Protein Interaction Domains and Motifs
Legame Di Proteine
Struttura Terziaria Della Proteina
Dati Di Sequenza Molecolare
Sequenza Aminoacidica
Tecniche Del Sistema Del Doppio Ibrido
Siti Di Legame
Motivi Strutturali Degli Aminoacidi
Dominio Di Omologia Con Il Gene Src
Omologia Di Sequenza Di Amino Acido
Protein Interaction Maps
Proteine Adattatrici Trasducenti Il Segnale
Proteine Nucleari
Proteine Leganti Dna
Proteine
Modelli Molecolari
Fattori Di Trascrizione
Proteine Di Trasporto
Mutazione
Trasduzione Del Segnale
Proteine Di Fusione Ricombinanti
Allineamento Di Sequenze
Sequenza Base
Sequenza Conservata
Conformazione Della Proteina
PDZ Domains
Mutagenesi Sito Diretta
Saccharomyces Cerevisiae
Basi Di Dati Di Proteine
Dimerizzazione
Struttura Secondaria Della Proteina
Proteine Della Membrana
Trasfezione
Relazione Struttura-Attività
Biologia Computazionale
Clonaggio Molecolare
Delezione Di Sequenza
Cellule Hela
Trascrizione Genetica
Repressori
Modelli Biologici
Cristallografia A Raggi X
Proteine Del Saccharomyces Cerevisiae
Complessi Multiproteici
Dna
Mutagenesi
Glutatione Transferasi
Fosforilazione
Dna Primers
Evoluzione Molecolare
Prove Di Precipitazione
Peptidi
Transattivatori
Immunoprecipitazione
Trasporto Proteico
Trans-Attivazione (Genetica)
Escherichia Coli
Algoritmi
Nucleo Cellulare
Frammenti Peptidici
Sostituzione Di Aminoacidi
Fosfoproteine
Cellule Cos
Proteine Del Tessuto Nervoso
Proteine Leganti Rna
Plasmidi
Ligandi
Promoter Regions, Genetic
Proteine Della Drosophila
Nucleotide Motifs
Citoplasma
Analisi Di Sequenza Proteica
Helix-Turn-Helix Motifs
Microscopia A Fluorescenza
Regolazione Dell'Espressione Genica
Protein Multimerization
Lieviti
Dna Complementare
Risonanza Di Superficie Dei Plasmageni
Risonanza Magnetica Nucleare Biomolecolare
Isoforme Proteiche
Cercopithecus aethiops
Sostanze Macromolecolari
Sequenza Consenso
Membrana Cellulare
Mutazione Puntiforme
Subunità Proteiche
HEK293 Cells
Dita Di Zinco
Struttura Proteica Quaternaria
Proteine Luminescenti
Proteine E Peptidi Del Segnale Intracellulare
Proteomica
Proteine Fluorescenti Verdi
Proteine Dell'Arabidopsis
Western Blotting
Proteine Degli Omeodomini
Rna Messaggero
Proteine Del Ciclo Cellulare
Cricetinae
Geni Reporter
Modelli Genetici
Delezione Genica
Arabidopsis
Cellule Coltivate
Nucleoside-Fosfato Chinasi
Splicing Alternativo
Not Translated
Mass Spectrometry
Genoteca
Drosophila
Not Translated
Segnali Di Localizzazione Nucleare
Proteine Del Citoscheletro
Drosophila Melanogaster
LIM Domain Proteins
Proteine Delle Piante
Fret
Reagenti Reticolanti
Elettroforesi Su Gel Di Poliacrilamide
Fosfotirosina
Ligasi Ubiquitina-Proteina
Cellule Cho
Simulazione Computerizzata
Leucine Zipper
Immunoblotting
Espressione Genica
Motivi Helix-Loop-Helix
Conformazione Dell'Acido Nucleico
Fenotipo
Mutazione Erronea
Trasporto Attivo Nel Nucleo Cellulare
Cellule 3T3
Proteine Protooncogene
Nuclear Receptor Co-Repressor 1
Analisi Di Mutazioni Del Dna
Rna
Rna Splicing
Recettori Citoplasmici E Nucleari
Interfaccia Utente-Computer
Tirosina
Dominio Catalitico
Proteine Del Caenorhabditis Elegans
Regolazione Dell'Espressione Genica Nello Sviluppo
Grafica Computerizzata
Sequenze Ripetute Di Aminoacidi
Termodinamica
Caenorhabditis elegans
Modelli Chimici
Not Translated
Cromatina
Cellule Tumorali In Coltura
Gene Regulatory Networks
Mappa Peptidica
Catalisi
Cluster Analysis
Omologia Strutturale Delle Proteine
Proteine 14-3-3
Specificità Del Substrato
Nuclear Receptor Coactivator 1
Proteine Leganti Gtp
Biologia Dei Sistemi
Specificità Delle Specie
Reazione Di Polimerizzazione A Catena
Frazioni Subcellulari
Proteine Neoplastiche
Attivazione Enzimatica
Elicasi Del Dna
Biosintesi Proteica
Proteine Adattatrici
Analisi Di Sequenze Di Dna
Internet
Fattori Temporali
Proteina-Serina-Treonina Chinasi
Legame Competitivo
Modificazioni Post-Traduzionali Delle Proteine
Spettroscopia Di Risonanza Magnetica
Proteinchinasi
Xenopus
Xenopus Laevis
Dicroismo Circolare
Mappa Del Cromosoma
RNA Interference
Le Protein Interaction Domains and Motifs (Domini e Motivi dei Domini di Interazione Proteica) si riferiscono a specifiche regioni o sequenze di amminoacidi all'interno di una proteina che sono responsabili dell'interazione con altre proteine o molecole. Questi domini e motivi svolgono un ruolo fondamentale nella regolazione delle funzioni cellulari, compreso il controllo dell'espressione genica, la segnalazione cellulare, l'assemblaggio dei complessi proteici e la localizzazione subcellulare.
I domini di interazione proteica sono strutture tridimensionali ben definite che si legano specificamente a sequenze o domini particolari in altre proteine. Questi domini possono essere costituiti da un numero variabile di residui di amminoacidi e possono essere presenti in diverse combinazioni all'interno di una singola proteina, permettendo così alla proteina di interagire con diversi partner.
Le motifs di interazione proteica, d'altra parte, sono sequenze più brevi di residui di amminoacidi che mediano l'interazione tra due proteine. A differenza dei domini, le motifs non hanno una struttura tridimensionale ben definita e possono essere presenti in diverse combinazioni all'interno di una singola proteina.
La comprensione dei Protein Interaction Domains and Motifs è fondamentale per comprendere il funzionamento delle reti di interazione proteica e la regolazione delle vie metaboliche e cellulari. L'identificazione e lo studio di queste regioni all'interno delle proteine possono fornire informazioni cruciali sulla funzione e sulla regolazione di queste proteine, nonché su come le mutazioni o le variazioni in queste regioni possano contribuire a malattie umane.
La mappatura delle interazioni tra proteine (PPI, Protein-Protein Interactions) si riferisce all'identificazione e allo studio sistematico degli specifici contatti fisici che si verificano quando due o più proteine si legano tra loro per svolgere una funzione biologica comune. Queste interazioni sono fondamentali per la maggior parte dei processi cellulari, compresi il segnalamento cellulare, l'espressione genica, la replicazione del DNA, la riparazione delle cellule e la regolazione enzimatica.
La mappatura di queste interazioni può essere eseguita utilizzando una varietà di tecniche sperimentali, come la biologia a sistema due ibridi (Y2H), il pull-down della chimica del surriscaldamento (HTP), la spettroscopia delle vibrazioni di risonanza della forza di legame (BLI), la risonanza plasmonica di superficie (SPR) e la crioelettromicroscopia (Cryo-EM). Questi metodi possono aiutare a determinare non solo quali proteine interagiscono, ma anche come e dove si legano tra loro, fornendo informazioni vitali sulla funzione e sulla regolazione delle proteine.
L'analisi computazionale e la bioinformatica stanno guadagnando importanza nella mappatura delle interazioni proteina-proteina, poiché possono integrare i dati sperimentali con informazioni sulle sequenze delle proteine, sulla struttura tridimensionale e sull'evoluzione. Questi approcci possono anche essere utilizzati per predire le interazioni tra proteine in organismi o sistemi biologici per i quali non sono disponibili dati sperimentali sufficienti.
La mappatura delle interazioni proteina-proteina è un'area di ricerca attiva e in continua evoluzione, che fornisce informazioni cruciali sulla funzione cellulare, sull'evoluzione molecolare e sulle basi della malattia. Queste conoscenze possono essere utilizzate per sviluppare nuovi farmaci e strategie terapeutiche, nonché per comprendere meglio i processi biologici alla base di varie patologie umane.
Un legame di proteine, noto anche come legame peptidico, è un tipo specifico di legame covalente che si forma tra il gruppo carbossilico (-COOH) di un amminoacido e il gruppo amminico (-NH2) di un altro amminoacido durante la formazione di una proteina. Questo legame chimico connette sequenzialmente gli amminoacidi insieme per formare catene polipeptidiche, che sono alla base della struttura primaria delle proteine. La formazione di un legame peptidico comporta la perdita di una molecola d'acqua (dehidratazione), con il risultato che il legame è costituito da un atomo di carbonio, due atomi di idrogeno, un ossigeno e un azoto (-CO-NH-). La specificità e la sequenza dei legami peptidici determinano la struttura tridimensionale delle proteine e, di conseguenza, le loro funzioni biologiche.
La struttura terziaria di una proteina si riferisce all'organizzazione spaziale tridimensionale delle sue catene polipeptidiche, che sono formate dalla piegatura e dall'avvolgimento delle strutture secondarie (α eliche e β foglietti) della proteina. Questa struttura è responsabile della funzione biologica della proteina e viene stabilita dalle interazioni non covalenti tra i diversi residui aminoacidici, come ponti salini, ponti idrogeno e interazioni idrofobiche. La struttura terziaria può essere mantenuta da legami disolfuro covalenti che si formano tra i residui di cisteina nella catena polipeptidica.
La conformazione della struttura terziaria è influenzata da fattori ambientali come il pH, la temperatura e la concentrazione di ioni, ed è soggetta a modifiche dinamiche durante le interazioni con altre molecole. La determinazione della struttura terziaria delle proteine è un'area attiva di ricerca nella biologia strutturale e svolge un ruolo cruciale nella comprensione del funzionamento dei sistemi biologici a livello molecolare.
I Dati di Sequenza Molecolare (DSM) si riferiscono a informazioni strutturali e funzionali dettagliate su molecole biologiche, come DNA, RNA o proteine. Questi dati vengono generati attraverso tecnologie di sequenziamento ad alta throughput e analisi bioinformatiche.
Nel contesto della genomica, i DSM possono includere informazioni sulla variazione genetica, come singole nucleotide polimorfismi (SNP), inserzioni/delezioni (indels) o varianti strutturali del DNA. Questi dati possono essere utilizzati per studi di associazione genetica, identificazione di geni associati a malattie e sviluppo di terapie personalizzate.
Nel contesto della proteomica, i DSM possono includere informazioni sulla sequenza aminoacidica delle proteine, la loro struttura tridimensionale, le interazioni con altre molecole e le modifiche post-traduzionali. Questi dati possono essere utilizzati per studi funzionali delle proteine, sviluppo di farmaci e diagnosi di malattie.
In sintesi, i Dati di Sequenza Molecolare forniscono informazioni dettagliate sulle molecole biologiche che possono essere utilizzate per comprendere meglio la loro struttura, funzione e varianti associate a malattie, con implicazioni per la ricerca biomedica e la medicina di precisione.
In medicina e biologia molecolare, la sequenza aminoacidica si riferisce all'ordine specifico e alla disposizione lineare degli aminoacidi che compongono una proteina o un peptide. Ogni proteina ha una sequenza aminoacidica unica, determinata dal suo particolare gene e dal processo di traduzione durante la sintesi proteica.
L'informazione sulla sequenza aminoacidica è codificata nel DNA del gene come una serie di triplette di nucleotidi (codoni). Ogni tripla nucleotidica specifica codifica per un particolare aminoacido o per un segnale di arresto che indica la fine della traduzione.
La sequenza aminoacidica è fondamentale per determinare la struttura e la funzione di una proteina. Le proprietà chimiche e fisiche degli aminoacidi, come la loro dimensione, carica e idrofobicità, influenzano la forma tridimensionale che la proteina assume e il modo in cui interagisce con altre molecole all'interno della cellula.
La determinazione sperimentale della sequenza aminoacidica di una proteina può essere ottenuta utilizzando tecniche come la spettrometria di massa o la sequenziazione dell'EDTA (endogruppo diazotato terminale). Queste informazioni possono essere utili per studiare le proprietà funzionali e strutturali delle proteine, nonché per identificarne eventuali mutazioni o variazioni che possono essere associate a malattie genetiche.
La definizione medica di "Tecniche del sistema a doppio ibrido" si riferisce a un approccio terapeutico che combina due diverse tecnologie o strategie per il trattamento di una condizione medica. Questo termine non ha una definizione specifica in medicina, ma viene talvolta utilizzato in riferimento alla terapia con cellule staminali, dove due tipi di cellule staminali (ad esempio, cellule staminali adulte e cellule staminali embrionali) vengono utilizzate insieme per ottenere un effetto terapeutico maggiore.
In particolare, il termine "doppio ibrido" si riferisce alla combinazione di due diverse fonti di cellule staminali che hanno proprietà complementari e possono lavorare insieme per promuovere la rigenerazione dei tessuti danneggiati o malati. Ad esempio, le cellule staminali adulte possono fornire una fonte autologa di cellule che possono essere utilizzate per il trattamento senza il rischio di rigetto, mentre le cellule staminali embrionali possono avere una maggiore capacità di differenziarsi in diversi tipi di tessuti.
Tuttavia, è importante notare che l'uso delle cellule staminali embrionali umane è ancora oggetto di controversie etiche e regolamentari, il che limita la loro applicazione clinica. Pertanto, le tecniche del sistema a doppio ibrido sono attualmente allo studio in laboratorio e non sono ancora state approvate per l'uso clinico diffuso.
In medicina e biologia, un "sito di legame" si riferisce a una particolare posizione o area su una molecola (come una proteina, DNA, RNA o piccolo ligando) dove un'altra molecola può attaccarsi o legarsi specificamente e stabilmente. Questo legame è spesso determinato dalla forma tridimensionale e dalle proprietà chimiche della superficie di contatto tra le due molecole. Il sito di legame può mostrare una specificità se riconosce e si lega solo a una particolare molecola o a un insieme limitato di molecole correlate.
Un esempio comune è il sito di legame di un enzima, che è la regione della sua struttura dove il suo substrato (la molecola su cui agisce) si attacca e subisce una reazione chimica catalizzata dall'enzima stesso. Un altro esempio sono i siti di legame dei recettori cellulari, che riconoscono e si legano a specifici messaggeri chimici (come ormoni, neurotrasmettitori o fattori di crescita) per iniziare una cascata di eventi intracellulari che portano alla risposta cellulare.
In genetica e biologia molecolare, il sito di legame può riferirsi a una sequenza specifica di basi azotate nel DNA o RNA a cui si legano proteine (come fattori di trascrizione, ligasi o polimerasi) per regolare l'espressione genica o svolgere altre funzioni cellulari.
In sintesi, i siti di legame sono cruciali per la comprensione dei meccanismi molecolari alla base di molti processi biologici e sono spesso obiettivi farmacologici importanti nello sviluppo di terapie mirate.
I motivi strutturali degli aminoacidi si riferiscono a particolari configurazioni spaziali che possono assumere i residui degli aminoacidi nelle proteine, contribuendo alla stabilità e alla funzione della proteina stessa. Questi motivi sono il risultato dell'interazione specifica tra diverse catene laterali di aminoacidi e possono essere classificati in base al numero di residui che li compongono e alla loro geometria spaziale.
Esempi comuni di motivi strutturali degli aminoacidi includono:
1. Il motivo alpha-elica, caratterizzato da una serie di residui aminoacidici che si avvolgono attorno a un asse centrale, formando una struttura elicoidale. Questo motivo è stabilizzato dalle interazioni idrogeno tra le catene laterali e il gruppo carbossilico (-COOH) di ogni quarto residuo.
2. Il motivo beta-foglietto, formato da due o più catene beta (strutture a nastro piatto) che si appaiano lateralmente tra loro, con le catene laterali rivolte verso l'esterno e i gruppi ammidici (-NH2) e carbossilici (-COOH) rivolti verso l'interno. Questo motivo è stabilizzato dalle interazioni idrogeno tra i gruppi ammidici e carbossilici delle catene beta adiacenti.
3. Il motivo giro, che consiste in una sequenza di residui aminoacidici che formano un'ansa o un cappio, con il gruppo N-terminale e C-terminale situati sui lati opposti del giro. Questo motivo è stabilizzato dalle interazioni idrogeno tra le catene laterali dei residui aminoacidici nel giro.
4. Il motivo loop, che è una struttura flessibile e meno ordinata rispetto agli altri motivi, composta da un numero variabile di residui aminoacidici che connettono due o più segmenti di catene beta o alfa-eliche.
Questi motivi strutturali possono combinarsi per formare strutture proteiche più complesse, come domini e molecole intere. La comprensione della struttura tridimensionale delle proteine è fondamentale per comprendere la loro funzione e il modo in cui interagiscono con altre molecole all'interno dell'organismo.
In medicina e biologia molecolare, il termine "dominio di omologia con il gene Src" si riferisce a una sequenza di DNA o di proteina che mostra un'elevata somiglianza o similarità strutturale con il gene Src. Il gene Src è un proto-oncogene, cioè un gene che può contribuire allo sviluppo del cancro quando subisce mutazioni o alterazioni nella sua espressione.
L'omologia con il gene Src indica spesso la presenza di una funzione o di una struttura simile tra due geni o proteine. Il dominio di omologia con il gene Src può essere utilizzato come marker per identificare e studiare le proteine che appartengono alla famiglia dei kinasi Src, un gruppo di enzimi che svolgono un ruolo importante nella regolazione della crescita cellulare, della differenziazione e dell'apoptosi (morte cellulare programmata).
La presenza di mutazioni o alterazioni nel dominio di omologia con il gene Src può essere associata allo sviluppo di diverse patologie, tra cui vari tipi di cancro. Pertanto, lo studio del dominio di omologia con il gene Src può fornire informazioni importanti sulla funzione e la regolazione delle proteine che contengono questo dominio, nonché sui meccanismi molecolari alla base dello sviluppo e della progressione dei tumori.
L'omologia di sequenza degli aminoacidi è un concetto utilizzato in biochimica e biologia molecolare per descrivere la somiglianza nella sequenza degli aminoacidi tra due o più proteine. Questa misura quantifica la similarità delle sequenze amminoacidiche di due proteine e può fornire informazioni importanti sulla loro relazione evolutiva, struttura e funzione.
L'omologia di sequenza degli aminoacidi si basa sull'ipotesi che le proteine con sequenze simili siano probabilmente derivate da un antenato comune attraverso processi evolutivi come la duplicazione del gene, l'inversione, la delezione o l'inserzione di nucleotidi. Maggiore è il grado di somiglianza nella sequenza amminoacidica, più alta è la probabilità che le due proteine siano evolutivamente correlate.
L'omologia di sequenza degli aminoacidi si calcola utilizzando algoritmi informatici che confrontano e allineano le sequenze amminoacidiche delle proteine in esame. Questi algoritmi possono identificare regioni di similarità o differenze tra le sequenze, nonché indici di somiglianza quantitativa come il punteggio di BLAST (Basic Local Alignment Search Tool) o il punteggio di Smith-Waterman.
L'omologia di sequenza degli aminoacidi è un importante strumento per la ricerca biologica, poiché consente di identificare proteine correlate evolutivamente, prevedere la loro struttura tridimensionale e funzione, e comprendere i meccanismi molecolari alla base delle malattie genetiche.
Le Mappe di Interazione Proteica (Protein Interaction Maps) sono rappresentazioni grafiche che mostrano le interazioni funzionali e fisiche tra differenti proteine all'interno di un sistema biologico. Queste mappe vengono costruite sulla base di dati sperimentali e forniscono informazioni su come le proteine si leghino e cooperino per svolgere determinate funzioni cellulari.
Le Protein Interaction Maps possono essere utilizzate per studiare la regolazione dei pathway cellulari, l'organizzazione delle reti di segnalazione, la struttura e la funzione delle macchine molecolari, e per identificare i bersagli terapeutici in ambito farmacologico.
Le interazioni proteiche possono essere studiate utilizzando diverse tecniche sperimentali, come ad esempio la co-immunoprecipitazione, il pull-down delle proteine, la biologia a due hybrid e le tecniche di spectrometry di massa. I dati ottenuti da queste tecniche vengono quindi integrati per creare una mappa rappresentativa delle interazioni proteiche all'interno del sistema studiato.
Le Protein Interaction Maps possono essere rappresentate come reti grafiche, con i nodi che rappresentano le proteine e gli edge che rappresentano le interazioni tra di esse. Queste mappe possono essere analizzate utilizzando algoritmi di network analysis per identificare i pattern di interazione, i moduli funzionali e le proprietà topologiche delle reti proteiche.
Le proteine adattatrici trasducenti il segnale sono una classe di proteine che svolgono un ruolo cruciale nella trasduzione del segnale, cioè nel processo di conversione e trasmissione dei segnali extracellulari in risposte intracellulari. Queste proteine non possiedono attività enzimatica diretta ma svolgono un'importante funzione regolatoria nella segnalazione cellulare attraverso l'interazione con altre proteine, come recettori, chinasi e fosfatasi.
Le proteine adattatrici trasducenti il segnale possono:
1. Agire come ponti molecolari che facilitano l'associazione tra proteine diverse, promuovendo la formazione di complessi proteici e facilitando la propagazione del segnale all'interno della cellula.
2. Funzionare come regolatori allosterici delle attività enzimatiche di chinasi e fosfatasi, influenzando il livello di fosforilazione di altre proteine e quindi modulando la trasduzione del segnale.
3. Partecipare alla localizzazione spaziale dei complessi proteici, guidandoli verso specifiche compartimenti cellulari o domini membranosi per garantire una risposta locale appropriata.
4. Agire come substrati di chinasi e altre enzimi, subendo modificazioni post-traduzionali che alterano la loro attività e influenzano il segnale trasdotto.
Un esempio ben noto di proteina adattatrice trasducente il segnale è la proteina Grb2 (growth factor receptor-bound protein 2), che interagisce con recettori tirosin chinasi e facilita l'attivazione della via di segnalazione Ras/MAPK, coinvolta nella regolazione della crescita cellulare e differenziamento.
Le proteine nucleari sono un tipo di proteine che si trovano all'interno del nucleo delle cellule. Sono essenziali per una varietà di funzioni nucleari, tra cui la replicazione e la trascrizione del DNA, la riparazione del DNA, la regolazione della cromatina e la sintesi degli RNA.
Le proteine nucleari possono essere classificate in diversi modi, a seconda delle loro funzioni e localizzazioni all'interno del nucleo. Alcune proteine nucleari sono associate al DNA, come i fattori di trascrizione che aiutano ad attivare o reprimere la trascrizione dei geni. Altre proteine nucleari sono componenti della membrana nucleare, che forma una barriera tra il nucleo e il citoplasma delle cellule.
Le proteine nucleari possono anche essere classificate in base alla loro struttura e composizione. Ad esempio, alcune proteine nucleari contengono domini strutturali specifici che consentono loro di legare il DNA o altre proteine. Altre proteine nucleari sono costituite da più subunità che lavorano insieme per svolgere una funzione specifica.
La maggior parte delle proteine nucleari sono sintetizzate nel citoplasma e quindi importate nel nucleo attraverso la membrana nucleare. Questo processo richiede l'interazione di segnali speciali presenti nelle proteine con i recettori situati sulla membrana nucleare. Una volta all'interno del nucleo, le proteine nucleari possono subire modifiche post-traduzionali che ne influenzano la funzione e l'interazione con altre proteine e molecole nel nucleo.
In sintesi, le proteine nucleari sono un gruppo eterogeneo di proteine che svolgono una varietà di funzioni importanti all'interno del nucleo delle cellule. La loro accuratezza e corretta regolazione sono essenziali per la normale crescita, sviluppo e funzione cellulare.
Le proteine leganti DNA, anche conosciute come proteine nucleiche, sono proteine che si legano specificamente al DNA per svolgere una varietà di funzioni importanti all'interno della cellula. Queste proteine possono legare il DNA in modo non specifico o specifico, a seconda del loro sito di legame e della sequenza di basi nucleotidiche con cui interagiscono.
Le proteine leganti DNA specifiche riconoscono sequenze di basi nucleotidiche particolari e si legano ad esse per regolare l'espressione genica, riparare il DNA danneggiato o mantenere la stabilità del genoma. Alcuni esempi di proteine leganti DNA specifiche includono i fattori di trascrizione, che si legano al DNA per regolare l'espressione dei geni, e le enzimi di riparazione del DNA, che riconoscono e riparano lesioni al DNA.
Le proteine leganti DNA non specifiche, d'altra parte, si legano al DNA in modo meno specifico e spesso svolgono funzioni strutturali o regolatorie all'interno della cellula. Ad esempio, le istone sono proteine leganti DNA non specifiche che aiutano a organizzare il DNA in una struttura compatta chiamata cromatina.
In sintesi, le proteine leganti DNA sono un gruppo eterogeneo di proteine che interagiscono con il DNA per svolgere funzioni importanti all'interno della cellula, tra cui la regolazione dell'espressione genica, la riparazione del DNA e la strutturazione del genoma.
In medicina e biologia, le proteine sono grandi molecole composte da catene di amminoacidi ed esse svolgono un ruolo cruciale nella struttura, funzione e regolazione di tutte le cellule e organismi viventi. Sono necessarie per la crescita, riparazione dei tessuti, difese immunitarie, equilibrio idrico-elettrolitico, trasporto di molecole, segnalazione ormonale, e molte altre funzioni vitali.
Le proteine sono codificate dal DNA attraverso la trascrizione in RNA messaggero (mRNA), che a sua volta viene tradotto in una sequenza specifica di amminoacidi per formare una catena polipeptidica. Questa catena può quindi piegarsi e unirsi ad altre catene o molecole per creare la struttura tridimensionale funzionale della proteina.
Le proteine possono essere classificate in base alla loro forma, funzione o composizione chimica. Alcune proteine svolgono una funzione enzimatica, accelerando le reazioni chimiche all'interno dell'organismo, mentre altre possono agire come ormoni, neurotrasmettitori o recettori per segnalare e regolare l'attività cellulare. Altre ancora possono avere una funzione strutturale, fornendo supporto e stabilità alle cellule e ai tessuti.
La carenza di proteine può portare a diversi problemi di salute, come la malnutrizione, il ritardo della crescita nei bambini, l'indebolimento del sistema immunitario e la disfunzione degli organi vitali. D'altra parte, un consumo eccessivo di proteine può anche avere effetti negativi sulla salute, come l'aumento del rischio di malattie renali e cardiovascolari.
In medicina e ricerca biomedica, i modelli molecolari sono rappresentazioni tridimensionali di molecole o complessi molecolari, creati utilizzando software specializzati. Questi modelli vengono utilizzati per visualizzare e comprendere la struttura, le interazioni e il funzionamento delle molecole, come proteine, acidi nucleici (DNA e RNA) ed altri biomolecole.
I modelli molecolari possono essere creati sulla base di dati sperimentali ottenuti da tecniche strutturali come la cristallografia a raggi X, la spettrometria di massa o la risonanza magnetica nucleare (NMR). Questi metodi forniscono informazioni dettagliate sulla disposizione degli atomi all'interno della molecola, che possono essere utilizzate per generare modelli tridimensionali accurati.
I modelli molecolari sono essenziali per comprendere le interazioni tra molecole e come tali interazioni contribuiscono a processi cellulari e fisiologici complessi. Ad esempio, i ricercatori possono utilizzare modelli molecolari per studiare come ligandi (come farmaci o substrati) si legano alle proteine bersaglio, fornendo informazioni cruciali per lo sviluppo di nuovi farmaci e terapie.
In sintesi, i modelli molecolari sono rappresentazioni digitali di molecole che vengono utilizzate per visualizzare, analizzare e comprendere la struttura, le interazioni e il funzionamento delle biomolecole, con importanti applicazioni in ricerca biomedica e sviluppo farmaceutico.
I fattori di trascrizione sono proteine che legano specifiche sequenze del DNA e facilitano o inibiscono la trascrizione dei geni in RNA messaggero (mRNA). Essenzialmente, agiscono come interruttori molecolari che controllano l'espressione genica, determinando se e quando un gene viene attivato per essere trascritto.
I fattori di trascrizione sono costituiti da diversi domini proteici funzionali: il dominio di legame al DNA, che riconosce ed è specifico per una particolare sequenza del DNA; e il dominio attivatore o repressore della trascrizione, che interagisce con l'apparato enzimatico responsabile della sintesi dell'RNA.
La regolazione dei geni da parte di questi fattori è un processo altamente complesso e dinamico, che può essere influenzato da vari segnali intracellulari ed extracellulari. Le alterazioni nella funzione o nell'espressione dei fattori di trascrizione possono portare a disfunzioni cellulari e patologiche, come ad esempio nel cancro e in altre malattie genetiche.
In sintesi, i fattori di trascrizione sono proteine chiave che regolano l'espressione genica, contribuendo a modulare la diversità e la dinamica delle risposte cellulari a stimoli interni o esterni.
Le proteine di trasporto sono tipi specifici di proteine che aiutano a muovere o trasportare molecole e ioni, come glucosio, aminoacidi, lipidi e altri nutrienti, attraverso membrane cellulari. Si trovano comunemente nelle membrane cellulari e lisosomi e svolgono un ruolo cruciale nel mantenere l'equilibrio chimico all'interno e all'esterno della cellula.
Le proteine di trasporto possono essere classificate in due categorie principali:
1. Proteine di trasporto passivo (o diffusione facilitata): permettono il movimento spontaneo delle molecole da un ambiente ad alta concentrazione a uno a bassa concentrazione, sfruttando il gradiente di concentrazione senza consumare energia.
2. Proteine di trasporto attivo: utilizzano l'energia (solitamente derivante dall'idrolisi dell'ATP) per spostare le molecole contro il gradiente di concentrazione, da un ambiente a bassa concentrazione a uno ad alta concentrazione.
Esempi di proteine di trasporto includono il glucosio transporter (GLUT-1), che facilita il passaggio del glucosio nelle cellule; la pompa sodio-potassio (Na+/K+-ATPasi), che mantiene i gradienti di concentrazione di sodio e potassio attraverso la membrana cellulare; e la proteina canalicolare della calcemina, che regola il trasporto del calcio nelle cellule.
Le proteine di trasporto svolgono un ruolo vitale in molti processi fisiologici, tra cui il metabolismo energetico, la segnalazione cellulare, l'equilibrio idrico ed elettrolitico e la regolazione del pH. Le disfunzioni nelle proteine di trasporto possono portare a varie condizioni patologiche, come diabete, ipertensione, malattie cardiovascolari e disturbi neurologici.
In medicina, una linea cellulare è una cultura di cellule che mantengono la capacità di dividersi e crescere in modo continuo in condizioni appropriate. Le linee cellulari sono comunemente utilizzate in ricerca per studiare il comportamento delle cellule, testare l'efficacia e la tossicità dei farmaci, e capire i meccanismi delle malattie.
Le linee cellulari possono essere derivate da diversi tipi di tessuti, come quelli tumorali o normali. Le linee cellulari tumorali sono ottenute da cellule cancerose prelevate da un paziente e successivamente coltivate in laboratorio. Queste linee cellulari mantengono le caratteristiche della malattia originale e possono essere utilizzate per studiare la biologia del cancro e testare nuovi trattamenti.
Le linee cellulari normali, d'altra parte, sono derivate da tessuti non cancerosi e possono essere utilizzate per studiare la fisiologia e la patofisiologia di varie malattie. Ad esempio, le linee cellulari epiteliali possono essere utilizzate per studiare l'infezione da virus o batteri, mentre le linee cellulari neuronali possono essere utilizzate per studiare le malattie neurodegenerative.
E' importante notare che l'uso di linee cellulari in ricerca ha alcune limitazioni e precauzioni etiche da considerare, come il consenso informato del paziente per la derivazione di linee cellulari tumorali, e la verifica dell'identità e della purezza delle linee cellulari utilizzate.
In campo medico e genetico, una mutazione è definita come un cambiamento permanente nel materiale genetico (DNA o RNA) di una cellula. Queste modifiche possono influenzare il modo in cui la cellula funziona e si sviluppa, compreso l'effetto sui tratti ereditari. Le mutazioni possono verificarsi naturalmente durante il processo di replicazione del DNA o come risultato di fattori ambientali dannosi come radiazioni, sostanze chimiche nocive o infezioni virali.
Le mutazioni possono essere classificate in due tipi principali:
1. Mutazioni germinali (o ereditarie): queste mutazioni si verificano nelle cellule germinali (ovuli e spermatozoi) e possono essere trasmesse dai genitori ai figli. Le mutazioni germinali possono causare malattie genetiche o predisporre a determinate condizioni mediche.
2. Mutazioni somatiche: queste mutazioni si verificano nelle cellule non riproduttive del corpo (somatiche) e di solito non vengono trasmesse alla prole. Le mutazioni somatiche possono portare a un'ampia gamma di effetti, tra cui lo sviluppo di tumori o il cambiamento delle caratteristiche cellulari.
Le mutazioni possono essere ulteriormente suddivise in base alla loro entità:
- Mutazione puntiforme: una singola base (lettera) del DNA viene modificata, eliminata o aggiunta.
- Inserzione: una o più basi vengono inserite nel DNA.
- Delezione: una o più basi vengono eliminate dal DNA.
- Duplicazione: una sezione di DNA viene duplicata.
- Inversione: una sezione di DNA viene capovolta end-to-end, mantenendo l'ordine delle basi.
- Traslocazione: due segmenti di DNA vengono scambiati tra cromosomi o all'interno dello stesso cromosoma.
Le mutazioni possono avere effetti diversi sul funzionamento delle cellule e dei geni, che vanno da quasi impercettibili a drammatici. Alcune mutazioni non hanno alcun effetto, mentre altre possono portare a malattie o disabilità.
La trasduzione del segnale è un processo fondamentale nelle cellule viventi che consente la conversione di un segnale esterno o interno in una risposta cellulare specifica. Questo meccanismo permette alle cellule di percepire e rispondere a stimoli chimici, meccanici ed elettrici del loro ambiente.
In termini medici, la trasduzione del segnale implica una serie di eventi molecolari che avvengono all'interno della cellula dopo il legame di un ligando (solitamente una proteina o un messaggero chimico) a un recettore specifico sulla membrana plasmatica. Il legame del ligando al recettore induce una serie di cambiamenti conformazionali nel recettore, che a sua volta attiva una cascata di eventi intracellulari, compreso l'attivazione di enzimi, la produzione di secondi messaggeri e l'attivazione o inibizione di fattori di trascrizione.
Questi cambiamenti molecolari interni alla cellula possono portare a una varietà di risposte cellulari, come il cambiamento della permeabilità ionica, l'attivazione o inibizione di canali ionici, la modulazione dell'espressione genica e la promozione o inibizione della proliferazione cellulare.
La trasduzione del segnale è essenziale per una vasta gamma di processi fisiologici, tra cui la regolazione endocrina, il controllo nervoso, la risposta immunitaria e la crescita e sviluppo cellulare. Tuttavia, errori nella trasduzione del segnale possono anche portare a una serie di patologie, tra cui malattie cardiovascolari, cancro, diabete e disturbi neurologici.
Le proteine di fusione ricombinanti sono costrutti proteici creati mediante tecniche di ingegneria genetica che combinano sequenze aminoacidiche da due o più proteine diverse. Queste sequenze vengono unite in un singolo gene, che viene quindi espresso all'interno di un sistema di espressione appropriato, come ad esempio batteri, lieviti o cellule di mammifero.
La creazione di proteine di fusione ricombinanti può servire a diversi scopi, come ad esempio:
1. Studiare la struttura e la funzione di proteine complesse che normalmente interagiscono tra loro;
2. Stabilizzare proteine instabili o difficili da produrre in forma pura;
3. Aggiungere etichette fluorescenti o epitopi per la purificazione o il rilevamento delle proteine;
4. Sviluppare farmaci terapeutici, come ad esempio enzimi ricombinanti utilizzati nel trattamento di malattie genetiche rare.
Tuttavia, è importante notare che la creazione di proteine di fusione ricombinanti può anche influenzare le proprietà delle proteine originali, come la solubilità, la stabilità e l'attività enzimatica, pertanto è necessario valutarne attentamente le conseguenze prima dell'utilizzo a scopo di ricerca o terapeutico.
L'allineamento di sequenze è un processo utilizzato nell'analisi delle sequenze biologiche, come il DNA, l'RNA o le proteine. L'obiettivo dell'allineamento di sequenze è quello di identificare regioni simili o omologhe tra due o più sequenze, che possono fornire informazioni su loro relazione evolutiva o funzionale.
L'allineamento di sequenze viene eseguito utilizzando algoritmi specifici che confrontano le sequenze carattere per carattere e assegnano punteggi alle corrispondenze, alle sostituzioni e alle operazioni di gap (inserimento o cancellazione di uno o più caratteri). I punteggi possono essere calcolati utilizzando matrici di sostituzione predefinite che riflettono la probabilità di una particolare sostituzione aminoacidica o nucleotidica.
L'allineamento di sequenze può essere globale, quando l'obiettivo è quello di allineare l'intera lunghezza delle sequenze, o locale, quando si cerca solo la regione più simile tra due o più sequenze. Gli allineamenti multipli possono anche essere eseguiti per confrontare simultaneamente più di due sequenze e identificare relazioni evolutive complesse.
L'allineamento di sequenze è una tecnica fondamentale in bioinformatica e ha applicazioni in vari campi, come la genetica delle popolazioni, la biologia molecolare, la genomica strutturale e funzionale, e la farmacologia.
In genetica, una "sequenza base" si riferisce all'ordine specifico delle quattro basi azotate che compongono il DNA: adenina (A), citosina (C), guanina (G) e timina (T). Queste basi si accoppiano in modo specifico, con l'adenina che si accoppia solo con la timina e la citosina che si accoppia solo con la guanina. La sequenza di queste basi contiene l'informazione genetica necessaria per codificare le istruzioni per la sintesi delle proteine.
Una "sequenza base" può riferirsi a un breve segmento del DNA, come una coppia di basi (come "AT"), o a un lungo tratto di DNA che può contenere migliaia o milioni di basi. L'analisi della sequenza del DNA è un importante campo di ricerca in genetica e biologia molecolare, poiché la comprensione della sequenza base può fornire informazioni cruciali sulla funzione genica, sull'evoluzione e sulla malattia.
In genetica, una "sequenza conservata" si riferisce a una sequenza di nucleotidi o amminoacidi che rimane relativamente invariata durante l'evoluzione tra diverse specie. Questa conservazione indica che la sequenza svolge probabilmente una funzione importante e vitale nella struttura o funzione delle proteine o del genoma. Le mutazioni in queste sequenze possono avere effetti deleteri o letali sulla fitness dell'organismo. Pertanto, le sequenze conservate sono spesso oggetto di studio per comprendere meglio la funzione e l'evoluzione delle proteine e dei genomi. Le sequenze conservate possono essere identificate attraverso tecniche di bioinformatica e comparazione di sequenze tra diverse specie.
La conformazione della proteina, nota anche come struttura terziaria delle proteine, si riferisce alla disposizione spaziale dei diversi segmenti che costituiscono la catena polipeptidica di una proteina. Questa conformazione è stabilita da legami chimici tra gli atomi di carbonio, zolfo, azoto e ossigeno presenti nella catena laterale degli aminoacidi, nonché dalle interazioni elettrostatiche e idrofobiche che si verificano tra di essi.
La conformazione delle proteine può essere influenzata da fattori ambientali come il pH, la temperatura e la concentrazione salina, e può variare in base alla funzione svolta dalla proteina stessa. Ad esempio, alcune proteine hanno una conformazione flessibile che consente loro di legarsi a diverse molecole target, mentre altre hanno una struttura più rigida che ne stabilizza la forma e la funzione.
La determinazione della conformazione delle proteine è un'area di ricerca attiva in biochimica e biologia strutturale, poiché la conoscenza della struttura tridimensionale di una proteina può fornire informazioni cruciali sulla sua funzione e su come interagisce con altre molecole nel corpo. Le tecniche sperimentali utilizzate per determinare la conformazione delle proteine includono la diffrazione dei raggi X, la risonanza magnetica nucleare (NMR) e la criomicroscopia elettronica (Cryo-EM).
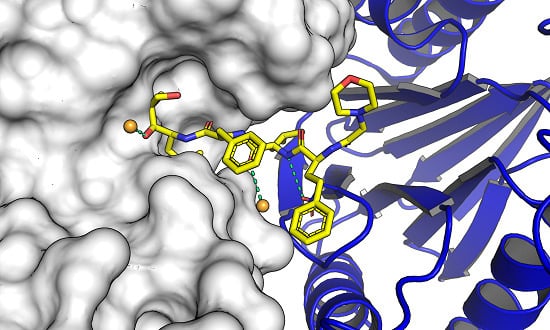
Le PDZ domini sono moduli proteici strutturali di circa 80-90 residui aminoacidici che si trovano in molte proteine e sono noti per legare specificamente i domini C-terminali di altre proteine. Il nome "PDZ" deriva dalle tre proteine originalmente identificate con questo dominio: PSD-95/SAP90 (postsinaptica densità 95 kDa), DLG1 (disks large 1) e ZO-1 (tight junction protein 1).
Le PDZ domini sono importanti per la formazione di complessi proteici e per l'ancoraggio di proteine alla membrana cellulare. Essi riconoscono e si legano a sequenze specifiche di amminoacidi nei loro partner di legame, spesso con una preferenza per i residui idrofobici o carichi positivamente.
Le PDZ domini sono anche note per la loro capacità di formare interazioni multi-proteiche complesse, che possono svolgere un ruolo importante nella regolazione della segnalazione cellulare e nell'organizzazione della membrana cellulare. Mutazioni o alterazioni nelle PDZ domini possono essere associate a diverse malattie umane, tra cui cancro, disturbi neurologici e cardiovascolari.
La mutagenesi sito-diretta è un processo di ingegneria genetica che comporta l'inserimento mirato di una specifica mutazione in un gene o in un determinato sito del DNA. A differenza della mutagenesi casuale, che produce mutazioni in posizioni casuali del DNA e può richiedere screening intensivi per identificare le mutazioni desiderate, la mutagenesi sito-diretta consente di introdurre selettivamente una singola mutazione in un gene targetizzato.
Questo processo si basa sull'utilizzo di enzimi di restrizione e oligonucleotidi sintetici marcati con nucleotidi modificati, come ad esempio desossiribonucleosidi trifosfati (dNTP) analoghi. Questi oligonucleotidi contengono la mutazione desiderata e sono progettati per abbinarsi specificamente al sito di interesse sul DNA bersaglio. Una volta che l'oligonucleotide marcato si lega al sito target, l'enzima di restrizione taglia il DNA in quel punto, consentendo all'oligonucleotide di sostituire la sequenza originale con la mutazione desiderata tramite un processo noto come ricostituzione dell'estremità coesiva.
La mutagenesi sito-diretta è una tecnica potente e precisa che viene utilizzata per studiare la funzione dei geni, creare modelli animali di malattie e sviluppare strategie terapeutiche innovative, come ad esempio la terapia genica. Tuttavia, questa tecnica richiede una progettazione accurata degli oligonucleotidi e un'elevata specificità dell'enzima di restrizione per garantire l'inserimento preciso della mutazione desiderata.
"Saccharomyces cerevisiae" è una specie di lievito unicellulare comunemente noto come "lievito da birra". È ampiamente utilizzato nell'industria alimentare e delle bevande per la fermentazione alcolica e nella produzione di pane, vino, birra e yogurt.
In ambito medico, S. cerevisiae è talvolta utilizzato come probiotico, in particolare per le persone con disturbi gastrointestinali. Alcuni studi hanno suggerito che questo lievito può aiutare a ripristinare l'equilibrio della flora intestinale e rafforzare il sistema immunitario.
Tuttavia, è importante notare che S. cerevisiae può anche causare infezioni opportunistiche, specialmente in individui con un sistema immunitario indebolito. Questi possono includere infezioni della pelle, delle vie urinarie e del tratto respiratorio.
In sintesi, "Saccharomyces cerevisiae" è un lievito utilizzato nell'industria alimentare e delle bevande, nonché come probiotico in ambito medico, sebbene possa anche causare infezioni opportunistiche in alcuni individui.
La definizione medica di "basi di dati di proteine" si riferisce a un tipo di database bioinformatico che archivia e organizza informazioni relative alle proteine. Queste basi di dati contengono una vasta gamma di informazioni sulle sequenze, la struttura, le funzioni e l'evoluzione delle proteine, nonché su come interagiscono con altre molecole all'interno dell'organismo.
Alcuni esempi di basi di dati di proteine includono UniProt, PDB (Protein Data Bank), e Pfam. UniProt è una risorsa completa che fornisce informazioni sulle sequenze, la struttura, la funzione e la variazione delle proteine in diverse specie. Il PDB contiene dati sperimentali sulla struttura tridimensionale delle proteine e di altre macromolecole biologiche. Pfam è un database di famiglie di proteine basate su modelli multipli allineamenti che fornisce informazioni sulla funzione e la struttura delle proteine.
Queste basi di dati sono utilizzate da ricercatori in molti campi della biologia, tra cui la genetica, la biochimica, la biologia molecolare e la farmacologia, per comprendere meglio le funzioni e le interazioni delle proteine all'interno dell'organismo. Inoltre, sono anche utilizzate nello sviluppo di nuovi farmaci e nella progettazione di proteine ingegnerizzate con proprietà specifiche.
In biochimica, la dimerizzazione è un processo in cui due molecole identiche o simili si legano e formano un complesso stabile chiamato dimero. Questo fenomeno è comune in molte proteine, compresi enzimi e recettori cellulari.
Nello specifico, per quanto riguarda la medicina e la fisiopatologia, il termine 'dimerizzazione' può riferirsi alla formazione di dimeri di fibrina durante il processo di coagulazione del sangue. La fibrina è una proteina solubile presente nel plasma sanguigno che gioca un ruolo cruciale nella formazione dei coaguli. Quando si verifica un'emorragia, la trombina converte la fibrinogeno in fibrina monomerica, che poi subisce una dimerizzazione spontanea per formare il fibrina dimero insolubile. Il fibrina dimero forma la base della matrice del coagulo di sangue, fornendo una struttura stabile per la retrazione e la stabilizzazione del coagulo.
La dimerizzazione della fibrina è un bersaglio terapeutico importante per lo sviluppo di farmaci anticoagulanti, come ad esempio i farmaci che inibiscono l'attività della trombina o dell'attivatore del plasminogeno (tPA), che prevengono la formazione di coaguli di sangue e il rischio di trombosi.
Le proteine ricombinanti sono proteine prodotte artificialmente mediante tecniche di ingegneria genetica. Queste proteine vengono create combinando il DNA di due organismi diversi in un unico organismo o cellula ospite, che poi produce la proteina desiderata.
Il processo di produzione di proteine ricombinanti inizia con l'identificazione di un gene che codifica per una specifica proteina desiderata. Il gene viene quindi isolato e inserito nel DNA di un organismo ospite, come batteri o cellule di lievito, utilizzando tecniche di biologia molecolare. L'organismo ospite viene quindi fatto crescere in laboratorio, dove produce la proteina desiderata durante il suo normale processo di sintesi proteica.
Le proteine ricombinanti hanno una vasta gamma di applicazioni nella ricerca scientifica, nella medicina e nell'industria. Ad esempio, possono essere utilizzate per produrre farmaci come l'insulina e il fattore di crescita umano, per creare vaccini contro malattie infettive come l'epatite B e l'influenza, e per studiare la funzione delle proteine in cellule e organismi viventi.
Tuttavia, la produzione di proteine ricombinanti presenta anche alcune sfide e rischi, come la possibilità di contaminazione con patogeni o sostanze indesiderate, nonché questioni etiche relative all'uso di organismi geneticamente modificati. Pertanto, è importante che la produzione e l'utilizzo di proteine ricombinanti siano regolamentati e controllati in modo appropriato per garantire la sicurezza e l'efficacia dei prodotti finali.
La struttura secondaria della proteina si riferisce al folding regolare e ripetitivo di sequenze aminoacidiche specifiche all'interno di una proteina, che dà origine a due conformazioni principali: l'elica alfa (α-elica) e il foglietto beta (β-foglietto). Queste strutture sono stabilite da legami idrogeno intramolecolari tra gli atomi di azoto e ossigeno presenti nel gruppo carbonilico (C=O) e ammidico (N-H) dei residui di amminoacidi adiacenti. Nell'elica alfa, ogni giro completo dell'elica contiene 3,6 residui di amminoacidi con un angolo di torsione di circa 100°, mentre nel foglietto beta le catene laterali idrofobe e polari dei residui di amminoacidi si alternano in modo da formare una struttura planare estesa. La struttura secondaria della proteina è influenzata dalla sequenza aminoacidica, dalle condizioni ambientali e dall'interazione con altre molecole.
Le proteine della membrana sono un tipo speciale di proteine che si trovano nella membrana cellulare e nelle membrane organellari all'interno delle cellule. Sono incaricate di svolgere una vasta gamma di funzioni cruciali per la vita e l'attività della cellula, tra cui il trasporto di molecole, il riconoscimento e il legame con altre cellule o sostanze estranee, la segnalazione cellulare e la comunicazione, nonché la struttura e la stabilità delle membrane.
Esistono diversi tipi di proteine della membrana, tra cui:
1. Proteine integrali di membrana: ancorate permanentemente alla membrana, possono attraversarla completamente o parzialmente.
2. Proteine periferiche di membrana: associate in modo non covalente alle superfici interne o esterne della membrana, ma possono essere facilmente separate dalle stesse.
3. Proteine transmembrana: sporgono da entrambe le facce della membrana e svolgono funzioni di canale o pompa per il trasporto di molecole attraverso la membrana.
4. Proteine di ancoraggio: mantengono unite le proteine della membrana a filamenti del citoscheletro, fornendo stabilità e supporto strutturale.
5. Proteine di adesione: mediano l'adesione cellulare e la comunicazione tra cellule o tra cellule e matrice extracellulare.
Le proteine della membrana sono bersagli importanti per i farmaci, poiché spesso svolgono un ruolo chiave nei processi patologici come il cancro, le infezioni e le malattie neurodegenerative.
In campo medico, la trasfezione si riferisce a un processo di introduzione di materiale genetico esogeno (come DNA o RNA) in una cellula vivente. Questo processo permette alla cellula di esprimere proteine codificate dal materiale genetico estraneo, alterandone potenzialmente il fenotipo. La trasfezione può essere utilizzata per scopi di ricerca di base, come lo studio della funzione genica, o per applicazioni terapeutiche, come la terapia genica.
Esistono diverse tecniche di trasfezione, tra cui:
1. Trasfezione chimica: utilizza agenti chimici come il calcio fosfato o lipidi cationici per facilitare l'ingresso del materiale genetico nelle cellule.
2. Elettroporazione: applica un campo elettrico alle cellule per creare pori temporanei nella membrana cellulare, permettendo al DNA di entrare nella cellula.
3. Trasfezione virale: utilizza virus modificati geneticamente per veicolare il materiale genetico desiderato all'interno delle cellule bersaglio. Questo metodo è spesso utilizzato in terapia genica a causa dell'elevata efficienza di trasfezione.
È importante notare che la trasfezione non deve essere confusa con la trasduzione, che si riferisce all'introduzione di materiale genetico da un batterio donatore a uno ricevente attraverso la fusione delle loro membrane cellulari.
La relazione struttura-attività (SAR (Structure-Activity Relationship)) è un concetto importante nella farmacologia e nella tossicologia. Si riferisce alla relazione quantitativa tra le modifiche chimiche apportate a una molecola e il suo effetto biologico, vale a dire la sua attività biologica o tossicità.
In altre parole, la SAR descrive come la struttura chimica di un composto influisce sulla sua capacità di interagire con bersagli biologici specifici, come proteine o recettori, e quindi su come tali interazioni determinano l'attività biologica del composto.
La relazione struttura-attività è uno strumento essenziale nella progettazione di farmaci, poiché consente ai ricercatori di prevedere come modifiche specifiche alla struttura chimica di un composto possono influire sulla sua attività biologica. Questo può guidare lo sviluppo di nuovi farmaci più efficaci e sicuri, oltre a fornire informazioni importanti sulla modalità d'azione dei farmaci esistenti.
La relazione struttura-attività si basa sull'analisi delle proprietà chimiche e fisiche di una molecola, come la sua forma geometrica, le sue dimensioni, la presenza di determinati gruppi funzionali e la sua carica elettrica. Questi fattori possono influenzare la capacità della molecola di legarsi a un bersaglio biologico specifico e quindi determinare l'entità dell'attività biologica del composto.
In sintesi, la relazione struttura-attività è una strategia per correlare le proprietà chimiche e fisiche di una molecola con il suo effetto biologico, fornendo informazioni preziose sulla progettazione e lo sviluppo di farmaci.
La biologia computazionale è un campo interdisciplinare che combina metodi e tecniche delle scienze della vita, dell'informatica, della matematica e delle statistiche per analizzare e interpretare i dati biologici su larga scala. Essenzialmente, si tratta di utilizzare approcci computazionali e algoritmi per analizzare e comprendere i processi biologici complessi a livello molecolare.
Questo campo include l'uso di modelli matematici e simulazioni per descrivere e predire il comportamento dei sistemi biologici, come ad esempio la struttura delle proteine, le interazioni geni-proteine, i meccanismi di regolazione genica e le reti metaboliche. Inoltre, la biologia computazionale può essere utilizzata per analizzare grandi dataset sperimentali, come quelli generati da tecnologie high-throughput come il sequenziamento dell'intero genoma, il microarray degli RNA e la proteomica.
Gli strumenti e le metodologie della biologia computazionale sono utilizzati in una vasta gamma di applicazioni, tra cui la ricerca farmaceutica, la medicina personalizzata, la biodiversità, l'ecologia e l'evoluzione. In sintesi, la biologia computazionale è uno strumento potente per integrare e analizzare i dati biologici complessi, fornendo informazioni preziose per comprendere i meccanismi alla base della vita e applicarli a scopi pratici.
Il clonaggio molecolare è una tecnica di laboratorio utilizzata per creare copie esatte di un particolare frammento di DNA. Questa procedura prevede l'isolamento del frammento desiderato, che può contenere un gene o qualsiasi altra sequenza specifica, e la sua integrazione in un vettore di clonazione, come un plasmide o un fago. Il vettore viene quindi introdotto in un organismo ospite, ad esempio batteri o cellule di lievito, che lo replicano producendo numerose copie identiche del frammento di DNA originale.
Il clonaggio molecolare è una tecnica fondamentale nella biologia molecolare e ha permesso importanti progressi in diversi campi, tra cui la ricerca genetica, la medicina e la biotecnologia. Ad esempio, può essere utilizzato per produrre grandi quantità di proteine ricombinanti, come enzimi o vaccini, oppure per studiare la funzione dei geni e le basi molecolari delle malattie.
Tuttavia, è importante sottolineare che il clonaggio molecolare non deve essere confuso con il clonazione umana o animale, che implica la creazione di organismi geneticamente identici a partire da cellule adulte differenziate. Il clonaggio molecolare serve esclusivamente a replicare frammenti di DNA e non interi organismi.
La delezione di sequenza in campo medico si riferisce a una mutazione genetica specifica che comporta la perdita di una porzione di una sequenza nucleotidica nel DNA. Questa delezione può verificarsi in qualsiasi parte del genoma e può variare in lunghezza, da pochi nucleotidi a grandi segmenti di DNA.
La delezione di sequenza può portare alla perdita di informazioni genetiche cruciali, il che può causare una varietà di disturbi genetici e malattie. Ad esempio, la delezione di una sequenza all'interno di un gene può comportare la produzione di una proteina anormalmente corta o difettosa, oppure può impedire la formazione della proteina del tutto.
La delezione di sequenza può essere causata da diversi fattori, come errori durante la replicazione del DNA, l'esposizione a agenti mutageni o processi naturali come il crossing over meiotico. La diagnosi di una delezione di sequenza può essere effettuata mediante tecniche di biologia molecolare, come la PCR quantitativa o la sequenziamento dell'intero genoma.
Le cellule HeLa sono una linea cellulare immortale che prende il nome da Henrietta Lacks, una paziente afroamericana a cui è stato diagnosticato un cancro cervicale invasivo nel 1951. Senza il suo consenso informato, le cellule cancerose del suo utero sono state prelevate e utilizzate per creare la prima linea cellulare umana immortale, che si è riprodotta indefinitamente in coltura.
Le cellule HeLa hanno avuto un impatto significativo sulla ricerca biomedica, poiché sono state ampiamente utilizzate nello studio di una varietà di processi cellulari e malattie umane, inclusi la divisione cellulare, la riparazione del DNA, la tossicità dei farmaci, i virus e le risposte immunitarie. Sono anche state utilizzate nello sviluppo di vaccini e nella ricerca sulla clonazione.
Tuttavia, l'uso delle cellule HeLa ha sollevato questioni etiche importanti relative al consenso informato, alla proprietà intellettuale e alla privacy dei pazienti. Nel 2013, il genoma completo delle cellule HeLa è stato sequenziato e pubblicato online, suscitando preoccupazioni per la possibilità di identificare geneticamente i parenti viventi di Henrietta Lacks senza il loro consenso.
In sintesi, le cellule HeLa sono una linea cellulare immortale derivata da un paziente con cancro cervicale invasivo che ha avuto un impatto significativo sulla ricerca biomedica, ma hanno anche sollevato questioni etiche importanti relative al consenso informato e alla privacy dei pazienti.
La trascrizione genetica è un processo fondamentale della biologia molecolare che coinvolge la produzione di una molecola di RNA (acido ribonucleico) a partire da un filamento stampo di DNA (acido desossiribonucleico). Questo processo è catalizzato dall'enzima RNA polimerasi e si verifica all'interno del nucleo delle cellule eucariotiche e nel citoplasma delle procarioti.
Nel dettaglio, la trascrizione genetica prevede l'apertura della doppia elica di DNA nella regione in cui è presente il gene da trascrivere, permettendo all'RNA polimerasi di legarsi al filamento stampo e di sintetizzare un filamento complementare di RNA utilizzando i nucleotidi contenuti nel nucleo cellulare. Il filamento di RNA prodotto è una copia complementare del filamento stampo di DNA, con le timine (T) dell'RNA che si accoppiano con le adenine (A) del DNA, e le citosine (C) dell'RNA che si accoppiano con le guanine (G) del DNA.
Esistono diversi tipi di RNA che possono essere sintetizzati attraverso il processo di trascrizione genetica, tra cui l'mRNA (RNA messaggero), il rRNA (RNA ribosomiale) e il tRNA (RNA transfer). L'mRNA è responsabile del trasporto dell'informazione genetica dal nucleo al citoplasma, dove verrà utilizzato per la sintesi delle proteine attraverso il processo di traduzione. Il rRNA e il tRNA, invece, sono componenti essenziali dei ribosomi e partecipano alla sintesi proteica.
La trascrizione genetica è un processo altamente regolato che può essere influenzato da diversi fattori, come i fattori di trascrizione, le modificazioni chimiche del DNA e l'organizzazione della cromatina. La sua corretta regolazione è essenziale per il corretto funzionamento delle cellule e per la loro sopravvivenza.
In un contesto medico o psicologico, i repressori si riferiscono a meccanismi mentali che sopprimono o trattengono pensieri, sentimenti, desideri o ricordi spiacevoli o minacciosi in modo inconscio. Questa difesa è un processo di coping che impedisce tali impulsi o materiale psichico di entrare nella consapevolezza per prevenire disagio, angoscia o conflitto interno. La repressione è considerata una forma di rimozione, un meccanismo di difesa più generale che allontana i pensieri ei ricordi spiacevoli dalla coscienza. Tuttavia, a differenza della repressione, la rimozione può anche riguardare eventi o materiale psichico che erano precedentemente consapevoli ma sono stati successivamente resi inconsci.
È importante notare che l'esistenza e il ruolo dei meccanismi di difesa come la repressione rimangono materia di dibattito nella comunità scientifica. Alcuni studiosi mettono in discussione la loro validità empirica, sostenendo che ci sono poche prove dirette a supporto della loro esistenza e che potrebbero riflettere più una teoria retrospettiva che un processo mentale reale.
In medicina e ricerca biomedica, i modelli biologici si riferiscono a sistemi o organismi viventi che vengono utilizzati per rappresentare e studiare diversi aspetti di una malattia o di un processo fisiologico. Questi modelli possono essere costituiti da cellule in coltura, tessuti, organoidi, animali da laboratorio (come topi, ratti o moscerini della frutta) e, in alcuni casi, persino piante.
I modelli biologici sono utilizzati per:
1. Comprendere meglio i meccanismi alla base delle malattie e dei processi fisiologici.
2. Testare l'efficacia e la sicurezza di potenziali terapie, farmaci o trattamenti.
3. Studiare l'interazione tra diversi sistemi corporei e organi.
4. Esplorare le risposte dei sistemi viventi a vari stimoli ambientali o fisiologici.
5. Predire l'esito di una malattia o la risposta al trattamento in pazienti umani.
I modelli biologici offrono un contesto più vicino alla realtà rispetto ad altri metodi di studio, come le simulazioni computazionali, poiché tengono conto della complessità e dell'interconnessione dei sistemi viventi. Tuttavia, è importante notare che i modelli biologici presentano anche alcune limitazioni, come la differenza di specie e le differenze individuali, che possono influenzare la rilevanza dei risultati ottenuti per l'uomo. Pertanto, i risultati degli studi sui modelli biologici devono essere interpretati con cautela e confermati in studi clinici appropriati sull'uomo.
La cristallografia a raggi X è una tecnica di fisica e chimica che consiste nell'esporre un cristallo a un fascio di radiazioni X e quindi analizzare il modello di diffrazione dei raggi X che ne risulta, noto come diagrammi di diffrazione. Questa tecnica permette di determinare la disposizione tridimensionale degli atomi all'interno del cristallo con una precisione atomica.
In pratica, quando i raggi X incidono sul cristallo, vengono diffusi in diverse direzioni e intensità, a seconda dell'arrangiamento spaziale e della distanza tra gli atomi all'interno del cristallo. L'analisi dei diagrammi di diffrazione fornisce informazioni sulla simmetria del cristallo, la lunghezza delle bond length (distanze chimiche) e gli angoli di bond angle (angoli chimici), nonché la natura degli atomi o delle molecole presenti nel cristallo.
La cristallografia a raggi X è una tecnica fondamentale in diversi campi della scienza, come la fisica, la chimica, la biologia strutturale e la scienza dei materiali, poiché fornisce informazioni dettagliate sulla struttura atomica e molecolare di un cristallo. Questa conoscenza è cruciale per comprendere le proprietà fisiche e chimiche dei materiali e per sviluppare nuovi materiali con proprietà desiderabili.
Le proteine del Saccharomyces cerevisiae, noto anche come lievito di birra, si riferiscono a una vasta gamma di proteine espressione da questa specie di lievito. Il Saccharomyces cerevisiae è un organismo eucariotico unicellulare comunemente utilizzato in studi di biologia molecolare e cellulare come modello sperimentale a causa della sua facilità di coltivazione, breve ciclo vitale, e la completa sequenza del genoma.
Le proteine di Saccharomyces cerevisiae sono ampiamente studiate e caratterizzate, con oltre 6.000 diversi tipi di proteine identificati fino ad oggi. Questi includono enzimi, proteine strutturali, proteine di trasporto, proteine di segnalazione, e molti altri.
Le proteine del Saccharomyces cerevisiae sono spesso utilizzate in ricerca biomedica per studiare la funzione e l'interazione delle proteine, la regolazione genica, il ciclo cellulare, lo stress cellulare, e molti altri processi cellulari. Inoltre, le proteine del Saccharomyces cerevisiae sono anche utilizzate in industrie come la produzione di alimenti e bevande, la bioenergetica, e la biotecnologia per una varietà di applicazioni pratiche.
In medicina e biologia molecolare, i complessi multiproteici sono aggregati formati dall'associazione di due o più proteine che interagiscono tra loro per svolgere una funzione specifica all'interno della cellula. Queste interazioni possono essere non covalenti e reversibili, come nel caso delle interazioni proteina-proteina mediata da domini di legame, o possono implicare la formazione di legami chimici covalenti, come nelle chinasi dipendenti dalla GTP.
I complessi multiproteici svolgono un ruolo fondamentale nella regolazione di molte vie cellulari, tra cui il metabolismo, la trasduzione del segnale, l'espressione genica e la risposta immunitaria. Possono essere transitori o permanenti, dipendentemente dalla loro funzione e dal contesto cellulare in cui operano.
La formazione di complessi multiproteici è spesso mediata da domini proteici specifici che riconoscono e si legano a sequenze aminoacidiche particolari presenti sulle altre proteine componenti del complesso. Queste interazioni possono essere modulate da fattori intracellulari, come la concentrazione di ioni calcio o il pH, o da fattori esterni, come i ligandi che legano specificamente alcune proteine del complesso.
La comprensione della struttura e della funzione dei complessi multiproteici è di fondamentale importanza per comprendere i meccanismi molecolari alla base delle malattie umane, come ad esempio le patologie neurodegenerative, le disfunzioni metaboliche e i tumori.
L'acido desossiribonucleico (DNA) è una molecola presente nel nucleo delle cellule che contiene le istruzioni genetiche utilizzate nella crescita, nello sviluppo e nella riproduzione di organismi viventi. Il DNA è fatto di due lunghi filamenti avvolti insieme in una forma a doppia elica. Ogni filamento è composto da unità chiamate nucleotidi, che sono costituite da un gruppo fosfato, uno zucchero deossiribosio e una delle quattro basi azotate: adenina (A), guanina (G), citosina (C) o timina (T). La sequenza di queste basi forma il codice genetico che determina le caratteristiche ereditarie di un individuo.
Il DNA è responsabile per la trasmissione dei tratti genetici da una generazione all'altra e fornisce le istruzioni per la sintesi delle proteine, che sono essenziali per lo sviluppo e il funzionamento di tutti gli organismi viventi. Le mutazioni nel DNA possono portare a malattie genetiche o aumentare il rischio di sviluppare alcuni tipi di cancro.
La mutagenesi è un processo che porta a modifiche permanenti e ereditarie nella sequenza del DNA, aumentando il tasso di mutazione oltre il livello spontaneo. Questi cambiamenti nella struttura del DNA possono provocare alterazioni nel materiale genetico che possono influenzare l'espressione dei geni e portare a effetti fenotipici, come malattie genetiche o cancerose.
I mutageni sono agenti fisici, chimici o biologici che causano danni al DNA, portando alla formazione di mutazioni. Gli esempi includono raggi X e altri tipi di radiazioni ionizzanti, sostanze chimiche come derivati dell'idrocarburo aromatico policiclico (PAH) e agenti infettivi come virus o batteri.
La mutagenesi può verificarsi in modo spontaneo a causa di errori durante la replicazione del DNA, ma l'esposizione a mutageni aumenta significativamente il tasso di mutazioni. La comprensione dei meccanismi della mutagenesi è fondamentale per lo sviluppo di strategie di prevenzione e trattamento delle malattie genetiche e del cancro.
La glutatione transferasi (GST) è un enzima appartenente alla classe delle transferasi che catalizza la reazione di trasferimento di gruppi funzionali da donatori a accettori specifici, agendo in particolare sul gruppo SH del glutatione e su varie sostanze elettrofile come l'epossido, il Michael acceptor o il gruppo carbonile.
Esistono diversi tipi di GST, ciascuno con diverse specificità di substrato e localizzazione cellulare. Queste enzimi svolgono un ruolo importante nella protezione delle cellule dai danni ossidativi e da sostanze tossiche, come i composti xenobiotici, attraverso la loro detossificazione.
La GST è anche implicata in diversi processi fisiologici, tra cui la sintesi di prostaglandine, la regolazione della risposta infiammatoria e l'apoptosi. Alterazioni nella funzione di questi enzimi sono state associate a diverse patologie, come il cancro, le malattie neurodegenerative e le malattie polmonari ossidative.
In sintesi, la glutatione transferasi è un enzima chiave che protegge le cellule dai danni causati da sostanze tossiche e radicali liberi, ed è implicata in diversi processi fisiologici e patologici.
In biochimica, la fosforilazione è un processo che consiste nell'aggiunta di uno o più gruppi fosfato a una molecola, principalmente proteine o lipidi. Questa reazione viene catalizzata da enzimi chiamati chinasi e richiede energia, spesso fornita dall'idrolisi dell'ATP (adenosina trifosfato) in ADP (adenosina difosfato).
La fosforilazione è un meccanismo importante nella regolazione delle proteine e dei loro processi cellulari, come la trasduzione del segnale, il metabolismo energetico e la divisione cellulare. L'aggiunta di gruppi fosfato può modificare la struttura tridimensionale della proteina, influenzandone l'attività enzimatica, le interazioni con altre molecole o la localizzazione subcellulare.
La rimozione dei gruppi fosfato dalle proteine è catalizzata da fosfatasi, che possono ripristinare lo stato originale della proteina e modulare i suoi processi cellulari. La fosforilazione e la defosforilazione sono quindi meccanismi di regolazione dinamici e reversibili che svolgono un ruolo cruciale nel mantenere l'equilibrio e le funzioni cellulari ottimali.
In genetica molecolare, un primer dell'DNA è una breve sequenza di DNA monocatenario che serve come punto di inizio per la reazione di sintesi dell'DNA catalizzata dall'enzima polimerasi. I primers sono essenziali nella reazione a catena della polimerasi (PCR), nella sequenziamento del DNA e in altre tecniche di biologia molecolare.
I primers dell'DNA sono generalmente sintetizzati in laboratorio e sono selezionati per essere complementari ad una specifica sequenza di DNA bersaglio. Quando il primer si lega alla sua sequenza target, forma una struttura a doppia elica che può essere estesa dall'enzima polimerasi durante la sintesi dell'DNA.
La lunghezza dei primers dell'DNA è generalmente compresa tra 15 e 30 nucleotidi, sebbene possa variare a seconda del protocollo sperimentale specifico. I primers devono essere sufficientemente lunghi da garantire una specificità di legame elevata alla sequenza target, ma non così lunghi da renderli suscettibili alla formazione di strutture secondarie che possono interferire con la reazione di sintesi dell'DNA.
In sintesi, i primers dell'DNA sono brevi sequenze di DNA monocatenario utilizzate come punto di inizio per la sintesi dell'DNA catalizzata dall'enzima polimerasi, e sono essenziali in diverse tecniche di biologia molecolare.
L'evoluzione molecolare si riferisce al processo di cambiamento e diversificazione delle sequenze del DNA, RNA e proteine nel corso del tempo. Questo campo di studio utilizza metodi matematici e statistici per analizzare le differenze nelle sequenze genetiche tra organismi correlati, con l'obiettivo di comprendere come e perché tali cambiamenti si verificano.
L'evoluzione molecolare può essere utilizzata per ricostruire la storia evolutiva delle specie, inclusa l'identificazione dei loro antenati comuni e la datazione delle divergenze evolutive. Inoltre, l'evoluzione molecolare può fornire informazioni sui meccanismi che guidano l'evoluzione, come la mutazione, la deriva genetica, la selezione naturale e il flusso genico.
L'analisi dell'evoluzione molecolare può essere applicata a una varietà di sistemi biologici, tra cui i genomi, le proteine e i virus. Questa area di ricerca ha importanti implicazioni per la comprensione della diversità biologica, dell'origine delle malattie e dello sviluppo di strategie per il controllo delle malattie infettive.
Le prove di precipitazione sono tipi di test di laboratorio utilizzati in medicina e patologia per verificare la presenza e identificare specifiche sostanze chimiche o proteine nelle urine, nel sangue o in altri fluidi corporei. Queste prove comportano l'aggiunta di un reagente chimico a un campione del fluido corporeo sospetto, che fa precipitare (formare un solido) la sostanza desiderata se presente.
Un esempio comune di prova di precipitazione è la "prova delle urine per proteine", che viene utilizzata per rilevare la proteinuria (proteine nelle urine). Nella maggior parte dei casi, le urine non dovrebbero contenere proteine in quantità significative. Tuttavia, se i reni sono danneggiati o malfunzionanti, possono consentire la fuoriuscita di proteine nelle urine.
Nella prova delle urine per proteine, un campione di urina viene miscelato con un reagente chimico come il nitrato d'argento o il solfato di rame. Se sono presenti proteine nelle urine, si formerà un precipitato che può essere rilevato visivamente o analizzato utilizzando tecniche strumentali come la spettrofotometria.
Le prove di precipitazione possono anche essere utilizzate per identificare specifiche proteine o anticorpi nel sangue, come nella nefelometria, una tecnica che misura la turbolenza causata dalla formazione di un precipitato per quantificare la concentrazione di anticorpi o altre proteine.
In sintesi, le prove di precipitazione sono metodi di laboratorio utilizzati per rilevare e identificare specifiche sostanze chimiche o proteine in fluidi corporei come urina e sangue, mediante la formazione di un precipitato visibile dopo l'aggiunta di un reagente appropriato.
I peptidi sono catene di due o più amminoacidi legati insieme da un legame peptidico. Un legame peptidico si forma quando il gruppo ammino dell'amminoacido reagisce con il gruppo carbossilico dell'amminoacido adiacente in una reazione di condensazione, rilasciando una molecola d'acqua. I peptidi possono variare in lunghezza da brevi catene di due o tre amminoacidi (chiamate oligopeptidi) a lunghe catene di centinaia o addirittura migliaia di amminoacidi (chiamate polipeptidi). Alcuni peptidi hanno attività biologica e svolgono una varietà di funzioni importanti nel corpo, come servire come ormoni, neurotrasmettitori e componenti delle membrane cellulari. Esempi di peptidi includono l'insulina, l'ossitocina e la vasopressina.
In medicina, le proteine dei funghi si riferiscono a particolari proteine prodotte da diversi tipi di funghi. Alcune di queste proteine possono avere effetti biologici significativi negli esseri umani e sono state studiate per le loro possibili applicazioni terapeutiche.
Un esempio ben noto è la lovanina, una proteina prodotta dal fungo Psilocybe mushrooms, che ha mostrato attività antimicrobica contro batteri come Staphylococcus aureus e Candida albicans. Altre proteine dei funghi possono avere proprietà enzimatiche uniche o potenziali effetti immunomodulatori, antinfiammatori o antitumorali.
Tuttavia, è importante notare che la ricerca sulle proteine dei funghi e le loro applicazioni mediche è ancora in una fase precoce e richiede ulteriori studi per comprendere appieno i loro meccanismi d'azione e sicurezza.
Nella medicina, i transattivatori sono proteine che svolgono un ruolo cruciale nella segnalazione cellulare e nella trasduzione del segnale. Essi facilitano la comunicazione tra le cellule e l'ambiente esterno, permettendo alle cellule di rispondere a vari stimoli e cambiamenti nelle condizioni ambientali.
I transattivatori sono in grado di legare specificamente a determinati ligandi (molecole segnale) all'esterno della cellula, subire una modifica conformazionale e quindi interagire con altre proteine all'interno della cellula. Questa interazione porta all'attivazione di cascate di segnalazione che possono influenzare una varietà di processi cellulari, come la proliferazione, la differenziazione e l'apoptosi (morte cellulare programmata).
Un esempio ben noto di transattivatore è il recettore tirosin chinasi, che è una proteina transmembrana con un dominio extracellulare che può legare specificamente a un ligando e un dominio intracellulare dotato di attività enzimatica. Quando il ligando si lega al dominio extracellulare, provoca una modifica conformazionale che attiva l'attività enzimatica del dominio intracellulare, portando all'attivazione della cascata di segnalazione.
I transattivatori svolgono un ruolo importante nella fisiologia e nella patologia umana, e la loro disfunzione è stata implicata in una varietà di malattie, tra cui il cancro e le malattie cardiovascolari.
L'immunoprecipitazione è una tecnica utilizzata in biologia molecolare e immunologia per isolare e purificare specifiche proteine o altri biomolecole da un campione complesso, come ad esempio un estratto cellulare o un fluido corporeo. Questa tecnica si basa sull'utilizzo di anticorpi specifici che riconoscono e si legano a una proteina target, formando un complesso immunocomplesso.
Il processo di immunoprecipitazione prevede inizialmente l'aggiunta di anticorpi specifici per la proteina bersaglio ad un campione contenente le proteine da analizzare. Gli anticorpi possono essere legati a particelle solide, come ad esempio perle di agarosio o magnetic beads, in modo che possano essere facilmente separate dal resto del campione. Una volta che gli anticorpi si sono legati alla proteina bersaglio, il complesso immunocomplesso può essere isolato attraverso centrifugazione o magneti, a seconda del supporto utilizzato per gli anticorpi.
Successivamente, il complesso immunocomplesso viene lavato ripetutamente con una soluzione tampone per rimuovere qualsiasi proteina non specificamente legata. Infine, la proteina bersaglio può essere eluita dal supporto degli anticorpi e analizzata mediante tecniche come l'elettroforesi su gel SDS-PAGE o la spettrometria di massa per identificarne la natura e le interazioni con altre proteine.
L'immunoprecipitazione è una tecnica molto utile per lo studio delle interazioni proteina-proteina, della modifica post-traduzionale delle proteine e dell'identificazione di proteine presenti in specifiche vie metaboliche o segnalazione cellulare. Tuttavia, questa tecnica richiede una buona conoscenza della biologia cellulare e della purificazione delle proteine per ottenere risultati affidabili e riproducibili.
In medicina e biologia, il termine "trasporto proteico" si riferisce alla capacità delle proteine di facilitare il movimento di molecole o ioni da un luogo all'altro all'interno di un organismo o sistema vivente. Queste proteine specializzate, note come proteine di trasporto o carrier proteine, sono presenti in membrane cellulari e intracellulari, dove svolgono un ruolo cruciale nel mantenere l'omeostasi e la regolazione dei processi metabolici.
Le proteine di trasporto possono essere classificate in due tipi principali:
1. Proteine di trasporto transmembrana: queste proteine attraversano interamente la membrana cellulare o le membrane organellari e facilitano il passaggio di molecole idrofobe o polari attraverso essa. Un esempio ben noto è la pompa sodio-potassio (Na+/K+-ATPasi), che utilizza l'energia dell'idrolisi dell'ATP per trasportare attivamente sodio e potassio contro il loro gradiente di concentrazione.
2. Proteine di trasporto intracellulari: queste proteine sono presenti all'interno delle cellule e facilitano il trasporto di molecole o ioni all'interno del citoplasma, tra diversi compartimenti cellulari o verso l'esterno della cellula. Un esempio è l'emoglobina, una proteina presente nei globuli rossi che trasporta ossigeno dai polmoni ai tessuti periferici e CO2 dai tessuti ai polmoni.
In sintesi, il trasporto proteico è un processo vitale che consente il movimento selettivo di molecole e ioni attraverso membrane biologiche, garantendo la corretta funzione cellulare e l'equilibrio fisiologico dell'organismo.
Escherichia coli (abbreviato come E. coli) è un batterio gram-negativo, non sporigeno, facoltativamente anaerobico, appartenente al genere Enterobacteriaceae. È comunemente presente nel tratto gastrointestinale inferiore dei mammiferi ed è parte integrante della normale flora intestinale umana. Tuttavia, alcuni ceppi di E. coli possono causare una varietà di malattie infettive che vanno da infezioni urinarie lievi a gravi condizioni come la meningite, sebbene ciò sia relativamente raro.
Alcuni ceppi di E. coli sono patogeni e producono tossine o altri fattori virulenti che possono causare diarrea acquosa, diarrea sanguinolenta (nota come colera emorragica), infezioni del tratto urinario, polmonite, meningite e altre malattie. L'esposizione a questi ceppi patogeni può verificarsi attraverso il consumo di cibi o bevande contaminati, il contatto con animali infetti o persone infette, o tramite l'acqua contaminata.
E. coli è anche ampiamente utilizzato in laboratorio come organismo modello per la ricerca biologica e medica a causa della sua facilità di crescita e manipolazione genetica.
In medicina, un algoritmo è una sequenza di istruzioni o passaggi standardizzati che vengono seguiti per raggiungere una diagnosi o prendere decisioni terapeutiche. Gli algoritmi sono spesso utilizzati nei processi decisionali clinici per fornire un approccio sistematico ed evidence-based alla cura dei pazienti.
Gli algoritmi possono essere basati su linee guida cliniche, raccomandazioni di esperti o studi di ricerca e possono includere fattori come i sintomi del paziente, i risultati dei test di laboratorio o di imaging, la storia medica precedente e le preferenze del paziente.
Gli algoritmi possono essere utilizzati in una varietà di contesti clinici, come la gestione delle malattie croniche, il triage dei pazienti nei pronto soccorso, la diagnosi e il trattamento delle emergenze mediche e la prescrizione dei farmaci.
L'utilizzo di algoritmi può aiutare a ridurre le variazioni nella pratica clinica, migliorare l'efficacia e l'efficienza delle cure, ridurre gli errori medici e promuovere una maggiore standardizzazione e trasparenza nei processi decisionali. Tuttavia, è importante notare che gli algoritmi non possono sostituire il giudizio clinico individuale e devono essere utilizzati in modo appropriato e flessibile per soddisfare le esigenze uniche di ogni paziente.
Il nucleo cellulare è una struttura membranosa e generalmente la porzione più grande di una cellula eucariota. Contiene la maggior parte del materiale genetico della cellula sotto forma di DNA organizzato in cromosomi. Il nucleo è circondato da una membrana nucleare formata da due membrane fosolipidiche interne ed esterne con pori nucleari che consentono il passaggio selettivo di molecole tra il citoplasma e il nucleoplasma (il fluido all'interno del nucleo).
Il nucleo svolge un ruolo fondamentale nella regolazione della attività cellulare, compresa la trascrizione dei geni in RNA e la replicazione del DNA prima della divisione cellulare. Inoltre, contiene importanti strutture come i nucleoli, che sono responsabili della sintesi dei ribosomi.
In sintesi, il nucleo cellulare è l'organulo centrale per la conservazione e la replicazione del materiale genetico di una cellula eucariota, essenziale per la crescita, lo sviluppo e la riproduzione delle cellule.
In medicina e biologia, i frammenti peptidici sono sequenze più brevi di aminoacidi rispetto alle proteine complete. Essi si formano quando le proteine vengono degradate in parti più piccole durante processi fisiologici come la digestione o patologici come la degenerazione delle proteine associate a malattie neurodegenerative. I frammenti peptidici possono anche essere sintetizzati in laboratorio per scopi di ricerca, come l'identificazione di epitodi antigenici o la progettazione di farmaci.
I frammenti peptidici possono variare in lunghezza da due a circa cinquanta aminoacidi e possono derivare da qualsiasi proteina dell'organismo. Alcuni frammenti peptidici hanno attività biologica intrinseca, come i peptidi oppioidi che si legano ai recettori degli oppioidi nel cervello e provocano effetti analgesici.
In diagnostica, i frammenti peptidici possono essere utilizzati come marcatori per malattie specifiche. Ad esempio, il dosaggio dell'amiloide-β 1-42 nel liquido cerebrospinale è un biomarcatore comunemente utilizzato per la diagnosi di malattia di Alzheimer.
In sintesi, i frammenti peptidici sono sequenze più brevi di aminoacidi derivanti dalla degradazione o sintesi di proteine, che possono avere attività biologica e utilizzati come marcatori di malattie.
La sostituzione degli aminoacidi si riferisce a un trattamento medico in cui gli aminoacidi essenziali vengono somministrati per via endovenosa o orale per compensare una carenza fisiologica o patologica. Gli aminoacidi sono i mattoni delle proteine e svolgono un ruolo cruciale nel mantenimento della funzione cellulare, della crescita e della riparazione dei tessuti.
Ci sono diverse condizioni che possono portare a una carenza di aminoacidi, come ad esempio:
1. Malassorbimento intestinale: una condizione in cui il corpo ha difficoltà ad assorbire i nutrienti dagli alimenti, compresi gli aminoacidi.
2. Carenza proteica: può verificarsi a causa di una dieta insufficiente o di un aumento delle esigenze di proteine, come durante la crescita, la gravidanza o l'esercizio fisico intenso.
3. Malattie genetiche rare che colpiscono il metabolismo degli aminoacidi: ad esempio, la fenilchetonuria (PKU), una malattia genetica in cui il corpo non è in grado di metabolizzare l'aminoacido fenilalanina.
Nella sostituzione degli aminoacidi, vengono somministrati aminoacidi essenziali o una miscela di aminoacidi che contengano tutti gli aminoacidi essenziali e non essenziali. Questo può essere fatto per via endovenosa (infusione) o per via orale (integratori alimentari).
La sostituzione degli aminoacidi deve essere prescritta e monitorata da un medico, poiché un'eccessiva assunzione di aminoacidi può portare a effetti collaterali indesiderati, come disidratazione, squilibri elettrolitici o danni ai reni.
Le fosfoproteine sono proteine che contengono gruppi fosfato covalentemente legati. Il gruppo fosfato è generalmente attaccato a residui di serina, treonina o tirosina attraverso un legame fosfoestere. Queste modificazioni post-traduzionali delle proteine sono importanti per la regolazione della funzione delle proteine, compreso il loro ripiegamento, stabilità, interazione con altre molecole e attività enzimatica. L'aggiunta e la rimozione di gruppi fosfato dalle fosfoproteine sono catalizzate da enzimi specifici chiamati kinasi e fosfatasi, rispettivamente. Le alterazioni nel livello o nella localizzazione delle fosfoproteine possono essere associate a varie condizioni patologiche, come il cancro e le malattie neurodegenerative.
La dicitura "cellule COs" non è un termine medico comunemente utilizzato o riconosciuto. Tuttavia, potrebbe essere una sigla o un acronimo per qualcosa di specifico in un particolare contesto medico o scientifico.
Tuttavia, in base alla mia conoscenza e alle mie ricerche, non sono riuscito a trovare alcuna definizione medica o scientifica per "cellule COs". È possibile che ci sia stato uno scambio di lettere o un errore nella digitazione del termine.
Se si dispone di informazioni aggiuntive sul contesto in cui è stata utilizzata questa sigla, sarò lieto di aiutare a chiarire il significato.
Le proteine del tessuto nervoso si riferiscono a specifiche proteine che sono presenti e svolgono funzioni cruciali nel tessuto nervoso, compreso il cervello, il midollo spinale e i nervi periferici. Queste proteine sono essenziali per la struttura, la funzione e la regolazione delle cellule nervose (neuroni) e dei loro supporti di comunicazione (sinapsi).
Esempi di proteine del tessuto nervoso includono:
1. Neurofilamenti: proteine strutturali che forniscono sostegno meccanico ai neuroni e sono coinvolte nel mantenimento della forma e delle dimensioni dei assoni (prolungamenti citoplasmatici dei neuroni).
2. Tubulina: una proteina globulare che compone i microtubuli, strutture cilindriche che svolgono un ruolo cruciale nel trasporto intracellulare e nella divisione cellulare nei neuroni.
3. Proteine di membrana sinaptica: proteine presenti nelle membrane presinaptiche e postsinaptiche, che sono responsabili della trasmissione dei segnali nervosi attraverso la sinapsi. Esempi includono i recettori ionotropici e metabotropici, canali ionici e proteine di adesione.
4. Canali ionici: proteine transmembrana che controllano il flusso degli ioni attraverso la membrana cellulare, svolgendo un ruolo cruciale nella generazione e trasmissione dell'impulso nervoso (potenziale d'azione).
5. Enzimi: proteine che catalizzano reazioni chimiche importanti per il metabolismo energetico, la neurotrasmissione e la segnalazione cellulare nel tessuto nervoso. Esempi includono l'acetilcolinesterasi, che degrada il neurotrasmettitore acetilcolina, e le chinasi e fosfatasi, che regolano i percorsi di segnalazione cellulare.
6. Proteine strutturali: proteine che forniscono supporto e stabilità alla cellula neuronale, come la tubulina, che forma il citoscheletro microtubulare, e le neurofilamenti, che costituiscono il citoscheletro intermedio.
7. Proteine di riparazione del DNA: proteine responsabili della riparazione del DNA danneggiato da fattori ambientali o processi cellulari normali, come la polimerasi beta e l'ossidoreduttasi PARP-1.
8. Fattori di trascrizione: proteine che legano il DNA e regolano l'espressione genica, svolgendo un ruolo cruciale nello sviluppo, nella differenziazione e nella plasticità sinaptica dei neuroni. Esempi includono CREB, NF-kB e STAT3.
9. Proteine di segnalazione cellulare: proteine che trasducono i segnali extracellulari in risposte intracellulari, come le tirosina chinasi, le serina/treonina chinasi e le GTPasi.
10. Proteine di degradazione delle proteine: proteine responsabili della degradazione delle proteine danneggiate o non più necessarie, come le proteasi e le ubiquitin ligasi.
Le proteine batteriche si riferiscono a varie proteine sintetizzate e presenti nelle cellule batteriche. Possono essere classificate in base alla loro funzione, come proteine strutturali (come la proteina di membrana o la proteina della parete cellulare), proteine enzimatiche (che catalizzano reazioni biochimiche), proteine regolatorie (che controllano l'espressione genica e altre attività cellulari) e proteine di virulenza (che svolgono un ruolo importante nell'infezione e nella malattia batterica). Alcune proteine batteriche sono specifiche per determinati ceppi o specie batteriche, il che le rende utili come bersagli per lo sviluppo di farmaci antimicrobici e test diagnostici.
Le proteine leganti RNA (RBP, RNA-binding protein) sono un gruppo eterogeneo di proteine che hanno la capacità di legare specificamente filamenti di acidi ribonucleici (RNA). Queste proteine svolgono un ruolo cruciale nella regolazione e controllo dei processi post-trascrizionali dell'RNA, compresi il splicing alternativo, la stabilità, il trasporto e la traduzione dell'mRNA. Le RBP interagiscono con sequenze specifiche o strutture secondarie nell'RNA per modulare le sue funzioni. Alterazioni nelle proteine leganti RNA possono contribuire allo sviluppo di diverse patologie, tra cui disturbi neurologici e cancro.
In medicina e biologia molecolare, un plasmide è definito come un piccolo cromosoma extracromosomale a doppia elica circolare presente in molti batteri e organismi unicellulari. I plasmidi sono separati dal cromosoma batterico principale e possono replicarsi autonomamente utilizzando i propri geni di replicazione.
I plasmidi sono costituiti da DNA a doppia elica circolare che varia in dimensioni, da poche migliaia a diverse centinaia di migliaia di coppie di basi. Essi contengono tipicamente geni responsabili della loro replicazione e mantenimento all'interno delle cellule ospiti. Alcuni plasmidi possono anche contenere geni che conferiscono resistenza agli antibiotici, la capacità di degradare sostanze chimiche specifiche o la virulenza per causare malattie.
I plasmidi sono utilizzati ampiamente in biologia molecolare e ingegneria genetica come vettori per clonare e manipolare geni. Essi possono essere facilmente modificati per contenere specifiche sequenze di DNA, che possono quindi essere introdotte nelle cellule ospiti per studiare la funzione dei geni o produrre proteine ricombinanti.
In biochimica e farmacologia, un ligando è una molecola che si lega a un'altra molecola, chiamata target biomolecolare, come un recettore, enzima o canale ionico. I ligandi possono essere naturali o sintetici e possono avere diverse finalità, come attivare, inibire o modulare la funzione della molecola target. Alcuni esempi di ligandi includono neurotrasmettitori, ormoni, farmaci, tossine e vitamine. La loro interazione con le molecole target svolge un ruolo cruciale nella regolazione di diversi processi cellulari e fisiologici. È importante notare che il termine "ligando" si riferisce specificamente all'entità chimica che si lega al bersaglio, mentre il termine "recettore" si riferisce alla proteina o biomolecola che viene legata dal ligando.
In termini medici, le "regioni promotrici genetiche" si riferiscono a specifiche sequenze di DNA situate in prossimità del sito di inizio della trascrizione di un gene. Queste regioni sono essenziali per il controllo e la regolazione dell'espressione genica, poiché forniscono il punto di attacco per le proteine e gli enzimi che avviano il processo di trascrizione del DNA in RNA.
Le regioni promotrici sono caratterizzate dalla presenza di sequenze specifiche, come il sito di legame della RNA polimerasi II e i fattori di trascrizione, che si legano al DNA per avviare la trascrizione. Una delle sequenze più importanti è il cosiddetto "sequenza di consenso TATA", situata a circa 25-30 paia di basi dal sito di inizio della trascrizione.
Le regioni promotrici possono essere soggette a vari meccanismi di regolazione, come la metilazione del DNA o l'interazione con fattori di trascrizione specifici, che possono influenzare il tasso di espressione genica. Alterazioni nelle regioni promotrici possono portare a disturbi dello sviluppo e malattie genetiche.
Le proteine della Drosophila si riferiscono a varie proteine identificate e studiate nella Drosophila melanogaster, comunemente nota come mosca della frutta. La Drosophila melanogaster è un organismo modello ampiamente utilizzato in biologia dello sviluppo, genetica e ricerca medica a causa della sua facile manipolazione sperimentale, breve ciclo di vita, elevata fecondità e conservazione dei percorsi genici e molecolari fondamentali con esseri umani.
Molte proteine della Drosophila sono state studiate in relazione a processi cellulari e sviluppo fondamentali, come la divisione cellulare, l'apoptosi, il differenziamento cellulare, la segnalazione cellulare, la riparazione del DNA e la neurobiologia. Alcune proteine della Drosophila sono anche importanti per lo studio di malattie umane, poiché i loro omologhi genici nei mammiferi sono associati a varie condizioni patologiche. Ad esempio, la proteina Hedgehog della Drosophila è correlata alla proteina Hedgehog umana, che svolge un ruolo cruciale nello sviluppo embrionale e nella crescita tumorale quando mutata o alterata.
Studiare le proteine della Drosophila fornisce informazioni vitali sulla funzione e l'interazione delle proteine, nonché sui meccanismi molecolari che sottendono i processi cellulari e lo sviluppo degli organismi. Queste conoscenze possono quindi essere applicate allo studio di malattie umane e alla ricerca di potenziali terapie.
In terminologia medica e biochimica, i "nucleotide motifs" si riferiscono a specifiche sequenze di nucleotidi che si ripetono in modo particolare all'interno del DNA o dell'RNA. Questi motivi possono essere composti da coppie di basi (come adenina-timina o guanina-citosina), tratti di tre o quattro basi, o persino sequenze più lunghe.
I nucleotide motifs sono importanti per diversi aspetti della biologia molecolare, compreso il riconoscimento e il legame delle proteine ai DNA o RNA, la regolazione dell'espressione genica, e la stabilità strutturale dei filamenti di DNA o RNA.
Alcuni esempi notevoli di nucleotide motifs includono le sequenze promotrici che avviano la trascrizione del DNA in RNA, i siti di legame per fattori di trascrizione e altri regolatori genici, e le strutture secondarie come gli hairpins e gli stem-loop nell'RNA.
In sintesi, i nucleotide motifs sono sequenze specifiche di basi che si ripetono all'interno del DNA o dell'RNA, e svolgono un ruolo cruciale nella regolazione dei processi cellulari e molecolari.
Il citoplasma è la componente principale e centrale della cellula, esclusa il nucleo. Si tratta di un materiale semifluido che riempie la membrana cellulare ed è costituito da una soluzione acquosa di diversi organelli, molecole inorganiche e organiche, inclusi carboidrati, lipidi, proteine, sali e altri composti. Il citoplasma svolge molte funzioni vitali per la cellula, come il metabolismo, la sintesi delle proteine, il trasporto di nutrienti ed altre molecole all'interno della cellula e la partecipazione a processi cellulari come il ciclo cellulare e la divisione cellulare.
In medicina e fisiologia, la cinetica si riferisce allo studio dei movimenti e dei processi che cambiano nel tempo, specialmente in relazione al funzionamento del corpo e dei sistemi corporei. Nella farmacologia, la cinetica delle droghe è lo studio di come il farmaco viene assorbito, distribuito, metabolizzato e eliminato dal corpo.
In particolare, la cinetica enzimatica si riferisce alla velocità e alla efficienza con cui un enzima catalizza una reazione chimica. Questa può essere descritta utilizzando i parametri cinetici come la costante di Michaelis-Menten (Km) e la velocità massima (Vmax).
La cinetica può anche riferirsi al movimento involontario o volontario del corpo, come nel caso della cinetica articolare, che descrive il movimento delle articolazioni.
In sintesi, la cinetica è lo studio dei cambiamenti e dei processi che avvengono nel tempo all'interno del corpo umano o in relazione ad esso.
L'analisi della sequenza proteica è un metodo di laboratorio utilizzato per determinare l'esatta sequenza degli aminoacidi che compongono una proteina. Questa analisi è spesso utilizzata per studiare le proprietà funzionali e strutturali delle proteine, nonché per identificare eventuali mutazioni o variazioni nella sequenza proteica che possono essere associate a malattie genetiche o a risposte immunitarie.
L'analisi della sequenza proteica può essere eseguita utilizzando diverse tecniche, come la digestione enzimatica seguita dalla cromatografia liquida ad alta prestazione (HPLC) o l'elettroforesi su gel di poliacrilammide (PAGE), oppure mediante sequenziamento diretto della proteina utilizzando un sequenziatore automatico di DNA ed Edman degradazione.
Il risultato dell'analisi della sequenza proteica è una serie di codoni, ognuno dei quali rappresenta un aminoacido specifico nella catena polipeptidica. Questa informazione può essere utilizzata per identificare la proteina, studiarne le proprietà funzionali e strutturali, e confrontarla con altre sequenze proteiche note per scopi di ricerca o clinici.
I motivi Helix-Turn-Helix (HTH) sono una classe comune di domini proteici responsabili del riconoscimento e del legame al DNA. Questi motivi si compongono di due eliche alfa antiparallele con una piccola struttura a gomitolo o "giro" che le collega. La seconda elica alfa, nota come elica di riconoscimento del DNA, interagisce direttamente con il solco maggiore della doppia elica del DNA, riconoscendo specifiche sequenze di basi azotate.
I motivi HTH sono ampiamente distribuiti in natura e svolgono un ruolo chiave nella regolazione della trascrizione genica in molti organismi. Ad esempio, i fattori di trascrizione batterici come il repressore del gene lac spesso contengono motivi HTH che riconoscono siti specifici sul DNA e regolano l'espressione dei geni correlati. Allo stesso modo, molti fattori di trascrizione eucariotici, come i membri della famiglia delle proteine homeodomain, utilizzano motivi HTH per legare specifiche sequenze di DNA e regolare l'espressione genica.
In sintesi, i motivi Helix-Turn-Helix sono importanti domini proteici che mediano il riconoscimento del DNA e la regolazione della trascrizione genica in una varietà di organismi.
La microscopia a fluorescenza è una tecnica di microscopia che utilizza la fluorescenza dei campioni per generare un'immagine. Viene utilizzata per studiare la struttura e la funzione delle cellule e dei tessuti, oltre che per l'identificazione e la quantificazione di specifiche molecole biologiche all'interno di campioni.
Nella microscopia a fluorescenza, i campioni vengono trattati con uno o più marcatori fluorescenti, noti come sonde, che si legano selettivamente alle molecole target di interesse. Quando il campione è esposto alla luce ad una specifica lunghezza d'onda, la sonda assorbe l'energia della luce e entra in uno stato eccitato. Successivamente, la sonda decade dallo stato eccitato allo stato fondamentale emettendo luce a una diversa lunghezza d'onda, che può essere rilevata e misurata dal microscopio.
La microscopia a fluorescenza offre un'elevata sensibilità e specificità, poiché solo le molecole marcate con la sonda fluorescente emetteranno luce. Inoltre, questa tecnica consente di ottenere immagini altamente risolvibili, poiché la lunghezza d'onda della luce emessa dalle sonde è generalmente più corta di quella della luce utilizzata per l'eccitazione, il che si traduce in una maggiore separazione tra le immagini delle diverse molecole target.
La microscopia a fluorescenza viene ampiamente utilizzata in diversi campi della biologia e della medicina, come la citologia, l'istologia, la biologia cellulare, la neurobiologia, l'immunologia e la virologia. Tra le applicazioni più comuni di questa tecnica ci sono lo studio delle interazioni proteina-proteina, la localizzazione subcellulare delle proteine, l'analisi dell'espressione genica e la visualizzazione dei processi dinamici all'interno delle cellule.
La regolazione dell'espressione genica è un processo biologico fondamentale che controlla la quantità e il momento in cui i geni vengono attivati per produrre proteine funzionali. Questo processo complesso include una serie di meccanismi a livello trascrizionale (modifiche alla cromatina, legame dei fattori di trascrizione e iniziazione della trascrizione) ed post-trascrizionali (modifiche all'mRNA, stabilità dell'mRNA e traduzione). La regolazione dell'espressione genica è essenziale per lo sviluppo, la crescita, la differenziazione cellulare e la risposta alle variazioni ambientali e ai segnali di stress. Diversi fattori genetici ed epigenetici, come mutazioni, varianti genetiche, metilazione del DNA e modifiche delle istone, possono influenzare la regolazione dell'espressione genica, portando a conseguenze fenotipiche e patologiche.
La "protein multimerization" (o formazione di multimeri proteici) si riferisce al processo di associazione e interazione tra più subunità proteiche identiche o simili per formare un complesso proteico più grande, detto multimero. Questo processo è mediato da interazioni non covalenti come legami idrogeno, forze di Van der Waals, ponti salini e interazioni idrofobiche.
I multimeri proteici possono essere omomultimeri (formati da più subunità identiche) o eteromultimeri (formati da diverse subunità). La formazione di multimeri è importante per la funzione, stabilità e regolazione delle proteine. Alterazioni nella protein multimerization possono essere associate a varie malattie, come disturbi neurologici, cancro e disordini metabolici.
I lieviti sono un gruppo di funghi unicellulari che appartengono al regno Fungi. Nella terminologia medica, il termine "lievito" si riferisce spesso a Saccharomyces cerevisiae, che è comunemente usato nell'industria alimentare e nelle applicazioni mediche.
Nel corpo umano, i lieviti possono essere presenti naturalmente sulla pelle e sulle mucose, senza causare generalmente problemi di salute. Tuttavia, in alcune condizioni, come un sistema immunitario indebolito, l'equilibrio dei microrganismi può essere alterato, permettendo ai lieviti di proliferare e causare infezioni opportunistiche, note come candidosi.
Le infezioni da lieviti possono verificarsi in diverse aree del corpo, tra cui la bocca (stomatite da lievito o mughetto), la pelle, le unghie, l'intestino e i genitali (vaginiti da lievito). I sintomi variano a seconda della localizzazione dell'infezione ma possono includere arrossamento, prurito, bruciore, dolore e secrezioni biancastre.
Per trattare le infezioni da lieviti, vengono utilizzati farmaci antifungini specifici, come la nistatina, il clotrimazolo o l'fluconazolo, che possono essere somministrati per via topica o sistemica a seconda della gravità e della localizzazione dell'infezione.
La definizione medica di "DNA complementare" si riferisce alla relazione tra due filamenti di DNA che sono legati insieme per formare una doppia elica. Ogni filamento del DNA è composto da una sequenza di nucleotidi, che contengono ciascuno uno zucchero deossiribosio, un gruppo fosfato e una base azotata (adenina, timina, guanina o citosina).
Nel DNA complementare, le basi azotate dei due filamenti si accoppiano in modo specifico attraverso legami idrogeno: adenina si accoppia con timina e guanina si accoppia con citosina. Ciò significa che se si conosce la sequenza di nucleotidi di un filamento di DNA, è possibile prevedere con precisione la sequenza dell'altro filamento, poiché sarà complementare ad esso.
Questa proprietà del DNA complementare è fondamentale per la replicazione e la trasmissione genetica, poiché consente alla cellula di creare una copia esatta del proprio DNA durante la divisione cellulare. Inoltre, è anche importante nella trascrizione genica, dove il filamento di DNA complementare al gene viene trascritto in un filamento di RNA messaggero (mRNA), che a sua volta viene tradotto in una proteina specifica.
La risonanza di superficie dei plasmageni (RSP) è una tecnica di diagnostica per immagini non invasiva che utilizza un campo magnetico e impulsi di radiofrequenza per produrre immagini dettagliate delle cellule sanguigne (plasmageni) vicino alla superficie del corpo. Questa tecnica è spesso utilizzata per valutare la funzionalità cerebrale, la circolazione sanguigna e l'ossigenazione dei tessuti in aree specifiche del corpo come il cervello, il cuore o i muscoli.
Nella RSP, un'antenna emette un campo magnetico a bassa frequenza che induce le molecole di idrogeno presenti nelle cellule sanguigne a produrre un segnale di risonanza. Questo segnale viene quindi rilevato e analizzato per creare immagini ad alta risoluzione delle aree interessate del corpo.
La RSP è considerata una tecnica sicura e indolore, che non utilizza radiazioni come la tomografia computerizzata (TC) o il contrasto come la risonanza magnetica (RM). Tuttavia, può essere meno sensibile di altre tecniche di imaging in alcuni casi e può richiedere una maggiore esperienza da parte dell'operatore per ottenere immagini di alta qualità.
La risonanza magnetica nucleare biomolecolare (NMR, Nuclear Magnetic Resonance) è una tecnica di risonanza magnetica che viene utilizzata per studiare la struttura, la dinamica e le interazioni delle molecole biologiche, come proteine, acidi nucleici e metaboliti. Questa tecnica si basa sul fatto che i protoni (nuclei di idrogeno) e altri nuclei atomici con spin non nullo, quando vengono sottoposti a un campo magnetico esterno, assorbono ed emettono energia a specifiche frequenze radio.
In particolare, la NMR biomolecolare consente di ottenere informazioni dettagliate sulla struttura tridimensionale delle proteine e degli acidi nucleici, nonché sui loro movimenti e flessibilità. Queste informazioni sono fondamentali per comprendere il funzionamento dei sistemi biologici a livello molecolare e per lo sviluppo di nuovi farmaci e terapie.
La NMR biomolecolare richiede l'uso di campi magnetici molto potenti, solitamente generati da grandi magneti superconduttori raffreddati a temperature criogeniche. Inoltre, è necessario utilizzare sofisticate tecniche di elaborazione dei dati per estrarre informazioni utili dalle misure sperimentali.
In sintesi, la risonanza magnetica nucleare biomolecolare è una potente tecnica di indagine strutturale e funzionale che permette di studiare la struttura e le interazioni delle molecole biologiche a livello atomico, fornendo informazioni fondamentali per la comprensione dei meccanismi molecolari alla base dei processi biologici.
Le isoforme proteiche sono diverse forme di una stessa proteina che risultano dall'espressione di geni diversamente spliced, da modificazioni post-traduzionali o da varianti di sequenze di mRNA codificanti per la stessa proteina. Queste isoforme possono avere diverse funzioni, localizzazioni subcellulari o interazioni con altre molecole, e possono svolgere un ruolo importante nella regolazione dei processi cellulari e nelle risposte fisiologiche e patologiche dell'organismo. Le isoforme proteiche possono essere identificate e caratterizzate utilizzando tecniche di biologia molecolare e di analisi delle proteine, come la spettroscopia di massa e l'immunochimica.
La definizione medica di 'Cercopithecus aethiops' si riferisce ad una specie di primati della famiglia Cercopithecidae, nota come il cercopiteco verde o il babbuino oliva. Questo primate originario dell'Africa ha una pelliccia di colore verde-oliva e presenta un distinto muso nudo con colorazione che varia dal rosa al nero a seconda del sesso e dello stato emotivo.
Il cercopiteco verde è noto per la sua grande agilità e abilità nel saltare tra gli alberi, oltre ad avere una dieta onnivora che include frutta, foglie, insetti e occasionalmente piccoli vertebrati. Questa specie vive in gruppi sociali complessi con gerarchie ben definite e comunicano tra loro utilizzando una varietà di suoni, espressioni facciali e gesti.
In termini medici, lo studio del cercopiteco verde può fornire informazioni importanti sulla biologia e sul comportamento dei primati non umani, che possono avere implicazioni per la comprensione della salute e dell'evoluzione degli esseri umani. Ad esempio, il genoma del cercopiteco verde è stato sequenziato ed è stato utilizzato per studiare l'origine e l'evoluzione dei virus che colpiscono gli esseri umani, come il virus dell'immunodeficienza umana (HIV).
In medicina e biologia, le "sostanze macromolecolari" si riferiscono a molecole molto grandi che sono costituite da un gran numero di atomi legati insieme. Queste molecole hanno una massa molecolare elevata e svolgono funzioni cruciali nelle cellule viventi.
Le sostanze macromolecolari possono essere classificate in quattro principali categorie:
1. Carboidrati: composti organici costituiti da carbonio, idrogeno e ossigeno, con un rapporto di idrogeno a ossigeno pari a 2:1 (come nel glucosio). I carboidrati possono essere semplici, come il glucosio, o complessi, come l'amido e la cellulosa.
2. Proteine: composti organici costituiti da catene di amminoacidi legati insieme da legami peptidici. Le proteine svolgono una vasta gamma di funzioni biologiche, come catalizzare reazioni chimiche, trasportare molecole e fornire struttura alle cellule.
3. Acidi nucleici: composti organici che contengono fosfati, zuccheri e basi azotate. Gli acidi nucleici includono DNA (acido desossiribonucleico) e RNA (acido ribonucleico), che sono responsabili della conservazione e dell'espressione genetica.
4. Lipidi: composti organici insolubili in acqua, ma solubili nei solventi organici come l'etere e il cloroformio. I lipidi includono grassi, cere, steroli e fosfolipidi, che svolgono funzioni strutturali e di segnalazione nelle cellule viventi.
Le sostanze macromolecolari possono essere naturali o sintetiche, e possono avere una vasta gamma di applicazioni in medicina, biologia, ingegneria e altre discipline scientifiche.
La "sequenza del consenso" è un termine utilizzato in genetica molecolare per descrivere una particolare disposizione dei nucleotidi nelle sequenze di DNA o RNA che si verifica quando due o più basi complementari si legano insieme in modo non standard, anziché formare la coppia di basi Watson-Crick tradizionale (Adenina-Timina o Citosina-Guanina).
La sequenza del consenso è spesso osservata nelle regioni ripetitive del DNA, come i introni e gli elementi trasponibili. La formazione di una sequenza del consenso può influenzare la struttura e la funzione del DNA o RNA, compresa la regolazione della trascrizione genica, la stabilità dell'mRNA e la traduzione proteica.
Una forma comune di sequenza del consenso è la coppia di basi G-U (Guanina-Uracile), che può formare una coppia di basi wobble nella struttura a doppio filamento del DNA o RNA. Questa coppia di basi non standard è meno stabile della coppia di basi Watson-Crick, ma può ancora fornire un legame sufficientemente stabile per mantenere l'integrità della struttura del DNA o RNA.
La sequenza del consenso può anche riferirsi alla disposizione preferenziale dei nucleotidi in una particolare posizione all'interno di una sequenza di DNA o RNA, che è stata determinata dall'analisi statistica di un gran numero di sequenze correlate. Questa sequenza del consenso può fornire informazioni utili sulla funzione e l'evoluzione delle sequenze genetiche.
La membrana cellulare, nota anche come membrana plasmatica, è una sottile barriera lipidico-proteica altamente selettiva che circonda tutte le cellule. Ha uno spessore di circa 7-10 nanometri ed è composta principalmente da due strati di fosfolipidi con molecole proteiche immerse in essi. Questa membrana svolge un ruolo cruciale nella separazione del citoplasma della cellula dal suo ambiente esterno, garantendo la stabilità e l'integrità strutturale della cellula.
Inoltre, la membrana cellulare regola il passaggio di sostanze all'interno e all'esterno della cellula attraverso un processo chiamato trasporto selettivo. Ciò include il trasferimento di nutrienti, ioni e molecole di segnalazione necessari per la sopravvivenza cellulare, nonché l'espulsione delle sostanze tossiche o di rifiuto. La membrana cellulare è anche responsabile della ricezione dei segnali esterni che influenzano il comportamento e le funzioni cellulari.
La sua struttura unica, composta da fosfolipidi con code idrofobiche e teste polari idrofile, consente alla membrana di essere flessibile e selettiva. Le molecole proteiche integrate nella membrana, come i canali ionici e i recettori, svolgono un ruolo chiave nel facilitare il trasporto attraverso la barriera lipidica e nella risposta ai segnali esterni.
In sintesi, la membrana cellulare è una struttura dinamica e vitale che protegge la cellula, regola il traffico di molecole e consente alla cellula di interagire con l'ambiente circostante. La sua integrità e funzionalità sono essenziali per la sopravvivenza, la crescita e la divisione cellulare.
Una mutazione puntiforme è un tipo specifico di mutazione genetica che comporta il cambiamento di una singola base azotata nel DNA. Poiché il DNA è composto da quattro basi nucleotidiche diverse (adenina, timina, citosina e guanina), una mutazione puntiforme può coinvolgere la sostituzione di una base con un'altra (chiamata sostituzione), l'inserzione di una nuova base o la delezione di una base esistente.
Le mutazioni puntiformi possono avere diversi effetti sul gene e sulla proteina che codifica, a seconda della posizione e del tipo di mutazione. Alcune mutazioni puntiformi non hanno alcun effetto, mentre altre possono alterare la struttura o la funzione della proteina, portando potenzialmente a malattie genetiche.
Le mutazioni puntiformi sono spesso associate a malattie monogeniche, che sono causate da difetti in un singolo gene. Ad esempio, la fibrosi cistica è una malattia genetica comune causata da una specifica mutazione puntiforme nel gene CFTR. Questa mutazione porta alla produzione di una proteina CFTR difettosa che non funziona correttamente, il che può portare a problemi respiratori e digestivi.
In sintesi, una mutazione puntiforme è un cambiamento in una singola base azotata del DNA che può avere diversi effetti sul gene e sulla proteina che codifica, a seconda della posizione e del tipo di mutazione.
In termini medici, le subunità proteiche si riferiscono a uno o più polipeptidi che compongono una proteina complessiva più grande. Queste subunità sono prodotte quando un singolo gene codifica per una catena polipeptidica più lunga che viene poi tagliata enzimaticamente in segmenti più piccoli, o quando diversi geni codificano per diverse catene polipeptidiche che si uniscono per formare la proteina completa.
Le subunità proteiche possono avere funzioni distinte all'interno della proteina complessiva e possono essere modificate post-traduzionalmente in modo diverso, il che può influenzare la loro attività e interazione con altre molecole.
La struttura e la composizione delle subunità proteiche sono spesso studiate utilizzando tecniche di biologia molecolare e biochimica, come l'elettroforesi su gel, la cromatografia e la spettroscopia. L'identificazione e la caratterizzazione delle subunità proteiche possono fornire informazioni importanti sulla funzione, la regolazione e la patologia di una proteina.
Il piegamento delle proteine è un processo cruciale per la funzione delle proteine nelle cellule. Si riferisce al modo in cui le catene polipeptidiche, costituite da una sequenza specifica di aminoacidi, si ripiegano su se stesse per assumere una struttura tridimensionale caratteristica e stabile. Questa forma definita consente alle proteine di svolgere le loro funzioni specifiche all'interno della cellula, come catalizzare reazioni chimiche, trasportare molecole o fornire supporto strutturale.
Il piegamento delle proteine è governato dalla sequenza degli aminoacidi e dalle interazioni tra di essi, che possono essere deboli (ad esempio, legami a idrogeno, interazioni ioniche e forze di van der Waals) o forti (ad esempio, ponti disolfuro). Durante il piegamento, le proteine attraversano diverse tappe, tra cui l'inizio del piegamento (formazione di strutture secondarie come α-eliche e β-foglietti), il ripiegamento locale (formazione di strutture terziarie) e il ripiegamento globale (formazione della struttura quaternaria, se la proteina è costituita da più di una catena polipeptidica).
Anomalie nel piegamento delle proteine possono portare a malattie note come "malattie da accumulo di proteine", nelle quali le proteine malpiegate si accumulano all'interno della cellula, formando aggregati insolubili e tossici. Esempi di tali malattie includono la malattia di Alzheimer, la malattia di Parkinson e la corea di Huntington.
HEK293 cells, o Human Embryonic Kidney 293 cells, sono linee cellulari immortalizzate utilizzate comunemente nella ricerca scientifica. Sono state originariamente derivate da un campione di cellule renali embrionali umane trasformate con un virus adenovirale in laboratorio all'inizio degli anni '70. HEK293 cells è ora una delle linee cellulari più comunemente utilizzate nella biologia molecolare e cellulare a causa della sua facilità di coltivazione, stabilità genetica e alto tasso di espressione proteica.
Le cellule HEK293 sono adesive e possono crescere in monostrato o come sferoidi tridimensionali. Possono essere trasfettate con facilità utilizzando una varietà di metodi, inclusa la trasfezione lipidica, la trasfezione a calcio e l'elettroporazione. Queste cellule sono anche suscettibili all'infezione da molti tipi diversi di virus, il che le rende utili per la produzione di virus ricombinanti e vettori virali.
Le cellule HEK293 sono state utilizzate in una vasta gamma di applicazioni di ricerca, tra cui l'espressione eterologa di proteine, lo studio della via del segnale cellulare, la citotossicità dei farmaci e la tossicologia. Tuttavia, è importante notare che le cellule HEK293 sono di origine umana ed esprimono una serie di recettori e proteine endogene che possono influenzare l'espressione eterologa delle proteine e la risposta ai farmaci. Pertanto, i ricercatori devono essere consapevoli di queste potenziali fonti di variabilità quando interpretano i loro dati sperimentali.
Le "Dita di Zinco" non sono un termine medico riconosciuto. Tuttavia, potresti fare riferimento a "Dito di Zinco" come un dispositivo medico utilizzato per la cura delle ulcere da pressione. Questo dispositivo è realizzato in schiuma di zinco e ha la forma di un dito o una punta, progettata per adattarsi alla forma del letto dell'ulcera. Viene utilizzato per proteggere l'ulcera da ulteriori lesioni o pressione, promuovere la guarigione e ridurre il dolore.
Le dita di zinco sono indicate per l'uso in pazienti con ulcere da pressione stadio II-III, che non presentano segni di infezione grave o necrosi tissutale. Sono disponibili in diverse dimensioni e possono essere tagliate e modellate per adattarsi alla forma specifica dell'ulcera.
Le dita di zinco sono facili da applicare e rimuovere, e possono essere lasciate in sede per diversi giorni alla volta, a seconda delle raccomandazioni del medico o del professionista sanitario. Durante l'uso, è importante monitorare attentamente la cute circostante l'ulcera per rilevare eventuali segni di irritazione o reazione allergica al materiale in schiuma di zinco.
La struttura proteica quaternaria si riferisce all'organizzazione e all'interazione di due o più subunità polipeptidiche distinte che compongono una proteina complessa. Ciascuna subunità è a sua volta costituita da una o più catene polipeptidiche, legate insieme dalla struttura proteica terziaria. Le subunità interagiscono tra loro attraverso forze deboli come ponti idrogeno, interazioni idrofobiche e ioni di sale, che consentono alle subunità di associarsi e dissociarsi in risposta a variazioni di pH, temperatura o concentrazione di ioni.
La struttura quaternaria è importante per la funzione delle proteine, poiché le subunità possono lavorare insieme per creare siti attivi più grandi e complessi, aumentando l'affinità di legame o la specificità del substrato. Alcune proteine che presentano struttura quaternaria includono emoglobina, DNA polimerasi e citocromo c ossidasi.
In medicina e biologia, il termine "proteoma" si riferisce all'insieme completo dei proteini espressi da un genoma, un organismo o una cellula in un determinato momento. Il proteoma varia tra diversi tipi di cellule e cambia nel tempo in risposta a fattori interni ed esterni.
Il proteoma include non solo le proteine presenti in una cellula, ma anche la loro localizzazione, modificazioni post-traduzionali, interazioni e quantità relative. L'analisi del proteoma può fornire informazioni importanti sulla funzione delle cellule e dei tessuti, nonché sulle risposte dell'organismo a varie condizioni fisiologiche e patologiche.
La determinazione del proteoma è un processo complesso che richiede l'uso di tecnologie avanzate come la spettrometria di massa e la cromatografia liquida accoppiata alla spettrometria di massa (LC-MS/MS). L'analisi del proteoma può essere utilizzata per identificare biomarcatori della malattia, monitorare l'efficacia dei trattamenti farmacologici e studiare i meccanismi molecolari alla base di varie patologie.
Le proteine virali sono molecole proteiche sintetizzate dalle particelle virali o dai genomi virali dopo l'infezione dell'ospite. Sono codificate dal genoma virale e svolgono un ruolo cruciale nel ciclo di vita del virus, inclusa la replicazione virale, l'assemblaggio dei virioni e la liberazione dalle cellule ospiti.
Le proteine virali possono essere classificate in diverse categorie funzionali, come le proteine strutturali, che costituiscono la capside e il rivestimento lipidico del virione, e le proteine non strutturali, che svolgono una varietà di funzioni accessorie durante l'infezione virale.
Le proteine virali possono anche essere utilizzate come bersagli per lo sviluppo di farmaci antivirali e vaccini. La comprensione della struttura e della funzione delle proteine virali è quindi fondamentale per comprendere il ciclo di vita dei virus e per sviluppare strategie efficaci per prevenire e trattare le infezioni virali.
Le proteine luminescenti sono un tipo di proteine che emettono luce come risultato di una reazione chimica. Questa reazione può essere causata da una varietà di fattori, come l'ossidazione, la chemiluminescenza o la bioluminescenza.
La luminescenza delle proteine è spesso utilizzata in applicazioni biochimiche e biomediche, come la rilevazione di specifiche molecole biologiche o eventi cellulari. Ad esempio, la luciferasi, una proteina luminescente presente nelle lucciole, può essere utilizzata per misurare l'attività enzimatica o la concentrazione di ATP in un campione.
Le proteine luminescenti possono anche essere utilizzate come marcatori fluorescenti per l'imaging cellulare e tissutale, poiché emettono luce visibile quando eccitate con luce ultravioletta o di altre lunghezze d'onda. Queste proteine sono spesso utilizzate in ricerca biomedica per studiare la localizzazione e l'espressione delle proteine all'interno delle cellule e dei tessuti.
In sintesi, le proteine luminescenti sono un importante strumento di ricerca e diagnostico che consentono di rilevare e visualizzare specifiche molecole biologiche o eventi cellulari in modo sensibile ed efficiente.
In termini medici, il software non ha una definizione specifica poiché si riferisce all'informatica e non alla medicina. Tuttavia, in un contesto più ampio che coinvolge l'informatica sanitaria o la telemedicina, il software può essere definito come un insieme di istruzioni e dati elettronici organizzati in modo da eseguire funzioni specifiche e risolvere problemi. Questi possono includere programmi utilizzati per gestire i sistemi informativi ospedalieri, supportare la diagnosi e il trattamento dei pazienti, o facilitare la comunicazione tra fornitori di assistenza sanitaria e pazienti. È importante notare che il software utilizzato nel campo medico deve essere affidabile, sicuro ed efficiente per garantire una cura adeguata e la protezione dei dati sensibili dei pazienti.
In terminologia medica, la filogenesi è lo studio e l'analisi della storia evolutiva e delle relazioni genealogiche tra differenti organismi viventi o taxa (gruppi di organismi). Questo campo di studio si basa principalmente sull'esame delle caratteristiche anatomiche, fisiologiche e molecolari condivise tra diverse specie, al fine di ricostruire la loro storia evolutiva comune e stabilire le relazioni gerarchiche tra i diversi gruppi.
Nello specifico, la filogenesi si avvale di metodi statistici e computazionali per analizzare dati provenienti da diverse fonti, come ad esempio sequenze del DNA o dell'RNA, caratteristiche morfologiche o comportamentali. Questi dati vengono quindi utilizzati per costruire alberi filogenetici, che rappresentano graficamente le relazioni evolutive tra i diversi taxa.
La filogenesi è un concetto fondamentale in biologia ed è strettamente legata alla sistematica, la scienza che classifica e nomina gli organismi viventi sulla base delle loro relazioni filogenetiche. La comprensione della filogenesi di un dato gruppo di organismi può fornire informazioni preziose sulle loro origini, la loro evoluzione e l'adattamento a differenti ambienti, nonché contribuire alla definizione delle strategie per la conservazione della biodiversità.
Le proteine e i peptidi del segnale intracellulare sono molecole di comunicazione che trasmettono informazioni all'interno della cellula per attivare risposte specifiche. Sono piccoli peptidi o proteine che si legano a recettori intracellulari e influenzano l'espressione genica, l'attivazione enzimatica o il trasporto di molecole all'interno della cellula.
Questi segnali intracellulari possono derivare da ormoni, fattori di crescita e neurotrasmettitori che si legano a recettori di membrana sulla superficie cellulare, attivando una cascata di eventi che portano alla produzione di proteine o peptidi del segnale intracellulare. Una volta generate, queste molecole possono influenzare una varietà di processi cellulari, tra cui la proliferazione, l'apoptosi, la differenziazione e il metabolismo.
Esempi di proteine e peptidi del segnale intracellulare includono i fattori di trascrizione, le proteine chinasi e le piccole proteine G. Le disfunzioni in queste molecole possono portare a una varietà di malattie, tra cui il cancro, le malattie cardiovascolari e le malattie neurodegenerative.
La proteomica è un campo di studio interdisciplinare che si occupa dello studio globale e sistematico dei proteomi, cioè l'insieme completo delle proteine espressione in una cellula, un tessuto o un organismo in un determinato momento. Essa integra diverse tecniche analitiche e computazionali per identificare, quantificare e caratterizzare le proteine e le loro interazioni funzionali, modifiche post-traduzionali e ruoli nella regolazione dei processi cellulari.
La proteomica può fornire informazioni importanti sulla fisiologia e la patologia delle cellule e degli organismi, nonché sui meccanismi di malattie complesse come il cancro, le malattie neurodegenerative e le infezioni. Essa può anche essere utilizzata per identificare nuovi bersagli terapeutici e biomarcatori di malattia, nonché per valutare l'efficacia dei trattamenti farmacologici.
Le tecniche comuni utilizzate nella proteomica includono la spettrometria di massa, la cromatografia liquida ad alta prestazione (HPLC), l'elettroforesi bidimensionale (2DE) e le array di proteine. La bioinformatica e la biologia computazionale svolgono anche un ruolo importante nella analisi e interpretazione dei dati proteomici.
Le Proteine Fluorescenti Verdi ( GFP, Green Fluorescent Protein) sono proteine originariamente isolate dalla medusa Aequorea victoria che brillano di verde quando esposte alla luce blu o ultravioletta. La GFP è composta da 238 aminoacidi e ha una massa molecolare di circa 27 kDa. Emette luce verde a una lunghezza d'onda di circa 509 nm quando viene eccitata con luce blu a 475 nm.
La GFP è ampiamente utilizzata in biologia molecolare e cellulare come marcatore fluorescente per studiare la localizzazione, l'espressione e le interazioni delle proteine all'interno delle cellule viventi. La GFP può essere fusa geneticamente a una proteina target di interesse, permettendo così di monitorarne la posizione e il comportamento all'interno della cellula.
Inoltre, sono state sviluppate varianti ingegnerizzate della GFP che emettono fluorescenza in diversi colori dello spettro visibile, come il giallo, il blu, il cyan e il rosso, offrendo così una gamma più ampia di applicazioni per la ricerca biologica.
Le proteine dell'Arabidopsis si riferiscono a specifiche proteine identificate e studiate principalmente nell'Arabidopsis thaliana, una pianta utilizzata ampiamente come organismo modello nel campo della biologia vegetale e delle scienze genetiche. L'Arabidopsis thaliana ha un genoma ben caratterizzato e relativamente semplice, con una dimensione di circa 135 megabasi paia (Mbp) e contenente circa 27.000 geni.
Poiché l'Arabidopsis thaliana è ampiamente studiata, sono state identificate e caratterizzate migliaia di proteine specifiche per questa pianta. Queste proteine svolgono una varietà di funzioni importanti per la crescita, lo sviluppo e la sopravvivenza della pianta. Alcune delle principali classi di proteine dell'Arabidopsis includono enzimi, proteine strutturali, proteine di trasporto, proteine di segnalazione e proteine di difesa.
Gli studiosi utilizzano spesso l'Arabidopsis thaliana per comprendere i meccanismi molecolari che regolano la crescita e lo sviluppo delle piante, nonché le risposte delle piante allo stress ambientale. Le proteine dell'Arabidopsis sono state studiate in diversi contesti, tra cui:
1. Risposta allo stress: Le proteine dell'Arabidopsis svolgono un ruolo cruciale nella risposta della pianta a varie forme di stress ambientale, come la siccità, il freddo e l'esposizione a metalli pesanti. Ad esempio, le proteine di shock termico (HSP) aiutano a proteggere le piante dallo stress termico, mentre le proteine di detossificazione aiutano a rimuovere i metalli pesanti tossici dall'ambiente cellulare.
2. Sviluppo delle piante: Le proteine dell'Arabidopsis sono state studiate per comprendere meglio il processo di sviluppo delle piante, come la germinazione dei semi, l'allungamento delle cellule e la differenziazione cellulare. Ad esempio, le proteine coinvolte nella divisione cellulare e nell'espansione contribuiscono alla crescita della pianta.
3. Fotosintesi: Le proteine dell'Arabidopsis sono state studiate per comprendere meglio il processo di fotosintesi, che è essenziale per la sopravvivenza delle piante. Ad esempio, le proteine Rubisco e le proteine leganti l'ossigeno svolgono un ruolo cruciale nella fase di luce della fotosintesi.
4. Risposta immunitaria: Le proteine dell'Arabidopsis sono state studiate per comprendere meglio la risposta immunitaria delle piante ai patogeni. Ad esempio, le proteine del recettore dei pattern associati al microbo (MAMP) e le proteine della chinasi riconoscono i patogeni e innescano una risposta immunitaria.
5. Metabolismo: Le proteine dell'Arabidopsis sono state studiate per comprendere meglio il metabolismo delle piante, come la biosintesi degli aminoacidi, dei lipidi e dei carboidrati. Ad esempio, le proteine enzimatiche svolgono un ruolo cruciale nel catalizzare le reazioni chimiche che si verificano durante il metabolismo.
In sintesi, le proteine dell'Arabidopsis sono state studiate per comprendere meglio una vasta gamma di processi biologici nelle piante, fornendo informazioni cruciali sulla funzione e l'interazione delle proteine all'interno della cellula vegetale. Queste conoscenze possono essere utilizzate per migliorare la resa e la resistenza alle malattie delle colture, nonché per sviluppare nuove tecnologie di bioingegneria vegetale.
La Western blotting, nota anche come immunoblotting occidentale, è una tecnica di laboratorio comunemente utilizzata in biologia molecolare e ricerca biochimica per rilevare e quantificare specifiche proteine in un campione. Questa tecnica combina l'elettroforesi delle proteine su gel (SDS-PAGE), il trasferimento elettroforetico delle proteine da gel a membrana e la rilevazione immunologica utilizzando anticorpi specifici per la proteina target.
Ecco i passaggi principali della Western blotting:
1. Estrarre le proteine dal campione (cellule, tessuti o fluidi biologici) e denaturarle con sodio dodecil solfato (SDS) e calore per dissociare le interazioni proteina-proteina e conferire una carica negativa a tutte le proteine.
2. Caricare le proteine denaturate in un gel di poliacrilammide preparato con SDS (SDS-PAGE), che separa le proteine in base al loro peso molecolare.
3. Eseguire l'elettroforesi per separare le proteine nel gel, muovendole verso la parte positiva del campo elettrico.
4. Trasferire le proteine dal gel alla membrana di nitrocellulosa o PVDF (polivinilidene fluoruro) utilizzando l'elettroblotting, che sposta le proteine dalla parte negativa del campo elettrico alla membrana posizionata sopra il gel.
5. Bloccare la membrana con un agente bloccante (ad esempio, latte in polvere scremato o albumina sierica) per prevenire il legame non specifico degli anticorpi durante la rilevazione immunologica.
6. Incubare la membrana con l'anticorpo primario marcato (ad esempio, con un enzima o una proteina fluorescente) che riconosce e si lega specificamente all'antigene di interesse.
7. Lavare la membrana per rimuovere l'anticorpo primario non legato.
8. Rivelare il segnale dell'anticorpo primario utilizzando un substrato appropriato (ad esempio, una soluzione contenente un cromogeno o una sostanza chimica che emette luce quando viene attivata dall'enzima legato all'anticorpo).
9. Analizzare e documentare il segnale rivelato utilizzando una fotocamera o uno scanner dedicati.
Il Western blotting è un metodo potente per rilevare e quantificare specifiche proteine in campioni complessi, come estratti cellulari o tissutali. Tuttavia, richiede attenzione ai dettagli e controlli appropriati per garantire la specificità e l'affidabilità dei risultati.
Le proteine degli omeodomini sono una famiglia di proteine transcrizionali che svolgono un ruolo cruciale nella regolazione della morfogenesi e dello sviluppo embrionale nei metazoi. Il dominio omeobox, una caratteristica distintiva di queste proteine, codifica per una sequenza di aminoacidi altamente conservata che funge da fattore di trascrizione del DNA.
Le proteine degli omeodomini sono coinvolte nella specificazione della identità cellulare e nell'organizzazione dei tessuti durante lo sviluppo embrionale, attraverso la regolazione dell'espressione genica in risposta a segnali morfogenetici. Si ritiene che siano responsabili della formazione di gradienti di espressione genica che determinano la differenziazione cellulare e l'organizzazione dei tessuti lungo gli assi del corpo.
Mutazioni nei geni che codificano per le proteine degli omeodomini possono portare a una varietà di difetti congeniti e malattie, come la sindrome di Di George, la sindrome di Waardenburg e l'aniridia. Inoltre, le proteine degli omeodomini sono anche implicate nella progressione del cancro, poiché possono influenzare la proliferazione cellulare, l'apoptosi e la differenziazione.
L'mRNA (acido Ribonucleico Messaggero) è il tipo di RNA che porta le informazioni genetiche codificate nel DNA dai nuclei delle cellule alle regioni citoplasmatiche dove vengono sintetizzate proteine. Una volta trascritto dal DNA, l'mRNA lascia il nucleo e si lega a un ribosoma, un organello presente nel citoplasma cellulare dove ha luogo la sintesi proteica. I tripleti di basi dell'mRNA (codoni) vengono letti dal ribosoma e tradotti in amminoacidi specifici, che vengono poi uniti insieme per formare una catena polipeptidica, ossia una proteina. Pertanto, l'mRNA svolge un ruolo fondamentale nella trasmissione dell'informazione genetica e nella sintesi delle proteine nelle cellule.
Le proteine del ciclo cellulare sono un gruppo di proteine che regolano e coordinano i eventi chiave durante il ciclo cellulare, che è la sequenza di eventi che una cellula attraversa dal momento in cui si divide fino alla successiva divisione. Il ciclo cellulare è composto da quattro fasi principali: fase G1, fase S, fase G2 e mitosi (o fase M).
Le proteine del ciclo cellulare possono essere classificate in diversi gruppi, a seconda delle loro funzioni specifiche. Alcuni di questi includono:
1. Ciclina-dipendenti chinasi (CDK): si tratta di enzimi che regolano la transizione tra le fasi del ciclo cellulare. Le CDK sono attivate quando si legano alle loro rispettive proteine chiamate cicline.
2. Inibitori delle chinasi ciclina-dipendenti (CKI): queste proteine inibiscono l'attività delle CDK, contribuendo a mantenere il controllo del ciclo cellulare.
3. Proteine che controllano i punti di controllo: si tratta di proteine che monitorano lo stato della cellula e impediscono la progressione del ciclo cellulare se la cellula non è pronta per dividersi.
4. Proteine che promuovono l'apoptosi: queste proteine inducono la morte programmata delle cellule quando sono danneggiate o malfunzionanti, prevenendo così la replicazione di cellule anormali.
Le proteine del ciclo cellulare svolgono un ruolo cruciale nel garantire che il ciclo cellulare proceda in modo ordinato ed efficiente. Eventuali disfunzioni nelle proteine del ciclo cellulare possono portare a una serie di problemi, tra cui il cancro e altre malattie.
La Cricetinae è una sottofamiglia di roditori appartenente alla famiglia Cricetidae, che include i criceti veri e propri. Questi animali sono noti per le loro guance gonfie quando raccolgono il cibo, un tratto distintivo della sottofamiglia. I criceti sono originari di tutto il mondo, con la maggior parte delle specie che si trovano in Asia centrale e settentrionale. Sono notturni o crepuscolari e hanno una vasta gamma di dimensioni, da meno di 5 cm a oltre 30 cm di lunghezza. I criceti sono popolari animali domestici a causa della loro taglia piccola, del facile mantenimento e del carattere giocoso. In medicina, i criceti vengono spesso utilizzati come animali da laboratorio per la ricerca biomedica a causa delle loro dimensioni gestibili, dei brevi tempi di generazione e della facilità di allevamento in cattività.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
In genetica, i geni reporter sono sequenze di DNA che sono state geneticamente modificate per produrre un prodotto proteico facilmente rilevabile quando il gene viene espresso. Questi geni codificano per enzimi o proteine fluorescenti che possono essere rilevati e misurati quantitativamente utilizzando tecniche di laboratorio standard. I geni reporter vengono spesso utilizzati negli esperimenti di biologia molecolare e di genomica per studiare l'espressione genica, la regolazione trascrizionale e le interazioni proteina-DNA in vivo. Ad esempio, un gene reporter può essere fuso con un gene sospetto di interesse in modo che l'espressione del gene reporter rifletta l'attività del gene sospetto. In questo modo, i ricercatori possono monitorare e valutare l'effetto di vari trattamenti o condizioni sperimentali sull'espressione genica.
I modelli genetici sono l'applicazione dei principi della genetica per descrivere e spiegare i modelli di ereditarietà delle malattie o dei tratti. Essi si basano sulla frequenza e la distribuzione delle malattie all'interno di famiglie e popolazioni, nonché sull'analisi statistica dell'eredità mendeliana di specifici geni associati a tali malattie o tratti. I modelli genetici possono essere utilizzati per comprendere la natura della trasmissione di una malattia e per identificare i fattori di rischio genetici che possono influenzare lo sviluppo della malattia. Questi modelli possono anche essere utilizzati per prevedere il rischio di malattie nelle famiglie e nei membri della popolazione, nonché per lo sviluppo di strategie di diagnosi e trattamento personalizzate. I modelli genetici possono essere classificati in diversi tipi, come i modelli monogenici, che descrivono l'eredità di una singola malattia associata a un gene specifico, e i modelli poligenici, che descrivono l'eredità di malattie complesse influenzate da molteplici geni e fattori ambientali.
La delezione genica è un tipo di mutazione cromosomica in cui una parte di un cromosoma viene eliminata o "cancellata". Questo può verificarsi durante la divisione cellulare e può essere causato da diversi fattori, come errori durante il processo di riparazione del DNA o l'esposizione a sostanze chimiche dannose o radiazioni.
La delezione genica può interessare una piccola regione del cromosoma che contiene uno o pochi geni, oppure può essere più ampia e interessare molti geni. Quando una parte di un gene viene eliminata, la proteina prodotta dal gene potrebbe non funzionare correttamente o non essere prodotta affatto. Ciò può portare a malattie genetiche o altri problemi di salute.
Le delezioni geniche possono essere ereditate da un genitore o possono verificarsi spontaneamente durante lo sviluppo dell'embrione. Alcune persone con delezioni geniche non presentano sintomi, mentre altre possono avere problemi di salute gravi che richiedono cure mediche specialistiche. I sintomi associati alla delezione genica dipendono dal cromosoma e dai geni interessati dalla mutazione.
"Arabidopsis" si riferisce principalmente alla pianta modello "Arabidopsis thaliana", ampiamente utilizzata in ricerca biologica, specialmente nello studio della genetica e della biologia molecolare delle piante. Questa piccola pianta appartiene alla famiglia delle Brassicaceae (cavoli) e ha un ciclo vitale breve, una facile coltivazione in laboratorio e un piccolo genoma ben studiato.
La pianta è originaria dell'Eurasia e cresce come una specie annuale o biennale, dipendente dalle condizioni ambientali. È nota per la sua resistenza alla siccità e alla crescita in terreni poveri di nutrienti, il che la rende un organismo eccellente per lo studio della tolleranza alla siccità e dell'assorbimento dei nutrienti nelle piante.
Il genoma di "Arabidopsis thaliana" è stato completamente sequenziato nel 2000, diventando il primo genoma di una pianta ad essere decifrato. Da allora, questa specie è stata utilizzata in numerosi studi per comprendere i meccanismi molecolari che regolano lo sviluppo delle piante, la risposta agli stress ambientali e l'interazione con altri organismi, come batteri e virus fitopatogeni.
In sintesi, "Arabidopsis" è una pianta modello importante in biologia vegetale che fornisce informazioni cruciali sulla funzione genica e sull'evoluzione delle piante superiori.
La definizione medica di "cellule coltivate" si riferisce a cellule vive che sono state prelevate da un tessuto o organismo e fatte crescere in un ambiente di laboratorio controllato, ad esempio in un piatto di Petri o in un bioreattore. Questo processo è noto come coltura cellulare ed è utilizzato per studiare il comportamento delle cellule, testare l'efficacia e la sicurezza dei farmaci, produrre vaccini e terapie cellulari avanzate, nonché per scopi di ricerca biologica di base.
Le cellule coltivate possono essere prelevate da una varietà di fonti, come linee cellulari immortalizzate, cellule primarie isolate da tessuti umani o animali, o cellule staminali pluripotenti indotte (iPSC). Le condizioni di coltura, come la composizione del mezzo di coltura, il pH, la temperatura e la presenza di fattori di crescita, possono essere regolate per supportare la crescita e la sopravvivenza delle cellule e per indurre differenti fenotipi cellulari.
La coltura cellulare è una tecnologia essenziale nella ricerca biomedica e ha contribuito a numerose scoperte scientifiche e innovazioni mediche. Tuttavia, la coltivazione di cellule in laboratorio presenta anche alcune sfide, come il rischio di contaminazione microbica, la difficoltà nella replicazione delle condizioni fisiologiche complessi dei tessuti e degli organismi viventi, e l'etica associata all'uso di cellule umane e animali in ricerca.
La nucleoside-fosfato chinasi (NPCK o NME, abbreviazione dell'inglese "nucleotide monophosphate kinase") è un enzima appartenente alla classe delle transferasi che catalizza la reazione di trasferimento di un gruppo fosfato da una molecola donatrice di fosfato, come l'ATP, a una molecola accettore di fosfato, come il nucleoside monofosfato (NMP), per produrre un nucleoside difosfato (NDP).
L'equazione chimica generale della reazione catalizzata dalla NPCK è:
NMP + ATP → NDP + ADP
La NPCK svolge un ruolo cruciale nel metabolismo dei nucleotidi e nella biosintesi dei nucleotidi de novo, poiché permette di mantenere l'equilibrio tra le diverse specie di nucleotidi all'interno della cellula. La NPCK è presente in molti organismi viventi, dalle batterie ai mammiferi, e mostra una specificità substrato relativamente ampia, essendo in grado di catalizzare la fosforilazione di una varietà di nucleosidi monofosfati.
La NPCK è stata identificata come un bersaglio terapeutico promettente per il trattamento del cancro, poiché l'inibizione dell'enzima può portare a un arresto della crescita cellulare e alla morte delle cellule tumorali. Inoltre, la NPCK è stata anche associata a diverse malattie genetiche umane, come la sindrome di Aicardi-Goutières, una rara malattia neurodegenerativa causata da mutazioni nel gene della NPCK.
In campo medico, il termine "splicing alternativo" (o "splice variants") si riferisce a un meccanismo di regolazione dell'espressione genica attraverso il quale possono essere generate diverse forme mature di RNA messaggero (mRNA) a partire da uno stesso gene.
Nel processo di splicing, le sequenze non codificanti (introni) vengono eliminate e quelle codificanti (esoni) vengono unite insieme per formare il mRNA maturo, che successivamente verrà tradotto in una proteina funzionale. Il splicing alternativo consiste nell'unione di diversi esoni o nella scelta di diverse porzioni di essi, dando origine a differenti combinazioni e quindi a mRNA con sequenze uniche.
Questo meccanismo permette di aumentare la diversità delle proteine prodotte da un genoma, poiché lo stesso gene può codificare per più di una proteina, ognuna con specifiche funzioni e proprietà. Il splicing alternativo è regolato a livello transcrizionale ed è soggetto a vari fattori che ne influenzano l'esito, come la presenza di sequenze specifiche, la struttura della molecola di RNA e le interazioni con proteine regolatrici.
L'alterazione del splicing alternativo può portare allo sviluppo di diverse patologie, tra cui malattie genetiche, cancro e disturbi neurodegenerativi.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
Le proteine mutanti si riferiscono a proteine che sono il risultato di una mutazione genetica. Una mutazione è una modifica permanente nella sequenza del DNA che può portare alla produzione di una proteina anormalmente strutturata o funzionale. Queste mutazioni possono verificarsi spontaneamente o essere ereditate.
Le mutazioni possono verificarsi in diversi punti della sequenza del DNA, inclusi i geni che codificano per proteine specifiche. Una volta che si verifica una mutazione in un gene, la traduzione di tale gene può portare a una proteina con una sequenza aminoacidica alterata. Questa modifica nella sequenza aminoacidica può influenzare la struttura tridimensionale della proteina e, di conseguenza, la sua funzione.
Le proteine mutanti possono essere classificate come:
1. Proteine loss-of-function: queste proteine hanno una ridotta o assente attività a causa della mutazione. Questo può portare a malattie genetiche, come la fibrosi cistica e l'anemia falciforme.
2. Proteine gain-of-function: queste proteine acquisiscono una nuova funzione o un'aumentata attività a causa della mutazione. Questo può portare a malattie genetiche, come la sindrome di Marfan e l'ipercolesterolemia familiare.
3. Proteine dominanti negative: queste proteine interferiscono con la funzione delle proteine normali, portando a malattie genetiche, come la neurofibromatosi di tipo 1 e il morbo di Huntington.
4. Proteine con attività chimica alterata: queste proteine hanno una modifica nella loro attività enzimatica o nella loro capacità di legare altre molecole a causa della mutazione. Questo può portare a malattie genetiche, come la fenilchetonuria e l'amiloidosi ereditaria.
In sintesi, le mutazioni genetiche possono causare cambiamenti nella struttura e nella funzione delle proteine, che possono portare a malattie genetiche. La comprensione di questi meccanismi è fondamentale per lo sviluppo di terapie efficaci per le malattie genetiche.
La spettrometria di massa (MS) è una tecnica di laboratorio utilizzata per analizzare e identificare molecole basate sulla misura delle masse relative delle loro particelle cariche (ioni). In questo processo, una campione viene vaporizzato in un vuoto parziale o totale e ionizzato, cioè gli atomi o le molecole del campione vengono caricati elettricamente. Quindi, gli ioni vengono accelerati ed esposti a un campo elettromagnetico che li deflette in base alle loro masse relative e cariche. Un rilevatore registra l'arrivo e la quantità degli ioni che raggiungono diversi punti di deflessione, producendo uno spettro di massa, un grafico con intensità (y-asse) contro rapporto massa/carica (x-asse).
Gli spettrometri di massa possono essere utilizzati per determinare la struttura molecolare, identificare e quantificare componenti chimici in un campione complesso, monitorare i processi biochimici e ambientali, ed eseguire ricerche forensi. Le tecniche di ionizzazione comunemente utilizzate includono l'ionizzazione elettronica (EI), l'ionizzazione chimica (CI) e la matrice assistita laser/desorzione-ionizzazione del tempo di volo (MALDI).
La genoteca è un'ampia raccolta o banca di campioni di DNA, che vengono tipicamente prelevati da diversi individui o specie. Viene utilizzata per archiviare e studiare i vari genotipi, cioè l'organizzazione e la sequenza specifica dei geni all'interno del DNA.
Le genoteche sono estremamente utili nella ricerca biomedica e genetica, poiché consentono di conservare e analizzare facilmente una grande varietà di campioni di DNA. Questo può aiutare i ricercatori a comprendere meglio le basi genetiche delle malattie, a sviluppare test diagnostici più precisi e persino a progettare trattamenti terapeutici personalizzati.
Le genoteche possono contenere campioni di DNA da una varietà di fonti, come sangue, tessuti o cellule. Possono anche essere create per studiare specifiche specie o popolazioni, o possono essere più ampie e includere campioni da una gamma più diversificata di individui.
In sintesi, la genoteca è uno strumento importante nella ricerca genetica che consente di archiviare, organizzare e analizzare i vari genotipi all'interno del DNA.
La 'Drosophila' è un genere di piccole mosche comunemente note come moscerini della frutta. Sono ampiamente utilizzate in diversi campi della ricerca scientifica, in particolare nella genetica e nella biologia dello sviluppo, a causa della loro facilità di allevamento, breve ciclo di vita, elevata fecondità e relativamente piccolo numero di cromosomi. Il moscerino della frutta più studiato è la specie Drosophila melanogaster, il cui genoma è stato completamente sequenziato. Gli scienziati utilizzano questi organismi per comprendere i principi fondamentali del funzionamento dei geni e degli esseri viventi in generale. Tuttavia, va notato che la 'Drosophila' è prima di tutto un termine tassonomico che si riferisce a un gruppo specifico di specie di mosche e non è intrinsecamente una definizione medica.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
In medicina e biologia cellulare, i "segnali di localizzazione nucleare" si riferiscono a specifiche sequenze amminoacidiche o motivi strutturali che sono presenti in alcune proteine e che facilitano il loro trasporto e localizzazione all'interno del nucleo cellulare. Il nucleo è la sede del materiale genetico della cellula, ed è circondato da una membrana nucleare che separa il suo contenuto dal citoplasma.
Le proteine del citoscheletro sono una classe speciale di proteine strutturali che giocano un ruolo fondamentale nel mantenere la forma e l'integrità delle cellule. Esse costituiscono il citoscheletro, una rete dinamica e complessa di filamenti all'interno della cellula, che fornisce supporto meccanico, permette il movimento intracellulare e media l'interazione tra la cellula e il suo ambiente esterno.
Il citoscheletro è composto da tre tipi principali di filamenti proteici: microfilamenti, microtubuli e filamenti intermedi. I microfilamenti sono formati principalmente dalla proteina actina e sono responsabili della motilità cellulare, del mantenimento della forma cellulare e del trasporto intracellulare di vescicole e organelli. I microtubuli, costituiti dalla proteina tubulina, svolgono un ruolo cruciale nel mantenimento della forma e della polarità cellulare, nonché nel trasporto intracellulare di molecole e organelli attraverso il citosol. I filamenti intermedi sono formati da diverse classi di proteine fibrose, come la cheratina, la vimentina e la desmina, e forniscono supporto meccanico alla cellula, mantenendo la sua forma e integrità strutturale.
Le proteine del citoscheletro sono anche coinvolte nella divisione cellulare, nell'adesione cellulare, nel movimento cellulare e nella segnalazione cellulare. Esse possono subire modifiche post-traduzionali, come la fosforilazione o la degradazione proteasica, che ne alterano le proprietà strutturali e funzionali, permettendo alla cellula di adattarsi a diversi stimoli ambientali e meccanici.
In sintesi, le proteine del citoscheletro sono un insieme eterogeneo di molecole proteiche che forniscono supporto strutturale e funzionale alla cellula, permettendole di mantenere la sua forma, polarità e integrità, nonché di rispondere a stimoli interni ed esterni.
La *Drosophila melanogaster*, comunemente nota come moscerino della frutta, è un piccolo insetto appartenente all'ordine dei Ditteri e alla famiglia dei Drosophilidi. È ampiamente utilizzato come organismo modello in biologia e genetica a causa del suo ciclo vitale breve, della facilità di allevamento e dell'elevata fecondità. Il suo genoma è stato completamente sequenziato, rendendolo un sistema ancora più prezioso per lo studio dei processi biologici fondamentali e delle basi molecolari delle malattie umane.
La *Drosophila melanogaster* è originaria dell'Africa subsahariana ma ora si trova in tutto il mondo. Predilige ambienti ricchi di sostanze zuccherine in decomposizione, come frutta e verdura marcite, dove le femmine depongono le uova. Il ciclo vitale comprende quattro stadi: uovo, larva, pupa e adulto. Gli adulti raggiungono la maturità sessuale dopo circa due giorni dalla schiusa delle uova e vivono per circa 40-50 giorni in condizioni di laboratorio.
In ambito medico, lo studio della *Drosophila melanogaster* ha contribuito a numerose scoperte scientifiche, tra cui il meccanismo dell'ereditarietà dei caratteri e la comprensione del funzionamento dei geni. Inoltre, è utilizzata per studiare i processi cellulari e molecolari che sono alla base di molte malattie umane, come il cancro, le malattie neurodegenerative e le malattie genetiche rare. Grazie alle sue caratteristiche uniche, la *Drosophila melanogaster* rimane uno degli organismi modello più importanti e utilizzati nella ricerca biomedica.
Le proteine del dominio LIM sono una classe di proteine che contengono almeno un dominio LIM, un motivo proteico composto da due zinchi finger Cys2-His2 e un dominio di legame a zinco HEAT (motivo ripetuto a helice-giro-elica-tomaia). Questi domini funzionano come moduli di interazione proteica e sono in grado di legare una varietà di ligandi, tra cui altre proteine, DNA e fosfolipidi.
Le proteine del dominio LIM sono coinvolte in una vasta gamma di processi cellulari, tra cui la trasduzione del segnale, l'organizzazione della citoarchitettura e la differenziazione cellulare. Alcune proteine del dominio LIM svolgono un ruolo importante nello sviluppo embrionale e nella morfogenesi dei tessuti.
Le proteine del dominio LIM sono state identificate in una varietà di organismi, dalle piante ai mammiferi. Negli esseri umani, ci sono circa 10 diverse proteine del dominio LIM che sono codificate da geni separati. Mutazioni in questi geni possono portare a diversi disturbi, tra cui malattie neurodegenerative e cardiovascolari.
In sintesi, le proteine del dominio LIM sono una classe di proteine che contengono almeno un dominio LIM e sono coinvolte in una varietà di processi cellulari. Sono presenti in una vasta gamma di organismi e mutazioni nei geni che codificano per queste proteine possono portare a diversi disturbi.
Le proteine delle piante, notoriamente conosciute come proteine vegetali, sono le proteine sintetizzate dalle piante. Sono costituite da aminoacidi e svolgono un ruolo cruciale nel sostegno della crescita, della riparazione e del mantenimento delle cellule vegetali. Si trovano in una vasta gamma di alimenti vegetali come cereali, frutta, verdura, legumi e noci.
Le proteine delle piante sono classificate in due tipi principali: proteine fibrose e proteine globulari. Le proteine fibrose, come le proteine strutturali, costituiscono la parete cellulare delle piante e forniscono supporto e resistenza meccanica. Le proteine globulari, d'altra parte, svolgono una varietà di funzioni enzimatiche e regolatorie all'interno della cellula vegetale.
Le proteine delle piante sono spesso considerate una fonte nutrizionale completa di proteine, poiché contengono tutti gli aminoacidi essenziali necessari per il sostegno della crescita e del mantenimento del corpo umano. Tuttavia, le fonti vegetali di proteine spesso mancano di alcuni aminoacidi essenziali in quantità sufficienti, quindi una dieta equilibrata che combini diverse fonti di proteine vegetali è raccomandata per garantire un apporto adeguato di tutti gli aminoacidi essenziali.
"Fret" non è un termine utilizzato nella medicina. Potrebbe essere che tu stia cercando la parola "frostbite", che descrive un danno ai tessuti causato dall'esposizione al freddo estremo. Il congelamento si verifica quando il corpo non può mantenere la temperatura corporea centrale sufficiente, portando a una riduzione del flusso sanguigno alle aree periferiche come le dita delle mani e dei piedi, le orecchie, il naso e il mento. Se non trattata, la congelazione può causare grave danno ai tessuti e persino la perdita di arti. I sintomi del congelamento possono includere intorpidimento, formicolio, pelle gonfia, arrossamento, cambiamenti di colore della pelle, dolore e prurito.
I reagenti reticolanti sono sostanze chimiche utilizzate in diversi processi di laboratorio per legare molecole o particelle insieme. Vengono chiamati "reticolanti" a causa della loro capacità di creare una rete o una struttura tridimensionale che può intrappolare altre sostanze.
Nella medicina diagnostica, i reagenti reticolanti possono essere utilizzati per marcare antigeni o anticorpi in test immunologici come l'immunoistochimica e l'immunofluorescenza. Questi reagenti contengono solitamente una parte che si lega specificamente a un antigene o a un anticorpo target, e una parte reticolante che sigilla la marcatura alla molecola bersaglio.
Inoltre, i reagenti reticolanti possono essere utilizzati nella terapia medica per legare farmaci o nanoparticelle a specifici siti di interesse all'interno del corpo. Questa tecnologia può migliorare l'efficacia dei trattamenti e ridurre al minimo gli effetti collaterali indesiderati.
Tuttavia, è importante notare che l'uso di reagenti reticolanti richiede una conoscenza approfondita della chimica e della biologia delle molecole in questione per garantire la specificità e l'efficacia del legame. Inoltre, l'uso improprio o l'esposizione a questi reagenti può causare effetti avversi sulla salute umana.
L'elettroforesi su gel di poliacrilamide (PAGE, Polyacrylamide Gel Electrophoresis) è una tecnica di laboratorio utilizzata in biologia molecolare e genetica per separare, identificare e analizzare macromolecole, come proteine o acidi nucleici (DNA ed RNA), sulla base delle loro dimensioni e cariche.
Nel caso specifico dell'elettroforesi su gel di poliacrilamide, il gel è costituito da una matrice tridimensionale di polimeri di acrilamide e bis-acrilamide, che formano una rete porosa e stabile. La dimensione dei pori all'interno del gel può essere modulata variando la concentrazione della soluzione di acrilamide, permettendo così di separare molecole con differenti dimensioni e pesi molecolari.
Durante l'esecuzione dell'elettroforesi, le macromolecole da analizzare vengono caricate all'interno di un pozzo scavato nel gel e sottoposte a un campo elettrico costante. Le molecole con carica negativa migreranno verso l'anodo (polo positivo), mentre quelle con carica positiva si sposteranno verso il catodo (polo negativo). A causa dell'interazione tra le macromolecole e la matrice del gel, le molecole più grandi avranno una mobilità ridotta e verranno trattenute all'interno dei pori del gel, mentre quelle più piccole riusciranno a muoversi più velocemente attraverso i pori e si separeranno dalle altre in base alle loro dimensioni.
Una volta terminata l'elettroforesi, il gel può essere sottoposto a diversi metodi di visualizzazione e rivelazione delle bande, come ad esempio la colorazione con coloranti specifici per proteine o acidi nucleici, la fluorescenza o la radioattività. L'analisi delle bande permetterà quindi di ottenere informazioni sulla composizione, le dimensioni e l'identità delle macromolecole presenti all'interno del campione analizzato.
L'elettroforesi su gel è una tecnica fondamentale in molti ambiti della biologia molecolare, come ad esempio la proteomica, la genomica e l'analisi delle interazioni proteina-proteina o proteina-DNA. Grazie alla sua versatilità, precisione e sensibilità, questa tecnica è ampiamente utilizzata per lo studio di una vasta gamma di sistemi biologici e per la caratterizzazione di molecole d'interesse in diversi campi della ricerca scientifica.
La fosfotirosina è un'importante molecola di segnalazione cellulare, prodotta dall'aggiunta di un gruppo fosfato a una tirosina, un aminoacido presente nelle proteine. Questa reazione è catalizzata da enzimi noti come tirosina chinasi.
La fosforilazione della tirosina, e quindi la formazione di fosfotirosina, svolge un ruolo cruciale nella trasduzione del segnale nelle cellule. Quando una proteina con tirosine viene attivata da un recettore o da un altro stimolo esterno, la tirosina chinasi aggiunge un gruppo fosfato alla tirosina. Ciò cambia la forma e la funzione della proteina, permettendole di interagire con altre proteine e di innescare una cascata di eventi che portano alla risposta cellulare appropriata.
La fosfotirosina è stata identificata per la prima volta nel 1980 ed è stata trovata in molte proteine diverse, tra cui recettori tirosin chinasi, adattori di segnalazione e enzimi che partecipano alla trasduzione del segnale. La sua scoperta ha contribuito a far luce sui meccanismi molecolari della segnalazione cellulare e sulla regolazione dei processi cellulari come la crescita, la differenziazione e la morte cellulare.
Tuttavia, è importante notare che questa non è una definizione esaustiva di fosfotirosina in un contesto medico, ma piuttosto una descrizione generale della sua natura e del suo ruolo nella biologia cellulare.
La ligasi ubiquitina-proteina è un enzima che svolge un ruolo cruciale nel processo di degradazione delle proteine attraverso il sistema di ubiquitinazione. Questo enzima catalizza l'unione covalente di ubiquitina, una piccola proteina altamente conservata, a specifiche proteine bersaglio.
L'ubiquitina viene legata alla lisina della proteina bersaglio attraverso un processo multi-step che implica tre diverse classi di enzimi: ubiquitin activating enzyme (E1), ubiquitin conjugating enzyme (E2) e ubiquitin ligase (E3). La ligasi ubiquitina-proteina appartiene alla classe E3 degli enzimi ubiquitina.
La ligasi ubiquitina-proteina riconosce specificamente le proteine bersaglio e catalizza il trasferimento dell'ubiquitina dall'E2 all'aminoacido lisina della proteina bersaglio, formando un legame isopeptidico. Questo processo può essere ripetuto più volte, portando alla formazione di catene poliubiquitiniche collegate a una singola proteina bersaglio.
La presenza di catene poliubiquitiniche sulla proteina bersaglio serve come segnale per il suo riconoscimento e degradazione da parte del proteasoma, un grande complesso enzimatico che svolge un ruolo centrale nella regolazione della proteostasi cellulare.
La ligasi ubiquitina-proteina è quindi essenziale per la regolazione della stabilità e dell'attività delle proteine, nonché per l'eliminazione di proteine danneggiate o difettose all'interno della cellula. Mutazioni o disfunzioni nella ligasi ubiquitina-proteina possono portare a una serie di patologie umane, tra cui malattie neurodegenerative e tumori.
La frase "Cellule Cho" non è una definizione medica standard o un termine comunemente utilizzato nella medicina o nella biologia. Esistono diversi termini che contengono la parola "Cho", come ad esempio "colesterolo" (un lipide importante per la membrana cellulare e il metabolismo ormonale) o "glicolchilina" (una classe di farmaci utilizzati nella chemioterapia). Tuttavia, senza un contesto più ampio o una maggiore chiarezza su ciò che si sta cercando di capire, è difficile fornire una risposta precisa.
Se si fa riferimento a "cellule Cho" come sinonimo di cellule cerebrali (neuroni e glia), allora il termine potrebbe derivare dalla parola "Cholin", un neurotrasmettitore importante per la funzione cerebrale. Tuttavia, questa è solo una possibilità e richiederebbe ulteriori informazioni per confermarlo.
In sintesi, senza un contesto più chiaro o maggiori dettagli, non è possibile fornire una definizione medica precisa delle "Cellule Cho".
La simulazione computerizzata in medicina è l'uso di tecnologie digitali e computazionali per replicare o mimare situazioni cliniche realistiche, processi fisiologici o anatomici, o scenari di apprendimento per scopi educativi, di ricerca, di pianificazione del trattamento o di valutazione. Essa può comprendere la creazione di ambienti virtuali immersivi, modelli 3D interattivi, pacienTIRI virtuali, o simulazioni procedurali che consentono agli utenti di sperimentare e praticare competenze cliniche in un contesto controllato e sicuro. La simulazione computerizzata può essere utilizzata in una varietà di contesti, tra cui l'istruzione medica, la formazione continua, la ricerca biomedica, la progettazione di dispositivi medici, e la pianificazione e valutazione di trattamenti clinici.
In biochimica e genetica, il termine "leucine zipper" (cerniera della leucina) si riferisce a un motivo strutturale comune trovato in alcune proteine che contengono una ripetizione di aminoacidi idrofobici, come la leucina, ogni sette-otto residui. Questa sequenza consente alle proteine di associarsi tra loro e formare complessi proteici stabili.
Le "leucine zipper" sono particolarmente importanti nella regolazione della trascrizione genica, dove le proteine che contengono questo dominio possono legarsi al DNA e influenzarne l'espressione. Il nome "leucine zipper" deriva dalla rappresentazione grafica di questa struttura, in cui due filamenti di eliche alpha si avvolgono insieme come una cerniera lampo, con i residui di leucina che si alternano su ogni filamento e si intercalano perfettamente quando le proteine si uniscono.
E' importante sottolineare che questa non è una definizione medica in senso stretto, ma piuttosto una nozione biochimica e genetica che può avere implicazioni mediche in alcune condizioni patologiche.
La cisteina è un aminoacido semi-essenziale, il che significa che sotto circostanze normali può essere sintetizzato dal corpo umano, ma in situazioni particolari come durante la crescita rapida, la gravidanza o in presenza di determinate condizioni mediche, può essere necessario assumerla con la dieta.
La cisteina contiene un gruppo funzionale sulfidrile (-SH), noto come gruppo tiolico, che conferisce alla molecola proprietà particolari, come la capacità di formare ponti disolfuro (-S-S-) con altre molecole di cisteina. Questa caratteristica è importante per la struttura e la funzione di molte proteine.
La cisteina svolge un ruolo cruciale nella produzione del tripeptide glutatione, uno degli antiossidanti più importanti nel corpo umano. Il glutatione aiuta a proteggere le cellule dai danni dei radicali liberi e supporta il sistema immunitario.
Inoltre, la cisteina è un componente della cheratina, una proteina fibrosa che costituisce i capelli, le unghie e la pelle. La sua presenza conferisce resistenza e flessibilità a questi tessuti.
È importante notare che la cisteina non deve essere confusa con la N-acetilcisteina (NAC), un derivato della cisteina comunemente usato come farmaco per scopi terapeutici, come il trattamento del sovradosaggio da paracetamolo e delle malattie polmonari ostruttive croniche.
L'immunoblotting, noto anche come Western blotting, è una tecnica di laboratorio utilizzata per rilevare e quantificare specifiche proteine in un campione biologico. Questa tecnica combina l'elettroforesi delle proteine su gel (SDS-PAGE) con la rilevazione immunochimica.
Il processo include:
1. Estrarre le proteine dal campione e separarle in base al loro peso molecolare utilizzando l'elettroforesi su gel di poliacrilammide sodio dodecil solfato (SDS-PAGE).
2. Il gel viene quindi trasferito a una membrana di nitrocellulosa o di policarbonato di piccole dimensioni, dove le proteine si legano covalentemente alla membrana.
3. La membrana viene poi incubata con anticorpi primari specifici per la proteina target, che si legheranno a epitopi (siti di legame) unici sulla proteina.
4. Dopo il lavaggio per rimuovere gli anticorpi non legati, vengono aggiunti anticorpi secondari marcati con enzimi o fluorescenza che si legano agli anticorpi primari.
5. Infine, dopo ulteriori lavaggi, viene rilevata la presenza della proteina target mediante l'uso di substrati cromogenici o fluorescenti.
L'immunoblotting è una tecnica sensibile e specifica che può rilevare quantità molto piccole di proteine e distinguere tra proteine di peso molecolare simile ma con differenze nella sequenza aminoacidica. Viene utilizzato in ricerca e diagnosi per identificare proteine patologiche, come le proteine virali o tumorali, e monitorare l'espressione delle proteine in vari processi biologici.
L'espressione genica è un processo biologico che comporta la trascrizione del DNA in RNA e la successiva traduzione dell'RNA in proteine. Questo processo consente alle cellule di leggere le informazioni contenute nel DNA e utilizzarle per sintetizzare specifiche proteine necessarie per svolgere varie funzioni cellulari.
Il primo passo dell'espressione genica è la trascrizione, durante la quale l'enzima RNA polimerasi legge il DNA e produce una copia di RNA complementare chiamata RNA messaggero (mRNA). Il mRNA poi lascia il nucleo e si sposta nel citoplasma dove subisce il processamento post-trascrizionale, che include la rimozione di introni e l'aggiunta di cappucci e code poli-A.
Il secondo passo dell'espressione genica è la traduzione, durante la quale il mRNA viene letto da un ribosoma e utilizzato come modello per sintetizzare una specifica proteina. Durante questo processo, gli amminoacidi vengono legati insieme in una sequenza specifica codificata dal mRNA per formare una catena polipeptidica che poi piega per formare una proteina funzionale.
L'espressione genica può essere regolata a livello di trascrizione o traduzione, e la sua regolazione è essenziale per il corretto sviluppo e la homeostasi dell'organismo. La disregolazione dell'espressione genica può portare a varie malattie, tra cui il cancro e le malattie genetiche.
I motivi Helix-Loop-Helix (HLH) sono dominii proteici strutturali composti da due alfa eliche amino-terminali e carboxi-terminali separate da una breve loop. Queste proteine giocano un ruolo cruciale nella regolazione della trascrizione genica, in particolare durante lo sviluppo embrionale e differenziamento cellulare.
Le proteine HLH si legano all'DNA attraverso il dominio HLH, che contiene una sequenza conservata di aminoacidi idrofobici che formano un'interfaccia di legame con l'DNA. Quando due proteine HLH si dimerizzano, le loro eliche alfa si avvolgono insieme per creare un dimero stabile che può legarsi all'DNA.
Le proteine HLH sono classificate in base alla presenza di altri domini proteici che influenzano la specificità del legame con l'DNA e le interazioni con altre proteine. Alcune proteine HLH, come MyoD e Myogenina, sono importanti per la differenziazione muscolare scheletrica, mentre altre, come Max e Mad, regolano la proliferazione cellulare e l'apoptosi.
Le mutazioni nei geni che codificano per le proteine HLH possono causare diverse malattie genetiche, tra cui alcune forme di cancro e disturbi neuromuscolari. Ad esempio, la mutazione del gene MYOD può portare all'distrofia muscolare dei cinghiali armati, una malattia caratterizzata da debolezza muscolare progressiva e atrofia.
La conformazione dell'acido nucleico si riferisce alla struttura tridimensionale che assume l'acido nucleico, sia DNA che RNA, quando interagisce con se stesso o con altre molecole. La conformazione più comune del DNA è la doppia elica, mentre il RNA può avere diverse conformazioni, come la singola elica o le strutture a forma di stella o a branchie, a seconda della sequenza delle basi e delle interazioni idrogeno.
La conformazione dell'acido nucleico può influenzare la sua funzione, ad esempio nella regolazione della trascrizione genica o nel ripiegamento delle proteine. La comprensione della conformazione dell'acido nucleico è quindi importante per comprendere il ruolo che svolge nell'espressione genica e nelle altre funzioni cellulari.
La determinazione della conformazione dell'acido nucleico può essere effettuata utilizzando diverse tecniche sperimentali, come la cristallografia a raggi X, la spettrometria di assorbimento UV-Visibile e la risonanza magnetica nucleare (NMR). Questi metodi forniscono informazioni sulla struttura atomica e sulle interazioni idrogeno che determinano la conformazione dell'acido nucleico.
In medicina e biologia, il termine "fenotipo" si riferisce alle caratteristiche fisiche, fisiologiche e comportamentali di un individuo che risultano dall'espressione dei geni in interazione con l'ambiente. Più precisamente, il fenotipo è il prodotto finale dell'interazione tra il genotipo (la costituzione genetica di un organismo) e l'ambiente in cui vive.
Il fenotipo può essere visibile o misurabile, come ad esempio il colore degli occhi, la statura, il peso corporeo, la pressione sanguigna, il livello di colesterolo nel sangue, la presenza o assenza di una malattia genetica. Alcuni fenotipi possono essere influenzati da più di un gene (fenotipi poligenici) o da interazioni complesse tra geni e ambiente.
In sintesi, il fenotipo è l'espressione visibile o misurabile dei tratti ereditari e acquisiti di un individuo, che risultano dall'interazione tra la sua costituzione genetica e l'ambiente in cui vive.
Una mutazione erronea, nota anche come "mutazione spontanea" o "mutazione somatica", si riferisce a un cambiamento nel DNA che si verifica durante la vita di un individuo e non è presente nei geni ereditati dai genitori. Queste mutazioni possono verificarsi in qualsiasi cellula del corpo, compresi i gameti (spermatozoi o ovuli), e possono essere il risultato di errori durante la replicazione del DNA, l'esposizione a sostanze chimiche o radiazioni dannose, o altri fattori ambientali.
Le mutazioni erronee possono avere diversi effetti sulla funzione delle cellule e dei tessuti in cui si verificano. Alcune mutazioni non hanno alcun effetto sulla salute dell'individuo, mentre altre possono aumentare il rischio di sviluppare determinate malattie o condizioni mediche. Ad esempio, le mutazioni erronee che si verificano nei geni oncosoppressori o nelle vie di segnalazione cellulare possono portare allo sviluppo del cancro.
È importante notare che la maggior parte delle mutazioni erronee sono rare e non sono ereditate dai figli dell'individuo interessato. Tuttavia, in alcuni casi, le mutazioni erronee possono verificarsi nei gameti e possono essere trasmesse alla prole. Queste mutazioni sono note come "mutazioni germinali" o "mutazioni ereditarie".
Il "Trasporto attivo nel nucleo cellulare" è un processo biologico altamente regolato che coinvolge il movimento di molecole, come proteine e acidi nucleici (DNA e RNA), all'interno del nucleo cellulare. Questo meccanismo è powered by energy-consuming molecular motors, such as karyopherins and importins, which recognize specific nuclear localization signals (NLS) or nuclear export signals (NES) on the cargo molecules. This active transport process allows for the precise regulation of nuclear contents, including gene expression, DNA replication, and repair.
Le cellule 3T3 sono una linea cellulare fibroblastica sviluppata per la prima volta nel 1962 da George Todaro e Howard Green. Il nome "3T3" deriva dalle iniziali del laboratorio di Todaro (Tissue Culture Team) e dal fatto che le cellule sono state ottenute dalla trecentotreesima piastrella (clone) durante il processo di clonazione.
In termini medici, i protooncogeni sono geni normalmente presenti nelle cellule che codificano per proteine che regolano la crescita, la divisione e la differenziazione cellulare. Questi geni svolgono un ruolo cruciale nel mantenere l'equilibrio tra la crescita e la morte cellulare (apoptosi). Tuttavia, quando subiscono mutazioni o vengono overexpressi, possono trasformarsi in oncogeni, che sono geni associati al cancro. Gli oncogeni possono contribuire allo sviluppo di tumori promuovendo la crescita cellulare incontrollata, l'inibizione dell'apoptosi e la promozione dell'angiogenesi (formazione di nuovi vasi sanguigni che sostengono la crescita del tumore).
Le proteine protooncogene possono essere tyrosine chinasi, serina/treonina chinasi o fattori di trascrizione, tra gli altri. Alcuni esempi di protooncogeni includono HER2/neu (erbB-2), c-MYC, RAS e BCR-ABL. Le mutazioni in questi geni possono portare a varie forme di cancro, come il cancro al seno, alla prostata, al colon e alle leucemie.
La comprensione dei protooncogeni e del loro ruolo nel cancro è fondamentale per lo sviluppo di terapie mirate contro i tumori, come gli inibitori delle tirosine chinasi e altri farmaci che mirano specificamente a queste proteine anomale.
Nuclear Receptor Co-Repressor 1 (NCOR1) è una proteina che interagisce con i recettori nucleari e funge da co-repressore, il quale reprime l'espressione genica. NCOR1 è noto per la sua capacità di legarsi a diversi recettori nucleari, inclusi recettori ormonali come quelli per gli steroidi, tiroidi e vitamina D, oltre che ad altri fattori di trascrizione. Quando un ligando (una molecola che si lega a un recettore) non è presente, NCOR1 reprime l'espressione genica attraverso la ricrutamento di enzimi che modificano la cromatina e alterano la struttura della cromatina attorno al sito del gene target. Ciò rende difficile il legame dei fattori di trascrizione con il DNA, impedendo l'espressione genica. Quando un ligando si lega al recettore nucleare corrispondente, NCOR1 viene dissociato dal complesso e l'espressione genica può verificarsi. Mutazioni in NCOR1 possono essere associate a diverse condizioni mediche, come la sindrome di Kleefstra, un disturbo genetico che colpisce lo sviluppo del cervello e causa ritardo mentale.
L'analisi delle mutazioni del DNA è un processo di laboratorio che si utilizza per identificare e caratterizzare qualsiasi cambiamento (mutazione) nel materiale genetico di una persona. Questa analisi può essere utilizzata per diversi scopi, come la diagnosi di malattie genetiche ereditarie o acquisite, la predisposizione a sviluppare determinate condizioni mediche, la determinazione della paternità o l'identificazione forense.
L'analisi delle mutazioni del DNA può essere eseguita su diversi tipi di campioni biologici, come il sangue, la saliva, i tessuti o le cellule tumorali. Il processo inizia con l'estrazione del DNA dal campione, seguita dalla sua amplificazione e sequenziazione. La sequenza del DNA viene quindi confrontata con una sequenza di riferimento per identificare eventuali differenze o mutazioni.
Le mutazioni possono essere puntiformi, ovvero coinvolgere un singolo nucleotide, oppure strutturali, come inversioni, delezioni o duplicazioni di grandi porzioni di DNA. L'analisi delle mutazioni del DNA può anche essere utilizzata per rilevare la presenza di varianti genetiche che possono influenzare il rischio di sviluppare una malattia o la risposta a un trattamento medico.
L'interpretazione dei risultati dell'analisi delle mutazioni del DNA richiede competenze specialistiche e deve essere eseguita da personale qualificato, come genetisti clinici o specialisti di laboratorio molecolare. I risultati devono essere considerati in combinazione con la storia medica e familiare del paziente per fornire una diagnosi accurata e un piano di trattamento appropriato.
L'RNA, o acido ribonucleico, è un tipo di nucleic acid presente nelle cellule di tutti gli organismi viventi e alcuni virus. Si tratta di una catena lunga di molecole chiamate nucleotidi, che sono a loro volta composte da zuccheri, fosfati e basi azotate.
L'RNA svolge un ruolo fondamentale nella sintesi delle proteine, trasportando l'informazione genetica codificata negli acidi nucleici (DNA) al ribosoma, dove viene utilizzata per la sintesi delle proteine. Esistono diversi tipi di RNA, tra cui RNA messaggero (mRNA), RNA di trasferimento (tRNA) e RNA ribosomiale (rRNA).
Il mRNA è l'intermediario che porta l'informazione genetica dal DNA al ribosoma, dove viene letto e tradotto in una sequenza di amminoacidi per formare una proteina. Il tRNA è responsabile del trasporto degli amminoacidi al sito di sintesi delle proteine sul ribosoma, mentre l'rRNA fa parte del ribosoma stesso e svolge un ruolo importante nella sintesi delle proteine.
L'RNA può anche avere funzioni regolatorie, come il miRNA (microRNA) che regola l'espressione genica a livello post-trascrizionale, e il siRNA (small interfering RNA) che svolge un ruolo nella difesa dell'organismo contro i virus e altri elementi genetici estranei.
L'RNA splicing è un processo post-trascrizionale che si verifica nelle cellule eucariotiche, durante il quale vengono rimossi gli introni (sequenze non codificanti) dall'mRNA (RNA messaggero) appena trascritto. Contemporaneamente, gli esoni (sequenze codificanti) vengono accoppiati insieme per formare una sequenza continua e matura dell'mRNA.
Questo processo è essenziale per la produzione di proteine funzionali, poiché l'ordine e la sequenza degli esoni determinano la struttura e la funzione della proteina finale. L'RNA splicing può anche generare diverse isoforme di mRNA a partire da un singolo gene, aumentando notevolmente la diversità del trascrittoma e della proteoma cellulari.
L'RNA splicing è catalizzato da una complessa macchina molecolare chiamata spliceosoma, che riconosce specifiche sequenze nucleotidiche negli introni e negli esoni per guidare il processo di taglio e giunzione. Il meccanismo di RNA splicing è altamente regolato e può essere influenzato da vari fattori, come la modificazione chimica dell'RNA e l'interazione con proteine regolatorie.
In sintesi, l'RNA splicing è un processo fondamentale per la maturazione degli mRNA eucariotici, che consente di generare una diversità di proteine a partire da un numero relativamente limitato di geni.
I recettori citoplasmatici e nucleari sono proteine transmembrana o intracellulari che svolgono un ruolo cruciale nella trasduzione del segnale all'interno della cellula. A differenza dei recettori accoppiati a proteine G o ai canali ionici, che trasducono il segnale attraverso modifiche immediate del potenziale di membrana o del flusso ionico, i recettori citoplasmatici e nucleari influenzano la trascrizione genica e il metabolismo cellulare.
I recettori citoplasmatici sono proteine che si trovano nel citoplasma e non attraversano la membrana plasmatica. Di solito, essi legano i loro ligandi all'interno della cellula e vengono attivati da molecole endogene o esogene come ormoni steroidei, tiroidi, vitamina D e prostaglandine. Una volta che il ligando si lega al recettore citoplasmatico, forma un complesso recettore-ligando che successivamente migra nel nucleo cellulare. Questo complesso si lega a specifiche sequenze di DNA note come elementi di risposta, che regolano l'espressione genica attraverso la modulazione dell'attività dei fattori di trascrizione.
I recettori nucleari sono proteine transcriptionally active che risiedono nel nucleo cellulare e legano i loro ligandi direttamente all'interno del nucleo. Questi recettori possiedono un dominio di legame al DNA (DBD) e un dominio di legame al ligando (LBD). Il LBD è responsabile del riconoscimento e della specificità del ligando, mentre il DBD media l'interazione con le sequenze di risposta del DNA. Quando il ligando si lega al recettore nucleare, questo subisce una modificazione conformazionale che ne favorisce l'associazione con i cofattori trascrizionali e l'attivazione o la repressione dell'espressione genica.
In sintesi, i recettori citoplasmatici e nucleari sono due classi di proteine che regolano l'espressione genica in risposta a specifici stimoli cellulari. I recettori citoplasmatici legano il ligando nel citoplasma e successivamente migrano nel nucleo, mentre i recettori nucleari legano direttamente il ligando all'interno del nucleo. Entrambi questi meccanismi permettono alla cellula di rispondere in modo specifico ed efficiente a una varietà di segnali extracellulari, garantendo l'equilibrio e la corretta funzione delle vie metaboliche e della fisiologia cellulare.
In medicina, il termine "Interfaccia Utente-Computer" (in inglese Computer-User Interface, CUI) non ha una definizione specifica. Tuttavia, in un contesto più ampio di tecnologia sanitaria e assistenza sanitaria digitale, l'interfaccia utente-computer si riferisce al mezzo di interazione tra un essere umano e un computer o sistema informatico. Ciò include tutte le componenti visive e funzionali che consentono all'utente di accedere, utilizzare ed eseguire attività su un dispositivo digitale, come ad esempio l'input tramite tastiera, mouse o touchscreen, e il feedback visivo sullo schermo.
In particolare, in ambito medico, le interfacce utente-computer sono fondamentali per la gestione dei dati sanitari, la comunicazione tra professionisti sanitari, l'interazione con i pazienti e il supporto alle decisioni cliniche. Un esempio comune di interfaccia utente-computer in ambito medico è un software di cartella clinica elettronica o un sistema di imaging medico che consente agli operatori sanitari di visualizzare, analizzare e gestire i dati dei pazienti.
La tirosina è un aminoacido essenziale, il quale significa che deve essere incluso nella dieta perché l'organismo non può sintetizzarlo autonomamente. È codificato nel DNA dal codone UAC. La tirosina viene sintetizzata nel corpo a partire dall'aminoacido essenziale fenilalanina e funge da precursore per la produzione di importanti ormoni e neurotrasmettitori, come adrenalina, noradrenalina e dopamina. Inoltre, è coinvolta nella sintesi dei pigmenti cutanei melanina e della tireoglobulina nella tiroide.
Una carenza di tirosina è rara, ma può causare una serie di problemi di salute, tra cui ritardo dello sviluppo, letargia, difficoltà di apprendimento e ipopigmentazione della pelle. Al contrario, un eccesso di tirosina può verificarsi in individui con fenilchetonuria (PKU), una malattia genetica che impedisce al corpo di metabolizzare la fenilalanina, portando ad un accumulo dannoso di questo aminoacido e della tirosina. Un'eccessiva assunzione di tirosina attraverso la dieta può anche avere effetti negativi sulla salute mentale, come l'aumento dell'ansia e della depressione in alcune persone.
In biochimica, il dominio catalitico si riferisce alla regione di una proteina o enzima responsabile della sua attività catalitica, che è la capacità di accelerare una reazione chimica. Questa regione contiene tipicamente residui amminoacidici chiave che interagiscono con il substrato della reazione e facilitano la formazione di un complesso enzima-substrato, abbassando l'energia di attivazione richiesta per avviare la reazione. Il dominio catalitico è spesso associato a specifiche strutture tridimensionali che permettono all'enzima di svolgere la sua funzione in modo efficiente ed efficace. La comprensione del dominio catalitico e dei meccanismi enzimatici ad esso associati è fondamentale per comprendere il funzionamento delle reazioni biochimiche all'interno degli organismi viventi.
La frase "Proteine del Caenorhabditis elegans" si riferisce specificamente alle proteine presenti e studiate nel organismo modello Caenorhabditis elegans, un nematode microscopico di circa 1 mm di lunghezza. Questo piccolo verme trasparente è ampiamente utilizzato in diversi campi della ricerca biologica, tra cui la genetica, la biologia cellulare e lo studio del sviluppo, poiché ha un corpo semplice con esattamente 959 cellule negli adulti, di cui 302 sono neuroni.
Poiché il suo genoma è completamente sequenziato e ben annotato, gli scienziati possono facilmente identificare e studiare i geni e le proteine specifiche del C. elegans. Il database dei prodotti genici di C. elegans (WormBase) fornisce informazioni dettagliate sulle funzioni, sulla struttura e sull'espressione di queste proteine.
Gli scienziati studiano le proteine del C. elegans per diversi motivi:
1. Modello di malattia: Le proteine del C. elegans possono essere utilizzate come modelli per studiare i meccanismi molecolari alla base di varie malattie umane, come il cancro, le malattie neurodegenerative e le infezioni microbiche.
2. Studio della funzione delle proteine: Gli scienziati possono manipolare geneticamente il C. elegans per studiare la funzione di una particolare proteina in vivo. Ad esempio, possono disattivare o sovraesprimere un gene che codifica una proteina specifica e quindi osservare gli effetti sull'organismo.
3. Studio dello sviluppo: Il C. elegans è un organismo ideale per lo studio dello sviluppo embrionale, poiché il suo sviluppo è ben caratterizzato e altamente sincronizzato. Gli scienziati possono utilizzare le proteine del C. elegans per comprendere meglio i processi di crescita e differenziazione cellulare.
4. Studio della tossicità dei farmaci: Il C. elegans può essere utilizzato come organismo modello per testare la tossicità dei farmaci e valutarne l'efficacia. Le proteine del C. elegans possono essere utilizzate per comprendere meglio i meccanismi d'azione dei farmaci e identificare nuovi bersagli terapeutici.
In sintesi, le proteine del C. elegans sono uno strumento prezioso nello studio della biologia molecolare e cellulare. Sono ampiamente utilizzate per comprendere meglio i processi fisiologici e patologici e identificare nuovi bersagli terapeutici per il trattamento di varie malattie umane.
La regolazione dell'espressione genica nello sviluppo si riferisce al processo di attivazione e disattivazione dei geni in diversi momenti e luoghi all'interno di un organismo durante lo sviluppo. Questo processo è fondamentale per la differenziazione cellulare, crescita e morfogenesi dell'organismo.
L'espressione genica è il processo attraverso cui l'informazione contenuta nel DNA viene trascritta in RNA e successivamente tradotta in proteine. Tuttavia, non tutti i geni sono attivi o espressi allo stesso modo in tutte le cellule del corpo in ogni momento. Al contrario, l'espressione genica è strettamente regolata a seconda del tipo di cellula e dello stadio di sviluppo.
La regolazione dell'espressione genica nello sviluppo può avvenire a diversi livelli, tra cui:
1. Regolazione della trascrizione: questo include meccanismi che influenzano l'accessibilità del DNA alla macchina transcrizionale o modifiche chimiche al DNA che ne promuovono o inibiscono la trascrizione.
2. Regolazione dell'RNA: dopo la trascrizione, l'RNA può essere sottoposto a processi di maturazione come il taglio e il giunzionamento, che possono influenzare la stabilità o la traduzione dell'mRNA.
3. Regolazione della traduzione: i fattori di traduzione possono influenzare la velocità e l'efficienza con cui i mRNA vengono tradotti in proteine.
4. Regolazione post-traduzionale: le proteine possono essere modificate dopo la loro sintesi attraverso processi come la fosforilazione, glicosilazione o ubiquitinazione, che possono influenzarne l'attività o la stabilità.
I meccanismi di regolazione dello sviluppo sono spesso complessi e coinvolgono una rete di interazioni tra geni, prodotti genici ed elementi del loro ambiente cellulare. La disregolazione di questi meccanismi può portare a malattie congenite o alla comparsa di tumori.
La Grafica Computerizzata (CG, Computer Graphics) in ambito medico si riferisce all'utilizzo di tecnologie informatiche per creare immagini e sequenze visive utili a scopi di diagnosi, pianificazione terapeutica o ricerca scientifica. Queste immagini possono rappresentare strutture anatomiche interne, funzioni fisiologiche o processi patologici.
Nella medicina, la grafica computerizzata è spesso utilizzata in combinazione con tecniche di imaging biomedico come radiografie, risonanze magnetiche (MRI), tomografie computerizzate (CT) e ultrasuoni. I dati grezzi ottenuti da queste indagini vengono processati ed analizzati attraverso algoritmi complessi che generano rappresentazioni grafiche dettagliate e realistiche del corpo umano o di specifiche aree interne.
La grafica computerizzata ha numerose applicazioni nella pratica clinica, tra cui:
1. Visualizzazione 3D delle strutture anatomiche: Aiuta i medici a comprendere meglio la posizione e l'estensione di lesioni o anomalie presenti nel corpo del paziente.
2. Pianificazione chirurgica: Consente ai chirurghi di visualizzare in anticipo il campo operatorio, identificare strutture critiche ed elaborare strategie per eseguire interventi complessi con maggiore precisione e sicurezza.
3. Simulazione medica: Fornisce agli studenti e ai professionisti sanitari un ambiente virtuale in cui praticare procedure e tecniche senza rischi per i pazienti reali.
4. Progettazione di protesi e dispositivi medici: Aiuta ingegneri biomedici a creare dispositivi su misura per ogni paziente, adattandoli perfettamente alle loro esigenze individuali.
5. Ricerca scientifica: Supporta la comprensione di processi fisiologici complessi e l'identificazione di nuovi bersagli terapeutici per lo sviluppo di farmaci innovativi.
In sintesi, la grafica computerizzata è una tecnologia essenziale nella medicina moderna che offre vantaggi significativi in termini di accuratezza diagnostica, pianificazione chirurgica, formazione medica e ricerca scientifica. Continuerà ad evolversi ed espandersi, aprendo nuove opportunità per il progresso della salute umana.
Le proteine dell'Escherichia coli (E. coli) si riferiscono a una vasta gamma di proteine espressione da ceppi specifici di batteri E. coli, che sono comunemente presenti nel tratto intestinale degli esseri umani e degli animali a sangue caldo. Alcune di queste proteine svolgono funzioni cruciali nella fisiologia dell'E. coli, come la replicazione del DNA, la trascrizione genica, il metabolismo, la sopravvivenza cellulare e la virulenza.
Le proteine E. coli sono ampiamente studiate in biologia molecolare e microbiologia a causa della facilità di coltivazione dei batteri e dell'abbondanza di strumenti genetici disponibili per manipolarli. Inoltre, poiché l'E. coli è un organismo modello, le sue proteine sono ben caratterizzate in termini di struttura, funzione e interazioni con altre molecole.
Alcune proteine E. coli sono note per essere tossine virulente che causano malattie infettive nell'uomo e negli animali. Ad esempio, le proteine Shiga tossina prodotte da alcuni ceppi di E. coli possono provocare gravi complicazioni renali e neurologiche, come l'insufficienza renale emolitica e la sindrome uremica hemolytic-uremic (HUS).
In sintesi, le proteine dell'Escherichia coli sono un vasto gruppo di molecole che svolgono funzioni vitali nei batteri E. coli e sono ampiamente studiate in biologia molecolare e microbiologia. Alcune di queste proteine possono essere tossine virulente che causano malattie infettive nell'uomo e negli animali.
Le sequenze ripetute di aminoacidi (RRAs) sono porzioni di una proteina in cui si ripete la stessa sequenza di uno o più aminoacidi, di solito per un numero insolitamente elevato di volte. Queste sequenze possono variare considerevolmente nella lunghezza e nel grado di complessità. Alcune RRAs possono contenere solo due-sei residui di aminoacidi ripetuti, mentre altre possono contenere decine o persino centinaia di residui ripetuti.
Le RRAs sono considerate un importante fattore che contribuisce alla struttura e alla funzione delle proteine. Possono influenzare la forma e le proprietà fisiche di una proteina, nonché la sua interazione con altre molecole. Tuttavia, le mutazioni nelle sequenze ripetute possono anche portare a disfunzioni proteiche e malattie genetiche.
Le RRAs sono state identificate in molte proteine diverse e sono particolarmente comuni nei tessuti del sistema nervoso centrale. Alcune condizioni neurologiche ereditarie, come l'atrofia muscolare spinale (SMA) e la malattia di Huntington, sono causate da espansioni patologiche delle RRAs in specifici geni. In queste malattie, il numero di ripetizioni della sequenza aumenta progressivamente con le generazioni successive, portando a un'insorgenza precoce e una maggiore gravità dei sintomi.
In termini medici, la termodinamica non è comunemente utilizzata come una disciplina autonoma, poiché si tratta principalmente di una branca della fisica che studia le relazioni tra il calore e altre forme di energia. Tuttavia, i concetti di termodinamica sono fondamentali in alcune aree della fisiologia e della medicina, come la biochimica e la neurobiologia.
La termodinamica si basa su quattro leggi fondamentali che descrivono il trasferimento del calore e l'efficienza dei dispositivi che sfruttano questo trasferimento per eseguire lavoro. Le due leggi di particolare importanza in contesti biologici sono:
1) Prima legge della termodinamica, o legge di conservazione dell'energia, afferma che l'energia non può essere creata né distrutta, ma solo convertita da una forma all'altra. Ciò significa che il totale dell'energia in un sistema isolato rimane costante, sebbene possa cambiare la sua forma o essere distribuita in modo diverso.
2) Seconda legge della termodinamica afferma che l'entropia (disordine) di un sistema isolato tende ad aumentare nel tempo. L'entropia misura la dispersione dell'energia in un sistema: quanto più è dispersa, tanto maggiore è l'entropia. Questa legge ha implicazioni importanti per i processi biologici, come il metabolismo e la crescita delle cellule, poiché richiedono input di energia per mantenere l'ordine e combattere l'aumento naturale dell'entropia.
In sintesi, mentre la termodinamica non è una definizione medica in sé, i suoi principi sono cruciali per comprendere alcuni aspetti della fisiologia e della biochimica.
"Caenorhabditis elegans" è una specie di nematode (verme rotondo) comunemente utilizzata come organismo modello in biologia e ricerca medica. È stato ampiamente studiato a causa della sua struttura corporea semplice, breve ciclo vitale, facilità di coltivazione e relativamente piccolo genoma contenente circa 20.000 geni, che è simile in complessità al genoma umano.
"C. elegans" misura meno di un millimetro di lunghezza e vive nel suolo. Il suo corpo trasparente facilita l'osservazione diretta dei suoi organi interni e del sistema nervoso, che è ben mappato e contiene esattamente 302 neuroni negli individui adulti hermaphrodites.
Gli scienziati utilizzano "C. elegans" per studiare una varietà di processi biologici, tra cui l'invecchiamento, lo sviluppo, il comportamento, la neurobiologia e le malattie umane come il cancro e le malattie neurodegenerative. Poiché circa l'83% dei geni di "C. elegans" ha equivalenti funzionali nei mammiferi, i risultati degli esperimenti su questo organismo possono spesso essere applicabili ad altri esseri viventi, compresi gli esseri umani.
I modelli chimici sono rappresentazioni grafiche o spaziali utilizzate per visualizzare e comprendere la struttura, le proprietà e il comportamento delle molecole e degli atomi. Essi forniscono una rappresentazione tridimensionale dei legami chimici e della disposizione spaziale degli elettroni e degli atomi all'interno di una molecola. I modelli chimici possono essere utilizzati per prevedere le reazioni chimiche, progettare nuovi composti e comprendere i meccanismi delle reazioni chimiche.
Esistono diversi tipi di modelli chimici, come:
1. Modelli a palle e bastoncini: utilizzano sfere di diverse dimensioni per rappresentare gli atomi e bastoncini per mostrare i legami chimici tra di essi. Questo tipo di modello è utile per illustrare la forma e la struttura delle molecole.
2. Modelli spaziali: forniscono una rappresentazione tridimensionale dettagliata della disposizione degli atomi e dei legami chimici all'interno di una molecola. Questi modelli possono essere creati utilizzando materiali fisici o software di modellazione chimica.
3. Modelli quantomeccanici: utilizzano calcoli matematici complessi per descrivere la distribuzione degli elettroni all'interno di una molecola. Questi modelli possono essere utilizzati per prevedere le proprietà chimiche e fisiche delle molecole, come la reattività, la stabilità e la conducibilità elettrica.
I modelli chimici sono uno strumento importante nella comprensione e nello studio della chimica, poiché forniscono una rappresentazione visiva e tangibile delle interazioni tra atomi e molecole.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
La cromatina è una struttura presente nel nucleo delle cellule eucariotiche, costituita da DNA ed estremamente importanti proteine chiamate istoni. La cromatina si organizza in unità ripetitive chiamate nucleosomi, che sono formati dal DNA avvolto intorno a un ottamero di istoni. L'organizzazione della cromatina è strettamente correlata ai processi di condensazione e decondensazione del DNA, che regolano l'accessibilità dei fattori di trascrizione e delle altre proteine alle sequenze geniche, influenzando così la loro espressione.
La cromatina può presentarsi in due stati principali: euchromatina ed eterocromatina. L'euchromatina è uno stato di condensazione relativamente basso del DNA, che lo rende accessibile alla trascrizione genica, mentre l'eterocromatina è altamente condensata e transcrizionalmente silente. La distribuzione della cromatina all'interno del nucleo cellulare è anche un fattore importante nella regolazione dell'espressione genica.
La modificazione post-traduzionale delle proteine istoniche, come la metilazione e l'acetilazione, svolge un ruolo cruciale nel determinare lo stato della cromatina e quindi il livello di espressione dei geni. Inoltre, la disorganizzazione della cromatina è stata associata a diverse malattie umane, come i tumori maligni.
Le "Cellule tumorali in coltura" si riferiscono al processo di crescita e moltiplicazione delle cellule tumorali prelevate da un paziente, in un ambiente di laboratorio controllato. Questo processo consente agli scienziati e ai ricercatori medici di studiare le caratteristiche e il comportamento delle cellule tumorali al di fuori dell'organismo vivente, con l'obiettivo di comprendere meglio i meccanismi della malattia e sviluppare strategie terapeutiche più efficaci.
Le cellule tumorali vengono isolate dal tessuto tumorale primario o dalle metastasi, e successivamente vengono coltivate in specifici nutrienti e condizioni di crescita che ne permettono la proliferazione in vitro. Durante questo processo, le cellule possono essere sottoposte a diversi trattamenti farmacologici o manipolazioni genetiche per valutarne la risposta e l'efficacia.
L'utilizzo di "Cellule tumorali in coltura" è fondamentale nello studio del cancro, poiché fornisce informazioni preziose sulla biologia delle cellule tumorali, sulla loro sensibilità o resistenza ai trattamenti e sull'identificazione di potenziali bersagli terapeutici. Tuttavia, è importante sottolineare che le "Cellule tumorali in coltura" possono presentare alcune limitazioni, come la perdita della complessità dei tessuti originali e l'assenza dell'influenza del microambiente tumorale. Pertanto, i risultati ottenuti da queste colture devono essere validati in modelli più complessi, come ad esempio organoidi o animali da laboratorio, prima di essere applicati alla pratica clinica.
I Gene Regulatory Networks (GRN) sono complessi sistemi di regolazione genica che controllano l'espressione dei geni nelle cellule. Essi consistono di diversi tipi di elementi, tra cui geni, proteine e molecole di RNA, che interagiscono tra loro per coordinare l'attivazione o la repressione dell'espressione genica.
In particolare, i GRN sono costituiti da geni regolatori, che codificano per fattori di trascrizione e altre proteine regulatory, e dai loro target genici, che sono i geni le cui espressioni vengono controllate da questi fattori di trascrizione.
I GRN possono essere molto complessi, con diversi livelli di regolazione e feedback negativo o positivo che permettono una risposta dinamica e flessibile alle variazioni delle condizioni cellulari e ambientali. Essi sono cruciali per la differenziazione cellulare, lo sviluppo embrionale, la risposta immunitaria e altri processi biologici complessi.
Le alterazioni nei GRN possono portare a malattie genetiche o acquisite, come il cancro, e sono quindi un'area di grande interesse per la ricerca biomedica.
La mappa peptidica, nota anche come "peptide map" o "peptide fingerprint", è un metodo di analisi proteomica che utilizza la cromatografia liquida ad alta efficienza (HPLC) e la spettrometria di massa per identificare e quantificare le proteine. Questa tecnica si basa sul fatto che peptidi generati da una specifica proteina dopo la digestione enzimatica producono un pattern caratteristico o "impronta digitale" di picchi nel cromatogramma HPLC e nei profili di spettrometria di massa.
Nel processo, una proteina viene dapprima digerita da enzimi specifici, come la tripsina o la chimotripsina, che tagliano la catena polipeptidica in peptidi più piccoli e carichi positivamente. Questi peptidi vengono poi separati mediante HPLC, utilizzando una colonna di cromatografia riempita con un materiale adsorbente come la sfera di silice o la polimeria porosa. I peptidi interagiscono con il materiale della colonna in base alle loro proprietà chimiche e fisiche, come la lunghezza, la carica e l'idrofobicità, portando a una separazione spaziale dei picchi nel cromatogramma HPLC.
I peptidi vengono quindi ionizzati ed analizzati mediante spettrometria di massa, producendo uno spettro di massa univoco per ogni peptide. L'insieme dei picchi nello spettro di massa costituisce la "mappa peptidica" della proteina originale. Questa mappa può essere confrontata con le mappe peptidiche note o analizzata mediante algoritmi di ricerca per identificare e quantificare la proteina iniziale.
La mappa peptidica è un metodo sensibile, specifico e affidabile per l'identificazione e la quantificazione delle proteine, ed è ampiamente utilizzata nelle scienze biomediche e nella ricerca proteomica.
In chimica e biochimica, la catalisi è un processo in cui una sostanza, chiamata catalizzatore, aumenta la velocità di una reazione chimica senza essere consumata nel processo. Il catalizzatore abbassa l'energia di attivazione richiesta per avviare e mantenere la reazione, il che significa che più molecole possono reagire a temperature e pressioni più basse rispetto alla reazione non catalizzata.
Nel contesto della biochimica, i catalizzatori sono spesso enzimi, proteine specializzate che accelerano specifiche reazioni chimiche all'interno di un organismo vivente. Gli enzimi funzionano abbassando l'energia di attivazione necessaria per avviare una reazione e creando un ambiente favorevole per le molecole a reagire. Questo permette al corpo di svolgere processi metabolici vitali, come la digestione dei nutrienti e la produzione di energia, in modo efficiente ed efficace.
È importante notare che un catalizzatore non cambia l'equilibrio chimico della reazione o il suo rendimento; semplicemente accelera il tasso al quale si verifica. Inoltre, un catalizzatore è specifico per una particolare reazione chimica e non influenzerà altre reazioni che potrebbero verificarsi contemporaneamente.
La cluster analysis è una tecnica statistica e computazionale, ma non strettamente una "definizione medica", utilizzata in vari campi tra cui la ricerca medica. Tuttavia, può essere descritta come un metodo di analisi dei dati che cerca di raggruppare osservazioni simili in sottoinsiemi distinti o cluster.
In altre parole, l'obiettivo della cluster analysis è quello di organizzare un insieme di oggetti (ad esempio, pazienti, malattie, geni) in modo che gli oggetti all'interno dello stesso cluster siano il più simili possibile, mentre gli oggetti in diversi cluster siano il più dissimili possibili. Questo approccio può essere utilizzato per identificare pattern o strutture nei dati e per formulare ipotesi su relazioni nascoste o sconosciute tra le variabili.
Nel contesto medico, la cluster analysis può essere applicata a una varietà di problemi, come l'identificazione di gruppi di pazienti con caratteristiche cliniche simili, il raggruppamento di malattie in base a sintomi o esiti comuni, o l'analisi della somiglianza genetica tra individui. Tuttavia, è importante notare che la cluster analysis non fornisce risposte definitive o conclusioni, ma piuttosto può essere utilizzata per generare ipotesi e guidare ulteriori indagini empiriche.
Le ribonucleoproteine (RNP) sono complessi formati dalla combinazione di proteine e acidi nucleici, specificamente RNA. Queste molecole svolgono un ruolo cruciale in diversi processi cellulari, tra cui la trascrizione, l'elaborazione dell'RNA, il trasporto dell'RNA e la traduzione.
Esistono diversi tipi di ribonucleoproteine, ciascuna con funzioni specifiche. Alcuni esempi includono:
1. Ribosomi: Sono particelle citoplasmatiche costituite da proteine e RNA ribosomiale (rRNA). I ribosomi sono responsabili della sintesi proteica, legandosi all'mRNA durante il processo di traduzione per unire gli aminoacidi secondo il codice genetico.
2. Complessi spliceosomali: Sono costituiti da diverse proteine e piccoli RNA nucleari (snRNA). Questi complessi svolgono un ruolo fondamentale nell'elaborazione dell'RNA pre-mRNA, rimuovendo gli introni e unendo gli esoni per formare l'mRNA maturo.
3. Complessi di trasporto dell'RNA: Sono costituiti da proteine e RNA non codificanti (ncRNA) che svolgono un ruolo cruciale nel trasporto dell'mRNA dalle zone di produzione all'interno del nucleo alle regioni citoplasmatiche dove avviene la traduzione.
4. Complessi enzimatici: Alcune proteine che contengono RNA svolgono funzioni enzimatiche, note come ribozimi. Un esempio è il complesso del gruppo di enzimi noto come ribonucleasi III (RNase III), che taglia specificamente l'RNA double-stranded in siti specifici.
5. Complessi di difesa dell'RNA: Alcune proteine associate all'RNA svolgono un ruolo nella difesa contro i virus e altri elementi genetici mobili, come i retrotrasposoni. Questi complessi possono degradare o sequestrare l'RNA virale per prevenire la replicazione virale.
La lisina è un aminoacido essenziale, il che significa che deve essere incluso nella dieta perché il corpo non può sintetizzarlo da solo. È importante per la crescita e il mantenimento dei tessuti del corpo, in particolare i muscoli. La lisina è anche necessaria per la produzione di enzimi, ormoni e anticorpi, ed è un componente chiave del collagene e dell'elastina, due proteine che forniscono struttura e elasticità ai tessuti connettivi.
La lisina svolge anche un ruolo nella produzione di carnitina, una sostanza chimica che aiuta a convertire i grassi in energia. Una carenza di lisina può causare stanchezza, debolezza muscolare, irritabilità e difficoltà di crescita nei bambini. Gli alimenti ricchi di lisina includono carne, pollame, pesce, uova, latticini, fagioli secchi, semi di zucca e noci di pinoli.
In termini medici, l'omologia strutturale delle proteine si riferisce alla similarità nella forma tridimensionale e nell'organizzazione spaziale dei domini o interi polipeptidi tra due o più proteine. Questa somiglianza è il risultato di una relazione evolutiva comune, dove le proteine omologhe condividono un antenato comune che ha subito eventi evolutivi come mutazioni, duplicazioni e ricombinazioni genetiche.
L'omologia strutturale non è influenzata da cambiamenti nella sequenza amminoacidica, il che significa che le proteine con una diversa sequenza di aminoacidi possono ancora avere una struttura simile se sono omologhe. Pertanto, l'omologia strutturale può essere utilizzata per inferire la funzione e l'evoluzione delle proteine, nonché per identificare legami funzionali o evolutivi tra diverse proteine.
La determinazione dell'omologia strutturale è spesso eseguita attraverso tecniche di bioinformatica come l'allineamento della struttura e la comparazione delle superfici di contatto, che consentono di identificare le somiglianze tra proteine a livello atomico. Queste informazioni possono essere utilizzate per comprendere meglio i meccanismi molecolari alla base della funzione delle proteine e per sviluppare nuove strategie terapeutiche.
Le proteine 14-3-3 sono una famiglia conservata di proteine eterodimeriche che legano e regolano una varietà di proteine target citosoliche e nucleari. Sono ubiquitarie nelle cellule eucariotiche e svolgono un ruolo cruciale nella regolazione della segnalazione cellulare, dell'apoptosi, del traffico delle vescicole, della riparazione del DNA e del ciclo cellulare.
Le proteine 14-3-3 si legano a una serie di substrati fosforilati, inclusi kinasi, fosfatasi, canali ionici, recettori e fattori di trascrizione, modulando la loro funzione e localizzazione cellulare. La loro espressione è strettamente regolata in risposta a diversi stimoli cellulari e sono state implicate nella patogenesi di diverse malattie umane, tra cui il cancro, le malattie neurodegenerative e le disfunzioni metaboliche.
Le proteine 14-3-3 sono note per la loro capacità di legare e regolare una vasta gamma di substrati, comprese le proteine che svolgono un ruolo nella segnalazione cellulare, nel traffico delle vescicole, nell'apoptosi, nel ciclo cellulare e nella riparazione del DNA. La loro capacità di legare e regolare questi substrati è mediata da domini di legame altamente specifici per il sito di fosforilazione, che riconoscono sequenze di aminoacidi circostanti i residui fosforilati dei substrati.
Le proteine 14-3-3 sono anche note per la loro capacità di formare dimeri stabili e possono esistere come monomeri o dimeri, a seconda delle condizioni cellulari. I dimeri di proteine 14-3-3 possono legarsi simultaneamente a due diverse molecole target, facilitando l'aggregazione e la regolazione di complessi multiproteici.
Le proteine 14-3-3 sono altamente conservate in molte specie ed esistono in diverse isoforme con differenze funzionali e strutturali. Le isoforme più studiate delle proteine 14-3-3 includono β, γ, ε, η, σ, τ, θ, ζ e ξ. Ogni isoforma ha una diversa distribuzione tissutale e può avere un ruolo specifico nella regolazione di processi cellulari specifici.
Le proteine 14-3-3 sono anche note per la loro capacità di interagire con altre proteine, comprese le chinasi, le fosfatasi e le ubiquitin ligasi, che possono influenzare la loro attività e la stabilità. Queste interazioni possono essere modulate da fattori ambientali, come lo stress o il segnale di crescita, e possono avere implicazioni per la regolazione della crescita cellulare, l'apoptosi e la differenziazione.
Le proteine 14-3-3 sono anche associate a diverse malattie umane, comprese le malattie neurodegenerative, il cancro e le malattie cardiovascolari. Le mutazioni delle proteine 14-3-3 possono influenzare la loro funzione e la stabilità, portando a disfunzioni cellulari e malattie.
In sintesi, le proteine 14-3-3 sono una famiglia di proteine altamente conservate che svolgono un ruolo importante nella regolazione dei processi cellulari, comprese la crescita cellulare, l'apoptosi e la differenziazione. Sono anche associate a diverse malattie umane e possono essere modulate da fattori ambientali e interazioni con altre proteine. La comprensione della funzione e della regolazione delle proteine 14-3-3 può fornire informazioni importanti sulla patogenesi di diverse malattie e sullo sviluppo di nuove strategie terapeutiche.
La specificità del substrato è un termine utilizzato in biochimica e farmacologia per descrivere la capacità di un enzima o una proteina di legarsi e agire su un singolo substrato o su un gruppo limitato di substrati simili, piuttosto che su una gamma più ampia di molecole.
In altre parole, l'enzima o la proteina mostra una preferenza marcata per il suo substrato specifico, con cui è in grado di interagire con maggiore affinità e velocità di reazione rispetto ad altri substrati. Questa specificità è dovuta alla forma tridimensionale dell'enzima o della proteina, che si adatta perfettamente al substrato come una chiave in una serratura, permettendo solo a determinate molecole di legarsi e subire la reazione enzimatica.
La specificità del substrato è un concetto fondamentale nella comprensione della regolazione dei processi metabolici e della farmacologia, poiché consente di prevedere quali molecole saranno più probabilmente influenzate da una particolare reazione enzimatica o da un farmaco che interagisce con una proteina specifica.
Nuclear Receptor Coactivator 1 (NCoA-1), anche noto come SRC-1 ( Steroid Receptor Coactivator-1), è una proteina che appartiene alla famiglia dei coattivatori dei recettori nucleari. Questi coattivatori giocano un ruolo fondamentale nella regolazione dell'espressione genica attraverso l'interazione con i recettori nucleari, che sono una classe di proteine intracellulari che legano specificamente i ligandi steroidei e tiroidici e altri effettori nucleari.
NCoA-1 è stato identificato come un coattivatore del recettore degli estrogeni (ER) e successivamente si è scoperto che interagisce anche con una varietà di altri recettori nucleari, tra cui il recettore degli androgeni (AR), il recettore del glucocorticoide (GR), il recettore del progesterone (PR) e il recettore della tiroxina (TR).
La proteina NCoA-1 contiene due domini di legame per i recettori nucleari, noti come domini LXXLL (dove L è leucina e X è qualsiasi amminoacido), che sono necessari per l'interazione con i recettori nucleari. Inoltre, NCoA-1 possiede un dominio di attivazione trascrizionale, noto come dominio CREB-binding protein (CBP)/p300 interacting domain (CID), che recluta enzimi modificanti della cromatina, come le istone acetiltransferasi (HAT), per promuovere l'attivazione genica.
Le mutazioni nel gene NCOA1 sono state associate a una serie di disturbi endocrini e metabolici, tra cui il cancro al seno, l'obesità e il diabete di tipo 2. Inoltre, la sovraespressione di NCoA-1 è stata osservata in diversi tipi di tumori, come il carcinoma mammario, il carcinoma prostatico e il cancro del colon-retto, suggerendo un ruolo oncogenico per questa proteina.
Le proteine leganti GTP (GTPase) sono un tipo di enzimi che legano e idrolizzano la guanosina trifosfato (GTP) in guanosina difosfato (GDP). Queste proteine giocano un ruolo cruciale nella regolazione di una varietà di processi cellulari, tra cui il controllo del ciclo cellulare, la segnalazione cellulare, il traffico intracellulare e il mantenimento della stabilità citoscheletrica.
Le proteine GTPasi sono costituite da una subunità catalitica che lega e idrolizza il GTP e da una o più subunità regolatorie che influenzano l'attività enzimatica. Quando la proteina legante GTP è inattiva, essa si trova nella forma legata al GDP. Tuttavia, quando viene attivata, la proteina legante GTP subisce un cambiamento conformazionale che favorisce il rilascio del GDP e il legame di una molecola di GTP. Questo processo porta all'attivazione dell'enzima e al conseguente innesco di una cascata di eventi cellulari specifici.
Le proteine leganti GTP sono soggette a un rigoroso controllo regolatorio, che include la modificazione post-traduzionale, l'associazione con cofattori e il ripiegamento delle proteine. Queste proteine possono anche essere attivate o inibite da altre molecole di segnalazione cellulare, come le chinasi e le fosfatasi.
In sintesi, le proteine leganti GTP sono enzimi che regolano una varietà di processi cellulari attraverso il legame e l'idrolisi della guanosina trifosfato (GTP). Queste proteine sono soggette a un rigoroso controllo regolatorio e possono essere attivate o inibite da altre molecole di segnalazione cellulare.
Una linea cellulare tumorale è un tipo di linea cellulare che viene coltivata in laboratorio derivando dalle cellule di un tumore. Queste linee cellulari sono ampiamente utilizzate nella ricerca scientifica e medica per studiare il comportamento delle cellule cancerose, testare l'efficacia dei farmaci antitumorali e comprendere meglio i meccanismi molecolari che stanno alla base dello sviluppo e della progressione del cancro.
Le linee cellulari tumorali possono essere derivate da una varietà di fonti, come ad esempio biopsie o resezioni chirurgiche di tumori solidi, oppure attraverso l'isolamento di cellule tumorali presenti nel sangue o in altri fluidi corporei. Una volta isolate, le cellule vengono mantenute in coltura e riprodotte per creare una popolazione omogenea di cellule cancerose che possono essere utilizzate a scopo di ricerca.
È importante sottolineare che le linee cellulari tumorali non sono identiche alle cellule tumorali originali presenti nel corpo umano, poiché durante il processo di coltivazione in laboratorio possono subire modificazioni genetiche e fenotipiche che ne alterano le caratteristiche. Pertanto, i risultati ottenuti utilizzando queste linee cellulari devono essere interpretati con cautela e validati attraverso ulteriori studi su modelli animali o su campioni umani.
La biologia dei sistemi è un approccio interdisciplinare allo studio dei sistemi viventi che integra concetti e metodi dalle biologia, fisica, matematica, ingegneria, informatica e altre scienze per comprendere il comportamento complessivo di sistemi biologici a diversi livelli di organizzazione, dal molecolare al sistema intero.
Questo campo di studio si concentra sulla comprensione delle proprietà emergenti dei sistemi biologici, che derivano dalle interazioni complesse e non lineari tra i loro componenti. Gli approcci utilizzati nella biologia dei sistemi includono la modellazione matematica, l'analisi di grandi dataset sperimentali, la simulazione al computer e l'ingegneria di sistemi biologici.
Gli obiettivi della biologia dei sistemi sono quelli di sviluppare una comprensione più profonda delle reti molecolari che governano le funzioni cellulari, di identificare i principi generali che regolano l'organizzazione e il comportamento dei sistemi viventi, e di applicare questa conoscenza per prevedere e controllare il comportamento dei sistemi biologici a scopo di ricerca, medicina e biotecnologia.
La specificità delle specie, nota anche come "specifità della specie ospite", è un termine utilizzato in microbiologia e virologia per descrivere il fenomeno in cui un microrganismo (come batteri o virus) infetta solo una o poche specie di organismi ospiti. Ciò significa che quel particolare patogeno non è in grado di replicarsi o causare malattie in altre specie diverse da quelle a cui è specifico.
Ad esempio, il virus dell'influenza aviaria (H5N1) ha una specificità delle specie molto elevata, poiché infetta principalmente uccelli e non si diffonde facilmente tra gli esseri umani. Tuttavia, in rare occasioni, può verificarsi un salto di specie, consentendo al virus di infettare e causare malattie negli esseri umani.
La specificità delle specie è determinata da una combinazione di fattori, tra cui le interazioni tra i recettori del patogeno e quelli dell'ospite, la capacità del sistema immunitario dell'ospite di rilevare e neutralizzare il patogeno, e altri aspetti della biologia molecolare del microrganismo e dell'ospite.
Comprendere la specificità delle specie è importante per prevedere e prevenire la diffusione di malattie infettive, nonché per lo sviluppo di strategie efficaci di controllo e trattamento delle infezioni.
La reazione di polimerizzazione a catena è un processo chimico in cui monomeri ripetuti, o unità molecolari semplici, si legane insieme per formare una lunga catena polimerica. Questo tipo di reazione è caratterizzato dalla formazione di un radicale libero, che innesca la reazione e causa la propagazione della catena.
Nel contesto medico, la polimerizzazione a catena può essere utilizzata per creare materiali biocompatibili come ad esempio idrogeli o polimeri naturali modificati chimicamente, che possono avere applicazioni in campo farmaceutico, come ad esempio nella liberazione controllata di farmaci, o in campo chirurgico, come ad esempio per la creazione di dispositivi medici impiantabili.
La reazione di polimerizzazione a catena può essere avviata da una varietà di fonti di radicali liberi, tra cui l'irradiazione con luce ultravioletta o raggi gamma, o l'aggiunta di un iniziatore chimico. Una volta iniziata la reazione, il radicale libero reagisce con un monomero per formare un radicale polimerico, che a sua volta può reagire con altri monomeri per continuare la crescita della catena.
La reazione di polimerizzazione a catena è un processo altamente controllabile e prevedibile, il che lo rende una tecnica utile per la creazione di materiali biomedici su misura con proprietà specifiche. Tuttavia, è importante notare che la reazione deve essere strettamente controllata per evitare la formazione di catene polimeriche troppo lunghe o ramificate, che possono avere proprietà indesiderate.
In campo medico e biologico, le frazioni subcellulari si riferiscono a componenti specifici e isolati di una cellula che sono state separate dopo la lisi (la rottura) della membrana cellulare. Questo processo viene comunemente eseguito in laboratorio per studiare e analizzare le diverse strutture e funzioni all'interno di una cellula.
Le frazioni subcellulari possono includere:
1. Nucleo: la parte della cellula che contiene il materiale genetico (DNA).
2. Citoplasma: il materiale fluido all'interno della cellula, al di fuori del nucleo.
3. Mitocondri: le centrali energetiche delle cellule che producono ATP.
4. Lisosomi: organelli che contengono enzimi digestivi che aiutano a degradare materiale indesiderato o danneggiato all'interno della cellula.
5. Ribosomi: strutture dove si sintetizza la maggior parte delle proteine all'interno della cellula.
6. Reticolo endoplasmatico rugoso (RER) e reticolo endoplasmatico liscio (REL): membrane intracellulari che svolgono un ruolo importante nel processare, trasportare e immagazzinare proteine e lipidi.
7. Apparato di Golgi: una struttura composta da vescicole e sacchi membranosie che modifica, classifica e trasporta proteine e lipidi.
8. Perossisomi: piccoli organelli che contengono enzimi che scompongono varie sostanze chimiche, inclusi alcuni tipi di grassi e aminoacidi.
L'isolamento di queste frazioni subcellulari richiede l'uso di tecniche specializzate, come centrifugazione differenziale e ultracentrifugazione, per separare i componenti cellulari in base alle loro dimensioni, forma e densità.
Le proteine neoplastiche si riferiscono a proteine anomale prodotte da cellule cancerose o neoplastiche. Queste proteine possono essere quantitative o qualitative diverse dalle proteine prodotte da cellule normali e sane. Possono esserci differenze nella struttura, nella funzione o nell'espressione di tali proteine.
Le proteine neoplastiche possono essere utilizzate come biomarker per la diagnosi, il monitoraggio della progressione della malattia e la risposta al trattamento del cancro. Ad esempio, l'elevata espressione di proteine come HER2/neu nel cancro al seno è associata a una prognosi peggiore, ma anche a una maggiore sensibilità a determinati farmaci chemioterapici e target terapeutici.
L'identificazione e la caratterizzazione di proteine neoplastiche possono essere effettuate utilizzando tecniche come l'immunochimica, la spettroscopia di massa e la citometria a flusso. Tuttavia, è importante notare che le differenze nelle proteine neoplastiche non sono specifiche per un particolare tipo di cancro e possono essere presenti anche in altre condizioni patologiche.
L'attivazione enzimatica si riferisce al processo di innesco o avvio dell'attività catalitica di un enzima. Gli enzimi sono proteine che accelerano reazioni chimiche specifiche all'interno di un organismo vivente. La maggior parte degli enzimi è prodotta in una forma inattiva, chiamata zymogeni o proenzimi. Questi devono essere attivati prima di poter svolgere la loro funzione catalitica.
L'attivazione enzimatica può verificarsi attraverso diversi meccanismi, a seconda del tipo di enzima. Uno dei meccanismi più comuni è la proteolisi, che implica la scissione della catena polipeptidica dell'enzima da parte di una peptidasi (un enzima che taglia le proteine in peptidi o amminoacidi). Questo processo divide lo zymogeno in due parti: una piccola porzione, chiamata frammento regolatorio, e una grande porzione, chiamata catena catalitica. La separazione di queste due parti consente all'enzima di assumere una conformazione tridimensionale attiva che può legare il substrato e catalizzare la reazione.
Un altro meccanismo di attivazione enzimatica è la rimozione di gruppi chimici inibitori, come i gruppi fosfati. Questo processo viene spesso catalizzato da altre proteine chiamate chinasi o fosfatasi. Una volta che il gruppo inibitorio è stato rimosso, l'enzima può assumere una conformazione attiva e svolgere la sua funzione catalitica.
Infine, alcuni enzimi possono essere attivati da cambiamenti ambientali, come variazioni di pH o temperatura. Questi enzimi contengono residui amminoacidici sensibili al pH o alla temperatura che possono alterare la conformazione dell'enzima quando le condizioni ambientali cambiano. Quando questo accade, l'enzima può legare il substrato e catalizzare la reazione.
In sintesi, l'attivazione enzimatica è un processo complesso che può essere causato da una varietà di fattori, tra cui la rimozione di gruppi inibitori, la modifica della conformazione dell'enzima e i cambiamenti ambientali. Comprendere questi meccanismi è fondamentale per comprendere il ruolo degli enzimi nella regolazione dei processi cellulari e nella patogenesi delle malattie.
L'elicasi del DNA è un enzima che svolge un ruolo cruciale nel processo di replicazione e riparazione del DNA. La sua funzione principale è separare le due catene complementari del DNA, convertendo la doppia elica in due singole eliche di DNA. Questo processo è essenziale per consentire alle polimerasi di sintetizzare nuove catene di DNA durante la replicazione o di riparare i danni al DNA.
L'elicasi del DNA utilizza l'energia fornita dall'idrolisi dell'ATP per scindere le interazioni idrogeno tra le basi azotate, consentendo alla doppia elica di aprirsi e formare due filamenti singoli. L'elicasi del DNA si muove lungo il filamento di DNA in direzione 5'-3', creando una bolla di separazione delle catene che viene poi estesa dalle altre proteine della forcella di replicazione.
La disfunzione dell'elicasi del DNA può portare a una serie di disturbi genetici e malattie, tra cui la sindrome di Bloom, la sindrome di Werner e il cancro. Pertanto, l'elicasi del DNA è un bersaglio importante per lo sviluppo di nuovi farmaci antitumorali.
La biosintesi proteica è un processo metabolico fondamentale che si verifica nelle cellule di organismi viventi, dove le proteine vengono sintetizzate dalle informazioni genetiche contenute nel DNA. Questo processo complesso può essere suddiviso in due fasi principali: la trascrizione e la traduzione.
1. Trascrizione: Durante questa fase, l'informazione codificata nel DNA viene copiata in una molecola di RNA messaggero (mRNA) attraverso un processo enzimatico catalizzato dall'enzima RNA polimerasi. L'mRNA contiene una sequenza di basi nucleotidiche complementare alla sequenza del DNA che codifica per una specifica proteina.
2. Traduzione: Nella fase successiva, nota come traduzione, il mRNA funge da matrice su cui vengono letti e interpretati i codoni (tripletti di basi) che ne costituiscono la sequenza. Questa operazione viene eseguita all'interno dei ribosomi, organelli citoplasmatici presenti in tutte le cellule viventi. I ribosomi sono costituiti da proteine e acidi ribonucleici (ARN) ribosomali (rRNA). Durante il processo di traduzione, i transfer RNA (tRNA), molecole ad "L" pieghevoli che contengono specifiche sequenze di tre basi chiamate anticodoni, legano amminoacidi specifici. Ogni tRNA ha un sito di legame per un particolare aminoacido e un anticodone complementare a uno o più codoni nel mRNA.
Nel corso della traduzione, i ribosomi si muovono lungo il filamento di mRNA, legano sequenzialmente i tRNA carichi con amminoacidi appropriati e catalizzano la formazione dei legami peptidici tra gli aminoacidi, dando origine a una catena polipeptidica in crescita. Una volta sintetizzata, questa catena polipeptidica può subire ulteriori modifiche post-traduzionali, come la rimozione di segmenti o l'aggiunta di gruppi chimici, per formare una proteina funzionale matura.
In sintesi, il processo di traduzione è un meccanismo altamente coordinato ed efficiente che permette alle cellule di decodificare le informazioni contenute nel DNA e di utilizzarle per produrre proteine essenziali per la vita.
Le proteine adattatrici, anche conosciute come chaperoni, sono proteine che assistono e regolano la corretta piegatura e l'assemblaggio delle altre proteine nel processo di ripiegamento proteico. Esse prevengono l'aggregazione indesiderata delle proteine e promuovono il loro corretto funzionamento all'interno della cellula. Le proteine adattatrici possono anche aiutare nella degradazione di proteine danneggiate o mal ripiegate, contribuendo a mantenere l'equilibrio proteico e la salute cellulare. Queste proteine svolgono un ruolo cruciale nel rispondere allo stress cellulare e nelle vie di segnalazione cellulare, nonché nella prevenzione e nella progressione di varie malattie, tra cui le malattie neurodegenerative e il cancro.
L'analisi delle sequenze del DNA è il processo di determinazione dell'ordine specifico delle basi azotate (adenina, timina, citosina e guanina) nella molecola di DNA. Questo processo fornisce informazioni cruciali sulla struttura, la funzione e l'evoluzione dei geni e dei genomi.
L'analisi delle sequenze del DNA può essere utilizzata per una varietà di scopi, tra cui:
1. Identificazione delle mutazioni associate a malattie genetiche: L'analisi delle sequenze del DNA può aiutare a identificare le mutazioni nel DNA che causano malattie genetiche. Questa informazione può essere utilizzata per la diagnosi precoce, il consiglio genetico e la pianificazione della terapia.
2. Studio dell'evoluzione e della diversità genetica: L'analisi delle sequenze del DNA può fornire informazioni sull'evoluzione e sulla diversità genetica di specie diverse. Questo può essere particolarmente utile nello studio di popolazioni in pericolo di estinzione o di malattie infettive emergenti.
3. Sviluppo di farmaci e terapie: L'analisi delle sequenze del DNA può aiutare a identificare i bersagli molecolari per i farmaci e a sviluppare terapie personalizzate per malattie complesse come il cancro.
4. Identificazione forense: L'analisi delle sequenze del DNA può essere utilizzata per identificare individui in casi di crimini o di identificazione di resti umani.
L'analisi delle sequenze del DNA è un processo altamente sofisticato che richiede l'uso di tecnologie avanzate, come la sequenziazione del DNA ad alto rendimento e l'analisi bioinformatica. Questi metodi consentono di analizzare grandi quantità di dati genetici in modo rapido ed efficiente, fornendo informazioni preziose per la ricerca scientifica e la pratica clinica.
In termini mediche, "Internet" non è propriamente definito come un termine relativo alla pratica clinica o alla salute. Tuttavia, in un contesto più ampio, l'Internet può essere considerato una rete globale di computer interconnessi che consentono la comunicazione e lo scambio di informazioni digitali.
In ambito medico, l'Internet è diventato una risorsa importante per l'acquisizione e la diffusione delle conoscenze, la formazione continua, la ricerca scientifica e la comunicazione tra professionisti sanitari, pazienti e caregiver. L'utilizzo di Internet ha notevolmente influenzato il modo in cui i servizi sanitari vengono erogati e fruiti, con l'emergere di nuove opportunità come la telemedicina e la teledermatologia, che permettono la diagnosi e la gestione a distanza dei pazienti.
Tuttavia, è importante sottolineare che l'affidabilità delle informazioni reperite online può variare notevolmente, pertanto i professionisti sanitari e i pazienti devono esercitare cautela e criterio nella valutazione e nell'utilizzo di tali informazioni.
In medicina, i "fattori temporali" si riferiscono alla durata o al momento in cui un evento medico o una malattia si verifica o progredisce. Questi fattori possono essere cruciali per comprendere la natura di una condizione medica, pianificare il trattamento e prevedere l'esito.
Ecco alcuni esempi di come i fattori temporali possono essere utilizzati in medicina:
1. Durata dei sintomi: La durata dei sintomi può aiutare a distinguere tra diverse condizioni mediche. Ad esempio, un mal di gola che dura solo pochi giorni è probabilmente causato da un'infezione virale, mentre uno che persiste per più di una settimana potrebbe essere causato da una infezione batterica.
2. Tempo di insorgenza: Il tempo di insorgenza dei sintomi può anche essere importante. Ad esempio, i sintomi che si sviluppano improvvisamente e rapidamente possono indicare un ictus o un infarto miocardico acuto.
3. Periodicità: Alcune condizioni mediche hanno una periodicità regolare. Ad esempio, l'emicrania può verificarsi in modo ricorrente con intervalli di giorni o settimane.
4. Fattori scatenanti: I fattori temporali possono anche includere eventi che scatenano la comparsa dei sintomi. Ad esempio, l'esercizio fisico intenso può scatenare un attacco di angina in alcune persone.
5. Tempo di trattamento: I fattori temporali possono influenzare il trattamento medico. Ad esempio, un intervento chirurgico tempestivo può essere vitale per salvare la vita di una persona con un'appendicite acuta.
In sintesi, i fattori temporali sono importanti per la diagnosi, il trattamento e la prognosi delle malattie e devono essere considerati attentamente in ogni valutazione medica.
La Proteina-Serina-Treonina Chinasi (PSTK o STK16) è un enzima che appartiene alla famiglia delle chinasi, le quali catalizzano la reazione di trasferimento di gruppi fosfato dal nucleotide trifosfato ad una proteina. Più specificamente, la PSTK è responsabile del trasferimento di un gruppo fosfato dal ATP alla serina o treonina di una proteina bersaglio.
Questo enzima svolge un ruolo importante nella regolazione della proliferazione e differenziazione cellulare, nonché nella risposta al danno del DNA. Mutazioni in questo gene sono state associate a diversi tipi di cancro, tra cui il carcinoma polmonare a cellule squamose e il carcinoma ovarico sieroso.
La PSTK è anche nota per essere regolata da fattori di trascrizione come la p53, un importante oncosoppressore che risponde al danno del DNA e inibisce la proliferazione cellulare. Quando il DNA è danneggiato, la p53 viene attivata e aumenta l'espressione della PSTK, che a sua volta promuove la riparazione del DNA e previene la propagazione di cellule con danni al DNA.
In sintesi, la Proteina-Serina-Treonina Chinasi è un enzima chiave nella regolazione della proliferazione e differenziazione cellulare, nonché nella risposta al danno del DNA, e le sue mutazioni sono state associate a diversi tipi di cancro.
In chimica e farmacologia, un legame competitivo si riferisce a un tipo di interazione tra due molecole che competono per lo stesso sito di legame su una proteina target, come un enzima o un recettore. Quando un ligando (una molecola che si lega a una biomolecola) si lega al suo sito di legame, impedisce all'altro ligando di legarsi nello stesso momento.
Nel caso specifico dell'inibizione enzimatica, un inibitore competitivo è una molecola che assomiglia alla struttura del substrato enzimatico e si lega al sito attivo dell'enzima, impedendo al substrato di accedervi. Ciò significa che l'inibitore compete con il substrato per il sito di legame sull'enzima.
L'effetto di un inibitore competitivo può essere annullato aumentando la concentrazione del substrato, poiché a dosi più elevate, il substrato è in grado di competere con l'inibitore per il sito di legame. La costante di dissociazione dell'inibitore (Ki) può essere utilizzata per descrivere la forza del legame competitivo tra l'inibitore e l'enzima.
In sintesi, un legame competitivo è una forma di interazione molecolare in cui due ligandi si contendono lo stesso sito di legame su una proteina target, con conseguente riduzione dell'efficacia dell'uno o dell'altro ligando.
Le modificazioni post-traduzionali delle proteine (PTM) sono processi biochimici che coinvolgono la modifica di una proteina dopo la sua sintesi tramite traduzione dell'mRNA. Queste modifiche possono influenzare diverse proprietà funzionali della proteina, come la sua attività enzimatica, la localizzazione subcellulare, la stabilità e l'interazione con altre molecole.
Le PTMs più comuni includono:
1. Fosforilazione: l'aggiunta di un gruppo fosfato ad una serina, treonina o tirosina residui della proteina, regolata da enzimi chiamati kinasi e fosfatasi.
2. Glicosilazione: l'aggiunta di uno o più zuccheri (o oligosaccaridi) alla proteina, che può influenzare la sua solubilità, stabilità e capacità di interagire con altre molecole.
3. Ubiquitinazione: l'aggiunta di una proteina chiamata ubiquitina alla proteina target, che segnala la sua degradazione da parte del proteasoma.
4. Metilazione: l'aggiunta di uno o più gruppi metile ad un residuo amminoacidico della proteina, che può influenzarne la stabilità e l'interazione con altre molecole.
5. Acetilazione: l'aggiunta di un gruppo acetile ad un residuo amminoacidico della proteina, che può influenzare la sua attività enzimatica e la sua interazione con il DNA.
Le modificazioni post-traduzionali delle proteine sono cruciali per la regolazione di molte vie cellulari e processi fisiologici, come il metabolismo, la crescita cellulare, la differenziazione, l'apoptosi e la risposta immunitaria. Tuttavia, possono anche essere associate a malattie, come il cancro, le malattie neurodegenerative e le infezioni virali.
La Spettroscopia di Risonanza Magnetica (MRS, Magnetic Resonance Spectroscopy) è una tecnica di imaging biomedico che fornisce informazioni metaboliche e biochimiche su tessuti viventi. Si basa sulle stesse principi della risonanza magnetica (MRI), ma invece di produrre immagini, MRS misura la concentrazione di diversi metaboliti all'interno di un volume specificato del tessuto.
Durante l'esame MRS, il paziente viene esposto a un campo magnetico statico e a impulsi di radiofrequenza, che inducono una risonanza magnetica nei nuclei atomici del tessuto target (solitamente atomi di idrogeno o 1H). Quando l'impulso di radiofrequenza viene interrotto, i nuclei ritornano al loro stato originale emettendo un segnale di rilassamento che è proporzionale alla concentrazione dei metaboliti presenti nel tessuto.
Questo segnale viene quindi elaborato per produrre uno spettro, che mostra picchi distintivi corrispondenti a diversi metaboliti. Ogni metabolita ha un pattern di picchi caratteristico, che consente l'identificazione e la quantificazione della sua concentrazione all'interno del tessuto target.
MRS è utilizzata principalmente per lo studio dei tumori cerebrali, dove può fornire informazioni sulla presenza di cellule tumorali e sulla risposta al trattamento. Tuttavia, questa tecnica ha anche applicazioni in altri campi della medicina, come la neurologia, la cardiologia e l'oncologia.
La proteichinasi è un termine generale che si riferisce a un gruppo di enzimi che svolgono un ruolo cruciale nella segnalazione cellulare e nella regolazione delle cellule. Essi catalizzano la fosforilazione (l'aggiunta di un gruppo fosfato) di specifiche proteine, modificandone l'attività e influenzando una varietà di processi cellulari come la crescita, la differenziazione e l'apoptosi (morte cellulare programmata).
Esistono diverse classi di proteichinasi, tra cui la serina/treonina proteichinasi e la tirosina proteichinasi. Le proteichinasi sono essenziali per il normale funzionamento delle cellule e sono anche implicate in diversi processi patologici, come l'infiammazione, il cancro e le malattie cardiovascolari. Un noto esempio di proteichinasi è la PKA (proteina chinasi A), che è coinvolta nella regolazione del metabolismo, dell'apprendimento e della memoria.
Tuttavia, un abuso di questo termine può essere riscontrato in alcune pubblicazioni, dove viene utilizzato per riferirsi specificamente alle chinasi che sono direttamente coinvolte nella reazione infiammatoria e nell'attivazione del sistema immunitario. Queste proteichinasi, note come "chinasi infiammatorie", svolgono un ruolo cruciale nel segnalare il danno tissutale e l'infezione alle cellule del sistema immunitario, attivandole per combattere i patogeni e riparare i tessuti danneggiati. Alcuni esempi di queste proteichinasi infiammatorie sono la IKK (IkB chinasi), la JNK (chinasi stress-attivata mitogeno-indotta) e la p38 MAPK (chinasi della via del segnale dell'MAP chinasi 38).
In termini medici, "Xenopus" si riferisce a un genere di rane della famiglia Pipidae originarie dell'Africa subsahariana. Queste rane sono note per la loro pelle asciutta e ruvida e per le ghiandole che secernono sostanze tossiche.
Uno dei rappresentanti più noti del genere Xenopus è Xenopus laevis, comunemente nota come rana africana delle paludi o rana africana da laboratorio. Questa specie è stata ampiamente utilizzata in ricerca scientifica, specialmente negli studi di embriologia e genetica, grazie alle sue uova grandi e facili da manipolare.
In particolare, l'utilizzo della Xenopus laevis come organismo modello ha contribuito in modo significativo alla comprensione dello sviluppo embrionale e dei meccanismi di regolazione genica. Gli esperimenti condotti su questa specie hanno portato a importanti scoperte, come l'identificazione del fattore di trascrizione NMYC e il ruolo delle chinasi nella regolazione della crescita cellulare.
In sintesi, "Xenopus" è un termine medico che si riferisce a un genere di rane utilizzate come organismi modello in ricerca scientifica, note per le loro uova grandi e la facilità di manipolazione genetica.
"Xenopus laevis" è una specie di rana originaria dell'Africa subsahariana, più precisamente dalle regioni umide del sud e dell'est del continente. In ambiente medico, questa rana è spesso utilizzata come organismo modello per la ricerca scientifica, in particolare negli studi di embriologia e genetica.
La sua popolarità come organismo da laboratorio deriva dalla sua resistenza alle malattie infettive, alla facilità di allevamento e manutenzione in cattività, e alla capacità della femmina di produrre una grande quantità di uova fecondate esternamente. Le uova e gli embrioni di Xenopus laevis sono trasparenti, il che permette agli scienziati di osservare direttamente lo sviluppo degli organi e dei sistemi interni.
In sintesi, "Xenopus laevis" è una specie di rana comunemente usata in ambito medico e di ricerca scientifica come organismo modello per lo studio dello sviluppo embrionale e genetico.
Il dicroismo circolare è un fenomeno ottico che si verifica quando la luce polarizzata attraversa un mezzo otticamente attivo, come una soluzione contenente molecole chirali. Nello specifico, il dicroismo circolare si riferisce alla differenza nell'assorbimento della luce polarizzata a sinistra rispetto a quella polarizzata a destra da parte di tali molecole. Questa differenza di assorbimento provoca una rotazione del piano di polarizzazione della luce, che può essere misurata e utilizzata per studiare la struttura e la conformazione delle molecole chirali.
In particolare, il dicroismo circolare viene spesso utilizzato in biochimica e biologia molecolare per analizzare la struttura secondaria delle proteine e degli acidi nucleici, come l'RNA e il DNA. La misurazione del dicroismo circolare può fornire informazioni sulla conformazione di tali molecole, ad esempio se sono presenti eliche o foglietti beta, e su eventuali cambiamenti conformazionali indotti da fattori come il pH, la temperatura o l'interazione con ligandi.
In sintesi, il dicroismo circolare è un importante strumento di analisi ottica che consente di studiare la struttura e le proprietà delle molecole chirali, con applicazioni particolari in biochimica e biologia molecolare.
Le proteine degli insetti, noto anche come proteine entomofaghe, si riferiscono a proteine estratte dagli insetti interi o da loro parti. Gli insetti sono una fonte ricca di proteine complete e contengono tutti gli aminoacidi essenziali necessari per il sostegno della crescita e del mantenimento dei tessuti corporei umani. Le specie di insetti comunemente utilizzate per l'estrazione delle proteine includono grilli, locuste, cavallette, vermi della farina e larve di scarafaggio.
Le proteine degli insetti hanno attirato un crescente interesse nella comunità scientifica e nell'industria alimentare a causa del loro potenziale ruolo nel soddisfare le esigenze nutrizionali globali, specialmente considerando l'aumento della popolazione mondiale e la crescente domanda di proteine animali. Inoltre, gli insetti hanno un basso impatto ambientale rispetto alla produzione di carne convenzionale, poiché richiedono meno terra, acqua ed energia per essere allevati.
Le proteine degli insetti possono essere utilizzate come ingredienti funzionali negli alimenti trasformati, fornendo proprietà nutrizionali e tecnologiche vantaggiose. Ad esempio, le proteine di grillo sono state studiate per la loro capacità di migliorare la consistenza e l'emulsionabilità dei prodotti a base di carne, mentre le proteine della farina del verme della mosca soldato nera hanno dimostrato di possedere proprietà antimicrobiche.
Tuttavia, è importante notare che il consumo di insetti come fonte di proteine non è universalmente accettato e può essere influenzato da fattori culturali, religiosi e personali. Pertanto, la promozione e l'integrazione delle proteine degli insetti nella dieta umana richiedono un approccio equilibrato che tenga conto di queste considerazioni.
In genetica, una "mappa del cromosoma" si riferisce a una rappresentazione grafica dettagliata della posizione relativa e dell'ordine dei geni, dei marcatori genetici e di altri elementi costitutivi presenti su un cromosoma. Viene creata attraverso l'analisi di vari tipi di markers genetici o molecolari, come polimorfismi a singolo nucleotide (SNP), Restriction Fragment Length Polymorphisms (RFLPs) e Variable Number Tandem Repeats (VNTRs).
Le mappe del cromosoma possono essere di due tipi: mappe fisiche e mappe genetiche. Le mappe fisiche mostrano la distanza tra i markers in termini di base di paia, mentre le mappe genetiche misurano la distanza in unità di mappa, che sono basate sulla frequenza di ricombinazione durante la meiosi.
Le mappe del cromosoma sono utili per studiare la struttura e la funzione dei cromosomi, nonché per identificare i geni associati a malattie ereditarie o suscettibili alla malattia. Aiutano anche nella mappatura fine dei geni e nel design di esperimenti di clonazione posizionale.
L'RNA interference (RNAi) è un meccanismo cellulare conservato evolutionisticamente che regola l'espressione genica attraverso la degradazione o il blocco della traduzione di specifici RNA messaggeri (mRNA). Questo processo è innescato dalla presenza di piccoli RNA a doppio filamento (dsRNA) che vengono processati in small interfering RNA (siRNA) o microRNA (miRNA) da un enzima chiamato Dicer. Questi siRNA e miRNA vengono poi incorporati nel complesso RISC (RNA-induced silencing complex), dove uno strand del dsRNA guida il riconoscimento e il legame specifico con l'mRNA bersaglio complementare. Questo legame porta alla degradazione dell'mRNA o al blocco della traduzione, impedendo così la sintesi della proteina corrispondente. L'RNAi è un importante meccanismo di difesa contro i virus e altri elementi genetici mobili, ma è anche utilizzato nella regolazione fine dell'espressione genica durante lo sviluppo e in risposta a vari stimoli cellulari.
L'omologia sequenziale degli acidi nucleici è un metodo di confronto e analisi delle sequenze di DNA o RNA per determinare la loro somiglianza o differenza. Questa tecnica si basa sulla comparazione dei singoli nucleotidi che compongono le sequenze, cioè adenina (A), timina (T)/uracile (U), citosina (C) e guanina (G).
Nell'omologia sequenziale degli acidi nucleici, due o più sequenze sono allineate in modo da massimizzare la somiglianza tra di esse. Questo allineamento può includere l'inserimento di spazi vuoti, noti come gap, per consentire un migliore adattamento delle sequenze. L'omologia sequenziale degli acidi nucleici è comunemente utilizzata in biologia molecolare e genetica per identificare le relazioni evolutive tra organismi, individuare siti di restrizione enzimatica, progettare primer per la reazione a catena della polimerasi (PCR) e studiare la diversità genetica.
L'omologia sequenziale degli acidi nucleici è misurata utilizzando diversi metodi, come il numero di identità delle basi, la percentuale di identità o la distanza evolutiva. Una maggiore somiglianza tra le sequenze indica una probabilità più elevata di una relazione filogenetica stretta o di una funzione simile. Tuttavia, è importante notare che l'omologia sequenziale non implica necessariamente un'omologia funzionale o strutturale, poiché le mutazioni possono influire sulla funzione e sulla struttura delle proteine codificate dalle sequenze di DNA.
La protein-tirosina chinasi (PTK) è un tipo di enzima che catalizza la fosforilazione delle tirosine, un particolare aminoacido presente nelle proteine. Questa reazione consiste nell'aggiunta di un gruppo fosfato, derivante dall'ATP, al residuo di tirosina della proteina.
La fosforilazione delle tirosine svolge un ruolo cruciale nella regolazione di numerosi processi cellulari, tra cui la trasduzione del segnale, la proliferazione cellulare, l'apoptosi e la differenziazione cellulare.
Le PTK possono essere classificate in due gruppi principali: le PTK intrinseche o non ricettoriali, che sono presenti all'interno della cellula e si legano a specifiche proteine bersaglio per fosforilarle; e le PTK ricettoriali, che sono integrate nella membrana plasmatica e possiedono un dominio extracellulare utilizzato per legare i ligandi (molecole segnale).
L'attivazione di una PTK ricettoriale avviene quando il suo ligando si lega al dominio extracellulare, provocando un cambiamento conformazionale che induce l'autofosforilazione della tirosina nel dominio intracellulare dell'enzima. Questa autofosforilazione crea siti di legame per le proteine adattatrici e altre PTK, dando inizio a una cascata di segnalazione che può influenzare l'esito di diversi processi cellulari.
Le disregolazioni nelle PTK possono portare allo sviluppo di diverse malattie, tra cui il cancro e le malattie cardiovascolari. Pertanto, le PTK sono spesso considerate bersagli terapeutici promettenti per lo sviluppo di farmaci mirati.
In medicina, il termine "famiglia multigenica" si riferisce a un gruppo di geni che sono ereditati insieme e che contribuiscono tutti alla suscettibilità o alla predisposizione a una particolare malattia o condizione. Queste famiglie di geni possono includere diversi geni che interagiscono tra loro o con fattori ambientali per aumentare il rischio di sviluppare la malattia.
Ad esempio, nella malattia di Alzheimer a insorgenza tardiva, si pensa che ci siano diverse famiglie multigeniche che contribuiscono alla suscettibilità alla malattia. I geni appartenenti a queste famiglie possono influenzare la produzione o la clearance della beta-amiloide, una proteina che si accumula nel cervello dei pazienti con Alzheimer e forma placche distintive associate alla malattia.
La comprensione delle famiglie multigeniche può aiutare i ricercatori a identificare i fattori di rischio genetici per una particolare malattia e a sviluppare strategie di prevenzione o trattamento più mirate. Tuttavia, è importante notare che l'ereditarietà multigenica è solo uno dei fattori che contribuiscono alla suscettibilità alla malattia, e che altri fattori come l'età, lo stile di vita e l'esposizione ambientale possono anche svolgere un ruolo importante.
Gli 'interaction host-pathogen' (interazioni ospite-patogeno) si riferiscono alla complessa relazione dinamica e reciproca che si verifica tra un organismo ospite (che può essere un essere umano, animale, piante o altri microrganismi) e un patogeno (un agente infettivo come batteri, virus, funghi o parassiti). Queste interazioni determinano l'esito dell'infezione e possono variare da asintomatiche a letali.
L'interazione inizia quando il patogeno cerca di entrare, sopravvivere e moltiplicarsi all'interno dell'ospite. L'ospite, d'altra parte, attiva le proprie risposte difensive per rilevare, neutralizzare e rimuovere il patogeno. Queste interazioni possono influenzare la virulenza del patogeno e la suscettibilità dell'ospite.
L'esito di queste interazioni dipende da diversi fattori, come le caratteristiche genetiche dell'ospite e del patogeno, l'ambiente in cui avviene l'infezione, la dose infettiva e il tempo di esposizione. Una migliore comprensione delle interazioni ospite-patogeno può aiutare nello sviluppo di strategie terapeutiche e preventive più efficaci per combattere le infezioni.
La medicina non utilizza direttamente il termine "elettrostatica" come parte della sua terminologia standard. Tuttavia, l'elettrostatica è un principio fisico che descrive la generazione e l'interazione delle forze tra oggetti carichi elettricamente a riposo (non in movimento).
In un contesto medico più ampio, l'elettrostatica può essere applicata in alcuni campi come la fisica medica, dove i fenomeni elettrostatici possono influenzare il funzionamento di apparecchiature elettromedicali o influenzare le proprietà di materiali utilizzati in dispositivi medici impiantabili. Ad esempio, l'elettrostatica può svolgere un ruolo nel modo in cui un defibrillatore eroga una scarica elettrica controllata per ripristinare il ritmo cardiaco normale o come le forze elettrostatiche possono influenzare l'adesione di farmaci a stent coronarici.
In sintesi, l'elettrostatica non è una nozione medica di per sé, ma un principio fisico che può avere applicazioni e implicazioni in alcuni campi della medicina.
In genetica, un vettore è comunemente definito come un veicolo che serve per trasferire materiale genetico da un organismo donatore a uno ricevente. I vettori genetici sono spesso utilizzati in biotecnologie e nella ricerca genetica per inserire specifici geni o segmenti di DNA in cellule o organismi target.
I vettori genetici più comuni includono plasmidi, fagi (batteriofagi) e virus engineered come adenovirus e lentivirus. Questi vettori sono progettati per contenere il gene di interesse all'interno della loro struttura e possono essere utilizzati per trasferire questo gene nelle cellule ospiti, dove può quindi esprimersi e produrre proteine.
In particolare, i vettori genetici sono ampiamente utilizzati nella terapia genica per correggere difetti genetici che causano malattie. Essi possono anche essere utilizzati in ricerca di base per studiare la funzione dei geni e per creare modelli animali di malattie umane.
Le proteine cromosomiali non istoniche sono un tipo di proteine associati al DNA che non includono le proteine histone. Le proteine histone sono ben note per il loro ruolo nella composizione dei nucleosomi, le unità fondamentali della struttura cromosomica. Tuttavia, il genoma umano codifica per migliaia di altre proteine che interagiscono con il DNA e svolgono una varietà di funzioni importanti, tra cui la regolazione della trascrizione, la riparazione del DNA, la replicazione e la condensazione cromosomica.
Queste proteine cromosomiali non istoniche possono essere classificate in base alla loro localizzazione spaziale e temporale durante il ciclo cellulare. Alcune di queste proteine sono costitutivamente associate al DNA, mentre altre si legano transitoriamente al DNA in risposta a specifici segnali cellulari o ambientali.
Le proteine cromosomiali non istoniche svolgono un ruolo cruciale nella regolazione dell'espressione genica, contribuendo alla formazione di complessi proteici che agiscono come attivatori o repressori della trascrizione. Inoltre, possono partecipare a processi epigenetici, come la metilazione del DNA e la modificazione delle histone, che influenzano l'accessibilità del DNA alla trascrizione e alla riparazione.
In sintesi, le proteine cromosomiali non istoniche sono un gruppo eterogeneo di proteine che interagiscono con il DNA al di fuori dei nucleosomi e svolgono un ruolo fondamentale nella regolazione della funzione genica.
La memorizzazione e il reperimento dell'informazione, anche noti come "memory and recall" in inglese, sono termini utilizzati per descrivere due processi cognitivi cruciali nella formazione e nel recupero delle informazioni all'interno della memoria.
La memorizzazione (memory) si riferisce alla fase di apprendimento durante la quale l'individuo acquisisce e immagazzina le informazioni nel cervello. Questo processo può essere ulteriormente suddiviso in tre stadi distinti:
1. Codifica: Durante questa fase, il cervello elabora ed analizza le informazioni ricevute dai sensi per convertirle in un formato che possa essere immagazzinato nella memoria. Ciò può avvenire attraverso la creazione di collegamenti tra nuove e vecchie informazioni o mediante l'utilizzo di strategie mnemoniche.
2. Archiviazione: Questa fase riguarda il processo di immagazzinamento delle informazioni codificate nella memoria a breve termine (STM) o in quella a lungo termine (LTM), a seconda dell'importanza e della rilevanza per l'individuo.
3. Consolidazione: Durante la consolidazione, le informazioni vengono rafforzate e stabilizzate all'interno della memoria, il che rende più probabile il loro successivo recupero.
Il reperimento dell'informazione (recall), invece, si riferisce alla capacità di accedere e riportare consapevolmente le informazioni precedentemente memorizzate quando necessario. Questo processo può essere suddiviso in due sottotipi:
1. Ricordo libero: Si tratta della capacità di produrre spontaneamente le informazioni memorizzate senza alcun aiuto o suggerimento esterno. Ad esempio, se ti viene chiesto di elencare i nomi dei pianeti del sistema solare, stai utilizzando il ricordo libero.
2. Ricognizione: Questa abilità consiste nel riconoscere e identificare le informazioni memorizzate tra un insieme di opzioni fornite. Ad esempio, se ti viene mostrata una serie di immagini e ti viene chiesto di scegliere quella che hai visto in precedenza, stai utilizzando la ricognizione.
È importante notare che il reperimento dell'informazione può essere influenzato da diversi fattori, come l'età, lo stress, la distrazione e le condizioni di salute mentale, tra cui disturbi quali la demenza o il disturbo da deficit di attenzione e iperattività (ADHD).
Le interazioni idrofobiche e idrofiliche sono fenomeni che si verificano a livello molecolare e svolgono un ruolo importante nella determinazione delle proprietà fisico-chimiche delle biomolecole, come proteine e lipidi, e dei loro complessi.
Le interazioni idrofobiche si verificano quando due o più gruppi chimici non polari (idrofobi) entrano in contatto tra loro in un ambiente acquoso. Queste interazioni sono il risultato dell'esclusione dell'acqua dalle superfici idrofobe, che tende a formare una struttura a gabbia intorno alle molecole non polari per minimizzare l'energia libera di solvatazione. Le interazioni idrofobiche svolgono un ruolo cruciale nella stabilizzazione delle proteine e dei lipidi, nonché nella determinazione della loro struttura tridimensionale.
D'altra parte, le interazioni idrofiliche si verificano quando gruppi chimici polari (idrofili) entrano in contatto con l'acqua. Queste interazioni includono legami a idrogeno, interazioni ioniche e interazioni di Van der Waals. Le interazioni idrofiliche svolgono un ruolo importante nella solubilizzazione delle molecole polari in acqua e nella stabilizzazione delle strutture secondarie delle proteine, come α-eliche e foglietti β.
In sintesi, le interazioni idrofobiche e idrofiliche sono fenomeni fondamentali che governano la struttura, la funzione e l'interazione delle biomolecole in soluzioni acquose.
L'espressione "analisi attraverso un pannello di proteine" si riferisce a un tipo di test di laboratorio in cui vengono misurate simultaneamente le concentrazioni di un gruppo selezionato di proteine presenti in una matrice biologica, come ad esempio il sangue o l'urina. Questo approccio consente di valutare lo stato di salute generale del paziente e/o la presenza o l'assenza di particolari condizioni patologiche che possono influenzare i livelli di tali proteine.
Il pannello di proteine è costituito da un insieme predefinito di biomarcatori, cioè molecole presenti nel corpo umano che possono essere utilizzate come indicatori di una specifica condizione o malattia. Questi biomarcatori possono essere proteine strutturali, enzimi, ormoni, fattori di crescita o altre molecole coinvolte in processi fisiologici e patologici.
L'analisi attraverso un pannello di proteine può fornire informazioni utili per la diagnosi precoce, il monitoraggio della progressione della malattia, l'identificazione delle risposte terapeutiche e la valutazione del rischio di complicanze o recidive. Tra gli esempi più noti di pannelli proteici utilizzati in ambito clinico vi sono quelli per la diagnosi di malattie infiammatorie, cardiovascolari, neurologiche e oncologiche.
È importante sottolineare che l'interpretazione dei risultati di un'analisi attraverso un pannello di proteine richiede competenze specialistiche e deve essere eseguita da personale sanitario qualificato, in quanto i livelli delle singole proteine possono essere influenzati da fattori come l'età, il sesso, lo stile di vita e la presenza di altre patologie concomitanti.
La locuzione "Integrazione di Sistemi" in ambito medico si riferisce al processo di combinare diversi sistemi informatici o tecnologici all'interno di un'organizzazione sanitaria, come ad esempio ospedali, cliniche o centri di ricerca, con lo scopo di ottimizzarne l'interoperabilità, la comunicazione e lo scambio dati.
L'obiettivo dell'integrazione di sistemi è quello di creare un ambiente informativo integrato che permetta una gestione efficiente ed efficace dei dati sanitari, migliorando la qualità e la sicurezza delle cure fornite ai pazienti.
L'integrazione di sistemi può riguardare diverse aree funzionali, come l'archiviazione e il recupero dei dati sanitari, la schedulazione degli appuntamenti, la gestione delle prescrizioni mediche, la documentazione clinica, la radiologia, il laboratorio, la farmacia, la telemedicina e la ricerca.
L'integrazione di sistemi richiede l'utilizzo di standard tecnologici e normativi condivisi, nonché la collaborazione tra diverse figure professionali, come informatici, clinici, amministratori e ingegneri biomedici.
L'adenosintrifosfatasi (ATPasi) è un enzima che catalizza la reazione di idrolisi dell'adenosintrifosfato (ATP) in adenosindifosfato (ADP) e fosfato inorganico, con il rilascio di energia. Questa reazione è fondamentale per molti processi cellulari, come la contrazione muscolare, il trasporto attivo di ioni e molecole attraverso le membrane cellulari e la sintesi di proteine e acidi nucleici.
L'ATPasi è presente in diverse forme nelle cellule, tra cui la forma più nota è la pompa sodio-potassio (Na+/K+-ATPasi), che regola il potenziale di membrana delle cellule mantenendo un gradiente di concentrazione di ioni sodio e potassio attraverso la membrana cellulare. Altri tipi di ATPasi includono la pompa calci-ATPasi, che regola i livelli di calcio all'interno e all'esterno delle cellule, e l'ATPasi mitocondriale, che svolge un ruolo importante nella produzione di ATP durante la respirazione cellulare.
L'attività dell'ATPasi è strettamente regolata a livello enzimatico e può essere influenzata da vari fattori, come il pH, la concentrazione di ioni e molecole substrato, e l'interazione con altre proteine. La disfunzione o l'inibizione dell'ATPasi possono portare a varie patologie, tra cui la debolezza muscolare, la cardiomiopatia, e la disfunzione renale.
In termini medici, il bestiame si riferisce comunemente al bestiame allevato per l'uso o il consumo umano, come manzo, vitello, montone, agnello, maiale e pollame. Possono verificarsi occasionalmente malattie zoonotiche (che possono essere trasmesse dagli animali all'uomo) o infezioni che possono diffondersi dagli animali da allevamento alle persone, pertanto i medici e altri operatori sanitari devono essere consapevoli di tali rischi e adottare misure appropriate per la prevenzione e il controllo delle infezioni. Tuttavia, il termine "bestiame" non ha una definizione medica specifica o un uso clinico comune.
Nuclear Receptor Co-Repressor 2 (NCOR2) è una proteina che svolge un ruolo importante nella regolazione dell'espressione genica. Si lega ai recettori nucleari, un gruppo di proteine che fungono da fattori di trascrizione e controllano l'espressione di geni specifici in risposta a segnali ormonali o molecolari.
NCOR2 agisce come co-repressore, il che significa che si lega ai recettori nucleari per sopprimere o reprimere l'attivazione della trascrizione dei geni bersaglio. Quando un recettore nucleare viene attivato da un segnale ormonale o molecolare, NCOR2 viene reclutato insieme ad altre proteine co-repressoriche per formare un complesso che si lega al DNA e impedisce la trascrizione dei geni.
NCOR2 è coinvolto nella regolazione di una varietà di processi fisiologici, tra cui il metabolismo energetico, lo sviluppo embrionale, la differenziazione cellulare e la risposta immunitaria. Mutazioni o alterazioni nel gene NCOR2 possono essere associate a diverse malattie genetiche, come la sindrome di Börjeson-Forssman-Lehmann, una rara condizione caratterizzata da ritardo mentale, obesità e anomalie facciali. Inoltre, alterazioni nell'espressione o nella funzione di NCOR2 possono anche contribuire allo sviluppo di diversi tipi di cancro.
Le proteine di trasporto vescicolare, notevoli anche come proteine di trasporto intracellulare o protein transport vesicles (PTVs), sono membrana-bound compartimenti citoplasmatici che svolgono un ruolo cruciale nel processo di trasporto vescicolare all'interno delle cellule. Queste strutture specializzate facilitano il movimento e lo scambio di molecole, come proteine e lipidi, tra diversi organelli cellulari e la membrana plasmatica durante l'endocitosi e l'esocitosi.
Le PTV sono costituite da una doppia membrana fosfolipidica che racchiude un volume citosolico chiamato lumen. La superficie interna della membrana è ricca di proteine di ancoraggio, mentre la superficie esterna contiene proteine di trasporto specifiche per il riconoscimento e il legame con i ligandi situati sui membrane donatrice (ad esempio, membrana del reticolo endoplasmatico rugoso o membrana Golgi).
I principali tipi di PTV comprendono vescicole endocitiche, vescicole secretorie e vescicole di trasporto. Le vescicole endocitiche sono implicate nel processo di endocitosi, durante il quale esse internalizzano molecole dall'ambiente extracellulare attraverso la membrana plasmatica. Le vescicole secretorie, invece, trasportano proteine e altri componenti verso la membrana plasmatica per essere rilasciati nell'ambiente extracellulare (esocitosi). Infine, le vescicole di trasporto sono responsabili del movimento di molecole tra diversi organelli cellulari, come il reticolo endoplasmatico e l'apparato di Golgi.
Il processo di formazione delle PTV inizia con il distacco della membrana donatrice, che forma un'invaginazione (tasca) contenente i ligandi desiderati. Questa tasca si stacca dalla membrana e matura in una vescicola, grazie all'azione di proteine coinvolte nella fase di scissione e nel ripiegamento della membrana. Una volta formate, le PTV possono viaggiare attraverso il citoplasma seguendo i microtubuli, con l'aiuto delle proteine motorie (come la dyneina e la kinesina). Durante questo spostamento, le vescicole possono fondersi con altre membrane o subire processi di maturazione che ne modificano il contenuto.
Le PTV svolgono un ruolo cruciale nel traffico intracellulare e nella regolazione delle vie di segnalazione cellulare, contribuendo alla corretta localizzazione e funzionalità delle proteine all'interno della cellula.
La definizione medica di "Basi di Dati Genetiche" si riferisce a un sistema organizzato di stoccaggio e gestione dei dati relativi al materiale genetico e alle informazioni genetiche delle persone. Queste basi di dati possono contenere informazioni su vari aspetti della genetica, come la sequenza del DNA, le mutazioni genetiche, le varianti genetiche, le associazioni geni-malattie e le storie familiari di malattie ereditarie.
Le basi di dati genetici possono essere utilizzate per una varietà di scopi, come la ricerca scientifica, la diagnosi e il trattamento delle malattie genetiche, la prevenzione delle malattie ereditarie, la medicina personalizzata e la criminalistica forense.
Le basi di dati genetici possono essere pubbliche o private, a seconda dell'uso previsto dei dati e della politica sulla privacy. Le basi di dati genetici pubbliche sono disponibili per la ricerca scientifica e possono contenere informazioni anonime o pseudonimizzate su un gran numero di persone. Le basi di dati genetiche private, invece, possono essere utilizzate da medici, ricercatori e aziende per scopi specifici, come la diagnosi e il trattamento delle malattie genetiche o lo sviluppo di farmaci.
E' importante sottolineare che l'utilizzo di queste basi di dati deve essere regolato da leggi e politiche sulla privacy per proteggere la riservatezza e l'integrità delle informazioni genetiche delle persone.
La prolina è un aminoacido non essenziale, il che significa che il corpo può sintetizzarlo da altre sostanze. È uno dei 20 aminoacidi comunemente trovati nelle proteine. La prolina si distingue dagli altri aminoacidi perché ha un gruppo funzionale di gruppi idrossile (-OH) e amminico (-NH2) legati allo stesso atomo di carbonio, formando un anello a sei termini chiamato pirrolidina.
La struttura ciclica della prolina conferisce alla catena proteica una conformazione rigida, il che può influenzare la forma e la funzione delle proteine in cui è presente. Ad esempio, la prolina svolge un ruolo importante nella stabilizzazione della struttura terziaria di alcune proteine, come il collagene, una proteina fibrosa che costituisce la maggior parte del tessuto connettivo nel corpo umano.
La prolina è anche un precursore della creatina, una sostanza naturalmente presente nelle cellule muscolari che fornisce energia per le contrazioni muscolari. Inoltre, la prolina può essere metabolizzata in diversi composti che svolgono un ruolo nella produzione di energia, nella sintesi del collagene e nell'eliminazione dei radicali liberi.
In sintesi, la prolina è un aminoacido importante che svolge un ruolo cruciale nella struttura e funzione delle proteine, nonché nel metabolismo energetico e nella protezione contro lo stress ossidativo. Tuttavia, non è considerata essenziale per l'alimentazione umana, poiché il corpo può sintetizzarla autonomamente a partire da altri aminoacidi.
Mi spiace, sembra che ci sia stato un malinteso. La parola "conigli" non ha una definizione medica specifica poiché si riferisce generalmente a un animale da fattoria o domestico della famiglia Leporidae. Tuttavia, i conigli possono essere utilizzati in alcuni contesti medici o di ricerca come animali da laboratorio per studiare varie condizioni o per testare la sicurezza e l'efficacia dei farmaci. In questo contesto, il termine "conigli" si riferirebbe all'animale utilizzato nello studio e non a una condizione medica specifica.
La Library (o Libreria) Peptidica è un termine utilizzato in biochimica e biologia molecolare per descrivere una raccolta di diversi peptidi sintetici, che possono essere utilizzati in vari studi scientifici, come la ricerca farmacologica, lo screening del ligando e l'identificazione di nuovi bersagli terapeutici. Essa contiene una vasta gamma di peptidi di diversa lunghezza, sequenza aminoacidica ed origine, progettati per interagire con specifici recettori o proteine bersaglio.
La libreria peptidica può essere creata mediante tecniche di sintesi chimica o enzimatica e può contenere peptidi naturali o sintetici, inclusi analoghi e mimetici. Questi peptidi possono essere utilizzati per identificare potenziali farmaci, determinare la specificità dei recettori, studiare le interazioni proteina-proteina e comprendere meglio i meccanismi molecolari alla base di varie funzioni cellulari.
Le librerie peptidiche sono uno strumento prezioso per la ricerca biomedica, poiché forniscono un metodo efficiente ed economico per testare e selezionare potenziali composti bioattivi in una vasta gamma di condizioni. Tuttavia, è importante notare che i peptidi presenti nelle librerie peptidiche possono avere proprietà farmacocinetiche limitate, come la scarsa stabilità e la difficoltà nell'attraversare le barriere cellulari, il che può rendere necessario un ulteriore sviluppo per trasformarli in farmaci efficaci.
In medicina, il termine "istologico" si riferisce alla struttura e alla composizione dei tessuti corporei a livello microscopico. Più specificamente, l'istologia è la branca della biologia che studia i tessuti sani e malati al microscopio per comprendere la loro struttura, funzione e interazioni con altri tessuti.
L'analisi istologica prevede la preparazione di campioni di tessuto prelevati da un paziente attraverso una biopsia o un'asportazione chirurgica. Il campione viene quindi fissato, incluso in paraffina, tagliato in sezioni sottili e colorato con coloranti specifici per evidenziare diverse componenti cellulari e strutture tissutali.
Le informazioni ricavate dall'esame istologico possono essere utilizzate per formulare una diagnosi, pianificare un trattamento o monitorare la risposta del paziente alla terapia. In sintesi, l'istologia fornisce preziose informazioni sulla natura e l'estensione delle lesioni tissutali, contribuendo a una migliore comprensione della fisiopatologia delle malattie e dei processi patologici.
La tecnica di immunofluorescenza (IF) è un metodo di laboratorio utilizzato in patologia e medicina di laboratorio per studiare la distribuzione e l'localizzazione dei vari antigeni all'interno dei tessuti, cellule o altri campioni biologici. Questa tecnica si basa sull'uso di anticorpi marcati fluorescentemente che si legano specificamente a determinati antigeni target all'interno del campione.
Il processo inizia con il pretrattamento del campione per esporre gli antigeni e quindi l'applicazione di anticorpi primari marcati fluorescentemente che si legano agli antigeni target. Dopo la rimozione degli anticorpi non legati, vengono aggiunti anticorpi secondari marcati fluorescentemente che si legano agli anticorpi primari, aumentando il segnale di fluorescenza e facilitandone la visualizzazione.
Il campione viene quindi esaminato utilizzando un microscopio a fluorescenza, che utilizza luce eccitante per far brillare i marcatori fluorescenti e consentire l'osservazione dei pattern di distribuzione degli antigeni all'interno del campione.
La tecnica di immunofluorescenza è ampiamente utilizzata in ricerca, patologia e diagnosi clinica per una varietà di applicazioni, tra cui la localizzazione di proteine specifiche nelle cellule, lo studio dell'espressione genica e la diagnosi di malattie autoimmuni e infettive.
L'ubiquitina è una piccola proteina altamente conservata che viene espressa in tutte le cellule viventi. Ha un ruolo fondamentale nella regolazione dei processi cellulari attraverso il meccanismo di ubiquitinazione, che consiste nell'aggiunta di molecole di ubiquitina a specifiche proteine bersaglio. Questo processo marca le proteine per la degradazione da parte del proteasoma, un complesso enzimatico che scompone le proteine danneggiate o non funzionali all'interno della cellula.
L'aggiunta di ubiquitina alle proteine avviene attraverso una serie di reazioni enzimatiche che comprendono l'attivazione, il trasferimento e la coniugazione dell'ubiquitina alla proteina bersaglio. Una volta che una proteina è marcata con più molecole di ubiquitina, viene riconosciuta dal proteasoma e sottoposta a degradazione.
Il sistema di ubiquitinazione svolge un ruolo cruciale nella regolazione della risposta cellulare allo stress, nell'eliminazione delle proteine danneggiate o mutate, nel controllo del ciclo cellulare e nell'attivazione o inibizione di vari percorsi di segnalazione cellulare. Pertanto, alterazioni nel sistema di ubiquitinazione possono portare a varie malattie, tra cui patologie neurodegenerative, cancro e disordini immunitari.
La luciferasi è un enzima che catalizza la reazione chimica che produce luce, nota come bioluminescenza. Viene trovata naturalmente in alcuni organismi viventi, come ad esempio le lucciole e alcune specie di batteri marini. Questi organismi producono una reazione enzimatica che comporta l'ossidazione di una molecola chiamata luciferina, catalizzata dalla luciferasi, con conseguente emissione di luce.
Nel contesto medico e scientifico, la luciferasi viene spesso utilizzata come marcatore per studiare processi biologici come l'espressione genica o la localizzazione cellulare. Ad esempio, un gene che si desidera studiare può essere fuso con il gene della luciferasi, in modo che quando il gene viene espresso, la luciferasi viene prodotta e può essere rilevata attraverso l'emissione di luce. Questa tecnica è particolarmente utile per lo studio delle interazioni geniche e proteiche, nonché per l'analisi dell'attività enzimatica e della citotossicità dei farmaci.
Le proteine microtubulo-associate (MAP, dall'inglese Microtubule-Associated Proteins) sono un gruppo eterogeneo di proteine che si legano e interagiscono con i microtubuli, componenti cruciali del citoscheletro. I microtubuli sono filamenti cilindrici formati da tubulina, una coppia di subunità globulari alfa e beta.
Le MAP svolgono un ruolo fondamentale nella stabilizzazione, organizzazione e dinamica dei microtubuli. Possono essere classificate in due categorie principali: proteine di stabilizzazione e proteine regolatrici.
1. Proteine di stabilizzazione: queste MAP si legano ai microtubuli per promuoverne l'assemblaggio, la stabilità e il mantenimento della struttura. Un esempio ben noto è la tau (MAPτ), che si lega preferenzialmente alla tubulina nella regione del protofilamento laterale dei microtubuli. La tau è stata intensamente studiata per il suo ruolo nella malattia di Alzheimer e in altre patologie neurodegenerative, dove l'iperfosforilazione e l'aggregazione della proteina portano alla formazione di grovigli neurofibrillari.
2. Proteine regolatrici: queste MAP contribuiscono alla dinamica dei microtubuli, influenzando la loro crescita e accorciamento. Sono spesso associate a complessi proteici che comprendono anche enzimi come la chinasi o la fosfatasi, che modificano reversibilmente le MAP stesse o i microtubuli stessi attraverso la fosforilazione o la defosforilazione.
In sintesi, le proteine microtubulo-associate sono un gruppo di proteine eterogenee che interagiscono con i microtubuli per regolarne la stabilità, l'organizzazione e la dinamica all'interno della cellula. Le alterazioni funzionali o strutturali delle MAP possono avere conseguenze patologiche, come nel caso di alcune malattie neurodegenerative.
In medicina e biologia molecolare, un profilo di espressione genica si riferisce all'insieme dei modelli di espressione genica in un particolare tipo di cellula o tessuto, sotto specifiche condizioni fisiologiche o patologiche. Esso comprende l'identificazione e la quantificazione relativa dei mRNA (acidi ribonucleici messaggeri) presenti in una cellula o un tessuto, che forniscono informazioni su quali geni sono attivamente trascritti e quindi probabilmente tradotti in proteine.
La tecnologia di microarray e la sequenzazione dell'RNA a singolo filamento (RNA-Seq) sono ampiamente utilizzate per generare profili di espressione genica su larga scala, consentendo agli scienziati di confrontare l'espressione genica tra diversi campioni e identificare i cambiamenti significativi associati a determinate condizioni o malattie. Questi dati possono essere utilizzati per comprendere meglio i processi biologici, diagnosticare le malattie, prevedere il decorso della malattia e valutare l'efficacia delle terapie.
La definizione medica di "Ingegneria delle Proteine" si riferisce alla manipolazione intenzionale e mirata della struttura e della funzione delle proteine attraverso tecniche di biologia molecolare, biochimica e biotecnologie. Lo scopo dell'ingegneria delle proteine è quello di creare o modificare proteine con proprietà specifiche desiderate per applicazioni in medicina, ricerca scientifica, industria e agricoltura.
Questa tecnica può essere utilizzata per creare enzimi più efficienti, vaccini migliori, farmaci mirati, materiali bio-compatibili e bio-ispirati, biosensori e sistemi di consegna dei farmaci. L'ingegneria delle proteine comporta spesso la modifica della sequenza aminoacidica delle proteine per influenzare la loro struttura tridimensionale, stabilità, attività enzimatica, interazioni con altre molecole e altri aspetti funzionali.
Le tecniche comuni di ingegneria delle proteine includono la mutagenesi sito-specifica, la ricombinazione del DNA, la selezione diretta delle proteine, la folding delle proteine e l'assemblaggio delle proteine. Queste tecniche possono essere utilizzate per creare proteine con nuove funzioni o per migliorare le proprietà di proteine esistenti.
L'ingegneria delle proteine è un campo interdisciplinare che richiede una comprensione approfondita della biologia molecolare, biochimica, fisica e matematica. Questo campo ha il potenziale per avere un impatto significativo sulla salute umana, sull'agricoltura e sull'industria, offrendo soluzioni innovative a sfide complesse in questi settori.
Le proteine Xenopus si riferiscono specificamente alle proteine identificate e isolate dal girino della rana Xenopus (Xenopus laevis o Xenopus tropicalis), un organismo modello comunemente utilizzato negli studi di biologia dello sviluppo. Queste proteine possono essere estratte e analizzate per comprendere meglio le loro funzioni, strutture e interazioni con altre molecole. Un esempio ben noto di proteina Xenopus è la proteina della fecondazione nota come "proteina sperma-uovo", che svolge un ruolo cruciale nell'attivazione dello sviluppo embrionale dopo la fecondazione. La rana Xenopus viene utilizzata frequentemente nella ricerca scientifica a causa del suo grande uovo, delle sue dimensioni cellulari relativamente grandi e della facilità di manipolazione genetica ed esperimentale.
La riparazione del DNA è un processo biologico essenziale che si verifica nelle cellule degli organismi viventi. Il DNA, o acido desossiribonucleico, è il materiale genetico che contiene le informazioni genetiche necessarie per lo sviluppo, la crescita e la riproduzione delle cellule. Tuttavia, il DNA è suscettibile al danno da varie fonti, come i radicali liberi, i raggi UV e altri agenti ambientali dannosi.
La riparazione del DNA si riferisce alle diverse strategie utilizzate dalle cellule per rilevare e correggere i danni al DNA. Questi meccanismi di riparazione sono cruciali per prevenire le mutazioni genetiche che possono portare allo sviluppo di malattie genetiche, al cancro e all'invecchiamento precoce.
Ci sono diversi tipi di danni al DNA che richiedono meccanismi di riparazione specifici. Alcuni dei principali tipi di danni al DNA e i relativi meccanismi di riparazione includono:
1. **Danno da singola lesione a base**: Questo tipo di danno si verifica quando una singola base del DNA viene danneggiata o modificata. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione della scissione dell'azoto della base" (BNER). Questo processo prevede l'identificazione e la rimozione della base danneggiata, seguita dalla sintesi di una nuova base da parte di un enzima noto come polimerasi.
2. **Danno da rottura del filamento singolo**: Questo tipo di danno si verifica quando una singola catena del DNA viene rotta o tagliata. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione della scissione dell'estremità libera" (NHEJ). Questo processo prevede il riconoscimento e la ricostituzione del filamento spezzato, seguita dalla saldatura delle estremità da parte di un enzima noto come ligasi.
3. **Danno da rottura del doppio filamento**: Questo tipo di danno si verifica quando entrambe le catene del DNA vengono rotte o tagliate. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione dell'incisione della doppia elica" (DSBR). Questo processo prevede il riconoscimento e la ricostituzione del doppio filamento spezzato, seguita dalla sintesi di una nuova sequenza da parte di un enzima noto come polimerasi.
4. **Danno ossidativo**: Questo tipo di danno si verifica quando il DNA viene esposto all'ossigeno reattivo o ad altri agenti ossidanti. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione del base excision" (BER). Questo processo prevede il riconoscimento e la rimozione della base danneggiata, seguita dalla sintesi di una nuova sequenza da parte di un enzima noto come polimerasi.
In generale, i meccanismi di riparazione del DNA sono altamente conservati tra le specie e svolgono un ruolo fondamentale nella prevenzione delle mutazioni e del cancro. Tuttavia, in alcuni casi, questi meccanismi possono anche essere utilizzati per introdurre deliberatamente mutazioni nel DNA, come avviene ad esempio durante il processo di ricombinazione omologa utilizzato in biologia molecolare.
La regolazione dell'espressione genica nelle piante si riferisce al processo complesso e altamente regolato che controlla l'attività dei geni nelle cellule vegetali. Questo processo determina quali geni vengono attivati o disattivati, e in quale misura, determinando così la produzione di specifiche proteine che svolgono una varietà di funzioni cellulari e sviluppo della pianta.
La regolazione dell'espressione genica nelle piante è influenzata da diversi fattori, tra cui il tipo di cellula, lo stadio di sviluppo della pianta, le condizioni ambientali e l'interazione con altri organismi. Il processo può essere controllato a livello di trascrizione genica, quando il DNA viene copiato in RNA, o a livello di traduzione, quando l'RNA viene convertito in proteine.
La regolazione dell'espressione genica è essenziale per la crescita, lo sviluppo e la risposta delle piante agli stimoli ambientali. Le mutazioni nei geni che controllano questo processo possono portare a difetti di sviluppo o malattie nelle piante. Pertanto, la comprensione dei meccanismi molecolari che regolano l'espressione genica nelle piante è un'area attiva di ricerca con importanti implicazioni per l'agricoltura e la biotecnologia.
In termini medici, la "conformazione molecolare" si riferisce all'arrangiamento spaziale delle particelle (atomi, gruppi di atomi o ioni) che costituiscono una molecola. Questa disposizione tridimensionale è determinata dalle legami chimici, dagli angoli di legame e dalle interazioni elettrostatiche tra i gruppi atomici presenti nella molecola.
La conformazione molecolare può avere un impatto significativo sulle proprietà chimiche e biologiche della molecola, compreso il modo in cui interagisce con altre molecole, come enzimi o farmaci. Ad esempio, piccole variazioni nella conformazione di una molecola possono influenzare la sua capacità di legarsi a un bersaglio specifico, modificandone l'attività biologica.
Pertanto, lo studio della conformazione molecolare è fondamentale in vari campi, tra cui la farmacologia, per comprendere il funzionamento dei farmaci e progettare nuovi composti terapeutici con proprietà migliorate.
Le proteine leganti il calcio sono un tipo specifico di proteine che hanno la capacità di legare e trasportare ioni calcio all'interno dell'organismo. Questi tipi di proteine svolgono un ruolo cruciale nel mantenere l'equilibrio del calcio nell'organismo, nonché nella regolazione di diversi processi fisiologici che dipendono dal calcio, come la contrazione muscolare, la coagulazione del sangue e la segnalazione cellulare.
Alcune proteine leganti il calcio ben note includono:
1. La vitamina D-dipendente calcibinding protein (CBP) è una proteina presente nel plasma sanguigno che si lega al calcio e ne facilita il trasporto ai tessuti bersaglio.
2. La parvalbumina è una proteina presente nelle cellule muscolari scheletriche e cardiache che si lega al calcio e regola la contrazione muscolare.
3. La calmodulina è una proteina presente in molti tessuti corporei che si lega al calcio e funge da secondo messaggero nella segnalazione cellulare.
4. L'osteocalcina è una proteina prodotta dalle ossa che si lega al calcio e contribuisce alla mineralizzazione ossea.
5. La caseina è una proteina del latte che si lega al calcio ed è nota per migliorare l'assorbimento del calcio nell'intestino tenue.
In sintesi, le proteine leganti il calcio sono un gruppo eterogeneo di proteine che svolgono un ruolo importante nella regolazione dell'omeostasi del calcio e nel mantenere la salute delle ossa e dei tessuti corporei.
La replicazione del virus è un processo biologico durante il quale i virus producono copie di sé stessi all'interno delle cellule ospiti. Questo processo consente ai virus di infettare altre cellule e diffondersi in tutto l'organismo ospite, causando malattie e danni alle cellule.
Il ciclo di replicazione del virus può essere suddiviso in diverse fasi:
1. Attaccamento e penetrazione: Il virus si lega a una specifica proteina presente sulla superficie della cellula ospite e viene internalizzato all'interno della cellula attraverso un processo chiamato endocitosi.
2. Decapsidazione: Una volta dentro la cellula, il virione (particella virale) si dissocia dalla sua capside proteica, rilasciando il genoma virale all'interno del citoplasma o del nucleo della cellula ospite.
3. Replicazione del genoma: Il genoma virale viene replicato utilizzando le macchinari e le molecole della cellula ospite. Ci sono due tipi di genomi virali: a RNA o a DNA. A seconda del tipo, il virus utilizzerà meccanismi diversi per replicare il proprio genoma.
4. Traduzione e assemblaggio delle proteine: Le informazioni contenute nel genoma virale vengono utilizzate per sintetizzare nuove proteine virali all'interno della cellula ospite. Queste proteine possono essere strutturali o enzimatiche, necessarie per l'assemblaggio di nuovi virioni.
5. Assemblaggio e maturazione: Le proteine virali e il genoma vengono assemblati insieme per formare nuovi virioni. Durante questo processo, i virioni possono subire modifiche post-traduzionali che ne consentono la maturazione e l'ulteriore stabilità.
6. Rilascio: I nuovi virioni vengono rilasciati dalla cellula ospite, spesso attraverso processi citolitici che causano la morte della cellula stessa. In altri casi, i virioni possono essere rilasciati senza uccidere la cellula ospite.
Una volta che i nuovi virioni sono stati rilasciati, possono infettare altre cellule e continuare il ciclo di replicazione. Il ciclo di vita dei virus può variare notevolmente tra specie diverse e può essere influenzato da fattori ambientali e interazioni con il sistema immunitario dell'ospite.
La riproducibilità dei risultati, nota anche come ripetibilità o ricercabilità, è un principio fondamentale nella ricerca scientifica e nella medicina. Si riferisce alla capacità di ottenere risultati simili o identici quando un esperimento o uno studio viene replicato utilizzando gli stessi metodi, procedure e condizioni sperimentali.
In altre parole, se due o più ricercatori eseguono lo stesso studio o esperimento in modo indipendente e ottengono risultati simili, si dice che l'esperimento è riproducibile. La riproducibilità dei risultati è essenziale per validare le scoperte scientifiche e garantire la loro affidabilità e accuratezza.
Nella ricerca medica, la riproducibilità dei risultati è particolarmente importante perché può influenzare direttamente le decisioni cliniche e di salute pubblica. Se i risultati di un esperimento o uno studio non sono riproducibili, possono portare a conclusioni errate, trattamenti inefficaci o persino dannosi per i pazienti.
Per garantire la riproducibilità dei risultati, è fondamentale che gli studi siano progettati e condotti in modo rigoroso, utilizzando metodi standardizzati e ben documentati. Inoltre, i dati e le analisi dovrebbero essere resi disponibili per la revisione da parte dei pari, in modo che altri ricercatori possano verificare e replicare i risultati.
Tuttavia, negli ultimi anni sono stati sollevati preoccupazioni sulla crisi della riproducibilità nella ricerca scientifica, con un numero crescente di studi che non riescono a replicare i risultati precedentemente pubblicati. Questo ha portato alla necessità di una maggiore trasparenza e rigore nella progettazione degli studi, nell'analisi dei dati e nella divulgazione dei risultati.
In medicina, il termine "trasporto biologico" si riferisce al movimento di sostanze, come molecole o gas, all'interno dell'organismo vivente da una posizione a un'altra. Questo processo è essenziale per la sopravvivenza e il funzionamento appropriato delle cellule e degli organi. Il trasporto biologico può avvenire attraverso diversi meccanismi, tra cui:
1. Diffusione: è il movimento spontaneo di molecole da un'area di alta concentrazione a un'area di bassa concentrazione, fino al raggiungimento dell'equilibrio. Non richiede l'utilizzo di energia ed è influenzato dalla solubilità delle molecole e dalle loro dimensioni.
2. Trasporto attivo: è il movimento di molecole contro il gradiente di concentrazione, utilizzando energia fornita dall'idrolisi dell'ATP (adenosina trifosfato). Questo meccanismo è essenziale per il trasporto di sostanze nutritive e ioni attraverso la membrana cellulare.
3. Trasporto facilitato: è un processo che utilizza proteine di trasporto (come i co-trasportatori e gli antiporti) per aiutare le molecole a spostarsi attraverso la membrana cellulare, contro o a favore del gradiente di concentrazione. A differenza del trasporto attivo, questo processo non richiede energia dall'idrolisi dell'ATP.
4. Flusso sanguigno: è il movimento di sostanze disciolte nel plasma sanguigno, come ossigeno, anidride carbonica e nutrienti, attraverso il sistema circolatorio per raggiungere le cellule e gli organi dell'organismo.
5. Flusso linfatico: è il movimento di linfa, un fluido simile al plasma, attraverso i vasi linfatici per drenare i fluidi interstiziali in eccesso e trasportare cellule del sistema immunitario.
Questi meccanismi di trasporto sono fondamentali per mantenere l'omeostasi dell'organismo, garantendo il corretto apporto di nutrienti e ossigeno alle cellule e la rimozione delle sostanze di rifiuto.
Il ciclo cellulare è un processo biologico continuo e coordinato che si verifica nelle cellule in cui esse crescono, si riproducono e si dividono. Esso consiste di una serie di eventi e fasi che comprendono la duplicazione del DNA (fase S), seguita dalla divisione del nucleo (mitosi o fase M), e successivamente dalla divisione citoplasmaticca (citocinesi) che separa le due cellule figlie. Queste due cellule figlie contengono esattamente la stessa quantità di DNA della cellula madre e sono quindi geneticamente identiche. Il ciclo cellulare è fondamentale per la crescita, lo sviluppo, la riparazione dei tessuti e il mantenimento dell'omeostasi tissutale negli organismi viventi. La regolazione del ciclo cellulare è strettamente controllata da una complessa rete di meccanismi di segnalazione che garantiscono la corretta progressione attraverso le fasi del ciclo e impediscono la proliferazione incontrollata delle cellule, riducendo il rischio di sviluppare tumori.
Le proteine dei microfilamenti, note anche come filamenti attinici, sono componenti cruciali del sistema di actina del citoscheletro cellulare. Sono costituite principalmente da actina globulare, una proteina fibrosa che si polimerizza per formare filamenti polarizzati e rigidi.
I microfilamenti svolgono un ruolo fondamentale nella determinazione della forma e della motilità cellulare, nonché nel mantenimento dell'integrità strutturale delle cellule. Essi interagiscono con altre proteine accessorie per formare una rete dinamica di fibre che supportano processi come il trasporto vescicolare, la divisione cellulare e l'adesione cellulare.
Le proteine dei microfilamenti sono anche bersaglio di molti patogeni intracellulari, che sfruttano queste strutture per entrare nelle cellule ospiti e replicarsi all'interno di esse. La disregolazione delle proteine dei microfilamenti è stata associata a diverse malattie umane, tra cui la distrofia muscolare, alcune forme di cardiopatie e il cancro.
La cromatografia ad affinità è una tecnica di separazione e purificazione di molecole basata sulla loro interazione specifica e reversibile con un ligando (una piccola molecola o una biomolecola) legato a una matrice solida. Questa tecnica sfrutta la diversa affinità delle diverse specie molecolari per il ligando, che può essere un anticorpo, un enzima, una proteina ricca di istidina o una sequenza di DNA, tra gli altri.
Nel processo di cromatografia ad affinità, la miscela da separare viene applicata alla colonna contenente il ligando legato alla matrice solida. Le molecole che interagiscono con il ligando vengono trattenute dalla matrice, mentre le altre molecole della miscela scorrono attraverso la colonna. Successivamente, la matrice viene eluita (lavata) con una soluzione appropriata per rilasciare le molecole trattenute. Le molecole che hanno interagito più fortemente con il ligando vengono eluate per ultime.
La cromatografia ad affinità è una tecnica molto utile in biologia molecolare, biochimica e farmacologia, poiché consente di purificare proteine, anticorpi, enzimi, recettori e altri ligandi con elevata selettività ed efficienza. Tuttavia, la sua applicazione è limitata dalla necessità di disporre di un ligando specifico per la molecola target e dal costo della matrice e del ligando stessi.
I recettori degli ormoni tiroidei (ROT) sono proteine transmembrana e citoplasmatiche che si legano specificamente agli ormoni tiroidei triiodotironina (T3) e tetraiodotironina (T4). Questi recettori appartengono alla superfamiglia dei recettori nucleari, che sono essenzialmente fattori di trascrizione che regolano l'espressione genica una volta attivati dal legame con il loro ligando ormonale.
I ROT si trovano principalmente nel nucleo delle cellule bersaglio e sono presenti in diversi tessuti, come quelli del sistema nervoso centrale, muscolare scheletrico, cardiovascolare, polmonare, gastrointestinale e surrenale. La loro attivazione influenza una vasta gamma di processi fisiologici, tra cui il metabolismo energetico, la crescita e lo sviluppo, la differenziazione cellulare e la funzione immunitaria.
Mutazioni nei geni che codificano per i ROT possono portare a disfunzioni tiroidee e altre patologie endocrine. Inoltre, l'esposizione ambientale a sostanze chimiche con struttura simile agli ormoni tiroidei, noti come disgreganti della plastica o interferenti endocrini, può alterare la funzione dei ROT e contribuire allo sviluppo di varie malattie.
La relazione farmacologica dose-risposta descrive la relazione quantitativa tra la dimensione della dose di un farmaco assunta e l'entità della risposta biologica o effetto clinico che si verifica come conseguenza. Questa relazione è fondamentale per comprendere l'efficacia e la sicurezza di un farmaco, poiché consente ai professionisti sanitari di prevedere gli effetti probabili di dosi specifiche sui pazienti.
La relazione dose-risposta può essere rappresentata graficamente come una curva dose-risposta, che spesso mostra un aumento iniziale rapido della risposta con l'aumentare della dose, seguito da un piatto o una diminuzione della risposta ad alte dosi. La pendenza di questa curva può variare notevolmente tra i farmaci e può essere influenzata da fattori quali la sensibilità individuale del paziente, la presenza di altre condizioni mediche e l'uso concomitante di altri farmaci.
L'analisi della relazione dose-risposta è un aspetto cruciale dello sviluppo dei farmaci, poiché può aiutare a identificare il range di dosaggio ottimale per un farmaco, minimizzando al contempo gli effetti avversi. Inoltre, la comprensione della relazione dose-risposta è importante per la pratica clinica, poiché consente ai medici di personalizzare le dosi dei farmaci in base alle esigenze individuali del paziente e monitorarne attentamente gli effetti.
Gli ovociti, noti anche come cellule uovo o ovuli, sono le più grandi cellule presenti nell'organismo umano. Si tratta delle cellule germinali femminili immaturi che hanno il potenziale di svilupparsi in un embrione dopo la fecondazione con uno spermatozoo.
Gli ovociti sono contenuti nelle ovaie e maturano durante il ciclo mestruale. Durante l'ovulazione, solitamente intorno al 14° giorno del ciclo mestruale, un follicolo ovarico si rompe e rilascia un ovocita maturo nella tuba di Falloppio, dove può essere fecondato da uno spermatozoo.
Gli ovociti contengono la metà del corredo cromosomico necessario per formare un embrione, mentre l'altra metà è fornita dallo spermatozoo maschile durante la fecondazione. Dopo la fecondazione, l'ovocita fecondato diventa uno zigote e inizia a dividersi e a svilupparsi nell'embrione.
È importante notare che la quantità di ovociti presenti nelle ovaie diminuisce con l'età, il che può influenzare la fertilità femminile. In particolare, dopo i 35 anni, la riserva ovarica tende a diminuire più rapidamente, aumentando il rischio di infertilità e di problemi di sviluppo embrionale.
La microscopia confocale è una tecnica avanzata di microscopia che utilizza un sistema di illuminazione e detezione focalizzati per produrre immagini ad alta risoluzione di campioni biologici. Questa tecnica consente l'osservazione ottica di sezioni sottili di un campione, riducendo al minimo il rumore di fondo e migliorando il contrasto dell'immagine.
Nella microscopia confocale, un fascio di luce laser viene focalizzato attraverso un obiettivo su un punto specifico del campione. La luce riflessa o fluorescente da questo punto è quindi raccolta e focalizzata attraverso una lente di ingrandimento su un detector. Un diaframma di pinhole posto davanti al detector permette solo alla luce proveniente dal piano focale di passare, mentre blocca la luce fuori fuoco, riducendo così il rumore di fondo e migliorando il contrasto dell'immagine.
Questa tecnica è particolarmente utile per l'osservazione di campioni vivi e di tessuti sottili, come le cellule e i tessuti nervosi. La microscopia confocale può anche essere utilizzata in combinazione con altre tecniche di imaging, come la fluorescenza o la two-photon excitation microscopy, per ottenere informazioni più dettagliate sui campioni.
In sintesi, la microscopia confocale è una tecnica avanzata di microscopia che utilizza un sistema di illuminazione e detezione focalizzati per produrre immagini ad alta risoluzione di campioni biologici, particolarmente utile per l'osservazione di campioni vivi e di tessuti sottili.
La cromatografia su gel è una tecnica di laboratorio utilizzata in ambito biochimico e biologico per separare, identificare e purificare macromolecole, come proteine, acidi nucleici (DNA e RNA) e carboidrati. Questa tecnica si basa sulla diversa velocità di migrazione delle molecole attraverso un gel poroso a grana fine, costituito solitamente da agarosio o acrilammide.
Il campione contenente le macromolecole da separare viene applicato su una linea di partenza del gel e quindi sottoposto ad un gradiente di concentrazione chimica (solitamente un sale o un detergentes) o a un campo elettrico. Le molecole presenti nel campione migreranno attraverso il gel con velocità diverse, in base alle loro dimensioni, forma e carica superficiale. Le macromolecole più grandi o con una maggiore carica migreranno più lentamente rispetto a quelle più piccole o meno cariche.
Una volta completata la migrazione, le bande di proteine o acidi nucleici separati possono essere visualizzate tramite colorazione specifica per ogni tipologia di molecola. Ad esempio, le proteine possono essere colorate con blu di Coomassie o argento, mentre gli acidi nucleici con bromuro di etidio o silver staining.
La cromatografia su gel è una tecnica fondamentale in diversi campi della ricerca biologica e medica, come la proteomica, la genetica e la biologia molecolare, poiché permette di analizzare e confrontare l'espressione e la purezza delle proteine o degli acidi nucleici di interesse.
Gli oligodeossiribonucleotidi (ODN) sono brevi segmenti di DNA sintetici che contengono generalmente da 15 a 30 basi deossiribosidiche. Gli ODN possono essere modificati chimicamente per migliorare la loro stabilità, specificità di legame e attività biologica.
Gli oligodeossiribonucleotidi sono spesso utilizzati in ricerca scientifica come strumenti per regolare l'espressione genica, attraverso meccanismi come il blocco della traduzione o l'attivazione/repressione della trascrizione. Possono anche essere utilizzati come farmaci antisenso o come immunostimolanti, in particolare per quanto riguarda la terapia del cancro e delle malattie infettive.
Gli ODN possono essere modificati con gruppi chimici speciali, come le catene laterali di zucchero modificate o i gruppi terminale di fosfato modificati, per migliorare la loro affinità di legame con il DNA bersaglio o per proteggerle dalla degradazione enzimatica. Alcuni ODN possono anche essere dotati di gruppi chimici che conferiscono proprietà fluorescenti, magnetiche o radioattive, rendendoli utili come marcatori molecolari in esperimenti di biologia cellulare e molecolare.
In sintesi, gli oligodeossiribonucleotidi sono brevi segmenti di DNA sintetici che possono essere utilizzati per regolare l'espressione genica, come farmaci antisenso o immunostimolanti, e come strumenti di ricerca in biologia molecolare.
La distribuzione nei tessuti, in campo medico e farmacologico, si riferisce al processo attraverso cui un farmaco o una sostanza chimica si diffonde dalle aree di somministrazione a diversi tessuti e fluidi corporei. Questo processo è influenzato da fattori quali la liposolubilità o idrosolubilità del farmaco, il flusso sanguigno nei tessuti, la perfusione (l'afflusso di sangue ricco di ossigeno in un tessuto), la dimensione molecolare del farmaco e il grado di legame del farmaco con le proteine plasmatiche.
La distribuzione dei farmaci nei tessuti è una fase importante nel processo farmacocinetico, che comprende anche assorbimento, metabolismo ed eliminazione. Una buona comprensione della distribuzione dei farmaci può aiutare a prevedere e spiegare le differenze interindividuali nelle risposte ai farmaci, nonché ad ottimizzare la terapia farmacologica per massimizzarne l'efficacia e minimizzarne gli effetti avversi.
La "Molecular Sequence Annotation" o annotazione della sequenza molecolare è un processo utilizzato in genetica e biologia molecolare per assegnare funzioni, caratteristiche o proprietà a specifiche sequenze di DNA, RNA o proteine. Questo processo comporta l'identificazione di regioni codificanti, siti di legame delle proteine, motivi strutturali e altre informazioni rilevanti che possono essere utilizzate per comprendere meglio la funzione e il ruolo della sequenza molecolare nell'organismo.
L'annotazione della sequenza molecolare può essere eseguita manualmente o tramite l'uso di software automatizzati che utilizzano algoritmi di ricerca di pattern, machine learning o approcci basati sull'intelligenza artificiale per prevedere le funzioni delle sequenze. Tuttavia, a causa della complessità e della variabilità delle sequenze molecolari, l'annotazione manuale eseguita da esperti umani è spesso considerata la forma più accurata di annotazione.
L'annotazione della sequenza molecolare è un passo cruciale nell'analisi dei dati genomici e transcrittomici, poiché fornisce informazioni importanti sulla funzione delle sequenze e su come esse interagiscono con altre molecole all'interno dell'organismo. Queste informazioni possono essere utilizzate per identificare geni associati a malattie, sviluppare farmaci mirati e comprendere meglio i processi biologici alla base della vita.
La reazione di polimerizzazione a catena dopo trascrizione inversa (RC-PCR) è una tecnica di biologia molecolare che combina la retrotrascrizione dell'RNA in DNA complementare (cDNA) con la reazione di amplificazione enzimatica della catena (PCR) per copiare rapidamente e specificamente segmenti di acido nucleico. Questa tecnica è ampiamente utilizzata nella ricerca biomedica per rilevare, quantificare e clonare specifiche sequenze di RNA in campioni biologici complessi.
Nella fase iniziale della RC-PCR, l'enzima reverse transcriptasi converte l'RNA target in cDNA utilizzando un primer oligonucleotidico specifico per il gene di interesse. Il cDNA risultante funge da matrice per la successiva amplificazione enzimatica della catena, che viene eseguita utilizzando una coppia di primer che flankano la regione del gene bersaglio desiderata. Durante il ciclo termico di denaturazione, allungamento ed ibridazione, la DNA polimerasi estende i primer e replica il segmento di acido nucleico target in modo esponenziale, producendo milioni di copie del frammento desiderato.
La RC-PCR offre diversi vantaggi rispetto ad altre tecniche di amplificazione dell'acido nucleico, come la sensibilità, la specificità e la velocità di esecuzione. Tuttavia, è anche suscettibile a errori di contaminazione e artifatti di amplificazione, pertanto è fondamentale seguire rigorose procedure di laboratorio per prevenire tali problemi e garantire risultati accurati e riproducibili.
L'idrolisi è un processo chimico che si verifica quando una molecola è divisa in due o più molecole più piccole con l'aggiunta di acqua. Nella reazione, l'acqua serve come solvente e contribuisce ai gruppi funzionali polari (-OH e -H) che vengono aggiunti alle molecole separate.
In un contesto medico-biologico, l'idrolisi è particolarmente importante nelle reazioni enzimatiche, dove gli enzimi catalizzano la rottura di legami chimici in molecole complesse come proteine, carboidrati e lipidi. Ad esempio, durante la digestione, enzimi specifici idrolizzano le grandi molecole alimentari nei loro costituenti più semplici, facilitandone così l'assorbimento attraverso la parete intestinale.
L'idrolisi è anche un meccanismo importante per la sintesi e la degradazione di macromolecole come polisaccaridi, proteine e lipidi all'interno delle cellule. Questi processi sono fondamentali per la crescita, la riparazione e il mantenimento dei tessuti e degli organismi.
In medicina, il termine "schemi di lettura aperti" non ha una definizione universalmente accettata o un'applicazione clinica specifica. Tuttavia, in un contesto più ampio e teorico, i "schemi di lettura aperti" si riferiscono ad approcci flessibili ed eclettici alla comprensione e all'interpretazione dei testi o dei segni e sintomi clinici.
Nell'ambito della semeiotica medica, i "schemi di lettura aperti" possono riferirsi a strategie di valutazione che considerano una vasta gamma di possibili cause e manifestazioni delle condizioni, piuttosto che limitarsi a un insieme predefinito di diagnosi o ipotesi. Ciò può implicare l'esplorazione di diverse teorie e framework per comprendere i fenomeni clinici, nonché la considerazione di fattori sociali, culturali e individuali che possono influenzare la presentazione e il decorso delle malattie.
In sintesi, sebbene non esista una definizione medica specifica per "schemi di lettura aperti", questo termine può essere utilizzato per descrivere approcci flessibili ed inclusivi alla comprensione e all'interpretazione dei segni e sintomi clinici, che considerano una vasta gamma di fattori e teorie.
L'endocitosi è un processo cellulare fondamentale in cui le membrane cellulari avvolgono attivamente sostanze solide o gocce di liquido dalle aree extracellulari, portandole all'interno della cellula all'interno di vescicole. Questo meccanismo consente alla cellula di acquisire materiali nutritivi, come proteine e lipidi, da ambienti esterni, nonché di degradare e rimuovere agenti patogeni o altre particelle indesiderate. Ci sono diversi tipi di endocitosi, tra cui la fagocitosi (che implica l'ingestione di particelle grandi), la pinocitosi (ingestione di gocce di liquido) e la ricicling endosomiale (trasporto di molecole dalla membrana cellulare all'interno della cellula). L'endocitosi è un processo altamente regolato che richiede l'interazione di una varietà di proteine membrana e citosoliche.
Un embrione non mammifero si riferisce allo stadio di sviluppo di un organismo che non è un mammifero, a partire dalla fertilizzazione fino al punto in cui si verifica la differenziazione degli organi e dei sistemi principali. Questa fase di sviluppo è caratterizzata da rapide divisioni cellulari, migrazione cellulare e formazione di strutture embrionali come blastula, gastrula e organogenesi. La durata di questo stadio dipende dalla specie e può variare notevolmente tra diversi gruppi di animali non mammiferi, come uccelli, rettili, anfibi, pesci e invertebrati.
Durante l'embrionogenesi, le cellule embrionali subiscono una serie di cambiamenti che portano alla formazione dei tessuti e degli organi principali dell'organismo in via di sviluppo. Questo processo è guidato da una complessa interazione di fattori genetici ed epigenetici, insieme a influenze ambientali esterne.
È importante notare che la definizione e la durata dello stadio embrionale possono variare in base alla specie e al contesto di riferimento. Ad esempio, in alcuni contesti, lo stadio embrionale può essere distinto dallo stadio di larva o giovane nei taxa che hanno una fase larvale distinta nel loro ciclo vitale.
L'ibridazione in situ (ISS) è una tecnica di biologia molecolare utilizzata per rilevare e localizzare specifiche sequenze di DNA o RNA all'interno di cellule e tessuti. Questa tecnica consiste nell'etichettare con marcatori fluorescenti o radioattivi una sonda di DNA complementare alla sequenza target, che viene quindi introdotta nelle sezioni di tessuto o cellule intere precedentemente fissate e permeabilizzate.
Durante l'ibridazione in situ, la sonda si lega specificamente alla sequenza target, permettendo così di visualizzare la sua localizzazione all'interno della cellula o del tessuto utilizzando microscopia a fluorescenza o radioattiva. Questa tecnica è particolarmente utile per studiare l'espressione genica a livello cellulare e tissutale, nonché per identificare specifiche specie di patogeni all'interno dei campioni biologici.
L'ibridazione in situ può essere eseguita su diversi tipi di campioni, come ad esempio sezioni di tessuto fresco o fissato, cellule in sospensione o colture cellulari. La sensibilità e la specificità della tecnica possono essere aumentate utilizzando sonde marcate con diversi coloranti fluorescenti o combinando l'ibridazione in situ con altre tecniche di biologia molecolare, come ad esempio l'amplificazione enzimatica del DNA (PCR).
Le proteine oncosoppressori sono proteine che normalmente regolano il ciclo cellulare, la proliferazione e l'apoptosi (morte cellulare programmata) in modo da prevenire la trasformazione delle cellule normali in cellule tumorali. Quando tali proteine sono mutate, deficitarie o assenti, possono verificarsi disregolazioni che portano all'insorgenza di tumori e alla progressione del cancro. Un esempio ben noto di proteina oncosoppressore è il gene suppressore del tumore p53, che svolge un ruolo cruciale nella prevenzione della cancerogenesi attraverso la riparazione del DNA danneggiato o l'induzione dell'apoptosi nelle cellule con danni al DNA irreparabili. Quando il gene p53 è mutato o non funzionante, le cellule possono accumulare danni al DNA e proliferare incontrollatamente, contribuendo allo sviluppo del cancro.
La replicazione del DNA è un processo fondamentale nella biologia cellulare che consiste nella duplicazione del materiale genetico delle cellule. Più precisamente, si riferisce alla produzione di due identiche molecole di DNA a partire da una sola molecola madre, utilizzando la molecola complementare come modello per la sintesi.
Questo processo è essenziale per la crescita e la divisione cellulare, poiché garantisce che ogni cellula figlia riceva una copia identica del materiale genetico della cellula madre. La replicazione del DNA avviene durante la fase S del ciclo cellulare, subito dopo l'inizio della mitosi o meiosi.
Il processo di replicazione del DNA inizia con l'apertura della doppia elica del DNA da parte dell'elicasi, che separa le due catene complementari. Successivamente, le due eliche separate vengono ricoperte da proteine chiamate single-strand binding proteins (SSBP) per prevenirne il riavvolgimento.
A questo punto, entra in gioco l'enzima DNA polimerasi, che sintetizza nuove catene di DNA utilizzando le catene originali come modelli. La DNA polimerasi si muove lungo la catena di DNA e aggiunge nucleotidi uno alla volta, formando legami fosfodiesterici tra di essi. Poiché il DNA è una molecola antiparallela, le due eliche separate hanno polarità opposte, quindi la sintesi delle nuove catene procede in direzioni opposte a partire dal punto di origine della replicazione.
La DNA polimerasi ha anche un'importante funzione di proofreading (controllo dell'errore), che le permette di verificare e correggere eventuali errori di inserimento dei nucleotidi durante la sintesi. Questo meccanismo garantisce l'accuratezza della replicazione del DNA, con un tasso di errore molto basso (circa 1 su 10 milioni di basi).
Infine, le due nuove catene di DNA vengono unite da enzimi chiamati ligasi, che formano legami covalenti tra i nucleotidi adiacenti. Questo processo completa la replicazione del DNA e produce due molecole identiche della stessa sequenza, ognuna delle quali contiene una nuova catena di DNA e una catena originale.
In sintesi, la replicazione del DNA è un processo altamente accurato e coordinato che garantisce la conservazione dell'integrità genetica durante la divisione cellulare. Grazie all'azione combinata di enzimi come le DNA polimerasi e le ligasi, il DNA viene replicato con grande precisione, minimizzando così il rischio di mutazioni dannose per l'organismo.
In genetica, un allele è una delle varie forme alternative di un gene che possono esistere alla stessa posizione (locus) su un cromosoma. Gli alleli si verificano quando ci sono diverse sequenze nucleotidiche in un gene e possono portare a differenze fenotipiche, il che significa che possono causare differenze nella comparsa o nell'funzionamento di un tratto o caratteristica.
Ad esempio, per il gene che codifica per il gruppo sanguigno ABO umano, ci sono tre principali alleli: A, B e O. Questi alleli determinano il tipo di gruppo sanguigno di una persona. Se una persona ha due copie dell'allele A, avrà il gruppo sanguigno di tipo A. Se ha due copie dell'allele B, avrà il gruppo sanguigno di tipo B. Se ha un allele A e un allele B, avrà il gruppo sanguigno di tipo AB. Infine, se una persona ha due copie dell'allele O, avrà il gruppo sanguigno di tipo O.
In alcuni casi, avere diversi alleli per un gene può portare a differenze significative nel funzionamento del gene e possono essere associati a malattie o altri tratti ereditari. In altri casi, i diversi alleli di un gene possono non avere alcun effetto evidente sul fenotipo della persona.
In chimica e biochimica, un legame idrogeno è un tipo specifico di interazione dipolo-dipolo debole che si verifica quando un atomo di idrogeno, legato covalentemente a un atomo elettronegativo come l'ossigeno, il fluoro o l'azoto, viene attratto da un altro atomo elettronegativo nelle vicinanze. Questa interazione è rappresentata simbolicamente come A-H...B, dove A e B sono elettronegativi e H è idrogeno. Il legame idrogeno è significativamente più debole di un tipico legame covalente o ionico e si spezza facilmente a temperatura ambiente. Tuttavia, i legami idrogeno svolgono comunque un ruolo cruciale in molti processi chimici e biologici, compresi la struttura dell'acqua, le proprietà delle soluzioni acquose, il riconoscimento molecolare e la catalisi enzimatica.
Il genoma fungino si riferisce all'intero insieme di materiale genetico presente in un fungo. Un genoma è l'insieme completo delle informazioni ereditarie contenute nel DNA di una cellula, ed è costituito da diversi tipi di molecole, tra cui i geni che codificano per proteine e gli elementi regolatori che controllano l'espressione genica.
Il genoma fungino è stato studiato ampiamente negli ultimi anni grazie allo sviluppo di tecnologie di sequenziamento del DNA ad alta velocità e a basso costo. Questo ha permesso di ottenere informazioni dettagliate sulla struttura, l'organizzazione e la funzione dei geni e degli altri elementi che compongono il genoma di diversi funghi.
L'analisi del genoma fungino può fornire informazioni importanti sulla biologia di questi organismi, tra cui la loro capacità di causare malattie negli esseri umani e negli altri animali, la loro interazione con l'ambiente e la loro evoluzione. Inoltre, lo studio del genoma fungino può aiutare a identificare nuovi bersagli terapeutici per il trattamento delle infezioni fungine e a sviluppare strategie di controllo delle malattie causate da questi organismi.
Il test di complementazione genetica è una tecnica di laboratorio utilizzata per identificare il locus specifico di un gene responsabile di una determinata malattia o fenotipo. Viene eseguito incrociando due individui geneticamente diversi che presentano entrambe le mutazioni in un singolo gene, ma in differenti posizioni (chiamate alleli).
I neuroni sono cellule specializzate del sistema nervoso che elaborano e trasmettono informazioni sotto forma di segnali elettrici e chimici. Sono costituiti da diversi compartimenti funzionali: il corpo cellulare (o soma), i dendriti e l'assone. Il corpo cellulare contiene il nucleo e la maggior parte degli organelli, mentre i dendriti sono brevi prolungamenti che ricevono input da altri neuroni o cellule effettrici. L'assone è un lungo prolungamento che può raggiungere anche diversi centimetri di lunghezza e serve a trasmettere il potenziale d'azione, il segnale elettrico generato dal neurone, ad altre cellule bersaglio.
I neuroni possono essere classificati in base alla loro forma, funzione e connettività. Alcuni tipi di neuroni includono i neuroni sensoriali, che rilevano stimoli dall'ambiente esterno o interno; i neuroni motori, che inviano segnali ai muscoli per provocare la contrazione; e i neuroni interneuroni, che collegano tra loro diversi neuroni formando circuiti neurali complessi.
La comunicazione tra i neuroni avviene attraverso sinapsi, giunzioni specializzate dove l'assone di un neurone pre-sinaptico entra in contatto con il dendrite o il corpo cellulare di un neurone post-sinaptico. Quando un potenziale d'azione raggiunge la terminazione sinaptica, induce il rilascio di neurotrasmettitori che diffondono nello spazio sinaptico e legano specifici recettori presenti sulla membrana plasmatica del neurone post-sinaptico. Questo legame determina l'apertura di canali ionici, alterando il potenziale di membrana del neurone post-sinaptico e dando origine a una risposta elettrica o chimica che può propagarsi all'interno della cellula.
I disturbi del sistema nervoso possono derivare da alterazioni nella struttura o nella funzione dei neuroni, delle sinapsi o dei circuiti neurali. Ad esempio, malattie neurodegenerative come il morbo di Alzheimer e il morbo di Parkinson sono caratterizzate dalla perdita progressiva di specifiche popolazioni di neuroni, mentre disordini psichiatrici come la depressione e la schizofrenia possono essere associati a alterazioni nella trasmissione sinaptica o nell'organizzazione dei circuiti neurali.
La neuroscienza è lo studio interdisciplinare del sistema nervoso, che integra conoscenze provenienti da diverse discipline come la biologia molecolare, la fisiologia, l'anatomia, la psicologia e la matematica per comprendere i meccanismi alla base della funzione cerebrale. Gli approcci sperimentali impiegati nella neuroscienza includono tecniche di registrazione elettrofisiologica, imaging ottico e di risonanza magnetica, manipolazione genetica e comportamentale, nonché modellazione computazionale.
La neuroscienza ha contribuito a far luce su molti aspetti della funzione cerebrale, come la percezione sensoriale, il movimento, l'apprendimento, la memoria, le emozioni e il pensiero. Tuttavia, rimangono ancora numerose domande irrisolte riguardanti i meccanismi alla base della cognizione e del comportamento umano. La neuroscienza continua a evolvere come disciplina, con l'obiettivo di fornire una comprensione sempre più approfondita dei principi fondamentali che governano il funzionamento del cervello e delle sue patologie.
In medicina, un esone è una porzione di un gene che codifica per una proteina o parte di una proteina. Più specificamente, si riferisce a una sequenza di DNA che, dopo la trascrizione in RNA, non viene rimossa durante il processo di splicing dell'RNA. Di conseguenza, l'esone rimane nella molecola di RNA maturo e contribuisce alla determinazione della sequenza aminoacidica finale della proteina tradotta.
Il processo di splicing dell'RNA è un meccanismo importante attraverso il quale le cellule possono generare una diversità di proteine a partire da un numero relativamente limitato di geni. Questo perché molti geni contengono sequenze ripetute o non codificanti, note come introni, intervallate da esoni. Durante il splicing, gli introni vengono rimossi e gli esoni adiacenti vengono uniti insieme, dando origine a una molecola di RNA maturo che può essere poi tradotta in una proteina funzionale.
Tuttavia, è importante notare che il processo di splicing non è sempre costante e prevedibile. Al contrario, può variare in modo condizionale o soggettivo a seconda del tipo cellulare, dello sviluppo dell'organismo o della presenza di determinate mutazioni genetiche. Questa variazione nella selezione degli esoni e nel loro ordine di combinazione può portare alla formazione di diverse isoforme proteiche a partire dal medesimo gene, con conseguenze importanti per la fisiologia e la patologia dell'organismo.
La spettrometria di fluorescenza è una tecnica spettroscopica che misura la luminescenza emessa da una sostanza (fluoroforo) dopo l'assorbimento di radiazioni elettromagnetiche, generalmente nel campo dell'ultravioletto o della luce visibile. Quando il fluoroforo assorbe energia, uno o più elettroni vengono eccitati a livelli energetici superiori. Durante il ritorno alla condizione di riposo, l'eccitazione degli elettroni decade e viene emessa radiazioni elettromagnetiche con una lunghezza d'onda diversa (di solito più lunga) rispetto a quella assorbita. Questa differenza di lunghezza d'onda è nota come spostamento di Stokes.
Lo spettrometro di fluorescenza separa la luce emessa in base alla sua lunghezza d'onda e misura l'intensità relativa della luminescenza per ogni lunghezza d'onda, producendo uno spettro di emissione. Questo spettro può fornire informazioni qualitative e quantitative sui componenti fluorescenti presenti nel campione, inclusa la loro concentrazione e l'ambiente molecolare circostante.
La spettrometria di fluorescenza è ampiamente utilizzata in vari campi, tra cui la chimica analitica, la biologia molecolare, la farmacologia e la medicina forense, per applicazioni che vanno dall'identificazione delle specie chimiche allo studio delle interazioni molecolari. Tuttavia, è importante notare che la misura della fluorescenza può essere influenzata da fattori ambientali come la presenza di assorbitori o emettitori di luce aggiuntivi, alterando potenzialmente l'accuratezza e l'affidabilità dei risultati.
I fattori di allungamento della trascrizione sono proteine o molecole che interagiscono con l'enzima RNA polimerasi e aumentano la durata del processo di inizio della trascrizione dei geni. Questi fattori svolgono un ruolo cruciale nell'amplificare l'espressione genica, specialmente per i geni che richiedono una maggiore produzione di mRNA. Essi facilitano il reclutamento dell'RNA polimerasi al promotore del gene e promuovono la formazione della bolla di trascrizione, aumentando così l'efficienza e la velocità del processo di inizio della trascrizione. I fattori di allungamento della trascrizione sono essenziali per il corretto funzionamento delle cellule e sono spesso regolati in modo complesso per garantire l'espressione genica appropriata in risposta a vari segnali cellulari e ambientali.
Le glicoproteine della membrana sono proteine transmembrana che contengono domini glucidici covalentemente legati. Questi zuccheri possono essere attaccati alla proteina in diversi punti, compresi i residui di asparagina (N-linked), serina/treonina (O-linked) o entrambi. Le glicoproteine della membrana svolgono una varietà di funzioni importanti, tra cui il riconoscimento cellulare, l'adesione e la segnalazione.
Le glicoproteine della membrana sono costituite da un dominio idrofobico che attraversa la membrana lipidica e da domini idrofilici situati su entrambi i lati della membrana. Il dominio idrofobo è composto da una sequenza di aminoacidi idrofobici che interagiscono con i lipidi della membrana, mentre i domini idrofili sono esposti all'ambiente acquoso all'interno o all'esterno della cellula.
Le glicoproteine della membrana possono essere classificate in base alla loro localizzazione e funzione. Alcune glicoproteine della membrana si trovano sulla superficie esterna della membrana plasmatica, dove svolgono funzioni di riconoscimento cellulare e adesione. Altre glicoproteine della membrana sono localizzate all'interno della cellula, dove svolgono funzioni di trasduzione del segnale e regolazione dell'attività enzimatica.
Le glicoproteine della membrana sono importanti bersagli per i virus e altri patogeni che utilizzano queste proteine per legarsi e infettare le cellule ospiti. Inoltre, le mutazioni nelle glicoproteine della membrana possono essere associate a malattie genetiche, come la fibrosi cistica e alcune forme di distrofia muscolare.
In sintesi, le glicoproteine della membrana sono una classe importante di proteine che svolgono funzioni vitali nella cellula, tra cui il riconoscimento cellulare, l'adesione e la trasduzione del segnale. La loro localizzazione e funzione specifiche dipendono dalla loro struttura e composizione glicanica, che possono essere modificate in risposta a stimoli ambientali o fisiologici. Le glicoproteine della membrana sono anche importanti bersagli per i virus e altri patogeni, nonché per lo sviluppo di farmaci e terapie innovative.
In medicina, una "mappa di restrizione" (o "mappa di restrizioni enzimatiche") si riferisce a un diagramma schematico che mostra la posizione e il tipo di siti di taglio per specifiche endonucleasi di restrizione su un frammento di DNA. Le endonucleasi di restrizione sono enzimi che taglano il DNA in punti specifici, detti siti di restrizione, determinati dalla sequenza nucleotidica.
La mappa di restrizione è uno strumento importante nell'analisi del DNA, poiché consente di identificare e localizzare i diversi frammenti di DNA ottenuti dopo la digestione con enzimi di restrizione. Questa rappresentazione grafica fornisce informazioni cruciali sulla struttura e l'organizzazione del DNA, come ad esempio il numero e la dimensione dei frammenti, la distanza tra i siti di taglio, e la presenza o assenza di ripetizioni sequenziali.
Le mappe di restrizione sono comunemente utilizzate in diverse applicazioni della biologia molecolare, come il clonaggio, l'ingegneria genetica, l'analisi filogenetica e la diagnosi di malattie genetiche.
La serina è un aminoacido non essenziale, il che significa che l'organismo può sintetizzarlo da altri composti. Il suo nome sistematico è acido 2-ammino-3-idrossipropanoico. La serina contiene un gruppo laterale idrossilico (-OH) ed è classificata come aminoacido polare e neutro.
La serina svolge un ruolo importante nel metabolismo degli acidi grassi, nella sintesi della fosfatidilserina (un componente delle membrane cellulari), nell'attivazione di alcuni enzimi e nella trasmissione degli impulsi nervosi.
Inoltre, la serina è un precursore per la sintesi di altri aminoacidi, compreso la glicina, e di alcune molecole biologicamente attive, come il neurotrasmettitore acido γ-amminobutirrico (GABA).
La serina può essere trovata in diverse proteine strutturali e enzimi. È presente anche nel glucosio, un carboidrato semplice che funge da fonte di energia per l'organismo.
In termini medici, la temperatura corporea è un indicatore della temperatura interna del corpo ed è generalmente misurata utilizzando un termometro sotto la lingua, nel retto o nell'orecchio. La normale temperatura corporea a riposo per un adulto sano varia da circa 36,5°C a 37,5°C (97,7°F a 99,5°F), sebbene possa variare leggermente durante il giorno e in risposta all'esercizio fisico, all'assunzione di cibo o ai cambiamenti ambientali.
Tuttavia, una temperatura superiore a 38°C (100,4°F) è generalmente considerata febbre e può indicare un'infezione o altri processi patologici che causano l'infiammazione nel corpo. Una temperatura inferiore a 35°C (95°F) è nota come ipotermia e può essere pericolosa per la vita, specialmente se persiste per un lungo periodo di tempo.
Monitorare la temperatura corporea è quindi un importante indicatore della salute generale del corpo e può fornire informazioni cruciali sulla presenza di malattie o condizioni mediche sottostanti.
In campo medico, la cristallizzazione si riferisce al processo di formazione di un cristallo solidificato da una sostanza che era precedentemente in soluzione o in stato liquido. Questo fenomeno è particolarmente importante in patologia clinica, dove la cristallizzazione di determinate sostanze all'interno del corpo può portare a diverse condizioni patologiche. Ad esempio, la formazione di cristalli di acido urico nei reni o nelle articolazioni è responsabile della gotta e dei calcoli renali. Allo stesso modo, la deposizione di cristalli di colesterolo nelle pareti arteriose può portare alla formazione di placche aterosclerotiche, aumentando il rischio di malattie cardiovascolari.
La comprensione del processo di cristallizzazione è fondamentale per la diagnosi e il trattamento di queste condizioni, poiché spesso l'identificazione dei cristalli all'interno dei tessuti o dei fluidi corporei può confermare la presenza della malattia. Inoltre, la modifica delle condizioni che favoriscono la cristallizzazione, come il controllo del pH o dell'iperuricemia, può essere un approccio terapeutico efficace per prevenire le recidive di queste patologie.
L'alanina è un aminoacido alpha-cheto, che viene classificato come glucogenico perché può essere convertito nel glucosio attraverso il ciclo di Krebs. Si trova comunemente negli alimenti ricchi di proteine e può anche essere sintetizzato dal corpo utilizzando altri aminoacidi.
L'alanina svolge un ruolo importante nel metabolismo energetico del corpo, poiché può essere utilizzata come fonte di energia dai muscoli scheletrici e dal tessuto cerebrale. Inoltre, l'alanina trasporta l'ammoniaca dai tessuti periferici al fegato, dove viene convertita in urea e quindi eliminata dal corpo attraverso i reni.
L'alanina transaminasi (ALT) è un enzima presente nel fegato, nelle cellule muscolari e in altri tessuti del corpo. Quando queste cellule vengono danneggiate o distrutte, l'ALT viene rilasciato nel sangue, causando un aumento dei livelli di ALT nel siero. Pertanto, i livelli elevati di ALT possono essere utilizzati come marker di danni al fegato o ad altri tessuti del corpo.
L'apoptosi è un processo programmato di morte cellulare che si verifica naturalmente nelle cellule multicellulari. È un meccanismo importante per l'eliminazione delle cellule danneggiate, invecchiate o potenzialmente cancerose, e per la regolazione dello sviluppo e dell'homeostasi dei tessuti.
Il processo di apoptosi è caratterizzato da una serie di cambiamenti cellulari specifici, tra cui la contrazione del citoplasma, il ripiegamento della membrana plasmatica verso l'interno per formare vescicole (blebbing), la frammentazione del DNA e la formazione di corpi apoptotici. Questi corpi apoptotici vengono quindi fagocitati da cellule immunitarie specializzate, come i macrofagi, evitando così una risposta infiammatoria dannosa per l'organismo.
L'apoptosi può essere innescata da diversi stimoli, tra cui la privazione di fattori di crescita o di attacco del DNA, l'esposizione a tossine o radiazioni, e il rilascio di specifiche molecole segnale. Il processo è altamente regolato da una rete complessa di proteine pro- e anti-apoptotiche che interagiscono tra loro per mantenere l'equilibrio tra la sopravvivenza e la morte cellulare programmata.
Un'alterazione del processo di apoptosi è stata associata a diverse malattie, tra cui il cancro, le malattie neurodegenerative e le infezioni virali.
La differenziazione cellulare è un processo biologico attraverso il quale una cellula indifferenziata o poco differenziata si sviluppa in una cellula specializzata con caratteristiche e funzioni distintive. Durante questo processo, le cellule subiscono una serie di cambiamenti morfologici e biochimici che portano all'espressione di un particolare insieme di geni responsabili della produzione di proteine specifiche per quella cellula. Questi cambiamenti consentono alla cellula di svolgere funzioni specializzate all'interno di un tessuto o organo.
La differenziazione cellulare è un processo cruciale nello sviluppo embrionale e nella crescita degli organismi, poiché permette la formazione dei diversi tipi di tessuti e organi necessari per la vita. Anche nelle cellule adulte, la differenziazione cellulare è un processo continuo che avviene durante il rinnovamento dei tessuti e la riparazione delle lesioni.
La differenziazione cellulare è regolata da una complessa rete di segnali intracellulari e intercellulari che controllano l'espressione genica e la modifica delle proteine. Questi segnali possono provenire dall'ambiente esterno, come fattori di crescita e morfogenetici, o da eventi intracellulari, come il cambiamento del livello di metilazione del DNA o della modificazione delle proteine.
La differenziazione cellulare è un processo irreversibile che porta alla perdita della capacità delle cellule di dividersi e riprodursi. Tuttavia, in alcuni casi, le cellule differenziate possono essere riprogrammate per diventare pluripotenti o totipotenti, ovvero capaci di differenziarsi in qualsiasi tipo di cellula del corpo. Questa scoperta ha aperto nuove prospettive per la terapia delle malattie degenerative e il trapianto di organi.
In medicina, il termine "geni fungini" non è comunemente utilizzato o riconosciuto. Tuttavia, in un contesto scientifico e genetico più ampio, i geni fungini si riferiscono ai geni presenti nel DNA dei funghi. I funghi sono organismi eucarioti che comprendono diversi gruppi, come lieviti, muffe e miceti. Il loro genoma contiene informazioni ereditarie essenziali per la loro crescita, sviluppo e sopravvivenza.
I ricercatori studiano i geni fungini per comprendere meglio le basi molecolari della fisiologia dei funghi, nonché per identificare potenziali bersagli terapeutici contro malattie causate da funghi come candidosi, aspergillosi e altri tipi di infezioni micotiche.
In sintesi, i geni fungini sono i segmenti del DNA che codificano le informazioni genetiche necessarie per la crescita, lo sviluppo e la sopravvivenza dei funghi.
L'istone deacetilasi (HDAC) è un enzima che catalizza la rimozione degli acetili dalle code N-terminali dell'istone, che sono molecole proteiche che compongono i nucleosomi, le unità di base della cromatina. La deacetilazione dell'istone provoca un cambiamento nella struttura della cromatina, passando da una forma "aperta" e trascrivibile a una forma "chiusa" e non trascrivibile. Di conseguenza, l'HDAC svolge un ruolo importante nel regolare l'espressione genica, la differenziazione cellulare, la proliferazione cellulare e l'apoptosi.
L'HDAC è anche noto per essere coinvolto nella patogenesi di varie malattie, come il cancro, le malattie neurodegenerative e le malattie cardiovascolari. Pertanto, gli inibitori dell'HDAC sono stati studiati come potenziali farmaci per il trattamento di queste condizioni. Tuttavia, l'uso degli inibitori dell'HDAC è limitato dalla loro tossicità e specificità insufficienti.
In sintesi, l'istone deacetilasi è un enzima che regola l'espressione genica attraverso la modifica della struttura della cromatina. Il suo ruolo nella patogenesi di varie malattie lo rende un bersaglio terapeutico promettente, sebbene siano necessari ulteriori studi per sviluppare inibitori più specifici e meno tossici dell'HDAC.
La stabilità della proteina si riferisce alla capacità di una proteina di mantenere la sua struttura tridimensionale e funzionalità in un determinato ambiente. Le proteine sono costituite da catene di aminoacidi ed esistono in equilibrio dinamico con le loro forme parzialmente piegate o denaturate. La stabilità della proteina è il risultato dell'equilibrio tra queste due forme e può essere influenzata da diversi fattori, come la concentrazione di ioni, pH, temperatura e presenza di ligandi o altri molecole.
La stabilità termodinamica di una proteina è definita come la differenza di energia libera tra la forma denaturata e la forma nativa della proteina. Una proteina con un'elevata stabilità termodinamica richiede più energia per passare dalla forma nativa alla forma denaturata, il che significa che è meno incline a subire cambiamenti conformazionali indotti da fattori ambientali.
La stabilità cinetica di una proteina si riferisce al tasso di transizione tra la forma nativa e la forma denaturata. Una proteina con una elevata stabilità cinetica ha un tasso di transizione più lento, il che significa che è meno incline a subire cambiamenti conformazionali indotti da fattori ambientali nel breve termine.
La stabilità della proteina è importante per la sua funzione e la sua sopravvivenza nell'organismo. Una proteina instabile può aggregare, precipitare o subire modifiche conformazionali che ne impediscono la corretta funzionalità. La comprensione dei meccanismi che regolano la stabilità delle proteine è quindi fondamentale per comprendere le basi molecolari delle malattie e per lo sviluppo di farmaci e terapie innovative.
L'actina è una proteina globulare che si trova nelle cellule di tutti gli organismi viventi. È un componente fondamentale del citoscheletro, il sistema di supporto e struttura della cellula. L'actina può esistere in due forme: come monomero globulare chiamato actina G ed è presente nel citoplasma; o come polimero filamentoso chiamato microfilamento (F-actina), che si forma quando gli actina G si uniscono tra loro.
Gli actina G sono assemblati in microfilamenti durante processi cellulari dinamici, come il movimento citoplasmatico, la divisione cellulare e il cambiamento di forma della cellula. I microfilamenti possono essere organizzati in reticoli o fasci che forniscono supporto meccanico alla cellula e partecipano al mantenimento della sua forma. Inoltre, i microfilamenti svolgono un ruolo importante nella motilità cellulare, nell'endocitosi e nell'esocitosi, nel trasporto intracellulare e nella regolazione dell'adesione cellula-matrice extracellulare.
L'actina è anche soggetta a modificazioni post-traduzionali che ne influenzano la funzione e l'interazione con altre proteine. Ad esempio, la fosforilazione dell'actina può regolare il suo legame con le proteine di legame dell'actina, alterando così la dinamica dei microfilamenti.
In sintesi, l'actina è una proteina essenziale per la struttura e la funzione cellulare, che partecipa a molti processi cellulari dinamici e interagisce con altre proteine per regolare le sue funzioni.
Le Sequenze Ripetitive degli Acidi Nucleici (NRPS, dall'inglese Non-ribosomal Peptide Synthetases) sono un tipo di sistemi enzimatici che sintetizzano peptidi senza l'utilizzo del ribosoma. Queste sequenze sono costituite da moduli enzimatici, ognuno dei quali è responsabile della formazione di un legame peptidico tra due aminoacidi. Ogni modulo contiene tre domini enzimatici principali: uno adenilante/condensazione (A), uno peptidil carrier protein (PCP) e uno che catalizza la formazione del legame peptidico (C).
Le NRPS sono in grado di sintetizzare una vasta gamma di peptidi, compresi alcuni con strutture altamente complesse e non standard. Queste sequenze enzimatiche sono presenti in molti organismi, tra cui batteri, funghi e piante, e sono responsabili della produzione di una varietà di metaboliti secondari, come antibiotici, toxine e siderofori.
Le NRPS sono anche note per la loro capacità di produrre peptidi con aminoacidi non proteinogenici, cioè aminoacidi che non sono codificati dal DNA e non vengono incorporati nei normali processi di traduzione. Questa caratteristica rende le NRPS un bersaglio interessante per lo sviluppo di nuovi farmaci e agenti terapeutici.
In medicina e ricerca sanitaria, i modelli statistici sono utilizzati per analizzare e interpretare i dati al fine di comprendere meglio i fenomeni biologici, clinici e comportamentali. Essi rappresentano una formalizzazione matematica di relazioni tra variabili che possono essere utilizzate per fare previsioni o testare ipotesi scientifiche.
I modelli statistici possono essere descrittivi, quando vengono utilizzati per riassumere e descrivere le caratteristiche di un insieme di dati, o predittivi, quando vengono utilizzati per prevedere il valore di una variabile in base al valore di altre variabili.
Esempi di modelli statistici comunemente utilizzati in medicina includono la regressione lineare e logistica, l'analisi della varianza (ANOVA), i test t, le curve ROC e il modello di Cox per l'analisi della sopravvivenza.
E' importante notare che la validità dei risultati ottenuti da un modello statistico dipende dalla qualità e dall'appropriatezza dei dati utilizzati, nonché dalla correttezza delle assunzioni sottostanti al modello stesso. Pertanto, è fondamentale una adeguata progettazione dello studio, una accurata raccolta dei dati e un'attenta interpretazione dei risultati.
In medicina, il termine "Sistemi di Gestione di Basi di Dati" (SGBD) si riferisce a un software complesso utilizzato per organizzare, gestire e manipolare grandi quantità di dati in modo efficiente e strutturato. Gli SGBD sono essenziali nelle applicazioni mediche che richiedono l'archiviazione, il recupero e l'elaborazione di informazioni relative ai pazienti, alla ricerca, alla gestione amministrativa e ad altri aspetti della pratica medica.
Gli SGBD offrono una serie di vantaggi per la gestione dei dati in ambito sanitario, tra cui:
1. Strutturazione dei dati: Gli SGBD consentono di definire e impostare una struttura logica per l'archiviazione dei dati, suddividendoli in tabelle e record, facilitando così la ricerca e il recupero delle informazioni.
2. Sicurezza e accesso controllato: Gli SGBD offrono meccanismi di sicurezza per proteggere le informazioni sensibili, garantendo l'accesso solo agli utenti autorizzati e tracciando le attività degli utenti all'interno del sistema.
3. Affidabilità ed efficienza: Gli SGBD sono progettati per gestire grandi volumi di dati, garantendo prestazioni elevate e ridondanza dei dati per prevenire la perdita di informazioni critiche.
4. Standardizzazione e integrazione: Gli SGBD possono essere utilizzati per normalizzare i dati, ovvero eliminare le duplicazioni e garantire la coerenza delle informazioni, facilitando l'integrazione con altri sistemi informativi sanitari.
5. Elaborazione dei dati: Gli SGBD offrono strumenti per eseguire query complesse, analisi statistiche e reporting, supportando la presa di decisioni cliniche e gestionali.
Esempi di sistemi informativi sanitari che utilizzano gli SGBD includono i sistemi di cartelle cliniche elettroniche (CCE), i sistemi di gestione delle risorse umane, i sistemi finanziari e amministrativi, i sistemi di laboratorio e di imaging diagnostico, e i sistemi di sorveglianza sanitaria pubblica.
I segnali di distribuzione proteica, noti anche come "protein distribution signals" (PDS) in inglese, si riferiscono a specifiche sequenze aminoacidiche o motivi strutturali che influenzano la localizzazione subcellulare e la distribuzione delle proteine all'interno della cellula. Questi segnali possono essere costituiti da residui di amminoacidi singoli o da sequenze di diversa lunghezza che interagiscono con specifici meccanismi intracellulari, come i sistemi di trasporto e localizzazione delle proteine.
Esempi di tali segnali includono:
1. Segnale di localizzazione nucleare (NLS): Una sequenza amminoacidica che dirige una proteina al nucleo cellulare. Di solito, è ricca di lisine o arginine e interagisce con importine, componenti del sistema di trasporto nucleare.
2. Segnale di localizzazione mitocondriale (MLS): Una sequenza amminoacidica che indirizza una proteina alle mitocondrie. Solitamente, è idrofobica e ricca di aminoacidi apolari, come la leucina, e interagisce con i recettori della membrana mitocondriale esterna.
3. Segnale di localizzazione perossisomiale (PLS): Una sequenza amminoacidica che dirige una proteina verso i perossisomi. Solitamente, è ricca di serine e arginine e interagisce con PEX5, un recettore del sistema di importazione perossisomiale.
4. Segnale di localizzazione endoplasmica reticolare (ERLS): Una sequenza amminoacidica che indirizza una proteina all'endoplasmatico reticolo. Solitamente, è idrofobica e ricca di aminoacidi apolari, come la fenilalanina, e interagisce con il traslocon della membrana ER.
5. Segnale di localizzazione lisosomiale (LLS): Una sequenza amminoacidica che indirizza una proteina ai lisosomi. Solitamente, è ricca di basici e/o acidi aminoacidi e interagisce con componenti del sistema di trasporto vescicolare.
Questi segnali di localizzazione sono riconosciuti e processati dal sistema di targeting cellulare, che garantisce il corretto posizionamento delle proteine all'interno della cellula.
La divisione cellulare è un processo fondamentale per la crescita, lo sviluppo e la riparazione dei tessuti in tutti gli organismi viventi. È il meccanismo attraverso cui una cellula madre si divide in due cellule figlie geneticamente identiche. Ci sono principalmente due tipi di divisione cellulare: mitosi e meiosi.
1. Mitosi: Questo tipo di divisione cellulare produce due cellule figlie geneticamente identiche alla cellula madre. E' il processo che si verifica durante la crescita e lo sviluppo normale, nonché nella riparazione dei tessuti danneggiati. Durante la mitosi, il materiale genetico della cellula (DNA) viene replicato ed equalmente distribuito alle due cellule figlie.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
Lo Studio del Genoma si riferisce alla raccolta, all'analisi e all'interpretazione sistematica delle informazioni contenute nel genoma umano. Il genoma è l'insieme completo di tutte le informazioni genetiche ereditarie presenti in un individuo, codificate nei suoi cromosomi e organizzate in circa 20.000-25.000 geni.
Lo Studio del Genoma può essere condotto a diversi livelli di complessità, dall'analisi di singoli geni o regioni genomiche specifiche, fino all'esame dell'intero genoma. L'obiettivo principale di questo studio è quello di comprendere come le variazioni genetiche influenzino la fisiologia, il fenotipo e la predisposizione a determinate malattie o condizioni patologiche.
Le tecnologie di sequenziamento dell'DNA di nuova generazione (NGS) hanno permesso di accelerare notevolmente lo Studio del Genoma, rendendolo più accessibile e conveniente. Questo ha aperto la strada allo sviluppo di approcci di medicina personalizzata, che tengono conto delle specifiche caratteristiche genetiche di un individuo per prevedere, diagnosticare e trattare le malattie in modo più preciso ed efficace.
Lo Studio del Genoma ha anche importanti implicazioni etiche, legali e sociali, che devono essere attentamente considerate e gestite a livello individuale e collettivo.
I recettori dell'acido retinoico (RAR) sono una classe di recettori nucleari che legano l'acido retinoico, un metabolita della vitamina A. Gli RAR giocano un ruolo cruciale nella regolazione della trascrizione genica e sono noti per essere coinvolti nello sviluppo embrionale, nella differenziazione cellulare, nella proliferazione cellulare, nell'apoptosi e nella risposta immunitaria.
Esistono tre diversi sottotipi di RAR (RARα, RARβ e RARγ), ciascuno dei quali è codificato da un gene diverso. Questi recettori formano eterodimeri con i recettori X retinoici (RXR) per legare specifiche sequenze di risposta dell'acido retinoico (RARE) nel DNA, che regolano l'espressione genica.
L'attivazione dei RAR da parte dell'acido retinoico può indurre o reprimere l'espressione genica in modo dipendente dal contesto e dallo stadio di sviluppo, a seconda del tipo di cellula e della presenza di cofattori di trascrizione.
Le anomalie nella funzione dei recettori dell'acido retinoico sono state implicate in una varietà di disturbi, tra cui il cancro, le malformazioni congenite e le malattie infiammatorie.
I chaperoni molecolari sono proteine assistenziali che aiutano nella corretta piegatura, ripiegatura e stabilizzazione delle altre proteine durante la loro sintesi e nel corso della loro vita. Essi giocano un ruolo cruciale nel mantenere la homeostasi proteica e prevenire l'aggregazione proteica dannosa. I chaperoni molecolari riconoscono le proteine instabili o mal piegate e le aiutano a ripiegarsi correttamente, promuovendo il loro corretto funzionamento o facilitandone la degradazione se non possono essere riparate. Questi chaperoni sono essenziali per la sopravvivenza cellulare e sono coinvolti in una varietà di processi cellulari, tra cui lo stress cellulare, l'invecchiamento, le malattie neurodegenerative e il cancro.
Gli aminoacidi sono composti organici essenziali per la vita che svolgono un ruolo fondamentale nella biologia delle forme di vita conosciute. Essi sono i building block delle proteine, costituendo le catene laterali idrofiliche e idrofobiche che determinano la struttura tridimensionale e la funzione delle proteine.
Esistono circa 500 diversi aminoacidi presenti in natura, ma solo 20 di essi sono codificati dal DNA e tradotti nei nostri corpi per formare proteine. Questi 20 aminoacidi sono classificati come essenziali, non essenziali o condizionatamente essenziali in base alla loro capacità di essere sintetizzati nel corpo umano.
Gli aminoacidi essenziali devono essere ottenuti attraverso la dieta, poiché il nostro corpo non è in grado di sintetizzarli autonomamente. Questi includono istidina, isoleucina, leucina, lisina, metionina, fenilalanina, treonina, triptofano e valina.
Gli aminoacidi non essenziali possono essere sintetizzati dal nostro corpo utilizzando altri composti come precursori. Questi includono alanina, aspartato, acido aspartico, cisteina, glutammato, glutammina, glicina, prolina, serina e tirosina.
Infine, ci sono aminoacidi condizionatamente essenziali che devono essere ottenuti attraverso la dieta solo in determinate situazioni, come ad esempio durante lo stress, la crescita o la malattia. Questi includono arginina, istidina, cisteina, tirosina, glutammina e prolina.
In sintesi, gli aminoacidi sono composti organici essenziali per la vita che svolgono un ruolo fondamentale nella sintesi delle proteine e di altri composti importanti per il nostro corpo. Una dieta equilibrata e varia dovrebbe fornire tutti gli aminoacidi necessari per mantenere una buona salute.
In medicina, un "rene" è un organo fondamentale del sistema urinario che svolge un ruolo chiave nella regolazione dell'equilibrio idrico ed elettrolitico e nell'escrezione dei rifiuti metabolici. Ogni rene è una struttura complessa composta da milioni di unità funzionali chiamate nefroni.
Ogni nefrone consiste in un glomerulo, che filtra il sangue per eliminare i rifiuti e l'acqua in eccesso, e un tubulo renale contorto, dove vengono riassorbite le sostanze utili e secrete ulteriormente alcune molecole indesiderate. Il liquido filtrato che risulta da questo processo diventa urina, la quale viene quindi convogliata attraverso i tubuli contorti, i tubuli rettilinei e le papille renali fino ai calici renali e infine alla pelvi renale.
L'urina prodotta da entrambi i reni fluisce poi nell'uretere e viene immagazzinata nella vescica prima di essere eliminata dal corpo attraverso l'uretra. I reni svolgono anche un ruolo importante nel mantenere la pressione sanguigna normale, producendo ormoni come l'enzima renina e l'ormone eritropoietina (EPO). Inoltre, i reni aiutano a mantenere il livello di pH del sangue attraverso la secrezione di ioni idrogeno e bicarbonato.
In genetica, un gene dominante è un gene che produce un fenotipo evidente quando è presente in almeno una copia (eterozigote) e maschera l'effetto del gene recessivo corrispondente sull'altro allele. Ciò significa che se un individuo eredita un gene dominante da uno solo dei genitori, esprimerà comunque le caratteristiche associate a quel gene. Un esempio classico di gene dominante è quello della malattia genetica nota come sindrome di Huntington, in cui la presenza di una singola copia del gene mutato è sufficiente per causare la malattia. Tuttavia, è importante notare che non tutti i tratti o le caratteristiche dominanti sono necessariamente dannosi o patologici; alcuni possono anche essere neutrali o addirittura vantaggiosi.
I canali del calcio sono proteine integrali di membrana che giocano un ruolo cruciale nella regolazione dell'ingresso di ioni calcio (Ca2+) nelle cellule. Essi sono costituiti da diversi domini strutturali, tra cui il dominio selettivo di filtro che permette la permeabilità specifica agli ioni calcio, e il dominio citosolico che è coinvolto nell'attivazione del canale.
I canali del calcio possono essere classificati in diverse categorie sulla base delle loro caratteristiche funzionali e strutturali, come i canali del calcio voltaggio-dipendenti (VDCC), che si aprono in risposta a un cambiamento nel potenziale di membrana, e i canali del calcio recettore-operati (ROCC), che sono attivati da specifiche molecole di segnalazione.
L'ingresso di ioni calcio attraverso questi canali è un evento cruciale in una varietà di processi cellulari, tra cui la contrazione muscolare, la secrezione di ormoni e neurotrasmettitori, l'espressione genica e la morte cellulare programmata. Pertanto, i canali del calcio sono bersagli importanti per una varietà di farmaci utilizzati nel trattamento di diverse condizioni mediche, come l'ipertensione, l'angina, l'aritmia e la malattia di Parkinson.
La 'Spodoptera' è un genere di lepidotteri notturni, comunemente noti come falene della notte o bruchi. Questo genere include diverse specie che sono importanti come parassiti delle colture in diversi habitat in tutto il mondo. Un esempio ben noto è la Spodoptera frugiperda, o falena del mais, che causa ingenti danni alle colture di mais, cotone, soia e altri raccolti. Questi insetti sono notturni e trascorrono il giorno come larve nascoste nelle piante o nel terreno. Le larve si nutrono avidamente della vegetazione delle piante, causando danni significativi alle colture. Il controllo di questi parassiti può essere difficile a causa del loro ciclo vitale e dell'abilità di alcune specie di sviluppare resistenza ai pesticidi.
"Polipo" è un termine medico utilizzato per descrivere una crescita benigna (non cancerosa) del tessuto che si protende da una mucosa sottostante. I polipi possono svilupparsi in diversi organi cavi del corpo umano, come il naso, l'orecchio, l'intestino tenue, il colon e il retto.
I polipi nasali si verificano comunemente nelle cavità nasali e nei seni paranasali. Possono causare sintomi come congestione nasale, perdite nasali, difficoltà respiratorie e perdita dell'olfatto.
I polipi auricolari possono svilupparsi nell'orecchio medio o nel canale uditivo esterno e possono causare sintomi come perdita dell'udito, acufene (ronzio nelle orecchie) e vertigini.
I polipi intestinali si verificano comunemente nel colon e nel retto e possono causare sintomi come sanguinamento rettale, dolore addominale, diarrea o stitichezza. Alcuni polipi intestinali possono anche avere il potenziale per diventare cancerosi se non vengono rimossi in modo tempestivo.
Il trattamento dei polipi dipende dalla loro posizione, dimensione e sintomi associati. Le opzioni di trattamento possono includere la rimozione chirurgica o l'asportazione endoscopica, a seconda della situazione specifica.
La mitosi è un processo fondamentale nella biologia cellulare che consiste nella divisione del nucleo e del citoplasma delle cellule eucariotiche, che porta alla formazione di due cellule figlie geneticamente identiche. Questo processo è essenziale per la crescita, lo sviluppo e la riparazione dei tessuti negli organismi viventi.
La mitosi può essere suddivisa in diverse fasi: profase, prometafase, metafase, anafase e telofase. Durante queste fasi, i cromosomi (strutture contenenti il DNA) si duplicano e si separano in modo che ogni cellula figlia riceva un set completo di cromosomi identici.
La mitosi è regolata da una complessa rete di proteine e segnali cellulari, e qualsiasi errore o disfunzione nel processo può portare a malattie genetiche o cancerose. Pertanto, la comprensione della mitosi e dei suoi meccanismi è fondamentale per la ricerca biomedica e per lo sviluppo di terapie efficaci contro il cancro.
In medicina e biologia molecolare, i termini "metabolic networks" e "pathways" si riferiscono alla descrizione dei processi biochimici che coinvolgono l'interazione di diverse molecole all'interno di una cellula.
Un metabolic pathway è una serie di reazioni chimiche catalizzate enzimaticamente che trasformano un substrato in un prodotto finale, con il rilascio o assorbimento di energia. Queste reazioni sono collegate da un comune pool di intermediari metabolici e sono strettamente regolate per garantire la corretta risposta cellulare a diversi stimoli ambientali.
Un metabolic network è l'insieme complesso di tutti i pathway metabolici all'interno di una cellula, che lavorano insieme per sostenere la crescita, la divisione e la sopravvivenza della cellula stessa. Questi network possono essere rappresentati come grafici matematici, con i nodi che rappresentano le molecole metaboliche e gli archi che rappresentano le reazioni chimiche tra di esse.
L'analisi dei metabolic network può fornire informazioni importanti sulla fisiologia cellulare e sull'adattamento delle cellule a diversi stati fisiologici o patologici, come la crescita tumorale o la risposta ai farmaci. Inoltre, l'ingegneria dei metabolic network può essere utilizzata per ottimizzare la produzione di composti di interesse industriale o medico, come i biofuels o i farmaci.
Le sequenze regolatorie degli acidi nucleici, anche note come elementi regolatori o siti di legame per fattori di trascrizione, sono specifiche sequenze di DNA o RNA che controllano l'espressione genica. Queste sequenze si legano a proteine regolatorie, come i fattori di trascrizione, che influenzano l'inizio, la velocità e la terminazione della trascrizione del gene adiacente. Le sequenze regolatorie possono trovarsi nel promotore, nell'enhancer o nel silencer del gene, e possono essere sia positive che negative nel loro effetto sull'espressione genica. Possono anche essere soggette a meccanismi di controllo epigenetici, come la metilazione del DNA, che influenzano il loro livello di attività.
Il peso molecolare (PM) è un'unità di misura che indica la massa di una molecola, calcolata come la somma dei pesi atomici delle singole particelle costituenti (atomi) della molecola stessa. Si misura in unità di massa atomica (UMA o dal simbolo chimico ufficiale 'amu') o, più comunemente, in Daltons (Da), dove 1 Da equivale a 1 u.
Nella pratica clinica e nella ricerca biomedica, il peso molecolare è spesso utilizzato per descrivere le dimensioni relative di proteine, peptidi, anticorpi, farmaci e altre macromolecole. Ad esempio, l'insulina ha un peso molecolare di circa 5.808 Da, mentre l'albumina sierica ha un peso molecolare di circa 66.430 Da.
La determinazione del peso molecolare è importante per comprendere le proprietà fisico-chimiche delle macromolecole e il loro comportamento in soluzioni, come la diffusione, la filtrazione e l'interazione con altre sostanze. Inoltre, può essere utile nella caratterizzazione di biomarcatori, farmaci e vaccini, oltre che per comprendere i meccanismi d'azione delle terapie biologiche.
Innanzitutto, è importante chiarire che "Data Mining" non è una definizione medica in sé. Il Data Mining è un termine utilizzato più ampiamente nella scienza dei dati e nell'informatica. Tuttavia, il Data Mining ha trovato la sua strada anche nel campo della medicina e della ricerca sanitaria, dove viene applicato per analizzare grandi set di dati medici ed estrarre informazioni utili a scopi di ricerca, prevenzione, diagnosi e trattamento.
Data Mining può essere definito come:
"L'estrazione e l'analisi sistematica di modelli, tendenze e pattern significativi e preziosi da grandi set di dati eterogenei e complessi, attraverso l'utilizzo di algoritmi avanzati, tecniche statistiche e metodi machine learning. L'obiettivo del Data Mining è quello di supportare la presa di decisioni cliniche informate, migliorare i risultati dei pazienti, identificare fattori di rischio, prevedere esiti clinici e promuovere la ricerca medica evidence-based."
In sintesi, il Data Mining è un processo di estrazione di conoscenze utili da grandi set di dati medici che può contribuire a migliorare la comprensione delle malattie, l'assistenza sanitaria e i risultati per i pazienti.
Gli Endosomal Sorting Complexes Required for Transport (ESCRT) sono complessi proteici essenziali per il processamento e il riciclo dei membrani endosomali. Essi svolgono un ruolo cruciale nella formazione di vescicole intraluminali all'interno degli endosomi multivesicolari tardivi (MVEs), che sono utilizzati per il trasporto e la degradazione di ligandi recettoriali interni.
L'ESCRT è costituito da diversi complessi proteici distinti, noti come ESCRT-0, -I, -II e -III, ognuno dei quali svolge una funzione specifica nel processo di triaggio endosomale.
L'ESCRT-0 è il primo complesso a legarsi ai domini ubiquitinati dei recettori transmembrana, reclutando e attivando l'ESCRT-I. L'ESCRT-I poi recluta e attiva l'ESCRT-II, che lavora con l'ESCRT-III per deformare la membrana endosomale e formare il budino intraluminale.
Una volta formate, le vescicole intraluminali sono separate dalla membrana endosomale principale e rilasciate all'interno del lume dell'MVE, dove possono essere degradate dal lisosoma.
L'ESCRT è anche implicato in una varietà di altri processi cellulari, tra cui la riparazione delle membrane, l'abscissione della citotomia e il rilascio di vescicole extracellulari. I difetti nell'ESCRT possono portare a una serie di patologie, tra cui malattie neurodegenerative, disturbi immunitari e cancro.
Le fosfoproteine fosfatasi (PPP) sono un gruppo di enzimi che svolgono un ruolo cruciale nella regolazione dei processi cellulari attraverso la dephosphorylazione delle proteine, cioè l' rimozione di gruppi fosfato dalle proteine fosforilate. Questo processo è fondamentale per il controllo della segnalazione cellulare, dell'espressione genica e della divisione cellulare.
Le fosfoproteine fosfatasi sono classificate in tre famiglie principali: PPP, PPM (protein phosphatase, Mg2+/Mn2+-dependent) e PTP (protein tyrosine phosphatase). La famiglia PPP include enzimi come la protein phosphatase 1 (PP1), la protein phosphatase 2A (PP2A), la protein phosphatase 2B (PP2B, anche nota come calcineurina) e la protein phosphatase 5 (PP5).
Ogni enzima della famiglia PPP ha una specificità substrato diversa e svolge funzioni distinte all'interno della cellula. Ad esempio, PP1 e PP2A sono ampiamente espressi e regolano molteplici processi cellulari, tra cui la glicogenolisi, il ciclo cellulare e la trasduzione del segnale. La calcineurina (PP2B) è una fosfatasi calcio-dipendente che svolge un ruolo cruciale nella regolazione dell'espressione genica e della risposta immunitaria.
Le disfunzioni delle fosfoproteine fosfatasi sono implicate in diverse patologie, tra cui il cancro, le malattie neurodegenerative e le disfunzioni cardiovascolari. Pertanto, lo studio di questi enzimi è di grande interesse per la comprensione dei meccanismi molecolari alla base di queste malattie e per lo sviluppo di nuove strategie terapeutiche.
Il genoma è l'intera sequenza dell'acido desossiribonucleico (DNA) contenuta in quasi tutte le cellule di un organismo. Esso include tutti i geni e le sequenze non codificanti che compongono il materiale genetico ereditato da entrambi i genitori. Il genoma umano, ad esempio, è costituito da circa 3 miliardi di paia di basi nucleotidiche e contiene circa 20.000-25.000 geni che forniscono le istruzioni per lo sviluppo e il funzionamento dell'organismo.
Il genoma può essere studiato a diversi livelli, tra cui la sequenza del DNA, la struttura dei cromosomi, l'espressione genica (l'attività dei geni) e la regolazione genica (il modo in cui i geni sono controllati). Lo studio del genoma è noto come genomica e ha importanti implicazioni per la comprensione delle basi molecolari delle malattie, lo sviluppo di nuove terapie farmacologiche e la diagnosi precoce delle malattie.
Le proteine E1A dell'adenovirus sono un tipo di proteina codificate dal gene E1A del genoma dell'adenovirus. Questi geni sono i primi a essere espressi dopo l'infezione da adenovirus e svolgono un ruolo cruciale nella regolazione dell'espressione dei geni virali successivi e nell'alterazione del ciclo cellulare della cellula ospite.
Le proteine E1A sono multifunzionali e possono legarsi a diverse proteine cellulari, compresi i fattori di trascrizione, per modulare l'espressione genica. Queste proteine possono anche indurre la degradazione di alcune proteine cellulari che normalmente inibiscono la replicazione del virus.
Le proteine E1A dell'adenovirus sono state ampiamente studiate come modelli per comprendere i meccanismi di regolazione della trascrizione genica e di alterazione del ciclo cellulare durante l'infezione virale. Inoltre, hanno anche attirato l'attenzione come potenziali agenti terapeutici o come vettori per la terapia genica a causa delle loro proprietà oncogeniche e della capacità di indurre l'espressione di geni specifici.
L'assemblaggio virale è un passaggio cruciale nel ciclo di vita del virus, durante il quale i componenti virali vengono riuniti per formare un nuovo virione infectivo. Questo processo si verifica dopo che il materiale genetico del virus (DNA o RNA) è stato replicato e trascritto all'interno della cellula ospite.
Gli elementi costitutivi del virione, come la capside proteica e l'involucro lipidico (nel caso di virus enveloped), si riuniscono attorno al materiale genetico per formare una particella virale completa e infettiva. Questo processo può verificarsi in diverse località all'interno della cellula ospite, come il citoplasma o il nucleo, a seconda del tipo di virus.
L'assemblaggio virale è un bersaglio importante per lo sviluppo di farmaci antivirali, poiché l'interruzione di questo processo può impedire la produzione di nuovi virioni e quindi la diffusione dell'infezione.
In medicina, una soluzione è un tipo specifico di miscela omogenea di due o più sostanze, in cui almeno una delle sostanze (il soluto) è dispersa in maniera uniforme nell'altra (il solvente). Il soluto può essere costituito da uno o più solidi, liquidi o gas, mentre il solvente di solito è un liquido, come l'acqua.
Le soluzioni sono classificate in base alla loro composizione e alle proprietà che ne derivano. Una soluzione è definita come:
1. Una soluzione acquosa: quando il solvente è costituito dall'acqua. Ad esempio, una soluzione di glucosio è una miscela di glucosio (soluto) disciolto in acqua (solvente).
2. Una soluzione concentrata o diluita: a seconda della quantità di soluto presente nella soluzione. Una soluzione concentrata contiene una grande quantità di soluto, mentre una soluzione diluita ne contiene una piccola quantità.
3. Una soluzione satura, sovrasatura o insatura: a seconda della capacità del solvente di dissolvere il soluto. In una soluzione satura, il solvente ha raggiunto la sua massima capacità di sciogliere il soluto a quella particolare temperatura e pressione. Una soluzione sovrasatura contiene una quantità superiore alla solubilità massima del soluto a quella determinata temperatura e pressione, il che significa che può verificarsi la precipitazione del soluto se le condizioni cambiano. Una soluzione insatura contiene meno soluto di quanto potrebbe dissolvere il solvente a quella particolare temperatura e pressione.
Le soluzioni sono ampiamente utilizzate in medicina per la preparazione di farmaci, fluidi endovenosi, elettroliti e altre miscele terapeutiche. La concentrazione della soluzione è spesso espressa in unità di peso per volume (ad esempio, mg/mL) o unità di volume per volume (ad esempio, mEq/L).
Le RecQ Helicases sono una famiglia di enzimi helicasi che svolgono un ruolo cruciale nella riparazione del DNA e nel mantenimento della stabilità genomica. Essi prendono il nome dalla proteina RecQ presente in Escherichia coli, che è stata la prima a essere scoperta in questa famiglia.
Le RecQ Helicases sono importanti per il riavvolgimento e lo srotolamento del DNA durante la replicazione e la riparazione del DNA. Essi aiutano a prevenire la rottura e la fusione dei cromosomi, che possono portare a malattie genetiche come la sindrome di Bloom, la sindrome di Werner e la sindrome di Rothmund-Thomson.
Le RecQ Helicases sono anche implicate nella riparazione delle rotture double-strand del DNA (DSB) attraverso i meccanismi di riparazione per scambio di segmenti (SBS) e riparazione omologa della rottura del filamento singolo (SSBR). Inoltre, svolgono un ruolo nella regolazione della transcrizione e nella stabilizzazione dei telomeri.
Le mutazioni nelle RecQ Helicases possono portare a una serie di malattie genetiche rare, tra cui la sindrome di Bloom, che è caratterizzata da un'alta incidenza di tumori e anomalie cromosomiche. La sindrome di Werner è invece caratterizzata da un invecchiamento precoce e un aumentato rischio di cancro. Infine, la sindrome di Rothmund-Thomson è una malattia genetica rara che colpisce la pelle, i capelli e le ossa.
La cristallografia è una tecnica scientifica utilizzata per lo studio della struttura dei cristalli, che sono solidi con una disposizione ordinata ed uniforme degli atomi, delle molecole o degli ioni. Questa disciplina combina diversi campi della fisica, della chimica e della matematica per analizzare la disposizione spaziale degli atomi all'interno di un cristallo.
In particolare, la cristallografia utilizza l'analisi dei raggi X diffusi da un cristallo per determinare la posizione e il tipo di atomi o molecole presenti nella sua struttura. Questa tecnica si basa sul fenomeno della diffrazione dei raggi X, che avviene quando i fotoni (particelle elementari di luce) vengono diffusi da un reticolo di atomi e interferiscono costruttivamente o distruttivamente tra loro, producendo un pattern di punti luminosi che può essere analizzato per rivelare la struttura del cristallo.
La cristallografia ha importanti applicazioni in diversi campi della scienza e della tecnologia, come la chimica, la fisica, la biologia strutturale, la farmaceutica e la nanotecnologia. Ad esempio, la conoscenza della struttura dei cristalli può essere utilizzata per sviluppare nuovi farmaci, materiali innovativi e tecnologie avanzate per l'archiviazione dei dati e la produzione di energia rinnovabile.
La "Regolazione Fungina dell'Espressione Genica" si riferisce ai meccanismi e processi biologici che controllano l'attivazione o la repressione dei geni nelle cellule fungine. Questo tipo di regolazione è essenziale per la crescita, lo sviluppo, la differenziazione e la risposta ambientale dei funghi.
La regolazione dell'espressione genica nei funghi può avvenire a diversi livelli, tra cui:
1. Trascrizione genica: il primo passo nella sintesi delle proteine, che comporta la produzione di mRNA a partire dal DNA. I fattori di trascrizione possono legarsi ai promotori dei geni per attivare o reprimere la trascrizione.
2. Modifiche post-trascrizionali dell'mRNA: processi come l'alternativa splicing, la degradazione dell'mRNA e la modificazione della sua stabilità possono influenzare il livello di espressione genica.
3. Traduzione proteica: il passaggio dalla produzione di mRNA alla sintesi delle proteine può essere regolato attraverso meccanismi come l'inibizione dell'inizio della traduzione o la degradazione delle proteine nascenti.
4. Modifiche post-traduzionali delle proteine: le proteine possono subire modificazioni chimiche, come la fosforilazione, l'ubiquitinazione e la glicosilazione, che influenzano la loro attività, stabilità o localizzazione cellulare.
La regolazione fungina dell'espressione genica è soggetta a una complessa rete di controllo che include fattori intracellulari e ambientali. I segnali esterni possono influenzare la regolazione dell'espressione genica attraverso il legame dei ligandi ai recettori cellulari, l'attivazione di cascate di segnalazione e la modulazione dell'attività di fattori di trascrizione.
La comprensione della regolazione fungina dell'espressione genica è fondamentale per comprendere i meccanismi molecolari che controllano lo sviluppo, la differenziazione e la patogenicità dei funghi. Questo può avere implicazioni importanti nella ricerca di nuovi farmaci antifungini e nella progettazione di strategie per il controllo delle malattie fungine.
Le cellule NIH 3T3 sono una linea cellulare fibroblastica sviluppata da topo embrioni che è stata ampiamente utilizzata in ricerca biomedica. Il nome "NIH 3T3" deriva dalle abbreviazioni di "National Institutes of Health" (NIH) e "tissue culture triplicate" (3T), indicando che le cellule sono state coltivate tre volte in laboratorio prima della loro caratterizzazione.
Le cellule NIH 3T3 sono fibroblasti, il che significa che producono collagene ed altre proteine del tessuto connettivo. Sono anche normalmente non tumorali, il che le rende utili come controllo negativo in esperimenti di trasformazione cellulare indotta da oncogeni o altri fattori cancerogeni.
Le cellule NIH 3T3 sono state utilizzate in una vasta gamma di studi, tra cui la ricerca sul cancro, l'invecchiamento, la differenziazione cellulare e lo sviluppo embrionale. Sono anche comunemente utilizzate per la produzione di virus utilizzati nei vaccini, come il vettore virale utilizzato nel vaccino contro il vaiolo.
In sintesi, le cellule NIH 3T3 sono una linea cellulare fibroblastica non tumorale derivata da topo embrioni, che è stata ampiamente utilizzata in ricerca biomedica per studiare una varietà di processi cellulari e malattie.
Gli elementi enhancer genetici sono sequenze di DNA regulatory che aumentano la trascrizione dei geni a cui sono legati. Gli enhancer possono essere trovati in diverse posizioni rispetto al gene bersaglio, sia upstream che downstream, e persino all'interno di introni o altri elementi regolatori come i silenziatori.
Gli enhancer sono costituiti da diversi fattori di trascrizione e cofattori che si legano a specifiche sequenze di DNA per formare un complesso proteico. Questo complesso interagisce con la polimerasi II, l'enzima responsabile della trascrizione dell'RNA, aumentando il tasso di inizio della trascrizione del gene bersaglio.
Gli enhancer possono essere specifici per un particolare tipo cellulare o essere attivi in più tipi cellulari. Possono anche mostrare una regolazione spaziale e temporale, essendo attivi solo in determinate condizioni di sviluppo o risposta a stimoli ambientali.
Le mutazioni negli enhancer possono portare a malattie genetiche, poiché possono influenzare la normale espressione dei geni e causare disfunzioni cellulari o sviluppo anormale.
I disolfuri sono composti chimici che contengono due atomi di zolfo legati insieme da un legame covalente. In biochimica, il termine "disolfuro" si riferisce spesso alla forma specifica di questo gruppo funzionale (-S-S-) che si trova comunemente nelle proteine. Questo legame disolfuro è importante per la stabilità e l'attività delle proteine, in particolare quelle esposte all'ambiente extracellulare o presenti nel citoplasma dei batteri. I legami disolfuro si formano attraverso un processo di ossidoriduzione che coinvolge la conversione di due gruppi solfidrilici (-SH) in un legame disolfuro (-S-S-). Questo processo può essere reversibile, consentendo la formazione e la rottura dei legami disolfuro in risposta a vari stimoli cellulari o ambientali. Tuttavia, i legami disolfuro possono anche formarsi irreversibilmente durante l'ossidazione delle proteine, portando potenzialmente alla denaturazione e all'inattivazione della proteina.
L'istidina è un aminoacido essenziale, il quale significa che deve essere incluso nella dieta perché il corpo non può sintetizzarlo da solo. Il suo codone è CAU o CAC. L'istidina gioca un ruolo importante nel metabolismo dell'uomo e degli animali, partecipando a diverse reazioni enzimatiche e alla biosintesi di importanti molecole biologiche.
L'istidina è coinvolta nella regolazione della risposta immunitaria del corpo, nella sintesi dell'emoglobina e della mioglobina (proteine che trasportano l'ossigeno), nonché nel mantenimento dell'equilibrio acido-base. Inoltre, l'istidina può essere decarbossilata per formare istamina, una molecola che svolge un ruolo cruciale nelle risposte infiammatorie e allergiche del corpo.
Una carenza di istidina può portare a diversi problemi di salute, tra cui ritardi nello sviluppo fisico e mentale, danni ai tessuti connettivi e una ridotta resistenza alle infezioni. Tuttavia, è raro che si verifichi una carenza clinicamente significativa di istidina, poiché questo aminoacido è presente in molte proteine alimentari diverse, tra cui carne, pesce, uova, latticini e legumi.
Le proteine attivanti la GTPasi (GAP, dall'inglese GTPase-activating protein) sono un gruppo di proteine che stimolano l'attività GTPasica di diverse GTPasi, enzimi che idrolizzano il legame fosfato ad alta energia tra il gruppo fosfato e la guanina nella molecola di GTP. Questo processo converte la GTP in GDP, con conseguente cambiamento conformazionale della proteina GTPasi e disattivazione dell'enzima.
Le proteine attivanti la GTPasi svolgono un ruolo cruciale nella regolazione dei segnali cellulari e del traffico intracellulare, compreso il trasporto vescicolare e l'organizzazione del citoscheletro. Le mutazioni in queste proteine possono portare a disfunzioni cellulari e malattie, come ad esempio alcuni tipi di cancro.
Le GAP sono caratterizzate dalla presenza di un dominio catalitico altamente conservato, chiamato dominio GAP, che interagisce con la proteina GTPasi target e ne aumenta l'attività GTPasica. Il meccanismo d'azione delle GAP prevede il contatto diretto con il sito di legame del nucleotide della proteina GTPasi, promuovendo il riposizionamento della molecola di acqua necessaria per l'idrolisi del legame fosfato ad alta energia.
In sintesi, le proteine attivanti la GTPasi sono enzimi che aumentano l'attività idrolitica delle GTPasi, contribuendo a regolare i segnali cellulari e il traffico intracellulare.
Il reticolo endoplasmatico (RE) è un complesso sistema interconnesso di membrane presenti nel citoplasma delle cellule eucariotiche. Esso svolge un ruolo fondamentale nella sintesi proteica, nel metabolismo lipidico, nel trasporto intracellulare e nella detossificazione cellulare.
Il RE è composto da due regioni principali: il reticolo endoplasmatico rugoso (RER) e il reticolo endoplasmatico liscio (REL). Il RER, così chiamato per la presenza di ribosomi sulla sua superficie, è specializzato nella sintesi proteica. I ribosomi traducono l'mRNA in catene polipeptidiche che vengono immediatamente trasportate nel lumen del RER dove subiscono processi di folding (piegamento) e modificazioni post-traduzionali.
Il REL, privo di ribosomi, è implicato invece nella sintesi dei lipidi, nello stoccaggio di calcio e nel metabolismo delle sostanze xenobiotiche (composti estranei all'organismo). Il RE è anche coinvolto nel trasporto intracellulare di molecole attraverso la formazione di vescicole che si originano dalle cisterne del RE e si fondono con altri organelli cellulari.
In sintesi, il reticolo endoplasmatico è un importante organello cellulare che svolge una varietà di funzioni essenziali per la sopravvivenza e l'integrità delle cellule eucariotiche.
I mammiferi sono una classe di vertebrati amnioti (Sauropsida) che comprende circa 5.400 specie esistenti. Sono caratterizzati dall'allattamento dei piccoli con il latte, prodotto dalle ghiandole mammarie presenti nelle femmine. Questa classe include una vasta gamma di animali, dai più piccoli toporagni ai grandi elefanti e balene.
Altre caratteristiche distintive dei mammiferi includono:
1. Presenza di peli o vibrisse (peli tattili) in varie parti del corpo.
2. Sistema nervoso ben sviluppato con un grande cervello relativo alle dimensioni corporee.
3. Struttura scheletrica complessa con arti portanti, che consentono il movimento quadrupede o bipede.
4. Apparato respiratorio dotato di polmoni divisi in lobi e segmenti, permettendo un efficiente scambio gassoso.
5. Cuore a quattro camere con valvole che garantiscono un flusso sanguigno unidirezionale.
6. Denti differenziati in incisivi, canini, premolari e molari, utilizzati per masticare e sminuzzare il cibo.
7. Alcune specie presentano la capacità di regolare la temperatura corporea (endotermia).
I mammiferi hanno un'ampia distribuzione geografica e occupano una vasta gamma di habitat, dal deserto all'acqua dolce o salata. Si evolvono da sinapsidi terapsidi durante il Mesozoico ed è l'unico gruppo di amnioti sopravvissuto fino ad oggi.
L'adenosina trifosfato (ATP) è una molecola organica che funge da principale fonte di energia nelle cellule di tutti gli esseri viventi. È un nucleotide composto da una base azotata, l'adenina, legata a un ribosio (uno zucchero a cinque atomi di carbonio) e tre gruppi fosfato.
L'ATP immagazzina energia chimica sotto forma di legami ad alta energia tra i suoi gruppi fosfato. Quando una cellula ha bisogno di energia, idrolizza (rompe) uno o più di questi legami, rilasciando energia che può essere utilizzata per svolgere lavoro cellulare, come la contrazione muscolare, il trasporto di sostanze attraverso membrane cellulari e la sintesi di altre molecole.
L'ATP viene continuamente riciclato nelle cellule: viene prodotto durante processi metabolici come la glicolisi, la beta-ossidazione degli acidi grassi e la fosforilazione ossidativa, e viene idrolizzato per fornire energia quando necessario. La sua concentrazione all'interno delle cellule è strettamente regolata, poiché livelli insufficienti possono compromettere la funzione cellulare, mentre livelli eccessivi possono essere dannosi.
Il zinco è un minerale essenziale che svolge un ruolo cruciale nel mantenimento della salute umana. È un componente importante di oltre 300 enzimi e proteine, che sono necessari per una vasta gamma di funzioni corporee, tra cui la sintesi del DNA, la divisione cellulare, il metabolismo, la riparazione dei tessuti e il sostegno del sistema immunitario. Il zinco è anche importante per la crescita e lo sviluppo, in particolare durante la gravidanza, l'infanzia e l'adolescenza.
Il corpo umano contiene circa 2-3 grammi di zinco, che si trova principalmente nelle ossa, nella muscolatura scheletrica e nei tessuti più attivi metabolicamente come il fegato, i reni, la prostata e l'occhio. Il fabbisogno giornaliero di zinco varia a seconda dell'età, del sesso e dello stato nutrizionale della persona, ma in generale è di circa 8-11 mg al giorno per gli adulti.
Una carenza di zinco può causare una serie di problemi di salute, tra cui la ridotta funzione immunitaria, la crescita stentata, la perdita dell'appetito, la diminuzione del gusto e dell'olfatto, la disfunzione sessuale e riproduttiva, e la pelle secca e fragile. Al contrario, un eccesso di zinco può essere tossico e causare nausea, vomito, diarrea, mal di testa, dolori articolari e anemia.
Il zinco è presente in una varietà di alimenti, tra cui carne rossa, pollame, pesce, frutti di mare, latticini, cereali integrali, legumi e noci. Tuttavia, il contenuto di zinco degli alimenti può essere influenzato da diversi fattori, come la presenza di sostanze che inibiscono l'assorbimento del minerale, come i fitati presenti nei cereali integrali e nelle legumi. Pertanto, è importante consumare una dieta equilibrata e variata per garantire un apporto adeguato di zinco.
La calmodulina è una piccola proteina citosolica che si trova nei batteri, nelle piante e negli animali. Nell'uomo, è codificata dal gene CALM ed è espressa in diverse forme (CALM1, CALM2, CALM3) che differiscono per pochi aminoacidi.
La calmodulina ha un ruolo fondamentale nella regolazione di molti processi cellulari, tra cui l'escitabilità neuronale, la contrazione muscolare, la proliferazione e la morte cellulare, a causa della sua capacità di legare ioni calcio (Ca2+).
Quando i livelli di Ca2+ intracellulari aumentano, la calmodulina si lega ai suoi ioni e subisce un cambiamento conformazionale che le permette di interagire con una varietà di target proteici. Queste interazioni possono portare all'attivazione o inibizione dell'enzima associato, a seconda del contesto cellulare.
La calmodulina è stata anche identificata come un fattore chiave nella risposta delle cellule ai cambiamenti di pH e temperatura, nonché allo stress ossidativo. Inoltre, la sua espressione è stata associata a diverse patologie umane, tra cui l'ipertensione, il diabete, la malattia di Alzheimer e alcuni tipi di cancro.
La calorimetria è una metodologia utilizzata nella fisica e nella fisiologia per misurare la quantità di calore assorbito o liberato durante un processo chimico o fisico. In medicina, la calorimetria indiretta è spesso utilizzata per misurare il dispendio energetico totale del corpo umano, che include il metabolismo basale e l'attività fisica.
La calorimetria si basa sulla legge di conservazione dell'energia, che afferma che l'energia non può essere creata o distrutta, ma solo convertita da una forma all'altra. In un calorimetro, un dispositivo utilizzato per misurare il flusso di calore, la variazione di temperatura è proporzionale all'energia scambiata tra il sistema studiato e l'ambiente circostante.
Nella pratica clinica, la calorimetria indiretta viene utilizzata per valutare lo stato nutrizionale dei pazienti e per monitorare il loro dispendio energetico durante il ricovero ospedaliero. Questa tecnica prevede la misurazione del consumo di ossigeno e della produzione di anidride carbonica del corpo umano, che sono correlati al dispendio energetico totale.
In sintesi, la calorimetria è una metodologia utilizzata per misurare il flusso di calore e l'energia scambiata tra un sistema e l'ambiente circostante. In medicina, la calorimetria indiretta viene utilizzata per valutare lo stato nutrizionale dei pazienti e monitorare il loro dispendio energetico totale durante il ricovero ospedaliero.
Gli epitopi, noti anche come determinanti antigenici, si riferiscono alle porzioni di un antigene che vengono riconosciute e legate dalle cellule del sistema immunitario, come i linfociti T e B. Sono generalmente costituiti da sequenze aminoacidiche o carboidrati specifici situati sulla superficie di proteine, glicoproteine o polisaccaridi. Gli epitopi possono essere lineari (continui) o conformazionali (discontinui), a seconda che le sequenze aminoacidiche siano adiacenti o separate nella struttura tridimensionale dell'antigene. Le molecole del complesso maggiore di istocompatibilità (MHC) presentano epitopi ai linfociti T, scatenando una risposta immunitaria cellulo-mediata, mentre gli anticorpi si legano agli epitopi sulle superfici di patogeni o cellule infette, dando inizio a una risposta umorale.
HIV-1 (Human Immunodeficiency Virus type 1) è un tipo di virus che colpisce il sistema immunitario umano, indebolendolo e rendendolo vulnerabile a varie infezioni e malattie. È la forma più comune e più diffusa di HIV nel mondo.
Il virus HIV-1 attacca e distrugge i linfociti CD4+ (un tipo di globuli bianchi che aiutano il corpo a combattere le infezioni), portando ad un progressivo declino della funzione immunitaria. Questo può portare allo stadio finale dell'infezione da HIV, nota come AIDS (Sindrome da Immunodeficienza Acquisita).
L'HIV-1 si trasmette principalmente attraverso il contatto sessuale non protetto con una persona infetta, l'uso di aghi o siringhe contaminati, la trasmissione verticale (da madre a figlio durante la gravidanza, il parto o l'allattamento) e la trasfusione di sangue infetto.
È importante notare che l'HIV non può essere trasmesso attraverso il contatto casuale o quotidiano con una persona infetta, come abbracciare, stringere la mano, baciare sulla guancia o sedersi accanto a qualcuno su un autobus.
Gli anticorpi monoclonali sono una tipologia specifica di anticorpi, proteine prodotte dal sistema immunitario che aiutano a identificare e neutralizzare sostanze estranee (come virus e batteri) nell'organismo. Gli anticorpi monoclonali sono prodotti in laboratorio e sono costituiti da cellule del sangue chiamate plasmacellule, che vengono stimolate a produrre copie identiche di un singolo tipo di anticorpo.
Questi anticorpi sono progettati per riconoscere e legarsi a specifiche proteine o molecole presenti su cellule o virus dannosi, come ad esempio le cellule tumorali o il virus della SARS-CoV-2 responsabile del COVID-19. Una volta che gli anticorpi monoclonali si legano al bersaglio, possono aiutare a neutralizzarlo o a marcarlo per essere distrutto dalle cellule immunitarie dell'organismo.
Gli anticorpi monoclonali sono utilizzati in diversi ambiti della medicina, come ad esempio nel trattamento di alcuni tipi di cancro, malattie autoimmuni e infiammatorie, nonché nelle terapie per le infezioni virali. Tuttavia, è importante sottolineare che l'uso degli anticorpi monoclonali deve essere attentamente monitorato e gestito da personale medico specializzato, poiché possono presentare effetti collaterali e rischi associati al loro impiego.
Mi dispiace, "Cricetulus" non è un termine utilizzato nella medicina. È in realtà un genere di roditori noti come gerbilli o piccoli criceti. Questi animali sono spesso studiati in campo biologico e medico per comprendere meglio i sistemi viventi, ma "Cricetulus" non è una definizione medica in sé. Se hai domande su una particolare specie di animale o su come vengano utilizzati nella ricerca medica, sarò lieto di aiutarti.
La parola "anchirina" non è comunemente utilizzata nella medicina o nella definizione medica. Tuttavia, in biologia cellulare, l'ancorina (o anchilina) si riferisce a una famiglia di proteine transmembrana che collegano le giunzioni interne con il citoscheletro della cellula. Questo collegamento è importante per la stabilità e la funzione delle giunzioni interne, che sono strutture specializzate che mantengono la coesione tra le cellule adiacenti.
Le ancorine svolgono un ruolo cruciale nella formazione e nel mantenimento della barriera emato-encefalica, una barriera altamente selettiva che separa il sangue dal tessuto cerebrale. Le mutazioni nei geni che codificano per le ancorine possono portare a disturbi come la malattia di Hirschsprung e la sindrome della costrizione intestinale, che colpiscono il sistema nervoso enterico.
Tuttavia, è importante notare che "anchirina" non è una parola comunemente utilizzata nella definizione medica o nelle diagnosi cliniche.
La spettrometria di massa con ionizzazione laser a desorbimento assistito da matrice (MALDI-TOF MS) è una tecnica di spettrometria di massa che utilizza un laser per desorbire e ionizzare molecole biomolecolari, come proteine o peptidi, da una matrice appropriata. Questa tecnica è ampiamente utilizzata in campo biochimico e clinico per l'identificazione e la caratterizzazione di biomolecole complesse, nonché per l'analisi di miscele biologiche.
Nel processo MALDI-TOF MS, le biomolecole vengono prima mescolate con una matrice organica, che assorbe energia laser a una lunghezza d'onda specifica. Quando il laser colpisce la matrice, l'energia viene trasferita alle molecole biomolecolari, causandone la desorbzione e l'ionizzazione. Le molecole cariche vengono quindi accelerate in un campo elettrico e attraversano un tubo di volo prima di entrare nello spettrometro di massa.
Lo spettrometro di massa utilizza un metodo di analisi chiamato tempo di volo (TOF), che misura il tempo impiegato dalle molecole cariche per attraversare il tubo di volo. Le molecole più leggere viaggiano più velocemente e raggiungono prima l'analizzatore TOF, mentre quelle più pesanti impiegano più tempo. In questo modo, lo spettrometro di massa produce uno spettro che mostra l'intensità relativa delle molecole in base al loro rapporto massa/carica (m/z).
L'identificazione e la caratterizzazione delle biomolecole vengono eseguite confrontando lo spettro MALDI-TOF MS con una biblioteca di spettrometria di massa nota o utilizzando algoritmi di ricerca di pattern. Questa tecnica è ampiamente utilizzata in vari campi, tra cui la biologia molecolare, la chimica analitica e la medicina forense.
Gli antigeni nucleari sono antigeni presenti all'interno del nucleo delle cellule. Essi comprendono una varietà di proteine e altre molecole che svolgono un ruolo importante nella regolazione delle funzioni cellulari, come la replicazione del DNA e la trascrizione dei geni.
Gli antigeni nucleari possono essere riconosciuti dal sistema immunitario come estranei o dannosi, in particolare in caso di malattie autoimmuni come il lupus eritematoso sistemico (LES) e la sclerodermia. In queste condizioni, il sistema immunitario produce anticorpi contro i propri antigeni nucleari, portando all'infiammazione e al danno dei tessuti.
Gli antigeni nucleari possono anche essere utilizzati come marcatori diagnostici per alcune malattie, come il cancro. Ad esempio, l'antigene proliferating cell nuclear (PCNA) è un marker tumorale che può essere utilizzato per valutare la crescita e la proliferazione delle cellule cancerose.
In sintesi, gli antigeni nucleari sono proteine e altre molecole presenti nel nucleo delle cellule che possono essere riconosciute dal sistema immunitario come estranee o dannose in caso di malattie autoimmuni o utilizzate come marcatori diagnostici per alcune malattie, compresi i tumori.
Gli introni sono sequenze di DNA non codificanti che si trovano all'interno di un gene. Quando un gene viene trascritto in RNA, l'RNA risultante contiene sia le sequenze codificanti (esoni) che quelle non codificanti (introni). Successivamente, gli introni vengono rimossi attraverso un processo noto come splicing dell'RNA, lasciando solo le sequenze esons con informazioni genetiche utili per la traduzione in proteine.
Pertanto, gli introni non hanno alcun ruolo diretto nella produzione di proteine funzionali, ma possono avere altre funzioni regolatorie all'interno della cellula, come influenzare il processamento dell'RNA o agire come siti di legame per le proteine che controllano l'espressione genica. Alcuni introni possono anche contenere piccoli RNA non codificanti con ruoli regolatori o funzioni catalitiche.
La proteina legante DNA rispondente all'AMP ciclico, nota anche come CAP (dall'inglese "catabolite activator protein"), è una proteina regolatrice dell'espressione genica presente in alcuni batteri. Questa proteina lega l'AMP ciclico (cAMP), un importante segnalatore intracellulare, e si attiva quando il livello di questo composto aumenta all'interno della cellula.
L'attivazione della CAP promuove il legame della proteina a specifiche sequenze di DNA, note come siti operatori, che si trovano a monte dei geni regolati. Questo legame favorisce l'interazione con l'RNA polimerasi, l'enzima responsabile della trascrizione del DNA in RNA, e ne stimola l'attività, aumentando la produzione di mRNA e quindi la sintesi proteica dei geni target.
La regolazione mediata dalla CAP è particolarmente importante nei batteri per il controllo dell'espressione genica in risposta a cambiamenti ambientali, come l'abbondanza o la scarsità di nutrienti. Ad esempio, quando i livelli di glucosio sono elevati, la cellula produce meno cAMP e la CAP è meno attiva, il che riduce la trascrizione dei geni responsabili della degradazione di altri substrati energetici, come il lattosio. Al contrario, quando i livelli di glucosio sono bassi, la cellula produce più cAMP, la CAP è più attiva e favorisce la trascrizione dei geni che codificano per enzimi responsabili della degradazione di altri substrati energetici.
Le proteine dei protozoi si riferiscono a varie proteine prodotte da organismi protozoi, che sono un gruppo eterogeneo di eucarioti unicellulari che comprendono diverse specie parassite responsabili di malattie infettive in esseri umani e animali. Queste proteine svolgono una vasta gamma di funzioni cruciali per la fisiologia dei protozoi, come la replicazione cellulare, la motilità, la segnalazione cellulare, l'attacco ospite-parassita e la difesa immunitaria.
Alcune proteine dei protozoi sono state ampiamente studiate come bersagli per lo sviluppo di farmaci antiparassitari a causa del loro ruolo cruciale nel ciclo vitale del parassita o nella sua interazione con l'ospite. Ad esempio, la proteina della superficie variabile (VSP) dei tripanosomi è nota per la sua capacità di eludere la risposta immunitaria dell'ospite e può essere un potenziale bersaglio terapeutico. Allo stesso modo, la tubulina dei protozoi, una proteina strutturale importante che forma i microtubuli, è stata studiata come possibile bersaglio per il trattamento dell'infezione da malaria.
Tuttavia, lo studio delle proteine dei protozoi è ancora in corso e sono necessari ulteriori approfondimenti per comprendere appieno la loro funzione e il loro potenziale come bersagli terapeutici.
L'Electrophoretic Mobility Shift Assay (EMSA), noto anche come gel shift assay, è un metodo di laboratorio utilizzato per studiare le interazioni tra acidi nucleici (DNA o RNA) e proteine. Questo metodo si basa sul principio che quando una miscela di acido nucleico marcato radioattivamente e la sua proteina associata viene sottoposta a elettroforesi su gel, la mobilità del complesso acido nucleico-proteina risultante è diversa dalla mobilità dell'acido nucleico libero.
Nel processo, il campione contenente l'acido nucleico e la proteina sospetta viene mescolato e incubato per consentire l'interazione tra di loro. Successivamente, il mix viene caricato su un gel di poliacrilammide o agarosio preparato con una matrice di buffer contenente ioni che conducono l'elettricità. Quando una corrente elettrica viene applicata, le molecole di acido nucleico migrano verso l'anodo a causa della carica negativa delle loro scheletri fosfato-deossiribosio/ribosio. Tuttavia, il complesso acido nucleico-proteina migrerà più lentamente del solo acido nucleico a causa dell'aumento di dimensioni e peso molecolare.
L'EMSA è spesso utilizzato per rilevare e analizzare la formazione di complessi proteina-DNA, determinare il numero di siti di legame delle proteine sul DNA bersaglio, studiare le modifiche post-traduzionali che influenzano l'affinità di legame della proteina e identificare i fattori di trascrizione specifici. Questa tecnica è anche utile per valutare il grado di purezza delle proteine preparate in vitro, nonché per studiare le interazioni RNA-proteina.
Le proteine immobilizzate sono proteine chimicamente o fisicamente legate a una superficie solida o a un supporto insolubile. Questo processo viene comunemente utilizzato in diversi campi della ricerca biomedica e bioingegneristica, come la biosensorestica, la cromatografia, l'immunoistochimica e l'ingegneria dei tessuti.
L'immobilizzazione delle proteine può avvenire mediante diversi metodi, tra cui l'adsorbimento fisico, il legame covalente, l'incapsulamento e la cross-linking. L'obiettivo principale dell'immobilizzazione delle proteine è quello di mantenere la loro attività catalitica o di legame specifico, mentre vengono utilizzate in diversi processi biotecnologici.
L'immobilizzazione delle proteine può anche migliorare la stabilità e la riutilizzabilità della proteina, ridurre l'inattivazione enzimatica e facilitare la separazione e il recupero della proteina dall'ambiente di reazione. Tuttavia, è importante notare che l'immobilizzazione delle proteine può anche influenzare la loro conformazione e attività, quindi è fondamentale ottimizzare le condizioni di immobilizzazione per mantenere l'attività desiderata della proteina.
L'arginina è un aminoacido essenziale, il quale significa che deve essere ottenuto attraverso la dieta o integratori alimentari. Il corpo non può sintetizzarla da solo in quantità sufficiente a soddisfare le sue esigenze.
L'arginina è importante per diversi processi nel corpo, tra cui il rilascio dell'ossido nitrico, un gas che aiuta i vasi sanguigni a rilassarsi e ad abbassare la pressione sanguigna. È anche usata dal corpo per produrre creatina, una sostanza chimica presente nelle cellule muscolari che aiuta a fornire energia per le attività fisiche ad alta intensità.
Inoltre, l'arginina è un precursore dell'urea, il principale metabolita azotato eliminato dai mammiferi attraverso i reni. Quindi, l'arginina svolge un ruolo importante nel mantenere l'equilibrio acido-base del corpo e nella detossificazione.
L'arginina è presente in molte fonti alimentari, come carne, pollame, pesce, latticini, noci e fagioli. Gli integratori di arginina sono spesso utilizzati per trattare varie condizioni, tra cui la disfunzione erettile, l'ipertensione arteriosa, il diabete e le malattie cardiovascolari. Tuttavia, gli effetti dell'integrazione di arginina su queste condizioni sono ancora oggetto di studio e non sono stati completamente dimostrati.
Il tabacco è una pianta (Nicotiana tabacum) originaria delle Americhe, i cui fogli essiccati vengono utilizzati per fumare, masticare o annusare. Il prodotto finale può contenere nicotina altamente additiva e altre sostanze chimiche dannose che possono portare a una serie di effetti negativi sulla salute, come il cancro ai polmoni, malattie cardiovascolari e problemi respiratori. Il fumo di tabacco è noto per essere una delle principali cause di morte prevenibile in tutto il mondo.
L'RNA elicasi è un enzima che svolge un ruolo cruciale nel processo di trascrizione dell'RNA nei organismi viventi. Più precisamente, l'RNA elicasi catalizza la separazione delle due catene complementari di RNA formate durante la fase di allungamento della trascrizione, trasformando così il doppio filamento di RNA in due filamenti singoli.
Questo processo è importante per consentire alla macchina molecolare della trascrizione, composta da diversi enzimi e fattori proteici, di continuare a svolgere la sua funzione senza interruzioni. Inoltre, l'RNA elicasi aiuta anche a rimuovere eventuali strutture secondarie che si possono formare nel filamento di RNA appena sintetizzato, rendendolo così più accessibile per le successive fasi del processo di elaborazione dell'RNA.
L'RNA elicasi è una proteina altamente conservata evolutivamente e presente in tutti i domini della vita. Ne esistono diverse classi, ciascuna con specifiche caratteristiche strutturali e funzionali, che intervengono in diversi processi cellulari, come la trascrizione, la riparazione del DNA, la replicazione virale e l'assemblaggio dei ribosomi.
La leucina è un aminoacido essenziale, il che significa che deve essere assunto attraverso la dieta perché il corpo non può sintetizzarlo da solo. È classificato come un aminoacido a catena ramificata (BCAA) ed è noto per giocare un ruolo cruciale nel processo di costruzione delle proteine e nella sintesi del muscolo scheletrico.
La leucina si trova in diversi alimenti ricchi di proteine, come carne, pesce, uova, latticini e fagioli. È anche disponibile come integratore alimentare, spesso commercializzato per gli atleti e coloro che cercano di migliorare la massa muscolare o la composizione corporea.
Nel contesto medico, la leucina è stata studiata per i suoi potenziali effetti terapeutici in diverse condizioni, come il cancro, l'obesità e la sarcopenia (perdita di massa muscolare correlata all'età). Tuttavia, sono necessarari ulteriori studi per confermare i suoi benefici e stabilire le dosi appropriate e le popolazioni target.
I coloranti fluorescenti sono sostanze chimiche che brillano o emettono luce visibile quando vengono esposte a una fonte di luce esterna, come la luce ultravioletta o una lampada a fluorescenza. Questi coloranti assorbono energia dalla sorgente di luce e la convertono in un'emissione di luce a diverse lunghezze d'onda, che appare spesso come un colore diverso rispetto alla luce incidente.
In ambito medico, i coloranti fluorescenti vengono utilizzati per diversi scopi, tra cui la marcatura e il tracciamento di cellule, proteine e altre biomolecole all'interno del corpo umano o in colture cellulari. Ciò può essere particolarmente utile nelle applicazioni di imaging medico, come la microscopia a fluorescenza, che consente agli scienziati e ai medici di osservare processi biologici complessi a livello cellulare o molecolare.
Un esempio comune di un colorante fluorescente utilizzato in medicina è la fluoresceina, che viene talvolta somministrata per via endovenosa durante gli esami oftalmici per evidenziare eventuali lesioni o anomalie della cornea e della congiuntiva. Altri coloranti fluorescenti possono essere utilizzati in diagnosi non invasive di malattie, come il cancro, attraverso la fluorescenza in vivo o l'imaging biomedico ottico.
Tuttavia, è importante notare che l'uso di coloranti fluorescenti deve essere attentamente monitorato e gestito, poiché possono presentare potenziali rischi per la salute se utilizzati in modo improprio o a dosaggi elevati.
La GTP fosfoidrolasi, nota anche come pirofosfato sintetasi, è un enzima che catalizza la reazione di conversione dell'ATP e della glicerolo-1-fosfato in difosfato di glicerolo (piridossal fosfato) e AMP. Questa reazione è fondamentale nel metabolismo dei lipidi, poiché il difosfato di glicerolo viene utilizzato come molecola di partenza per la sintesi dei trigliceridi e dei fosfolipidi.
L'attività enzimatica della GTP fosfoidrolasi richiede l'utilizzo di un cofattore, la vitamina B6 (piridossale 5'-fosfato), che svolge un ruolo cruciale nel trasferimento del gruppo fosfato dal glicerolo-1-fosfato all'AMP.
La GTP fosfoidrolasi è presente in molti tessuti e organismi, compreso l'uomo, ed è stata identificata come una possibile target terapeutica per il trattamento di alcune malattie metaboliche, come la steatosi epatica non alcolica (NAFLD) e la sindrome metabolica.
In termini medici, una malattia è generalmente definita come un disturbo o disfunzione del corpo o della mente. Di solito, si riferisce a una condizione che causa determinati sintomi e segni clinici, può influenzare la capacità di una persona di funzionare normalmente, e spesso è associata a cambiamenti patologici o anomalie strutturali nel corpo. Una malattia può essere causata da fattori genetici, infezioni, lesioni, stress ambientali o stile di vita, ed è spesso trattata con terapie mediche, chirurgiche o comportamentali. Tuttavia, è importante notare che ci sono anche condizioni soggettive e alterazioni dello stato di salute percepite dal paziente, che possono rientrare nella definizione di malattia in un'accezione più ampia, soprattutto nel contesto della medicina centrata sul paziente.
Le serine endopeptidasi, notevoli anche come serin proteasi, sono un gruppo di enzimi proteolitici che tagliano specificamente i legami peptidici interni (endopeptidici) delle catene polipeptidiche. Il sito attivo di questi enzimi contiene un residuo di serina cataliticamente attivo, che svolge un ruolo chiave nel meccanismo della loro attività proteolitica.
Questi enzimi sono ampiamente distribuiti in natura e partecipano a una varietà di processi biologici, come la coagulazione del sangue, la digestione, l'immunità e la risposta infiammatoria. Alcuni esempi ben noti di serine endopeptidasi includono la tripsina, la chimotripsina, l'elastasi e la trombina.
Le disfunzioni o le alterazioni dell'attività delle serine endopeptidasi sono state associate a diverse condizioni patologiche, come l'emofilia, la fibrosi cistica, l'aterosclerosi e alcune malattie infiammatorie croniche. Pertanto, il monitoraggio e la modulazione dell'attività di questi enzimi possono avere importanti implicazioni cliniche per la diagnosi e la terapia di tali disturbi.
L'adesività cellulare è un termine utilizzato in biologia e medicina per descrivere la capacità delle cellule di aderire tra loro o ad altre strutture. Questo processo è mediato da molecole adesive chiamate "adhesion molecules" che si trovano sulla superficie cellulare e interagiscono con altre molecole adesive presenti su altre cellule o su matrici extracellulari.
L'adesività cellulare svolge un ruolo fondamentale in una varietà di processi biologici, tra cui lo sviluppo embrionale, la riparazione dei tessuti, l'infiammazione e l'immunità. Ad esempio, durante lo sviluppo embrionale, le cellule devono aderire tra loro per formare strutture complesse come gli organi. Inoltre, nelle risposte infiammatorie, i globuli bianchi devono aderire alle pareti dei vasi sanguigni e migrare attraverso di essi per raggiungere il sito dell'infiammazione.
Tuttavia, un'eccessiva adesività cellulare può anche contribuire allo sviluppo di malattie come l'aterosclerosi, in cui le cellule endoteliali che rivestono i vasi sanguigni diventano iperadessive e permettono ai lipidi e alle cellule immunitarie di accumularsi nella parete del vaso. Questo accumulo può portare alla formazione di placche che possono ostruire il flusso sanguigno e aumentare il rischio di eventi cardiovascolari avversi come l'infarto miocardico o l'ictus.
In sintesi, l'adesività cellulare è un processo complesso e fondamentale che regola una varietà di funzioni cellulari e può avere implicazioni importanti per la salute e la malattia.
La simulazione di dinamica molecolare (MDS) è un metodo computazionale utilizzato in scienze biomediche e chimiche per studiare il movimento e il comportamento delle molecole a livello atomico. Questa tecnica si basa sulla meccanica classica newtoniana e consente di simulare il movimento delle particelle (atomi o gruppi di atomi) nel tempo, tenendo conto delle forze interattive tra esse.
Nel processo di MDS, le posizioni iniziali e le velocità dei singoli atomi vengono assegnate come input. Successivamente, il software calcola le forze che agiscono su ogni atomo utilizzando un potenziale di forza predefinito, che descrive l'energia associata alla posizione relativa degli atomi. Queste forze vengono quindi utilizzate per calcolare gli spostamenti e le velocità degli atomi in base alle equazioni del moto newtoniane.
Le simulazioni di dinamica molecolare possono essere applicate a una varietà di sistemi, tra cui proteine, acidi nucleici, lipidi e altri biomolecole, fornendo informazioni dettagliate sui loro meccanismi funzionali, la stabilità strutturale, le interazioni con ligandi o altre biomolecole, e il riconoscimento molecolare.
In sintesi, la simulazione di dinamica molecolare è un metodo computazionale che permette di studiare il movimento e il comportamento delle molecole a livello atomico, fornendo informazioni preziose per comprendere i meccanismi biologici e chimici alla base dei processi cellulari.
Le cellule Jurkat sono una linea cellulare umana utilizzata comunemente nella ricerca scientifica. Si tratta di un tipo di cellula T, una particolare sottopopolazione di globuli bianchi che svolgono un ruolo chiave nel sistema immunitario.
Le cellule Jurkat sono state isolate per la prima volta da un paziente affetto da leucemia linfoblastica acuta, un tipo di cancro del sangue. Queste cellule sono state trasformate in una linea cellulare immortale, il che significa che possono essere coltivate e riprodotte in laboratorio per un periodo di tempo prolungato.
Le cellule Jurkat sono spesso utilizzate negli esperimenti di laboratorio per studiare la funzione delle cellule T, nonché per indagare i meccanismi alla base della leucemia linfoblastica acuta e di altri tipi di cancro del sangue. Sono anche utilizzate come modello per testare l'efficacia di potenziali farmaci antitumorali.
E' importante notare che, poiché le cellule Jurkat sono state isolate da un paziente con una malattia specifica, i risultati ottenuti utilizzando queste cellule in esperimenti di laboratorio potrebbero non essere completamente rappresentativi della funzione delle cellule T sane o del comportamento di altri tipi di cancro del sangue.
L'apparato del Golgi, anche noto come complesso di Golgi o dictyosoma, è una struttura membranosa presente nelle cellule eucariotiche. Si tratta di un organello intracellulare che svolge un ruolo fondamentale nel processamento e nella modificazione delle proteine e dei lipidi sintetizzati all'interno della cellula.
L'apparato del Golgi è costituito da una serie di sacche membranose disposte in modo parallelo, chiamate cisterne, che sono circondate da vescicole e tubuli. Le proteine e i lipidi sintetizzati nel reticolo endoplasmatico rugoso (RER) vengono trasportati all'apparato del Golgi attraverso vescicole di trasporto.
Una volta all'interno dell'apparato del Golgi, le proteine e i lipidi subiscono una serie di modificazioni post-traduzionali, come la glicosilazione, la fosforilazione e la sulfatazione. Queste modifiche sono necessarie per garantire che le proteine e i lipidi raggiungano la loro destinazione finale all'interno della cellula e svolgano correttamente la loro funzione.
Dopo essere state modificate, le proteine e i lipidi vengono imballati in vescicole di secrezione e trasportati verso la membrana plasmatica o verso altri organelli cellulari. L'apparato del Golgi svolge quindi un ruolo cruciale nel mantenere la corretta funzionalità delle cellule e nella regolazione dei processi cellulari.
Le glicoproteine sono un tipo specifico di proteine che contengono uno o più carboidrati (zuccheri) legati chimicamente ad esse. Questa unione di proteina e carboidrato si chiama glicosilazione. I carboidrati sono attaccati alla proteina in diversi punti, che possono influenzare la struttura tridimensionale e le funzioni della glicoproteina.
Le glicoproteine svolgono un ruolo cruciale in una vasta gamma di processi biologici, tra cui il riconoscimento cellulare, l'adesione cellulare, la segnalazione cellulare, la protezione delle cellule e la loro idratazione, nonché la determinazione del gruppo sanguigno. Sono presenti in molti fluidi corporei, come il sangue e le secrezioni mucose, nonché nelle membrane cellulari di organismi viventi.
Un esempio ben noto di glicoproteina è l'emoglobina, una proteina presente nei globuli rossi che trasporta ossigeno e anidride carbonica nel sangue. Altre glicoproteine importanti comprendono le mucine, che lubrificano e proteggono le superfici interne dei tessuti, e i recettori di membrana, che mediano la risposta cellulare a vari segnali chimici esterni.
Le proteine contenenti domini MADS sono una classe di fattori di trascrizione che giocano un ruolo cruciale nello sviluppo e nella differenziazione delle cellule vegetali. Il nome "MADS" è un acronimo derivato dalle quattro prime proteine identificate in questa classe: MCM1 delle lieviti, AGAMOUS delle piante, DEFICIENS dei fiori di Drosophila e SRF (Serum Response Factor) degli animali.
Il dominio MADS è un motivo proteico altamente conservato che si lega al DNA e media l'interazione con altri fattori di trascrizione per regolare l'espressione genica. Queste proteine sono coinvolte in una varietà di processi biologici, tra cui la florogenesi, la morfogenesi delle foglie, il mantenimento dell'identità dei tessuti e la risposta allo stress ambientale nelle piante.
Le proteine contenenti domini MADS formano complessi eterodimerici o omodimerici che si legano a specifiche sequenze di DNA, chiamate elementi di risposta cis-attivatori (CARE), per regolare l'espressione genica. La specificità della legame al DNA e la formazione dei complessi dipendono dalla struttura tridimensionale del dominio MADS, che è altamente conservato tra le diverse specie vegetali.
Le mutazioni nei geni che codificano per le proteine contenenti domini MADS possono portare a difetti nello sviluppo e nella differenziazione delle cellule vegetali, con conseguenze negative sulla crescita e la produttività delle piante. Pertanto, l'identificazione e lo studio di queste proteine sono importanti per comprendere i meccanismi molecolari che regolano lo sviluppo e la differenziazione delle cellule vegetali e per migliorare le colture attraverso tecniche di ingegneria genetica.
La tripsina è un enzima proteolitico presente nel succo pancreatico e nell'intestino tenue. È prodotto dalle cellule acinari del pancreas come precursore inattivo, la tripsinogeno, che viene attivata a tripsina quando entra nel duodeno dell'intestino tenue.
La glicosilazione è un processo post-traduzionale che si verifica nelle cellule viventi, in cui una o più molecole di zucchero vengono aggiunte a una proteina o a un lipide. Questa reazione è catalizzata da enzimi chiamati glicosiltransferasi e può avvenire in diversi siti della proteina o del lipide.
Nella glicosilazione delle proteine, i monosaccaridi vengono uniti a specifici aminoacidi della catena peptidica, come serina, treonina e asparagina. Questo processo può influenzare la struttura, la funzione e l'interazione con altre molecole delle proteine glicosilate.
La glicosilazione è un processo importante per la regolazione di molte funzioni cellulari, come il riconoscimento cellulare, l'adesione cellulare, la segnalazione cellulare e la protezione delle proteine dalla degradazione enzimatica.
Anomalie nella glicosilazione possono portare a diverse patologie, come malattie genetiche rare, cancro, diabete e malattie infiammatorie croniche.
La concentrazione di idrogenioni (più comunemente indicata come pH) è una misura della quantità di ioni idrogeno presenti in una soluzione. Viene definita come il logaritmo negativo di base 10 dell'attività degli ioni idrogeno. Un pH inferiore a 7 indica acidità, mentre un pH superiore a 7 indica basicità. Il pH fisiologico del sangue umano è leggermente alcalino, con un range stretto di normalità compreso tra 7,35 e 7,45. Valori al di fuori di questo intervallo possono indicare condizioni patologiche come l'acidosi o l'alcalosi.
Il citoscheletro è un complesso reticolo dinamico e strutturale all'interno della cellula che svolge un ruolo fondamentale nella mantenimento della forma cellulare, nel movimento intracellulare e nella divisione cellulare. È costituito da tre tipi principali di filamenti proteici: actina, tubulina e intermediate filaments (filamenti intermedi).
1. Filamenti di actina: sono fibre sottili e flessibili composte dalla proteina actina globulare. Sono presenti principalmente nel citoplasma e giocano un ruolo cruciale nella determinazione della forma cellulare, nel movimento delle membrane cellulari e nell'organizzazione del nucleo.
2. Microtubuli: sono formati dalla proteina tubulina e hanno una struttura rigida e cilindrica. Sono i componenti principali dei mitotici e meiosici spindle apparatus, che sono essenziali per la divisione cellulare. Inoltre, svolgono un ruolo nella locomozione cellulare, nel trasporto intracellulare e nell'organizzazione del Golgi e dei centrioli.
3. Filamenti intermedi: sono i filamenti più grandi e resistenti del citoscheletro, composti da diverse proteine fibrose come la cheratina, la vimentina e la desmina. Sono presenti in tutte le cellule e forniscono supporto meccanico, mantenendo l'integrità strutturale della cellula. Inoltre, svolgono un ruolo nella determinazione dell'identità cellulare, nell'adesione cellulare e nel trasporto intracellulare.
Il citoscheletro è altamente dinamico e in grado di subire modifiche strutturali rapide in risposta a stimoli interni ed esterni. Questa proprietà gli conferisce la capacità di regolare una varietà di processi cellulari, tra cui la divisione cellulare, il movimento cellulare e il trasporto intracellulare.
Il cervello è la struttura più grande del sistema nervoso centrale ed è responsabile del controllo e della coordinazione delle funzioni corporee, dei pensieri, delle emozioni, dei ricordi e del comportamento. È diviso in due emisferi cerebrali separati da una fessura chiamata falce cerebrale. Ogni emisfero è ulteriormente suddiviso in lobi: frontale, parietale, temporale e occipitale.
Il cervello contiene circa 86 miliardi di neuroni che comunicano tra loro attraverso connessioni sinaptiche. Queste connessioni formano reti neurali complesse che elaborano informazioni sensoriali, motorie ed emotive. Il cervello è anche responsabile della produzione di ormoni e neurotrasmettitori che regolano molte funzioni corporee, come l'appetito, il sonno, l'umore e la cognizione.
Il cervello umano pesa circa 1,3-1,4 kg ed è protetto dal cranio. È diviso in tre parti principali: il tronco encefalico, il cervelletto e il telencefalo. Il tronco encefalico contiene i centri di controllo vitali per la respirazione, la frequenza cardiaca e la pressione sanguigna. Il cervelletto è responsabile dell'equilibrio, della coordinazione motoria e del controllo muscolare fine. Il telencefalo è la parte più grande del cervello ed è responsabile delle funzioni cognitive superiori, come il pensiero, il linguaggio, la memoria e l'emozione.
In sintesi, il cervello è un organo complesso che svolge un ruolo fondamentale nel controllare e coordinare le funzioni corporee, i pensieri, le emozioni e il comportamento.
In campo medico, un'endopeptidasi è un enzima che taglia i legami peptidici all'interno di una catena polipeptidica, ovvero all'interno della stessa proteina. Questo processo è noto come proteolisi o degradazione proteica e svolge un ruolo fondamentale in molti processi biologici, tra cui la digestione, l'attivazione o l'inattivazione di altre proteine e la risposta immunitaria.
Le endopeptidasi sono classificate in base al loro sito specifico di taglio all'interno della catena polipeptidica e alla loro struttura tridimensionale. Alcune endopeptidasi richiedono ioni metallici o altri cofattori per svolgere la loro attività enzimatica, mentre altre sono attive come enzimi singoli.
Esempi di endopeptidasi includono la tripsina e la chimotripsina, che sono enzimi digestivi presenti nel succo pancreatico e svolgono un ruolo cruciale nella digestione delle proteine ingerite. Altre endopeptidasi importanti sono le caspasi, che sono enzimi coinvolti nell'apoptosi o morte cellulare programmata, e le proteasi della matrice extracellulare (MMP), che svolgono un ruolo nella rimodellazione dei tessuti e nella patogenesi di malattie come il cancro e l'artrite reumatoide.
Gli "EF-hand motifs" sono strutture proteiche caratteristiche che si legano al calcio, presenti in molte proteine intracellulari. Questi motivi sono costituiti da due domini globulari a foglia piatta di circa 30 aminoacidi ciascuno, con una struttura simile ad un'elsa (da cui il nome "EF"), che si avvolgono intorno a un sito di legame per il calcio.
Gli EF-hand motifs sono in grado di subire cambiamenti conformazionali quando si legano al calcio, il che può indurre la formazione di dimeri o oligomeri proteici e l'attivazione di diverse funzioni enzimatiche. Queste funzioni includono la regolazione della contrazione muscolare, la segnalazione cellulare, l'esocitosi vescicolare e la trasduzione del segnale.
Le proteine che contengono EF-hand motifs sono altamente conservate evolutivamente e sono presenti in una varietà di organismi, dal batterio alla pianta alla mammifero. Gli EF-hand motifs possono essere trovati come singoli domini o ripetuti più volte all'interno della stessa proteina, a seconda delle funzioni specifiche che la proteina deve svolgere.
Gli oligopeptidi sono catene di aminoacidi relativamente corte che contengono da due a circa dieci unità aminoacidiche. Sono più corti dei polipeptidi, che ne contengono più di dieci. Gli oligopeptidi si formano quando diversi aminoacidi sono legati insieme da un legame peptidico, che è un tipo di legame covalente formato tra il gruppo carbossilico (-COOH) di un aminoacido e il gruppo amminico (-NH2) dell'aminoacido successivo.
Gli oligopeptidi possono essere sintetizzati dal corpo umano o ingeriti attraverso la dieta. Svolgono una varietà di funzioni biologiche, tra cui quella di ormoni e neurotrasmettitori, che trasmettono segnali all'interno del corpo. Alcuni esempi di oligopeptidi includono l'enkefalina, la dinorfina e la casomorfinna.
È importante notare che il termine "oligopeptide" non è rigorosamente definito da un numero specifico di aminoacidi e può variare a seconda della fonte o del contesto.
Le proteine oncogeniche di fusione sono tipi anormali di proteine che risultano dall'unione di due geni normalmente separati, spesso a causa di una traslocazione cromosomica o di un'altra riarrangiamento cromosomico. Questa fusione dei geni porta alla formazione di un gene chimera che codifica per una proteina chimera con proprietà e funzioni alterate.
Nelle cellule tumorali, queste proteine oncogeniche di fusione possono contribuire all'insorgenza, alla crescita e alla progressione del cancro promuovendo la proliferazione cellulare incontrollata, l'inibizione dell'apoptosi (morte cellulare programmata) e altri fenomeni tipici delle cellule tumorali.
Un esempio ben noto di proteina oncogenica di fusione è il prodotto del gene BCR-ABL, che si trova nei pazienti con leucemia mieloide cronica (LMC). Questa proteina chimera ha un'attività tirosin chinasi costitutivamente attiva, che porta a una proliferazione cellulare incontrollata e alla resistenza all'apoptosi. L'identificazione di queste proteine oncogeniche di fusione può essere utile per la diagnosi, la prognosi e il trattamento del cancro, poiché possono essere mirati con terapie specifiche come l'inibitore tirosin chinasi imatinib (Gleevec).
La Sindrome di Liddle è una forma rara di ipertensione ereditaria causata da mutazioni genetiche che portano all'aumento dell'attività del canale sodio epiteliale (ENaC) nei reni. Questa iperattività comporta un aumento del riassorbimento di sodio e acqua nel sangue, con conseguente ritenzione di fluidi e ipertensione. I sintomi possono includere mal di testa, vertigini, affaticamento, visione offuscata e problemi renali a lungo termine. La diagnosi si basa generalmente su test genetici e misurazioni del livello di renina nel sangue. Il trattamento prevede l'uso di diuretici risparmiatori di potassio, come la spironolattone o l'eplerenone, per controllare l'ipertensione e prevenire complicanze renali.
I fibroblasti sono cellule presenti nel tessuto connettivo dell'organismo, che sintetizzano e secernono collagene ed altre componenti della matrice extracellulare. Essi giocano un ruolo cruciale nella produzione del tessuto connettivo e nella sua riparazione in seguito a lesioni o danni. I fibroblasti sono anche in grado di contrarsi, contribuendo alla rigidezza e alla stabilità meccanica del tessuto connettivo. Inoltre, possono secernere fattori di crescita e altre molecole che regolano la risposta infiammatoria e l'immunità dell'organismo.
In condizioni patologiche, come nel caso di alcune malattie fibrotiche, i fibroblasti possono diventare iperattivi e produrre quantità eccessive di collagene ed altre proteine della matrice extracellulare, portando alla formazione di tessuto cicatriziale e alla compromissione della funzione degli organi interessati.
I piccoli RNA di interferenza (siRNA) sono molecole di acido ribonucleico (RNA) corti e double-stranded che svolgono un ruolo cruciale nella regolazione genica e nella difesa dell'organismo contro il materiale genetico estraneo, come i virus. Essi misurano solitamente 20-25 paia di basi in lunghezza e sono generati dal taglio di lunghi RNA double-stranded (dsRNA) da parte di un enzima chiamato Dicer.
Una volta generati, i siRNA vengono incorporati nella proteina argonauta (AGO), che fa parte del complesso RISC (RNA-induced silencing complex). Il filamento guida del siRNA all'interno di RISC viene quindi utilizzato per riconoscere e legare specificamente l'mRNA complementare, portando all'attivazione di due possibili vie:
1. Cleavage dell'mRNA: L'AGO taglia l'mRNA in corrispondenza del sito di complementarietà con il siRNA, producendo frammenti di mRNA più corti che vengono successivamente degradati.
2. Ripressione della traduzione: Il legame tra il siRNA e l'mRNA impedisce la formazione del complesso di inizio della traduzione, bloccando così la sintesi proteica.
I piccoli RNA di interferenza sono essenziali per la regolazione dell'espressione genica e giocano un ruolo importante nella difesa contro i virus e altri elementi genetici estranei. Essi hanno anche mostrato il potenziale come strumento terapeutico per il trattamento di varie malattie, tra cui alcune forme di cancro e disturbi genetici. Tuttavia, l'uso clinico dei siRNA è ancora in fase di sviluppo e sono necessari ulteriori studi per valutarne la sicurezza ed efficacia.
La biotinidazione è un processo enzimatico che attacca la biotina, una vitamina idrosolubile del complesso B, alle proteine. Questo processo è catalizzato dall'enzima biotinil-proteina sintetasi e si verifica principalmente nel fegato.
La biotinidazione svolge un ruolo importante nella regolazione del metabolismo di diversi aminoacidi e acidi grassi, in quanto la biotina funge da cofattore per diverse carboxilasi che sono essenziali per queste reazioni. La carenza di biotinidazione può portare a una serie di sintomi, tra cui ritardo dello sviluppo, convulsioni, eczema, perdita di capelli e disturbi neurologici.
La biotinidazione è anche un processo importante nella produzione di cheratina, la proteina principale che costituisce i capelli, le unghie e la pelle. Una carenza di biotina può portare a fragilità e rottura dei capelli e delle unghie, nonché alla secchezza e screpolatura della pelle.
In sintesi, la biotinidazione è un processo enzimatico che attacca la biotina alle proteine, svolgendo un ruolo importante nella regolazione del metabolismo degli aminoacidi e degli acidi grassi e nella produzione di cheratina.
Gli oligonucleotidi sono brevi catene di nucleotidi, che sono i componenti costitutivi degli acidi nucleici come DNA e RNA. Solitamente, gli oligonucleotidi contengono da 2 a 20 unità di nucleotidi, ciascuna delle quali è composta da un gruppo fosfato, una base azotata (adenina, timina, guanina, citosina o uracile) e uno zucchero deossiribosio o ribosio.
Gli oligonucleotidi sintetici sono ampiamente utilizzati in biologia molecolare, genetica e medicina come sonde per la rilevazione di specifiche sequenze di DNA o RNA, nella terapia genica, nell'ingegneria genetica e nella ricerca farmacologica. Possono anche essere utilizzati come inibitori enzimatici o farmaci antisenso per il trattamento di varie malattie, compresi i tumori e le infezioni virali.
Gli oligonucleotidi possono presentare diverse modifiche chimiche per migliorarne la stabilità, la specificità e l'affinità di legame con il bersaglio desiderato. Tra queste modifiche vi sono la sostituzione di zuccheri o basi azotate naturali con analoghi sintetici, la introduzione di gruppi chimici protettivi o reattivi, e l'estensione della catena con linker o gruppi terminali.
In sintesi, gli oligonucleotidi sono brevi sequenze di nucleotidi utilizzate in diversi campi della biologia molecolare e della medicina come strumenti diagnostici e terapeutici, grazie alle loro proprietà di legame specifico con le sequenze target di DNA o RNA.
L'ubiquitinazione è un processo post-traduzionale fondamentale che si verifica nelle cellule viventi. Si riferisce all'aggiunta di ubiquitina, una piccola proteina altamente conservata, a una proteina bersaglio specifica. Questo processo è catalizzato da un complesso enzimatico multi-subunità che comprende ubiquitina attivante (E1), ubiquitina legando (E2) e ubiquitina ligasi (E3).
L'ubiquitinazione svolge un ruolo cruciale nella regolazione di varie funzioni cellulari, tra cui la degradazione delle proteine, l'endocitosi, il traffico intracellulare, la risposta allo stress e l'infiammazione. La forma più comune di ubiquitinazione comporta l'aggiunta di una catena di poliubiquitina a un residuo di lisina sulla proteina bersaglio, che segnala la sua destinazione alla proteolisi mediata dal proteasoma. Tuttavia, ci sono anche forme atipiche di ubiquitinazione che non comportano la formazione di catene poliubiquitiniche e possono avere effetti diversi sulla funzione della proteina bersaglio.
In sintesi, l'ubiquitinazione è un processo regolatorio importante che modifica le proteine e influenza la loro localizzazione, stabilità e funzionalità.
I complessi multienzimatici sono aggregati proteici formati da più di un enzima e altre proteine non enzimatiche, che lavorano insieme per catalizzare una serie di reazioni chimiche correlate all'interno di una cellula. Questi complessi consentono di coordinare e accelerare le reazioni metaboliche, aumentando l'efficienza e la specificità dei processi biochimici. Un esempio ben noto è il complesso della fosfatidilcolina sintasi, che catalizza la sintesi di fosfatidilcolina, un importante componente strutturale delle membrane cellulari.
In termini medici, la polarizzazione della fluorescenza si riferisce a una tecnica utilizzata in microscopia per studiare le proprietà spaziali e temporali dell'emissione di fluorescenza da campioni biologici. Questa tecnica prevede l'illuminazione del campione con luce polarizzata, seguita dalla misurazione della polarizzazione dell'emissione di fluorescenza risultante.
Nello specifico, la luce polarizzata viene proiettata sul campione in modo che le sue oscillazioni elettriche siano allineate in una direzione particolare. I fluorofori nel campione assorbono questa luce polarizzata e quindi riemettono luce a diverse lunghezze d'onda, che possono anche essere polarizzate.
La polarizzazione della fluorescenza può fornire informazioni sulla mobilità e l'orientamento molecolare dei fluorofori all'interno del campione, nonché sulla struttura e la funzione delle biomolecole a cui sono legati. Ad esempio, questa tecnica può essere utilizzata per studiare le interazioni tra proteine, il ripiegamento delle proteine e la dinamica dei lipidi nelle membrane cellulari.
In sintesi, la polarizzazione della fluorescenza è una potente tecnica di microscopia che consente agli scienziati di ottenere informazioni dettagliate sulla struttura e la funzione delle biomolecole all'interno dei sistemi viventi.
In medicina, l'intelligenza artificiale (IA) non ha una definizione formalizzata specifica come in altri campi della scienza e dell'ingegneria. Tuttavia, si può descrivere l'intelligenza artificiale in un contesto medico come la capacità di macchine e computer di eseguire compiti che normalmente richiederebbero intelligenza umana per essere svolti, come il riconoscimento vocale, il processamento del linguaggio naturale, l'interpretazione di immagini e la presa di decisioni basate su dati complessi.
L'IA viene sempre più utilizzata nella medicina per supportare la diagnosi, la prognosi e la terapia di malattie complesse, nonché per l'analisi dei big data sanitari e la personalizzazione della cura del paziente. Alcuni esempi di applicazioni mediche dell'IA includono il rilevamento automatico delle lesioni tumorali nelle immagini radiologiche, la previsione del rischio di malattie cardiovascolari sulla base di dati clinici e l'assistenza alla formulazione di diagnosi differenziali complesse.
L'IA può anche essere utilizzata per automatizzare processi amministrativi complessi, come la gestione dei registri medici elettronici, la schedulazione degli appuntamenti e il monitoraggio della conformità alle linee guida cliniche. In questo modo, l'IA può contribuire a migliorare l'efficienza e la qualità delle cure sanitarie, nonché a ridurre gli errori umani e i costi associati.
In medicina e biologia cellulare, i microdomini della membrana, anche noti come "rafts" o "rafti" di lipidi, si riferiscono a regioni altamente organizzate e dinamiche del foglietto lipidico della membrana plasmatica delle cellule. Questi microambienti sono arricchiti in specifiche classi di lipidi, come colesterolo e glicosfingolipidi, che conferiscono loro proprietà uniche di ordine e stabilità strutturale.
I microdomini della membrana ospitano una varietà di proteine integrali e periferiche altamente selettive, tra cui canali ionici, pompe di ioni, recettori accoppiati a proteine G, enzimi, e molecole di adesione cellulare. La co-localizzazione di queste proteine con specifici lipidi nei microdomini della membrana facilita la formazione di complessi multiproteici e l'organizzazione di segnali intracellulari altamente regolati, compresi quelli associati alla trasduzione del segnale, endocitosi, traffico vescicolare, e processi infiammatori.
I microdomini della membrana sono soggetti a dinamiche spazio-temporali complesse, che ne consentono l'assemblaggio, la disgregazione e il riassemblaggio in risposta a stimoli cellulari e ambientali. La loro importanza funzionale nella regolazione di una varietà di processi cellulari ha attratto un crescente interesse per il potenziale ruolo dei microdomini della membrana nelle malattie umane, tra cui patologie neurodegenerative, infezioni virali e batteriche, e tumori.
Gli spliceosomi sono complessi ribonucleoproteici presenti nel nucleo delle cellule eucariotiche che catalizzano il processo di rimozione di introni (sequenze non codificanti) e la giunzione di esoni (sequenze codificanti) durante la maturazione dell'mRNA. Questo processo, noto come splicing dell'mRNA, consente di generare una grande varietà di proteine a partire da un numero relativamente limitato di geni.
Gli spliceosomi sono costituiti da cinque snRNP (small nuclear ribonucleoproteins) principali (U1, U2, U4/U6 e U5), ognuno dei quali contiene un piccolo RNA non codificante associato a proteine specifiche. Questi snRNP si associano transitoriamente per formare il complesso spliceosomiale attivo, che attraversa diverse fasi di assemblaggio e catalisi prima di dissociarsi dopo il completamento del splicing.
Il processo di splicing è essenziale per la corretta espressione genica ed è regolato da una serie di fattori che influenzano l'accuratezza e la specificità della rimozione degli introni e della giunzione degli esoni. Errori nel splicing possono portare a malattie genetiche o alla disregolazione dell'espressione genica, con conseguenze negative per lo sviluppo e la funzione cellulare.
Le molecole di adesione cellulare (CAM), in terminologia medica, si riferiscono a una classe di proteine transmembrana che giocano un ruolo cruciale nella mediazione delle interazioni tra le cellule e tra le cellule e la matrice extracellulare. Queste molecole sono essenziali per una varietà di processi biologici, come l'adesione cellulare, la migrazione cellulare, la differenziazione cellulare e la segnalazione cellulare.
Le CAM possono essere classificate in diversi tipi, tra cui le selectine, le immunoglobuline (Ig) a superficie cellulare, le integrine e le cadherine. Le selectine mediano l'adesione dei leucociti alle cellule endoteliali e sono importanti nella risposta infiammatoria. Le Ig a superficie cellulare sono implicate nell'interazione tra cellule immunitarie e nella regolazione della risposta immune. Le integrine svolgono un ruolo cruciale nell'adesione cellulare alla matrice extracellulare e nella segnalazione cellulare, mentre le cadherine mediano l'adesione tra cellule adiacenti ed è importante per la formazione di giunzioni aderenti.
Le alterazioni nelle espressioni o nelle funzioni delle molecole di adesione cellulare possono contribuire allo sviluppo e alla progressione di una varietà di malattie, come il cancro, le malattie cardiovascolari e le malattie infiammatorie. Pertanto, l'identificazione e lo studio delle CAM sono stati fonte di grande interesse nella ricerca biomedica.
La denaturazione delle proteine è un processo che altera la struttura tridimensionale delle proteine native, causandone la perdita della loro funzione originaria. Normalmente, le proteine hanno una conformazione ben definita, mantenuta da legami chimici tra gli aminoacidi che compongono la catena polipeptidica. Questa struttura è essenziale per l'attività e la funzionalità della proteina.
La denaturazione può essere causata da diversi fattori, come variazioni di pH, temperatura elevata, agenti chimici (come detergenti o solventi), radiazioni ionizzanti o forze meccaniche. Questi fattori rompono i legami che mantengono la struttura proteica, portando alla rottura o al ripiegamento alterato della catena polipeptidica. Di conseguenza, le proteine denaturate perdono la loro attività enzimatica, di trasporto o di altro tipo, poiché la conformazione necessaria per svolgere tali funzioni non è più presente.
È importante notare che, sebbene la denaturazione alteri la struttura e la funzione delle proteine, non sempre ne causa la completa distruzione. In alcuni casi, le proteine denaturate possono essere rinaturate, riacquistando la loro conformazione originaria e quindi la loro funzionalità, se vengono riportate alle condizioni ambientali appropriate. Tuttavia, questo non è sempre possibile, soprattutto quando la denaturazione è causata da danni irreversibili alla catena polipeptidica o a residui aminoacidici critici per la funzione proteica.
Le proteine RGS (sigla dell'inglese "Regulator of G-protein Signaling") sono una famiglia di proteine che agiscono come regolatori negativi dei segnali mediati dalle proteine G, che sono a loro volta coinvolte in diversi processi cellulari, tra cui la trasduzione del segnale e il controllo della crescita e differenziazione cellulare.
Le proteine RGS contengono un dominio conservato di circa 120 amminoacidi chiamato "dominio RGS box", che è responsabile dell'interazione con le subunità alfa delle proteine G attivate. Quando una proteina G viene attivata, scinde il suo legame con il recettore e dissocia la sua subunità alfa dalle subunità beta-gamma. La subunità alfa attivata è in grado di interagire con diverse enzimi, come le adenilato ciclasi o le fosfolipasi C, che producono secondi messaggeri intracellulari e quindi amplificano il segnale.
Le proteine RGS accelerano il riassorbimento della subunità alfa attivata nel suo stato inattivo legandosi ad essa e aumentando la sua velocità di idrolisi del GTP, che è un passaggio necessario per il riassorbimento della subunità alfa nella forma inattiva di GDP. In questo modo, le proteine RGS svolgono una funzione importante nel controllare l'intensità e la durata dei segnali mediati dalle proteine G.
Le proteine RGS sono coinvolte in diversi processi fisiologici e patologici, come il controllo della pressione sanguigna, la risposta infiammatoria, l'apprendimento e la memoria, e la progressione di alcuni tumori.
Il "gene silencing" o "silenziamento genico" si riferisce a una serie di meccanismi cellulari che portano al silenziamento o alla ridotta espressione dei geni. Ciò può avvenire attraverso diversi meccanismi, come la metilazione del DNA, l'interferenza dell'RNA e la degradazione dell'mRNA.
La metilazione del DNA è un processo epigenetico che comporta l'aggiunta di gruppi metile al DNA, il quale può impedire la trascrizione del gene in RNA messaggero (mRNA). L'interferenza dell'RNA si verifica quando piccole molecole di RNA, note come small interfering RNA (siRNA) o microRNA (miRNA), si legano all'mRNA complementare e impediscono la traduzione del mRNA in proteine. Infine, la degradazione dell'mRNA comporta la distruzione dell'mRNA prima che possa essere utilizzato per la sintesi delle proteine.
Il gene silencing è un processo importante nella regolazione dell'espressione genica e può essere utilizzato in terapia genica per trattare malattie causate da geni iperattivi o sovraespressi. Tuttavia, il gene silencing può anche avere implicazioni negative sulla salute, come nel caso del cancro, dove i meccanismi di silenziamento genico possono essere utilizzati dalle cellule tumorali per sopprimere l'espressione di geni che codificano proteine tumor-suppressive.
I Fattori di Scambio del Nucleotide Guanina (GSNF, dall'inglese Guanine Nucleotide Exchange Factors) sono una classe di proteine che stimolano lo scambio di guanina trifosfato (GTP) con guanina difosfato (GDP) su piccole proteine G (G-proteine). Questo processo attiva le G-proteine, che svolgono un ruolo cruciale nella trasduzione del segnale in cellule.
Le G-proteine sono regolate da un ciclo di legame e idrolisi di GTP: quando una G-proteina è legata a GDP, si trova nello stato inattivo; al contrario, quando è legata a GTP, è attiva e può interagire con altri partner proteici per trasmettere il segnale. I GSNF catalizzano lo scambio di GDP con GTP, favorendo così l'attivazione della G-proteina.
I GSNF sono essenziali per la regolazione di molte vie di segnalazione cellulare, tra cui le cascate di segnalazione mediata dai recettori accoppiati a proteine G (GPCR) e le vie di segnalazione Rho. Le disfunzioni nei GSNF possono portare a varie patologie, come ad esempio malattie cardiovascolari, neurologiche e tumorali.
La biologica evoluzione è il processo di cambiamento che si verifica nel tempo nelle popolazioni di organismi viventi, in cui nuove specie si formano e altre scompaiono. Questo processo è guidato dalla selezione naturale, che agisce sulle variazioni genetiche casuali che si verificano all'interno delle popolazioni.
L'evoluzione biologica include diversi meccanismi, tra cui la mutazione, il riarrangiamento cromosomico, la deriva genetica e la selezione naturale. La mutazione è una modifica casuale del DNA che può portare a nuove varianti di un gene. Il riarrangiamento cromosomico si riferisce alla ricombinazione di parti dei cromosomi, che può anche portare a variazioni genetiche.
La deriva genetica è un'altra forza evolutiva che opera nelle piccole popolazioni e consiste nella perdita casuale di varianti genetiche. Infine, la selezione naturale è il meccanismo più noto di evoluzione biologica, in cui alcune variazioni genetiche conferiscono a un organismo una maggiore probabilità di sopravvivenza e riproduzione rispetto ad altri.
L'evoluzione biologica ha portato alla diversificazione della vita sulla Terra, con la comparsa di una vasta gamma di specie che si sono adattate a diversi ambienti e nicchie ecologiche. Questo processo è continuo e avviene ancora oggi, come dimostrano le continue modifiche genetiche e l'emergere di nuove varianti di virus e batteri resistenti ai farmaci.
L'RNA virale si riferisce al genoma di virus che utilizzano RNA (acido ribonucleico) come materiale genetico anziché DNA (acido desossiribonucleico). Questi virus possono avere diversi tipi di genomi RNA, come ad esempio:
1. Virus a RNA a singolo filamento (ssRNA): questi virus hanno un singolo filamento di RNA come genoma. Possono essere ulteriormente classificati in due categorie:
a) Virus a RNA a singolo filamento positivo (+ssRNA): il loro genoma funge da mRNA (RNA messaggero) e può essere direttamente tradotto nelle cellule ospiti per produrre proteine virali.
b) Virus a RNA a singolo filamento negativo (-ssRNA): il loro genoma non può essere direttamente utilizzato come mRNA e richiede la trascrizione in mRNA complementare prima della traduzione in proteine virali.
2. Virus a RNA a doppio filamento (dsRNA): questi virus hanno un doppio filamento di RNA come genoma. Il loro genoma deve essere trascritto in mRNA prima che possa essere utilizzato per la sintesi delle proteine virali.
Gli RNA virali possono avere diversi meccanismi di replicazione e transcrizione, alcuni dei quali possono avvenire nel citoplasma della cellula ospite, mentre altri richiedono l'ingresso del genoma virale nel nucleo. Esempi di virus a RNA includono il virus dell'influenza, il virus della poliomielite, il virus della corona (SARS-CoV-2), e il virus dell'epatite C.
Gli anticorpi sono proteine specializzate del sistema immunitario che vengono prodotte in risposta alla presenza di sostanze estranee, note come antigeni. Gli antigeni possono essere batteri, virus, funghi, parassiti o altre sostanze chimiche estranee all'organismo.
Gli anticorpi sono anche chiamati immunoglobuline e sono prodotti dalle cellule B del sistema immunitario. Ogni anticorpo ha una forma unica che gli permette di riconoscere e legarsi a un particolare antigene. Quando un anticorpo si lega a un antigene, aiuta a neutralizzarlo o a marcarlo per essere distrutto dalle altre cellule del sistema immunitario.
Gli anticorpi possono esistere in diversi tipi, come IgA, IgD, IgE, IgG e IgM, ciascuno con una funzione specifica nel sistema immunitario. Ad esempio, gli anticorpi IgG sono i più abbondanti e forniscono l'immunità umorale contro le infezioni batteriche e virali, mentre gli anticorpi IgE svolgono un ruolo importante nella risposta allergica.
In sintesi, gli anticorpi sono proteine importanti del sistema immunitario che aiutano a identificare e neutralizzare sostanze estranee per mantenere la salute dell'organismo.
La specificità d'organo, nota anche come "tropismo d'organo", si riferisce alla preferenza di un agente patogeno (come virus o batteri) ad infettare e moltiplicarsi in uno specifico tipo o tessuto di organo, rispetto ad altri, nel corpo. Ciò significa che il microrganismo ha una particolare affinità per quell'organo o tessuto, il che può portare a sintomi e danni mirati in quella specifica area del corpo.
Un esempio comune di specificità d'organo è il virus della varicella-zoster (VZV), che tipicamente infetta la pelle e i gangli nervosi, causando varicella (una malattia esantematica) in seguito a una primoinfezione. Tuttavia, dopo la guarigione clinica, il virus può rimanere in uno stato latente nei gangli nervosi cranici o spinali per anni. In alcuni individui, lo stress, l'invecchiamento o un sistema immunitario indebolito possono far riattivare il virus, causando herpes zoster (fuoco di Sant'Antonio), che si manifesta con un'eruzione cutanea dolorosa limitata a una o due dermatomeri (aree della pelle innervate da un singolo ganglio nervoso spinale). Questo esempio illustra la specificità d'organo del virus VZV per i gangli nervosi e la pelle.
La comprensione della specificità d'organo di diversi agenti patogeni è fondamentale per lo sviluppo di strategie di prevenzione, diagnosi e trattamento efficaci delle malattie infettive.
La Fluorescence Recovery After Photobleaching (FRAP) è una tecnica microscopica avanzata utilizzata in biologia molecolare per studiare la mobilità e le dinamiche delle molecole fluorescenti etichettate all'interno di cellule viventi.
La Northern blotting è una tecnica di laboratorio utilizzata in biologia molecolare per rilevare e quantificare specifiche sequenze di RNA all'interno di campioni biologici. Questa tecnica prende il nome dal suo inventore, James Alwyn Northern, ed è un'evoluzione della precedente Southern blotting, che viene utilizzata per rilevare e analizzare l'acido desossiribonucleico (DNA).
La Northern blotting prevede i seguenti passaggi principali:
1. Estrarre e purificare l'RNA dai campioni biologici, ad esempio cellule o tessuti.
2. Separare le diverse specie di RNA in base alla loro dimensione utilizzando l'elettroforesi su gel di agarosio.
3. Trasferire (o "blot") l'RNA separato da gel a una membrana di supporto, come la nitrocellulosa o la membrana di nylon.
4. Ibridare la membrana con una sonda marcata specifica per la sequenza di RNA di interesse. La sonda può essere marcata con radioisotopi, enzimi o fluorescenza.
5. Lavare la membrana per rimuovere le sonde non legate e rilevare l'ibridazione tra la sonda e l'RNA di interesse utilizzando un sistema di rivelazione appropriato.
6. Quantificare l'intensità del segnale di ibridazione per determinare la quantità relativa della sequenza di RNA target nei diversi campioni.
La Northern blotting è una tecnica sensibile e specifica che può rilevare quantità molto piccole di RNA, rendendola utile per lo studio dell'espressione genica a livello molecolare. Tuttavia, la procedura è relativamente laboriosa e richiede attrezzature specialistiche, il che limita la sua applicazione a laboratori ben equipaggiati con personale esperto.
Le proteine muscolari sono un tipo specifico di proteine che si trovano nelle cellule muscolari, costituendo la maggior parte del volume e della massa dei muscoli scheletrici. Esse svolgono un ruolo fondamentale nella contrazione muscolare, permettendo al corpo di muoversi e mantenere la postura.
Le proteine muscolari sono composte da due filamenti principali: actina e miosina. L'actina forma filamenti sottili, mentre la miosina forma filamenti spessi. Durante la contrazione muscolare, i filamenti di miosina si legano agli actina, provocando lo scorrimento dei filamenti l'uno sull'altro e causando così il restringimento del muscolo.
Le proteine muscolari possono essere classificate in due tipi principali: proteine contrattili e proteine strutturali. Le proteine contrattili sono quelle direttamente coinvolte nella generazione della forza di contrazione, come actina e miosina. Le proteine strutturali, invece, forniscono la struttura e il supporto al muscolo, come titina, nebulina e distrofina.
La salute e la funzione dei muscoli dipendono dalla sintesi e dalla degradazione appropriate delle proteine muscolari. Una disregolazione di questi processi può portare a diverse patologie, come ad esempio la distrofia muscolare o la sarcopenia, una condizione associata alla perdita di massa muscolare e forza con l'età.
I processi fisiologici si riferiscono alle funzioni e ai meccanismi normalmente che si verificano all'interno di un organismo vivente per mantenere la vita, la crescita e l'homeostasi. Essi comprendono una vasta gamma di attività, tra cui la respirazione, la circolazione, la digestione, il metabolismo, la sintesi delle proteine, la riproduzione cellulare e la neurotrasmissione. Questi processi sono regolati da complessi sistemi di controllo che comprendono ormoni, nervi e altri meccanismi di feedback. I processi fisiologici possono essere influenzati da fattori interni ed esterni, come l'età, l'esercizio fisico, la dieta, le malattie e l'esposizione a sostanze chimiche o ambientali. La comprensione dei processi fisiologici è fondamentale per la pratica della medicina, poiché fornisce una base per la diagnosi e il trattamento delle malattie e delle condizioni di salute.
L'omologia di sequenza è un concetto utilizzato in genetica e biologia molecolare per descrivere la somiglianza nella serie di nucleotidi che compongono due o più segmenti di DNA o RNA. Questa similarità nella sequenza suggerisce una comune origine evolutiva dei segmenti, il che significa che sono stati ereditati da un antenato comune o si sono verificati eventi di duplicazione genica all'interno della stessa specie.
L'omologia di sequenza è comunemente utilizzata nell'analisi di DNA e proteine per identificare geni correlati, prevedere la funzione delle proteine e ricostruire l'evoluzione delle specie. Ad esempio, se due specie hanno una regione del DNA con un'elevata omologia di sequenza, è probabile che questa regione svolga una funzione simile nelle due specie e possa essere stata ereditata da un antenato comune.
L'omologia di sequenza può essere misurata utilizzando vari algoritmi e metriche, come la percentuale di nucleotidi o amminoacidi che sono identici o simili tra due sequenze. Una maggiore somiglianza nella sequenza indica una probabilità più elevata di omologia, ma è importante considerare altri fattori, come la lunghezza della sequenza e le differenze nella pressione selettiva, che possono influenzare l'interpretazione dell'omologia.
Le piccole ribonucleoproteine nucleari (snRNP, spesso pronunciate "snurps") sono complessi proteici che contengono molecole di piccolo RNA nucleare (snRNA). Si trovano nel nucleo delle cellule eucariotiche e svolgono un ruolo cruciale nella maturazione dell'mRNA, compreso il processamento del pre-mRNA, l'assemblaggio dei complessi spliceosomiali e la regolazione della trascrizione genica.
Le snRNP sono costituite da diversi tipi di proteine e da uno o più snRNA, che insieme formano un nucleo catalitico responsabile dell'attività di splicing dell'mRNA. Le snRNP sono classificate in base al tipo di snRNA che contengono, come U1, U2, U4/U6 e U5.
Le snRNP sono coinvolte nella rimozione dei segmenti non codificanti (introni) dal pre-mRNA durante il processo di splicing dell'mRNA. Questo processo è essenziale per la produzione di proteine funzionali e per la regolazione della espressione genica.
Le anomalie nelle snRNP possono portare a una serie di malattie genetiche, come la distrofia miotonica, la sindrome di Prader-Willi e la sindrome di Di George. Inoltre, le snRNP sono anche bersagli di virus come l'HIV e il citomegalovirus, che utilizzano queste molecole per replicarsi all'interno delle cellule ospiti.
L'analisi di sequenze attraverso un pannello di oligonucleotidi è una tecnica di biologia molecolare utilizzata per rilevare variazioni genetiche in specifici geni associati a particolari malattie ereditarie. Questa metodologia si basa sull'impiego di un pannello composto da una matrice di oligonucleotidi sintetici, progettati per legarsi selettivamente a sequenze nucleotidiche specifiche all'interno dei geni target.
Durante l'analisi, il DNA del soggetto viene estratto e amplificato mediante PCR (Reazione a Catena della Polimerasi) per le regioni di interesse. Successivamente, i frammenti amplificati vengono applicati al pannello di oligonucleotidi e sottoposti a un processo di ibridazione, in cui le sequenze complementari si legano tra loro. Utilizzando tecniche di rilevazione sensibili, come la fluorescenza o l'elettrochemiluminescenza, è possibile identificare eventuali variazioni nella sequenza del DNA del soggetto rispetto a quella di riferimento.
Questa metodologia offre diversi vantaggi, tra cui:
1. Maggiore accuratezza e sensibilità nel rilevamento di mutazioni puntiformi, piccole inserzioni/delezioni (indel) o variazioni copy number (CNV).
2. Possibilità di analizzare simultaneamente numerosi geni associati a una specifica malattia o fenotipo, riducendo i tempi e i costi rispetto all'analisi singola di ciascun gene.
3. Standardizzazione del processo di rilevamento delle varianti, facilitando il confronto e la comparabilità dei dati ottenuti in diversi laboratori.
L'analisi di sequenze attraverso un pannello di oligonucleotidi è ampiamente utilizzata nella diagnostica molecolare per identificare mutazioni associate a malattie genetiche, tumori e altre condizioni cliniche. Tuttavia, è importante considerare che questa tecnica non rileva tutte le possibili varianti presenti nel DNA, pertanto potrebbe essere necessario ricorrere ad altri metodi di indagine, come la sequenziamento dell'intero esoma o del genoma, per ottenere un quadro completo della situazione genetica del soggetto.
Le cellule eucariote sono le unità strutturali e funzionali più grandi e complesse degli organismi viventi, che comprendono animali, piante, funghi e protisti. A differenza delle cellule procariotiche, come i batteri, le cellule eucariote sono caratterizzate da una serie di organuli membranosi specializzati, tra cui il nucleo, mitocondri, cloroplasti (nei vegetali), reticolo endoplasmatico rugoso e liscio, apparato di Golgi e lisosomi.
Il nucleo è la caratteristica distintiva delle cellule eucariote, contenente il materiale genetico dell'organismo sotto forma di DNA linearmente organizzato in cromosomi. La membrana nucleare che circonda il nucleo regola il traffico di molecole tra il nucleo e il citoplasma circostante.
Le cellule eucariote possono variare notevolmente in termini di dimensione, forma e complessità, a seconda del tipo di organismo e della funzione specifica che svolgono. Tuttavia, tutte le cellule eucariotiche condividono caratteristiche comuni come la presenza di un nucleo ben definito, una cospicua quantità di citoplasma e una serie di organuli specializzati che svolgono funzioni specifiche all'interno della cellula.
Le cellule eucariote possono riprodursi asessualmente o sessualmente, a seconda del tipo di organismo. Durante la divisione cellulare, le cellule eucariotiche subiscono una serie di processi complessi che garantiscono una corretta separazione dei cromosomi e della membrana nucleare, nonché l'equa distribuzione degli organuli tra le due cellule figlie.
La polarità cellulare è un concetto biochimico e strutturale che si riferisce alla distribuzione asimmetrica dei componenti intracellulari all'interno di una cellula. Questa asimmetria molecolare dà origine a diverse proprietà funzionali e regioni specializzate nella cellula, che ne influenzano il comportamento e la risposta agli stimoli esterni.
In particolare, la polarità cellulare è fondamentale per processi come la divisione cellulare, la migrazione cellulare, l'adesione cellulare, la differenziazione cellulare e il trasporto di molecole attraverso la membrana plasmatica.
La polarità cellulare è caratterizzata dalla presenza di diversi domini o regioni all'interno della cellula, come l'apice e la base della cellula epiteliale, che presentano una composizione proteica e lipidica distinta. Questa distribuzione asimmetrica dei componenti è mantenuta da complessi sistemi di segnalazione intracellulare che regolano il traffico vescicolare, l'organizzazione del citoscheletro e la localizzazione delle proteine.
La comprensione della polarità cellulare è essenziale per comprendere i meccanismi molecolari alla base di molte funzioni cellulari normali e patologiche, come il cancro e le malattie neurodegenerative.
Gli enzimi coniuganti l'ubiquitina sono una classe di enzimi che giocano un ruolo cruciale nel processo di degradazione delle proteine attraverso il sistema ubiquitin-proteasoma. Questo meccanismo è essenziale per la regolazione della proteostasi cellulare, la risposta al danno alle proteine e l'eliminazione delle proteine danneggiate o mutate.
Il processo di coniugazione dell'ubiquitina implica tre fasi enzimatiche distinte:
1. Attivazione (E1): L'enzima di attivazione dell'ubiquitina (E1) attiva l'ubiquitina, un piccolo polipeptide conservato, legandola covalentemente a una sua residuo di cisteina mediante una reazione a carico di ATP.
2. Trasferimento (E2): L'ubiquitina attivata viene quindi trasferita all'enzima coniugante l'ubiquitina (E2), che funge da vettore per il trasferimento dell'ubiquitina alla proteina bersaglio.
3. Ligasi (E3): Infine, un enzima ligasi dell'ubiquitina (E3) media il trasferimento covalente dell'ubiquitina dalla molecola E2 alla specifica proteina bersaglio. Questo processo può essere ripetuto più volte per formare catene di ubiquitina, che segnalano la degradazione della proteina attraverso il proteasoma.
Le ligasi dell'ubiquitina (E3) sono particolarmente importanti nella specificità del riconoscimento delle proteine bersaglio e possono essere classificate in base al loro meccanismo di azione:
- Ligasi a rilegatura RING (Really Interesting New Gene): Le ligasi a rilegatura RING catalizzano il trasferimento diretto dell'ubiquitina dalla molecola E2 alla proteina bersaglio.
- Ligasi HECT (Homologous to the E6AP Carboxyl Terminus): Le ligasi HECT fungono da intermediari nel processo di coniugazione, accettando l'ubiquitina dalla molecola E2 e trasferendola successivamente alla proteina bersaglio.
Le diverse classi di enzimi coniuganti l'ubiquitina (E2) e ligasi dell'ubiquitina (E3) lavorano insieme per garantire la specificità e il corretto funzionamento del sistema di coniugazione dell'ubiquitina, che regola una vasta gamma di processi cellulari, tra cui la degradazione delle proteine, l'assemblaggio dei complessi proteici e la risposta al danno da stress.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
Il precursore della proteina beta-amiloide, noto anche come beta-amiloide precursor protein (APP), è una proteina transmembrana che svolge un ruolo importante nello sviluppo e nel mantenimento del sistema nervoso centrale. Viene espressa ampiamente in varie cellule, tra cui le cellule neuronali.
La proteina APP è soggetta a una serie di processi enzimatici che possono portare alla formazione di diversi frammenti, tra cui i peptidi beta-amiloidi, che sono il principale componente dei depositi di placche amiloidi, una caratteristica patologica della malattia di Alzheimer.
L'accumulo e l'aggregazione di questi peptidi beta-amiloidi nei neuroni e nelle aree vascolari del cervello sono considerati fattori chiave nello sviluppo della patologia della malattia di Alzheimer. Tuttavia, il ruolo esatto dei peptidi beta-amiloidi e della proteina APP nella malattia di Alzheimer non è ancora del tutto chiaro e sono in corso ricerche per comprendere meglio i loro meccanismi patologici.
La definizione medica di "Basi di dati fattuali" (o "Fonti di dati fattuali") si riferisce a raccolte strutturate e sistematiche di informazioni relative a fatti ed eventi medici documentati, come ad esempio diagnosi, procedure, farmaci prescritti, risultati dei test di laboratorio e altri dati clinici relativi ai pazienti.
Queste basi di dati sono spesso utilizzate per la ricerca medica, l'analisi delle tendenze epidemiologiche, il monitoraggio della sicurezza dei farmaci, la valutazione dell'efficacia dei trattamenti e altre attività di sorveglianza sanitaria.
Le basi di dati fattuali possono essere generate da diversi tipi di fonti, come cartelle cliniche elettroniche, registri di ricovero ospedaliero, database amministrativi delle cure sanitarie, sistemi di sorveglianza delle malattie infettive e altri.
È importante notare che le basi di dati fattuali non devono essere confuse con le "basi di conoscenza medica", che sono invece raccolte di informazioni relative a principi teorici, linee guida e raccomandazioni cliniche.
Acetiltransferasi è un termine utilizzato in biochimica per descrivere un tipo di enzimi che facilitano il trasferimento di un gruppo acetile (un gruppo funzionale composto da un atomo di carbonio e tre atomi di idrogeno, -COCH3) da una molecola donatrice ad una molecola accettore.
Questo processo è noto come acetilazione e può verificarsi su diverse molecole bersaglio, come proteine o altri metaboliti. L'acetilazione svolge un ruolo importante nella regolazione di varie funzioni cellulari, compreso il controllo dell'espressione genica e la modulazione delle attività enzimatiche.
L'acetiltransferasi più nota è probabilmente l'acetilcolinesterasi, un enzima che degrada l'acetilcolina, un neurotrasmettitore importante nel sistema nervoso centrale e periferico. La sua inibizione è il meccanismo d'azione di diversi farmaci utilizzati per trattare condizioni come la miastenia gravis e il glaucoma.
Il citosol, noto anche come matrice citoplasmatica o hyloplasm, è la fase fluida interna del citoplasma presente nelle cellule. Costituisce la parte acquosa della cellula al di fuori dei organelli e delle inclusioni cellulari. Contiene un'ampia varietà di molecole, tra cui ioni, piccole molecole organiche e inorganiche, metaboliti, enzimi e molte altre proteine. Il citosol svolge un ruolo cruciale nella regolazione della concentrazione degli ioni e delle molecole all'interno della cellula, nel trasporto di sostanze all'interno e all'esterno della cellula e nel metabolismo cellulare. È importante notare che il citosol non include i ribosomi, che sono considerati organelli separati pur essendo dispersi nel citoplasma.
La treonina è un aminoacido essenziale, il che significa che deve essere assunto attraverso la dieta perché il corpo umano non può sintetizzarlo autonomamente. È una componente importante delle proteine e svolge un ruolo cruciale nel mantenimento dell'equilibrio proteico nell'organismo.
La treonina è fondamentale per la crescita, lo sviluppo e il metabolismo corporeo. Viene utilizzata nella produzione di collagene ed elastina, due proteine che forniscono struttura e integrità ai tessuti connettivi del corpo, come pelle, tendini, legamenti e vasi sanguigni.
Inoltre, la treonina è importante per il funzionamento del sistema immunitario, in quanto supporta la produzione di anticorpi e altre proteine che aiutano a combattere le infezioni. È anche necessaria per la digestione e l'assorbimento dei nutrienti, poiché è coinvolta nella produzione di enzimi digestivi nello stomaco.
Fonti alimentari di treonina includono carne, pesce, uova, latte, formaggio, soia, fagioli e altri legumi. Una carenza di treonina può portare a sintomi come debolezza muscolare, ritardo della crescita, perdita di capelli, problemi alla pelle e un sistema immunitario indebolito.
High-throughput screening (HTS) assays sono tipi di test di laboratorio progettati per svolgere un gran numero di analisi in un breve lasso di tempo. Queste assay vengono utilizzate comunemente nella ricerca biomedica e farmacologica per identificare potenziali candidati terapeutici o bersagli molecolari.
Nello specifico, un HTS assay è una tecnologia che consente di testare simultaneamente migliaia o addirittura milioni di composti chimici, cellule o geni in modo da identificare quelli con attività biologiche desiderabili. Questa tecnica è particolarmente utile nella fase iniziale della scoperta dei farmaci, dove può essere utilizzata per identificare i composti che interagiscono con un bersaglio molecolare specifico, come un enzima o un recettore.
Gli HTS assay si basano su piattaforme automatizzate e robotiche che possono processare grandi quantità di campioni in modo efficiente ed affidabile. Questi test possono essere utilizzati per misurare una varietà di endpoint biologici, come l'attività enzimatica, la citotossicità, la modulazione del gene o la segnalazione cellulare.
In sintesi, gli High-throughput screening assays sono tecniche di laboratorio avanzate che permettono di testare un gran numero di campioni in modo rapido ed efficiente, con l'obiettivo di identificare composti o molecole con attività biologica desiderabile per scopi terapeutici o di ricerca.
La simulazione di "Molecular Docking" è un metodo computazionale utilizzato in bioinformatica e scienze biomolecolari per prevedere e visualizzare l'interazione tra due molecole, ad esempio una piccola molecola (come un farmaco) e una macromolecola bersaglio (come una proteina). Questa tecnica combina la fisica computazionale, la chimica quantistica e le teorie della forza debole per simulare il processo di legame molecolare.
Il processo di docking inizia con la creazione di un modello tridimensionale delle due molecole interagenti. Successivamente, vengono applicate diverse tecniche di minimizzazione dell'energia e algoritmi di ricerca per posizionare e ruotare la piccola molecola all'interno della cavità del sito attivo della macromolecola bersaglio, al fine di trovare la conformazione con l'energia di legame più bassa possibile.
L'output di una simulazione di docking è costituito da un insieme di pose (conformazioni) della piccola molecola all'interno del sito attivo, complete di punteggi di affinità che riflettono la forza prevista dell'interazione molecolare. Questi risultati possono essere utilizzati per selezionare i composti più promettenti per ulteriori studi sperimentali, ad esempio screening farmacologici o test di attività enzimatica.
In sintesi, la simulazione di molecular docking è un utile strumento computazionale che permette di predire e comprendere i meccanismi di interazione molecolare, supportando lo sviluppo di nuovi farmaci e la comprensione dei processi biomolecolari.
Il complesso proteasoma endopeptidasi, noto anche come proteasoma 26S o semplicemente proteasoma, è un importante complesso enzimatico presente nella maggior parte delle cellule eucariotiche. Esso svolge un ruolo fondamentale nel controllo della regolazione delle proteine attraverso il processo di degradazione selettiva delle proteine danneggiate, malfolded o non più necessarie all'interno della cellula.
Il proteasoma è costituito da due subcomplessi principali: il core 20S e uno o due regolatori 19S. Il core 20S contiene quattro anelli di subunità, formati ciascuno da sette diverse subunità, che insieme formano una camera catalitica dove avvengono le reazioni di degradazione proteica. I regolatori 19S sono responsabili del riconoscimento e della legatura delle proteine da degradare, dell'apertura della camera catalitica e dell'introduzione delle proteine all'interno del core 20S per la loro degradazione.
Il complesso proteasoma endopeptidasi è in grado di tagliare le proteine in peptidi più piccoli, utilizzando una serie di attività enzimatiche diverse, tra cui l'attività endopeptidasi, che taglia le proteine all'interno della loro sequenza aminoacidica. Questa attività è essenziale per la regolazione delle vie cellulari e la risposta immunitaria, poiché permette di smaltire rapidamente le proteine non più necessarie o danneggiate, come quelle ubiquitinate, e di generare peptidi presentabili alle cellule del sistema immunitario.
In sintesi, il complesso proteasoma endopeptidasi è un importante regolatore della proteostasi cellulare, che svolge un ruolo cruciale nella degradazione delle proteine e nel mantenimento dell'equilibrio cellulare. La sua attività è strettamente legata alla risposta immunitaria e alla regolazione di numerose vie cellulari, rendendola un bersaglio terapeutico promettente per il trattamento di diverse malattie, tra cui i tumori e le malattie neurodegenerative.
In medicina, la fluorescenza si riferisce a un fenomeno in cui una sostanza emette luce visibile dopo essere stata esposta alla luce UV o ad altre radiazioni ad alta energia. Quando questa sostanza assorbe radiazioni, alcuni dei suoi elettroni vengono eccitati a livelli energetici più alti. Quando questi elettroni ritornano al loro stato di riposo, emettono energia sotto forma di luce visibile.
La fluorescenza è utilizzata in diversi campi della medicina, come la diagnosi e la ricerca medica. Ad esempio, nella microscopia a fluorescenza, i campioni biologici vengono colorati con sostanze fluorescenti che si legano specificamente a determinate proteine o strutture cellulari. Quando il campione viene illuminato con luce UV, solo le aree che contengono la sostanza fluorescente emetteranno luce visibile, permettendo agli scienziati di osservare e analizzare specifiche caratteristiche del campione.
Inoltre, la fluorescenza è anche utilizzata nella medicina per la diagnosi di alcune malattie, come il cancro. Alcuni farmaci fluorescenti possono essere somministrati ai pazienti e quindi osservati al microscopio a fluorescenza per rilevare la presenza di cellule cancerose o altre anomalie. Questo metodo può fornire informazioni dettagliate sulla localizzazione e l'estensione del tumore, aiutando i medici a pianificare il trattamento più appropriato.
La Elaborazione del Linguaggio Naturale (NLP, Natural Language Processing) è una branca della Intelligenza Artificiale e dell'Informatica che si occupa dello sviluppo di algoritmi e modelli computazionali in grado di analizzare, comprendere e generare il linguaggio umano sotto forma di testo scritto o parlato.
L'obiettivo della NLP è quello di permettere alle macchine di processare, interpretare e generare il linguaggio umano in modo simile a come farebbe un essere umano, al fine di creare interazioni più naturali ed efficienti tra esseri umani e sistemi informatici.
La NLP combina tecniche di elaborazione del segnale, statistica, apprendimento automatico, linguistica computazionale e teoria dell'informazione per analizzare la struttura e il significato delle frasi e dei testi in linguaggio naturale. Alcune delle attività comuni della NLP includono l'analisi grammaticale, la traduzione automatica, la sintesi vocale, la comprensione del linguaggio parlato, l'estrazione di informazioni e la classificazione dei testi.
La NLP ha applicazioni in molti campi diversi, come ad esempio il riconoscimento vocale, i chatbot, i sistemi di domande e risposte automatiche, la ricerca semantica, l'analisi del sentiment, la prevenzione delle frodi finanziarie e la medicina computazionale.
In campo medico, la metilazione si riferisce a un processo biochimico che comporta l'aggiunta di un gruppo metile (-CH3) a una molecola. Questa reazione è catalizzata da enzimi specifici e può influenzare la funzione della molecola target, come DNA o proteine.
Nel caso del DNA, la metilazione avviene quando un gruppo metile viene aggiunto al gruppo aminico di una base azotata, comunemente la citosina. Questa modifica può influenzare l'espressione genica, poiché i promotori dei geni metilati sono meno accessibili ai fattori di trascrizione, il che porta a una ridotta espressione del gene. La metilazione del DNA è un meccanismo importante per la regolazione dell'espressione genica e può anche svolgere un ruolo nella inattivazione del cromosoma X, nell'impronta genetica e nel silenziamento dei trasposoni.
La metilazione delle proteine si verifica quando i gruppi metile vengono aggiunti a specifici residui di aminoacidi nelle proteine, alterandone la struttura tridimensionale e influenzando le loro funzioni. Questo processo è catalizzato da enzimi chiamati metiltransferasi e svolge un ruolo importante nella regolazione della funzione delle proteine, compresi i processi di segnalazione cellulare, la stabilità delle proteine e l'interazione proteina-proteina.
La definizione medica di "Cell Physiological Phenomena" si riferisce alle varie funzioni e processi fisiologici che si verificano all'interno di una cellula. Queste funzioni includono:
1. Respirazione cellulare: il processo mediante cui le cellule convertono il glucosio e l'ossigeno in acqua, anidride carbonica e ATP (adenosina trifosfato), che fornisce energia alla cellula.
2. Fermentazione: un processo metabolico alternativo che produce ATP in assenza di ossigeno.
3. Sintesi delle proteine: il processo di produzione di proteine a partire da amminoacidi, che è essenziale per la crescita e la riparazione cellulare.
4. Trasporto attivo e passivo: i meccanismi utilizzati dalle cellule per trasportare molecole attraverso la membrana cellulare. Il trasporto attivo richiede l'utilizzo di energia, mentre il trasporto passivo no.
5. Segnalazione cellulare: i meccanismi utilizzati dalle cellule per comunicare tra loro e coordinare le loro funzioni.
6. Ciclo cellulare: il processo di crescita, divisione e duplicazione del DNA delle cellule.
7. Apoptosi: la morte programmata delle cellule, che è un processo normale e importante per lo sviluppo e la homeostasi dell'organismo.
8. Meccanismi di riparazione del DNA: i meccanismi utilizzati dalle cellule per riparare i danni al DNA, che possono essere causati da fattori ambientali o errori durante la replicazione del DNA.
9. Autofagia: il processo di degradazione e riciclaggio delle componenti cellulari danneggiate o non funzionali.
10. Omeostasi ionica: il mantenimento dell'equilibrio dei livelli di ioni all'interno e all'esterno della cellula, che è importante per la sua funzione e sopravvivenza.
La spectrina è una proteina strutturale importante che si trova principalmente nelle membrane plasmatiche delle cellule. Nello specifico, la spectrina è un componente cruciale della "rete di spectrin" o "spettroscopia", che fornisce supporto meccanico e organizzazione alle membrane cellulari.
La spectrina è composta da due catene polipeptidiche, alpha e beta, che si avvolgono insieme per formare un eterotetramero a forma di ferro di cavallo. Questa struttura consente alla spectrina di legarsi a diverse proteine e lipidi della membrana plasmatica, nonché ad altre proteine strutturali come l'actina.
Nel sistema nervoso, la spectrina svolge un ruolo particolarmente importante nella stabilizzazione dei nodi di Ranvier, che sono siti specializzati delle cellule nervose dove avvengono i potenziali d'azione. La spectrina aiuta a mantenere l'integrità della membrana plasmatica in queste regioni, garantendo la corretta trasmissione dei segnali elettrici attraverso il sistema nervoso.
In sintesi, la spectrina è una proteina strutturale che fornisce supporto e organizzazione alle membrane cellulari, con particolare importanza nel sistema nervoso per la stabilizzazione dei nodi di Ranvier.
La microscopia elettronica è una tecnica di microscopia che utilizza un fascio di elettroni invece della luce visibile per ampliare gli oggetti. Questo metodo consente un ingrandimento molto maggiore rispetto alla microscopia ottica convenzionale, permettendo agli studiosi di osservare dettagli strutturali a livello molecolare e atomico. Ci sono diversi tipi di microscopia elettronica, tra cui la microscopia elettronica a trasmissione (TEM), la microscopia elettronica a scansione (SEM) e la microscopia elettronica a scansione in trasmissione (STEM). Queste tecniche vengono ampiamente utilizzate in molte aree della ricerca biomedica, inclusa la patologia, per studiare la morfologia e la struttura delle cellule, dei tessuti e dei batteri, oltre che per analizzare la composizione chimica e le proprietà fisiche di varie sostanze.
Le proteine da shock termico (HSP, Heat Shock Proteins) sono un gruppo eterogeneo di proteine altamente conservate che vengono prodotte in risposta a stress cellulari come l'aumento della temperatura, l'esposizione a tossici, radiazioni, ischemia e infezioni. Le HSP svolgono un ruolo cruciale nella proteostasi assistendo alla piegatura corretta delle proteine, al trasporto transmembrana e all'assemblaggio di oligomeri proteici. Inoltre, esse partecipano al processo di riparazione e degradazione delle proteine denaturate o danneggiate, prevenendone l'aggregazione dannosa per la cellula.
Le HSP sono classificate in base alle loro dimensioni molecolari e sequenze aminoacidiche conservate. Alcune famiglie importanti di HSP includono HSP70, HSP90, HSP60 (chiamati anche chaperonine), piccole HSP (sHSP) e HSP100. Ciascuna di queste famiglie ha funzioni specifiche ma sovrapposte nella proteostasi cellulare.
L'espressione delle proteine da shock termico è regolata principalmente a livello trascrizionale dal fattore di trascrizione heat shock factor 1 (HSF1). In condizioni basali, HSF1 esiste come monomero inattivo associato alle proteine HSP70 e HSP90. Quando la cellula subisce stress, le proteine HSP si legano a HSF1 per inibirne l'attivazione. Tuttavia, quando il danno alle proteine supera la capacità delle HSP di gestirlo, HSF1 viene liberato, trimerizzato e traslocato nel nucleo dove promuove la trascrizione dei geni HSP.
Le proteine da shock termico hanno dimostrato di avere effetti protettivi contro varie forme di stress cellulare e sono state implicate nella patogenesi di diverse malattie, tra cui le malattie neurodegenerative, il cancro e le malattie cardiovascolari. Pertanto, la comprensione dei meccanismi molecolari che regolano l'espressione delle proteine da shock termico offre opportunità per lo sviluppo di strategie terapeutiche per il trattamento di queste condizioni.
La regolazione virale dell'espressione genica si riferisce al meccanismo attraverso il quale i virus controllano l'espressione dei geni delle cellule ospiti che infettano, al fine di promuovere la loro replicazione e sopravvivenza. I virus dipendono dai meccanismi della cellula ospite per la trascrizione e traduzione dei propri genomi. Pertanto, i virus hanno sviluppato strategie per manipolare e regolare l'apparato di espressione genica della cellula ospite a loro vantaggio.
I meccanismi specifici di regolazione virale dell'espressione genica possono variare notevolmente tra i diversi tipi di virus. Alcuni virus codificano per fattori di trascrizione o proteine che interagiscono con il complesso di trascrizione della cellula ospite, alterando l'espressione genica a livello transcrizionale. Altri virus possono influenzare l'espressione genica a livello post-transcrizionale, attraverso meccanismi come il taglio e la giunzione dell'RNA o la modificazione delle code poli-A.
Inoltre, i virus possono anche interferire con il sistema di controllo della cellula ospite, come il sistema di soppressione dell'interferone, per evitare la risposta immunitaria dell'ospite e garantire la loro replicazione.
La comprensione dei meccanismi di regolazione virale dell'espressione genica è fondamentale per comprendere il ciclo di vita dei virus, nonché per lo sviluppo di strategie efficaci per il trattamento e la prevenzione delle malattie infettive.
Le proteine del capside sono una componente strutturale importante dei virus. Essi formano il capside, la shell protettiva che circonda il materiale genetico virale (DNA o RNA). Le proteine del capside si legano insieme per formare un'impalcatura simmetrica che racchiude e protegge il genoma virale. Questa struttura fornisce stabilità al virus e facilita il suo attacco e l'infezione delle cellule ospiti. La composizione e la disposizione delle proteine del capside variano tra i diversi tipi di virus, ma svolgono tutte funzioni simili nella protezione e nella consegna del materiale genetico virale. Le proteine del capside possono anche avere un ruolo nel legame del virus alle cellule ospiti durante l'infezione.
In medicina e biologia, le tecniche biosensoriali si riferiscono a metodi analitici che utilizzano un dispositivo chiamato biosensore per rilevare e misurare specifiche molecole biologiche, composti chimici o fenomeni biologici. Un biosensore è costituito da due parti principali: un elemento di riconoscimento biomolecolare (come anticorpi, enzimi, DNA, cellule viventi o recettori) e un trasduttore che converte il segnale generato dal riconoscimento molecolare in un segnale misurabile elettrico, termico, ottico o magnetico.
Le tecniche biosensoriali sono utilizzate in una vasta gamma di applicazioni, tra cui:
1. Diagnosi medica: per rilevare e monitorare biomarcatori associati a malattie, come glucosio nel sangue per il diabete, proteine tumorali per il cancro o marker infettivi per malattie infettive.
2. Monitoraggio ambientale: per rilevare e misurare la presenza di sostanze chimiche tossiche o contaminanti nell'aria, nell'acqua o nel suolo.
3. Sicurezza alimentare: per rilevare e quantificare microrganismi patogeni, allergeni o sostanze chimiche nocive negli alimenti e nelle bevande.
4. Ricerca biomedica di base: per studiare le interazioni molecolari tra biomolecole, come proteine, DNA, lipidi e carboidrati.
5. Sviluppo farmaceutico: per valutare l'efficacia e la sicurezza dei farmaci, nonché per monitorare i livelli di farmaci nel sangue durante il trattamento.
Le tecniche biosensoriali offrono diversi vantaggi rispetto ad altri metodi analitici, tra cui:
1. Alta sensibilità e specificità: le tecniche biosensoriali possono rilevare e quantificare molecole a basse concentrazioni con un'elevata selettività.
2. Velocità e semplicità: le tecniche biosensoriali richiedono meno tempo e sono più facili da eseguire rispetto ad altri metodi analitici tradizionali.
3. Basso costo: le tecniche biosensoriali possono essere realizzate con materiali a basso costo, rendendole accessibili per un'ampia gamma di applicazioni.
4. Miniaturizzazione e integrazione: le tecniche biosensoriali possono essere miniaturizzate e integrate in dispositivi portatili o wearable, offrendo la possibilità di misurazioni continue e in tempo reale.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
La proteina I legante il tacrolimus, nota anche come FKBP12 (FK506 binding protein of 12 kDa), è una proteina intracellulare che si lega specificamente al farmaco immunosoppressore tacrolimus (FK506) e al suo analogo, la pimecrolimus. Questa proteina appartiene alla famiglia delle proteine FKBP (FK506 binding proteins), che sono una classe di proteine chaperon che svolgono un ruolo importante nella regolazione della stabilità e dell'attività delle proteine.
La formazione del complesso tra il tacrolimus e la FKBP12 inibisce la calcineurina, un enzima fosfatasi che svolge un ruolo chiave nella regolazione della risposta immunitaria. L'inibizione della calcineurina previene la dephosphorylation e l'attivazione di NF-AT (nuclear factor of activated T cells), un fattore di trascrizione che è essenziale per l'espressione dei geni delle citochine proinfiammatorie. Di conseguenza, il complesso tacrolimus-FKBP12 sopprime l'attivazione e la proliferazione dei linfociti T, riducendo così la risposta immunitaria e prevenendo il rigetto del trapianto.
In sintesi, la proteina I legante il tacrolimus è una proteina intracellulare che si lega specificamente al farmaco immunosoppressore tacrolimus e inibisce l'attività della calcineurina, contribuendo a sopprimere la risposta immunitaria e prevenire il rigetto del trapianto.
La duplicazione genica si riferisce a un particolare tipo di mutazione genetica che comporta la copia completa o parziale di un gene, portando alla presenza di due o più copie del gene nello stesso genoma. Questa duplicazione può verificarsi in diversi modi, come ad esempio attraverso il meccanismo di "slippage" durante la replicazione del DNA, trasposizione genetica, o a seguito di riarrangiamenti cromosomici come le delezioni, inversioni o traslocazioni.
Le duplicazioni geniche possono avere effetti neutrali, deleteri o persino vantaggiosi sull'organismo che li porta. Neutralmente, la seconda copia del gene può non subire alcuna modifica funzionale e rimanere inattiva (silente). In alternativa, la duplicazione genica può comportare una perdita di funzione o malfunzionamento del gene duplicato, portando a effetti deleteri. Tuttavia, in alcuni casi, le duplicazioni geniche possono fornire materiale sufficiente per l'evoluzione di nuove funzioni (innovazione funzionale) o aumentare l'espressione del gene, che può essere vantaggioso per l'organismo in determinate condizioni.
In sintesi, la duplicazione genica è un evento che comporta la presenza di due o più copie di un gene nello stesso genoma, con conseguenze variabili che possono essere neutre, deleterie o persino vantaggiose per l'organismo.
Le infezioni da Rubulavirus si riferiscono a malattie causate dal genere Rubulavirus, che include il virus della parotite (o virus della parotite) e il virus del morbillo. Questi virus sono contagiosi e possono causare infezioni nel sistema respiratorio e in altri organi.
Il virus della parotite, noto anche come "orecchione", provoca generalmente una malattia lieve con sintomi quali gonfiore delle ghiandole salivari (parotiti), febbre, mal di testa e dolori muscolari. Tuttavia, in alcuni casi, può causare complicazioni più gravi, come l'infiammazione del cervello (encefalite) o dei testicoli (orchite).
Il virus del morbillo è una malattia altamente contagiosa che causa febbre alta, tosse, congestione nasale, occhi rossi e una eruzione cutanea. Anche se nella maggior parte dei casi il morbillo si risolve spontaneamente, può causare complicazioni gravi, come polmonite, encefalite o morte, soprattutto nei bambini molto piccoli e negli individui con sistema immunitario indebolito.
La prevenzione delle infezioni da Rubulavirus si ottiene attraverso la vaccinazione. Il vaccino contro il morbillo, la parotite e la rosolia (MMR) protegge contro il virus della parotite e il virus del morbillo.
La "TATA box" è un termine utilizzato in biologia molecolare per descrivere una sequenza specifica di DNA che si trova nel promotore dei geni eucariotici. La TATA box, che prende il nome dalla sua sequenza nucleotidica caratteristica (TATAAA), è riconosciuta e legata da un fattore di trascrizione generale chiamato TBP (TATA-binding protein). Questa interazione è uno dei primi passi nel processo di inizio della trascrizione, durante il quale l'informazione genetica contenuta nel DNA viene copiata in RNA. La TATA box serve come punto di ancoraggio per l'assemblaggio dell'apparato di trascrizione, composto da altre proteine di legame al DNA e cofattori enzimatici che lavorano insieme per sintetizzare l'RNA messaggero (mRNA). La corretta posizionamento e sequenza della TATA box sono cruciali per il corretto inizio e la regolazione dell'espressione genica.
L'analisi di sequenze, in ambito medico, si riferisce ad un insieme di tecniche di biologia molecolare utilizzate per studiare la struttura e la funzione delle sequenze del DNA o dell'RNA. Queste analisi sono particolarmente utili nella diagnosi e nella comprensione delle basi molecolari di diverse malattie genetiche, nonché nello studio dell'evoluzione e della diversità biologica.
L'analisi di sequenze può essere utilizzata per identificare mutazioni o variazioni a livello del DNA che possono essere associate a specifiche malattie ereditarie o acquisite. Ad esempio, l'identificazione di una mutazione in un gene noto per essere associato ad una particolare malattia può confermare la diagnosi della malattia stessa.
L'analisi di sequenze può anche essere utilizzata per studiare la variabilità genetica all'interno di popolazioni o tra specie diverse, fornendo informazioni importanti sulla storia evolutiva e sull'origine delle specie.
In sintesi, l'analisi di sequenze è una tecnica fondamentale in molte aree della ricerca biomedica e clinica, che consente di comprendere la struttura e la funzione del DNA e dell'RNA a livello molecolare.
La proteina legante TATA-box, nota anche come TBP (dall'inglese TATA-binding protein), è una proteina fondamentale che svolge un ruolo chiave nella regolazione dell'espressione genica. Essa lega specificamente la sequenza nucleotidica TATA presente nel sito di inizio della trascrizione dei geni eucariotici, nota come promotore. Questa interazione assiste nella formazione del complesso di pre-iniziazione della trascrizione, composto anche da altre proteine, che successivamente recluta l'RNA polimerasi II per avviare la trascrizione dell'mRNA. La TBP è altamente conservata evolutivamente e svolge un ruolo cruciale nel garantire la specificità e l'efficienza della trascrizione genica in tutti gli eucarioti.
In termini medici, il "doppio strato lipidico" si riferisce alla struttura di base della membrana cellulare che circonda tutte le cellule viventi. È chiamato "doppio strato" perché è composto da due layer o strati di molecole lipidiche, principalmente fosfolipidi, disposte in modo tale che le loro code idrofobe (repellenti all'acqua) siano rivolte verso l'interno e le teste idrofile (attratte dall'acqua) siano rivolte verso l'esterno. Questa disposizione permette al doppio strato lipidico di essere una barriera selettivamente permabile, consentendo il passaggio di alcune molecole mentre ne blocca altre, e contribuisce a mantenere l'integrità e la funzione della cellula.
La composizione esatta del doppio strato lipidico può variare tra diversi tipi di cellule e tessuti, ma in generale è costituito da una miscela di fosfolipidi, colesterolo e proteine integrali. Il rapporto tra queste molecole può influenzare le proprietà fisiche del doppio strato lipidico, come la fluidità e la permeabilità, che a loro volta possono influenzare la funzione cellulare. Ad esempio, alcuni virus e tossine sono in grado di interagire con il doppio strato lipidico delle membrane cellulari per infettare o danneggiare le cellule.
La regolazione batterica dell'espressione genica si riferisce al meccanismo di controllo delle cellule batteriche sulla sintesi delle proteine, che è mediata dall'attivazione o dalla repressione della trascrizione dei geni. Questo processo consente ai batteri di adattarsi a varie condizioni ambientali e di sopravvivere.
La regolazione dell'espressione genica nei batteri è controllata da diversi fattori, tra cui operoni, promotori, operatori, attivatori e repressori della trascrizione. Gli operoni sono gruppi di geni che vengono trascritte insieme come un'unità funzionale. I promotori e gli operatori sono siti specifici del DNA a cui si legano i fattori di trascrizione, che possono essere attivatori o repressori.
Gli attivatori della trascrizione si legano agli operatori per promuovere la trascrizione dei geni adiacenti, mentre i repressori della trascrizione si legano agli operatori per prevenire la trascrizione dei geni adiacenti. Alcuni repressori sono inattivi a meno che non siano legati a un ligando specifico, come un metabolita o un effettore ambientale. Quando il ligando si lega al repressore, questo cambia conformazione e non può più legarsi all'operatore, permettendo così la trascrizione dei geni adiacenti.
In sintesi, la regolazione batterica dell'espressione genica è un meccanismo di controllo cruciale che consente ai batteri di adattarsi a varie condizioni ambientali e di sopravvivere. Questo processo è mediato da diversi fattori, tra cui operoni, promotori, operatori, attivatori e repressori della trascrizione.
Gli isoenzimi sono enzimi con diverse strutture proteiche ma con attività enzimatiche simili o identiche. Sono codificati da geni diversi e possono essere presenti nello stesso organismo, tissue o cellula. Gli isoenzimi possono essere utilizzati come marcatori biochimici per identificare specifici tipi di tessuti o cellule, monitorare il danno tissutale o la malattia, e talvolta per diagnosticare e monitorare lo stato di avanzamento di alcune condizioni patologiche. Un esempio comune di isoenzimi sono le tre forme dell'enzima lactato deidrogenasi (LD1, LD2, LD3, LD4, LD5) che possono essere trovati in diversi tessuti e hanno diverse proprietà cinetiche.
Le proteine degli elminti si riferiscono a specifiche sequenze proteiche uniche che sono esclusive dei parassiti noti come elminti, che includono vermi piatti (trematodi e cestodi) e vermi rotondi (nematodi). Queste proteine possono essere utilizzate come bersagli per lo sviluppo di farmaci antiparassitari, poiché svolgono funzioni vitali per la sopravvivenza, la riproduzione e la virulenza dei elminti.
Le proteine degli elminti possono essere classificate in diversi gruppi, come enzimi, proteine di superficie, proteine di secrezione ed escrezione, e proteine strutturali. Alcune di queste proteine sono state identificate come antigeni importanti per la diagnosi e il monitoraggio delle infezioni da elminti.
L'identificazione e la caratterizzazione delle proteine degli elminti possono essere effettuate utilizzando tecniche di biologia molecolare, come la genetica e la genomica funzionale, che consentono di identificare i geni e le vie metaboliche associate a queste proteine. Queste informazioni possono essere utilizzate per sviluppare farmaci antiparassitari mirati e strategie di controllo delle malattie infettive causate da elminti.
In genetica, il termine "geni essenziali" si riferisce a quei geni che sono fondamentali per la sopravvivenza e la riproduzione di un organismo. Questi geni codificano per proteine vitali necessarie per le funzioni cellulari basiche, come la replicazione del DNA, la trascrizione e la traduzione, il metabolismo, la divisione cellulare e la risposta al danno cellulare. L'inattivazione o la mutazione di geni essenziali in genere portano a malfunzionamenti cellulari significativi che possono causare gravi malattie o persino la morte dell'organismo. Pertanto, i geni essenziali sono considerati essenziali per la vita e la salute di un organismo. Tuttavia, la definizione esatta di "geni essenziali" può variare a seconda del contesto sperimentale o della specie studiata.
La progettazione della struttura molecolare di un farmaco (in inglese: "De novo drug design" o "Rational drug design") è un approccio alla scoperta di nuovi farmaci che utilizza la conoscenza della struttura tridimensionale delle proteine bersaglio e dei meccanismi d'azione molecolare per creare composti chimici con attività terapeutica desiderata. Questo processo prevede l'identificazione di siti attivi o altre aree chiave sulla superficie della proteina bersaglio, seguita dalla progettazione e sintesi di molecole che possono interagire specificamente con tali siti, modulando l'attività della proteina.
La progettazione della struttura molecolare di un farmaco può essere suddivisa in due categorie principali:
1. Progettazione basata sulla liganda (in inglese: "Lead-based design"): Questa strategia inizia con la scoperta di un composto chimico, noto come "lead," che mostra attività biologica promettente contro il bersaglio proteico. Gli scienziati quindi utilizzano tecniche computazionali e strumenti di modellazione molecolare per analizzare l'interazione tra il lead e la proteina, identificando i punti di contatto cruciali e apportando modifiche mirate alla struttura del composto per migliorarne l'affinità di legame, la selettività e l'attività farmacologica.
2. Progettazione basata sulla struttura (in inglese: "Structure-based design"): Questa strategia si avvale della conoscenza della struttura tridimensionale della proteina bersaglio, ottenuta attraverso tecniche di cristallografia a raggi X o risonanza magnetica nucleare (NMR). Gli scienziati utilizzano queste informazioni per identificare siti di legame potenziali e progettare molecole sintetiche che si leghino specificamente a tali siti, mirando ad influenzare la funzione della proteina e ottenere un effetto terapeutico desiderato.
Entrambe le strategie di progettazione basate sulla liganda e sulla struttura possono essere combinate per creare una pipeline di sviluppo dei farmaci più efficiente ed efficace, accelerando il processo di scoperta e consentendo la produzione di nuovi farmaci mirati con maggiore precisione e minor tossicità.
RNA polimerasi II è un enzima chiave nel processo di trascrizione del DNA nei eucarioti. È responsabile della sintesi dell'mRNA (RNA messaggero) e diversi tipi di RNA non codificanti, come l'RNA ribosomale e l'RNA intronico. L'RNA polimerasi II lega il DNA promotore a monte del gene da trascrivere e, insieme ad altri fattori di trascrizione, inizia la sintesi dell'mRNA utilizzando il DNA come matrice. Questo enzima è soggetto a una regolazione complessa che influenza l'espressione genica e, di conseguenza, la determinazione del fenotipo cellulare.
L'immunoprecipitazione cromatinica (ChIP) è una tecnica di biologia molecolare utilizzata per studiare le interazioni tra proteine e DNA all'interno del nucleo cellulare. Questa tecnica consente di identificare i siti specifici di legame delle proteine sulla doppia elica del DNA, comprese le modifiche post-traduzionali delle proteine associate al DNA.
Nel processo ChIP, le cellule vengono trattate con un fissativo chimico per mantenere intatte le interazioni proteina-DNA. Successivamente, il DNA viene frammentato in pezzi di dimensioni comprese tra 200 e 1000 paia di basi mediante sonicazione o digestione enzimatica. Le proteine vengono quindi precipitate utilizzando anticorpi specifici per la proteina di interesse, seguite da un'estrazione del DNA legato alla proteina. Il DNA immunoprecipitato viene poi purificato e analizzato mediante tecniche come PCR quantitativa o sequenziamento dell'intero genoma (WGS) per identificare i siti di legame della proteina sul DNA.
La ChIP è una tecnica potente che può essere utilizzata per studiare una varietà di processi cellulari, tra cui la regolazione trascrizionale, il ripiegamento della cromatina e la riparazione del DNA. Tuttavia, questa tecnica richiede un'elevata specificità degli anticorpi utilizzati per l'immunoprecipitazione e una rigorosa validazione dei dati ottenuti.
"Anethum Graveolens" è la definizione botanica della pianta nota comunemente come aneto. L'aneto è una pianta erbacea annuale appartenente alla famiglia delle Apiaceae (o Umbelliferae), che include anche carote, prezzemolo e finocchi.
L'aneto è originario dell'Europa meridionale e dell'Asia occidentale, ed è ampiamente coltivato in tutto il mondo per le sue foglie e semi aromatici, che vengono utilizzati come condimento in cucina.
Le foglie di aneto hanno un sapore simile al prezzemolo, mentre i suoi piccoli semi sono noti per il loro sapore dolce e leggermente amaro, con note di agrumi e musk. I semi di aneto vengono spesso utilizzati come spezia in cucina, mentre le foglie fresche o essiccate possono essere utilizzate per insaporire piatti freddi o caldi.
In campo medico, l'aneto è stato storicamente utilizzato per trattare una varietà di disturbi, tra cui problemi digestivi, mal di testa e dolori articolari. Tuttavia, sono necessarie ulteriori ricerche per confermare i suoi effetti terapeutici.
È importante notare che l'aneto può avere interazioni con alcuni farmaci, quindi è sempre consigliabile consultare un medico o un farmacista prima di utilizzarlo come integratore o rimedio erboristico.
Baculoviridae è una famiglia di virus a DNA bicatenaio che infetta esclusivamente artropodi, in particolare lepidotteri (farfalle e falene). Questi virus sono caratterizzati da un'ampia gamma di dimensioni e forme, ma la maggior parte ha una forma di bastone o baculoide, da cui deriva il nome "Baculoviridae".
I Baculovirus più studiati sono quelli che infettano le specie agricole dannose, come la farfalla processionaria del pino (Thaumetopoea pityocampa) e la spongia della soia (Helicoverpa zea). Questi virus sono noti per causare malattie letali negli insetti ospiti e possono provocarne la morte entro pochi giorni dall'infezione.
I Baculovirus hanno un genoma a DNA bicatenaio lineare che codifica per circa 100-180 proteine, a seconda della specie. Il loro capside virale è avvolto in una membrana lipidica ed è associato a una proteina fibrosa che forma un nucleocapside rigido. Questo nucleocapside è inserito in una matrice proteica chiamata envelope, che contiene glicoproteine virali essenziali per l'ingresso cellulare e la diffusione del virus.
I Baculovirus sono noti per avere un ciclo di replicazione complesso, che include due fasi principali: la fase di replicazione nucleare e la fase di b Budding. Durante la fase di replicazione nucleare, il virus si riproduce all'interno del nucleo cellulare, producendo una grande quantità di nuovi virioni. Questi virioni maturi vengono quindi rilasciati dalla cellula ospite attraverso un processo noto come b Budding, in cui i virioni si accumulano sotto la membrana plasmatica e vengono rilasciati attraverso una struttura simile a un poro.
I Baculovirus sono stati ampiamente studiati per le loro proprietà di espressione genica altamente efficienti, che consentono la produzione di grandi quantità di proteine recombinanti in cellule di insetti. Questa caratteristica ha reso i Baculovirus un importante strumento nella ricerca biomedica e nell'industria farmaceutica per la produzione di vaccini e proteine terapeutiche. Inoltre, i Baculivirus sono stati utilizzati come agenti di controllo delle popolazioni di insetti nocivi nelle colture agricole.
Tuttavia, l'uso dei Baculovirus come agenti di controllo biologici ha sollevato preoccupazioni per la possibilità che i virus possano infettare specie non target e causare effetti negativi sull'ecosistema. Pertanto, è importante condurre ulteriori ricerche per comprendere meglio il potenziale impatto dei Baculovirus sulla biodiversità e l'ambiente prima di utilizzarli su larga scala come agenti di controllo biologici.
In sintesi, i Baculovirus sono un gruppo di virus che infettano gli insetti e hanno dimostrato di avere proprietà uniche per l'espressione genica altamente efficiente. Sono stati ampiamente studiati per le loro applicazioni nella ricerca biomedica e nell'industria farmaceutica, nonché come agenti di controllo delle popolazioni di insetti nocivi nelle colture agricole. Tuttavia, è importante condurre ulteriori ricerche per comprendere meglio il potenziale impatto dei Baculovirus sulla biodiversità e l'ambiente prima di utilizzarli su larga scala come agenti di controllo biologici.
Le proteine del sangue sono un tipo di proteina presente nel plasma sanguigno, che svolge diverse funzioni importanti per il corretto funzionamento dell'organismo. Esistono diversi tipi di proteine del sangue, tra cui:
1. Albumina: è la proteina più abbondante nel plasma sanguigno e svolge un ruolo importante nel mantenere la pressione oncotica, cioè la pressione osmotica generata dalle proteine plasmatiche, che aiuta a trattenere i fluidi nei vasi sanguigni e prevenire l'edema.
2. Globuline: sono un gruppo eterogeneo di proteine che comprendono immunoglobuline (anticorpi), enzimi, proteine di trasporto e fattori della coagulazione. Le immunoglobuline svolgono un ruolo cruciale nel sistema immunitario, mentre le proteine di trasporto aiutano a trasportare molecole come ormoni, vitamine e farmaci in tutto l'organismo. I fattori della coagulazione sono essenziali per la normale coagulazione del sangue.
3. Fibrinogeno: è una proteina plasmatica che svolge un ruolo cruciale nella coagulazione del sangue. Quando si verifica un'emorragia, il fibrinogeno viene convertito in fibrina, che forma un coagulo di sangue per fermare l'emorragia.
Un esame del sangue può essere utilizzato per misurare i livelli delle proteine del sangue e valutare la loro funzionalità. Livelli anormali di proteine del sangue possono indicare la presenza di diverse condizioni mediche, come malattie renali, malattie epatiche, malnutrizione, infezioni o disturbi del sistema immunitario.
In genetica, un gene è una sequenza specifica di DNA che contiene informazioni genetiche ereditarie. I geni forniscono istruzioni per la sintesi delle proteine, che sono essenziali per lo sviluppo e il funzionamento delle cellule e degli organismi viventi. Ogni gene occupa una posizione specifica su un cromosoma e può esistere in forme alternative chiamate alle varianti. Le mutazioni genetiche, che sono cambiamenti nella sequenza del DNA, possono portare a malattie genetiche o predisporre a determinate condizioni di salute. I geni possono anche influenzare caratteristiche fisiche e comportamentali individuali.
In sintesi, i geni sono unità fondamentali dell'ereditarietà che codificano le informazioni per la produzione di proteine e influenzano una varietà di tratti e condizioni di salute. La scoperta e lo studio dei geni hanno portato a importanti progressi nella comprensione delle basi molecolari della vita e alla possibilità di sviluppare terapie geniche per il trattamento di malattie genetiche.
La diffusione ad angolo piccolo (in inglese "Small Angle Scattering" o SAS) è un metodo di fisica che viene utilizzato in biologia strutturale e in scienze dei materiali per studiare la struttura a livello nanostrutturale di una varietà di campioni, come proteine, polimeri, colloidi e materiali porosi.
Il metodo si basa sulla diffusione elastica di radiazione ionizzante (come raggi X o neutroni) da parte di particelle di dimensioni nanometriche presenti nel campione. La diffusione avviene ad angoli molto piccoli, dell'ordine di pochi gradi, e l'analisi dei dati ottenuti consente di ricostruire la forma e la distribuzione delle particelle che hanno causato la diffusione.
In particolare, per quanto riguarda il campo biomedico, la SAS viene utilizzata per studiare la struttura di macromolecole biologiche come proteine e acidi nucleici, fornendo informazioni sulla loro forma, dimensione e orientamento. Queste informazioni possono essere utili per comprendere il meccanismo d'azione delle proteine e per lo sviluppo di farmaci.
In sintesi, la diffusione ad angolo piccolo è una tecnica di fisica che permette di studiare la struttura nanostrutturale di campioni biologici e non, fornendo informazioni utili per la comprensione dei meccanismi molecolari e per lo sviluppo di nuove applicazioni tecnologiche.
Le Proteine Non Strutturali Virali (NS, da Non-Structural Proteins in inglese) sono proteine virali che non fanno parte del virione, l'involucro proteico che circonda il materiale genetico del virus. A differenza delle proteine strutturali, che svolgono un ruolo nella composizione e nella forma del virione, le proteine NS sono implicate nei processi di replicazione e trascrizione del genoma virale, nella regolazione dell'espressione genica, nell'interazione con il sistema immunitario ospite e in altri processi vitali per il ciclo di vita del virus.
Le proteine NS sono codificate dal genoma virale e vengono sintetizzate all'interno delle cellule infettate dall'organismo ospite. Poiché non sono incorporate nel virione, le proteine NS non sono presenti nei virioni liberi e possono essere difficili da rilevare nelle analisi di laboratorio che si concentrano sulle particelle virali isolate. Tuttavia, il loro ruolo cruciale nella replicazione virale e nell'interazione con l'ospite li rende importanti bersagli per lo sviluppo di farmaci antivirali e strategie di immunoterapia.
Un esempio ben noto di proteine NS sono quelle codificate dal virus dell'epatite C (HCV), che svolgono un ruolo cruciale nella replicazione del genoma virale, nell'assemblaggio e nel rilascio delle particelle virali. Lo studio delle proteine NS ha contribuito allo sviluppo di farmaci antivirali altamente efficaci contro l'HCV, che hanno trasformato la gestione clinica dell'epatite C cronica e migliorato notevolmente i risultati per i pazienti infetti.
La famiglia Src-Chinasi è un gruppo di enzimi appartenenti alla superfamiglia delle chinasi a tirosina, che sono importanti nella regolazione della segnalazione cellulare e dell'attività cellulare. Questi enzimi sono caratterizzati dalla loro capacità di fosforilare (aggiungere un gruppo fosfato) alle tyrosine (un tipo di aminoacido) delle proteine, il che può modificarne l'attività e la funzione.
La famiglia Src-Chinasi include diversi membri, tra cui Src, Yes, Fyn, Yrk, Blk, Hck, Lck e Fgr. Questi enzimi sono coinvolti in una varietà di processi cellulari, come la proliferazione, la differenziazione, l'apoptosi (morte cellulare programmata), la motilità cellulare e la regolazione della risposta immunitaria.
Le Src-Chinasi sono regolate da una varietà di meccanismi, tra cui la fosforilazione e la defofosforilazione (rimozione del gruppo fosfato) delle tyrosine, nonché l'interazione con altre proteine. Quando attivate, le Src-Chinasi possono influenzare una serie di processi cellulari attraverso la fosforilazione di altri enzimi e proteine regolatorie.
Le disregolazioni delle Src-Chinasi sono state implicate in diverse malattie, tra cui il cancro, le malattie cardiovascolari e le malattie neurodegenerative. Pertanto, l'identificazione e la comprensione dei meccanismi di regolazione delle Src-Chinasi sono importanti per lo sviluppo di nuove strategie terapeutiche per il trattamento di queste malattie.
I Fattori Di Trascrizione Basici Helix-Loop-Helix (bHLH) sono una classe di fattori di trascrizione che giocano un ruolo cruciale nella regolazione dell'espressione genica nelle cellule eucariotiche. Questi fattori condividono una struttura proteica distintiva, costituita da due alfa eliche separate da una loop.
Le due alfa eliche sono fondamentali per il funzionamento dei bHLH. La prima alfa elica, chiamata anche regione di base, è responsabile del riconoscimento e del legame al DNA in siti specifici noti come elementi E-box, che hanno la sequenza nucleotidica 5'-CANNTG-3'. La seconda alfa elica, invece, media le interazioni proteina-proteina con altri fattori di trascrizione bHLH o cofattori, permettendo la formazione di eterodimeri o omodimeri che influenzano l'attività trascrizionale.
I fattori bHLH sono coinvolti in una vasta gamma di processi biologici, tra cui lo sviluppo embrionale, la differenziazione cellulare, la proliferazione e l'apoptosi. Alcuni esempi ben noti di fattori bHLH includono MYC, MAX, USF1 e USF2.
Mutazioni nei geni che codificano per i fattori bHLH possono portare a diversi disturbi e malattie, come ad esempio tumori e disordini neuropsichiatrici.
In medicina, il riconoscimento di forma si riferisce alla capacità del cervello o di un sistema artificiale di identificare, classificare o categorizzare correttamente oggetti, immagini, segni o simboli sulla base della loro forma o configurazione geometrica.
Nel contesto della percezione visiva umana, il riconoscimento di forma è un processo cognitivo complesso che implica l'elaborazione e l'interpretazione delle informazioni visive da parte del sistema visivo, composto dalla retina, dal midollo ottico, dai centri visivi del cervello e dalle aree corticali associate.
Il riconoscimento di forma è un'abilità fondamentale per la visione e la cognizione umana, poiché consente di identificare rapidamente e accuratamente gli oggetti familiari nel mondo circostante, facilitando così l'interazione con l'ambiente.
Inoltre, il riconoscimento di forma è anche un concetto importante nell'ingegneria informatica e nell'intelligenza artificiale, dove si riferisce alla capacità dei sistemi informatici di identificare e classificare automaticamente forme o oggetti in immagini o video. Questa tecnologia è ampiamente utilizzata in una varietà di applicazioni, come la visione artificiale, il rilevamento di oggetti, la realtà aumentata e la robotica.
Il genoma virale si riferisce al complesso degli acidi nucleici (DNA o RNA) che costituiscono il materiale genetico di un virus. Esso contiene tutte le informazioni genetiche necessarie per la replicazione del virus e per l'espressione dei suoi geni all'interno delle cellule ospiti che infetta.
Il genoma virale può avere diverse configurazioni, a seconda del tipo di virus. Alcuni virus hanno un genoma a singolo filamento di RNA, mentre altri hanno un genoma a doppio filamento di DNA. Alcuni virus ancora possono presentare un genoma a singolo filamento di DNA o RNA, ma circolare invece che lineare.
La dimensione del genoma virale può variare notevolmente, da poche centinaia a decine di migliaia di paia di basi. Il contenuto del genoma virale include anche sequenze regolatorie necessarie per l'espressione dei geni e per la replicazione del virus.
Lo studio del genoma virale è importante per comprendere la biologia dei virus, la loro patogenesi e per lo sviluppo di strategie di controllo e prevenzione delle malattie infettive da essi causate.
In medicina, il termine "distillazione" si riferisce a un processo di purificazione che separa i componenti di una miscela in base al loro punto di ebollizione e alla condensazione. Viene comunemente utilizzato nella preparazione di soluzioni, estratti o principi attivi medicinali altamente concentrati e purificati.
Nel processo di distillazione, la miscela viene riscaldata fino a quando uno o più componenti evaporano. Questi vapori vengono quindi convogliati attraverso un condensatore raffreddato, che li fa ricondurre in forma liquida pura. I diversi componenti della miscela hanno punti di ebollizione differenti, il che permette di separarli e raccoglierli separatamente come distillati puri.
Un esempio comune di applicazione medica della distillazione è la produzione di alcool etilico medicinale, ottenuto per distillazione di soluzioni alcoliche fermentate. Altri usi includono la preparazione di oli essenziali e acqua distillata, che vengono impiegati in vari ambiti terapeutici e cosmetici.
Le proteine dell'occhio, notoriamente denominate proteome oculare, si riferiscono all'insieme completo delle proteine presenti nell'occhio. Queste proteine svolgono una vasta gamma di funzioni cruciali per la salute e il corretto funzionamento dell'occhio. Alcune di queste proteine sono implicate nella visione, come ad esempio l'opsina che si combina con il retinaldeide per formare la rodopsina, una proteina essenziale per la visione notturna. Altre proteine oculari svolgono importanti funzioni strutturali, come la crioglobulina e le cristalline che costituiscono il cristallino dell'occhio. Inoltre, ci sono proteine che partecipano a processi metabolici, immunitari e di riparazione cellulare nell'occhio. L'analisi del proteoma oculare fornisce informazioni vitali sulla fisiologia e la patofisiologia dell'occhio, nonché sullo sviluppo di nuove strategie terapeutiche per le malattie oculari.
Le tecniche di chimica combinatoria sono metodologie utilizzate nella scienza dei materiali e nel campo della farmacologia per sintetizzare in modo efficiente e sistematico un gran numero di composti organici, al fine di identificare potenziali candidati terapeutici o per studiare le relazioni struttura-attività. Queste tecniche si basano sulla creazione di library di composti sintetizzando sistematicamente una serie di building block (frammenti molecolari) in diverse combinazioni e sequenze. Ciò consente la produzione di un gran numero di composti in modo rapido ed efficiente, che possono quindi essere testati per le loro proprietà biologiche o chimiche desiderate.
Le tecniche di chimica combinatoria possono essere classificate in due categorie principali: la sintesi parallela e la sintesi a split-pool. Nella sintesi parallela, vengono create piccole library di composti sintetizzando simultaneamente diverse reazioni chimiche utilizzando gli stessi building block. Al contrario, nella sintesi a split-pool, vengono creati grandi array di composti attraverso una serie di cicli di reazione e separazione (split) degli intermedi di reazione, seguiti da un'ulteriore combinazione (pool) dei frammenti. Questo processo consente la creazione di library di composti altamente diversificati e complessi.
Le tecniche di chimica combinatoria sono diventate uno strumento essenziale nella ricerca farmaceutica e nelle scienze dei materiali, poiché consentono lo screening ad alta velocità di un gran numero di composti per identificare quelli con proprietà desiderabili. Questo approccio ha notevolmente accelerato il processo di scoperta dei farmaci e ha portato a una maggiore comprensione delle relazioni struttura-attività, contribuendo all'identificazione di nuovi bersagli terapeutici e alla progettazione razionale di farmaci.
In medicina, la parola "luce" si riferisce spesso all'uso di radiazioni elettromagnetiche visibili nello spettro della luce per scopi diagnostici o terapeutici. Ad esempio, la fototerapia è un trattamento che utilizza luci speciali per aiutare a migliorare alcuni disturbi della pelle come l'eczema e la dermatite.
In oftalmologia, "luce" può anche riferirsi alla capacità dell'occhio di ricevere ed elaborare la luce in modo da poter vedere. Questo include la misurazione della sensibilità della pupilla alla luce (riflesso fotomotore), che è un test comune utilizzato per valutare il funzionamento del nervo ottico e del cervello.
Tuttavia, va notato che la definizione di "luce" in sé non è limitata al contesto medico ed è utilizzata più ampiamente per descrivere la radiazione elettromagnetica visibile nello spettro della luce.
La spettrometria di massa tandem (MS/MS o MS2) è una tecnica avanzata di rilevamento e analisi che utilizza due o più stadi di spettrometria di massa in linea per identificare e caratterizzare molecole, specialmente biomolecole come proteine e peptidi. Nella sua applicazione nella chimica clinica e nell'analisi delle sostanze biochimiche, la tandem mass spectrometry è spesso utilizzata in combinazione con la separazione cromatografica per analizzare miscele complesse di composti, come quelle trovate nei campioni biologici.
Nel primo stadio della tandem mass spectrometry (MS1), le molecole vengono ionizzate e separate in base al loro rapporto massa-carica (m/z). Quindi, una selezione di ione precursore viene fatta, isolando un particolare picco di interesse. Nel secondo stadio (MS2), questi ioni selezionati vengono frammentati in pezzi più piccoli, generando una serie di frammenti ionici con rapporti massa-carica distintivi. Questi frammenti vengono quindi rilevati e analizzati nel terzo stadio (MS3 opzionale), fornendo informazioni strutturali dettagliate sulle molecole originali.
La spettrometria di massa tandem è ampiamente utilizzata nella ricerca proteomica, diagnosi clinica e monitoraggio terapeutico per l'identificazione e la quantificazione di proteine e peptidi, nonché nello studio delle interazioni molecolari e nelle indagini forensi.
Le proteine di trasporto della membrana sono tipi specifici di proteine integrate nella membrana cellulare che regolano il passaggio selettivo di molecole e ioni attraverso la barriera lipidica delle membrane cellulari. Esse giocano un ruolo cruciale nel mantenere l'equilibrio chimico all'interno e all'esterno della cellula, nonché nella comunicazione tra le cellule e il loro ambiente.
Esistono due principali categorie di proteine di trasporto della membrana: canali ionici e carrier (o pompe). I canali ionici consentono il passaggio rapido ed efficiente degli ioni attraverso la membrana, mentre i carrier facilitano il trasporto di molecole più grandi o di molecole che altrimenti non potrebbero diffondere liberamente attraverso la membrana. Alcune proteine di trasporto richiedono l'energia fornita dall'idrolisi dell'ATP per funzionare, mentre altre operano spontaneamente in risposta a gradienti chimici o elettrici esistenti.
Le proteine di trasporto della membrana sono fondamentali per una vasta gamma di processi cellulari, tra cui la regolazione del potenziale di membrana, il mantenimento dell'equilibrio osmotico, l'assorbimento dei nutrienti e l'eliminazione delle tossine. Le disfunzioni nelle proteine di trasporto della membrana possono portare a varie patologie, come la fibrosi cistica, la malattia di Darier e alcune forme di diabete.
La mutagenesi da inserzione è un tipo specifico di mutazione genetica che si verifica quando un elemento estraneo, come un transposone o un vettore virale, si inserisce all'interno di un gene, alterandone la sequenza nucleotidica e quindi la funzione. Questo evento può portare a una variazione del fenotipo dell'organismo che lo ospita e, in alcuni casi, può essere associato allo sviluppo di patologie, come ad esempio alcune forme di cancro.
L'inserzione di un elemento estraneo all'interno del gene può avvenire in modo casuale o indotto, ad esempio attraverso l'utilizzo di tecniche di ingegneria genetica. In quest'ultimo caso, la mutagenesi da inserzione è spesso utilizzata come strumento per lo studio della funzione dei geni o per la creazione di modelli animali di malattie umane.
E' importante sottolineare che l'inserimento di un elemento estraneo all'interno del gene può portare a diverse conseguenze, a seconda della posizione e dell'orientamento dell'elemento inserito. Ad esempio, l'inserzione può causare la disattivazione del gene (knock-out), la sua sovraespressione o l'alterazione della sua sequenza di lettura, con conseguenti modifiche nella produzione di proteine e nell'espressione genica.
La fibronectina è una glicoproteina dimerica ad alto peso molecolare che si trova in diversi tessuti connettivi, fluido extracellulare e fluidi biologici come plasma sanguigno. È una proteina multifunzionale che svolge un ruolo cruciale nella interazione cellula-matrice extracellulare e nella regolazione di una varietà di processi cellulari, tra cui adesione cellulare, migrazione, proliferazione, differenziazione e sopravvivenza.
La fibronectina è costituita da due catene identiche o simili legate da ponti disolfuro, ciascuna delle quali contiene tre domini ricchi di tirrosina ripetuti: il dominio di tipo I (FNI), il dominio di tipo II (FNII) e il dominio di tipo III (FNIII). Questi domini sono organizzati in modo da formare due regioni globulari, la regione N-terminale e la regione C-terminale, che mediano l'interazione con vari ligandi extracellulari come collagene, fibrillina, emosiderina, fibroglicani ed integrine.
La fibronectina è prodotta da diversi tipi di cellule, tra cui fibroblasti, condrociti, epitelio e cellule endoteliali. La sua espressione e deposizione nella matrice extracellulare sono strettamente regolate a livello trascrizionale e post-trascrizionale in risposta a vari stimoli fisiologici e patologici, come l'infiammazione, la guarigione delle ferite e il cancro.
In sintesi, la fibronectina è una proteina multifunzionale che svolge un ruolo importante nella interazione cellula-matrice extracellulare e nella regolazione di diversi processi cellulari. La sua espressione e deposizione sono strettamente regolate in risposta a vari stimoli fisiologici e patologici, il che la rende un marker importante per la diagnosi e la prognosi di diverse malattie.
I geni delle piante si riferiscono a specifiche sequenze di DNA presenti nelle cellule delle piante che codificano per informazioni ereditarie e istruzioni utilizzate nella sintesi di proteine e RNA. Questi geni svolgono un ruolo cruciale nello sviluppo, nella crescita, nella fioritura, nella produzione di semi e nell'adattamento ambientale delle piante.
I geni delle piante sono organizzati in cromosomi all'interno del nucleo cellulare. La maggior parte dei geni delle piante si trova nel DNA nucleare, ma alcuni geni si trovano anche nel DNA degli organelli come mitocondri e cloroplasti.
I geni delle piante sono soggetti a vari meccanismi di regolazione genica che controllano la loro espressione spaziale e temporale. Questi meccanismi includono l'interazione con fattori di trascrizione, modifiche epigenetiche del DNA e RNA non codificante.
L'identificazione e lo studio dei geni delle piante sono fondamentali per comprendere i processi biologici delle piante e per sviluppare colture geneticamente modificate con caratteristiche desiderabili, come resistenza ai parassiti, tolleranza alla siccità e maggiore produttività.
In medicina, il termine "proprietà superficiali" si riferisce alle caratteristiche fisiche e chimiche delle superfici dei materiali utilizzati in contatto con la pelle, le mucose o altre superfici del corpo. Queste proprietà possono influenzare il comfort, la sicurezza e l'efficacia di dispositivi medici, farmaci e altri prodotti sanitari.
Esempi di proprietà superficiali includono:
1. Rugosità: La rugosità della superficie può influenzare il comfort e la facilità di pulizia del dispositivo. Superfici più lisce possono essere più comode per il paziente, ma possono anche essere più difficili da pulire e disinfettare.
2. Idrofilia/idrofobia: La idrofilia o idrofobia della superficie può influenzare l'adesione delle proteine e dei microrganismi alla superficie. Superfici più idrofile tendono ad essere meno suscettibili all'adesione di proteine e microrganismi, il che può ridurre il rischio di infezione.
3. Energia superficiale: L'energia superficiale può influenzare l'adesione delle particelle e delle cellule alla superficie. Superfici con alta energia superficiale tendono ad avere una maggiore adesione di particelle e cellule, il che può essere vantaggioso in alcuni casi (ad esempio, per la promozione della guarigione delle ferite) ma dannoso in altri (ad esempio, per la prevenzione dell'infezione).
4. Carica superficiale: La carica superficiale può influenzare l'interazione tra la superficie e gli ioni o le molecole cariche nell'ambiente circostante. Superfici con carica positiva tendono ad attrarre molecole negative, mentre superfici con carica negativa tendono ad attrarre molecole positive.
5. Topografia della superficie: La topografia della superficie può influenzare la risposta cellulare alla superficie. Superfici lisce tendono a ridurre l'adesione delle cellule e la formazione di biofilm, mentre superfici ruvide tendono ad aumentarla.
In sintesi, le proprietà fisiche e chimiche della superficie possono influenzare significativamente l'interazione tra la superficie e il suo ambiente circostante, compresi i microrganismi e le cellule. La comprensione di queste proprietà può aiutare a progettare superfici con proprietà antimicrobiche o promuovere la guarigione delle ferite.
Il Gruppo dei Citocromi C è una classe di citocromi che sono proteine hem-contenenti presenti nei mitocondri delle cellule. Essi svolgono un ruolo cruciale nel processo di ossidazione cellulare e nella produzione di energia tramite la catena di trasporto degli elettroni.
Il Citocromo C è particolarmente importante perché funge da mediatore tra le due principali componenti della catena di trasporto degli elettroni, il complesso I/II e il complesso III. Esso accetta gli elettroni dal complesso III e li trasferisce al complesso IV, contribuendo alla produzione di ATP (adenosina trifosfato), la molecola che fornisce energia alle cellule.
Il Citocromo C è anche noto per il suo ruolo nella apoptosi o morte cellulare programmata. Quando una cellula deve essere eliminata, le proteine pro-apoptotiche vengono attivate e causano la fuoriuscita del citocromo C dal mitocondrio. Una volta nel citoplasma, il citocromo C si lega alla procaspasi 9, un enzima che viene poi attivato e innesca una cascata di eventi che portano alla morte cellulare.
In sintesi, il Gruppo dei Citocromi C è una classe importante di proteine hem-contenenti che svolgono un ruolo cruciale nella produzione di energia cellulare e nella regolazione della apoptosi.
PUBMED è un servizio di database online gratuito che fornisce accesso a citazioni e abstracts di letteratura biomedica e life science, inclusi articoli di riviste peer-reviewed, report, meeting abstracts, e book chapters. PubMed è sviluppato e gestito dal National Center for Biotechnology Information (NCBI) presso la National Library of Medicine (NLM) degli Stati Uniti. Include la copertura della bibliografia MEDLINE, che contiene oltre 26 milioni di record di articoli risalenti al 1946, nonché citazioni da fonti aggiuntive selezionate. Gli utenti possono cercare e accedere ai documenti completi attraverso collegamenti a servizi di abbonamento o open access. PubMed supporta anche la ricerca avanzata con operatori booleani, filtri e altri strumenti per restringere i risultati in base alle esigenze dell'utente.
Gli animali geneticamente modificati (AGM) sono organismi viventi che sono stati creati attraverso la manipolazione intenzionale del loro materiale genetico, utilizzando tecniche di ingegneria genetica. Queste tecniche possono includere l'inserimento, la delezione o la modifica di uno o più geni all'interno del genoma dell'animale, al fine di ottenere specifiche caratteristiche o funzioni desiderate.
Gli AGM possono essere utilizzati per una varietà di scopi, come la ricerca scientifica, la produzione di farmaci e vaccini, la bioremediation, l'agricoltura e la medicina veterinaria. Ad esempio, gli AGM possono essere creati per produrre proteine umane terapeutiche in grado di trattare malattie genetiche o altre condizioni mediche.
Tuttavia, l'uso di AGM è anche oggetto di dibattito etico e regolamentare, poiché solleva preoccupazioni relative al benessere degli animali, all'impatto ambientale e alla sicurezza alimentare. Pertanto, la creazione e l'uso di AGM sono soggetti a rigide normative e linee guida in molti paesi, al fine di garantire che vengano utilizzati in modo sicuro ed etico.
DNA footprinting è una tecnica di biologia molecolare utilizzata per identificare siti di legame specifici delle proteine sul DNA. Viene eseguita mediante la digestione dell'acido desossiribonucleico (DNA) con enzimi di restrizione o endonucleasi dopo l'unione di una proteina al suo sito di legame specifico. L'enzima di restrizione non è in grado di tagliare il DNA nei punti in cui la proteina è legata, lasciando così un "footprint" o impronta digitale protetta dall'enzima.
La tecnica prevede l'isolamento del DNA trattato con la proteina e l'enzima di restrizione, seguita dalla separazione elettroforetica delle molecole di DNA su un gel di agarosio per determinare le dimensioni relative dei frammenti. Questi frammenti vengono quindi visualizzati utilizzando una tecnica di rilevamento radioattivo o fluorescente, rivelando così i punti in cui il DNA non è stato tagliato dall'enzima di restrizione a causa del legame della proteina.
La tecnica del DNA footprinting è particolarmente utile per lo studio dei meccanismi di regolazione genica, poiché consente di identificare i siti di legame specifici delle proteine che controllano l'espressione genica. Inoltre, può essere utilizzata per studiare le interazioni tra proteine e DNA in diversi stati fisiologici o patologici, come la cancerogenesi o lo stress ossidativo.
Non esiste una definizione medica specifica per "Cane Domestico", poiché si riferisce principalmente al rapporto e all'allevamento dei cani come animali domestici, piuttosto che a una specie o condizione particolare. Tuttavia, i cani da compagnia sono generalmente considerati come appartenenti alla specie Canis lupus familiaris, che è la sottospecie del lupo grigio (Canis lupus) addomesticata dall'uomo. I cani domestici mostrano una notevole variazione fenotipica a causa della selezione artificiale e dell'allevamento selettivo, con diverse razze, taglie e forme sviluppate per adattarsi a diversi scopi e preferenze umane.
I cani domestici svolgono numerosi ruoli all'interno delle famiglie umane, tra cui la compagnia, la protezione, l'assistenza, il soccorso e le attività ricreative. Essere un proprietario responsabile di un cane domestico include fornire cure adeguate, inclusa una dieta equilibrata, esercizio fisico regolare, interazione sociale, cure sanitarie preventive e gestione del comportamento appropriato.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
Le proteine da shock termico Hsp90 (Heat Shock Protein 90) sono una classe di chaperone molecolari altamente conservati che svolgono un ruolo cruciale nella proteostasi cellulare, aiutando nella piegatura, assemblaggio e stabilizzazione delle proteine. Hsp90 è uno dei chaperoni più abondanti nella maggior parte delle cellule ectodermiche e mesodermali, costituendo circa il 1-2% del totale delle proteine citosoliche.
Le proteine Hsp90 sono espresse a livelli basali in condizioni fisiologiche normali, ma la loro espressione viene drammaticamente indotta in risposta a stress cellulari come l'esposizione a temperature elevate, radiazioni, tossici o farmaci che interferiscono con la piegatura delle proteine.
Le Hsp90 svolgono un ruolo importante nell'attivazione e stabilizzazione di una varietà di clienti proteici chiave, tra cui kinasi, recettori nucleari, proteine di trasporto e fattori di trascrizione. Queste interazioni sono dinamiche e dipendenti dall'ATP, con il dominio N-terminale ATPasico della Hsp90 che svolge un ruolo centrale nel ciclo di legame/idrolisi dell'ATP e nella modulazione conformazionale del cliente proteico.
L'importanza delle proteine Hsp90 è evidenziata dal fatto che sono essenziali per la sopravvivenza cellulare in molti organismi, compreso l'uomo. Inoltre, le mutazioni genetiche che alterano l'attività di Hsp90 sono state associate a diverse malattie umane, tra cui il cancro e le malattie neurodegenerative.
In sintesi, le proteine da shock termico Hsp90 sono chaperoni molecolari cruciali che aiutano nella piegatura, stabilizzazione e attivazione di una varietà di clienti proteici chiave, con implicazioni importanti per la fisiologia cellulare e lo sviluppo di malattie.
Il DNA batterico si riferisce al materiale genetico presente nei batteri, che sono microrganismi unicellulari procarioti. Il DNA batterico è circolare e contiene tutti i geni necessari per la crescita, la replicazione e la sopravvivenza dell'organismo batterico. Rispetto al DNA degli organismi eucariotici (come piante, animali e funghi), il DNA batterico è relativamente semplice e contiene meno sequenze ripetitive non codificanti.
Il genoma batterico è organizzato in una singola molecola circolare di DNA chiamata cromosoma batterico. Alcuni batteri possono anche avere piccole molecole di DNA circolari extra chiamate plasmidi, che contengono geni aggiuntivi che conferiscono caratteristiche speciali al batterio, come la resistenza agli antibiotici o la capacità di degradare determinati tipi di sostanze chimiche.
Il DNA batterico è una componente importante dell'analisi microbiologica e della diagnosi delle infezioni batteriche. L'identificazione dei batteri può essere effettuata mediante tecniche di biologia molecolare, come la reazione a catena della polimerasi (PCR) o l' sequenziamento del DNA, che consentono di identificare specifiche sequenze di geni batterici. Queste informazioni possono essere utilizzate per determinare il tipo di batterio che causa un'infezione e per guidare la selezione di antibiotici appropriati per il trattamento.
Le proteine leganti il tacrolimus, noti anche come FK-binding protein (FKBP), sono una classe di proteine citoplasmatiche che si legano specificamente al farmaco immunosoppressivo tacrolimus (FK506). Il complesso tacrolimus-FKBP inibisce la calcineurina, un enzima fosfatasi, che porta all'inibizione dell'attivazione dei linfociti T e alla conseguente soppressione della risposta immunitaria. Questa via di azione è importante nel trattamento del rigetto d'organo dopo il trapianto e in alcune malattie autoimmuni.
Le proteine leganti il tacrolimus sono presenti in molti tipi di cellule, compresi i linfociti T e le cellule endoteliali. Esistono diversi isoforme di FKBP, tra cui FKBP12, che è il sito di legame primario per il tacrolimus. La specificità del legame tra il tacrolimus e FKBP12 è elevata, con una costante di dissociazione (Kd) nella gamma di nanomoli per litro.
L'affinità di legame elevata tra il tacrolimus e le proteine FKBP gioca un ruolo cruciale nel determinare l'efficacia del farmaco e la sua tossicità. L'interazione tra il tacrolimus e FKBP porta alla formazione di un complesso stabile che inibisce l'attività della calcineurina, con conseguente soppressione dell'attivazione dei linfociti T e della risposta immunitaria.
In sintesi, le proteine leganti il tacrolimus sono una classe di proteine citoplasmatiche che si legano specificamente al farmaco immunosoppressivo tacrolimus, inibendo l'attività della calcineurina e sopprimendo la risposta immunitaria. L'affinità di legame elevata tra il tacrolimus e FKBP12 è un fattore chiave che determina l'efficacia del farmaco e la sua tossicità.
Il chimotripsinogeno è una proteina inattiva, o zimogeno, che si trova nel pancreas. Una volta attivato, si trasforma nella chimotripsina, un enzima proteolitico importante per la digestione delle proteine nei cibi. Questo processo di attivazione avviene all'interno dell'intestino tenue quando il chimotripsinogeno entra in contatto con la tripsina, un altro enzima pancreatico. La conversione del chimotripsinogeno in chimotripsina è un esempio di autocatalisi, poiché la tripsina stessa facilita questa reazione.
La chimotripsina svolge un ruolo cruciale nella digestione dei polipeptidi e delle proteine alimentari nei singoli aminoacidi o piccoli peptidi, che possono quindi essere assorbiti attraverso la parete intestinale. La sua attività enzimatica è specifica per i legami peptidici adiacenti a residui di triptofano, tirosina, fenilalanina e treonina, che contengono gruppi aromatici o idrofobici.
Un disturbo nel rilascio o nell'attivazione del chimotripsinogeno può portare a una serie di problemi digestivi e patologie pancreatiche, come la pancreatite acuta o cronica.
Le proteine protooncogene C-Ets sono una famiglia di fattori di trascrizione che giocano un ruolo cruciale nello sviluppo, nella differenziazione cellulare e nella proliferazione. Questi protooncogeni codificano per enzimi che contengono un dominio di legame al DNA chiamato "dominio Ets", che riconosce ed è specifico per una sequenza nucleotidica particolare nel DNA.
I protooncogeni C-Ets possono essere attivati in modo anomalo o sovraespressi, il che può portare a malattie come il cancro. Quando questo accade, i protooncogeni C-Ets vengono chiamati oncogeni e sono associati a una varietà di tumori solidi e ematologici.
Le proteine C-Ets sono coinvolte in diversi processi cellulari, tra cui la regolazione della proliferazione cellulare, l'apoptosi, l'angiogenesi e la differenziazione cellulare. Possono anche interagire con altre proteine per modulare la loro attività trascrizionale.
In sintesi, le proteine protooncogene C-Ets sono fattori di trascrizione importanti che possono essere coinvolti nello sviluppo del cancro quando vengono attivati o sovraespressi in modo anomalo.
La proteina p53, anche nota come "guardiano del genoma", è una proteina importante che svolge un ruolo cruciale nella prevenzione del cancro. Funziona come un fattore di trascrizione, il che significa che aiuta a controllare l'espressione dei geni. La proteina p53 è prodotta dalle cellule in risposta a diversi tipi di stress cellulare, come danni al DNA o carenza di ossigeno.
La proteina Sumo-1, nota anche come SMT3C o SUMO1, è una piccola proteina ubiquitin-like che partecipa al processo di modificazione post-traduzionale delle proteine chiamato sumoylazione. La sumoylazione prevede l'attacco covalente di una molecola Sumo (Small Ubiquitin-like Modifier) a specifiche residenze di lisina sulla proteina bersaglio, alterandone la funzione e il destino cellulare.
La regolazione allosterica è un meccanismo di controllo della velocità di reazione enzimatica che avviene quando una molecola, chiamata effettore allosterico, si lega a un sito diverso dal sito attivo dell'enzima, noto come sito allosterico. Questa interazione cambia la forma dell'enzima, alterandone l'attività e modulandone la velocità di reazione. L'effettore allosterico può essere un ligando, una molecola che si lega a un enzima, o una proteina, come nel caso della regolazione enzimatica eterotropa.
L'effetto dell'effettore allosterico può essere sia positivo che negativo. Nel primo caso, l'effettore aumenta l'attività enzimatica e la reazione è accelerata; nel secondo caso, invece, l'effettore diminuisce l'attività enzimatica e la reazione è rallentata. Questo tipo di regolazione è importante per il controllo delle vie metaboliche e per l'adattamento dell'organismo a diverse condizioni fisiologiche.
Le proteine della matrice extracellulare (ECM) sono un insieme eterogeneo di molecole organiche che si trovano al di fuori delle cellule e costituiscono la maggior parte della matrice extracellulare. La matrice extracellulare è l'ambiente fisico in cui risiedono le cellule e fornisce supporto strutturale, regola la comunicazione intercellulare e influenza la crescita, la differenziazione e il movimento delle cellule.
Le proteine della matrice extracellulare possono essere classificate in diversi gruppi, tra cui:
1. Collagene: è la proteina più abbondante nell'ECM e fornisce resistenza meccanica alla matrice. Esistono diverse tipologie di collagene, ciascuna con una struttura e una funzione specifiche.
2. Proteoglicani: sono molecole costituite da un core proteico a cui sono legate catene di glicosaminoglicani (GAG), lunghi polisaccaridi ad alto peso molecolare che possono trattenere acqua e ioni, conferendo alla matrice una proprietà idrofilica.
3. Glicoproteine: sono proteine ricche di zuccheri che svolgono un ruolo importante nella regolazione dell'adesione cellulare, della crescita e della differenziazione cellulare.
4. Elastina: è una proteina elastica che conferisce flessibilità ed elasticità alla matrice extracellulare.
Le proteine della matrice extracellulare svolgono un ruolo cruciale nella fisiologia e nella patologia di molti tessuti e organi, compreso il cuore, i vasi sanguigni, i polmoni, la pelle e il tessuto connettivo. Le alterazioni della composizione e della struttura delle proteine della matrice extracellulare possono contribuire allo sviluppo di malattie come l'aterosclerosi, la fibrosi polmonare, l'artrite reumatoide e il cancro.
La proteolisi è un processo biochimico che consiste nella degradazione enzimatica delle proteine in catene polipeptidiche più piccole o singli amminoacidi. Questo processo è catalizzato da enzimi noti come proteasi o peptidasi, che tagliano i legami peptidici tra specifici amminoacidi all'interno della catena polipeptidica.
La proteolisi svolge un ruolo fondamentale in diversi processi fisiologici, come la digestione, l'eliminazione di proteine danneggiate o difettose, la modulazione dell'attività delle proteine e la regolazione dei processi cellulari. Tuttavia, un'eccessiva o inappropriata proteolisi può contribuire allo sviluppo di diverse patologie, come malattie neurodegenerative, infiammazioni e tumori.
In medicina e biologia, una linea cellulare trasformata si riferisce a un tipo di linea cellulare che è stata modificata geneticamente o indotta chimicamente in modo da mostrare caratteristiche tipiche delle cellule cancerose. Queste caratteristiche possono includere una crescita illimitata, anormalità nel controllo del ciclo cellulare, resistenza all'apoptosi (morte cellulare programmata), e la capacità di invadere i tessuti circostanti.
Le linee cellulari trasformate sono spesso utilizzate in ricerca scientifica per lo studio dei meccanismi molecolari alla base del cancro, nonché per lo screening di farmaci e terapie antitumorali. Tuttavia, è importante notare che le linee cellulari trasformate possono comportarsi in modo diverso dalle cellule tumorali originali, quindi i risultati ottenuti con queste linee cellulari devono essere interpretati con cautela e confermati con modelli più complessi.
Le linee cellulari trasformate possono essere generate in laboratorio attraverso diversi metodi, come l'esposizione a virus oncogenici o alla radiazione ionizzante, l'introduzione di geni oncogenici (come H-ras o c-myc), o la disattivazione di geni soppressori del tumore. Una volta trasformate, le cellule possono essere mantenute in coltura e propagate per un periodo prolungato, fornendo un'importante fonte di materiale biologico per la ricerca scientifica.
La "programmazione lineare" non è specificamente una definizione medica, ma è in realtà un termine utilizzato nel campo della matematica e dell'informatica. Tuttavia, a volte può essere applicata o menzionata nei contesti medici o sanitari, specialmente quando si discute di argomenti come la ricerca operativa, l'analisi delle politiche sanitarie o l'allocazione delle risorse.
La programmazione lineare è una tecnica matematica utilizzata per ottimizzare (massimizzare o minimizzare) una funzione obiettivo lineare soggetta a vincoli lineari. La formulazione di un problema di programmazione lineare include:
1. Variabili decisionale: queste sono le variabili che si desidera ottimizzare o per le quali si prendono decisioni. Possono rappresentare, ad esempio, la quantità di risorse da assegnare, il numero di pazienti da trattare, ecc.
2. Funzione obiettivo: è l'obiettivo che si desidera massimizzare o minimizzare, spesso rappresentato come una combinazione lineare delle variabili decisionali. Ad esempio, la funzione obiettivo potrebbe essere il costo minimo totale o il beneficio massimo complessivo.
3. Vincoli: sono limitazioni che devono essere soddisfatte dalle soluzioni accettabili. Possono rappresentare, ad esempio, la disponibilità di risorse, i requisiti minimi o massimi per le variabili decisionali, ecc.
In sintesi, la programmazione lineare è un metodo matematico per trovare la soluzione ottimale (massima o minima) a un problema soggetto a vincoli lineari. Anche se non è strettamente una definizione medica, può essere applicata in vari contesti sanitari e medici per analizzare e prendere decisioni basate su dati.
In medicina, "elementi di risposta" si riferiscono alle variazioni fisiologiche o ai segni osservabili che si verificano in risposta a una determinata condizione patologica, terapia o stimolo. Questi elementi possono essere soggettivi, come i sintomi riportati dai pazienti, o oggettivi, come i segni vitali misurabili o i risultati di test di laboratorio.
Ad esempio, in un paziente con polmonite batterica, gli elementi di risposta possono includere febbre, aumento della frequenza respiratoria e battito cardiaco, diminuzione dell'ossigenazione del sangue e produzione di espettorato purulento. Nello stesso paziente, la risposta alla terapia antibiotica può essere monitorata attraverso l'osservazione della riduzione della febbre, dei miglioramenti nei segni vitali e dei risultati dei test di laboratorio, come il numero di globuli bianchi e la clearance delle vie respiratorie.
Pertanto, gli elementi di risposta sono fondamentali per la diagnosi, il trattamento e il monitoraggio dell'efficacia della terapia in medicina.
La clatrina è una proteina importante nel sistema endomembranoso delle cellule eucariotiche. Svolge un ruolo cruciale nella formazione di vescicole rivestite da clatrina, che sono implicate nel trasporto intracellulare di molecole tra diversi compartimenti cellulari. La clatrina si organizza in una struttura a forma di gabbia chiamata "coat protein complex" (CPC) o "coat proteins of clathrin-associated vesicles" (CLAP). Questa struttura aiuta nella curvatura della membrana e nella successiva fissione per formare una vescicola. La clatrina è nota anche per essere implicata nel processo di endocitosi, durante il quale le molecole dall'esterno della cellula vengono internalizzate all'interno di vescicole rivestite da clatrina.
In sintesi, la clatrina è una proteina essenziale per la formazione e il funzionamento delle vescicole intracellulari, ed è particolarmente importante per il trasporto di molecole tra i compartimenti cellulari e per l'endocitosi.
I topi inbred C57BL (o C57 Black) sono una particolare linea genetica di topi da laboratorio comunemente utilizzati in ricerca biomedica. Il termine "inbred" si riferisce al fatto che questi topi sono stati allevati per molte generazioni con riproduzione tra fratelli e sorelle, il che ha portato alla formazione di una linea genetica altamente uniforme e stabile.
La linea C57BL è stata sviluppata presso la Harvard University nel 1920 ed è ora mantenuta e distribuita da diversi istituti di ricerca, tra cui il Jackson Laboratory. Questa linea genetica è nota per la sua robustezza e longevità, rendendola adatta per una vasta gamma di studi sperimentali.
I topi C57BL sono spesso utilizzati come modelli animali in diversi campi della ricerca biomedica, tra cui la genetica, l'immunologia, la neurobiologia e la farmacologia. Ad esempio, questa linea genetica è stata ampiamente studiata per quanto riguarda il comportamento, la memoria e l'apprendimento, nonché le risposte immunitarie e la suscettibilità a varie malattie, come il cancro, le malattie cardiovascolari e le malattie neurodegenerative.
È importante notare che, poiché i topi C57BL sono un ceppo inbred, presentano una serie di caratteristiche genetiche fisse e uniformi. Ciò può essere vantaggioso per la riproducibilità degli esperimenti e l'interpretazione dei risultati, ma può anche limitare la generalizzabilità delle scoperte alla popolazione umana più diversificata. Pertanto, è fondamentale considerare i potenziali limiti di questo modello animale quando si interpretano i risultati della ricerca e si applicano le conoscenze acquisite all'uomo.
Le cellule PC12 sono una linea cellulare derivata da un tumore neuroendocrino della cresta neurale del sistema nervoso simpatico di un topo. Queste cellule hanno la capacità di differenziarsi in neuroni quando vengono trattate con fattori di crescita nerve growth factor (NGF).
Dopo la differenziazione, le cellule PC12 mostrano caratteristiche tipiche dei neuroni, come l'emissione di processi neuritici e l'espressione di proteine specifiche dei neuroni. Per questi motivi, le cellule PC12 sono spesso utilizzate come modello sperimentale in studi che riguardano la neurobiologia, la neurofarmacologia e la tossicologia.
In particolare, l'esposizione a sostanze tossiche o stress ambientali può indurre alterazioni morfologiche e biochimiche nelle cellule PC12, che possono essere utilizzate come indicatori di potenziale neurotossicità. Inoltre, le cellule PC12 sono anche utili per lo studio dei meccanismi molecolari della differenziazione neuronale e dell'espressione genica correlata alla differenziazione.
I Canali del Calcio Tipo L sono un tipo di canale ionico voltaggio-dipendente che svolgono un ruolo importante nella regolazione dell'equilibrio elettrolitico e dell'eccitabilità cellulare, specialmente nelle cellule muscolari e nervose.
Questi canali sono permeabili al calcio (Ca2+) e si aprono in risposta a un aumento del potenziale di membrana. Una volta aperti, permettono al calcio di fluire all'interno della cellula, dove può svolgere una serie di funzioni importanti, come l'attivazione dell'excitabilità cellulare e la regolazione della contrazione muscolare.
I Canali del Calcio Tipo L sono anche noti per essere influenzati da una varietà di farmaci e sostanze chimiche, il che li rende un bersaglio importante per lo sviluppo di terapie per una serie di condizioni mediche, tra cui l'ipertensione, l'angina, l'aritmia cardiaca e la malattia di Alzheimer.
È importante notare che un'alterazione del funzionamento dei Canali del Calcio Tipo L è stata associata a diverse patologie, tra cui la distrofia muscolare di Duchenne, la fibrosi cistica e alcune forme di epilessia.
I geni batterici si riferiscono a specifiche sequenze di DNA presenti nel genoma di batteri che codificano per proteine o RNA con funzioni specifiche. Questi geni svolgono un ruolo cruciale nello sviluppo, nella crescita e nella sopravvivenza dei batteri, determinando le loro caratteristiche distintive come la forma, il metabolismo, la resistenza ai farmaci e la patogenicità.
I geni batterici possono essere studiati per comprendere meglio la biologia dei batteri, nonché per sviluppare strategie di controllo e prevenzione delle malattie infettive. Ad esempio, l'identificazione di geni specifici che conferiscono resistenza agli antibiotici può aiutare a sviluppare nuovi farmaci per combattere le infezioni resistenti ai farmaci.
Inoltre, i geni batterici possono essere modificati o manipolati utilizzando tecniche di ingegneria genetica per creare batteri geneticamente modificati con applicazioni potenziali in vari campi, come la biotecnologia, l'agricoltura e la medicina.
Le proteine leganti GTP eterotrimeriche, notevoli anche come G-proteine, sono un tipo specifico di proteine che giocano un ruolo cruciale nella trasduzione del segnale nelle cellule. Esse sono composte da tre subunità: alpha (α), beta (β) e gamma (γ). Queste subunità si legano a una molecola di guanosina trifosfato (GTP) e formano un complesso eterotrimerico.
Le G-proteine sono attivate quando una proteina recettore accoppiata a G-proteina (GPCR) viene stimolata da un ligando specifico, che porta alla dissociazione della subunità alfa dal complesso beta-gamma. La subunità alfa, ora attivata, può legare e idrolizzare il GTP in guanosina difosfato (GDP), cambiando la sua conformazione strutturale e interagendo con altre proteine target per trasmettere il segnale all'interno della cellula.
Una volta che il GDP si lega alla subunità alfa, questa può riassociarsi con la subunità beta-gamma, formando nuovamente l'eterotrimero inattivo. Le proteine leganti GTP eterotrimeriche sono essenziali per una varietà di processi cellulari, tra cui la regolazione dell'espressione genica, il metabolismo, la crescita e la differenziazione cellulare, nonché la modulazione della risposta immunitaria.
La guanosina trifosfato (GTP) è una nucleotide trifosfato che svolge un ruolo cruciale come fonte di energia e come molecola segnalatrice in molti processi cellulari. È strettamente correlata alla più nota adenosina trifosfato (ATP), poiché entrambe le molecole sono utilizzate per fornire energia alle reazioni chimiche all'interno della cellula.
La GTP è costituita da una base azotata, la guanina, un gruppo fosfato e uno zucchero pentoso, il ribosio. La sua forma a triphosphate conferisce alla molecola un alto livello di energia chimica che può essere rilasciata attraverso l'idrolisi del legame fosfoanidride ad alta energia tra i gruppi fosfato. Questo processo rilascia una grande quantità di energia che può essere utilizzata per guidare altre reazioni cellulari, come la sintesi delle proteine e il trasporto di molecole attraverso le membrane cellulari.
Oltre al suo ruolo come fonte di energia, la GTP è anche un importante regolatore della segnalazione cellulare. Ad esempio, è utilizzata dalle proteine G, una classe di proteine che trasducono i segnali extracellulari all'interno della cellula. Quando una proteina G lega il suo ligando specifico, subisce un cambiamento conformazionale che attiva l'idrolisi del GTP in GDP, rilasciando energia e alterando l'attività della proteina G.
In sintesi, la guanosina trifosfato è una molecola chiave nella cellula che fornisce energia per le reazioni chimiche e regola i processi di segnalazione cellulare.
I neuropeptidi sono piccole proteine che svolgono un ruolo cruciale nella comunicazione intercellulare nel sistema nervoso centrale e periferico. Essi sono syntetizzati all'interno dei neuroni come precursori più grandi, che vengono poi processati in peptidi attivi più corti da enzimi specifici. I neuropeptidi possono avere effetti sia eccitatori che inibitori sui neuroni target e sono coinvolti in una varietà di funzioni biologiche, tra cui il controllo del dolore, l'appetito, l'umore, la memoria e l'apprendimento. Essi possono anche agire come ormoni quando rilasciati nel flusso sanguigno. Gli esempi di neuropeptidi includono endorfine, encefaline, sostanza P, orexina e corticotropina releasing hormone (CRH).
La biofisica è una disciplina scientifica interdisciplinare che si occupa dell'applicazione dei principi e dei metodi della fisica alle strutture, alle funzioni e ai processi biologici. Gli argomenti di studio nella biofisica possono includere la struttura e la dinamica delle molecole biologiche, come proteine e acidi nucleici; i meccanismi fisici che stanno alla base della comunicazione cellulare, come il trasporto di ioni attraverso membrane cellulari; e i processi su larga scala all'interno degli organismi viventi, come la locomozione e la percezione sensoriale.
Gli strumenti e le tecniche utilizzati nella biofisica possono includere la spettroscopia, la microscopia, la termodinamica, la meccanica statistica e la modellazione matematica. Gli obiettivi della ricerca in biofisica possono variare dalla comprensione dei meccanismi fondamentali alla base dei processi biologici alla progettazione di nuove terapie e tecnologie mediche.
La biofisica è una disciplina altamente interdisciplinare che richiede una conoscenza approfondita della fisica, della chimica e della biologia. I ricercatori in questo campo possono provenire da background accademici diversi, tra cui la fisica, la chimica, la biologia, l'ingegneria e le scienze informatiche.
I recettori tirosin chinasi (RTK) sono una classe di recettori transmembrana che svolgono un ruolo cruciale nella trasduzione del segnale nelle cellule. Sono costituiti da una porzione extracellulare, una porzione transmembrana e una porzione intracellulare. La porzione extracellulare è responsabile del legame con il ligando specifico, come fattori di crescita o ormoni. Il legame del ligando induce una dimerizzazione dei recettori RTK, che porta all'attivazione della tirosina chinasi nella porzione intracellulare.
L'attivazione della tirosina chinasi comporta l'autofosforilazione di specifici residui di tirosina sui monomeri del recettore RTK, che a sua volta crea siti di docking per le proteine adattatrici e le chinasi associate. Questo porta all'attivazione di una cascata di segnali intracellulari che regolano una varietà di processi cellulari, come la proliferazione, la differenziazione, la sopravvivenza e la motilità cellulare.
I recettori RTK sono importanti nella normale fisiologia, ma anche nelle malattie, in particolare nel cancro. Le mutazioni nei geni che codificano per i recettori RTK o le loro vie di segnalazione possono portare a una disregolazione della crescita e proliferazione cellulare, contribuendo all'insorgenza e alla progressione del cancro.
Il Fattore Cellulare dell'Ospite C1, noto anche come fattore di von Willebrand chimiotattico (vWF-CPP), è una proteina proinfiammatoria che svolge un ruolo cruciale nella regolazione della coagulazione del sangue e dell'infiammazione. È prodotta dalle cellule endoteliali, i cui lini interni rivestono la superficie interna dei vasi sanguigni.
La proteina C1 è secreta in risposta a stimoli infiammatori o lesioni vascolari e attira vari tipi di globuli bianchi (leucociti) nel sito dell'infiammazione o della lesione, promuovendo l'adesione dei leucociti alle cellule endoteliali. Ciò è fondamentale per il reclutamento e l'attivazione dei leucociti, che aiutano a combattere l'infezione e a riparare i tessuti danneggiati.
La proteina C1 svolge anche un ruolo nella regolazione della coagulazione del sangue, interagendo con il fattore VIII e aumentandone l'emivita, contribuendo così alla formazione di coaguli di sangue. Tuttavia, un'eccessiva attivazione o secrezione della proteina C1 può portare a disfunzioni endoteliali, trombosi e infiammazione sistemica, che sono state associate a varie condizioni patologiche, tra cui l'aterosclerosi, la sindrome metabolica e le malattie cardiovascolari.
La caseina chinasi II, nota anche come CK2, è un enzima serina/treonina proteinchinasi che svolge un ruolo importante nella regolazione di una varietà di processi cellulari, tra cui la proliferazione, l'apoptosi e la trascrizione genica.
L'enzima è costituito da due subunità catalitiche (α e α') e due subunità regolatorie (β). La caseina chinasi II è nota per la sua attività costitutiva, il che significa che non richiede l'attivazione da parte di altri fattori.
La caseina chinasi II può fosforilare una vasta gamma di substrati, tra cui proteine nucleari e citoplasmatiche, e ha dimostrato di svolgere un ruolo importante nella regolazione della stabilità delle proteine, dell'attività enzimatica e del traffico intracellulare.
L'enzima è stato anche implicato in una serie di processi patologici, tra cui il cancro, le malattie neurodegenerative e l'infiammazione. In particolare, la caseina chinasi II è stata trovata overexpressed in diversi tipi di tumori e ha dimostrato di promuovere la proliferazione cellulare e la sopravvivenza delle cellule tumorali.
In sintesi, la caseina chinasi II è un enzima multifunzionale che regola una varietà di processi cellulari ed è implicata in diversi processi patologici, il che la rende un bersaglio interessante per lo sviluppo di terapie mirate.
L'ultracentrifugazione è una tecnica di laboratorio utilizzata per separare particelle, come macromolecole o particelle subcellulari, presenti in una miscela eterogenea sulla base della loro differenza di massa, dimensioni e forma. Questo processo viene eseguito utilizzando un'apparecchiatura chiamata ultracentrifuga, che può raggiungere velocità di rotazione molto elevate (fino a 100.000 g o più), permettendo così la sedimentazione delle particelle più dense e grandi verso l'esterno del tubo di centrifugazione.
Esistono due tipi principali di ultracentrifugazione:
1. Ultracentrifugazione analitica: utilizzata per misurare le proprietà fisiche delle particelle, come la massa molecolare, la dimensione e la forma, attraverso l'analisi della velocità di sedimentazione o del coefficiente di sedimentazione.
2. Ultracentrifugazione preparativa: utilizzata per separare e purificare le frazioni di interesse dalle miscele complesse, come ad esempio la separazione di diversi tipi di ribosomi, vescicole o virus.
L'ultracentrifugazione è una tecnica fondamentale in biologia molecolare, biochimica e biologia cellulare per lo studio delle particelle subcellulari e la purificazione di macromolecole come proteine, acidi nucleici e particelle virali.
'Schizosaccharomyces' non è una condizione medica o un termine utilizzato nella medicina. È un genere di lieviti che comprende diversi tipi di funghi unicellulari. Questi lieviti sono noti per la loro capacità di riprodursi asessualmente attraverso la fissione binaria, dove il nucleo della cellula si divide in due e le due parti vengono separate da una parete cellulare che cresce tra di esse.
Uno dei tipi più noti di Schizosaccharomyces è Schizosaccharomyces pombe, che viene spesso utilizzato come organismo modello in studi di biologia cellulare e genetica a causa della sua facilità di coltivazione e manipolazione genetica. Questo lievito è stato particolarmente utile nello studio dei meccanismi che controllano la divisione cellulare, il ciclo cellulare e la risposta al danno del DNA.
Un virione è la forma completa e infettiva di un virus. Si compone di un genoma nucleico (che può essere DNA o RNA) avvolto in una proteina capside, che a sua volta può essere circondata da un lipidico involucro esterno. I virioni sono in grado di infettare cellule ospiti e utilizzarne le risorse per replicarsi, rilasciando nuovi virioni nell'organismo ospite.
In medicina, il "trasferimento di energia" si riferisce al processo in cui l'energia viene trasferita da una fonte o un sistema ad un altro. Ci sono diversi meccanismi attraverso i quali questo può avvenire, tra cui:
1. Conduttività: il trasferimento di energia sotto forma di calore attraverso la conduzione, che si verifica quando due oggetti a contatto diretto hanno temperature diverse e l'energia si sposta dal corpo più caldo al corpo più freddo.
2. Convezione: il trasferimento di energia sotto forma di calore attraverso il movimento di fluidi, come l'aria o l'acqua.
3. Radiazione: il trasferimento di energia sotto forma di radiazioni elettromagnetiche, come la luce solare o le radiazioni ionizzanti utilizzate in terapie mediche.
4. Meccanico: il trasferimento di energia attraverso forze meccaniche, come nel caso dell'esercizio fisico o degli urti.
5. Elettrochimico: il trasferimento di energia attraverso reazioni elettrochimiche, come nella respirazione cellulare o nelle batterie.
Il trasferimento di energia è un concetto fondamentale in fisica e in molte aree della medicina, compresa la fisiologia, la biochimica e la terapia.
La proteina adattatrice Grb2, nota anche come Growth Factor Receptor-Bound Protein 2, è una proteina intracellulare che svolge un ruolo cruciale nella trasduzione del segnale nelle cellule eucariotiche. Essa media l'interazione tra il recettore del fattore di crescita epidermico (EGFR) o altri recettori tirosina chinasi e le proteine chinasi della famiglia Src, attivando una cascata di eventi che portano alla proliferazione cellulare, sopravvivenza e differenziazione.
Grb2 è costituita da un dominio SH2 (Src Homology 2) e due domini SH3, che le permettono di legarsi a specifiche sequenze di tirosina fosforilate sui recettori del fattore di crescita e ad altre proteine adattatrici. Quando un ligando si lega al recettore del fattore di crescita, questo viene attivato e la tirosina viene fosforilata. Grb2 può quindi legarsi a questa tirosina fosforilata e reclutare altre proteine, come la Ras GTPasi, per formare un complesso multiproteico che inizia una cascata di segnalazione cellulare.
La proteina adattatrice Grb2 è essenziale per la regolazione della crescita e della differenziazione cellulare ed è stata implicata nella patogenesi di diversi tipi di cancro, inclusi il cancro al polmone, al seno e al colon. Mutazioni o alterazioni dell'espressione di Grb2 possono portare a disregolazione della segnalazione cellulare e alla progressione del tumore.
La diffusione della radiazione è un termine medico utilizzato per descrivere la dispersione delle particelle o delle onde elettromagnetiche, come i raggi X o la radiazione gamma, nello spazio. Questo processo si verifica quando le particelle o le onde colpiscono gli atomi o le molecole nel mezzo attraversato, causando l'eiezione di elettroni e creando ioni carichi positivamente.
L'entità della diffusione dipende da diversi fattori, come l'energia delle particelle o delle onde, la densità del mezzo attraversato e la lunghezza del percorso coperto dalla radiazione. La diffusione può causare danni ai tessuti circostanti, soprattutto se la dose assorbita è elevata, ed è per questo che la protezione dai raggi X e dalle altre forme di radiazione ionizzante è un aspetto importante della sicurezza in ambito medico.
In radiologia, la diffusione della radiazione può influenzare la qualità dell'immagine e la dose di radiazioni assorbita dal paziente. Per questo motivo, i tecnici sanitari di radiologia medica utilizzano tecniche specifiche per minimizzare la diffusione e garantire l'esposizione alle radiazioni solo alla parte del corpo interessata dall'esame.
Le metalloproteine sono proteine che contengono uno o più ioni metallici come parte integrante della loro struttura. Questi ioni metallici sono essenziali per la funzione delle metalloproteine, poiché svolgono un ruolo cruciale nella catalisi enzimatica, nel trasporto di elettroni e nell'interazione con molecole di segnalazione. Le metalloproteine possono essere classificate in base al tipo di ione metallico presente, come ad esempio emoproteine (con ferro), ferrodossine (con ferro), proteine contenenti rame e zinco, ecc. Alcune famose metalloproteine includono l'emoglobina, la mioglobina e le diverse ossidoreduttasi. Le alterazioni nella struttura o nella funzione delle metalloproteine possono essere associate a varie patologie umane, come ad esempio malattie neurodegenerative, cancro e disturbi del metabolismo.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
La nucleocapside è una struttura composta dal materiale genetico (acido nucleico, sia RNA che DNA) e dalle proteine che lo ricoprono, formando una complessa struttura protetta all'interno di virus. Nella maggior parte dei virus, la nucleocapside è responsabile dell'interazione con l'involucro virale esterno, composto da lipidi e proteine, che si fonde con la membrana cellulare ospite durante il processo di infezione. La nucleocapside svolge un ruolo cruciale nella replicazione del virus, nell'assemblaggio dei nuovi virioni e nella protezione dell'acido nucleico virale dall'ambiente esterno e dai meccanismi di difesa dell'ospite.
La peptidilprolilisomerasi, nota anche come ciclofilina o FK506-binding protein (FKBP), è un'enzima che appartiene alla famiglia delle isomerasi. Questa particolare classe di enzimi catalizza la reazione di isomerizzazione dei peptidi bond prolinici, convertendo le conformazioni cis e trans.
Nella fisiologia umana, le peptidilprolilisomerasi svolgono un ruolo cruciale nella piegatura proteica corretta e nell'assemblaggio di alcuni complessi multiproteici. Sono anche note per legare farmaci immunosoppressori come la ciclosporina A e il tacrolimus (FK506), che vengono utilizzati in ambito clinico per prevenire il rigetto dei trapianti d'organo.
L'attività enzimatica della peptidilprolilisomerasi può essere influenzata da questi farmaci, che si legano alla sua tasca di legame e inibiscono la sua funzione, portando a un effetto immunosoppressivo.
In sintesi, la peptidilprolilisomerasi è un enzima chiave nella piegatura proteica e nell'assemblaggio dei complessi multiproteici, che può essere inibito da farmaci immunosoppressori per prevenire il rigetto dei trapianti d'organo.
I microtubuli sono sottili strutture tubulari cilindriche presenti nel citoplasma delle cellule, che costituiscono uno dei tre componenti principali del citoscheletro, insieme a actina e intermediate filamenti. Sono costituiti da proteine tubuline globulari disposte in modo ordinato a formare protofilamenti, che a loro volta si organizzano per formare il tubulo microtubulare.
I microtubuli svolgono diverse funzioni importanti all'interno della cellula, tra cui il mantenimento della forma e della struttura cellulare, la divisione cellulare, il trasporto intracellulare di organelli e vescicole, e la motilità cellulare. Inoltre, i microtubuli sono anche componenti essenziali del flagello e del cilio, strutture che permettono alla cellula di muoversi o di muovere fluidi sulla sua superficie.
I farmaci che interferiscono con la formazione o la stabilità dei microtubuli, come i taxani e le vinca-alcaloidi, sono utilizzati in terapia oncologica per il trattamento di diversi tipi di cancro. Questi farmaci agiscono bloccando la divisione cellulare e inducono l'apoptosi (morte cellulare programmata) nelle cellule tumorali.
Le proteine dello Schizosaccharomyces pombe, noto anche come lievito fissione, si riferiscono a specifiche proteine identificate e studiate in questo particolare organismo modello. Lo Schizosaccharomyces pombe è un tipo di lievito unicellulare che viene utilizzato in ricerca per comprendere meccanismi cellulari fondamentali, poiché ha un ciclo cellulare complesso e conserva molti processi cellulari comuni con cellule umane.
Le proteine di Schizosaccharomyces pombe sono state ampiamente studiate per comprendere una varietà di funzioni cellulari, tra cui la divisione cellulare, il ciclo cellulare, la replicazione del DNA, la trascrizione genica, la traduzione proteica e la risposta al danno ambientale. Uno dei vantaggi dell'utilizzo di Schizosaccharomyces pombe come organismo modello è che ha un background genetico ben caratterizzato e strumenti molecolari potenti sono disponibili per manipolarlo ed esaminarne le funzioni proteiche.
Alcune proteine specifiche di Schizosaccharomyces pombe che sono state studiate includono la proteina del checkpoint del ciclo cellulare Cdc2, la topoisomerasi II cut5-mus101 e la chinasi della parete cellulare Pom1. La comprensione di come funzionano queste proteine nello Schizosaccharomyces pombe può fornire informazioni cruciali su come funzionino le proteine omologhe nelle cellule umane e possa contribuire allo sviluppo di nuove strategie terapeutiche per malattie umane.
I precursori dell'RNA, noti anche come pre-mRNA o RNA primario, si riferiscono a lunghe molecole di RNA che vengono sintetizzate durante il processo di trascrizione a partire dal DNA. Questi precursori contengono sequenze che codificano per proteine, nonché regioni non codificanti chiamate introni e esoni.
Dopo la trascrizione, i precursori dell'RNA subiscono una serie di modifiche post-trascrizionali, tra cui il processamento dell'RNA, che include la rimozione degli introni e l'unione degli esoni per formare un RNA maturo e funzionale. Questo RNA maturo può essere un mRNA (RNA messaggero) che verrà successivamente tradotto in una proteina, o un altro tipo di RNA come rRNA (RNA ribosomiale) o tRNA (RNA transfer).
La corretta elaborazione dei precursori dell'RNA è essenziale per la produzione di proteine funzionali e per il mantenimento della stabilità del genoma. Eventuali errori nel processo di sintesi o elaborazione dei precursori dell'RNA possono portare a malattie genetiche o a un aumento del rischio di sviluppare patologie tumorali.
Phosphatidylinositol 4,5-diphosphate (PIP2) è un importante fosfolipide presente nella membrana cellulare. Si tratta di una molecola polare con due acidi grassi a catena lunga legati a un glicerolo attraverso esteri, e un gruppo fosfato legato a due gruppi inositolo fosfati.
PIP2 svolge un ruolo cruciale nella segnalazione cellulare, essendo un substrato per diverse importanti chinasi e fosfolipasi. Ad esempio, è un substrato per la produzione di inositolo trisfosfato (IP3) e diossiacetilglicerolo (DAG), due importanti secondi messaggeri nella segnalazione cellulare.
PIP2 è anche importante per la regolazione dell'attività dei canali ionici, compresi i canali del calcio voltaggio-dipendenti e i canali del potassio dipendenti dal voltage. Inoltre, PIP2 è essenziale per la formazione e il mantenimento della struttura delle membrane cellulari e svolge un ruolo importante nella traffico intracellulare e nella endocitosi.
Una carenza di PIP2 o una sua alterata regolazione possono portare a disfunzioni cellulari e a diverse patologie, tra cui malattie neurodegenerative, diabete e cancro.
La medicina definisce le neoplasie come un'eccessiva proliferazione di cellule che si accumulano e danno origine a una massa tissutale anomala. Queste cellule possono essere normali, anormali o precancerose. Le neoplasie possono essere benigne (non cancerose) o maligne (cancerose).
Le neoplasie benigne sono generalmente più lente a crescere e non invadono i tessuti circostanti né si diffondono ad altre parti del corpo. Possono comunque causare problemi se premono su organi vitali o provocano sintomi come dolore, perdita di funzionalità o sanguinamento.
Le neoplasie maligne, invece, hanno la capacità di invadere i tessuti circostanti e possono diffondersi ad altre parti del corpo attraverso il sistema circolatorio o linfatico, dando origine a metastasi. Queste caratteristiche le rendono pericolose per la salute e possono portare a gravi complicazioni e, in alcuni casi, alla morte se non trattate adeguatamente.
Le neoplasie possono svilupparsi in qualsiasi parte del corpo e possono avere diverse cause, come fattori genetici, ambientali o comportamentali. Tra i fattori di rischio più comuni per lo sviluppo di neoplasie ci sono il fumo, l'esposizione a sostanze chimiche nocive, una dieta scorretta, l'obesità e l'età avanzata.
I precursori delle proteine, noti anche come pre-protéine o proproteine, si riferiscono a forme iniziali di proteine che subiscono modificazioni post-traduzionali prima di raggiungere la loro forma attiva e funzionale. Queste proteine iniziali contengono sequenze aggiuntive chiamate segnali o peptidi leader, che guidano il loro trasporto all'interno della cellula e ne facilitano l'esportazione o l'inserimento nelle membrane.
Durante la maturazione di queste proteine, i seguenti eventi possono verificarsi:
1. Rimozione del peptide leader: Dopo la sintesi delle pre-protéine nel reticolo endoplasmatico rugoso (RER), il peptide leader viene tagliato da specifiche peptidasi, lasciando una proproteina o propeptide.
2. Folding e assemblaggio: Le proproteine subiscono piegamenti (folding) corretti e possono formare complessi multimerici con altre proteine.
3. Modificazioni chimiche: Possono verificarsi modificazioni chimiche, come la glicosilazione (aggiunta di zuccheri), la fosforilazione (aggiunta di gruppi fosfato) o la amidazione (aggiunta di gruppi amminici).
4. Rimozione della proproteina o del propeptide: La rimozione della proproteina o del propeptide può attivare direttamente la proteina o esporre siti attivi per l'ulteriore maturazione enzimatica.
5. Ulteriori tagli e modifiche: Alcune proteine possono subire ulteriori tagli o modifiche per raggiungere la loro forma finale e funzionale.
Esempi di precursori delle proteine includono l'insulina, che è sintetizzata come preproinsulina e subisce diverse modificazioni prima di diventare l'ormone attivo; e la proenzima, un enzima inattivo che richiede la rimozione di una proproteina o di un propeptide per essere attivato.
L'immunoistochimica è una tecnica di laboratorio utilizzata in patologia e ricerca biomedica per rilevare e localizzare specifiche proteine o antigeni all'interno di cellule, tessuti o organismi. Questa tecnica combina l'immunochimica, che studia le interazioni tra anticorpi e antigeni, con la chimica istologica, che analizza i componenti chimici dei tessuti.
Nell'immunoistochimica, un anticorpo marcato (con un enzima o fluorocromo) viene applicato a una sezione di tessuto fissato e tagliato sottilmente. L'anticorpo si lega specificamente all'antigene desiderato. Successivamente, un substrato appropriato viene aggiunto, che reagisce con il marcatore enzimatico o fluorescente per produrre un segnale visibile al microscopio. Ciò consente di identificare e localizzare la proteina o l'antigene target all'interno del tessuto.
L'immunoistochimica è una tecnica sensibile e specifica che fornisce informazioni cruciali sulla distribuzione, l'identità e l'espressione di proteine e antigeni in vari processi fisiologici e patologici, come infiammazione, infezione, tumori e malattie neurodegenerative.
Gli "Biophysical Phenomena" sono fenomeni che si verificano a livello cellulare, molecolare o fisiologico e che possono essere descritti e misurati utilizzando le leggi e i principi della fisica. Questi fenomeni riguardano l'interazione tra strutture biologiche e forze fisiche, come ad esempio il movimento degli ioni attraverso la membrana cellulare, il legame delle molecole di DNA, il trasporto di sostanze attraverso i pori della membrana, l'assorbimento di luce da parte delle cellule, e così via.
Gli scienziati biologici e medici utilizzano spesso la fisica per comprendere meglio questi fenomeni e sviluppare nuove tecniche di diagnosi e trattamento. Ad esempio, l'imaging medico come la risonanza magnetica (MRI) e la tomografia computerizzata (CT) si basano sulla fisica per creare immagini dettagliate delle strutture interne del corpo umano.
In sintesi, "Biophysical Phenomena" sono fenomeni che si verificano a livello biologico e che possono essere studiati e compresi utilizzando i principi della fisica.
La proliferazione cellulare è un processo biologico durante il quale le cellule si dividono attivamente e aumentano in numero. Questo meccanismo è essenziale per la crescita, la riparazione dei tessuti e la guarigione delle ferite. Tuttavia, una proliferazione cellulare incontrollata può anche portare allo sviluppo di tumori o neoplasie.
Nel corso della divisione cellulare, una cellula madre si duplica il suo DNA e poi si divide in due cellule figlie identiche. Questo processo è noto come mitosi. Prima che la mitosi abbia luogo, tuttavia, la cellula deve replicare il suo DNA durante un'altra fase del ciclo cellulare chiamato S-fase.
La capacità di una cellula di proliferare è regolata da diversi meccanismi di controllo che coinvolgono proteine specifiche, come i ciclina-dipendenti chinasi (CDK). Quando questi meccanismi sono compromessi o alterati, come nel caso di danni al DNA o mutazioni genetiche, la cellula può iniziare a dividersi in modo incontrollato, portando all'insorgenza di patologie quali il cancro.
In sintesi, la proliferazione cellulare è un processo fondamentale per la vita e la crescita delle cellule, ma deve essere strettamente regolata per prevenire l'insorgenza di malattie.
La regolazione enzimologica dell'espressione genica si riferisce al processo di controllo e modulazione dell'attività enzimatica che influenza la trascrizione, il montaggio e la traduzione dei geni in proteine funzionali. Questo meccanismo complesso è essenziale per la corretta espressione genica e la regolazione delle vie metaboliche all'interno di una cellula.
La regolazione enzimologica può verificarsi a diversi livelli:
1. Trascrizione: L'attività enzimatica può influenzare il processo di inizio della trascrizione, attraverso l'interazione con fattori di trascrizione o modifiche chimiche al DNA. Questo può portare all'attivazione o alla repressione dell'espressione genica.
2. Montaggio: Dopo la trascrizione, il trascritto primario subisce il processo di montaggio, che include la rimozione delle sequenze non codificanti e l'unione dei frammenti di mRNA per formare un singolo mRNA maturo. L'attività enzimatica può influenzare questo processo attraverso l'interazione con enzimi specifici, come le nucleasi o le ligasi.
3. Traduzione: Durante la traduzione, il mRNA viene letto da ribosomi e utilizzato per sintetizzare proteine funzionali. L'attività enzimatica può influenzare questo processo attraverso l'interazione con fattori di inizio o arresto della traduzione, oppure attraverso la modificazione chimica delle sequenze di mRNA.
4. Modifiche post-traduzionali: Dopo la sintesi proteica, le proteine possono subire una serie di modifiche post-traduzionali che influenzano la loro funzione e stabilità. L'attività enzimatica può influenzare queste modifiche attraverso l'interazione con enzimi specifici, come le proteasi o le chinasi.
In sintesi, l'attività enzimatica svolge un ruolo fondamentale nel regolare i processi di espressione genica e può influenzare la funzione e la stabilità delle proteine. La comprensione dei meccanismi molecolari che governano queste interazioni è essenziale per comprendere il funzionamento dei sistemi biologici e per sviluppare nuove strategie terapeutiche.
Le proteine dei nucleocapsidi, in termini medici, si riferiscono a proteine che avvolgono il materiale genetico (acido nucleico) di un virus, formando una struttura chiamata nucleocapside. Questa struttura è spesso resistente alle interruzioni enzimatiche e ai detergenti, rendendola protetta all'esterno della membrana virale.
Le proteine dei nucleocapsidi svolgono un ruolo cruciale nella replicazione del virus, nell'assemblaggio di nuovi virioni e nella regolazione dell'attività genetica del virus. Possono anche avere proprietà immunologiche importanti, poiché possono indurre una risposta immune quando un organismo ospite viene infettato da un virus.
Le proteine dei nucleocapsidi sono tipicamente specifiche per ogni tipo di virus e possono variare notevolmente nella loro struttura, composizione e funzione. Pertanto, la comprensione delle proteine dei nucleocapsidi è fondamentale per comprendere il ciclo di vita dei virus e per lo sviluppo di strategie di prevenzione e trattamento delle malattie infettive.
Le endopeptidasi della cisteina sono un gruppo di enzimi proteolitici che tagliano le proteine e i peptidi all'interno delle loro sequenze aminoacidiche, specificamente in siti con residui di cisteina. Questi enzimi svolgono un ruolo cruciale nella regolazione di varie funzioni cellulari, come l'eliminazione di proteine danneggiate o non funzionali, la maturazione e l'attivazione di proteine e peptidi a funzione specifica.
Le endopeptidasi della cisteina sono caratterizzate dalla presenza di un residuo catalitico di cisteina nella loro struttura, che partecipa alla reazione di idrolisi dei legami peptidici attraverso un meccanismo catalitico nucleofilo. Questi enzimi sono anche noti come proteasi a cisteina o cisteinil proteasi.
Esempi di endopeptidasi della cisteina includono la papaina, derivata dalla papaia, e la tripsina, derivata dal pancreas bovino. Questi enzimi sono ampiamente utilizzati in biologia molecolare e biochimica per la digestione controllata di proteine e peptidi a scopo analitico o preparativo.
Le endopeptidasi della cisteina sono anche implicate in varie patologie, come l'infiammazione, il cancro e le malattie neurodegenerative. Pertanto, gli inibitori di questi enzimi sono stati studiati come potenziali farmaci terapeutici per tali condizioni.
La pantetina, nota anche come pantotenato di calcio o vitamina B5, è una forma solubile in acqua della vitamina B5. Si trova naturalmente in una varietà di alimenti, tra cui carni, pesce, cereali integrali, fagioli e verdure a foglia verde.
La pantetina svolge un ruolo importante nel metabolismo dei carboidrati, dei lipidi e delle proteine, nonché nella produzione di ormoni steroidei e acidi grassi essenziali nel corpo. Funziona anche come antiossidante, aiutando a proteggere le cellule dai danni dei radicali liberi.
La pantetina è spesso utilizzata come integratore alimentare per trattare o prevenire una varietà di condizioni, tra cui l'affaticamento, lo stress, le allergie e le malattie cardiovascolari. Tuttavia, sono necessarie ulteriori ricerche per confermare i suoi benefici per la salute.
In forma di supplemento, la pantetina è disponibile come capsule o compresse e può essere assunta per via orale. Gli effetti collaterali della pantetina sono generalmente lievi e possono includere mal di stomaco, diarrea o eruttazione. Tuttavia, in dosi elevate, la pantetina può causare problemi al fegato o ai reni. Pertanto, è importante consultare un operatore sanitario prima di assumere qualsiasi integratore alimentare, compresa la pantetina.
Un topo knockout è un tipo di topo da laboratorio geneticamente modificato in cui uno o più geni sono stati "eliminati" o "disattivati" per studiarne la funzione e l'effetto su vari processi biologici, malattie o tratti. Questa tecnica di manipolazione genetica viene eseguita introducendo una mutazione nel gene bersaglio che causa l'interruzione della sua espressione o funzione. I topi knockout sono ampiamente utilizzati negli studi di ricerca biomedica per comprendere meglio la funzione dei geni e il loro ruolo nelle malattie, poiché i topi congeniti con queste mutazioni possono manifestare fenotipi o sintomi simili a quelli osservati in alcune condizioni umane. Questa tecnica fornisce un modello animale prezioso per testare farmaci, sviluppare terapie e studiare i meccanismi molecolari delle malattie.
"Ring finger domains" (RFIDs) sono proteine della famiglia BBOX che contengono un dominio caratteristico noto come "ring finger." Questi domini sono chiamati così per la loro struttura a forma di anello, formata da un motivo a zinco finger-loop contenente cisteine altamente conservate.
Gli RFIDs sono coinvolti in una varietà di processi cellulari, tra cui l'ubiquitinazione e la regolazione della trascrizione genica. L'ubiquitinazione è un processo post-traduzionale che modifica le proteine aggiungendo una molecola di ubiquitina, segnalando così la degradazione delle proteine. Gli RFIDs fungono da E3 ligasi, che catalizzano l'ultimo passaggio dell'ubiquitinazione, legando l'ubiquitina alle proteine bersaglio.
Inoltre, alcuni RFIDs sono associati a complessi co-trascrizionali e possono fungere da regolatori della trascrizione genica. Possono interagire con altri fattori di trascrizione e modificare la struttura della cromatina, influenzando così l'espressione genica.
Le mutazioni nei geni che codificano per RFIDs sono state associate a diverse malattie umane, tra cui alcuni tipi di cancro e disturbi neurologici. Pertanto, la comprensione della funzione e del meccanismo d'azione degli RFIDs è importante per comprendere i processi cellulari normali e le basi molecolari delle malattie umane.
Le piante geneticamente modificate (PGM) sono organismi vegetali che hanno subito un processo di ingegneria genetica al fine di ottenere caratteristiche desiderabili che non si trovano naturalmente nelle loro varietà originali. Questo processo comporta l'inserimento di uno o più geni esogeni (provenienti da altri organismi) nel genoma della pianta, utilizzando tecniche di biologia molecolare avanzate.
Gli obiettivi dell'ingegneria genetica delle piante possono includere la resistenza a parassiti o malattie, l'aumento della tolleranza a erbicidi, l'incremento del valore nutrizionale, la produzione di proteine terapeutiche e l'adattamento alle condizioni ambientali avverse. Le piante geneticamente modificate sono regolamentate da autorità governative per garantire la sicurezza alimentare e ambientale prima della loro commercializzazione.
Esempi di PGM comuni includono il mais Bt resistente agli insetti, la soia Roundup Ready tollerante all'erbicida e il cotone Bollgard resistente ai parassiti. Tuttavia, è importante notare che l'uso e l'accettazione delle piante geneticamente modificate variano ampiamente in diverse parti del mondo, con alcuni paesi che le adottano diffusamente e altri che ne limitano o vietano l'utilizzo.
L'iperglicemia non chetonica è un termine utilizzato in medicina per descrivere un elevato livello di glucosio nel sangue (glucosiemia) superiore a 200 mg/dL, senza la presenza di chetoni elevati nelle urine o nel sangue. Questa condizione è spesso associata al diabete mellito, in particolare al diabete di tipo 2, ma può anche verificarsi in altre situazioni come durante una malattia grave, stress fisico o emotivo, gravidanza, assunzione di corticosteroidi o altri farmaci che aumentano la glicemia.
L'iperglicemia non chetonica è caratterizzata da un'alterazione del metabolismo glucidico, con una ridotta capacità delle cellule di utilizzare il glucosio a causa dell'insulino-resistenza o di una carenza insulinica assoluta. Ciò può portare a sintomi come poliuria (minzione frequente), polidipsia (sete eccessiva), debolezza, affaticamento, visione offuscata e infezioni ricorrenti.
La diagnosi di iperglicemia non chetonica si basa sui valori della glicemia a digiuno o casuale, associati alla presenza o assenza di chetoni nelle urine o nel sangue. Il trattamento prevede il controllo della glicemia attraverso una dieta equilibrata, l'esercizio fisico regolare e la terapia farmacologica con farmaci antidiabetici orali o insulina, a seconda della causa sottostante.
In medicina e ricerca scientifica, i modelli teorici sono rappresentazioni concettuali o matematiche di sistemi, processi o fenomeni biologici che forniscono una comprensione astratta degli eventi e dei meccanismi alla base delle osservazioni empiriche. Essi possono essere utilizzati per formulare ipotesi, fare previsioni e progettare esperimenti o interventi. I modelli teorici possono prendere la forma di diagrammi schematici, equazioni matematiche o simulazioni al computer che descrivono le relazioni tra variabili e parametri del sistema in esame.
Ad esempio, nel campo della farmacologia, i modelli teorici possono essere utilizzati per descrivere come un farmaco viene assorbito, distribuito, metabolizzato ed eliminato dall'organismo (noto come PK/PD o pharmacokinetic/pharmacodynamic modeling). Questo tipo di modello può aiutare a prevedere la risposta individuale al farmaco e ad ottimizzarne la posologia.
In epidemiologia, i modelli teorici possono essere utilizzati per studiare la diffusione delle malattie infettive all'interno di una popolazione e per valutare l'efficacia di interventi di sanità pubblica come la vaccinazione o il distanziamento sociale.
In sintesi, i modelli teorici forniscono un framework concettuale per comprendere e analizzare i fenomeni biologici complessi, contribuendo a informare le decisioni cliniche e di salute pubblica.
Il DNA virale si riferisce al genoma costituito da DNA che è presente nei virus. I virus sono entità biologiche obbligate che infettano le cellule ospiti e utilizzano il loro macchinario cellulare per la replicazione del proprio genoma e la sintesi delle proteine.
Esistono due tipi principali di DNA virale: a doppio filamento (dsDNA) e a singolo filamento (ssDNA). I virus a dsDNA, come il citomegalovirus e l'herpes simplex virus, hanno un genoma costituito da due filamenti di DNA complementari. Questi virus replicano il loro genoma utilizzando enzimi come la DNA polimerasi e la ligasi per sintetizzare nuove catene di DNA.
I virus a ssDNA, come il parvovirus e il papillomavirus, hanno un genoma costituito da un singolo filamento di DNA. Questi virus utilizzano enzimi come la reverse transcriptasi per sintetizzare una forma a doppio filamento del loro genoma prima della replicazione.
Il DNA virale può causare una varietà di malattie, dalle infezioni respiratorie e gastrointestinali alle neoplasie maligne. La comprensione del DNA virale e dei meccanismi di replicazione è fondamentale per lo sviluppo di strategie di prevenzione e trattamento delle infezioni virali.
In medicina e biologia, i "Modelli Strutturali" si riferiscono a rappresentazioni tridimensionali dettagliate delle strutture anatomiche o molecolari create utilizzando diversi metodi e tecnologie. Questi modelli possono essere creati per vari scopi, come la comprensione della forma e della funzione di una particolare struttura, lo studio dei processi patologici o per pianificare interventi chirurgici complessi.
I Modelli Strutturali possono essere creati utilizzando diverse tecniche, come la ricostruzione tridimensionale di immagini mediche (come risonanze magnetiche o tomografie computerizzate), l'ingegneria dei tessuti o la stampa 3D. Questi modelli possono essere utilizzati per visualizzare e analizzare le strutture interne del corpo, come gli organi, i vasi sanguigni o le articolazioni, o per studiare la struttura delle molecole biologiche, come le proteine o l'acido desossiribonucleico (DNA).
I Modelli Strutturali sono utilizzati in una varietà di campi, tra cui l'anatomia, la fisiologia, la biochimica, la farmacologia e la chirurgia. Essi possono aiutare i ricercatori a comprendere meglio le basi molecolari delle malattie e a sviluppare nuovi trattamenti e terapie. Inoltre, possono essere utilizzati per l'insegnamento e la formazione medica, permettendo agli studenti di visualizzare e interagire con le strutture anatomiche o molecolari in modo più realistico ed efficace rispetto alle tradizionali illustrazioni bidimensionali.
Le proteine attivanti la Ras GTPasi, anche conosciute come Ras guanina nucleotide dissociation stimulator (Ras-GDS) o Ras guanine nucleotide exchange factor (Ras-GEF), sono una classe di enzimi che facilitano il cambio di stato conformazionale delle proteine Ras dalla forma inattiva (legata a GDP) alla forma attiva (legata a GTP).
Le proteine Ras appartengono alla famiglia delle piccole GTPasi e svolgono un ruolo cruciale nella trasduzione del segnale cellulare, regolando una varietà di processi biologici come la proliferazione, la differenziazione e l'apoptosi.
Le proteine attivanti la Ras GTPasi catalizzano il rilascio di GDP dalle proteine Ras, permettendo alla cellula di scambiarlo con una molecola di GTP più abbondante all'interno della cellula. Questo processo porta all'attivazione della proteina Ras e al conseguente innesco di una cascata di segnali intracellulari.
Le proteine attivanti la Ras GTPasi sono regolate da una varietà di meccanismi, tra cui la fosforilazione, l'interazione con altre proteine e il legame con ligandi specifici. Le disregolazioni nelle vie di segnalazione delle proteine Ras possono portare allo sviluppo di una serie di malattie, tra cui i tumori maligni.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
Le proteine della matrice virale, nota anche come proteine VM, sono un tipo di proteina strutturale che si trova sulla superficie dei virus. Esse formano una sorta di "guscio" esterno o involucro che circonda il materiale genetico del virus e ne facilita l'ingresso nelle cellule ospiti.
Le proteine VM sono sintetizzate all'interno della cellula ospite durante il processo di replicazione virale. Una volta sintetizzate, queste proteine si fondono con la membrana cellulare dell'ospite e vengono espulse dalla cellula insieme al materiale genetico del virus.
Le proteine VM possono avere diverse funzioni importanti per il ciclo di vita del virus, come ad esempio aiutare il virus ad attaccarsi alle cellule ospiti, facilitare la fusione della membrana virale con la membrana cellulare dell'ospite, e proteggere il materiale genetico del virus dall'attacco del sistema immunitario dell'ospite.
Le proteine VM sono un bersaglio importante per lo sviluppo di farmaci antivirali, poiché l'interferenza con la loro funzione può impedire al virus di infettare le cellule ospiti e di replicarsi all'interno dell'organismo.
Le ribonucleoproteine nucleari eterogenee (RNPE) sono un gruppo diversificato di ribonucleoproteine presenti nel nucleo delle cellule eucariotiche. Sono costituite da proteine e acidi ribonucleici (ARN) non codificanti, principalmente ARN a lunghezza frazionata (fraRNA).
Le RNPE sono coinvolte in una varietà di processi cellulari, tra cui la modificazione e il processing dell'ARN, la regolazione della trascrizione genica, la degradazione dell'ARN e la protezione dei telomeri. Alcune RNPE svolgono anche un ruolo nella patogenesi di alcune malattie, come i disturbi neuromuscolari e il cancro.
Le RNPE sono classificate in base alla loro composizione proteica e all'ARN associato. Le principali classi di RNPE includono i complessi spliceosomali, i parascopi, i corpi nucleolari e i corpi Cajal.
I complessi spliceosomali sono responsabili dell'eliminazione delle introni e del joining degli esoni durante il processing dell'ARN messaggero (mRNA). I parascopi sono coinvolti nella regolazione della trascrizione genica e nel processing dell'ARN. I corpi nucleolari sono siti di produzione e maturazione dei ribosomi, mentre i corpi Cajal sono associati alla modificazione e al processing dell'ARN non codificante.
Le RNPE possono anche essere classificate in base alle loro dimensioni e alla loro localizzazione all'interno del nucleo. Alcune RNPE sono grandi complessi multimerici che contengono decine di proteine e diversi tipi di ARN, mentre altre sono costituite da poche proteine e un singolo tipo di ARN.
In sintesi, le ribonucleoproteine nucleari (RNPN) o RNPE sono complessi formati da una o più molecole di RNA associate a proteine specifiche che svolgono funzioni importanti nella regolazione dell'espressione genica e nel processing dell'ARN.
I fattori di trascrizione a cerniera a leucina basica (bZIP) sono una classe di fattori di trascrizione che condividono un dominio strutturale conservato noto come dominio a cerniera a leucina basica. Questo dominio è costituito da una sequenza di aminoacidi idrofobici che forma una struttura a "cerniera" o "bottoni" che consente a due molecole di bZIP di dimerizzare o associarsi tra loro.
I fattori di trascrizione bZIP sono coinvolti nella regolazione dell'espressione genica in risposta a vari segnali cellulari e ambientali, come lo stress ossidativo, l'infiammazione e la differenziazione cellulare. Essi legano il DNA in regioni promotrici specifiche, note come elementi di risposta alle citochine (CRE), che contengono una sequenza nucleotidica conservata palindromica con una coppia di basi di timina separate da tre basi di adenina (TGACGTCA).
Una volta legati al DNA, i fattori di trascrizione bZIP reclutano altre proteine coinvolte nella regolazione dell'espressione genica, come le co-attivatori o le co-repressori, per modulare l'attività della polimerasi II e influenzare la trascrizione dei geni bersaglio.
I fattori di trascrizione bZIP sono presenti in molte specie viventi, dalle batteri alle piante e agli animali, e svolgono un ruolo cruciale nella regolazione dell'espressione genica in una varietà di processi cellulari e fisiologici.
In enzimologia, un oloenzima è l'intero complesso formato da un enzima e il suo cofattore. Il cofattore può essere un metallo inorganico o una piccola molecola organica che si lega all'apoenzima (la forma proteica dell'enzima) per formare l'oloenzima attivo. Questa interazione aumenta l'efficienza e la specificità della reazione catalizzata dall'enzima.
L'unione di un apoenzima con il suo cofattore è spesso necessaria affinché l'enzima esplichi la sua funzione biologica corretta. A volte, il termine oloenzima viene utilizzato in modo intercambiabile con il termine enzima, sebbene questo non sia tecnicamente corretto.
Esempio: La lattasi è un enzima che aiuta a digerire il lattosio, uno zucchero presente nel latte. Il cofattore della lattasi è lo ione zinco (Zn2+). Quando la lattasi si lega allo ione zinco, forma l'oloenzima attivo, che può quindi svolgere la sua funzione catalitica.
La piccola ribonucleoproteina nucleare (snRNP) U4-U6 è una componente importante del complesso spliceosomale, che svolge un ruolo cruciale nel processo di splicing dell'RNA. Lo snRNP U4-U6 è costituito da tre piccole molecole di RNA non codificanti (U4, U6 e U5) e diverse proteine.
L'RNA U4 e U6 sono legati tra loro in una struttura complessa chiamata "diossina" che si dissocia durante il processo di splicing dell'RNA. Quando un trascritto pre-mRNA viene riconosciuto dal complesso spliceosomale, lo snRNP U1 e U2 si legano alle sequenze di riconoscimento del sito di splicing (sequenze conservate di AG e GU) nel pre-mRNA. Successivamente, lo snRNP U4-U6 viene reclutato insieme allo snRNP U5 per formare il complesso spliceosomale attivo.
Durante il processo di splicing, la diossina tra l'RNA U4 e U6 si dissocia, permettendo alla regione terminale 5' dell'RNA U6 di interagire con lo snRNP U2 per formare un nuovo complesso chiamato "complesso C". Questo complesso è essenziale per il taglio e la ricostituzione delle estremità del pre-mRNA, che porta alla formazione dell'mRNA maturo.
In sintesi, lo snRNP U4-U6 è un componente cruciale del complesso spliceosomale che svolge un ruolo importante nel processo di splicing dell'RNA, aiutando a tagliare e ricostituire le estremità del pre-mRNA per formare l'mRNA maturo.
In medicina e fisiologia, gli ioni sono atomi o molecole che hanno acquisito una carica elettrica positiva o negativa a seguito della perdita o del guadagno di uno o più elettroni. Gli ioni possono formarsi naturalmente nel corpo umano attraverso processi biochimici, come ad esempio il trasporto ionico attraverso membrane cellulari, che è fondamentale per la trasmissione degli impulsi nervosi e la contrazione muscolare. Inoltre, gli ioni sono presenti in soluzioni fisiologiche come il sangue e il liquido interstiziale, dove svolgono un ruolo cruciale nel mantenimento dell'equilibrio elettrolitico e del pH corporeo. Alcuni trattamenti medici, come la terapia con ioni negativi, si basano sull'utilizzo di queste particelle cariche per promuovere il benessere e la salute.
In medicina, il termine "movimento cellulare" si riferisce al movimento spontaneo o diretto di cellule viventi, che può verificarsi a causa della contrazione dei propri meccanismi interni o in risposta a stimoli esterni.
Un esempio ben noto di movimento cellulare è quello delle cellule muscolari scheletriche, che si accorciano e si ispessiscono per causare la contrazione muscolare e il movimento del corpo. Altre cellule, come i globuli bianchi nel sangue, possono muoversi spontaneamente per aiutare a combattere le infezioni.
Inoltre, il termine "movimento cellulare" può anche riferirsi alla migrazione di cellule durante lo sviluppo embrionale o la riparazione dei tessuti, come quando le cellule staminali si muovono verso un'area danneggiata del corpo per aiutare a ripararla.
Tuttavia, è importante notare che il movimento cellulare può anche essere alterato in alcune condizioni patologiche, come nel caso di malattie neuromuscolari o immunitarie, dove la capacità delle cellule di muoversi correttamente può essere compromessa.
Gli autoantigeni sono sostanze, generalmente proteine o peptidi, che si trovano normalmente all'interno del corpo e possono stimolare una risposta immunitaria quando vengono riconosciuti come estranei o dannosi dal sistema immunitario. In condizioni normali, il sistema immunitario è in grado di distinguere tra le proprie cellule e proteine (autoantigeni) e quelle estranee (antigeni). Tuttavia, in alcune malattie autoimmuni, il sistema immunitario perde questa capacità di discriminazione e attacca i propri tessuti e organi, riconoscendo gli autoantigeni come minacce. Questa risposta immunitaria anomala può causare infiammazione, danno tissutale e una varietà di sintomi clinici a seconda dell'organo o del tessuto interessato. Esempi di malattie autoimmuni includono il lupus eritematoso sistemico, la artrite reumatoide e la diabete di tipo 1.
La desossiribonucleasi I, nota anche come DNase I, è un enzima che catalizza la degradazione delle molecole di DNA (deossiribonucleico acid) mono o double-stranded. L'enzima taglia le molecole di DNA in frammenti di circa 200-300 paia di basi, preferibilmente dove ci sono singoli filamenti con estremità 3'-OH e 5'-fosfato.
La DNase I è prodotta principalmente dalle cellule del pancreas esocrino e viene secreta nel duodeno, dove svolge un ruolo importante nella digestione dei residui di DNA presenti negli alimenti. L'enzima è anche presente in molti tessuti e organi del corpo umano, come il fegato, i reni, la milza e il cervello, dove svolge funzioni diverse, tra cui il mantenimento dell'equilibrio cellulare e la regolazione della risposta immunitaria.
La DNase I è stata anche studiata come potenziale trattamento per malattie infiammatorie croniche, come la fibrosi polmonare, poiché sembra essere in grado di ridurre l'infiammazione e la formazione di tessuto cicatriziale. Tuttavia, sono necessari ulteriori studi per confermare questi effetti e determinare la sicurezza e l'efficacia dell'uso clinico della DNase I come farmaco.
Le proteine da shock termico Hsp70, noto anche come proteine da stress riscaldante o HSP70, sono una classe di proteine chaperon che giocano un ruolo cruciale nella proteostasi assistendo alla piegatura e all'assemblaggio delle proteine. Sono espresse in modo ubiquitario in quasi tutti gli organismi viventi e sono altamente conservate evolutivamente.
Le Hsp70 sono nominate in base al loro peso molecolare di circa 70 kDa. Queste proteine contengono un dominio N-terminale ATPasi e un dominio C-terminale substrato-binding che lavorano insieme per legarsi e rilasciare i substrati proteici in modo dipendente dall'ATP.
Le Hsp70 svolgono diverse funzioni cellulari, tra cui:
1. Assistenza alla piegatura e all'assemblaggio delle proteine: Le Hsp70 prevengono l'aggregazione delle proteine nascenti o denaturate e facilitano il loro ripiegamento corretto.
2. Protezione contro lo stress cellulare: Durante lo stress cellulare, come l'esposizione a temperature elevate o tossiche, le Hsp70 prevengono l'aggregazione delle proteine danneggiate e promuovono la loro riparazione o degradazione.
3. Regolazione dell'attività enzimatica: Le Hsp70 regolano l'attività di alcuni enzimi legandosi ai loro siti attivi e impedendo il legame con i substrati.
4. Rimozione delle proteine danneggiate: Le Hsp70 lavorano in collaborazione con altre proteine chaperon per identificare e rimuovere le proteine danneggiate o denaturate, prevenendo così la formazione di aggregati tossici.
5. Riparazione del DNA: Alcune Hsp70 sono state implicate nella riparazione del DNA, in particolare durante l'esposizione a radiazioni ionizzanti.
In sintesi, le proteine Hsp70 svolgono un ruolo cruciale nel mantenere la homeostasi cellulare e nell'adattamento alle varie forme di stress cellulare.
La Chloramphenicol O-acetyltransferase (OAT) è un enzima che catalizza la reazione di acetilazione del cloramfenicolo, un antibiotico a largo spettro. Questa acetilazione inattiva l'attività antibatterica del cloramfenicolo, conferendo resistenza all'antibiotico nelle batteri che esprimono questo enzima.
L'OAT è codificato da geni plasmidici o cromosomici e la sua presenza può essere utilizzata come marcatore per identificare ceppi batterici resistenti al cloramfenicolo. L'espressione di questo enzima è clinicamente significativa, poiché i pazienti infetti con batteri che esprimono l'OAT possono non rispondere alla terapia con cloramfenicolo.
La struttura e la funzione dell'OAT sono state ampiamente studiate come modello per comprendere il meccanismo di resistenza agli antibiotici mediato dagli enzimi. La sua sequenza aminoacidica, la struttura tridimensionale e le interazioni con il cloramfenicolo sono state caratterizzate in dettaglio, fornendo informazioni preziose sulla progettazione di strategie per superare la resistenza agli antibiotici.
La peptidasi idrolasi, nota anche come peptidasi o esopeptidasi, è un enzima che catalizza la rottura dei legami peptidici nelle proteine e nei peptidi per formare amminoacidi liberi o piccoli peptidi. Questo processo viene svolto attraverso una reazione di idrolisi, in cui l'enzima facilita l'aggiunta di una molecola d'acqua al legame peptidico per scindere le due catene aminoacidiche adiacenti.
Le peptidasi idrolasi possono essere classificate in base alla specificità del sito di taglio:
1. Endopeptidasi (o endopeptidasi): questi enzimi scindono i legami peptidici all'interno della catena polipeptidica, producendo più frammenti di peptidi.
2. Exopeptidasi: questi enzimi tagliano i legami peptidici vicino ai terminali della catena polipeptidica, rilasciando singoli amminoacidi o dipeptidi. Le exopeptidasi possono essere ulteriormente suddivise in due sottoclassi:
* Amminopeptidasi: tagliano il legame peptidico vicino al terminale N-terminale della catena polipeptidica, rilasciando un amminoacido libero o un dipeptide.
* Carbossipeptidasi: tagliano il legame peptidico vicino al terminale C-terminale della catena polipeptidica, rilasciando un amminoacido libero o un dipeptide.
Le peptidasi idrolasi svolgono un ruolo cruciale in numerosi processi biologici, come la digestione, l'eliminazione delle proteine danneggiate e il riutilizzo degli amminoacidi riciclati.
L'immunoelettronmicroscopia (IEM) è una tecnica di microscopia elettronica che combina l'immunoistochimica con la microscopia elettronica per visualizzare e localizzare specifiche proteine o antigeni all'interno delle cellule o dei tessuti. Questa tecnica utilizza anticorpi marcati con etichette di elettroni, come oro colloidale o enzimi che producono depositi di elettroni, per legare selettivamente l'antigene target. L'IEM fornisce immagini ad alta risoluzione delle strutture cellulari e dell'ubicazione degli antigeni, con una risoluzione spaziale fino a pochi nanometri. Ci sono due approcci principali nell'uso dell'immunoelettronmicroscopia: l'immunooro colloidale marking (ICM) e l'immunoperossidasi marking (IPM). L'IEM è ampiamente utilizzata in ricerca biomedica e diagnostica per studiare la struttura e la funzione delle cellule, nonché per indagare su varie malattie, tra cui le malattie infettive, le neoplasie e le malattie neurodegenerative.
La protein chinasi AMP ciclico-dipendente, nota anche come PKA o protein kinase A, è un enzima intracellulare che partecipa alla trasduzione del segnale e regola una varietà di processi cellulari, tra cui il metabolismo energetico, la crescita cellulare, l'apoptosi e la differenziazione.
La PKA è attivata dal legame con il secondo messaggero AMP ciclico (cAMP), che si forma quando l'adenilato ciclasi è stimolata da ormoni o neurotrasmettitori come adrenalina, glucagone e peptide intestinale vasoattivo. Quando il cAMP si lega alla subunità di regolazione della PKA, questa dissocia dalla subunità catalitica, che è quindi in grado di fosforilare e attivare specifiche proteine bersaglio all'interno della cellula.
La PKA svolge un ruolo importante nella risposta cellulare a diversi stimoli fisiologici e patologici, come lo stress ossidativo, l'infiammazione e il cancro. Pertanto, la sua regolazione è strettamente controllata da meccanismi di feedback negativi che coinvolgono la degradazione dell'cAMP e l'inibizione della formazione di adenilato ciclasi.
In sintesi, la protein chinasi AMP ciclico-dipendente è un enzima chiave nella trasduzione del segnale cellulare che risponde alla concentrazione di cAMP e regola una serie di processi cellulari essenziali per il mantenimento dell'omeostasi.
Support Vector Machines (SVM) è un algoritmo di apprendimento automatico utilizzato principalmente per la classificazione e la regressione. SVM è un tipo di metodo basato sui margini che cerca di trovare il classificatore che produce il più ampio margine di separazione tra le due classi nel caso di una classificazione binaria.
In termini medici, SVM può essere applicato a problemi di diagnosi o predizione di malattie. Ad esempio, in un problema di classificazione binaria dove l'obiettivo è distinguere tra pazienti sani e malati sulla base di dati clinici, SVM può essere addestrato per trovare il miglior iperpiano che separa i due gruppi con il più ampio margine possibile. I punti più vicini ai bordi dell'iperpiano sono chiamati support vector, da cui prende il nome l'algoritmo.
SVM è particolarmente utile quando si lavora con dati ad alta dimensionalità e/o dati non linearmente separabili. In questi casi, SVM può utilizzare la cosiddetta "kernel trick", che mappa implicitamente i dati in uno spazio di dimensioni più elevate dove possono essere linearmente separabili.
In sintesi, Support Vector Machines è un algoritmo di apprendimento automatico utilizzato per la classificazione e la regressione che cerca di trovare l'iperpiano o il confine decisionale più ampio possibile tra due classi, anche in presenza di dati non linearmente separabili.
Le proteine degli Archea, noti anche come archeoproteine, sono proteine prodotte ed espresse dalle cellule di Archaea, un dominio della vita che include organismi unicellulari che vivono in ambienti estremi come quelli ad alta salinità, acidi o alcalini, termofili e pressioni elevate.
Le archeoproteine sono costituite da amminoacidi e hanno una struttura tridimensionale simile a quella delle proteine degli altri due domini della vita, Bacteria ed Eukarya. Tuttavia, presentano alcune differenze uniche nella loro composizione di amminoacidi e sequenze di aminoacidi, nonché nella struttura e funzione di alcuni dei loro domini proteici.
Le archeoproteine sono importanti per la sopravvivenza degli Archea in ambienti estremi e svolgono una varietà di funzioni vitali, come catalizzare reazioni enzimatiche, mantenere la struttura cellulare, trasportare molecole attraverso la membrana cellulare e rispondere a stimoli ambientali.
Le archeoproteine sono anche oggetto di studio per le loro possibili applicazioni in biotecnologie e bioingegneria, data la loro resistenza alle condizioni estreme e la loro capacità di catalizzare reazioni chimiche uniche.
Le proteine del pesce zebra si riferiscono specificamente alle proteine identificate e studiate nel pesce zebrafish (Danio rerio), un organismo modello comunemente utilizzato in biologia dello sviluppo, genetica e ricerca biomedica. Il pesce zebra è noto per la sua facilità di riproduzione, lo sviluppo trasparente delle uova e l'elevata omologia genetica con gli esseri umani, il che lo rende un sistema di studio ideale per comprendere i meccanismi molecolari e cellulari alla base di vari processi fisiologici e patologici.
Le proteine del pesce zebra possono essere classificate in diverse categorie funzionali, come proteine strutturali, enzimi, proteine di segnalazione, proteine di trasporto e così via. Un esempio ben noto di proteina del pesce zebra è la GFP (Green Fluorescent Protein), originariamente isolata dalla medusa Aequorea victoria, che è stata ampiamente utilizzata come marcatore fluorescente nelle ricerche biologiche. Oltre a questo, molte proteine del pesce zebra sono state identificate e caratterizzate per svolgere un ruolo cruciale nello sviluppo embrionale, nella differenziazione cellulare, nella morfogenesi dei tessuti, nella riparazione dei danni al DNA e nell'insorgenza di malattie.
In sintesi, le proteine del pesce zebra sono un vasto insieme di molecole proteiche presenti nel pesce zebrafish che svolgono una varietà di funzioni essenziali per lo sviluppo, la crescita e la homeostasi dell'organismo. Lo studio di queste proteine ha contribuito in modo significativo alla nostra comprensione dei processi biologici fondamentali e allo sviluppo di terapie innovative per una serie di malattie umane.
"Abstracting and Indexing" è un termine utilizzato nella medicina e in altre discipline accademiche per descrivere l'attività di selezionare, riassumere e organizzare in modo sistematico le informazioni contenute nelle pubblicazioni scientifiche.
L'abstracting consiste nel creare un riassunto conciso di un articolo o di uno studio, che ne metta in evidenza i punti chiave, come l'obiettivo della ricerca, il metodo utilizzato, i risultati ottenuti e le conclusioni raggiunte. Questo processo è utile per fornire una panoramica rapida ed efficace del contenuto dell'articolo, permettendo ai lettori di decidere se vale la pena leggerlo interamente o no.
L'indexing, invece, consiste nell'assegnare a ciascun articolo una serie di parole chiave o termini di ricerca standardizzati, che ne descrivano il contenuto e ne facilitino la ricerca. Questo processo è utile per creare indici tematici o bibliografici, che permettano agli utenti di trovare rapidamente le pubblicazioni relative a un determinato argomento o area di interesse.
L'abstracting e l'indexing sono attività fondamentali per la disseminazione delle conoscenze scientifiche, in quanto permettono di organizzare e rendere accessibili le informazioni contenute nelle pubblicazioni scientifiche. Esistono numerose banche dati specializzate che si occupano di abstracting e indexing, come PubMed, Medline, Embase, PsycINFO e molte altre. Queste banche dati sono utilizzate da ricercatori, medici, studenti e altri professionisti per tenersi aggiornati sulle ultime ricerche e sviluppi nel loro campo di interesse.
In medicina e biologia, un liposoma è una vescicola sferica costituita da uno o più strati di fosfolipidi che racchiudono un compartimento acquoso. I liposomi sono simili nella loro struttura di base ai normali involucri membranoscellulari, poiché sono formati dagli stessi fosfolipidi e colesterolo che costituiscono le membrane cellulari.
A causa della loro composizione lipidica, i liposomi hanno la capacità di legare sia sostanze idrofile che idrofobe. Quando dispersi in un ambiente acquoso, i fosfolipidi si auto-organizzano in doppi strati con le teste polari rivolte verso l'esterno e le code idrofobiche all'interno, formando una membrana bilayer. Questa configurazione bilayer può quindi avvolgersi su se stessa per creare una vescicola chiusa contenente uno spazio acquoso interno.
I liposomi sono ampiamente utilizzati in ricerca e applicazioni biomediche, specialmente nella terapia farmacologica. A causa della loro struttura simile alla membrana cellulare, i liposomi possono fondersi con le cellule bersaglio e rilasciare il loro contenuto all'interno della cellula, aumentando l'efficacia dei farmaci e riducendo al minimo gli effetti collaterali indesiderati. Inoltre, i liposomi possono essere utilizzati per encapsulate vari tipi di molecole, come farmaci, geni, proteine o altri biomarcatori, fornendo un metodo efficiente per il trasporto e la consegna di queste sostanze a specifici siti all'interno dell'organismo.
Luteoviridae è una famiglia di virus a singolo filamento di RNA positivo che infettano principalmente piante. Questi virus sono noti per causare diverse malattie delle colture, tra cui la più famosa è la "gialla avvizzita della barbabietola da zucchero". I virioni dei Luteoviridae sono privi di involucro, hanno forma sferica e misurano circa 25-30 nanometri di diametro.
Il genoma di questi virus è costituito da un singolo filamento di RNA monocatena di circa 5,6-6 kilobasi che codifica quattro proteine strutturali e diverse proteine non strutturali. Le proteine strutturali includono la capside (CP), la proteina di movimento (MP) e due proteine della membrana (M1 e M2). Le proteine non strutturali sono coinvolte nella replicazione, trascrizione e patogenicità del virus.
I Luteoviridae sono trasmessi principalmente dalle specie di afidi in un modo circolare persistente non propagativo, il che significa che l'afide deve nutrirsi della linfa delle piante infette per acquisire il virus e può trasmetterlo ad altre piante solo durante la nutrizione. Questi virus non si moltiplicano negli afidi ospiti e possono persistere nell'organismo dell'insetto per tutta la vita.
La famiglia Luteoviridae è stata divisa in due generi: Luteovirus e Polerovirus, che differiscono principalmente nella composizione del genoma e nelle proprietà biologiche. I membri di entrambe le specie sono importanti patogeni delle piante e causano gravi perdite economiche in diverse colture.
La guanosina difosfato (GDP) è un nucleotide essenziale presente nelle cellule che svolge un ruolo cruciale nella produzione di energia e nel trasporto di molecole all'interno della cellula. È costituita da una molecola di zucchero chiamata ribosio, due gruppi fosfato e la base azotata guanina.
La GDP è un intermedio importante nella produzione di adenosina trifosfato (ATP), la principale fonte di energia cellulare. Durante questo processo, la GDP viene convertita in guanosina trifosfato (GTP) attraverso l'aggiunta di un gruppo fosfato, una reazione catalizzata dall'enzima nucleoside difosfochinasi. Il GTP può quindi essere utilizzato per produrre ATP attraverso la fosforilazione ossidativa.
La GDP è anche un importante regolatore della segnalazione cellulare, in particolare nella via del segnale dei Ras. I Ras sono proteine che trasmettono segnali all'interno delle cellule e la loro attività è regolata dalla conversione tra GDP e GTP. Quando i Ras sono legati a GTP, sono attivi e possono trasmittere il segnale, mentre quando sono legati a GDP, sono inattivi e non possono trasmettere il segnale.
In sintesi, la guanosina difosfato è un nucleotide essenziale che svolge un ruolo cruciale nella produzione di energia cellulare e nella regolazione della segnalazione cellulare.
I danni al DNA si riferiscono a qualsiasi alterazione della struttura o sequenza del DNA che può verificarsi naturalmente o come risultato dell'esposizione a fattori ambientali avversi. Questi danni possono includere lesioni chimiche, mutazioni genetiche, rotture dei filamenti di DNA, modifiche epigenetiche e altri cambiamenti che possono influenzare la stabilità e la funzionalità del DNA.
I danni al DNA possono verificarsi a causa di fattori endogeni, come errori durante la replicazione o la riparazione del DNA, o a causa di fattori esogeni, come radiazioni ionizzanti, sostanze chimiche cancerogene e agenti infettivi.
I danni al DNA possono avere conseguenze negative sulla salute, poiché possono portare a malfunzionamenti cellulari, mutazioni genetiche, invecchiamento precoce, malattie neurodegenerative, cancro e altre patologie. Il corpo ha meccanismi di riparazione del DNA che lavorano continuamente per rilevare e correggere i danni al DNA, ma quando questi meccanismi sono compromessi o superati, i danni al DNA possono accumularsi e portare a effetti negativi sulla salute.
DEAD-box RNA Helicases sono una famiglia conservata di enzimi che utilizzano l'energia dell'idrolisi dell'ATP per svolgere e riorganizzare strutture a doppia elica di RNA, o complessi RNA-proteina. Questi enzimi sono chiamati "DEAD-box" a causa della presenza di un motivo conservato di sequenza aminoacidica nella loro regione catalitica, che contiene le residui Asp-Glu-Ala-Asp (DEAD).
Le DEAD-box RNA Helicases svolgono un ruolo cruciale in una varietà di processi cellulari che implicano l'RNA, come l'inizio e il terminazione della traduzione, la maturazione dell'rRNA, la splicing dell'RNA, il trasporto nucleare dell'RNA e la degradazione dell'RNA. La loro attività elicasica aiuta a separare le strutture a doppia elica di RNA o a dissociare i complessi RNA-proteina, facilitando così processi come l'assemblaggio dei ribosomi e il ripiegamento dell'RNA.
Le DEAD-box RNA Helicases sono anche spesso associate con malattie umane, compresi i tumori e le malattie neurologiche, sebbene il meccanismo esatto di queste associazioni non sia ancora del tutto chiaro.
L'ubiquitina tiolesterasi, nota anche come deubiquitinasi (DUB), è un enzima che svolge un ruolo cruciale nel processo di deubiquitinazione. Questo processo comporta la rimozione dei gruppi ubiquitina dalle proteine target, che sono state precedentemente marcate per la degradazione attraverso la procedura di ubiquitinazione.
L'ubiquitina tiolesterasi catalizza la reazione che rompe il legame tiolesterico tra l'ubiquitina e la cisteina dell'enzima responsabile dell'aggiunta degli ubiquitina (E2) o dell'enzima ubiquitina ligasi (E3). Di conseguenza, l'ubiquitina viene rilasciata dalla proteina bersaglio e può essere riutilizzata per ulteriori cicli di ubiquitinazione.
Le ubiquitina tiolesterasi sono classificate in quattro famiglie enzimatiche: ubiquitina specifica peptidasi (USP), ubiquitina C-terminale idrolasi (UCH), ovaria tumore proteasi (OTU) e Machado-Joseph dominio proteasi (MJD).
La deubiquitinazione svolge un ruolo importante nella regolazione di una varietà di processi cellulari, tra cui la risposta al danno dell'DNA, il ciclo cellulare, l'apoptosi e la risposta infiammatoria. Pertanto, le disfunzioni nelle ubiquitina tiolesterasi possono portare a una serie di patologie, tra cui vari tipi di cancro, malattie neurodegenerative e disturbi immunitari.
L'acetilazione è un processo metabolico che si verifica all'interno delle cellule. Precisamente, è una reazione enzimatica che comporta l'aggiunta di un gruppo acetile (un gruppo funzionale composto da due atomi di carbonio e tre di idrogeno, con una carica formale positiva sull'atomo di carbonio) a una proteina o a un altro tipo di molecola biologica.
L'enzima chiave che catalizza questo processo è chiamato N-acetiltransferasi. L'acetilazione svolge un ruolo importante nella regolazione dell'attività delle proteine e può influenzare la loro stabilità, localizzazione all'interno della cellula e interazioni con altre molecole.
Un esempio ben noto di acetilazione è quello che riguarda l'istone, una proteina che fa parte della struttura del DNA. L'acetilazione degli istoni può modificare la struttura della cromatina, rendendo il DNA più accessibile alla trascrizione e influenzando l'espressione genica.
L'acetilazione è anche un meccanismo di detossificazione importante per il fegato. Alcuni farmaci e sostanze chimiche tossiche vengono acetilati e quindi resi più solubili in acqua, facilitandone l'eliminazione dall'organismo.
 LORENZI, Pamela
LORENZI, Pamela Interfaccia utente computer. Ricerca medica. Definizioni
Interfaccia utente computer. Ricerca medica. Definizioni

![Recombinant Anti-p53 antibody [E26] KO Tested (ab32389) | Abcam](https://www.abcam.com/ps/products/32/ab32389/Images/ab32389-389819-antip53antibodyimmunocytochemistryimmunofluorescencehap1human.jpg)