Transcription Factor CHOP
Structural Homology, Protein
Amino Acid Sequence
Molecular Sequence Data
Sequence Homology, Amino Acid
Models, Molecular
Sequence Homology, Nucleic Acid
Base Sequence
Protein Conformation
Protein Structure, Tertiary
Sequence Alignment
Cloning, Molecular
Crystallography, X-Ray
Binding Sites
Protein Binding
Protein Structure, Secondary
Escherichia coli
Peptide Fragments
Structure-Activity Relationship
Species Specificity
Conserved Sequence
Catalytic Domain
DNA
Cross Reactions
Substrate Specificity
src Homology Domains
Electrophoresis, Polyacrylamide Gel
DNA, Complementary
Thermotoga maritima
Mutagenesis, Site-Directed
Trypsin
Mutation
Dimerization
Carrier Proteins
Crystallography
Peptides
Sequence Homology
Proteins
Membrane Proteins
RNA, Messenger
Saccharomyces cerevisiae
Cattle
Restriction Mapping
RNA
Plasmids
DNA Primers
Macromolecular Substances
Nucleic Acid Conformation
DNA-Binding Proteins
Genes
Ligands
Crystallization
Multigene Family
Nucleic Acid Hybridization
Nuclear Magnetic Resonance, Biomolecular
Hidden Markov models-based system (HMMSPECTR) for detecting structural homologies on the basis of sequential information. (1/1667)
HMMSPECTR is a tool for finding putative structural homologs for proteins with known primary sequences. HMMSPECTR contains four major components: a data warehouse with the hidden Markov models (HMM) and alignment libraries; a search program which compares the initial protein sequences with the libraries of HMMs; a secondary structure prediction and comparison program; and a dominant protein selection program that prepares the set of 10-15 "best" proteins from the chosen HMMs. The data warehouse contains four libraries of HMMs. The first two libraries were constructed using different HHM preparation options of the HAMMER program. The third library contains parts ("partial HMM") of initial alignments. The fourth library contains trained HMMs. We tested our program against all of the protein targets proposed in the CASP4 competition. The data warehouse included libraries of structural alignments and HMMs constructed on the basis of proteins publicly available in the Protein Data Bank before the CASP4 meeting. The newest fully automated versions of HMMSPECTR 1.02 and 1.02ss produced better results than the best result reported at CASP4 either by r.m.s.d. or by length (or both) in 64% (HMMSPECTR 1.02) and 79% (HMMSPECTR 1.02ss) of the cases. The improvement is most notable for the targets with complexity 4 (difficult fold recognition cases). (+info)Modelling the structure of the fusion protein from human respiratory syncytial virus. (2/1667)
The fusion protein of respiratory syncytial virus (RSV-F) is responsible for fusion of virion with host cells and infection of neighbouring cells through the formation of syncytia. A three-dimensional model structure of RSV-F was derived by homology modelling from the structure of the equivalent protein in Newcastle disease virus (NDV). Despite very low sequence homology between the two structures, most features of the model appear to have high credibility, although a few small regions in RSV-F whose secondary structure is predicted to be different to that in NDV are likely to be poorly modelled. The organization of individual residues identified in escape mutants against monoclonal antibodies correlates well with known antigenic sites. The location of residues involved in point mutations in several drug-resistant variants is also examined. (+info)Novel carbohydrate specificity of the 16-kDa galectin from Caenorhabditis elegans: binding to blood group precursor oligosaccharides (type 1, type 2, Talpha, and Tbeta) and gangliosides. (3/1667)
Galectins, a family of soluble beta-galactosyl-binding lectins, are believed to mediate cell-cell and cell-extracellular matrix interactions during development, inflammation, apoptosis, and tumor metastasis. However, neither the detailed mechanisms of their function(s) nor the identities of their natural ligands have been unequivocally elucidated. Of the several galectins present in the nematode Caenorhabditis elegans, the 16-kDa "proto" type and the 32-kDa "tandem-repeat" type are the best characterized so far, but their carbohydrate specificities have not been examined in detail. Here, we report the carbohydrate-binding specificity of the recombinant C. elegans 16-kDa galectin and the structural analysis of its binding site by homology modeling. Our results indicate that unlike the galectins characterized so far, the C. elegans 16-kDa galectin interacts with most blood group precursor oligosaccharides (type 1, Galbeta1,3GlcNAc, and type 2, Galbeta1,4GlcNAc; Talpha, Galbeta1,3GalNAcalpha; Tbeta, Galbeta1,3GalNAcbeta) and gangliosides containing the Tbeta structure. Homology modeling of the C. elegans 16-kDa galectin CRD revealed that a shorter loop containing residues 66-69, which enables interactions of Glu(67) with both axial and equatorial -OH at C-3 of GlcNAc (in Galbeta1,4GlcNAc) or at C-4 of GalNAc (in Galbeta1,3GalNAc), provides the structural basis for this novel carbohydrate specificity. (+info)A comprehensive analysis of 40 blind protein structure predictions. (4/1667)
BACKGROUND: We thoroughly analyse the results of 40 blind predictions for which an experimental answer was made available at the fourth meeting on the critical assessment of protein structure methods (CASP4). Using our comparative modelling and fold recognition methodologies, we made 29 predictions for targets that had sequence identities ranging from 50% to 10% to the nearest related protein with known structure. Using our ab initio methodologies, we made eleven predictions for targets that had no detectable sequence relationships. RESULTS: For 23 of these proteins, we produced models ranging from 1.0 to 6.0 A root mean square deviation (RMSD) for the Calpha atoms between the model and the corresponding experimental structure for all or large parts of the protein, with model accuracies scaling fairly linearly with respect to sequence identity (i.e., the higher the sequence identity, the better the prediction). We produced nine models with accuracies ranging from 4.0 to 6.0 A Calpha RMSD for 60-100 residue proteins (or large fragments of a protein), with a prediction accuracy of 4.0 A Calpha RMSD for residues 1-80 for T110/rbfa. CONCLUSIONS: The areas of protein structure prediction that work well, and areas that need improvement, are discernable by examining how our methods have performed over the past four CASP experiments. These results have implications for modelling the structure of all tractable proteins encoded by the genome of an organism. (+info)The SBP2 and 15.5 kD/Snu13p proteins share the same RNA binding domain: identification of SBP2 amino acids important to SECIS RNA binding. (5/1667)
Selenoprotein synthesis in eukaryotes requires the selenocysteine insertion sequence (SECIS) RNA, a hairpin in the 3' untranslated region of selenoprotein mRNAs. The SECIS RNA is recognized by the SECIS-binding protein 2 (SBP2), which is a key player in this specialized translation machinery. The objective of this work was to obtain structural insight into the SBP2-SECIS RNA complex. Multiple sequence alignment revealed that SBP2 and the U4 snRNA-binding protein 15.5 kD/Snu13p share the same RNA binding domain of the L7A/L30 family, also found in the box H/ACA snoRNP protein Nhp2p and several ribosomal proteins. In corollary, we have detected a similar secondary structure motif in the SECIS and U4 RNAs. Combining the data of the crystal structure of the 15.5 kD-U4 snRNA complex, and the SBP2/15.5 kD sequence similarities, we designed a structure-guided strategy predicting 12 SBP2 amino acids that should be critical for SECIS RNA binding. Alanine substitution of these amino acids followed by gel shift assays of the SBP2 mutant proteins identified four residues whose mutation severely diminished or abolished SECIS RNA binding, the other eight provoking intermediate down effects. In addition to identifying key amino acids for SECIS recognition by SBP2, our findings led to the proposal that some of the recognition principles governing the 15.5 kD-U4 snRNA interaction must be similar in the SBP2-SECIS RNA complex. (+info)Group D prothrombin activators from snake venom are structural homologues of mammalian blood coagulation factor Xa. (6/1667)
Procoagulant venoms of several Australian elapids contain proteinases that specifically activate prothrombin; among these, Group D activators are functionally similar to coagulation factor Xa (FXa). Structural information on this class of prothrombin activators will contribute significantly towards understanding the mechanism of FXa-mediated prothrombin activation. Here we present the purification of Group D prothrombin activators from three Australian snake venoms (Hoplocephalus stephensi, Notechis scutatus scutatus and Notechis ater niger) using a single-step method, and their N-terminal sequences. The N-terminal sequence of the heavy chain of hopsarin D (H. stephensi) revealed that a fully conserved Cys-7 was substituted with a Ser residue. We therefore determined the complete amino acid sequence of hopsarin D. Hopsarin D shows approximately 70% similarity with FXa and approximately 98% similarity with trocarin D, a Group D prothrombin activator from Tropidechis carinatus. It possesses the characteristic Gla domain, two epidermal growth factor-like domains and a serine proteinase domain. All residues important for catalysis are conserved, as are most regions involved in interactions with factor Va and prothrombin. However, there are some structural differences. Unlike FXa, hopsarin D is glycosylated in both its chains: in light-chain residue 52 and heavy-chain residue 45. The glycosylation on the heavy chain is a large carbohydrate moiety adjacent to the active-site pocket. Overall, hopsarin D is structurally and functionally similar to mammalian coagulation FXa. (+info)Structural aspects of oligomerization taking place between the transmembrane alpha-helices of bitopic membrane proteins. (7/1667)
Recent advances in biophysical methods have been able to shed more light on the structures of helical bundles formed by the transmembrane segments of bitopic membrane proteins. In this manuscript, I attempt to review the biological importance and diversity of these interactions, the energetics of bundle formation, motifs capable of inducing oligomerization and methods capable of detecting, solving and predicting the structures of these oligomeric bundles. Finally, the structures of the best characterized instances of transmembrane alpha-helical bundles formed by bitopic membrane proteins are described in detail. (+info)Interaction of three Caenorhabditis elegans isoforms of translation initiation factor eIF4E with mono- and trimethylated mRNA 5' cap analogues. (8/1667)
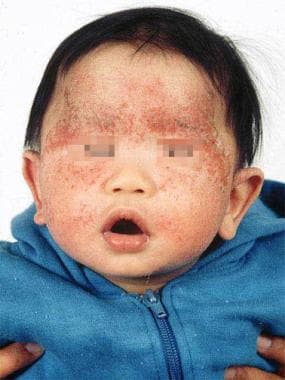
Translation initiation factor eIF4E binds the m(7)G cap of eukaryotic mRNAs and mediates recruitment of mRNA to the ribosome during cap-dependent translation initiation. This event is the rate-limiting step of translation and a major target for translational control. In the nematode Caenorhabditis elegans, about 70% of genes express mRNAs with an unusual cap structure containing m(3)(2,2,7)G, which is poorly recognized by mammalian eIF4E. C. elegans expresses five isoforms of eIF4E (IFE-1, IFE-2, etc.). Three of these (IFE-3, IFE-4 and IFE-5) were investigated by means of spectroscopy and structural modelling based on mouse eIF4E bound to m(7)GDP. Intrinsic fluorescence quenching of Trp residues in the IFEs by iodide ions indicated structural differences between the apo and m(7)G cap bound proteins. Fluorescence quenching by selected cap analogues showed that only IFE-5 forms specific complexes with both m(7)G- and m(3)(2,2,7)G-containing caps (K(as) 2 x 10(6) M(-1) to 7 x 10(6) M(-1)) whereas IFE-3 and IFE-4 discriminated strongly in favor of m(7)G-containing caps. These spectroscopic results quantitatively confirm earlier qualitative data derived from affinity chromatography. The dependence of K(as) on pH indicated optimal cap binding of IFE-3, IFE-4 and IFE-5 at pH 7.2, lower by 0.4 pH units than that of eIF4E from human erythrocytes. These results provide insight into the molecular mechanism of recognition of structurally different caps by the highly homologous IFEs. (+info)Transcription Factor CHOP, also known as DNA Binding Protein C/EBP Homologous Protein or GADD153 (Growth Arrest and DNA Damage-inducible protein 153), is a transcription factor that is involved in the regulation of gene expression in response to various stress stimuli, such as endoplasmic reticulum (ER) stress, hypoxia, and DNA damage.
CHOP is a member of the C/EBP (CCAAT/enhancer-binding protein) family of transcription factors, which bind to specific DNA sequences called cis-acting elements in the promoter regions of target genes. CHOP can form heterodimers with other C/EBP family members and bind to their target DNA sequences, thereby regulating gene expression.
Under normal physiological conditions, CHOP is expressed at low levels. However, under stress conditions, such as ER stress, the expression of CHOP is upregulated through the activation of the unfolded protein response (UPR) signaling pathways. Once activated, CHOP can induce the transcription of genes involved in apoptosis, cell cycle arrest, and oxidative stress response, leading to programmed cell death or survival, depending on the severity and duration of the stress signal.
Therefore, CHOP plays a critical role in maintaining cellular homeostasis by regulating gene expression in response to various stress stimuli, and its dysregulation has been implicated in several pathological conditions, including neurodegenerative diseases, cancer, and metabolic disorders.
'Structural homology' in the context of proteins refers to the similarity in the three-dimensional structure of proteins that are not necessarily related by sequence. This similarity arises due to the fact that these proteins have a common evolutionary ancestor or because they share a similar function and have independently evolved to adopt a similar structure. The structural homology is often identified using bioinformatics tools, such as fold recognition algorithms, that compare the three-dimensional structures of proteins to identify similarities. This concept is important in understanding protein function and evolution, as well as in the design of new drugs and therapeutic strategies.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
Sequence homology, amino acid, refers to the similarity in the order of amino acids in a protein or a portion of a protein between two or more species. This similarity can be used to infer evolutionary relationships and functional similarities between proteins. The higher the degree of sequence homology, the more likely it is that the proteins are related and have similar functions. Sequence homology can be determined through various methods such as pairwise alignment or multiple sequence alignment, which compare the sequences and calculate a score based on the number and type of matching amino acids.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
Sequence homology in nucleic acids refers to the similarity or identity between the nucleotide sequences of two or more DNA or RNA molecules. It is often used as a measure of biological relationship between genes, organisms, or populations. High sequence homology suggests a recent common ancestry or functional constraint, while low sequence homology may indicate a more distant relationship or different functions.
Nucleic acid sequence homology can be determined by various methods such as pairwise alignment, multiple sequence alignment, and statistical analysis. The degree of homology is typically expressed as a percentage of identical or similar nucleotides in a given window of comparison.
It's important to note that the interpretation of sequence homology depends on the biological context and the evolutionary distance between the sequences compared. Therefore, functional and experimental validation is often necessary to confirm the significance of sequence homology.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
Protein conformation refers to the specific three-dimensional shape that a protein molecule assumes due to the spatial arrangement of its constituent amino acid residues and their associated chemical groups. This complex structure is determined by several factors, including covalent bonds (disulfide bridges), hydrogen bonds, van der Waals forces, and ionic bonds, which help stabilize the protein's unique conformation.
Protein conformations can be broadly classified into two categories: primary, secondary, tertiary, and quaternary structures. The primary structure represents the linear sequence of amino acids in a polypeptide chain. The secondary structure arises from local interactions between adjacent amino acid residues, leading to the formation of recurring motifs such as α-helices and β-sheets. Tertiary structure refers to the overall three-dimensional folding pattern of a single polypeptide chain, while quaternary structure describes the spatial arrangement of multiple folded polypeptide chains (subunits) that interact to form a functional protein complex.
Understanding protein conformation is crucial for elucidating protein function, as the specific three-dimensional shape of a protein directly influences its ability to interact with other molecules, such as ligands, nucleic acids, or other proteins. Any alterations in protein conformation due to genetic mutations, environmental factors, or chemical modifications can lead to loss of function, misfolding, aggregation, and disease states like neurodegenerative disorders and cancer.
Tertiary protein structure refers to the three-dimensional arrangement of all the elements (polypeptide chains) of a single protein molecule. It is the highest level of structural organization and results from interactions between various side chains (R groups) of the amino acids that make up the protein. These interactions, which include hydrogen bonds, ionic bonds, van der Waals forces, and disulfide bridges, give the protein its unique shape and stability, which in turn determines its function. The tertiary structure of a protein can be stabilized by various factors such as temperature, pH, and the presence of certain ions. Any changes in these factors can lead to denaturation, where the protein loses its tertiary structure and thus its function.
In genetics, sequence alignment is the process of arranging two or more DNA, RNA, or protein sequences to identify regions of similarity or homology between them. This is often done using computational methods to compare the nucleotide or amino acid sequences and identify matching patterns, which can provide insight into evolutionary relationships, functional domains, or potential genetic disorders. The alignment process typically involves adjusting gaps and mismatches in the sequences to maximize the similarity between them, resulting in an aligned sequence that can be visually represented and analyzed.
Molecular cloning is a laboratory technique used to create multiple copies of a specific DNA sequence. This process involves several steps:
1. Isolation: The first step in molecular cloning is to isolate the DNA sequence of interest from the rest of the genomic DNA. This can be done using various methods such as PCR (polymerase chain reaction), restriction enzymes, or hybridization.
2. Vector construction: Once the DNA sequence of interest has been isolated, it must be inserted into a vector, which is a small circular DNA molecule that can replicate independently in a host cell. Common vectors used in molecular cloning include plasmids and phages.
3. Transformation: The constructed vector is then introduced into a host cell, usually a bacterial or yeast cell, through a process called transformation. This can be done using various methods such as electroporation or chemical transformation.
4. Selection: After transformation, the host cells are grown in selective media that allow only those cells containing the vector to grow. This ensures that the DNA sequence of interest has been successfully cloned into the vector.
5. Amplification: Once the host cells have been selected, they can be grown in large quantities to amplify the number of copies of the cloned DNA sequence.
Molecular cloning is a powerful tool in molecular biology and has numerous applications, including the production of recombinant proteins, gene therapy, functional analysis of genes, and genetic engineering.
X-ray crystallography is a technique used in structural biology to determine the three-dimensional arrangement of atoms in a crystal lattice. In this method, a beam of X-rays is directed at a crystal and diffracts, or spreads out, into a pattern of spots called reflections. The intensity and angle of each reflection are measured and used to create an electron density map, which reveals the position and type of atoms in the crystal. This information can be used to determine the molecular structure of a compound, including its shape, size, and chemical bonds. X-ray crystallography is a powerful tool for understanding the structure and function of biological macromolecules such as proteins and nucleic acids.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
Protein binding, in the context of medical and biological sciences, refers to the interaction between a protein and another molecule (known as the ligand) that results in a stable complex. This process is often reversible and can be influenced by various factors such as pH, temperature, and concentration of the involved molecules.
In clinical chemistry, protein binding is particularly important when it comes to drugs, as many of them bind to proteins (especially albumin) in the bloodstream. The degree of protein binding can affect a drug's distribution, metabolism, and excretion, which in turn influence its therapeutic effectiveness and potential side effects.
Protein-bound drugs may be less available for interaction with their target tissues, as only the unbound or "free" fraction of the drug is active. Therefore, understanding protein binding can help optimize dosing regimens and minimize adverse reactions.
Secondary protein structure refers to the local spatial arrangement of amino acid chains in a protein, typically described as regular repeating patterns held together by hydrogen bonds. The two most common types of secondary structures are the alpha-helix (α-helix) and the beta-pleated sheet (β-sheet). In an α-helix, the polypeptide chain twists around itself in a helical shape, with each backbone atom forming a hydrogen bond with the fourth amino acid residue along the chain. This forms a rigid rod-like structure that is resistant to bending or twisting forces. In β-sheets, adjacent segments of the polypeptide chain run parallel or antiparallel to each other and are connected by hydrogen bonds, forming a pleated sheet-like arrangement. These secondary structures provide the foundation for the formation of tertiary and quaternary protein structures, which determine the overall three-dimensional shape and function of the protein.
Bacterial proteins are a type of protein that are produced by bacteria as part of their structural or functional components. These proteins can be involved in various cellular processes, such as metabolism, DNA replication, transcription, and translation. They can also play a role in bacterial pathogenesis, helping the bacteria to evade the host's immune system, acquire nutrients, and multiply within the host.
Bacterial proteins can be classified into different categories based on their function, such as:
1. Enzymes: Proteins that catalyze chemical reactions in the bacterial cell.
2. Structural proteins: Proteins that provide structural support and maintain the shape of the bacterial cell.
3. Signaling proteins: Proteins that help bacteria to communicate with each other and coordinate their behavior.
4. Transport proteins: Proteins that facilitate the movement of molecules across the bacterial cell membrane.
5. Toxins: Proteins that are produced by pathogenic bacteria to damage host cells and promote infection.
6. Surface proteins: Proteins that are located on the surface of the bacterial cell and interact with the environment or host cells.
Understanding the structure and function of bacterial proteins is important for developing new antibiotics, vaccines, and other therapeutic strategies to combat bacterial infections.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
A peptide fragment is a short chain of amino acids that is derived from a larger peptide or protein through various biological or chemical processes. These fragments can result from the natural breakdown of proteins in the body during regular physiological processes, such as digestion, or they can be produced experimentally in a laboratory setting for research or therapeutic purposes.
Peptide fragments are often used in research to map the structure and function of larger peptides and proteins, as well as to study their interactions with other molecules. In some cases, peptide fragments may also have biological activity of their own and can be developed into drugs or diagnostic tools. For example, certain peptide fragments derived from hormones or neurotransmitters may bind to receptors in the body and mimic or block the effects of the full-length molecule.
A Structure-Activity Relationship (SAR) in the context of medicinal chemistry and pharmacology refers to the relationship between the chemical structure of a drug or molecule and its biological activity or effect on a target protein, cell, or organism. SAR studies aim to identify patterns and correlations between structural features of a compound and its ability to interact with a specific biological target, leading to a desired therapeutic response or undesired side effects.
By analyzing the SAR, researchers can optimize the chemical structure of lead compounds to enhance their potency, selectivity, safety, and pharmacokinetic properties, ultimately guiding the design and development of novel drugs with improved efficacy and reduced toxicity.
Species specificity is a term used in the field of biology, including medicine, to refer to the characteristic of a biological entity (such as a virus, bacterium, or other microorganism) that allows it to interact exclusively or preferentially with a particular species. This means that the biological entity has a strong affinity for, or is only able to infect, a specific host species.
For example, HIV is specifically adapted to infect human cells and does not typically infect other animal species. Similarly, some bacterial toxins are species-specific and can only affect certain types of animals or humans. This concept is important in understanding the transmission dynamics and host range of various pathogens, as well as in developing targeted therapies and vaccines.
A conserved sequence in the context of molecular biology refers to a pattern of nucleotides (in DNA or RNA) or amino acids (in proteins) that has remained relatively unchanged over evolutionary time. These sequences are often functionally important and are highly conserved across different species, indicating strong selection pressure against changes in these regions.
In the case of protein-coding genes, the corresponding amino acid sequence is deduced from the DNA sequence through the genetic code. Conserved sequences in proteins may indicate structurally or functionally important regions, such as active sites or binding sites, that are critical for the protein's activity. Similarly, conserved non-coding sequences in DNA may represent regulatory elements that control gene expression.
Identifying conserved sequences can be useful for inferring evolutionary relationships between species and for predicting the function of unknown genes or proteins.
Molecular weight, also known as molecular mass, is the mass of a molecule. It is expressed in units of atomic mass units (amu) or daltons (Da). Molecular weight is calculated by adding up the atomic weights of each atom in a molecule. It is a useful property in chemistry and biology, as it can be used to determine the concentration of a substance in a solution, or to calculate the amount of a substance that will react with another in a chemical reaction.
A catalytic domain is a portion or region within a protein that contains the active site, where the chemical reactions necessary for the protein's function are carried out. This domain is responsible for the catalysis of biological reactions, hence the name "catalytic domain." The catalytic domain is often composed of specific amino acid residues that come together to form the active site, creating a unique three-dimensional structure that enables the protein to perform its specific function.
In enzymes, for example, the catalytic domain contains the residues that bind and convert substrates into products through chemical reactions. In receptors, the catalytic domain may be involved in signal transduction or other regulatory functions. Understanding the structure and function of catalytic domains is crucial to understanding the mechanisms of protein function and can provide valuable insights for drug design and therapeutic interventions.
Deoxyribonucleic acid (DNA) is the genetic material present in the cells of organisms where it is responsible for the storage and transmission of hereditary information. DNA is a long molecule that consists of two strands coiled together to form a double helix. Each strand is made up of a series of four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - that are linked together by phosphate and sugar groups. The sequence of these bases along the length of the molecule encodes genetic information, with A always pairing with T and C always pairing with G. This base-pairing allows for the replication and transcription of DNA, which are essential processes in the functioning and reproduction of all living organisms.
Cross reactions, in the context of medical diagnostics and immunology, refer to a situation where an antibody or a immune response directed against one antigen also reacts with a different antigen due to similarities in their molecular structure. This can occur in allergy testing, where a person who is allergic to a particular substance may have a positive test result for a different but related substance because of cross-reactivity between them. For example, some individuals who are allergic to birch pollen may also have symptoms when eating certain fruits, such as apples, due to cross-reactive proteins present in both.
Substrate specificity in the context of medical biochemistry and enzymology refers to the ability of an enzyme to selectively bind and catalyze a chemical reaction with a particular substrate (or a group of similar substrates) while discriminating against other molecules that are not substrates. This specificity arises from the three-dimensional structure of the enzyme, which has evolved to match the shape, charge distribution, and functional groups of its physiological substrate(s).
Substrate specificity is a fundamental property of enzymes that enables them to carry out highly selective chemical transformations in the complex cellular environment. The active site of an enzyme, where the catalysis takes place, has a unique conformation that complements the shape and charge distribution of its substrate(s). This ensures efficient recognition, binding, and conversion of the substrate into the desired product while minimizing unwanted side reactions with other molecules.
Substrate specificity can be categorized as:
1. Absolute specificity: An enzyme that can only act on a single substrate or a very narrow group of structurally related substrates, showing no activity towards any other molecule.
2. Group specificity: An enzyme that prefers to act on a particular functional group or class of compounds but can still accommodate minor structural variations within the substrate.
3. Broad or promiscuous specificity: An enzyme that can act on a wide range of structurally diverse substrates, albeit with varying catalytic efficiencies.
Understanding substrate specificity is crucial for elucidating enzymatic mechanisms, designing drugs that target specific enzymes or pathways, and developing biotechnological applications that rely on the controlled manipulation of enzyme activities.
SRC homology domains, often abbreviated as SH domains, are conserved protein modules that were first identified in the SRC family of non-receptor tyrosine kinases. These domains are involved in various intracellular signaling processes and mediate protein-protein interactions. There are several types of SH domains, including:
1. SH2 domain: This domain is approximately 100 amino acids long and binds to specific phosphotyrosine-containing motifs in other proteins, thereby mediating signal transduction.
2. SH3 domain: This domain is about 60 amino acids long and recognizes proline-rich sequences in target proteins, playing a role in protein-protein interactions and intracellular signaling.
3. SH1 domain: Also known as the tyrosine kinase catalytic domain, this region contains the active site responsible for transferring a phosphate group from ATP to specific tyrosine residues on target proteins.
4. SH4 domain: This domain is present in some SRC family members and serves as a membrane-targeting module by interacting with lipids or transmembrane proteins.
These SH domains allow SRC kinases and other proteins containing them to participate in complex signaling networks that regulate various cellular processes, such as proliferation, differentiation, survival, and migration.
Protein folding is the process by which a protein molecule naturally folds into its three-dimensional structure, following the synthesis of its amino acid chain. This complex process is determined by the sequence and properties of the amino acids, as well as various environmental factors such as temperature, pH, and the presence of molecular chaperones. The final folded conformation of a protein is crucial for its proper function, as it enables the formation of specific interactions between different parts of the molecule, which in turn define its biological activity. Protein misfolding can lead to various diseases, including neurodegenerative disorders such as Alzheimer's and Parkinson's disease.
Electrophoresis, polyacrylamide gel (EPG) is a laboratory technique used to separate and analyze complex mixtures of proteins or nucleic acids (DNA or RNA) based on their size and electrical charge. This technique utilizes a matrix made of cross-linked polyacrylamide, a type of gel, which provides a stable and uniform environment for the separation of molecules.
In this process:
1. The polyacrylamide gel is prepared by mixing acrylamide monomers with a cross-linking agent (bis-acrylamide) and a catalyst (ammonium persulfate) in the presence of a buffer solution.
2. The gel is then poured into a mold and allowed to polymerize, forming a solid matrix with uniform pore sizes that depend on the concentration of acrylamide used. Higher concentrations result in smaller pores, providing better resolution for separating smaller molecules.
3. Once the gel has set, it is placed in an electrophoresis apparatus containing a buffer solution. Samples containing the mixture of proteins or nucleic acids are loaded into wells on the top of the gel.
4. An electric field is applied across the gel, causing the negatively charged molecules to migrate towards the positive electrode (anode) while positively charged molecules move toward the negative electrode (cathode). The rate of migration depends on the size, charge, and shape of the molecules.
5. Smaller molecules move faster through the gel matrix and will migrate farther from the origin compared to larger molecules, resulting in separation based on size. Proteins and nucleic acids can be selectively stained after electrophoresis to visualize the separated bands.
EPG is widely used in various research fields, including molecular biology, genetics, proteomics, and forensic science, for applications such as protein characterization, DNA fragment analysis, cloning, mutation detection, and quality control of nucleic acid or protein samples.
Complementary DNA (cDNA) is a type of DNA that is synthesized from a single-stranded RNA molecule through the process of reverse transcription. In this process, the enzyme reverse transcriptase uses an RNA molecule as a template to synthesize a complementary DNA strand. The resulting cDNA is therefore complementary to the original RNA molecule and is a copy of its coding sequence, but it does not contain non-coding regions such as introns that are present in genomic DNA.
Complementary DNA is often used in molecular biology research to study gene expression, protein function, and other genetic phenomena. For example, cDNA can be used to create cDNA libraries, which are collections of cloned cDNA fragments that represent the expressed genes in a particular cell type or tissue. These libraries can then be screened for specific genes or gene products of interest. Additionally, cDNA can be used to produce recombinant proteins in heterologous expression systems, allowing researchers to study the structure and function of proteins that may be difficult to express or purify from their native sources.
Recombinant proteins are artificially created proteins produced through the use of recombinant DNA technology. This process involves combining DNA molecules from different sources to create a new set of genes that encode for a specific protein. The resulting recombinant protein can then be expressed, purified, and used for various applications in research, medicine, and industry.
Recombinant proteins are widely used in biomedical research to study protein function, structure, and interactions. They are also used in the development of diagnostic tests, vaccines, and therapeutic drugs. For example, recombinant insulin is a common treatment for diabetes, while recombinant human growth hormone is used to treat growth disorders.
The production of recombinant proteins typically involves the use of host cells, such as bacteria, yeast, or mammalian cells, which are engineered to express the desired protein. The host cells are transformed with a plasmid vector containing the gene of interest, along with regulatory elements that control its expression. Once the host cells are cultured and the protein is expressed, it can be purified using various chromatography techniques.
Overall, recombinant proteins have revolutionized many areas of biology and medicine, enabling researchers to study and manipulate proteins in ways that were previously impossible.
"Thermotoga maritima" is not a medical term, but rather a scientific name for a specific type of bacterium. It belongs to the domain Archaea and is commonly found in marine environments with high temperatures, such as hydrothermal vents. The bacterium is known for its ability to survive in extreme conditions and has been studied for its potential industrial applications, including the production of biofuels and enzymes.
In a medical context, "Thermotoga maritima" may be relevant in research related to the development of new drugs or therapies, particularly those that involve extremophile organisms or their enzymes. However, it is not a term used to describe a specific medical condition or treatment.
Site-directed mutagenesis is a molecular biology technique used to introduce specific and targeted changes to a specific DNA sequence. This process involves creating a new variant of a gene or a specific region of interest within a DNA molecule by introducing a planned, deliberate change, or mutation, at a predetermined site within the DNA sequence.
The methodology typically involves the use of molecular tools such as PCR (polymerase chain reaction), restriction enzymes, and/or ligases to introduce the desired mutation(s) into a plasmid or other vector containing the target DNA sequence. The resulting modified DNA molecule can then be used to transform host cells, allowing for the production of large quantities of the mutated gene or protein for further study.
Site-directed mutagenesis is a valuable tool in basic research, drug discovery, and biotechnology applications where specific changes to a DNA sequence are required to understand gene function, investigate protein structure/function relationships, or engineer novel biological properties into existing genes or proteins.
Trypsin is a proteolytic enzyme, specifically a serine protease, that is secreted by the pancreas as an inactive precursor, trypsinogen. Trypsinogen is converted into its active form, trypsin, in the small intestine by enterokinase, which is produced by the intestinal mucosa.
Trypsin plays a crucial role in digestion by cleaving proteins into smaller peptides at specific arginine and lysine residues. This enzyme helps to break down dietary proteins into amino acids, allowing for their absorption and utilization by the body. Additionally, trypsin can activate other zymogenic pancreatic enzymes, such as chymotrypsinogen and procarboxypeptidases, thereby contributing to overall protein digestion.
A mutation is a permanent change in the DNA sequence of an organism's genome. Mutations can occur spontaneously or be caused by environmental factors such as exposure to radiation, chemicals, or viruses. They may have various effects on the organism, ranging from benign to harmful, depending on where they occur and whether they alter the function of essential proteins. In some cases, mutations can increase an individual's susceptibility to certain diseases or disorders, while in others, they may confer a survival advantage. Mutations are the driving force behind evolution, as they introduce new genetic variability into populations, which can then be acted upon by natural selection.
Dimerization is a process in which two molecules, usually proteins or similar structures, bind together to form a larger complex. This can occur through various mechanisms, such as the formation of disulfide bonds, hydrogen bonding, or other non-covalent interactions. Dimerization can play important roles in cell signaling, enzyme function, and the regulation of gene expression.
In the context of medical research and therapy, dimerization is often studied in relation to specific proteins that are involved in diseases such as cancer. For example, some drugs have been developed to target and inhibit the dimerization of certain proteins, with the goal of disrupting their function and slowing or stopping the progression of the disease.
Carrier proteins, also known as transport proteins, are a type of protein that facilitates the movement of molecules across cell membranes. They are responsible for the selective and active transport of ions, sugars, amino acids, and other molecules from one side of the membrane to the other, against their concentration gradient. This process requires energy, usually in the form of ATP (adenosine triphosphate).
Carrier proteins have a specific binding site for the molecule they transport, and undergo conformational changes upon binding, which allows them to move the molecule across the membrane. Once the molecule has been transported, the carrier protein returns to its original conformation, ready to bind and transport another molecule.
Carrier proteins play a crucial role in maintaining the balance of ions and other molecules inside and outside of cells, and are essential for many physiological processes, including nerve impulse transmission, muscle contraction, and nutrient uptake.
Crystallography is a branch of science that deals with the geometric properties, internal arrangement, and formation of crystals. It involves the study of the arrangement of atoms, molecules, or ions in a crystal lattice and the physical properties that result from this arrangement. Crystallographers use techniques such as X-ray diffraction to determine the structure of crystals at the atomic level. This information is important for understanding the properties of various materials and can be used in fields such as materials science, chemistry, and biology.
Peptides are short chains of amino acid residues linked by covalent bonds, known as peptide bonds. They are formed when two or more amino acids are joined together through a condensation reaction, which results in the elimination of a water molecule and the formation of an amide bond between the carboxyl group of one amino acid and the amino group of another.
Peptides can vary in length from two to about fifty amino acids, and they are often classified based on their size. For example, dipeptides contain two amino acids, tripeptides contain three, and so on. Oligopeptides typically contain up to ten amino acids, while polypeptides can contain dozens or even hundreds of amino acids.
Peptides play many important roles in the body, including serving as hormones, neurotransmitters, enzymes, and antibiotics. They are also used in medical research and therapeutic applications, such as drug delivery and tissue engineering.
Sequence homology is a term used in molecular biology to describe the similarity between the nucleotide or amino acid sequences of two or more genes or proteins. It is a measure of the degree to which the sequences are related, indicating a common evolutionary origin.
In other words, sequence homology implies that the compared sequences have a significant number of identical or similar residues in the same order, suggesting that they share a common ancestor and have diverged over time through processes such as mutation, insertion, deletion, or rearrangement. The higher the degree of sequence homology, the more closely related the sequences are likely to be.
Sequence homology is often used to identify similarities between genes or proteins from different species, which can provide valuable insights into their functions, structures, and evolutionary relationships. It is commonly assessed using various bioinformatics tools and algorithms, such as BLAST (Basic Local Alignment Search Tool), Clustal Omega, and multiple sequence alignment (MSA) methods.
In the context of medicine and pharmacology, "kinetics" refers to the study of how a drug moves throughout the body, including its absorption, distribution, metabolism, and excretion (often abbreviated as ADME). This field is called "pharmacokinetics."
1. Absorption: This is the process of a drug moving from its site of administration into the bloodstream. Factors such as the route of administration (e.g., oral, intravenous, etc.), formulation, and individual physiological differences can affect absorption.
2. Distribution: Once a drug is in the bloodstream, it gets distributed throughout the body to various tissues and organs. This process is influenced by factors like blood flow, protein binding, and lipid solubility of the drug.
3. Metabolism: Drugs are often chemically modified in the body, typically in the liver, through processes known as metabolism. These changes can lead to the formation of active or inactive metabolites, which may then be further distributed, excreted, or undergo additional metabolic transformations.
4. Excretion: This is the process by which drugs and their metabolites are eliminated from the body, primarily through the kidneys (urine) and the liver (bile).
Understanding the kinetics of a drug is crucial for determining its optimal dosing regimen, potential interactions with other medications or foods, and any necessary adjustments for special populations like pediatric or geriatric patients, or those with impaired renal or hepatic function.
Proteins are complex, large molecules that play critical roles in the body's functions. They are made up of amino acids, which are organic compounds that are the building blocks of proteins. Proteins are required for the structure, function, and regulation of the body's tissues and organs. They are essential for the growth, repair, and maintenance of body tissues, and they play a crucial role in many biological processes, including metabolism, immune response, and cellular signaling. Proteins can be classified into different types based on their structure and function, such as enzymes, hormones, antibodies, and structural proteins. They are found in various foods, especially animal-derived products like meat, dairy, and eggs, as well as plant-based sources like beans, nuts, and grains.
A cell line is a culture of cells that are grown in a laboratory for use in research. These cells are usually taken from a single cell or group of cells, and they are able to divide and grow continuously in the lab. Cell lines can come from many different sources, including animals, plants, and humans. They are often used in scientific research to study cellular processes, disease mechanisms, and to test new drugs or treatments. Some common types of human cell lines include HeLa cells (which come from a cancer patient named Henrietta Lacks), HEK293 cells (which come from embryonic kidney cells), and HUVEC cells (which come from umbilical vein endothelial cells). It is important to note that cell lines are not the same as primary cells, which are cells that are taken directly from a living organism and have not been grown in the lab.
Membrane proteins are a type of protein that are embedded in the lipid bilayer of biological membranes, such as the plasma membrane of cells or the inner membrane of mitochondria. These proteins play crucial roles in various cellular processes, including:
1. Cell-cell recognition and signaling
2. Transport of molecules across the membrane (selective permeability)
3. Enzymatic reactions at the membrane surface
4. Energy transduction and conversion
5. Mechanosensation and signal transduction
Membrane proteins can be classified into two main categories: integral membrane proteins, which are permanently associated with the lipid bilayer, and peripheral membrane proteins, which are temporarily or loosely attached to the membrane surface. Integral membrane proteins can further be divided into three subcategories based on their topology:
1. Transmembrane proteins, which span the entire width of the lipid bilayer with one or more alpha-helices or beta-barrels.
2. Lipid-anchored proteins, which are covalently attached to lipids in the membrane via a glycosylphosphatidylinositol (GPI) anchor or other lipid modifications.
3. Monotopic proteins, which are partially embedded in the membrane and have one or more domains exposed to either side of the bilayer.
Membrane proteins are essential for maintaining cellular homeostasis and are targets for various therapeutic interventions, including drug development and gene therapy. However, their structural complexity and hydrophobicity make them challenging to study using traditional biochemical methods, requiring specialized techniques such as X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and single-particle cryo-electron microscopy (cryo-EM).
Messenger RNA (mRNA) is a type of RNA (ribonucleic acid) that carries genetic information copied from DNA in the form of a series of three-base code "words," each of which specifies a particular amino acid. This information is used by the cell's machinery to construct proteins, a process known as translation. After being transcribed from DNA, mRNA travels out of the nucleus to the ribosomes in the cytoplasm where protein synthesis occurs. Once the protein has been synthesized, the mRNA may be degraded and recycled. Post-transcriptional modifications can also occur to mRNA, such as alternative splicing and addition of a 5' cap and a poly(A) tail, which can affect its stability, localization, and translation efficiency.
"Saccharomyces cerevisiae" is not typically considered a medical term, but it is a scientific name used in the field of microbiology. It refers to a species of yeast that is commonly used in various industrial processes, such as baking and brewing. It's also widely used in scientific research due to its genetic tractability and eukaryotic cellular organization.
However, it does have some relevance to medical fields like medicine and nutrition. For example, certain strains of S. cerevisiae are used as probiotics, which can provide health benefits when consumed. They may help support gut health, enhance the immune system, and even assist in the digestion of certain nutrients.
In summary, "Saccharomyces cerevisiae" is a species of yeast with various industrial and potential medical applications.
"Cattle" is a term used in the agricultural and veterinary fields to refer to domesticated animals of the genus *Bos*, primarily *Bos taurus* (European cattle) and *Bos indicus* (Zebu). These animals are often raised for meat, milk, leather, and labor. They are also known as bovines or cows (for females), bulls (intact males), and steers/bullocks (castrated males). However, in a strict medical definition, "cattle" does not apply to humans or other animals.
Restriction mapping is a technique used in molecular biology to identify the location and arrangement of specific restriction endonuclease recognition sites within a DNA molecule. Restriction endonucleases are enzymes that cut double-stranded DNA at specific sequences, producing fragments of various lengths. By digesting the DNA with different combinations of these enzymes and analyzing the resulting fragment sizes through techniques such as agarose gel electrophoresis, researchers can generate a restriction map - a visual representation of the locations and distances between recognition sites on the DNA molecule. This information is crucial for various applications, including cloning, genome analysis, and genetic engineering.
RNA (Ribonucleic Acid) is a single-stranded, linear polymer of ribonucleotides. It is a nucleic acid present in the cells of all living organisms and some viruses. RNAs play crucial roles in various biological processes such as protein synthesis, gene regulation, and cellular signaling. There are several types of RNA including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), small nuclear RNA (snRNA), microRNA (miRNA), and long non-coding RNA (lncRNA). These RNAs differ in their structure, function, and location within the cell.
A plasmid is a small, circular, double-stranded DNA molecule that is separate from the chromosomal DNA of a bacterium or other organism. Plasmids are typically not essential for the survival of the organism, but they can confer beneficial traits such as antibiotic resistance or the ability to degrade certain types of pollutants.
Plasmids are capable of replicating independently of the chromosomal DNA and can be transferred between bacteria through a process called conjugation. They often contain genes that provide resistance to antibiotics, heavy metals, and other environmental stressors. Plasmids have also been engineered for use in molecular biology as cloning vectors, allowing scientists to replicate and manipulate specific DNA sequences.
Plasmids are important tools in genetic engineering and biotechnology because they can be easily manipulated and transferred between organisms. They have been used to produce vaccines, diagnostic tests, and genetically modified organisms (GMOs) for various applications, including agriculture, medicine, and industry.
DNA primers are short single-stranded DNA molecules that serve as a starting point for DNA synthesis. They are typically used in laboratory techniques such as the polymerase chain reaction (PCR) and DNA sequencing. The primer binds to a complementary sequence on the DNA template through base pairing, providing a free 3'-hydroxyl group for the DNA polymerase enzyme to add nucleotides and synthesize a new strand of DNA. This allows for specific and targeted amplification or analysis of a particular region of interest within a larger DNA molecule.
Macromolecular substances, also known as macromolecules, are large, complex molecules made up of repeating subunits called monomers. These substances are formed through polymerization, a process in which many small molecules combine to form a larger one. Macromolecular substances can be naturally occurring, such as proteins, DNA, and carbohydrates, or synthetic, such as plastics and synthetic fibers.
In the context of medicine, macromolecular substances are often used in the development of drugs and medical devices. For example, some drugs are designed to bind to specific macromolecules in the body, such as proteins or DNA, in order to alter their function and produce a therapeutic effect. Additionally, macromolecular substances may be used in the creation of medical implants, such as artificial joints and heart valves, due to their strength and durability.
It is important for healthcare professionals to have an understanding of macromolecular substances and how they function in the body, as this knowledge can inform the development and use of medical treatments.
A bacterial gene is a segment of DNA (or RNA in some viruses) that contains the genetic information necessary for the synthesis of a functional bacterial protein or RNA molecule. These genes are responsible for encoding various characteristics and functions of bacteria such as metabolism, reproduction, and resistance to antibiotics. They can be transmitted between bacteria through horizontal gene transfer mechanisms like conjugation, transformation, and transduction. Bacterial genes are often organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule.
It's important to note that the term "bacterial gene" is used to describe genetic elements found in bacteria, but not all genetic elements in bacteria are considered genes. For example, some DNA sequences may not encode functional products and are therefore not considered genes. Additionally, some bacterial genes may be plasmid-borne or phage-borne, rather than being located on the bacterial chromosome.
Nucleic acid conformation refers to the three-dimensional structure that nucleic acids (DNA and RNA) adopt as a result of the bonding patterns between the atoms within the molecule. The primary structure of nucleic acids is determined by the sequence of nucleotides, while the conformation is influenced by factors such as the sugar-phosphate backbone, base stacking, and hydrogen bonding.
Two common conformations of DNA are the B-form and the A-form. The B-form is a right-handed helix with a diameter of about 20 Å and a pitch of 34 Å, while the A-form has a smaller diameter (about 18 Å) and a shorter pitch (about 25 Å). RNA typically adopts an A-form conformation.
The conformation of nucleic acids can have significant implications for their function, as it can affect their ability to interact with other molecules such as proteins or drugs. Understanding the conformational properties of nucleic acids is therefore an important area of research in molecular biology and medicine.
DNA-binding proteins are a type of protein that have the ability to bind to DNA (deoxyribonucleic acid), the genetic material of organisms. These proteins play crucial roles in various biological processes, such as regulation of gene expression, DNA replication, repair and recombination.
The binding of DNA-binding proteins to specific DNA sequences is mediated by non-covalent interactions, including electrostatic, hydrogen bonding, and van der Waals forces. The specificity of binding is determined by the recognition of particular nucleotide sequences or structural features of the DNA molecule.
DNA-binding proteins can be classified into several categories based on their structure and function, such as transcription factors, histones, and restriction enzymes. Transcription factors are a major class of DNA-binding proteins that regulate gene expression by binding to specific DNA sequences in the promoter region of genes and recruiting other proteins to modulate transcription. Histones are DNA-binding proteins that package DNA into nucleosomes, the basic unit of chromatin structure. Restriction enzymes are DNA-binding proteins that recognize and cleave specific DNA sequences, and are widely used in molecular biology research and biotechnology applications.
A gene is a specific sequence of nucleotides in DNA that carries genetic information. Genes are the fundamental units of heredity and are responsible for the development and function of all living organisms. They code for proteins or RNA molecules, which carry out various functions within cells and are essential for the structure, function, and regulation of the body's tissues and organs.
Each gene has a specific location on a chromosome, and each person inherits two copies of every gene, one from each parent. Variations in the sequence of nucleotides in a gene can lead to differences in traits between individuals, including physical characteristics, susceptibility to disease, and responses to environmental factors.
Medical genetics is the study of genes and their role in health and disease. It involves understanding how genes contribute to the development and progression of various medical conditions, as well as identifying genetic risk factors and developing strategies for prevention, diagnosis, and treatment.
Cysteine is a semi-essential amino acid, which means that it can be produced by the human body under normal circumstances, but may need to be obtained from external sources in certain conditions such as illness or stress. Its chemical formula is HO2CCH(NH2)CH2SH, and it contains a sulfhydryl group (-SH), which allows it to act as a powerful antioxidant and participate in various cellular processes.
Cysteine plays important roles in protein structure and function, detoxification, and the synthesis of other molecules such as glutathione, taurine, and coenzyme A. It is also involved in wound healing, immune response, and the maintenance of healthy skin, hair, and nails.
Cysteine can be found in a variety of foods, including meat, poultry, fish, dairy products, eggs, legumes, nuts, seeds, and some grains. It is also available as a dietary supplement and can be used in the treatment of various medical conditions such as liver disease, bronchitis, and heavy metal toxicity. However, excessive intake of cysteine may have adverse effects on health, including gastrointestinal disturbances, nausea, vomiting, and headaches.
'Escherichia coli (E. coli) proteins' refer to the various types of proteins that are produced and expressed by the bacterium Escherichia coli. These proteins play a critical role in the growth, development, and survival of the organism. They are involved in various cellular processes such as metabolism, DNA replication, transcription, translation, repair, and regulation.
E. coli is a gram-negative, facultative anaerobe that is commonly found in the intestines of warm-blooded organisms. It is widely used as a model organism in scientific research due to its well-studied genetics, rapid growth, and ability to be easily manipulated in the laboratory. As a result, many E. coli proteins have been identified, characterized, and studied in great detail.
Some examples of E. coli proteins include enzymes involved in carbohydrate metabolism such as lactase, sucrase, and maltose; proteins involved in DNA replication such as the polymerases, single-stranded binding proteins, and helicases; proteins involved in transcription such as RNA polymerase and sigma factors; proteins involved in translation such as ribosomal proteins, tRNAs, and aminoacyl-tRNA synthetases; and regulatory proteins such as global regulators, two-component systems, and transcription factors.
Understanding the structure, function, and regulation of E. coli proteins is essential for understanding the basic biology of this important organism, as well as for developing new strategies for combating bacterial infections and improving industrial processes involving bacteria.
A ligand, in the context of biochemistry and medicine, is a molecule that binds to a specific site on a protein or a larger biomolecule, such as an enzyme or a receptor. This binding interaction can modify the function or activity of the target protein, either activating it or inhibiting it. Ligands can be small molecules, like hormones or neurotransmitters, or larger structures, like antibodies. The study of ligand-protein interactions is crucial for understanding cellular processes and developing drugs, as many therapeutic compounds function by binding to specific targets within the body.
Crystallization is a process in which a substance transitions from a liquid or dissolved state to a solid state, forming a crystal lattice. In the medical context, crystallization can refer to the formation of crystals within the body, which can occur under certain conditions such as changes in pH, temperature, or concentration of solutes. These crystals can deposit in various tissues and organs, leading to the formation of crystal-induced diseases or disorders.
For example, in patients with gout, uric acid crystals can accumulate in joints, causing inflammation, pain, and swelling. Similarly, in nephrolithiasis (kidney stones), minerals in the urine can crystallize and form stones that can obstruct the urinary tract. Crystallization can also occur in other medical contexts, such as in the formation of dental calculus or plaque, and in the development of cataracts in the eye.
A multigene family is a group of genetically related genes that share a common ancestry and have similar sequences or structures. These genes are arranged in clusters on a chromosome and often encode proteins with similar functions. They can arise through various mechanisms, including gene duplication, recombination, and transposition. Multigene families play crucial roles in many biological processes, such as development, immunity, and metabolism. Examples of multigene families include the globin genes involved in oxygen transport, the immune system's major histocompatibility complex (MHC) genes, and the cytochrome P450 genes associated with drug metabolism.
Nucleic acid hybridization is a process in molecular biology where two single-stranded nucleic acids (DNA, RNA) with complementary sequences pair together to form a double-stranded molecule through hydrogen bonding. The strands can be from the same type of nucleic acid or different types (i.e., DNA-RNA or DNA-cDNA). This process is commonly used in various laboratory techniques, such as Southern blotting, Northern blotting, polymerase chain reaction (PCR), and microarray analysis, to detect, isolate, and analyze specific nucleic acid sequences. The hybridization temperature and conditions are critical to ensure the specificity of the interaction between the two strands.
Nuclear Magnetic Resonance (NMR) Biomolecular is a research technique that uses magnetic fields and radio waves to study the structure and dynamics of biological molecules, such as proteins and nucleic acids. This technique measures the magnetic properties of atomic nuclei within these molecules, specifically their spin, which can be influenced by the application of an external magnetic field.
When a sample is placed in a strong magnetic field, the nuclei absorb and emit electromagnetic radiation at specific frequencies, known as resonance frequencies, which are determined by the molecular structure and environment of the nuclei. By analyzing these resonance frequencies and their interactions, researchers can obtain detailed information about the three-dimensional structure, dynamics, and interactions of biomolecules.
NMR spectroscopy is a non-destructive technique that allows for the study of biological molecules in solution, which makes it an important tool for understanding the function and behavior of these molecules in their natural environment. Additionally, NMR can be used to study the effects of drugs, ligands, and other small molecules on biomolecular structure and dynamics, making it a valuable tool in drug discovery and development.
Amino acid motifs are recurring patterns or sequences of amino acids in a protein molecule. These motifs can be identified through various sequence analysis techniques and often have functional or structural significance. They can be as short as two amino acids in length, but typically contain at least three to five residues.
Some common examples of amino acid motifs include:
1. Active site motifs: These are specific sequences of amino acids that form the active site of an enzyme and participate in catalyzing chemical reactions. For example, the catalytic triad in serine proteases consists of three residues (serine, histidine, and aspartate) that work together to hydrolyze peptide bonds.
2. Signal peptide motifs: These are sequences of amino acids that target proteins for secretion or localization to specific organelles within the cell. For example, a typical signal peptide consists of a positively charged n-region, a hydrophobic h-region, and a polar c-region that directs the protein to the endoplasmic reticulum membrane for translocation.
3. Zinc finger motifs: These are structural domains that contain conserved sequences of amino acids that bind zinc ions and play important roles in DNA recognition and regulation of gene expression.
4. Transmembrane motifs: These are sequences of hydrophobic amino acids that span the lipid bilayer of cell membranes and anchor transmembrane proteins in place.
5. Phosphorylation sites: These are specific serine, threonine, or tyrosine residues that can be phosphorylated by protein kinases to regulate protein function.
Understanding amino acid motifs is important for predicting protein structure and function, as well as for identifying potential drug targets in disease-associated proteins.
 Homology modeling
Homology modeling
Pleckstrin homology domain
ABCG2
Phyre
Ataxin 3
TIM barrel
Perforin-1
Protein tandem repeats
Homology (biology)
Homology-derived Secondary Structure of Proteins
Marta Filizola
YjeF N terminal protein domain
Benzoate:H symporter
Ground squirrel hepatitis virus
Molecular dynamics
WWTR1
Membrane topology
Cyanase
MAP1LC3B
Signal transduction
Protein superfamily
Ribose repressor
Domain of unknown function
Swiss-model
Integrin-like receptors
Ribose-5-phosphate isomerase
Protein engineering
Protein structure prediction
FKBP6
Phospholipase D
Protein
Heterologous
Collagen, type XXIII, alpha 1
Protein family
Homology modeling - Wikipedia
 Homology modeling reveals the structural background of the striking difference in thermal stability between two related [NiFe...
Homology modeling reveals the structural background of the striking difference in thermal stability between two related [NiFe...
ModBase, a database of annotated comparative protein structure models and associated resources
 Three Dimensional Structural Modelling of Lipase Encoding Gene from Soil Bacterium Alcaligenes sp. JG3 Using Automated...
Three Dimensional Structural Modelling of Lipase Encoding Gene from Soil Bacterium Alcaligenes sp. JG3 Using Automated...
 Cryo-EM structures of holo condensin reveal a subunit flip-flop mechanism | Nature Structural & Molecular Biology
Cryo-EM structures of holo condensin reveal a subunit flip-flop mechanism | Nature Structural & Molecular Biology
 Soy Protein Intolerance: Background, Pathophysiology, Epidemiology
Soy Protein Intolerance: Background, Pathophysiology, Epidemiology
 SCOPe 2.08: Superfamily a.40.1: Calponin-homology domain, CH-domain
SCOPe 2.08: Superfamily a.40.1: Calponin-homology domain, CH-domain
SCOPe 2.08: Superfamily e.40.1: Cullin homology domain
 Bisulfite mapping - SIB Swiss Institute of Bioinformatics | Expasy
Bisulfite mapping - SIB Swiss Institute of Bioinformatics | Expasy
Proteins - SIB Swiss Institute of Bioinformatics | Expasy
 Computational Design of a DNA- and Fc-Binding Fusion Protein
Computational Design of a DNA- and Fc-Binding Fusion Protein
Highly Pathogenic Avian Influenza Virus (H5N8) Clade 2.3.4.4 Infection in Migratory Birds, Egypt - Volume 23, Number 6-June...
 JCI -
Functional redundancy of Rab27 proteins and the pathogenesis of Griscelli syndrome
JCI -
Functional redundancy of Rab27 proteins and the pathogenesis of Griscelli syndrome
Structural basis of phosphatidylinositol 3-kinase C2α function | Nature Structural & Molecular Biology
 The Three Dimensional Structure of Proteins Flashcards
The Three Dimensional Structure of Proteins Flashcards
 Viruses | Special Issue : In Memory of Michael Rossmann
Viruses | Special Issue : In Memory of Michael Rossmann
 Our Team | Texas Children's Hospital
Our Team | Texas Children's Hospital
 transgenic technology - GMO SAFETY
transgenic technology - GMO SAFETY
 Comparing function and structure between entire proteomes | ROSTLAB.ORG
Comparing function and structure between entire proteomes | ROSTLAB.ORG
 Publication : USDA ARS
Publication : USDA ARS
 Theo SCHETTERS | Professor | Extraordinary Professor; PhD | University of Pretoria, Pretoria | UP | Department of Veterinary...
Theo SCHETTERS | Professor | Extraordinary Professor; PhD | University of Pretoria, Pretoria | UP | Department of Veterinary...
 Ovulation Induced by a Nerve Growth Factor | The Scientist Magazine®
Ovulation Induced by a Nerve Growth Factor | The Scientist Magazine®
RIM Promotes Calcium Channel Accumulation at Active Zones of the Drosophila Neuromuscular Junction | Journal of Neuroscience
 Publications - Structural Cell Biology Section - NIDDK
Publications - Structural Cell Biology Section - NIDDK
 Human Endoglycan/PODXL2 Antibody MAB1524: R&D Systems
Human Endoglycan/PODXL2 Antibody MAB1524: R&D Systems
Ophthalmic phenotype of TCIRG1 gene mutations in Chinese infantile malignant osteopetrosis | BMJ Open Ophthalmology
 Researchers Use Mass Spec, Structural Data to Devise 'Periodic Table' of Protein Complexes | GenomeWeb
Researchers Use Mass Spec, Structural Data to Devise 'Periodic Table' of Protein Complexes | GenomeWeb
 ALMS1 and Alström syndrome: a recessive form of metabolic, neurosensory and cardiac deficits | Journal of Molecular Medicine
ALMS1 and Alström syndrome: a recessive form of metabolic, neurosensory and cardiac deficits | Journal of Molecular Medicine
IUCr) Wheat germ cell-free expression system as a pathway to improve protein yield and solubility for the SSGCID pipeline
 Frontiers | Identification of Amino Acids Essential for Viral Replication in the HCMV Helicase-Primase Complex
Frontiers | Identification of Amino Acids Essential for Viral Replication in the HCMV Helicase-Primase Complex
Prediction12
- Like other methods of structure prediction, current practice in homology modeling is assessed in a biennial large-scale experiment known as the Critical Assessment of Techniques for Protein Structure Prediction, or CASP. (wikipedia.org)
- Based on the genome sequencing results, an analysis of structural proteins and prediction of putative microRNAs of Hz-2V was performed. (umass.edu)
- A recent dividend has been paid in the success of PDB-trained artificial intelligence approaches for protein structure prediction. (iucr.org)
- Stress-Induced Accumulation of DcAOX1 and DcAOX2a Transcripts Coincides with Critical Time Point for Structural Biomass Prediction in Carrot Primary Cultures (Daucus carota L. (frontiersin.org)
- Prediction of structures of zinc-binding proteins through explicit modeling of metal coordination geometry. (rosettacommons.org)
- Matching of structural motifs using hashing on residue labels and geometric filtering for protein function prediction. (uni-marburg.de)
- Overview over prediction of protein function. (tum.de)
- Prediction of the effect of single point mutations (sequence variants) on protein function and the organism. (tum.de)
- As for the first part (Protein Prediction I), the module include an introduction into machine learning with particular focus on how to avoid over-estimating performance. (tum.de)
- As opposed to the first part (Protein Prediction I), protein structure has only played a minor role: it has been introduced if it has been helpful to further our understanding of function. (tum.de)
- Students understand the principle concepts in protein sequence analysis with focus on protein function and protein function prediction and are able to evaluate these. (tum.de)
- Lectures, Seminars, Exercises, Problems for individual and team study: The students apply the theory presented in the lecture by writing a protein function prediction method in the exercise starting from data in varying form (depending on the problem at hand). (tum.de)
Similarity11
- Because protein structures are more conserved than DNA sequences, and detectable levels of sequence similarity usually imply significant structural similarity. (wikipedia.org)
- Thus, even proteins that have diverged appreciably in sequence but still share detectable similarity will also share common structural properties, particularly the overall fold. (wikipedia.org)
- the principal aim of this is to determine whether and to what level does the protein produced by the genetically modified foods have similarity to other known proteins that have the potential of causing allergies among humans and animals. (gmo-safety.eu)
- This is through the determination of the overall structure of the protein of interest and its similarity to allergens that are known. (gmo-safety.eu)
- The use of the protein database offers the possibility of determining the similarity of the novel protein of interest with those of allergens that are known on their sequence alignments homology. (gmo-safety.eu)
- This could also be compared to discrete motifs and domains in the protein where there is complete sequence similarity with that which is present in known allergens, therefore, indicating possibility of shared protein epitopes. (gmo-safety.eu)
- It belongs to the CD34/Podocalyxin family of sialomucins that share structural similarity and sequence homology. (rndsystems.com)
- How to Measure the Similarity Between Protein Ligand-binding Sites. (uni-marburg.de)
- Efficient Similarity Retrieval for Protein Binding Sites based on Histogram Comparison. (uni-marburg.de)
- Predicting protein function using structure: structural alignments, structural motifs, annotation transfer via structure similarity. (tum.de)
- The degree of 3-dimensional shape similarity between proteins. (bvsalud.org)
Transmembrane6
- In this update, we also highlight two applications of ModBase: a PSI:Biology initiative to maximize the structural coverage of the human alpha-helical transmembrane proteome and a determination of structural determinants of human immunodeficiency virus-1 protease specificity. (nih.gov)
- We predicted that approximately 15%-30% of all proteins contained transmembrane helices. (rostlab.org)
- However, we found more proteins with seven transmembrane helices in eukaryotes and more with six and 12 transmembrane helices in prokaryotes. (rostlab.org)
- Endoglycan, also named Podocalyxin-like 2 protein, is a type I transmembrane glycoprotein. (rndsystems.com)
- Two transmembrane domains were predicted in p11.7, and a DNA binding motif was found in p31.7 by amino acid sequence analysis, therefore p11.7 and p31.7 were predicted to be envelope and capsid protein, respectively. (umass.edu)
- Both are transmembrane proteins sharing 30% protein sequence homology in their extracellular domains, but little homology in intracellular domains. (jefferson.edu)
Superfamily2
- Palecek, J. J. & Gruber, S. Kite proteins: a superfamily of SMC/Kleisin partners conserved across bacteria, archaea, and eukaryotes. (nature.com)
- Structural Insights into the Mechanism of Dynamin Superfamily Proteins. (nih.gov)
Molecular3
- Two heat-stable globulins constitute 90% of the pulp-derived proteins: beta-conglycinin, which has a molecular weight (MW) of 180,000, and glycinin, which has an MW of 320,000. (medscape.com)
- However, molecular weight is also important due to potential steric incompatibilities within protein cores. (hindawi.com)
- Characteristic biochemical properties of allergens are that they are proteins or glycoproteins with molecular weights between about 5-100 kDa, which are usually abundant in the food source and often stable to digestion by gastrointestinal enzymes. (usda.gov)
Protease2
- Therefore, the present study proposes the three‑dimensional structure of the helicase/protease enzyme of SPONV through homology modeling, using the crystal structure of the Dengue virus‑4 helicase/protease of the same viral family as a template. (spandidos-publications.com)
- Specific structural features and functional similarities, such as protease activity, have also been associated with both food and inhaled allergens (i.e. pollen, cat, dog, dust mite, etc). (usda.gov)
Sequences9
- It has been seen that protein structures are more conserved than protein sequences amongst homologues, but sequences falling below a 20% sequence identity can have very different structure. (wikipedia.org)
- Evolutionarily related proteins have similar sequences and naturally occurring homologous proteins have similar protein structure. (wikipedia.org)
- However, the errors are significantly higher in the loop regions, where the amino acid sequences of the target and template proteins may be completely different. (wikipedia.org)
- ModBase currently contains almost 30 million reliable models for domains in 4.7 million unique protein sequences. (nih.gov)
- By using in silico tools, LipJG3 was related to the transporter protein sequences. (ugm.ac.id)
- Protein design methods use trial and error or more sophisticated methods like directed evolution or inverse folding to generate novel scaffolds or to find novel protein sequences folding into a defined scaffold, respectively. (hindawi.com)
- Given the intimate relationship between a protein's structure and function, a way to design proteins with targeted properties is to start from a desired structure and find sequences able to fold into it, imposing additional constraints in the process [ 1 ]. (hindawi.com)
- Analysis of the protein sequences of the three CpHsps indicated the presence of 83 amino acids with homology to the a-crystallin domain. (usda.gov)
- These sequences represent the protein coding region of the Sh2b2 cDNA ORF which is encoded by the open reading frame (ORF) sequence. (genscript.com)
Helicase1
- The most crucial NS proteins are the viral helicase and the viral RNA-dependent RNA polymerase (RdRp) ( 2 ). (spandidos-publications.com)
Potentially allergenic1
- The intestinal mucosa damaged by cow's milk proteins may allow increased uptake of the potentially allergenic soy proteins. (medscape.com)
Folds2
- Homology modeling can produce high-quality structural models when the target and template are closely related, which has inspired the formation of a structural genomics consortium dedicated to the production of representative experimental structures for all classes of protein folds. (wikipedia.org)
- These numbers may or may not suggest that there are 1200-2600 folds in the universe of protein structures. (rostlab.org)
Fold5
- There are exceptions to the general rule that proteins sharing significant sequence identity will share a fold. (wikipedia.org)
- For example, a judiciously chosen set of mutations of less than 50% of a protein can cause the protein to adopt a completely different fold. (wikipedia.org)
- However, such a massive structural rearrangement is unlikely to occur in evolution, especially since the protein is usually under the constraint that it must fold properly and carry out its function in the cell. (wikipedia.org)
- It would be far better design logic just to put that protein fold into the first cells. (evcforum.net)
- Considering the widely acknowledged Accordingly, theoretical models of the MG state invariably invoke importance of protein-solvent interactions for stability and fold- a substantial internal hydration20-22. (lu.se)
Allergenic2
- The theory, in this case, is that relative resistance plays a role in inducing allergic responses on condition that the protein of interest possesses allergenic characteristics. (gmo-safety.eu)
- Some of the immunological properties of allergenic proteins include their ability to stimulate Th-2 type T-cell proliferation, bind serum IgE, elicit a positive prick skin test, and cause histamine and mediator release from mast cells and basophils of sensitive individuals. (usda.gov)
Biology3
- Computational design of novel proteins with well-defined functions is an ongoing topic in computational biology. (hindawi.com)
- Here, I discuss how we - myself, my laboratory and the diffraction community - have faced the phase problem, considering the evolution of methods for phase evaluation as structural biology developed to the present day. (iucr.org)
- The project should involve both studies of protein function by the applicant researchers and structural studies by the PSI:Biology network. (nih.gov)
Modeling6
- Homology modeling relies on the identification of one or more known protein structures likely to resemble the structure of the query sequence, and on the production of an alignment that maps residues in the query sequence to residues in the template sequence. (wikipedia.org)
- The chief inaccuracies in homology modeling, which worsen with lower sequence identity, derive from errors in the initial sequence alignment and from improper template selection. (wikipedia.org)
- The method of homology modeling is based on the observation that protein tertiary structure is better conserved than amino acid sequence. (wikipedia.org)
- Because it is difficult and time-consuming to obtain experimental structures from methods such as X-ray crystallography and protein NMR for every protein of interest, homology modeling can provide useful structural models for generating hypotheses about a protein's function and directing further experimental work. (wikipedia.org)
- Structural and phylogenetic modeling of highly pathogenic avian influenza virus (H5N8), EG-CA285, from migratory birds, Egypt, 2016. (cdc.gov)
- We also constructed, by homology modeling, a theoretical structure of the pUL105 N-terminal domain which indicates that the mutated conserved amino acids in this domain could be involved in ATP hydrolysis. (frontiersin.org)
Biol1
- A pig sperm protein that binds to the extracellular matrix of the egg in a species-specific manner was recently identified and named zonadhesin (Hardy, D. M., and Garbers, D. L. (1995) J. Biol. (embl.de)
Intracellular1
- SH2 (Src Homology 2) is a protein domain found in many intracellular signal-transducing proteins. (nersc.gov)
Integral membrane1
- They have been defined as monotropic integral membrane proteins located primarily in the endoplasmic reticulum (COX-1) and the perinuclear envelope (COX-2). (medscape.com)
Subunit2
- even the quaternary structure of a protein may be difficult to predict from homology models of its subunit(s). (wikipedia.org)
- The comparison of the models reveals that the higher stability of HydSL can be attributed to increased inter-subunit electrostatic interactions: the homology models reliably predict that HydSL contains at least five more inter-subunit ion pairs than HupSL. (nih.gov)
Mutations5
- A team of researchers from Harvard Medical School, using computing resources at the U.S. Department of Energy's National Energy Research Scientific Computing Center (NERSC), have demonstrated a mathematical toolkit that can turn cancer-mutation data into multidimensional models to show how specific mutations alter the social networks of proteins in cells. (nersc.gov)
- As a result, he was able to generate detailed schematics of how certain mutations altered the vast, complex cellular world of protein social networks-networks that largely determine a cell's health, or lack thereof. (nersc.gov)
- AlQuraishi found that common and rare mutations are equally likely to affect the protein network. (nersc.gov)
- Because the mutations do happen, and over deep time, a protein sequence can change quite extensively - to the point that it is no longer the original protein (but structurally similar, nonetheless, and this is what matters). (evcforum.net)
- Computational design of second-site suppressor mutations at protein-protein interfaces. (rosettacommons.org)
Docking3
- SnugDock: paratope structural optimization during antibody-antigen docking compensates for errors in antibody homology models. (rosettacommons.org)
- Methods for the assessment of ligand poses in protein binding sites are also used in the early phase of drug development within docking programs. (uni-marburg.de)
- Following Libdock score screening, the protein-ligand poses were docked using docking optimization (Cdocker) method. (bvsalud.org)
Homologs1
- The paper I cited describes the structural similarities between ubiquitin and its prokaryotic homologs. (evcforum.net)
Novel proteins1
- Selenomethionyl SAD and MAD were the mainstays of structural genomics efforts to populate the PDB with novel proteins. (iucr.org)
Functional2
- Projects may focus on proteins that are the subject of other grant applications, but the specific aims must clearly differ, both with respect to functional studies to be conducted and with respect to the goal of structure determination. (nih.gov)
- Moreover, binding site comparisons are used as an idea generator for bioisosteric replacements of individual functional groups of the newly developed drug and to unravel the function of hitherto orphan proteins. (uni-marburg.de)
Classification3
- SCOPe: Structural Classification of Proteins - extended. (berkeley.edu)
- A classification by cellular function verified that eukaryotes have a higher proportion of proteins for communication with the environment. (rostlab.org)
- The current view of protein folding and stability is largely based on SAXS and DLS data13-16 and the extensive exposure of hydropho- a generic structural classification into native (N), compact dena- bic residues suggested by the finding that the heat capacity of the tured or molten globule (MG), and unfolded or denatured (D) MG state is midway between that of the N and D states7 have been conformational states1-10. (lu.se)
Interactions4
- The results are in accord with the general observation that with increasing temperature, the role of electrostatic interactions in protein stability increases. (nih.gov)
- Hydrophobicity was one of the most important physicochemical properties, due to the fact that it is involved in protein interactions, for example, by forming hydrophobic cores. (hindawi.com)
- long range interactions within the protein molecule. (flashcardmachine.com)
- The motor domain of MYH8 was modeled in order to know what are the interactions altered in the mutant protein. (eurekaselect.com)
Allergens3
- However, other soy proteins can act as allergens in humans. (medscape.com)
- This means that taking into consideration the possibility that the transgene produces toxins that are known such as protein allergens. (gmo-safety.eu)
- Whereas many of the structural characteristics, homology and cross reactivity of food allergens have been explained, specific immunological and biophysical properties of the allergens that contribute to IgE antibody formation are not fully understood. (usda.gov)
Biochemical1
- Due to the structural and biochemical homology between IGF-2 and insulin, elevated levels of IGF-2 can result in hypoglycemia. (medscape.com)
Amino acid seq2
- The structural comparison of binding sites is especially useful when applied on distantly related proteins as a comparison solely based on the amino acid sequence is not sufficient in such cases. (uni-marburg.de)
- It can be an indication of distant AMINO ACID SEQUENCE HOMOLOGY and used for rational DRUG DESIGN. (bvsalud.org)
Residues5
- Nevertheless, homology models can be useful in reaching qualitative conclusions about the biochemistry of the query sequence, especially in formulating hypotheses about why certain residues are conserved, which may in turn lead to experiments to test those hypotheses. (wikipedia.org)
- For example, the spatial arrangement of conserved residues may suggest whether a particular residue is conserved to stabilize the folding, to participate in binding some small molecule, or to foster association with another protein or nucleic acid. (wikipedia.org)
- VH is derived from a single protein domain of 35 residues [ 9 ]. (hindawi.com)
- the regions with structural homology covered 20%-30% of all residues. (rostlab.org)
- SP-4 (residues 192-203), SP-8 (residues 483-494), and SP-10 (residues 668-679) significantly blocked the interaction between S protein and ACE2 by biotinylated enzyme-linked immunosorbent assay, with IC 50 values of 4.30 ± 2.18, 6.99 ± 0.71, and 1.88 ± 0.52 nmol, respectively. (scienceopen.com)
Structures5
- Hopfner, K. P. & Tainer, J. A. Rad50/SMC proteins and ABC transporters: unifying concepts from high-resolution structures. (nature.com)
- Cryo-EM structures reveal multiple stages of bacterial outer membrane protein folding. (nih.gov)
- Applicants to this FOA should propose work to solve a substantial biological problem for which the determination of many protein structures is necessary. (nih.gov)
- Ideally, the solution of these protein structures will also contribute to the understanding of protein sequence-structure relationships in general. (nih.gov)
- For -lactalbu- min, only water molecules conserved in the human and baboon structures are shown (the structure of the bovine protein has not been reported). (lu.se)
Helical2
- most prevalent and stable form of helical structure in naturally occurring proteins. (flashcardmachine.com)
- In particular, we did not find significantly higher percentages of helical membrane proteins in eukaryotes than in prokaryotes or archae. (rostlab.org)
Complexes4
- Complexes containing a pair of structural maintenance of chromosomes (SMC) family proteins are fundamental for the three-dimensional (3D) organization of genomes in all domains of life. (nature.com)
- Gligoris, T. & Löwe, J. Structural insights into ring formation of cohesin and related SMC complexes. (nature.com)
- Complexes of Vps34, the sole class III PI3K member, produce PI 3-phosphate (PI(3)P) in the endolysosomal system and during autophagy to regulate vesicle-mediated sorting en route to lysosomes 1 . (nature.com)
- the calicivirus NTPase was found in membranous replication complexes" /protein_id="NP_786946.1" mat_peptide 2288. (cdc.gov)
Genes6
- Homologies were found to 38 of the 113 ORFs predicted for genes with known functions. (umass.edu)
- Four of structural genes, p11.7, p15.1, p28.4, and p31.7 were identified by matrix assisted laser desorption/ionization time-of-flight mass spectroscopy. (umass.edu)
- Eukaryotic expression vectors containing genes encoding plant proteins for killing of cancer cells. (weeksmd.com)
- consequently, genes encoding some of these proteins are being used to design constructs for the inhibition of multiplying cancer cells. (weeksmd.com)
- Plants respond to various stimuli under abiotic or biotic stress condition and express certain genes either structural or regulatory genes which maintain the plant integrity. (scielo.br)
- Finally, by successful identification of TNF-induced genes, including MCP-1 (monocyte chemoattractant protein-1), in human monocyrtic leukemia cells ML-1a using a modified differential display technique, we showed that this new technique is a powerful tool in identifying TNF-regulated genes involved in different biological activities. (jefferson.edu)
Binds1
- p27 is a protein that binds to and prevents the activation of different G1. (lu.se)
Crystallography3
- The approach can be complicated by the presence of alignment gaps (commonly called indels) that indicate a structural region present in the target but not in the template, and by structure gaps in the template that arise from poor resolution in the experimental procedure (usually X-ray crystallography) used to solve the structure. (wikipedia.org)
- X-ray crystallography of OIF and NGF-beta confirmed their structural and sequence homology. (the-scientist.com)
- Cryo-EM analysis is an attractive alternative to crystallography for many applications faced by today's structural biologists. (iucr.org)
Domain5
- We have successfully combined two unrelated naturally occurring binding sites, the immunoglobin Fc-binding site of the Z domain and the DNA-binding motif of MyoD bHLH, into a novel stable protein. (hindawi.com)
- For each of the CpHsps, the a-crystallin domain was surrounded by divergent N- and C-terminal regions, consistent with the conserved structural features of sHsps. (usda.gov)
- Taxonomic distribution of proteins containing VWD domain. (embl.de)
- The complete taxonomic breakdown of all proteins with VWD domain is also avaliable . (embl.de)
- Click on the protein counts, or double click on taxonomic names to display all proteins containing VWD domain in the selected taxonomic class. (embl.de)
Interaction3
- Heat map of the average magnitude of interaction energies projected onto a structural representation of SH2 domains (white) in complex with phosphopeptide (green). (nersc.gov)
- The interaction between the adaptor protein APS and Enigma is involved in actin organisation. (genscript.com)
- Binding energy were calculated for the protein-ligand poses of lowest -Cdocker Energy and -Cdocker Interaction. (bvsalud.org)
Induce1
- Does the transgenic approach employ induce alteration of the level of expression of the proteins that exist in the host crop? (gmo-safety.eu)
Structure determination3
- The proteins should be amenable to high-throughput structure determination and/or should provide suitable targets to motivate new technology development. (nih.gov)
- NMR structure determination for larger proteins using backbone-only data. (rosettacommons.org)
- Accurate automated protein NMR structure determination using unassigned NOESY data. (rosettacommons.org)
Humans2
- Do the products of the novel gene inserted into plants elicit allergic reactions in humans or animals that are already sensitized to the same protein? (gmo-safety.eu)
- The third approach is the use of serological techniques to determine whether there are specific IgE antibodies present in the serum of sensitized humans or animals capable of recognizing the protein of interest. (gmo-safety.eu)
Soybean1
- All soybean proteins and foods currently available for human consumption contain significant amounts of the isoflavones daidzein and genistein, either in the unconjugate form or as different types of glycoside conjugates. (medscape.com)
Genome1
- I personally favor the hypothesis that the LUCA was prokaryotic, and not eukaryotic, although some researchers say that the LUCA was more of a eukaryote precisely because of its complexity and the large number of proteins its genome encoded. (evcforum.net)
Organism1
- We could not find a correlation between the content of membrane proteins and the complexity of the organism. (rostlab.org)
Capsid1
- The translated polyprotein consists of three structural [capsid (C), membrane (M) and envelope (E)] and seven non-structural proteins (NS1, NS2A, NS2B, NS3, NS4A, NS4B and NS5). (spandidos-publications.com)
Encodes3
- ALMS1 encodes a ~ 0.5 megadalton protein that localises to the base of centrioles. (springer.com)
- The transcription of COX-1 yields a 2.7-kilobase (kb) messenger ribonucleic acid (mRNA) that encodes a 576-residue, 65-kd protein. (medscape.com)
- Conversely, the transcription of COX-2 yields a 4.5-kb mRNA that encodes a 70-kd protein with roughly 70-75% homology to the COX-1 protein. (medscape.com)
Nonallergic1
- Authorities have failed to reach consensus on the risk of feeding allergic or nonallergic infants with soy protein milks. (medscape.com)
Membrane protein1
- Species diversity in the structure of zonadhesin, a sperm-specific membrane protein containing multiple cell adhesion molecule-like domains. (embl.de)
Mechanism1
- We unravel a coincident mechanism of lipid-induced activation of PI3KC2α at membranes that involves large-scale repositioning of its Ras-binding and lipid-binding distal Phox-homology and C-C2 domains, and can serve as a model for the entire class II PI3K family. (nature.com)
Naturally1
- Structural studies of the D and MG states have naturally focused ed in controversy23. (lu.se)
Models2
Domains2
- There are 25698 VWD domains in 12416 proteins in SMART's nrdb database. (embl.de)
- Structural basis for phosphotyrosine recognition by the Src homology-2 domains of the adapter proteins SH2-B and APS. (genscript.com)
MRNA2
- Expression of mouse zonadhesin mRNA is evident only within the testis, and the protein is found exclusively on the apical region of the sperm head. (embl.de)
- Rattus norvegicus SH2B adaptor protein 2 (Sh2b2), mRNA. (genscript.com)
Viral1
- New drugs targeting essential viral proteins other than pUL54 are therefore urgently needed. (frontiersin.org)
Isoforms1
- In line with a more complex picture, multiple isoforms of the protein likely exist and non-centrosomal sites of localisation have been reported. (springer.com)
Endothelial1
- Mammalian bone morphogenetic protein-binding (BMP-binding) endothelial regulator protein. (embl.de)
Determination1
- Recombinant expression of proteins of interest in Escherichia coli is an important tool in the determination of protein structure. (iucr.org)
Pathway1
- Findings suggest that fibrodysplasia ossificans progressiva maps to band 4q27-31, a region that contains at least 1 gene involved in the bone morphogenic protein (BMP) signaling pathway. (medscape.com)
Polyprotein1
- The latter region of NS proteins, at the C-terminal part of the polyprotein, has a great contribution in the RNA replication process. (spandidos-publications.com)
Gene4
- Three Dimensional Structural Modelling of Lipase Encoding Gene from Soil Bacterium Alcaligenes sp. (ugm.ac.id)
- To understand the structural basis of TPS, we utilize a large number of software packages to estimate how the Arg674Gln mutation would affect the structure and stability of MyH8 gene product. (eurekaselect.com)
- In this disturbance the maintenance involve the gene expression under the stress either in the form of structural gene or regulatory. (scielo.br)
- The gene expression of DNA damage inducible protein and DNA damage in response to head DNA % and tail DNA % was protected by Mn-NPs diets. (bvsalud.org)
Stability3
- One of the methods that have been proposed is a multiobjective optimization, in which protein stability and catalytic activity are simultaneously optimized [ 4 , 5 ]. (hindawi.com)
- Several methods have been proposed to design novel stable proteins, such as multi-objective optimization, in which protein stability and catalytic activity are simultaneously optimized. (hindawi.com)
- The hydration of nonnative states is central to protein folding and stability but has been probed mainly by indirect methods. (lu.se)