Repressor Proteins
Operator Regions, Genetic
Lac Repressors
Molecular Sequence Data
Transcription Factors
DNA-Binding Proteins
Base Sequence
Operon
Isopropyl Thiogalactoside
Escherichia coli
Transcription, Genetic
Promoter Regions, Genetic
Amino Acid Sequence
Protein Binding
Binding Sites
Gene Expression Regulation, Bacterial
Viral Regulatory and Accessory Proteins
Genes, Regulator
Plasmids
Mutation
DNA
Lysogeny
Lac Operon
Zinc Fingers
Cloning, Molecular
Bacteriophage lambda
Gene Expression Regulation
Recombinant Fusion Proteins
Nuclear Proteins
Lactose
DNA Footprinting
Histone Deacetylases
Enzyme Repression
Trans-Activators
Regulatory Sequences, Nucleic Acid
Tetracycline
RNA, Messenger
Electrophoretic Mobility Shift Assay
Restriction Mapping
Carbon Dioxide
Consensus Sequence
Deoxyribonuclease I
Two-Hybrid System Techniques
Protein Structure, Tertiary
Genes, Reporter
Carrier Proteins
Dimerization
Protein Biosynthesis
Protein Conformation
Sequence Homology, Amino Acid
Drosophila Proteins
Mutagenesis, Site-Directed
beta-Galactosidase
Gene Expression Regulation, Fungal
Transfection
Sequence Alignment
Basic Helix-Loop-Helix Transcription Factors
Homeodomain Proteins
Models, Molecular
Gene Expression Regulation, Developmental
Nucleic Acid Conformation
Cell Nucleus
HeLa Cells
Models, Genetic
Saccharomyces cerevisiae
Transcriptional Activation
Saccharomyces cerevisiae Proteins
Sequence Homology, Nucleic Acid
Alcohol Oxidoreductases
RNA-Binding Proteins
Gene Silencing
Drosophila
Tryptophan
Arabidopsis Proteins
Models, Biological
Genetic Complementation Test
DNA Transposable Elements
Signal Transduction
Phenotype
Chloramphenicol O-Acetyltransferase
Mutagenesis
Genes
Structure-Activity Relationship
Cyclic AMP Response Element Modulator
Allosteric Regulation
Gene Expression
DNA Primers
Arabidopsis
Macromolecular Substances
Gene Expression Regulation, Viral
Iron
Carbon Monoxide
Circular Dichroism
Amino Acid Motifs
Enhancer Elements, Genetic
Enzyme Induction
Cells, Cultured
Drosophila melanogaster
Phosphoproteins
Crystallography, X-Ray
Electrophoresis, Polyacrylamide Gel
Genetic Vectors
Sequence Analysis, DNA
COS Cells
Blotting, Western
Membrane Transport Proteins
Cell Differentiation
RNA, Bacterial
Kruppel-Like Transcription Factors
Reverse Transcriptase Polymerase Chain Reaction
Thermodynamics
Blotting, Northern
Cycloheximide
Helix-Turn-Helix Motifs
Oligonucleotide Probes
Protein Structure, Secondary
Phosphorylation
Open Reading Frames
DNA, Complementary
Amino Acids
Chromosome Mapping
Glucose
Proteins
Tumor Cells, Cultured
Polymerase Chain Reaction
Chromatin Immunoprecipitation
Cobalt
Regulon
Gene Expression Regulation, Plant
Response Elements
Co-Repressor Proteins
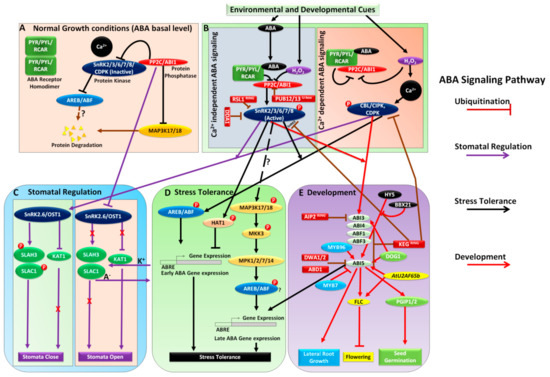
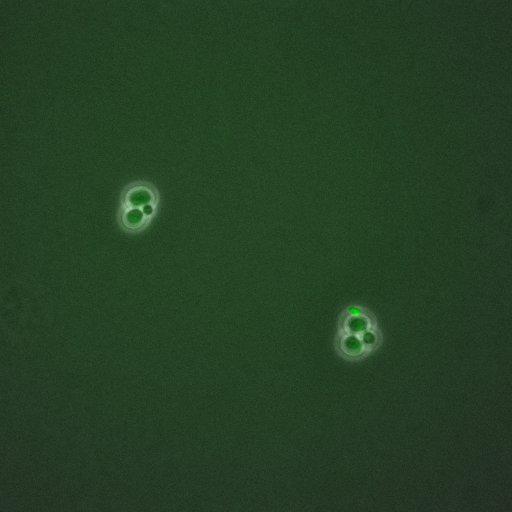
Induction of apoptosis by overexpression of the DNA-binding and DNA-PK-activating protein C1D. (1/209)
Apoptosis is induced in various tumor cell lines by vector-dependent overexpression of the conserved gene C1D that encodes a DNA-binding and DNA-PK-activating protein. C1D is physiologically expressed in 50 human tissues tested, which points to its basic cellular function. The expression of this gene must be tightly regulated because elevated levels of C1D protein, e.g. those induced by transient vector-dependent expression, result in apoptotic cell death. Cells transfected with C1D-expressing constructs show terminal deoxynucleotidyl transferase-mediated dUTP nick end-labeling of DNA ends. Transfections with constructs in which C1D is expressed in fusion with the (enhanced) green fluorescent protein from A. victoria (EGFP) allow the transfected cells to be identified and the morphological changes induced to be traced. Starting from intense nuclear spots, green fluorescence reflecting C1D expression increases dramatically at 12-24 hours post-transfection. Expression of C1D-EGFP protein is accompanied by morphological changes typical of apoptotic cell death, e.g. cytoplasmic vacuolation, membrane blebbing and nuclear disintegration. Cell shrinkage and detachment from extracellular matrix are observed in monolayer cultures while suspension cells become progressively flattened. The facility to differentiate between transfected and non-transfected cells reveals that non-transfected cells co-cultured with transfected cells also show the morphological changes of apoptosis, which points to a bystander effect. C1D-dependent apoptosis is not induced in cells with non-functional p53. Accordingly, C1D-induced apoptosis is discussed in relation to its potential to activate DNA-PK, which has been considered to act as an upstream activator of p53. (+info)SMRTER, a Drosophila nuclear receptor coregulator, reveals that EcR-mediated repression is critical for development. (2/209)
The Drosophila ecdysone receptor (EcR)/ultraspiracle (USP) heterodimer is a key regulator in molting and metamorphoric processes, activating and repressing transcription in a sequence-specific manner. Here, we report the isolation of an EcR-interacting protein, SMRTER, which is structurally divergent but functionally similar to the vertebrate nuclear corepressors SMRT and N-CoR. SMRTER mediates repression by interacting with Sin3A, a repressor known to form a complex with the histone deacetylase Rpd3/HDAC. Importantly, we identify an EcR mutant allele that fails to bind SMRTER and is characterized by developmental defects and lethality. Together, these results reveal a novel nuclear receptor cofactor that exhibits evolutionary conservation in the mechanism to achieve repression and demonstrate the essential role of repression in hormone signaling. (+info)Differential expression of the Groucho-related genes 4 and 5 during early development of Xenopus laevis. (3/209)
Recently, we demonstrated that the Xenopus Wnt effector XTcf-3 interacts with Groucho-related transcriptional repressors (Roose et al., 1998. Nature 395, 608-612). A long form of the Groucho-related genes, XGrg-4, was shown to repress axis formation in the Xenopus embryo, whereas a short form, XGrg-5, acted as a potentiator. In this study, the temporal and spatial expression of XGrg-4 and XGrg-5 is described in Xenopus laevis embryos. Both genes are maternally expressed. In the gastrula, transcripts of both genes are present in the animal as well as the vegetal region. At later stages, XGrg-4 and XGrg-5 show specific patterns of expression in the central nervous system (CNS), cranial ganglia, eyes, otic vesicles, stomodeal-hypophyseal anlage, cement gland, head mesenchyme, branchial arches, neural crest and derivatives, somites, pronephros, pronephric duct, heart and tailbud. Differences in the expression of XGrg-4 and XGrg-5 were found in the CNS, cranial ganglia, olfactory placodes, stomodeal-pharyngeal anlage, cement gland, head mesenchyme and ectoderm. (+info)Disrupted development of the cerebral hemispheres in transgenic mice expressing the mammalian Groucho homologue transducin-like-enhancer of split 1 in postmitotic neurons. (4/209)
Transducin-like Enhancer of split (TLE) 1 is a mammalian transcriptional corepressor homologous to Drosophila Groucho. In Drosophila, Groucho acts together with bHLH proteins of the Hairy/Enhancer of split (HES) family to negatively regulate neuronal differentiation. Loss of the functions of Groucho or HES proteins results in supernumerary central and peripheral neurons. This suggests that mammalian TLE/Groucho family members may also be involved in the regulation of neuronal differentiation. Consistent with this possibility, TLE1 is expressed in proliferating neural progenitor cells of the central nervous system, but its expression is transiently down-regulated in newly generated postmitotic neurons. Based on these observations, we investigated whether persistent TLE1 expression in postmitotic neurons would perturb the normal course of neuronal development. Transgenic mice were derived in which the human TLE1 gene is regulated by the promoter of the Talpha1 alpha-tubulin gene, which is exclusively expressed in postmitotic neurons. In these mice, constitutive expression of TLE1 inhibits neuronal development in the embryonic forebrain leading to increased apoptosis and neuronal loss in the ventral and dorsal telencephalon. These results provide the first direct evidence that TLE1 is an important negative regulator of postmitotic neuronal differentiation in the mammalian central nervous system. (+info)Promoter of the gene encoding the 16 kDa DNA-binding and apoptosis-inducing C1D protein. (5/209)
The 5' region of the gene encoding the human 16 kDa DNA-binding and apoptosis-inducing C1D protein was analysed for promoter activity. Sections of this region were cloned into a promoterless vector containing the enhanced green fluorescent protein (EGFP) as reporter gene. Expressed EGFP was estimated in transfected cells by quantitative fluorescence microscopy. The sequence between mRNA positions ATG -868 and ATG -12 results in relatively highest EGFP expression in transiently transfected human and murine cells. The upstream segment immediately adjacent to the 5' end of the most active fragment was identified as an inverted LINE-1 repeat element. Transient transfection experiments point to the presence of cis-acting repressing sequences on this LINE-1 element which reduce the transcriptional activity of the basal C1D promoter in human and murine cells by more than 95%. This result supports previous evidence suggesting that LINE-1 sequences may function as regulatory elements to control the expression of nearby genes. (+info)Molecular cloning and characterization of PELP1, a novel human coregulator of estrogen receptor alpha. (6/209)
Nuclear hormone receptors (NRs) are transcription factors whose activity is regulated by ligands and by coactivators or corepressors. We report the characterization of a new NR coregulator: proline-, glutamic acid-, leucine-rich protein 1 (PELP1), a novel human protein that comprises 1,282 amino acids and is localized on chromosome 17. The primary structure of PELP1 consists of several motifs present in most transcriptional regulators including nine NR-interacting boxes (LXXLL motifs), a zinc finger, and glutamic acid- and proline-rich regions. We demonstrate that PELP1 is a coactivator of estrogen receptor alpha (ERalpha). PELP1 enhances 17beta-estradiol-dependent transcriptional activation from the estrogen response element in a dose-dependent manner. PELP1 interacts with ERalpha and also with general transcriptional coactivators p300 and cAMP response element-binding protein-binding protein. PELP1 was differentially expressed in various human and murine tissues with the highest expression levels in the testes, mammary glands, and brain. We also provide evidence supporting the developmental regulation of PELP1 expression in murine mammary glands, the detectable expression of PELP1 in human mammary cancer cell lines, and the enhanced expression of PELP1 in human breast tumors. These findings suggest that PELP1 is a novel coregulator of ERalpha and may have a role in breast cancer tumorigenesis. (+info)The E2A-HLF oncoprotein activates Groucho-related genes and suppresses Runx1. (7/209)
The E2A-HLF fusion gene, formed by the t(17;19)(q22;p13) chromosomal translocation in leukemic pro-B cells, encodes a chimeric transcription factor consisting of the transactivation domain of E2A linked to the bZIP DNA-binding and protein dimerization domain of hepatic leukemia factor (HLF). This oncoprotein blocks apoptosis induced by growth factor deprivation or irradiation, but the mechanism for this effect remains unclear. We therefore performed representational difference analysis (RDA) to identify downstream genetic targets of E2A-HLF, using a murine FL5.12 pro-B cell line that had been stably transfected with E2A-HLF cDNA under the control of a zinc-regulated metallothionein promoter. Two RDA clones, designated RDA1 and RDA3, were differentially upregulated in E2A-HLF-positive cells after zinc induction. The corresponding cDNAs encoded two WD40 repeat-containing proteins, Grg2 and Grg6. Both are related to the Drosophila protein Groucho, a transcriptional corepressor that lacks DNA-binding activity on its own but can act in concert with other proteins to regulate embryologic development of the fly. Expression of both Grg2 and Grg6 was upregulated 10- to 50-fold by E2A-HLF. Immunoblot analysis detected increased amounts of two additional Groucho-related proteins, Grg1 and Grg4, in cells expressing E2A-HLF. A mutant E2A-HLF protein with a disabled DNA-binding region also mediated pro-B cell survival and activated Groucho-related genes. Among the transcription factors known to interact with Groucho-related protein, only RUNX1 was appreciably downregulated by E2A-HLF. Our results identify a highly conserved family of transcriptional corepressors that are activated by E2A-HLF, and they suggest that downregulation of RUNX1 may contribute to E2A-HLF-mediated leukemogenesis. (+info)HES6 acts as a transcriptional repressor in myoblasts and can induce the myogenic differentiation program. (8/209)
HES6 is a novel member of the family of basic helix-loop-helix mammalian homologues of Drosophila Hairy and Enhancer of split. We have analyzed the biochemical and functional roles of HES6 in myoblasts. HES6 interacted with the corepressor transducin-like Enhancer of split 1 in yeast and mammalian cells through its WRPW COOH-terminal motif. HES6 repressed transcription from an N box-containing template and also when tethered to DNA through the GAL4 DNA binding domain. On N box-containing promoters, HES6 cooperated with HES1 to achieve maximal repression. An HES6-VP16 activation domain fusion protein activated the N box-containing reporter, confirming that HES6 bound the N box in muscle cells. The expression of HES6 was induced when myoblasts fused to become differentiated myotubes. Constitutive expression of HES6 in myoblasts inhibited expression of MyoR, a repressor of myogenesis, and induced differentiation, as evidenced by fusion into myotubes and expression of the muscle marker myosin heavy chain. Reciprocally, blocking endogenous HES6 function by using a WRPW-deleted dominant negative HES6 mutant led to increased expression of MyoR and completely blocked the muscle development program. Our results show that HES6 is an important regulator of myogenesis and suggest that MyoR is a target for HES6-dependent transcriptional repression. (+info)Repressor proteins are a type of regulatory protein in molecular biology that suppress the transcription of specific genes into messenger RNA (mRNA) by binding to DNA. They function as part of gene regulation processes, often working in conjunction with an operator region and a promoter region within the DNA molecule. Repressor proteins can be activated or deactivated by various signals, allowing for precise control over gene expression in response to changing cellular conditions.
There are two main types of repressor proteins:
1. DNA-binding repressors: These directly bind to specific DNA sequences (operator regions) near the target gene and prevent RNA polymerase from transcribing the gene into mRNA.
2. Allosteric repressors: These bind to effector molecules, which then cause a conformational change in the repressor protein, enabling it to bind to DNA and inhibit transcription.
Repressor proteins play crucial roles in various biological processes, such as development, metabolism, and stress response, by controlling gene expression patterns in cells.
Operator regions in genetics refer to specific DNA sequences that regulate the transcription of nearby genes. These regions are binding sites for proteins called transcription factors, which control the rate at which genetic information is copied into RNA. Operator regions are typically located near the promoter region of a gene and can influence the expression of one or multiple genes in a coordinated manner.
In some cases, operator regions may be shared by several genes that are organized into a single operon, a genetic unit consisting of a cluster of genes that are transcribed together as a single mRNA molecule. Operators play a crucial role in the regulation of gene expression and help to ensure that genes are turned on or off at appropriate times during development and in response to environmental signals.
A lac repressor is a protein in the lactose operon system of the bacterium Escherichia coli (E. coli) that regulates the expression of genes responsible for lactose metabolism. The lac repressor binds to specific DNA sequences called operators, preventing the transcription of nearby structural genes when lactose is not present. When lactose is available, a molecule derived from lactose, allolactose, binds to the lac repressor, causing a conformational change that prevents it from binding to the operator, allowing transcription and gene expression. This regulatory mechanism ensures that the cells only produce the enzymes required for lactose metabolism when lactose is available as a food source.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
Transcription factors are proteins that play a crucial role in regulating gene expression by controlling the transcription of DNA to messenger RNA (mRNA). They function by binding to specific DNA sequences, known as response elements, located in the promoter region or enhancer regions of target genes. This binding can either activate or repress the initiation of transcription, depending on the properties and interactions of the particular transcription factor. Transcription factors often act as part of a complex network of regulatory proteins that determine the precise spatiotemporal patterns of gene expression during development, differentiation, and homeostasis in an organism.
DNA-binding proteins are a type of protein that have the ability to bind to DNA (deoxyribonucleic acid), the genetic material of organisms. These proteins play crucial roles in various biological processes, such as regulation of gene expression, DNA replication, repair and recombination.
The binding of DNA-binding proteins to specific DNA sequences is mediated by non-covalent interactions, including electrostatic, hydrogen bonding, and van der Waals forces. The specificity of binding is determined by the recognition of particular nucleotide sequences or structural features of the DNA molecule.
DNA-binding proteins can be classified into several categories based on their structure and function, such as transcription factors, histones, and restriction enzymes. Transcription factors are a major class of DNA-binding proteins that regulate gene expression by binding to specific DNA sequences in the promoter region of genes and recruiting other proteins to modulate transcription. Histones are DNA-binding proteins that package DNA into nucleosomes, the basic unit of chromatin structure. Restriction enzymes are DNA-binding proteins that recognize and cleave specific DNA sequences, and are widely used in molecular biology research and biotechnology applications.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
Bacterial proteins are a type of protein that are produced by bacteria as part of their structural or functional components. These proteins can be involved in various cellular processes, such as metabolism, DNA replication, transcription, and translation. They can also play a role in bacterial pathogenesis, helping the bacteria to evade the host's immune system, acquire nutrients, and multiply within the host.
Bacterial proteins can be classified into different categories based on their function, such as:
1. Enzymes: Proteins that catalyze chemical reactions in the bacterial cell.
2. Structural proteins: Proteins that provide structural support and maintain the shape of the bacterial cell.
3. Signaling proteins: Proteins that help bacteria to communicate with each other and coordinate their behavior.
4. Transport proteins: Proteins that facilitate the movement of molecules across the bacterial cell membrane.
5. Toxins: Proteins that are produced by pathogenic bacteria to damage host cells and promote infection.
6. Surface proteins: Proteins that are located on the surface of the bacterial cell and interact with the environment or host cells.
Understanding the structure and function of bacterial proteins is important for developing new antibiotics, vaccines, and other therapeutic strategies to combat bacterial infections.
An operon is a genetic unit in prokaryotic organisms (like bacteria) consisting of a cluster of genes that are transcribed together as a single mRNA molecule, which then undergoes translation to produce multiple proteins. This genetic organization allows for the coordinated regulation of genes that are involved in the same metabolic pathway or functional process. The unit typically includes promoter and operator regions that control the transcription of the operon, as well as structural genes encoding the proteins. Operons were first discovered in bacteria, but similar genetic organizations have been found in some eukaryotic organisms, such as yeast.
IsoPROPYL THIO-galacto-side (IPTG) is a chemical compound used in molecular biology as an inducer of gene transcription. It is a synthetic analog of allolactose, which is the natural inducer of the lac operon in E. coli bacteria. The lac operon contains genes that code for enzymes involved in the metabolism of lactose, and its expression is normally repressed when lactose is not present. However, when lactose or IPTG is added to the growth medium, it binds to the repressor protein (lac repressor) and prevents it from binding to the operator region of the lac operon, thereby allowing transcription of the structural genes.
IPTG is often used in laboratory experiments to induce the expression of cloned genes that have been placed under the control of the lac promoter. When IPTG is added to the bacterial culture, it binds to the lac repressor and allows for the transcription and translation of the gene of interest. This can be useful for producing large quantities of a particular protein or for studying the regulation of gene expression in bacteria.
It's important to note that IPTG is not metabolized by E.coli, so it remains active in the growth medium throughout the experiment and can be added at any point during the growth cycle.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
Genetic transcription is the process by which the information in a strand of DNA is used to create a complementary RNA molecule. This process is the first step in gene expression, where the genetic code in DNA is converted into a form that can be used to produce proteins or functional RNAs.
During transcription, an enzyme called RNA polymerase binds to the DNA template strand and reads the sequence of nucleotide bases. As it moves along the template, it adds complementary RNA nucleotides to the growing RNA chain, creating a single-stranded RNA molecule that is complementary to the DNA template strand. Once transcription is complete, the RNA molecule may undergo further processing before it can be translated into protein or perform its functional role in the cell.
Transcription can be either "constitutive" or "regulated." Constitutive transcription occurs at a relatively constant rate and produces essential proteins that are required for basic cellular functions. Regulated transcription, on the other hand, is subject to control by various intracellular and extracellular signals, allowing cells to respond to changing environmental conditions or developmental cues.
Promoter regions in genetics refer to specific DNA sequences located near the transcription start site of a gene. They serve as binding sites for RNA polymerase and various transcription factors that regulate the initiation of gene transcription. These regulatory elements help control the rate of transcription and, therefore, the level of gene expression. Promoter regions can be composed of different types of sequences, such as the TATA box and CAAT box, and their organization and composition can vary between different genes and species.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
Protein binding, in the context of medical and biological sciences, refers to the interaction between a protein and another molecule (known as the ligand) that results in a stable complex. This process is often reversible and can be influenced by various factors such as pH, temperature, and concentration of the involved molecules.
In clinical chemistry, protein binding is particularly important when it comes to drugs, as many of them bind to proteins (especially albumin) in the bloodstream. The degree of protein binding can affect a drug's distribution, metabolism, and excretion, which in turn influence its therapeutic effectiveness and potential side effects.
Protein-bound drugs may be less available for interaction with their target tissues, as only the unbound or "free" fraction of the drug is active. Therefore, understanding protein binding can help optimize dosing regimens and minimize adverse reactions.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
Gene expression regulation in bacteria refers to the complex cellular processes that control the production of proteins from specific genes. This regulation allows bacteria to adapt to changing environmental conditions and ensure the appropriate amount of protein is produced at the right time.
Bacteria have a variety of mechanisms for regulating gene expression, including:
1. Operon structure: Many bacterial genes are organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule. The expression of these genes can be coordinately regulated by controlling the transcription of the entire operon.
2. Promoter regulation: Transcription is initiated at promoter regions upstream of the gene or operon. Bacteria have regulatory proteins called sigma factors that bind to the promoter and recruit RNA polymerase, the enzyme responsible for transcribing DNA into RNA. The binding of sigma factors can be influenced by environmental signals, allowing for regulation of transcription.
3. Attenuation: Some operons have regulatory regions called attenuators that control transcription termination. These regions contain hairpin structures that can form in the mRNA and cause transcription to stop prematurely. The formation of these hairpins is influenced by the concentration of specific metabolites, allowing for regulation of gene expression based on the availability of those metabolites.
4. Riboswitches: Some bacterial mRNAs contain regulatory elements called riboswitches that bind small molecules directly. When a small molecule binds to the riboswitch, it changes conformation and affects transcription or translation of the associated gene.
5. CRISPR-Cas systems: Bacteria use CRISPR-Cas systems for adaptive immunity against viruses and plasmids. These systems incorporate short sequences from foreign DNA into their own genome, which can then be used to recognize and cleave similar sequences in invading genetic elements.
Overall, gene expression regulation in bacteria is a complex process that allows them to respond quickly and efficiently to changing environmental conditions. Understanding these regulatory mechanisms can provide insights into bacterial physiology and help inform strategies for controlling bacterial growth and behavior.
Viral regulatory and accessory proteins are a type of viral protein that play a role in the regulation of viral replication, gene expression, and host immune response. These proteins are not directly involved in the structural components of the virus but instead help to modulate the environment inside the host cell to facilitate viral replication and evade the host's immune system.
Regulatory proteins control various stages of the viral life cycle, such as transcription, translation, and genome replication. They may also interact with host cell regulatory proteins to alter their function and promote viral replication. Accessory proteins, on the other hand, are non-essential for viral replication but can enhance viral pathogenesis or modulate the host's immune response.
The specific functions of viral regulatory and accessory proteins vary widely among different viruses. For example, in human immunodeficiency virus (HIV), the Tat protein is a regulatory protein that activates transcription of the viral genome, while the Vpu protein is an accessory protein that downregulates the expression of CD4 receptors on host cells to prevent superinfection.
Understanding the functions of viral regulatory and accessory proteins is important for developing antiviral therapies and vaccines, as these proteins can be potential targets for inhibiting viral replication or modulating the host's immune response.
Regulator genes are a type of gene that regulates the activity of other genes in an organism. They do not code for a specific protein product but instead control the expression of other genes by producing regulatory proteins such as transcription factors, repressors, or enhancers. These regulatory proteins bind to specific DNA sequences near the target genes and either promote or inhibit their transcription into mRNA. This allows regulator genes to play a crucial role in coordinating complex biological processes, including development, differentiation, metabolism, and response to environmental stimuli.
There are several types of regulator genes, including:
1. Constitutive regulators: These genes are always active and produce regulatory proteins that control the expression of other genes in a consistent manner.
2. Inducible regulators: These genes respond to specific signals or environmental stimuli by producing regulatory proteins that modulate the expression of target genes.
3. Negative regulators: These genes produce repressor proteins that bind to DNA and inhibit the transcription of target genes, thereby reducing their expression.
4. Positive regulators: These genes produce activator proteins that bind to DNA and promote the transcription of target genes, thereby increasing their expression.
5. Master regulators: These genes control the expression of multiple downstream target genes involved in specific biological processes or developmental pathways.
Regulator genes are essential for maintaining proper gene expression patterns and ensuring normal cellular function. Mutations in regulator genes can lead to various diseases, including cancer, developmental disorders, and metabolic dysfunctions.
A plasmid is a small, circular, double-stranded DNA molecule that is separate from the chromosomal DNA of a bacterium or other organism. Plasmids are typically not essential for the survival of the organism, but they can confer beneficial traits such as antibiotic resistance or the ability to degrade certain types of pollutants.
Plasmids are capable of replicating independently of the chromosomal DNA and can be transferred between bacteria through a process called conjugation. They often contain genes that provide resistance to antibiotics, heavy metals, and other environmental stressors. Plasmids have also been engineered for use in molecular biology as cloning vectors, allowing scientists to replicate and manipulate specific DNA sequences.
Plasmids are important tools in genetic engineering and biotechnology because they can be easily manipulated and transferred between organisms. They have been used to produce vaccines, diagnostic tests, and genetically modified organisms (GMOs) for various applications, including agriculture, medicine, and industry.
A mutation is a permanent change in the DNA sequence of an organism's genome. Mutations can occur spontaneously or be caused by environmental factors such as exposure to radiation, chemicals, or viruses. They may have various effects on the organism, ranging from benign to harmful, depending on where they occur and whether they alter the function of essential proteins. In some cases, mutations can increase an individual's susceptibility to certain diseases or disorders, while in others, they may confer a survival advantage. Mutations are the driving force behind evolution, as they introduce new genetic variability into populations, which can then be acted upon by natural selection.
'Escherichia coli (E. coli) proteins' refer to the various types of proteins that are produced and expressed by the bacterium Escherichia coli. These proteins play a critical role in the growth, development, and survival of the organism. They are involved in various cellular processes such as metabolism, DNA replication, transcription, translation, repair, and regulation.
E. coli is a gram-negative, facultative anaerobe that is commonly found in the intestines of warm-blooded organisms. It is widely used as a model organism in scientific research due to its well-studied genetics, rapid growth, and ability to be easily manipulated in the laboratory. As a result, many E. coli proteins have been identified, characterized, and studied in great detail.
Some examples of E. coli proteins include enzymes involved in carbohydrate metabolism such as lactase, sucrase, and maltose; proteins involved in DNA replication such as the polymerases, single-stranded binding proteins, and helicases; proteins involved in transcription such as RNA polymerase and sigma factors; proteins involved in translation such as ribosomal proteins, tRNAs, and aminoacyl-tRNA synthetases; and regulatory proteins such as global regulators, two-component systems, and transcription factors.
Understanding the structure, function, and regulation of E. coli proteins is essential for understanding the basic biology of this important organism, as well as for developing new strategies for combating bacterial infections and improving industrial processes involving bacteria.
Bacterial DNA refers to the genetic material found in bacteria. It is composed of a double-stranded helix containing four nucleotide bases - adenine (A), thymine (T), guanine (G), and cytosine (C) - that are linked together by phosphodiester bonds. The sequence of these bases in the DNA molecule carries the genetic information necessary for the growth, development, and reproduction of bacteria.
Bacterial DNA is circular in most bacterial species, although some have linear chromosomes. In addition to the main chromosome, many bacteria also contain small circular pieces of DNA called plasmids that can carry additional genes and provide resistance to antibiotics or other environmental stressors.
Unlike eukaryotic cells, which have their DNA enclosed within a nucleus, bacterial DNA is present in the cytoplasm of the cell, where it is in direct contact with the cell's metabolic machinery. This allows for rapid gene expression and regulation in response to changing environmental conditions.
Deoxyribonucleic acid (DNA) is the genetic material present in the cells of organisms where it is responsible for the storage and transmission of hereditary information. DNA is a long molecule that consists of two strands coiled together to form a double helix. Each strand is made up of a series of four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - that are linked together by phosphate and sugar groups. The sequence of these bases along the length of the molecule encodes genetic information, with A always pairing with T and C always pairing with G. This base-pairing allows for the replication and transcription of DNA, which are essential processes in the functioning and reproduction of all living organisms.
Lysogeny is a process in the life cycle of certain viruses, known as bacteriophages or phages, which can infect bacteria. In lysogeny, the viral DNA integrates into the chromosome of the host bacterium and replicates along with it, remaining dormant and not producing any new virus particles. This state is called lysogeny or the lysogenic cycle.
The integrated viral DNA is known as a prophage. The bacterial cell that contains a prophage is called a lysogen. The lysogen can continue to grow and divide normally, passing the prophage onto its daughter cells during reproduction. This dormant state can last for many generations of the host bacterium.
However, under certain conditions such as DNA damage or exposure to UV radiation, the prophage can be induced to excise itself from the bacterial chromosome and enter the lytic cycle. In the lytic cycle, the viral DNA replicates rapidly, producing many new virus particles, which eventually leads to the lysis (breaking open) of the host cell and the release of the newly formed virions.
Lysogeny is an important mechanism for the spread and survival of bacteriophages in bacterial populations. It also plays a role in horizontal gene transfer between bacteria, as genes carried by prophages can be transferred to other bacteria during transduction.
A bacterial gene is a segment of DNA (or RNA in some viruses) that contains the genetic information necessary for the synthesis of a functional bacterial protein or RNA molecule. These genes are responsible for encoding various characteristics and functions of bacteria such as metabolism, reproduction, and resistance to antibiotics. They can be transmitted between bacteria through horizontal gene transfer mechanisms like conjugation, transformation, and transduction. Bacterial genes are often organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule.
It's important to note that the term "bacterial gene" is used to describe genetic elements found in bacteria, but not all genetic elements in bacteria are considered genes. For example, some DNA sequences may not encode functional products and are therefore not considered genes. Additionally, some bacterial genes may be plasmid-borne or phage-borne, rather than being located on the bacterial chromosome.
The lac operon is a genetic regulatory system found in the bacteria Escherichia coli that controls the expression of genes responsible for the metabolism of lactose as a source of energy. It consists of three structural genes (lacZ, lacY, and lacA) that code for enzymes involved in lactose metabolism, as well as two regulatory elements: the lac promoter and the lac operator.
The lac repressor protein, produced by the lacI gene, binds to the lac operator sequence when lactose is not present, preventing RNA polymerase from transcribing the structural genes. When lactose is available, it is converted into allolactose, which acts as an inducer and binds to the lac repressor protein, causing a conformational change that prevents it from binding to the operator sequence. This allows RNA polymerase to bind to the promoter and transcribe the structural genes, leading to the production of enzymes necessary for lactose metabolism.
In summary, the lac operon is a genetic regulatory system in E. coli that controls the expression of genes involved in lactose metabolism based on the availability of lactose as a substrate.
Zinc fingers are a type of protein structural motif involved in specific DNA binding and, by extension, in the regulation of gene expression. They are so named because of their characteristic "finger-like" shape that is formed when a zinc ion binds to the amino acids within the protein. This structure allows the protein to interact with and recognize specific DNA sequences, thereby playing a crucial role in various biological processes such as transcription, repair, and recombination of genetic material.
Molecular cloning is a laboratory technique used to create multiple copies of a specific DNA sequence. This process involves several steps:
1. Isolation: The first step in molecular cloning is to isolate the DNA sequence of interest from the rest of the genomic DNA. This can be done using various methods such as PCR (polymerase chain reaction), restriction enzymes, or hybridization.
2. Vector construction: Once the DNA sequence of interest has been isolated, it must be inserted into a vector, which is a small circular DNA molecule that can replicate independently in a host cell. Common vectors used in molecular cloning include plasmids and phages.
3. Transformation: The constructed vector is then introduced into a host cell, usually a bacterial or yeast cell, through a process called transformation. This can be done using various methods such as electroporation or chemical transformation.
4. Selection: After transformation, the host cells are grown in selective media that allow only those cells containing the vector to grow. This ensures that the DNA sequence of interest has been successfully cloned into the vector.
5. Amplification: Once the host cells have been selected, they can be grown in large quantities to amplify the number of copies of the cloned DNA sequence.
Molecular cloning is a powerful tool in molecular biology and has numerous applications, including the production of recombinant proteins, gene therapy, functional analysis of genes, and genetic engineering.
Bacteriophage lambda, often simply referred to as phage lambda, is a type of virus that infects the bacterium Escherichia coli (E. coli). It is a double-stranded DNA virus that integrates its genetic material into the bacterial chromosome as a prophage when it infects the host cell. This allows the phage to replicate along with the bacterium until certain conditions trigger the lytic cycle, during which new virions are produced and released by lysing, or breaking open, the host cell.
Phage lambda is widely studied in molecular biology due to its well-characterized life cycle and genetic structure. It has been instrumental in understanding various fundamental biological processes such as gene regulation, DNA recombination, and lysis-lysogeny decision.
'Gene expression regulation' refers to the processes that control whether, when, and where a particular gene is expressed, meaning the production of a specific protein or functional RNA encoded by that gene. This complex mechanism can be influenced by various factors such as transcription factors, chromatin remodeling, DNA methylation, non-coding RNAs, and post-transcriptional modifications, among others. Proper regulation of gene expression is crucial for normal cellular function, development, and maintaining homeostasis in living organisms. Dysregulation of gene expression can lead to various diseases, including cancer and genetic disorders.
Recombinant fusion proteins are artificially created biomolecules that combine the functional domains or properties of two or more different proteins into a single protein entity. They are generated through recombinant DNA technology, where the genes encoding the desired protein domains are linked together and expressed as a single, chimeric gene in a host organism, such as bacteria, yeast, or mammalian cells.
The resulting fusion protein retains the functional properties of its individual constituent proteins, allowing for novel applications in research, diagnostics, and therapeutics. For instance, recombinant fusion proteins can be designed to enhance protein stability, solubility, or immunogenicity, making them valuable tools for studying protein-protein interactions, developing targeted therapies, or generating vaccines against infectious diseases or cancer.
Examples of recombinant fusion proteins include:
1. Etaglunatide (ABT-523): A soluble Fc fusion protein that combines the heavy chain fragment crystallizable region (Fc) of an immunoglobulin with the extracellular domain of the human interleukin-6 receptor (IL-6R). This fusion protein functions as a decoy receptor, neutralizing IL-6 and its downstream signaling pathways in rheumatoid arthritis.
2. Etanercept (Enbrel): A soluble TNF receptor p75 Fc fusion protein that binds to tumor necrosis factor-alpha (TNF-α) and inhibits its proinflammatory activity, making it a valuable therapeutic option for treating autoimmune diseases like rheumatoid arthritis, ankylosing spondylitis, and psoriasis.
3. Abatacept (Orencia): A fusion protein consisting of the extracellular domain of cytotoxic T-lymphocyte antigen 4 (CTLA-4) linked to the Fc region of an immunoglobulin, which downregulates T-cell activation and proliferation in autoimmune diseases like rheumatoid arthritis.
4. Belimumab (Benlysta): A monoclonal antibody that targets B-lymphocyte stimulator (BLyS) protein, preventing its interaction with the B-cell surface receptor and inhibiting B-cell activation in systemic lupus erythematosus (SLE).
5. Romiplostim (Nplate): A fusion protein consisting of a thrombopoietin receptor agonist peptide linked to an immunoglobulin Fc region, which stimulates platelet production in patients with chronic immune thrombocytopenia (ITP).
6. Darbepoetin alfa (Aranesp): A hyperglycosylated erythropoiesis-stimulating protein that functions as a longer-acting form of recombinant human erythropoietin, used to treat anemia in patients with chronic kidney disease or cancer.
7. Palivizumab (Synagis): A monoclonal antibody directed against the F protein of respiratory syncytial virus (RSV), which prevents RSV infection and is administered prophylactically to high-risk infants during the RSV season.
8. Ranibizumab (Lucentis): A recombinant humanized monoclonal antibody fragment that binds and inhibits vascular endothelial growth factor A (VEGF-A), used in the treatment of age-related macular degeneration, diabetic retinopathy, and other ocular disorders.
9. Cetuximab (Erbitux): A chimeric monoclonal antibody that binds to epidermal growth factor receptor (EGFR), used in the treatment of colorectal cancer and head and neck squamous cell carcinoma.
10. Adalimumab (Humira): A fully humanized monoclonal antibody that targets tumor necrosis factor-alpha (TNF-α), used in the treatment of various inflammatory diseases, including rheumatoid arthritis, psoriasis, and Crohn's disease.
11. Bevacizumab (Avastin): A recombinant humanized monoclonal antibody that binds to VEGF-A, used in the treatment of various cancers, including colorectal, lung, breast, and kidney cancer.
12. Trastuzumab (Herceptin): A humanized monoclonal antibody that targets HER2/neu receptor, used in the treatment of breast cancer.
13. Rituximab (Rituxan): A chimeric monoclonal antibody that binds to CD20 antigen on B cells, used in the treatment of non-Hodgkin's lymphoma and rheumatoid arthritis.
14. Palivizumab (Synagis): A humanized monoclonal antibody that binds to the F protein of respiratory syncytial virus, used in the prevention of respiratory syncytial virus infection in high-risk infants.
15. Infliximab (Remicade): A chimeric monoclonal antibody that targets TNF-α, used in the treatment of various inflammatory diseases, including Crohn's disease, ulcerative colitis, rheumatoid arthritis, and ankylosing spondylitis.
16. Natalizumab (Tysabri): A humanized monoclonal antibody that binds to α4β1 integrin, used in the treatment of multiple sclerosis and Crohn's disease.
17. Adalimumab (Humira): A fully human monoclonal antibody that targets TNF-α, used in the treatment of various inflammatory diseases, including rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, Crohn's disease, and ulcerative colitis.
18. Golimumab (Simponi): A fully human monoclonal antibody that targets TNF-α, used in the treatment of rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, and ulcerative colitis.
19. Certolizumab pegol (Cimzia): A PEGylated Fab' fragment of a humanized monoclonal antibody that targets TNF-α, used in the treatment of rheumatoid arthritis, psoriatic arthritis, ankylosing spondylitis, and Crohn's disease.
20. Ustekinumab (Stelara): A fully human monoclonal antibody that targets IL-12 and IL-23, used in the treatment of psoriasis, psoriatic arthritis, and Crohn's disease.
21. Secukinumab (Cosentyx): A fully human monoclonal antibody that targets IL-17A, used in the treatment of psoriasis, psoriatic arthritis, and ankylosing spondylitis.
22. Ixekizumab (Taltz): A fully human monoclonal antibody that targets IL-17A, used in the treatment of psoriasis and psoriatic arthritis.
23. Brodalumab (Siliq): A fully human monoclonal antibody that targets IL-17 receptor A, used in the treatment of psoriasis.
24. Sarilumab (Kevzara): A fully human monoclonal antibody that targets the IL-6 receptor, used in the treatment of rheumatoid arthritis.
25. Tocilizumab (Actemra): A humanized monoclonal antibody that targets the IL-6 receptor, used in the treatment of rheumatoid arthritis, systemic juvenile idiopathic arthritis, polyarticular juvenile idiopathic arthritis, giant cell arteritis, and chimeric antigen receptor T-cell-induced cytokine release syndrome.
26. Siltuximab (Sylvant): A chimeric monoclonal antibody that targets IL-6, used in the treatment of multicentric Castleman disease.
27. Satralizumab (Enspryng): A humanized monoclonal antibody that targets IL-6 receptor alpha, used in the treatment of neuromyelitis optica spectrum disorder.
28. Sirukumab (Plivensia): A human monoclonal antibody that targets IL-6, used in the treatment
Nuclear proteins are a category of proteins that are primarily found in the nucleus of a eukaryotic cell. They play crucial roles in various nuclear functions, such as DNA replication, transcription, repair, and RNA processing. This group includes structural proteins like lamins, which form the nuclear lamina, and regulatory proteins, such as histones and transcription factors, that are involved in gene expression. Nuclear localization signals (NLS) often help target these proteins to the nucleus by interacting with importin proteins during active transport across the nuclear membrane.
Lactose is a disaccharide, a type of sugar, that is naturally found in milk and dairy products. It is made up of two simple sugars, glucose and galactose, linked together. In order for the body to absorb and use lactose, it must be broken down into these simpler sugars by an enzyme called lactase, which is produced in the lining of the small intestine.
People who have a deficiency of lactase are unable to fully digest lactose, leading to symptoms such as bloating, diarrhea, and abdominal cramps, a condition known as lactose intolerance.
DNA footprinting is a laboratory technique used to identify specific DNA-protein interactions and map the binding sites of proteins on a DNA molecule. This technique involves the use of enzymes or chemicals that can cleave the DNA strand, but are prevented from doing so when a protein is bound to the DNA. By comparing the pattern of cuts in the presence and absence of the protein, researchers can identify the regions of the DNA where the protein binds.
The process typically involves treating the DNA-protein complex with a chemical or enzymatic agent that cleaves the DNA at specific sequences or sites. After the reaction is stopped, the DNA is separated into single strands and analyzed using techniques such as gel electrophoresis to visualize the pattern of cuts. The regions of the DNA where protein binding has occurred are protected from cleavage and appear as gaps or "footprints" in the pattern of cuts.
DNA footprinting is a valuable tool for studying gene regulation, as it can provide insights into how proteins interact with specific DNA sequences to control gene expression. It can also be used to study protein-DNA interactions involved in processes such as DNA replication, repair, and recombination.
Histone deacetylases (HDACs) are a group of enzymes that play a crucial role in the regulation of gene expression. They work by removing acetyl groups from histone proteins, which are the structural components around which DNA is wound to form chromatin, the material that makes up chromosomes.
Histone acetylation is a modification that generally results in an "open" chromatin structure, allowing for the transcription of genes into proteins. When HDACs remove these acetyl groups, the chromatin becomes more compact and gene expression is reduced or silenced.
HDACs are involved in various cellular processes, including development, differentiation, and survival. Dysregulation of HDAC activity has been implicated in several diseases, such as cancer, neurodegenerative disorders, and cardiovascular diseases. As a result, HDAC inhibitors have emerged as promising therapeutic agents for these conditions.
Enzyme repression is a type of gene regulation in which the production of an enzyme is inhibited or suppressed, thereby reducing the rate of catalysis of the chemical reaction that the enzyme facilitates. This process typically occurs when the end product of the reaction binds to the regulatory protein, called a repressor, which then binds to the operator region of the operon (a group of genes that are transcribed together) and prevents transcription of the structural genes encoding for the enzyme. Enzyme repression helps maintain homeostasis within the cell by preventing the unnecessary production of enzymes when they are not needed, thus conserving energy and resources.
Viral proteins are the proteins that are encoded by the viral genome and are essential for the viral life cycle. These proteins can be structural or non-structural and play various roles in the virus's replication, infection, and assembly process. Structural proteins make up the physical structure of the virus, including the capsid (the protein shell that surrounds the viral genome) and any envelope proteins (that may be present on enveloped viruses). Non-structural proteins are involved in the replication of the viral genome and modulation of the host cell environment to favor viral replication. Overall, a thorough understanding of viral proteins is crucial for developing antiviral therapies and vaccines.
Trans-activators are proteins that increase the transcriptional activity of a gene or a set of genes. They do this by binding to specific DNA sequences and interacting with the transcription machinery, thereby enhancing the recruitment and assembly of the complexes needed for transcription. In some cases, trans-activators can also modulate the chromatin structure to make the template more accessible to the transcription machinery.
In the context of HIV (Human Immunodeficiency Virus) infection, the term "trans-activator" is often used specifically to refer to the Tat protein. The Tat protein is a viral regulatory protein that plays a critical role in the replication of HIV by activating the transcription of the viral genome. It does this by binding to a specific RNA structure called the Trans-Activation Response Element (TAR) located at the 5' end of all nascent HIV transcripts, and recruiting cellular cofactors that enhance the processivity and efficiency of RNA polymerase II, leading to increased viral gene expression.
Regulatory sequences in nucleic acid refer to specific DNA or RNA segments that control the spatial and temporal expression of genes without encoding proteins. They are crucial for the proper functioning of cells as they regulate various cellular processes such as transcription, translation, mRNA stability, and localization. Regulatory sequences can be found in both coding and non-coding regions of DNA or RNA.
Some common types of regulatory sequences in nucleic acid include:
1. Promoters: DNA sequences typically located upstream of the gene that provide a binding site for RNA polymerase and transcription factors to initiate transcription.
2. Enhancers: DNA sequences, often located at a distance from the gene, that enhance transcription by binding to specific transcription factors and increasing the recruitment of RNA polymerase.
3. Silencers: DNA sequences that repress transcription by binding to specific proteins that inhibit the recruitment of RNA polymerase or promote chromatin compaction.
4. Intron splice sites: Specific nucleotide sequences within introns (non-coding regions) that mark the boundaries between exons (coding regions) and are essential for correct splicing of pre-mRNA.
5. 5' untranslated regions (UTRs): Regions located at the 5' end of an mRNA molecule that contain regulatory elements affecting translation efficiency, stability, and localization.
6. 3' untranslated regions (UTRs): Regions located at the 3' end of an mRNA molecule that contain regulatory elements influencing translation termination, stability, and localization.
7. miRNA target sites: Specific sequences in mRNAs that bind to microRNAs (miRNAs) leading to translational repression or degradation of the target mRNA.
Tetracycline is a broad-spectrum antibiotic, which is used to treat various bacterial infections. It works by preventing the growth and multiplication of bacteria. It is a part of the tetracycline class of antibiotics, which also includes doxycycline, minocycline, and others.
Tetracycline is effective against a wide range of gram-positive and gram-negative bacteria, as well as some atypical organisms such as rickettsia, chlamydia, mycoplasma, and spirochetes. It is commonly used to treat respiratory infections, skin infections, urinary tract infections, sexually transmitted diseases, and other bacterial infections.
Tetracycline is available in various forms, including tablets, capsules, and liquid solutions. It should be taken orally with a full glass of water, and it is recommended to take it on an empty stomach, at least one hour before or two hours after meals. The drug can cause tooth discoloration in children under the age of 8, so it is generally not recommended for use in this population.
Like all antibiotics, tetracycline should be used only to treat bacterial infections and not viral infections, such as the common cold or flu. Overuse or misuse of antibiotics can lead to antibiotic resistance, which makes it harder to treat infections in the future.
Messenger RNA (mRNA) is a type of RNA (ribonucleic acid) that carries genetic information copied from DNA in the form of a series of three-base code "words," each of which specifies a particular amino acid. This information is used by the cell's machinery to construct proteins, a process known as translation. After being transcribed from DNA, mRNA travels out of the nucleus to the ribosomes in the cytoplasm where protein synthesis occurs. Once the protein has been synthesized, the mRNA may be degraded and recycled. Post-transcriptional modifications can also occur to mRNA, such as alternative splicing and addition of a 5' cap and a poly(A) tail, which can affect its stability, localization, and translation efficiency.
An Electrophoretic Mobility Shift Assay (EMSA) is a laboratory technique used to detect and analyze protein-DNA interactions. In this assay, a mixture of proteins and fluorescently or radioactively labeled DNA probes are loaded onto a native polyacrylamide gel matrix and subjected to an electric field. The negatively charged DNA probe migrates towards the positive electrode, and the rate of migration (mobility) is dependent on the size and charge of the molecule. When a protein binds to the DNA probe, it forms a complex that has a different size and/or charge than the unbound probe, resulting in a shift in its mobility on the gel.
The EMSA can be used to identify specific protein-DNA interactions, determine the binding affinity of proteins for specific DNA sequences, and investigate the effects of mutations or post-translational modifications on protein-DNA interactions. The technique is widely used in molecular biology research, including studies of gene regulation, DNA damage repair, and epigenetic modifications.
In summary, Electrophoretic Mobility Shift Assay (EMSA) is a laboratory technique that detects and analyzes protein-DNA interactions by subjecting a mixture of proteins and labeled DNA probes to an electric field in a native polyacrylamide gel matrix. The binding of proteins to the DNA probe results in a shift in its mobility on the gel, allowing for the detection and analysis of specific protein-DNA interactions.
Restriction mapping is a technique used in molecular biology to identify the location and arrangement of specific restriction endonuclease recognition sites within a DNA molecule. Restriction endonucleases are enzymes that cut double-stranded DNA at specific sequences, producing fragments of various lengths. By digesting the DNA with different combinations of these enzymes and analyzing the resulting fragment sizes through techniques such as agarose gel electrophoresis, researchers can generate a restriction map - a visual representation of the locations and distances between recognition sites on the DNA molecule. This information is crucial for various applications, including cloning, genome analysis, and genetic engineering.
Coliphages are viruses that infect and replicate within certain species of bacteria that belong to the coliform group, particularly Escherichia coli (E. coli). These viruses are commonly found in water and soil environments and are frequently used as indicators of fecal contamination in water quality testing. Coliphages are not harmful to humans or animals, but their presence in water can suggest the potential presence of pathogenic bacteria or other microorganisms that may pose a health risk. There are two main types of coliphages: F-specific RNA coliphages and somatic (or non-F specific) DNA coliphages.
Carbon dioxide (CO2) is a colorless, odorless gas that is naturally present in the Earth's atmosphere. It is a normal byproduct of cellular respiration in humans, animals, and plants, and is also produced through the combustion of fossil fuels such as coal, oil, and natural gas.
In medical terms, carbon dioxide is often used as a respiratory stimulant and to maintain the pH balance of blood. It is also used during certain medical procedures, such as laparoscopic surgery, to insufflate (inflate) the abdominal cavity and create a working space for the surgeon.
Elevated levels of carbon dioxide in the body can lead to respiratory acidosis, a condition characterized by an increased concentration of carbon dioxide in the blood and a decrease in pH. This can occur in conditions such as chronic obstructive pulmonary disease (COPD), asthma, or other lung diseases that impair breathing and gas exchange. Symptoms of respiratory acidosis may include shortness of breath, confusion, headache, and in severe cases, coma or death.
A consensus sequence in genetics refers to the most common nucleotide (DNA or RNA) or amino acid at each position in a multiple sequence alignment. It is derived by comparing and analyzing several sequences of the same gene or protein from different individuals or organisms. The consensus sequence provides a general pattern or motif that is shared among these sequences and can be useful in identifying functional regions, conserved domains, or evolutionary relationships. However, it's important to note that not every sequence will exactly match the consensus sequence, as variations can occur naturally due to mutations or genetic differences among individuals.
Deoxyribonuclease I (DNase I) is an enzyme that cleaves the phosphodiester bonds in the DNA molecule, breaking it down into smaller pieces. It is also known as DNase A or bovine pancreatic deoxyribonuclease. This enzyme specifically hydrolyzes the internucleotide linkages of DNA by cleaving the phosphodiester bond between the 3'-hydroxyl group of one deoxyribose sugar and the phosphate group of another, leaving 3'-phosphomononucleotides as products.
DNase I plays a crucial role in various biological processes, including DNA degradation during apoptosis (programmed cell death), DNA repair, and host defense against pathogens by breaking down extracellular DNA from invading microorganisms or damaged cells. It is widely used in molecular biology research for applications such as DNA isolation, removing contaminating DNA from RNA samples, and generating defined DNA fragments for cloning purposes. DNase I can be found in various sources, including bovine pancreas, human tears, and bacterial cultures.
A two-hybrid system technique is a type of genetic screening method used in molecular biology to identify protein-protein interactions within an organism, most commonly baker's yeast (Saccharomyces cerevisiae) or Escherichia coli. The name "two-hybrid" refers to the fact that two separate proteins are being examined for their ability to interact with each other.
The technique is based on the modular nature of transcription factors, which typically consist of two distinct domains: a DNA-binding domain (DBD) and an activation domain (AD). In a two-hybrid system, one protein of interest is fused to the DBD, while the second protein of interest is fused to the AD. If the two proteins interact, the DBD and AD are brought in close proximity, allowing for transcriptional activation of a reporter gene that is linked to a specific promoter sequence recognized by the DBD.
The main components of a two-hybrid system include:
1. Bait protein (fused to the DNA-binding domain)
2. Prey protein (fused to the activation domain)
3. Reporter gene (transcribed upon interaction between bait and prey proteins)
4. Promoter sequence (recognized by the DBD when brought in proximity due to interaction)
The two-hybrid system technique has several advantages, including:
1. Ability to screen large libraries of potential interacting partners
2. High sensitivity for detecting weak or transient interactions
3. Applicability to various organisms and protein types
4. Potential for high-throughput analysis
However, there are also limitations to the technique, such as false positives (interactions that do not occur in vivo) and false negatives (lack of detection of true interactions). Additionally, the fusion proteins may not always fold or localize correctly, leading to potential artifacts. Despite these limitations, two-hybrid system techniques remain a valuable tool for studying protein-protein interactions and have contributed significantly to our understanding of various cellular processes.
Tertiary protein structure refers to the three-dimensional arrangement of all the elements (polypeptide chains) of a single protein molecule. It is the highest level of structural organization and results from interactions between various side chains (R groups) of the amino acids that make up the protein. These interactions, which include hydrogen bonds, ionic bonds, van der Waals forces, and disulfide bridges, give the protein its unique shape and stability, which in turn determines its function. The tertiary structure of a protein can be stabilized by various factors such as temperature, pH, and the presence of certain ions. Any changes in these factors can lead to denaturation, where the protein loses its tertiary structure and thus its function.
A "reporter gene" is a type of gene that is linked to a gene of interest in order to make the expression or activity of that gene detectable. The reporter gene encodes for a protein that can be easily measured and serves as an indicator of the presence and activity of the gene of interest. Commonly used reporter genes include those that encode for fluorescent proteins, enzymes that catalyze colorimetric reactions, or proteins that bind to specific molecules.
In the context of genetics and genomics research, a reporter gene is often used in studies involving gene expression, regulation, and function. By introducing the reporter gene into an organism or cell, researchers can monitor the activity of the gene of interest in real-time or after various experimental treatments. The information obtained from these studies can help elucidate the role of specific genes in biological processes and diseases, providing valuable insights for basic research and therapeutic development.
A cell line is a culture of cells that are grown in a laboratory for use in research. These cells are usually taken from a single cell or group of cells, and they are able to divide and grow continuously in the lab. Cell lines can come from many different sources, including animals, plants, and humans. They are often used in scientific research to study cellular processes, disease mechanisms, and to test new drugs or treatments. Some common types of human cell lines include HeLa cells (which come from a cancer patient named Henrietta Lacks), HEK293 cells (which come from embryonic kidney cells), and HUVEC cells (which come from umbilical vein endothelial cells). It is important to note that cell lines are not the same as primary cells, which are cells that are taken directly from a living organism and have not been grown in the lab.
Carrier proteins, also known as transport proteins, are a type of protein that facilitates the movement of molecules across cell membranes. They are responsible for the selective and active transport of ions, sugars, amino acids, and other molecules from one side of the membrane to the other, against their concentration gradient. This process requires energy, usually in the form of ATP (adenosine triphosphate).
Carrier proteins have a specific binding site for the molecule they transport, and undergo conformational changes upon binding, which allows them to move the molecule across the membrane. Once the molecule has been transported, the carrier protein returns to its original conformation, ready to bind and transport another molecule.
Carrier proteins play a crucial role in maintaining the balance of ions and other molecules inside and outside of cells, and are essential for many physiological processes, including nerve impulse transmission, muscle contraction, and nutrient uptake.
Dimerization is a process in which two molecules, usually proteins or similar structures, bind together to form a larger complex. This can occur through various mechanisms, such as the formation of disulfide bonds, hydrogen bonding, or other non-covalent interactions. Dimerization can play important roles in cell signaling, enzyme function, and the regulation of gene expression.
In the context of medical research and therapy, dimerization is often studied in relation to specific proteins that are involved in diseases such as cancer. For example, some drugs have been developed to target and inhibit the dimerization of certain proteins, with the goal of disrupting their function and slowing or stopping the progression of the disease.
Protein biosynthesis is the process by which cells generate new proteins. It involves two major steps: transcription and translation. Transcription is the process of creating a complementary RNA copy of a sequence of DNA. This RNA copy, or messenger RNA (mRNA), carries the genetic information to the site of protein synthesis, the ribosome. During translation, the mRNA is read by transfer RNA (tRNA) molecules, which bring specific amino acids to the ribosome based on the sequence of nucleotides in the mRNA. The ribosome then links these amino acids together in the correct order to form a polypeptide chain, which may then fold into a functional protein. Protein biosynthesis is essential for the growth and maintenance of all living organisms.
Protein conformation refers to the specific three-dimensional shape that a protein molecule assumes due to the spatial arrangement of its constituent amino acid residues and their associated chemical groups. This complex structure is determined by several factors, including covalent bonds (disulfide bridges), hydrogen bonds, van der Waals forces, and ionic bonds, which help stabilize the protein's unique conformation.
Protein conformations can be broadly classified into two categories: primary, secondary, tertiary, and quaternary structures. The primary structure represents the linear sequence of amino acids in a polypeptide chain. The secondary structure arises from local interactions between adjacent amino acid residues, leading to the formation of recurring motifs such as α-helices and β-sheets. Tertiary structure refers to the overall three-dimensional folding pattern of a single polypeptide chain, while quaternary structure describes the spatial arrangement of multiple folded polypeptide chains (subunits) that interact to form a functional protein complex.
Understanding protein conformation is crucial for elucidating protein function, as the specific three-dimensional shape of a protein directly influences its ability to interact with other molecules, such as ligands, nucleic acids, or other proteins. Any alterations in protein conformation due to genetic mutations, environmental factors, or chemical modifications can lead to loss of function, misfolding, aggregation, and disease states like neurodegenerative disorders and cancer.
Sequence homology, amino acid, refers to the similarity in the order of amino acids in a protein or a portion of a protein between two or more species. This similarity can be used to infer evolutionary relationships and functional similarities between proteins. The higher the degree of sequence homology, the more likely it is that the proteins are related and have similar functions. Sequence homology can be determined through various methods such as pairwise alignment or multiple sequence alignment, which compare the sequences and calculate a score based on the number and type of matching amino acids.
'Drosophila proteins' refer to the proteins that are expressed in the fruit fly, Drosophila melanogaster. This organism is a widely used model system in genetics, developmental biology, and molecular biology research. The study of Drosophila proteins has contributed significantly to our understanding of various biological processes, including gene regulation, cell signaling, development, and aging.
Some examples of well-studied Drosophila proteins include:
1. HSP70 (Heat Shock Protein 70): A chaperone protein involved in protein folding and protection from stress conditions.
2. TUBULIN: A structural protein that forms microtubules, important for cell division and intracellular transport.
3. ACTIN: A cytoskeletal protein involved in muscle contraction, cell motility, and maintenance of cell shape.
4. BETA-GALACTOSIDASE (LACZ): A reporter protein often used to monitor gene expression patterns in transgenic flies.
5. ENDOGLIN: A protein involved in the development of blood vessels during embryogenesis.
6. P53: A tumor suppressor protein that plays a crucial role in preventing cancer by regulating cell growth and division.
7. JUN-KINASE (JNK): A signaling protein involved in stress response, apoptosis, and developmental processes.
8. DECAPENTAPLEGIC (DPP): A member of the TGF-β (Transforming Growth Factor Beta) superfamily, playing essential roles in embryonic development and tissue homeostasis.
These proteins are often studied using various techniques such as biochemistry, genetics, molecular biology, and structural biology to understand their functions, interactions, and regulation within the cell.
Site-directed mutagenesis is a molecular biology technique used to introduce specific and targeted changes to a specific DNA sequence. This process involves creating a new variant of a gene or a specific region of interest within a DNA molecule by introducing a planned, deliberate change, or mutation, at a predetermined site within the DNA sequence.
The methodology typically involves the use of molecular tools such as PCR (polymerase chain reaction), restriction enzymes, and/or ligases to introduce the desired mutation(s) into a plasmid or other vector containing the target DNA sequence. The resulting modified DNA molecule can then be used to transform host cells, allowing for the production of large quantities of the mutated gene or protein for further study.
Site-directed mutagenesis is a valuable tool in basic research, drug discovery, and biotechnology applications where specific changes to a DNA sequence are required to understand gene function, investigate protein structure/function relationships, or engineer novel biological properties into existing genes or proteins.
Beta-galactosidase is an enzyme that catalyzes the hydrolysis of beta-galactosides into monosaccharides. It is found in various organisms, including bacteria, yeast, and mammals. In humans, it plays a role in the breakdown and absorption of certain complex carbohydrates, such as lactose, in the small intestine. Deficiency of this enzyme in humans can lead to a disorder called lactose intolerance. In scientific research, beta-galactosidase is often used as a marker for gene expression and protein localization studies.
Gene expression regulation in fungi refers to the complex cellular processes that control the production of proteins and other functional gene products in response to various internal and external stimuli. This regulation is crucial for normal growth, development, and adaptation of fungal cells to changing environmental conditions.
In fungi, gene expression is regulated at multiple levels, including transcriptional, post-transcriptional, translational, and post-translational modifications. Key regulatory mechanisms include:
1. Transcription factors (TFs): These proteins bind to specific DNA sequences in the promoter regions of target genes and either activate or repress their transcription. Fungi have a diverse array of TFs that respond to various signals, such as nutrient availability, stress, developmental cues, and quorum sensing.
2. Chromatin remodeling: The organization and compaction of DNA into chromatin can influence gene expression. Fungi utilize ATP-dependent chromatin remodeling complexes and histone modifying enzymes to alter chromatin structure, thereby facilitating or inhibiting the access of transcriptional machinery to genes.
3. Non-coding RNAs: Small non-coding RNAs (sncRNAs) play a role in post-transcriptional regulation of gene expression in fungi. These sncRNAs can guide RNA-induced transcriptional silencing (RITS) complexes to specific target loci, leading to the repression of gene expression through histone modifications and DNA methylation.
4. Alternative splicing: Fungi employ alternative splicing mechanisms to generate multiple mRNA isoforms from a single gene, thereby increasing proteome diversity. This process can be regulated by RNA-binding proteins that recognize specific sequence motifs in pre-mRNAs and promote or inhibit splicing events.
5. Protein stability and activity: Post-translational modifications (PTMs) of proteins, such as phosphorylation, ubiquitination, and sumoylation, can influence their stability, localization, and activity. These PTMs play a crucial role in regulating various cellular processes, including signal transduction, stress response, and cell cycle progression.
Understanding the complex interplay between these regulatory mechanisms is essential for elucidating the molecular basis of fungal development, pathogenesis, and drug resistance. This knowledge can be harnessed to develop novel strategies for combating fungal infections and improving agricultural productivity.
Transfection is a term used in molecular biology that refers to the process of deliberately introducing foreign genetic material (DNA, RNA or artificial gene constructs) into cells. This is typically done using chemical or physical methods, such as lipofection or electroporation. Transfection is widely used in research and medical settings for various purposes, including studying gene function, producing proteins, developing gene therapies, and creating genetically modified organisms. It's important to note that transfection is different from transduction, which is the process of introducing genetic material into cells using viruses as vectors.
In genetics, sequence alignment is the process of arranging two or more DNA, RNA, or protein sequences to identify regions of similarity or homology between them. This is often done using computational methods to compare the nucleotide or amino acid sequences and identify matching patterns, which can provide insight into evolutionary relationships, functional domains, or potential genetic disorders. The alignment process typically involves adjusting gaps and mismatches in the sequences to maximize the similarity between them, resulting in an aligned sequence that can be visually represented and analyzed.
Basic Helix-Loop-Helix (bHLH) transcription factors are a type of proteins that regulate gene expression through binding to specific DNA sequences. They play crucial roles in various biological processes, including cell growth, differentiation, and apoptosis. The bHLH domain is composed of two amphipathic α-helices separated by a loop region. This structure allows the formation of homodimers or heterodimers, which then bind to the E-box DNA motif (5'-CANNTG-3') to regulate transcription.
The bHLH family can be further divided into several subfamilies based on their sequence similarities and functional characteristics. Some members of this family are involved in the development and function of the nervous system, while others play critical roles in the development of muscle and bone. Dysregulation of bHLH transcription factors has been implicated in various human diseases, including cancer and neurodevelopmental disorders.
Homeodomain proteins are a group of transcription factors that play crucial roles in the development and differentiation of cells in animals and plants. They are characterized by the presence of a highly conserved DNA-binding domain called the homeodomain, which is typically about 60 amino acids long. The homeodomain consists of three helices, with the third helix responsible for recognizing and binding to specific DNA sequences.
Homeodomain proteins are involved in regulating gene expression during embryonic development, tissue maintenance, and organismal growth. They can act as activators or repressors of transcription, depending on the context and the presence of cofactors. Mutations in homeodomain proteins have been associated with various human diseases, including cancer, congenital abnormalities, and neurological disorders.
Some examples of homeodomain proteins include PAX6, which is essential for eye development, HOX genes, which are involved in body patterning, and NANOG, which plays a role in maintaining pluripotency in stem cells.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
In the context of medicine and pharmacology, "kinetics" refers to the study of how a drug moves throughout the body, including its absorption, distribution, metabolism, and excretion (often abbreviated as ADME). This field is called "pharmacokinetics."
1. Absorption: This is the process of a drug moving from its site of administration into the bloodstream. Factors such as the route of administration (e.g., oral, intravenous, etc.), formulation, and individual physiological differences can affect absorption.
2. Distribution: Once a drug is in the bloodstream, it gets distributed throughout the body to various tissues and organs. This process is influenced by factors like blood flow, protein binding, and lipid solubility of the drug.
3. Metabolism: Drugs are often chemically modified in the body, typically in the liver, through processes known as metabolism. These changes can lead to the formation of active or inactive metabolites, which may then be further distributed, excreted, or undergo additional metabolic transformations.
4. Excretion: This is the process by which drugs and their metabolites are eliminated from the body, primarily through the kidneys (urine) and the liver (bile).
Understanding the kinetics of a drug is crucial for determining its optimal dosing regimen, potential interactions with other medications or foods, and any necessary adjustments for special populations like pediatric or geriatric patients, or those with impaired renal or hepatic function.
Developmental gene expression regulation refers to the processes that control the activation or repression of specific genes during embryonic and fetal development. These regulatory mechanisms ensure that genes are expressed at the right time, in the right cells, and at appropriate levels to guide proper growth, differentiation, and morphogenesis of an organism.
Developmental gene expression regulation is a complex and dynamic process involving various molecular players, such as transcription factors, chromatin modifiers, non-coding RNAs, and signaling molecules. These regulators can interact with cis-regulatory elements, like enhancers and promoters, to fine-tune the spatiotemporal patterns of gene expression during development.
Dysregulation of developmental gene expression can lead to various congenital disorders and developmental abnormalities. Therefore, understanding the principles and mechanisms governing developmental gene expression regulation is crucial for uncovering the etiology of developmental diseases and devising potential therapeutic strategies.
Nucleic acid conformation refers to the three-dimensional structure that nucleic acids (DNA and RNA) adopt as a result of the bonding patterns between the atoms within the molecule. The primary structure of nucleic acids is determined by the sequence of nucleotides, while the conformation is influenced by factors such as the sugar-phosphate backbone, base stacking, and hydrogen bonding.
Two common conformations of DNA are the B-form and the A-form. The B-form is a right-handed helix with a diameter of about 20 Å and a pitch of 34 Å, while the A-form has a smaller diameter (about 18 Å) and a shorter pitch (about 25 Å). RNA typically adopts an A-form conformation.
The conformation of nucleic acids can have significant implications for their function, as it can affect their ability to interact with other molecules such as proteins or drugs. Understanding the conformational properties of nucleic acids is therefore an important area of research in molecular biology and medicine.
Recombinant proteins are artificially created proteins produced through the use of recombinant DNA technology. This process involves combining DNA molecules from different sources to create a new set of genes that encode for a specific protein. The resulting recombinant protein can then be expressed, purified, and used for various applications in research, medicine, and industry.
Recombinant proteins are widely used in biomedical research to study protein function, structure, and interactions. They are also used in the development of diagnostic tests, vaccines, and therapeutic drugs. For example, recombinant insulin is a common treatment for diabetes, while recombinant human growth hormone is used to treat growth disorders.
The production of recombinant proteins typically involves the use of host cells, such as bacteria, yeast, or mammalian cells, which are engineered to express the desired protein. The host cells are transformed with a plasmid vector containing the gene of interest, along with regulatory elements that control its expression. Once the host cells are cultured and the protein is expressed, it can be purified using various chromatography techniques.
Overall, recombinant proteins have revolutionized many areas of biology and medicine, enabling researchers to study and manipulate proteins in ways that were previously impossible.
The cell nucleus is a membrane-bound organelle found in the eukaryotic cells (cells with a true nucleus). It contains most of the cell's genetic material, organized as DNA molecules in complex with proteins, RNA molecules, and histones to form chromosomes.
The primary function of the cell nucleus is to regulate and control the activities of the cell, including growth, metabolism, protein synthesis, and reproduction. It also plays a crucial role in the process of mitosis (cell division) by separating and protecting the genetic material during this process. The nuclear membrane, or nuclear envelope, surrounding the nucleus is composed of two lipid bilayers with numerous pores that allow for the selective transport of molecules between the nucleoplasm (nucleus interior) and the cytoplasm (cell exterior).
The cell nucleus is a vital structure in eukaryotic cells, and its dysfunction can lead to various diseases, including cancer and genetic disorders.
HeLa cells are a type of immortalized cell line used in scientific research. They are derived from a cancer that developed in the cervical tissue of Henrietta Lacks, an African-American woman, in 1951. After her death, cells taken from her tumor were found to be capable of continuous division and growth in a laboratory setting, making them an invaluable resource for medical research.
HeLa cells have been used in a wide range of scientific studies, including research on cancer, viruses, genetics, and drug development. They were the first human cell line to be successfully cloned and are able to grow rapidly in culture, doubling their population every 20-24 hours. This has made them an essential tool for many areas of biomedical research.
It is important to note that while HeLa cells have been instrumental in numerous scientific breakthroughs, the story of their origin raises ethical questions about informed consent and the use of human tissue in research.
Genetic models are theoretical frameworks used in genetics to describe and explain the inheritance patterns and genetic architecture of traits, diseases, or phenomena. These models are based on mathematical equations and statistical methods that incorporate information about gene frequencies, modes of inheritance, and the effects of environmental factors. They can be used to predict the probability of certain genetic outcomes, to understand the genetic basis of complex traits, and to inform medical management and treatment decisions.
There are several types of genetic models, including:
1. Mendelian models: These models describe the inheritance patterns of simple genetic traits that follow Mendel's laws of segregation and independent assortment. Examples include autosomal dominant, autosomal recessive, and X-linked inheritance.
2. Complex trait models: These models describe the inheritance patterns of complex traits that are influenced by multiple genes and environmental factors. Examples include heart disease, diabetes, and cancer.
3. Population genetics models: These models describe the distribution and frequency of genetic variants within populations over time. They can be used to study evolutionary processes, such as natural selection and genetic drift.
4. Quantitative genetics models: These models describe the relationship between genetic variation and phenotypic variation in continuous traits, such as height or IQ. They can be used to estimate heritability and to identify quantitative trait loci (QTLs) that contribute to trait variation.
5. Statistical genetics models: These models use statistical methods to analyze genetic data and infer the presence of genetic associations or linkage. They can be used to identify genetic risk factors for diseases or traits.
Overall, genetic models are essential tools in genetics research and medical genetics, as they allow researchers to make predictions about genetic outcomes, test hypotheses about the genetic basis of traits and diseases, and develop strategies for prevention, diagnosis, and treatment.
"Saccharomyces cerevisiae" is not typically considered a medical term, but it is a scientific name used in the field of microbiology. It refers to a species of yeast that is commonly used in various industrial processes, such as baking and brewing. It's also widely used in scientific research due to its genetic tractability and eukaryotic cellular organization.
However, it does have some relevance to medical fields like medicine and nutrition. For example, certain strains of S. cerevisiae are used as probiotics, which can provide health benefits when consumed. They may help support gut health, enhance the immune system, and even assist in the digestion of certain nutrients.
In summary, "Saccharomyces cerevisiae" is a species of yeast with various industrial and potential medical applications.
Transcriptional activation is the process by which a cell increases the rate of transcription of specific genes from DNA to RNA. This process is tightly regulated and plays a crucial role in various biological processes, including development, differentiation, and response to environmental stimuli.
Transcriptional activation occurs when transcription factors (proteins that bind to specific DNA sequences) interact with the promoter region of a gene and recruit co-activator proteins. These co-activators help to remodel the chromatin structure around the gene, making it more accessible for the transcription machinery to bind and initiate transcription.
Transcriptional activation can be regulated at multiple levels, including the availability and activity of transcription factors, the modification of histone proteins, and the recruitment of co-activators or co-repressors. Dysregulation of transcriptional activation has been implicated in various diseases, including cancer and genetic disorders.
Saccharomyces cerevisiae proteins are the proteins that are produced by the budding yeast, Saccharomyces cerevisiae. This organism is a single-celled eukaryote that has been widely used as a model organism in scientific research for many years due to its relatively simple genetic makeup and its similarity to higher eukaryotic cells.
The genome of Saccharomyces cerevisiae has been fully sequenced, and it is estimated to contain approximately 6,000 genes that encode proteins. These proteins play a wide variety of roles in the cell, including catalyzing metabolic reactions, regulating gene expression, maintaining the structure of the cell, and responding to environmental stimuli.
Many Saccharomyces cerevisiae proteins have human homologs and are involved in similar biological processes, making this organism a valuable tool for studying human disease. For example, many of the proteins involved in DNA replication, repair, and recombination in yeast have human counterparts that are associated with cancer and other diseases. By studying these proteins in yeast, researchers can gain insights into their function and regulation in humans, which may lead to new treatments for disease.
Sequence homology in nucleic acids refers to the similarity or identity between the nucleotide sequences of two or more DNA or RNA molecules. It is often used as a measure of biological relationship between genes, organisms, or populations. High sequence homology suggests a recent common ancestry or functional constraint, while low sequence homology may indicate a more distant relationship or different functions.
Nucleic acid sequence homology can be determined by various methods such as pairwise alignment, multiple sequence alignment, and statistical analysis. The degree of homology is typically expressed as a percentage of identical or similar nucleotides in a given window of comparison.
It's important to note that the interpretation of sequence homology depends on the biological context and the evolutionary distance between the sequences compared. Therefore, functional and experimental validation is often necessary to confirm the significance of sequence homology.
Alcohol oxidoreductases are a class of enzymes that catalyze the oxidation of alcohols to aldehydes or ketones, while reducing nicotinamide adenine dinucleotide (NAD+) to NADH. These enzymes play an important role in the metabolism of alcohols and other organic compounds in living organisms.
The most well-known example of an alcohol oxidoreductase is alcohol dehydrogenase (ADH), which is responsible for the oxidation of ethanol to acetaldehyde in the liver during the metabolism of alcoholic beverages. Other examples include aldehyde dehydrogenases (ALDH) and sorbitol dehydrogenase (SDH).
These enzymes are important targets for the development of drugs used to treat alcohol use disorder, as inhibiting their activity can help to reduce the rate of ethanol metabolism and the severity of its effects on the body.
RNA-binding proteins (RBPs) are a class of proteins that selectively interact with RNA molecules to form ribonucleoprotein complexes. These proteins play crucial roles in the post-transcriptional regulation of gene expression, including pre-mRNA processing, mRNA stability, transport, localization, and translation. RBPs recognize specific RNA sequences or structures through their modular RNA-binding domains, which can be highly degenerate and allow for the recognition of a wide range of RNA targets. The interaction between RBPs and RNA is often dynamic and can be regulated by various post-translational modifications of the proteins or by environmental stimuli, allowing for fine-tuning of gene expression in response to changing cellular needs. Dysregulation of RBP function has been implicated in various human diseases, including neurological disorders and cancer.
Gene silencing is a process by which the expression of a gene is blocked or inhibited, preventing the production of its corresponding protein. This can occur naturally through various mechanisms such as RNA interference (RNAi), where small RNAs bind to and degrade specific mRNAs, or DNA methylation, where methyl groups are added to the DNA molecule, preventing transcription. Gene silencing can also be induced artificially using techniques such as RNAi-based therapies, antisense oligonucleotides, or CRISPR-Cas9 systems, which allow for targeted suppression of gene expression in research and therapeutic applications.
"Drosophila" is a genus of small flies, also known as fruit flies. The most common species used in scientific research is "Drosophila melanogaster," which has been a valuable model organism for many areas of biological and medical research, including genetics, developmental biology, neurobiology, and aging.
The use of Drosophila as a model organism has led to numerous important discoveries in genetics and molecular biology, such as the identification of genes that are associated with human diseases like cancer, Parkinson's disease, and obesity. The short reproductive cycle, large number of offspring, and ease of genetic manipulation make Drosophila a powerful tool for studying complex biological processes.
Tryptophan is an essential amino acid, meaning it cannot be synthesized by the human body and must be obtained through dietary sources. Its chemical formula is C11H12N2O2. Tryptophan plays a crucial role in various biological processes as it serves as a precursor to several important molecules, including serotonin, melatonin, and niacin (vitamin B3). Serotonin is a neurotransmitter involved in mood regulation, appetite control, and sleep-wake cycles, while melatonin is a hormone that regulates sleep-wake patterns. Niacin is essential for energy production and DNA repair.
Foods rich in tryptophan include turkey, chicken, fish, eggs, cheese, milk, nuts, seeds, and whole grains. In some cases, tryptophan supplementation may be recommended to help manage conditions related to serotonin imbalances, such as depression or insomnia, but this should only be done under the guidance of a healthcare professional due to potential side effects and interactions with other medications.
Arabidopsis proteins refer to the proteins that are encoded by the genes in the Arabidopsis thaliana plant, which is a model organism commonly used in plant biology research. This small flowering plant has a compact genome and a short life cycle, making it an ideal subject for studying various biological processes in plants.
Arabidopsis proteins play crucial roles in many cellular functions, such as metabolism, signaling, regulation of gene expression, response to environmental stresses, and developmental processes. Research on Arabidopsis proteins has contributed significantly to our understanding of plant biology and has provided valuable insights into the molecular mechanisms underlying various agronomic traits.
Some examples of Arabidopsis proteins include transcription factors, kinases, phosphatases, receptors, enzymes, and structural proteins. These proteins can be studied using a variety of techniques, such as biochemical assays, protein-protein interaction studies, and genetic approaches, to understand their functions and regulatory mechanisms in plants.
Biological models, also known as physiological models or organismal models, are simplified representations of biological systems, processes, or mechanisms that are used to understand and explain the underlying principles and relationships. These models can be theoretical (conceptual or mathematical) or physical (such as anatomical models, cell cultures, or animal models). They are widely used in biomedical research to study various phenomena, including disease pathophysiology, drug action, and therapeutic interventions.
Examples of biological models include:
1. Mathematical models: These use mathematical equations and formulas to describe complex biological systems or processes, such as population dynamics, metabolic pathways, or gene regulation networks. They can help predict the behavior of these systems under different conditions and test hypotheses about their underlying mechanisms.
2. Cell cultures: These are collections of cells grown in a controlled environment, typically in a laboratory dish or flask. They can be used to study cellular processes, such as signal transduction, gene expression, or metabolism, and to test the effects of drugs or other treatments on these processes.
3. Animal models: These are living organisms, usually vertebrates like mice, rats, or non-human primates, that are used to study various aspects of human biology and disease. They can provide valuable insights into the pathophysiology of diseases, the mechanisms of drug action, and the safety and efficacy of new therapies.
4. Anatomical models: These are physical representations of biological structures or systems, such as plastic models of organs or tissues, that can be used for educational purposes or to plan surgical procedures. They can also serve as a basis for developing more sophisticated models, such as computer simulations or 3D-printed replicas.
Overall, biological models play a crucial role in advancing our understanding of biology and medicine, helping to identify new targets for therapeutic intervention, develop novel drugs and treatments, and improve human health.
'Bacillus subtilis' is a gram-positive, rod-shaped bacterium that is commonly found in soil and vegetation. It is a facultative anaerobe, meaning it can grow with or without oxygen. This bacterium is known for its ability to form durable endospores during unfavorable conditions, which allows it to survive in harsh environments for long periods of time.
'Bacillus subtilis' has been widely studied as a model organism in microbiology and molecular biology due to its genetic tractability and rapid growth. It is also used in various industrial applications, such as the production of enzymes, antibiotics, and other bioproducts.
Although 'Bacillus subtilis' is generally considered non-pathogenic, there have been rare cases of infection in immunocompromised individuals. It is important to note that this bacterium should not be confused with other pathogenic species within the genus Bacillus, such as B. anthracis (causative agent of anthrax) or B. cereus (a foodborne pathogen).
A genetic complementation test is a laboratory procedure used in molecular genetics to determine whether two mutated genes can complement each other's function, indicating that they are located at different loci and represent separate alleles. This test involves introducing a normal or wild-type copy of one gene into a cell containing a mutant version of the same gene, and then observing whether the presence of the normal gene restores the normal function of the mutated gene. If the introduction of the normal gene results in the restoration of the normal phenotype, it suggests that the two genes are located at different loci and can complement each other's function. However, if the introduction of the normal gene does not restore the normal phenotype, it suggests that the two genes are located at the same locus and represent different alleles of the same gene. This test is commonly used to map genes and identify genetic interactions in a variety of organisms, including bacteria, yeast, and animals.
DNA transposable elements, also known as transposons or jumping genes, are mobile genetic elements that can change their position within a genome. They are composed of DNA sequences that include genes encoding the enzymes required for their own movement (transposase) and regulatory elements. When activated, the transposase recognizes specific sequences at the ends of the element and catalyzes the excision and reintegration of the transposable element into a new location in the genome. This process can lead to genetic variation, as the insertion of a transposable element can disrupt the function of nearby genes or create new combinations of gene regulatory elements. Transposable elements are widespread in both prokaryotic and eukaryotic genomes and are thought to play a significant role in genome evolution.
Signal transduction is the process by which a cell converts an extracellular signal, such as a hormone or neurotransmitter, into an intracellular response. This involves a series of molecular events that transmit the signal from the cell surface to the interior of the cell, ultimately resulting in changes in gene expression, protein activity, or metabolism.
The process typically begins with the binding of the extracellular signal to a receptor located on the cell membrane. This binding event activates the receptor, which then triggers a cascade of intracellular signaling molecules, such as second messengers, protein kinases, and ion channels. These molecules amplify and propagate the signal, ultimately leading to the activation or inhibition of specific cellular responses.
Signal transduction pathways are highly regulated and can be modulated by various factors, including other signaling molecules, post-translational modifications, and feedback mechanisms. Dysregulation of these pathways has been implicated in a variety of diseases, including cancer, diabetes, and neurological disorders.
A phenotype is the physical or biochemical expression of an organism's genes, or the observable traits and characteristics resulting from the interaction of its genetic constitution (genotype) with environmental factors. These characteristics can include appearance, development, behavior, and resistance to disease, among others. Phenotypes can vary widely, even among individuals with identical genotypes, due to differences in environmental influences, gene expression, and genetic interactions.
I'm sorry for any confusion, but "Insect Proteins" is not a recognized medical term. However, I can provide some information about insect protein from a nutritional and food science perspective.
Insect proteins refer to the proteins that are obtained from insects. Insects are a rich source of protein, and their protein content varies by species. For example, mealworms and crickets have been found to contain approximately 47-63% and 60-72% protein by dry weight, respectively.
In recent years, insect proteins have gained attention as a potential sustainable source of nutrition due to their high protein content, low environmental impact, and the ability to convert feed into protein more efficiently compared to traditional livestock. Insect proteins can be used in various applications such as food and feed additives, nutritional supplements, and even cosmetics.
However, it's important to note that the use of insect proteins in human food is not widely accepted in many Western countries due to cultural and regulatory barriers. Nonetheless, research and development efforts continue to explore the potential benefits and applications of insect proteins in the global food system.
Chloramphenicol O-acetyltransferase is an enzyme that is encoded by the cat gene in certain bacteria. This enzyme is responsible for adding acetyl groups to chloramphenicol, which is an antibiotic that inhibits bacterial protein synthesis. When chloramphenicol is acetylated by this enzyme, it becomes inactivated and can no longer bind to the ribosome and prevent bacterial protein synthesis.
Bacteria that are resistant to chloramphenicol often have a plasmid-borne cat gene, which encodes for the production of Chloramphenicol O-acetyltransferase. This enzyme allows the bacteria to survive in the presence of chloramphenicol by rendering it ineffective. The transfer of this plasmid between bacteria can also confer resistance to other susceptible strains.
In summary, Chloramphenicol O-acetyltransferase is an enzyme that inactivates chloramphenicol by adding acetyl groups to it, making it an essential factor in bacterial resistance to this antibiotic.
Mutagenesis is the process by which the genetic material (DNA or RNA) of an organism is changed in a way that can alter its phenotype, or observable traits. These changes, known as mutations, can be caused by various factors such as chemicals, radiation, or viruses. Some mutations may have no effect on the organism, while others can cause harm, including diseases and cancer. Mutagenesis is a crucial area of study in genetics and molecular biology, with implications for understanding evolution, genetic disorders, and the development of new medical treatments.
A gene is a specific sequence of nucleotides in DNA that carries genetic information. Genes are the fundamental units of heredity and are responsible for the development and function of all living organisms. They code for proteins or RNA molecules, which carry out various functions within cells and are essential for the structure, function, and regulation of the body's tissues and organs.
Each gene has a specific location on a chromosome, and each person inherits two copies of every gene, one from each parent. Variations in the sequence of nucleotides in a gene can lead to differences in traits between individuals, including physical characteristics, susceptibility to disease, and responses to environmental factors.
Medical genetics is the study of genes and their role in health and disease. It involves understanding how genes contribute to the development and progression of various medical conditions, as well as identifying genetic risk factors and developing strategies for prevention, diagnosis, and treatment.
Viral DNA refers to the genetic material present in viruses that consist of DNA as their core component. Deoxyribonucleic acid (DNA) is one of the two types of nucleic acids that are responsible for storing and transmitting genetic information in living organisms. Viruses are infectious agents much smaller than bacteria that can only replicate inside the cells of other organisms, called hosts.
Viral DNA can be double-stranded (dsDNA) or single-stranded (ssDNA), depending on the type of virus. Double-stranded DNA viruses have a genome made up of two complementary strands of DNA, while single-stranded DNA viruses contain only one strand of DNA.
Examples of dsDNA viruses include Adenoviruses, Herpesviruses, and Poxviruses, while ssDNA viruses include Parvoviruses and Circoviruses. Viral DNA plays a crucial role in the replication cycle of the virus, encoding for various proteins necessary for its multiplication and survival within the host cell.
A Structure-Activity Relationship (SAR) in the context of medicinal chemistry and pharmacology refers to the relationship between the chemical structure of a drug or molecule and its biological activity or effect on a target protein, cell, or organism. SAR studies aim to identify patterns and correlations between structural features of a compound and its ability to interact with a specific biological target, leading to a desired therapeutic response or undesired side effects.
By analyzing the SAR, researchers can optimize the chemical structure of lead compounds to enhance their potency, selectivity, safety, and pharmacokinetic properties, ultimately guiding the design and development of novel drugs with improved efficacy and reduced toxicity.
Cyclic AMP Response Element Modulator (CREM) is a protein that functions as a transcription factor, which binds to specific DNA sequences called cis-acting elements in the promoter region of target genes and regulates their expression. The CREM protein is activated by cyclic AMP (cAMP), a second messenger molecule involved in various cellular signaling pathways.
The CREM protein contains several functional domains, including a DNA-binding domain that recognizes the cAMP response element (CRE) sequence, and a transactivation domain that interacts with other proteins to activate or repress gene transcription. The CREM protein can exist in multiple forms, including activated and repressed isoforms, which are generated by alternative splicing of its pre-mRNA.
The CREM protein plays important roles in various biological processes, such as neuronal development, circadian rhythm regulation, and immune response. Dysregulation of CREM has been implicated in several diseases, including cancer, neurodegenerative disorders, and metabolic disorders.
Allosteric regulation is a process that describes the way in which the binding of a molecule (known as a ligand) to an enzyme or protein at one site affects the ability of another molecule to bind to a different site on the same enzyme or protein. This interaction can either enhance (positive allosteric regulation) or inhibit (negative allosteric regulation) the activity of the enzyme or protein, depending on the nature of the ligand and its effect on the shape and/or conformation of the enzyme or protein.
In an allosteric regulatory system, the binding of the first molecule to the enzyme or protein causes a conformational change in the protein structure that alters the affinity of the second site for its ligand. This can result in changes in the activity of the enzyme or protein, allowing for fine-tuning of biochemical pathways and regulatory processes within cells.
Allosteric regulation is a fundamental mechanism in many biological systems, including metabolic pathways, signal transduction cascades, and gene expression networks. Understanding allosteric regulation can provide valuable insights into the mechanisms underlying various physiological and pathological processes, and can inform the development of novel therapeutic strategies for the treatment of disease.
A sequence deletion in a genetic context refers to the removal or absence of one or more nucleotides (the building blocks of DNA or RNA) from a specific region in a DNA or RNA molecule. This type of mutation can lead to the loss of genetic information, potentially resulting in changes in the function or expression of a gene. If the deletion involves a critical portion of the gene, it can cause diseases, depending on the role of that gene in the body. The size of the deleted sequence can vary, ranging from a single nucleotide to a large segment of DNA.
Gene expression is the process by which the information encoded in a gene is used to synthesize a functional gene product, such as a protein or RNA molecule. This process involves several steps: transcription, RNA processing, and translation. During transcription, the genetic information in DNA is copied into a complementary RNA molecule, known as messenger RNA (mRNA). The mRNA then undergoes RNA processing, which includes adding a cap and tail to the mRNA and splicing out non-coding regions called introns. The resulting mature mRNA is then translated into a protein on ribosomes in the cytoplasm through the process of translation.
The regulation of gene expression is a complex and highly controlled process that allows cells to respond to changes in their environment, such as growth factors, hormones, and stress signals. This regulation can occur at various stages of gene expression, including transcriptional activation or repression, RNA processing, mRNA stability, and translation. Dysregulation of gene expression has been implicated in many diseases, including cancer, genetic disorders, and neurological conditions.
DNA primers are short single-stranded DNA molecules that serve as a starting point for DNA synthesis. They are typically used in laboratory techniques such as the polymerase chain reaction (PCR) and DNA sequencing. The primer binds to a complementary sequence on the DNA template through base pairing, providing a free 3'-hydroxyl group for the DNA polymerase enzyme to add nucleotides and synthesize a new strand of DNA. This allows for specific and targeted amplification or analysis of a particular region of interest within a larger DNA molecule.
'Arabidopsis' is a genus of small flowering plants that are part of the mustard family (Brassicaceae). The most commonly studied species within this genus is 'Arabidopsis thaliana', which is often used as a model organism in plant biology and genetics research. This plant is native to Eurasia and Africa, and it has a small genome that has been fully sequenced. It is known for its short life cycle, self-fertilization, and ease of growth, making it an ideal subject for studying various aspects of plant biology, including development, metabolism, and response to environmental stresses.
Macromolecular substances, also known as macromolecules, are large, complex molecules made up of repeating subunits called monomers. These substances are formed through polymerization, a process in which many small molecules combine to form a larger one. Macromolecular substances can be naturally occurring, such as proteins, DNA, and carbohydrates, or synthetic, such as plastics and synthetic fibers.
In the context of medicine, macromolecular substances are often used in the development of drugs and medical devices. For example, some drugs are designed to bind to specific macromolecules in the body, such as proteins or DNA, in order to alter their function and produce a therapeutic effect. Additionally, macromolecular substances may be used in the creation of medical implants, such as artificial joints and heart valves, due to their strength and durability.
It is important for healthcare professionals to have an understanding of macromolecular substances and how they function in the body, as this knowledge can inform the development and use of medical treatments.
Fungal proteins are a type of protein that is specifically produced and present in fungi, which are a group of eukaryotic organisms that include microorganisms such as yeasts and molds. These proteins play various roles in the growth, development, and survival of fungi. They can be involved in the structure and function of fungal cells, metabolism, pathogenesis, and other cellular processes. Some fungal proteins can also have important implications for human health, both in terms of their potential use as therapeutic targets and as allergens or toxins that can cause disease.
Fungal proteins can be classified into different categories based on their functions, such as enzymes, structural proteins, signaling proteins, and toxins. Enzymes are proteins that catalyze chemical reactions in fungal cells, while structural proteins provide support and protection for the cell. Signaling proteins are involved in communication between cells and regulation of various cellular processes, and toxins are proteins that can cause harm to other organisms, including humans.
Understanding the structure and function of fungal proteins is important for developing new treatments for fungal infections, as well as for understanding the basic biology of fungi. Research on fungal proteins has led to the development of several antifungal drugs that target specific fungal enzymes or other proteins, providing effective treatment options for a range of fungal diseases. Additionally, further study of fungal proteins may reveal new targets for drug development and help improve our ability to diagnose and treat fungal infections.
"Terminator regions" is a term used in molecular biology and genetics to describe specific sequences within DNA that control the termination of transcription, which is the process of creating an RNA copy of a sequence of DNA. These regions are also sometimes referred to as "transcription termination sites."
In the context of genetic terminators, the term "terminator" refers to the sequence of nucleotides that signals the end of the gene and the beginning of the termination process. The terminator region typically contains a specific sequence of nucleotides that recruits proteins called termination factors, which help to disrupt the transcription bubble and release the newly synthesized RNA molecule from the DNA template.
It's important to note that there are different types of terminators in genetics, including "Rho-dependent" and "Rho-independent" terminators, which differ in their mechanisms for terminating transcription. Rho-dependent terminators rely on the action of a protein called Rho, while Rho-independent terminators form a stable hairpin structure that causes the transcription machinery to stall and release the RNA.
In summary, "Terminator regions" in genetics are specific sequences within DNA that control the termination of transcription by signaling the end of the gene and recruiting proteins or forming structures that disrupt the transcription bubble and release the newly synthesized RNA molecule.
Gene expression regulation, viral, refers to the processes that control the production of viral gene products, such as proteins and nucleic acids, during the viral life cycle. This can involve both viral and host cell factors that regulate transcription, RNA processing, translation, and post-translational modifications of viral genes.
Viral gene expression regulation is critical for the virus to replicate and produce progeny virions. Different types of viruses have evolved diverse mechanisms to regulate their gene expression, including the use of promoters, enhancers, transcription factors, RNA silencing, and epigenetic modifications. Understanding these regulatory processes can provide insights into viral pathogenesis and help in the development of antiviral therapies.
Fungal genes refer to the genetic material present in fungi, which are eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. The genetic material of fungi is composed of DNA, just like in other eukaryotes, and is organized into chromosomes located in the nucleus of the cell.
Fungal genes are segments of DNA that contain the information necessary to produce proteins and RNA molecules required for various cellular functions. These genes are transcribed into messenger RNA (mRNA) molecules, which are then translated into proteins by ribosomes in the cytoplasm.
Fungal genomes have been sequenced for many species, revealing a diverse range of genes that encode proteins involved in various cellular processes such as metabolism, signaling, and regulation. Comparative genomic analyses have also provided insights into the evolutionary relationships among different fungal lineages and have helped to identify unique genetic features that distinguish fungi from other eukaryotes.
Understanding fungal genes and their functions is essential for advancing our knowledge of fungal biology, as well as for developing new strategies to control fungal pathogens that can cause diseases in humans, animals, and plants.
In the context of medicine, iron is an essential micromineral and key component of various proteins and enzymes. It plays a crucial role in oxygen transport, DNA synthesis, and energy production within the body. Iron exists in two main forms: heme and non-heme. Heme iron is derived from hemoglobin and myoglobin in animal products, while non-heme iron comes from plant sources and supplements.
The recommended daily allowance (RDA) for iron varies depending on age, sex, and life stage:
* For men aged 19-50 years, the RDA is 8 mg/day
* For women aged 19-50 years, the RDA is 18 mg/day
* During pregnancy, the RDA increases to 27 mg/day
* During lactation, the RDA for breastfeeding mothers is 9 mg/day
Iron deficiency can lead to anemia, characterized by fatigue, weakness, and shortness of breath. Excessive iron intake may result in iron overload, causing damage to organs such as the liver and heart. Balanced iron levels are essential for maintaining optimal health.
Carbon monoxide (CO) is a colorless, odorless, and tasteless gas that is slightly less dense than air. It is toxic to hemoglobic animals when encountered in concentrations above about 35 ppm. This compound is a product of incomplete combustion of organic matter, and is a major component of automobile exhaust.
Carbon monoxide is poisonous because it binds to hemoglobin in red blood cells much more strongly than oxygen does, forming carboxyhemoglobin. This prevents the transport of oxygen throughout the body, which can lead to suffocation and death. Symptoms of carbon monoxide poisoning include headache, dizziness, weakness, nausea, vomiting, confusion, and disorientation. Prolonged exposure can lead to unconsciousness and death.
Carbon monoxide detectors are commonly used in homes and other buildings to alert occupants to the presence of this dangerous gas. It is important to ensure that these devices are functioning properly and that they are placed in appropriate locations throughout the building. Additionally, it is essential to maintain appliances and heating systems to prevent the release of carbon monoxide into living spaces.
Circular dichroism (CD) is a technique used in physics and chemistry to study the structure of molecules, particularly large biological molecules such as proteins and nucleic acids. It measures the difference in absorption of left-handed and right-handed circularly polarized light by a sample. This difference in absorption can provide information about the three-dimensional structure of the molecule, including its chirality or "handedness."
In more technical terms, CD is a form of spectroscopy that measures the differential absorption of left and right circularly polarized light as a function of wavelength. The CD signal is measured in units of millidegrees (mdeg) and can be positive or negative, depending on the type of chromophore and its orientation within the molecule.
CD spectra can provide valuable information about the secondary and tertiary structure of proteins, as well as the conformation of nucleic acids. For example, alpha-helical proteins typically exhibit a strong positive band near 190 nm and two negative bands at around 208 nm and 222 nm, while beta-sheet proteins show a strong positive band near 195 nm and two negative bands at around 217 nm and 175 nm.
CD spectroscopy is a powerful tool for studying the structural changes that occur in biological molecules under different conditions, such as temperature, pH, or the presence of ligands or other molecules. It can also be used to monitor the folding and unfolding of proteins, as well as the binding of drugs or other small molecules to their targets.
Amino acid motifs are recurring patterns or sequences of amino acids in a protein molecule. These motifs can be identified through various sequence analysis techniques and often have functional or structural significance. They can be as short as two amino acids in length, but typically contain at least three to five residues.
Some common examples of amino acid motifs include:
1. Active site motifs: These are specific sequences of amino acids that form the active site of an enzyme and participate in catalyzing chemical reactions. For example, the catalytic triad in serine proteases consists of three residues (serine, histidine, and aspartate) that work together to hydrolyze peptide bonds.
2. Signal peptide motifs: These are sequences of amino acids that target proteins for secretion or localization to specific organelles within the cell. For example, a typical signal peptide consists of a positively charged n-region, a hydrophobic h-region, and a polar c-region that directs the protein to the endoplasmic reticulum membrane for translocation.
3. Zinc finger motifs: These are structural domains that contain conserved sequences of amino acids that bind zinc ions and play important roles in DNA recognition and regulation of gene expression.
4. Transmembrane motifs: These are sequences of hydrophobic amino acids that span the lipid bilayer of cell membranes and anchor transmembrane proteins in place.
5. Phosphorylation sites: These are specific serine, threonine, or tyrosine residues that can be phosphorylated by protein kinases to regulate protein function.
Understanding amino acid motifs is important for predicting protein structure and function, as well as for identifying potential drug targets in disease-associated proteins.
Genetic enhancer elements are DNA sequences that increase the transcription of specific genes. They work by binding to regulatory proteins called transcription factors, which in turn recruit RNA polymerase II, the enzyme responsible for transcribing DNA into messenger RNA (mRNA). This results in the activation of gene transcription and increased production of the protein encoded by that gene.
Enhancer elements can be located upstream, downstream, or even within introns of the genes they regulate, and they can act over long distances along the DNA molecule. They are an important mechanism for controlling gene expression in a tissue-specific and developmental stage-specific manner, allowing for the precise regulation of gene activity during embryonic development and throughout adult life.
It's worth noting that genetic enhancer elements are often referred to simply as "enhancers," and they are distinct from other types of regulatory DNA sequences such as promoters, silencers, and insulators.
Enzyme induction is a process by which the activity or expression of an enzyme is increased in response to some stimulus, such as a drug, hormone, or other environmental factor. This can occur through several mechanisms, including increasing the transcription of the enzyme's gene, stabilizing the mRNA that encodes the enzyme, or increasing the translation of the mRNA into protein.
In some cases, enzyme induction can be a beneficial process, such as when it helps the body to metabolize and clear drugs more quickly. However, in other cases, enzyme induction can have negative consequences, such as when it leads to the increased metabolism of important endogenous compounds or the activation of harmful procarcinogens.
Enzyme induction is an important concept in pharmacology and toxicology, as it can affect the efficacy and safety of drugs and other xenobiotics. It is also relevant to the study of drug interactions, as the induction of one enzyme by a drug can lead to altered metabolism and effects of another drug that is metabolized by the same enzyme.
"Cells, cultured" is a medical term that refers to cells that have been removed from an organism and grown in controlled laboratory conditions outside of the body. This process is called cell culture and it allows scientists to study cells in a more controlled and accessible environment than they would have inside the body. Cultured cells can be derived from a variety of sources, including tissues, organs, or fluids from humans, animals, or cell lines that have been previously established in the laboratory.
Cell culture involves several steps, including isolation of the cells from the tissue, purification and characterization of the cells, and maintenance of the cells in appropriate growth conditions. The cells are typically grown in specialized media that contain nutrients, growth factors, and other components necessary for their survival and proliferation. Cultured cells can be used for a variety of purposes, including basic research, drug development and testing, and production of biological products such as vaccines and gene therapies.
It is important to note that cultured cells may behave differently than they do in the body, and results obtained from cell culture studies may not always translate directly to human physiology or disease. Therefore, it is essential to validate findings from cell culture experiments using additional models and ultimately in clinical trials involving human subjects.
'Drosophila melanogaster' is the scientific name for a species of fruit fly that is commonly used as a model organism in various fields of biological research, including genetics, developmental biology, and evolutionary biology. Its small size, short generation time, large number of offspring, and ease of cultivation make it an ideal subject for laboratory studies. The fruit fly's genome has been fully sequenced, and many of its genes have counterparts in the human genome, which facilitates the understanding of genetic mechanisms and their role in human health and disease.
Here is a brief medical definition:
Drosophila melanogaster (droh-suh-fih-luh meh-lon-guh-ster): A species of fruit fly used extensively as a model organism in genetic, developmental, and evolutionary research. Its genome has been sequenced, revealing many genes with human counterparts, making it valuable for understanding genetic mechanisms and their role in human health and disease.
Phosphoproteins are proteins that have been post-translationally modified by the addition of a phosphate group (-PO3H2) onto specific amino acid residues, most commonly serine, threonine, or tyrosine. This process is known as phosphorylation and is mediated by enzymes called kinases. Phosphoproteins play crucial roles in various cellular processes such as signal transduction, cell cycle regulation, metabolism, and gene expression. The addition or removal of a phosphate group can activate or inhibit the function of a protein, thereby serving as a switch to control its activity. Phosphoproteins can be detected and quantified using techniques such as Western blotting, mass spectrometry, and immunofluorescence.
X-ray crystallography is a technique used in structural biology to determine the three-dimensional arrangement of atoms in a crystal lattice. In this method, a beam of X-rays is directed at a crystal and diffracts, or spreads out, into a pattern of spots called reflections. The intensity and angle of each reflection are measured and used to create an electron density map, which reveals the position and type of atoms in the crystal. This information can be used to determine the molecular structure of a compound, including its shape, size, and chemical bonds. X-ray crystallography is a powerful tool for understanding the structure and function of biological macromolecules such as proteins and nucleic acids.
Electrophoresis, polyacrylamide gel (EPG) is a laboratory technique used to separate and analyze complex mixtures of proteins or nucleic acids (DNA or RNA) based on their size and electrical charge. This technique utilizes a matrix made of cross-linked polyacrylamide, a type of gel, which provides a stable and uniform environment for the separation of molecules.
In this process:
1. The polyacrylamide gel is prepared by mixing acrylamide monomers with a cross-linking agent (bis-acrylamide) and a catalyst (ammonium persulfate) in the presence of a buffer solution.
2. The gel is then poured into a mold and allowed to polymerize, forming a solid matrix with uniform pore sizes that depend on the concentration of acrylamide used. Higher concentrations result in smaller pores, providing better resolution for separating smaller molecules.
3. Once the gel has set, it is placed in an electrophoresis apparatus containing a buffer solution. Samples containing the mixture of proteins or nucleic acids are loaded into wells on the top of the gel.
4. An electric field is applied across the gel, causing the negatively charged molecules to migrate towards the positive electrode (anode) while positively charged molecules move toward the negative electrode (cathode). The rate of migration depends on the size, charge, and shape of the molecules.
5. Smaller molecules move faster through the gel matrix and will migrate farther from the origin compared to larger molecules, resulting in separation based on size. Proteins and nucleic acids can be selectively stained after electrophoresis to visualize the separated bands.
EPG is widely used in various research fields, including molecular biology, genetics, proteomics, and forensic science, for applications such as protein characterization, DNA fragment analysis, cloning, mutation detection, and quality control of nucleic acid or protein samples.
A genetic vector is a vehicle, often a plasmid or a virus, that is used to introduce foreign DNA into a host cell as part of genetic engineering or gene therapy techniques. The vector contains the desired gene or genes, along with regulatory elements such as promoters and enhancers, which are needed for the expression of the gene in the target cells.
The choice of vector depends on several factors, including the size of the DNA to be inserted, the type of cell to be targeted, and the efficiency of uptake and expression required. Commonly used vectors include plasmids, adenoviruses, retroviruses, and lentiviruses.
Plasmids are small circular DNA molecules that can replicate independently in bacteria. They are often used as cloning vectors to amplify and manipulate DNA fragments. Adenoviruses are double-stranded DNA viruses that infect a wide range of host cells, including human cells. They are commonly used as gene therapy vectors because they can efficiently transfer genes into both dividing and non-dividing cells.
Retroviruses and lentiviruses are RNA viruses that integrate their genetic material into the host cell's genome. This allows for stable expression of the transgene over time. Lentiviruses, a subclass of retroviruses, have the advantage of being able to infect non-dividing cells, making them useful for gene therapy applications in post-mitotic tissues such as neurons and muscle cells.
Overall, genetic vectors play a crucial role in modern molecular biology and medicine, enabling researchers to study gene function, develop new therapies, and modify organisms for various purposes.
DNA Sequence Analysis is the systematic determination of the order of nucleotides in a DNA molecule. It is a critical component of modern molecular biology, genetics, and genetic engineering. The process involves determining the exact order of the four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - in a DNA molecule or fragment. This information is used in various applications such as identifying gene mutations, studying evolutionary relationships, developing molecular markers for breeding, and diagnosing genetic diseases.
The process of DNA Sequence Analysis typically involves several steps, including DNA extraction, PCR amplification (if necessary), purification, sequencing reaction, and electrophoresis. The resulting data is then analyzed using specialized software to determine the exact sequence of nucleotides.
In recent years, high-throughput DNA sequencing technologies have revolutionized the field of genomics, enabling the rapid and cost-effective sequencing of entire genomes. This has led to an explosion of genomic data and new insights into the genetic basis of many diseases and traits.
COS cells are a type of cell line that are commonly used in molecular biology and genetic research. The name "COS" is an acronym for "CV-1 in Origin," as these cells were originally derived from the African green monkey kidney cell line CV-1. COS cells have been modified through genetic engineering to express high levels of a protein called SV40 large T antigen, which allows them to efficiently take up and replicate exogenous DNA.
There are several different types of COS cells that are commonly used in research, including COS-1, COS-3, and COS-7 cells. These cells are widely used for the production of recombinant proteins, as well as for studies of gene expression, protein localization, and signal transduction.
It is important to note that while COS cells have been a valuable tool in scientific research, they are not without their limitations. For example, because they are derived from monkey kidney cells, there may be differences in the way that human genes are expressed or regulated in these cells compared to human cells. Additionally, because COS cells express SV40 large T antigen, they may have altered cell cycle regulation and other phenotypic changes that could affect experimental results. Therefore, it is important to carefully consider the choice of cell line when designing experiments and interpreting results.
Western blotting is a laboratory technique used in molecular biology to detect and quantify specific proteins in a mixture of many different proteins. This technique is commonly used to confirm the expression of a protein of interest, determine its size, and investigate its post-translational modifications. The name "Western" blotting distinguishes this technique from Southern blotting (for DNA) and Northern blotting (for RNA).
The Western blotting procedure involves several steps:
1. Protein extraction: The sample containing the proteins of interest is first extracted, often by breaking open cells or tissues and using a buffer to extract the proteins.
2. Separation of proteins by electrophoresis: The extracted proteins are then separated based on their size by loading them onto a polyacrylamide gel and running an electric current through the gel (a process called sodium dodecyl sulfate-polyacrylamide gel electrophoresis or SDS-PAGE). This separates the proteins according to their molecular weight, with smaller proteins migrating faster than larger ones.
3. Transfer of proteins to a membrane: After separation, the proteins are transferred from the gel onto a nitrocellulose or polyvinylidene fluoride (PVDF) membrane using an electric current in a process called blotting. This creates a replica of the protein pattern on the gel but now immobilized on the membrane for further analysis.
4. Blocking: The membrane is then blocked with a blocking agent, such as non-fat dry milk or bovine serum albumin (BSA), to prevent non-specific binding of antibodies in subsequent steps.
5. Primary antibody incubation: A primary antibody that specifically recognizes the protein of interest is added and allowed to bind to its target protein on the membrane. This step may be performed at room temperature or 4°C overnight, depending on the antibody's properties.
6. Washing: The membrane is washed with a buffer to remove unbound primary antibodies.
7. Secondary antibody incubation: A secondary antibody that recognizes the primary antibody (often coupled to an enzyme or fluorophore) is added and allowed to bind to the primary antibody. This step may involve using a horseradish peroxidase (HRP)-conjugated or alkaline phosphatase (AP)-conjugated secondary antibody, depending on the detection method used later.
8. Washing: The membrane is washed again to remove unbound secondary antibodies.
9. Detection: A detection reagent is added to visualize the protein of interest by detecting the signal generated from the enzyme-conjugated or fluorophore-conjugated secondary antibody. This can be done using chemiluminescent, colorimetric, or fluorescent methods.
10. Analysis: The resulting image is analyzed to determine the presence and quantity of the protein of interest in the sample.
Western blotting is a powerful technique for identifying and quantifying specific proteins within complex mixtures. It can be used to study protein expression, post-translational modifications, protein-protein interactions, and more. However, it requires careful optimization and validation to ensure accurate and reproducible results.
Membrane transport proteins are specialized biological molecules, specifically integral membrane proteins, that facilitate the movement of various substances across the lipid bilayer of cell membranes. They are responsible for the selective and regulated transport of ions, sugars, amino acids, nucleotides, and other molecules into and out of cells, as well as within different cellular compartments. These proteins can be categorized into two main types: channels and carriers (or pumps). Channels provide a passive transport mechanism, allowing ions or small molecules to move down their electrochemical gradient, while carriers actively transport substances against their concentration gradient, requiring energy usually in the form of ATP. Membrane transport proteins play a crucial role in maintaining cell homeostasis, signaling processes, and many other physiological functions.
Cell differentiation is the process by which a less specialized cell, or stem cell, becomes a more specialized cell type with specific functions and structures. This process involves changes in gene expression, which are regulated by various intracellular signaling pathways and transcription factors. Differentiation results in the development of distinct cell types that make up tissues and organs in multicellular organisms. It is a crucial aspect of embryonic development, tissue repair, and maintenance of homeostasis in the body.
Bacterial RNA refers to the genetic material present in bacteria that is composed of ribonucleic acid (RNA). Unlike higher organisms, bacteria contain a single circular chromosome made up of DNA, along with smaller circular pieces of DNA called plasmids. These bacterial genetic materials contain the information necessary for the growth and reproduction of the organism.
Bacterial RNA can be divided into three main categories: messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). mRNA carries genetic information copied from DNA, which is then translated into proteins by the rRNA and tRNA molecules. rRNA is a structural component of the ribosome, where protein synthesis occurs, while tRNA acts as an adapter that brings amino acids to the ribosome during protein synthesis.
Bacterial RNA plays a crucial role in various cellular processes, including gene expression, protein synthesis, and regulation of metabolic pathways. Understanding the structure and function of bacterial RNA is essential for developing new antibiotics and other therapeutic strategies to combat bacterial infections.
Kruppel-like transcription factors (KLFs) are a family of transcription factors that are characterized by their highly conserved DNA-binding domain, known as the Kruppel-like zinc finger domain. This domain consists of approximately 30 amino acids and is responsible for binding to specific DNA sequences, thereby regulating gene expression.
KLFs play important roles in various biological processes, including cell proliferation, differentiation, apoptosis, and inflammation. They are involved in the development and function of many tissues and organs, such as the hematopoietic system, cardiovascular system, nervous system, and gastrointestinal tract.
There are 17 known members of the KLF family in humans, each with distinct functions and expression patterns. Some KLFs act as transcriptional activators, while others function as repressors. Dysregulation of KLFs has been implicated in various diseases, including cancer, cardiovascular disease, and diabetes.
Overall, Kruppel-like transcription factors are crucial regulators of gene expression that play important roles in normal development and physiology, as well as in the pathogenesis of various diseases.
Reverse Transcriptase Polymerase Chain Reaction (RT-PCR) is a laboratory technique used in molecular biology to amplify and detect specific DNA sequences. This technique is particularly useful for the detection and quantification of RNA viruses, as well as for the analysis of gene expression.
The process involves two main steps: reverse transcription and polymerase chain reaction (PCR). In the first step, reverse transcriptase enzyme is used to convert RNA into complementary DNA (cDNA) by reading the template provided by the RNA molecule. This cDNA then serves as a template for the PCR amplification step.
In the second step, the PCR reaction uses two primers that flank the target DNA sequence and a thermostable polymerase enzyme to repeatedly copy the targeted cDNA sequence. The reaction mixture is heated and cooled in cycles, allowing the primers to anneal to the template, and the polymerase to extend the new strand. This results in exponential amplification of the target DNA sequence, making it possible to detect even small amounts of RNA or cDNA.
RT-PCR is a sensitive and specific technique that has many applications in medical research and diagnostics, including the detection of viruses such as HIV, hepatitis C virus, and SARS-CoV-2 (the virus that causes COVID-19). It can also be used to study gene expression, identify genetic mutations, and diagnose genetic disorders.
I'm sorry for any confusion, but "thermodynamics" is not a term that has a specific medical definition. It is a branch of physics that deals with the relationships between heat and other forms of energy. However, the principles of thermodynamics can be applied to biological systems, including those in the human body, such as in the study of metabolism or muscle function. But in a medical context, "thermodynamics" would not be a term used independently as a diagnosis, treatment, or any medical condition.
Northern blotting is a laboratory technique used in molecular biology to detect and analyze specific RNA molecules (such as mRNA) in a mixture of total RNA extracted from cells or tissues. This technique is called "Northern" blotting because it is analogous to the Southern blotting method, which is used for DNA detection.
The Northern blotting procedure involves several steps:
1. Electrophoresis: The total RNA mixture is first separated based on size by running it through an agarose gel using electrical current. This separates the RNA molecules according to their length, with smaller RNA fragments migrating faster than larger ones.
2. Transfer: After electrophoresis, the RNA bands are denatured (made single-stranded) and transferred from the gel onto a nitrocellulose or nylon membrane using a technique called capillary transfer or vacuum blotting. This step ensures that the order and relative positions of the RNA fragments are preserved on the membrane, similar to how they appear in the gel.
3. Cross-linking: The RNA is then chemically cross-linked to the membrane using UV light or heat treatment, which helps to immobilize the RNA onto the membrane and prevent it from washing off during subsequent steps.
4. Prehybridization: Before adding the labeled probe, the membrane is prehybridized in a solution containing blocking agents (such as salmon sperm DNA or yeast tRNA) to minimize non-specific binding of the probe to the membrane.
5. Hybridization: A labeled nucleic acid probe, specific to the RNA of interest, is added to the prehybridization solution and allowed to hybridize (form base pairs) with its complementary RNA sequence on the membrane. The probe can be either a DNA or an RNA molecule, and it is typically labeled with a radioactive isotope (such as ³²P) or a non-radioactive label (such as digoxigenin).
6. Washing: After hybridization, the membrane is washed to remove unbound probe and reduce background noise. The washing conditions (temperature, salt concentration, and detergent concentration) are optimized based on the stringency required for specific hybridization.
7. Detection: The presence of the labeled probe is then detected using an appropriate method, depending on the type of label used. For radioactive probes, this typically involves exposing the membrane to X-ray film or a phosphorimager screen and analyzing the resulting image. For non-radioactive probes, detection can be performed using colorimetric, chemiluminescent, or fluorescent methods.
8. Data analysis: The intensity of the signal is quantified and compared to controls (such as housekeeping genes) to determine the relative expression level of the RNA of interest. This information can be used for various purposes, such as identifying differentially expressed genes in response to a specific treatment or comparing gene expression levels across different samples or conditions.
Cycloheximide is an antibiotic that is primarily used in laboratory settings to inhibit protein synthesis in eukaryotic cells. It is derived from the actinobacteria species Streptomyces griseus. In medical terms, it is not used as a therapeutic drug in humans due to its significant side effects, including liver toxicity and potential neurotoxicity. However, it remains a valuable tool in research for studying protein function and cellular processes.
The antibiotic works by binding to the 60S subunit of the ribosome, thereby preventing the transfer RNA (tRNA) from delivering amino acids to the growing polypeptide chain during translation. This inhibition of protein synthesis can be lethal to cells, making cycloheximide a useful tool in studying cellular responses to protein depletion or misregulation.
In summary, while cycloheximide has significant research applications due to its ability to inhibit protein synthesis in eukaryotic cells, it is not used as a therapeutic drug in humans because of its toxic side effects.
A cell line that is derived from tumor cells and has been adapted to grow in culture. These cell lines are often used in research to study the characteristics of cancer cells, including their growth patterns, genetic changes, and responses to various treatments. They can be established from many different types of tumors, such as carcinomas, sarcomas, and leukemias. Once established, these cell lines can be grown and maintained indefinitely in the laboratory, allowing researchers to conduct experiments and studies that would not be feasible using primary tumor cells. It is important to note that tumor cell lines may not always accurately represent the behavior of the original tumor, as they can undergo genetic changes during their time in culture.
Helix-Turn-Helix (HTH) motif is a common structural feature found in DNA-binding proteins, where a pair of alpha-helices are connected by a short loop or "turn." The second helix, often referred to as the recognition helix, fits into the major groove of the DNA double helix and makes specific contacts with the bases, thereby determining the binding specificity of the protein to its target DNA sequence. This motif is widely found in transcription factors and other regulatory proteins that control gene expression in all living organisms.
An oligonucleotide probe is a short, single-stranded DNA or RNA molecule that contains a specific sequence of nucleotides designed to hybridize with a complementary sequence in a target nucleic acid (DNA or RNA). These probes are typically 15-50 nucleotides long and are used in various molecular biology techniques, such as polymerase chain reaction (PCR), DNA sequencing, microarray analysis, and blotting methods.
Oligonucleotide probes can be labeled with various reporter molecules, like fluorescent dyes or radioactive isotopes, to enable the detection of hybridized targets. The high specificity of oligonucleotide probes allows for the precise identification and quantification of target nucleic acids in complex biological samples, making them valuable tools in diagnostic, research, and forensic applications.
Secondary protein structure refers to the local spatial arrangement of amino acid chains in a protein, typically described as regular repeating patterns held together by hydrogen bonds. The two most common types of secondary structures are the alpha-helix (α-helix) and the beta-pleated sheet (β-sheet). In an α-helix, the polypeptide chain twists around itself in a helical shape, with each backbone atom forming a hydrogen bond with the fourth amino acid residue along the chain. This forms a rigid rod-like structure that is resistant to bending or twisting forces. In β-sheets, adjacent segments of the polypeptide chain run parallel or antiparallel to each other and are connected by hydrogen bonds, forming a pleated sheet-like arrangement. These secondary structures provide the foundation for the formation of tertiary and quaternary protein structures, which determine the overall three-dimensional shape and function of the protein.
Phosphorylation is the process of adding a phosphate group (a molecule consisting of one phosphorus atom and four oxygen atoms) to a protein or other organic molecule, which is usually done by enzymes called kinases. This post-translational modification can change the function, localization, or activity of the target molecule, playing a crucial role in various cellular processes such as signal transduction, metabolism, and regulation of gene expression. Phosphorylation is reversible, and the removal of the phosphate group is facilitated by enzymes called phosphatases.
An open reading frame (ORF) is a continuous stretch of DNA or RNA sequence that has the potential to be translated into a protein. It begins with a start codon (usually "ATG" in DNA, which corresponds to "AUG" in RNA) and ends with a stop codon ("TAA", "TAG", or "TGA" in DNA; "UAA", "UAG", or "UGA" in RNA). The sequence between these two points is called a coding sequence (CDS), which, when transcribed into mRNA and translated into amino acids, forms a polypeptide chain.
In eukaryotic cells, ORFs can be located in either protein-coding genes or non-coding regions of the genome. In prokaryotic cells, multiple ORFs may be present on a single strand of DNA, often organized into operons that are transcribed together as a single mRNA molecule.
It's important to note that not all ORFs necessarily represent functional proteins; some may be pseudogenes or result from errors in genome annotation. Therefore, additional experimental evidence is typically required to confirm the expression and functionality of a given ORF.
Viral genes refer to the genetic material present in viruses that contains the information necessary for their replication and the production of viral proteins. In DNA viruses, the genetic material is composed of double-stranded or single-stranded DNA, while in RNA viruses, it is composed of single-stranded or double-stranded RNA.
Viral genes can be classified into three categories: early, late, and structural. Early genes encode proteins involved in the replication of the viral genome, modulation of host cell processes, and regulation of viral gene expression. Late genes encode structural proteins that make up the viral capsid or envelope. Some viruses also have structural genes that are expressed throughout their replication cycle.
Understanding the genetic makeup of viruses is crucial for developing antiviral therapies and vaccines. By targeting specific viral genes, researchers can develop drugs that inhibit viral replication and reduce the severity of viral infections. Additionally, knowledge of viral gene sequences can inform the development of vaccines that stimulate an immune response to specific viral proteins.
Complementary DNA (cDNA) is a type of DNA that is synthesized from a single-stranded RNA molecule through the process of reverse transcription. In this process, the enzyme reverse transcriptase uses an RNA molecule as a template to synthesize a complementary DNA strand. The resulting cDNA is therefore complementary to the original RNA molecule and is a copy of its coding sequence, but it does not contain non-coding regions such as introns that are present in genomic DNA.
Complementary DNA is often used in molecular biology research to study gene expression, protein function, and other genetic phenomena. For example, cDNA can be used to create cDNA libraries, which are collections of cloned cDNA fragments that represent the expressed genes in a particular cell type or tissue. These libraries can then be screened for specific genes or gene products of interest. Additionally, cDNA can be used to produce recombinant proteins in heterologous expression systems, allowing researchers to study the structure and function of proteins that may be difficult to express or purify from their native sources.
Amino acids are organic compounds that serve as the building blocks of proteins. They consist of a central carbon atom, also known as the alpha carbon, which is bonded to an amino group (-NH2), a carboxyl group (-COOH), a hydrogen atom (H), and a variable side chain (R group). The R group can be composed of various combinations of atoms such as hydrogen, oxygen, sulfur, nitrogen, and carbon, which determine the unique properties of each amino acid.
There are 20 standard amino acids that are encoded by the genetic code and incorporated into proteins during translation. These include:
1. Alanine (Ala)
2. Arginine (Arg)
3. Asparagine (Asn)
4. Aspartic acid (Asp)
5. Cysteine (Cys)
6. Glutamine (Gln)
7. Glutamic acid (Glu)
8. Glycine (Gly)
9. Histidine (His)
10. Isoleucine (Ile)
11. Leucine (Leu)
12. Lysine (Lys)
13. Methionine (Met)
14. Phenylalanine (Phe)
15. Proline (Pro)
16. Serine (Ser)
17. Threonine (Thr)
18. Tryptophan (Trp)
19. Tyrosine (Tyr)
20. Valine (Val)
Additionally, there are several non-standard or modified amino acids that can be incorporated into proteins through post-translational modifications, such as hydroxylation, methylation, and phosphorylation. These modifications expand the functional diversity of proteins and play crucial roles in various cellular processes.
Amino acids are essential for numerous biological functions, including protein synthesis, enzyme catalysis, neurotransmitter production, energy metabolism, and immune response regulation. Some amino acids can be synthesized by the human body (non-essential), while others must be obtained through dietary sources (essential).
Molecular weight, also known as molecular mass, is the mass of a molecule. It is expressed in units of atomic mass units (amu) or daltons (Da). Molecular weight is calculated by adding up the atomic weights of each atom in a molecule. It is a useful property in chemistry and biology, as it can be used to determine the concentration of a substance in a solution, or to calculate the amount of a substance that will react with another in a chemical reaction.
Chromosome mapping, also known as physical mapping, is the process of determining the location and order of specific genes or genetic markers on a chromosome. This is typically done by using various laboratory techniques to identify landmarks along the chromosome, such as restriction enzyme cutting sites or patterns of DNA sequence repeats. The resulting map provides important information about the organization and structure of the genome, and can be used for a variety of purposes, including identifying the location of genes associated with genetic diseases, studying evolutionary relationships between organisms, and developing genetic markers for use in breeding or forensic applications.
Glucose is a simple monosaccharide (or single sugar) that serves as the primary source of energy for living organisms. It's a fundamental molecule in biology, often referred to as "dextrose" or "grape sugar." Glucose has the molecular formula C6H12O6 and is vital to the functioning of cells, especially those in the brain and nervous system.
In the body, glucose is derived from the digestion of carbohydrates in food, and it's transported around the body via the bloodstream to cells where it can be used for energy. Cells convert glucose into a usable form through a process called cellular respiration, which involves a series of metabolic reactions that generate adenosine triphosphate (ATP)—the main currency of energy in cells.
Glucose is also stored in the liver and muscles as glycogen, a polysaccharide (multiple sugar) that can be broken down back into glucose when needed for energy between meals or during physical activity. Maintaining appropriate blood glucose levels is crucial for overall health, and imbalances can lead to conditions such as diabetes mellitus.
Proteins are complex, large molecules that play critical roles in the body's functions. They are made up of amino acids, which are organic compounds that are the building blocks of proteins. Proteins are required for the structure, function, and regulation of the body's tissues and organs. They are essential for the growth, repair, and maintenance of body tissues, and they play a crucial role in many biological processes, including metabolism, immune response, and cellular signaling. Proteins can be classified into different types based on their structure and function, such as enzymes, hormones, antibodies, and structural proteins. They are found in various foods, especially animal-derived products like meat, dairy, and eggs, as well as plant-based sources like beans, nuts, and grains.
'Tumor cells, cultured' refers to the process of removing cancerous cells from a tumor and growing them in controlled laboratory conditions. This is typically done by isolating the tumor cells from a patient's tissue sample, then placing them in a nutrient-rich environment that promotes their growth and multiplication.
The resulting cultured tumor cells can be used for various research purposes, including the study of cancer biology, drug development, and toxicity testing. They provide a valuable tool for researchers to better understand the behavior and characteristics of cancer cells outside of the human body, which can lead to the development of more effective cancer treatments.
It is important to note that cultured tumor cells may not always behave exactly the same way as they do in the human body, so findings from cell culture studies must be validated through further research, such as animal models or clinical trials.
Polymerase Chain Reaction (PCR) is a laboratory technique used to amplify specific regions of DNA. It enables the production of thousands to millions of copies of a particular DNA sequence in a rapid and efficient manner, making it an essential tool in various fields such as molecular biology, medical diagnostics, forensic science, and research.
The PCR process involves repeated cycles of heating and cooling to separate the DNA strands, allow primers (short sequences of single-stranded DNA) to attach to the target regions, and extend these primers using an enzyme called Taq polymerase, resulting in the exponential amplification of the desired DNA segment.
In a medical context, PCR is often used for detecting and quantifying specific pathogens (viruses, bacteria, fungi, or parasites) in clinical samples, identifying genetic mutations or polymorphisms associated with diseases, monitoring disease progression, and evaluating treatment effectiveness.
Chromatin Immunoprecipitation (ChIP) is a molecular biology technique used to analyze the interaction between proteins and DNA in the cell. It is a powerful tool for studying protein-DNA binding, such as transcription factor binding to specific DNA sequences, histone modification, and chromatin structure.
In ChIP assays, cells are first crosslinked with formaldehyde to preserve protein-DNA interactions. The chromatin is then fragmented into small pieces using sonication or other methods. Specific antibodies against the protein of interest are added to precipitate the protein-DNA complexes. After reversing the crosslinking, the DNA associated with the protein is purified and analyzed using PCR, sequencing, or microarray technologies.
ChIP assays can provide valuable information about the regulation of gene expression, epigenetic modifications, and chromatin structure in various biological processes and diseases, including cancer, development, and differentiation.
Cobalt is a chemical element with the symbol Co and atomic number 27. It is a hard, silver-white, lustrous, and brittle metal that is found naturally only in chemically combined form, except for small amounts found in meteorites. Cobalt is used primarily in the production of magnetic, wear-resistant, and high-strength alloys, as well as in the manufacture of batteries, magnets, and pigments.
In a medical context, cobalt is sometimes used in the form of cobalt-60, a radioactive isotope, for cancer treatment through radiation therapy. Cobalt-60 emits gamma rays that can be directed at tumors to destroy cancer cells. Additionally, small amounts of cobalt are present in some vitamin B12 supplements and fortified foods, as cobalt is an essential component of vitamin B12. However, exposure to high levels of cobalt can be harmful and may cause health effects such as allergic reactions, lung damage, heart problems, and neurological issues.
A regulon is a group of genes that are regulated together in response to a specific signal or stimulus, often through the action of a single transcription factor or regulatory protein. This means that when the transcription factor binds to specific DNA sequences called operators, it can either activate or repress the transcription of all the genes within the regulon.
This type of gene regulation is important for coordinating complex biological processes, such as cellular metabolism, stress responses, and developmental programs. By regulating a group of genes together, cells can ensure that they are all turned on or off in a coordinated manner, allowing for more precise control over the overall response to a given signal.
It's worth noting that the term "regulon" is not commonly used in clinical medicine, but rather in molecular biology and genetics research.
Gene expression regulation in plants refers to the processes that control the production of proteins and RNA from the genes present in the plant's DNA. This regulation is crucial for normal growth, development, and response to environmental stimuli in plants. It can occur at various levels, including transcription (the first step in gene expression, where the DNA sequence is copied into RNA), RNA processing (such as alternative splicing, which generates different mRNA molecules from a single gene), translation (where the information in the mRNA is used to produce a protein), and post-translational modification (where proteins are chemically modified after they have been synthesized).
In plants, gene expression regulation can be influenced by various factors such as hormones, light, temperature, and stress. Plants use complex networks of transcription factors, chromatin remodeling complexes, and small RNAs to regulate gene expression in response to these signals. Understanding the mechanisms of gene expression regulation in plants is important for basic research, as well as for developing crops with improved traits such as increased yield, stress tolerance, and disease resistance.
"Response elements" is a term used in molecular biology, particularly in the study of gene regulation. Response elements are specific DNA sequences that can bind to transcription factors, which are proteins that regulate gene expression. When a transcription factor binds to a response element, it can either activate or repress the transcription of the nearby gene.
Response elements are often found in the promoter region of genes and are typically short, conserved sequences that can be recognized by specific transcription factors. The binding of a transcription factor to a response element can lead to changes in chromatin structure, recruitment of co-activators or co-repressors, and ultimately, the regulation of gene expression.
Response elements are important for many biological processes, including development, differentiation, and response to environmental stimuli such as hormones, growth factors, and stress. The specificity of transcription factor binding to response elements allows for precise control of gene expression in response to changing conditions within the cell or organism.
Co-repressor proteins are regulatory molecules that bind to DNA-bound transcription factors, forming a complex that prevents the transcription of genes. These proteins function to repress gene expression by inhibiting the recruitment of RNA polymerase or other components required for transcription. They can be recruited directly by transcription factors or through interactions with other corepressor molecules.
Co-repressors often possess enzymatic activity, such as histone deacetylase (HDAC) or methyltransferase activity, which modifies histone proteins and condenses chromatin structure, making it less accessible to the transcription machinery. This results in a decrease in gene expression.
Examples of co-repressor proteins include:
1. Histone deacetylases (HDACs): These enzymes remove acetyl groups from histone proteins, leading to chromatin condensation and transcriptional repression.
2. Nucleosome remodeling and histone deacetylation (NuRD) complex: This multi-protein complex contains HDACs, histone demethylases, and ATP-dependent chromatin remodeling proteins that work together to repress gene expression.
3. Sin3A/Sin3B: These are corepressor proteins that interact with various transcription factors and recruit HDACs to specific genomic loci for transcriptional repression.
4. CoREST (Co-Repressor of RE1 Silencing Transcription factor): This is a complex containing HDACs, LSD1 (lysine-specific demethylase 1), and other proteins that mediate transcriptional repression through histone modifications.
5. CtBP (C-terminal binding protein): These are co-repressors that interact with various transcription factors and recruit HDACs, leading to chromatin condensation and gene silencing.
These co-repressor proteins play crucial roles in various cellular processes, including development, differentiation, and homeostasis, by fine-tuning gene expression patterns. Dysregulation of these proteins has been implicated in several diseases, such as cancer and neurological disorders.
Down-regulation is a process that occurs in response to various stimuli, where the number or sensitivity of cell surface receptors or the expression of specific genes is decreased. This process helps maintain homeostasis within cells and tissues by reducing the ability of cells to respond to certain signals or molecules.
In the context of cell surface receptors, down-regulation can occur through several mechanisms:
1. Receptor internalization: After binding to their ligands, receptors can be internalized into the cell through endocytosis. Once inside the cell, these receptors may be degraded or recycled back to the cell surface in smaller numbers.
2. Reduced receptor synthesis: Down-regulation can also occur at the transcriptional level, where the expression of genes encoding for specific receptors is decreased, leading to fewer receptors being produced.
3. Receptor desensitization: Prolonged exposure to a ligand can lead to a decrease in receptor sensitivity or affinity, making it more difficult for the cell to respond to the signal.
In the context of gene expression, down-regulation refers to the decreased transcription and/or stability of specific mRNAs, leading to reduced protein levels. This process can be induced by various factors, including microRNA (miRNA)-mediated regulation, histone modification, or DNA methylation.
Down-regulation is an essential mechanism in many physiological processes and can also contribute to the development of several diseases, such as cancer and neurodegenerative disorders.
 Chromatography
Chromatography
Repressor
Cro repressor family
Iron dependent repressor
Lac repressor
Jun dimerization protein
Nuclear receptor co-repressor 1
Kv channel interacting protein
Krüppel
Nuclear receptor co-repressor 2
Deficiency of RbAp48 protein and memory loss
Drosophila embryogenesis
Fatty acid synthesis
Adaptive enzyme
Pyruvate kinase
Capicua (protein)
QKI
NHL repeat
ZNF160
Regulator gene
RBBP8
Transcription factor
TFAP2B
Cyanobacterial clock proteins
FHAD1
Zinc finger protein 516
SSX1
SSX5
SSX4 (gene)
SSX6
SSX2
 3WOA: Crystal structure of lambda repressor (1-45) fused with maltose-binding protein
3WOA: Crystal structure of lambda repressor (1-45) fused with maltose-binding protein
 SCOP 1.69: Protein: Heat-inducible transcription repressor HrcA, N-terminal domain
SCOP 1.69: Protein: Heat-inducible transcription repressor HrcA, N-terminal domain
Academia Sinica-Structural convergence endows nuclear transport receptor Kap114p with a transcriptional repressor function...
Cro repressor protein and its interaction with DNA<...
repressor proteins QuickView - Correlation Engine
Isolation and structure of repressor-like proteins from the archaeon Sulfolobus solfataricus. Co-purification of RNase A with...
 The AP-1 repressor protein, JDP2, potentiates hepatocellular carcinoma in mice | Molecular Cancer | Full Text
The AP-1 repressor protein, JDP2, potentiates hepatocellular carcinoma in mice | Molecular Cancer | Full Text
 Rosetta(DE3)pLacI Competent Cells - Novagen Rosetta strains are BL21 derivatives designed to enhance the expression of...
Rosetta(DE3)pLacI Competent Cells - Novagen Rosetta strains are BL21 derivatives designed to enhance the expression of...
 Arabidopsis thaliana calcium-dependent lipid-binding protein (AtCLB): a novel repressor of abiotic stress response
Arabidopsis thaliana calcium-dependent lipid-binding protein (AtCLB): a novel repressor of abiotic stress response
Chromatography - Wikipedia
 Genome sequencing of SHH medulloblastoma predicts genotype-related response to smoothened inhibition
Genome sequencing of SHH medulloblastoma predicts genotype-related response to smoothened inhibition
Microbial food biotechnology
ATF7IP-Mediated Stabilization of the Histone Methyltransferase SETDB1 Is Essential for Heterochromatin Formation by the HUSH...
Genomic analyses of gynaecologic carcinosarcomas reveal frequent mutations in chromatin remodelling genes
The bHLH protein SCL/Tal-l interacts with the co-repressor ETO-2 in erythroid cells and megakaryocytes. - Immunology
 Three-dimensional solution NMR structure of Apo-L75F-TrpR, a temperature-sensitive mutant of the tryptophan repressor protein<...
Three-dimensional solution NMR structure of Apo-L75F-TrpR, a temperature-sensitive mutant of the tryptophan repressor protein<...
 Independent and interactive effects of DOF affecting germination 1 (DAG1) and the Della proteins GA insensitive (GAI) and...
Independent and interactive effects of DOF affecting germination 1 (DAG1) and the Della proteins GA insensitive (GAI) and...
 A single aromatic residue in transcriptional repressor protein KorA is critical for co-operativity with its co-regulator KorB ...
A single aromatic residue in transcriptional repressor protein KorA is critical for co-operativity with its co-regulator KorB ...
 Reciprocal expression of the endocytic protein HIP1R and its repressor FOXP1 predicts outcome in R-CHOP-treated diffuse large B...
Reciprocal expression of the endocytic protein HIP1R and its repressor FOXP1 predicts outcome in R-CHOP-treated diffuse large B...
 Response to Copper Stress in Streptomyces lividans Extends beyond Genes under Direct Control of a Copper-sensitive Operon...
Response to Copper Stress in Streptomyces lividans Extends beyond Genes under Direct Control of a Copper-sensitive Operon...
Smad-Dependent Recruitment of a Histone Deacetylase/Sin3A Complex Modulates the Bone Morphogenetic Protein-Dependent...
 Integrative genome-wide analysis of dopaminergic neuron-specific PARIS expression in Drosophila dissects recognition of...
Integrative genome-wide analysis of dopaminergic neuron-specific PARIS expression in Drosophila dissects recognition of...
Integrated DNA methylome and transcriptome analysis reveals the ethylene-induced flowering pathway genes in pineapple |...
 Amparo Cuéllar Pérez
Amparo Cuéllar Pérez
 ATN1 gene: MedlinePlus Genetics
ATN1 gene: MedlinePlus Genetics
 Staff Profile | Faculty of Medical Sciences | Newcastle University
Staff Profile | Faculty of Medical Sciences | Newcastle University
SCOPe 2.06: Structural Classification of Proteins - extended
 Lac repressor - Proteopedia, life in 3D
Lac repressor - Proteopedia, life in 3D
Transcriptional14
- The Drosophila extra sex combs (esc) protein, a member of the Polycomb group (PcG), is a transcriptional repressor of homeotic genes. (umn.edu)
- Thus, the existence of repressor-like proteins was demonstrated at the protein level in archaea, raising the question of structural and functional consequences of these proteins on the otherwise eukaryotic-like basal transcriptional machinery in archaea. (ox.ac.uk)
- We have previously shown that Nkx3.2, a transcriptional repressor that is expressed in the sclerotome and developing cartilage, can activate the chondrocyte differentiation program in somitic mesoderm in a bone morphogenetic protein (BMP)-dependent manner. (elsevierpure.com)
- In this work, we elucidate how BMP signaling modulates the transcriptional repressor activity of Nkx3.2. (elsevierpure.com)
- The homeodomain and NK domain of Nkx3.2 support the interaction of this transcription factor with HDAC1 and Smad1, respectively, and both of these domains are required for the transcriptional repressor activity of Nkx3.2. (elsevierpure.com)
- In this respect, the transcriptional repressor PARIS (ZNF746) was identified by our group in 2011 6 among several other co-substrates of PINK1 and parkin as a promising candidate to shed light on possible contributions of a defective mitochondrial biogenesis to PD pathogenesis. (nature.com)
- Researchers speculate that atrophin 1 may act as a transcriptional co-repressor. (medlineplus.gov)
- A transcriptional co-repressor is a protein that interacts with other DNA-binding proteins to suppress the activity of certain genes, although it cannot attach (bind) to DNA by itself. (medlineplus.gov)
- Transcriptional repressor. (antikoerper-online.de)
- Transcriptional repressor during pronephros development. (xenbase.org)
- Different dimer combinations act as transcriptional activators or repressors, respectively. (abcam.com)
- can function as a transcriptional repressor. (atlasgeneticsoncology.org)
- Transcriptional regulator proteins are closely involved in essential survival strategies in bacteria. (rcsb.org)
- In differentiating neuroblastoma cells, HASH-1 is down-regulated, and there is coincident up-regulation of the transcriptional repressor HES-1, which is known to bind the HASH-1 promoter. (lu.se)
Genes8
- In Rosetta(DE3)pLacI, the rare tRNA genes are present on the same plasmid that carries the lac repressor gene. (sigmaaldrich.com)
- Such strains are suitable for production of protein from target genes cloned in pET vectors by induction with IPTG. (sigmaaldrich.com)
- Among others, PIL5 induces the expression of the genes encoding the two DELLA proteins GA INSENSITIVE 1 (GAI) and REPRESSOR OF ga1-3 (RGA). (inrae.fr)
- Each repressor targets a specific co-regulated group of genes by recognizing a specific sequence of DNA, called the operator in bacteria . (proteopedia.org)
- Repressor proteins are coded for by regulatory genes. (proteopedia.org)
- The lac repressor, and the group of genes it controls, which is called an operon , were the first such gene regulatory system to be discovered. (proteopedia.org)
- AcrR is a one-component allosteric repressor of the genes associated with lipid transport and antibiotic resistance. (rcsb.org)
- Transcription factor Nrf2 is a key regulator of genes encoding phase II detoxification enzymes and antioxidant proteins in response to environmental chemical insults. (cdc.gov)
Molecule3
- For a general introduction to the lac repressor, please see David Goodsell's Introduction to the lac repressor in his series Molecule of the Month , and the article in Wikipedia on the lac repressor . (proteopedia.org)
- An amino acid is the fundamental molecule that serves as the building block for proteins. (genome.gov)
- Each time an amino acid is added to a growing polypeptide during protein synthesis, a tRNA anticodon pairs with its complementary codon on the mRNA molecule, ensuring that the appropriate amino acid is inserted into the polypeptide. (genome.gov)
Metabolism2
- Originally discovered as a chief regulatory protein of glucose and lipid metabolism and cell differentiation, the peroxisome proliferator-activated receptor gamma (PPARγ) is a ligand-activated transcription factor of the nuclear hormone receptor superfamily 8 . (nature.com)
- The lactose ("lac") repressor controls the expression of bacterial enzymes involved in the metabolism of of the sugar lactose. (proteopedia.org)
Structural Classifi2
- SCOP: Structural Classification of Proteins and ASTRAL. (berkeley.edu)
- SCOPe: Structural Classification of Proteins - extended. (berkeley.edu)
Transcription Factors1
- It is assumed that the Id helix-loop-helix (HLH) proteins act by associating with ubiquitously expressed basic HLH (bHLH) transcription factors, such as E47 and E2-2, which prevents these factors from forming functional hetero- or homodimeric DNA binding complexes. (lu.se)
Binding8
- The transcription factor TATA-box binding protein (TBP) modulates gene expression in nuclei. (sinica.edu.tw)
- The team led by Dr. Kuo-Chiang Hsia (Institute of Molecular Biology, Academia Sinica) and Dr. Wei-Yi Chen (Institute of Biochemistry and Molecular Biology, College of Life Sciences, National Yang Ming Chiao Tung University) presents a cryo-EM structure of Kap114p, one of the Kap-βs, in complex with TATA box binding protein and reveals a non-canonical function beyond nuclear transport that modulates TBP-dependent transcription. (sinica.edu.tw)
- L75F-TrpR is a temperature-sensitive mutant of the tryptophan repressor protein of Escherichia coli in which surface-exposed residue leucine 75 in the DNA binding domain is replaced with phenylalanine. (princeton.edu)
- Translational operator of mRNA on the ribosome: how repressor proteins exclude ribosome binding. (igbmc.fr)
- retinoblastoma binding protein 2. (atlasgeneticsoncology.org)
- RS is related to various mutations on the MECP2 gene, which codes for methyl-CpG binding protein-2 (MECP2). (medscape.com)
- The tox gene is regulated by a corynebacterial iron-binding repressor (DtxR). (medscape.com)
- However, the Id proteins did complex with HES-1, and increased levels of Id2 reduced the DNA binding activity of HES-1. (lu.se)
Promoter1
- The pLacI plasmid confers chloramphenicol resistance and provides enough lac repressor to inhibit transcription from the T7 lac promoter in the absence of inducer. (sigmaaldrich.com)
Bacterial1
- The remaining two proteins obtained after HPLC separation were identified as homologues of bacterial repressor-like proteins. (ox.ac.uk)
Interacts2
- The bHLH protein SCL/Tal-l interacts with the co-repressor ETO-2 in erythroid cells and megakaryocytes. (ox.ac.uk)
- The extended CAG region changes the structure of atrophin 1 and how the protein interacts with other proteins to control gene function. (medlineplus.gov)
Binds1
- When the lac repressor binds lactose, it changes to an inactive conformation that cannot repress the production of these enzymes. (proteopedia.org)
Neurons2
- Although the exact function of this protein is unknown, it appears to play an important role in nerve cells (neurons) in many areas of the brain. (medlineplus.gov)
- This altered protein accumulates in neurons and interferes with normal cell functions. (medlineplus.gov)
Dimerization1
- The c-Jun dimerization protein 2, JDP2 is an AP-1 repressor protein that potently inhibits AP-1 transcription. (biomedcentral.com)
MRNA2
- In a cell, antisense DNA serves as the template for producing messenger RNA (mRNA), which directs the synthesis of a protein. (genome.gov)
- In MEF cells with wild type Nrf2 and mouse hepa 1c1c7 cells, Cd increased the Nrf2 protein level but not the Nrf2 mRNA level dose-dependently. (cdc.gov)
BHLH1
- Several tissue-specific bHLH proteins, including HASH-1, dHAND, and HES-1, are important for development of the nervous system. (lu.se)
Drosophila3
- We report that esc protein is highly conserved in housefly (72% identical to Drosophila esc), butterfly (55% identical), and grasshopper (56% identical). (umn.edu)
- This study used Drosophila melanogaster wing vein and scutellar bristle development to screen Rab proteins predicted to be substrates for ICMT ( Ste14 in flies). (sdbonline.org)
- Screening more than 200,000 fragments covering the coding sequences of all transcription-related proteins in Drosophila melanogaster, this study identified 195 RDs in known repressors and in proteins not previously associated with repression. (sdbonline.org)
Arabidopsis1
- TcMYC2a was also found to bind with TcJAZ3 in yeast, which was a homolog of Arabidopsis JASMONATE ZIM-domain JAZ proteins, indicating that TcMYC2a had a similar function to AtMYC2 of JA signal transduction. (frontiersin.org)
Species1
- To further investigate the domain organization of esc protein, we have isolated and characterized esc homologs from divergent insect species. (umn.edu)
Predicts2
- Homology modeling using the crystal structure of another WD repeat protein, the G-protein β- subunit, predicts that esc protein adopts a β-propeller structure. (umn.edu)
- Reciprocal expression of the endocytic protein HIP1R and its repressor FOXP1 predicts outcome in R-CHOP-treated diffuse large B-cell lymphoma patients. (ox.ac.uk)
Recombinant1
- Engineering lactic acid bacteria (LAB) is of growing importance for food and feed industry as well as for in vivo vaccination or the production of recombinant proteins in food grade organisms. (biomedcentral.com)
Homeotic1
- Genetic studies have shown that esc protein is required in early embryos at about the time that other PcG proteins become engaged in homeotic gene repression. (umn.edu)
Complex4
- NF-kappa-B is a homo- or heterodimeric complex formed by the Rel-like domain-containing proteins RELA/p65, RELB, NFKB1/p105, NFKB1/p50, REL and NFKB2/p52. (abcam.com)
- 17-mer used in this work and for the crystal structure of the 2:1 trp repressor/operator complex by Lawson & Carey (1993). (lu.se)
- 1988) for the d-(ACT)Ád-(AGT) halfsites contacting the repressor in the 1:1 complex. (lu.se)
- Modulation of Basic Helix-Loop-Helix Transcription Complex Formation by Id Proteins during Neuronal Differentiation. (lu.se)
Expression2
- Novagen Rosetta strains are BL21 derivatives designed to enhance the expression of eukaryotic proteins that contain codons rarely used in E. coli. (sigmaaldrich.com)
- Expression host strains for pETBlue and pTriEx vectors are lDE3 lysogens that also carry the compatible pLacI plasmid, encoding the lac repressor. (sigmaaldrich.com)
Differentiation2
- We found that the three Id proteins expressed in neuroblastoma cells (Id1, Id2, and Id3) were down-regulated during induced differentiation, indicating that Id proteins help keep the tumor cells in an undifferentiated state. (lu.se)
- The ability of Id proteins to affect HES-1 activity is of particular interest in neuronal cells, where regulation of HES-1 is essential for the timing of neuronal differentiation. (lu.se)
Functional1
- These findings advance understanding of repressors, their sequences, and the functional impact of sequence-altering mutations and should provide a valuable resource for further studies. (sdbonline.org)
Sequence3
- The sequence comparisons and modeling suggest that there are seven WD repeats in esc protein which together form a seven-bladed β-propeller. (umn.edu)
- What percentage of time this DNA sequence spends in a kinked state, in the absence of bound lac repressor protein, is not known, but it may be a significant percentage (see next section below). (proteopedia.org)
- A protein consists of one or more chains of amino acids (called polypeptides) whose sequence is encoded in a gene. (genome.gov)
Histone Deacetylase1
- A nuclear protein, HDAC-9 belongs to the histone deacetylase family with several isoforms and is inhibited by Trichostatin A (TSA) and suberoylanilide hydroxamic acid. (novusbio.com)
Synthesis1
- The phosphorylated enzyme catalyzes the phosphorylation of the alpha subunit of EUKARYOTIC INITIATION FACTOR-2, leading to the inhibition of protein synthesis. (bvsalud.org)
Function3
- Site-directed mutagenesis of specific loops, predicted to extend from the propeller surface, identifies conserved parts of esc protein required for function in vivo. (umn.edu)
- Most of the important insights regarding the specific function of AP-1 proteins have been established through the use of mice with either loss- or gain-of-function manipulations of various members of the bZIP protein family [ 13 ]. (biomedcentral.com)
- As a result, the protein is altered and cannot function normally, though it is unclear how these changes lead to the specific features of CHEDDA syndrome. (medlineplus.gov)
Structure2
Serine1
- A dsRNA-activated cAMP-independent protein serine/threonine kinase that is induced by interferon. (bvsalud.org)
Resistance1
- Vgsc-interacting proteins are genetically associated with pyrethroid resistance in Aedes aegypti. (cdc.gov)
Operator1
- Chemistry Department be a major determinant of trp repressor/operator recognition. (lu.se)
Similarities2
- Despite their many similarities, wild-type and mutant proteins display significant chemical shift differences, one cluster of which is in the B-C turn, too distant to be ascribed solely to ring current effects from Phe75. (princeton.edu)
- BLAST databases using TBLASTX ( 13 ), to find similarities at protein level. (cdc.gov)
Interaction2
Subunit1
- This protein is the full-length p52 subunit and partial p100 subunit. (abcam.com)
Interactions2
- water-mediated interactions resulted in severely [email protected] reduced af®nities for trp repressor (Joachimi ak et al. (lu.se)
- Studying interactions, we noted that all four Id proteins could dimerize with E47 or E2-2, but not with HASH-1 or dHAND. (lu.se)
Primarily1
- AP-1 proteins are primarily considered to be oncogenic. (biomedcentral.com)
Repeats1
- The NUP98/KDM5A fusion protein contains the Phe-Gly (FG) repeats of the N-terminal part of NUP98. (atlasgeneticsoncology.org)
Regulation2
- who also correctly proposed the general mechanism of regulation by the lac repressor. (proteopedia.org)
- To understand the role of the epigenetic co-repressor protein TRIM28 in the control of transposable elements (TEs) and how TEs control gene regulation in the developing and adult brain. (lu.se)