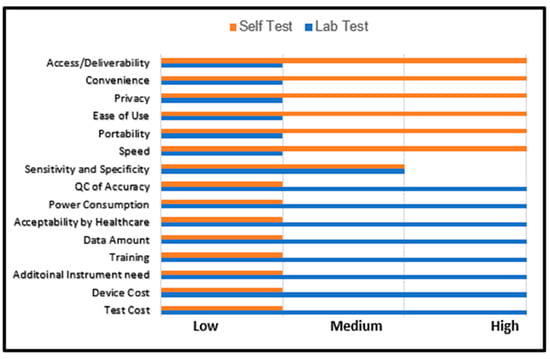
DNA Polymerase II
RNA Polymerase II
DNA-Directed DNA Polymerase
DNA Polymerase I
DNA Polymerase III
DNA Polymerase beta
Templates, Genetic
DNA Nucleotidyltransferases
Pyrococcus abyssi
Molecular Sequence Data
Base Sequence
Escherichia coli
SOS Response (Genetics)
Transcription, Genetic
Saccharomyces cerevisiae
Exodeoxyribonucleases
RNA-Directed DNA Polymerase
Inteins
Polydeoxyribonucleotides
Polymerase Chain Reaction
Mutation
Amino Acid Sequence
Transcriptional Elongation Factors
DNA
DNA-Directed RNA Polymerases
Mutagenesis
Transcription Factors, TFII
Amanitins
Ultraviolet Rays
Chromatography, DEAE-Cellulose
DNA Primase
Plasmids
Deoxyribonucleotides
Centrifugation, Density Gradient
Exonucleases
Promoter Regions, Genetic
Chromatography, Ion Exchange
HeLa Cells
Transcription Factors
Thymine Nucleotides
Cloning, Molecular
Restriction Mapping
Transcription Factors, General
RNA Polymerase III
RNA Nucleotidyltransferases
DNA Repair
Aphidicolin
Saccharomyces cerevisiae Proteins
Protein Binding
RNA Polymerase I
DNA-Binding Proteins
Binding Sites
Proliferating Cell Nuclear Antigen
DNA Primers
Exodeoxyribonuclease V
Nucleotides
DNA, Single-Stranded
Mediator Complex
Macromolecular Substances
Transcription Factor TFIIB
Transcription Factor TFIID
Transcription Factor TFIIH
Taq Polymerase
Cell Nucleus
Chromatin
Protein Structure, Tertiary
RNA
Bacteriophage T7
DNA Damage
TATA-Box Binding Protein
Dichlororibofuranosylbenzimidazole
T-Phages
RNA, Messenger
Substrate Specificity
Polynucleotides
Transcription Elongation, Genetic
Phosphonoacetic Acid
Nuclear Proteins
Sequence Homology, Amino Acid
Models, Molecular
Histones
Protein Subunits
DNA Helicases
TATA Box
Positive Transcriptional Elongation Factor B
Poly T
Nucleic Acid Conformation
Cyclin-Dependent Kinase 9
Cyclin-Dependent Kinase 8
Holoenzymes
Base Pair Mismatch
Oligodeoxyribonucleotides
TATA-Binding Protein Associated Factors
Electrophoresis, Polyacrylamide Gel
Oligonucleotides
Chromatin Immunoprecipitation
Gene Expression Regulation, Fungal
Guanine
Uracil
Catalytic Domain
Temperature
Poly dA-dT
Bacillus Phages
Manganese
Cell-Free System
Phosphorylation
Base Pairing
Virus Replication
Cattle
Bacteriophage T4
Thymus Gland
Models, Genetic
Sequence Alignment
Replication Protein C
Ribonucleotides
Pyrimidine Dimers
Protein Conformation
Nucleic Acid Hybridization
Sulfolobus solfataricus
Thermus
Recombinant Fusion Proteins
Reverse Transcriptase Polymerase Chain Reaction
Avian leukosis virus
Magnesium
Gene Expression Regulation
Catalysis
Structure-Activity Relationship
Mutagenesis, Site-Directed
Transcription Initiation Site
Chromatography, Affinity
RNA Replicase
Genes
Bacteriophage phi X 174
Cyclin-Dependent Kinases
Nucleosomes
DNA Adducts
Alpha-Amanitin
Frameshift Mutation
RNA, Small Nuclear
Transcription Initiation, Genetic
Sequence Analysis, DNA
Conserved Sequence
Poly(ADP-ribose) Polymerases
RNA, Fungal
Simplexvirus
Precipitin Tests
Transcription Factor TFIIA
RNA Processing, Post-Transcriptional
Foscarnet
Thymine
Ribonuclease H
Schizosaccharomyces
DNA, Circular
Drosophila melanogaster
Poly A
Trans-Activators
Transcriptional Activation
Gene Deletion
Deoxycytidine Monophosphate
Bacteriophage M13
Chromatography
Crystallography, X-Ray
RNA Precursors
Point Mutation
Chromatography, Gel
Sequence Homology, Nucleic Acid
DNA Ligases
Cytosine Nucleotides
Action of partially thiolated polynucleotides on the DNA polymerase alpha from regenerating rat liver. (1/944)
The effects of partially thiolated polynucleotides on the DNA polymerase alpha from regenerating rat liver were investigated. The enzyme was isolated from the nuclear fraction essentially according to the method of Baril et al.; it was characterized as the alpha polymerase on the basis of its response to synthetic templates and its inhibition with N-ethylmaleimide. Although polycytidylic acid had no effect on the DNA polymerase alpha either as a template or as an inhibitor, partially thiolated polycytidylic acid (MPC) was found to be a potent inhibitor, its activity being directly related to its extent of thiolation (percentage of 5-mercaptocytidylate units in the polymer). In comparison, the DNA polymerase beta which was purified from normal rat liver nuclear fraction, was much less sensitive to inhibition by MPC. Analysis of the inhibition of the alpha polymerase by the method of Lineweaver and Burk showed that the inhibitory action of MPC was competitively reversible with the DNA template, but the binding of the 7.2%-thiolated MPC to the enzyme was much stronger than that of the template (Ki/Km less than 0.03). Polyuridylic acid as such showed some inhibitory activity which increased on partial thiolation, but the 8.4%-thiolated polyuridylic acid was less active than the 7.2% MPC. When MPC was annealed with polyinosinic acid, it lost 80% of its inhibitory activity in the double-stranded configuration. However, 1 to 2%-thiolated DNA isolates were significantly more potent inhibitors than were comparable (1.2%-thiolated) MPC and showed competitive reversibility with the unmodified (but "activated") DNA template. These results indicate that the inhibitory activities of partially thiolated polynucleotides depend not only on the percentage of 5-mercapto groups but also on the configuration, base composition, and other specific structural properties. (+info)The 3'-->5' exonucleases of DNA polymerases delta and epsilon and the 5'-->3' exonuclease Exo1 have major roles in postreplication mutation avoidance in Saccharomyces cerevisiae. (2/944)
Replication fidelity is controlled by DNA polymerase proofreading and postreplication mismatch repair. We have genetically characterized the roles of the 5'-->3' Exo1 and the 3'-->5' DNA polymerase exonucleases in mismatch repair in the yeast Saccharomyces cerevisiae by using various genetic backgrounds and highly sensitive mutation detection systems that are based on long and short homonucleotide runs. Genetic interactions were examined among DNA polymerase epsilon (pol2-4) and delta (pol3-01) mutants defective in 3'-->5' proofreading exonuclease, mutants defective in the 5'-->3' exonuclease Exo1, and mismatch repair mutants (msh2, msh3, or msh6). These three exonucleases play an important role in mutation avoidance. Surprisingly, the mutation rate in an exo1 pol3-01 mutant was comparable to that in an msh2 pol3-01 mutant, suggesting that they participate directly in postreplication mismatch repair as well as in other DNA metabolic processes. (+info)Double-strand break repair in yeast requires both leading and lagging strand DNA polymerases. (3/944)
Mitotic double-strand break (DSB)-induced gene conversion at MAT in Saccharomyces cerevisiae was analyzed molecularly in mutant strains thermosensitive for essential replication factors. The processivity cofactors PCNA and RFC are essential even to synthesize as little as 30 nucleotides following strand invasion. Both PCNA-associated DNA polymerases delta and epsilon are important for gene conversion, though a temperature-sensitive Pol epsilon mutant is more severe than one in Pol delta. Surprisingly, mutants of lagging strand replication, DNA polymerase alpha (pol1-17), DNA primase (pri2-1), and Rad27p (rad27 delta) also greatly inhibit completion of DSB repair, even in G1-arrested cells. We propose a novel model for DSB-induced gene conversion in which a strand invasion creates a modified replication fork, involving leading and lagging strand synthesis from the donor template. Replication is terminated by capture of the second end of the DSB. (+info)Differential transcriptional activity associated with chromatin configuration in fully grown mouse germinal vesicle oocytes. (4/944)
It was previously shown that fully grown ovarian germinal vesicle (GV) oocytes of adult mice exhibit several nuclear configurations that differ essentially by the presence or absence of a ring of condensed chromatin around the nucleolus. These configurations have been termed, respectively, SN (surrounded nucleolus) and NSN (nonsurrounded nucleolus). Work from our and other laboratories has revealed ultrastructural and functional differences between these two configurations. The aims of the present study were 1) to analyze the equilibrium between the SN and the NSN population as a function of the age of the mice and the time after hCG-induced ovulation and 2) to study the polymerase I (pol I)- and polymerase II (pol II)-dependent transcription in both types of oocytes through the detection of bromouridine incorporated into nascent RNA. We show 1) that ovarian GV oocytes exhibiting the SN-type configuration can be found as soon as 17 days after birth in the C57/CBA mouse strain and 2) that the SN:NSN ratio of ovarian GV oocytes is very low just after hCG-induced ovulation and then increases progressively with the time after ovulation. Furthermore, we demonstrate that the SN configuration correlates strictly with the arrest of both pol I- and pol II-dependent transcription in mice at any age. Finally, we show that ribosomal genes are located at the outer periphery of the nucleolus in the NSN configuration and that pol I-dependent perinucleolar transcription sites correspond to specific ultrastructural features of the nucleolus. Altogether, these results provide clear-cut criteria delineating transcriptionally active GV oocytes from those that are inactive, and confirm that the SN-type configuration is mostly present in preovulatory oocytes. (+info)Nuclear location of mammalian DNA polymerase activities. (5/944)
Nuclei were isolated from monolayer cultures of mouse and human cells using a nonaqueous procedure of cell fractionation in which lyophilized cells were homogenized and centrifuged in 100% glycerol. In previous work we have shown that the nuclear pellet and cytoplasmic supernatant fraction contained 10% or less of the nucleic acids characteristic of the other cell fraction. Aqueous extracts made from fresh cultures and from nonaqueous material at each step of the fractionation procedure were assayed fro DNA polymerase activity. Activities were normalized to DNA contents of extracted material. Specific activity was preserved quantitatively through freezing and drying the cells, but was found to be unstable in glycerol suspensions with approximate half-lives and 1 h at 23 degrees and 4 h at 0-4 degrees. Activities were relatively stable at -25 degrees, however, so that by homogenizing only 15 min at 4 degrees and centrifuging at -25 degrees we preserved approximately 85% of the specific activity of fresh cultures in the nonaqueous nuclear fraction. Sedimentation analyses showed that the nuclear fraction contained both DNA polymerase-alpha and-beta in approximately the proportions expected if all polymerase activities were confined to the nucleus in living cells. DNA polymerase-alpha was found to be more unstable in glycerol suspensions than DNA polymerase-beta. Nuclear location of both activities was found in exponential cultures and in 3T3 mouse cultures synchronized in the G1 and S phases of the cell division cycle. We found no evidence for cytoplasmic factors affecting nuclear polymerase activities. We have concluded that the two major DNA polymerases are nuclear although one, DNA polymerase-alpha, frequently is present as a weakly bound nuclear protein. (+info)Structure and function of the human transcription elongation factor DSIF. (6/944)
5,6-Dichloro-1-beta-D-ribofuranosylbenzimidazole (DRB) is a classic inhibitor of transcription elongation by RNA polymerase II (pol II). We have previously identified and purified a novel transcription elongation factor, termed DSIF (for DRB sensitivity-inducing factor), that makes transcription sensitive to DRB. DSIF is composed of 160- and 14-kDa subunits, which are homologs of the Saccharomyces cerevisiae transcription factors Spt5 and Spt4. DSIF may either repress or stimulate transcription in vitro, depending on conditions, but its physiological function remains elusive. Here we characterize the structure and function of DSIF p160. p160 is shown to be a ubiquitous nuclear protein that forms a stable complex with p14 and interacts directly with the pol II largest subunit. Mutation analysis of p160 is used to identify structural features essential for its in vitro activity and to map the domains required for its interaction with p14 and pol II. Finally, a p160 mutant that represses DSIF activity in a dominant-negative manner is identified and used to demonstrate that DSIF represses transcription from various promoters in vivo. (+info)DRC1, DNA replication and checkpoint protein 1, functions with DPB11 to control DNA replication and the S-phase checkpoint in Saccharomyces cerevisiae. (7/944)
In addition to DNA polymerase complexes, DNA replication requires the coordinate action of a series of proteins, including regulators Cdc28/Clb and Dbf4/Cdc7 kinases, Orcs, Mcms, Cdc6, Cdc45, and Dpb11. Of these, Dpb11, an essential BRCT repeat protein, has remained particularly enigmatic. The Schizosaccharomyces pombe homolog of DPB11, cut5, has been implicated in the DNA replication checkpoint as has the POL2 gene with which DPB11 genetically interacts. Here we describe a gene, DRC1, isolated as a dosage suppressor of dpb11-1. DRC1 is an essential cell cycle-regulated gene required for DNA replication. We show that both Dpb11 and Drc1 are required for the S-phase checkpoint, including the proper activation of the Rad53 kinase in response to DNA damage and replication blocks. Dpb11 is the second BRCT-repeat protein shown to control Rad53 function, possibly indicating a general function for this class of proteins. DRC1 and DPB11 show synthetic lethality and reciprocal dosage suppression. The Drc1 and Dpb11 proteins physically associate and function together to coordinate DNA replication and the cell cycle. (+info)Structural organization and splice variants of the POLE1 gene encoding the catalytic subunit of human DNA polymerase epsilon. (8/944)
The catalytic subunit of human DNA polymerase epsilon, an enzyme involved in nuclear DNA replication and repair, is encoded by the POLE1 gene. This gene is composed of 51 exons spanning at least 97 kb of genomic DNA. It was found to encode three alternative mRNA splice variants that differ in their 5'-terminal sequences and in the N-termini of the predicted proteins. A CpG island covers the promoter region for the major transcript in HeLa cells. This promoter is TATA-less and contains several putative binding sites for transcription factors typical of S-phase-up-regulated and serum-responsive promoters. Potential promoter regions were also identified for the two other alternative transcripts. Interestingly, no nuclear polyadenylation signal sequence was detected in the 3'-untranslated region, although a poly(A) tail was present. These results suggest a complicated regulatory machinery for the expression of the human POLE1 gene, including three alternative transcripts expressed from three promoters. (+info)DNA Polymerase II is a type of enzyme involved in DNA replication and repair in eukaryotic cells. It plays a crucial role in the process of proofreading and correcting errors that may occur during DNA synthesis.
During DNA replication, DNA polymerase II helps to fill in gaps or missing nucleotides behind the main replicative enzyme, DNA Polymerase epsilon. It also plays a significant role in repairing damaged DNA by removing and replacing incorrect or damaged nucleotides.
DNA Polymerase II is highly accurate and has a strong proofreading activity, which allows it to correct most of the errors that occur during DNA synthesis. This enzyme is also involved in the process of translesion synthesis, where it helps to bypass lesions or damage in the DNA template, allowing replication to continue.
Overall, DNA Polymerase II is an essential enzyme for maintaining genomic stability and preventing the accumulation of mutations in eukaryotic cells.
RNA Polymerase II is a type of enzyme responsible for transcribing DNA into RNA in eukaryotic cells. It plays a crucial role in the process of gene expression, where the information stored in DNA is used to create proteins. Specifically, RNA Polymerase II transcribes protein-coding genes to produce precursor messenger RNA (pre-mRNA), which is then processed into mature mRNA. This mature mRNA serves as a template for protein synthesis during translation.
RNA Polymerase II has a complex structure, consisting of multiple subunits, and it requires the assistance of various transcription factors and coactivators to initiate and regulate transcription. The enzyme recognizes specific promoter sequences in DNA, unwinds the double-stranded DNA, and synthesizes a complementary RNA strand using one of the unwound DNA strands as a template. This process results in the formation of a nascent RNA molecule that is further processed into mature mRNA for protein synthesis or other functional RNAs involved in gene regulation.
DNA-directed DNA polymerase is a type of enzyme that synthesizes new strands of DNA by adding nucleotides to an existing DNA template in a 5' to 3' direction. These enzymes are essential for DNA replication, repair, and recombination. They require a single-stranded DNA template, a primer with a free 3' hydroxyl group, and the four deoxyribonucleoside triphosphates (dNTPs) as substrates to carry out the polymerization reaction.
DNA polymerases also have proofreading activity, which allows them to correct errors that occur during DNA replication by removing mismatched nucleotides and replacing them with the correct ones. This helps ensure the fidelity of the genetic information passed from one generation to the next.
There are several different types of DNA polymerases, each with specific functions and characteristics. For example, DNA polymerase I is involved in both DNA replication and repair, while DNA polymerase III is the primary enzyme responsible for DNA replication in bacteria. In eukaryotic cells, DNA polymerase alpha, beta, gamma, delta, and epsilon have distinct roles in DNA replication, repair, and maintenance.
DNA Polymerase I is a type of enzyme that plays a crucial role in DNA replication and repair in prokaryotic cells, such as bacteria. It is responsible for synthesizing new strands of DNA by adding nucleotides to the 3' end of an existing strand, using the complementary strand as a template.
DNA Polymerase I has several key functions during DNA replication:
1. **5' to 3' exonuclease activity:** It can remove nucleotides from the 5' end of a DNA strand in a process called excision repair, which helps to correct errors that may have occurred during DNA replication.
2. **3' to 5' exonuclease activity:** This enzyme can also proofread newly synthesized DNA by removing incorrect nucleotides from the 3' end of a strand, ensuring accurate replication.
3. **Polymerase activity:** DNA Polymerase I adds new nucleotides to the 3' end of an existing strand, extending the length of the DNA molecule during replication and repair processes.
4. **Pyrophosphorolysis:** It can reverse the polymerization reaction by removing a nucleotide from the 3' end of a DNA strand while releasing pyrophosphate, which is an important step in some DNA repair pathways.
In summary, DNA Polymerase I is a versatile enzyme involved in various aspects of DNA replication and repair, contributing to the maintenance of genetic information in prokaryotic cells.
DNA Polymerase III is a critical enzyme in the process of DNA replication in bacteria. It is responsible for synthesizing new strands of DNA by adding nucleotides to the growing chain, based on the template provided by the existing DNA strand. This enzyme has multiple subunits and possesses both polymerase and exonuclease activities. The polymerase activity adds nucleotides to the growing DNA strand, while the exonuclease activity proofreads and corrects any errors that occur during replication. Overall, DNA Polymerase III plays a crucial role in maintaining the accuracy and integrity of genetic information during bacterial cell division.
DNA polymerase beta is a type of enzyme that plays a crucial role in the repair and maintenance of DNA in cells. It is a member of the DNA polymerase family, which are enzymes responsible for synthesizing new strands of DNA during replication and repair processes.
More specifically, DNA polymerase beta is involved in the base excision repair (BER) pathway, which is a mechanism for correcting damaged or mismatched bases in DNA. This enzyme functions by removing the damaged or incorrect base and replacing it with a new, correct one, using the undamaged strand as a template.
DNA polymerase beta has several key features that make it well-suited to its role in BER. It is highly processive, meaning that it can add many nucleotides to the growing DNA chain before dissociating from the template. It also has a high catalytic rate and is able to efficiently incorporate new nucleotides into the DNA chain.
Overall, DNA polymerase beta is an essential enzyme for maintaining genomic stability and preventing the accumulation of mutations in cells. Defects in this enzyme have been linked to various human diseases, including cancer and neurodegenerative disorders.
A genetic template refers to the sequence of DNA or RNA that contains the instructions for the development and function of an organism or any of its components. These templates provide the code for the synthesis of proteins and other functional molecules, and determine many of the inherited traits and characteristics of an individual. In this sense, genetic templates serve as the blueprint for life and are passed down from one generation to the next through the process of reproduction.
In molecular biology, the term "template" is used to describe the strand of DNA or RNA that serves as a guide or pattern for the synthesis of a complementary strand during processes such as transcription and replication. During transcription, the template strand of DNA is transcribed into a complementary RNA molecule, while during replication, each parental DNA strand serves as a template for the synthesis of a new complementary strand.
In genetic engineering and synthetic biology, genetic templates can be manipulated and modified to introduce new functions or alter existing ones in organisms. This is achieved through techniques such as gene editing, where specific sequences in the genetic template are targeted and altered using tools like CRISPR-Cas9. Overall, genetic templates play a crucial role in shaping the structure, function, and evolution of all living organisms.
DNA replication is the biological process by which DNA makes an identical copy of itself during cell division. It is a fundamental mechanism that allows genetic information to be passed down from one generation of cells to the next. During DNA replication, each strand of the double helix serves as a template for the synthesis of a new complementary strand. This results in the creation of two identical DNA molecules. The enzymes responsible for DNA replication include helicase, which unwinds the double helix, and polymerase, which adds nucleotides to the growing strands.
DNA nucleotidyltransferases are a class of enzymes that catalyze the addition of one or more nucleotides to the 3'-hydroxyl end of a DNA molecule. These enzymes play important roles in various biological processes, including DNA repair, recombination, and replication.
The reaction catalyzed by DNA nucleotidyltransferases involves the transfer of a nucleotide triphosphate (NTP) to the 3'-hydroxyl end of a DNA molecule, resulting in the formation of a phosphodiester bond and the release of pyrophosphate. The enzymes can add a single nucleotide or multiple nucleotides, depending on the specific enzyme and its function.
DNA nucleotidyltransferases are classified into several subfamilies based on their sequence similarity and function, including polymerases, terminal transferases, and primases. These enzymes have been extensively studied for their potential applications in biotechnology and medicine, such as in DNA sequencing, diagnostics, and gene therapy.
I apologize for any confusion, but "Pyrococcus abyssi" is not a medical term or concept. It is actually the scientific name of an organism, specifically a species of archaea (single-celled microorganisms).
"Pyrococcus abyssi" is a hyperthermophilic archaeon, first isolated from a deep-sea hydrothermal vent, that grows optimally at a temperature of around 98°C. This organism has great biotechnological potential due to its ability to produce various enzymes that function optimally under extreme conditions.
I hope this clarifies any confusion. If you have any further questions or concerns about biology, microbiology, or other scientific topics, please don't hesitate to ask!
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
Genetic transcription is the process by which the information in a strand of DNA is used to create a complementary RNA molecule. This process is the first step in gene expression, where the genetic code in DNA is converted into a form that can be used to produce proteins or functional RNAs.
During transcription, an enzyme called RNA polymerase binds to the DNA template strand and reads the sequence of nucleotide bases. As it moves along the template, it adds complementary RNA nucleotides to the growing RNA chain, creating a single-stranded RNA molecule that is complementary to the DNA template strand. Once transcription is complete, the RNA molecule may undergo further processing before it can be translated into protein or perform its functional role in the cell.
Transcription can be either "constitutive" or "regulated." Constitutive transcription occurs at a relatively constant rate and produces essential proteins that are required for basic cellular functions. Regulated transcription, on the other hand, is subject to control by various intracellular and extracellular signals, allowing cells to respond to changing environmental conditions or developmental cues.
"Saccharomyces cerevisiae" is not typically considered a medical term, but it is a scientific name used in the field of microbiology. It refers to a species of yeast that is commonly used in various industrial processes, such as baking and brewing. It's also widely used in scientific research due to its genetic tractability and eukaryotic cellular organization.
However, it does have some relevance to medical fields like medicine and nutrition. For example, certain strains of S. cerevisiae are used as probiotics, which can provide health benefits when consumed. They may help support gut health, enhance the immune system, and even assist in the digestion of certain nutrients.
In summary, "Saccharomyces cerevisiae" is a species of yeast with various industrial and potential medical applications.
Exodeoxyribonucleases are a type of enzyme that cleave (break) nucleotides from the ends of DNA molecules. They are further classified into 5' exodeoxyribonucleases and 3' exodeoxyribonucleases based on the end of the DNA molecule they act upon.
5' Exodeoxyribonucleases remove nucleotides from the 5' end (phosphate group) of a DNA strand, while 3' exodeoxyribonucleases remove nucleotides from the 3' end (hydroxyl group) of a DNA strand.
These enzymes play important roles in various biological processes such as DNA replication, repair, and degradation. They are also used in molecular biology research for various applications such as DNA sequencing, cloning, and genetic engineering.
RNA-directed DNA polymerase is a type of enzyme that can synthesize DNA using an RNA molecule as a template. This process is called reverse transcription, and it is the mechanism by which retroviruses, such as HIV, replicate their genetic material. The enzyme responsible for this reaction in retroviruses is called reverse transcriptase.
Reverse transcriptase is an important target for antiretroviral therapy used to treat HIV infection and AIDS. In addition to its role in viral replication, RNA-directed DNA polymerase also has applications in molecular biology research, such as in the production of complementary DNA (cDNA) copies of RNA molecules for use in downstream applications like cloning and sequencing.
An intein is a type of mobile genetic element that can be found within the proteins of various organisms, including bacteria, archaea, and eukaryotes. Inteins are intervening sequences of amino acids that are capable of self-excising from their host protein through a process called protein splicing.
Protein splicing involves the cleavage of the intein from the flanking sequences (known as exteins) and the formation of a peptide bond between the two exteins, resulting in a mature, functional protein. Inteins can also ligate themselves to form circular proteins or can be transferred horizontally between different organisms through various mechanisms.
Inteins have been identified as potential targets for drug development due to their essential role in the survival and virulence of certain pathogenic bacteria. Additionally, the protein splicing mechanism of inteins has been harnessed for various biotechnological applications, such as the production of recombinant proteins and the development of biosensors.
I'm sorry for any confusion, but "Polydeoxyribonucleotides" is not a widely recognized or established medical term. It seems to be a made-up or very obscure term that combines "poly," meaning many, "deoxy," referring to the lack of a hydroxyl group at the 2' carbon position in the ribose sugar, and "ribonucleotides," which are the building blocks of RNA.
If you meant "Polydeoxynucleotides" instead, it would refer to long, synthetic chains of deoxynucleotides, which are the building blocks of DNA. These chains can be used in various biochemical and biological research applications, such as studying enzyme mechanisms or constructing genetic circuits.
Polymerase Chain Reaction (PCR) is a laboratory technique used to amplify specific regions of DNA. It enables the production of thousands to millions of copies of a particular DNA sequence in a rapid and efficient manner, making it an essential tool in various fields such as molecular biology, medical diagnostics, forensic science, and research.
The PCR process involves repeated cycles of heating and cooling to separate the DNA strands, allow primers (short sequences of single-stranded DNA) to attach to the target regions, and extend these primers using an enzyme called Taq polymerase, resulting in the exponential amplification of the desired DNA segment.
In a medical context, PCR is often used for detecting and quantifying specific pathogens (viruses, bacteria, fungi, or parasites) in clinical samples, identifying genetic mutations or polymorphisms associated with diseases, monitoring disease progression, and evaluating treatment effectiveness.
In the context of medicine and pharmacology, "kinetics" refers to the study of how a drug moves throughout the body, including its absorption, distribution, metabolism, and excretion (often abbreviated as ADME). This field is called "pharmacokinetics."
1. Absorption: This is the process of a drug moving from its site of administration into the bloodstream. Factors such as the route of administration (e.g., oral, intravenous, etc.), formulation, and individual physiological differences can affect absorption.
2. Distribution: Once a drug is in the bloodstream, it gets distributed throughout the body to various tissues and organs. This process is influenced by factors like blood flow, protein binding, and lipid solubility of the drug.
3. Metabolism: Drugs are often chemically modified in the body, typically in the liver, through processes known as metabolism. These changes can lead to the formation of active or inactive metabolites, which may then be further distributed, excreted, or undergo additional metabolic transformations.
4. Excretion: This is the process by which drugs and their metabolites are eliminated from the body, primarily through the kidneys (urine) and the liver (bile).
Understanding the kinetics of a drug is crucial for determining its optimal dosing regimen, potential interactions with other medications or foods, and any necessary adjustments for special populations like pediatric or geriatric patients, or those with impaired renal or hepatic function.
A mutation is a permanent change in the DNA sequence of an organism's genome. Mutations can occur spontaneously or be caused by environmental factors such as exposure to radiation, chemicals, or viruses. They may have various effects on the organism, ranging from benign to harmful, depending on where they occur and whether they alter the function of essential proteins. In some cases, mutations can increase an individual's susceptibility to certain diseases or disorders, while in others, they may confer a survival advantage. Mutations are the driving force behind evolution, as they introduce new genetic variability into populations, which can then be acted upon by natural selection.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
Transcriptional elongation factors are a type of protein involved in the process of transcription, which is the synthesis of an RNA molecule from a DNA template. Specifically, transcriptional elongation factors play a role in the elongation phase of transcription, which is the stage at which the RNA polymerase enzyme moves along the DNA template and adds nucleotides to the growing RNA chain.
These factors help to regulate the speed and processivity of RNA polymerase, allowing for the accurate and efficient production of RNA molecules. They can also play a role in the coordination of transcription with other cellular processes, such as mRNA processing and translation. Some examples of transcriptional elongation factors include the TFIIS complex, SII complex, and elongin. Defects in these factors can lead to abnormalities in gene expression and have been implicated in various diseases, including cancer.
Deoxyribonucleic acid (DNA) is the genetic material present in the cells of organisms where it is responsible for the storage and transmission of hereditary information. DNA is a long molecule that consists of two strands coiled together to form a double helix. Each strand is made up of a series of four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - that are linked together by phosphate and sugar groups. The sequence of these bases along the length of the molecule encodes genetic information, with A always pairing with T and C always pairing with G. This base-pairing allows for the replication and transcription of DNA, which are essential processes in the functioning and reproduction of all living organisms.
DNA-directed RNA polymerases are enzymes that synthesize RNA molecules using a DNA template in a process called transcription. These enzymes read the sequence of nucleotides in a DNA molecule and use it as a blueprint to construct a complementary RNA strand.
The RNA polymerase moves along the DNA template, adding ribonucleotides one by one to the growing RNA chain. The synthesis is directional, starting at the promoter region of the DNA and moving towards the terminator region.
In bacteria, there is a single type of RNA polymerase that is responsible for transcribing all types of RNA (mRNA, tRNA, and rRNA). In eukaryotic cells, however, there are three different types of RNA polymerases: RNA polymerase I, II, and III. Each type is responsible for transcribing specific types of RNA.
RNA polymerases play a crucial role in gene expression, as they link the genetic information encoded in DNA to the production of functional proteins. Inhibition or mutation of these enzymes can have significant consequences for cellular function and survival.
Mutagenesis is the process by which the genetic material (DNA or RNA) of an organism is changed in a way that can alter its phenotype, or observable traits. These changes, known as mutations, can be caused by various factors such as chemicals, radiation, or viruses. Some mutations may have no effect on the organism, while others can cause harm, including diseases and cancer. Mutagenesis is a crucial area of study in genetics and molecular biology, with implications for understanding evolution, genetic disorders, and the development of new medical treatments.
Transcription factors (TFs) are proteins that regulate the transcription of genetic information from DNA to RNA by binding to specific DNA sequences. They play a crucial role in controlling gene expression, which is the process by which information in genes is converted into a functional product, such as a protein.
TFII, on the other hand, refers to a general class of transcription factors that are involved in the initiation of RNA polymerase II-dependent transcription. These proteins are often referred to as "general transcription factors" because they are required for the transcription of most protein-coding genes in eukaryotic cells.
TFII factors help to assemble the preinitiation complex (PIC) at the promoter region of a gene, which is a group of proteins that includes RNA polymerase II and other cofactors necessary for transcription. Once the PIC is assembled, TFII factors help to recruit RNA polymerase II to the promoter and initiate transcription.
Some examples of TFII factors include TFIIA, TFIIB, TFIID, TFIIE, TFIIF, and TFIIH. Each of these factors plays a specific role in the initiation of transcription, such as recognizing and binding to specific DNA sequences or modifying the chromatin structure around the promoter to make it more accessible to RNA polymerase II.
Amanitins are a type of bicyclic octapeptide toxin found in several species of mushrooms belonging to the Amanita genus, including the death cap (Amanita phalloides) and the destroying angel (Amanita virosa). These toxins are part of the group of compounds known as amatoxins.
Amanitins are highly toxic to humans and other animals, affecting the liver and kidneys in particular. They work by inhibiting RNA polymerase II, an enzyme that plays a crucial role in gene expression by transcribing DNA into messenger RNA (mRNA). This interference with protein synthesis can lead to severe damage to cells and tissues, potentially resulting in organ failure and death if left untreated.
Symptoms of amanitin poisoning typically appear in two phases. The first phase, which occurs within 6-24 hours after ingestion, includes gastrointestinal distress such as vomiting, diarrhea, and abdominal pain. This initial phase may subside for a short period, giving a false sense of recovery. However, the second phase, which can occur 3-7 days later, is characterized by liver and kidney damage, with symptoms such as jaundice, disorientation, seizures, coma, and ultimately, multiple organ failure if not treated promptly and effectively.
Treatment for amanitin poisoning usually involves supportive care, such as fluid replacement and addressing any complications that arise. In some cases, medications like silibinin (from milk thistle) or activated charcoal may be used to help reduce the absorption and toxicity of the amanitins. Additionally, liver transplantation might be considered in severe cases where organ failure is imminent. Prevention is key when it comes to amanitin poisoning, as there is no antidote available. Being able to identify and avoid potentially deadly mushrooms is essential for foragers and those who enjoy gathering wild fungi.
According to the medical definition, ultraviolet (UV) rays are invisible radiations that fall in the range of the electromagnetic spectrum between 100-400 nanometers. UV rays are further divided into three categories: UVA (320-400 nm), UVB (280-320 nm), and UVC (100-280 nm).
UV rays have various sources, including the sun and artificial sources like tanning beds. Prolonged exposure to UV rays can cause damage to the skin, leading to premature aging, eye damage, and an increased risk of skin cancer. UVA rays penetrate deeper into the skin and are associated with skin aging, while UVB rays primarily affect the outer layer of the skin and are linked to sunburns and skin cancer. UVC rays are the most harmful but fortunately, they are absorbed by the Earth's atmosphere and do not reach the surface.
Healthcare professionals recommend limiting exposure to UV rays, wearing protective clothing, using broad-spectrum sunscreen with an SPF of at least 30, and avoiding tanning beds to reduce the risk of UV-related health problems.
Molecular weight, also known as molecular mass, is the mass of a molecule. It is expressed in units of atomic mass units (amu) or daltons (Da). Molecular weight is calculated by adding up the atomic weights of each atom in a molecule. It is a useful property in chemistry and biology, as it can be used to determine the concentration of a substance in a solution, or to calculate the amount of a substance that will react with another in a chemical reaction.
DEAE-cellulose chromatography is a method of purification and separation of biological molecules such as proteins, nucleic acids, and enzymes. DEAE stands for diethylaminoethyl, which is a type of charged functional group that is covalently bound to cellulose, creating a matrix with positive charges.
In this method, the mixture of biological molecules is applied to a column packed with DEAE-cellulose. The positively charged DEAE groups attract and bind negatively charged molecules in the mixture, such as nucleic acids and proteins, while allowing uncharged or neutrally charged molecules to pass through.
By adjusting the pH, ionic strength, or concentration of salt in the buffer solution used to elute the bound molecules from the column, it is possible to selectively elute specific molecules based on their charge and binding affinity to the DEAE-cellulose matrix. This makes DEAE-cellulose chromatography a powerful tool for purifying and separating biological molecules with high resolution and efficiency.
DNA primase is a type of enzyme that plays a crucial role in the process of DNA replication. Its primary function is to synthesize short RNA segments, known as primers, that are required for the initiation of DNA synthesis.
In more detail, during DNA replication, an enzyme called helicase unwinds the double-stranded DNA molecule and creates a replication fork, where the two strands are separated. However, before DNA polymerase can add nucleotides to the new strand, it requires a free 3'-OH group to which it can add the next nucleotide. This free 3'-OH group is provided by the RNA primer synthesized by DNA primase.
DNA primase recognizes and binds to single-stranded DNA (ssDNA) at the replication fork, where it initiates the synthesis of an RNA primer. The primer consists of a short stretch of RNA nucleotides, typically around 10 bases long, that are added to the ssDNA template in a specific sequence. Once the RNA primer is in place, DNA polymerase can begin adding DNA nucleotides to the new strand, starting from the 3'-end of the RNA primer.
After DNA replication is complete, another enzyme called DNA polymerase I removes the RNA primers and replaces them with DNA nucleotides. The resulting gaps are then sealed by DNA ligase, which forms a phosphodiester bond between the adjacent nucleotides to create a continuous strand of DNA.
Overall, DNA primase is an essential enzyme that plays a critical role in the initiation and completion of DNA replication, ensuring the accurate duplication of genetic information from one generation to the next.
A plasmid is a small, circular, double-stranded DNA molecule that is separate from the chromosomal DNA of a bacterium or other organism. Plasmids are typically not essential for the survival of the organism, but they can confer beneficial traits such as antibiotic resistance or the ability to degrade certain types of pollutants.
Plasmids are capable of replicating independently of the chromosomal DNA and can be transferred between bacteria through a process called conjugation. They often contain genes that provide resistance to antibiotics, heavy metals, and other environmental stressors. Plasmids have also been engineered for use in molecular biology as cloning vectors, allowing scientists to replicate and manipulate specific DNA sequences.
Plasmids are important tools in genetic engineering and biotechnology because they can be easily manipulated and transferred between organisms. They have been used to produce vaccines, diagnostic tests, and genetically modified organisms (GMOs) for various applications, including agriculture, medicine, and industry.
Deoxyribonucleotides are the building blocks of DNA (deoxyribonucleic acid). They consist of a deoxyribose sugar, a phosphate group, and one of four nitrogenous bases: adenine (A), guanine (G), cytosine (C), or thymine (T). A deoxyribonucleotide is formed when a nucleotide loses a hydroxyl group from its sugar molecule. In DNA, deoxyribonucleotides link together to form a long, double-helix structure through phosphodiester bonds between the sugar of one deoxyribonucleotide and the phosphate group of another. The sequence of these nucleotides carries genetic information that is essential for the development and function of all known living organisms and many viruses.
Centrifugation, Density Gradient is a medical laboratory technique used to separate and purify different components of a mixture based on their size, density, and shape. This method involves the use of a centrifuge and a density gradient medium, such as sucrose or cesium chloride, to create a stable density gradient within a column or tube.
The sample is carefully layered onto the top of the gradient and then subjected to high-speed centrifugation. During centrifugation, the particles in the sample move through the gradient based on their size, density, and shape, with heavier particles migrating faster and further than lighter ones. This results in the separation of different components of the mixture into distinct bands or zones within the gradient.
This technique is commonly used to purify and concentrate various types of biological materials, such as viruses, organelles, ribosomes, and subcellular fractions, from complex mixtures. It allows for the isolation of pure and intact particles, which can then be collected and analyzed for further study or use in downstream applications.
In summary, Centrifugation, Density Gradient is a medical laboratory technique used to separate and purify different components of a mixture based on their size, density, and shape using a centrifuge and a density gradient medium.
Exonucleases are a type of enzyme that cleaves nucleotides from the ends of a DNA or RNA molecule. They differ from endonucleases, which cut internal bonds within the nucleic acid chain. Exonucleases can be further classified based on whether they remove nucleotides from the 5' or 3' end of the molecule.
5' exonucleases remove nucleotides from the 5' end of the molecule, starting at the terminal phosphate group and working their way towards the interior of the molecule. This process releases nucleotide monophosphates (NMPs) as products.
3' exonucleases, on the other hand, remove nucleotides from the 3' end of the molecule, starting at the terminal hydroxyl group and working their way towards the interior of the molecule. This process releases nucleoside diphosphates (NDPs) as products.
Exonucleases play important roles in various biological processes, including DNA replication, repair, and degradation, as well as RNA processing and turnover. They are also used in molecular biology research for a variety of applications, such as DNA sequencing, cloning, and genome engineering.
Promoter regions in genetics refer to specific DNA sequences located near the transcription start site of a gene. They serve as binding sites for RNA polymerase and various transcription factors that regulate the initiation of gene transcription. These regulatory elements help control the rate of transcription and, therefore, the level of gene expression. Promoter regions can be composed of different types of sequences, such as the TATA box and CAAT box, and their organization and composition can vary between different genes and species.
Ion exchange chromatography is a type of chromatography technique used to separate and analyze charged molecules (ions) based on their ability to exchange bound ions in a solid resin or gel with ions of similar charge in the mobile phase. The stationary phase, often called an ion exchanger, contains fixed ated functional groups that can attract counter-ions of opposite charge from the sample mixture.
In this technique, the sample is loaded onto an ion exchange column containing the charged resin or gel. As the sample moves through the column, ions in the sample compete for binding sites on the stationary phase with ions already present in the column. The ions that bind most strongly to the stationary phase will elute (come off) slower than those that bind more weakly.
Ion exchange chromatography can be performed using either cation exchangers, which exchange positive ions (cations), or anion exchangers, which exchange negative ions (anions). The pH and ionic strength of the mobile phase can be adjusted to control the binding and elution of specific ions.
Ion exchange chromatography is widely used in various applications such as water treatment, protein purification, and chemical analysis.
HeLa cells are a type of immortalized cell line used in scientific research. They are derived from a cancer that developed in the cervical tissue of Henrietta Lacks, an African-American woman, in 1951. After her death, cells taken from her tumor were found to be capable of continuous division and growth in a laboratory setting, making them an invaluable resource for medical research.
HeLa cells have been used in a wide range of scientific studies, including research on cancer, viruses, genetics, and drug development. They were the first human cell line to be successfully cloned and are able to grow rapidly in culture, doubling their population every 20-24 hours. This has made them an essential tool for many areas of biomedical research.
It is important to note that while HeLa cells have been instrumental in numerous scientific breakthroughs, the story of their origin raises ethical questions about informed consent and the use of human tissue in research.
Transcription factors are proteins that play a crucial role in regulating gene expression by controlling the transcription of DNA to messenger RNA (mRNA). They function by binding to specific DNA sequences, known as response elements, located in the promoter region or enhancer regions of target genes. This binding can either activate or repress the initiation of transcription, depending on the properties and interactions of the particular transcription factor. Transcription factors often act as part of a complex network of regulatory proteins that determine the precise spatiotemporal patterns of gene expression during development, differentiation, and homeostasis in an organism.
Thymine nucleotides are biochemical components that play a crucial role in the structure and function of DNA (deoxyribonucleic acid), which is the genetic material present in living organisms. A thymine nucleotide consists of three parts: a sugar molecule called deoxyribose, a phosphate group, and a nitrogenous base called thymine.
Thymine is one of the four nucleobases in DNA, along with adenine, guanine, and cytosine. It specifically pairs with adenine through hydrogen bonding, forming a base pair that is essential for maintaining the structure and stability of the double helix. Thymine nucleotides are linked together by phosphodiester bonds between the sugar molecules of adjacent nucleotides, creating a long, linear polymer known as a DNA strand.
In summary, thymine nucleotides are building blocks of DNA that consist of deoxyribose, a phosphate group, and the nitrogenous base thymine, which pairs with adenine in the double helix structure.
Bacterial DNA refers to the genetic material found in bacteria. It is composed of a double-stranded helix containing four nucleotide bases - adenine (A), thymine (T), guanine (G), and cytosine (C) - that are linked together by phosphodiester bonds. The sequence of these bases in the DNA molecule carries the genetic information necessary for the growth, development, and reproduction of bacteria.
Bacterial DNA is circular in most bacterial species, although some have linear chromosomes. In addition to the main chromosome, many bacteria also contain small circular pieces of DNA called plasmids that can carry additional genes and provide resistance to antibiotics or other environmental stressors.
Unlike eukaryotic cells, which have their DNA enclosed within a nucleus, bacterial DNA is present in the cytoplasm of the cell, where it is in direct contact with the cell's metabolic machinery. This allows for rapid gene expression and regulation in response to changing environmental conditions.
Molecular cloning is a laboratory technique used to create multiple copies of a specific DNA sequence. This process involves several steps:
1. Isolation: The first step in molecular cloning is to isolate the DNA sequence of interest from the rest of the genomic DNA. This can be done using various methods such as PCR (polymerase chain reaction), restriction enzymes, or hybridization.
2. Vector construction: Once the DNA sequence of interest has been isolated, it must be inserted into a vector, which is a small circular DNA molecule that can replicate independently in a host cell. Common vectors used in molecular cloning include plasmids and phages.
3. Transformation: The constructed vector is then introduced into a host cell, usually a bacterial or yeast cell, through a process called transformation. This can be done using various methods such as electroporation or chemical transformation.
4. Selection: After transformation, the host cells are grown in selective media that allow only those cells containing the vector to grow. This ensures that the DNA sequence of interest has been successfully cloned into the vector.
5. Amplification: Once the host cells have been selected, they can be grown in large quantities to amplify the number of copies of the cloned DNA sequence.
Molecular cloning is a powerful tool in molecular biology and has numerous applications, including the production of recombinant proteins, gene therapy, functional analysis of genes, and genetic engineering.
Restriction mapping is a technique used in molecular biology to identify the location and arrangement of specific restriction endonuclease recognition sites within a DNA molecule. Restriction endonucleases are enzymes that cut double-stranded DNA at specific sequences, producing fragments of various lengths. By digesting the DNA with different combinations of these enzymes and analyzing the resulting fragment sizes through techniques such as agarose gel electrophoresis, researchers can generate a restriction map - a visual representation of the locations and distances between recognition sites on the DNA molecule. This information is crucial for various applications, including cloning, genome analysis, and genetic engineering.
Viral DNA refers to the genetic material present in viruses that consist of DNA as their core component. Deoxyribonucleic acid (DNA) is one of the two types of nucleic acids that are responsible for storing and transmitting genetic information in living organisms. Viruses are infectious agents much smaller than bacteria that can only replicate inside the cells of other organisms, called hosts.
Viral DNA can be double-stranded (dsDNA) or single-stranded (ssDNA), depending on the type of virus. Double-stranded DNA viruses have a genome made up of two complementary strands of DNA, while single-stranded DNA viruses contain only one strand of DNA.
Examples of dsDNA viruses include Adenoviruses, Herpesviruses, and Poxviruses, while ssDNA viruses include Parvoviruses and Circoviruses. Viral DNA plays a crucial role in the replication cycle of the virus, encoding for various proteins necessary for its multiplication and survival within the host cell.
Transcription factors are proteins that play a crucial role in regulating gene expression by controlling the transcription of DNA to messenger RNA (mRNA). When referring to "General Transcription Factors," it indicates a specific group of these proteins that are involved in the basal transcription machinery, which is necessary for the transcription of protein-coding genes in all organisms. These general transcription factors are required for the initiation of transcription and include several conserved components:
1. TFIIA (Transcription Factor II A) - a heterotrimeric complex that binds to the TATA box region of the promoter, enhancing the stability and specificity of the pre-initiation complex.
2. TFIID (Transcription Factor II D) - a multi-subunit complex containing the TATA-binding protein (TBP) and several TBP-associated factors (TAFs). TBP recognizes and binds to the TATA box, while TAFs contribute to promoter recognition, chromatin remodeling, and transcription activation.
3. TFIIB - a single polypeptide that interacts with both TFIID and RNA polymerase II, helping to position the polymerase correctly at the transcription start site.
4. TFIIF - a heterotrimeric complex that stabilizes the interaction between TFIIB and RNA polymerase II, promoting the formation of the pre-initiation complex.
5. TFIIE - a heterodimeric complex that interacts with TFIIB, TFIIF, and RNA polymerase II, playing a role in promoter clearance and the transition from initiation to elongation.
6. TFIIH - a multi-subunit complex containing helicase and kinase activities. It is involved in promoter opening, DNA melting at the transcription start site, and phosphorylation of the C-terminal domain (CTD) of RNA polymerase II to facilitate elongation.
These general transcription factors work together to form a pre-initiation complex that enables RNA polymerase II to initiate transcription accurately and efficiently.
RNA Polymerase III is a type of enzyme that carries out the transcription of DNA into RNA, specifically functioning in the synthesis of small, stable RNAs. These RNAs include 5S rRNA, transfer RNAs (tRNAs), and other small nuclear RNAs (snRNAs). The enzyme recognizes specific promoter sequences in DNA and catalyzes the formation of phosphodiester bonds between ribonucleotides to create a complementary RNA strand. RNA Polymerase III is essential for protein synthesis and cell survival, and its activity is tightly regulated within the cell.
RNA nucleotidyltransferases are a class of enzymes that catalyze the template-independent addition of nucleotides to the 3' end of RNA molecules, using nucleoside triphosphates as substrates. These enzymes play crucial roles in various biological processes, including RNA maturation, quality control, and regulation.
The reaction catalyzed by RNA nucleotidyltransferases involves the formation of a phosphodiester bond between the 3'-hydroxyl group of the RNA substrate and the alpha-phosphate group of the incoming nucleoside triphosphate. This results in the elongation of the RNA molecule by one or more nucleotides, depending on the specific enzyme and context.
Examples of RNA nucleotidyltransferases include poly(A) polymerases, which add poly(A) tails to mRNAs during processing, and terminal transferases, which are involved in DNA repair and V(D)J recombination in the immune system. These enzymes have been implicated in various diseases, including cancer and neurological disorders, making them potential targets for therapeutic intervention.
DNA repair is the process by which cells identify and correct damage to the DNA molecules that encode their genome. DNA can be damaged by a variety of internal and external factors, such as radiation, chemicals, and metabolic byproducts. If left unrepaired, this damage can lead to mutations, which may in turn lead to cancer and other diseases.
There are several different mechanisms for repairing DNA damage, including:
1. Base excision repair (BER): This process repairs damage to a single base in the DNA molecule. An enzyme called a glycosylase removes the damaged base, leaving a gap that is then filled in by other enzymes.
2. Nucleotide excision repair (NER): This process repairs more severe damage, such as bulky adducts or crosslinks between the two strands of the DNA molecule. An enzyme cuts out a section of the damaged DNA, and the gap is then filled in by other enzymes.
3. Mismatch repair (MMR): This process repairs errors that occur during DNA replication, such as mismatched bases or small insertions or deletions. Specialized enzymes recognize the error and remove a section of the newly synthesized strand, which is then replaced by new nucleotides.
4. Double-strand break repair (DSBR): This process repairs breaks in both strands of the DNA molecule. There are two main pathways for DSBR: non-homologous end joining (NHEJ) and homologous recombination (HR). NHEJ directly rejoins the broken ends, while HR uses a template from a sister chromatid to repair the break.
Overall, DNA repair is a crucial process that helps maintain genome stability and prevent the development of diseases caused by genetic mutations.
Aphidicolin is an antimicrotubule agent that is specifically a inhibitor of DNA polymerase alpha. It is an antibiotic that is produced by the fungus Cephalosporium aphidicola and is used in research to study the cell cycle and DNA replication. In clinical medicine, it has been explored as a potential anticancer agent, although its use is not currently approved for this indication.
Saccharomyces cerevisiae proteins are the proteins that are produced by the budding yeast, Saccharomyces cerevisiae. This organism is a single-celled eukaryote that has been widely used as a model organism in scientific research for many years due to its relatively simple genetic makeup and its similarity to higher eukaryotic cells.
The genome of Saccharomyces cerevisiae has been fully sequenced, and it is estimated to contain approximately 6,000 genes that encode proteins. These proteins play a wide variety of roles in the cell, including catalyzing metabolic reactions, regulating gene expression, maintaining the structure of the cell, and responding to environmental stimuli.
Many Saccharomyces cerevisiae proteins have human homologs and are involved in similar biological processes, making this organism a valuable tool for studying human disease. For example, many of the proteins involved in DNA replication, repair, and recombination in yeast have human counterparts that are associated with cancer and other diseases. By studying these proteins in yeast, researchers can gain insights into their function and regulation in humans, which may lead to new treatments for disease.
Fungal genes refer to the genetic material present in fungi, which are eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. The genetic material of fungi is composed of DNA, just like in other eukaryotes, and is organized into chromosomes located in the nucleus of the cell.
Fungal genes are segments of DNA that contain the information necessary to produce proteins and RNA molecules required for various cellular functions. These genes are transcribed into messenger RNA (mRNA) molecules, which are then translated into proteins by ribosomes in the cytoplasm.
Fungal genomes have been sequenced for many species, revealing a diverse range of genes that encode proteins involved in various cellular processes such as metabolism, signaling, and regulation. Comparative genomic analyses have also provided insights into the evolutionary relationships among different fungal lineages and have helped to identify unique genetic features that distinguish fungi from other eukaryotes.
Understanding fungal genes and their functions is essential for advancing our knowledge of fungal biology, as well as for developing new strategies to control fungal pathogens that can cause diseases in humans, animals, and plants.
Protein binding, in the context of medical and biological sciences, refers to the interaction between a protein and another molecule (known as the ligand) that results in a stable complex. This process is often reversible and can be influenced by various factors such as pH, temperature, and concentration of the involved molecules.
In clinical chemistry, protein binding is particularly important when it comes to drugs, as many of them bind to proteins (especially albumin) in the bloodstream. The degree of protein binding can affect a drug's distribution, metabolism, and excretion, which in turn influence its therapeutic effectiveness and potential side effects.
Protein-bound drugs may be less available for interaction with their target tissues, as only the unbound or "free" fraction of the drug is active. Therefore, understanding protein binding can help optimize dosing regimens and minimize adverse reactions.
RNA Polymerase I is a type of enzyme that carries out the transcription of ribosomal RNA (rRNA) genes in eukaryotic cells. These enzymes are responsible for synthesizing the rRNA molecules, which are crucial components of ribosomes, the cellular structures where protein synthesis occurs. RNA Polymerase I is found in the nucleolus, a specialized region within the nucleus of eukaryotic cells, and it primarily transcribes the 5S, 18S, and 28S rRNA genes. The enzyme binds to the promoter regions of these genes and synthesizes the rRNA molecules by adding ribonucleotides in a template-directed manner, using DNA as a template. This process is essential for maintaining normal cellular function and for the production of proteins required for growth, development, and homeostasis.
DNA-binding proteins are a type of protein that have the ability to bind to DNA (deoxyribonucleic acid), the genetic material of organisms. These proteins play crucial roles in various biological processes, such as regulation of gene expression, DNA replication, repair and recombination.
The binding of DNA-binding proteins to specific DNA sequences is mediated by non-covalent interactions, including electrostatic, hydrogen bonding, and van der Waals forces. The specificity of binding is determined by the recognition of particular nucleotide sequences or structural features of the DNA molecule.
DNA-binding proteins can be classified into several categories based on their structure and function, such as transcription factors, histones, and restriction enzymes. Transcription factors are a major class of DNA-binding proteins that regulate gene expression by binding to specific DNA sequences in the promoter region of genes and recruiting other proteins to modulate transcription. Histones are DNA-binding proteins that package DNA into nucleosomes, the basic unit of chromatin structure. Restriction enzymes are DNA-binding proteins that recognize and cleave specific DNA sequences, and are widely used in molecular biology research and biotechnology applications.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
Proliferating Cell Nuclear Antigen (PCNA) is a protein that plays an essential role in the process of DNA replication and repair in eukaryotic cells. It functions as a cofactor for DNA polymerase delta, enhancing its activity during DNA synthesis. PCNA forms a sliding clamp around DNA, allowing it to move along the template and coordinate the actions of various enzymes involved in DNA metabolism.
PCNA is often used as a marker for cell proliferation because its levels increase in cells that are actively dividing or have been stimulated to enter the cell cycle. Immunostaining techniques can be used to detect PCNA and determine the proliferative status of tissues or cultures. In this context, 'proliferating' refers to the rapid multiplication of cells through cell division.
Deoxycytosine nucleotides are chemical compounds that are the building blocks of DNA, one of the two nucleic acids found in cells. Specifically, deoxycytosine nucleotides consist of a deoxyribose sugar, a phosphate group, and the nitrogenous base cytosine.
In DNA, deoxycytosine nucleotides pair with deoxyguanosine nucleotides through hydrogen bonding between the bases to form a stable structure that stores genetic information. The synthesis of deoxycytosine nucleotides is tightly regulated in cells to ensure proper replication and repair of DNA.
Disruptions in the regulation of deoxycytosine nucleotide metabolism can lead to various genetic disorders, including mitochondrial DNA depletion syndromes and cancer. Therefore, understanding the biochemistry and regulation of deoxycytosine nucleotides is crucial for developing effective therapies for these conditions.
DNA primers are short single-stranded DNA molecules that serve as a starting point for DNA synthesis. They are typically used in laboratory techniques such as the polymerase chain reaction (PCR) and DNA sequencing. The primer binds to a complementary sequence on the DNA template through base pairing, providing a free 3'-hydroxyl group for the DNA polymerase enzyme to add nucleotides and synthesize a new strand of DNA. This allows for specific and targeted amplification or analysis of a particular region of interest within a larger DNA molecule.
Exodeoxyribonuclease V, also known as RecJ or ExoV, is an enzyme that belongs to the family of exodeoxyribonucleases. It functions by removing nucleotides from the 3'-end of a DNA strand in a stepwise manner, leaving 5'-phosphate and 3'-hydroxyl groups after each cleavage event. Exodeoxyribonuclease V plays a crucial role in various DNA metabolic processes, including DNA repair, recombination, and replication. It is highly specific for double-stranded DNA substrates and requires the presence of a 5'-phosphate group at the cleavage site. Exodeoxyribonuclease V has been identified in several organisms, including bacteria and archaea, and its activity is tightly regulated to ensure proper maintenance and protection of genomic integrity.
Nucleotides are the basic structural units of nucleic acids, such as DNA and RNA. They consist of a nitrogenous base (adenine, guanine, cytosine, thymine or uracil), a pentose sugar (ribose in RNA and deoxyribose in DNA) and one to three phosphate groups. Nucleotides are linked together by phosphodiester bonds between the sugar of one nucleotide and the phosphate group of another, forming long chains known as polynucleotides. The sequence of these nucleotides determines the genetic information carried in DNA and RNA, which is essential for the functioning, reproduction and survival of all living organisms.
Deoxyguanine nucleotides are chemical compounds that are the building blocks of DNA, one of the fundamental molecules of life. Specifically, deoxyguanine nucleotides contain a sugar molecule called deoxyribose, a phosphate group, and the nitrogenous base guanine.
Guanine is one of the four nitrogenous bases found in DNA, along with adenine, thymine, and cytosine. In DNA, guanine always pairs with cytosine through hydrogen bonding, forming a stable base pair that is crucial for maintaining the structure and integrity of the genetic code.
Deoxyguanine nucleotides are synthesized in cells during the process of DNA replication, which occurs prior to cell division. During replication, the double helix structure of DNA is unwound, and each strand serves as a template for the synthesis of a new complementary strand. Deoxyguanine nucleotides are added to the growing chain of nucleotides by an enzyme called DNA polymerase, which catalyzes the formation of a phosphodiester bond between the deoxyribose sugar of one nucleotide and the phosphate group of the next.
Abnormalities in the synthesis or metabolism of deoxyguanine nucleotides can lead to genetic disorders and cancer. For example, mutations in genes that encode enzymes involved in the synthesis of deoxyguanine nucleotides have been linked to inherited diseases such as xeroderma pigmentosum and Bloom syndrome, which are characterized by increased sensitivity to sunlight and a predisposition to cancer. Additionally, defects in the repair of damaged deoxyguanine nucleotides can lead to the accumulation of mutations and contribute to the development of cancer.
Single-stranded DNA (ssDNA) is a form of DNA that consists of a single polynucleotide chain. In contrast, double-stranded DNA (dsDNA) consists of two complementary polynucleotide chains that are held together by hydrogen bonds.
In the double-helix structure of dsDNA, each nucleotide base on one strand pairs with a specific base on the other strand through hydrogen bonding: adenine (A) with thymine (T), and guanine (G) with cytosine (C). This base pairing provides stability to the double-stranded structure.
Single-stranded DNA, on the other hand, lacks this complementary base pairing and is therefore less stable than dsDNA. However, ssDNA can still form secondary structures through intrastrand base pairing, such as hairpin loops or cruciform structures.
Single-stranded DNA is found in various biological contexts, including viral genomes, transcription bubbles during gene expression, and in certain types of genetic recombination. It also plays a critical role in some laboratory techniques, such as polymerase chain reaction (PCR) and DNA sequencing.
The Mediator complex is a multi-subunit protein structure that acts as a bridge in the communication between regulatory elements, such as transcription factors, and the RNA polymerase II enzyme. It plays a crucial role in the regulation of gene expression by modulating the initiation and rate of transcription.
The Mediator complex is composed of approximately 30 subunits that are highly conserved across eukaryotes. The complex can be divided into four modules: the head, middle, tail, and kinase modules. Each module has a unique set of functions in regulating gene expression. For example, the tail module interacts with transcription factors to receive signals about which genes should be activated or repressed, while the kinase module phosphorylates the carboxy-terminal domain (CTD) of RNA polymerase II to promote its recruitment and activation at gene promoters.
Overall, the Mediator complex is an essential component of the eukaryotic transcriptional machinery, playing a critical role in regulating various cellular processes such as development, differentiation, and metabolism. Dysregulation of the Mediator complex has been implicated in several human diseases, including cancer and neurological disorders.
Deoxyadenine nucleotides are the chemical components that make up DNA, one of the building blocks of life. Specifically, deoxyadenine nucleotides contain a sugar molecule called deoxyribose, a phosphate group, and the nitrogenous base adenine. Adenine always pairs with thymine in DNA through hydrogen bonding. Together, these components form the building blocks of the genetic code that determines many of an organism's traits and characteristics.
Macromolecular substances, also known as macromolecules, are large, complex molecules made up of repeating subunits called monomers. These substances are formed through polymerization, a process in which many small molecules combine to form a larger one. Macromolecular substances can be naturally occurring, such as proteins, DNA, and carbohydrates, or synthetic, such as plastics and synthetic fibers.
In the context of medicine, macromolecular substances are often used in the development of drugs and medical devices. For example, some drugs are designed to bind to specific macromolecules in the body, such as proteins or DNA, in order to alter their function and produce a therapeutic effect. Additionally, macromolecular substances may be used in the creation of medical implants, such as artificial joints and heart valves, due to their strength and durability.
It is important for healthcare professionals to have an understanding of macromolecular substances and how they function in the body, as this knowledge can inform the development and use of medical treatments.
Transcription Factor IIB (TFIIB) is a general transcription factor that plays an essential role in the initiation of gene transcription by RNA polymerase II in eukaryotic cells. It is a small protein consisting of approximately 350 amino acids and has several functional domains, including a zinc-binding domain, a helix-turn-helix motif, and a cyclin-like fold.
TFIIB acts as a bridge between the RNA polymerase II complex and the promoter DNA, recognizing and binding to specific sequences in the promoter region known as the B recognition element (BRE) and the TATA box. By interacting with other transcription factors, such as TFIIF and TFIIH, TFIIB helps to position RNA polymerase II correctly on the promoter DNA and to unwind the double helix, allowing for the initiation of transcription.
TFIIB is a highly conserved protein across eukaryotes, and mutations in the gene encoding TFIIB have been associated with several human diseases, including developmental disorders and cancer.
Viral proteins are the proteins that are encoded by the viral genome and are essential for the viral life cycle. These proteins can be structural or non-structural and play various roles in the virus's replication, infection, and assembly process. Structural proteins make up the physical structure of the virus, including the capsid (the protein shell that surrounds the viral genome) and any envelope proteins (that may be present on enveloped viruses). Non-structural proteins are involved in the replication of the viral genome and modulation of the host cell environment to favor viral replication. Overall, a thorough understanding of viral proteins is crucial for developing antiviral therapies and vaccines.
Transcription Factor TFIID is a multi-subunit protein complex that plays a crucial role in the process of transcription, which is the first step in gene expression. In eukaryotic cells, TFIID is responsible for recognizing and binding to the promoter region of genes, specifically to the TATA box, a sequence found in many promoters that acts as a binding site for the general transcription factors.
TFIID is composed of the TATA-box binding protein (TBP) and several TBP-associated factors (TAFs). The TBP subunit initially recognizes and binds to the TATA box, followed by the recruitment of other general transcription factors and RNA polymerase II to form a preinitiation complex. This complex then initiates the transcription of DNA into messenger RNA (mRNA), allowing for the production of proteins and the regulation of gene expression.
Transcription Factor TFIID is essential for accurate and efficient transcription, and its dysfunction can lead to various developmental and physiological abnormalities, including diseases such as cancer.
Transcription Factor IIH (TFIIH) is a multi-subunit protein complex that plays a crucial role in the process of transcription, which is the synthesis of RNA from DNA. Specifically, TFIIH is involved in the initiation phase of transcription for protein-coding genes in eukaryotic cells.
TFIIH has two main enzymatic activities: helicase and kinase. The helicase activity is provided by the XPB and XPD subunits, which are responsible for unwinding the DNA double helix at the transcription start site. This creates a single-stranded DNA template for the RNA polymerase II (Pol II) enzyme to bind and begin transcribing the gene.
The kinase activity of TFIIH is provided by the CAK subcomplex, which consists of the CDK7, Cyclin H, and MAT1 proteins. This kinase phosphorylates the carboxy-terminal domain (CTD) of the largest subunit of Pol II, leading to the recruitment of additional transcription factors and the initiation of RNA synthesis.
In addition to its role in transcription, TFIIH is also involved in DNA repair processes, particularly nucleotide excision repair (NER). During NER, TFIIH helps to recognize and remove damaged DNA lesions, such as those caused by UV radiation or chemical mutagens. The XPB and XPD subunits of TFIIH are essential for this process, as they help to unwind the DNA around the damage site and create a bubble structure that allows other repair factors to access and fix the lesion.
Mutations in the genes encoding various subunits of TFIIH can lead to several human diseases, including xeroderma pigmentosum (XP), Cockayne syndrome (CS), trichothiodystrophy (TTD), and combined XP/CS/TTD. These disorders are characterized by increased sensitivity to UV radiation, developmental abnormalities, and neurological dysfunction.
Taq polymerase is not a medical term per se, but it is a biological term commonly used in the field of molecular biology and genetics. It's often mentioned in medical contexts related to DNA analysis and amplification. Here's a definition:
Taq polymerase is a thermostable enzyme originally isolated from the bacterium Thermus aquaticus, which lives in hot springs. This enzyme has the ability to synthesize new strands of DNA by adding nucleotides complementary to a given DNA template, a process known as DNA polymerization. It plays a crucial role in the polymerase chain reaction (PCR), a technique used to amplify specific DNA sequences exponentially. The thermostability of Taq polymerase allows it to withstand the high temperatures required during PCR cycling, making it an essential tool for various genetic analyses and diagnostic applications in medicine.
The cell nucleus is a membrane-bound organelle found in the eukaryotic cells (cells with a true nucleus). It contains most of the cell's genetic material, organized as DNA molecules in complex with proteins, RNA molecules, and histones to form chromosomes.
The primary function of the cell nucleus is to regulate and control the activities of the cell, including growth, metabolism, protein synthesis, and reproduction. It also plays a crucial role in the process of mitosis (cell division) by separating and protecting the genetic material during this process. The nuclear membrane, or nuclear envelope, surrounding the nucleus is composed of two lipid bilayers with numerous pores that allow for the selective transport of molecules between the nucleoplasm (nucleus interior) and the cytoplasm (cell exterior).
The cell nucleus is a vital structure in eukaryotic cells, and its dysfunction can lead to various diseases, including cancer and genetic disorders.
A cell line is a culture of cells that are grown in a laboratory for use in research. These cells are usually taken from a single cell or group of cells, and they are able to divide and grow continuously in the lab. Cell lines can come from many different sources, including animals, plants, and humans. They are often used in scientific research to study cellular processes, disease mechanisms, and to test new drugs or treatments. Some common types of human cell lines include HeLa cells (which come from a cancer patient named Henrietta Lacks), HEK293 cells (which come from embryonic kidney cells), and HUVEC cells (which come from umbilical vein endothelial cells). It is important to note that cell lines are not the same as primary cells, which are cells that are taken directly from a living organism and have not been grown in the lab.
Chromatin is the complex of DNA, RNA, and proteins that make up the chromosomes in the nucleus of a cell. It is responsible for packaging the long DNA molecules into a more compact form that fits within the nucleus. Chromatin is made up of repeating units called nucleosomes, which consist of a histone protein octamer wrapped tightly by DNA. The structure of chromatin can be altered through chemical modifications to the histone proteins and DNA, which can influence gene expression and other cellular processes.
Tertiary protein structure refers to the three-dimensional arrangement of all the elements (polypeptide chains) of a single protein molecule. It is the highest level of structural organization and results from interactions between various side chains (R groups) of the amino acids that make up the protein. These interactions, which include hydrogen bonds, ionic bonds, van der Waals forces, and disulfide bridges, give the protein its unique shape and stability, which in turn determines its function. The tertiary structure of a protein can be stabilized by various factors such as temperature, pH, and the presence of certain ions. Any changes in these factors can lead to denaturation, where the protein loses its tertiary structure and thus its function.
RNA (Ribonucleic Acid) is a single-stranded, linear polymer of ribonucleotides. It is a nucleic acid present in the cells of all living organisms and some viruses. RNAs play crucial roles in various biological processes such as protein synthesis, gene regulation, and cellular signaling. There are several types of RNA including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), small nuclear RNA (snRNA), microRNA (miRNA), and long non-coding RNA (lncRNA). These RNAs differ in their structure, function, and location within the cell.
A bacterial gene is a segment of DNA (or RNA in some viruses) that contains the genetic information necessary for the synthesis of a functional bacterial protein or RNA molecule. These genes are responsible for encoding various characteristics and functions of bacteria such as metabolism, reproduction, and resistance to antibiotics. They can be transmitted between bacteria through horizontal gene transfer mechanisms like conjugation, transformation, and transduction. Bacterial genes are often organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule.
It's important to note that the term "bacterial gene" is used to describe genetic elements found in bacteria, but not all genetic elements in bacteria are considered genes. For example, some DNA sequences may not encode functional products and are therefore not considered genes. Additionally, some bacterial genes may be plasmid-borne or phage-borne, rather than being located on the bacterial chromosome.
Bacteriophage T7 is a type of virus that infects and replicates within the bacterium Escherichia coli (E. coli). It is a double-stranded DNA virus that specifically recognizes and binds to the outer membrane of E. coli bacteria through its tail fibers. After attachment, the viral genome is injected into the host cell, where it hijacks the bacterial machinery to produce new phage particles. The rapid reproduction of T7 phages within the host cell often results in lysis, or rupture, of the bacterial cell, leading to the release of newly formed phage virions. Bacteriophage T7 is widely studied as a model system for understanding virus-host interactions and molecular biology.
DNA damage refers to any alteration in the structure or composition of deoxyribonucleic acid (DNA), which is the genetic material present in cells. DNA damage can result from various internal and external factors, including environmental exposures such as ultraviolet radiation, tobacco smoke, and certain chemicals, as well as normal cellular processes such as replication and oxidative metabolism.
Examples of DNA damage include base modifications, base deletions or insertions, single-strand breaks, double-strand breaks, and crosslinks between the two strands of the DNA helix. These types of damage can lead to mutations, genomic instability, and chromosomal aberrations, which can contribute to the development of diseases such as cancer, neurodegenerative disorders, and aging-related conditions.
The body has several mechanisms for repairing DNA damage, including base excision repair, nucleotide excision repair, mismatch repair, and double-strand break repair. However, if the damage is too extensive or the repair mechanisms are impaired, the cell may undergo apoptosis (programmed cell death) to prevent the propagation of potentially harmful mutations.
The TATA-box binding protein (TBP) is a general transcription factor that plays a crucial role in the initiation of transcription of protein-coding genes in archaea and eukaryotes. It is named after its ability to bind to the TATA box, a conserved DNA sequence found in the promoter regions of many genes.
TBP is a key component of the transcription preinitiation complex (PIC), which also includes other general transcription factors and RNA polymerase II in eukaryotes. The TBP protein has a unique structure, characterized by a saddle-shaped DNA-binding domain that allows it to recognize and bind to the TATA box in a sequence-specific manner.
By binding to the TATA box, TBP helps to position the RNA polymerase II complex at the start site of transcription, allowing for the initiation of RNA synthesis. TBP also plays a role in regulating gene expression by interacting with various coactivators and corepressors that modulate its activity.
Mutations in the TBP gene have been associated with several human diseases, including some forms of cancer and neurodevelopmental disorders.
Dichlororibofuranosylbenzimidazole is not a medical term, but it is a chemical compound with the formula C6H5Cl2N2O4. It is also known as tribuzole or 1-(2'-deoxy-2'-fluoro-β-D-erythro-pentofuranosyl)-2,2-dichlorobenzimidazole.
Tribuzole is an antiviral drug that has been studied for the treatment of HIV infection. It works by inhibiting the reverse transcriptase enzyme of the virus, which is necessary for the replication of the viral RNA into DNA. However, tribuzole has not been approved for clinical use due to its limited efficacy and unfavorable side effects profile.
Therefore, there is no medical definition for 'dichlororibofuranosylbenzimidazole' as it is not a term used in medical practice or literature.
I believe there might be a slight confusion in your question. T-phages are not a medical term, but rather a term used in the field of molecular biology and virology. T-phages refer to specific bacteriophages (viruses that infect bacteria) that belong to the family of Podoviridae and have a tail structure with a contractile sheath.
To be more specific, T-even phages are a group of T-phages that include well-studied bacteriophages like T2, T4, and T6. These phages infect Escherichia coli bacteria and have been extensively researched to understand their life cycles, genetic material packaging, and molecular mechanisms of infection.
In summary, T-phages are not a medical term but rather refer to specific bacteriophages used in scientific research.
Messenger RNA (mRNA) is a type of RNA (ribonucleic acid) that carries genetic information copied from DNA in the form of a series of three-base code "words," each of which specifies a particular amino acid. This information is used by the cell's machinery to construct proteins, a process known as translation. After being transcribed from DNA, mRNA travels out of the nucleus to the ribosomes in the cytoplasm where protein synthesis occurs. Once the protein has been synthesized, the mRNA may be degraded and recycled. Post-transcriptional modifications can also occur to mRNA, such as alternative splicing and addition of a 5' cap and a poly(A) tail, which can affect its stability, localization, and translation efficiency.
Substrate specificity in the context of medical biochemistry and enzymology refers to the ability of an enzyme to selectively bind and catalyze a chemical reaction with a particular substrate (or a group of similar substrates) while discriminating against other molecules that are not substrates. This specificity arises from the three-dimensional structure of the enzyme, which has evolved to match the shape, charge distribution, and functional groups of its physiological substrate(s).
Substrate specificity is a fundamental property of enzymes that enables them to carry out highly selective chemical transformations in the complex cellular environment. The active site of an enzyme, where the catalysis takes place, has a unique conformation that complements the shape and charge distribution of its substrate(s). This ensures efficient recognition, binding, and conversion of the substrate into the desired product while minimizing unwanted side reactions with other molecules.
Substrate specificity can be categorized as:
1. Absolute specificity: An enzyme that can only act on a single substrate or a very narrow group of structurally related substrates, showing no activity towards any other molecule.
2. Group specificity: An enzyme that prefers to act on a particular functional group or class of compounds but can still accommodate minor structural variations within the substrate.
3. Broad or promiscuous specificity: An enzyme that can act on a wide range of structurally diverse substrates, albeit with varying catalytic efficiencies.
Understanding substrate specificity is crucial for elucidating enzymatic mechanisms, designing drugs that target specific enzymes or pathways, and developing biotechnological applications that rely on the controlled manipulation of enzyme activities.
Polynucleotides are long, chain-like molecules composed of repeating units called nucleotides. Each nucleotide contains a sugar molecule (deoxyribose in DNA or ribose in RNA), a phosphate group, and a nitrogenous base (adenine, guanine, cytosine, thymine in DNA or adenine, guanine, uracil, cytosine in RNA). In DNA, the nucleotides are joined together by phosphodiester bonds between the sugar of one nucleotide and the phosphate group of the next, creating a double helix structure. In RNA, the nucleotides are also joined by phosphodiester bonds but form a single strand. Polynucleotides play crucial roles in storing and transmitting genetic information within cells.
Base composition in genetics refers to the relative proportion of the four nucleotide bases (adenine, thymine, guanine, and cytosine) in a DNA or RNA molecule. In DNA, adenine pairs with thymine, and guanine pairs with cytosine, so the base composition is often expressed in terms of the ratio of adenine + thymine (A-T) to guanine + cytosine (G-C). This ratio can vary between species and even between different regions of the same genome. The base composition can provide important clues about the function, evolution, and structure of genetic material.
Transcription elongation, genetic is the process in which RNA polymerase synthesizes an RNA molecule from DNA template by adding nucleotides one by one to the growing chain in a continuous manner, after the initiation of transcription has occurred. During this process, the RNA polymerase moves along the DNA template, reading the sequence of nucleotide bases and adding complementary RNA nucleotides to the growing RNA strand until the end of the gene is reached. Transcription elongation is regulated by various factors, including protein complexes that interact with the RNA polymerase and modify its activity. Dysregulation of transcription elongation has been implicated in several human diseases, including cancer.
Phosphonoacetic acid (PAA) is not a naturally occurring substance, but rather a synthetic compound that is used in medical and scientific research. It is a colorless, crystalline solid that is soluble in water.
In a medical context, PAA is an inhibitor of certain enzymes that are involved in the replication of viruses, including HIV. It works by binding to the active site of these enzymes and preventing them from carrying out their normal functions. As a result, PAA has been studied as a potential antiviral agent, although it is not currently used as a medication.
It's important to note that while PAA has shown promise in laboratory studies, its safety and efficacy have not been established in clinical trials, and it is not approved for use as a drug by regulatory agencies such as the U.S. Food and Drug Administration (FDA).
Nuclear proteins are a category of proteins that are primarily found in the nucleus of a eukaryotic cell. They play crucial roles in various nuclear functions, such as DNA replication, transcription, repair, and RNA processing. This group includes structural proteins like lamins, which form the nuclear lamina, and regulatory proteins, such as histones and transcription factors, that are involved in gene expression. Nuclear localization signals (NLS) often help target these proteins to the nucleus by interacting with importin proteins during active transport across the nuclear membrane.
Sequence homology, amino acid, refers to the similarity in the order of amino acids in a protein or a portion of a protein between two or more species. This similarity can be used to infer evolutionary relationships and functional similarities between proteins. The higher the degree of sequence homology, the more likely it is that the proteins are related and have similar functions. Sequence homology can be determined through various methods such as pairwise alignment or multiple sequence alignment, which compare the sequences and calculate a score based on the number and type of matching amino acids.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
Histones are highly alkaline proteins found in the chromatin of eukaryotic cells. They are rich in basic amino acid residues, such as arginine and lysine, which give them their positive charge. Histones play a crucial role in packaging DNA into a more compact structure within the nucleus by forming a complex with it called a nucleosome. Each nucleosome contains about 146 base pairs of DNA wrapped around an octamer of eight histone proteins (two each of H2A, H2B, H3, and H4). The N-terminal tails of these histones are subject to various post-translational modifications, such as methylation, acetylation, and phosphorylation, which can influence chromatin structure and gene expression. Histone variants also exist, which can contribute to the regulation of specific genes and other nuclear processes.
A protein subunit refers to a distinct and independently folding polypeptide chain that makes up a larger protein complex. Proteins are often composed of multiple subunits, which can be identical or different, that come together to form the functional unit of the protein. These subunits can interact with each other through non-covalent interactions such as hydrogen bonds, ionic bonds, and van der Waals forces, as well as covalent bonds like disulfide bridges. The arrangement and interaction of these subunits contribute to the overall structure and function of the protein.
DNA helicases are a group of enzymes that are responsible for separating the two strands of DNA during processes such as replication and transcription. They do this by unwinding the double helix structure of DNA, using energy from ATP to break the hydrogen bonds between the base pairs. This allows other proteins to access the individual strands of DNA and carry out functions such as copying the genetic code or transcribing it into RNA.
During replication, DNA helicases help to create a replication fork, where the two strands of DNA are separated and new complementary strands are synthesized. In transcription, DNA helicases help to unwind the DNA double helix at the promoter region, allowing the RNA polymerase enzyme to bind and begin transcribing the DNA into RNA.
DNA helicases play a crucial role in maintaining the integrity of the genetic code and are essential for the normal functioning of cells. Defects in DNA helicases have been linked to various diseases, including cancer and neurological disorders.
I'm sorry for any confusion, but "TATA box" is actually a term used in molecular biology, specifically in the field of genetics and gene regulation. It does not have a direct medical definition.
The TATA box is a DNA sequence located in the promoter region of many genes, which serves as a binding site for certain proteins involved in the initiation of transcription. Transcription is the first step in gene expression, where the information in a gene is used to create a corresponding protein or RNA molecule.
The TATA box is typically found about 25-30 base pairs upstream of the transcription start site and has the consensus sequence "TATAAA". It is recognized by the TATA-binding protein (TBP), which is a component of the transcription factor II D (TFIIB) complex. The binding of TBP to the TATA box helps to position the RNA polymerase enzyme properly for the initiation of transcription.
While not a medical term per se, understanding the function of the TATA box and other cis-acting elements in gene regulation is important for understanding how genes are turned on and off in various cellular processes and how this can go awry in certain diseases.
Positive Transcriptional Elongation Factor B (P-TEFb) is a crucial protein complex in the process of transcription, which is the first step in gene expression. The main function of P-TEFb is to help RNA polymerase II, the enzyme responsible for transcribing DNA into RNA, to continue and complete the transcription of genes.
P-TEFb is composed of two subunits: cyclin T (CYCT) and CDK9 (cyclin-dependent kinase 9). The complex acts by phosphorylating several proteins that associate with RNA polymerase II, including the negative elongation factors NELF and DSIF. This phosphorylation converts NELF from a repressor to an activator of transcription elongation and relieves DSIF-mediated pausing of RNA polymerase II, allowing it to transcribe genes efficiently.
P-TEFb plays a significant role in regulating the expression of numerous genes, including those involved in cell growth, differentiation, and survival. Its dysregulation has been implicated in several diseases, such as cancer and HIV infection. In cancer, P-TEFb can contribute to oncogene activation and tumor progression, while in HIV, it is required for the transcription of viral genes during the early and late stages of infection.
I'm sorry for any confusion, but "Poly T" is not a standard medical term that I am aware of. It is possible that it could be an abbreviation or shorthand used in a specific context, such as a medical report or research study. If you have more information about where this term came from or how it is being used, I may be able to provide a more accurate and helpful response.
However, if "Poly T" is meant to refer to polycythemia vera, which is a type of blood cancer characterized by an overproduction of red blood cells, then here's the definition:
Polycythemia Vera (PV) is a myeloproliferative neoplasm (MPN), a type of blood cancer that affects the bone marrow. In PV, the body produces too many red blood cells, white blood cells, and platelets, leading to an increased risk of blood clots, enlargement of the spleen, and other complications. The exact cause of PV is not known, but it is thought to be related to genetic mutations that affect the regulation of cell growth and division in the bone marrow. Symptoms of PV can include fatigue, headache, dizziness, shortness of breath, and a bluish or reddish tint to the skin. Treatment for PV typically involves medications to reduce the production of blood cells, as well as regular monitoring to manage complications and prevent progression of the disease.
Recombinant proteins are artificially created proteins produced through the use of recombinant DNA technology. This process involves combining DNA molecules from different sources to create a new set of genes that encode for a specific protein. The resulting recombinant protein can then be expressed, purified, and used for various applications in research, medicine, and industry.
Recombinant proteins are widely used in biomedical research to study protein function, structure, and interactions. They are also used in the development of diagnostic tests, vaccines, and therapeutic drugs. For example, recombinant insulin is a common treatment for diabetes, while recombinant human growth hormone is used to treat growth disorders.
The production of recombinant proteins typically involves the use of host cells, such as bacteria, yeast, or mammalian cells, which are engineered to express the desired protein. The host cells are transformed with a plasmid vector containing the gene of interest, along with regulatory elements that control its expression. Once the host cells are cultured and the protein is expressed, it can be purified using various chromatography techniques.
Overall, recombinant proteins have revolutionized many areas of biology and medicine, enabling researchers to study and manipulate proteins in ways that were previously impossible.
Nucleic acid conformation refers to the three-dimensional structure that nucleic acids (DNA and RNA) adopt as a result of the bonding patterns between the atoms within the molecule. The primary structure of nucleic acids is determined by the sequence of nucleotides, while the conformation is influenced by factors such as the sugar-phosphate backbone, base stacking, and hydrogen bonding.
Two common conformations of DNA are the B-form and the A-form. The B-form is a right-handed helix with a diameter of about 20 Å and a pitch of 34 Å, while the A-form has a smaller diameter (about 18 Å) and a shorter pitch (about 25 Å). RNA typically adopts an A-form conformation.
The conformation of nucleic acids can have significant implications for their function, as it can affect their ability to interact with other molecules such as proteins or drugs. Understanding the conformational properties of nucleic acids is therefore an important area of research in molecular biology and medicine.
Fungal DNA refers to the genetic material present in fungi, which are a group of eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. The DNA of fungi, like that of all living organisms, is made up of nucleotides that are arranged in a double helix structure.
Fungal DNA contains the genetic information necessary for the growth, development, and reproduction of fungi. This includes the instructions for making proteins, which are essential for the structure and function of cells, as well as other important molecules such as enzymes and nucleic acids.
Studying fungal DNA can provide valuable insights into the biology and evolution of fungi, as well as their potential uses in medicine, agriculture, and industry. For example, researchers have used genetic engineering techniques to modify the DNA of fungi to produce drugs, biofuels, and other useful products. Additionally, understanding the genetic makeup of pathogenic fungi can help scientists develop new strategies for preventing and treating fungal infections.
Cyclin-Dependent Kinase 9 (CDK9) is a type of serine/threonine protein kinase that plays a crucial role in the regulation of transcription. It forms a complex with cyclin T1, K or H and gets activated by phosphorylation. This complex, known as P-TEFb, is involved in the phosphorylation and activation of the C-terminal domain of RNA polymerase II, which is essential for the transcription elongation of most protein-coding genes. CDK9 also regulates other cellular processes such as apoptosis, differentiation, and cell cycle progression. Dysregulation of CDK9 has been implicated in various diseases including cancer.
Cyclin-Dependent Kinase 8 (CDK8) is a type of serine/threonine protein kinase that plays a crucial role in the regulation of gene transcription. It forms a complex with cyclin C, and its activity is required for various cellular processes such as cell cycle progression, differentiation, and apoptosis. CDK8 has been shown to phosphorylate several transcription factors and coactivators, thereby modulating their activities and contributing to the control of gene expression. Dysregulation of CDK8 activity has been implicated in various diseases, including cancer, making it a potential target for therapeutic intervention.
A holozyme is not a specific medical term, but rather a term used in biochemistry to refer to the complete, active form of an enzyme. An enzyme is a biological molecule that catalyzes chemical reactions in the body, and it is often made up of several different subunits or components.
The term "holozyme" comes from the Greek words "holos," meaning whole, and "enzyma," meaning in yeast. It was originally used to describe the active form of enzymes found in yeast cells, but it is now used more broadly to refer to any complete, active enzyme complex.
A holozyme typically consists of two types of subunits: a catalytic subunit, which contains the active site where the substrate binds and the reaction takes place, and one or more regulatory subunits, which control the activity of the enzyme under different conditions. The regulatory subunits may be activated or inhibited by various signals, such as hormones, metabolites, or other molecules, allowing the enzyme to respond to changes in the cellular environment.
In summary, a holozyme is the fully assembled and functional form of an enzyme, consisting of one or more catalytic subunits and one or more regulatory subunits that work together to carry out specific biochemical reactions in the body.
Avian myeloblastosis virus (AMV) is a type of retrovirus that primarily infects birds, particularly chickens. It is named after the disease it causes, avian myeloblastosis, which is a malignant condition affecting the bone marrow and blood cells of infected birds.
AMV is classified as an alpharetrovirus and has a single-stranded RNA genome. When the virus infects a host cell, its RNA genome is reverse transcribed into DNA, which then integrates into the host's chromosomal DNA. This integrated viral DNA, known as a provirus, can then direct the production of new virus particles.
AMV has been extensively studied as a model system for retroviruses and has contributed significantly to our understanding of their replication and pathogenesis. The virus is also used in laboratory research as a tool for generating genetically modified animals and for studying the regulation of gene expression. However, it is not known to infect or cause disease in humans or other mammals.
A base pair mismatch is a type of mutation that occurs during the replication or repair of DNA, where two incompatible nucleotides pair up instead of the usual complementary bases (adenine-thymine or cytosine-guanine). This can result in the substitution of one base pair for another and may lead to changes in the genetic code, potentially causing errors in protein synthesis and possibly contributing to genetic disorders or diseases, including cancer.
Oligodeoxyribonucleotides (ODNs) are relatively short, synthetic single-stranded DNA molecules. They typically contain 15 to 30 nucleotides, but can range from 2 to several hundred nucleotides in length. ODNs are often used as tools in molecular biology research for various applications such as:
1. Nucleic acid detection and quantification (e.g., real-time PCR)
2. Gene regulation (antisense, RNA interference)
3. Gene editing (CRISPR-Cas systems)
4. Vaccine development
5. Diagnostic purposes
Due to their specificity and affinity towards complementary DNA or RNA sequences, ODNs can be designed to target a particular gene or sequence of interest. This makes them valuable tools in understanding gene function, regulation, and interaction with other molecules within the cell.
TATA-binding protein associated factors (TAFs) are a group of proteins that associate with the TATA-binding protein (TBP) to form the basal transcription complex, which is involved in the initiation of gene transcription. In eukaryotes, TBP is a general transcription factor that recognizes and binds to the TATA box, a conserved DNA sequence found in the promoter regions of many genes. TAFs interact with TBP and other proteins to form the multi-subunit complex known as TFIID (transcription factor II D).
TAFs can be classified into two categories: TAF1 subunits and TAF2 subunits. The TAF1 subunits are characterized by a conserved histone fold motif, which is also found in the core histones of nucleosomes. These TAF1 subunits play a role in stabilizing the interaction between TBP and DNA, as well as recruiting additional transcription factors to the promoter. The TAF2 subunits, on the other hand, do not contain the histone fold motif and are involved in mediating interactions with other proteins and regulatory elements.
Together, TBP and TAFs help to position the RNA polymerase II enzyme at the start site of transcription and facilitate the assembly of the pre-initiation complex (PIC), which includes additional general transcription factors and mediator proteins. The PIC then initiates the synthesis of mRNA, allowing for the expression of specific genes.
In summary, TATA-binding protein associated factors are a group of proteins that associate with TBP to form the basal transcription complex, which plays a crucial role in the initiation of gene transcription by recruiting RNA polymerase II and other general transcription factors to the promoter region.
Fungal proteins are a type of protein that is specifically produced and present in fungi, which are a group of eukaryotic organisms that include microorganisms such as yeasts and molds. These proteins play various roles in the growth, development, and survival of fungi. They can be involved in the structure and function of fungal cells, metabolism, pathogenesis, and other cellular processes. Some fungal proteins can also have important implications for human health, both in terms of their potential use as therapeutic targets and as allergens or toxins that can cause disease.
Fungal proteins can be classified into different categories based on their functions, such as enzymes, structural proteins, signaling proteins, and toxins. Enzymes are proteins that catalyze chemical reactions in fungal cells, while structural proteins provide support and protection for the cell. Signaling proteins are involved in communication between cells and regulation of various cellular processes, and toxins are proteins that can cause harm to other organisms, including humans.
Understanding the structure and function of fungal proteins is important for developing new treatments for fungal infections, as well as for understanding the basic biology of fungi. Research on fungal proteins has led to the development of several antifungal drugs that target specific fungal enzymes or other proteins, providing effective treatment options for a range of fungal diseases. Additionally, further study of fungal proteins may reveal new targets for drug development and help improve our ability to diagnose and treat fungal infections.
Electrophoresis, polyacrylamide gel (EPG) is a laboratory technique used to separate and analyze complex mixtures of proteins or nucleic acids (DNA or RNA) based on their size and electrical charge. This technique utilizes a matrix made of cross-linked polyacrylamide, a type of gel, which provides a stable and uniform environment for the separation of molecules.
In this process:
1. The polyacrylamide gel is prepared by mixing acrylamide monomers with a cross-linking agent (bis-acrylamide) and a catalyst (ammonium persulfate) in the presence of a buffer solution.
2. The gel is then poured into a mold and allowed to polymerize, forming a solid matrix with uniform pore sizes that depend on the concentration of acrylamide used. Higher concentrations result in smaller pores, providing better resolution for separating smaller molecules.
3. Once the gel has set, it is placed in an electrophoresis apparatus containing a buffer solution. Samples containing the mixture of proteins or nucleic acids are loaded into wells on the top of the gel.
4. An electric field is applied across the gel, causing the negatively charged molecules to migrate towards the positive electrode (anode) while positively charged molecules move toward the negative electrode (cathode). The rate of migration depends on the size, charge, and shape of the molecules.
5. Smaller molecules move faster through the gel matrix and will migrate farther from the origin compared to larger molecules, resulting in separation based on size. Proteins and nucleic acids can be selectively stained after electrophoresis to visualize the separated bands.
EPG is widely used in various research fields, including molecular biology, genetics, proteomics, and forensic science, for applications such as protein characterization, DNA fragment analysis, cloning, mutation detection, and quality control of nucleic acid or protein samples.
Oligonucleotides are short sequences of nucleotides, the building blocks of DNA and RNA. They typically contain fewer than 100 nucleotides, and can be synthesized chemically to have specific sequences. Oligonucleotides are used in a variety of applications in molecular biology, including as probes for detecting specific DNA or RNA sequences, as inhibitors of gene expression, and as components of diagnostic tests and therapies. They can also be used in the study of protein-nucleic acid interactions and in the development of new drugs.
Chromatin Immunoprecipitation (ChIP) is a molecular biology technique used to analyze the interaction between proteins and DNA in the cell. It is a powerful tool for studying protein-DNA binding, such as transcription factor binding to specific DNA sequences, histone modification, and chromatin structure.
In ChIP assays, cells are first crosslinked with formaldehyde to preserve protein-DNA interactions. The chromatin is then fragmented into small pieces using sonication or other methods. Specific antibodies against the protein of interest are added to precipitate the protein-DNA complexes. After reversing the crosslinking, the DNA associated with the protein is purified and analyzed using PCR, sequencing, or microarray technologies.
ChIP assays can provide valuable information about the regulation of gene expression, epigenetic modifications, and chromatin structure in various biological processes and diseases, including cancer, development, and differentiation.
Gene expression regulation in fungi refers to the complex cellular processes that control the production of proteins and other functional gene products in response to various internal and external stimuli. This regulation is crucial for normal growth, development, and adaptation of fungal cells to changing environmental conditions.
In fungi, gene expression is regulated at multiple levels, including transcriptional, post-transcriptional, translational, and post-translational modifications. Key regulatory mechanisms include:
1. Transcription factors (TFs): These proteins bind to specific DNA sequences in the promoter regions of target genes and either activate or repress their transcription. Fungi have a diverse array of TFs that respond to various signals, such as nutrient availability, stress, developmental cues, and quorum sensing.
2. Chromatin remodeling: The organization and compaction of DNA into chromatin can influence gene expression. Fungi utilize ATP-dependent chromatin remodeling complexes and histone modifying enzymes to alter chromatin structure, thereby facilitating or inhibiting the access of transcriptional machinery to genes.
3. Non-coding RNAs: Small non-coding RNAs (sncRNAs) play a role in post-transcriptional regulation of gene expression in fungi. These sncRNAs can guide RNA-induced transcriptional silencing (RITS) complexes to specific target loci, leading to the repression of gene expression through histone modifications and DNA methylation.
4. Alternative splicing: Fungi employ alternative splicing mechanisms to generate multiple mRNA isoforms from a single gene, thereby increasing proteome diversity. This process can be regulated by RNA-binding proteins that recognize specific sequence motifs in pre-mRNAs and promote or inhibit splicing events.
5. Protein stability and activity: Post-translational modifications (PTMs) of proteins, such as phosphorylation, ubiquitination, and sumoylation, can influence their stability, localization, and activity. These PTMs play a crucial role in regulating various cellular processes, including signal transduction, stress response, and cell cycle progression.
Understanding the complex interplay between these regulatory mechanisms is essential for elucidating the molecular basis of fungal development, pathogenesis, and drug resistance. This knowledge can be harnessed to develop novel strategies for combating fungal infections and improving agricultural productivity.
Diterpenes are a class of naturally occurring compounds that are composed of four isoprene units, which is a type of hydrocarbon. They are synthesized by a wide variety of plants and animals, and are found in many different types of organisms, including fungi, insects, and marine organisms.
Diterpenes have a variety of biological activities and are used in medicine for their therapeutic effects. Some diterpenes have anti-inflammatory, antimicrobial, and antiviral properties, and are used to treat a range of conditions, including respiratory infections, skin disorders, and cancer.
Diterpenes can be further classified into different subgroups based on their chemical structure and biological activity. Some examples of diterpenes include the phytocannabinoids found in cannabis plants, such as THC and CBD, and the paclitaxel, a diterpene found in the bark of the Pacific yew tree that is used to treat cancer.
It's important to note that while some diterpenes have therapeutic potential, others may be toxic or have adverse effects, so it is essential to use them under the guidance and supervision of a healthcare professional.
Guanine is not a medical term per se, but it is a biological molecule that plays a crucial role in the body. Guanine is one of the four nucleobases found in the nucleic acids DNA and RNA, along with adenine, cytosine, and thymine (in DNA) or uracil (in RNA). Specifically, guanine pairs with cytosine via hydrogen bonds to form a base pair.
Guanine is a purine derivative, which means it has a double-ring structure. It is formed through the synthesis of simpler molecules in the body and is an essential component of genetic material. Guanine's chemical formula is C5H5N5O.
While guanine itself is not a medical term, abnormalities or mutations in genes that contain guanine nucleotides can lead to various medical conditions, including genetic disorders and cancer.
Uracil is not a medical term, but it is a biological molecule. Medically or biologically, uracil can be defined as one of the four nucleobases in the nucleic acid of RNA (ribonucleic acid) that is linked to a ribose sugar by an N-glycosidic bond. It forms base pairs with adenine in double-stranded RNA and DNA. Uracil is a pyrimidine derivative, similar to thymine found in DNA, but it lacks the methyl group (-CH3) that thymine has at the 5 position of its ring.
Sarcosine is not a medical condition or disease, but rather it is an organic compound that is classified as a natural amino acid. It is a metabolite that can be found in the human body, and it is involved in various biochemical processes. Specifically, sarcosine is formed from the conversion of the amino acid glycine by the enzyme glycine sarcosine N-methyltransferase (GSMT) and is then converted to glycine betaine (also known as trimethylglycine) by the enzyme betaine-homocysteine S-methyltransferase (BHMT).
Abnormal levels of sarcosine have been found in various disease states, including cancer. Some studies have suggested that high levels of sarcosine in urine or prostate tissue may be associated with an increased risk of developing prostate cancer or a more aggressive form of the disease. However, more research is needed to confirm these findings and establish the clinical significance of sarcosine as a biomarker for cancer or other diseases.
A catalytic domain is a portion or region within a protein that contains the active site, where the chemical reactions necessary for the protein's function are carried out. This domain is responsible for the catalysis of biological reactions, hence the name "catalytic domain." The catalytic domain is often composed of specific amino acid residues that come together to form the active site, creating a unique three-dimensional structure that enables the protein to perform its specific function.
In enzymes, for example, the catalytic domain contains the residues that bind and convert substrates into products through chemical reactions. In receptors, the catalytic domain may be involved in signal transduction or other regulatory functions. Understanding the structure and function of catalytic domains is crucial to understanding the mechanisms of protein function and can provide valuable insights for drug design and therapeutic interventions.
Temperature, in a medical context, is a measure of the degree of hotness or coldness of a body or environment. It is usually measured using a thermometer and reported in degrees Celsius (°C), degrees Fahrenheit (°F), or kelvin (K). In the human body, normal core temperature ranges from about 36.5-37.5°C (97.7-99.5°F) when measured rectally, and can vary slightly depending on factors such as time of day, physical activity, and menstrual cycle. Elevated body temperature is a common sign of infection or inflammation, while abnormally low body temperature can indicate hypothermia or other medical conditions.
"Poly dA-dT" is not a medical term, but rather a molecular biology term that refers to a synthetic double-stranded DNA molecule. It is composed of two complementary strands: one strand consists of repeated adenine (dA) nucleotides, while the other strand consists of repeated thymine (dT) nucleotides. The "poly" prefix indicates that multiple units of these nucleotides are linked together in a chain-like structure.
This type of synthetic DNA molecule is often used as a substrate for various molecular biology techniques, such as in vitro transcription or translation assays, where it serves as a template for the production of RNA or proteins. It can also be used to study the interactions between DNA and proteins, such as transcription factors, that bind specifically to certain nucleotide sequences.
Bacillus phages are viruses that infect and replicate within bacteria of the genus Bacillus. These phages, also known as bacteriophages or simply phages, are a type of virus that is specifically adapted to infect and multiply within bacteria. They use the bacterial cell's machinery to produce new copies of themselves, often resulting in the lysis (breakdown) of the bacterial cell. Bacillus phages are widely studied for their potential applications in biotechnology, medicine, and basic research.
Manganese is not a medical condition, but it's an essential trace element that is vital for human health. Here is the medical definition of Manganese:
Manganese (Mn) is a trace mineral that is present in tiny amounts in the body. It is found mainly in bones, the liver, kidneys, and pancreas. Manganese helps the body form connective tissue, bones, blood clotting factors, and sex hormones. It also plays a role in fat and carbohydrate metabolism, calcium absorption, and blood sugar regulation. Manganese is also necessary for normal brain and nerve function.
The recommended dietary allowance (RDA) for manganese is 2.3 mg per day for adult men and 1.8 mg per day for adult women. Good food sources of manganese include nuts, seeds, legumes, whole grains, green leafy vegetables, and tea.
In some cases, exposure to high levels of manganese can cause neurological symptoms similar to Parkinson's disease, a condition known as manganism. However, this is rare and usually occurs in people who are occupationally exposed to manganese dust or fumes, such as welders.
A cell-free system is a biochemical environment in which biological reactions can occur outside of an intact living cell. These systems are often used to study specific cellular processes or pathways, as they allow researchers to control and manipulate the conditions in which the reactions take place. In a cell-free system, the necessary enzymes, substrates, and cofactors for a particular reaction are provided in a test tube or other container, rather than within a whole cell.
Cell-free systems can be derived from various sources, including bacteria, yeast, and mammalian cells. They can be used to study a wide range of cellular processes, such as transcription, translation, protein folding, and metabolism. For example, a cell-free system might be used to express and purify a specific protein, or to investigate the regulation of a particular metabolic pathway.
One advantage of using cell-free systems is that they can provide valuable insights into the mechanisms of cellular processes without the need for time-consuming and resource-intensive cell culture or genetic manipulation. Additionally, because cell-free systems are not constrained by the limitations of a whole cell, they offer greater flexibility in terms of reaction conditions and the ability to study complex or transient interactions between biological molecules.
Overall, cell-free systems are an important tool in molecular biology and biochemistry, providing researchers with a versatile and powerful means of investigating the fundamental processes that underlie life at the cellular level.
Phosphorylation is the process of adding a phosphate group (a molecule consisting of one phosphorus atom and four oxygen atoms) to a protein or other organic molecule, which is usually done by enzymes called kinases. This post-translational modification can change the function, localization, or activity of the target molecule, playing a crucial role in various cellular processes such as signal transduction, metabolism, and regulation of gene expression. Phosphorylation is reversible, and the removal of the phosphate group is facilitated by enzymes called phosphatases.
"Terminator regions" is a term used in molecular biology and genetics to describe specific sequences within DNA that control the termination of transcription, which is the process of creating an RNA copy of a sequence of DNA. These regions are also sometimes referred to as "transcription termination sites."
In the context of genetic terminators, the term "terminator" refers to the sequence of nucleotides that signals the end of the gene and the beginning of the termination process. The terminator region typically contains a specific sequence of nucleotides that recruits proteins called termination factors, which help to disrupt the transcription bubble and release the newly synthesized RNA molecule from the DNA template.
It's important to note that there are different types of terminators in genetics, including "Rho-dependent" and "Rho-independent" terminators, which differ in their mechanisms for terminating transcription. Rho-dependent terminators rely on the action of a protein called Rho, while Rho-independent terminators form a stable hairpin structure that causes the transcription machinery to stall and release the RNA.
In summary, "Terminator regions" in genetics are specific sequences within DNA that control the termination of transcription by signaling the end of the gene and recruiting proteins or forming structures that disrupt the transcription bubble and release the newly synthesized RNA molecule.
Base pairing is a specific type of chemical bonding that occurs between complementary base pairs in the nucleic acid molecules DNA and RNA. In DNA, these bases are adenine (A), thymine (T), guanine (G), and cytosine (C). Adenine always pairs with thymine via two hydrogen bonds, while guanine always pairs with cytosine via three hydrogen bonds. This precise base pairing is crucial for the stability of the double helix structure of DNA and for the accurate replication and transcription of genetic information. In RNA, uracil (U) takes the place of thymine and pairs with adenine.
A viral RNA (ribonucleic acid) is the genetic material found in certain types of viruses, as opposed to viruses that contain DNA (deoxyribonucleic acid). These viruses are known as RNA viruses. The RNA can be single-stranded or double-stranded and can exist as several different forms, such as positive-sense, negative-sense, or ambisense RNA. Upon infecting a host cell, the viral RNA uses the host's cellular machinery to translate the genetic information into proteins, leading to the production of new virus particles and the continuation of the viral life cycle. Examples of human diseases caused by RNA viruses include influenza, COVID-19 (SARS-CoV-2), hepatitis C, and polio.
Virus replication is the process by which a virus produces copies or reproduces itself inside a host cell. This involves several steps:
1. Attachment: The virus attaches to a specific receptor on the surface of the host cell.
2. Penetration: The viral genetic material enters the host cell, either by invagination of the cell membrane or endocytosis.
3. Uncoating: The viral genetic material is released from its protective coat (capsid) inside the host cell.
4. Replication: The viral genetic material uses the host cell's machinery to produce new viral components, such as proteins and nucleic acids.
5. Assembly: The newly synthesized viral components are assembled into new virus particles.
6. Release: The newly formed viruses are released from the host cell, often through lysis (breaking) of the cell membrane or by budding off the cell membrane.
The specific mechanisms and details of virus replication can vary depending on the type of virus. Some viruses, such as DNA viruses, use the host cell's DNA polymerase to replicate their genetic material, while others, such as RNA viruses, use their own RNA-dependent RNA polymerase or reverse transcriptase enzymes. Understanding the process of virus replication is important for developing antiviral therapies and vaccines.
"Cattle" is a term used in the agricultural and veterinary fields to refer to domesticated animals of the genus *Bos*, primarily *Bos taurus* (European cattle) and *Bos indicus* (Zebu). These animals are often raised for meat, milk, leather, and labor. They are also known as bovines or cows (for females), bulls (intact males), and steers/bullocks (castrated males). However, in a strict medical definition, "cattle" does not apply to humans or other animals.
Bacteriophage T4, also known as T4 phage, is a type of virus that infects and replicates within the bacterium Escherichia coli (E. coli). It is one of the most well-studied bacteriophages and has been used as a model organism in molecular biology research for many decades.
T4 phage has a complex structure, with an icosahedral head that contains its genetic material (DNA) and a tail that attaches to the host cell and injects the DNA inside. The T4 phage genome is around 169 kilobases in length and encodes approximately 289 proteins.
Once inside the host cell, the T4 phage DNA takes over the bacterial machinery to produce new viral particles. The host cell eventually lyses (bursts), releasing hundreds of new phages into the environment. T4 phage is a lytic phage, meaning that it only replicates through the lytic cycle and does not integrate its genome into the host's chromosome.
T4 phage has been used in various applications, including bacterial typing, phage therapy, and genetic engineering. Its study has contributed significantly to our understanding of molecular biology, genetics, and virology.
The thymus gland is an essential organ of the immune system, located in the upper chest, behind the sternum and surrounding the heart. It's primarily active until puberty and begins to shrink in size and activity thereafter. The main function of the thymus gland is the production and maturation of T-lymphocytes (T-cells), which are crucial for cell-mediated immunity, helping to protect the body from infection and cancer.
The thymus gland provides a protected environment where immune cells called pre-T cells develop into mature T cells. During this process, they learn to recognize and respond appropriately to foreign substances while remaining tolerant to self-tissues, which is crucial for preventing autoimmune diseases.
Additionally, the thymus gland produces hormones like thymosin that regulate immune cell activities and contribute to the overall immune response.
Nucleotidyltransferases are a class of enzymes that catalyze the transfer of nucleotides to an acceptor molecule, such as RNA or DNA. These enzymes play crucial roles in various biological processes, including DNA replication, repair, and recombination, as well as RNA synthesis and modification.
The reaction catalyzed by nucleotidyltransferases typically involves the donation of a nucleoside triphosphate (NTP) to an acceptor molecule, resulting in the formation of a phosphodiester bond between the nucleotides. The reaction can be represented as follows:
NTP + acceptor → NMP + pyrophosphate
where NTP is the nucleoside triphosphate donor and NMP is the nucleoside monophosphate product.
There are several subclasses of nucleotidyltransferases, including polymerases, ligases, and terminases. These enzymes have distinct functions and substrate specificities, but all share the ability to transfer nucleotides to an acceptor molecule.
Examples of nucleotidyltransferases include DNA polymerase, RNA polymerase, reverse transcriptase, telomerase, and ligase. These enzymes are essential for maintaining genome stability and function, and their dysregulation has been implicated in various diseases, including cancer and neurodegenerative disorders.
Genetic models are theoretical frameworks used in genetics to describe and explain the inheritance patterns and genetic architecture of traits, diseases, or phenomena. These models are based on mathematical equations and statistical methods that incorporate information about gene frequencies, modes of inheritance, and the effects of environmental factors. They can be used to predict the probability of certain genetic outcomes, to understand the genetic basis of complex traits, and to inform medical management and treatment decisions.
There are several types of genetic models, including:
1. Mendelian models: These models describe the inheritance patterns of simple genetic traits that follow Mendel's laws of segregation and independent assortment. Examples include autosomal dominant, autosomal recessive, and X-linked inheritance.
2. Complex trait models: These models describe the inheritance patterns of complex traits that are influenced by multiple genes and environmental factors. Examples include heart disease, diabetes, and cancer.
3. Population genetics models: These models describe the distribution and frequency of genetic variants within populations over time. They can be used to study evolutionary processes, such as natural selection and genetic drift.
4. Quantitative genetics models: These models describe the relationship between genetic variation and phenotypic variation in continuous traits, such as height or IQ. They can be used to estimate heritability and to identify quantitative trait loci (QTLs) that contribute to trait variation.
5. Statistical genetics models: These models use statistical methods to analyze genetic data and infer the presence of genetic associations or linkage. They can be used to identify genetic risk factors for diseases or traits.
Overall, genetic models are essential tools in genetics research and medical genetics, as they allow researchers to make predictions about genetic outcomes, test hypotheses about the genetic basis of traits and diseases, and develop strategies for prevention, diagnosis, and treatment.
In genetics, sequence alignment is the process of arranging two or more DNA, RNA, or protein sequences to identify regions of similarity or homology between them. This is often done using computational methods to compare the nucleotide or amino acid sequences and identify matching patterns, which can provide insight into evolutionary relationships, functional domains, or potential genetic disorders. The alignment process typically involves adjusting gaps and mismatches in the sequences to maximize the similarity between them, resulting in an aligned sequence that can be visually represented and analyzed.
Replication Protein C (RPC or RFC) is not a single protein but a complex of five different proteins, which are essential for the process of DNA replication in eukaryotic cells. The individual subunits of the RPC complex are designated as RFC1, RFC2, RFC3, RFC4, and RFC5.
The primary function of the RPC complex is to load the clamp protein, proliferating cell nuclear antigen (PCNA), onto DNA at the primer-template junction during DNA replication. PCNA acts as a sliding clamp that encircles the DNA duplex and tethers the DNA polymerase to the template, thereby increasing its processivity.
RPC also plays a role in various other cellular processes, including nucleotide excision repair, DNA damage bypass, and checkpoint control during DNA replication. Defects in RPC have been linked to several human genetic disorders, such as cerebro-oculo-facio-skeletal syndrome (COFS) and xeroderma pigmentosum complementation group E (XP-E).
Ribonucleotides are organic compounds that consist of a ribose sugar, a phosphate group, and a nitrogenous base. They are the building blocks of RNA (ribonucleic acid), one of the essential molecules in all living organisms. The nitrogenous bases found in ribonucleotides include adenine, uracil, guanine, and cytosine. These molecules play crucial roles in various biological processes, such as protein synthesis, gene expression, and cellular energy production. Ribonucleotides can also be involved in cell signaling pathways and serve as important cofactors for enzymatic reactions.
Pyrimidine dimers are a type of DNA lesion that form when two adjacent pyrimidine bases on the same strand of DNA become covalently linked, usually as a result of exposure to ultraviolet (UV) light. The most common type of pyrimidine dimer is the cyclobutane pyrimidine dimer (CPD), which forms when two thymine bases are linked together in a cyclobutane ring structure.
Pyrimidine dimers can distort the DNA helix and interfere with normal replication and transcription processes, leading to mutations and potentially cancer. The formation of pyrimidine dimers is a major mechanism by which UV radiation causes skin damage and increases the risk of skin cancer.
The body has several mechanisms for repairing pyrimidine dimers, including nucleotide excision repair (NER) and base excision repair (BER). However, if these repair mechanisms are impaired or overwhelmed, pyrimidine dimers can persist and contribute to the development of cancer.
Protein conformation refers to the specific three-dimensional shape that a protein molecule assumes due to the spatial arrangement of its constituent amino acid residues and their associated chemical groups. This complex structure is determined by several factors, including covalent bonds (disulfide bridges), hydrogen bonds, van der Waals forces, and ionic bonds, which help stabilize the protein's unique conformation.
Protein conformations can be broadly classified into two categories: primary, secondary, tertiary, and quaternary structures. The primary structure represents the linear sequence of amino acids in a polypeptide chain. The secondary structure arises from local interactions between adjacent amino acid residues, leading to the formation of recurring motifs such as α-helices and β-sheets. Tertiary structure refers to the overall three-dimensional folding pattern of a single polypeptide chain, while quaternary structure describes the spatial arrangement of multiple folded polypeptide chains (subunits) that interact to form a functional protein complex.
Understanding protein conformation is crucial for elucidating protein function, as the specific three-dimensional shape of a protein directly influences its ability to interact with other molecules, such as ligands, nucleic acids, or other proteins. Any alterations in protein conformation due to genetic mutations, environmental factors, or chemical modifications can lead to loss of function, misfolding, aggregation, and disease states like neurodegenerative disorders and cancer.
Nucleic acid hybridization is a process in molecular biology where two single-stranded nucleic acids (DNA, RNA) with complementary sequences pair together to form a double-stranded molecule through hydrogen bonding. The strands can be from the same type of nucleic acid or different types (i.e., DNA-RNA or DNA-cDNA). This process is commonly used in various laboratory techniques, such as Southern blotting, Northern blotting, polymerase chain reaction (PCR), and microarray analysis, to detect, isolate, and analyze specific nucleic acid sequences. The hybridization temperature and conditions are critical to ensure the specificity of the interaction between the two strands.
"Sulfolobus solfataricus" is not a medical term, but rather a scientific name used in the field of microbiology. It refers to a species of archaea (single-celled microorganisms) that is thermoacidophilic, meaning it thrives in extremely high temperature and acidic environments. This organism is commonly found in volcanic hot springs and solfataras, which are areas with high sulfur content and acidic pH levels.
While not directly related to medical terminology, the study of extremophiles like "Sulfolobus solfataricus" can provide insights into the limits of life and the potential for the existence of microbial life in extreme environments on Earth and potentially on other planets.
"Thermus" is not a medical term, but rather a genus of bacteria that are capable of growing in extreme temperatures. These bacteria are named after the Greek word "therme," which means heat. They are commonly found in hot springs and deep-sea hydrothermal vents, where the temperature can reach up to 70°C (158°F).
Some species of Thermus have been found to produce enzymes that remain active at high temperatures, making them useful in various industrial applications such as molecular biology and DNA amplification techniques like polymerase chain reaction (PCR). However, Thermus itself is not a medical term or concept.
Recombinant fusion proteins are artificially created biomolecules that combine the functional domains or properties of two or more different proteins into a single protein entity. They are generated through recombinant DNA technology, where the genes encoding the desired protein domains are linked together and expressed as a single, chimeric gene in a host organism, such as bacteria, yeast, or mammalian cells.
The resulting fusion protein retains the functional properties of its individual constituent proteins, allowing for novel applications in research, diagnostics, and therapeutics. For instance, recombinant fusion proteins can be designed to enhance protein stability, solubility, or immunogenicity, making them valuable tools for studying protein-protein interactions, developing targeted therapies, or generating vaccines against infectious diseases or cancer.
Examples of recombinant fusion proteins include:
1. Etaglunatide (ABT-523): A soluble Fc fusion protein that combines the heavy chain fragment crystallizable region (Fc) of an immunoglobulin with the extracellular domain of the human interleukin-6 receptor (IL-6R). This fusion protein functions as a decoy receptor, neutralizing IL-6 and its downstream signaling pathways in rheumatoid arthritis.
2. Etanercept (Enbrel): A soluble TNF receptor p75 Fc fusion protein that binds to tumor necrosis factor-alpha (TNF-α) and inhibits its proinflammatory activity, making it a valuable therapeutic option for treating autoimmune diseases like rheumatoid arthritis, ankylosing spondylitis, and psoriasis.
3. Abatacept (Orencia): A fusion protein consisting of the extracellular domain of cytotoxic T-lymphocyte antigen 4 (CTLA-4) linked to the Fc region of an immunoglobulin, which downregulates T-cell activation and proliferation in autoimmune diseases like rheumatoid arthritis.
4. Belimumab (Benlysta): A monoclonal antibody that targets B-lymphocyte stimulator (BLyS) protein, preventing its interaction with the B-cell surface receptor and inhibiting B-cell activation in systemic lupus erythematosus (SLE).
5. Romiplostim (Nplate): A fusion protein consisting of a thrombopoietin receptor agonist peptide linked to an immunoglobulin Fc region, which stimulates platelet production in patients with chronic immune thrombocytopenia (ITP).
6. Darbepoetin alfa (Aranesp): A hyperglycosylated erythropoiesis-stimulating protein that functions as a longer-acting form of recombinant human erythropoietin, used to treat anemia in patients with chronic kidney disease or cancer.
7. Palivizumab (Synagis): A monoclonal antibody directed against the F protein of respiratory syncytial virus (RSV), which prevents RSV infection and is administered prophylactically to high-risk infants during the RSV season.
8. Ranibizumab (Lucentis): A recombinant humanized monoclonal antibody fragment that binds and inhibits vascular endothelial growth factor A (VEGF-A), used in the treatment of age-related macular degeneration, diabetic retinopathy, and other ocular disorders.
9. Cetuximab (Erbitux): A chimeric monoclonal antibody that binds to epidermal growth factor receptor (EGFR), used in the treatment of colorectal cancer and head and neck squamous cell carcinoma.
10. Adalimumab (Humira): A fully humanized monoclonal antibody that targets tumor necrosis factor-alpha (TNF-α), used in the treatment of various inflammatory diseases, including rheumatoid arthritis, psoriasis, and Crohn's disease.
11. Bevacizumab (Avastin): A recombinant humanized monoclonal antibody that binds to VEGF-A, used in the treatment of various cancers, including colorectal, lung, breast, and kidney cancer.
12. Trastuzumab (Herceptin): A humanized monoclonal antibody that targets HER2/neu receptor, used in the treatment of breast cancer.
13. Rituximab (Rituxan): A chimeric monoclonal antibody that binds to CD20 antigen on B cells, used in the treatment of non-Hodgkin's lymphoma and rheumatoid arthritis.
14. Palivizumab (Synagis): A humanized monoclonal antibody that binds to the F protein of respiratory syncytial virus, used in the prevention of respiratory syncytial virus infection in high-risk infants.
15. Infliximab (Remicade): A chimeric monoclonal antibody that targets TNF-α, used in the treatment of various inflammatory diseases, including Crohn's disease, ulcerative colitis, rheumatoid arthritis, and ankylosing spondylitis.
16. Natalizumab (Tysabri): A humanized monoclonal antibody that binds to α4β1 integrin, used in the treatment of multiple sclerosis and Crohn's disease.
17. Adalimumab (Humira): A fully human monoclonal antibody that targets TNF-α, used in the treatment of various inflammatory diseases, including rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, Crohn's disease, and ulcerative colitis.
18. Golimumab (Simponi): A fully human monoclonal antibody that targets TNF-α, used in the treatment of rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, and ulcerative colitis.
19. Certolizumab pegol (Cimzia): A PEGylated Fab' fragment of a humanized monoclonal antibody that targets TNF-α, used in the treatment of rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, and Crohn's disease.
20. Ustekinumab (Stelara): A fully human monoclonal antibody that targets IL-12 and IL-23, used in the treatment of psoriasis, psoriatic arthritis, and Crohn's disease.
21. Secukinumab (Cosentyx): A fully human monoclonal antibody that targets IL-17A, used in the treatment of psoriasis, psoriatic arthritis, and ankylosing spondylitis.
22. Ixekizumab (Taltz): A fully human monoclonal antibody that targets IL-17A, used in the treatment of psoriasis and psoriatic arthritis.
23. Brodalumab (Siliq): A fully human monoclonal antibody that targets IL-17 receptor A, used in the treatment of psoriasis.
24. Sarilumab (Kevzara): A fully human monoclonal antibody that targets the IL-6 receptor, used in the treatment of rheumatoid arthritis.
25. Tocilizumab (Actemra): A humanized monoclonal antibody that targets the IL-6 receptor, used in the treatment of rheumatoid arthritis, systemic juvenile idiopathic arthritis, polyarticular juvenile idiopathic arthritis, giant cell arteritis, and chimeric antigen receptor T-cell-induced cytokine release syndrome.
26. Siltuximab (Sylvant): A chimeric monoclonal antibody that targets IL-6, used in the treatment of multicentric Castleman disease.
27. Satralizumab (Enspryng): A humanized monoclonal antibody that targets IL-6 receptor alpha, used in the treatment of neuromyelitis optica spectrum disorder.
28. Sirukumab (Plivensia): A human monoclonal antibody that targets IL-6, used in the treatment
Reverse Transcriptase Polymerase Chain Reaction (RT-PCR) is a laboratory technique used in molecular biology to amplify and detect specific DNA sequences. This technique is particularly useful for the detection and quantification of RNA viruses, as well as for the analysis of gene expression.
The process involves two main steps: reverse transcription and polymerase chain reaction (PCR). In the first step, reverse transcriptase enzyme is used to convert RNA into complementary DNA (cDNA) by reading the template provided by the RNA molecule. This cDNA then serves as a template for the PCR amplification step.
In the second step, the PCR reaction uses two primers that flank the target DNA sequence and a thermostable polymerase enzyme to repeatedly copy the targeted cDNA sequence. The reaction mixture is heated and cooled in cycles, allowing the primers to anneal to the template, and the polymerase to extend the new strand. This results in exponential amplification of the target DNA sequence, making it possible to detect even small amounts of RNA or cDNA.
RT-PCR is a sensitive and specific technique that has many applications in medical research and diagnostics, including the detection of viruses such as HIV, hepatitis C virus, and SARS-CoV-2 (the virus that causes COVID-19). It can also be used to study gene expression, identify genetic mutations, and diagnose genetic disorders.
Deoxyribonucleases (DNases) are a group of enzymes that cleave, or cut, the phosphodiester bonds in the backbone of deoxyribonucleic acid (DNA) molecules. DNases are classified based on their mechanism of action into two main categories: double-stranded DNases and single-stranded DNases.
Double-stranded DNases cleave both strands of the DNA duplex, while single-stranded DNases cleave only one strand. These enzymes play important roles in various biological processes, such as DNA replication, repair, recombination, and degradation. They are also used in research and clinical settings for applications such as DNA fragmentation analysis, DNA sequencing, and treatment of cystic fibrosis.
It's worth noting that there are many different types of DNases with varying specificities and activities, and the medical definition may vary depending on the context.
Avian leukosis virus (ALV) is a type of retrovirus that primarily affects chickens and other birds. It is responsible for a group of diseases known as avian leukosis, which includes various types of tumors and immunosuppressive conditions. The virus is transmitted horizontally through the shedder's dander, feathers, and vertical transmission through infected eggs.
There are several subgroups of ALV (A, B, C, D, E, and J), each with different host ranges and pathogenicity. Some strains can cause rapid death in young chickens, while others may take years to develop clinical signs. The most common form of the disease is neoplastic, characterized by the development of various types of tumors such as lymphomas, myelomas, and sarcomas.
Avian leukosis virus infection can have significant economic impacts on the poultry industry due to decreased growth rates, increased mortality, and condemnation of infected birds at processing. Control measures include eradication programs, biosecurity practices, vaccination, and breeding for genetic resistance.
Dideoxynucleotides are analogs of nucleotides, which are the building blocks of DNA and RNA. In a nucleotide, there is a sugar molecule (deoxyribose in DNA and ribose in RNA) attached to a phosphate group and one of four nitrogenous bases (adenine, guanine, cytosine, or thymine in DNA; adenine, guanine, cytosine, or uracil in RNA).
In a dideoxynucleotide, there are two fewer oxygen molecules on the sugar component. Specifically, instead of having a hydroxyl group (-OH) at both the 2' and 3' carbons of the sugar, a dideoxynucleotide has a hydrogen atom (-H) at the 3' carbon and a hydroxyl or another group at the 2' carbon.
Dideoxynucleotides are used in scientific research and medical diagnostics, most notably in the Sanger method of DNA sequencing. In this process, DNA polymerase adds nucleotides to a single-stranded DNA template during replication. When a dideoxynucleotide is incorporated into the growing DNA chain, it acts as a terminator because there is no 3' hydroxyl group for the next nucleotide to be added. By running multiple reactions with different dideoxynucleotides and comparing the lengths of the resulting DNA fragments, researchers can determine the sequence of the template DNA.
Dideoxynucleotides are also used as antiretroviral drugs in the treatment of HIV infection. They inhibit the reverse transcriptase enzyme that HIV uses to convert its RNA genome into DNA, thus preventing the virus from replicating. Examples of dideoxynucleoside analog reverse transcriptase inhibitors (ddNRTIs) include zidovudine (AZT), didanosine (ddI), stavudine (d4T), and lamivudine (3TC).
Viral genes refer to the genetic material present in viruses that contains the information necessary for their replication and the production of viral proteins. In DNA viruses, the genetic material is composed of double-stranded or single-stranded DNA, while in RNA viruses, it is composed of single-stranded or double-stranded RNA.
Viral genes can be classified into three categories: early, late, and structural. Early genes encode proteins involved in the replication of the viral genome, modulation of host cell processes, and regulation of viral gene expression. Late genes encode structural proteins that make up the viral capsid or envelope. Some viruses also have structural genes that are expressed throughout their replication cycle.
Understanding the genetic makeup of viruses is crucial for developing antiviral therapies and vaccines. By targeting specific viral genes, researchers can develop drugs that inhibit viral replication and reduce the severity of viral infections. Additionally, knowledge of viral gene sequences can inform the development of vaccines that stimulate an immune response to specific viral proteins.
Magnesium is an essential mineral that plays a crucial role in various biological processes in the human body. It is the fourth most abundant cation in the body and is involved in over 300 enzymatic reactions, including protein synthesis, muscle and nerve function, blood glucose control, and blood pressure regulation. Magnesium also contributes to the structural development of bones and teeth.
In medical terms, magnesium deficiency can lead to several health issues, such as muscle cramps, weakness, heart arrhythmias, and seizures. On the other hand, excessive magnesium levels can cause symptoms like diarrhea, nausea, and muscle weakness. Magnesium supplements or magnesium-rich foods are often recommended to maintain optimal magnesium levels in the body.
Some common dietary sources of magnesium include leafy green vegetables, nuts, seeds, legumes, whole grains, and dairy products. Magnesium is also available in various forms as a dietary supplement, including magnesium oxide, magnesium citrate, magnesium chloride, and magnesium glycinate.
'Gene expression regulation' refers to the processes that control whether, when, and where a particular gene is expressed, meaning the production of a specific protein or functional RNA encoded by that gene. This complex mechanism can be influenced by various factors such as transcription factors, chromatin remodeling, DNA methylation, non-coding RNAs, and post-transcriptional modifications, among others. Proper regulation of gene expression is crucial for normal cellular function, development, and maintaining homeostasis in living organisms. Dysregulation of gene expression can lead to various diseases, including cancer and genetic disorders.
Catalysis is the process of increasing the rate of a chemical reaction by adding a substance known as a catalyst, which remains unchanged at the end of the reaction. A catalyst lowers the activation energy required for the reaction to occur, thereby allowing the reaction to proceed more quickly and efficiently. This can be particularly important in biological systems, where enzymes act as catalysts to speed up metabolic reactions that are essential for life.
A Structure-Activity Relationship (SAR) in the context of medicinal chemistry and pharmacology refers to the relationship between the chemical structure of a drug or molecule and its biological activity or effect on a target protein, cell, or organism. SAR studies aim to identify patterns and correlations between structural features of a compound and its ability to interact with a specific biological target, leading to a desired therapeutic response or undesired side effects.
By analyzing the SAR, researchers can optimize the chemical structure of lead compounds to enhance their potency, selectivity, safety, and pharmacokinetic properties, ultimately guiding the design and development of novel drugs with improved efficacy and reduced toxicity.
Site-directed mutagenesis is a molecular biology technique used to introduce specific and targeted changes to a specific DNA sequence. This process involves creating a new variant of a gene or a specific region of interest within a DNA molecule by introducing a planned, deliberate change, or mutation, at a predetermined site within the DNA sequence.
The methodology typically involves the use of molecular tools such as PCR (polymerase chain reaction), restriction enzymes, and/or ligases to introduce the desired mutation(s) into a plasmid or other vector containing the target DNA sequence. The resulting modified DNA molecule can then be used to transform host cells, allowing for the production of large quantities of the mutated gene or protein for further study.
Site-directed mutagenesis is a valuable tool in basic research, drug discovery, and biotechnology applications where specific changes to a DNA sequence are required to understand gene function, investigate protein structure/function relationships, or engineer novel biological properties into existing genes or proteins.
A Transcription Initiation Site (TIS) is a specific location within the DNA sequence where the process of transcription is initiated. In other words, it is the starting point where the RNA polymerase enzyme binds to the DNA template and begins synthesizing an RNA molecule. The TIS is typically located just upstream of the coding region of a gene and is often marked by specific sequences or structures that help regulate transcription, such as promoters and enhancers.
During the initiation of transcription, the RNA polymerase recognizes and binds to the promoter region, which lies adjacent to the TIS. The promoter contains cis-acting elements, including the TATA box and the initiator (Inr) element, that are recognized by transcription factors and other regulatory proteins. These proteins help position the RNA polymerase at the correct location on the DNA template and facilitate the initiation of transcription.
Once the RNA polymerase is properly positioned, it begins to unwind the double-stranded DNA at the TIS, creating a transcription bubble where the single-stranded DNA template can be accessed. The RNA polymerase then adds nucleotides one by one to the growing RNA chain, synthesizing an mRNA molecule that will ultimately be translated into a protein or, in some cases, serve as a non-coding RNA with regulatory functions.
In summary, the Transcription Initiation Site (TIS) is a crucial component of gene expression, marking the location where transcription begins and playing a key role in regulating this essential biological process.
Arabinonucleotides are nucleotides that contain arabinose sugar instead of the more common ribose or deoxyribose. Nucleotides are organic molecules consisting of a nitrogenous base, a pentose sugar, and at least one phosphate group. They serve as the monomeric units of nucleic acids, which are essential biopolymers involved in genetic storage, transmission, and expression.
Arabinonucleotides have arabinose, a five-carbon sugar with a slightly different structure than ribose or deoxyribose, as their pentose component. Arabinose is a monosaccharide that can be found in various plants and microorganisms but is not typically a part of nucleic acids in higher organisms.
Arabinonucleotides may have potential applications in biochemistry, molecular biology, and medicine; however, their use and significance are not as widespread or well-studied as those of the more common ribonucleotides and deoxyribonucleotides.
Affinity chromatography is a type of chromatography technique used in biochemistry and molecular biology to separate and purify proteins based on their biological characteristics, such as their ability to bind specifically to certain ligands or molecules. This method utilizes a stationary phase that is coated with a specific ligand (e.g., an antibody, antigen, receptor, or enzyme) that selectively interacts with the target protein in a sample.
The process typically involves the following steps:
1. Preparation of the affinity chromatography column: The stationary phase, usually a solid matrix such as agarose beads or magnetic beads, is modified by covalently attaching the ligand to its surface.
2. Application of the sample: The protein mixture is applied to the top of the affinity chromatography column, allowing it to flow through the stationary phase under gravity or pressure.
3. Binding and washing: As the sample flows through the column, the target protein selectively binds to the ligand on the stationary phase, while other proteins and impurities pass through. The column is then washed with a suitable buffer to remove any unbound proteins and contaminants.
4. Elution of the bound protein: The target protein can be eluted from the column using various methods, such as changing the pH, ionic strength, or polarity of the buffer, or by introducing a competitive ligand that displaces the bound protein.
5. Collection and analysis: The eluted protein fraction is collected and analyzed for purity and identity, often through techniques like SDS-PAGE or mass spectrometry.
Affinity chromatography is a powerful tool in biochemistry and molecular biology due to its high selectivity and specificity, enabling the efficient isolation of target proteins from complex mixtures. However, it requires careful consideration of the binding affinity between the ligand and the protein, as well as optimization of the elution conditions to minimize potential damage or denaturation of the purified protein.
RNA-dependent RNA polymerase, also known as RNA replicase, is an enzyme that catalyzes the production of RNA from an RNA template. It plays a crucial role in the replication of certain viruses, such as positive-strand RNA viruses and retroviruses, which use RNA as their genetic material. The enzyme uses the existing RNA strand as a template to create a new complementary RNA strand, effectively replicating the viral genome. This process is essential for the propagation of these viruses within host cells and is a target for antiviral therapies.
A gene is a specific sequence of nucleotides in DNA that carries genetic information. Genes are the fundamental units of heredity and are responsible for the development and function of all living organisms. They code for proteins or RNA molecules, which carry out various functions within cells and are essential for the structure, function, and regulation of the body's tissues and organs.
Each gene has a specific location on a chromosome, and each person inherits two copies of every gene, one from each parent. Variations in the sequence of nucleotides in a gene can lead to differences in traits between individuals, including physical characteristics, susceptibility to disease, and responses to environmental factors.
Medical genetics is the study of genes and their role in health and disease. It involves understanding how genes contribute to the development and progression of various medical conditions, as well as identifying genetic risk factors and developing strategies for prevention, diagnosis, and treatment.
Bacteriophage phi X 174, also known as Phi X 174 or ΦX174, is a bacterial virus that infects the bacterium Escherichia coli (E. coli). It is a small, icosahedral-shaped virus with a diameter of about 30 nanometers and belongs to the family Podoviridae in the order Caudovirales.
Phi X 174 has a single-stranded DNA genome that is circular and consists of 5,386 base pairs. It is one of the smallest viruses known to infect bacteria, and its simplicity has made it a model system for studying bacteriophage biology and molecular biology.
Phi X 174 was first discovered in 1962 by American scientist S.E. Luria and his colleagues. It is able to infect E. coli cells that lack the F-pilus, a hair-like structure on the surface of the bacterial cell. Once inside the host cell, phi X 174 uses the host's machinery to replicate its DNA and produce new viral particles, which are then released from the host cell by lysis, causing the cell to burst open and release the new viruses.
Phi X 174 has been extensively studied for its unique biological properties, including its small size, simple genome, and ability to infect E. coli cells. It has also been used as a tool in molecular biology research, such as in the development of DNA sequencing techniques and the study of gene regulation.
Cyclin-dependent kinases (CDKs) are a family of serine/threonine protein kinases that play crucial roles in regulating the cell cycle, transcription, and other cellular processes. They are activated by binding to cyclin proteins, which accumulate and degrade at specific stages of the cell cycle. The activation of CDKs leads to phosphorylation of various downstream target proteins, resulting in the promotion or inhibition of different cell cycle events. Dysregulation of CDKs has been implicated in several human diseases, including cancer, and they are considered important targets for drug development.
A nucleosome is a basic unit of DNA packaging in eukaryotic cells, consisting of a segment of DNA coiled around an octamer of histone proteins. This structure forms a repeating pattern along the length of the DNA molecule, with each nucleosome resembling a "bead on a string" when viewed under an electron microscope. The histone octamer is composed of two each of the histones H2A, H2B, H3, and H4, and the DNA wraps around it approximately 1.65 times. Nucleosomes play a crucial role in compacting the large DNA molecule within the nucleus and regulating access to the DNA for processes such as transcription, replication, and repair.
'Escherichia coli (E. coli) proteins' refer to the various types of proteins that are produced and expressed by the bacterium Escherichia coli. These proteins play a critical role in the growth, development, and survival of the organism. They are involved in various cellular processes such as metabolism, DNA replication, transcription, translation, repair, and regulation.
E. coli is a gram-negative, facultative anaerobe that is commonly found in the intestines of warm-blooded organisms. It is widely used as a model organism in scientific research due to its well-studied genetics, rapid growth, and ability to be easily manipulated in the laboratory. As a result, many E. coli proteins have been identified, characterized, and studied in great detail.
Some examples of E. coli proteins include enzymes involved in carbohydrate metabolism such as lactase, sucrase, and maltose; proteins involved in DNA replication such as the polymerases, single-stranded binding proteins, and helicases; proteins involved in transcription such as RNA polymerase and sigma factors; proteins involved in translation such as ribosomal proteins, tRNAs, and aminoacyl-tRNA synthetases; and regulatory proteins such as global regulators, two-component systems, and transcription factors.
Understanding the structure, function, and regulation of E. coli proteins is essential for understanding the basic biology of this important organism, as well as for developing new strategies for combating bacterial infections and improving industrial processes involving bacteria.
DNA adducts are chemical modifications or alterations that occur when DNA molecules become attached to or bound with certain harmful substances, such as toxic chemicals or carcinogens. These attachments can disrupt the normal structure and function of the DNA, potentially leading to mutations, genetic damage, and an increased risk of cancer and other diseases.
DNA adducts are formed when a reactive molecule from a chemical agent binds covalently to a base in the DNA molecule. This process can occur either spontaneously or as a result of exposure to environmental toxins, such as those found in tobacco smoke, certain industrial chemicals, and some medications.
The formation of DNA adducts is often used as a biomarker for exposure to harmful substances, as well as an indicator of potential health risks associated with that exposure. Researchers can measure the levels of specific DNA adducts in biological samples, such as blood or urine, to assess the extent and duration of exposure to certain chemicals or toxins.
It's important to note that not all DNA adducts are necessarily harmful, and some may even play a role in normal cellular processes. However, high levels of certain DNA adducts have been linked to an increased risk of cancer and other diseases, making them a focus of ongoing research and investigation.
Alpha-Amanitin is a bicyclic octapeptide and the main toxic component found in several species of mushrooms, including the deadly "death cap" (Amanita phalloides) and "destroying angel" (Amanita virosa). It is a potent inhibitor of RNA polymerase II, which is an enzyme responsible for transcribing DNA into messenger RNA (mRNA) in eukaryotic cells. This specific mode of action disrupts protein synthesis and leads to severe cellular damage, primarily affecting the liver, kidneys, and central nervous system.
Clinical symptoms of alpha-amanitin poisoning include gastrointestinal distress (nausea, vomiting, diarrhea) within a few hours after ingestion, followed by a symptom-free period of up to 24 hours. After this latent phase, symptoms reappear and can progress to liver and kidney failure, coma, and even death in severe cases. There is no specific antidote for alpha-amanitin poisoning, and treatment primarily focuses on supportive care, such as fluid replacement, electrolyte management, and organ function support.
A frameshift mutation is a type of genetic mutation that occurs when the addition or deletion of nucleotides in a DNA sequence is not divisible by three. Since DNA is read in groups of three nucleotides (codons), which each specify an amino acid, this can shift the "reading frame," leading to the insertion or deletion of one or more amino acids in the resulting protein. This can cause a protein to be significantly different from the normal protein, often resulting in a nonfunctional protein and potentially causing disease. Frameshift mutations are typically caused by insertions or deletions of nucleotides, but they can also result from more complex genetic rearrangements.
Small nuclear RNA (snRNA) are a type of RNA molecules that are typically around 100-300 nucleotides in length. They are found within the nucleus of eukaryotic cells and are components of small nuclear ribonucleoproteins (snRNPs), which play important roles in various aspects of RNA processing, including splicing of pre-messenger RNA (pre-mRNA) and regulation of transcription.
There are several classes of snRNAs, each with a distinct function. The most well-studied class is the spliceosomal snRNAs, which include U1, U2, U4, U5, and U6 snRNAs. These snRNAs form complexes with proteins to form small nuclear ribonucleoprotein particles (snRNPs) that recognize specific sequences in pre-mRNA and catalyze the removal of introns during splicing.
Other classes of snRNAs include signal recognition particle (SRP) RNA, which is involved in targeting proteins to the endoplasmic reticulum, and Ro60 RNA, which is associated with autoimmune diseases such as systemic lupus erythematosus.
Overall, small nuclear RNAs are essential components of the cellular machinery that regulates gene expression and protein synthesis in eukaryotic cells.
Transcription initiation, genetic is the process by which the transcription of a gene is initiated. It is the first step in gene expression, where the information encoded in DNA is copied into RNA. This process involves the unwinding of the double-stranded DNA at the promoter region of the gene, followed by the recruitment of the RNA polymerase enzyme and other transcription factors to the promoter site. Once assembled, the RNA polymerase begins to synthesize an RNA copy of the gene's sequence, starting from the transcription start site (TSS). This RNA molecule, known as messenger RNA (mRNA), will then be translated into a protein or used to produce non-coding RNAs with various functions. Transcription initiation is tightly regulated and can be influenced by various factors such as promoter strength, transcription factor availability, and chromatin structure.
DNA Sequence Analysis is the systematic determination of the order of nucleotides in a DNA molecule. It is a critical component of modern molecular biology, genetics, and genetic engineering. The process involves determining the exact order of the four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - in a DNA molecule or fragment. This information is used in various applications such as identifying gene mutations, studying evolutionary relationships, developing molecular markers for breeding, and diagnosing genetic diseases.
The process of DNA Sequence Analysis typically involves several steps, including DNA extraction, PCR amplification (if necessary), purification, sequencing reaction, and electrophoresis. The resulting data is then analyzed using specialized software to determine the exact sequence of nucleotides.
In recent years, high-throughput DNA sequencing technologies have revolutionized the field of genomics, enabling the rapid and cost-effective sequencing of entire genomes. This has led to an explosion of genomic data and new insights into the genetic basis of many diseases and traits.
A sequence deletion in a genetic context refers to the removal or absence of one or more nucleotides (the building blocks of DNA or RNA) from a specific region in a DNA or RNA molecule. This type of mutation can lead to the loss of genetic information, potentially resulting in changes in the function or expression of a gene. If the deletion involves a critical portion of the gene, it can cause diseases, depending on the role of that gene in the body. The size of the deleted sequence can vary, ranging from a single nucleotide to a large segment of DNA.
A conserved sequence in the context of molecular biology refers to a pattern of nucleotides (in DNA or RNA) or amino acids (in proteins) that has remained relatively unchanged over evolutionary time. These sequences are often functionally important and are highly conserved across different species, indicating strong selection pressure against changes in these regions.
In the case of protein-coding genes, the corresponding amino acid sequence is deduced from the DNA sequence through the genetic code. Conserved sequences in proteins may indicate structurally or functionally important regions, such as active sites or binding sites, that are critical for the protein's activity. Similarly, conserved non-coding sequences in DNA may represent regulatory elements that control gene expression.
Identifying conserved sequences can be useful for inferring evolutionary relationships between species and for predicting the function of unknown genes or proteins.
Ribonucleic acid (RNA) is a type of nucleic acid that plays a crucial role in the process of gene expression. There are several types of RNA molecules, including messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). These RNA molecules help to transcribe DNA into mRNA, which is then translated into proteins by the ribosomes.
Fungi are a group of eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. Like other eukaryotes, fungi contain DNA and RNA as part of their genetic material. The RNA in fungi is similar to the RNA found in other organisms, including humans, and plays a role in gene expression and protein synthesis.
A specific medical definition of "RNA, fungal" does not exist, as RNA is a fundamental component of all living organisms, including fungi. However, RNA can be used as a target for antifungal drugs, as certain enzymes involved in RNA synthesis and processing are unique to fungi and can be inhibited by these drugs. For example, the antifungal drug flucytosine is converted into a toxic metabolite that inhibits fungal RNA and DNA synthesis.
Simplexvirus is a genus of viruses in the family Herpesviridae, subfamily Alphaherpesvirinae. This genus contains two species: Human alphaherpesvirus 1 (also known as HSV-1 or herpes simplex virus type 1) and Human alphaherpesvirus 2 (also known as HSV-2 or herpes simplex virus type 2). These viruses are responsible for causing various medical conditions, most commonly oral and genital herpes. They are characterized by their ability to establish lifelong latency in the nervous system and reactivate periodically to cause recurrent symptoms.
Coliphages are viruses that infect and replicate within certain species of bacteria that belong to the coliform group, particularly Escherichia coli (E. coli). These viruses are commonly found in water and soil environments and are frequently used as indicators of fecal contamination in water quality testing. Coliphages are not harmful to humans or animals, but their presence in water can suggest the potential presence of pathogenic bacteria or other microorganisms that may pose a health risk. There are two main types of coliphages: F-specific RNA coliphages and somatic (or non-F specific) DNA coliphages.
A precipitin test is a type of immunodiagnostic test used to detect and measure the presence of specific antibodies or antigens in a patient's serum. The test is based on the principle of antigen-antibody interaction, where the addition of an antigen to a solution containing its corresponding antibody results in the formation of an insoluble immune complex known as a precipitin.
In this test, a small amount of the patient's serum is added to a solution containing a known antigen or antibody. If the patient has antibodies or antigens that correspond to the added reagent, they will bind and form a visible precipitate. The size and density of the precipitate can be used to quantify the amount of antibody or antigen present in the sample.
Precipitin tests are commonly used in the diagnosis of various infectious diseases, autoimmune disorders, and allergies. They can also be used in forensic science to identify biological samples. However, they have largely been replaced by more modern immunological techniques such as enzyme-linked immunosorbent assays (ELISAs) and radioimmunoassays (RIAs).
Transcription Factor TFIIA is not a specific transcription factor itself, but rather a general term that refers to one of the several protein complexes that make up the larger Preinitiation Complex (PIC) in eukaryotic transcription. The PIC is responsible for the accurate initiation of transcription by RNA polymerase II, which transcribes most protein-coding genes in eukaryotes.
TFIIA is a heterotrimeric complex composed of three subunits: TAF1 (also known as TCP14/TCP22), TAF2 (also known as TCP80), and TAF3 (also known as GTF2A1). It plays a crucial role in the early stages of transcription initiation by helping to stabilize the binding of RNA polymerase II to the promoter region of the gene, as well as facilitating the correct positioning of other general transcription factors.
In addition to its role in the PIC, TFIIA has also been shown to have a function in regulating chromatin structure and accessibility, which can impact gene expression. Overall, Transcription Factor TFIIA is an essential component of the eukaryotic transcription machinery that helps ensure accurate and efficient initiation of gene transcription.
Post-transcriptional RNA processing refers to the modifications and regulations that occur on RNA molecules after the transcription of DNA into RNA. This process includes several steps:
1. 5' capping: The addition of a cap structure, usually a methylated guanosine triphosphate (GTP), to the 5' end of the RNA molecule. This helps protect the RNA from degradation and plays a role in its transport, stability, and translation.
2. 3' polyadenylation: The addition of a string of adenosine residues (poly(A) tail) to the 3' end of the RNA molecule. This process is important for mRNA stability, export from the nucleus, and translation initiation.
3. Intron removal and exon ligation: Eukaryotic pre-messenger RNAs (pre-mRNAs) contain intronic sequences that do not code for proteins. These introns are removed by a process called splicing, where the flanking exons are joined together to form a continuous mRNA sequence. Alternative splicing can lead to different mature mRNAs from a single pre-mRNA, increasing transcriptomic and proteomic diversity.
4. RNA editing: Specific nucleotide changes in RNA molecules that alter the coding potential or regulatory functions of RNA. This process is catalyzed by enzymes like ADAR (Adenosine Deaminases Acting on RNA) and APOBEC (Apolipoprotein B mRNA Editing Catalytic Polypeptide-like).
5. Chemical modifications: Various chemical modifications can occur on RNA nucleotides, such as methylation, pseudouridination, and isomerization. These modifications can influence RNA stability, localization, and interaction with proteins or other RNAs.
6. Transport and localization: Mature mRNAs are transported from the nucleus to the cytoplasm for translation. In some cases, specific mRNAs are localized to particular cellular compartments to ensure local protein synthesis.
7. Degradation: RNA molecules have finite lifetimes and undergo degradation by various ribonucleases (RNases). The rate of degradation can be influenced by factors such as RNA structure, modifications, or interactions with proteins.
Foscarnet is an antiviral medication used to treat infections caused by viruses, particularly herpes simplex virus (HSV) and varicella-zoster virus (VZV). It is a pyrophosphate analog that inhibits viral DNA polymerase, preventing the replication of viral DNA.
Foscarnet is indicated for the treatment of severe HSV infections, such as mucocutaneous HSV in immunocompromised patients, and acyclovir-resistant HSV infections. It is also used to treat VZV infections, including shingles and varicella zoster virus (VZV) infection in immunocompromised patients.
Foscarnet is administered intravenously and its use requires careful monitoring of renal function and electrolyte levels due to the potential for nephrotoxicity and electrolyte imbalances. Common side effects include nausea, vomiting, diarrhea, and headache.
Thymine is a pyrimidine nucleobase that is one of the four nucleobases in the nucleic acid double helix of DNA (the other three being adenine, guanine, and cytosine). It is denoted by the letter T in DNA notation and pairs with adenine via two hydrogen bonds. Thymine is not typically found in RNA, where uracil takes its place pairing with adenine. The structure of thymine consists of a six-membered ring (pyrimidine) fused to a five-membered ring containing two nitrogen atoms and a ketone group.
Bacterial proteins are a type of protein that are produced by bacteria as part of their structural or functional components. These proteins can be involved in various cellular processes, such as metabolism, DNA replication, transcription, and translation. They can also play a role in bacterial pathogenesis, helping the bacteria to evade the host's immune system, acquire nutrients, and multiply within the host.
Bacterial proteins can be classified into different categories based on their function, such as:
1. Enzymes: Proteins that catalyze chemical reactions in the bacterial cell.
2. Structural proteins: Proteins that provide structural support and maintain the shape of the bacterial cell.
3. Signaling proteins: Proteins that help bacteria to communicate with each other and coordinate their behavior.
4. Transport proteins: Proteins that facilitate the movement of molecules across the bacterial cell membrane.
5. Toxins: Proteins that are produced by pathogenic bacteria to damage host cells and promote infection.
6. Surface proteins: Proteins that are located on the surface of the bacterial cell and interact with the environment or host cells.
Understanding the structure and function of bacterial proteins is important for developing new antibiotics, vaccines, and other therapeutic strategies to combat bacterial infections.
Ribonuclease H (RNase H) is an enzyme that specifically degrades the RNA portion of an RNA-DNA hybrid. It cleaves the phosphodiester bond between the ribose sugar and the phosphate group in the RNA strand, leaving the DNA strand intact. This enzyme plays a crucial role in several cellular processes, including DNA replication, repair, and transcription.
There are two main types of RNase H: type 1 and type 2. Type 1 RNase H is found in both prokaryotic and eukaryotic cells, while type 2 RNase H is primarily found in eukaryotes. The primary function of RNase H is to remove RNA primers that are synthesized during DNA replication. These RNA primers are replaced with DNA nucleotides by another enzyme called polymerase δ, leaving behind a gap in the DNA strand. RNase H then cleaves the RNA-DNA hybrid, allowing for the repair of the gap and the completion of DNA replication.
RNase H has also been implicated in the regulation of gene expression, as it can degrade RNA-DNA hybrids formed during transcription. This process, known as transcription-coupled RNA decay, helps to prevent the accumulation of aberrant RNA molecules and ensures proper gene expression.
In addition to its cellular functions, RNase H has been studied for its potential therapeutic applications. For example, inhibitors of RNase H have been shown to have antiviral activity against HIV-1, as they prevent the degradation of viral RNA during reverse transcription. On the other hand, activators of RNase H have been explored as a means to enhance the efficiency of RNA interference (RNAi) therapies by promoting the degradation of target RNA molecules.
I apologize for any confusion, but "Schizosaccharomyces" is not a medical term. It is a genus name in the field of microbiology and genetics, referring to a group of budding, tear-shaped yeasts that are widely used as model organisms in scientific research. The most well-known species within this genus is Schizosaccharomyces pombe, which has been extensively studied for its cell cycle regulation, DNA repair mechanisms, and other fundamental biological processes.
If you have any questions related to medical terminology or health-related topics, I would be happy to help.
Circular DNA is a type of DNA molecule that forms a closed loop, rather than the linear double helix structure commonly associated with DNA. This type of DNA is found in some viruses, plasmids (small extrachromosomal DNA molecules found in bacteria), and mitochondria and chloroplasts (organelles found in plant and animal cells).
Circular DNA is characterized by the absence of telomeres, which are the protective caps found on linear chromosomes. Instead, circular DNA has a specific sequence where the two ends join together, known as the origin of replication and the replication terminus. This structure allows for the DNA to be replicated efficiently and compactly within the cell.
Because of its circular nature, circular DNA is more resistant to degradation by enzymes that cut linear DNA, making it more stable in certain environments. Additionally, the ability to easily manipulate and clone circular DNA has made it a valuable tool in molecular biology and genetic engineering.
'Drosophila melanogaster' is the scientific name for a species of fruit fly that is commonly used as a model organism in various fields of biological research, including genetics, developmental biology, and evolutionary biology. Its small size, short generation time, large number of offspring, and ease of cultivation make it an ideal subject for laboratory studies. The fruit fly's genome has been fully sequenced, and many of its genes have counterparts in the human genome, which facilitates the understanding of genetic mechanisms and their role in human health and disease.
Here is a brief medical definition:
Drosophila melanogaster (droh-suh-fih-luh meh-lon-guh-ster): A species of fruit fly used extensively as a model organism in genetic, developmental, and evolutionary research. Its genome has been sequenced, revealing many genes with human counterparts, making it valuable for understanding genetic mechanisms and their role in human health and disease.
"Poly A" is an abbreviation for "poly(A) tail" or "polyadenylation." It refers to the addition of multiple adenine (A) nucleotides to the 3' end of eukaryotic mRNA molecules during the process of transcription. This poly(A) tail plays a crucial role in various aspects of mRNA metabolism, including stability, transport, and translation. The length of the poly(A) tail can vary from around 50 to 250 nucleotides depending on the cell type and developmental stage.
Cell extracts refer to the mixture of cellular components that result from disrupting or breaking open cells. The process of obtaining cell extracts is called cell lysis. Cell extracts can contain various types of molecules, such as proteins, nucleic acids (DNA and RNA), carbohydrates, lipids, and metabolites, depending on the methods used for cell disruption and extraction.
Cell extracts are widely used in biochemical and molecular biology research to study various cellular processes and pathways. For example, cell extracts can be used to measure enzyme activities, analyze protein-protein interactions, characterize gene expression patterns, and investigate metabolic pathways. In some cases, specific cellular components can be purified from the cell extracts for further analysis or application, such as isolating pure proteins or nucleic acids.
It is important to note that the composition of cell extracts may vary depending on the type of cells, the growth conditions, and the methods used for cell disruption and extraction. Therefore, it is essential to optimize the experimental conditions to obtain representative and meaningful results from cell extract studies.
Trans-activators are proteins that increase the transcriptional activity of a gene or a set of genes. They do this by binding to specific DNA sequences and interacting with the transcription machinery, thereby enhancing the recruitment and assembly of the complexes needed for transcription. In some cases, trans-activators can also modulate the chromatin structure to make the template more accessible to the transcription machinery.
In the context of HIV (Human Immunodeficiency Virus) infection, the term "trans-activator" is often used specifically to refer to the Tat protein. The Tat protein is a viral regulatory protein that plays a critical role in the replication of HIV by activating the transcription of the viral genome. It does this by binding to a specific RNA structure called the Trans-Activation Response Element (TAR) located at the 5' end of all nascent HIV transcripts, and recruiting cellular cofactors that enhance the processivity and efficiency of RNA polymerase II, leading to increased viral gene expression.
Ribonucleases (RNases) are a group of enzymes that catalyze the degradation of ribonucleic acid (RNA) molecules by hydrolyzing the phosphodiester bonds. These enzymes play crucial roles in various biological processes, such as RNA processing, turnover, and quality control. They can be classified into several types based on their specificities, mechanisms, and cellular localizations.
Some common classes of ribonucleases include:
1. Endoribonucleases: These enzymes cleave RNA internally, at specific sequences or structural motifs. Examples include RNase A, which targets single-stranded RNA; RNase III, which cuts double-stranded RNA at specific stem-loop structures; and RNase T1, which recognizes and cuts unpaired guanosine residues in RNA molecules.
2. Exoribonucleases: These enzymes remove nucleotides from the ends of RNA molecules. They can be further divided into 5'-3' exoribonucleases, which degrade RNA starting from the 5' end, and 3'-5' exoribonucleases, which start at the 3' end. Examples include Xrn1, a 5'-3' exoribonuclease involved in mRNA decay; and Dis3/RRP6, a 3'-5' exoribonuclease that participates in ribosomal RNA processing and degradation.
3. Specific ribonucleases: These enzymes target specific RNA molecules or regions with high precision. For example, RNase P is responsible for cleaving the 5' leader sequence of precursor tRNAs (pre-tRNAs) during their maturation; and RNase MRP is involved in the processing of ribosomal RNA and mitochondrial RNA molecules.
Dysregulation or mutations in ribonucleases have been implicated in various human diseases, such as neurological disorders, cancer, and viral infections. Therefore, understanding their functions and mechanisms is crucial for developing novel therapeutic strategies.
Transcriptional activation is the process by which a cell increases the rate of transcription of specific genes from DNA to RNA. This process is tightly regulated and plays a crucial role in various biological processes, including development, differentiation, and response to environmental stimuli.
Transcriptional activation occurs when transcription factors (proteins that bind to specific DNA sequences) interact with the promoter region of a gene and recruit co-activator proteins. These co-activators help to remodel the chromatin structure around the gene, making it more accessible for the transcription machinery to bind and initiate transcription.
Transcriptional activation can be regulated at multiple levels, including the availability and activity of transcription factors, the modification of histone proteins, and the recruitment of co-activators or co-repressors. Dysregulation of transcriptional activation has been implicated in various diseases, including cancer and genetic disorders.
Gene deletion is a type of mutation where a segment of DNA, containing one or more genes, is permanently lost or removed from a chromosome. This can occur due to various genetic mechanisms such as homologous recombination, non-homologous end joining, or other types of genomic rearrangements.
The deletion of a gene can have varying effects on the organism, depending on the function of the deleted gene and its importance for normal physiological processes. If the deleted gene is essential for survival, the deletion may result in embryonic lethality or developmental abnormalities. However, if the gene is non-essential or has redundant functions, the deletion may not have any noticeable effects on the organism's phenotype.
Gene deletions can also be used as a tool in genetic research to study the function of specific genes and their role in various biological processes. For example, researchers may use gene deletion techniques to create genetically modified animal models to investigate the impact of gene deletion on disease progression or development.
Deoxycytidine monophosphate (dCMP) is a nucleotide that is a building block of DNA. It consists of the sugar deoxyribose, the base cytosine, and one phosphate group. Nucleotides like dCMP are linked together through the phosphate groups to form long chains of DNA. In this way, dCMP plays an essential role in the structure and function of DNA, including the storage and transmission of genetic information.
Bacteriophage M13 is a type of bacterial virus that infects and replicates within the bacterium Escherichia coli (E. coli). It is a filamentous phage, meaning it has a long, thin, and flexible structure. The M13 phage specifically infects only the F pili of E. coli bacteria, which are hair-like appendages found on the surface of certain strains of E. coli.
Once inside the host cell, the M13 phage uses the bacterial machinery to produce new viral particles, or progeny phages, without killing the host cell. The phage genome is made up of a single-stranded circular DNA molecule that encodes for about 10 genes. These genes are involved in various functions such as replication, packaging, and assembly of the phage particles.
Bacteriophage M13 is widely used in molecular biology research due to its ability to efficiently incorporate foreign DNA sequences into its genome. This property has been exploited for a variety of applications, including DNA sequencing, gene cloning, and protein expression. The M13 phage can display foreign peptides or proteins on the surface of its coat protein, making it useful for screening antibodies or identifying ligands in phage display technology.
Chromatography is a technique used in analytical chemistry for the separation, identification, and quantification of the components of a mixture. It is based on the differential distribution of the components of a mixture between a stationary phase and a mobile phase. The stationary phase can be a solid or liquid, while the mobile phase is a gas, liquid, or supercritical fluid that moves through the stationary phase carrying the sample components.
The interaction between the sample components and the stationary and mobile phases determines how quickly each component will move through the system. Components that interact more strongly with the stationary phase will move more slowly than those that interact more strongly with the mobile phase. This difference in migration rates allows for the separation of the components, which can then be detected and quantified.
There are many different types of chromatography, including paper chromatography, thin-layer chromatography (TLC), gas chromatography (GC), liquid chromatography (LC), and high-performance liquid chromatography (HPLC). Each type has its own strengths and weaknesses, and is best suited for specific applications.
In summary, chromatography is a powerful analytical technique used to separate, identify, and quantify the components of a mixture based on their differential distribution between a stationary phase and a mobile phase.
X-ray crystallography is a technique used in structural biology to determine the three-dimensional arrangement of atoms in a crystal lattice. In this method, a beam of X-rays is directed at a crystal and diffracts, or spreads out, into a pattern of spots called reflections. The intensity and angle of each reflection are measured and used to create an electron density map, which reveals the position and type of atoms in the crystal. This information can be used to determine the molecular structure of a compound, including its shape, size, and chemical bonds. X-ray crystallography is a powerful tool for understanding the structure and function of biological macromolecules such as proteins and nucleic acids.
Nucleic acid synthesis inhibitors are a class of antimicrobial, antiviral, or antitumor agents that block the synthesis of nucleic acids (DNA or RNA) by interfering with enzymes involved in their replication. These drugs can target various stages of nucleic acid synthesis, including DNA transcription, replication, and repair, as well as RNA transcription and processing.
Examples of nucleic acid synthesis inhibitors include:
1. Antibiotics like quinolones (e.g., ciprofloxacin), rifamycins (e.g., rifampin), and trimethoprim, which target bacterial DNA gyrase, RNA polymerase, or dihydrofolate reductase, respectively.
2. Antiviral drugs like reverse transcriptase inhibitors (e.g., zidovudine, lamivudine) and integrase strand transfer inhibitors (e.g., raltegravir), which target HIV replication by interfering with viral enzymes required for DNA synthesis.
3. Antitumor drugs like antimetabolites (e.g., methotrexate, 5-fluorouracil) and topoisomerase inhibitors (e.g., etoposide, doxorubicin), which interfere with DNA replication and repair in cancer cells.
These drugs have been widely used for treating various bacterial and viral infections, as well as cancers, due to their ability to selectively inhibit the growth of target cells without affecting normal cellular functions significantly. However, they may also cause side effects related to their mechanism of action or off-target effects on non-target cells.
RNA precursors, also known as primary transcripts or pre-messenger RNAs (pre-mRNAs), refer to the initial RNA molecules that are synthesized during the transcription process in which DNA is copied into RNA. These precursor molecules still contain non-coding sequences and introns, which need to be removed through a process called splicing, before they can become mature and functional RNAs such as messenger RNAs (mRNAs), ribosomal RNAs (rRNAs), or transfer RNAs (tRNAs).
Pre-mRNAs undergo several processing steps, including 5' capping, 3' polyadenylation, and splicing, to generate mature mRNA molecules that can be translated into proteins. The accurate and efficient production of RNA precursors and their subsequent processing are crucial for gene expression and regulation in cells.
A point mutation is a type of genetic mutation where a single nucleotide base (A, T, C, or G) in DNA is altered, deleted, or substituted with another nucleotide. Point mutations can have various effects on the organism, depending on the location of the mutation and whether it affects the function of any genes. Some point mutations may not have any noticeable effect, while others might lead to changes in the amino acids that make up proteins, potentially causing diseases or altering traits. Point mutations can occur spontaneously due to errors during DNA replication or be inherited from parents.
Gel chromatography is a type of liquid chromatography that separates molecules based on their size or molecular weight. It uses a stationary phase that consists of a gel matrix made up of cross-linked polymers, such as dextran, agarose, or polyacrylamide. The gel matrix contains pores of various sizes, which allow smaller molecules to penetrate deeper into the matrix while larger molecules are excluded.
In gel chromatography, a mixture of molecules is loaded onto the top of the gel column and eluted with a solvent that moves down the column by gravity or pressure. As the sample components move down the column, they interact with the gel matrix and get separated based on their size. Smaller molecules can enter the pores of the gel and take longer to elute, while larger molecules are excluded from the pores and elute more quickly.
Gel chromatography is commonly used to separate and purify proteins, nucleic acids, and other biomolecules based on their size and molecular weight. It is also used in the analysis of polymers, colloids, and other materials with a wide range of applications in chemistry, biology, and medicine.
Sequence homology in nucleic acids refers to the similarity or identity between the nucleotide sequences of two or more DNA or RNA molecules. It is often used as a measure of biological relationship between genes, organisms, or populations. High sequence homology suggests a recent common ancestry or functional constraint, while low sequence homology may indicate a more distant relationship or different functions.
Nucleic acid sequence homology can be determined by various methods such as pairwise alignment, multiple sequence alignment, and statistical analysis. The degree of homology is typically expressed as a percentage of identical or similar nucleotides in a given window of comparison.
It's important to note that the interpretation of sequence homology depends on the biological context and the evolutionary distance between the sequences compared. Therefore, functional and experimental validation is often necessary to confirm the significance of sequence homology.
Ammonium sulfate is a chemical compound with the formula (NH4)2SO4. It is a white crystalline solid that is highly soluble in water and is commonly used in fertilizers due to its high nitrogen content. In a medical context, it can be used as a laxative or for lowering the pH of the gastrointestinal tract in certain medical conditions. It may also be used in the treatment of metabolic alkalosis, a condition characterized by an excessively high pH in the blood. However, its use in medical treatments is less common than its use in agricultural and industrial applications.
DNA ligases are enzymes that catalyze the formation of a phosphodiester bond between two compatible ends of DNA molecules, effectively joining or "ligating" them together. There are several types of DNA ligases found in nature, each with specific functions and preferences for the type of DNA ends they can seal.
The most well-known DNA ligase is DNA ligase I, which plays a crucial role in replicating and repairing DNA in eukaryotic cells. It seals nicks or gaps in double-stranded DNA during replication and participates in the final step of DNA excision repair by rejoining the repaired strand to the original strand.
DNA ligase IV, another important enzyme, is primarily involved in the repair of double-strand breaks through a process called non-homologous end joining (NHEJ). This pathway is essential for maintaining genome stability and preventing chromosomal abnormalities.
Bacterial DNA ligases, such as T4 DNA ligase, are often used in molecular biology techniques due to their ability to join various types of DNA ends with high efficiency. These enzymes have been instrumental in the development of recombinant DNA technology and gene cloning methods.
Cytosine nucleotides are the chemical units or building blocks that make up DNA and RNA, one of the four nitrogenous bases that form the rung of the DNA ladder. A cytosine nucleotide is composed of a cytosine base attached to a sugar molecule (deoxyribose in DNA and ribose in RNA) and at least one phosphate group. The sequence of these nucleotides determines the genetic information stored in an organism's genome. In particular, cytosine nucleotides pair with guanine nucleotides through hydrogen bonding to form base pairs that are held together by weak interactions. This pairing is specific and maintains the structure and integrity of the DNA molecule during replication and transcription.
Simian Virus 40 (SV40) is a polyomavirus that is found in both monkeys and humans. It is a DNA virus that has been extensively studied in laboratory settings due to its ability to transform cells and cause tumors in animals. In fact, SV40 was discovered as a contaminant of poliovirus vaccines that were prepared using rhesus monkey kidney cells in the 1950s and 1960s.
SV40 is not typically associated with human disease, but there has been some concern that exposure to the virus through contaminated vaccines or other means could increase the risk of certain types of cancer, such as mesothelioma and brain tumors. However, most studies have failed to find a consistent link between SV40 infection and cancer in humans.
The medical community generally agrees that SV40 is not a significant public health threat, but researchers continue to study the virus to better understand its biology and potential impact on human health.
I'm sorry for any confusion, but there seems to be no established medical definition or recognition of a "Rauscher Virus" in human or veterinary medicine. It is possible that you may have misspelled or misremembered the name of a specific virus or medical term. If you have more information or context about where this term was used, I'd be happy to help you further research the topic.
mRNA cleavage and polyadenylation factors are a group of proteins that play a crucial role in the post-transcriptional modification of messenger RNA (mRNA). This process involves two main steps: mRNA cleavage and polyadenylation.
1. Cleavage: During this step, the mRNA molecule is cut at a specific site, resulting in the formation of two separate fragments. The fragment that will become the mature mRNA is called the 3' untranslated region (3' UTR).
2. Polyadenylation: Following cleavage, a string of adenine nucleotides (poly(A) tail) is added to the 3' end of the newly formed 3' UTR. This poly(A) tail plays an essential role in mRNA stability, transport from the nucleus to the cytoplasm, and translation initiation.
mRNA cleavage and polyadenylation factors include various proteins that orchestrate these events, such as:
* Cleavage and polyadenylation specificity factor (CPSF) complex: This complex recognizes and binds to the polyadenylation signal sequence in the pre-mRNA. It contains several subunits, including CPSF1, CPSF2, CPSF3, CPSF4, and CPSF7.
* Cleavage stimulation factor (CstF) complex: This complex recognizes and binds to the GU-rich region downstream of the polyadenylation signal sequence. It contains several subunits, including CstF50, CstF64, CstF77, and CstF80.
* Cleavage factors I (CFIm) and II (CFIIm): These complexes help position the CPSF complex at the correct site for cleavage and polyadenylation. CFIm contains the subunits CFIm25, CFIm59, and CFIm68, while CFIIm consists of the subunits CLIP1 and PAP73.
* Poly(A) polymerase (PAP): This enzyme adds the string of adenine residues to the 3' end of the pre-mRNA after cleavage.
Together, these factors work together to ensure accurate and efficient cleavage and polyadenylation of pre-mRNAs during gene expression.
DNA nucleotidylexotransferase is not a widely recognized or established medical term. It appears to be a combination of the terms "DNA," "nucleotide," and "lexotransferase," but the specific meaning or function of this enzyme is unclear.
"DNA" refers to deoxyribonucleic acid, which is the genetic material found in the cells of most living organisms.
"Nucleotide" refers to a molecule that consists of a nitrogenous base, a sugar, and one or more phosphate groups. Nucleotides are the building blocks of DNA and RNA.
"Lexotransferase" is not a recognized enzyme class or function. It may be a typographical error or a term that has been misused or misunderstood.
Therefore, it is not possible to provide a medical definition for 'DNA nucleotidylexotransferase'. If you have more information about the context in which this term was used, I may be able to provide further clarification.
Deoxyuracil nucleotides are chemical compounds that are the building blocks of DNA. Specifically, they are the form of nucleotides that contain the sugar deoxyribose and the nucleobase deoxyuracil. In DNA, deoxyuracil nucleotides pair with deoxyadenosine nucleotides through base pairing.
Deoxyuracil is a nucleobase that is similar to thymine, but it lacks a methyl group. Thymine is the usual nucleobase that pairs with adenine in DNA, while uracil is typically found in RNA paired with adenine. However, in certain circumstances, such as during DNA repair or damage, deoxyuracil can be incorporated into DNA instead of thymine.
Deoxyuracil nucleotides are important for understanding DNA replication, repair, and mutation. Abnormalities in the incorporation or removal of deoxyuracil nucleotides can lead to genetic disorders, cancer, and other diseases.
Tritium is not a medical term, but it is a term used in the field of nuclear physics and chemistry. Tritium (symbol: T or 3H) is a radioactive isotope of hydrogen with two neutrons and one proton in its nucleus. It is also known as heavy hydrogen or superheavy hydrogen.
Tritium has a half-life of about 12.3 years, which means that it decays by emitting a low-energy beta particle (an electron) to become helium-3. Due to its radioactive nature and relatively short half-life, tritium is used in various applications, including nuclear weapons, fusion reactors, luminous paints, and medical research.
In the context of medicine, tritium may be used as a radioactive tracer in some scientific studies or medical research, but it is not a term commonly used to describe a medical condition or treatment.
Transcription termination in genetics refers to the process by which RNA polymerase, the enzyme responsible for transcribing DNA into RNA, releases the newly synthesized RNA molecule and detaches from the DNA template after reaching the end of a gene. This process is an essential step in gene expression, as it ensures that the correct length of RNA is produced and that the transcription machinery can be recycled for use in other transcription events.
There are two main mechanisms of transcription termination: Rho-dependent and Rho-independent. In Rho-dependent termination, a protein factor called Rho binds to the newly synthesized RNA and translocates along it towards the RNA polymerase, disrupting the interaction between the RNA and the enzyme and causing the release of the RNA. In Rho-independent termination, also known as intrinsic termination, a stem-loop structure forms in the RNA at the end of the gene, which causes the RNA polymerase to stall and eventually fall off the DNA template.
Transcription termination is tightly regulated, and defects in this process can lead to abnormal gene expression and disease. For example, mutations that affect transcription termination have been associated with certain types of cancer and neurological disorders.
Deoxyguanosine is a chemical compound that is a component of DNA (deoxyribonucleic acid), one of the nucleic acids. It is a nucleoside, which is a molecule consisting of a sugar (in this case, deoxyribose) and a nitrogenous base (in this case, guanine). Deoxyguanosine plays a crucial role in the structure and function of DNA, as it pairs with deoxycytidine through hydrogen bonding to form a rung in the DNA double helix. It is involved in the storage and transmission of genetic information.
In a medical context, "hot temperature" is not a standard medical term with a specific definition. However, it is often used in relation to fever, which is a common symptom of illness. A fever is typically defined as a body temperature that is higher than normal, usually above 38°C (100.4°F) for adults and above 37.5-38°C (99.5-101.3°F) for children, depending on the source.
Therefore, when a medical professional talks about "hot temperature," they may be referring to a body temperature that is higher than normal due to fever or other causes. It's important to note that a high environmental temperature can also contribute to an elevated body temperature, so it's essential to consider both the body temperature and the environmental temperature when assessing a patient's condition.
A phenotype is the physical or biochemical expression of an organism's genes, or the observable traits and characteristics resulting from the interaction of its genetic constitution (genotype) with environmental factors. These characteristics can include appearance, development, behavior, and resistance to disease, among others. Phenotypes can vary widely, even among individuals with identical genotypes, due to differences in environmental influences, gene expression, and genetic interactions.
Bacteriophages, often simply called phages, are viruses that infect and replicate within bacteria. They consist of a protein coat, called the capsid, that encases the genetic material, which can be either DNA or RNA. Bacteriophages are highly specific, meaning they only infect certain types of bacteria, and they reproduce by hijacking the bacterial cell's machinery to produce more viruses.
Once a phage infects a bacterium, it can either replicate its genetic material and create new phages (lytic cycle), or integrate its genetic material into the bacterial chromosome and replicate along with the bacterium (lysogenic cycle). In the lytic cycle, the newly formed phages are released by lysing, or breaking open, the bacterial cell.
Bacteriophages play a crucial role in shaping microbial communities and have been studied as potential alternatives to antibiotics for treating bacterial infections.
Species specificity is a term used in the field of biology, including medicine, to refer to the characteristic of a biological entity (such as a virus, bacterium, or other microorganism) that allows it to interact exclusively or preferentially with a particular species. This means that the biological entity has a strong affinity for, or is only able to infect, a specific host species.
For example, HIV is specifically adapted to infect human cells and does not typically infect other animal species. Similarly, some bacterial toxins are species-specific and can only affect certain types of animals or humans. This concept is important in understanding the transmission dynamics and host range of various pathogens, as well as in developing targeted therapies and vaccines.
Biological models, also known as physiological models or organismal models, are simplified representations of biological systems, processes, or mechanisms that are used to understand and explain the underlying principles and relationships. These models can be theoretical (conceptual or mathematical) or physical (such as anatomical models, cell cultures, or animal models). They are widely used in biomedical research to study various phenomena, including disease pathophysiology, drug action, and therapeutic interventions.
Examples of biological models include:
1. Mathematical models: These use mathematical equations and formulas to describe complex biological systems or processes, such as population dynamics, metabolic pathways, or gene regulation networks. They can help predict the behavior of these systems under different conditions and test hypotheses about their underlying mechanisms.
2. Cell cultures: These are collections of cells grown in a controlled environment, typically in a laboratory dish or flask. They can be used to study cellular processes, such as signal transduction, gene expression, or metabolism, and to test the effects of drugs or other treatments on these processes.
3. Animal models: These are living organisms, usually vertebrates like mice, rats, or non-human primates, that are used to study various aspects of human biology and disease. They can provide valuable insights into the pathophysiology of diseases, the mechanisms of drug action, and the safety and efficacy of new therapies.
4. Anatomical models: These are physical representations of biological structures or systems, such as plastic models of organs or tissues, that can be used for educational purposes or to plan surgical procedures. They can also serve as a basis for developing more sophisticated models, such as computer simulations or 3D-printed replicas.
Overall, biological models play a crucial role in advancing our understanding of biology and medicine, helping to identify new targets for therapeutic intervention, develop novel drugs and treatments, and improve human health.
An amino acid substitution is a type of mutation in which one amino acid in a protein is replaced by another. This occurs when there is a change in the DNA sequence that codes for a particular amino acid in a protein. The genetic code is redundant, meaning that most amino acids are encoded by more than one codon (a sequence of three nucleotides). As a result, a single base pair change in the DNA sequence may not necessarily lead to an amino acid substitution. However, if a change does occur, it can have a variety of effects on the protein's structure and function, depending on the nature of the substituted amino acids. Some substitutions may be harmless, while others may alter the protein's activity or stability, leading to disease.
Adenosine Triphosphate (ATP) is a high-energy molecule that stores and transports energy within cells. It is the main source of energy for most cellular processes, including muscle contraction, nerve impulse transmission, and protein synthesis. ATP is composed of a base (adenine), a sugar (ribose), and three phosphate groups. The bonds between these phosphate groups contain a significant amount of energy, which can be released when the bond between the second and third phosphate group is broken, resulting in the formation of adenosine diphosphate (ADP) and inorganic phosphate. This process is known as hydrolysis and can be catalyzed by various enzymes to drive a wide range of cellular functions. ATP can also be regenerated from ADP through various metabolic pathways, such as oxidative phosphorylation or substrate-level phosphorylation, allowing for the continuous supply of energy to cells.
Gene expression regulation, viral, refers to the processes that control the production of viral gene products, such as proteins and nucleic acids, during the viral life cycle. This can involve both viral and host cell factors that regulate transcription, RNA processing, translation, and post-translational modifications of viral genes.
Viral gene expression regulation is critical for the virus to replicate and produce progeny virions. Different types of viruses have evolved diverse mechanisms to regulate their gene expression, including the use of promoters, enhancers, transcription factors, RNA silencing, and epigenetic modifications. Understanding these regulatory processes can provide insights into viral pathogenesis and help in the development of antiviral therapies.
Repressor proteins are a type of regulatory protein in molecular biology that suppress the transcription of specific genes into messenger RNA (mRNA) by binding to DNA. They function as part of gene regulation processes, often working in conjunction with an operator region and a promoter region within the DNA molecule. Repressor proteins can be activated or deactivated by various signals, allowing for precise control over gene expression in response to changing cellular conditions.
There are two main types of repressor proteins:
1. DNA-binding repressors: These directly bind to specific DNA sequences (operator regions) near the target gene and prevent RNA polymerase from transcribing the gene into mRNA.
2. Allosteric repressors: These bind to effector molecules, which then cause a conformational change in the repressor protein, enabling it to bind to DNA and inhibit transcription.
Repressor proteins play crucial roles in various biological processes, such as development, metabolism, and stress response, by controlling gene expression patterns in cells.
I'm sorry for any confusion, but "Poly C" is not a widely recognized medical term or abbreviation in the field of medicine or biology. It might be a typographical error or a shorthand notation used in a specific context. If you could provide more context or clarify what you mean by "Poly C," I would be happy to help further.
"Pyrococcus" is not a medical term, but rather a genus of archaea (single-celled microorganisms) that are extremophiles, meaning they thrive in extreme environments. The name "Pyrococcus" comes from the Greek words "pyr" meaning fire and "kokkos" meaning berry, which refers to their ability to grow at very high temperatures, up to 105 degrees Celsius. These microorganisms are often found in hydrothermal vents and deep-sea sediments. They have potential applications in biotechnology due to their heat-stable enzymes.
Antiviral agents are a class of medications that are designed to treat infections caused by viruses. Unlike antibiotics, which target bacteria, antiviral agents interfere with the replication and infection mechanisms of viruses, either by inhibiting their ability to replicate or by modulating the host's immune response to the virus.
Antiviral agents are used to treat a variety of viral infections, including influenza, herpes simplex virus (HSV) infections, human immunodeficiency virus (HIV) infection, hepatitis B and C, and respiratory syncytial virus (RSV) infections.
These medications can be administered orally, intravenously, or topically, depending on the type of viral infection being treated. Some antiviral agents are also used for prophylaxis, or prevention, of certain viral infections.
It is important to note that antiviral agents are not effective against all types of viruses and may have significant side effects. Therefore, it is essential to consult with a healthcare professional before starting any antiviral therapy.
RNA-binding proteins (RBPs) are a class of proteins that selectively interact with RNA molecules to form ribonucleoprotein complexes. These proteins play crucial roles in the post-transcriptional regulation of gene expression, including pre-mRNA processing, mRNA stability, transport, localization, and translation. RBPs recognize specific RNA sequences or structures through their modular RNA-binding domains, which can be highly degenerate and allow for the recognition of a wide range of RNA targets. The interaction between RBPs and RNA is often dynamic and can be regulated by various post-translational modifications of the proteins or by environmental stimuli, allowing for fine-tuning of gene expression in response to changing cellular needs. Dysregulation of RBP function has been implicated in various human diseases, including neurological disorders and cancer.
A genetic complementation test is a laboratory procedure used in molecular genetics to determine whether two mutated genes can complement each other's function, indicating that they are located at different loci and represent separate alleles. This test involves introducing a normal or wild-type copy of one gene into a cell containing a mutant version of the same gene, and then observing whether the presence of the normal gene restores the normal function of the mutated gene. If the introduction of the normal gene results in the restoration of the normal phenotype, it suggests that the two genes are located at different loci and can complement each other's function. However, if the introduction of the normal gene does not restore the normal phenotype, it suggests that the two genes are located at the same locus and represent different alleles of the same gene. This test is commonly used to map genes and identify genetic interactions in a variety of organisms, including bacteria, yeast, and animals.
RNA splicing is a post-transcriptional modification process in which the non-coding sequences (introns) are removed and the coding sequences (exons) are joined together in a messenger RNA (mRNA) molecule. This results in a continuous mRNA sequence that can be translated into a single protein. Alternative splicing, where different combinations of exons are included or excluded, allows for the creation of multiple proteins from a single gene.
Cyclin T is a type of cyclin protein that is encoded by the CCNT2 gene in humans. Cyclins are a family of regulatory proteins that play a crucial role in the cell cycle, which is the series of events that cells undergo as they grow and divide. Specifically, cyclin T is a component of the CDK9/cyclin T complex, also known as positive transcription elongation factor b (P-TEFb), which plays a key role in regulating gene expression by controlling the elongation phase of RNA polymerase II-mediated transcription.
Cyclin T is expressed at various stages of the cell cycle and has been shown to interact with several other proteins involved in cell cycle regulation, including the retinoblastoma protein (pRb) and the E2F family of transcription factors. Dysregulation of cyclin T expression or activity has been implicated in several human diseases, including cancer.
Translational peptide chain elongation is the process during protein synthesis where activated amino acids are added to the growing peptide chain in a sequence determined by the genetic code present in messenger RNA (mRNA). This process involves several steps:
1. Recognition of the start codon on the mRNA by the small ribosomal subunit, which binds to the mRNA and brings an initiator tRNA with a methionine or formylmethionine amino acid attached into the P site (peptidyl site) of the ribosome.
2. The large ribosomal subunit then joins the small subunit, forming a complete ribosome complex.
3. An incoming charged tRNA with an appropriate amino acid, complementary to the next codon on the mRNA, binds to the A site (aminoacyl site) of the ribosome.
4. Peptidyl transferase, a catalytic domain within the large ribosomal subunit, facilitates the formation of a peptide bond between the amino acids attached to the tRNAs in the P and A sites. The methionine or formylmethionine initiator amino acid is now covalently linked to the second amino acid via this peptide bond.
5. Translocation occurs, moving the tRNA with the growing peptide chain from the P site to the E site (exit site) and shifting the mRNA by one codon relative to the ribosome. The uncharged tRNA is then released from the E site.
6. The next charged tRNA carrying an appropriate amino acid binds to the A site, and the process repeats until a stop codon is reached on the mRNA.
7. Upon encountering a stop codon, release factors recognize it and facilitate the release of the completed polypeptide chain from the final tRNA in the P site. The ribosome then dissociates from the mRNA, allowing for further translational events to occur.
Translational peptide chain elongation is a crucial step in protein synthesis and requires precise coordination between various components of the translation machinery, including ribosomes, tRNAs, amino acids, and numerous accessory proteins.
Transfection is a term used in molecular biology that refers to the process of deliberately introducing foreign genetic material (DNA, RNA or artificial gene constructs) into cells. This is typically done using chemical or physical methods, such as lipofection or electroporation. Transfection is widely used in research and medical settings for various purposes, including studying gene function, producing proteins, developing gene therapies, and creating genetically modified organisms. It's important to note that transfection is different from transduction, which is the process of introducing genetic material into cells using viruses as vectors.
An open reading frame (ORF) is a continuous stretch of DNA or RNA sequence that has the potential to be translated into a protein. It begins with a start codon (usually "ATG" in DNA, which corresponds to "AUG" in RNA) and ends with a stop codon ("TAA", "TAG", or "TGA" in DNA; "UAA", "UAG", or "UGA" in RNA). The sequence between these two points is called a coding sequence (CDS), which, when transcribed into mRNA and translated into amino acids, forms a polypeptide chain.
In eukaryotic cells, ORFs can be located in either protein-coding genes or non-coding regions of the genome. In prokaryotic cells, multiple ORFs may be present on a single strand of DNA, often organized into operons that are transcribed together as a single mRNA molecule.
It's important to note that not all ORFs necessarily represent functional proteins; some may be pseudogenes or result from errors in genome annotation. Therefore, additional experimental evidence is typically required to confirm the expression and functionality of a given ORF.
Chromosomal proteins, non-histone, are a diverse group of proteins that are associated with chromatin, the complex of DNA and histone proteins, but do not have the characteristic structure of histones. These proteins play important roles in various nuclear processes such as DNA replication, transcription, repair, recombination, and chromosome condensation and segregation during cell division. They can be broadly classified into several categories based on their functions, including architectural proteins, enzymes, transcription factors, and structural proteins. Examples of non-histone chromosomal proteins include high mobility group (HMG) proteins, poly(ADP-ribose) polymerases (PARPs), and condensins.
Genetic recombination is the process by which genetic material is exchanged between two similar or identical molecules of DNA during meiosis, resulting in new combinations of genes on each chromosome. This exchange occurs during crossover, where segments of DNA are swapped between non-sister homologous chromatids, creating genetic diversity among the offspring. It is a crucial mechanism for generating genetic variability and facilitating evolutionary change within populations. Additionally, recombination also plays an essential role in DNA repair processes through mechanisms such as homologous recombinational repair (HRR) and non-homologous end joining (NHEJ).
Diphosphates, also known as pyrophosphates, are chemical compounds that contain two phosphate groups joined together by an oxygen atom. The general formula for a diphosphate is P~PO3~2-, where ~ represents a bond. Diphosphates play important roles in various biological processes, such as energy metabolism and cell signaling. In the context of nutrition, diphosphates can be found in some foods, including milk and certain vegetables.
Methylation, in the context of genetics and epigenetics, refers to the addition of a methyl group (CH3) to a molecule, usually to the nitrogenous base of DNA or to the side chain of amino acids in proteins. In DNA methylation, this process typically occurs at the 5-carbon position of cytosine residues that precede guanine residues (CpG sites) and is catalyzed by enzymes called DNA methyltransferases (DNMTs).
DNA methylation plays a crucial role in regulating gene expression, genomic imprinting, X-chromosome inactivation, and suppression of repetitive elements. Hypermethylation or hypomethylation of specific genes can lead to altered gene expression patterns, which have been associated with various human diseases, including cancer.
In summary, methylation is a fundamental epigenetic modification that influences genomic stability, gene regulation, and cellular function by introducing methyl groups to DNA or proteins.
"Drosophila" is a genus of small flies, also known as fruit flies. The most common species used in scientific research is "Drosophila melanogaster," which has been a valuable model organism for many areas of biological and medical research, including genetics, developmental biology, neurobiology, and aging.
The use of Drosophila as a model organism has led to numerous important discoveries in genetics and molecular biology, such as the identification of genes that are associated with human diseases like cancer, Parkinson's disease, and obesity. The short reproductive cycle, large number of offspring, and ease of genetic manipulation make Drosophila a powerful tool for studying complex biological processes.
Mitochondrial DNA (mtDNA) is the genetic material present in the mitochondria, which are specialized structures within cells that generate energy. Unlike nuclear DNA, which is present in the cell nucleus and inherited from both parents, mtDNA is inherited solely from the mother.
MtDNA is a circular molecule that contains 37 genes, including 13 genes that encode for proteins involved in oxidative phosphorylation, a process that generates energy in the form of ATP. The remaining genes encode for rRNAs and tRNAs, which are necessary for protein synthesis within the mitochondria.
Mutations in mtDNA can lead to a variety of genetic disorders, including mitochondrial diseases, which can affect any organ system in the body. These mutations can also be used in forensic science to identify individuals and establish biological relationships.
Endodeoxyribonucleases are a type of enzyme that cleave, or cut, phosphodiester bonds within the backbone of DNA molecules. These enzymes are also known as restriction endonucleases or simply restriction enzymes. They are called "restriction" enzymes because they were first discovered in bacteria, where they function to protect the organism from foreign DNA by cleaving and destroying invading viral DNA.
Endodeoxyribonucleases recognize specific sequences of nucleotides within the DNA molecule, known as recognition sites or restriction sites, and cut the phosphodiester bonds at specific locations within these sites. The cuts made by endodeoxyribonucleases can be either "sticky" or "blunt," depending on whether the enzyme leaves single-stranded overhangs or creates blunt ends at the site of cleavage, respectively.
Endodeoxyribonucleases are widely used in molecular biology research for various applications, including DNA cloning, genome mapping, and genetic engineering. They allow researchers to cut DNA molecules at specific sites, creating defined fragments that can be manipulated and recombined in a variety of ways.
Medical Definition of "Multiprotein Complexes" :
Multiprotein complexes are large molecular assemblies composed of two or more proteins that interact with each other to carry out specific cellular functions. These complexes can range from relatively simple dimers or trimers to massive structures containing hundreds of individual protein subunits. They are formed through a process known as protein-protein interaction, which is mediated by specialized regions on the protein surface called domains or motifs.
Multiprotein complexes play critical roles in many cellular processes, including signal transduction, gene regulation, DNA replication and repair, protein folding and degradation, and intracellular transport. The formation of these complexes is often dynamic and regulated in response to various stimuli, allowing for precise control of their function.
Disruption of multiprotein complexes can lead to a variety of diseases, including cancer, neurodegenerative disorders, and infectious diseases. Therefore, understanding the structure, composition, and regulation of these complexes is an important area of research in molecular biology and medicine.
Enzyme stability refers to the ability of an enzyme to maintain its structure and function under various environmental conditions, such as temperature, pH, and the presence of denaturants or inhibitors. A stable enzyme retains its activity and conformation over time and across a range of conditions, making it more suitable for industrial and therapeutic applications.
Enzymes can be stabilized through various methods, including chemical modification, immobilization, and protein engineering. Understanding the factors that affect enzyme stability is crucial for optimizing their use in biotechnology, medicine, and research.
Methyl methanesulfonate (MMS) is not a medication, but rather a chemical compound with the formula CH3SO3CH3. It's an alkylating agent that is used in laboratory settings for various research purposes, including as a methylating agent in biochemical and genetic studies.
MMS works by transferring its methyl group (CH3) to other molecules, which can result in the modification of DNA and other biological macromolecules. This property makes it useful in laboratory research, but it also means that MMS is highly reactive and toxic. Therefore, it must be handled with care and appropriate safety precautions.
It's important to note that MMS is not used as a therapeutic agent in medicine due to its high toxicity and potential to cause serious harm if mishandled or misused.
Cytosine is one of the four nucleobases in the nucleic acid molecules DNA and RNA, along with adenine, guanine, and thymine (in DNA) or uracil (in RNA). The single-letter abbreviation for cytosine is "C."
Cytosine base pairs specifically with guanine through hydrogen bonding, forming a base pair. In DNA, the double helix consists of two complementary strands of nucleotides held together by these base pairs, such that the sequence of one strand determines the sequence of the other. This property is critical for DNA replication and transcription, processes that are essential for life.
Cytosine residues in DNA can undergo spontaneous deamination to form uracil, which can lead to mutations if not corrected by repair mechanisms. In RNA, cytosine can be methylated at the 5-carbon position to form 5-methylcytosine, a modification that plays a role in regulating gene expression and other cellular processes.
Adenosine triphosphatases (ATPases) are a group of enzymes that catalyze the conversion of adenosine triphosphate (ATP) into adenosine diphosphate (ADP) and inorganic phosphate. This reaction releases energy, which is used to drive various cellular processes such as muscle contraction, transport of ions across membranes, and synthesis of proteins and nucleic acids.
ATPases are classified into several types based on their structure, function, and mechanism of action. Some examples include:
1. P-type ATPases: These ATPases form a phosphorylated intermediate during the reaction cycle and are involved in the transport of ions across membranes, such as the sodium-potassium pump and calcium pumps.
2. F-type ATPases: These ATPases are found in mitochondria, chloroplasts, and bacteria, and are responsible for generating a proton gradient across the membrane, which is used to synthesize ATP.
3. V-type ATPases: These ATPases are found in vacuolar membranes and endomembranes, and are involved in acidification of intracellular compartments.
4. A-type ATPases: These ATPases are found in the plasma membrane and are involved in various functions such as cell signaling and ion transport.
Overall, ATPases play a crucial role in maintaining the energy balance of cells and regulating various physiological processes.
Genetic suppression is a concept in genetics that refers to the phenomenon where the expression or function of one gene is reduced or silenced by another gene. This can occur through various mechanisms such as:
* Allelic exclusion: When only one allele (version) of a gene is expressed, while the other is suppressed.
* Epigenetic modifications: Chemical changes to the DNA or histone proteins that package DNA can result in the suppression of gene expression.
* RNA interference: Small RNAs can bind to and degrade specific mRNAs (messenger RNAs), preventing their translation into proteins.
* Transcriptional repression: Proteins called transcription factors can bind to DNA and prevent the recruitment of RNA polymerase, which is necessary for gene transcription.
Genetic suppression plays a crucial role in regulating gene expression and maintaining proper cellular function. It can also contribute to diseases such as cancer when genes that suppress tumor growth are suppressed themselves.
Repetitive sequences in nucleic acid refer to repeated stretches of DNA or RNA nucleotide bases that are present in a genome. These sequences can vary in length and can be arranged in different patterns such as direct repeats, inverted repeats, or tandem repeats. In some cases, these repetitive sequences do not code for proteins and are often found in non-coding regions of the genome. They can play a role in genetic instability, regulation of gene expression, and evolutionary processes. However, certain types of repeat expansions have been associated with various neurodegenerative disorders and other human diseases.
"Cells, cultured" is a medical term that refers to cells that have been removed from an organism and grown in controlled laboratory conditions outside of the body. This process is called cell culture and it allows scientists to study cells in a more controlled and accessible environment than they would have inside the body. Cultured cells can be derived from a variety of sources, including tissues, organs, or fluids from humans, animals, or cell lines that have been previously established in the laboratory.
Cell culture involves several steps, including isolation of the cells from the tissue, purification and characterization of the cells, and maintenance of the cells in appropriate growth conditions. The cells are typically grown in specialized media that contain nutrients, growth factors, and other components necessary for their survival and proliferation. Cultured cells can be used for a variety of purposes, including basic research, drug development and testing, and production of biological products such as vaccines and gene therapies.
It is important to note that cultured cells may behave differently than they do in the body, and results obtained from cell culture studies may not always translate directly to human physiology or disease. Therefore, it is essential to validate findings from cell culture experiments using additional models and ultimately in clinical trials involving human subjects.
An oligonucleotide probe is a short, single-stranded DNA or RNA molecule that contains a specific sequence of nucleotides designed to hybridize with a complementary sequence in a target nucleic acid (DNA or RNA). These probes are typically 15-50 nucleotides long and are used in various molecular biology techniques, such as polymerase chain reaction (PCR), DNA sequencing, microarray analysis, and blotting methods.
Oligonucleotide probes can be labeled with various reporter molecules, like fluorescent dyes or radioactive isotopes, to enable the detection of hybridized targets. The high specificity of oligonucleotide probes allows for the precise identification and quantification of target nucleic acids in complex biological samples, making them valuable tools in diagnostic, research, and forensic applications.
Cytomegalovirus (CMV) is a type of herpesvirus that can cause infection in humans. It is characterized by the enlargement of infected cells (cytomegaly) and is typically transmitted through close contact with an infected person, such as through saliva, urine, breast milk, or sexual contact.
CMV infection can also be acquired through organ transplantation, blood transfusions, or during pregnancy from mother to fetus. While many people infected with CMV experience no symptoms, it can cause serious complications in individuals with weakened immune systems, such as those undergoing cancer treatment or those who have HIV/AIDS.
In newborns, congenital CMV infection can lead to hearing loss, vision problems, and developmental delays. Pregnant women who become infected with CMV for the first time during pregnancy are at higher risk of transmitting the virus to their unborn child. There is no cure for CMV, but antiviral medications can help manage symptoms and reduce the risk of complications in severe cases.
Polynucleotide adenylyltransferase is not a medical term per se, but rather a biological term used to describe an enzyme that catalyzes the addition of adenine residues to the 3'-hydroxyl end of polynucleotides. In other words, these enzymes transfer AMP (adenosine monophosphate) molecules to the ends of DNA or RNA strands, creating a chain of adenine nucleotides.
One of the most well-known examples of this class of enzyme is terminal transferase, which is often used in research settings for various molecular biology techniques such as adding homopolymeric tails to DNA molecules. It's worth noting that while these enzymes have important applications in scientific research, they are not typically associated with medical diagnoses or treatments.
DNA Mutational Analysis is a laboratory test used to identify genetic variations or changes (mutations) in the DNA sequence of a gene. This type of analysis can be used to diagnose genetic disorders, predict the risk of developing certain diseases, determine the most effective treatment for cancer, or assess the likelihood of passing on an inherited condition to offspring.
The test involves extracting DNA from a patient's sample (such as blood, saliva, or tissue), amplifying specific regions of interest using polymerase chain reaction (PCR), and then sequencing those regions to determine the precise order of nucleotide bases in the DNA molecule. The resulting sequence is then compared to reference sequences to identify any variations or mutations that may be present.
DNA Mutational Analysis can detect a wide range of genetic changes, including single-nucleotide polymorphisms (SNPs), insertions, deletions, duplications, and rearrangements. The test is often used in conjunction with other diagnostic tests and clinical evaluations to provide a comprehensive assessment of a patient's genetic profile.
It is important to note that not all mutations are pathogenic or associated with disease, and the interpretation of DNA Mutational Analysis results requires careful consideration of the patient's medical history, family history, and other relevant factors.
"Spodoptera" is not a medical term, but a genus name in the insect family Noctuidae. It includes several species of moths commonly known as armyworms or cutworms due to their habit of consuming leaves and roots of various plants, causing significant damage to crops.
Some well-known species in this genus are Spodoptera frugiperda (fall armyworm), Spodoptera litura (tobacco cutworm), and Spodoptera exigua (beet armyworm). These pests can be a concern for medical entomology when they transmit pathogens or cause allergic reactions. For instance, their frass (feces) and shed skins may trigger asthma symptoms in susceptible individuals. However, the insects themselves are not typically considered medical issues unless they directly affect human health.
Cell cycle proteins are a group of regulatory proteins that control the progression of the cell cycle, which is the series of events that take place in a eukaryotic cell leading to its division and duplication. These proteins can be classified into several categories based on their functions during different stages of the cell cycle.
The major groups of cell cycle proteins include:
1. Cyclin-dependent kinases (CDKs): CDKs are serine/threonine protein kinases that regulate key transitions in the cell cycle. They require binding to a regulatory subunit called cyclin to become active. Different CDK-cyclin complexes are activated at different stages of the cell cycle.
2. Cyclins: Cyclins are a family of regulatory proteins that bind and activate CDKs. Their levels fluctuate throughout the cell cycle, with specific cyclins expressed during particular phases. For example, cyclin D is important for the G1 to S phase transition, while cyclin B is required for the G2 to M phase transition.
3. CDK inhibitors (CKIs): CKIs are regulatory proteins that bind to and inhibit CDKs, thereby preventing their activation. CKIs can be divided into two main families: the INK4 family and the Cip/Kip family. INK4 family members specifically inhibit CDK4 and CDK6, while Cip/Kip family members inhibit a broader range of CDKs.
4. Anaphase-promoting complex/cyclosome (APC/C): APC/C is an E3 ubiquitin ligase that targets specific proteins for degradation by the 26S proteasome. During the cell cycle, APC/C regulates the metaphase to anaphase transition and the exit from mitosis by targeting securin and cyclin B for degradation.
5. Other regulatory proteins: Several other proteins play crucial roles in regulating the cell cycle, such as p53, a transcription factor that responds to DNA damage and arrests the cell cycle, and the polo-like kinases (PLKs), which are involved in various aspects of mitosis.
Overall, cell cycle proteins work together to ensure the proper progression of the cell cycle, maintain genomic stability, and prevent uncontrolled cell growth, which can lead to cancer.
A nucleic acid heteroduplex is a double-stranded structure formed by the pairing of two complementary single strands of nucleic acids (DNA or RNA) that are derived from different sources. The term "hetero" refers to the fact that the two strands are not identical and come from different parents, genes, or organisms.
Heteroduplexes can form spontaneously during processes like genetic recombination, where DNA repair mechanisms may mistakenly pair complementary regions between two different double-stranded DNA molecules. They can also be generated intentionally in laboratory settings for various purposes, such as analyzing the similarity of DNA sequences or detecting mutations.
Heteroduplexes are often used in molecular biology techniques like polymerase chain reaction (PCR) and DNA sequencing, where they can help identify mismatches, insertions, deletions, or other sequence variations between the two parental strands. These variations can provide valuable information about genetic diversity, evolutionary relationships, and disease-causing mutations.
A two-hybrid system technique is a type of genetic screening method used in molecular biology to identify protein-protein interactions within an organism, most commonly baker's yeast (Saccharomyces cerevisiae) or Escherichia coli. The name "two-hybrid" refers to the fact that two separate proteins are being examined for their ability to interact with each other.
The technique is based on the modular nature of transcription factors, which typically consist of two distinct domains: a DNA-binding domain (DBD) and an activation domain (AD). In a two-hybrid system, one protein of interest is fused to the DBD, while the second protein of interest is fused to the AD. If the two proteins interact, the DBD and AD are brought in close proximity, allowing for transcriptional activation of a reporter gene that is linked to a specific promoter sequence recognized by the DBD.
The main components of a two-hybrid system include:
1. Bait protein (fused to the DNA-binding domain)
2. Prey protein (fused to the activation domain)
3. Reporter gene (transcribed upon interaction between bait and prey proteins)
4. Promoter sequence (recognized by the DBD when brought in proximity due to interaction)
The two-hybrid system technique has several advantages, including:
1. Ability to screen large libraries of potential interacting partners
2. High sensitivity for detecting weak or transient interactions
3. Applicability to various organisms and protein types
4. Potential for high-throughput analysis
However, there are also limitations to the technique, such as false positives (interactions that do not occur in vivo) and false negatives (lack of detection of true interactions). Additionally, the fusion proteins may not always fold or localize correctly, leading to potential artifacts. Despite these limitations, two-hybrid system techniques remain a valuable tool for studying protein-protein interactions and have contributed significantly to our understanding of various cellular processes.
Serine is an amino acid, which is a building block of proteins. More specifically, it is a non-essential amino acid, meaning that the body can produce it from other compounds, and it does not need to be obtained through diet. Serine plays important roles in the body, such as contributing to the formation of the protective covering of nerve fibers (myelin sheath), helping to synthesize another amino acid called tryptophan, and taking part in the metabolism of fatty acids. It is also involved in the production of muscle tissues, the immune system, and the forming of cell structures. Serine can be found in various foods such as soy, eggs, cheese, meat, peanuts, lentils, and many others.
Nucleic acid denaturation is the process of separating the two strands of a double-stranded DNA molecule, or unwinding the helical structure of an RNA molecule, by disrupting the hydrogen bonds that hold the strands together. This process is typically caused by exposure to high temperatures, changes in pH, or the presence of chemicals called denaturants.
Denaturation can also cause changes in the shape and function of nucleic acids. For example, it can disrupt the secondary and tertiary structures of RNA molecules, which can affect their ability to bind to other molecules and carry out their functions within the cell.
In molecular biology, nucleic acid denaturation is often used as a tool for studying the structure and function of nucleic acids. For example, it can be used to separate the two strands of a DNA molecule for sequencing or amplification, or to study the interactions between nucleic acids and other molecules.
It's important to note that denaturation is a reversible process, and under the right conditions, the double-stranded structure of DNA can be restored through a process called renaturation or annealing.
Acyclovir is an antiviral medication used for the treatment of infections caused by herpes simplex viruses (HSV) including genital herpes, cold sores, and shingles (varicella-zoster virus). It works by interfering with the replication of the virus's DNA, thereby preventing the virus from multiplying further. Acyclovir is available in various forms such as oral tablets, capsules, creams, and intravenous solutions.
The medical definition of 'Acyclovir' is:
Acyclovir (brand name Zovirax) is a synthetic nucleoside analogue that functions as an antiviral agent, specifically against herpes simplex viruses (HSV) types 1 and 2, varicella-zoster virus (VZV), and Epstein-Barr virus (EBV). Acyclovir is converted to its active form, acyclovir triphosphate, by viral thymidine kinase. This activated form then inhibits viral DNA polymerase, preventing further replication of the virus's DNA.
Acyclovir has a relatively low toxicity profile and is generally well-tolerated, although side effects such as nausea, vomiting, diarrhea, and headache can occur. In rare cases, more serious side effects such as kidney damage, seizures, or neurological problems may occur. It is important to take acyclovir exactly as directed by a healthcare provider and to report any unusual symptoms promptly.
Chromatin assembly and disassembly refer to the processes by which chromatin, the complex of DNA, histone proteins, and other molecules that make up chromosomes, is organized within the nucleus of a eukaryotic cell.
Chromatin assembly refers to the process by which DNA wraps around histone proteins to form nucleosomes, which are then packed together to form higher-order structures. This process is essential for compacting the vast amount of genetic material contained within the cell nucleus and for regulating gene expression. Chromatin assembly is mediated by a variety of protein complexes, including the histone chaperones and ATP-dependent chromatin remodeling enzymes.
Chromatin disassembly, on the other hand, refers to the process by which these higher-order structures are disassembled during cell division, allowing for the equal distribution of genetic material to daughter cells. This process is mediated by phosphorylation of histone proteins by kinases, which leads to the dissociation of nucleosomes and the decondensation of chromatin.
Both Chromatin assembly and disassembly are dynamic and highly regulated processes that play crucial roles in the maintenance of genome stability and the regulation of gene expression.
Flap endonucleases are a type of enzyme that are involved in the repair of damaged DNA. They are named for their ability to cleave or cut the "flaps" of single-stranded DNA that extend beyond the ends of double-stranded DNA. These flaps can occur as a result of DNA damage, such as oxidation or exposure to UV light, or during the normal process of DNA replication.
Flap endonucleases play an important role in several DNA repair pathways, including base excision repair and nucleotide excision repair. In these pathways, the enzyme recognizes and cleaves the flaps, allowing for the damaged or incorrect nucleotides to be removed and replaced with correct ones.
Flap endonucleases are highly conserved across different species, indicating their important role in maintaining genomic stability. Defects in these enzymes have been linked to increased susceptibility to cancer and other diseases associated with DNA damage.
An allele is a variant form of a gene that is located at a specific position on a specific chromosome. Alleles are alternative forms of the same gene that arise by mutation and are found at the same locus or position on homologous chromosomes.
Each person typically inherits two copies of each gene, one from each parent. If the two alleles are identical, a person is said to be homozygous for that trait. If the alleles are different, the person is heterozygous.
For example, the ABO blood group system has three alleles, A, B, and O, which determine a person's blood type. If a person inherits two A alleles, they will have type A blood; if they inherit one A and one B allele, they will have type AB blood; if they inherit two B alleles, they will have type B blood; and if they inherit two O alleles, they will have type O blood.
Alleles can also influence traits such as eye color, hair color, height, and other physical characteristics. Some alleles are dominant, meaning that only one copy of the allele is needed to express the trait, while others are recessive, meaning that two copies of the allele are needed to express the trait.
Ethylmaleimide is a chemical compound that is commonly used in research and scientific studies. Its chemical formula is C7H10N2S. It is known to modify proteins by forming covalent bonds with them, which can alter their function or structure. This property makes it a useful tool in the study of protein function and interactions.
In a medical context, Ethylmaleimide is not used as a therapeutic agent due to its reactivity and potential toxicity. However, it has been used in research to investigate various physiological processes, including the regulation of ion channels and the modulation of enzyme activity. It is important to note that the use of Ethylmaleimide in medical research should be carried out with appropriate precautions and safety measures due to its potential hazards.
Yeasts are single-celled microorganisms that belong to the fungus kingdom. They are characterized by their ability to reproduce asexually through budding or fission, and they obtain nutrients by fermenting sugars and other organic compounds. Some species of yeast can cause infections in humans, known as candidiasis or "yeast infections." These infections can occur in various parts of the body, including the skin, mouth, genitals, and internal organs. Common symptoms of a yeast infection may include itching, redness, irritation, and discharge. Yeast infections are typically treated with antifungal medications.
Western blotting is a laboratory technique used in molecular biology to detect and quantify specific proteins in a mixture of many different proteins. This technique is commonly used to confirm the expression of a protein of interest, determine its size, and investigate its post-translational modifications. The name "Western" blotting distinguishes this technique from Southern blotting (for DNA) and Northern blotting (for RNA).
The Western blotting procedure involves several steps:
1. Protein extraction: The sample containing the proteins of interest is first extracted, often by breaking open cells or tissues and using a buffer to extract the proteins.
2. Separation of proteins by electrophoresis: The extracted proteins are then separated based on their size by loading them onto a polyacrylamide gel and running an electric current through the gel (a process called sodium dodecyl sulfate-polyacrylamide gel electrophoresis or SDS-PAGE). This separates the proteins according to their molecular weight, with smaller proteins migrating faster than larger ones.
3. Transfer of proteins to a membrane: After separation, the proteins are transferred from the gel onto a nitrocellulose or polyvinylidene fluoride (PVDF) membrane using an electric current in a process called blotting. This creates a replica of the protein pattern on the gel but now immobilized on the membrane for further analysis.
4. Blocking: The membrane is then blocked with a blocking agent, such as non-fat dry milk or bovine serum albumin (BSA), to prevent non-specific binding of antibodies in subsequent steps.
5. Primary antibody incubation: A primary antibody that specifically recognizes the protein of interest is added and allowed to bind to its target protein on the membrane. This step may be performed at room temperature or 4°C overnight, depending on the antibody's properties.
6. Washing: The membrane is washed with a buffer to remove unbound primary antibodies.
7. Secondary antibody incubation: A secondary antibody that recognizes the primary antibody (often coupled to an enzyme or fluorophore) is added and allowed to bind to the primary antibody. This step may involve using a horseradish peroxidase (HRP)-conjugated or alkaline phosphatase (AP)-conjugated secondary antibody, depending on the detection method used later.
8. Washing: The membrane is washed again to remove unbound secondary antibodies.
9. Detection: A detection reagent is added to visualize the protein of interest by detecting the signal generated from the enzyme-conjugated or fluorophore-conjugated secondary antibody. This can be done using chemiluminescent, colorimetric, or fluorescent methods.
10. Analysis: The resulting image is analyzed to determine the presence and quantity of the protein of interest in the sample.
Western blotting is a powerful technique for identifying and quantifying specific proteins within complex mixtures. It can be used to study protein expression, post-translational modifications, protein-protein interactions, and more. However, it requires careful optimization and validation to ensure accurate and reproducible results.
Oncogenic viruses are a type of viruses that have the ability to cause cancer in host cells. They do this by integrating their genetic material into the DNA of the infected host cell, which can lead to the disruption of normal cellular functions and the activation of oncogenes (genes that have the potential to cause cancer). This can result in uncontrolled cell growth and division, ultimately leading to the formation of tumors. Examples of oncogenic viruses include human papillomavirus (HPV), hepatitis B virus (HBV), and human T-cell leukemia virus type 1 (HTLV-1). It is important to note that only a small proportion of viral infections lead to cancer, and the majority of cancers are not caused by viruses.
The cell cycle is a series of events that take place in a cell leading to its division and duplication. It consists of four main phases: G1 phase, S phase, G2 phase, and M phase.
During the G1 phase, the cell grows in size and synthesizes mRNA and proteins in preparation for DNA replication. In the S phase, the cell's DNA is copied, resulting in two complete sets of chromosomes. During the G2 phase, the cell continues to grow and produces more proteins and organelles necessary for cell division.
The M phase is the final stage of the cell cycle and consists of mitosis (nuclear division) and cytokinesis (cytoplasmic division). Mitosis results in two genetically identical daughter nuclei, while cytokinesis divides the cytoplasm and creates two separate daughter cells.
The cell cycle is regulated by various checkpoints that ensure the proper completion of each phase before progressing to the next. These checkpoints help prevent errors in DNA replication and division, which can lead to mutations and cancer.
Lysine is an essential amino acid, which means that it cannot be synthesized by the human body and must be obtained through the diet. Its chemical formula is (2S)-2,6-diaminohexanoic acid. Lysine is necessary for the growth and maintenance of tissues in the body, and it plays a crucial role in the production of enzymes, hormones, and antibodies. It is also essential for the absorption of calcium and the formation of collagen, which is an important component of bones and connective tissue. Foods that are good sources of lysine include meat, poultry, fish, eggs, and dairy products.
Eukaryotic cells are complex cells that characterize the cells of all living organisms except bacteria and archaea. They are typically larger than prokaryotic cells and contain a true nucleus and other membrane-bound organelles. The nucleus houses the genetic material, DNA, which is organized into chromosomes. Other organelles include mitochondria, responsible for energy production; chloroplasts, present in plant cells and responsible for photosynthesis; endoplasmic reticulum, involved in protein synthesis; Golgi apparatus, involved in the processing and transport of proteins and lipids; lysosomes, involved in digestion and waste disposal; and vacuoles, involved in storage and waste management. Eukaryotic cells also have a cytoskeleton made up of microtubules, intermediate filaments, and actin filaments that provide structure, support, and mobility to the cell.
Potassium permanganate is not a medical term, but it is a chemical compound with the formula KMnO4. It's a dark purple crystalline solid that is soluble in water and has strong oxidizing properties. In a medical context, potassium permanganate is occasionally used as a topical antiseptic and disinfectant, particularly for treating minor wounds, burns, and ulcers. It's also used to treat certain skin conditions such as eczema and psoriasis. However, its use is limited due to the potential for skin irritation and staining of the skin and clothing. It should always be used under medical supervision and with caution.
In the field of medicine, "time factors" refer to the duration of symptoms or time elapsed since the onset of a medical condition, which can have significant implications for diagnosis and treatment. Understanding time factors is crucial in determining the progression of a disease, evaluating the effectiveness of treatments, and making critical decisions regarding patient care.
For example, in stroke management, "time is brain," meaning that rapid intervention within a specific time frame (usually within 4.5 hours) is essential to administering tissue plasminogen activator (tPA), a clot-busting drug that can minimize brain damage and improve patient outcomes. Similarly, in trauma care, the "golden hour" concept emphasizes the importance of providing definitive care within the first 60 minutes after injury to increase survival rates and reduce morbidity.
Time factors also play a role in monitoring the progression of chronic conditions like diabetes or heart disease, where regular follow-ups and assessments help determine appropriate treatment adjustments and prevent complications. In infectious diseases, time factors are crucial for initiating antibiotic therapy and identifying potential outbreaks to control their spread.
Overall, "time factors" encompass the significance of recognizing and acting promptly in various medical scenarios to optimize patient outcomes and provide effective care.
Replication Protein A (RPA) is a single-stranded DNA binding protein complex that plays a crucial role in the process of DNA replication, repair, and recombination. In eukaryotic cells, RPA is composed of three subunits: RPA70, RPA32, and RPA14. The primary function of RPA is to coat single-stranded DNA (ssDNA) generated during these processes, protecting it from degradation, preventing the formation of secondary structures, and promoting the recruitment of other proteins involved in DNA metabolism.
RPA binds ssDNA with high affinity and specificity, forming a stable complex that protects the DNA from nucleases, chemical modifications, and other damaging agents. The protein also participates in the regulation of various enzymatic activities, such as helicase loading and activation, end processing, and polymerase processivity.
During DNA replication, RPA is essential for the initiation and elongation phases. It facilitates the assembly of the pre-replicative complex (pre-RC) at origins of replication, aids in the recruitment and activation of helicases, and promotes the switch from MCM2-7 helicase to polymerase processivity during DNA synthesis.
In addition to its role in DNA replication, RPA is involved in various DNA repair pathways, including nucleotide excision repair (NER), base excision repair (BER), mismatch repair (MMR), and double-strand break repair (DSBR). It also plays a critical role in meiotic recombination during sexual reproduction.
In summary, Replication Protein A (RPA) is a eukaryotic single-stranded DNA binding protein complex that protects, stabilizes, and regulates ssDNA during DNA replication, repair, and recombination processes.
Phylogeny is the evolutionary history and relationship among biological entities, such as species or genes, based on their shared characteristics. In other words, it refers to the branching pattern of evolution that shows how various organisms have descended from a common ancestor over time. Phylogenetic analysis involves constructing a tree-like diagram called a phylogenetic tree, which depicts the inferred evolutionary relationships among organisms or genes based on molecular sequence data or other types of characters. This information is crucial for understanding the diversity and distribution of life on Earth, as well as for studying the emergence and spread of diseases.
Archaeal proteins are proteins that are encoded by the genes found in archaea, a domain of single-celled microorganisms. These proteins are crucial for various cellular functions and structures in archaea, which are adapted to survive in extreme environments such as high temperatures, high salt concentrations, and low pH levels.
Archaeal proteins share similarities with both bacterial and eukaryotic proteins, but they also have unique features that distinguish them from each other. For example, many archaeal proteins contain unusual amino acids or modifications that are not commonly found in other organisms. Additionally, the three-dimensional structures of some archaeal proteins are distinct from their bacterial and eukaryotic counterparts.
Studying archaeal proteins is important for understanding the biology of these unique organisms and for gaining insights into the evolution of life on Earth. Furthermore, because some archaea can survive in extreme environments, their proteins may have properties that make them useful in industrial and medical applications.
Polyadenylation is a post-transcriptional modification process in which a string of adenine (A) nucleotides, known as a poly(A) tail, is added to the 3' end of a newly transcribed eukaryotic mRNA molecule. This process is essential for the stability, export, and translation of the mRNA. The addition of the poly(A) tail is catalyzed by a complex containing several proteins and the enzyme poly(A) polymerase. The length of the poly(A) tail typically ranges from 50 to 250 nucleotides and can be shortened or lengthened in response to various cellular signals, which contributes to the regulation of gene expression.
Gene expression is the process by which the information encoded in a gene is used to synthesize a functional gene product, such as a protein or RNA molecule. This process involves several steps: transcription, RNA processing, and translation. During transcription, the genetic information in DNA is copied into a complementary RNA molecule, known as messenger RNA (mRNA). The mRNA then undergoes RNA processing, which includes adding a cap and tail to the mRNA and splicing out non-coding regions called introns. The resulting mature mRNA is then translated into a protein on ribosomes in the cytoplasm through the process of translation.
The regulation of gene expression is a complex and highly controlled process that allows cells to respond to changes in their environment, such as growth factors, hormones, and stress signals. This regulation can occur at various stages of gene expression, including transcriptional activation or repression, RNA processing, mRNA stability, and translation. Dysregulation of gene expression has been implicated in many diseases, including cancer, genetic disorders, and neurological conditions.
Acetylation is a chemical process that involves the addition of an acetyl group (-COCH3) to a molecule. In the context of medical biochemistry, acetylation often refers to the post-translational modification of proteins, where an acetyl group is added to the amino group of a lysine residue in a protein by an enzyme called acetyltransferase. This modification can alter the function or stability of the protein and plays a crucial role in regulating various cellular processes such as gene expression, DNA repair, and cell signaling. Acetylation can also occur on other types of molecules, including lipids and carbohydrates, and has important implications for drug metabolism and toxicity.
DNA restriction enzymes, also known as restriction endonucleases, are a type of enzyme that cut double-stranded DNA at specific recognition sites. These enzymes are produced by bacteria and archaea as a defense mechanism against foreign DNA, such as that found in bacteriophages (viruses that infect bacteria).
Restriction enzymes recognize specific sequences of nucleotides (the building blocks of DNA) and cleave the phosphodiester bonds between them. The recognition sites for these enzymes are usually palindromic, meaning that the sequence reads the same in both directions when facing the opposite strands of DNA.
Restriction enzymes are widely used in molecular biology research for various applications such as genetic engineering, genome mapping, and DNA fingerprinting. They allow scientists to cut DNA at specific sites, creating precise fragments that can be manipulated and analyzed. The use of restriction enzymes has been instrumental in the development of recombinant DNA technology and the Human Genome Project.
Recombinant DNA is a term used in molecular biology to describe DNA that has been created by combining genetic material from more than one source. This is typically done through the use of laboratory techniques such as molecular cloning, in which fragments of DNA are inserted into vectors (such as plasmids or viruses) and then introduced into a host organism where they can replicate and produce many copies of the recombinant DNA molecule.
Recombinant DNA technology has numerous applications in research, medicine, and industry, including the production of recombinant proteins for use as therapeutics, the creation of genetically modified organisms (GMOs) for agricultural or industrial purposes, and the development of new tools for genetic analysis and manipulation.
It's important to note that while recombinant DNA technology has many potential benefits, it also raises ethical and safety concerns, and its use is subject to regulation and oversight in many countries.
Electrophoresis, Agar Gel is a laboratory technique used to separate and analyze DNA, RNA, or proteins based on their size and electrical charge. In this method, the sample is mixed with agarose gel, a gelatinous substance derived from seaweed, and then solidified in a horizontal slab-like format. An electric field is applied to the gel, causing the negatively charged DNA or RNA molecules to migrate towards the positive electrode. The smaller molecules move faster through the gel than the larger ones, resulting in their separation based on size. This technique is widely used in molecular biology and genetics research, as well as in diagnostic testing for various genetic disorders.
Amino acid motifs are recurring patterns or sequences of amino acids in a protein molecule. These motifs can be identified through various sequence analysis techniques and often have functional or structural significance. They can be as short as two amino acids in length, but typically contain at least three to five residues.
Some common examples of amino acid motifs include:
1. Active site motifs: These are specific sequences of amino acids that form the active site of an enzyme and participate in catalyzing chemical reactions. For example, the catalytic triad in serine proteases consists of three residues (serine, histidine, and aspartate) that work together to hydrolyze peptide bonds.
2. Signal peptide motifs: These are sequences of amino acids that target proteins for secretion or localization to specific organelles within the cell. For example, a typical signal peptide consists of a positively charged n-region, a hydrophobic h-region, and a polar c-region that directs the protein to the endoplasmic reticulum membrane for translocation.
3. Zinc finger motifs: These are structural domains that contain conserved sequences of amino acids that bind zinc ions and play important roles in DNA recognition and regulation of gene expression.
4. Transmembrane motifs: These are sequences of hydrophobic amino acids that span the lipid bilayer of cell membranes and anchor transmembrane proteins in place.
5. Phosphorylation sites: These are specific serine, threonine, or tyrosine residues that can be phosphorylated by protein kinases to regulate protein function.
Understanding amino acid motifs is important for predicting protein structure and function, as well as for identifying potential drug targets in disease-associated proteins.
"RNA 3' end processing" refers to the post-transcriptional modifications that occur at the 3' end of RNA transcripts. While "RNA 3' end processing" is not a specific medical term, it is a fundamental biological process that has implications in various areas of medicine, such as gene regulation and disease pathogenesis.
During RNA 3' end processing, several enzymatic activities take place to generate a mature and functional RNA molecule. These modifications typically include the removal of unnecessary sequences, the addition of a poly(A) tail, and sometimes the incorporation of a specific nucleotide called a "cap."
1. Removal of unnecessary sequences: In many cases, the initial RNA transcript contains non-coding regions (introns) that need to be removed to generate a mature RNA molecule. This process is known as splicing, and it results in the formation of an mRNA (messenger RNA) or other types of functional RNAs, such as rRNA (ribosomal RNA), tRNA (transfer RNA), or snRNA (small nuclear RNA).
2. Addition of a poly(A) tail: After splicing, the 3' end of the RNA molecule is further processed by adding a string of adenine nucleotides, known as a poly(A) tail. This modification is catalyzed by an enzyme called poly(A) polymerase and plays a crucial role in stabilizing the RNA molecule, promoting its export from the nucleus to the cytoplasm, and facilitating translation.
3. Incorporation of a cap: At the 5' end of the RNA molecule, a special structure called a "cap" is added. This cap consists of a modified guanine nucleotide that is linked to the first nucleotide of the RNA via a triphosphate bridge. The cap helps protect the RNA from degradation and plays a role in translation initiation by recruiting ribosomes and other translation factors.
Dysregulation of RNA 3' end processing has been implicated in various diseases, including cancer, neurological disorders, and viral infections. Understanding the molecular mechanisms underlying these processes can provide valuable insights into disease pathogenesis and potential therapeutic targets.
Endonucleases are enzymes that cleave, or cut, phosphodiester bonds within a polynucleotide chain, specifically within the same molecule of DNA or RNA. They can be found in all living organisms and play crucial roles in various biological processes, such as DNA replication, repair, and recombination.
Endonucleases can recognize specific nucleotide sequences (sequence-specific endonucleases) or have no sequence preference (non-specific endonucleases). Some endonucleases generate sticky ends, overhangs of single-stranded DNA after cleavage, while others produce blunt ends without any overhang.
These enzymes are widely used in molecular biology techniques, such as restriction digestion, cloning, and genome editing (e.g., CRISPR-Cas9 system). Restriction endonucleases recognize specific DNA sequences called restriction sites and cleave the phosphodiester bonds at or near these sites, generating defined fragment sizes that can be separated by agarose gel electrophoresis. This property is essential for various applications in genetic engineering and biotechnology.
Adenoviruses, Human: A group of viruses that commonly cause respiratory illnesses, such as bronchitis, pneumonia, and croup, in humans. They can also cause conjunctivitis (pink eye), cystitis (bladder infection), and gastroenteritis (stomach and intestinal infection).
Human adenoviruses are non-enveloped, double-stranded DNA viruses that belong to the family Adenoviridae. There are more than 50 different types of human adenoviruses, which can be classified into seven species (A-G). Different types of adenoviruses tend to cause specific illnesses, such as respiratory or gastrointestinal infections.
Human adenoviruses are highly contagious and can spread through close personal contact, respiratory droplets, or contaminated surfaces. They can also be transmitted through contaminated water sources. Some people may become carriers of the virus and experience no symptoms but still spread the virus to others.
Most human adenovirus infections are mild and resolve on their own within a few days to a week. However, some types of adenoviruses can cause severe illness, particularly in people with weakened immune systems, such as infants, young children, older adults, and individuals with HIV/AIDS or organ transplants.
There are no specific antiviral treatments for human adenovirus infections, but supportive care, such as hydration, rest, and fever reduction, can help manage symptoms. Preventive measures include practicing good hygiene, such as washing hands frequently, avoiding close contact with sick individuals, and not sharing personal items like towels or utensils.
Dactinomycin is an antineoplastic antibiotic, which means it is used to treat cancer. It is specifically used to treat certain types of testicular cancer, Wilms' tumor (a type of kidney cancer that occurs in children), and some gestational trophoblastic tumors (a type of tumor that can develop in the uterus after pregnancy). Dactinomycin works by interfering with the DNA in cancer cells, which prevents them from dividing and growing. It is often used in combination with other chemotherapy drugs as part of a treatment regimen.
Dactinomycin is administered intravenously (through an IV) and its use is usually limited to hospitals or specialized cancer treatment centers due to the need for careful monitoring during administration. Common side effects include nausea, vomiting, and hair loss. More serious side effects can include bone marrow suppression, which can lead to an increased risk of infection, and tissue damage at the site where the drug is injected. Dactinomycin can also cause severe allergic reactions in some people.
It's important to note that dactinomycin should only be used under the supervision of a qualified healthcare professional, as its use requires careful monitoring and management of potential side effects.
Histone Acetyltransferases (HATs) are a group of enzymes that play a crucial role in the regulation of gene expression. They function by adding acetyl groups to specific lysine residues on the N-terminal tails of histone proteins, which make up the structural core of nucleosomes - the fundamental units of chromatin.
The process of histone acetylation neutralizes the positive charge of lysine residues, reducing their attraction to the negatively charged DNA backbone. This leads to a more open and relaxed chromatin structure, facilitating the access of transcription factors and other regulatory proteins to the DNA, thereby promoting gene transcription.
HATs are classified into two main categories: type A HATs, which are primarily found in the nucleus and associated with transcriptional activation, and type B HATs, which are located in the cytoplasm and participate in chromatin assembly during DNA replication and repair. Dysregulation of HAT activity has been implicated in various human diseases, including cancer, neurodevelopmental disorders, and cardiovascular diseases.
Southern blotting is a type of membrane-based blotting technique that is used in molecular biology to detect and locate specific DNA sequences within a DNA sample. This technique is named after its inventor, Edward M. Southern.
In Southern blotting, the DNA sample is first digested with one or more restriction enzymes, which cut the DNA at specific recognition sites. The resulting DNA fragments are then separated based on their size by gel electrophoresis. After separation, the DNA fragments are denatured to convert them into single-stranded DNA and transferred onto a nitrocellulose or nylon membrane.
Once the DNA has been transferred to the membrane, it is hybridized with a labeled probe that is complementary to the sequence of interest. The probe can be labeled with radioactive isotopes, fluorescent dyes, or chemiluminescent compounds. After hybridization, the membrane is washed to remove any unbound probe and then exposed to X-ray film (in the case of radioactive probes) or scanned (in the case of non-radioactive probes) to detect the location of the labeled probe on the membrane.
The position of the labeled probe on the membrane corresponds to the location of the specific DNA sequence within the original DNA sample. Southern blotting is a powerful tool for identifying and characterizing specific DNA sequences, such as those associated with genetic diseases or gene regulation.
Protein kinases are a group of enzymes that play a crucial role in many cellular processes by adding phosphate groups to other proteins, a process known as phosphorylation. This modification can activate or deactivate the target protein's function, thereby regulating various signaling pathways within the cell. Protein kinases are essential for numerous biological functions, including metabolism, signal transduction, cell cycle progression, and apoptosis (programmed cell death). Abnormal regulation of protein kinases has been implicated in several diseases, such as cancer, diabetes, and neurological disorders.
Complementary DNA (cDNA) is a type of DNA that is synthesized from a single-stranded RNA molecule through the process of reverse transcription. In this process, the enzyme reverse transcriptase uses an RNA molecule as a template to synthesize a complementary DNA strand. The resulting cDNA is therefore complementary to the original RNA molecule and is a copy of its coding sequence, but it does not contain non-coding regions such as introns that are present in genomic DNA.
Complementary DNA is often used in molecular biology research to study gene expression, protein function, and other genetic phenomena. For example, cDNA can be used to create cDNA libraries, which are collections of cloned cDNA fragments that represent the expressed genes in a particular cell type or tissue. These libraries can then be screened for specific genes or gene products of interest. Additionally, cDNA can be used to produce recombinant proteins in heterologous expression systems, allowing researchers to study the structure and function of proteins that may be difficult to express or purify from their native sources.
RNA caps are structures found at the 5' end of RNA molecules, including messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). These caps consist of a modified guanine nucleotide (called 7-methylguanosine) that is linked to the first nucleotide of the RNA chain through a triphosphate bridge. The RNA cap plays several important roles in regulating RNA metabolism, including protecting the RNA from degradation by exonucleases, promoting the recognition and binding of the RNA by ribosomes during translation, and modulating the stability and transport of the RNA within the cell.
Oligoribonucleotides are short, synthetic chains of ribonucleotides, which are the building blocks of RNA (ribonucleic acid). These chains typically contain fewer than 20 ribonucleotide units, and can be composed of all four types of nucleotides found in RNA: adenine (A), uracil (U), guanine (G), and cytosine (C). They are often used in research for various purposes, such as studying RNA function, regulating gene expression, or serving as potential therapeutic agents.
The "tat" gene in the Human Immunodeficiency Virus (HIV) produces the Tat protein, which is a regulatory protein that plays a crucial role in the replication of the virus. The Tat protein functions by enhancing the transcription of the viral genome, increasing the production of viral RNA and ultimately leading to an increase in the production of new virus particles. This protein is essential for the efficient replication of HIV and is a target for potential antiretroviral therapies.
Uracil-DNA glycosylase (UDG) is an enzyme that plays a crucial role in the maintenance of genomic stability by removing uracil residues from DNA. These enzymes are essential because uracil can arise in DNA through the deamination of cytosine or through the misincorporation of dUMP during DNA replication. If left unrepaired, uracil can pair with adenine, leading to C:G to T:A transitions during subsequent rounds of replication.
UDGs initiate the base excision repair (BER) pathway by cleaving the N-glycosidic bond between the uracil base and the deoxyribose sugar, releasing the uracil base and creating an abasic site. The resulting apurinic/apyrimidinic (AP) site is then processed further by AP endonucleases, DNA polymerases, and ligases to complete the repair process.
There are several subtypes of UDGs that differ in their substrate specificity, cellular localization, and regulation. For example, some UDGs specifically remove uracil from single-stranded or double-stranded DNA, while others have broader substrate specificity and can also remove other damaged bases. Understanding the function and regulation of these enzymes is important for understanding the mechanisms that maintain genomic stability and prevent mutations.
I'm sorry for any confusion, but "Schizosaccharomyces pombe proteins" is not a medical term or concept. Schizosaccharomyces pombe is a type of single-celled microorganism called a yeast, which is often used as a model organism in scientific research. Proteins are complex molecules that do most of the work in cells and are necessary for the structure, function, and regulation of the body's tissues and organs.
In the context of scientific research, "Schizosaccharomyces pombe proteins" would refer to the specific proteins found in or studied using this particular type of yeast. These proteins may have similarities to human proteins and can be used to help understand basic biological processes, as well as diseases that occur in humans. However, it is important to note that while research using model organisms like Schizosaccharomyces pombe has led to many important discoveries, the findings may not always translate directly to humans.
Xeroderma Pigmentosum (XP) is a rare, genetic disorder that affects the body's ability to repair damage to DNA caused by ultraviolet (UV) radiation from sunlight. The condition results in extreme sensitivity to UV light. People with XP develop freckles and moles on sun-exposed skin at an early age, and are prone to developing various forms of skin cancer. In severe cases, the disease may also affect the eyes and nervous system.
The disorder is caused by mutations in genes that are responsible for repairing damaged DNA. If not diagnosed and managed properly, XP can lead to serious health complications, including disability and death. Treatment typically involves strict sun protection measures, such as avoiding sunlight, using sunscreen, wearing protective clothing, and in some cases, medication or surgery.
2-Aminopurine is a fluorescent purine analog, which means it is a compound that is similar in structure to the naturally occurring molecule called purines, which are building blocks of DNA and RNA. 2-Aminopurine is used in research to study the structure and function of nucleic acids (DNA and RNA) due to its fluorescent properties. It can be incorporated into oligonucleotides (short stretches of nucleic acids) to allow for the monitoring of interactions between nucleic acids, such as during DNA replication or transcription. The fluorescence of 2-Aminopurine changes upon excitation with light and can be used to detect structural changes in nucleic acids or to measure the distance between two fluorophores.
Reverse Transcriptase Inhibitors (RTIs) are a class of antiretroviral drugs that are primarily used in the treatment and management of HIV (Human Immunodeficiency Virus) infection. They work by inhibiting the reverse transcriptase enzyme, which is essential for the replication of HIV.
HIV is a retrovirus, meaning it has an RNA genome and uses a unique enzyme called reverse transcriptase to convert its RNA into DNA. This process is necessary for the virus to integrate into the host cell's genome and replicate. Reverse Transcriptase Inhibitors interfere with this process by binding to the reverse transcriptase enzyme, preventing it from converting the viral RNA into DNA.
RTIs can be further divided into two categories: nucleoside/nucleotide reverse transcriptase inhibitors (NRTIs) and non-nucleoside reverse transcriptase inhibitors (NNRTIs). NRTIs are analogs of the building blocks of DNA, which get incorporated into the growing DNA chain during replication, causing termination of the chain. NNRTIs bind directly to the reverse transcriptase enzyme, causing a conformational change that prevents it from functioning.
By inhibiting the reverse transcriptase enzyme, RTIs can prevent the virus from replicating and reduce the viral load in an infected individual, thereby slowing down the progression of HIV infection and AIDS (Acquired Immunodeficiency Syndrome).
Peptide elongation factors are a group of proteins that play a crucial role in the process of protein synthesis in cells, specifically during the elongation stage of translation. They assist in the addition of amino acids to the growing polypeptide chain by facilitating the binding of aminoacyl-tRNAs (transfer RNAs with attached amino acids) to the ribosome, where protein synthesis occurs.
In prokaryotic cells, there are two main peptide elongation factors: EF-Tu and EF-G. EF-Tu forms a complex with aminoacyl-tRNA and delivers it to the ribosome's acceptor site (A-site), where the incoming amino acid is matched with the corresponding codon on the mRNA. Once the correct match is made, GTP hydrolysis occurs, releasing EF-Tu from the complex, allowing for peptide bond formation between the new amino acid and the growing polypeptide chain.
EF-G then enters the scene to facilitate translocation, the movement of the ribosome along the mRNA, which shifts the newly formed peptidyl-tRNA from the A-site to the P-site (peptidyl-tRNA site) and makes room for another aminoacyl-tRNA in the A-site. This process continues until protein synthesis is complete.
In eukaryotic cells, the equivalent proteins are called EF1α, EF1β, EF1γ, and EF2 (also known as eEF1A, eEF1B, eEF1G, and eEF2). The overall function remains similar to that in prokaryotes, but the specific mechanisms and protein names differ.
A "gene product" is the biochemical material that results from the expression of a gene. This can include both RNA and protein molecules. In the case of the tat (transactivator of transcription) gene in human immunodeficiency virus (HIV), the gene product is a regulatory protein that plays a crucial role in the viral replication cycle.
The tat protein is a viral transactivator, which means it increases the transcription of HIV genes by interacting with various components of the host cell's transcription machinery. Specifically, tat binds to a complex called TAR (transactivation response element), which is located in the 5' untranslated region of all nascent HIV mRNAs. By binding to TAR, tat recruits and activates positive transcription elongation factor b (P-TEFb), which then phosphorylates the carboxy-terminal domain of RNA polymerase II, leading to efficient elongation of HIV transcripts.
The tat protein is essential for HIV replication, as it enhances viral gene expression and promotes the production of new virus particles. Inhibiting tat function has been a target for developing antiretroviral therapies against HIV infection.
Protein biosynthesis is the process by which cells generate new proteins. It involves two major steps: transcription and translation. Transcription is the process of creating a complementary RNA copy of a sequence of DNA. This RNA copy, or messenger RNA (mRNA), carries the genetic information to the site of protein synthesis, the ribosome. During translation, the mRNA is read by transfer RNA (tRNA) molecules, which bring specific amino acids to the ribosome based on the sequence of nucleotides in the mRNA. The ribosome then links these amino acids together in the correct order to form a polypeptide chain, which may then fold into a functional protein. Protein biosynthesis is essential for the growth and maintenance of all living organisms.
Cytidine triphosphate (CTP) is a nucleotide that plays a crucial role in the synthesis of RNA. It consists of a cytosine base, a ribose sugar, and three phosphate groups. Cytidine triphosphate is one of the four main building blocks of RNA, along with adenosine triphosphate (ATP), guanosine triphosphate (GTP), and uridine triphosphate (UTP). These nucleotides are essential for various cellular processes, including energy transfer, signal transduction, and biosynthesis. CTP is also involved in the regulation of several metabolic pathways and serves as a cofactor for enzymes that catalyze biochemical reactions. Like other triphosphate nucleotides, CTP provides energy for cellular functions by donating its phosphate groups in energy-consuming processes.
"Thermococcus" is not a medical term, but rather a genus of archaea (single-celled microorganisms) that are extremophiles, meaning they thrive in extreme environments. Specifically, Thermococcus species are found in hydrothermal vents and other high-temperature, high-pressure, and anaerobic environments. They are known for their ability to grow at very high temperatures, with some species able to grow at temperatures up to 122°C (252°F). These microorganisms play a significant role in the global carbon cycle and have potential applications in biotechnology.
I'm sorry for any confusion, but "Carcinoma, Ehrlich Tumor" is not a recognized medical term or a valid medical definition. The term "Ehrlich tumor" is sometimes used to refer to a type of transplantable tumor that was first developed by the German physician Paul Ehrlich in the early 20th century for cancer research purposes. However, it's important to note that this type of tumor is not a naturally occurring cancer and is typically used only in laboratory experiments.
Carcinoma, on the other hand, is a medical term that refers to a type of cancer that starts in cells that line the inner or outer surfaces of organs. Carcinomas can develop in various parts of the body, including the lungs, breasts, colon, and skin.
If you have any specific questions about cancer or a particular medical condition, I would be happy to try to help answer them for you.
Thymidine Monophosphate (TMP or dTMP) is a nucleotide that is a ester of phosphoric acid with thymidine, a nucleoside consisting of deoxyribose sugar linked to the nitrogenous base thymine. It is one of the four monophosphate nucleotides that are the building blocks of DNA, along with adenosine monophosphate (AMP), guanosine monophosphate (GMP), and cytidine monophosphate (CMP). TMP plays a crucial role in DNA replication and repair processes. It is also used as a marker in biochemical research and medical diagnostics.
Adenoviridae is a family of viruses that includes many species that can cause various types of illnesses in humans and animals. These viruses are non-enveloped, meaning they do not have a lipid membrane, and have an icosahedral symmetry with a diameter of approximately 70-90 nanometers.
The genome of Adenoviridae is composed of double-stranded DNA, which contains linear chromosomes ranging from 26 to 45 kilobases in length. The family is divided into five genera: Mastadenovirus, Aviadenovirus, Atadenovirus, Siadenovirus, and Ichtadenovirus.
Human adenoviruses are classified under the genus Mastadenovirus and can cause a wide range of illnesses, including respiratory infections, conjunctivitis, gastroenteritis, and upper respiratory tract infections. Some serotypes have also been associated with more severe diseases such as hemorrhagic cystitis, hepatitis, and meningoencephalitis.
Adenoviruses are highly contagious and can be transmitted through respiratory droplets, fecal-oral route, or by contact with contaminated surfaces. They can also be spread through contaminated water sources. Infections caused by adenoviruses are usually self-limiting, but severe cases may require hospitalization and supportive care.
Dimerization is a process in which two molecules, usually proteins or similar structures, bind together to form a larger complex. This can occur through various mechanisms, such as the formation of disulfide bonds, hydrogen bonding, or other non-covalent interactions. Dimerization can play important roles in cell signaling, enzyme function, and the regulation of gene expression.
In the context of medical research and therapy, dimerization is often studied in relation to specific proteins that are involved in diseases such as cancer. For example, some drugs have been developed to target and inhibit the dimerization of certain proteins, with the goal of disrupting their function and slowing or stopping the progression of the disease.
Cross-linking reagents are chemical agents that are used to create covalent bonds between two or more molecules, creating a network of interconnected molecules known as a cross-linked structure. In the context of medical and biological research, cross-linking reagents are often used to stabilize protein structures, study protein-protein interactions, and develop therapeutic agents.
Cross-linking reagents work by reacting with functional groups on adjacent molecules, such as amino groups (-NH2) or sulfhydryl groups (-SH), to form a covalent bond between them. This can help to stabilize protein structures and prevent them from unfolding or aggregating.
There are many different types of cross-linking reagents, each with its own specificity and reactivity. Some common examples include glutaraldehyde, formaldehyde, disuccinimidyl suberate (DSS), and bis(sulfosuccinimidyl) suberate (BS3). The choice of cross-linking reagent depends on the specific application and the properties of the molecules being cross-linked.
It is important to note that cross-linking reagents can also have unintended effects, such as modifying or disrupting the function of the proteins they are intended to stabilize. Therefore, it is essential to use them carefully and with appropriate controls to ensure accurate and reliable results.
Deoxyribonuclease I (DNase I) is an enzyme that cleaves the phosphodiester bonds in the DNA molecule, breaking it down into smaller pieces. It is also known as DNase A or bovine pancreatic deoxyribonuclease. This enzyme specifically hydrolyzes the internucleotide linkages of DNA by cleaving the phosphodiester bond between the 3'-hydroxyl group of one deoxyribose sugar and the phosphate group of another, leaving 3'-phosphomononucleotides as products.
DNase I plays a crucial role in various biological processes, including DNA degradation during apoptosis (programmed cell death), DNA repair, and host defense against pathogens by breaking down extracellular DNA from invading microorganisms or damaged cells. It is widely used in molecular biology research for applications such as DNA isolation, removing contaminating DNA from RNA samples, and generating defined DNA fragments for cloning purposes. DNase I can be found in various sources, including bovine pancreas, human tears, and bacterial cultures.
Globins are a group of proteins that contain a heme prosthetic group, which binds and transports oxygen in the blood. The most well-known globin is hemoglobin, which is found in red blood cells and is responsible for carrying oxygen from the lungs to the body's tissues. Other members of the globin family include myoglobin, which is found in muscle tissue and stores oxygen, and neuroglobin and cytoglobin, which are found in the brain and other organs and may have roles in protecting against oxidative stress and hypoxia (low oxygen levels). Globins share a similar structure, with a folded protein surrounding a central heme group. Mutations in globin genes can lead to various diseases, such as sickle cell anemia and thalassemia.
Potassium chloride is an essential electrolyte that is often used in medical settings as a medication. It's a white, crystalline salt that is highly soluble in water and has a salty taste. In the body, potassium chloride plays a crucial role in maintaining fluid and electrolyte balance, nerve function, and muscle contraction.
Medically, potassium chloride is commonly used to treat or prevent low potassium levels (hypokalemia) in the blood. Hypokalemia can occur due to various reasons such as certain medications, kidney diseases, vomiting, diarrhea, or excessive sweating. Potassium chloride is available in various forms, including tablets, capsules, and liquids, and it's usually taken by mouth.
It's important to note that potassium chloride should be used with caution and under the supervision of a healthcare provider, as high levels of potassium (hyperkalemia) can be harmful and even life-threatening. Hyperkalemia can cause symptoms such as muscle weakness, irregular heartbeat, and cardiac arrest.
Ribonucleoproteins (RNPs) are complexes composed of ribonucleic acid (RNA) and proteins. They play crucial roles in various cellular processes, including gene expression, RNA processing, transport, stability, and degradation. Different types of RNPs exist, such as ribosomes, spliceosomes, and signal recognition particles, each having specific functions in the cell.
Ribosomes are large RNP complexes responsible for protein synthesis, where messenger RNA (mRNA) is translated into proteins. They consist of two subunits: a smaller subunit containing ribosomal RNA (rRNA) and proteins that recognize the start codon on mRNA, and a larger subunit with rRNA and proteins that facilitate peptide bond formation during translation.
Spliceosomes are dynamic RNP complexes involved in pre-messenger RNA (pre-mRNA) splicing, where introns (non-coding sequences) are removed, and exons (coding sequences) are joined together to form mature mRNA. Spliceosomes consist of five small nuclear ribonucleoproteins (snRNPs), each containing a specific small nuclear RNA (snRNA) and several proteins, as well as numerous additional proteins.
Other RNP complexes include signal recognition particles (SRPs), which are responsible for targeting secretory and membrane proteins to the endoplasmic reticulum during translation, and telomerase, an enzyme that maintains the length of telomeres (the protective ends of chromosomes) by adding repetitive DNA sequences using its built-in RNA component.
In summary, ribonucleoproteins are essential complexes in the cell that participate in various aspects of RNA metabolism and protein synthesis.
DNA repair enzymes are a group of enzymes that are responsible for identifying and correcting damage to the DNA molecule. These enzymes play a critical role in maintaining the integrity of an organism's genetic material, as they help to ensure that the information stored in DNA is accurately transmitted during cell division and reproduction.
There are several different types of DNA repair enzymes, each responsible for correcting specific types of damage. For example, base excision repair enzymes remove and replace damaged or incorrect bases, while nucleotide excision repair enzymes remove larger sections of damaged DNA and replace them with new nucleotides. Other types of DNA repair enzymes include mismatch repair enzymes, which correct errors that occur during DNA replication, and double-strand break repair enzymes, which are responsible for fixing breaks in both strands of the DNA molecule.
Defects in DNA repair enzymes have been linked to a variety of diseases, including cancer, neurological disorders, and premature aging. For example, individuals with xeroderma pigmentosum, a rare genetic disorder characterized by an increased risk of skin cancer, have mutations in genes that encode nucleotide excision repair enzymes. Similarly, defects in mismatch repair enzymes have been linked to hereditary nonpolyposis colorectal cancer, a type of colon cancer that is inherited and tends to occur at a younger age than sporadic colon cancer.
Overall, DNA repair enzymes play a critical role in maintaining the stability and integrity of an organism's genetic material, and defects in these enzymes can have serious consequences for human health.
Uridine Triphosphate (UTP) is a nucleotide that plays a crucial role in the synthesis and repair of DNA and RNA. It consists of a nitrogenous base called uracil, a pentose sugar (ribose), and three phosphate groups. UTP is one of the four triphosphates used in the biosynthesis of RNA during transcription, where it donates its uracil base to the growing RNA chain. Additionally, UTP serves as an energy source and a substrate in various biochemical reactions within the cell, including phosphorylation processes and the synthesis of glycogen and other molecules.
HIV Reverse Transcriptase is an enzyme that is encoded by the HIV-1 and HIV-2 viruses. It plays a crucial role in the replication cycle of the human immunodeficiency virus (HIV), which causes AIDS.
Reverse transcriptase is responsible for transcribing the viral RNA genome into DNA, a process known as reverse transcription. This allows the viral genetic material to integrate into the host cell's DNA and replicate along with it, leading to the production of new virus particles.
The enzyme has three distinct activities: a polymerase activity that synthesizes DNA using RNA as a template, an RNase H activity that degrades the RNA template during reverse transcription, and a DNA-dependent DNA polymerase activity that synthesizes DNA using a DNA template.
Reverse transcriptase inhibitors are a class of antiretroviral drugs used to treat HIV infection. They work by binding to and inhibiting the activity of the reverse transcriptase enzyme, thereby preventing the virus from replicating.
Gene expression regulation, enzymologic refers to the biochemical processes and mechanisms that control the transcription and translation of specific genes into functional proteins or enzymes. This regulation is achieved through various enzymatic activities that can either activate or repress gene expression at different levels, such as chromatin remodeling, transcription factor activation, mRNA processing, and protein degradation.
Enzymologic regulation of gene expression involves the action of specific enzymes that catalyze chemical reactions involved in these processes. For example, histone-modifying enzymes can alter the structure of chromatin to make genes more or less accessible for transcription, while RNA polymerase and its associated factors are responsible for transcribing DNA into mRNA. Additionally, various enzymes are involved in post-transcriptional modifications of mRNA, such as splicing, capping, and tailing, which can affect the stability and translation of the transcript.
Overall, the enzymologic regulation of gene expression is a complex and dynamic process that allows cells to respond to changes in their environment and maintain proper physiological function.
Chromosome mapping, also known as physical mapping, is the process of determining the location and order of specific genes or genetic markers on a chromosome. This is typically done by using various laboratory techniques to identify landmarks along the chromosome, such as restriction enzyme cutting sites or patterns of DNA sequence repeats. The resulting map provides important information about the organization and structure of the genome, and can be used for a variety of purposes, including identifying the location of genes associated with genetic diseases, studying evolutionary relationships between organisms, and developing genetic markers for use in breeding or forensic applications.
Molecular structure, in the context of biochemistry and molecular biology, refers to the arrangement and organization of atoms and chemical bonds within a molecule. It describes the three-dimensional layout of the constituent elements, including their spatial relationships, bond lengths, and angles. Understanding molecular structure is crucial for elucidating the functions and reactivities of biological macromolecules such as proteins, nucleic acids, lipids, and carbohydrates. Various experimental techniques, like X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and cryo-electron microscopy (cryo-EM), are employed to determine molecular structures at atomic resolution, providing valuable insights into their biological roles and potential therapeutic targets.
Cyclin C is a type of cyclin protein that plays a crucial role in the regulation of the cell cycle, which is the process by which cells grow and divide. Specifically, Cyclin C is involved in the transition from the G1 phase to the S phase of the cell cycle, during which DNA replication occurs.
Cyclin C forms a complex with cyclin-dependent kinase 8 (CDK8) and other regulatory subunits to form the CDK8 module, which is part of the mediator complex that regulates gene transcription. The activity of Cyclin C/CDK8 is regulated by various mechanisms, including phosphorylation and degradation, to ensure proper control of the cell cycle and prevent uncontrolled cell growth and division.
Mutations in the gene encoding Cyclin C have been associated with certain types of cancer, highlighting its importance in maintaining genomic stability and preventing tumorigenesis.
DNA viruses are a type of virus that contain DNA (deoxyribonucleic acid) as their genetic material. These viruses replicate by using the host cell's machinery to synthesize new viral components, which are then assembled into new viruses and released from the host cell.
DNA viruses can be further classified based on the structure of their genomes and the way they replicate. For example, double-stranded DNA (dsDNA) viruses have a genome made up of two strands of DNA, while single-stranded DNA (ssDNA) viruses have a genome made up of a single strand of DNA.
Examples of DNA viruses include herpes simplex virus, varicella-zoster virus, human papillomavirus, and adenoviruses. Some DNA viruses are associated with specific diseases, such as cancer (e.g., human papillomavirus) or neurological disorders (e.g., herpes simplex virus).
It's important to note that while DNA viruses contain DNA as their genetic material, RNA viruses contain RNA (ribonucleic acid) as their genetic material. Both DNA and RNA viruses can cause a wide range of diseases in humans, animals, and plants.
Organophosphorus compounds are a class of chemical substances that contain phosphorus bonded to organic compounds. They are used in various applications, including as plasticizers, flame retardants, pesticides (insecticides, herbicides, and nerve gases), and solvents. In medicine, they are also used in the treatment of certain conditions such as glaucoma. However, organophosphorus compounds can be toxic to humans and animals, particularly those that affect the nervous system by inhibiting acetylcholinesterase, an enzyme that breaks down the neurotransmitter acetylcholine. Exposure to these compounds can cause symptoms such as nausea, vomiting, muscle weakness, and in severe cases, respiratory failure and death.
A viral genome is the genetic material (DNA or RNA) that is present in a virus. It contains all the genetic information that a virus needs to replicate itself and infect its host. The size and complexity of viral genomes can vary greatly, ranging from a few thousand bases to hundreds of thousands of bases. Some viruses have linear genomes, while others have circular genomes. The genome of a virus also contains the information necessary for the virus to hijack the host cell's machinery and use it to produce new copies of the virus. Understanding the genetic makeup of viruses is important for developing vaccines and antiviral treatments.
RNA interference (RNAi) is a biological process in which RNA molecules inhibit the expression of specific genes. This process is mediated by small RNA molecules, including microRNAs (miRNAs) and small interfering RNAs (siRNAs), that bind to complementary sequences on messenger RNA (mRNA) molecules, leading to their degradation or translation inhibition.
RNAi plays a crucial role in regulating gene expression and defending against foreign genetic elements, such as viruses and transposons. It has also emerged as an important tool for studying gene function and developing therapeutic strategies for various diseases, including cancer and viral infections.
Cyclin H is a type of protein that is classified as a cyclin, which is a regulatory subunit of cyclin-dependent kinases (CDKs). Specifically, Cyclin H forms a complex with CDK7 and functions as an essential component of the cell cycle transcriptional coactivator known as TFIIH.
TFIIH plays a crucial role in the initiation of transcription by RNA polymerase II and also participates in the process of DNA repair. The Cyclin H-CDK7 complex phosphorylates the carboxy-terminal domain (CTD) of the largest subunit of RNA polymerase II, which is a critical step in the transcription cycle. Additionally, Cyclin H-CDK7 also plays a role in regulating the cell cycle by controlling the activity of certain cell cycle regulators, such as E2F transcription factors.
Mutations in the gene that encodes Cyclin H have been associated with certain human diseases, including a rare inherited disorder called Cockayne syndrome, which is characterized by developmental abnormalities, neurological dysfunction, and premature aging.
Ribosomal RNA (rRNA) is a type of RNA molecule that is a key component of ribosomes, which are the cellular structures where protein synthesis occurs in cells. In ribosomes, rRNA plays a crucial role in the process of translation, where genetic information from messenger RNA (mRNA) is translated into proteins.
Ribosomal RNA is synthesized in the nucleus and then transported to the cytoplasm, where it assembles with ribosomal proteins to form ribosomes. Within the ribosome, rRNA provides a structural framework for the assembly of the ribosome and also plays an active role in catalyzing the formation of peptide bonds between amino acids during protein synthesis.
There are several different types of rRNA molecules, including 5S, 5.8S, 18S, and 28S rRNA, which vary in size and function. These rRNA molecules are highly conserved across different species, indicating their essential role in protein synthesis and cellular function.
Retroviridae is a family of viruses that includes human immunodeficiency virus (HIV) and other viruses that primarily use RNA as their genetic material. The name "retrovirus" comes from the fact that these viruses reverse transcribe their RNA genome into DNA, which then becomes integrated into the host cell's genome. This is a unique characteristic of retroviruses, as most other viruses use DNA as their genetic material.
Retroviruses can cause a variety of diseases in animals and humans, including cancer, neurological disorders, and immunodeficiency syndromes like AIDS. They have a lipid membrane envelope that contains glycoprotein spikes, which allow them to attach to and enter host cells. Once inside the host cell, the viral RNA is reverse transcribed into DNA by the enzyme reverse transcriptase, which is then integrated into the host genome by the enzyme integrase.
Retroviruses can remain dormant in the host genome for extended periods of time, and may be reactivated under certain conditions to produce new viral particles. This ability to integrate into the host genome has also made retroviruses useful tools in molecular biology, where they are used as vectors for gene therapy and other genetic manipulations.
DNA footprinting is a laboratory technique used to identify specific DNA-protein interactions and map the binding sites of proteins on a DNA molecule. This technique involves the use of enzymes or chemicals that can cleave the DNA strand, but are prevented from doing so when a protein is bound to the DNA. By comparing the pattern of cuts in the presence and absence of the protein, researchers can identify the regions of the DNA where the protein binds.
The process typically involves treating the DNA-protein complex with a chemical or enzymatic agent that cleaves the DNA at specific sequences or sites. After the reaction is stopped, the DNA is separated into single strands and analyzed using techniques such as gel electrophoresis to visualize the pattern of cuts. The regions of the DNA where protein binding has occurred are protected from cleavage and appear as gaps or "footprints" in the pattern of cuts.
DNA footprinting is a valuable tool for studying gene regulation, as it can provide insights into how proteins interact with specific DNA sequences to control gene expression. It can also be used to study protein-DNA interactions involved in processes such as DNA replication, repair, and recombination.
'Drosophila proteins' refer to the proteins that are expressed in the fruit fly, Drosophila melanogaster. This organism is a widely used model system in genetics, developmental biology, and molecular biology research. The study of Drosophila proteins has contributed significantly to our understanding of various biological processes, including gene regulation, cell signaling, development, and aging.
Some examples of well-studied Drosophila proteins include:
1. HSP70 (Heat Shock Protein 70): A chaperone protein involved in protein folding and protection from stress conditions.
2. TUBULIN: A structural protein that forms microtubules, important for cell division and intracellular transport.
3. ACTIN: A cytoskeletal protein involved in muscle contraction, cell motility, and maintenance of cell shape.
4. BETA-GALACTOSIDASE (LACZ): A reporter protein often used to monitor gene expression patterns in transgenic flies.
5. ENDOGLIN: A protein involved in the development of blood vessels during embryogenesis.
6. P53: A tumor suppressor protein that plays a crucial role in preventing cancer by regulating cell growth and division.
7. JUN-KINASE (JNK): A signaling protein involved in stress response, apoptosis, and developmental processes.
8. DECAPENTAPLEGIC (DPP): A member of the TGF-β (Transforming Growth Factor Beta) superfamily, playing essential roles in embryonic development and tissue homeostasis.
These proteins are often studied using various techniques such as biochemistry, genetics, molecular biology, and structural biology to understand their functions, interactions, and regulation within the cell.
The "3' flanking region" in molecular biology refers to the DNA sequence that is located immediately downstream (towards the 3' end) of a gene. This region does not code for the protein or functional RNA that the gene produces, but it can contain regulatory elements such as enhancers and silencers that influence the transcription of the gene. The 3' flanking region typically contains the polyadenylation signal, which is necessary for the addition of a string of adenine nucleotides (the poly(A) tail) to the messenger RNA (mRNA) molecule during processing. This modification helps protect the mRNA from degradation and facilitates its transport out of the nucleus and translation into protein.
It is important to note that the "3'" in 3' flanking region refers to the orientation of the DNA sequence relative to the coding (or transcribed) strand, which is the strand that contains the gene sequence and is used as a template for transcription. In this context, the 3' end of the coding strand corresponds to the 5' end of the mRNA molecule after transcription.
'Cercopithecus aethiops' is the scientific name for the monkey species more commonly known as the green monkey. It belongs to the family Cercopithecidae and is native to western Africa. The green monkey is omnivorous, with a diet that includes fruits, nuts, seeds, insects, and small vertebrates. They are known for their distinctive greenish-brown fur and long tail. Green monkeys are also important animal models in biomedical research due to their susceptibility to certain diseases, such as SIV (simian immunodeficiency virus), which is closely related to HIV.
Enzyme inhibitors are substances that bind to an enzyme and decrease its activity, preventing it from catalyzing a chemical reaction in the body. They can work by several mechanisms, including blocking the active site where the substrate binds, or binding to another site on the enzyme to change its shape and prevent substrate binding. Enzyme inhibitors are often used as drugs to treat various medical conditions, such as high blood pressure, abnormal heart rhythms, and bacterial infections. They can also be found naturally in some foods and plants, and can be used in research to understand enzyme function and regulation.
Genotype, in genetics, refers to the complete heritable genetic makeup of an individual organism, including all of its genes. It is the set of instructions contained in an organism's DNA for the development and function of that organism. The genotype is the basis for an individual's inherited traits, and it can be contrasted with an individual's phenotype, which refers to the observable physical or biochemical characteristics of an organism that result from the expression of its genes in combination with environmental influences.
It is important to note that an individual's genotype is not necessarily identical to their genetic sequence. Some genes have multiple forms called alleles, and an individual may inherit different alleles for a given gene from each parent. The combination of alleles that an individual inherits for a particular gene is known as their genotype for that gene.
Understanding an individual's genotype can provide important information about their susceptibility to certain diseases, their response to drugs and other treatments, and their risk of passing on inherited genetic disorders to their offspring.
Medical Definition of "Herpesvirus 1, Human" (also known as Human Herpesvirus 1 or HHV-1):
Herpesvirus 1, Human is a type of herpesvirus that primarily causes infection in humans. It is also commonly referred to as human herpesvirus 1 (HHV-1) or oral herpes. This virus is highly contagious and can be transmitted through direct contact with infected saliva, skin, or mucous membranes.
After initial infection, the virus typically remains dormant in the body's nerve cells and may reactivate later, causing recurrent symptoms. The most common manifestation of HHV-1 infection is oral herpes, characterized by cold sores or fever blisters around the mouth and lips. In some cases, HHV-1 can also cause other conditions such as encephalitis (inflammation of the brain) and keratitis (inflammation of the eye's cornea).
There is no cure for HHV-1 infection, but antiviral medications can help manage symptoms and reduce the severity and frequency of recurrent outbreaks.
In the context of cell biology, "S phase" refers to the part of the cell cycle during which DNA replication occurs. The "S" stands for synthesis, reflecting the active DNA synthesis that takes place during this phase. It is preceded by G1 phase (gap 1) and followed by G2 phase (gap 2), with mitosis (M phase) being the final stage of the cell cycle.
During S phase, the cell's DNA content effectively doubles as each chromosome is replicated to ensure that the two resulting daughter cells will have the same genetic material as the parent cell. This process is carefully regulated and coordinated with other events in the cell cycle to maintain genomic stability.
Vidarabine phosphate is a antiviral medication used to treat herpes simplex encephalitis, a severe form of brain infection caused by the herpes simplex virus. It works by inhibiting the replication of the virus in human cells. Vidarabine phosphate is the salt of vidarabine, which is a nucleoside analogue that gets incorporated into viral DNA during replication, leading to termination of the DNA chain and preventing further viral reproduction. It is administered through intravenous (IV) infusion in a hospital setting.
Carrier proteins, also known as transport proteins, are a type of protein that facilitates the movement of molecules across cell membranes. They are responsible for the selective and active transport of ions, sugars, amino acids, and other molecules from one side of the membrane to the other, against their concentration gradient. This process requires energy, usually in the form of ATP (adenosine triphosphate).
Carrier proteins have a specific binding site for the molecule they transport, and undergo conformational changes upon binding, which allows them to move the molecule across the membrane. Once the molecule has been transported, the carrier protein returns to its original conformation, ready to bind and transport another molecule.
Carrier proteins play a crucial role in maintaining the balance of ions and other molecules inside and outside of cells, and are essential for many physiological processes, including nerve impulse transmission, muscle contraction, and nutrient uptake.
Herpesviridae is a family of large, double-stranded DNA viruses that includes several important pathogens affecting humans and animals. The herpesviruses are characterized by their ability to establish latency in infected host cells, allowing them to persist for the lifetime of the host and leading to recurrent episodes of disease.
The family Herpesviridae is divided into three subfamilies: Alphaherpesvirinae, Betaherpesvirinae, and Gammaherpesvirinae. Each subfamily includes several genera and species that infect various hosts, including humans, primates, rodents, birds, and reptiles.
Human herpesviruses include:
* Alphaherpesvirinae: Herpes simplex virus type 1 (HSV-1), Herpes simplex virus type 2 (HSV-2), and Varicella-zoster virus (VZV)
* Betaherpesvirinae: Human cytomegalovirus (HCMV), Human herpesvirus 6A (HHV-6A), Human herpesvirus 6B (HHV-6B), and Human herpesvirus 7 (HHV-7)
* Gammaherpesvirinae: Epstein-Barr virus (EBV) and Kaposi's sarcoma-associated herpesvirus (KSHV, also known as HHV-8)
These viruses are responsible for a wide range of clinical manifestations, from mild skin lesions to life-threatening diseases. Primary infections usually occur during childhood or adolescence and can be followed by recurrent episodes due to virus reactivation from latency.
Magnesium Chloride is an inorganic compound with the chemical formula MgCl2. It is a white, deliquescent solid that is highly soluble in water. Medically, magnesium chloride is used as a source of magnesium ions, which are essential for many biochemical reactions in the human body.
It can be administered orally, intravenously, or topically to treat or prevent magnesium deficiency, cardiac arrhythmias, seizures, and preterm labor. Topical application is also used as a mineral supplement and for skin care purposes due to its moisturizing properties. However, high doses of magnesium chloride can have side effects such as diarrhea, nausea, and muscle weakness, and should be used under medical supervision.
Baculoviridae is a family of large, double-stranded DNA viruses that infect arthropods, particularly insects. The virions (virus particles) are enclosed in a rod-shaped or occlusion body called a polyhedron, which provides protection and stability in the environment. Baculoviruses have a wide host range within the order Lepidoptera (moths and butterflies), Hymenoptera (sawflies, bees, wasps, and ants), and Diptera (flies). They are important pathogens in agriculture and forestry, causing significant damage to insect pests.
The Baculoviridae family is divided into four genera: Alphabaculovirus, Betabaculovirus, Gammabaculovirus, and Deltabaculovirus. The two most well-studied and economically important genera are Alphabaculovirus (nuclear polyhedrosis viruses or NPVs) and Betabaculovirus (granulosis viruses or GVs).
Baculoviruses have a biphasic replication cycle, consisting of a budded phase and an occluded phase. During the budded phase, the virus infects host cells and produces enveloped virions that can spread to other cells within the insect. In the occluded phase, large numbers of non-enveloped virions are produced and encapsidated in a protein matrix called a polyhedron. These polyhedra accumulate in the infected insect's tissues, providing protection from environmental degradation and facilitating transmission to new hosts through oral ingestion or other means.
Baculoviruses have been extensively studied as models for understanding viral replication, gene expression, and host-pathogen interactions. They also have potential applications in biotechnology and pest control, including the production of recombinant proteins, gene therapy vectors, and environmentally friendly insecticides.
Enzyme activation refers to the process by which an enzyme becomes biologically active and capable of carrying out its specific chemical or biological reaction. This is often achieved through various post-translational modifications, such as proteolytic cleavage, phosphorylation, or addition of cofactors or prosthetic groups to the enzyme molecule. These modifications can change the conformation or structure of the enzyme, exposing or creating a binding site for the substrate and allowing the enzymatic reaction to occur.
For example, in the case of proteolytic cleavage, an inactive precursor enzyme, known as a zymogen, is cleaved into its active form by a specific protease. This is seen in enzymes such as trypsin and chymotrypsin, which are initially produced in the pancreas as inactive precursors called trypsinogen and chymotrypsinogen, respectively. Once they reach the small intestine, they are activated by enteropeptidase, a protease that cleaves a specific peptide bond, releasing the active enzyme.
Phosphorylation is another common mechanism of enzyme activation, where a phosphate group is added to a specific serine, threonine, or tyrosine residue on the enzyme by a protein kinase. This modification can alter the conformation of the enzyme and create a binding site for the substrate, allowing the enzymatic reaction to occur.
Enzyme activation is a crucial process in many biological pathways, as it allows for precise control over when and where specific reactions take place. It also provides a mechanism for regulating enzyme activity in response to various signals and stimuli, such as hormones, neurotransmitters, or changes in the intracellular environment.
Gene silencing is a process by which the expression of a gene is blocked or inhibited, preventing the production of its corresponding protein. This can occur naturally through various mechanisms such as RNA interference (RNAi), where small RNAs bind to and degrade specific mRNAs, or DNA methylation, where methyl groups are added to the DNA molecule, preventing transcription. Gene silencing can also be induced artificially using techniques such as RNAi-based therapies, antisense oligonucleotides, or CRISPR-Cas9 systems, which allow for targeted suppression of gene expression in research and therapeutic applications.
Northern blotting is a laboratory technique used in molecular biology to detect and analyze specific RNA molecules (such as mRNA) in a mixture of total RNA extracted from cells or tissues. This technique is called "Northern" blotting because it is analogous to the Southern blotting method, which is used for DNA detection.
The Northern blotting procedure involves several steps:
1. Electrophoresis: The total RNA mixture is first separated based on size by running it through an agarose gel using electrical current. This separates the RNA molecules according to their length, with smaller RNA fragments migrating faster than larger ones.
2. Transfer: After electrophoresis, the RNA bands are denatured (made single-stranded) and transferred from the gel onto a nitrocellulose or nylon membrane using a technique called capillary transfer or vacuum blotting. This step ensures that the order and relative positions of the RNA fragments are preserved on the membrane, similar to how they appear in the gel.
3. Cross-linking: The RNA is then chemically cross-linked to the membrane using UV light or heat treatment, which helps to immobilize the RNA onto the membrane and prevent it from washing off during subsequent steps.
4. Prehybridization: Before adding the labeled probe, the membrane is prehybridized in a solution containing blocking agents (such as salmon sperm DNA or yeast tRNA) to minimize non-specific binding of the probe to the membrane.
5. Hybridization: A labeled nucleic acid probe, specific to the RNA of interest, is added to the prehybridization solution and allowed to hybridize (form base pairs) with its complementary RNA sequence on the membrane. The probe can be either a DNA or an RNA molecule, and it is typically labeled with a radioactive isotope (such as ³²P) or a non-radioactive label (such as digoxigenin).
6. Washing: After hybridization, the membrane is washed to remove unbound probe and reduce background noise. The washing conditions (temperature, salt concentration, and detergent concentration) are optimized based on the stringency required for specific hybridization.
7. Detection: The presence of the labeled probe is then detected using an appropriate method, depending on the type of label used. For radioactive probes, this typically involves exposing the membrane to X-ray film or a phosphorimager screen and analyzing the resulting image. For non-radioactive probes, detection can be performed using colorimetric, chemiluminescent, or fluorescent methods.
8. Data analysis: The intensity of the signal is quantified and compared to controls (such as housekeeping genes) to determine the relative expression level of the RNA of interest. This information can be used for various purposes, such as identifying differentially expressed genes in response to a specific treatment or comparing gene expression levels across different samples or conditions.
Thymidine is a pyrimidine nucleoside that consists of a thymine base linked to a deoxyribose sugar by a β-N1-glycosidic bond. It plays a crucial role in DNA replication and repair processes as one of the four nucleosides in DNA, along with adenosine, guanosine, and cytidine. Thymidine is also used in research and clinical settings for various purposes, such as studying DNA synthesis or as a component of antiviral and anticancer therapies.
 DNA polymerase II - Wikipedia
DNA polymerase II - Wikipedia
![POLE2 DNA polymerase epsilon 2, accessory subunit [Homo sapiens (human)] - Gene - NCBI](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAB1ElEQVQ4jaWSPWgTcRjGf/ehuWhobO2JxGJRY3taTTRV2yoqSpW6iIWO4iAoUsRBioNDKUWKLU7i4KA4OfhVREQnETRia03k7IdiS0LaQYKJQg3mLtfc30GySNUDn/V5nx/vy/vAf0pqad3db2xquiBJku93s2Tb2eEHdw1rTcsxol23sObTjN7oIp9KVmaU9kMdTxcLAyiqGtA0bfms+XKQULSdQG2EmnUx0q9ughAA8p/CFW0IN3Sv0vUI5p2zIMpUrd5JeP/Jii//80ZJUlrb9lyV8qn3zI5dB8A4MoBWtcITAKBmZe3eRmPzccYf9uIUsyzx6zQd7fMMAIjFdgxpkuPy4clFANbu6qa6fouybXtznxeAoqoBn0/zz5kvBqVQ5DBasJ5gXaPnDQAWFpwCkiwLZekyAMp2wTPAsqy5d8nEZcIHThPQo7jlIua9854BibdvekqKX8PouARAOn6F+c8pT4Bc7svz6U8f77O1cwDVV439PcPU4yHw8AUhhDPyOn4OfWOMuuZfBZp41INTLACorhC2/Jc2zsxMX8vl8lMcPBUHFL5mnpEZGa748sS42esKYS8WLtl2NjE22s/6fScIhtr48W2S5O0zIFwvp3vST6Z+myCvkaonAAAAAElFTkSuQmCC) POLE2 DNA polymerase epsilon 2, accessory subunit [Homo sapiens (human)] - Gene - NCBI
POLE2 DNA polymerase epsilon 2, accessory subunit [Homo sapiens (human)] - Gene - NCBI
 Taq DNA Polymerase with 10× PCR reaction buffer containing MgCl2 9012-90-2
Taq DNA Polymerase with 10× PCR reaction buffer containing MgCl2 9012-90-2
CIPSM - DNA photodamage recognition by RNA polymerase II
Antitumor Activity of 2′,3′-Dideoxycytidine Nucleotide Analog Against Tumors Up-Regulating DNA Polymerase β | Molecular...
Plectocarpon lichenum voucher Thor 26770 DNA-directed RNA polymerase I - Nucleotide - NCBI
 NZYTaq II DNA polymerase
NZYTaq II DNA polymerase
 positive regulation of DNA-directed DNA polymerase activity - Ontology Report - Rat Genome Database
positive regulation of DNA-directed DNA polymerase activity - Ontology Report - Rat Genome Database
 Recombinant Cenarchaeum symbiosum DNA polymerase II large subunit (polC), partial
Recombinant Cenarchaeum symbiosum DNA polymerase II large subunit (polC), partial
 5x Hot Start Omni Klentaq 2 PCR Kit | DNA Polymerase Technology
5x Hot Start Omni Klentaq 2 PCR Kit | DNA Polymerase Technology
 EZ Turbo Taq DNA Polymerase with Red Reaction Buffer-P2001-2
EZ Turbo Taq DNA Polymerase with Red Reaction Buffer-P2001-2
Polbase - Reference: Trypanosoma brucei has two distinct mitochondrial DNA polymerase beta enzymes.
 Characterization of Two Novel Mutants of DNA Polymerase Delta in Drosophila melanogaster
Characterization of Two Novel Mutants of DNA Polymerase Delta in Drosophila melanogaster
 Smarter PCR with Platinum II Taq DNA Polymerase - Scientific Videos | Thermo Fisher Scientific US
Smarter PCR with Platinum II Taq DNA Polymerase - Scientific Videos | Thermo Fisher Scientific US
 Trypanosoma brucei has two distinct mitochondrial DNA polymerase beta enzymes. | Department of Microbiology at UMass Amherst
Trypanosoma brucei has two distinct mitochondrial DNA polymerase beta enzymes. | Department of Microbiology at UMass Amherst
 RCSB PDB - 2FMS: DNA Polymerase beta with a gapped DNA substrate and dUMPNPP with magnesium in the catalytic site
RCSB PDB - 2FMS: DNA Polymerase beta with a gapped DNA substrate and dUMPNPP with magnesium in the catalytic site
 SCOPe 2.05: Family a.237.1.1: DNA polymerase III theta subunit-like
SCOPe 2.05: Family a.237.1.1: DNA polymerase III theta subunit-like
 Promoter-proximal pausing of RNA polymerase II: emerging roles in metazoans | Nature Reviews Genetics
Promoter-proximal pausing of RNA polymerase II: emerging roles in metazoans | Nature Reviews Genetics
Role of the 2-amino group of purines during dNTP polymerization by human DNA polymerase alpha | CU Experts | CU Boulder
Sodium in PDB 2pxi: Ternary Complex of Dna Polymerase Beta with A Dideoxy Terminated Primer and 2'-Deoxyguanosine 5'-Beta,...
Role of Escherichia coli DNA Polymerase I in Conferring Viability upon the dnaN159 Mutant Strain | Journal of Bacteriology
 Anti-DNA polymerase delta p125 Monoclonal Antibody Suppliers @ BiosciRegister.com
Anti-DNA polymerase delta p125 Monoclonal Antibody Suppliers @ BiosciRegister.com
 SciELO - Brazil - Molecular characterisation and disease severity of leptospirosis in Sri Lanka Molecular characterisation and...
SciELO - Brazil - Molecular characterisation and disease severity of leptospirosis in Sri Lanka Molecular characterisation and...
 Synthesis and recognition by DNA polymerases of a reactive nucleoside, 1-(2-deoxy-beta-D-erythro-pentofuranosyl)-imidazole-4...
Synthesis and recognition by DNA polymerases of a reactive nucleoside, 1-(2-deoxy-beta-D-erythro-pentofuranosyl)-imidazole-4...
Miscoding properties of 8-chloro-2′-deoxyguanosine, a hypochlorous acid-induced DNA adduct, catalysed by human DNA polymerases<...
Platinum™ Taq Green Hot Start DNA Polymerase
 Q5U® Hot Start High-Fidelity DNA Polymerase | NEB
Q5U® Hot Start High-Fidelity DNA Polymerase | NEB
 Amatoxin Toxicity: Practice Essentials, Pathophysiology, Etiology
Amatoxin Toxicity: Practice Essentials, Pathophysiology, Etiology
컨텐츠 | Nature Portfolio
Subunit11
- The other members of group B do have at least one other subunit which makes the DNA Pol II unique. (wikipedia.org)
- DNA polymerase epsilon, which is involved in DNA repair and replication, is composed of a large catalytic subunit and a small accessory subunit. (nih.gov)
- Mutations/polymorphisms in the 55 kDa subunit of DNA polymerase epsilon in human colorectal cancer. (nih.gov)
- The solution structure of the amino-terminal domain of human DNA polymerase epsilon subunit B is homologous to C-domains of AAA+ proteins. (nih.gov)
- Purification, cDNA cloning, and gene mapping of the small subunit of human DNA polymerase epsilon. (nih.gov)
- Recombinant Cenarchaeum symbiosum DNA polymerase II large subunit (polC), partial is available at Gentaur for Next week Delivery. (orlaproteins.com)
- Since Pol III replication is abated in strains bearing the dnaN159 allele ( 14 , 35 , 38 ), due to the impaired ability of β159 to interact with the α catalytic subunit of Pol III ( 38 ), we hypothesized that the requirement for Pol I function in the dnaN159 strain might stem from its ability to augment Pol III function in DNA replication. (asm.org)
- Polymerase (RNA) II (DNA directed) Polypeptide K, also known as POLR2K is am ember of the archaeal RpoP/eukaryotic RPC10 RNA polymerase subunit family. (prospecbio.com)
- In addition, the other two DNA-directed RNA polymerases share this subunit. (prospecbio.com)
- 39504) translation initiation factor 2%2C alpha subunit CP001857 CDS Arcpr_0045 complement(39546. (go.jp)
- This gene provides instructions for making one part, the alpha subunit, of a protein called polymerase gamma (pol γ). (medlineplus.gov)
Synthesis11
- The enzyme has 5′→3′ DNA synthesis capability as well as 3′→5′ exonuclease proofreading activity. (wikipedia.org)
- Using in vitro single- and double-stranded DNA synthesis assays, we demonstrated that excess Pol β perturbs the replicative machinery, favors ddC-TP incorporation into DNA, and consequently promotes chain termination. (aspetjournals.org)
- Possesses two activities: a DNA synthesis (polymerase) and an exonucleolytic activity that degrades single-stranded DNA in the 3'- to 5'-direction. (orlaproteins.com)
- however, DNA polymerase delta (pol [delta]) carries much of the load by replicating a major portion of the genome in both leading and lagging strand synthesis. (ecu.edu)
- Recent years have witnessed a sea change in our understanding of transcription regulation: whereas traditional models focused solely on the events that brought RNA polymerase II (Pol II) to a gene promoter to initiate RNA synthesis, emerging evidence points to the pausing of Pol II during early elongation as a widespread regulatory mechanism in higher eukaryotes. (nature.com)
- We report the synthesis of a new nucleoside, 1-(2-deoxy-beta-D-erythro-pentofuranosyl)-imidazole-4-hydrazide (dY(NH2)) as a reactive monomer for DNA diversification. (pasteur.fr)
- DNA polymerases are enzymes that catalyze the synthesis DNA.There are at least fifteen different DNA polymerases known in eukaryotes. (tocris.com)
- It is also a vital medium in protein synthesis because it is the main molecules in DNA translation and transcription (wiki, translation) (wiki, transcription). (bartleby.com)
- 3. A strand of DNA serves as a template (model) for the synthesis of RNA molecules. (bartleby.com)
- Prodrug that when biotransformed into active metabolite, penciclovir, may inhibit viral DNA synthesis/replication. (medscape.com)
- Reverse transcription is the synthesis of a complementary DNA sequence from an RNA template using reverse transcriptase, which is an RNA-dependent DNA polymerase. (medscape.com)
Exonuclease8
- It displays both 5′ to 3′ polymerase and exonuclease activities. (sigmaaldrich.com)
- It has both 5′→3′ polymerase and exonuclease activity. (sigmaaldrich.com)
- NZYTaq II DNA polymerase lacks 3'→5' exonuclease activity and supports the robust and reliable amplification of a wide range of DNA templates up to 6 kb. (nzytech.com)
- Q5U Hot Start High-Fidelity DNA Polymerase is a modified version of Q5 ® High-Fidelity DNA Polymerase, a novel thermostable DNA polymerase that possesses 3′ to 5′ exonuclease activity, and is fused to a processivity-enhancing Sso7d domain. (neb.com)
- Just as with Taq DNA Polymerase, Platinum Taq DNA Polymerase has a non-template-dependent terminal transferase activity that adds a 3' deoxyadenosine to product ends and has a 5'→3' exonuclease activity. (thermofisher.com)
- DNA polymerases I, II and III have 3' to 5' exonuclease activity and they can remove incorrectly newly incorporated nucleotides. (tocris.com)
- 2022. Probing the mechanisms of two exonuclease domain mutators of DNA polymerase ε. (nih.gov)
- Bst 2.0 WarmStart DNA Polymerase contains 5´→3´ DNA polymerase activity and strong strand-displacement activity but lacks 5´→3´ exonuclease activity. (neb.com)
Replication28
- The in vivo functionality of Pol II is under debate, yet consensus shows that Pol II is primarily involved as a backup enzyme in prokaryotic DNA replication. (wikipedia.org)
- Several studies involving this isolated enzyme indicated that DNA pol I was most likely involved in repair replication and was not the main replicative polymerase. (wikipedia.org)
- As characterized, this new mutant strain was more sensitive to ultraviolet light, corroborating the hypothesis that DNA pol I was involved in repair replication. (wikipedia.org)
- The mutant grew at the same rate as the wild type, indicating the presence of another enzyme responsible for DNA replication. (wikipedia.org)
- The isolation and characterization of this new polymerase involved in semiconservative DNA replication followed, in parallel studies conducted by several labs. (wikipedia.org)
- Polymerases all are involved with DNA replication in some capacity, synthesizing chains of nucleic acids. (wikipedia.org)
- DNA replication is a vital aspect of a cell's proliferation. (wikipedia.org)
- In prokaryotes, like E. coli, DNA Pol III is the major polymerase involved with DNA replication. (wikipedia.org)
- While DNA Pol II is not a major factor in chromosome replication, it has other roles to fill. (wikipedia.org)
- DNA Pol II does participate in DNA replication. (wikipedia.org)
- showed that DNA Pol II is involved with replication but it is strand dependent and preferentially replicates the lagging strand. (wikipedia.org)
- A proposed mechanism suggests that when DNA Pol III stalls or becomes non-functional, then DNA Pol II is able to be specifically recruited to the replication point and continue replication. (wikipedia.org)
- DNA Pol II is not the most studied polymerase so there are many proposed functions of this enzyme which are all likely functions but are ultimately unconfirmed: repair of DNA damaged by UV irradiation replication restart in UV-irradiated E. coli adaptive mutagenesis long-term survival During DNA replication, base pairs are subject to damage in the sequence. (wikipedia.org)
- In contrast to these three Pols, which under certain conditions impede growth of the dnaN159 strain ( 29 , 39 , 40 ), presumably by impairing DNA replication, the catalytic DNA polymerase activity of Pol I ( polA ) is essential for viability of the dnaN159 strain ( 38 ). (asm.org)
- Since Pol I is a multifunctional protein that participates in DNA replication, as well as numerous DNA repair pathways, several possibilities exist, including Okazaki fragment maturation ( 21 , 31 ) and single-stranded DNA (ssDNA) gap repair ( 16 , 22 ). (asm.org)
- Many proofreading polymerases derived from archaeal Family B DNA polymerases stall replication in response to uracil bases in DNA templates (Wardle, J. et al. (neb.com)
- These enzymes have roles in DNA repair, as well as DNA replication. (tocris.com)
- This makes the error rate during DNA replication very low, hence maintaining the integrity of the genome. (tocris.com)
- The accuracy of mitochondrial DNA (mtDNA) replication depends on the coordinated action of many nuclear-encoded proteins and on the correct balance of nucleotides within the mitochondrial matrix. (novusbio.com)
- Originrecognitioncomplex(ORC) Actsasthe initiator of eukaryotic DNA replication. (slideshare.net)
- Telomeres and DNA Replication Telomeres: Theendsof eukaryoticchromosomes (chromosomes arelinear) Neededfor chromosomal integrity andstability. (slideshare.net)
- Cells contain several types of DNA polymerase, some of which are required for replication of DNA, and are indispensable for multipliation and division of cells. (definitions.net)
- An enzyme that assists DNA replication. (definitions.net)
- DNA polymerase is an enzyme that plays a crucial role in DNA replication, assisting in the process of duplicating DNA strands accurately and efficiently. (definitions.net)
- DNA polymerase also possesses proofreading capabilities, allowing it to correct any potential mistakes made during the replication process. (definitions.net)
- DNA polymerases are essential for DNA replication, and usually function in pairs while copying one double-stranded DNA molecule into two double-stranded DNAs in a process termed semiconservative DNA replication. (definitions.net)
- Pol γ "reads" sequences of mtDNA and uses them as templates to produce new copies of mtDNA in a process called DNA replication . (medlineplus.gov)
- Inhibitor of DNA polymerase in HSV-1 and HSV-2 strains, inhibiting viral replication. (medscape.com)
Transcription9
- In 2023 it was reported that ageing-related accelerated transcription causes Pol II to make more mistakes, leading to flawed copies that can cause numerous diseases. (wikipedia.org)
- During gene transcription, RNA polymerase (Pol) II encounters obstacles, including lesions in the DNA template. (cipsm.de)
- The study provided the molecular basis for recognition of a damaged DNA by Pol II, which is the first step in transcription- coupled DNA repair (TCR). (cipsm.de)
- Amatoxins inhibit RNA polymerase II, thereby interfering with DNA and RNA transcription. (medscape.com)
- Structural basis of initial RNA polymerase II transcription. (expasy.org)
- Predicted to enable RNA polymerase II-specific DNA-binding transcription factor binding activity. (jax.org)
- Transcription is the formation of an RNA strand from a DNA template within the nucleus of a cell. (bartleby.com)
- This transcription from DNA to mRNA happens by an RNA polymerase II. (bartleby.com)
- DNA polymerases also play key roles in other processes within cells, including DNA repair, genetic recombination, reverse transcription, and the generation of antibody diversity via the specialized DNA polymerase, terminal deoxynucleotidyl transferase. (definitions.net)
Thermostable5
- Taq DNA Polymerase is a thermostable enzyme derived from the thermophilic bacterium Thermus aquaticus . (sigmaaldrich.com)
- Platinum Taq DNA Polymerase is a convenient and reliable 'hot start' thermostable DNA polymerase for PCR that provides enhanced specificity over that of Taq DNA Polymerase. (thermofisher.com)
- In PCR, a thermostable DNA polymerase is used to amplify target DNA 2-fold with each temperature cycle. (medscape.com)
- Initially, DNA is taken from the clinical specimen, as well as certain sequence-specific oligonucleotide primers, thermostable DNA polymerase, nucleotides, and buffer. (medscape.com)
- Finally, nucleotides complementary to the target DNA are added extending each primer by the thermostable DNA polymerase. (medscape.com)
Start DNA Polymerase8
- Simpler, cleaner, smarter--these are some PCR benefits you can achieve with Invitrogen Platinum II Taq Hot-Start DNA Polymerase. (thermofisher.com)
- Amplification of bisulfite-converted human genomic DNA targets using Q5U Hot Start High-Fidelity DNA Polymerase (Q5U), Phusion U Hot Start DNA Polymerase (P) and KAPA Hifi HotStart Uracil+ ReadyMix PCR Kit (K). Amplicon name and sizes are indicated above the gel. (neb.com)
- For superior PCR performance, upgrade to Invitrogen's new Platinum II Taq Hot-start DNA Polymerase . (thermofisher.com)
- Invitrogen Platinum Taq Green Hot Start DNA Polymerase provides Platinum Taq DNA Polymerase with a 10X Green PCR Buffer. (thermofisher.com)
- Platinum Taq Green Hot Start DNA Polymerase is provided with green PCR buffer that contains a density reagent and two tracking dyes and allows for direct gel loading of PCR products. (thermofisher.com)
- Use Platinum Taq Green Hot Start DNA Polymerase for the amplification of DNA from complex genomic, viral, and plasmid templates, as well as in RT-PCR. (thermofisher.com)
- For superior PCR performance, we recommend the next-generation enzyme Platinum II Taq Hot-start DNA Polymerase . (thermofisher.com)
- Platinum II Taq Hot-Start DNA Polymerase is designed for universal primer annealing and fast, easy PCR with its unique combination of innovative buffer, high-performance engineered Taq DNA polymerase, and superior hot-start technology. (thermofisher.com)
Amplification11
- Each lot of Taq DNA Polymerase is tested for PCR amplification and double-stranded sequencing. (sigmaaldrich.com)
- The enzyme was optimized to provide higher sensitivity, allowing amplification of different DNA fragments from as little as 5 pg of human genomic DNA. (nzytech.com)
- The mutagenicity of dYNH2TP was evaluated by PCR amplification using Vent (exo-) DNA polymerase. (pasteur.fr)
- The triphosphate dY(NH2)TP was preferentially incorporated as a dATP or dGTP analogue and led to misincorporations at frequencies of approximately 2 x 10(-2) per base per amplification. (pasteur.fr)
- Achieve superior amplification of bisulfite-converted, deaminated, or damaged DNA (e.g. (neb.com)
- Q5U is a hot start polymerase containing a unique aptamer selected for polymerase inhibition at room temperature and optimal amplification during typical PCR conditions. (neb.com)
- Amplification of FFPE normal lung DNA (Biochain). (neb.com)
- The BDProbeTec CT Chlamydia trachomatis Amplified DNA Assays are based on the simultaneous amplification and detection of target DNA, using amplification primers and a fluorescent labeled detector probe. (cdc.gov)
- The Strand Displacement Amplification (SDA) reagents are dried in two separate disposable microwell strips. (cdc.gov)
- After incubation, the reaction mixture is transferred to the Amplification Microwell, which contains two enzymes (a DNA polymerase and a restriction endonuclease) necessary for SDA. (cdc.gov)
- Bst 2.0 WarmStart DNA Polymerase displays improved amplification speed, yield, salt tolerance, and thermostability compared to wild-type Bst DNA Polymerase, Large Fragment. (neb.com)
Primer8
- Taq polymerase catalyzes oligonucleotide primer-driven, DNA template dependent incorporation of dNTPs into complimentary DNA strands. (sigmaaldrich.com)
- Here, we present a crystal structure of a precatalytic complex of a DNA polymerase with bound substrates that include the primer 3'-OH and catalytic Mg2+. (rcsb.org)
- Primer extension reactions showed that dYNH2TP was well tolerated by KF (exo(-)) and Vent (exo-) DNA polymerases. (pasteur.fr)
- During the primer extension reaction in the presence of four dNTPs, pol κ promoted one-base deletion (6.4%), accompanied by the misincorporation of 2′-deoxyguanosine monophosphate (5.5%), dAMP (3.7%), and dTMP (3.5%) opposite the lesion. (elsevierpure.com)
- PCR uses repetitive cycles of primer‐dependent polymerization to amplify a given DNA. (cliffsnotes.com)
- Each cycle of PCR involves three steps: DNA double strand separation, primer hybridization, and copying. (cliffsnotes.com)
- This enzyme synthesizes new strands of DNA by adding nucleotides to a pre-existing DNA strand or RNA primer, following the rules of base pairing. (definitions.net)
- contained 0.5 µL of each primer (10 with serology suggestive of past HBV pmol/µL) and the probe (SP2, 10 infection and clearance of HBsAg [1,2]. (who.int)
Eukaryotes1
- POLR2K is one of the smallest subunits of RNA polymerase II, the polymerase is responsible for synthesizing messenger RNA in eukaryotes. (prospecbio.com)
Replicative3
- The new polymerase was termed DNA polymerase II, and was believed to be the main replicative enzyme of E. coli for a time. (wikipedia.org)
- The Escherichia coli dnaN159 allele encodes a mutant form of the β-sliding clamp (β159) that is impaired for interaction with the replicative DNA polymerase (Pol), Pol III. (asm.org)
- These phenotypes appear to result, at least in part, from impaired interactions of the mutant β159 clamp protein with the replicative DNA polymerase, Pol III ( 38 ). (asm.org)
Nucleotide1
- A DNA polymerase is a cellular or viral polymerase enzyme that synthesizes DNA molecules from their nucleotide building blocks. (definitions.net)
Protein10
- DNA Polymerase II is an 89.9-kDa protein and is a member of the B family of DNA polymerases. (wikipedia.org)
- DNA Pol II is an 89.9 kD protein, composed of 783 amino acids, that is encoded by the polB (dinA) gene. (wikipedia.org)
- A globular protein, DNA Pol II functions as a monomer, whereas many other polymerases will form complexes. (wikipedia.org)
- Remarkably, green fluorescent protein fusion proteins and immunofluorescence demonstrate that both are mitochondrial, but their locations with respect to the mitochondrial DNA (kinetoplast DNA network) in this organism are strikingly different. (neb.com)
- We show here that PLASTID REDOX INSENSITIVE 2 (PRIN2) and CHLOROPLAST STEM-LOOP BINDING PROTEIN 41 kDa (CSP41b), two proteins identified in plastid nucleoid preparations, are essential for proper plant embryo development. (frontiersin.org)
- Moreover, PRIN2 and CSP41b form a distinct protein complex in vitro that binds DNA. (frontiersin.org)
- Taken together, our results suggest that PEP activity and consequently the switch from NEP to PEP activity, is essential during embryo development and that the PRIN2-CSP41b DNA binding protein complex possibly is important for full PEP activity during this process. (frontiersin.org)
- Download DNA or protein sequence, view genomic context and coordinates. (yeastgenome.org)
- Bst 2.0 WarmStart DNA Polymerase is prepared from an E. coli strain that expresses the Bst 2.0 DNA Polymerase protein from an inducible promoter. (neb.com)
- This protein plays a pivotal role in DNA recombination and repair. (medscape.com)
Enzymes2
Quantitative4
- Utility of quantitative polymerase chain reaction in leptospirosis diagnosis: association of level of leptospiremia and clinical manifestations in Sri Lanka. (scielo.br)
- Mycobacterial DNA was not detected with quantitative polymerase chain reaction. (cdc.gov)
- In this 2007 photograph, Centers for Disease Control and Prevention (CDC) Biologist, Damien Danavall was shown setting up a liquid handling robot, to perform a quantitative PCR (polymerase chain reaction) analysis, able to detect the presence of herpes simplex virus-2 (HSV-2). (cdc.gov)
- Day 2 and day 3 CM corresponding to each one of the embryos was analyzed, by quantitative PCR, for estimation of Cell-free DNA levels. (who.int)
Proteins2
- Upon searching the nearly completed genome data base of the related parasite Trypanosoma brucei, we discovered genes for two pol beta-like proteins. (neb.com)
- Both proteins, when expressed recombinantly, are active as DNA polymerases and deoxyribose phosphate lyases, but their polymerase activity optima differ with respect to pH and KCl and MgCl2 concentrations. (neb.com)
Nucleotides3
- One region corresponds with the polymerase's ability to polymerize new nucleotides onto an existing strand of DNA. (ecu.edu)
- Archaeal family B-type polymerases can incorporate/tolerate a variety of modified nucleotides but will stall upon encountering uracil and inosine residues. (neb.com)
- There are four nucleotides of DNA. (bartleby.com)
Mitochondrial3
- The DNA polymerase beta from the trypanosomatid Crithidia fasciculata, however, was the first mitochondrial enzyme of this type described. (neb.com)
- Furthermore, we systematically characterized mitochondria during disease progression starting before the onset of muscle damage, noting additional changes in mitochondrial DNA copy number and regulators of mitochondrial size. (frontiersin.org)
- Mitochondria each contain a small amount of DNA, known as mitochondrial DNA (mtDNA), which is essential for the normal function of these structures. (medlineplus.gov)
Viral1
- The diagnosis of many infectious diseases, both viral and bacterial, may include the use of reverse transcriptase-polymerase chain reaction (RT-PCR). (medscape.com)
Genomic3
- Some DNA isolation procedures, particularly genomic DNA isolation, can result in the co-purification of PCR inhibitors. (nzytech.com)
- BML mutations thus result in defects in DNA repair and genomic instability in the somatic cells, predisposing the patients to cancer development. (medscape.com)
- Overall, the Committee judged that significant progress had been made during the past year, particularly in further characterization of the isolates held in the two collections, the development of diagnostic tests for smallpox, and in understanding the genomic diversity of variola virus. (who.int)
Catalytic2
- The palm of the complex contains three catalytic residues that will coordinate with two divalent metal ions in order to function. (wikipedia.org)
- Comparison with two new structures of DNA polymerase beta lacking the 3'-OH or catalytic Mg2+ is described. (rcsb.org)
Strands5
- Repairing these lesions is difficult because both DNA strands have been damaged by the chemical agent and thus the genetic information on both strands is incorrect. (wikipedia.org)
- First, the original DNA is denatured by heat treatment to make two separated strands. (cliffsnotes.com)
- Then the two primers are hybridized to the DNA, one to each of the two separated strands. (cliffsnotes.com)
- The original two strands of DNA now become four strands, which are then denatured. (cliffsnotes.com)
- The temperature of these is increased to 90-95°C in order to separate (denature) the 2 strands of target DNA. (medscape.com)
Primers5
- The reaction mix composition may affect the melting properties of primers and DNA. (nzytech.com)
- The 'hot start' property of the enzyme is conferred by thermolabile monoclonal antibodies that render Taq DNA polymerase inactive until the initial PCR denaturation step, thus preventing the extention of nonspecifically annealed primers and improving product yield. (thermofisher.com)
- Very little original DNA is required, as long as two unique primers are available. (cliffsnotes.com)
- These primers act as initiators for DNA polymerase, which copies each strand of the original double‐stranded DNA. (cliffsnotes.com)
- In the second step, the temperature decreases (45-60°C), depending on the primers, to permit annealing (strengthening) of the target DNA primers. (medscape.com)
Escherichia1
- The Escherichia coli dnaN -encoded β-sliding clamp functions as a homodimer and is "loaded" onto primed DNA by the multisubunit DnaX clamp loader complex ( 5 , 21 ). (asm.org)
PolB2
- DNA polymerase II (also known as DNA Pol II or Pol II) is a prokaryotic DNA-dependent DNA polymerase encoded by the PolB gene. (wikipedia.org)
- As a result of the impaired β159-Pol III interaction, E. coli strains bearing the dnaN159 allele display increased utilization of the three SOS-regulated DNA polymerases, Pol II ( polB ), Pol IV ( dinB ), and Pol V ( umuDC ) ( 29 , 38 - 40 ). (asm.org)
Gene1
- Figure 2: Patterns of Pol II distribution across gene regions. (nature.com)
Assays2
- The optional KB Extender used with Platinum Taq DNA Polymerase enables more versatility in PCR assays with long or GC-rich amplicons. (thermofisher.com)
- Polymerase chain reaction (PCR) assays and sequencing was used to determine the presence of β-lactamase encoding genes (bla) including bla NDM-1 and plasmid-mediated quinolone and aminoglycoside resistance determinants. (who.int)
Activity4
- Any process that activates or increases the frequency, rate or extent of DNA-directed DNA polymerase activity. (mcw.edu)
- We speculate that by coupling RNA processing to the status and activity of Pol II itself, the cell ensures that nascent RNA is properly protected from degradation and efficiently matures into a functional mRNA. (nature.com)
- The antibodies dissociate during the initial PCR denaturation step and the DNA polymerase regains its full activity. (thermofisher.com)
- Bst 2.0 WarmStart DNA Polymerase is an in silico designed homologue of Bacillus stearothermophilus DNA Polymerase I, Large Fragment ( Bst DNA Polymerase, Large Fragment) with a reversibly-bound aptamer, which inhibits polymerase activity at temperatures below 45°C. The aptamer rapidly releases the Bst 2.0 WarmStart DNA Polymerase above 45°C and therefore no special activation step is needed to activate the polymerase. (neb.com)
Promoter4
- The nomenclature of different promoter-associated RNA polymerase II (Pol II) species is explicitly defined in an effort to provide consistency in future literature. (nature.com)
- Multiple lines of evidence support the idea that Pol II and nucleosomes compete for promoter binding and suggest that a crucial role of paused Pol II involves maintenance of accessible promoter chromatin architecture. (nature.com)
- Here the evidence for pausing of Pol II from recent high-throughput studies will be discussed, as well as the potential interconnected functions of promoter-proximally paused Pol II. (nature.com)
- Figure 1: Defining the terms used to describe promoter-associated Pol II complexes. (nature.com)
Specificity2
- The fully extended products were analysed to quantify the miscoding frequency and specificity of 8-Cl-dG using two-phased polyacrylamide gel electrophoresis (PAGE). (elsevierpure.com)
- the miscoding frequency and specificity varies depending on the DNA polymerase used. (elsevierpure.com)
Molecular2
- DNA polymerases are widely used in molecular biology laboratories, notably for the polymerase chain reaction, DNA sequencing, and molecular cloning. (definitions.net)
- PCR produces large amounts of replicated DNA, or RNA molecular sequences. (cdc.gov)
Pols1
- In this study, we explored the miscoding properties of the 8-Cl-dG adduct generated by human DNA polymerases (pols). (elsevierpure.com)
Eukaryotic1
- 2022. Ribonucleotide incorporation by eukaryotic B-family DNA replicases and its consequences. (nih.gov)
Reverse transcriptase1
- Delavirdine binds directly to reverse transcriptase (RT) and blocks RNA-dependent and DNA-dependent DNA polymerase activities. (drugs.com)
Species1
- In opinion of De Vries, these mutations give origin to a new species that he named "elementary species" [ 1 ], [ 2 ]. (intechopen.com)
Complexes1
- Both diseases involve the BRAFT and FANCM complexes, which are important in DNA repair. (medscape.com)
Magnesium1
- Optimise magnesium concentration by supplementing M g Cl 2 in 0.5 increments up to 4 mM. (nzytech.com)
Vitro3
- In this study, we show that treatment with the 2′,3′-dideoxycytidine (ddC) nucleoside analog inhibited in vitro and in vivo the proliferation of Pol β-transfected B16 melanoma cells, which up-regulate Pol β compared with control isogenic cells. (aspetjournals.org)
- The reduced ability of β159 to stimulate Pol I in vitro correlates with our finding that single-stranded DNA (ssDNA) gap repair is impaired in the dnaN159 strain. (asm.org)
- The 5′-triphosphate derivative (dY(NH2)TP, 1) was evaluated in vitro as a substrate for several DNA polymerases. (pasteur.fr)
Assay2
- The steady-state kinetic studies supported the results obtained from the two-phased PAGE assay. (elsevierpure.com)
- Aurelius E, Johansson B, Skoldenberg B, Staland A, Forsgren M. Rapid diagnosis of herpes simplex encephalitis by nested polymerase chain reaction assay of cerebrospinal fluid. (medscape.com)
Reaction8
- Taq DNA polymerase comes with the choice of an optimized 10× reaction buffer including MgCl 2 (D1806) or a 10× reaction buffer without MgCl 2 plus a separate tube of MgCl 2 for titration (D4545). (sigmaaldrich.com)
- Reduce the volume of template DNA in reaction or dilute template DNA prior to adding to the reaction. (nzytech.com)
- Our 5x ready-to-use PCR kit contains Hot Start Omni Klentaq 2, made with aptamer-based technology, enabling room temperature reaction set-up. (klentaq.com)
- In this study immunochromatography, microscopic agglutination test and polymerase chain reaction were used to diagnose leptospirosis. (scielo.br)
- Each 25 μl reaction contained 12 ng of bisulfite-converted DNA (Qiagen). (neb.com)
- Each 25 μl reaction contained 18 ng of FFPE DNA (Biochain). (neb.com)
- You can isolate virtually any DNA sequence by means of the polymerase chain reaction , or PCR . (cliffsnotes.com)
- [ 1 ] The resultant complementary DNA is amplified by polymerase chain reaction (PCR). (medscape.com)
Cellular3
- Pausing provides a point of regulation that is distinct from Pol II recruitment and initiation, and this may facilitate the integration of multiple cellular signals. (nature.com)
- At the site of inflammation, cellular DNA is damaged by hypochlorous acid (HOCl), a potent oxidant generated by myeloperoxidase. (elsevierpure.com)
- HIV-2 RT and human cellular DNA polymerases α, γ, or δ are not inhibited by delavirdine. (drugs.com)
Recombinant1
- Platinum Taq DNA Polymerase is a recombinant Taq DNA polymerase complexed with proprietary Platinum antibodies. (thermofisher.com)
Strains2
- E. coli strains bearing the dnaN159 allele display temperature-sensitive growth ( 14 , 35 , 38 ) and altered DNA polymerase (Pol) usage ( 29 , 38 - 40 ). (asm.org)
- Further restriction fragment length polymorphism and DNA sequencing methods were used to identify the circulating strains in two selected geographical regions of Sri Lanka. (scielo.br)
Phosphate1
- Phosphate group 2. (slideshare.net)
Phosphorylation1
- Pol II pausing and release occur at a point when 5′ end RNA processing and phosphorylation of the Pol II carboxy-terminal domain occurs. (nature.com)
Reactions2
- Generally, 2-3 mM M g Cl 2 , typically 2.5 mM final concentration, works well for the majority of PCR reactions. (nzytech.com)
- Identical LAMP reactions were run either immediately after setup (solid line) or after a 2 hour incubation at 25 °C. Without the protection from Bst 2.0 WarmStart, this room temperature incubation results in variable LAMP performance. (neb.com)
Organism1
- Using the model organism, Drosophila melanogaster, we investigate two novel mutations in two different evolutionary conserved regions. (ecu.edu)
Detectable3
- Specific DNA present in small amounts in a clinical specimen are amplified by PCR so they become detectable. (medscape.com)
- About half (54.3%) of the patients had elevated alanine aminotransfe-rase levels and detectable serum HBV DNA. (who.int)
- HBV-DNA was detectable in sera from 3 patients out of the 40 patients who were positive for hepatitis B core antibody. (who.int)
Chain1
- When the phosphorylated form of ddC was electrotransfered into Pol β-transfected melanoma, the cell growth inhibition was strengthened, strongly suggesting that the cytotoxic effect results from incorporation of the chain terminator into DNA. (aspetjournals.org)


























.jpg)