce milk to feed their young), hair or fur, three middle ear bones, and a neocortex region in their brain. They are found in a diverse range of habitats and come in various sizes, from tiny shrews to large whales. Examples of mammals include humans, apes, monkeys, dogs, cats, bats, mice, raccoons, seals, dolphins, horses, and elephants.
Cyclic adenosine monophosphate (cAMP) is a key secondary messenger in many biological processes, including the regulation of metabolism, gene expression, and cellular excitability. It is synthesized from adenosine triphosphate (ATP) by the enzyme adenylyl cyclase and is degraded by the enzyme phosphodiesterase.
In the body, cAMP plays a crucial role in mediating the effects of hormones and neurotransmitters on target cells. For example, when a hormone binds to its receptor on the surface of a cell, it can activate a G protein, which in turn activates adenylyl cyclase to produce cAMP. The increased levels of cAMP then activate various effector proteins, such as protein kinases, which go on to regulate various cellular processes.
Overall, the regulation of cAMP levels is critical for maintaining proper cellular function and homeostasis, and abnormalities in cAMP signaling have been implicated in a variety of diseases, including cancer, diabetes, and neurological disorders.
MAPKKK1 or Mitogen-Activated Protein Kinase Kinase Kinase 1 is a serine/threonine protein kinase that belongs to the MAP3K family. It plays a crucial role in intracellular signal transduction pathways, particularly in the MAPK/ERK cascade, which is involved in various cellular processes such as proliferation, differentiation, and survival.
MAPKKK1 activates MAPKKs (Mitogen-Activated Protein Kinase Kinases) through phosphorylation of specific serine and threonine residues. In turn, activated MAPKKs phosphorylate and activate MAPKs (Mitogen-Activated Protein Kinases), which then regulate the activity of various transcription factors and other downstream targets to elicit appropriate cellular responses.
Mutations in MAPKKK1 have been implicated in several human diseases, including cancer and developmental disorders. Therefore, understanding its function and regulation is essential for developing novel therapeutic strategies to treat these conditions.
Calcineurin is a calcium-calmodulin-activated serine/threonine protein phosphatase that plays a crucial role in signal transduction pathways involved in immune response and neuronal development. It consists of two subunits: the catalytic A subunit (calcineurin A) and the regulatory B subunit (calcineurin B). Calcineurin is responsible for dephosphorylating various substrates, including transcription factors, which leads to changes in their activity and ultimately affects gene expression. In the immune system, calcineurin plays a critical role in T-cell activation by dephosphorylating the nuclear factor of activated T-cells (NFAT), allowing it to translocate into the nucleus and induce the expression of cytokines and other genes involved in the immune response. Inhibitors of calcineurin, such as cyclosporine A and tacrolimus, are commonly used as immunosuppressive drugs to prevent organ rejection after transplantation.
PII nitrogen regulatory proteins are a type of signal transduction protein involved in the regulation of nitrogen metabolism in bacteria and archaea. They are named "PII" because they contain two identical subunits, each with a molecular weight of approximately 12 kilodaltons. These proteins play a crucial role in sensing and responding to changes in the energy status and nitrogen availability within the cell.
The PII protein is composed of three domains: the T-domain, which binds ATP and ADP; the N-domain, which binds 2-oxoglutarate (an indicator of carbon and nitrogen status); and the B-domain, which is involved in signal transduction. The PII protein can exist in different conformational states depending on whether it is bound to ATP or ADP, and this affects its ability to interact with downstream effectors.
One of the primary functions of PII proteins is to regulate the activity of glutamine synthetase (GS), an enzyme that catalyzes the conversion of glutamate to glutamine. When nitrogen is abundant, PII proteins bind to GS and stimulate its activity, promoting the assimilation of ammonia into organic compounds. Conversely, when nitrogen is scarce, PII proteins dissociate from GS, allowing it to be inhibited by other regulatory proteins.
PII proteins can also interact with other enzymes and regulators involved in nitrogen metabolism, such as nitrogenase, uridylyltransferase/uridylyl-removing enzyme (UT/UR), and transcriptional regulators. Through these interactions, PII proteins help to coordinate the cell's response to changes in nitrogen availability and energy status, ensuring that resources are allocated efficiently and effectively.
Ubiquitin-protein ligases, also known as E3 ubiquitin ligases, are a group of enzymes that play a crucial role in the ubiquitination process. Ubiquitination is a post-translational modification where ubiquitin molecules are attached to specific target proteins, marking them for degradation by the proteasome or for other regulatory functions.
Ubiquitin-protein ligases catalyze the final step in this process by binding to both the ubiquitin protein and the target protein, facilitating the transfer of ubiquitin from an E2 ubiquitin-conjugating enzyme to the target protein. There are several different types of ubiquitin-protein ligases, each with their own specificity for particular target proteins and regulatory functions.
Ubiquitin-protein ligases have been implicated in various cellular processes such as protein degradation, DNA repair, signal transduction, and regulation of the cell cycle. Dysregulation of ubiquitination has been associated with several diseases, including cancer, neurodegenerative disorders, and inflammatory responses. Therefore, understanding the function and regulation of ubiquitin-protein ligases is an important area of research in biology and medicine.
High Mobility Group Box (HMGB) proteins are a family of nuclear proteins that are highly conserved and expressed in eukaryotic cells. They play a crucial role in the regulation of gene expression, DNA repair, and maintenance of nucleosome structure. HMGB proteins contain two positively charged DNA-binding domains (HMG boxes) and a negatively charged acidic tail. These proteins can bind to DNA in a variety of ways, bending it and altering its structure, which in turn affects the binding of other proteins and the transcriptional activity of genes. HMGB proteins can also be released from cells under conditions of stress or injury, where they act as damage-associated molecular patterns (DAMPs) and contribute to the inflammatory response.
A protein subunit refers to a distinct and independently folding polypeptide chain that makes up a larger protein complex. Proteins are often composed of multiple subunits, which can be identical or different, that come together to form the functional unit of the protein. These subunits can interact with each other through non-covalent interactions such as hydrogen bonds, ionic bonds, and van der Waals forces, as well as covalent bonds like disulfide bridges. The arrangement and interaction of these subunits contribute to the overall structure and function of the protein.
K562 cells are a type of human cancer cell that are commonly used in scientific research. They are derived from a patient with chronic myelogenous leukemia (CML), a type of cancer that affects the blood and bone marrow.
K562 cells are often used as a model system to study various biological processes, including cell signaling, gene expression, differentiation, and apoptosis (programmed cell death). They are also commonly used in drug discovery and development, as they can be used to test the effectiveness of potential new therapies against cancer.
K562 cells have several characteristics that make them useful for research purposes. They are easy to grow and maintain in culture, and they can be manipulated genetically to express or knock down specific genes. Additionally, K562 cells are capable of differentiating into various cell types, such as red blood cells and megakaryocytes, which allows researchers to study the mechanisms of cell differentiation.
It's important to note that while K562 cells are a valuable tool for research, they do not fully recapitulate the complexity of human CML or other cancers. Therefore, findings from studies using K562 cells should be validated in more complex model systems or in clinical trials before they can be translated into treatments for patients.
Interferon-Stimulated Gene Factor 3 (ISGF3) is a protein complex that acts as a transcription factor in the immune response. It is formed by the combination of three proteins: STAT1 (Signal Transducer and Activator of Transcription 1), STAT2, and IRF9 (Interferon Regulatory Factor 9).
ISGF3 is produced upon the activation of the JAK-STAT signaling pathway by type I interferons (IFNs), such as IFN-α and IFN-β. Once activated, STAT1 and STAT2 are phosphorylated and then form a complex with IRF9. This ISGF3 complex translocates to the nucleus where it binds to specific DNA sequences, known as interferon-stimulated response elements (ISREs), in the promoter regions of interferon-stimulated genes (ISGs). The binding and activation of these genes lead to the expression of proteins involved in the antiviral response, inflammation, cell growth regulation, and differentiation.
In summary, Interferon-Stimulated Gene Factor 3 (ISGF3) is a protein complex that plays a crucial role in the immune response by regulating the transcription of interferon-stimulated genes upon type I interferon signaling.
Chromosome mapping, also known as physical mapping, is the process of determining the location and order of specific genes or genetic markers on a chromosome. This is typically done by using various laboratory techniques to identify landmarks along the chromosome, such as restriction enzyme cutting sites or patterns of DNA sequence repeats. The resulting map provides important information about the organization and structure of the genome, and can be used for a variety of purposes, including identifying the location of genes associated with genetic diseases, studying evolutionary relationships between organisms, and developing genetic markers for use in breeding or forensic applications.
Retinoblastoma Protein (pRb or RB1) is a tumor suppressor protein that plays a critical role in regulating the cell cycle and preventing uncontrolled cell growth. It is encoded by the RB1 gene, located on chromosome 13. The retinoblastoma protein functions as a regulatory checkpoint in the cell cycle, preventing cells from progressing into the S phase (DNA synthesis phase) until certain conditions are met.
When pRb is in its active state, it binds to and inhibits the activity of E2F transcription factors, which promote the expression of genes required for DNA replication and cell cycle progression. Phosphorylation of pRb by cyclin-dependent kinases (CDKs) leads to the release of E2F factors, allowing them to activate their target genes and drive the cell into S phase.
Mutations in the RB1 gene can result in the production of a nonfunctional or reduced amount of pRb protein, leading to uncontrolled cell growth and an increased risk of developing retinoblastoma, a rare form of eye cancer, as well as other types of tumors.
Protein interaction domains and motifs refer to specific regions or sequences within proteins that are involved in mediating interactions between two or more proteins. These elements can be classified into two main categories: domains and motifs.
Domains are structurally conserved regions of a protein that can fold independently and perform specific functions, such as binding to other molecules like DNA, RNA, or other proteins. They typically range from 25 to 500 amino acids in length and can be found in multiple copies within a single protein or shared among different proteins.
Motifs, on the other hand, are shorter sequences of 3-10 amino acids that mediate more localized interactions with other molecules. Unlike domains, motifs may not have well-defined structures and can be found in various contexts within a protein.
Together, these protein interaction domains and motifs play crucial roles in many biological processes, including signal transduction, gene regulation, enzyme function, and protein complex formation. Understanding the specificity and dynamics of these interactions is essential for elucidating cellular functions and developing therapeutic strategies.
Genetically modified plants (GMPs) are plants that have had their DNA altered through genetic engineering techniques to exhibit desired traits. These modifications can be made to enhance certain characteristics such as increased resistance to pests, improved tolerance to environmental stresses like drought or salinity, or enhanced nutritional content. The process often involves introducing genes from other organisms, such as bacteria or viruses, into the plant's genome. Examples of GMPs include Bt cotton, which has a gene from the bacterium Bacillus thuringiensis that makes it resistant to certain pests, and golden rice, which is engineered to contain higher levels of beta-carotene, a precursor to vitamin A. It's important to note that genetically modified plants are subject to rigorous testing and regulation to ensure their safety for human consumption and environmental impact before they are approved for commercial use.
STAT6 (Signal Transducer and Activator of Transcription 6) is a transcription factor that plays a crucial role in the immune response, particularly in the development of Th2 cells and the production of cytokines. It is activated by cytokines such as IL-4 and IL-13 through phosphorylation, which leads to its dimerization and translocation into the nucleus where it binds to specific DNA sequences and regulates the expression of target genes. STAT6 is involved in a variety of biological processes including allergic responses, inflammation, and tumorigenesis. Mutations in the STAT6 gene have been associated with immunodeficiency disorders and certain types of cancer.
Steroidogenic Factor 1 (SF-1 or NR5A1) is a nuclear receptor protein that functions as a transcription factor, playing a crucial role in the development and regulation of the endocrine system. It is involved in the differentiation and maintenance of steroidogenic tissues such as the adrenal glands, gonads (ovaries and testes), and the hypothalamus and pituitary glands in the brain.
SF-1 regulates the expression of genes that are essential for steroid hormone biosynthesis, including enzymes involved in the production of cortisol, aldosterone, and sex steroids (androgens, estrogens). Mutations in the SF-1 gene can lead to various disorders related to sexual development, adrenal function, and fertility.
In summary, Steroidogenic Factor 1 is a critical transcription factor that regulates the development and function of steroidogenic tissues and the biosynthesis of steroid hormones.
Breast neoplasms refer to abnormal growths in the breast tissue that can be benign or malignant. Benign breast neoplasms are non-cancerous tumors or growths, while malignant breast neoplasms are cancerous tumors that can invade surrounding tissues and spread to other parts of the body.
Breast neoplasms can arise from different types of cells in the breast, including milk ducts, milk sacs (lobules), or connective tissue. The most common type of breast cancer is ductal carcinoma, which starts in the milk ducts and can spread to other parts of the breast and nearby structures.
Breast neoplasms are usually detected through screening methods such as mammography, ultrasound, or MRI, or through self-examination or clinical examination. Treatment options for breast neoplasms depend on several factors, including the type and stage of the tumor, the patient's age and overall health, and personal preferences. Treatment may include surgery, radiation therapy, chemotherapy, hormone therapy, or targeted therapy.
LIM domain proteins are a group of transcription factors that contain LIM domains, which are cysteine-rich zinc-binding motifs. These proteins play crucial roles in various cellular processes such as gene regulation, cell proliferation, differentiation, and migration. They are involved in the development and functioning of several organ systems including the nervous system, cardiovascular system, and musculoskeletal system. LIM domain proteins can interact with other proteins and DNA to regulate gene expression and have been implicated in various diseases such as cancer and neurological disorders.
T-lymphocytes, also known as T-cells, are a type of white blood cell that plays a key role in the adaptive immune system's response to infection. They are produced in the bone marrow and mature in the thymus gland. There are several different types of T-cells, including CD4+ helper T-cells, CD8+ cytotoxic T-cells, and regulatory T-cells (Tregs).
CD4+ helper T-cells assist in activating other immune cells, such as B-lymphocytes and macrophages. They also produce cytokines, which are signaling molecules that help coordinate the immune response. CD8+ cytotoxic T-cells directly kill infected cells by releasing toxic substances. Regulatory T-cells help maintain immune tolerance and prevent autoimmune diseases by suppressing the activity of other immune cells.
T-lymphocytes are important in the immune response to viral infections, cancer, and other diseases. Dysfunction or depletion of T-cells can lead to immunodeficiency and increased susceptibility to infections. On the other hand, an overactive T-cell response can contribute to autoimmune diseases and chronic inflammation.
Cyclic AMP (cAMP)-dependent protein kinases, also known as protein kinase A (PKA), are a family of enzymes that play a crucial role in intracellular signaling pathways. These enzymes are responsible for the regulation of various cellular processes, including metabolism, gene expression, and cell growth and differentiation.
PKA is composed of two regulatory subunits and two catalytic subunits. When cAMP binds to the regulatory subunits, it causes a conformational change that leads to the dissociation of the catalytic subunits. The freed catalytic subunits then phosphorylate specific serine and threonine residues on target proteins, thereby modulating their activity.
The cAMP-dependent protein kinases are activated in response to a variety of extracellular signals, such as hormones and neurotransmitters, that bind to G protein-coupled receptors (GPCRs) or receptor tyrosine kinases (RTKs). These signals lead to the activation of adenylyl cyclase, which catalyzes the conversion of ATP to cAMP. The resulting increase in intracellular cAMP levels triggers the activation of PKA and the downstream phosphorylation of target proteins.
Overall, cAMP-dependent protein kinases are essential regulators of many fundamental cellular processes and play a critical role in maintaining normal physiology and homeostasis. Dysregulation of these enzymes has been implicated in various diseases, including cancer, diabetes, and neurological disorders.
Cytochrome P-450 CYP1A2 is a specific isoform of the cytochrome P-450 enzyme system, which is involved in the metabolism of various xenobiotics, including drugs and toxins, in the body. This enzyme is primarily located in the endoplasmic reticulum of hepatocytes, or liver cells, and plays a significant role in the oxidative metabolism of certain medications, such as caffeine, theophylline, and some antidepressants.
CYP1A2 is induced by various factors, including smoking, charcoal-grilled foods, and certain medications, which can increase its enzymatic activity and potentially affect the metabolism and clearance of drugs that are substrates for this enzyme. Genetic polymorphisms in the CYP1A2 gene can also lead to differences in enzyme activity among individuals, resulting in variable drug responses and potential adverse effects.
In summary, Cytochrome P-450 CYP1A2 is a liver enzyme involved in the metabolism of various drugs and toxins, with genetic and environmental factors influencing its activity and impacting individual responses to medications.
Transcription Factor 7-Like 1 Protein (TF7L1P) is not a widely recognized or established term in medical literature or clinical medicine. However, based on the individual terms:
Transcription factor: These are proteins that regulate gene expression by binding to specific DNA sequences, thus controlling the rate of transcription of genetic information from DNA to RNA.
7-Like: This suggests similarity to a particular class or family of proteins. In this case, it likely refers to the nuclear receptor subfamily 7 (NR7).
TF7L1P would then refer to a protein that is a member of the nuclear receptor subfamily 7 and functions as a transcription factor. However, I couldn't find specific information on a protein named 'Transcription Factor 7-Like 1 Protein'. It is possible that you may be referring to a specific protein within the NR7 family, such as NR7A1 (also known as EAR2 or ESRRG), but further clarification would be needed.
'Desulfitobacterium' is a genus of anaerobic, gram-positive bacteria that are capable of dehalogenating and reducing chlorinated organic compounds. These organisms play a significant role in the bioremediation of contaminated environments, as they can transform harmful pollutants into less toxic forms. The name 'Desulfitobacterium' is derived from the Latin words "de," meaning "from," "sulfur," referring to the sulfur-containing compounds these bacteria use for energy, and "bacterium," meaning "rod" or "staff."
Some notable species within this genus include:
* Desulfitobacterium dehalogenans: This species is well-known for its ability to reductively dechlorinate a wide range of chlorinated organic compounds, including polychlorinated biphenyls (PCBs) and trichloroethylene (TCE).
* Desulfitobacterium hafniense: This species is capable of reducing various halogenated compounds, such as tetrachloroethene (PCE), TCE, and polychlorinated phenols. It can also use nitrate, sulfate, or metal ions as electron acceptors for energy metabolism.
* Desulfitobacterium frappieri: This species is known to dechlorinate chlorinated ethenes, such as PCE and TCE, and can also reduce iron(III) and manganese(IV) compounds.
These bacteria are typically found in anaerobic environments, such as soil, groundwater, sediments, and the gastrointestinal tracts of animals. They play a crucial role in maintaining the balance of these ecosystems by breaking down complex organic compounds and contributing to nutrient cycling.
STAT2 (Signal Transducer and Activator of Transcription 2) is a protein that functions as a transcription factor. It is not a medical condition or diagnosis, but rather a component of the human body's immune response system. When activated through phosphorylation by receptor-associated kinases, STAT2 forms a complex with other proteins such as STAT1 and IRF9 to form the interferon-stimulated gene factor 3 (ISGF3) complex. This complex translocates to the nucleus and binds to specific DNA sequences, leading to the transcription of interferon-stimulated genes (ISGs). ISGs play crucial roles in the body's defense against viral infections by inhibiting various steps of the viral replication cycle.
Defects or mutations in STAT2 can lead to impaired immune responses and increased susceptibility to certain viral infections, such as herpes simplex virus encephalitis and severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). However, a medical definition would typically refer to a specific disease or condition associated with the protein, which is not the case for STAT2.
DNA methylation is a process by which methyl groups (-CH3) are added to the cytosine ring of DNA molecules, often at the 5' position of cytospine phosphate-deoxyguanosine (CpG) dinucleotides. This modification is catalyzed by DNA methyltransferase enzymes and results in the formation of 5-methylcytosine.
DNA methylation plays a crucial role in the regulation of gene expression, genomic imprinting, X chromosome inactivation, and suppression of transposable elements. Abnormal DNA methylation patterns have been associated with various diseases, including cancer, where tumor suppressor genes are often silenced by promoter methylation.
In summary, DNA methylation is a fundamental epigenetic modification that influences gene expression and genome stability, and its dysregulation has important implications for human health and disease.
Phosphoserine is not a medical term per se, but rather a biochemical term. It refers to a post-translationally modified amino acid called serine that has a phosphate group attached to its side chain. This modification plays a crucial role in various cellular processes, including signal transduction and regulation of protein function. In medical contexts, abnormalities in the regulation of phosphorylation (the addition of a phosphate group) and dephosphorylation (the removal of a phosphate group) have been implicated in several diseases, such as cancer and neurological disorders.
The Heat-Shock Response is a complex and highly conserved stress response mechanism present in virtually all living organisms. It is activated when the cell encounters elevated temperatures or other forms of proteotoxic stress, such as exposure to toxins, radiation, or infectious agents. This response is primarily mediated by a group of proteins known as heat-shock proteins (HSPs) or chaperones, which play crucial roles in protein folding, assembly, transport, and degradation.
The primary function of the Heat-Shock Response is to protect the cell from damage caused by misfolded or aggregated proteins that can accumulate under stress conditions. The activation of this response leads to the rapid transcription and translation of HSP genes, resulting in a significant increase in the intracellular levels of these chaperone proteins. These chaperones then assist in the refolding of denatured proteins or target damaged proteins for degradation via the proteasome or autophagy pathways.
The Heat-Shock Response is critical for maintaining cellular homeostasis and ensuring proper protein function under stress conditions. Dysregulation of this response has been implicated in various diseases, including neurodegenerative disorders, cancer, and cardiovascular diseases.
Medical Definition:
Mammary tumor virus, mouse (MMTV) is a type of retrovirus that specifically infects mice and is associated with the development of mammary tumors or breast cancer in these animals. The virus is primarily transmitted through mother's milk, leading to a high incidence of mammary tumors in female offspring.
MMTV contains an oncogene, which can integrate into the host's genome and induce uncontrolled cell growth and division, ultimately resulting in the formation of tumors. While MMTV is not known to infect humans, it has been a valuable model for studying retroviral pathogenesis and cancer biology.
'Arabidopsis' is a genus of small flowering plants that are part of the mustard family (Brassicaceae). The most commonly studied species within this genus is 'Arabidopsis thaliana', which is often used as a model organism in plant biology and genetics research. This plant is native to Eurasia and Africa, and it has a small genome that has been fully sequenced. It is known for its short life cycle, self-fertilization, and ease of growth, making it an ideal subject for studying various aspects of plant biology, including development, metabolism, and response to environmental stresses.
Hepatocyte Nuclear Factor 1-beta (HNF-1β) is a transcription factor that plays crucial roles in the development and function of various organs, including the liver, kidneys, pancreas, and genitourinary system. It belongs to the PPAR/RXR heterodimer family of transcription factors and regulates the expression of several genes involved in cell growth, differentiation, metabolism, and transport processes.
In the liver, HNF-1β is essential for maintaining the structural organization and function of hepatocytes, which are the primary functional cells of the liver. It helps regulate the expression of genes involved in glucose and lipid metabolism, bile acid synthesis, and detoxification processes.
Mutations in the HNF-1β gene have been associated with several genetic disorders, such as maturity-onset diabetes of the young (MODY5), renal cysts and diabetes syndrome (RCAD), and congenital abnormalities of the kidneys and urinary tract (CAKUT). These conditions often present with a combination of liver, pancreas, and kidney dysfunctions.
Homeobox genes are a specific class of genes that play a crucial role in the development and regulation of an organism's body plan. They encode transcription factors, which are proteins that regulate the expression of other genes. The homeobox region within these genes contains a highly conserved sequence of about 180 base pairs that encodes a DNA-binding domain called the homeodomain. This domain is responsible for recognizing and binding to specific DNA sequences, thereby controlling the transcription of target genes.
Homeobox genes are particularly important during embryonic development, where they help establish the anterior-posterior axis and regulate the development of various organs and body segments. They also play a role in maintaining adult tissue homeostasis and have been implicated in certain diseases, including cancer. Mutations in homeobox genes can lead to developmental abnormalities and congenital disorders.
Some examples of homeobox gene families include HOX genes, PAX genes, and NKX genes, among others. These genes are highly conserved across species, indicating their fundamental role in the development and regulation of body plans throughout the animal kingdom.
Arabidopsis proteins refer to the proteins that are encoded by the genes in the Arabidopsis thaliana plant, which is a model organism commonly used in plant biology research. This small flowering plant has a compact genome and a short life cycle, making it an ideal subject for studying various biological processes in plants.
Arabidopsis proteins play crucial roles in many cellular functions, such as metabolism, signaling, regulation of gene expression, response to environmental stresses, and developmental processes. Research on Arabidopsis proteins has contributed significantly to our understanding of plant biology and has provided valuable insights into the molecular mechanisms underlying various agronomic traits.
Some examples of Arabidopsis proteins include transcription factors, kinases, phosphatases, receptors, enzymes, and structural proteins. These proteins can be studied using a variety of techniques, such as biochemical assays, protein-protein interaction studies, and genetic approaches, to understand their functions and regulatory mechanisms in plants.
Triiodothyronine (T3) is a thyroid hormone, specifically the active form of thyroid hormone, that plays a critical role in the regulation of metabolism, growth, and development in the human body. It is produced by the thyroid gland through the iodination and coupling of the amino acid tyrosine with three atoms of iodine. T3 is more potent than its precursor, thyroxine (T4), which has four iodine atoms, as T3 binds more strongly to thyroid hormone receptors and accelerates metabolic processes at the cellular level.
In circulation, about 80% of T3 is bound to plasma proteins, while the remaining 20% is unbound or free, allowing it to enter cells and exert its biological effects. The primary functions of T3 include increasing the rate of metabolic reactions, promoting protein synthesis, enhancing sensitivity to catecholamines (e.g., adrenaline), and supporting normal brain development during fetal growth and early infancy. Imbalances in T3 levels can lead to various medical conditions, such as hypothyroidism or hyperthyroidism, which may require clinical intervention and management.
Wilms' Tumor 1 (WT1) proteins are a group of transcription factors that play crucial roles in the development of the human body, particularly in the formation of the urinary and reproductive systems. The WT1 gene encodes these proteins, and mutations in this gene have been associated with several diseases, most notably Wilms' tumor, a type of kidney cancer in children.
WT1 proteins contain four domains: an N-terminal transcriptional activation domain, a zinc finger domain that binds to DNA, a nuclear localization signal, and a C-terminal transcriptional repression domain. These proteins regulate the expression of various target genes involved in cell growth, differentiation, and apoptosis (programmed cell death).
Abnormalities in WT1 protein function or expression have been linked to several developmental disorders, including Denys-Drash syndrome, Frasier syndrome, and Wilms' tumor. These conditions are characterized by genitourinary abnormalities, such as kidney dysplasia, ambiguous genitalia, and an increased risk of developing Wilms' tumor.
Cyclin-dependent kinases (CDKs) are a family of serine/threonine protein kinases that play crucial roles in regulating the cell cycle, transcription, and other cellular processes. They are activated by binding to cyclin proteins, which accumulate and degrade at specific stages of the cell cycle. The activation of CDKs leads to phosphorylation of various downstream target proteins, resulting in the promotion or inhibition of different cell cycle events. Dysregulation of CDKs has been implicated in several human diseases, including cancer, and they are considered important targets for drug development.
Mediator Complex Subunit 1 (MED1) is a protein that is a component of the mediator complex, which is a multi-protein complex that acts as a bridge between transcription factors and RNA polymerase II to regulate gene expression. MED1 is also known as TRAP220 or DRIP205, and it plays a role in the recruitment of the mediator complex to specific target genes. It contains several domains that are involved in protein-protein interactions, including a PHD finger domain, a bromodomain, and a proline-rich region. MED1 has been implicated in various cellular processes, such as cell cycle regulation, differentiation, and development, and its dysregulation has been associated with several diseases, including cancer.
Minichromosome Maintenance 1 Protein (MCM1) is a protein that belongs to the minichromosome maintenance proteins complex, which is essential for the initiation and regulation of eukaryotic DNA replication. MCM1 is a crucial component of this complex, and it functions as a transcription factor that regulates the expression of genes involved in various cellular processes such as cell cycle progression, DNA repair, and development. In addition to its role in DNA replication and gene regulation, MCM1 has also been implicated in the development of certain types of cancer, making it an important area of research in cancer biology.
Glucocorticoids are a class of steroid hormones that are naturally produced in the adrenal gland, or can be synthetically manufactured. They play an essential role in the metabolism of carbohydrates, proteins, and fats, and have significant anti-inflammatory effects. Glucocorticoids suppress immune responses and inflammation by inhibiting the release of inflammatory mediators from various cells, such as mast cells, eosinophils, and lymphocytes. They are frequently used in medical treatment for a wide range of conditions, including allergies, asthma, rheumatoid arthritis, dermatological disorders, and certain cancers. Prolonged use or high doses of glucocorticoids can lead to several side effects, such as weight gain, mood changes, osteoporosis, and increased susceptibility to infections.
Transcription Factor 7-Like 2 Protein (TF7L2) is a transcription factor that plays a crucial role in the Wnt signaling pathway, which is essential for cell differentiation, proliferation, and apoptosis. It is primarily expressed in the pancreas, brain, and muscle tissues.
TF7L2 is involved in the regulation of gene expression, particularly those related to insulin synthesis and secretion in the pancreatic beta-cells. Variations in the TF7L2 gene have been associated with an increased risk of developing type 2 diabetes, as they can affect insulin sensitivity and glucose metabolism.
Mutations in the TF7L2 gene may lead to abnormal regulation of genes involved in glucose homeostasis, which can contribute to impaired insulin secretion and the development of type 2 diabetes. However, the exact mechanisms by which TF7L2 variants increase the risk of type 2 diabetes are not fully understood and are an area of ongoing research.
Nuclear receptor coactivators are a group of proteins that interact with nuclear receptors, which are transcription factors that regulate gene expression in response to various signals such as hormones and metabolites. Nuclear receptor coactivators function to enhance the ability of nuclear receptors to activate transcription of their target genes. They do this by binding to nuclear receptors and recruiting additional proteins, including histone modifiers and chromatin remodeling complexes, which help to create a permissive environment for transcription. Nuclear receptor coactivators play important roles in various physiological processes, including development, metabolism, and reproduction, and their dysregulation has been implicated in several diseases, including cancer.
Dactinomycin is an antineoplastic antibiotic, which means it is used to treat cancer. It is specifically used to treat certain types of testicular cancer, Wilms' tumor (a type of kidney cancer that occurs in children), and some gestational trophoblastic tumors (a type of tumor that can develop in the uterus after pregnancy). Dactinomycin works by interfering with the DNA in cancer cells, which prevents them from dividing and growing. It is often used in combination with other chemotherapy drugs as part of a treatment regimen.
Dactinomycin is administered intravenously (through an IV) and its use is usually limited to hospitals or specialized cancer treatment centers due to the need for careful monitoring during administration. Common side effects include nausea, vomiting, and hair loss. More serious side effects can include bone marrow suppression, which can lead to an increased risk of infection, and tissue damage at the site where the drug is injected. Dactinomycin can also cause severe allergic reactions in some people.
It's important to note that dactinomycin should only be used under the supervision of a qualified healthcare professional, as its use requires careful monitoring and management of potential side effects.
Ras proteins are a group of small GTPases that play crucial roles as regulators of intracellular signaling pathways in cells. They are involved in various cellular processes, such as cell growth, differentiation, and survival. Ras proteins cycle between an inactive GDP-bound state and an active GTP-bound state to transmit signals from membrane receptors to downstream effectors. Mutations in Ras genes can lead to constitutive activation of Ras proteins, which has been implicated in various human cancers and developmental disorders.
Cyclin-Dependent Kinase 8 (CDK8) is a type of serine/threonine protein kinase that plays a crucial role in the regulation of gene transcription. It forms a complex with cyclin C, and its activity is required for various cellular processes such as cell cycle progression, differentiation, and apoptosis. CDK8 has been shown to phosphorylate several transcription factors and coactivators, thereby modulating their activities and contributing to the control of gene expression. Dysregulation of CDK8 activity has been implicated in various diseases, including cancer, making it a potential target for therapeutic intervention.
An ankyrin repeat is a protein structural motif, which is characterized by the repetition of a 33-amino acid long sequence. This motif is responsible for mediating protein-protein interactions and is found in a wide variety of proteins with diverse functions. Ankyrin repeats are known to play a role in various cellular processes such as signal transduction, cell cycle regulation, and ion transport. In particular, ankyrin repeat-containing proteins have been implicated in various human diseases, including cardiovascular disease, neurological disorders, and cancer.
Cyclin G is a type of protein that belongs to the cyclin family, which are involved in the regulation of the cell cycle. The human Cyclin G gene encodes two isoforms, Cyclin G1 and Cyclin G2, which share a similar structure but have different functions.
Cyclin G1 is known to play a role in the negative regulation of the cell cycle, particularly during the G1 phase. It interacts with several proteins, including CDKs (cyclin-dependent kinases), to regulate the activity of various transcription factors and other signaling pathways that control cell growth and division.
Cyclin G2, on the other hand, has been implicated in the regulation of DNA damage response and apoptosis (programmed cell death). It interacts with CDKs and other proteins to modulate the activity of various signaling pathways involved in these processes.
Overall, Cyclin G plays important roles in regulating cell cycle progression, DNA damage response, and apoptosis, and its dysregulation has been linked to several human diseases, including cancer.
Zebrafish proteins refer to the diverse range of protein molecules that are produced by the organism Danio rerio, commonly known as the zebrafish. These proteins play crucial roles in various biological processes such as growth, development, reproduction, and response to environmental stimuli. They are involved in cellular functions like enzymatic reactions, signal transduction, structural support, and regulation of gene expression.
Zebrafish is a popular model organism in biomedical research due to its genetic similarity with humans, rapid development, and transparent embryos that allow for easy observation of biological processes. As a result, the study of zebrafish proteins has contributed significantly to our understanding of protein function, structure, and interaction in both zebrafish and human systems.
Some examples of zebrafish proteins include:
* Transcription factors that regulate gene expression during development
* Enzymes involved in metabolic pathways
* Structural proteins that provide support to cells and tissues
* Receptors and signaling molecules that mediate communication between cells
* Heat shock proteins that assist in protein folding and protect against stress
The analysis of zebrafish proteins can be performed using various techniques, including biochemical assays, mass spectrometry, protein crystallography, and computational modeling. These methods help researchers to identify, characterize, and understand the functions of individual proteins and their interactions within complex networks.
Epithelial cells are types of cells that cover the outer surfaces of the body, line the inner surfaces of organs and glands, and form the lining of blood vessels and body cavities. They provide a protective barrier against the external environment, regulate the movement of materials between the internal and external environments, and are involved in the sense of touch, temperature, and pain. Epithelial cells can be squamous (flat and thin), cuboidal (square-shaped and of equal height), or columnar (tall and narrow) in shape and are classified based on their location and function.
The lac operon is a genetic regulatory system found in the bacteria Escherichia coli that controls the expression of genes responsible for the metabolism of lactose as a source of energy. It consists of three structural genes (lacZ, lacY, and lacA) that code for enzymes involved in lactose metabolism, as well as two regulatory elements: the lac promoter and the lac operator.
The lac repressor protein, produced by the lacI gene, binds to the lac operator sequence when lactose is not present, preventing RNA polymerase from transcribing the structural genes. When lactose is available, it is converted into allolactose, which acts as an inducer and binds to the lac repressor protein, causing a conformational change that prevents it from binding to the operator sequence. This allows RNA polymerase to bind to the promoter and transcribe the structural genes, leading to the production of enzymes necessary for lactose metabolism.
In summary, the lac operon is a genetic regulatory system in E. coli that controls the expression of genes involved in lactose metabolism based on the availability of lactose as a substrate.
Xenobiotics are substances that are foreign to a living organism and usually originate outside of the body. This term is often used in the context of pharmacology and toxicology to refer to drugs, chemicals, or other agents that are not naturally produced by or expected to be found within the body.
When xenobiotics enter the body, they undergo a series of biotransformation processes, which involve metabolic reactions that convert them into forms that can be more easily excreted from the body. These processes are primarily carried out by enzymes in the liver and other organs.
It's worth noting that some xenobiotics can have beneficial effects on the body when used as medications or therapeutic agents, while others can be harmful or toxic. Therefore, understanding how the body metabolizes and eliminates xenobiotics is important for developing safe and effective drugs, as well as for assessing the potential health risks associated with exposure to environmental chemicals and pollutants.
Ras genes are a group of genes that encode for proteins involved in cell signaling pathways that regulate cell growth, differentiation, and survival. Mutations in Ras genes have been associated with various types of cancer, as well as other diseases such as developmental disorders and autoimmune diseases. The Ras protein family includes H-Ras, K-Ras, and N-Ras, which are activated by growth factor receptors and other signals to activate downstream effectors involved in cell proliferation and survival. Abnormal activation of Ras signaling due to mutations or dysregulation can contribute to tumor development and progression.
Cell extracts refer to the mixture of cellular components that result from disrupting or breaking open cells. The process of obtaining cell extracts is called cell lysis. Cell extracts can contain various types of molecules, such as proteins, nucleic acids (DNA and RNA), carbohydrates, lipids, and metabolites, depending on the methods used for cell disruption and extraction.
Cell extracts are widely used in biochemical and molecular biology research to study various cellular processes and pathways. For example, cell extracts can be used to measure enzyme activities, analyze protein-protein interactions, characterize gene expression patterns, and investigate metabolic pathways. In some cases, specific cellular components can be purified from the cell extracts for further analysis or application, such as isolating pure proteins or nucleic acids.
It is important to note that the composition of cell extracts may vary depending on the type of cells, the growth conditions, and the methods used for cell disruption and extraction. Therefore, it is essential to optimize the experimental conditions to obtain representative and meaningful results from cell extract studies.
p53 is a tumor suppressor gene that encodes a protein responsible for controlling cell growth and division. The p53 protein plays a crucial role in preventing the development of cancer by regulating the cell cycle and activating DNA repair processes when genetic damage is detected. If the damage is too severe to be repaired, p53 can trigger apoptosis, or programmed cell death, to prevent the propagation of potentially cancerous cells. Mutations in the TP53 gene, which encodes the p53 protein, are among the most common genetic alterations found in human cancers and are often associated with a poor prognosis.
The Retinoid X Receptor beta (RXR-beta) is a type of nuclear receptor protein that functions as a transcription factor, playing a crucial role in the regulation of gene expression. RXR-beta binds to specific DNA sequences called hormone response elements and regulates the expression of target genes in response to various signals, including retinoids and thyroid hormones. It can also form heterodimers with other nuclear receptors, such as the vitamin D receptor and the peroxisome proliferator-activated receptor (PPAR), to modulate their transcriptional activity. RXR-beta is widely expressed in various tissues, including the retina, brain, liver, and adipose tissue, and has been implicated in a variety of physiological processes, such as cell differentiation, development, metabolism, and homeostasis.
Multienzyme complexes are specialized protein structures that consist of multiple enzymes closely associated or bound together, often with other cofactors and regulatory subunits. These complexes facilitate the sequential transfer of substrates along a series of enzymatic reactions, also known as a metabolic pathway. By keeping the enzymes in close proximity, multienzyme complexes enhance reaction efficiency, improve substrate specificity, and maintain proper stoichiometry between different enzymes involved in the pathway. Examples of multienzyme complexes include the pyruvate dehydrogenase complex, the citrate synthase complex, and the fatty acid synthetase complex.
TATA box binding protein-like proteins (TBP-like proteins or TBPLs) are a family of transcription factors that share structural and functional similarities with the TATA box binding protein (TBP). TBP is a critical component of the initiation complex that binds to the TATA box, a specific DNA sequence found in the promoter regions of many genes.
TBPLs are involved in regulating gene expression by recognizing and binding to specific DNA sequences, similar to TBP. However, TBPLs have distinct roles in transcriptional regulation compared to TBP. They can either act as activators or repressors of transcription, depending on the context and the target genes they interact with.
TBPLs are found in various organisms, including animals, plants, and fungi. In humans, there are three known TBPLs: TBPL1 (also known as TRF3), TBPL2 (also known as TRF2), and TBPL3 (also known as DR1). These proteins have been implicated in various cellular processes, such as development, differentiation, and stress response.
In summary, TATA box binding protein-like proteins are a family of transcription factors that share structural and functional similarities with TBP but have distinct roles in regulating gene expression.
Cyclin D1 is a type of cyclin protein that plays a crucial role in the regulation of the cell cycle, which is the process by which cells divide and grow. Specifically, Cyclin D1 is involved in the transition from the G1 phase to the S phase of the cell cycle. It does this by forming a complex with and acting as a regulatory subunit of cyclin-dependent kinase 4 (CDK4) or CDK6, which phosphorylates and inactivates the retinoblastoma protein (pRb). This allows the E2F transcription factors to be released and activate the transcription of genes required for DNA replication and cell cycle progression.
Overexpression of Cyclin D1 has been implicated in the development of various types of cancer, as it can lead to uncontrolled cell growth and division. Therefore, Cyclin D1 is an important target for cancer therapy, and inhibitors of CDK4/6 have been developed to treat certain types of cancer that overexpress Cyclin D1.
GATA4 is a transcription factor that belongs to the GATA family of zinc finger proteins, which are characterized by their ability to bind to DNA sequences containing the core motif (A/T)GATA(A/G). GATA4 specifically recognizes and binds to GATA motifs in the promoter and enhancer regions of target genes, where it can modulate their transcription.
GATA4 is widely expressed in various tissues, including the heart, gut, lungs, and gonads. In the heart, GATA4 plays critical roles during cardiac development, such as promoting cardiomyocyte differentiation and regulating heart tube formation. It also continues to be expressed in adult hearts, where it helps maintain cardiac function and can contribute to heart repair after injury.
Mutations in the GATA4 gene have been associated with congenital heart defects, suggesting its essential role in heart development. Additionally, GATA4 has been implicated in cancer progression, particularly in gastrointestinal and lung cancers, where it can act as an oncogene by promoting cell proliferation and survival.
Molecular chaperones are a group of proteins that assist in the proper folding and assembly of other protein molecules, helping them achieve their native conformation. They play a crucial role in preventing protein misfolding and aggregation, which can lead to the formation of toxic species associated with various neurodegenerative diseases. Molecular chaperones are also involved in protein transport across membranes, degradation of misfolded proteins, and protection of cells under stress conditions. Their function is generally non-catalytic and ATP-dependent, and they often interact with their client proteins in a transient manner.
Hepatocellular carcinoma (HCC) is the most common type of primary liver cancer in adults. It originates from the hepatocytes, which are the main functional cells of the liver. This type of cancer is often associated with chronic liver diseases such as cirrhosis caused by hepatitis B or C virus infection, alcohol abuse, non-alcoholic fatty liver disease (NAFLD), and aflatoxin exposure.
The symptoms of HCC can vary but may include unexplained weight loss, lack of appetite, abdominal pain or swelling, jaundice, and fatigue. The diagnosis of HCC typically involves imaging tests such as ultrasound, CT scan, or MRI, as well as blood tests to measure alpha-fetoprotein (AFP) levels. Treatment options for Hepatocellular carcinoma depend on the stage and extent of the cancer, as well as the patient's overall health and liver function. Treatment options may include surgery, radiation therapy, chemotherapy, targeted therapy, or liver transplantation.
Fluorescence microscopy is a type of microscopy that uses fluorescent dyes or proteins to highlight and visualize specific components within a sample. In this technique, the sample is illuminated with high-energy light, typically ultraviolet (UV) or blue light, which excites the fluorescent molecules causing them to emit lower-energy, longer-wavelength light, usually visible light in the form of various colors. This emitted light is then collected by the microscope and detected to produce an image.
Fluorescence microscopy has several advantages over traditional brightfield microscopy, including the ability to visualize specific structures or molecules within a complex sample, increased sensitivity, and the potential for quantitative analysis. It is widely used in various fields of biology and medicine, such as cell biology, neuroscience, and pathology, to study the structure, function, and interactions of cells and proteins.
There are several types of fluorescence microscopy techniques, including widefield fluorescence microscopy, confocal microscopy, two-photon microscopy, and total internal reflection fluorescence (TIRF) microscopy, each with its own strengths and limitations. These techniques can provide valuable insights into the behavior of cells and proteins in health and disease.
Adenoviridae is a family of viruses that includes many species that can cause various types of illnesses in humans and animals. These viruses are non-enveloped, meaning they do not have a lipid membrane, and have an icosahedral symmetry with a diameter of approximately 70-90 nanometers.
The genome of Adenoviridae is composed of double-stranded DNA, which contains linear chromosomes ranging from 26 to 45 kilobases in length. The family is divided into five genera: Mastadenovirus, Aviadenovirus, Atadenovirus, Siadenovirus, and Ichtadenovirus.
Human adenoviruses are classified under the genus Mastadenovirus and can cause a wide range of illnesses, including respiratory infections, conjunctivitis, gastroenteritis, and upper respiratory tract infections. Some serotypes have also been associated with more severe diseases such as hemorrhagic cystitis, hepatitis, and meningoencephalitis.
Adenoviruses are highly contagious and can be transmitted through respiratory droplets, fecal-oral route, or by contact with contaminated surfaces. They can also be spread through contaminated water sources. Infections caused by adenoviruses are usually self-limiting, but severe cases may require hospitalization and supportive care.
Tissue distribution, in the context of pharmacology and toxicology, refers to the way that a drug or xenobiotic (a chemical substance found within an organism that is not naturally produced by or expected to be present within that organism) is distributed throughout the body's tissues after administration. It describes how much of the drug or xenobiotic can be found in various tissues and organs, and is influenced by factors such as blood flow, lipid solubility, protein binding, and the permeability of cell membranes. Understanding tissue distribution is important for predicting the potential effects of a drug or toxin on different parts of the body, and for designing drugs with improved safety and efficacy profiles.
Transcriptional regulatory elements are specific DNA sequences within the genome that bind to proteins or protein complexes known as transcription factors. These binding interactions control the initiation, rate, and termination of gene transcription, which is the process by which the information encoded in DNA is copied into RNA. Transcriptional regulatory elements can be classified into several categories, including promoters, enhancers, silencers, and insulators.
Promoters are located near the beginning of a gene, usually immediately upstream of the transcription start site. They provide a binding platform for the RNA polymerase enzyme and other general transcription factors that are required to initiate transcription. Promoters often contain a conserved sequence known as the TATA box, which is recognized by the TATA-binding protein (TBP) and helps position the RNA polymerase at the correct location.
Enhancers are DNA sequences that can be located far upstream or downstream of the gene they regulate, sometimes even in introns or exons within the gene itself. They serve to increase the transcription rate of a gene by providing binding sites for specific transcription factors that recruit coactivators and other regulatory proteins. These interactions lead to the formation of an active chromatin structure that facilitates transcription.
Silencers are DNA sequences that, like enhancers, can be located at various distances from the genes they regulate. However, instead of increasing transcription, silencers repress gene expression by binding to transcriptional repressors or corepressors. These proteins recruit chromatin-modifying enzymes that introduce repressive histone modifications or compact the chromatin structure, making it less accessible for transcription factors and RNA polymerase.
Insulators are DNA sequences that act as boundaries between transcriptional regulatory elements, preventing inappropriate interactions between enhancers, silencers, and promoters. Insulators can also protect genes from the effects of nearby chromatin modifications or positioning effects that might otherwise interfere with their normal expression patterns.
Collectively, these transcriptional regulatory elements play a crucial role in ensuring proper gene expression in response to developmental cues, environmental stimuli, and various physiological processes. Dysregulation of these elements can contribute to the development of various diseases, including cancer and genetic disorders.
NCOR1 (Nuclear Receptor Co-Repressor 1) is a corepressor protein that interacts with nuclear receptors and other transcription factors to regulate gene expression. It functions as a part of large multiprotein complexes, which also include histone deacetylases (HDACs), to mediate the repression of gene transcription. NCOR1 is involved in various cellular processes, including development, differentiation, and metabolism. Mutations in the NCOR1 gene have been associated with certain genetic disorders, such as Rubinstein-Taybi syndrome.
A nonmammalian embryo refers to the developing organism in animals other than mammals, from the fertilized egg (zygote) stage until hatching or birth. In nonmammalian species, the developmental stages and terminology differ from those used in mammals. The term "embryo" is generally applied to the developing organism up until a specific stage of development that is characterized by the formation of major organs and structures. After this point, the developing organism is referred to as a "larva," "juvenile," or other species-specific terminology.
The study of nonmammalian embryos has played an important role in our understanding of developmental biology and evolutionary developmental biology (evo-devo). By comparing the developmental processes across different animal groups, researchers can gain insights into the evolutionary origins and diversification of body plans and structures. Additionally, nonmammalian embryos are often used as model systems for studying basic biological processes, such as cell division, gene regulation, and pattern formation.
Methylcholanthrene is a polycyclic aromatic hydrocarbon that is used in research to induce skin tumors in mice. It is a potent carcinogen and mutagen, and exposure to it can increase the risk of cancer in humans. It is not typically found in medical treatments or therapies.
Cell compartmentation, also known as intracellular compartmentalization, refers to the organization of cells into distinct functional and spatial domains. This is achieved through the separation of cellular components and biochemical reactions into membrane-bound organelles or compartments. Each compartment has its unique chemical composition and environment, allowing for specific biochemical reactions to occur efficiently and effectively without interfering with other processes in the cell.
Some examples of membrane-bound organelles include the nucleus, mitochondria, chloroplasts, endoplasmic reticulum, Golgi apparatus, lysosomes, peroxisomes, and vacuoles. These organelles have specific functions, such as energy production (mitochondria), protein synthesis and folding (endoplasmic reticulum and Golgi apparatus), waste management (lysosomes), and lipid metabolism (peroxisomes).
Cell compartmentation is essential for maintaining cellular homeostasis, regulating metabolic pathways, protecting the cell from potentially harmful substances, and enabling complex biochemical reactions to occur in a controlled manner. Dysfunction of cell compartmentation can lead to various diseases, including neurodegenerative disorders, cancer, and metabolic disorders.
Nerve tissue proteins are specialized proteins found in the nervous system that provide structural and functional support to nerve cells, also known as neurons. These proteins include:
1. Neurofilaments: These are type IV intermediate filaments that provide structural support to neurons and help maintain their shape and size. They are composed of three subunits - NFL (light), NFM (medium), and NFH (heavy).
2. Neuronal Cytoskeletal Proteins: These include tubulins, actins, and spectrins that provide structural support to the neuronal cytoskeleton and help maintain its integrity.
3. Neurotransmitter Receptors: These are specialized proteins located on the postsynaptic membrane of neurons that bind neurotransmitters released by presynaptic neurons, triggering a response in the target cell.
4. Ion Channels: These are transmembrane proteins that regulate the flow of ions across the neuronal membrane and play a crucial role in generating and transmitting electrical signals in neurons.
5. Signaling Proteins: These include enzymes, receptors, and adaptor proteins that mediate intracellular signaling pathways involved in neuronal development, differentiation, survival, and death.
6. Adhesion Proteins: These are cell surface proteins that mediate cell-cell and cell-matrix interactions, playing a crucial role in the formation and maintenance of neural circuits.
7. Extracellular Matrix Proteins: These include proteoglycans, laminins, and collagens that provide structural support to nerve tissue and regulate neuronal migration, differentiation, and survival.
Tumor suppressor genes are a type of gene that helps to regulate and prevent cells from growing and dividing too rapidly or in an uncontrolled manner. They play a critical role in preventing the formation of tumors and cancer. When functioning properly, tumor suppressor genes help to repair damaged DNA, control the cell cycle, and trigger programmed cell death (apoptosis) when necessary. However, when these genes are mutated or altered, they can lose their ability to function correctly, leading to uncontrolled cell growth and the development of tumors. Examples of tumor suppressor genes include TP53, BRCA1, and BRCA2.
Myogenin is defined as a protein that belongs to the family of myogenic regulatory factors (MRFs). These proteins play crucial roles in the development, growth, and repair of skeletal muscle cells. Myogenin is specifically involved in the differentiation and fusion of myoblasts to form multinucleated myotubes, which are essential for the formation of mature skeletal muscle fibers. It functions as a transcription factor that binds to specific DNA sequences, thereby regulating the expression of genes required for muscle cell differentiation. Myogenin also plays a role in maintaining muscle homeostasis and may contribute to muscle regeneration following injury or disease.
Ubiquitin is a small protein that is present in all eukaryotic cells and plays a crucial role in the regulation of various cellular processes, such as protein degradation, DNA repair, and stress response. It is involved in marking proteins for destruction by attaching to them, a process known as ubiquitination. This modification can target proteins for degradation by the proteasome, a large protein complex that breaks down unneeded or damaged proteins in the cell. Ubiquitin also has other functions, such as regulating the localization and activity of certain proteins. The ability of ubiquitin to modify many different proteins and play a role in multiple cellular processes makes it an essential player in maintaining cellular homeostasis.
DNA helicases are a group of enzymes that are responsible for separating the two strands of DNA during processes such as replication and transcription. They do this by unwinding the double helix structure of DNA, using energy from ATP to break the hydrogen bonds between the base pairs. This allows other proteins to access the individual strands of DNA and carry out functions such as copying the genetic code or transcribing it into RNA.
During replication, DNA helicases help to create a replication fork, where the two strands of DNA are separated and new complementary strands are synthesized. In transcription, DNA helicases help to unwind the DNA double helix at the promoter region, allowing the RNA polymerase enzyme to bind and begin transcribing the DNA into RNA.
DNA helicases play a crucial role in maintaining the integrity of the genetic code and are essential for the normal functioning of cells. Defects in DNA helicases have been linked to various diseases, including cancer and neurological disorders.
Electrophoresis, polyacrylamide gel (EPG) is a laboratory technique used to separate and analyze complex mixtures of proteins or nucleic acids (DNA or RNA) based on their size and electrical charge. This technique utilizes a matrix made of cross-linked polyacrylamide, a type of gel, which provides a stable and uniform environment for the separation of molecules.
In this process:
1. The polyacrylamide gel is prepared by mixing acrylamide monomers with a cross-linking agent (bis-acrylamide) and a catalyst (ammonium persulfate) in the presence of a buffer solution.
2. The gel is then poured into a mold and allowed to polymerize, forming a solid matrix with uniform pore sizes that depend on the concentration of acrylamide used. Higher concentrations result in smaller pores, providing better resolution for separating smaller molecules.
3. Once the gel has set, it is placed in an electrophoresis apparatus containing a buffer solution. Samples containing the mixture of proteins or nucleic acids are loaded into wells on the top of the gel.
4. An electric field is applied across the gel, causing the negatively charged molecules to migrate towards the positive electrode (anode) while positively charged molecules move toward the negative electrode (cathode). The rate of migration depends on the size, charge, and shape of the molecules.
5. Smaller molecules move faster through the gel matrix and will migrate farther from the origin compared to larger molecules, resulting in separation based on size. Proteins and nucleic acids can be selectively stained after electrophoresis to visualize the separated bands.
EPG is widely used in various research fields, including molecular biology, genetics, proteomics, and forensic science, for applications such as protein characterization, DNA fragment analysis, cloning, mutation detection, and quality control of nucleic acid or protein samples.
Exons are the coding regions of DNA that remain in the mature, processed mRNA after the removal of non-coding intronic sequences during RNA splicing. These exons contain the information necessary to encode proteins, as they specify the sequence of amino acids within a polypeptide chain. The arrangement and order of exons can vary between different genes and even between different versions of the same gene (alternative splicing), allowing for the generation of multiple protein isoforms from a single gene. This complexity in exon structure and usage significantly contributes to the diversity and functionality of the proteome.
Butyrates are a type of fatty acid, specifically called short-chain fatty acids (SCFAs), that are produced in the gut through the fermentation of dietary fiber by gut bacteria. The name "butyrate" comes from the Latin word for butter, "butyrum," as butyrate was first isolated from butter.
Butyrates have several important functions in the body. They serve as a primary energy source for colonic cells and play a role in maintaining the health and integrity of the intestinal lining. Additionally, butyrates have been shown to have anti-inflammatory effects, regulate gene expression, and may even help prevent certain types of cancer.
In medical contexts, butyrate supplements are sometimes used to treat conditions such as ulcerative colitis, a type of inflammatory bowel disease (IBD), due to their anti-inflammatory properties and ability to promote gut health. However, more research is needed to fully understand the potential therapeutic uses of butyrates and their long-term effects on human health.
A transgene is a segment of DNA that has been artificially transferred from one organism to another, typically between different species, to introduce a new trait or characteristic. The term "transgene" specifically refers to the genetic material that has been transferred and has become integrated into the host organism's genome. This technology is often used in genetic engineering and biomedical research, including the development of genetically modified organisms (GMOs) for agricultural purposes or the creation of animal models for studying human diseases.
Transgenes can be created using various techniques, such as molecular cloning, where a desired gene is isolated, manipulated, and then inserted into a vector (a small DNA molecule, such as a plasmid) that can efficiently enter the host organism's cells. Once inside the cell, the transgene can integrate into the host genome, allowing for the expression of the new trait in the resulting transgenic organism.
It is important to note that while transgenes can provide valuable insights and benefits in research and agriculture, their use and release into the environment are subjects of ongoing debate due to concerns about potential ecological impacts and human health risks.
Embryonal carcinoma is a rare and aggressive type of cancer that arises from primitive germ cells. It typically occurs in the gonads (ovaries or testicles), but can also occur in other areas of the body such as the mediastinum, retroperitoneum, or sacrococcygeal region.
Embryonal carcinoma is called "embryonal" because the cancerous cells resemble those found in an embryo during early stages of development. These cells are capable of differentiating into various cell types, which can lead to a mix of cell types within the tumor.
Embryonal carcinoma is a highly malignant tumor that tends to grow and spread quickly. It can metastasize to other parts of the body, including the lungs, liver, brain, and bones. Treatment typically involves surgical removal of the tumor, followed by chemotherapy and/or radiation therapy to kill any remaining cancer cells.
Prognosis for embryonal carcinoma depends on several factors, including the stage of the disease at diagnosis, the location of the tumor, and the patient's overall health. In general, this type of cancer has a poor prognosis, with a high risk of recurrence even after treatment.
A chromosome deletion is a type of genetic abnormality that occurs when a portion of a chromosome is missing or deleted. Chromosomes are thread-like structures located in the nucleus of cells that contain our genetic material, which is organized into genes.
Chromosome deletions can occur spontaneously during the formation of reproductive cells (eggs or sperm) or can be inherited from a parent. They can affect any chromosome and can vary in size, from a small segment to a large portion of the chromosome.
The severity of the symptoms associated with a chromosome deletion depends on the size and location of the deleted segment. In some cases, the deletion may be so small that it does not cause any noticeable symptoms. However, larger deletions can lead to developmental delays, intellectual disabilities, physical abnormalities, and various medical conditions.
Chromosome deletions are typically detected through a genetic test called karyotyping, which involves analyzing the number and structure of an individual's chromosomes. Other more precise tests, such as fluorescence in situ hybridization (FISH) or chromosomal microarray analysis (CMA), may also be used to confirm the diagnosis and identify the specific location and size of the deletion.
Notch 1 is a type of receptor that belongs to the family of single-transmembrane receptors known as Notch receptors. It is a heterodimeric transmembrane protein composed of an extracellular domain and an intracellular domain, which play crucial roles in cell fate determination, proliferation, differentiation, and apoptosis during embryonic development and adult tissue homeostasis.
The Notch 1 receptor is activated through a conserved mechanism of ligand-receptor interaction, where the extracellular domain of the receptor interacts with the membrane-bound ligands Jagged 1 or 2 and Delta-like 1, 3, or 4 expressed on adjacent cells. This interaction triggers a series of proteolytic cleavages that release the intracellular domain of Notch 1 (NICD) from the membrane. NICD then translocates to the nucleus and interacts with the DNA-binding protein CSL (CBF1/RBPJκ in mammals) and coactivators Mastermind-like proteins to regulate the expression of target genes, including members of the HES and HEY families.
Mutations in NOTCH1 have been associated with various human diseases, such as T-cell acute lymphoblastic leukemia (T-ALL), a type of cancer that affects the immune system's T cells, and vascular diseases, including arterial calcification, atherosclerosis, and aneurysms.
GATA transcription factors are a group of proteins that regulate gene expression by binding to specific DNA sequences called GATA motifs. These transcription factors contain one or two conserved domains known as GATA-type zinc fingers, which recognize and bind to the consensus sequence (A/T)GATA(A/G). They are widely expressed in various tissues, including hematopoietic cells, endothelial cells, and neuronal cells. In hematopoiesis, GATA transcription factors play critical roles in cell fate determination, proliferation, and differentiation. For example, GATA-1 is essential for erythroid and megakaryocyte development, while GATA-2 is required for the development of hematopoietic stem cells and progenitor cells. Dysregulation of GATA transcription factors has been implicated in various diseases, including cancer and genetic disorders.
Milk proteins are a complex mixture of proteins that are naturally present in milk, consisting of casein and whey proteins. Casein makes up about 80% of the total milk protein and is divided into several types including alpha-, beta-, gamma- and kappa-casein. Whey proteins account for the remaining 20% and include beta-lactoglobulin, alpha-lactalbumin, bovine serum albumin, and immunoglobulins. These proteins are important sources of essential amino acids and play a crucial role in the nutrition of infants and young children. Additionally, milk proteins have various functional properties that are widely used in the food industry for their gelling, emulsifying, and foaming abilities.
Interferon Regulatory Factors (IRFs) are a family of transcription factors that play crucial roles in the regulation of immune responses, particularly in the expression of interferons (IFNs) and other genes involved in innate immunity and inflammation. In humans, there are nine known IRF proteins (IRF1-9), each with distinct functions and patterns of expression.
The primary function of IRFs is to regulate the transcription of type I IFNs (IFN-α and IFN-β) and other immune response genes in response to various stimuli, such as viral infections, bacterial components, and proinflammatory cytokines. IRFs can either activate or repress gene expression by binding to specific DNA sequences called interferon-stimulated response elements (ISREs) and/or IFN consensus sequences (ICSs) in the promoter regions of target genes.
IRF1, IRF3, and IRF7 are primarily involved in type I IFN regulation, with IRF1 acting as a transcriptional activator for IFN-β and various ISRE-containing genes, while IRF3 and IRF7 function as master regulators of the type I IFN response to viral infections. Upon viral recognition by pattern recognition receptors (PRRs), IRF3 and IRF7 are activated through phosphorylation and translocate to the nucleus, where they induce the expression of type I IFNs and other antiviral genes.
IRF2, IRF4, IRF5, and IRF8 have more diverse roles in immune regulation, including the control of T-cell differentiation, B-cell development, and myeloid cell function. For example, IRF4 is essential for the development and function of Th2 cells, while IRF5 and IRF8 are involved in the differentiation of dendritic cells and macrophages.
IRF6 and IRF9 have unique functions compared to other IRFs. IRF6 is primarily involved in epithelial cell development and differentiation, while IRF9 forms a complex with STAT1 and STAT2 to regulate the transcription of IFN-stimulated genes (ISGs) during the type I IFN response.
In summary, IRFs are a family of transcription factors that play crucial roles in various aspects of immune regulation, including antiviral responses, T-cell and B-cell development, and myeloid cell function. Dysregulation of IRF activity can lead to the development of autoimmune diseases, chronic inflammation, and cancer.
Forkhead transcription factors (FOX) are a family of proteins that play crucial roles in the regulation of gene expression through the process of binding to specific DNA sequences, thereby controlling various biological processes such as cell growth, differentiation, and apoptosis. These proteins are characterized by a conserved DNA-binding domain, known as the forkhead box or FOX domain, which adopts a winged helix structure that recognizes and binds to the consensus sequence 5'-(G/A)(T/C)AA(C/A)A-3'.
The FOX family is further divided into subfamilies based on the structure of their DNA-binding domains, with each subfamily having distinct functions. For example, FOXP proteins are involved in brain development and function, while FOXO proteins play a key role in regulating cellular responses to stress and metabolism. Dysregulation of forkhead transcription factors has been implicated in various diseases, including cancer, diabetes, and neurodegenerative disorders.
Genes in insects refer to the hereditary units of DNA that are passed down from parents to offspring and contain the instructions for the development, function, and reproduction of an organism. These genetic materials are located within the chromosomes in the nucleus of insect cells. They play a crucial role in determining various traits such as physical characteristics, behavior, and susceptibility to diseases.
Insect genes, like those of other organisms, consist of exons (coding regions) that contain information for protein synthesis and introns (non-coding regions) that are removed during the process of gene expression. The expression of insect genes is regulated by various factors such as transcription factors, enhancers, and silencers, which bind to specific DNA sequences to activate or repress gene transcription.
Understanding the genetic makeup of insects has important implications for various fields, including agriculture, public health, and evolutionary biology. For example, genes associated with insect pests' resistance to pesticides can be identified and targeted to develop more effective control strategies. Similarly, genes involved in disease transmission by insect vectors such as mosquitoes can be studied to develop novel interventions for preventing the spread of infectious diseases.
Butyric acid is a type of short-chain fatty acid that is naturally produced in the human body through the fermentation of dietary fiber in the colon. Its chemical formula is C4H8O2. It has a distinctive, rancid odor and is used in the production of perfumes, flavorings, and certain types of plasticizers. In addition to its natural occurrence in the human body, butyric acid is also found in some foods such as butter, parmesan cheese, and fermented foods like sauerkraut. It has been studied for its potential health benefits, including its role in gut health, immune function, and cancer prevention.
Cyclin G1 is a type of protein that belongs to the cyclin family, which are involved in the regulation of the cell cycle. The cell cycle is the series of events that take place as a cell grows, copies its DNA, and divides into two daughter cells.
Cyclin G1 regulates the cell cycle by interacting with various cyclin-dependent kinases (CDKs), which are enzymes that help control the progression of the cell cycle. Specifically, Cyclin G1 has been shown to inhibit the activity of CDK1 and CDK2, which play important roles in regulating the transition from the G1 phase to the S phase of the cell cycle.
Cyclin G1 has also been implicated in other cellular processes, including DNA damage repair, apoptosis (programmed cell death), and tumor suppression. Dysregulation of Cyclin G1 has been linked to various types of cancer, making it a potential target for cancer therapy.
Paired box (PAX) transcription factors are a group of proteins that regulate gene expression during embryonic development and in some adult tissues. They are characterized by the presence of a paired box domain, a conserved DNA-binding motif that recognizes specific DNA sequences. PAX proteins play crucial roles in various developmental processes, such as the formation of the nervous system, eyes, and pancreas. Dysregulation of PAX genes has been implicated in several human diseases, including cancer.
NF-κB (Nuclear Factor kappa-light-chain-enhancer of activated B cells) p50 subunit, also known as NFKB1, is a protein that plays a crucial role in regulating the immune response, inflammation, and cell survival. The NF-κB p50 subunit can form homodimers or heterodimers with other NF-κB family members, such as p65 (RelA) or c-Rel, to bind to specific DNA sequences called κB sites in the promoter regions of target genes.
The activation of NF-κB signaling leads to the nuclear translocation of these dimers and the regulation of gene expression involved in various biological processes, including immune response, inflammation, differentiation, cell growth, and apoptosis. The p50 subunit can act as a transcriptional activator or repressor, depending on its partner and the context.
In summary, NF-κB p50 Subunit is a protein involved in the regulation of gene expression, particularly in immune response, inflammation, and cell survival, through its ability to bind to specific DNA sequences as part of homodimers or heterodimers with other NF-κB family members.
Wnt1 protein is a member of the Wnt family, which is a group of secreted signaling proteins that play crucial roles in embryonic development and tissue homeostasis in adults. Specifically, Wnt1 is a highly conserved gene that encodes a glycoprotein with a molecular weight of approximately 40 kDa. It is primarily expressed in the developing nervous system, where it functions as a key regulator of neural crest cell migration and differentiation during embryogenesis.
Wnt1 protein mediates its effects by binding to Frizzled receptors on the surface of target cells, leading to the activation of several intracellular signaling pathways, including the canonical Wnt/β-catenin pathway and non-canonical Wnt/planar cell polarity (PCP) pathway. In the canonical pathway, Wnt1 protein stabilizes β-catenin, which then translocates to the nucleus and interacts with TCF/LEF transcription factors to regulate gene expression.
Dysregulation of Wnt1 signaling has been implicated in several human diseases, including cancer. For example, aberrant activation of the Wnt/β-catenin pathway by Wnt1 protein has been observed in various types of tumors, such as medulloblastomas and breast cancers, leading to uncontrolled cell proliferation and tumor growth. Therefore, understanding the molecular mechanisms underlying Wnt1 signaling is essential for developing novel therapeutic strategies for treating these diseases.
Nitrogen fixation is a process by which nitrogen gas (N2) in the air is converted into ammonia (NH3) or other chemically reactive forms, making it available to plants and other organisms for use as a nutrient. This process is essential for the nitrogen cycle and for the growth of many types of plants, as most plants cannot utilize nitrogen gas directly from the air.
In the medical field, nitrogen fixation is not a commonly used term. However, in the context of microbiology and infectious diseases, some bacteria are capable of fixing nitrogen and this ability can contribute to their pathogenicity. For example, certain species of bacteria that colonize the human body, such as those found in the gut or on the skin, may be able to fix nitrogen and use it for their own growth and survival. In some cases, these bacteria may also release fixed nitrogen into the environment, which can have implications for the ecology and health of the host and surrounding ecosystems.
Stat5 (Signal Transducer and Activator of Transcription 5) is a transcription factor that plays a crucial role in various cellular processes, including growth, survival, and differentiation. It exists in two closely related isoforms, Stat5a and Stat5b, which are encoded by separate genes but share significant sequence homology and functional similarity.
When activated through phosphorylation by receptor or non-receptor tyrosine kinases, Stat5 forms homodimers or heterodimers that translocate to the nucleus. Once in the nucleus, these dimers bind to specific DNA sequences called Stat-binding elements (SBEs) in the promoter regions of target genes, leading to their transcriptional activation or repression.
Stat5 is involved in various physiological and pathological conditions, such as hematopoiesis, lactation, immune response, and cancer progression. Dysregulation of Stat5 signaling has been implicated in several malignancies, including leukemias, lymphomas, and breast cancer, making it an attractive therapeutic target for these diseases.
A sigma factor is a type of protein in bacteria that plays an essential role in the initiation of transcription, which is the first step of gene expression. Sigma factors recognize and bind to specific sequences on DNA, known as promoters, enabling the attachment of RNA polymerase, the enzyme responsible for synthesizing RNA.
In bacteria, RNA polymerase is made up of several subunits, including a core enzyme and a sigma factor. The sigma factor confers specificity to the RNA polymerase by recognizing and binding to the promoter region of the DNA, allowing transcription to begin. Once transcription starts, the sigma factor is released from the RNA polymerase, which then continues to synthesize RNA until it reaches the end of the gene.
Bacteria have multiple sigma factors that allow them to respond to different environmental conditions and stresses by regulating the expression of specific sets of genes. For example, some sigma factors are involved in the regulation of genes required for growth and metabolism under normal conditions, while others are involved in the response to heat shock, starvation, or other stressors.
Overall, sigma factors play a crucial role in regulating gene expression in bacteria, allowing them to adapt to changing environmental conditions and maintain cellular homeostasis.
Flavonoids are a type of plant compounds with antioxidant properties that are beneficial to health. They are found in various fruits, vegetables, grains, and wine. Flavonoids have been studied for their potential to prevent chronic diseases such as heart disease and cancer due to their ability to reduce inflammation and oxidative stress.
There are several subclasses of flavonoids, including:
1. Flavanols: Found in tea, chocolate, grapes, and berries. They have been shown to improve blood flow and lower blood pressure.
2. Flavones: Found in parsley, celery, and citrus fruits. They have anti-inflammatory and antioxidant properties.
3. Flavanonols: Found in citrus fruits, onions, and tea. They have been shown to improve blood flow and reduce inflammation.
4. Isoflavones: Found in soybeans and legumes. They have estrogen-like effects and may help prevent hormone-related cancers.
5. Anthocyanidins: Found in berries, grapes, and other fruits. They have antioxidant properties and may help improve vision and memory.
It is important to note that while flavonoids have potential health benefits, they should not be used as a substitute for medical treatment or a healthy lifestyle. It is always best to consult with a healthcare professional before starting any new supplement regimen.
Ewing Sarcoma (EWS) RNA-Binding Protein, also known as EWSR1, is a protein that plays a role in gene expression by binding to RNA. It is a member of the FET family of proteins, which also includes FUS and TAF15. These proteins are involved in various cellular processes such as transcription, splicing, and translation.
Mutations in the EWSR1 gene have been associated with several types of cancer, most notably Ewing sarcoma, a rare tumor that typically affects children and adolescents. In Ewing sarcoma, a fusion protein is formed when EWSR1 combines with another protein, most commonly ETS translocation variant 1 (ETV1), FLI1, ERG or FEV. This fusion protein can lead to abnormal gene expression and tumor formation.
EWSR1 has also been found to be involved in other types of cancer such as acute myeloid leukemia, clear cell sarcoma, desmoplastic small round cell tumors and liposarcomas.
It's important to note that while EWSR1 is a RNA-binding protein, it can also bind to DNA in certain contexts, such as when it forms a fusion protein with an ETS transcription factor in Ewing sarcoma.
Nucleic acid conformation refers to the three-dimensional structure that nucleic acids (DNA and RNA) adopt as a result of the bonding patterns between the atoms within the molecule. The primary structure of nucleic acids is determined by the sequence of nucleotides, while the conformation is influenced by factors such as the sugar-phosphate backbone, base stacking, and hydrogen bonding.
Two common conformations of DNA are the B-form and the A-form. The B-form is a right-handed helix with a diameter of about 20 Å and a pitch of 34 Å, while the A-form has a smaller diameter (about 18 Å) and a shorter pitch (about 25 Å). RNA typically adopts an A-form conformation.
The conformation of nucleic acids can have significant implications for their function, as it can affect their ability to interact with other molecules such as proteins or drugs. Understanding the conformational properties of nucleic acids is therefore an important area of research in molecular biology and medicine.
GATA1 (Global Architecture of Tissue/stage-specific Transcription Factors 1) is a transcription factor that belongs to the GATA family, which recognizes and binds to the (A/T)GATA(A/G) motif in the DNA. It plays a crucial role in the development and differentiation of hematopoietic cells, particularly erythroid, megakaryocytic, eosinophilic, and mast cell lineages.
GATA1 regulates gene expression by binding to specific DNA sequences and recruiting other co-factors that modulate chromatin structure and transcriptional activity. Mutations in the GATA1 gene can lead to various blood disorders such as congenital dyserythropoietic anemia type II, Diamond-Blackfan anemia, acute megakaryoblastic leukemia (AMKL), and myelodysplastic syndrome.
In summary, GATA1 Transcription Factor is a protein that binds to specific DNA sequences in the genome and regulates gene expression, playing a critical role in hematopoietic cell development and differentiation.
Cyclin-Dependent Kinase 9 (CDK9) is a type of serine/threonine protein kinase that plays a crucial role in the regulation of transcription. It forms a complex with cyclin T1, K or H and gets activated by phosphorylation. This complex, known as P-TEFb, is involved in the phosphorylation and activation of the C-terminal domain of RNA polymerase II, which is essential for the transcription elongation of most protein-coding genes. CDK9 also regulates other cellular processes such as apoptosis, differentiation, and cell cycle progression. Dysregulation of CDK9 has been implicated in various diseases including cancer.
I believe there may be some confusion in your question. "Quail" is typically used to refer to a group of small birds that belong to the family Phasianidae and the subfamily Perdicinae. There is no established medical definition for "quail."
However, if you're referring to the verb "to quail," it means to shrink back, draw back, or cower, often due to fear or intimidation. In a medical context, this term could be used metaphorically to describe a patient's psychological response to a threatening situation, such as receiving a difficult diagnosis. But again, "quail" itself is not a medical term.
Core binding factors (CBFs) are a group of proteins that play critical roles in the development and differentiation of hematopoietic cells, which are the cells responsible for the formation of blood and immune systems. The term "core binding factor" refers to the ability of these proteins to bind to specific DNA sequences, known as core binding sites, and regulate gene transcription.
The two main CBFs are:
1. Core Binding Factor Alpha (CBF-α): Also known as RUNX1 or AML1, this protein forms a complex with Core Binding Factor Beta (CBF-β) to regulate the expression of genes involved in hematopoiesis. Mutations in CBF-α have been associated with various types of leukemia and myelodysplastic syndromes.
2. Core Binding Factor Beta (CBF-β): Also known as PEBP2B, this protein partners with CBF-α to form the active transcription factor complex. CBF-β enhances the DNA binding affinity and stability of the CBF-α/CBF-β heterodimer.
In certain types of leukemia, chromosomal abnormalities can lead to the formation of fusion proteins involving CBF-α or CBF-β. These fusion proteins disrupt normal hematopoiesis and contribute to the development of cancer. Examples include the t(8;21) translocation that creates the AML1/ETO fusion protein in acute myeloid leukemia (AML) and the inv(16) inversion that forms the CBFB-MYH11 fusion protein in AML.
Mitogen-Activated Protein Kinase 7 (MAPK7), also known as Extracellular Signal-Regulated Kinase 5 (ERK5), is a serine/threonine protein kinase that plays a crucial role in signal transduction pathways involved in various cellular processes, including proliferation, differentiation, survival, and migration. MAPK7 is the least studied member of the MAPK family and is activated by the upstream MAPKKs, MAP2K5/MEK5 and MAP3K1/2/5/11/14. Once activated, MAPK7 can phosphorylate and regulate various transcription factors and other downstream targets, ultimately leading to changes in gene expression and cellular responses. Dysregulation of the MAPK7 pathway has been implicated in several diseases, including cancer and neurological disorders.
Interferon-gamma (IFN-γ) is a soluble cytokine that is primarily produced by the activation of natural killer (NK) cells and T lymphocytes, especially CD4+ Th1 cells and CD8+ cytotoxic T cells. It plays a crucial role in the regulation of the immune response against viral and intracellular bacterial infections, as well as tumor cells. IFN-γ has several functions, including activating macrophages to enhance their microbicidal activity, increasing the presentation of major histocompatibility complex (MHC) class I and II molecules on antigen-presenting cells, stimulating the proliferation and differentiation of T cells and NK cells, and inducing the production of other cytokines and chemokines. Additionally, IFN-γ has direct antiproliferative effects on certain types of tumor cells and can enhance the cytotoxic activity of immune cells against infected or malignant cells.
Protein synthesis inhibitors are a class of medications or chemical substances that interfere with the process of protein synthesis in cells. Protein synthesis is the biological process by which cells create proteins, essential components for the structure, function, and regulation of tissues and organs. This process involves two main stages: transcription and translation.
Translation is the stage where the genetic information encoded in messenger RNA (mRNA) is translated into a specific sequence of amino acids, resulting in a protein molecule. Protein synthesis inhibitors work by targeting various components of the translation machinery, such as ribosomes, transfer RNAs (tRNAs), or translation factors, thereby preventing or disrupting the formation of new proteins.
These inhibitors have clinical applications in treating various conditions, including bacterial and viral infections, cancer, and autoimmune disorders. Some examples of protein synthesis inhibitors include:
1. Antibiotics: Certain antibiotics, like tetracyclines, macrolides, aminoglycosides, and chloramphenicol, target bacterial ribosomes and inhibit their ability to synthesize proteins, thereby killing or inhibiting the growth of bacteria.
2. Antiviral drugs: Protein synthesis inhibitors are used to treat viral infections by targeting various stages of the viral replication cycle, including protein synthesis. For example, ribavirin is an antiviral drug that can inhibit viral RNA-dependent RNA polymerase and mRNA capping, which are essential for viral protein synthesis.
3. Cancer therapeutics: Some chemotherapeutic agents target rapidly dividing cancer cells by interfering with their protein synthesis machinery. For instance, puromycin is an aminonucleoside antibiotic that can be incorporated into elongating polypeptide chains during translation, causing premature termination and inhibiting overall protein synthesis in cancer cells.
4. Immunosuppressive drugs: Protein synthesis inhibitors are also used as immunosuppressants to treat autoimmune disorders and prevent organ rejection after transplantation. For example, tacrolimus and cyclosporine bind to and inhibit the activity of calcineurin, a protein phosphatase that plays a crucial role in T-cell activation and cytokine production.
In summary, protein synthesis inhibitors are valuable tools for treating various diseases, including bacterial and viral infections, cancer, and autoimmune disorders. By targeting the protein synthesis machinery of pathogens or abnormal cells, these drugs can selectively inhibit their growth and proliferation while minimizing harm to normal cells.
I'm sorry for any confusion, but "Mink" is not a medical term. It refers to a species of small, semiaquatic carnivorous mammals that are known for their sleek fur. They belong to the family Mustelidae, which also includes otters, weasels, and ferrets. If you have any questions about medical terminology or health-related topics, I'd be happy to help!
Genetically modified animals (GMAs) are those whose genetic makeup has been altered using biotechnological techniques. This is typically done by introducing one or more genes from another species into the animal's genome, resulting in a new trait or characteristic that does not naturally occur in that species. The introduced gene is often referred to as a transgene.
The process of creating GMAs involves several steps:
1. Isolation: The desired gene is isolated from the DNA of another organism.
2. Transfer: The isolated gene is transferred into the target animal's cells, usually using a vector such as a virus or bacterium.
3. Integration: The transgene integrates into the animal's chromosome, becoming a permanent part of its genetic makeup.
4. Selection: The modified cells are allowed to multiply, and those that contain the transgene are selected for further growth and development.
5. Breeding: The genetically modified individuals are bred to produce offspring that carry the desired trait.
GMAs have various applications in research, agriculture, and medicine. In research, they can serve as models for studying human diseases or testing new therapies. In agriculture, GMAs can be developed to exhibit enhanced growth rates, improved disease resistance, or increased nutritional value. In medicine, GMAs may be used to produce pharmaceuticals or other therapeutic agents within their bodies.
Examples of genetically modified animals include mice with added genes for specific proteins that make them useful models for studying human diseases, goats that produce a human protein in their milk to treat hemophilia, and pigs with enhanced resistance to certain viruses that could potentially be used as organ donors for humans.
It is important to note that the use of genetically modified animals raises ethical concerns related to animal welfare, environmental impact, and potential risks to human health. These issues must be carefully considered and addressed when developing and implementing GMA technologies.
An allele is a variant form of a gene that is located at a specific position on a specific chromosome. Alleles are alternative forms of the same gene that arise by mutation and are found at the same locus or position on homologous chromosomes.
Each person typically inherits two copies of each gene, one from each parent. If the two alleles are identical, a person is said to be homozygous for that trait. If the alleles are different, the person is heterozygous.
For example, the ABO blood group system has three alleles, A, B, and O, which determine a person's blood type. If a person inherits two A alleles, they will have type A blood; if they inherit one A and one B allele, they will have type AB blood; if they inherit two B alleles, they will have type B blood; and if they inherit two O alleles, they will have type O blood.
Alleles can also influence traits such as eye color, hair color, height, and other physical characteristics. Some alleles are dominant, meaning that only one copy of the allele is needed to express the trait, while others are recessive, meaning that two copies of the allele are needed to express the trait.
Ubiquitination is a post-translational modification process in which a ubiquitin protein is covalently attached to a target protein. This process plays a crucial role in regulating various cellular functions, including protein degradation, DNA repair, and signal transduction. The addition of ubiquitin can lead to different outcomes depending on the number and location of ubiquitin molecules attached to the target protein. Monoubiquitination (the attachment of a single ubiquitin molecule) or multiubiquitination (the attachment of multiple ubiquitin molecules) can mark proteins for degradation by the 26S proteasome, while specific types of ubiquitination (e.g., K63-linked polyubiquitination) can serve as a signal for nonproteolytic functions such as endocytosis, autophagy, or DNA repair. Ubiquitination is a highly regulated process that involves the coordinated action of three enzymes: E1 ubiquitin-activating enzyme, E2 ubiquitin-conjugating enzyme, and E3 ubiquitin ligase. Dysregulation of ubiquitination has been implicated in various diseases, including cancer, neurodegenerative disorders, and inflammatory conditions.
Sprague-Dawley rats are a strain of albino laboratory rats that are widely used in scientific research. They were first developed by researchers H.H. Sprague and R.C. Dawley in the early 20th century, and have since become one of the most commonly used rat strains in biomedical research due to their relatively large size, ease of handling, and consistent genetic background.
Sprague-Dawley rats are outbred, which means that they are genetically diverse and do not suffer from the same limitations as inbred strains, which can have reduced fertility and increased susceptibility to certain diseases. They are also characterized by their docile nature and low levels of aggression, making them easier to handle and study than some other rat strains.
These rats are used in a wide variety of research areas, including toxicology, pharmacology, nutrition, cancer, and behavioral studies. Because they are genetically diverse, Sprague-Dawley rats can be used to model a range of human diseases and conditions, making them an important tool in the development of new drugs and therapies.
Simian Virus 40 (SV40) is a polyomavirus that is found in both monkeys and humans. It is a DNA virus that has been extensively studied in laboratory settings due to its ability to transform cells and cause tumors in animals. In fact, SV40 was discovered as a contaminant of poliovirus vaccines that were prepared using rhesus monkey kidney cells in the 1950s and 1960s.
SV40 is not typically associated with human disease, but there has been some concern that exposure to the virus through contaminated vaccines or other means could increase the risk of certain types of cancer, such as mesothelioma and brain tumors. However, most studies have failed to find a consistent link between SV40 infection and cancer in humans.
The medical community generally agrees that SV40 is not a significant public health threat, but researchers continue to study the virus to better understand its biology and potential impact on human health.
CREB-1, or cAMP Response Element-Binding Protein 1, is a transcription factor that plays a crucial role in regulating gene expression in response to various cellular signals. It binds to the cAMP response element (CRE) sequence in the promoter region of target genes and activates their transcription. CREB-1 is widely expressed in different tissues and is involved in several biological processes, including metabolism, learning, memory, and stress responses. Phosphorylation of CREB-1 at specific serine residues, such as Ser-133, is required for its activation and subsequent binding to the CRE sequence.
Estrogen antagonists, also known as antiestrogens, are a class of drugs that block the effects of estrogen in the body. They work by binding to estrogen receptors and preventing the natural estrogen from attaching to them. This results in the inhibition of estrogen-mediated activities in various tissues, including breast and uterine tissue.
There are two main types of estrogen antagonists: selective estrogen receptor modulators (SERMs) and pure estrogen receptor downregulators (PERDS), also known as estrogen receptor downregulators (ERDs). SERMs, such as tamoxifen and raloxifene, can act as estrogen agonists or antagonists depending on the tissue type. For example, they may block the effects of estrogen in breast tissue while acting as an estrogen agonist in bone tissue, helping to prevent osteoporosis.
PERDS, such as fulvestrant, are pure estrogen receptor antagonists and do not have any estrogen-like activity. They are used primarily for the treatment of hormone receptor-positive breast cancer in postmenopausal women.
Overall, estrogen antagonists play an important role in the management of hormone receptor-positive breast cancer and other conditions where inhibiting estrogen activity is beneficial.
MAFK (Musculoaponeurotic fibrosarcoma oncogene homolog K) is a transcription factor that belongs to the basic region-leucine zipper (bZIP) family. Transcription factors are proteins that regulate gene expression by binding to specific DNA sequences and controlling the initiation of transcription. The bZIP family of transcription factors is characterized by a highly conserved basic region for DNA binding and a leucine zipper domain for dimerization.
MAFK can form homodimers or heterodimers with other bZIP proteins, which allows it to regulate the expression of various genes involved in different cellular processes such as proliferation, differentiation, and stress response. Dysregulation of MAFK has been implicated in several diseases, including cancer, where it can act as an oncogene by promoting cell growth and survival.
MAFK is also known to play a role in the development and function of the nervous system. It is widely expressed in the brain, where it regulates the expression of genes involved in neuronal differentiation, synaptic plasticity, and neuroprotection. Mutations in MAFK have been associated with neurological disorders such as intellectual disability and epilepsy.
In summary, MafK transcription factor is a bZIP protein that regulates gene expression through DNA binding and dimerization. It plays important roles in cellular processes such as proliferation, differentiation, and stress response, and has been implicated in various diseases, including cancer and neurological disorders.
Cell surface receptors, also known as membrane receptors, are proteins located on the cell membrane that bind to specific molecules outside the cell, known as ligands. These receptors play a crucial role in signal transduction, which is the process of converting an extracellular signal into an intracellular response.
Cell surface receptors can be classified into several categories based on their structure and mechanism of action, including:
1. Ion channel receptors: These receptors contain a pore that opens to allow ions to flow across the cell membrane when they bind to their ligands. This ion flux can directly activate or inhibit various cellular processes.
2. G protein-coupled receptors (GPCRs): These receptors consist of seven transmembrane domains and are associated with heterotrimeric G proteins that modulate intracellular signaling pathways upon ligand binding.
3. Enzyme-linked receptors: These receptors possess an intrinsic enzymatic activity or are linked to an enzyme, which becomes activated when the receptor binds to its ligand. This activation can lead to the initiation of various signaling cascades within the cell.
4. Receptor tyrosine kinases (RTKs): These receptors contain intracellular tyrosine kinase domains that become activated upon ligand binding, leading to the phosphorylation and activation of downstream signaling molecules.
5. Integrins: These receptors are transmembrane proteins that mediate cell-cell or cell-matrix interactions by binding to extracellular matrix proteins or counter-receptors on adjacent cells. They play essential roles in cell adhesion, migration, and survival.
Cell surface receptors are involved in various physiological processes, including neurotransmission, hormone signaling, immune response, and cell growth and differentiation. Dysregulation of these receptors can contribute to the development of numerous diseases, such as cancer, diabetes, and neurological disorders.
Nuclear localization signals (NLSs) are specific short sequences of amino acids in a protein that serve as a targeting signal for nuclear import. They are recognized by import receptors, which facilitate the translocation of the protein through the nuclear pore complex and into the nucleus. NLSs typically contain one or more basic residues, such as lysine or arginine, and can be monopartite (a single stretch of basic amino acids) or bipartite (two stretches of basic amino acids separated by a spacer region). Once inside the nucleus, the protein can perform its specific function, such as regulating gene expression.
Secondary protein structure refers to the local spatial arrangement of amino acid chains in a protein, typically described as regular repeating patterns held together by hydrogen bonds. The two most common types of secondary structures are the alpha-helix (α-helix) and the beta-pleated sheet (β-sheet). In an α-helix, the polypeptide chain twists around itself in a helical shape, with each backbone atom forming a hydrogen bond with the fourth amino acid residue along the chain. This forms a rigid rod-like structure that is resistant to bending or twisting forces. In β-sheets, adjacent segments of the polypeptide chain run parallel or antiparallel to each other and are connected by hydrogen bonds, forming a pleated sheet-like arrangement. These secondary structures provide the foundation for the formation of tertiary and quaternary protein structures, which determine the overall three-dimensional shape and function of the protein.
CLOCK proteins are a pair of transcription factors, CIRCADIAN LOComotor OUTPUT Cycles Kaput (CLOCK) and BMAL1 (brain and muscle ARNT-like 1), that play a critical role in the regulation of circadian rhythms. Circadian rhythms are biological processes that follow an approximately 24-hour cycle, driven by molecular mechanisms within cells.
The CLOCK and BMAL1 proteins form a heterodimer, which binds to E-box elements in the promoter regions of target genes. This binding activates the transcription of these genes, leading to the production of proteins that are involved in various cellular processes. After being transcribed and translated, some of these proteins feed back to inhibit the activity of the CLOCK-BMAL1 heterodimer, forming a negative feedback loop that is essential for the oscillation of circadian rhythms.
The regulation of circadian rhythms by CLOCK proteins has implications in many physiological processes, including sleep-wake cycles, metabolism, hormone secretion, and cellular proliferation. Dysregulation of these rhythms has been linked to various diseases, such as sleep disorders, metabolic disorders, and cancer.
Interferon-beta (IFN-β) is a type of cytokine - specifically, it's a protein that is produced and released by cells in response to stimulation by a virus or other foreign substance. It belongs to the interferon family of cytokines, which play important roles in the body's immune response to infection.
IFN-β has antiviral properties and helps to regulate the immune system. It works by binding to specific receptors on the surface of cells, which triggers a signaling cascade that leads to the activation of genes involved in the antiviral response. This results in the production of proteins that inhibit viral replication and promote the death of infected cells.
IFN-β is used as a medication for the treatment of certain autoimmune diseases, such as multiple sclerosis (MS). In MS, the immune system mistakenly attacks the protective coating around nerve fibers in the brain and spinal cord, causing inflammation and damage to the nerves. IFN-β has been shown to reduce the frequency and severity of relapses in people with MS, possibly by modulating the immune response and reducing inflammation.
It's important to note that while IFN-β is an important component of the body's natural defense system, it can also have side effects when used as a medication. Common side effects of IFN-β therapy include flu-like symptoms such as fever, chills, and muscle aches, as well as injection site reactions. More serious side effects are rare but can occur, so it's important to discuss the risks and benefits of this treatment with a healthcare provider.
High Mobility Group AT-Hook 1 (HMGA1) is a non-histone chromosomal protein that belongs to the HMGA family. The HMGA proteins are characterized by their ability to bind to AT-rich regions in the minor groove of DNA and modulate the chromatin structure, thereby regulating gene transcription.
The HMGA1 protein exists in two isoforms, HMGA1a and HMGA1b, which differ in their amino acid sequences due to alternative splicing of the HMGA1 pre-mRNA. The HMGA1a isoform has 108 amino acids, while HMGA1b has 109 amino acids.
HMGA1 proteins play crucial roles in various cellular processes, including proliferation, differentiation, and apoptosis. Dysregulation of HMGA1 expression has been implicated in several human diseases, such as cancer, where it functions as a transcriptional regulator of genes involved in tumorigenesis.
In situ hybridization (ISH) is a molecular biology technique used to detect and localize specific nucleic acid sequences, such as DNA or RNA, within cells or tissues. This technique involves the use of a labeled probe that is complementary to the target nucleic acid sequence. The probe can be labeled with various types of markers, including radioisotopes, fluorescent dyes, or enzymes.
During the ISH procedure, the labeled probe is hybridized to the target nucleic acid sequence in situ, meaning that the hybridization occurs within the intact cells or tissues. After washing away unbound probe, the location of the labeled probe can be visualized using various methods depending on the type of label used.
In situ hybridization has a wide range of applications in both research and diagnostic settings, including the detection of gene expression patterns, identification of viral infections, and diagnosis of genetic disorders.
Mitogen-Activated Protein Kinase 1 (MAPK1), also known as Extracellular Signal-Regulated Kinase 2 (ERK2), is a protein kinase that plays a crucial role in intracellular signal transduction pathways. It is a member of the MAPK family, which regulates various cellular processes such as proliferation, differentiation, apoptosis, and stress response.
MAPK1 is activated by a cascade of phosphorylation events initiated by upstream activators like MAPKK (Mitogen-Activated Protein Kinase Kinase) in response to various extracellular signals such as growth factors, hormones, and mitogens. Once activated, MAPK1 phosphorylates downstream targets, including transcription factors and other protein kinases, thereby modulating their activities and ultimately influencing gene expression and cellular responses.
MAPK1 is widely expressed in various tissues and cells, and its dysregulation has been implicated in several pathological conditions, including cancer, inflammation, and neurodegenerative diseases. Therefore, understanding the regulation and function of MAPK1 signaling pathways has important implications for developing therapeutic strategies to treat these disorders.
'Swiss 3T3 cells' are a specific type of cell line that is derived from mouse embryo fibroblasts. They were first developed in the 1960s by Swiss scientists and have since become one of the most widely used cell lines in scientific research. These cells are capable of growing and dividing in culture, and they can be used to study various biological processes such as cell growth, differentiation, and motility. They are also commonly used in toxicity testing and drug screening assays due to their stability and ease of cultivation. It is important to note that while Swiss 3T3 cells are of mouse origin, they should not be used for research involving human subjects or for the development of therapies intended for use in humans.
Medical Definition of "Herpesvirus 4, Human" (Epstein-Barr Virus)
"Herpesvirus 4, Human," also known as Epstein-Barr virus (EBV), is a member of the Herpesviridae family and is one of the most common human viruses. It is primarily transmitted through saliva and is often referred to as the "kissing disease."
EBV is the causative agent of infectious mononucleosis (IM), also known as glandular fever, which is characterized by symptoms such as fatigue, sore throat, fever, and swollen lymph nodes. The virus can also cause other diseases, including certain types of cancer, such as Burkitt's lymphoma, Hodgkin's lymphoma, and nasopharyngeal carcinoma.
Once a person becomes infected with EBV, the virus remains in the body for the rest of their life, residing in certain white blood cells called B lymphocytes. In most people, the virus remains dormant and does not cause any further symptoms. However, in some individuals, the virus may reactivate, leading to recurrent or persistent symptoms.
EBV infection is diagnosed through various tests, including blood tests that detect antibodies against the virus or direct detection of the virus itself through polymerase chain reaction (PCR) assays. There is no cure for EBV infection, and treatment is generally supportive, focusing on relieving symptoms and managing complications. Prevention measures include practicing good hygiene, avoiding close contact with infected individuals, and not sharing personal items such as toothbrushes or drinking glasses.
"Xenopus" is not a medical term, but it is a genus of highly invasive aquatic frogs native to sub-Saharan Africa. They are often used in scientific research, particularly in developmental biology and genetics. The most commonly studied species is Xenopus laevis, also known as the African clawed frog.
In a medical context, Xenopus might be mentioned when discussing their use in research or as a model organism to study various biological processes or diseases.
Serine endopeptidases are a type of enzymes that cleave peptide bonds within proteins (endopeptidases) and utilize serine as the nucleophilic amino acid in their active site for catalysis. These enzymes play crucial roles in various biological processes, including digestion, blood coagulation, and programmed cell death (apoptosis). Examples of serine endopeptidases include trypsin, chymotrypsin, thrombin, and elastase.
Small Ubiquitin-Related Modifier (SUMO) proteins are a type of post-translational modifier, similar to ubiquitin, that can be covalently attached to other proteins in a process called sumoylation. This modification plays a crucial role in regulating various cellular processes such as nuclear transport, transcriptional regulation, DNA repair, and protein stability. Sumoylation is a dynamic and reversible process, which allows for precise control of these functions under different physiological conditions.
The human genome encodes four SUMO paralogs (SUMO1-4), among which SUMO2 and SUMO3 share 97% sequence identity and are often referred to as a single entity, SUMO2/3. The fourth member, SUMO4, is less conserved and has a more restricted expression pattern compared to the other three paralogs.
Similar to ubiquitination, sumoylation involves an enzymatic cascade consisting of an E1 activating enzyme (SAE1/UBA2 heterodimer), an E2 conjugating enzyme (UBC9), and an E3 ligase that facilitates the transfer of SUMO from the E2 to the target protein. The process can be reversed by SUMO-specific proteases, which cleave the isopeptide bond between the modified lysine residue on the target protein and the C-terminal glycine of the SUMO molecule.
Dysregulation of sumoylation has been implicated in various human diseases, including cancer, neurodegenerative disorders, and viral infections. Therefore, understanding the molecular mechanisms governing this post-translational modification is essential for developing novel therapeutic strategies targeting these conditions.
Protein stability refers to the ability of a protein to maintain its native structure and function under various physiological conditions. It is determined by the balance between forces that promote a stable conformation, such as intramolecular interactions (hydrogen bonds, van der Waals forces, and hydrophobic effects), and those that destabilize it, such as thermal motion, chemical denaturation, and environmental factors like pH and salt concentration. A protein with high stability is more resistant to changes in its structure and function, even under harsh conditions, while a protein with low stability is more prone to unfolding or aggregation, which can lead to loss of function or disease states, such as protein misfolding diseases.
Peptides are short chains of amino acid residues linked by covalent bonds, known as peptide bonds. They are formed when two or more amino acids are joined together through a condensation reaction, which results in the elimination of a water molecule and the formation of an amide bond between the carboxyl group of one amino acid and the amino group of another.
Peptides can vary in length from two to about fifty amino acids, and they are often classified based on their size. For example, dipeptides contain two amino acids, tripeptides contain three, and so on. Oligopeptides typically contain up to ten amino acids, while polypeptides can contain dozens or even hundreds of amino acids.
Peptides play many important roles in the body, including serving as hormones, neurotransmitters, enzymes, and antibiotics. They are also used in medical research and therapeutic applications, such as drug delivery and tissue engineering.
A Transcription Initiation Site (TIS) is a specific location within the DNA sequence where the process of transcription is initiated. In other words, it is the starting point where the RNA polymerase enzyme binds to the DNA template and begins synthesizing an RNA molecule. The TIS is typically located just upstream of the coding region of a gene and is often marked by specific sequences or structures that help regulate transcription, such as promoters and enhancers.
During the initiation of transcription, the RNA polymerase recognizes and binds to the promoter region, which lies adjacent to the TIS. The promoter contains cis-acting elements, including the TATA box and the initiator (Inr) element, that are recognized by transcription factors and other regulatory proteins. These proteins help position the RNA polymerase at the correct location on the DNA template and facilitate the initiation of transcription.
Once the RNA polymerase is properly positioned, it begins to unwind the double-stranded DNA at the TIS, creating a transcription bubble where the single-stranded DNA template can be accessed. The RNA polymerase then adds nucleotides one by one to the growing RNA chain, synthesizing an mRNA molecule that will ultimately be translated into a protein or, in some cases, serve as a non-coding RNA with regulatory functions.
In summary, the Transcription Initiation Site (TIS) is a crucial component of gene expression, marking the location where transcription begins and playing a key role in regulating this essential biological process.
Membrane glycoproteins are proteins that contain oligosaccharide chains (glycans) covalently attached to their polypeptide backbone. They are integral components of biological membranes, spanning the lipid bilayer and playing crucial roles in various cellular processes.
The glycosylation of these proteins occurs in the endoplasmic reticulum (ER) and Golgi apparatus during protein folding and trafficking. The attached glycans can vary in structure, length, and composition, which contributes to the diversity of membrane glycoproteins.
Membrane glycoproteins can be classified into two main types based on their orientation within the lipid bilayer:
1. Type I (N-linked): These glycoproteins have a single transmembrane domain and an extracellular N-terminus, where the oligosaccharides are predominantly attached via asparagine residues (Asn-X-Ser/Thr sequon).
2. Type II (C-linked): These glycoproteins possess two transmembrane domains and an intracellular C-terminus, with the oligosaccharides linked to tryptophan residues via a mannose moiety.
Membrane glycoproteins are involved in various cellular functions, such as:
* Cell adhesion and recognition
* Receptor-mediated signal transduction
* Enzymatic catalysis
* Transport of molecules across membranes
* Cell-cell communication
* Immunological responses
Some examples of membrane glycoproteins include cell surface receptors (e.g., growth factor receptors, cytokine receptors), adhesion molecules (e.g., integrins, cadherins), and transporters (e.g., ion channels, ABC transporters).
Proto-oncogene proteins c-RAF, also known as RAF kinases, are serine/threonine protein kinases that play crucial roles in regulating cell growth, differentiation, and survival. They are part of the RAS/RAF/MEK/ERK signaling pathway, which is a key intracellular signaling cascade that conveys signals from various extracellular stimuli, such as growth factors and hormones, to the nucleus.
The c-RAF protein exists in three isoforms: A-RAF, B-RAF, and C-RAF (also known as RAF-1). These isoforms share a common structure, consisting of several functional domains, including an N-terminal regulatory region, a central kinase domain, and a C-terminal autoinhibitory region. In their inactive state, c-RAF proteins are bound to the cell membrane through interactions with RAS GTPases and other regulatory proteins.
Upon activation of RAS GTPases by upstream signals, c-RAF becomes recruited to the plasma membrane, where it undergoes a conformational change that leads to its activation. Activated c-RAF then phosphorylates and activates MEK (MAPK/ERK kinase) proteins, which in turn phosphorylate and activate ERK (Extracellular Signal-Regulated Kinase) proteins. Activated ERK proteins can translocate to the nucleus and regulate the expression of various genes involved in cell growth, differentiation, and survival.
Mutations in c-RAF proto-oncogenes can lead to their constitutive activation, resulting in uncontrolled cell growth and division, which can contribute to the development of various types of cancer. In particular, B-RAF mutations have been identified in several human malignancies, including melanoma, colorectal cancer, and thyroid cancer.
Cell transformation, viral refers to the process by which a virus causes normal cells to become cancerous or tumorigenic. This occurs when the genetic material of the virus integrates into the DNA of the host cell and alters its regulation, leading to uncontrolled cell growth and division. Some viruses known to cause cell transformation include human papillomavirus (HPV), hepatitis B virus (HBV), and certain types of herpesviruses.
Lipopolysaccharides (LPS) are large molecules found in the outer membrane of Gram-negative bacteria. They consist of a hydrophilic polysaccharide called the O-antigen, a core oligosaccharide, and a lipid portion known as Lipid A. The Lipid A component is responsible for the endotoxic activity of LPS, which can trigger a powerful immune response in animals, including humans. This response can lead to symptoms such as fever, inflammation, and septic shock, especially when large amounts of LPS are introduced into the bloodstream.
Gene expression regulation in leukemia refers to the processes that control the production or activation of specific proteins encoded by genes in leukemic cells. These regulatory mechanisms include various molecular interactions that can either promote or inhibit gene transcription and translation. In leukemia, abnormal gene expression regulation can lead to uncontrolled proliferation, differentiation arrest, and accumulation of malignant white blood cells (leukemia cells) in the bone marrow and peripheral blood.
Dysregulated gene expression in leukemia may involve genetic alterations such as mutations, chromosomal translocations, or epigenetic changes that affect DNA methylation patterns and histone modifications. These changes can result in the overexpression of oncogenes (genes with cancer-promoting functions) or underexpression of tumor suppressor genes (genes that prevent uncontrolled cell growth).
Understanding gene expression regulation in leukemia is crucial for developing targeted therapies and improving diagnostic, prognostic, and treatment strategies.
Bone Morphogenetic Proteins (BMPs) are a group of growth factors that play crucial roles in the development, growth, and repair of bones and other tissues. They belong to the Transforming Growth Factor-β (TGF-β) superfamily and were first discovered when researchers found that certain proteins extracted from demineralized bone matrix had the ability to induce new bone formation.
BMPs stimulate the differentiation of mesenchymal stem cells into osteoblasts, which are the cells responsible for bone formation. They also promote the recruitment and proliferation of these cells, enhancing the overall process of bone regeneration. In addition to their role in bone biology, BMPs have been implicated in various other biological processes, including embryonic development, wound healing, and the regulation of fat metabolism.
There are several types of BMPs (BMP-2, BMP-4, BMP-7, etc.) that exhibit distinct functions and expression patterns. Due to their ability to stimulate bone formation, recombinant human BMPs have been used in clinical applications, such as spinal fusion surgery and non-healing fracture treatment. However, the use of BMPs in medicine has been associated with certain risks and complications, including uncontrolled bone growth, inflammation, and cancer development, which necessitates further research to optimize their therapeutic potential.
Viral genes refer to the genetic material present in viruses that contains the information necessary for their replication and the production of viral proteins. In DNA viruses, the genetic material is composed of double-stranded or single-stranded DNA, while in RNA viruses, it is composed of single-stranded or double-stranded RNA.
Viral genes can be classified into three categories: early, late, and structural. Early genes encode proteins involved in the replication of the viral genome, modulation of host cell processes, and regulation of viral gene expression. Late genes encode structural proteins that make up the viral capsid or envelope. Some viruses also have structural genes that are expressed throughout their replication cycle.
Understanding the genetic makeup of viruses is crucial for developing antiviral therapies and vaccines. By targeting specific viral genes, researchers can develop drugs that inhibit viral replication and reduce the severity of viral infections. Additionally, knowledge of viral gene sequences can inform the development of vaccines that stimulate an immune response to specific viral proteins.
Osteosarcoma is defined as a type of cancerous tumor that arises from the cells that form bones (osteoblasts). It's the most common primary bone cancer, and it typically develops in the long bones of the body, such as the arms or legs, near the growth plates. Osteosarcoma can metastasize (spread) to other parts of the body, including the lungs, making it a highly malignant form of cancer. Symptoms may include bone pain, swelling, and fractures. Treatment usually involves a combination of surgery, chemotherapy, and/or radiation therapy.
Interleukin-6 (IL-6) is a cytokine, a type of protein that plays a crucial role in communication between cells, especially in the immune system. It is produced by various cells including T-cells, B-cells, fibroblasts, and endothelial cells in response to infection, injury, or inflammation.
IL-6 has diverse effects on different cell types. In the immune system, it stimulates the growth and differentiation of B-cells into plasma cells that produce antibodies. It also promotes the activation and survival of T-cells. Moreover, IL-6 plays a role in fever induction by acting on the hypothalamus to raise body temperature during an immune response.
In addition to its functions in the immune system, IL-6 has been implicated in various physiological processes such as hematopoiesis (the formation of blood cells), bone metabolism, and neural development. However, abnormal levels of IL-6 have also been associated with several diseases, including autoimmune disorders, chronic inflammation, and cancer.
Hepatocyte Nuclear Factor 3-beta (HNF-3β, also known as FOXA3) is a transcription factor that plays crucial roles in the development and function of various organs, including the liver, pancreas, and kidneys. It belongs to the forkhead box (FOX) family of proteins, which are characterized by a conserved DNA-binding domain known as the forkhead box or winged helix domain.
In the liver, HNF-3β is essential for the differentiation and maintenance of hepatocytes, the primary functional cells of the liver. It regulates the expression of several genes involved in liver-specific functions such as glucose metabolism, bile acid synthesis, and detoxification.
HNF-3β also has important roles in the pancreas, where it helps regulate the development and function of insulin-producing beta cells. In the kidneys, HNF-3β is involved in the differentiation and maintenance of the nephron, the functional unit responsible for filtering blood and maintaining water and electrolyte balance.
Mutations in the gene encoding HNF-3β have been associated with several genetic disorders, including maturity-onset diabetes of the young (MODY) and renal cysts and diabetes syndrome (RCAD).
RNA (Ribonucleic acid) is a single-stranded molecule similar in structure to DNA, involved in the process of protein synthesis in the cell. It acts as a messenger carrying genetic information from DNA to the ribosomes, where proteins are produced.
A neoplasm, on the other hand, is an abnormal growth of cells, which can be benign or malignant. Benign neoplasms are not cancerous and do not invade nearby tissues or spread to other parts of the body. Malignant neoplasms, however, are cancerous and have the potential to invade surrounding tissues and spread to distant sites in the body through a process called metastasis.
Therefore, an 'RNA neoplasm' is not a recognized medical term as RNA is not a type of growth or tumor. However, there are certain types of cancer-causing viruses known as oncoviruses that contain RNA as their genetic material and can cause neoplasms. For example, human T-cell leukemia virus (HTLV-1) and hepatitis C virus (HCV) are RNA viruses that can cause certain types of cancer in humans.
The Myeloid-Lymphoid Leukemia (MLL) protein, also known as MLL1 or HRX, is a histone methyltransferase that plays a crucial role in the regulation of gene expression. It is involved in various cellular processes, including embryonic development and hematopoiesis (the formation of blood cells).
The MLL protein is encoded by the MLL gene, which is located on chromosome 11q23. This gene is frequently rearranged or mutated in certain types of leukemia, leading to the production of abnormal fusion proteins that contribute to tumor development and progression. These MLL-rearranged leukemias are aggressive and have a poor prognosis, making them an important area of research in the field of oncology.
Alanine is an alpha-amino acid that is used in the biosynthesis of proteins. The molecular formula for alanine is C3H7NO2. It is a non-essential amino acid, which means that it can be produced by the human body through the conversion of other nutrients, such as pyruvate, and does not need to be obtained directly from the diet.
Alanine is classified as an aliphatic amino acid because it contains a simple carbon side chain. It is also a non-polar amino acid, which means that it is hydrophobic and tends to repel water. Alanine plays a role in the metabolism of glucose and helps to regulate blood sugar levels. It is also involved in the transfer of nitrogen between tissues and helps to maintain the balance of nitrogen in the body.
In addition to its role as a building block of proteins, alanine is also used as a neurotransmitter in the brain and has been shown to have a calming effect on the nervous system. It is found in many foods, including meats, poultry, fish, eggs, dairy products, and legumes.
Calcitriol receptors, also known as Vitamin D receptors (VDR), are nuclear receptor proteins that bind to calcitriol (1,25-dihydroxyvitamin D3), the active form of vitamin D. These receptors are found in various tissues and cells throughout the body, including the small intestine, bone, kidney, and parathyroid gland.
When calcitriol binds to its receptor, it forms a complex that regulates the expression of genes involved in calcium and phosphate homeostasis, cell growth, differentiation, and immune function. Calcitriol receptors play a critical role in maintaining normal levels of calcium and phosphate in the blood by increasing the absorption of these minerals from the gut, promoting bone mineralization, and regulating the production of parathyroid hormone (PTH).
Calcitriol receptors have also been implicated in various disease processes, including cancer, autoimmune disorders, and infectious diseases. Modulation of calcitriol receptor activity has emerged as a potential therapeutic strategy for the treatment of these conditions.
Nuclear Receptor Subfamily 4, Group A, Member 2 (NR4A2) is a gene that encodes for a protein called Nurr1, which belongs to the nuclear receptor superfamily. These are transcription factors that regulate gene expression by binding to specific DNA sequences. Nurr1 plays crucial roles in the development and function of dopaminergic neurons, which are critical for movement control and are affected in neurodegenerative disorders such as Parkinson's disease. Additionally, Nurr1 has been implicated in various biological processes, including inflammation, immunity, and cancer.
Hepatocytes are the predominant type of cells in the liver, accounting for about 80% of its cytoplasmic mass. They play a key role in protein synthesis, protein storage, transformation of carbohydrates, synthesis of cholesterol, bile salts and phospholipids, detoxification, modification, and excretion of exogenous and endogenous substances, initiation of formation and secretion of bile, and enzyme production. Hepatocytes are essential for the maintenance of homeostasis in the body.
Retinoids are a class of chemical compounds that are derivatives of vitamin A. They are widely used in dermatology for the treatment of various skin conditions, including acne, psoriasis, and photoaging. Retinoids can help to reduce inflammation, improve skin texture and tone, and stimulate collagen production.
Retinoids work by binding to specific receptors in the skin cells, which triggers a series of biochemical reactions that regulate gene expression and promote cell differentiation and turnover. This can help to unclog pores, reduce the appearance of fine lines and wrinkles, and improve the overall health and appearance of the skin.
There are several different types of retinoids used in skincare products, including retinoic acid, retinaldehyde, and retinol. Retinoic acid is the most potent form of retinoid and is available by prescription only. Retinaldehyde and retinol are weaker forms of retinoid that can be found in over-the-counter skincare products.
While retinoids can be highly effective for treating various skin conditions, they can also cause side effects such as dryness, irritation, and sensitivity to the sun. It is important to use retinoids as directed by a healthcare professional and to follow proper sun protection measures when using these products.
Hepatocyte Nuclear Factor 3-alpha (HNF-3α), also known as FoxA1, is a transcription factor that plays a crucial role in the development and function of the liver. It belongs to the forkhead box (Fox) family of proteins, which are characterized by a conserved DNA-binding domain called the forkhead box or winged helix domain.
HNF-3α is primarily expressed in the liver, pancreas, and intestine, where it regulates the expression of various genes involved in glucose and lipid metabolism, bile acid synthesis, and other liver-specific functions. It acts by binding to specific DNA sequences called FOX or HNF-3 response elements, thereby modulating the transcriptional activity of target genes.
Mutations in the gene encoding HNF-3α have been associated with several human diseases, including maturity-onset diabetes of the young (MODY) and liver dysfunction. In MODY, mutations in HNF-3α impair its ability to regulate glucose metabolism, leading to impaired insulin secretion and hyperglycemia. In the liver, HNF-3α plays a critical role in maintaining the differentiated state of hepatocytes and regulating their response to various hormonal and metabolic signals.
A missense mutation is a type of point mutation in which a single nucleotide change results in the substitution of a different amino acid in the protein that is encoded by the affected gene. This occurs when the altered codon (a sequence of three nucleotides that corresponds to a specific amino acid) specifies a different amino acid than the original one. The function and/or stability of the resulting protein may be affected, depending on the type and location of the missense mutation. Missense mutations can have various effects, ranging from benign to severe, depending on the importance of the changed amino acid for the protein's structure or function.
The Fluorescent Antibody Technique (FAT) is a type of immunofluorescence assay used in laboratory medicine and pathology for the detection and localization of specific antigens or antibodies in tissues, cells, or microorganisms. In this technique, a fluorescein-labeled antibody is used to selectively bind to the target antigen or antibody, forming an immune complex. When excited by light of a specific wavelength, the fluorescein label emits light at a longer wavelength, typically visualized as green fluorescence under a fluorescence microscope.
The FAT is widely used in diagnostic microbiology for the identification and characterization of various bacteria, viruses, fungi, and parasites. It has also been applied in the diagnosis of autoimmune diseases and certain cancers by detecting specific antibodies or antigens in patient samples. The main advantage of FAT is its high sensitivity and specificity, allowing for accurate detection and differentiation of various pathogens and disease markers. However, it requires specialized equipment and trained personnel to perform and interpret the results.
E-box elements are specific DNA sequences found in the promoter regions of many genes, particularly those involved in controlling the circadian rhythm (the biological "body clock") in mammals. These sequences are binding sites for various transcription factors that regulate gene expression. The E-box element is typically a 12-base pair sequence (5'-CACGTG-3') that can form a stem-loop structure, making it an ideal recognition site for helix-loop-helix (HLH) transcription factors.
There are two types of E-box elements: the canonical E-box (also called the ' evening element' or EE), and the non-canonical E-box (also known as the ' dawn element' or DE). The canonical E-box has a palindromic sequence (5'-CACGTG-3'), while the non-canonical E-box contains a single copy of the core motif (5'-CACGT-3').
The most well-known transcription factors that bind to E-box elements are CLOCK and BMAL1, which form heterodimers through their HLH domains. These heterodimers bind to the canonical E-box element in the promoter regions of target genes, leading to the recruitment of other coactivators and histone acetyltransferases that ultimately result in transcriptional activation.
The activity of CLOCK-BMAL1 complexes follows a circadian rhythm, with peak binding and gene expression occurring during the early night (evening) phase. In contrast, non-canonical E-box elements are bound by other transcription factors such as PERIOD (PER) proteins, which accumulate and repress CLOCK-BMAL1-mediated transcription during the late night to early morning (dawn) phase.
Overall, E-box elements play a crucial role in regulating circadian rhythm-controlled gene expression, contributing to various physiological processes such as sleep-wake cycles, metabolism, and hormone secretion.
COUP (Chicken Ovalbumin Upstream Promoter-element) transcription factors are a family of proteins that regulate gene expression in various biological processes, including embryonic development, cell fate determination, and metabolism. They function by binding to specific DNA sequences called COUP elements, located in the upstream regulatory regions of their target genes. This binding results in either activation or repression of transcription, depending on the context and the specific COUP protein involved. There are two main types of COUP transcription factors, COUP-TF1 (also known as NRF-1) and COUP-TF2 (also known as ARP-1), which share structural similarities but have distinct functions and target genes.
Retinoblastoma-Binding Protein 2 (RBP2) is a protein that is encoded by the EZH2 gene in humans. It is a core component of the Polycomb Repressive Complex 2 (PRC2), which is a multi-subunit protein complex involved in the epigenetic regulation of gene expression through histone modification. Specifically, RBP2/EZH2 functions as a histone methyltransferase that trimethylates lysine 27 on histone H3 (H3K27me3), leading to transcriptional repression of target genes. Retinoblastoma-Binding Protein 2 was so named because it was initially identified as a protein that interacts with the retinoblastoma protein (pRb), a tumor suppressor that regulates cell cycle progression and differentiation. However, its role in the development of retinoblastoma or other cancers is not well understood.
"Lithospermum" is a botanical term that refers to a genus of plants commonly known as "stone seeds" or "gromwells." These plants are part of the forget-me-not family (Boraginaceae) and are native to North America, Europe, and Asia. The name "Lithospermum" comes from the Greek words "lithos," meaning stone, and "sperma," meaning seed, which refers to the hard, stony seeds found in these plants.
While "Lithospermum" is not a medical term itself, some species of this plant genus have been used in traditional medicine for various purposes. For example, Lithospermum officinale (also known as common gromwell) has been used in traditional Chinese medicine to treat inflammation and skin conditions. However, it's important to note that the use of these plants in medical treatments should be based on scientific research and under the guidance of a healthcare professional.
Protein methyltransferases (PMTs) are a family of enzymes that transfer methyl groups from a donor, such as S-adenosylmethionine (SAM), to specific residues on protein substrates. This post-translational modification plays a crucial role in various cellular processes, including epigenetic regulation, signal transduction, and protein stability.
PMTs can methylate different amino acid residues, such as lysine, arginine, and histidine, on proteins. The methylation of these residues can lead to changes in the charge, hydrophobicity, or interaction properties of the target protein, thereby modulating its function.
For example, lysine methyltransferases (KMTs) are a subclass of PMTs that specifically methylate lysine residues on histone proteins, which are the core components of nucleosomes in chromatin. Histone methylation can either activate or repress gene transcription, depending on the specific residue and degree of methylation.
Protein arginine methyltransferases (PRMTs) are another subclass of PMTs that methylate arginine residues on various protein substrates, including histones, transcription factors, and RNA-binding proteins. Arginine methylation can also affect protein function by altering its interaction with other molecules or modulating its stability.
Overall, protein methyltransferases are essential regulators of cellular processes and have been implicated in various diseases, including cancer, neurodegenerative disorders, and cardiovascular diseases. Therefore, understanding the mechanisms and functions of PMTs is crucial for developing novel therapeutic strategies to target these diseases.
The Cytochrome P-450 (CYP450) enzyme system is a group of enzymes found primarily in the liver, but also in other organs such as the intestines, lungs, and skin. These enzymes play a crucial role in the metabolism and biotransformation of various substances, including drugs, environmental toxins, and endogenous compounds like hormones and fatty acids.
The name "Cytochrome P-450" refers to the unique property of these enzymes to bind to carbon monoxide (CO) and form a complex that absorbs light at a wavelength of 450 nm, which can be detected spectrophotometrically.
The CYP450 enzyme system is involved in Phase I metabolism of xenobiotics, where it catalyzes oxidation reactions such as hydroxylation, dealkylation, and epoxidation. These reactions introduce functional groups into the substrate molecule, which can then undergo further modifications by other enzymes during Phase II metabolism.
There are several families and subfamilies of CYP450 enzymes, each with distinct substrate specificities and functions. Some of the most important CYP450 enzymes include:
1. CYP3A4: This is the most abundant CYP450 enzyme in the human liver and is involved in the metabolism of approximately 50% of all drugs. It also metabolizes various endogenous compounds like steroids, bile acids, and vitamin D.
2. CYP2D6: This enzyme is responsible for the metabolism of many psychotropic drugs, including antidepressants, antipsychotics, and beta-blockers. It also metabolizes some endogenous compounds like dopamine and serotonin.
3. CYP2C9: This enzyme plays a significant role in the metabolism of warfarin, phenytoin, and nonsteroidal anti-inflammatory drugs (NSAIDs).
4. CYP2C19: This enzyme is involved in the metabolism of proton pump inhibitors, antidepressants, and clopidogrel.
5. CYP2E1: This enzyme metabolizes various xenobiotics like alcohol, acetaminophen, and carbon tetrachloride, as well as some endogenous compounds like fatty acids and prostaglandins.
Genetic polymorphisms in CYP450 enzymes can significantly affect drug metabolism and response, leading to interindividual variability in drug efficacy and toxicity. Understanding the role of CYP450 enzymes in drug metabolism is crucial for optimizing pharmacotherapy and minimizing adverse effects.
The NF-E2 (Nuclear Factor, Erythroid-derived 2) transcription factor is a heterodimeric protein that plays a crucial role in the regulation of gene expression. It is composed of two subunits: p18 and p45. The p45 subunit, also known as NFE2L2 or GABPalpha, is a member of the basic region-leucine zipper (bZIP) family of transcription factors.
The p45 subunit forms a complex with the p18 subunit, and this complex binds to specific DNA sequences called antioxidant response elements (AREs) or electrophile response elements (EpREs), which are present in the promoter regions of various genes involved in cellular defense against oxidative stress and xenobiotic metabolism.
The p45 subunit is responsible for recognizing and binding to the DNA sequence, while the p18 subunit stabilizes the complex and enhances its DNA-binding affinity. Together, they regulate the expression of genes involved in heme biosynthesis, cytochrome P450 activity, antioxidant defense, and other cellular processes.
Mutations in the NFE2L2 gene, which encodes the p45 subunit, have been associated with various diseases, including chronic obstructive pulmonary disease (COPD), neurodegenerative disorders, and cancer.
"Xenopus laevis" is not a medical term itself, but it refers to a specific species of African clawed frog that is often used in scientific research, including biomedical and developmental studies. Therefore, its relevance to medicine comes from its role as a model organism in laboratories.
In a broader sense, Xenopus laevis has contributed significantly to various medical discoveries, such as the understanding of embryonic development, cell cycle regulation, and genetic research. For instance, the Nobel Prize in Physiology or Medicine was awarded in 1963 to John R. B. Gurdon and Sir Michael J. Bishop for their discoveries concerning the genetic mechanisms of organism development using Xenopus laevis as a model system.
Mitogen-Activated Protein Kinase 3 (MAPK3), also known as extracellular signal-regulated kinase 1 (ERK1), is a serine/threonine protein kinase that plays a crucial role in intracellular signal transduction pathways. It is involved in the regulation of various cellular processes, including proliferation, differentiation, and survival, in response to extracellular stimuli such as growth factors, hormones, and stress.
MAPK3 is activated through a phosphorylation cascade that involves the activation of upstream MAPK kinases (MKK or MEK). Once activated, MAPK3 can phosphorylate and activate various downstream targets, including transcription factors, to regulate gene expression. Dysregulation of MAPK3 signaling has been implicated in several diseases, including cancer and neurological disorders.
Ionomycin is not a medical term per se, but it is a chemical compound used in medical and biological research. Ionomycin is a type of ionophore, which is a molecule that can transport ions across cell membranes. Specifically, ionomycin is known to transport calcium ions (Ca²+).
In medical research, ionomycin is often used to study the role of calcium in various cellular processes, such as signal transduction, gene expression, and muscle contraction. It can be used to selectively increase intracellular calcium concentrations in experiments, allowing researchers to observe the effects on cell function. Ionomycin is also used in the study of calcium-dependent enzymes and channels.
It's important to note that ionomycin is not used as a therapeutic agent in clinical medicine due to its potential toxicity and narrow range of applications.
Integration Host Factors (IHF) are small, DNA-binding proteins that play a crucial role in the organization and regulation of DNA in many bacteria. They function by binding to specific sequences of DNA and causing a bend or kink in the double helix. This bending of the DNA brings distant regions of the genome into close proximity, allowing for interactions between different regulatory elements and facilitating various DNA transactions such as transcription, replication, and repair. IHF also plays a role in protecting the genome from damage by preventing the invasion of foreign DNA and promoting the specific recognition of bacterial chromosomal sites during partitioning. Overall, IHF is an essential protein that helps regulate gene expression and maintain genomic stability in bacteria.
A genetic template refers to the sequence of DNA or RNA that contains the instructions for the development and function of an organism or any of its components. These templates provide the code for the synthesis of proteins and other functional molecules, and determine many of the inherited traits and characteristics of an individual. In this sense, genetic templates serve as the blueprint for life and are passed down from one generation to the next through the process of reproduction.
In molecular biology, the term "template" is used to describe the strand of DNA or RNA that serves as a guide or pattern for the synthesis of a complementary strand during processes such as transcription and replication. During transcription, the template strand of DNA is transcribed into a complementary RNA molecule, while during replication, each parental DNA strand serves as a template for the synthesis of a new complementary strand.
In genetic engineering and synthetic biology, genetic templates can be manipulated and modified to introduce new functions or alter existing ones in organisms. This is achieved through techniques such as gene editing, where specific sequences in the genetic template are targeted and altered using tools like CRISPR-Cas9. Overall, genetic templates play a crucial role in shaping the structure, function, and evolution of all living organisms.
HL-60 cells are a type of human promyelocytic leukemia cell line that is commonly used in scientific research. They are named after the hospital where they were first isolated, the Hospital of the University of Pennsylvania (HUP) and the 60th culture attempt to grow these cells.
HL-60 cells have the ability to differentiate into various types of blood cells, such as granulocytes, monocytes, and macrophages, when exposed to certain chemical compounds or under specific culturing conditions. This makes them a valuable tool for studying the mechanisms of cell differentiation, proliferation, and apoptosis (programmed cell death).
HL-60 cells are also often used in toxicity studies, drug discovery and development, and research on cancer, inflammation, and infectious diseases. They can be easily grown in the lab and have a stable genotype, making them ideal for use in standardized experiments and comparisons between different studies.
Ubiquitin is a small protein that is present in most tissues in the body. It plays a critical role in regulating many important cellular processes, such as protein degradation and DNA repair. Ubiquitin can attach to other proteins in a process called ubiquitination, which can target the protein for degradation or modify its function.
Ubiquitination involves a series of enzymatic reactions that ultimately result in the attachment of ubiquitin molecules to specific lysine residues on the target protein. The addition of a single ubiquitin molecule is called monoubiquitination, while the addition of multiple ubiquitin molecules is called polyubiquitination.
Polyubiquitination can serve as a signal for proteasomal degradation, where the target protein is broken down into its component amino acids by the 26S proteasome complex. Monoubiquitination and other forms of ubiquitination can also regulate various cellular processes, such as endocytosis, DNA repair, and gene expression.
Dysregulation of ubiquitin-mediated protein degradation has been implicated in a variety of diseases, including cancer, neurodegenerative disorders, and inflammatory conditions.
Histone demethylases are enzymes that remove methyl groups from histone proteins, which are the structural components around which DNA is wound in chromosomes. These enzymes play a crucial role in regulating gene expression by modifying the chromatin structure and influencing the accessibility of DNA to transcription factors and other regulatory proteins.
Histones can be methylated at various residues, including lysine and arginine residues, and different histone demethylases specifically target these modified residues. Histone demethylases are classified into two main categories based on their mechanisms of action:
1. Lysine-specific demethylases (LSDs): These enzymes belong to the flavin adenine dinucleotide (FAD)-dependent amine oxidase family and specifically remove methyl groups from lysine residues. They target mono- and di-methylated lysines but cannot act on tri-methylated lysines.
2. Jumonji C (JmjC) domain-containing histone demethylases: These enzymes utilize Fe(II) and α-ketoglutarate as cofactors to hydroxylate methyl groups on lysine residues, leading to their removal. JmjC domain-containing histone demethylases can target all three states of lysine methylation (mono-, di-, and tri-methylated).
Dysregulation of histone demethylases has been implicated in various human diseases, including cancer, neurological disorders, and cardiovascular diseases. Therefore, understanding the functions and regulation of these enzymes is essential for developing novel therapeutic strategies to target these conditions.
Proto-oncogene protein c-ets-2 is a transcription factor that regulates gene expression in various cellular processes, including cell growth, differentiation, and apoptosis. It belongs to the ETS family of transcription factors, which are characterized by a highly conserved DNA-binding domain known as the ETS domain. The c-ets-2 protein binds to specific DNA sequences called ETS response elements (EREs) in the promoter regions of target genes and regulates their expression.
Proto-oncogenes are normal genes that can become oncogenes when they are mutated or overexpressed, leading to uncontrolled cell growth and cancer. The c-ets-2 gene can be activated by various mechanisms, including chromosomal translocations, gene amplification, and point mutations, resulting in the production of abnormal c-ets-2 proteins that contribute to tumorigenesis.
Abnormal expression or activity of c-ets-2 has been implicated in several types of cancer, such as leukemia, breast cancer, and prostate cancer. Therefore, understanding the role of c-ets-2 in cellular processes and its dysregulation in cancer can provide insights into the development of novel therapeutic strategies for cancer treatment.
Cell survival refers to the ability of a cell to continue living and functioning normally, despite being exposed to potentially harmful conditions or treatments. This can include exposure to toxins, radiation, chemotherapeutic drugs, or other stressors that can damage cells or interfere with their normal processes.
In scientific research, measures of cell survival are often used to evaluate the effectiveness of various therapies or treatments. For example, researchers may expose cells to a particular drug or treatment and then measure the percentage of cells that survive to assess its potential therapeutic value. Similarly, in toxicology studies, measures of cell survival can help to determine the safety of various chemicals or substances.
It's important to note that cell survival is not the same as cell proliferation, which refers to the ability of cells to divide and multiply. While some treatments may promote cell survival, they may also inhibit cell proliferation, making them useful for treating diseases such as cancer. Conversely, other treatments may be designed to specifically target and kill cancer cells, even if it means sacrificing some healthy cells in the process.
Receptor cross-talk, also known as receptor crosstalk or cross-communication, refers to the phenomenon where two or more receptors in a cell interact with each other and modulate their signals in a coordinated manner. This interaction can occur at various levels, such as sharing downstream signaling pathways, physically interacting with each other, or influencing each other's expression or activity.
In the context of G protein-coupled receptors (GPCRs), which are a large family of membrane receptors that play crucial roles in various physiological processes, cross-talk can occur between different GPCRs or between GPCRs and other types of receptors. For example, one GPCR may activate a signaling pathway that inhibits the activity of another GPCR, leading to complex regulatory mechanisms that allow cells to fine-tune their responses to various stimuli.
Receptor cross-talk can have important implications for drug development and therapy, as it can affect the efficacy and safety of drugs that target specific receptors. Understanding the mechanisms of receptor cross-talk can help researchers design more effective and targeted therapies for a wide range of diseases.
BRCA1 protein is a tumor suppressor protein that plays a crucial role in repairing damaged DNA and maintaining genomic stability. The BRCA1 gene provides instructions for making this protein. Mutations in the BRCA1 gene can lead to impaired function of the BRCA1 protein, significantly increasing the risk of developing breast, ovarian, and other types of cancer.
The BRCA1 protein forms complexes with several other proteins to participate in various cellular processes, such as:
1. DNA damage response and repair: BRCA1 helps recognize and repair double-strand DNA breaks through homologous recombination, a precise error-free repair mechanism.
2. Cell cycle checkpoints: BRCA1 is involved in regulating the G1/S and G2/M cell cycle checkpoints to ensure proper DNA replication and cell division.
3. Transcription regulation: BRCA1 can act as a transcriptional co-regulator, influencing the expression of genes involved in various cellular processes, including DNA repair and cell cycle control.
4. Apoptosis: In cases of severe or irreparable DNA damage, BRCA1 helps trigger programmed cell death (apoptosis) to eliminate potentially cancerous cells.
Individuals with inherited mutations in the BRCA1 gene have a higher risk of developing breast and ovarian cancers compared to the general population. Genetic testing for BRCA1 mutations is available for individuals with a family history of these cancers or those who meet specific clinical criteria. Identifying carriers of BRCA1 mutations allows for enhanced cancer surveillance, risk reduction strategies, and potential targeted therapies.
Leucine is an essential amino acid, meaning it cannot be produced by the human body and must be obtained through the diet. It is one of the three branched-chain amino acids (BCAAs), along with isoleucine and valine. Leucine is critical for protein synthesis and muscle growth, and it helps to regulate blood sugar levels, promote wound healing, and produce growth hormones.
Leucine is found in various food sources such as meat, dairy products, eggs, and certain plant-based proteins like soy and beans. It is also available as a dietary supplement for those looking to increase their intake for athletic performance or muscle recovery purposes. However, it's important to consult with a healthcare professional before starting any new supplement regimen.
Adenovirus E1B proteins are proteins encoded by the early region 1B (E1B) gene of adenoviruses. There are two main E1B proteins, E1B-55kD and E1B-19kD, which play crucial roles during the viral life cycle and in tumorigenesis.
1. E1B-55kD: This protein is a potent transcriptional repressor that inhibits the expression of host cell genes involved in DNA damage response, apoptosis, and antiviral defense mechanisms. By doing so, it creates a favorable environment for viral replication and evades the host's immune surveillance. E1B-55kD also interacts with p53, a tumor suppressor protein, leading to its degradation and further contributing to oncogenesis.
2. E1B-19kD: This protein is involved in blocking apoptosis or programmed cell death, which would otherwise be triggered by the host's defense mechanisms during viral infection. E1B-19kD forms a complex with another adenoviral protein, E4orf6, and together they inhibit the activity of several pro-apoptotic proteins, thus promoting viral replication and persistence in the host cell.
In summary, Adenovirus E1B proteins are essential for the viral life cycle by counteracting host defense mechanisms, particularly through the inhibition of apoptosis and transcriptional repression. Additionally, their interaction with crucial cellular regulatory proteins like p53 contributes to oncogenic transformation in certain contexts.
RNA stability refers to the duration that a ribonucleic acid (RNA) molecule remains intact and functional within a cell before it is degraded or broken down into its component nucleotides. Various factors can influence RNA stability, including:
1. Primary sequence: Certain sequences in the RNA molecule may be more susceptible to degradation by ribonucleases (RNases), enzymes that break down RNA.
2. Secondary structure: The formation of stable secondary structures, such as hairpins or stem-loop structures, can protect RNA from degradation.
3. Presence of RNA-binding proteins: Proteins that bind to RNA can either stabilize or destabilize the RNA molecule, depending on the type and location of the protein-RNA interaction.
4. Chemical modifications: Modifications to the RNA nucleotides, such as methylation, can increase RNA stability by preventing degradation.
5. Subcellular localization: The subcellular location of an RNA molecule can affect its stability, with some locations providing more protection from ribonucleases than others.
6. Cellular conditions: Changes in cellular conditions, such as pH or temperature, can also impact RNA stability.
Understanding RNA stability is important for understanding gene regulation and the function of non-coding RNAs, as well as for developing RNA-based therapeutic strategies.
"Spodoptera" is not a medical term, but a genus name in the insect family Noctuidae. It includes several species of moths commonly known as armyworms or cutworms due to their habit of consuming leaves and roots of various plants, causing significant damage to crops.
Some well-known species in this genus are Spodoptera frugiperda (fall armyworm), Spodoptera litura (tobacco cutworm), and Spodoptera exigua (beet armyworm). These pests can be a concern for medical entomology when they transmit pathogens or cause allergic reactions. For instance, their frass (feces) and shed skins may trigger asthma symptoms in susceptible individuals. However, the insects themselves are not typically considered medical issues unless they directly affect human health.
Cytomegalovirus (CMV) is a type of herpesvirus that can cause infection in humans. It is characterized by the enlargement of infected cells (cytomegaly) and is typically transmitted through close contact with an infected person, such as through saliva, urine, breast milk, or sexual contact.
CMV infection can also be acquired through organ transplantation, blood transfusions, or during pregnancy from mother to fetus. While many people infected with CMV experience no symptoms, it can cause serious complications in individuals with weakened immune systems, such as those undergoing cancer treatment or those who have HIV/AIDS.
In newborns, congenital CMV infection can lead to hearing loss, vision problems, and developmental delays. Pregnant women who become infected with CMV for the first time during pregnancy are at higher risk of transmitting the virus to their unborn child. There is no cure for CMV, but antiviral medications can help manage symptoms and reduce the risk of complications in severe cases.
Genetic transformation is the process by which an organism's genetic material is altered or modified, typically through the introduction of foreign DNA. This can be achieved through various techniques such as:
* Gene transfer using vectors like plasmids, phages, or artificial chromosomes
* Direct uptake of naked DNA using methods like electroporation or chemically-mediated transfection
* Use of genome editing tools like CRISPR-Cas9 to introduce precise changes into the organism's genome.
The introduced DNA may come from another individual of the same species (cisgenic), from a different species (transgenic), or even be synthetically designed. The goal of genetic transformation is often to introduce new traits, functions, or characteristics that do not exist naturally in the organism, or to correct genetic defects.
This technique has broad applications in various fields, including molecular biology, biotechnology, and medical research, where it can be used to study gene function, develop genetically modified organisms (GMOs), create cell lines for drug screening, and even potentially treat genetic diseases through gene therapy.
Macrophages are a type of white blood cell that are an essential part of the immune system. They are large, specialized cells that engulf and destroy foreign substances, such as bacteria, viruses, parasites, and fungi, as well as damaged or dead cells. Macrophages are found throughout the body, including in the bloodstream, lymph nodes, spleen, liver, lungs, and connective tissues. They play a critical role in inflammation, immune response, and tissue repair and remodeling.
Macrophages originate from monocytes, which are a type of white blood cell produced in the bone marrow. When monocytes enter the tissues, they differentiate into macrophages, which have a larger size and more specialized functions than monocytes. Macrophages can change their shape and move through tissues to reach sites of infection or injury. They also produce cytokines, chemokines, and other signaling molecules that help coordinate the immune response and recruit other immune cells to the site of infection or injury.
Macrophages have a variety of surface receptors that allow them to recognize and respond to different types of foreign substances and signals from other cells. They can engulf and digest foreign particles, bacteria, and viruses through a process called phagocytosis. Macrophages also play a role in presenting antigens to T cells, which are another type of immune cell that helps coordinate the immune response.
Overall, macrophages are crucial for maintaining tissue homeostasis, defending against infection, and promoting wound healing and tissue repair. Dysregulation of macrophage function has been implicated in a variety of diseases, including cancer, autoimmune disorders, and chronic inflammatory conditions.
Hep G2 cells are a type of human liver cancer cell line that were isolated from a well-differentiated hepatocellular carcinoma (HCC) in a patient with hepatitis C virus (HCV) infection. These cells have the ability to grow and divide indefinitely in culture, making them useful for research purposes. Hep G2 cells express many of the same markers and functions as normal human hepatocytes, including the ability to take up and process lipids and produce bile. They are often used in studies related to hepatitis viruses, liver metabolism, drug toxicity, and cancer biology. It is important to note that Hep G2 cells are tumorigenic and should be handled with care in a laboratory setting.
A "gene library" is not a recognized term in medical genetics or molecular biology. However, the closest concept that might be referred to by this term is a "genomic library," which is a collection of DNA clones that represent the entire genetic material of an organism. These libraries are used for various research purposes, such as identifying and studying specific genes or gene functions.
Insect hormones are chemical messengers that regulate various physiological and behavioral processes in insects. They are produced and released by endocrine glands and organs, such as the corpora allata, prothoracic glands, and neurosecretory cells located in the brain. Insect hormones play crucial roles in the regulation of growth and development, reproduction, diapause (a state of dormancy), metamorphosis, molting, and other vital functions. Some well-known insect hormones include juvenile hormone (JH), ecdysteroids (such as 20-hydroxyecdysone), and neuropeptides like the brain hormone and adipokinetic hormone. These hormones act through specific receptors, often transmembrane proteins, to elicit intracellular signaling cascades that ultimately lead to changes in gene expression, cell behavior, or organ function. Understanding insect hormones is essential for developing novel strategies for pest management and control, as well as for advancing our knowledge of insect biology and evolution.
Virus replication is the process by which a virus produces copies or reproduces itself inside a host cell. This involves several steps:
1. Attachment: The virus attaches to a specific receptor on the surface of the host cell.
2. Penetration: The viral genetic material enters the host cell, either by invagination of the cell membrane or endocytosis.
3. Uncoating: The viral genetic material is released from its protective coat (capsid) inside the host cell.
4. Replication: The viral genetic material uses the host cell's machinery to produce new viral components, such as proteins and nucleic acids.
5. Assembly: The newly synthesized viral components are assembled into new virus particles.
6. Release: The newly formed viruses are released from the host cell, often through lysis (breaking) of the cell membrane or by budding off the cell membrane.
The specific mechanisms and details of virus replication can vary depending on the type of virus. Some viruses, such as DNA viruses, use the host cell's DNA polymerase to replicate their genetic material, while others, such as RNA viruses, use their own RNA-dependent RNA polymerase or reverse transcriptase enzymes. Understanding the process of virus replication is important for developing antiviral therapies and vaccines.
Interleukin-8 (IL-8) is a type of cytokine, which is a small signaling protein involved in immune response and inflammation. IL-8 is also known as neutrophil chemotactic factor or NCF because it attracts neutrophils, a type of white blood cell, to the site of infection or injury.
IL-8 is produced by various cells including macrophages, epithelial cells, and endothelial cells in response to bacterial or inflammatory stimuli. It acts by binding to specific receptors called CXCR1 and CXCR2 on the surface of neutrophils, which triggers a series of intracellular signaling events leading to neutrophil activation, migration, and degranulation.
IL-8 plays an important role in the recruitment of neutrophils to the site of infection or tissue damage, where they can phagocytose and destroy invading microorganisms. However, excessive or prolonged production of IL-8 has been implicated in various inflammatory diseases such as chronic obstructive pulmonary disease (COPD), rheumatoid arthritis, and cancer.
In the context of cell biology, "S phase" refers to the part of the cell cycle during which DNA replication occurs. The "S" stands for synthesis, reflecting the active DNA synthesis that takes place during this phase. It is preceded by G1 phase (gap 1) and followed by G2 phase (gap 2), with mitosis (M phase) being the final stage of the cell cycle.
During S phase, the cell's DNA content effectively doubles as each chromosome is replicated to ensure that the two resulting daughter cells will have the same genetic material as the parent cell. This process is carefully regulated and coordinated with other events in the cell cycle to maintain genomic stability.
A mutant protein is a protein that has undergone a genetic mutation, resulting in an altered amino acid sequence and potentially changed structure and function. These changes can occur due to various reasons such as errors during DNA replication, exposure to mutagenic substances, or inherited genetic disorders. The alterations in the protein's structure and function may have no significant effects, lead to benign phenotypic variations, or cause diseases, depending on the type and location of the mutation. Some well-known examples of diseases caused by mutant proteins include cystic fibrosis, sickle cell anemia, and certain types of cancer.
Jumonji domain-containing histone demethylases (JHDMs) are a family of enzymes that are responsible for removing methyl groups from specific residues on histone proteins. These enzymes play crucial roles in the regulation of gene expression by modifying the chromatin structure and influencing the accessibility of transcription factors to DNA.
JHDMs contain a conserved Jumonji C (JmjC) domain, which is responsible for their demethylase activity. They are classified into two main groups based on the type of methyl group they remove: lysine-specific demethylases (KDMs) and arginine-specific demethylases (RDMs).
KDMs can be further divided into several subfamilies, including KDM2/7, KDM3, KDM4, KDM5, and KDM6, based on their substrate specificity and the number of methyl groups they remove. For example, KDM4 enzymes specifically demethylate di- and tri-methylated lysine 9 and lysine 36 residues on histone H3, while KDM5 enzymes target mono-, di-, and tri-methylated lysine 4 residues on histone H3.
RDMs, on the other hand, are responsible for demethylating arginine residues on histones, including symmetrically or asymmetrically dimethylated arginine 2, 8, 17, and 26 residues on histone H3 and H4.
Dysregulation of JHDMs has been implicated in various human diseases, including cancer, neurological disorders, and cardiovascular diseases. Therefore, understanding the functions and regulation of JHDMs is essential for developing novel therapeutic strategies to treat these diseases.
Phosphatidylinositol 3-Kinases (PI3Ks) are a family of enzymes that play a crucial role in intracellular signal transduction. They phosphorylate the 3-hydroxyl group of the inositol ring in phosphatidylinositol and its derivatives, which results in the production of second messengers that regulate various cellular processes such as cell growth, proliferation, differentiation, motility, and survival.
PI3Ks are divided into three classes based on their structure and substrate specificity. Class I PI3Ks are further subdivided into two categories: class IA and class IB. Class IA PI3Ks are heterodimers consisting of a catalytic subunit (p110α, p110β, or p110δ) and a regulatory subunit (p85α, p85β, p55γ, or p50γ). They are primarily activated by receptor tyrosine kinases and G protein-coupled receptors. Class IB PI3Ks consist of a catalytic subunit (p110γ) and a regulatory subunit (p101 or p84/87). They are mainly activated by G protein-coupled receptors.
Dysregulation of PI3K signaling has been implicated in various human diseases, including cancer, diabetes, and autoimmune disorders. Therefore, PI3Ks have emerged as important targets for drug development in these areas.
Luminescent proteins are a type of protein that emit light through a chemical reaction, rather than by absorbing and re-emitting light like fluorescent proteins. This process is called bioluminescence. The light emitted by luminescent proteins is often used in scientific research as a way to visualize and track biological processes within cells and organisms.
One of the most well-known luminescent proteins is Green Fluorescent Protein (GFP), which was originally isolated from jellyfish. However, GFP is actually a fluorescent protein, not a luminescent one. A true example of a luminescent protein is the enzyme luciferase, which is found in fireflies and other bioluminescent organisms. When luciferase reacts with its substrate, luciferin, it produces light through a process called oxidation.
Luminescent proteins have many applications in research, including as reporters for gene expression, as markers for protein-protein interactions, and as tools for studying the dynamics of cellular processes. They are also used in medical imaging and diagnostics, as well as in the development of new therapies.
Liver neoplasms refer to abnormal growths in the liver that can be benign or malignant. Benign liver neoplasms are non-cancerous tumors that do not spread to other parts of the body, while malignant liver neoplasms are cancerous tumors that can invade and destroy surrounding tissue and spread to other organs.
Liver neoplasms can be primary, meaning they originate in the liver, or secondary, meaning they have metastasized (spread) to the liver from another part of the body. Primary liver neoplasms can be further classified into different types based on their cell of origin and behavior, including hepatocellular carcinoma, cholangiocarcinoma, and hepatic hemangioma.
The diagnosis of liver neoplasms typically involves a combination of imaging studies, such as ultrasound, CT scan, or MRI, and biopsy to confirm the type and stage of the tumor. Treatment options depend on the type and extent of the neoplasm and may include surgery, radiation therapy, chemotherapy, or liver transplantation.
Protein-kinase B, also known as AKT, is a group of intracellular proteins that play a crucial role in various cellular processes such as glucose metabolism, apoptosis, cell proliferation, transcription, and cell migration. The AKT family includes three isoforms: AKT1, AKT2, and AKT3, which are encoded by the genes PKBalpha, PKBbeta, and PKBgamma, respectively.
Proto-oncogene proteins c-AKT refer to the normal, non-mutated forms of these proteins that are involved in the regulation of cell growth and survival under physiological conditions. However, when these genes are mutated or overexpressed, they can become oncogenes, leading to uncontrolled cell growth and cancer development.
Activation of c-AKT occurs through a signaling cascade that begins with the binding of extracellular ligands such as insulin-like growth factor 1 (IGF-1) or epidermal growth factor (EGF) to their respective receptors on the cell surface. This triggers a series of phosphorylation events that ultimately lead to the activation of c-AKT, which then phosphorylates downstream targets involved in various cellular processes.
In summary, proto-oncogene proteins c-AKT are normal intracellular proteins that play essential roles in regulating cell growth and survival under physiological conditions. However, their dysregulation can contribute to cancer development and progression.
14-3-3 proteins are a family of conserved regulatory molecules found in eukaryotic cells. They are involved in various cellular processes, such as signal transduction, cell cycle regulation, and apoptosis (programmed cell death). These proteins bind to specific phosphoserine-containing motifs on their target proteins, thereby modulating their activity, localization, or stability. Dysregulation of 14-3-3 proteins has been implicated in several human diseases, including cancer, neurodegenerative disorders, and diabetes.
Ovotesticular Disorders of Sex Development (OT-DSD), also known as true gonadal intersex, are rare conditions where the individual has both ovarian and testicular tissue in their gonads. This condition is characterized by the presence of both ovarian and testicular structures in the same person, which can be found in various combinations and locations within the body.
Individuals with OT-DSD may have varying degrees of development of internal reproductive organs (such as the uterus, fallopian tubes, or vas deferens) and external genitalia that may not clearly fit typical definitions of male or female. The chromosomal patterns in these individuals can also vary, with 46,XX, 46,XY, or mosaic karyotypes (a combination of both).
The diagnosis of OT-DSD is typically made during infancy, adolescence, or adulthood, depending on the individual's presentation. Treatment usually involves surgical management of the gonads and genitalia, hormone replacement therapy, and psychological support for the person and their family. The ultimate goal is to help the individual establish a gender identity that aligns with their personal sense of self while ensuring their physical health and well-being.
Co-repressor proteins are regulatory molecules that bind to DNA-bound transcription factors, forming a complex that prevents the transcription of genes. These proteins function to repress gene expression by inhibiting the recruitment of RNA polymerase or other components required for transcription. They can be recruited directly by transcription factors or through interactions with other corepressor molecules.
Co-repressors often possess enzymatic activity, such as histone deacetylase (HDAC) or methyltransferase activity, which modifies histone proteins and condenses chromatin structure, making it less accessible to the transcription machinery. This results in a decrease in gene expression.
Examples of co-repressor proteins include:
1. Histone deacetylases (HDACs): These enzymes remove acetyl groups from histone proteins, leading to chromatin condensation and transcriptional repression.
2. Nucleosome remodeling and histone deacetylation (NuRD) complex: This multi-protein complex contains HDACs, histone demethylases, and ATP-dependent chromatin remodeling proteins that work together to repress gene expression.
3. Sin3A/Sin3B: These are corepressor proteins that interact with various transcription factors and recruit HDACs to specific genomic loci for transcriptional repression.
4. CoREST (Co-Repressor of RE1 Silencing Transcription factor): This is a complex containing HDACs, LSD1 (lysine-specific demethylase 1), and other proteins that mediate transcriptional repression through histone modifications.
5. CtBP (C-terminal binding protein): These are co-repressors that interact with various transcription factors and recruit HDACs, leading to chromatin condensation and gene silencing.
These co-repressor proteins play crucial roles in various cellular processes, including development, differentiation, and homeostasis, by fine-tuning gene expression patterns. Dysregulation of these proteins has been implicated in several diseases, such as cancer and neurological disorders.
Immunohistochemistry (IHC) is a technique used in pathology and laboratory medicine to identify specific proteins or antigens in tissue sections. It combines the principles of immunology and histology to detect the presence and location of these target molecules within cells and tissues. This technique utilizes antibodies that are specific to the protein or antigen of interest, which are then tagged with a detection system such as a chromogen or fluorophore. The stained tissue sections can be examined under a microscope, allowing for the visualization and analysis of the distribution and expression patterns of the target molecule in the context of the tissue architecture. Immunohistochemistry is widely used in diagnostic pathology to help identify various diseases, including cancer, infectious diseases, and immune-mediated disorders.
Nuclear factor, erythroid-derived 2 (NFE2), also known as NF-E2 transcription factor, is a protein that plays a crucial role in the regulation of gene expression. It belongs to the cap'n'collar (CNC) subfamily of basic region-leucine zipper (bZIP) transcription factors.
NFE2 forms a heterodimer with small Maf proteins and binds to antioxidant response elements (AREs) in the promoter regions of target genes. These target genes are often involved in cellular defense against oxidative stress, electrophiles, and inflammation. NFE2 regulates the expression of various enzymes and proteins that protect cells from damage caused by reactive oxygen species (ROS) and other harmful substances.
Mutations in the NFE2 gene have been associated with several diseases, including chronic obstructive pulmonary disease (COPD), acute respiratory distress syndrome (ARDS), and certain types of cancer. Proper regulation of NFE2 is essential for maintaining cellular homeostasis and preventing the development of various pathological conditions.
Protein multimerization refers to the process where multiple protein subunits assemble together to form a complex, repetitive structure called a multimer or oligomer. This can involve the association of identical or similar protein subunits through non-covalent interactions such as hydrogen bonding, ionic bonding, and van der Waals forces. The resulting multimeric structures can have various shapes, sizes, and functions, including enzymatic activity, transport, or structural support. Protein multimerization plays a crucial role in many biological processes and is often necessary for the proper functioning of proteins within cells.
Early Growth Response Protein 2 (EGR2) is a transcription factor that belongs to the EGR family of proteins, which are involved in various biological processes such as cell proliferation, differentiation, and apoptosis. EGR2 is specifically known to play crucial roles in the development and function of the nervous system, including the regulation of neuronal survival, axon guidance, and myelination. It is also expressed in immune cells and has been implicated in the regulation of immune responses. Mutations in the EGR2 gene have been associated with certain neurological disorders and diseases, such as Charcot-Marie-Tooth disease type 1B and congenital hypomyelinating neuropathy.
Synthetic genes are artificially created DNA (deoxyribonucleic acid) molecules that do not exist in nature. They are designed and constructed through genetic engineering techniques to encode specific functionalities or properties that do not occur in the original organism's genome. These synthetic genes can be used for various purposes, such as introducing new traits into organisms, producing novel enzymes or proteins, or developing new biotechnological applications.
The creation of synthetic genes involves designing and synthesizing DNA sequences that code for desired proteins or regulatory elements. This is achieved through chemical synthesis methods or using automated DNA synthesizers that can produce short DNA fragments, which are then assembled into longer sequences to form the complete synthetic gene. Once created, these synthetic genes can be introduced into living cells through various techniques like transfection or transformation, enabling the expression of the desired protein or functional trait.
Myo-Inositol-1-Phosphate Synthase (MIPS) is an enzyme that catalyzes the conversion of glucose-6-phosphate to inositol 1,4-bisphosphate, which is the first and rate-limiting step in the biosynthesis of myo-inositol. Myo-inositol is a six-carbon cyclic polyol that serves as a precursor for various secondary messengers and structural lipids, including phosphatidylinositols and inositol phosphates, which play crucial roles in cell signaling pathways.
MIPS is widely distributed in nature and has been identified in bacteria, plants, fungi, and animals. In humans, MIPS is encoded by the ISO1 gene and is primarily localized in the cytoplasm of cells. Defects in MIPS have been associated with several diseases, including neurological disorders and cancer, highlighting its importance in maintaining cellular homeostasis.
Keratolytic agents are substances that cause the softening and sloughing off of excess keratin, the protein that makes up the outermost layer of the skin (stratum corneum). These agents help to break down and remove dead skin cells, increase moisture retention, and promote the growth of new skin cells. They are commonly used in the treatment of various dermatological conditions such as psoriasis, eczema, warts, calluses, and ichthyosis. Examples of keratolytic agents include salicylic acid, urea, lactic acid, and retinoic acid.
Nucleotide mapping is not a widely recognized medical term, but it is commonly used in the field of molecular biology and genetics. It generally refers to the process of determining the precise order of nucleotides (adenine, thymine, guanine, and cytosine) in a DNA or RNA molecule using various sequencing techniques.
Mapping the nucleotide sequence is crucial for understanding the genetic makeup and function of an organism, identifying genetic variations associated with diseases, developing diagnostic tests, and designing personalized treatments. The term "nucleotide mapping" may also be used to describe the alignment of short DNA or RNA sequences to a reference genome to identify their location and any potential mutations.
Interferon Regulatory Factor-3 (IRF-3) is a transcription factor that plays a crucial role in the innate immune response. It is part of the Interferon Regulatory Factor family, which consists of several proteins involved in regulating the expression of genes related to the immune system.
IRF-3 is primarily known for its role in the production of type I interferons (IFNs), which are cytokines that help mediate the body's response to viral infections and other threats. When activated, IRF-3 translocates to the nucleus and binds to specific DNA sequences, promoting the expression of genes involved in the production of type I IFNs.
IRF-3 is typically kept in an inactive state in the cytoplasm of unstimulated cells. However, when a cell detects pathogen-associated molecular patterns (PAMPs) or danger-associated molecular patterns (DAMPs), signaling cascades are triggered that lead to the activation of IRF-3. This activation involves phosphorylation and dimerization of IRF-3, which then translocates to the nucleus and induces the expression of type I IFN genes.
Overall, Interferon Regulatory Factor-3 is a key player in the body's early defense against viral infections and other threats, helping to initiate the production of type I interferons and coordinate the immune response.
A Twist Transcription Factor is a family of proteins that regulate gene expression through the process of transcription. The name "Twist" comes from the Drosophila melanogaster (fruit fly) gene, which was first identified due to its role in causing twisted or spiral patterns during embryonic development.
The Twist protein is a basic helix-loop-helix (bHLH) transcription factor that binds to specific DNA sequences and regulates the expression of target genes. It forms homodimers or heterodimers with other bHLH proteins, which then recognize and bind to E-box motifs in the promoter regions of target genes.
Twist proteins have been shown to play critical roles in various biological processes, including cell differentiation, proliferation, migration, and survival. In particular, they have been implicated in cancer progression and metastasis, as they can promote epithelial-mesenchymal transition (EMT), a key step in tumor invasion and dissemination.
Abnormal expression or mutations of Twist transcription factors have been associated with several human diseases, including various types of cancer, developmental disorders, and neurological conditions.
Phosphoprotein phosphatases (PPPs) are a family of enzymes that play a crucial role in the regulation of various cellular processes by removing phosphate groups from serine, threonine, and tyrosine residues on proteins. Phosphorylation is a post-translational modification that regulates protein function, localization, and stability, and dephosphorylation by PPPs is essential for maintaining the balance of this regulation.
The PPP family includes several subfamilies, such as PP1, PP2A, PP2B (also known as calcineurin), PP4, PP5, and PP6. Each subfamily has distinct substrate specificities and regulatory mechanisms. For example, PP1 and PP2A are involved in the regulation of metabolism, signal transduction, and cell cycle progression, while PP2B is involved in immune response and calcium signaling.
Dysregulation of PPPs has been implicated in various diseases, including cancer, neurodegenerative disorders, and cardiovascular disease. Therefore, understanding the function and regulation of PPPs is important for developing therapeutic strategies to target these diseases.
A regulon is a group of genes that are regulated together in response to a specific signal or stimulus, often through the action of a single transcription factor or regulatory protein. This means that when the transcription factor binds to specific DNA sequences called operators, it can either activate or repress the transcription of all the genes within the regulon.
This type of gene regulation is important for coordinating complex biological processes, such as cellular metabolism, stress responses, and developmental programs. By regulating a group of genes together, cells can ensure that they are all turned on or off in a coordinated manner, allowing for more precise control over the overall response to a given signal.
It's worth noting that the term "regulon" is not commonly used in clinical medicine, but rather in molecular biology and genetics research.
In a medical context, "hot temperature" is not a standard medical term with a specific definition. However, it is often used in relation to fever, which is a common symptom of illness. A fever is typically defined as a body temperature that is higher than normal, usually above 38°C (100.4°F) for adults and above 37.5-38°C (99.5-101.3°F) for children, depending on the source.
Therefore, when a medical professional talks about "hot temperature," they may be referring to a body temperature that is higher than normal due to fever or other causes. It's important to note that a high environmental temperature can also contribute to an elevated body temperature, so it's essential to consider both the body temperature and the environmental temperature when assessing a patient's condition.
A "histone code" is a term used in molecular biology to describe the various chemical modifications that can occur on the histone proteins around which DNA is wound. These modifications include methylation, acetylation, phosphorylation, ubiquitination, and others, and they can affect the structure of the chromatin (the complex of DNA and histones) and thus regulate gene expression.
Different patterns of histone modifications are associated with different functional states of the chromatin, such as active or repressed transcription, and so the "histone code" provides a way for cells to control gene expression in a precise and nuanced manner. The study of histone codes and their role in regulating gene expression is an active area of research in molecular biology and genetics.
Tobacco is not a medical term, but it refers to the leaves of the plant Nicotiana tabacum that are dried and fermented before being used in a variety of ways. Medically speaking, tobacco is often referred to in the context of its health effects. According to the World Health Organization (WHO), "tobacco" can also refer to any product prepared from the leaf of the tobacco plant for smoking, sucking, chewing or snuffing.
Tobacco use is a major risk factor for a number of diseases, including cancer, heart disease, stroke, lung disease, and various other medical conditions. The smoke produced by burning tobacco contains thousands of chemicals, many of which are toxic and can cause serious health problems. Nicotine, one of the primary active constituents in tobacco, is highly addictive and can lead to dependence.
HIV-1 (Human Immunodeficiency Virus type 1) is a species of the retrovirus genus that causes acquired immunodeficiency syndrome (AIDS). It is primarily transmitted through sexual contact, exposure to infected blood or blood products, and from mother to child during pregnancy, childbirth, or breastfeeding. HIV-1 infects vital cells in the human immune system, such as CD4+ T cells, macrophages, and dendritic cells, leading to a decline in their numbers and weakening of the immune response over time. This results in the individual becoming susceptible to various opportunistic infections and cancers that ultimately cause death if left untreated. HIV-1 is the most prevalent form of HIV worldwide and has been identified as the causative agent of the global AIDS pandemic.
Vascular Endothelial Growth Factor A (VEGFA) is a specific isoform of the vascular endothelial growth factor (VEGF) family. It is a well-characterized signaling protein that plays a crucial role in angiogenesis, the process of new blood vessel formation from pre-existing vessels. VEGFA stimulates the proliferation and migration of endothelial cells, which line the interior surface of blood vessels, thereby contributing to the growth and development of new vasculature. This protein is essential for physiological processes such as embryonic development and wound healing, but it has also been implicated in various pathological conditions, including cancer, age-related macular degeneration, and diabetic retinopathy. The regulation of VEGFA expression and activity is critical to maintaining proper vascular function and homeostasis.
Estrogen Receptor beta (ER-β) is a protein that is encoded by the gene ESR2 in humans. It belongs to the family of nuclear receptors, which are transcription factors that regulate gene expression in response to hormonal signals. ER-β is one of two main estrogen receptors, the other being Estrogen Receptor alpha (ER-α), and it plays an important role in mediating the effects of estrogens in various tissues, including the breast, uterus, bone, brain, and cardiovascular system.
Estrogens are steroid hormones that play a critical role in the development and maintenance of female reproductive and sexual function. They also have important functions in other tissues, such as maintaining bone density and promoting cognitive function. ER-β is widely expressed in many tissues, including those outside of the reproductive system, suggesting that it may have diverse physiological roles beyond estrogen-mediated reproduction.
ER-β has been shown to have both overlapping and distinct functions from ER-α, and its expression patterns differ between tissues. For example, in the breast, ER-β is expressed at higher levels in normal tissue compared to cancerous tissue, suggesting that it may play a protective role against breast cancer development. In contrast, in the uterus, ER-β has been shown to have anti-proliferative effects and may protect against endometrial cancer.
Overall, ER-β is an important mediator of estrogen signaling and has diverse physiological roles in various tissues. Understanding its functions and regulation may provide insights into the development of novel therapies for a range of diseases, including cancer, osteoporosis, and cardiovascular disease.
Post-transcriptional RNA processing refers to the modifications and regulations that occur on RNA molecules after the transcription of DNA into RNA. This process includes several steps:
1. 5' capping: The addition of a cap structure, usually a methylated guanosine triphosphate (GTP), to the 5' end of the RNA molecule. This helps protect the RNA from degradation and plays a role in its transport, stability, and translation.
2. 3' polyadenylation: The addition of a string of adenosine residues (poly(A) tail) to the 3' end of the RNA molecule. This process is important for mRNA stability, export from the nucleus, and translation initiation.
3. Intron removal and exon ligation: Eukaryotic pre-messenger RNAs (pre-mRNAs) contain intronic sequences that do not code for proteins. These introns are removed by a process called splicing, where the flanking exons are joined together to form a continuous mRNA sequence. Alternative splicing can lead to different mature mRNAs from a single pre-mRNA, increasing transcriptomic and proteomic diversity.
4. RNA editing: Specific nucleotide changes in RNA molecules that alter the coding potential or regulatory functions of RNA. This process is catalyzed by enzymes like ADAR (Adenosine Deaminases Acting on RNA) and APOBEC (Apolipoprotein B mRNA Editing Catalytic Polypeptide-like).
5. Chemical modifications: Various chemical modifications can occur on RNA nucleotides, such as methylation, pseudouridination, and isomerization. These modifications can influence RNA stability, localization, and interaction with proteins or other RNAs.
6. Transport and localization: Mature mRNAs are transported from the nucleus to the cytoplasm for translation. In some cases, specific mRNAs are localized to particular cellular compartments to ensure local protein synthesis.
7. Degradation: RNA molecules have finite lifetimes and undergo degradation by various ribonucleases (RNases). The rate of degradation can be influenced by factors such as RNA structure, modifications, or interactions with proteins.
"Cattle" is a term used in the agricultural and veterinary fields to refer to domesticated animals of the genus *Bos*, primarily *Bos taurus* (European cattle) and *Bos indicus* (Zebu). These animals are often raised for meat, milk, leather, and labor. They are also known as bovines or cows (for females), bulls (intact males), and steers/bullocks (castrated males). However, in a strict medical definition, "cattle" does not apply to humans or other animals.
MAP (Mitogen-Activated Protein) Kinase Kinase Kinases (MAP3K or MAPKKK) are a group of protein kinases that play a crucial role in intracellular signal transduction pathways, which regulate various cellular processes such as proliferation, differentiation, survival, and apoptosis. They are called "kinases" because they catalyze the transfer of a phosphate group from ATP to specific serine or threonine residues on their target proteins.
MAP3Ks function upstream of MAP Kinase Kinases (MKKs or MAP2K) and MAP Kinases (MPKs or MAPK) in the MAP kinase cascade. Upon activation by various extracellular signals, such as growth factors, cytokines, stress, and hormones, MAP3Ks phosphorylate and activate MKKs, which subsequently phosphorylate and activate MPKs. Activated MPKs then regulate the activity of downstream transcription factors and other target proteins to elicit appropriate cellular responses.
There are several subfamilies of MAP3Ks, including ASK, DLK, TAK, MEKK, MLK, and ZAK, among others. Each subfamily has distinct structural features and functions in different signaling pathways. Dysregulation of MAP kinase cascades, including MAP3Ks, has been implicated in various human diseases, such as cancer, inflammation, and neurodegenerative disorders.
Heterochromatin is a type of chromatin (the complex of DNA, RNA, and proteins that make up chromosomes) that is characterized by its tightly packed structure and reduced genetic activity. It is often densely stained with certain dyes due to its high concentration of histone proteins and other chromatin-associated proteins. Heterochromatin can be further divided into two subtypes: constitutive heterochromatin, which is consistently highly condensed and transcriptionally inactive throughout the cell cycle, and facultative heterochromatin, which can switch between a condensed, inactive state and a more relaxed, active state depending on the needs of the cell. Heterochromatin plays important roles in maintaining the stability and integrity of the genome by preventing the transcription of repetitive DNA sequences and protecting against the spread of transposable elements.
Adenosine triphosphatases (ATPases) are a group of enzymes that catalyze the conversion of adenosine triphosphate (ATP) into adenosine diphosphate (ADP) and inorganic phosphate. This reaction releases energy, which is used to drive various cellular processes such as muscle contraction, transport of ions across membranes, and synthesis of proteins and nucleic acids.
ATPases are classified into several types based on their structure, function, and mechanism of action. Some examples include:
1. P-type ATPases: These ATPases form a phosphorylated intermediate during the reaction cycle and are involved in the transport of ions across membranes, such as the sodium-potassium pump and calcium pumps.
2. F-type ATPases: These ATPases are found in mitochondria, chloroplasts, and bacteria, and are responsible for generating a proton gradient across the membrane, which is used to synthesize ATP.
3. V-type ATPases: These ATPases are found in vacuolar membranes and endomembranes, and are involved in acidification of intracellular compartments.
4. A-type ATPases: These ATPases are found in the plasma membrane and are involved in various functions such as cell signaling and ion transport.
Overall, ATPases play a crucial role in maintaining the energy balance of cells and regulating various physiological processes.
The endothelium is a thin layer of simple squamous epithelial cells that lines the interior surface of blood vessels, lymphatic vessels, and heart chambers. The vascular endothelium, specifically, refers to the endothelial cells that line the blood vessels. These cells play a crucial role in maintaining vascular homeostasis by regulating vasomotor tone, coagulation, platelet activation, inflammation, and permeability of the vessel wall. They also contribute to the growth and repair of the vascular system and are involved in various pathological processes such as atherosclerosis, hypertension, and diabetes.
Substrate specificity in the context of medical biochemistry and enzymology refers to the ability of an enzyme to selectively bind and catalyze a chemical reaction with a particular substrate (or a group of similar substrates) while discriminating against other molecules that are not substrates. This specificity arises from the three-dimensional structure of the enzyme, which has evolved to match the shape, charge distribution, and functional groups of its physiological substrate(s).
Substrate specificity is a fundamental property of enzymes that enables them to carry out highly selective chemical transformations in the complex cellular environment. The active site of an enzyme, where the catalysis takes place, has a unique conformation that complements the shape and charge distribution of its substrate(s). This ensures efficient recognition, binding, and conversion of the substrate into the desired product while minimizing unwanted side reactions with other molecules.
Substrate specificity can be categorized as:
1. Absolute specificity: An enzyme that can only act on a single substrate or a very narrow group of structurally related substrates, showing no activity towards any other molecule.
2. Group specificity: An enzyme that prefers to act on a particular functional group or class of compounds but can still accommodate minor structural variations within the substrate.
3. Broad or promiscuous specificity: An enzyme that can act on a wide range of structurally diverse substrates, albeit with varying catalytic efficiencies.
Understanding substrate specificity is crucial for elucidating enzymatic mechanisms, designing drugs that target specific enzymes or pathways, and developing biotechnological applications that rely on the controlled manipulation of enzyme activities.
CCAAT-Enhancer-Binding Protein-alpha (CEBPA) is a transcription factor that plays a crucial role in the regulation of genes involved in the differentiation and proliferation of hematopoietic cells, which are the precursor cells to all blood cells. The protein binds to the CCAAT box, a specific DNA sequence found in the promoter regions of many genes, and activates or represses their transcription.
Mutations in the CEBPA gene have been associated with acute myeloid leukemia (AML), a type of cancer that affects the blood and bone marrow. These mutations can lead to an increased risk of developing AML, as well as resistance to chemotherapy treatments. Therefore, understanding the function of CEBPA and its role in hematopoiesis is essential for the development of new therapies for AML and other hematological disorders.
I-kappa B kinase (IKK) is a protein complex that plays a crucial role in the activation of NF-kB (nuclear factor kappa-light-chain-enhancer of activated B cells), a transcription factor involved in the regulation of immune response, inflammation, cell survival, and proliferation.
The IKK complex is composed of two catalytic subunits, IKKα and IKKβ, and a regulatory subunit, IKKγ (also known as NEMO). Upon stimulation by various signals such as cytokines, pathogens, or stress, the IKK complex becomes activated and phosphorylates I-kappa B (IkB), an inhibitor protein that keeps NF-kB in an inactive state in the cytoplasm.
Once IkB is phosphorylated by the IKK complex, it undergoes ubiquitination and degradation, leading to the release and nuclear translocation of NF-kB, where it can bind to specific DNA sequences and regulate gene expression. Dysregulation of IKK activity has been implicated in various pathological conditions, including chronic inflammation, autoimmune diseases, and cancer.
Extracellular signal-regulated mitogen-activated protein kinases (ERKs or Extracellular signal-regulated kinases) are a subfamily of the MAPK (mitogen-activated protein kinase) family, which are serine/threonine protein kinases that regulate various cellular processes such as proliferation, differentiation, migration, and survival in response to extracellular signals.
ERKs are activated by a cascade of phosphorylation events initiated by the binding of growth factors, hormones, or other extracellular molecules to their respective receptors. This activation results in the formation of a complex signaling pathway that involves the sequential activation of several protein kinases, including Ras, Raf, MEK (MAPK/ERK kinase), and ERK.
Once activated, ERKs translocate to the nucleus where they phosphorylate and activate various transcription factors, leading to changes in gene expression that ultimately result in the appropriate cellular response. Dysregulation of the ERK signaling pathway has been implicated in a variety of diseases, including cancer, diabetes, and neurological disorders.
Glycogen Synthase Kinase 3 (GSK-3) is a serine/threonine protein kinase that plays a crucial role in the regulation of several cellular processes, including glycogen metabolism, cell signaling, gene transcription, and apoptosis. It was initially discovered as a key enzyme involved in glycogen metabolism due to its ability to phosphorylate and inhibit glycogen synthase, an enzyme responsible for the synthesis of glycogen from glucose.
GSK-3 exists in two isoforms, GSK-3α and GSK-3β, which share a high degree of sequence similarity and are widely expressed in various tissues. Both isoforms are constitutively active under normal conditions and are regulated through inhibitory phosphorylation by several upstream signaling pathways, such as insulin, Wnt, and Hedgehog signaling.
Dysregulation of GSK-3 has been implicated in the pathogenesis of various diseases, including diabetes, neurodegenerative disorders, and cancer. In recent years, GSK-3 has emerged as an attractive therapeutic target for the development of novel drugs to treat these conditions.
A kidney, in medical terms, is one of two bean-shaped organs located in the lower back region of the body. They are essential for maintaining homeostasis within the body by performing several crucial functions such as:
1. Regulation of water and electrolyte balance: Kidneys help regulate the amount of water and various electrolytes like sodium, potassium, and calcium in the bloodstream to maintain a stable internal environment.
2. Excretion of waste products: They filter waste products from the blood, including urea (a byproduct of protein metabolism), creatinine (a breakdown product of muscle tissue), and other harmful substances that result from normal cellular functions or external sources like medications and toxins.
3. Endocrine function: Kidneys produce several hormones with important roles in the body, such as erythropoietin (stimulates red blood cell production), renin (regulates blood pressure), and calcitriol (activated form of vitamin D that helps regulate calcium homeostasis).
4. pH balance regulation: Kidneys maintain the proper acid-base balance in the body by excreting either hydrogen ions or bicarbonate ions, depending on whether the blood is too acidic or too alkaline.
5. Blood pressure control: The kidneys play a significant role in regulating blood pressure through the renin-angiotensin-aldosterone system (RAAS), which constricts blood vessels and promotes sodium and water retention to increase blood volume and, consequently, blood pressure.
Anatomically, each kidney is approximately 10-12 cm long, 5-7 cm wide, and 3 cm thick, with a weight of about 120-170 grams. They are surrounded by a protective layer of fat and connected to the urinary system through the renal pelvis, ureters, bladder, and urethra.
Erythroblastic Leukemia, Acute (also known as Acute Erythroid Leukemia or AEL) is a subtype of acute myeloid leukemia (AML), which is a type of cancer affecting the blood and bone marrow. In this condition, there is an overproduction of erythroblasts (immature red blood cells) in the bone marrow, leading to their accumulation and interference with normal blood cell production. This results in a decrease in the number of functional red blood cells, white blood cells, and platelets in the body. Symptoms may include fatigue, weakness, frequent infections, and easy bruising or bleeding. AEL is typically treated with chemotherapy and sometimes requires stem cell transplantation.
Cysteine endopeptidases are a type of enzymes that cleave peptide bonds within proteins. They are also known as cysteine proteases or cysteine proteinases. These enzymes contain a catalytic triad consisting of three amino acids: cysteine, histidine, and aspartate. The thiol group (-SH) of the cysteine residue acts as a nucleophile and attacks the carbonyl carbon of the peptide bond, leading to its cleavage.
Cysteine endopeptidases play important roles in various biological processes, including protein degradation, cell signaling, and inflammation. They are involved in many physiological and pathological conditions, such as apoptosis, immune response, and cancer. Some examples of cysteine endopeptidases include cathepsins, caspases, and calpains.
It is important to note that these enzymes require a reducing environment to maintain the reduced state of their active site cysteine residue. Therefore, they are sensitive to oxidizing agents and inhibitors that target the thiol group. Understanding the structure and function of cysteine endopeptidases is crucial for developing therapeutic strategies that target these enzymes in various diseases.
Mifepristone is a synthetic steroid that is used in the medical termination of pregnancy (also known as medication abortion or RU-486). It works by blocking the action of progesterone, a hormone necessary for maintaining pregnancy. Mifepristone is often used in combination with misoprostol to cause uterine contractions and expel the products of conception from the uterus.
It's also known as an antiprogestin or progesterone receptor modulator, which means it can bind to progesterone receptors in the body and block their activity. In addition to its use in pregnancy termination, mifepristone has been studied for its potential therapeutic uses in conditions such as Cushing's syndrome, endometriosis, uterine fibroids, and hormone-dependent cancers.
It is important to note that Mifepristone should be administered under the supervision of a licensed healthcare professional and it is not available over the counter. Also, it has some contraindications and potential side effects, so it's essential to have a consultation with a doctor before taking this medication.
Oxidative stress is defined as an imbalance between the production of reactive oxygen species (free radicals) and the body's ability to detoxify them or repair the damage they cause. This imbalance can lead to cellular damage, oxidation of proteins, lipids, and DNA, disruption of cellular functions, and activation of inflammatory responses. Prolonged or excessive oxidative stress has been linked to various health conditions, including cancer, cardiovascular diseases, neurodegenerative disorders, and aging-related diseases.
Ribonucleic acid (RNA) is a type of nucleic acid that plays a crucial role in the process of gene expression. There are several types of RNA molecules, including messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). These RNA molecules help to transcribe DNA into mRNA, which is then translated into proteins by the ribosomes.
Fungi are a group of eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. Like other eukaryotes, fungi contain DNA and RNA as part of their genetic material. The RNA in fungi is similar to the RNA found in other organisms, including humans, and plays a role in gene expression and protein synthesis.
A specific medical definition of "RNA, fungal" does not exist, as RNA is a fundamental component of all living organisms, including fungi. However, RNA can be used as a target for antifungal drugs, as certain enzymes involved in RNA synthesis and processing are unique to fungi and can be inhibited by these drugs. For example, the antifungal drug flucytosine is converted into a toxic metabolite that inhibits fungal RNA and DNA synthesis.
Physiological stress is a response of the body to a demand or threat that disrupts homeostasis and activates the autonomic nervous system and hypothalamic-pituitary-adrenal (HPA) axis. This results in the release of stress hormones such as adrenaline, cortisol, and noradrenaline, which prepare the body for a "fight or flight" response. Increased heart rate, rapid breathing, heightened sensory perception, and increased alertness are some of the physiological changes that occur during this response. Chronic stress can have negative effects on various bodily functions, including the immune, cardiovascular, and nervous systems.
PC12 cells are a type of rat pheochromocytoma cell line, which are commonly used in scientific research. Pheochromocytomas are tumors that develop from the chromaffin cells of the adrenal gland, and PC12 cells are a subtype of these cells.
PC12 cells have several characteristics that make them useful for research purposes. They can be grown in culture and can be differentiated into a neuron-like phenotype when treated with nerve growth factor (NGF). This makes them a popular choice for studies involving neuroscience, neurotoxicity, and neurodegenerative disorders.
PC12 cells are also known to express various neurotransmitter receptors, ion channels, and other proteins that are relevant to neuronal function, making them useful for studying the mechanisms of drug action and toxicity. Additionally, PC12 cells can be used to study the regulation of cell growth and differentiation, as well as the molecular basis of cancer.
Keratinocytes are the predominant type of cells found in the epidermis, which is the outermost layer of the skin. These cells are responsible for producing keratin, a tough protein that provides structural support and protection to the skin. Keratinocytes undergo constant turnover, with new cells produced in the basal layer of the epidermis and older cells moving upward and eventually becoming flattened and filled with keratin as they reach the surface of the skin, where they are then shed. They also play a role in the immune response and can release cytokines and other signaling molecules to help protect the body from infection and injury.
Erythroid cells are a type of blood cell that develops in the bone marrow and mature into red blood cells (RBCs), also known as erythrocytes. These cells play a crucial role in the body's oxygen-carrying capacity by transporting oxygen from the lungs to the body's tissues and carbon dioxide from the tissues to the lungs.
The development of erythroid cells begins with hematopoietic stem cells, which can differentiate into various types of blood cells. Through a series of maturation stages, including proerythroblasts, basophilic erythroblasts, polychromatophilic erythroblasts, and orthochromatic erythroblasts, these cells gradually lose their nuclei and organelles to become reticulocytes. Reticulocytes are immature RBCs that still contain some residual ribosomes and are released into the bloodstream. Over time, they mature into fully functional RBCs, which have a biconcave shape and a flexible membrane that allows them to navigate through small blood vessels.
Erythroid cells are essential for maintaining adequate oxygenation of body tissues, and their production is tightly regulated by various hormones and growth factors, such as erythropoietin (EPO), which stimulates the proliferation and differentiation of erythroid progenitor cells. Abnormalities in erythroid cell development or function can lead to various blood disorders, including anemia, polycythemia, and myelodysplastic syndromes.
Cyclooxygenase-2 (COX-2) is an enzyme involved in the synthesis of prostaglandins, which are hormone-like substances that play a role in inflammation, pain, and fever. COX-2 is primarily expressed in response to stimuli such as cytokines and growth factors, and its expression is associated with the development of inflammation.
COX-2 inhibitors are a class of nonsteroidal anti-inflammatory drugs (NSAIDs) that selectively block the activity of COX-2, reducing the production of prostaglandins and providing analgesic, anti-inflammatory, and antipyretic effects. These medications are often used to treat pain and inflammation associated with conditions such as arthritis, menstrual cramps, and headaches.
It's important to note that while COX-2 inhibitors can be effective in managing pain and inflammation, they may also increase the risk of cardiovascular events such as heart attack and stroke, particularly when used at high doses or for extended periods. Therefore, it's essential to use these medications under the guidance of a healthcare provider and to follow their instructions carefully.
Supravalvular Aortic Stenosis (SVAS) is a rare congenital heart defect that affects the narrowing of the aorta just above the aortic valve. This condition is caused by a genetic disorder that affects the development of the elastic fibers in the media layer of the artery.
In SVAS, the narrowing or obstruction can occur in various locations along the aorta and its major branches, leading to varying degrees of severity. The aortic valve itself is usually normal, but the narrowing can affect the blood flow from the heart to the rest of the body, causing the left ventricle to work harder and potentially leading to heart failure over time.
Symptoms of SVAS may include chest pain, shortness of breath, fatigue, and poor growth in children. The diagnosis is typically made through imaging tests such as echocardiography or cardiac catheterization. Treatment options for SVAS may include medication to manage symptoms, balloon dilation or surgical repair to widen the narrowed area, or in severe cases, heart transplantation.
Muscle proteins are a type of protein that are found in muscle tissue and are responsible for providing structure, strength, and functionality to muscles. The two major types of muscle proteins are:
1. Contractile proteins: These include actin and myosin, which are responsible for the contraction and relaxation of muscles. They work together to cause muscle movement by sliding along each other and shortening the muscle fibers.
2. Structural proteins: These include titin, nebulin, and desmin, which provide structural support and stability to muscle fibers. Titin is the largest protein in the human body and acts as a molecular spring that helps maintain the integrity of the sarcomere (the basic unit of muscle contraction). Nebulin helps regulate the length of the sarcomere, while desmin forms a network of filaments that connects adjacent muscle fibers together.
Overall, muscle proteins play a critical role in maintaining muscle health and function, and their dysregulation can lead to various muscle-related disorders such as muscular dystrophy, myopathies, and sarcopenia.
Experimental liver neoplasms refer to abnormal growths or tumors in the liver that are intentionally created or manipulated in a laboratory setting for the purpose of studying their development, progression, and potential treatment options. These experimental models can be established using various methods such as chemical induction, genetic modification, or transplantation of cancerous cells or tissues. The goal of this research is to advance our understanding of liver cancer biology and develop novel therapies for liver neoplasms in humans. It's important to note that these experiments are conducted under strict ethical guidelines and regulations to minimize harm and ensure the humane treatment of animals involved in such studies.
Amino acid repetitive sequences refer to patterns of amino acids that are repeated in a polypeptide chain. These repetitions can vary in length and can be composed of a single type of amino acid or a combination of different types. In some cases, expansions of these repetitive sequences can lead to the production of abnormal proteins that are associated with certain genetic disorders. The expansion of trinucleotide repeats that code for particular amino acids is one example of this phenomenon. These expansions can result in protein misfolding and aggregation, leading to neurodegenerative diseases such as Huntington's disease and spinocerebellar ataxias.
Interferon Regulatory Factor-7 (IRF-7) is a transcription factor that plays a crucial role in the induction of type I interferons (IFNs) and proinflammatory cytokines in response to viral infections. It belongs to the Interferon Regulatory Factor family, which consists of nine members (IRF-1 to IRF-9) that regulate various biological processes, including immune responses, cell growth, and differentiation.
IRF-7 is primarily expressed at low levels in most cells but can be strongly induced during viral infections. Once activated, IRF-7 forms a complex with other transcription factors, such as phosphorylated interferon response factors 3 (IRF-3) and activating transcription factor 2 (ATF-2/c-Jun), to bind to the promoter regions of type I IFN genes, including IFN-α and IFN-β. This binding leads to the transcriptional activation of these genes, resulting in the production of type I IFNs.
Type I IFNs are critical components of the innate immune response against viral infections, as they can induce an antiviral state in infected and neighboring cells by upregulating various interferon-stimulated genes (ISGs). These ISGs encode proteins that inhibit different stages of the viral life cycle, thereby preventing viral replication and spread.
In summary, Interferon Regulatory Factor-7 is a key transcription factor involved in the induction of type I interferons during viral infections, playing a critical role in the early innate immune response against pathogens.
"Pseudomonas putida" is a species of gram-negative, rod-shaped bacteria that is commonly found in soil and water environments. It is a non-pathogenic, opportunistic microorganism that is known for its versatile metabolism and ability to degrade various organic compounds. This bacterium has been widely studied for its potential applications in bioremediation and industrial biotechnology due to its ability to break down pollutants such as toluene, xylene, and other aromatic hydrocarbons. It is also known for its resistance to heavy metals and antibiotics, making it a valuable tool in the study of bacterial survival mechanisms and potential applications in bioremediation and waste treatment.
Cyclin T is a type of cyclin protein that is encoded by the CCNT2 gene in humans. Cyclins are a family of regulatory proteins that play a crucial role in the cell cycle, which is the series of events that cells undergo as they grow and divide. Specifically, cyclin T is a component of the CDK9/cyclin T complex, also known as positive transcription elongation factor b (P-TEFb), which plays a key role in regulating gene expression by controlling the elongation phase of RNA polymerase II-mediated transcription.
Cyclin T is expressed at various stages of the cell cycle and has been shown to interact with several other proteins involved in cell cycle regulation, including the retinoblastoma protein (pRb) and the E2F family of transcription factors. Dysregulation of cyclin T expression or activity has been implicated in several human diseases, including cancer.
Drug synergism is a pharmacological concept that refers to the interaction between two or more drugs, where the combined effect of the drugs is greater than the sum of their individual effects. This means that when these drugs are administered together, they produce an enhanced therapeutic response compared to when they are given separately.
Drug synergism can occur through various mechanisms, such as:
1. Pharmacodynamic synergism - When two or more drugs interact with the same target site in the body and enhance each other's effects.
2. Pharmacokinetic synergism - When one drug affects the metabolism, absorption, distribution, or excretion of another drug, leading to an increased concentration of the second drug in the body and enhanced therapeutic effect.
3. Physiochemical synergism - When two drugs interact physically, such as when one drug enhances the solubility or permeability of another drug, leading to improved absorption and bioavailability.
It is important to note that while drug synergism can result in enhanced therapeutic effects, it can also increase the risk of adverse reactions and toxicity. Therefore, healthcare providers must carefully consider the potential benefits and risks when prescribing combinations of drugs with known or potential synergistic effects.
Thymidine kinase (TK) is an enzyme that plays a crucial role in the synthesis of thymidine triphosphate (dTMP), a nucleotide required for DNA replication and repair. It catalyzes the phosphorylation of thymidine to thymidine monophosphate (dTMP) by transferring a phosphate group from adenosine triphosphate (ATP).
There are two major isoforms of thymidine kinase in humans: TK1 and TK2. TK1 is primarily found in the cytoplasm of proliferating cells, such as those involved in the cell cycle, while TK2 is located mainly in the mitochondria and is responsible for maintaining the dNTP pool required for mtDNA replication and repair.
Thymidine kinase activity has been used as a marker for cell proliferation, particularly in cancer cells, which often exhibit elevated levels of TK1 due to their high turnover rates. Additionally, measuring TK1 levels can help monitor the effectiveness of certain anticancer therapies that target DNA replication.
Catechol 1,2-dioxygenase is an enzyme that catalyzes the conversion of catechols to muconic acids as part of the meta-cleavage pathway in the breakdown of aromatic compounds in bacteria. The enzyme requires iron as a cofactor and functions by cleaving the aromatic ring between the two hydroxyl groups in the catechol molecule. This reaction is an important step in the degradation of various environmental pollutants, such as polychlorinated biphenyls (PCBs) and lignin, by certain bacterial species.
Butadienes are a class of organic compounds that contain a chemical structure consisting of two carbon-carbon double bonds arranged in a conjugated system. The most common butadiene is 1,3-butadiene, which is an important industrial chemical used in the production of synthetic rubber and plastics.
1,3-Butadiene is a colorless gas that is highly flammable and has a mild sweet odor. It is produced as a byproduct of petroleum refining and is also released during the combustion of fossil fuels. Exposure to butadienes can occur through inhalation, skin contact, or ingestion, and prolonged exposure has been linked to an increased risk of cancer, particularly leukemia.
Other forms of butadiene include 1,2-butadiene and 1,4-butadiene, which have different chemical properties and uses. Overall, butadienes are important industrial chemicals with a wide range of applications, but their potential health hazards require careful handling and regulation.
Glutamine is defined as a conditionally essential amino acid in humans, which means that it can be produced by the body under normal circumstances, but may become essential during certain conditions such as stress, illness, or injury. It is the most abundant free amino acid found in the blood and in the muscles of the body.
Glutamine plays a crucial role in various biological processes, including protein synthesis, energy production, and acid-base balance. It serves as an important fuel source for cells in the intestines, immune system, and skeletal muscles. Glutamine has also been shown to have potential benefits in wound healing, gut function, and immunity, particularly during times of physiological stress or illness.
In summary, glutamine is a vital amino acid that plays a critical role in maintaining the health and function of various tissues and organs in the body.
CpG islands are defined as short stretches of DNA that are characterized by a higher than expected frequency of CpG dinucleotides. A dinucleotide is a pair of adjacent nucleotides, and in the case of CpG, C represents cytosine and G represents guanine. These islands are typically found in the promoter regions of genes, where they play important roles in regulating gene expression.
Under normal circumstances, the cytosine residue in a CpG dinucleotide is often methylated, meaning that a methyl group (-CH3) is added to the cytosine base. However, in CpG islands, methylation is usually avoided, and these regions tend to be unmethylated. This has important implications for gene expression because methylation of CpG dinucleotides in promoter regions can lead to the silencing of genes.
CpG islands are also often targets for transcription factors, which bind to specific DNA sequences and help regulate gene expression. The unmethylated state of CpG islands is thought to be important for maintaining the accessibility of these regions to transcription factors and other regulatory proteins.
Abnormal methylation patterns in CpG islands have been associated with various diseases, including cancer. In many cancers, CpG islands become aberrantly methylated, leading to the silencing of tumor suppressor genes and contributing to the development and progression of the disease.
Adenoviruses, Human: A group of viruses that commonly cause respiratory illnesses, such as bronchitis, pneumonia, and croup, in humans. They can also cause conjunctivitis (pink eye), cystitis (bladder infection), and gastroenteritis (stomach and intestinal infection).
Human adenoviruses are non-enveloped, double-stranded DNA viruses that belong to the family Adenoviridae. There are more than 50 different types of human adenoviruses, which can be classified into seven species (A-G). Different types of adenoviruses tend to cause specific illnesses, such as respiratory or gastrointestinal infections.
Human adenoviruses are highly contagious and can spread through close personal contact, respiratory droplets, or contaminated surfaces. They can also be transmitted through contaminated water sources. Some people may become carriers of the virus and experience no symptoms but still spread the virus to others.
Most human adenovirus infections are mild and resolve on their own within a few days to a week. However, some types of adenoviruses can cause severe illness, particularly in people with weakened immune systems, such as infants, young children, older adults, and individuals with HIV/AIDS or organ transplants.
There are no specific antiviral treatments for human adenovirus infections, but supportive care, such as hydration, rest, and fever reduction, can help manage symptoms. Preventive measures include practicing good hygiene, such as washing hands frequently, avoiding close contact with sick individuals, and not sharing personal items like towels or utensils.
Polyomavirus transforming antigens refer to specific proteins expressed by polyomaviruses that can induce cellular transformation and lead to the development of cancer. These antigens are called large T antigen (T-Ag) and small t antigen (t-Ag). They manipulate key cellular processes, such as cell cycle regulation and DNA damage response, leading to uncontrolled cell growth and malignant transformation.
The large T antigen is a multifunctional protein that plays a crucial role in viral replication and transformation. It has several domains with different functions:
1. Origin binding domain (OBD): Binds to the viral origin of replication, initiating DNA synthesis.
2. Helicase domain: Unwinds double-stranded DNA during replication.
3. DNA binding domain: Binds to specific DNA sequences and acts as a transcriptional regulator.
4. Protein phosphatase 1 (PP1) binding domain: Recruits PP1 to promote viral DNA replication and inhibit host cell defense mechanisms.
5. p53-binding domain: Binds and inactivates the tumor suppressor protein p53, promoting cell cycle progression and preventing apoptosis.
6. Rb-binding domain: Binds to and inactivates the retinoblastoma protein (pRb), leading to deregulation of the cell cycle and uncontrolled cell growth.
The small t antigen shares a common N-terminal region with large T antigen but lacks some functional domains, such as the OBD and helicase domain. Small t antigen can also bind to and inactivate PP1 and pRb, contributing to transformation. However, its primary role is to stabilize large T antigen by preventing its proteasomal degradation.
Polyomavirus transforming antigens are associated with various human cancers, such as Merkel cell carcinoma (caused by Merkel cell polyomavirus) and some forms of brain tumors, sarcomas, and lymphomas (associated with simian virus 40).
I'm not aware of a specific medical definition for "Avian Proteins." The term "avian" generally refers to birds or their characteristics. Therefore, "avian proteins" would likely refer to proteins that are found in birds or are produced by avian cells. These proteins could have various functions and roles, depending on the specific protein in question.
For example, avian proteins might be of interest in medical research if they have similarities to human proteins and can be used as models to study protein function, structure, or interaction with other molecules. Additionally, some avian proteins may have potential applications in therapeutic development, such as using chicken egg-derived proteins for wound healing or as vaccine components.
However, without a specific context or reference, it's difficult to provide a more precise definition of "avian proteins" in a medical context.
The Mi-2/NuRD (Nucleosome Remodeling and Deacetylase) complex is a large, multi-subunit protein complex that plays a crucial role in epigenetic regulation of gene expression. It is highly conserved across many species, including humans. The complex is named after its core ATP-dependent chromatin remodeling factor, Mi-2 (also known as CHD3 or CHD4), which can reposition, eject, or slide nucleosomes along DNA to alter the accessibility of DNA to transcription factors and other regulatory proteins.
The NuRD complex also contains several histone deacetylases (HDACs), specifically HDAC1 and HDAC2, that remove acetyl groups from histone tails, leading to a more compact chromatin structure and repression of gene transcription. Additionally, the complex includes other accessory proteins, such as MTA (Metastasis Associated) proteins, RbAP46/48 (Retinoblastoma-Associated Proteins), MBD (Methyl-CpG Binding Domain) proteins, and others.
The Mi-2/NuRD complex is involved in various cellular processes, including development, differentiation, and tumor suppression. Dysregulation of this complex has been implicated in several human diseases, particularly cancers.
GATA6 (GATA binding protein 6) is a transcription factor that belongs to the GATA family, which are characterized by their ability to bind to the DNA sequence (A/T)GATA(A/G). GATA6 plays crucial roles in the development and function of various tissues, particularly in the digestive system.
As a transcription factor, GATA6 regulates gene expression by binding to specific DNA sequences in the promoter or enhancer regions of target genes. This binding either activates or represses the transcription of these genes, thereby controlling cellular processes such as proliferation, differentiation, and survival.
In the context of the digestive system, GATA6 is essential for the development of the pancreas and small intestine. It promotes the differentiation of pancreatic progenitor cells into exocrine cells (such as acinar and ductal cells) and inhibits their differentiation into endocrine cells (such as β-cells). In the small intestine, GATA6 is involved in maintaining the identity and function of Paneth cells, which are specialized epithelial cells that play a role in innate immunity.
Mutations in the GATA6 gene have been associated with various human diseases, including pancreatic agenesis or hypoplasia, small intestinal atresia, and congenital diaphragmatic hernia. Additionally, altered GATA6 expression has been implicated in several types of cancer, such as pancreatic ductal adenocarcinoma and colorectal cancer.
Goosecoid protein is not a term that has a specific medical definition. However, it is a biological term related to the field of developmental biology and genetics.
Goosecoid protein is a transcription factor that plays a crucial role in embryonic development, particularly during gastrulation - an early stage of embryogenesis where the three germ layers (ectoderm, mesoderm, and endoderm) are formed. The goosecoid gene encodes this protein, and it is primarily expressed in the Spemann-Mangold organizer, a structure located in the dorsal blastopore lip of amphibian embryos. This organizer region is essential for establishing the body axis and inducing the formation of the central nervous system.
In humans, goosecoid protein homologs have been identified, and they are involved in various developmental processes, including limb development and craniofacial morphogenesis. Dysregulation of goosecoid protein expression or function has been implicated in several congenital disorders and cancer types. However, a direct medical definition focusing on 'Goosecoid Protein' is not available due to its broader biological context.
Virus latency, also known as viral latency, refers to a state of infection in which a virus remains dormant or inactive within a host cell for a period of time. During this phase, the virus does not replicate or cause any noticeable symptoms. However, under certain conditions such as stress, illness, or a weakened immune system, the virus can become reactivated and begin to produce new viruses, potentially leading to disease.
One well-known example of a virus that exhibits latency is the varicella-zoster virus (VZV), which causes chickenpox in children. After a person recovers from chickenpox, the virus remains dormant in the nervous system for years or even decades. In some cases, the virus can reactivate later in life, causing shingles, a painful rash that typically occurs on one side of the body.
Virus latency is an important concept in virology and infectious disease research, as it has implications for understanding the persistence of viral infections, developing treatments and vaccines, and predicting the risk of disease recurrence.
GTP-binding proteins, also known as G proteins, are a family of molecular switches present in many organisms, including humans. They play a crucial role in signal transduction pathways, particularly those involved in cellular responses to external stimuli such as hormones, neurotransmitters, and sensory signals like light and odorants.
G proteins are composed of three subunits: α, β, and γ. The α-subunit binds GTP (guanosine triphosphate) and acts as the active component of the complex. When a G protein-coupled receptor (GPCR) is activated by an external signal, it triggers a conformational change in the associated G protein, allowing the α-subunit to exchange GDP (guanosine diphosphate) for GTP. This activation leads to dissociation of the G protein complex into the GTP-bound α-subunit and the βγ-subunit pair. Both the α-GTP and βγ subunits can then interact with downstream effectors, such as enzymes or ion channels, to propagate and amplify the signal within the cell.
The intrinsic GTPase activity of the α-subunit eventually hydrolyzes the bound GTP to GDP, which leads to re-association of the α and βγ subunits and termination of the signal. This cycle of activation and inactivation makes G proteins versatile signaling elements that can respond quickly and precisely to changing environmental conditions.
Defects in G protein-mediated signaling pathways have been implicated in various diseases, including cancer, neurological disorders, and cardiovascular diseases. Therefore, understanding the function and regulation of GTP-binding proteins is essential for developing targeted therapeutic strategies.
"MDR" is an abbreviation for "Multidrug Resistance." In the context of genetics, MDR genes are those that encode for proteins, typically transmembrane pumps, which can actively transport various drugs out of cells. This results in reduced drug accumulation within cells and decreased effectiveness of these drugs.
MDR genes play a crucial role in conferring resistance to chemotherapy agents in cancer cells, making treatment more challenging. One well-known MDR gene is the ABCB1 (ATP Binding Cassette Subfamily B Member 1) gene, which encodes for the P-glycoprotein efflux pump. Overexpression of such MDR genes can lead to cross-resistance to multiple drugs, further complicating treatment strategies.
U937 cells are a type of human histiocytic lymphoma cell line that is commonly used in scientific research and studies. They are derived from the peripheral blood of a patient with histiocytic lymphoma, which is a rare type of cancer that affects the immune system's cells called histiocytes.
U937 cells have a variety of uses in research, including studying the mechanisms of cancer cell growth and proliferation, testing the effects of various drugs and treatments on cancer cells, and investigating the role of different genes and proteins in cancer development and progression. These cells are easy to culture and maintain in the laboratory, making them a popular choice for researchers in many fields.
It is important to note that while U937 cells can provide valuable insights into the behavior of cancer cells, they do not necessarily reflect the complexity and diversity of human cancers. Therefore, findings from studies using these cells should be validated in more complex models or clinical trials before being applied to patient care.
Virulence, in the context of medicine and microbiology, refers to the degree or severity of damage or harm that a pathogen (like a bacterium, virus, fungus, or parasite) can cause to its host. It is often associated with the ability of the pathogen to invade and damage host tissues, evade or suppress the host's immune response, replicate within the host, and spread between hosts.
Virulence factors are the specific components or mechanisms that contribute to a pathogen's virulence, such as toxins, enzymes, adhesins, and capsules. These factors enable the pathogen to establish an infection, cause tissue damage, and facilitate its transmission between hosts. The overall virulence of a pathogen can be influenced by various factors, including host susceptibility, environmental conditions, and the specific strain or species of the pathogen.
Skeletal muscle, also known as striated or voluntary muscle, is a type of muscle that is attached to bones by tendons or aponeuroses and functions to produce movements and support the posture of the body. It is composed of long, multinucleated fibers that are arranged in parallel bundles and are characterized by alternating light and dark bands, giving them a striped appearance under a microscope. Skeletal muscle is under voluntary control, meaning that it is consciously activated through signals from the nervous system. It is responsible for activities such as walking, running, jumping, and lifting objects.
Imidazoles are a class of heterocyclic organic compounds that contain a double-bonded nitrogen atom and two additional nitrogen atoms in the ring. They have the chemical formula C3H4N2. In a medical context, imidazoles are commonly used as antifungal agents. Some examples of imidazole-derived antifungals include clotrimazole, miconazole, and ketoconazole. These medications work by inhibiting the synthesis of ergosterol, a key component of fungal cell membranes, leading to increased permeability and death of the fungal cells. Imidazoles may also have anti-inflammatory, antibacterial, and anticancer properties.
SOX9 (SRY-related HMG-box gene 9) is a transcription factor that belongs to the SOX family of proteins, which are characterized by a high mobility group (HMG) box DNA-binding domain. SOX9 plays crucial roles in various developmental processes, including sex determination, chondrogenesis, and neurogenesis.
As a transcription factor, SOX9 binds to specific DNA sequences in the promoter or enhancer regions of its target genes and regulates their expression. In the context of sex determination, SOX9 is essential for the development of Sertoli cells in the male gonad, which are responsible for supporting sperm production. SOX9 also plays a role in maintaining the undifferentiated state of stem cells and promoting cell differentiation in various tissues.
Mutations in the SOX9 gene have been associated with several human genetic disorders, including campomelic dysplasia, a severe skeletal disorder characterized by bowed legs, and sex reversal in individuals with XY chromosomes.
A genomic library is a collection of cloned DNA fragments that represent the entire genetic material of an organism. It serves as a valuable resource for studying the function, organization, and regulation of genes within a given genome. Genomic libraries can be created using different types of vectors, such as bacterial artificial chromosomes (BACs), yeast artificial chromosomes (YACs), or plasmids, to accommodate various sizes of DNA inserts. These libraries facilitate the isolation and manipulation of specific genes or genomic regions for further analysis, including sequencing, gene expression studies, and functional genomics research.
Untranslated regions (UTRs) are sections of an mRNA molecule that do not contain information for protein synthesis. There are two types of UTRs: 5' UTR, which is located at the 5' end of the mRNA molecule, and 3' UTR, which is located at the 3' end.
The 5' UTR typically contains regulatory elements that control the translation of the mRNA into protein. These elements can affect the efficiency and timing of translation, as well as the stability of the mRNA molecule. The 5' UTR may also contain upstream open reading frames (uORFs), which are short sequences that can be translated into small peptides and potentially regulate the translation of the main coding sequence.
The length and sequence composition of the 5' UTR can have significant impacts on gene expression, and variations in these regions have been associated with various diseases, including cancer and neurological disorders. Therefore, understanding the structure and function of 5' UTRs is an important area of research in molecular biology and genetics.
MAP Kinase Kinase 6 (MAP2K6) is a serine/threonine protein kinase that plays a crucial role in intracellular signaling transduction pathways. It is also known as MKK6 or MITogen-Activated Protein Kinase Kinase 6. This enzyme is a member of the MAPK kinase family, which activates mitogen-activated protein kinases (MAPKs) by phosphorylating their activation loop residues.
MAP2K6 specifically activates p38 MAPK, another serine/threonine protein kinase involved in various cellular responses to stress stimuli, cytokines, and hormones. The MAP2K6-p38 MAPK signaling pathway is essential for regulating processes such as inflammation, differentiation, apoptosis, and autophagy. Dysregulation of this pathway has been implicated in several diseases, including cancer, cardiovascular disease, and neurodegenerative disorders.
A peptide fragment is a short chain of amino acids that is derived from a larger peptide or protein through various biological or chemical processes. These fragments can result from the natural breakdown of proteins in the body during regular physiological processes, such as digestion, or they can be produced experimentally in a laboratory setting for research or therapeutic purposes.
Peptide fragments are often used in research to map the structure and function of larger peptides and proteins, as well as to study their interactions with other molecules. In some cases, peptide fragments may also have biological activity of their own and can be developed into drugs or diagnostic tools. For example, certain peptide fragments derived from hormones or neurotransmitters may bind to receptors in the body and mimic or block the effects of the full-length molecule.
Sterol Regulatory Element Binding Protein 1 (SREBP-1) is a transcription factor that plays a crucial role in the regulation of lipid metabolism, primarily cholesterol and fatty acid biosynthesis. It binds to specific DNA sequences called sterol regulatory elements (SREs), which are present in the promoter regions of genes involved in lipid synthesis.
SREBP-1 exists in two isoforms, SREBP-1a and SREBP-1c, encoded by a single gene through alternative splicing. SREBP-1a is a stronger transcriptional activator than SREBP-1c and can activate both cholesterol and fatty acid synthesis genes. In contrast, SREBP-1c primarily regulates fatty acid synthesis genes.
Under normal conditions, SREBP-1 is found in the endoplasmic reticulum (ER) membrane as an inactive precursor bound to another protein called SREBP cleavage-activating protein (SCAP). When cells detect low levels of cholesterol or fatty acids, SCAP escorts SREBP-1 to the Golgi apparatus, where it undergoes proteolytic processing to release the active transcription factor. The active SREBP-1 then translocates to the nucleus and binds to SREs, promoting the expression of genes involved in lipid synthesis.
Overall, SREBP-1 is a critical regulator of lipid homeostasis, and its dysregulation has been implicated in various diseases, including obesity, insulin resistance, nonalcoholic fatty liver disease (NAFLD), and atherosclerosis.
Casein Kinase II (CK2) is a serine/threonine protein kinase that is widely expressed in eukaryotic cells and is involved in the regulation of various cellular processes. It is a heterotetrameric enzyme, consisting of two catalytic subunits (alpha and alpha') and two regulatory subunits (beta).
CK2 phosphorylates a wide range of substrates, including transcription factors, signaling proteins, and other kinases. It is known to play roles in cell cycle regulation, apoptosis, DNA damage response, and protein stability, among others. CK2 activity is often found to be elevated in various types of cancer, making it a potential target for cancer therapy.
Interleukin-1 (IL-1) is a type of cytokine, which are proteins that play a crucial role in cell signaling. Specifically, IL-1 is a pro-inflammatory cytokine that is involved in the regulation of immune and inflammatory responses in the body. It is produced by various cells, including monocytes, macrophages, and dendritic cells, in response to infection or injury.
IL-1 exists in two forms, IL-1α and IL-1β, which have similar biological activities but are encoded by different genes. Both forms of IL-1 bind to the same receptor, IL-1R, and activate intracellular signaling pathways that lead to the production of other cytokines, chemokines, and inflammatory mediators.
IL-1 has a wide range of biological effects, including fever induction, activation of immune cells, regulation of hematopoiesis (the formation of blood cells), and modulation of bone metabolism. Dysregulation of IL-1 production or activity has been implicated in various inflammatory diseases, such as rheumatoid arthritis, gout, and inflammatory bowel disease. Therefore, IL-1 is an important target for the development of therapies aimed at modulating the immune response and reducing inflammation.
Activating Transcription Factor 6 (ATF6) is a protein that plays a crucial role in the endoplasmic reticulum (ER) stress response, also known as the unfolded protein response (UPR). The UPR is a cellular signaling pathway that is activated when misfolded proteins accumulate in the ER, which can be caused by various stressors such as nutrient deprivation, hypoxia, or infection.
ATF6 is a transcription factor that is normally located in the ER membrane. When ER stress occurs, ATF6 is cleaved and activated, allowing it to translocate to the nucleus where it binds to specific DNA sequences and activates the transcription of genes involved in the UPR. These genes encode proteins that help to restore ER homeostasis by increasing protein folding capacity, reducing protein synthesis, and promoting protein degradation.
ATF6 is also involved in other cellular processes such as inflammation, apoptosis, and autophagy. Dysregulation of the UPR and ATF6 activation has been implicated in various diseases, including neurodegenerative disorders, cancer, and metabolic diseases.
Azacitidine is a medication that is primarily used to treat myelodysplastic syndrome (MDS), a type of cancer where the bone marrow does not produce enough healthy blood cells. It is also used to treat acute myeloid leukemia (AML) in some cases.
Azacitidine is a type of drug known as a hypomethylating agent, which means that it works by modifying the way that genes are expressed in cancer cells. Specifically, azacitidine inhibits the activity of an enzyme called DNA methyltransferase, which adds methyl groups to the DNA molecule and can silence the expression of certain genes. By inhibiting this enzyme, azacitidine can help to restore the normal function of genes that have been silenced in cancer cells.
Azacitidine is typically given as a series of subcutaneous (under the skin) or intravenous (into a vein) injections over a period of several days, followed by a rest period of several weeks before the next cycle of treatment. The specific dosage and schedule may vary depending on the individual patient's needs and response to treatment.
Like all medications, azacitidine can have side effects, which may include nausea, vomiting, diarrhea, constipation, fatigue, fever, and decreased appetite. More serious side effects are possible, but relatively rare, and may include bone marrow suppression, infections, and liver damage. Patients receiving azacitidine should be closely monitored by their healthcare provider to manage any side effects that may occur.
BCL-1 (B-cell leukemia/lymphoma 1) is not a gene itself but rather a chromosomal translocation that results in the formation of an abnormal fusion gene. The BCL-1 translocation, also known as t(14;18)(q32;q21), is most commonly found in follicular lymphoma, a type of slow-growing non-Hodgkin lymphoma.
The BCL-1 translocation involves the juxtaposition of the BCL-2 gene, which is located on chromosome 18, with the IGH (immunoglobulin heavy chain) gene, which is located on chromosome 14. This translocation results in the overexpression of the BCL-2 protein, which inhibits apoptosis or programmed cell death. The overexpression of BCL-2 leads to the accumulation of cancer cells and contributes to the development and progression of follicular lymphoma.
It is important to note that while BCL-1 is a chromosomal translocation, it can also refer to the protein encoded by the BCL-2 gene when it is overexpressed due to the t(14;18) translocation. In this context, BCL-1 is considered a proto-oncogene because its overexpression promotes cancer development and progression.
Calcium-calmodulin-dependent protein kinase type 1 (CAMK1) is a type of serine/threonine protein kinase that plays a crucial role in signal transduction pathways involved in various cellular processes, including synaptic plasticity, learning, and memory. It is activated by the binding of calcium ions (Ca2+) and calmodulin, a ubiquitous calcium-binding protein, to its regulatory domain.
Once activated, CAMK1 phosphorylates various downstream target proteins, leading to changes in their activity or function. In the brain, CAMK1 is primarily expressed in neurons and has been implicated in the regulation of synaptic strength and transmission, as well as in the modulation of gene expression and cell survival. Dysregulation of CAMK1 has been associated with several neurological disorders, including Alzheimer's disease, Parkinson's disease, and epilepsy.
Peptide mapping is a technique used in proteomics and analytical chemistry to analyze and identify the sequence and structure of peptides or proteins. This method involves breaking down a protein into smaller peptide fragments using enzymatic or chemical digestion, followed by separation and identification of these fragments through various analytical techniques such as liquid chromatography (LC) and mass spectrometry (MS).
The resulting peptide map serves as a "fingerprint" of the protein, providing information about its sequence, modifications, and structure. Peptide mapping can be used for a variety of applications, including protein identification, characterization of post-translational modifications, and monitoring of protein degradation or cleavage.
In summary, peptide mapping is a powerful tool in proteomics that enables the analysis and identification of proteins and their modifications at the peptide level.
Neurons, also known as nerve cells or neurocytes, are specialized cells that constitute the basic unit of the nervous system. They are responsible for receiving, processing, and transmitting information and signals within the body. Neurons have three main parts: the dendrites, the cell body (soma), and the axon. The dendrites receive signals from other neurons or sensory receptors, while the axon transmits these signals to other neurons, muscles, or glands. The junction between two neurons is called a synapse, where neurotransmitters are released to transmit the signal across the gap (synaptic cleft) to the next neuron. Neurons vary in size, shape, and structure depending on their function and location within the nervous system.
Hydroquinones are a type of chemical compound that belong to the group of phenols. In a medical context, hydroquinones are often used as topical agents for skin lightening and the treatment of hyperpigmentation disorders such as melasma, age spots, and freckles. They work by inhibiting the enzyme tyrosinase, which is necessary for the production of melanin, the pigment that gives skin its color.
It's important to note that hydroquinones can have side effects, including skin irritation, redness, and contact dermatitis. Prolonged use or high concentrations may also cause ochronosis, a condition characterized by blue-black discoloration of the skin. Therefore, they should be used under the supervision of a healthcare provider and for limited periods of time.
Viral activation, also known as viral reactivation or virus reactivation, refers to the process in which a latent or dormant virus becomes active and starts to replicate within a host cell. This can occur when the immune system is weakened or compromised, allowing the virus to evade the body's natural defenses and cause disease.
In some cases, viral activation can be triggered by certain environmental factors, such as stress, exposure to UV light, or infection with another virus. Once activated, the virus can cause symptoms similar to those seen during the initial infection, or it may lead to new symptoms depending on the specific virus and the host's immune response.
Examples of viruses that can remain dormant in the body and be reactivated include herpes simplex virus (HSV), varicella-zoster virus (VZV), cytomegalovirus (CMV), and Epstein-Barr virus (EBV). It is important to note that not all viruses can be reactivated, and some may remain dormant in the body indefinitely without causing any harm.
Interleukin-2 (IL-2) is a type of cytokine, which are signaling molecules that mediate and regulate immunity, inflammation, and hematopoiesis. Specifically, IL-2 is a growth factor for T cells, a type of white blood cell that plays a central role in the immune response. It is primarily produced by CD4+ T cells (also known as T helper cells) and stimulates the proliferation and differentiation of activated T cells, including effector T cells and regulatory T cells. IL-2 also has roles in the activation and function of other immune cells, such as B cells, natural killer cells, and dendritic cells. Dysregulation of IL-2 production or signaling can contribute to various pathological conditions, including autoimmune diseases, chronic infections, and cancer.
Hydrogen peroxide (H2O2) is a colorless, odorless, clear liquid with a slightly sweet taste, although drinking it is harmful and can cause poisoning. It is a weak oxidizing agent and is used as an antiseptic and a bleaching agent. In diluted form, it is used to disinfect wounds and kill bacteria and viruses on the skin; in higher concentrations, it can be used to bleach hair or remove stains from clothing. It is also used as a propellant in rocketry and in certain industrial processes. Chemically, hydrogen peroxide is composed of two hydrogen atoms and two oxygen atoms, and it is structurally similar to water (H2O), with an extra oxygen atom. This gives it its oxidizing properties, as the additional oxygen can be released and used to react with other substances.
Nucleic acid hybridization is a process in molecular biology where two single-stranded nucleic acids (DNA, RNA) with complementary sequences pair together to form a double-stranded molecule through hydrogen bonding. The strands can be from the same type of nucleic acid or different types (i.e., DNA-RNA or DNA-cDNA). This process is commonly used in various laboratory techniques, such as Southern blotting, Northern blotting, polymerase chain reaction (PCR), and microarray analysis, to detect, isolate, and analyze specific nucleic acid sequences. The hybridization temperature and conditions are critical to ensure the specificity of the interaction between the two strands.
Androgens are a class of hormones that are primarily responsible for the development and maintenance of male sexual characteristics and reproductive function. Testosterone is the most well-known androgen, but other androgens include dehydroepiandrosterone (DHEA), androstenedione, and dihydrotestosterone (DHT).
Androgens are produced primarily by the testes in men and the ovaries in women, although small amounts are also produced by the adrenal glands in both sexes. They play a critical role in the development of male secondary sexual characteristics during puberty, such as the growth of facial hair, deepening of the voice, and increased muscle mass.
In addition to their role in sexual development and function, androgens also have important effects on bone density, mood, and cognitive function. Abnormal levels of androgens can contribute to a variety of medical conditions, including infertility, erectile dysfunction, acne, hirsutism (excessive hair growth), and prostate cancer.
Interferons (IFNs) are a group of signaling proteins made and released by host cells in response to the presence of pathogens such as viruses, bacteria, parasites, or tumor cells. They belong to the larger family of cytokines and are crucial for the innate immune system's defense against infections. Interferons exist in multiple forms, classified into three types: type I (alpha and beta), type II (gamma), and type III (lambda). These proteins play a significant role in modulating the immune response, inhibiting viral replication, regulating cell growth, and promoting apoptosis of infected cells. Interferons are used as therapeutic agents for various medical conditions, including certain viral infections, cancers, and autoimmune diseases.
Adipocytes are specialized cells that comprise adipose tissue, also known as fat tissue. They are responsible for storing energy in the form of lipids, particularly triglycerides, and releasing energy when needed through a process called lipolysis. There are two main types of adipocytes: white adipocytes and brown adipocytes. White adipocytes primarily store energy, while brown adipocytes dissipate energy as heat through the action of uncoupling protein 1 (UCP1).
In addition to their role in energy metabolism, adipocytes also secrete various hormones and signaling molecules that contribute to whole-body homeostasis. These include leptin, adiponectin, resistin, and inflammatory cytokines. Dysregulation of adipocyte function has been implicated in the development of obesity, insulin resistance, type 2 diabetes, and cardiovascular disease.
Actin is a type of protein that forms part of the contractile apparatus in muscle cells, and is also found in various other cell types. It is a globular protein that polymerizes to form long filaments, which are important for many cellular processes such as cell division, cell motility, and the maintenance of cell shape. In muscle cells, actin filaments interact with another type of protein called myosin to enable muscle contraction. Actins can be further divided into different subtypes, including alpha-actin, beta-actin, and gamma-actin, which have distinct functions and expression patterns in the body.
The Fluorescent Antibody Technique (FAT), Indirect is a type of immunofluorescence assay used to detect the presence of specific antigens in a sample. In this method, the sample is first incubated with a primary antibody that binds to the target antigen. After washing to remove unbound primary antibodies, a secondary fluorescently labeled antibody is added, which recognizes and binds to the primary antibody. This indirect labeling approach allows for amplification of the signal, making it more sensitive than direct methods. The sample is then examined under a fluorescence microscope to visualize the location and amount of antigen based on the emitted light from the fluorescent secondary antibody. It's commonly used in diagnostic laboratories for detection of various bacteria, viruses, and other antigens in clinical specimens.
Core Binding Factor Alpha 1 Subunit, also known as CBF-A1 or RUNX1, is a protein that plays a crucial role in hematopoiesis, which is the process of blood cell development. It is a member of the core binding factor (CBF) complex, which regulates gene transcription and is essential for the differentiation and maturation of hematopoietic stem cells into mature blood cells.
The CBF complex consists of three subunits: CBF-A, CBF-B, and a histone deacetylase (HDAC). The CBF-A subunit can have several isoforms, including CBF-A1, which is encoded by the RUNX1 gene. Mutations in the RUNX1 gene have been associated with various hematological disorders, such as acute myeloid leukemia (AML), familial platelet disorder with propensity to develop AML, and thrombocytopenia with absent radii syndrome.
CBF-A1/RUNX1 functions as a transcription factor that binds to DNA at specific sequences called core binding factors, thereby regulating the expression of target genes involved in hematopoiesis. Proper regulation of these genes is essential for normal blood cell development and homeostasis.
Recombinant DNA is a term used in molecular biology to describe DNA that has been created by combining genetic material from more than one source. This is typically done through the use of laboratory techniques such as molecular cloning, in which fragments of DNA are inserted into vectors (such as plasmids or viruses) and then introduced into a host organism where they can replicate and produce many copies of the recombinant DNA molecule.
Recombinant DNA technology has numerous applications in research, medicine, and industry, including the production of recombinant proteins for use as therapeutics, the creation of genetically modified organisms (GMOs) for agricultural or industrial purposes, and the development of new tools for genetic analysis and manipulation.
It's important to note that while recombinant DNA technology has many potential benefits, it also raises ethical and safety concerns, and its use is subject to regulation and oversight in many countries.
Antioxidants are substances that can prevent or slow damage to cells caused by free radicals, which are unstable molecules that the body produces as a reaction to environmental and other pressures. Antioxidants are able to neutralize free radicals by donating an electron to them, thus stabilizing them and preventing them from causing further damage to the cells.
Antioxidants can be found in a variety of foods, including fruits, vegetables, nuts, and grains. Some common antioxidants include vitamins C and E, beta-carotene, and selenium. Antioxidants are also available as dietary supplements.
In addition to their role in protecting cells from damage, antioxidants have been studied for their potential to prevent or treat a number of health conditions, including cancer, heart disease, and age-related macular degeneration. However, more research is needed to fully understand the potential benefits and risks of using antioxidant supplements.
POU domain factors are a family of transcription factors that play crucial roles in the development and function of various organisms, including humans. The name "POU" is an acronym derived from the names of three genes in which these domains were first identified: Pit-1, Oct-1, and Unc-86.
The POU domain is a conserved DNA-binding motif that consists of two subdomains: a POU-specific domain (POUs) and a POU homeodomain (POUh). The POUs domain recognizes and binds to specific DNA sequences, while the POUh domain enhances the binding affinity and specificity.
POU domain factors regulate gene expression by binding to regulatory elements in the promoter or enhancer regions of their target genes. They are involved in various biological processes, such as cell fate determination, development, differentiation, and metabolism. Some examples of POU domain factors include Oct-1, Oct-2, Oct-3/4, Sox2, and Brn-2.
Mutations or dysregulation of POU domain factors have been implicated in several human diseases, such as cancer, diabetes, and neurological disorders. Therefore, understanding the function and regulation of these transcription factors is essential for developing new therapeutic strategies to treat these conditions.
Protein Tyrosine Phosphatases (PTPs) are a group of enzymes that play a crucial role in the regulation of various cellular processes, including cell growth, differentiation, and signal transduction. PTPs function by removing phosphate groups from tyrosine residues on proteins, thereby counteracting the effects of tyrosine kinases, which add phosphate groups to tyrosine residues to activate proteins.
PTPs are classified into several subfamilies based on their structure and function, including classical PTPs, dual-specificity PTPs (DSPs), and low molecular weight PTPs (LMW-PTPs). Each subfamily has distinct substrate specificities and regulatory mechanisms.
Classical PTPs are further divided into receptor-like PTPs (RPTPs) and non-receptor PTPs (NRPTPs). RPTPs contain a transmembrane domain and extracellular regions that mediate cell-cell interactions, while NRPTPs are soluble enzymes located in the cytoplasm.
DSPs can dephosphorylate both tyrosine and serine/threonine residues on proteins and play a critical role in regulating various signaling pathways, including the mitogen-activated protein kinase (MAPK) pathway.
LMW-PTPs are a group of small molecular weight PTPs that localize to different cellular compartments, such as the endoplasmic reticulum and mitochondria, and regulate various cellular processes, including protein folding and apoptosis.
Overall, PTPs play a critical role in maintaining the balance of phosphorylation and dephosphorylation events in cells, and dysregulation of PTP activity has been implicated in various diseases, including cancer, diabetes, and neurological disorders.
Cysteine is a semi-essential amino acid, which means that it can be produced by the human body under normal circumstances, but may need to be obtained from external sources in certain conditions such as illness or stress. Its chemical formula is HO2CCH(NH2)CH2SH, and it contains a sulfhydryl group (-SH), which allows it to act as a powerful antioxidant and participate in various cellular processes.
Cysteine plays important roles in protein structure and function, detoxification, and the synthesis of other molecules such as glutathione, taurine, and coenzyme A. It is also involved in wound healing, immune response, and the maintenance of healthy skin, hair, and nails.
Cysteine can be found in a variety of foods, including meat, poultry, fish, dairy products, eggs, legumes, nuts, seeds, and some grains. It is also available as a dietary supplement and can be used in the treatment of various medical conditions such as liver disease, bronchitis, and heavy metal toxicity. However, excessive intake of cysteine may have adverse effects on health, including gastrointestinal disturbances, nausea, vomiting, and headaches.
HLA-DR alpha-chains are a type of major histocompatibility complex (MHC) class II protein that is found on the surface of antigen-presenting cells, such as dendritic cells, macrophages, and B lymphocytes. The HLA-DR alpha-chain combines with an HLA-DR beta-chain to form a heterodimer, which then associates with another heterodimer (HLA-DR alpha/beta + HLA-DR beta/alpha) to create an HLA-DR tetramer.
These tetramers play a critical role in the adaptive immune response by presenting peptide antigens to CD4+ T cells, also known as helper T cells. The peptides are derived from extracellular proteins that have been processed and loaded onto the HLA-DR molecules within the antigen-presenting cell.
The binding of the CD4+ T cell receptor (TCR) to the HLA-DR-peptide complex results in T cell activation, which leads to the production of cytokines and the initiation of an immune response against the presented antigen. Genetic variations in HLA-DR alpha-chains can influence individual susceptibility to various autoimmune diseases and other immune-mediated disorders.
A gene in plants, like in other organisms, is a hereditary unit that carries genetic information from one generation to the next. It is a segment of DNA (deoxyribonucleic acid) that contains the instructions for the development and function of an organism. Genes in plants determine various traits such as flower color, plant height, resistance to diseases, and many others. They are responsible for encoding proteins and RNA molecules that play crucial roles in the growth, development, and reproduction of plants. Plant genes can be manipulated through traditional breeding methods or genetic engineering techniques to improve crop yield, enhance disease resistance, and increase nutritional value.
Microarray analysis is a laboratory technique used to measure the expression levels of large numbers of genes (or other types of DNA sequences) simultaneously. This technology allows researchers to monitor the expression of thousands of genes in a single experiment, providing valuable information about which genes are turned on or off in response to various stimuli or diseases.
In microarray analysis, samples of RNA from cells or tissues are labeled with fluorescent dyes and then hybridized to a solid surface (such as a glass slide) onto which thousands of known DNA sequences have been spotted in an organized array. The intensity of the fluorescence at each spot on the array is proportional to the amount of RNA that has bound to it, indicating the level of expression of the corresponding gene.
Microarray analysis can be used for a variety of applications, including identifying genes that are differentially expressed between healthy and diseased tissues, studying genetic variations in populations, and monitoring gene expression changes over time or in response to environmental factors. However, it is important to note that microarray data must be analyzed carefully using appropriate statistical methods to ensure the accuracy and reliability of the results.
 Tetracycline-controlled transcriptional activation
Tetracycline-controlled transcriptional activation
Transcription factor
ALYREF
Tuberous sclerosis protein
Activator (genetics)
Actin
Mothers against decapentaplegic homolog 4
RNA activation
Juliet Daniel
CRISPR activation
H4K20me
Avery August
Doris Wagner (scientist)
Transcriptional regulation
MAFK
Doxycycline
Cyclin-dependent kinase 7
XPB
GTF2H1
GTF2H4
CTCF
MNAT1
Cyclin H
GTF2H2
Mediator (coactivator)
SaRNA
Autoimmune regulator
RNA interference
TFEB
Activation-induced cell death
Tetracycline-controlled transcriptional activation - Wikipedia
 Activation of p53 transcriptional activity by SMRT: a histone deacetylase 3-independent function of a transcriptional...
Activation of p53 transcriptional activity by SMRT: a histone deacetylase 3-independent function of a transcriptional...
 Sirt1 Mediates Neuroprotection from Mutant Huntingtin by Activation of TORC1 and CREB Transcriptional Pathway
Sirt1 Mediates Neuroprotection from Mutant Huntingtin by Activation of TORC1 and CREB Transcriptional Pathway
 Description: Transcriptional activation and sensing propertiesof DegS-DegU: a two-component system involvedin the osmotic...
Description: Transcriptional activation and sensing propertiesof DegS-DegU: a two-component system involvedin the osmotic...
 Characterization of 5'-flanking region of rat somatostatin receptor sst2 gene: transcriptional regulatory elements and...
Characterization of 5'-flanking region of rat somatostatin receptor sst2 gene: transcriptional regulatory elements and...
 1509-C Transcriptional activation of mouse LINE-1 promoter by transcription factor YY1 | Journal for ImmunoTherapy of Cancer
1509-C Transcriptional activation of mouse LINE-1 promoter by transcription factor YY1 | Journal for ImmunoTherapy of Cancer
 Endothelial NOS, estrogen receptor beta, and HIFs cooperate in the activation of a prognostic transcriptional pattern in...
Endothelial NOS, estrogen receptor beta, and HIFs cooperate in the activation of a prognostic transcriptional pattern in...
 Transcriptional activation of the tyrosine phosphatase gene, OST-PTP, during osteoblast differentiation<...
Transcriptional activation of the tyrosine phosphatase gene, OST-PTP, during osteoblast differentiation<...
 Lactate dehydrogenase activity drives hair follicle stem cell activation | Nature Cell Biology
Lactate dehydrogenase activity drives hair follicle stem cell activation | Nature Cell Biology
 Genome-scale transcriptional activation by an engineered CRISPR-Cas9 complex
Genome-scale transcriptional activation by an engineered CRISPR-Cas9 complex
Site-directed targeting of transcriptional activation-associated proteins to repressed chromatin restores CRISPR activity | APL...
The interaction of Pax5 (BSAP) with Daxx can result in transcriptional activation in B cells<...
Autocrine transforming growth factor-{beta}1 activation mediated by integrin {alpha}V{beta}3 regulates transcriptional...
 Constitutive transcriptional activation by a beta-catenin-Tcf complex in APC-/- colon carcinoma.
Constitutive transcriptional activation by a beta-catenin-Tcf complex in APC-/- colon carcinoma.
 Activation of Multiple Transcriptional Regulators by Growth Restriction in
Activation of Multiple Transcriptional Regulators by Growth Restriction in
Cardiac hypertrophy is inhibited by antagonism of ADAM12 processing of HB-EGF: metalloproteinase inhibitors as a new therapy
 Spiral: Activation and transcriptional profile of monocytes and CD8+ T cells are altered in checkpoint inhibitor-related...
Spiral: Activation and transcriptional profile of monocytes and CD8+ T cells are altered in checkpoint inhibitor-related...
 Echinacoside-Zinc Nanomaterial Inhibits Skin Glycation by Suppressing the Transcriptional Activation of the Receptor for...
Echinacoside-Zinc Nanomaterial Inhibits Skin Glycation by Suppressing the Transcriptional Activation of the Receptor for...
Promoter-proximal pausing of RNA polymerase II: emerging roles in metazoans | Nature Reviews Genetics
 NWO Veni grants for research into frontline workers, social media and more | Radboud University
NWO Veni grants for research into frontline workers, social media and more | Radboud University
The role of basal and myogenic factors in the transcriptional activation of utrophin promoter A: implications for therapeutic...
 NK-cell activation is associated with increased HIV transcriptional activity following allogeneic hematopoietic cell...
NK-cell activation is associated with increased HIV transcriptional activity following allogeneic hematopoietic cell...
 ZNF322, a novel human C2H2 Kruppel-like zinc-finger protein, regulates transcriptional activation in MAPK signaling pathways. |...
ZNF322, a novel human C2H2 Kruppel-like zinc-finger protein, regulates transcriptional activation in MAPK signaling pathways. |...
 A transgenerational role of the germline nuclear RNAi pathway in repressing heat stress-induced transcriptional activation in C...
A transgenerational role of the germline nuclear RNAi pathway in repressing heat stress-induced transcriptional activation in C...
 Altmetric - NF-κB transcriptional activation by TNFα requires phospholipase C, extracellular signal-regulated kinase 2 and poly...
Altmetric - NF-κB transcriptional activation by TNFα requires phospholipase C, extracellular signal-regulated kinase 2 and poly...
LATS1 | Cancer Genetics Web
 Cancers | Free Full-Text | Transcriptional Control of Regulatory T Cells in Cancer: Toward Therapeutic Targeting?
Cancers | Free Full-Text | Transcriptional Control of Regulatory T Cells in Cancer: Toward Therapeutic Targeting?
HDAC3 | Cancer Genetics Web
 Frontiers | Long Non-coding RNAs as Functional and Structural Chromatin Modulators in Acute Myeloid Leukemia
Frontiers | Long Non-coding RNAs as Functional and Structural Chromatin Modulators in Acute Myeloid Leukemia
 Molecular Vision: Anti-inflammatory and anti-oxidative effects of the green tea polyphenol epigallocatechin gallate in human...
Molecular Vision: Anti-inflammatory and anti-oxidative effects of the green tea polyphenol epigallocatechin gallate in human...
Regulation10
- Taken together, the data from the present work shed a light on the transcriptional regulation of DegS-DegU two-component system in B. subtilis and implicated intracellular glutamate as a positive stimulus involved as a transducer of the information from the environment to the intracellular apparatus. (uni-marburg.de)
- Therefore, investigating LINE-1 transcriptional regulation is important for our understanding of LINE-1's role in cancer. (bmj.com)
- Conclusions Findings from our study increase our understanding of the transcriptional regulation of different mouse LINE-1 subfamilies, highlight the differing roles of YY1 in regulating human and mouse L1 transcription, and have important implications in the role of LINE-1s during cancer development. (bmj.com)
- Lis, J. Promoter-associated pausing in promoter architecture and postinitiation transcriptional regulation. (nature.com)
- The role of basal and myogenic factors in the transcriptional activation of utrophin promoter A: implications for therapeutic up-regulation in Duchenne muscular dystrophy. (ox.ac.uk)
- Histones play a critical role in transcriptional regulation, cell cycle progression, and developmental events. (cancerindex.org)
- The purpose of this study was to clarify the roles of paraspeckles in PXR-mediated transcriptional regulation. (aspetjournals.org)
- The major events in the regulation of the host response on a transcriptional level occur within the first 3 days after infection. (biomedcentral.com)
- Activation of Btk results in a cascade of signaling events resulting in calcium mobilization and fluxes, cytoskeletal rearrangements, and transcriptional regulation involving nuclear factor-kappaB (NF-kappaB) and nuclear factor of activated T cells (NFAT). (medscape.com)
- We provide a new mechanism for the regulation of heart development by PITX2 isoforms through the regulation of ANF and PLOD1 gene expression and Nkx2.5 transcriptional activity. (lu.se)
Repressor5
- The Tet-Off system makes use of the tetracycline transactivator (tTA) protein, which is created by fusing one protein, TetR (tetracycline repressor), found in Escherichia coli bacteria, with the activation domain of another protein, VP16, found in the herpes simplex virus. (wikipedia.org)
- Pax5 (BSAP) is essential for B cell development and acts both as a transcriptional activator and a repressor. (elsevierpure.com)
- These data suggest that Daxx can affect Pax5's roles as an activator or repressor in B cells and describe a role for Daxx as a transcriptional coactivator. (elsevierpure.com)
- It uses transcription activator-like effector (TALE) technology combined with VP64 activator or Kruppel-associated box (KRAB) repressor, both of which are potent transcriptional regulators that modify the epigenetic state of endogenous DNA loci. (springer.com)
- Cong L, Zhou R, Kuo YC et al (2012) Comprehensive interrogation of natural TALE DNA-binding modules and transcriptional repressor domains. (springer.com)
Repression2
- In plants and Schizosaccharomyces pombe , small interfering RNA (siRNA)-directed chromatin modifications (DNA methylation for plants and H3K9 methylation [H3K9me] for S. pombe ) lead to transcriptional repression. (biomedcentral.com)
- This protocol describes methods to design, assemble, and validate tools for targeted activation or repression of single-copy and multi-copy genes, including repetitive and transposable elements. (springer.com)
Chromatin4
- combinatorial complexes led to chromatin remodeling and transcriptional induction of prognostic genes. (tcd.ie)
- We also tested DNA-binding, transiently expressed activation-associated proteins (AAPs) that are known to support an open, transcriptionally active chromatin state. (aip.org)
- AML has a characteristic dependency on chromatin and transcriptional regulators, which has been discussed in many reviews. (frontiersin.org)
- Jachowicz JW, Bing X, Pontabry J et al (2017) Activation of LINE-1 after fertilisation regulates global chromatin accessibility. (springer.com)
Activator3
- These results indicate that YY1 is a transcriptional activator of mouse LINE-1 Tf_I subfamily. (bmj.com)
- Reporter gene assays show that ZNF322 is a transcriptional activator. (anthropogeny.org)
- Effects of EGCG on nuclear factor kappa B (NFκB) and activator protein-1 (AP-1) transcriptional activity were assessed by reporter gene assay. (molvis.org)
Genes5
- Although pausing has been connected to extremely rapid and synchronous activation of genes, pausing is also highly associated with constitutively expressed genes that encode signalling and transcription factors. (nature.com)
- Distinct signals that act through diverse targeted transcription factors can regulate different steps in the transcription pathway and provide a highly modulated transcriptional response at individual genes. (nature.com)
- By examining the mRNA, small RNA, RNA polymerase II, and H3K9 trimethylation profiles at the whole-genome level, we revealed an epigenetic role of HRDE-1 in repressing heat stress-induced transcriptional activation of over 280 genes. (biomedcentral.com)
- Strikingly, for some of these genes, the heat stress-induced transcriptional activation in the hrde - 1 mutant intensifies in the late generations under the heat stress and is heritable for at least two generations after the mutant animals are shifted back to lower temperature. (biomedcentral.com)
- Maeder ML, Angstman JF, Richardson ME et al (2013) Targeted DNA demethylation and activation of endogenous genes using programmable TALE-TET1 fusion proteins. (springer.com)
Regulators3
- Here we found that some physiologically important transcriptional regulators of Pseudomonas aeruginosa including QscR, a quorum sensing (QS) receptor, SoxR, a superoxide sensorregulator, and AntR, a regulator of anthranilate-related secondary metabolism, are activated by various growthrestricted conditions. (molcells.org)
- However, LasR and PqsR, other QS receptors of P. aeruginosa , were not activated, suggesting that only a specific set of transcriptional regulators is activated by growth restriction. (molcells.org)
- A unified nomenclature for protein subunits of mediator complexes linking transcriptional regulators to RNA polymerase II. (umu.se)
Post-transcriptional1
- In this review, we focus on the impact of ncRNA post-transcriptional regulatory mechanisms, especially those of microRNAs and lncRNAs, in RA signalling pathways during differentiation and disease. (mdpi.com)
Corepressor2
- The silencing mediator of retinoic acid and thyroid hormone receptors (SMRT) is an established histone deacetylase 3 (HDAC3)-dependent transcriptional corepressor. (nih.gov)
- A component of promyelocytic leukemia protein nuclear bodies, Daxx has been implicated in apoptosis and characterized as a transcriptional corepressor. (elsevierpure.com)
Regulates2
- Autocrine transforming growth factor-{beta}1 activation mediated by integrin {alpha}V{beta}3 regulates transcriptional expression of laminin-332 in Madin-Darby canine kidney epithelial cells. (uchicago.edu)
- ZNF322, a novel human C2H2 Kruppel-like zinc-finger protein, regulates transcriptional activation in MAPK signaling pathways. (anthropogeny.org)
Endogenous4
- Transient transfection of the OST promoter in differentiating MC3T3 results in a significant increase in transcriptional activation from day 0 to day 5 of differentiation, similar in timing and intensity to the observed upregulation of the endogenous gene. (umn.edu)
- Here we describe structure-guided engineering of a CRISPR-Cas9 complex to mediate efficient transcriptional activation at endogenous genomic loci. (cdc.gov)
- Upon transient transfection assay of Daxx in B cells expressing endogenous Daxx and Pax5, we observed not only transcriptional corepression but also, unexpectedly, coactivation in M12.4.1 and A20 mouse B cell lines. (elsevierpure.com)
- Our study demonstrated that a large number of the endogenous targets of the germline nuclear RNAi pathway in C. elegans are sensitive to heat-induced transcriptional activation. (biomedcentral.com)
Pathways1
- Genotoxic damage causes robust alterations to pathways associated with B cell activation and increased proliferation, suggesting that genotoxic damage initiates not only the normal B cell maturation processes but also mimics activated B cell response to antigenic agents. (biomedcentral.com)
Transactivation3
- Reintroduction of APC removed beta-catenin from hTcf-4 and abrogated the transcriptional transactivation. (bioseek.eu)
- We found that the shedding of heparin-binding epidermal growth factor (HB-EGF) resulting from metalloproteinase activation and subsequent transactivation of the epidermal growth factor receptor occurred when cardiomyocytes were stimulated by GPCR agonists, leading to cardiac hypertrophy. (nih.gov)
- The NTD of the hGRα contains a major transactivation domain, termed activation function (AF)-1, which is located between amino acids 77 and 262 of the hGRα and is ligand-independent. (medscape.com)
Protein3
- In parallel to exploring the role of the DegS-DegU system at the transcriptional and at the protein level, some additional experiments were performed in order to identify possible downstream regulated targets of the system. (uni-marburg.de)
- Non (protein)-coding RNAs are the most abundant transcriptional products of the coding genome, and comprise several different classes of molecules with unique lengths, conformations and targets. (frontiersin.org)
- Its activation is tightly controlled by numerous other signaling proteins including protein kinase C (PKC), Sab/SH3BP, and caveolin-1. (medscape.com)
Promoter2
- Investigations of the main degS-degU promoter in the presence of different charged and non-charged compound, which raised the surrounding osmolarity to an equal extent, demonstrated that the activation of the system is rather an osmotic response and not consequence of salt-specific stimulation. (uni-marburg.de)
- activation is via the proximal promoter. (lu.se)
Activity8
- Moreover, an HDAC3 binding-deficient SMRT DAD mutant coactivated p53 transcriptional activity. (nih.gov)
- We identified BDNF as an important target of Sirt1 and TORC1 transcriptional activity in normal and HD neurons. (harvard.edu)
- Genetic or pharmacologic modulation of eNOS expression and activity resulted in reciprocal conversion of the transcriptional signature in cells from patients with bad or good outcome, respectively, highlighting the relevance of eNOS in PCa progression. (tcd.ie)
- This activation appears to be specific to osteoblasts, since progression to a myoblast phenotype results in no change in reporter gene activity. (umn.edu)
- Figure 2: Ldh activity increases during HFSC activation. (nature.com)
- NK-cell activation is associated with increased HIV transcriptional activity following allogeneic hematopoietic cell transplantation. (harvard.edu)
- Furthermore, overexpression of ZNF322 in COS-7 cells activates the transcriptional activity of SRE and AP-1. (anthropogeny.org)
- and exerts a dominant negative effect on the transcriptional activity of hGRα. (medscape.com)
Gene expression4
- Tetracycline-controlled transcriptional activation is a method of inducible gene expression where transcription is reversibly turned on or off in the presence of the antibiotic tetracycline or one of its derivatives (e.g. doxycycline). (wikipedia.org)
- Whereas in the acute phase of the disease immunoregulatory processes prevail in the hippocampus and the cortex, we observed a strong activation of neurogenic processes in the hippocampal dentate gyrus, both by gene expression and immunohistology starting as early as 3 days after infection. (biomedcentral.com)
- Effect of AhR activation on STAT1, cell-cycle and gene expression in macrophages. (elifesciences.org)
- Transcription factors (TFs) are critical for B-cell differentiation, affecting gene expression both by repres- sion and transcriptional activation. (lu.se)
Regulatory1
- Transcriptional Control of Regulatory T Cells in Cancer: Toward Therapeutic Targeting? (mdpi.com)
Differentiation4
- Culturing these preosteoblast cells in the absence of critical co-factors results in an inhibition of differentiation and leads to a delayed induction of OST transcripts as well as the attenuation of transcriptional activation. (umn.edu)
- These results show that the murine OST gene is regulated at the transcriptional level in an osteoblast-specific, differentiation-dependent manner during the differentiation of MC3T3 osteoblasts. (umn.edu)
- Comparing these transcriptional responses provides a greater understanding of the mechanisms cells use in the differentiation between types of DNA damage and the potential consequences of different sources of damage. (biomedcentral.com)
- The excessive activation of AhR resulted in neural differentiation of Neuro2a cells. (biomedcentral.com)
Receptor2
- Endothelial NOS, estrogen receptor beta, and HIFs cooperate in the activation of a prognostic transcriptional pattern in aggressive human prostate cancer. (tcd.ie)
- Echinacoside-Zinc Nanomaterial Inhibits Skin Glycation by Suppressing the Transcriptional Activation of the Receptor for Advanced Glycation End-Products. (bvsalud.org)
Transfection1
- Surprisingly, PITX2A activation of the ANF and PLOD1 promoters is repressed by co- transfection of Nkx2.5 in the C3H10T1/ 2 embryonic fibroblast cell line. (lu.se)
Cytoskeletal1
- The neurological properties of N2a-Rα based on AhR activation were evaluated by immunohistochemical analysis of cytoskeletal molecules and by RT-PCR analysis of mRNA expression of neurotransmitter-production related molecules, such as tyrosine hydroxylase (TH). (biomedcentral.com)
Vitro3
- In vitro monocyte-derived macrophages (MoMFs) were assessed for activation and cytokine production. (imperial.ac.uk)
- This macrophage polarization can be simulated in vitro using lipopolysaccharide (LPS) and interferon (IFN)-γ stimulation for a proinflammatory subset termed classical activation and stimulation with interleukin (IL)-4 and IL-13 for an alternative polarization phenotype. (haematologica.org)
- Although the signaling mechanisms governing myelination are not fully understood, NF-κB activation in Schwann cells has been implicated as a key regulator in vitro . (jneurosci.org)
Genome3
- 2014). Genome-scale transcriptional activation by an engineered CRISPR-Cas9 complex. (cdc.gov)
- These genome wide transcriptional responses are very tightly regulated and complex. (biomedcentral.com)
- While it is known that genotoxic agents, such as IR, activate transcriptional programs involved in maintaining the integrity of the genome, we also want to investigate whether or not the genotoxic breaks could affect lymphocyte-specific maturation transcriptional responses similar to those we observed following RAG-induced physiological DSBs. (biomedcentral.com)
Alterations1
- Aberrant vascular remodeling contributes to the progression of many aging-associated diseases, including idiopathic pulmonary fibrosis (IPF), where heterogeneous capillary density, endothelial transcriptional alterations and increased vascular permeability correlate with poor disease outcomes. (researchgate.net)
Conclusions1
- Conclusions: CPI-Hep is associated with activation of peripheral monocytes and an enhanced cytotoxic, effector CD8+ T cell phenotype. (imperial.ac.uk)
Distinct1
- The blood microvascular endothelium consists of a heterogeneous population of cells with regionally distinct morphologies and transcriptional signatures in different tissues and organs. (researchgate.net)
Cells5
- In addition, its expression is considered to be more stable in eukaryotic cells due to being human codon optimized and utilizing three minimal transcriptional activation domains. (wikipedia.org)
- Effects of AhR activation in PBMC and purified CD4+ T cells. (elifesciences.org)
- Using a mouse model, we show that nuclear factor κB activation in Schwann cells is not required for myelination in vivo . (jneurosci.org)
- The activation of exogenous AhR in N2a-Rα cells was confirmed using RNAi, with si-AhR suppressing the expression of exogenous AhR. (biomedcentral.com)
- N2a-Rα cells exhibited constant activation of the exogenous AhR. (biomedcentral.com)
Reporter1
- WC-Co treatment also increased transcriptional activation of AP-1, NF-?B, and VEGF by reporter assay. (cdc.gov)
Role2
- These studies suggest a key role of Sirt1 in transcriptional networks in normal and HD brain and offer an opportunity for therapeutic development. (harvard.edu)
- Germline nuclear RNAi antagonizes this temperature effect at the transcriptional level and therefore may play a key role in heat stress response in C. elegans . (biomedcentral.com)
Level1
- Mechanistic studies at the cellular level showed that MDM2 can interact with STAT2 to form a transcriptional complex and thus promote RAGE transcriptional activation . (bvsalud.org)
Kinase1
- EGCG significantly inhibited phosphorylation of the MAPKs p38 and c-Jun N-terminal kinase (JNK), and NFκB and AP-1 transcriptional activities. (molvis.org)
Macrophages3
- To understand if polarization of macrophages can lead to a procoagulant macrophage subset we polarized human monocyte derived macrophages to a proinflammatory and an alternative activation state. (haematologica.org)
- AhR activation inhibits HIV-1 replication in macrophages. (elifesciences.org)
- Reduced CDK/cyclin, phospho-SAMHD1 and dTNP levels in macrophages following activation of AhR. (elifesciences.org)
Monocyte1
- Transcriptional profiling indicated the presence of activated monocyte and enhanced effector CD8+ T cell populations in CPI-Hep. (imperial.ac.uk)
Function1
- It inhibited the function of the MDM2/STAT2 complex and suppressed the transcriptional activation of RAGE , thereby exerting antiglycation effects. (bvsalud.org)
Response1
- We identified a central lymphocyte-specific transcriptional response common to both physiologic and genotoxic breaks, which includes many lymphocyte developmental processes. (biomedcentral.com)
Complex1
- Constitutive transcriptional activation by a beta-catenin-Tcf complex in APC-/- colon carcinoma. (bioseek.eu)
Vivo1
- Here, we show that NF-κB activation in SCs is dispensable for myelination in vivo . (jneurosci.org)
Results1
- These results suggest that PXR is trapped in paraspeckles and that the activation of PXR by its ligands facilitates its disassociation from paraspeckles. (aspetjournals.org)
Stimulation2
- Figure 6: Stimulation of Myc levels promotes HFSC activation. (nature.com)
- Previous polarization to either a proinflammatory or an alternative activation subset does not change the subsequent stimulation of TF. (haematologica.org)
Effect2
- Effect of AhR activation on HIV-1 replication. (elifesciences.org)
- This study focused on the effect of AhR activation in the developing neuron. (biomedcentral.com)
Human1
- It is also human codon optimized and composed of three minimal VP16 activation domains. (wikipedia.org)
Damage2
- Here we compare transcriptional responses to physiological DNA breaks with responses to genotoxic DNA damage induced by ionizing radiation. (biomedcentral.com)
- By comparing the transcriptional responses to both types of DNA damage, we can compare the similarities in the responses to damage as well as the differences induced by genotoxic damage. (biomedcentral.com)
Specific1
- We previously showed that physiologic breaks initiate lymphocyte development-specific transcriptional programs. (biomedcentral.com)
![Recombinant Anti-p53 antibody [E26] KO Tested (ab32389) | Abcam](https://www.abcam.com/ps/products/32/ab32389/Images/ab32389-389819-antip53antibodyimmunocytochemistryimmunofluorescencehap1human.jpg)