Pyrimidine Nucleotides
Purine Nucleotides
Pyrimidines
Nucleotides
Uridine Triphosphate
Orotic Acid
Orotate Phosphoribosyltransferase
Uracil Nucleotides
Dihydroorotase
Pyrimidine Nucleosides
Uridine Monophosphate
Aspartate Carbamoyltransferase
Pyrimidine Dimers
Orotidine-5'-Phosphate Decarboxylase
Carbamoyl-Phosphate Synthase (Glutamine-Hydrolyzing)
Uridine Kinase
Uridine
Cytidine Triphosphate
Uracil
Dihydroorotate Oxidase
Cytidine
Cytosine Nucleotides
Uridine Diphosphate
Ribonucleotides
3-Deazauridine
Pentosyltransferases
Nucleotide Transport Proteins
5'-Nucleotidase
Molecular Sequence Data
Carbamoyl-Phosphate Synthase (Ammonia)
Phosphonoacetic Acid
Phosphoribosyl Pyrophosphate
Purines
Deoxycytidine Monophosphate
Adenosine Triphosphate
Guanine Nucleotides
Escherichia coli
ortho-Aminobenzoates
Base Sequence
Nucleosides
Oxidoreductases Acting on CH-CH Group Donors
Nucleotidases
Substrate Specificity
Receptors, Purinergic P2
Amino Acid Sequence
DNA
Aspartic Acid
Nucleic Acid Conformation
Guanosine Triphosphate
Phosphotransferases
Adenosine Diphosphate
Adenine Nucleotides
Polymorphism, Single Nucleotide
Deoxyribonuclease (Pyrimidine Dimer)
Thymidine
Pyrimidine Phosphorylases
Ultraviolet Rays
Models, Molecular
Structure-Activity Relationship
RNA
Binding Sites
Catalytic Domain
Cloning, Molecular
Deoxyribodipyrimidine Photo-Lyase
DNA Repair
Synthesis and characterization of stacked and quenched uridine nucleotide fluorophores. (1/218)
Intramolecular aromatic interactions in aqueous solution often lead to stacked conformation for model organic molecules. This designing principle was used to develop stacked and folded uridine nucleotide analogs that showed highly quenched fluoroscence in aqueous solution by attaching the fluorophore 1-aminonaphthalene-5-sulfonate (AmNS) to the terminal phosphate via a phosphoramidate bond. Severalfold enhancement of fluorescence could be observed by destacking the molecules in organic solvents, such as isopropanol and dimethylsulfoxide or by enzymatic cleavage of the pyrophosphate bond. Stacking and destacking were confirmed by 1-H NMR spectroscopy. The extent of quenching of the uridine derivatives correlated very well with the extent of stacking. Taking 5-H as the monitor, temperature-variable NMR studies demonstrated the presence of a rapid interconversionary equilibrium between the stacked and open forms for uridine-5'-diphosphoro-beta-1-(5-sulfonic acid) naphthylamidate (UDPAmNS) in aqueous solution. DeltaH was calculated to be -2.3 Kcal/mol, with 43-50% of the population in stacked conformation. Fluorescence lifetime for UDPAmNS in water was determined to be 2.5 ns as against 11 ns in dimethyl sulfoxide or 15 ns for the pyrophosphate adduct of AmNS in water. Such a greatly reduced lifetime for UDPAmNS in water suggests collisional interaction between the pyrimidine and thefluorophore moieties to be responsible for quenching. The potential usefulness of such stacked and quenched nucleotide fluorophores as probes for protein-ligand interaction studies has been briefly discussed. (+info)Histidine 179 mutants of GTP cyclohydrolase I catalyze the formation of 2-amino-5-formylamino-6-ribofuranosylamino-4(3H)-pyrimidinone triphosphate. (2/218)
GTP cyclohydrolase I catalyzes the conversion of GTP to dihydroneopterin triphosphate. The replacement of histidine 179 by other amino acids affords mutant enzymes that do not catalyze the formation of dihydroneopterin triphosphate. However, some of these mutant proteins catalyze the conversion of GTP to 2-amino-5-formylamino-6-ribofuranosylamino-4(3H)-pyrimidinone 5'-triphosphate as shown by multinuclear NMR analysis. The equilibrium constant for the reversible conversion of GTP to the ring-opened derivative is approximately 0.1. The wild-type enzyme converts the formylamino pyrimidine derivative to dihydroneopterin triphosphate; the rate is similar to that observed with GTP as substrate. The data support the conclusion that the formylamino pyrimidine derivative is an intermediate in the overall reaction catalyzed by GTP cyclohydrolase I. (+info)Nucleotide sequence of an RNA polymerase binding site from the DNA of bacteriophage fd. (3/218)
The primary structure of a strong RNA polymerase binding site in the replicative form DNA of phage fd has been determined by direct DNA sequencing. It is: (see article). The molecule contains regions with 2-fold symmetry and sequence homologies to promoter regions from other DNAs. The startpoint of transcription is located in the center of the binding site. (+info)A search for base analogs to enhance third-strand binding to 'inverted' target base pairs of triplexes in the pyrimidine/parallel motif. (4/218)
Eight base analogs were tested as third strand residues in otherwise homopyrimidine strands opposite each of the 'direct' (A.T and G.C) and 'inverted' (T.A and C.G) Watson-Crick base pairs, using UV melting profiles to assess triplex stability. The target duplexes contained 20 A.T base pairs and a central test base pair X.Y, while the third strand contained 20 T residues and a central Z test base. Z included 5-bromo-uracil, 5-propynyluracil, 5-propynylcytosine, 5-methyl-cytosine, 5-bromocytosine, hypoxanthine, 2-amino-purine and 2,6-diaminopurine. Some of the base analogs enhanced third strand binding to the target duplex with one or other 'inverted' central base pair relative to the binding afforded by any of the canonical bases. Other analogs did the same for the duplexes with the 'direct' target pairs. The increasing order of triplex stabilization by these base analogs is: opposite the 'inverted' base pairs, for T.A, A < C < 5-pC < 5-pU < T < 5-BrC < 5-meC < 5-BrU < 2-AP < 2,6-DAP < Hy < G, for C.G, 2-AP < A < Hy < G < 5-pC < 5-BrC < 5-meC < C < 2,6-DAP < T < 5-BrU < 5-pU; opposite the 'direct' base pairs, for A.T, 2-AP < A < 5-meC < C < G < Hy < 2,6-DAP < 5-pU < T = 5-BrU < 5-BrC < 5-pC, for G.C, G < 2,6-DAP < 2-AP < A < Hy < T < 5-BrU < 5-pU < 5-pC < 5-BrC < C < 5-meC. (+info)Growth factor-regulated expression of enzymes involved in nucleotide biosynthesis: a novel mechanism of growth factor action. (5/218)
Keratinocyte growth factor (KGF) is a potent and specific mitogen for epithelial cells, including the keratinocytes of the skin. We investigated the mechanisms of action of KGF by searching for genes which are regulated by this growth factor in cultured human keratinocytes. Using the differential display RT-PCR technology we identified the gene encoding adenylosuccinate lyase [EC 4.3.2.2] as a novel KGF-regulated gene. Adenylosuccinate lyase plays an important role in purine de novo synthesis. To gain further insight into the potential role of nucleotide biosynthesis in the mitogenic effect of KGF, we cloned cDNA fragments of the key regulatory enzymes involved in purine and pyrimidine metabolism (adenylosuccinate synthetase [EC 6.3.4.4], phosphoribosyl pyrophosphate synthetase [EC 2.7.6.1], amidophosphoribosyl transferase [EC 2.4.2.14], hypoxanthine guanine phosphoribosyl transferase [EC 2.4.2.8] and the multifunctional protein CAD which includes the enzymatic activities of carbamoyl-phosphate synthetase II [EC 6.3.5.59], aspartate transcarbamylase [EC 2.1.3.2] and dihydroorotase [EC 3.5.2.3]). Expression of all of these enzymes was upregulated after treatment with KGF and also with epidermal growth factor (EGF), indicating that these mitogens stimulate nucleotide production by induction of these enzymes. To determine a possible in vivo correlation between the expression of KGF, EGF and the enzymes mentioned above, we analysed the expression of the enzymes during cutaneous wound repair, where high levels of these mitogens are present. Indeed, we found a strong mRNA expression of all of these enzymes in the EGF- and KGF-responsive keratinocytes of the hyperproliferative epithelium at the wound edge, indicating that their expression might also be regulated by growth factors during wound healing. (+info)In vitro recycling of alpha-D-ribose 1-phosphate for the salvage of purine bases. (6/218)
In this paper, we extend our previous observation on the mobilization of the ribose moiety from a purine nucleoside to a pyrimidine base, with subsequent pyrimidine nucleotides formation (Cappiello et al., Biochim. Biophys. Acta 1425 (1998) 273-281). The data show that, at least in vitro, also the reverse process is possible. In rat brain extracts, the activated ribose, stemming from uridine as ribose 1-phosphate, can be used to salvage adenine and hypoxanthine to their respective nucleotides. Since the salvage of purine bases is a 5-phosphoribosyl 1-pyrophosphate-dependent process, catalyzed by adenine phosphoribosyltransferase and hypoxanthine guanine phosphoribosyltransferase, our results imply that Rib-1P must be transformed into 5-phosphoribosyl 1-pyrophosphate, via the successive action of phosphopentomutase and 5-phosphoribosyl 1-pyrophosphate synthetase; and,in fact, no adenosine could be found as an intermediate when rat brain extracts were incubated with adenine, Rib-1P and ATP, showing that adenine salvage does not imply adenine ribosylation, followed by adenosine phosphorylation. Taken together with our previous results on the Rib-1P-dependent salvage of pyrimidine nucleotides, our results give a clear picture of the in vitro Rib-1P recycling, for both purine and pyrimidine salvage. (+info)Aliphatic analogues of nucleotides: synthesis and affinity towards nucleases. (7/218)
DL-1-(2,3-Dihydroxypropyl)thymine was prepared by Hilbert-Johnson reaction of 2,4-dinethoxy-5-methylpyrimidine with allyl bromide followed by the osmium tetroxide catalyzed hydroxylation of the l-allyl-4-methoxy-5-methylpyrimidin-2-one obtained as an intermediate. The D-glycero enantiomer, R-1-(2,3-dihydroxypropyl)thymine and the corresponding 1-substituted uracil derivative were prepared from 3-O-p-toluenesulfonyl-1, 2-O-isopropylidene-D-glycerine and sodium salt of 4-methoxy-5-methylpyrimidin-2-one or 4-methoxypyrimidin-2-one followed by treatment with hydrogen chloride in ethanol. The phosphorylation of the above 2,3-dihydroxypropyl derivatives with phosphoryl chloride in triethyl phosphate afforded the corresponding 3-phosphates which were transformed into the 2',3'-cyclic phosphates by the condensation with N,N'-dicyclohexylcarbodiimide. The latter compounds of the D-glycero configuration are split by some microbial RNases to the 3-phosphates. (+info)Cleavage of the glycosidic linkage of pyrimidine ribonucleosides by the bisulfite-oxygen system. (8/218)
When a solution containing 2 mM uridine, 20 mM sodium bisulfite, 0.1 mM MnCl(2), and 100 mM sodium phosphate buffer of pH 7.0 was incubated aerobically at 37 degrees or 0 degrees , partial cleavage of the glycosidic linkage of uridine took place. About 20% of the uridine was converted to uracil by the incubation for 4 hrs. Cytosine was produced from cytidine by similar treatment with bisulfite. These reactions were caused by free radicals generated by Mn(2+)-catalyzed autoxidation of bisulfite. Glycosidic bond cleavage by the bisulfite-oxygen system was not detected for adenosine, AMP, guanosine, GMP, thymidine, TMP, deoxyuridine, dCMP, dAMP, and dGMP. When poly(U) and poly(C) were treated with 20 mM sodium bisulfite in the same manner, chain fission of the polymer occurred as judged by the elution-pattern change in gel filtration through Sephadex columns. No change in the elution pattern was observed for bisulfite-treated poly(A), poly(U). poly(A) or tRNA. (+info)Pyrimidine nucleotides are organic compounds that play crucial roles in various biological processes, particularly in the field of genetics and molecular biology. They are the building blocks of nucleic acids, which include DNA and RNA, and are essential for the storage, transmission, and expression of genetic information within cells.
Pyrimidine is a heterocyclic aromatic organic compound similar to benzene and pyridine, containing two nitrogen atoms at positions 1 and 3 of the six-member ring. Pyrimidine nucleotides are derivatives of pyrimidine, which contain a phosphate group, a pentose sugar (ribose or deoxyribose), and one of three pyrimidine bases: cytosine (C), thymine (T), or uracil (U).
* Cytosine is present in both DNA and RNA. It pairs with guanine via hydrogen bonding during DNA replication and transcription.
* Thymine is exclusively found in DNA, where it pairs with adenine through two hydrogen bonds.
* Uracil is a pyrimidine base that replaces thymine in RNA molecules and pairs with adenine via two hydrogen bonds during RNA transcription.
Pyrimidine nucleotides, along with purine nucleotides (adenine, guanine, and their derivatives), form the fundamental units of nucleic acids, contributing to the structure, function, and regulation of genetic material in living organisms.
Purine nucleotides are fundamental units of life that play crucial roles in various biological processes. A purine nucleotide is a type of nucleotide, which is the basic building block of nucleic acids such as DNA and RNA. Nucleotides consist of a nitrogenous base, a pentose sugar, and at least one phosphate group.
In purine nucleotides, the nitrogenous bases are either adenine (A) or guanine (G). These bases are attached to a five-carbon sugar called ribose in the case of RNA or deoxyribose for DNA. The sugar and base together form the nucleoside, while the addition of one or more phosphate groups creates the nucleotide.
Purine nucleotides have several vital functions within cells:
1. Energy currency: Adenosine triphosphate (ATP) is a purine nucleotide that serves as the primary energy currency in cells, storing and transferring chemical energy for various cellular processes.
2. Genetic material: Both DNA and RNA contain purine nucleotides as essential components of their structures. Adenine pairs with thymine (in DNA) or uracil (in RNA), while guanine pairs with cytosine.
3. Signaling molecules: Purine nucleotides, such as adenosine monophosphate (AMP) and cyclic adenosine monophosphate (cAMP), act as intracellular signaling molecules that regulate various cellular functions, including metabolism, gene expression, and cell growth.
4. Coenzymes: Purine nucleotides can also function as coenzymes, assisting enzymes in catalyzing biochemical reactions. For example, nicotinamide adenine dinucleotide (NAD+) is a purine nucleotide that plays a critical role in redox reactions and energy metabolism.
In summary, purine nucleotides are essential biological molecules involved in various cellular functions, including energy transfer, genetic material formation, intracellular signaling, and enzyme cofactor activity.
Pyrimidines are heterocyclic aromatic organic compounds similar to benzene and pyridine, containing two nitrogen atoms at positions 1 and 3 of the six-member ring. They are one of the two types of nucleobases found in nucleic acids, the other being purines. The pyrimidine bases include cytosine (C) and thymine (T) in DNA, and uracil (U) in RNA, which pair with guanine (G) and adenine (A), respectively, through hydrogen bonding to form the double helix structure of nucleic acids. Pyrimidines are also found in many other biomolecules and have various roles in cellular metabolism and genetic regulation.
Nucleotides are the basic structural units of nucleic acids, such as DNA and RNA. They consist of a nitrogenous base (adenine, guanine, cytosine, thymine or uracil), a pentose sugar (ribose in RNA and deoxyribose in DNA) and one to three phosphate groups. Nucleotides are linked together by phosphodiester bonds between the sugar of one nucleotide and the phosphate group of another, forming long chains known as polynucleotides. The sequence of these nucleotides determines the genetic information carried in DNA and RNA, which is essential for the functioning, reproduction and survival of all living organisms.
Uridine Triphosphate (UTP) is a nucleotide that plays a crucial role in the synthesis and repair of DNA and RNA. It consists of a nitrogenous base called uracil, a pentose sugar (ribose), and three phosphate groups. UTP is one of the four triphosphates used in the biosynthesis of RNA during transcription, where it donates its uracil base to the growing RNA chain. Additionally, UTP serves as an energy source and a substrate in various biochemical reactions within the cell, including phosphorylation processes and the synthesis of glycogen and other molecules.
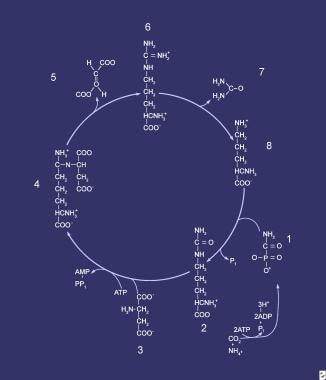
Orotic acid, also known as pyrmidine carboxylic acid, is a organic compound that plays a role in the metabolic pathway for the biosynthesis of pyrimidines, which are nitrogenous bases found in nucleotides and nucleic acids such as DNA and RNA. Orotic acid is not considered to be a vitamin, but it is sometimes referred to as vitamin B13 or B15, although these designations are not widely recognized by the scientific community.
In the body, orotic acid is converted into orotidine monophosphate (OMP) by the enzyme orotate phosphoribosyltransferase. OMP is then further metabolized to form uridine monophosphate (UMP), a pyrimidine nucleotide that is an important precursor for the synthesis of RNA and other molecules.
Elevated levels of orotic acid in the urine, known as orotic aciduria, can be a sign of certain genetic disorders that affect the metabolism of pyrimidines. These conditions can lead to an accumulation of orotic acid and other pyrimidine precursors in the body, which can cause a range of symptoms including developmental delays, neurological problems, and kidney stones. Treatment for these disorders typically involves dietary restrictions and supplementation with nucleotides or nucleosides to help support normal pyrimidine metabolism.
Orotate phosphoribosyltransferase (OPRT) is an enzyme that catalyzes the conversion of orotate to oximine monophosphate (OMP), which is a key step in the biosynthesis of pyrimidines, a type of nucleotide. This enzyme plays a crucial role in the metabolism of nucleic acids, which are the building blocks of DNA and RNA.
The reaction catalyzed by OPRT is as follows:
orotate + phosphoribosyl pyrophosphate (PRPP) -> oximine monophosphate (OMP) + pyrophosphate
Defects in the gene that encodes for OPRT can lead to orotic aciduria, a rare genetic disorder characterized by an accumulation of orotic acid and other pyrimidines in the urine and other body fluids. Symptoms of this condition may include developmental delay, mental retardation, seizures, and megaloblastic anemia.
Uracil nucleotides are chemical compounds that play a crucial role in the synthesis, repair, and replication of DNA and RNA. Specifically, uracil nucleotides refer to the group of molecules that contain the nitrogenous base uracil, which is linked to a ribose sugar through a beta-glycosidic bond. This forms the nucleoside uridine, which can then be phosphorylated to create the uracil nucleotide.
Uracil nucleotides are important in the formation of RNA, where uracil base pairs with adenine through two hydrogen bonds during transcription. However, uracil is not typically found in DNA, and its presence in DNA can indicate damage or mutation. When uracil is found in DNA, it is usually the result of a process called deamination, where the nitrogenous base cytosine is spontaneously converted to uracil. This can lead to errors during replication, as uracil will pair with adenine instead of guanine, leading to a C-to-T or G-to-A mutation.
To prevent this type of mutation, cells have enzymes called uracil DNA glycosylases that recognize and remove uracil from DNA. This initiates the base excision repair pathway, which removes the damaged nucleotide and replaces it with a correct one. Overall, uracil nucleotides are essential for proper cellular function, but their misincorporation into DNA can have serious consequences for genome stability.
Dihydroorotase is an enzyme that plays a crucial role in the synthesis of pyrimidines, which are essential components of nucleic acids such as DNA and RNA. Specifically, dihydroorotase catalyzes the conversion of N-carbamoyl-L-aspartate into L-dihydroorotate and L-carbamoyl aspartate in the third step of de novo pyrimidine biosynthesis.
The reaction catalyzed by dihydroorotase is:
N-carbamoyl-L-aspartate + H2O → L-dihydroorotate + L-carbamoyl aspartate
Dihydroorotase is a member of the amidohydrolase superfamily and functions as a homodimer or homotetramer. In humans, dihydroorotase is encoded by the DHODH gene and is found in the cytoplasm of cells. Defects in this enzyme can lead to a rare genetic disorder called dihydropyrimidine dehydrogenase deficiency, which is characterized by an accumulation of pyrimidines and their precursors in the body.
Pyrimidine nucleosides are organic compounds that consist of a pyrimidine base (a heterocyclic aromatic ring containing two nitrogen atoms and four carbon atoms) linked to a sugar molecule, specifically ribose or deoxyribose, via a β-glycosidic bond. The pyrimidine bases found in nucleosides can be cytosine (C), thymine (T), or uracil (U). When the sugar component is ribose, it is called a pyrimidine nucleoside, and when it is linked to deoxyribose, it is referred to as a deoxy-pyrimidine nucleoside. These molecules play crucial roles in various biological processes, particularly in the structure and function of nucleic acids such as DNA and RNA.
Uridine Monophosphate (UMP) is a nucleotide that is a constituent of RNA (Ribonucleic Acid). It consists of a nitrogenous base called Uridine, linked to a sugar molecule (ribose) and a phosphate group. UMP plays a crucial role in various biochemical reactions within the body, including energy transfer and cellular metabolism. It is also involved in the synthesis of other nucleotides and serves as an important precursor in the production of genetic material during cell division.
Aspartate carbamoyltransferase (ACT) is a crucial enzyme in the urea cycle, which is the biochemical pathway responsible for the elimination of excess nitrogen waste from the body. This enzyme catalyzes the second step of the urea cycle, where it facilitates the transfer of a carbamoyl group from carbamoyl phosphate to aspartic acid, forming N-acetylglutamic semialdehyde and releasing phosphate in the process.
The reaction catalyzed by aspartate carbamoyltransferase is as follows:
Carbamoyl phosphate + L-aspartate → N-acetylglutamic semialdehyde + P\_i + CO\_2
This enzyme plays a critical role in maintaining nitrogen balance and preventing the accumulation of toxic levels of ammonia in the body. Deficiencies or mutations in aspartate carbamoyltransferase can lead to serious metabolic disorders, such as citrullinemia and hyperammonemia, which can have severe neurological consequences if left untreated.
Pyrimidine dimers are a type of DNA lesion that form when two adjacent pyrimidine bases on the same strand of DNA become covalently linked, usually as a result of exposure to ultraviolet (UV) light. The most common type of pyrimidine dimer is the cyclobutane pyrimidine dimer (CPD), which forms when two thymine bases are linked together in a cyclobutane ring structure.
Pyrimidine dimers can distort the DNA helix and interfere with normal replication and transcription processes, leading to mutations and potentially cancer. The formation of pyrimidine dimers is a major mechanism by which UV radiation causes skin damage and increases the risk of skin cancer.
The body has several mechanisms for repairing pyrimidine dimers, including nucleotide excision repair (NER) and base excision repair (BER). However, if these repair mechanisms are impaired or overwhelmed, pyrimidine dimers can persist and contribute to the development of cancer.
Orotidine-5’-phosphate decarboxylase (ODC) is an enzyme that is involved in the synthesis of pyrimidines, which are essential nucleotides required for the production of DNA and RNA. The gene that encodes this enzyme is called UMPS.
ODC catalyzes the decarboxylation of orotidine-5’-phosphate (OMP) to form uridine monophosphate (UMP), which is a precursor to other pyrimidines such as cytidine triphosphate (CTP) and thymidine triphosphate (TTP). This reaction is the fifth step in the de novo synthesis of pyrimidines.
Defects in the ODC enzyme can lead to a rare genetic disorder called orotic aciduria, which is characterized by an accumulation of orotic acid and orotidine in the urine, as well as neurological symptoms such as developmental delay, seizures, and ataxia. Treatment for this condition typically involves supplementation with uridine and a low-protein diet to reduce the production of excess orotic acid.
Uridine kinase is an enzyme that phosphorylates the pyrimidine nucleoside uridine to produce uridine monophosphate (UMP). This reaction plays a crucial role in the salvage pathway of pyrimidine nucleotide synthesis, which recycles nucleosides generated from the degradation of RNA.
The human genome encodes two isoforms of uridine kinase, UCK1 and UCK2, which share a high degree of sequence similarity but have distinct tissue expression patterns and subcellular localization. UCK1 is primarily expressed in the liver and kidney, while UCK2 is more widely expressed in various tissues.
Uridine kinase activity has been implicated in several physiological processes, including the regulation of intracellular nucleotide pools, the biosynthesis of glycosaminoglycans and proteoglycans, and the modulation of antiviral responses. Dysregulation of uridine kinase activity has been associated with various pathological conditions, such as cancer, viral infections, and neurological disorders.
Uridine is a nucleoside that consists of a pyrimidine base (uracil) linked to a pentose sugar (ribose). It is a component of RNA, where it pairs with adenine. Uridine can also be found in various foods such as beer, broccoli, yeast, and meat. In the body, uridine can be synthesized from orotate or from the breakdown of RNA. It has several functions, including acting as a building block for RNA, contributing to energy metabolism, and regulating cell growth and differentiation. Uridine is also available as a dietary supplement and has been studied for its potential benefits in various health conditions.
Cytidine triphosphate (CTP) is a nucleotide that plays a crucial role in the synthesis of RNA. It consists of a cytosine base, a ribose sugar, and three phosphate groups. Cytidine triphosphate is one of the four main building blocks of RNA, along with adenosine triphosphate (ATP), guanosine triphosphate (GTP), and uridine triphosphate (UTP). These nucleotides are essential for various cellular processes, including energy transfer, signal transduction, and biosynthesis. CTP is also involved in the regulation of several metabolic pathways and serves as a cofactor for enzymes that catalyze biochemical reactions. Like other triphosphate nucleotides, CTP provides energy for cellular functions by donating its phosphate groups in energy-consuming processes.
Uracil is not a medical term, but it is a biological molecule. Medically or biologically, uracil can be defined as one of the four nucleobases in the nucleic acid of RNA (ribonucleic acid) that is linked to a ribose sugar by an N-glycosidic bond. It forms base pairs with adenine in double-stranded RNA and DNA. Uracil is a pyrimidine derivative, similar to thymine found in DNA, but it lacks the methyl group (-CH3) that thymine has at the 5 position of its ring.
Dihydroorotate oxidase is a mitochondrial enzyme that plays a crucial role in the de novo biosynthesis of pyrimidines, which are essential nucleotides required for the synthesis of DNA, RNA, and other vital molecules in the body.
The enzyme catalyzes the oxidation of dihydroorotate to orotate, using molecular oxygen as an electron acceptor. This reaction is the third step in the pyrimidine biosynthesis pathway, following the condensation of carbamoyl phosphate and aspartate to form carbamoylaspartate, and the decarboxylation of carbamoylaspartate to form dihydroorotate.
Dihydroorotate oxidase is a flavoprotein that contains a FAD cofactor, which accepts electrons from dihydroorotate and transfers them to molecular oxygen, generating hydrogen peroxide as a byproduct. The enzyme is inhibited by the drug leflunomide, which is used in the treatment of rheumatoid arthritis and other autoimmune diseases.
In humans, dihydroorotate oxidase is encoded by two genes, DHODH and SUOX, which are located on different chromosomes. Mutations in these genes can lead to deficiencies in pyrimidine biosynthesis and result in various genetic disorders, such as Miller syndrome, a rare autosomal recessive disorder characterized by craniofacial abnormalities, limb defects, and hearing loss.
Cytidine is a nucleoside, which consists of the sugar ribose and the nitrogenous base cytosine. It is an important component of RNA (ribonucleic acid), where it pairs with guanosine via hydrogen bonding to form a base pair. Cytidine can also be found in some DNA (deoxyribonucleic acid) sequences, particularly in viral DNA and in mitochondrial DNA.
Cytidine can be phosphorylated to form cytidine monophosphate (CMP), which is a nucleotide that plays a role in various biochemical reactions in the body. CMP can be further phosphorylated to form cytidine diphosphate (CDP) and cytidine triphosphate (CTP), which are involved in the synthesis of lipids, glycogen, and other molecules.
Cytidine is also available as a dietary supplement and has been studied for its potential benefits in treating various health conditions, such as liver disease and cancer. However, more research is needed to confirm these potential benefits and establish safe and effective dosages.
Cytosine nucleotides are the chemical units or building blocks that make up DNA and RNA, one of the four nitrogenous bases that form the rung of the DNA ladder. A cytosine nucleotide is composed of a cytosine base attached to a sugar molecule (deoxyribose in DNA and ribose in RNA) and at least one phosphate group. The sequence of these nucleotides determines the genetic information stored in an organism's genome. In particular, cytosine nucleotides pair with guanine nucleotides through hydrogen bonding to form base pairs that are held together by weak interactions. This pairing is specific and maintains the structure and integrity of the DNA molecule during replication and transcription.
Uridine diphosphate (UDP) is a nucleotide diphosphate that consists of a pyrophosphate group, a ribose sugar, and the nucleobase uracil. It plays a crucial role as a coenzyme in various biosynthetic reactions, including the synthesis of glycogen, proteoglycans, and other polysaccharides. UDP is also involved in the detoxification of bilirubin, an end product of hemoglobin breakdown, by converting it to a water-soluble form that can be excreted through the bile. Additionally, UDP serves as a precursor for the synthesis of other nucleotides and their derivatives.
Ribonucleotides are organic compounds that consist of a ribose sugar, a phosphate group, and a nitrogenous base. They are the building blocks of RNA (ribonucleic acid), one of the essential molecules in all living organisms. The nitrogenous bases found in ribonucleotides include adenine, uracil, guanine, and cytosine. These molecules play crucial roles in various biological processes, such as protein synthesis, gene expression, and cellular energy production. Ribonucleotides can also be involved in cell signaling pathways and serve as important cofactors for enzymatic reactions.
3-Deazauridine is a chemical compound that is an analog of the nucleoside uridine. In this case, the nitrogen atom at the 3 position of the uracil ring has been replaced with a carbon atom. This modification can affect the way the molecule is processed in cells and can be used in research to study various biological processes. It's important to note that 3-Deazauridine itself does not have any specific medical definition or application, but it might be used in certain biochemical or pharmacological studies.
Pentosyltransferases are a group of enzymes that catalyze the transfer of a pentose (a sugar containing five carbon atoms) molecule from one compound to another. These enzymes play important roles in various biochemical pathways, including the biosynthesis of nucleotides, glycoproteins, and other complex carbohydrates.
One example of a pentosyltransferase is the enzyme that catalyzes the addition of a ribose sugar to form a glycosidic bond with a purine or pyrimidine base during the biosynthesis of nucleotides, which are the building blocks of DNA and RNA.
Another example is the enzyme that adds xylose residues to proteins during the formation of glycoproteins, which are proteins that contain covalently attached carbohydrate chains. These enzymes are essential for many biological processes and have been implicated in various diseases, including cancer and neurodegenerative disorders.
Nucleotide transport proteins are specialized membrane-bound proteins that facilitate the passive or active transport of nucleotides, such as adenosine triphosphate (ATP), guanosine triphosphate (GTP), and their precursors, across biological membranes. These proteins play a crucial role in maintaining the intracellular concentration of nucleotides, which are essential for various cellular processes, including energy metabolism, biosynthesis, and signal transduction.
There are two main types of nucleotide transport proteins: equilibrative nucleoside transporters (ENTs) and concentrative nucleoside transporters (CNTs). ENTs facilitate the passive diffusion of nucleosides and some nucleotides down their concentration gradient, while CNTs actively transport these molecules against their concentration gradient using energy derived from sodium or proton gradients.
These proteins are vital for cellular homeostasis and have been implicated in several diseases, including cancer and neurological disorders. Understanding the structure, function, and regulation of nucleotide transport proteins can provide valuable insights into their role in health and disease, potentially leading to the development of novel therapeutic strategies.
5'-Nucleotidase is an enzyme that is found on the outer surface of cell membranes, including those of liver cells and red blood cells. Its primary function is to catalyze the hydrolysis of nucleoside monophosphates, such as adenosine monophosphate (AMP) and guanosine monophosphate (GMP), to their corresponding nucleosides, such as adenosine and guanosine, by removing a phosphate group from the 5' position of the nucleotide.
Abnormal levels of 5'-Nucleotidase in the blood can be indicative of liver or bone disease. For example, elevated levels of this enzyme in the blood may suggest liver damage or injury, such as that caused by hepatitis, cirrhosis, or alcohol abuse. Conversely, low levels of 5'-Nucleotidase may be associated with certain types of anemia, including aplastic anemia and paroxysmal nocturnal hemoglobinuria.
Medical professionals may order a 5'-Nucleotidase test to help diagnose or monitor the progression of these conditions. It is important to note that other factors, such as medication use or muscle damage, can also affect 5'-Nucleotidase levels, so results must be interpreted in conjunction with other clinical findings and diagnostic tests.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
Phosphonoacetic acid (PAA) is not a naturally occurring substance, but rather a synthetic compound that is used in medical and scientific research. It is a colorless, crystalline solid that is soluble in water.
In a medical context, PAA is an inhibitor of certain enzymes that are involved in the replication of viruses, including HIV. It works by binding to the active site of these enzymes and preventing them from carrying out their normal functions. As a result, PAA has been studied as a potential antiviral agent, although it is not currently used as a medication.
It's important to note that while PAA has shown promise in laboratory studies, its safety and efficacy have not been established in clinical trials, and it is not approved for use as a drug by regulatory agencies such as the U.S. Food and Drug Administration (FDA).
Phosphoribosyl Pyrophosphate (PRPP) is defined as a key intracellular nucleotide metabolite that plays an essential role in the biosynthesis of purine and pyrimidine nucleotides, which are the building blocks of DNA and RNA. PRPP is synthesized from ribose 5-phosphate and ATP by the enzyme PRPP synthase. It contributes a phosphoribosyl group in the conversion of purines and pyrimidines to their corresponding nucleotides, which are critical for various cellular processes such as DNA replication, repair, and gene expression. Abnormal levels of PRPP have been implicated in several genetic disorders, including Lesch-Nyhan syndrome and PRPP synthetase superactivity.
Purines are heterocyclic aromatic organic compounds that consist of a pyrimidine ring fused to an imidazole ring. They are fundamental components of nucleotides, which are the building blocks of DNA and RNA. In the body, purines can be synthesized endogenously or obtained through dietary sources such as meat, seafood, and certain vegetables.
Once purines are metabolized, they are broken down into uric acid, which is excreted by the kidneys. Elevated levels of uric acid in the body can lead to the formation of uric acid crystals, resulting in conditions such as gout or kidney stones. Therefore, maintaining a balanced intake of purine-rich foods and ensuring proper kidney function are essential for overall health.
Deoxycytidine monophosphate (dCMP) is a nucleotide that is a building block of DNA. It consists of the sugar deoxyribose, the base cytosine, and one phosphate group. Nucleotides like dCMP are linked together through the phosphate groups to form long chains of DNA. In this way, dCMP plays an essential role in the structure and function of DNA, including the storage and transmission of genetic information.
Organomercury compounds are organic chemical compounds that contain at least one mercury atom bonded to carbon. These compounds can be divided into two main categories: those with a covalent bond between carbon and mercury (carbon-mercury bonds), and those with a coordination bond where mercury acts as a ligand to a metal center.
The carbon-mercury bonds are typically found in organometallic compounds, which contain at least one direct bond between a carbon atom and a metal. Examples of organomercury compounds include methylmercury (CH3Hg+) and phenylmercury (C6H5Hg+). These types of organomercury compounds are often used in industry as catalysts, fungicides, and disinfectants. However, they can be highly toxic to humans and the environment, particularly methylmercury which is a potent neurotoxin that can accumulate in the food chain.
The coordination compounds of mercury are those where mercury acts as a ligand, binding to a metal center through a coordinate covalent bond. These types of organomercury compounds are less common and tend to be less toxic than those with carbon-mercury bonds. They may be used in some chemical reactions or as reagents in laboratory settings.
It is important to note that exposure to organomercury compounds should be avoided, as they can have serious health effects even at low levels of exposure.
Adenosine Triphosphate (ATP) is a high-energy molecule that stores and transports energy within cells. It is the main source of energy for most cellular processes, including muscle contraction, nerve impulse transmission, and protein synthesis. ATP is composed of a base (adenine), a sugar (ribose), and three phosphate groups. The bonds between these phosphate groups contain a significant amount of energy, which can be released when the bond between the second and third phosphate group is broken, resulting in the formation of adenosine diphosphate (ADP) and inorganic phosphate. This process is known as hydrolysis and can be catalyzed by various enzymes to drive a wide range of cellular functions. ATP can also be regenerated from ADP through various metabolic pathways, such as oxidative phosphorylation or substrate-level phosphorylation, allowing for the continuous supply of energy to cells.
Guanine nucleotides are molecules that play a crucial role in intracellular signaling, cellular regulation, and various biological processes within cells. They consist of a guanine base, a sugar (ribose or deoxyribose), and one or more phosphate groups. The most common guanine nucleotides are GDP (guanosine diphosphate) and GTP (guanosine triphosphate).
GTP is hydrolyzed to GDP and inorganic phosphate by certain enzymes called GTPases, releasing energy that drives various cellular functions such as protein synthesis, signal transduction, vesicle transport, and cell division. On the other hand, GDP can be rephosphorylated back to GTP by nucleotide diphosphate kinases, allowing for the recycling of these molecules within the cell.
In addition to their role in signaling and regulation, guanine nucleotides also serve as building blocks for RNA (ribonucleic acid) synthesis during transcription, where they pair with cytosine nucleotides via hydrogen bonds to form base pairs in the resulting RNA molecule.
In the context of medicine and pharmacology, "kinetics" refers to the study of how a drug moves throughout the body, including its absorption, distribution, metabolism, and excretion (often abbreviated as ADME). This field is called "pharmacokinetics."
1. Absorption: This is the process of a drug moving from its site of administration into the bloodstream. Factors such as the route of administration (e.g., oral, intravenous, etc.), formulation, and individual physiological differences can affect absorption.
2. Distribution: Once a drug is in the bloodstream, it gets distributed throughout the body to various tissues and organs. This process is influenced by factors like blood flow, protein binding, and lipid solubility of the drug.
3. Metabolism: Drugs are often chemically modified in the body, typically in the liver, through processes known as metabolism. These changes can lead to the formation of active or inactive metabolites, which may then be further distributed, excreted, or undergo additional metabolic transformations.
4. Excretion: This is the process by which drugs and their metabolites are eliminated from the body, primarily through the kidneys (urine) and the liver (bile).
Understanding the kinetics of a drug is crucial for determining its optimal dosing regimen, potential interactions with other medications or foods, and any necessary adjustments for special populations like pediatric or geriatric patients, or those with impaired renal or hepatic function.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
Ortho-Aminobenzoates are chemical compounds that contain a benzene ring substituted with an amino group in the ortho position and an ester group in the form of a benzoate. They are often used as pharmaceutical intermediates, plastic additives, and UV stabilizers. In medical contexts, one specific ortho-aminobenzoate, para-aminosalicylic acid (PABA), is an antibiotic used in the treatment of tuberculosis. However, it's important to note that "ortho-aminobenzoates" in general do not have a specific medical definition and can refer to any compound with this particular substitution pattern on a benzene ring.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
A nucleoside is a biochemical molecule that consists of a pentose sugar (a type of simple sugar with five carbon atoms) covalently linked to a nitrogenous base. The nitrogenous base can be one of several types, including adenine, guanine, cytosine, thymine, or uracil. Nucleosides are important components of nucleic acids, such as DNA and RNA, which are the genetic materials found in cells. They play a crucial role in various biological processes, including cell division, protein synthesis, and gene expression.
Oxidoreductases acting on CH-CH group donors are a class of enzymes within the larger group of oxidoreductases, which are responsible for catalyzing oxidation-reduction reactions. Specifically, this subclass of enzymes acts upon donors containing a carbon-carbon (CH-CH) bond, where one atom or group of atoms is oxidized and another is reduced during the reaction process. These enzymes play crucial roles in various metabolic pathways, including the breakdown and synthesis of carbohydrates, lipids, and amino acids.
The reactions catalyzed by these enzymes involve the transfer of electrons and hydrogen atoms between the donor and an acceptor molecule. This process often results in the formation or cleavage of carbon-carbon bonds, making them essential for numerous biological processes. The systematic name for this class of enzymes is typically structured as "donor:acceptor oxidoreductase," where donor and acceptor represent the molecules involved in the electron transfer process.
Examples of enzymes that fall under this category include:
1. Aldehyde dehydrogenases (EC 1.2.1.3): These enzymes catalyze the oxidation of aldehydes to carboxylic acids, using NAD+ as an electron acceptor.
2. Dihydrodiol dehydrogenase (EC 1.3.1.14): This enzyme is responsible for the oxidation of dihydrodiols to catechols in the biodegradation of aromatic compounds.
3. Succinate dehydrogenase (EC 1.3.5.1): A key enzyme in the citric acid cycle, succinate dehydrogenase catalyzes the oxidation of succinate to fumarate and reduces FAD to FADH2.
4. Xylose reductase (EC 1.1.1.307): This enzyme is involved in the metabolism of pentoses, where it reduces xylose to xylitol using NADPH as a cofactor.
Nucleotidases are a class of enzymes that catalyze the hydrolysis of nucleotides into nucleosides and phosphate groups. Nucleotidases play important roles in various biological processes, including the regulation of nucleotide concentrations within cells, the salvage pathways for nucleotide synthesis, and the breakdown of nucleic acids during programmed cell death (apoptosis).
There are several types of nucleotidases that differ in their substrate specificity and subcellular localization. These include:
1. Nucleoside monophosphatases (NMPs): These enzymes hydrolyze nucleoside monophosphates (NMPs) into nucleosides and inorganic phosphate.
2. Nucleoside diphosphatases (NDPs): These enzymes hydrolyze nucleoside diphosphates (NDPs) into nucleoside monophosphates (NMPs) and inorganic phosphate.
3. Nucleoside triphosphatases (NTPs): These enzymes hydrolyze nucleoside triphosphates (NTPs) into nucleoside diphosphates (NDPs) and inorganic phosphate.
4. 5'-Nucleotidase: This enzyme specifically hydrolyzes the phosphate group from the 5' position of nucleoside monophosphates, producing nucleosides.
5. Pyrophosphatases: These enzymes hydrolyze pyrophosphates into two phosphate groups and play a role in regulating nucleotide metabolism.
Nucleotidases are widely distributed in nature and can be found in various tissues, organs, and biological fluids, including blood, urine, and cerebrospinal fluid. Dysregulation of nucleotidase activity has been implicated in several diseases, such as cancer, neurodegenerative disorders, and infectious diseases.
Substrate specificity in the context of medical biochemistry and enzymology refers to the ability of an enzyme to selectively bind and catalyze a chemical reaction with a particular substrate (or a group of similar substrates) while discriminating against other molecules that are not substrates. This specificity arises from the three-dimensional structure of the enzyme, which has evolved to match the shape, charge distribution, and functional groups of its physiological substrate(s).
Substrate specificity is a fundamental property of enzymes that enables them to carry out highly selective chemical transformations in the complex cellular environment. The active site of an enzyme, where the catalysis takes place, has a unique conformation that complements the shape and charge distribution of its substrate(s). This ensures efficient recognition, binding, and conversion of the substrate into the desired product while minimizing unwanted side reactions with other molecules.
Substrate specificity can be categorized as:
1. Absolute specificity: An enzyme that can only act on a single substrate or a very narrow group of structurally related substrates, showing no activity towards any other molecule.
2. Group specificity: An enzyme that prefers to act on a particular functional group or class of compounds but can still accommodate minor structural variations within the substrate.
3. Broad or promiscuous specificity: An enzyme that can act on a wide range of structurally diverse substrates, albeit with varying catalytic efficiencies.
Understanding substrate specificity is crucial for elucidating enzymatic mechanisms, designing drugs that target specific enzymes or pathways, and developing biotechnological applications that rely on the controlled manipulation of enzyme activities.
Purinergic P2 receptors are a type of cell surface receptor that bind to purine nucleotides and nucleosides, such as ATP (adenosine triphosphate) and ADP (adenosine diphosphate), and mediate various physiological responses. These receptors are divided into two main families: P2X and P2Y.
P2X receptors are ionotropic receptors, meaning they form ion channels that allow the flow of ions across the cell membrane upon activation. There are seven subtypes of P2X receptors (P2X1-7), each with distinct functional and pharmacological properties.
P2Y receptors, on the other hand, are metabotropic receptors, meaning they activate intracellular signaling pathways through G proteins. There are eight subtypes of P2Y receptors (P2Y1, P2Y2, P2Y4, P2Y6, P2Y11, P2Y12, P2Y13, and P2Y14), each with different G protein coupling specificities and downstream signaling pathways.
Purinergic P2 receptors are widely expressed in various tissues, including the nervous system, cardiovascular system, respiratory system, gastrointestinal tract, and immune system. They play important roles in regulating physiological functions such as neurotransmission, vasodilation, platelet aggregation, smooth muscle contraction, and inflammation. Dysregulation of purinergic P2 receptors has been implicated in various pathological conditions, including pain, ischemia, hypertension, atherosclerosis, and cancer.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
Deoxyribonucleic acid (DNA) is the genetic material present in the cells of organisms where it is responsible for the storage and transmission of hereditary information. DNA is a long molecule that consists of two strands coiled together to form a double helix. Each strand is made up of a series of four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - that are linked together by phosphate and sugar groups. The sequence of these bases along the length of the molecule encodes genetic information, with A always pairing with T and C always pairing with G. This base-pairing allows for the replication and transcription of DNA, which are essential processes in the functioning and reproduction of all living organisms.
Aspartic acid is an α-amino acid with the chemical formula HO2CCH(NH2)CO2H. It is one of the twenty standard amino acids, and it is a polar, negatively charged, and hydrophilic amino acid. In proteins, aspartic acid usually occurs in its ionized form, aspartate, which has a single negative charge.
Aspartic acid plays important roles in various biological processes, including metabolism, neurotransmitter synthesis, and energy production. It is also a key component of many enzymes and proteins, where it often contributes to the formation of ionic bonds and helps stabilize protein structure.
In addition to its role as a building block of proteins, aspartic acid is also used in the synthesis of other important biological molecules, such as nucleotides, which are the building blocks of DNA and RNA. It is also a component of the dipeptide aspartame, an artificial sweetener that is widely used in food and beverages.
Like other amino acids, aspartic acid is essential for human health, but it cannot be synthesized by the body and must be obtained through the diet. Foods that are rich in aspartic acid include meat, poultry, fish, dairy products, eggs, legumes, and some fruits and vegetables.
Nucleic acid conformation refers to the three-dimensional structure that nucleic acids (DNA and RNA) adopt as a result of the bonding patterns between the atoms within the molecule. The primary structure of nucleic acids is determined by the sequence of nucleotides, while the conformation is influenced by factors such as the sugar-phosphate backbone, base stacking, and hydrogen bonding.
Two common conformations of DNA are the B-form and the A-form. The B-form is a right-handed helix with a diameter of about 20 Å and a pitch of 34 Å, while the A-form has a smaller diameter (about 18 Å) and a shorter pitch (about 25 Å). RNA typically adopts an A-form conformation.
The conformation of nucleic acids can have significant implications for their function, as it can affect their ability to interact with other molecules such as proteins or drugs. Understanding the conformational properties of nucleic acids is therefore an important area of research in molecular biology and medicine.
Guanosine triphosphate (GTP) is a nucleotide that plays a crucial role in various cellular processes, such as protein synthesis, signal transduction, and regulation of enzymatic activities. It serves as an energy currency, similar to adenosine triphosphate (ATP), and undergoes hydrolysis to guanosine diphosphate (GDP) or guanosine monophosphate (GMP) to release energy required for these processes. GTP is also a precursor for the synthesis of other essential molecules, including RNA and certain signaling proteins. Additionally, it acts as a molecular switch in many intracellular signaling pathways by binding and activating specific GTPase proteins.
Phosphotransferases are a group of enzymes that catalyze the transfer of a phosphate group from a donor molecule to an acceptor molecule. This reaction is essential for various cellular processes, including energy metabolism, signal transduction, and biosynthesis.
The systematic name for this group of enzymes is phosphotransferase, which is derived from the general reaction they catalyze: D-donor + A-acceptor = D-donor minus phosphate + A-phosphate. The donor molecule can be a variety of compounds, such as ATP or a phosphorylated protein, while the acceptor molecule is typically a compound that becomes phosphorylated during the reaction.
Phosphotransferases are classified into several subgroups based on the type of donor and acceptor molecules they act upon. For example, kinases are a subgroup of phosphotransferases that transfer a phosphate group from ATP to a protein or other organic compound. Phosphatases, another subgroup, remove phosphate groups from molecules by transferring them to water.
Overall, phosphotransferases play a critical role in regulating many cellular functions and are important targets for drug development in various diseases, including cancer and neurological disorders.
Adenosine diphosphate (ADP) is a chemical compound that plays a crucial role in energy transfer within cells. It is a nucleotide, which consists of a adenosine molecule (a sugar molecule called ribose attached to a nitrogenous base called adenine) and two phosphate groups.
In the cell, ADP functions as an intermediate in the conversion of energy from one form to another. When a high-energy phosphate bond in ADP is broken, energy is released and ADP is converted to adenosine triphosphate (ATP), which serves as the main energy currency of the cell. Conversely, when ATP donates a phosphate group to another molecule, it is converted back to ADP, releasing energy for the cell to use.
ADP also plays a role in blood clotting and other physiological processes. In the coagulation cascade, ADP released from damaged red blood cells can help activate platelets and initiate the formation of a blood clot.
Adenine nucleotides are molecules that consist of a nitrogenous base called adenine, which is linked to a sugar molecule (ribose in the case of adenosine monophosphate or AMP, and deoxyribose in the case of adenosine diphosphate or ADP and adenosine triphosphate or ATP) and one, two, or three phosphate groups. These molecules play a crucial role in energy transfer and metabolism within cells.
AMP contains one phosphate group, while ADP contains two phosphate groups, and ATP contains three phosphate groups. When a phosphate group is removed from ATP, energy is released, which can be used to power various cellular processes such as muscle contraction, nerve impulse transmission, and protein synthesis. The reverse reaction, in which a phosphate group is added back to ADP or AMP to form ATP, requires energy input and often involves the breakdown of nutrients such as glucose or fatty acids.
In addition to their role in energy metabolism, adenine nucleotides also serve as precursors for other important molecules, including DNA and RNA, coenzymes, and signaling molecules.
Single Nucleotide Polymorphism (SNP) is a type of genetic variation that occurs when a single nucleotide (A, T, C, or G) in the DNA sequence is altered. This alteration must occur in at least 1% of the population to be considered a SNP. These variations can help explain why some people are more susceptible to certain diseases than others and can also influence how an individual responds to certain medications. SNPs can serve as biological markers, helping scientists locate genes that are associated with disease. They can also provide information about an individual's ancestry and ethnic background.
Thymidine is a pyrimidine nucleoside that consists of a thymine base linked to a deoxyribose sugar by a β-N1-glycosidic bond. It plays a crucial role in DNA replication and repair processes as one of the four nucleosides in DNA, along with adenosine, guanosine, and cytidine. Thymidine is also used in research and clinical settings for various purposes, such as studying DNA synthesis or as a component of antiviral and anticancer therapies.
Pyrimidine phosphorylases are a group of enzymes that play a crucial role in the metabolism of pyrimidines, which are nitrogenous bases found in nucleic acids such as DNA and RNA. These enzymes catalyze the reversible phosphorolytic cleavage of pyrimidine nucleosides into ribose-1-phosphate and a free base.
There are two main types of pyrimidine phosphorylases: cytosine phosphorylase (CP) and thymidine phosphorylase (TP). CP catalyzes the conversion of cytosine to uracil, while TP converts thymidine to thymine. These enzymes are important in maintaining the balance of pyrimidines in cells and are also involved in the salvage pathway for nucleotide synthesis.
Deficiencies or mutations in these enzymes can lead to various genetic disorders, including neurological and developmental abnormalities. Additionally, TP has been studied as a potential target for cancer therapy due to its role in angiogenesis and tumor growth.
According to the medical definition, ultraviolet (UV) rays are invisible radiations that fall in the range of the electromagnetic spectrum between 100-400 nanometers. UV rays are further divided into three categories: UVA (320-400 nm), UVB (280-320 nm), and UVC (100-280 nm).
UV rays have various sources, including the sun and artificial sources like tanning beds. Prolonged exposure to UV rays can cause damage to the skin, leading to premature aging, eye damage, and an increased risk of skin cancer. UVA rays penetrate deeper into the skin and are associated with skin aging, while UVB rays primarily affect the outer layer of the skin and are linked to sunburns and skin cancer. UVC rays are the most harmful but fortunately, they are absorbed by the Earth's atmosphere and do not reach the surface.
Healthcare professionals recommend limiting exposure to UV rays, wearing protective clothing, using broad-spectrum sunscreen with an SPF of at least 30, and avoiding tanning beds to reduce the risk of UV-related health problems.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
A Structure-Activity Relationship (SAR) in the context of medicinal chemistry and pharmacology refers to the relationship between the chemical structure of a drug or molecule and its biological activity or effect on a target protein, cell, or organism. SAR studies aim to identify patterns and correlations between structural features of a compound and its ability to interact with a specific biological target, leading to a desired therapeutic response or undesired side effects.
By analyzing the SAR, researchers can optimize the chemical structure of lead compounds to enhance their potency, selectivity, safety, and pharmacokinetic properties, ultimately guiding the design and development of novel drugs with improved efficacy and reduced toxicity.
RNA (Ribonucleic Acid) is a single-stranded, linear polymer of ribonucleotides. It is a nucleic acid present in the cells of all living organisms and some viruses. RNAs play crucial roles in various biological processes such as protein synthesis, gene regulation, and cellular signaling. There are several types of RNA including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), small nuclear RNA (snRNA), microRNA (miRNA), and long non-coding RNA (lncRNA). These RNAs differ in their structure, function, and location within the cell.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
A cell line is a culture of cells that are grown in a laboratory for use in research. These cells are usually taken from a single cell or group of cells, and they are able to divide and grow continuously in the lab. Cell lines can come from many different sources, including animals, plants, and humans. They are often used in scientific research to study cellular processes, disease mechanisms, and to test new drugs or treatments. Some common types of human cell lines include HeLa cells (which come from a cancer patient named Henrietta Lacks), HEK293 cells (which come from embryonic kidney cells), and HUVEC cells (which come from umbilical vein endothelial cells). It is important to note that cell lines are not the same as primary cells, which are cells that are taken directly from a living organism and have not been grown in the lab.
A catalytic domain is a portion or region within a protein that contains the active site, where the chemical reactions necessary for the protein's function are carried out. This domain is responsible for the catalysis of biological reactions, hence the name "catalytic domain." The catalytic domain is often composed of specific amino acid residues that come together to form the active site, creating a unique three-dimensional structure that enables the protein to perform its specific function.
In enzymes, for example, the catalytic domain contains the residues that bind and convert substrates into products through chemical reactions. In receptors, the catalytic domain may be involved in signal transduction or other regulatory functions. Understanding the structure and function of catalytic domains is crucial to understanding the mechanisms of protein function and can provide valuable insights for drug design and therapeutic interventions.
Molecular cloning is a laboratory technique used to create multiple copies of a specific DNA sequence. This process involves several steps:
1. Isolation: The first step in molecular cloning is to isolate the DNA sequence of interest from the rest of the genomic DNA. This can be done using various methods such as PCR (polymerase chain reaction), restriction enzymes, or hybridization.
2. Vector construction: Once the DNA sequence of interest has been isolated, it must be inserted into a vector, which is a small circular DNA molecule that can replicate independently in a host cell. Common vectors used in molecular cloning include plasmids and phages.
3. Transformation: The constructed vector is then introduced into a host cell, usually a bacterial or yeast cell, through a process called transformation. This can be done using various methods such as electroporation or chemical transformation.
4. Selection: After transformation, the host cells are grown in selective media that allow only those cells containing the vector to grow. This ensures that the DNA sequence of interest has been successfully cloned into the vector.
5. Amplification: Once the host cells have been selected, they can be grown in large quantities to amplify the number of copies of the cloned DNA sequence.
Molecular cloning is a powerful tool in molecular biology and has numerous applications, including the production of recombinant proteins, gene therapy, functional analysis of genes, and genetic engineering.
Deoxyribodipyrimidine photo-lyase is an enzyme involved in the repair of DNA damage, specifically the repair of cyclobutane pyrimidine dimers (CPDs) that are formed when DNA is exposed to ultraviolet (UV) light. CPDs can distort the structure of DNA and interfere with replication and transcription, so it's important for cells to have mechanisms to repair this damage.
Deoxyribodipyrimidine photo-lyase works by cleaving the bond between two adjacent pyrimidines in the DNA strand that form the CPD, releasing one of the pyrimidines and allowing the remaining portion of the strand to be repaired. This enzyme is also known as photolyase or DNA repair photolyase.
It's worth noting that there are different types of photolyases that can repair different kinds of DNA damage, but deoxyribodipyrimidine photo-lyase specifically repairs CPDs caused by UV light.
DNA repair is the process by which cells identify and correct damage to the DNA molecules that encode their genome. DNA can be damaged by a variety of internal and external factors, such as radiation, chemicals, and metabolic byproducts. If left unrepaired, this damage can lead to mutations, which may in turn lead to cancer and other diseases.
There are several different mechanisms for repairing DNA damage, including:
1. Base excision repair (BER): This process repairs damage to a single base in the DNA molecule. An enzyme called a glycosylase removes the damaged base, leaving a gap that is then filled in by other enzymes.
2. Nucleotide excision repair (NER): This process repairs more severe damage, such as bulky adducts or crosslinks between the two strands of the DNA molecule. An enzyme cuts out a section of the damaged DNA, and the gap is then filled in by other enzymes.
3. Mismatch repair (MMR): This process repairs errors that occur during DNA replication, such as mismatched bases or small insertions or deletions. Specialized enzymes recognize the error and remove a section of the newly synthesized strand, which is then replaced by new nucleotides.
4. Double-strand break repair (DSBR): This process repairs breaks in both strands of the DNA molecule. There are two main pathways for DSBR: non-homologous end joining (NHEJ) and homologous recombination (HR). NHEJ directly rejoins the broken ends, while HR uses a template from a sister chromatid to repair the break.
Overall, DNA repair is a crucial process that helps maintain genome stability and prevent the development of diseases caused by genetic mutations.