Algoritmos
Software
Reconhecimento Automatizado de Padrão
Simulação por Computador
Biologia Computacional
Reprodutibilidade dos Testes
Inteligência Artificial
Modelos Estatísticos
Sensibilidade e Especificidade
Análise por Conglomerados
Processamento de Imagem Assistida por Computador
Análise de Sequência de Proteína
Alinhamento de Sequência
Interpretação de Imagem Assistida por Computador
Imagens de Fantasmas
Modelos Genéticos
Processamento de Sinais Assistido por Computador
Validação de Programas de Computador
Imagem Tridimensional
Análise de Sequência de DNA
Aumento da Imagem
Cadeias de Markov
Proteínas
Bases de Dados de Proteínas
Teorema de Bayes
Perfilação da Expressão Gênica
Método de Monte Carlo
Gráficos por Computador
Automação
Bases de Dados Factuais
Análise de Sequência com Séries de Oligonucleotídeos
Redes Neurais (Computação)
Análise Numérica Assistida por Computador
Modelos Teóricos
Interface Usuário-Computador
Compressão de Dados
Lógica Fuzzy
Artefatos
Diagnóstico por Computador
Bases de Dados Genéticas
Interpretação Estatística de Dados
Modelos Biológicos
Distribuição Normal
Armazenamento e Recuperação da Informação
Funções Verossimilhança
Interpretação de Imagem Radiográfica Assistida por Computador
Internet
Árvores de Decisões
Intensificação de Imagem Radiográfica
Técnica de Subtração
Análise de Ondaletas
Razão Sinal-Ruído
Mineração de Dados
Modelos Moleculares
Tecnologia sem Fio
Máquinas de Vetores de Suporte
Processamento Automatizado de Dados
Desenho de Programas de Computador
Análise de Sequência de RNA
Computadores
Dados de Sequência Molecular
Processos Estocásticos
Genoma
Redes Reguladoras de Genes
Curva ROC
Modelos Químicos
Probabilidade
Valor Preditivo dos Testes
Mapeamento Cromossômico
Imagem por Ressonância Magnética
Fatores de Tempo
Sequência de Bases
Análise Discriminante
Tomografia Computadorizada de Feixe Cônico
Tomografia Computadorizada por Raios X
Análise dos Mínimos Quadrados
Dinâmica não Linear
Programação Linear
Análise de Falha de Equipamento
Genoma Humano
Bases de Dados de Ácidos Nucleicos
Análise de Componente Principal
Polimorfismo de Nucleotídeo Único
Sequência de Aminoácidos
Redes de Comunicação de Computadores
Processamento de Linguagem Natural
Tomografia
Algoritmo, em medicina e saúde digital, refere-se a um conjunto de instruções ou passos sistemáticos e bem definidos que são seguidos para resolver problemas ou realizar tarefas específicas relacionadas ao diagnóstico, tratamento, monitoramento ou pesquisa clínica. Esses algoritmos podem ser implementados em diferentes formatos, como fluxogramas, tabelas decisiomais, ou programação computacional, e são frequentemente utilizados em processos de tomada de decisão clínica, para ajudar os profissionais de saúde a fornecer cuidados seguros, eficazes e padronizados aos pacientes.
Existem diferentes tipos de algoritmos utilizados em diferentes contextos da medicina. Alguns exemplos incluem:
1. Algoritmos diagnósticos: Utilizados para guiar o processo de diagnóstico de doenças ou condições clínicas, geralmente por meio de uma série de perguntas e exames clínicos.
2. Algoritmos terapêuticos: Fornecem diretrizes para o tratamento de doenças ou condições específicas, levando em consideração fatores como a gravidade da doença, história clínica do paciente e preferências individuais.
3. Algoritmos de triagem: Ajudam a identificar pacientes que necessitam de cuidados adicionais ou urgentes, baseado em sinais vitais, sintomas e outras informações clínicas.
4. Algoritmos de monitoramento: Fornecem diretrizes para o monitoramento contínuo da saúde dos pacientes, incluindo a frequência e os métodos de avaliação dos sinais vitais, funções orgânicas e outras métricas relevantes.
5. Algoritmos de pesquisa clínica: Utilizados em estudos clínicos para padronizar procedimentos, coletar dados e analisar resultados, garantindo a integridade e a comparabilidade dos dados entre diferentes centros de pesquisa.
Os algoritmos clínicos são frequentemente desenvolvidos por organizações profissionais, sociedades científicas e agências governamentais, com base em evidências científicas e consensos de especialistas. Eles podem ser implementados em diferentes formatos, como fluxogramas, tabelas ou softwares, e são frequentemente incorporados a sistemas de informação clínica e às práticas clínicas diárias para apoiar a tomada de decisões e melhorar os resultados dos pacientes.
De acordo com a medicina, o software não é geralmente definido porque não se refere especificamente a ela. Em vez disso, o termo "software" é usado em um sentido geral para descrever programas computacionais e sistemas de computador que são usados em uma variedade de contextos, incluindo ambientes clínicos e de pesquisa.
Em geral, o software pode ser definido como um conjunto de instruções ou diretrizes escritas em um determinado idioma de programação que podem ser executadas por hardware, como uma computadora, para realizar tarefas específicas. Isso inclui sistemas operacionais, aplicativos, scripts, macros e outras formas de software personalizado ou comercialmente disponíveis.
Em um contexto médico, o software pode ser usado para automatizar tarefas, analisar dados, gerenciar registros, fornecer cuidados ao paciente e realizar outras funções importantes. Exemplos de software usados em um ambiente clínico incluem sistemas de registro eletrônico de saúde (EHR), softwares de imagem médica, softwares de monitoramento de sinais vitais e outros aplicativos especializados.
O Reconhecimento Automatizado de Padrões (RAP) é um ramo da inteligência artificial e computacional que se refere a capacidade de um sistema de identificar, classificar e analisar automaticamente padrões em dados ou processos. Isso pode envolver o reconhecimento de padrões em imagens, sons, sinais elétricos ou outras formas de informação.
No campo da medicina, o RAP tem uma variedade de aplicações importantes, incluindo:
1. Análise de imagens médicas: O RAP pode ser usado para analisar imagens de ressonância magnética (RM), tomografia computadorizada (TC) e outras modalidades de imagem para detectar sinais de doenças ou lesões.
2. Monitoramento contínuo de sinais vitais: O RAP pode ser usado para analisar sinais vitais contínuos, como batimentos cardíacos e respiração, para detectar padrões anormais que possam indicar problemas de saúde.
3. Análise de dados clínicos: O RAP pode ser usado para analisar grandes conjuntos de dados clínicos para identificar padrões e tendências que possam ajudar a diagnosticar e tratar doenças.
4. Reconhecimento de fala e escrita: O RAP pode ser usado para reconhecer e transcrever fala e escrita, o que pode ser útil em aplicações como transcrição automática de consultas médicas ou análise de notas clínicas.
Em geral, o RAP tem o potencial de melhorar a precisão e eficiência dos cuidados de saúde, auxiliando os profissionais de saúde a tomar decisões informadas mais rápido e com maior confiança.
Computer Simulation, em um contexto médico ou de saúde, refere-se ao uso de modelos computacionais e algoritmos para imitar ou simular processos, fenômenos ou situações clínicas reais. Essas simulações podem ser utilizadas para testar hipóteses, avaliar estratégias, treinar profissionais de saúde, desenvolver novas tecnologias ou terapêuticas e prever resultados clínicos. Ao utilizar dados reais ou derivados de estudos, as simulações permitem a análise de cenários complexos e a obtenção de insights que poderiam ser difíceis ou impraticáveis de obter através de métodos experimentais tradicionais. Além disso, as simulações por computador podem fornecer um ambiente seguro para o treinamento e avaliação de habilidades clínicas, minimizando os riscos associados a práticas em pacientes reais.
A Biologia Computacional é uma área da ciência que se encontra no interface entre a biologia, computação e matemática. Ela utiliza técnicas e métodos computacionais para analisar dados biológicos e para modelar sistemas biológicos complexos. Isto inclui o desenvolvimento e aplicação de algoritmos e modelos matemáticos para estudar problemas em genética, genómica, proteômica, biofísica, biologia estrutural e outras áreas da biologia. A Biologia Computacional também pode envolver o desenvolvimento de ferramentas e recursos computacionais para ajudar os cientistas a armazenar, gerenciar e analisar dados biológicos em larga escala.
Reprodutibilidade de testes, em medicina e ciências da saúde, refere-se à capacidade de um exame, procedimento diagnóstico ou teste estatístico obter resultados consistentes e semelhantes quando repetido sob condições semelhantes. Isto é, se o mesmo método for aplicado para medir uma determinada variável ou observação, os resultados devem ser semelhantes, independentemente do momento em que o teste for realizado ou quem o realiza.
A reprodutibilidade dos testes é um aspecto crucial na validação e confiabilidade dos métodos diagnósticos e estudos científicos. Ela pode ser avaliada por meio de diferentes abordagens, como:
1. Reproduzibilidade intra-observador: consistência dos resultados quando o mesmo examinador realiza o teste várias vezes no mesmo indivíduo ou amostra.
2. Reproduzibilidade inter-observador: consistência dos resultados quando diferentes examinadores realizam o teste em um mesmo indivíduo ou amostra.
3. Reproduzibilidade temporal: consistência dos resultados quando o mesmo teste é repetido no mesmo indivíduo ou amostra após um determinado período de tempo.
A avaliação da reprodutibilidade dos testes pode ser expressa por meio de diferentes estatísticas, como coeficientes de correlação, concordância kappa e intervalos de confiança. A obtenção de resultados reprodutíveis é essencial para garantir a fiabilidade dos dados e as conclusões obtidas em pesquisas científicas e na prática clínica diária.
Inteligência Artificial (IA) pode ser definida, em termos médicos ou científicos, como a capacidade de um sistema de computador ou software de realizar tarefas que normalmente requeriam inteligência humana para serem concluídas. Isto inclui habilidades como aprendizagem e adaptação, raciocínio e resolução de problemas, compreensão do idioma natural, percepção visual e reconhecimento de padrões. A Inteligência Artificial tem aplicações em diversos campos da medicina, tais como diagnóstico médico, pesquisa clínica, assistência a deficiências e tratamentos personalizados. No entanto, é importante notar que a IA não possui consciência ou emoção, e sua "inteligência" é limitada às tarefas para as quais foi especificamente programada.
Em medicina e ciências da saúde, modelos estatísticos são usados para analisar e interpretação de dados experimentais ou observacionais. Eles fornecem uma representação matemática de um processo ou fenômeno, permitindo prever resultados futuros com base em dados históricos.
Modelos estatísticos geralmente envolvem a especificação de uma equação que descreva a relação entre variáveis dependentes (aquelas que são medidas ou observadas) e independentes (aquelas que são manipuladas ou controladas). Essas equações podem incluir termos de erro para levar em conta a variação aleatória nos dados.
Existem diferentes tipos de modelos estatísticos, dependendo da natureza dos dados e do objetivo da análise. Alguns exemplos comuns incluem:
1. Modelos lineares: esses modelos assumem que a relação entre as variáveis é linear. Eles podem ser usados para analisar dados contínuos e são frequentemente usados em estudos epidemiológicos e ensaios clínicos.
2. Modelos de regressão logística: esses modelos são usados quando a variável dependente é categórica (por exemplo, presença ou ausência de uma doença). Eles permitem estimar as probabilidades de diferentes resultados com base nas variáveis independentes.
3. Modelos de sobrevivência: esses modelos são usados para analisar dados de tempo até um evento, como a morte ou falha de um tratamento. Eles permitem estimar as taxas de falha e os fatores associados à falha precoce ou tardia.
4. Modelos mistos: esses modelos são usados quando os dados contêm vários níveis hierárquicos, como pacientes dentro de centros de tratamento. Eles permitem estimar as variações entre e dentro dos grupos e os fatores associados às diferenças.
Em geral, os modelos estatísticos são usados para analisar dados complexos e estimar as associações entre variáveis. Eles podem ajudar a identificar fatores de risco e proteção, testar hipóteses e informar a tomada de decisões em saúde pública e clínica. No entanto, é importante lembrar que os modelos estatísticos são apenas uma ferramenta e não podem substituir o julgamento clínico ou a experiência do profissional de saúde. Além disso, é essencial garantir que os dados sejam coletados, analisados e interpretados corretamente para evitar conclusões enganosas ou imprecisas.
Sensibilidade e especificidade são conceitos importantes no campo do teste diagnóstico em medicina.
A sensibilidade de um teste refere-se à probabilidade de que o teste dê um resultado positivo quando a doença está realmente presente. Em outras palavras, é a capacidade do teste em identificar corretamente as pessoas doentes. Um teste com alta sensibilidade produzirá poucos falso-negativos.
A especificidade de um teste refere-se à probabilidade de que o teste dê um resultado negativo quando a doença está realmente ausente. Em outras palavras, é a capacidade do teste em identificar corretamente as pessoas saudáveis. Um teste com alta especificidade produzirá poucos falso-positivos.
Em resumo, a sensibilidade de um teste diz-nos quantos casos verdadeiros de doença ele detecta e a especificidade diz-nos quantos casos verdadeiros de saúde ele detecta. Ambas as medidas são importantes para avaliar a precisão de um teste diagnóstico.
Cluster analysis, ou análise por conglomerados em português, é um método de análise de dados não supervisionado utilizado na estatística e ciência de dados. A análise por conglomerados tem como objetivo agrupar observações ou variáveis que sejam semelhantes entre si em termos de suas características ou propriedades comuns. Esses grupos formados são chamados de "conglomerados" ou "clusters".
Existem diferentes técnicas e algoritmos para realizar a análise por conglomerados, como o método de ligação hierárquica (aglomerative hierarchical clustering), k-means, DBSCAN, entre outros. Cada um desses métodos tem suas próprias vantagens e desvantagens, dependendo do tipo de dados e da questão de pesquisa em análise.
A análise por conglomerados é amplamente utilizada em diferentes campos, como biologia, genética, marketing, finanças, ciências sociais e outros. Ela pode ajudar a identificar padrões e estruturas ocultas nos dados, facilitando a interpretação e a tomada de decisões informadas. Além disso, ela é frequentemente usada em conjunto com outras técnicas de análise de dados, como análise de componentes principais (Principal Component Analysis - PCA) e redução de dimensionalidade, para obter insights ainda mais robustos e precisos.
Computer-Aided Image Processing (CAIP) se refere ao uso de tecnologias e algoritmos de computador para a aquisição, armazenamento, visualização, segmentação e análise de diferentes tipos de imagens médicas, tais como radiografias, ressonâncias magnéticas (MRI), tomografias computadorizadas (CT), ultrassom e outras. O processamento de imagem assistido por computador é uma ferramenta essencial na medicina moderna, pois permite aos médicos visualizar e analisar detalhadamente as estruturas internas do corpo humano, detectar anomalias, monitorar doenças e planejar tratamentos.
Alguns dos principais objetivos e aplicações do CAIP incluem:
1. Melhorar a qualidade da imagem: O processamento de imagens pode ser usado para ajustar os parâmetros da imagem, como o contraste, a nitidez e a iluminação, para fornecer uma melhor visualização dos detalhes anatômicos e patológicos.
2. Remoção de ruídos e artefatos: O CAIP pode ajudar a eliminar os efeitos indesejáveis, como o ruído e os artefatos, que podem ser introduzidos durante a aquisição da imagem ou por causa do movimento do paciente.
3. Segmentação de estruturas anatômicas: O processamento de imagens pode ser usado para identificar e isolar diferentes estruturas anatômicas, como órgãos, tecidos e tumores, a fim de facilitar a avaliação e o diagnóstico.
4. Medição e quantificação: O CAIP pode ajudar a medir tamanhos, volumes e outras propriedades dos órgãos e tecidos, bem como monitorar o progresso da doença ao longo do tempo.
5. Apoio à intervenção cirúrgica: O processamento de imagens pode fornecer informações detalhadas sobre a anatomia e a patologia subjacentes, auxiliando os médicos em procedimentos cirúrgicos minimamente invasivos e outras terapêuticas.
6. Análise de imagens avançada: O CAIP pode incorporar técnicas de aprendizagem de máquina e inteligência artificial para fornecer análises mais precisas e automatizadas das imagens médicas, como a detecção de lesões e o diagnóstico diferencial.
Em resumo, o processamento de imagens médicas desempenha um papel fundamental na interpretação e no uso clínico das imagens médicas, fornecendo informações precisas e confiáveis sobre a anatomia e a patologia subjacentes. Com o advento da inteligência artificial e do aprendizado de máquina, as técnicas de processamento de imagens estão se tornando cada vez mais sofisticadas e automatizadas, promovendo uma melhor compreensão das condições clínicas e ajudando os médicos a tomar decisões informadas sobre o tratamento dos pacientes.
A "Análise de Sequência de Proteína" é um ramo da biologia molecular e computacional que se concentra no estudo das sequências de aminoácidos que formam as proteínas. A análise envolve a interpretação de dados experimentais obtidos por meio de técnicas de sequenciamento de proteínas, como a espectrometria de massa.
O objetivo da análise de sequência de proteína é identificar e caracterizar as propriedades estruturais, funcionais e evolucionárias das proteínas. Isso pode incluir a predição de domínios estruturais, localização de sinais de localização subcelular, identificação de motivos funcionais, como sítios de ligação e modificações pós-traducionais, e análise filogenética para inferir relações evolucionárias entre proteínas relacionadas.
Além disso, a análise de sequência de proteína pode ser usada para identificar proteínas desconhecidas por comparação com bancos de dados de sequências conhecidas e para prever as propriedades físicas e químicas das proteínas, como o ponto isoelétrico e a solubilidade. A análise de sequência de proteína é uma ferramenta essencial na pesquisa biomédica e na indústria biofarmacêutica, fornecendo informações valiosas sobre as funções e interações das proteínas no contexto da saúde e da doença.
O alinhamento de sequências é um método utilizado em bioinformática e genética para comparar e analisar duas ou mais sequências de DNA, RNA ou proteínas. Ele consiste em ajustar as sequências de modo a maximizar as similaridades entre elas, o que permite identificar regiões conservadas, mutações e outras características relevantes para a compreensão da função, evolução e relação filogenética das moléculas estudadas.
Existem dois tipos principais de alinhamento de sequências: o global e o local. O alinhamento global compara as duas sequências em sua totalidade, enquanto o alinhamento local procura por regiões similares em meio a sequências mais longas e divergentes. Além disso, os alinhamentos podem ser diretos ou não-diretos, dependendo da possibilidade de inserção ou exclusão de nucleotídeos ou aminoácidos nas sequências comparadas.
O processo de alinhamento pode ser realizado manualmente, mas é mais comum utilizar softwares especializados que aplicam algoritmos matemáticos e heurísticas para otimizar o resultado. Alguns exemplos de ferramentas populares para alinhamento de sequências incluem BLAST (Basic Local Alignment Search Tool), Clustal Omega, e Muscle.
Em suma, o alinhamento de sequências é uma técnica fundamental em biologia molecular e genética, que permite a comparação sistemática de moléculas biológicas e a análise de suas relações evolutivas e funções.
A Interpretação de Imagem Assistida por Computador (Computer-Aided Image Interpretation - CAII) refere-se ao uso de tecnologias computacionais avançadas, como sistemas de inteligência artificial e aprendizagem de máquina, para ajudar profissionais de saúde na análise e interpretação de imagens médicas. Esses sistemas podem processar e analisar dados de imagem, identificando padrões, formas e outras características relevantes que possam indicar a presença de doenças ou condições médicas específicas. A CAII pode ser usada em uma variedade de contextos clínicos, incluindo radiologia, patologia, oftalmologia e outros, auxiliando os profissionais na tomada de decisões diagnósticas e terapêuticas mais precisas e objetivas. No entanto, é importante ressaltar que a CAII é um recurso complementar à avaliação humana e não deve ser utilizado como o único método de interpretação de imagens médicas.
As "Imagens de Fantasmas" não são um termo médico amplamente reconhecido ou estabelecido. No entanto, em um contexto técnico específico, às vezes é usado para descrever um fenômeno observado em sistemas de imagem por ressonância magnética (MRI). Neste contexto, as "Imagens de Fantasmas" podem referir-se a artefatos de imagem que ocorrem como resultado da interferência entre sinais de dois elementos de recepção adjacentes em um sistema de matriz de recepção MRI. Essas imagens fantasma geralmente aparecem como sinais duplicados ou distorcidos ao longo de uma linha no centro da imagem. No entanto, é importante notar que esse uso do termo não é universal e outros termos podem ser usados para descrever esses artefatos de imagem.
Modelos genéticos em medicina e biologia são representações teóricas ou computacionais usadas para explicar a relação entre genes, variantes genéticas e fenótipos (características observáveis) de um organismo. Eles podem ser utilizados para simular a transmissão de genes em famílias, a expressão gênica e a interação entre genes e ambiente. Modelos genéticos ajudam a compreender como certas variações genéticas podem levar ao desenvolvimento de doenças ou à variação na resposta a tratamentos médicos, o que pode contribuir para um melhor diagnóstico, terapêutica e prevenção de doenças.
Existem diferentes tipos de modelos genéticos, como modelos de herança mendeliana simples ou complexa, modelos de rede reguladora gênica, modelos de genoma completo e modelos de simulação de populações. Cada um desses modelos tem suas próprias vantagens e desvantagens e é usado em diferentes contextos, dependendo da complexidade dos sistemas biológicos sendo estudados e do nível de detalhe necessário para responder às questões de pesquisa.
'Processamento de Sinais Assistido por Computador' (em inglês, 'Computer-Aided Processing of Signals') refere-se ao uso de tecnologias computacionais para a aquisição, análise, interpretação e visualização de sinais. Neste contexto, um sinal pode ser definido como qualquer coisa que carregue informação, geralmente em forma de variações de amplitude, frequência ou tempo. Exemplos comuns de sinais incluem sons, imagens e dados fisiológicos.
O processamento de sinais assistido por computador pode envolver uma variedade de técnicas, incluindo filtragem, transformada de Fourier, análise espectral, detecção de padrões e aprendizado de máquina. Essas técnicas podem ser usadas para fins como a remoção de ruído, a extração de recursos relevantes, a classificação e a compressão de dados.
No campo da medicina, o processamento de sinais assistido por computador tem uma variedade de aplicações, incluindo a análise de imagens médicas (como radiografias, ressonâncias magnéticas e tomografias computadorizadas), a monitorização de sinais fisiológicos (como eletrocardiogramas e eletroencefalogramas) e a análise de dados clínicos. Essas técnicas podem ajudar os profissionais médicos a fazer diagnósticos mais precisos, a monitorar a progressão de doenças e a avaliar a eficácia dos tratamentos.
A validação de programas de computador é um processo sistemático e objetivo para determinar se um programa ou sistema de software é capaz de satisfazer os requisitos especificados e atingir os objetivos desejados em determinadas condições de operação. Ela verifica se o programa está funcionando corretamente e produzindo resultados consistentes e precisos, de acordo com as necessidades dos usuários e as normas e regulamentações aplicáveis. A validação geralmente envolve a análise do código-fonte, testes de unidade, integração e sistemas, inspeções e revisões, além da verificação dos documentos relacionados ao desenvolvimento do software. O objetivo final da validação é fornecer confiança razoável de que o programa ou sistema de software é adequado para o seu uso previsto e não apresentará riscos inaceitáveis à saúde, segurança ou qualidade dos dados.
Em medicina, uma imagem tridimensional (3D) refere-se a uma representação visual de volumes corporais ou estruturas anatômicas obtidas por meios de imagiologia médica. Ao contrário das tradicionais imagens bidimensionais (2D), as 3D fornecem informações adicionais sobre o volume, a forma e a posição espacial das estruturas, proporcionando uma visão mais completa e detalhada do órgão ou tecido em questão. Essas imagens podem ser criadas por diferentes técnicas de aquisição de dados, como tomografia computadorizada (TC), ressonância magnética (RM) e ultrassom 3D. Além disso, eles são frequentemente utilizados em procedimentos cirúrgicos e intervencionistas para planejar tratamentos, guiar biopsias e avaliar os resultados do tratamento.
A definição médica de "Análise de Sequência de DNA" refere-se ao processo de determinação e interpretação da ordem exata dos nucleotídeos (adenina, timina, citosina e guanina) em uma molécula de DNA. Essa análise fornece informações valiosas sobre a estrutura genética, função e variação de um gene ou genoma inteiro. É amplamente utilizada em diversas áreas da medicina, biologia e pesquisa genética para fins como diagnóstico de doenças hereditárias, identificação de suspeitos em investigações forenses, estudos evolucionários, entre outros.
Em termos médicos, "aumento de imagem" refere-se a um procedimento diagnóstico que utiliza diferentes técnicas para obter uma visualização detalhada e ampliada de uma parte específica do corpo humano. Existem vários métodos para realizar o aumento de imagem, incluindo radiografia, ultrassom, tomografia computadorizada (TC), ressonância magnética (RM) e endoscopia.
Cada um desses métodos tem suas próprias vantagens e desvantagens, dependendo da região do corpo a ser examinada e da condição clínica em questão. Alguns deles podem expor o paciente a radiação, enquanto outros não.
A radiografia é uma forma simples de aumento de imagem que utiliza raios-X para produzir imagens detalhadas de estruturas internas do corpo. O ultrassom utiliza ondas sonoras de alta frequência para produzir imagens em tempo real do interior do corpo, geralmente sem exposição a radiação.
A tomografia computadorizada (TC) e a ressonância magnética (RM) fornecem imagens detalhadas em camadas de diferentes partes do corpo, mas podem expor o paciente a quantidades significativas de radiação na TC ou requerer que o paciente seja colocado em um campo magnético potente na RM.
A endoscopia é um método minimamente invasivo de aumento de imagem que utiliza um tubo flexível com uma câmera e luz à sua extremidade para examinar o interior do corpo, geralmente por meio de uma pequena incisão ou orifício natural.
As cadeias de Markov são um conceito matemático usado em probabilidade e estatística, que pode ser aplicado em vários campos, incluindo a medicina. Uma cadeia de Markov é um modelo probabilístico de uma sequência de eventos ou estados, no qual a probabilidade de cada evento ou estado depende apenas do evento ou estado imediatamente anterior.
Em outras palavras, a probabilidade de transição entre diferentes estados não é influenciada pelos estados anteriores além do estado imediatamente anterior. Este conceito é chamado de "markoviano" e refere-se à propriedade de memória curta do modelo.
No contexto médico, as cadeias de Markov podem ser usadas para modelar a progressão de doenças ou o tratamento de pacientes com condições crônicas. Por exemplo, um modelo de cadeia de Markov pode ser usado para prever a probabilidade de um paciente com diabetes desenvolver complicações renais ao longo do tempo, levando em consideração os diferentes estágios da doença e as opções de tratamento disponíveis.
As cadeias de Markov podem ajudar a analisar a dinâmica dos sistemas complexos e fornecer insights sobre a probabilidade de diferentes resultados clínicos, o que pode ser útil para a tomada de decisões clínicas e a alocação de recursos em saúde.
Proteínas são macromoléculas compostas por cadeias de aminoácidos ligados entre si por ligações peptídicas. Elas desempenham um papel fundamental na estrutura, função e regulação de todos os órgãos e tecidos do corpo humano. As proteínas são necessárias para a crescimento, reparo e manutenção dos tecidos corporais, além de desempenharem funções importantes como enzimas, hormônios, anticorpos e transportadores. Existem diferentes tipos de proteínas, cada uma com sua própria estrutura e função específicas. A síntese de proteínas é regulada geneticamente, ou seja, o tipo e a quantidade de proteínas produzidas em um determinado momento dependem dos genes ativados na célula.
Protein databases are repositories that store information about protein sequences, structures, functions, and interactions. These databases are essential tools in proteomics research, providing a platform for the analysis, comparison, and prediction of protein properties. Some commonly used protein databases include:
1. UniProtKB (Universal Protein Resource): It is a comprehensive database that provides information about protein sequences, functions, and structures. It contains both reviewed (curated) and unreviewed (uncurated) entries.
2. PDB (Protein Data Bank): It is a database of three-dimensional structures of proteins, nucleic acids, and complex assemblies. The structures are determined experimentally using techniques such as X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and cryo-electron microscopy (cryo-EM).
3. Pfam: It is a database of protein families that provides information about the domains and motifs present in proteins. It uses hidden Markov models to identify and classify protein sequences into families based on their conserved domains.
4. PROSITE: It is a database of protein domains, families, and functional sites that provides information about the sequence patterns and profiles that characterize these features.
5. MINT (Molecular INTeraction database): It is a database of protein-protein interactions that provides information about the physical interactions between proteins in various organisms.
6. IntAct: It is a molecular interaction database that provides information about protein-protein, protein-DNA, and protein-small molecule interactions.
7. BindingDB: It is a public, web-accessible database of measured binding affinities, focusing chiefly on the interactions of proteins considered to be drug targets with small molecules.
These databases can be used for various purposes such as identifying homologous proteins, predicting protein structure and function, studying protein evolution, and understanding protein-protein interactions.
O Teorema de Bayes é um princípio fundamental na teoria da probabilidade, desenvolvido pelo reverendo Thomas Bayes. Ele fornece uma maneira de atualizar as crenças ou probabilidades sobre a ocorrência de um evento, com base em novas evidências ou informações.
Em termos médicos, o Teorema de Bayes pode ser usado para reavaliar a probabilidade diagnóstica de uma doença, considerando os resultados de um teste diagnóstico e as prevalências da doença na população. A fórmula básica do teorema é:
P(A|B) = [P(B|A) * P(A)] / P(B)
Neste contexto, A representa a hipótese (por exemplo, a presença de uma doença), e B representa a evidência (por exemplo, um resultado positivo no teste diagnóstico). As probabilidades anteriores P(A) e P(B) são as probabilidades da ocorrência dos eventos A e B, respectivamente, antes de novas informações serem consideradas. A probabilidade condicional P(B|A) é a probabilidade do evento B, dado que o evento A ocorreu.
Ao aplicar o Teorema de Bayes em medicina, os médicos podem calcular a probabilidade posterior de uma doença, levando em conta as prevalências da doença e os resultados dos testes diagnósticos. Isso pode ajudar a tomar decisões clínicas mais informadas e a reduzir possíveis falhas diagnósticas, como falsos positivos ou falsos negativos.
A perfilagem da expressão gênica é um método de avaliação das expressões gênicas em diferentes tecidos, células ou indivíduos. Ele utiliza técnicas moleculares avançadas, como microarranjos de DNA e sequenciamento de RNA de alta-travessia (RNA-seq), para medir a atividade de um grande número de genes simultaneamente. Isso permite aos cientistas identificar padrões e diferenças na expressão gênica entre diferentes amostras, o que pode fornecer informações valiosas sobre os mecanismos biológicos subjacentes a várias doenças e condições de saúde.
A perfilagem da expressão gênica é amplamente utilizada em pesquisas biomédicas para identificar genes que estão ativos ou desativados em diferentes situações, como durante o desenvolvimento embrionário, em resposta a estímulos ambientais ou em doenças específicas. Ela também pode ser usada para ajudar a diagnosticar e classificar doenças, bem como para avaliar a eficácia de terapias e tratamentos.
Além disso, a perfilagem da expressão gênica pode ser útil na descoberta de novos alvos terapêuticos e no desenvolvimento de medicina personalizada, uma abordagem que leva em consideração as diferenças individuais na genética, expressão gênica e ambiente para fornecer tratamentos mais precisos e eficazes.
O Método de Monte Carlo é uma técnica estatística e probabilística usada para analisar problemas matemáticos, físicos e computacionais complexos por meio da simulação de eventos aleatórios. Ele foi desenvolvido durante a Segunda Guerra Mundial por Stanislaw Ulam, Nicholas Metropolis e outros cientistas enquanto trabalhavam no Projeto Manhattan.
Em termos médicos, o Método de Monte Carlo pode ser usado em diversas áreas, como na física médica, biologia teórica, farmacologia computacional e imagens médicas. Alguns exemplos de aplicações incluem:
1. Dosimetria radiológica: O método pode ser empregado para calcular a distribuição de dose em pacientes submetidos a radioterapia, levando em consideração fatores como a geometria do corpo, a energia e o espectro dos raios X ou partículas carregadas.
2. Dinâmica molecular: A técnica pode ser utilizada para simular o comportamento de moléculas complexas, como proteínas e DNA, em diferentes condições físico-químicas, ajudando a entender seus mecanismos de ligação e interação.
3. Farmacocinética e farmacodinâmica: O Método de Monte Carlo pode ser empregado para modelar a absorção, distribuição, metabolismo e excreção (ADME) de fármacos no organismo, bem como sua interação com alvos moleculares, o que pode ajudar no desenvolvimento e otimização de novas drogas.
4. Imagens médicas: O método pode ser usado para processar e analisar dados obtidos por meio de técnicas de imagem, como tomografia computadorizada (TC), ressonância magnética (RM) e tomografia por emissão de pósitrons (PET), a fim de melhorar a qualidade das imagens e extrair informações relevantes sobre o estado de saúde dos pacientes.
5. Análise de risco: A técnica pode ser empregada para estimar os riscos associados a diferentes procedimentos médicos, tratamentos ou intervenções, levando em consideração as características individuais do paciente e outros fatores relevantes.
Em resumo, o Método de Monte Carlo é uma poderosa ferramenta estatística que pode ser aplicada em diversas áreas da medicina e saúde pública, fornecendo insights valiosos sobre processos complexos e ajudando a tomar decisões informadas sobre diagnóstico, tratamento e prevenção de doenças.
Computer graphics, em um contexto médico ou de saúde, refere-se ao uso de tecnologia de computador para gerar e manipular imagens digitais. Isso pode incluir a criação de imagens 2D estáticas ou animadas, bem como modelos 3D complexos usados em simulações e visualizações avançadas.
Em medicina, o uso de gráficos por computador é amplamente difundido em uma variedade de aplicações, como:
1. Radiologia e Imagem Médica: Os gráficos por computador são essenciais para a aquisição, processamento, visualização e análise de imagens médicas, como radiografias, TCs, RMs e ultrassons. Eles permitem a manipulação de dados complexos, a extração de medidas precisas e a criação de reconstruções 3D detalhadas do corpo humano.
2. Cirurgia Assistida por Computador: Neste campo, os gráficos por computador são usados para planejar cirurgias complexas, guiar instrumentos cirúrgicos e fornecer feedback em tempo real durante procedimentos minimamente invasivos. Isso pode incluir a sobreposição de imagens pré-operatórias em um paciente durante a cirurgia para ajudar a orientar o cirurgião.
3. Projeto e Fabricação de Dispositivos Médicos: Os engenheiros médicos usam gráficos por computador para projetar e testar dispositivos médicos, como implantes ortopédicos e próteses, antes da fabricação. Isso pode ajudar a garantir que os dispositivos sejam seguros, eficazes e adequados ao paciente.
4. Educação Médica: Os gráficos por computador são usados em simulações interativas para ensinar conceitos anatômicos, fisiológicos e quirúrgicos a estudantes de medicina e profissionais de saúde. Isso pode ajudar a melhorar a compreensão dos alunos e prepará-los para situações clínicas reais.
5. Pesquisa Médica: Os cientistas usam gráficos por computador para visualizar dados complexos, como imagens de ressonância magnética e tomografia computadorizada, ajudando-os a identificar padrões, tendências e correlações. Isso pode levar ao desenvolvimento de novas terapias e tratamentos.
Em resumo, os gráficos por computador desempenham um papel fundamental em diversas áreas da medicina, auxiliando na prestação de cuidados de saúde seguros, eficazes e personalizados aos pacientes.
Em um contexto médico, "automação" geralmente se refere ao uso de tecnologia e dispositivos eletrônicos para automatizar tarefas ou processos que normalmente seriam realizados por profissionais humanos. Isso pode incluir a automação de sistemas de registro médico eletrônico, monitoramento remoto de pacientes, administração de medicamentos e outras atividades clínicas.
A automação na medicina tem o potencial de melhorar a eficiência, reduzir erros e melhorar a qualidade dos cuidados de saúde. No entanto, é importante garantir que os sistemas de automação sejam desenvolvidos e implementados de forma segura e responsável, levando em consideração os potenciais riscos e desafios, tais como a privacidade dos pacientes e a possibilidade de falhas técnicas.
Em resumo, a automação na medicina refere-se ao uso de tecnologia para automatizar tarefas clínicas, com o potencial de melhorar a eficiência e a qualidade dos cuidados de saúde, mas também exigindo atenção à segurança e responsabilidade no desenvolvimento e implementação.
Em medicina, "Bases de Dados Factuais" (ou "knowledge bases" em inglês) geralmente se referem a sistemas computacionais que armazenam e organizam informações clínicas estruturadas e validadas, como dados sobre doenças, sinais e sintomas, exames laboratoriais, imagens médicas, tratamentos efetivos, entre outros. Essas bases de dados são frequentemente utilizadas por sistemas de apoio à decisão clínica, como sistemas expertos e sistemas de raciocínio baseado em casos, para fornecer informações relevantes e atualizadas a profissionais de saúde durante o processo de diagnóstico e tratamento de doenças.
As Bases de Dados Factuais podem ser classificadas em diferentes categorias, dependendo da natureza das informações que armazenam. Algumas exemplos incluem:
* Bases de dados de termos médicos e ontologias, como o SNOMED CT (Sistema Nacional de Classificação de Doenças Clínicas) e o UMLS (Unified Medical Language System), que fornecem uma estrutura hierárquica para classificar e codificar termos médicos relacionados a doenças, procedimentos, anormalidades e outros conceitos relevantes à saúde humana.
* Bases de dados clínicas, como o MIMIC (Medical Information Mart for Intensive Care), que armazenam informações detalhadas sobre pacientes hospitalizados, incluindo dados fisiológicos, laboratoriais e de imagens médicas.
* Bases de dados farmacológicas, como o DrugBank, que fornece informações detalhadas sobre medicamentos, incluindo sua estrutura química, mecanismo de ação, efeitos adversos e interações com outras drogas.
* Bases de dados genéticas, como o 1000 Genomes Project, que fornece informações detalhadas sobre variações genéticas em humanos e sua relação com doenças e traços fenotípicos.
Em geral, as bases de dados médicas são uma ferramenta essencial para a pesquisa e prática clínica, fornecendo informações precisas e atualizadas sobre conceitos relacionados à saúde humana. Além disso, eles também podem ser usados para desenvolver modelos de aprendizado de máquina e sistemas de inteligência artificial que ajudam a diagnosticar doenças, prever resultados clínicos e personalizar tratamentos.
A análise de sequência com séries de oligonucleotídeos, também conhecida como DNA microarray ou array de genes, é uma técnica de laboratório utilizada para a medição simultânea da expressão gênica em um grande número de genes. Neste método, milhares de diferentes sondas de oligonucleotídeos são arranjados em uma superfície sólida, como um slide de vidro ou uma lâmina de silício.
Cada sonda de oligonucleotídeo é projetada para se hibridizar especificamente com um fragmento de RNA mensageiro (mRNA) correspondente a um gene específico. Quando um tecido ou célula é preparado e marcado com fluorescência, o mRNA presente no material biológico é extraído e marcado com uma etiqueta fluorescente. Em seguida, este material é misturado com as sondas de oligonucleotídeos no array e a hibridização é permitida.
Após a hibridização, o array é analisado em um equipamento especializado que detecta a intensidade da fluorescência em cada sonda. A intensidade da fluorescência é proporcional à quantidade de mRNA presente no material biológico que se hibridizou com a sonda específica. Desta forma, é possível medir a expressão gênica relativa de cada gene presente no array.
A análise de sequência com séries de oligonucleotídeos pode ser utilizada em diversas áreas da biologia e medicina, como na pesquisa básica para estudar a expressão gênica em diferentes tecidos ou células, no desenvolvimento de novos fármacos, na identificação de genes associados a doenças e no diagnóstico e prognóstico de doenças.
A definição médica de "Análise Numérica Assistida por Computador" refere-se ao uso de computadores e algoritmos matemáticos para realizar cálculos e analisar problemas envolvendo números e variáveis contínuas ou discretas. A análise numérica é uma área da matemática aplicada que lida com a aproximação de soluções para problemas difíceis ou impossíveis de serem resolvidos analiticamente, como equações diferenciais parciais, integrais múltiplas e outros problemas envolvendo funções complexas.
A análise numérica assistida por computador pode ser usada em uma variedade de campos, incluindo engenharia, física, química, biologia e economia, para ajudar a modelar e prever fenômenos naturais ou artificiais. Os métodos numéricos assistidos por computador podem incluir métodos iterativos, como o método de Newton, ou métodos de aproximação, como a interpolação polinomial ou a decomposição espectral.
É importante notar que a análise numérica assistida por computador requer cuidado e atenção às questões de precisão e estabilidade numérica, pois pequenas flutuações nos valores iniciais ou nas aproximações intermediárias podem levar a resultados significativamente diferentes. Portanto, é essencial validar e verificar cuidadosamente as soluções obtidas por meio de análise numérica assistida por computador.
Modelos Teóricos em ciências da saúde e medicina referem-se a representações abstratas ou conceituais de fenômenos, processos ou estruturas relacionados à saúde e doença. Eles são construídos com base em teorias, evidências empíricas e suposições para explicar, prever ou dar sentido a determinados aspectos da realidade observável.
Modelos Teóricos podem ser classificados em diferentes categorias, dependendo do nível de abstração, propósito e método utilizado para sua construção. Alguns exemplos incluem:
1. Modelos biológicos: representações mecanicistas dos processos fisiológicos e bioquímicos que ocorrem no corpo humano, como modelos de doenças genéticas ou modelos de interação entre drogas e receptores celulares.
2. Modelos psicológicos: abordagens teóricas para entender os processos cognitivos, emocionais e comportamentais que influenciam a saúde e doença, como modelos de cognição social, modelos de estresse e resiliência ou modelos de mudança de comportamento.
3. Modelos sociais: representações dos fatores sociais, culturais e ambientais que desempenham um papel na saúde e doença das populações, como modelos de determinantes sociais da saúde, modelos de disparidades em saúde ou modelos de intervenção em saúde pública.
4. Modelos epidemiológicos: abordagens matemáticas e estatísticas para entender a disseminação e controle de doenças infecciosas e outros problemas de saúde pública, como modelos de transmissão de doenças, modelos de vigilância em saúde pública ou modelos de avaliação de intervenções em saúde pública.
Modelos são úteis para a pesquisa e prática em saúde porque fornecem uma estrutura conceitual para entender os fenômenos complexos que desempenham um papel na saúde e doença. Eles podem ajudar a identificar as relações causais entre diferentes fatores, prever os resultados de intervenções e informar a tomada de decisões sobre políticas e práticas de saúde. No entanto, é importante lembrar que os modelos são simplificações da realidade e podem estar sujeitos a limitações e incertezas. Portanto, eles devem ser usados com cautela e em combinação com outras fontes de evidência para informar as decisões sobre saúde.
Em termos médicos, a expressão "Interface Usuário-Computador" (IUC) não é comumente usada, pois ela se enquadra mais em contextos relacionados à tecnologia e à informática. No entanto, posso fornecer uma definição geral da interface homem-computador para você:
A Interface Usuário-Computador (IUC), também conhecida como Interface Homem-Computador (IHC) ou simplesmente Interface, refere-se ao local de encontro entre os humanos e sistemas computacionais. Ela é composta por hardware e software que permitem a interação entre as pessoas e os dispositivos eletrônicos, como teclados, mouse, telas sensíveis ao toque, monitores, além dos softwares responsáveis pela apresentação de informações e processamento das entradas do usuário.
A IUC tem por objetivo facilitar a comunicação entre os humanos e as máquinas, tornando possível o acesso às funcionalidades dos sistemas computacionais de forma intuitiva e amigável, minimizando a curva de aprendizado e maximizando a eficiência e satisfação do usuário.
A compressão de dados é um processo usado em medicina e em outras áreas para reduzir o tamanho de arquivos de dados ou streams de dados, tornando-os mais fáceis e eficientes de armazenar, transmitir ou processar. Isso geralmente é feito por meios algortítmicos que identificam e aproveitam padrões repetitivos ou redundantes em dados brutos, substituindo-os por representações mais concisas. Em medicina, a compressão de dados pode ser usada para otimizar o armazenamento e a transmissão de imagens médicas volumosas, como radiografias, ressonâncias magnéticas (RMs) e tomografias computadorizadas (TCs). No entanto, é importante notar que a compressão de dados pode introduzir distorções ou perda de informação, o que pode ser um fator importante a ser considerado em aplicações clínicas, especialmente quando a integridade dos dados é crucial.
A 'Lógica Fuzzy' (ou Lógica Borrosa) é um sistema de lógica multivalorada que permite a expressão de graus de verdade entre verdadeiro e falso. A diferencia da lógica clássica, que trabalha com proposições binárias (verdadeiro ou falso), a lógica fuzzy permite a representação de conceitos e variáveis contínuas, onde os limites entre as categorias não são claros ou precisos.
Nesta lógica, as variáveis podem ter um valor de verdade que varia entre 0 (falso) e 1 (verdadeiro), o que permite representar situações em que a transição entre os estados é gradual ou contínua. Por exemplo, em vez de classificar uma pessoa como "jovem" ou "velha", a lógica fuzzy pode atribuir um grau de "juventude" ou "idade" que varia entre 0 e 1, dependendo de sua idade real.
A lógica fuzzy tem aplicação em diversas áreas, como o controle de sistemas complexos, o processamento de sinais e imagens, o reconhecimento de padrões e a tomada de decisões, entre outros. Ela permite modelar situações imprecisas ou incertas, onde as informações disponíveis não são suficientes para tomar uma decisão clara e precisa.
Em medicina e ciências da saúde, um "artefato" geralmente se refere a algo que é criado durante o processo de coleta, geração ou análise de dados que não é uma característica inherente ao fenômeno ou objeto em estudo. Em outras palavras, um artefato é um erro ou distorção acidental que é introduzido no processo de pesquisa e pode levar a conclusões incorretas ou enganosas se não for detectado e corrigido.
Existem diferentes tipos de artefatos que podem ocorrer em diferentes contextos de pesquisa. Por exemplo, em estudos de imagem médica, um artefato pode ser uma mancha ou distorção na imagem causada por fatores como movimento do paciente, ruído de fundo ou falha no equipamento. Em análises estatísticas, um artefato pode resultar de violações de suposições estatísticas, como a normalidade dos dados ou a independência dos erros.
Em geral, é importante que os pesquisadores estejam cientes dos potenciais artefatos que podem ocorrer em seus estudos e tomem medidas para minimizá-los ou corrigi-los, quando possível. Isso pode incluir a padronização de procedimentos de coleta de dados, a calibração regular de equipamentos, a aplicação adequada de técnicas estatísticas e a comunicação aberta e transparente sobre os limites e suposições dos seus estudos.
O Diagnóstico por Computador (ou Imagem por Ressonância Magnética Assistida por Computador, "Computer-Aided Diagnosis" ou "CAD" em inglês) é um método de análise de imagens médicas que utiliza algoritmos e softwares computacionais para ajudar no processo de diagnóstico. Através da detecção, marcação e classificação de características ou anomalias presentes em uma imagem, o CAD fornece insights adicionais e sugestões ao médico especialista, auxiliando-o a tomar decisões mais informadas e precisas sobre o estado de saúde do paciente.
Essa tecnologia é amplamente utilizada em diversas áreas da medicina, como no ramo da radiologia, oncologia, cardiologia e neurologia, entre outras. O CAD pode ser empregado em diferentes modalidades de imagens médicas, tais como radiografias, tomografias computadorizadas (TC), ressonâncias magnéticas (RM) e mamografias, por exemplo.
Embora o Diagnóstico por Computador não seja um substituto para a análise e julgamento clínicos do profissional de saúde, ele pode servir como uma ferramenta complementar valiosa no processo diagnóstico, auxiliando na detecção precoce de doenças e melhorando a acurácia geral dos resultados.
Uma base de dados genética é uma coleção organizada e eletronicamente processável de dados relacionados à genética, geralmente armazenados em computadores e disponíveis para consulta e análise. Essas bases de dados contêm informações sobre genes, sequências de DNA, variações genéticas, haplótipos, expressão gênica, função gênica, estrutura e função de proteínas, interações genéticas e genoma completo de indivíduos ou populações. Além disso, essas bases de dados podem incluir informações clínicas, epidemiológicas e ambientais relacionadas à saúde e doenças humanas, além de dados de pesquisas em modelos animais e vegetais.
As bases de dados genéticas são utilizadas em diversas áreas da biologia e medicina, como genômica, proteômica, bioinformática, farmacogenômica, epidemiologia genética e medicina personalizada. Elas permitem a análise de grandes volumes de dados, identificação de padrões e associações entre variantes genéticas e fenótipos, além do desenvolvimento de modelos preditivos e terapêuticos.
Existem diferentes tipos de bases de dados genéticas, especializadas em diferentes aspectos da genética e genômica. Algumas das principais bases de dados genéticas incluem:
1. Bases de dados de sequências de DNA: como GenBank, EMBL e DDBJ, que armazenam milhões de sequências de DNA de diferentes espécies.
2. Bases de dados de variação genética: como dbSNP, 1000 Genomes Project e HapMap, que contêm informações sobre variantes genéticas em humanos e outras espécies.
3. Bases de dados de expressão gênica: como Gene Expression Omnibus (GEO) e ArrayExpress, que armazenam dados de expressão gênica em diferentes tecidos e condições experimentais.
4. Bases de dados de interação proteína-ADN/ARN: como Protein Data Bank (PDB) e STRING, que fornecem informações sobre as interações entre proteínas e ácidos nucleicos ou outras proteínas.
5. Bases de dados de anotação genômica: como Ensembl e UCSC Genome Browser, que fornecem informações detalhadas sobre a estrutura e função dos genes em diferentes espécies.
6. Bases de dados farmacogenéticas: como PharmGKB e DrugBank, que contêm informações sobre as relações entre variantes genéticas e respostas a medicamentos.
A interpretação estatística de dados refere-se ao processo de analisar, interpretar e extrair conclusões a partir de dados empíricos usando métodos estatísticos. Ela envolve a aplicação de técnicas estatísticas para identificar padrões, tendências e relações entre variáveis em um conjunto de dados, bem como a avaliação da significância e confiabilidade desses achados.
A interpretação estatística de dados pode incluir a calculação de medidas estatísticas descritivas, como médias, mediana, moda e desvio padrão, bem como a realização de análises inferenciais, como testes de hipóteses e regressões. Essas técnicas podem ajudar os investigadores a entender as relações entre variáveis, a identificar fatores de risco ou proteção, a testar teorias e a fazer previsões.
No entanto, é importante lembrar que a interpretação estatística de dados é apenas uma parte do processo de análise de dados e deve ser interpretada com cautela. É essencial considerar os limites dos métodos estatísticos utilizados, as suposições subjacentes a esses métodos e a relevância prática dos resultados estatísticos para a pesquisa em questão. Além disso, a interpretação estatística de dados deve ser feita em conjunto com outras formas de análise de dados, como a análise qualitativa e a revisão da literatura, para fornecer uma compreensão mais completa do fenômeno em estudo.
Biological models, em um contexto médico ou científico, referem-se a sistemas ou organismos vivos utilizados para entender, demonstrar ou predizer respostas biológicas ou fenômenos. Eles podem ser usados para estudar doenças, testar novos tratamentos ou investigar processos fisiológicos. Existem diferentes tipos de modelos biológicos, incluindo:
1. Modelos in vitro: experimentos realizados em ambientes controlados fora de um organismo vivo, geralmente em células cultivadas em placa ou tubo de petri.
2. Modelos animais: utilizam animais como ratos, camundongos, coelhos, porcos e primatas para estudar doenças e respostas a tratamentos. Esses modelos permitem o estudo de processos fisiológicos complexos em um organismo inteiro.
3. Modelos celulares: utilizam células humanas ou animais cultivadas para investigar processos biológicos, como proliferação celular, morte celular programada (apoptose) e sinalização celular.
4. Modelos computacionais/matemáticos: simulam sistemas biológicos ou processos usando algoritmos e equações matemáticas para predizer resultados e comportamentos. Eles podem ser baseados em dados experimentais ou teóricos.
5. Modelos humanos: incluem estudos clínicos em pacientes humanos, bancos de dados médicos e técnicas de imagem como ressonância magnética (RM) e tomografia computadorizada (TC).
Modelos biológicos ajudam os cientistas a testar hipóteses, desenvolver novas terapias e entender melhor os processos biológicos que ocorrem em nossos corpos. No entanto, é importante lembrar que nem todos os resultados obtidos em modelos animais ou in vitro podem ser diretamente aplicáveis ao ser humano devido às diferenças entre espécies e contextos fisiológicos.
Em estatística e teoria da probabilidade, a Distribuição Normal, às vezes chamada de Distribuição de Gauss ou Curva de Campana, é um tipo comum de distribuição contínua de probabilidade. É descrita por duas parâmetros: média (μ) e desvio padrão (σ). A maioria dos dados reais segue aproximadamente uma distribuição normal.
A função densidade de probabilidade (PDF) para a distribuição normal é dada pela seguinte fórmula:
f(x) = 1/σ√(2π) * e^[-((x-μ)^2 / (2σ^2))]
O gráfico da função tem uma forma de campana simétrica em relação à média. Quanto maior for o desvio padrão, mais larga será a campanha. A distribuição normal é importante porque ela pode ser usada para modelar muitos fenômenos naturais e sociais, como altura humana, erros de medição e outras variáveis contínuas que tendem a se concentrarem em torno de um valor médio com uma certa quantidade de variação.
A definição médica de "Armazenamento e Recuperação de Informações" refere-se aos processos utilizados para guardar, organizar e recuperar dados relacionados à saúde de um indivíduo ou paciente. Esses processos são fundamentais em ambientes clínicos e hospitalares, pois permitem que profissionais de saúde acedam a informações relevantes sobre o histórico médico do paciente, diagnósticos, tratamentos, exames laboratoriais, imagens e outros dados importantes para a prestação de cuidados de saúde adequados e seguros.
O armazenamento de informações pode ser realizado em diferentes suportes, como prontuários médicos em papel, sistemas eletrônicos de gravação ou bancos de dados especializados. A recuperação de informações é geralmente facilitada por mecanismos de busca e classificação que permitem aos profissionais de saúde localizar rapidamente os dados relevantes para cada caso clínico específico.
A Armazenamento e Recuperação de Informações em saúde está cada vez mais associada às tecnologias da informação e comunicação, com a implementação de sistemas eletrônicos de saúde (SES) e históricos médicos eletrônicos (HME), que proporcionam uma melhor qualidade e segurança na prestação dos cuidados de saúde, além de facilitar a comunicação entre os profissionais envolvidos no atendimento do paciente. No entanto, esses sistemas também podem apresentar desafios em termos de privacidade e proteção de dados dos pacientes, o que exige a implementação de medidas de segurança adequadas para garantir o acesso controlado e autorizado às informações.
Em estatística, a função de verossimilhança é uma função que expressa a probabilidade de um conjunto de parâmetros dada uma determinada amostra de dados. É usado no método de máxima verossimilhança, que é uma técnica estatística para estimar os valores dos parâmetros desconhecidos de uma distribuição de probabilidade subjacente a partir da qual os dados foram gerados.
A função de verossimilhança é definida como a função que mapeia um conjunto de possíveis valores de parâmetros, θ, para a probabilidade dos dados observados, D, dado esse conjunto de parâmetros:
L(θ|D) = P(D|θ)
Esta função é usada para encontrar o valor máximo de θ que maximiza a probabilidade dos dados observados. O valor máximo de θ é então usado como a estimativa do parâmetro verdadeiro.
Em resumo, a função de verossimilhança é uma ferramenta matemática importante para inferência estatística e é usada para estimar os valores dos parâmetros desconhecidos de uma distribuição de probabilidade subjacente a partir da qual os dados foram gerados.
A Interpretação de Imagem Radiográfica Assistida por Computador (em inglês, Computer-Aided Radiographic Image Interpretation - CARII) refere-se a um sistema que utiliza tecnologias computacionais avançadas para ajudar profissionais de saúde, geralmente radiólogos, no processo de análise e interpretação de imagens radiográficas. Esses sistemas podem incluir algoritmos de detecção automatizada de anomalias, marcadores inteligentes, e ferramentas de medição, entre outros recursos, que visam fornecer insights mais precisos e consistentes durante o processo diagnóstico.
É importante notar que a CARII não substitui a expertise humana, mas sim serve como um complemento para auxiliar os profissionais de saúde no processo de interpretação das imagens médicas. Ainda assim, esses sistemas estão em constante evolução e podem oferecer grandes vantagens na prática clínica, como a redução do tempo gasto na análise das imagens, a melhoria da precisão diagnóstica, e a minimização da possibilidade de erros humanos.
Genômica é um ramo da biologia que se concentra no estudo do genoma, que é a totalidade do material genético contida em um conjunto de cromossomos de um indivíduo ou espécie. Ela envolve o mapeamento, análise e compreensão da função e interação dos genes, bem como sua relação com outras características biológicas, como a expressão gênica e a regulação. A genômica utiliza técnicas de biologia molecular e bioinformática para analisar dados genéticos em grande escala, fornecendo informações importantes sobre a diversidade genética, evolução, doenças genéticas e desenvolvimento de organismos. Além disso, a genômica tem implicações significativas para a medicina personalizada, agricultura e biotecnologia.
De acordo com a definição do National Institute of Health (NIH), a Internet pode ser definida como:
"Uma rede global de computadores interconectados que utiliza o protocolo TCP/IP para permitir comunicações e a partilha de informação entre sistemas distribuídos em todo o mundo. A internet fornece uma variedade de serviços, incluindo World Wide Web, email, FTP, telnet e outros, que são acessíveis a milhões de usuários em todo o mundo."
Em resumo, a Internet é uma rede mundial de computadores e dispositivos eletrônicos interconectados que permitem a comunicação e compartilhamento de informações entre usuários e sistemas em diferentes locais geográficos.
Em medicina, "árvores de decisão" é um termo utilizado para descrever um tipo de modelo estatístico ou algoritmo de aprendizagem de máquina que é usado para ajudar a tomar decisiones clínicas. Esses modelos são construídos a partir de dados clínicos e podem ser usados para prever o risco de doenças, a resposta ao tratamento ou outros resultados clínicos.
As árvores de decisão funcionam criando um diagrama em forma de árvore, onde cada ramo representa uma questão de decisão clínica e cada nó final (chamado de "nó folha") representa um resultado ou aconselhamento clínico. O algoritmo vai dividir os dados em diferentes subconjuntos com base em características clínicas relevantes, como idade, gênero, sintomas e exames laboratoriais, até que ele encontre um padrão ou relação entre essas características e o resultado desejado.
As árvores de decisão são frequentemente usadas em medicina devido à sua facilidade de interpretação e visualização. Além disso, elas podem ser construídas a partir de dados clínicos relativamente simples e podem ser usadas para prever uma variedade de resultados clínicos importantes. No entanto, é importante lembrar que esses modelos não são perfeitos e suas previsões devem ser interpretadas com cautela e em conjunto com outras informações clínicas relevantes.
A intensificação de imagem radiográfica é um processo que aumenta a contraste e a clareza das imagens produzidas por radografia, fluoroscopia ou outras formas de imagem médica. Isto geralmente é alcançado através do uso de dispositivos eletrônicos chamados intensificadores de imagem que convertem os raios X em luz visível, a qual pode então ser amplificada e processada para produzir uma imagem clara e nítida. A intensificação de imagem radiográfica é particularmente útil em procedimentos médicos em que sejam necessárias imagens detalhadas e de alta qualidade, como na cirurgia, na angiografia e na diagnose de doenças ósseas ou tumorais.
A "Técnica de Subtração" é um método de processamento de imagem utilizado em radiologia e neurologia para identificar e subtrair a imagem de estruturas ou sinais não desejados, tais como o crânio ou o sangue, a fim de obter uma imagem mais clara e precisa de outras estruturas alvo, como vasos sanguíneos ou tumores cerebrais.
Este método geralmente envolve a aquisição de duas imagens, uma com um contraste específico e outra sem esse contraste, seguida pela subtração da segunda imagem da primeira. Isso pode ser feito por meio de diferentes técnicas, como a "angiografia por subtração digital", que é amplamente utilizada em procedimentos de angiografia para visualizar os vasos sanguíneos e detectar possíveis anomalias ou doenças.
A Técnica de Subtração pode ser usada em diferentes modalidades de imagem, como radiografia, tomografia computadorizada (TC), ressonância magnética (RM) e angiografia por infusão de contraste, fornecendo informações detalhadas sobre as estruturas internas do corpo humano e ajudando os médicos a fazer diagnósticos precisos e planejar tratamentos adequados.
Linguagens de programação são conjuntos de regras sintáticas e semânticas que permitem a expressão de algoritmos e a especificação de suas estruturas de controle, variáveis e dados em forma de texto (código-fonte), para ser processado por um computador. Elas fornecem uma interface abstrata entre os humanos e a máquina, tornando possível a comunicação e a execução de tarefas específicas. Existem diferentes tipos de linguagens de programação, cada uma com suas próprias características e aplicações, como por exemplo: procedural, orientada a objetos, funcional, lógica e de script.
"Ondaleta" é um termo utilizado em fisiologia cardiovascular para descrever as pequenas ondas de pressão que viajam através do sistema arterial. A análise de ondaletas refere-se ao processo de avaliar e interpretar essas ondas, geralmente usando técnicas de análise de sinais e métodos matemáticos sofisticados.
A análise de ondaletas pode fornecer informações importantes sobre a rigidez arterial, função endotelial, e outros aspectos da saúde cardiovascular. Por exemplo, alterações na forma e amplitude das ondaletas podem indicar um aumento na rigidez arterial, o que é um fator de risco importante para doenças cardiovasculares como a hipertensão arterial e a doença coronária.
A análise de ondaletas geralmente requer a aquisição de sinais de pressão arterial contínua, que pode ser obtida por meio de um cateter especial ou por técnicas de fotopletismografia (PPG). O sinal é então analisado usando algoritmos específicos para extrair as características das ondaletas e avaliar sua forma, amplitude e frequência.
Em suma, a análise de ondaletas é uma técnica avançada de avaliação da saúde cardiovascular que pode fornecer informações importantes sobre a rigidez arterial e outros fatores de risco para doenças cardiovasculares.
A definição médica de "Metodologias Computacionais" não é tão comum, una vez que este termo se refere a um campo interdisciplinar que utiliza teorias e métodos computacionais para analisar fenômenos em outras áreas do conhecimento. No entanto, em um contexto mais amplo, as Metodologias Computacionais podem ser definidas como:
As Metodologias Computacionais são abordagens sistemáticas e estruturadas para modelar, simular e analisar fenômenos complexos usando técnicas e ferramentas computacionais. Essas metodologias envolvem uma variedade de técnicas, incluindo modelagem matemática, simulação por computador, análise de dados e visualização científica, entre outras. Elas são amplamente aplicadas em diferentes campos do conhecimento, como física, química, biologia, engenharia, ciências sociais e humanidades, para listar alguns.
Em suma, as Metodologias Computacionais referem-se a um conjunto de técnicas e ferramentas computacionais usadas para modelar, simular e analisar fenômenos complexos em diferentes contextos científicos e acadêmicos.
A razão sinal-ruído (RSR) é um termo utilizado na área da processamento de sinais e telecomunicações, mas que também se aplica à áreas como a audiologia e psicologia. A RSR refere-se à relação entre o sinal (a informação útil ou desejada) e o ruído (a interferência indesejável ou não intencional).
Em termos médicos, a razão sinal-ruído é frequentemente usada para descrever a relação entre o nível de um sinal perceptível (como um som ou uma imagem) e o ruído de fundo que pode estar presente. Por exemplo, em audiologia, a RSR pode ser usada para medir a capacidade auditiva de uma pessoa em diferentes frequências sonoras. Um valor de RSR mais alto indica que o sinal é mais forte em relação ao ruído de fundo e, portanto, é mais fácil de ser percebido ou distinguido.
Em geral, quanto maior a razão sinal-ruído, melhor a qualidade do sinal e menor a interferência do ruído. Em situações clínicas, uma RSR mais alta pode indicar uma melhor capacidade perceptiva ou funcional em relação a um determinado estímulo ou tarefa.
A mineração de dados é um processo que envolve a utilização de algoritmos avançados e estatísticas para descobrir padrões, tendências e correlações em conjuntos grandes e complexos de dados. Também conhecida como análise de dados, a mineração de dados é uma ferramenta importante na área da medicina, pois pode ajudar no diagnóstico e tratamento de doenças, bem como no desenvolvimento de novos medicamentos e terapias.
Em um contexto médico, a mineração de dados pode ser utilizada para analisar registros eletrônicos de saúde, resultados de exames laboratoriais, imagens médicas e outras fontes de dados para identificar fatores de risco para doenças, prever o desfecho de doentes e avaliar a eficácia de diferentes tratamentos. Além disso, a mineração de dados pode ser utilizada para identificar tendências em saúde pública, tais como a propagação de doenças infecciosas ou o aumento dos casos de determinadas condições de saúde.
No entanto, é importante notar que a mineração de dados não é uma solução mágica para todos os problemas em medicina e deve ser utilizada com cautela, levando em consideração as limitações dos dados e das técnicas de análise. Além disso, é essencial garantir a privacidade e a proteção dos dados pessoais dos pacientes durante o processo de mineração de dados.
O mapeamento de interação de proteínas (PPI, do inglês Protein-Protein Interaction) refere-se ao estudo e análise das interações físicas e funcionais entre diferentes proteínas em um organismo vivo. Essas interações desempenham papéis cruciais no processo de regulação celular, sinalização intracelular, formação de complexos multiproteicos, e na organização da arquitetura celular.
A compreensão dos mapas de interação de proteínas é fundamental para elucidar os mecanismos moleculares subjacentes a diversos processos biológicos e patológicos, como o desenvolvimento de doenças genéticas, neurodegenerativas e câncer. Além disso, esses mapas podem fornecer insights valiosos sobre as redes moleculares que governam a organização e regulação dos sistemas celulares, bem como auxiliar no desenvolvimento de novas estratégias terapêuticas.
Diversas técnicas experimentais são empregadas para mapear essas interações, incluindo a biologia de sistemas, bioquímica, genética e biologia computacional. Algumas das principais abordagens experimentais utilizadas no mapeamento de interação de proteínas incluem:
1. Espectrometria de massa (MS): Através da análise de fragmentos de proteínas, é possível identificar e quantificar as interações entre diferentes proteínas em uma amostra biológica.
2. Co-imunoprecipitação (Co-IP): Essa técnica consiste na utilização de anticorpos específicos para capturar e purificar uma proteína-alvo, levando consigo as proteínas com as quais interage.
3. Biotinayladação: Através da ligação covalente de biotina a proteínas, é possível isolar e identificar as interações entre diferentes proteínas em uma amostra biológica.
4. Hi-5: Essa técnica combina a expressão de proteínas marcadas com GFP e a microscopia de fluorescência para detectar as interações entre diferentes proteínas em células vivas.
5. Proteínas de fusão: Através da criação de proteínas híbridas, é possível detectar as interações entre diferentes proteínas por meio de técnicas como a reconstituição de domínios de ligação ou a quimiotaxia bacteriana.
6. Análise de sequência: Através da comparação de sequências de aminoácidos, é possível inferir as interações entre diferentes proteínas com base em suas estruturas tridimensionais e domínios funcionais.
7. Modelagem molecular: Através do uso de algoritmos computacionais, é possível prever as interações entre diferentes proteínas com base em suas estruturas tridimensionais e propriedades físico-químicas.
Modelos moleculares são representações físicas ou gráficas de moléculas e suas estruturas químicas. Eles são usados para visualizar, compreender e estudar a estrutura tridimensional, as propriedades e os processos envolvendo moléculas em diferentes campos da química, biologia e física.
Existem vários tipos de modelos moleculares, incluindo:
1. Modelos espaciais tridimensionais: Esses modelos são construídos com esferas e haste que representam átomos e ligações químicas respectivamente. Eles fornecem uma visão tridimensional da estrutura molecular, facilitando o entendimento dos arranjos espaciais de átomos e grupos funcionais.
2. Modelos de bolas e haste: Esses modelos são semelhantes aos modelos espaciais tridimensionais, mas as esferas são conectadas por hastes flexíveis em vez de haste rígidas. Isso permite que os átomos se movam uns em relação aos outros, demonstrando a natureza dinâmica das moléculas e facilitando o estudo dos mecanismos reacionais.
3. Modelos de nuvem eletrônica: Esses modelos representam a distribuição de elétrons em torno do núcleo atômico, fornecendo informações sobre a densidade eletrônica e as interações entre moléculas.
4. Modelos computacionais: Utilizando softwares especializados, é possível construir modelos moleculares virtuais em computadores. Esses modelos podem ser usados para simular a dinâmica molecular, calcular propriedades físico-químicas e predizer interações entre moléculas.
Modelos moleculares são úteis no ensino e aprendizagem de conceitos químicos, na pesquisa científica e no desenvolvimento de novos materiais e medicamentos.
A tecnologia sem fio, também conhecida como wireless, refere-se a um tipo de tecnologia que permite a comunicação e transmissão de dados entre dispositivos eletrônicos sem a necessidade de fios ou cabos conectores. Isso é possível através do uso de sinais de rádio, micro-ondas, infravermelhos ou outras ondas eletromagnéticas para transferir informações entre dispositivos.
Existem diferentes tecnologias sem fio disponíveis atualmente, incluindo Bluetooth, Wi-Fi, redes celulares, rádio frequency identification (RFID), e zigbee, entre outras. Estas tecnologias são amplamente utilizadas em diversos dispositivos eletrônicos, como smartphones, tablets, computadores, impressoras, sistemas de áudio e vídeo, sensores, dispositivos médicos e muito mais.
A tecnologia sem fio tem muitas vantagens em comparação com as tecnologias com fios tradicionais, como maior mobilidade, flexibilidade, facilidade de instalação e menor custo. No entanto, também apresenta desafios, tais como limitações de largura de banda, interferência de sinais, segurança e privacidade dos dados transmitidos.
Na medicina, a tecnologia sem fio tem sido cada vez mais utilizada em dispositivos médicos implantáveis, como marcapassos, desfibriladores cardioversores e sensores de glucose, entre outros. Esses dispositivos permitem que os pacientes se movam livremente enquanto ainda são monitorados remotamente por profissionais de saúde. Além disso, a tecnologia sem fio também é usada em ambientes hospitalares para a comunicação entre diferentes equipamentos médicos e para o acesso à internet em dispositivos móveis.
Support Vector Machines (SVMs) são um tipo de algoritmo de aprendizagem de máquina baseado em conceitos de estatística e teoria de funcionais. Eles são frequentemente usados para classificação e regressão, sendo particularmente úteis em problemas de classificação de dados com um grande número de recursos ou dimensões.
Em termos médicos, SVMs podem ser aplicadas em diversos cenários, tais como:
1. Classificação de imagens médicas: SVMs podem ser treinados para classificar diferentes tipos de lesões ou doenças com base em características extraídas de imagens médicas, como ressonâncias magnéticas (MRI) ou tomografias computadorizadas (CT).
2. Análise de genômica: SVMs podem ser usados para identificar genes associados a doenças específicas, analisando padrões de expressão gênica em amostras saudáveis e doentes.
3. Diagnóstico de doenças: SVMs podem ser treinados com dados clínicos e laboratoriais para ajudar no diagnóstico de diferentes condições médicas, como câncer ou diabetes.
4. Análise de tempo-sequência: SVMs podem ser usadas para analisar sinais fisiológicos contínuos, como eletrocardiogramas (ECG) ou eletroencefalogramas (EEG), a fim de identificar padrões anormais associados a doenças cardiovasculares ou neurológicas.
Em geral, o objetivo dos SVMs é encontrar um hiperplano que maximize a margem entre duas classes em um espaço de recursos de alta dimensão. Isso é feito através do uso de funções de kernel, que permitem mapear os dados para um espaço de dimensões mais altas onde é possível separar as classes com maior facilidade. Ao encontrar este hiperplano ótimo, os SVMs podem então ser usados para classificar novos exemplos e prever a classe a que pertencem.
'Processamento Automatizado de Dados' (em inglês, 'Automated Data Processing' - ADP) é um termo da área de tecnologia e se refere ao uso de sistemas computacionais para capturar, processar, transmitir e armazenar dados de forma mecanizada e sem intervenção humana significativa. Isso pode incluir uma variedade de tarefas, desde a coleta e registro de dados até o processamento e análise de grandes volumes de informação. O ADP é amplamente utilizado em diversos setores, como finanças, saúde, educação e comércio, para aumentar a eficiência, acurácia e velocidade dos processos de negócios. Alguns exemplos de tecnologias associadas ao ADP incluem sistemas de gerenciamento de bancos de dados, processamento de transações online e software de análise de dados.
Na medicina, o termo "Desenho de Programas de Computador" não é amplamente utilizado ou reconhecido. No entanto, em geral, o "desenho de programas de computador" refere-se ao processo de planejamento e projeto da estrutura lógica e das interações de um programa de computador ou sistema de software. Isso inclui a definição dos algoritmos, fluxogramas, diagramas de atividade, esquemas de banco de dados e outras representações gráficas que descrevem o comportamento do software e sua arquitetura. O objetivo é criar um design claro, eficiente e bem-estruturado que possa ser implementado, testado e mantido facilmente.
Em alguns contextos médicos, como a área de saúde eletrônica ou bioinformática, o desenho de programas de computador pode se referir ao processo de design e desenvolvimento de sistemas de software específicos para a gestão de dados clínicos, análise de genomas ou outras aplicações relacionadas à saúde. Nesses casos, o conhecimento especializado em ciências da vida e práticas médicas pode ser necessário para garantir que os sistemas sejam adequados, precisos e confiáveis no processo de desenho do programa de computador.
A "RNA Sequence Analysis" é um termo usado na medicina e genética para descrever o processo de identificação e análise de sequências de nucleotídeos em moléculas de RNA (ácido ribonucleico). Essa análise pode fornecer informações valiosas sobre a função, estrutura e regulação gênica dos genes em um genoma.
O processo geralmente começa com a extração e purificação do RNA a partir de tecidos ou células, seguido pelo sequenciamento do RNA usando tecnologias de alta-travessia como a sequenciação de RNA de próxima geração (RNA-Seq). Isso gera um grande volume de dados brutos que são então analisados usando métodos bioinformáticos para mapear as sequências de RNA de volta ao genoma de referência e identificar variantes e expressões gênicas.
A análise da sequência de RNA pode ser usada para detectar mutações, variações de expressão gênica, splicing alternativo e outras alterações na regulação gênica que podem estar associadas a doenças genéticas ou cancerígenas. Além disso, essa análise pode ajudar a identificar novos genes e RNA não-codificantes, além de fornecer informações sobre a evolução e diversidade dos genomas.
De acordo com a definição da American Heritage Medical Dictionary, um computador é "um dispositivo eletrônico capaz de receber e processar automaticamente informações digitais, geralmente em forma de números."
Computadores são usados em uma variedade de aplicações na medicina, incluindo o registro e armazenamento de dados do paciente, análise de imagens médicas, simulação de procedimentos cirúrgicos, pesquisa biomédica e muito mais. Existem diferentes tipos de computadores, como computadores desktop, laptops, servidores, smartphones e tablets, todos eles capazes de processar informações digitais para fornecer saídas úteis para os usuários.
"Dados de sequência molecular" referem-se a informações sobre a ordem ou seqüência dos constituintes moleculares em uma molécula biológica específica, particularmente ácidos nucléicos (como DNA ou RNA) e proteínas. Esses dados são obtidos através de técnicas experimentais, como sequenciamento de DNA ou proteínas, e fornecem informações fundamentais sobre a estrutura, função e evolução das moléculas biológicas. A análise desses dados pode revelar padrões e características importantes, tais como genes, sítios de ligação regulatórios, domínios proteicos e motivos estruturais, que podem ser usados para fins de pesquisa científica, diagnóstico clínico ou desenvolvimento de biotecnologia.
Em termos médicos ou científicos, um "processo estocástico" é frequentemente mencionado em estatística e teoria da probabilidade. É um conceito matemático usado para descrever uma sequência de eventos ou variáveis aleatórias que evoluem ao longo do tempo ou outras dimensões contínuas.
Em outras palavras, um processo estocástico é um conjunto de funções aleatórias indexadas por algum parâmetro contínuo, geralmente o tempo. Essas funções descrevem a evolução probabilística de um sistema, onde cada possível trajetória do sistema corresponde a um caminho diferente da função aleatória.
Existem muitos tipos diferentes de processos estocásticos, incluindo processos de Markov, processos de Gauss e movimentos brownianos, entre outros. Cada tipo tem suas próprias propriedades e características únicas que o tornam adequado para descrever diferentes fenômenos aleatórios em uma variedade de campos, como física, engenharia, economia e biologia.
Em resumo, um processo estocástico é um conceito matemático usado para descrever a evolução probabilística de sistemas complexos ao longo do tempo ou outras dimensões contínuas.
O genoma é a totalidade do material genético hereditário de um organismo ou célula, armazenado em cromossomos e organizado em genes, que contém todas as informações genéticas necessárias para o desenvolvimento, funcionamento e reprodução desse organismo. Em humanos, o genoma é composto por aproximadamente 3 bilhões de pares de bases de DNA, organizados em 23 pares de cromossomos, com exceção dos homens que têm um cromossomo Y adicional. O genoma humano contém aproximadamente 20.000-25.000 genes, que codificam proteínas e outros RNAs funcionais. O estudo do genoma é chamado de genomica e tem implicações importantes em áreas como medicina, biologia evolutiva, agricultura e biotecnologia.
As Redes Reguladoras de Genes (RRGs) referem-se a um complexo sistema de interações entre diferentes moléculas que controlam a expressão gênica. Elas consistem em uma variedade de elementos, incluindo fatores de transcrição, proteínas reguladoras e elementos do DNA não codificante, como enhancers e silencers. Esses elementos trabalham juntos para coordenar a ativação ou desativação da transcrição de genes específicos em diferentes condições e tecidos.
As RRGs podem ser desencadeadas por sinais internos ou externos, como estressores ambientais ou sinais de outras células. A ativação das RRGs pode levar à expressão de genes que desencadeiam uma resposta específica, como a resposta imune ou o desenvolvimento celular.
A compreensão das RRGs é crucial para entender a regulação gênica e a formação de redes complexas de interação molecular em organismos vivos. Elas desempenham um papel fundamental no desenvolvimento, na diferenciação celular, na resposta ao estresse e em doenças como o câncer.
A Curva ROC (Receiver Operating Characteristic) é um gráfico usado na avaliação de desempenho de um teste diagnóstico ou modelo preditivo. A curva mostra a relação entre a sensibilidade (taxa de verdadeiros positivos) e a especificidade (taxa de verdadeiros negativos) do teste em diferentes pontos de corte.
A abscissa da curva representa o valor de probabilidade de um resultado positivo (1 - especificidade), enquanto que a ordenada representa a sensibilidade. A área sob a curva ROC (AUC) é usada como um resumo do desempenho global do teste, com valores mais próximos de 1 indicando melhor desempenho.
Em resumo, a Curva ROC fornece uma representação visual da capacidade do teste em distinguir entre os resultados positivos e negativos, tornando-se útil na comparação de diferentes métodos diagnósticos ou preditivos.
Desenho de equipamento, em termos médicos ou de engenharia biomédica, refere-se ao processo de projetar e desenvolver dispositivos, instrumentos ou sistemas que sejam seguros, eficazes e ergonômicos para uso em contextos clínicos ou hospitalares. Isso pode incluir uma ampla gama de produtos, desde equipamentos simples como seringas e bisturis até dispositivos complexos como monitores cardíacos, ressonâncias magnéticas e sistemas de imagem médica.
O processo de design de equipamento envolve uma série de etapas, incluindo a pesquisa de necessidades dos usuários, definição do problema, geração de ideias, prototipagem, testes e avaliação. A segurança e a eficácia são considerações fundamentais em todos os aspectos do design, e os designers devem seguir as normas e regulamentos relevantes para garantir que o equipamento seja adequado ao seu propósito e não cause danos aos pacientes ou operadores.
Além disso, o design de equipamento também deve levar em conta considerações ergonômicas, tais como a facilidade de uso, a acessibilidade e a comodidade do usuário. Isso pode envolver a seleção de materiais adequados, a criação de interfaces intuitivas e a minimização da fadiga relacionada ao uso do equipamento.
Em resumo, o design de equipamento é um processo complexo e multidisciplinar que envolve uma combinação de ciência, engenharia, arte e design centrado no usuário para criar soluções inovadoras e eficazes para as necessidades dos pacientes e dos profissionais de saúde.
Modelos químicos são representações gráficas ou físicas de estruturas moleculares e reações químicas. Eles são usados para visualizar, compreender e prever o comportamento e as propriedades das moléculas e ions. Existem diferentes tipos de modelos químicos, incluindo:
1. Modelos de Lewis: representam a estrutura de ligação de uma molécula usando símbolos de elementos químicos e traços para mostrar ligações covalentes entre átomos.
2. Modelos espaciais: fornecem uma representação tridimensional da estrutura molecular, permitindo que os químicos visualizem a orientação dos grupos funcionais e a forma geral da molécula.
3. Modelos de orbital moleculares: utilizam diagramas de energia para mostrar a distribuição de elétrons em uma molécula, fornecendo informações sobre sua reatividade e estabilidade.
4. Modelos de superfície de energia potencial: são usados para visualizar as mudanças de energia durante uma reação química, ajudando a prever os estados de transição e os produtos formados.
5. Modelos computacionais: utilizam softwares especializados para simular a estrutura e o comportamento das moléculas, fornecendo previsões quantitativas sobre propriedades como energia de ligação, polaridade e reatividade.
Em resumo, modelos químicos são ferramentas essenciais na compreensão e no estudo da química, fornecendo uma representação visual e quantitativa dos conceitos químicos abstratos.
Em um contexto médico ou científico, a probabilidade é geralmente definida como a chance ou a frequência relativa com que um evento específico ocorre. É expressa como um valor numérico que varia entre 0 e 1, onde 0 representa um evento que nunca acontece e 1 representa um evento que sempre acontece. Valores intermediários indicam diferentes graus de probabilidade, com valores mais próximos de 1 indicando uma maior chance do evento ocorrer.
A probabilidade é frequentemente usada em pesquisas clínicas e estudos epidemiológicos para avaliar os riscos associados a diferentes fatores de saúde, bem como para prever a eficácia e os possíveis efeitos colaterais de diferentes intervenções e tratamentos. Também é usada em diagnóstico médico, especialmente em situações em que os sinais e sintomas podem ser interpretados de várias maneiras ou quando a precisão dos testes diagnósticos é limitada.
Em geral, a probabilidade fornece uma forma objetiva e quantitativa de avaliar as incertezas inerentes à prática clínica e à pesquisa em saúde, auxiliando os profissionais de saúde e os investigadores a tomar decisões informadas e a comunicar riscos e benefícios de forma clara e transparente.
O Valor Preditivo dos Testes (VPT) é um conceito utilizado em medicina para avaliar a capacidade de um teste diagnóstico ou exame em prever a presença ou ausência de uma doença ou condição clínica em indivíduos assintomáticos ou com sintomas. Existem dois tipos principais de VPT:
1. Valor Preditivo Positivo (VPP): É a probabilidade de que um resultado positivo no teste seja realmente indicativo da presença da doença. Em outras palavras, é a chance de ter a doença quando o teste for positivo. Um VPP alto indica que o teste tem boa precisão em identificar aqueles que realmente possuem a doença.
2. Valor Preditivo Negativo (VPN): É a probabilidade de que um resultado negativo no teste seja verdadeiramente indicativo da ausência da doença. Em outras palavras, é a chance de não ter a doença quando o teste for negativo. Um VPN alto indica que o teste tem boa precisão em identificar aqueles que realmente não possuem a doença.
Os Valores Preditivos dos Testes dependem de vários fatores, incluindo a prevalência da doença na população estudada, a sensibilidade e especificidade do teste, e a probabilidade prévia (prior) ou pré-teste da doença. Eles são úteis para ajudar os clínicos a tomar decisões sobre o manejo e tratamento dos pacientes, especialmente quando os resultados do teste podem levar a intervenções clínicas importantes ou consequências significativas para a saúde do paciente.
O mapeamento cromossômico é um processo usado em genética para determinar a localização e o arranjo de genes, marcadores genéticos ou outros segmentos de DNA em um cromossomo. Isso é frequentemente realizado por meio de técnicas de hibridização in situ fluorescente (FISH) ou análise de sequência de DNA. O mapeamento cromossômico pode ajudar a identificar genes associados a doenças genéticas e a entender como esses genes são regulados e interagem um com o outro. Além disso, é útil na identificação de variações estruturais dos cromossomos, como inversões, translocações e deleções, que podem estar associadas a várias condições genéticas.
Filogenia é um termo da biologia que se refere à história evolutiva e relacionamento evolucionário entre diferentes grupos de organismos. É a disciplina científica que estuda as origens e desenvolvimento dos grupos taxonômicos, incluindo espécies, gêneros e outras categorias hierárquicas de classificação biológica. A filogenia é baseada em evidências fósseis, anatomia comparada, biologia molecular e outros dados que ajudam a inferir as relações entre diferentes grupos de organismos. O objetivo da filogenia é construir árvores filogenéticas, que são diagramas que representam as relações evolutivas entre diferentes espécies ou outros táxons. Essas árvores podem ser usadas para fazer inferências sobre a história evolutiva de organismos e características biológicas. Em resumo, filogenia é o estudo da genealogia dos organismos vivos e extintos.
A Imagem por Ressonância Magnética (IRM) é um exame diagnóstico não invasivo que utiliza campos magnéticos fortes e ondas de rádio para produzir imagens detalhadas e cross-sectionais do corpo humano. A técnica explora as propriedades de ressonância de certos núcleos atômicos (geralmente o carbono-13, o flúor-19 e o hidrogênio-1) quando submetidos a um campo magnético estático e exposição a ondas de rádio.
No contexto médico, a IRM é frequentemente usada para obter imagens do cérebro, medula espinhal, órgãos abdominais, articulações e outras partes do corpo. As vantagens da IRM incluem sua capacidade de fornecer imagens em alta resolução com contraste entre tecidos diferentes, o que pode ajudar no diagnóstico e acompanhamento de uma variedade de condições clínicas, como tumores, derrames cerebrais, doenças articulares e outras lesões.
Apesar de ser geralmente segura, existem algumas contraindicações para a IRM, incluindo o uso de dispositivos médicos implantados (como marcapassos cardíacos ou clipes aneurismáticos), tatuagens contendo metal, e certos tipos de ferrossa ou implantes metálicos. Além disso, as pessoas com claustrofobia podem experimentar ansiedade durante o exame devido ao ambiente fechado do equipamento de IRM.
'Fatores de tempo', em medicina e nos cuidados de saúde, referem-se a variáveis ou condições que podem influenciar o curso natural de uma doença ou lesão, bem como a resposta do paciente ao tratamento. Esses fatores incluem:
1. Duração da doença ou lesão: O tempo desde o início da doença ou lesão pode afetar a gravidade dos sintomas e a resposta ao tratamento. Em geral, um diagnóstico e tratamento precoces costumam resultar em melhores desfechos clínicos.
2. Idade do paciente: A idade de um paciente pode influenciar sua susceptibilidade a determinadas doenças e sua resposta ao tratamento. Por exemplo, crianças e idosos geralmente têm riscos mais elevados de complicações e podem precisar de abordagens terapêuticas adaptadas.
3. Comorbidade: A presença de outras condições médicas ou psicológicas concomitantes (chamadas comorbidades) pode afetar a progressão da doença e o prognóstico geral. Pacientes com várias condições médicas costumam ter piores desfechos clínicos e podem precisar de cuidados mais complexos e abrangentes.
4. Fatores socioeconômicos: As condições sociais e econômicas, como renda, educação, acesso a cuidados de saúde e estilo de vida, podem desempenhar um papel importante no desenvolvimento e progressão de doenças. Por exemplo, indivíduos com baixa renda geralmente têm riscos mais elevados de doenças crônicas e podem experimentar desfechos clínicos piores em comparação a indivíduos de maior renda.
5. Fatores comportamentais: O tabagismo, o consumo excessivo de álcool, a má nutrição e a falta de exercícios físicos regularmente podem contribuir para o desenvolvimento e progressão de doenças. Pacientes que adotam estilos de vida saudáveis geralmente têm melhores desfechos clínicos e uma qualidade de vida superior em comparação a pacientes com comportamentos de risco.
6. Fatores genéticos: A predisposição genética pode influenciar o desenvolvimento, progressão e resposta ao tratamento de doenças. Pacientes com uma história familiar de determinadas condições médicas podem ter um risco aumentado de desenvolver essas condições e podem precisar de monitoramento mais apertado e intervenções preventivas mais agressivas.
7. Fatores ambientais: A exposição a poluentes do ar, água e solo, agentes infecciosos e outros fatores ambientais pode contribuir para o desenvolvimento e progressão de doenças. Pacientes que vivem em áreas com altos níveis de poluição ou exposição a outros fatores ambientais de risco podem precisar de monitoramento mais apertado e intervenções preventivas mais agressivas.
8. Fatores sociais: A pobreza, o isolamento social, a violência doméstica e outros fatores sociais podem afetar o acesso aos cuidados de saúde, a adesão ao tratamento e os desfechos clínicos. Pacientes que experimentam esses fatores de estresse podem precisar de suporte adicional e intervenções voltadas para o contexto social para otimizar seus resultados de saúde.
9. Fatores sistêmicos: As disparidades raciais, étnicas e de gênero no acesso aos cuidados de saúde, na qualidade dos cuidados e nos desfechos clínicos podem afetar os resultados de saúde dos pacientes. Pacientes que pertencem a grupos minoritários ou marginalizados podem precisar de intervenções específicas para abordar essas disparidades e promover a equidade em saúde.
10. Fatores individuais: As características do paciente, como idade, sexo, genética, história clínica e comportamentos relacionados à saúde, podem afetar o risco de doenças e os desfechos clínicos. Pacientes com fatores de risco individuais mais altos podem precisar de intervenções preventivas personalizadas para reduzir seu risco de doenças e melhorar seus resultados de saúde.
Em resumo, os determinantes sociais da saúde são múltiplos e interconectados, abrangendo fatores individuais, sociais, sistêmicos e ambientais que afetam o risco de doenças e os desfechos clínicos. A compreensão dos determinantes sociais da saúde é fundamental para promover a equidade em saúde e abordar as disparidades em saúde entre diferentes grupos populacionais. As intervenções que abordam esses determinantes podem ter um impacto positivo na saúde pública e melhorar os resultados de saúde dos indivíduos e das populações.
Uma "sequência de bases" é um termo usado em genética e biologia molecular para se referir à ordem específica dos nucleotides (adenina, timina, guanina e citosina) que formam o DNA. Essa sequência contém informação genética hereditária que determina as características de um organismo vivo. Ela pode ser representada como uma cadeia linear de letras A, T, G e C, onde cada letra corresponde a um nucleotide específico (A para adenina, T para timina, G para guanina e C para citosina). A sequência de bases é crucial para a expressão gênica, pois codifica as instruções para a síntese de proteínas.
Na estatística e na análise de dados, a análise discriminante é uma técnica utilizada para classificar ou distinguir indivíduos ou objetos em diferentes grupos com base em variáveis ou características quantitativas. Ela é amplamente empregada em áreas como psicologia, sociologia, biologia, engenharia e medicina.
A análise discriminante envolve a construção de um modelo estatístico que permite prever a qual grupo um indivíduo pertence com base em suas variáveis preditoras. O modelo é desenvolvido a partir dos dados de um conjunto de treinamento, no qual os grupos aos quais cada indivíduo pertence são conhecidos. A análise discriminante determina as combinações lineares ou não lineares das variáveis preditoras que melhor distinguem os diferentes grupos.
Existem dois tipos principais de análises discriminantes: a análise discriminante linear (ADL) e a análise discriminante quadrática (ADQ). A ADL assume que as distribuições das variáveis preditoras são multivariadas normais com variâncias iguais em todos os grupos. Nesse caso, o modelo é representado por uma única equação linear que associa a probabilidade de pertencer a um grupo com as variáveis preditoras. Já a ADQ não faz essas suposições e permite que as distribuições sejam diferentes em cada grupo, resultando em modelos mais complexos e flexíveis.
A análise discriminante é útil em diversas situações, como:
1. Diagnóstico médico: A análise discriminante pode ser usada para distinguir entre diferentes doenças ou condições de saúde com base em sinais e sintomas clínicos.
2. Marketing: A técnica pode ajudar as empresas a identificar grupos de clientes com características semelhantes e a desenvolver estratégias de marketing personalizadas para cada grupo.
3. Análise de risco: A análise discriminante pode ser usada para prever o risco de eventos adversos, como falência empresarial ou insolvência financeira.
4. Psicologia e ciências sociais: A técnica é amplamente utilizada em pesquisas que envolvem a classificação de indivíduos em categorias baseadas em características psicológicas, demográficas ou comportamentais.
Em resumo, a análise discriminante é uma técnica estatística poderosa para classificar e prever a pertencência de indivíduos a diferentes grupos com base em um conjunto de variáveis preditoras. Ela pode ser usada em diversos campos, desde o diagnóstico médico até o marketing e análise de risco, fornecendo insights valiosos sobre as diferenças e semelhanças entre grupos de indivíduos.
A Tomografia Computadorizada por Feixe Cônico (CBCT, do inglês Cone Beam Computed Tomography) é um tipo de exame de imagem tridimensional (3D) que utiliza um feixe cônico de raios-X para capturar dados de uma ampla área anatômica em apenas um único gantry rotacionamento em oposição a múltiplas projeções necessárias em sistemas de TC convencionais.
Este exame é particularmente útil em odontologia e maxilofacial, fornecendo imagens detalhadas das estruturas dentárias, articulação temporomandibular, osso nasal, senos paranasais e outras áreas da região maxilofacial. A vantagem do CBCT em comparação com a TC convencional é a menor dose de radiação necessária para obter imagens de alta qualidade e detalhadas.
Além disso, o CBCT pode fornecer informações volumétricas completas, permitindo a visualização de estruturas em diferentes planos (axial, sagital e coronal), facilitando o diagnóstico e planejamento de tratamentos em cirurgia oral e maxilofacial, implantologia dentária, ortodontia e outras especialidades odontológicas.
A tomografia computadorizada por raios X, frequentemente abreviada como TC ou CAT (do inglês Computerized Axial Tomography), é um exame de imagem diagnóstico que utiliza raios X para obter imagens detalhadas e transversais de diferentes partes do corpo. Neste processo, uma máquina gira em torno do paciente, enviando raios X a partir de vários ângulos, os quais são então captados por detectores localizados no outro lado do paciente.
Os dados coletados são posteriormente processados e analisados por um computador, que gera seções transversais (ou "cortes") de diferentes tecidos e órgãos, fornecendo assim uma visão tridimensional do interior do corpo. A TC é particularmente útil para detectar lesões, tumores, fraturas ósseas, vasos sanguíneos bloqueados ou danificados, e outras anormalidades estruturais em diversas partes do corpo, como o cérebro, pulmões, abdômen, pélvis e coluna vertebral.
Embora a TC utilize radiação ionizante, assim como as radiografias simples, a exposição é mantida em níveis baixos e justificados, considerando-se os benefícios diagnósticos potenciais do exame. Além disso, existem protocolos especiais para minimizar a exposição à radiação em pacientes pediátricos ou em situações que requerem repetição dos exames.
A Análise dos Mínimos Quadrados (Least Squares Analysis em inglês) é um método estatístico e matemático utilizado para ajustar modelos às medições experimentais, com o objetivo de minimizar a soma dos quadrados das diferenças entre os valores observados e os valores previstos pelo modelo.
Em outras palavras, dada uma coleção de dados empíricos e um modelo matemático que tenta descrever esses dados, a análise de mínimos quadrados procura encontrar os parâmetros do modelo que melhor se ajustam aos dados experimentais, no sentido de minimizar a distância entre as previsões do modelo e os valores observados.
Este método é amplamente utilizado em diversas áreas da ciência e engenharia, como na regressão linear, análise de séries temporais, processamento de sinais e imagens, entre outras. Além disso, a análise de mínimos quadrados pode ser usada para testar hipóteses estatísticas e estimar incertezas associadas aos parâmetros do modelo.
Na física e matemática aplicada, a dinâmica não linear é um ramo do estudo da dinâmica que se ocupa de sistemas nos quais as leis que governam o comportamento dos mesmos não são descritas por funções lineares, ou seja, relacionamentos diretos e proporcionais entre causa e efeito. Em outras palavras, em sistemas dinâmicos lineares, uma mudança constante na entrada resultará em uma mudança constante na saída. No entanto, em sistemas dinâmicos não lineares, a mesma mudança na entrada pode resultar em diferentes saídas dependendo de outros fatores, como o estado atual do sistema ou a magnitude da própria entrada.
Esses sistemas podem exibir comportamentos complexos e imprevisíveis, como ciclos limites, bifurcações, caos e comportamento fractal. A dinâmica não linear tem aplicações em diversas áreas da ciência, tais como física, química, biologia, economia e engenharia.
Na ciência da computação e matemática aplicada, programação linear é um método para encontrar o valor ótimo ou melhor de uma variável dependente em relação às outras variáveis independentes e parâmetros constates. É considerado um problema de otimização linear porque as relações entre as variáveis e a função objetivo a ser otimizada são expressas como equações ou desigualdades lineares.
Em uma formulação geral, um problema de programação linear pode ser escrito como:
Função Objetivo: maximizar/minimizar (c^t * x)
sujeito às restrições:
A * x = 0
Onde "x" é o vetor de variáveis de decisão, "c" é um vetor de coeficientes associados com as variáveis de decisão, "A" é uma matriz de coeficientes associados com as restrições e "b" é um vetor de termos constantes associados com as restrições.
Este método tem aplicações em diversas áreas, como engenharia, economia, finanças e logística, entre outras.
A "Análise de Falha de Equipamento" (Equipment Failure Analysis, em inglês) é um processo sistemático e investigativo utilizado na engenharia e medicina para identificar e compreender as causas raízes de falhas em equipamentos ou sistemas. Ela envolve uma análise minuciosa dos componentes, materiais, design, manuseio, operação e histórico de manutenção do equipamento, a fim de determinar os fatores que contribuíram para a falha. A análise de falha de equipamento é essencial para a prevenção de falhas futuras, a melhoria da confiabilidade e segurança dos sistemas, e o desenvolvimento de soluções de engenharia eficazes.
Em um contexto médico, a análise de falha de equipamento pode ser usada para investigar incidentes relacionados à saúde, como falhas em dispositivos médicos ou equipamentos hospitalares, que possam ter resultado em lesões ou danos aos pacientes. O processo geralmente inclui as seguintes etapas:
1. Coleta e documentação de dados: Isso pode incluir registros de manutenção, especificações do fabricante, relatos de testemunhas e outras informações relevantes sobre o equipamento e a falha.
2. Inspeção visual e análise dos componentes: Os componentes do equipamento podem ser examinados para identificar sinais de desgaste, corrosão, fadiga ou outros danos que possam ter contribuído para a falha.
3. Análise do histórico de falhas e manutenção: Os registros de falhas anteriores e a história de manutenção do equipamento podem fornecer informações valiosas sobre tendências ou padrões que possam estar relacionados à falha atual.
4. Análise do design e operação: Os engenheiros especializados analisarão o projeto e a operação do equipamento para identificar quaisquer deficiências de design ou falhas no processo que possam ter contribuído para a falha.
5. Determinação da causa raiz: A equipe de análise determinará a causa mais provável da falha, levando em consideração as evidências coletadas e a análise do design, operação e histórico de manutenção.
6. Recomendações para a correção de problemas: A equipe de análise fará recomendações sobre como corrigir o problema e prevenir falhas semelhantes no futuro, incluindo possíveis modificações de design, procedimentos de manutenção aprimorados ou outras ações corretivas.
A análise rigorosa da causa raiz é essencial para garantir a segurança dos pacientes e minimizar o risco de falhas futuras em dispositivos médicos e equipamentos hospitalares.
O genoma humano refere-se à totalidade da sequência de DNA presente em quase todas as células do corpo humano, exceto as células vermelhas do sangue. Ele contém aproximadamente 3 bilhões de pares de bases e é organizado em 23 pares de cromossomos, além de um pequeno cromossomo X ou Y adicional no caso das mulheres (XX) ou dos homens (XY), respectivamente.
O genoma humano inclui aproximadamente 20.000 a 25.000 genes que fornecem as instruções para produzir proteínas, que são fundamentais para a estrutura e função das células. Além disso, o genoma humano também contém uma grande quantidade de DNA não-codificante, que pode desempenhar um papel importante na regulação da expressão gênica e outros processos celulares.
A sequência completa do genoma humano foi determinada pela Iniciativa do Genoma Humano, um esforço internacional de pesquisa que teve início em 1990 e foi concluída em 2003. A determinação da sequência do genoma humano tem fornecido informações valiosas sobre a biologia humana e tem potencial para contribuir para o desenvolvimento de novas terapias e tratamentos para doenças.
Proteómica é um campo interdisciplinar da ciência que envolve o estudo em grande escala dos proteomas, que são os conjuntos completos de proteínas produzidas ou modificadas por um organismo, tecido ou célula em particular. A proteômica combina métodos e técnicas de biologia molecular, bioquímica, estatística e informática para analisar a expressão das proteínas, suas interações, modificações pós-traducionais, função e estrutura.
Este campo tem como objetivo fornecer uma visão abrangente dos processos biológicos, melhorando o entendimento de doenças complexas e ajudando no desenvolvimento de novas terapias e diagnósticos mais precisos. Algumas das técnicas utilizadas em proteômica incluem espectrometria de massa, cromatografia líquida de alta performance (HPLC), Western blotting, ELISA e microscopia de fluorescência, entre outras.
As "Bases de Dados de Ácidos Nucleicos" referem-se a grandes repositórios digitais que armazenam informações sobre ácidos nucleicos, como DNA e RNA. Estes bancos de dados desempenham um papel fundamental na biologia molecular e genômica, fornecendo uma rica fonte de informação para a comunidade científica.
Existem diferentes tipos de bases de dados de ácidos nucleicos, cada uma com seu próprio foco e finalidade. Alguns exemplos incluem:
1. GenBank: É um dos bancos de dados de DNA e RNA mais conhecidos e amplamente utilizados, mantido pelo National Center for Biotechnology Information (NCBI) dos Estados Unidos. GenBank armazena sequências de ácidos nucleicos de diferentes espécies, juntamente com informações sobre a organização genômica, função e expressão gênica.
2. European Nucleotide Archive (ENA): É o banco de dados de ácidos nucleicos da Europa, mantido pelo European Bioinformatics Institute (EBI). O ENA armazena sequências de DNA e RNA, além de metadados associados, como informações sobre a amostra, técnicas experimentais e anotações funcionais.
3. DNA Data Bank of Japan (DDBJ): É o banco de dados de ácidos nucleicos do Japão, mantido pelo National Institute of Genetics. O DDBJ é um dos três principais bancos de dados internacionais que compartilham e sincronizam suas informações com GenBank e ENA.
4. RefSeq: É uma base de dados de referência mantida pelo NCBI, que fornece conjuntos curados e anotados de sequências de DNA, RNA e proteínas para diferentes espécies. As anotações em RefSeq são derivadas de pesquisas experimentais e previsões computacionais, fornecendo uma fonte confiável de informações sobre a função gênica e a estrutura dos genes.
5. Ensembl: É um projeto colaborativo entre o EBI e o Wellcome Sanger Institute que fornece anotações genômicas e recursos de visualização para várias espécies, incluindo humanos, modelos animais e plantas. O Ensembl integra dados de sequência, variação genética, expressão gênica e função, fornecendo um recurso único para a análise e interpretação dos genomas.
Esses bancos de dados são essenciais para a pesquisa em biologia molecular, genômica e bioinformática, fornecendo uma fonte centralizada de informações sobre sequências, funções e variações genéticas em diferentes organismos. Além disso, eles permitem que os cientistas compartilhem e acessem dados abertamente, promovendo a colaboração e o avanço do conhecimento na biologia e na medicina.
A Análise de Componentes Principais (Principal Component Analysis, ou PCA em inglês) é uma técnica estatística e de análise de dados utilizada para identificar padrões e reduzir a dimensionalidade de conjuntos de dados complexos. Ela faz isso através da transformação dos dados originais em novas variáveis, chamadas componentes principais, que são combinações lineares dos dados originais e são ordenadas por magnitude de variância, explicando a maior parte da variação presente nos dados.
Em termos médicos, a PCA pode ser usada para analisar diferentes tipos de dados biomédicos, como imagens, sinais ou genômica, com o objetivo de identificar padrões e reduzir a dimensionalidade dos dados. Isso pode ser útil em diversas aplicações clínicas, como no diagnóstico de doenças, análise de imagens médicas, pesquisa genética e outras áreas da saúde.
Em resumo, a Análise de Componentes Principais é uma ferramenta poderosa para analisar e compreender dados complexos em contextos médicos, fornecendo insights valiosos sobre padrões e relacionamentos entre diferentes variáveis.
O Polimorfismo de Nucleotídeo Único (PNU), em termos médicos, refere-se a uma variação natural e comum na sequência do DNA humano. Ele consiste em um ponto específico no DNA onde existe uma escolha entre diferentes nucleotídeos (as "letras" que formam a molécula de DNA) que podem ocorrer. Essas variações são chamadas de polimorfismos porque eles resultam em diferentes versões da mesma sequência de DNA.
Em geral, os PNUs não causam alterações na função dos genes e são considerados normalmente inócuos. No entanto, alguns PNUs podem ocorrer em locais importantes do DNA, como no interior de um gene ou próximo a ele, e podem afetar a forma como os genes são lidos e traduzidos em proteínas. Nesses casos, os PNUs podem estar associados a um risco aumentado de desenvolver determinadas doenças genéticas ou condições de saúde.
É importante notar que o PNU é uma forma comum de variação no DNA humano e a maioria das pessoas carrega vários PNUs em seu genoma. A análise de PNUs pode ser útil em estudos de associação genética, na investigação da doença genética e no desenvolvimento de testes genéticos para a predição de risco de doenças.
Uma sequência de aminoácidos refere-se à ordem exata em que aminoácidos específicos estão ligados por ligações peptídicas para formar uma cadeia polipeptídica ou proteína. Existem 20 aminoácidos diferentes que podem ocorrer naturalmente nas sequências de proteínas, cada um com sua própria propriedade química distinta. A sequência exata dos aminoácidos em uma proteína é geneticamente determinada e desempenha um papel crucial na estrutura tridimensional, função e atividade biológica da proteína. Alterações na sequência de aminoácidos podem resultar em proteínas anormais ou não funcionais, o que pode contribuir para doenças humanas.
As redes de comunicação de computadores são sistemas de hardware e software que permitem que diferentes dispositivos de computação, como computadores, smartphones, servidores e outros dispositivos inteligentes, se conectem e troquem dados entre si. Essas redes podem ser classificadas em diferentes categorias com base em sua extensão geográfica, topologia, arquitetura e protocolos de comunicação.
Existem basicamente dois tipos principais de redes de computadores: redes de área local (LAN) e redes de área ampla (WAN). As LANs são usadas para conectar dispositivos em uma área geográfica limitada, como um escritório ou campus universitário. Já as WANs são usadas para conectar redes locais em diferentes locais geográficos, geralmente através de uma rede pública de comunicações, como a Internet.
As redes de computadores podem ser também classificadas com base em sua topologia, que é a maneira como os dispositivos estão conectados entre si. As topologias mais comuns incluem:
* Topologia em linha reta (bus): Todos os dispositivos estão conectados a um único canal de comunicação.
* Topologia em anel: Cada dispositivo está conectado a dois outros dispositivos, formando assim um anel fechado.
* Topologia em estrela: Todos os dispositivos estão conectados a um único ponto central, como um switch ou hub.
* Topologia em árvore: É uma combinação de topologias em linha reta e em estrela.
* Topologia em malha: Cada dispositivo está conectado diretamente a todos os outros dispositivos na rede.
Além disso, as redes de computadores podem ser classificadas com base em sua arquitetura, que é a maneira como os dados são transmitidos entre os dispositivos. As arquiteturas mais comuns incluem:
* Arquitetura em camada (layered): Os protocolos de comunicação são divididos em diferentes camadas, cada uma delas responsável por uma tarefa específica.
* Arquitetura sem fio (wireless): A transmissão de dados é feita através de ondas de rádio ou infravermelho.
Em resumo, as redes de computadores são sistemas complexos que permitem a comunicação e o compartilhamento de recursos entre diferentes dispositivos conectados em uma mesma rede. Existem diferentes tipos de redes, classificadas com base em vários critérios, como o tamanho, a topologia, a arquitetura e o tipo de conexão. A escolha do tipo de rede depende dos requisitos específicos de cada aplicação.
Na área da ciência da computação e da pesquisa em inteligência artificial, o Processamento de Linguagem Natural (Natural Language Processing, NLP) refere-se a uma gama de métodos computacionais utilizados para analisar, compreender e gerar linguagem humana natural. A linguagem natural é o tipo de linguagem falada ou escrita que as pessoas usam em suas vidas diárias.
O NLP envolve técnicas como a extração de informações estruturadas a partir de textos desestruturados, tradução automática entre idiomas, reconhecimento de entidades nomeadas (pessoas, lugares e coisas), análise sintática e semântica do texto, resposta a perguntas, geração de linguagem natural e muito mais. O objetivo final é desenvolver sistemas computacionais que possam compreender, interpretar e gerar linguagem humana de forma fluente e precisa, permitindo uma melhor interação entre humanos e máquinas.
Em suma, o Processamento de Linguagem Natural é um campo multidisciplinar que combina conhecimentos de ciência da computação, linguística, psicolinguística e outras áreas relacionadas para desenvolver métodos e técnicas que permitam aos computadores processar e entender a linguagem humana natural.
Tomografia é um método de diagnóstico por imagem que utiliza radiação ou ondas sonoras para produzir cortes transversais detalhados de estruturas internas do corpo humano. A tomografia computadorizada (TC) e a tomografia por emissão de positrons (PET) são os dois tipos mais comuns de tomografia.
Na TC, um equipamento gira ao redor do corpo, enviando raios X através dele a partir de diferentes ângulos. Os dados coletados são processados por um computador para criar imagens detalhadas de seções transversais do corpo. A TC pode ajudar a diagnosticar uma variedade de condições, como tumores, fraturas ósseas, infecções e outras lesões.
A PET é um tipo de tomografia que usa pequenas quantidades de glicose radioativa para produzir imagens do metabolismo das células em diferentes partes do corpo. É frequentemente utilizada em conjunto com a TC para detectar e diagnosticar vários tipos de câncer, doenças cardiovasculares e outras condições médicas.
Em resumo, a tomografia é um método de diagnóstico por imagem que fornece informações detalhadas sobre as estruturas internas do corpo humano, auxiliando no diagnóstico e no tratamento de diversas condições médicas.
O proteoma refere-se ao conjunto completo de proteínas produzidas ou presentes em um organismo, tipo celular específico ou sistema biológico em um dado momento. É um termo geral que abrange todo o espectro deproteínas, desde as mais abundantes até às menos abundantes, e inclui proteínas que estão envolvidas em diferentes processos bioquímicos e funções celulares. O estudo do proteoma, conhecido como proteómica, pode fornecer informações importantes sobre a expressão gênica, regulação das vias metabólicas, resposta às mudanças ambientais e patologia de doenças, entre outros aspectos.
 Algoritmos responsabilizáveis
Algoritmos responsabilizáveis
Lista de algoritmos
Projeto de algoritmos
Algoritmos de Berkeley
Análise de algoritmos
Algoritmos de multiplicação
Engenharia de algoritmos
Transparência em algoritmos
Algoritmo
Teorema mestre (análise de algoritmos)
Algoritmos de estimação de distribuição
Técnicas de projeto de algoritmos
Algoritmo RANDU
Algoritmo apriori
Algoritmo C4.5
Algoritmo simplex
Algoritmo A*
Algoritmo quântico
Algoritmo Doomsday
Algoritmo evolutivo
CLEAN (algoritmo)
Algoritmo determinístico
Algoritmo Paramétrico
Algoritmo yarrow
Algoritmo astronómico
Algoritmo DPLL
Algoritmo probabilístico
Algoritmo CYK
Algoritmo Chaff
Algoritmo guloso
Algoritmos responsabilizáveis - Wikipedia
 Algoritmos: planejamento e analise
Algoritmos: planejamento e analise
 Arquivos algoritmos - Página 2 de 2
Arquivos algoritmos - Página 2 de 2
 Google anuncia grandes mudanças em seus algoritmos de busca
Google anuncia grandes mudanças em seus algoritmos de busca
 Algoritmo das emoções
Algoritmo das emoções
 Categoria:Livro/Algoritmos e Estruturas de Dados - Wikilivros
Categoria:Livro/Algoritmos e Estruturas de Dados - Wikilivros
 Em reflexão sobre diversidade, Shutterstock convida a reprogramar algoritmos
Em reflexão sobre diversidade, Shutterstock convida a reprogramar algoritmos
 Algoritmo ajuda na restauração da Mata Atlântica
Algoritmo ajuda na restauração da Mata Atlântica
 Publicações do PESC Algoritmos para Localização de Pontos em Faces de Grafos Planares
Publicações do PESC Algoritmos para Localização de Pontos em Faces de Grafos Planares
Virgílio Almeida: "É necessário estudar as questões éticas associadas aos algoritmos".
 Novo algoritmo do Google pode deixar internet mais veloz
Novo algoritmo do Google pode deixar internet mais veloz
Algoritmos/Reconhecimento de padrões/Algoritmo KMP - Wikilivros
 Link deste artigo
Link deste artigo
 Frédéric Neyrat: "A nossa voz está colonizada por algoritmos" | Entrevista | PÚBLICO
Frédéric Neyrat: "A nossa voz está colonizada por algoritmos" | Entrevista | PÚBLICO
 Algoritmos e inteligência artificial podem ajudar Brasil a decidir sobre leitos de UTI - 24/03/2020 - Equilíbrio e Saúde - Folha
Algoritmos e inteligência artificial podem ajudar Brasil a decidir sobre leitos de UTI - 24/03/2020 - Equilíbrio e Saúde - Folha
 Algoritmos e Programação | Instituto Mauá de Tecnologia
Algoritmos e Programação | Instituto Mauá de Tecnologia
Google desenvolve algoritmo para identificar funcionários que planejam se demitir
 Algoritmo constrangedor do dia pode te identificar mesmo em fotos sem marcação alguma
Algoritmo constrangedor do dia pode te identificar mesmo em fotos sem marcação alguma
 Algoritmos: potencial extraordinário ou risco existencial? | FFMS
Algoritmos: potencial extraordinário ou risco existencial? | FFMS
Algoritmos de computador encontram 'pontos fracos moleculares' dos tumores
 'Machine Behaviour'' e Inteligência Artificial: nomear os medos, governar os algoritmos. Artigo de Paolo Benanti - Instituto...
'Machine Behaviour'' e Inteligência Artificial: nomear os medos, governar os algoritmos. Artigo de Paolo Benanti - Instituto...
 Dissertação 29/08 - Simulação de Algoritmos Quânticos Considerando a Teoria Quântica Modal em Haskell - PPGCC
Dissertação 29/08 - Simulação de Algoritmos Quânticos Considerando a Teoria Quântica Modal em Haskell - PPGCC
 A mística dos algoritmos | Página 13
A mística dos algoritmos | Página 13
 Algoritmo prevê o tempo real de usinagem em máquinas CNC
Algoritmo prevê o tempo real de usinagem em máquinas CNC
 Arquivos algoritmo - Assespro-Paraná
Arquivos algoritmo - Assespro-Paraná
Professor da UFMG desenvolve algoritmos para cirurgias feitas por robôs - Faculdade de Medicina da UFMG
 Aprendendo a construir algoritmos através da mediação digital
| Revista Novas Tecnologias na Educação
Aprendendo a construir algoritmos através da mediação digital
| Revista Novas Tecnologias na Educação
 A gênese no algoritmo da imaginação | Revista Missões
A gênese no algoritmo da imaginação | Revista Missões
 A ERA DOS ALGORITMOS - PARTE IV: É POSSÍVEL HUMANIZAR A INTELIGÊNCIA ARTIFICIAL? - Psychiatry on line brasil
A ERA DOS ALGORITMOS - PARTE IV: É POSSÍVEL HUMANIZAR A INTELIGÊNCIA ARTIFICIAL? - Psychiatry on line brasil
 Como funciona a busca do algoritmo dos mecanismos de busca?
Como funciona a busca do algoritmo dos mecanismos de busca?
Dados14
- Segundo Cathy O'Neil, para seus propósitos, algoritmos são apenas sistemas treinados por dados históricos otimizados para alguma definição de sucesso. (wikipedia.org)
- Esta categoria contém os módulos (capítulos e subcapítulos) que fazem parte do wikilivro " Algoritmos e Estruturas de Dados ", ordenados pelo nome do capítulo. (wikibooks.org)
- Por meio dessa técnica, são utilizados algoritmos que aprendem interativamente a partir de dados, ou seja, conforme os modelos são expostos a novos dados, eles são capazes de se adaptar de forma independente. (bvs.br)
- Segundo informações do Wall Street Journal , o Google desenvolveu internamente um algoritmo matemático capaz de analisar dados provenientes de seus funcionários e identificar quais estariam planejando pedir as contas no futuro. (googlediscovery.com)
- Atualmente a aplicação do algoritmo é principalmente para pesquisa, mas Aarabi pretende vê-lo incorporado em grandes bancos de dados de imagem ou redes sociais. (meiobit.com)
- O preconceito, ou melhor o racismo, estava codificado no algoritmo de reconhecimento, que usa dados massivos, ou big data, e nos dados utilizados. (pagina13.org.br)
- Para grandes bancos de dados, possivelmente o algoritmo CART é mais indicado do que o algoritmo CTREE. (bvsalud.org)
- Modelos e algoritmos de Aprendizado de Máquina (ML) constituem a espinha dorsal dessa disciplina tecnológica em constante evolução, constituindo a chave para transformar dados brutos em insights valiosos, permitindo que as máquinas aprendam a partir de padrões e tomem decisões inteligentes. (cieda.com.br)
- Os algoritmos são a essência do ML, determinando como os modelos aprendem dos dados. (cieda.com.br)
- As Máquinas de Vetores de Suporte são algoritmos de ML usados principalmente para classificar padrões, separando eficazmente diferentes classes em conjuntos de dados. (cieda.com.br)
- Os algoritmos KNN, abreviação de "K-Nearest Neighbors", são empregados para classificar padrões com base na proximidade entre os pontos de dados. (cieda.com.br)
- Antes de aplicar um algoritmo de ML, é crucial pré-processar os dados. (cieda.com.br)
- A interpretação diagnóstica dos dados a seguir é feita de acordo com os algoritmos. (medscape.com)
- O repositório será dotado de motor de busca baseado em algoritmo de relevância estatística, que ordenará os dados de acordo com o termo buscado pelo usuário. (bvsalud.org)
Pessoas8
- Algoritmo do amor Muitas pessoas utilizam sites de namoro para encontrar a pessoa ideal, um dos sites mais conhecidos é o eHarmony, que para se ter um perfil completo era preciso responder quatrocentas perguntas. (wikipedia.org)
- Em aeroportos, por exemplo, esses algoritmos podem ser utilizados para interpretar a reação não verbal das pessoas e detectar possíveis ameaças. (bvs.br)
- Esse motorista, quando foi contratado, interagiu com algoritmos e não com pessoas. (comciencia.br)
- O Facebook tem quase meio trilhão de fotos, de mais de um bilhão de usuários e um algoritmo assim no back-end poderia diminuir em várias ordens de magnitude o tempo necessário para determinar o relacionamento entre as pessoas. (meiobit.com)
- E não é somente a intervenção pesada desses algoritmos em nossas relações pessoas e sociais que precisamos entender muito bem. (pagina13.org.br)
- Sabemos agora que algoritmos que selecionam conteúdos podem influenciar bilhões de pessoas e afetar o mundo. (med.br)
- O exemplo atual mais alarmante que está afetando bilhões de pessoas é o do YouTube que, com o objetivo de maximizar o tempo de visualização, implantou algoritmos de recomendação de conteúdo baseados em IA. (med.br)
- Em uma série de vídeos foi demonstrado como diferentes algoritmos de ordenação funcionam por meio de pessoas numeradas dançando umas em volta das outras e se rearranjando do menor para o maior número. (programasprontos.com)
Podem ser4
- Algoritmos responsabilizáveis têm vários exemplos práticos que são utilizados com propósitos que podem ser bem distintos. (wikipedia.org)
- E, na área da saúde, esses algoritmos podem ser utilizados para detectar o grau de ansiedade do paciente e até mesmo captar indícios de depressão. (bvs.br)
- As Redes Neurais Artificiais são algoritmos de ML poderosos e versáteis que podem ser usados para classificar padrões e também para realizar tarefas complexas de aprendizado profundo. (cieda.com.br)
- Além disso', acrescentou Elisabeth Lex, 'nossos resultados indicam que as preferências musicais daqueles que mais ouvem música, como o ambiente, podem ser mais facilmente previstas por algoritmos de recomendação musical do que as preferências de quem ouve música como hard rock e hip-hop. (neurocienciasdrnasser.com)
Categoria2
- De uma forma geral, nessa categoria de algoritmos, um certo conjunto de exemplos do que se quer determinar (por exemplo, estado emocional feliz) são apresentados ao algoritmo, que determina as características que indicam esse estado. (bvs.br)
- Nesta categoria encontram-se diversos algoritmos da área de inteligência artificial. (computacaointeligente.com.br)
Artificial3
- O uso de algoritmos , de inteligência artificial e de eventuais medidas adotadas em outros países que enfrentam o mesmo dilema estão entre as possibilidades, segundo especialistas. (uol.com.br)
- Machine Behaviour'' e Inteligência Artificial: nomear os medos, governar os algoritmos. (unisinos.br)
- Parcialidade / Algoritmos Alguns algoritmos de inteligência artificial (IA) são desenvolvidos para aprender a reconhecer a música preferida do usuário, o gênero de filmes que lhe interessa, os assuntos que busca no jornal. (ufpr.br)
Tomada3
- A história de algoritmos responsabilizáveis é diluída em algoritmos de tomada de decisão, isto é, não há um marco de quando eles começaram. (wikipedia.org)
- Forte participou de um estudo feito na Faculdade de Medicina da USP que desenvolveu um algoritmo para auxiliar médicos no momento de tomada de decisão, tornando o processo de triagem de leitos de UTI mais transparente. (uol.com.br)
- A rigor a decisão de qual entregador deveria ser chamado para a entrega deveria ser tomada de forma neutra por um algoritmo que avaliasse condições objetivas. (pagina13.org.br)
Artigo5
- O contributo do PÚBLICO para a vida democrática e cívica do país reside na força da relação que estabelece com os seus leitores.Para continuar a ler este artigo assine o PÚBLICO.Ligue - nos através do 808 200 095 ou envie-nos um email para [email protected] . (publico.pt)
- Este artigo identifica os erros na obtenção de estimativas de tempo de usinagem e apresenta um algoritmo desenvolvido por pesquisadores brasileiros para prever o tempo real de usinagem de formas complexas, para qualquer configuração de máquina CNC. (arandanet.com.br)
- O presente artigo identifica inicialmente as origens dos erros dos tempos estimados pelos sistemas CAM e apresenta também um novo algoritmo desenvolvido pelo Grupo de Pesquisa em Manufatura Auxiliada por Computador (GPCAM-UFSC) para prever o tempo real de usinagem de formas complexas, para qualquer configuração de máquina CNC. (arandanet.com.br)
- Este artigo apresenta uma abordagem que busca as condições que favoreçam o aprendizado da construção de algoritmos mediado por tecnologia digital. (ufrgs.br)
- Este artigo considera esse problema e compara os algoritmos CART e CTREE, este considerado não enviesado, tomando como resultado seu poder preditivo. (bvsalud.org)
Novo algoritmo desenvolvido1
- Um novo algoritmo desenvolvido pela Universidade de Toronto tem o poder de mudar profundamente a nossa maneira de encontrar fotos entre as bilhões disponiveis em sites de mídia social como o Facebook e Google Plus. (meiobit.com)
Resultados2
- Em "Refinar por" é possível filtrar o total das pesquisas com o assunto Algoritmos , conforme os seguintes parâmetros: por modalidades de Auxílios à pesquisa, por modalidades de Bolsas, por Área do conhecimento, por Instituição e por Ano de início, e gerar resultados mais específicos. (fapesp.br)
- Um algoritmo usado em análise de decisão e APRENDIZAGEM DE MÁQUINA que usa um conjunto de árvores para combinar resultados de múltiplas ÁRVORES DE DECISÃO, geradas aleatoriamente. (bvsalud.org)
Google7
- Internet ficará mais rápida com algoritmo do Google. (oficinadanet.com.br)
- O BBR, algoritmo de controle de congestionamento de TCP (protocolo de controle de transmissão) começará a ser usado na plataforma de nuvem do Google. (oficinadanet.com.br)
- Através do novo algoritmo do Google , o controle de congestionamento é feito de modo mais eficiente para que a perda de informações seja calculada de modo mais rápido. (oficinadanet.com.br)
- O algoritmo já é utilizado pelo Google.com e pelo YouTube , e agora também estará disponível para sites que utilizam o GCP (Google Cloud Platform) como servidor em nuvem. (oficinadanet.com.br)
- Cardwell, em entrevista ao site Business, disse que o Google espera que o BBR se torne o algoritmo padrão para controle de congestionamento em todos os servidores da rede do mundo. (oficinadanet.com.br)
- Como funciona a busca do algoritmo do Google? (businessconnection.com.br)
- Confira nesse post como funciona o algoritmo do Google. (businessconnection.com.br)
Busca5
- O algoritmo introduz o conceito de autômato de estados e é usado para busca de cadeias. (wikibooks.org)
- O código de busca do KMP é muito parecido com o código da segunda versão do Algoritmo de força bruta. (wikibooks.org)
- Algoritmo KMP para busca de substring. (wikibooks.org)
- O algoritmo batizado de Busca Social por Imagens Relacionais , apresenta uma alta confiabilidade sem utilizar processamento computacional intensivo ou software de reconhecimento facial. (meiobit.com)
- Como funciona a busca do algoritmo dos mecanismos de busca? (businessconnection.com.br)
Pesquisa3
- As empresas de propaganda e marketing vêm investindo pesadamente no desenvolvimento de algoritmos que podem detectar emoções para maximizar suas campanhas publicitárias e de pesquisa de mercado. (bvs.br)
- Por meio de um acordo de colaboração entre a UFMG e a Universidade de Tóquio, Adorno participa, desde 2017, da pesquisa Estudo sobre controle de robôs para aplicações cirúrgicas , na qual é um dos responsáveis pela elaboração de modelos matemáticos e algoritmos que norteiam o funcionamento "inteligente" de robôs-cirurgiões. (ufmg.br)
- Esta página da Biblioteca Virtual da FAPESP reúne informações referenciais de bolsas e auxílios de diversas modalidades de pesquisa apoiada pela FAPESP, que possuem o assunto Algoritmos . (fapesp.br)
Desenvolvimento3
- Este trabalho, apresenta o desenvolvimento da biblioteca MQS (Modal Quantum Simulation) um modelo de computação quântica escrita em Haskell capaz de desenvolver a implementação de algoritmos considerando a Teoria Quântica Modal. (ufsm.br)
- Lise Bjerre, falou ao Medscape sobre o uso generalizado destas drogas e sobre o desenvolvimento das diretrizes e do algoritmo. (medscape.com)
- Este projeto propõe o desenvolvimento de novos conceitos, algoritmos e aplicações para acesso à internet através de redes de comunicações sem fio 6G e do conceito Open RAN baseado na experiência e habilidades da equipe executora. (fapesp.br)
Conforme1
- Conforme as respostas, o algoritmo classifica o paciente na prioridade correspondente. (uol.com.br)
Computacionais1
- No que pese o sentido quase místico que damos hoje a palavra, ela se aplica desde a coisas muito simples de nosso dia a dia a complexos algoritmos matemáticos ou computacionais. (pagina13.org.br)
Desenvolveu1
- Uma equipe internacional, liderada por um pesquisador da Pontifícia Universidade Católica do Rio de Janeiro (PUC-Rio), desenvolveu um algoritmo que permite encontrar áreas prioritárias para restauração da Mata Atlântica. (catracalivre.com.br)
Sendo2
- O algoritmo também já está sendo replicado para outros países e biomas. (catracalivre.com.br)
- É preciso pensar, então, sobre como os algoritmos estão sendo construídos? (comciencia.br)
Python1
- Introdução à programação com Python: algoritmos e lógica de programação para iniciantes. (maua.br)
Encontrar2
- Recentemente esta empresa fez mudanças no algoritmo para encontrar a pessoa ideal, deixando de lado a obrigatoriedade de responder todas as perguntas. (wikipedia.org)
- E o algoritmo vai seguindo até encontrar um conflito, quando chega na substring ablwa , o prefixo a já é igual ao sufixo próprio a que termina a substring, ficando 00001. (wikibooks.org)
Muitas3
- Muitas vezes as causas do viés se encontram nos processos sociais, e não no código, mesmo que sejam utilizadas técnicas de restrições no processo de decisão, não será totalmente certo que algum algoritmo não apresente nenhum conceito moralmente errado. (wikipedia.org)
- No entanto, as insistentes solicitações possuem um motivo: muitas marcas perderão milhares de visualizações com o novo algoritmo do Instagram. (apptuts.net)
- No entanto, os algoritmos muitas vezes perdem a marca quando se trata de recomendações para aqueles que ouvem gêneros musicais não mainstream como hip-hop ou heavy metal. (neurocienciasdrnasser.com)
Diferentes1
- Os autores então usaram as histórias de escuta dos usuários e um modelo computacional para prever a probabilidade de os diferentes grupos de ouvintes de música não-mainstream gostarem das recomendações musicais geradas pelos quatro algoritmos comuns de recomendação musical. (neurocienciasdrnasser.com)
Mundo4
- nossos próprios preconceitos que somos capazes de treinar um algoritmo para retratar um mundo mais aberto e inclusivo", diz. (propmark.com.br)
- Os algoritmos são a ferramenta que mais depressa está a mudar o mundo. (ffms.pt)
- Mas com a digitalização desses conteúdos começamos a viver em um mundo de algoritmos que acaba conduzindo nossas escolhas e dificultando esse processo de se deparar com ideias realmente novas pra gente e até mesmo conflitantes ou que a gente discorde. (cophygital.com)
- Pois essa digitalização produziu um mundo de algoritmos que organizam músicas, séries e artigos em torno das nossas preferências. (cophygital.com)
Respostas2
- As respostas num debate, em que participam o autor do livro «Algoritmos, Uma Revolução em Curso» de Diogo Queiroz de Andrade, e os políticos Maria Manuel Leitão Marques e Hugo Carvalho. (ffms.pt)
- Os algoritmos são fórmulas responsáveis por transformar as perguntas em respostas para o usuário em suas buscas. (businessconnection.com.br)
Determinar3
- O que ele quis dizer com isso é que empresas atualmente preferem utilizar algoritmos para determinar se um candidato é mais apto para a vaga disponível que métodos tradicionais de contratação como entrevistas. (wikipedia.org)
- Os algoritmos (sequência de instruções que mostra os procedimentos necessários para a resolução de uma tarefa) de análise de sentimentos processam a linguagem - tanto verbal, como em um texto, quanto não verbal, como a expressão facial em uma foto - para determinar seu teor emocional. (bvs.br)
- O algoritmo procura a ocorrência de uma palavra ou caractere dentro de um texto e quando aparece uma diferença, a palavra tem em si a informação necessária para determinar onde começar a próxima comparação. (wikibooks.org)
Assunto2
- A caixa de "Apoio FAPESP em Números" permite a visualização da totalidade de auxílios e bolsas concedidos, em andamento ou concluídos, com o assunto Algoritmos . (fapesp.br)
- Os Mapas e Gráficos contribuem visualmente para a identificação da distribuição geográfica do fomento da FAPESP no Estado de São Paulo, e do histórico do fomento, por ano, das pesquisas vigentes com o assunto Algoritmos . (fapesp.br)
Aprendizado3
- Várias empresas, principalmente as de comércio eletrônico e de entretenimento, como Amazon e Netflix, investem em algoritmos de aprendizado de máquina. (bvs.br)
- Algoritmos de detecção de emoções, e todo o aprendizado de máquina de forma geral, é uma área que vem crescendo muito e atraindo investimentos de diversos setores. (bvs.br)
- Especificamente, os autores propõem estudar não apenas como os algoritmos de aprendizado automático funcionam, mas também de que modo eles são influenciados e influenciam o ambiente em que funcionam. (unisinos.br)
Computadores1
- Algoritmos são conjuntos de regras que os computadores seguem para resolver problemas e tomar decisões sobre um determinado curso de ação. (wikipedia.org)
Melhor1
- A árvore do algoritmo CART apresentou uma melhor predição. (bvsalud.org)
Candegabe2
Usados1
- Algoritmos de IA usados por serviços de streaming de música são melhores em fornecer recomendações precisas para aqueles que gostam de música mainstream. (neurocienciasdrnasser.com)
Janeiro1
- Relato de experiência, do período de janeiro de 2018 a setembro de 2019, sobre o processo de construção de um algoritmo para indicação de equipamento coletor para estomias de eliminação. (bvsalud.org)
Impacto3
- Você trabalha com o impacto social dos algoritmos. (comciencia.br)
- Os algoritmos têm um impacto muito grande, várias ações do dia-a-dia são controladas por eles. (comciencia.br)
- Os algoritmos não agem intencionalmente, não têm intenção de ter efeitos negativos e positivos, mas têm impacto social. (comciencia.br)
Empregados1
- Os algoritmos de regressão linear são empregados para prever valores contínuos, o que os torna úteis para tarefas de regressão. (cieda.com.br)
20181
- Informe de experiencia, de enero de 2018 a septiembre de 2019, sobre el proceso de construcción de un algoritmo para indicar equipos colectores para estomas de eliminación. (bvsalud.org)
Tratamento1
- Diabetes gestacional: um algoritmo de tratamento multidisciplinar. (bvs.br)
Inteligente1
- Os algoritmos, como qualquer entidade inteligente, aprende a modificar o estado do ambiente - no caso, a mente do usuário - de modo a maximizar sua própria recompensa. (med.br)
Baseado1
- Otimização por enxame de partículas é um algoritmo heurístico baseado no comportamento social de um bando de pássaros e tem como objetivo buscar a solução ót. (computacaointeligente.com.br)
Imaginou1
- Você já imaginou aprender algoritmos dançando? (programasprontos.com)
Selecionam1
- Quando o motorista de Uber recebe a comunicação de chamada, são os algoritmos que selecionam os carros mais próximos. (comciencia.br)
Selecionados1
- Introdu o teor a de complexidade e problemas NP-completos, t picos selecionados em algoritmos para lidar com problemas NP-completos. (uottawa.ca)
Larga escala1
- Atualmente dedica-se às pesquisas focadas na interação entre sistemas sociais e sistemas distribuídos em larga escala, como big data, algoritmos e machine learning. (comciencia.br)
Modelos1
- Algoritmos de ensemble , como florestas aleatórias ( random forests ) e aumento de gradiente ( gradient boosting ), são amplamente utilizados para melhorar o desempenho de modelos. (cieda.com.br)
Problema1
- Vamos supor que ocorra um problema com um algoritmo que controla uma situação, como um carro autônomo. (comciencia.br)
Leia1
- faça um algoritmo que leia o codigo,o salario e o cargo de 50 funcionários de empresa e calcule o novo salário.se o cargo do funcionário não estiver na tabela, ele deverá receber 40% de aumento.mostre o salário antigo, o novo salário e a diferença entre os salarios. (googlediscovery.com)
Obter1
- Busque aumentar a sua taxa de aprovação mitigando maiores riscos ao obter uma visão mais ampla do consumidor através do TruVision Atributos e Algoritmos. (transunion.com.br)
Empresas2
- Algoritmos de análise de emoções já são utilizados rotineiramente por várias empresas em diversos setores. (bvs.br)
- As empresas que desenvolveram os algoritmos? (comciencia.br)
PESQUISAS1
- As análises teriam como base informações de pesquisas e revisões feitas por especialistas, o que possibilitaria ao algoritmo também identificar funcionários desmotivados, um dos principais fatores para as demissões mais recentes. (googlediscovery.com)
Multidisciplinar1
- Em vez de simplesmente se assustar com as máquinas inteligentes , afirmam os pesquisadores do Media Lab do MIT, a sociedade deve estudar algoritmos com uma abordagem multidisciplinar semelhante ao campo da etologia. (unisinos.br)









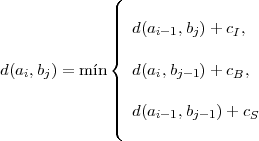
![Hardware Upgrade Forum - [Thread Ufficiale] Caricabatterie](https://lygte-info.dk/pic/SkyRC/MC3000/SkyRC%20MC3000%20charge%200.2A%20(eneloop)%20%231.png)