Support Vector Machines
Artificial Intelligence
Algorithms
Pattern Recognition, Automated
Sequence Analysis, Protein
Computational Biology
Databases, Protein
Software
Neural Networks (Computer)
Genetic Vectors
Reproducibility of Results
Diagnosis, Computer-Assisted
Proteins
Discriminant Analysis
ROC Curve
Least-Squares Analysis
Decision Trees
Sensitivity and Specificity
Fuzzy Logic
Models, Statistical
Image Interpretation, Computer-Assisted
Classification
Computer Simulation
Quantitative Structure-Activity Relationship
Sequence Alignment
Cluster Analysis
Gene Expression Profiling
Oligonucleotide Array Sequence Analysis
Principal Component Analysis
Data Mining
Wavelet Analysis
Natural Language Processing
Databases, Factual
Internet
Bayes Theorem
Area Under Curve
Brain-Computer Interfaces
Markov Chains
Models, Chemical
Amino Acid Sequence
Normal Distribution
Automation
Image Enhancement
Information Storage and Retrieval
Signal Processing, Computer-Assisted
Data Interpretation, Statistical
Position-Specific Scoring Matrices
Models, Molecular
Molecular Sequence Data
Sequence Analysis, RNA
Models, Theoretical
Space Simulation
PubMed
Dictionaries as Topic
Image Processing, Computer-Assisted
Radiographic Image Interpretation, Computer-Assisted
Biometric Identification
Insect Vectors
Binding Sites
Predictive Value of Tests
Pharmaceutical Preparations
Amino Acids
Models, Genetic
Magnetic Resonance Imaging
Expert Systems
Nonlinear Dynamics
User-Computer Interface
Models, Biological
Retinoscopy
Neoplasms
Sequence Analysis, DNA
Protein Structure, Secondary
MEDLINE
Enzymes
Imaging, Three-Dimensional
Protein Interaction Maps
Protein Binding
Brain
Terminology as Topic
Epitopes, B-Lymphocyte
Tumor Markers, Biological
Protein Conformation
Calibration
Base Sequence
Linear Models
Protein Array Analysis
Amino Acid Motifs
Disease Vectors
Peptides
MicroRNAs
Mild Cognitive Impairment
Predicting complexation thermodynamic parameters of beta-cyclodextrin with chiral guests by using swarm intelligence and support vector machines. (1/585)
(+info)Identifying protein-protein interaction sites using covering algorithm. (2/585)
(+info)Prediction of skin sensitization with a particle swarm optimized support vector machine. (3/585)
(+info)Improvement of structure conservation index with centroid estimators. (4/585)
RNAz, a support vector machine (SVM) approach for identifying functional non-coding RNAs (ncRNAs), has been proven to be one of the most accurate tools for this goal. Among the measurements used in RNAz, the Structure Conservation Index (SCI) which evaluates the evolutionary conservation of RNA secondary structures in terms of folding energies, has been reported to have an extremely high discrimination capability. However, for practical use of RNAz on the genome-wide search, a relatively high false discovery rate has unfortunately been estimated. It is conceivable that multiple alignments produced by a standard aligner that does not consider any secondary structures are not suitable for identifying ncRNAs in some cases and incur high false discovery rate. In this study, we propose C-SCI, an improved measurement based on the SCI applying gamma-centroid estimators to incorporate the robustness against low quality multiple alignments. Our experiments show that the C-SCI achieves higher accuracy than the original SCI for not only human-curated structural alignments but also low quality alignments produced by CLUSTAL W. Furthermore, the accuracy of the C-SCI on CLUSTAL W alignments is comparable with that of the original SCI on structural alignments generated with RAF for which 4.7-fold expensive computational time is required on average. (+info)Classification of 5-HT(1A) receptor ligands on the basis of their binding affinities by using PSO-Adaboost-SVM. (5/585)
(+info)Predicting phospholipidosis using machine learning. (6/585)
(+info)Brainstorming: weighted voting prediction of inhibitors for protein targets. (7/585)
(+info)A machine learning-based method to improve docking scoring functions and its application to drug repurposing. (8/585)
(+info)Support Vector Machines (SVM) is not a medical term, but a concept in machine learning, a branch of artificial intelligence. SVM is used in various fields including medicine for data analysis and pattern recognition. Here's a brief explanation of SVM:
Support Vector Machines is a supervised learning algorithm which analyzes data and recognizes patterns, used for classification and regression analysis. The goal of SVM is to find the optimal boundary or hyperplane that separates data into different classes with the maximum margin. This margin is the distance between the hyperplane and the nearest data points, also known as support vectors. By finding this optimal boundary, SVM can effectively classify new data points.
In the context of medical research, SVM has been used for various applications such as:
* Classifying medical images (e.g., distinguishing between cancerous and non-cancerous tissues)
* Predicting patient outcomes based on clinical or genetic data
* Identifying biomarkers associated with diseases
* Analyzing electronic health records to predict disease risk or treatment response
Therefore, while SVM is not a medical term per se, it is an important tool in the field of medical informatics and bioinformatics.
Artificial Intelligence (AI) in the medical context refers to the simulation of human intelligence processes by machines, particularly computer systems. These processes include learning (the acquisition of information and rules for using the information), reasoning (using the rules to reach approximate or definite conclusions), and self-correction.
In healthcare, AI is increasingly being used to analyze large amounts of data, identify patterns, make decisions, and perform tasks that would normally require human intelligence. This can include tasks such as diagnosing diseases, recommending treatments, personalizing patient care, and improving clinical workflows.
Examples of AI in medicine include machine learning algorithms that analyze medical images to detect signs of disease, natural language processing tools that extract relevant information from electronic health records, and robot-assisted surgery systems that enable more precise and minimally invasive procedures.
An algorithm is not a medical term, but rather a concept from computer science and mathematics. In the context of medicine, algorithms are often used to describe step-by-step procedures for diagnosing or managing medical conditions. These procedures typically involve a series of rules or decision points that help healthcare professionals make informed decisions about patient care.
For example, an algorithm for diagnosing a particular type of heart disease might involve taking a patient's medical history, performing a physical exam, ordering certain diagnostic tests, and interpreting the results in a specific way. By following this algorithm, healthcare professionals can ensure that they are using a consistent and evidence-based approach to making a diagnosis.
Algorithms can also be used to guide treatment decisions. For instance, an algorithm for managing diabetes might involve setting target blood sugar levels, recommending certain medications or lifestyle changes based on the patient's individual needs, and monitoring the patient's response to treatment over time.
Overall, algorithms are valuable tools in medicine because they help standardize clinical decision-making and ensure that patients receive high-quality care based on the latest scientific evidence.
Automated Pattern Recognition in a medical context refers to the use of computer algorithms and artificial intelligence techniques to identify, classify, and analyze specific patterns or trends in medical data. This can include recognizing visual patterns in medical images, such as X-rays or MRIs, or identifying patterns in large datasets of physiological measurements or electronic health records.
The goal of automated pattern recognition is to assist healthcare professionals in making more accurate diagnoses, monitoring disease progression, and developing personalized treatment plans. By automating the process of pattern recognition, it can help reduce human error, increase efficiency, and improve patient outcomes.
Examples of automated pattern recognition in medicine include using machine learning algorithms to identify early signs of diabetic retinopathy in eye scans or detecting abnormal heart rhythms in electrocardiograms (ECGs). These techniques can also be used to predict patient risk based on patterns in their medical history, such as identifying patients who are at high risk for readmission to the hospital.
Protein sequence analysis is the systematic examination and interpretation of the amino acid sequence of a protein to understand its structure, function, evolutionary relationships, and other biological properties. It involves various computational methods and tools to analyze the primary structure of proteins, which is the linear arrangement of amino acids along the polypeptide chain.
Protein sequence analysis can provide insights into several aspects, such as:
1. Identification of functional domains, motifs, or sites within a protein that may be responsible for its specific biochemical activities.
2. Comparison of homologous sequences from different organisms to infer evolutionary relationships and determine the degree of similarity or divergence among them.
3. Prediction of secondary and tertiary structures based on patterns of amino acid composition, hydrophobicity, and charge distribution.
4. Detection of post-translational modifications that may influence protein function, localization, or stability.
5. Identification of protease cleavage sites, signal peptides, or other sequence features that play a role in protein processing and targeting.
Some common techniques used in protein sequence analysis include:
1. Multiple Sequence Alignment (MSA): A method to align multiple protein sequences to identify conserved regions, gaps, and variations.
2. BLAST (Basic Local Alignment Search Tool): A widely-used tool for comparing a query protein sequence against a database of known sequences to find similarities and infer function or evolutionary relationships.
3. Hidden Markov Models (HMMs): Statistical models used to describe the probability distribution of amino acid sequences in protein families, allowing for more sensitive detection of remote homologs.
4. Protein structure prediction: Methods that use various computational approaches to predict the three-dimensional structure of a protein based on its amino acid sequence.
5. Phylogenetic analysis: The construction and interpretation of evolutionary trees (phylogenies) based on aligned protein sequences, which can provide insights into the historical relationships among organisms or proteins.
I'm happy to help! However, I believe there might be a bit of confusion in your question. "Computing methodologies" is a broad term that refers to the various approaches, techniques, and tools used to develop and implement computer systems, software, and solutions. It encompasses many different fields, including algorithms, data structures, programming languages, human-computer interaction, artificial intelligence, and more.
There isn't a specific medical definition for "computing methodologies" as it is not a term that is typically used within the medical field. However, if you have any specific questions about how computing methodologies are applied in healthcare or biomedical research, I would be happy to help! Just let me know what you're interested in learning more about.
Computational biology is a branch of biology that uses mathematical and computational methods to study biological data, models, and processes. It involves the development and application of algorithms, statistical models, and computational approaches to analyze and interpret large-scale molecular and phenotypic data from genomics, transcriptomics, proteomics, metabolomics, and other high-throughput technologies. The goal is to gain insights into biological systems and processes, develop predictive models, and inform experimental design and hypothesis testing in the life sciences. Computational biology encompasses a wide range of disciplines, including bioinformatics, systems biology, computational genomics, network biology, and mathematical modeling of biological systems.
A protein database is a type of biological database that contains information about proteins and their structures, functions, sequences, and interactions with other molecules. These databases can include experimentally determined data, such as protein sequences derived from DNA sequencing or mass spectrometry, as well as predicted data based on computational methods.
Some examples of protein databases include:
1. UniProtKB: a comprehensive protein database that provides information about protein sequences, functions, and structures, as well as literature references and links to other resources.
2. PDB (Protein Data Bank): a database of three-dimensional protein structures determined by experimental methods such as X-ray crystallography and nuclear magnetic resonance (NMR) spectroscopy.
3. BLAST (Basic Local Alignment Search Tool): a web-based tool that allows users to compare a query protein sequence against a protein database to identify similar sequences and potential functional relationships.
4. InterPro: a database of protein families, domains, and functional sites that provides information about protein function based on sequence analysis and other data.
5. STRING (Search Tool for the Retrieval of Interacting Genes/Proteins): a database of known and predicted protein-protein interactions, including physical and functional associations.
Protein databases are essential tools in proteomics research, enabling researchers to study protein function, evolution, and interaction networks on a large scale.
I am not aware of a widely accepted medical definition for the term "software," as it is more commonly used in the context of computer science and technology. Software refers to programs, data, and instructions that are used by computers to perform various tasks. It does not have direct relevance to medical fields such as anatomy, physiology, or clinical practice. If you have any questions related to medicine or healthcare, I would be happy to try to help with those instead!
A genetic vector is a vehicle, often a plasmid or a virus, that is used to introduce foreign DNA into a host cell as part of genetic engineering or gene therapy techniques. The vector contains the desired gene or genes, along with regulatory elements such as promoters and enhancers, which are needed for the expression of the gene in the target cells.
The choice of vector depends on several factors, including the size of the DNA to be inserted, the type of cell to be targeted, and the efficiency of uptake and expression required. Commonly used vectors include plasmids, adenoviruses, retroviruses, and lentiviruses.
Plasmids are small circular DNA molecules that can replicate independently in bacteria. They are often used as cloning vectors to amplify and manipulate DNA fragments. Adenoviruses are double-stranded DNA viruses that infect a wide range of host cells, including human cells. They are commonly used as gene therapy vectors because they can efficiently transfer genes into both dividing and non-dividing cells.
Retroviruses and lentiviruses are RNA viruses that integrate their genetic material into the host cell's genome. This allows for stable expression of the transgene over time. Lentiviruses, a subclass of retroviruses, have the advantage of being able to infect non-dividing cells, making them useful for gene therapy applications in post-mitotic tissues such as neurons and muscle cells.
Overall, genetic vectors play a crucial role in modern molecular biology and medicine, enabling researchers to study gene function, develop new therapies, and modify organisms for various purposes.
Reproducibility of results in a medical context refers to the ability to obtain consistent and comparable findings when a particular experiment or study is repeated, either by the same researcher or by different researchers, following the same experimental protocol. It is an essential principle in scientific research that helps to ensure the validity and reliability of research findings.
In medical research, reproducibility of results is crucial for establishing the effectiveness and safety of new treatments, interventions, or diagnostic tools. It involves conducting well-designed studies with adequate sample sizes, appropriate statistical analyses, and transparent reporting of methods and findings to allow other researchers to replicate the study and confirm or refute the results.
The lack of reproducibility in medical research has become a significant concern in recent years, as several high-profile studies have failed to produce consistent findings when replicated by other researchers. This has led to increased scrutiny of research practices and a call for greater transparency, rigor, and standardization in the conduct and reporting of medical research.
Computer-assisted diagnosis (CAD) is the use of computer systems to aid in the diagnostic process. It involves the use of advanced algorithms and data analysis techniques to analyze medical images, laboratory results, and other patient data to help healthcare professionals make more accurate and timely diagnoses. CAD systems can help identify patterns and anomalies that may be difficult for humans to detect, and they can provide second opinions and flag potential errors or uncertainties in the diagnostic process.
CAD systems are often used in conjunction with traditional diagnostic methods, such as physical examinations and patient interviews, to provide a more comprehensive assessment of a patient's health. They are commonly used in radiology, pathology, cardiology, and other medical specialties where imaging or laboratory tests play a key role in the diagnostic process.
While CAD systems can be very helpful in the diagnostic process, they are not infallible and should always be used as a tool to support, rather than replace, the expertise of trained healthcare professionals. It's important for medical professionals to use their clinical judgment and experience when interpreting CAD results and making final diagnoses.
Proteins are complex, large molecules that play critical roles in the body's functions. They are made up of amino acids, which are organic compounds that are the building blocks of proteins. Proteins are required for the structure, function, and regulation of the body's tissues and organs. They are essential for the growth, repair, and maintenance of body tissues, and they play a crucial role in many biological processes, including metabolism, immune response, and cellular signaling. Proteins can be classified into different types based on their structure and function, such as enzymes, hormones, antibodies, and structural proteins. They are found in various foods, especially animal-derived products like meat, dairy, and eggs, as well as plant-based sources like beans, nuts, and grains.
Discriminant analysis is a statistical method used for classifying observations or individuals into distinct categories or groups based on multiple predictor variables. It is commonly used in medical research to help diagnose or predict the presence or absence of a particular condition or disease.
In discriminant analysis, a linear combination of the predictor variables is created, and the resulting function is used to determine the group membership of each observation. The function is derived from the means and variances of the predictor variables for each group, with the goal of maximizing the separation between the groups while minimizing the overlap.
There are two types of discriminant analysis:
1. Linear Discriminant Analysis (LDA): This method assumes that the predictor variables are normally distributed and have equal variances within each group. LDA is used when there are two or more groups to be distinguished.
2. Quadratic Discriminant Analysis (QDA): This method does not assume equal variances within each group, allowing for more flexibility in modeling the distribution of predictor variables. QDA is used when there are two or more groups to be distinguished.
Discriminant analysis can be useful in medical research for developing diagnostic models that can accurately classify patients based on a set of clinical or laboratory measures. It can also be used to identify which predictor variables are most important in distinguishing between different groups, providing insights into the underlying biological mechanisms of disease.
A Receiver Operating Characteristic (ROC) curve is a graphical representation used in medical decision-making and statistical analysis to illustrate the performance of a binary classifier system, such as a diagnostic test or a machine learning algorithm. It's a plot that shows the tradeoff between the true positive rate (sensitivity) and the false positive rate (1 - specificity) for different threshold settings.
The x-axis of an ROC curve represents the false positive rate (the proportion of negative cases incorrectly classified as positive), while the y-axis represents the true positive rate (the proportion of positive cases correctly classified as positive). Each point on the curve corresponds to a specific decision threshold, with higher points indicating better performance.
The area under the ROC curve (AUC) is a commonly used summary measure that reflects the overall performance of the classifier. An AUC value of 1 indicates perfect discrimination between positive and negative cases, while an AUC value of 0.5 suggests that the classifier performs no better than chance.
ROC curves are widely used in healthcare to evaluate diagnostic tests, predictive models, and screening tools for various medical conditions, helping clinicians make informed decisions about patient care based on the balance between sensitivity and specificity.
Least-Squares Analysis is not a medical term, but rather a statistical method that is used in various fields including medicine. It is a way to find the best fit line or curve for a set of data points by minimizing the sum of the squared distances between the observed data points and the fitted line or curve. This method is often used in medical research to analyze data, such as fitting a regression line to a set of data points to make predictions or identify trends. The goal is to find the line or curve that most closely represents the pattern of the data, which can help researchers understand relationships between variables and make more informed decisions based on their analysis.
A decision tree is a graphical representation of possible solutions to a decision based on certain conditions. It is a predictive modeling tool commonly used in statistics, data mining, and machine learning. In the medical field, decision trees can be used for clinical decision-making and predicting patient outcomes based on various factors such as symptoms, test results, or demographic information.
In a decision tree, each internal node represents a feature or attribute, and each branch represents a possible value or outcome of that feature. The leaves of the tree represent the final decisions or predictions. Decision trees are constructed by recursively partitioning the data into subsets based on the most significant attributes until a stopping criterion is met.
Decision trees can be used for both classification and regression tasks, making them versatile tools in medical research and practice. They can help healthcare professionals make informed decisions about patient care, identify high-risk patients, and develop personalized treatment plans. However, it's important to note that decision trees are only as good as the data they are trained on, and their accuracy may be affected by biases or limitations in the data.
Sensitivity and specificity are statistical measures used to describe the performance of a diagnostic test or screening tool in identifying true positive and true negative results.
* Sensitivity refers to the proportion of people who have a particular condition (true positives) who are correctly identified by the test. It is also known as the "true positive rate" or "recall." A highly sensitive test will identify most or all of the people with the condition, but may also produce more false positives.
* Specificity refers to the proportion of people who do not have a particular condition (true negatives) who are correctly identified by the test. It is also known as the "true negative rate." A highly specific test will identify most or all of the people without the condition, but may also produce more false negatives.
In medical testing, both sensitivity and specificity are important considerations when evaluating a diagnostic test. High sensitivity is desirable for screening tests that aim to identify as many cases of a condition as possible, while high specificity is desirable for confirmatory tests that aim to rule out the condition in people who do not have it.
It's worth noting that sensitivity and specificity are often influenced by factors such as the prevalence of the condition in the population being tested, the threshold used to define a positive result, and the reliability and validity of the test itself. Therefore, it's important to consider these factors when interpreting the results of a diagnostic test.
I'm sorry for any confusion, but "Fuzzy Logic" is actually a term from the field of mathematics and computer science, not medicine. It is a form of many-valued logic that deals with reasoning that is approximate rather than fixed and exact. In contrast to traditional logic, where binary sets have distinct boundaries (true or false, 0 or 1, etc.), fuzzy logic allows for continuous values between 0 and 1, making it particularly useful in areas where precise definitions are difficult, such as medical diagnosis or robotics.
Statistical models are mathematical representations that describe the relationship between variables in a given dataset. They are used to analyze and interpret data in order to make predictions or test hypotheses about a population. In the context of medicine, statistical models can be used for various purposes such as:
1. Disease risk prediction: By analyzing demographic, clinical, and genetic data using statistical models, researchers can identify factors that contribute to an individual's risk of developing certain diseases. This information can then be used to develop personalized prevention strategies or early detection methods.
2. Clinical trial design and analysis: Statistical models are essential tools for designing and analyzing clinical trials. They help determine sample size, allocate participants to treatment groups, and assess the effectiveness and safety of interventions.
3. Epidemiological studies: Researchers use statistical models to investigate the distribution and determinants of health-related events in populations. This includes studying patterns of disease transmission, evaluating public health interventions, and estimating the burden of diseases.
4. Health services research: Statistical models are employed to analyze healthcare utilization, costs, and outcomes. This helps inform decisions about resource allocation, policy development, and quality improvement initiatives.
5. Biostatistics and bioinformatics: In these fields, statistical models are used to analyze large-scale molecular data (e.g., genomics, proteomics) to understand biological processes and identify potential therapeutic targets.
In summary, statistical models in medicine provide a framework for understanding complex relationships between variables and making informed decisions based on data-driven insights.
Computer-assisted image interpretation is the use of computer algorithms and software to assist healthcare professionals in analyzing and interpreting medical images. These systems use various techniques such as pattern recognition, machine learning, and artificial intelligence to help identify and highlight abnormalities or patterns within imaging data, such as X-rays, CT scans, MRI, and ultrasound images. The goal is to increase the accuracy, consistency, and efficiency of image interpretation, while also reducing the potential for human error. It's important to note that these systems are intended to assist healthcare professionals in their decision making process and not to replace them.
In the context of medicine, classification refers to the process of categorizing or organizing diseases, disorders, injuries, or other health conditions based on their characteristics, symptoms, causes, or other factors. This helps healthcare professionals to understand, diagnose, and treat various medical conditions more effectively.
There are several well-known classification systems in medicine, such as:
1. The International Classification of Diseases (ICD) - developed by the World Health Organization (WHO), it is used worldwide for mortality and morbidity statistics, reimbursement systems, and automated decision support in health care. This system includes codes for diseases, signs and symptoms, abnormal findings, social circumstances, and external causes of injury or diseases.
2. The Diagnostic and Statistical Manual of Mental Disorders (DSM) - published by the American Psychiatric Association, it provides a standardized classification system for mental health disorders to improve communication between mental health professionals, facilitate research, and guide treatment.
3. The International Classification of Functioning, Disability and Health (ICF) - developed by the WHO, this system focuses on an individual's functioning and disability rather than solely on their medical condition. It covers body functions and structures, activities, and participation, as well as environmental and personal factors that influence a person's life.
4. The TNM Classification of Malignant Tumors - created by the Union for International Cancer Control (UICC), it is used to describe the anatomical extent of cancer, including the size of the primary tumor (T), involvement of regional lymph nodes (N), and distant metastasis (M).
These classification systems help medical professionals communicate more effectively about patients' conditions, make informed treatment decisions, and track disease trends over time.
A computer simulation is a process that involves creating a model of a real-world system or phenomenon on a computer and then using that model to run experiments and make predictions about how the system will behave under different conditions. In the medical field, computer simulations are used for a variety of purposes, including:
1. Training and education: Computer simulations can be used to create realistic virtual environments where medical students and professionals can practice their skills and learn new procedures without risk to actual patients. For example, surgeons may use simulation software to practice complex surgical techniques before performing them on real patients.
2. Research and development: Computer simulations can help medical researchers study the behavior of biological systems at a level of detail that would be difficult or impossible to achieve through experimental methods alone. By creating detailed models of cells, tissues, organs, or even entire organisms, researchers can use simulation software to explore how these systems function and how they respond to different stimuli.
3. Drug discovery and development: Computer simulations are an essential tool in modern drug discovery and development. By modeling the behavior of drugs at a molecular level, researchers can predict how they will interact with their targets in the body and identify potential side effects or toxicities. This information can help guide the design of new drugs and reduce the need for expensive and time-consuming clinical trials.
4. Personalized medicine: Computer simulations can be used to create personalized models of individual patients based on their unique genetic, physiological, and environmental characteristics. These models can then be used to predict how a patient will respond to different treatments and identify the most effective therapy for their specific condition.
Overall, computer simulations are a powerful tool in modern medicine, enabling researchers and clinicians to study complex systems and make predictions about how they will behave under a wide range of conditions. By providing insights into the behavior of biological systems at a level of detail that would be difficult or impossible to achieve through experimental methods alone, computer simulations are helping to advance our understanding of human health and disease.
Quantitative Structure-Activity Relationship (QSAR) is a method used in toxicology and medicinal chemistry that attempts to establish mathematical relationships between the chemical structure of a compound and its biological activity. QSAR models are developed using statistical methods to analyze a set of compounds with known biological activities and their structural properties, which are represented as numerical or categorical descriptors. These models can then be used to predict the biological activity of new, structurally similar compounds.
QSAR models have been widely used in drug discovery and development, as well as in chemical risk assessment, to predict the potential toxicity of chemicals based on their structural properties. The accuracy and reliability of QSAR predictions depend on various factors, including the quality and diversity of the data used to develop the models, the choice of descriptors and statistical methods, and the applicability domain of the models.
In summary, QSAR is a quantitative method that uses mathematical relationships between chemical structure and biological activity to predict the potential toxicity or efficacy of new compounds based on their structural properties.
In genetics, sequence alignment is the process of arranging two or more DNA, RNA, or protein sequences to identify regions of similarity or homology between them. This is often done using computational methods to compare the nucleotide or amino acid sequences and identify matching patterns, which can provide insight into evolutionary relationships, functional domains, or potential genetic disorders. The alignment process typically involves adjusting gaps and mismatches in the sequences to maximize the similarity between them, resulting in an aligned sequence that can be visually represented and analyzed.
Cluster analysis is a statistical method used to group similar objects or data points together based on their characteristics or features. In medical and healthcare research, cluster analysis can be used to identify patterns or relationships within complex datasets, such as patient records or genetic information. This technique can help researchers to classify patients into distinct subgroups based on their symptoms, diagnoses, or other variables, which can inform more personalized treatment plans or public health interventions.
Cluster analysis involves several steps, including:
1. Data preparation: The researcher must first collect and clean the data, ensuring that it is complete and free from errors. This may involve removing outlier values or missing data points.
2. Distance measurement: Next, the researcher must determine how to measure the distance between each pair of data points. Common methods include Euclidean distance (the straight-line distance between two points) or Manhattan distance (the distance between two points along a grid).
3. Clustering algorithm: The researcher then applies a clustering algorithm, which groups similar data points together based on their distances from one another. Common algorithms include hierarchical clustering (which creates a tree-like structure of clusters) or k-means clustering (which assigns each data point to the nearest centroid).
4. Validation: Finally, the researcher must validate the results of the cluster analysis by evaluating the stability and robustness of the clusters. This may involve re-running the analysis with different distance measures or clustering algorithms, or comparing the results to external criteria.
Cluster analysis is a powerful tool for identifying patterns and relationships within complex datasets, but it requires careful consideration of the data preparation, distance measurement, and validation steps to ensure accurate and meaningful results.
Gene expression profiling is a laboratory technique used to measure the activity (expression) of thousands of genes at once. This technique allows researchers and clinicians to identify which genes are turned on or off in a particular cell, tissue, or organism under specific conditions, such as during health, disease, development, or in response to various treatments.
The process typically involves isolating RNA from the cells or tissues of interest, converting it into complementary DNA (cDNA), and then using microarray or high-throughput sequencing technologies to determine which genes are expressed and at what levels. The resulting data can be used to identify patterns of gene expression that are associated with specific biological states or processes, providing valuable insights into the underlying molecular mechanisms of diseases and potential targets for therapeutic intervention.
In recent years, gene expression profiling has become an essential tool in various fields, including cancer research, drug discovery, and personalized medicine, where it is used to identify biomarkers of disease, predict patient outcomes, and guide treatment decisions.
Oligonucleotide Array Sequence Analysis is a type of microarray analysis that allows for the simultaneous measurement of the expression levels of thousands of genes in a single sample. In this technique, oligonucleotides (short DNA sequences) are attached to a solid support, such as a glass slide, in a specific pattern. These oligonucleotides are designed to be complementary to specific target mRNA sequences from the sample being analyzed.
During the analysis, labeled RNA or cDNA from the sample is hybridized to the oligonucleotide array. The level of hybridization is then measured and used to determine the relative abundance of each target sequence in the sample. This information can be used to identify differences in gene expression between samples, which can help researchers understand the underlying biological processes involved in various diseases or developmental stages.
It's important to note that this technique requires specialized equipment and bioinformatics tools for data analysis, as well as careful experimental design and validation to ensure accurate and reproducible results.
Principal Component Analysis (PCA) is not a medical term, but a statistical technique that is used in various fields including bioinformatics and medicine. It is a method used to identify patterns in high-dimensional data by reducing the dimensionality of the data while retaining most of the variation in the dataset.
In medical or biological research, PCA may be used to analyze large datasets such as gene expression data or medical imaging data. By applying PCA, researchers can identify the principal components, which are linear combinations of the original variables that explain the maximum amount of variance in the data. These principal components can then be used for further analysis, visualization, and interpretation of the data.
PCA is a widely used technique in data analysis and has applications in various fields such as genomics, proteomics, metabolomics, and medical imaging. It helps researchers to identify patterns and relationships in complex datasets, which can lead to new insights and discoveries in medical research.
Data mining, in the context of health informatics and medical research, refers to the process of discovering patterns, correlations, and insights within large sets of patient or clinical data. It involves the use of advanced analytical techniques such as machine learning algorithms, statistical models, and artificial intelligence to identify and extract useful information from complex datasets.
The goal of data mining in healthcare is to support evidence-based decision making, improve patient outcomes, and optimize resource utilization. Applications of data mining in healthcare include predicting disease outbreaks, identifying high-risk patients, personalizing treatment plans, improving clinical workflows, and detecting fraud and abuse in healthcare systems.
Data mining can be performed on various types of healthcare data, including electronic health records (EHRs), medical claims databases, genomic data, imaging data, and sensor data from wearable devices. However, it is important to ensure that data mining techniques are used ethically and responsibly, with appropriate safeguards in place to protect patient privacy and confidentiality.
Protein interaction mapping is a research approach used to identify and characterize the physical interactions between different proteins within a cell or organism. This process often involves the use of high-throughput experimental techniques, such as yeast two-hybrid screening, mass spectrometry-based approaches, or protein fragment complementation assays, to detect and quantify the binding affinities of protein pairs. The resulting data is then used to construct a protein interaction network, which can provide insights into functional relationships between proteins, help elucidate cellular pathways, and inform our understanding of biological processes in health and disease.
Wavelet analysis is not a medical term, but rather a mathematical technique that has been applied in various fields, including medicine. It is a method used to analyze data signals or functions by decomposing them into different frequency components and time-shifted versions of the original signal. This allows for the examination of how the frequency content of a signal changes over time.
In the medical field, wavelet analysis has been applied in various ways such as:
1. Image processing: Wavelet analysis can be used to enhance medical images like MRI and CT scans by reducing noise while preserving important details.
2. Signal processing: It can be used to analyze physiological signals like ECG, EEG, and blood pressure waves to detect anomalies or patterns that may indicate diseases or conditions.
3. Data compression: Wavelet analysis is employed in the compression of large medical datasets, such as those generated by functional magnetic resonance imaging (fMRI) and positron emission tomography (PET) scans.
4. Biomedical engineering: Wavelet analysis can be used to model and simulate complex biological systems, like the cardiovascular system or the nervous system.
In summary, wavelet analysis is a mathematical technique that has been applied in various medical fields for image processing, signal processing, data compression, and biomedical engineering purposes.
I'm sorry for any confusion, but "Natural Language Processing" (NLP) is actually a subfield of artificial intelligence that focuses on the interaction between computers and human language. It involves developing algorithms and software to understand, interpret, and generate human language in a valuable way.
In a medical context, NLP can be used to analyze electronic health records, clinical notes, and other forms of medical documentation to extract meaningful information, support clinical decision-making, and improve patient care. For example, NLP can help identify patients at risk for certain conditions, monitor treatment responses, and detect adverse drug events.
However, NLP is not a medical term or concept itself, so it doesn't have a specific medical definition.
A genetic database is a type of biomedical or health informatics database that stores and organizes genetic data, such as DNA sequences, gene maps, genotypes, haplotypes, and phenotype information. These databases can be used for various purposes, including research, clinical diagnosis, and personalized medicine.
There are different types of genetic databases, including:
1. Genomic databases: These databases store whole genome sequences, gene expression data, and other genomic information. Examples include the National Center for Biotechnology Information's (NCBI) GenBank, the European Nucleotide Archive (ENA), and the DNA Data Bank of Japan (DDBJ).
2. Gene databases: These databases contain information about specific genes, including their location, function, regulation, and evolution. Examples include the Online Mendelian Inheritance in Man (OMIM) database, the Universal Protein Resource (UniProt), and the Gene Ontology (GO) database.
3. Variant databases: These databases store information about genetic variants, such as single nucleotide polymorphisms (SNPs), insertions/deletions (INDELs), and copy number variations (CNVs). Examples include the Database of Single Nucleotide Polymorphisms (dbSNP), the Catalogue of Somatic Mutations in Cancer (COSMIC), and the International HapMap Project.
4. Clinical databases: These databases contain genetic and clinical information about patients, such as their genotype, phenotype, family history, and response to treatments. Examples include the ClinVar database, the Pharmacogenomics Knowledgebase (PharmGKB), and the Genetic Testing Registry (GTR).
5. Population databases: These databases store genetic information about different populations, including their ancestry, demographics, and genetic diversity. Examples include the 1000 Genomes Project, the Human Genome Diversity Project (HGDP), and the Allele Frequency Net Database (AFND).
Genetic databases can be publicly accessible or restricted to authorized users, depending on their purpose and content. They play a crucial role in advancing our understanding of genetics and genomics, as well as improving healthcare and personalized medicine.
A factual database in the medical context is a collection of organized and structured data that contains verified and accurate information related to medicine, healthcare, or health sciences. These databases serve as reliable resources for various stakeholders, including healthcare professionals, researchers, students, and patients, to access evidence-based information for making informed decisions and enhancing knowledge.
Examples of factual medical databases include:
1. PubMed: A comprehensive database of biomedical literature maintained by the US National Library of Medicine (NLM). It contains citations and abstracts from life sciences journals, books, and conference proceedings.
2. MEDLINE: A subset of PubMed, MEDLINE focuses on high-quality, peer-reviewed articles related to biomedicine and health. It is the primary component of the NLM's database and serves as a critical resource for healthcare professionals and researchers worldwide.
3. Cochrane Library: A collection of systematic reviews and meta-analyses focused on evidence-based medicine. The library aims to provide unbiased, high-quality information to support clinical decision-making and improve patient outcomes.
4. OVID: A platform that offers access to various medical and healthcare databases, including MEDLINE, Embase, and PsycINFO. It facilitates the search and retrieval of relevant literature for researchers, clinicians, and students.
5. ClinicalTrials.gov: A registry and results database of publicly and privately supported clinical studies conducted around the world. The platform aims to increase transparency and accessibility of clinical trial data for healthcare professionals, researchers, and patients.
6. UpToDate: An evidence-based, physician-authored clinical decision support resource that provides information on diagnosis, treatment, and prevention of medical conditions. It serves as a point-of-care tool for healthcare professionals to make informed decisions and improve patient care.
7. TRIP Database: A search engine designed to facilitate evidence-based medicine by providing quick access to high-quality resources, including systematic reviews, clinical guidelines, and practice recommendations.
8. National Guideline Clearinghouse (NGC): A database of evidence-based clinical practice guidelines and related documents developed through a rigorous review process. The NGC aims to provide clinicians, healthcare providers, and policymakers with reliable guidance for patient care.
9. DrugBank: A comprehensive, freely accessible online database containing detailed information about drugs, their mechanisms, interactions, and targets. It serves as a valuable resource for researchers, healthcare professionals, and students in the field of pharmacology and drug discovery.
10. Genetic Testing Registry (GTR): A database that provides centralized information about genetic tests, test developers, laboratories offering tests, and clinical validity and utility of genetic tests. It serves as a resource for healthcare professionals, researchers, and patients to make informed decisions regarding genetic testing.
I'm sorry for any confusion, but "Internet" is a term that pertains to the global network of interconnected computers and servers that enable the transmission and reception of data via the internet protocol (IP). It is not a medical term and does not have a specific medical definition. If you have any questions related to medicine or health, I'd be happy to try to help answer them for you!
Bayes' theorem, also known as Bayes' rule or Bayes' formula, is a fundamental principle in the field of statistics and probability theory. It describes how to update the probability of a hypothesis based on new evidence or data. The theorem is named after Reverend Thomas Bayes, who first formulated it in the 18th century.
In mathematical terms, Bayes' theorem states that the posterior probability of a hypothesis (H) given some observed evidence (E) is proportional to the product of the prior probability of the hypothesis (P(H)) and the likelihood of observing the evidence given the hypothesis (P(E|H)):
Posterior Probability = P(H|E) = [P(E|H) x P(H)] / P(E)
Where:
* P(H|E): The posterior probability of the hypothesis H after observing evidence E. This is the probability we want to calculate.
* P(E|H): The likelihood of observing evidence E given that the hypothesis H is true.
* P(H): The prior probability of the hypothesis H before observing any evidence.
* P(E): The marginal likelihood or probability of observing evidence E, regardless of whether the hypothesis H is true or not. This value can be calculated as the sum of the products of the likelihood and prior probability for all possible hypotheses: P(E) = Σ[P(E|Hi) x P(Hi)]
Bayes' theorem has many applications in various fields, including medicine, where it can be used to update the probability of a disease diagnosis based on test results or other clinical findings. It is also widely used in machine learning and artificial intelligence algorithms for probabilistic reasoning and decision making under uncertainty.
The term "Area Under Curve" (AUC) is commonly used in the medical field, particularly in the analysis of diagnostic tests or pharmacokinetic studies. The AUC refers to the mathematical calculation of the area between a curve and the x-axis in a graph, typically representing a concentration-time profile.
In the context of diagnostic tests, the AUC is used to evaluate the performance of a test by measuring the entire two-dimensional area underneath the receiver operating characteristic (ROC) curve, which plots the true positive rate (sensitivity) against the false positive rate (1-specificity) at various threshold settings. The AUC ranges from 0 to 1, where a higher AUC indicates better test performance:
* An AUC of 0.5 suggests that the test is no better than chance.
* An AUC between 0.7 and 0.8 implies moderate accuracy.
* An AUC between 0.8 and 0.9 indicates high accuracy.
* An AUC greater than 0.9 signifies very high accuracy.
In pharmacokinetic studies, the AUC is used to assess drug exposure over time by calculating the area under a plasma concentration-time curve (AUC(0-t) or AUC(0-\∞)) following drug administration. This value can help determine dosing regimens and evaluate potential drug interactions:
* AUC(0-t): Represents the area under the plasma concentration-time curve from time zero to the last measurable concentration (t).
* AUC(0-\∞): Refers to the area under the plasma concentration-time curve from time zero to infinity, which estimates total drug exposure.
A Brain-Computer Interface (BCI), also known as a neural-control interface or a brain-machine interface, is a system that enables direct communication and interaction between the human brain and an external electronic device. BCI technology translates brain signals into commands that can control artificial devices, such as computers, prosthetic limbs, or other assistive technologies.
There are primarily two types of BCIs: invasive and non-invasive. Invasive BCIs involve the surgical implantation of electrodes directly onto the surface or within the brain tissue to record neural activity with high resolution. Non-invasive BCIs, on the other hand, utilize external sensors, like electroencephalography (EEG) caps, to measure brain signals through the scalp.
The applications of BCIs are vast and varied, including communication aids for individuals with severe motor disabilities, rehabilitation tools for stroke patients, and assistive devices for people with amputations or spinal cord injuries. Additionally, BCI technology holds potential for enhancing human performance in various fields, such as gaming, education, and military applications. However, it is essential to consider the ethical implications and potential risks associated with BCI use as the technology continues to advance.
I'm sorry for any confusion, but "Markov Chains" is a term from the field of mathematics and probability theory, not medicine. Markov Chains are mathematical systems that undergo transitions from one state to another according to certain probabilistic rules. They are named after Russian mathematician Andrey Markov. These chains are used in various fields, including computer science, physics, economics, and engineering, but not commonly in medical definitions or contexts.
A chemical model is a simplified representation or description of a chemical system, based on the laws of chemistry and physics. It is used to explain and predict the behavior of chemicals and chemical reactions. Chemical models can take many forms, including mathematical equations, diagrams, and computer simulations. They are often used in research, education, and industry to understand complex chemical processes and develop new products and technologies.
For example, a chemical model might be used to describe the way that atoms and molecules interact in a particular reaction, or to predict the properties of a new material. Chemical models can also be used to study the behavior of chemicals at the molecular level, such as how they bind to each other or how they are affected by changes in temperature or pressure.
It is important to note that chemical models are simplifications of reality and may not always accurately represent every aspect of a chemical system. They should be used with caution and validated against experimental data whenever possible.
'Abbreviations as Topic' in medical terms refers to the use and interpretation of abbreviated words or phrases that are commonly used in the field of medicine. These abbreviations can represent various concepts, such as medical conditions, treatments, procedures, diagnostic tests, and more.
Medical abbreviations are often used in clinical documentation, including patient records, progress notes, orders, and medication administration records. They help healthcare professionals communicate efficiently and effectively, reducing the need for lengthy descriptions and improving clarity in written communication.
However, medical abbreviations can also be a source of confusion and error if they are misinterpreted or used incorrectly. Therefore, it is essential to use standardized abbreviations that are widely recognized and accepted within the medical community. Additionally, healthcare professionals should always ensure that their use of abbreviations does not compromise patient safety or lead to misunderstandings in patient care.
Examples of commonly used medical abbreviations include:
* PT: Physical Therapy
* BP: Blood Pressure
* HR: Heart Rate
* Rx: Prescription
* NPO: Nothing by Mouth
* IV: Intravenous
* IM: Intramuscular
* COPD: Chronic Obstructive Pulmonary Disease
* MI: Myocardial Infarction (Heart Attack)
* Dx: Diagnosis
It is important to note that some medical abbreviations can have multiple meanings, and their interpretation may depend on the context in which they are used. Therefore, it is essential to use caution when interpreting medical abbreviations and seek clarification if necessary to ensure accurate communication and patient care.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
To the best of my knowledge, "Normal Distribution" is not a term that has a specific medical definition. It is a statistical concept that describes a distribution of data points in which the majority of the data falls around a central value, with fewer and fewer data points appearing as you move further away from the center in either direction. This type of distribution is also known as a "bell curve" because of its characteristic shape.
In medical research, normal distribution may be used to describe the distribution of various types of data, such as the results of laboratory tests or patient outcomes. For example, if a large number of people are given a particular laboratory test, their test results might form a normal distribution, with most people having results close to the average and fewer people having results that are much higher or lower than the average.
It's worth noting that in some cases, data may not follow a normal distribution, and other types of statistical analyses may be needed to accurately describe and analyze the data.
Automation in the medical context refers to the use of technology and programming to allow machines or devices to operate with minimal human intervention. This can include various types of medical equipment, such as laboratory analyzers, imaging devices, and robotic surgical systems. Automation can help improve efficiency, accuracy, and safety in healthcare settings by reducing the potential for human error and allowing healthcare professionals to focus on higher-level tasks. It is important to note that while automation has many benefits, it is also essential to ensure that appropriate safeguards are in place to prevent accidents and maintain quality of care.
Image enhancement in the medical context refers to the process of improving the quality and clarity of medical images, such as X-rays, CT scans, MRI scans, or ultrasound images, to aid in the diagnosis and treatment of medical conditions. Image enhancement techniques may include adjusting contrast, brightness, or sharpness; removing noise or artifacts; or applying specialized algorithms to highlight specific features or structures within the image.
The goal of image enhancement is to provide clinicians with more accurate and detailed information about a patient's anatomy or physiology, which can help inform medical decision-making and improve patient outcomes.
'Information Storage and Retrieval' in the context of medical informatics refers to the processes and systems used for the recording, storing, organizing, protecting, and retrieving electronic health information (e.g., patient records, clinical data, medical images) for various purposes such as diagnosis, treatment planning, research, and education. This may involve the use of electronic health record (EHR) systems, databases, data warehouses, and other digital technologies that enable healthcare providers to access and share accurate, up-to-date, and relevant information about a patient's health status, medical history, and care plan. The goal is to improve the quality, safety, efficiency, and coordination of healthcare delivery by providing timely and evidence-based information to support clinical decision-making and patient engagement.
Computer-assisted signal processing is a medical term that refers to the use of computer algorithms and software to analyze, interpret, and extract meaningful information from biological signals. These signals can include physiological data such as electrocardiogram (ECG) waves, electromyography (EMG) signals, electroencephalography (EEG) readings, or medical images.
The goal of computer-assisted signal processing is to automate the analysis of these complex signals and extract relevant features that can be used for diagnostic, monitoring, or therapeutic purposes. This process typically involves several steps, including:
1. Signal acquisition: Collecting raw data from sensors or medical devices.
2. Preprocessing: Cleaning and filtering the data to remove noise and artifacts.
3. Feature extraction: Identifying and quantifying relevant features in the signal, such as peaks, troughs, or patterns.
4. Analysis: Applying statistical or machine learning algorithms to interpret the extracted features and make predictions about the underlying physiological state.
5. Visualization: Presenting the results in a clear and intuitive way for clinicians to review and use.
Computer-assisted signal processing has numerous applications in healthcare, including:
* Diagnosing and monitoring cardiac arrhythmias or other heart conditions using ECG signals.
* Assessing muscle activity and function using EMG signals.
* Monitoring brain activity and diagnosing neurological disorders using EEG readings.
* Analyzing medical images to detect abnormalities, such as tumors or fractures.
Overall, computer-assisted signal processing is a powerful tool for improving the accuracy and efficiency of medical diagnosis and monitoring, enabling clinicians to make more informed decisions about patient care.
Statistical data interpretation involves analyzing and interpreting numerical data in order to identify trends, patterns, and relationships. This process often involves the use of statistical methods and tools to organize, summarize, and draw conclusions from the data. The goal is to extract meaningful insights that can inform decision-making, hypothesis testing, or further research.
In medical contexts, statistical data interpretation is used to analyze and make sense of large sets of clinical data, such as patient outcomes, treatment effectiveness, or disease prevalence. This information can help healthcare professionals and researchers better understand the relationships between various factors that impact health outcomes, develop more effective treatments, and identify areas for further study.
Some common statistical methods used in data interpretation include descriptive statistics (e.g., mean, median, mode), inferential statistics (e.g., hypothesis testing, confidence intervals), and regression analysis (e.g., linear, logistic). These methods can help medical professionals identify patterns and trends in the data, assess the significance of their findings, and make evidence-based recommendations for patient care or public health policy.
Position-Specific Scoring Matrices (PSSMs) are a type of statistical model used in bioinformatics and computational biology, particularly in the field of protein and DNA sequence analysis. They are used to represent the probability of finding each possible amino acid or nucleotide at each position in a multiple sequence alignment.
In a PSSM, each position in the alignment is represented by a row in the matrix, and each possible amino acid or nucleotide is represented by a column. The entry in the matrix at the intersection of a position and an amino acid or nucleotide represents the log-odds score of finding that amino acid or nucleotide at that position, relative to the background frequency of that amino acid or nucleotide in all possible sequences.
PSSMs are often used as input to profile hidden Markov models (HMMs) and other machine learning algorithms for protein and DNA sequence analysis. They can be generated from a multiple sequence alignment using tools such as PSI-BLAST or HMMER. The use of PSSMs allows for more sensitive and accurate identification of conserved motifs and patterns in biological sequences, compared to simple sequence alignments or pattern matching approaches.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
Software validation, in the context of medical devices and healthcare, is the process of evaluating software to ensure that it meets specified requirements for its intended use and that it performs as expected. This process is typically carried out through testing and other verification methods to ensure that the software functions correctly, safely, and reliably in a real-world environment. The goal of software validation is to provide evidence that the software is fit for its intended purpose and complies with relevant regulations and standards. It is an important part of the overall process of bringing a medical device or healthcare technology to market, as it helps to ensure patient safety and regulatory compliance.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
RNA Sequence Analysis is a branch of bioinformatics that involves the determination and analysis of the nucleotide sequence of Ribonucleic Acid (RNA) molecules. This process includes identifying and characterizing the individual RNA molecules, determining their functions, and studying their evolutionary relationships.
RNA Sequence Analysis typically involves the use of high-throughput sequencing technologies to generate large datasets of RNA sequences, which are then analyzed using computational methods. The analysis may include comparing the sequences to reference databases to identify known RNA molecules or discovering new ones, identifying patterns and features in the sequences, such as motifs or domains, and predicting the secondary and tertiary structures of the RNA molecules.
RNA Sequence Analysis has many applications in basic research, including understanding gene regulation, identifying novel non-coding RNAs, and studying evolutionary relationships between organisms. It also has practical applications in clinical settings, such as diagnosing and monitoring diseases, developing new therapies, and personalized medicine.
The term "Theoretical Models" is used in various scientific fields, including medicine, to describe a representation of a complex system or phenomenon. It is a simplified framework that explains how different components of the system interact with each other and how they contribute to the overall behavior of the system. Theoretical models are often used in medical research to understand and predict the outcomes of diseases, treatments, or public health interventions.
A theoretical model can take many forms, such as mathematical equations, computer simulations, or conceptual diagrams. It is based on a set of assumptions and hypotheses about the underlying mechanisms that drive the system. By manipulating these variables and observing the effects on the model's output, researchers can test their assumptions and generate new insights into the system's behavior.
Theoretical models are useful for medical research because they allow scientists to explore complex systems in a controlled and systematic way. They can help identify key drivers of disease or treatment outcomes, inform the design of clinical trials, and guide the development of new interventions. However, it is important to recognize that theoretical models are simplifications of reality and may not capture all the nuances and complexities of real-world systems. Therefore, they should be used in conjunction with other forms of evidence, such as experimental data and observational studies, to inform medical decision-making.
I'm sorry for any confusion, but "space simulation" is not a term typically used in medical definitions. It is a concept more commonly found in the fields of aerospace engineering and virtual reality technology. In those contexts, space simulation refers to the creation of artificial environments intended to replicate various aspects of outer space, such as zero gravity or the appearance of celestial bodies. These simulations can be used for training astronauts, testing spacecraft and equipment, or for entertainment purposes like video games. If you have any questions related to medical definitions, I'd be happy to help with those!
PubMed is not a medical condition or term, but rather a biomedical literature search engine and database maintained by the National Center for Biotechnology Information (NCBI), a division of the U.S. National Library of Medicine (NLM). It provides access to life sciences literature, including journal articles in medicine, nursing, dentistry, veterinary medicine, health care systems, and preclinical sciences.
PubMed contains more than 30 million citations and abstracts from MEDLINE, life science journals, and online books. Many of the citations include links to full-text articles on publishers' websites or through NCBI's DocSumo service. Researchers, healthcare professionals, students, and the general public use PubMed to find relevant and reliable information in the biomedical literature for research, education, and patient care purposes.
"Dictionaries as Topic" is a medical subject heading (MeSH) that refers to the study or discussion of dictionaries as a reference source in the field of medicine. Dictionaries used in this context are specialized works that provide definitions and explanations of medical terms, concepts, and technologies. They serve as important tools for healthcare professionals, researchers, students, and patients to communicate effectively and accurately about health and disease.
Medical dictionaries can cover a wide range of topics, including anatomy, physiology, pharmacology, pathology, diagnostic procedures, treatment methods, and medical ethics. They may also provide information on medical eponyms, abbreviations, symbols, and units of measurement. Some medical dictionaries are general in scope, while others focus on specific areas of medicine or healthcare, such as nursing, dentistry, veterinary medicine, or alternative medicine.
The use of medical dictionaries can help to ensure that medical terminology is used consistently and correctly, which is essential for accurate diagnosis, treatment planning, and communication among healthcare providers and between providers and patients. Medical dictionaries can also be useful for non-medical professionals who need to understand medical terms in the context of their work, such as lawyers, journalists, and policymakers.
Computer-assisted image processing is a medical term that refers to the use of computer systems and specialized software to improve, analyze, and interpret medical images obtained through various imaging techniques such as X-ray, CT (computed tomography), MRI (magnetic resonance imaging), ultrasound, and others.
The process typically involves several steps, including image acquisition, enhancement, segmentation, restoration, and analysis. Image processing algorithms can be used to enhance the quality of medical images by adjusting contrast, brightness, and sharpness, as well as removing noise and artifacts that may interfere with accurate diagnosis. Segmentation techniques can be used to isolate specific regions or structures of interest within an image, allowing for more detailed analysis.
Computer-assisted image processing has numerous applications in medical imaging, including detection and characterization of lesions, tumors, and other abnormalities; assessment of organ function and morphology; and guidance of interventional procedures such as biopsies and surgeries. By automating and standardizing image analysis tasks, computer-assisted image processing can help to improve diagnostic accuracy, efficiency, and consistency, while reducing the potential for human error.
Proteomics is the large-scale study and analysis of proteins, including their structures, functions, interactions, modifications, and abundance, in a given cell, tissue, or organism. It involves the identification and quantification of all expressed proteins in a biological sample, as well as the characterization of post-translational modifications, protein-protein interactions, and functional pathways. Proteomics can provide valuable insights into various biological processes, diseases, and drug responses, and has applications in basic research, biomedicine, and clinical diagnostics. The field combines various techniques from molecular biology, chemistry, physics, and bioinformatics to study proteins at a systems level.
Computer-assisted radiographic image interpretation is the use of computer algorithms and software to assist and enhance the interpretation and analysis of medical images produced by radiography, such as X-rays, CT scans, and MRI scans. The computer-assisted system can help identify and highlight certain features or anomalies in the image, such as tumors, fractures, or other abnormalities, which may be difficult for the human eye to detect. This technology can improve the accuracy and speed of diagnosis, and may also reduce the risk of human error. It's important to note that the final interpretation and diagnosis is always made by a qualified healthcare professional, such as a radiologist, who takes into account the computer-assisted analysis in conjunction with their clinical expertise and knowledge.
Pharmaceutical databases are collections of information related to pharmaceuticals and medications. These databases can contain a variety of data types, including:
1. Drug information: This includes details about the chemical properties, therapeutic uses, dosages, side effects, interactions, and contraindications of medications.
2. Clinical trials data: Information on ongoing or completed clinical trials, including study design, participant demographics, outcomes, and safety data.
3. Prescription data: Data related to prescribing patterns, medication utilization, and adherence.
4. Pharmacoeconomic data: Cost-effectiveness analyses, budget impact models, and other economic evaluations of medications.
5. Regulatory information: Details about drug approvals, labeling changes, and safety alerts from regulatory agencies such as the US Food and Drug Administration (FDA) or the European Medicines Agency (EMA).
6. Pharmacovigilance data: Information on adverse events, medication errors, and other safety concerns reported to pharmacovigilance databases.
7. Literature databases: Citations and abstracts from medical literature related to pharmaceuticals and medications.
Pharmaceutical databases can be used by healthcare professionals, researchers, regulatory agencies, and the pharmaceutical industry for a variety of purposes, including drug development, clinical decision making, post-marketing surveillance, and health policy planning.
Biometric identification is the use of automated processes to identify a person based on their unique physical or behavioral characteristics. These characteristics, known as biometrics, can include fingerprints, facial recognition, iris scans, voice patterns, and other distinctive traits that are difficult to replicate or forge. Biometric identification systems work by capturing and analyzing these features with specialized hardware and software, comparing them against a database of known individuals to find a match.
Biometric identification is becoming increasingly popular in security applications, such as access control for buildings and devices, border control, and law enforcement. It offers several advantages over traditional methods of identification, such as passwords or ID cards, which can be lost, stolen, or easily replicated. By contrast, biometric traits are unique to each individual and cannot be easily changed or duplicated.
However, there are also concerns around privacy and the potential for misuse of biometric data. It is important that appropriate safeguards are in place to protect individuals' personal information and prevent unauthorized access or use.
Insect vectors are insects that transmit disease-causing pathogens (such as viruses, bacteria, parasites) from one host to another. They do this while feeding on the host's blood or tissues. The insects themselves are not infected by the pathogen but act as mechanical carriers that pass it on during their bite. Examples of diseases spread by insect vectors include malaria (transmitted by mosquitoes), Lyme disease (transmitted by ticks), and plague (transmitted by fleas). Proper prevention measures, such as using insect repellent and reducing standing water where mosquitoes breed, can help reduce the risk of contracting these diseases.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
The Predictive Value of Tests, specifically the Positive Predictive Value (PPV) and Negative Predictive Value (NPV), are measures used in diagnostic tests to determine the probability that a positive or negative test result is correct.
Positive Predictive Value (PPV) is the proportion of patients with a positive test result who actually have the disease. It is calculated as the number of true positives divided by the total number of positive results (true positives + false positives). A higher PPV indicates that a positive test result is more likely to be a true positive, and therefore the disease is more likely to be present.
Negative Predictive Value (NPV) is the proportion of patients with a negative test result who do not have the disease. It is calculated as the number of true negatives divided by the total number of negative results (true negatives + false negatives). A higher NPV indicates that a negative test result is more likely to be a true negative, and therefore the disease is less likely to be present.
The predictive value of tests depends on the prevalence of the disease in the population being tested, as well as the sensitivity and specificity of the test. A test with high sensitivity and specificity will generally have higher predictive values than a test with low sensitivity and specificity. However, even a highly sensitive and specific test can have low predictive values if the prevalence of the disease is low in the population being tested.
Pharmaceutical preparations refer to the various forms of medicines that are produced by pharmaceutical companies, which are intended for therapeutic or prophylactic use. These preparations consist of an active ingredient (the drug) combined with excipients (inactive ingredients) in a specific formulation and dosage form.
The active ingredient is the substance that has a therapeutic effect on the body, while the excipients are added to improve the stability, palatability, bioavailability, or administration of the drug. Examples of pharmaceutical preparations include tablets, capsules, solutions, suspensions, emulsions, ointments, creams, and injections.
The production of pharmaceutical preparations involves a series of steps that ensure the quality, safety, and efficacy of the final product. These steps include the selection and testing of raw materials, formulation development, manufacturing, packaging, labeling, and storage. Each step is governed by strict regulations and guidelines to ensure that the final product meets the required standards for use in medical practice.
Amino acids are organic compounds that serve as the building blocks of proteins. They consist of a central carbon atom, also known as the alpha carbon, which is bonded to an amino group (-NH2), a carboxyl group (-COOH), a hydrogen atom (H), and a variable side chain (R group). The R group can be composed of various combinations of atoms such as hydrogen, oxygen, sulfur, nitrogen, and carbon, which determine the unique properties of each amino acid.
There are 20 standard amino acids that are encoded by the genetic code and incorporated into proteins during translation. These include:
1. Alanine (Ala)
2. Arginine (Arg)
3. Asparagine (Asn)
4. Aspartic acid (Asp)
5. Cysteine (Cys)
6. Glutamine (Gln)
7. Glutamic acid (Glu)
8. Glycine (Gly)
9. Histidine (His)
10. Isoleucine (Ile)
11. Leucine (Leu)
12. Lysine (Lys)
13. Methionine (Met)
14. Phenylalanine (Phe)
15. Proline (Pro)
16. Serine (Ser)
17. Threonine (Thr)
18. Tryptophan (Trp)
19. Tyrosine (Tyr)
20. Valine (Val)
Additionally, there are several non-standard or modified amino acids that can be incorporated into proteins through post-translational modifications, such as hydroxylation, methylation, and phosphorylation. These modifications expand the functional diversity of proteins and play crucial roles in various cellular processes.
Amino acids are essential for numerous biological functions, including protein synthesis, enzyme catalysis, neurotransmitter production, energy metabolism, and immune response regulation. Some amino acids can be synthesized by the human body (non-essential), while others must be obtained through dietary sources (essential).
Genetic models are theoretical frameworks used in genetics to describe and explain the inheritance patterns and genetic architecture of traits, diseases, or phenomena. These models are based on mathematical equations and statistical methods that incorporate information about gene frequencies, modes of inheritance, and the effects of environmental factors. They can be used to predict the probability of certain genetic outcomes, to understand the genetic basis of complex traits, and to inform medical management and treatment decisions.
There are several types of genetic models, including:
1. Mendelian models: These models describe the inheritance patterns of simple genetic traits that follow Mendel's laws of segregation and independent assortment. Examples include autosomal dominant, autosomal recessive, and X-linked inheritance.
2. Complex trait models: These models describe the inheritance patterns of complex traits that are influenced by multiple genes and environmental factors. Examples include heart disease, diabetes, and cancer.
3. Population genetics models: These models describe the distribution and frequency of genetic variants within populations over time. They can be used to study evolutionary processes, such as natural selection and genetic drift.
4. Quantitative genetics models: These models describe the relationship between genetic variation and phenotypic variation in continuous traits, such as height or IQ. They can be used to estimate heritability and to identify quantitative trait loci (QTLs) that contribute to trait variation.
5. Statistical genetics models: These models use statistical methods to analyze genetic data and infer the presence of genetic associations or linkage. They can be used to identify genetic risk factors for diseases or traits.
Overall, genetic models are essential tools in genetics research and medical genetics, as they allow researchers to make predictions about genetic outcomes, test hypotheses about the genetic basis of traits and diseases, and develop strategies for prevention, diagnosis, and treatment.
Medical Definition:
Magnetic Resonance Imaging (MRI) is a non-invasive diagnostic imaging technique that uses a strong magnetic field and radio waves to create detailed cross-sectional or three-dimensional images of the internal structures of the body. The patient lies within a large, cylindrical magnet, and the scanner detects changes in the direction of the magnetic field caused by protons in the body. These changes are then converted into detailed images that help medical professionals to diagnose and monitor various medical conditions, such as tumors, injuries, or diseases affecting the brain, spinal cord, heart, blood vessels, joints, and other internal organs. MRI does not use radiation like computed tomography (CT) scans.
An Expert System is a type of artificial intelligence (AI) program that emulates the decision-making ability of a human expert in a specific field or domain. It is designed to solve complex problems by using a set of rules, heuristics, and knowledge base derived from human expertise. The system can simulate the problem-solving process of a human expert, allowing it to provide advice, make recommendations, or diagnose problems in a similar manner. Expert systems are often used in fields such as medicine, engineering, finance, and law where specialized knowledge and experience are critical for making informed decisions.
The medical definition of 'Expert Systems' refers to AI programs that assist healthcare professionals in diagnosing and treating medical conditions, based on a large database of medical knowledge and clinical expertise. These systems can help doctors and other healthcare providers make more accurate diagnoses, recommend appropriate treatments, and provide patient education. They may also be used for research, training, and quality improvement purposes.
Expert systems in medicine typically use a combination of artificial intelligence techniques such as rule-based reasoning, machine learning, natural language processing, and pattern recognition to analyze medical data and provide expert advice. Examples of medical expert systems include MYCIN, which was developed to diagnose infectious diseases, and Internist-1, which assists in the diagnosis and management of internal medicine cases.
"Nonlinear dynamics is a branch of mathematics and physics that deals with the study of systems that exhibit nonlinear behavior, where the output is not directly proportional to the input. In the context of medicine, nonlinear dynamics can be used to model complex biological systems such as the human cardiovascular system or the brain, where the interactions between different components can lead to emergent properties and behaviors that are difficult to predict using traditional linear methods. Nonlinear dynamic models can help to understand the underlying mechanisms of these systems, make predictions about their behavior, and develop interventions to improve health outcomes."
A User-Computer Interface (also known as Human-Computer Interaction) refers to the point at which a person (user) interacts with a computer system. This can include both hardware and software components, such as keyboards, mice, touchscreens, and graphical user interfaces (GUIs). The design of the user-computer interface is crucial in determining the usability and accessibility of a computer system for the user. A well-designed interface should be intuitive, efficient, and easy to use, minimizing the cognitive load on the user and allowing them to effectively accomplish their tasks.
Biological models, also known as physiological models or organismal models, are simplified representations of biological systems, processes, or mechanisms that are used to understand and explain the underlying principles and relationships. These models can be theoretical (conceptual or mathematical) or physical (such as anatomical models, cell cultures, or animal models). They are widely used in biomedical research to study various phenomena, including disease pathophysiology, drug action, and therapeutic interventions.
Examples of biological models include:
1. Mathematical models: These use mathematical equations and formulas to describe complex biological systems or processes, such as population dynamics, metabolic pathways, or gene regulation networks. They can help predict the behavior of these systems under different conditions and test hypotheses about their underlying mechanisms.
2. Cell cultures: These are collections of cells grown in a controlled environment, typically in a laboratory dish or flask. They can be used to study cellular processes, such as signal transduction, gene expression, or metabolism, and to test the effects of drugs or other treatments on these processes.
3. Animal models: These are living organisms, usually vertebrates like mice, rats, or non-human primates, that are used to study various aspects of human biology and disease. They can provide valuable insights into the pathophysiology of diseases, the mechanisms of drug action, and the safety and efficacy of new therapies.
4. Anatomical models: These are physical representations of biological structures or systems, such as plastic models of organs or tissues, that can be used for educational purposes or to plan surgical procedures. They can also serve as a basis for developing more sophisticated models, such as computer simulations or 3D-printed replicas.
Overall, biological models play a crucial role in advancing our understanding of biology and medicine, helping to identify new targets for therapeutic intervention, develop novel drugs and treatments, and improve human health.
Retinoscopy is a diagnostic technique used in optometry and ophthalmology to estimate the refractive error of the eye, or in other words, to determine the prescription for eyeglasses or contact lenses. This procedure involves shining a light into the patient's pupil and observing the reflection off the retina while introducing different lenses in front of the patient's eye. The examiner then uses specific movements and observations to determine the amount and type of refractive error, such as myopia (nearsightedness), hyperopia (farsightedness), astigmatism, or presbyopia. Retinoscopy is a fundamental skill for eye care professionals and helps ensure that patients receive accurate prescriptions for corrective lenses.
Neoplasms are abnormal growths of cells or tissues in the body that serve no physiological function. They can be benign (non-cancerous) or malignant (cancerous). Benign neoplasms are typically slow growing and do not spread to other parts of the body, while malignant neoplasms are aggressive, invasive, and can metastasize to distant sites.
Neoplasms occur when there is a dysregulation in the normal process of cell division and differentiation, leading to uncontrolled growth and accumulation of cells. This can result from genetic mutations or other factors such as viral infections, environmental exposures, or hormonal imbalances.
Neoplasms can develop in any organ or tissue of the body and can cause various symptoms depending on their size, location, and type. Treatment options for neoplasms include surgery, radiation therapy, chemotherapy, immunotherapy, and targeted therapy, among others.
Automatic Data Processing (ADP) is not a medical term, but a general business term that refers to the use of computers and software to automate and streamline administrative tasks and processes. In a medical context, ADP may be used in healthcare settings to manage electronic health records (EHRs), billing and coding, insurance claims processing, and other data-intensive tasks.
The goal of using ADP in healthcare is to improve efficiency, accuracy, and timeliness of administrative processes, while reducing costs and errors associated with manual data entry and management. By automating these tasks, healthcare providers can focus more on patient care and less on paperwork, ultimately improving the quality of care delivered to patients.
DNA Sequence Analysis is the systematic determination of the order of nucleotides in a DNA molecule. It is a critical component of modern molecular biology, genetics, and genetic engineering. The process involves determining the exact order of the four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - in a DNA molecule or fragment. This information is used in various applications such as identifying gene mutations, studying evolutionary relationships, developing molecular markers for breeding, and diagnosing genetic diseases.
The process of DNA Sequence Analysis typically involves several steps, including DNA extraction, PCR amplification (if necessary), purification, sequencing reaction, and electrophoresis. The resulting data is then analyzed using specialized software to determine the exact sequence of nucleotides.
In recent years, high-throughput DNA sequencing technologies have revolutionized the field of genomics, enabling the rapid and cost-effective sequencing of entire genomes. This has led to an explosion of genomic data and new insights into the genetic basis of many diseases and traits.
Secondary protein structure refers to the local spatial arrangement of amino acid chains in a protein, typically described as regular repeating patterns held together by hydrogen bonds. The two most common types of secondary structures are the alpha-helix (α-helix) and the beta-pleated sheet (β-sheet). In an α-helix, the polypeptide chain twists around itself in a helical shape, with each backbone atom forming a hydrogen bond with the fourth amino acid residue along the chain. This forms a rigid rod-like structure that is resistant to bending or twisting forces. In β-sheets, adjacent segments of the polypeptide chain run parallel or antiparallel to each other and are connected by hydrogen bonds, forming a pleated sheet-like arrangement. These secondary structures provide the foundation for the formation of tertiary and quaternary protein structures, which determine the overall three-dimensional shape and function of the protein.
Medline is not a medical condition or term, but rather a biomedical bibliographic database, which is a component of the U.S. National Library of Medicine (NLM)'s PubMed system. It contains citations and abstracts from scientific literature in the fields of life sciences, biomedicine, and clinical medicine, with a focus on articles published in peer-reviewed journals. Medline covers a wide range of topics, including research articles, reviews, clinical trials, and case reports. The database is updated daily and provides access to over 26 million references from the years 1946 to the present. It's an essential resource for healthcare professionals, researchers, and students in the biomedical field.
Genomics is the scientific study of genes and their functions. It involves the sequencing and analysis of an organism's genome, which is its complete set of DNA, including all of its genes. Genomics also includes the study of how genes interact with each other and with the environment. This field of study can provide important insights into the genetic basis of diseases and can lead to the development of new diagnostic tools and treatments.
Drug discovery is the process of identifying new chemical entities or biological agents that have the potential to be used as therapeutic or preventive treatments for diseases. This process involves several stages, including target identification, lead identification, hit-to-lead optimization, lead optimization, preclinical development, and clinical trials.
Target identification is the initial stage of drug discovery, where researchers identify a specific molecular target, such as a protein or gene, that plays a key role in the disease process. Lead identification involves screening large libraries of chemical compounds or natural products to find those that interact with the target molecule and have potential therapeutic activity.
Hit-to-lead optimization is the stage where researchers optimize the chemical structure of the lead compound to improve its potency, selectivity, and safety profile. Lead optimization involves further refinement of the compound's structure to create a preclinical development candidate. Preclinical development includes studies in vitro (in test tubes or petri dishes) and in vivo (in animals) to evaluate the safety, efficacy, and pharmacokinetics of the drug candidate.
Clinical trials are conducted in human volunteers to assess the safety, tolerability, and efficacy of the drug candidate in treating the disease. If the drug is found to be safe and effective in clinical trials, it may be approved by regulatory agencies such as the U.S. Food and Drug Administration (FDA) for use in patients.
Overall, drug discovery is a complex and time-consuming process that requires significant resources, expertise, and collaboration between researchers, clinicians, and industry partners.
Enzymes are complex proteins that act as catalysts to speed up chemical reactions in the body. They help to lower activation energy required for reactions to occur, thereby enabling the reaction to happen faster and at lower temperatures. Enzymes work by binding to specific molecules, called substrates, and converting them into different molecules, called products. This process is known as catalysis.
Enzymes are highly specific and will only catalyze one particular reaction with a specific substrate. The shape of the enzyme's active site, where the substrate binds, determines this specificity. Enzymes can be regulated by various factors such as temperature, pH, and the presence of inhibitors or activators. They play a crucial role in many biological processes, including digestion, metabolism, and DNA replication.
Three-dimensional (3D) imaging in medicine refers to the use of technologies and techniques that generate a 3D representation of internal body structures, organs, or tissues. This is achieved by acquiring and processing data from various imaging modalities such as X-ray computed tomography (CT), magnetic resonance imaging (MRI), ultrasound, or confocal microscopy. The resulting 3D images offer a more detailed visualization of the anatomy and pathology compared to traditional 2D imaging techniques, allowing for improved diagnostic accuracy, surgical planning, and minimally invasive interventions.
In 3D imaging, specialized software is used to reconstruct the acquired data into a volumetric model, which can be manipulated and viewed from different angles and perspectives. This enables healthcare professionals to better understand complex anatomical relationships, detect abnormalities, assess disease progression, and monitor treatment response. Common applications of 3D imaging include neuroimaging, orthopedic surgery planning, cancer staging, dental and maxillofacial reconstruction, and interventional radiology procedures.
Protein interaction maps are graphical representations that illustrate the physical interactions and functional relationships between different proteins in a cell or organism. These maps can be generated through various experimental techniques such as yeast two-hybrid screens, affinity purification mass spectrometry (AP-MS), and co-immunoprecipitation (Co-IP) followed by mass spectrometry. The resulting data is then visualized as a network where nodes represent proteins and edges represent the interactions between them. Protein interaction maps can provide valuable insights into cellular processes, signal transduction pathways, and disease mechanisms, and are widely used in systems biology and network medicine research.
Protein binding, in the context of medical and biological sciences, refers to the interaction between a protein and another molecule (known as the ligand) that results in a stable complex. This process is often reversible and can be influenced by various factors such as pH, temperature, and concentration of the involved molecules.
In clinical chemistry, protein binding is particularly important when it comes to drugs, as many of them bind to proteins (especially albumin) in the bloodstream. The degree of protein binding can affect a drug's distribution, metabolism, and excretion, which in turn influence its therapeutic effectiveness and potential side effects.
Protein-bound drugs may be less available for interaction with their target tissues, as only the unbound or "free" fraction of the drug is active. Therefore, understanding protein binding can help optimize dosing regimens and minimize adverse reactions.
The brain is the central organ of the nervous system, responsible for receiving and processing sensory information, regulating vital functions, and controlling behavior, movement, and cognition. It is divided into several distinct regions, each with specific functions:
1. Cerebrum: The largest part of the brain, responsible for higher cognitive functions such as thinking, learning, memory, language, and perception. It is divided into two hemispheres, each controlling the opposite side of the body.
2. Cerebellum: Located at the back of the brain, it is responsible for coordinating muscle movements, maintaining balance, and fine-tuning motor skills.
3. Brainstem: Connects the cerebrum and cerebellum to the spinal cord, controlling vital functions such as breathing, heart rate, and blood pressure. It also serves as a relay center for sensory information and motor commands between the brain and the rest of the body.
4. Diencephalon: A region that includes the thalamus (a major sensory relay station) and hypothalamus (regulates hormones, temperature, hunger, thirst, and sleep).
5. Limbic system: A group of structures involved in emotional processing, memory formation, and motivation, including the hippocampus, amygdala, and cingulate gyrus.
The brain is composed of billions of interconnected neurons that communicate through electrical and chemical signals. It is protected by the skull and surrounded by three layers of membranes called meninges, as well as cerebrospinal fluid that provides cushioning and nutrients.
"Terminology as a topic" in the context of medical education and practice refers to the study and use of specialized language and terms within the field of medicine. This includes understanding the meaning, origins, and appropriate usage of medical terminology in order to effectively communicate among healthcare professionals and with patients. It may also involve studying the evolution and cultural significance of medical terminology. The importance of "terminology as a topic" lies in promoting clear and accurate communication, which is essential for providing safe and effective patient care.
An epitope is a specific region on an antigen (a substance that triggers an immune response) that is recognized and bound by an antibody or a B-lymphocyte (a type of white blood cell that produces antibodies). Epitopes are also sometimes referred to as antigenic determinants.
B-lymphocytes, or B cells, are a type of immune cell that plays a key role in the humoral immune response. They produce and secrete antibodies, which are proteins that recognize and bind to specific epitopes on antigens. When a B cell encounters an antigen, it binds to the antigen at its surface receptor, which recognizes a specific epitope on the antigen. This binding activates the B cell, causing it to divide and differentiate into plasma cells, which produce and secrete large amounts of antibody that is specific for the epitope on the antigen.
The ability of an antibody or a B cell to recognize and bind to a specific epitope is determined by the structure of the variable region of the antibody or B cell receptor. The variable region is made up of several loops of amino acids, called complementarity-determining regions (CDRs), that form a binding site for the antigen. The CDRs are highly variable in sequence and length, allowing them to recognize and bind to a wide variety of different epitopes.
In summary, an epitope is a specific region on an antigen that is recognized and bound by an antibody or a B-lymphocyte. The ability of an antibody or a B cell to recognize and bind to a specific epitope is determined by the structure of the variable region of the antibody or B cell receptor.
The proteome is the entire set of proteins produced or present in an organism, system, organ, or cell at a certain time under specific conditions. It is a dynamic collection of protein species that changes over time, responding to various internal and external stimuli such as disease, stress, or environmental factors. The study of the proteome, known as proteomics, involves the identification and quantification of these protein components and their post-translational modifications, providing valuable insights into biological processes, functional pathways, and disease mechanisms.
Tumor markers are substances that can be found in the body and their presence can indicate the presence of certain types of cancer or other conditions. Biological tumor markers refer to those substances that are produced by cancer cells or by other cells in response to cancer or certain benign (non-cancerous) conditions. These markers can be found in various bodily fluids such as blood, urine, or tissue samples.
Examples of biological tumor markers include:
1. Proteins: Some tumor markers are proteins that are produced by cancer cells or by other cells in response to the presence of cancer. For example, prostate-specific antigen (PSA) is a protein produced by normal prostate cells and in higher amounts by prostate cancer cells.
2. Genetic material: Tumor markers can also include genetic material such as DNA, RNA, or microRNA that are shed by cancer cells into bodily fluids. For example, circulating tumor DNA (ctDNA) is genetic material from cancer cells that can be found in the bloodstream.
3. Metabolites: Tumor markers can also include metabolic products produced by cancer cells or by other cells in response to cancer. For example, lactate dehydrogenase (LDH) is an enzyme that is released into the bloodstream when cancer cells break down glucose for energy.
It's important to note that tumor markers are not specific to cancer and can be elevated in non-cancerous conditions as well. Therefore, they should not be used alone to diagnose cancer but rather as a tool in conjunction with other diagnostic tests and clinical evaluations.
Protein conformation refers to the specific three-dimensional shape that a protein molecule assumes due to the spatial arrangement of its constituent amino acid residues and their associated chemical groups. This complex structure is determined by several factors, including covalent bonds (disulfide bridges), hydrogen bonds, van der Waals forces, and ionic bonds, which help stabilize the protein's unique conformation.
Protein conformations can be broadly classified into two categories: primary, secondary, tertiary, and quaternary structures. The primary structure represents the linear sequence of amino acids in a polypeptide chain. The secondary structure arises from local interactions between adjacent amino acid residues, leading to the formation of recurring motifs such as α-helices and β-sheets. Tertiary structure refers to the overall three-dimensional folding pattern of a single polypeptide chain, while quaternary structure describes the spatial arrangement of multiple folded polypeptide chains (subunits) that interact to form a functional protein complex.
Understanding protein conformation is crucial for elucidating protein function, as the specific three-dimensional shape of a protein directly influences its ability to interact with other molecules, such as ligands, nucleic acids, or other proteins. Any alterations in protein conformation due to genetic mutations, environmental factors, or chemical modifications can lead to loss of function, misfolding, aggregation, and disease states like neurodegenerative disorders and cancer.
In the context of medicine and medical devices, calibration refers to the process of checking, adjusting, or confirming the accuracy of a measurement instrument or system. This is typically done by comparing the measurements taken by the device being calibrated to those taken by a reference standard of known accuracy. The goal of calibration is to ensure that the medical device is providing accurate and reliable measurements, which is critical for making proper diagnoses and delivering effective treatment. Regular calibration is an important part of quality assurance and helps to maintain the overall performance and safety of medical devices.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
I'm sorry for any confusion, but "Linear Models" is actually a term from the field of statistics and machine learning, rather than medicine. A linear model is a type of statistical model that is used to analyze the relationship between two or more variables. In a linear model, the relationship between the dependent variable (the outcome or result) and the independent variable(s) (the factors being studied) is assumed to be linear, meaning that it can be described by a straight line on a graph.
The equation for a simple linear model with one independent variable (x) and one dependent variable (y) looks like this:
y = β0 + β1*x + ε
In this equation, β0 is the y-intercept or the value of y when x equals zero, β1 is the slope or the change in y for each unit increase in x, and ε is the error term or the difference between the actual values of y and the predicted values of y based on the linear model.
Linear models are widely used in medical research to study the relationship between various factors (such as exposure to a risk factor or treatment) and health outcomes (such as disease incidence or mortality). They can also be used to adjust for confounding variables, which are factors that may influence both the independent variable and the dependent variable, and thus affect the observed relationship between them.
I'm sorry for any confusion, but "semantics" is not a term that has a specific medical definition. Semantics is actually a branch of linguistics that deals with the study of meaning, reference, and the interpretation of signs and symbols, either individually or in combination. It is used in various fields including computer science, anthropology, psychology, and philosophy.
However, if you have any medical terms or concepts that you would like me to explain, I'd be happy to help!
Protein array analysis is a high-throughput technology used to detect and measure the presence and activity of specific proteins in biological samples. This technique utilizes arrays or chips containing various capture agents, such as antibodies or aptamers, that are designed to bind to specific target proteins. The sample is then added to the array, allowing the target proteins to bind to their corresponding capture agents. After washing away unbound materials, a detection system is used to identify and quantify the bound proteins. This method can be used for various applications, including protein-protein interaction studies, biomarker discovery, and drug development. The results of protein array analysis provide valuable information about the expression levels, post-translational modifications, and functional states of proteins in complex biological systems.
Amino acid motifs are recurring patterns or sequences of amino acids in a protein molecule. These motifs can be identified through various sequence analysis techniques and often have functional or structural significance. They can be as short as two amino acids in length, but typically contain at least three to five residues.
Some common examples of amino acid motifs include:
1. Active site motifs: These are specific sequences of amino acids that form the active site of an enzyme and participate in catalyzing chemical reactions. For example, the catalytic triad in serine proteases consists of three residues (serine, histidine, and aspartate) that work together to hydrolyze peptide bonds.
2. Signal peptide motifs: These are sequences of amino acids that target proteins for secretion or localization to specific organelles within the cell. For example, a typical signal peptide consists of a positively charged n-region, a hydrophobic h-region, and a polar c-region that directs the protein to the endoplasmic reticulum membrane for translocation.
3. Zinc finger motifs: These are structural domains that contain conserved sequences of amino acids that bind zinc ions and play important roles in DNA recognition and regulation of gene expression.
4. Transmembrane motifs: These are sequences of hydrophobic amino acids that span the lipid bilayer of cell membranes and anchor transmembrane proteins in place.
5. Phosphorylation sites: These are specific serine, threonine, or tyrosine residues that can be phosphorylated by protein kinases to regulate protein function.
Understanding amino acid motifs is important for predicting protein structure and function, as well as for identifying potential drug targets in disease-associated proteins.
A disease vector is a living organism that transmits infectious pathogens from one host to another. These vectors can include mosquitoes, ticks, fleas, and other arthropods that carry viruses, bacteria, parasites, or other disease-causing agents. The vector becomes infected with the pathogen after biting an infected host, and then transmits the infection to another host through its saliva or feces during a subsequent blood meal.
Disease vectors are of particular concern in public health because they can spread diseases rapidly and efficiently, often over large geographic areas. Controlling vector-borne diseases requires a multifaceted approach that includes reducing vector populations, preventing bites, and developing vaccines or treatments for the associated diseases.
Peptides are short chains of amino acid residues linked by covalent bonds, known as peptide bonds. They are formed when two or more amino acids are joined together through a condensation reaction, which results in the elimination of a water molecule and the formation of an amide bond between the carboxyl group of one amino acid and the amino group of another.
Peptides can vary in length from two to about fifty amino acids, and they are often classified based on their size. For example, dipeptides contain two amino acids, tripeptides contain three, and so on. Oligopeptides typically contain up to ten amino acids, while polypeptides can contain dozens or even hundreds of amino acids.
Peptides play many important roles in the body, including serving as hormones, neurotransmitters, enzymes, and antibiotics. They are also used in medical research and therapeutic applications, such as drug delivery and tissue engineering.
MicroRNAs (miRNAs) are a class of small non-coding RNAs, typically consisting of around 20-24 nucleotides, that play crucial roles in post-transcriptional regulation of gene expression. They primarily bind to the 3' untranslated region (3' UTR) of target messenger RNAs (mRNAs), leading to mRNA degradation or translational repression. MicroRNAs are involved in various biological processes, including development, differentiation, proliferation, and apoptosis, and have been implicated in numerous diseases, such as cancers and neurological disorders. They can be found in various organisms, from plants to animals, and are often conserved across species. MicroRNAs are usually transcribed from DNA sequences located in introns or exons of protein-coding genes or in intergenic regions. After transcription, they undergo a series of processing steps, including cleavage by ribonucleases Drosha and Dicer, to generate mature miRNA molecules capable of binding to their target mRNAs.
Mild Cognitive Impairment (MCI) is a medical term used to describe a stage between the cognitive changes seen in normal aging and the more serious decline of dementia. It's characterized by a slight but noticeable decline in cognitive abilities, such as memory or thinking skills, that are greater than expected for an individual's age and education level, but not significant enough to interfere with daily life.
People with MCI have an increased risk of developing dementia, particularly Alzheimer's disease, compared to those without MCI. However, it's important to note that not everyone with MCI will develop dementia; some may remain stable, and others may even improve over time.
The diagnosis of MCI is typically made through a comprehensive medical evaluation, including a detailed medical history, cognitive testing, and sometimes brain imaging or laboratory tests.
A nucleic acid database is a type of biological database that contains sequence, structure, and functional information about nucleic acids, such as DNA and RNA. These databases are used in various fields of biology, including genomics, molecular biology, and bioinformatics, to store, search, and analyze nucleic acid data.
Some common types of nucleic acid databases include:
1. Nucleotide sequence databases: These databases contain the primary nucleotide sequences of DNA and RNA molecules from various organisms. Examples include GenBank, EMBL-Bank, and DDBJ.
2. Structure databases: These databases contain three-dimensional structures of nucleic acids determined by experimental methods such as X-ray crystallography or nuclear magnetic resonance (NMR) spectroscopy. Examples include the Protein Data Bank (PDB) and the Nucleic Acid Database (NDB).
3. Functional databases: These databases contain information about the functions of nucleic acids, such as their roles in gene regulation, transcription, and translation. Examples include the Gene Ontology (GO) database and the RegulonDB.
4. Genome databases: These databases contain genomic data for various organisms, including whole-genome sequences, gene annotations, and genetic variations. Examples include the Human Genome Database (HGD) and the Ensembl Genome Browser.
5. Comparative databases: These databases allow for the comparison of nucleic acid sequences or structures across different species or conditions. Examples include the Comparative RNA Web (CRW) Site and the Sequence Alignment and Modeling (SAM) system.
Nucleic acid databases are essential resources for researchers to study the structure, function, and evolution of nucleic acids, as well as to develop new tools and methods for analyzing and interpreting nucleic acid data.
 Support vector machine
Support vector machine
Structured support vector machine
Least-squares support vector machine
Regularization perspectives on support vector machines
Relevance vector machine
Surrogate model
Kernel method
LIBSVM
Adversarial machine learning
Oracle Data Mining
Automatic image annotation
Radial basis function
Bernhard Schölkopf
MNIST database
Tree kernel
Uplift modelling
Sepp Hochreiter
Edward Y. Chang
Mlpy
Chih-Jen Lin
Sequential minimal optimization
Non-negative matrix factorization
Multiple instance learning
Elastic net regularization
Platt scaling
Receiver Operating Characteristic Curve Explorer and Tester
Quantum machine learning
Hyperparameter optimization
List of important publications in computer science
Optical sorting
Structured support vector machine - Wikipedia
Support vector machine - Wikipedia
 Support vector machine regression model - MATLAB
Support vector machine regression model - MATLAB
SVM-Struct Support Vector Machine for Complex Outputs
Fit a support vector machine regression model - MATLAB fitrsvm
 What is Support Vector Machine | IGI Global
What is Support Vector Machine | IGI Global
 Kapita Selekta TugasKe2 Artificial Neural Network & Support Vector Machine IKONE
Kapita Selekta TugasKe2 Artificial Neural Network & Support Vector Machine IKONE
 Support Vector Machine Model Report
Support Vector Machine Model Report
 An Image Watermarking Scheme Using Arnold Transform and Fuzzy Smooth Support Vector Machine
An Image Watermarking Scheme Using Arnold Transform and Fuzzy Smooth Support Vector Machine
![R] Extract hyperplane from kernlabs Support Vector Machine model](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAMAAAAoLQ9TAAAAM1BMVEX///8AAADc3Nxvb2+xsbGcnJx9fX08PDzNzc2jo6OsrKyOjo5TU1MWFhb39/cpKSl2dnYYi1fjAAAAOklEQVQYlWNgoBdgY4QABkYmiAA7MwsDMysHIysjVAUjJxcDIwc3DzM7hM/EyMjLwMjHzyIgQDdXAgBiSgDHBRvE2AAAAABJRU5ErkJggg==) R] Extract hyperplane from kernlab's Support Vector Machine model
R] Extract hyperplane from kernlab's Support Vector Machine model
 ITcon papers tagged with: support vector machine
ITcon papers tagged with: support vector machine Active Support Vector Machine Classification
Active Support Vector Machine Classification
 Remote Sensing | Free Full-Text | Active-Learning Approaches for Landslide Mapping Using Support Vector Machines
Remote Sensing | Free Full-Text | Active-Learning Approaches for Landslide Mapping Using Support Vector Machines
 Robust Support Vector Machine Training via Convex Outlier Ablation | Sciweavers
Robust Support Vector Machine Training via Convex Outlier Ablation | Sciweavers
 Transformer Incipient fault prediction using Support Vector Machine (SVM) - Amrita Vishwa Vidyapeetham
Transformer Incipient fault prediction using Support Vector Machine (SVM) - Amrita Vishwa Vidyapeetham
 ATM: Automated Trust Management for Mobile Ad-hoc Networks Using Support Vector Machine
ATM: Automated Trust Management for Mobile Ad-hoc Networks Using Support Vector Machine
 Classification of Spontaneous Speech of Individuals with Dementia Based on Automatic Prosody Analysis Using Support Vector...
Classification of Spontaneous Speech of Individuals with Dementia Based on Automatic Prosody Analysis Using Support Vector...
 Support Vector Machine Call For Papers for Conferences, Workshops and Journals at WikiCFP
Support Vector Machine Call For Papers for Conferences, Workshops and Journals at WikiCFP
 What is a Support Vector Machine (SVM)? - Definition from Techopedia
What is a Support Vector Machine (SVM)? - Definition from Techopedia
 crossvalidation` and random search for calibrating support vector machines | R-bloggers
crossvalidation` and random search for calibrating support vector machines | R-bloggers
 Gender classification in human gait using support vector machine - ePrints Soton
Gender classification in human gait using support vector machine - ePrints Soton
Penerapan Support Vector Machine Dengan Optimasi Particle Swarm Optimization Untuk Mendeteksi Penyakit Malaria - Repository
Support Vector Machine using python
 Mining by Integrating Support Vector Machine Priors in the Bayesian Restoration | CREATIS
Mining by Integrating Support Vector Machine Priors in the Bayesian Restoration | CREATIS
 Tag: support vector machine | Primary Objects
Tag: support vector machine | Primary Objects
DISSERTATIONS.SE: High-Performance Computing For Support Vector Machines
 ICCES | Unsupervised Support Vector Machine Based Principal Component Analysis for Structural Health Monitoring
ICCES | Unsupervised Support Vector Machine Based Principal Component Analysis for Structural Health Monitoring
 Diagnosis of long QT syndrome via support vector machines classification
Diagnosis of long QT syndrome via support vector machines classification
 Dryad | Data -- Phylogeography and support vector machine classification of colour variation in panther chameleons
Dryad | Data -- Phylogeography and support vector machine classification of colour variation in panther chameleons
 Health Risk Prediction Using Support Vector Machine with Gray Wolf Optimization in Covid 19 Pandemic Crisis
Health Risk Prediction Using Support Vector Machine with Gray Wolf Optimization in Covid 19 Pandemic Crisis
Algorithm16
- The structured support-vector machine is a machine learning algorithm that generalizes the Support-Vector Machine (SVM) classifier. (wikipedia.org)
- The support vector clustering algorithm, created by Hava Siegelmann and Vladimir Vapnik, applies the statistics of support vectors, developed in the support vector machines algorithm, to categorize unlabeled data. (wikipedia.org)
- Character vector containing the name of the algorithm used to remove entries from the cache when its capacity is exceeded. (mathworks.com)
- SVM struct is a Support Vector Machine (SVM) algorithm for predicting multivariate or structured outputs. (cornell.edu)
- A support vector machine (SVM) is machine learning algorithm that analyzes data for classification and regression analysis. (techopedia.com)
- A support vector machine is a supervised learning algorithm that sorts data into two categories. (techopedia.com)
- explains the Support Vector Machine algorithm. (franksworld.com)
- This method combines a generative, profile hidden Markov model (HMM) with a discriminative classification algorithm known as a support vector machine (SVM). (columbia.edu)
- We have applied a machine learning algorithm, called the support vector machine, to discriminate between correctly and incorrectly identified peptides using SEQUEST output. (washington.edu)
- I understand - most courses and experts don't even mention Support Vector Regression (SVR) as a machine learning algorithm. (analyticsvidhya.com)
- A Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification and regression tasks. (analyticsvidhya.com)
- Support Vector Regression (SVR) is a type of machine learning algorithm used for regression analysis. (analyticsvidhya.com)
- The Support Vector Machine (SVM) is a supervised algorithm for the solution of classification and regression problems. (uni-tuebingen.de)
- A support vector machine-based algorithm to identify bisphosphonate-related osteonecrosis throughout the mandibular bone by using cone beam computerized tomography images. (bvsalud.org)
- To automate the process, the researchers sought to develop a differential diagnostic algorithm that combined FDG-PET scan features with machine learning to differentiate between parkinsonian syndromes. (medscape.com)
- 4. Enzo Zerega (2018): Assessing edge pixel classification and growing stock volume in forest stands using a machine learning algorithm and Sentinel-2 data. (lu.se)
Classifier6
- Whereas the SVM classifier supports binary classification , multiclass classification and regression , the structured SVM allows training of a classifier for general structured output labels . (wikipedia.org)
- DeCoste, 2002), we propose a new and efficient approach based on treating the kernel machine classifier as a special form of k nearest-neighbor. (aaai.org)
- In this paper, an Automated Trust Management (ATM) system is described for MANETs that uses a support vector machine classifier to detect malicious MANET nodes. (umbc.edu)
- We introduce a Least Square-Support Vector Machine (LS-SVM) classifier for the first time (to the best of our knowledge) to label automatically arterioles and venules. (sinapse.ac.uk)
- In a SVM classifier/predictor the analysis of the distance between input data and support vectors in the feature space gives useful information about the novelty of an input. (iaea.org)
- Finally, a predictor (PDNAsite) was developed through the integration of the support vector machines (SVM) classifier and ensemble learning. (nature.com)
SVMs5
- In machine learning, support vector machines (SVMs, also support vector networks) are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. (wikipedia.org)
- One of the well known risks of large margin training methods, such as boosting and support vector machines (SVMs), is their sensitivity to outliers. (sciweavers.org)
- Unlike Support Vector Machines (SVMs) used for classification tasks, SVR seeks to find a hyperplane that best fits the data points in a continuous space. (analyticsvidhya.com)
- Support vector machines (SVMs) based framework for classification of fallers and non-fallers. (cdc.gov)
- As such, the aim of this study is to investigate the critical gait and postural parameters contributing to falls, then further to classify fallers and non-fallers by utilizing gait and postural parameters and machine learning techniques, e.g. support vector machines (SVMs). (cdc.gov)
Prediction7
- A. Kumar and Vidya H. A., "Transformer Incipient fault prediction using Support Vector Machine (SVM) ", Journal of University of Shanghai for Science and Technology (JUSST), vol. 23, no. 5, pp. 737-744, 2021. (amrita.edu)
- Sep-Oct 2021 Page 230 Health Risk Prediction Using Support Vector Machine with Gray Wolf Optimization in Covid-19 Pandemic Crisis Swati Shilpi 1 , Dr. Damodar Prasad Tiwari 2 1PG Scholar, 2Assistant Professor, 1,2Department of CSE, BIST, Bhopal, Madhya Pradesh, India ABSTRACT The opinion of disease is important for Covid 19 as the antigen kit and RTPCR are unperfect and should be better for diagnosing such disease. (edocr.com)
- Support Vector Machines for the disruption prediction and nov. (iaea.org)
- In this work, both the prediction and the novelty detector tasks are performed by the same system using a Support Vector Machine (SVM) instead of a Multi-layer perceptron neural network. (iaea.org)
- Lu, C., Van Gestel, T., Suykens, J.A.K., Van Huffel, S., Vergote, I., Timmerman, D.: Preoperative prediction of malignancy of ovarian tumors using least squares support vector machines. (crossref.org)
- In this work, we analyze the structure and failure behavior of two-dimensional silica glasses by machine learning methods and illustrate how accurate failure prediction can be achieved while preserving the qualitative interpretability of the results. (nature.com)
- The main emphasis is on supervised machine learning methods for classification and prediction of tumor gene expression profiles. (lu.se)
Particle Swarm Optimi1
- This paper proposes a new differential particle swarm optimization (DPSO) method for obtaining optimum support vector machine (SVM) parameters used for electrical fault diagnosis in radial distribution systems. (aece.ro)
Positive integers1
- Categorical predictor indices, specified as a vector of positive integers. (mathworks.com)
Data20
- Classifying data is a common task in machine learning. (wikipedia.org)
- In the case of support vector machines, a data point is viewed as a p {\displaystyle p} -dimensional vector (a list of p {\displaystyle p} numbers), and we want to know whether we can separate such points with a ( p − 1 ) {\displaystyle (p-1)} -dimensional hyperplane. (wikipedia.org)
- To keep the computational load reasonable, the mappings used by SVM schemes are designed to ensure that dot products of pairs of input data vectors may be computed easily in terms of the variables in the original space, by defining them in terms of a kernel function k ( x , y ) {\displaystyle k(x,y)} selected to suit the problem. (wikipedia.org)
- The vectors defining the hyperplanes can be chosen to be linear combinations with parameters α i {\displaystyle \alpha _{i}} of images of feature vectors x i {\displaystyle x_{i}} that occur in the data base. (wikipedia.org)
- trains or cross-validates a support vector machine (SVM) regression model on a low- through moderate-dimensional predictor data set. (mathworks.com)
- supports mapping the predictor data using kernel functions, and supports SMO, ISDA, or L 1 soft-margin minimization via quadratic programming for objective-function minimization. (mathworks.com)
- Train a support vector machine (SVM) regression model using sample data stored in matrices. (mathworks.com)
- Train a support vector machine regression model using the abalone data from the UCI Machine Learning Repository. (mathworks.com)
- However, the manual labelling of instances for training machine learning models is time-consuming given the data requirements of flexible data-driven algorithms and the small percentage of area covered by landslides. (mdpi.com)
- Machine learning algorithms are very successful in solving classification and regression problems, however the immense amount of data created by digitalization slows down the training and predicting processes, if solvable at all. (dissertations.se)
- Support Vector Machines(SVM) is one of the most popular supervised machine learning techniques that enjoy the advancement of HPC to overcome the problems regarding big data, however, efficient parallel implementations of SVM is a complex endeavour. (dissertations.se)
- Use of the support vector machine and these additional parameters resulted in a more accurate interpretation of peptide MS/MS spectra, and is an important step towards automated interpretation of peptide tandem mass spectrometry data in proteomics. (washington.edu)
- Cross Validated is a question and answer site for people interested in statistics, machine learning, data analysis, data mining, and data visualization. (stackexchange.com)
- All the derivations I've seen seem to assume that (1) the data set consists of vectors on $\mathbb{R}^n$ and that (2) the inner product is the dot product. (stackexchange.com)
- Predictor means of the training data, specified as a numeric vector. (mathworks.com)
- Predictor standard deviations of the training data, specified as a numeric vector. (mathworks.com)
- Using EEG and eye gaze data collected from these experiments as an input, different machine learning models are implemented to solve a binary classification task to. (lu.se)
- One of the most common forms of AI applied to health care is machine learning (ML), a statistical technique for training algorithms to learn from and make predictions using data. (cdc.gov)
- includes published scientific literature on the translation of big data, data science and machine learning methods into improved health care and population health. (cdc.gov)
- Using the collected data, machine-learning classifiers were trained to detect tobacco-related vs irrelevant tweets as well as positive vs negative sentiment, using Naive Bayes, k-nearest neighbors, and Support Vector Machine (SVM) algorithms. (who.int)
Hyperplane2
- citation needed] More formally, a support vector machine constructs a hyperplane or set of hyperplanes in a high or infinite-dimensional space, which can be used for classification, regression, or other tasks like outliers detection. (wikipedia.org)
- The hyperplanes in the higher-dimensional space are defined as the set of points whose dot product with a vector in that space is constant, where such a set of vectors is an orthogonal (and thus minimal) set of vectors that defines a hyperplane. (wikipedia.org)
Predictors2
- Primal linear problem coefficients, stored as a numeric vector of length p , where p is the number of predictors in the SVM regression model. (mathworks.com)
- Many machine learning based predictors have been developed for the aforementioned task. (nature.com)
Multiclass1
- Second, using a supervised multiclass support vector machine approach on five anatomical components, we identify patterns in 3D colour space that efficiently predict assignment of male individuals to mitochondrial haplogroups. (datadryad.org)
Classifiers3
- Suykens, J.A.K., Vandewalle, J.: Least squares support vector machine classifiers. (crossref.org)
- Van Gestel, T., Suykens, J.A.K., Lanckriet, G., Lambrechts, A., De Moor, B., Vandewalle, J.: Bayesian framework for least-squares support vector machine classifiers, Gaussian processes, and kernel Fisher discriminant analysis. (crossref.org)
- OBJECTIVE: To develop a content and sentiment analysis of tobacco-related Twitter posts and build machine learning classifiers to detect tobacco-relevant posts and sentiment towards tobacco, with a particular focus on new and emerging products like hookah and electronic cigarettes. (who.int)
Outlier detection2
- In particular, we show how outlier detection can be encoded in the large margin training principle of support vector machines. (sciweavers.org)
- Patient classification as an outlier detection problem: An application of the One-Class Support Vector Machine. (bvsalud.org)
Artificial Intelligence2
- Developers looking for their first machine learning or artificial intelligence project often start by trying the handwritten digit recognition problem. (primaryobjects.com)
- Two recent systematic reviews reveal the high risk of bias present in randomized controlled trials (RCTs) and observational studies based on machine learning and artificial intelligence. (cdc.gov)
Proteins2
- In this paper, we propose a novel predictive method that uses a Support Vector Machine (SVM) and physicochemical properties to predict bioluminescent proteins. (biomedcentral.com)
- Using sparse support vector machine-based classification technique, we identified a small subset of proteins clearly distinguishing each exposure. (cdc.gov)
Python1
- We will first quickly understand what SVM is, before diving into the world of Support Vector Regression in machine learning and how to implement it in Python! (analyticsvidhya.com)
Classification and regression1
- The most common algorithms used in the studies were classification and regression tree, support vector machine, and random forest. (cdc.gov)
Feature3
- is a feature function, extracting some feature vector from a given sample and label. (wikipedia.org)
- A function for computing the feature vector Psi. (cornell.edu)
- The team derived three datasets for the machine learning models: one based on previously validated clinical features in the Slovenian cohort, another on analogous feature patterns in the US cohort, and the third using a support vector machine based on 95 brain ROIs. (medscape.com)
Outputs2
- Platt, J.: Probabilistic outputs for support vector machines and comparison to regularized likelihood methods. (crossref.org)
- Lin, H.-T., Lin, C.-J., Weng, R.C.: A note on Platt’s probabilistic outputs for support vector machines. (crossref.org)
Neural network2
Coefficients1
- Dual problem coefficients, specified as a vector of numeric values. (mathworks.com)
Performs1
- The second part is a Support Vector Machine which performs the classification task. (uoguelph.ca)
Abstract1
- This supports the exploration of machine learning methods for predicting gait dysfunction in Parkinson's disease" using region-of-interest (ROI) brain scans, the team writes in the abstract to the study. (medscape.com)
Optimization1
- In order to classify Covid 19 disease datasets such mild, middle and severe diseases, the proposed model utilizes the notion of controlled machine education and GWO-optimization to regulate if the patient is affecting or not. (edocr.com)
Learning18
- Support vector machines (and other kernel machines) offer robust modern machine learning methods for nonlinear classification. (aaai.org)
- High-Performance Computing(HPC) and particularly parallel computing are promising tools for improving the performance of machine learning algorithms in terms of time. (dissertations.se)
- Machine learning sounds like a fancy term. (primaryobjects.com)
- Olivier Chapelle is Senior Research Scientist in Machine Learning at Yahoo. (mit.edu)
- Support Vector Machines (SVM) are popularly and widely used for classification problems in machine learning. (analyticsvidhya.com)
- I've often relied on this not just in machine learning projects but when I want a quick result in a hackathon. (analyticsvidhya.com)
- And even now when I bring up "Support Vector Regression" in front of machine learning beginners, I often get a bemused expression. (analyticsvidhya.com)
- Here we address this issue and use machine learning methods to predict the failure of simulated two dimensional silica glasses from their initial undeformed structure. (nature.com)
- c Local learning approach that uses Support Vector Machine to predict the elastic/plastic nature of individual atoms. (nature.com)
- Here, we addressed the problem through sparse classification method, a supervised machine learning approach that can reduce the noise contained in redundant variables for discriminating among MWCNT-exposed and MWCNT-unexposed groups. (cdc.gov)
- These studies demonstrate the feasibility of machine learning-based molecular cancer classification. (lu.se)
- COPENHAGEN, Denmark - Machine learning techniques could soon be used for the differential diagnosis of parkinsonian syndromes and to predict gait dysfunction for patients with Parkinson's disease (PD) if validated in further studies, two new studies suggest. (medscape.com)
- In the first, 18F-fluorodeoxyglucose (FDG) positron-emission tomography (PET) scans from more than 260 individuals with parkinsonian syndromes across sites in Slovenia and the US were analyzed using three machine learning models. (medscape.com)
- This suggests machine learning tools "may be very useful, as they do not necessarily need to prespecify a specific pattern. (medscape.com)
- 001 cramer="" v="0.36)," and="" the="" most="" discriminating="" unigram="" features="" for="" positive="" negative="" sentiment="" ranked="" by="" log="" odds="" ratio="" in="" machine="" learning="" component="" of="" study. (who.int)
- 2/ 4 · describe the statistical principles that form the basis for machine learning. (lu.se)
- Recent development in machine learning have led to a surge of interest in artificial neural networks (ANN). (lu.se)
- Basic concepts in machine learning till also be introduced. (lu.se)
Detect1
- Character vector indicating the criterion the software used to detect convergence. (mathworks.com)
Model3
- contains m elements, where m is the number of support vectors in the trained SVM regression model. (mathworks.com)
- To estimate our model more precisely we will get some metrics, namely precision, recall, f1-score, and support. (datacareer.ch)
- Model for noise -induced hearing loss using support vector machine. (cdc.gov)
Kernel3
- Our approach improves upon a traditional k-NN by determining at query-time a good k for each query, based on pre-query analysis guided by the original robust kernel machine. (aaai.org)
- Zhu, J., Hastie, T.: Kernel logistic regression and the import vector machine. (crossref.org)
- In addition, we address the serious problem of scaling Support Vector Machines by using the Kernel Fisher Discriminant. (ed.ac.uk)
Perceptron1
- For the support vector machine and the multilayer perceptron models, more compact representations of the time series arrays are used as inputs. (lu.se)
Describe1
- We describe the use of Support Vector Machines for phonetic classification on the TIMIT corpus. (ed.ac.uk)
Models1
- LABEL was designed for the rapid annotation of influenza (or other virus) clades using profile Hidden Markov models and support vector machines. (cdc.gov)
Gait1
- Yoo, Jang , Hwang, D and Nixon, Mark (2006) Gender classification in human gait using support vector machine. (soton.ac.uk)
Spaces2
- Would Support Vector Machines work on arbitrary Hilbert spaces? (stackexchange.com)
- Support vector machines are often used to classify points in Hilbert spaces of infinite dimension. (stackexchange.com)
Transform1
- This paper presents a new image watermarking scheme based on Arnold Transform (AT) and Fuzzy Smooth Support Vector Machine (FSSVM). (hindawi.com)
Approach1
- By expressing a convex relaxation of the joint training problem as a semidefinite program, one can use this approach to robustly train a support vector machine while suppressing outliers. (sciweavers.org)
Metrics1
- Three separate metrics converged to support an emergent distinction between, on one hand, hookah and electronic cigarettes corresponding to positive sentiment, and on the other hand, traditional tobacco products and more general references corresponding to negative sentiment. (who.int)
Linear1
- An active set strategy is applied to the dual of a simple reformula(cid:173) tion of the standard quadratic program of a linear support vector machine. (nips.cc)
Known as a support1
- A support vector machine is also known as a support vector network (SVN). (techopedia.com)
Problem2
- The dual problem introduces two Lagrange multipliers for each support vector. (mathworks.com)
- Find support for a specific problem in the support section of our website. (mdpi.com)
Problems3
- en] Disruptions are an endemic and likely unavoidable aspect of tokamak operation that poses serious problems to the integrity and the machine lifetime. (iaea.org)
- Note: You can learn about Support Vector Machines and Regression problems in course format here (it's free! (analyticsvidhya.com)
- We therefore avoid the problems of classifying variable-length vectors. (ed.ac.uk)

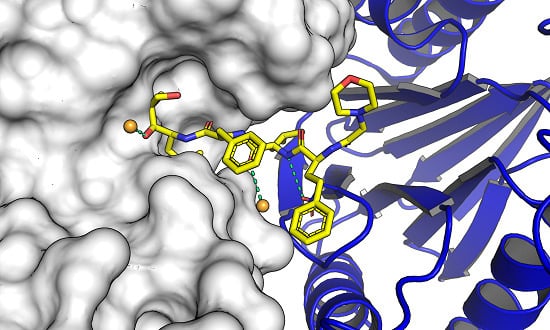



![Data Science and Machine Learning with Python - Hands-On! [Video]](https://cdn.oreillystatic.com/oreilly/images/report-software-architecture-patterns-553x420.jpg)











![Advanced Programming [DidaWiki]](http://didawiki.di.unipi.it/lib/exe/fetch.php/dm/c641dad03aacb3d94ad6f575d6a43ac4.jpg?w=90&h=67&t=1392379832&tok=e3af1a)










