Algoritmos
Programas Informáticos
Reconocimiento de Normas Patrones Automatizadas
Simulación por Computador
Biología Computacional
Reproducibilidad de Resultados
Inteligencia Artificial
Modelos Estadísticos
Sensibilidad y Especificidad
Análisis por Conglomerados
Procesamiento de Imagen Asistida por Computador
Análisis de Secuencia de Proteína
Alineación de Secuencia
Interpretación de Imagen Asistida por Computador
Fantasmas de Imagen
Modelos Genéticos
Procesamiento de Señales Asistido por Computador
Validación de Programas de Computación
Imagen Tridimensional
Análisis de Secuencia de ADN
Aumento de la Imagen
Cadenas de Markov
Proteínas
Bases de Datos de Proteínas
Teorema de Bayes
Perfilación de la Expresión Génica
Método de Montecarlo
Gráficos por Computador
Automatización
Bases de Datos Factuales
Análisis de Secuencia por Matrices de Oligonucleótidos
Redes Neurales (Computación)
Análisis Numérico Asistido por Computador
Modelos Teóricos
Interfaz Usuario-Computador
Compresión de Datos
Lógica Difusa
Artefactos
Diagnóstico por Computador
Bases de Datos Genéticas
Interpretación Estadística de Datos
Modelos Biológicos
Distribución Normal
Almacenamiento y Recuperación de la Información
Funciones de Verosimilitud
Interpretación de Imagen Radiográfica Asistida por Computador
Internet
Árboles de Decisión
Intensificación de Imagen Radiográfica
Técnica de Sustracción
Lenguajes de Programación
Análisis de Ondículas
Metodologias Computacionales
Relación Señal-Ruido
Minería de Datos
Modelos Moleculares
Tecnología Inalámbrica
Máquinas de Vectores de Soporte
Procesamiento Automatizado de Datos
Diseño de Programas Informáticos
Análisis de Secuencia de ARN
Computadores
Datos de Secuencia Molecular
Procesos Estocásticos
Genoma
Redes Reguladoras de Genes
Curva ROC
Modelos Químicos
Probabilidad
Valor Predictivo de las Pruebas
Mapeo Cromosómico
Imagen por Resonancia Magnética
Factores de Tiempo
Secuencia de Bases
Análisis Discriminante
Tomografía Computarizada de Haz Cónico
Tomografía Computarizada por Rayos X
Análisis de los Mínimos Cuadrados
Dinámicas no Lineales
Programación Lineal
Análisis de Falla de Equipo
Genoma Humano
Bases de Datos de Ácidos Nucleicos
Análisis de Componente Principal
Polimorfismo de Nucleótido Simple
Secuencia de Aminoácidos
Redes de Comunicación de Computadores
Procesamiento de Lenguaje Natural
Tomografía
En medicina, el término "algoritmos" se refiere a un conjunto de pasos sistemáticos y estandarizados que se utilizan para resolver problemas clínicos específicos o tomar decisiones terapéuticas. Los algoritmos suelen estar representados en forma de diagramas de flujo o tablas, y pueden incluir recomendaciones sobre la recopilación y análisis de datos clínicos, el diagnóstico diferencial y las opciones de tratamiento.
Los algoritmos se utilizan a menudo en la práctica clínica como una herramienta para ayudar a los profesionales sanitarios a tomar decisiones informadas y consistentes sobre el manejo de pacientes con condiciones específicas. Por ejemplo, un algoritmo podría utilizarse para guiar la evaluación y el tratamiento de un paciente con sospecha de enfermedad cardiovascular, o para ayudar a los médicos a determinar la dosis óptima de un medicamento específico en función del peso y la función renal del paciente.
Los algoritmos también se utilizan en investigación clínica y epidemiológica para estandarizar los procedimientos de recopilación y análisis de datos, lo que facilita la comparación y el análisis de resultados entre diferentes estudios.
En general, los algoritmos son una herramienta útil en la práctica clínica y la investigación médica, ya que pueden ayudar a garantizar que se sigan procedimientos estandarizados y consistentes, lo que puede mejorar la calidad de la atención y los resultados para los pacientes.
En la medicina, los términos "programas informáticos" o "software" no tienen una definición específica como concepto médico en sí mismos. Sin embargo, el uso de programas informáticos es fundamental en muchos aspectos de la atención médica y la medicina modernas.
Se pueden utilizar para gestionar registros médicos electrónicos, realizar análisis de laboratorio, planificar tratamientos, realizar cirugías asistidas por computadora, proporcionar educación a los pacientes, investigar enfermedades y desarrollar nuevos fármacos y terapias, entre muchas otras aplicaciones.
Los programas informáticos utilizados en estos contextos médicos deben cumplir con estándares específicos de seguridad, privacidad y eficacia para garantizar la calidad de la atención médica y la protección de los datos sensibles de los pacientes.
El término "Reconocimiento de Normas Patrones Automatizado" no es específicamente una definición médica, sino más bien un término relacionado con la tecnología y la informática. Sin embargo, en el contexto médico, este proceso se puede referir al uso de sistemas computarizados o dispositivos electrónicos para analizar y reconocer patrones específicos en los datos médicos, como por ejemplo:
* Reconocimiento automatizado de patrones en imágenes médicas (radiografías, resonancias magnéticas, etc.) para ayudar en el diagnóstico y seguimiento de enfermedades.
* Sistemas de monitoreo de signos vitales que utilizan algoritmos para detectar patrones anormales o desviaciones en los parámetros fisiológicos de un paciente.
* Análisis automatizado de grandes conjuntos de datos clínicos (como historiales médicos electrónicos) para identificar tendencias, riesgos y oportunidades de mejora en la atención médica.
En resumen, el reconocimiento de patrones automatizado en un entorno médico implica el uso de tecnología y análisis de datos para mejorar la precisión, eficiencia y calidad de los procesos clínicos y diagnósticos.
La simulación por computador en el contexto médico es el uso de modelos computacionales y algoritmos para imitar o replicar situaciones clínicas, procesos fisiológicos o escenarios de atención médica. Se utiliza a menudo en la educación médica, la investigación biomédica y la planificación del cuidado del paciente. La simulación por computador puede variar desde modelos matemáticos abstractos hasta representaciones gráficas detalladas de órganos y sistemas corporales.
En la educación médica, la simulación por computador se utiliza a menudo para entrenar a los estudiantes y profesionales médicos en habilidades clínicas, toma de decisiones y juicio clínico. Esto puede incluir el uso de pacientes simulados virtuales que responden a las intervenciones del usuario, lo que permite a los estudiantes practicar procedimientos y tomar decisiones en un entorno controlado y seguro.
En la investigación biomédica, la simulación por computador se utiliza a menudo para modelar y analizar procesos fisiológicos complejos, como el flujo sanguíneo, la respiración y la difusión de fármacos en el cuerpo. Esto puede ayudar a los investigadores a entender mejor los mecanismos subyacentes de las enfermedades y a desarrollar nuevas estrategias de tratamiento.
En la planificación del cuidado del paciente, la simulación por computador se utiliza a menudo para predecir los resultados clínicos y los riesgos asociados con diferentes opciones de tratamiento. Esto puede ayudar a los médicos y a los pacientes a tomar decisiones informadas sobre el cuidado del paciente.
En resumen, la simulación por computador es una herramienta valiosa en el campo médico que se utiliza para entrenar a los profesionales médicos, investigar procesos fisiológicos complejos y ayudar a tomar decisiones informadas sobre el cuidado del paciente.
La biología computacional es una rama interdisciplinaria de la ciencia que aplica técnicas y métodos de la informática, matemáticas y estadística al análisis y modelado de sistemas biológicos complejos. Esta área de estudio combina el conocimiento de la biología molecular, celular y de sistemas con herramientas computacionales y algoritmos avanzados para entender los procesos biológicos a nivel molecular y sistémico.
La biología computacional se utiliza en diversas áreas de investigación, incluyendo la genómica, la proteómica, la bioinformática, la sistemática molecular, la biología de sistemas y la medicina personalizada. Algunos ejemplos específicos de aplicaciones de la biología computacional incluyen el análisis de secuencias genéticas, el modelado de interacciones proteína-proteína, el diseño de fármacos y la simulación de redes metabólicas.
La biología computacional requiere una sólida formación en ciencias biológicas, matemáticas y computacionales. Los científicos que trabajan en esta área suelen tener un doctorado en biología, bioquímica, física, matemáticas o informática, y poseen habilidades en programación, análisis de datos y modelado matemático.
En resumen, la biología computacional es una disciplina que utiliza herramientas computacionales y matemáticas para analizar y modelar sistemas biológicos complejos, con el objetivo de entender los procesos biológicos a nivel molecular y sistémico.
La reproducibilidad de resultados en el contexto médico se refiere a la capacidad de obtener los mismos resultados o conclusiones experimentales cuando un estudio u observación científica es repetido por diferentes investigadores e incluso en diferentes muestras o poblaciones. Es una piedra angular de la metodología científica, ya que permite confirmar o refutar los hallazgos iniciales. La reproducibilidad ayuda a establecer la validez y confiabilidad de los resultados, reduciendo así la posibilidad de conclusiones falsas positivas o negativas. Cuando los resultados no son reproducibles, pueden indicar errores en el diseño del estudio, falta de rigor en la metodología, variabilidad biológica u otros factores que deben abordarse para garantizar la precisión y exactitud de las investigaciones médicas.
La Inteligencia Artificial (IA) es una rama de la ciencia de la computación que se enfoca en el desarrollo de sistemas o programas informáticos capaces de realizar tareas que normalmente requerirían inteligencia humana para ser resueltas. Estas tareas pueden incluir cosas como el aprendizaje, el razonamiento, la percepción, la comprensión del lenguaje natural y la toma de decisiones. La IA puede ser dividida en dos categorías principales: la IA simbólica o débil, que se basa en reglas y estructuras lógicas predefinidas para resolver problemas, y la IA subsimbólica o fuerte, que busca crear máquinas con capacidades cognitivas comparables a las de los humanos. Sin embargo, es importante notar que actualmente no existe una definición médica universalmente aceptada de Inteligencia Artificial.
Los Modelos Estadísticos son representaciones matemáticas o algoritmos que describen y resumen patrones y relaciones en datos basados en la estadística. Se utilizan para predecir resultados, inferir procesos subyacentes desconocidos a partir de datos observables y probar hipótesis en contextos médicos y de salud pública.
En el campo médico, los modelos estadísticos pueden ayudar a analizar la relación entre diferentes variables como factores de riesgo y desenlaces de salud, evaluar la eficacia de intervenciones terapéuticas o preventivas, o pronosticar el curso probable de una enfermedad.
Estos modelos pueden variar desde regresiones lineales simples hasta sofisticados análisis multivariantes y aprendizaje automático. La construcción de un modelo estadístico adecuado requiere una comprensión sólida de los supuestos subyacentes, la selección apropiada de variables predictoras y criterios de evaluación, y la validación cruzada para garantizar su generalización a nuevos conjuntos de datos.
En resumen, los modelos estadísticos son herramientas poderosas en medicina que permiten a los profesionales de la salud comprender mejor los fenómenos biomédicos y tomar decisiones informadas sobre el diagnóstico, tratamiento e investigación.
En medicina y epidemiología, sensibilidad y especificidad son términos utilizados para describir la precisión de una prueba diagnóstica.
La sensibilidad se refiere a la probabilidad de que una prueba dé un resultado positivo en individuos que realmente tienen la enfermedad. Es decir, es la capacidad de la prueba para identificar correctamente a todos los individuos que están enfermos. Se calcula como el número de verdaderos positivos (personas enfermas diagnosticadas correctamente) dividido por el total de personas enfermas (verdaderos positivos más falsos negativos).
Especifidad, por otro lado, se refiere a la probabilidad de que una prueba dé un resultado negativo en individuos que no tienen la enfermedad. Es decir, es la capacidad de la prueba para identificar correctamente a todos los individuos que están sanos. Se calcula como el número de verdaderos negativos (personas sanas diagnosticadas correctamente) dividido por el total de personas sanas (verdaderos negativos más falsos positivos).
En resumen, la sensibilidad mide la proporción de enfermos que son identificados correctamente por la prueba, mientras que la especificidad mide la proporción de sanos que son identificados correctamente por la prueba.
El análisis por conglomerados es un método estadístico utilizado en el campo del análisis de datos. No se trata específicamente de un término médico, sino más bien de una técnica utilizada en la investigación y análisis de conjuntos de datos complejos.
En el contexto de los estudios epidemiológicos o clínicos, el análisis por conglomerados puede ser utilizado para agrupar a los participantes del estudio en función de sus características comunes, como edad, sexo, factores de riesgo, síntomas u otras variables relevantes. Estos grupos se denominan conglomerados o clusters.
La técnica de análisis por conglomerados puede ayudar a identificar patrones y relaciones entre las variables en un conjunto de datos grande y complejo, lo que puede ser útil para la investigación médica y la práctica clínica. Por ejemplo, el análisis por conglomerados se puede utilizar para identificar grupos de pacientes con características similares que puedan responder de manera diferente a un tratamiento específico o estar en riesgo de desarrollar ciertas enfermedades.
Sin embargo, es importante tener en cuenta que el análisis por conglomerados no es una herramienta diagnóstica y no debe utilizarse como sustituto de la evaluación clínica y el juicio profesional de un médico o proveedor de atención médica calificado.
El procesamiento de imagen asistido por computador (CIAP, Computer-Aided Image Processing) es un campo de la medicina que se refiere al uso de tecnologías informáticas para mejorar, analizar y extraer datos importantes de imágenes médicas. Estas imágenes pueden ser obtenidas a través de diferentes métodos, como radiografías, resonancias magnéticas (RM), tomografías computarizadas (TC) o ecografías.
El objetivo principal del CIAP es ayudar a los profesionales médicos en el diagnóstico y tratamiento de diversas condiciones de salud al proporcionar herramientas avanzadas que permitan una interpretación más precisa e informada de las imágenes. Algunos ejemplos de aplicaciones del CIAP incluyen:
1. Mejora de la calidad de imagen: Técnicas como el filtrado, la suavización y la eliminación de ruido pueden ayudar a mejorar la claridad y detalle de las imágenes médicas, facilitando así su análisis.
2. Segmentación de estructuras anatómicas: El CIAP puede ayudar a identificar y separar diferentes tejidos u órganos dentro de una imagen, lo que permite a los médicos medir volúmenes, analizar formas y cuantificar características específicas.
3. Detección y clasificación de lesiones o enfermedades: A través del aprendizaje automático e inteligencia artificial, el CIAP puede ayudar a detectar la presencia de lesiones o patologías en imágenes médicas, así como a clasificarlas según su gravedad o tipo.
4. Seguimiento y evaluación del tratamiento: El procesamiento de imágenes asistido por computador también puede ser útil para monitorizar el progreso de un paciente durante el tratamiento, comparando imágenes obtenidas en diferentes momentos y evaluando la evolución de las lesiones o patologías.
En resumen, el procesamiento de imágenes asistido por computador es una herramienta cada vez más importante en el campo de la medicina, ya que permite analizar y extraer información valiosa de imágenes médicas, facilitando el diagnóstico, tratamiento e investigación de diversas enfermedades y patologías.
El análisis de secuencia de proteínas es el proceso de examinar y estudiar la secuencia completa o parcial de aminoácidos que forman una proteína específica. La secuencia de proteínas se deriva del ADN que codifica la proteína y proporciona información importante sobre la estructura, función y evolución de la proteína.
El análisis de secuencia de proteínas puede implicar comparar la secuencia de una proteína desconocida con secuencias conocidas en bases de datos para identificar similitudes y determinar su función probable o clasificarla en una familia de proteínas. También se pueden utilizar técnicas computacionales para predecir la estructura tridimensional de la proteína a partir de su secuencia, lo que puede ayudar a comprender cómo funciona la proteína a nivel molecular.
El análisis de secuencia de proteínas es una herramienta importante en la investigación biomédica y la biología molecular, ya que permite a los científicos estudiar las relaciones evolutivas entre diferentes especies, identificar mutaciones genéticas asociadas con enfermedades y desarrollar nuevos fármacos y terapias.
La alineación de secuencias es un proceso utilizado en bioinformática y genética para comparar dos o más secuencias de ADN, ARN o proteínas. El objetivo es identificar regiones similares o conservadas entre las secuencias, lo que puede indicar una relación evolutiva o una función biológica compartida.
La alineación se realiza mediante el uso de algoritmos informáticos que buscan coincidencias y similitudes en las secuencias, teniendo en cuenta factores como la sustitución de un aminoácido o nucleótido por otro (puntos de mutación), la inserción o eliminación de uno o más aminoácidos o nucleótidos (eventos de inserción/deleción o indels) y la brecha o espacio entre las secuencias alineadas.
Existen diferentes tipos de alineamientos, como los globales que consideran toda la longitud de las secuencias y los locales que solo consideran regiones específicas con similitudes significativas. La representación gráfica de una alineación se realiza mediante el uso de caracteres especiales que indican coincidencias, sustituciones o brechas entre las secuencias comparadas.
La alineación de secuencias es una herramienta fundamental en la investigación genética y biomédica, ya que permite identificar relaciones evolutivas, determinar la función de genes y proteínas, diagnosticar enfermedades genéticas y desarrollar nuevas terapias y fármacos.
La interpretación de imagen asistida por computador es un proceso en el que se utilizan algoritmos y software avanzado para analizar, procesar e interpretar imágenes médicas adquiridas a través de diferentes modalidades, como radiografías, tomografías computarizadas (TC), resonancias magnéticas (RM) o ecografías. El objetivo principal es ayudar a los radiólogos y otros especialistas médicos en el diagnóstico, la detección de patologías, el seguimiento de enfermedades y la toma de decisiones terapéuticas.
El procesamiento de imágenes puede incluir técnicas como filtrado, segmentación, registro y reconocimiento de patrones, que permiten extraer información relevante, eliminar ruido o artefactos, y normalizar las imágenes para una mejor visualización y comparabilidad. Algunos ejemplos de aplicaciones de la interpretación de imagen asistida por computador incluyen:
1. Detección automática de lesiones, tumores o órganos: El software puede identificar regiones de interés en las imágenes y proporcionar mediciones precisas de tamaño, forma y localización, lo que facilita la evaluación de cambios en el seguimiento de enfermedades.
2. Caracterización de tejidos: A través del análisis de texturas, intensidades y otras propiedades de las imágenes, es posible diferenciar entre diferentes tipos de tejidos y detectar anomalías, como infiltraciones tumorales o inflamatorias.
3. Diagnóstico diferencial: El uso de redes neuronales profundas y aprendizaje automático permite clasificar lesiones y enfermedades según su probabilidad, lo que ayuda a los médicos a tomar decisiones más informadas sobre el tratamiento.
4. Planificación y guía de procedimientos terapéuticos: La interpretación de imagen asistida por computador puede utilizarse para planificar cirugías, radioterapia o ablaciones, así como para guiar instrumental médico durante intervenciones mínimamente invasivas.
La interpretación de imagen asistida por computador sigue evolucionando y mejorando gracias al desarrollo de nuevas técnicas de aprendizaje automático e inteligencia artificial, lo que promete una mayor precisión y eficiencia en el diagnóstico y tratamiento de enfermedades.
Los "fantasmas de imagen" no son un término médico establecido. Sin embargo, en el contexto de la radioterapia y la resonancia magnética (RM), a veces se utiliza el término "fantasma de imagen" para describir una situación en la que las imágenes previas pueden influir o distorsionar las imágenes actuales.
En la RM, esto puede suceder cuando las secuencias de adquisición de imágenes anteriores se almacenan en la memoria del sistema y, posteriormente, influyen en las imágenes adquiridas más tarde. Este fenómeno se conoce como "efecto de recuerdo" o "sobrecarga de memoria".
En el contexto de la radioterapia, los "fantasmas de imagen" pueden referirse a las marcas de radioterapia previas que permanecen visibles en las imágenes posteriores, incluso después de que haya transcurrido un tiempo considerable desde el tratamiento. Estas marcas pueden hacer que sea más difícil identificar claramente las estructuras anatómicas y planificar adecuadamente la radioterapia en curso.
Por lo tanto, aunque "fantasmas de imagen" no es un término médico formal, se utiliza ocasionalmente para describir situaciones específicas en el campo de la medicina relacionadas con la adquisición y visualización de imágenes.
Los Modelos Genéticos son representaciones simplificadas y teóricas de sistemas genéticos complejos que se utilizan en la investigación médica y biológica. Estos modelos ayudan a los científicos a entender cómo las interacciones entre genes, ambiente y comportamiento contribuyen a la manifestación de características, trastornos o enfermedades hereditarias.
Los modelos genéticos pueden adoptar diversas formas, desde esquemas matemáticos y computacionales hasta diagramas y mapas que ilustran las relaciones entre genes y sus productos. Estos modelos permiten a los investigadores hacer predicciones sobre los resultados de los experimentos, identificar posibles dianas terapéuticas y evaluar el riesgo de enfermedades hereditarias en poblaciones específicas.
En medicina, los modelos genéticos se utilizan a menudo para estudiar la transmisión de enfermedades hereditarias dentro de las familias, analizar la variación genética entre individuos y comprender cómo los factores ambientales y lifestyle pueden influir en la expresión de genes asociados con enfermedades.
Es importante tener en cuenta que los modelos genéticos son representaciones aproximadas y simplificadas de sistemas biológicos reales, por lo que siempre están sujetos a limitaciones y pueden no capturar toda la complejidad y variabilidad de los sistemas vivos.
El procesamiento de señales asistido por computador (CSAP) es un campo multidisciplinario que implica la aplicación de métodos informáticos y técnicas de procesamiento de señales para analizar, manipular e interpretar datos médicos en forma digital. Estos datos pueden incluir señales fisiológicas como electrocardiogramas (ECG), electroencefalogramas (EEG), imágenes médicas y otra variedad de datos clínicos.
El objetivo del CSAP es mejorar la precisión, eficiencia y rapidez en el análisis de estas señales, lo que puede ayudar a los profesionales médicos en el diagnóstico, tratamiento y seguimiento de diversas condiciones clínicas. Algunos ejemplos de aplicaciones del CSAP incluyen la detección automática de patrones anormales en ECG y EEG, el segmentación y clasificación de lesiones en imágenes médicas, y el pronóstico de enfermedades basado en datos clínicos.
El CSAP se basa en una variedad de técnicas matemáticas y estadísticas, como la transformada de Fourier, la descomposición en valores singulares y los algoritmos de aprendizaje automático. Además, el desarrollo de herramientas y software especializado es una parte importante del CSAP, ya que permite a los profesionales médicos acceder y analizar fácilmente los datos clínicos en forma digital.
La validación de programas de computación en el contexto médico se refiere al proceso de demostrar que un programa o sistema informático utilizado en la atención médica produce resultados precisos y confiables según lo especificado. Esto implica comparar los resultados del programa con los resultados esperados o conocidos, generalmente mediante el uso de datos de prueba y métodos estadísticos. La validación es una parte importante del proceso de desarrollo y implementación de sistemas informáticos en la medicina para garantizar su fiabilidad y seguridad en el manejo de la información clínica.
La definición médica de 'Imagen Tridimensional' se refiere a una representación gráfica o visual de estructuras anatómicas obtenida mediante técnicas de adquisición y procesamiento de imágenes que permiten obtener una vista en tres dimensiones (3D) de un objeto, órgano o región del cuerpo humano. Estas técnicas incluyen la tomografía computarizada (TC), la resonancia magnética (RM), la ecografía tridimensional y la imagen por resonancia magnética de difusión tensorial (DTI).
La imagen tridimensional se construye a partir de una serie de imágenes bidimensionales adquiridas en diferentes planos o ángulos, que se procesan y combinan mediante algoritmos informáticos específicos para generar una representación volumétrica del objeto de estudio. Esta técnica permite obtener una visión más completa y detallada de la anatomía y la fisiología de los órganos y tejidos, lo que puede ser útil en el diagnóstico y planificación de tratamientos médicos y quirúrgicos.
La imagen tridimensional también se utiliza en investigación biomédica y en la enseñanza de anatomía, ya que permite a los estudiantes y profesionales visualizar y explorar las estructuras corporales con mayor detalle y precisión que las técnicas de imagen bidimensionales.
El análisis de secuencia de ADN se refiere al proceso de determinar la exacta ordenación de las bases nitrogenadas en una molécula de ADN. La secuencia de ADN es el código genético que contiene la información genética hereditaria y guía la síntesis de proteínas y la expresión génica.
El análisis de secuencia de ADN se realiza mediante técnicas de biología molecular, como la reacción en cadena de la polimerasa (PCR) y la secuenciación por Sanger o secuenciación de nueva generación. Estos métodos permiten leer la secuencia de nucleótidos que forman el ADN, normalmente representados como una serie de letras (A, C, G y T), que corresponden a las cuatro bases nitrogenadas del ADN: adenina, citosina, guanina y timina.
El análisis de secuencia de ADN se utiliza en diversas áreas de la investigación biomédica y clínica, como el diagnóstico genético, la identificación de mutaciones asociadas a enfermedades hereditarias o adquiridas, el estudio filogenético y evolutivo, la investigación forense y la biotecnología.
El término "aumento de la imagen" no es un término médico estándar. Sin embargo, en el contexto médico, el término "imágenes diagnósticas" se refiere a los diferentes métodos utilizados para obtener imágenes del cuerpo humano con fines de diagnóstico y tratamiento. Algunos ejemplos de aumento de la imagen pueden incluir:
* Imagen por resonancia magnética (IRM): Esta técnica utiliza un campo magnético y ondas de radio para crear imágenes detalladas de los órganos y tejidos del cuerpo.
* Tomografía computarizada (TC): Una TC utiliza rayos X para obtener imágenes transversales del cuerpo, lo que permite a los médicos ver estructuras internas en detalle.
* Ultrasonido: Esta técnica utiliza ondas sonoras de alta frecuencia para crear imágenes de los órganos y tejidos del cuerpo.
* Mamografía: Es una radiografía de la mama que se utiliza para detectar el cáncer de mama en las etapas iniciales.
* Tomografía por emisión de positrones (PET): Esta técnica utiliza pequeñas cantidades de material radiactivo para producir imágenes detalladas del metabolismo y la actividad celular dentro del cuerpo.
En resumen, el "aumento de la imagen" se refiere a los diferentes métodos utilizados en medicina para obtener imágenes detalladas del cuerpo humano con fines diagnósticos y terapéuticos.
En teoría de la probabilidad, una cadena de Márkov es un modelo matemático de un proceso estocástico (aleatorio) con la propiedad de que la probabilidad de cualquier estado futuro depende solo del estado actual y no de los eventos pasados. Esta propiedad se conoce como "propiedad de Markov".
Las cadenas de Márkov se nombran en honor al matemático ruso Andrey Márkov, quien las introdujo a principios del siglo XX. Se han utilizado en una variedad de campos, incluidos la física, la química, la biología, la economía y la ingeniería, así como en la medicina y la salud pública.
En el contexto médico, las cadenas de Márkov se han utilizado para modelar la progresión de enfermedades crónicas, como la enfermedad renal y la diabetes, y predecir los resultados del tratamiento. También se han utilizado para estudiar la propagación de enfermedades infecciosas, como la tuberculosis y el VIH/SIDA.
En un modelo de cadena de Márkov, el sistema se representa como un conjunto finito de estados, y las transiciones entre los estados se representan mediante probabilidades de transición. La matriz de probabilidades de transición describe la probabilidad de pasar de un estado a otro en un solo paso. Las cadenas de Márkov se pueden utilizar para calcular la probabilidad de estar en cualquier estado en cualquier momento dado, dada la distribución inicial de probabilidades y la matriz de probabilidades de transición.
Las cadenas de Márkov tienen varias propiedades útiles que las hacen atractivas para su uso en modelado médico. Por ejemplo, son relativamente simples de calcular y analizar, y pueden representar procesos estocásticos complejos con una cantidad relativamente pequeña de parámetros. Además, las cadenas de Márkov se pueden utilizar para predecir el comportamiento del sistema a largo plazo, lo que puede ser útil en la planificación y evaluación de intervenciones de salud pública.
En la terminología médica, las proteínas se definen como complejas moléculas biológicas formadas por cadenas de aminoácidos. Estas moléculas desempeñan un papel crucial en casi todos los procesos celulares.
Las proteínas son esenciales para la estructura y función de los tejidos y órganos del cuerpo. Ayudan a construir y reparar tejidos, actúan como catalizadores en reacciones químicas, participan en el transporte de sustancias a través de las membranas celulares, regulan los procesos hormonales y ayudan al sistema inmunológico a combatir infecciones y enfermedades.
La secuencia específica de aminoácidos en una proteína determina su estructura tridimensional y, por lo tanto, su función particular. La genética dicta la secuencia de aminoácidos en las proteínas, ya que el ADN contiene los planos para construir cada proteína.
Es importante destacar que un aporte adecuado de proteínas en la dieta es fundamental para mantener una buena salud, ya que intervienen en numerosas funciones corporales vitales.
Las Bases de Datos de Proteínas (PDB, por sus siglas en inglés) son colecciones de información sobre las estructuras tridimensionales de proteínas y ácidos nucleicos (como el ADN y el ARN), así como de complejos formados por ellas. La PDB es administrada por la Worldwide Protein Data Bank, una organización que cuenta con el apoyo de varios centros de investigación alrededor del mundo.
La información contenida en las Bases de Datos de Proteínas incluye los datos experimentales obtenidos mediante técnicas como la cristalografía de rayos X o la resonancia magnética nuclear, así como modelos computacionales y anotaciones sobre su función biológica, interacciones moleculares y relaciones evolutivas.
Esta información es de gran importancia para la comunidad científica, ya que permite el avance en el estudio de las funciones moleculares de las proteínas y otros biomoléculas, lo que a su vez tiene implicaciones en diversas áreas de la investigación biomédica y biotecnológica.
El teorema de Bayes es un teorema de probabilidad que describe la probabilidad condicional de un evento en términos de sus probabilidades previas y las probabilidades condicionales inversas. Es nombrado en honor al Reverendo Thomas Bayes.
En términos médicos, el teorema de Bayes se puede aplicar en el diagnóstico médico para actualizar la probabilidad de una enfermedad dada una prueba diagnóstica específica. La fórmula del teorema de Bayes es:
P(A|B) = [P(B|A) * P(A)] / P(B)
Donde:
- P(A|B) es la probabilidad de que el evento A ocurra dado que el evento B ha ocurrido.
- P(B|A) es la probabilidad de que el evento B ocurra dado que el evento A ha ocurrido.
- P(A) es la probabilidad previa o marginal de que el evento A ocurra.
- P(B) es la probabilidad previa o marginal de que el evento B ocurra.
En un contexto médico, A podría representar una enfermedad específica y B podría representar un resultado positivo en una prueba diagnóstica. La fórmula permitiría calcular la probabilidad de que un paciente tenga realmente la enfermedad dada una prueba positiva, teniendo en cuenta la prevalencia de la enfermedad y la sensibilidad y especificidad de la prueba diagnóstica.
La perfilación de la expresión génica es un proceso de análisis molecular que mide la actividad o el nivel de expresión de genes específicos en un genoma. Este método se utiliza a menudo para investigar los patrones de expresión génica asociados con diversos estados fisiológicos o patológicos, como el crecimiento celular, la diferenciación, la apoptosis y la respuesta inmunitaria.
La perfilación de la expresión génica se realiza típicamente mediante la amplificación y detección de ARN mensajero (ARNm) utilizando técnicas como la hibridación de microarranjos o la secuenciación de alto rendimiento. Estos métodos permiten el análisis simultáneo de la expresión de miles de genes en muestras biológicas, lo que proporciona una visión integral del perfil de expresión génica de un tejido o célula en particular.
Los datos obtenidos de la perfilación de la expresión génica se pueden utilizar para identificar genes diferencialmente expresados entre diferentes grupos de muestras, como células sanas y enfermas, y para inferir procesos biológicos y redes de regulación genética que subyacen a los fenotipos observados. Esta información puede ser útil en la investigación básica y clínica, incluidos el diagnóstico y el tratamiento de enfermedades.
El Método de Montecarlo es un tipo de simulación computacional que utiliza generadores de números aleatorios para resolver problemas matemáticos y físicos. Se basa en la teoría de probabilidad y estadística. Aunque no es exclusivamente un método médico, se ha aplicado en diversas áreas de la medicina, como la dosimetría radiológica, el análisis de imágenes médicas y los estudios clínicos.
En la dosimetría radiológica, por ejemplo, el Método de Montecarlo se utiliza para simular la interacción de las partículas radiactivas con los tejidos humanos y determinar la distribución de dosis absorbida en un paciente durante un tratamiento de radioterapia. Esto permite a los médicos optimizar los planes de tratamiento y minimizar los efectos secundarios para el paciente.
En resumen, el Método de Montecarlo es una herramienta computacional que utiliza técnicas probabilísticas y estadísticas para modelar y analizar sistemas complejos en diversas áreas de la medicina, incluyendo la dosimetría radiológica, el análisis de imágenes médicas y los estudios clínicos.
No existe una definición médica específica para "Gráficos por Computador" ya que este término se relaciona más con la informática y la ingeniería que con la medicina. Sin embargo, en el contexto médico, los gráficos por computadora se utilizan a menudo en áreas como la visualización médica, la planificación quirúrgica, la investigación biomédica y la educación médica para representar datos médicos de una manera visual y comprensible.
Los gráficos por computadora pueden incluir imágenes 2D o 3D generadas por computadora, animaciones, simulaciones y otros medios visuales que ayudan a los profesionales médicos a entender mejor los datos y tomar decisiones clínicas informadas. Por ejemplo, en la planificación quirúrgica, los gráficos por computadora pueden utilizarse para crear modelos 3D de órganos o tejidos que necesitan ser operados, lo que permite a los cirujanos practicar y planificar la cirugía antes de realizar el procedimiento en el paciente.
La automatización en el contexto médico se refiere al uso de tecnología y sistemas computarizados para realizar procesos y tareas previamente realizadas por personal médico o pacientes, con el objetivo de mejorar la eficiencia, precisión, seguridad y accesibilidad.
Esto puede incluir una variedad de aplicaciones, como:
1. Sistemas de historiales médicos electrónicos (HME) para automatizar el registro y seguimiento de la información del paciente.
2. Sistemas de monitoreo remoto y dispositivos wearables que recopilan y analizan datos fisiológicos de forma automática, permitiendo un mejor seguimiento y manejo de enfermedades crónicas.
3. Sistemas de dosis y administración de medicamentos automatizados para garantizar la precisión y seguridad en la entrega de fármacos a los pacientes.
4. Robótica quirúrgica que permite procedimientos más precisos y menos invasivos, reduciendo el riesgo de complicaciones y acelerando la recuperación del paciente.
5. Inteligencia artificial y aprendizaje automático para analizar grandes cantidades de datos médicos y ayudar en el diagnóstico y tratamiento de enfermedades, así como en la investigación y desarrollo de nuevos fármacos y terapias.
La automatización en el campo de la medicina tiene el potencial de mejorar significativamente la calidad de atención, reducir errores humanos, optimizar recursos y mejorar la experiencia del paciente. Sin embargo, también plantea desafíos importantes en términos de privacidad, seguridad y ética que deben abordarse cuidadosamente.
No existe una definición médica específica para "Bases de Datos Factuales" ya que este término se refiere más a una aplicación en informática y no a un concepto médico. Sin embargo, las Bases de Datos Factuales son colecciones estructuradas de datos que contienen hechos objetivos y comprobables sobre diversos temas, incluyendo aquellos relacionados con la medicina y la salud.
En el contexto médico, las Bases de Datos Factuales pueden ser utilizadas para almacenar y organizar información sobre diferentes aspectos de la atención médica, como por ejemplo:
* Datos demográficos de los pacientes
* Resultados de pruebas diagnósticas y laboratoriales
* Historial clínico y de enfermedades previas
* Guías de práctica clínica y recomendaciones terapéuticas
* Información sobre medicamentos, dispositivos médicos y procedimientos quirúrgicos
Estas bases de datos pueden ser utilizadas por profesionales de la salud para tomar decisiones clínicas informadas, realizar investigaciones y analizar tendencias en la atención médica. Además, también pueden ser útiles para la formación continuada de los profesionales sanitarios y para mejorar la seguridad del paciente.
El análisis de secuencia por matrices de oligonucleótidos (OSA, por sus siglas en inglés) es una técnica utilizada en bioinformática y genómica para identificar y analizar patrones específicos de secuencias de ADN o ARN. Esta técnica implica el uso de matrices de oligonucleótidos, que son matrices bidimensionales que representan la frecuencia relativa de diferentes nucleótidos en una posición particular dentro de una secuencia dada.
La matriz de oligonucleótidos se construye mediante el alineamiento múltiple de secuencias relacionadas y el cálculo de la frecuencia de cada nucleótido en cada posición. La matriz resultante se utiliza luego para buscar patrones específicos de secuencias en otras secuencias desconocidas.
El análisis de secuencia por matrices de oligonucleótidos se puede utilizar para una variedad de propósitos, como la identificación de sitios de unión de factores de transcripción, la detección de secuencias repetitivas y la búsqueda de motivos en secuencias genómicas. También se puede utilizar para el análisis filogenético y la comparación de secuencias entre diferentes especies.
Sin embargo, es importante tener en cuenta que esta técnica tiene algunas limitaciones, como la posibilidad de identificar falsos positivos o negativos, dependiendo de los parámetros utilizados en el análisis. Además, la matriz de oligonucleótidos puede no ser adecuada para secuencias largas o complejas, y por lo tanto, otras técnicas como el alineamiento de secuencias múltiples pueden ser más apropiadas en tales casos.
El término "Análisis Numérico Asistido por Computador" se refiere al uso de computadoras para realizar cálculos y análisis en el campo del análisis numérico. El análisis numérico es una rama de las matemáticas aplicadas que se ocupa del desarrollo y estudio de métodos para resolver problemas matemáticos aproximadamente, mediante algoritmos computacionales.
En el análisis numérico asistido por computador, se utilizan programas informáticos específicos para llevar a cabo cálculos complejos y realizar simulaciones de problemas matemáticos que serían difíciles o imposibles de resolver a mano. Estos programas pueden variar en su complejidad, desde sencillas herramientas en línea hasta sofisticados paquetes de software especializados.
Algunos ejemplos de problemas que se abordan en el análisis numérico asistido por computador incluyen la solución de ecuaciones diferenciales, el cálculo de integrales y la optimización de funciones. La precisión y la eficiencia de los algoritmos utilizados en estos cálculos son de vital importancia, ya que pueden afectar significativamente la fiabilidad y la validez de los resultados obtenidos.
En resumen, el análisis numérico asistido por computador es una herramienta poderosa y eficaz para resolver problemas matemáticos complejos y realizar simulaciones precisas y confiables en diversos campos, como la ingeniería, la física, la química y las finanzas.
Los Modelos Teóricos en el contexto médico y de la salud, se refieren a representaciones conceptuales que intentan explicar cómo funcionan los sistemas, procesos o fenómenos relacionados con la salud y la enfermedad. Estos modelos teóricos pueden provenir de diversas disciplinas, como la biología, la psicología, la sociología o la antropología, y son utilizados para entender y explicar los aspectos complejos de la salud y la enfermedad.
Por ejemplo, el modelo teórico de la determinación social de la salud, propuesto por la Comisión sobre Determinantes Sociales de la Salud de la Organización Mundial de la Salud (OMS), sugiere que los factores sociales, económicos y políticos desempeñan un papel importante en la determinación de la salud y las desigualdades en la salud. Este modelo teórico se utiliza para guiar la investigación y la formulación de políticas en el campo de la promoción de la salud y la reducción de las desigualdades en la salud.
De manera similar, el modelo teórico de la fisiopatología de una enfermedad específica puede ayudar a los médicos y científicos a entender cómo se desarrolla y progresa esa enfermedad, lo que puede conducir al descubrimiento de nuevas opciones de tratamiento.
En resumen, los modelos teóricos son herramientas importantes para la comprensión y el estudio de los fenómenos relacionados con la salud y la enfermedad, ya que ofrecen una representación conceptual simplificada de sistemas o procesos complejos.
La Interfaz Usuario-Computador (IUC) es un término que se utiliza en la medicina y la tecnología sanitaria para describir el sistema o dispositivo que permite la interacción entre un usuario, generalmente un profesional de la salud o un paciente, y una computadora. Esta interfaz puede incluir elementos como pantallas táctiles, teclados, ratones, comandos de voz y otros dispositivos de entrada y salida de datos.
La IUC desempeña un papel fundamental en la medicina, especialmente en el contexto de la historia clínica electrónica, la telemedicina y la atención médica móvil. Una interfaz de usuario bien diseñada puede ayudar a mejorar la eficiencia y la precisión de la atención médica, reducir los errores médicos y mejorar la satisfacción del usuario.
La definición médica de IUC se centra en su aplicación en el campo de la salud, donde es especialmente importante garantizar que la interfaz sea intuitiva, fácil de usar y accesible para una amplia gama de usuarios, incluidos aquellos con diferentes niveles de experiencia técnica y habilidades de computación. Además, la IUC en el ámbito médico debe cumplir con los estándares de privacidad y seguridad de los datos para proteger la información confidencial del paciente.
La compresión de datos es un proceso utilizado en el campo de la medicina y la tecnología de la salud para reducir el tamaño de los archivos de datos sin perder información importante. Esto se logra mediante algoritmos matemáticos que identifican y eliminan las redundancias y patrones repetitivos en los datos, lo que permite almacenar o transmitir los datos comprimidos de manera más eficiente y rápida.
En el contexto médico, la compresión de datos se utiliza a menudo para reducir el tamaño de grandes archivos de imágenes médicas, como las tomografías computarizadas (TC) y las resonancias magnéticas (RM), antes de su almacenamiento o transmisión. Esto puede ayudar a mejorar la eficiencia del flujo de trabajo clínico y reducir los costos asociados con el almacenamiento y la transferencia de grandes cantidades de datos.
Es importante destacar que, aunque la compresión de datos puede ser muy útil en el campo médico, también puede presentar riesgos potenciales, como la introducción de errores o artefactos en las imágenes comprimidas, lo que podría afectar negativamente la precisión del diagnóstico y el tratamiento. Por lo tanto, es importante utilizar métodos de compresión de datos aprobados y validados clínicamente para garantizar la integridad y la fiabilidad de los datos médicos comprimidos.
La lógica difusa es un sistema de lógica multivaluada en el que la verdad o falsedad de una proposición puede ser representada por cualquier valor dentro de un rango continuo, como entre 0 y 1, en lugar de solo por los valores tradicionales de "verdadero" (1) o "falso" (0). Esto permite una representación más matizada y flexible de la realidad, especialmente útil en situaciones en las que las variables implicadas son ambiguas, subjetivas o inciertas.
En el contexto médico, la lógica difusa se ha utilizado en diversas aplicaciones, como el diagnóstico clínico y la toma de decisiones terapéuticas. Por ejemplo, un sistema experto basado en lógica difusa podría utilizar reglas if-then (si... entonces) para inferir la probabilidad de una determinada enfermedad en función de los síntomas y signos presentados por el paciente.
La lógica difusa se ha mostrado útil en situaciones en las que es necesario modelar relaciones complejas e inciertas entre variables, como en la evaluación del riesgo cardiovascular o en el diagnóstico de enfermedades mentales. Sin embargo, su uso en aplicaciones clínicas requiere una validación rigurosa y un cuidadoso análisis de los datos utilizados para entrenar los modelos difusos.
En el contexto médico, un artefacto se refiere a algo que es creado artificialmente y que aparece en los resultados de una prueba diagnóstica o estudio médico. Por lo general, se trata de algún tipo de interferencia o ruido que altera la señal original y produce una imagen distorsionada o un resultado inexacto.
Por ejemplo, en una radiografía, un artefacto podría ser un objeto metálico que se encuentra cerca del paciente y que produce una sombra oscura en la imagen. En un electrocardiograma (ECG), un artefacto podría deberse a movimientos musculares involuntarios o a interferencias eléctricas que hacen que la traza sea irregular y difícil de interpretar.
Es importante identificar y tener en cuenta los artefactos para evitar diagnósticos incorrectos o innecesarios tratamientos. En algunos casos, es posible repetir la prueba o utilizar técnicas especiales para minimizar el efecto de los artefactos y obtener imágenes o resultados más precisos.
El término 'Diagnóstico por Computador' se refiere a un proceso en el campo de la medicina donde se utilizan sofisticados sistemas informáticos y algoritmos avanzados para analizar los datos médicos de un paciente, con el fin de ayudar a los profesionales sanitarios a realizar un diagnóstico clínico.
Este proceso puede involucrar la interpretación de diferentes tipos de imágenes médicas, como radiografías, tomografías computarizadas (TC), resonancias magnéticas (RM) o ultrasonidos, así como el análisis de pruebas de laboratorio y otras variables clínicas.
El objetivo del diagnóstico por computador es proporcionar una ayuda a la decisión clínica, ayudando a los médicos a identificar patrones y anomalías que podrían ser difíciles de detectar con el ojo humano. Esto puede conducir a un diagnóstico más rápido, preciso y confiable, lo que puede mejorar la atención al paciente y, en última instancia, conducir a mejores resultados clínicos.
Es importante destacar que el diagnóstico por computador no reemplaza el juicio clínico humano, sino que se utiliza como una herramienta adicional para ayudar a los médicos en el proceso de diagnóstico.
Una Base de Datos Genética es una colección organizada y electrónica de información sobre genes, mutaciones genéticas, marcadores genéticos, secuencias de ADN, fenotipos y enfermedades hereditarias. Estas bases de datos se utilizan en la investigación biomédica y en la práctica clínica para ayudar a entender las causas subyacentes de las enfermedades genéticas, identificar los factores de riesgo, establecer diagnósticos precisos y desarrollar tratamientos personalizados.
Las bases de datos genéticas pueden contener información sobre una sola enfermedad o cubrir un rango más amplio de trastornos genéticos. Algunas bases de datos se centran en la relación entre los genes y las enfermedades, mientras que otras incluyen información sobre la variación genética normal en la población.
Algunos ejemplos de bases de datos genéticas incluyen:
1. OMIM (Online Mendelian Inheritance in Man): una base de datos curada que proporciona información sobre los genes y las enfermedades hereditarias humanas.
2. dbSNP (Single Nucleotide Polymorphism database): una base de datos que contiene información sobre variantes de secuencia de ADN, incluyendo polimorfismos de un solo nucleótido (SNPs).
3. ClinVar: una base de datos que reúne información sobre las variantes genéticas y su relación con enfermedades humanas, incluidos los resultados de pruebas clínicas y la interpretación de variantes.
4. 1000 Genomes Project: una base de datos que proporciona información sobre la diversidad genética humana, incluyendo las frecuencias allelicas y los patrones de variación genética en poblaciones de todo el mundo.
5. HGMD (Human Gene Mutation Database): una base de datos que contiene información sobre mutaciones humanas conocidas asociadas con enfermedades genéticas.
Las bases de datos genéticas son herramientas importantes para la investigación y la práctica clínica, ya que ayudan a los científicos y los médicos a entender mejor las relaciones entre los genes y las enfermedades humanas.
La interpretación estadística de datos se refiere al proceso de analizar, evaluar e interpetar los resultados obtenidos a través del uso de métodos y técnicas estadísticas sobre un conjunto de datos específico. Este proceso implica identificar patrones, tendencias y relaciones importantes en los datos, así como evaluar la incertidumbre y variabilidad asociadas con las medidas y estimaciones estadísticas.
La interpretación estadística de datos puede incluir la comparación de grupos, el análisis de relaciones entre variables, la predicción de resultados futuros y la evaluación de la precisión y fiabilidad de los hallazgos. Los resultados de la interpretación estadística de datos pueden utilizarse para informar decisiones clínicas, políticas públicas y otras áreas donde se necesita una comprensión objetiva e informada de los datos.
Es importante tener en cuenta que la interpretación estadística de datos requiere un conocimiento sólido de los métodos estadísticos utilizados, así como una comprensión clara de las limitaciones y suposiciones asociadas con cada método. Además, es fundamental comunicar los resultados de manera clara y precisa, destacando la incertidumbre y la significancia estadística de los hallazgos.
Los Modelos Biológicos en el contexto médico se refieren a la representación fisiopatológica de un proceso o enfermedad particular utilizando sistemas vivos o componentes biológicos. Estos modelos pueden ser creados utilizando organismos enteros, tejidos, células, órganos o sistemas bioquímicos y moleculares. Se utilizan ampliamente en la investigación médica y biomédica para estudiar los mecanismos subyacentes de una enfermedad, probar nuevos tratamientos, desarrollar fármacos y comprender mejor los procesos fisiológicos normales.
Los modelos biológicos pueden ser categorizados en diferentes tipos:
1. Modelos animales: Se utilizan animales como ratones, ratas, peces zebra, gusanos nematodos y moscas de la fruta para entender diversas patologías y probar terapias. La similitud genética y fisiológica entre humanos y estos organismos facilita el estudio de enfermedades complejas.
2. Modelos celulares: Las líneas celulares aisladas de tejidos humanos o animales se utilizan para examinar los procesos moleculares y celulares específicos relacionados con una enfermedad. Estos modelos ayudan a evaluar la citotoxicidad, la farmacología y la eficacia de los fármacos.
3. Modelos in vitro: Son experimentos que se llevan a cabo fuera del cuerpo vivo, utilizando células o tejidos aislados en condiciones controladas en el laboratorio. Estos modelos permiten un estudio detallado de los procesos bioquímicos y moleculares.
4. Modelos exvivo: Implican el uso de tejidos u órganos extraídos del cuerpo humano o animal para su estudio en condiciones controladas en el laboratorio. Estos modelos preservan la arquitectura y las interacciones celulares presentes in vivo, lo que permite un análisis más preciso de los procesos fisiológicos y patológicos.
5. Modelos de ingeniería de tejidos: Involucran el crecimiento de células en matrices tridimensionales para imitar la estructura y función de un órgano o tejido específico. Estos modelos se utilizan para evaluar la eficacia y seguridad de los tratamientos farmacológicos y terapias celulares.
6. Modelos animales: Se utilizan diversas especies de animales, como ratones, peces zebra, gusanos y moscas de la fruta, para comprender mejor las enfermedades humanas y probar nuevos tratamientos. La elección de la especie depende del tipo de enfermedad y los objetivos de investigación.
Los modelos animales y celulares siguen siendo herramientas esenciales en la investigación biomédica, aunque cada vez se utilizan más modelos alternativos y complementarios, como los basados en células tridimensionales o los sistemas de cultivo orgánico. Estos nuevos enfoques pueden ayudar a reducir el uso de animales en la investigación y mejorar la predictividad de los resultados obtenidos in vitro para su posterior validación clínica.
La Distribución Normal, también conocida como la Curva de Campana o Distribución Gaussiana, es un tipo de distribución de probabilidad continua que se utiliza ampliamente en estadística. Esta distribución se caracteriza por su forma simétrica y bell-shaped, que se asemeja a una campana.
En términos médicos, la Distribución Normal puede ser útil en el análisis de datos médicos y científicos, especialmente cuando se trata de medir rasgos continuos como la presión arterial, el peso corporal o los niveles de colesterol. La Distribución Normal puede ayudar a los investigadores a describir la variabilidad natural de estas variables y a identificar valores atípicos o outliers que puedan indicar condiciones médicas anormales.
La Distribución Normal se define por dos parámetros: la media (μ) y la desviación estándar (σ). La media representa el valor central de la distribución, mientras que la desviación estándar mide la dispersión o variabilidad de los datos alrededor de la media. En una Distribución Normal, aproximadamente el 68% de los valores se encuentran dentro de una desviación estándar de la media, el 95% están dentro de dos desviaciones estándar y el 99,7% están dentro de tres desviaciones estándar.
La Distribución Normal es importante en la investigación médica porque muchas variables biológicas siguen una distribución normal o aproximadamente normal. Esto significa que los datos recopilados sobre estas variables pueden analizarse utilizando técnicas estadísticas basadas en la Distribución Normal, como las pruebas de t-test y análisis de varianza (ANOVA). Además, la Distribución Normal también se utiliza en la construcción de modelos predictivos y en el cálculo de intervalos de confianza y pruebas de hipótesis.
El término "almacenamiento y recuperación de información" se refiere a la capacidad del cerebro o de un sistema de tecnología de almacenar datos y luego acceder a ellos cuando sea necesario. En el contexto médico, especialmente en neurología y psiquiatría, este término se utiliza a menudo para describir la forma en que el cerebro humano procesa, almacena y recuerda información.
El cerebro humano es capaz de almacenar una gran cantidad de información gracias a la interconexión compleja de neuronas y su capacidad para cambiar y adaptarse en respuesta a estímulos, lo que se conoce como neuroplasticidad. La memoria a corto plazo y la memoria a largo plazo son los dos tipos principales de almacenamiento de información en el cerebro.
La memoria a corto plazo, también conocida como memoria de trabajo, permite al cerebro retener pequeñas cantidades de información durante un breve período de tiempo. Por otro lado, la memoria a largo plazo es donde se almacena la información importante y duradera, como hechos, habilidades y experiencias personales.
La recuperación de información implica el proceso de acceder y recordar la información almacenada en la memoria. La eficacia de la recuperación de información depende de varios factores, incluyendo la fuerza de la memoria, la relevancia de la información para el individuo y la capacidad del individuo para concentrarse y prestar atención al momento de codificar y recuperar la memoria.
Los trastornos neurológicos y psiquiátricos pueden afectar la capacidad del cerebro para almacenar y recuperar información, lo que puede dar lugar a problemas de memoria y dificultades de aprendizaje. Por ejemplo, enfermedades como el Alzheimer y la demencia pueden causar pérdida de memoria y dificultad para recordar eventos recientes o lejanos.
En resumen, el proceso de almacenamiento y recuperación de información es fundamental para el aprendizaje y la memoria. Los trastornos neurológicos y psiquiátricos pueden afectar negativamente esta capacidad, lo que puede dar lugar a problemas de memoria y dificultades de aprendizaje.
En estadística y teoría de la probabilidad, las funciones de verosimilitud se utilizan en el análisis de los datos para estimar los parámetros desconocidos de un modelo probabilístico. La función de verosimilitud es una función que describe la plausibilidad de obtener los datos observados, dados diferentes valores posibles de los parámetros del modelo.
En términos formales, sea X un conjunto de datos observados y θ un vector de parámetros desconocidos del modelo probabilístico que genera los datos. La función de verosimilitud L(θ;X) se define como la probabilidad de obtener los datos X dado el valor específico del parámetro θ:
L(θ;X) = P(X|θ)
La función de verosimilitud mide la probabilidad de observar los datos en función de los valores posibles de los parámetros. Los valores del parámetro que maximizan la función de verosimilitud se consideran los más plausibles dados los datos observados. Por lo tanto, el proceso de estimación de parámetros consiste en encontrar el valor óptimo de θ que maximiza la función de verosimilitud L(θ;X).
En resumen, las funciones de verosimilitud son herramientas estadísticas utilizadas para estimar los parámetros desconocidos de un modelo probabilístico, y se definen como la probabilidad de obtener los datos observados dado un valor específico del parámetro.
La interpretación de imagen radiográfica asistida por computador es un proceso en el que se utilizan sistemas informáticos y software especializados para analizar y ayudar a interpretar imágenes médicas obtenidas a través de radiografías. Este proceso puede involucrar diversas técnicas, como la detección automática de anomalías, el marcado de estructuras anatómicas, la medición de dimensiones y la caracterización de lesiones o tejidos.
El objetivo principal de la interpretación de imagen radiográfica asistida por computador es mejorar la precisión y eficiencia en el diagnóstico médico al proporcionar herramientas que ayuden a los radiólogos a identificar y evaluar cambios patológicos en las imágenes. Esto puede incluir la detección de masas, fracturas, tumores, infecciones o cualquier otra alteración anatómica o funcional.
Es importante mencionar que aunque estos sistemas pueden ser muy útiles para apoyar el proceso diagnóstico, no reemplazan la experiencia y el juicio clínico del radiólogo. La toma de decisiones finales sobre el diagnóstico y el tratamiento siempre debe realizarse bajo la responsabilidad y supervisión de profesionales médicos calificados.
La genómica es el estudio integral y sistemático de la estructura, función, interacción y variación de los genes en un genoma completo. Incluye el mapeo, secuenciado y análisis de los genomas, así como también la interpretación y aplicación de los datos resultantes. La genómica se ha vuelto fundamental en diversas áreas de la medicina, incluyendo la investigación de enfermedades genéticas, el desarrollo de terapias personalizadas y la predicción de respuesta a tratamientos farmacológicos. Además, tiene implicaciones importantes en la comprensión de la evolución biológica y la diversidad entre especies.
La medicina define 'Internet' como un sistema global interconectado de computadoras y redes informáticas que utilizan el protocolo de Internet para comunicarse entre sí. Ofrece a los usuarios acceso a una gran cantidad de recursos y servicios, como correo electrónico, grupos de noticias, World Wide Web, transferencia de archivos (FTP), chat en línea y videoconferencia. La World Wide Web es la parte más visible e interactiva de Internet, donde se pueden encontrar una gran cantidad de páginas web con información sobre diversos temas, incluidos recursos médicos y de salud. El acceso a Internet ha revolucionado el campo de la medicina, permitiendo la comunicación rápida y eficiente entre profesionales de la salud, el intercambio de información científica y la disponibilidad de recursos educativos en línea. Además, ha facilitado el acceso a la atención médica remota y a los servicios de telemedicina, especialmente útiles en áreas remotas o durante situaciones de emergencia.
Los Árboles de Decisión son un tipo de modelo de aprendizaje automático utilizado en el análisis de decisiones y la inteligencia artificial. Se basan en la representación de datos en forma de un diagrama de flujo en forma de árbol, donde cada interior representa una característica o variable del conjunto de datos, y cada rama representa una posible decisión o resultado.
En medicina, los Árboles de Decisión se utilizan a menudo para ayudar a tomar decisiones clínicas complejas, como el diagnóstico diferencial de enfermedades o la selección del tratamiento más apropiado para un paciente específico. Se construyen mediante el análisis de datos clínicos y la evaluación de las probabilidades asociadas con cada decisión y resultado posible.
El proceso de crear un Árbol de Decisión comienza con la identificación de la pregunta clínica que se desea abordar, seguido del análisis de los datos disponibles y la selección de las variables más relevantes para incluir en el árbol. Luego, se utiliza un algoritmo de aprendizaje automático para construir el árbol, optimizando las decisiones en función del resultado deseado, como la precisión diagnóstica o la selección del tratamiento más efectivo.
Una vez construido, el Árbol de Decisión puede utilizarse para guiar el proceso de toma de decisiones clínicas, ayudando a los médicos a evaluar las diferentes opciones y sus posibles consecuencias en función de las características del paciente. Sin embargo, es importante tener en cuenta que los Árboles de Decisión son solo una herramienta de apoyo y no reemplazan el juicio clínico y la experiencia del médico tratante.
La intensificación de imagen radiográfica es un proceso en el campo de la medicina y la radiología que se utiliza para mejorar la calidad de las imágenes radiográficas, haciéndolas más nítidas, claras y precisas. Esto se logra mediante la adición de diferentes técnicas o dispositivos que aumentan la cantidad de luz que llega a la placa fotográfica o al detector digital, lo que permite capturar detalles más finos y sutiles de las estructuras internas del cuerpo.
Existen varias formas de intensificar una imagen radiográfica, incluyendo:
1. Uso de intensificadores de imagen: Son dispositivos que reciben los rayos X y los convierten en luz visible, la cual es amplificada y dirigida hacia una placa fotográfica o un detector digital. Esto permite obtener imágenes más brillantes y con mayor contraste.
2. Utilización de pantallas de imagen: Se trata de capas delgadas de material fluorescente que se colocan detrás de la placa radiográfica o del detector digital. Cuando los rayos X atraviesan el cuerpo y chocan contra estas pantallas, éstas emiten luz, aumentando la cantidad de luz que llega al sensor y mejorando la calidad de la imagen.
3. Aumento de la exposición a los rayos X: Otra forma de intensificar la imagen radiográfica es incrementando la dosis de rayos X administrada al paciente. Sin embargo, este método debe ser utilizado con cautela, ya que aumenta la exposición del paciente a la radiación y puede tener efectos negativos en su salud.
4. Mejora de los procesos de desarrollo: El proceso de desarrollo de la placa radiográfica o del detector digital también puede ser optimizado para obtener imágenes más nítidas y precisas. Esto incluye el ajuste de los tiempos de exposición, la temperatura del baño químico y la concentración de los productos químicos utilizados en el proceso de desarrollo.
En conclusión, existen diversas técnicas y métodos que pueden ser empleados para intensificar las imágenes radiográficas, mejorando su calidad y permitiendo un diagnóstico más preciso y efectivo. No obstante, es fundamental considerar los riesgos asociados a cada uno de estos procedimientos y tomar las medidas necesarias para minimizar la exposición del paciente a la radiación y garantizar su seguridad en todo momento.
La "Técnica de Sustracción" no es un término médico ampliamente reconocido o utilizado en la práctica clínica. Sin embargo, en el contexto quirúrgico, a veces se utiliza una técnica llamada "técnica de sustracción" para reducir el tamaño de las hernias, especialmente las hernias inguinales y femorales.
Esta técnica implica la reducción o "sustracción" del contenido herniario (normalmente grasa o intestino) de regreso a su ubicación correcta dentro de la cavidad abdominal, seguida del reforzamiento de la pared muscular débil para prevenir una recurrencia de la hernia. Esto a menudo se realiza mediante el uso de mallas protésicas para proporcionar un soporte adicional.
Sin embargo, es importante destacar que este término no está ampliamente estandarizado o utilizado en la literatura médica y su uso puede variar según el contexto y la preferencia del cirujano.
En realidad, los "Lenguajes de Programación" no se consideran un término médico. Se trata más bien de un concepto relacionado con la informática y la programación. Sin embargo, a continuación te proporciono una definición general de lo que son los lenguajes de programación:
Los lenguajes de programación son conjuntos de reglas sintácticas y semánticas que permiten a los desarrolladores de software escribir instrucciones para ser ejecutadas por máquinas, como computadoras. Estos lenguajes utilizan una estructura y sintaxis específicas para definir cómo las operaciones deben ser realizadas por la computadora. Existen diferentes tipos de lenguajes de programación, cada uno con sus propias características y aplicaciones, como por ejemplo:
1. Lenguajes de bajo nivel: se acercan más a la arquitectura de la computadora y suelen ser difíciles de aprender y usar, pero ofrecen un control total sobre el hardware. Ejemplos incluyen lenguaje ensamblador y machine code.
2. Lenguajes de alto nivel: son más cercanos al lenguaje humano y más fáciles de leer y escribir, pero requieren una capa adicional de software (un compilador o interpretador) para convertirlos en instrucciones que la computadora pueda ejecutar. Algunos ejemplos son Python, Java, C++ y JavaScript.
3. Lenguajes de scripting: se utilizan típicamente para automatizar tareas y trabajar con datos, especialmente en aplicaciones web. Ejemplos incluyen PHP, Perl y Ruby.
4. Lenguajes declarativos: describen los resultados deseados sin especificar explícitamente el proceso para alcanzarlos. SQL es un ejemplo común de este tipo de lenguaje.
5. Lenguajes funcionales: se basan en conceptos matemáticos y enfatizan la composición de funciones sin efectos secundarios. Haskell y ML son ejemplos de lenguajes funcionales puros, mientras que Scala y F# combinan aspectos funcionales con otros paradigmas.
En resumen, los lenguajes de programación son herramientas que permiten a los desarrolladores crear software para una variedad de propósitos e industrias. Cada lenguaje tiene sus propias fortalezas y debilidades, y elegir el correcto depende del problema que se esté tratando de resolver, las preferencias personales y la experiencia previa del desarrollador.
El análisis de ondículas es un método de descomposición y análisis de señales que se utiliza en el campo de la medicina, especialmente en áreas como la radiología y la cardiología. Esta técnica permite representar una señal compleja como una suma ponderada de ondículas, que son funciones matemáticas con propiedades similares a las ondas.
En el contexto médico, el análisis de ondículas se ha utilizado en diversas aplicaciones clínicas, como la detección y caracterización de arritmias cardíacas, el análisis de imágenes médicas y la evaluación de señales respiratorias.
En el análisis de ECG (electrocardiograma), por ejemplo, el análisis de ondículas puede ayudar a identificar y cuantificar diferentes componentes del complejo QRS y las ondas P y T, lo que puede ser útil en el diagnóstico y seguimiento de diversas patologías cardíacas.
En el análisis de imágenes médicas, como la resonancia magnética o la tomografía computarizada, el análisis de ondículas puede ayudar a identificar patrones y características relevantes en las imágenes, lo que puede ser útil en el diagnóstico y seguimiento de diversas patologías.
En resumen, el análisis de ondículas es una técnica matemática y computacional que se utiliza en medicina para descomponer y analizar señales complejas, con aplicaciones en diversas áreas clínicas, como la cardiología y la radiología.
No existe una definición médica específica para "Metodologías Computacionales" ya que este término se relaciona más con el campo de la informática y la ciencia de la computación que con la medicina. Sin embargo, podemos dar una definición general de las Metodologías Computacionales y su aplicación en el campo médico.
Las Metodologías Computacionales se refieren al uso estructurado y sistemático de técnicas y métodos computacionales para resolver problemas y analizar datos en diversos campos, como la ciencia, la ingeniería y la medicina. Esto incluye el desarrollo y aplicación de algoritmos, modelos matemáticos, simulaciones por computadora, y otras herramientas y técnicas informáticas para apoyar el análisis, la toma de decisiones y la investigación.
En el campo médico, las Metodologías Computacionales se utilizan cada vez más en áreas como la investigación biomédica, el análisis de imágenes médicas, la medicina personalizada, la simulación quirúrgica y la asistencia sanitaria electrónica. Algunos ejemplos concretos incluyen:
1. Análisis de genomas y datos "omics": Las Metodologías Computacionales se utilizan para analizar grandes conjuntos de datos generados por secuenciadores de ADN y otras tecnologías "omics" (como la proteómica, metabolómica y transcriptómica) con el fin de identificar patrones y relaciones que puedan ayudar a comprender las enfermedades y desarrollar nuevas estrategias terapéuticas.
2. Modelado y simulación de sistemas biológicos: Los científicos utilizan modelos computacionales para representar y simular sistemas biológicos complejos, como las vías metabólicas, los circuitos genéticos y las redes de interacción proteína-proteína. Esto permite a los investigadores explorar cómo funcionan estos sistemas y cómo pueden ser manipulados para tratar enfermedades.
3. Procesamiento y análisis de imágenes médicas: Las Metodologías Computacionales se emplean para mejorar la calidad de las imágenes médicas, segmentarlas y extraer características relevantes que puedan ayudar en el diagnóstico y seguimiento de enfermedades.
4. Diseño y optimización de fármacos: Los algoritmos computacionales se utilizan para predecir cómo interactúan las moléculas con los objetivos terapéuticos y evaluar su eficacia y seguridad potencial. Esto puede ayudar a acelerar el proceso de descubrimiento de fármacos y reducir costes.
5. Asistencia sanitaria electrónica: Las Metodologías Computacionales se emplean en la creación de sistemas de información sanitaria que permiten a los profesionales médicos acceder rápidamente a los datos de los pacientes, compartir información y tomar decisiones clínicas más informadas.
En resumen, las Metodologías Computacionales desempeñan un papel fundamental en la investigación biomédica y clínica, ya que permiten analizar grandes cantidades de datos, realizar simulaciones complejas y desarrollar nuevas herramientas y técnicas para mejorar el diagnóstico, tratamiento y seguimiento de enfermedades.
La relación señal-ruido (RSN) es un término utilizado en el campo de la medicina y la fisiología para describir la relación entre la amplitud de una señal biológica específica y la interferencia o ruido de fondo. La señal representa generalmente la información relevante que se desea medir, como ondas cerebrales en un electroencefalograma (EEG) o pulsos doppler en un ultrasonido. Por otro lado, el ruido se refiere a cualquier interferencia no deseada que pueda afectar la precisión y claridad de la señal.
La RSN se expresa como una relación matemática entre la amplitud de la señal y la amplitud del ruido. Una RSN más alta indica que la señal es más fuerte en comparación con el ruido, lo que resulta en una mejor calidad de la señal y una medición más precisa. Por el contrario, una RSN más baja sugiere que el ruido está interfiriendo significativamente con la señal, lo que puede dificultar la interpretación y la precisión de la medición.
En resumen, la relación señal-ruido es un parámetro importante en muchas aplicaciones médicas y de investigación biomédica, ya que proporciona una medida cuantitativa de la calidad de una señal biológica en presencia de interferencias no deseadas.
La minería de datos, en el contexto médico y de salud pública, se refiere al proceso de descubrir patrones y conocimientos ocultos y potencialmente útiles en grandes conjuntos de datos médicos estructurados y no estructurados. Esto implica el uso de técnicas avanzadas de análisis de datos, aprendizaje automático e inteligencia artificial para analizar registros electrónicos de historias clínicas, imágenes médicas, genómica, datos de sensores portables y otros tipos de datos relacionados con la salud. El objetivo es mejorar la atención médica, la investigación biomédica, la toma de decisiones clínicas y la prevención de enfermedades mediante el aprovechamiento de los hallazgos obtenidos a través del análisis de datos.
Ejemplos de aplicaciones de minería de datos en el campo médico incluyen:
1. Predicción de resultados clínicos y riesgo de enfermedades.
2. Descubrimiento de biomarcadores para diagnóstico y seguimiento de enfermedades.
3. Personalización del tratamiento médico y recomendaciones de medicamentos.
4. Detección temprana y prevención de brotes epidémicos o pandémicos.
5. Mejora de la eficiencia y calidad de los servicios de salud.
6. Investigación en inteligencia artificial médica y aprendizaje profundo para el análisis de imágenes y datos genómicos.
El mapeo de interacciones de proteínas (PPI, por sus siglas en inglés) es un término utilizado en la biología molecular y la genética para describir el proceso de identificar y analizar las interacciones físicas y funcionales entre diferentes proteínas dentro de una célula u organismo. Estas interacciones son cruciales para la mayoría de los procesos celulares, incluyendo la señalización celular, el control del ciclo celular, la regulación génica y la respuesta al estrés.
El mapeo PPI se realiza mediante una variedad de técnicas experimentales y computacionales. Los métodos experimentales incluyen la co-inmunoprecipitación, el método de dos híbridos de levadura, la captura de interacciones proteína-proteína masivas (MAPPs) y la resonancia paramagnética electrónica (EPR). Estos métodos permiten a los científicos identificar pares de proteínas que se unen entre sí, así como determinar las condiciones bajo las cuales esas interacciones ocurren.
Los métodos computacionales, por otro lado, utilizan algoritmos y herramientas bioinformáticas para predecir posibles interacciones PPI basadas en datos estructurales y secuenciales de proteínas. Estos métodos pueden ayudar a inferir redes de interacción de proteínas a gran escala, lo que puede proporcionar información importante sobre los procesos celulares y las vías moleculares subyacentes.
El mapeo PPI es una área activa de investigación en la actualidad, ya que una mejor comprensión de las interacciones proteicas puede ayudar a desarrollar nuevas estrategias terapéuticas para una variedad de enfermedades, incluyendo el cáncer y las enfermedades neurodegenerativas.
Los Modelos Moleculares son representaciones físicas o gráficas de moléculas y sus estructuras químicas. Estos modelos se utilizan en el campo de la química y la bioquímica para visualizar, comprender y estudiar las interacciones moleculares y la estructura tridimensional de las moléculas. Pueden ser construidos a mano o generados por computadora.
Existen diferentes tipos de modelos moleculares, incluyendo:
1. Modelos espaciales: Representan la forma y el tamaño real de las moléculas, mostrando los átomos como esferas y los enlaces como palos rígidos o flexibles que conectan las esferas.
2. Modelos de barras y bolas: Consisten en una serie de esferas (átomos) unidas por varillas o palos (enlaces químicos), lo que permite representar la geometría molecular y la disposición espacial de los átomos.
3. Modelos callejones y zigzag: Estos modelos representan las formas planas de las moléculas, con los átomos dibujados como puntos y los enlaces como líneas que conectan esos puntos.
4. Modelos de superficies moleculares: Representan la distribución de carga eléctrica alrededor de las moléculas, mostrando áreas de alta densidad electrónica como regiones sombreadas o coloreadas.
5. Modelos computacionales: Son representaciones digitales generadas por computadora que permiten realizar simulaciones y análisis de las interacciones moleculares y la dinámica estructural de las moléculas.
Estos modelos son herramientas esenciales en el estudio de la química, ya que ayudan a los científicos a visualizar y comprender cómo interactúan las moléculas entre sí, lo que facilita el diseño y desarrollo de nuevos materiales, fármacos y tecnologías.
La tecnología inalámbrica en el ámbito médico se refiere al uso de dispositivos, sistemas y soluciones que transmiten y reciben datos o energía a través de ondas electromagnéticas o campos magnéticos, en lugar de utilizar cables o conexiones físicas. Esto incluye una variedad de aplicaciones, como la telemedicina, el monitoreo remoto de pacientes, los dispositivos médicos wearables (de uso diario) y los implantes médicos activos. La tecnología inalámbrica permite una mayor movilidad y flexibilidad en la atención médica, así como la capacidad de recopilar y analizar datos de salud en tiempo real para mejorar los resultados del paciente.
Las Máquinas de Vectores de Soporte (SVM, por sus siglas en inglés, Support Vector Machines) no son específicamente un tema de medicina, sino más bien una técnica utilizada en el campo del aprendizaje automático y la inteligencia artificial. Sin embargo, se han aplicado en algunos contextos médicos para el análisis y clasificación de datos complejos.
En términos generales, una Máquina de Vectores de Soporte es un modelo de aprendizaje supervisado que utiliza algoritmos de entrenamiento para clasificar o predecir categorías en función de datos de entrada. El objetivo de una SVM es encontrar el mejor hiperplano que pueda separar los datos en diferentes clases. La "mejor" división es aquella que maximiza la distancia (o margen) entre el hiperplano y los ejemplos de entrenamiento más cercanos de cada clase, llamados vectores de soporte.
En resumen, una Máquina de Vectores de Soporte es un método de aprendizaje automático que puede ser utilizado en análisis médicos para clasificar o predecir resultados en función de datos complejos, buscando la mejor separación entre diferentes categorías.
El término "Procesamiento Automatizado de Datos" no es específicamente una definición médica, sino que se relaciona más con la informática y la tecnología. Sin embargo, en el contexto médico, el procesamiento automatizado de datos se refiere al uso de sistemas computarizados y software especializado para capturar, procesar, analizar e interpretar datos clínicos y de salud con el fin de apoyar la toma de decisiones clínicas, mejorar la eficiencia de los procesos de atención médica y facilitar la investigación y el análisis de datos en salud pública.
Esto puede incluir una variedad de aplicaciones, como el procesamiento de imágenes médicas, el análisis de historiales clínicos electrónicos, la monitorización remota de pacientes, la toma de decisiones clínicas asistidas por computadora y el análisis de datos a gran escala para la investigación y la vigilancia de enfermedades.
El procesamiento automatizado de datos puede ayudar a mejorar la precisión, la velocidad y la eficiencia de los procesos de atención médica, pero también plantea desafíos importantes en términos de privacidad, seguridad y fiabilidad de los datos. Por lo tanto, es importante asegurarse de que se implementen estrictas medidas de seguridad y éticas para garantizar la protección de la información confidencial del paciente y la integridad de los datos.
No existe una definición médica específica para "Diseño de Programas Informáticos" ya que este término se relaciona más con la informática y la programación que con la medicina. Sin embargo, el Diseño de Programas Informáticos es un proceso fundamental en el desarrollo de software y sistemas utilizados en diversos campos, incluyendo la medicina.
El Diseño de Programas Informáticos implica la planificación, diseño e ingeniería de software y sistemas informáticos para satisfacer necesidades específicas. Esto puede incluir el desarrollo de aplicaciones médicas, sistemas de información clínica, herramientas de análisis de datos médicos, y otros sistemas informáticos utilizados en el cuidado de la salud.
El proceso de diseño implica la identificación de los requisitos del sistema, la creación de un diseño arquitectónico y de interfaz de usuario, la especificación de algoritmos y estructuras de datos, y la planificación de pruebas y validaciones. Todo esto se realiza con el objetivo de garantizar que el software o sistema informático sea seguro, eficaz, eficiente y fácil de usar.
En resumen, aunque no existe una definición médica específica para "Diseño de Programas Informáticos", este proceso es fundamental en el desarrollo de software y sistemas informáticos utilizados en la medicina y el cuidado de la salud.
El análisis de secuencia de ARN es el proceso de examinar y analizar la secuencia de nucleótidos en una molécula de ARN. Este análisis puede proporcionar información sobre la estructura, función y evolución del ARN.
El ARN es un ácido nucleico que desempeña varias funciones importantes en la célula, como el transporte de aminoácidos para la síntesis de proteínas y la regulación de la expresión génica. Existen diferentes tipos de ARN, cada uno con su propia secuencia única de nucleótidos (adenina, uracilo, guanina y citosina).
El análisis de secuencia de ARN puede implicar la comparación de secuencias de ARN entre diferentes organismos para identificar similitudes y diferencias, lo que puede ayudar a entender su evolución y relaciones filogenéticas. También puede implicar el análisis de la estructura secundaria del ARN, que se forma como resultado de las interacciones entre pares complementarios de nucleótidos dentro de una molécula de ARN individual.
El análisis de secuencia de ARN también puede utilizarse para identificar posibles sitios de unión de proteínas o pequeñas moléculas, lo que puede ser útil en el diseño de fármacos y la comprensión de los mecanismos moleculares de enfermedades. Además, el análisis de secuencia de ARN se utiliza a menudo en la investigación de las enfermedades humanas, como el cáncer, donde los patrones anormales de expresión génica y la alteración de la estructura del ARN pueden desempeñar un papel importante.
Los computadores, también conocidos como ordenadores en algunos países de habla hispana, se definen en términos médicos como herramientas electrónicas que almacenan, recuperan, procesan y brindan información importante para el campo médico. Estos dispositivos son esenciales en la actualidad para el funcionamiento de hospitales, clínicas y centros de salud en general.
Existen diferentes tipos de computadores que se utilizan en el ámbito médico:
1. Computadoras de escritorio: Se utilizan en consultorios médicos y hospitales para llevar a cabo diversas tareas, como la gestión de historiales clínicos, la programación de citas o el análisis de resultados de laboratorio.
2. Portátiles: Son computadores más pequeños y livianos que se pueden llevar fácilmente a diferentes áreas del hospital o clínica. Se utilizan para tareas similares a las de los computadores de escritorio, pero con la ventaja de ser móviles.
3. Tabletas: Son dispositivos electrónicos más pequeños y livianos que se pueden utilizar con una sola mano. Se utilizan en diversas áreas del campo médico, como la toma de notas durante las rondas o la consulta de historiales clínicos en tiempo real.
4. Dispositivos wearables: Son pequeños dispositivos electrónicos que se pueden llevar en el cuerpo, como relojes inteligentes o pulseras de actividad física. Se utilizan para monitorear diversos parámetros vitales del paciente y enviar la información a un computador o servidor central para su análisis.
5. Servidores: Son computadores potentes que se utilizan para almacenar y procesar grandes cantidades de datos médicos. Se utilizan en hospitales y clínicas para gestionar historiales clínicos, realizar análisis estadísticos o incluso para la investigación médica.
En resumen, los computadores y dispositivos electrónicos son herramientas esenciales en el campo de la medicina moderna. Desde los computadores de escritorio hasta los dispositivos wearables, cada uno de ellos tiene una función específica que contribuye al cuidado y tratamiento de los pacientes. La tecnología seguirá evolucionando y se espera que en el futuro haya nuevas herramientas que mejoren aún más la atención médica.
Los Datos de Secuencia Molecular se refieren a la información detallada y ordenada sobre las unidades básicas que componen las moléculas biológicas, como ácidos nucleicos (ADN y ARN) y proteínas. Esta información está codificada en la secuencia de nucleótidos en el ADN o ARN, o en la secuencia de aminoácidos en las proteínas.
En el caso del ADN y ARN, los datos de secuencia molecular revelan el orden preciso de las cuatro bases nitrogenadas: adenina (A), timina/uracilo (T/U), guanina (G) y citosina (C). La secuencia completa de estas bases proporciona información genética crucial que determina la función y la estructura de genes y proteínas.
En el caso de las proteínas, los datos de secuencia molecular indican el orden lineal de los veinte aminoácidos diferentes que forman la cadena polipeptídica. La secuencia de aminoácidos influye en la estructura tridimensional y la función de las proteínas, por lo que es fundamental para comprender su papel en los procesos biológicos.
La obtención de datos de secuencia molecular se realiza mediante técnicas experimentales especializadas, como la reacción en cadena de la polimerasa (PCR), la secuenciación de ADN y las técnicas de espectrometría de masas. Estos datos son esenciales para la investigación biomédica y biológica, ya que permiten el análisis de genes, genomas, proteínas y vías metabólicas en diversos organismos y sistemas.
Los procesos estocásticos son un concepto fundamental en teoría de probabilidades y estadística matemática, y tienen aplicaciones en diversas áreas de la medicina, como la biomedicina, la neurociencia y la epidemiología. A continuación, se presenta una definición médica de procesos estocásticos:
Un proceso estocástico es una secuencia de variables aleatorias indexadas en el tiempo o en otro parámetro continuo. Cada variable aleatoria representa un estado del sistema en un momento dado o en un valor específico del parámetro. La evolución del proceso a través del tiempo o del parámetro se describe mediante una función de distribución de probabilidad, que especifica la probabilidad de que el proceso tome ciertos valores en diferentes momentos o puntos del parámetro.
En medicina, los procesos estocásticos se utilizan para modelar sistemas complejos y dinámicos, como la propagación de enfermedades infecciosas, el crecimiento y desarrollo de tumores cancerígenos, o la actividad neuronal en el cerebro. Estos modelos permiten a los investigadores simular diferentes escenarios y analizar el impacto de diferentes intervenciones o tratamientos en la evolución del sistema.
Por ejemplo, en epidemiología, un proceso estocástico puede utilizarse para modelar la propagación de una enfermedad infecciosa en una población. Cada individuo en la población se representa mediante una variable aleatoria que indica su estado de salud (sano, infectado o recuperado), y el proceso evoluciona a través del tiempo según las tasas de transmisión y recuperación de la enfermedad. En oncología, un proceso estocástico puede utilizarse para modelar el crecimiento y desarrollo de un tumor cancerígeno, teniendo en cuenta los factores genéticos y ambientales que influyen en su evolución.
En resumen, los procesos estocásticos son una herramienta poderosa para modelar sistemas complejos y dinámicos en diversos campos de la ciencia y la ingeniería. Permiten a los investigadores simular diferentes escenarios y analizar el impacto de diferentes intervenciones o tratamientos en la evolución del sistema, lo que puede ayudar a tomar decisiones más informadas y eficaces en situaciones reales.
El genoma es el conjunto completo de genes o la secuencia completa del ADN que contiene toda la información genética heredada de nuestros padres. Es único para cada individuo, excepto en el caso de los gemelos idénticos, y constituye el mapa fundamental de la herencia biológica. El genoma humano está compuesto por aproximadamente 3 mil millones de pares de bases de ADN, organizados en 23 pares de cromosomas en el núcleo de cada célula.
La información contenida en el genoma instruye a las células sobre cómo funcionar y mantenerse, desde el crecimiento y desarrollo hasta la reparación y defensa del organismo. Los genes son segmentos específicos de ADN que contienen instrucciones para producir proteínas, moléculas cruciales involucradas en la estructura, función y regulación de las células y tejidos.
El Proyecto Genoma Humano, un esfuerzo internacional masivo completado en 2003, mapeó y secuenció el genoma humano por primera vez, proporcionando a la comunidad científica una herramienta poderosa para comprender mejor las enfermedades humanas, desarrollar nuevas estrategias de diagnóstico y tratamiento, y avanzar en nuestra comprensión general de la biología humana.
Las redes reguladoras de genes son complejos sistemas interconectados de factores de transcripción, ARN no codificante y elementos reguladores del genoma que trabajan juntos para controlar la expresión génica en una célula. Estas redes coordinan los procesos celulares al asegurarse de que los genes se activen o desactiven en el momento adecuado y en la cantidad correcta. Los factores de transcripción son proteínas que se unen a las secuencias específicas de ADN para iniciar o reprimir la transcripción de un gen. El ARN no codificante es un tipo de ARN que no se traduce en proteínas, sino que desempeña funciones reguladoras importantes en la expresión génica. Los elementos reguladores del genoma son secuencias de ADN que sirven como puntos de unión para los factores de transcripción y otros reguladores, controlándose entre sí mediante bucles de retroalimentación positiva o negativa. Las disfunciones en estas redes reguladoras de genes se han relacionado con diversas enfermedades, como el cáncer y los trastornos neurodegenerativos.
La curva ROC (Receiver Operating Characteristic) es un término utilizado en el análisis de pruebas diagnósticas y estadísticas. Es una representación gráfica de la relación entre la sensibilidad o la verdadera positiva (TP) y la especificidad o falsa positiva (FP) de una prueba diagnóstica en función del umbral de corte utilizado para clasificar los resultados como positivos o negativos.
La curva ROC se construye mediante la representación de la tasa de verdaderos positivos (TPR = TP / (TP + FN)) en el eje y y la tasa de falsos positivos (FPR = FP / (FP + TN)) en el eje x, donde FN es el número de falsos negativos y TN es el número de verdaderos negativos.
La curva ROC permite evaluar la precisión diagnóstica de una prueba al comparar su capacidad para distinguir entre enfermos y sanos a diferentes umbrales de corte. Un área bajo la curva ROC (AUC) cercana a 1 indica una buena discriminación entre los grupos, mientras que un AUC cercano a 0,5 sugiere una capacidad de discriminación limitada.
En resumen, la curva ROC es una herramienta útil en el análisis de pruebas diagnósticas para evaluar su precisión y capacidad de distinguir entre diferentes estados de salud o enfermedad.
En realidad, "Diseño de Equipo" no es un término médico específico. Sin embargo, en el contexto más amplio de la ingeniería biomédica y la ergonomía, el diseño de equipos se refiere al proceso de crear dispositivos, sistemas o entornos que puedan ser utilizados de manera segura y eficaz por personas en diversas poblaciones, teniendo en cuenta una variedad de factores, como la antropometría, la fisiología y las capacidades cognitivas.
El objetivo del diseño de equipos es garantizar que los productos sean accesibles, cómodos y seguros para su uso por parte de una amplia gama de usuarios, incluidas aquellas personas con diferentes habilidades, tamaños y necesidades. Esto puede implicar la selección de materiales adecuados, la definición de formas ergonómicas, la incorporación de características de accesibilidad y la evaluación del rendimiento y la seguridad del equipo en diferentes situaciones de uso.
En resumen, el diseño de equipos es un proceso interdisciplinario que involucra la colaboración entre profesionales de diversas áreas, como la medicina, la ingeniería, la psicología y la antropometría, con el fin de crear productos que mejoren la calidad de vida de las personas y reduzcan el riesgo de lesiones y enfermedades relacionadas con el uso de equipos.
En la medicina y la farmacología, los modelos químicos se utilizan para representar, comprender y predecir el comportamiento y las interacciones de moléculas, fármacos y sistemas biológicos. Estos modelos pueden variar desde representaciones simples en 2D hasta complejos simulacros computacionales en 3D. Los modelos químicos ayudan a los científicos a visualizar y entender las interacciones moleculares, predecir propiedades farmacocinéticas y farmacodinámicas de fármacos, optimizar la estructura de los ligandos y receptores, y desarrollar nuevas terapias. Algunas técnicas comunes para crear modelos químicos incluyen la estereoquímica, la dinámica molecular y la química cuántica. Estos modelos pueden ser particularmente útiles en el diseño de fármacos y la investigación toxicológica.
En el contexto médico, la probabilidad se refiere a la posibilidad o frecuencia esperada de que un evento específico ocurra. Se mide como una relación entre el número de casos favorables y el total de casos posibles, expresado como un valor decimal o fraccional entre 0 y 1 (o como un porcentaje entre 0% y 100%).
En la investigación médica y clínica, la probabilidad se utiliza a menudo en el análisis de datos y la toma de decisiones. Por ejemplo, los estudios clínicos pueden informar sobre la probabilidad de que un tratamiento específico sea eficaz o tenga efectos adversos. Los médicos también pueden utilizar la probabilidad para evaluar el riesgo de enfermedades o complicaciones en pacientes individuales, teniendo en cuenta factores como su edad, sexo, historial médico y resultados de pruebas diagnósticas.
La probabilidad puede ser difícil de calcular con precisión en algunos casos, especialmente cuando se trata de eventos raros o complejos que involucran múltiples factores de riesgo. Además, la interpretación y aplicación clínica de las probabilidades pueden ser complejas y requerir un juicio experto y una consideración cuidadosa de los beneficios y riesgos potenciales para cada paciente individual.
El Valor Predictivo de las Pruebas (VPP) en medicina se refiere a la probabilidad de que un resultado específico de una prueba diagnóstica indique correctamente la presencia o ausencia de una determinada condición médica. Existen dos tipos principales: Valor Predictivo Positivo (VPP+) y Valor Predictivo Negativo (VPP-).
1. Valor Predictivo Positivo (VPP+): Es la probabilidad de que un individuo tenga realmente la enfermedad, dado un resultado positivo en la prueba diagnóstica. Matemáticamente se calcula como: VPP+ = verdaderos positivos / (verdaderos positivos + falsos positivos).
2. Valor Predictivo Negativo (VPP-): Es la probabilidad de que un individuo no tenga realmente la enfermedad, dado un resultado negativo en la prueba diagnóstica. Se calcula como: VPP- = verdaderos negativos / (verdaderos negativos + falsos negativos).
Estos valores son importantes para interpretar adecuadamente los resultados de las pruebas diagnósticas y tomar decisiones clínicas informadas. Sin embargo, su utilidad depende del contexto clínico, la prevalencia de la enfermedad en la población estudiada y las características de la prueba diagnóstica utilizada.
El mapeo cromosómico es un proceso en genética molecular que se utiliza para determinar la ubicación y orden relativo de los genes y marcadores genéticos en un cromosoma. Esto se realiza mediante el análisis de las frecuencias de recombinación entre estos marcadores durante la meiosis, lo que permite a los genetistas dibujar un mapa de la posición relativa de estos genes y marcadores en un cromosoma.
El mapeo cromosómico se utiliza a menudo en la investigación genética para ayudar a identificar los genes que contribuyen a enfermedades hereditarias y otros rasgos complejos. También se puede utilizar en la medicina forense para ayudar a identificar individuos o determinar la relación entre diferentes individuos.
Existen diferentes tipos de mapeo cromosómico, incluyendo el mapeo físico y el mapeo genético. El mapeo físico implica la determinación de la distancia física entre los marcadores genéticos en un cromosoma, medida en pares de bases. Por otro lado, el mapeo genético implica la determinación del orden y distancia relativa de los genes y marcadores genéticos en términos del número de recombinaciones que ocurren entre ellos durante la meiosis.
En resumen, el mapeo cromosómico es una técnica importante en genética molecular que se utiliza para determinar la ubicación y orden relativo de los genes y marcadores genéticos en un cromosoma, lo que puede ayudar a identificar genes asociados con enfermedades hereditarias y otros rasgos complejos.
La filogenia, en el contexto de la biología y la medicina, se refiere al estudio de los ancestros comunes y las relaciones evolutivas entre diferentes organismos vivos o extintos. Es una rama de la ciencia que utiliza principalmente la información genética y morfológica para construir árboles filogenéticos, también conocidos como árboles evolutivos, con el fin de representar visualmente las relaciones ancestrales entre diferentes especies o grupos taxonómicos.
En la medicina, la filogenia puede ser útil en el estudio de la evolución de patógenos y en la identificación de sus posibles orígenes y vías de transmisión. Esto puede ayudar a desarrollar estrategias más efectivas para prevenir y controlar enfermedades infecciosas. Además, el análisis filogenético se utiliza cada vez más en la investigación médica para comprender mejor la evolución de los genes y las proteínas humanos y sus posibles implicaciones clínicas.
La Imagen por Resonancia Magnética (IRM) es una técnica de diagnóstico médico no invasiva que utiliza un campo magnético potente, radiaciones ionizantes no dañinas y ondas de radio para crear imágenes detalladas de las estructuras internas del cuerpo. Este procedimiento médico permite obtener vistas en diferentes planos y con excelente contraste entre los tejidos blandos, lo que facilita la identificación de tumores y otras lesiones.
Durante un examen de IRM, el paciente se introduce en un túnel o tubo grande y estrecho donde se encuentra con un potente campo magnético. Las ondas de radio se envían a través del cuerpo, provocando que los átomos de hidrógeno presentes en las células humanas emitan señales de radiofrecuencia. Estas señales son captadas por antenas especializadas y procesadas por un ordenador para generar imágenes detalladas de los tejidos internos.
La IRM se utiliza ampliamente en la práctica clínica para evaluar diversas condiciones médicas, como enfermedades del cerebro y la columna vertebral, trastornos musculoesqueléticos, enfermedades cardiovasculares, tumores y cánceres, entre otras afecciones. Es una herramienta valiosa para el diagnóstico, planificación del tratamiento y seguimiento de la evolución de las enfermedades.
En realidad, "factores de tiempo" no es un término médico específico. Sin embargo, en un contexto más general o relacionado con la salud y el bienestar, los "factores de tiempo" podrían referirse a diversos aspectos temporales que pueden influir en la salud, las intervenciones terapéuticas o los resultados de los pacientes. Algunos ejemplos de estos factores de tiempo incluyen:
1. Duración del tratamiento: La duración óptima de un tratamiento específico puede influir en su eficacia y seguridad. Un tratamiento demasiado corto o excesivamente largo podría no producir los mejores resultados o incluso causar efectos adversos.
2. Momento de la intervención: El momento adecuado para iniciar un tratamiento o procedimiento puede ser crucial para garantizar una mejoría en el estado del paciente. Por ejemplo, tratar una enfermedad aguda lo antes posible puede ayudar a prevenir complicaciones y reducir la probabilidad de secuelas permanentes.
3. Intervalos entre dosis: La frecuencia y el momento en que se administran los medicamentos o tratamientos pueden influir en su eficacia y seguridad. Algunos medicamentos necesitan ser administrados a intervalos regulares para mantener niveles terapéuticos en el cuerpo, mientras que otros requieren un tiempo específico entre dosis para minimizar los efectos adversos.
4. Cronobiología: Se trata del estudio de los ritmos biológicos y su influencia en diversos procesos fisiológicos y patológicos. La cronobiología puede ayudar a determinar el momento óptimo para administrar tratamientos o realizar procedimientos médicos, teniendo en cuenta los patrones circadianos y ultradianos del cuerpo humano.
5. Historia natural de la enfermedad: La evolución temporal de una enfermedad sin intervención terapéutica puede proporcionar información valiosa sobre su pronóstico, así como sobre los mejores momentos para iniciar o modificar un tratamiento.
En definitiva, la dimensión temporal es fundamental en el campo de la medicina y la salud, ya que influye en diversos aspectos, desde la fisiología normal hasta la patogénesis y el tratamiento de las enfermedades.
La secuencia de bases, en el contexto de la genética y la biología molecular, se refiere al orden específico y lineal de los nucleótidos (adenina, timina, guanina y citosina) en una molécula de ADN. Cada tres nucleótidos representan un codón que especifica un aminoácido particular durante la traducción del ARN mensajero a proteínas. Por lo tanto, la secuencia de bases en el ADN determina la estructura y función de las proteínas en un organismo. La determinación de la secuencia de bases es una tarea central en la genómica y la biología molecular moderna.
El análisis discriminante es una técnica estadística utilizada en el campo del aprendizaje automático y la investigación médica para clasificar observaciones o individuos en diferentes grupos o categorías basándose en variables predictoras continuas. En medicina, esta técnica se utiliza a menudo para diagnosticar enfermedades o condiciones de salud, predecir el riesgo de desarrollar una enfermedad o determinar la eficacia de un tratamiento.
En un análisis discriminante, se identifican variables predictoras que son significativamente diferentes entre dos o más grupos y luego se utiliza una función matemática para combinar esas variables en una puntuación o índice que pueda utilizarse para clasificar nuevas observaciones. La función de discriminante se deriva mediante el análisis de las diferencias entre los grupos en las variables predictoras y la asignación de pesos a cada variable en función de su capacidad para predecir la pertenencia al grupo.
El análisis discriminante es una técnica útil en medicina porque puede ayudar a identificar individuos con alto riesgo de desarrollar una enfermedad o complicaciones, lo que permite una intervención temprana y preventiva. También se puede utilizar para evaluar la eficacia de diferentes tratamientos o intervenciones al comparar los resultados entre grupos de pacientes tratados de manera diferente.
Sin embargo, el análisis discriminante también tiene limitaciones y supuestos que deben tenerse en cuenta al aplicarlo en la práctica médica. Por ejemplo, se asume que las variables predictoras siguen una distribución normal en cada grupo y que las varianzas entre los grupos son iguales. Además, el análisis discriminante solo es adecuado cuando el número de observaciones es mayor que el número de variables predictoras. Por lo tanto, es importante considerar cuidadosamente estos factores al decidir si utilizar el análisis discriminante en un contexto médico específico.
La tomografía computarizada de haz cónico (CBCT, por sus siglas en inglés) es un tipo de tecnología de escaneo médico que utiliza rayos X para crear imágenes detalladas y tridimensionales de estructuras dentales y maxilofaciales. A diferencia de la tomografía computarizada tradicional (CT), que utiliza un haz de rayos X giratorio, el CBCT emite un haz cónico estrecho que rodea al paciente, lo que resulta en una exposición a dosis más bajas de radiación.
Este tipo de tomografía se utiliza comúnmente en odontología y maxilofacial para planificar tratamientos dentales complejos, como la colocación de implantes dentales, el diagnóstico y tratamiento de trastornos temporomandibulares (ATM), el análisis de lesiones faciales y craneales, y el estudio de crecimiento y desarrollo craneofacial en niños.
La CBCT ofrece una serie de ventajas sobre la tomografía computarizada tradicional, como una menor exposición a la radiación, un tiempo de escaneo más corto, una resolución espacial superior y una mejor visualización de las estructuras dentales y óseas. Sin embargo, también conlleva algunos riesgos potenciales asociados con la exposición a los rayos X, por lo que su uso debe restringirse a situaciones clínicas en las que los beneficios superen los posibles riesgos.
La tomografía computarizada por rayos X, también conocida como TC o CAT (por sus siglas en inglés: Computerized Axial Tomography), es una técnica de diagnóstico por imágenes que utiliza radiación para obtener detalladas vistas tridimensionales de las estructuras internas del cuerpo. Durante el procedimiento, el paciente se coloca sobre una mesa que se desliza dentro de un anillo hueco (túnel) donde se encuentran los emisores y receptores de rayos X. El equipo gira alrededor del paciente, tomando varias radiografías en diferentes ángulos.
Las imágenes obtenidas son procesadas por un ordenador, el cual las combina para crear "rebanadas" transversales del cuerpo, mostrando secciones del tejido blando, huesos y vasos sanguíneos en diferentes grados de claridad. Estas imágenes pueden ser visualizadas como rebanadas individuales o combinadas para formar una representación tridimensional completa del área escaneada.
La TC es particularmente útil para detectar tumores, sangrado interno, fracturas y otras lesiones; así como también para guiar procedimientos quirúrgicos o biopsias. Sin embargo, su uso está limitado en pacientes embarazadas debido al potencial riesgo de daño fetal asociado con la exposición a la radiación.
El análisis de mínimos cuadrados es una técnica estadística y matemática utilizada en el ámbito médico, especialmente en el análisis de datos clínicos y de investigación. Consiste en ajustar una curva o función a un conjunto de datos puntuales, de manera que la suma de los cuadrados de las diferencias entre los valores observados y los valores estimados por la curva sea minimizada.
En otras palabras, se trata de encontrar la mejor recta o curva que se ajuste a un conjunto de puntos en un diagrama, donde "mejor" se define como aquella que minimiza la suma de los cuadrados de las distancias verticales entre los puntos y la curva.
Este método es ampliamente utilizado en el análisis de regresión lineal y no lineal, así como en el análisis de series temporales y en la estimación de parámetros en modelos estadísticos. En medicina, se utiliza para analizar datos experimentales y observacionales, como por ejemplo, en el estudio de la relación entre dos variables continuas, como la dosis de un fármaco y su efecto terapéutico o tóxico.
La ventaja del análisis de mínimos cuadrados es que proporciona una estimación objetiva e inparcial de los parámetros del modelo, lo que permite realizar inferencias estadísticas y hacer predicciones sobre la base de los datos observados. Además, este método es relativamente sencillo de implementar y está disponible en la mayoría de los paquetes de software estadístico.
En realidad, "dinámicas no lineales" no es una definición médica específica, sino más bien un término usado en las matemáticas y física teórica que se ha aplicado en algunos contextos de la investigación biomédica.
Las dinámicas no lineales son el estudio de sistemas donde los cambios en la entrada no producen cambios proporcionales en la salida. Es decir, un pequeño cambio en la entrada puede dar lugar a una gran variación en la salida o viceversa. Estos sistemas son comunes en la naturaleza y pueden ser vistos en fenómenos como el clima, la ecología, la economía y también en algunos sistemas biológicos complejos.
En medicina y biología, las dinámicas no lineales se han utilizado para modelar y analizar sistemas complejos como los ritmos cardíacos, la propagación de enfermedades infecciosas o el crecimiento tumoral. Por ejemplo, un pequeño cambio en el ambiente o en las condiciones iniciales puede desencadenar una respuesta drástica en el sistema cardiovascular o en la progresión de un cáncer.
Sin embargo, es importante señalar que este término no se refiere a un concepto médico específico sino más bien a un enfoque matemático y teórico que se ha aplicado a diversos sistemas biomédicos complejos.
La Programación Lineal (PL) no es un término médico, sino matemático y computacional. Se refiere a un método para optimizar (maximizar o minimizar) una función objetivo lineal, sujeta a restricciones lineales. Es ampliamente utilizada en diversas áreas, incluyendo la medicina, para tomar decisiones sobre el uso óptimo de recursos limitados. Por ejemplo, en la planificación de la asignación de quirófanos o en la determinación del mejor curso de tratamiento para un paciente dado.
El análisis de falla de equipo (también conocido como análisis de fallos o investigación de averías) es un proceso sistemático y multidisciplinario utilizado en medicina y otras industrias para identificar las causas subyacentes de una falla de equipo, sistema o proceso. En el contexto médico, esto se refiere a la evaluación de eventos adversos relacionados con la atención médica, como errores de medicación, infecciones nosocomiales y eventos relacionados con dispositivos médicos.
El objetivo del análisis de falla de equipo es determinar las causas raíz de un incidente y establecer recomendaciones para prevenir futuras fallas y mejorar la seguridad del paciente. Esto se logra mediante el uso de herramientas y técnicas de análisis, como diagramas de flujo, análisis de árbol de fallos, y entrevistas estructuradas con los miembros del equipo involucrados en el incidente.
El análisis de falla de equipo se realiza de manera sistemática y objetiva, considerando todos los factores que pueden haber contribuido a la falla, incluyendo factores humanos, organizacionales y tecnológicos. Los resultados del análisis se utilizan para mejorar los procesos y sistemas de atención médica, reducir el riesgo de eventos adversos y promover una cultura de seguridad en la que las preocupaciones por la seguridad se aborden abiertamente y sin temor a represalias.
El genoma humano se refiere al conjunto completo de genes o la secuencia de ADN que contiene toda la información hereditaria de un ser humano. Es el mapa completo de instrucciones genéticas para desarrollar y mantener las funciones de los organismos humanos. El genoma humano está compuesto por aproximadamente 3 mil millones de pares de bases de ADN y contiene entre 20,000 y 25,000 genes. Fue completamente secuenciado por primera vez en 2003 como parte del Proyecto Genoma Humano. La comprensión del genoma humano ha proporcionado información importante sobre cómo funciona el cuerpo humano y tiene implicaciones importantes para la medicina, incluyendo el diagnóstico y tratamiento de enfermedades genéticas.
La proteómica es el estudio sistemático y exhaustivo de los proteomas, que son los conjuntos completos de proteínas producidas o modificadas por un organismo o sistema biológico en particular. Esto incluye la identificación y cuantificación de las proteínas, su estructura, función, interacciones y cambios a lo largo del tiempo y en diferentes condiciones. La proteómica utiliza técnicas integrales que combinan biología molecular, bioquímica, genética y estadísticas, así como herramientas informáticas para el análisis de datos a gran escala.
Este campo científico es fundamental en la investigación biomédica y farmacéutica, ya que las proteínas desempeñan un papel crucial en casi todos los procesos celulares y son objetivos terapéuticos importantes para el desarrollo de nuevos fármacos y tratamientos. Además, la proteómica puede ayudar a comprender las bases moleculares de diversas enfermedades y a identificar biomarcadores que permitan un diagnóstico más temprano y preciso, así como monitorizar la eficacia de los tratamientos.
Las Bases de Datos de Ácidos Nucleicos son colecciones organizadas y electrónicas de información sobre ácidos nucleicos, como el ADN y el ARN. Estas bases de datos contienen secuencias genéticas, estructuras tridimensionales, funciones génicas y otra información relevante sobre los ácidos nucleicos.
Algunos ejemplos populares de Bases de Datos de Ácidos Nucleicos incluyen:
1. GenBank: una base de datos mantenida por el National Center for Biotechnology Information (NCBI) que contiene secuencias genéticas de diversas especies.
2. European Nucleotide Archive (ENA): una base de datos europea que almacena secuencias de ácidos nucleicos y metadatos asociados.
3. DNA Data Bank of Japan (DDBJ): una base de datos japonesa que contiene secuencias genéticas y otra información relacionada con los ácidos nucleicos.
4. Protein Data Bank (PDB): aunque no es específicamente una base de datos de ácidos nucleicos, PDB contiene estructuras tridimensionales de proteínas y ácidos nucleicos, incluyendo ARN y ADN.
Estas bases de datos son herramientas importantes en la investigación biomédica y la genómica, ya que permiten a los científicos comparar secuencias genéticas, identificar genes y analizar la función y evolución de los ácidos nucleicos.
El análisis de componentes principales (PCA, por sus siglas en inglés) es una técnica estadística utilizada para analizar y resumir los datos en un conjunto de variables, con el objetivo de reducir la dimensionalidad de los datos mientras se preserva la mayor cantidad posible de variación en los datos originales.
En el contexto médico, el análisis de componentes principales puede ser utilizado para identificar patrones y relaciones en un gran conjunto de variables clínicas o de laboratorio, con el fin de facilitar la interpretación y comprensión de los datos. Por ejemplo, PCA se puede aplicar a los datos de perfiles genéticos o de expresión génica para identificar grupos de genes que trabajan juntos en la regulación de procesos biológicos específicos.
El análisis de componentes principales funciona mediante la transformación de los datos originales en una serie de nuevas variables, llamadas componentes principales, que son combinaciones lineales de las variables originales. Los componentes principales se ordenan por la cantidad de variación que representan en los datos originales, con el primer componente principal explicando la mayor cantidad posible de variación, seguido del segundo componente principal y así sucesivamente.
En resumen, el análisis de componentes principales es una técnica útil para reducir la dimensionalidad y visualizar los datos médicos complejos, lo que puede ayudar a identificar patrones y relaciones importantes en los datos clínicos o de laboratorio.
El polimorfismo de nucleótido simple (SNP, del inglés Single Nucleotide Polymorphism) es un tipo común de variación en la secuencia de ADN que ocurre cuando una sola base nitrogenada (A, T, C o G) en el ADN es reemplazada por otra. Los SNPs pueden ocurrir en cualquier parte del genoma y suceden, en promedio, cada 300 pares de bases a lo largo del genoma humano.
La mayoría de los SNPs no tienen un efecto directo sobre la función de los genes, pero pueden influir en el riesgo de desarrollar ciertas enfermedades al afectar la forma en que los genes funcionan o interactúan con el ambiente. También se utilizan como marcadores genéticos en estudios de asociación del genoma completo (GWAS) para identificar regiones del genoma asociadas con enfermedades y rasgos específicos.
Los SNPs pueden ser heredados de los padres y pueden utilizarse en la identificación genética individual, como en el caso de las pruebas de paternidad o para rastrear la ascendencia genética. Además, los SNPs también se utilizan en la investigación biomédica y farmacológica para desarrollar medicamentos personalizados y determinar la eficacia y seguridad de un fármaco en diferentes poblaciones.
La secuencia de aminoácidos se refiere al orden específico en que los aminoácidos están unidos mediante enlaces peptídicos para formar una proteína. Cada proteína tiene su propia secuencia única, la cual es determinada por el orden de los codones (secuencias de tres nucleótidos) en el ARN mensajero (ARNm) que se transcribe a partir del ADN.
Las cadenas de aminoácidos pueden variar en longitud desde unos pocos aminoácidos hasta varios miles. El plegamiento de esta larga cadena polipeptídica y la interacción de diferentes regiones de la misma dan lugar a la estructura tridimensional compleja de las proteínas, la cual desempeña un papel crucial en su función biológica.
La secuencia de aminoácidos también puede proporcionar información sobre la evolución y la relación filogenética entre diferentes especies, ya que las regiones conservadas o similares en las secuencias pueden indicar una ascendencia común o una función similar.
La expresión "Redes de Comunicación de Computadores" no es un término médico, sino más bien una área de tecnología de la información y las comunicaciones (TIC). Sin embargo, dado que la tecnología se utiliza cada vez más en el campo médico, puede ser útil conocer su definición.
Las Redes de Comunicación de Computadores son sistemas interconectados de dispositivos informáticos y otros recursos que pueden comunicarse e interactuar entre sí para compartir recursos y datos. Esto permite a los usuarios acceder y compartir información desde diferentes lugares y dispositivos, lo que facilita la colaboración y el intercambio de conocimientos.
En el contexto médico, las redes de comunicación de computadores pueden utilizarse para diversos fines, como el intercambio de historiales clínicos electrónicos entre proveedores de atención médica, la telemedicina, la monitorización remota de pacientes y la investigación médica. Estas redes pueden ayudar a mejorar la eficiencia y la calidad de la atención médica, así como a reducir costos y aumentar el acceso a los servicios de salud en áreas remotas o desatendidas.
El Processamiento de Lenguaje Natural (PLN) o Natural Language Processing (NLP) en inglés, es un campo interdisciplinario que combina la lingüística, la informática y las ciencias cognitivas. Se encarga del desarrollo de métodos, técnicas y sistemas computacionales para analizar, sintetizar, entender y generar lenguaje natural humano.
El objetivo principal del PLN es permitir que las máquinas interactúen con el lenguaje humano de una manera más natural y comprensible, lo que implica abordar tareas como el reconocimiento del habla, la traducción automática, la detección de sentimientos, el análisis de temas y la respuesta a preguntas, entre otras.
El PLN tiene una gran variedad de aplicaciones en el campo médico, como el procesamiento de historias clínicas electrónicas, la detección de eventos adversos relacionados con los medicamentos, el diagnóstico automatizado y la asistencia en la toma de decisiones clínicas. Además, también se utiliza en la investigación biomédica para analizar grandes cantidades de texto no estructurado y extraer información relevante.
La tomografía es una técnica de diagnóstico por imágenes médicas que utiliza diferentes métodos para obtener imágenes transversales (o secciones) del cuerpo humano. Existen varios tipos de tomografías, incluyendo:
1. Tomografía Axial Computarizada (TAC o CAT en inglés): Esta técnica utiliza rayos X y una computadora para generar imágenes detalladas de las estructuras internas del cuerpo. Durante el procedimiento, el paciente se coloca sobre una mesa que se desliza a través de un anillo donut-shaped (gantry) mientras la máquina toma varias radiografías desde diferentes ángulos. Luego, una computadora combina estas imágenes para crear "cortes" transversales del cuerpo.
2. Tomografía por Emisión de Positrones (PET en inglés): Esta técnica utiliza pequeñas cantidades de material radiactivo inyectadas en el torrente sanguíneo para ayudar a detectar células cancerosas y otras anomalías en el cuerpo. El material radiactivo se une a las células activas, como las células cancerosas, y emite partículas llamadas positrones. Los detectores de la máquina PET capturan los positrones y crean imágenes que muestran dónde están las células más activas en el cuerpo.
3. Tomografía de Coherencia Óptica (OCT en inglés): Esta técnica utiliza luz infrarroja para obtener imágenes detalladas de tejidos blandos, como la retina del ojo. La OCT se utiliza comúnmente en oftalmología para diagnosticar y monitorear enfermedades oculares.
4. Tomografía de Resonancia Magnética (MRI en inglés): Esta técnica utiliza campos magnéticos y ondas de radio para crear imágenes detalladas de los órganos y tejidos del cuerpo. La MRI no utiliza radiación y se utiliza comúnmente para diagnosticar y monitorear una variedad de condiciones médicas.
En resumen, la tomografía es una técnica de diagnóstico que utiliza diferentes métodos para crear imágenes detalladas de los órganos y tejidos del cuerpo. Las diferentes formas de tomografía incluyen TC, PET, OCT y MRI, cada una con sus propias aplicaciones clínicas y ventajas.
El proteoma se refiere al conjunto completo de proteínas producidas o expresadas por un genoma, un organelo celular específico, o en respuesta a un estímulo particular en un determinado tipo de célula, tejido u organismo en un momento dado. Estudiar el proteoma es importante porque las proteínas son responsables de la mayoría de las funciones celulares y su expresión puede cambiar en respuesta a factores internos o externos. La caracterización del proteoma implica técnicas como la electroforesis bidimensional y la espectrometría de masas para identificar y cuantificar las proteínas individuales.
 Diseño de algoritmos
Diseño de algoritmos
Regulación de algoritmos
Análisis de algoritmos
Gobierno por algoritmos
Introducción a los algoritmos
Algoritmo
Algoritmos para calcular la varianza
Algoritmos de búsqueda en grafos
Algoritmos de búsqueda de subcadenas
Algoritmo cuántico
Algoritmo iterativo
Algoritmo genético
Algoritmo QR
Algoritmo Remez
Algoritmo memético
Algoritmo adaptativo
Algoritmo CYK
Algoritmo Adam7
Algoritmo abusón
Algoritmo radial
Algoritmo QMR
Algoritmo DPLL
Algoritmo firefly
Algoritmo probabilista
Algoritmo paralelo
Algoritmo galáctico
Algoritmo determinista
Algoritmo RLS
Algoritmo HITS
Algoritmo SSS
Google7
- Google cambios en el algoritmo. (forosdelweb.com)
- hoy mismo estudiando a mi competencia me he encontrado con webs en los top 10 de google con menos de 200 palabras de contenido en algunas keywords muy competidas y es ah donde uno dice, pues de a como $$$$ le hacen? (forosdelweb.com)
- Lo claro aqu es que hay m s de tres google en la web, pero por lo que veo no se ponen de acuerdo entre ellos para trabajar. (forosdelweb.com)
- Algoritmos transparentes: ¿Por qué Google y Facebook no liberan sus algoritmos como Open Source? (xataka.com)
- Tras el acuerdo tentativo para evitar que empresas como Apple o Google den un trato preferencial a sus propias aplicaciones en sus dispositivos, ahora el Parlamento Europeo habría comenzado a avanzar en un acuerdo que podría revelar algunos de los secretos mejores guardados por Google: su algoritmo. (muycomputer.com)
- Otra posible solución es un sistema similar a lo que usa Google News para jerarquizar las noticias principales, que es permitirle a ciertas editoriales aprobadas que señalen contenidos relevantes. (enter.co)
- El algoritmo PageRank no es una idea original de Google. (eventoblog.com)
Facebook14
- Pero qué pasa cuando es nuestra personalidad la que es evaluada en base a nuestros estados de Facebook? (neoteo.com)
- La característica Trending de Facebook es un buen ejemplo de este tipo de algoritmos. (xataka.com)
- El algoritmo de Facebook tiene una limitación: que está creado, gestionado y alimentado por los seres humanos . (xataka.com)
- Que un algoritmo se comporte de mejor o peor forma no es solo culpa de Facebook, sino nuestra, de los usuarios, que alimentamos ese algoritmo con nuestra actividad y nuestros comentarios. (xataka.com)
- En Slate trataban de explicar cómo funciona ese algoritmo en las oficinas de Facebook en Menlo Park, California. (xataka.com)
- Y ahí es donde entra en juego la relevancia de cada artículo que se publica en el mundo: probablemente tendrá más valor si ha sido compartido por uno de nuestros contactos en Facebook, y si es de una temática que normalmente nos interesa, por ejemplo. (xataka.com)
- Esas son en realidad dos variables que el algoritmo toma en cuenta, pero en Facebook confiesan que su algoritmo toma en cuenta cientos de variables . (xataka.com)
- el algoritmo solo resuelve parte de las necesidades , y de hecho un reciente artículo de Gizmodo revelaba cómo esas noticias sugeridas tenían poco de algoritmo y mucho de filtrado por seres humanos: un grupo de periodistas ex-empleados (subcontratados, eso sí) de Facebook hablaban de su periodo como editores en jefe de una sección que puede llegar a condicionar nuestra forma de ver el mundo. (xataka.com)
- Transparencia forzada sobre cómo funcionan los algoritmos de contenido, como el suministro de noticias de Facebook. (muycomputer.com)
- Los algoritmos de las principales redes sociales como Facebook, Instagram, Twitter y TikTok evolucionan constantemente. (italiafutura.it)
- Cómo funciona el algoritmo de Facebook? (larioja.com)
- Expliquemos, de una vez por todas, cómo funciona el algoritmo de Facebook. (larioja.com)
- Según un reporte de The Washington Post , la sección de Tendencias de Facebook sigue arrojando noticias falsas desde que despidió al personal encargado para reemplazarlo por un algoritmo. (enter.co)
- La función de Tendencias de Facebook se supone que es un vistazo a las noticias más importantes y más discutidas del día. (enter.co)
Identificar4
- El Observatorio de Ciudades del Tecnológico de Monterrey presentó un avanzado algoritmo que permite identificar las distancias en una ciudad, considerando los diversos factores del territorio circundante, de tal forma que se puede comprender la distancia y el tiempo reales que las personas requieren para alcanzar los espacios donde llevan a cabo sus actividades diarias. (cronica.com.mx)
- Este video es de la serie 'Cómo identificar información falsa en internet' del programa MediaWise en español. (telemundo.com)
- e identificar los algoritmos y recursos de las pruebas de laboratorio para el virus del Zika. (cdc.gov)
- El rol que le compete a la OPS en este campo es asegurar que se genere, se disemine, se conozca y se utilice la información correcta y necesaria para identificar las inequidades en salud y sus determinantes a fin de establecer políticas, iniciativas y procesos que puedan revertir estas brechas injustas y corregir sus efectos más negativos. (bvsalud.org)
Detectar6
- Ahora se trata de un nuevo algoritmo para detectar las llamadas imágenes falsas profundas, aquellas alteradas imperceptiblemente por los sistemas de inteligencia artificial. (wwwhatsnew.com)
- Ahora, desde el IEEE Transactions on Image Processing , avisan que los algoritmos para detectar estos engaños suelen funcionar, pero que no dejan de ser sistemas probabilísticos, por lo que no tienen la verdad absoluta, a veces se equivocan. (wwwhatsnew.com)
- De hecho, podríamos incluso plantearnos utilizar algoritmos para detectar ese tipo de sesgos en nuestros procesos de selección , dado que podrían encontrarse también en las personas de la compañía que la llevan a cabo. (enriquedans.com)
- La prevención de plagio con IA puede incluir herramientas de detección de plagio y educación sobre ética y atribución en la producción de contenido, sin embargo, un estudio realizado por expertos de la Universidad de Maryland demostró que es matemáticamente imposible detectar de forma confiable un texto escrito por IA. (andinalink.com)
- El algoritmo desarrollado por científicos suizos podría detectar la fuente de un ataque online analizando el 10% de las conexiones de red. (itespresso.es)
- Con el algoritmo se podría detectar el ordenador de una red desde el que se está enviando el spam de forma que el proveedor podría apagarlo, por ejemplo. (itespresso.es)
Dictadura del algoritmo2
- Indudablemente, La Dictadura del Algoritmo analiza un entramado complejo y apasionante, que seguirá teniendo muchísimos adeptos. (lajiribilla.cu)
- La Dictadura del Algoritmo es solo un paso, pero falta mucho en un camino que nunca tendrá fin. (lajiribilla.cu)
Utilizado4
- Este es un algoritmo utilizado para trabajar con puntos muertos en programación si se considera que el impase será muy raro y el costo para prevenirlo muy alto. (geeks.ms)
- El algoritmo es utilizado en sistemas operativos, por ejemplo, para chequear el riesgo de que el sistema deje de funcionar porque un programa está pidiendo demasiados recursos (de CPU o memoria, por ejemplo). (geeks.ms)
- El algoritmo CART es ampliamente utilizado en análisis predictivos. (bvsalud.org)
- Algoritmo utilizado en el análisis de decisiones y en el APRENDIZAJE AUTOMÁTICO que utiliza un conjunto de árboles para combinar la salida de múltiples ÁRBOLES DE DECISIONES generados aleatoriamente. (bvsalud.org)
Tipos4
- Lo que queremos hacer en este proyecto es entender mejor cómo funcionan esos algoritmos y qué tipos de burbuja crean. (uc3m.es)
- La principal ventaja de esta técnica es la universalidad de sus identificaciones, ya que, a día de hoy, ciertas personas todavía no pueden ser reconocidas por determinados tipos de biometría -en casos de lesiones, amputaciones o características físicas discapacitantes-, pero el latido del corazón es una bioseñal que está presente en todos los seres humanos, sin excepción. (uc3m.es)
- Según estos investigadores, si los cerebros de las mujeres y los cerebros de los hombres pueden ser clasificados con tanta eficacia es porque estos algoritmos son capaces de desentrañar diferencias subyacentes y evidenciar dos tipos de cerebros. (elmostrador.cl)
- Tipos de prueba y algoritmos. (bvsalud.org)
Iniciar1
- Es decir al iniciar el algoritmo, el primero elegido se remplaza por el último, en el siguiente ciclo se elige al azar entre todos menos el último, que ahora se remplaza por el penúltimo, y de nuevo se elige otro al azar entre todos menos los dos últimos, etc. (wikipedia.org)
Comportamiento1
- Desde hace años, los científicos y los responsables de la lucha contra los incendios forestales colaboran para elaborar algoritmos que simulen el comportamiento de los incendios, lo que tiene varias utilidades. (elconfidencial.com)
Problema13
- En ciencias de la computación, el diseño de algoritmos es un método específico para poder crear un modelo matemático ajustado a un problema específico para resolverlo. (wikipedia.org)
- Existen varias técnicas de diseño de algoritmos que permiten desarrollar la solución al problema planteado, algunas de ellas son: Algoritmo divide y vencerás: El método está basado en la resolución recursiva de un problema dividiéndolo en dos o más subproblemas de igual tipo o similar. (wikipedia.org)
- Algoritmos paralelos: permiten la división de un problema en subproblemas de forma que se puedan ejecutar de forma simultánea en varios procesadores. (wikipedia.org)
- El problema es que no siempre se tienen en cuenta las necesidades y competencias de los empleados cuando se introducen nuevas tecnologías. (uniglobalunion.org)
- El problema es que en los últimos años, con el aumento imparable de la vegetación seca y nuevas condiciones ambientales, está apareciendo un nuevo tipo de incendios, tan gigantes y voraces que son imposibles de apagar. (elconfidencial.com)
- El problema de COMPAS es que los jueces lo han tomado demasiado en serio, y eso ha hecho que algunas decisiones hayan sido muy criticadas y hayan detonado el debate sobre la validez de este algoritmo. (xataka.com)
- Esto asume que es mucho más efectivo desde el punto de vista económico permitir que el problema ocurra que intentar prevenirlo. (geeks.ms)
- Gawdat reconoce que el problema de la infelicidad es m s acusado en los pa ses m s pr speros. (expansion.com)
- Cita de: t4r0x en 12 Agosto 2013, 03:11 am conozco los algoritmos basicos como el de burbuja , esos algoritmos estan bien y ordenan como yo quiero pero mi problema principal es que quiero saber una manera al menos un poco eficiente de saber como restaurar estas cadenas a su forma original Lo primero que debes indicar es el lenguaje de programaci n que estas utilizando. (elhacker.net)
- algunos, tales como el problema de la mochila , pueden ser aproximados mediante cualquier factor superior a 1 (tal familia de algoritmos de aproximación se conoce como esquema de aproximación de tiempo polinomial o PTAS ). (wikipedia.org)
- Otra limitación de la aproximación es que esta solo es aplicable a los problemas de optimización, y no a los problemas de decisión en estado "puro", tales como SAT (a pesar de que es posible representar versiones de optimización para tales problemas, como el respectivo Problema de satisfacibilidad máximo ). (wikipedia.org)
- El algoritmo es capaz de encontrar la fuente del problema comprobando un pequeño porcentaje de las conexiones en una red, ha asegurado Pedro Pinto, investigador de Laboratorio de Comunicaciones Audiovisuales del Swiss Federal Institute of Technology (EPFL). (itespresso.es)
- Teniendo en cuenta este problema, el presente artículo compara el algoritmo CART y un algoritmo imparcial (CTREE) con relación a su poder predictivo. (bvsalud.org)
Tratamiento1
- Es un valioso recurso para administrar la fibrilación auricular paroxística y persistente en pacientes seleccionados, que necesitan de estimulación según las indicaciones, produciendo reducción benéfica de los síntomas y de los costos del tratamiento de la FA. (bvsalud.org)
Ordenamiento4
- El algoritmo Fisher-Yates es un algoritmo de permutaciones que técnicamente encaja en la categoría de los algoritmos de ordenamiento, aunque en este caso, el fin perseguido es el opuesto, desordenar los ítems que contiene. (wikipedia.org)
- Algoritmo de ordenamiento? (elhacker.net)
- Un algoritmo de ordenamiento b sico, como el 'Burbuja', ordenar a eso eficientemente. (elhacker.net)
- El algoritmo de ordenamiento era, pues, muy importante. (teknoplof.com)
Crean1
- Queremos comprobar si dichos algoritmos de personalización de publicidad crean ciertos filtros que fomentan o incluyen sesgos (edad, ingresos, sexo, salud) que puedan estar creando burbujas que fomentan la desigualdad", apunta otro de los investigadores del proyecto, Esteban Moro, que es profesor del departamento de Matemáticas de la UC3M y profesor visitante del MIT Media Lab de Cambridge (EEUU). (uc3m.es)
Cambios2
- Al comprender estas tendencias podremos evolucionar y adaptarnos a los cambios en los algoritmos sociales. (italiafutura.it)
- Pero igualmente importante es colocar esta información sobre la equidad en salud a disposición de los actores y agentes que puedan utilizarla en forma efectiva para transformar las realidades y lograr los cambios que se necesitan. (bvsalud.org)
Llevar a cabo1
- La descripción de Fisher y Yates exige el uso de 2 matrices (en los trabajos de campo, es simplemente anotar en dos partes de un papel, aunque bien podría reutilizarse borrando y rescribiendo en el mismo sitio), mientras que Durstenfeld usa la propia matriz para llevar a cabo todo el algoritmo, necesitando solo como memoria extra una variable temporal. (wikipedia.org)
Datos8
- Esta cuestión es especialmente importante porque el 25 de mayo de 2018 entra en vigor el nuevo Reglamento General de Protección de Datos (GDPR) adoptado por la Unión Europea, cuyos principales objetivos son devolver a los ciudadanos el control sobre su información personal y unificar el marco regulador para las multinacionales. (uc3m.es)
- Se enmarcan, pues, en la medicina de precisión y, dentro de esta, en la especialidad que se conoce como radiómica, esto es, una tecnología que, mediante el uso de la Inteligencia Artificial, convierte un gran número de imágenes médicas en datos cuantificables. (emprendedores.es)
- De esta forma, donde el ojo humano del especialista médico alcanza a ver en esa imagen la presencia de una mancha con determinado tamaño y ciertas variaciones en su crecimiento, las biopsias virtuales de Quibim dan un paso más allá y convierten los pixeles de esa imagen en miles y miles de datos útiles en los que basan sus algoritmos de Inteligencia Artificial. (emprendedores.es)
- Sin embargo, los opositores a la hipótesis de los mosaicos cerebrales señalan -y no sin razón- que algunos algoritmos de aprendizaje automático pueden usar datos neuroanatómicos para "predecir" correctamente el sexo de un individuo en un 80-90 % de los casos . (elmostrador.cl)
- A menudo utilizan resolvedores (solvers) de IP, LP y programación semidefinida, estructuras de datos complejas o técnicas de algoritmos sofisticadas que tienden a dificultar los problemas de implementación. (wikipedia.org)
- Dentro de la inteligencia artificial tenemos el machine learning, que es el aprendizaje automático en español, un subtipo de inteligencia artificial bastante específico, con programas que tienen la característica diferencial con el resto de los programas de inteligencia artificial, que aprenden de los datos. (medscape.com)
- Es como si se programara de una forma, eso es aprendizaje automático, se aprende de los datos. (medscape.com)
- La CIE-11 es la norma internacional para el registro, la notificación, el análisis, la interpretación y la comparación sistemáticos de los datos de mortalidad y morbilidad. (who.int)
Decisiones3
- En él se destaca la importancia de que los trabajadores participen en las decisiones sobre el uso de las nuevas tecnologías, especialmente las basadas en algoritmos. (uniglobalunion.org)
- Un algoritmo aleatorizado es un algoritmo que toma decisiones aleatorias como parte de su lógica. (upc.edu)
- Hoy, el poder se ha dronificado, opera de manera invisible y le ha encargado a un sofisticado amo del calabozo matemático, el algoritmo, demasiadas decisiones sobre nuestras vidas. (catarata.org)
Desarrollado3
- Científicos del Cuerpo Nacional de Policía y de la Universidad de Granada han desarrollado un sistema informático basado en algoritmos para predecir cuántos delitos y de qué tipo se van a producir en el próximo turno policial. (agenciasinc.es)
- Gawdat ha desarrollado lo que ha bautizado como el "algoritmo de la felicidad" , que adem s da nombre a su ltimo libro. (expansion.com)
- Científicos de Suiza han desarrollado un algoritmo que podría ayudar a frenar la lacra del spam y de los ataques online ya que es capaz de localizar a los spammers y la fuente de un malware insertado en un sistema. (itespresso.es)
Artificial9
- Eso sí: ese grupo de aproximadamente 20 editores ha ido reduciéndose, y algunos creen que el futuro de esta tarea de filtrado estará dominado por un algoritmo o sistema de inteligencia artificial que simplemente ha ido aprendiendo la forma de trabajar de estos expertos. (xataka.com)
- La inteligencia artificial (IA) es de odios o amores. (andinalink.com)
- Los debates van y vienen: que la inteligencia artificial (IA) va a reemplazar a los seres humanos, que hará que las personas seamos mediocres, que es el fin de las profesiones… En fin. (andinalink.com)
- Los debates van y vienen, pero lo que sí llegó para quedarse es la inteligencia artificial, y ahora, más que nunca, la encontramos en todas partes. (andinalink.com)
- Estas plataformas son cajas negras, combinaciones de algoritmos, sistemas de inteligencia artificial y curadores humanos secretos, sobre las cuales no existen posibilidades de auditoría. (razonpublica.com)
- La inteligencia artificial es un concepto muy grande, dentro del cual está aprendizaje automático que a su vez contiene aprendizaje profundo. (medscape.com)
- La idea es que tengamos una charla en relación a la inteligencia artificial, un tema del que se habla mucho y pareciera que es un término relativamente nuevo, cuando en realidad apareció en 1956, año en que se empezó a utilizar. (medscape.com)
- La inteligencia artificial es un término que el informático John McCarthy acuñó por primera vez en la conferencia de Darmouth de 1956, que ahora es legendaria. (medscape.com)
- Según lo que comentaste, inteligencia artificial es un concepto muy grande, dentro del cual está aprendizaje automático que a su vez contiene aprendizaje profundo. (medscape.com)
Programa5
- Si acertamos la clave, mostrar la clave es correcta y finalizar el programa. (scribd.com)
- Aunque se supone que quien realmente potencia ese algoritmo son los usuarios y su forma de utilizar la red social, el funcionamiento de ese programa es totalmente desconocido. (xataka.com)
- ALGORITMOS ABN Programa informátivo para trabajar el algoritmo ABN de la suma y de la resta. (diigo.com)
- El objetivo de un programa de gestión de incidencias es corregir los errores del análisis y de la comunicación que resulten de un incidente y cambiar el proceso de forma que sea poco probable que el error se repita. (who.int)
- La CIE-11 es fácil de instalar y usar en línea o fuera de línea utilizando un programa informático «contenedor» gratuito. (who.int)
Ordenador4
- Fue Durstenfeld quien primero hizo una transcripción en la forma de algoritmo para usarse en un ordenador. (wikipedia.org)
- Los algoritmos de ordenación fueron para mí, en un época de mi vida, una especie de obsesión geek que me llevó a investigar, en los albores de Internet, miles de horas delante de la pantalla del ordenador con el único objeto de diseñar algo que fuera más rápido que lo que yo ya conocía. (teknoplof.com)
- Un ordenador es incapaz de ordenar inteligentemente una lista de valores simplemente contemplándolos, como haría un ser humano. (teknoplof.com)
- Posteriormente, estos algoritmos se codifican en un lenguaje de programación para que un ordenador los entienda y los maneje convenientemente. (teknoplof.com)
Transparencia3
- Lógicamente, este tipo de aplicaciones demandan transparencia en el funcionamiento de los algoritmos. (enriquedans.com)
- El debate sobre la transparencia de los algoritmos está más de moda que nunca. (xataka.com)
- Imposible saber a ciencia cierta si es válido o no sin poder auditarlo, y de ahí la creciente presión por esa transparencia de los algoritmos que dominan nuestras vidas. (xataka.com)
Computacional1
- El análisis probabilístico de algoritmos estima la complejidad computacional de algoritmos o problemas asumiendo alguna distribución probabilística del conjunto de todas las entradas posibles. (upc.edu)
Sugiere2
- En primer lugar, el informe sugiere negociar los algoritmos, dando a los empleados influencia sobre cómo se introducen y utilizan los sistemas controlados por algoritmos. (uniglobalunion.org)
- Un algoritmo resalta temas usualmente populares, un humano los examina y los selecciona, y otro algoritmo sugiere las noticias a las personas que podrían estar interesadas. (enter.co)
Usar3
- Examinar las condiciones bajo las cuales se pueden usar algoritmos aleatorios. (upc.edu)
- Es posible usar Codetective de forma independiente (standalone) o como un plugin para el framework de Volatility. (segu-info.com.ar)
- Es más importante que un ingeniero conozca (y mejor si domina) esos principios fundamentales que la tecnología, lo demás es sólo aprender a usar una herramienta o aplicación. (eventoblog.com)
Respuesta2
- Si la respuesta es "Sí", proporcionar el número de mesas con el algoritmo o el cuestionario y el número total de mesas evaluadas en las columnas (N.o) y (N.o total). (cdc.gov)
- Si la respuesta es "Sí", proporcionar el número de puestos para higiene de manos funcionales en la zona de triaje y el número total de puestos evaluados en las columnas (N.o) y (N.o total). (cdc.gov)
Predecir1
- En cambio, para los opositores de la hipótesis de los mosaicos cerebrales lo realmente importante es que estos algoritmos pueden predecir el sexo de un individuo. (elmostrador.cl)
Contenido5
- Asumimos que el contenido personalizado que vemos es, en gran medida, el resultado de los gustos e intereses que expresamos durante nuestras búsquedas y mientras realizamos cualquier otra actividad en línea. (uc3m.es)
- Este contenido es inapropiado? (scribd.com)
- Entendemos que la colocaci n de anuncios por encima del contenido es bastante com n para muchos sitios web y los anuncios a menudo tienen un buen desempe o y ayudan a los editores a monetizar el contenido online. (forosdelweb.com)
- Escándalos continuos, residencia en paraísos fiscales, algoritmos de IA que deciden el contenido que se verá, censura incontestada, incitación al uso desenfrenado, y un largo etcétera. (cadenaser.com)
- Una red social española, que además se expande por Sudamérica, quiere remodelar la experiencia en sí misma, transformándola en algo más genuino y sereno, donde el usuario elige el contenido que quiere ver, donde prima la calidad sobre la cantidad y donde la persona está en el centro y no es el producto. (cadenaser.com)
Adecuados1
- No todos los algoritmos de aproximación son adecuados para todas las aplicaciones prácticas. (wikipedia.org)
Humano1
- En Quibim desarrollamos herramientas pioneras capaces de extraer la información oculta de las imágenes médicas convencionales, aquello que el ojo humano no es capaz de apreciar. (emprendedores.es)
Comprender2
- De alguna manera, creamos un laboratorio de experimentación social, no para comprender a los individuos, sino para comprender los algoritmos", comenta Esteban Moro. (uc3m.es)
- Uno de sus aspectos favorables es el análisis más allá de tecnicismos, con mezcla de vivencias personales, argumentos y rigor profesional, autocrítica, emociones y un lenguaje fácil de comprender para las mayorías. (lajiribilla.cu)
Operaciones2
- El diseño de algoritmos o algorítmica es un área central de las ciencias de la computación, también muy importante para la investigación de operaciones (también conocida como investigación operativa), en ingeniería del software y en otras disciplinas afines. (wikipedia.org)
- En ciencias de la computación e investigación de operaciones , un algoritmo de aproximación es un algoritmo usado para encontrar soluciones aproximadas a problemas de optimización . (wikipedia.org)
Personas4
- Posteriormente, se analizará la publicidad mostrada a estas personas para modelar las respuestas de los algoritmos de los sitios web. (uc3m.es)
- Así es que sí, los algoritmos pueden acarrear y de hecho acarrean, los prejuicios de las personas que los diseñan y aplican. (elpais.com)
- Al aplicar esta metodología, es latente el impacto en las ciudades del documento aprobado recientemente por el Infonavit sobre las Reglas de Carácter General, se han detectado áreas de oportunidad y alternativas para medir la cercanía que se propone, ya que las distancias recorridas por las personas pudieran ser más largas en detrimiento del objetivo establecido por el instituto de la vivienda. (cronica.com.mx)
- Por fortuna, este tipo de visión de negocio no es compartido por todas las personas, ni mucho menos. (cadenaser.com)
Capaz2
- Codetective es una herramienta de Francisco Gama capaz de reconocer el formato de salida de muchos algoritmos diferentes con muchas codificaciones posibles para facilitar el análisis. (segu-info.com.ar)
- Según parece, el algoritmo del App Store está fallando y no es capaz de mostrar las aplicaciones en su sección correcta. (actualidadiphone.com)
Basan2
- Si los algoritmos 'sugieren' más visualización basados en lo que ya ha visto, y las sugerencias se basan solo en el tema o el género, ¿qué le hace eso al arte del cine? (latercera.com)
- Los algoritmos, por definición, se basan en cálculos que tratan al espectador como un consumidor y nada más", añadió destacando el trabajo en plataformas como Criterion Channel, MUBI y TCM, quienes -a juicio de Scorsese- realizan una curatoría a conciencia. (latercera.com)
Pautas1
- Entonces, los algoritmos de ordenación son pautas que un software debe seguir para lograr ordenar una lista de elementos rápida y adecuadamente . (teknoplof.com)
Sistemas4
- Indica que la mayoría de ellos utilizan sistemas digitales en los que algoritmos, robots y cadenas de montaje controlan y supervisan el trabajo. (uniglobalunion.org)
- Al igual que queremos negociar sobre otras condiciones que afectan al entorno laboral, queremos negociar sobre algoritmos y sistemas de alta tecnología en el lugar de trabajo", escribe Linda Palmetzhofer, Presidenta de Handels, en un artículo de opinión del que es coautora la investigadora del informe. (uniglobalunion.org)
- En realidad el nombre y la definición del algoritmo estaban metidos en algún rincón olvidado de mi memoria, almacenado allí en alguna de las innumerables y aburridoras lecciones de diseño de sistemas operativos en interminables tardes de estudio, hace ya más años de los que me quiero acordar. (geeks.ms)
- Estos sistemas aprenden solos y la diferencia con otros, principalmente con la programación tradicional, es que cuando se programaba un software con una computadora se aplicaba mucho conocimiento. (medscape.com)
Permiten1
- 4. La mayoría de las pruebas disponibles no distinguen los subtipos de virus de la influenza A, y no permiten distinguir entre los virus de la influenza A estacional y los virus más nuevos de la influenza A, y posiblemente no detecten todos los virus nuevos de la influenza A. Si es necesario conocer el subtipo, se deben enviar los especímenes a un laboratorio de salud pública estatal. (cdc.gov)
Controlan1
- Pero eso no es lo más preocupante, los algoritmos controlan el mundo y las mujeres no pueden estar ausentes de los puestos de mando. (elpais.com)
Aleatorios1
- El objetivo de este curso es presentar el poder y la variedad de algoritmos aleatorios y profundizar en el análisis probabilístico de algoritmos. (upc.edu)
Realidad3
- Los algoritmos nos envuelven, pero lo hacen sin que sepamos qué hacen en realidad. (xataka.com)
- Existen muchas guías a nivel mundial, pero la realidad es que a veces es difícil que se utilicen y muchas veces los pacientes que reciben glucocortico[estero]ides no tienen esta protección. (medscape.com)
- Para ello, el acercamiento a los centros de investigación y análisis es fundamental, a fin de promover que la realidad de la Regiòn sea mejor conocida y comprendida. (bvsalud.org)
Usado1
- El algoritmo de Tonelli-Shanks (o algoritmo RESSOL) es el más usado. (wikibooks.org)
Crear1
- 3.- Crear un algoritmo que calcule la raz cuadrada del nmero que introduzca el usuario. (scribd.com)
Teniendo1
- Hola people necesito un algoritmo que me permita generar arboles, de forma aleatoria, teniendo por supuesto un arreglo de posibles valores que pueden tomar los nodos del arbol a generar. (lawebdelprogramador.com)
Caso4
- Hablábamos recientemente del caso de COMPAS , un algoritmo que sirve como polémico "ayudante" para los jueces del sistema judicial en Estados Unidos: este sistema aconseja a los magistrados sobre las penas que se deben imponer a aquellos declarados culpables de algún delito. (xataka.com)
- Lo que no está claro sin embargo es la repercusión global que tendrá esta ley en caso de finalmente, tal y como está previsto, es aprobada. (muycomputer.com)
- En su caso, este es un riesgo inherente que acompaña a una compañía que destina gran parte de las ganancias al I+D cuyos resultados son siempre inciertos. (emprendedores.es)
- El lector es responsable de la interpretación y el uso que haga de ese material, y en ningún caso la Organización Mundial de la Salud podrá ser considerada responsable de daño alguno causado por su utilización. (who.int)
Vida1
- El Algoritmo de la Vida. (lu.se)
Capaces1
- Si además buscamos, como ocurre en la actualidad, candidatos capaces de interactuar de manera adecuada a través de un canal en remoto, muchos de los criterios evaluados de esta manera pueden incluso convertirse en más relevantes: si no te encuentras cómodo interaccionando o hablando con una pantalla, es posible que debas empezar a preocuparte. (enriquedans.com)
Influencia1
- Una incidencia es cualquier acontecimiento que tenga una influencia negativa sobre una organización, incluidos su personal, el producto de la organización, los equipos o el entorno en el que opera. (who.int)
Inteligencia1
- La sociedad admira de los bomberos su valentía para estar en primera línea de fuego , pero hay una característica que destaca más dentro de su estrategia para la extinción, que es la inteligencia . (elconfidencial.com)
Muestra1
- Concretamente, ahora el algoritmo muestra preferentemente en el feed las publicaciones con mayor probabilidad de generar conversación y engagement entre conocidos . (italiafutura.it)
Utilizados1
- D., especialista en reumatología y clínica médica, directora de la Maestría en Osteología de la Facultad de Ciencias Médicas de la Universidad Nacional de Rosario (UNR), en Rosario, Argentina, y actual vicepresidenta de la Asociación Argentina de Osteología y Metabolismo Mineral, el estudio de la osteoporosis inducida por glucocorticoesteroides es "sumamente importante" porque son fármacos frecuentemente utilizados en variadas patologías. (medscape.com)
Laboral1
- La negociación de algoritmos, el aprovechamiento de los conocimientos y la experiencia de los empleados y el desarrollo de sus capacidades son pasos cruciales para mejorar el entorno laboral. (uniglobalunion.org)
Resultados2
- Además sólo revisaron resultados durante horas de trabajo, así que es probable que no hayan captado todos los errores. (enter.co)
- Si bien la mayoría de las pruebas de detección de la influenza tienen especificidad alta, los resultados falsos positivos son más comunes cuando la actividad de la influenza es baja. (cdc.gov)









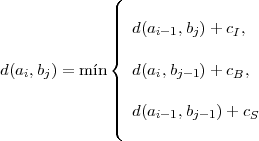
![Hardware Upgrade Forum - [Thread Ufficiale] Caricabatterie](https://lygte-info.dk/pic/SkyRC/MC3000/SkyRC%20MC3000%20charge%200.2A%20(eneloop)%20%231.png)