Bactériophage T4
Bactériophage Lambda
Bactériophage T7
Lysogénie
Phages T
Bactériophage Mu
Bactériophage Phi 6
Escherichia Coli
Bactériophage Phi X 174
Bactériophage P2
Bactériophage M13
Bactériophage T3
Typage Bactériophage
Bactériophage P1
Phages De Salmonella
Siphoviridae
Phages
Bactériolyse
Bactériophage Prd1
Phages De Pseudomonas
Phages De Bacillus
Séquence Nucléotidique
Mutation
Données Séquence Moléculaire
Protéines Virales Queue
Levivirus
Génome Viral
Adsorption
Encapsidation De L'Adn
Plasmides
Prophages
Inovirus
Gènes
Génétique Microbienne
Dna-Directed Rna Polymerases
Sites D'Attachement (Microbiologie)
Recombinaison Génétique
Dna Restriction Enzymes
Séquence Des Acides Aminés
Viral Plaque Assay
Réplication Virale
Transduction (Génétique)
Adn Monocaténaire
Clonage Moléculaire
Centrifugation Gradient Densité
Microanalyse Par Sonde
Conformation Acide Nucléique
Cystoviridae
Bactériophage Pf1
Chloramphénicol
Température
Cartographie Chromosomique
Caudovirales
Isotopes Du Phosphore
Transcription Génétique
Dna-Directed Dna Polymérase
Test De Complémentation
Dna Primase
Tritium
Traitement Biologique
Microscopie Cryoélectronique
Host Specificity
Dna Nucleotidyltransferases
Matrice (Génétique)
Viral Regulatory and Accessory Proteins
Hybridation Acide Nucléique
Protéines Virales Structure
Opéron
Chromosomes Artificiels De Bactérie
Acide Phosphotungstique
Détermination Séquence Adn
Dénaturation Acide Nucléique
Thymine
Cadre Lecture Ouvert
Rayonnement Ultraviolet
Adn Recombinant
Cartographie De Restriction
Mitomycines
Polynucleotide Ligases
Site Fixation
Mycobactériophages
Adn Circulaire
Endodeoxyribonucleases
Effet Radiations
Integrases
Operator Regions, Genetic
Assemblage Virus
Exonucleases
Hélicase
Lactococcus Lactis
Microviridae
Adn
Rna Nucleotidyltransferases
Salmonella Typhimurium
Uracile
Modèle Moléculaire
Virion
Electrophoresis, Polyacrylamide Gel
Bactériophage Hk022
Régulation Expression Génique Virale
Corticoviridae
Endonucléases
Tectiviridae
Lysozyme
N-Acetylmuramoyl-L-Alanine Amidase
Thymidine
Récepteur Complément 3D
Pseudomonas
Nucléotide Thymidylique
Spécificité Espèce
Microbiologie Eau
Facteur F
Protéines Fixant Adn
Suppression Génétique
Electrophoresis, Agar Gel
Promoter Regions, Genetic
Liaison
Code Génétique
Conjugaison Génétique
Interférence Virale
Centrifugation De Zone
Homologie Séquentielle Acide Nucléique
Transformation Génétique
Gène Régulateur
Conformation Protéine
Système Acellulaire
Nucleotide Cytidylique
Transposons
Site-Specific Dna-Methyltransferase (Adenine-Specific)
Biosynthèse Des Protéines
Toxine Shiga
Facteurs D'Intégration De L'Hôte
Arn Bactérien
Pseudomonas Aeruginosa
Résistance Microbienne Aux Médicaments
Rna Ligase (Atp)
Colicines
Oligoribonucléotides
Rifampicine
Polynucleotide 5'-Hydroxyl-Kinase
Homologie Séquentielle Acides Aminés
Milieux De Culture
Césium
Biological Control Agents
Hot Temperature
Nucléotide
Répresseurs
Intégration Du Virus
Lactococcus
Alignement Séquences
Polynucléotides
Radio-Isotopes Du Phosphore
Paroi Cellulaire
Composition En Bases Nucléiques
Structure Tertiaire Protéine
Viabilité Microbienne
Spécificité Selon Substrat
Activation Virale
Bacillus
Renaturation Acide Nucléique
Shiga Toxin 2
Désoxyribonucléotide
Escherichia Coli O157
Acridines
Microscope
Bactériophage Ike
Streptococcus
Microvirus
Arn Bicaténaire
Phénotype
Adenosine Triphosphatases
Adn Superhélicoïdal
Chloroforme
Rec A Recombinases
Les bactériophages, également connus sous le nom de phages, sont des virus qui infectent et se répliquent dans les bactéries. Ils sont extrêmement spécifiques aux souches bactériennes hôtes et ne infectent pas les cellules humaines ou animales. Les bactériophages peuvent être trouvés dans une variété d'environnements, y compris l'eau, le sol, les plantes et les animaux.
Les bactériophages se lient à des récepteurs spécifiques sur la surface de la bactérie hôte et insèrent leur matériel génétique dans la cellule bactérienne. Ils peuvent ensuite suivre l'un des deux parcours de réplication : le chemin lytique ou le chemin lysogénique.
Dans le chemin lytique, les bactériophages prennent le contrôle du métabolisme de la cellule hôte et utilisent ses ressources pour se répliquer. Ils produisent de nombreuses copies d'eux-mêmes et finissent par lyser (rompre) la membrane cellulaire bactérienne, libérant de nouvelles particules virales dans l'environnement.
Dans le chemin lysogénique, les bactériophages s'intègrent dans le génome de la bactérie hôte et restent inactifs pendant plusieurs générations. Lorsque certaines conditions sont remplies, comme une quantité adéquate de dommages à l'ADN de la bactérie hôte, les bactériophages peuvent devenir actifs, se répliquer et libérer de nouvelles particules virales.
Les bactériophages ont été découverts en 1915 par Frederick Twort au Royaume-Uni et Félix d'Hérelle en France. Ils ont été largement étudiés comme agents thérapeutiques potentiels contre les infections bactériennes, connus sous le nom de phagothérapie. Cependant, l'avènement des antibiotiques a éclipsé cette approche dans la plupart des pays développés. Avec la montée des bactéries résistantes aux antibiotiques, les bactériophages sont à nouveau considérés comme une alternative prometteuse pour traiter ces infections.
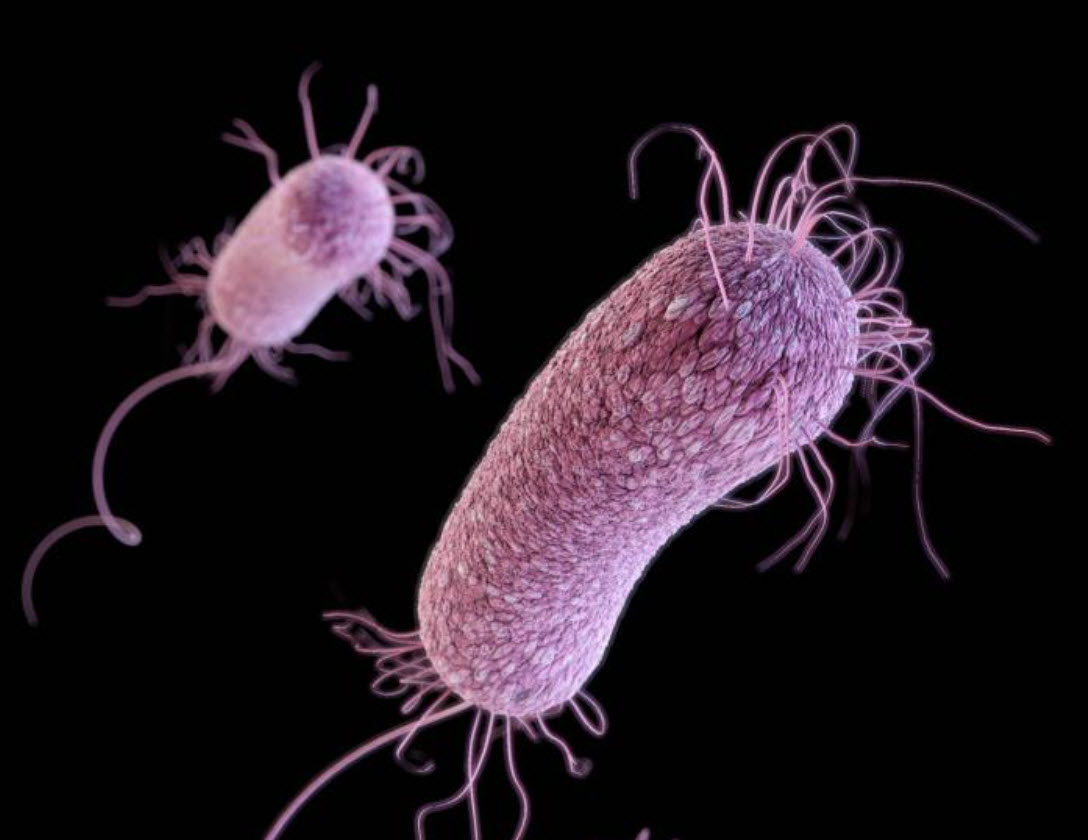
Un bactériophage T4, également connu sous le nom de phage T4, est un type spécifique de virus qui infecte exclusivement certaines souches de la bactérie Escherichia coli (E. coli). Il s'agit d'un grand virus avec une structure complexe constituée d'une capside icosaédrique et d'une queue longue et contractile.
Le bactériophage T4 se lie à des récepteurs spécifiques situés sur la surface de la bactérie hôte, ce qui permet au virus d'injecter son matériel génétique dans la cellule bactérienne. Une fois à l'intérieur de la bactérie, le matériel génétique du phage T4 prend le contrôle du métabolisme de la cellule hôte et force la bactérie à produire de nouvelles particules virales.
Au cours de ce processus, le phage T4 modifie également la paroi cellulaire de l'hôte pour faciliter la libération des nouveaux virus formés. En fin de compte, cela entraîne la lyse (rupture) de la bactérie hôte et la libération de centaines de nouvelles particules virales dans l'environnement, où elles peuvent infecter d'autres cellules bactériennes sensibles.
Le bactériophage T4 est largement étudié en raison de sa structure complexe et de son cycle de vie bien compris. Il sert de modèle pour l'étude des interactions entre les virus et leurs hôtes, ainsi que pour la compréhension des mécanismes moléculaires impliqués dans la réplication virale et l'assemblage des particules virales.
Un bactériophage lambda, souvent simplement appelé phage lambda, est un virus qui infecte exclusivement certaines souches de la bactérie E. coli. Il s'agit d'un virus très étudié en biologie moléculaire en raison de sa structure relativement simple et de son cycle de vie intéressant.
Le phage lambda a un génome constitué d'ADN double brin et est encapsulé dans une capside protectrice. Lorsqu'il infecte une bactérie E. coli, il peut suivre l'un des deux chemins possibles : le chemin lytique ou le chemin lysogénique.
Dans le chemin lytique, le phage lambda prend le contrôle de la machinerie cellulaire de la bactérie et utilise ses ressources pour se répliquer et produire de nouvelles particules virales. Ce processus entraîne finalement la lyse (la rupture) de la bactérie, libérant ainsi de nombreuses nouvelles particules virales dans l'environnement pour infecter d'autres bactéries.
Dans le chemin lysogénique, le phage lambda insère son génome dans celui de la bactérie hôte sous forme de prophage. Le prophage est répliqué avec la bactérie et transmis à sa descendance. Dans des conditions spécifiques, le prophage peut être induit pour suivre le chemin lytique et produire de nouvelles particules virales.
Le bactériophage lambda est un outil important en biologie moléculaire, utilisé notamment dans la génie génétique pour la construction de bibliothèques génomiques et pour l'ingénierie du génome.
Les coliphages sont des bacteriophages, ou virus qui infectent les bactéries, spécifiques aux souches de Escherichia coli (E. coli). Ils sont largement utilisés comme indicateurs de contamination fécale dans l'eau en raison de leur présence courante dans les déjections des animaux à sang chaud et des humains. Les coliphages peuvent survivre plus longtemps dans l'environnement que les bactéries pathogènes d'origine fécale, ce qui en fait un outil sensible pour la détection de la contamination potentielle par des agents pathogènes.
Les coliphages sont classés en deux groupes principaux : les coliphages F rares (ou narrow host range) et les coliphages M (ou broad host range). Les coliphages F rares infectent uniquement certaines souches d'E. coli qui portent le facteur de fructose (F), tandis que les coliphages M peuvent infecter un large éventail de souches d'E. coli et d'autres espèces bactériennes apparentées, telles que Shigella et Salmonella.
Les coliphages sont couramment détectés en utilisant des méthodes culturales, où des milieux nutritifs spécifiques sont inoculés avec des échantillons d'eau suspects et des bactéries indicatrices sensibles aux coliphages. Après incubation, la présence de plaques de lyse (zones claires entourant les colonies de bactéries lysées) indique la présence de coliphages infectieux dans l'échantillon.
En plus d'être utilisés comme indicateurs de contamination fécale, les coliphages sont également étudiés pour leur potentiel en thérapie phagique, une approche alternative aux antibiotiques pour traiter les infections bactériennes.
Un bactériophage T7 est un type spécifique de virus qui infecte exclusivement certaines souches de la bactérie Escherichia coli (E. coli). Il s'attache et se lie aux récepteurs sur la surface de la bactérie, puis insère son matériel génétique dans le génome bactérien. Après la réplication, les nouveaux virus se forment et finissent par éclater hors de la cellule hôte, entraînant souvent sa mort.
Le bactériophage T7 est largement étudié en virologie et en biologie moléculaire en raison de sa petite taille, de son cycle de vie court et de son génome simple composé d'ADN à double brin. Il a été utilisé comme modèle pour comprendre les mécanismes fondamentaux de la réplication virale, de la transcription et de l'assemblage.
Le bactériophage T7 est également étudié dans le contexte de la thérapie phagique, une stratégie visant à utiliser des virus pour traiter les infections bactériennes. Cette approche pourrait offrir une alternative ou un complément aux antibiotiques traditionnels, en particulier face à l'augmentation de la résistance antimicrobienne.
La lysogénie est un processus dans lequel un bacteriophage, un type de virus qui infecte les bactéries, s'intègre dans le génome de la bactérie hôte au lieu de suivre son cycle de réplication et de lyse normaux. Dans ce processus, l'ADN du bacteriophage est inséré dans l'ADN de la bactérie hôte sous forme de prophage. Le bacteriophage reste alors inactif, souvent pendant plusieurs générations, sans perturber les fonctions normales de la bactérie hôte.
Cependant, des conditions spécifiques peuvent activer le prophage, ce qui entraîne la transcription et la traduction des gènes du bacteriophage. Cela conduit à la production de nouveaux virus et finalement à la lyse de la bactérie hôte, libérant ainsi de nombreux nouveaux bacteriophages dans l'environnement pour infecter d'autres bactéries.
La lysogénie est un exemple important de relation symbiotique entre les virus et leurs hôtes, avec des implications significatives pour la génétique, la biologie évolutive et la pathogenèse bactérienne.
Les bacteriophages, souvent simplement appelés phages, sont des virus qui infectent et se répliquent dans les bactéries. Les phages thérapeutiques (Phages T) font référence à l'utilisation de ces virus pour traiter les infections bactériennes.
Chaque type de phage est spécifique à une certaine souche ou espèce de bactérie, ce qui signifie qu'ils ne tuent que les bactéries ciblées sans affecter les cellules humaines ou d'autres micro-organismes. Cela en fait un outil potentiellement précieux dans le traitement des infections bactériennes résistantes aux antibiotiques.
Les phages thérapeutiques peuvent être administrés par voie topique, orale ou intraveineuse, selon l'emplacement et la gravité de l'infection. Bien que cette forme de thérapie ait été utilisée dans le passé, en particulier en Europe de l'Est, avant l'ère des antibiotiques, elle n'est pas largement acceptée ou approuvée par les organismes de réglementation médicale aux États-Unis et dans d'autres pays développés. Cependant, face à la crise croissante de la résistance aux antimicrobiens, il y a un regain d'intérêt pour explorer le potentiel des phages thérapeutiques comme alternative ou complément aux antibiotiques traditionnels.
Un bactériophage Mu, également connu sous le nom de bacteriophage φX174, est un type de virus qui infecte exclusivement les bactéries. Plus précisément, il s'attaque à la bactérie Escherichia coli (E. coli). Le bactériophage Mu est un virus à ADN non enveloppé, ce qui signifie qu'il n'a pas de membrane lipidique entourant son matériel génétique.
Ce type de bactériophage est connu pour sa capacité à s'intégrer dans le génome de la bactérie hôte, ou autrement dit, il peut insérer son propre matériel génétique dans l'ADN de la bactérie. Cela permet au virus de se répliquer avec la bactérie et de se propager plus efficacement. Lorsque la bactérie hôte se divise, le bactériophage Mu est également dupliqué, ce qui entraîne la production de nouvelles particules virales.
Le bactériophage Mu est un sujet d'étude important en virologie et en biologie moléculaire en raison de sa capacité à se réarranger génétiquement et à évoluer rapidement, ce qui le rend particulièrement intéressant pour les recherches sur l'évolution des virus et la manipulation génétique.
Le bactériophage Phi 6 est un type spécifique de virus qui infecte exclusivement certaines souches de bactéries. Dans ce cas, le bactériophage Phi 6 est connu pour infecter la bactérie Pseudomonas syringae pathovar phaseolicola. Ce phage est souvent étudié en raison de sa structure complexe et de son cycle de vie intéressant, qui comprend des étapes de réplication lytique et lysogénique.
Le bactériophage Phi 6 a une capside icosaédrique composée de trois types différents de protéines de capside. Il possède également une queue complexe avec des fibres terminales qui lui permettent de se lier spécifiquement à la surface de sa bactérie hôte. Une fois lié, le phage peut injecter son matériel génétique dans la cellule bactérienne et commencer le processus de réplication.
Le cycle de vie du bactériophage Phi 6 peut être lytique ou lysogénique, selon les conditions environnementales. Dans le cycle lytique, le phage prend le contrôle de la machinerie cellulaire de la bactérie et produit de nombreuses copies de lui-même avant que la cellule ne soit lysée (détruite) et que les nouveaux phages soient libérés dans l'environnement. Dans le cycle lysogénique, le matériel génétique du phage s'intègre dans le génome de la bactérie hôte et peut rester inactif pendant plusieurs générations avant d'être activé et de commencer à se répliquer.
Le bactériophage Phi 6 est souvent utilisé comme modèle pour étudier les interactions entre les virus et les bactéries, ainsi que pour comprendre les mécanismes moléculaires impliqués dans la réplication virale et l'évolution des phages.
L'ADN viral fait référence à l'acide désoxyribonucléique (ADN) qui est présent dans le génome des virus. Le génome d'un virus peut être composé d'ADN ou d'ARN (acide ribonucléique). Les virus à ADN ont leur matériel génétique sous forme d'ADN, soit en double brin (dsDNA), soit en simple brin (ssDNA).
Les virus à ADN peuvent infecter les cellules humaines et utiliser le mécanisme de réplication de la cellule hôte pour se multiplier. Certains virus à ADN peuvent s'intégrer dans le génome de la cellule hôte et devenir partie intégrante du matériel génétique de la cellule. Cela peut entraîner des changements permanents dans les cellules infectées et peut contribuer au développement de certaines maladies, telles que le cancer.
Il est important de noter que la présence d'ADN viral dans l'organisme ne signifie pas nécessairement qu'une personne est malade ou présentera des symptômes. Cependant, dans certains cas, l'ADN viral peut entraîner une infection active et provoquer des maladies.
Escherichia coli (E. coli) est une bactérie gram-negative, anaérobie facultative, en forme de bâtonnet, appartenant à la famille des Enterobacteriaceae. Elle est souvent trouvée dans le tractus gastro-intestinal inférieur des humains et des animaux warms blooded. La plupart des souches d'E. coli sont inoffensives et font partie de la flore intestinale normale, mais certaines souches peuvent causer des maladies graves telles que des infections urinaires, des méningites, des septicémies et des gastro-entérites. La souche la plus courante responsable d'infections diarrhéiques est E. coli entérotoxigénique (ETEC). Une autre souche préoccupante est E. coli producteur de shigatoxines (STEC), y compris la souche hautement virulente O157:H7, qui peut provoquer des colites hémorragiques et le syndrome hémolytique et urémique. Les infections à E. coli sont généralement traitées avec des antibiotiques, mais certaines souches sont résistantes aux médicaments couramment utilisés.
Le bactériophage Phi X 174 est un type spécifique de virus qui infecte exclusivement certaines souches de la bactérie E. coli. Il s'agit d'un petit virus à ADN monocaténaire, ce qui signifie qu'il contient une seule molécule d'ADN circulaire simple brin. Ce bactériophage est largement étudié en virologie et en biologie moléculaire en raison de sa petite taille, de sa structure relativement simple et de son génome bien caractérisé.
Le Phi X 174 a un diamètre d'environ 25 nanomètres et une capside icosaédrique, qui est la forme géométrique protectrice entourant le matériel génétique du virus. Sa petite taille et sa structure simple en ont fait un organisme modèle important pour étudier les interactions entre les virus et leurs hôtes bactériens, ainsi que pour comprendre les mécanismes fondamentaux de la réplication, de la transcription et de la traduction de l'ADN.
Le Phi X 174 est également connu pour sa capacité à empaqueter son génome sous forme d'une molécule d'ADN circulaire double brin dans la capside du virus, ce qui en fait un membre des Caudovirales, un ordre de virus à queue. Ce virus a été le premier dont le génome a été entièrement séquencé, ce qui s'est produit en 1977. Depuis lors, il continue d'être un organisme modèle important pour la recherche en virologie et en biologie moléculaire.
Les protéines virales sont des molécules protéiques essentielles à la structure et à la fonction des virus. Elles jouent un rôle crucial dans presque tous les aspects du cycle de vie d'un virus, y compris l'attachement et l'entrée dans une cellule hôte, la réplication du génome viral, l'assemblage de nouvelles particules virales et la libération de ces particules pour infecter d'autres cellules.
Les protéines virales peuvent être classées en plusieurs catégories fonctionnelles :
1. Protéines de capside : Ces protéines forment la structure protectrice qui entoure le matériel génétique du virus. Elles sont souvent organisées en une structure géométrique complexe et stable.
2. Protéines d'enveloppe : Certaines espèces de virus possèdent une membrane lipidique externe, ou enveloppe virale, qui est dérivée de la membrane cellulaire de l'hôte infecté. Les protéines virales intégrées dans cette enveloppe jouent un rôle important dans le processus d'infection, comme l'attachement aux récepteurs de la cellule hôte et la fusion avec la membrane cellulaire.
3. Protéines de matrice : Ces protéines se trouvent sous la membrane lipidique externe des virus enveloppés et sont responsables de l'organisation et de la stabilité de cette membrane. Elles peuvent également participer à d'autres étapes du cycle viral, comme la réplication et l'assemblage.
4. Protéines non structurées : Ces protéines n'ont pas de rôle direct dans la structure du virus mais sont importantes pour les fonctions régulatrices et enzymatiques pendant le cycle de vie du virus. Par exemple, certaines protéines virales peuvent agir comme des polymerases, des protéases ou des ligases, catalysant des réactions chimiques essentielles à la réplication et à l'assemblage du génome viral.
5. Protéines d'évasion immunitaire : Certains virus produisent des protéines qui aident à échapper aux défenses de l'hôte, comme les interférons, qui sont des molécules clés du système immunitaire inné. Ces protéines peuvent inhiber la production ou l'activation des interférons, permettant au virus de se répliquer plus efficacement et d'éviter la détection par le système immunitaire.
En résumé, les protéines virales jouent un rôle crucial dans tous les aspects du cycle de vie des virus, y compris l'attachement aux cellules hôtes, la pénétration dans ces cellules, la réplication et l'assemblage du génome viral, et l'évasion des défenses immunitaires de l'hôte. Comprendre la structure et la fonction de ces protéines est essentiel pour développer des stratégies thérapeutiques et préventives contre les maladies infectieuses causées par les virus.
Un bactériophage P2 est un type spécifique de virus qui infecte exclusivement certaines souches de bactéries, en particulier E. coli. Les bactériophages sont des virus qui infectent et se répliquent dans les bactéries, ce qui peut entraîner la mort ou l'inactivation de ces dernières.
Le bactériophage P2 est un virus à double brin à ADN, ce qui signifie qu'il contient deux molécules d'ADN complémentaires qui forment une structure en forme de double hélice. Il a un génome relativement petit et code pour environ 20 protéines différentes.
Le bactériophage P2 se lie à la surface des bactéries cibles en reconnaissant des récepteurs spécifiques sur leur surface. Une fois lié, il injecte son ADN dans la bactérie et prend le contrôle de son métabolisme pour produire de nouvelles particules virales. Après avoir assemblé de nombreuses copies de lui-même, le bactériophage P2 déclenche la lyse de la bactérie, ce qui libère les nouveaux virus dans l'environnement et permet ainsi leur propagation.
Le bactériophage P2 est un outil important en biologie moléculaire car il peut être utilisé pour introduire des gènes étrangers dans des bactéries hôtes, ce qui permet de produire des protéines recombinantes à grande échelle. Il est également étudié comme agent thérapeutique potentiel contre les infections bactériennes, en particulier celles résistantes aux antibiotiques.
Un bactériophage M13 est un type spécifique de virus qui infecte exclusivement certaines souches de la bactérie E. coli. Il est classé comme un filamenteux, ou « filamenteux », car il a une forme allongée et fine qui ressemble à une tige. Le bactériophage M1
Un bactériophage T3 est un type spécifique de virus qui infecte exclusivement certaines souches de la bactérie Escherichia coli (E. coli). Il s'attache et s'injecte dans la bactérie, où il utilise le matériel génétique de la cellule hôte pour se répliquer et produire de nouvelles particules virales. Après avoir terminé ce processus, le bactériophage T3 déclenche la lyse (explosion) de la bactérie, libérant ainsi de nombreuses copies du virus dans l'environnement pour infecter d'autres cellules hôtes.
Le bactériophage T3 est un virus à ADN non enveloppé, ce qui signifie qu'il ne possède pas d'enveloppe lipidique externe. Son génome est constitué d'une molécule d'ADN linéaire double brin d'environ 40 kilobases de paires de bases. Le bactériophage T3 se lie et infecte les souches d'E. coli qui expriment le récepteur de la lysozyme E, ce qui lui permet de reconnaître et d'infecter spécifiquement ces cellules hôtes.
Le bactériophage T3 est un virus très bien étudié et a été utilisé comme modèle pour comprendre les mécanismes moléculaires de la réplication, de l'assemblage et du cycle de vie des bactériophages. Il sert également de vecteur clonage dans la recherche génétique et moléculaire en raison de sa capacité à transporter et à exprimer des fragments d'ADN étrangers dans les cellules hôtes E. coli.
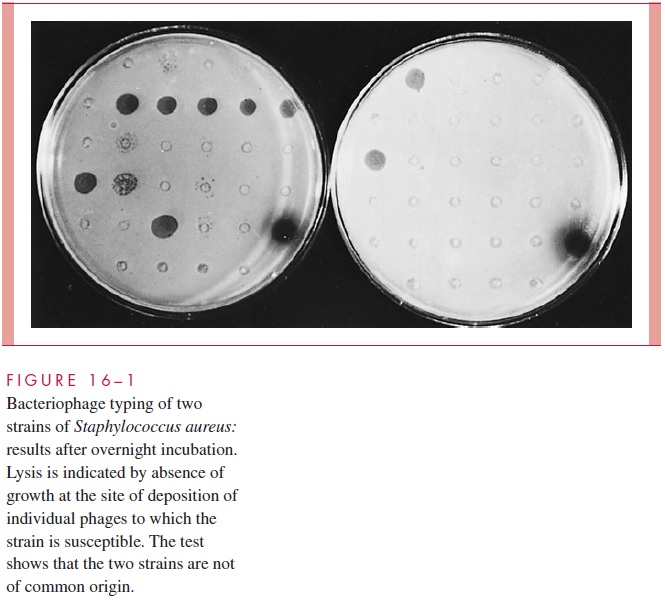
Le typage bactériophage est un processus utilisé en microbiologie pour classer et identifier différents types (ou souches) de bactériophages, qui sont des virus qui infectent et se répliquent dans des bactéries. Ce processus consiste généralement à examiner les propriétés morphologiques et physiologiques des bactériophages, telles que leur forme, leur taille, leur structure, leur mode de réplication et leur hôte préféré.
Le typage bactériophage peut être effectué en utilisant une variété de techniques, y compris la microscopie électronique, l'analyse de séquences génomiques, l'hôte-gamme et les tests d'inactivation. Les résultats de ces tests peuvent être utilisés pour classer les bactériophages en différents types ou groupes, ce qui peut aider à prédire leur comportement dans des environnements spécifiques et à déterminer leur potentiel d'utilisation en thérapie phagique, une forme de thérapie antimicrobienne qui utilise des bactériophages pour traiter les infections bactériennes.
Il est important de noter que le typage bactériophage est un domaine en évolution rapide, car de nouvelles techniques et méthodes sont constamment développées pour améliorer la précision et la sensibilité du processus de classification.
Un bactériophage P1 est un type spécifique de virus qui infecte exclusivement les bactéries, en particulier Escherichia coli (E. coli). Il s'agit d'un virus à double brin à ADN, appartenant à la famille des Myoviridae.
Le bactériophage P1 est connu pour sa capacité à se répliquer de manière lytique et lysogénique dans les hôtes bactériens. Dans le mode de réplication lytique, il s'attache à la surface de la bactérie, injecte son ADN dans le cytoplasme et utilise le métabolisme de la cellule hôte pour se répliquer et produire de nouvelles particules virales. Ce processus entraîne finalement la lyse (éclatement) de la bactérie, libérant ainsi les nouveaux virus dans l'environnement.
Dans le mode de réplication lysogénique, le bactériophage P1 s'intègre dans le génome de l'hôte bactérien sous forme de prophage et se réplique passivement avec la cellule hôte sans provoquer de lyse. Le virus peut rester latent pendant plusieurs générations avant d'être déclenché pour passer en mode de réplication lytique.
Le bactériophage P1 est également connu pour son utilisation dans les techniques de clonage et d'ingénierie génétique, car il peut transporter des fragments d'ADN étrangers importants dans sa capside lorsqu'il infecte une nouvelle cellule hôte. Cela en fait un outil précieux pour la manipulation et le transfert de gènes entre différentes souches bactériennes ou même entre les bactéries et d'autres organismes.
Les phages de Salmonella sont des virus qui infectent spécifiquement les bactéries du genre Salmonella. Ces bactéries sont souvent à l'origine d'intoxications alimentaires courantes, provoquant des symptômes tels que la diarrhée, des nausées, des vomissements et des crampes abdominales.
Les phages de Salmonella se lient aux récepteurs spécifiques à la surface des bactéries hôtes et s'injectent ensuite leur matériel génétique. Ce processus peut entraîner la lyse de la bactérie hôte, ce qui signifie qu'elle est décomposée et détruite par le phage. Les phages de Salmonella peuvent être utilisés comme un moyen possible de contrôle des infections à Salmonella, bien que leur utilisation soit encore expérimentale et fasse l'objet de recherches en cours.
Il est important de noter que les phages ne sont pas nocifs pour les humains ou les animaux, car ils ne infectent que des bactéries spécifiques. Cependant, comme avec tout traitement expérimental, il est important de consulter un professionnel de la santé avant de décider d'un plan de traitement.
Siphoviridae est une famille de virus appartenant à l'ordre des Caudovirales, qui sont des virus à double brin à ADN. Les membres de cette famille sont caractérisés par leur queue longue et flexible, qui est non contractile. La longueur de la queue peut varier considérablement d'un membre à l'autre.
Les virions (particules virales) des Siphoviridae ont une tête icosaédrique régulière avec un diamètre d'environ 60 nanomètres. La queue est attachée à l'une des faces de la tête et se compose d'une base plate et d'une longue tige flexible qui se termine par six fibres terminales.
Les Siphoviridae infectent une grande variété d'hôtes, y compris les bactéries, les archées et les levures. Ils sont largement répandus dans l'environnement et jouent un rôle important dans la régulation des populations microbiennes. Les membres de cette famille comprennent des phages bien connus tels que le phage lambda, qui infecte Escherichia coli, et le phage T4, qui infecte les bactéries du genre Bacillus.
Les Siphoviridae sont également étudiés pour leur potentiel en thérapie génique et en biocontrôle, car ils peuvent être utilisés pour délivrer des gènes dans des cellules cibles ou pour lutter contre les bactéries pathogènes.
Les gènes viraux se réfèrent aux segments d'ADN ou d'ARN qui composent le génome des virus et codent pour les protéines virales essentielles à leur réplication, infection et propagation. Ces gènes peuvent inclure ceux responsables de la production de capside (protéines structurelles formant l'enveloppe du virus), des enzymes de réplication et de transcription, ainsi que des protéines régulatrices impliquées dans le contrôle du cycle de vie viral.
Dans certains cas, les gènes viraux peuvent également coder pour des facteurs de pathogénicité, tels que des protéines qui suppriment la réponse immunitaire de l'hôte ou favorisent la libération et la transmission du virus. L'étude des gènes viraux est cruciale pour comprendre les mécanismes d'infection et de pathogenèse des virus, ce qui permet le développement de stratégies thérapeutiques et préventives ciblées contre ces agents infectieux.
Bactériolyse est le processus par lequel certaines bactéries sont détruites ou digérées par des enzymes produites par d'autres micro-organismes, des phagocytes ou des cellules immunitaires. Ce terme est souvent utilisé dans le contexte de la recherche médicale et microbiologique pour décrire l'action de certaines bactériophages (virus qui infectent et se multiplient dans les bactéries) ou de certains composés antibactériens qui peuvent provoquer la lyse, ou la destruction, des parois cellulaires bactériennes. La bactériolyse est un mécanisme important de défense de l'organisme contre les infections bactériennes et joue également un rôle dans le contrôle de la croissance des populations bactériennes dans les milieux naturels.
Le bactériophage Prd1 est un type spécifique de virus qui infecte exclusivement certaines souches de bactéries, en l'occurrence les bactéries Gram-négatives du genre Photobacterium profundum. Ces bactériophages ont une structure complexe et se caractérisent par la présence d'une queue longue et flexible, ce qui leur permet de reconnaître et d'attaquer sélectivement leurs hôtes bactériens spécifiques.
Le bactériophage Prd1 possède un génome à ADN double brin et suit un cycle de réplication virale complexe impliquant l'assemblage de protéines structurales et la réplication de son matériel génétique dans le cytoplasme de la bactérie hôte. Une fois que le virus a assemblé ses composants, il est capable de se libérer de la cellule bactérienne en lyseant la membrane cellulaire, ce qui permet au virus d'infecter d'autres bactéries et de poursuivre son cycle de réplication.
Les bactériophages comme Prd1 sont des agents potentiellement utiles dans le traitement des infections bactériennes, car ils peuvent cibler spécifiquement certaines souches de bactéries sans affecter les cellules humaines ou animales. Cette propriété en fait des candidats prometteurs pour une thérapie antimicrobienne ciblée et pourrait offrir une alternative aux antibiotiques traditionnels, qui sont souvent moins spécifiques et peuvent entraîner une résistance bactérienne accrue.
Les phages de Pseudomonas sont des types spécifiques de bacteriophages, qui sont des virus qui infectent et se répliquent dans les bactéries. Plus précisément, ils infectent la bactérie Pseudomonas aeruginosa, une bactérie gram-négative courante qui peut causer des infections opportunistes chez l'homme.
Les phages de Pseudomonas sont étudiés pour leur potentiel thérapeutique dans le traitement des infections à Pseudomonas aeruginosa, en particulier chez les patients atteints de fibrose kystique et d'autres maladies chroniques qui peuvent développer une résistance aux antibiotiques. Les phages de Pseudomonas se lient spécifiquement à des récepteurs situés sur la surface de Pseudomonas aeruginosa, ce qui leur permet de s'y fixer et d'injecter leur matériel génétique dans la bactérie.
Une fois que le phage a infecté la bactérie, il utilise les mécanismes cellulaires de la bactérie pour se répliquer et produire de nouvelles particules virales. Ce processus peut entraîner la lyse de la bactérie, ce qui signifie qu'elle éclate et meurt, libérant ainsi de nouvelles particules virales dans l'environnement pour infecter d'autres bactéries Pseudomonas aeruginosa.
Les phages de Pseudomonas sont un domaine de recherche actif en raison de leur potentiel à fournir une alternative aux antibiotiques pour traiter les infections résistantes, ainsi que pour leur capacité à cibler spécifiquement certaines souches de bactéries sans affecter les autres micro-organismes bénéfiques.
Les phages de Staphylococcus, également connus sous le nom de bacteriophages de Staphylococcus aureus, sont des virus qui infectent et se répliquent dans les bactéries du genre Staphylococcus, en particulier Staphylococcus aureus. Ces phages sont spécialisés et ne peuvent infecter que certaines souches de staphylocoques. Ils jouent un rôle important dans la régulation des populations bactériennes dans les environnements naturels.
Les phages de Staphylococcus peuvent être utilisés comme agents thérapeutiques potentiels pour traiter les infections à staphylocoques, en particulier celles qui sont résistantes aux antibiotiques. Cette approche, appelée phagothérapie, consiste à utiliser des phages spécifiques pour cibler et éliminer les bactéries pathogènes sans affecter les bactéries bénéfiques. Cependant, l'utilisation de la phagothérapie est encore expérimentale et nécessite davantage de recherches et de preuves pour établir son efficacité et sa sécurité dans le traitement des infections bactériennes.
Les "Phages de Bacillus" se réfèrent à des bacteriophages, qui sont des virus qui infectent et se répliquent dans des bactéries, spécifiquement celles de l'espèce Bacillus. Les bacteriophages sont des prédateurs naturels des bactéries et peuvent être utilisés comme un agent de contrôle des bactéries dans les applications médicales et industrielles. Les phages de Bacillus ont démontré un potentiel particulier dans le traitement des infections causées par des souches résistantes aux antibiotiques de Bacillus, telles que Bacillus anthracis (anthrax) et Bacillus cereus (intoxications alimentaires). Cependant, il est important de noter que l'utilisation de phages thérapeutiques est encore en cours d'étude et n'est pas largement approuvée dans de nombreux pays.
Podoviridae est une famille de virus à ADN double brin qui infectent principalement les bactéries. Ils sont classés dans l'ordre Caudovirales et possèdent une queue courte et non contractile attachée à leur capside icosaédrique. Les membres de cette famille comprennent des phages tels que le T7, qui est bien étudié pour son cycle de réplication lytique rapide et efficace. Les podoviridés se lient et injectent leur ADN dans la bactérie hôte en perçant sa membrane cellulaire avec leur queue. Une fois à l'intérieur, le génome viral prend le contrôle de la machinerie cellulaire bactérienne pour produire de nouvelles particules virales avant que le phage ne se libère en lyse de la cellule hôte. Ces virus jouent un rôle important dans l'écologie microbienne et sont étudiés comme agents potentiels de biocontrôle des bactéries pathogènes.
Les phages de Streptococcus, également connus sous le nom de bacteriophages streptococciques, sont des virus qui infectent et se répliquent dans les bactéries du genre Streptococcus. Ces bactéries comprennent diverses espèces pathogènes pour l'homme, telles que Streptococcus pyogenes (streptocoque bêta-hémolytique du groupe A), Streptococcus pneumoniae (pneumocoque) et Streptococcus agalactiae (streptocoque du groupe B).
Les phages de Streptococcus sont étudiés dans le cadre de la recherche sur les thérapies antimicrobiennes, en particulier pour lutter contre les infections résistantes aux antibiotiques. Les phages peuvent être spécifiques à une souche bactérienne donnée, ce qui permet une thérapie ciblée et évite de perturber la microflore normale. Cependant, il est important de noter que l'utilisation de phages comme traitement médical fait toujours l'objet de recherches et n'est pas largement adoptée dans la pratique clinique actuelle.
Une séquence nucléotidique est l'ordre spécifique et linéaire d'une série de nucléotides dans une molécule d'acide nucléique, comme l'ADN ou l'ARN. Chaque nucléotide se compose d'un sucre (désoxyribose dans le cas de l'ADN et ribose dans le cas de l'ARN), d'un groupe phosphate et d'une base azotée. Les bases azotées peuvent être adénine (A), guanine (G), cytosine (C) et thymine (T) dans l'ADN, tandis que dans l'ARN, la thymine est remplacée par l'uracile (U).
La séquence nucléotidique d'une molécule d'ADN ou d'ARN contient des informations génétiques cruciales qui déterminent les caractéristiques et les fonctions de tous les organismes vivants. La décodage de ces séquences, appelée génomique, est essentiel pour comprendre la biologie moléculaire, la médecine et la recherche biologique en général.
En génétique, une mutation est une modification permanente et héréditaire de la séquence nucléotidique d'un gène ou d'une région chromosomique. Elle peut entraîner des changements dans la structure et la fonction des protéines codées par ce gène, conduisant ainsi à une variété de phénotypes, allant de neutres (sans effet apparent) à délétères (causant des maladies génétiques). Les mutations peuvent être causées par des erreurs spontanées lors de la réplication de l'ADN, l'exposition à des agents mutagènes tels que les radiations ou certains produits chimiques, ou encore par des mécanismes de recombinaison génétique.
Il existe différents types de mutations, telles que les substitutions (remplacement d'un nucléotide par un autre), les délétions (suppression d'une ou plusieurs paires de bases) et les insertions (ajout d'une ou plusieurs paires de bases). Les conséquences des mutations sur la santé humaine peuvent être très variables, allant de maladies rares à des affections courantes telles que le cancer.
Les données de séquence moléculaire se réfèrent aux informations génétiques ou protéomiques qui décrivent l'ordre des unités constitutives d'une molécule biologique spécifique. Dans le contexte de la génétique, cela peut inclure les séquences d'ADN ou d'ARN, qui sont composées d'une série de nucléotides (adénine, thymine, guanine et cytosine pour l'ADN; adénine, uracile, guanine et cytosine pour l'ARN). Dans le contexte de la protéomique, cela peut inclure la séquence d'acides aminés qui composent une protéine.
Ces données sont cruciales dans divers domaines de la recherche biologique et médicale, y compris la génétique, la biologie moléculaire, la médecine personnalisée, la pharmacologie et la pathologie. Elles peuvent aider à identifier des mutations ou des variations spécifiques qui peuvent être associées à des maladies particulières, à prédire la structure et la fonction des protéines, à développer de nouveaux médicaments ciblés, et à comprendre l'évolution et la diversité biologique.
Les technologies modernes telles que le séquençage de nouvelle génération (NGS) ont rendu possible l'acquisition rapide et économique de vastes quantités de données de séquence moléculaire, ce qui a révolutionné ces domaines de recherche. Cependant, l'interprétation et l'analyse de ces données restent un défi important, nécessitant des méthodes bioinformatiques sophistiquées et une expertise spécialisée.
Les protéines virales queue, également connues sous le nom de protéines virales de capside, sont des protéines structurales que l'on trouve à l'extrémité des virus non enveloppés. Ces protéines forment une structure en forme de queue à une extrémité du virion et jouent un rôle crucial dans le processus d'infection du virus.
La queue de la protéine virale est souvent composée de plusieurs molécules répétitives de protéines qui sont disposées de manière ordonnée pour former une structure en forme de tige ou de tube. Cette structure permet au virus d'interagir avec les récepteurs des cellules hôtes et de faciliter l'entrée du génome viral dans la cellule hôte.
Les protéines virales queue peuvent également jouer un rôle dans la détermination de l'hôte spécifique du virus, ainsi que dans la médiation de l'assemblage et de la libération du virion à partir de la cellule hôte infectée.
Il est important de noter que toutes les souches de virus ne possèdent pas de protéines virales queue, car cette caractéristique structurelle est limitée aux virus non enveloppés. Les virus enveloppés, qui ont une membrane lipidique externe, n'ont pas de queue de protéine virale et utilisent plutôt des glycoprotéines pour interagir avec les récepteurs des cellules hôtes.
Les Leviviruses, également connus sous le nom de Leviviridae, sont des virus à ARN monocaténaire qui infectent principalement les bactéries. Ils sont classés dans le groupe IV de la classification de Baltimore des virus. Les levivirus ont une structure nucléocapsidique et ne possèdent pas d'enveloppe lipidique. Leur génome est constitué d'un seul brin d'ARN qui code pour quatre protéines structurales et une protéine de replication. Les levivirus sont responsables de diverses maladies chez les bactéries, entraînant souvent des lésions cellulaires et la mort de la cellule hôte. Cependant, il convient de noter que les levivirus ne sont pas considérés comme des agents pathogènes humains et ne présentent donc pas de risque pour la santé humaine.
Le génome viral se réfère à l'ensemble complet de gènes ou matériel génétique qu'un virus contient. Il peut être composé d'ADN (acide désoxyribonucléique) ou d'ARN (acide ribonucléique), et peut être soit à double brin, soit à simple brin. La taille du génome viral varie considérablement selon les différents types de virus, allant de quelques kilobases à plusieurs centaines de kilobases. Le génome viral contient toutes les informations nécessaires à la réplication et à la propagation du virus dans l'hôte infecté.
L'adsorption est un processus dans lequel des atomes, des ions ou des molécules se fixent à la surface d'un matériau adsorbant. Dans un contexte médical, l'adsorption est importante dans plusieurs domaines, tels que la pharmacologie et la toxicologie.
Dans la pharmacologie, l'adsorption fait référence à la fixation des médicaments sur les surfaces des matériaux avec lesquels ils entrent en contact après l'administration. Ce processus affecte la biodisponibilité et la vitesse d'action du médicament. Par exemple, lorsque vous prenez un médicament par voie orale, il doit d'abord être adsorbé dans le tractus gastro-intestinal avant de pénétrer dans la circulation sanguine et d'atteindre ses sites cibles dans le corps.
Dans la toxicologie, l'adsorption est un mécanisme important de détoxification. Les toxines peuvent être adsorbées par des charbons activés ou d'autres matériaux absorbants, ce qui empêche leur absorption dans le corps et favorise leur élimination.
En résumé, l'adsorption est un processus crucial dans la médecine car il affecte la façon dont les médicaments sont distribués et éliminés dans le corps, ainsi que la manière dont les toxines sont neutralisées et éliminées.
L'encapsidation de l'ADN est un processus dans lequel l'acide désoxyribonucléique (ADN) d'un virus est empaqueté dans une protéine appelée capside pour former une particule virale infectieuse. La capside protège l'ADN du virus contre les enzymes et autres défenses de l'hôte, permettant ainsi au virus de survivre à l'extérieur d'une cellule hôte et de se répliquer une fois qu'il a infecté une nouvelle cellule.
Le processus d'encapsidation est spécifique à chaque type de virus et peut être déclenché par des signaux moléculaires spécifiques. Dans certains cas, l'ADN du virus doit être coupé ou modifié avant qu'il ne puisse être encapsidé. Une fois que l'ADN est empaqueté dans la capside, il peut être recouvert d'une enveloppe lipidique supplémentaire pour former un virion mature.
L'encapsidation de l'ADN est une étape clé du cycle de réplication des virus et est donc un domaine important de recherche dans le développement de thérapies antivirales.
La réplication de l'ADN est un processus biologique essentiel à la vie qui consiste à dupliquer ou à copier l'information génétique contenue dans l'acide désoxyribonucléique (ADN) avant que la cellule ne se divise. Ce processus permet de transmettre fidèlement les informations génétiques des parents aux nouvelles cellules filles lors de la division cellulaire.
La réplication de l'ADN est initiée au niveau d'une région spécifique de l'ADN appelée origine de réplication, où une enzyme clé, l'hélicase, se lie et commence à dérouler la double hélice d'ADN pour exposer les brins complémentaires. Une autre enzyme, la primase, synthétise ensuite des courtes séquences de ARN messager (ARNm) qui servent de point de départ à l'élongation de nouveaux brins d'ADN.
Deux autres enzymes, les polymerases, se lient alors aux brins d'ADN exposés et commencent à synthétiser des copies complémentaires en utilisant les bases nucléiques libres correspondantes (A avec T, C avec G) pour former de nouvelles liaisons hydrogène. Ce processus se poursuit jusqu'à ce que les deux nouveaux brins d'ADN soient complètement synthétisés et que la fourche de réplication se referme.
La réplication de l'ADN est un processus très précis qui permet de minimiser les erreurs de copie grâce à des mécanismes de correction d'erreur intégrés. Cependant, certaines mutations peuvent quand même survenir et être transmises aux générations suivantes, ce qui peut entraîner des variations dans les caractéristiques héréditaires.
Les plasmides sont des molécules d'ADN extrachromosomiques double brin, circulaires et autonomes qui se répliquent indépendamment du chromosome dans les bactéries. Ils peuvent également être trouvés dans certains archées et organismes eucaryotes. Les plasmides sont souvent associés à des fonctions particulières telles que la résistance aux antibiotiques, la dégradation des molécules organiques ou la production de toxines. Ils peuvent être transférés entre bactéries par conjugaison, transformation ou transduction, ce qui en fait des vecteurs importants pour l'échange de gènes et la propagation de caractères phénotypiques dans les populations bactériennes. Les plasmides ont une grande importance en biotechnologie et en génie génétique en raison de leur utilité en tant que vecteurs clonage et d'expression des gènes.
Les prophages sont des bacteriophages (virus qui infectent les bactéries) intégrés dans le génome d'une bactérie hôte. Ils existent sous forme inactive et se répliquent avec l'ADN de la bactérie hôte sans perturber sa fonction. Les prophages peuvent rester dormants indéfiniment ou peuvent être induits pour produire de nouvelles particules virales, ce qui peut entraîner la lyse (destruction) de la bactérie hôte. Ce processus est souvent déclenché par des facteurs de stress environnementaux tels que les dommages à l'ADN ou l'exposition aux UV. Les prophages peuvent également fournir des gènes bénéfiques à la bactérie hôte, ce qui peut contribuer à sa virulence ou à sa résistance aux antibiotiques.
Je suis désolé, mais après avoir vérifié diverses sources de renommée mondiale, y compris ICD10, MeSH, MedlinePlus, et même la littérature médicale publique, je n'ai trouvé aucune information sur un agent pathogène ou une condition médicale appelée "Inovirus". Il est possible que ce terme ne soit pas reconnu dans le domaine médical ou qu'il y ait une faute d'orthographe. Je vous recommande de vérifier l'orthographe et de consulter des sources médicales fiables pour obtenir des informations précises.
En termes simples, un gène est une séquence d'acide désoxyribonucléique (ADN) qui contient les instructions pour la production de molécules appelées protéines. Les protéines sont des composants fondamentaux des cellules et remplissent une multitude de fonctions vitales, telles que la structure, la régulation, la signalisation et les catalyseurs des réactions chimiques dans le corps.
Les gènes représentent environ 1 à 5 % du génome humain complet. Chaque gène est une unité discrète d'hérédité qui code généralement pour une protéine spécifique, bien que certains gènes fournissent des instructions pour produire des ARN non codants, qui ont divers rôles dans la régulation de l'expression génétique et d'autres processus cellulaires.
Les mutations ou variations dans les séquences d'ADN des gènes peuvent entraîner des changements dans les protéines qu'ils codent, ce qui peut conduire à des maladies génétiques ou prédisposer une personne à certaines conditions médicales. Par conséquent, la compréhension des gènes et de leur fonction est essentielle pour la recherche biomédicale et les applications cliniques telles que le diagnostic, le traitement et la médecine personnalisée.
La génétique microbienne est l'étude des gènes et de l'hérédité chez les micro-organismes, y compris les bactéries, les virus, les champignons et les parasites. Elle traite de la manière dont ces organismes héritent, expriment et transmettent leurs gènes, ainsi que des mécanismes par lesquels ils évoluent et adaptent leur génome en réponse à l'environnement.
Les micro-organismes ont souvent des systèmes de génétique complexes qui peuvent inclure des plasmides (petits cercles d'ADN), des transposons (segments d'ADN mobiles) et des mécanismes de recombinaison génétique. L'étude de la génétique microbienne peut fournir des informations importantes sur la pathogenèse, l'écologie, l'évolution et la résistance aux antibiotiques de ces organismes.
Les techniques modernes de génétique moléculaire, telles que la séquence d'ADN à haut débit et l'édition de gènes, ont considérablement élargi notre compréhension de la génétique microbienne et ont ouvert de nouvelles voies pour le développement de thérapies et de vaccins ciblés contre les maladies infectieuses.
Dans le domaine de la biologie moléculaire, les "DNA-directed RNA polymerases" sont des enzymes clés responsables de la transcription de l'information génétique contenue dans l'ADN en ARN. Plus précisément, ces enzymes synthétisent une molécule d'ARN complémentaire à une séquence spécifique d'ADN en utilisant le brin matrice comme modèle. Ce processus est essentiel pour la production de protéines fonctionnelles dans les cellules vivantes, car l'ARN messager (ARNm) produit par ces polymerases sert de support intermédiaire entre l'ADN et les ribosomes, où se déroule la traduction en une chaîne polypeptidique.
Les "DNA-directed RNA polymerases" sont classées en plusieurs types selon leur localisation cellulaire et leurs propriétés catalytiques spécifiques. Par exemple, dans les bactéries, on trouve principalement l'enzyme appelée RNA polymerase de type VII, qui est composée de plusieurs sous-unités protéiques différentes. Dans les eucaryotes, il existe plusieurs types d'ARN polymérases, chacune étant responsable de la transcription d'un type spécifique d'ARN : ARNm, ARNr, ARNt et divers petits ARNs non codants.
En résumé, les "DNA-directed RNA polymerases" sont des enzymes qui catalysent la synthèse d'ARN à partir d'une matrice ADN, jouant un rôle central dans l'expression génétique et la régulation de l'activité cellulaire.
La recombinaison génétique est un processus biologique qui se produit pendant la méiose, une forme spécialisée de division cellulaire qui conduit à la production de cellules sexuelles (gamètes) dans les organismes supérieurs. Ce processus implique l'échange réciproque de segments d'ADN entre deux molécules d'ADN homologues, résultant en des combinaisons uniques et nouvelles de gènes sur chaque molécule.
La recombinaison génétique est importante pour la diversité génétique au sein d'une population, car elle permet la création de nouveaux arrangements de gènes sur les chromosomes. Ces nouveaux arrangements peuvent conférer des avantages évolutifs aux organismes qui les portent, tels qu'une meilleure adaptation à l'environnement ou une résistance accrue aux maladies.
Le processus de recombinaison génétique implique plusieurs étapes, y compris la synapse des chromosomes homologues, la formation de chiasmas (points où les chromosomes s'entrecroisent), l'échange de segments d'ADN entre les molécules d'ADN homologues et la séparation finale des chromosomes homologues. Ce processus est médié par une série de protéines spécialisées qui reconnaissent et lient les séquences d'ADN homologues, catalysant ainsi l'échange de segments d'ADN entre elles.
La recombinaison génétique peut également se produire dans des cellules somatiques (cellules non sexuelles) en réponse à des dommages à l'ADN ou lors de processus tels que la réparation de brèches dans l'ADN. Ce type de recombinaison génétique est appelé recombinaison homologue et peut contribuer à la stabilité du génome en réparant les dommages à l'ADN.
Cependant, une recombinaison génétique excessive ou incorrecte peut entraîner des mutations et des instabilités chromosomiques, ce qui peut conduire au développement de maladies telles que le cancer. Par conséquent, la régulation de la recombinaison génétique est essentielle pour maintenir l'intégrité du génome et prévenir les maladies associées à des mutations et des instabilités chromosomiques.
Les enzymes de restriction de l'ADN sont des endonucléases qui coupent l'ADN (acide désoxyribonucléique) à des sites spécifiques déterminés par la séquence nucléotidique. Elles sont largement utilisées dans les techniques de biologie moléculaire, telles que le clonage et l'analyse de l'ADN.
Les enzymes de restriction sont produites principalement par des bactéries et des archées comme mécanisme de défense contre les virus (bactériophages). Elles coupent l'ADN viral, empêchant ainsi la réplication du virus dans la cellule hôte.
Chaque enzyme de restriction reconnaît une séquence nucléotidique spécifique dans l'ADN, appelée site de restriction. La plupart des enzymes de restriction coupent les deux brins de l'ADN au milieu du site de restriction, générant des extrémités cohésives ou collantes. Certaines enzymes de restriction coupent chaque brin à des distances différentes du site de restriction, produisant des extrémités décalées ou émoussées.
Les enzymes de restriction sont classées en fonction de la manière dont elles coupent l'ADN. Les deux principaux types sont les endonucléases de type II et les endonucléases de type I et III. Les endonucléases de type II sont les plus couramment utilisées dans les applications de recherche en biologie moléculaire en raison de leur spécificité élevée pour des séquences d'ADN particulières et de leurs propriétés d'endonucléase.
Les enzymes de restriction sont un outil essentiel dans les techniques de génie génétique, notamment le clonage moléculaire, l'analyse des gènes et la cartographie de l'ADN. Ils permettent aux scientifiques de manipuler et d'étudier l'ADN avec une grande précision et flexibilité.
Une séquence d'acides aminés est une liste ordonnée d'acides aminés qui forment une chaîne polypeptidique dans une protéine. Chaque protéine a sa propre séquence unique d'acides aminés, qui est déterminée par la séquence de nucléotides dans l'ADN qui code pour cette protéine. La séquence des acides aminés est cruciale pour la structure et la fonction d'une protéine. Les différences dans les séquences d'acides aminés peuvent entraîner des différences importantes dans les propriétés de deux protéines, telles que leur activité enzymatique, leur stabilité thermique ou leur interaction avec d'autres molécules. La détermination de la séquence d'acides aminés d'une protéine est une étape clé dans l'étude de sa structure et de sa fonction.
Un essai de plaque virale est une méthode de laboratoire utilisée pour quantifier le nombre de virus infectieux dans un échantillon. Cette technique consiste à mélanger l'échantillon avec des cellules sensibles aux virus en culture, qui sont ensuite réparties dans un plateau à fond plat et incubées pendant plusieurs heures. Au cours de cette incubation, les virus infectent et tuent les cellules, créant des zones claires ou "plaques" visibles à l'œil nu contre le fond opaque des cellules vivantes.
L'étape suivante consiste à ajouter une substance qui réagit avec les protéines des cellules mortes, comme un colorant vital ou un anticorps marqué, produisant une réaction visible dans les plaques. En comptant le nombre de plaques dans chaque puits et en tenant compte du volume d'échantillon utilisé pour l'infection, on peut calculer le titre viral, exprimé comme le nombre de particules virales infectieuses par millilitre (pvu/mL).
Cette méthode est largement utilisée dans la recherche et le diagnostic des maladies infectieuses pour déterminer la charge virale, évaluer l'efficacité des traitements antiviraux et étudier les propriétés des virus. Cependant, il convient de noter que tous les types de virus ne forment pas de plaques visibles, ce qui limite l'utilité de cette méthode à certains types de virus.
La réplication virale est le processus par lequel un virus produit plusieurs copies de lui-même dans une cellule hôte. Cela se produit lorsqu'un virus infecte une cellule et utilise les mécanismes cellulaires pour créer de nouvelles particules virales, qui peuvent ensuite infecter d'autres cellules et continuer le cycle de réplication.
Le processus de réplication virale peut être divisé en plusieurs étapes :
1. Attachement et pénétration : Le virus s'attache à la surface de la cellule hôte et insère son matériel génétique dans la cellule.
2. Décapsidation : Le matériel génétique du virus est libéré dans le cytoplasme de la cellule hôte.
3. Réplication du génome viral : Selon le type de virus, son génome sera soit transcrit en ARNm, soit répliqué directement.
4. Traduction : Les ARNm produits sont traduits en protéines virales par les ribosomes de la cellule hôte.
5. Assemblage et libération : Les nouveaux génomes viraux et les protéines virales s'assemblent pour former de nouvelles particules virales, qui sont ensuite libérées de la cellule hôte pour infecter d'autres cellules.
La réplication virale est un processus complexe qui dépend fortement des mécanismes cellulaires de l'hôte. Les virus ont évolué pour exploiter ces mécanismes à leur avantage, ce qui rend difficile le développement de traitements efficaces contre les infections virales.
Bacillus subtilis est une bactérie gram-positive, en forme de bâtonnet, facultativement anaérobie et sporulante. Elle est largement répandue dans l'environnement, notamment dans le sol, l'eau et les végétaux. Cette bactérie est souvent utilisée comme modèle dans la recherche en biologie moléculaire et est également étudiée pour ses propriétés industrielles, telles que sa production d'enzymes et de métabolites utiles.
Bien que Bacillus subtilis ne soit pas considérée comme une bactérie pathogène pour les humains, elle peut causer des infections opportunistes chez les personnes dont le système immunitaire est affaibli. Cependant, ces infections sont rares et généralement traitées avec succès avec des antibiotiques appropriés.
En plus de ses applications en recherche et en industrie, Bacillus subtilis est également utilisée dans l'alimentation humaine et animale comme probiotique, car elle peut aider à prévenir la croissance de bactéries nocives dans l'intestin et stimuler le système immunitaire.
Un capside est une structure protectrice constituée de protéines qui entoure le génome d'un virus. Il s'agit d'une couche extérieure rigide ou semi-rigide qui protège l'acide nucléique du virus contre les enzymes et autres agents dégradants présents dans l'environnement extracellulaire. Le capside est généralement constitué de plusieurs copies d'une ou quelques protéines différentes, qui s'assemblent pour former une structure géométrique symétrique.
Le capside joue un rôle important dans la reconnaissance et l'entrée du virus dans la cellule hôte. Il contient souvent des sites de liaison spécifiques aux récepteurs qui permettent au virus d'interagir avec les molécules situées à la surface de la cellule hôte, déclenchant ainsi le processus d'infection.
Le capside est l'une des deux principales structures constituant un virus, l'autre étant l'enveloppe virale, une membrane lipidique qui peut être présente chez certains virus et absente chez d'autres. Les virus dont le génome est entouré par un capside mais pas par une enveloppe sont appelés virus nus ou non enveloppés.
L'ADN monocaténaire est une forme d'acide désoxyribonucléique qui ne contient qu'une seule chaîne ou brin de nucléotides. Dans la plupart des cellules, l'ADN existe sous forme de double hélice, composée de deux brins complémentaires qui s'enroulent ensemble. Cependant, dans certaines circonstances, comme lors du processus de réplication ou de réparation de l'ADN, il peut être temporairement présenté sous forme monocaténaire.
L'ADN monocaténaire est également observé dans certains virus à ADN, tels que les parvovirus, qui ont un génome d'ADN simple brin. Dans ces virus, l'ADN monocaténaire est la forme infectieuse et doit être converti en double brin pour permettre la réplication et la transcription de son génome.
Il convient de noter que l'ADN monocaténaire est plus fragile et sujet à la dégradation par les nucléases, qui sont des enzymes qui coupent l'ADN, que l'ADN double brin. Par conséquent, il doit être stabilisé et protégé pour maintenir son intégrité structurelle et fonctionnelle.
L'ADN bactérien fait référence à l'acide désoxyribonucléique présent dans les bactéries. Il s'agit du matériel génétique héréditaire des bactéries, qui contient toutes les informations nécessaires à leur croissance, leur développement et leur fonctionnement.
Contrairement à l'ADN des cellules humaines, qui est organisé en chromosomes situés dans le noyau de la cellule, l'ADN bactérien se présente sous forme d'une unique molécule circulaire située dans le cytoplasme de la cellule. Cette molécule d'ADN bactérien est également appelée chromosome bactérien.
L'ADN bactérien peut contenir des gènes codant pour des protéines, des ARN non codants et des éléments régulateurs qui contrôlent l'expression des gènes. Les bactéries peuvent également posséder de l'ADN extrachromosomique sous forme de plasmides, qui sont des petites molécules d'ADN circulaires contenant un ou plusieurs gènes.
L'étude de l'ADN bactérien est importante pour comprendre la physiologie et le métabolisme des bactéries, ainsi que pour développer des stratégies de lutte contre les infections bactériennes. Elle permet également d'identifier des marqueurs spécifiques qui peuvent être utilisés pour caractériser et classer différentes espèces bactériennes.
Le clonage moléculaire est une technique de laboratoire qui permet de créer plusieurs copies identiques d'un fragment d'ADN spécifique. Cette méthode implique l'utilisation de divers outils et processus moléculaires, tels que des enzymes de restriction, des ligases, des vecteurs d'ADN (comme des plasmides ou des phages) et des hôtes cellulaires appropriés.
Le fragment d'ADN à cloner est d'abord coupé de sa source originale en utilisant des enzymes de restriction, qui reconnaissent et coupent l'ADN à des séquences spécifiques. Le vecteur d'ADN est également coupé en utilisant les mêmes enzymes de restriction pour créer des extrémités compatibles avec le fragment d'ADN cible. Les deux sont ensuite mélangés dans une réaction de ligation, où une ligase (une enzyme qui joint les extrémités de l'ADN) est utilisée pour fusionner le fragment d'ADN et le vecteur ensemble.
Le produit final de cette réaction est un nouvel ADN hybride, composé du vecteur et du fragment d'ADN cloné. Ce nouvel ADN est ensuite introduit dans un hôte cellulaire approprié (comme une bactérie ou une levure), où il peut se répliquer et produire de nombreuses copies identiques du fragment d'ADN original.
Le clonage moléculaire est largement utilisé en recherche biologique pour étudier la fonction des gènes, produire des protéines recombinantes à grande échelle, et développer des tests diagnostiques et thérapeutiques.
La centrifugation en gradient de densité est une technique de séparation utilisée dans le domaine de la biologie et de la médecine. Elle consiste à utiliser une force centrifuge pour séparer des particules ou des molécules en fonction de leur masse et de leur taille, mais aussi de leur densité.
Cette technique utilise un milieu de densité contrôlée, constitué d'une solution de saccharose ou de percoll par exemple, dans laquelle on dispose l'échantillon à séparer. Lors de la centrifugation, les particules ou molécules se déplacent à travers le gradient de densité et s'arrêtent à un niveau correspondant à leur propre densité.
Cette méthode est couramment utilisée pour séparer des fractions cellulaires hétérogènes telles que les sous-populations de cellules sanguines ou les différents organites présents dans une cellule. Elle permet également de purifier des virus, des exosomes ou des ARN messagers.
Il est important de noter que la centrifugation en gradient de densité nécessite un matériel spécifique et doit être réalisée avec soin pour éviter toute contamination ou dommage aux échantillons.
La conformation d'acide nucléique fait référence à la structure tridimensionnelle que prend une molécule d'acide nucléique, comme l'ADN ou l'ARN, en fonction de la manière dont ses sucres et ses bases sont liés les uns aux autres. La conformation la plus courante de l'ADN est la double hélice de B-DNA, dans laquelle deux brins antiparallèles d'acide nucléique s'enroulent l'un autour de l'autre en formant des paires de bases complémentaires. Cependant, l'ADN et l'ARN peuvent adopter une variété de conformations différentes, y compris l'A-DNA, le Z-DNA, l'ADN triplex et les structures d'ARN à boucle en puits. Ces différentes conformations peuvent influencer la fonction des acides nucléiques dans des processus tels que la réplication, la transcription et la traduction de l'ADN.
Je suis désolé, mais il semble y avoir une confusion dans votre question. "Cystoviridae" n'est pas une définition médicale ou un terme médical reconnu. Cependant, c'est le nom d'une famille de virus qui comprend le phage φ6 et des virus apparentés. Ces virus infectent les bactéries et possèdent un génome segmenté à ARN double brin. Si vous cherchiez une définition ou une information sur ce sujet, je serais heureux de vous aider avec plaisir.
Un bactériophage Pf1 est un type spécifique de virus qui infecte exclusivement certaines souches de la bactérie Pseudomonas aeruginosa. Ce bactériophage se compose d'une capside, qui protège son matériel génétique, et d'une queue flexible qui lui permet de se lier à des récepteurs spécifiques sur la surface de la bactérie hôte. Une fois lié, le bactériophage Pf1 injecte son matériel génétique dans la bactérie, entraînant éventuellement la lyse (la destruction) de la cellule hôte et la libération de nouveaux virus infectieux.
Les bactériophages tels que Pf1 sont souvent étudiés en raison de leur potentiel comme agents thérapeutiques alternatifs pour lutter contre les infections bactériennes résistantes aux antibiotiques. Cependant, il est important de noter que chaque souche de bactériophage est spécifique à une certaine souche de bactérie hôte, ce qui signifie qu'un bactériophage Pf1 ne sera pas efficace contre d'autres types de bactéries ou même contre toutes les souches de P. aeruginosa.
Les déoxyribonucleases (DNases) sont des enzymes qui catalysent la dégradation des acides nucléiques, plus spécifiquement l'ADN (acide désoxyribonucléique). Elles coupent les molécules d'ADN en fragments plus petits en hydrolysant les liaisons phosphodiester entre les désoxynucléotides.
Les DNases sont classées en fonction de leur mécanisme catalytique et de leur spécificité pour différentes séquences ou structures d'ADN. Par exemple, certaines DNases peuvent ne couper que l'ADN simple brin, tandis que d'autres coupent préférentiellement l'ADN double brin.
Ces enzymes jouent un rôle important dans de nombreux processus biologiques, tels que la réparation de l'ADN, l'apoptose (mort cellulaire programmée), la régulation de la transcription génétique et la défense contre les infections virales et bactériennes.
Dans le contexte médical, certaines DNases sont utilisées comme thérapies pour traiter des maladies telles que la mucoviscidose (fibrose kystique), où l'accumulation d'ADN dans les sécrétions des voies respiratoires peut entraver la fonction pulmonaire. En dégradant l'ADN présent dans ces sécrétions, les DNases peuvent aider à fluidifier les mucosités et faciliter leur expectoration, améliorant ainsi la fonction respiratoire des patients atteints de mucoviscidose.
Le chloramphénicol est un antibiotique à large spectre qui est utilisé pour traiter une variété d'infections bactériennes. Il agit en inhibant la synthèse des protéines bactériennes, ce qui empêche les bactéries de se multiplier.
Le chloramphénicol est souvent utilisé pour traiter les infections graves telles que la méningite, la fièvre typhoïde et les infections du sang. Il est également utilisé pour traiter certaines formes d'infections oculaires et cutanées.
Le chloramphénicol est disponible sous forme de comprimés, de suspensions liquides et d'injections. Les effets secondaires courants du chloramphénicol peuvent inclure des nausées, des vomissements, des diarrhées et des maux de tête. Dans de rares cas, le chloramphénicol peut provoquer une grave suppression de la moelle osseuse, entraînant une anémie, une diminution du nombre de plaquettes sanguines et une diminution du nombre de globules blancs.
En raison de ses effets secondaires potentiellement graves, le chloramphénicol est généralement réservé au traitement des infections bactériennes graves qui ne peuvent pas être traitées avec d'autres antibiotiques moins toxiques.
En termes médicaux, la température fait référence à la mesure de la chaleur produite par le métabolisme d'un organisme et maintenue dans des limites relativement étroites grâce à un équilibre entre la production de chaleur et sa perte. La température corporelle normale humaine est généralement considérée comme comprise entre 36,5 et 37,5 degrés Celsius (97,7 à 99,5 degrés Fahrenheit).
Des écarts par rapport à cette plage peuvent indiquer une variété de conditions allant d'un simple rhume à des infections plus graves. Une température corporelle élevée, également appelée fièvre, est souvent un signe que l'organisme combat une infection. D'autre part, une température basse, ou hypothermie, peut être le résultat d'une exposition prolongée au froid.
Il existe plusieurs sites sur le corps où la température peut être mesurée, y compris sous l'aisselle (axillaire), dans l'anus (rectale) ou dans la bouche (orale). Chacun de ces sites peut donner des lectures légèrement différentes, il est donc important d'être cohérent sur le site de mesure utilisé pour suivre les changements de température au fil du temps.
Les protéines de capside sont des protéines structurales importantes dans la composition de la capside, qui est la couche protectrice externe de certains virus. La capside entoure le matériel génétique du virus et joue un rôle crucial dans la reconnaissance et l'attachement du virus à une cellule hôte, ainsi que dans la facilitation de l'infection de la cellule hôte. Les protéines de capside sont synthétisées à partir des informations génétiques contenues dans le matériel génétique du virus et s'assemblent pour former la structure complexe de la capside. Ces protéines peuvent être organisées en une variété de formes géométriques, y compris icosaédrique et hélicoïdale, selon le type de virus.
La cartographie chromosomique est une discipline de la génétique qui consiste à déterminer l'emplacement et l'ordre relatif des gènes et des marqueurs moléculaires sur les chromosomes. Cette technique utilise généralement des méthodes de laboratoire pour analyser l'ADN, comme la polymerase chain reaction (PCR) et la Southern blotting, ainsi que des outils d'informatique pour visualiser et interpréter les données.
La cartographie chromosomique est un outil important dans la recherche génétique, car elle permet aux scientifiques de comprendre comment les gènes sont organisés sur les chromosomes et comment ils interagissent entre eux. Cela peut aider à identifier les gènes responsables de certaines maladies héréditaires et à développer des traitements pour ces conditions.
Il existe deux types de cartographie chromosomique : la cartographie physique et la cartographie génétique. La cartographie physique consiste à déterminer l'emplacement exact d'un gène ou d'un marqueur sur un chromosome en termes de distance physique, exprimée en nucléotides. La cartographie génétique, quant à elle, consiste à déterminer l'ordre relatif des gènes et des marqueurs sur un chromosome en fonction de la fréquence de recombinaison entre eux lors de la méiose.
En résumé, la cartographie chromosomique est une technique utilisée pour déterminer l'emplacement et l'ordre relatif des gènes et des marqueurs moléculaires sur les chromosomes, ce qui permet aux scientifiques de mieux comprendre comment les gènes sont organisés et interagissent entre eux.
Le terme "Caudovirales" est un nom de taxon utilisé en virologie pour décrire un ordre de virus qui ont des queues virales complexes. Ces virus infectent principalement les bactéries et sont donc également appelés bacteriophages ou simplement phages.
Les membres de l'ordre Caudovirales ont une structure similaire, comprenant une tête icosaédrique qui contient l'acide nucléique viral et une queue longue et fine qui est utilisée pour se lier aux récepteurs sur la surface des bactéries hôtes. La queue peut être contractile ou non contractile, mais elle est toujours équipée d'une base plate avec des fibres terminales qui permettent au virus de se fixer à la membrane externe de la cellule bactérienne.
Les virus de l'ordre Caudovirales sont classés en plusieurs familles, dont les plus importantes sont les Myoviridae, les Siphoviridae et les Podoviridae. Chaque famille a des caractéristiques uniques qui permettent de les distinguer les uns des autres, telles que la longueur et la structure de la queue, ainsi que le mode de réplication du virus.
En général, les virus de l'ordre Caudovirales sont considérés comme des agents antimicrobiens prometteurs en raison de leur capacité à infecter et à tuer sélectivement certaines bactéries sans affecter les cellules humaines ou animales. Ils ont été étudiés pour une utilisation potentielle dans le traitement des infections bactériennes résistantes aux antibiotiques, ainsi que dans la biocontrôle des bactéries pathogènes dans l'environnement.
L'ARN viral (acide ribonucléique viral) est le matériel génétique présent dans les virus qui utilisent l'ARN comme matériel génétique, à la place de l'ADN. L'ARN viral peut être de simple brin ou double brin et peut avoir différentes structures en fonction du type de virus.
Les virus à ARN peuvent être classés en plusieurs groupes en fonction de leur structure et de leur cycle de réplication, notamment:
1. Les virus à ARN monocaténaire (ARNmc) positif : l'ARN viral peut servir directement de matrice pour la synthèse des protéines après avoir été traduit en acides aminés par les ribosomes de la cellule hôte.
2. Les virus à ARN monocaténaire (ARNmc) négatif : l'ARN viral ne peut pas être directement utilisé pour la synthèse des protéines et doit d'abord être transcrit en ARNmc positif par une ARN polymérase spécifique du virus.
3. Les virus à ARN bicaténaire (ARNbc) : ils possèdent deux brins complémentaires d'ARN qui peuvent être soit segmentés (comme dans le cas de la grippe) ou non segmentés.
Les virus à ARN sont responsables de nombreuses maladies humaines, animales et végétales importantes sur le plan épidémiologique et socio-économique, telles que la grippe, le rhume, l'hépatite C, la poliomyélite, la rougeole, la rubéole, la sida, etc.
Les isotopes du phosphore sont des variantes du élément chimique phosphore qui ont le même nombre d'protons dans leur noyau atomique, mais un nombre différent de neutrons. Cela signifie qu'ils ont les mêmes propriétés chimiques, car le nombre de protons détermine les propriétés chimiques d'un élément, mais ils diffèrent dans leurs propriétés physiques en raison du nombre différent de neutrons.
Le phosphore a 15 isotopes connus, allant de ^{25}P à ^{40}P. Seul l'isotope ^{31}P est stable et se trouve naturellement dans l'environnement. Tous les autres isotopes sont radioactifs et se désintègrent spontanément en d'autres éléments.
Les isotopes du phosphore ont des demi-vies variées, allant de fractions de seconde à des milliers d'années. Certains isotopes du phosphore sont utilisés dans la datation radiométrique, comme le ^{32}P, qui a une demi-vie de 14,26 jours et est utilisé dans la recherche médicale et biologique pour étiqueter des molécules et suivre leur métabolisme.
Dans l'organisme humain, le phosphore est un élément essentiel qui joue un rôle important dans de nombreuses fonctions biologiques, telles que la production d'énergie, la structure des os et des dents, et la transmission des signaux nerveux. Le phosphore stable ^{31}P est le principal isotope présent dans l'organisme humain.
La transcription génétique est un processus biologique essentiel à la biologie cellulaire, impliqué dans la production d'une copie d'un brin d'ARN (acide ribonucléique) à partir d'un brin complémentaire d'ADN (acide désoxyribonucléique). Ce processus est catalysé par une enzyme appelée ARN polymérase, qui lit la séquence de nucléotides sur l'ADN et synthétise un brin complémentaire d'ARN en utilisant des nucléotides libres dans le cytoplasme.
L'ARN produit pendant ce processus est appelé ARN pré-messager (pré-mRNA), qui subit ensuite plusieurs étapes de traitement, y compris l'épissage des introns et la polyadénylation, pour former un ARN messager mature (mRNA). Ce mRNA sert ensuite de modèle pour la traduction en une protéine spécifique dans le processus de biosynthèse des protéines.
La transcription génétique est donc un processus crucial qui permet aux informations génétiques codées dans l'ADN de s'exprimer sous forme de protéines fonctionnelles, nécessaires au maintien de la structure et de la fonction cellulaires, ainsi qu'à la régulation des processus métaboliques et de développement.
Les protéines bactériennes se réfèrent aux différentes protéines produites et présentes dans les bactéries. Elles jouent un rôle crucial dans divers processus métaboliques, structurels et fonctionnels des bactéries. Les protéines bactériennes peuvent être classées en plusieurs catégories, notamment :
1. Protéines structurales : Ces protéines sont impliquées dans la formation de la paroi cellulaire, du cytosquelette et d'autres structures cellulaires importantes.
2. Protéines enzymatiques : Ces protéines agissent comme des catalyseurs pour accélérer les réactions chimiques nécessaires au métabolisme bactérien.
3. Protéines de transport : Elles facilitent le mouvement des nutriments, des ions et des molécules à travers la membrane cellulaire.
4. Protéines de régulation : Ces protéines contrôlent l'expression génétique et la transduction du signal dans les bactéries.
5. Protéines de virulence : Certaines protéines bactériennes contribuent à la pathogénicité des bactéries, en facilitant l'adhésion aux surfaces cellulaires, l'invasion tissulaire et l'évasion du système immunitaire de l'hôte.
L'étude des protéines bactériennes est importante dans la compréhension de la physiologie bactérienne, le développement de vaccins et de thérapies antimicrobiennes, ainsi que dans l'élucidation des mécanismes moléculaires de maladies infectieuses.
Dans le domaine de la biologie moléculaire, une "DNA-directed DNA polymerase" (ou ADN polymérase dirigée par ADN en français) se réfère à un type spécifique d'enzyme qui catalyse la synthèse d'une chaîne complémentaire d'ADN en utilisant une molécule d'ADN comme modèle.
Ces enzymes jouent un rôle crucial dans la réplication de l'ADN, où elles créent une copie exacte de chaque brin d'ADN avant que la cellule ne se divise. Elles fonctionnent en ajoutant des nucléotides (les building blocks de l'ADN) un par un à l'extrémité 3' d'une chaîne naissante d'ADN, en s'assurant que chaque nucléotide nouvellement ajouté est complémentaire au brin d'ADN modèle.
Il existe plusieurs types différents de "DNA-directed DNA polymerases", chacun ayant des propriétés uniques et des rôles spécifiques dans la cellule. Par exemple, l'enzyme "Polymerase alpha" est responsable de l'initiation de la réplication de l'ADN, tandis que les enzymes "Polymerases delta" et "Polymerases epsilon" sont responsables de la synthèse des nouveaux brins d'ADN pendant la phase de croissance de la réplication.
En plus de leur rôle dans la réplication de l'ADN, ces enzymes sont également utilisées dans une variété de techniques de biologie moléculaire, telles que la PCR (réaction en chaîne par polymérase) et le séquençage de l'ADN.
Un test de complémentation est un type de test génétique utilisé pour identifier des mutations spécifiques dans les gènes qui peuvent être à l'origine d'une maladie héréditaire. Ce test consiste à combiner du matériel génétique provenant de deux individus différents et à observer la manière dont il interagit, ou se complète, pour effectuer une fonction spécifique.
Le principe de ce test repose sur le fait que certains gènes codent pour des protéines qui travaillent ensemble pour former un complexe fonctionnel. Si l'un des deux gènes est muté et ne produit pas une protéine fonctionnelle, le complexe ne sera pas formé ou ne fonctionnera pas correctement.
Le test de complémentation permet donc d'identifier si les deux individus portent une mutation dans le même gène en observant la capacité de leurs matériels génétiques à se compléter et à former un complexe fonctionnel. Si les deux échantillons ne peuvent pas se compléter, cela suggère que les deux individus sont porteurs d'une mutation dans le même gène.
Ce type de test est particulièrement utile pour déterminer la cause génétique de certaines maladies héréditaires rares et complexes, telles que les troubles neuromusculaires et les maladies métaboliques. Il permet également d'identifier des individus qui sont à risque de transmettre une maladie héréditaire à leur descendance.
La DNA primase est une enzyme qui joue un rôle crucial dans la réplication de l'ADN. Elle est responsable de la synthèse d'un court segment d'ARN, appelé "grappe d'ARN", qui sert de point de départ (ou de primer) pour la synthèse ultérieure de la chaîne d'ADN par l'ADN polymérase.
La DNA primase est généralement composée de deux sous-unités protéiques distinctes, qui travaillent ensemble pour accomplir cette tâche. La première sous-unité, appelée petit sous-unité, reconnaît et se lie à l'ADN simple brin au niveau du site d'initiation de la réplication. La deuxième sous-unité, appelée grande sous-unité, possède une activité polymérase ARN qui permet la synthèse de la grappe d'ARN.
La DNA primase est essentielle à la réplication de l'ADN car elle permet à l'ADN polymérase de commencer la synthèse de la nouvelle chaîne d'ADN en utilisant la grappe d'ARN comme point de départ. Après la synthèse initiale de quelques nucléotides, l'ADN polymérase remplace l'ARN par de l'ADN, étendant ainsi la nouvelle chaîne.
La DNA primase est donc une enzyme clé dans le processus de réplication de l'ADN et est présente chez tous les organismes vivants. Des mutations ou des défauts dans la fonction de la DNA primase peuvent entraîner des maladies génétiques graves, telles que des troubles du développement et des cancers.
Le tritium est un isotope radioactif de l'hydrogène avec deux neutrons supplémentaires dans le noyau atomique. Sa période de demi-vie est d'environ 12,3 ans. Dans le contexte médical, il peut être utilisé dans des applications telles que les marqueurs radioactifs dans la recherche et la médecine nucléaire. Cependant, l'exposition au tritium peut présenter un risque pour la santé en raison de sa radioactivité, pouvant entraîner une contamination interne si ingéré, inhalé ou entré en contact avec la peau. Les effets sur la santé peuvent inclure des dommages à l'ADN et un risque accru de cancer.
Un traitement biologique, également connu sous le nom de thérapie biologique ou immunothérapie, est un type de traitement médical qui utilise des substances dérivées du vivant – des composants naturels du corps humain, des micro-organismes ou des tissus animaux – pour combattre les maladies. Ces traitements sont souvent conçus pour cibler spécifiquement certaines parties du système immunitaire et aider à réguler ou améliorer ses fonctions.
Dans le domaine de la médecine, les traitements biologiques sont couramment utilisés dans le traitement de divers types de cancers et de maladies auto-immunes. Par exemple, certains médicaments biologiques peuvent être capables d'identifier et de détruire les cellules cancéreuses, tandis que d'autres peuvent aider à contrôler l'inflammation dans le cadre d'une maladie auto-immune.
Les traitements biologiques comprennent des vaccins thérapeutiques, des anticorps monoclonaux, des protéines de fusion, des thérapies cellulaires et d'autres molécules complexes qui sont produites par la biotechnologie moderne. Contrairement aux médicaments traditionnels qui sont synthétisés chimiquement, ces traitements sont généralement créés à l'aide de techniques de génie génétique ou d'ingénierie des protéines.
Il est important de noter que les traitements biologiques peuvent entraîner des effets secondaires uniques et parfois plus graves que ceux associés aux médicaments traditionnels, tels que des réactions allergiques, une activation excessive du système immunitaire ou une susceptibilité accrue aux infections. Par conséquent, il est essentiel de suivre attentivement les recommandations posologiques et de surveillance établies par le professionnel de santé pour minimiser ces risques potentiels.
La cryo-microscopie électronique (Cryo-ME) est une technique de microscopie avancée qui permet d'observer des structures biologiques à l'état naturel, sans coloration ni fixation chimique. Cette méthode consiste à plonger rapidement un échantillon dans de l'azote liquide pour le vitrifier, c'est-à-dire le refroidir brutalement afin qu'il conserve sa structure native et éviter ainsi les dommages causés par la cristallisation de l'eau.
L'échantillon vitrifié est ensuite observé sous un microscope électronique à transmission (TEM) fonctionnant à des températures extrêmement basses, généralement autour de -170°C. Les électrons interagissent avec la matière de l'échantillon et créent des contrastes qui peuvent être enregistrés par un détecteur de type caméra. Les images obtenues sont ensuite traitées numériquement pour améliorer leur qualité et permettre une analyse détaillée des structures observées.
La cryo-microscopie électronique est particulièrement utile pour l'étude des macromolécules biologiques telles que les protéines, les ARN et les complexes supramoléculaires. Elle a récemment connu un essor considérable grâce au développement de détecteurs directs d'électrons (DDE) qui ont permis d'obtenir des résolutions atomiques sur certains échantillons, ouvrant ainsi la voie à une meilleure compréhension des mécanismes moléculaires impliqués dans divers processus biologiques.
En 2017, Jacques Dubochet, Joachim Frank et Richard Henderson ont reçu le prix Nobel de chimie pour leurs travaux sur le développement et l'application de la cryo-microscopie électronique en biologie structurale.
En biologie et en médecine, le terme "host specificity" (spécificité hôte) se réfère à la préférence ou à la capacité d'un organisme, tel qu'un parasite, un virus, une bactérie ou un autre micro-organisme, à infecter et à survivre dans un type spécifique d'hôte.
La spécificité hôte peut être déterminée par divers facteurs, tels que les récepteurs de surface de l'hôte, la composition du microbiome de l'hôte, le système immunitaire de l'hôte et d'autres caractéristiques hôtes. Certains agents pathogènes peuvent infecter une large gamme d'hôtes (spécificité hôte large), tandis que d'autres ne peuvent infecter qu'un seul type d'hôte ou un petit nombre d'espèces apparentées (spécificité hôte étroite).
La compréhension de la spécificité hôte est importante pour comprendre les épidémiologies des maladies infectieuses, développer des stratégies de prévention et de contrôle des infections, et concevoir des thérapies antimicrobiennes et des vaccins.
Les DNA nucleotidyltransferases sont un groupe d'enzymes qui catalysent l'ajout de nucléotides à l'extrémité d'une chaîne d'ADN. Elles jouent un rôle crucial dans les processus biologiques tels que la réparation de l'ADN, la recombinaison de l'ADN et la biosynthèse de l'ADN.
Les DNA nucleotidyltransferases peuvent être divisées en plusieurs sous-familles en fonction de leur activité spécifique. Les plus courantes sont les terminales déoxynucleotidyltransferases (TdT), les polynucleotide kinases (PNK) et les poly(ADP-ribose)polymérases (PARP).
Les TdT, par exemple, ajoutent des nucléotides aléatoirement à l'extrémité 3' d'une chaîne d'ADN, ce qui est important pour la diversification de la jonction V(D)J dans les lymphocytes B et T.
Les PNK, quant à elles, ajoutent un groupe phosphate à l'extrémité 5' d'une chaîne d'ADN et enlèvent le groupe pyrophosphate de l'extrémité 3', ce qui est important pour la réparation des cassures de l'ADN.
Les PARP, enfin, ajoutent des groupes poly(ADP-ribose) aux protéines impliquées dans la réparation de l'ADN et d'autres processus cellulaires, ce qui est important pour la régulation de ces processus.
Des mutations ou des dysfonctionnements de ces enzymes peuvent entraîner des maladies génétiques graves telles que les cancers et les troubles neurologiques.
La masse moléculaire est un concept utilisé en chimie et en biochimie qui représente la masse d'une molécule. Elle est généralement exprimée en unités de masse atomique unifiée (u), également appelées dalton (Da).
La masse moléculaire d'une molécule est déterminée en additionnant les masses molaires des atomes qui la composent. La masse molaire d'un atome est elle-même définie comme la masse d'un atome en grammes divisée par sa quantité de substance, exprimée en moles.
Par exemple, l'eau est composée de deux atomes d'hydrogène et un atome d'oxygène. La masse molaire de l'hydrogène est d'environ 1 u et celle de l'oxygène est d'environ 16 u. Ainsi, la masse moléculaire de l'eau est d'environ 18 u (2 x 1 u pour l'hydrogène + 16 u pour l'oxygène).
La détermination de la masse moléculaire est importante en médecine et en biochimie, par exemple dans l'identification et la caractérisation des protéines et des autres biomolécules.
Les gènes bactériens sont des segments d'ADN dans le génome d'une bactérie qui portent l'information génétique nécessaire à la synthèse des protéines et à d'autres fonctions cellulaires essentielles. Ils contrôlent des caractéristiques spécifiques telles que la croissance, la reproduction, la résistance aux antibiotiques et la production de toxines. Chaque gène a un code spécifique qui détermine la séquence d'acides aminés dans une protéine particulière. Les gènes bactériens peuvent être étudiés pour comprendre les mécanismes de la maladie, développer des thérapies et des vaccins, et améliorer les processus industriels tels que la production de médicaments et d'aliments.
Les protéines régulatrices et accessoires virales sont des protéines codées par les génomes des virus qui jouent un rôle crucial dans la régulation de la réplication virale, de l'assemblage des particules virales, de la modulation de la réponse immunitaire de l'hôte et de la pathogenèse. Contrairement aux protéines structurales qui sont essentielles à la formation du virion, les protéines régulatrices et accessoires ne sont pas toujours nécessaires à la production de particules virales infectieuses.
Ces protéines peuvent agir en interagissant avec les protéines cellulaires hôtes pour modifier leur fonctionnement et favoriser l'infection virale. Elles peuvent également jouer un rôle dans l'évasion immunitaire du virus en inhibant la reconnaissance et la réponse du système immunitaire de l'hôte.
Les protéines régulatrices et accessoires varient considérablement d'un virus à l'autre, et leur identification et leur caractérisation sont importantes pour comprendre les mécanismes moléculaires de la réplication virale et de la pathogenèse. Elles peuvent également constituer des cibles thérapeutiques prometteuses pour le développement de nouveaux antiviraux.
L'hybridation d'acides nucléiques est un processus dans lequel deux molécules d'acides nucléiques, généralement une molécule d'ADN et une molécule d'ARN ou deux molécules d'ADN complémentaires, s'apparient de manière spécifique par des interactions hydrogène entre leurs bases nucléotidiques correspondantes. Ce processus est largement utilisé en biologie moléculaire et en génétique pour identifier, localiser et manipuler des séquences d'ADN ou d'ARN spécifiques.
L'hybridation a lieu lorsque les deux brins d'acides nucléiques sont mélangés et portés à des températures et des concentrations de sel optimales pour permettre la formation de paires de bases complémentaires. Les conditions d'hybridation doivent être soigneusement contrôlées pour assurer la spécificité et la stabilité de l'appariement des bases.
L'hybridation d'acides nucléiques est une technique sensible et fiable qui peut être utilisée pour détecter la présence de séquences d'ADN ou d'ARN spécifiques dans un échantillon, pour mesurer l'abondance relative de ces séquences, et pour analyser les relations évolutives entre différentes espèces ou populations. Elle est largement utilisée dans la recherche en génétique, en médecine, en biologie moléculaire, en agriculture et dans d'autres domaines où l'identification et l'analyse de séquences d'acides nucléiques sont importantes.
En médecine et en pharmacologie, la cinétique fait référence à l'étude des changements quantitatifs dans la concentration d'une substance (comme un médicament) dans le corps au fil du temps. Cela inclut les processus d'absorption, de distribution, de métabolisme et d'excrétion de cette substance.
1. Absorption: Il s'agit du processus par lequel une substance est prise par l'organisme, généralement à travers la muqueuse gastro-intestinale après ingestion orale.
2. Distribution: C'est le processus par lequel une substance se déplace dans différents tissus et fluides corporels.
3. Métabolisme: Il s'agit du processus par lequel l'organisme décompose ou modifie la substance, souvent pour la rendre plus facile à éliminer. Ce processus peut également activer ou désactiver certains médicaments.
4. Excrétion: C'est le processus d'élimination de la substance du corps, généralement par les reins dans l'urine, mais aussi par les poumons, la peau et les intestins.
La cinétique est utilisée pour prédire comment une dose unique ou répétée d'un médicament affectera le patient, ce qui aide à déterminer la posologie appropriée et le schéma posologique.
Les protéines virales structurelles sont des protéines qui jouent un rôle crucial dans la composition de la capside et de l'enveloppe du virus. Elles sont essentielles à la formation de la structure externe du virus et assurent sa protection, ainsi que la protection de son matériel génétique. Les protéines virales structurelles peuvent être classées en trois catégories principales : les protéines de capside, qui forment la coque protectrice autour du matériel génétique du virus ; les protéines d'enveloppe, qui constituent la membrane externe du virus et facilitent l'entrée et la sortie du virus des cellules hôtes ; et les protéines de matrice, qui se trouvent entre la capside et l'enveloppe et fournissent une structure supplémentaire au virus. Ensemble, ces protéines travaillent pour assurer la réplication et la propagation du virus dans l'organisme hôte.
Un opéron est une unité fonctionnelle d'expression génétique chez les bactéries et certains archées. Il se compose d'un ou plusieurs gènes fonctionnellement liés, qui sont transcrits en un seul ARN messager polycistronique, suivis d'un site régulateur de l'expression génétique. Ce site régulateur comprend généralement une séquence d'ADN qui sert de site d'attachement pour des protéines régulatrices qui contrôlent la transcription des gènes de l'opéron.
L'opéron a été découvert par Jacob et Monod dans les années 1960, lorsqu'ils ont étudié le métabolisme du lactose chez Escherichia coli. Ils ont constaté que les gènes responsables de la dégradation du lactose étaient situés à proximité les uns des autres sur le chromosome bactérien et qu'ils étaient transcrits ensemble sous forme d'un seul ARN messager polycistronique. Ce concept a révolutionné notre compréhension de la régulation génétique chez les prokaryotes.
Les opérons sont souvent régulés en fonction des conditions environnementales, telles que la disponibilité des nutriments ou l'exposition à des produits toxiques. Par exemple, dans le cas de l'opéron du lactose, lorsque le lactose est présent dans l'environnement, les protéines régulatrices se lient au site régulateur et activent la transcription des gènes de l'opéron, permettant ainsi à la bactérie de dégrader le lactose pour en tirer de l'énergie. En l'absence de lactose, les protéines régulatrices se lient au site régulateur et répriment la transcription des gènes de l'opéron, économisant ainsi de l'énergie pour la bactérie.
Les opérons sont donc un mécanisme important de régulation génétique chez les prokaryotes, permettant aux cellules de s'adapter rapidement et efficacement à leur environnement.
Les chromosomes artificiels de bactéries sont des vecteurs d'ADN artificiels créés en laboratoire qui peuvent être utilisés pour transférer des gènes ou des segments d'ADN spécifiques dans des bactéries hôtes. Ils sont souvent fabriqués en prenant un plasmide, une petite molécule d'ADN circulaire autoreproductible trouvée dans de nombreuses bactéries, et en y insérant des gènes ou des segments d'ADN d'intérêt.
Ces chromosomes artificiels peuvent être utilisés pour étudier la fonction des gènes, produire des protéines recombinantes à grande échelle, ou créer des organismes génétiquement modifiés avec des propriétés améliorées. Ils sont un outil important en biologie moléculaire et en biotechnologie.
Cependant, il est important de noter que le terme "chromosome artificiel" peut être trompeur, car ces structures ne sont pas vraiment des chromosomes au sens où les cellules eucaryotes les définissent. Elles n'ont pas la même structure complexe et ne se comportent pas de la même manière pendant la division cellulaire.
L'acide phosphotungstique est un composé chimique qui est souvent utilisé dans la préparation de solutions pour colorer des échantillons en microscopie électronique à transmission (MET). Il s'agit d'un acide complexe de formule chimique PW12O40, qui contient des ions tungstate (WO42-) et des ions hydrogène (H+) liés à un ion phosphate (PO43-).
Dans le contexte médical, l'acide phosphotungstique est utilisé comme agent de contraste négatif pour améliorer le contraste des structures cellulaires et tissulaires dans les échantillons préparés pour la MET. Il peut être particulièrement utile pour mettre en évidence les membranes cellulaires, les ribosomes et d'autres structures intracellulaires.
Cependant, il est important de noter que l'utilisation de l'acide phosphotungstique en microscopie électronique nécessite une certaine expertise technique et des précautions doivent être prises pour éviter toute exposition inutile à ce composé potentiellement dangereux.
La détermination de la séquence d'ADN est un processus de laboratoire qui consiste à déterminer l'ordre des nucléotides dans une molécule d'ADN. Les nucléotides sont les unités de base qui composent l'ADN, et chacun d'entre eux contient un des quatre composants différents appelés bases : adénine (A), guanine (G), cytosine (C) et thymine (T). La séquence spécifique de ces bases dans une molécule d'ADN fournit les instructions génétiques qui déterminent les caractéristiques héréditaires d'un organisme.
La détermination de la séquence d'ADN est généralement effectuée en utilisant des méthodes de séquençage de nouvelle génération (NGS), telles que le séquençage Illumina ou le séquençage Ion Torrent. Ces méthodes permettent de déterminer rapidement et à moindre coût la séquence d'un grand nombre de molécules d'ADN en parallèle, ce qui les rend utiles pour une variété d'applications, y compris l'identification des variations génétiques associées à des maladies humaines, la surveillance des agents pathogènes et la recherche biologique fondamentale.
Il est important de noter que la détermination de la séquence d'ADN ne fournit qu'une partie de l'information génétique d'un organisme. Pour comprendre pleinement les effets fonctionnels des variations génétiques, il est souvent nécessaire d'effectuer d'autres types d'analyses, tels que la détermination de l'expression des gènes et la caractérisation des interactions protéine-protéine.
La dénaturation des acides nucléiques est un processus qui se produit lorsque vous exposez l'ADN ou l'ARN à des conditions extrêmes, telles qu'une chaleur élevée, des agents chimiques agressifs ou des changements de pH. Cela entraîne la séparation des deux brins d'acide nucléique en rompant les liaisons hydrogène entre eux, ce qui modifie leur structure tridimensionnelle normale. Dans le cas d'une dénaturation acide spécifiquement, cela se réfère généralement à l'exposition de l'acide nucléique à des conditions de pH très bas (inférieur à 5,0), ce qui peut également affaiblir ou briser ces liaisons hydrogène et provoquer la dénaturation.
Il est important de noter que la dénaturation des acides nucléiques est souvent un événement indésirable dans de nombreux contextes de recherche biomédicale, car elle peut interférer avec des processus tels que la réplication de l'ADN et la transcription de l'ARN. Cependant, il existe également des situations où la dénaturation intentionnelle des acides nucléiques est souhaitable, comme dans les techniques de PCR (réaction en chaîne par polymérase) où la séparation des brins d'ADN est une étape clé du processus.
En bref, la dénaturation acide des acides nucléiques fait référence au processus de séparation des deux brins d'acide nucléique en exposant l'ADN ou l'ARN à des conditions de pH très bas, ce qui entraîne la modification de leur structure tridimensionnelle normale.
La thymine est un nucleobase présent dans l'ADN, l'acide désoxyribonucléique, qui est la molécule porteuse de l'information génétique dans presque toutes les formes de vie. Elle forme des paires de bases avec l'adénine, une autre nucleobase, grâce à des liaisons hydrogène. Chaque paire de thymine-adénine contient deux liaisons hydrogène et est stabilisée par ces interactions.
Dans la structure en double hélice de l'ADN, les deux brins d'acide nucléique sont complémentaires : chaque thymine sur un brin fait face à une adénine sur l'autre brin. Cette complémentarité est cruciale pour la réplication et la transcription de l'ADN, processus essentiels à la division cellulaire et à la synthèse des protéines.
Il est important de noter que dans l'ARN, l'acide ribonucléique, la thymine est remplacée par l'uracile comme nucleobase complémentaire de l'adénine. Cela s'explique par le fait que l'ARN est une molécule à chaîne simple et qu'il n'a pas besoin d'être aussi stable que l'ADN, ce qui permet à l'uracile d'être utilisé à la place de la thymine.
En résumé, la thymine est un nucleobase essentiel dans la structure et la fonction de l'ADN, où elle forme des paires de bases avec l'adénine grâce à des liaisons hydrogène.
Je suis désolé, mais la phrase "Cadre Lecture Ouvert" ne correspond pas à une définition médicale établie. Le terme "cadre de lecture ouvert" peut être utilisé dans un contexte littéraire ou universitaire pour décrire un cadre théorique ou conceptuel qui est large et inclusif, permettant différentes interprétations et perspectives.
Cependant, si vous cherchez des informations médicales sur un sujet spécifique, n'hésitez pas à me fournir plus de détails et je ferai de mon mieux pour vous aider.
Le rayonnement ultraviolet (UV) est une forme de radiation électromagnétique avec des longueurs d'onde plus courtes que la lumière visible, ce qui signifie qu'il a une énergie plus élevée. Il se situe dans le spectre électromagnétique entre les rayons X et la lumière visible.
Les rayons UV sont classiquement divisés en trois catégories: UVA, UVB et UVC. Les UVA ont les longueurs d'onde les plus longues (320-400 nm), suivis des UVB (280-320 nm) et des UVC (100-280 nm).
L'exposition aux rayons UV peut avoir des effets à la fois bénéfiques et nocifs sur la santé. D'une part, une certaine exposition au soleil est nécessaire à la synthèse de la vitamine D dans la peau. D'autre part, une exposition excessive aux UV, en particulier aux UVB, peut endommager l'ADN des cellules cutanées, entraînant un bronzage, des coups de soleil, un vieillissement prématuré de la peau et, dans les cas graves, un risque accru de cancer de la peau.
Les UVC sont complètement filtrés par la couche d'ozone de l'atmosphère et ne représentent donc pas de risque pour la santé humaine. En revanche, les UVA et les UVB peuvent pénétrer dans l'atmosphère et atteindre la surface de la Terre, où ils peuvent avoir des effets néfastes sur la santé humaine et environnementale.
L'ADN recombinant est une technologie de génie génétique qui consiste à combiner des molécules d'ADN de différentes sources pour créer une nouvelle séquence d'ADN. Cette technique permet aux scientifiques de manipuler et de modifier l'information génétique pour diverses applications, telles que la production de protéines thérapeutiques, la recherche biologique, l'amélioration des cultures agricoles et la médecine personnalisée.
L'ADN recombinant est créé en laboratoire en utilisant des enzymes de restriction pour couper les molécules d'ADN à des endroits spécifiques, ce qui permet de séparer et d'échanger des segments d'ADN entre eux. Les fragments d'ADN peuvent ensuite être liés ensemble à l'aide d'enzymes appelées ligases pour former une nouvelle molécule d'ADN recombinant.
Cette technologie a révolutionné la biologie et la médecine en permettant de mieux comprendre les gènes et leur fonction, ainsi que de développer de nouveaux traitements pour les maladies génétiques et infectieuses. Cependant, l'utilisation de l'ADN recombinant soulève également des préoccupations éthiques et réglementaires en raison de son potentiel de modification irréversible du génome humain et non humain.
La « cartographie des restrictions » est une technique utilisée en génétique et en biologie moléculaire pour déterminer l'emplacement et l'ordre des sites de restriction sur un fragment d'ADN. Les sites de restriction sont des séquences spécifiques d'une certaine longueur où une enzyme de restriction peut couper ou cliver l'ADN.
La cartographie des restrictions implique la digestion de l'ADN avec différentes enzymes de restriction, suivie de l'analyse de la taille des fragments résultants par électrophorèse sur gel d'agarose. Les tailles des fragments sont ensuite utilisées pour déduire l'emplacement et l'ordre relatifs des sites de restriction sur le fragment d'ADN.
Cette technique est utile dans divers domaines, tels que la génétique humaine, la génomique, la biologie moléculaire et la biotechnologie, pour étudier la structure et l'organisation de l'ADN, identifier les mutations et les réarrangements chromosomiques, et caractériser les gènes et les régions régulatrices.
En résumé, la cartographie des restrictions est une méthode pour déterminer l'emplacement et l'ordre des sites de restriction sur un fragment d'ADN en utilisant des enzymes de restriction et l'analyse de la taille des fragments résultants.
Les mitomycines sont un groupe d'agents antinéoplasiques, qui sont dérivés de certaines souches de streptomyces. Elles ont des propriétés alkylantes et intercalantes, ce qui signifie qu'elles peuvent se lier à l'ADN et empêcher la réplication cellulaire.
Elles sont couramment utilisées dans le traitement de certains cancers, tels que le cancer de la vessie, le cancer de l'estomac et les carcinomes épidermoïdes. Les mitomycines peuvent être administrées par voie intraveineuse ou intravésicale (dans la vessie).
Les effets secondaires courants des mitomycines comprennent la nausée, la vomissement, la diarrhée, la fatigue et une diminution du nombre de cellules sanguines. Les patients peuvent également présenter une inflammation de la muqueuse buccale et une sensibilité accrue à l'infection.
Les mitomycines sont des médicaments puissants qui nécessitent une surveillance étroite pour détecter les effets secondaires et ajuster le traitement en conséquence.
Les polynucléotides ligases sont des enzymes qui catalysent la formation d'un lien covalent entre deux chaînes de polynucléotides, telles que l'ADN ou l'ARN, en joignant leurs extrémités 3'-OH et 5'-phosphate. Ces enzymes jouent un rôle crucial dans les processus de réparation et de réplication de l'ADN, ainsi que dans le mécanisme de biosynthèse de l'ARN.
Dans le contexte de la réparation de l'ADN, les polynucléotides ligases aident à réunir les extrémités des brins d'ADN après qu'ils ont été coupés et traités par des enzymes de réparation telles que les endonucléases. Cela permet de rétablir l'intégrité de la molécule d'ADN et de préserver la stabilité du génome.
Dans le cadre de la réplication de l'ADN, ces enzymes facilitent la jonction des fragments d'Okazaki sur l'ARN prémessager pendant la synthèse de l'ADN au cours de la réplication semi-conservative.
Les polynucléotides ligases sont également importantes dans le processus de maturation de certains ARN, comme les ARN ribosomiques et les ARN de transfert. Elles participent à la jonction des fragments d'ARN précurseurs pour former l'ARN mature fonctionnel.
Il existe plusieurs types de polynucléotides ligases, chacune ayant une spécificité et un rôle particuliers dans les processus cellulaires mentionnés ci-dessus.
Dans le contexte médical, un "site de fixation" fait référence à l'endroit spécifique où un organisme étranger, comme une bactérie ou un virus, s'attache et se multiplie dans le corps. Cela peut également faire référence au point d'ancrage d'une prothèse ou d'un dispositif médical à l'intérieur du corps.
Par exemple, dans le cas d'une infection, les bactéries peuvent se fixer sur un site spécifique dans le corps, comme la muqueuse des voies respiratoires ou le tractus gastro-intestinal, et s'y multiplier, entraînant une infection.
Dans le cas d'une prothèse articulaire, le site de fixation fait référence à l'endroit où la prothèse est attachée à l'os ou au tissu environnant pour assurer sa stabilité et sa fonction.
Il est important de noter que le site de fixation peut être un facteur critique dans le développement d'infections ou de complications liées aux dispositifs médicaux, car il peut fournir un point d'entrée pour les bactéries ou autres agents pathogènes.
Les mycobactériophages sont des bacteriophages, ou simplement des phages, qui sont des virus qui infectent et se répliquent dans les bactéries. Plus précisément, les mycobactériophages sont des phages qui ciblent spécifiquement les bactéries du genre Mycobacterium, qui comprend des pathogènes humains importants tels que Mycobacterium tuberculosis (la cause de la tuberculose) et Mycobacterium leprae (la cause de la lèpre). Les mycobactériophages sont étudiés dans le cadre de la recherche sur le développement de nouveaux outils thérapeutiques pour traiter les infections à Mycobacterium résistantes aux médicaments.
L'ADN circulaire est une forme d'ADN (acide désoxyribonucléique) qui forme une boucle fermée sur elle-même, contrairement à l'ADN linéaire qui possède des extrémités libres. Cette structure se retrouve dans certains virus, plasmides bactériens et mitochondries.
Les plasmides bactériens sont des petits cercles d'ADN qui peuvent se répliquer indépendamment du chromosome bactérien et sont souvent responsables de la résistance aux antibiotiques chez les bactéries. Les mitochondries, organites présents dans les cellules eucaryotes, possèdent également leur propre ADN circulaire qui code pour certaines de leurs propres protéines.
L'ADN circulaire peut aussi être le résultat d'une réparation de l'ADN endommagé ou d'un processus de recombinaison génétique. Dans certains cas, des fragments d'ADN linéaire peuvent se rejoindre pour former une boucle fermée, créant ainsi une molécule d'ADN circulaire.
Les avantages de l'ADN circulaire comprennent sa stabilité structurelle et sa capacité à se répliquer indépendamment du chromosome hôte. Cependant, elle peut également présenter des inconvénients, tels que la susceptibilité à l'accumulation de mutations et la difficulté à réguler l'expression génétique.
Endodeoxyribonucleases sont des enzymes qui coupent les brins d'ADN internes à des sites spécifiques. Elles sont également connues sous le nom de endonucléases ou restriction endonucléases. Ces enzymes jouent un rôle crucial dans la réplication, la réparation et la recombinaison de l'ADN, ainsi que dans les processus de défense contre les infections virales chez les bactéries.
Les endodeoxyribonucleases reconnaissent des séquences nucléotidiques spécifiques sur l'ADN et coupent les deux brins de la molécule d'ADN à des distances définies par rapport au site de reconnaissance. Les sites de coupure peuvent être symétriques ou asymétriques, ce qui entraîne des extrémités différentes sur les fragments d'ADN produits.
Certaines endodeoxyribonucleases sont utilisées en biologie moléculaire pour manipuler l'ADN, par exemple pour la cartographie de gènes, le clonage et l'analyse de séquences d'ADN. Ces enzymes sont donc des outils essentiels dans les laboratoires de recherche en biologie et médecine.
Les radiations sont des particules ou des ondes énergétiques, telles que les rayons X et les rayons gamma, qui peuvent traverser le tissu corporel et causer des dommages aux cellules en endommageant leur ADN. Un «effet de radiation» fait référence à toute modification ou effet néfaste sur la santé résultant de l'exposition aux radiations.
Les effets des radiations peuvent être aigus, se développant rapidement après une exposition importante, ou chroniques, se développant progressivement au fil du temps en raison d'une exposition répétée ou à long terme à de faibles doses de radiation. Les effets aigus des radiations peuvent inclure la fatigue, les nausées, les vomissements, la diarrhée, les brûlures cutanées et une diminution du nombre de globules blancs, ce qui peut entraîner une augmentation du risque d'infections. Les effets chroniques des radiations peuvent inclure un risque accru de cancer, en particulier des leucémies et des cancers solides, ainsi que des dommages aux organes reproducteurs et au cerveau.
L'ampleur des effets des radiations dépend de plusieurs facteurs, notamment la dose de radiation, la durée de l'exposition, le type de rayonnement et la sensibilité individuelle de l'organisme aux radiations. Les professionnels de la santé utilisent des mesures de protection pour minimiser l'exposition aux radiations, telles que l'utilisation de boucliers de plomb et d'autres matériaux absorbants les radiations, ainsi que l'utilisation de techniques d'imagerie à faible dose.
Integrases sont des enzymes qui sont produites par certains virus, y compris le VIH (virus de l'immunodéficience humaine), et jouent un rôle crucial dans l'intégration du matériel génétique viral dans l'ADN de la cellule hôte. Ces enzymes coupent les extrémités des brins d'ADN viral, puis insèrent ces extrémités dans l'ADN de la cellule hôte, permettant ainsi au matériel génétique viral de s'intégrer de manière permanente dans le génome de la cellule. Cette intégration est un événement clé dans le cycle de réplication du virus et est donc considérée comme une cible importante pour le développement de médicaments antirétroviraux. Les inhibiteurs d'integrases sont une classe de médicaments utilisés dans le traitement de l'infection par le VIH.
Les « Régions Génétiques Opérateur » sont des régions spécifiques du génome qui régulent l'expression des gènes. Elles sont composées d'une séquence d'ADN qui se lie à des protéines régulatrices, appelées protéines de liaison à l'opérateur, pour contrôler la transcription des gènes situés à proximité. Ces protéines peuvent activer ou réprimer la transcription en fonction des signaux reçus dans l'environnement cellulaire.
Les opérateurs sont souvent trouvés dans les systèmes bactériens et archaebactériens, où ils font partie de régions plus larges appelées « opérons ». Un opéron est un groupe de gènes qui sont transcrits ensemble en une seule molécule d'ARN messager (ARNm). Les opérateurs permettent aux cellules de coordonner l'expression de plusieurs gènes en réponse à des signaux internes ou externes.
Les mutations dans les régions génétiques opérateur peuvent entraîner une expression altérée des gènes qu'elles régulent, ce qui peut avoir des conséquences importantes sur la fonction cellulaire et l'homéostasie de l'organisme. Par exemple, des mutations dans les opérateurs peuvent être associées à des maladies génétiques ou à une résistance aux antibiotiques chez les bactéries.
Un assemblage viral est le processus par lequel les composants individuels d'un virus, tels que l'ARN ou l'ADN viral, la capside protéique et, dans certains cas, une enveloppe lipidique, sont assemblés pour former un virion infectieux mature. Ce processus est médié par des interactions spécifiques entre les composants viraux et peut être régulé par des facteurs hôtes. L'assemblage a généralement lieu à l'intérieur d'une cellule hôte infectée, après que le génome viral se soit répliqué et que les protéines virales aient été synthétisées. Une fois l'assemblage terminé, les virions peuvent être libérés de la cellule hôte par bourgeonnement ou par lyse de la cellule.
Il est important de noter qu'il existe différentes stratégies d'assemblage pour différents types de virus. Par exemple, certains virus à ARN simple brin (+) peuvent utiliser une stratégie d'assemblage en une seule étape, dans laquelle le génome viral et les protéines structurales s'assemblent spontanément pour former un virion infectieux. D'autres virus, tels que les rétrovirus, nécessitent plusieurs étapes pour assembler leurs composants, y compris la reverse transcription du génome ARN en ADNc et l'intégration de l'ADNc dans le génome de l'hôte.
L'assemblage viral est un domaine de recherche actif en virologie, car une meilleure compréhension de ce processus peut fournir des cibles pour le développement de nouveaux médicaments antiviraux et de stratégies d'intervention.
Les exonucléases sont des enzymes qui coupent et éliminent les nucléotides individuellement d'une extrémité d'une chaîne d'acide nucléique (ADN ou ARN), en direction de l'extrémité opposée. Elles jouent un rôle crucial dans les processus de réparation et de recombinaison de l'ADN, ainsi que dans la régulation de la synthèse des ARN.
Les exonucléases peuvent être classées en fonction de leur spécificité pour l'extrémité 5' ou 3' de la chaîne d'acide nucléique, et selon qu'elles agissent sur l'ADN ou l'ARN. Par exemple, une exonucléase 5'-3' spécifique à l'ADN éliminera les nucléotides de l'extrémité 5' vers l'extrémité 3', tandis qu'une exonucléase 3'-5' spécifique à l'ARN éliminera les nucléotides de l'extrémité 3' vers l'extrémité 5'.
Les exonucléases sont importantes pour maintenir l'intégrité du génome en éliminant les nucléotides endommagés ou incorrectement appariés, et en participant à des processus tels que la réplication de l'ADN, la recombinaison homologue et la dégradation des ARN. Les anomalies dans le fonctionnement des exonucléases peuvent entraîner diverses maladies génétiques et contribuer au développement du cancer.
En médecine et en biologie moléculaire, une hélicase est une enzyme qui a la capacité de séparer les brins d'ADN ou d'ARN dans une double hélice, consommant de l'ATP (adénosine triphosphate) comme source d'énergie. Ce processus est crucial dans divers processus cellulaires tels que la réplication de l'ADN, la réparation de l'ADN et la transcription de l'ARN. Les hélicases sont donc essentielles à la stabilité et à la reproduction des organismes vivants. Des anomalies dans le fonctionnement des hélicases peuvent entraîner diverses affections médicales, notamment des maladies génétiques et un risque accru de cancer.
Je suis désolé, mais il semble y avoir une petite erreur dans votre requête. « Lactococcus lactis » ne devrait pas être entre apostrophes. Il s'agit du nom d'une bactérie spécifique et non d'une expression ou d'un terme médical particulier.
Passant outre cette erreur, « Lactococcus lactis » est une bactérie Gram-positive, catalase-négative, de forme coccique (en forme de sphère) qui se divise généralement en chaînes courtes. Elle est non mobile et appartient au genre Lactococcus. Cette bactérie est fréquemment trouvée dans la nature, surtout dans les produits laitiers fermentés comme le yaourt et le fromage.
« Lactococcus lactis » joue un rôle crucial dans l'industrie alimentaire en participant à la fermentation du lait pour produire de l'acide lactique, ce qui entraîne la coagulation du lait et la formation de caillé. Ce processus est important dans la fabrication de fromages et de yaourts.
Dans un contexte médical, « Lactococcus lactis » peut être utilisé comme probiotique pour promouvoir la santé intestinale en restaurant l'équilibre des bactéries bénéfiques dans le tractus gastro-intestinal. Cependant, il est important de noter que les avantages potentiels pour la santé de « Lactococcus lactis » et d'autres probiotiques doivent encore faire l'objet de recherches plus poussées.
Microviridae est une famille de virus à ADN simple brin qui infectent principalement des bactéries. Ces virus sont très petits, d'où le nom "micro", et ont un génome d'environ 5 kb. Ils se répliquent en utilisant une méthode de réplication rolling hairpin et sont empaquetés dans une capside icosaédrique sans envelope. Les membres les plus connus de cette famille comprennent le bacteriophage G4, qui infecte Escherichia coli, et le bacteriophage φX174, qui a été le premier ADN à être séquencé en entier. Ces virus sont largement étudiés en raison de leur petite taille, de leur génome simple et de leur réplication unique. Cependant, ils ne sont pas considérés comme ayant une importance clinique majeure pour la santé humaine.
L'ADN (acide désoxyribonucléique) est une molécule complexe qui contient les instructions génétiques utilisées dans le développement et la fonction de tous les organismes vivants connus et certains virus. L'ADN est un long polymère d'unités simples appelées nucléotides, avec des séquences de ces nucléotides qui forment des gènes. Ces gènes sont responsables de la synthèse des protéines et de la régulation des processus cellulaires.
L'ADN est organisé en une double hélice, où deux chaînes polynucléotidiques s'enroulent autour d'un axe commun. Les chaînes sont maintenues ensemble par des liaisons hydrogène entre les bases complémentaires : adénine (A) avec thymine (T), et guanine (G) avec cytosine (C).
L'ADN est présent dans le noyau de la cellule, ainsi que dans certaines mitochondries et chloroplastes. Il joue un rôle crucial dans l'hérédité, la variation génétique et l'évolution des espèces. Les mutations de l'ADN peuvent entraîner des changements dans les gènes qui peuvent avoir des conséquences sur le fonctionnement normal de la cellule et être associées à des maladies génétiques ou cancéreuses.
Les ARN nucleotidyltransferases sont un type d'enzymes qui catalysent l'ajout de nucléotides à l'extrémité d'un ARN, dans une réaction de transfert de nucléotides. Ces enzymes jouent un rôle important dans la biogenèse des telomères, la régulation de l'expression génétique et la défense contre les agents infectieux.
Il existe plusieurs types d'ARN nucleotidyltransferases, chacune avec une fonction spécifique. Par exemple, les ARN polymérases ajoutent des nucléotides à une chaîne naissante d'ARN pendant la transcription, tandis que les terminalnes transferases ajoutent des nucléotides à l'extrémité 3' des ARN.
Les ARN nucleotidyltransferases utilisent généralement un ARN ou un ADN comme matrice pour guider l'addition de nucléotides, et nécessitent de l'ATP ou d'autres triphosphates nucléosidiques comme donneurs de nucléotides. Ces enzymes sont importantes pour la stabilité des ARN, la traduction des ARN messagers en protéines, et la réponse immunitaire contre les virus et autres agents infectieux.
Des anomalies dans l'activité des ARN nucleotidyltransferases peuvent être associées à des maladies telles que le cancer, les maladies neurodégénératives et les infections virales.
Salmonella Typhimurium est un type spécifique de bactérie appartenant au genre Salmonella. Elle est souvent associée aux maladies infectieuses chez l'homme et les animaux. Cette souche est particulièrement connue pour provoquer une forme de salmonellose, qui se traduit par des symptômes gastro-intestinaux tels que la diarrhée, des crampes abdominales, des nausées et des vomissements.
Chez l'homme, Salmonella Typhimurium est généralement contractée après avoir ingéré de la nourriture ou de l'eau contaminées. Les aliments couramment associés à cette infection comprennent la viande crue ou insuffisamment cuite, les œufs, les produits laitiers non pasteurisés et les légumes verts feuillus.
Chez les animaux, en particulier chez les rongeurs comme les souris et les hamsters, Salmonella Typhimurium peut provoquer une maladie systémique similaire à la typhoïde humaine, d'où son nom. Cependant, contrairement à la typhoïde humaine, qui est généralement causée par une autre souche de Salmonella (Salmonella Typhi), l'infection par Salmonella Typhimurium chez l'homme ne se transforme pas en maladie systémique aussi grave.
Il est important de noter que certaines souches de Salmonella, y compris Salmonella Typhimurium, peuvent développer une résistance aux antibiotiques, ce qui rend le traitement plus difficile. Par conséquent, la prévention reste essentielle pour contrôler la propagation de cette bactérie. Cela inclut des pratiques adéquates d'hygiène alimentaire, comme cuire complètement les aliments, surtout ceux d'origine animale, et séparer correctement les aliments crus des aliments cuits.
L'uracile est une base nucléique qui fait partie de la structure de l'ARN, contrairement à l'ADN qui contient de la thymine à sa place. L'uracile s'appaire avec l'adénine via deux liaisons hydrogène lors de la formation de la double hélice d'ARN. Dans le métabolisme des nucléotides, l'uracile est dérivé de la cytosine par désamination. En médecine, des taux anormalement élevés d'uracile dans l'urine peuvent indiquer certaines conditions, telles qu'un déficit en enzyme cytosine déaminase ou une infection des voies urinaires.
Un modèle moléculaire est un outil utilisé en chimie et en biologie pour représenter visuellement la structure tridimensionnelle d'une molécule. Il peut être construit à partir de matériaux réels, tels que des balles et des bâtons, ou créé numériquement sur un ordinateur.
Les modèles moléculaires aident les scientifiques à comprendre comment les atomes sont liés les uns aux autres dans une molécule et comment ils interagissent entre eux. Ils peuvent être utilisés pour étudier la forme d'une molécule, son arrangement spatial, sa flexibilité et ses propriétés chimiques.
Dans un modèle moléculaire physique, les atomes sont représentés par des boules de différentes couleurs (selon leur type) et les liaisons chimiques entre eux sont représentées par des bâtons ou des tiges rigides. Dans un modèle numérique, ces éléments sont représentés à l'écran sous forme de graphismes 3D.
Les modèles moléculaires sont particulièrement utiles dans les domaines de la chimie organique, de la biochimie et de la pharmacologie, où ils permettent d'étudier la structure des protéines, des acides nucléiques (ADN et ARN) et des autres molécules biologiques complexes.
Un virion est la forme extérieure et complète d'un virus. Il se compose du matériel génétique du virus (ARN ou ADN) enfermé dans une coque de protéines appelée capside. Certains virus ont également une enveloppe lipidique externe qui est dérivée de l'hôte cellulaire infecté. Les virions sont la forme infectieuse des virus, capables de se lier et d'infecter les cellules hôtes pour assurer leur réplication.
Les protéines E. coli se réfèrent aux différentes protéines produites par la bactérie Escherichia coli (E. coli). Ces protéines sont codées par les gènes du chromosome bactérien et peuvent avoir diverses fonctions dans le métabolisme, la régulation, la structure et la pathogénicité de la bactérie.
Escherichia coli est une bactérie intestinale commune chez l'homme et les animaux à sang chaud. La plupart des souches d'E. coli sont inoffensives, mais certaines souches peuvent causer des maladies allant de gastro-entérites légères à des infections graves telles que la pneumonie, la méningite et les infections urinaires. Les protéines E. coli jouent un rôle crucial dans la virulence de ces souches pathogènes.
Par exemple, certaines protéines E. coli peuvent aider la bactérie à adhérer aux parois des cellules humaines, ce qui permet à l'infection de se propager. D'autres protéines peuvent aider la bactérie à échapper au système immunitaire de l'hôte ou à produire des toxines qui endommagent les tissus de l'hôte.
Les protéines E. coli sont largement étudiées en raison de leur importance dans la compréhension de la physiologie et de la pathogenèse d'E. coli, ainsi que pour leur potentiel en tant que cibles thérapeutiques ou vaccinales.
L'électrophorèse sur gel de polyacrylamide (PAGE) est une technique de laboratoire couramment utilisée dans le domaine du testing et de la recherche médico-légales, ainsi que dans les sciences biologiques, y compris la génétique et la biologie moléculaire. Elle permet la séparation et l'analyse des macromolécules, telles que les protéines et l'ADN, en fonction de leur taille et de leur charge.
Le processus implique la création d'un gel de polyacrylamide, qui est un réseau tridimensionnel de polymères synthétiques. Ce gel sert de matrice pour la séparation des macromolécules. Les échantillons contenant les molécules à séparer sont placés dans des puits creusés dans le gel. Un courant électrique est ensuite appliqué, ce qui entraîne le mouvement des molécules vers la cathode (pôle négatif) ou l'anode (pôle positif), selon leur charge. Les molécules plus petites se déplacent généralement plus rapidement à travers le gel que les molécules plus grandes, ce qui permet de les séparer en fonction de leur taille.
La PAGE est souvent utilisée dans des applications telles que l'analyse des protéines et l'étude de la structure et de la fonction des protéines, ainsi que dans le séquençage de l'ADN et l'analyse de fragments d'ADN. Elle peut également être utilisée pour détecter et identifier des modifications post-traductionnelles des protéines, telles que les phosphorylations et les glycosylations.
Dans le contexte médical, la PAGE est souvent utilisée dans le diagnostic et la recherche de maladies génétiques et infectieuses. Par exemple, elle peut être utilisée pour identifier des mutations spécifiques dans l'ADN qui sont associées à certaines maladies héréditaires. Elle peut également être utilisée pour détecter et identifier des agents pathogènes tels que les virus et les bactéries en analysant des échantillons de tissus ou de fluides corporels.
Le bactériophage HK022 est un type spécifique de virus qui infecte et se réplique dans des bactéries hôtes spécifiques, en particulier les souches d'Escherichia coli (E. coli) résistantes aux antibiotiques. Les bactériophages sont également connus sous le nom de «phages» et ils jouent un rôle important dans la régulation des populations bactériennes dans l'environnement.
Le bactériophage HK022 a été découvert et caractérisé par une équipe de chercheurs sud-coréens en 2014. Il appartient à la famille des Myoviridae, qui sont des bactériophages avec une queue longue et flexible. Le bactériophage HK022 a un génome linéaire double brin d'ADN de 153 kilobases pairs (kbp) et code pour environ 240 protéines différentes.
Le bactériophage HK022 est capable d'infecter et de tuer les souches d'E. coli qui sont résistantes aux antibiotiques couramment utilisés, telles que les souches productrices de bêta-lactamases à spectre étendu (BLSE) et les souches productrices de carbapénémases. Il a été proposé comme un traitement possible pour les infections bactériennes résistantes aux antibiotiques, en particulier dans les cas où les options thérapeutiques sont limitées.
Cependant, il convient de noter que l'utilisation de bactériophages à des fins thérapeutiques est encore expérimentale et nécessite une évaluation plus poussée avant d'être largement adoptée dans la pratique clinique.
La régulation de l'expression génique virale est un processus complexe et crucial dans le cycle de vie des virus. Il décrit la manière dont les virus contrôlent l
Je suis désolé, mais il semble y avoir une erreur dans votre requête. "Corticoviridae" n'est pas un terme médical reconnu comme étant lié à la médecine ou à la santé. Il s'agit plutôt d'une famille de virus qui infectent les bactéries, également connus sous le nom de bacteriophages. Les corticovirus ont une structure unique avec une capside en forme de tonneau et un génome à ARN monocaténaire. Ils infectent principalement des bactéries appartenant à la classe des Mollicutes, qui comprend des pathogènes humains courants tels que Mycoplasma pneumoniae.
Si vous cherchiez une définition médicale pour un terme différent, n'hésitez pas à me le demander et je ferai de mon mieux pour vous fournir une réponse précise et utile.
Les endonucléases sont des enzymes qui coupent les brins d'acide nucléique (ADN ou ARN) à des sites spécifiques internes, contrairement aux exonucléases qui éliminent des nucléotides de l'extrémité des brins. Les endonucléases jouent un rôle crucial dans divers processus biologiques, tels que la réparation et le réarrangement de l'ADN, le traitement de l'ARN et la défense contre les agents infectieux comme les virus et les plasmides.
Il existe différents types d'endonucléases, chacune avec une spécificité pour un site de coupure particulier sur l'acide nucléique. Par exemple, certaines endonucléases reconnaissent et coupent des séquences palindromiques (identiques à l'envers) dans l'ADN double brin, tandis que d'autres se lient et clivent des structures secondaires spécifiques dans l'ARN.
Les endonucléases sont largement utilisées en biotechnologie et en recherche scientifique pour des applications telles que la manipulation de gènes, le clonage moléculaire, l'analyse de séquences d'acides nucléiques et la détection de pathogènes.
Je suis désolé, mais il semble y avoir une confusion dans votre question. Tectiviridae n'est pas une définition médicale ou un terme médical reconnu. Il s'agit en fait d'une famille de virus connus sous le nom de bacteriophages, qui infectent et se répliquent dans des bactéries. Les membres de cette famille ont une capside icosaédrique avec une coque interne protéique appelée lipomembrane. Ils ont un génome à ADN double brin et suivent généralement un cycle de réplication lysogénique, ce qui signifie qu'ils peuvent s'intégrer dans le génome de la bactérie hôte et se répliquer avec elle sans la tuer immédiatement. Cependant, sous certaines conditions, ils peuvent aussi suivre un cycle lytique, entraînant la lyse de la bactérie hôte et la libération de nouveaux virions.
Le lysozyme est une enzyme naturellement présente dans divers fluides corporels, tels que les larmes, la salive, le sang et le mucus. Elle est également présente dans certains blancs d'œufs et certaines sécrétions muqueuses.
Sa fonction principale est de dégrader la paroi cellulaire des bactéries, en particulier des gram positifs, ce qui entraîne leur mort. Cela fait du lysozyme une enzyme importante dans notre système immunitaire, car il aide à combattre les infections.
Le lysozyme est également utilisé dans l'industrie alimentaire et pharmaceutique comme conservateur, grâce à sa capacité à détruire les parois bactériennes.
La N-acétylmuramoyl-L-alanine amidase est une enzyme qui joue un rôle crucial dans le processus de dégradation et de recyclage des peptidoglycanes, un composant majeur de la paroi cellulaire bactérienne. Cette enzyme est responsable de la coupure spécifique du lien amide entre l'acétyl muramique et l'alanine dans le peptidoglycane. Ce processus permet la libération de peptides et d'oligosaccharides qui peuvent être réutilisés pour la synthèse de nouveaux peptidoglycanes ou dégradés en acides aminés et sucres simples pour fournir de l'énergie à la cellule bactérienne. La N-acétylmuramoyl-L-alanine amidase est donc une enzyme importante dans le métabolisme des bactéries et peut être une cible thérapeutique intéressante pour le développement de nouveaux antibiotiques.
La thymidine est un nucléoside constitué d'une base azotée, la thymine, et du sucre pentose désoxyribose. Elle joue un rôle crucial dans la biosynthèse de l'ADN, où elle est intégrée sous forme de désoxynucléotide de thymidine (dTTP). La thymidine est essentielle à la réplication et à la réparation de l'ADN. Elle est également importante dans le métabolisme cellulaire, en particulier pendant la phase S du cycle cellulaire, lorsque la synthèse d'ADN a lieu. Des carences en thymidine peuvent entraîner une instabilité génomique et des mutations, ce qui peut avoir des conséquences néfastes sur la croissance, le développement et la fonction cellulaire normaux.
Le récepteur du complément 3d, également connu sous le nom de CD21 ou CR2, est un glycoprotéine transmem molecular qui sert de récepteur pour le fragment C3d du complément et joue un rôle important dans l'activation du système immunitaire. Il est exprimé à la surface des cellules B matures, des folliculaires dendritiques et d'autres types cellulaires. Le récepteur du complément 3d fonctionne en se liant au fragment C3d pour faciliter l'interaction entre les cellules présentatrices d'antigène et les lymphocytes B, ce qui entraîne une activation des lymphocytes B et une réponse immunitaire adaptative. Des mutations dans le gène du récepteur du complément 3d ont été associées à certaines maladies auto-immunes, telles que le syndrome de Sjögren et le lupus érythémateux disséminé.
"Pseudomonas" est un genre de bactéries à gram négatif, en forme de bâtonnet, largement répandues dans l'environnement. Elles peuvent être trouvées dans des sources d'eau douce et salée, dans le sol, sur les plantes et dans les systèmes de distribution d'eau. Certaines espèces de Pseudomonas sont opportunistes et peuvent causer des infections chez l'homme, en particulier chez les personnes dont le système immunitaire est affaibli. L'espèce la plus courante responsable d'infections humaines est Pseudomonas aeruginosa. Ces infections peuvent affecter divers sites du corps, y compris la peau, les poumons, le sang et les voies urinaires. Les infections à Pseudomonas sont souvent difficiles à traiter en raison de la résistance de ces bactéries aux antibiotiques couramment utilisés.
Un nucléotide thymidylate, également connu sous le nom de deoxythymidine monophosphate (dTMP), est un type de nucléotide qui joue un rôle crucial dans la biosynthèse de l'ADN. Il se compose d'une base nucléique, la thymine, liée à un sucre pentose déoxyribose et à un groupe phosphate. Les nucléotides thymidylates sont assemblés en chaînes pour former des brins d'ADN pendant le processus de réplication de l'ADN.
Je suis désolé, mais la phrase que vous avez demandée à définir ne semble pas être une expression ou un terme médical standard. "Spécificité Espèce" ne donne aucun résultat pertinent dans les contextes médicaux ou scientifiques.
Si vous cherchez des informations sur la spécificité en général dans le contexte médical, cela fait référence à la capacité d'un test diagnostique à correctement identifier les individus sans une certaine condition. En d'autres termes, la spécificité est le rapport entre le nombre de vrais négatifs et le total des personnes négatives (saines) dans une population donnée.
Si vous cherchiez des informations sur la taxonomie biologique ou l'identification des espèces, "spécificité d'espèce" pourrait faire référence à des caractéristiques uniques qui définissent et différencient une espèce donnée des autres.
Si vous pouviez me fournir plus de contexte ou clarifier votre question, je serais heureux de vous aider davantage.
La microbiologie de l'eau est la branche de la microbiologie qui étudie les micro-organismes présents dans l'eau, y compris les bactéries, les virus, les champignons, les protozoaires et les algues. Elle se concentre sur l'identification, la quantification, le rôle éco-physiologique, la surveillance et le contrôle de ces micro-organismes dans l'eau douce, les eaux usées, les eaux côtières et marines.
L'objectif principal de la microbiologie de l'eau est d'assurer la sécurité sanitaire de l'eau potable, de protéger l'environnement aquatique contre la pollution microbienne et de prévenir la propagation des maladies hydriques. Les professionnels de la microbiologie de l'eau travaillent dans divers domaines tels que la santé publique, l'industrie alimentaire, l'aquaculture, l'ingénierie environnementale et la recherche scientifique.
Les méthodes d'analyse couramment utilisées en microbiologie de l'eau comprennent la culture traditionnelle, la PCR en temps réel, la spectrométrie de masse et les techniques immunologiques. Les paramètres microbiologiques couramment surveillés dans l'eau potable comprennent les coliformes fécaux, les entérocoques intestinaux et les Escherichia coli, qui sont des indicateurs de contamination fécale et de risque de maladies d'origine hydrique.
Le facteur F, également connu sous le nom de facteur anti-hémophilique B ou factor VIII, est une protéine essentielle dans la coagulation sanguine. Il est synthétisé principalement par les cellules endothéliales du foie et des cellules du tissu conjonctif. Le facteur F fonctionne comme un catalyseur pour l'activation du facteur X, une étape cruciale dans la cascade de coagulation qui conduit à la formation d'un caillot sanguin et arrête ainsi le saignement.
Un déficit en facteur F est responsable de l'hémophilie A, une maladie héréditaire caractérisée par des saignements prolongés et souvent spontanés, principalement dans les articulations et les muscles. Le traitement pour l'hémophilie A implique généralement des perfusions régulières de concentré de facteur F pour prévenir ou traiter les épisodes hémorragiques.
Les protéines fixant l'ADN, également connues sous le nom de protéines liant l'ADN ou protéines nucléaires, sont des protéines qui se lient spécifiquement à l'acide désoxyribonucléique (ADN). Elles jouent un rôle crucial dans la régulation de la transcription et de la réplication de l'ADN, ainsi que dans la maintenance de l'intégrité du génome.
Les protéines fixant l'ADN se lient à des séquences d'ADN spécifiques grâce à des domaines de liaison à l'ADN qui reconnaissent et se lient à des motifs particuliers dans la structure de l'ADN. Ces protéines peuvent agir comme facteurs de transcription, aidant à activer ou à réprimer la transcription des gènes en régulant l'accès des polymérases à l'ADN. Elles peuvent également jouer un rôle dans la réparation de l'ADN, en facilitant la reconnaissance et la réparation des dommages à l'ADN.
Les protéines fixant l'ADN sont souvent régulées elles-mêmes par des mécanismes post-traductionnels tels que la phosphorylation, la méthylation ou l'acétylation, ce qui permet de moduler leur activité en fonction des besoins cellulaires. Des anomalies dans les protéines fixant l'ADN peuvent entraîner diverses maladies génétiques et sont souvent associées au cancer.
La suppression génétique, également connue sous le nom d'inactivation génique ou de silençage génique, est un processus par lequel l'expression des gènes est réduite ou éliminée. Cela peut se produire de plusieurs manières, notamment par la méthylation de l'ADN, l'interférence par ARN ou la modification des histones.
Dans le contexte médical, la suppression génétique est souvent utilisée comme un moyen de traiter les maladies causées par des gènes surexprimés ou mutés. Par exemple, dans le cas du cancer, certaines cellules cancéreuses ont des gènes surexprimés qui contribuent à leur croissance et à leur propagation. En supprimant l'expression de ces gènes, il est possible de ralentir ou d'arrêter la progression du cancer.
La suppression génétique peut être obtenue en utilisant diverses techniques, telles que l'utilisation de molécules d'ARN interférent (ARNi) pour bloquer la traduction des ARN messagers (ARNm) en protéines, ou en modifiant les histones pour rendre les gènes moins accessibles à la transcription.
Cependant, il est important de noter que la suppression génétique peut également entraîner des effets secondaires indésirables, tels que l'inhibition de l'expression de gènes non ciblés ou l'activation de voies de signalisation compensatoires. Par conséquent, il est essentiel de comprendre pleinement les mécanismes impliqués dans la suppression génétique avant de l'utiliser comme traitement médical.
La electrophorèse sur gel d'agarose est un type de méthode d'électrophorèse utilisée dans la séparation et l'analyse des macromolécules, en particulier l'ADN, l'ARN et les protéines. Dans cette technique, une solution d'agarose est préparée et versée dans un moule pour former un gel. Une fois le gel solidifié, il est placé dans un réservoir rempli d'une solution tampon et des échantillons contenant les macromolécules à séparer sont appliqués sur le gel.
Lorsque le courant électrique est appliqué, les molécules chargées migrent vers l'anode ou la cathode en fonction de leur charge et de leur poids moléculaire. Les molécules plus petites et/ou moins chargées se déplacent plus rapidement que les molécules plus grandes et/ou plus chargées, ce qui entraîne une séparation des macromolécules en fonction de leur taille et de leur charge.
La electrophorèse sur gel d'agarose est souvent utilisée dans la recherche en biologie moléculaire pour analyser la taille et la pureté des fragments d'ADN ou d'ARN, tels que ceux obtenus par PCR ou digestion enzymatique. Les gels peuvent être colorés avec des colorants tels que le bleu de bromophénol ou l'éthidium bromure pour faciliter la visualisation et l'analyse des bandes de macromolécules séparées.
En résumé, la electrophorèse sur gel d'agarose est une technique couramment utilisée en biologie moléculaire pour séparer et analyser les macromolécules telles que l'ADN, l'ARN et les protéines en fonction de leur taille et de leur charge.
Les régions promotrices génétiques sont des séquences d'ADN situées en amont du gène, qui servent à initier et à réguler la transcription de l'ARN messager (ARNm) à partir de l'ADN. Ces régions contiennent généralement des séquences spécifiques appelées "sites d'initiation de la transcription" où se lie l'ARN polymérase, l'enzyme responsable de la synthèse de l'ARNm.
Les régions promotrices peuvent être courtes ou longues et peuvent contenir des éléments de régulation supplémentaires tels que des sites d'activation ou de répression de la transcription, qui sont reconnus par des facteurs de transcription spécifiques. Ces facteurs de transcription peuvent activer ou réprimer la transcription du gène en fonction des signaux cellulaires et des conditions environnementales.
Les mutations dans les régions promotrices peuvent entraîner une altération de l'expression génique, ce qui peut conduire à des maladies génétiques ou à une susceptibilité accrue aux maladies complexes telles que le cancer. Par conséquent, la compréhension des mécanismes régissant les régions promotrices est essentielle pour comprendre la régulation de l'expression génique et son rôle dans la santé et la maladie.
Le code génétique est un ensemble de règles dans la biologie moléculaire qui décrit comment les informations stockées dans l'ADN sont converties en protéines. Il s'agit d'un processus complexe appelé traduction, qui se produit dans les ribosomes des cellules vivantes.
Dans le code génétique, chaque groupe de trois nucléotides (ou codon) de l'ARN messager (ARNm), une copie complémentaire d'une partie de l'ADN, spécifie un acide aminé particulier. Par exemple, le codon AUG code pour l'acide aminé méthionine.
Il y a 64 combinaisons possibles de quatre nucléotides (A, U, G, C) dans des groupes de trois, mais seulement 20 acides aminés différents sont utilisés pour construire des protéines. Cela signifie que certains acides aminés sont codés par plus d'un codon - c'est ce qu'on appelle la dégénérescence du code génétique. De plus, trois codons (UAA, UAG, UGA) servent de signaux d'arrêt pour indiquer où une protéine doit commencer et se terminer.
En résumé, le code génétique est essentiellement un langage chimique qui permet aux cellules de lire les instructions contenues dans l'ADN et de produire des protéines fonctionnelles, ce qui joue un rôle crucial dans la croissance, le développement et la reproduction des organismes vivants.
La conjugaison génétique est un processus biologique par lequel deux organismes échangent du matériel génétique, principalement sous la forme d'ADN, pour se récombiner et former de nouvelles combinaisons génétiques. Cependant, dans un contexte médical plus restreint, le terme «conjugaison» est souvent utilisé pour décrire le transfert d'ADN entre bactéries, en particulier dans le cadre du développement de la résistance aux antibiotiques.
Dans ce processus, une bactérie donneuse, appelée donneur, transfère une partie de son ADN à une bactérie réceptrice, ou receveuse, via un pont cytoplasmique appelé pilus sexuel. Ce transfert d'ADN peut entraîner des modifications permanentes du génome de la bactérie réceptrice, y compris l'acquisition de gènes de résistance aux antibiotiques.
Il est important de noter que ce mécanisme de conjugaison joue un rôle crucial dans l'évolution et l'adaptation des bactéries, mais il peut également contribuer à la propagation de gènes indésirables, tels que les gènes de résistance aux antibiotiques, ce qui pose des défis importants en matière de santé publique.
La cytosine est un nucléotide qui fait partie des quatre bases azotées qui composent l'ADN et l'ARN. Dans l'ADN, la cytosine s'apparie avec la guanine via trois liaisons hydrogènes. Dans l'ARN, elle s'apparie avec l'uracile via deux liaisons hydrogènes. La cytosine est désaminée en uracile dans l'ADN, ce qui peut entraîner une mutation si non corrigée par les mécanismes de réparation de l'ADN.
L'interférence virale est un phénomène dans lequel l'infection d'une cellule par un virus induit une résistance à une infection supplémentaire par un autre virus. Cela se produit lorsque le premier virus libère des interférons, qui sont des protéines de signalisation produites par les cellules en réponse à une infection virale. Les interférons activent certaines réponses dans la cellule hôte pour inhiber la réplication d'autres virus, empêchant ainsi l'infection secondaire. Ce mécanisme de défense est important dans la réponse immunitaire innée et adaptative contre les virus.
La centrifugation en zone est une technique de séparation utilisée dans le domaine du laboratoire médical et de la recherche biologique. Elle consiste à séparer des composants ou particules ayant différentes densités dans un échantillon, grâce à l'action d'une force centrifuge.
Dans cette méthode, on place délicatement l'échantillon (généralement liquide) dans un tube à essai spécial, appelé tube de centrifugation en zone, qui contient une couche de solution de densité connue et supérieure à celle des composants à séparer. Lorsque le tube est soumis à la force centrifuge, les composants se déplacent radialement vers l'extérieur du tube sous l'effet de cette force. Les particules ou composants les plus denses migrent vers le bas du tube, tandis que ceux qui sont moins denses restent plus près du haut du tube.
Cette technique permet ainsi de séparer et de récupérer des fractions distinctes de l'échantillon en fonction de leurs densités, telles que les globules rouges, les globules blancs, les plaquettes sanguines ou d'autres composants cellulaires ou moléculaires.
La centrifugation en zone est fréquemment utilisée dans le cadre du diagnostic médical et de la recherche biologique pour l'isolement, la purification et la caractérisation de divers types de cellules, d'organites, de virus ou d'autres particules.
La séquentielle acide nucléique homologie (SANH) est un concept dans la biologie moléculaire qui décrit la similarité ou la ressemblance dans la séquence de nucléotides entre deux ou plusieurs brins d'acide nucléique (ADN ou ARN). Cette similitude peut être mesurée et exprimée en pourcentage, représentant le nombre de nucléotides correspondants sur une certaine longueur de la séquence.
La SANH est souvent utilisée dans l'étude de l'évolution moléculaire, où elle peut indiquer une relation évolutive entre deux organismes ou gènes. Plus la similarité de la séquence est élevée, plus les deux séquences sont susceptibles d'avoir un ancêtre commun récent.
Dans le contexte médical, la SANH peut être utilisée pour diagnostiquer des maladies génétiques ou infectieuses. Par exemple, l'analyse de la SANH entre un échantillon inconnu et une base de données de séquences connues peut aider à identifier le pathogène responsable d'une infection. De même, la comparaison de la séquence d'un gène suspect dans un patient avec des séquences normales peut aider à détecter les mutations associées à une maladie génétique particulière.
Cependant, il est important de noter que la SANH seule ne suffit pas pour établir une relation évolutive ou diagnostiquer une maladie. D'autres facteurs tels que la longueur de la séquence comparée, le contexte biologique et les preuves expérimentales doivent également être pris en compte.
La transformation génétique est un processus dans lequel des matériels génétiques, tels que l'ADN ou l'ARN, sont introduits dans des cellules ou des organismes pour y être incorporés de façon stable et permanente. Cela permet à la cellule ou à l'organisme d'exprimer les gènes contenus dans ces matériels génétiques étrangers, conduisant ainsi à des changements dans ses caractéristiques phénotypiques.
Dans le contexte de la recherche en biologie moléculaire et cellulaire, la transformation génétique est souvent utilisée pour étudier les fonctions des gènes, pour produire des protéines recombinantes à grande échelle ou encore pour créer des organismes modifiés génétiquement (OGM) ayant des propriétés particulières.
Le processus de transformation génétique peut être réalisé en utilisant diverses méthodes, telles que la transfection (utilisation d'agents chimiques ou physiques pour rendre les membranes cellulaires perméables à l'ADN), la transduction (utilisation de virus comme vecteurs pour introduire l'ADN étranger) ou le clonage (création de molécules d'ADN recombinant en laboratoire avant de les introduire dans des cellules hôtes).
Il est important de noter que, bien que la transformation génétique soit un outil puissant et largement utilisé en recherche biomédicale, elle soulève également des préoccupations éthiques et réglementaires lorsqu'elle est appliquée à des organismes entiers, en particulier dans le domaine de l'agriculture et de l'alimentation.
Un gène régulateur, dans le contexte de la génétique et de la biologie moléculaire, est un segment d'ADN qui code pour des protéines ou des molécules d'ARN non codantes qui jouent un rôle crucial dans la régulation de l'expression des gènes. Ces gènes régulateurs contrôlent l'activité d'autres gènes en influençant la transcription et la traduction de leur information génétique respective. Ils peuvent agir en tant que facteurs de transcription, qui se lient à des séquences spécifiques d'ADN pour activer ou réprimer la transcription des gènes cibles. Les gènes régulateurs peuvent également produire des molécules d'ARN non codantes, telles que les microARN et les ARN interférents à longue chaîne, qui régulent l'expression des gènes au niveau post-transcriptionnel en ciblant et dégradant certains ARN messagers ou en inhibant leur traduction en protéines. Les perturbations dans l'activité de ces gènes régulateurs peuvent entraîner diverses maladies, y compris des troubles du développement, des cancers et des maladies génétiques.
La conformation protéique fait référence à la forme tridimensionnelle spécifique qu'une protéine adopte en raison de l'arrangement spatial particulier de ses chaînes d'acides aminés. Cette structure tridimensionnelle est déterminée par la séquence de acides aminés dans la protéine, ainsi que par des interactions entre ces acides aminés, y compris les liaisons hydrogène, les interactions hydrophobes et les ponts disulfure.
La conformation protéique est cruciale pour la fonction d'une protéine, car elle détermine la manière dont la protéine interagit avec d'autres molécules dans la cellule. Les changements dans la conformation protéique peuvent entraîner des maladies, telles que les maladies neurodégénératives et les maladies cardiovasculaires. La conformation protéique peut être étudiée à l'aide de diverses techniques expérimentales, y compris la cristallographie aux rayons X, la résonance magnétique nucléaire (RMN) et la microscopie électronique cryogénique.
Un système acellulaire, dans le contexte de la biologie et de la médecine, se réfère à un environnement ou une structure qui ne contient pas de cellules vivantes. Cela peut inclure des matrices extracellulaires, des composants de matrice extracellulaire ou des substituts synthétiques utilisés dans les greffes de tissus et les ingénieries tissulaires. Ces systèmes acellulaires fournissent un support structurel et chimique pour la croissance, la différenciation et l'organisation des cellules lors de la régénération des tissus.
Un nucleotide cytidylique est un type de nucleotide qui est l'unité de base des acides nucléiques, tels que l'ARN. Il se compose d'une base azotée appelée cytosine, un sucre à cinq carbones appelé ribose et au moins un groupe phosphate. La séquence de nucleotides cytidyliques dans l'ARN code pour des acides aminés spécifiques qui forment des protéines. Les nucleotides cytidyliques peuvent également jouer d'autres rôles importants dans la cellule, tels que la régulation de l'expression des gènes et la protection contre les dommages à l'ADN.
Les transposons, également connus sous le nom de sautons ou éléments génétiques mobiles, sont des segments d'ADN qui peuvent se déplacer et s'intégrer à différents endroits du génome. Ils ont été découverts pour la première fois par Barbara McClintock dans les années 1940 chez le maïs.
Les transposons sont capables de se "copier-coller" ou de "couper-coller" à d'autres endroits du génome, ce qui peut entraîner des modifications de la structure et de la fonction des gènes environnants. Ces insertions peuvent désactiver les gènes en interférant avec leur expression ou en provoquant des mutations.
On distingue deux types de transposons : les transposons à copies directes (ou DNA transposons) et les éléments transposables à ARN (ou retrotransposons). Les premiers se déplacent en créant une copie d'eux-mêmes dans le génome, tandis que les seconds utilisent un intermédiaire d'ARN pour se déplacer.
Les transposons sont largement répandus dans les génomes des organismes vivants et représentent une source importante de variabilité génétique. Cependant, ils peuvent également être à l'origine de maladies génétiques ou de résistances aux antibiotiques chez les bactéries.
La biosynthèse des protéines est le processus biologique au cours duquel une protéine est synthétisée à partir d'un acide aminé. Ce processus se déroule en deux étapes principales: la transcription et la traduction.
La transcription est la première étape de la biosynthèse des protéines, au cours de laquelle l'information génétique codée dans l'ADN est utilisée pour synthétiser un brin complémentaire d'ARN messager (ARNm). Cette étape a lieu dans le noyau cellulaire.
La traduction est la deuxième étape de la biosynthèse des protéines, au cours de laquelle l'ARNm est utilisé comme modèle pour synthétiser une chaîne polypeptidique dans le cytoplasme. Cette étape a lieu sur les ribosomes, qui sont des complexes d'ARN ribosomal et de protéines situés dans le cytoplasme.
Au cours de la traduction, chaque codon (une séquence de trois nucléotides) de l'ARNm spécifie un acide aminé particulier qui doit être ajouté à la chaîne polypeptidique en croissance. Cette information est déchiffrée par des ARN de transfert (ARNt), qui transportent les acides aminés correspondants vers le site actif du ribosome.
La biosynthèse des protéines est un processus complexe et régulé qui joue un rôle crucial dans la croissance, le développement et la fonction cellulaire normaux. Des anomalies dans ce processus peuvent entraîner une variété de maladies, y compris des maladies génétiques et des cancers.
La toxine Shiga, également connue sous le nom de vérotoxine ou toxine de type Stx, est un type de toxine produite par certaines souches de bactéries, y compris Escherichia coli (E. coli) O157:H7 et d'autres sérotypes d'E. coli entérohémorragiques (EHEC). Les toxines Shiga sont des protéines qui inhibent la synthèse des protéines dans les cellules en interférant avec le processus de traduction, ce qui peut entraîner une variété d'effets pathologiques.
Les toxines Shiga sont nommées d'après Kiyoshi Shiga, un médecin et scientifique japonais qui a découvert la bactérie E. coli O157:H7 en 1897. Les toxines Shiga sont classées en deux types principaux : Stx1 et Stx2, chacune ayant des sous-types supplémentaires.
L'infection par des bactéries produisant des toxines Shiga peut entraîner une gamme de symptômes, notamment des crampes abdominales, de la diarrhée (souvent sanglante) et des vomissements. Dans certains cas graves, l'infection peut entraîner un syndrome hémolytique et urémique (SHU), une complication potentiellement mortelle qui affecte le système circulatoire et les reins.
Les toxines Shiga sont généralement transmises à l'homme par la consommation d'aliments ou d'eau contaminés, tels que de la viande hachée insuffisamment cuite, des produits laitiers non pasteurisés, des légumes crus et de l'eau contaminée. Les personnes atteintes de SHU peuvent nécessiter une hospitalisation et un traitement de soutien, y compris des transfusions sanguines et une dialyse rénale. Il n'existe actuellement aucun vaccin ou traitement spécifique contre les toxines Shiga.
Les facteurs d'intégration de l'hôte (FIH) sont des éléments du système immunitaire de l'organisme qui jouent un rôle crucial dans la régulation et la limitation de la réponse immune, en particulier dans le contexte des infections et des greffes. Les FIH comprennent des mécanismes cellulaires et moléculaires qui favorisent la tolérance immunologique, prévenant ainsi les dommages excessifs aux tissus de l'hôte.
Les principaux composants des FIH sont :
1. Les cellules régulatrices T (Tregs) : Ces cellules T spécifiques produisent des cytokines inhibitrices et expriment des molécules telles que le récepteur de l'antigène CD25 et la protéine Foxp3, qui aident à supprimer les réponses immunitaires excessives.
2. Les macrophages régulateurs : Ces macrophages présentent des caractéristiques anti-inflammatoires et favorisent la cicatrisation tissulaire en produisant des cytokines telles que l'IL-10 et le TGF-β.
3. Les cellules dendritiques régulatrices : Ces cellules dendritiques présentent des antigènes aux lymphocytes T, favorisant la différenciation des cellules T régulatrices et limitant les réponses immunitaires excessives.
4. Les molécules de tolérance : Des molécules telles que le PD-L1 (programmed death ligand 1) et le CTLA-4 (cytotoxic T-lymphocyte antigen 4) sont exprimées par les cellules immunitaires et contribuent à la suppression des réponses immunitaires excessives.
5. Les cytokines régulatrices : Des cytokines telles que l'IL-10, le TGF-β et l'IL-35 favorisent la différenciation des cellules T régulatrices et limitent les réponses immunitaires excessives.
Les facteurs de transcription impliqués dans la régulation des gènes associés aux fonctions des cellules immunitaires régulatrices comprennent FoxP3, RORγt, GATA-3 et T-bet. Ces facteurs de transcription jouent un rôle crucial dans le développement et l'activation des cellules immunitaires régulatrices, ainsi que dans la modulation de leur fonction.
Les mécanismes moléculaires impliqués dans les fonctions des cellules immunitaires régulatrices comprennent :
1. L'inhibition de l'activation des lymphocytes T conventionnels par contact direct entre les cellules immunitaires régulatrices et les lymphocytes T conventionnels, entraînant la suppression de la prolifération et de la production de cytokines.
2. La sécrétion de cytokines inhibitrices telles que l'IL-10, le TGF-β et l'IL-35, qui peuvent inhiber l'activation des cellules immunitaires conventionnelles.
3. L'induction de la mort cellulaire programmée (apoptose) des lymphocytes T conventionnels par contact direct entre les cellules immunitaires régulatrices et les lymphocytes T conventionnels, entraînant la suppression de la prolifération et de la production de cytokines.
4. La modulation de l'activation des cellules dendritiques par contact direct entre les cellules immunitaires régulatrices et les cellules dendritiques, entraînant la suppression de la présentation des antigènes et de la production de cytokines.
5. La modulation de l'activation des macrophages par contact direct entre les cellules immunitaires régulatrices et les macrophages, entraînant la suppression de la production de cytokines et de médiateurs inflammatoires.
Les cellules immunitaires régulatrices jouent un rôle crucial dans le maintien de l'homéostasie du système immunitaire et dans la prévention des réponses auto-immunes et inflammatoires excessives. Cependant, une dysrégulation de leur activité peut contribuer au développement de maladies auto-immunes et inflammatoires. Par conséquent, une meilleure compréhension de la régulation de l'activité des cellules immunitaires régulatrices est essentielle pour le développement de nouvelles stratégies thérapeutiques dans le traitement de ces maladies.
L'ARN (acide ribonucléique) bactérien est le matériel génétique à base d'ARN présent dans certaines bactéries. Contrairement aux cellules eucaryotes, qui utilisent principalement l'ADN comme support de l'information génétique, certaines bactéries peuvent contenir des éléments génétiques fonctionnels sous forme d'ARN.
Il existe différents types d'ARN bactériens, notamment :
1. ARN messager (ARNm) : il s'agit de molécules d'ARN qui transportent l'information génétique codée dans l'ADN vers les ribosomes, où la synthèse des protéines a lieu.
2. ARN de transfert (ARNt) : ce sont des petites molécules d'ARN qui transportent les acides aminés vers les ribosomes pendant la synthèse des protéines. Elles reconnaissent les codons spécifiques sur l'ARNm et assurent le bon alignement des acides aminés lors de la formation de chaînes polypeptidiques.
3. ARN ribosomique (ARNr) : il s'agit d'une composante structurelle importante des ribosomes, où se déroule la synthèse des protéines. Les ARNr sont essentiels pour former les sites actifs du ribosome et faciliter l'interaction entre l'ARNm et les ARNt pendant le processus de traduction.
4. ARN régulateurs : ce sont des molécules d'ARN qui jouent un rôle important dans la régulation de l'expression génétique chez les bactéries. Elles peuvent se lier à l'ADN ou à d'autres ARN pour moduler la transcription, la traduction ou la dégradation des molécules d'ARNm.
Il est important de noter que tous les types d'ARN mentionnés ci-dessus sont également présents dans les cellules eucaryotes, mais ils ont des structures et des fonctions similaires chez les bactéries et les eucaryotes.
*Pseudomonas aeruginosa* est une bactérie gram-négative couramment trouvée dans les environnements humides tels que l'eau et le sol. Elle est capable de survivre dans diverses conditions, y compris celles qui sont hostiles à la plupart des autres organismes. Cette bactérie est un agent pathogène opportuniste important, ce qui signifie qu'elle provoque généralement une infection uniquement lorsqu'elle pénètre dans des tissus stériles ou des sites où les défenses de l'hôte sont affaiblies.
*Pseudomonas aeruginosa* est notoire pour sa capacité à développer une résistance aux antibiotiques, ce qui rend les infections par cette bactérie difficiles à traiter. Elle produit plusieurs enzymes et toxines qui endommagent les tissus et contribuent à la virulence de l'infection.
Les infections à *Pseudomonas aeruginosa* peuvent survenir dans divers sites, y compris la peau, les poumons (pneumonie), le sang (bactériémie) et le tractus urinaire. Ces infections sont particulièrement préoccupantes pour les personnes dont le système immunitaire est affaibli, telles que les patients cancéreux, ceux atteints de fibrose kystique ou ceux qui ont subi une greffe d'organe.
Le diagnostic d'une infection à *Pseudomonas aeruginosa* repose généralement sur la culture d'un échantillon du site infecté. Le traitement implique typiquement l'utilisation d'antibiotiques, bien que la résistance puisse être un défi.
Les ribonucléases (RNases) sont des enzymes qui catalysent la dégradation de l'acide ribonucléique (ARN) en nucléotides ou oligonucléotides. Il existe plusieurs types de RNases, chacune avec une spécificité pour un substrat ARN particulier et un mécanisme d'action distinct. Les RNases jouent un rôle important dans la régulation de l'expression génétique, la défense immunitaire et le recyclage des acides nucléiques. Elles sont également utilisées en recherche biologique pour diverses applications telles que la purification d'ARN, l'analyse structurale et fonctionnelle de l'ARN et la thérapie génique. Les RNases peuvent être trouvées dans les cellules vivantes ainsi que dans les milieux extracellulaires et sont souvent utilisées comme marqueurs diagnostiques pour certaines maladies.
La résistance microbienne aux médicaments, également connue sous le nom de résistance aux antibiotiques ou de résistance aux antimicrobiens, est la capacité d'un microorganisme (comme une bactérie, un champignon, un parasite ou un virus) à survivre et à se multiplier malgré l'exposition à des médicaments conçus pour le tuer ou l'inhiber. Cela se produit lorsque les micro-organismes développent des mécanismes qui permettent de neutraliser l'action des agents antimicrobiens, ce qui rend ces médicaments moins efficaces ou inefficaces contre eux.
La résistance microbienne aux médicaments peut être naturelle ou acquise. La résistance naturelle est observée lorsque certains microorganismes sont intrinsèquement résistants à certaines classes d'agents antimicrobiens en raison de leurs caractéristiques génétiques et de leur métabolisme uniques. D'un autre côté, la résistance acquise se produit lorsque les microorganismes développent des mécanismes de résistance au fil du temps en réponse à l'exposition aux agents antimicrobiens.
La résistance microbienne aux médicaments est un problème de santé publique mondial croissant, car elle compromet notre capacité à traiter et à prévenir les infections causées par des microorganismes pathogènes. Cela entraîne une augmentation de la morbidité, de la mortalité et des coûts des soins de santé, ainsi qu'une menace pour la sécurité alimentaire et le développement économique. Pour lutter contre ce problème, il est essentiel d'améliorer la stewardship des antimicrobiens, qui consiste à promouvoir une utilisation appropriée et prudente des agents antimicrobiens chez les humains, les animaux et dans l'environnement.
Les colicines sont des protéines toxiques produites par certaines souches de bactéries Escherichia coli (E. coli). Elles peuvent être sécrétées dans le milieu extracellulaire et ont la capacité de tuer d'autres bactéries sensibles en formant des pores dans leur membrane cellulaire, ce qui entraîne une fuite d'ions et de molécules essentielles à la survie de ces bactéries.
Les colicines sont codées par des gènes situés sur des plasmides, des petits morceaux d'ADN extrachromosomique qui peuvent être transférés entre bactéries par conjugaison. Les bactéries produisant des colicines ont un avantage sélectif dans les environnements concurrentiels, car elles peuvent éliminer d'autres souches bactériennes et ainsi accéder plus facilement aux nutriments nécessaires à leur croissance.
Les colicines sont classées en fonction de leur mécanisme d'action et de leur structure protéique. Elles ont été étudiées comme des agents potentiels de biocontrôle pour lutter contre les infections bactériennes, mais leur utilisation est limitée par le fait qu'elles peuvent également être toxiques pour les cellules eucaryotes.
Les oligoribonucléotides (ou ORN) sont de courtes molécules d'acide ribonucléique (ARN) composées d'un petit nombre de nucléotides. Ils contiennent généralement moins de 30 nucléotides et peuvent être synthétisés chimiquement ou produits par des enzymes spécifiques dans les cellules vivantes.
Les oligoribonucléotides ont divers rôles biologiques importants, notamment dans la régulation de l'expression génétique et la défense contre les agents pathogènes tels que les virus. Par exemple, certains oligoribonucléotides peuvent se lier à des molécules d'ARN messager (ARNm) spécifiques et empêcher leur traduction en protéines, ce qui permet de réguler l'expression génétique. D'autres oligoribonucléotides peuvent activer des voies de défense cellulaire en se liant à des molécules d'ARN viral et en déclenchant une réponse immunitaire.
En médecine, les oligoribonucléotides sont également utilisés comme outils de recherche pour étudier la fonction des gènes et des protéines, ainsi que dans le développement de thérapies ciblées contre certaines maladies. Par exemple, certains oligoribonucléotides peuvent être conçus pour se lier spécifiquement à des molécules d'ARN anormales ou surexprimées dans une maladie donnée, ce qui permet de réduire leur expression et de traiter la maladie.
La rifampicine est un antibiotique puissant utilisé pour traiter une variété d'infections bactériennes. Elle appartient à la classe des médicaments appelés rifamycines. La rifampicine agit en inhibant l'activité de l'ARN polymérase bactérienne, ce qui empêche les bactéries de se multiplier.
Cet antibiotique est souvent utilisé pour traiter des infections graves telles que la tuberculose et la méningite. Il peut également être utilisé pour prévenir l'infection du sang par le staphylocoque doré après une intervention chirurgicale.
La rifampicine est généralement administrée par voie orale, mais elle peut aussi être donnée par injection dans certains cas. Les effets secondaires courants de ce médicament incluent des nausées, des vomissements, des douleurs abdominales, une perte d'appétit et une coloration rouge-brun des urines, des larmes, de la sueur et des sécrétions nasales.
Bien que la rifampicine soit un antibiotique très efficace, il est important de noter qu'elle ne doit pas être utilisée de manière inappropriée ou sans prescription médicale, car une utilisation excessive ou incorrecte peut entraîner une résistance bactérienne à ce médicament.
La Polynucléotide 5'-Hydroxyl-Kinase, également connue sous le nom de polynucléotide kinase (PNK), est une enzyme qui joue un rôle crucial dans les processus de réparation et de réplication de l'ADN. Elle catalyse l'ajout d'un groupe phosphate à l'extrémité 5' des brins d'ADN ou d'ARN, créant ainsi une extrémité 5'-phosphate. Cette activité est particulièrement importante dans les processus de réparation des dommages à l'ADN, où elle contribue à restaurer les extrémités 5'-phosphates après la suppression de nucléotides endommagés ou incorrects. La Polynucléotide 5'-Hydroxyl-Kinase peut également être utilisée dans des applications de biologie moléculaire pour préparer des extrémités d'ADN appropriées pour la ligation et d'autres manipulations.
La séquence d'acides aminés homologue se réfère à la similarité dans l'ordre des acides aminés dans les protéines ou les gènes de différentes espèces. Cette similitude est due au fait que ces protéines ou gènes partagent un ancêtre commun et ont évolué à partir d'une séquence originale par une série de mutations.
Dans le contexte des acides aminés, l'homologie signifie que les deux séquences partagent une similitude dans la position et le type d'acides aminés qui se produisent à ces positions. Plus la similarité est grande entre les deux séquences, plus il est probable qu'elles soient étroitement liées sur le plan évolutif.
L'homologie de la séquence d'acides aminés est souvent utilisée dans l'étude de l'évolution des protéines et des gènes, ainsi que dans la recherche de fonctions pour les nouvelles protéines ou gènes. Elle peut également être utilisée dans le développement de médicaments et de thérapies, en identifiant des cibles potentielles pour les traitements et en comprenant comment ces cibles interagissent avec d'autres molécules dans le corps.
En médecine et en biologie, un milieu de culture est un mélange spécialement préparé de nutriments et d'autres facteurs chimiques qui favorisent la croissance des micro-organismes tels que les bactéries, les champignons ou les cellules de tissus. Les milieux de culture peuvent être solides (gélosés) ou liquides (broths). Ils sont souvent utilisés dans les laboratoires pour identifier et isoler des micro-organismes spécifiques, déterminer leur sensibilité aux antibiotiques, étudier leurs caractéristiques biochimiques et mettre en évidence leur capacité à provoquer des maladies. Les milieux de culture peuvent contenir des agents chimiques inhibiteurs pour empêcher la croissance de certains types de micro-organismes et favoriser la croissance d'autres.
Le césium est un élément chimique qui ne joue pas de rôle connu dans le fonctionnement du corps humain. Il n'existe aucune définition médicale spécifique pour ce terme. Cependant, en général, le césium est un métal alcalin mou et réactif qui peut être trouvé en très petites quantités dans l'environnement.
Certaines personnes peuvent être exposées au césium à des niveaux dangereux en raison d'une contamination environnementale, telle que celle causée par un accident nucléaire ou la libération intentionnelle de matériaux radioactifs. L'exposition à des niveaux élevés de césium peut entraîner une intoxication au césium et des effets néfastes sur la santé, tels que des dommages aux organes internes et un risque accru de cancer.
Si vous pensez avoir été exposé à des niveaux dangereux de césium ou présentez des symptômes inquiétants, consultez immédiatement un médecin ou une autre autorité médicale qualifiée pour obtenir des soins médicaux appropriés.
Les agents de contrôle biologique, également connus sous le nom d'agents de biocontrôle, sont des organismes vivants ou des substances d'origine naturelle utilisés pour gérer ou réguler les populations de ravageurs ou de nuisibles qui causent des dommages aux cultures, aux animaux ou à l'environnement.
Les agents de contrôle biologique peuvent inclure des prédateurs, des parasites, des pathogènes, des antagonistes microbiens et des substances naturelles telles que les phéromones et les kairomones qui interfèrent avec le comportement ou la physiologie des ravageurs.
L'utilisation d'agents de contrôle biologique est considérée comme une méthode écologiquement durable pour gérer les ravageurs, car elle réduit la dépendance aux pesticides chimiques et favorise la biodiversité. Cependant, il est important de noter que l'utilisation d'agents de contrôle biologique doit être soigneusement planifiée et gérée pour assurer son efficacité et minimiser les risques potentiels pour l'environnement.
Dans un contexte médical, une température élevée ou "hot temperature" fait généralement référence à une fièvre, qui est une élévation de la température corporelle centrale au-dessus de la plage normale. La température normale du corps se situe généralement entre 36,5 et 37,5 degrés Celsius (97,7 à 99,5 degrés Fahrenheit). Une fièvre est définie comme une température corporelle supérieure à 38 degrés Celsius (100,4 degrés Fahrenheit).
Il est important de noter que la température du corps peut varier tout au long de la journée et en fonction de l'activité physique, de l'âge, des hormones et d'autres facteurs. Par conséquent, une seule mesure de température peut ne pas être suffisante pour diagnostiquer une fièvre ou une température élevée.
Les causes courantes de fièvre comprennent les infections, telles que les rhumes et la grippe, ainsi que d'autres affections médicales telles que les maladies inflammatoires et certains cancers. Dans certains cas, une température élevée peut être le signe d'une urgence médicale nécessitant des soins immédiats. Si vous soupçonnez que vous ou un proche avez une fièvre ou une température élevée, il est important de consulter un professionnel de la santé pour obtenir un diagnostic et un traitement appropriés.
Un nucléotide est l'unité structurelle et building block fondamental des acides nucléiques, tels que l'ADN et l'ARN. Il se compose d'une base azotée (adénine, guanine, cytosine, uracile ou thymine), d'un pentose (ribose ou désoxyribose) et d'un ou plusieurs groupes phosphate. Les nucléotides sont liés les uns aux autres par des liaisons phosphodiester pour former une chaîne, créant ainsi la structure en double hélice de l'ADN ou la structure à simple brin de l'ARN. Les nucléotides jouent un rôle crucial dans le stockage, la transmission et l'expression de l'information génétique, ainsi que dans divers processus biochimiques, tels que la signalisation cellulaire et l'énergétique.
Dans le contexte médical, les répresseurs sont des agents ou des substances qui inhibent, réduisent ou suppriment l'activité d'une certaine molécule, processus biologique ou fonction corporelle. Ils agissent généralement en se liant à des protéines spécifiques, telles que des facteurs de transcription ou des enzymes, et en empêchant leur activation ou leur interaction avec d'autres composants cellulaires.
Un exemple bien connu de répresseurs sont les médicaments antihypertenseurs qui inhibent le système rénine-angiotensine-aldostérone pour abaisser la tension artérielle. Un autre exemple est l'utilisation de répresseurs de la pompe à protons dans le traitement des brûlures d'estomac et du reflux gastro-œsophagien, qui fonctionnent en supprimant la sécrétion acide gastrique.
Il est important de noter que les répresseurs peuvent avoir des effets secondaires indésirables, car ils peuvent également inhiber ou perturber d'autres processus biologiques non intentionnels. Par conséquent, il est crucial de prescrire et d'utiliser ces médicaments avec prudence, en tenant compte des avantages potentiels et des risques pour chaque patient individuel.
L'intégration du virus est un processus dans lequel le matériel génétique d'un virus s'incorpore de manière stable dans le génome de l'hôte. Cela permet au virus de se répliquer avec les propres mécanismes de réplication cellulaire, assurant ainsi sa propre survie et persistance à long terme. Ce phénomène est observé dans certains types de virus, tels que les rétrovirus (y compris le VIH), qui ont la capacité d'inverser leur transcriptase pour créer une copie d'ADN du génome viral, puis l'insérer dans le génome de l'hôte. Cette intégration peut entraîner des modifications durables de l'expression des gènes et des fonctions cellulaires, ce qui peut contribuer au développement de maladies associées à l'infection virale.
Lactococcus est un genre de bactéries à gram positif, anaérobies facultatives, appartenant à la famille des Streptococcaceae. Ces bactéries sont sphériques ou ovoïdes et se regroupent souvent en paires ou en chaînes courtes. Elles sont non-encapsulées, non-motiles et ne forment pas de spores.
Lactococcus est fréquemment trouvé dans la nature, notamment dans les produits laitiers où il joue un rôle important dans la fermentation fromagère. Certaines espèces, comme Lactococcus lactis, sont d'ailleurs largement utilisées dans l'industrie alimentaire pour la production de yaourts, fromages et autres produits fermentés.
Dans le contexte médical, certaines souches de Lactococcus peuvent être impliquées dans des infections opportunistes, surtout chez les personnes dont les défenses immunitaires sont affaiblies. Ces infections sont généralement traitées avec des antibiotiques appropriés.
L'alignement des séquences en génétique et en bioinformatique est un processus permettant d'identifier et d'afficher les similitudes entre deux ou plusieurs séquences biologiques, telles que l'ADN, l'ARN ou les protéines. Cette méthode consiste à aligner les séquences de nucléotides ou d'acides aminés de manière à mettre en évidence les régions similaires et les correspondances entre elles.
L'alignement des séquences peut être utilisé pour diverses applications, telles que l'identification des gènes et des fonctions protéiques, la détection de mutations et de variations génétiques, la phylogénie moléculaire et l'analyse évolutive.
Il existe deux types d'alignement de séquences : l'alignement global et l'alignement local. L'alignement global compare l'intégralité des séquences et est utilisé pour aligner des séquences complètes, tandis que l'alignement local ne compare qu'une partie des séquences et est utilisé pour identifier les régions similaires entre des séquences partiellement homologues.
Les algorithmes d'alignement de séquences utilisent des matrices de score pour évaluer la similarité entre les nucléotides ou les acides aminés correspondants, en attribuant des scores plus élevés aux paires de résidus similaires et des scores plus faibles ou négatifs aux paires dissemblables. Les algorithmes peuvent également inclure des pénalités pour les écarts entre les séquences, tels que les insertions et les délétions.
Les méthodes d'alignement de séquences comprennent la méthode de Needleman-Wunsch pour l'alignement global et la méthode de Smith-Waterman pour l'alignement local, ainsi que des algorithmes plus rapides tels que BLAST (Basic Local Alignment Search Tool) et FASTA.
Les polynucléotides sont des biomolécules constituées d'une chaîne linéaire de nucléotides, qui sont les unités de base des acides nucléiques. Les polynucléotides peuvent être soit des molécules d'ARN (acide ribonucléique) ou d'ADN (acide désoxyribonucléique).
Dans les molécules d'ARN, chaque nucléotide contient un ribose (sucre pentose), une base azotée (adénine, uracile, guanine ou cytosine) et au moins un groupe phosphate. Dans les molécules d'ADN, chaque nucléotide contient un désoxyribose (un sucre pentose qui a remplacé une molécule d'hydrogène par un atome d'hydrogène), une base azotée (adénine, thymine, guanine ou cytosine) et au moins un groupe phosphate.
Les polynucléotides jouent un rôle crucial dans la synthèse des protéines, le stockage et la transmission de l'information génétique, ainsi que dans divers processus régulateurs cellulaires.
Les radio-isotopes du phosphore sont des variantes d'isotopes du phosphore qui émettent des radiations. Ils sont largement utilisés dans le domaine de la médecine nucléaire, en particulier dans l'imagerie médicale et le traitement de certaines maladies.
Le radio-isotope le plus couramment utilisé est le phosphore 32 (P-32), qui a une demi-vie d'environ 14,3 jours. Il se désintègre en soufre émettant des particules bêta négatives et des rayons gamma. Le P-32 est souvent utilisé dans le traitement de certains cancers du sang tels que la leucémie et les lymphomes, ainsi que dans le traitement d'autres maladies telles que la polycythémie vraie.
Un autre radio-isotope du phosphore est le phosphore 33 (P-33), qui a une demi-vie plus courte de seulement 25,4 jours. Il se désintègre en soufre émettant des rayons gamma et des positrons. Le P-33 est utilisé dans l'imagerie médicale pour étudier la distribution du phosphore dans le corps humain.
Il est important de noter que les radio-isotopes du phosphore sont des substances hautement radioactives et doivent être manipulés avec précaution par des professionnels formés et équipés pour travailler en toute sécurité avec ces matériaux.
L'ordre des gènes, également connu sous le nom d'orientation génomique, se réfère à l'organisation linéaire des gènes sur un chromosome ou un segment d'ADN. Il décrit la séquence dans laquelle les gènes sont disposés les uns par rapport aux autres sur une molécule d'ADN.
Dans le génome humain, il y a environ 20 000 à 25 000 gènes répartis sur 23 paires de chromosomes. Chaque chromosome contient des centaines ou des milliers de gènes, qui sont disposés dans un ordre spécifique. Les gènes peuvent être orientés dans les deux sens, c'est-à-dire qu'ils peuvent être lus soit de gauche à droite (sens 5' vers 3'), soit de droite à gauche (sens 3' vers 5') sur l'ADN.
L'ordre des gènes est important car il peut influencer la régulation de l'expression génique et la manière dont les gènes interagissent entre eux. Des mutations dans l'ordre des gènes peuvent entraîner des maladies génétiques ou des troubles du développement. Par conséquent, la compréhension de l'ordre des gènes est essentielle pour comprendre les mécanismes moléculaires qui sous-tendent le fonctionnement normal et anormal du génome humain.
La paroi cellulaire est une structure rigide ou semi-rigide qui se trouve à l'extérieur de la membrane plasmique de certaines cellules. Elle est principalement composée de polysaccharides, de protéines et sometimes de lipides. Chez les plantes, les algues et les champignons, la paroi cellulaire fournit une protection mécanique à la cellule, maintient sa forme et offre une barrière contre les agents pathogènes. La composition chimique et la structure de la paroi cellulaire varient selon le type de cellule et l'organisme auquel elle appartient. Par exemple, la paroi cellulaire des plantes est composée principalement de cellulose, tandis que celle des champignons contient principalement du chitine.
La composition en bases nucléiques fait référence à la proportion ou au pourcentage des quatre différentes bases nucléotidiques dans une molécule d'acide nucléique donnée, comme l'ADN ou l'ARN. Les quatre bases nucléotidiques sont l'adénine (A), la thymine (T) ou l'uracile (U) et la guanine (G) pour l'ADN et l'ARN respectivement, et la cytosine (C).
Le calcul de la composition en bases nucléiques peut être utile dans divers contextes, tels que l'analyse des séquences génomiques ou d'autres acides nucléiques. Par exemple, une composition en bases nucléiques déséquilibrée peut indiquer la présence de régions répétitives, de gènes viraux intégrés ou d'autres caractéristiques structurelles et fonctionnelles importantes dans l'acide nucléique.
Il est important de noter que la composition en bases nucléiques peut varier considérablement entre différents organismes, tissus et types d'acides nucléiques. Par exemple, les gènes codants pour des protéines ont tendance à avoir une composition en bases nucléiques différente de celle des régions non codantes de l'ADN. De même, l'ARN messager a généralement une composition en bases nucléiques différente de celle de l'ADN génomique.
Dans l'ensemble, la composition en bases nucléiques est un aspect important de l'analyse des acides nucléiques et peut fournir des informations précieuses sur leur structure, leur fonction et leur évolution.
La structure tertiaire d'une protéine se réfère à l'organisation spatiale des différents segments de la chaîne polypeptidique qui forment la protéine. Cela inclut les arrangements tridimensionnels des différents acides aminés et des régions flexibles ou rigides de la molécule, tels que les hélices alpha, les feuillets bêta et les boucles. La structure tertiaire est déterminée par les interactions non covalentes entre résidus d'acides aminés, y compris les liaisons hydrogène, les interactions ioniques, les forces de Van der Waals et les ponts disulfures. Elle est influencée par des facteurs tels que le pH, la température et la présence de certains ions ou molécules. La structure tertiaire joue un rôle crucial dans la fonction d'une protéine, car elle détermine sa forme active et son site actif, où les réactions chimiques ont lieu.
La viabilité microbienne fait référence à la capacité d'un micro-organisme, comme une bactérie, un champignon ou un virus, à survivre et à se reproduire dans des conditions environnementales spécifiques. Dans un contexte médical, cela peut faire référence à la capacité d'un agent pathogène à survivre et à causer une infection dans un hôte vivant. Par exemple, certains traitements peuvent viser à réduire la viabilité microbienne d'une infection en utilisant des antibiotiques ou d'autres agents antimicrobiens pour tuer les bactéries ou ralentir leur croissance.
Il est important de noter que la viabilité microbienne ne doit pas être confondue avec la virulence, qui fait référence à la capacité d'un micro-organisme à causer des dommages à son hôte. Un micro-organisme peut être viable mais non virulent, ce qui signifie qu'il est capable de survivre et de se reproduire, mais ne cause pas de maladie. D'un autre côté, un micro-organisme peut être viabilité mais moins virulent en raison d'une résistance aux traitements ou à l'immunité de l'hôte.
La « Spécificité selon le substrat » est un terme utilisé en pharmacologie et en toxicologie pour décrire la capacité d'un médicament ou d'une substance toxique à agir spécifiquement sur une cible moléculaire particulière dans un tissu ou une cellule donnée. Cette spécificité est déterminée par les propriétés chimiques et structurelles de la molécule, qui lui permettent de se lier sélectivement à sa cible, telles qu'un récepteur, un canal ionique ou une enzyme, sans affecter d'autres composants cellulaires.
La spécificité selon le substrat est importante pour minimiser les effets secondaires indésirables des médicaments et des toxines, car elle permet de cibler l'action thérapeutique ou toxique sur la zone affectée sans altérer les fonctions normales des tissus environnants. Cependant, il est important de noter que même les molécules les plus spécifiques peuvent avoir des effets hors cible à des concentrations élevées ou en présence de certaines conditions physiologiques ou pathologiques.
Par exemple, un médicament conçu pour se lier spécifiquement à un récepteur dans le cerveau peut également affecter d'autres récepteurs similaires dans d'autres organes à des doses plus élevées, entraînant ainsi des effets secondaires indésirables. Par conséquent, la spécificité selon le substrat est un facteur important à prendre en compte lors du développement et de l'utilisation de médicaments et de substances toxiques.
L'activation virale est un processus dans lequel un virus inactif ou latent devient actif et se réplique dans l'hôte qu'il infecte. Cela peut se produire lorsque les mécanismes de défense de l'organisme, tels que le système immunitaire, sont affaiblis ou compromis, permettant au virus de se multiplier et de provoquer une infection symptomatique.
Dans certains cas, des facteurs spécifiques peuvent déclencher l'activation virale, tels que le stress, l'exposition à des radiations, la chimiothérapie ou d'autres médicaments qui affaiblissent le système immunitaire.
L'activation virale peut entraîner une variété de symptômes dépendant du type de virus en cause. Par exemple, l'activation du virus de l'herpès peut causer des boutons de fièvre ou des lésions génitales, tandis que l'activation du virus de la varicelle-zona peut entraîner une éruption cutanée douloureuse connue sous le nom de zona.
Il est important de noter que certaines personnes peuvent être infectées par un virus et ne jamais présenter de symptômes, même en cas d'activation virale. Cependant, elles peuvent quand même transmettre le virus à d'autres personnes.
"Bacillus" est un genre de bactéries en forme de bâtonnet qui sont gram-positives, aérobies facultatives et immobiles. Ces bactéries sont largement répandues dans l'environnement, notamment dans le sol, l'eau et les plantes. L'espèce la plus connue est Bacillus anthracis, qui cause la maladie du charbon chez les animaux et les humains.
Certaines espèces de Bacillus sont capables de former des endospores résistantes à l'environnement, ce qui leur permet de survivre dans des conditions hostiles pendant de longues périodes. Ces endospores peuvent être trouvées dans divers environnements, y compris le sol, l'eau et les intestins des animaux et des humains.
Les bactéries du genre Bacillus ont une grande variété d'applications industrielles et médicales. Par exemple, certaines espèces sont utilisées dans la production de probiotiques pour améliorer la santé intestinale, tandis que d'autres sont utilisées dans la production d'enzymes industrielles et de produits agrochimiques.
Cependant, certaines espèces de Bacillus peuvent également être pathogènes pour les humains et les animaux, causant des infections telles que la pneumonie, l'infection du sang et l'intoxication alimentaire. Par conséquent, il est important de manipuler ces bactéries avec soin dans les laboratoires et les installations de production.
La renaturation d'acide nucléique fait référence au processus par lequel des acides nucléiques simples ou complémentaires, qui ont été préalablement dénaturés (par exemple, par chauffage ou par l'ajout de agents chimiques), sont remis dans leur état d'origine, avec la formation de double hélice ou de structures secondaires stables. Ce processus est également connu sous le nom de rebrassage ou d'hybridation.
Dans le contexte de l'ADN, la renaturation implique généralement la reformulation des brins complémentaires en une double hélice. Cela peut être utilisé dans diverses techniques de laboratoire, telles que la Southern blotting et la polymerase chain reaction (PCR), pour détecter ou amplifier des séquences d'ADN spécifiques.
Dans le contexte de l'ARN, la renaturation peut faire référence à la reformulation de structures secondaires intramoléculaires stables, telles que les pseudonœuds et les boucles stem-loop. Ce processus est souvent utilisé dans l'étude des interactions ARN-protéines et des fonctions structurelles de l'ARN.
La vitesse et l'efficacité de la renaturation dépendent d'une variété de facteurs, notamment la concentration en acide nucléique, la température, la force ionique et la présence de composés qui peuvent stabiliser ou destabiliser les structures d'acide nucléique.
Le Shiga Toxine 2 (Stx2) est une toxine produite principalement par certaines souches d'Escherichia coli (E. coli), telles que E. coli producteur de shigatoxines de type 2 (STEC 2) ou entérohémorragiques (EHEC). Cette toxine est un puissant facteur de virulence qui peut causer des dommages graves aux tissus, en particulier au niveau des intestins et des reins.
Stx2 est une protéine complexe composée de deux sous-unités A et cinq sous-unités B. Les sous-unités B se lient aux récepteurs spécifiques situés sur la membrane cellulaire des cellules cibles, permettant ainsi l'internalisation de la toxine. La sous-unité A possède une activité enzymatique qui inhibe la synthèse des protéines en clivant une adénine spécifique de l'ARN ribosomal 28S, entraînant ainsi la mort cellulaire et l'inflammation.
L'exposition à Stx2 peut provoquer des symptômes gastro-intestinaux sévères, tels que la diarrhée sanglante, les crampes abdominales et le vomissement, ainsi qu'une maladie rénale potentiellement mortelle appelée syndrome hémolytique et urémique (SHU). Les infections à E. coli producteurs de Stx2 sont souvent associées à la consommation d'aliments contaminés, comme la viande crue ou insuffisamment cuite, les produits laitiers non pasteurisés, et l'eau contaminée.
Un désoxyribonucléotide est l'unité structurelle et building block des acides désoxyribonucléiques (ADN). Il se compose d'une base nucléique (adénine, thymine, guanine ou cytosine), un pentose désoxysugar (désoxyribose) et au moins un groupe phosphate. Les désoxyribonucléotides sont liés les uns aux autres par des liaisons phosphodiester pour former une chaîne de polymère, créant ainsi la structure en double hélice caractéristique de l'ADN.
Escherichia coli (E. coli) O157:H7 est un sous-type spécifique de la bactérie E. coli, qui est normalement présente dans l'intestin des humains et des animaux à sang chaud. Cependant, contrairement aux souches d'E. coli plus courantes qui sont généralement inoffensives, cette souche particulière produit une toxine appelée Shiga toxine, ce qui la rend hautement pathogène pour l'homme.
L'infection par E. coli O157:H7 peut entraîner une gamme de symptômes allant de crampes abdominales légères à des diarrhées sanglantes sévères, ainsi qu'à un risque accru de complications graves telles que le syndrome hémolytique et urémique (SHU), qui peut entraîner une insuffisance rénale aiguë, une anémie hémolytique microangiopathique et une thrombocytopénie.
Les infections à E. coli O157:H7 sont souvent associées à la consommation d'aliments contaminés, tels que de la viande crue ou insuffisamment cuite, en particulier du bœuf haché, ainsi qu'à des produits laitiers non pasteurisés et à des légumes crus. L'infection peut également se propager par contact direct avec des animaux infectés ou par contact avec des surfaces contaminées.
Les acridines sont une classe de composés organiques hétérocycliques qui contiennent un ou plusieurs systèmes d'anneaux fusionnés à deux cycles benzéniques et un cycle pyridine. Les acridines ont des propriétés antimicrobiennes, antipaludéennes, et antitumorales. Elles peuvent intercaler entre les bases azotées de l'ADN, ce qui en fait des agents chimiques utiles dans la recherche biologique pour étudier la structure et la fonction de l'ADN. Les acridines sont également utilisées comme colorants fluorescents pour la microscopie.
Les acridines ont été découvertes en 1877 par Carl Gräbe et Heinrich Caro lorsqu'ils ont synthétisé le premier composé de cette classe, l'acridine jaune. Depuis lors, de nombreux autres composés acridiniques ont été synthétisés et étudiés pour leurs propriétés pharmacologiques et chimiques.
Les acridines sont souvent utilisées dans la thérapie du cancer en raison de leur capacité à interférer avec la réplication de l'ADN des cellules cancéreuses. Cependant, elles peuvent également affecter les cellules saines et entraîner des effets secondaires indésirables. Par conséquent, les acridines sont généralement utilisées en combinaison avec d'autres médicaments pour traiter le cancer et réduire les effets secondaires.
En plus de leurs propriétés antimicrobiennes et antitumorales, les acridines ont également été étudiées pour leur potentiel à traiter d'autres maladies, telles que la maladie de Parkinson et l'épilepsie. Cependant, davantage de recherches sont nécessaires pour déterminer leur efficacité et leur sécurité dans ces applications.
La phylogénie est une discipline scientifique qui étudie et reconstruit l'histoire évolutive des espèces ou groupes d'organismes vivants, en se basant sur leurs caractères biologiques partagés. Elle vise à déterminer les relations de parenté entre ces différents taxons (unités systématiques) et à établir leur arbre évolutif, appelé également phylogramme ou cladogramme.
Dans un contexte médical, la phylogénie peut être utilisée pour comprendre l'évolution des agents pathogènes, tels que les virus, bactéries ou parasites. Cette approche permet de mieux appréhender leur diversité génétique, l'origine et la diffusion des épidémies, ainsi que d'identifier les facteurs responsables de leur virulence ou résistance aux traitements. En conséquence, elle contribue au développement de stratégies préventives et thérapeutiques plus efficaces contre les maladies infectieuses.
Je suis désolé, mais en tant qu'assistant d'écriture, je n'ai pas la capacité de rechercher des informations ou des définitions médicales spécifiques. Cependant, je peux vous aider à construire une phrase ou un texte si vous me fournissez les informations pertinentes sur le sujet.
Selon mes connaissances préprogrammées, un bactériophage est un virus qui infecte et se multiplie dans des bactéries. Ils sont spécifiques à certaines souches bactériennes et peuvent être utilisés comme agents thérapeutiques pour lutter contre les infections bactériennes. Cependant, je n'ai pas trouvé de références spécifiques au bactériophage "Ike". Il est possible que ce nom se réfère à une souche particulière ou à un variant d'un bactériophage déjà connu. Je vous recommande de consulter des sources médicales et scientifiques fiables pour obtenir des informations précises sur ce sujet.
Streptococcus est un genre de bactéries sphériques (cocci) Gram-positives qui ont tendance à se regrouper en chaînes et en paires. Elles sont des microorganismes commensaux couramment trouvés dans la flore humaine normale, principalement dans la gorge et sur la peau. Cependant, certaines espèces de Streptococcus peuvent causer des infections graves chez l'homme, telles que la pharyngite streptococcique, la scarlatine, l'impétigo, la pneumonie, la méningite, la bactériémie et le rhumatisme articulaire aigu.
Les streptocoques sont classés en plusieurs groupes en fonction de leur virulence, de leurs antigènes capsulaires et de leur sensibilité à la bêta-lactamine. Les groupes les plus cliniquement pertinents comprennent le Groupe A Streptococcus (GAS), qui est responsable de la plupart des infections streptococciques humaines, et le Groupe B Streptococcus (GBS), qui est un important pathogène néonatal.
Les streptocoques peuvent être transmis par contact direct avec des sécrétions respiratoires ou cutanées infectées, ainsi que par l'ingestion d'aliments contaminés. Le diagnostic repose généralement sur la culture et l'identification de la bactérie à partir d'un échantillon clinique approprié, suivies d'une antibiogramme pour guider le traitement antimicrobien approprié.
Je suis désolé, mais il semble y avoir une certaine confusion dans votre question. Le terme "microvirus" ne fait pas réellement partie de la terminologie médicale standard ou des classifications virales établies. Il est possible que vous fassiez référence à des virus très petits, mais même dans ce cas, il n'y a pas de catégorie spécifique appelée "microvirus" en virologie. Si vous pourriez me fournir plus de détails ou si vous vouliez peut-être parler d'un virus spécifique ou d'une taille de virus spécifique, je serais heureux de vous aider davantage.
La proflavine est un composé chimique qui appartient à la classe des agents thérapeutiques connus sous le nom de médicaments antimicrobiens, et plus spécifiquement aux colorants antibactériens. Il est structurellement lié à l'acridine et a une activité antibactérienne contre un large éventail de bactéries, y compris les organismes gram positifs et gram négatifs.
La proflavine fonctionne en intercalant son noyau plan entre les bases adjacentes dans l'ADN, ce qui provoque des dommages à l'ADN et une inhibition de la réplication de l'ADN, entraînant finalement la mort cellulaire bactérienne.
Historiquement, la proflavine a été utilisée dans le traitement des infections cutanées et oculaires bactériennes. Cependant, en raison de sa toxicité pour les cellules humaines et du développement d'autres agents antimicrobiens moins toxiques, l'utilisation de la proflavine en médecine clinique est actuellement limitée.
Actuellement, la proflavine est principalement utilisée dans la recherche biomédicale comme agent mutagène et carcinogène pour étudier les mécanismes moléculaires de la réparation de l'ADN et de la cancérogenèse.
ARN bicaténaire, ou ARN double brin, est un type d'acide ribonucléique qui a une structure secondaire avec deux brins complémentaires s'appariant l'un à l'autre, créant ainsi une configuration en forme de double hélice similaire à celle de l'ADN. Cependant, contrairement à l'ADN, les deux brins d'ARN bicaténaire sont constitués d'unités ribonucléotidiques, qui contiennent du ribose au lieu de déoxyribose et peuvent contenir des bases modifiées.
Les ARN bicaténaires jouent un rôle important dans divers processus cellulaires, notamment la régulation génétique et l'interférence ARN. Ils sont également associés à certaines maladies humaines, telles que les infections virales et certains troubles neurologiques.
Les ARN bicaténaires peuvent être produits de manière endogène par la cellule elle-même ou peuvent provenir d'agents infectieux tels que des virus. Les ARN bicaténaires viraux sont souvent une cible pour les défenses immunitaires de l'hôte, car ils peuvent être reconnus et dégradés par des enzymes telles que la DICER, qui est responsable de la production de petits ARN interférents (siARN) à partir d'ARN bicaténaires.
En résumé, l'ARN bicaténaire est un type important d'acide ribonucléique qui joue un rôle clé dans la régulation génétique et la défense contre les agents infectieux. Sa structure en double brin le distingue de l'ARN monocaténaire plus courant, qui ne contient qu'un seul brin d'acide nucléique.
Le phénotype est le résultat observable de l'expression des gènes en interaction avec l'environnement et d'autres facteurs. Il s'agit essentiellement des manifestations physiques, biochimiques ou développementales d'un génotype particulier.
Dans un contexte médical, le phénotype peut se rapporter à n'importe quelle caractéristique mesurable ou observable résultant de l'interaction entre les gènes et l'environnement, y compris la couleur des yeux, la taille, le poids, certaines maladies ou conditions médicales, voire même la réponse à un traitement spécifique.
Il est important de noter que deux individus ayant le même génotype (c'est-à-dire la même séquence d'ADN) ne seront pas nécessairement identiques dans leur phénotype, car des facteurs environnementaux peuvent influencer l'expression des gènes. De même, des individus avec des génotypes différents peuvent partager certains traits phénotypiques en raison de similitudes dans leurs environnements ou dans d'autres facteurs non génétiques.
Les adénosine triphosphatases (ATPases) sont des enzymes qui catalysent la réaction qui convertit l'adénosine triphosphate (ATP) en adénosine diphosphate (ADP), libérant de l'énergie dans le processus. Cette réaction est essentielle pour de nombreux processus cellulaires, tels que la contraction musculaire, le transport actif d'ions et la synthèse des protéines.
Les ATPases sont classées en deux types principaux : les ATPases de type P (pour "phosphorylated") et les ATPases de type F (pour "F1F0-ATPase"). Les ATPases de type P sont également appelées pompes à ions, car elles utilisent l'énergie libérée par la hydrolyse de l'ATP pour transporter des ions contre leur gradient électrochimique. Les ATPases de type F, quant à elles, sont des enzymes complexes qui se trouvent dans les membranes mitochondriales et chloroplastiques, où elles jouent un rôle clé dans la génération d'ATP pendant la respiration cellulaire et la photosynthèse.
Les ATPases sont des protéines transmembranaires qui traversent la membrane cellulaire et présentent une tête globulaire située du côté cytoplasmique de la membrane, où se produit la catalyse de l'hydrolyse de l'ATP. La queue de ces protéines est ancrée dans la membrane et contient des segments hydrophobes qui s'insèrent dans la bicouche lipidique.
Les ATPases sont régulées par divers mécanismes, tels que la liaison de ligands, les modifications post-traductionnelles et les interactions avec d'autres protéines. Des mutations dans les gènes qui codent pour les ATPases peuvent entraîner des maladies humaines graves, telles que des cardiomyopathies, des myopathies et des neuropathies.
L'ADN superhélicoïdal se réfère à une forme de ADN qui est tordu ou torsadé plus que la structure normale en double hélice. Cette torsion supplémentaire est mesurée comme le nombre de tours additionnels d'hélice par tour de la molécule d'ADN, et peut être positive ou négative.
Dans une molécule d'ADN superhélicoïdale positive, l'hélice est tordue dans le sens horaire (vue de l'extrémité 5'). Cela entraîne une compression de l'hélice et un rétrécissement de la molécule. À l'inverse, dans une molécule d'ADN superhélicoïdale négative, l'hélice est tordue dans le sens antihoraire (vue de l'extrémité 5'), ce qui entraîne un étirement de la molécule.
L'ADN superhélicoïdal se produit naturellement dans les cellules vivantes et joue un rôle important dans la compaction et l'organisation de l'ADN dans le noyau cellulaire. Il est également important pour les processus de réplication et de transcription de l'ADN, car il peut affecter la structure et l'accessibilité de la molécule d'ADN aux protéines impliquées dans ces processus.
Les enzymes telles que les topoisomérases sont responsables de l'introduction ou de la suppression de la torsion superhélicoïdale dans l'ADN, ce qui permet de maintenir une quantité appropriée de torsion et d'éviter une surtension ou un sous-tension excessive.
Le chloroforme est un liquide incolore, volatil et non inflammable avec une odeur sucrée. Sa formule chimique est CHCl3. Il a été utilisé dans le passé comme anesthésique général pour provoquer l'inconscience et la perte de sensation douloureuse pendant les procédures médicales. Cependant, en raison des risques associés à son utilisation, tels que les dommages au foie, le décès cardiaque et les réactions allergiques, il est rarement utilisé en médecine moderne.
Le chloroforme agit en supprimant l'activité du cerveau et en ralentissant la fonction respiratoire. Il peut être administré par inhalation ou ingestion. L'utilisation de chloroforme comme anesthésique nécessite une surveillance étroite des patients car elle peut entraîner une dépression respiratoire profonde et même l'arrêt cardiaque.
Outre son utilisation en anesthésie, le chloroforme a également été utilisé comme solvant industriel et dans la production de certains produits chimiques. Cependant, en raison de ses effets nocifs sur la santé humaine et l'environnement, son utilisation est strictement réglementée dans de nombreux pays.
Les RecA Recombinases sont des enzymes qui jouent un rôle crucial dans le processus de recombinaison homologue, qui est un mécanisme important pour la réparation de l'ADN endommagé et le maintien de la stabilité génétique. Ces enzymes sont capables de faciliter l'échange de matériel génétique entre deux molécules d'ADN identiques ou très similaires, ce qui permet de réparer les brins d'ADN endommagés et de restaurer l'intégrité du génome.
Les RecA Recombinases se lient à l'ADN simple brin et facilitent la recherche d'une région homologue sur une autre molécule d'ADN, ce qui permet la formation d'un complexe de recombinaison. Ce complexe peut ensuite servir de site pour l'action d'autres enzymes qui catalysent les étapes finales du processus de recombinaison homologue.
Les RecA Recombinases sont largement distribuées dans le règne vivant et sont particulièrement bien étudiées chez les bactéries, où elles jouent un rôle important dans la réparation de l'ADN et la résistance aux agents mutagènes. Chez les eucaryotes, des protéines homologues aux RecA Recombinases, telles que Rad51 et Dmc1, sont également essentielles au processus de recombinaison homologue et à la réparation de l'ADN.
Le facteur Rho, également connu sous le nom de Ras homologue de la moisissure, est un type de protéine G régulatrice de petite taille dans les cellules. Il joue un rôle crucial dans la régulation du réarrangement des actines et de la formation de structures appelées "structures d'adhésion focales" dans les cellules. Ces structures sont importantes pour la migration cellulaire, l'adhésion cellulaire et la signalisation cellulaire. Les mutations du facteur Rho ont été associées à diverses maladies, y compris le cancer et les maladies cardiovasculaires.
La mutagénèse est un processus par lequel l'ADN (acide désoxyribonucléique) d'un organisme est modifié, entraînant des modifications génétiques héréditaires. Ces modifications peuvent être causées par des agents physiques ou chimiques appelés mutagènes. Les mutations peuvent entraîner une variété d'effets, allant de neutre à nocif pour l'organisme. Elles jouent un rôle important dans l'évolution et la diversité génétique, mais elles peuvent également contribuer au développement de maladies, en particulier le cancer.
Il existe différents types de mutations, y compris les point mutations (qui affectent une seule base nucléotidique), les délétions (perte d'une partie de la séquence d'ADN) et les insertions (ajout d'une partie de la séquence d'ADN). La mutagénèse est un domaine important de l'étude de la génétique et de la biologie moléculaire, car elle peut nous aider à comprendre comment fonctionnent les gènes et comment ils peuvent être affectés par des facteurs environnementaux.
Un vecteur génétique est un outil utilisé en génétique moléculaire pour introduire des gènes ou des fragments d'ADN spécifiques dans des cellules cibles. Il s'agit généralement d'un agent viral ou bactérien modifié qui a été désarmé, de sorte qu'il ne peut plus causer de maladie, mais conserve sa capacité à infecter et à introduire son propre matériel génétique dans les cellules hôtes.
Les vecteurs génétiques sont couramment utilisés dans la recherche biomédicale pour étudier l'expression des gènes, la fonction des protéines et les mécanismes de régulation de l'expression génétique. Ils peuvent également être utilisés en thérapie génique pour introduire des gènes thérapeutiques dans des cellules humaines afin de traiter ou de prévenir des maladies causées par des mutations génétiques.
Les vecteurs viraux les plus couramment utilisés sont les virus adéno-associés (AAV), les virus lentiviraux et les rétrovirus. Les vecteurs bactériens comprennent les plasmides, qui sont des petites molécules d'ADN circulaires que les bactéries utilisent pour transférer du matériel génétique entre elles.
Il est important de noter que l'utilisation de vecteurs génétiques comporte certains risques, tels que l'insertion aléatoire de gènes dans le génome de l'hôte, ce qui peut entraîner des mutations indésirables ou la activation de gènes oncogéniques. Par conséquent, il est essentiel de mettre en place des protocoles de sécurité rigoureux pour minimiser ces risques et garantir l'innocuité des applications thérapeutiques des vecteurs génétiques.
Le saccharose est un type de sucre naturellement présent dans de nombreux aliments tels que la canne à sucre, la betterave sucrière et divers fruits. Il s'agit d'un disaccharide, ce qui signifie qu'il est composé de deux molécules de monosaccharides : le glucose et le fructose. Dans notre organisme, les enzymes digestives décomposent le saccharose en glucose et en fructose pour faciliter son absorption dans l'intestin grêle. Le saccharose est largement utilisé comme édulcorant dans l'industrie alimentaire et est souvent appelé «sucre de table» lorsqu'il est raffiné et purifié à des fins de consommation.
Un oligodésoxyribonucléotide est un court segment d'acides désoxyribonucléiques (ADN) composé d'un petit nombre de nucléotides. Les nucléotides sont les unités structurelles de base des acides nucléiques, et chaque nucléotide contient un désoxyribose (un sucre à cinq carbones), une base azotée (adénine, thymine, guanine ou cytosine) et un groupe phosphate.
Les oligodésoxyribonucléotides sont souvent utilisés en recherche biomédicale pour étudier les interactions entre l'ADN et d'autres molécules, telles que les protéines ou les médicaments. Ils peuvent également être utilisés dans des applications thérapeutiques, comme les vaccins à ARN messager (ARNm) qui ont été développés pour prévenir la COVID-19. Dans ce cas, l'ARNm est encapsulé dans des nanoparticules lipidiques et injecté dans le corps, où il est utilisé comme modèle pour produire une protéine spécifique du virus SARS-CoV-2. Cette protéine stimule ensuite une réponse immunitaire protectrice contre l'infection.
En général, les oligodésoxyribonucléotides sont synthétisés en laboratoire et peuvent être modifiés chimiquement pour présenter des caractéristiques spécifiques, telles qu'une stabilité accrue ou une affinité accrue pour certaines protéines. Ces propriétés les rendent utiles dans de nombreuses applications en biologie moléculaire et en médecine.
La cristallographie aux rayons X est une technique d'analyse utilisée en physique, en chimie et en biologie pour étudier la structure tridimensionnelle des matériaux cristallins à l'échelle atomique. Cette méthode consiste à exposer un échantillon de cristal à un faisceau de rayons X, qui est ensuite diffracté par les atomes du cristal selon un motif caractéristique de la structure interne du matériau.
Lorsque les rayons X frappent les atomes du cristal, ils sont déviés et diffusés dans toutes les directions. Cependant, certains angles de diffusion sont privilégiés, ce qui entraîne des interférences constructives entre les ondes diffusées, donnant lieu à des pics d'intensité lumineuse mesurables sur un détecteur. L'analyse de ces pics d'intensité permet de remonter à la disposition spatiale des atomes dans le cristal grâce à des méthodes mathématiques telles que la transformation de Fourier.
La cristallographie aux rayons X est une technique essentielle en sciences des matériaux, car elle fournit des informations détaillées sur la structure et l'organisation atomique des cristaux. Elle est largement utilisée dans divers domaines, tels que la découverte de nouveaux médicaments, la conception de matériaux avancés, la compréhension des propriétés physiques et chimiques des matériaux, ainsi que l'étude de processus biologiques à l'échelle moléculaire.
La transformation bactérienne est un processus par lequel des bactéries prennent up et assimilate de l'ADN (acide désoxyribonucléique) d'une autre cellule bactérienne morte ou vivante, ce qui entraîne un changement permanent dans leur génome. Ce phénomène a été découvert par Frederick Griffith en 1928 et joue un rôle crucial dans la biologie moléculaire et la génétique bactérienne.
Dans le processus de transformation, l'ADN exogène est transporté à travers la membrane cellulaire de la bactérie réceptrice, où il peut être incorporé dans le chromosome bactérien ou existant sous forme de plasmide (petite molécule d'ADN circulaire). Ce processus permet aux bactéries de s'adapter rapidement à des conditions environnementales changeantes en acquérant de nouveaux gènes codant pour des caractéristiques utiles, telles que la résistance aux antibiotiques ou la capacité de dégrader certains types de composés organiques.
Il est important de noter que tous les types de bactéries ne sont pas capables de transformation. Seules certaines espèces, comme Streptococcus pneumoniae et Haemophilus influenzae, ont démontré cette capacité. De plus, des conditions spécifiques doivent être réunies pour que la transformation ait lieu, telles qu'une compétence bactérienne accrue (capacité à absorber l'ADN exogène) et la présence d'ADN nu (libre de protéines protectrices).
La transformation bactérienne est un outil important dans les laboratoires de recherche biomédicale, car elle permet aux scientifiques d'étudier la fonction des gènes spécifiques et de manipuler le génome bactérien pour diverses applications, y compris la production de vaccins et la biotechnologie.
Je suis désolé, mais la combinaison de termes "Banque" et "Peptide" ne renvoie à aucune définition médicale établie ou concept médical largement accepté.
Un peptide est une chaîne courte d'acides aminés, les blocs de construction des protéines. Ils jouent divers rôles dans le corps et sont un domaine de recherche actif en médecine. Une banque, quant à elle, est généralement une institution qui détient et gère des dépôts pour la sécurité et la conservation.
Si quelqu'un utilise l'expression "Banque Peptide" dans un contexte spécifique, je devrais comprendre ce contexte pour vous donner une réponse plus éclairée. Actuellement, cela ne semble pas être un terme médical standard.
La chromatographie est une méthode d'analyse et de séparation utilisée en chimie et en biologie. Elle consiste à séparer les composants d'un mélange en les faisant migrer dans un milieu stationnaire, sous l'effet d'une force physique provoquée par une phase mobile.
Il existe plusieurs types de chromatographie, mais les deux principaux sont la chromatographie en phase gazeuse (CPG) et la chromatographie en phase liquide (CPL). Dans la CPG, le mélange à séparer est vaporisé et transporté par un gaz inerte à travers une colonne remplie d'une substance absorbante. Les composants du mélange sont alors séparés en fonction de leurs interactions avec la phase stationnaire et la phase mobile. Dans la CPL, le mélange est dissous dans un liquide qui est ensuite forcé à traverser une colonne contenant une phase stationnaire solide. Les composants du mélange se séparent également en fonction de leurs interactions avec les deux phases.
La chromatographie est largement utilisée en médecine et en biologie pour l'analyse et la purification de diverses substances, telles que les protéines, les acides nucléiques, les métabolites, les drogues et les toxines. Elle permet également de déterminer la composition quantitative et qualitative des mélanges complexes, ce qui en fait un outil essentiel pour le diagnostic et le traitement des maladies.
Je suis désolé, mais la terminologie «Terminator Regions» dans un contexte génétique ne semble pas faire référence à un concept ou une définition médicale établie. Le terme «terminateur» est cependant utilisé en biologie moléculaire pour se référer à une séquence d'ADN qui marque la fin de la transcription d'un gène. Après avoir lu et transcrit l'ARN messager (ARNm) jusqu'au terminateur, l'enzyme ARN polymérase se détache du ADN template et relâche l'ARNm mature.
Les «régions terminales» peuvent généralement faire référence aux extrémités des chromosomes, qui sont protégées par les telomères, ou aux extrémités des ARNm et des ADN plasmidiques, qui contiennent des séquences spécifiques.
Si vous pouviez fournir plus de contexte sur l'endroit où vous avez rencontré cette phrase, je serais heureux de vous aider davantage.
Les oligonucléotides sont des petites molécules d'acide nucléique composées d'un petit nombre de nucléotides, généralement moins de 100. Ils peuvent être synthétisés chimiquement ou isolés à partir d'organismes vivants. Les oligonucléotides sont souvent utilisés en recherche biologique et médicale comme sondes pour la détection d'acides nucléiques spécifiques, dans les thérapies géniques et comme candidats pour le développement de médicaments.
Les oligonucléotides peuvent être modifiés chimiquement pour augmenter leur stabilité, améliorer leur affinité pour des cibles spécifiques ou conférer d'autres propriétés utiles. Par exemple, les oligonucléotides antisens sont des molécules d'oligonucléotides qui se lient à l'ARN messager (mRNA) pour inhiber la production de protéines spécifiques. Les oligonucléotides interférents avec l'ARN (siARN) sont des molécules d'oligonucléotides qui se lient à l'ARN messager pour le dégrader et ainsi inhiber la production de protéines spécifiques.
Les oligonucléotides sont également utilisés dans les tests de diagnostic moléculaire, tels que la réaction en chaîne par polymérase (PCR) et l'hybridation in situ en fluorescence (FISH), pour détecter des séquences d'acide nucléique spécifiques dans des échantillons biologiques.
En résumé, les oligonucléotides sont de petites molécules d'acide nucléique utilisées en recherche et en médecine pour détecter et cibler des séquences spécifiques d'acide nucléique dans des échantillons biologiques. Ils peuvent être utilisés pour inhiber la production de protéines spécifiques, diagnostiquer des maladies et développer de nouveaux médicaments.
Je suis désolé, mais la terminologie «polyosides bactériens» ne semble pas être reconnue dans la littérature médicale ou scientifique. Il est possible que vous ayez fait une erreur de frappe ou que ce terme spécifique ne soit pas largement utilisé ou reconnu dans le domaine médical.
Cependant, les polyosides sont des polymères d'oses (sucres) qui peuvent être trouvés dans divers organismes, y compris les bactéries. Dans un contexte plus large, on peut faire référence aux polysaccharides bactériens, qui sont des composants structurels importants de certaines bactéries et jouent un rôle crucial dans leur virulence, la reconnaissance cellulaire et l'adhésion.
Si vous cherchiez une information spécifique sur un sujet connexe, veuillez me fournir plus de détails afin que je puisse vous aider au mieux.
Le croisement génétique est un processus dans le domaine de la génétique qui consiste à faire se reproduire deux individus présentant des caractéristiques différentes pour obtenir une progéniture avec des traits spécifiques. Cela permet d'étudier les combinaisons de gènes et l'hérédité de certains caractères.
Il existe plusieurs types de croisements génétiques, mais le plus courant est le croisement monohybride, dans lequel on ne considère qu'un seul trait distinct. Dans ce cas, deux parents sont choisis de manière à ce que l'un soit homozygote dominant (AA) et l'autre homozygote récessif (aa) pour un gène particulier. Tous les individus de la première génération issue du croisement (F1) seront alors hétérozygotes (Aa) et présenteront le même phénotype, celui du trait dominant.
Lorsque ces individus F1 sont autorisés à se reproduire entre eux, ils produiront une deuxième génération (F2) composée d'individus présentant des phénotypes liés aux deux allèles du gène étudié. La distribution de ces phénotypes dans la génération F2 suit des lois bien définies, appelées lois de Mendel, du nom du moine Augustin Mendel qui a établi ces principes fondamentaux de la génétique au XIXe siècle.
Le croisement génétique est un outil essentiel pour comprendre les mécanismes d'hérédité et de transmission des caractères, ainsi que pour l'amélioration des plantes et des animaux dans le cadre de la sélection artificielle.
Les endopeptidases sont des enzymes qui coupent les protéines ou les peptides en fragments plus petits en clivant les liaisons peptidiques à l'intérieur de la chaîne polypeptidique, contrairement aux exopeptidases qui coupent les acides aminés terminaux. Elles jouent un rôle crucial dans la digestion des protéines alimentaires, la signalisation cellulaire, la régulation hormonale et la neurotransmission, entre autres processus biologiques importants. Les endopeptidases peuvent être classées en fonction de leur site spécifique de clivage ou de leur structure tridimensionnelle. Des exemples bien connus d'endopeptidases comprennent la trypsine, la chymotrypsine et l'élastase, qui sont des enzymes digestives produites par le pancréas.
Les amorces d'ADN sont de courtes séquences de nucléotides, généralement entre 15 et 30 bases, qui sont utilisées en biologie moléculaire pour initier la réplication ou l'amplification d'une région spécifique d'une molécule d'ADN. Elles sont conçues pour être complémentaires à la séquence d'ADN cible et se lier spécifiquement à celle-ci grâce aux interactions entre les bases azotées complémentaires (A-T et C-G).
Les amorces d'ADN sont couramment utilisées dans des techniques telles que la réaction en chaîne par polymérase (PCR) ou la séquençage de l'ADN. Dans ces méthodes, les amorces d'ADN se lient aux extrémités des brins d'ADN cibles et servent de point de départ pour la synthèse de nouveaux brins d'ADN par une ADN polymérase.
Les amorces d'ADN sont généralement synthétisées chimiquement en laboratoire et peuvent être modifiées chimiquement pour inclure des marqueurs fluorescents ou des groupes chimiques qui permettent de les détecter ou de les séparer par électrophorèse sur gel.
La morphogénèse est un terme utilisé en biologie du développement pour décrire le processus par lequel l'organisation spatiale et la forme des cellules, des tissus et des organes émergent et se différencient dans un embryon en croissance. Ce processus est orchestré par une combinaison complexe de facteurs, y compris des interactions cellulaires, des changements chimiques et physiques, et l'expression génétique spatio-temporelle précise.
Au cours de la morphogénèse, les cellules peuvent se déplacer, se diviser, s'allonger, se différencier ou mourir, ce qui entraîne des changements dans la forme et la fonction des tissus. Ces processus sont régis par des morphogènes, qui sont des molécules signalant spécifiques qui diffusent à travers les tissus pour fournir des informations positionnelles aux cellules environnantes.
La morphogénèse est un domaine important de l'étude du développement car il joue un rôle crucial dans la détermination de la forme et de la fonction des organismes. Les anomalies dans les processus de morphogénèse peuvent entraîner des malformations congénitales et d'autres problèmes de santé.
ARN messager (ARNm) est une molécule d'acide ribonucléique simple brin qui transporte l'information génétique codée dans l'ADN vers les ribosomes, où elle dirige la synthèse des protéines. Après la transcription de l'ADN en ARNm dans le noyau cellulaire, ce dernier est transloqué dans le cytoplasme et fixé aux ribosomes. Les codons (séquences de trois nucléotides) de l'ARNm sont alors traduits en acides aminés spécifiques qui forment des chaînes polypeptidiques, qui à leur tour se replient pour former des protéines fonctionnelles. Les ARNm peuvent être régulés au niveau de la transcription, du traitement post-transcriptionnel et de la dégradation, ce qui permet une régulation fine de l'expression génique.
Dans le contexte actuel, les vaccins à ARNm contre la COVID-19 ont été développés en utilisant des morceaux d'ARNm synthétiques qui codent pour une protéine spécifique du virus SARS-CoV-2. Lorsque ces vaccins sont administrés, les cellules humaines produisent cette protéine virale étrangère, ce qui déclenche une réponse immunitaire protectrice contre l'infection par le vrai virus.
Shigella sonnei, également connu sous le nom de bacille de Shiga, est une bactérie responsable d'infections intestinales aiguës couramment appelées shigellose ou dysenterie bacillaire. Cette bactérie appartient au genre Shigella et est l'une des quatre espèces principales qui causent des maladies chez l'homme, avec Shigella dysenteriae, Shigella flexneri et Shigella boydii.
Shigella sonnei est responsable d'environ un tiers des cas de shigellose dans les pays développés et est particulièrement fréquente chez les enfants en bas âge. La transmission se produit principalement par voie fécale-orale, c'est-à-dire lorsque des particules fécales contenant la bactérie sont ingérées, souvent via de l'eau ou des aliments contaminés.
Les symptômes de l'infection à Shigella sonnei peuvent varier en gravité mais comprennent généralement une diarrhée aqueuse, des crampes abdominales, des nausées, des vomissements et, dans les cas plus sévères, une dysenterie avec selles sanglantes et mucopurulentes. Les complications graves sont rares mais peuvent inclure une déshydratation sévère, une méningite bactérienne ou une insuffisance rénale aiguë.
Le diagnostic de l'infection à Shigella sonnei repose sur la culture des selles et l'identification de la bactérie en laboratoire. Le traitement standard consiste en une antibiothérapie adaptée à la sensibilité de la souche bactérienne, bien que certaines souches résistantes aux antibiotiques aient été récemment identifiées. Des mesures d'hygiène strictes, telles que le lavage des mains régulier et l'isolement des personnes infectées, sont essentielles pour prévenir la propagation de l'infection.
Un virus est un agent infectieux submicroscopique qui se compose d'une coque de protéine protectrice appelée capside et, dans la plupart des cas, d'un noyau central d'acide nucléique (ADN ou ARN) contenant l'information génétique. Les virus ne peuvent se multiplier qu'en parasitant les cellules vivantes d'un organisme hôte. Ils sont responsables de nombreuses maladies allant du rhume et la grippe aux hépatites, poliomyélite et SIDA. Les virus ont été trouvés dans presque tous les types d'organismes vivants, des plantes et les animaux aux bactéries et les archées.
Le magnésium est un minéral essentiel qui joue un rôle crucial dans plus de 300 réactions enzymatiques dans l'organisme. Il contribue au maintien des fonctions nerveuses et musculaires, à la régulation de la glycémie, à la pression artérielle et au rythme cardiaque, ainsi qu'à la synthèse des protéines et des acides nucléiques. Le magnésium est également important pour le métabolisme énergétique, la production de glutathion antioxydant et la relaxation musculaire.
On trouve du magnésium dans une variété d'aliments tels que les légumes verts feuillus, les noix, les graines, les haricots, le poisson et les céréales complètes. Les carences en magnésium sont relativement rares mais peuvent survenir chez certaines personnes atteintes de maladies chroniques, d'alcoolisme ou prenant certains médicaments. Les symptômes d'une carence en magnésium peuvent inclure des crampes musculaires, des spasmes, de la fatigue, des troubles du rythme cardiaque et une faiblesse musculaire.
En médecine, le magnésium peut être utilisé comme supplément ou administré par voie intraveineuse pour traiter les carences en magnésium, les crampes musculaires, les spasmes, l'hypertension artérielle et certaines arythmies cardiaques. Il est également utilisé dans le traitement de l'intoxication au digitalique et comme antidote à certains médicaments toxiques.
Les structures macromoléculaires sont des entités biologiques complexes formées par l'assemblage de molécules simples en vastes structures tridimensionnelles. Dans un contexte médical et biochimique, ces structures comprennent généralement des protéines, des acides nucléiques (ADN et ARN), les glucides complexes et certains lipides. Elles jouent souvent un rôle crucial dans la fonction cellulaire et les processus physiologiques, y compris la catalyse enzymatique, le stockage d'énergie, la signalisation cellulaire, la régulation génétique et la reconnaissance moléculaire.
Les protéines macromoléculaires sont formées par des chaînes polypeptidiques qui se plient dans des structures tridimensionnelles complexes pour exercer leurs fonctions spécifiques, telles que les enzymes, les canaux ioniques, les transporteurs et les récepteurs. Les acides nucléiques, tels que l'ADN et l'ARN, sont des polymères d'unités nucléotidiques qui stockent et transmettent des informations génétiques et jouent un rôle dans la synthèse des protéines. Les glucides complexes, comme l'amidon et la cellulose, sont des polymères de sucres simples qui fournissent de l'énergie et assurent une structure aux cellules végétales. Certains lipides, tels que les lipoprotéines, peuvent également former des structures macromoléculaires impliquées dans le transport des lipides dans l'organisme.
Les virus satellites sont des types de virus qui ne peuvent pas se répliquer sans l'aide d'un autre virus, appelé helper virus. Ils n'ont pas certains gènes essentiels à la réplication et doivent donc dépendre du helper virus pour fournir ces fonctions. Les virus satellites peuvent parfois interférer avec la réplication du helper virus et modifier l'expression des gènes du helper virus, ce qui peut affecter la virulence ou la pathogénicité de l'infection. Ils sont souvent associés à une maladie plus grave que le helper virus seul. Un exemple bien connu d'un virus satellite est le virus de l'hépatite D, qui nécessite la co-infection avec le virus de l'hépatite B pour se répliquer.
Les acides aminés sont des molécules organiques qui jouent un rôle crucial dans la biologie. Ils sont les éléments constitutifs des protéines et des peptides, ce qui signifie qu'ils se combinent pour former des chaînes de polymères qui forment ces macromolécules importantes.
Il existe 20 acides aminés standard qui sont encodés dans le code génétique et sont donc considérés comme des «acides aminés protéinogéniques». Parmi ceux-ci, 9 sont dits «essentiels» pour les humains, ce qui signifie qu'ils doivent être obtenus par l'alimentation car notre corps ne peut pas les synthétiser.
Chaque acide aminé a une structure commune composée d'un groupe amino (-NH2) et d'un groupe carboxyle (-COOH), ainsi que d'une chaîne latérale unique qui détermine ses propriétés chimiques et biologiques. Les acides aminés peuvent se lier entre eux par des liaisons peptidiques pour former des chaînes polypeptidiques, aboutissant finalement à la formation de protéines complexes avec une grande variété de fonctions dans le corps humain.
Les acides aminés sont également importants en tant que précurseurs de divers métabolites et messagers chimiques dans l'organisme, tels que les neurotransmetteurs et les hormones. Ils jouent donc un rôle essentiel dans la régulation des processus physiologiques et des fonctions corporelles.
La mutagénèse ponctuelle dirigée est une technique de génie génétique qui consiste à introduire des modifications spécifiques et ciblées dans l'ADN d'un organisme en utilisant des méthodes chimiques ou enzymatiques. Cette technique permet aux chercheurs de créer des mutations ponctuelles, c'est-à-dire des changements dans une seule base nucléotidique spécifique de l'ADN, ce qui peut entraîner des modifications dans la séquence d'acides aminés d'une protéine et, par conséquent, modifier sa fonction.
La mutagénèse ponctuelle dirigée est souvent utilisée pour étudier les fonctions des gènes et des protéines, ainsi que pour créer des modèles animaux de maladies humaines. Cette technique implique généralement la création d'un oligonucléotide, qui est un court brin d'ADN synthétisé en laboratoire, contenant la mutation souhaitée. Cet oligonucléotide est ensuite utilisé pour remplacer la séquence d'ADN correspondante dans le génome de l'organisme cible.
La mutagénèse ponctuelle dirigée peut être effectuée en utilisant une variété de méthodes, y compris la recombinaison homologue, la transfection de plasmides ou la modification de l'ADN par des enzymes de restriction. Ces méthodes permettent aux chercheurs de cibler spécifiquement les gènes et les régions d'ADN qu'ils souhaitent modifier, ce qui rend cette technique très précise et efficace pour étudier les fonctions des gènes et des protéines.
Les sphéroplastes sont des structures cellulaires qui résultent du processus d'étape finale de la lyse (c'est-à-dire la dégradation ou la destruction) de certaines bactéries gram-négatives et cyanobactéries. Durant ce processus, la paroi bactérienne est éliminée chimiquement en utilisant des enzymes spécifiques telles que la lysoïne ou l'lysine déshydrogenase. Cela conduit à la formation de cellules sans paroi, appelées protoplastes.
Les protoplastes peuvent ensuite être transformés en sphéroplastes en les traitant avec des agents tensioactifs tels que l'EDTA (éthylènediaminetétraacétate) ou le Triton X-100. Ces agents modifient la perméabilité de la membrane plasmique, permettant ainsi aux ions et à d'autres molécules de pénétrer dans la cellule. En conséquence, les protoplastes gonflent et forment des sphéroplastes qui ont une forme plus ou moins sphérique.
Les sphéroplastes sont souvent utilisés en microbiologie pour étudier divers aspects de la physiologie bactérienne, tels que le transport membranaire, la synthèse des parois cellulaires et la régulation de l'osmolarité intracellulaire. Ils sont également importants dans les techniques de génie génétique pour faciliter l'introduction de matériel génétique exogène dans les bactéries, telles que les plasmides ou les gènes d'intérêt, via des méthodes telles que la transformation et la transduction.
La microbiologie alimentaire est une sous-spécialité de la microbiologie qui se concentre sur l'étude des microorganismes (y compris les bactéries, les champignons, les virus et les parasites) dans le contexte des aliments et des boissons. Elle implique l'étude de la croissance, de la survie, du métabolisme et de l'interaction de ces microorganismes avec les aliments.
Cette discipline vise à comprendre comment ces microorganismes affectent la qualité, la sécurité et la salubrité des aliments. Elle joue un rôle crucial dans la prévention des maladies d'origine alimentaire en identifiant les sources de contamination, en établissant des limites de sécurité pour les pathogènes dans les aliments et en développant des méthodes pour inactiver ou réduire ces microorganismes.
Les professionnels de la microbiologie alimentaire travaillent souvent dans l'industrie alimentaire, les agences gouvernementales de réglementation, les laboratoires de recherche et les établissements d'enseignement supérieur. Leurs tâches peuvent inclure la surveillance de la contamination microbienne dans les aliments, le développement et la validation de méthodes d'analyse microbiologique, l'évaluation des risques pour la sécurité alimentaire et la formation des autres sur les principes de la microbiologie alimentaire.
La recombinaison des protéines est un processus biologique au cours duquel des segments d'ADN sont échangés entre deux molécules différentes de ADN, généralement dans le génome d'un organisme. Ce processus est médié par certaines protéines spécifiques qui jouent un rôle crucial dans la reconnaissance et l'échange de segments d'ADN compatibles.
Dans le contexte médical, la recombinaison des protéines est particulièrement importante dans le domaine de la thérapie génique. Les scientifiques peuvent exploiter ce processus pour introduire des gènes sains dans les cellules d'un patient atteint d'une maladie génétique, en utilisant des vecteurs viraux tels que les virus adéno-associés (AAV). Ces vecteurs sont modifiés de manière à inclure le gène thérapeutique souhaité ainsi que des protéines de recombinaison spécifiques qui favorisent l'intégration du gène dans le génome du patient.
Cependant, il est important de noter que la recombinaison des protéines peut également avoir des implications négatives en médecine, telles que la résistance aux médicaments. Par exemple, les bactéries peuvent utiliser des protéines de recombinaison pour échanger des gènes de résistance aux antibiotiques entre elles, ce qui complique le traitement des infections bactériennes.
En résumé, la recombinaison des protéines est un processus biologique important impliquant l'échange de segments d'ADN entre molécules différentes de ADN, médié par certaines protéines spécifiques. Ce processus peut être exploité à des fins thérapeutiques dans le domaine de la médecine, mais il peut également avoir des implications négatives telles que la résistance aux médicaments.
Les transférases sont des enzymes qui facilitent le transfert d'un groupe fonctionnel (comme un groupe méthyle, acétyle, ou amine) d'une molécule donatrice à une molécule acceptrice. Elles jouent un rôle crucial dans de nombreux processus métaboliques dans le corps humain. Un exemple bien connu de transférase est l'alanine transaminase (ALT), qui participe au métabolisme des acides aminés et dont les taux élevés dans le sang peuvent indiquer une maladie hépatique.
Les bactéries sont des organismes unicellulaires microscopiques qui se composent d'une cellule procaryote, ce qui signifie qu'ils n'ont pas de noyau ni d'autres membranes internes. Ils font partie du règne Monera et sont largement répandus dans la nature.
Les bactéries peuvent être trouvées dans presque tous les environnements sur Terre, y compris l'eau, le sol, les plantes, les animaux et les êtres humains. Elles jouent un rôle crucial dans de nombreux processus naturels, tels que la décomposition des matières organiques, la fixation de l'azote dans l'air et la production de vitamines.
Certaines bactéries sont bénéfiques pour les êtres humains et peuvent aider à la digestion des aliments, à protéger contre les maladies en empêchant la croissance de bactéries nocives et même à produire des médicaments utiles. Cependant, d'autres bactéries peuvent être pathogènes et provoquer des infections et des maladies graves.
Les bactéries se reproduisent rapidement par un processus de division cellulaire appelé scission binaire, où la cellule mère se divise en deux cellules filles identiques. Elles peuvent également échanger du matériel génétique par conjugaison, transformation et transduction, ce qui leur permet de s'adapter rapidement à des environnements changeants.
Les bactéries ont une grande variété de formes et de tailles, y compris des cocci (formes sphériques), des bacilles (formes cylindriques) et des spirales. Elles peuvent également produire diverses structures extracellulaires, telles que des capsules, des flagelles et des fimbriae, qui leur permettent de se déplacer, d'adhérer à des surfaces et de communiquer avec d'autres bactéries.
Les bactéries sont largement distribuées dans l'environnement et jouent un rôle important dans les cycles biogéochimiques, tels que la décomposition de la matière organique, la fixation de l'azote et la production d'oxygène. Elles sont également utilisées dans diverses applications industrielles et médicales, telles que la fermentation alimentaire, la biodégradation des polluants et la bioremédiation.
Les protéines de fusion recombinantes sont des biomolécules artificielles créées en combinant les séquences d'acides aminés de deux ou plusieurs protéines différentes par la technologie de génie génétique. Cette méthode permet de combiner les propriétés fonctionnelles de chaque protéine, créant ainsi une nouvelle entité avec des caractéristiques uniques et souhaitables pour des applications spécifiques en médecine et en biologie moléculaire.
Dans le contexte médical, ces protéines de fusion recombinantes sont souvent utilisées dans le développement de thérapies innovantes, telles que les traitements contre le cancer et les maladies rares. Elles peuvent également être employées comme vaccins, agents diagnostiques ou outils de recherche pour mieux comprendre les processus biologiques complexes.
L'un des exemples les plus connus de protéines de fusion recombinantes est le facteur VIII recombinant, utilisé dans le traitement de l'hémophilie A. Il s'agit d'une combinaison de deux domaines fonctionnels du facteur VIII humain, permettant une activité prolongée et une production plus efficace par génie génétique, comparativement au facteur VIII dérivé du plasma.
Un modèle génétique est une représentation théorique ou mathématique d'un trait, d'une maladie ou d'une caractéristique héréditaire donnée, qui tente de décrire et d'expliquer la manière dont les gènes et l'environnement interagissent pour influencer ce trait. Il s'appuie sur des études épidémiologiques, statistiques et moléculaires pour comprendre la transmission héréditaire d'un trait particulier au sein d'une population. Les modèles génétiques peuvent aider à prédire le risque de développer une maladie, à identifier les gènes associés à un trait et à élucider les mécanismes sous-jacents des maladies complexes.
Les modèles génétiques peuvent être simples ou complexes, selon la nature du trait étudié. Dans le cas d'un trait monogénique, où une seule mutation dans un gène spécifique est suffisante pour provoquer la maladie, le modèle peut être relativement simple et basé sur les lois de Mendel. Cependant, pour les traits complexes ou quantitatifs, qui sont influencés par plusieurs gènes et l'environnement, les modèles génétiques peuvent être plus sophistiqués et prendre en compte des facteurs tels que la pénétrance incomplète, l'effet de dosage, l'épistasie et l'interaction entre gènes et environnement.
Les modèles génétiques sont largement utilisés dans la recherche médicale et la médecine prédictive pour comprendre les causes sous-jacentes des maladies et améliorer le diagnostic, le pronostic et le traitement des patients.
Les hydroxylamines sont des composés organiques ou inorganiques qui contiennent le groupe fonctionnel hydroxylamine (-NH2OH). L'hydroxylamine elle-même est une substance inorganique avec la formule NH2OH. Ces composés sont caractérisés par la présence d'un atome d'azote lié à un groupe hydroxyle (-OH).
Dans un contexte médical, les hydroxylamines peuvent être rencontrées dans le cadre de la chimie pharmaceutique et de la toxicologie. Certaines hydroxylamines sont utilisées dans la synthèse de médicaments et d'autres composés chimiques thérapeutiques. Cependant, certaines hydroxylamines peuvent également être toxiques ou cancérigènes. Par exemple, les nitroamines, qui sont largement utilisées dans les explosifs et les propulseurs de fusée, se décomposent en hydroxylamines hautement réactives lorsqu'elles sont exposées à des températures élevées ou à des radiations. Ces hydroxylamines peuvent réagir avec l'ADN et d'autres biomolécules, entraînant des dommages cellulaires et potentiallement cancérigènes.
Il est important de noter que les hydroxylamines ne sont pas couramment utilisées comme médicaments ou agents thérapeutiques eux-mêmes en raison de leur réactivité et de leur potentiel toxicité.
Les protéines de la membrane externe bactérienne se réfèrent à des protéines spécifiques qui sont intégrées dans la membrane externe de certaines bactéries gram-négatives. La membrane externe est une structure unique à ces bactéries, séparée de la membrane cytoplasmique par une région intermédiaire appelée le périplasme.
Les protéines de la membrane externe jouent un rôle crucial dans la survie et la pathogénicité des bactéries. Elles sont souvent impliquées dans des processus tels que l'adhésion à des surfaces, la formation de biofilms, la résistance aux antibiotiques, la lyse de cellules hôtes, et le transport de nutriments.
Les protéines les plus abondantes de la membrane externe bactérienne sont appelées protéines de porine. Elles forment des canaux qui permettent le passage de molécules hydrophiles à travers la membrane externe. D'autres protéines de la membrane externe, telles que les lipoprotéines et les protéines d'ancrage, sont ancrées dans la membrane et jouent des rôles structurels ou enzymatiques spécifiques.
La composition et la fonction des protéines de la membrane externe peuvent varier considérablement selon le type de bactérie. Cependant, leur étude est importante pour comprendre la physiologie bactérienne et pour développer de nouvelles stratégies thérapeutiques contre les infections bactériennes.
L'hydrolyse est un processus chimique important qui se produit dans le corps et dans les réactions biochimiques. Dans un contexte médical ou biochimique, l'hydrolyse décrit la décomposition d'une molécule en deux parties par l'ajout d'une molécule d'eau. Ce processus se produit lorsqu'une liaison covalente entre deux atomes est rompue par la réaction avec une molécule d'eau, qui agit comme un nucléophile.
Dans cette réaction, le groupe hydroxyle (-OH) de la molécule d'eau se lie à un atome de la liaison covalente originale, et le groupe partant (le groupe qui était lié à l'autre atome de la liaison covalente) est libéré. Ce processus conduit à la formation de deux nouvelles molécules, chacune contenant un fragment de la molécule d'origine.
L'hydrolyse est essentielle dans diverses fonctions corporelles, telles que la digestion des glucides, des protéines et des lipides. Par exemple, les liaisons entre les sucres dans les molécules de polysaccharides (comme l'amidon et le glycogène) sont clivées par l'hydrolyse pour produire des monosaccharides simples et digestibles. De même, les protéines sont décomposées en acides aminés par l'hydrolyse, et les lipides sont scindés en glycérol et acides gras.
L'hydrolyse est également utilisée dans le traitement de diverses affections médicales, telles que la dialyse rénale, où l'hémoglobine et d'autres protéines sont décomposées par hydrolyse pour faciliter leur élimination par les reins. En outre, certains compléments alimentaires et suppléments nutritionnels contiennent des peptides et des acides aminés issus de l'hydrolyse de protéines pour une meilleure absorption et digestion.
La réparation de l'ADN est le processus biologique par lequel les cellules identifient et corrigent les dommages à l'acide désoxyribonucléique (ADN), qui est le matériel génétique présent dans les chromosomes des cellules. L'ADN peut être endommagé par divers facteurs, y compris les radiations, les produits chimiques et les erreurs de réplication qui se produisent lorsque l'ADN est copié avant que la cellule ne se divise.
Il existe plusieurs mécanismes de réparation de l'ADN, chacun étant spécialisé dans la correction de certains types de dommages à l'ADN. Les principaux types de réparation de l'ADN comprennent :
1. Réparation par excision de nucléotides (NER) : Ce processus répare les dommages causés aux segments individuels de la chaîne d'ADN en coupant et en éliminant les nucléotides endommagés, puis en remplaçant les nucléotides manquants par des nucléotides non endommagés.
2. Réparation de jonction d'extrémités ouverte (NHEJ) : Ce processus répare les dommages aux extrémités des brins d'ADN en joignant simplement les extrémités ensemble, souvent avec une petite perte de matériel génétique.
3. Réparation par excision de base (BER) : Ce processus répare les dommages causés à un seul nucléotide en coupant et en éliminant le nucléotide endommagé, puis en remplaçant le nucléotide manquant.
4. Réparation de recombinaison homologue (HRR) : Ce processus répare les dommages plus graves à l'ADN en utilisant une molécule d'ADN non endommagée comme modèle pour remplacer le matériel génétique manquant ou endommagé.
Les défauts dans ces systèmes de réparation peuvent entraîner des mutations et des maladies, telles que les cancers. Les chercheurs étudient actuellement comment améliorer ces systèmes de réparation pour prévenir ou traiter les maladies.
Exodeoxyribonuclease V, également connue sous le nom d'exonucléase X, est une enzyme impliquée dans la réparation des dommages à l'ADN. Elle joue un rôle crucial dans le processus de réparation par excision de nucléotides (NER), qui est un mécanisme de réparation de l'ADN endogène et exogène.
L'exodeoxyribonuclease V agit en éliminant les nucléotides individuels du brin d'ADN endommagé, en commençant par l'extrémité 3' de la région endommagée. Elle travaille en collaboration avec d'autres enzymes impliquées dans le processus NER pour éliminer les dommages à l'ADN et rétablir l'intégrité du génome.
Les mutations dans le gène codant pour l'exodeoxyribonuclease V ont été associées à une augmentation de la sensibilité aux agents cancérigènes et aux dommages causés par les rayons ultraviolets, ainsi qu'à un risque accru de développer certains types de cancer.
Salmonella est un genre de bactéries gram-négatives appartenant à la famille des Enterobacteriaceae. Ces bactéries sont souvent trouvées dans les intestins de certains animaux, y compris les oiseaux et les mammifères. Il existe plus de 2500 souches différentes de Salmonella. Les deux souches les plus courantes responsables des maladies humaines sont Salmonella enterica et Salmonella bongori.
L'infection par Salmonella, appelée salmonellose, se produit généralement après l'ingestion d'aliments ou d'eau contaminés par les matières fécales d'animaux infectés ou par une personne malade. Les aliments les plus souvent associés à cette infection sont la viande crue ou insuffisamment cuite, les œufs, le lait et les produits laitiers, ainsi que les fruits et légumes crus.
Les symptômes de la salmonellose comprennent la diarrhée, des crampes abdominales, de la fièvre et des nausées. Dans la plupart des cas, l'infection se résout d'elle-même en une semaine sans traitement spécifique. Toutefois, dans certains cas, surtout chez les jeunes enfants, les personnes âgées, et les individus dont le système immunitaire est affaibli, l'infection peut se propager au-delà de l'intestin et causer une maladie plus grave, nécessitant un traitement antibiotique.
Il est important de noter que certaines souches de Salmonella peuvent provoquer des infections plus graves et sont résistantes aux médicaments couramment utilisés pour traiter les infections. Par conséquent, il est crucial d'éviter la contamination croisée lors de la manipulation et de la préparation des aliments, ainsi que de cuire correctement les aliments pour réduire le risque d'infection par Salmonella.
Les virus défectueux, également connus sous le nom de viruses déficientes ou defective interfering particles (DIPs), sont des versions dégénérées ou altérées d'un virus qui ont perdu la capacité de se répliquer de manière autonome. Ils manquent généralement de certaines parties de leur génome nécessaires à la réplication complète, telles que des gènes essentiels ou des segments d'ARN/ADN. Par conséquent, ils dépendent des virus helper (aides) normaux et fonctionnels pour compléter leur cycle de réplication.
Les virus défectueux peuvent interférer avec la réplication des virus helper en raison de leur capacité à se lier aux molécules d'ARN/ADN ou aux protéines nécessaires à la réplication, ce qui entraîne une diminution de l'efficacité de la réplication des virus helper et, par conséquent, une réduction de la production virale.
Les virus défectueux sont souvent étudiés dans le cadre de la recherche sur les vaccins et les thérapies antivirales, car ils peuvent offrir une protection contre les infections virales en induisant une réponse immunitaire spécifique au virus sans provoquer de maladie. Cependant, leur utilisation dans les applications cliniques est encore à l'étude et nécessite des recherches supplémentaires pour évaluer leur sécurité et leur efficacité.
Les nitrosoguanidines sont un type de composé organique qui contient un groupe fonctionnel nitroso (-N=O) et un groupe guanidino (-NH-C(=NH)-NH2). Ils sont souvent utilisés en recherche biomédicale comme agents alkylants, ce qui signifie qu'ils peuvent se lier de manière covalente à l'ADN et d'autres molécules biologiques. Cette propriété est à l'origine de leur utilisation dans l'étude des mécanismes de réparation de l'ADN et de la mutagénèse.
Certaines nitrosoguanidines, telles que la N-méthyl-N'-nitro-N-nitrosoguanidine (MNNG), sont également bien connues pour leur activité carcinogène. Elles peuvent induire des mutations dans l'ADN qui peuvent conduire au développement de cancer. Pour cette raison, ils sont souvent utilisés dans les études sur le cancer pour induire des tumeurs et étudier les mécanismes du cancer.
Cependant, il est important de noter que les nitrosoguanidines ne sont pas couramment utilisées en médecine humaine en raison de leur toxicité et de leur potentiel cancérigène.
Staphylococcus aureus (S. aureus) est un type courant de bactérie gram-positive qui peut être trouvé dans le nez, sur la peau et dans les voies respiratoires supérieures d'environ 30% des personnes en bonne santé. Cependant, il peut également causer une variété d'infections allant de légères à graves, telles que des infections cutanées, des poumons, du cœur, des os et des articulations.
Dans le contexte médical, un « culture virus » ne fait pas référence à un type spécifique de virus ou d'agent infectieux. Il s'agit plutôt d'un terme utilisé dans les sciences sociales et comportementales pour décrire l'influence des normes, des valeurs et des pratiques partagées au sein d'une communauté ou d'une organisation sur le comportement et les croyances de ses membres.
Cependant, il est important de noter que dans certains contextes, en particulier dans les médias populaires et la culture Internet, le terme « culture virus » peut être utilisé de manière informelle pour décrire une idée, un comportement ou une tendance qui se propage rapidement et devient largement adopté au sein d'un groupe ou d'une population.
Dans aucun cas, cependant, le terme « culture virus » ne fait référence à un agent pathogène ou infectieux dans la médecine ou la biologie.
L'attachement viral est le processus par lequel un virus se lie et pénètre dans une cellule hôte pour y établir une infection. Cela implique généralement l'interaction entre des protéines de surface du virus et des récepteurs spécifiques situés sur la membrane plasmique de la cellule cible. Ce mécanisme est crucial pour le cycle de vie des virus, car il permet leur entrée dans les cellules et leur réplication ultérieure.
Dans le contexte médical, l'attachement viral est un domaine d'étude important dans la compréhension des infections virales et le développement de stratégies thérapeutiques et préventives. Par exemple, les recherches sur l'attachement viral ont conduit au développement de médicaments antiviraux qui ciblent spécifiquement ces interactions protéine-récepteur pour empêcher l'infection virale. De plus, la connaissance des mécanismes d'attachement viral peut également informer le développement de vaccins et d'autres interventions de santé publique visant à prévenir la propagation des maladies infectieuses.
Un modèle structural en médecine et en biologie moléculaire est une représentation tridimensionnelle d'une macromolécule biologique, telle qu'une protéine ou un acide nucléique (ADN ou ARN), qui montre la disposition spatiale de ses atomes constitutifs. Il est généré à partir des données expérimentales obtenues par des techniques telles que la diffraction des rayons X, la résonance magnétique nucléaire (RMN) ou le cryo-microscopie électronique (cryo-EM). Le modèle structural permet d'analyser et de comprendre les interactions moléculaires, la fonction, la dynamique et l'évolution des macromolécules. Il est essentiel pour la conception rationnelle de médicaments, l'ingénierie des protéines et l'étude des processus biologiques fondamentaux.
Je suis désolé, mais la requête « Coquillages et Crustacés » ne correspond à aucun terme médical connu. Les coquillages et les crustacés sont des types d'organismes marins que l'on trouve dans la zoologie. Si vous cherchez une information médicale, pouvez-vous s'il vous plaît préciser votre demande ? Je suis là pour vous aider.
L'évolution moléculaire est un domaine de la biologie qui étudie les changements dans les séquences d'acides nucléiques et des protéines au fil du temps. Il s'appuie sur des disciplines telles que la génétique, la biochimie et la biophysique pour comprendre comment les organismes évoluent au niveau moléculaire.
L'évolution moléculaire examine les mutations, les réarrangements chromosomiques, les duplications de gènes, les transferts horizontaux de gènes et d'autres processus qui modifient la composition génétique des populations. Elle cherche à déterminer comment ces modifications influencent la forme, la fonction et le fitness des organismes.
Les analyses d'évolution moléculaire comprennent souvent des comparaisons de séquences entre différentes espèces ou populations, ainsi que l'inférence de phylogénies (arbres évolutifs) qui représentent les relations historiques entre ces groupes. Ces approches peuvent aider à répondre à des questions sur l'origine et la diversification des espèces, l'adaptation aux environnements changeants et l'évolution de la complexité biologique.
En résumé, l'évolution moléculaire est une branche importante de la biologie évolutive qui étudie les processus et les mécanismes sous-jacents à l'évolution des gènes et des protéines au fil du temps.
Les exodeoxyribonucleases sont des enzymes qui catalysent la coupure exonucléolytique des liaisons phosphodiester dans les acides désoxyribonucléiques (ADN), entraînant la libération de nucléotides monophosphates à partir d'une extrémité de la chaîne d'acide nucléique. Elles agissent en éliminant séquentiellement des nucléotides, un par un, à partir d'une extrémité spécifique de la molécule d'ADN, soit l'extrémité 3' (exodeoxyribonucléase III) ou l'extrémité 5' (exodeoxyribonucléase I). Ces enzymes jouent un rôle crucial dans les processus de réparation et de recombinaison de l'ADN, ainsi que dans la régulation de la taille des extrémités des molécules d'ADN.
Je suis désolé, mais la requête que vous avez formulée est incorrecte ou manque de précision. Le terme "Sérums Immuns" ne semble pas être une expression reconnue dans le domaine médical. Il se peut que vous ayez fait une faute d'orthographe ou que vous cherchiez un terme similaire mais différent.
Cependant, je peux vous fournir des informations sur les sérums immuns en général, qui sont des solutions stériles contenant des anticorps spécifiques contre certaines maladies. Les sérums immuns peuvent être utilisés pour prévenir ou traiter des infections chez les personnes exposées à un risque élevé d'infection ou chez celles qui ont déjà été infectées.
Si vous cherchiez une définition différente, pouvez-vous svp préciser votre demande ? Je suis là pour vous aider.
La désoxyribonucléoprotéine est un terme qui décrit une structure complexe composée d'acides nucléiques (généralement de l'ADN) et de protéines. Ces deux composants sont étroitement associés et forment des structures organisées appelées chromosomes, qui sont les supports de l'information génétique dans les cellules.
L'ADN est le matériel génétique qui code pour toutes les caractéristiques héréditaires d'un organisme. Il se présente sous la forme d'une double hélice, composée de deux brins antiparallèles enroulés l'un autour de l'autre. Les bases azotées (adénine, thymine, guanine et cytosine) de chaque brin s'apparient spécifiquement : adénine avec thymine et guanine avec cytosine.
Les protéines associées à l'ADN forment des structures appelées histones, qui sont responsables de la condensation et de l'organisation de l'ADN en nucléosomes. Les nucléosomes sont des unités fondamentales d'emballage de l'ADN, composées d'un octamère d'histones autour duquel s'enroule environ 146 paires de bases d'ADN. Ces nucléosomes sont ensuite organisés en fibres plus grossières, qui forment finalement les chromosomes.
Les désoxyribonucléoprotéines jouent un rôle crucial dans la régulation de l'expression des gènes et la réplication de l'ADN. Les modifications chimiques des histones et de l'ADN, telles que la méthylation et l'acétylation, peuvent influencer l'accès à l'information génétique et donc réguler l'activité des gènes.
Le Southern Blot est une méthode de laboratoire utilisée en biologie moléculaire pour détecter et identifier des séquences d'ADN spécifiques dans un échantillon d'acide désoxyribonucléique (ADN). Cette technique a été nommée d'après son inventeur, le scientifique britannique Edwin Southern.
Le processus implique plusieurs étapes :
1. L'échantillon d'ADN est d'abord coupé en fragments de taille égale à l'aide d'une enzyme de restriction.
2. Ces fragments sont ensuite séparés par électrophorèse sur gel d'agarose, une méthode qui permet de les organiser selon leur longueur.
3. Le gel est ensuite transféré sur une membrane de nitrocellulose ou de nylon, créant ainsi un "blot" du patron de bandes des fragments d'ADN.
4. La membrane est alors exposée à une sonde d'ADN marquée, qui se lie spécifiquement aux séquences d'intérêt.
5. Enfin, l'emplacement des bandes sur la membrane est détecté par autoradiographie ou par d'autres méthodes de visualisation, révélant ainsi la présence et la quantité relative des séquences d'ADN cibles dans l'échantillon.
Le Southern Blot est une technique sensible et spécifique qui permet non seulement de détecter des séquences d'ADN particulières, mais aussi de distinguer des variantes subtiles telles que les mutations ponctuelles ou les polymorphismes. Il s'agit d'une méthode fondamentale en biologie moléculaire et en génétique, largement utilisée dans la recherche et le diagnostic de maladies génétiques, ainsi que dans l'analyse des gènes et des génomes.
Un modèle biologique est une représentation simplifiée et schématisée d'un système ou processus biologique, conçue pour améliorer la compréhension des mécanismes sous-jacents et faciliter l'étude de ces phénomènes. Il s'agit souvent d'un organisme, d'un tissu, d'une cellule ou d'un système moléculaire qui est utilisé pour étudier les réponses à des stimuli spécifiques, les interactions entre composants biologiques, ou les effets de divers facteurs environnementaux. Les modèles biologiques peuvent être expérimentaux (in vivo ou in vitro) ou théoriques (mathématiques ou computationnels). Ils sont largement utilisés en recherche fondamentale et appliquée, notamment dans le développement de médicaments, l'étude des maladies et la médecine translationnelle.
Les enzymes de restriction-modification d'ADN sont des systèmes enzymatiques présents dans les bactéries et les archées qui fournissent une défense contre l'infection par des virus bactériens (bactériophages). Elles fonctionnent en protégeant l'ADN de l'hôte en coupant l'ADN étranger invasif, tout en laissant intact l'ADN de l'hôte.
Ce système est composé de deux types d'enzymes : les endonucléases de restriction et les méthyltransférases d'ADN. Les endonucléases de restriction coupent l'ADN étranger en reconnaissant des séquences spécifiques d'ADN, appelées sites de restriction. En revanche, les méthyltransférases d'ADN méthylent ces mêmes séquences sur l'ADN de l'hôte, ce qui empêche la coupure par les endonucléases de restriction.
Ces enzymes sont largement utilisées dans la recherche biologique pour des applications telles que le clonage moléculaire et l'analyse de l'ADN. Elles sont classées selon leur cofacteur, leur spécificité de reconnaissance du site et leur activité d'endonucléase. Les enzymes de restriction les plus couramment utilisées sont les enzymes de type II, qui coupent l'ADN au milieu de leur site de reconnaissance.
La rhamnose est un sucre simple (monosaccharide) présent dans certains glycosides et polysaccharides de plantes. Elle est classée comme une désoxyhexose, ce qui signifie qu'elle est une forme hexose (un sucre à six atomes de carbone) qui ne contient pas de groupe hydroxyle (-OH) sur le sixième atome de carbone. La rhamnose peut exister sous deux formes isomères, L-rhamnose et D-rhamnose, mais la forme naturelle la plus courante est L-rhamnose.
Dans le contexte médical, la rhamnose est parfois mentionnée en relation avec des maladies héréditaires du métabolisme telles que l'intolérance au fructose et la déficience en aldolase B, où elle peut s'accumuler dans le foie et entraîner une toxicité. Cependant, ces situations sont rares et ne concernent qu'une petite population de personnes atteintes de troubles héréditaires du métabolisme spécifiques.
Dans l'ensemble, la rhamnose est plus largement étudiée dans le contexte de la biochimie et de la biologie cellulaire que dans le domaine médical direct.
Un nucléotide désoxyguanylique est un type de nucléotide présent dans l'ADN, qui est le matériel génétique des cellules. Il se compose d'une molécule de désoxiribose, qui est un sucre à cinq carbones, liée à une base guanine et à un groupe phosphate. Les nucléotides désoxyguanyliques s'associent les uns aux autres par leurs groupes phosphate pour former des chaînes d'ADN. La guanine est l'une des quatre bases qui composent l'ADN, les trois autres étant l'adénine, la thymine et la cytosine. Les paires de bases guanine-cytosine forment une liaison hydrogène stable, ce qui permet à l'ADN de maintenir sa structure en double hélice caractéristique.
Je suis désolé, "facteur temps" n'a pas de définition spécifique dans le domaine médical. Le terme "facteur temps" est plutôt utilisé en général pour décrire la durée pendant laquelle quelque chose se produit ou évolue, ou il peut également faire référence à l'importance de considérer le moment et la planification dans un contexte médical. Par exemple, l'administration d'un médicament à un moment précis ("facteur temps critique") ou la progression d'une maladie au fil du temps ("évolution temporelle de la maladie") peuvent être décrites en utilisant le terme "facteur temps". Cependant, il n'y a pas de définition médicale universellement acceptée pour ce terme.
Je suis désolé, mais la recherche que j'ai menée ne donne pas de résultats clairs pour "pyocines" dans le contexte d'une définition médicale spécifique. Le terme "pyocines" semble être associé à la biologie des bactéries, en particulier Pseudomonas aeruginosa, où il se réfère à des protéines spécialisées qui peuvent tuer d'autres cellules bactériennes concurrentes. Cependant, ce n'est pas une terminologie médicale largement utilisée ou standardisée dans le domaine de la médecine clinique.
Si vous cherchez des informations sur les pyocines dans le contexte de la biologie des bactéries, je peux vous fournir plus d'informations à ce sujet. Sinon, je suis désolé de ne pas pouvoir répondre à votre question comme vous l'aviez demandé en raison de la nature spécialisée et non médicale du terme.
L'ultracentrifugation est une technique de séparation avancée utilisée en biologie et en biochimie. Il s'agit d'une méthode d'ultrafiltration qui utilise une force centrifuge élevée, générée par une centrifugeuse spécialisée appelée ultracentrifuge, pour séparer des particules ou des molécules de tailles et de poids moléculaires différents dans un mélange.
Cette méthode est couramment utilisée pour la purification et l'isolement d'éléments biologiques tels que les protéines, les acides nucléiques (ADN et ARN), les ribosomes, les virus, les exosomes et d'autres particules similaires. L'ultracentrifugation peut être effectuée à des vitesses allant jusqu'à plusieurs centaines de milliers de fois la force gravitationnelle normale (g), ce qui permet de séparer efficacement ces éléments en fonction de leur masse, de leur forme et de leur densité.
Il existe différents types d'ultracentrifugation, tels que l'ultracentrifugation différentielle, l'ultracentrifugation analytique et l'ultracentrifugation isopycnique, qui sont utilisés dans des contextes spécifiques en fonction des propriétés des échantillons et des objectifs de la séparation.
Les acides aminés sont les unités structurales et fonctionnelles fondamentales des protéines. Chaque acide aminé est composé d'un groupe amino (composé de l'atome d'azote et des atomes d'hydrogène) et d'un groupe carboxyle (composé d'atomes de carbone, d'oxygène et d'hydrogène), reliés par un atome de carbone central appelé le carbone alpha. Un side-chain, qui est unique pour chaque acide aminé, se projette à partir du carbone alpha.
Les motifs des acides aminés sont des arrangements spécifiques et répétitifs de ces acides aminés dans une protéine. Ces modèles peuvent être déterminés par la séquence d'acides aminés ou par la structure tridimensionnelle de la protéine. Les motifs des acides aminés jouent un rôle important dans la fonction et la structure des protéines, y compris l'activation enzymatique, la reconnaissance moléculaire, la localisation subcellulaire et la stabilité structurelle.
Par exemple, certains motifs d'acides aminés peuvent former des structures secondaires telles que les hélices alpha et les feuillets bêta, qui sont importantes pour la stabilité de la protéine. D'autres motifs peuvent faciliter l'interaction entre les protéines ou entre les protéines et d'autres molécules, telles que les ligands ou les substrats.
Les motifs des acides aminés sont souvent conservés dans les familles de protéines apparentées, ce qui permet de prédire la fonction des protéines inconnues et de comprendre l'évolution moléculaire. Des anomalies dans les motifs d'acides aminés peuvent entraîner des maladies génétiques ou contribuer au développement de maladies telles que le cancer.
La réaction de polymérisation en chaîne est un processus chimique au cours duquel des molécules de monomères réagissent ensemble pour former de longues chaînes de polymères. Ce type de réaction se caractérise par une vitesse de réaction rapide et une exothermie, ce qui signifie qu'elle dégage de la chaleur.
Dans le contexte médical, les réactions de polymérisation en chaîne sont importantes dans la production de matériaux biomédicaux tels que les implants et les dispositifs médicaux. Par exemple, certains types de plastiques et de résines utilisés dans les équipements médicaux sont produits par polymérisation en chaîne.
Cependant, il est important de noter que certaines réactions de polymérisation en chaîne peuvent également être impliquées dans des processus pathologiques, tels que la formation de plaques amyloïdes dans les maladies neurodégénératives telles que la maladie d'Alzheimer. Dans ces cas, les protéines se polymérisent en chaînes anormales qui s'accumulent et endommagent les tissus cérébraux.
La guanine est une base nucléique présente dans l'ADN et l'ARN. Elle s'apparie avec la cytosine par liaison hydrogène pour former des paires de bases complémentaires dans la structure en double hélice de ces acides nucléiques. La guanine est une purine, ce qui signifie qu'elle contient un cycle aromatique à six membres et un cycle imidazole à cinq membres. Elle se présente sous forme de glycosylamines, avec le groupe amino attaché à C1 du cycle aromatique et le groupe fonctionnel oxyde attaché au N9. Dans l'ADN et l'ARN, la guanine est liée à des résidus de ribose via une liaison glycosidique entre le N9 de la guanine et le C1' du ribose pour former des nucléosides, qui sont ensuite phosphorylés pour former des nucléotides. La guanine est essentielle à la réplication, à la transcription et à la traduction de l'information génétique dans les cellules vivantes.
La pollution de l'eau est un type de contamination qui affecte l'état naturel des ressources hydriques, telles que les rivières, les lacs, les océans et les eaux souterraines. Elle se produit lorsque des substances nocives ou des agents pathogènes sont introduits dans ces sources d'eau, les rendant impropres à une utilisation sûre et réduisant la qualité de l'habitat pour les organismes aquatiques.
Les sources courantes de pollution de l'eau comprennent :
1. Décharge industrielle : Les eaux usées industrielles peuvent contenir une variété de produits chimiques dangereux, y compris des métaux lourds, des solvants et des composés organiques, qui peuvent être toxiques pour la vie aquatique et présenter des risques pour la santé humaine.
2. Eaux usées domestiques : Les eaux usées provenant des ménages peuvent contenir des agents pathogènes, des nutriments (comme l'azote et le phosphore) et des produits chimiques ménagers, ce qui peut entraîner une prolifération d'algues nocives et perturber les écosystèmes aquatiques.
3. Agriculture : L'utilisation de pesticides et d'engrais dans l'agriculture peut entraîner la contamination des eaux souterraines et de surface, entraînant une augmentation des niveaux de nutriments et de produits chimiques toxiques.
4. Ruissellement urbain : Les précipitations qui s'écoulent sur les surfaces pavées dans les zones urbaines peuvent collecter une variété de polluants, y compris des hydrocarbures, des métaux lourds et des débris, avant d'être déversées dans les cours d'eau.
5. Déversements accidentels : Les déversements accidentels de pétrole, de produits chimiques et d'autres substances nocives peuvent avoir un impact dévastateur sur les écosystèmes aquatiques.
La pollution de l'eau peut entraîner une variété d'effets néfastes, notamment la diminution de la qualité de l'eau potable, la réduction de la biodiversité, la perturbation des écosystèmes et la menace pour la santé humaine. Par conséquent, il est essentiel de prendre des mesures pour prévenir et contrôler la pollution de l'eau.
En médecine, la filtration est un processus utilisé pour séparer des substances ou des cellules d'une solution liquide à travers un matériau poreux ou un filtre. Ce procédé permet de retenir les particules ou molécules plus larges ou plus grossières, tandis que le liquide et les composants plus petits peuvent traverser le filtre.
La filtration est fréquemment employée dans divers contextes médicaux, tels que :
1. Hémodialyse : Pendant ce traitement de suppléance rénal, le sang du patient passe à travers un filtre (appelé dialyseur ou néphron artificiel) qui retient les déchets et l'excès de liquide, permettant au sang épuré de retourner dans le corps.
2. Plasmaphérèse : Ce procédé thérapeutique consiste à séparer le plasma du sang en utilisant une centrifugeuse ou un filtre spécifique, puis à échanger ce plasma contre un plasma sain ou une solution de remplacement.
3. Prélèvement et analyse de liquides biologiques : Lorsqu'il est nécessaire d'examiner des fluides corporels tels que l'urine, le liquide céphalo-rachidien ou l'ascite, la filtration peut être utilisée pour éliminer les cellules et les débris avant l'analyse.
4. Stérilisation : La filtration des solutions ou des médicaments à l'aide de filtres stériles permet d'éliminer les bactéries, les virus et d'autres micro-organismes, assurant ainsi la stérilité du produit final.
En résumé, la filtration est une technique essentielle en médecine pour purifier, séparer et traiter divers liquides biologiques dans le cadre du diagnostic, de la thérapie et de la prévention des maladies.
Le dodécyl sulfate de sodium (SDS) est un détergent anionique couramment utilisé en recherche biomédicale et dans divers produits industriels et domestiques. Sa formule moléculaire est CH3(CH2)11OSO3Na. Il se présente sous la forme d'une poudre blanche ou cristalline soluble dans l'eau, qui forme une solution moussante à des concentrations élevées.
Dans un contexte médical, le SDS est souvent utilisé comme agent tensioactif dans les solutions de lavage gastro-intestinal et comme ingrédient dans certains laxatifs stimulants. Il peut également être utilisé en dermatologie pour traiter certaines affections cutanées, telles que l'eczéma séborrhéique, en raison de ses propriétés nettoyantes et kératolytiques.
Cependant, le SDS peut être irritant pour la peau, les yeux et les muqueuses à des concentrations élevées. Par conséquent, son utilisation doit être effectuée avec prudence et conformément aux directives d'utilisation appropriées.
Le génie génétique est une discipline scientifique et technologique qui consiste à manipuler le matériel génétique, y compris l'ADN et l'ARN, pour modifier des organismes vivants. Cette technique permet aux chercheurs de créer des organismes avec des caractéristiques spécifiques souhaitées en insérant, supprimant, ou modifiant des gènes dans leur génome.
Le processus implique généralement les étapes suivantes :
1. Isolation et clonage de gènes d'intérêt à partir d'un organisme donneur
2. Insertion de ces gènes dans un vecteur, tel qu'un plasmide ou un virus, pour faciliter leur transfert vers l'organisme cible
3. Transformation de l'organisme cible en insérant le vecteur contenant les gènes d'intérêt dans son génome
4. Sélection et culture des organismes transformés pour produire une population homogène présentant la caractéristique souhaitée
Le génie génétique a de nombreuses applications, notamment en médecine (thérapie génique, production de médicaments), agriculture (amélioration des plantes et des animaux), biotechnologie industrielle (production de protéines recombinantes) et recherche fondamentale.
Cependant, il convient également de noter que le génie génétique soulève des questions éthiques, juridiques et environnementales complexes qui nécessitent une réglementation stricte et une surveillance continue pour garantir son utilisation sûre et responsable.
ARN (acide ribonucléique) est une molécule présente dans toutes les cellules vivantes et certains virus. Il s'agit d'un acide nucléique, tout comme l'ADN, mais il a une structure et une composition chimique différentes.
L'ARN se compose de chaînes de nucléotides qui contiennent un sucre pentose appelé ribose, ainsi que des bases azotées : adénine (A), uracile (U), cytosine (C) et guanine (G).
Il existe plusieurs types d'ARN, chacun ayant une fonction spécifique dans la cellule. Les principaux types sont :
* ARN messager (ARNm) : il s'agit d'une copie de l'ADN qui sort du noyau et se rend vers les ribosomes pour servir de matrice à la synthèse des protéines.
* ARN de transfert (ARNt) : ce sont de petites molécules qui transportent les acides aminés jusqu'aux ribosomes pendant la synthèse des protéines.
* ARN ribosomique (ARNr) : il s'agit d'une composante structurelle des ribosomes, où se déroule la synthèse des protéines.
* ARN interférent (ARNi) : ce sont de petites molécules qui régulent l'expression des gènes en inhibant la traduction de l'ARNm en protéines.
L'ARN joue un rôle crucial dans la transmission de l'information génétique et dans la régulation de l'expression des gènes, ce qui en fait une cible importante pour le développement de thérapies et de médicaments.
Le pH est une mesure de l'acidité ou de la basicité d'une solution. Il s'agit d'un échelle logarithmique qui va de 0 à 14. Un pH de 7 est neutre, moins de 7 est acide et plus de 7 est basique. Chaque unité de pH représente une différence de concentration d'ions hydrogène (H+) d'un facteur de 10. Par exemple, une solution avec un pH de 4 est 10 fois plus acide qu'une solution avec un pH de 5.
Dans le contexte médical, le pH est souvent mesuré dans les fluides corporels tels que le sang, l'urine et l'estomac pour évaluer l'équilibre acido-basique du corps. Un déséquilibre peut indiquer un certain nombre de problèmes de santé, tels qu'une insuffisance rénale ou une acidose métabolique.
Le pH normal du sang est d'environ 7,35 à 7,45. Un pH inférieur à 7,35 est appelé acidose et un pH supérieur à 7,45 est appelé alcalose. Les deux peuvent être graves et même mortelles si elles ne sont pas traitées.
En résumé, le pH est une mesure de l'acidité ou de la basicité d'une solution, qui est importante dans le contexte médical pour évaluer l'équilibre acido-basique du corps et détecter les problèmes de santé sous-jacents.
La relation structure-activité (SAR, Structure-Activity Relationship) est un principe fondamental en pharmacologie et toxicologie qui décrit la relation entre les caractéristiques structurales d'une molécule donnée (généralement un médicament ou une substance chimique) et ses effets biologiques spécifiques. En d'autres termes, il s'agit de l'étude des relations entre la structure chimique d'une molécule et son activité biologique, y compris son affinité pour des cibles spécifiques (telles que les récepteurs ou enzymes) et sa toxicité.
L'analyse de la relation structure-activité permet aux scientifiques d'identifier et de prédire les propriétés pharmacologiques et toxicologiques d'une molécule, ce qui facilite le processus de conception et de développement de médicaments. En modifiant la structure chimique d'une molécule, il est possible d'optimiser ses effets thérapeutiques tout en minimisant ses effets indésirables ou sa toxicité.
La relation structure-activité peut être représentée sous forme de graphiques, de tableaux ou de modèles mathématiques qui montrent comment différentes modifications structurales affectent l'activité biologique d'une molécule. Ces informations peuvent ensuite être utilisées pour guider la conception rationnelle de nouveaux composés chimiques ayant des propriétés pharmacologiques et toxicologiques optimisées.
Il est important de noter que la relation structure-activité n'est pas toujours linéaire ou prévisible, car d'autres facteurs tels que la biodisponibilité, la distribution, le métabolisme et l'excrétion peuvent également influencer les effets biologiques d'une molécule. Par conséquent, une compréhension approfondie de ces facteurs est essentielle pour développer des médicaments sûrs et efficaces.
Le déterminisme génétique extrachromosomique fait référence à l'influence des facteurs génétiques qui ne sont pas situés sur les chromosomes conventionnels. Cela inclut généralement les gènes localisés dans l'ADN mitochondrial ou l'ADN des plastides chez les plantes. Ces gènes sont hérités de manière non mendelienne, ce qui signifie qu'ils ne suivent pas les lois traditionnelles de l'hérédité proposées par Gregor Mendel. Contrairement aux gènes chromosomiques, ces facteurs génétiques sont hérités soit uniquement de la mère (dans le cas de l'ADN mitochondrial), soit peuvent être hérités des deux parents dans des proportions variables (comme c'est le cas pour certains systèmes d'hérédité extranucléaires chez les plantes). Cependant, il est important de noter que l'influence de ces facteurs génétiques sur les caractères phénotypiques est souvent plus subtile et moins bien comprise que celle des gènes chromosomiques.
La chromatographie sur DEAE-cellulose est une technique de séparation et d'analyse utilisée en biochimie et en biologie moléculaire. DEAE (diethylaminoethyl) est un type de groupe fonctionnel chargé positivement qui est attaché à la cellulose, un polysaccharide naturel.
Dans cette technique, un échantillon contenant des mélanges de protéines ou d'acides nucléiques est appliqué sur une colonne remplie de DEAE-cellulose. Les composants de l'échantillon interagissent avec le groupe fonctionnel DEAE en fonction de leur charge et de leur taille moléculaire.
Les composants chargés négativement, tels que les acides nucléiques ou les protéines acides, sont retenus par la colonne car ils sont attirés par la charge positive du DEAE. Les composants neutres ou chargés positivement, en revanche, passent à travers la colonne sans être retenus.
En appliquant une solution saline de concentration croissante (appelée élution) à la colonne, les composants chargés négativement sont élués séquentiellement en fonction de leur charge et de leur taille moléculaire. Les composants les plus fortement chargés sont élués en premier, suivis des composants moins chargés.
La chromatographie sur DEAE-cellulose est donc une méthode utile pour séparer et purifier des mélanges complexes de protéines ou d'acides nucléiques, ainsi que pour étudier leurs propriétés physico-chimiques. Elle est souvent utilisée en combinaison avec d'autres techniques chromatographiques pour obtenir une séparation et une purification optimales des composants d'intérêt.
L'adénosine triphosphate (ATP) est une molécule organique qui est essentielle à la production d'énergie dans les cellules. Elle est composée d'une base azotée appelée adénine, du sucre ribose et de trois groupes phosphate.
Dans le processus de respiration cellulaire, l'ATP est produite lorsque des électrons sont transportés le long d'une chaîne de transporteurs dans la membrane mitochondriale interne, entraînant la synthèse d'ATP à partir d'ADP et de phosphate inorganique. Cette réaction est catalysée par l'enzyme ATP synthase.
L'ATP stocke l'énergie chimique dans les liaisons hautement énergétiques entre ses groupes phosphate. Lorsque ces liaisons sont rompues, de l'énergie est libérée et peut être utilisée pour alimenter d'autres réactions chimiques dans la cellule.
L'ATP est rapidement hydrolisée en ADP et phosphate inorganique pour fournir de l'énergie aux processus cellulaires tels que la contraction musculaire, le transport actif de molécules à travers les membranes cellulaires et la biosynthèse de macromolécules.
L'ATP est donc considérée comme la "monnaie énergétique" des cellules, car elle est utilisée pour transférer et stocker l'énergie nécessaire aux processus cellulaires vitaux.
Les composants du génome se réfèrent aux différentes molécules et structures qui constituent l'ensemble des gènes et des séquences non codantes d'un organisme. Dans la plupart des êtres vivants, le génome est essentiellement contenu dans le noyau de la cellule et se compose principalement de deux molécules : l'ADN (acide désoxyribonucléique) et l'ARN (acide ribonucléique).
1. ADN: L'ADN est une longue molécule composée de deux brins enroulés en double hélice, qui contient les instructions génétiques utilisées dans le développement et la fonction de tous les organismes vivants et certains virus. L'information génétique est encodée dans la séquence des nucléotides - adénine (A), guanine (G), cytosine (C) et thymine (T).
2. ARN: L'ARN est une molécule similaire à l'ADN, mais elle est généralement plus courte et comporte des nucléotides différents : adénine (A), guanine (G), cytosine (C) et uracile (U) à la place de la thymine. Il existe plusieurs types d'ARN qui jouent divers rôles dans la cellule, tels que l'ARN messager (ARNm), l'ARN ribosomal (ARNr) et l'ARN de transfert (ARNt). L'ARNm transporte une copie du code génétique à partir de l'ADN vers les ribosomes, où il est utilisé pour synthétiser des protéines. Les ARNr et ARNt sont essentiels à la traduction, le processus par lequel l'information contenue dans l'ARNm est utilisée pour fabriquer des protéines.
En plus de l'ADN et de l'ARN, d'autres composants du génome peuvent inclure des éléments régulateurs tels que les promoteurs, les enhancers et les silencers, qui contrôlent l'expression des gènes. Les épigénomes, qui comprennent des modifications chimiques de l'ADN et des histones, ainsi que la distribution des ARN non codants, peuvent également influencer l'activité génique sans modifier directement la séquence d'ADN sous-jacente.
L'effet génétique des radiations fait référence aux changements héréditaires dans l'information génétique (ADN) qui peuvent être causés par une exposition aux rayonnements ionisants. Ces changements peuvent se produire dans les cellules reproductrices (gamètes), ce qui signifie qu'ils peuvent être transmis aux générations futures. Les effets génétiques des radiations sont un sujet de préoccupation particulier pour les populations exposées à des niveaux élevés de rayonnement, tels que les travailleurs du nucléaire et les personnes vivant près de centrales nucléaires ou de sites de tests d'armes nucléaires.
Les radiations peuvent causer des dommages à l'ADN en brisant les chaînes d'ADN, ce qui peut entraîner des mutations génétiques. Ces mutations peuvent être préjudiciables et entraîner des maladies héréditaires ou des anomalies congénitales chez les descendants. Cependant, il est important de noter que la plupart des mutations sont réparées par les mécanismes de réparation de l'ADN de l'organisme, et seules certaines d'entre elles peuvent entraîner des effets néfastes.
Les effets génétiques des radiations sont généralement considérés comme un risque à long terme, car ils peuvent ne pas apparaître avant plusieurs générations après l'exposition initiale aux rayonnements. Il est donc difficile d'évaluer avec précision les risques associés à ces effets, et des recherches supplémentaires sont nécessaires pour comprendre pleinement leurs implications pour la santé publique.
La microbiologie du sol est une sous-discipline spécialisée de la microbiologie qui se concentre sur l'étude des communautés microbiennes dans les sols, y compris les bactéries, les archées, les champignons, les algues, les protozoaires et d'autres micro-organismes. Ces organismes jouent un rôle crucial dans le cycle des nutriments du sol, la décomposition de la matière organique, la fixation de l'azote, la dénitrification, la méthanogenèse et la bioremédiation des polluants du sol.
La microbiologie du sol examine les interactions entre ces micro-organismes et leur environnement physico-chimique, y compris les facteurs abiotiques tels que le pH, l'humidité, la température et la disponibilité des nutriments qui influencent leur croissance, leur activité métabolique et leur survie. Les chercheurs en microbiologie du sol utilisent une gamme de techniques pour étudier ces communautés microbiennes, y compris la culture traditionnelle, la biologie moléculaire, l'écologie microbienne et les méthodes bioinformatiques.
Les connaissances en microbiologie du sol sont importantes pour une variété d'applications pratiques, notamment l'agriculture durable, la gestion des déchets, la bioremédiation des sols contaminés et la production de biocarburants. En comprenant les processus microbiens qui sous-tendent la fonction du sol, nous pouvons développer des stratégies pour améliorer la santé et la productivité des sols, atténuer les impacts des changements climatiques et promouvoir la durabilité environnementale.
Les galactosidases sont des enzymes qui catalysent la dégradation du lactose et d'autres galactosides. L'hydrolyse du lactose en glucose et galactose est la réaction la plus couramment associée à ces enzymes.
Il existe deux types principaux de galactosidases :
1. La β-galactosidase, également appelée lactase, qui se trouve principalement dans l'intestin grêle et est responsable de la dégradation du lactose dans le régime alimentaire. Les personnes atteintes d'une déficience en lactase peuvent présenter des symptômes d'intolérance au lactose.
2. La α-galactosidase, qui est une enzyme produite par certaines bactéries et champignons. Elle est responsable de la dégradation des galactosides complexes dans les aliments comme les haricots, le chou et les légumineuses. Une carence en α-galactosidase peut entraîner des symptômes de ballonnements, de gaz et de diarrhée après avoir mangé ces types d'aliments.
Les galactosidases sont également utilisées dans le traitement de certaines maladies héréditaires telles que la maladie de Fabry, où une mutation du gène GLA entraîne l'accumulation de globotriaosylcéramide (GL-3) dans divers tissus. La supplémentation en α-galactosidase A réduit l'accumulation de GL-3 et améliore les symptômes de la maladie.
Je suis désolé, mais il semble y avoir une petite erreur dans votre question. Deoxyribonuclease (DNase) n'est pas spécifiquement associée à la restriction enzyme EcoRI. DNases sont des enzymes qui coupent l'acide désoxyribonucléique (ADN) en différents endroits.
Cependant, pour clarifier, EcoRI est une enzyme de restriction spécifique qui coupe l'ADN à des séquences particulières. Elle est isolée de la bactérie Escherichia coli et reconnait et clive la séquence GAATTC dans l'ADN.
Donc, pour répondre à votre question, Deoxyribonuclease EcoRI n'est pas une définition médicale établie car EcoRI n'est pas une DNase. Ce sont deux types d'enzymes différents qui ont des fonctions différentes dans la biologie moléculaire.
« Vibrio cholerae » est une bactérie gram-négative en forme de bâtonnet, mobile et oxydase-négative. Elle est à l'origine du choléra, une maladie diarrhéique aiguë souvent sévère et caractérisée par des vomissements et une déshydratation rapide. La bactérie se retrouve généralement dans les eaux côtières et sa transmission à l'homme se fait principalement par ingestion d'eau ou d'aliments contaminés. Il existe plus de 200 sérogroupes de Vibrio cholerae, mais seulement deux d'entre eux, O1 et O139, sont responsables des épidémies de choléra.
Selon la définition médicale, "Micrococcus" est un genre de bactéries gram-positives qui sont généralement présentes dans l'environnement et sur la peau humaine. Ces bactéries sont des cocci (bactéries sphériques) et se regroupent souvent en grappes, ce qui leur a valu le surnom de "bactéries à fourmis".
Les espèces de Micrococcus sont généralement non pathogènes, ce qui signifie qu'elles ne causent pas habituellement de maladies chez les humains. Cependant, elles peuvent être impliquées dans des infections opportunistes, en particulier chez les personnes dont le système immunitaire est affaibli.
Les bactéries du genre Micrococcus sont souvent utilisées dans la recherche médicale et biologique comme modèles pour étudier la physiologie des bactéries gram-positives, ainsi que pour tester l'activité antibactérienne de nouveaux médicaments.
La biologie évolutive est une discipline scientifique qui étudie les processus et les schémas de changement au fil du temps dans les populations vivantes. Elle combine des concepts et des principes provenant de plusieurs domaines, notamment la génétique, la génomique, la biologie moléculaire, la biostatistique, la écologie et la systématique.
Les processus évolutifs comprennent la sélection naturelle, la dérive génétique, le flux de gènes, la mutation et la recombinaison génétique. Ces processus peuvent entraîner des changements dans les fréquences alléliques au sein d'une population, ce qui peut conduire à l'apparition de nouvelles caractéristiques ou traits.
La sélection naturelle est un mécanisme important de l'évolution biologique, où certains traits héréditaires deviennent plus courants ou moins courants dans une population en fonction de leur impact sur la capacité des organismes à survivre et à se reproduire dans leur environnement.
La dérive génétique est un autre mécanisme évolutif qui résulte du hasard et peut entraîner des changements aléatoires dans les fréquences alléliques au sein d'une population, en particulier dans les populations de petite taille.
Le flux de gènes se produit lorsque les gènes sont échangés entre les populations voisines, ce qui peut entraîner une homogénéisation des fréquences alléliques entre ces populations.
La mutation et la recombinaison génétique peuvent également contribuer à l'évolution biologique en introduisant de nouveaux allèles dans une population, ce qui peut conduire à la variation génétique nécessaire pour que la sélection naturelle agisse.
Dans l'ensemble, la biologie évolutive offre un cadre conceptuel pour comprendre les origines, les relations et la diversité des organismes vivants sur Terre. Elle permet de mieux comprendre comment les populations évoluent au fil du temps en réponse aux changements environnementaux et aux pressions sélectives, ce qui a des implications importantes pour la conservation de la biodiversité et la santé publique.
Brevibacterium flavum est une espèce de bactéries gram-positives, anaérobies facultatives, appartenant au genre Brevibacterium. Ces bactéries sont généralement trouvées dans les environnements riches en protéines et en matières organiques, tels que le sol, l'eau et la nourriture.
Brevibacterium flavum est connu pour sa capacité à produire des enzymes qui décomposent les protéines et les lipides, ce qui en fait un acteur important dans les processus de dégradation naturels. Cette bactérie joue également un rôle important dans la production de certains types de fromages, où elle contribue à la formation de la croûte et au développement de l'arôme et de la saveur typiques du fromage.
Cependant, Brevibacterium flavum peut également être associé à certaines infections humaines, en particulier celles qui affectent la peau et les tissus mous. Ces infections sont généralement opportunistes et surviennent chez des personnes dont le système immunitaire est affaibli ou chez qui il existe une blessure cutanée ou une plaie ouverte. Les symptômes d'une infection à Brevibacterium flavum peuvent inclure des rougeurs, des gonflements, des douleurs et des écoulements purulents au site de l'infection.
Le traitement d'une infection à Brevibacterium flavum dépend généralement de la gravité de l'infection et de la santé globale du patient. Dans les cas légers, un traitement topique avec des antibiotiques peut être suffisant pour éliminer l'infection. Cependant, dans les cas plus graves, une hospitalisation et une administration intraveineuse d'antibiotiques peuvent être nécessaires.
Il est important de noter que Brevibacterium flavum n'est pas considéré comme une bactérie résistante aux antibiotiques, mais des cas de résistance ont été signalés chez certaines souches. Par conséquent, il est important de suivre les instructions du médecin pour tout traitement prescrit et de terminer le cours complet d'antibiotiques pour éviter une récidive de l'infection.
L'ARN de transfert (ARNt) est une petite molécule d'acide ribonucléique qui joue un rôle crucial dans la traduction de l'ARN messager (ARNm) en protéines. Pendant le processus de traduction, l'ARNt transporte des acides aminés spécifiques vers le site de synthèse des protéines sur les ribosomes et les ajoute à la chaîne polypeptidique croissante selon le code génétique spécifié dans l'ARNm.
Chaque ARNt contient une séquence d'au moins trois nucléotides, appelée anticodon, qui peut s'apparier avec un codon spécifique sur l'ARNm. L'extrémité 3' de l'ARNt se lie à l'acide aminé correspondant grâce à une enzyme appelée aminoacyl-ARNt synthétase. Lorsque le ribosome lit le codon sur l'ARNm, l'anticodon de l'ARNt s'apparie avec ce codon, et l'acide aminé attaché à l'ARNt est ajouté à la chaîne polypeptidique.
Les ARNt sont essentiels au processus de traduction et assurent ainsi la précision et l'efficacité de la synthèse des protéines dans les cellules vivantes.
Les recombinases sont des enzymes qui catalysent le processus de recombinaison génétique, dans lequel des segments spécifiques d'ADN ou d'ARN sont échangés entre deux molécules différentes. Ce processus est essentiel pour les mécanismes naturels de réparation et de recombinaison de l'ADN, ainsi que pour la régulation génétique et l'expression des gènes.
Les recombinases peuvent être classées en deux catégories principales : les recombinases site-spécifiques et les recombinases à large spectre. Les recombinases site-spécifiques reconnaissent et se lient à des séquences d'ADN spécifiques, appelées sites de liaison, avant de catalyser la recombinaison entre ces sites. Les exemples bien connus de recombinases site-spécifiques comprennent Cre, Flp et λ Int.
Les recombinases à large spectre, en revanche, ne sont pas limitées par des séquences d'ADN spécifiques et peuvent catalyser la recombinaison entre des segments d'ADN non apparentés. Les exemples de recombinases à large spectre comprennent les rad51, rad54 et recA.
Les recombinases sont largement utilisées dans la recherche biomédicale pour l'ingénierie génétique et la manipulation de l'ADN, y compris la création de modèles animaux de maladies humaines, l'analyse fonctionnelle des gènes et la thérapie génique. Cependant, il est important de noter que les recombinases peuvent également induire des effets indésirables, tels que des réarrangements chromosomiques et des mutations, ce qui peut entraîner des conséquences négatives pour la santé. Par conséquent, il est essentiel de comprendre les mécanismes d'action des recombinases et de développer des stratégies pour minimiser les risques associés à leur utilisation.
L'adénine est une base nucléique purique qui forme une paire de bases avec l'uracile dans les molécules d'ARN et avec la thymine dans les molécules d'ADN. Elle fait partie des quatre bases nucléiques fondamentales qui composent l'ADN aux côtés de la thymine, de la guanine et de la cytosine.
L'adénine est également un composant important de l'ATP (adénosine triphosphate), une molécule essentielle à la production d'énergie dans les cellules. Dans l'ATP, l'adénine est liée à un sucre ribose et à trois groupes phosphate.
En médecine, des anomalies dans le métabolisme de l'adénine peuvent être associées à certaines maladies génétiques rares, telles que les syndromes d'épargne d'adénine et les défauts du cycle de purines. Ces conditions peuvent entraîner une accumulation anormale d'acide urique dans le sang et l'urine, ce qui peut provoquer des calculs rénaux et d'autres complications.
La leucine est un acide aminé essentiel, ce qui signifie qu'il ne peut pas être produit par l'organisme et doit être obtenu à travers l'alimentation ou les suppléments. Elle joue un rôle crucial dans la synthèse des protéines et est souvent décrite comme un acide aminé anabolisant en raison de sa capacité à stimuler la croissance et la réparation des tissus musculaires.
La leucine est également importante pour la régulation du métabolisme énergétique, en particulier pendant l'exercice physique intense. Elle peut aider à prévenir la dégradation des protéines et à favoriser la synthèse de nouvelles protéines, ce qui en fait un complément populaire pour les athlètes et les personnes cherchant à améliorer leur composition corporelle.
En termes de valeur nutritionnelle, la leucine est présente dans une variété d'aliments riches en protéines, tels que la viande, les œufs, les produits laitiers et certaines légumineuses comme les lentilles et les pois chiches. Cependant, il est important de noter que les régimes végétaliens peuvent être à risque de carence en leucine en raison de la faible teneur en cette substance dans les aliments d'origine végétale. Par conséquent, il peut être nécessaire pour les personnes suivant un régime végétalien de surveiller leur apport en leucine et éventuellement de prendre des suppléments pour répondre à leurs besoins nutritionnels.
La "hybridation génétique" est un terme utilisé en génétique et en biologie pour décrire le processus de croisement entre deux individus d'espèces, de sous-espèces ou de variétés différentes, mais qui sont suffisamment étroitement liées pour être capable de se reproduire et de produire des descendants fertiles. Les descendants de cette hybridation sont appelés hybrides et héritent généralement des caractéristiques génétiques des deux parents, ce qui peut entraîner une combinaison unique de traits.
L'hybridation génétique peut se produire naturellement dans la nature lorsque différentes populations d'une même espèce se rencontrent et se croisent, ou elle peut être provoquée expérimentalement en laboratoire par des scientifiques pour étudier les effets de la combinaison de gènes de différentes souches.
L'hybridation génétique peut avoir des conséquences importantes sur l'évolution des espèces, car elle peut entraîner l'introduction de nouveaux gènes dans une population, ce qui peut conduire à une augmentation de la variabilité génétique et à une adaptation accrue aux changements environnementaux. Cependant, l'hybridation peut également entraîner une perte de diversité génétique et de biodiversité si elle conduit à la disparition de sous-espèces ou de variétés uniques.
Staphylococcus est un genre de bactéries sphériques gram-positives qui ont tendance à s'agréger en grappes (d'où le nom dérivé du grec staphyle, raisin et kokkos, grain ou baie). Ces bactéries sont fréquemment trouvées sur la peau et les muqueuses des êtres humains et des animaux. Certaines espèces, en particulier Staphylococcus aureus, peuvent causer une variété d'infections allant de lésions cutanées mineures à des infections potentiellement mortelles telles que la pneumonie, l'endocardite et la septicémie. La résistance aux antibiotiques, y compris la méthicilline (MRSA) et la vancomycine (VRSA), est un sujet de préoccupation croissant dans le domaine médical.
Le transfert génétique horizontal (TGH), également connu sous le nom de transfert de gènes latéral ou transfert de gènes sideways, est un processus biologique dans lequel un organisme transfère son matériel génétique à un autre organisme qui n'est pas sa progéniture. Ce phénomène est différent de la reproduction sexuée et asexuée traditionnelle où le matériel génétique est hérité des parents d'une génération précédente.
Dans le TGH, les gènes peuvent être transférés entre organismes par divers mécanismes, tels que la transformation (l'absorption de libre ADN), la transduction (le transfert de gènes via des bactériophages ou virus) et la conjugaison (le transfert direct de matériel génétique entre deux organismes).
Le TGH est courant dans le monde microbien, en particulier chez les bactéries et les archées. Il joue un rôle important dans l'évolution et la propagation de gènes résistants aux antibiotiques et à d'autres gènes adaptatifs. Cependant, il peut également poser des risques pour la santé publique en facilitant la propagation de gènes responsables de maladies infectieuses.
Les radio-isotopes du carbone sont des variantes d'atomes de carbone qui contiennent un nombre différent de neutrons dans leur noyau, ce qui les rend instables et leur fait émettre des radiations. Le plus couramment utilisé en médecine est le carbone 14 (C-14), qui est un isotope radioactif du carbone.
En médecine, on utilise souvent le C-14 pour la datation au radiocarbone de matériaux organiques dans des études anthropologiques et archéologiques. Cependant, en médecine nucléaire diagnostique, un isotope du carbone plus stable, le carbone 11 (C-11), est utilisé pour effectuer des scintigraphies cérébrales et cardiaques. Ces procédures permettent de visualiser et d'étudier les processus métaboliques dans le corps humain.
Le C-11 a une courte demi-vie (environ 20 minutes), ce qui signifie qu'il se désintègre rapidement et n'expose pas le patient à des radiations pendant de longues périodes. Il est produit dans un cyclotron, généralement sur place dans les centres de médecine nucléaire, et est ensuite utilisé pour marquer des composés chimiques spécifiques qui sont injectés dans le corps du patient. Les images obtenues à l'aide d'une caméra gamma permettent aux médecins de visualiser et d'analyser les fonctions corporelles, telles que la consommation d'oxygène et le métabolisme du glucose dans le cerveau ou le myocarde.
Un hétéroduplexe est un type de structure d'ADN ou d'ARN qui se forme lorsque deux brins complémentaires d'acides nucléiques ne sont pas parfaitement appariés. Cela peut se produire lorsque les séquences des deux brins ne sont pas identiques, ce qui entraîne la formation de paires de bases non complémentaires ou supplémentaires dans certaines régions du duplex. Les hétéroduplexes peuvent être formés par l'appariement d'un brin d'ADN avec un brin d'ARN, ou entre deux brins d'ADN ou d'ARN différents.
Les hétéroduplexes sont souvent instables et peuvent entraîner des mutations ou des réarrangements chromosomiques s'ils ne sont pas corrigés par les mécanismes de réparation de l'ADN de la cellule. Cependant, ils peuvent également jouer un rôle important dans certains processus biologiques, tels que la recombinaison génétique et la régulation de l'expression des gènes.
Dans le contexte médical, les hétéroduplexes peuvent être impliqués dans certaines maladies génétiques, telles que les maladies liées aux répétitions de nucléotides expansées. Dans ces cas, l'expansion de la répétition peut entraîner la formation d'hétéroduplexes qui peuvent perturber la structure et la fonction des gènes, conduisant à des maladies telles que la maladie de Huntington et l'ataxie spinocérébelleuse.
Une délétion chromosomique est un type d'anomalie chromosomique qui se produit lorsqu'une partie d'un chromosome est manquante ou absente. Cela se produit lorsque des segments du chromosome se cassent et que les morceaux perdus ne sont pas correctement réintégrés. Les délétions chromosomiques peuvent être héréditaires ou spontanées, et leur taille et leur emplacement varient considérablement.
Les conséquences d'une délétion chromosomique dépendent de la taille et de l'emplacement de la région déléguée. Les petites délétions peuvent ne provoquer aucun symptôme, tandis que les grandes délétions peuvent entraîner des anomalies congénitales graves, un retard mental et d'autres problèmes de santé.
Les délétions chromosomiques peuvent être détectées avant la naissance par le biais de tests prénataux tels que l'amniocentèse ou le prélèvement de villosités choriales. Les nouveau-nés atteints d'une délétion chromosomique peuvent présenter des caractéristiques physiques uniques, telles qu'un visage allongé, une petite tête, des yeux largement séparés et des oreilles bas situées.
Le traitement d'une délétion chromosomique dépend de la gravité des symptômes et peut inclure une thérapie physique, une thérapie occupationnelle, une éducation spécialisée et d'autres interventions de soutien. Dans certains cas, les personnes atteintes d'une délétion chromosomique peuvent mener une vie relativement normale avec un traitement et un soutien appropriés.
En terme médical, une méthode fait référence à un ensemble systématique et structuré de procédures ou d'étapes utilisées pour accomplir un objectif spécifique dans le domaine de la médecine ou de la santé. Il peut s'agir d'une technique pour effectuer un examen, un diagnostic ou un traitement médical. Une méthode peut également se rapporter à une approche pour évaluer l'efficacité d'un traitement ou d'une intervention de santé. Les méthodes sont souvent fondées sur des preuves et des données probantes, et peuvent être élaborées par des organisations médicales ou des experts dans le domaine.
Dans le contexte de la biologie moléculaire, l'origine de réplication est un site spécifique sur un brin d'ADN où la réplication de l'ADN commence. Il s'agit essentiellement du point de départ à partir duquel les enzymes responsables de la réplication, telles que l'hélicase et la polymérase, initient le processus de copie de l'information génétique contenue dans l'ADN.
Aux origines de réplication, l'ADN se déroule et s'ouvre pour former une structure en forme de fourche de réplication. Les deux brins d'ADN sont séparés et servent de modèles pour la synthèse des nouveaux brins complémentaires. Ce processus génère deux molécules d'ADN identiques à l'original, assurant ainsi la préservation et la transmission fidèle de l'information génétique d'une génération à l'autre.
Il est important de noter que les origines de réplication peuvent varier considérablement en termes de complexité et de régulation selon les organismes. Par exemple, certains virus ont des origines de réplication très simples, tandis que les chromosomes des eucaryotes plus complexes peuvent contenir plusieurs origines de réplication distinctes.
 Bactériophage
Bactériophage
Bactériophage T5
Bactériophage MS2
Infection nosocomiale
Classification des virus
Transduction (génétique)
Phagothérapie
Félix d'Hérelle
T4
T5
Cellule procaryote
Virus
Préparation bactériophagique
Antibactérien
Shunt viral
Podoviridae
Phagespoirs
Eugène Wollman
CRO
Constantin Levaditi
Microbiologie
Acide désoxyribonucléique
Réplication virale
Pilus
Vectorisation
Narnaviridae
Frederick Twort
Primase
Stabilisation des plasmides
Antibiotique
L'utilisation6
- L'utilisation des bactériophages en médecine engage aussi d'autres représentations du soin et des organismes, dans lesquelles la santé n'apparaît plus tant comme l'exclusion et l'annihilation de microorganismes, mais bien davantage comme la coexistence entre plusieurs espèces, humaines et microbiennes, dans un équilibre dynamique. (pasteur.fr)
- En France, une société privée fabrique des bactériophages dirigés contre le staphylocoque doré et des bactériophages dirigés contre Pseudomonas aeruginosa , une autre bactérie mais elle n'a pas le statut de laboratoire pharmaceutique ce qui est un frein à l'utilisation de ses bactériophages. (chu-lyon.fr)
- La recherche de Sylvain Moineau contribuera grandement à faciliter l'utilisation des bactériophages et à réduire leurs caractéristiques nuisibles. (gc.ca)
- Dans ce pays, l'utilisation des bactériophages est courante et on peut penser que la majorité de la population en a déjà bénéficié au moins une fois dans sa vie, que ce soit pour traiter une conjonctivite, une otite ou une blessure infectée par un staphylocoque », explique le Dr -Laurent Debarbieux, spécialiste du sujet à l'Institut Pasteur. (topsante.com)
- Aux États-Unis, l'utilisation de certains bactériophages a été accordée. (agro-media.fr)
- Alexander Harms explore la biologie moléculaire des bactériophages, avec pour objectif principal l'utilisation de processus récemment découverts dans la biotechnologie ou dans la lutte contre les infections bactériennes. (ethrat.ch)
Phages6
- Les bactériophages, également appelés phages, sont des virus qui infectent les bactéries. (sesoignerengeorgie.com)
- Les bactériophages (ou simplement phages) sont des virus qui ont la capacité d'infecter les bactéries et, dans la plupart des cas, de les tuer. (ethicseido.com)
- Mener à de nouvelles approches pour éliminer les bactériophages dans l'industrie agroalimentaire et utiliser les phages pour détruire des bactéries pathogènes. (gc.ca)
- Sylvain Moineau, titulaire de la Chaire de recherche du Canada sur les bactériophages, s'est donné comme objectif d'approfondir les connaissances sur la biologie des phages. (gc.ca)
- Il est maintenant reconnu que les bactériophages (ou phages) sont les entités biologiques les plus abondantes de la planète. (acfas.ca)
- Ceux qui lysent les bactéries sont appelés « bactériophages » ou « phages » tout court. (gaullistelibre.com)
Antibiotiques4
- L'étude des bactériophages et de leurs interactions avec les bactéries a débuté il y a un siècle par la reconnaissance de leur action bactéricide, guidant Félix d'Hérelle vers une application en médecine humaine bien avant la découverte des antibiotiques. (pasteur.fr)
- Une équipe multidisciplinaire des HUG et de l'Université de Genève est parvenue pour la première fois, à l'aide de bactériophages, à traiter avec succès un patient souffrant d'une infection bactérienne pulmonaire chronique résistante aux antibiotiques. (hug.ch)
- Une famille de virus, les bactériophages, a la particularité d'être à la fois un ennemi néfaste qui contribue à la résistance aux antibiotiques des bactéries mais également un allié précieux dans la lutte contre les infections bactériennes. (ethicseido.com)
- Les bactériophages présentent cependant un avantage énorme sur les antibiotiques : ils co-évoluent avec leur hôte, ce qui dissipe la crainte d'apparition de résistances. (gaullistelibre.com)
Ennemis3
- Les bactériophages peuvent être à la fois nos amis et nos ennemis. (gc.ca)
- Cependant, les bactériophages deviennent nos ennemis lorsqu'ils détruisent des bactéries jouant un rôle important, en particulier dans l'industrie alimentaire. (gc.ca)
- Son principe : tirer profit des pires ennemis des bactéries, les bactériophages. (palais-decouverte.fr)
Cellulaire2
- Mais c'est surtout lorsqu'ils ont été choisis comme objets d'études pour appréhender les mécanismes fondamentaux de la vie cellulaire que les bactériophages ont permis des découvertes majeures, dont les acteurs ont été, et sont encore, récompensés par plusieurs prix Nobel. (pasteur.fr)
- Certains bactériophages ont également une enveloppe protéique qui les protège lorsqu'ils traversent la paroi cellulaire de la bactérie. (sesoignerengeorgie.com)
Phage1
- Lors de cette étape, le bactériophage se lie à la surface de la bactérie hôte en reconnaissant des récepteurs spécifiques .Chaque type de phage a une affinité différente pour les récepteurs de surface des bactéries. (sesoignerengeorgie.com)
D'une3
- Les bactériophages fabriqués en Géorgie ne sont pas disponibles en France, ne sont pas fabriqués selon les normes Européennes, et peuvent entrainer des réactions potentiellement sévères, du fait d'une purification insuffisante, s'ils sont utilisés par voie intraveineuse ou directement dans une articulation. (chu-lyon.fr)
- Le bactériophage dispose d'une structure relativement simple, composée d'un génome d'ADN ou d'ARN encapsulé dans une protéine appelée capside. (sesoignerengeorgie.com)
- Bactériophages adsorbés à la surface d'une bactérie (source libre Commons). (gaullistelibre.com)
Scientifique1
- Le Moineauvirus, un bactériophage, a d'ailleurs été nommé en l'honneur de ce scientifique par l'International Committee on Taxonomy of Viruses. (ulaval.ca)
Virus14
- Les bactériophages sont des virus spécifiques de bactérie. (chu-lyon.fr)
- Les bactériophages, ces virus « mangeurs » de bactéries, pourraient bien être un élément de réponse. (emiliegillet.fr)
- Cette première suisse a été réalisée grâce à une approche multidisciplinaire et hautement personnalisée consistant à sélectionner un bactériophage (virus qui s'attaque aux bactéries) spécifique aux bactéries multirésistantes du patient. (hug.ch)
- Un bactériophage est un virus qui infecte les bactéries. (sesoignerengeorgie.com)
- Ce processus est très important pour la reproduction des bactériophages car il permet au virus de s'attacher spécifiquement à la bactérie hôte. (sesoignerengeorgie.com)
- Étudier les bactériophages (virus qui infectent et détruisent les bactéries) pour réduire le plus possible leurs impacts négatifs sur la production d'aliments et en biotechnologie et maximiser leur utilisation comme agents antibactériens. (gc.ca)
- Les bactériophages sont des virus qui infectent et détruisent les bactéries. (gc.ca)
- Nous remercions la Chaire de recherche du Canada sur les bactériophages et le Centre de référence pour virus bactériens Félix d'Hérelle. (acfas.ca)
- Les virus intestinaux, principalement des bactériophages, ont été peu étudiés, malgré leur abondance. (acfas.ca)
- Leur nom : les bactériophages, des virus inoffensifs pour l'homme, mais capables de « manger » des bactéries ou plus exactement de les détruire. (topsante.com)
- Selon les chercheurs, le nouveau virus découvert dans la fosse des Mariannes pourrait être le bactériophage le plus profond découvert dans l'océan. (yahoo.com)
- Notre projet s'attaque à ce problème en s'intéressant aux bactériophages, des virus connus pour spécifiquement attaquer des bactéries. (ionis-group.com)
- Sylvain Moineau est reconnu pour ses travaux influents sur les bactériophages, ces virus qui détectent et détruisent les bactéries. (ulaval.ca)
- Par abus de langage, le terme fermentation est couramment utilisé en industrie pour désigner le procédé qui permet de réaliser les cultures cellulaires (de bactéries, levures et champignons, de cellules animales, végétales et d'insectes, de virus et bactériophages) et d'effectuer les réactions de bioconversion, qu'elles soient aérobies ou anaérobies. (techniques-ingenieur.fr)
États-Unis1
- L'absence de publications scientifiques conformes aux standards occidentaux fait que les bactériophages ne sont toujours pas reconnus comme médicaments en Europe ou aux États-Unis. (topsante.com)
Cellules1
- Ils détruisent alors la cellule bactérienne, libérant les bactériophages pour infecter d'autres cellules. (sesoignerengeorgie.com)
Capables1
- Ces bactériophages sont donc capables de détruire spécifiquement des bactéries pathogènes : salmonelles, streptocoques, staphylocoques, pseudomonas, pneumocoques… sans s'attaquer au microbiote de notre intestin, ces bactéries qui y vivent, nous aident à digérer et occupent l'espace en ne laissant pas la place aux bactéries dangereuses. (gaullistelibre.com)
S'est1
- Une fois que le bactériophage s'est attaché à la surface de la bactérie hôte , il doit pénétrer à l'intérieur de celle-ci pour pouvoir se reproduire. (sesoignerengeorgie.com)
19151
- Découverts en 1915, les bactériophages ont même connu leur heure de gloire dans les années 1920. (topsante.com)
Capside1
- Pour cela, ils ont commencé par exprimer des peptides (ou chaînes d'amino-acides) présentant une forte affinité pour des matériaux particuliers sur la capside de bactériophages M13. (infogm.org)
Approches1
- assemblage macromoléculaires, régulation de l'expression des gènes viraux) aux défenses bactériennes mise en place pour les contrecarrer (systèmes de restriction modification et Crispr-Cas9), l'étude des bactériophages, par des approches multidisciplinaires, a provoqué de véritables ruptures dans l'avancée des connaissances sur le vivant. (pasteur.fr)
Alors1
- Certaines firmes pharmaceutiques commercialisant alors des préparations à base de bactériophages pour soigner la dysenterie ou le choléra. (topsante.com)
L'ANSM1
- Phagothérapie : L'ANSM autorise un accès compassionnel pour des bactériophages dans les infections ostéo-articulaires. (pharmacovigilance-reims.fr)
Traiter2
- Dès leur découverte, c'est leur potentiel thérapeutique qui a promu les bactériophages sur le devant de la scène en permettant de traiter des infections bactériennes. (pasteur.fr)
- Il y a plusieurs options pour bénéficier de la phagothérapie en France ou hors de France: Option 1: aller dans un pays proposant un traitement par bactériophage et s'y faire traiter par le corps. (europhages.com)
Biologie1
- Alexander Harms (*1987), actuellement responsable de groupe junior à l'Université de Bâle, est nommé professeur assistant de biologie moléculaire des bactériophages au Département des sciences et des technologies de santé. (ethrat.ch)
Naturels1
- Les bactériophages sont les prédateurs naturels des bactéries, et jouent un rôle important dans la régulation de la population bactérienne. (sesoignerengeorgie.com)
Reproduire3
- Les bactériophages, incapables de se reproduire par leurs propres moyens, injectent leur matériel génétique dans des bactéries hôtes. (wikipedia.org)
- Les bactériophages ont une relation étroite avec leur hôte bactérien, car ils ont besoin de se reproduire à l'intérieur de celui-ci. (sesoignerengeorgie.com)
- Une fois à l'intérieur, le matériel génétique viral utilise les ressources de la bactérie pour se reproduire, produisant des centaines de copies du bactériophage. (sesoignerengeorgie.com)
L'information1
- Le support de l'information génétique (génome) des bactériophages peut être un ADN ou un ARN. (wikipedia.org)
Recours2
- Le recours aux bactériophages par la phagothérapie revient sur le devant de la scène comme une des voies les plus avérées, prometteuses et durables pour l'avenir. (pasteur.fr)
- Le recours (et le retour) aux bactériophages par la phagothérapie est sans doute une des voies les plus avérées, prometteuses et durables. (pasteur.fr)
Maladies2
- Durant cette présentation, je parlerai de nos projets explorant le rôle des bactériophages dans le contexte de maladies inflammatoires intestinales. (acfas.ca)
- En Russie et en Géorgie, des solutions de bactériophages sont même en vente libre dans les pharmacies' ajoute le Dr Olivier Patey, chef du service des maladies infectieuses à l'hôpital de Villeneuve-Saint-Georges. (topsante.com)
Pasteur1
- Du 24 au 26 avril 2017, l'Institut Pasteur célèbre le centenaire de la recherche sur les bactériophages. (pasteur.fr)
Processus2
- La reproduction des bactériophages est un processus crucial pour leur survie et leur propagation. (sesoignerengeorgie.com)
- La troisième étape du processus de reproduction des bactériophages est la réplication. (sesoignerengeorgie.com)
Recherche1
- De son côté, la recherche occidentale semble de nouveau s'intéresser aux bactériophages. (topsante.com)
Principe1
- Le principe de l'existence des bactériophages est posé. (pasteur.fr)
Utiliser2
- La phagothérapie consiste à produire des bactériophages spécifiques et à les utiliser pour une infection bactérienne. (chu-lyon.fr)
- Il cherche à mettre point de nouveaux outils pour éliminer les bactériophages dans les fermentations laitières et les utiliser comme antibactériens en santé publique et dans une grande variété de secteurs. (gc.ca)
France1
- Les bactériophages ont été utilisés en France à des fins thérapeutiques de 1920 à 1990 environ et le sont toujours dans l'ex-bloc de l'Est, où l'on peut acheter des bactériophagiques en pharmacie sans ordonnance. (wikipedia.org)
Surface1
- Lorsqu'un bactériophage infecte une bactérie, il se fixe sur sa surface et injecte son matériel génétique dans la cellule bactérienne. (sesoignerengeorgie.com)