Oligonucleotidi
Oligonucleotidi Antisenso
Sequenza Base
Oligodeossiribonucleotidi
Oligoribonucleotidi
Dati Di Sequenza Molecolare
Phosphorothioate Oligonucleotides
Oligodeossiribonucleotidi Antisenso
Dna
Conformazione Dell'Acido Nucleico
Sonde Di Oligonucleotide
Denaturazione Dell'Acido Nucleico
Oligoribonucleotidi Antisenso
Ibridazione Dell'Acido Nucleico
Rna Messaggero
Ribonuclease H
Composti Organofosforici
Rna
Dna A Singola Elica
Reazione Di Polimerizzazione A Catena
Acidi Nucleici
Clonaggio Molecolare
Sequenza Aminoacidica
Dna Antisenso
Ribonucleasi T1
Guanina
Siti Di Legame
Indicatori E Reagenti
Proteine Leganti Dna
Appaiamento Delle Basi
Agenti Intercalanti
Trascrizione Genetica
Dna Primers
Trasfezione
Psoraleni
Sonde Di Dna
Acidi Fosforici
Escherichia Coli
Coloranti Fluorescenti
Peptide Nucleic Acids
Polideossiribonucleotidi
Promoter Regions, Genetic
Centratura Imperfetta Di Basi Appaiate
Cellule Tumorali In Coltura
Eterodoppi Di Acidi Nucleici
Not Translated
Cellule Coltivate
Struttura Molecolare
Temperatura
Morpholinos
Poliribonucleotidi
Specificità Del Substrato
Termodinamica
Poli T
Plasmidi
Gene Targeting
Timina
Regolazione Dell'Espressione Genica
Cellule Hela
Fattori Di Trascrizione
Ficusina
Espressione Genica
Pesce Zebra
G-Quadruplexes
Relazione Struttura-Attività
Mutazione
Divisione Cellulare
Analisi Di Sequenze Attraverso Un Pannello Di Oligonucleotidi
Guanosina
Rna Antisenso
Cromatografia Liquida Ad Alta Pressione
Fosfodiesterasi I
Legame Di Proteine
Reagenti Reticolanti
Omologia Sequenziale Degli Acidi Nucleici
Polinucleotidi
Nucleosidi
Dicroismo Circolare
Stampi Genetici
Purine
Vetro
Spettroscopia Di Risonanza Magnetica
Esonucleasi
Analisi Di Sequenze Di Dna
Dna Complementare
Elettroforesi Su Gel Di Poliacrilamide
Repressione Genetica
Proteine Del Pesce Zebra
Xantopterina
Genoteca
Legame Competitivo
Spettrofotometria Nell'Ultravioletto
Deossiuridina
Rna Splicing
Desossiribonucleasi I
Dna Footprinting
Sequenza Consenso
Vettori Farmacologici
Sequenze Ripetitive Degli Acidi Nucleici
Uridina
Genetic Therapy
Raggi Ultravioletti
Not Translated
Biotina
Biosintesi Proteica
Composti Organotiofosforici
Sistemi Di Somministrazione Farmacologica
Modelli Molecolari
Composti Di Trifenilmetile
Apoptosi
Riparazione Del Dna
Reazione Di Polimerizzazione A Catena Dopo Trascrizione Inversa
Tecnica Ad Aptameri Selex
Desossiribonucleasi
Proteine Nucleari
Radioisotopi Di Fosforo
Nucleo Cellulare
Northern Blotting
Temperatura Di Transizione
Piccoli Rna Di Interferenza
Western Blotting
Esoni
Liposomi
Isole Cpg
Mappa Di Restrizione
Amidi
Targeted Gene Repair
Luciferasi
Rna Catalitico
Acridine
Alchilazione
Idrolasi Del Diestere Fosforico
Geni
Deossiadenosine
Fattori Temporali
Progettazione Della Struttura Molecolare Di Un Farmaco
Addotti Del Dna
Cationi
Deossiribonucleotidi
Fluorosceina-5-Isotiocianato
Oro
Nucleotidi
Embrione Non Mammifero
Metilazione
Omologia Di Sequenza Di Amino Acido
Soluzioni
Rna Ribosomiale
Concentrazione Di Idrogenionica
Allineamento Di Sequenze
Fosfati Di Dinucleoside
Elementi Antisenso (Genetica)
Fluoresceina
Relazione Farmacologica Dose-Risposta
Poli G
Streptavidina
Dna Polimerasi Dna Dipendenti
Danni Al Dna
Electrophoretic Mobility Shift Assay
Rna Batterico
Amine
Trioxalene
Codone
Polinucleotide 5'-Idrossile-Chinasi
Legame Idrogeno
Tecniche Genetiche
Regolazione Dell'Espressione Genica Nello Sviluppo
Poli A
Citidina
Dna Ligasi
Trasduzione Del Segnale
Inosina
Rna Ligasi (Atp)
Fotochimica
Endoribonucleasi
Desossiribonucleasi Di Tipo Ii Sito-Specifica
Vettori Genetici
Microiniezioni
Gli oligonucleotidi sono brevi catene di nucleotidi, che sono i componenti costitutivi degli acidi nucleici come DNA e RNA. Solitamente, gli oligonucleotidi contengono da 2 a 20 unità di nucleotidi, ciascuna delle quali è composta da un gruppo fosfato, una base azotata (adenina, timina, guanina, citosina o uracile) e uno zucchero deossiribosio o ribosio.
Gli oligonucleotidi sintetici sono ampiamente utilizzati in biologia molecolare, genetica e medicina come sonde per la rilevazione di specifiche sequenze di DNA o RNA, nella terapia genica, nell'ingegneria genetica e nella ricerca farmacologica. Possono anche essere utilizzati come inibitori enzimatici o farmaci antisenso per il trattamento di varie malattie, compresi i tumori e le infezioni virali.
Gli oligonucleotidi possono presentare diverse modifiche chimiche per migliorarne la stabilità, la specificità e l'affinità di legame con il bersaglio desiderato. Tra queste modifiche vi sono la sostituzione di zuccheri o basi azotate naturali con analoghi sintetici, la introduzione di gruppi chimici protettivi o reattivi, e l'estensione della catena con linker o gruppi terminali.
In sintesi, gli oligonucleotidi sono brevi sequenze di nucleotidi utilizzate in diversi campi della biologia molecolare e della medicina come strumenti diagnostici e terapeutici, grazie alle loro proprietà di legame specifico con le sequenze target di DNA o RNA.
Gli oligonucleotidi antisenso sono brevi sequenze di DNA o RNA sintetici che sono complementari a specifiche sequenze di RNA messaggero (mRNA) presenti nelle cellule. Questi oligonucleotidi possono legarsi specificamente al loro mRNA target attraverso l'interazione della base azotata, formando una struttura a doppia elica che impedisce la traduzione del mRNA in proteine.
Gli oligonucleotidi antisenso possono essere utilizzati come farmaci per il trattamento di varie malattie genetiche e tumorali, poiché possono bloccare l'espressione di geni specifici che contribuiscono alla patologia. Una volta all'interno della cellula, gli oligonucleotidi antisenso vengono processati da enzimi specifici che li rendono più stabili e capaci di legarsi al loro bersaglio con maggiore efficacia.
Tuttavia, l'uso degli oligonucleotidi antisenso come farmaci è ancora oggetto di ricerca attiva, poiché ci sono diverse sfide da affrontare, come la difficoltà nella consegna dei farmaci alle cellule bersaglio e la possibilità di effetti off-target che possono causare tossicità.
In genetica, una "sequenza base" si riferisce all'ordine specifico delle quattro basi azotate che compongono il DNA: adenina (A), citosina (C), guanina (G) e timina (T). Queste basi si accoppiano in modo specifico, con l'adenina che si accoppia solo con la timina e la citosina che si accoppia solo con la guanina. La sequenza di queste basi contiene l'informazione genetica necessaria per codificare le istruzioni per la sintesi delle proteine.
Una "sequenza base" può riferirsi a un breve segmento del DNA, come una coppia di basi (come "AT"), o a un lungo tratto di DNA che può contenere migliaia o milioni di basi. L'analisi della sequenza del DNA è un importante campo di ricerca in genetica e biologia molecolare, poiché la comprensione della sequenza base può fornire informazioni cruciali sulla funzione genica, sull'evoluzione e sulla malattia.
Gli oligodeossiribonucleotidi (ODN) sono brevi segmenti di DNA sintetici che contengono generalmente da 15 a 30 basi deossiribosidiche. Gli ODN possono essere modificati chimicamente per migliorare la loro stabilità, specificità di legame e attività biologica.
Gli oligodeossiribonucleotidi sono spesso utilizzati in ricerca scientifica come strumenti per regolare l'espressione genica, attraverso meccanismi come il blocco della traduzione o l'attivazione/repressione della trascrizione. Possono anche essere utilizzati come farmaci antisenso o come immunostimolanti, in particolare per quanto riguarda la terapia del cancro e delle malattie infettive.
Gli ODN possono essere modificati con gruppi chimici speciali, come le catene laterali di zucchero modificate o i gruppi terminale di fosfato modificati, per migliorare la loro affinità di legame con il DNA bersaglio o per proteggerle dalla degradazione enzimatica. Alcuni ODN possono anche essere dotati di gruppi chimici che conferiscono proprietà fluorescenti, magnetiche o radioattive, rendendoli utili come marcatori molecolari in esperimenti di biologia cellulare e molecolare.
In sintesi, gli oligodeossiribonucleotidi sono brevi segmenti di DNA sintetici che possono essere utilizzati per regolare l'espressione genica, come farmaci antisenso o immunostimolanti, e come strumenti di ricerca in biologia molecolare.
Gli oligoribonucleotidi (ORM) sono brevi catene di ribonucleotidi, legate insieme da legami fosfodiesterici. Di solito contengono meno di 30-40 unità di ribonucleotidi e possono essere mono-, bi- o polifunzionali, a seconda del numero di gruppi chimicamente reattivi presenti alla fine della catena.
Gli oligoribonucleotidi svolgono un ruolo importante in diversi processi cellulari, come la regolazione dell'espressione genica, la traduzione proteica e la difesa contro l'invasione di acidi nucleici estranei. Sono anche ampiamente utilizzati nella ricerca scientifica come strumenti per studiare l'interazione tra RNA e proteine, nonché come farmaci antisenso e terapie a RNA interferente (RNAi).
Gli oligoribonucleotidi possono essere sintetizzati chimicamente o enzimaticamente, con diversi metodi disponibili per la loro produzione. Tra i metodi più comuni vi sono la sintesi solid-phase e la sintesi enzimatica utilizzando polimerasi RNA. La purezza e l'omogeneità degli ORM sintetici dipendono dalla lunghezza della catena, dal numero di basi modificate e dalla scala di sintesi. Pertanto, è importante caratterizzare e purificare gli ORM prima del loro utilizzo in applicazioni biologiche o terapeutiche.
I Dati di Sequenza Molecolare (DSM) si riferiscono a informazioni strutturali e funzionali dettagliate su molecole biologiche, come DNA, RNA o proteine. Questi dati vengono generati attraverso tecnologie di sequenziamento ad alta throughput e analisi bioinformatiche.
Nel contesto della genomica, i DSM possono includere informazioni sulla variazione genetica, come singole nucleotide polimorfismi (SNP), inserzioni/delezioni (indels) o varianti strutturali del DNA. Questi dati possono essere utilizzati per studi di associazione genetica, identificazione di geni associati a malattie e sviluppo di terapie personalizzate.
Nel contesto della proteomica, i DSM possono includere informazioni sulla sequenza aminoacidica delle proteine, la loro struttura tridimensionale, le interazioni con altre molecole e le modifiche post-traduzionali. Questi dati possono essere utilizzati per studi funzionali delle proteine, sviluppo di farmaci e diagnosi di malattie.
In sintesi, i Dati di Sequenza Molecolare forniscono informazioni dettagliate sulle molecole biologiche che possono essere utilizzate per comprendere meglio la loro struttura, funzione e varianti associate a malattie, con implicazioni per la ricerca biomedica e la medicina di precisione.
I Phosphorothioate Oligonucleotides sono un particolare tipo di oligonucleotidi sintetici in cui uno o più gruppi sulfuro (-SH) sostituiscono i normalmente presenti gruppi fosfato (-PO4) nella catena di zucchero-fosfato dell'acido nucleico. Questa modifica conferisce all'oligonucleotide una maggiore resistenza alla degradazione enzimatica e aumenta la sua stabilità, rendendolo quindi un candidato promettente per l'uso in terapie geniche e come farmaci antisenso.
I Phosphorothioate Oligonucleotides possono legarsi a proteine della famiglia delle endonucleasi, che normalmente tagliano le molecole di acido nucleico, impedendo loro di svolgere questa funzione e stabilizzizzando così l'oligonucleotide. Inoltre, i Phosphorothioate Oligonucleotides possono legarsi a recettori cellulari della famiglia dei Toll-like (TLR), che svolgono un ruolo importante nel sistema immunitario e nell'infiammazione, attivando così una risposta immunitaria.
A causa di queste proprietà, i Phosphorothioate Oligonucleotides sono stati studiati come potenziali trattamenti per varie malattie, tra cui infezioni virali, tumori e disturbi neurodegenerativi. Tuttavia, l'uso di queste molecole come farmaci è ancora sperimentale e richiede ulteriori ricerche per valutarne la sicurezza ed efficacia.
Gli oligodeossiribonucleotidi antisenso (AS-ODNs) sono brevi sequenze sintetiche di DNA che vengono progettate per essere complementari a specifiche sequenze di RNA messaggero (mRNA) target. Una volta che l'AS-ODN si lega al suo mRNA bersaglio, forma un complesso chiamato duplex RNA-DNA che impedisce la traduzione del mRNA in proteine. Questo processo è noto come "interferenza dell'RNA" e può essere utilizzato per ridurre l'espressione genica di specifici geni target.
Gli AS-ODNs sono stati ampiamente studiati come potenziali agenti terapeutici per il trattamento di una varietà di malattie, tra cui tumori, virus e disturbi genetici. Tuttavia, l'uso clinico degli AS-ODNs è ancora in fase di sviluppo a causa di alcune sfide tecniche, come la stabilità dei farmaci e la difficoltà di consegna alle cellule bersaglio.
È importante notare che gli AS-ODNs possono anche avere effetti off-target, il che significa che possono legarsi e inibire l'espressione genica di mRNA non intenzionali. Pertanto, è fondamentale progettare e utilizzare AS-ODNs con grande attenzione per garantire la specificità e l'efficacia del trattamento.
L'acido desossiribonucleico (DNA) è una molecola presente nel nucleo delle cellule che contiene le istruzioni genetiche utilizzate nella crescita, nello sviluppo e nella riproduzione di organismi viventi. Il DNA è fatto di due lunghi filamenti avvolti insieme in una forma a doppia elica. Ogni filamento è composto da unità chiamate nucleotidi, che sono costituite da un gruppo fosfato, uno zucchero deossiribosio e una delle quattro basi azotate: adenina (A), guanina (G), citosina (C) o timina (T). La sequenza di queste basi forma il codice genetico che determina le caratteristiche ereditarie di un individuo.
Il DNA è responsabile per la trasmissione dei tratti genetici da una generazione all'altra e fornisce le istruzioni per la sintesi delle proteine, che sono essenziali per lo sviluppo e il funzionamento di tutti gli organismi viventi. Le mutazioni nel DNA possono portare a malattie genetiche o aumentare il rischio di sviluppare alcuni tipi di cancro.
La conformazione dell'acido nucleico si riferisce alla struttura tridimensionale che assume l'acido nucleico, sia DNA che RNA, quando interagisce con se stesso o con altre molecole. La conformazione più comune del DNA è la doppia elica, mentre il RNA può avere diverse conformazioni, come la singola elica o le strutture a forma di stella o a branchie, a seconda della sequenza delle basi e delle interazioni idrogeno.
La conformazione dell'acido nucleico può influenzare la sua funzione, ad esempio nella regolazione della trascrizione genica o nel ripiegamento delle proteine. La comprensione della conformazione dell'acido nucleico è quindi importante per comprendere il ruolo che svolge nell'espressione genica e nelle altre funzioni cellulari.
La determinazione della conformazione dell'acido nucleico può essere effettuata utilizzando diverse tecniche sperimentali, come la cristallografia a raggi X, la spettrometria di assorbimento UV-Visibile e la risonanza magnetica nucleare (NMR). Questi metodi forniscono informazioni sulla struttura atomica e sulle interazioni idrogeno che determinano la conformazione dell'acido nucleico.
Le sonde di oligonucleotidi sono brevi sequenze di DNA o RNA sintetiche che vengono utilizzate in vari metodi di biologia molecolare per identificare e rilevare specifiche sequenze di acido nucleico. Queste sonde sono composte da un numero relativamente piccolo di nucleotidi, di solito tra i 15 e i 30, sebbene possano contenere fino a circa 80 nucleotidi.
Le sonde di oligonucleotidi possono essere marcate con diversi tipi di etichette, come fluorofori, che consentono la loro rilevazione e quantificazione quando si legano alla sequenza target. Alcuni metodi comuni che utilizzano sonde di oligonucleotidi includono la reazione a catena della polimerasi (PCR) in tempo reale, l'ibridazione del DNA in situ e l'analisi dell'espressione genica su vasta scala, come i microarray.
Le sonde di oligonucleotidi sono progettate per essere altamente specifiche della sequenza target, il che significa che hanno una probabilità molto elevata di legarsi solo alla sequenza desiderata e non a sequenze simili, ma non identiche. Questa specificità è dovuta al fatto che le basi complementari si accoppiano con elevata affinità e stabilità, il che rende le sonde di oligonucleotidi uno strumento potente per rilevare e analizzare gli acidi nucleici in una varietà di contesti biologici.
I tionucleotidi sono composti organici che consistono in un gruppo tiolico (-SH) legato a un nucleotide. I nucleotidi sono molecole costituite da una base azotata, un pentoso (zucchero a cinque atomi di carbonio) e un gruppo fosfato.
I tionucleotidi sono importanti nella regolazione della funzione cellulare e dell'espressione genica. Ad esempio, i tionucleotidi come l'acido lipoico e la coenzima A (CoA) svolgono un ruolo cruciale nei processi metabolici, come l'ossidazione dei carboidrati, dei lipidi e degli aminoacidi.
Inoltre, i tionucleotidi possono anche agire come agenti antinfiammatori e antiossidanti, proteggendo le cellule dai danni ossidativi e regolando la risposta immunitaria. Tuttavia, un eccesso di tionucleotidi può anche essere dannoso per le cellule e contribuire allo sviluppo di malattie come il cancro e le malattie neurodegenerative.
In sintesi, i tionucleotidi sono composti organici importanti nella regolazione della funzione cellulare e dell'espressione genica, con ruoli cruciali nei processi metabolici e nella protezione delle cellule dai danni ossidativi.
La denaturazione dell'acido nucleico è un processo che consiste nel separare le due catene polinucleotidiche della doppia elica degli acidi nucleici (DNA o RNA) mediante la rottura delle legami idrogeno che le mantengono unite. Ciò avviene generalmente quando si esponono gli acidi nucleici a temperature elevate, a basi organiche come il cloruro di guanidinio o alla presenza di agenti chimici denaturanti come formaldeide e formammide.
Nel processo di denaturazione, le coppie di basi che compongono la doppia elica si separano, portando a un'alterazione della struttura secondaria dell'acido nucleico. Di conseguenza, l'acido nucleico denaturato non è più in grado di replicarsi o trascriversi correttamente, poiché le sequenze di basi che codificano per specifiche proteine o funzioni geniche vengono interrotte.
La denaturazione dell'acido nucleico è un fenomeno importante nella biologia molecolare e nella genomica, in quanto viene utilizzata come tecnica per studiare la struttura degli acidi nucleici, per identificare mutazioni geniche e per amplificare specifiche sequenze di DNA mediante reazione a catena della polimerasi (PCR). Inoltre, la denaturazione dell'acido nucleico è anche un fattore critico nella diagnosi e nel trattamento delle malattie genetiche e infettive.
Gli oligoribonucleotidi antisenso sono brevi molecole di RNA monocatenario che sono complementari a specifiche sequenze di mRNA (RNA messaggero) target. Questi oligoribonucleotidi vengono utilizzati per inibire la traduzione dell'mRNA in proteine, attraverso un meccanismo noto come RNA interference (RNAi). L'RNAi comporta la degradazione dell'mRNA target da parte di enzimi specifici, come la ribonucleasi Dicer e l'endonucleasi Argonaute, che sono componenti del complesso RISC (RNA-induced silencing complex).
Gli oligoribonucleotidi antisenso possono essere sintetizzati chimicamente o prodotti da tecnologie di biologia molecolare come la transcrizione in vitro. Possono anche essere modificati chimicamente per migliorarne la stabilità, la specificità e l'efficacia.
Gli oligoribonucleotidi antisenso hanno trovato applicazione in diversi campi della ricerca biomedica, come la regolazione dell'espressione genica, il trattamento di malattie genetiche e il controllo delle infezioni virali. Tuttavia, l'uso clinico degli oligoribonucleotidi antisenso è ancora limitato a causa di problemi legati alla loro stabilità, biodistribuzione e tossicità.
L'ibridazione dell'acido nucleico è un processo in cui due singole catene di acidi nucleici (solitamente DNA o RNA) si legano formando una doppia elica. Ciò accade quando le sequenze di basi azotate complementari delle due catene si accoppiano, con l'adenina che si lega alla timina e la citosina che si lega alla guanina.
L'ibridazione dell'acido nucleico è una tecnica fondamentale in biologia molecolare e genetica. Viene utilizzata per identificare e localizzare specifiche sequenze di DNA o RNA all'interno di un campione, come nella reazione a catena della polimerasi (PCR), nell'ibridazione fluorescente in situ (FISH) e nell'analisi dell'espressione genica.
L'ibridazione dell'acido nucleico può essere eseguita in condizioni controllate di temperatura e salinità, che influenzano la stabilità dell'ibrido formatosi. Queste condizioni possono essere utilizzate per regolare la specificità e la sensibilità della reazione di ibridazione, permettendo agli scienziati di rilevare anche piccole quantità di acidi nucleici target in un campione complesso.
L'mRNA (acido Ribonucleico Messaggero) è il tipo di RNA che porta le informazioni genetiche codificate nel DNA dai nuclei delle cellule alle regioni citoplasmatiche dove vengono sintetizzate proteine. Una volta trascritto dal DNA, l'mRNA lascia il nucleo e si lega a un ribosoma, un organello presente nel citoplasma cellulare dove ha luogo la sintesi proteica. I tripleti di basi dell'mRNA (codoni) vengono letti dal ribosoma e tradotti in amminoacidi specifici, che vengono poi uniti insieme per formare una catena polipeptidica, ossia una proteina. Pertanto, l'mRNA svolge un ruolo fondamentale nella trasmissione dell'informazione genetica e nella sintesi delle proteine nelle cellule.
La Ribonucleasi H (RNase H) è un enzima che catalizza la specifica scissione idrolitica del legame fosfodiesterico tra la ribosa e il deossiribosio nelle catene di RNA-DNA ibridate. Questo enzima svolge un ruolo importante nella replicazione, riparazione e regolazione dell'espressione genica, in particolare nel processo di eliminazione dell'RNA primers utilizzati durante la replicazione del DNA. RNase H è presente in molti organismi viventi, compresi i batteri, gli archaea e gli eucarioti, e ne esistono diverse forme con differenti specificità di substrato e meccanismi catalitici. L'attività di RNase H è essenziale per la stabilità del genoma e la corretta espressione dei geni.
Gli composti organofosforici sono composti chimici che contengono legami covalenti tra atomi di carbonio e fosforo. Questi composti sono ampiamente utilizzati in agricoltura come pesticidi, in particolare insetticidi, erbicidi e fungicidi. Alcuni esempi ben noti di composti organofosforici includono il malathion, il parathion e il glyphosate.
In medicina, i composti organofosforici sono anche noti per la loro tossicità per l'uomo e possono causare una varietà di effetti avversi sulla salute, tra cui la soppressione del sistema nervoso centrale, la paralisi muscolare, la difficoltà respiratoria e la morte in caso di esposizione acuta ad alte dosi. L'esposizione cronica a basse dosi può anche causare effetti avversi sulla salute, come danni al fegato e ai reni, alterazioni del sistema nervoso e cancro.
I composti organofosforici sono anche noti per la loro capacità di inibire l'acetilcolinesterasi, un enzima importante che svolge un ruolo chiave nella trasmissione degli impulsi nervosi nel corpo. Questa proprietà è alla base dell'uso di alcuni composti organofosforici come agenti nervini e armi chimiche.
In sintesi, i composti organofosforici sono una classe importante di composti chimici con ampie applicazioni in agricoltura e medicina, ma che possono anche presentare rischi per la salute umana se utilizzati o esposti in modo improprio.
L'RNA, o acido ribonucleico, è un tipo di nucleic acid presente nelle cellule di tutti gli organismi viventi e alcuni virus. Si tratta di una catena lunga di molecole chiamate nucleotidi, che sono a loro volta composte da zuccheri, fosfati e basi azotate.
L'RNA svolge un ruolo fondamentale nella sintesi delle proteine, trasportando l'informazione genetica codificata negli acidi nucleici (DNA) al ribosoma, dove viene utilizzata per la sintesi delle proteine. Esistono diversi tipi di RNA, tra cui RNA messaggero (mRNA), RNA di trasferimento (tRNA) e RNA ribosomiale (rRNA).
Il mRNA è l'intermediario che porta l'informazione genetica dal DNA al ribosoma, dove viene letto e tradotto in una sequenza di amminoacidi per formare una proteina. Il tRNA è responsabile del trasporto degli amminoacidi al sito di sintesi delle proteine sul ribosoma, mentre l'rRNA fa parte del ribosoma stesso e svolge un ruolo importante nella sintesi delle proteine.
L'RNA può anche avere funzioni regolatorie, come il miRNA (microRNA) che regola l'espressione genica a livello post-trascrizionale, e il siRNA (small interfering RNA) che svolge un ruolo nella difesa dell'organismo contro i virus e altri elementi genetici estranei.
In termini medici, "DNA a singola elica" si riferisce ad una struttura del DNA (acido desossiribonucleico) che consiste in due filamenti antiparalleli avvolti l'uno intorno all'altro a formare una doppia elica. Nel DNA a singola elica, questo tradizionale schema di doppia elica è assente e invece è presente un solo filamento di DNA.
Questa forma di DNA può verificarsi naturalmente in alcuni organismi, come i virus a DNA monocatenario, o può essere prodotta sinteticamente in laboratorio per scopi di ricerca scientifica e applicazioni biotecnologiche. Il DNA a singola elica è più flessibile e meno stabile della sua controparte a doppia elica, il che lo rende adatto per alcuni usi specifici in genetica e biologia molecolare.
La reazione di polimerizzazione a catena è un processo chimico in cui monomeri ripetuti, o unità molecolari semplici, si legane insieme per formare una lunga catena polimerica. Questo tipo di reazione è caratterizzato dalla formazione di un radicale libero, che innesca la reazione e causa la propagazione della catena.
Nel contesto medico, la polimerizzazione a catena può essere utilizzata per creare materiali biocompatibili come ad esempio idrogeli o polimeri naturali modificati chimicamente, che possono avere applicazioni in campo farmaceutico, come ad esempio nella liberazione controllata di farmaci, o in campo chirurgico, come ad esempio per la creazione di dispositivi medici impiantabili.
La reazione di polimerizzazione a catena può essere avviata da una varietà di fonti di radicali liberi, tra cui l'irradiazione con luce ultravioletta o raggi gamma, o l'aggiunta di un iniziatore chimico. Una volta iniziata la reazione, il radicale libero reagisce con un monomero per formare un radicale polimerico, che a sua volta può reagire con altri monomeri per continuare la crescita della catena.
La reazione di polimerizzazione a catena è un processo altamente controllabile e prevedibile, il che lo rende una tecnica utile per la creazione di materiali biomedici su misura con proprietà specifiche. Tuttavia, è importante notare che la reazione deve essere strettamente controllata per evitare la formazione di catene polimeriche troppo lunghe o ramificate, che possono avere proprietà indesiderate.
Gli acidi nucleici sono catene lunghe e complesse di molecole organiche presenti nel nucleo delle cellule. Essi sono costituiti da unità ripetitive chiamate nucleotidi, che contengono fosfati, zuccheri (solitamente deossiribosio o ribosio) e basi azotate (adenina, timina, guanina, citosina e uracile).
Esistono due tipi principali di acidi nucleici: DNA (acido desossiribonucleico) ed RNA (acido ribonucleico). Il DNA è responsabile del mantenimento e della trasmissione dell'informazione genetica, mentre l'RNA svolge un ruolo chiave nella sintesi delle proteine.
Il DNA è una doppia elica formata da due catene di nucleotidi che si avvolgono intorno a un asse comune. Le basi azotate dei due filamenti sono accoppiate in modo specifico, con l'adenina che si abbina alla timina e la guanina che si abbina alla citosina. Questa struttura garantisce la stabilità dell'informazione genetica e ne facilita la replicazione.
L'RNA è invece una singola catena di nucleotidi, con l'uracile che sostituisce la timina come base complementare all'adenina. Esistono diversi tipi di RNA, ognuno dei quali svolge un ruolo specifico nella sintesi delle proteine, come il mRNA (RNA messaggero), il tRNA (RNA transfer) e il rRNA (RNA ribosomiale).
Gli acidi nucleici sono fondamentali per la vita e svolgono un ruolo chiave in molti processi biologici, tra cui la replicazione cellulare, la trascrizione genetica e la traduzione proteica.
Il clonaggio molecolare è una tecnica di laboratorio utilizzata per creare copie esatte di un particolare frammento di DNA. Questa procedura prevede l'isolamento del frammento desiderato, che può contenere un gene o qualsiasi altra sequenza specifica, e la sua integrazione in un vettore di clonazione, come un plasmide o un fago. Il vettore viene quindi introdotto in un organismo ospite, ad esempio batteri o cellule di lievito, che lo replicano producendo numerose copie identiche del frammento di DNA originale.
Il clonaggio molecolare è una tecnica fondamentale nella biologia molecolare e ha permesso importanti progressi in diversi campi, tra cui la ricerca genetica, la medicina e la biotecnologia. Ad esempio, può essere utilizzato per produrre grandi quantità di proteine ricombinanti, come enzimi o vaccini, oppure per studiare la funzione dei geni e le basi molecolari delle malattie.
Tuttavia, è importante sottolineare che il clonaggio molecolare non deve essere confuso con il clonazione umana o animale, che implica la creazione di organismi geneticamente identici a partire da cellule adulte differenziate. Il clonaggio molecolare serve esclusivamente a replicare frammenti di DNA e non interi organismi.
In medicina e biologia molecolare, la sequenza aminoacidica si riferisce all'ordine specifico e alla disposizione lineare degli aminoacidi che compongono una proteina o un peptide. Ogni proteina ha una sequenza aminoacidica unica, determinata dal suo particolare gene e dal processo di traduzione durante la sintesi proteica.
L'informazione sulla sequenza aminoacidica è codificata nel DNA del gene come una serie di triplette di nucleotidi (codoni). Ogni tripla nucleotidica specifica codifica per un particolare aminoacido o per un segnale di arresto che indica la fine della traduzione.
La sequenza aminoacidica è fondamentale per determinare la struttura e la funzione di una proteina. Le proprietà chimiche e fisiche degli aminoacidi, come la loro dimensione, carica e idrofobicità, influenzano la forma tridimensionale che la proteina assume e il modo in cui interagisce con altre molecole all'interno della cellula.
La determinazione sperimentale della sequenza aminoacidica di una proteina può essere ottenuta utilizzando tecniche come la spettrometria di massa o la sequenziazione dell'EDTA (endogruppo diazotato terminale). Queste informazioni possono essere utili per studiare le proprietà funzionali e strutturali delle proteine, nonché per identificarne eventuali mutazioni o variazioni che possono essere associate a malattie genetiche.
L'DNA antisenso si riferisce a una sequenza di DNA che è complementare alla sequenza di DNA sense o codificante all'interno di un gene. Mentre la sequenza di DNA sense codifica per l'mRNA e le proteine, la sequenza di DNA antisenso non lo fa direttamente. Tuttavia, l'mRNA prodotto dalla trascrizione della sequenza di DNA sense può formare una duplex con l'mRNA antisenso trascritto dalla sequenza di DNA antisenso attraverso un processo noto come interferenza dell'RNA (RNAi). Questo processo regola l'espressione genica a livello post-trascrizionale e svolge un ruolo importante nella difesa contro i virus e altri elementi transponibili.
In alcuni casi, le sequenze di DNA antisenso possono essere trascritte in RNA antisenso non codificanti (ncRNA) che hanno una varietà di funzioni regolatorie all'interno della cellula. Gli ncRNA antisenso possono legare mRNA o altri ncRNA e influenzarne l'espressione, la localizzazione o la stabilità. Le alterazioni nella regolazione dell'espressione genica da parte degli ncRNA antisenso sono state implicate in una varietà di malattie umane, tra cui il cancro e le malattie neurologiche.
In sintesi, l'DNA antisenso è una sequenza di DNA complementare alla sequenza di DNA sense all'interno di un gene che può essere trascritto in RNA antisenso non codificante e partecipare alla regolazione dell'espressione genica attraverso il processo di interferenza dell'RNA.
La Ribonucleasi T1 è un enzima (una proteina che accelera una reazione chimica) che appartiene alla classe delle ribonucleasi, enzimi che catalizzano la rottura dei legami fosfodiesterici nelle molecole di RNA.
Più precisamente, la Ribonucleasi T1 è un enzima di origine batterica (isolato per la prima volta dal batterio streptomyces griseus) che taglia specificamente il legame fosfodiesterico tra l'adenosina e la prima guanosina successiva in una molecola di RNA, producendo mononucleotidi terminali con gruppi 3'-fosfato.
Questo enzima è spesso utilizzato nella ricerca scientifica per analisi strutturali e funzionali dell'RNA, poiché la sua specificità di taglio consente una precisa mappatura dei siti di adenina all'interno delle molecole di RNA.
La guanina è una base azotata presente nelle purine, che compongono i nucleotidi del DNA e dell'RNA. Nella struttura del DNA, la guanina si accoppia sempre con la citosina tramite legami idrogeno. La guanina ha una struttura a doppio anello, costituita da un anello a sei atomi di carbonio (un anello benzenico) fuso con un anello a cinque atomi di carbonio contenente azoto. È una delle quattro basi nucleotidiche standard presenti nel DNA e nell'RNA insieme ad adenina, timina e citosina (nel DNA) o uracile (nell'RNA).
In medicina e biologia, un "sito di legame" si riferisce a una particolare posizione o area su una molecola (come una proteina, DNA, RNA o piccolo ligando) dove un'altra molecola può attaccarsi o legarsi specificamente e stabilmente. Questo legame è spesso determinato dalla forma tridimensionale e dalle proprietà chimiche della superficie di contatto tra le due molecole. Il sito di legame può mostrare una specificità se riconosce e si lega solo a una particolare molecola o a un insieme limitato di molecole correlate.
Un esempio comune è il sito di legame di un enzima, che è la regione della sua struttura dove il suo substrato (la molecola su cui agisce) si attacca e subisce una reazione chimica catalizzata dall'enzima stesso. Un altro esempio sono i siti di legame dei recettori cellulari, che riconoscono e si legano a specifici messaggeri chimici (come ormoni, neurotrasmettitori o fattori di crescita) per iniziare una cascata di eventi intracellulari che portano alla risposta cellulare.
In genetica e biologia molecolare, il sito di legame può riferirsi a una sequenza specifica di basi azotate nel DNA o RNA a cui si legano proteine (come fattori di trascrizione, ligasi o polimerasi) per regolare l'espressione genica o svolgere altre funzioni cellulari.
In sintesi, i siti di legame sono cruciali per la comprensione dei meccanismi molecolari alla base di molti processi biologici e sono spesso obiettivi farmacologici importanti nello sviluppo di terapie mirate.
Gli indicatori e i reagenti sono termini utilizzati in ambito medico e di laboratorio per descrivere sostanze che vengono utilizzate per testare o misurare determinate caratteristiche o proprietà di un campione o di una sostanza.
Un indicatore è una sostanza che cambia colore in risposta a un cambiamento di certaine condizioni fisiche o chimiche, come il pH o la presenza di ioni metallici specifici. Ad esempio, il pH degli indicatori viene spesso utilizzato per testare l'acidità o la basicità di una soluzione. Un esempio comune di un indicatore è il blu di bromotimolo, che cambia colore da giallo a blu in una gamma di pH tra 6,0 e 7,6.
Un reagente, d'altra parte, è una sostanza chimica specifica che reagisce con un'altra sostanza per formare un prodotto chimico misurabile o rilevabile. Ad esempio, il glucosio nel sangue può essere misurato utilizzando un reagente chiamato glucosio ossidasi, che reagisce con il glucosio per produrre perossido di idrogeno, che può quindi essere rilevato e misurato.
In sintesi, gli indicatori e i reagenti sono strumenti importanti utilizzati in medicina e in laboratorio per testare e misurare le proprietà chimiche e fisiche di campioni e sostanze.
Le proteine leganti DNA, anche conosciute come proteine nucleiche, sono proteine che si legano specificamente al DNA per svolgere una varietà di funzioni importanti all'interno della cellula. Queste proteine possono legare il DNA in modo non specifico o specifico, a seconda del loro sito di legame e della sequenza di basi nucleotidiche con cui interagiscono.
Le proteine leganti DNA specifiche riconoscono sequenze di basi nucleotidiche particolari e si legano ad esse per regolare l'espressione genica, riparare il DNA danneggiato o mantenere la stabilità del genoma. Alcuni esempi di proteine leganti DNA specifiche includono i fattori di trascrizione, che si legano al DNA per regolare l'espressione dei geni, e le enzimi di riparazione del DNA, che riconoscono e riparano lesioni al DNA.
Le proteine leganti DNA non specifiche, d'altra parte, si legano al DNA in modo meno specifico e spesso svolgono funzioni strutturali o regolatorie all'interno della cellula. Ad esempio, le istone sono proteine leganti DNA non specifiche che aiutano a organizzare il DNA in una struttura compatta chiamata cromatina.
In sintesi, le proteine leganti DNA sono un gruppo eterogeneo di proteine che interagiscono con il DNA per svolgere funzioni importanti all'interno della cellula, tra cui la regolazione dell'espressione genica, la riparazione del DNA e la strutturazione del genoma.
L'appaiamento delle basi, noto anche come "base pairing" o "complementary base pairing", è un concetto fondamentale nella genetica e nella biologia molecolare. Si riferisce alla specifica interazione che si verifica tra le basi azotate presenti nelle catene di DNA o RNA, grazie alle quali si formano le coppie di basi A-T (adenina-timina) e G-C (guanina-citosina) nel DNA, e le coppie di basi A-U (adenina-uracile) nell'RNA. Questa interazione è guidata dalle geometrie molecolari e dalle forze elettrostatiche tra le basi, ed è essenziale per la replicazione, la trascrizione e la traduzione del genoma.
Gli agenti intercalanti sono una classe di molecole che si legano al DNA in modo non covalente, letteralmente "inserendosi" tra le basi azotate della doppia elica. Questo tipo di legame è possibile perché la forma planare delle molecole di agenti intercalanti permette loro di inserirsi nello spazio lasciato libero dalle basi azotate, allargando così la distanza tra esse e destabilizzando la struttura del DNA.
Gli agenti intercalanti sono spesso utilizzati come marcatori fluorescenti per studiare la struttura e la funzione del DNA, poiché l'intercalazione causa un cambiamento conformazionale che può essere rilevato mediante spettroscopia. Tuttavia, gli agenti intercalanti possono anche avere effetti dannosi sul DNA, poiché la loro presenza può bloccare la replicazione e la trascrizione del DNA, con conseguente inibizione della crescita cellulare o morte cellulare.
Alcuni agenti intercalanti sono noti per avere proprietà antitumorali, poiché possono legarsi selettivamente al DNA dei tumori e inibire la loro replicazione. Tuttavia, l'uso di questi farmaci può anche causare effetti collaterali indesiderati, come danni ai tessuti sani che contengono DNA con una struttura simile a quella del DNA tumorale.
Esempi di agenti intercalanti includono etidio bromuro, proflavina e doxorubicina.
La trascrizione genetica è un processo fondamentale della biologia molecolare che coinvolge la produzione di una molecola di RNA (acido ribonucleico) a partire da un filamento stampo di DNA (acido desossiribonucleico). Questo processo è catalizzato dall'enzima RNA polimerasi e si verifica all'interno del nucleo delle cellule eucariotiche e nel citoplasma delle procarioti.
Nel dettaglio, la trascrizione genetica prevede l'apertura della doppia elica di DNA nella regione in cui è presente il gene da trascrivere, permettendo all'RNA polimerasi di legarsi al filamento stampo e di sintetizzare un filamento complementare di RNA utilizzando i nucleotidi contenuti nel nucleo cellulare. Il filamento di RNA prodotto è una copia complementare del filamento stampo di DNA, con le timine (T) dell'RNA che si accoppiano con le adenine (A) del DNA, e le citosine (C) dell'RNA che si accoppiano con le guanine (G) del DNA.
Esistono diversi tipi di RNA che possono essere sintetizzati attraverso il processo di trascrizione genetica, tra cui l'mRNA (RNA messaggero), il rRNA (RNA ribosomiale) e il tRNA (RNA transfer). L'mRNA è responsabile del trasporto dell'informazione genetica dal nucleo al citoplasma, dove verrà utilizzato per la sintesi delle proteine attraverso il processo di traduzione. Il rRNA e il tRNA, invece, sono componenti essenziali dei ribosomi e partecipano alla sintesi proteica.
La trascrizione genetica è un processo altamente regolato che può essere influenzato da diversi fattori, come i fattori di trascrizione, le modificazioni chimiche del DNA e l'organizzazione della cromatina. La sua corretta regolazione è essenziale per il corretto funzionamento delle cellule e per la loro sopravvivenza.
In genetica molecolare, un primer dell'DNA è una breve sequenza di DNA monocatenario che serve come punto di inizio per la reazione di sintesi dell'DNA catalizzata dall'enzima polimerasi. I primers sono essenziali nella reazione a catena della polimerasi (PCR), nella sequenziamento del DNA e in altre tecniche di biologia molecolare.
I primers dell'DNA sono generalmente sintetizzati in laboratorio e sono selezionati per essere complementari ad una specifica sequenza di DNA bersaglio. Quando il primer si lega alla sua sequenza target, forma una struttura a doppia elica che può essere estesa dall'enzima polimerasi durante la sintesi dell'DNA.
La lunghezza dei primers dell'DNA è generalmente compresa tra 15 e 30 nucleotidi, sebbene possa variare a seconda del protocollo sperimentale specifico. I primers devono essere sufficientemente lunghi da garantire una specificità di legame elevata alla sequenza target, ma non così lunghi da renderli suscettibili alla formazione di strutture secondarie che possono interferire con la reazione di sintesi dell'DNA.
In sintesi, i primers dell'DNA sono brevi sequenze di DNA monocatenario utilizzate come punto di inizio per la sintesi dell'DNA catalizzata dall'enzima polimerasi, e sono essenziali in diverse tecniche di biologia molecolare.
In medicina e fisiologia, la cinetica si riferisce allo studio dei movimenti e dei processi che cambiano nel tempo, specialmente in relazione al funzionamento del corpo e dei sistemi corporei. Nella farmacologia, la cinetica delle droghe è lo studio di come il farmaco viene assorbito, distribuito, metabolizzato e eliminato dal corpo.
In particolare, la cinetica enzimatica si riferisce alla velocità e alla efficienza con cui un enzima catalizza una reazione chimica. Questa può essere descritta utilizzando i parametri cinetici come la costante di Michaelis-Menten (Km) e la velocità massima (Vmax).
La cinetica può anche riferirsi al movimento involontario o volontario del corpo, come nel caso della cinetica articolare, che descrive il movimento delle articolazioni.
In sintesi, la cinetica è lo studio dei cambiamenti e dei processi che avvengono nel tempo all'interno del corpo umano o in relazione ad esso.
La ribonucleasi (RNasi) è un'amilasi che catalizza la scissione idrolitica delle legature fosfodiesteriche nelle molecole di RNA, svolgendo un ruolo importante nella regolazione dell'espressione genica e nel metabolismo degli acidi nucleici. Esistono diversi tipi di ribonucleasi con differenti specificità di substrato e funzioni biologiche. Ad esempio, la ribonucleasi A è una endoribonucleasi che taglia il filamento singolo dell'RNA a livello delle sequenze pyrophosphate, mentre la ribonucleasi T1 è una endoribonucleasi che taglia specificamente i legami fosfodiesterici dopo le guanine. Le ribonucleasi sono presenti in molti organismi e possono avere attività antimicrobica, antifungina o antivirale. Nel corpo umano, le ribonucleasi svolgono un ruolo importante nella difesa immunitaria, nel metabolismo delle cellule e nell'elaborazione degli RNA messaggeri (mRNA) nelle cellule.
La "Composizione di Base" (nota anche come "Composition of Matter") è un termine utilizzato nel campo della proprietà intellettuale e del diritto d'autore per riferirsi a una forma specifica di invenzione brevettabile. In particolare, si riferisce alla creazione di una nuova sostanza o materia, che può essere un composto chimico, una miscela, un farmaco, un vaccino o qualsiasi altra forma di materiale che abbia una composizione e una struttura molecolare specifiche.
Nel contesto medico, la "Composizione di Base" può riferirsi a una formulazione specifica di un farmaco o di un vaccino, che include i suoi ingredienti attivi e inattivi, nonché le relative concentrazioni e proporzioni. Ad esempio, il vaccino contro l'influenza stagionale può avere una "Composizione di Base" specifica che include diversi ceppi virali del virus dell'influenza, insieme ad altri ingredienti come conservanti, stabilizzatori e adiuvanti.
La creazione di una nuova "Composizione di Base" richiede spesso un notevole sforzo di ricerca e sviluppo, nonché la conoscenza approfondita della chimica, della biologia e della farmacologia. Pertanto, le invenzioni che coinvolgono una "Composizione di Base" possono essere brevettate per proteggere i diritti di proprietà intellettuale del loro creatore e garantire un ritorno sull'investimento per il finanziamento della ricerca e dello sviluppo.
In sintesi, la "Composizione di Base" è un termine medico e legale che si riferisce alla creazione di una nuova sostanza o materia con una composizione e una struttura molecolare specifiche, che può essere utilizzata come farmaco, vaccino o qualsiasi altra forma di trattamento terapeutico.
In medicina, una linea cellulare è una cultura di cellule che mantengono la capacità di dividersi e crescere in modo continuo in condizioni appropriate. Le linee cellulari sono comunemente utilizzate in ricerca per studiare il comportamento delle cellule, testare l'efficacia e la tossicità dei farmaci, e capire i meccanismi delle malattie.
Le linee cellulari possono essere derivate da diversi tipi di tessuti, come quelli tumorali o normali. Le linee cellulari tumorali sono ottenute da cellule cancerose prelevate da un paziente e successivamente coltivate in laboratorio. Queste linee cellulari mantengono le caratteristiche della malattia originale e possono essere utilizzate per studiare la biologia del cancro e testare nuovi trattamenti.
Le linee cellulari normali, d'altra parte, sono derivate da tessuti non cancerosi e possono essere utilizzate per studiare la fisiologia e la patofisiologia di varie malattie. Ad esempio, le linee cellulari epiteliali possono essere utilizzate per studiare l'infezione da virus o batteri, mentre le linee cellulari neuronali possono essere utilizzate per studiare le malattie neurodegenerative.
E' importante notare che l'uso di linee cellulari in ricerca ha alcune limitazioni e precauzioni etiche da considerare, come il consenso informato del paziente per la derivazione di linee cellulari tumorali, e la verifica dell'identità e della purezza delle linee cellulari utilizzate.
In campo medico, la trasfezione si riferisce a un processo di introduzione di materiale genetico esogeno (come DNA o RNA) in una cellula vivente. Questo processo permette alla cellula di esprimere proteine codificate dal materiale genetico estraneo, alterandone potenzialmente il fenotipo. La trasfezione può essere utilizzata per scopi di ricerca di base, come lo studio della funzione genica, o per applicazioni terapeutiche, come la terapia genica.
Esistono diverse tecniche di trasfezione, tra cui:
1. Trasfezione chimica: utilizza agenti chimici come il calcio fosfato o lipidi cationici per facilitare l'ingresso del materiale genetico nelle cellule.
2. Elettroporazione: applica un campo elettrico alle cellule per creare pori temporanei nella membrana cellulare, permettendo al DNA di entrare nella cellula.
3. Trasfezione virale: utilizza virus modificati geneticamente per veicolare il materiale genetico desiderato all'interno delle cellule bersaglio. Questo metodo è spesso utilizzato in terapia genica a causa dell'elevata efficienza di trasfezione.
È importante notare che la trasfezione non deve essere confusa con la trasduzione, che si riferisce all'introduzione di materiale genetico da un batterio donatore a uno ricevente attraverso la fusione delle loro membrane cellulari.
I psoraleni sono composti organici naturalmente presenti in alcune piante, come la figanella (Ficus carica), il gelsomino bianco (Jasminum sambac), e soprattutto nella famiglia delle Rutaceae, che include agrumi come limoni e bergamotti. I psoraleni sono noti per la loro capacità di aumentare la sensibilità della pelle ai raggi UV, il che ha portato al loro utilizzo in terapie fotochemiche, note come PUVA (psoraleni più UVA), nel trattamento di alcune malattie della pelle come la psoriasi e l'eczema.
Tuttavia, l'esposizione ai psoraleni e alla luce UV può anche aumentare il rischio di cancro della pelle, quindi queste terapie devono essere attentamente monitorate e gestite da professionisti sanitari qualificati. I psoraleni possono anche causare reazioni allergiche in alcune persone.
In medicina, l'espressione "sonde di DNA" si riferisce a brevi frammenti di DNA marcati chimicamente o radioattivamente, utilizzati in tecniche di biologia molecolare per identificare e localizzare specifiche sequenze di DNA all'interno di un campione di acido nucleico. Le sonde di DNA possono essere create in laboratorio mediante la reazione a catena della polimerasi (PCR) o l'isolamento da banche di DNA, e possono essere marcate con fluorofori, enzimi, isotiocianati o radioisotopi. Una volta create, le sonde vengono utilizzate in esperimenti come Northern blotting, Southern blotting, in situ hybridization e microarray, al fine di rilevare la presenza o l'assenza di specifiche sequenze di DNA target all'interno del campione. Queste tecniche sono fondamentali per la ricerca genetica, la diagnosi delle malattie genetiche e lo studio dei microrganismi patogeni.
I geni sintetici sono sequenze di DNA progettate e create artificialmente che codificano per una specifica funzione o proteina. Essi non si trovano naturalmente nelle forme viventi, ma sono creati da biologi molecolari e geneticisti sintetizzando pezzi di DNA in laboratorio e assemblando insieme per formare un gene con una funzione desiderata. Questi geni possono quindi essere inseriti nelle cellule o gli organismi viventi per esprimere la proteina codificata dal gene sintetico, il che può essere utilizzato per studiare la funzione della proteina, per creare nuovi sistemi di produzione di proteine o per sviluppare terapie geniche.
La tecnologia dei geni sintetici è un campo in rapida crescita nell'ingegneria genetica e nella biologia sintetica, con il potenziale per una vasta gamma di applicazioni, tra cui la produzione di farmaci, la creazione di combustibili rinnovabili, e la progettazione di organismi viventi con proprietà desiderate. Tuttavia, ci sono anche preoccupazioni etiche e di sicurezza associate alla tecnologia dei geni sintetici che devono essere considerate e regolamentate.
Gli acidi fosforici sono una classe di composti chimici organici o inorganici che contengono gruppi funzionali di acido fosforico (-H2PO4). Nella loro forma inorganica, gli acidi fosforici sono ampiamente utilizzati nell'industria alimentare come conservanti, emulsionificanti e acidificanti. Sono indicati con il codice E E338 e possono essere trovati in una varietà di prodotti, tra cui bevande gassate, succhi di frutta, salse e condimenti.
Gli acidi fosforici possono anche essere presenti nell'organismo umano come parte dei processi metabolici. Ad esempio, l'acido fosforico è un componente importante delle molecole di ATP (adenosina trifosfato), che forniscono energia alle cellule del corpo.
Tuttavia, un consumo eccessivo di acidi fosforici può avere effetti negativi sulla salute, tra cui l'aumento del rischio di osteoporosi, malattie renali e calcificazione delle arterie. Pertanto, è importante limitare l'assunzione di acidi fosforici a livelli raccomandati per mantenere una buona salute.
Escherichia coli (abbreviato come E. coli) è un batterio gram-negativo, non sporigeno, facoltativamente anaerobico, appartenente al genere Enterobacteriaceae. È comunemente presente nel tratto gastrointestinale inferiore dei mammiferi ed è parte integrante della normale flora intestinale umana. Tuttavia, alcuni ceppi di E. coli possono causare una varietà di malattie infettive che vanno da infezioni urinarie lievi a gravi condizioni come la meningite, sebbene ciò sia relativamente raro.
Alcuni ceppi di E. coli sono patogeni e producono tossine o altri fattori virulenti che possono causare diarrea acquosa, diarrea sanguinolenta (nota come colera emorragica), infezioni del tratto urinario, polmonite, meningite e altre malattie. L'esposizione a questi ceppi patogeni può verificarsi attraverso il consumo di cibi o bevande contaminati, il contatto con animali infetti o persone infette, o tramite l'acqua contaminata.
E. coli è anche ampiamente utilizzato in laboratorio come organismo modello per la ricerca biologica e medica a causa della sua facilità di crescita e manipolazione genetica.
I coloranti fluorescenti sono sostanze chimiche che brillano o emettono luce visibile quando vengono esposte a una fonte di luce esterna, come la luce ultravioletta o una lampada a fluorescenza. Questi coloranti assorbono energia dalla sorgente di luce e la convertono in un'emissione di luce a diverse lunghezze d'onda, che appare spesso come un colore diverso rispetto alla luce incidente.
In ambito medico, i coloranti fluorescenti vengono utilizzati per diversi scopi, tra cui la marcatura e il tracciamento di cellule, proteine e altre biomolecole all'interno del corpo umano o in colture cellulari. Ciò può essere particolarmente utile nelle applicazioni di imaging medico, come la microscopia a fluorescenza, che consente agli scienziati e ai medici di osservare processi biologici complessi a livello cellulare o molecolare.
Un esempio comune di un colorante fluorescente utilizzato in medicina è la fluoresceina, che viene talvolta somministrata per via endovenosa durante gli esami oftalmici per evidenziare eventuali lesioni o anomalie della cornea e della congiuntiva. Altri coloranti fluorescenti possono essere utilizzati in diagnosi non invasive di malattie, come il cancro, attraverso la fluorescenza in vivo o l'imaging biomedico ottico.
Tuttavia, è importante notare che l'uso di coloranti fluorescenti deve essere attentamente monitorato e gestito, poiché possono presentare potenziali rischi per la salute se utilizzati in modo improprio o a dosaggi elevati.
Le Acidi Peptidici Nucleici (PNA) sono artificiali molecole analoghe al DNA, scoperte per la prima volta nel 1991. A differenza del DNA e dell'RNA, che utilizzano zuccheri deossiribosio e ribosio come componenti di backbone, rispettivamente, i PNA hanno un backbone completamente peptidico. Questo conferisce loro alcune proprietà uniche, come una maggiore affinità per il DNA e l'RNA, resistenza alla degradazione enzimatica e stabilità termica superiore.
I PNA sono costituiti da unità monomere chiamate N- (2-aminoetil)glicina, legate insieme da legami amide. Ogni unità monomera contiene anche un gruppo connettore che lega uno dei quattro diversi nucleobasi: adenina, citosina, guanina e timina. Poiché i PNA non hanno cariche negative come il DNA o l'RNA, possono facilmente formare strutture a doppia elica con il DNA o l'RNA attraverso legami idrogeno, il che li rende utili come agenti di riconoscimento molecolare e di regolazione genica.
I PNA hanno dimostrato un grande potenziale in una varietà di applicazioni biomediche, tra cui la diagnosi e il trattamento delle malattie genetiche, il rilevamento di agenti patogeni e l'inibizione dell'espressione genica. Tuttavia, ci sono anche sfide associate al loro sviluppo e utilizzo, come la difficoltà nella sintesi di sequenze lunghe e la scarsa solubilità in acqua.
I polideossiribonucleotidi (abbreviati in PDRN) sono lunghi segmenti di DNA derivanti da cellule procariote, tipicamente batteri. Essi consistono in catene di deossiribonucleotidi uniti insieme attraverso legami fosfodiesterei.
I PDRN hanno dimostrato di avere proprietà biologiche che promuovono la rigenerazione dei tessuti e la guarigione delle ferite, il che li ha resi un interesse per la ricerca medica e cosmetica. In particolare, i PDRN sembrano stimolare la proliferazione cellulare e l'attività dei fibroblasti, che sono cellule importanti nella produzione di collagene ed altri componenti della matrice extracellulare.
Tuttavia, è importante notare che la ricerca sui PDRN è ancora in una fase precoce e sono necessari ulteriori studi per comprendere appieno i loro meccanismi d'azione e le potenziali applicazioni terapeutiche.
In termini medici, le "regioni promotrici genetiche" si riferiscono a specifiche sequenze di DNA situate in prossimità del sito di inizio della trascrizione di un gene. Queste regioni sono essenziali per il controllo e la regolazione dell'espressione genica, poiché forniscono il punto di attacco per le proteine e gli enzimi che avviano il processo di trascrizione del DNA in RNA.
Le regioni promotrici sono caratterizzate dalla presenza di sequenze specifiche, come il sito di legame della RNA polimerasi II e i fattori di trascrizione, che si legano al DNA per avviare la trascrizione. Una delle sequenze più importanti è il cosiddetto "sequenza di consenso TATA", situata a circa 25-30 paia di basi dal sito di inizio della trascrizione.
Le regioni promotrici possono essere soggette a vari meccanismi di regolazione, come la metilazione del DNA o l'interazione con fattori di trascrizione specifici, che possono influenzare il tasso di espressione genica. Alterazioni nelle regioni promotrici possono portare a disturbi dello sviluppo e malattie genetiche.
La "centratura imperfetta di basi appaiate" è un termine utilizzato in biochimica e genetica per descrivere una situazione in cui le coppie di basi azotate (adenina-timina o citosina-guanina) nelle due eliche complementari del DNA non sono perfettamente allineate durante la replicazione o la riparazione del DNA.
Normalmente, durante la replicazione del DNA, le due eliche si separano e ogni filamento serve come modello per la sintesi di un nuovo filamento complementare. Questo processo avviene in modo che le coppie di basi appaiate (adenina con timina e citosina con guanina) si riuniscano esattamente nello stesso punto del filamento originale, mantenendo la sequenza nucleotidica intatta.
Tuttavia, a volte possono verificarsi errori di centratura, in cui le basi non sono perfettamente allineate durante la replicazione o la riparazione del DNA. Questo può portare a mutazioni puntuali, che sono cambiamenti nella sequenza nucleotidica del DNA che possono avere effetti variabili sulla funzione genica e sull'espressione genica.
La centratura imperfetta di basi appaiate può essere causata da diversi fattori, come la presenza di lesioni nel DNA, l'instabilità della sequenza nucleotidica o l'invecchiamento cellulare. Può anche essere influenzata dalla disponibilità di enzimi di riparazione del DNA e dalla loro efficacia nel rilevare e correggere gli errori di centratura.
In generale, la centratura imperfetta di basi appaiate è un processo naturale che può avere conseguenze negative sulla stabilità del genoma e sulla funzione cellulare. Tuttavia, in alcuni casi, può anche essere sfruttata come meccanismo per introdurre diversità genetica e promuovere l'evoluzione delle specie.
Le "Cellule tumorali in coltura" si riferiscono al processo di crescita e moltiplicazione delle cellule tumorali prelevate da un paziente, in un ambiente di laboratorio controllato. Questo processo consente agli scienziati e ai ricercatori medici di studiare le caratteristiche e il comportamento delle cellule tumorali al di fuori dell'organismo vivente, con l'obiettivo di comprendere meglio i meccanismi della malattia e sviluppare strategie terapeutiche più efficaci.
Le cellule tumorali vengono isolate dal tessuto tumorale primario o dalle metastasi, e successivamente vengono coltivate in specifici nutrienti e condizioni di crescita che ne permettono la proliferazione in vitro. Durante questo processo, le cellule possono essere sottoposte a diversi trattamenti farmacologici o manipolazioni genetiche per valutarne la risposta e l'efficacia.
L'utilizzo di "Cellule tumorali in coltura" è fondamentale nello studio del cancro, poiché fornisce informazioni preziose sulla biologia delle cellule tumorali, sulla loro sensibilità o resistenza ai trattamenti e sull'identificazione di potenziali bersagli terapeutici. Tuttavia, è importante sottolineare che le "Cellule tumorali in coltura" possono presentare alcune limitazioni, come la perdita della complessità dei tessuti originali e l'assenza dell'influenza del microambiente tumorale. Pertanto, i risultati ottenuti da queste colture devono essere validati in modelli più complessi, come ad esempio organoidi o animali da laboratorio, prima di essere applicati alla pratica clinica.
Gli eteroduplex di acidi nucleici sono strutture formate dalla ricombinazione di due filamenti di acidi nucleici (DNA o RNA) con differenti sequenze nucleotidiche. Questa interazione può verificarsi naturalmente durante il processo di ricombinazione genetica, come ad esempio durante la meiosi, dove i cromosomi scambiano porzioni di materiale genetico attraverso il crossing-over.
Gli eteroduplex possono anche essere creati in vitro attraverso tecniche sperimentali, come l'ibridazione molecolare o la reazione a catena della polimerasi (PCR). Quando due filamenti di acidi nucleici con differenti sequenze vengono fusi insieme, possono formarsi regioni di omologia dove le sequenze sono simili o identiche. In queste regioni, i filamenti possono formare legami idrogeno tra le basi complementari, creando una struttura a doppia elica instabile.
Gli eteroduplex di acidi nucleici sono importanti in genetica e biologia molecolare perché possono essere utilizzati per identificare mutazioni o varianti genetiche. Ad esempio, se due sequenze di DNA differiscono per una singola base, la formazione di un eteroduplex può portare alla formazione di una bolla o di una regione instabile nella struttura a doppia elica. Queste anomalie possono essere rilevate utilizzando tecniche sperimentali come la digestione con enzimi di restrizione o la sequenzazione del DNA.
Inoltre, gli eteroduplex di acidi nucleici sono anche utilizzati in biotecnologie e nella terapia genica per il rilevamento e la correzione di mutazioni genetiche. Ad esempio, le tecniche di editing genico come CRISPR-Cas9 sfruttano la formazione di eteroduplex per identificare e tagliare specifiche sequenze di DNA, permettendo l'inserimento di nuove sequenze o la correzione di mutazioni.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
La definizione medica di "cellule coltivate" si riferisce a cellule vive che sono state prelevate da un tessuto o organismo e fatte crescere in un ambiente di laboratorio controllato, ad esempio in un piatto di Petri o in un bioreattore. Questo processo è noto come coltura cellulare ed è utilizzato per studiare il comportamento delle cellule, testare l'efficacia e la sicurezza dei farmaci, produrre vaccini e terapie cellulari avanzate, nonché per scopi di ricerca biologica di base.
Le cellule coltivate possono essere prelevate da una varietà di fonti, come linee cellulari immortalizzate, cellule primarie isolate da tessuti umani o animali, o cellule staminali pluripotenti indotte (iPSC). Le condizioni di coltura, come la composizione del mezzo di coltura, il pH, la temperatura e la presenza di fattori di crescita, possono essere regolate per supportare la crescita e la sopravvivenza delle cellule e per indurre differenti fenotipi cellulari.
La coltura cellulare è una tecnologia essenziale nella ricerca biomedica e ha contribuito a numerose scoperte scientifiche e innovazioni mediche. Tuttavia, la coltivazione di cellule in laboratorio presenta anche alcune sfide, come il rischio di contaminazione microbica, la difficoltà nella replicazione delle condizioni fisiologiche complessi dei tessuti e degli organismi viventi, e l'etica associata all'uso di cellule umane e animali in ricerca.
In termini medici, la "struttura molecolare" si riferisce alla disposizione spaziale e all'organizzazione dei diversi atomi che compongono una molecola. Essa descrive come gli atomi sono legati tra loro e la distanza che li separa, fornendo informazioni sui loro angoli di legame, orientamento nello spazio e altre proprietà geometriche. La struttura molecolare è fondamentale per comprendere le caratteristiche chimiche e fisiche di una sostanza, poiché influenza le sue proprietà reattive, la sua stabilità termodinamica e altri aspetti cruciali della sua funzione biologica.
La determinazione della struttura molecolare può essere effettuata sperimentalmente attraverso tecniche come la diffrazione dei raggi X o la spettroscopia, oppure può essere prevista mediante calcoli teorici utilizzando metodi di chimica quantistica. Questa conoscenza è particolarmente importante in campo medico, dove la comprensione della struttura molecolare dei farmaci e delle loro interazioni con le molecole bersaglio può guidare lo sviluppo di terapie più efficaci ed efficienti.
L'RNA virale si riferisce al genoma di virus che utilizzano RNA (acido ribonucleico) come materiale genetico anziché DNA (acido desossiribonucleico). Questi virus possono avere diversi tipi di genomi RNA, come ad esempio:
1. Virus a RNA a singolo filamento (ssRNA): questi virus hanno un singolo filamento di RNA come genoma. Possono essere ulteriormente classificati in due categorie:
a) Virus a RNA a singolo filamento positivo (+ssRNA): il loro genoma funge da mRNA (RNA messaggero) e può essere direttamente tradotto nelle cellule ospiti per produrre proteine virali.
b) Virus a RNA a singolo filamento negativo (-ssRNA): il loro genoma non può essere direttamente utilizzato come mRNA e richiede la trascrizione in mRNA complementare prima della traduzione in proteine virali.
2. Virus a RNA a doppio filamento (dsRNA): questi virus hanno un doppio filamento di RNA come genoma. Il loro genoma deve essere trascritto in mRNA prima che possa essere utilizzato per la sintesi delle proteine virali.
Gli RNA virali possono avere diversi meccanismi di replicazione e transcrizione, alcuni dei quali possono avvenire nel citoplasma della cellula ospite, mentre altri richiedono l'ingresso del genoma virale nel nucleo. Esempi di virus a RNA includono il virus dell'influenza, il virus della poliomielite, il virus della corona (SARS-CoV-2), e il virus dell'epatite C.
In termini medici, la temperatura corporea è un indicatore della temperatura interna del corpo ed è generalmente misurata utilizzando un termometro sotto la lingua, nel retto o nell'orecchio. La normale temperatura corporea a riposo per un adulto sano varia da circa 36,5°C a 37,5°C (97,7°F a 99,5°F), sebbene possa variare leggermente durante il giorno e in risposta all'esercizio fisico, all'assunzione di cibo o ai cambiamenti ambientali.
Tuttavia, una temperatura superiore a 38°C (100,4°F) è generalmente considerata febbre e può indicare un'infezione o altri processi patologici che causano l'infiammazione nel corpo. Una temperatura inferiore a 35°C (95°F) è nota come ipotermia e può essere pericolosa per la vita, specialmente se persiste per un lungo periodo di tempo.
Monitorare la temperatura corporea è quindi un importante indicatore della salute generale del corpo e può fornire informazioni cruciali sulla presenza di malattie o condizioni mediche sottostanti.
Gli Morpholinos sono una classe di oligomeri sintetici azotati che vengono utilizzati come strumento per la regolazione genica. Essi sono costituiti da una catena di unità etere-correlate di N-metilmorfolina, con un gruppo idrossi sostituito in posizione 2' di ogni unità. A causa della loro struttura chimica, gli Morpholinos hanno proprietà uniche che li rendono utili per la modulazione dell'espressione genica.
In particolare, gli Morpholinos sono in grado di legarsi specificamente all'RNA messaggero (mRNA) mediante l'interazione Watson-Crick con le basi azotate, bloccando così il processo di traduzione e impedendo la produzione della proteina corrispondente. Questa proprietà viene sfruttata per studiare la funzione dei geni, sopprimere l'espressione di geni specifici o interferire con l'attività di microRNA.
Gli Morpholinos sono comunemente utilizzati in biologia molecolare e nella ricerca biomedica, specialmente in studi su modelli animali come il pesce zebrafish (Danio rerio). Tuttavia, è importante notare che l'uso di Morpholinos può presentare alcune limitazioni e sfide, tra cui la possibilità di off-target effects e la difficoltà nella consegna intracellulare. Pertanto, i risultati ottenuti utilizzando questa tecnologia devono essere interpretati con cautela e validati mediante metodi alternativi.
I poliribonucleotidi sono lunghi filamenti di RNA (acido ribonucleico) composti da catene di nucleotidi ripetuti. Sono simili ai polinucleotidi, che sono catene di DNA, ma differiscono nella composizione degli zuccheri e dei gruppi fosfato nelle loro molecole.
I poliribonucleotidi svolgono un ruolo importante in diversi processi cellulari, tra cui la traduzione (il processo di conversione dell'informazione genetica contenuta nel DNA in proteine funzionali). Essi possono anche avere proprietà enzimatiche e immunologiche.
I poliribonucleotidi sono utilizzati in diversi campi della ricerca biomedica, come ad esempio nella terapia genica, per la produzione di vaccini e come agenti antivirali. Tuttavia, l'uso di poliribonucleotidi in ambito clinico è ancora relativamente nuovo e sono necessarie ulteriori ricerche per comprendere appieno i loro potenziali benefici e rischi.
La specificità del substrato è un termine utilizzato in biochimica e farmacologia per descrivere la capacità di un enzima o una proteina di legarsi e agire su un singolo substrato o su un gruppo limitato di substrati simili, piuttosto che su una gamma più ampia di molecole.
In altre parole, l'enzima o la proteina mostra una preferenza marcata per il suo substrato specifico, con cui è in grado di interagire con maggiore affinità e velocità di reazione rispetto ad altri substrati. Questa specificità è dovuta alla forma tridimensionale dell'enzima o della proteina, che si adatta perfettamente al substrato come una chiave in una serratura, permettendo solo a determinate molecole di legarsi e subire la reazione enzimatica.
La specificità del substrato è un concetto fondamentale nella comprensione della regolazione dei processi metabolici e della farmacologia, poiché consente di prevedere quali molecole saranno più probabilmente influenzate da una particolare reazione enzimatica o da un farmaco che interagisce con una proteina specifica.
In termini medici, la termodinamica non è comunemente utilizzata come una disciplina autonoma, poiché si tratta principalmente di una branca della fisica che studia le relazioni tra il calore e altre forme di energia. Tuttavia, i concetti di termodinamica sono fondamentali in alcune aree della fisiologia e della medicina, come la biochimica e la neurobiologia.
La termodinamica si basa su quattro leggi fondamentali che descrivono il trasferimento del calore e l'efficienza dei dispositivi che sfruttano questo trasferimento per eseguire lavoro. Le due leggi di particolare importanza in contesti biologici sono:
1) Prima legge della termodinamica, o legge di conservazione dell'energia, afferma che l'energia non può essere creata né distrutta, ma solo convertita da una forma all'altra. Ciò significa che il totale dell'energia in un sistema isolato rimane costante, sebbene possa cambiare la sua forma o essere distribuita in modo diverso.
2) Seconda legge della termodinamica afferma che l'entropia (disordine) di un sistema isolato tende ad aumentare nel tempo. L'entropia misura la dispersione dell'energia in un sistema: quanto più è dispersa, tanto maggiore è l'entropia. Questa legge ha implicazioni importanti per i processi biologici, come il metabolismo e la crescita delle cellule, poiché richiedono input di energia per mantenere l'ordine e combattere l'aumento naturale dell'entropia.
In sintesi, mentre la termodinamica non è una definizione medica in sé, i suoi principi sono cruciali per comprendere alcuni aspetti della fisiologia e della biochimica.
La definizione medica di "Poli T" si riferisce a un tipo di vaccino combinato che offre protezione contro tre malattie infettive: tetano, difterite e pertosse. Il termine "Poli" sta per "poliomielite", ma nel contesto del vaccino Poli T, non fornisce alcuna protezione contro la poliomielite. Invece, il nome si riferisce alla combinazione di antigeni tetanici e difterici (da cui il nome "T") con l'antigene della pertosse.
Il vaccino Poli T è generalmente somministrato come parte del programma di immunizzazione di routine per i bambini, con dosi raccomandate a intervalli specifici durante l'infanzia e l'adolescenza. Il vaccino aiuta a proteggere contro le complicazioni gravi e potenzialmente letali associate a queste malattie infettive, come la paralisi da tetano, la miocardite da difterite e la polmonite da pertosse.
È importante notare che esistono diversi tipi di vaccini Poli T disponibili, tra cui formulazioni a dose singola e combinate con altri antigeni, come quelli contro l'epatite B, l'Haemophilus influenzae tipo b (Hib) e la poliomielite. La scelta del vaccino specifico da utilizzare può dipendere da una serie di fattori, tra cui l'età del paziente, lo stato di immunizzazione precedente e le preferenze personali.
In medicina e biologia molecolare, un plasmide è definito come un piccolo cromosoma extracromosomale a doppia elica circolare presente in molti batteri e organismi unicellulari. I plasmidi sono separati dal cromosoma batterico principale e possono replicarsi autonomamente utilizzando i propri geni di replicazione.
I plasmidi sono costituiti da DNA a doppia elica circolare che varia in dimensioni, da poche migliaia a diverse centinaia di migliaia di coppie di basi. Essi contengono tipicamente geni responsabili della loro replicazione e mantenimento all'interno delle cellule ospiti. Alcuni plasmidi possono anche contenere geni che conferiscono resistenza agli antibiotici, la capacità di degradare sostanze chimiche specifiche o la virulenza per causare malattie.
I plasmidi sono utilizzati ampiamente in biologia molecolare e ingegneria genetica come vettori per clonare e manipolare geni. Essi possono essere facilmente modificati per contenere specifiche sequenze di DNA, che possono quindi essere introdotte nelle cellule ospiti per studiare la funzione dei geni o produrre proteine ricombinanti.
Il "gene targeting" è una tecnica di ingegneria genetica che consente la modifica specifica e mirata del DNA in un gene particolare all'interno dell'genoma. Questa tecnica utilizza sequenze di DNA omologhe al gene bersaglio per dirigere l'inserimento o la correzione di mutazioni nel gene, spesso attraverso l'uso di sistemi di ricombinazione omologa o altre tecniche di editing del genoma come CRISPR-Cas9. Il gene targeting è una potente tecnica che viene utilizzata per studiare la funzione dei geni e per creare modelli animali di malattie umane in cui i geni possono essere manipolati per mimare le mutazioni associate a determinate condizioni.
La timina è un nucleotide pirimidinico che fa parte della struttura del DNA. Si trova sul lato posteriore della catena dolce dello scheletro azotato, complementare all'adenina sulla catena opposta. La timina e l'adenina formano una coppia di basi con due legami idrogeno tra di loro. Quando il DNA viene trascritto in RNA, la timina viene sostituita dall'uracile durante la sintesi dell'RNA. È importante notare che la timina si trova solo nel DNA e non nell'RNA.
La regolazione dell'espressione genica è un processo biologico fondamentale che controlla la quantità e il momento in cui i geni vengono attivati per produrre proteine funzionali. Questo processo complesso include una serie di meccanismi a livello trascrizionale (modifiche alla cromatina, legame dei fattori di trascrizione e iniziazione della trascrizione) ed post-trascrizionali (modifiche all'mRNA, stabilità dell'mRNA e traduzione). La regolazione dell'espressione genica è essenziale per lo sviluppo, la crescita, la differenziazione cellulare e la risposta alle variazioni ambientali e ai segnali di stress. Diversi fattori genetici ed epigenetici, come mutazioni, varianti genetiche, metilazione del DNA e modifiche delle istone, possono influenzare la regolazione dell'espressione genica, portando a conseguenze fenotipiche e patologiche.
Le cellule HeLa sono una linea cellulare immortale che prende il nome da Henrietta Lacks, una paziente afroamericana a cui è stato diagnosticato un cancro cervicale invasivo nel 1951. Senza il suo consenso informato, le cellule cancerose del suo utero sono state prelevate e utilizzate per creare la prima linea cellulare umana immortale, che si è riprodotta indefinitamente in coltura.
Le cellule HeLa hanno avuto un impatto significativo sulla ricerca biomedica, poiché sono state ampiamente utilizzate nello studio di una varietà di processi cellulari e malattie umane, inclusi la divisione cellulare, la riparazione del DNA, la tossicità dei farmaci, i virus e le risposte immunitarie. Sono anche state utilizzate nello sviluppo di vaccini e nella ricerca sulla clonazione.
Tuttavia, l'uso delle cellule HeLa ha sollevato questioni etiche importanti relative al consenso informato, alla proprietà intellettuale e alla privacy dei pazienti. Nel 2013, il genoma completo delle cellule HeLa è stato sequenziato e pubblicato online, suscitando preoccupazioni per la possibilità di identificare geneticamente i parenti viventi di Henrietta Lacks senza il loro consenso.
In sintesi, le cellule HeLa sono una linea cellulare immortale derivata da un paziente con cancro cervicale invasivo che ha avuto un impatto significativo sulla ricerca biomedica, ma hanno anche sollevato questioni etiche importanti relative al consenso informato e alla privacy dei pazienti.
I fattori di trascrizione sono proteine che legano specifiche sequenze del DNA e facilitano o inibiscono la trascrizione dei geni in RNA messaggero (mRNA). Essenzialmente, agiscono come interruttori molecolari che controllano l'espressione genica, determinando se e quando un gene viene attivato per essere trascritto.
I fattori di trascrizione sono costituiti da diversi domini proteici funzionali: il dominio di legame al DNA, che riconosce ed è specifico per una particolare sequenza del DNA; e il dominio attivatore o repressore della trascrizione, che interagisce con l'apparato enzimatico responsabile della sintesi dell'RNA.
La regolazione dei geni da parte di questi fattori è un processo altamente complesso e dinamico, che può essere influenzato da vari segnali intracellulari ed extracellulari. Le alterazioni nella funzione o nell'espressione dei fattori di trascrizione possono portare a disfunzioni cellulari e patologiche, come ad esempio nel cancro e in altre malattie genetiche.
In sintesi, i fattori di trascrizione sono proteine chiave che regolano l'espressione genica, contribuendo a modulare la diversità e la dinamica delle risposte cellulari a stimoli interni o esterni.
La parola "Ficusina" non è comunemente utilizzata nella medicina o nella terminologia medica. Tuttavia, in campo microbiologico, Ficusina è il nome di un genere di batteri appartenente alla famiglia delle Hyphomicrobiaceae. Questi batteri sono stati isolati da diverse fonti ambientali, come l'acqua e il suolo. Al momento non ci sono informazioni mediche specifiche o dirette associate a questo termine.
L'espressione genica è un processo biologico che comporta la trascrizione del DNA in RNA e la successiva traduzione dell'RNA in proteine. Questo processo consente alle cellule di leggere le informazioni contenute nel DNA e utilizzarle per sintetizzare specifiche proteine necessarie per svolgere varie funzioni cellulari.
Il primo passo dell'espressione genica è la trascrizione, durante la quale l'enzima RNA polimerasi legge il DNA e produce una copia di RNA complementare chiamata RNA messaggero (mRNA). Il mRNA poi lascia il nucleo e si sposta nel citoplasma dove subisce il processamento post-trascrizionale, che include la rimozione di introni e l'aggiunta di cappucci e code poli-A.
Il secondo passo dell'espressione genica è la traduzione, durante la quale il mRNA viene letto da un ribosoma e utilizzato come modello per sintetizzare una specifica proteina. Durante questo processo, gli amminoacidi vengono legati insieme in una sequenza specifica codificata dal mRNA per formare una catena polipeptidica che poi piega per formare una proteina funzionale.
L'espressione genica può essere regolata a livello di trascrizione o traduzione, e la sua regolazione è essenziale per il corretto sviluppo e la homeostasi dell'organismo. La disregolazione dell'espressione genica può portare a varie malattie, tra cui il cancro e le malattie genetiche.
Il Pesce Zebra, noto in campo medico come "Danio rerio", è un tipo di pesce tropicale d'acqua dolce ampiamente utilizzato come organismo modello in biologia e nella ricerca medica. Il suo genoma è ben caratterizzato e completamente sequenziato, il che lo rende un soggetto di studio ideale per la comprensione dei meccanismi molecolari e cellulari alla base dello sviluppo embrionale, della genetica, della tossicologia e della farmacologia.
In particolare, i ricercatori sfruttano le sue caratteristiche uniche, come la trasparenza delle larve e la facilità di manipolazione genetica, per studiare il comportamento dei geni e dei sistemi biologici in risposta a vari stimoli e condizioni. Questo ha portato alla scoperta di numerosi principi fondamentali della biologia e alla comprensione di molte malattie umane, tra cui i disturbi neurologici, le malformazioni congenite e il cancro.
In sintesi, il Pesce Zebra è un organismo modello importante in biologia e ricerca medica, utilizzato per comprendere i meccanismi molecolari e cellulari alla base di vari processi fisiologici e patologici.
In farmacologia, la stabilità si riferisce alla capacità di un farmaco di mantenere le sue proprietà fisiche, chimiche e biologiche nel tempo, senza subire alterazioni che possano influenzarne l'efficacia o la sicurezza.
La stabilità farmacologica può essere valutata in diversi modi, a seconda del contesto:
1. Stabilità chimica: si riferisce alla capacità di un farmaco di mantenere la sua struttura molecolare e la sua purezza chimica nel tempo. Un farmaco instabile può degradarsi in composti più semplici o inattivi, con conseguente perdita di efficacia terapeutica.
2. Stabilità fisica: si riferisce alla capacità di un farmaco di mantenere le sue proprietà fisiche, come il colore, l'aspetto, la consistenza e la solubilità. Un farmaco instabile può subire cambiamenti fisici che ne rendano difficile o impossibile l'utilizzo.
3. Stabilità biologica: si riferisce alla capacità di un farmaco di mantenere la sua attività biologica nel tempo, senza essere inattivato da fattori enzimatici o altri fattori biologici. Un farmaco instabile può essere rapidamente metabolizzato o eliminato dall'organismo, con conseguente riduzione dell'efficacia terapeutica.
La stabilità farmacologica è un fattore importante da considerare nella formulazione, conservazione e somministrazione dei farmaci, per garantire la loro sicurezza ed efficacia nel tempo. La valutazione della stabilità farmacologica può essere effettuata attraverso diversi metodi di test, come la cromatografia liquida ad alta prestazione (HPLC), la spettroscopia e la microbiologia, a seconda del tipo di stabilità da valutare.
G-Quadruplexes sono strutture secondarie della DNA o RNA che si formano in presenza di sequenze ripetute di guanina (G). Queste sequenze possono formare un complesso a stacking di plani multipli di ioni potassio o sodio circondati da quattro basi guanine, legate tra loro tramite ponti di idrogeno. Si trovano comunemente in regioni promotrici dei geni, telomeri e sequenze microsatelliti. Le strutture G-Quadruplexes sono considerate importanti nella regolazione della trascrizione genica, replicazione del DNA e nella stabilizzazione dei telomeri. Possono anche svolgere un ruolo nell'inibizione dell'attività di certaini enzimi come la telomerasi, il che le rende un bersaglio interessante per lo sviluppo di farmaci antitumorali.
La relazione struttura-attività (SAR (Structure-Activity Relationship)) è un concetto importante nella farmacologia e nella tossicologia. Si riferisce alla relazione quantitativa tra le modifiche chimiche apportate a una molecola e il suo effetto biologico, vale a dire la sua attività biologica o tossicità.
In altre parole, la SAR descrive come la struttura chimica di un composto influisce sulla sua capacità di interagire con bersagli biologici specifici, come proteine o recettori, e quindi su come tali interazioni determinano l'attività biologica del composto.
La relazione struttura-attività è uno strumento essenziale nella progettazione di farmaci, poiché consente ai ricercatori di prevedere come modifiche specifiche alla struttura chimica di un composto possono influire sulla sua attività biologica. Questo può guidare lo sviluppo di nuovi farmaci più efficaci e sicuri, oltre a fornire informazioni importanti sulla modalità d'azione dei farmaci esistenti.
La relazione struttura-attività si basa sull'analisi delle proprietà chimiche e fisiche di una molecola, come la sua forma geometrica, le sue dimensioni, la presenza di determinati gruppi funzionali e la sua carica elettrica. Questi fattori possono influenzare la capacità della molecola di legarsi a un bersaglio biologico specifico e quindi determinare l'entità dell'attività biologica del composto.
In sintesi, la relazione struttura-attività è una strategia per correlare le proprietà chimiche e fisiche di una molecola con il suo effetto biologico, fornendo informazioni preziose sulla progettazione e lo sviluppo di farmaci.
In campo medico e genetico, una mutazione è definita come un cambiamento permanente nel materiale genetico (DNA o RNA) di una cellula. Queste modifiche possono influenzare il modo in cui la cellula funziona e si sviluppa, compreso l'effetto sui tratti ereditari. Le mutazioni possono verificarsi naturalmente durante il processo di replicazione del DNA o come risultato di fattori ambientali dannosi come radiazioni, sostanze chimiche nocive o infezioni virali.
Le mutazioni possono essere classificate in due tipi principali:
1. Mutazioni germinali (o ereditarie): queste mutazioni si verificano nelle cellule germinali (ovuli e spermatozoi) e possono essere trasmesse dai genitori ai figli. Le mutazioni germinali possono causare malattie genetiche o predisporre a determinate condizioni mediche.
2. Mutazioni somatiche: queste mutazioni si verificano nelle cellule non riproduttive del corpo (somatiche) e di solito non vengono trasmesse alla prole. Le mutazioni somatiche possono portare a un'ampia gamma di effetti, tra cui lo sviluppo di tumori o il cambiamento delle caratteristiche cellulari.
Le mutazioni possono essere ulteriormente suddivise in base alla loro entità:
- Mutazione puntiforme: una singola base (lettera) del DNA viene modificata, eliminata o aggiunta.
- Inserzione: una o più basi vengono inserite nel DNA.
- Delezione: una o più basi vengono eliminate dal DNA.
- Duplicazione: una sezione di DNA viene duplicata.
- Inversione: una sezione di DNA viene capovolta end-to-end, mantenendo l'ordine delle basi.
- Traslocazione: due segmenti di DNA vengono scambiati tra cromosomi o all'interno dello stesso cromosoma.
Le mutazioni possono avere effetti diversi sul funzionamento delle cellule e dei geni, che vanno da quasi impercettibili a drammatici. Alcune mutazioni non hanno alcun effetto, mentre altre possono portare a malattie o disabilità.
La citosina è uno dei quattro nucleotidi che costituiscono le unità fondamentali delle molecole di DNA e RNA. È rappresentata dal simbolo "C" ed è specificamente una base azotata pirimidinica. Nella struttura del DNA, la citosina si accoppia sempre con la guanina (G) tramite legami a idrogeno, formando una coppia di basi GC stabile. Questa relazione è importante per la replicazione e la trascrizione genetica. Nel RNA, tuttavia, l'uracile sostituisce la citosina come partner della guanina. La citosina svolge un ruolo cruciale nella regolazione dell'espressione genica e nelle mutazioni genetiche quando viene deaminata in uracile, il che può portare a errori di replicazione o riparazione del DNA. È importante notare che questa definizione si riferisce specificamente alla citosina nel contesto della biologia molecolare e genetica.
La divisione cellulare è un processo fondamentale per la crescita, lo sviluppo e la riparazione dei tessuti in tutti gli organismi viventi. È il meccanismo attraverso cui una cellula madre si divide in due cellule figlie geneticamente identiche. Ci sono principalmente due tipi di divisione cellulare: mitosi e meiosi.
1. Mitosi: Questo tipo di divisione cellulare produce due cellule figlie geneticamente identiche alla cellula madre. E' il processo che si verifica durante la crescita e lo sviluppo normale, nonché nella riparazione dei tessuti danneggiati. Durante la mitosi, il materiale genetico della cellula (DNA) viene replicato ed equalmente distribuito alle due cellule figlie.
L'analisi di sequenze attraverso un pannello di oligonucleotidi è una tecnica di biologia molecolare utilizzata per rilevare variazioni genetiche in specifici geni associati a particolari malattie ereditarie. Questa metodologia si basa sull'impiego di un pannello composto da una matrice di oligonucleotidi sintetici, progettati per legarsi selettivamente a sequenze nucleotidiche specifiche all'interno dei geni target.
Durante l'analisi, il DNA del soggetto viene estratto e amplificato mediante PCR (Reazione a Catena della Polimerasi) per le regioni di interesse. Successivamente, i frammenti amplificati vengono applicati al pannello di oligonucleotidi e sottoposti a un processo di ibridazione, in cui le sequenze complementari si legano tra loro. Utilizzando tecniche di rilevazione sensibili, come la fluorescenza o l'elettrochemiluminescenza, è possibile identificare eventuali variazioni nella sequenza del DNA del soggetto rispetto a quella di riferimento.
Questa metodologia offre diversi vantaggi, tra cui:
1. Maggiore accuratezza e sensibilità nel rilevamento di mutazioni puntiformi, piccole inserzioni/delezioni (indel) o variazioni copy number (CNV).
2. Possibilità di analizzare simultaneamente numerosi geni associati a una specifica malattia o fenotipo, riducendo i tempi e i costi rispetto all'analisi singola di ciascun gene.
3. Standardizzazione del processo di rilevamento delle varianti, facilitando il confronto e la comparabilità dei dati ottenuti in diversi laboratori.
L'analisi di sequenze attraverso un pannello di oligonucleotidi è ampiamente utilizzata nella diagnostica molecolare per identificare mutazioni associate a malattie genetiche, tumori e altre condizioni cliniche. Tuttavia, è importante considerare che questa tecnica non rileva tutte le possibili varianti presenti nel DNA, pertanto potrebbe essere necessario ricorrere ad altri metodi di indagine, come la sequenziamento dell'intero esoma o del genoma, per ottenere un quadro completo della situazione genetica del soggetto.
La guanosina è una nucleoside formata dalla combinazione di una base purina, chiamata guanina, e uno zucchero a cinque atomi di carbonio, chiamato ribosio. Nella biologia molecolare, la guanosina svolge un ruolo importante nelle comunicazioni cellulari e nell'archiviazione dell'informazione genetica. Si trova comunemente come parte della struttura degli acidi nucleici, come il DNA e l'RNA.
In un contesto clinico o di ricerca medica, la guanosina può essere rilevante in vari scenari. Ad esempio, i livelli anormali di guanosina nel fluido corporeo possono essere indicativi di alcune condizioni patologiche, come danni ai tessuti o malattie neurodegenerative. Inoltre, la guanosina e i suoi derivati sono stati studiati per il loro potenziale ruolo nel trattamento di varie malattie, tra cui l'ictus, le lesioni cerebrali traumatiche e alcune condizioni cardiovascolari.
Tuttavia, è importante notare che la guanosina non viene solitamente utilizzata come farmaco o trattamento specifico, ma piuttosto come potenziale bersaglio terapeutico o biomarcatore di malattia in studi di ricerca.
"Acidi nucleici immobilizzati" si riferisce a acidi nucleici (come DNA o RNA) che sono stati fisicamente fissati o adesi a una superficie solida o a un supporto solido. Questo processo di immobilizzazione può essere realizzato utilizzando vari metodi, come l'incorporazione chimica o fisica degli acidi nucleici in matrici polimeriche, magnetiche o di vetro.
L'immobilizzazione degli acidi nucleici è una tecnica ampiamente utilizzata nella ricerca biomedica e bioingegneristica per applicazioni quali la separazione, l'identificazione, la purificazione, la detezione e l'analisi di molecole biologiche. Ad esempio, gli acidi nucleici immobilizzati possono essere utilizzati in esperimenti di sequenziamento del DNA, PCR, ibridazione del DNA, elettroforesi su gel e microarray di acidi nucleici.
L'immobilizzazione degli acidi nucleici può anche essere utilizzata per creare biosensori o dispositivi biochimici che sfruttano le interazioni specifiche tra gli acidi nucleici e altre molecole biologiche, come proteine o piccoli molecole. Questi biosensori possono essere utilizzati per rilevare la presenza di specifiche sequenze di DNA o RNA in campioni biologici o ambientali, o per monitorare l'attività enzimatica o le interazioni molecolari in tempo reale.
L'RNA antisenso si riferisce a un tipo di RNA che non codifica per proteine e che ha una sequenza nucleotidica complementare a un altro RNA, noto come RNA senso o mRNA (RNA messaggero). Quando l'RNA antisenso entra in contatto con il suo corrispondente RNA senso, può formare una struttura a doppia elica che impedisce la traduzione del mRNA in proteine.
L'RNA antisenso svolge un ruolo importante nella regolazione dell'espressione genica attraverso meccanismi come l'interferenza dell'RNA (RNAi), il silenziamento genico e la degradazione dell'mRNA. Può derivare da regioni specifiche di un gene che codifica per proteine, oppure può essere trascritto da geni non codificanti per proteine, noti come geni di RNA non codificanti (ncRNA).
L'RNA antisenso è stato identificato in diversi organismi viventi, dai batteri alle piante e agli animali, e svolge un ruolo cruciale nella regolazione dei processi cellulari e nell'adesione delle cellule.
La cromatografia liquida ad alta pressione (HPLC, High Performance Liquid Chromatography) è una tecnica analitica e preparativa utilizzata in chimica, biochimica e nelle scienze biomediche per separare, identificare e quantificare diversi componenti di miscele complesse.
In questo metodo, la fase stazionaria è costituita da una colonna riempita con particelle solide (ad esempio silice, zirconia o polimeri organici) mentre la fase mobile è un liquido che fluisce attraverso la colonna sotto alta pressione (fino a 400 bar). Le molecole della miscela da analizzare vengono caricate sulla colonna e interagiscono con la fase stazionaria in modo differente, a seconda delle loro proprietà chimico-fisiche (ad esempio dimensioni, carica elettrica, idrofobicità). Di conseguenza, le diverse specie chimiche vengono trattenute dalla colonna per periodi di tempo diversi, determinando la separazione spaziale delle componenti.
L'eluizione (cioè l'uscita) delle sostanze separate viene rilevata e registrata da un detector, che può essere di vario tipo a seconda dell'applicazione (ad esempio UV-Vis, fluorescenza, rifrattometria, massa). I dati ottenuti possono quindi essere elaborati per ottenere informazioni qualitative e quantitative sulle sostanze presenti nella miscela iniziale.
L'HPLC è una tecnica molto versatile, che può essere applicata a un'ampia gamma di composti, dalle piccole molecole organiche ai biomolecolari complessi (come proteine e oligonucleotidi). Grazie alla sua elevata risoluzione, sensibilità e riproducibilità, l'HPLC è diventata uno strumento fondamentale in numerosi campi, tra cui la chimica analitica, la farmaceutica, la biologia molecolare e la medicina di laboratorio.
La fosfodiesterasi (PDE) I è un tipo specifico di enzima che catalizza la degradazione dell'AMP ciclico (cAMP) in AMP. Il cAMP è una importante molecola secondaria di segnalazione intracellulare che svolge un ruolo chiave nella regolazione di diversi processi cellulari, come la contrattilità muscolare liscia, il rilascio di ormoni e neurotrasmettitori, e la risposta infiammatoria.
L'inibizione della PDE I può causare un aumento dei livelli intracellulari di cAMP, con conseguenti effetti farmacologici. Infatti, alcuni farmaci utilizzati per trattare l'ipertensione polmonare, come il sildenafil e il tadalafil, agiscono come inibitori della PDE I.
La PDE I è presente principalmente a livello cerebrale e vascolare, dove svolge un ruolo importante nella regolazione della funzione cognitiva e della pressione sanguigna. Tuttavia, l'esatta distribuzione tissutale e la funzione della PDE I possono variare in base al tipo isoenzimatico (PDE1A, PDE1B, PDE1C) e all'organismo considerato.
Un legame di proteine, noto anche come legame peptidico, è un tipo specifico di legame covalente che si forma tra il gruppo carbossilico (-COOH) di un amminoacido e il gruppo amminico (-NH2) di un altro amminoacido durante la formazione di una proteina. Questo legame chimico connette sequenzialmente gli amminoacidi insieme per formare catene polipeptidiche, che sono alla base della struttura primaria delle proteine. La formazione di un legame peptidico comporta la perdita di una molecola d'acqua (dehidratazione), con il risultato che il legame è costituito da un atomo di carbonio, due atomi di idrogeno, un ossigeno e un azoto (-CO-NH-). La specificità e la sequenza dei legami peptidici determinano la struttura tridimensionale delle proteine e, di conseguenza, le loro funzioni biologiche.
I reagenti reticolanti sono sostanze chimiche utilizzate in diversi processi di laboratorio per legare molecole o particelle insieme. Vengono chiamati "reticolanti" a causa della loro capacità di creare una rete o una struttura tridimensionale che può intrappolare altre sostanze.
Nella medicina diagnostica, i reagenti reticolanti possono essere utilizzati per marcare antigeni o anticorpi in test immunologici come l'immunoistochimica e l'immunofluorescenza. Questi reagenti contengono solitamente una parte che si lega specificamente a un antigene o a un anticorpo target, e una parte reticolante che sigilla la marcatura alla molecola bersaglio.
Inoltre, i reagenti reticolanti possono essere utilizzati nella terapia medica per legare farmaci o nanoparticelle a specifici siti di interesse all'interno del corpo. Questa tecnologia può migliorare l'efficacia dei trattamenti e ridurre al minimo gli effetti collaterali indesiderati.
Tuttavia, è importante notare che l'uso di reagenti reticolanti richiede una conoscenza approfondita della chimica e della biologia delle molecole in questione per garantire la specificità e l'efficacia del legame. Inoltre, l'uso improprio o l'esposizione a questi reagenti può causare effetti avversi sulla salute umana.
L'omologia sequenziale degli acidi nucleici è un metodo di confronto e analisi delle sequenze di DNA o RNA per determinare la loro somiglianza o differenza. Questa tecnica si basa sulla comparazione dei singoli nucleotidi che compongono le sequenze, cioè adenina (A), timina (T)/uracile (U), citosina (C) e guanina (G).
Nell'omologia sequenziale degli acidi nucleici, due o più sequenze sono allineate in modo da massimizzare la somiglianza tra di esse. Questo allineamento può includere l'inserimento di spazi vuoti, noti come gap, per consentire un migliore adattamento delle sequenze. L'omologia sequenziale degli acidi nucleici è comunemente utilizzata in biologia molecolare e genetica per identificare le relazioni evolutive tra organismi, individuare siti di restrizione enzimatica, progettare primer per la reazione a catena della polimerasi (PCR) e studiare la diversità genetica.
L'omologia sequenziale degli acidi nucleici è misurata utilizzando diversi metodi, come il numero di identità delle basi, la percentuale di identità o la distanza evolutiva. Una maggiore somiglianza tra le sequenze indica una probabilità più elevata di una relazione filogenetica stretta o di una funzione simile. Tuttavia, è importante notare che l'omologia sequenziale non implica necessariamente un'omologia funzionale o strutturale, poiché le mutazioni possono influire sulla funzione e sulla struttura delle proteine codificate dalle sequenze di DNA.
In campo medico, i polinucleotidi sono lunghe catene di nucleotidi, i componenti costitutivi degli acidi nucleici come DNA e RNA. Ogni nucleotide è composto da un gruppo fosfato, uno zucchero deossiribosio o ribosio, e una base azotata (adenina, guanina, citosina, timina o uracile).
I polinucleotidi possono essere monostrand (una singola catena di nucleotidi) o doppi strand (due catene complementari avvolte una sull'altra), a seconda del tipo di acido nucleico di cui fanno parte. Sono importanti nella replicazione, trascrizione e traduzione del DNA e dell'RNA, nonché in altre funzioni cellulari come la riparazione del DNA e l'attivazione degli enzimi.
I polinucleotidi sintetici sono utilizzati in diversi campi della ricerca biomedica, tra cui la genomica, la proteomica e la terapia genica, per sequenziare, modificare o regolare l'espressione dei geni.
I nucleosidi sono composti organici costituiti da una base azotata legata a un pentoso (zucchero a cinque atomi di carbonio). Nella maggior parte dei nucleosidi naturalmente presenti, la base azotata è legata al carbonio 1' dello zucchero attraverso una glicosidica beta-N9-etere bond (negli purine) o un legame N1-glicosidico (negli pirimidini).
I nucleosidi svolgono un ruolo fondamentale nella biologia cellulare, poiché sono i precursori dei nucleotidi, che a loro volta sono componenti essenziali degli acidi nucleici (DNA e RNA) e di importanti molecole energetiche come l'ATP (adenosina trifosfato).
Esempi comuni di nucleosidi includono adenosina, guanosina, citidina, uridina e timidina. Questi composti sono cruciali per la replicazione, la trascrizione e la traduzione del DNA e dell'RNA, processi fondamentali per la crescita, lo sviluppo e la riproduzione cellulare.
In sintesi, i nucleosidi sono molecole organiche composte da una base azotata legata a un pentoso attraverso un legame glicosidico. Sono importanti precursori dei nucleotidi e svolgono un ruolo cruciale nella biologia cellulare, in particolare nei processi di replicazione, trascrizione e traduzione del DNA e dell'RNA.
Il dicroismo circolare è un fenomeno ottico che si verifica quando la luce polarizzata attraversa un mezzo otticamente attivo, come una soluzione contenente molecole chirali. Nello specifico, il dicroismo circolare si riferisce alla differenza nell'assorbimento della luce polarizzata a sinistra rispetto a quella polarizzata a destra da parte di tali molecole. Questa differenza di assorbimento provoca una rotazione del piano di polarizzazione della luce, che può essere misurata e utilizzata per studiare la struttura e la conformazione delle molecole chirali.
In particolare, il dicroismo circolare viene spesso utilizzato in biochimica e biologia molecolare per analizzare la struttura secondaria delle proteine e degli acidi nucleici, come l'RNA e il DNA. La misurazione del dicroismo circolare può fornire informazioni sulla conformazione di tali molecole, ad esempio se sono presenti eliche o foglietti beta, e su eventuali cambiamenti conformazionali indotti da fattori come il pH, la temperatura o l'interazione con ligandi.
In sintesi, il dicroismo circolare è un importante strumento di analisi ottica che consente di studiare la struttura e le proprietà delle molecole chirali, con applicazioni particolari in biochimica e biologia molecolare.
In medicina e genetica, il termine "stampi genetici" (in inglese "genetic imprints" o "genomic imprinting") si riferisce a un fenomeno epigenetico attraverso il quale l'espressione genica di alcuni geni viene silenziata in modo permanente, a seconda dell'origine del cromosoma (se è materno o paterno). Questo processo comporta modifiche chimiche alle molecole di DNA e di istone che compongono il cromosoma, senza alterarne la sequenza nucleotidica. Di conseguenza, un gene ereditato dal padre potrebbe essere espresso in modo diverso rispetto allo stesso gene ereditato dalla madre.
Gli stampi genetici svolgono un ruolo cruciale nello sviluppo embrionale e fetale, nella crescita e nella regolazione dell'equilibrio energetico. Alcune malattie genetiche rare sono causate da anomalie nel processo di imprinting, come il sindrome di Prader-Willi e la sindrome di Angelman. Questi disturbi si verificano quando manca l'espressione di geni specifici su uno dei due cromosomi 15, a seconda che provengano dal padre o dalla madre.
In sintesi, gli stampi genetici sono modifiche epigenetiche che alterano l'espressione genica in base all'origine del cromosoma, con importanti implicazioni per lo sviluppo e la salute umana.
Il DNA virale si riferisce al genoma costituito da DNA che è presente nei virus. I virus sono entità biologiche obbligate che infettano le cellule ospiti e utilizzano il loro macchinario cellulare per la replicazione del proprio genoma e la sintesi delle proteine.
Esistono due tipi principali di DNA virale: a doppio filamento (dsDNA) e a singolo filamento (ssDNA). I virus a dsDNA, come il citomegalovirus e l'herpes simplex virus, hanno un genoma costituito da due filamenti di DNA complementari. Questi virus replicano il loro genoma utilizzando enzimi come la DNA polimerasi e la ligasi per sintetizzare nuove catene di DNA.
I virus a ssDNA, come il parvovirus e il papillomavirus, hanno un genoma costituito da un singolo filamento di DNA. Questi virus utilizzano enzimi come la reverse transcriptasi per sintetizzare una forma a doppio filamento del loro genoma prima della replicazione.
Il DNA virale può causare una varietà di malattie, dalle infezioni respiratorie e gastrointestinali alle neoplasie maligne. La comprensione del DNA virale e dei meccanismi di replicazione è fondamentale per lo sviluppo di strategie di prevenzione e trattamento delle infezioni virali.
Le purine sono composti organici azotati che svolgono un ruolo cruciale nel metabolismo cellulare. Essi si trovano naturalmente in alcuni alimenti e sono anche prodotti dal corpo umano come parte del normale processo di riciclo delle cellule.
In termini medici, le purine sono importanti per la produzione di DNA e RNA, nonché per la sintesi dell'energia nelle cellule attraverso la produzione di ATP (adenosina trifosfato). Tuttavia, un eccesso di purine nel corpo può portare all'accumulo di acido urico, che a sua volta può causare malattie come la gotta.
Alcuni farmaci possono anche influenzare il metabolismo delle purine, ad esempio alcuni chemioterapici utilizzati per trattare il cancro possono interferire con la sintesi delle purine e portare a effetti collaterali come la neutropenia (riduzione dei globuli bianchi).
In termini medici, il termine "vetro" non ha una definizione specifica. Tuttavia, in un contesto generale, il vetro è un materiale solido e fragile che si forma quando il silicio (un elemento chimico) viene fuso con altri minerali a temperature molto elevate.
In alcuni casi, il termine "vetro" può essere usato in modo figurativo per descrivere una condizione o uno stato del corpo che è trasparente o fragile, come ad esempio la "membrana vetrosa" dell'occhio, che è una membrana sottile e trasparente che riveste il bulbo oculare.
Inoltre, il termine "vetro" può anche essere usato per descrivere un tipo di frattura ossea in cui l'osso si rompe in pezzi irregolari e taglienti, simili a schegge di vetro. Questa condizione è nota come "frattura da stress comunemente chiamata frattura da stress da fatica o frattura da stress da sovraccarico".
In sintesi, il termine "vetro" non ha una definizione medica specifica, ma può essere usato in vari contesti per descrivere diversi aspetti del corpo umano.
La Spettroscopia di Risonanza Magnetica (MRS, Magnetic Resonance Spectroscopy) è una tecnica di imaging biomedico che fornisce informazioni metaboliche e biochimiche su tessuti viventi. Si basa sulle stesse principi della risonanza magnetica (MRI), ma invece di produrre immagini, MRS misura la concentrazione di diversi metaboliti all'interno di un volume specificato del tessuto.
Durante l'esame MRS, il paziente viene esposto a un campo magnetico statico e a impulsi di radiofrequenza, che inducono una risonanza magnetica nei nuclei atomici del tessuto target (solitamente atomi di idrogeno o 1H). Quando l'impulso di radiofrequenza viene interrotto, i nuclei ritornano al loro stato originale emettendo un segnale di rilassamento che è proporzionale alla concentrazione dei metaboliti presenti nel tessuto.
Questo segnale viene quindi elaborato per produrre uno spettro, che mostra picchi distintivi corrispondenti a diversi metaboliti. Ogni metabolita ha un pattern di picchi caratteristico, che consente l'identificazione e la quantificazione della sua concentrazione all'interno del tessuto target.
MRS è utilizzata principalmente per lo studio dei tumori cerebrali, dove può fornire informazioni sulla presenza di cellule tumorali e sulla risposta al trattamento. Tuttavia, questa tecnica ha anche applicazioni in altri campi della medicina, come la neurologia, la cardiologia e l'oncologia.
In medicina e biologia, un'esonucleasi è un enzima che catalizza la rimozione sequenziale di nucleotidi da una estremità di una molecola di acido nucleico (DNA o RNA), lavorando dall'estremità esposta verso l'interno. Queste importanti enzimi sono coinvolti in vari processi cellulari, come la riparazione del DNA, il mantenimento dell'integrità del genoma e il controllo della replicazione e della trascrizione dei geni.
Esistono diversi tipi di esonucleasi, classificati in base alla loro specificità per il substrato (DNA o RNA), la direzionalità (3'-5' o 5'-3') e il meccanismo di rimozione dei nucleotidi. Ad esempio, un'esonucleasi 3'-5' DNA rimuove i nucleotidi dall'estremità 3' dell'DNA, mentre un'esonucleasi 5'-3' RNA agisce sull'estremità 5' del filamento di RNA.
L'attività esonucleasica è fondamentale per il corretto funzionamento delle cellule e dei sistemi viventi, poiché contribuisce a mantenere l'equilibrio tra la sintesi e la degradazione dei nucleotidi, garantendo la stabilità del genoma e la corretta espressione genica. Tuttavia, un'attività esonucleasica anomala o disregolata può anche portare a diversi disturbi e patologie, come ad esempio i danni al DNA, le mutazioni genetiche e lo sviluppo di vari tipi di cancro.
L'analisi delle sequenze del DNA è il processo di determinazione dell'ordine specifico delle basi azotate (adenina, timina, citosina e guanina) nella molecola di DNA. Questo processo fornisce informazioni cruciali sulla struttura, la funzione e l'evoluzione dei geni e dei genomi.
L'analisi delle sequenze del DNA può essere utilizzata per una varietà di scopi, tra cui:
1. Identificazione delle mutazioni associate a malattie genetiche: L'analisi delle sequenze del DNA può aiutare a identificare le mutazioni nel DNA che causano malattie genetiche. Questa informazione può essere utilizzata per la diagnosi precoce, il consiglio genetico e la pianificazione della terapia.
2. Studio dell'evoluzione e della diversità genetica: L'analisi delle sequenze del DNA può fornire informazioni sull'evoluzione e sulla diversità genetica di specie diverse. Questo può essere particolarmente utile nello studio di popolazioni in pericolo di estinzione o di malattie infettive emergenti.
3. Sviluppo di farmaci e terapie: L'analisi delle sequenze del DNA può aiutare a identificare i bersagli molecolari per i farmaci e a sviluppare terapie personalizzate per malattie complesse come il cancro.
4. Identificazione forense: L'analisi delle sequenze del DNA può essere utilizzata per identificare individui in casi di crimini o di identificazione di resti umani.
L'analisi delle sequenze del DNA è un processo altamente sofisticato che richiede l'uso di tecnologie avanzate, come la sequenziazione del DNA ad alto rendimento e l'analisi bioinformatica. Questi metodi consentono di analizzare grandi quantità di dati genetici in modo rapido ed efficiente, fornendo informazioni preziose per la ricerca scientifica e la pratica clinica.
La definizione medica di "DNA complementare" si riferisce alla relazione tra due filamenti di DNA che sono legati insieme per formare una doppia elica. Ogni filamento del DNA è composto da una sequenza di nucleotidi, che contengono ciascuno uno zucchero deossiribosio, un gruppo fosfato e una base azotata (adenina, timina, guanina o citosina).
Nel DNA complementare, le basi azotate dei due filamenti si accoppiano in modo specifico attraverso legami idrogeno: adenina si accoppia con timina e guanina si accoppia con citosina. Ciò significa che se si conosce la sequenza di nucleotidi di un filamento di DNA, è possibile prevedere con precisione la sequenza dell'altro filamento, poiché sarà complementare ad esso.
Questa proprietà del DNA complementare è fondamentale per la replicazione e la trasmissione genetica, poiché consente alla cellula di creare una copia esatta del proprio DNA durante la divisione cellulare. Inoltre, è anche importante nella trascrizione genica, dove il filamento di DNA complementare al gene viene trascritto in un filamento di RNA messaggero (mRNA), che a sua volta viene tradotto in una proteina specifica.
L'elettroforesi su gel di poliacrilamide (PAGE, Polyacrylamide Gel Electrophoresis) è una tecnica di laboratorio utilizzata in biologia molecolare e genetica per separare, identificare e analizzare macromolecole, come proteine o acidi nucleici (DNA ed RNA), sulla base delle loro dimensioni e cariche.
Nel caso specifico dell'elettroforesi su gel di poliacrilamide, il gel è costituito da una matrice tridimensionale di polimeri di acrilamide e bis-acrilamide, che formano una rete porosa e stabile. La dimensione dei pori all'interno del gel può essere modulata variando la concentrazione della soluzione di acrilamide, permettendo così di separare molecole con differenti dimensioni e pesi molecolari.
Durante l'esecuzione dell'elettroforesi, le macromolecole da analizzare vengono caricate all'interno di un pozzo scavato nel gel e sottoposte a un campo elettrico costante. Le molecole con carica negativa migreranno verso l'anodo (polo positivo), mentre quelle con carica positiva si sposteranno verso il catodo (polo negativo). A causa dell'interazione tra le macromolecole e la matrice del gel, le molecole più grandi avranno una mobilità ridotta e verranno trattenute all'interno dei pori del gel, mentre quelle più piccole riusciranno a muoversi più velocemente attraverso i pori e si separeranno dalle altre in base alle loro dimensioni.
Una volta terminata l'elettroforesi, il gel può essere sottoposto a diversi metodi di visualizzazione e rivelazione delle bande, come ad esempio la colorazione con coloranti specifici per proteine o acidi nucleici, la fluorescenza o la radioattività. L'analisi delle bande permetterà quindi di ottenere informazioni sulla composizione, le dimensioni e l'identità delle macromolecole presenti all'interno del campione analizzato.
L'elettroforesi su gel è una tecnica fondamentale in molti ambiti della biologia molecolare, come ad esempio la proteomica, la genomica e l'analisi delle interazioni proteina-proteina o proteina-DNA. Grazie alla sua versatilità, precisione e sensibilità, questa tecnica è ampiamente utilizzata per lo studio di una vasta gamma di sistemi biologici e per la caratterizzazione di molecole d'interesse in diversi campi della ricerca scientifica.
La repressione genetica è un processo epigenetico attraverso il quale l'espressione dei geni viene silenziata o ridotta. Ciò si verifica quando specifiche proteine, chiamate repressori genici, si legano a sequenze di DNA specifiche, impedendo la trascrizione del gene in mRNA. Questo processo è fondamentale per il corretto sviluppo e la funzione dell'organismo, poiché consente di controllare l'espressione genica in modo spaziale e temporale appropriato. La repressione genetica può essere causata da vari fattori, tra cui modifiche chimiche del DNA o delle proteine storiche, interazioni proteina-proteina e cambiamenti nella struttura della cromatina. In alcuni casi, la disregolazione della repressione genetica può portare a malattie, come il cancro.
Le proteine del pesce zebra si riferiscono specificamente alle proteine identificate e studiate nel pesce zebrafish (Danio rerio), un organismo modello comunemente utilizzato in biologia dello sviluppo, genetica e ricerca biomedica. Il pesce zebra è noto per la sua facilità di riproduzione, lo sviluppo trasparente delle uova e l'elevata omologia genetica con gli esseri umani, il che lo rende un sistema di studio ideale per comprendere i meccanismi molecolari e cellulari alla base di vari processi fisiologici e patologici.
Le proteine del pesce zebra possono essere classificate in diverse categorie funzionali, come proteine strutturali, enzimi, proteine di segnalazione, proteine di trasporto e così via. Un esempio ben noto di proteina del pesce zebra è la GFP (Green Fluorescent Protein), originariamente isolata dalla medusa Aequorea victoria, che è stata ampiamente utilizzata come marcatore fluorescente nelle ricerche biologiche. Oltre a questo, molte proteine del pesce zebra sono state identificate e caratterizzate per svolgere un ruolo cruciale nello sviluppo embrionale, nella differenziazione cellulare, nella morfogenesi dei tessuti, nella riparazione dei danni al DNA e nell'insorgenza di malattie.
In sintesi, le proteine del pesce zebra sono un vasto insieme di molecole proteiche presenti nel pesce zebrafish che svolgono una varietà di funzioni essenziali per lo sviluppo, la crescita e la homeostasi dell'organismo. Lo studio di queste proteine ha contribuito in modo significativo alla nostra comprensione dei processi biologici fondamentali e allo sviluppo di terapie innovative per una serie di malattie umane.
La xantopterina è una biomolecola appartenente alla famiglia delle pirimidine. Si tratta di un derivato della nucleotide xantosina, che a sua volta deriva dalla guanosina tramite una modificazione enzimatica. La xantopterina svolge un ruolo importante nella produzione del cofattore flavin mononucleotide (FMN) e flavin adenin dinucleotide (FAD), che sono essenziali per la catena di trasporto degli elettroni nei mitocondri e per molte reazioni enzimatiche.
Inoltre, la xantopterina è stata identificata come un componente della melanina gialla, un pigmento presente in alcuni animali come uccelli, rettili e insetti. La presenza di questo pigmento conferisce a questi animali una colorazione giallo-arancione o verde, nota come xantocromia.
Non esiste una definizione medica specifica per la xantopterina, poiché non è un composto utilizzato direttamente in medicina. Tuttavia, può essere coinvolta in alcune reazioni metaboliche anormali che possono portare a patologie umane, come ad esempio nella sindrome dell'xantomatosi cerebrotendinea, una malattia genetica rara causata da un difetto enzimatico che porta all'accumulo di xantina e di altri lipidi nel tessuto cerebrale e nelle articolazioni.
La genoteca è un'ampia raccolta o banca di campioni di DNA, che vengono tipicamente prelevati da diversi individui o specie. Viene utilizzata per archiviare e studiare i vari genotipi, cioè l'organizzazione e la sequenza specifica dei geni all'interno del DNA.
Le genoteche sono estremamente utili nella ricerca biomedica e genetica, poiché consentono di conservare e analizzare facilmente una grande varietà di campioni di DNA. Questo può aiutare i ricercatori a comprendere meglio le basi genetiche delle malattie, a sviluppare test diagnostici più precisi e persino a progettare trattamenti terapeutici personalizzati.
Le genoteche possono contenere campioni di DNA da una varietà di fonti, come sangue, tessuti o cellule. Possono anche essere create per studiare specifiche specie o popolazioni, o possono essere più ampie e includere campioni da una gamma più diversificata di individui.
In sintesi, la genoteca è uno strumento importante nella ricerca genetica che consente di archiviare, organizzare e analizzare i vari genotipi all'interno del DNA.
In chimica e farmacologia, un legame competitivo si riferisce a un tipo di interazione tra due molecole che competono per lo stesso sito di legame su una proteina target, come un enzima o un recettore. Quando un ligando (una molecola che si lega a una biomolecola) si lega al suo sito di legame, impedisce all'altro ligando di legarsi nello stesso momento.
Nel caso specifico dell'inibizione enzimatica, un inibitore competitivo è una molecola che assomiglia alla struttura del substrato enzimatico e si lega al sito attivo dell'enzima, impedendo al substrato di accedervi. Ciò significa che l'inibitore compete con il substrato per il sito di legame sull'enzima.
L'effetto di un inibitore competitivo può essere annullato aumentando la concentrazione del substrato, poiché a dosi più elevate, il substrato è in grado di competere con l'inibitore per il sito di legame. La costante di dissociazione dell'inibitore (Ki) può essere utilizzata per descrivere la forza del legame competitivo tra l'inibitore e l'enzima.
In sintesi, un legame competitivo è una forma di interazione molecolare in cui due ligandi si contendono lo stesso sito di legame su una proteina target, con conseguente riduzione dell'efficacia dell'uno o dell'altro ligando.
La spettrofotometria nell'ultravioletto (UV) è una tecnica strumentale utilizzata in analisi chimiche e fisiche per misurare l'assorbimento della radiazione ultravioletta da parte di una sostanza. Questa tecnica si basa sulla relazione tra l'intensità della luce incidente e quella trasmessa attraverso la sostanza, che dipende dalla lunghezza d'onda della luce utilizzata.
Nello specifico, la spettrofotometria UV misura l'assorbimento della radiazione UV da parte di una sostanza in soluzione, determinando il coefficiente di assorbimento o la sua trasmissione a diverse lunghezze d'onda all'interno dello spettro ultravioletto. Questa informazione può essere utilizzata per identificare e quantificare la concentrazione di una sostanza chimica specifica presente in una miscela, sulla base delle sue proprietà di assorbimento UV uniche.
La spettrofotometria nell'ultravioletto è ampiamente utilizzata in diversi campi della scienza e della tecnologia, tra cui la chimica analitica, la biochimica, la farmacologia e la fisica, per l'analisi di composti organici e inorganici, come pigmenti, vitamine, farmaci, proteine, acidi nucleici e altri biomolecole.
Una linea cellulare tumorale è un tipo di linea cellulare che viene coltivata in laboratorio derivando dalle cellule di un tumore. Queste linee cellulari sono ampiamente utilizzate nella ricerca scientifica e medica per studiare il comportamento delle cellule cancerose, testare l'efficacia dei farmaci antitumorali e comprendere meglio i meccanismi molecolari che stanno alla base dello sviluppo e della progressione del cancro.
Le linee cellulari tumorali possono essere derivate da una varietà di fonti, come ad esempio biopsie o resezioni chirurgiche di tumori solidi, oppure attraverso l'isolamento di cellule tumorali presenti nel sangue o in altri fluidi corporei. Una volta isolate, le cellule vengono mantenute in coltura e riprodotte per creare una popolazione omogenea di cellule cancerose che possono essere utilizzate a scopo di ricerca.
È importante sottolineare che le linee cellulari tumorali non sono identiche alle cellule tumorali originali presenti nel corpo umano, poiché durante il processo di coltivazione in laboratorio possono subire modificazioni genetiche e fenotipiche che ne alterano le caratteristiche. Pertanto, i risultati ottenuti utilizzando queste linee cellulari devono essere interpretati con cautela e validati attraverso ulteriori studi su modelli animali o su campioni umani.
La deossiuridina (dU) è un nucleoside pirimidinico che si trova naturalmente nelle cellule viventi. È uno dei quattro principali nucleosidi che compongono l'acido nucleico, gli altri sono la deossiadenosina, la deossiguanosina e la deossicitidina.
Nell'ambito della medicina e della biochimica, la deossiuridina è spesso studiata in relazione al DNA sintesi e riparazione. Il livello di incorporazione della deossiuridina nel DNA può essere utilizzato come biomarcatore per monitorare il tasso di divisione cellulare, che è particolarmente utile nello studio del cancro e delle malattie infiammatorie.
L'analisi dell'incorporazione della deossiuridina nel DNA può essere utilizzata anche come indicatore dello stress ossidativo nelle cellule, poiché l'aumento dei livelli di specie reattive dell'ossigeno (ROS) può causare danni al DNA e aumentare la probabilità che vengano incorporati nucleosidi anormali come la deossiuridina.
In sintesi, la deossiuridina è un importante biomarcatore e indicatore della salute cellulare, con implicazioni particolari per lo studio del cancro e delle malattie infiammatorie.
L'RNA splicing è un processo post-trascrizionale che si verifica nelle cellule eucariotiche, durante il quale vengono rimossi gli introni (sequenze non codificanti) dall'mRNA (RNA messaggero) appena trascritto. Contemporaneamente, gli esoni (sequenze codificanti) vengono accoppiati insieme per formare una sequenza continua e matura dell'mRNA.
Questo processo è essenziale per la produzione di proteine funzionali, poiché l'ordine e la sequenza degli esoni determinano la struttura e la funzione della proteina finale. L'RNA splicing può anche generare diverse isoforme di mRNA a partire da un singolo gene, aumentando notevolmente la diversità del trascrittoma e della proteoma cellulari.
L'RNA splicing è catalizzato da una complessa macchina molecolare chiamata spliceosoma, che riconosce specifiche sequenze nucleotidiche negli introni e negli esoni per guidare il processo di taglio e giunzione. Il meccanismo di RNA splicing è altamente regolato e può essere influenzato da vari fattori, come la modificazione chimica dell'RNA e l'interazione con proteine regolatorie.
In sintesi, l'RNA splicing è un processo fondamentale per la maturazione degli mRNA eucariotici, che consente di generare una diversità di proteine a partire da un numero relativamente limitato di geni.
La desossiribonucleasi I, nota anche come DNase I, è un enzima che catalizza la degradazione delle molecole di DNA (deossiribonucleico acid) mono o double-stranded. L'enzima taglia le molecole di DNA in frammenti di circa 200-300 paia di basi, preferibilmente dove ci sono singoli filamenti con estremità 3'-OH e 5'-fosfato.
La DNase I è prodotta principalmente dalle cellule del pancreas esocrino e viene secreta nel duodeno, dove svolge un ruolo importante nella digestione dei residui di DNA presenti negli alimenti. L'enzima è anche presente in molti tessuti e organi del corpo umano, come il fegato, i reni, la milza e il cervello, dove svolge funzioni diverse, tra cui il mantenimento dell'equilibrio cellulare e la regolazione della risposta immunitaria.
La DNase I è stata anche studiata come potenziale trattamento per malattie infiammatorie croniche, come la fibrosi polmonare, poiché sembra essere in grado di ridurre l'infiammazione e la formazione di tessuto cicatriziale. Tuttavia, sono necessari ulteriori studi per confermare questi effetti e determinare la sicurezza e l'efficacia dell'uso clinico della DNase I come farmaco.
DNA footprinting è una tecnica di biologia molecolare utilizzata per identificare siti di legame specifici delle proteine sul DNA. Viene eseguita mediante la digestione dell'acido desossiribonucleico (DNA) con enzimi di restrizione o endonucleasi dopo l'unione di una proteina al suo sito di legame specifico. L'enzima di restrizione non è in grado di tagliare il DNA nei punti in cui la proteina è legata, lasciando così un "footprint" o impronta digitale protetta dall'enzima.
La tecnica prevede l'isolamento del DNA trattato con la proteina e l'enzima di restrizione, seguita dalla separazione elettroforetica delle molecole di DNA su un gel di agarosio per determinare le dimensioni relative dei frammenti. Questi frammenti vengono quindi visualizzati utilizzando una tecnica di rilevamento radioattivo o fluorescente, rivelando così i punti in cui il DNA non è stato tagliato dall'enzima di restrizione a causa del legame della proteina.
La tecnica del DNA footprinting è particolarmente utile per lo studio dei meccanismi di regolazione genica, poiché consente di identificare i siti di legame specifici delle proteine che controllano l'espressione genica. Inoltre, può essere utilizzata per studiare le interazioni tra proteine e DNA in diversi stati fisiologici o patologici, come la cancerogenesi o lo stress ossidativo.
La "sequenza del consenso" è un termine utilizzato in genetica molecolare per descrivere una particolare disposizione dei nucleotidi nelle sequenze di DNA o RNA che si verifica quando due o più basi complementari si legano insieme in modo non standard, anziché formare la coppia di basi Watson-Crick tradizionale (Adenina-Timina o Citosina-Guanina).
La sequenza del consenso è spesso osservata nelle regioni ripetitive del DNA, come i introni e gli elementi trasponibili. La formazione di una sequenza del consenso può influenzare la struttura e la funzione del DNA o RNA, compresa la regolazione della trascrizione genica, la stabilità dell'mRNA e la traduzione proteica.
Una forma comune di sequenza del consenso è la coppia di basi G-U (Guanina-Uracile), che può formare una coppia di basi wobble nella struttura a doppio filamento del DNA o RNA. Questa coppia di basi non standard è meno stabile della coppia di basi Watson-Crick, ma può ancora fornire un legame sufficientemente stabile per mantenere l'integrità della struttura del DNA o RNA.
La sequenza del consenso può anche riferirsi alla disposizione preferenziale dei nucleotidi in una particolare posizione all'interno di una sequenza di DNA o RNA, che è stata determinata dall'analisi statistica di un gran numero di sequenze correlate. Questa sequenza del consenso può fornire informazioni utili sulla funzione e l'evoluzione delle sequenze genetiche.
In farmacologia, un vettore è comunemente definito come un agente che trasporta una determinata sostanza, come un farmaco, ad un bersaglio specifico all'interno dell'organismo. I vettori farmacologici sono quindi veicoli specializzati utilizzati per la consegna di farmaci a siti target specifici all'interno del corpo, con l'obiettivo di migliorare l'efficacia e la sicurezza dei trattamenti farmacologici.
I vettori farmacologici possono essere classificati in diverse categorie, a seconda del loro meccanismo d'azione o della loro composizione chimica. Alcuni esempi di vettori farmacologici includono:
1. Liposomi: piccole vescicole sferiche fatte di fosfolipidi che possono encapsulare farmaci idrofobi e idrofili, proteggendoli dal metabolismo enzimatico e dai sistemi immunitari e facilitandone il trasporto attraverso le membrane cellulari.
2. Nanoparticelle: particelle solide di dimensioni nanometriche che possono essere realizzate con una varietà di materiali, come polimeri, metalli o lipidi, e utilizzate per veicolare farmaci idrofobi e idrofili.
3. Virus vector: virus geneticamente modificati che possono trasportare geni terapeutici all'interno delle cellule bersaglio, con l'obiettivo di esprimere proteine terapeutiche o inibire la produzione di proteine dannose.
4. Peptidi vettori: peptidi sintetici o naturali che possono legare selettivamente recettori o antigeni specifici, facilitando il trasporto di farmaci all'interno delle cellule bersaglio.
5. Monoclonali Anticorpi vettori: anticorpi monoclonali geneticamente modificati che possono legare selettivamente antigeni specifici, facilitando il trasporto di farmaci all'interno delle cellule bersaglio.
Questi vettori possono essere utilizzati per veicolare una varietà di farmaci, come chemioterapici, immunomodulatori, geni terapeutici o vaccini, con l'obiettivo di aumentare la specificità e l'efficacia del trattamento. Tuttavia, è importante notare che i vettori possono anche presentare rischi, come la possibilità di infezione o immunogenicità, e devono essere utilizzati con cautela e sotto stretto controllo medico.
Le Sequenze Ripetitive degli Acidi Nucleici (NRPS, dall'inglese Non-ribosomal Peptide Synthetases) sono un tipo di sistemi enzimatici che sintetizzano peptidi senza l'utilizzo del ribosoma. Queste sequenze sono costituite da moduli enzimatici, ognuno dei quali è responsabile della formazione di un legame peptidico tra due aminoacidi. Ogni modulo contiene tre domini enzimatici principali: uno adenilante/condensazione (A), uno peptidil carrier protein (PCP) e uno che catalizza la formazione del legame peptidico (C).
Le NRPS sono in grado di sintetizzare una vasta gamma di peptidi, compresi alcuni con strutture altamente complesse e non standard. Queste sequenze enzimatiche sono presenti in molti organismi, tra cui batteri, funghi e piante, e sono responsabili della produzione di una varietà di metaboliti secondari, come antibiotici, toxine e siderofori.
Le NRPS sono anche note per la loro capacità di produrre peptidi con aminoacidi non proteinogenici, cioè aminoacidi che non sono codificati dal DNA e non vengono incorporati nei normali processi di traduzione. Questa caratteristica rende le NRPS un bersaglio interessante per lo sviluppo di nuovi farmaci e agenti terapeutici.
L'uridina è un nucleoside formato dalla combinazione di un anello di zucchero pentoso (ribosio) con la base azotata uracile. Si trova comunemente nelle molecole di RNA e svolge un ruolo importante nella sintesi delle proteine, nella regolazione del metabolismo energetico e nella riparazione del DNA. L'uridina può anche essere trovata in alcuni alimenti come lievito, fegato e latte materno. In medicina, l'uridina monofosfato (UMP) è usata come integratore alimentare per trattare alcune condizioni associate a carenze enzimatiche che portano a una ridotta sintesi di uridina. Tuttavia, l'uso dell'uridina come farmaco o integratore deve essere attentamente monitorato e gestito da un operatore sanitario qualificato a causa del potenziale rischio di effetti avversi.
La terapia genetica è un approccio terapeutico che mira a trattare o prevenire malattie mediante la modifica o la correzione dei geni difettosi o anomali. Ciò può essere ottenuto introducendo una copia funzionale di un gene sano nel DNA delle cellule del paziente, in modo da compensare l'effetto della versione difettosa del gene.
La terapia genetica può essere somministrata in diversi modi, a seconda del tipo di malattia e del tipo di cellule interessate. Ad esempio, la terapia genetica può essere somministrata direttamente nelle cellule del corpo (come nel caso delle malattie genetiche che colpiscono i muscoli o il cervello), oppure può essere somministrata alle cellule staminali, che possono quindi essere trapiantate nel paziente.
La terapia genetica è ancora una forma relativamente nuova di terapia e sono in corso studi clinici per valutarne l'efficacia e la sicurezza. Tuttavia, ci sono state alcune segnalazioni di successo nel trattamento di malattie genetiche rare e gravi, come la sindrome di Wiskott-Aldrich e la deficienza dell'immunità combinata grave (SCID).
Come con qualsiasi forma di terapia, la terapia genetica presenta anche dei rischi, come la possibilità di una risposta immunitaria avversa al vettore utilizzato per introdurre il gene sano, o la possibilità che il gene sano si inserisca nel DNA in modo errato, con conseguenze impreviste. Pertanto, è importante che la terapia genetica sia somministrata solo sotto la supervisione di medici esperti e in centri specializzati nella sua applicazione.
La deossiguanosina (dG) è un nucleoside formato dalla base azotata guanina legata al pentoso deossiribosio. Nella dG, il gruppo 2'-idrossile del ribosio viene sostituito con un atomo di idrogeno, rendendolo un deossiribosio.
La deossiguanosina svolge un ruolo importante nella biologia molecolare come costituente delle molecole di DNA. Nel DNA, due molecole di deossiribosio legate insieme formano una coppia base con la deossiadenosina (dA), grazie alla formazione di legami idrogeno tra le basi guanina e adenina. Questa specifica interazione è nota come coppia GC, che è una delle due principali coppie di basi che formano la struttura a doppia elica del DNA (l'altra è la coppia AT, tra la deossitimidina e la deossiadenosina).
La deossiguanosina può anche essere coinvolta nel metabolismo cellulare come intermedio nella sintesi di nucleotidi. Può essere convertita in deossiguanosin monofosfato (dGMP) da una chinasi specifica, che a sua volta può essere utilizzata per sintetizzare altri nucleotidi o incorporata nel DNA durante la replicazione del DNA.
In patologia, l'accumulo di deossiguanosina e dei suoi derivati può essere associato a condizioni come l'ipossia, l'ischemia e il danno da radicali liberi. Questi composti possono causare danni al DNA e contribuire allo sviluppo di malattie croniche come il cancro e le malattie neurodegenerative.
In termini medici, i raggi ultravioletti (UV) sono una forma di radiazione elettromagnetica con una lunghezza d'onda più corta della luce visibile, che si trova nello spettro elettromagnetico tra la luce blu a circa 400 nanometri (nm) e i raggi X a circa 10 nm.
I raggi UV sono classificati in tre bande principali in base alla loro lunghezza d'onda:
1. UVA (lunghezza d'onda 320-400 nm): questi raggi UV penetrano più profondamente nella pelle, causando l'invecchiamento cutaneo e aumentando il rischio di cancro della pelle.
2. UVB (lunghezza d'onda 280-320 nm): questi raggi UV sono i principali responsabili delle scottature solari e del cancro della pelle.
3. UVC (lunghezza d'onda 100-280 nm): questi raggi UV sono bloccati dall'atmosfera terrestre e non raggiungono la superficie della terra, ma possono essere presenti in alcune sorgenti artificiali di luce UV.
L'esposizione ai raggi UV può avere effetti sia positivi che negativi sulla salute umana. Da un lato, l'esposizione alla luce solare, che include i raggi UV, è essenziale per la produzione di vitamina D nel corpo umano. D'altra parte, l'esposizione eccessiva ai raggi UV può causare scottature, invecchiamento precoce della pelle e aumentare il rischio di cancro della pelle. Pertanto, è importante proteggersi adeguatamente quando si è esposti alla luce solare, soprattutto durante le ore di punta della giornata e in luoghi con forti radiazioni UV.
'Non Translated' non è una definizione medica riconosciuta, poiché si riferisce più probabilmente a un contesto di traduzione o linguistico piuttosto che a uno strettamente medico. Tuttavia, in un contesto medico, "non tradotto" potrebbe essere usato per descrivere una situazione in cui i risultati di un test di laboratorio o di imaging non sono chiari o presentano anomalie che devono ancora essere interpretate o "tradotte" in termini di diagnosi o significato clinico. In altre parole, il medico potrebbe dire che i risultati del test non sono stati "tradotti" in una conclusione definitiva o in un piano di trattamento specifico.
La biotina, anche conosciuta come vitamina H o vitamina B7, è una vitamina idrosolubile che svolge un ruolo importante nel metabolismo energetico del corpo. È essenziale per la sintesi e il funzionamento di enzimi chiave che sono coinvolti nella produzione di grassi, carboidrati e amminoacidi.
La biotina è presente in una varietà di alimenti come fegato, tuorli d'uovo, noci, semi, verdure a foglia verde scura, avocado e salmone. È anche prodotta naturalmente da alcuni batteri intestinali.
La carenza di biotina è rara, ma può causare sintomi come affaticamento, perdita di capelli, eruzioni cutanee, depressione e neurologici. Alcune persone possono avere una maggiore necessità di biotina, come le donne in gravidanza o che allattano, le persone con diabete e quelle con disturbi digestivi cronici.
L'integrazione di biotina è spesso utilizzata per promuovere la salute dei capelli, della pelle e delle unghie, sebbene siano necessarie ulteriori ricerche per confermare i suoi benefici per questi usi. In generale, una dieta equilibrata che include una varietà di cibi ricchi di biotina dovrebbe fornire la quantità giornaliera raccomandata di questa vitamina.
La biosintesi proteica è un processo metabolico fondamentale che si verifica nelle cellule di organismi viventi, dove le proteine vengono sintetizzate dalle informazioni genetiche contenute nel DNA. Questo processo complesso può essere suddiviso in due fasi principali: la trascrizione e la traduzione.
1. Trascrizione: Durante questa fase, l'informazione codificata nel DNA viene copiata in una molecola di RNA messaggero (mRNA) attraverso un processo enzimatico catalizzato dall'enzima RNA polimerasi. L'mRNA contiene una sequenza di basi nucleotidiche complementare alla sequenza del DNA che codifica per una specifica proteina.
2. Traduzione: Nella fase successiva, nota come traduzione, il mRNA funge da matrice su cui vengono letti e interpretati i codoni (tripletti di basi) che ne costituiscono la sequenza. Questa operazione viene eseguita all'interno dei ribosomi, organelli citoplasmatici presenti in tutte le cellule viventi. I ribosomi sono costituiti da proteine e acidi ribonucleici (ARN) ribosomali (rRNA). Durante il processo di traduzione, i transfer RNA (tRNA), molecole ad "L" pieghevoli che contengono specifiche sequenze di tre basi chiamate anticodoni, legano amminoacidi specifici. Ogni tRNA ha un sito di legame per un particolare aminoacido e un anticodone complementare a uno o più codoni nel mRNA.
Nel corso della traduzione, i ribosomi si muovono lungo il filamento di mRNA, legano sequenzialmente i tRNA carichi con amminoacidi appropriati e catalizzano la formazione dei legami peptidici tra gli aminoacidi, dando origine a una catena polipeptidica in crescita. Una volta sintetizzata, questa catena polipeptidica può subire ulteriori modifiche post-traduzionali, come la rimozione di segmenti o l'aggiunta di gruppi chimici, per formare una proteina funzionale matura.
In sintesi, il processo di traduzione è un meccanismo altamente coordinato ed efficiente che permette alle cellule di decodificare le informazioni contenute nel DNA e di utilizzarle per produrre proteine essenziali per la vita.
Le proteine ricombinanti sono proteine prodotte artificialmente mediante tecniche di ingegneria genetica. Queste proteine vengono create combinando il DNA di due organismi diversi in un unico organismo o cellula ospite, che poi produce la proteina desiderata.
Il processo di produzione di proteine ricombinanti inizia con l'identificazione di un gene che codifica per una specifica proteina desiderata. Il gene viene quindi isolato e inserito nel DNA di un organismo ospite, come batteri o cellule di lievito, utilizzando tecniche di biologia molecolare. L'organismo ospite viene quindi fatto crescere in laboratorio, dove produce la proteina desiderata durante il suo normale processo di sintesi proteica.
Le proteine ricombinanti hanno una vasta gamma di applicazioni nella ricerca scientifica, nella medicina e nell'industria. Ad esempio, possono essere utilizzate per produrre farmaci come l'insulina e il fattore di crescita umano, per creare vaccini contro malattie infettive come l'epatite B e l'influenza, e per studiare la funzione delle proteine in cellule e organismi viventi.
Tuttavia, la produzione di proteine ricombinanti presenta anche alcune sfide e rischi, come la possibilità di contaminazione con patogeni o sostanze indesiderate, nonché questioni etiche relative all'uso di organismi geneticamente modificati. Pertanto, è importante che la produzione e l'utilizzo di proteine ricombinanti siano regolamentati e controllati in modo appropriato per garantire la sicurezza e l'efficacia dei prodotti finali.
Gli organotiofosforici sono composti organici che contengono un atomo di fosforo legato a uno o più atomi di zolfo. Questi composti sono noti per le loro proprietà tossiche e vengono utilizzati in una varietà di applicazioni, tra cui pesticidi, plastificanti, lubrificanti e agenti antischiuma. Alcuni esempi comuni di organotiofosforici includono il parathion, il malatione e l'esanoetiltiorifosfato.
In medicina, gli organotiofosforici sono noti per la loro capacità di inibire l'acetilcolinesterasi, un enzima importante nel sistema nervoso centrale e periferico. Questa inibizione può portare ad un accumulo di acetilcolina, un neurotrasmettitore, nei collegamenti neuromuscolari, causando una varietà di sintomi che possono includere crampi muscolari, tremori, convulsioni, paralisi e, in casi gravi, morte.
L'esposizione agli organotiofosforici può verificarsi attraverso l'inalazione, il contatto con la pelle o il consumo di cibi o bevande contaminate. Il trattamento per l'avvelenamento da organotiofosforici include il supporto delle funzioni vitali, la decontaminazione e l'uso di farmaci anticolinergici per contrastare gli effetti dell'inibizione dell'acetilcolinesterasi.
Il DNA batterico si riferisce al materiale genetico presente nei batteri, che sono microrganismi unicellulari procarioti. Il DNA batterico è circolare e contiene tutti i geni necessari per la crescita, la replicazione e la sopravvivenza dell'organismo batterico. Rispetto al DNA degli organismi eucariotici (come piante, animali e funghi), il DNA batterico è relativamente semplice e contiene meno sequenze ripetitive non codificanti.
Il genoma batterico è organizzato in una singola molecola circolare di DNA chiamata cromosoma batterico. Alcuni batteri possono anche avere piccole molecole di DNA circolari extra chiamate plasmidi, che contengono geni aggiuntivi che conferiscono caratteristiche speciali al batterio, come la resistenza agli antibiotici o la capacità di degradare determinati tipi di sostanze chimiche.
Il DNA batterico è una componente importante dell'analisi microbiologica e della diagnosi delle infezioni batteriche. L'identificazione dei batteri può essere effettuata mediante tecniche di biologia molecolare, come la reazione a catena della polimerasi (PCR) o l' sequenziamento del DNA, che consentono di identificare specifiche sequenze di geni batterici. Queste informazioni possono essere utilizzate per determinare il tipo di batterio che causa un'infezione e per guidare la selezione di antibiotici appropriati per il trattamento.
I sistemi di somministrazione farmacologica si riferiscono a diversi metodi e dispositivi utilizzati per veicolare, distribuire e consegnare un farmaco al sito d'azione desiderato all'interno del corpo umano. L'obiettivo principale di questi sistemi è quello di ottimizzare l'efficacia terapeutica del farmaco, minimizzando al contempo gli effetti avversi indesiderati e migliorando la compliance del paziente.
Esistono diversi tipi di sistemi di somministrazione farmacologica, tra cui:
1. Via orale (per os): il farmaco viene assunto per via orale sotto forma di compresse, capsule, soluzioni o sospensioni e viene assorbito a livello gastrointestinale prima di entrare nel circolo sistemico.
2. Via parenterale: il farmaco viene somministrato direttamente nel flusso sanguigno attraverso iniezioni intramuscolari, sottocutanee o endovenose. Questo metodo garantisce una biodisponibilità più elevata e un'insorgenza d'azione più rapida rispetto ad altri metodi di somministrazione.
3. Via transdermica: il farmaco viene assorbito attraverso la pelle utilizzando cerotti, gel o creme contenenti il principio attivo desiderato. Questo metodo è particolarmente utile per l'amministrazione di farmaci a rilascio prolungato e per trattare condizioni locali come dolori articolari o muscolari.
4. Via respiratoria: il farmaco viene somministrato sotto forma di aerosol, spray o polvere secca ed è assorbito attraverso le vie respiratorie. Questo metodo è comunemente utilizzato per trattare disturbi polmonari come l'asma e la broncopneumopatia cronica ostruttiva (BPCO).
5. Via orale: il farmaco viene assunto per via orale sotto forma di compresse, capsule, soluzioni o sospensioni. Questo metodo è uno dei più comuni e convenienti, ma la biodisponibilità può essere influenzata da fattori come l'assorbimento gastrointestinale e il metabolismo epatico.
6. Via oftalmica: il farmaco viene instillato direttamente nell'occhio sotto forma di colliri o unguenti. Questo metodo è utilizzato per trattare condizioni oculari come congiuntiviti, cheratiti e glaucomi.
7. Via vaginale: il farmaco viene inserito direttamente nella vagina sotto forma di creme, ovuli o supposte. Questo metodo è comunemente utilizzato per trattare infezioni vaginali e altri disturbi ginecologici.
8. Via rettale: il farmaco viene somministrato sotto forma di supposte o enema. Questo metodo è utilizzato per bypassare la digestione e l'assorbimento gastrointestinale, aumentando la biodisponibilità del farmaco.
In medicina e ricerca biomedica, i modelli molecolari sono rappresentazioni tridimensionali di molecole o complessi molecolari, creati utilizzando software specializzati. Questi modelli vengono utilizzati per visualizzare e comprendere la struttura, le interazioni e il funzionamento delle molecole, come proteine, acidi nucleici (DNA e RNA) ed altri biomolecole.
I modelli molecolari possono essere creati sulla base di dati sperimentali ottenuti da tecniche strutturali come la cristallografia a raggi X, la spettrometria di massa o la risonanza magnetica nucleare (NMR). Questi metodi forniscono informazioni dettagliate sulla disposizione degli atomi all'interno della molecola, che possono essere utilizzate per generare modelli tridimensionali accurati.
I modelli molecolari sono essenziali per comprendere le interazioni tra molecole e come tali interazioni contribuiscono a processi cellulari e fisiologici complessi. Ad esempio, i ricercatori possono utilizzare modelli molecolari per studiare come ligandi (come farmaci o substrati) si legano alle proteine bersaglio, fornendo informazioni cruciali per lo sviluppo di nuovi farmaci e terapie.
In sintesi, i modelli molecolari sono rappresentazioni digitali di molecole che vengono utilizzate per visualizzare, analizzare e comprendere la struttura, le interazioni e il funzionamento delle biomolecole, con importanti applicazioni in ricerca biomedica e sviluppo farmaceutico.
I composti di trifenilmetile sono una classe di composti organici caratterizzati dalla struttura chimica C(C6H5)3, dove un atomo di carbonio è legato a tre gruppi fenili. Questi composti sono noti per le loro proprietà lipofile e stabilità chimica. Alcuni composti di trifenilmetile possono avere effetti sedativi o depressivi sul sistema nervoso centrale e sono stati utilizzati in passato in anestesia, sebbene l'uso clinico sia attualmente limitato a causa dei loro effetti collaterali avversi. È importante notare che alcuni composti di trifenilmetile possono anche essere tossici o cancerogeni e devono essere maneggiati con cautela.
L'apoptosi è un processo programmato di morte cellulare che si verifica naturalmente nelle cellule multicellulari. È un meccanismo importante per l'eliminazione delle cellule danneggiate, invecchiate o potenzialmente cancerose, e per la regolazione dello sviluppo e dell'homeostasi dei tessuti.
Il processo di apoptosi è caratterizzato da una serie di cambiamenti cellulari specifici, tra cui la contrazione del citoplasma, il ripiegamento della membrana plasmatica verso l'interno per formare vescicole (blebbing), la frammentazione del DNA e la formazione di corpi apoptotici. Questi corpi apoptotici vengono quindi fagocitati da cellule immunitarie specializzate, come i macrofagi, evitando così una risposta infiammatoria dannosa per l'organismo.
L'apoptosi può essere innescata da diversi stimoli, tra cui la privazione di fattori di crescita o di attacco del DNA, l'esposizione a tossine o radiazioni, e il rilascio di specifiche molecole segnale. Il processo è altamente regolato da una rete complessa di proteine pro- e anti-apoptotiche che interagiscono tra loro per mantenere l'equilibrio tra la sopravvivenza e la morte cellulare programmata.
Un'alterazione del processo di apoptosi è stata associata a diverse malattie, tra cui il cancro, le malattie neurodegenerative e le infezioni virali.
La riparazione del DNA è un processo biologico essenziale che si verifica nelle cellule degli organismi viventi. Il DNA, o acido desossiribonucleico, è il materiale genetico che contiene le informazioni genetiche necessarie per lo sviluppo, la crescita e la riproduzione delle cellule. Tuttavia, il DNA è suscettibile al danno da varie fonti, come i radicali liberi, i raggi UV e altri agenti ambientali dannosi.
La riparazione del DNA si riferisce alle diverse strategie utilizzate dalle cellule per rilevare e correggere i danni al DNA. Questi meccanismi di riparazione sono cruciali per prevenire le mutazioni genetiche che possono portare allo sviluppo di malattie genetiche, al cancro e all'invecchiamento precoce.
Ci sono diversi tipi di danni al DNA che richiedono meccanismi di riparazione specifici. Alcuni dei principali tipi di danni al DNA e i relativi meccanismi di riparazione includono:
1. **Danno da singola lesione a base**: Questo tipo di danno si verifica quando una singola base del DNA viene danneggiata o modificata. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione della scissione dell'azoto della base" (BNER). Questo processo prevede l'identificazione e la rimozione della base danneggiata, seguita dalla sintesi di una nuova base da parte di un enzima noto come polimerasi.
2. **Danno da rottura del filamento singolo**: Questo tipo di danno si verifica quando una singola catena del DNA viene rotta o tagliata. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione della scissione dell'estremità libera" (NHEJ). Questo processo prevede il riconoscimento e la ricostituzione del filamento spezzato, seguita dalla saldatura delle estremità da parte di un enzima noto come ligasi.
3. **Danno da rottura del doppio filamento**: Questo tipo di danno si verifica quando entrambe le catene del DNA vengono rotte o tagliate. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione dell'incisione della doppia elica" (DSBR). Questo processo prevede il riconoscimento e la ricostituzione del doppio filamento spezzato, seguita dalla sintesi di una nuova sequenza da parte di un enzima noto come polimerasi.
4. **Danno ossidativo**: Questo tipo di danno si verifica quando il DNA viene esposto all'ossigeno reattivo o ad altri agenti ossidanti. Il meccanismo di riparazione più comune per questo tipo di danno è noto come "riparazione del base excision" (BER). Questo processo prevede il riconoscimento e la rimozione della base danneggiata, seguita dalla sintesi di una nuova sequenza da parte di un enzima noto come polimerasi.
In generale, i meccanismi di riparazione del DNA sono altamente conservati tra le specie e svolgono un ruolo fondamentale nella prevenzione delle mutazioni e del cancro. Tuttavia, in alcuni casi, questi meccanismi possono anche essere utilizzati per introdurre deliberatamente mutazioni nel DNA, come avviene ad esempio durante il processo di ricombinazione omologa utilizzato in biologia molecolare.
La reazione di polimerizzazione a catena dopo trascrizione inversa (RC-PCR) è una tecnica di biologia molecolare che combina la retrotrascrizione dell'RNA in DNA complementare (cDNA) con la reazione di amplificazione enzimatica della catena (PCR) per copiare rapidamente e specificamente segmenti di acido nucleico. Questa tecnica è ampiamente utilizzata nella ricerca biomedica per rilevare, quantificare e clonare specifiche sequenze di RNA in campioni biologici complessi.
Nella fase iniziale della RC-PCR, l'enzima reverse transcriptasi converte l'RNA target in cDNA utilizzando un primer oligonucleotidico specifico per il gene di interesse. Il cDNA risultante funge da matrice per la successiva amplificazione enzimatica della catena, che viene eseguita utilizzando una coppia di primer che flankano la regione del gene bersaglio desiderata. Durante il ciclo termico di denaturazione, allungamento ed ibridazione, la DNA polimerasi estende i primer e replica il segmento di acido nucleico target in modo esponenziale, producendo milioni di copie del frammento desiderato.
La RC-PCR offre diversi vantaggi rispetto ad altre tecniche di amplificazione dell'acido nucleico, come la sensibilità, la specificità e la velocità di esecuzione. Tuttavia, è anche suscettibile a errori di contaminazione e artifatti di amplificazione, pertanto è fondamentale seguire rigorose procedure di laboratorio per prevenire tali problemi e garantire risultati accurati e riproducibili.
La parola "pireni" non esiste nel vocabolario medico come termine specifico. Tuttavia, il termine "pirogeni" è comunemente usato in medicina per riferirsi a sostanze o agenti che provocano febbre. I pirogeni possono essere di due tipi: esogeni e endogeni.
I pirogeni esogeni sono agenti fisici o chimici presenti nell'ambiente esterno che causano la produzione di prostaglandine nella ipotalamo, che a sua volta innalza la temperatura corporea centrale, provocando febbre. Esempi di pirogeni esogeni includono alcuni batteri e i loro endotossini, farmaci come il vancomicina e la mezlocillina, e anche alcune sostanze chimiche presenti nell'aria o nel cibo contaminato.
I pirogeni endogeni sono invece sostanze prodotte dall'organismo stesso in risposta a un'infezione o infiammazione. Anche in questo caso, la produzione di prostaglandine nell'ipotalamo porta all'insorgenza della febbre.
Quindi, se hai cercato "pireni" come possibile variante ortografica di "pirogeni", spero che questa risposta ti sia stata utile.
La tecnica Ad Aptameri SELEX (Systematic Evolution of Ligands by EXponential enrichment) è un metodo di laboratorio per selezionare e identificare aptameri, brevi sequenze di oligonucleotidi singoli filamento che possono legarsi specificamente a bersagli molecolari come proteine, piccole molecole o cellule.
Il processo SELEX comporta diversi cicli di selezione e amplificazione. In ogni ciclo, una libreria iniziale di aptameri casuali viene incubata con il bersaglio desiderato. Gli aptameri che si legano al bersaglio vengono quindi separati dagli aptameri non leganti e amplificati mediante PCR (Reazione a Catena della Polimerasi) o transcrizione in vitro. I prodotti amplificati vengono poi utilizzati nel ciclo di selezione successivo, con una maggiore prevalenza degli aptameri che si legano più strettamente al bersaglio.
Dopo diversi cicli di selezione e amplificazione, gli aptameri selezionati vengono sequenziati e analizzati per identificare quelli con la migliore affinità e specificità per il bersaglio desiderato. Questi aptameri possono essere utilizzati in una varietà di applicazioni biomediche, come la diagnosi e il trattamento delle malattie, la ricerca farmacologica e la biodeterminazione.
In sintesi, la tecnica Ad Aptameri SELEX è un metodo potente ed efficace per selezionare e identificare aptameri specifici per un bersaglio molecolare desiderato, con una vasta gamma di applicazioni biomediche.
La desossiribonucleasi (DNase) è un enzima che catalizza la rottura dei legami fosfodiesterici nelle molecole di DNA, portando alla sua degradazione. Esistono diversi tipi di DNasi presenti in natura, ciascuna con caratteristiche e funzioni specifiche.
Le proteine nucleari sono un tipo di proteine che si trovano all'interno del nucleo delle cellule. Sono essenziali per una varietà di funzioni nucleari, tra cui la replicazione e la trascrizione del DNA, la riparazione del DNA, la regolazione della cromatina e la sintesi degli RNA.
Le proteine nucleari possono essere classificate in diversi modi, a seconda delle loro funzioni e localizzazioni all'interno del nucleo. Alcune proteine nucleari sono associate al DNA, come i fattori di trascrizione che aiutano ad attivare o reprimere la trascrizione dei geni. Altre proteine nucleari sono componenti della membrana nucleare, che forma una barriera tra il nucleo e il citoplasma delle cellule.
Le proteine nucleari possono anche essere classificate in base alla loro struttura e composizione. Ad esempio, alcune proteine nucleari contengono domini strutturali specifici che consentono loro di legare il DNA o altre proteine. Altre proteine nucleari sono costituite da più subunità che lavorano insieme per svolgere una funzione specifica.
La maggior parte delle proteine nucleari sono sintetizzate nel citoplasma e quindi importate nel nucleo attraverso la membrana nucleare. Questo processo richiede l'interazione di segnali speciali presenti nelle proteine con i recettori situati sulla membrana nucleare. Una volta all'interno del nucleo, le proteine nucleari possono subire modifiche post-traduzionali che ne influenzano la funzione e l'interazione con altre proteine e molecole nel nucleo.
In sintesi, le proteine nucleari sono un gruppo eterogeneo di proteine che svolgono una varietà di funzioni importanti all'interno del nucleo delle cellule. La loro accuratezza e corretta regolazione sono essenziali per la normale crescita, sviluppo e funzione cellulare.
I radioisotopi di fosforo sono forme radioattive del fosforo, un elemento chimico essenziale per la vita. I due radioisotopi più comunemente utilizzati sono il fosforo-32 (^32P) e il fosforo-33 (^33P).
Il fosforo-32 ha una emivita di 14,3 giorni e decade attraverso la emissione beta negativa. Viene comunemente utilizzato in medicina nucleare per trattare alcuni tipi di tumori del sangue come leucemie e linfomi. Inoltre, viene anche impiegato nella ricerca biomedica per etichettare molecole biologiche e studiarne il comportamento all'interno delle cellule.
Il fosforo-33 ha una emivita più breve di 25,4 giorni e decade attraverso la emissione beta positiva. Viene utilizzato in ricerca biomedica per etichettare molecole biologiche e studiarne il comportamento all'interno delle cellule, specialmente quando sono richiesti tempi di decadimento più brevi rispetto a quelli forniti dal fosforo-32.
L'uso dei radioisotopi di fosforo deve essere eseguito con cautela e sotto la supervisione di personale qualificato, poiché l'esposizione alle radiazioni può comportare rischi per la salute.
Il nucleo cellulare è una struttura membranosa e generalmente la porzione più grande di una cellula eucariota. Contiene la maggior parte del materiale genetico della cellula sotto forma di DNA organizzato in cromosomi. Il nucleo è circondato da una membrana nucleare formata da due membrane fosolipidiche interne ed esterne con pori nucleari che consentono il passaggio selettivo di molecole tra il citoplasma e il nucleoplasma (il fluido all'interno del nucleo).
Il nucleo svolge un ruolo fondamentale nella regolazione della attività cellulare, compresa la trascrizione dei geni in RNA e la replicazione del DNA prima della divisione cellulare. Inoltre, contiene importanti strutture come i nucleoli, che sono responsabili della sintesi dei ribosomi.
In sintesi, il nucleo cellulare è l'organulo centrale per la conservazione e la replicazione del materiale genetico di una cellula eucariota, essenziale per la crescita, lo sviluppo e la riproduzione delle cellule.
La Northern blotting è una tecnica di laboratorio utilizzata in biologia molecolare per rilevare e quantificare specifiche sequenze di RNA all'interno di campioni biologici. Questa tecnica prende il nome dal suo inventore, James Alwyn Northern, ed è un'evoluzione della precedente Southern blotting, che viene utilizzata per rilevare e analizzare l'acido desossiribonucleico (DNA).
La Northern blotting prevede i seguenti passaggi principali:
1. Estrarre e purificare l'RNA dai campioni biologici, ad esempio cellule o tessuti.
2. Separare le diverse specie di RNA in base alla loro dimensione utilizzando l'elettroforesi su gel di agarosio.
3. Trasferire (o "blot") l'RNA separato da gel a una membrana di supporto, come la nitrocellulosa o la membrana di nylon.
4. Ibridare la membrana con una sonda marcata specifica per la sequenza di RNA di interesse. La sonda può essere marcata con radioisotopi, enzimi o fluorescenza.
5. Lavare la membrana per rimuovere le sonde non legate e rilevare l'ibridazione tra la sonda e l'RNA di interesse utilizzando un sistema di rivelazione appropriato.
6. Quantificare l'intensità del segnale di ibridazione per determinare la quantità relativa della sequenza di RNA target nei diversi campioni.
La Northern blotting è una tecnica sensibile e specifica che può rilevare quantità molto piccole di RNA, rendendola utile per lo studio dell'espressione genica a livello molecolare. Tuttavia, la procedura è relativamente laboriosa e richiede attrezzature specialistiche, il che limita la sua applicazione a laboratori ben equipaggiati con personale esperto.
La "temperatura di transizione" è un termine utilizzato nella fisica e nella chimica, ma può anche avere rilevanza in medicina in relazione alla proprietà dei materiali. In particolare, la temperatura di transizione di un polimero si riferisce alla temperatura specifica a cui avvengono modifiche significative nelle sue proprietà fisiche e strutturali, come ad esempio il passaggio da uno stato amorfo a uno stato semicristallino o viceversa.
Tuttavia, in un contesto medico più generale, la "temperatura di transizione" può riferirsi alla temperatura corporea limite al di sopra della quale un individuo inizia a manifestare sintomi di febbre. Questa temperatura può variare leggermente da persona a persona, ma di solito si colloca intorno ai 37,2-38°C (99-100,4°F). Al di sopra di questa temperatura di transizione, il corpo umano attiva meccanismi di difesa per combattere infezioni o infiammazioni, aumentando la produzione di proteine della febbre e accelerando il metabolismo.
È importante notare che questa definizione è meno precisa della prima e può variare a seconda delle fonti mediche consultate.
La tiouridina è un composto organico che contiene zolfo e si trova naturalmente in alcuni acidi nucleici, come l'RNA. È simile alla uridina, ma con un atomo di zolfo (in forma di gruppo solfidrilico, -SH) sostituito al posto di un atomo di idrogeno nell'anello aromatico.
In biochimica, la tiouridina svolge un ruolo importante nella struttura e funzione degli RNA. Ad esempio, può essere coinvolta nella stabilizzazione della struttura dell'RNA a doppia elica e nell'interazione con proteine e altri composti. Tuttavia, non è presente nel DNA.
La tiouridina ha anche un ruolo importante in alcuni processi fisiologici e può essere utilizzata come marcatore per studiare la sintesi e il metabolismo degli RNA. In medicina, l'analisi dell'RNA contenente tiouridina può fornire informazioni sui processi cellulari e molecolari che sono alterati in varie malattie, come i tumori.
I piccoli RNA di interferenza (siRNA) sono molecole di acido ribonucleico (RNA) corti e double-stranded che svolgono un ruolo cruciale nella regolazione genica e nella difesa dell'organismo contro il materiale genetico estraneo, come i virus. Essi misurano solitamente 20-25 paia di basi in lunghezza e sono generati dal taglio di lunghi RNA double-stranded (dsRNA) da parte di un enzima chiamato Dicer.
Una volta generati, i siRNA vengono incorporati nella proteina argonauta (AGO), che fa parte del complesso RISC (RNA-induced silencing complex). Il filamento guida del siRNA all'interno di RISC viene quindi utilizzato per riconoscere e legare specificamente l'mRNA complementare, portando all'attivazione di due possibili vie:
1. Cleavage dell'mRNA: L'AGO taglia l'mRNA in corrispondenza del sito di complementarietà con il siRNA, producendo frammenti di mRNA più corti che vengono successivamente degradati.
2. Ripressione della traduzione: Il legame tra il siRNA e l'mRNA impedisce la formazione del complesso di inizio della traduzione, bloccando così la sintesi proteica.
I piccoli RNA di interferenza sono essenziali per la regolazione dell'espressione genica e giocano un ruolo importante nella difesa contro i virus e altri elementi genetici estranei. Essi hanno anche mostrato il potenziale come strumento terapeutico per il trattamento di varie malattie, tra cui alcune forme di cancro e disturbi genetici. Tuttavia, l'uso clinico dei siRNA è ancora in fase di sviluppo e sono necessari ulteriori studi per valutarne la sicurezza ed efficacia.
La Western blotting, nota anche come immunoblotting occidentale, è una tecnica di laboratorio comunemente utilizzata in biologia molecolare e ricerca biochimica per rilevare e quantificare specifiche proteine in un campione. Questa tecnica combina l'elettroforesi delle proteine su gel (SDS-PAGE), il trasferimento elettroforetico delle proteine da gel a membrana e la rilevazione immunologica utilizzando anticorpi specifici per la proteina target.
Ecco i passaggi principali della Western blotting:
1. Estrarre le proteine dal campione (cellule, tessuti o fluidi biologici) e denaturarle con sodio dodecil solfato (SDS) e calore per dissociare le interazioni proteina-proteina e conferire una carica negativa a tutte le proteine.
2. Caricare le proteine denaturate in un gel di poliacrilammide preparato con SDS (SDS-PAGE), che separa le proteine in base al loro peso molecolare.
3. Eseguire l'elettroforesi per separare le proteine nel gel, muovendole verso la parte positiva del campo elettrico.
4. Trasferire le proteine dal gel alla membrana di nitrocellulosa o PVDF (polivinilidene fluoruro) utilizzando l'elettroblotting, che sposta le proteine dalla parte negativa del campo elettrico alla membrana posizionata sopra il gel.
5. Bloccare la membrana con un agente bloccante (ad esempio, latte in polvere scremato o albumina sierica) per prevenire il legame non specifico degli anticorpi durante la rilevazione immunologica.
6. Incubare la membrana con l'anticorpo primario marcato (ad esempio, con un enzima o una proteina fluorescente) che riconosce e si lega specificamente all'antigene di interesse.
7. Lavare la membrana per rimuovere l'anticorpo primario non legato.
8. Rivelare il segnale dell'anticorpo primario utilizzando un substrato appropriato (ad esempio, una soluzione contenente un cromogeno o una sostanza chimica che emette luce quando viene attivata dall'enzima legato all'anticorpo).
9. Analizzare e documentare il segnale rivelato utilizzando una fotocamera o uno scanner dedicati.
Il Western blotting è un metodo potente per rilevare e quantificare specifiche proteine in campioni complessi, come estratti cellulari o tissutali. Tuttavia, richiede attenzione ai dettagli e controlli appropriati per garantire la specificità e l'affidabilità dei risultati.
In medicina, un esone è una porzione di un gene che codifica per una proteina o parte di una proteina. Più specificamente, si riferisce a una sequenza di DNA che, dopo la trascrizione in RNA, non viene rimossa durante il processo di splicing dell'RNA. Di conseguenza, l'esone rimane nella molecola di RNA maturo e contribuisce alla determinazione della sequenza aminoacidica finale della proteina tradotta.
Il processo di splicing dell'RNA è un meccanismo importante attraverso il quale le cellule possono generare una diversità di proteine a partire da un numero relativamente limitato di geni. Questo perché molti geni contengono sequenze ripetute o non codificanti, note come introni, intervallate da esoni. Durante il splicing, gli introni vengono rimossi e gli esoni adiacenti vengono uniti insieme, dando origine a una molecola di RNA maturo che può essere poi tradotta in una proteina funzionale.
Tuttavia, è importante notare che il processo di splicing non è sempre costante e prevedibile. Al contrario, può variare in modo condizionale o soggettivo a seconda del tipo cellulare, dello sviluppo dell'organismo o della presenza di determinate mutazioni genetiche. Questa variazione nella selezione degli esoni e nel loro ordine di combinazione può portare alla formazione di diverse isoforme proteiche a partire dal medesimo gene, con conseguenze importanti per la fisiologia e la patologia dell'organismo.
In medicina e biologia, un liposoma è una vescicola sferica costituita da uno o più strati di fosfolipidi che racchiudono un compartimento acquoso. I liposomi sono simili nella loro struttura di base ai normali involucri membranoscellulari, poiché sono formati dagli stessi fosfolipidi e colesterolo che costituiscono le membrane cellulari.
A causa della loro composizione lipidica, i liposomi hanno la capacità di legare sia sostanze idrofile che idrofobe. Quando dispersi in un ambiente acquoso, i fosfolipidi si auto-organizzano in doppi strati con le teste polari rivolte verso l'esterno e le code idrofobiche all'interno, formando una membrana bilayer. Questa configurazione bilayer può quindi avvolgersi su se stessa per creare una vescicola chiusa contenente uno spazio acquoso interno.
I liposomi sono ampiamente utilizzati in ricerca e applicazioni biomediche, specialmente nella terapia farmacologica. A causa della loro struttura simile alla membrana cellulare, i liposomi possono fondersi con le cellule bersaglio e rilasciare il loro contenuto all'interno della cellula, aumentando l'efficacia dei farmaci e riducendo al minimo gli effetti collaterali indesiderati. Inoltre, i liposomi possono essere utilizzati per encapsulate vari tipi di molecole, come farmaci, geni, proteine o altri biomarcatori, fornendo un metodo efficiente per il trasporto e la consegna di queste sostanze a specifici siti all'interno dell'organismo.
Le "Isole CpG" sono sequenze specifiche di DNA che si trovano comunemente nel genoma. Si riferiscono a una sequenza in cui una citosina (C) è seguita da una guanina (G), dove il gruppo fosfato che normalmente collega le due basi azotate è seguito da un gruppo metile (-CH3). Queste isole sono importanti per la regolazione dell'espressione genica, poiché la metilazione delle isole CpG può sopprimere l'espressione dei geni. Le isole CpG si trovano spesso nei promotori dei geni e nelle regioni regulatory del DNA. Sono particolarmente dense nel genoma dei mammiferi, ma sono relativamente rare in altri organismi.
In medicina, una "mappa di restrizione" (o "mappa di restrizioni enzimatiche") si riferisce a un diagramma schematico che mostra la posizione e il tipo di siti di taglio per specifiche endonucleasi di restrizione su un frammento di DNA. Le endonucleasi di restrizione sono enzimi che taglano il DNA in punti specifici, detti siti di restrizione, determinati dalla sequenza nucleotidica.
La mappa di restrizione è uno strumento importante nell'analisi del DNA, poiché consente di identificare e localizzare i diversi frammenti di DNA ottenuti dopo la digestione con enzimi di restrizione. Questa rappresentazione grafica fornisce informazioni cruciali sulla struttura e l'organizzazione del DNA, come ad esempio il numero e la dimensione dei frammenti, la distanza tra i siti di taglio, e la presenza o assenza di ripetizioni sequenziali.
Le mappe di restrizione sono comunemente utilizzate in diverse applicazioni della biologia molecolare, come il clonaggio, l'ingegneria genetica, l'analisi filogenetica e la diagnosi di malattie genetiche.
Gli amidi sono un tipo di carboidrati complessi che svolgono un ruolo importante come fonte di energia nell'alimentazione umana. Si trovano naturalmente in una varietà di cibi, tra cui cereali, legumi e tuberi come patate e mais.
Gli amidi sono costituiti da catene di molecole di glucosio ed esistono in due forme principali: amilosio e amilopectina. L'amilosio è una catena lineare di molecole di glucosio, mentre l'amilopectina ha una struttura ramificata con numerose catene laterali di glucosio.
Quando si consumano cibi che contengono amidi, questi vengono digeriti dall'organismo e convertiti in glucosio semplice, che viene quindi utilizzato come fonte di energia per le cellule del corpo. Tuttavia, se l'assunzione di amidi è eccessiva o non viene adeguatamente metabolizzata, può portare a un aumento dei livelli di glucosio nel sangue e, in ultima analisi, al diabete di tipo 2.
In sintesi, gli amidi sono un importante nutriente presente nella nostra dieta che fornisce energia al nostro corpo, ma è importante consumarli con moderazione e abbinarli a una dieta equilibrata per mantenere la salute generale.
La spettrometria di fluorescenza è una tecnica spettroscopica che misura la luminescenza emessa da una sostanza (fluoroforo) dopo l'assorbimento di radiazioni elettromagnetiche, generalmente nel campo dell'ultravioletto o della luce visibile. Quando il fluoroforo assorbe energia, uno o più elettroni vengono eccitati a livelli energetici superiori. Durante il ritorno alla condizione di riposo, l'eccitazione degli elettroni decade e viene emessa radiazioni elettromagnetiche con una lunghezza d'onda diversa (di solito più lunga) rispetto a quella assorbita. Questa differenza di lunghezza d'onda è nota come spostamento di Stokes.
Lo spettrometro di fluorescenza separa la luce emessa in base alla sua lunghezza d'onda e misura l'intensità relativa della luminescenza per ogni lunghezza d'onda, producendo uno spettro di emissione. Questo spettro può fornire informazioni qualitative e quantitative sui componenti fluorescenti presenti nel campione, inclusa la loro concentrazione e l'ambiente molecolare circostante.
La spettrometria di fluorescenza è ampiamente utilizzata in vari campi, tra cui la chimica analitica, la biologia molecolare, la farmacologia e la medicina forense, per applicazioni che vanno dall'identificazione delle specie chimiche allo studio delle interazioni molecolari. Tuttavia, è importante notare che la misura della fluorescenza può essere influenzata da fattori ambientali come la presenza di assorbitori o emettitori di luce aggiuntivi, alterando potenzialmente l'accuratezza e l'affidabilità dei risultati.
La "Targeted Gene Repair" (o Riparazione Genica mirata) è una tecnologia emergente in biomedicina che mira a correggere specifiche mutazioni genetiche causative di malattie ereditarie o acquisite. Questa strategia utilizza diversi approcci, tra cui l'utilizzo di sistemi di editing del genoma come CRISPR-Cas9, TALENs e ZFNs, per introdurre modifiche precise nel DNA nelle posizioni desiderate all'interno del genoma.
Nel caso della riparazione genica mirata, si utilizzano sequenze guide specifiche per il gene bersaglio che contengono la mutazione da correggere. Queste sequenze guidano l'endonucleasi (come Cas9) alla posizione desiderata nel DNA, dove viene introdotta una rottura mirata nella doppia elica. Successivamente, il meccanismo naturale di riparazione del DNA della cellula (principalmente la via dell'omologia ricombinazione) può essere sfruttato per introdurre la correzione desiderata all'interno del gene bersaglio.
La riparazione genica mirata ha il potenziale per trattare una vasta gamma di malattie, tra cui le malattie genetiche monogeniche come la fibrosi cistica, l'anemia falciforme e la distrofia muscolare di Duchenne. Tuttavia, questa tecnologia è ancora in fase di sviluppo e presenta diverse sfide, tra cui l'efficienza della modifica genica, l'accuratezza della riparazione e i potenziali effetti off-target (modifiche indesiderate in altre parti del genoma).
La luciferasi è un enzima che catalizza la reazione chimica che produce luce, nota come bioluminescenza. Viene trovata naturalmente in alcuni organismi viventi, come ad esempio le lucciole e alcune specie di batteri marini. Questi organismi producono una reazione enzimatica che comporta l'ossidazione di una molecola chiamata luciferina, catalizzata dalla luciferasi, con conseguente emissione di luce.
Nel contesto medico e scientifico, la luciferasi viene spesso utilizzata come marcatore per studiare processi biologici come l'espressione genica o la localizzazione cellulare. Ad esempio, un gene che si desidera studiare può essere fuso con il gene della luciferasi, in modo che quando il gene viene espresso, la luciferasi viene prodotta e può essere rilevata attraverso l'emissione di luce. Questa tecnica è particolarmente utile per lo studio delle interazioni geniche e proteiche, nonché per l'analisi dell'attività enzimatica e della citotossicità dei farmaci.
L'RNA catalitico, noto anche come ribozima, si riferisce a un tipo di RNA che ha attività catalitica, il quale significa che può accelerare o facilitare una reazione chimica. Questa scoperta ha sfidato la nozione precedente secondo cui solo le proteine potevano servire come catalizzatori biologici.
Gli ribozimi sono in grado di tagliare e legare altri RNA, svolgendo un ruolo cruciale nella maturazione del trascrittoma ribosomiale (rRNA) e nell'eliminazione delle introni dai pre-mRNA. Un esempio ben noto di ribozima è il sito attivo dell'RNA nel complesso del gruppo di inizio I (ILS) durante l'inizio della traduzione, dove catalizza la formazione del legame peptidico tra i due primi aminoacidi del polipeptide nascente.
La scoperta degli ribozimi ha contribuito a rafforzare la teoria dell'Origine della vita secondo cui l'RNA potrebbe aver svolto un ruolo cruciale come molecola sia genetica che catalitica nelle prime forme di vita.
L'acridina è un composto organico eterociclico con formula molecolare C13H9N. È costituita da un anello benzene fuso con un anello piridinico, che contiene un atomo di azoto e due doppi legami.
In campo medico, l'acridina è utilizzata principalmente nella ricerca scientifica e in diagnostica di laboratorio. Ad esempio, alcuni derivati dell'acridina sono impiegati come coloranti fluorescenti per la visualizzazione di acidi nucleici (DNA ed RNA) nelle tecniche di microscopia a fluorescenza e nella citogenetica. Questi composti si legano specificamente all'acido nucleico, emettendo luce visibile quando vengono eccitati con luce ultravioletta.
Tuttavia, è importante notare che l'uso di acridina e dei suoi derivati non è privo di rischi. Alcuni studi hanno dimostrato che queste sostanze possono avere effetti citotossici e mutageni, il che significa che possono danneggiare le cellule e causare mutazioni genetiche. Pertanto, è fondamentale maneggiarle con cura e seguire rigorosamente le procedure di sicurezza durante la loro manipolazione in laboratorio.
L'alchilazione è un termine che si riferisce a una reazione chimica in cui un gruppo alchile viene aggiunto a una molecola. In ambito medico e biologico, l'alchilazione è particolarmente importante quando riguarda il DNA. L'alchilazione del DNA può essere causata da agenti chimici o fisici come i raggi ultravioletti e può portare a mutazioni genetiche o addirittura alla morte cellulare se la lesione al DNA è grave.
L'alchilazione del DNA avviene quando un gruppo alchile, costituito da un atomo di carbonio legato ad uno o più gruppi idrogeno (-CH3, -C2H5, -C3H7 ecc.), si lega a una delle quattro basi azotate che compongono la struttura del DNA (adenina, timina, citosina e guanina). Questa modifica può interferire con la replicazione e la trascrizione del DNA, portando a errori nella sintesi proteica e potenzialmente a effetti dannosi per la cellula.
Alcuni farmaci utilizzati nella chemioterapia cancerosa agiscono attraverso il meccanismo di alchilazione delle basi azotate del DNA, con l'obiettivo di danneggiare e uccidere le cellule tumorali. Tuttavia, questi farmaci possono anche avere effetti collaterali dannosi sulle normali cellule dell'organismo, compresi i tessuti in rapida crescita come quelli del midollo osseo e del tratto gastrointestinale.
L'idrolasi del diestere fosforico è una reazione enzimatica che coinvolge l'idrolisi (la scissione di un legame chimico con l'aggiunta di acqua) di un diestere fosforico, un composto organico contenente due gruppi esterici legati a un atomo di fosforo. L'enzima che catalizza questa reazione è noto come diesterasi fosfatica o fosfoDIEsterasi.
Questa reazione enzimatica svolge un ruolo cruciale nella regolazione di diversi processi cellulari, compresi il metabolismo dei lipidi e la segnalazione cellulare. Ad esempio, l'idrolisi del diestere fosforico nei fosfolipidi delle membrane cellulari contribuisce alla rimodellamento e al riciclo delle membrane, mentre l'idrolisi di molecole di segnalazione come i nucleotidi ciclici influenza la trasduzione del segnale e la regolazione dell'espressione genica.
L'idrolasi del diestere fosforico è altamente specifica per il substrato e richiede condizioni ottimali di pH e temperatura per svolgere efficacemente la sua funzione. La disfunzione o l'inibizione di questo enzima può avere conseguenze negative sulla salute, compreso lo sviluppo di patologie come il morbo di Alzheimer, il Parkinson e altre malattie neurodegenerative.
In genetica, un gene è una sequenza specifica di DNA che contiene informazioni genetiche ereditarie. I geni forniscono istruzioni per la sintesi delle proteine, che sono essenziali per lo sviluppo e il funzionamento delle cellule e degli organismi viventi. Ogni gene occupa una posizione specifica su un cromosoma e può esistere in forme alternative chiamate alle varianti. Le mutazioni genetiche, che sono cambiamenti nella sequenza del DNA, possono portare a malattie genetiche o predisporre a determinate condizioni di salute. I geni possono anche influenzare caratteristiche fisiche e comportamentali individuali.
In sintesi, i geni sono unità fondamentali dell'ereditarietà che codificano le informazioni per la produzione di proteine e influenzano una varietà di tratti e condizioni di salute. La scoperta e lo studio dei geni hanno portato a importanti progressi nella comprensione delle basi molecolari della vita e alla possibilità di sviluppare terapie geniche per il trattamento di malattie genetiche.
L'adenina è una base nitrogenata presente nelle purine, che a sua volta è una delle componenti fondamentali dei nucleotidi e dell'acido nucleico (DNA e RNA). Nell'adenina, il gruppo amminico (-NH2) è attaccato al carbonio in posizione 6 della struttura della purina.
Nel DNA e nell'RNA, l'adenina forma coppie di basi con la timina (nel DNA) o l'uracile (nell'RNA) tramite due legami idrogeno. Questa interazione è nota come coppia A-T / A-U ed è fondamentale per la struttura a doppio filamento e la stabilità dell'acido nucleico.
Inoltre, l'adenina svolge un ruolo importante nella produzione di energia nelle cellule, poiché fa parte dell'adenosina trifosfato (ATP), la molecola utilizzata dalle cellule come fonte primaria di energia.
La deossiadenosina è un nucleoside formato dalla base azotata adenina legata al carboidrato desossiribosio. A differenza del normale nucleoside adenosina, che contiene uno zucchero a cinque atomi di carbonio (ribosio), la deossiadenosina ha un desossiribosio, che è un ribosio con un atomo di idrogeno al posto di un gruppo ossidrilico (-OH) sul secondo carbonio.
In medicina e biochimica, il termine "deossi" si riferisce spesso alla mancanza di uno o più gruppi ossidrile (-OH). Pertanto, la deossiadenosina è priva del gruppo ossidrilico che normalmente si trova sul secondo carbonio del ribosio.
La deossiadenosina svolge un ruolo importante nella biologia cellulare e può essere coinvolta in alcuni processi patologici. Ad esempio, i livelli elevati di deossiadenosina possono inibire l'enzima S-adenosil metionina sintasi (MAT), che è essenziale per la biosintesi dell'aminoacido metionina e della molecola donatrice di gruppi metile, S-adenosil metionina (SAM). Questo può portare a una serie di effetti negativi sulla cellula, tra cui l'inibizione della sintesi proteica e dell'attività enzimatica.
Inoltre, la deossiadenosina può essere coinvolta nella patogenesi di alcune malattie genetiche rare, come il deficit di adenosina deaminasi (ADA), una condizione che provoca un accumulo di deossiadenosina e diossipurine nel sangue e nelle cellule. Ciò può portare a danni ai globuli bianchi, immunodeficienza e altri problemi di salute.
In medicina, i "fattori temporali" si riferiscono alla durata o al momento in cui un evento medico o una malattia si verifica o progredisce. Questi fattori possono essere cruciali per comprendere la natura di una condizione medica, pianificare il trattamento e prevedere l'esito.
Ecco alcuni esempi di come i fattori temporali possono essere utilizzati in medicina:
1. Durata dei sintomi: La durata dei sintomi può aiutare a distinguere tra diverse condizioni mediche. Ad esempio, un mal di gola che dura solo pochi giorni è probabilmente causato da un'infezione virale, mentre uno che persiste per più di una settimana potrebbe essere causato da una infezione batterica.
2. Tempo di insorgenza: Il tempo di insorgenza dei sintomi può anche essere importante. Ad esempio, i sintomi che si sviluppano improvvisamente e rapidamente possono indicare un ictus o un infarto miocardico acuto.
3. Periodicità: Alcune condizioni mediche hanno una periodicità regolare. Ad esempio, l'emicrania può verificarsi in modo ricorrente con intervalli di giorni o settimane.
4. Fattori scatenanti: I fattori temporali possono anche includere eventi che scatenano la comparsa dei sintomi. Ad esempio, l'esercizio fisico intenso può scatenare un attacco di angina in alcune persone.
5. Tempo di trattamento: I fattori temporali possono influenzare il trattamento medico. Ad esempio, un intervento chirurgico tempestivo può essere vitale per salvare la vita di una persona con un'appendicite acuta.
In sintesi, i fattori temporali sono importanti per la diagnosi, il trattamento e la prognosi delle malattie e devono essere considerati attentamente in ogni valutazione medica.
La progettazione della struttura molecolare di un farmaco (in inglese: "De novo drug design" o "Rational drug design") è un approccio alla scoperta di nuovi farmaci che utilizza la conoscenza della struttura tridimensionale delle proteine bersaglio e dei meccanismi d'azione molecolare per creare composti chimici con attività terapeutica desiderata. Questo processo prevede l'identificazione di siti attivi o altre aree chiave sulla superficie della proteina bersaglio, seguita dalla progettazione e sintesi di molecole che possono interagire specificamente con tali siti, modulando l'attività della proteina.
La progettazione della struttura molecolare di un farmaco può essere suddivisa in due categorie principali:
1. Progettazione basata sulla liganda (in inglese: "Lead-based design"): Questa strategia inizia con la scoperta di un composto chimico, noto come "lead," che mostra attività biologica promettente contro il bersaglio proteico. Gli scienziati quindi utilizzano tecniche computazionali e strumenti di modellazione molecolare per analizzare l'interazione tra il lead e la proteina, identificando i punti di contatto cruciali e apportando modifiche mirate alla struttura del composto per migliorarne l'affinità di legame, la selettività e l'attività farmacologica.
2. Progettazione basata sulla struttura (in inglese: "Structure-based design"): Questa strategia si avvale della conoscenza della struttura tridimensionale della proteina bersaglio, ottenuta attraverso tecniche di cristallografia a raggi X o risonanza magnetica nucleare (NMR). Gli scienziati utilizzano queste informazioni per identificare siti di legame potenziali e progettare molecole sintetiche che si leghino specificamente a tali siti, mirando ad influenzare la funzione della proteina e ottenere un effetto terapeutico desiderato.
Entrambe le strategie di progettazione basate sulla liganda e sulla struttura possono essere combinate per creare una pipeline di sviluppo dei farmaci più efficiente ed efficace, accelerando il processo di scoperta e consentendo la produzione di nuovi farmaci mirati con maggiore precisione e minor tossicità.
Gli addotti del DNA sono lesioni che si verificano quando le molecole di DNA vengono modificate chimicamente a seguito dell'esposizione a determinate sostanze chimiche o radiazioni. Questi addotti possono alterare la struttura del DNA e interferire con la replicazione e la trascrizione del DNA, il che può portare a mutazioni genetiche e, in alcuni casi, al cancro.
Le sostanze chimiche più comunemente associate alla formazione di addotti del DNA includono composti aromatici policiclici (CAP), idrocarburi policiclici aromatici (IPA) e aflatossine. Anche l'esposizione alle radiazioni ionizzanti, come quelle utilizzate nella terapia del cancro o in seguito a incidenti nucleari, può causare la formazione di addotti del DNA.
Gli addotti del DNA possono essere riparati dal corpo attraverso meccanismi enzimatici, ma se la lesione è grave o se i meccanismi di riparazione sono danneggiati o deficitari, l'addotto può persistere e portare a mutazioni genetiche. La prevenzione dell'esposizione alle sostanze chimiche e alle radiazioni dannose è quindi un approccio importante per ridurre il rischio di formazione di addotti del DNA e di conseguenza di malattie associate.
In genetica e biologia molecolare, il termine "DNA catalitico" o "enzima a DNA" si riferisce a un tipo particolare di enzima che è composto da sequenze di DNA anziché proteine. Questi enzymi sono in grado di accelerare e dirigere specifiche reazioni chimiche all'interno di un organismo, proprio come fanno gli enzimi proteici convenzionali.
La scoperta degli enzimi a DNA ha rappresentato una svolta significativa nella comprensione della biologia molecolare, poiché ha sfidato la precedente convinzione che solo le proteine potessero svolgere funzioni enzimatiche.
Gli enzimi a DNA sono costituiti da sequenze di DNA che formano strutture tridimensionali complesse, note come deoxyribozymes o DNAzymes. Queste strutture contengono regioni catalitiche attive che possono legare specificamente determinati substrati e facilitare reazioni chimiche quali la scissione o la ligation di molecole di DNA o RNA.
La scoperta degli enzimi a DNA ha aperto nuove prospettive per la ricerca biomedica, poiché tali enzimi possono essere utilizzati in applicazioni terapeutiche e diagnostiche innovative, come la regolazione dell'espressione genica o il rilevamento di specifiche sequenze di DNA o RNA.
In terminologia medica, un catione è un'ionetta carica positivamente che risulta dalla dissociazione elettrolitica di una sostanza. In particolare, i cationi sono ioni con carica elettrica positiva che si formano quando un atomo o una molecola perdono uno o più elettroni.
I cationi possono essere costituiti da diversi elementi, come sodio (Na+), potassio (K+), calcio (Ca2+) e magnesio (Mg2+). Essi svolgono un ruolo fondamentale nella fisiologia umana, poiché sono componenti essenziali di fluidi corporei, cellule e tessuti. Ad esempio, il sodio e il potassio sono importanti per la regolazione del bilancio idrico ed elettrolitico, mentre il calcio è necessario per la contrazione muscolare e la coagulazione del sangue.
Le concentrazioni di cationi nel corpo umano vengono mantenute costanti attraverso meccanismi di regolazione ormonale e renale, che aiutano a garantire il normale funzionamento dei processi fisiologici. Squilibri nei livelli di cationi possono causare varie condizioni patologiche, come disidratazione, ipokaliemia (bassi livelli di potassio nel sangue), iperkaliemia (elevati livelli di potassio nel sangue) e altre ancora.
I geni virali si riferiscono a specifiche sequenze di DNA o RNA che codificano per proteine o molecole funzionali presenti nei virus. Questi geni sono responsabili della replicazione del virus e della sua interazione con le cellule ospiti. Essi determinano la patogenicità, la virulenza e il tropismo tissutale del virus. I geni virali possono anche subire mutazioni che portano a una resistenza ai farmaci antivirali o alla modifica delle caratteristiche immunologiche del virus. L'analisi dei geni virali è importante per la comprensione della biologia dei virus, nonché per lo sviluppo di strategie di prevenzione e trattamento delle malattie infettive causate da virus.
Deossiribonucleotidi sono molecole organiche che costituiscono i building block (unità strutturali e funzionali) dei deossiribonucleotidi acidi (DNA). Sono formati dalla combinazione di una base azotata, un pentoso zucchero deossiribosio e uno o più gruppi fosfato.
Esistono quattro tipi di deossiribonucleotidi che differiscono nella loro base azotata: deossiadenosina monofosfato (dAMP), deossitimidina monofosfato (dTMP), deossiguanosina monofosfato (dGMP) e deossicitosina monofosfato (dCMP). Questi deossiribonucleotidi vengono assemblati in una sequenza specifica per formare la struttura a doppia elica del DNA, che codifica le informazioni genetiche.
Le reazioni di sintesi e riparazione del DNA richiedono l'aggiunta o la rimozione di deossiribonucleotidi alla catena di DNA esistente. Questi processi sono mediati da enzimi specializzati, come le polimerasi del DNA e le nucleasi, che catalizzano la formazione o la scissione dei legami fosfodiesterici tra i deossiribonucleotidi.
La Fluoroscéina-5-Isotiocianato (FITC) è un composto fluorescente comunemente utilizzato come marcatore fluorescente in biologia molecolare e nella ricerca scientifica. Si tratta di una sostanza chimica derivata dalla fluoroscéina, un colorante giallo utilizzato per la colorazione istologica.
L'FITC è un agente legante che può essere accoppiato a proteine o altre biomolecole per consentirne la visualizzazione e il tracciamento mediante microscopia a fluorescenza. Il gruppo isotiocianato (-N=C=S) dell'FITC reagisce con i gruppi amminici (-NH2) delle proteine o altre biomolecole, formando un legame covalente stabile che mantiene il composto legato alla molecola bersaglio.
Una volta accoppiato alla biomolecola di interesse, l'FITC emette una fluorescenza verde brillante quando esposto a luce ultravioletta o a radiazione laser con lunghezza d'onda di circa 495 nm. Questa proprietà rende l'FITC un utile strumento per la visualizzazione e il tracciamento di biomolecole in una varietà di applicazioni, tra cui l'immunofluorescenza, la citometria a flusso e la microscopia confocale.
Tuttavia, è importante notare che l'FITC può essere soggetto a fotobleaching, il che significa che la sua fluorescenza può diminuire o scomparire dopo un'esposizione prolungata alla luce. Pertanto, è necessario prestare attenzione alla gestione della luce durante l'utilizzo di questo marcatore fluorescente per ottenere risultati affidabili e riproducibili.
'Oro' è un termine che non ha una definizione medica specifica. Tuttavia, in senso generale, l'oro è un elemento chimico con simbolo Au e numero atomico 79. È un metallo di transizione morbido, denso, brillante, giallo, che è bello, altamente prezioso e resistente alla corrosione.
In medicina, l'oro viene occasionalmente utilizzato in alcuni farmaci, come il solfato di auranofin, che viene talvolta usato per trattare l'artrite reumatoide. Questi farmaci contengono oro in forma ionica e agiscono immunomodulando e anti-infiammatorio. Tuttavia, i loro effetti collaterali possono essere gravi e limitano il loro uso comune.
I nucleotidi sono le unità fondamentali che costituiscono l'acido nucleico, compreso il DNA e l'RNA. Un nucleotide è formato dalla combinazione di una base azotata, un pentoso (un zucchero a cinque atomi di carbonio) e un gruppo fosfato. Le basi azotate possono essere adenina (A), guanina (G), citosina (C) e uracile (U) nell'RNA o timina (T) nel DNA. Il pentoso può essere deossiribosio nel DNA o ribosio nell'RNA. I nucleotidi sono legati insieme in una sequenza specifica per formare catene di DNA o RNA. Oltre alla loro funzione strutturale, i nucleotidi svolgono anche un ruolo cruciale nella trasmissione dell'informazione genetica, nel metabolismo energetico e nella segnalazione cellulare.
Un embrione non mammifero si riferisce allo stadio di sviluppo di un organismo che non è un mammifero, a partire dalla fertilizzazione fino al punto in cui si verifica la differenziazione degli organi e dei sistemi principali. Questa fase di sviluppo è caratterizzata da rapide divisioni cellulari, migrazione cellulare e formazione di strutture embrionali come blastula, gastrula e organogenesi. La durata di questo stadio dipende dalla specie e può variare notevolmente tra diversi gruppi di animali non mammiferi, come uccelli, rettili, anfibi, pesci e invertebrati.
Durante l'embrionogenesi, le cellule embrionali subiscono una serie di cambiamenti che portano alla formazione dei tessuti e degli organi principali dell'organismo in via di sviluppo. Questo processo è guidato da una complessa interazione di fattori genetici ed epigenetici, insieme a influenze ambientali esterne.
È importante notare che la definizione e la durata dello stadio embrionale possono variare in base alla specie e al contesto di riferimento. Ad esempio, in alcuni contesti, lo stadio embrionale può essere distinto dallo stadio di larva o giovane nei taxa che hanno una fase larvale distinta nel loro ciclo vitale.
In campo medico, la metilazione si riferisce a un processo biochimico che comporta l'aggiunta di un gruppo metile (-CH3) a una molecola. Questa reazione è catalizzata da enzimi specifici e può influenzare la funzione della molecola target, come DNA o proteine.
Nel caso del DNA, la metilazione avviene quando un gruppo metile viene aggiunto al gruppo aminico di una base azotata, comunemente la citosina. Questa modifica può influenzare l'espressione genica, poiché i promotori dei geni metilati sono meno accessibili ai fattori di trascrizione, il che porta a una ridotta espressione del gene. La metilazione del DNA è un meccanismo importante per la regolazione dell'espressione genica e può anche svolgere un ruolo nella inattivazione del cromosoma X, nell'impronta genetica e nel silenziamento dei trasposoni.
La metilazione delle proteine si verifica quando i gruppi metile vengono aggiunti a specifici residui di aminoacidi nelle proteine, alterandone la struttura tridimensionale e influenzando le loro funzioni. Questo processo è catalizzato da enzimi chiamati metiltransferasi e svolge un ruolo importante nella regolazione della funzione delle proteine, compresi i processi di segnalazione cellulare, la stabilità delle proteine e l'interazione proteina-proteina.
L'omologia di sequenza degli aminoacidi è un concetto utilizzato in biochimica e biologia molecolare per descrivere la somiglianza nella sequenza degli aminoacidi tra due o più proteine. Questa misura quantifica la similarità delle sequenze amminoacidiche di due proteine e può fornire informazioni importanti sulla loro relazione evolutiva, struttura e funzione.
L'omologia di sequenza degli aminoacidi si basa sull'ipotesi che le proteine con sequenze simili siano probabilmente derivate da un antenato comune attraverso processi evolutivi come la duplicazione del gene, l'inversione, la delezione o l'inserzione di nucleotidi. Maggiore è il grado di somiglianza nella sequenza amminoacidica, più alta è la probabilità che le due proteine siano evolutivamente correlate.
L'omologia di sequenza degli aminoacidi si calcola utilizzando algoritmi informatici che confrontano e allineano le sequenze amminoacidiche delle proteine in esame. Questi algoritmi possono identificare regioni di similarità o differenze tra le sequenze, nonché indici di somiglianza quantitativa come il punteggio di BLAST (Basic Local Alignment Search Tool) o il punteggio di Smith-Waterman.
L'omologia di sequenza degli aminoacidi è un importante strumento per la ricerca biologica, poiché consente di identificare proteine correlate evolutivamente, prevedere la loro struttura tridimensionale e funzione, e comprendere i meccanismi molecolari alla base delle malattie genetiche.
In medicina, una soluzione è un tipo specifico di miscela omogenea di due o più sostanze, in cui almeno una delle sostanze (il soluto) è dispersa in maniera uniforme nell'altra (il solvente). Il soluto può essere costituito da uno o più solidi, liquidi o gas, mentre il solvente di solito è un liquido, come l'acqua.
Le soluzioni sono classificate in base alla loro composizione e alle proprietà che ne derivano. Una soluzione è definita come:
1. Una soluzione acquosa: quando il solvente è costituito dall'acqua. Ad esempio, una soluzione di glucosio è una miscela di glucosio (soluto) disciolto in acqua (solvente).
2. Una soluzione concentrata o diluita: a seconda della quantità di soluto presente nella soluzione. Una soluzione concentrata contiene una grande quantità di soluto, mentre una soluzione diluita ne contiene una piccola quantità.
3. Una soluzione satura, sovrasatura o insatura: a seconda della capacità del solvente di dissolvere il soluto. In una soluzione satura, il solvente ha raggiunto la sua massima capacità di sciogliere il soluto a quella particolare temperatura e pressione. Una soluzione sovrasatura contiene una quantità superiore alla solubilità massima del soluto a quella determinata temperatura e pressione, il che significa che può verificarsi la precipitazione del soluto se le condizioni cambiano. Una soluzione insatura contiene meno soluto di quanto potrebbe dissolvere il solvente a quella particolare temperatura e pressione.
Le soluzioni sono ampiamente utilizzate in medicina per la preparazione di farmaci, fluidi endovenosi, elettroliti e altre miscele terapeutiche. La concentrazione della soluzione è spesso espressa in unità di peso per volume (ad esempio, mg/mL) o unità di volume per volume (ad esempio, mEq/L).
Gli acidi undecilenici sono una classe di acidi grassi a catena media che contengono 11 atomi di carbonio. Essi sono comunemente usati in prodotti farmaceutici e cosmetici come agenti antimicotici, con attività specifica contro lieviti e funghi dermatofiti.
Uno degli acidi undecilenici più comuni è l'acido undecilenedioico, che è il principale ingrediente attivo nel farmaco antifungino Nizoral. Questo acido ha dimostrato di essere efficace contro una varietà di funghi, tra cui Candida albicans e Trichophyton spp., che causano infezioni della pelle e delle unghie.
Gli acidi undecilenici agiscono interferendo con la membrana cellulare dei funghi, alterandone la permeabilità e provocando la morte delle cellule fungine. Sono considerati sicuri ed efficaci, con pochi effetti collaterali sistemici quando applicati localmente sulla pelle o sulle unghie.
Tuttavia, è importante notare che l'uso di acidi undecilenici dovrebbe essere sotto la supervisione medica per garantire una corretta diagnosi e trattamento dell'infezione fungina sottostante.
L'RNA ribosomale (rRNA) è un tipo di acido ribonucleico che si trova all'interno dei ribosomi, le strutture cellulari responsabili della sintesi delle proteine. Gli rRNA sono essenziali per la formazione del sito attivo del ribosoma e partecipano al processo di traduzione, durante il quale il DNA viene trasformato in proteine.
Esistono diversi tipi di rRNA che si trovano all'interno dei ribosomi, ciascuno con una funzione specifica. Ad esempio, l'rRNA 16S e 23S sono presenti nei ribosomi procariotici, mentre l'rRNA 18S, 5,8S e 28S si trovano nei ribosomi eucariotici.
Gli rRNA svolgono un ruolo importante nella formazione del sito attivo del ribosoma, dove avviene la sintesi proteica. Essi interagiscono con gli aminoacidi e i transfer RNA (tRNA) per facilitare il processo di traduzione. Inoltre, alcuni rRNA hanno anche attività catalitiche e possono svolgere funzioni enzimatiche all'interno del ribosoma.
L'rRNA è trascritto da specifici geni presenti nel DNA cellulare e la sua sintesi è strettamente regolata durante lo sviluppo e in risposta a vari stimoli ambientali. Mutazioni nei geni che codificano per l'rRNA possono causare malattie genetiche e alterazioni nella sintesi proteica.
La concentrazione di idrogenioni (più comunemente indicata come pH) è una misura della quantità di ioni idrogeno presenti in una soluzione. Viene definita come il logaritmo negativo di base 10 dell'attività degli ioni idrogeno. Un pH inferiore a 7 indica acidità, mentre un pH superiore a 7 indica basicità. Il pH fisiologico del sangue umano è leggermente alcalino, con un range stretto di normalità compreso tra 7,35 e 7,45. Valori al di fuori di questo intervallo possono indicare condizioni patologiche come l'acidosi o l'alcalosi.
L'allineamento di sequenze è un processo utilizzato nell'analisi delle sequenze biologiche, come il DNA, l'RNA o le proteine. L'obiettivo dell'allineamento di sequenze è quello di identificare regioni simili o omologhe tra due o più sequenze, che possono fornire informazioni su loro relazione evolutiva o funzionale.
L'allineamento di sequenze viene eseguito utilizzando algoritmi specifici che confrontano le sequenze carattere per carattere e assegnano punteggi alle corrispondenze, alle sostituzioni e alle operazioni di gap (inserimento o cancellazione di uno o più caratteri). I punteggi possono essere calcolati utilizzando matrici di sostituzione predefinite che riflettono la probabilità di una particolare sostituzione aminoacidica o nucleotidica.
L'allineamento di sequenze può essere globale, quando l'obiettivo è quello di allineare l'intera lunghezza delle sequenze, o locale, quando si cerca solo la regione più simile tra due o più sequenze. Gli allineamenti multipli possono anche essere eseguiti per confrontare simultaneamente più di due sequenze e identificare relazioni evolutive complesse.
L'allineamento di sequenze è una tecnica fondamentale in bioinformatica e ha applicazioni in vari campi, come la genetica delle popolazioni, la biologia molecolare, la genomica strutturale e funzionale, e la farmacologia.
I fosfati di dinucleosidi sono composti chimici presenti nel DNA e nell'RNA che svolgono un ruolo importante nella replicazione, trascrizione e traduzione del materiale genetico. Essi consistono in due nucleotidi uniti insieme da un ponte fosfato. Nel DNA, i fosfati di dinucleosidi collegano le basi azotate tra loro per formare la catena polimerica della molecola. Nel RNA, i fosfati di dinucleosidi svolgono un ruolo simile nella formazione della struttura secondaria dell'RNA e nell'iniziare il processo di traduzione durante la sintesi delle proteine.
I fosfati di dinucleosidi sono anche utilizzati in biologia molecolare come marcatori fluorescenti o radioattivi per studiare la replicazione, la riparazione e la degradazione del DNA e dell'RNA. Tuttavia, un uso improprio dei fosfati di dinucleosidi può portare a mutazioni genetiche e malattie, come il cancro.
La fluoresceina è un colorante fluorescente comunemente utilizzato in campo oftalmologico per test di diagnosi e valutazione della funzionalità corneale e della condotta dell'occhio. Viene anche impiegata come marcatore nella medicina di emergenza per la rilevazione di sanguinamenti occulti nelle cavità corporee.
Nell'ambito oftalmologico, una soluzione contenente fluoresceina viene instillata nell'occhio del paziente e successivamente esaminato con l'aiuto di un filtro cobalto blu. Questo permette di evidenziare eventuali lesioni o difetti della cornea o della congiuntiva, come abrasioni, ulcere o ferite lacero-contuse, grazie alla fluorescenza gialla-verde emessa dalla sostanza quando esposta a luce blu.
In medicina di emergenza, la fluoresceina può essere somministrata per via endovenosa come marcatore per rilevare sanguinamenti occulti all'interno del corpo umano, ad esempio durante le indagini radiologiche. Il colorante viene eliminato rapidamente dall'organismo attraverso i reni e non presenta tossicità significativa.
La relazione farmacologica dose-risposta descrive la relazione quantitativa tra la dimensione della dose di un farmaco assunta e l'entità della risposta biologica o effetto clinico che si verifica come conseguenza. Questa relazione è fondamentale per comprendere l'efficacia e la sicurezza di un farmaco, poiché consente ai professionisti sanitari di prevedere gli effetti probabili di dosi specifiche sui pazienti.
La relazione dose-risposta può essere rappresentata graficamente come una curva dose-risposta, che spesso mostra un aumento iniziale rapido della risposta con l'aumentare della dose, seguito da un piatto o una diminuzione della risposta ad alte dosi. La pendenza di questa curva può variare notevolmente tra i farmaci e può essere influenzata da fattori quali la sensibilità individuale del paziente, la presenza di altre condizioni mediche e l'uso concomitante di altri farmaci.
L'analisi della relazione dose-risposta è un aspetto cruciale dello sviluppo dei farmaci, poiché può aiutare a identificare il range di dosaggio ottimale per un farmaco, minimizzando al contempo gli effetti avversi. Inoltre, la comprensione della relazione dose-risposta è importante per la pratica clinica, poiché consente ai medici di personalizzare le dosi dei farmaci in base alle esigenze individuali del paziente e monitorarne attentamente gli effetti.
La definizione medica di "Poli G" si riferisce a un ceppo specifico del batterio Streptococcus agalactiae, noto anche come gruppo B streptococco (GBS). Questo tipo di streptococco è comunemente presente nella flora microbica del tratto gastrointestinale e genitourinario di circa il 10-30% degli adulti sani, senza causare alcun disturbo o malattia. Tuttavia, i polisaccaridi capsulari G dei batteri Streptococcus agalactiae possono causare infezioni gravi e invasive, soprattutto nelle donne in gravidanza, nei neonati e negli anziani.
Nei neonati, l'infezione da GBS può verificarsi durante il parto se la madre è colonizzata dal batterio. Questa infezione può causare polmonite, meningite, sepsi e altre complicanze gravi che possono mettere a rischio la vita del bambino. Per questo motivo, alle donne in gravidanza viene spesso offerto uno screening per il GBS intorno alla 35-37a settimana di gestazione, al fine di identificare e trattare tempestivamente le madri positive al GBS prima del parto.
In sintesi, "Poli G" è un termine medico che si riferisce a un ceppo specifico di batteri Streptococcus agalactiae, che possono causare infezioni gravi e invasive, soprattutto nelle donne in gravidanza, nei neonati e negli anziani.
La streptavidina è una proteina batterica tetramerica ad alto peso molecolare, derivata da Streptomyces avidinii, che ha la capacità di legarsi in modo molto forte e specifico con la biotina (vitamina H). Questa interazione proteina-biotina è una delle più forti tra tutte le interazioni non covalenti note in natura.
La streptavidina è spesso utilizzata in applicazioni di biotecnologia, come la purificazione dell'RNA e del DNA, l'immunochimica, la citometria a flusso e l'istochimica, grazie alla sua alta affinità per la biotina. La streptavidina è anche nota per essere più stabile e meno suscettibile ai cambiamenti di pH e temperatura rispetto all'avidina, una proteina simile derivata dalle uova.
La struttura della streptavidina è costituita da quattro subunità identiche disposte in un tetramero con un sito di legame per la biotina in ciascuna subunità. Il sito di legame è composto da una tasca idrofobica che interagisce con l'anello tetraidrotioftalico della biotina e da residui di aminoacidi che formano legami idrogeni con gruppi funzionali della biotina.
In sintesi, la streptavidina è una proteina batterica ad alto peso molecolare che si lega in modo specifico e forte alla biotina, rendendola utile in varie applicazioni di biotecnologia.
La DNA polimerasi DNA-dipendente è un enzima che sintetizza nuove catene di DNA utilizzando una catena di DNA esistente come modello. Questo processo si verifica durante la replicazione del DNA, dove l'enzima legge la sequenza nucleotidica della catena template e aggiunge i nucleotidi complementari alla nuova catena in crescita. La DNA polimerasi DNA-dipendente ha anche attività di proofreading o correzione degli errori, il che significa che può rilevare e correggere la maggior parte degli errori di coppia dei nucleotidi durante la replicazione del DNA per garantire l'accuratezza della nuova catena. Ci sono diverse forme di DNA polimerasi DNA-dipendenti, ognuna delle quali svolge un ruolo specifico nella replicazione, riparazione e ricombinazione del DNA.
I danni al DNA si riferiscono a qualsiasi alterazione della struttura o sequenza del DNA che può verificarsi naturalmente o come risultato dell'esposizione a fattori ambientali avversi. Questi danni possono includere lesioni chimiche, mutazioni genetiche, rotture dei filamenti di DNA, modifiche epigenetiche e altri cambiamenti che possono influenzare la stabilità e la funzionalità del DNA.
I danni al DNA possono verificarsi a causa di fattori endogeni, come errori durante la replicazione o la riparazione del DNA, o a causa di fattori esogeni, come radiazioni ionizzanti, sostanze chimiche cancerogene e agenti infettivi.
I danni al DNA possono avere conseguenze negative sulla salute, poiché possono portare a malfunzionamenti cellulari, mutazioni genetiche, invecchiamento precoce, malattie neurodegenerative, cancro e altre patologie. Il corpo ha meccanismi di riparazione del DNA che lavorano continuamente per rilevare e correggere i danni al DNA, ma quando questi meccanismi sono compromessi o superati, i danni al DNA possono accumularsi e portare a effetti negativi sulla salute.
L'Electrophoretic Mobility Shift Assay (EMSA), noto anche come gel shift assay, è un metodo di laboratorio utilizzato per studiare le interazioni tra acidi nucleici (DNA o RNA) e proteine. Questo metodo si basa sul principio che quando una miscela di acido nucleico marcato radioattivamente e la sua proteina associata viene sottoposta a elettroforesi su gel, la mobilità del complesso acido nucleico-proteina risultante è diversa dalla mobilità dell'acido nucleico libero.
Nel processo, il campione contenente l'acido nucleico e la proteina sospetta viene mescolato e incubato per consentire l'interazione tra di loro. Successivamente, il mix viene caricato su un gel di poliacrilammide o agarosio preparato con una matrice di buffer contenente ioni che conducono l'elettricità. Quando una corrente elettrica viene applicata, le molecole di acido nucleico migrano verso l'anodo a causa della carica negativa delle loro scheletri fosfato-deossiribosio/ribosio. Tuttavia, il complesso acido nucleico-proteina migrerà più lentamente del solo acido nucleico a causa dell'aumento di dimensioni e peso molecolare.
L'EMSA è spesso utilizzato per rilevare e analizzare la formazione di complessi proteina-DNA, determinare il numero di siti di legame delle proteine sul DNA bersaglio, studiare le modifiche post-traduzionali che influenzano l'affinità di legame della proteina e identificare i fattori di trascrizione specifici. Questa tecnica è anche utile per valutare il grado di purezza delle proteine preparate in vitro, nonché per studiare le interazioni RNA-proteina.
Scuso, ma la terminologia "RNA batterico" è un po' imprecisa e non esiste una definizione medica specifica per essa. I batteri non contengono RNA (acido ribonucleico) come parte del loro genoma, a differenza degli organismi virali che utilizzano RNA o DNA come materiale genetico. Tuttavia, i batteri sintetizzano diversi tipi di RNA durante la trascrizione dei loro genomi di DNA. Questi includono RNA messaggero (mRNA), RNA transfer (tRNA) e RNA ribosomale (rRNA).
Quindi, se stai cercando una definizione per un particolare tipo di RNA associato ai batteri, si prega di fornire maggiori dettagli.
Le ammine sono composti organici derivati dagli ammoniaci per sostituzione di uno o più idrogeni con radicali alchilici o arilici. In chimica, le ammine sono classificate come derivati dell'ammoniaca in cui uno o più atomi di idrogeno sono sostituiti da gruppi radicali organici.
In biochimica e fisiologia, il termine "amine" si riferisce spesso a composti specifici che contengono un gruppo funzionale amminico (-NH2, -NHR, o -NR2), come ad esempio neurotrasmettitori (come dopamina, serotonina, e istamina) e alcuni ormoni (come adrenalina e noradrenalina). Queste ammine biogene svolgono un ruolo cruciale nella regolazione di una varietà di processi fisiologici, tra cui l'umore, il sonno, l'appetito, la memoria, l'apprendimento e la pressione sanguigna.
Le ammine possono avere effetti tossici o farmacologici sull'organismo, a seconda della loro struttura chimica e della dose assunta. Alcune ammine sono presenti naturalmente negli alimenti come pesce, carne e formaggi fermentati, mentre altre possono essere prodotte durante la lavorazione o la cottura del cibo. Un esempio di ammina tossica è l'istamina, che può causare sintomi gastrointestinali e allergici se consumata in grandi quantità.
Spiacenti, ma "Trioxalene" non è un termine riconosciuto o utilizzato comunemente nella medicina o nel campo della salute. Sembra che tu possa aver fatto un errore ortografico o di fraseggio. Forse stavi cercando informazioni su un farmaco, un trattamento o una condizione medica specifici? Se fornisci maggiori dettagli o precisazioni, sarò lieto di aiutarti con le informazioni appropriate.
Tuttavia, nel campo della chimica, Trioxalene si riferisce a un composto organico eterociclico con la formula (COCNH)3. Questo composto non ha applicazioni mediche note o dirette.
In medicina e biologia molecolare, un codone è una sequenza specifica di tre nucleotidi in una molecola di acido ribonucleico (RNA) che codifica per un particolare aminoacido durante la sintesi delle proteine. Il codice genetico è l'insieme di tutte le possibili combinazioni dei quattro diversi nucleotidi che compongono l'RNA (adenina, citosina, guanina e uracile) organizzati in gruppi di tre, cioè i codoni.
Il codice genetico è quasi universale in tutti gli esseri viventi e contiene 64 diversi codoni che codificano per 20 differenti aminoacidi. Ci sono anche tre codoni di arresto (UAA, UAG e UGA) che segnalano la fine della sintesi delle proteine. In alcuni casi, più di un codone può codificare per lo stesso aminoacido, il che è noto come degenerazione del codice genetico.
In sintesi, i codoni sono sequenze cruciali di RNA che forniscono le istruzioni per la costruzione delle proteine e giocano un ruolo fondamentale nel processo di traduzione dell'informazione genetica dall'RNA alle proteine.
La polinucleotide 5'-idrossile-chinasi, nota anche come polinucleotide chinasi o PNK, è un enzima chiave nel processo di riparazione e recombinazione del DNA. L'enzima catalizza l'aggiunta di un gruppo fosfato al 5'-terminale e un gruppo idrossile al 3'-terminale dei filamenti di DNA o RNA mono o policlonali, che sono stati tagliati o danneggiati.
Questa reazione è importante per la corretta riparazione delle rotture del DNA a singolo e doppio filamento, nonché per la preparazione dei substrati per le reazioni di clonaggio molecolare e sequenziamento del DNA. La polinucleotide 5'-idrossile-chinasi è quindi un enzima essenziale in molte applicazioni di biologia molecolare e genetica.
L'attività enzimatica della polinucleotide 5'-idrossile-chinasi richiede l'utilizzo di ATP come donatore di fosfato, e il prodotto finale dell'attività enzimatica è un filamento di DNA o RNA con un gruppo fosfato al 5'-terminale e un gruppo idrossile al 3'-terminale. L'enzima è altamente specifico per i substrati a singolo e doppio filamento, e mostra una preferenza per i nucleotidi purinici rispetto ai pirimidinici.
La polinucleotide 5'-idrossile-chinasi è stata identificata in molte specie viventi, dalle batterie agli esseri umani, e svolge un ruolo importante nella regolazione della risposta cellulare al danno del DNA. In particolare, l'enzima è stato implicato nel processo di riparazione dell'DNA noto come recombinazione omologa, che consente la correzione degli errori di ricombinazione genetica e la prevenzione della formazione di strutture anormali del DNA.
In sintesi, la polinucleotide 5'-idrossile-chinasi è un enzima fondamentale per la regolazione della risposta cellulare al danno del DNA e per il mantenimento dell'integrità genetica. L'attività enzimatica dell'enzima consente la correzione degli errori di ricombinazione genetica e la prevenzione della formazione di strutture anormali del DNA, e l'enzima è stato identificato in molte specie viventi, dalle batterie agli esseri umani.
In chimica e biochimica, un legame idrogeno è un tipo specifico di interazione dipolo-dipolo debole che si verifica quando un atomo di idrogeno, legato covalentemente a un atomo elettronegativo come l'ossigeno, il fluoro o l'azoto, viene attratto da un altro atomo elettronegativo nelle vicinanze. Questa interazione è rappresentata simbolicamente come A-H...B, dove A e B sono elettronegativi e H è idrogeno. Il legame idrogeno è significativamente più debole di un tipico legame covalente o ionico e si spezza facilmente a temperatura ambiente. Tuttavia, i legami idrogeno svolgono comunque un ruolo cruciale in molti processi chimici e biologici, compresi la struttura dell'acqua, le proprietà delle soluzioni acquose, il riconoscimento molecolare e la catalisi enzimatica.
Le tecniche genetiche si riferiscono a diversi metodi e procedure scientifiche utilizzate per studiare, manipolare e modificare il materiale genetico, o DNA, nelle cellule. Queste tecniche sono ampiamente utilizzate nella ricerca genetica, nella biologia molecolare e nella medicina per comprendere meglio i meccanismi genetici alla base delle malattie, dello sviluppo e dell'ereditarietà.
Ecco alcune tecniche genetiche comuni:
1. Restriction Fragment Length Polymorphism (RFLP): Questa tecnica viene utilizzata per identificare variazioni nel DNA tra individui. Implica la digestione del DNA con enzimi di restrizione specifici che tagliano il DNA in frammenti di lunghezza diversa, a seconda della sequenza del DNA. Questi frammenti vengono quindi separati mediante elettroforesi su gel e visualizzati utilizzando sondaggi marcati.
2. Polymerase Chain Reaction (PCR): Questa tecnica viene utilizzata per amplificare rapidamente e specificamente piccole quantità di DNA. Implica l'utilizzo di due primer, enzimi DNA polimerasi termostabili e nucleotidi per copiare ripetutamente una determinata sequenza di DNA.
3. Southern Blotting: Questa tecnica viene utilizzata per rilevare specifiche sequenze di DNA in un campione di DNA complesso. Implica la digestione del DNA con enzimi di restrizione, l'elettroforesi su gel e il trasferimento del DNA su una membrana. La membrana viene quindi hybridizzata con una sonda marcata che si lega specificamente alla sequenza desiderata.
4. Sequenziamento del DNA: Questa tecnica viene utilizzata per determinare l'ordine esatto delle basi nel DNA. Implica la sintesi di brevi frammenti di DNA utilizzando una miscela di dideossinucleotidi marcati e DNA polimerasi. Ogni frammento rappresenta una porzione della sequenza desiderata.
5. Clonaggio del DNA: Questa tecnica viene utilizzata per creare copie multiple di un gene o di una sequenza di interesse. Implica la creazione di una biblioteca genica, l'identificazione di cloni che contengono la sequenza desiderata e la purificazione dei cloni.
6. CRISPR-Cas9: Questa tecnica viene utilizzata per modificare geneticamente le cellule viventi mediante la cancellazione o l'inserimento di specifiche sequenze di DNA. Implica la progettazione di guide RNA che si legano a una sequenza target e l'attivazione dell'enzima Cas9, che taglia il DNA in quella posizione.
7. Microarray: Questa tecnica viene utilizzata per misurare l'espressione genica su larga scala. Implica la marcatura di molecole di RNA o DNA e l'ibridazione con una matrice di sonde che rappresentano i geni desiderati.
8. Next-generation sequencing: Questa tecnica viene utilizzata per determinare la sequenza del DNA o dell'RNA a livello di genoma o di transcriptoma. Implica la creazione di milioni di frammenti di DNA o RNA e la lettura della loro sequenza mediante tecniche di sequenziamento ad alta velocità.
9. Single-cell sequencing: Questa tecnica viene utilizzata per analizzare il genoma o l'espressione genica a livello cellulare. Implica la separazione delle cellule individuali, la preparazione del DNA o dell'RNA e la lettura della loro sequenza mediante tecniche di sequenziamento ad alta velocità.
10. Epigenomics: Questa tecnica viene utilizzata per studiare i cambiamenti epigenetici che influenzano l'espressione genica. Implica la misurazione della metilazione del DNA, delle modifiche dei residui di istone e dell'interazione con fattori di trascrizione.
La regolazione dell'espressione genica nello sviluppo si riferisce al processo di attivazione e disattivazione dei geni in diversi momenti e luoghi all'interno di un organismo durante lo sviluppo. Questo processo è fondamentale per la differenziazione cellulare, crescita e morfogenesi dell'organismo.
L'espressione genica è il processo attraverso cui l'informazione contenuta nel DNA viene trascritta in RNA e successivamente tradotta in proteine. Tuttavia, non tutti i geni sono attivi o espressi allo stesso modo in tutte le cellule del corpo in ogni momento. Al contrario, l'espressione genica è strettamente regolata a seconda del tipo di cellula e dello stadio di sviluppo.
La regolazione dell'espressione genica nello sviluppo può avvenire a diversi livelli, tra cui:
1. Regolazione della trascrizione: questo include meccanismi che influenzano l'accessibilità del DNA alla macchina transcrizionale o modifiche chimiche al DNA che ne promuovono o inibiscono la trascrizione.
2. Regolazione dell'RNA: dopo la trascrizione, l'RNA può essere sottoposto a processi di maturazione come il taglio e il giunzionamento, che possono influenzare la stabilità o la traduzione dell'mRNA.
3. Regolazione della traduzione: i fattori di traduzione possono influenzare la velocità e l'efficienza con cui i mRNA vengono tradotti in proteine.
4. Regolazione post-traduzionale: le proteine possono essere modificate dopo la loro sintesi attraverso processi come la fosforilazione, glicosilazione o ubiquitinazione, che possono influenzarne l'attività o la stabilità.
I meccanismi di regolazione dello sviluppo sono spesso complessi e coinvolgono una rete di interazioni tra geni, prodotti genici ed elementi del loro ambiente cellulare. La disregolazione di questi meccanismi può portare a malattie congenite o alla comparsa di tumori.
La terminologia "Poli A" si riferisce a un elemento specifico della struttura del DNA e dell'RNA chiamato "sequenza di poliadenilazione." Questa sequenza è costituita da una ripetizione di unità di adenina (simbolizzata come "A") alla fine della molecola di RNA.
Nel dettaglio, la sequenza di poliadenilazione dell'RNA eucariotico consiste comunemente in una serie di circa 100-250 basi azotate di adenina che vengono aggiunte alla fine della molecola di RNA durante il processo di maturazione noto come "poliadenilazione." Questa modifica post-trascrizionale è essenziale per la stabilità, l'efficienza dell'esportazione nucleare e la traduzione dell'mRNA.
Pertanto, quando si parla di "Poli A" in un contesto medico o biochimico, ci si riferisce generalmente a questa sequenza ripetitiva di adenina alla fine delle molecole di RNA.
La citidina è un nucleoside naturalmente presente, costituito da una molecola di citosina legata a un gruppo fosfato. Nella citidina, il gruppo fosfato è attaccato al carbonio in posizione 1' del anello pirimidinico della citosina.
La citidina svolge un ruolo importante nella biologia cellulare come costituente dei nucleotidi che formano l'acido ribonucleico (RNA). In particolare, la citidina è incorporata nei residui di citosina nelle catene di RNA.
La citidina può anche essere fosforilata per formare citidina monofosfato (CMP), citidina difosfato (CDP) e citidina trifosfato (CTP), che sono importanti cofattori enzimatici e substrati per la sintesi di altri composti biologici.
La citidina ha anche applicazioni cliniche come farmaco antivirale, utilizzato nel trattamento dell'epatite C cronica. Il farmaco agisce inibendo l'RNA-dipendente RNA polimerasi virale, impedendo così la replicazione del virus.
In sintesi, la citidina è un nucleoside importante nella biologia cellulare e ha applicazioni cliniche come farmaco antivirale.
In medicina, il termine "metodi" generalmente si riferisce a approcci sistematici o procedure utilizzate per la diagnosi, il trattamento, la prevenzione o la ricerca di condizioni e malattie. Questi possono includere:
1. Metodi diagnostici: Procedure utilizzate per identificare e confermare la presenza di una particolare condizione o malattia. Esempi includono test di laboratorio, imaging medico, esami fisici e storia clinica del paziente.
2. Metodi terapeutici: Approcci utilizzati per trattare o gestire una condizione o malattia. Questi possono includere farmaci, chirurgia, radioterapia, chemioterapia, fisioterapia e cambiamenti nello stile di vita.
3. Metodi preventivi: Strategie utilizzate per prevenire l'insorgenza o la progressione di una condizione o malattia. Questi possono includere vaccinazioni, screening regolari, modifiche dello stile di vita e farmaci preventivi.
4. Metodi di ricerca: Procedure utilizzate per condurre ricerche mediche e scientifiche. Questi possono includere studi clinici controllati randomizzati, revisioni sistematiche della letteratura, meta-analisi e ricerca di base in laboratorio.
In sintesi, i metodi sono fondamentali per la pratica medica evidence-based, poiché forniscono un framework per prendere decisioni informate sulla salute dei pazienti e avanzare nella conoscenza medica attraverso la ricerca.
La DNA Ligasi è un enzima che catalizza la reazione di giunzione di due filamenti di DNA a singolo filamento per riparare rotture del DNA o per unire frammenti di DNA durante la ricombinazione genetica e la clonazione molecolare. Esistono diversi tipi di DNA Ligasi, ma le più studiate sono la DNA Ligasi I e III, presenti nei mammiferi, e la DNA Ligasi IV, che è essenziale per il riparo delle rotture del DNA a doppio filamento e per la ricombinazione V(D)J durante la riproduzione dei linfociti. La DNA Ligasi utilizza ATP come fonte di energia per catalizzare la formazione di un legame fosfodiesterico tra le estremità 3'-OH e 5'-fosfato dei frammenti di DNA, consentendo loro di essere uniti in modo stabile.
La trasduzione del segnale è un processo fondamentale nelle cellule viventi che consente la conversione di un segnale esterno o interno in una risposta cellulare specifica. Questo meccanismo permette alle cellule di percepire e rispondere a stimoli chimici, meccanici ed elettrici del loro ambiente.
In termini medici, la trasduzione del segnale implica una serie di eventi molecolari che avvengono all'interno della cellula dopo il legame di un ligando (solitamente una proteina o un messaggero chimico) a un recettore specifico sulla membrana plasmatica. Il legame del ligando al recettore induce una serie di cambiamenti conformazionali nel recettore, che a sua volta attiva una cascata di eventi intracellulari, compreso l'attivazione di enzimi, la produzione di secondi messaggeri e l'attivazione o inibizione di fattori di trascrizione.
Questi cambiamenti molecolari interni alla cellula possono portare a una varietà di risposte cellulari, come il cambiamento della permeabilità ionica, l'attivazione o inibizione di canali ionici, la modulazione dell'espressione genica e la promozione o inibizione della proliferazione cellulare.
La trasduzione del segnale è essenziale per una vasta gamma di processi fisiologici, tra cui la regolazione endocrina, il controllo nervoso, la risposta immunitaria e la crescita e sviluppo cellulare. Tuttavia, errori nella trasduzione del segnale possono anche portare a una serie di patologie, tra cui malattie cardiovascolari, cancro, diabete e disturbi neurologici.
L'inosina è un nucleoside formato dalla purina, l'adenina, legata al ribosio. Si trova naturalmente nel corpo umano e svolge un ruolo importante nella produzione di energia nelle cellule. Inoltre, l'inosina può essere prodotta in laboratorio ed è disponibile come integratore alimentare.
Nel corpo, l'inosina viene convertita in ipoxantina, che a sua volta viene convertita in xantina e infine in acido urico. L'acido urico è il prodotto finale del metabolismo delle purine nel corpo umano.
In medicina, l'inosina ha diversi usi. Ad esempio, può essere utilizzata come farmaco per trattare la deficit di inosina monofosfato (IMP) sintasi, una rara malattia genetica che colpisce il metabolismo delle purine. Inoltre, l'inosina è stata studiata come possibile trattamento per altre condizioni, come la malattia di Parkinson e alcune forme di cancro.
Tuttavia, l'uso dell'inosina come farmaco o integratore alimentare deve essere attentamente monitorato, poiché alti livelli di acido urico nel sangue possono aumentare il rischio di sviluppare calcoli renali e gotta. Inoltre, l'uso di inosina durante la gravidanza e l'allattamento deve essere evitato a causa della mancanza di dati sufficienti sulla sua sicurezza.
L'idrolisi è un processo chimico che si verifica quando una molecola è divisa in due o più molecole più piccole con l'aggiunta di acqua. Nella reazione, l'acqua serve come solvente e contribuisce ai gruppi funzionali polari (-OH e -H) che vengono aggiunti alle molecole separate.
In un contesto medico-biologico, l'idrolisi è particolarmente importante nelle reazioni enzimatiche, dove gli enzimi catalizzano la rottura di legami chimici in molecole complesse come proteine, carboidrati e lipidi. Ad esempio, durante la digestione, enzimi specifici idrolizzano le grandi molecole alimentari nei loro costituenti più semplici, facilitandone così l'assorbimento attraverso la parete intestinale.
L'idrolisi è anche un meccanismo importante per la sintesi e la degradazione di macromolecole come polisaccaridi, proteine e lipidi all'interno delle cellule. Questi processi sono fondamentali per la crescita, la riparazione e il mantenimento dei tessuti e degli organismi.
La fotochimica è una branca della chimica che si occupa degli effetti delle radiazioni elettromagnetiche, in particolare la luce visibile, sull'equilibrio e sulla reattività dei sistemi chimici. In ambito medico, il termine "fotochimica" viene talvolta utilizzato per descrivere le reazioni chimiche che avvengono nella pelle in risposta all'esposizione alla luce solare o ad altre fonti di radiazione elettromagnetica.
Ad esempio, quando la pelle umana viene esposta ai raggi ultravioletti (UV) del sole, possono verificarsi reazioni fotochimiche che portano alla formazione di molecole chiamate radicali liberi. Questi radicali liberi possono danneggiare le cellule della pelle e contribuire all'invecchiamento precoce della pelle, nonché aumentare il rischio di sviluppare tumori cutanei.
La fotochimica è anche alla base della fototerapia, un trattamento medico che utilizza la luce per alleviare i sintomi o curare alcune condizioni mediche. Ad esempio, la fotochemioterapia è un trattamento per il cancro della pelle che combina l'esposizione alla luce con la somministrazione di farmaci fotosensibilizzanti, che diventano attivi quando esposti alla luce. Questo tipo di trattamento può essere utilizzato per distruggere le cellule tumorali senza danneggiare le cellule sane circostanti.
In campo medico, un'endoribonucleasi è un enzima (precisamente una nucleasi) che catalizza la rottura dei legami fosfodiesterici all'interno delle molecole di RNA, scindendo cioè le catene di RNA in sequenze più piccole. Queste endoribonucleasi possono essere classificate in base alla loro specificità di substrato e al meccanismo d'azione. Alcune endoribonucleasi sono parte integrante del sistema immunitario, come ad esempio le ribonucleasi presenti nei granulociti neutrofili, che svolgono un ruolo importante nella difesa contro i patogeni infettivi degradando il loro RNA. Altre endoribonucleasi sono invece implicate in processi cellulari fondamentali quali l'elaborazione e il degrado dell'RNA.
La deossiribonucleasi di tipo II sito-specifica, nota anche come endonucleasi di restrizione, è un enzima che taglia il DNA in siti specifici della sequenza del nucleotide. Questo enzima riconosce una sequenza palindromica particolare nella doppia elica del DNA e taglia entrambe le catene all'interno di questa sequenza, producendo estremità appiccicose recise.
Gli enzimi di restrizione sono parte integrante della risposta batterica alla infezione da virus (batteriofagi). I batteri utilizzano questi enzimi per proteggersi dall'invasione dei batteriofagi tagliando il loro DNA e rendendolo non funzionale.
La deossiribonucleasi di tipo II sito-specifica è comunemente utilizzata in biologia molecolare per manipolare il DNA, ad esempio per la clonazione o per l'analisi della struttura del DNA. Questo enzima viene spesso utilizzato insieme con la DNA ligasi per unire frammenti di DNA diversi in modo preciso e specifico.
In genetica, un vettore è comunemente definito come un veicolo che serve per trasferire materiale genetico da un organismo donatore a uno ricevente. I vettori genetici sono spesso utilizzati in biotecnologie e nella ricerca genetica per inserire specifici geni o segmenti di DNA in cellule o organismi target.
I vettori genetici più comuni includono plasmidi, fagi (batteriofagi) e virus engineered come adenovirus e lentivirus. Questi vettori sono progettati per contenere il gene di interesse all'interno della loro struttura e possono essere utilizzati per trasferire questo gene nelle cellule ospiti, dove può quindi esprimersi e produrre proteine.
In particolare, i vettori genetici sono ampiamente utilizzati nella terapia genica per correggere difetti genetici che causano malattie. Essi possono anche essere utilizzati in ricerca di base per studiare la funzione dei geni e per creare modelli animali di malattie umane.
In medicina, le microiniezioni si riferiscono a un metodo di somministrazione di farmaci o altri agenti terapeutici che prevede l'iniezione di piccole quantità di sostanza direttamente nel tessuto corporeo utilizzando aghi sottili. Questa tecnica è spesso utilizzata per fornire una dose precisa e concentrata del farmaco in un'area specifica, riducendo al minimo gli effetti sistemici indesiderati che possono verificarsi con la somministrazione sistemica.
Le microiniezioni possono essere utilizzate per trattare una varietà di condizioni mediche, tra cui il dolore cronico, le malattie neurologiche e i disturbi muscoloscheletrici. Ad esempio, i farmaci antinfiammatori o analgesici possono essere iniettati direttamente nei tessuti molli circostanti un'articolazione dolorante per fornire sollievo dal dolore mirato e ridurre l'infiammazione locale.
Le microiniezioni sono anche comunemente utilizzate in estetica medica, dove vengono iniettati agenti come tossine botuliniche o filler dermici per ridurre le rughe o ripristinare il volume del viso. In questi casi, l'uso di aghi sottili e la precisione della tecnica di microiniezione aiutano a minimizzare i rischi di complicazioni come lividi, gonfiore o danni ai tessuti circostanti.
In generale, le microiniezioni sono considerate una procedura sicura ed efficace quando eseguite da un operatore esperto e qualificato, con un rischio relativamente basso di effetti avversi o complicazioni a breve e lungo termine. Tuttavia, come con qualsiasi procedura medica, è importante discutere i potenziali rischi e benefici con il proprio operatore sanitario prima di sottoporsi a una microiniezione.
La mutagenesi è un processo che porta a modifiche permanenti e ereditarie nella sequenza del DNA, aumentando il tasso di mutazione oltre il livello spontaneo. Questi cambiamenti nella struttura del DNA possono provocare alterazioni nel materiale genetico che possono influenzare l'espressione dei geni e portare a effetti fenotipici, come malattie genetiche o cancerose.
I mutageni sono agenti fisici, chimici o biologici che causano danni al DNA, portando alla formazione di mutazioni. Gli esempi includono raggi X e altri tipi di radiazioni ionizzanti, sostanze chimiche come derivati dell'idrocarburo aromatico policiclico (PAH) e agenti infettivi come virus o batteri.
La mutagenesi può verificarsi in modo spontaneo a causa di errori durante la replicazione del DNA, ma l'esposizione a mutageni aumenta significativamente il tasso di mutazioni. La comprensione dei meccanismi della mutagenesi è fondamentale per lo sviluppo di strategie di prevenzione e trattamento delle malattie genetiche e del cancro.
"Silani" non è un termine comunemente utilizzato nella medicina. Tuttavia, in chimica, i "silani" si riferiscono a composti organici che contengono uno o più gruppi funzionali sililiani (-Si-H). Questi composti sono simili ai alcani, ma con uno o più atomi di idrogeno sostituiti da gruppi sililiani. Non ho informazioni mediche specifiche su "silani" poiché non è un termine utilizzato nella pratica clinica o nelle scienze mediche.
C-Bcl-2 (B-cell lymphoma 2) è una proteina che appartiene alla classe delle proteine proto-oncogene. Normalmente, la proteina C-Bcl-2 si trova nel mitocondrio e nei membrana del reticolo endoplasmatico liscio, dove aiuta a regolare l'apoptosi (morte cellulare programmata).
Il proto-oncogene C-Bcl-2 è stato originariamente identificato come un gene che, quando traslocato e sopraespresso nel cancro del sangue noto come leucemia linfocitica a cellule B croniche (CLL), contribuisce alla patogenesi della malattia. La proteina C-Bcl-2 sopprime l'apoptosi, promuovendo così la sopravvivenza e l'accumulo di cellule tumorali.
La proteina C-Bcl-2 è anche espressa in molti altri tipi di cancro, inclusi linfomi non Hodgkin, carcinoma del polmone a piccole cellule, carcinoma mammario e carcinoma ovarico. L'espressione della proteina C-Bcl-2 è spesso associata a una prognosi peggiore nei pazienti con cancro.
Vari farmaci sono stati sviluppati per inibire l'attività della proteina C-Bcl-2, inclusi anticorpi monoclonali e small molecule inhibitors. Questi farmaci hanno mostrato attività antitumorale promettente in diversi studi clinici e sono attualmente utilizzati nel trattamento di alcuni tipi di cancro.
Il peso molecolare (PM) è un'unità di misura che indica la massa di una molecola, calcolata come la somma dei pesi atomici delle singole particelle costituenti (atomi) della molecola stessa. Si misura in unità di massa atomica (UMA o dal simbolo chimico ufficiale 'amu') o, più comunemente, in Daltons (Da), dove 1 Da equivale a 1 u.
Nella pratica clinica e nella ricerca biomedica, il peso molecolare è spesso utilizzato per descrivere le dimensioni relative di proteine, peptidi, anticorpi, farmaci e altre macromolecole. Ad esempio, l'insulina ha un peso molecolare di circa 5.808 Da, mentre l'albumina sierica ha un peso molecolare di circa 66.430 Da.
La determinazione del peso molecolare è importante per comprendere le proprietà fisico-chimiche delle macromolecole e il loro comportamento in soluzioni, come la diffusione, la filtrazione e l'interazione con altre sostanze. Inoltre, può essere utile nella caratterizzazione di biomarcatori, farmaci e vaccini, oltre che per comprendere i meccanismi d'azione delle terapie biologiche.
In genetica, i geni reporter sono sequenze di DNA che sono state geneticamente modificate per produrre un prodotto proteico facilmente rilevabile quando il gene viene espresso. Questi geni codificano per enzimi o proteine fluorescenti che possono essere rilevati e misurati quantitativamente utilizzando tecniche di laboratorio standard. I geni reporter vengono spesso utilizzati negli esperimenti di biologia molecolare e di genomica per studiare l'espressione genica, la regolazione trascrizionale e le interazioni proteina-DNA in vivo. Ad esempio, un gene reporter può essere fuso con un gene sospetto di interesse in modo che l'espressione del gene reporter rifletta l'attività del gene sospetto. In questo modo, i ricercatori possono monitorare e valutare l'effetto di vari trattamenti o condizioni sperimentali sull'espressione genica.
La "click chemistry" non è propriamente una definizione medica, ma piuttosto un termine utilizzato in chimica per descrivere una classe specifica di reazioni chimiche che sono caratterizzate da alta velocità, alti rendimenti, semplicità e modularità. Queste reazioni spesso comportano la formazione di legami covalenti tra due molecole in condizioni estremamente mite, il più delle volte a temperatura e pressione ambiente.
In biochimica e nella ricerca biomedica, la "click chemistry" è talvolta utilizzata per creare etichette fluorescenti o gruppi chimici specifici che consentono di monitorare e studiare i processi cellulari e molecolari. Ad esempio, un gruppo funzionale può essere "cliccato" su una proteina bersaglio per facilitarne l'identificazione e lo studio.
Tuttavia, è importante notare che la "click chemistry" non è limitata all'uso in medicina o biologia, ma è ampiamente utilizzata anche in altri campi della chimica, come la sintesi di materiali e farmaci.
L'ingegneria genetica è una disciplina scientifica che utilizza tecniche di biologia molecolare per modificare geneticamente gli organismi, introducendo specifiche sequenze di DNA nei loro genomi. Questo processo può coinvolgere la rimozione, l'aggiunta o il cambiamento di geni in un organismo, al fine di produrre particolari caratteristiche o funzioni desiderate.
Nella pratica dell'ingegneria genetica, i ricercatori isolano prima il gene o la sequenza di DNA desiderata da una fonte donatrice (ad esempio, un batterio, un virus o un altro organismo). Successivamente, utilizzando enzimi di restrizione e ligasi, incorporano questo frammento di DNA in un vettore appropriato, come un plasmide o un virus, che funge da veicolo per l'introduzione del gene nella cellula ospite. La cellula ospite può essere una cellula batterica, vegetale, animale o umana, a seconda dell'applicazione specifica dell'ingegneria genetica.
L'ingegneria genetica ha numerose applicazioni in vari campi, tra cui la medicina, l'agricoltura, l'industria e la ricerca di base. Alcuni esempi includono la produzione di insulina umana mediante batteri geneticamente modificati, la creazione di piante resistenti alle malattie o adattabili al clima, e lo studio delle funzioni geniche e dei meccanismi molecolari alla base di varie patologie.
Come con qualsiasi tecnologia avanzata, l'ingegneria genetica deve essere regolamentata ed eseguita in modo responsabile, tenendo conto delle possibili implicazioni etiche e ambientali.
La 2-Aminopurina, nota anche come Teofillina, è una metilxantina che viene utilizzata come broncodilatatore per il trattamento dell'asma e della malattia polmonare ostruttiva cronica (BPCO). Agisce rilassando i muscoli lisci delle vie respiratorie, aumentando così il flusso d'aria nei polmoni.
La 2-Aminopurina è anche un inibitore della fosfodiesterasi, che aumenta i livelli di AMP ciclico (cAMP) all'interno delle cellule, portando alla relazione del broncodilatatore. Viene assorbita rapidamente dopo l'ingestione e ha una emivita di circa 4-9 ore.
Gli effetti avversi della 2-Aminopurina possono includere nausea, vomito, mal di testa, palpitazioni cardiache, tachicardia, aritmie e agitazione. L'uso a lungo termine può causare osteoporosi, aumento della pressione endoculare e complicanze gastrointestinali.
L'uso di 2-Aminopurina deve essere monitorato attentamente dal medico per garantire un dosaggio sicuro ed efficace, poiché la clearance individuale della teofillina può variare notevolmente tra i pazienti.
In campo medico, l'endonucleasi è un enzima che taglia le molecole di DNA in punti specifici all'interno della stessa catena, piuttosto che tra due differenti catene come fa la esonucleasi. Queste endonucleasi possono essere classificate in base al meccanismo d'azione e alla specificità del sito di taglio. Alcune endonucleasi, come le restriction enzymes, riconoscono sequenze palindromiche specifiche di DNA e ne determinano il taglio, mentre altre possono avere un meccanismo meno selettivo. Le endonucleasi sono ampiamente utilizzate nella biologia molecolare per la manipolazione del DNA, ad esempio per la clonazione o l'analisi delle sequenze genomiche.
I geni Myc sono una famiglia di geni che codificano per le proteine Myc, che svolgono un ruolo importante nella regolazione della trascrizione genica. Questi geni sono altamente conservati evolutivamente e sono presenti in molti organismi viventi, compresi gli esseri umani.
Nell'uomo, la famiglia dei geni Myc comprende tre membri principali: c-Myc, N-Myc e L-Myc. Questi geni codificano per le proteine Myc, che formano eterodimeri con il fattore di trascrizione Max e regolano l'espressione di una vasta gamma di geni che controllano la crescita cellulare, la proliferazione, la differenziazione e l'apoptosi.
L'alterazione dell'espressione dei geni Myc è stata associata a diverse malattie, tra cui il cancro. In particolare, l'amplificazione o l'espressione anomala del gene c-Myc è stata osservata in molti tipi di tumori, come il carcinoma polmonare, il carcinoma mammario e il linfoma di Burkitt. Pertanto, i geni Myc sono considerati oncogeni e sono considerati importanti bersagli terapeutici per lo sviluppo di nuovi trattamenti contro il cancro.
Le proteine Xenopus si riferiscono specificamente alle proteine identificate e isolate dal girino della rana Xenopus (Xenopus laevis o Xenopus tropicalis), un organismo modello comunemente utilizzato negli studi di biologia dello sviluppo. Queste proteine possono essere estratte e analizzate per comprendere meglio le loro funzioni, strutture e interazioni con altre molecole. Un esempio ben noto di proteina Xenopus è la proteina della fecondazione nota come "proteina sperma-uovo", che svolge un ruolo cruciale nell'attivazione dello sviluppo embrionale dopo la fecondazione. La rana Xenopus viene utilizzata frequentemente nella ricerca scientifica a causa del suo grande uovo, delle sue dimensioni cellulari relativamente grandi e della facilità di manipolazione genetica ed esperimentale.
La Taq polimerasi è un enzima termostabile utilizzato comunemente nella biologia molecolare, in particolare nella reazione a catena della polimerasi (PCR). Deriva dalla batteria termofila Thermus aquaticus e ha la capacità di sintetizzare nuove catene di DNA a temperature elevate. L'enzima Taq polimerasi catalizza la sintesi dell'DNA per aggiungere nucleotidi ad un filamento di DNA singolo utilizzando il filamento complementare come matrice, durante il processo noto come estensione del filamento. Questa proprietà lo rende particolarmente utile nella PCR, dove le alte temperature sono necessarie per separare i filamenti di DNA e consentire all'enzima Taq polimerasi di sintetizzare nuove copie del DNA target.
In medicina, sensibilità e specificità sono due termini utilizzati per descrivere le prestazioni di un test diagnostico.
La sensibilità di un test si riferisce alla sua capacità di identificare correttamente i pazienti con una determinata condizione. Viene definita come la probabilità che il test dia un risultato positivo in presenza della malattia. In formula, è calcolata come:
Sensibilità = Numero di veri positivi / (Numero di veri positivi + Numero di falsi negativi)
Un test con alta sensibilità evita i falsi negativi, il che significa che se il test è positivo, è molto probabile che il paziente abbia effettivamente la malattia. Tuttavia, un test ad alto livello di sensibilità può anche avere un'alta frequenza di falsi positivi, il che significa che potrebbe identificare erroneamente alcuni individui sani come malati.
La specificità di un test si riferisce alla sua capacità di identificare correttamente i pazienti senza una determinata condizione. Viene definita come la probabilità che il test dia un risultato negativo in assenza della malattia. In formula, è calcolata come:
Specificità = Numero di veri negativi / (Numero di veri negativi + Numero di falsi positivi)
Un test con alta specificità evita i falsi positivi, il che significa che se il test è negativo, è molto probabile che il paziente non abbia la malattia. Tuttavia, un test ad alto livello di specificità può anche avere un'alta frequenza di falsi negativi, il che significa che potrebbe mancare alcuni casi di malattia vera.
In sintesi, la sensibilità e la specificità sono due aspetti importanti da considerare quando si valuta l'accuratezza di un test diagnostico. Un test con alta sensibilità è utile per escludere una malattia, mentre un test con alta specificità è utile per confermare una diagnosi. Tuttavia, nessuno dei due parametri da solo fornisce informazioni sufficienti sull'accuratezza complessiva del test, ed entrambi dovrebbero essere considerati insieme ad altri fattori come la prevalenza della malattia e le conseguenze di una diagnosi errata.
Gli "endonucleasi a singolo filamento specifiche per il DNA e l'RNA" sono enzimi che tagliano specificamente le molecole di DNA o RNA a singolo filamento in siti specifici della sequenza. Questi enzimi catalizzano la rottura dei legami fosfodiesterici all'interno della catena polinucleotidica, producendo frammenti con estremità 3'-OH e 5'-fosfato.
Le endonucleasi a singolo filamento specifiche per il DNA sono spesso utilizzate in biologia molecolare come strumenti di ricerca per la mappatura dei genomi, l'ingegneria del DNA e l'analisi della funzione delle proteine. Un esempio ben noto è la restriction endonuclease, che taglia il DNA a doppio filamento in siti specifici della sequenza dopo aver riconosciuto una sequenza palindromica di basi azotate. Quando questo enzima taglia il DNA, produce estremità appiccicose che possono essere utilizzate per legare diversi frammenti di DNA insieme mediante la ligation del DNA.
Le endonucleasi a singolo filamento specifiche per l'RNA sono anch'esse ampiamente utilizzate in biologia molecolare, ad esempio per analizzare e manipolare l'espressione genica. Questi enzimi possono essere utilizzati per tagliare l'RNA a singolo filamento in siti specifici della sequenza, il che può essere utile per studiare la struttura e la funzione dell'RNA o per regolare l'espressione genica.
In sintesi, le endonucleasi a singolo filamento specifiche per il DNA e l'RNA sono enzimi importanti che vengono utilizzati in biologia molecolare per studiare e manipolare la struttura e la funzione del DNA e dell'RNA.
Le proteine di fusione ricombinanti sono costrutti proteici creati mediante tecniche di ingegneria genetica che combinano sequenze aminoacidiche da due o più proteine diverse. Queste sequenze vengono unite in un singolo gene, che viene quindi espresso all'interno di un sistema di espressione appropriato, come ad esempio batteri, lieviti o cellule di mammifero.
La creazione di proteine di fusione ricombinanti può servire a diversi scopi, come ad esempio:
1. Studiare la struttura e la funzione di proteine complesse che normalmente interagiscono tra loro;
2. Stabilizzare proteine instabili o difficili da produrre in forma pura;
3. Aggiungere etichette fluorescenti o epitopi per la purificazione o il rilevamento delle proteine;
4. Sviluppare farmaci terapeutici, come ad esempio enzimi ricombinanti utilizzati nel trattamento di malattie genetiche rare.
Tuttavia, è importante notare che la creazione di proteine di fusione ricombinanti può anche influenzare le proprietà delle proteine originali, come la solubilità, la stabilità e l'attività enzimatica, pertanto è necessario valutarne attentamente le conseguenze prima dell'utilizzo a scopo di ricerca o terapeutico.
In biochimica, la globina è una proteina che fa parte dell'emoglobina e della mioglobina, due importanti componenti dei globuli rossi e delle fibre muscolari rispettivamente. Nell'emoglobina, le catene globiniche si combinano con un gruppo eme contenente ferro per formare i gruppi eme che trasportano l'ossigeno nei globuli rossi.
Esistono diversi tipi di catene globiniche, identificate come alfa (α), beta (β), gamma (γ), delta (δ) e epsilon (ε). Le diverse combinazioni di queste catene globiniche formano le diverse forme di emoglobina presenti nell'organismo in diversi stadi dello sviluppo. Ad esempio, l'emoglobina fetale (HbF) è costituita da due catene alfa e due catene gamma, mentre l'emoglobina adulta (HbA) è costituita da due catene alfa e due catene beta.
Le mutazioni nei geni che codificano per le catene globiniche possono causare diverse malattie ereditarie, come l'anemia falciforme e la talassemia.
Il "gene silencing" o "silenziamento genico" si riferisce a una serie di meccanismi cellulari che portano al silenziamento o alla ridotta espressione dei geni. Ciò può avvenire attraverso diversi meccanismi, come la metilazione del DNA, l'interferenza dell'RNA e la degradazione dell'mRNA.
La metilazione del DNA è un processo epigenetico che comporta l'aggiunta di gruppi metile al DNA, il quale può impedire la trascrizione del gene in RNA messaggero (mRNA). L'interferenza dell'RNA si verifica quando piccole molecole di RNA, note come small interfering RNA (siRNA) o microRNA (miRNA), si legano all'mRNA complementare e impediscono la traduzione del mRNA in proteine. Infine, la degradazione dell'mRNA comporta la distruzione dell'mRNA prima che possa essere utilizzato per la sintesi delle proteine.
Il gene silencing è un processo importante nella regolazione dell'espressione genica e può essere utilizzato in terapia genica per trattare malattie causate da geni iperattivi o sovraespressi. Tuttavia, il gene silencing può anche avere implicazioni negative sulla salute, come nel caso del cancro, dove i meccanismi di silenziamento genico possono essere utilizzati dalle cellule tumorali per sopprimere l'espressione di geni che codificano proteine tumor-suppressive.
Le proteine virali sono molecole proteiche sintetizzate dalle particelle virali o dai genomi virali dopo l'infezione dell'ospite. Sono codificate dal genoma virale e svolgono un ruolo cruciale nel ciclo di vita del virus, inclusa la replicazione virale, l'assemblaggio dei virioni e la liberazione dalle cellule ospiti.
Le proteine virali possono essere classificate in diverse categorie funzionali, come le proteine strutturali, che costituiscono la capside e il rivestimento lipidico del virione, e le proteine non strutturali, che svolgono una varietà di funzioni accessorie durante l'infezione virale.
Le proteine virali possono anche essere utilizzate come bersagli per lo sviluppo di farmaci antivirali e vaccini. La comprensione della struttura e della funzione delle proteine virali è quindi fondamentale per comprendere il ciclo di vita dei virus e per sviluppare strategie efficaci per prevenire e trattare le infezioni virali.
La recombinasi RecA è un processo enzimatico importante nella riparazione del DNA e nella ricombinazione genetica in molti organismi, tra cui i batteri. Il sistema di recombinazione RecA è particolarmente ben studiato nel batterio Escherichia coli (E. coli).
L'enzima centrale del sistema di recombinazione RecA è la proteina RecA stessa, che svolge un ruolo chiave nella riparazione dei danni al DNA e nella ricombinazione genetica. La proteina RecA si lega al filamento singolo di DNA con una struttura specifica, formando un nucleoproteina chiamata complesso presinaptico. Questo complesso è in grado di cercare e riconoscere sequenze omologhe di DNA complementari, il che consente alla proteina RecA di facilitare l'invio di informazioni genetiche tra due molecole di DNA.
Nel contesto della riparazione del DNA, la recombinasi RecA può essere utilizzata per riparare i danni al DNA causati da rotture a singolo filamento o doppio filamento. Quando si verifica una rottura a singolo filamento, il complesso presinaptico di proteina RecA può cercare e trovare una sequenza omologa di DNA complementare su un altro filamento di DNA, quindi facilitare l'invio di informazioni genetiche per riempire la rottura.
Nella ricombinazione genetica, il sistema di recombinazione RecA può essere utilizzato per scambiare informazioni genetiche tra due molecole di DNA omologhe. Questo processo è particolarmente importante durante la meiosi, quando le cellule germinali si dividono per formare gameti con combinazioni uniche di geni.
In sintesi, la recombinasi RecA è un processo enzimatico cruciale nella riparazione del DNA e nella ricombinazione genetica in molti organismi, compresi gli esseri umani. Il sistema di proteina RecA può cercare e trovare sequenze omologhe di DNA complementari, quindi facilitare l'invio di informazioni genetiche per riparare i danni al DNA o scambiare informazioni genetiche durante la ricombinazione genetica.
I precursori dell'RNA, noti anche come pre-mRNA o RNA primario, si riferiscono a lunghe molecole di RNA che vengono sintetizzate durante il processo di trascrizione a partire dal DNA. Questi precursori contengono sequenze che codificano per proteine, nonché regioni non codificanti chiamate introni e esoni.
Dopo la trascrizione, i precursori dell'RNA subiscono una serie di modifiche post-trascrizionali, tra cui il processamento dell'RNA, che include la rimozione degli introni e l'unione degli esoni per formare un RNA maturo e funzionale. Questo RNA maturo può essere un mRNA (RNA messaggero) che verrà successivamente tradotto in una proteina, o un altro tipo di RNA come rRNA (RNA ribosomiale) o tRNA (RNA transfer).
La corretta elaborazione dei precursori dell'RNA è essenziale per la produzione di proteine funzionali e per il mantenimento della stabilità del genoma. Eventuali errori nel processo di sintesi o elaborazione dei precursori dell'RNA possono portare a malattie genetiche o a un aumento del rischio di sviluppare patologie tumorali.
La DNA polimerasi RNA dipendente, nota anche come transcrittasi inversa, è un enzima che catalizza la sintesi dell'DNA utilizzando un filamento di RNA come matrice. Questo tipo di DNA polimerasi è fondamentale per il ciclo vitale dei retrovirus, come il virus HIV, poiché permette loro di inserire il proprio genoma nell'DNA della cellula ospite durante il processo di replicazione.
L'enzima RNA-dipendente DNA polimerasi è costituito da diverse subunità che svolgono funzioni specifiche nella catalisi della reazione di sintesi dell'DNA. La subunità più importante, nota come RT (Reverse Transcriptase), è responsabile della retrotrascrizione del filamento di RNA in DNA.
La transcrittasi inversa è un bersaglio terapeutico importante per il trattamento delle malattie infettive causate da retrovirus, come l'AIDS. L'uso di farmaci antiretrovirali che inibiscono l'attività della transcrittasi inversa può impedire la replicazione del virus e rallentare la progressione della malattia.
Il tetrossido di osmio, anche noto come OsO4, è un composto chimico inorganico altamente tossico e volatile che contiene osmio nell'ossidazione +8. Viene comunemente utilizzato nel campo della microscopia elettronica a trasmissione (TEM) come fissativo per i campioni biologici, poiché è in grado di stabilizzare le membrane cellulari e fornire un'eccellente conservazione strutturale dei tessuti. Tuttavia, a causa della sua elevata tossicità, il suo utilizzo richiede precauzioni rigorose per garantire la sicurezza dell'operatore e dell'ambiente di lavoro.
In termini medici, i protooncogeni sono geni normalmente presenti nelle cellule che codificano per proteine che regolano la crescita, la divisione e la differenziazione cellulare. Questi geni svolgono un ruolo cruciale nel mantenere l'equilibrio tra la crescita e la morte cellulare (apoptosi). Tuttavia, quando subiscono mutazioni o vengono overexpressi, possono trasformarsi in oncogeni, che sono geni associati al cancro. Gli oncogeni possono contribuire allo sviluppo di tumori promuovendo la crescita cellulare incontrollata, l'inibizione dell'apoptosi e la promozione dell'angiogenesi (formazione di nuovi vasi sanguigni che sostengono la crescita del tumore).
Le proteine protooncogene possono essere tyrosine chinasi, serina/treonina chinasi o fattori di trascrizione, tra gli altri. Alcuni esempi di protooncogeni includono HER2/neu (erbB-2), c-MYC, RAS e BCR-ABL. Le mutazioni in questi geni possono portare a varie forme di cancro, come il cancro al seno, alla prostata, al colon e alle leucemie.
La comprensione dei protooncogeni e del loro ruolo nel cancro è fondamentale per lo sviluppo di terapie mirate contro i tumori, come gli inibitori delle tirosine chinasi e altri farmaci che mirano specificamente a queste proteine anomale.
I tionucleosidi sono anologhi sintetici dei nucleosidi naturali che contengono un gruppo tiolo (-SH) al posto del gruppo ossidrile (-OH) sulla posizione 3' del pirano degli zuccheri. Questi composti sono di interesse per la chimica medicinale e la biologia molecolare a causa della loro capacità di essere incorporati nelle catene di DNA e RNA durante la replicazione o la trascrizione, con conseguente inibizione della sintesi dell'acido nucleico. Questa proprietà è stata sfruttata nello sviluppo di farmaci antivirali come il trattamento per l'HIV e l'epatite B. Un esempio comune di tionucleoside è il didanosina (ddI), un inibitore della trascrittasi inversa utilizzato nel trattamento dell'HIV.
Gli organotiofosfati sono composti organici che contengono un legame fosforo-zolfo. Sono derivati dagli esteri dell'acido fosforico sostituendo uno o più gruppi idrossilo (-OH) con gruppi organici e uno o più di questi gruppi idrossilo vengono sostituiti con un gruppo tiolo (-SH).
Questi composti sono ampiamente utilizzati come plastificanti, lubrificanti, stabilizzatori di gomma, agenti antischiuma, e fluidi idraulici. Tuttavia, alcuni organotiofosfati sono anche noti per le loro proprietà insetticide e sono comunemente usati come pesticidi e agenti antiparassitari. Un esempio ben noto di organotiofosfato è il malathion, un insetticida comunemente usato.
Tuttavia, è importante notare che alcuni organotiofosfati possono essere tossici e persino letali per l'uomo e altri animali a causa della loro capacità di interferire con la trasmissione degli impulsi nervosi. L'esposizione a questi composti può causare sintomi come nausea, vomito, crampi muscolari, convulsioni e, in casi gravi, possono portare al coma o alla morte.
In medicina e biologia, le tecniche biosensoriali si riferiscono a metodi analitici che utilizzano un dispositivo chiamato biosensore per rilevare e misurare specifiche molecole biologiche, composti chimici o fenomeni biologici. Un biosensore è costituito da due parti principali: un elemento di riconoscimento biomolecolare (come anticorpi, enzimi, DNA, cellule viventi o recettori) e un trasduttore che converte il segnale generato dal riconoscimento molecolare in un segnale misurabile elettrico, termico, ottico o magnetico.
Le tecniche biosensoriali sono utilizzate in una vasta gamma di applicazioni, tra cui:
1. Diagnosi medica: per rilevare e monitorare biomarcatori associati a malattie, come glucosio nel sangue per il diabete, proteine tumorali per il cancro o marker infettivi per malattie infettive.
2. Monitoraggio ambientale: per rilevare e misurare la presenza di sostanze chimiche tossiche o contaminanti nell'aria, nell'acqua o nel suolo.
3. Sicurezza alimentare: per rilevare e quantificare microrganismi patogeni, allergeni o sostanze chimiche nocive negli alimenti e nelle bevande.
4. Ricerca biomedica di base: per studiare le interazioni molecolari tra biomolecole, come proteine, DNA, lipidi e carboidrati.
5. Sviluppo farmaceutico: per valutare l'efficacia e la sicurezza dei farmaci, nonché per monitorare i livelli di farmaci nel sangue durante il trattamento.
Le tecniche biosensoriali offrono diversi vantaggi rispetto ad altri metodi analitici, tra cui:
1. Alta sensibilità e specificità: le tecniche biosensoriali possono rilevare e quantificare molecole a basse concentrazioni con un'elevata selettività.
2. Velocità e semplicità: le tecniche biosensoriali richiedono meno tempo e sono più facili da eseguire rispetto ad altri metodi analitici tradizionali.
3. Basso costo: le tecniche biosensoriali possono essere realizzate con materiali a basso costo, rendendole accessibili per un'ampia gamma di applicazioni.
4. Miniaturizzazione e integrazione: le tecniche biosensoriali possono essere miniaturizzate e integrate in dispositivi portatili o wearable, offrendo la possibilità di misurazioni continue e in tempo reale.
L'ibridazione in situ (ISS) è una tecnica di biologia molecolare utilizzata per rilevare e localizzare specifiche sequenze di DNA o RNA all'interno di cellule e tessuti. Questa tecnica consiste nell'etichettare con marcatori fluorescenti o radioattivi una sonda di DNA complementare alla sequenza target, che viene quindi introdotta nelle sezioni di tessuto o cellule intere precedentemente fissate e permeabilizzate.
Durante l'ibridazione in situ, la sonda si lega specificamente alla sequenza target, permettendo così di visualizzare la sua localizzazione all'interno della cellula o del tessuto utilizzando microscopia a fluorescenza o radioattiva. Questa tecnica è particolarmente utile per studiare l'espressione genica a livello cellulare e tissutale, nonché per identificare specifiche specie di patogeni all'interno dei campioni biologici.
L'ibridazione in situ può essere eseguita su diversi tipi di campioni, come ad esempio sezioni di tessuto fresco o fissato, cellule in sospensione o colture cellulari. La sensibilità e la specificità della tecnica possono essere aumentate utilizzando sonde marcate con diversi coloranti fluorescenti o combinando l'ibridazione in situ con altre tecniche di biologia molecolare, come ad esempio l'amplificazione enzimatica del DNA (PCR).
La ricombinazione genetica è un processo naturale che si verifica durante la meiosi, una divisione cellulare che produce cellule sessuali o gameti (ovuli e spermatozoi) con metà del numero di cromosomi rispetto alla cellula originaria. Questo processo consente di generare diversità genetica tra gli individui di una specie.
Nella ricombinazione genetica, segmenti di DNA vengono scambiati tra due cromatidi non fratelli (due copie identiche di un cromosoma che si trovano in una cellula durante la profase I della meiosi). Questo scambio avviene attraverso un evento chiamato crossing-over.
I punti di ricombinazione, o punti di incrocio, sono siti specifici lungo i cromosomi dove si verifica lo scambio di segmenti di DNA. Gli enzimi responsabili di questo processo identificano e tagliano i filamenti di DNA in questi punti specifici, quindi le estremità vengono unite tra loro, formando una nuova configurazione di cromatidi non fratelli con materiale genetico ricombinato.
Di conseguenza, la ricombinazione genetica produce nuove combinazioni di alleli (varianti di un gene) su ciascun cromosoma, aumentando notevolmente la diversità genetica tra i gameti e, successivamente, tra gli individui della specie. Questa diversità è fondamentale per l'evoluzione delle specie e per la loro capacità di adattarsi a nuovi ambienti e condizioni.
In sintesi, la ricombinazione genetica è un processo cruciale che si verifica durante la meiosi, consentendo lo scambio di segmenti di DNA tra cromatidi non fratelli e producendo nuove combinazioni di alleli, il che aumenta notevolmente la diversità genetica tra gli individui di una specie.
L'endodesossiribonucleasi (ENDO) è un enzima che taglia specificamente le molecole di RNA all'interno della sua sequenza, lasciando intatta la struttura esterna del filamento. Questo enzima svolge un ruolo cruciale nella regolazione dell'espressione genica e nel mantenimento dell'equilibrio dei livelli di RNA nelle cellule.
Esistono diversi tipi di endodesossiribonucleasi, ciascuna con una specifica sequenza di riconoscimento e un meccanismo di taglio. Ad esempio, l'RNasi H è un enzima che taglia il filamento RNA in un duplex DNA-RNA ibrido, mentre la ribonucleasi III (RNase III) taglia i loop a bulbo presenti in alcuni tipi di RNA.
Le endodesossiribonucleasi sono utilizzate in diversi campi della ricerca biomedica per studiare la struttura e la funzione dell'RNA, nonché per manipolare i livelli di espressione genica in modelli sperimentali. Tuttavia, un uso improprio o eccessivo di questi enzimi può portare a effetti dannosi sulla cellula, come l'interruzione della normale regolazione dell'espressione genica e la morte cellulare.
L'RNA di trasferimento, noto anche come tRNA, è un tipo di RNA presente nelle cellule che svolge un ruolo cruciale nella sintesi delle proteine. I tRNA sono molecole relativamente piccole, composte da circa 70-90 nucleotidi, e hanno una forma a "L" distinta.
La funzione principale dei tRNA è quella di portare specifici aminoacidi al sito di sintesi delle proteine all'interno del ribosoma durante il processo di traduzione dell'mRNA. Ogni tRNA contiene un anticodone, una sequenza di tre nucleotidi che si accoppiano con una sequenza complementare di tre nucleotidi, nota come codone, nell'mRNA. Quando l'anticodone del tRNA si accoppia al codone dell'mRNA, l'aminoacido specifico associato a quel particolare tRNA viene aggiunto alla catena crescente di aminoacidi che formerà la proteina finale.
Pertanto, i tRNA svolgono un ruolo fondamentale nel processo di traduzione dell'mRNA in una proteina funzionale e sono essenziali per la corretta decodifica del codice genetico.
Le tecniche a sonde molecolari sono metodi di analisi che utilizzano sonde, o brevi sequenze di DNA o RNA marcate, per identificare e quantificare specifiche molecole target in un campione. Queste tecniche sono ampiamente utilizzate nella ricerca biomedica e nella diagnostica clinica per rilevare la presenza di patogeni, come batteri e virus, o per monitorare l'espressione genica e le alterazioni genomiche in varie condizioni di malattia.
Esempi di tecniche a sonde molecolari includono:
1. Ibridazione fluorescente in situ (FISH): Questa tecnica utilizza sonde marcate con fluorofori per rilevare e localizzare specifiche sequenze di DNA o RNA all'interno di cellule o tessuti. Le sonde ibridano con le sequenze complementari nel campione, producendo un segnale fluorescente visibile al microscopio.
2. Southern blotting: Questo metodo prevede la separazione dei frammenti di DNA mediante elettroforesi su gel, seguita dal trasferimento del DNA su una membrana di nitrocellulosa o nylon. Le sonde marcate vengono quindi utilizzate per rilevare specifiche sequenze di DNA sulla membrana.
3. Northern blotting: Simile al Southern blotting, ma utilizza RNA invece di DNA. L'RNA viene separato mediante elettroforesi su gel, trasferito su una membrana e quindi rilevato con sonde marcate specifiche per le sequenze di interesse.
4. Polymerase chain reaction (PCR) in situ: Questa tecnica combina l'amplificazione dell'acido nucleico mediante PCR con la visualizzazione spaziale delle sonde fluorescenti FISH. Ciò consente di rilevare e quantificare specifiche sequenze di DNA o RNA all'interno di cellule individuali o tessuti.
5. Microarray: I microarray sono matrici di acidi nucleici marcati che vengono utilizzati per rilevare l'espressione genica simultanea di migliaia di geni in un singolo esperimento. Le sonde marcate vengono applicate a una superficie solida, come un vetrino o una scheda, e i campioni di RNA o DNA vengono ibridati con le sonde per rilevare l'espressione relativa dei geni.
In sintesi, le tecniche basate sulle sonde sono ampiamente utilizzate in biologia molecolare per rilevare e analizzare specifiche sequenze di acidi nucleici. Questi metodi forniscono informazioni cruciali sulla struttura, la funzione e l'espressione genica, contribuendo alla comprensione dei meccanismi biologici e delle basi molecolari delle malattie.
La nanotecnologia è un ramo della scienza e dell'ingegneria che si occupa dello studio, della progettazione, della sintesi, della manipolazione e dell'applicazione di materiali, dispositivi e sistemi a livello atomico, molecolare e macromolecolare con dimensioni comprese tra 1 e 100 nanometri (nm). Questa area di ricerca interdisciplinare combina principi di fisica, chimica, biologia, ingegneria e informatica per creare soluzioni innovative a problemi in vari campi, tra cui medicina, farmaceutica, elettronica, energia e ambiente.
In medicina, la nanotecnologia ha il potenziale per trasformare la diagnostica, la terapia e il monitoraggio dei disturbi della salute umana. Ad esempio, i nanomateriali possono essere utilizzati nello sviluppo di farmaci mirati che si accumulano selettivamente nei tessuti malati, riducendo al minimo gli effetti avversi sui tessuti sani. Inoltre, la nanotecnologia può contribuire all'identificazione precoce e alla diagnosi di malattie mediante l'uso di sensori e dispositivi nanometrici altamente sensibili e specifici.
Tuttavia, è importante notare che la nanotecnologia è ancora una tecnologia emergente e sono necessari ulteriori studi per comprendere appieno i suoi potenziali rischi e benefici per la salute umana e l'ambiente.
La polinucleotide ligasi è un enzima importante che svolge un ruolo cruciale nella riparazione del DNA e nel processo di replicazione. Nella sua forma più semplice, la polinucleotide ligasi si lega e unisce due filamenti di DNA a singolo filamento insieme, formando un singolo filamento continuo. Questo enzima è essenziale per riparare i punti di rottura del singolo filamento che possono verificarsi naturalmente o come risultato di danni al DNA.
Nei processi di replicazione e riparazione del DNA, la polinucleotide ligasi svolge un ruolo particolarmente importante nella chiusura dell'interruzione della forca di replicazione, che si verifica quando i due filamenti di DNA vengono separati per consentire la replicazione. Dopo che il DNA polimerasi ha aggiunto nucleotidi a ciascun filamento, rimane una breve interruzione nel backbone fosfodiesterico del DNA. La polinucleotide ligasi ripara queste interruzioni unendo i due frammenti di DNA insieme.
In sintesi, la polinucleotide ligasi è un enzima cruciale che facilita il processo di riparazione e replicazione del DNA, unendoli insieme dopo che sono stati separati o danneggiati.
"Xenopus laevis" è una specie di rana originaria dell'Africa subsahariana, più precisamente dalle regioni umide del sud e dell'est del continente. In ambiente medico, questa rana è spesso utilizzata come organismo modello per la ricerca scientifica, in particolare negli studi di embriologia e genetica.
La sua popolarità come organismo da laboratorio deriva dalla sua resistenza alle malattie infettive, alla facilità di allevamento e manutenzione in cattività, e alla capacità della femmina di produrre una grande quantità di uova fecondate esternamente. Le uova e gli embrioni di Xenopus laevis sono trasparenti, il che permette agli scienziati di osservare direttamente lo sviluppo degli organi e dei sistemi interni.
In sintesi, "Xenopus laevis" è una specie di rana comunemente usata in ambito medico e di ricerca scientifica come organismo modello per lo studio dello sviluppo embrionale e genetico.
In medicina, la sopravvivenza cellulare si riferisce alla capacità delle cellule di continuare a vivere e mantenere le loro funzioni vitali. In particolare, questo termine è spesso utilizzato nel contesto della terapia cancerosa per descrivere la capacità delle cellule tumorali di resistere al trattamento e continuare a crescere e dividersi.
La sopravvivenza cellulare può essere misurata in vari modi, come il conteggio delle cellule vitali dopo un determinato periodo di tempo o la valutazione della proliferazione cellulare utilizzando marcatori specifici. Questi test possono essere utilizzati per valutare l'efficacia di diversi trattamenti antitumorali e per identificare i fattori che influenzano la resistenza alla terapia.
La sopravvivenza cellulare è un fattore critico nella progressione del cancro e nella risposta al trattamento. Una migliore comprensione dei meccanismi che regolano la sopravvivenza cellulare può aiutare a sviluppare nuove strategie terapeutiche per il trattamento del cancro e altre malattie.
Il sistema cell-free (SCF) è un termine generale utilizzato per descrivere i sistemi biologici che contengono componenti cellulari disciolti in soluzioni liquide, senza la presenza di membrane cellulari intatte. Questi sistemi possono includere una varietà di molecole intracellulari functionalmente attive, come proteine, ribosomi, RNA, metaboliti e ioni, che svolgono una serie di funzioni biologiche importanti al di fuori della cellula.
Uno dei sistemi cell-free più comunemente utilizzati è il sistema di traduzione cell-free (CTFS), che consiste in estratti citoplasmatici di cellule batteriche o eucariotiche, insieme a substrati e cofattori necessari per sostenere la sintesi delle proteine. Il CTFS può essere utilizzato per studiare la traduzione dell'mRNA, la regolazione genica e l'espressione delle proteine in vitro, con un controllo preciso sull'ambiente di reazione e la composizione del substrato.
Un altro esempio di sistema cell-free è il sistema di replicazione cell-free (CRFS), che può essere utilizzato per studiare i meccanismi della replicazione del DNA e l'attività enzimatica correlata, come la polimerasi del DNA e la ligasi.
I sistemi cell-free offrono una serie di vantaggi rispetto ai sistemi cellulari tradizionali, tra cui la facilità di manipolazione e controllo dell'ambiente di reazione, la velocità e la sensibilità delle analisi, e la possibilità di studiare i processi biologici in assenza di interferenze da parte di altri processi cellulari. Tuttavia, ci sono anche alcuni svantaggi associati all'uso dei sistemi cell-free, come la mancanza di feedback e regolazione complessi che si verificano nelle cellule viventi.
Una mutazione puntiforme è un tipo specifico di mutazione genetica che comporta il cambiamento di una singola base azotata nel DNA. Poiché il DNA è composto da quattro basi nucleotidiche diverse (adenina, timina, citosina e guanina), una mutazione puntiforme può coinvolgere la sostituzione di una base con un'altra (chiamata sostituzione), l'inserzione di una nuova base o la delezione di una base esistente.
Le mutazioni puntiformi possono avere diversi effetti sul gene e sulla proteina che codifica, a seconda della posizione e del tipo di mutazione. Alcune mutazioni puntiformi non hanno alcun effetto, mentre altre possono alterare la struttura o la funzione della proteina, portando potenzialmente a malattie genetiche.
Le mutazioni puntiformi sono spesso associate a malattie monogeniche, che sono causate da difetti in un singolo gene. Ad esempio, la fibrosi cistica è una malattia genetica comune causata da una specifica mutazione puntiforme nel gene CFTR. Questa mutazione porta alla produzione di una proteina CFTR difettosa che non funziona correttamente, il che può portare a problemi respiratori e digestivi.
In sintesi, una mutazione puntiforme è un cambiamento in una singola base azotata del DNA che può avere diversi effetti sul gene e sulla proteina che codifica, a seconda della posizione e del tipo di mutazione.
Gli enzimi di restrizione del DNA sono enzimi che tagliano specificamente e deliberatamente le molecole di DNA in punti specifici chiamati siti di restrizione. Questi enzimi sono originariamente derivati da batteri e altri organismi, dove svolgono un ruolo cruciale nel sistema immunitario dei batteri tagliando e distruggendo il DNA estraneo che entra nelle loro cellule.
Gli enzimi di restrizione del DNA riconoscono sequenze di basi specifiche di lunghezza variabile, a seconda dell'enzima specifico. Una volta che la sequenza è riconosciuta, l'enzima taglia il filamento di DNA in modo preciso, producendo estremità appiccicose o staggite. Questa proprietà degli enzimi di restrizione del DNA li rende uno strumento essenziale nella biologia molecolare e nella genetica, dove sono ampiamente utilizzati per la clonazione, il sequenziamento del DNA e l'analisi delle mutazioni.
Gli enzimi di restrizione del DNA sono classificati in base al modo in cui tagliano il DNA. Alcuni enzimi tagliano i due filamenti di DNA contemporaneamente, producendo estremità compatibili o appaiate. Altri enzimi tagliano un solo filamento di DNA, producendo estremità a singolo filamento o sovrapposte.
In sintesi, gli enzimi di restrizione del DNA sono enzimi che tagliano il DNA in modo specifico e preciso, riconoscendo sequenze particolari di basi. Questi enzimi sono ampiamente utilizzati nella biologia molecolare e nella genetica per una varietà di applicazioni, tra cui la clonazione, il sequenziamento del DNA e l'analisi delle mutazioni.
L'RNA complementare (cRNA) si riferisce a una molecola di RNA che è trascritto in senso opposto e ha una sequenza nucleotidica complementare a un altro filamento di RNA o DNA. Nello specifico, il cRNA viene creato come una copia complementare di un filamento di RNA messaggero (mRNA) durante il processo di reazione a catena della polimerasi (PCR) inversa o trascrizione inversa, che è utilizzata in varie tecniche di biologia molecolare come la RT-PCR e l'amplificazione isotermica mediata da loop (LAMP).
Nella RT-PCR, il cRNA viene sintetizzato utilizzando la reverse transcriptasi, un enzima che utilizza il mRNA come matrice per creare una copia complementare di DNA chiamata DNA complementare (cDNA). Il cDNA può quindi essere amplificato utilizzando la PCR per produrre molte copie della sequenza desiderata.
Nell'amplificazione isotermica mediata da loop (LAMP), il cRNA viene creato come una parte del processo di amplificazione del DNA, dove vengono utilizzati quattro diversi primer per creare un loop a doppia elica che può essere rilevato e quantificato mediante tecniche di colorimetria o fluorescenza.
In sintesi, l'RNA complementare è una molecola di RNA che ha una sequenza nucleotidica complementare a un altro filamento di RNA o DNA, ed è spesso utilizzato nelle tecniche di biologia molecolare per amplificare e rilevare specifiche sequenze geniche.
In campo medico, il termine "splicing alternativo" (o "splice variants") si riferisce a un meccanismo di regolazione dell'espressione genica attraverso il quale possono essere generate diverse forme mature di RNA messaggero (mRNA) a partire da uno stesso gene.
Nel processo di splicing, le sequenze non codificanti (introni) vengono eliminate e quelle codificanti (esoni) vengono unite insieme per formare il mRNA maturo, che successivamente verrà tradotto in una proteina funzionale. Il splicing alternativo consiste nell'unione di diversi esoni o nella scelta di diverse porzioni di essi, dando origine a differenti combinazioni e quindi a mRNA con sequenze uniche.
Questo meccanismo permette di aumentare la diversità delle proteine prodotte da un genoma, poiché lo stesso gene può codificare per più di una proteina, ognuna con specifiche funzioni e proprietà. Il splicing alternativo è regolato a livello transcrizionale ed è soggetto a vari fattori che ne influenzano l'esito, come la presenza di sequenze specifiche, la struttura della molecola di RNA e le interazioni con proteine regolatrici.
L'alterazione del splicing alternativo può portare allo sviluppo di diverse patologie, tra cui malattie genetiche, cancro e disturbi neurodegenerativi.
La polietileneimina (PEI) è un tipo di polimero sintetico, più precisamente una poliammina, che presenta numerose ammine primarie e secondarie nella sua struttura. Nella comunità scientifica e medica, PEI viene spesso utilizzato come vettore non virale per la consegna di farmaci e molecole terapeutiche, come le particelle di RNA interferente (RNAi), nelle cellule bersaglio.
La PEI è nota per la sua elevata capacità di legare e comprimere il DNA o l'RNA, formando nanoparticelle che proteggono il carico utile dalla degradazione enzimatica e facilitano il trasporto attraverso le membrane cellulari. Questa proprietà rende PEI un vettore efficace per la terapia genica e altre applicazioni farmacologiche. Tuttavia, l'uso di PEI come vettore può essere limitato dalla sua citotossicità, che dipende dal grado di ramificazione e dal peso molecolare del polimero.
È importante notare che la definizione medica di "polietileneimina" si riferisce principalmente alle sue applicazioni come vettore farmaceutico e non alla sua composizione chimica o struttura di base.
In medicina, l'argento è un metallo che ha proprietà antibatteriche e antinfiammatorie. Viene utilizzato in diversi campi della medicina, come ad esempio:
1. Medicazione: L'argento colloidale o l'argento nanocristallino vengono applicati su cerotti o bende per prevenire l'infezione nelle ferite aperte e promuovere la guarigione.
2. Oftalmologia: L'argento viene utilizzato in alcuni colliri per trattare le infezioni degli occhi.
3. Odontoiatria: L'argento è usato nei riempimenti dentali e nelle otturazioni per prevenire la carie.
4. Implantologia: Gli impianti in argento possono essere utilizzati come alternativa agli impianti in titanio, specialmente per i pazienti allergici al titanio.
5. Ortopedia: L'argento può essere usato nelle protesi articolari per ridurre il rischio di infezione.
6. Dermatologia: Alcuni prodotti per la cura della pelle, come creme e lozioni, possono contenere argento per le sue proprietà antibatteriche e antinfiammatorie.
Tuttavia, l'uso di argento in medicina deve essere attentamente monitorato, poiché un uso eccessivo o prolungato può causare effetti collaterali indesiderati, come l'argiria, una condizione che causa la pigmentazione grigio-bluastra della pelle.
In realtà, "formamide" non è un termine medico comune. La formamide è una sostanza chimica con la formula HCONH2. È il più semplice degli amidi, che sono solitamente definiti come polimeri del glucosio in chimica organica e biochimica.
Tuttavia, in alcuni contesti medici o tossicologici rari, "formamide" può essere menzionata per descrivere una sostanza chimica presente in alcuni prodotti industriali o farmaceutici, oppure come possibile contaminante ambientale. In questi casi, la formamide viene solitamente trattata come una sostanza chimica potenzialmente pericolosa e le sue esposizioni vengono gestite e monitorate in base alle linee guida appropriate fornite dalle autorità sanitarie e ambientali.
HIV-1 (Human Immunodeficiency Virus type 1) è un tipo di virus che colpisce il sistema immunitario umano, indebolendolo e rendendolo vulnerabile a varie infezioni e malattie. È la forma più comune e più diffusa di HIV nel mondo.
Il virus HIV-1 attacca e distrugge i linfociti CD4+ (un tipo di globuli bianchi che aiutano il corpo a combattere le infezioni), portando ad un progressivo declino della funzione immunitaria. Questo può portare allo stadio finale dell'infezione da HIV, nota come AIDS (Sindrome da Immunodeficienza Acquisita).
L'HIV-1 si trasmette principalmente attraverso il contatto sessuale non protetto con una persona infetta, l'uso di aghi o siringhe contaminati, la trasmissione verticale (da madre a figlio durante la gravidanza, il parto o l'allattamento) e la trasfusione di sangue infetto.
È importante notare che l'HIV non può essere trasmesso attraverso il contatto casuale o quotidiano con una persona infetta, come abbracciare, stringere la mano, baciare sulla guancia o sedersi accanto a qualcuno su un autobus.
La citometria a flusso è una tecnologia di laboratorio utilizzata per analizzare le proprietà fisiche e biochimiche delle cellule e delle particelle biologiche in sospensione. Viene comunemente utilizzato nella ricerca, nel monitoraggio del trattamento del cancro e nella diagnosi di disturbi ematologici e immunologici.
Nella citometria a flusso, un campione di cellule o particelle viene fatto fluire in un singolo file attraverso un fascio laser. Il laser illumina le cellule o le particelle, provocando la diffrazione della luce e l'emissione di fluorescenza da parte di molecole marcate con coloranti fluorescenti. I sensori rilevano quindi i segnali luminosi risultanti e li convertono in dati che possono essere analizzati per determinare le caratteristiche delle cellule o delle particelle, come la dimensione, la forma, la complessità interna e l'espressione di proteine o altri marcatori specifici.
La citometria a flusso può analizzare rapidamente un gran numero di cellule o particelle, fornendo informazioni dettagliate sulla loro composizione e funzione. Questa tecnologia è ampiamente utilizzata in una varietà di campi, tra cui la ricerca biomedica, l'immunologia, la genetica e la medicina di traslazione.
Il fegato è un organo glandolare grande e complesso situato nella parte superiore destra dell'addome, protetto dall'ossa delle costole. È il più grande organo interno nel corpo umano, pesando circa 1,5 chili in un adulto medio. Il fegato svolge oltre 500 funzioni vitali per mantenere la vita e promuovere la salute, tra cui:
1. Filtrazione del sangue: Rimuove le tossine, i batteri e le sostanze nocive dal flusso sanguigno.
2. Metabolismo dei carboidrati: Regola il livello di glucosio nel sangue convertendo gli zuccheri in glicogeno per immagazzinamento ed è rilasciato quando necessario fornire energia al corpo.
3. Metabolismo delle proteine: Scompone le proteine in aminoacidi e aiuta nella loro sintesi, nonché nella produzione di albumina, una proteina importante per la pressione sanguigna regolare.
4. Metabolismo dei lipidi: Sintetizza il colesterolo e le lipoproteine, scompone i grassi complessi in acidi grassi e glicerolo, ed è responsabile dell'eliminazione del colesterolo cattivo (LDL).
5. Depurazione del sangue: Neutralizza e distrugge i farmaci e le tossine chimiche nel fegato attraverso un processo chiamato glucuronidazione.
6. Produzione di bilirubina: Scompone l'emoglobina rossa in bilirubina, che viene quindi eliminata attraverso la bile.
7. Coagulazione del sangue: Produce importanti fattori della coagulazione del sangue come il fattore I (fibrinogeno), II (protrombina), V, VII, IX, X e XI.
8. Immunologia: Contiene cellule immunitarie che aiutano a combattere le infezioni.
9. Regolazione degli zuccheri nel sangue: Produce glucosio se necessario per mantenere i livelli di zucchero nel sangue costanti.
10. Stoccaggio delle vitamine e dei minerali: Conserva le riserve di glicogeno, vitamina A, D, E, K, B12 e acidi grassi essenziali.
Il fegato è un organo importante che svolge molte funzioni vitali nel nostro corpo. È fondamentale mantenerlo in buona salute attraverso una dieta equilibrata, l'esercizio fisico regolare e la riduzione dell'esposizione a sostanze tossiche come alcol, fumo e droghe illecite.
Le sequenze regolatorie degli acidi nucleici, anche note come elementi regolatori o siti di legame per fattori di trascrizione, sono specifiche sequenze di DNA o RNA che controllano l'espressione genica. Queste sequenze si legano a proteine regolatorie, come i fattori di trascrizione, che influenzano l'inizio, la velocità e la terminazione della trascrizione del gene adiacente. Le sequenze regolatorie possono trovarsi nel promotore, nell'enhancer o nel silencer del gene, e possono essere sia positive che negative nel loro effetto sull'espressione genica. Possono anche essere soggette a meccanismi di controllo epigenetici, come la metilazione del DNA, che influenzano il loro livello di attività.
N-Glicosilidasi, noto anche come N-glicanosidasi o N-glicosil hydrolases, sono enzimi che catalizzano l'idrolisi dei legami glicosidici nelle catene di zucchero N-legate delle glicoproteine. Queste idrolasi svolgono un ruolo cruciale nella degradazione e nel riciclaggio delle glicoproteine, nonché nella modifica post-traduzionale e nel processing of glycoproteins.
Gli enzimi N-glicosilidasi tagliano specificamente il legame β(1,4) tra il N-acetilglucosamina (GlcNAc) e l'asparagina (Asn) nelle glicoproteine. Questo processo di rimozione dei gruppi glicani dalle proteine è noto come deglingazione e può verificarsi in due modi:
1. Trimming deglycosylation: Questa via comporta la rimozione sequenziale di zuccheri singoli o oligosaccaridi corti dalle glicoproteine da parte di una serie di enzimi N-glicosilidasi con specificità diverse.
2. Peeling deglycosylation: Questa via comporta la rimozione sequenziale degli zuccheri dalla estremità non riducente del glicano, iniziando dal monosaccaride terminale più lontano dall'asparagina.
Gli enzimi N-glicosilidasi sono ampiamente utilizzati nella ricerca biomedica per analizzare la struttura e la funzione dei glicani nelle glicoproteine, nonché nello studio di varie malattie associate a modifiche anormali dei glicani. Ad esempio, possono essere utilizzati per studiare le interazioni proteina-zucchero, la patogenesi delle infezioni e il rilevamento di tumori.
In campo medico, il termine "RNA caps" (o "cappucci dell'RNA") si riferisce a una struttura chimica presente all'estremità 5' delle molecole di RNA messaggero (mRNA), RNA ribosomiale (rRNA) e alcuni tipi di RNA transfer (tRNA).
Un cappuccio dell'RNA è costituito da un gruppo metilato che consiste in una molecola di guanosina monofosfato (GMP) legata in modo non enzimatico all'estremità 5' del pre-mRNA tramite un triphosphate bridge. Questa struttura protegge l'RNA dalle esonucleasi, enzimi che degradano le molecole di RNA, e facilita il processo di splicing dell'RNA e il trasporto del mRNA dal nucleo al citoplasma.
Il cappuccio dell'RNA è importante per la stabilità e l'efficienza della traduzione delle molecole di mRNA ed è quindi un componente essenziale del processo di espressione genica.
DNA Glicosilasi sono enzimi che svolgono un ruolo cruciale nel processo di riparazione del DNA noto come riparazione dell'escissione della base (BER). Queste glicosilasi identificano e rimuovono specifiche basi danneggiate o erroneamente incorporate nel DNA, attraverso un meccanismo di reazione a due stadi.
Nel primo stadio, la DNA glicosilasi riconosce una base danneggiata o erroneamente incorporata e scinde il legame glicosidico tra quella base e il deossiribosio adiacente, lasciando un sito apurinico/apirimidinico aperto. Nel secondo stadio, altre enzimi del sistema BER intervengono per rimuovere il residuo di zucchero rimanente e ripristinare l'integrità della struttura del DNA attraverso la replicazione e la ricostituzione del filamento danneggiato.
Le diverse classi di DNA glicosilasi mostrano specificità per diversi tipi di lesioni al DNA, come le basi ossidate, desaminate, alchilate o idratate, e possono essere attivate da differenti segnali cellulari in risposta a varie forme di stress o danno al DNA. La loro accuratezza e precisione sono fondamentali per prevenire mutazioni dannose e mantenere la stabilità del genoma.
Gli coadiuvanti immunologici sono sostanze che vengono aggiunte ai vaccini per migliorarne l'efficacia e la risposta immunitaria. Essi non contengono alcun antigene, ma stimolano il sistema immunitario a reagire più fortemente ai componenti del vaccino.
Gli coadiuvanti immunologici possono aumentare la produzione di anticorpi, attivare cellule T e prolungare la durata della risposta immunitaria al vaccino. Essi possono essere costituiti da una varietà di sostanze, come ad esempio:
* Sali di alluminio (allume): sono i più comunemente usati negli vaccini e aiutano a stimolare la produzione di anticorpi.
* Olio di squalene: è un olio naturale presente nel corpo umano che può aumentare la risposta immunitaria al vaccino.
* Monofosfato di guanosina (MPG): è una sostanza chimica che può stimolare la produzione di cellule T e aumentare la risposta immunitaria al vaccino.
* Lipidi: alcuni lipidi possono essere usati come coadiuvanti per stimolare la risposta immunitaria ai vaccini.
Gli coadiuvanti immunologici sono importanti per migliorare l'efficacia dei vaccini, specialmente per quelli che richiedono una forte risposta immunitaria, come i vaccini contro l'influenza o il virus dell'epatite B. Tuttavia, essi possono anche causare effetti collaterali indesiderati, come ad esempio dolore, arrossamento e gonfiore al sito di iniezione, febbre o malessere generale.
In sintesi, gli coadiuvanti immunologici sono sostanze aggiunte ai vaccini per aumentarne l'efficacia e la risposta immunitaria. Essi possono causare effetti collaterali indesiderati, ma sono importanti per migliorare la protezione offerta dai vaccini.
La Southern blotting è una tecnica di laboratorio utilizzata in biologia molecolare per identificare e localizzare specifiche sequenze di DNA in un campione di DNA digerito con enzimi di restrizione. Questa tecnica prende il nome dal suo inventore, Edwin Southern.
Il processo di Southern blotting include i seguenti passaggi:
1. Il DNA viene estratto da una cellula o un tessuto e quindi sottoposto a digestione enzimatica con enzimi di restrizione specifici che tagliano il DNA in frammenti di dimensioni diverse.
2. I frammenti di DNA digeriti vengono quindi separati in base alle loro dimensioni utilizzando l'elettroforesi su gel di agarosio.
3. Il gel di agarosio contenente i frammenti di DNA viene quindi trasferito su una membrana di nitrocellulosa o nylon.
4. La membrana viene poi esposta a una sonda di DNA marcata radioattivamente o con un marker fluorescente che è complementare alla sequenza di interesse.
5. Attraverso il processo di ibridazione, la sonda si lega specificamente alla sequenza di DNA desiderata sulla membrana.
6. Infine, la membrana viene esposta a un foglio fotografico o ad una lastra per rilevare la posizione della sequenza di interesse marcata radioattivamente o con un marker fluorescente.
La Southern blotting è una tecnica sensibile e specifica che può essere utilizzata per rilevare la presenza o l'assenza di specifiche sequenze di DNA in un campione, nonché per determinare il numero di copie della sequenza presenti nel campione. Questa tecnica è ampiamente utilizzata in ricerca e in diagnostica molecolare per identificare mutazioni genetiche, duplicazioni o delezioni del DNA, e per studiare l'espressione genica.
Le sonde di RNA sono segmenti di RNA marcati chimicamente o con fluorofori che vengono utilizzate nella ricerca molecolare per identificare e quantificare specifiche sequenze di RNA in un campione. Vengono spesso utilizzate nelle tecniche di biologia molecolare come la Northern blotting, l'ibridazione in situ e il reverse transcription polymerase chain reaction (RT-PCR). Le sonde di RNA possono essere progettate per riconoscere sequenze specifiche di RNA messaggero (mRNA), RNA ribosomale (rRNA) o altri tipi di RNA. La marcatura delle sonde permette la loro rilevazione e visualizzazione dopo l'ibridazione con le sequenze complementari nel campione target. Questa tecnica è ampiamente utilizzata in vari campi della ricerca biomedica, come la genomica funzionale, la biologia cellulare e lo studio delle malattie infettive.
In medicina, il termine "polimeri" si riferisce a lunghe catene di molecole ripetitive chiamate monomeri, che possono essere utilizzate in diversi ambiti terapeutici. Un esempio comune di polimero utilizzato in medicina è il polimetilmetacrilato (PMMA), un materiale comunemente usato nelle applicazioni oftalmiche come lenti intraoculari.
Inoltre, i polimeri sono anche utilizzati nella produzione di biomateriali e dispositivi medici impiantabili, come ad esempio gli idrogeli, che possono essere utilizzati in applicazioni chirurgiche come i tessuti di sostituzione o le membrane per la rigenerazione dei tessuti.
Infine, i polimeri sono anche utilizzati nella formulazione di farmaci a rilascio controllato, che possono fornire un rilascio graduale e prolungato del farmaco nel tempo, migliorando l'efficacia terapeutica e riducendo la frequenza delle dosi. Questi polimeri possono essere naturali o sintetici e vengono selezionati in base alle loro proprietà fisiche e chimiche per ottenere il rilascio desiderato del farmaco.
Gli Sprague-Dawley (SD) sono una particolare razza di ratti comunemente usati come animali da laboratorio nella ricerca biomedica. Questa linea di ratti fu sviluppata per la prima volta nel 1925 da H.H. Sprague e R.C. Dawley presso l'Università del Wisconsin-Madison.
Gli Sprague-Dawley sono noti per la loro robustezza, facilità di riproduzione e bassa incidenza di tumori spontanei, il che li rende una scelta popolare per una vasta gamma di studi, tra cui quelli relativi alla farmacologia, tossicologia, fisiologia, neuroscienze e malattie infettive.
Questi ratti sono allevati in condizioni controllate per mantenere la coerenza genetica e ridurre la variabilità fenotipica all'interno della linea. Sono disponibili in diverse età, dai neonati alle femmine gravide, e possono essere acquistati da diversi fornitori di animali da laboratorio in tutto il mondo.
È importante sottolineare che, come per qualsiasi modello animale, gli Sprague-Dawley hanno i loro limiti e non sempre sono rappresentativi delle risposte umane a farmaci o condizioni patologiche. Pertanto, è fondamentale considerarli come uno strumento tra molti altri nella ricerca biomedica e interpretare i dati ottenuti da tali studi con cautela.
La definizione medica di "Elettroforesi su gel di agar" è un metodo di elettroforesi utilizzato in laboratorio per separare e analizzare macromolecole, come proteine o acidi nucleici (DNA o RNA), basato sulla loro mobilità elettroforetica attraverso un gel di agaroso sottoposto a un campo elettrico.
L'elettroforesi su gel di agar è una tecnica di laboratorio comunemente utilizzata in biologia molecolare, genetica e biochimica per separare, identificare e quantificare macromolecole di interesse. Il gel di agaroso è un polisaccaride idrofilo derivato dall'alga marina rossa (agar) che forma una matrice tridimensionale porosa quando si solidifica a temperatura ambiente. Quando il gel è posto in un sistema di buffer elettrico, le macromolecole cariche migrano attraverso la matrice del gel in risposta al campo elettrico applicato.
Le proteine o gli acidi nucleici con differenti cariche nette, dimensioni o forme migreranno a velocità diverse attraverso il gel di agaroso, consentendo così la separazione delle diverse specie molecolari in base alle loro proprietà fisico-chimiche. Una volta completata la migrazione, le bande di proteine o acidi nucleici separate possono essere visualizzate utilizzando coloranti specifici per tali macromolecole, come il blu di Evans per le proteine o il bromuro di etidio per gli acidi nucleici.
L'elettroforesi su gel di agar è una tecnica versatile e ampiamente utilizzata in ricerca e diagnostica a causa della sua relativa semplicità, economicità e capacità di separare e analizzare una vasta gamma di macromolecole biologiche.
In medicina, la chimica si riferisce alla scienza che studia la struttura, la composizione, le proprietà e le reazioni delle sostanze di origine organica o inorganica. La comprensione dei principi chimici è fondamentale per comprendere i processi biologici a livello molecolare e cellulare, nonché per lo sviluppo di farmaci e terapie mediche.
La chimica svolge un ruolo cruciale nella comprensione della struttura e della funzione delle proteine, dei carboidrati, dei lipidi, degli acidi nucleici e di altri componenti cellulari. Inoltre, la chimica è alla base della comprensione dei processi metabolici, della segnalazione cellulare e dell'interazione tra farmaci e bersagli molecolari.
La ricerca medica moderna si avvale di tecniche chimiche avanzate per sintetizzare e caratterizzare nuove sostanze con proprietà terapeutiche, nonché per sviluppare metodi di imaging e diagnosi più sensibili e specifici. Inoltre, la comprensione dei meccanismi chimici alla base delle malattie è essenziale per lo sviluppo di strategie preventive e terapeutiche efficaci.
In sintesi, la chimica è una scienza fondamentale che supporta molte aree della medicina, dalla comprensione dei processi biologici alla scoperta e allo sviluppo di farmaci e terapie innovative.
La distrofina è una proteina essenziale per la struttura e la funzione dei muscoli scheletrici. Si trova principalmente nel citoplasma delle fibre muscolari striate e svolge un ruolo cruciale nella riparazione e nella protezione delle membrane cellulari durante il normale esercizio fisico. Nell'uomo, la distrofina è codificata dal gene DMD (distrofina) situato sul cromosoma X (Xp21.2-p11.2).
Le mutazioni nel gene DMD possono causare diversi disturbi neuromuscolari, tra cui la distrofia muscolare di Duchenne e Becker, che sono caratterizzate da debolezza muscolare progressiva, atrofia muscolare e compromissione della funzione cardiorespiratoria. Nella distrofia muscolare di Duchenne, la proteina distrofina è gravemente alterata o assente, il che porta a lesioni ripetitive delle membrane cellulari durante l'esercizio fisico e alla degenerazione muscolare. Nella distrofia muscolare di Becker, invece, la proteina distrofina è presente ma alterata, con una forma più lieve della malattia rispetto alla distrofia muscolare di Duchenne.
L'RNA interference (RNAi) è un meccanismo cellulare conservato evolutionisticamente che regola l'espressione genica attraverso la degradazione o il blocco della traduzione di specifici RNA messaggeri (mRNA). Questo processo è innescato dalla presenza di piccoli RNA a doppio filamento (dsRNA) che vengono processati in small interfering RNA (siRNA) o microRNA (miRNA) da un enzima chiamato Dicer. Questi siRNA e miRNA vengono poi incorporati nel complesso RISC (RNA-induced silencing complex), dove uno strand del dsRNA guida il riconoscimento e il legame specifico con l'mRNA bersaglio complementare. Questo legame porta alla degradazione dell'mRNA o al blocco della traduzione, impedendo così la sintesi della proteina corrispondente. L'RNAi è un importante meccanismo di difesa contro i virus e altri elementi genetici mobili, ma è anche utilizzato nella regolazione fine dell'espressione genica durante lo sviluppo e in risposta a vari stimoli cellulari.
La desossiribonucleasi "EcoRI" è un enzima di restrizione derivato dalla batteria Esherichia coli che riconosce e taglia specificamente il DNA in siti palindromici con la sequenza specifica di riconoscimento 5'-GAATTC-3'. Questo enzima produce tagli simmetrici, producendo estremità coesive a singolo filamento che possono essere utilizzate per facilitare il processo di clonazione molecolare.
Le desossiribonucleasi di restrizione sono enzimi che tagliano il DNA in siti specifici, consentendo agli scienziati di manipolare e modificare il DNA in vari modi. L'enzima EcoRI è uno dei più comunemente utilizzati enzimi di restrizione ed è stato ampiamente studiato e caratterizzato a livello molecolare.
È importante notare che l'uso di questi enzimi richiede una grande precisione e accuratezza, poiché tagli errati o non specifici possono portare a risultati imprevisti o indesiderati nelle applicazioni di biologia molecolare.
La replicazione del DNA è un processo fondamentale nella biologia cellulare che consiste nella duplicazione del materiale genetico delle cellule. Più precisamente, si riferisce alla produzione di due identiche molecole di DNA a partire da una sola molecola madre, utilizzando la molecola complementare come modello per la sintesi.
Questo processo è essenziale per la crescita e la divisione cellulare, poiché garantisce che ogni cellula figlia riceva una copia identica del materiale genetico della cellula madre. La replicazione del DNA avviene durante la fase S del ciclo cellulare, subito dopo l'inizio della mitosi o meiosi.
Il processo di replicazione del DNA inizia con l'apertura della doppia elica del DNA da parte dell'elicasi, che separa le due catene complementari. Successivamente, le due eliche separate vengono ricoperte da proteine chiamate single-strand binding proteins (SSBP) per prevenirne il riavvolgimento.
A questo punto, entra in gioco l'enzima DNA polimerasi, che sintetizza nuove catene di DNA utilizzando le catene originali come modelli. La DNA polimerasi si muove lungo la catena di DNA e aggiunge nucleotidi uno alla volta, formando legami fosfodiesterici tra di essi. Poiché il DNA è una molecola antiparallela, le due eliche separate hanno polarità opposte, quindi la sintesi delle nuove catene procede in direzioni opposte a partire dal punto di origine della replicazione.
La DNA polimerasi ha anche un'importante funzione di proofreading (controllo dell'errore), che le permette di verificare e correggere eventuali errori di inserimento dei nucleotidi durante la sintesi. Questo meccanismo garantisce l'accuratezza della replicazione del DNA, con un tasso di errore molto basso (circa 1 su 10 milioni di basi).
Infine, le due nuove catene di DNA vengono unite da enzimi chiamati ligasi, che formano legami covalenti tra i nucleotidi adiacenti. Questo processo completa la replicazione del DNA e produce due molecole identiche della stessa sequenza, ognuna delle quali contiene una nuova catena di DNA e una catena originale.
In sintesi, la replicazione del DNA è un processo altamente accurato e coordinato che garantisce la conservazione dell'integrità genetica durante la divisione cellulare. Grazie all'azione combinata di enzimi come le DNA polimerasi e le ligasi, il DNA viene replicato con grande precisione, minimizzando così il rischio di mutazioni dannose per l'organismo.
In medicina, "Poli C" si riferisce a un integratore alimentare che contiene acido ascorbico (vitamina C) e due aminoacidi polari: la lisina e la prolina. Questo integratore è spesso commercializzato per il trattamento o la prevenzione di vari disturbi, tra cui infezioni virali, stanchezza cronica, sindrome da affaticamento cronico (CFS), dolori articolari e altri ancora.
Tuttavia, è importante sottolineare che l'efficacia dei poli C per il trattamento di queste condizioni non è stata scientificamente dimostrata in modo conclusivo. Alcuni studi hanno suggerito che la vitamina C e gli aminoacidi possono avere effetti benefici su alcune funzioni del corpo, ma sono necessarie ulteriori ricerche per confermare questi risultati e stabilire una relazione causale.
Come sempre, è importante consultare un medico o un operatore sanitario qualificato prima di iniziare qualsiasi trattamento a base di integratori alimentari, compresi i poli C, per assicurarsi che siano sicuri ed efficaci per la propria situazione specifica.
Nella medicina, i transattivatori sono proteine che svolgono un ruolo cruciale nella segnalazione cellulare e nella trasduzione del segnale. Essi facilitano la comunicazione tra le cellule e l'ambiente esterno, permettendo alle cellule di rispondere a vari stimoli e cambiamenti nelle condizioni ambientali.
I transattivatori sono in grado di legare specificamente a determinati ligandi (molecole segnale) all'esterno della cellula, subire una modifica conformazionale e quindi interagire con altre proteine all'interno della cellula. Questa interazione porta all'attivazione di cascate di segnalazione che possono influenzare una varietà di processi cellulari, come la proliferazione, la differenziazione e l'apoptosi (morte cellulare programmata).
Un esempio ben noto di transattivatore è il recettore tirosin chinasi, che è una proteina transmembrana con un dominio extracellulare che può legare specificamente a un ligando e un dominio intracellulare dotato di attività enzimatica. Quando il ligando si lega al dominio extracellulare, provoca una modifica conformazionale che attiva l'attività enzimatica del dominio intracellulare, portando all'attivazione della cascata di segnalazione.
I transattivatori svolgono un ruolo importante nella fisiologia e nella patologia umana, e la loro disfunzione è stata implicata in una varietà di malattie, tra cui il cancro e le malattie cardiovascolari.
La Distrofia Muscolare di Duchenne (DMD) è un disturbo genetico progressivo che causa debolezza muscolare. Si tratta di una forma grave di distrofia muscolare, che colpisce prevalentemente i maschi. La DMD si manifesta di solito entro i primi anni di vita e peggiora rapidamente. I bambini con questa malattia possono avere difficoltà a camminare, alzarsi da terra e climbar le scale. Spesso, i bambini con DMD perdono la capacità di camminare intorno all'età di 12 anni. La debolezza muscolare si estende anche ai muscoli respiratori e cardiaci, il che può causare problemi di respirazione e insufficienza cardiaca.
La DMD è causata da una mutazione nel gene della distrofina, che codifica per una proteina importante per la salute dei muscoli. Questa mutazione provoca una carenza o assenza totale di distrofina, portando alla degenerazione e alla morte delle cellule muscolari (fibre).
La diagnosi di DMD si basa solitamente su esami del sangue per la misurazione dell'enzima creatinfosfochinasi (CPK), che è elevato in presenza di danni ai muscoli. La conferma della diagnosi può essere ottenuta attraverso una biopsia muscolare o un test genetico.
Attualmente, non esiste una cura per la DMD, ma i trattamenti possono alleviare i sintomi e migliorare la qualità della vita. Questi possono includere fisioterapia, farmaci per controllare la rigidità muscolare (spasticità) e dispositivi di supporto come sedie a rotelle o ausili respiratori. La ricerca è in corso per trovare nuove terapie e trattamenti per questa malattia debilitante.
L'acido aminoetilfosfonico, noto anche come AEP o AEEA (etan-1,1-diimina tetraacetato), è un farmaco utilizzato principalmente nel trattamento dell'osteoporosi e del dolore osseo associato a tumori maligni.
L'AEP appartiene alla classe dei bisfosfonati, che sono composti in grado di legarsi all'idrossiapatite delle ossa, riducendone il turnover e aumentandone la densità mineralizzata. Ciò si traduce in un rallentamento della perdita ossea e nella prevenzione di fratture.
L'AEP è disponibile per uso endovenoso (EV) e viene solitamente somministrato una volta al mese o ogni tre mesi, a seconda del protocollo prescritto dal medico. Gli effetti collaterali più comuni dell'AEP includono reazioni allergiche, nausea, vomito, diarrea, costipazione, dolori articolari e muscolari, mal di testa, anemia e aumento della creatinina sierica.
In rari casi, l'uso prolungato di AEP può causare osteonecrosi della mandibola, una condizione in cui il tessuto osseo della mascella si degrada e muore. Pertanto, è importante che i pazienti sottoposti a terapia con AEP siano strettamente monitorati dal medico per rilevare tempestivamente eventuali effetti collaterali indesiderati.
In medicina, il termine "chemical phenomena" si riferisce a processi o reazioni chimiche che accadono all'interno del corpo umano. Queste reazioni possono essere catalizzate da enzimi o altre proteine e sono fondamentali per la regolazione di molte funzioni cellulari e fisiologiche.
Ad esempio, il metabolismo dei carboidrati, grassi e proteine è un tipo comune di chemical phenomena che avviene all'interno del corpo umano. Questo processo comporta una serie di reazioni chimiche che scompongono i nutrienti ingeriti in molecole più semplici, fornendo energia e materiale da costruzione per la crescita e la riparazione dei tessuti.
Altri esempi di chemical phenomena comprendono la coagulazione del sangue, la neurotrasmissione (comunicazione tra cellule nervose), la sintesi di ormoni e altre sostanze chimiche importanti per il corretto funzionamento dell'organismo.
Inoltre, i chemical phenomena possono anche essere coinvolti in patologie e disfunzioni del corpo umano. Ad esempio, alcune malattie genetiche sono causate da mutazioni che alterano la struttura o l'attività di enzimi o altre proteine coinvolte nei processi chimici. Inoltre, fattori ambientali come inquinanti o sostanze tossiche possono interferire con i chemical phenomena e causare danni ai tessuti e alle cellule.
In sintesi, i chemical phenomena sono una parte fondamentale della fisiologia umana e sono coinvolti in molte funzioni vitali del corpo. La comprensione di questi processi chimici è cruciale per la diagnosi e il trattamento delle malattie e per lo sviluppo di nuove strategie terapeutiche.
La timidina è un nucleoside naturalmente presente, costituito dalla base azotata timina legata al residuo di zucchero desossiribosio. È uno dei componenti fondamentali degli acidi nucleici, come il DNA, dove due molecole di timidina formano una coppia di basi con due molecole di adenina utilizzando le loro strutture a doppio anello. La timidina svolge un ruolo cruciale nella replicazione e nella trascrizione del DNA, contribuendo alla conservazione e all'espressione dell'informazione genetica. Inoltre, la timidina viene utilizzata in ambito clinico come farmaco antivirale per trattare l'herpes simplex, poiché può essere incorporata nelle catene di DNA virali in crescita, interrompendone così la replicazione. Tuttavia, un uso eccessivo o improprio della timidina come farmaco può causare effetti avversi, tra cui tossicità mitocondriale e danni al fegato.
I deossinucleotidi sono molecole costituite da una base azotata, un pentoso (deossiribosio in questo caso) e uno o più gruppi fosfato. I nucleotidi della deossicitosina specificamente si riferiscono a quelli che contengono la base azotata deossicitosina. La deossicitosina è una delle quattro basi azotate che vengono incorporate nel DNA, insieme alla deossiadenosina, la deossiguanosina e la timidina (o deossitimidina).
A differenza dei nucleotidi RNA, che contengono ribosio come pentoso, i nucleotidi del DNA contengono deossiribosio, che manca di un gruppo idrossile (-OH) sulla sua posizione 2' (due prime). Questa piccola differenza nella struttura chimica conferisce al DNA una maggiore stabilità e resistenza alla degradazione rispetto all'RNA.
I nucleotidi della deossicitosina sono importanti per la replicazione e la riparazione del DNA, nonché per la sintesi delle proteine. Sono anche il bersaglio di alcuni farmaci antivirali e agenti chemioterapici utilizzati nel trattamento di malattie come l'HIV e il cancro.
Il fattore di trascrizione SP1 (Specificity Protein 1) è una proteina nucleare appartenente alla famiglia delle proteine SP/KLF (Specificity Protein/Krüppel-like Factor). È codificato dal gene Sp1, situato sul braccio lungo del cromosoma 12 (12q13.1).
SP1 è un regolatore trascrizionale importante che lega specifiche sequenze GC-ricche nel DNA, comprese le sequenze GC box, attraverso i suoi domini delle dita di zinco. Queste interazioni consentono a SP1 di svolgere un ruolo cruciale nell'attivazione o nella repressione della trascrizione di diversi geni target, inclusi quelli che codificano per enzimi metabolici, fattori di crescita e proteine strutturali.
La regolazione dell'espressione genica da parte di SP1 è complessa e può essere influenzata da vari meccanismi post-traduzionali, come la fosforilazione, l'acetilazione e la sumoylazione, che modulano la sua affinità per il DNA o le interazioni con altri cofattori.
SP1 è essenziale per lo sviluppo embrionale e la differenziazione cellulare e svolge un ruolo importante nella risposta cellulare a vari stimoli, come stress ossidativo, danno del DNA e fattori di crescita. Alterazioni nell'espressione o nella funzione di SP1 sono state associate a diverse patologie, tra cui cancro, diabete e malattie neurodegenerative.
I peptidi sono catene di due o più amminoacidi legati insieme da un legame peptidico. Un legame peptidico si forma quando il gruppo ammino dell'amminoacido reagisce con il gruppo carbossilico dell'amminoacido adiacente in una reazione di condensazione, rilasciando una molecola d'acqua. I peptidi possono variare in lunghezza da brevi catene di due o tre amminoacidi (chiamate oligopeptidi) a lunghe catene di centinaia o addirittura migliaia di amminoacidi (chiamate polipeptidi). Alcuni peptidi hanno attività biologica e svolgono una varietà di funzioni importanti nel corpo, come servire come ormoni, neurotrasmettitori e componenti delle membrane cellulari. Esempi di peptidi includono l'insulina, l'ossitocina e la vasopressina.
"Saccharomyces cerevisiae" è una specie di lievito unicellulare comunemente noto come "lievito da birra". È ampiamente utilizzato nell'industria alimentare e delle bevande per la fermentazione alcolica e nella produzione di pane, vino, birra e yogurt.
In ambito medico, S. cerevisiae è talvolta utilizzato come probiotico, in particolare per le persone con disturbi gastrointestinali. Alcuni studi hanno suggerito che questo lievito può aiutare a ripristinare l'equilibrio della flora intestinale e rafforzare il sistema immunitario.
Tuttavia, è importante notare che S. cerevisiae può anche causare infezioni opportunistiche, specialmente in individui con un sistema immunitario indebolito. Questi possono includere infezioni della pelle, delle vie urinarie e del tratto respiratorio.
In sintesi, "Saccharomyces cerevisiae" è un lievito utilizzato nell'industria alimentare e delle bevande, nonché come probiotico in ambito medico, sebbene possa anche causare infezioni opportunistiche in alcuni individui.
I fosfati sono composti organici o inorganici che contengono un gruppo funzionale di fosfato, che è costituito da un atomo di fosforo legato a quattro atomi di ossigeno con una carica negativa complessiva di -3. Nella biochimica, i fosfati svolgono un ruolo cruciale in molti processi cellulari, tra cui la trasmissione dell'energia (come ATP), la regolazione delle proteine e l'attivazione enzimatica. Nel corpo umano, i fosfati sono presenti nel tessuto osseo e nelle cellule, e sono importanti per il mantenimento della salute delle ossa e dei denti, nonché per la regolazione del pH e dell'equilibrio elettrolitico. Gli squilibri nei livelli di fosfato nel sangue possono portare a condizioni mediche come l'ipofosfatemia o l'iperfosfatemia, che possono avere conseguenze negative sulla salute.
La distribuzione nei tessuti, in campo medico e farmacologico, si riferisce al processo attraverso cui un farmaco o una sostanza chimica si diffonde dalle aree di somministrazione a diversi tessuti e fluidi corporei. Questo processo è influenzato da fattori quali la liposolubilità o idrosolubilità del farmaco, il flusso sanguigno nei tessuti, la perfusione (l'afflusso di sangue ricco di ossigeno in un tessuto), la dimensione molecolare del farmaco e il grado di legame del farmaco con le proteine plasmatiche.
La distribuzione dei farmaci nei tessuti è una fase importante nel processo farmacocinetico, che comprende anche assorbimento, metabolismo ed eliminazione. Una buona comprensione della distribuzione dei farmaci può aiutare a prevedere e spiegare le differenze interindividuali nelle risposte ai farmaci, nonché ad ottimizzare la terapia farmacologica per massimizzarne l'efficacia e minimizzarne gli effetti avversi.
La risonanza magnetica nucleare biomolecolare (NMR, Nuclear Magnetic Resonance) è una tecnica di risonanza magnetica che viene utilizzata per studiare la struttura, la dinamica e le interazioni delle molecole biologiche, come proteine, acidi nucleici e metaboliti. Questa tecnica si basa sul fatto che i protoni (nuclei di idrogeno) e altri nuclei atomici con spin non nullo, quando vengono sottoposti a un campo magnetico esterno, assorbono ed emettono energia a specifiche frequenze radio.
In particolare, la NMR biomolecolare consente di ottenere informazioni dettagliate sulla struttura tridimensionale delle proteine e degli acidi nucleici, nonché sui loro movimenti e flessibilità. Queste informazioni sono fondamentali per comprendere il funzionamento dei sistemi biologici a livello molecolare e per lo sviluppo di nuovi farmaci e terapie.
La NMR biomolecolare richiede l'uso di campi magnetici molto potenti, solitamente generati da grandi magneti superconduttori raffreddati a temperature criogeniche. Inoltre, è necessario utilizzare sofisticate tecniche di elaborazione dei dati per estrarre informazioni utili dalle misure sperimentali.
In sintesi, la risonanza magnetica nucleare biomolecolare è una potente tecnica di indagine strutturale e funzionale che permette di studiare la struttura e le interazioni delle molecole biologiche a livello atomico, fornendo informazioni fondamentali per la comprensione dei meccanismi molecolari alla base dei processi biologici.
Le carbocianine sono un gruppo di coloranti sintetici fluorescenti che vengono utilizzati in campo medico, biologico e biochimico come marcatori per la microscopia a fluorescenza. Sono caratterizzate da una struttura chimica contenente un anello aromatico con un gruppo cianina (-CN) e un gruppo isotiocianato (-N=C=S).
In medicina, le carbocianine vengono utilizzate come coloranti vitali per la colorazione dei tessuti viventi. Ad esempio, il blu di metilene, una carbocianina, viene impiegato come marcatore vascolare per evidenziare i vasi sanguigni durante gli interventi chirurgici. Altre carbocianine, come la DiI e la DiO, sono utilizzate in ricerca per studiare il trasporto di lipidi e la dinamica delle membrane cellulari.
Le carbocianine presentano un'elevata affinità per le membrane cellulari, specialmente quelle ricche di fosfolipidi, e possono essere utilizzate per studiare il trasporto di lipidi e la fusione delle membrane. Inoltre, alcune carbocianine sono in grado di attraversare la barriera emato-encefalica, rendendole utili come marcatori fluorescenti per l'imaging cerebrale.
È importante notare che l'uso delle carbocianine deve essere effettuato con cautela e sotto la guida di personale medico qualificato, poiché possono presentare potenziali effetti tossici se utilizzate in modo improprio o a dosaggi elevati.
In medicina e scienze biologiche, le nanoparticelle sono particelle microscopiche con dimensioni comprese tra 1 e 100 nanometri (nm) che presentano proprietà uniche dovute alle loro piccole dimensioni. Queste particelle possono essere prodotte da una varietà di sostanze, come metalli, polimeri o ceramici, e sono utilizzate in una vasta gamma di applicazioni biomediche, tra cui la diagnostica, la terapia e l'imaging.
Le nanoparticelle possono interagire con le cellule e i tessuti a livello molecolare, il che può portare a effetti sia positivi che negativi sulla salute. Ad esempio, le nanoparticelle possono essere utilizzate per veicolare farmaci direttamente alle cellule tumorali, riducendo al minimo gli effetti collaterali sui tessuti sani circostanti. Tuttavia, l'esposizione prolungata o ad alti livelli di nanoparticelle può causare infiammazione, danni ai polmoni e altri problemi di salute.
Pertanto, è importante condurre ulteriori ricerche per comprendere meglio i potenziali rischi e benefici delle nanoparticelle in ambito biomedico, nonché sviluppare metodi sicuri ed efficaci per la loro produzione e utilizzo.
L'RNA polimerasi DNA dipendente è un enzima fondamentale per la replicazione e la trascrizione del DNA. Più specificamente, svolge il ruolo chiave nella sintesi dell'RNA durante il processo di trascrizione, in cui una sequenza di DNA viene copiata in una sequenza complementare di RNA.
L'RNA polimerasi DNA dipendente si lega al filamento di DNA a monte del sito di inizio della trascrizione e lo scorre mentre catalizza l'aggiunta di nucleotidi all'estremità 5' dell'mRNA in crescita. L'enzima utilizza il filamento template di DNA come matrice per selezionare i nucleotidi corretti da incorporare nella nuova catena di RNA, utilizzando le coppie Watson-Crick standard per garantire la correttezza della sequenza.
L'RNA polimerasi DNA dipendente è altamente conservata in tutti i domini della vita e svolge un ruolo fondamentale nel controllo dell'espressione genica, essendo responsabile della produzione di RNA messaggero (mRNA), RNA ribosomiale (rRNA) e RNA transfer (tRNA). Esistono diverse forme di RNA polimerasi DNA dipendente in diversi organismi, ognuna delle quali è specializzata nella trascrizione di specifiche classi di geni.
In sintesi, l'RNA polimerasi DNA dipendente è un enzima essenziale per la replicazione e la trascrizione del DNA, che catalizza la produzione di RNA utilizzando il DNA come matrice.
Le tecniche di protezione della nucleasi sono approcci utilizzati in biologia molecolare per proteggere l'attività delle nucleasi durante processi sperimentali, come la reazione a catena della polimerasi (PCR) o il clonaggio. Le nucleasi sono enzimi che tagliano specificamente le sequenze di DNA o RNA.
Esistono due principali tipi di tecniche di protezione della nucleasi:
1. L'uso di inibitori delle nucleasi: questi sono composti chimici che impediscono l'attività delle nucleasi. Possono essere aggiunti al buffer di reazione per prevenire il taglio accidentale del DNA o RNA durante la preparazione dell'esperimento.
2. L'uso di strategie di progettazione di sequenze: questo implica la progettazione di primer o sonde che contengono sequenze che non sono riconosciute dalle nucleasi utilizzate nell'esperimento. In questo modo, le nucleasi non saranno in grado di tagliare il DNA o l'RNA durante il processo sperimentale.
Queste tecniche sono particolarmente importanti quando si lavora con campioni delicati o preziosi, come il DNA genomico o il materiale genetico di organismi rari, dove il danneggiamento accidentale può compromettere i risultati sperimentali.
Gli estratti cellulari sono soluzioni che contengono composti chimici derivati da cellule, ottenuti attraverso vari metodi di estrazione. Questi composti possono includere una vasta gamma di sostanze, come proteine, lipidi, carboidrati, acidi nucleici (DNA e RNA), metaboliti e altri componenti cellulari.
L'obiettivo dell'estrazione cellulare è quello di isolare specifiche molecole o frazioni di interesse per scopi di ricerca scientifica, diagnosticati o terapeutici. Ad esempio, gli estratti cellulari possono essere utilizzati per studiare la composizione e le funzioni delle cellule, identificare biomarcatori associati a malattie, valutare l'efficacia di farmaci o composti chimici, o sviluppare vaccini e terapie cellulari.
I metodi di estrazione variano a seconda del tipo di campione cellulare (ad esempio, linee cellulari, tessuti solidi, sangue, urina) e della natura delle molecole target. Alcuni approcci comuni includono l'uso di solventi organici, detergenti, enzimi, calore, shock osmotico o meccanici per rompere la membrana cellulare e rilasciare i componenti intracellulari. Successivamente, possono essere applicati ulteriori passaggi di purificazione e concentrazione per ottenere l'estrattto desiderato.
È importante notare che l'ottenimento e il trattamento degli estratti cellulari devono seguire rigide procedure controllate e validate, al fine di garantire la riproducibilità dei risultati e la sicurezza delle applicazioni cliniche.
Gli "Topi Inbred Balb C" sono una particolare linea genetica di topi da laboratorio utilizzati comunemente in ricerca scientifica. Sono noti anche come "topi BALB/c" o semplicemente "Balb C". Questi topi sono allevati in modo inbred, il che significa che provengono da una linea geneticamente omogenea e strettamente correlata, con la stessa sequenza di DNA ereditata da ogni generazione.
I Topi Inbred Balb C sono particolarmente noti per avere un sistema immunitario ben caratterizzato, il che li rende utili in studi sull'immunologia e sulla risposta del sistema immunitario alle malattie e ai trattamenti. Ad esempio, i Balb C sono spesso usati negli esperimenti di vaccinazione perché hanno una forte risposta umorale (produzione di anticorpi) alla maggior parte dei vaccini.
Tuttavia, è importante notare che ogni linea genetica di topo ha i suoi vantaggi e svantaggi in termini di utilità per la ricerca scientifica. Pertanto, i ricercatori devono scegliere con cura il tipo di topo più appropriato per il loro particolare studio o esperimento.
La parola "alchini" non sembra far riferimento a una definizione medica specifica o ad un termine comunemente utilizzato nel campo della medicina. Tuttavia, il termine "alchino" è utilizzato in chimica per descrivere un idrocarburo insaturo contenente almeno una tripla legame carbonio-carbonio nella sua struttura molecolare.
Gli alchini sono composti organici che appartengono alla classe degli idrocarburi, che contengono solo atomi di carbonio e idrogeno. Questi composti possono essere trovati in natura o sintetizzati in laboratorio. Un esempio comune di alchino è l'acetilene (C2H2), che viene utilizzato come combustibile industriale e in alcune applicazioni mediche, come la chirurgia laser.
Tuttavia, se si sta cercando una definizione medica specifica, potrebbe essere necessario fornire più informazioni o chiarire la domanda per ottenere una risposta più precisa.
I geni batterici si riferiscono a specifiche sequenze di DNA presenti nel genoma di batteri che codificano per proteine o RNA con funzioni specifiche. Questi geni svolgono un ruolo cruciale nello sviluppo, nella crescita e nella sopravvivenza dei batteri, determinando le loro caratteristiche distintive come la forma, il metabolismo, la resistenza ai farmaci e la patogenicità.
I geni batterici possono essere studiati per comprendere meglio la biologia dei batteri, nonché per sviluppare strategie di controllo e prevenzione delle malattie infettive. Ad esempio, l'identificazione di geni specifici che conferiscono resistenza agli antibiotici può aiutare a sviluppare nuovi farmaci per combattere le infezioni resistenti ai farmaci.
Inoltre, i geni batterici possono essere modificati o manipolati utilizzando tecniche di ingegneria genetica per creare batteri geneticamente modificati con applicazioni potenziali in vari campi, come la biotecnologia, l'agricoltura e la medicina.
MicroRNA (miRNA) sono piccoli frammenti di acidi nucleici non codificanti, che misurano circa 22-25 nucleotidi di lunghezza. Sono presenti in molte specie viventi e svolgono un ruolo importante nella regolazione dell'espressione genica a livello post-trascrizionale.
I miRNA sono sintetizzati all'interno della cellula come precursori primari più lunghi, che vengono processati in pre-miRNA di circa 70 nucleotidi di lunghezza da un enzima chiamato Drosha nel nucleo. I pre-miRNA vengono quindi trasportati nel citoplasma, dove vengono ulteriormente tagliati da un altro enzima chiamato Dicer in miRNA maturi.
Una volta formati, i miRNA si legano a specifiche sequenze di mRNA (acidi messaggeri) complementari attraverso il complesso RISC (RNA-induced silencing complex). Questo legame può portare all'inibizione della traduzione del mRNA o alla sua degradazione, a seconda della perfetta o imperfetta complementarietà tra miRNA e mRNA.
I miRNA sono coinvolti in una vasta gamma di processi biologici, come lo sviluppo embrionale, la differenziazione cellulare, l'apoptosi, la proliferazione cellulare e la risposta immunitaria. Le alterazioni nell'espressione dei miRNA sono state associate a diverse malattie umane, tra cui il cancro, le malattie cardiovascolari e neurologiche. Pertanto, i miRNA rappresentano un importante bersaglio terapeutico per lo sviluppo di nuove strategie di trattamento delle malattie.
La microscopia a fluorescenza è una tecnica di microscopia che utilizza la fluorescenza dei campioni per generare un'immagine. Viene utilizzata per studiare la struttura e la funzione delle cellule e dei tessuti, oltre che per l'identificazione e la quantificazione di specifiche molecole biologiche all'interno di campioni.
Nella microscopia a fluorescenza, i campioni vengono trattati con uno o più marcatori fluorescenti, noti come sonde, che si legano selettivamente alle molecole target di interesse. Quando il campione è esposto alla luce ad una specifica lunghezza d'onda, la sonda assorbe l'energia della luce e entra in uno stato eccitato. Successivamente, la sonda decade dallo stato eccitato allo stato fondamentale emettendo luce a una diversa lunghezza d'onda, che può essere rilevata e misurata dal microscopio.
La microscopia a fluorescenza offre un'elevata sensibilità e specificità, poiché solo le molecole marcate con la sonda fluorescente emetteranno luce. Inoltre, questa tecnica consente di ottenere immagini altamente risolvibili, poiché la lunghezza d'onda della luce emessa dalle sonde è generalmente più corta di quella della luce utilizzata per l'eccitazione, il che si traduce in una maggiore separazione tra le immagini delle diverse molecole target.
La microscopia a fluorescenza viene ampiamente utilizzata in diversi campi della biologia e della medicina, come la citologia, l'istologia, la biologia cellulare, la neurobiologia, l'immunologia e la virologia. Tra le applicazioni più comuni di questa tecnica ci sono lo studio delle interazioni proteina-proteina, la localizzazione subcellulare delle proteine, l'analisi dell'espressione genica e la visualizzazione dei processi dinamici all'interno delle cellule.
La Chloramphenicol O-acetyltransferase (OAT) è un enzima che catalizza la reazione di acetilazione del cloramfenicolo, un antibiotico a largo spettro. Questa acetilazione inattiva l'attività antibatterica del cloramfenicolo, conferendo resistenza all'antibiotico nelle batteri che esprimono questo enzima.
L'OAT è codificato da geni plasmidici o cromosomici e la sua presenza può essere utilizzata come marcatore per identificare ceppi batterici resistenti al cloramfenicolo. L'espressione di questo enzima è clinicamente significativa, poiché i pazienti infetti con batteri che esprimono l'OAT possono non rispondere alla terapia con cloramfenicolo.
La struttura e la funzione dell'OAT sono state ampiamente studiate come modello per comprendere il meccanismo di resistenza agli antibiotici mediato dagli enzimi. La sua sequenza aminoacidica, la struttura tridimensionale e le interazioni con il cloramfenicolo sono state caratterizzate in dettaglio, fornendo informazioni preziose sulla progettazione di strategie per superare la resistenza agli antibiotici.
La mutagenesi sito-diretta è un processo di ingegneria genetica che comporta l'inserimento mirato di una specifica mutazione in un gene o in un determinato sito del DNA. A differenza della mutagenesi casuale, che produce mutazioni in posizioni casuali del DNA e può richiedere screening intensivi per identificare le mutazioni desiderate, la mutagenesi sito-diretta consente di introdurre selettivamente una singola mutazione in un gene targetizzato.
Questo processo si basa sull'utilizzo di enzimi di restrizione e oligonucleotidi sintetici marcati con nucleotidi modificati, come ad esempio desossiribonucleosidi trifosfati (dNTP) analoghi. Questi oligonucleotidi contengono la mutazione desiderata e sono progettati per abbinarsi specificamente al sito di interesse sul DNA bersaglio. Una volta che l'oligonucleotide marcato si lega al sito target, l'enzima di restrizione taglia il DNA in quel punto, consentendo all'oligonucleotide di sostituire la sequenza originale con la mutazione desiderata tramite un processo noto come ricostituzione dell'estremità coesiva.
La mutagenesi sito-diretta è una tecnica potente e precisa che viene utilizzata per studiare la funzione dei geni, creare modelli animali di malattie e sviluppare strategie terapeutiche innovative, come ad esempio la terapia genica. Tuttavia, questa tecnica richiede una progettazione accurata degli oligonucleotidi e un'elevata specificità dell'enzima di restrizione per garantire l'inserimento preciso della mutazione desiderata.
In termini medici, il bestiame si riferisce comunemente al bestiame allevato per l'uso o il consumo umano, come manzo, vitello, montone, agnello, maiale e pollame. Possono verificarsi occasionalmente malattie zoonotiche (che possono essere trasmesse dagli animali all'uomo) o infezioni che possono diffondersi dagli animali da allevamento alle persone, pertanto i medici e altri operatori sanitari devono essere consapevoli di tali rischi e adottare misure appropriate per la prevenzione e il controllo delle infezioni. Tuttavia, il termine "bestiame" non ha una definizione medica specifica o un uso clinico comune.
In medicina e scienza, il termine "nanostrutture" si riferisce a strutture create dall'uomo o presenti in natura con dimensioni comprese tra 1 e 100 nanometri (nm). Una nanometro è un miliardesimo di metro.
Le nanostrutture possono essere costituite da diversi materiali, come metalli, semiconduttori o polimeri, e possono avere forme e proprietà diverse. Alcune nanostrutture si verificano naturalmente, come le proteine, i virus e alcuni tipi di minerali. Tuttavia, la maggior parte delle nanostrutture sono progettate e create dall'uomo utilizzando tecniche di fabbricazione avanzate.
Le nanostrutture hanno proprietà uniche che dipendono dalle loro dimensioni ridotte. Ad esempio, possono avere una maggiore area superficiale rispetto alle strutture più grandi, il che può renderle più reattive o conduttive. Queste proprietà possono essere sfruttate in vari campi, come la medicina, l'ingegneria e l'elettronica.
In medicina, le nanostrutture vengono studiate per una varietà di applicazioni, tra cui il rilascio controllato di farmaci, la diagnosi precoce delle malattie e la terapia mirata dei tumori. Ad esempio, i nanomateriali possono essere utilizzati per creare sistemi di consegna di farmaci che proteggono il farmaco dal sistema immunitario fino a quando non raggiunge il bersaglio desiderato, come una cellula cancerosa. Inoltre, le nanostrutture possono essere utilizzate per creare sensori altamente sensibili e specifici che possono rilevare biomarcatori delle malattie a livelli estremamente bassi.
Tuttavia, l'uso di nanostrutture in medicina presenta anche alcune sfide e preoccupazioni, come la tossicità dei nanomateriali e la loro distribuzione nel corpo. Pertanto, è importante condurre ulteriori ricerche per comprendere meglio i potenziali rischi e benefici delle nanostrutture in medicina.
In medicina, "hot temperature" non è una condizione o un termine medico standardmente definito. Tuttavia, in alcuni contesti, come ad esempio nella storia clinica di un paziente, potrebbe riferirsi a una situazione in cui una persona sperimenta febbre o ipertermia, che si verifica quando la temperatura corporea centrale supera i 37,5-38°C (99,5-100,4°F). La febbre è spesso un segno di una risposta infiammatoria o infettiva del corpo.
Tuttavia, se si intende la temperatura ambientale elevata, allora si parla di "alte temperature", che può avere effetti negativi sulla salute umana, specialmente per i neonati, i bambini piccoli e gli anziani, o per chi soffre di determinate condizioni mediche. L'esposizione prolungata ad alte temperature può portare a disidratazione, caldo estremo, colpo di calore e altri problemi di salute.
L'acido apurinico è un composto chimico che si forma quando un nucleotide, specificamente la purina, viene rimossa da una molecola di DNA. Questo processo può verificarsi naturalmente a causa dell'azione enzimatica o come conseguenza di danni al DNA.
In particolare, l'acido apurinico si riferisce all'estruttura residua che rimane dopo la rimozione di una base azotata adenina da un deossiribosio. Questo residuo è costituito dal deossiribosio legato a uno zucchero, il 2-desossiribosio, e a un gruppo fosfato.
L'acido apurinico può essere dannoso per la cellula se non viene correttamente riparato, poiché può portare a mutazioni genetiche o alla degradazione del DNA. Il nostro corpo ha meccanismi di riparazione del DNA che lavorano per rilevare e correggere queste lesioni, ma se tali meccanismi falliscono, possono verificarsi effetti negativi sulla salute, come l'insorgenza di tumori o altre malattie.
In chimica e farmacologia, la stereoisomeria è un tipo specifico di isomeria, una proprietà strutturale che due o più molecole possono avere quando hanno gli stessi tipi e numeri di atomi, ma differiscono nella loro disposizione nello spazio. Più precisamente, la stereoisomeria si verifica quando le molecole contengono atomi carbono chirali che sono legati ad altri quattro atomi o gruppi diversi in modo tale che non possono essere superponibili l'una all'altra attraverso rotazione o traslazione.
Esistono due tipi principali di stereoisomeria: enantiomeri e diastereoisomeri. Gli enantiomeri sono coppie di molecole che sono immagini speculari l'una dell'altra, proprio come le mani destra e sinistra. Possono essere distinte solo quando vengono osservate la loro interazione con altri composti chirali, come ad esempio il modo in cui ruotano il piano della luce polarizzata. I diastereoisomeri, d'altra parte, non sono immagini speculari l'una dell'altra e possono essere distinte anche quando vengono osservate indipendentemente dalla loro interazione con altri composti chirali.
La stereoisomeria è importante in medicina perché gli enantiomeri di un farmaco possono avere effetti diversi sul corpo umano, anche se hanno una struttura chimica molto simile. Ad esempio, uno dei due enantiomeri può essere attivo come farmaco, mentre l'altro è inattivo o persino tossico. Pertanto, la produzione e l'uso di farmaci stereoisomericamente puri possono migliorare la sicurezza ed efficacia del trattamento.
Il deossiribosio, noto anche come 2-deossiribofuranosio, è un monosaccaride pentoso (una forma semplice di zucchero a cinque atomi di carbonio) che si trova nella struttura della molecola di DNA. Si differenzia dal ribosio, lo zucchero presente nell'RNA, per l'assenza di un gruppo idrossile (-OH) sul secondo carbonio (il carbonio 2' o deossigeno). Questa piccola differenza nella struttura chimica conferisce al DNA una maggiore stabilità rispetto all'RNA, rendendolo più adatto a svolgere la sua funzione di archiviazione e trasmissione delle informazioni genetiche.
La formula chimica del deossiribosio è C5H10O4. Nella molecola di DNA, il deossiribosio si lega a basi azotate (adenina, timina, guanina e citosina) formando unità chiamate deossiribonucleotidi, che poi si uniscono per formare la catena del DNA.
In medicina e biologia molecolare, il termine "mappa nucleotidica" (o "mappa del DNA") si riferisce a una rappresentazione grafica della disposizione relativa dei nucleotidi che compongono una particolare sequenza di DNA. In altre parole, mostra la posizione e l'ordine degli adenini (A), timini (T), citosine (C) e guanina (G) in un tratto specifico di DNA.
La mappa nucleotidica è uno strumento essenziale per comprendere le caratteristiche funzionali e strutturali del DNA, come la localizzazione dei geni, i siti di restrizione enzimatica, le ripetizioni nucleotidiche e altri elementi importanti. Viene creata attraverso il processo di sequenziamento del DNA, che determina l'ordine esatto delle basi azotate in un tratto di DNA.
Le mappe nucleotidiche sono fondamentali per la ricerca genetica e biomedica, poiché consentono agli scienziati di identificare mutazioni o variazioni nel DNA che possono essere associate a malattie ereditarie o acquisite. Inoltre, le mappe nucleotidiche sono utili per lo sviluppo di farmaci e terapie geniche, poiché permettono agli scienziati di identificare i bersagli molecolari specifici e progettare interventi mirati.
In medicina e biologia, la sovraregolazione si riferisce a un fenomeno in cui un gene o un prodotto genico (come un enzima) viene overexpressed o attivato a livelli superiori al normale. Ciò può verificarsi a causa di vari fattori, come mutazioni genetiche, influenze ambientali o interazioni farmacologiche.
La sovraregolazione di un gene o di un prodotto genico può portare a una serie di conseguenze negative per la salute, a seconda del ruolo svolto dal gene o dal prodotto genico in questione. Ad esempio, se un enzima cancerogeno viene sovraregolato, ciò può aumentare il rischio di sviluppare il cancro. Allo stesso modo, la sovraregolazione di un recettore cellulare può portare a una maggiore sensibilità o resistenza ai farmaci, a seconda del contesto.
La sovraregolazione è spesso studiata nel contesto della ricerca sul cancro e delle malattie genetiche, nonché nello sviluppo di farmaci e terapie. Attraverso la comprensione dei meccanismi di sovraregolazione, i ricercatori possono sviluppare strategie per modulare l'espressione genica e il funzionamento dei prodotti genici, con l'obiettivo di prevenire o trattare le malattie.
I modelli genetici sono l'applicazione dei principi della genetica per descrivere e spiegare i modelli di ereditarietà delle malattie o dei tratti. Essi si basano sulla frequenza e la distribuzione delle malattie all'interno di famiglie e popolazioni, nonché sull'analisi statistica dell'eredità mendeliana di specifici geni associati a tali malattie o tratti. I modelli genetici possono essere utilizzati per comprendere la natura della trasmissione di una malattia e per identificare i fattori di rischio genetici che possono influenzare lo sviluppo della malattia. Questi modelli possono anche essere utilizzati per prevedere il rischio di malattie nelle famiglie e nei membri della popolazione, nonché per lo sviluppo di strategie di diagnosi e trattamento personalizzate. I modelli genetici possono essere classificati in diversi tipi, come i modelli monogenici, che descrivono l'eredità di una singola malattia associata a un gene specifico, e i modelli poligenici, che descrivono l'eredità di malattie complesse influenzate da molteplici geni e fattori ambientali.
Le tecniche di knockdown del gene sono metodi di laboratorio utilizzati per ridurre l'espressione genica di un particolare gene di interesse in organismi viventi o cellule. Queste tecniche mirano a inibire la traduzione dell'mRNA del gene bersaglio in proteine funzionali, il che può portare a una ridotta attività del prodotto genico e quindi consentire agli scienziati di studiarne le funzioni e i meccanismi d'azione.
Una tecnica comunemente utilizzata per il knockdown del gene è l'impiego di RNA interferente (RNAi), che sfrutta il meccanismo cellulare endogeno di degradazione dell'mRNA. L'RNAi viene in genere somministrato alle cellule sotto forma di piccoli RNA doppi a prevalenza di basi G (gRNA, small interfering RNA o siRNA) che vengono processati dalla ribonucleasi Dicer per formare piccoli RNA bicatenari. Questi piccoli RNA bicatenari vengono quindi incorporati nella proteina argonauta (AGO), un componente del complesso RISC (RNA-induced silencing complex). Il complesso RISC guida quindi il sito di legame dell'mRNA complementare al siRNA, che viene successivamente tagliato e degradato dalla proteina AGO.
Un altro metodo per il knockdown del gene è l'utilizzo di antisenso RNA (asRNA), che sono sequenze nucleotidiche singole complementari all'mRNA bersaglio. L'asRNA si lega all'mRNA bersaglio, impedendone la traduzione in proteine funzionali o marcandolo per la degradazione da parte di enzimi cellulari specifici come la ribonucleasi H (RNase H).
Le tecniche di knockdown del gene sono spesso utilizzate nella ricerca biomedica e nelle scienze della vita per studiare le funzioni dei geni, l'espressione genica e i meccanismi molecolari delle malattie. Tuttavia, è importante notare che queste tecniche possono avere effetti off-target e influenzare la regolazione di più geni oltre al bersaglio desiderato, il che può portare a risultati non specifici o inaccurati. Pertanto, è fondamentale utilizzare queste tecniche con cautela ed eseguire ulteriori verifiche sperimentali per confermare i risultati ottenuti.
Gli elementi enhancer genetici sono sequenze di DNA regulatory che aumentano la trascrizione dei geni a cui sono legati. Gli enhancer possono essere trovati in diverse posizioni rispetto al gene bersaglio, sia upstream che downstream, e persino all'interno di introni o altri elementi regolatori come i silenziatori.
Gli enhancer sono costituiti da diversi fattori di trascrizione e cofattori che si legano a specifiche sequenze di DNA per formare un complesso proteico. Questo complesso interagisce con la polimerasi II, l'enzima responsabile della trascrizione dell'RNA, aumentando il tasso di inizio della trascrizione del gene bersaglio.
Gli enhancer possono essere specifici per un particolare tipo cellulare o essere attivi in più tipi cellulari. Possono anche mostrare una regolazione spaziale e temporale, essendo attivi solo in determinate condizioni di sviluppo o risposta a stimoli ambientali.
Le mutazioni negli enhancer possono portare a malattie genetiche, poiché possono influenzare la normale espressione dei geni e causare disfunzioni cellulari o sviluppo anormale.
Le tecniche di trasferimento genico, noto anche come ingegneria genetica, si riferiscono a una serie di metodi utilizzati per introdurre specifiche sequenze di DNA (geni) in un organismo o cellula vivente. Queste tecniche sono ampiamente utilizzate nella ricerca biomedica e biotecnologica per studiare la funzione genica, creare modelli animali di malattie umane, sviluppare terapie geniche e produrre organismi geneticamente modificati con applicazioni industriali o agricole.
Ecco alcune tecniche di trasferimento genico comuni:
1. Trasfezione: è il processo di introduzione di DNA esogeno (estraneo) nelle cellule. Ciò può essere fatto utilizzando vari metodi, come elettroporazione, microiniezione o l'uso di agenti transfettivi come liposomi o complessi polionici eterogenei (PEI).
2. Trasduzione: è un processo in cui il materiale genetico viene trasferito da un batterio donatore a un batterio ricevente attraverso un virus batteriofago. Il fago infetta prima il batterio donatore, incorpora il suo DNA nel proprio genoma e quindi infetta il batterio ricevente, introducendo così il DNA estraneo all'interno della cellula ricevente.
3. Infezione da virus: i virus possono essere utilizzati come vettori per introdurre specifiche sequenze di DNA in una cellula ospite. Il DNA del virus viene modificato geneticamente per contenere il gene d'interesse, che viene quindi integrato nel genoma dell'ospite dopo l'infezione. I virus più comunemente usati come vettori sono i retrovirus e gli adenovirus.
4. Agrobacterium tumefaciens-mediated gene transfer: Questo è un metodo per introdurre geni in piante utilizzando il batterio Agrobacterium tumefaciens. Il plasmide Ti di A. tumefaciens contiene sequenze T-DNA che possono essere integrate nel genoma della pianta ospite, consentendo l'espressione del gene d'interesse.
5. Elettroporazione: è un metodo per introdurre DNA esogeno nelle cellule utilizzando campi elettrici ad alta intensità. I pori temporanei si formano nella membrana cellulare, consentendo il passaggio di molecole più grandi come il DNA plasmidico o lineare.
6. Microiniezione: questo metodo comporta l'inserimento diretto del DNA esogeno all'interno del citoplasma o del nucleo della cellula utilizzando un microaghetto sottile. Questo metodo è comunemente usato per introdurre geni nelle uova di animali o nelle cellule embrionali.
7. Biolistica: questo metodo comporta l'uso di una pistola gene per sparare microparticelle rivestite di DNA esogeno all'interno delle cellule. Questo metodo è comunemente usato per introdurre geni nelle piante o nelle cellule animali.
L'etilendiamina è una sostanza chimica organica con la formula H2N-CH2-CH2-NH2. È un liquido chiaro e incolore con un forte odore ammoniacale. Viene utilizzata come intermedio nella sintesi di altri composti chimici, tra cui farmaci, resine e coloranti.
In medicina, l'etilendiamina non ha un ruolo diretto come farmaco o terapia. Tuttavia, può essere impiegata come agente chelante per rimuovere ioni di metalli pesanti tossici dal corpo umano. Ad esempio, può essere usata in combinazione con il bicarbonato di sodio per trattare l'avvelenamento da piombo o mercurio.
È importante notare che l'esposizione all'etilendiamina può causare irritazioni alla pelle, agli occhi e alle vie respiratorie. Pertanto, deve essere maneggiata con cura ed eventuali esposizioni accidentali devono essere trattate immediatamente per prevenire danni alla salute.
Gli inibitori enzimatici sono molecole o composti che hanno la capacità di ridurre o bloccare completamente l'attività di un enzima. Si legano al sito attivo dell'enzima, impedendo al substrato di legarsi e quindi di subire la reazione catalizzata dall'enzima. Gli inibitori enzimatici possono essere reversibili o irreversibili, a seconda che il loro legame con l'enzima sia temporaneo o permanente. Questi composti sono utilizzati in medicina come farmaci per trattare varie patologie, poiché possono bloccare la sovrapproduzione di enzimi dannosi o ridurre l'attività di enzimi coinvolti in processi metabolici anomali. Tuttavia, è importante notare che un eccessivo utilizzo di inibitori enzimatici può portare a effetti collaterali indesiderati, poiché molti enzimi svolgono anche funzioni vitali per il corretto funzionamento dell'organismo.
La digossigenina è un glicoside cardiotonico steroideo, originariamente isolato dalla digitale lanata (Digitalis lanata). Viene utilizzato in medicina come farmaco per trattare alcune condizioni cardiache, come la fibrillazione atriale e il flutter atriale. Il suo meccanismo d'azione si basa sull'inibizione della pompa sodio-potassio (Na+/K+-ATPasi) nelle membrane cellulari, aumentando così la concentrazione di calcio intracellulare e rafforzando le contrazioni cardiache. Tuttavia, a causa dei suoi effetti tossici e della disponibilità di farmaci alternativi con profili di sicurezza migliori, l'uso clinico della digossigenina è limitato.
In laboratorio, la digossigenina viene spesso utilizzata per marchiare molecole biologiche, come anticorpi o oligonucleotidi, con isotiocianati o altri reagenti che si legano covalentemente alla digossigenina. Ciò consente la rilevazione e il monitoraggio di tali molecole marcate in varie applicazioni biochimiche e biomediche.
Si prega di notare che l'uso della digossigenina o dei suoi derivati deve essere eseguito sotto la supervisione e la guida di un professionista sanitario qualificato, poiché può causare effetti avversi pericolosi se utilizzato in modo improprio.
Le sonde molecolari in ambito medico sono strumenti di diagnostica altamente specifici e sensibili utilizzati per identificare e quantificare specifiche sequenze di DNA o RNA, o altre molecole target come proteine o metaboliti. Queste sonde sono progettate per legarsi specificamente al bersaglio desiderato attraverso interazioni chimiche o biologiche, come l'ibridazione del DNA o la rilevazione di enzimi specifici.
Le sonde molecolari possono essere utilizzate in una varietà di applicazioni, tra cui la diagnosi di malattie infettive, il monitoraggio della risposta al trattamento e la ricerca biomedica di base. Ad esempio, le sonde molecolari possono essere utilizzate per rilevare la presenza di patogeni come batteri o virus, identificare mutazioni genetiche associate a malattie ereditarie o acquisite, o monitorare l'espressione genica in cellule e tessuti.
Le sonde molecolari possono essere realizzate utilizzando una varietà di tecnologie, tra cui la reazione a catena della polimerasi (PCR), la sequenzazione del DNA, l'ibridazione fluorescente in situ (FISH) e il microarray dell'espressione genica. Queste tecniche consentono la rilevazione altamente sensibile e specifica di molecole bersaglio a livelli molto bassi, offrendo informazioni preziose per la diagnosi e il trattamento delle malattie.
In termini medici, "Xenopus" si riferisce a un genere di rane della famiglia Pipidae originarie dell'Africa subsahariana. Queste rane sono note per la loro pelle asciutta e ruvida e per le ghiandole che secernono sostanze tossiche.
Uno dei rappresentanti più noti del genere Xenopus è Xenopus laevis, comunemente nota come rana africana delle paludi o rana africana da laboratorio. Questa specie è stata ampiamente utilizzata in ricerca scientifica, specialmente negli studi di embriologia e genetica, grazie alle sue uova grandi e facili da manipolare.
In particolare, l'utilizzo della Xenopus laevis come organismo modello ha contribuito in modo significativo alla comprensione dello sviluppo embrionale e dei meccanismi di regolazione genica. Gli esperimenti condotti su questa specie hanno portato a importanti scoperte, come l'identificazione del fattore di trascrizione NMYC e il ruolo delle chinasi nella regolazione della crescita cellulare.
In sintesi, "Xenopus" è un termine medico che si riferisce a un genere di rane utilizzate come organismi modello in ricerca scientifica, note per le loro uova grandi e la facilità di manipolazione genetica.
NF-kB (nuclear factor kappa-light-chain-enhancer of activated B cells) è un importante fattore di trascrizione che regola l'espressione genica in risposta a una varietà di stimoli cellulari, come citochine, radicali liberi e radiazioni. È coinvolto nella modulazione delle risposte infiammatorie, immunitarie, di differenziazione e di sopravvivenza cellulare.
In condizioni di riposo, NF-kB si trova in forma inattiva nel citoplasma legato all'inibitore IkB (inhibitor of kappa B). Quando la cellula viene stimolata, l'IkB viene degradato, permettendo a NF-kB di dissociarsi e traslocare nel nucleo, dove può legarsi al DNA e promuovere l'espressione genica.
Un'attivazione eccessiva o prolungata di NF-kB è stata associata a una serie di malattie infiammatorie croniche, come l'artrite reumatoide, il diabete di tipo 2, la malattia di Crohn, l'asma e il cancro. Pertanto, NF-kB è considerato un bersaglio terapeutico promettente per lo sviluppo di farmaci anti-infiammatori e antitumorali.
In medicina e biologia, una chimera è un organismo geneticamente ibrido che contiene due o più popolazioni di cellule geneticamente distinte, originariamente derivate da diversi zigoti. Ciò significa che due (o più) embrioni si fondono insieme e continuano a svilupparsi come un singolo organismo. Questo fenomeno può verificarsi naturalmente in alcune specie animali o può essere creato artificialmente in laboratorio attraverso tecniche di ingegneria genetica, come la fusione delle cellule staminali embrionali.
Il termine "chimera" deriva dal nome di un mostro mitologico greco che aveva una testa di leone, un corpo di capra e una coda di serpente. La creazione di una chimera in medicina e biologia è spesso utilizzata per scopi di ricerca scientifica, come lo studio dello sviluppo embrionale o la creazione di organi da trapiantare che non verranno respinti dal sistema immunitario del ricevente. Tuttavia, l'uso di chimere è anche oggetto di dibattito etico e morale a causa delle implicazioni potenzialmente insolute sulla definizione di vita e identità.
Il DNA circolare è una forma di DNA in cui le estremità della molecola sono connesse, formando un anello continuo. Questa struttura si trova comunemente nei genomi dei virus, nelle plasmidi batterici e in alcuni mitocondri e cloroplasti delle cellule eucariotiche. Il DNA circolare è topologicamente distinto dal DNA lineare, che ha estremità libere. La forma circolare del DNA può facilitare la replicazione e il mantenimento della stabilità genomica, poiché le estremità non sono suscettibili alle stesse instabilità o al danno che possono verificarsi nelle estremità dei filamenti di DNA lineari.
Il rodaminio è una classe di coloranti fluorescenti comunemente utilizzati in biochimica e biologia molecolare per la marcatura e la visualizzazione di varie biomolecole, organelli cellulari e strutture tissutali. Esistono diversi tipi di rodaminio, tra cui rodamina B, rodaminia 6G e rodaminia 123, ognuno con diverse proprietà chimiche e spettroscopiche.
In generale, i rodamianti sono coloranti brillantemente colorati che emettono luce fluorescente di colore arancione-rosso quando vengono esposti a luce ultravioletta o a lunghezze d'onda della luce visibile. Questa proprietà li rende utili come marcatori fluorescenti per la microscopia a fluorescenza, la citometria a flusso e altre tecniche di imaging biologico.
I rodamianti possono legarsi covalentemente o non covalentemente a proteine, acidi nucleici e altri biomolecole, permettendo agli scienziati di studiare la loro localizzazione, interazione e dinamica all'interno delle cellule e degli organismi. Tuttavia, è importante notare che l'uso dei rodamianti può presentare alcune limitazioni e sfide, come la fotosensibilità, l'autoquenching e il potenziale di interferire con le funzioni biologiche delle molecole marcate.
La regolazione neoplastica dell'espressione genica si riferisce ai meccanismi alterati che controllano l'attività dei geni nelle cellule cancerose. Normalmente, l'espressione genica è strettamente regolata da una complessa rete di fattori di trascrizione, modifiche epigenetiche, interazioni proteina-DNA e altri meccanismi molecolari.
Tuttavia, nelle cellule neoplastiche (cancerose), questi meccanismi regolatori possono essere alterati a causa di mutazioni genetiche, amplificazioni o delezioni cromosomiche, modifiche epigenetiche anormali e altri fattori. Di conseguenza, i geni che promuovono la crescita cellulare incontrollata, l'invasione dei tessuti circostanti e la resistenza alla morte cellulare possono essere sovraespressi o sottoespressi, portando allo sviluppo e alla progressione del cancro.
La regolazione neoplastica dell'espressione genica può avvenire a diversi livelli, tra cui:
1. Mutazioni dei geni che codificano per fattori di trascrizione o cofattori, che possono portare a un'errata attivazione o repressione della trascrizione genica.
2. Modifiche epigenetiche, come la metilazione del DNA o le modifiche delle istone, che possono influenzare l'accessibilità del DNA alla machineria transcrizionale e quindi alterare l'espressione genica.
3. Disregolazione dei microRNA (miRNA), piccole molecole di RNA non codificanti che regolano l'espressione genica a livello post-trascrizionale, attraverso il processo di interferenza dell'RNA.
4. Alterazioni della stabilità dell'mRNA, come la modifica dei siti di legame per le proteine di stabilizzazione o degradazione dell'mRNA, che possono influenzare la durata e l'espressione dell'mRNA.
5. Disfunzioni delle vie di segnalazione cellulare, come la via del fattore di trascrizione NF-κB o la via MAPK, che possono portare a un'errata regolazione dell'espressione genica.
La comprensione dei meccanismi alla base della regolazione neoplastica dell'espressione genica è fondamentale per lo sviluppo di nuove strategie terapeutiche contro il cancro, come l'identificazione di nuovi bersagli molecolari o la progettazione di farmaci in grado di modulare l'espressione genica.
La differenziazione cellulare è un processo biologico attraverso il quale una cellula indifferenziata o poco differenziata si sviluppa in una cellula specializzata con caratteristiche e funzioni distintive. Durante questo processo, le cellule subiscono una serie di cambiamenti morfologici e biochimici che portano all'espressione di un particolare insieme di geni responsabili della produzione di proteine specifiche per quella cellula. Questi cambiamenti consentono alla cellula di svolgere funzioni specializzate all'interno di un tessuto o organo.
La differenziazione cellulare è un processo cruciale nello sviluppo embrionale e nella crescita degli organismi, poiché permette la formazione dei diversi tipi di tessuti e organi necessari per la vita. Anche nelle cellule adulte, la differenziazione cellulare è un processo continuo che avviene durante il rinnovamento dei tessuti e la riparazione delle lesioni.
La differenziazione cellulare è regolata da una complessa rete di segnali intracellulari e intercellulari che controllano l'espressione genica e la modifica delle proteine. Questi segnali possono provenire dall'ambiente esterno, come fattori di crescita e morfogenetici, o da eventi intracellulari, come il cambiamento del livello di metilazione del DNA o della modificazione delle proteine.
La differenziazione cellulare è un processo irreversibile che porta alla perdita della capacità delle cellule di dividersi e riprodursi. Tuttavia, in alcuni casi, le cellule differenziate possono essere riprogrammate per diventare pluripotenti o totipotenti, ovvero capaci di differenziarsi in qualsiasi tipo di cellula del corpo. Questa scoperta ha aperto nuove prospettive per la terapia delle malattie degenerative e il trapianto di organi.
In medicina e biologia, le proteine sono grandi molecole composte da catene di amminoacidi ed esse svolgono un ruolo cruciale nella struttura, funzione e regolazione di tutte le cellule e organismi viventi. Sono necessarie per la crescita, riparazione dei tessuti, difese immunitarie, equilibrio idrico-elettrolitico, trasporto di molecole, segnalazione ormonale, e molte altre funzioni vitali.
Le proteine sono codificate dal DNA attraverso la trascrizione in RNA messaggero (mRNA), che a sua volta viene tradotto in una sequenza specifica di amminoacidi per formare una catena polipeptidica. Questa catena può quindi piegarsi e unirsi ad altre catene o molecole per creare la struttura tridimensionale funzionale della proteina.
Le proteine possono essere classificate in base alla loro forma, funzione o composizione chimica. Alcune proteine svolgono una funzione enzimatica, accelerando le reazioni chimiche all'interno dell'organismo, mentre altre possono agire come ormoni, neurotrasmettitori o recettori per segnalare e regolare l'attività cellulare. Altre ancora possono avere una funzione strutturale, fornendo supporto e stabilità alle cellule e ai tessuti.
La carenza di proteine può portare a diversi problemi di salute, come la malnutrizione, il ritardo della crescita nei bambini, l'indebolimento del sistema immunitario e la disfunzione degli organi vitali. D'altra parte, un consumo eccessivo di proteine può anche avere effetti negativi sulla salute, come l'aumento del rischio di malattie renali e cardiovascolari.
I geni Ras sono una famiglia di geni oncogeni che codificano proteine con attività GTPasi. Questi geni svolgono un ruolo cruciale nella regolazione della crescita cellulare, differenziazione e apoptosi. Le mutazioni dei geni Ras sono comunemente associate a diversi tipi di cancro, come il cancro del polmone, del colon-retto e del pancreas. Queste mutazioni portano alla produzione di una forma costitutivamente attiva della proteina Ras, che promuove la proliferazione cellulare incontrollata e può contribuire allo sviluppo del cancro. I geni Ras più studiati sono HRAS, KRAS e NRAS. Le mutazioni dei geni Ras possono anche essere implicate nello sviluppo di malattie ereditarie come la neurofibromatosi di tipo 1 e il syndrome Noonan.
Gli fagi del E. coli, noti anche come batteriofagi del E. coli o fagi colici, si riferiscono a virus che infettano specificamente i batteri Escherichia coli (E. coli). Questi fagi utilizzano l'E. coli come ospite per la replicazione e possono causare lisi cellulare, portando alla morte del batterio ospite.
Esistono diversi tipi di fagi del E. coli, che sono classificati in base alla loro morfologia, genoma e ciclo di vita. I due principali tipi di fagi del E. coli sono i fagi a coda corta e i fagi a coda lunga.
I fagi a coda corta, come il fago T4, hanno una testa icosaedrica e una coda corta e rigida. Questi fagi utilizzano un meccanismo di iniezione di DNA per infettare le cellule batteriche, iniettando il loro genoma nella cellula ospite prima della lisi cellulare.
I fagi a coda lunga, come il fago lambda, hanno una testa icosaedrica e una coda lunga e flessibile. Questi fagi utilizzano un meccanismo di iniezione di DNA simile, ma la loro coda più lunga consente loro di attaccarsi a specifici recettori sulla superficie batterica, aumentando la specificità dell'infezione.
Gli fagi del E. coli sono ampiamente studiati come modelli sperimentali per comprendere i meccanismi molecolari della replicazione virale e dell'interazione virus-ospite. Inoltre, alcuni fagi del E. coli hanno mostrato il potenziale come agenti terapeutici contro infezioni batteriche resistenti ai antibiotici.
Gli introni sono sequenze di DNA non codificanti che si trovano all'interno di un gene. Quando un gene viene trascritto in RNA, l'RNA risultante contiene sia le sequenze codificanti (esoni) che quelle non codificanti (introni). Successivamente, gli introni vengono rimossi attraverso un processo noto come splicing dell'RNA, lasciando solo le sequenze esons con informazioni genetiche utili per la traduzione in proteine.
Pertanto, gli introni non hanno alcun ruolo diretto nella produzione di proteine funzionali, ma possono avere altre funzioni regolatorie all'interno della cellula, come influenzare il processamento dell'RNA o agire come siti di legame per le proteine che controllano l'espressione genica. Alcuni introni possono anche contenere piccoli RNA non codificanti con ruoli regolatori o funzioni catalitiche.
Le proteine di trasporto sono tipi specifici di proteine che aiutano a muovere o trasportare molecole e ioni, come glucosio, aminoacidi, lipidi e altri nutrienti, attraverso membrane cellulari. Si trovano comunemente nelle membrane cellulari e lisosomi e svolgono un ruolo cruciale nel mantenere l'equilibrio chimico all'interno e all'esterno della cellula.
Le proteine di trasporto possono essere classificate in due categorie principali:
1. Proteine di trasporto passivo (o diffusione facilitata): permettono il movimento spontaneo delle molecole da un ambiente ad alta concentrazione a uno a bassa concentrazione, sfruttando il gradiente di concentrazione senza consumare energia.
2. Proteine di trasporto attivo: utilizzano l'energia (solitamente derivante dall'idrolisi dell'ATP) per spostare le molecole contro il gradiente di concentrazione, da un ambiente a bassa concentrazione a uno ad alta concentrazione.
Esempi di proteine di trasporto includono il glucosio transporter (GLUT-1), che facilita il passaggio del glucosio nelle cellule; la pompa sodio-potassio (Na+/K+-ATPasi), che mantiene i gradienti di concentrazione di sodio e potassio attraverso la membrana cellulare; e la proteina canalicolare della calcemina, che regola il trasporto del calcio nelle cellule.
Le proteine di trasporto svolgono un ruolo vitale in molti processi fisiologici, tra cui il metabolismo energetico, la segnalazione cellulare, l'equilibrio idrico ed elettrolitico e la regolazione del pH. Le disfunzioni nelle proteine di trasporto possono portare a varie condizioni patologiche, come diabete, ipertensione, malattie cardiovascolari e disturbi neurologici.
L'elettroporazione è un processo che utilizza campi elettrici ad alta intensità per aumentare temporaneamente la permeabilità della membrana cellulare, permettendo così l'ingresso di molecole generalmente escluse dalle cellule. Questa tecnica è ampiamente utilizzata in campo biomedico e bioingegneristico per la delivery di farmaci, DNA, RNA e altri agenti terapeutici nelle cellule. L'elettroporazione può anche essere utilizzata per studiare il funzionamento delle cellule e per la ricerca di base in biologia cellulare.
Si noti che l'esposizione prolungata o ad alti livelli di campi elettrici può causare danni permanenti alle cellule, pertanto è importante utilizzare questa tecnica con cautela e sotto la guida di personale qualificato.
I veleni dei serpenti, noti anche come envenomazione, si riferiscono alla secrezione di sostanze tossiche dalle ghiandole situate nella testa di alcuni serpenti. Queste tossine vengono iniettate nel corpo della vittima attraverso i loro denti appuntiti e cave, noti come zanne, durante il morso.
I veleni dei serpenti possono contenere una varietà di sostanze chimiche tossiche, tra cui enzimi, proteine, polipeptidi e neurotossine, che possono causare diversi effetti dannosi sul corpo umano. I sintomi dell'envenomazione possono variare notevolmente a seconda del tipo di serpente e della quantità di veleno iniettato, ma possono includere dolore e gonfiore al sito del morso, rossore, formicolio, debolezza muscolare, nausea, vomito, difficoltà respiratorie e, in casi gravi, paralisi e insufficienza d'organo.
L'envenomazione può essere trattata con antiveleni specifici per il tipo di serpente che ha causato il morso. Il trattamento tempestivo con l'antiveleno appropriato può prevenire complicazioni gravi e salvare la vita della vittima. Tuttavia, in alcuni casi, potrebbe essere necessario un trattamento di supporto per gestire i sintomi dell'envenomazione, come la ventilazione meccanica o la dialisi renale.
Prevenire l'envenomazione è fondamentale per ridurre il rischio di morso dei serpenti. Ciò può essere ottenuto evitando di manipolare i serpenti, indossando scarpe e pantaloni lunghi quando si cammina in aree boschive o erbose, mantenendo una distanza di sicurezza dai serpenti e cercando assistenza medica immediata se si viene morsi.
I nucleotidi dell'adenina sono composti organici che svolgono un ruolo cruciale nella biologia cellulare. L'adenina è una delle quattro basi azotate presenti nei nucleotidi che formano il DNA e l'RNA, gli acidi nucleici fondamentali per la vita.
Nel DNA, l'adenina forma coppie di basi con la timina utilizzando due legami idrogeno. Nel processo di replicazione del DNA, le due eliche si separano e ogni filamento serve come matrice per la sintesi di un nuovo filamento complementare. L'enzima DNA polimerasi riconosce l'adenina sulla matrice e aggiunge il nucleotide dell'adenina corrispondente al nuovo filamento, garantendo in questo modo la corretta replicazione del DNA.
Nell'RNA, l'adenina forma coppie di basi con l'uracile utilizzando due legami idrogeno. L'RNA svolge diverse funzioni all'interno della cellula, tra cui il trasporto dell'informazione genetica dal DNA alle ribosomi per la sintesi delle proteine e la regolazione dell'espressione genica.
I nucleotidi dell'adenina sono anche componenti importanti del cofattore ATP (adenosina trifosfato), la molecola utilizzata dalle cellule come fonte di energia per le reazioni biochimiche. L'ATP è costituito da un gruppo adenina, uno zucchero a cinque atomi di carbonio chiamato ribosio e tre gruppi fosfato ad alta energia. Quando una delle molecole di fosfato viene rimossa dall'ATP, si libera energia che la cellula può utilizzare per svolgere il suo lavoro.
In sintesi, i nucleotidi dell'adenina sono componenti essenziali del DNA e dell'RNA e svolgono un ruolo cruciale nella regolazione dei processi metabolici all'interno della cellula.
Il DNA dei funghi, noto anche come genoma dei funghi, si riferisce al materiale genetico presente nelle cellule dei funghi. I funghi appartengono al regno Fungi e hanno una forma di vita caratterizzata da cellule eucariotiche, cioè cellule contenenti un nucleo ben definito che include la maggior parte del loro DNA.
Il genoma dei funghi è costituito da diversi filamenti di DNA lineare o circolare, organizzati in diverse strutture chiamate cromosomi. Il numero e la forma dei cromosomi possono variare notevolmente tra le diverse specie di funghi.
Il DNA dei funghi contiene informazioni genetiche che codificano per una varietà di proteine e altri prodotti genici necessari per la crescita, lo sviluppo e la sopravvivenza del fungo. Questi includono enzimi digestivi, proteine strutturali, proteine di segnalazione cellulare e molti altri.
L'analisi del DNA dei funghi è un importante campo di ricerca che può fornire informazioni preziose sulla classificazione, l'evoluzione e la fisiologia dei funghi. In particolare, la sequenzazione del genoma completo di diversi funghi ha permesso di identificare i geni unici e le vie metaboliche che caratterizzano questi organismi, offrendo nuove opportunità per lo sviluppo di farmaci antifungini e di altri prodotti utili per l'uomo.
Gli isoenzimi sono enzimi con diverse strutture proteiche ma con attività enzimatiche simili o identiche. Sono codificati da geni diversi e possono essere presenti nello stesso organismo, tissue o cellula. Gli isoenzimi possono essere utilizzati come marcatori biochimici per identificare specifici tipi di tessuti o cellule, monitorare il danno tissutale o la malattia, e talvolta per diagnosticare e monitorare lo stato di avanzamento di alcune condizioni patologiche. Un esempio comune di isoenzimi sono le tre forme dell'enzima lactato deidrogenasi (LD1, LD2, LD3, LD4, LD5) che possono essere trovati in diversi tessuti e hanno diverse proprietà cinetiche.
Gli organofosfati sono un gruppo di composti chimici che contengono fosforo e ossigeno, utilizzati in vari settori come pesticidi agricoli, solventi industriali e additivi per carburanti. In medicina, gli organofosfati sono noti principalmente per le loro proprietà anticolinesterasiche, il che significa che possono inibire l'enzima acetilcolinesterasi (AChE), responsabile della degradazione dell'acetilcolina, un neurotrasmettitore importante nel sistema nervoso parasimpatico e nel sistema nervoso periferico.
L'inibizione di AChE provoca un accumulo di acetilcolina nei collegamenti neuromuscolari e sinaptici, portando a una serie di sintomi tossici nota come avvelenamento da organofosfati o sindrome anticolinergica. I sintomi possono variare da lievi a gravi, a seconda della dose e dell'esposizione, e includono:
1. Nausea e vomito
2. Diarrea
3. Sudorazione e lacrimazione eccessive
4. Midriasi (pupille dilatate)
5. Tachicardia (frequenza cardiaca accelerata)
6. Ipotensione (pressione sanguigna bassa)
7. Debolezza muscolare e fascicolazioni (contrazioni muscolari involontarie)
8. Confusione mentale, agitazione o sonnolenza
9. Difficoltà respiratorie
10. Convulsioni e coma in casi gravi
L'esposizione agli organofosfati può verificarsi per via cutanea, respiratoria o orale, con il rischio maggiore di avvelenamento associato all'ingestione o all'inalazione di queste sostanze. Il trattamento dell'avvelenamento da organofosfati prevede l'uso di farmaci anticolinergici come l'atropina, che aiuta a bloccare gli effetti della sovra-stimolazione del sistema nervoso parasimpatico, e l'ossigenoterapia per supportare la funzione respiratoria. La prevenzione dell'esposizione agli organofosfati attraverso l'uso di dispositivi di protezione individuale (DPI) e il rispetto delle normative di sicurezza è fondamentale per ridurre il rischio di avvelenamento.
La microscopia confocale è una tecnica avanzata di microscopia che utilizza un sistema di illuminazione e detezione focalizzati per produrre immagini ad alta risoluzione di campioni biologici. Questa tecnica consente l'osservazione ottica di sezioni sottili di un campione, riducendo al minimo il rumore di fondo e migliorando il contrasto dell'immagine.
Nella microscopia confocale, un fascio di luce laser viene focalizzato attraverso un obiettivo su un punto specifico del campione. La luce riflessa o fluorescente da questo punto è quindi raccolta e focalizzata attraverso una lente di ingrandimento su un detector. Un diaframma di pinhole posto davanti al detector permette solo alla luce proveniente dal piano focale di passare, mentre blocca la luce fuori fuoco, riducendo così il rumore di fondo e migliorando il contrasto dell'immagine.
Questa tecnica è particolarmente utile per l'osservazione di campioni vivi e di tessuti sottili, come le cellule e i tessuti nervosi. La microscopia confocale può anche essere utilizzata in combinazione con altre tecniche di imaging, come la fluorescenza o la two-photon excitation microscopy, per ottenere informazioni più dettagliate sui campioni.
In sintesi, la microscopia confocale è una tecnica avanzata di microscopia che utilizza un sistema di illuminazione e detezione focalizzati per produrre immagini ad alta risoluzione di campioni biologici, particolarmente utile per l'osservazione di campioni vivi e di tessuti sottili.
La spettrometria di massa con ionizzazione laser a desorbimento assistito da matrice (MALDI-TOF MS) è una tecnica di spettrometria di massa che utilizza un laser per desorbire e ionizzare molecole biomolecolari, come proteine o peptidi, da una matrice appropriata. Questa tecnica è ampiamente utilizzata in campo biochimico e clinico per l'identificazione e la caratterizzazione di biomolecole complesse, nonché per l'analisi di miscele biologiche.
Nel processo MALDI-TOF MS, le biomolecole vengono prima mescolate con una matrice organica, che assorbe energia laser a una lunghezza d'onda specifica. Quando il laser colpisce la matrice, l'energia viene trasferita alle molecole biomolecolari, causandone la desorbzione e l'ionizzazione. Le molecole cariche vengono quindi accelerate in un campo elettrico e attraversano un tubo di volo prima di entrare nello spettrometro di massa.
Lo spettrometro di massa utilizza un metodo di analisi chiamato tempo di volo (TOF), che misura il tempo impiegato dalle molecole cariche per attraversare il tubo di volo. Le molecole più leggere viaggiano più velocemente e raggiungono prima l'analizzatore TOF, mentre quelle più pesanti impiegano più tempo. In questo modo, lo spettrometro di massa produce uno spettro che mostra l'intensità relativa delle molecole in base al loro rapporto massa/carica (m/z).
L'identificazione e la caratterizzazione delle biomolecole vengono eseguite confrontando lo spettro MALDI-TOF MS con una biblioteca di spettrometria di massa nota o utilizzando algoritmi di ricerca di pattern. Questa tecnica è ampiamente utilizzata in vari campi, tra cui la biologia molecolare, la chimica analitica e la medicina forense.
Le proteine batteriche si riferiscono a varie proteine sintetizzate e presenti nelle cellule batteriche. Possono essere classificate in base alla loro funzione, come proteine strutturali (come la proteina di membrana o la proteina della parete cellulare), proteine enzimatiche (che catalizzano reazioni biochimiche), proteine regolatorie (che controllano l'espressione genica e altre attività cellulari) e proteine di virulenza (che svolgono un ruolo importante nell'infezione e nella malattia batterica). Alcune proteine batteriche sono specifiche per determinati ceppi o specie batteriche, il che le rende utili come bersagli per lo sviluppo di farmaci antimicrobici e test diagnostici.
La replicazione del virus è un processo biologico durante il quale i virus producono copie di sé stessi all'interno delle cellule ospiti. Questo processo consente ai virus di infettare altre cellule e diffondersi in tutto l'organismo ospite, causando malattie e danni alle cellule.
Il ciclo di replicazione del virus può essere suddiviso in diverse fasi:
1. Attaccamento e penetrazione: Il virus si lega a una specifica proteina presente sulla superficie della cellula ospite e viene internalizzato all'interno della cellula attraverso un processo chiamato endocitosi.
2. Decapsidazione: Una volta dentro la cellula, il virione (particella virale) si dissocia dalla sua capside proteica, rilasciando il genoma virale all'interno del citoplasma o del nucleo della cellula ospite.
3. Replicazione del genoma: Il genoma virale viene replicato utilizzando le macchinari e le molecole della cellula ospite. Ci sono due tipi di genomi virali: a RNA o a DNA. A seconda del tipo, il virus utilizzerà meccanismi diversi per replicare il proprio genoma.
4. Traduzione e assemblaggio delle proteine: Le informazioni contenute nel genoma virale vengono utilizzate per sintetizzare nuove proteine virali all'interno della cellula ospite. Queste proteine possono essere strutturali o enzimatiche, necessarie per l'assemblaggio di nuovi virioni.
5. Assemblaggio e maturazione: Le proteine virali e il genoma vengono assemblati insieme per formare nuovi virioni. Durante questo processo, i virioni possono subire modifiche post-traduzionali che ne consentono la maturazione e l'ulteriore stabilità.
6. Rilascio: I nuovi virioni vengono rilasciati dalla cellula ospite, spesso attraverso processi citolitici che causano la morte della cellula stessa. In altri casi, i virioni possono essere rilasciati senza uccidere la cellula ospite.
Una volta che i nuovi virioni sono stati rilasciati, possono infettare altre cellule e continuare il ciclo di replicazione. Il ciclo di vita dei virus può variare notevolmente tra specie diverse e può essere influenzato da fattori ambientali e interazioni con il sistema immunitario dell'ospite.
La Cricetinae è una sottofamiglia di roditori appartenente alla famiglia Cricetidae, che include i criceti veri e propri. Questi animali sono noti per le loro guance gonfie quando raccolgono il cibo, un tratto distintivo della sottofamiglia. I criceti sono originari di tutto il mondo, con la maggior parte delle specie che si trovano in Asia centrale e settentrionale. Sono notturni o crepuscolari e hanno una vasta gamma di dimensioni, da meno di 5 cm a oltre 30 cm di lunghezza. I criceti sono popolari animali domestici a causa della loro taglia piccola, del facile mantenimento e del carattere giocoso. In medicina, i criceti vengono spesso utilizzati come animali da laboratorio per la ricerca biomedica a causa delle loro dimensioni gestibili, dei brevi tempi di generazione e della facilità di allevamento in cattività.
Gli esteri dell'acido solforico sono composti organici che si formano quando l'acido solforico reagisce con alcoli in presenza di un catalizzatore, come il pentossido di fosforo. Questi esteri contengono il gruppo funzionale -SO3H e sono noti come esteri dell'acido solfonico.
Gli esteri dell'acido solforico sono utilizzati in una varietà di applicazioni, tra cui la produzione di detergenti, farmaci, resine e coloranti. Sono anche usati come intermedi nella sintesi di altri composti organici.
Gli esteri dell'acido solforico sono generalmente stabili, ma possono decomporsi se riscaldati o trattati con basi forti. La loro idrolisi produce l'alcol corrispondente e acido solforico.
È importante notare che gli esteri dell'acido solforico non devono essere confusi con i solfuri organici, che contengono il gruppo funzionale -SH o -S-. Questi due tipi di composti hanno proprietà chimiche e reattività molto diverse.
Le metal nanoparticles (MNPs), o particole metalliche ultrafini, sono particelle sintetizzate dall'uomo con dimensioni generalmente comprese tra 1 e 100 nanometri (nm). Queste nanoparticelle sono costituite da metalli come oro, argento, ferro, titanio e altri.
Le MNPs hanno proprietà uniche dovute alla loro piccola dimensione e grande superficie specifica, che le rendono utili in una varietà di applicazioni biomediche, tra cui la diagnosi e il trattamento delle malattie. Ad esempio, le nanoparticelle d'oro possono essere utilizzate per la rilevazione di biomolecole specifiche, mentre le nanoparticelle d'argento hanno proprietà antibatteriche.
Tuttavia, l'uso delle MNPs in applicazioni biomediche può anche comportare rischi per la salute, come l'accumulo tossico nelle cellule e negli organismi viventi. Pertanto, è importante studiare attentamente le proprietà e i potenziali effetti avversi delle MNPs prima del loro impiego in ambito clinico.
Deossiribonucleosidi sono composti organici che si formano quando una base azotata (che può essere adenina, guanina, citosina o timina) si lega a deossiribosio, un carboidrato derivato dal glucosio. Sono componenti fondamentali delle molecole di DNA, insieme ai deossiribonucleotidi, che sono i deossiribonucleosidi con uno o più gruppi fosfati aggiunti.
Nel DNA, le basi azotate dei deossiribonucleosidi si accoppiano in modo specifico attraverso legami idrogeno: adenina con timina e citosina con guanina. Questa sequenza di coppie di basi costituisce l'informazione genetica che viene trasmessa durante la replicazione del DNA e la trascrizione dell'RNA.
I deossiribonucleosidi sono importanti anche in medicina, poiché possono essere utilizzati come farmaci antivirali per il trattamento di malattie infettive come l'HIV o l'herpes simplex. Questi farmaci agiscono bloccando la replicazione del virus interferendo con la sintesi dell'DNA virale.
Le pirimidine sono basi azotate presenti negli acidi nucleici, come il DNA e l'RNA. Si tratta di composti eterociclici aromatici che contengono due anelli fused, uno dei quali è un anello benzenico a sei membri e l'altro è un anello a sei membri contenente due atomi di azoto.
Le tre principali pirimidine presenti nel DNA sono la timina, la citosina e l'uracile (quest'ultima si trova solo nell'RNA). La timina forma una coppia di basi con l'adenina utilizzando due legami idrogeno, mentre la citosina forma una coppia di basi con la guanina utilizzando tre legami idrogeno.
Le pirimidine svolgono un ruolo fondamentale nella replicazione e nella trascrizione del DNA e dell'RNA, nonché nella sintesi delle proteine. Eventuali mutazioni o alterazioni nelle sequenze di pirimidina possono avere conseguenze significative sulla stabilità e sulla funzionalità del DNA e dell'RNA, e possono essere associate a varie malattie genetiche e tumorali.
La 5-metilcitosina è una forma metilata della citosina, uno dei quattro nucleotidi che costituiscono le basi azotate delle molecole di DNA. La metilazione della citosina si verifica quando un gruppo metile (-CH3) viene aggiunto alla citosina, alterandone la funzionalità chimica e influenzando l'espressione genica.
La 5-metilcitosina è particolarmente importante per la regolazione dell'espressione genica durante lo sviluppo embrionale e può anche svolgere un ruolo nella regolazione della espressione genica nelle cellule adulte. L'ipermetilazione delle regioni promotrici dei geni, che è l'aggiunta di gruppi metile in eccesso, può portare al silenziamento genico e alla repressione dell'espressione genica.
La 5-metilcitosina è anche soggetta a demetilazione, un processo che comporta la rimozione del gruppo metile dalla citosina. Questo processo può riattivare i geni precedentemente silenziati e svolge quindi un ruolo importante nella regolazione dell'espressione genica.
La disfunzione dei meccanismi di metilazione e demetilazione della citosina è stata associata a varie malattie, tra cui il cancro. Ad esempio, l'ipermetilazione dei promotori dei geni oncosoppressori può portare alla loro inattivazione e alla progressione del cancro.
L'analisi delle mutazioni del DNA è un processo di laboratorio che si utilizza per identificare e caratterizzare qualsiasi cambiamento (mutazione) nel materiale genetico di una persona. Questa analisi può essere utilizzata per diversi scopi, come la diagnosi di malattie genetiche ereditarie o acquisite, la predisposizione a sviluppare determinate condizioni mediche, la determinazione della paternità o l'identificazione forense.
L'analisi delle mutazioni del DNA può essere eseguita su diversi tipi di campioni biologici, come il sangue, la saliva, i tessuti o le cellule tumorali. Il processo inizia con l'estrazione del DNA dal campione, seguita dalla sua amplificazione e sequenziazione. La sequenza del DNA viene quindi confrontata con una sequenza di riferimento per identificare eventuali differenze o mutazioni.
Le mutazioni possono essere puntiformi, ovvero coinvolgere un singolo nucleotide, oppure strutturali, come inversioni, delezioni o duplicazioni di grandi porzioni di DNA. L'analisi delle mutazioni del DNA può anche essere utilizzata per rilevare la presenza di varianti genetiche che possono influenzare il rischio di sviluppare una malattia o la risposta a un trattamento medico.
L'interpretazione dei risultati dell'analisi delle mutazioni del DNA richiede competenze specialistiche e deve essere eseguita da personale qualificato, come genetisti clinici o specialisti di laboratorio molecolare. I risultati devono essere considerati in combinazione con la storia medica e familiare del paziente per fornire una diagnosi accurata e un piano di trattamento appropriato.
In genetica, un allele è una delle varie forme alternative di un gene che possono esistere alla stessa posizione (locus) su un cromosoma. Gli alleli si verificano quando ci sono diverse sequenze nucleotidiche in un gene e possono portare a differenze fenotipiche, il che significa che possono causare differenze nella comparsa o nell'funzionamento di un tratto o caratteristica.
Ad esempio, per il gene che codifica per il gruppo sanguigno ABO umano, ci sono tre principali alleli: A, B e O. Questi alleli determinano il tipo di gruppo sanguigno di una persona. Se una persona ha due copie dell'allele A, avrà il gruppo sanguigno di tipo A. Se ha due copie dell'allele B, avrà il gruppo sanguigno di tipo B. Se ha un allele A e un allele B, avrà il gruppo sanguigno di tipo AB. Infine, se una persona ha due copie dell'allele O, avrà il gruppo sanguigno di tipo O.
In alcuni casi, avere diversi alleli per un gene può portare a differenze significative nel funzionamento del gene e possono essere associati a malattie o altri tratti ereditari. In altri casi, i diversi alleli di un gene possono non avere alcun effetto evidente sul fenotipo della persona.
I topi inbred C57BL (o C57 Black) sono una particolare linea genetica di topi da laboratorio comunemente utilizzati in ricerca biomedica. Il termine "inbred" si riferisce al fatto che questi topi sono stati allevati per molte generazioni con riproduzione tra fratelli e sorelle, il che ha portato alla formazione di una linea genetica altamente uniforme e stabile.
La linea C57BL è stata sviluppata presso la Harvard University nel 1920 ed è ora mantenuta e distribuita da diversi istituti di ricerca, tra cui il Jackson Laboratory. Questa linea genetica è nota per la sua robustezza e longevità, rendendola adatta per una vasta gamma di studi sperimentali.
I topi C57BL sono spesso utilizzati come modelli animali in diversi campi della ricerca biomedica, tra cui la genetica, l'immunologia, la neurobiologia e la farmacologia. Ad esempio, questa linea genetica è stata ampiamente studiata per quanto riguarda il comportamento, la memoria e l'apprendimento, nonché le risposte immunitarie e la suscettibilità a varie malattie, come il cancro, le malattie cardiovascolari e le malattie neurodegenerative.
È importante notare che, poiché i topi C57BL sono un ceppo inbred, presentano una serie di caratteristiche genetiche fisse e uniformi. Ciò può essere vantaggioso per la riproducibilità degli esperimenti e l'interpretazione dei risultati, ma può anche limitare la generalizzabilità delle scoperte alla popolazione umana più diversificata. Pertanto, è fondamentale considerare i potenziali limiti di questo modello animale quando si interpretano i risultati della ricerca e si applicano le conoscenze acquisite all'uomo.
"Regioni Non Tradotte al 5" (RNT5 o UNT5) è un termine utilizzato in neurologia e neurochirurgia per descrivere l'assenza di riflessi plantari a entrambi i piedi dopo una stimolazione dolorosa. Questa condizione indica una lesione del midollo spinale al livello della quinta vertebra lombare (L5) o al di sopra di essa.
Nella valutazione clinica, il riflesso plantare viene testato applicando uno stimolo doloroso sotto la punta dell'alluce del paziente. In condizioni normali, questa stimolazione provoca una flessione dei alluci (riflesso plantare flexorio), che è innervato dal nervo tibiale. Tuttavia, in caso di lesioni al midollo spinale a livello di L5 o superiormente, questo riflesso può essere assente o alterato.
L'assenza bilaterale dei riflessi plantari indica una lesione almeno parziale del midollo spinale che interrompe la conduzione nervosa tra il midollo spinale e i muscoli delle gambe. Questa condizione può essere associata a diversi disturbi neurologici, come lesioni del midollo spinale, malattie degenerative del sistema nervoso centrale o periferico, tumori spinali o altre patologie che colpiscono il midollo spinale.
È importante notare che la presenza di RNT5 non è specifica per una particolare condizione e deve essere interpretata nel contesto dei segni e sintomi clinici complessivi del paziente, nonché in combinazione con altri test diagnostici appropriati.
La specificità delle specie, nota anche come "specifità della specie ospite", è un termine utilizzato in microbiologia e virologia per descrivere il fenomeno in cui un microrganismo (come batteri o virus) infetta solo una o poche specie di organismi ospiti. Ciò significa che quel particolare patogeno non è in grado di replicarsi o causare malattie in altre specie diverse da quelle a cui è specifico.
Ad esempio, il virus dell'influenza aviaria (H5N1) ha una specificità delle specie molto elevata, poiché infetta principalmente uccelli e non si diffonde facilmente tra gli esseri umani. Tuttavia, in rare occasioni, può verificarsi un salto di specie, consentendo al virus di infettare e causare malattie negli esseri umani.
La specificità delle specie è determinata da una combinazione di fattori, tra cui le interazioni tra i recettori del patogeno e quelli dell'ospite, la capacità del sistema immunitario dell'ospite di rilevare e neutralizzare il patogeno, e altri aspetti della biologia molecolare del microrganismo e dell'ospite.
Comprendere la specificità delle specie è importante per prevedere e prevenire la diffusione di malattie infettive, nonché per lo sviluppo di strategie efficaci di controllo e trattamento delle infezioni.
Le Tecniche di Amplificazione dell'Acido Nucleico (NAATs, Nucleic Acid Amplification Techniques) sono metodi utilizzati in laboratorio per aumentare la quantità di acidi nucleici, come DNA o RNA, presenti in un campione biologico. Queste tecniche sono particolarmente utili quando il materiale genetico di interesse è presente in quantità molto piccole o quando è necessario rilevare la presenza di specifiche sequenze di acidi nucleici in un campione complesso.
Esistono diverse NAATs, ma le due più comuni sono la Reazione a Catena della Polimerasi (PCR) e l'Amplificazione Sensibile dell'Acido Nucleico (NASBA).
La PCR è una tecnica che consente di amplificare una specifica sequenza di DNA molteplici volte, producendo milioni di copie della sequenza desiderata. Questa tecnica si basa sulla reazione enzimatica catalizzata dalla polimerasi, un enzima che sintetizza il DNA a partire da una matrice di DNA. La PCR richiede tre fasi principali: denaturazione, annealing e estensione.
La NASBA è una tecnica che amplifica l'RNA utilizzando due enzimi, la trascrittasi inversa e la RNAsi H. Questa tecnica si basa sulla reazione a catena dell'amplificazione transcrizionale (TAS) ed è particolarmente utile per rilevare l'RNA virale o batterico in un campione biologico.
Le NAATs sono utilizzate in diversi campi della medicina, come la diagnostica molecolare, la genetica e la ricerca biomedica, per identificare patogeni, malattie genetiche, marcatori tumorali e altri fattori di interesse clinico.
La poliribonucleotide nucleotidiltransferasi, nota anche come RNA polimerasi non specifica o RNA polimerasi III, è un enzima fondamentale per la sintesi dell'RNA nelle cellule. Più precisamente, questa classe di enzimi catalizza la formazione di legami fosfodiesterici tra nucleosidi trifosfati (NTP) per allungare una catena polinucleotidica in direzione 5'-3'.
La RNA polimerasi III è specializzata nella trascrizione di piccoli geni non codificanti, come quelli che codificano per l'RNA transfer (tRNA) e l'RNA ribosomale 5S. A differenza di altri enzimi della famiglia delle RNA polimerasi, la RNA polimerasi III è in grado di iniziare la trascrizione senza un promotore specifico, il che le conferisce una notevole flessibilità funzionale.
L'attività di questa classe di enzimi dipende dalla disponibilità di substrati adeguati (NTP) e dall'interazione con fattori di trascrizione specifici, che ne regolano l'attività in risposta a stimoli intracellulari o ambientali. La sua accuratezza e processività sono garantite da un meccanismo di proofreading (correzione degli errori) integrato, che minimizza la formazione di trascritti anomali e ne assicura l'integrità funzionale.
In sintesi, la poliribonucleotide nucleotidiltransferasi è un enzima chiave per la sintesi dell'RNA, che catalizza la formazione di legami fosfodiesterici tra nucleosidi trifosfati (NTP) e si specializza nella trascrizione di piccoli geni non codificanti come quelli che codificano per l'RNA transfer (tRNA) e altri RNA non codificanti.
La DNA Topoisomerasi di Tipo I è un enzima che svolge un ruolo cruciale nel controllare e modificare la topologia del DNA, ossia la disposizione spaziale delle sue singole eliche. Questo enzima agisce tagliando una sola delle due catene che costituiscono la doppia elica del DNA, producendo una rottura transitoria della sua struttura.
Esistono due sottotipi di DNA Topoisomerasi di Tipo I: la Topoisomerasi I e la Topoisomerasi III. Entrambi i sottotipi catalizzano la rottura di un singolo filamento del DNA, ma utilizzano meccanismi differenti per riparare la rottura una volta completata la loro funzione.
La Topoisomerasi I è in grado di tagliare e ricongiungere il filamento del DNA senza l'ausilio di ATP, mentre la Topoisomerasi III richiede l'idrolisi di ATP per svolgere la sua attività enzimatica.
La funzione principale della DNA Topoisomerasi di Tipo I è quella di facilitare il superavvolgimento o lo srotolamento del DNA, processi necessari durante la replicazione e la trascrizione del DNA stesso. Inoltre, questo enzima svolge un ruolo importante nella risoluzione di nodi e intrecci che possono formarsi naturalmente all'interno della struttura del DNA.
La disfunzione o l'inibizione della DNA Topoisomerasi di Tipo I può portare a gravi conseguenze per la cellula, tra cui l'arresto della replicazione e trascrizione del DNA, nonché l'accumulo di nodi e intrecci che possono danneggiare irreparabilmente la struttura del DNA.
In medicina, la fluorescenza si riferisce a un fenomeno in cui una sostanza emette luce visibile dopo essere stata esposta alla luce UV o ad altre radiazioni ad alta energia. Quando questa sostanza assorbe radiazioni, alcuni dei suoi elettroni vengono eccitati a livelli energetici più alti. Quando questi elettroni ritornano al loro stato di riposo, emettono energia sotto forma di luce visibile.
La fluorescenza è utilizzata in diversi campi della medicina, come la diagnosi e la ricerca medica. Ad esempio, nella microscopia a fluorescenza, i campioni biologici vengono colorati con sostanze fluorescenti che si legano specificamente a determinate proteine o strutture cellulari. Quando il campione viene illuminato con luce UV, solo le aree che contengono la sostanza fluorescente emetteranno luce visibile, permettendo agli scienziati di osservare e analizzare specifiche caratteristiche del campione.
Inoltre, la fluorescenza è anche utilizzata nella medicina per la diagnosi di alcune malattie, come il cancro. Alcuni farmaci fluorescenti possono essere somministrati ai pazienti e quindi osservati al microscopio a fluorescenza per rilevare la presenza di cellule cancerose o altre anomalie. Questo metodo può fornire informazioni dettagliate sulla localizzazione e l'estensione del tumore, aiutando i medici a pianificare il trattamento più appropriato.
I modelli chimici sono rappresentazioni grafiche o spaziali utilizzate per visualizzare e comprendere la struttura, le proprietà e il comportamento delle molecole e degli atomi. Essi forniscono una rappresentazione tridimensionale dei legami chimici e della disposizione spaziale degli elettroni e degli atomi all'interno di una molecola. I modelli chimici possono essere utilizzati per prevedere le reazioni chimiche, progettare nuovi composti e comprendere i meccanismi delle reazioni chimiche.
Esistono diversi tipi di modelli chimici, come:
1. Modelli a palle e bastoncini: utilizzano sfere di diverse dimensioni per rappresentare gli atomi e bastoncini per mostrare i legami chimici tra di essi. Questo tipo di modello è utile per illustrare la forma e la struttura delle molecole.
2. Modelli spaziali: forniscono una rappresentazione tridimensionale dettagliata della disposizione degli atomi e dei legami chimici all'interno di una molecola. Questi modelli possono essere creati utilizzando materiali fisici o software di modellazione chimica.
3. Modelli quantomeccanici: utilizzano calcoli matematici complessi per descrivere la distribuzione degli elettroni all'interno di una molecola. Questi modelli possono essere utilizzati per prevedere le proprietà chimiche e fisiche delle molecole, come la reattività, la stabilità e la conducibilità elettrica.
I modelli chimici sono uno strumento importante nella comprensione e nello studio della chimica, poiché forniscono una rappresentazione visiva e tangibile delle interazioni tra atomi e molecole.
Il magnesio è un minerale essenziale per il corretto funzionamento dell'organismo umano. Viene classificato come elettrolita ed è importante per molte funzioni biologiche, tra cui la sintesi di proteine e DNA, la produzione di energia, la contrazione muscolare, la trasmissione nervosa e la regolazione del ritmo cardiaco.
Il magnesio si trova naturalmente in molti alimenti come verdure a foglia verde, noci, semi, fagioli secchi, cereali integrali e frutta secca. Inoltre, il magnesio è disponibile anche sotto forma di integratori alimentari o di farmaci da prescrizione per trattare o prevenire carenze di questo minerale.
La carenza di magnesio può causare sintomi come crampi muscolari, debolezza, spasmi, irregolarità del battito cardiaco, pressione alta e alterazioni del sonno. Al contrario, un'eccessiva assunzione di magnesio può portare a effetti collaterali come nausea, vomito, diarrea, bassa pressione sanguigna, debolezza, sonnolenza e difficoltà respiratorie.
In campo medico, il magnesio viene utilizzato per trattare o prevenire diverse condizioni come l'ipertensione arteriosa, la malattia coronarica, il diabete di tipo 2, le convulsioni e le sindromi da deficit di attenzione/iperattività (ADHD). Inoltre, il magnesio può essere utilizzato anche come trattamento di supporto per alcune patologie acute come l'intossicazione da farmaci o la sindrome delle apnee notturne.
L'elettroforesi è una tecnica di laboratorio utilizzata per separare e identificare macromolecole, come proteine o acidi nucleici (DNA ed RNA), sulla base delle loro dimensioni, forme e cariche elettriche. Questo processo sfrutta il principio dell'elettroforesi, che descrive il movimento di particelle cariche in un campo elettrico.
Nell'elettroforesi, le macromolecole da analizzare vengono poste in una matrice gelatinosa, come ad esempio un gel di agarosio o un gel di poliacrilammide. Quando viene applicato un campo elettrico, le molecole cariche si spostano all'interno del gel verso l'elettrodo con carica opposta. Le macromolecole più grandi e/o meno cariche si muovono più lentamente rispetto a quelle più piccole e/o maggiormente cariche, il che permette la loro separazione spaziale all'interno del gel.
L'elettroforesi è una tecnica di grande importanza in diversi campi della biologia e della medicina, tra cui la diagnostica delle malattie genetiche, l'identificazione di proteine anomale associate a patologie, la caratterizzazione di frammenti di DNA o RNA per studi di espressione genica, e la purificazione di macromolecole per utilizzi in ricerca e terapia.
La biotinidazione è un processo enzimatico che attacca la biotina, una vitamina idrosolubile del complesso B, alle proteine. Questo processo è catalizzato dall'enzima biotinil-proteina sintetasi e si verifica principalmente nel fegato.
La biotinidazione svolge un ruolo importante nella regolazione del metabolismo di diversi aminoacidi e acidi grassi, in quanto la biotina funge da cofattore per diverse carboxilasi che sono essenziali per queste reazioni. La carenza di biotinidazione può portare a una serie di sintomi, tra cui ritardo dello sviluppo, convulsioni, eczema, perdita di capelli e disturbi neurologici.
La biotinidazione è anche un processo importante nella produzione di cheratina, la proteina principale che costituisce i capelli, le unghie e la pelle. Una carenza di biotina può portare a fragilità e rottura dei capelli e delle unghie, nonché alla secchezza e screpolatura della pelle.
In sintesi, la biotinidazione è un processo enzimatico che attacca la biotina alle proteine, svolgendo un ruolo importante nella regolazione del metabolismo degli aminoacidi e degli acidi grassi e nella produzione di cheratina.
La fenantrolina è un composto organico eterociclico che contiene due anelli piridinici fusi con un atomo di carbonio sostituito da un gruppo funzionale bidentato, noto come "gruppo fenantrolina". Questo gruppo bidentato ha la capacità di formare complessi stabili con ioni metallici e viene utilizzato in chimica per sintetizzare tali composti.
In medicina, i derivati della fenantrolina sono stati studiati come farmaci, principalmente per le loro proprietà chelanti (cioè la capacità di legarsi a ioni metallici presenti nell'organismo). Alcuni derivati della fenantrolina sono stati utilizzati in passato come agenti chelanti del ferro nel trattamento dell'intossicazione da ferro, sebbene siano stati per lo più sostituiti da altri farmaci più efficaci e con meno effetti collaterali.
Tuttavia, è importante notare che l'uso di fenantrolina e dei suoi derivati in medicina è limitato e non viene considerata una definizione medica ampiamente utilizzata o riconosciuta. Di conseguenza, potrebbe non esserci un'entrata specifica per "fenantrolina" nella maggior parte delle fonti di definizioni mediche standard.
Gli alcoli degli zuccheri, noti anche come gliciti o polioli, sono composti organici con una struttura simile a quella dello zucchero ma con un gruppo alcolico (-OH) aggiuntivo. Questi composti possono verificarsi naturalmente in alcuni frutti e verdure, ma possono anche essere prodotti sinteticamente per scopi commerciali.
Gli alcoli degli zuccheri sono utilizzati come dolcificanti alternativi in alcuni cibi e bevande a causa del loro sapore dolce, che è simile a quello dello zucchero ma con meno calorie. Tuttavia, l'uso eccessivo di alcoli degli zuccheri può causare effetti collaterali indesiderati, come crampi allo stomaco, diarrea e gonfiore, soprattutto nelle persone con disturbi gastrointestinali o intolleranza al lattosio.
Inoltre, gli alcoli degli zuccheri possono avere un effetto sulla regolazione della glicemia, poiché il loro assorbimento è più lento rispetto allo zucchero e possono causare un aumento dei livelli di glucosio nel sangue. Pertanto, le persone con diabete dovrebbero consumarli con cautela e sotto la guida di un operatore sanitario.
In sintesi, gli alcoli degli zuccheri sono composti organici dolci che possono verificarsi naturalmente o essere prodotti sinteticamente, utilizzati come dolcificanti alternativi in alcuni cibi e bevande. Tuttavia, l'uso eccessivo può causare effetti collaterali indesiderati e dovrebbe essere consumato con cautela dalle persone con disturbi gastrointestinali o diabete.
La Protein Kinase C-alpha (PKC-α) è un enzima appartenente alla famiglia delle protein chinasi, che giocano un ruolo cruciale nella regolazione della trasduzione del segnale nelle cellule. La PKC-α è specificamente coinvolta nel processo di fosforilazione delle proteine, una reazione che modifica le proteine alterandone l'attività e la funzionalità.
L'enzima PKC-α viene attivato da diversi segnali cellulari, come i secondi messaggeri di calcio e diacilglicerolo (DAG), generati in risposta a stimoli esterni o interni alla cellula. Una volta attivata, la PKC-α si lega alle sue proteine bersaglio e trasferisce un gruppo fosfato da una molecola di ATP alla proteina, modificandone la struttura e l'attività enzimatica.
La PKC-α è espressa in molti tessuti e ha un ruolo importante nella regolazione di diversi processi cellulari, tra cui la proliferazione, la differenziazione, l'apoptosi e la sopravvivenza cellulare. Alterazioni nell'espressione o nell'attività della PKC-α sono state associate a diverse patologie, come il cancro, le malattie cardiovascolari e il diabete.
In sintesi, la Protein Kinase C-alpha è un enzima chiave nella regolazione dei processi cellulari, che modifica l'attività delle proteine attraverso la fosforilazione, e le cui alterazioni possono contribuire allo sviluppo di diverse malattie.
In medicina e biologia, le "sostanze macromolecolari" si riferiscono a molecole molto grandi che sono costituite da un gran numero di atomi legati insieme. Queste molecole hanno una massa molecolare elevata e svolgono funzioni cruciali nelle cellule viventi.
Le sostanze macromolecolari possono essere classificate in quattro principali categorie:
1. Carboidrati: composti organici costituiti da carbonio, idrogeno e ossigeno, con un rapporto di idrogeno a ossigeno pari a 2:1 (come nel glucosio). I carboidrati possono essere semplici, come il glucosio, o complessi, come l'amido e la cellulosa.
2. Proteine: composti organici costituiti da catene di amminoacidi legati insieme da legami peptidici. Le proteine svolgono una vasta gamma di funzioni biologiche, come catalizzare reazioni chimiche, trasportare molecole e fornire struttura alle cellule.
3. Acidi nucleici: composti organici che contengono fosfati, zuccheri e basi azotate. Gli acidi nucleici includono DNA (acido desossiribonucleico) e RNA (acido ribonucleico), che sono responsabili della conservazione e dell'espressione genetica.
4. Lipidi: composti organici insolubili in acqua, ma solubili nei solventi organici come l'etere e il cloroformio. I lipidi includono grassi, cere, steroli e fosfolipidi, che svolgono funzioni strutturali e di segnalazione nelle cellule viventi.
Le sostanze macromolecolari possono essere naturali o sintetiche, e possono avere una vasta gamma di applicazioni in medicina, biologia, ingegneria e altre discipline scientifiche.
Gli agenti antineoplastici sono farmaci utilizzati nel trattamento del cancro. Questi farmaci agiscono interferendo con la crescita e la divisione delle cellule cancerose, che hanno una crescita e una divisione cellulare più rapide rispetto alle cellule normali. Tuttavia, gli agenti antineoplastici possono anche influenzare le cellule normali, il che può causare effetti collaterali indesiderati.
Esistono diversi tipi di farmaci antineoplastici, tra cui:
1. Chemioterapia: farmaci che interferiscono con la replicazione del DNA o della sintesi delle proteine nelle cellule cancerose.
2. Terapia ormonale: farmaci che alterano i livelli di ormoni nel corpo per rallentare la crescita delle cellule cancerose.
3. Terapia mirata: farmaci che colpiscono specificamente le proteine o i geni che contribuiscono alla crescita e alla diffusione del cancro.
4. Immunoterapia: trattamenti che utilizzano il sistema immunitario del corpo per combattere il cancro.
Gli agenti antineoplastici possono essere somministrati da soli o in combinazione con altri trattamenti, come la radioterapia o la chirurgia. La scelta del farmaco e della strategia di trattamento dipende dal tipo e dallo stadio del cancro, nonché dalla salute generale del paziente.
Gli effetti collaterali degli agenti antineoplastici possono variare notevolmente a seconda del farmaco e della dose utilizzata. Alcuni effetti collaterali comuni includono nausea, vomito, perdita di capelli, affaticamento, anemia, infezioni e danni ai tessuti sani, come la bocca o la mucosa del tratto gastrointestinale. Questi effetti collaterali possono essere gestiti con farmaci di supporto, modifiche alla dieta e altri interventi.
La "capillary action", o azione capillare, è un fenomeno osservabile nei liquidi che si verifica quando sono posti in contatto con superfici solide, come quelle dei vasi sanguigni o di tubi di piccolo diametro. Questo effetto è dovuto alla tensione superficiale del liquido e all'attrazione intermolecolare tra il liquido e la superficie solida.
In particolare, le molecole del liquido adiacenti alla superficie solida tendono ad essere attratte dalla superficie stessa, creando una forza di coesione che fa risalire il livello del liquido all'interno dei capillari o di altri piccoli spazi. La misura in cui questo accade dipende dal tipo di liquido e dalla natura della superficie solida.
L'azione capillare è importante in molti processi biologici, come ad esempio il trasporto dell'acqua e dei nutrienti dalle radici alle foglie delle piante attraverso i piccoli vasi presenti nel loro sistema vascolare. Inoltre, questo fenomeno è anche sfruttato in diversi dispositivi tecnologici, come ad esempio le penne a sfera o i termometri a mercurio.
L'attivazione enzimatica si riferisce al processo di innesco o avvio dell'attività catalitica di un enzima. Gli enzimi sono proteine che accelerano reazioni chimiche specifiche all'interno di un organismo vivente. La maggior parte degli enzimi è prodotta in una forma inattiva, chiamata zymogeni o proenzimi. Questi devono essere attivati prima di poter svolgere la loro funzione catalitica.
L'attivazione enzimatica può verificarsi attraverso diversi meccanismi, a seconda del tipo di enzima. Uno dei meccanismi più comuni è la proteolisi, che implica la scissione della catena polipeptidica dell'enzima da parte di una peptidasi (un enzima che taglia le proteine in peptidi o amminoacidi). Questo processo divide lo zymogeno in due parti: una piccola porzione, chiamata frammento regolatorio, e una grande porzione, chiamata catena catalitica. La separazione di queste due parti consente all'enzima di assumere una conformazione tridimensionale attiva che può legare il substrato e catalizzare la reazione.
Un altro meccanismo di attivazione enzimatica è la rimozione di gruppi chimici inibitori, come i gruppi fosfati. Questo processo viene spesso catalizzato da altre proteine chiamate chinasi o fosfatasi. Una volta che il gruppo inibitorio è stato rimosso, l'enzima può assumere una conformazione attiva e svolgere la sua funzione catalitica.
Infine, alcuni enzimi possono essere attivati da cambiamenti ambientali, come variazioni di pH o temperatura. Questi enzimi contengono residui amminoacidici sensibili al pH o alla temperatura che possono alterare la conformazione dell'enzima quando le condizioni ambientali cambiano. Quando questo accade, l'enzima può legare il substrato e catalizzare la reazione.
In sintesi, l'attivazione enzimatica è un processo complesso che può essere causato da una varietà di fattori, tra cui la rimozione di gruppi inibitori, la modifica della conformazione dell'enzima e i cambiamenti ambientali. Comprendere questi meccanismi è fondamentale per comprendere il ruolo degli enzimi nella regolazione dei processi cellulari e nella patogenesi delle malattie.
 Oligonucleotide - Wikipedia
Oligonucleotide - Wikipedia Terapia oncologica Newsletter
Terapia oncologica Newsletter Inside the Cell - Viaggio nella biologia cellulare e molecolare
Inside the Cell - Viaggio nella biologia cellulare e molecolare Tumore Alla Prostata: Scoperto Meccanismo Che Lo Favorisce - Sanihelp.it
Tumore Alla Prostata: Scoperto Meccanismo Che Lo Favorisce - Sanihelp.it L'Azienda farmaceutica Wave Life Science annuncia l'interruzione degli studi clinici con suvodirsen, l'oligonucleotide...
L'Azienda farmaceutica Wave Life Science annuncia l'interruzione degli studi clinici con suvodirsen, l'oligonucleotide... PRIMA TERAPIA GENICA PER LA DISTROFIA DI DUCHENNE Genetica
PRIMA TERAPIA GENICA PER LA DISTROFIA DI DUCHENNE Genetica Informazione indipendente sulle nuove biotecnologie applicate in ambito medico - Osservatorio Terapie Avanzate - Pagina 153
Informazione indipendente sulle nuove biotecnologie applicate in ambito medico - Osservatorio Terapie Avanzate - Pagina 153 FOCUS SLA A GENOVA: RICERCA RIPARTE DAL PAZIENTE PER ARRIVARE A TERAPIE EFFICACI
FOCUS SLA A GENOVA: RICERCA RIPARTE DAL PAZIENTE PER ARRIVARE A TERAPIE EFFICACI L'inibizione dell'aldosterone sintetasi: una nuova potenziale "arma" contro l'ipertensione resistente - SIIA
L'inibizione dell'aldosterone sintetasi: una nuova potenziale "arma" contro l'ipertensione resistente - SIIA Prossimi farmaci contro la calvizie ? (II° parte) | Calvizie.net
Prossimi farmaci contro la calvizie ? (II° parte) | Calvizie.net leucemia indotta da radiazioni
leucemia indotta da radiazioni Abnova™ Human RBBP6 Full-length ORF (NP 116015.2, 1 a.a. - 118 a.a.) Recombinant Protein with GST-tag at N-terminal 10μg Abnova...
Abnova™ Human RBBP6 Full-length ORF (NP 116015.2, 1 a.a. - 118 a.a.) Recombinant Protein with GST-tag at N-terminal 10μg Abnova... Banca di oligo
Banca di oligo Tecnologia e laboratorio
Tecnologia e laboratorio SPARQL Endpoint
SPARQL Endpoint Naviga UNITESI
Naviga UNITESI Types of changes in the SCN2A gene and how they may affect clinical trial eligibility - SCN2A Clinical Trials
Types of changes in the SCN2A gene and how they may affect clinical trial eligibility - SCN2A Clinical Trials DOLZANI, LUCILLA
DOLZANI, LUCILLA Enzima nucleasi in polvere CAS 60675-83-4 - enzymes.bio
Enzima nucleasi in polvere CAS 60675-83-4 - enzymes.bio Sintesi organica - Chimica "Giacomo Ciamician"
Sintesi organica - Chimica "Giacomo Ciamician"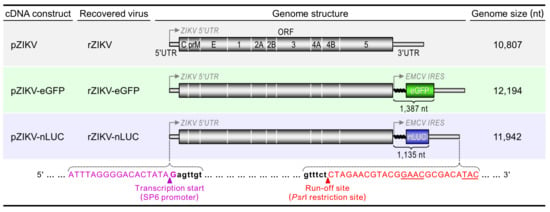






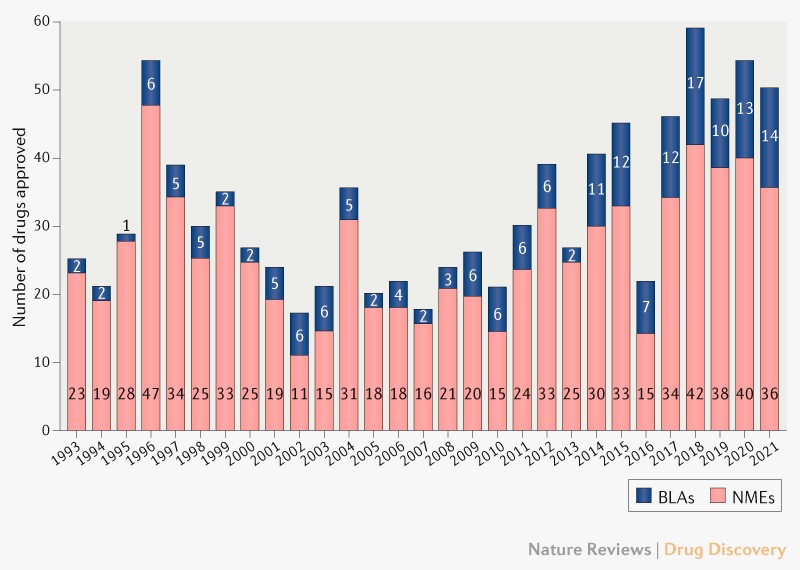








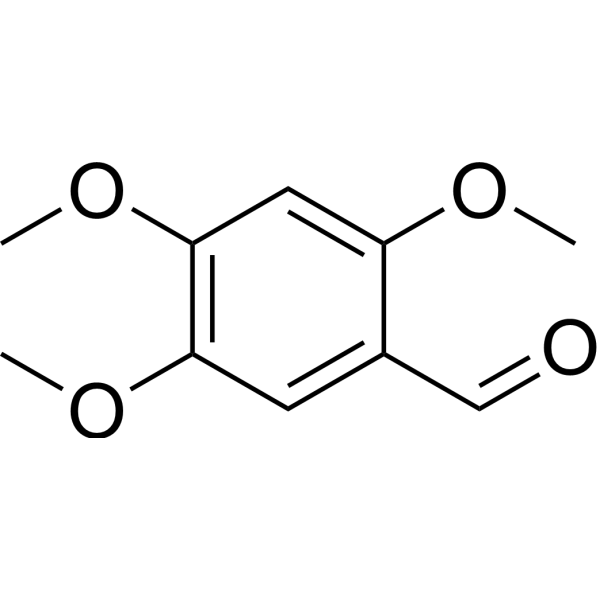
![Start [Demichelis Lab - Computational Oncology]](https://demichelislab.unitn.it/lib/exe/fetch.php?w=100&media=unitn_tondo.png)