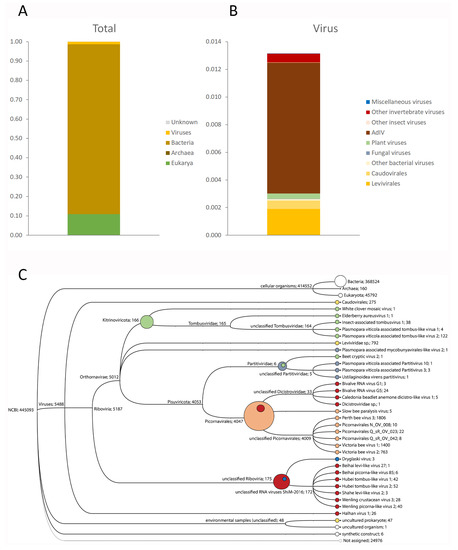
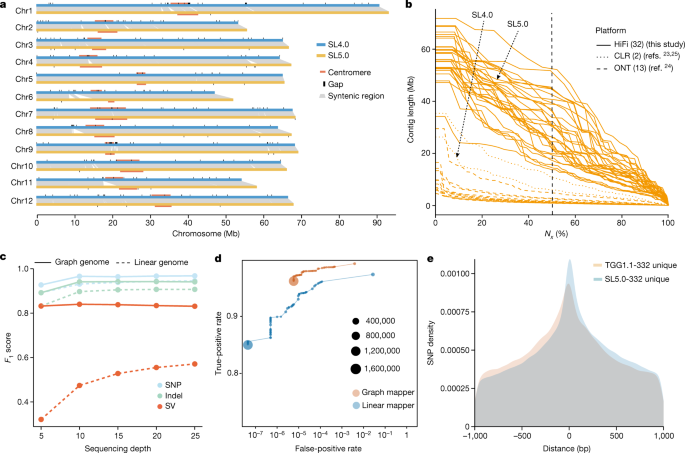
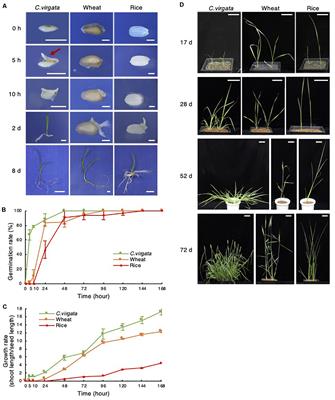
Contig Mapping
Mappa Del Cromosoma
Cromosomi Dei Lieviti Artificiali
Siti Tagged Su Una Sequenza
Mappa Fisica Del Cromosoma
Chromosome Walking
Cromosomi Batterici Artificiali
Fago P1
Cosmidi
Marker Genetici
Dati Di Sequenza Molecolare
Analisi Di Sequenze Di Dna
Indicatori Di Sequenza Espressa
Genoteca
Sequenza Base
Mappatura Di Ibridi Irradiati
Mappa Di Restrizione
Libreria Genomica
Genetic Linkage
Mappa Peptidica
Mappa Di Determinanti Antigenici
Clonaggio Molecolare
Mappa Cerebrale
Cromosomi Delle Piante
Ibridazione In Situ A Fluorescenza
Mappatura Dei Potenziali Della Superficie Corporea
Genoma
Sequenze Microsatelliti
Cromosomi Dei Batteri
Sequenza Aminoacidica
Algoritmi
Epicardial Mapping
Dna Complementare
Sintenia
Cromosomi Umani, Coppia 3
Genoma Umano
Pedigree
Famiglia Multigenica
High-Throughput Nucleotide Sequencing
Sequenze Ripetitive Degli Acidi Nucleici
Dna Fingerprinting
Allineamento Di Sequenze
Aplotipi
Biologia Computazionale
Modelli Genetici
Sonde Di Dna
Cellule Ibride
La mappatura contigua (o contig mapping) è una tecnica utilizzata in genomica per determinare l'ordine e l'orientamento relativo dei frammenti di DNA (conosciuti come contigs) che sono stati precedentemente assemblati da letture di sequenziamento del DNA. Questa tecnica si basa sull'identificazione di sovrapposizioni tra i bordi dei contigs, che vengono quindi utilizzate per unire i frammenti in un singolo contig continuo o in un assembly genomico più ampio.
La mappatura contigua può essere eseguita utilizzando diversi metodi, come l'uso di marcatori genetici o fisici, la sequenza dei bordi dei contigs stessi o la comparazione con altri genomi di riferimento. L'obiettivo finale della mappatura contigua è quello di creare un assembly genomico continuo e accurato che possa essere utilizzato per studi funzionali, evolutivi e applicativi del genoma in questione.
In genetica, una "mappa del cromosoma" si riferisce a una rappresentazione grafica dettagliata della posizione relativa e dell'ordine dei geni, dei marcatori genetici e di altri elementi costitutivi presenti su un cromosoma. Viene creata attraverso l'analisi di vari tipi di markers genetici o molecolari, come polimorfismi a singolo nucleotide (SNP), Restriction Fragment Length Polymorphisms (RFLPs) e Variable Number Tandem Repeats (VNTRs).
Le mappe del cromosoma possono essere di due tipi: mappe fisiche e mappe genetiche. Le mappe fisiche mostrano la distanza tra i markers in termini di base di paia, mentre le mappe genetiche misurano la distanza in unità di mappa, che sono basate sulla frequenza di ricombinazione durante la meiosi.
Le mappe del cromosoma sono utili per studiare la struttura e la funzione dei cromosomi, nonché per identificare i geni associati a malattie ereditarie o suscettibili alla malattia. Aiutano anche nella mappatura fine dei geni e nel design di esperimenti di clonazione posizionale.
Non esiste una definizione medica standard per "cromosomi dei lieviti artificiali" poiché non è un termine utilizzato nella medicina. Tuttavia, in biologia molecolare e genetica, i cromosomi dei lieviti artificiali si riferiscono a sistemi sintetici creati in laboratorio che mimano la struttura e la funzione dei cromosomi naturali nei lieviti. Questi possono essere utilizzati per studiare il comportamento e l'evoluzione dei cromosomi, nonché per progettare e costruire organismi geneticamente modificati con applicazioni potenziali in biotecnologia e medicina.
"Siti taggati su una sequenza" è un termine utilizzato in genetica molecolare per descrivere mutazioni specifiche o variazioni in un gene o in una sequenza di DNA. Questi "siti taggati" sono posizioni specifiche all'interno della sequenza genetica che sono state identificate come importanti per la funzione del gene o per la suscettibilità a una malattia.
Quando si esegue un'analisi di associazione dell'intero genoma (GWAS), i ricercatori confrontano le sequenze genomiche di individui sani con quelle di individui malati per identificare variazioni comuni che possono essere associate alla malattia. I "siti taggati" sono marcatori genetici selezionati in modo da rappresentare adeguatamente la diversità genetica della popolazione studiata, consentendo così di identificare le associazioni tra variazioni genetiche e malattie.
In breve, "siti taggati su una sequenza" sono punti specifici all'interno del DNA che vengono utilizzati come riferimento per identificare e studiare le variazioni genetiche associate a determinate caratteristiche o malattie.
La "mappa fisica del cromosoma" è un tipo di mappa genetica che fornisce una rappresentazione dettagliata della posizione e dell'ordine relativo dei diversi geni e sequenze di DNA all'interno di un cromosoma. Essa viene creata attraverso l'identificazione di specifici punti di riferimento fisici, come i marcatori molecolari o le sequenze ripetute di DNA, che possono essere utilizzati per orientare e collocare con precisione i geni e altri elementi funzionali sul cromosoma.
La mappa fisica del cromosoma è uno strumento essenziale per la ricerca genomica e genetica, poiché consente di identificare e caratterizzare i geni associati a malattie ereditarie o altre condizioni mediche. Inoltre, può essere utilizzata per studiare le variazioni genetiche tra individui e popolazioni, nonché per comprendere meglio l'evoluzione e la funzione dei cromosomi.
La creazione di una mappa fisica del cromosoma richiede tecnologie avanzate di sequenziamento del DNA e di analisi bioinformatica, che consentono di identificare e caratterizzare i marcatori molecolari e altri elementi di riferimento utilizzati per costruire la mappa. Una volta completata, la mappa fisica del cromosoma può essere utilizzata per orientare e collocare con precisione i geni e altri elementi funzionali sul cromosoma, fornendo una base solida per ulteriori ricerche genetiche e genomiche.
La "chromosome walking" è una tecnica di biologia molecolare utilizzata per clonare e mappare geni o sequenze specifiche di DNA all'interno di un cromosoma. Questa tecnica prevede l'identificazione di clone dopo clone che contengono porzioni adiacenti della sequenza di interesse, permettendo agli scienziati di "camminare" progressivamente verso entrambi i lati del cromosoma fino a quando la sequenza desiderata non viene identificata.
La tecnica si basa sull'utilizzo di sonde di DNA marcate che vengono utilizzate per identificare cloni contenenti porzioni adiacenti della sequenza di interesse. Una volta identificato un clone, la sonda viene utilizzata per cercare un clone adiacente, e questo processo viene ripetuto fino a quando l'intera sequenza desiderata non viene mappata.
La "chromosome walking" è stata una tecnica importante nello studio della genetica e della biologia molecolare, ed è stata utilizzata per identificare e clonare molti geni associati a malattie umane. Tuttavia, con l'avvento di tecnologie di sequenziamento del DNA ad alto rendimento e a basso costo, questa tecnica è meno comunemente utilizzata rispetto al passato.
Come specialista in genetica medica, posso informarti che non esiste un concetto noto come "cromosomi batterici artificiali" nella medicina o nella genetica. Il termine "cromosomi artificiali" si riferisce a veicoli sintetici di DNA creati in laboratorio per condurre studi sulla regolazione e l'espressione genica. Tuttavia, questo concetto non è applicabile ai batteri, poiché i loro genomi sono organizzati in modo diverso dai cromosomi degli eucarioti.
I batteri possiedono un singolo cromosoma circolare, che contiene la maggior parte del loro materiale genetico. Possono anche avere plasmidi, che sono piccole molecole di DNA circolare, che possono essere trasferite orizzontalmente tra batteri e talvolta utilizzate in ingegneria genetica per clonare geni o eseguire altri esperimenti.
Mi scuso per qualsiasi confusione che il termine "cromosomi batterici artificiali" possa aver causato. Se hai altre domande sulla genetica o la medicina, sono qui per aiutarti.
Il fago P1 è un batteriofago, cioè un virus che infetta i batteri. Più precisamente, il fago P1 è un batteriofago temperato (ovvero in grado di integrarsi nel genoma batterico come un plasmide) appartenente alla famiglia dei Myoviridae e al genere dei Peduvirosso.
Il fago P1 ha una particolarità: infetta esclusivamente i batteri del genere Escherichia, in particolare la specie E. coli. Una volta che il fago P1 ha infettato un batterio E. coli, può seguire due diversi percorsi:
1. **Lisi lattico**: il fago si riproduce all'interno del batterio e, una volta raggiunto un certo numero di copie, causa la lisi (ovvero la rottura) della cellula ospite, rilasciando così nuovi virioni (particelle virali) nel mezzo esterno.
2. **Lisogenia**: il fago integra il suo genoma in quello del batterio, diventando un plasmide a tutti gli effetti e replicandosi insieme ad esso senza causare danni alla cellula ospite. In questo stato, il fago è detto **profilo**.
La scelta tra i due percorsi dipende da diversi fattori, come lo stato del batterio ospite e le condizioni ambientali esterne. Il fago P1 è stato ampiamente studiato a livello molecolare ed è utilizzato in vari laboratori di ricerca biomedica come un utile strumento per la manipolazione genetica dei batteri.
In genetica molecolare, un cosmid è un vettore plasmidico derivato da un plasmide batterico chiamato CoELI, che è stato modificato per contenere un sito di clonazione del fago lambda. I cosmidi hanno una capacità di inserimento di circa 40-52 kilobasi di paia (kb) di DNA, il che li rende utili per la clonazione di frammenti di DNA genomico più grandi rispetto ad altri vettori plasmidici.
I cosmidi sono comunemente usati nella costruzione di biblioteche genomiche, dove un intero genoma viene frammentato in pezzi più piccoli e poi clonato in diversi cosmidi. Questo permette la creazione di una collezione di clone che rappresentano l'intero genoma dell'organismo di interesse. I cosmidi sono anche utilizzati nella mappatura fisica del DNA genomico, poiché i frammenti clonati possono essere ordinati in base alla loro posizione relativa sul cromosoma.
In sintesi, i cosmidi sono vettori di clonazione che consentono l'inserimento e la replicazione di frammenti di DNA genomici più grandi rispetto ad altri vettori plasmidici, rendendoli utili per la creazione di biblioteche genomiche e la mappatura fisica del DNA.
In medicina e biologia molecolare, un marcatore genetico è un segmento di DNA con caratteristiche distintive che può essere utilizzato per identificare specifici cromosomi, geni o mutazioni genetiche. I marker genetici possono essere utilizzati in diversi campi della ricerca e della medicina, come la diagnosi prenatale, il consulenza genetica, la medicina forense e lo studio delle malattie genetiche.
Esistono diversi tipi di marcatori genetici, tra cui:
1. Polimorfismi a singolo nucleotide (SNP): sono le variazioni più comuni del DNA umano, che si verificano quando una singola lettera del DNA (un nucleotide) è sostituita da un'altra in una determinata posizione del genoma.
2. Ripetizioni di sequenze brevi (STR): sono segmenti di DNA ripetuti in tandem, che si verificano in diverse copie e combinazioni all'interno del genoma.
3. Varianti della lunghezza dei frammenti di restrizione (RFLP): si verificano quando una sequenza specifica di DNA è tagliata da un enzima di restrizione, producendo frammenti di DNA di diverse dimensioni che possono essere utilizzati come marcatori genetici.
4. Variazioni del numero di copie (CNV): sono differenze nel numero di copie di un gene o di una sequenza di DNA all'interno del genoma, che possono influenzare la funzione genica e essere associate a malattie genetiche.
I marcatori genetici sono utili per identificare tratti ereditari, tracciare la storia evolutiva delle specie, studiare la diversità genetica e individuare le basi genetiche di molte malattie umane. Inoltre, possono essere utilizzati per identificare individui in casi di crimini violenti o per escludere sospetti in indagini forensi.
I Dati di Sequenza Molecolare (DSM) si riferiscono a informazioni strutturali e funzionali dettagliate su molecole biologiche, come DNA, RNA o proteine. Questi dati vengono generati attraverso tecnologie di sequenziamento ad alta throughput e analisi bioinformatiche.
Nel contesto della genomica, i DSM possono includere informazioni sulla variazione genetica, come singole nucleotide polimorfismi (SNP), inserzioni/delezioni (indels) o varianti strutturali del DNA. Questi dati possono essere utilizzati per studi di associazione genetica, identificazione di geni associati a malattie e sviluppo di terapie personalizzate.
Nel contesto della proteomica, i DSM possono includere informazioni sulla sequenza aminoacidica delle proteine, la loro struttura tridimensionale, le interazioni con altre molecole e le modifiche post-traduzionali. Questi dati possono essere utilizzati per studi funzionali delle proteine, sviluppo di farmaci e diagnosi di malattie.
In sintesi, i Dati di Sequenza Molecolare forniscono informazioni dettagliate sulle molecole biologiche che possono essere utilizzate per comprendere meglio la loro struttura, funzione e varianti associate a malattie, con implicazioni per la ricerca biomedica e la medicina di precisione.
L'analisi delle sequenze del DNA è il processo di determinazione dell'ordine specifico delle basi azotate (adenina, timina, citosina e guanina) nella molecola di DNA. Questo processo fornisce informazioni cruciali sulla struttura, la funzione e l'evoluzione dei geni e dei genomi.
L'analisi delle sequenze del DNA può essere utilizzata per una varietà di scopi, tra cui:
1. Identificazione delle mutazioni associate a malattie genetiche: L'analisi delle sequenze del DNA può aiutare a identificare le mutazioni nel DNA che causano malattie genetiche. Questa informazione può essere utilizzata per la diagnosi precoce, il consiglio genetico e la pianificazione della terapia.
2. Studio dell'evoluzione e della diversità genetica: L'analisi delle sequenze del DNA può fornire informazioni sull'evoluzione e sulla diversità genetica di specie diverse. Questo può essere particolarmente utile nello studio di popolazioni in pericolo di estinzione o di malattie infettive emergenti.
3. Sviluppo di farmaci e terapie: L'analisi delle sequenze del DNA può aiutare a identificare i bersagli molecolari per i farmaci e a sviluppare terapie personalizzate per malattie complesse come il cancro.
4. Identificazione forense: L'analisi delle sequenze del DNA può essere utilizzata per identificare individui in casi di crimini o di identificazione di resti umani.
L'analisi delle sequenze del DNA è un processo altamente sofisticato che richiede l'uso di tecnologie avanzate, come la sequenziazione del DNA ad alto rendimento e l'analisi bioinformatica. Questi metodi consentono di analizzare grandi quantità di dati genetici in modo rapido ed efficiente, fornendo informazioni preziose per la ricerca scientifica e la pratica clinica.
Gli "Indicatori di Sequenza Espressa" (ESI) sono un sistema di triage utilizzato nelle emergenze mediche per valutare la gravità della condizione dei pazienti e stabilire le priorità di trattamento. L'ESI assegna un punteggio da 1 a 5, con 1 che indica la massima urgenza e 5 la minima urgenza.
Il sistema ESI considera diversi fattori per assegnare il punteggio, tra cui:
* La gravità dei sintomi del paziente
* L'entità delle lesioni o malattie presenti
* Il rischio di deterioramento della condizione del paziente
* I fattori sociali e psicologici che possono influenzare la cura del paziente
L'ESI è uno strumento importante per i professionisti sanitari che lavorano nelle emergenze, poiché consente di identificare rapidamente i pazienti che necessitano di cure immediate e di allocare le risorse in modo efficiente. Il sistema ESI è stato ampiamente adottato in tutto il mondo ed è considerato uno standard di riferimento per la gestione delle emergenze mediche.
La genoteca è un'ampia raccolta o banca di campioni di DNA, che vengono tipicamente prelevati da diversi individui o specie. Viene utilizzata per archiviare e studiare i vari genotipi, cioè l'organizzazione e la sequenza specifica dei geni all'interno del DNA.
Le genoteche sono estremamente utili nella ricerca biomedica e genetica, poiché consentono di conservare e analizzare facilmente una grande varietà di campioni di DNA. Questo può aiutare i ricercatori a comprendere meglio le basi genetiche delle malattie, a sviluppare test diagnostici più precisi e persino a progettare trattamenti terapeutici personalizzati.
Le genoteche possono contenere campioni di DNA da una varietà di fonti, come sangue, tessuti o cellule. Possono anche essere create per studiare specifiche specie o popolazioni, o possono essere più ampie e includere campioni da una gamma più diversificata di individui.
In sintesi, la genoteca è uno strumento importante nella ricerca genetica che consente di archiviare, organizzare e analizzare i vari genotipi all'interno del DNA.
In genetica, una "sequenza base" si riferisce all'ordine specifico delle quattro basi azotate che compongono il DNA: adenina (A), citosina (C), guanina (G) e timina (T). Queste basi si accoppiano in modo specifico, con l'adenina che si accoppia solo con la timina e la citosina che si accoppia solo con la guanina. La sequenza di queste basi contiene l'informazione genetica necessaria per codificare le istruzioni per la sintesi delle proteine.
Una "sequenza base" può riferirsi a un breve segmento del DNA, come una coppia di basi (come "AT"), o a un lungo tratto di DNA che può contenere migliaia o milioni di basi. L'analisi della sequenza del DNA è un importante campo di ricerca in genetica e biologia molecolare, poiché la comprensione della sequenza base può fornire informazioni cruciali sulla funzione genica, sull'evoluzione e sulla malattia.
La "mappatura di ibridi irradiati" è un metodo utilizzato in citogenetica per identificare e localizzare specifiche bande cromosomiche che sono alterate, come delezioni o duplicazioni. Questo processo comporta l'incrocio tra due specie o varietà diverse di organismi, seguita dall'esposizione dei loro ibridi F1 a radiazioni ionizzanti per indurre la rottura e il riassortimento dei cromosomi.
Dopo l'irradiazione, le cellule sono coltivate in un mezzo di coltura appropriato e quindi viene eseguita una tecnica di colorazione speciale, come la bande G o R, che rivela bande caratteristiche lungo i cromosomi. Questi modelli di bande vengono quindi confrontati con quelli dei genitori normali per identificare le differenze e determinare la posizione delle alterazioni cromosomiche.
La mappatura di ibridi irradiati è stata uno strumento importante nella ricerca citogenetica, in particolare nello studio delle malattie genetiche umane e nel mapping dei geni su specifiche bande cromosomiche. Tuttavia, con l'avvento di tecnologie più avanzate come la microarray e la sequenza del DNA, questo metodo è meno comunemente utilizzato rispetto al passato.
In medicina, una "mappa di restrizione" (o "mappa di restrizioni enzimatiche") si riferisce a un diagramma schematico che mostra la posizione e il tipo di siti di taglio per specifiche endonucleasi di restrizione su un frammento di DNA. Le endonucleasi di restrizione sono enzimi che taglano il DNA in punti specifici, detti siti di restrizione, determinati dalla sequenza nucleotidica.
La mappa di restrizione è uno strumento importante nell'analisi del DNA, poiché consente di identificare e localizzare i diversi frammenti di DNA ottenuti dopo la digestione con enzimi di restrizione. Questa rappresentazione grafica fornisce informazioni cruciali sulla struttura e l'organizzazione del DNA, come ad esempio il numero e la dimensione dei frammenti, la distanza tra i siti di taglio, e la presenza o assenza di ripetizioni sequenziali.
Le mappe di restrizione sono comunemente utilizzate in diverse applicazioni della biologia molecolare, come il clonaggio, l'ingegneria genetica, l'analisi filogenetica e la diagnosi di malattie genetiche.
In medicina e biologia, il termine "libreria genomica" si riferisce a un'ampia raccolta di fragmenti di DNA o RNA preparati in modo tale da consentire la loro ripetuta analisi e sequenziamento. Più precisamente, una libreria genomica è costituita da una popolazione di molecole di acido nucleico (DNA o RNA) che sono state estratte da un campione biologico e trattate in modo tale da poter essere clonate e successivamente analizzate attraverso tecniche di sequenziamento di nuova generazione.
La preparazione di una libreria genomica prevede diversi passaggi, tra cui l'estrazione dell'acido nucleico dal campione biologico, la frammentazione delle molecole in pezzi di dimensioni uniformi e la loro modifica con adattatori specifici che ne consentano la clonazione e il sequenziamento. Una volta preparata, la libreria genomica può essere utilizzata per identificare e caratterizzare vari tipi di elementi genetici, come geni, mutazioni, varianti genetiche o esoni, all'interno del genoma di interesse.
Le librerie genomiche sono uno strumento fondamentale nella ricerca genetica e genomica, poiché permettono di analizzare in modo efficiente ed economico grandi quantità di materiale genetico, aprendo la strada alla scoperta di nuovi marcatori genetici associati a malattie o alla comprensione dei meccanismi molecolari che sottendono lo sviluppo e la progressione delle patologie.
La "genetic linkage" (o legame genetico) è un fenomeno in genetica che descrive la tendenza per due o più loci genici (posizioni su un cromosoma dove si trova un gene) ad essere ereditati insieme durante la meiosi a causa della loro prossimità fisica sulla stessa molecola di DNA. Ciò significa che i geni strettamente legati hanno una probabilità maggiore di essere ereditati insieme rispetto ai geni non correlati o lontani.
Quando due loci genici sono abbastanza vicini, il loro tasso di ricombinazione (cioè la frequenza con cui vengono scambiati materiale genetico durante la meiosi) è basso. Questo si traduce in un'elevata probabilità che i due alleli (varianti dei geni) siano ereditati insieme, il che può essere utilizzato per tracciare la posizione relativa di diversi geni su un cromosoma e per mappare i geni associati a malattie o caratteristiche ereditarie.
La misura del grado di legame genetico tra due loci genici è definita dalla distanza di mapping, che viene comunemente espressa in unità di centimorgan (cM). Un centimorgan corrisponde a un tasso di ricombinazione del 1%, il che significa che due loci con una distanza di mapping di 1 cM hanno una probabilità dell'1% di essere separati da un evento di ricombinazione durante la meiosi.
In sintesi, il legame genetico è un importante principio in genetica che descrive come i geni sono ereditati insieme a causa della loro posizione fisica sui cromosomi e può essere utilizzato per studiare la struttura dei cromosomi, l'ereditarietà delle malattie e le relazioni evolutive tra specie.
La mappa peptidica, nota anche come "peptide map" o "peptide fingerprint", è un metodo di analisi proteomica che utilizza la cromatografia liquida ad alta efficienza (HPLC) e la spettrometria di massa per identificare e quantificare le proteine. Questa tecnica si basa sul fatto che peptidi generati da una specifica proteina dopo la digestione enzimatica producono un pattern caratteristico o "impronta digitale" di picchi nel cromatogramma HPLC e nei profili di spettrometria di massa.
Nel processo, una proteina viene dapprima digerita da enzimi specifici, come la tripsina o la chimotripsina, che tagliano la catena polipeptidica in peptidi più piccoli e carichi positivamente. Questi peptidi vengono poi separati mediante HPLC, utilizzando una colonna di cromatografia riempita con un materiale adsorbente come la sfera di silice o la polimeria porosa. I peptidi interagiscono con il materiale della colonna in base alle loro proprietà chimiche e fisiche, come la lunghezza, la carica e l'idrofobicità, portando a una separazione spaziale dei picchi nel cromatogramma HPLC.
I peptidi vengono quindi ionizzati ed analizzati mediante spettrometria di massa, producendo uno spettro di massa univoco per ogni peptide. L'insieme dei picchi nello spettro di massa costituisce la "mappa peptidica" della proteina originale. Questa mappa può essere confrontata con le mappe peptidiche note o analizzata mediante algoritmi di ricerca per identificare e quantificare la proteina iniziale.
La mappa peptidica è un metodo sensibile, specifico e affidabile per l'identificazione e la quantificazione delle proteine, ed è ampiamente utilizzata nelle scienze biomediche e nella ricerca proteomica.
In medicina, una "mappa di determinanti antigenici" si riferisce a una rappresentazione grafica o schematica che mostra la posizione e la funzione dei diversi epitopi (o determinanti antigenici) su un antigene. Gli epitopi sono regioni specifiche di una molecola antigenica che possono essere riconosciute e legate dalle cellule del sistema immunitario, come i linfociti T o B.
La mappa di determinanti antigenici può essere utilizzata per comprendere meglio la struttura e il comportamento di un antigene, nonché per identificare potenziali siti di vulnerabilità che possono essere mirati da farmaci o vaccini. Questa mappa può essere creata attraverso tecniche sperimentali come la mutagenesi alfanumerica e l'analisi dei legami tra antigeni e anticorpi, nonché tramite simulazioni computazionali e modellazione molecolare.
Una migliore comprensione della mappa di determinanti antigenici può aiutare a sviluppare strategie più efficaci per il trattamento di malattie infettive, tumori e altre condizioni mediche.
Il clonaggio molecolare è una tecnica di laboratorio utilizzata per creare copie esatte di un particolare frammento di DNA. Questa procedura prevede l'isolamento del frammento desiderato, che può contenere un gene o qualsiasi altra sequenza specifica, e la sua integrazione in un vettore di clonazione, come un plasmide o un fago. Il vettore viene quindi introdotto in un organismo ospite, ad esempio batteri o cellule di lievito, che lo replicano producendo numerose copie identiche del frammento di DNA originale.
Il clonaggio molecolare è una tecnica fondamentale nella biologia molecolare e ha permesso importanti progressi in diversi campi, tra cui la ricerca genetica, la medicina e la biotecnologia. Ad esempio, può essere utilizzato per produrre grandi quantità di proteine ricombinanti, come enzimi o vaccini, oppure per studiare la funzione dei geni e le basi molecolari delle malattie.
Tuttavia, è importante sottolineare che il clonaggio molecolare non deve essere confuso con il clonazione umana o animale, che implica la creazione di organismi geneticamente identici a partire da cellule adulte differenziate. Il clonaggio molecolare serve esclusivamente a replicare frammenti di DNA e non interi organismi.
Il genoma delle piante si riferisce all'intero insieme di materiale genetico o DNA presente in una pianta. Comprende tutti i geni e le sequenze non codificanti che costituiscono l'architettura genetica di quella specie vegetale. Il genoma delle piante varia notevolmente per dimensioni e complessità tra diverse specie, con alcuni genomi che contengono solo poche migliaia di geni, mentre altri possono contenere decine di migliaia o più.
Il sequenziamento del genoma delle piante è diventato uno strumento importante per la ricerca in biologia vegetale e nella selezione assistita da marcatori nelle colture geneticamente modificate. Fornisce informazioni vitali sui meccanismi di sviluppo, la resistenza ai patogeni, lo stress abiotico e l'adattamento ambientale delle piante, nonché sulla biodiversità e l'evoluzione delle specie vegetali.
Tuttavia, il sequenziamento del genoma di una pianta è solo l'inizio del processo di comprensione della sua funzione e interazione con altri organismi e fattori ambientali. L'analisi funzionale dei genomi delle piante richiede anche la caratterizzazione dei singoli geni, le loro espressioni spaziali e temporali, nonché l'interazione tra di essi e con altri componenti cellulari.
In termini medici, il termine "mappa cerebrale" non ha una definizione standard o un significato specifico universalmente accettato. Tuttavia, in senso generale, la mappatura cerebrale si riferisce all'identificazione e alla visualizzazione delle aree funzionali del cervello e dei loro collegamenti. Questo processo può essere svolto utilizzando diverse tecniche di neuroimaging, come fMRI (risonanza magnetica funzionale), PET (tomografia ad emissione di positroni) o EEG (elettroencefalogramma).
L'obiettivo della mappatura cerebrale è comprendere meglio come il cervello sia organizzato e come svolga diverse funzioni cognitive, emotive e motorie. Questa conoscenza può essere particolarmente utile in contesti clinici, ad esempio durante la pianificazione di interventi chirurgici cerebrali o nel trattamento di disturbi neurologici e psichiatrici.
Tuttavia, è importante notare che le mappe cerebrali possono variare significativamente da individuo a individuo, il che rende difficile generalizzare i risultati della ricerca o applicare direttamente le conoscenze acquisite da un soggetto all'altro.
In genetica, i cromosomi delle piante si riferiscono ai cromosomi presenti nelle cellule delle piante. I cromosomi sono strutture presenti nel nucleo delle cellule che contengono il materiale genetico dell'organismo sotto forma di DNA.
Nelle piante, i cromosomi si trovano all'interno del nucleo delle cellule vegetali e sono costituiti da lunghe molecole di DNA avvolte intorno a proteine histone. Ogni pianta ha un numero specifico di cromosomi che varia tra le specie, ad esempio, il granturco ha 10 paia di cromosomi (2n=20), mentre l'uva ha 19 paia di cromosomi (2n=38).
I cromosomi delle piante sono essenziali per la trasmissione dei geni dalle generazioni precedenti a quelle successive e svolgono un ruolo cruciale nella regolazione dell'espressione genica, contribuendo alla variabilità fenotipica all'interno di una specie.
In aggiunta, i cromosomi delle piante possono presentare strutture speciali come centromeri, telomeri e nucleoli che svolgono un ruolo importante nella divisione cellulare e nella stabilità del genoma. Alcune piante hanno anche cromosomi sessuali che determinano il sesso dell'individuo.
In sintesi, i cromosomi delle piante sono le strutture che contengono il materiale genetico nelle cellule vegetali e sono essenziali per la trasmissione dei geni, la regolazione dell'espressione genica e la stabilità del genoma.
In situ fluorescence hybridization (FISH) is a medical laboratory technique used to detect and localize the presence or absence of specific DNA sequences on chromosomes. This technique involves the use of fluorescent probes that bind to complementary DNA sequences on chromosomes. The probes are labeled with different fluorescent dyes, allowing for the visualization of specific chromosomal regions or genetic abnormalities using a fluorescence microscope.
FISH is often used in medical diagnostics to identify genetic disorders, chromosomal abnormalities, and certain types of cancer. It can be used to detect gene amplifications, deletions, translocations, and other structural variations in the genome. FISH can also be used to monitor disease progression and response to treatment in patients with cancer or other genetic disorders.
The process of FISH involves several steps, including denaturation of the DNA in the sample, hybridization of the fluorescent probes to the complementary DNA sequences, washing to remove unbound probes, and detection of the fluorescent signal using a specialized microscope. The resulting images can be analyzed to determine the presence or absence of specific genetic abnormalities.
Overall, FISH is a powerful tool in molecular biology and medical diagnostics, providing valuable information about chromosomal abnormalities and genetic disorders that can inform clinical decision-making and improve patient outcomes.
La mappatura dei potenziali della superficie corporea, nota anche come "mappatura somatotopica", è un metodo utilizzato in neurologia e fisioterapia per visualizzare e documentare la distribuzione dei diversi livelli di sensibilità o risposte motorie su diverse aree della superficie corporea. Questa tecnica prevede l'applicazione di stimoli leggeri, come tocchi o vibrazioni, a diverse parti del corpo e la registrazione delle relative risposte sensoriali o motorie.
In particolare, la mappatura dei potenziali della superficie corporea può essere utilizzata per valutare la funzione del sistema nervoso periferico e centrale, ad esempio dopo un danno neurologico come una lesione del midollo spinale o un ictus. Questa tecnica può fornire informazioni importanti sulla localizzazione e l'estensione del danno nervoso, nonché sullo stato di riabilitazione e recovery del paziente.
In sintesi, la mappatura dei potenziali della superficie corporea è una metodologia di valutazione neurologica che consente di visualizzare e documentare la distribuzione dei diversi livelli di sensibilità o risposte motorie su diverse aree del corpo, fornendo informazioni importanti sulla funzione del sistema nervoso periferico e centrale.
In termini medici, il software non ha una definizione specifica poiché si riferisce all'informatica e non alla medicina. Tuttavia, in un contesto più ampio che coinvolge l'informatica sanitaria o la telemedicina, il software può essere definito come un insieme di istruzioni e dati elettronici organizzati in modo da eseguire funzioni specifiche e risolvere problemi. Questi possono includere programmi utilizzati per gestire i sistemi informativi ospedalieri, supportare la diagnosi e il trattamento dei pazienti, o facilitare la comunicazione tra fornitori di assistenza sanitaria e pazienti. È importante notare che il software utilizzato nel campo medico deve essere affidabile, sicuro ed efficiente per garantire una cura adeguata e la protezione dei dati sensibili dei pazienti.
Il genoma è l'intera sequenza dell'acido desossiribonucleico (DNA) contenuta in quasi tutte le cellule di un organismo. Esso include tutti i geni e le sequenze non codificanti che compongono il materiale genetico ereditato da entrambi i genitori. Il genoma umano, ad esempio, è costituito da circa 3 miliardi di paia di basi nucleotidiche e contiene circa 20.000-25.000 geni che forniscono le istruzioni per lo sviluppo e il funzionamento dell'organismo.
Il genoma può essere studiato a diversi livelli, tra cui la sequenza del DNA, la struttura dei cromosomi, l'espressione genica (l'attività dei geni) e la regolazione genica (il modo in cui i geni sono controllati). Lo studio del genoma è noto come genomica e ha importanti implicazioni per la comprensione delle basi molecolari delle malattie, lo sviluppo di nuove terapie farmacologiche e la diagnosi precoce delle malattie.
Le sequenze microsatelliti, noti anche come "simple sequence repeats" (SSR) o "short tandem repeats" (STR), sono brevi sequenze ripetute di DNA che si trovano in tutto il genoma. Queste sequenze consistono di unità ripetute di 1-6 basi azotate, che vengono ripetute diverse volte in fila. Un esempio potrebbe essere (CA)n, dove n indica il numero di ripetizioni dell'unità "CA".
Le sequenze microsatelliti sono particolarmente utili in genetica e medicina a causa della loro alta variabilità all'interno della popolazione. Infatti, il numero di ripetizioni può variare notevolmente tra individui diversi, il che rende possibile utilizzarle come marcatori genetici per identificare singoli individui o famiglie.
In medicina, le sequenze microsatelliti sono spesso utilizzate in test di paternità, per identificare i criminali attraverso l'analisi del DNA, e per studiare la base genetica di varie malattie. Ad esempio, mutazioni nelle sequenze microsatelliti possono essere associate a malattie genetiche come la corea di Huntington, la malattia di Creutzfeldt-Jakob e alcuni tumori.
In sintesi, le sequenze microsatelliti sono brevi sequenze ripetute di DNA che presentano una notevole variabilità all'interno della popolazione umana. Queste sequenze possono essere utilizzate come marcatori genetici per identificare singoli individui o famiglie, e possono anche essere associate a malattie genetiche e tumori.
La domanda contiene un'imprecisione, poiché i batteri non hanno cromosomi nel modo in cui gli eucarioti (cellule con un nucleo ben definito) ce li hanno. I batteri possiedono un unico cromosoma circolare, chiamato cromosoma batterico, che contiene la maggior parte del loro materiale genetico. Questo cromosoma batterico è costituito da DNA a doppia elica e codifica per i geni necessari alla sopravvivenza e alla riproduzione dell'organismo.
Quindi, una definizione medica corretta di "cromosomi dei batteri" dovrebbe essere:
Il cromosoma batterico è l'unica struttura simile a un cromosoma presente nei batteri. Si tratta di un'unica molecola circolare di DNA a doppia elica che contiene la maggior parte del materiale genetico dell'organismo e codifica per i geni necessari alla sua sopravvivenza e riproduzione.
La coppia di cromosomi umani 11, indicata come 11 paio (2n = 22), sono autosomi (cromosomi non sessuali) presenti nel genoma umano. Ciascun individuo normalmente ha due copie di questo cromosoma, una ereditata dalla madre e l'altra dal padre. Il cromosoma 11 è uno dei più grandi tra i cromosomi autosomici umani, costituito da circa 135 milioni di paia di basi (DNA).
Il cromosoma 11 contiene oltre 1.400 geni noti che forniscono istruzioni per la produzione di proteine e giocano un ruolo cruciale nello sviluppo, nella crescita e nell'integrità funzionale dell'organismo. Alcune condizioni genetiche associate a mutazioni o alterazioni del cromosoma 11 includono:
1. Sindrome di Wilms (nefroblastoma): un tumore renale comune nei bambini, causato da una delezione nel braccio corto del cromosoma 11 (11p13).
2. Anemia falciforme: una malattia genetica che colpisce la produzione di emoglobina, può essere associata a mutazioni nel gene HBB localizzato sul braccio corto del cromosoma 11 (11p15.4).
3. Sindrome di Beckwith-Wiedemann: una condizione che causa un'eccessiva crescita fetale e altre anomalie, può essere causata da alterazioni nel gene CDKN1C sul braccio lungo del cromosoma 11 (11p15.5).
4. Sindrome di Smith-Magenis: una condizione che colpisce lo sviluppo e comporta ritardo mentale, problemi di sonno e anomalie fisiche, causata da una delezione nel braccio lungo del cromosoma 11 (11q13).
5. Sindrome di Potocki-Lupski: una condizione che causa ritardo dello sviluppo, problemi comportamentali e anomalie fisiche, causata da una duplicazione nel braccio lungo del cromosoma 11 (11p13).
Le alterazioni del cromosoma 11 possono avere conseguenze gravi per lo sviluppo e la salute. Pertanto, è importante comprendere le funzioni dei geni presenti in questo cromosoma e i meccanismi che portano alle malattie associate.
Il DNA delle piante si riferisce al materiale genetico presente nelle cellule delle piante. Come il DNA degli animali, anche il DNA delle piante è composto da due filamenti avvolti in una struttura a doppia elica, con ciascun filamento che contiene una sequenza di quattro basi azotate: adenina (A), citosina (C), guanina (G) e timina (T).
Tuttavia, il DNA delle piante presenta alcune caratteristiche uniche. Ad esempio, le piante hanno regioni ripetitive di DNA chiamate centromeri e telomeri che svolgono un ruolo importante nella divisione cellulare e nella stabilità del genoma. Inoltre, il DNA delle piante contiene sequenze specifiche chiamate introni che vengono rimosse dopo la trascrizione dell'mRNA.
Il genoma delle piante è notevolmente più grande di quello degli animali e può contenere da diverse centinaia a migliaia di geni. Gli scienziati stanno attivamente studiando il DNA delle piante per comprendere meglio i meccanismi che regolano la crescita, lo sviluppo e la risposta alle stress ambientali delle piante, con l'obiettivo di migliorare le colture alimentari e la produzione di biocarburanti.
In medicina e biologia molecolare, la sequenza aminoacidica si riferisce all'ordine specifico e alla disposizione lineare degli aminoacidi che compongono una proteina o un peptide. Ogni proteina ha una sequenza aminoacidica unica, determinata dal suo particolare gene e dal processo di traduzione durante la sintesi proteica.
L'informazione sulla sequenza aminoacidica è codificata nel DNA del gene come una serie di triplette di nucleotidi (codoni). Ogni tripla nucleotidica specifica codifica per un particolare aminoacido o per un segnale di arresto che indica la fine della traduzione.
La sequenza aminoacidica è fondamentale per determinare la struttura e la funzione di una proteina. Le proprietà chimiche e fisiche degli aminoacidi, come la loro dimensione, carica e idrofobicità, influenzano la forma tridimensionale che la proteina assume e il modo in cui interagisce con altre molecole all'interno della cellula.
La determinazione sperimentale della sequenza aminoacidica di una proteina può essere ottenuta utilizzando tecniche come la spettrometria di massa o la sequenziazione dell'EDTA (endogruppo diazotato terminale). Queste informazioni possono essere utili per studiare le proprietà funzionali e strutturali delle proteine, nonché per identificarne eventuali mutazioni o variazioni che possono essere associate a malattie genetiche.
In medicina, un algoritmo è una sequenza di istruzioni o passaggi standardizzati che vengono seguiti per raggiungere una diagnosi o prendere decisioni terapeutiche. Gli algoritmi sono spesso utilizzati nei processi decisionali clinici per fornire un approccio sistematico ed evidence-based alla cura dei pazienti.
Gli algoritmi possono essere basati su linee guida cliniche, raccomandazioni di esperti o studi di ricerca e possono includere fattori come i sintomi del paziente, i risultati dei test di laboratorio o di imaging, la storia medica precedente e le preferenze del paziente.
Gli algoritmi possono essere utilizzati in una varietà di contesti clinici, come la gestione delle malattie croniche, il triage dei pazienti nei pronto soccorso, la diagnosi e il trattamento delle emergenze mediche e la prescrizione dei farmaci.
L'utilizzo di algoritmi può aiutare a ridurre le variazioni nella pratica clinica, migliorare l'efficacia e l'efficienza delle cure, ridurre gli errori medici e promuovere una maggiore standardizzazione e trasparenza nei processi decisionali. Tuttavia, è importante notare che gli algoritmi non possono sostituire il giudizio clinico individuale e devono essere utilizzati in modo appropriato e flessibile per soddisfare le esigenze uniche di ogni paziente.
L'epicardico mapping è una tecnica diagnostica utilizzata in cardiologia per creare una mappa dettagliata dell'attività elettrica del miocardio (il tessuto muscolare del cuore) durante il suo normale funzionamento o durante un'aritmia. Viene eseguito posizionando una sonda speciale a contatto con l'epicardio, la superficie esterna del cuore. Questa procedura è spesso utilizzata per localizzare precisamente le aree di origine delle aritmie cardiache focali o ricostruire i complessi circuiti di re-entrata responsabili di aritmie più complesse, come la fibrillazione atriale. I dati ottenuti dall'epicardico mapping possono guidare il trattamento terapeutico, ad esempio tramite l'ablazione con radiofrequenza o crioterapia, per creare lesioni controllate che isolino o distruggano le aree responsabili dell'aritmia.
La definizione medica di "DNA complementare" si riferisce alla relazione tra due filamenti di DNA che sono legati insieme per formare una doppia elica. Ogni filamento del DNA è composto da una sequenza di nucleotidi, che contengono ciascuno uno zucchero deossiribosio, un gruppo fosfato e una base azotata (adenina, timina, guanina o citosina).
Nel DNA complementare, le basi azotate dei due filamenti si accoppiano in modo specifico attraverso legami idrogeno: adenina si accoppia con timina e guanina si accoppia con citosina. Ciò significa che se si conosce la sequenza di nucleotidi di un filamento di DNA, è possibile prevedere con precisione la sequenza dell'altro filamento, poiché sarà complementare ad esso.
Questa proprietà del DNA complementare è fondamentale per la replicazione e la trasmissione genetica, poiché consente alla cellula di creare una copia esatta del proprio DNA durante la divisione cellulare. Inoltre, è anche importante nella trascrizione genica, dove il filamento di DNA complementare al gene viene trascritto in un filamento di RNA messaggero (mRNA), che a sua volta viene tradotto in una proteina specifica.
La sintecia, in genetica, si riferisce alla situazione in cui due o più geni si trovano su lo stesso cromosoma e tendono a essere ereditati insieme durante la ricombinazione genetica. I geni in sintecia sono detti esserlo "in linkage stretto". Questo fenomeno è importante nello studio della genetica, poiché i geni in sintecia possono fornire informazioni sulla loro posizione relativa su un cromosoma e sulla frequenza di ricombinazione tra di loro. La misura del grado di sintecia tra due geni è data dal tasso di ricombinazione osservato tra di essi, che può essere calcolato mediante l'analisi delle discendenze familiari o attraverso tecniche di mapping genetico. I geni in completa sintecia (con un tasso di ricombinazione pari a zero) sono detti essere "legati".
I cromosomi umani, coppia 7, si riferiscono a due dei 46 cromosomi presenti nelle cellule umane. Ogni persona ha due copie di questo cromosoma, una ereditata dalla madre e l'altra dal padre. Il cromosoma 7 è uno dei 22 autosomi, o cromosomi non sessuali, e si trova nella parte centrale del cariotipo umano.
Il cromosoma 7 contiene geni che codificano per proteine importanti e altri RNA regolatori. Tra i geni presenti sul cromosoma 7 ci sono quelli responsabili della produzione di enzimi coinvolti nel metabolismo, nella risposta immunitaria, nello sviluppo embrionale e in altre funzioni cellulari essenziali.
Le anomalie del cromosoma 7 possono causare diverse condizioni genetiche, come la sindrome di Williams, la sindrome di Wagner, la sindrome di Alagille e la neurofibromatosi di tipo 1. Queste condizioni sono caratterizzate da una serie di sintomi che possono includere ritardo nello sviluppo, difetti cardiaci, anomalie scheletriche, problemi renali, disturbi della vista e dell'udito, e altre manifestazioni cliniche.
La diagnosi di anomalie del cromosoma 7 si basa sull'analisi citogenetica dei campioni di tessuto prelevati dal paziente, come il sangue o le cellule della mucosa orale. Questa analisi può rilevare eventuali cambiamenti nella struttura o nel numero dei cromosomi 7, che possono essere causati da errori durante la divisione cellulare o dall'esposizione a fattori ambientali dannosi.
Lo Studio del Genoma si riferisce alla raccolta, all'analisi e all'interpretazione sistematica delle informazioni contenute nel genoma umano. Il genoma è l'insieme completo di tutte le informazioni genetiche ereditarie presenti in un individuo, codificate nei suoi cromosomi e organizzate in circa 20.000-25.000 geni.
Lo Studio del Genoma può essere condotto a diversi livelli di complessità, dall'analisi di singoli geni o regioni genomiche specifiche, fino all'esame dell'intero genoma. L'obiettivo principale di questo studio è quello di comprendere come le variazioni genetiche influenzino la fisiologia, il fenotipo e la predisposizione a determinate malattie o condizioni patologiche.
Le tecnologie di sequenziamento dell'DNA di nuova generazione (NGS) hanno permesso di accelerare notevolmente lo Studio del Genoma, rendendolo più accessibile e conveniente. Questo ha aperto la strada allo sviluppo di approcci di medicina personalizzata, che tengono conto delle specifiche caratteristiche genetiche di un individuo per prevedere, diagnosticare e trattare le malattie in modo più preciso ed efficace.
Lo Studio del Genoma ha anche importanti implicazioni etiche, legali e sociali, che devono essere attentamente considerate e gestite a livello individuale e collettivo.
La coppia 3 dei cromosomi umani, nota anche come cromosoma 3, è uno dei 23 paia di cromosomi presenti nelle cellule umane. Ogni persona normale ha due copie di cromosoma 3, una ereditata dalla madre e l'altra dal padre durante la fecondazione. Il cromosoma 3 è uno dei autosomi acrocentrici, il che significa che il centromero si trova vicino a un braccio corto del cromosoma.
Il cromosoma 3 contiene geni che codificano per proteine e RNA non codificanti necessari per una varietà di funzioni cellulari e sviluppo dell'organismo. Alcuni tratti e condizioni associate al cromosoma 3 includono la sindrome di Waardenburg, la malattia di Wilson e alcune forme di cancro come il carcinoma polmonare a piccole cellule.
Le anomalie del numero o della struttura dei cromosomi 3 possono causare varie condizioni genetiche. Ad esempio, una trisomia del cromosoma 3 (presenza di tre copie invece delle due normali) causa la sindrome di Patau, che è associata a gravi disabilità intellettive e fisiche e spesso letale nell'infanzia. Una delezione o una traslocazione del cromosoma 3 può anche causare varie condizioni genetiche, a seconda della parte del cromosoma interessata.
I geni delle piante si riferiscono a specifiche sequenze di DNA presenti nelle cellule delle piante che codificano per informazioni ereditarie e istruzioni utilizzate nella sintesi di proteine e RNA. Questi geni svolgono un ruolo cruciale nello sviluppo, nella crescita, nella fioritura, nella produzione di semi e nell'adattamento ambientale delle piante.
I geni delle piante sono organizzati in cromosomi all'interno del nucleo cellulare. La maggior parte dei geni delle piante si trova nel DNA nucleare, ma alcuni geni si trovano anche nel DNA degli organelli come mitocondri e cloroplasti.
I geni delle piante sono soggetti a vari meccanismi di regolazione genica che controllano la loro espressione spaziale e temporale. Questi meccanismi includono l'interazione con fattori di trascrizione, modifiche epigenetiche del DNA e RNA non codificante.
L'identificazione e lo studio dei geni delle piante sono fondamentali per comprendere i processi biologici delle piante e per sviluppare colture geneticamente modificate con caratteristiche desiderabili, come resistenza ai parassiti, tolleranza alla siccità e maggiore produttività.
Il genoma umano si riferisce all'intera sequenza di DNA presente nelle cellule umane, ad eccezione delle cellule germinali (ovuli e spermatozoi). Esso comprende tutti i geni (circa 20.000-25.000) responsabili della codifica delle proteine, nonché una grande quantità di DNA non codificante che regola l'espressione genica e svolge altre funzioni importanti. Il genoma umano è costituito da circa 3 miliardi di paia di basi nucleotidiche (adenina, timina, guanina e citosina) disposte in una sequenza unica che varia leggermente tra individui. La completa mappatura e sequenziamento del genoma umano è stato raggiunto dal Progetto Genoma Umano nel 2003, fornendo importanti informazioni sulla base genetica delle malattie e della diversità umana.
In medicina, il termine "pedigree" si riferisce a un diagramma genealogico che mostra la storia familiare di una malattia ereditaria o di una particolare caratteristica genetica. Viene utilizzato per tracciare e visualizzare la trasmissione dei geni attraverso diverse generazioni di una famiglia, aiutando i medici e i genetisti a identificare i modelli ereditari e ad analizzare il rischio di malattie genetiche in individui e famiglie.
Nel pedigree, i simboli standard rappresentano vari membri della famiglia, mentre le linee tra di essi indicano i legami di parentela. Le malattie o le caratteristiche genetiche vengono comunemente denotate con specifici simboli e codici per facilitarne l'interpretazione.
È importante notare che un pedigree non è semplicemente un albero genealogico, ma uno strumento medico-genetico utilizzato per comprendere la probabilità di insorgenza di una malattia ereditaria e fornire consulenze genetiche appropriate.
In medicina, il termine "famiglia multigenica" si riferisce a un gruppo di geni che sono ereditati insieme e che contribuiscono tutti alla suscettibilità o alla predisposizione a una particolare malattia o condizione. Queste famiglie di geni possono includere diversi geni che interagiscono tra loro o con fattori ambientali per aumentare il rischio di sviluppare la malattia.
Ad esempio, nella malattia di Alzheimer a insorgenza tardiva, si pensa che ci siano diverse famiglie multigeniche che contribuiscono alla suscettibilità alla malattia. I geni appartenenti a queste famiglie possono influenzare la produzione o la clearance della beta-amiloide, una proteina che si accumula nel cervello dei pazienti con Alzheimer e forma placche distintive associate alla malattia.
La comprensione delle famiglie multigeniche può aiutare i ricercatori a identificare i fattori di rischio genetici per una particolare malattia e a sviluppare strategie di prevenzione o trattamento più mirate. Tuttavia, è importante notare che l'ereditarietà multigenica è solo uno dei fattori che contribuiscono alla suscettibilità alla malattia, e che altri fattori come l'età, lo stile di vita e l'esposizione ambientale possono anche svolgere un ruolo importante.
La "High-Throughput Nucleotide Sequencing" (HTS), nota anche come "next-generation sequencing" (NGS), è una tecnologia avanzata per il sequenziamento del DNA che consente l'analisi parallela di milioni di frammenti di DNA in modo simultaneo, fornendo un'elevata resa e accuratezza nella determinazione dell'ordine delle basi nucleotidiche (adenina, citosina, guanina e timina) che compongono il genoma.
HTS è uno strumento potente per l'analisi genomica, che ha rivoluzionato la ricerca biomedica e la diagnostica clinica. Consente di sequenziare interi genomi, esoni, transcrittomi o metilomi in modo rapido ed efficiente, con una copertura profonda e a costi contenuti. Questa tecnologia ha numerose applicazioni, tra cui l'identificazione di varianti genetiche associate a malattie ereditarie o acquisite, la caratterizzazione di patogeni infettivi, lo studio dell'espressione genica e della regolazione epigenetica.
HTS è diventato uno strumento essenziale per la ricerca biomedica e la medicina personalizzata, fornendo informazioni dettagliate sulle basi molecolari delle malattie e consentendo una diagnosi più precisa, un monitoraggio della progressione della malattia e l'identificazione di terapie mirate.
Le Sequenze Ripetitive degli Acidi Nucleici (NRPS, dall'inglese Non-ribosomal Peptide Synthetases) sono un tipo di sistemi enzimatici che sintetizzano peptidi senza l'utilizzo del ribosoma. Queste sequenze sono costituite da moduli enzimatici, ognuno dei quali è responsabile della formazione di un legame peptidico tra due aminoacidi. Ogni modulo contiene tre domini enzimatici principali: uno adenilante/condensazione (A), uno peptidil carrier protein (PCP) e uno che catalizza la formazione del legame peptidico (C).
Le NRPS sono in grado di sintetizzare una vasta gamma di peptidi, compresi alcuni con strutture altamente complesse e non standard. Queste sequenze enzimatiche sono presenti in molti organismi, tra cui batteri, funghi e piante, e sono responsabili della produzione di una varietà di metaboliti secondari, come antibiotici, toxine e siderofori.
Le NRPS sono anche note per la loro capacità di produrre peptidi con aminoacidi non proteinogenici, cioè aminoacidi che non sono codificati dal DNA e non vengono incorporati nei normali processi di traduzione. Questa caratteristica rende le NRPS un bersaglio interessante per lo sviluppo di nuovi farmaci e agenti terapeutici.
L'espressione "DNA fingerprinting" o "profilo del DNA" si riferisce a un metodo di analisi genetica che consente di identificare in modo univoco gli individui sulla base della variazione delle sequenze ripetute nel loro DNA. Questo processo, noto anche come profiling genetico o tipizzazione del DNA, viene utilizzato principalmente a scopi forensi per l'identificazione di soggetti sconosciuti, la risoluzione di casi controversi e la verifica delle relazioni biologiche.
Nel DNA fingerprinting vengono analizzate specifiche regioni del genoma umano, chiamate "polimorfismi a singolo nucleotide" (SNP) o "microsatelliti", che presentano sequenze ripetute di breve lunghezza. La composizione e la lunghezza di queste sequenze variano considerevolmente tra gli individui, tranne che per i gemelli monozigoti, il che rende possibile l'identificazione univoca delle persone.
Il processo di DNA fingerprinting prevede diversi passaggi:
1. Estrazione del DNA: Il materiale biologico (come sangue, saliva o capelli) viene sottoposto a una procedura di estrazione per isolare il DNA contenuto nelle cellule.
2. Amplificazione dei marcatori genetici: Vengono selezionate specifiche regioni del DNA da analizzare e vengono amplificate mediante la tecnica della reazione a catena della polimerasi (PCR). Questo processo consente di ottenere molte copie delle sequenze ripetute per un'analisi più accurata.
3. Separazione ed elettroforesi: Le copie amplificate vengono separate in base alla loro lunghezza mediante una tecnica chiamata elettroforesi su gel di agarosio. I frammenti di DNA con differenti lunghezze migrano a velocità diverse, creando un pattern distintivo per ogni individuo.
4. Visualizzazione e analisi: Il gel viene trattato con sostanze chimiche che consentono la visualizzazione dei frammenti di DNA come bande scure. Questi pattern vengono confrontati con altri campioni per determinare se corrispondono o meno all'individuo sospettato.
Il DNA fingerprinting è uno strumento potente e affidabile per l'identificazione individuale, utilizzato in vari settori come la medicina forense, la genetica delle popolazioni e la ricerca biologica. Tuttavia, è importante considerare le implicazioni etiche e legali associate all'uso di questa tecnologia, assicurandosi che vengano rispettati i diritti individuali e la privacy.
La coppia di cromosomi umani nota come "Coppie 16" si riferisce specificamente a due cromosomi a forma di bastoncino presenti nel nucleo delle cellule umane che contengono geni e materiale genetico ereditato dai genitori. Nella specie umana, ci sono in totale 23 coppie di cromosomi, il che significa che ogni persona ha 46 cromosomi in totale (22 coppie di autosomi e una coppia di cromosomi sessuali).
La coppia 16, quindi, è costituita da due cromosomi identici chiamati "cromosoma 16 paterno" e "cromosoma 16 materno", che sono stati ereditati uno dal padre e l'altro dalla madre. Il cromosoma 16 è un autosoma, il che significa che non ha alcun ruolo nel determinare il sesso di una persona.
Il cromosoma 16 è composto da due bracci, chiamati "braccio p" e "braccio q", separati da un centromero. Il braccio p è più corto del braccio q. Entrambi i bracci contengono geni che codificano per proteine importanti per il corretto funzionamento dell'organismo umano.
Alcune condizioni genetiche sono state associate a mutazioni o anomalie nel cromosoma 16, come la sindrome di Prader-Willi e la sindrome di Angelman, che si verificano quando manca una copia funzionale del gene critico su uno dei due cromosomi 15. Tuttavia, non esiste una condizione nota associata specificamente alla coppia 16 in sé.
In sintesi, la coppia di cromosomi umani nota come "Coppie 16" si riferisce a due cromosomi identici che contengono geni importanti per il corretto funzionamento dell'organismo umano. Anomalie o mutazioni in questo cromosoma possono essere associate a determinate condizioni genetiche, ma non esiste una condizione nota associata specificamente alla coppia 16 in sé.
L'allineamento di sequenze è un processo utilizzato nell'analisi delle sequenze biologiche, come il DNA, l'RNA o le proteine. L'obiettivo dell'allineamento di sequenze è quello di identificare regioni simili o omologhe tra due o più sequenze, che possono fornire informazioni su loro relazione evolutiva o funzionale.
L'allineamento di sequenze viene eseguito utilizzando algoritmi specifici che confrontano le sequenze carattere per carattere e assegnano punteggi alle corrispondenze, alle sostituzioni e alle operazioni di gap (inserimento o cancellazione di uno o più caratteri). I punteggi possono essere calcolati utilizzando matrici di sostituzione predefinite che riflettono la probabilità di una particolare sostituzione aminoacidica o nucleotidica.
L'allineamento di sequenze può essere globale, quando l'obiettivo è quello di allineare l'intera lunghezza delle sequenze, o locale, quando si cerca solo la regione più simile tra due o più sequenze. Gli allineamenti multipli possono anche essere eseguiti per confrontare simultaneamente più di due sequenze e identificare relazioni evolutive complesse.
L'allineamento di sequenze è una tecnica fondamentale in bioinformatica e ha applicazioni in vari campi, come la genetica delle popolazioni, la biologia molecolare, la genomica strutturale e funzionale, e la farmacologia.
In genetica, un aplotipo è un gruppo di geni e markers genetici che sono ereditati insieme su un singolo cromosoma. L'aplotipo viene definito dal particolare allele di ogni gene nel gruppo e dai marcatori genetici (come SNP o VNTR) che si trovano tra quei geni.
Gli aplotipi sono utili nella medicina e nella ricerca genetica perché possono fornire informazioni sulla storia evolutiva di una popolazione, nonché sul rischio individuale di sviluppare determinate malattie o rispondere a determinati trattamenti. Ad esempio, l'analisi degli aplotipi può essere utilizzata per identificare i portatori di malattie genetiche, valutare la suscettibilità individuale alle malattie infettive e prevedere la risposta al trapianto d'organo o alla terapia farmacologica.
Gli aplotipi sono ereditati in blocchi da ciascun genitore, il che significa che un individuo eredita l'intero aplotipo da ogni genitore, piuttosto che una combinazione casuale di alleli. Ciò è dovuto al fenomeno della ricombinazione genetica, che si verifica durante la meiosi e può causare il riarrangiamento dei geni e dei marcatori all'interno di un cromosoma. Tuttavia, la frequenza con cui si verificano i riarrangiamentici dipende dalla distanza tra i geni e i marcatori, quindi gli aplotipi che contengono geni e marcatori strettamente legati sono più probabilità di essere ereditati insieme.
In sintesi, l'aplotipo è un importante concetto in genetica che descrive il pattern di ereditarietà di un gruppo di geni e markers genetici su un singolo cromosoma. Gli aplotipi possono fornire informazioni utili sulla storia evolutiva delle popolazioni, nonché sulla suscettibilità individuale alle malattie e alla risposta alla terapia.
La biologia computazionale è un campo interdisciplinare che combina metodi e tecniche delle scienze della vita, dell'informatica, della matematica e delle statistiche per analizzare e interpretare i dati biologici su larga scala. Essenzialmente, si tratta di utilizzare approcci computazionali e algoritmi per analizzare e comprendere i processi biologici complessi a livello molecolare.
Questo campo include l'uso di modelli matematici e simulazioni per descrivere e predire il comportamento dei sistemi biologici, come ad esempio la struttura delle proteine, le interazioni geni-proteine, i meccanismi di regolazione genica e le reti metaboliche. Inoltre, la biologia computazionale può essere utilizzata per analizzare grandi dataset sperimentali, come quelli generati da tecnologie high-throughput come il sequenziamento dell'intero genoma, il microarray degli RNA e la proteomica.
Gli strumenti e le metodologie della biologia computazionale sono utilizzati in una vasta gamma di applicazioni, tra cui la ricerca farmaceutica, la medicina personalizzata, la biodiversità, l'ecologia e l'evoluzione. In sintesi, la biologia computazionale è uno strumento potente per integrare e analizzare i dati biologici complessi, fornendo informazioni preziose per comprendere i meccanismi alla base della vita e applicarli a scopi pratici.
I modelli genetici sono l'applicazione dei principi della genetica per descrivere e spiegare i modelli di ereditarietà delle malattie o dei tratti. Essi si basano sulla frequenza e la distribuzione delle malattie all'interno di famiglie e popolazioni, nonché sull'analisi statistica dell'eredità mendeliana di specifici geni associati a tali malattie o tratti. I modelli genetici possono essere utilizzati per comprendere la natura della trasmissione di una malattia e per identificare i fattori di rischio genetici che possono influenzare lo sviluppo della malattia. Questi modelli possono anche essere utilizzati per prevedere il rischio di malattie nelle famiglie e nei membri della popolazione, nonché per lo sviluppo di strategie di diagnosi e trattamento personalizzate. I modelli genetici possono essere classificati in diversi tipi, come i modelli monogenici, che descrivono l'eredità di una singola malattia associata a un gene specifico, e i modelli poligenici, che descrivono l'eredità di malattie complesse influenzate da molteplici geni e fattori ambientali.
In medicina, l'espressione "sonde di DNA" si riferisce a brevi frammenti di DNA marcati chimicamente o radioattivamente, utilizzati in tecniche di biologia molecolare per identificare e localizzare specifiche sequenze di DNA all'interno di un campione di acido nucleico. Le sonde di DNA possono essere create in laboratorio mediante la reazione a catena della polimerasi (PCR) o l'isolamento da banche di DNA, e possono essere marcate con fluorofori, enzimi, isotiocianati o radioisotopi. Una volta create, le sonde vengono utilizzate in esperimenti come Northern blotting, Southern blotting, in situ hybridization e microarray, al fine di rilevare la presenza o l'assenza di specifiche sequenze di DNA target all'interno del campione. Queste tecniche sono fondamentali per la ricerca genetica, la diagnosi delle malattie genetiche e lo studio dei microrganismi patogeni.
Il genoma batterico si riferisce all'intero insieme di materiale genetico presente nel DNA di un batterio. Generalmente, il genoma batterico è formato da un unico cromosoma circolare, sebbene alcuni batteri possano avere più di un cromosoma o persino dei plasmidi, che sono piccole molecole di DNA extracromosomiale.
Il genoma batterico contiene tutte le informazioni genetiche necessarie per la crescita, lo sviluppo e la riproduzione del batterio. Ciò include i geni responsabili della sintesi delle proteine, del metabolismo dei nutrienti, della risposta ai segnali ambientali e della resistenza agli antibiotici, tra gli altri.
Negli ultimi anni, la tecnologia di sequenziamento dell'DNA ha permesso di determinare il genoma batterico di molti batteri diversi, fornendo informazioni preziose sulla loro biologia, evoluzione e patogenicità. L'analisi del genoma batterico può anche essere utilizzata per identificare i batteri a livello di specie e ceppo, nonché per rilevare eventuali mutazioni o variazioni che possano influenzare il loro comportamento o la loro interazione con l'ospite.
In biologia, le cellule ibride sono cellule che risultano dall'unione di due cellule diverse, generalmente attraverso un processo chiamato fusione cellulare. Questa tecnica è spesso utilizzata in laboratorio per creare cellule ibridi con specifiche caratteristiche desiderate. Ad esempio, una cellula umana e una cellula animale possono essere fuse insieme per creare una cellula ibrida che contenga il nucleo di entrambe le cellule.
Le cellule ibride possono anche verificarsi naturalmente in alcuni casi, come nella formazione dei globuli rossi nel midollo osseo. In questo caso, una cellula staminala ematopoietica si fonde con una cellula progenitrice eritroide per formare un precursore ibrido che poi maturerà in un globulo rosso funzionale.
Tuttavia, il termine "cellule ibride" è spesso associato alla tecnologia dei hybridoma, sviluppata da Georges Köhler e César Milstein nel 1975. Questa tecnica consiste nella fusione di un linfocita B (una cellula del sistema immunitario che produce anticorpi) con una linea cellulare tumorale immortale, come un mioloma. Il risultato è una cellula ibrida che ha le caratteristiche delle due cellule originali: produce anticorpi specifici come il linfocita B e può replicarsi indefinitamente come la linea cellulare tumorale. Queste cellule ibride, chiamate anche ibridomi, sono utilizzate nella produzione di anticorpi monoclonali per uso diagnostico e terapeutico.
I comosomi umani, anche noti come cromosomi, sono strutture a forma di bastoncello presenti nel nucleo delle cellule che contengono la maggior parte del DNA dell'organismo. L'uomo ha 23 coppie di cromosomi per un totale di 46 cromosomi in ogni cellula somatica. La coppia 12 dei comosomi umani è una delle 22 coppie di autosomi, che sono cromosomi non sessuali.
Ogni cromosoma della coppia 12 contiene due cromatidi identici legati insieme al centro da un centromero. I cromatidi sono costituiti da una lunga stringa di DNA che contiene migliaia di geni, che forniscono le istruzioni per la produzione delle proteine necessarie per lo sviluppo e il funzionamento dell'organismo.
La coppia 12 dei comosomi umani è relativamente grande e contiene circa 133 milioni di paia di basi di DNA ciascuno. I geni presenti su questo cromosoma sono responsabili di una varietà di caratteristiche e funzioni, tra cui il metabolismo, lo sviluppo degli arti superiori e la risposta immunitaria.
Le anomalie nella struttura o nel numero dei comosomi umani possono causare una serie di disturbi genetici e malattie. Ad esempio, una delezione o una duplicazione di una parte del cromosoma 12 può portare a disordini come la sindrome di Wolf-Hirschhorn o la sindrome di Potocki-Lupski. Inoltre, una coppia in più o in meno di comosomi umani (anomalie nel numero dei cromosomi, o aneuploidie) può causare condizioni come la sindrome di Down o la sindrome di Turner.
 Grafo d'intervallo
Grafo d'intervallo