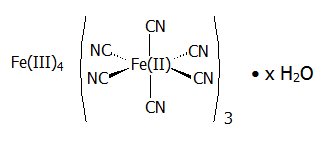
Cesium Isotopes
Cesium
Isotopes
Cesium Radioisotopes
Isotope Labeling
Nitrogen Isotopes
Carbon Isotopes
Oxygen Isotopes
Stomach Ulcer
Selenoproteins
Pressure Ulcer
Radiation, Ionizing
Leg Ulcer
Peptic Ulcer
Interacting populations affecting proliferation of leukemic cells in culture. (1/32)
Peripheral blood cells from three patients with acute leukemic have been studied using a suspension culture method previously described.1 Cytogenetic studies in two of the patients permitted the identification of the proliferating cells in the cultures as being derived from a leukemic population. Cell separation studies using velocity sedimentation supported the concept that growth of the leukemic cells in culture is dependent on an interaction between two populations of leukemic cells. (+info)Thallium-201 for medical use. I. (2/32)
Thallium-201 merits evaluation for myocardial visualization, kidney studies, and tumor diagnosis because of its physical and biologic properties. A method is described for preparation of this radiopharmaceutical for human use. A critical evaluation of 201Tl and other radiopharmaceuticals for myocardial visualization is given. (+info)Permeability of squid axon membrane to various ions. (3/32)
The permeability of the squid axon membrane was determined by the use of radioisotopes of Na, K, Ca, Cs, and Br. Effluxes of these isotopes were measured mainly by the method of intracellular injection. Measurements of influxes were carried out under continuous intracellular perfusion with an isotonic solution of potassium sulfate. The Na permeability of the resting (excitable) axonal membrane was found to be roughly equal to the K permeability. The permeability to anion was far smaller than that to cations. It is emphasized that the axonal membrane has properties of a cation exchanger. The physicochemical nature of the "two stable states" of the excitable membrane is discussed on the basis of ion exchange isotherms. (+info)EFFECT OF CHLOROTHIAZIDE ON CESIUM-137 EXCRETION IN HUMAN SUBJECTS. (4/32)
The therapeutic value of the diuretic, chlorothiazide (Diuril), in reducing the body burden of cesium-137 in human subjects was investigated. Two subjects were given chlorothiazide, 2 g./day, following a single oral intake of cesium-137. The urinary excretion and the per cent retention of cesium-137 were compared with similar data obtained from two control subjects. Although chlorothiazide produced a marked potassium diuresis, it had no significant effect in reducing the body burden of cesium.Analysis was made of the rate of turnover of cesium and potassium in the two control subjects, who were followed up for 320 days. The biological half-lives, T(b), of K were 42 and 41 days. In both subjects a small fraction of the cesium-137 was rapidly excreted. The remainder (88% and 83% in the two cases) was excreted at a slower constant rate. The concentrations further decreased to 44% and 41.5% in 90 and 155 days, respectively. (+info)Cs + ADC in rat brain decreases markedly at death. (5/32)
Spectroscopic resolution of intracellular and extracellular compartments can be used to probe the kinetic environment of those spaces and the compartment-specific changes that occur following injury. This is important for understanding the biophysical mechanisms that underlie the remarkable diffusion-weighted MRI contrast of injured central nervous system (CNS) tissue. Cesium-133 is a physiologic analog of potassium that is actively taken up by cells and resides primarily in the intracellular space. The (133)Cs(+) signal can, thus, be exploited to probe the kinetic environment of the intracellular space. Two principal (133)Cs(+) resonances were observed at 11.74 T. These resonances arise separately from (133)Cs(+) in brain and temporalis muscle. The apparent diffusion coefficient (ADC) of Cs(+) in brain decreased from 1.0 +/- 0.2 microm(2)/ms in healthy tissue to 0.24 +/- 0.04 microm(2)/ms following global ischemia (average ADC +/- average uncertainty), while there was no significant change in the ADC of Cs(+) in temporalis muscle after injury. This finding underscores the tissue-specific nature of the decrease in ADC that accompanies brain injury. Further, as the Cs(+) ADC should reflect water ADC in the intracellular space, these results strongly support the hypothesis that the decrease in water ADC associated with CNS injury arises largely from kinetic changes taking place in the intracellular space. (+info)Hippocampal neuron number is unchanged 1 year after fractionated whole-brain irradiation at middle age. (6/32)
(+info)Retention of potentially mobile radiocesium in forest surface soils affected by the Fukushima nuclear accident. (7/32)
(+info)Direct enzymatic repair of deoxyribonucleic acid single-strand breaks in dormant spores. (8/32)
With the alkaline sucrose gradient centrifugation method, it was found that dormant spores of Clostridium botulinum subjected to 300 krads of gamma radiation showed a distinct decrease in deoxyribonucleic acid (DNA) fragment size, indicating induction of single-strand breaks (SSB). A two- to threefold difference in radiation resistance of spores of two strains of C. botulinum, 33A (37% survival dose [D(37)] = 110 krads) and 51B (D(37) = 47 krads), was accompanied by relatively larger DNA fragments (molecular weight 7.9 x 10(7)) obtained during extraction from the radiation-resistant strain 33A and smaller DNA fragments (molecular weight 1.8 x 10(7)) obtained under identical conditions from radiation-sensitive strain 51B. The apparent number of DNA SSB produced by 300 krads in strains 33A and 51B was 0.37 and 3.50, respectively, per 10(8) daltons of DNA. Addition of 0.02 M ethylenediaminetetraacetic acid (EDTA) to spore suspensions during irradiation doubled the apparent number of SSB in strain 33A but had no effect on strain 51B. In vivo, 0.02 M EDTA present during irradiation to 100 to 300 krads decreased survival of spores of 33A by about 30% but had little or no effect on 51B. Survival of 33A was also reduced by about 45% when the spores were irradiated while frozen in dry ice (-75 C) and, after irradiation, immediately exposed to 0.03 M EDTA for 1 h to inhibit repair in the dormant spores. These results suggest that the highly radiation-resistant strain 33A may be able to accomplish repair of SSB during irradiation or after irradiation under nonphysiological conditions, i.e., in the dormant state. This repair can be inhibited by EDTA. Sedimentation patterns show that DNA from spores of both strains 33A and 51B did not show any postirradiation repair during the first 6 h of germination, as opposed to Bacillus subtilis spores, which exhibit repair immediately after germination. These observations suggest the existence of direct repair in physiological dormant spores of strain 33A in the cryptobiotic resting state in the absence of germination. The repair seems to be similar to that of polynucleotide ligase activity shown to be operative in some vegetative cells. Apparently radiation-sensitive strains such as 51B and B. subtilis are generally poor in DNA repair enzyme activity under conditions of spore dormancy, which may account for the approximately threefold difference in radiation sensitivity or DNA fragility of different strains, or both. (+info)Cesium is a chemical element with the atomic number 55 and the symbol Cs. There are several isotopes of cesium, which are variants of the element that have different numbers of neutrons in their nuclei. The most stable and naturally occurring cesium isotope is cesium-133, which has 78 neutrons and a half-life of more than 3 x 10^20 years (effectively stable).
However, there are also radioactive isotopes of cesium, including cesium-134 and cesium-137. Cesium-134 has a half-life of about 2 years, while cesium-137 has a half-life of about 30 years. These isotopes are produced naturally in trace amounts by the decay of uranium and thorium in the Earth's crust, but they can also be produced artificially in nuclear reactors and nuclear weapons tests.
Cesium isotopes are commonly used in medical research and industrial applications. For example, cesium-137 is used as a radiation source in cancer therapy and industrial radiography. However, exposure to high levels of radioactive cesium can be harmful to human health, causing symptoms such as nausea, vomiting, diarrhea, and potentially more serious effects such as damage to the central nervous system and an increased risk of cancer.
Cesium is a chemical element with the symbol "Cs" and atomic number 55. It is a soft, silvery-golden alkali metal that is highly reactive. Cesium is never found in its free state in nature due to its high reactivity. Instead, it is found in minerals such as pollucite.
In the medical field, cesium-137 is a radioactive isotope of cesium that has been used in certain medical treatments and diagnostic procedures. For example, it has been used in the treatment of cancer, particularly in cases where other forms of radiation therapy have not been effective. It can also be used as a source of radiation in brachytherapy, a type of cancer treatment that involves placing radioactive material directly into or near tumors.
However, exposure to high levels of cesium-137 can be harmful and may increase the risk of cancer and other health problems. Therefore, its use in medical treatments is closely regulated and monitored to ensure safety.
Isotopes are variants of a chemical element that have the same number of protons in their atomic nucleus, but a different number of neutrons. This means they have different atomic masses, but share similar chemical properties. Some isotopes are stable and do not decay naturally, while others are unstable and radioactive, undergoing radioactive decay and emitting radiation in the process. These radioisotopes are often used in medical imaging and treatment procedures.
Cesium radioisotopes are different forms of the element cesium that have unstable nuclei and emit radiation. Some commonly used medical cesium radioisotopes include Cs-134 and Cs-137, which are produced from nuclear reactions in nuclear reactors or during nuclear weapons testing.
In medicine, cesium radioisotopes have been used in cancer treatment for the brachytherapy of certain types of tumors. Brachytherapy involves placing a small amount of radioactive material directly into or near the tumor to deliver a high dose of radiation to the cancer cells while minimizing exposure to healthy tissues.
Cesium-137, for example, has been used in the treatment of cervical, endometrial, and prostate cancers. However, due to concerns about potential long-term risks associated with the use of cesium radioisotopes, their use in cancer therapy is becoming less common.
It's important to note that handling and using radioactive materials requires specialized training and equipment to ensure safety and prevent radiation exposure.
Isotope labeling is a scientific technique used in the field of medicine, particularly in molecular biology, chemistry, and pharmacology. It involves replacing one or more atoms in a molecule with a radioactive or stable isotope of the same element. This modified molecule can then be traced and analyzed to study its structure, function, metabolism, or interaction with other molecules within biological systems.
Radioisotope labeling uses unstable radioactive isotopes that emit radiation, allowing for detection and quantification of the labeled molecule using various imaging techniques, such as positron emission tomography (PET) or single-photon emission computed tomography (SPECT). This approach is particularly useful in tracking the distribution and metabolism of drugs, hormones, or other biomolecules in living organisms.
Stable isotope labeling, on the other hand, employs non-radioactive isotopes that do not emit radiation. These isotopes have different atomic masses compared to their natural counterparts and can be detected using mass spectrometry. Stable isotope labeling is often used in metabolic studies, protein turnover analysis, or for identifying the origin of specific molecules within complex biological samples.
In summary, isotope labeling is a versatile tool in medical research that enables researchers to investigate various aspects of molecular behavior and interactions within biological systems.
Nitrogen isotopes are different forms of the nitrogen element (N), which have varying numbers of neutrons in their atomic nuclei. The most common nitrogen isotope is N-14, which contains 7 protons and 7 neutrons in its nucleus. However, there are also heavier stable isotopes such as N-15, which contains one extra neutron.
In medical terms, nitrogen isotopes can be used in research and diagnostic procedures to study various biological processes. For example, N-15 can be used in a technique called "nitrogen-15 nuclear magnetic resonance (NMR) spectroscopy" to investigate the metabolism of nitrogen-containing compounds in the body. Additionally, stable isotope labeling with nitrogen-15 has been used in clinical trials and research studies to track the fate of drugs and nutrients in the body.
In some cases, radioactive nitrogen isotopes such as N-13 or N-16 may also be used in medical imaging techniques like positron emission tomography (PET) scans to visualize and diagnose various diseases and conditions. However, these applications are less common than the use of stable nitrogen isotopes.
Carbon isotopes are variants of the chemical element carbon that have different numbers of neutrons in their atomic nuclei. The most common and stable isotope of carbon is carbon-12 (^{12}C), which contains six protons and six neutrons. However, carbon can also come in other forms, known as isotopes, which contain different numbers of neutrons.
Carbon-13 (^{13}C) is a stable isotope of carbon that contains seven neutrons in its nucleus. It makes up about 1.1% of all carbon found on Earth and is used in various scientific applications, such as in tracing the metabolic pathways of organisms or in studying the age of fossilized materials.
Carbon-14 (^{14}C), also known as radiocarbon, is a radioactive isotope of carbon that contains eight neutrons in its nucleus. It is produced naturally in the atmosphere through the interaction of cosmic rays with nitrogen gas. Carbon-14 has a half-life of about 5,730 years, which makes it useful for dating organic materials, such as archaeological artifacts or fossils, up to around 60,000 years old.
Carbon isotopes are important in many scientific fields, including geology, biology, and medicine, and are used in a variety of applications, from studying the Earth's climate history to diagnosing medical conditions.
Oxygen isotopes are different forms or varieties of the element oxygen that have the same number of protons in their atomic nuclei, which is 8, but a different number of neutrons. The most common oxygen isotopes are oxygen-16 (^{16}O), which contains 8 protons and 8 neutrons, and oxygen-18 (^{18}O), which contains 8 protons and 10 neutrons.
The ratio of these oxygen isotopes can vary in different substances, such as water molecules, and can provide valuable information about the origins and history of those substances. For example, scientists can use the ratio of oxygen-18 to oxygen-16 in ancient ice cores or fossilized bones to learn about past climate conditions or the diets of ancient organisms.
In medical contexts, oxygen isotopes may be used in diagnostic tests or treatments, such as positron emission tomography (PET) scans, where a radioactive isotope of oxygen (such as oxygen-15) is introduced into the body and emits positrons that can be detected by specialized equipment to create detailed images of internal structures.
A stomach ulcer, also known as a gastric ulcer, is a sore that forms in the lining of the stomach. It's caused by a breakdown in the mucous layer that protects the stomach from digestive juices, allowing acid to come into contact with the stomach lining and cause an ulcer. The most common causes are bacterial infection (usually by Helicobacter pylori) and long-term use of nonsteroidal anti-inflammatory drugs (NSAIDs). Stomach ulcers may cause symptoms such as abdominal pain, bloating, heartburn, and nausea. If left untreated, they can lead to more serious complications like internal bleeding, perforation, or obstruction.
A duodenal ulcer is a type of peptic ulcer that develops in the lining of the first part of the small intestine, called the duodenum. It is characterized by a break in the mucosal layer of the duodinal wall, leading to tissue damage and inflammation. Duodenal ulcers are often caused by an imbalance between digestive acid and mucus production, which can be exacerbated by factors such as bacterial infection (commonly with Helicobacter pylori), nonsteroidal anti-inflammatory drug use, smoking, and stress. Symptoms may include gnawing or burning abdominal pain, often occurring a few hours after meals or during the night, bloating, nausea, vomiting, loss of appetite, and weight loss. Complications can be severe, including bleeding, perforation, and obstruction of the duodenum. Diagnosis typically involves endoscopy, and treatment may include antibiotics (if H. pylori infection is present), acid-suppressing medications, lifestyle modifications, and potentially surgery in severe cases.
Selenoproteins are a specific group of proteins that contain the essential micronutrient selenium in the form of selenocysteine (Sec), which is a naturally occurring amino acid. Selenocysteine is encoded by the opal codon UGA, which typically serves as a stop codon in mRNA.
There are 25 known human selenoproteins, and they play crucial roles in various physiological processes, including antioxidant defense, DNA synthesis, thyroid hormone metabolism, and immune function. Some of the well-known selenoproteins include glutathione peroxidases (GPxs), thioredoxin reductases (TrxRs), and iodothyronine deiodinases (IDIs).
The presence of selenocysteine in these proteins makes them particularly efficient at catalyzing redox reactions, which involve the gain or loss of electrons. This property is essential for their functions as antioxidants and regulators of cellular signaling pathways.
Deficiencies in selenium can lead to impaired function of selenoproteins, potentially resulting in various health issues, such as increased oxidative stress, weakened immune response, and disrupted thyroid hormone metabolism.
A pressure ulcer, also known as a pressure injury or bedsore, is defined by the National Pressure Injury Advisory Panel (NPIAP) as "localized damage to the skin and/or underlying soft tissue usually over a bony prominence or related to a medical or other device." The damage can be caused by intense and/or prolonged pressure or shear forces, or a combination of both. Pressure ulcers are staged based on their severity, ranging from an initial reddening of the skin (Stage 1) to full-thickness tissue loss that extends down to muscle and bone (Stage 4). Unstageable pressure ulcers are those in which the base of the wound is covered by yellow, tan, green or brown tissue and the extent of tissue damage is not visible. Suspected deep tissue injury (Suspected DTI) describes intact skin or non-blanchable redness of a localized area usually over a bony prominence due to pressure and/or shear. The area may be preceded by tissue that is painful, firm, mushy, boggy, warmer or cooler as compared to adjacent tissue.
Ionizing radiation is a type of radiation that carries enough energy to ionize atoms or molecules, which means it can knock electrons out of their orbits and create ions. These charged particles can cause damage to living tissue and DNA, making ionizing radiation dangerous to human health. Examples of ionizing radiation include X-rays, gamma rays, and some forms of subatomic particles such as alpha and beta particles. The amount and duration of exposure to ionizing radiation are important factors in determining the potential health effects, which can range from mild skin irritation to an increased risk of cancer and other diseases.
A leg ulcer is a chronic wound that occurs on the lower extremities, typically on the inner or outer ankle. It's often caused by poor circulation, venous insufficiency, or diabetes. Leg ulcers can also result from injury, infection, or inflammatory diseases such as rheumatoid arthritis or lupus. These ulcers can be painful, and they may take a long time to heal, making them prone to infection. Proper diagnosis, treatment, and wound care are essential for healing leg ulcers and preventing complications.
A peptic ulcer is a sore or erosion in the lining of your stomach and the first part of your small intestine (duodenum). The most common causes of peptic ulcers are bacterial infection and long-term use of nonsteroidal anti-inflammatory drugs (NSAIDs) such as aspirin, ibuprofen, or naproxen.
The symptoms of a peptic ulcer include abdominal pain, often in the upper middle part of your abdomen, which can be dull, sharp, or burning and may come and go for several days or weeks. Other symptoms can include bloating, burping, heartburn, nausea, vomiting, loss of appetite, and weight loss. Severe ulcers can cause bleeding in the digestive tract, which can lead to anemia, black stools, or vomit that looks like coffee grounds.
If left untreated, peptic ulcers can result in serious complications such as perforation (a hole through the wall of the stomach or duodenum), obstruction (blockage of the digestive tract), and bleeding. Treatment for peptic ulcers typically involves medications to reduce acid production, neutralize stomach acid, and kill the bacteria causing the infection. In severe cases, surgery may be required.
 Isotopes of caesium
Isotopes of caesium
James M. Cork
Caesium
Fukushima disaster cleanup
Median lethal dose
C-137
Cesium 137 (band)
Nuclear fuel cycle
Eddy diffusion
IsoRay
Chenghai Lake
Behavior of nuclear fuel during a reactor accident
Environmental radioactivity
Nuclear and radiation accidents and incidents
Chernobyl groundwater contamination
In Eker
Mononuclidic element
Marshall Brucer
Nuclear program of Iran
Ford Nuclear Reactor
Cortinarius caperatus
Dreams (1990 film)
Chernobyl disaster
Discharge of radioactive water of the Fukushima Daiichi Nuclear Power Plant
Nuclear fission product
Relative density
Radioactive tracer
Nuclear detonation detection system
Radioactive source
Underground nuclear weapons testing
Isotopes of caesium - Wikipedia
 Isotope data for cesium-151 in the Periodic Table
Isotope data for cesium-151 in the Periodic Table
Isotope data for cesium-142 in the Periodic Table
 villains-caesium - IUPAC 100
villains-caesium - IUPAC 100
 Initial Elements and Isotopes - Maple Help
Initial Elements and Isotopes - Maple Help
 CDC Radiation Emergencies | Radioisotope Brief: Cesium-137 (Cs-137)
CDC Radiation Emergencies | Radioisotope Brief: Cesium-137 (Cs-137)
 Department of Energy (DOE) OpenNet documents
Department of Energy (DOE) OpenNet documents
Cesium | Toxic Substances | Toxic Substance Portal | ATSDR
 Why Are Wild Pigs in Germany So Radioactive? | Discover Magazine
Why Are Wild Pigs in Germany So Radioactive? | Discover Magazine
 50 years after the blast: Recovery in Bikini Atoll's coral reef
50 years after the blast: Recovery in Bikini Atoll's coral reef
 Isotope Disk Set (5 disk) Isotope Disk Set(5 disk) : United Nuclear , Scientific Equipment & Supplies, United Nuclear ,...
Isotope Disk Set (5 disk) Isotope Disk Set(5 disk) : United Nuclear , Scientific Equipment & Supplies, United Nuclear ,...
 Facts, Health Benefits and Side Effects of Cesium Supplements
Facts, Health Benefits and Side Effects of Cesium Supplements
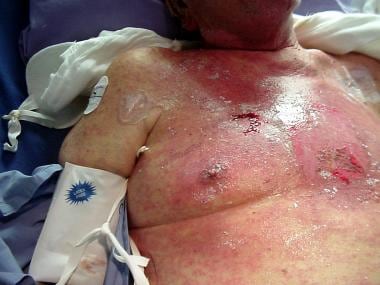
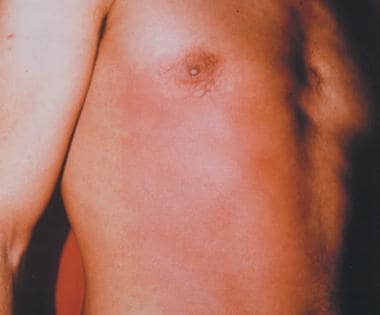
 Radiation Ulcers: Practice Essentials, History of the Procedure, Problem
Radiation Ulcers: Practice Essentials, History of the Procedure, Problem
After Japan Nuclear Power Plant Disaster: How Much Radioactivity in the Oceans? | NSF - National Science Foundation
 The Best Nuclear Option | MIT Technology Review
The Best Nuclear Option | MIT Technology Review
 Why the California water crisis will lead to a housing collapse, municipal bankruptcies and a mass exodus of climate refugees -...
Why the California water crisis will lead to a housing collapse, municipal bankruptcies and a mass exodus of climate refugees -...
 Radioactive Capsule Safely Recovered in Western Australia | Smart News|
Smithsonian Magazine
Radioactive Capsule Safely Recovered in Western Australia | Smart News|
Smithsonian Magazine
 Glossary
Glossary
The EPA National Library Catalog | EPA National Library Network | US EPA
 10 Shocking Reasons For Product Recalls - Listverse
10 Shocking Reasons For Product Recalls - Listverse
 Electrochemical Behaviour of Actinides and Fission Products in Room-Temperature Ionic Liquids
Electrochemical Behaviour of Actinides and Fission Products in Room-Temperature Ionic Liquids
 Midweek Unthreaded « JoNova
Midweek Unthreaded « JoNova
 Has Fukushima Radiation Reached North America? - Barbra Streisand
Has Fukushima Radiation Reached North America? - Barbra Streisand
 He's almost 30 with no teeth or claws, but he's still my gorgeous old man! : r/aww
He's almost 30 with no teeth or claws, but he's still my gorgeous old man! : r/aww
 Fukushima by the Numbers, page 1
Fukushima by the Numbers, page 1
 Fukushima: It's Much Worse Than You Think
Fukushima: It's Much Worse Than You Think
STRONTIUM5
- You can also tell if a cat was born before 1945 if it doesn't contain any strontium-90 or cesium-137 isotopes. (reddit.com)
- The submarine's reactor, loaded with nuclear fuel, is a source of other radioactive isotopes like cesium 137 and strontium 90. (bellona.org)
- If any of the 6 nuclear reactors in Ukraine's nuclear plant are hit, radioactive isotopes: cesium-137, iodine-131, strontium-90, and plutonium-239 will be released into our air and water. (change.org)
- The habitation and environment are affected by the stable isotopes of caesium (Cs) and strontium (Sr), as well as by their radioactive isotopes. (bvsalud.org)
- The current work gives insight on Alstonia scholaris' capacity to phytoextract stable caesium (Cs) and strontium (Sr), as well as the plant's ability to protect against the toxicity of both elements. (bvsalud.org)
Stable14
- Only one isotope, 133Cs, is stable. (wikipedia.org)
- Caesium-133 is the only stable isotope of caesium. (wikipedia.org)
- Caesium-134 is not produced via beta decay of other fission product nuclides of mass 134 since beta decay stops at stable 134Xe. (wikipedia.org)
- It decays via emission of a low-energy beta particle into the stable isotope barium-135. (wikipedia.org)
- Compared to the other stable alkali metals, cesium has the lowest boiling point and melting point, highest vapor pressure, highest density, and lowest ionization potential. (cdc.gov)
- Naturally occurring cesium is not radioactive and is referred to as stable cesium. (cdc.gov)
- There is only one stable form of cesium naturally present in the environment, 133 Cs (read as cesium one-thirty-three). (cdc.gov)
- Cesium chloride is a more stable and nonradioactive form of cesium. (diethealthclub.com)
- Hg-196, 198-201, and 204 are stable mercury isotopes. (harvard.edu)
- Selenium and stable mercury isotopes provide new insights into mercury toxicokinetics in pilot whales. (harvard.edu)
- Mercury Stable Isotopes Reveal Influence of Foraging Depth on Mercury Concentrations and Growth in Pacific Bluefin Tuna. (harvard.edu)
- Environmental Origins of Methylmercury Accumulated in Subarctic Estuarine Fish Indicated by Mercury Stable Isotopes. (harvard.edu)
- Assessing sources of human methylmercury exposure using stable mercury isotopes. (harvard.edu)
- Stable isotope (N, C, Hg) study of methylmercury sources and trophic transfer in the northern gulf of Mexico. (harvard.edu)
Fukushima6
- The samples are then analyzed for cesium isotopes, whose signature allows scientists to identify radionuclides released from Fukushima. (nsf.gov)
- According to Buesseler, based on those models, initial traces of radioactive isotopes from Fukushima should be detectable along the Pacific coast of the United States in April. (barbrastreisand.com)
- Approximately 800 trillion becquerel of Cesium-137 is expected to reach the West Coast of North America by 2016, according to Michio Aoyama, a professor at Japan's Fukushima University Institute of Environmental Radioactivity. (unknowncountry.com)
- The Woods Hole Oceanographic Institute has detected the presence of Cesium-134 off of the coast of California, of which can only have come from the Fukushima site in Japan, due to it's half-life of only two years. (unknowncountry.com)
- Ocean simulations showed that the plume of radioactive cesium-137 released by the Fukushima disaster in 2011 could begin flowing into U.S. coastal waters starting in early 2014 and peak in 2016. (southernfriedscience.com)
- Pacific bluefin tuna migrating last year from coastal Japan to the waters off Southern California contained radioactive cesium isotopes from the Fukushima nuclear disaster, scientists reported Monday. (giantrobot.com)
Iodine6
- A result of the loss of electricity, overheating at the power plant led to significant releases of iodine, cesium and other radioisotopes to the environment. (nsf.gov)
- Body distribution of cesium, iodine, chlormerodrin, as determined by sequential observations using the Spintharicon. (harvard.edu)
- In addition to radioactive iodine, the body may also be exposed to a radioactive isotope of caesium known as Cesium-137 . (lewrockwell.com)
- processed, packed into plastic vessels, and placed for one hour in a $200,000 germanium semiconductor detector to test for the presence of radioactive isotopes iodine, Cesium-137 and 134. (cbsnews.com)
- Many radioactive isotopes are used, such as iodine-125, gold-198, and cesium-137. (medscape.com)
- Beta particles are high-energy electrons that are emitted from the nuclei of unstable atoms (eg, cesium-137, iodine-131). (msdmanuals.com)
Brachytherapy5
- Used to define the second Fission product Theoretically capable of spontaneous fission Caesium-131, introduced in 2004 for brachytherapy by Isoray, has a half-life of 9.7 days and 30.4 keV energy. (wikipedia.org)
- It is known as Cesium-131 brachytherapy. (diethealthclub.com)
- Cesium-131 brachytherapy or internal radiation treatment has demonstrated significantly positive results for prostate cancer. (healthguideinfo.com)
- Cesium-131 is essentially an advanced brachytherapy isotope, commonly known as a radioactive seed that is implanted directly into the tumor cavity. (healthguideinfo.com)
- The short half-life of Cesium-131 helps to cut down the severity and duration of these symptoms commonly associated with brachytherapy. (healthguideinfo.com)
137Cs3
- The low decay energy, lack of gamma radiation, and long half-life of 135Cs make this isotope much less hazardous than 137Cs or 134Cs. (wikipedia.org)
- The radioactive isotopes 137Cs and 134Cs are significant fission products because of their high fission yield, and their relatively long half-lives. (cdc.gov)
- For right now I am only providing figures for two Isotopes Cesium-137 (137Cs) and Plutonium-241 (241Pu). (abovetopsecret.com)
Chloride6
- Cesium supplements are available in the market and are promoted as cesium chloride pills. (diethealthclub.com)
- Some experts are of the opinion that cesium chloride could be beneficial in treating various types of cancers. (diethealthclub.com)
- Cesium chloride helps to create an oxygen rich environment for the cancer cells. (diethealthclub.com)
- large amounts of cesium chloride can make you lose consciousness. (diethealthclub.com)
- Taking large amounts of cesium chloride could also result in diarrhea. (diethealthclub.com)
- This is yet another dangerous side effect that could occur after taking large amounts of cesium chloride. (diethealthclub.com)
Radioisotopes2
- Beginning in 1945 with the commencement of nuclear testing, caesium radioisotopes were released into the atmosphere where caesium is absorbed readily into solution and is returned to the surface of the Earth as a component of radioactive fallout. (wikipedia.org)
- Cesium-131 is one of the latest and most advanced radioisotopes, which is helping to achieve more successful breakthroughs in cancer radiation treatment. (healthguideinfo.com)
Effectiveness of cesium2
- This is where the effectiveness of cesium comes in. (diethealthclub.com)
- Trials for the use of this therapy were carried out on mice to see the effectiveness of cesium in treating cancer. (diethealthclub.com)
Soil8
- Once caesium enters the ground water, it is deposited on soil surfaces and removed from the landscape primarily by particle transport. (wikipedia.org)
- Cesium is a naturally occurring element found combined with other elements in rocks, soil, and dust in low amounts. (cdc.gov)
- Cesium is present naturally in the soil and also as isotope 133. (diethealthclub.com)
- Radiation exposure to food typically declines faster, since the cesium has travelled far since Chernobyl - washed out by rainwater , or driven down into the soil, so it stops being absorbed by plants and animals in the same initial quantities. (euronews.com)
- The cesium migrates downwards through the soil very slowly, sometimes only about one millimetre per year. (euronews.com)
- Nearly 30 years ago the explosion sent radioactive caesium-137 particles into the atmosphere, eventually drifting into Norway where they landed and absorbed into the soil. (barentsobserver.com)
- The mushroom acts as a sponge for leaching caesium-137 out of the soil and scientists are certain it's the cause of the spike this year. (barentsobserver.com)
- Quantification, nature and bioavailability of bound 14C-pesticide residues in soil, plants and food : proceedings of the Final Research Co-ordination Meeting on Isotopic Tracer-Aided Studies of Unextractable or Bound Pesticide Residues in Soil, Plants and Food / organized by the Joint FAO/IAEA Division of Isotope and Radiation Applications of Atomic Energy for Food and Agricultural Development and held in Gainesville, Florida, from 25 to 29 March 1985. (who.int)
Becquerel1
- The jump this year was significant: this September the reading was 8,200 becquerel of caesium-137 per kilo versus September 2012 when the reindeer were averaging 1,500 becquerel of caesium-137 per kilo. (barentsobserver.com)
Atomic5
- The atomic masses of these isotopes range from 112 to 151. (wikipedia.org)
- The symbol of Cesium is Cs and the atomic number is 55. (diethealthclub.com)
- Cesium is used in atomic clocks, which are accurate to 5 s in 300 years. (lanl.gov)
- Also in the 1960's the (former) US Atomic Energy Commission subjected sections of El Yunque to Gamma Rays emitted by radioactive isotopes such as Cesium 134 for 92 days in a row. (thepetitionsite.com)
- Joint FAO/IAEA Division of Isotope and Radiation Applications of Atomic Energy for Food and Agricultural Development. (who.int)
Chernobyl2
- Over time, though, as the cesium-137 from Chernobyl dispersed, the radiation levels of most animals within the massive fallout zone dropped to less-than-dangerous levels. (discovermagazine.com)
- The results showed that while a total of about 90 per cent of the cesium-137 in Central Europe comes from Chernobyl, the proportion in the wild boar samples is much lower. (euronews.com)
Hydroxide2
Alkali metal3
- These properties make cesium far more reactive than the other members of the alkali metal group. (cdc.gov)
- An alkali metal that melts at 28°C (82 °F), the physical properties of cesium are similar to that of potassium and rubidium. (diethealthclub.com)
- Cesium, an alkali metal, occurs in lepidolite, pollucte (a hydrated silicate of aluminum and cesium), and in other sources. (lanl.gov)
Prostate cancer6
- Before understanding how cesium helps to treat prostate cancer, it is important to look at how cesium and cancer are connected. (diethealthclub.com)
- Prostate cancer may be treated with cesium. (diethealthclub.com)
- Cesium-131 was approved by the FDA in 2003 for treatment of prostate cancer and other malignant tumors. (healthguideinfo.com)
- Another key benefit of Cesium-131 is that in comparison to other radioactive seeds used to treat prostate cancer, it has the shortest half-life of only about 10 days. (healthguideinfo.com)
- Cesium-131 also ensures relatively rapid resolution of common side effects of prostate cancer. (healthguideinfo.com)
- Cesium-131 has been in use for the treatment of prostate cancer with very successful results. (healthguideinfo.com)
Alkaline element1
- Cesium is an alkaline element and has a high pH value. (diethealthclub.com)
Wild boar1
- Instead, a large proportion of the cesium in wild boar meat tracks back to nuclear weapons testing - up to 68 per cent in some samples. (euronews.com)
Barium1
- Caesium (55Cs) has 40 known isotopes, making it, along with barium and mercury, one of the elements with the most isotopes. (wikipedia.org)
Fission2
- Caesium-135 is one of the seven long-lived fission products and the only alkaline one. (wikipedia.org)
- In most types of nuclear reprocessing, it stays with the medium-lived fission products (including 137 Cs which can only be separated from Cs-135 via isotope separation) rather than with other long-lived fission products. (wikipedia.org)
Periodic Table1
- Different primary-ion sources (cesium and oxygen) allow the choice of conditions for the best analytical sensitivity across the periodic table, down to parts per billion for many elements. (nrel.gov)
Mercury6
- Mercury Isotopes" is a descriptor in the National Library of Medicine's controlled vocabulary thesaurus, MeSH (Medical Subject Headings) . (harvard.edu)
- This graph shows the total number of publications written about "Mercury Isotopes" by people in Harvard Catalyst Profiles by year, and whether "Mercury Isotopes" was a major or minor topic of these publication. (harvard.edu)
- Below are the most recent publications written about "Mercury Isotopes" by people in Profiles. (harvard.edu)
- Elevated Mercury Concentrations and Isotope Signatures (N, C, Hg) in Yellowfin Tuna (Thunnus albacares) from the Galápagos Marine Reserve and Waters off Ecuador. (harvard.edu)
- Mercury isotope study of sources and exposure pathways of methylmercury in estuarine food webs in the Northeastern U.S. Environ Sci Technol. (harvard.edu)
- Cesium, gallium , and mercury are the only three metals that are liquid at room temperature. (lanl.gov)
Reacts2
- The nausea occurs because cesium is a highly alkaline mineral and reacts with anything acidic. (diethealthclub.com)
- Cesium reacts explosively with cold water, and reacts with ice at temperatures above -116C. (lanl.gov)
Radioactive seeds1
- Compared to other common radioactive seeds, Cesium-131 has a strong energy level. (healthguideinfo.com)
Atmosphere1
- And in 1986, one particular nuclear reactor emitted a whole bunch of cesium-137 into the atmosphere. (discovermagazine.com)
Half-life7
- Caesium-134 has a half-life of 2.0652 years. (wikipedia.org)
- Caesium-135 is a mildly radioactive isotope of caesium with a half-life of 2.3 million years. (wikipedia.org)
- Another isotope, cesium-137, decays very slowly with a half-life of 30 years. (barbrastreisand.com)
- For example, they do not only release cesium-137, but also cesium-135, a cesium isotope with a much longer half-life. (euronews.com)
- One is that you are unable to slaughter [the reindeer] now - you have to wait until November because the caesium has a half-life in the animal. (barentsobserver.com)
- The caesium-137 particles are set to reach their "half-life" expectancy in 2016 - a milestone that renders them half as radioactive as when they first landed in 1986 - but "it will take a very long time before the last part of it goes," says Eikelmann. (barentsobserver.com)
- FOREVER STORAGE (not zero carbon) Due to its highly radioactive garbage in our backyards in 48 states because of man-made, radioactive isotope, plutonium-239 with a half life of 24,100 YEARS. (change.org)
Silvery2
- Cesium is a silvery white, soft, ductile metal with only one oxidation state (+1). (cdc.gov)
- Cesium is a silvery, soft metal that is found in nature. (diethealthclub.com)
Decay2
- Caesium-134 undergoes beta decay (β−), producing 134Ba directly and emitting on average 2.23 gamma ray photons (mean energy 0.698 MeV). (wikipedia.org)
- Both isotopes decay into non-radioactive elements. (cdc.gov)
Isoray2
- The manufacturer of Cesium-131 internal radiation therapy seeds, IsoRay, Inc. has recently announced a multi-institutional study of the isotope for its effectiveness to treat Non Small Cell Lung Cancers (NSCLC). (healthguideinfo.com)
- The manufacturer IsoRay expects that Cesium-131 will be available for wide usage to treat a number of cancers in the coming years. (healthguideinfo.com)
Compounds1
- Cesium salts and most cesium compounds are generally very water soluble, with the exception of cesium alkyl and aryl compounds, which have low water solubility. (cdc.gov)
Traces3
- Monitors along the Pacific U.S. coast have yet to detect any traces of cesium-134, said Ken Buesseler, a chemical oceanographer at the Woods Hole Oceanographic Institution (WHOI), speaking on a panel at the meeting of the American Geophysical Union's Ocean Sciences. (barbrastreisand.com)
- Though traces of cesium-137 have been detected in the world's oceans, their source may be attributed to previous nuclear-weapons tests. (barbrastreisand.com)
- Nonetheless, traces of the radioactive isotopes pop up every summer in the plant life - particularly the gypsy mushroom, a delicacy for both humans and reindeer. (barentsobserver.com)
Atom2
- Since 1967, the official definition of a second is: The second, symbol s, is defined by taking the fixed numerical value of the caesium frequency, ΔνCs, the unperturbed ground-state hyperfine transition frequency of the caesium-133 atom, to be 9192631770 when expressed in the unit Hz, which is equal to s−1. (wikipedia.org)
- Caesium-137 is a radioactive isotope - or charged atom - that is a byproduct of a nuclear chain reaction. (barentsobserver.com)
World's1
- One of the world's richest sources of cesium is located at Bernic Lake, Manitoba. (lanl.gov)
Explosion1
- The burning cesium can ignite the liberated hydrogen gas and produce an explosion. (cdc.gov)
Exposure1
- It also neutralizes exposure from radio-isotopes. (lewrockwell.com)
19861
- Termes sources en cas d' accident de réacteur nucléaire : rapport d'un Groupe d' experts de l' AEN, mars 1986. (who.int)
Cubic meter1
- WHOI's recent readings for the longer-lived Cesium-137 isotope have been found to be 6.9 Bq per cubic meter. (unknowncountry.com)
Hydrogen1
- Identifies all elements or isotopes present in a material, from hydrogen to uranium. (nrel.gov)
Concentrations1
- However, in functional experiments ex vivo the HCN inhibitors ivabradine, ZD7288, and cesium failed to lower contraction frequency: conversely, all three antagonists induced a positive chronotropic effect with concurrent negative inotropic action, though these effects first occurred at concentrations regarded as supramaximal for HCN inhibition. (bvsalud.org)
Found3
- Cesium is also found as a contaminant in places that process used nuclear fuel as well as in nuclear reactors. (diethealthclub.com)
- Individuals have recently spread alarm about the presence of radioactive isotopes already found along the Pacific coast, although those concerns were debunked. (barbrastreisand.com)
- A " State of the Environment " report, released by the Norwegian Radiation Protection Authority this week, found elevated caesium-137 levels in wild reindeer living in the Våga reinlag AS in central Jotunheimen National Park. (barentsobserver.com)
Potassium4
- Potassium orotates can prevent the accumulation of Cesium-137. (lewrockwell.com)
- In fact, getting enough potassium from food such as bananas is a good first step at preventing radioactive cesium 137 retention. (lewrockwell.com)
- Cesium (Cs) in the environment is primarily absorbed by a potassium (K) transporter. (bvsalud.org)
- In of ion competition experiments, indicating that potassium, rubid- particular, the cryogenic temperatures used in all recent crys- ium, and cesium ions bind to the minor groove with similarly weak tallographic work may drastically shift the enthalpy-entropy affinity as sodium ions, whereas ammonium ion binding is some- balance of ion-water substitution. (lu.se)
Drugs1
- The use of cesium along with other drugs like diuretics may result in hypokalemia. (diethealthclub.com)
Levels4
- For years, researchers didn't know why Bavarian feral pigs contained serious levels of radioactive isotopes. (discovermagazine.com)
- The stomach and tissue samples of the boars that researchers tested still continued to exhibit unsafe levels of cesium isotopes. (discovermagazine.com)
- It turns out that feral pigs go hog-wild for a certain type of truffle - they rely on it as a major food source at certain times of the year - and that truffle tends to absorb high levels of radioactive cesium. (discovermagazine.com)
- Smith and his colleagues tracked rising levels of cesium-134 at several ocean monitoring stations west of Vancouver in the North Pacific beginning in 2011. (barbrastreisand.com)
PHYSICAL2
- Information regarding the physical and chemical properties of cesium is located in Table 4-2. (cdc.gov)
- This is possible because different sources of radioactive isotopes have different physical fingerprints," explains Dr Bin Feng, who conducts his research at the Institute of Inorganic Chemistry at Leibniz Universität Hannover and the TRIGA Center Atominstitut at TU Wien. (euronews.com)
Risks1
- Both the tailing impoundment sites and so-called 'orphan' sources, which could contain reactor-produced isotopes,[1] might present security risks if left unmonitored. (nti.org)
Mineral1
- Cesium was discovered spectroscopically in 1860 by Bunsen and Kirchhoff in mineral water from Durkheim. (lanl.gov)
WATER2
Elements1
- Nuclear explosions or the breakdown of uranium in fuel elements can produce two radioactive forms of cesium, 134 Cs and 137 Cs. (cdc.gov)
Food1
- We have two different ways of getting rid of the caesium from the food system. (barentsobserver.com)