Codon
Codon, Initiator-
Codon, Terminations-
Base Sequence
RNA, Transfer-, Met-
Molekülsequenzdaten
Codon, Nonsens-
Peptide Chain Initiation, Translational
Protein Biosynthesis
RNA, Transfer-
Amino Acid Sequence
Mutation
Escherichia coli
Anticodon
Caspasen, Initiator-
Plasmids
Nucleic Acid Conformation
Replication Origin
Ribosomen
Genetic Code
DNA Replication
RNA, Messenger-
Transcription, Genetic
TATA Box
Klonierung, molekulare
DNA-bindende Proteine
RNA, Transfer-, Aminoacyl-
Promoter Regions, Genetic
Hydroxymethyl- und Formyl-Transferasen
Bakterielle Proteine
Prokaryoter Initiationsfaktor 2
Peptidketten-Initiationsfaktoren
DNA-Helikasen
Binding Sites
DNA
Base Composition
Genes
Sequence Homology, Nucleic Acid
Restriktions-Mapping
Genes, Bacterial
Prokaryoter Initiationsfaktor 3
Exons
Polymerase-Kettenreaktion
Point Mutation
Methionin-tRNA-Ligase
Eukaryoter Initiationsfaktor-1
Peptide Chain Termination, Translational
Virusproteine
Methionin
Caspasen
Bakterien-DNA
DNA-Mutationsanalyse
Sequenzanalyse, DNA-
Saccharomyces cerevisiae
Caspase 2
N-Formylmethionin
Models, Genetic
RNA, Transfer-, aminosäurenspezifische
Oligoribonucleotide
Protein Binding
DNA-Primer
Benzoylperoxid
RNA, bakterielle
Peptide Chain Elongation, Translational
Mutagenese, lokalspezifische
Sequenzvergleich
Evolution, Molecular
Trans-Activators
Caspase 9
Sequence Homology, Amino Acid
Thromboplastin
Transkriptionsfaktoren
Zellinie
Genes, ras
Caspase 8
Hela-Zellen
Eukaryoter Initiationsfaktor-2
Gene Expression Regulation, Bacterial
Suppression, Genetic
Introns
Caspase 10
Genes, Viral
Peptidketten-Terminationsfaktoren
Conserved Sequence
Transfektion
Sequence Deletion
Kokarzinogenese
5'-Nicht-translatierte Regionen
Transkriptionsfaktor TFIID
Kinetics
Gene Expression Regulation
Oligonucleotide
Proteine
Origin-Recognition-Complex
Oligodesoxyribonucleotide
DNA-Restriktionsenzyme
Escherichia-coli-Proteine
Aminoacyl-tRNA-Ligasen
Alanin-tRNA-Ligase
Apoptosis
Mutagenesis
Regulatory Sequences, Nucleic Acid
Replicon
Species Specificity
Reading Frames
Karzinogene
Phylogeny
Rekombinante Proteine
Caspase Inhibitors
Papillom
Operon
Alleles
Transcription Initiation Site
Polymorphism, Genetic
DNA, komplementäre
Retikulozyten
Selection, Genetic
DNA-Fu
Toluidine
Phenotype
Consensus Sequence
Single-Strand Specific DNA and RNA Endonucleases
RNA, Pilz-
Protein Structure, Tertiary
Models, Molecular
Genes, Reporter
Chromosomenkartierung
Genes, Regulator
Rekombinant-Fusions-Proteine
CRADD-Signal-Adaptor-Protein
Edein
Oligonucleotid-Sonden
Zellfreies System
Erblichkeit
Apoptosomen
Structure-Activity Relationship
Ribonuclease T1
Eukaryoter Initiationsfaktor 3
Eukaryotische Zellen
Polymerization
Gene Expression
Aminosäuren
Guanosintriphosphat
Aminosäuresubstitution
Chromosomen, Bakterien-
Elektrophorese, Polyacrylamidgel-
Photoinitiators, Dental
Methylmethacrylat
Methylmethacrylate
Ribosomale Proteine
Bovines Papillomavirus 1
Amidine
Genes, Fungal
tRNA-Methyltransferasen
9,10-Dimethyl-1,2-Benzanthracen
Nucleotide
Mitochondrien
Repressorproteine
Transfer RNA Aminoacylation
Polymorphism, Single-Stranded Conformational
Frameshifting, Ribosomal
Polymethyl-methacrylat
Virus Replication
Saccharomyces-cerevisiae-Proteine
Dimerization
RNA, Transfer-, Gln-
RNA
DNA, Virus-
Base Pairing
Stammbaum
Kaliumpermanganat
DNA, recombinante
Ribonucleasen
Methacrylate
Blotting, Northern
Genes, p53
Nanovirus
DNA, Einzelstrang-
Sp1-Transkriptionsfaktor
Repetitive Sequences, Nucleic Acid
RNA Splicing
Enzyme Activation
Nucleinsäurehybridisierung
Genetic Variation
RNA, Transfer-, Ser-
Beta-Galactosidase
Prokaryotische Zellen
Zellen, kultivierte
RNA, Transfer-, Arg-
Hauttumoren
Genes, Suppressor
Gene Expression Regulation, Viral
Phosphine
Protein Conformation
Caspase 6
Alternative Splicing
Peptidketten-Verlängerungsfaktor Tu
Chloramphenicol-O-Acetyltransferase
Methionyl Aminopeptidases
Kaninchen
Mutagenese, Insertions-
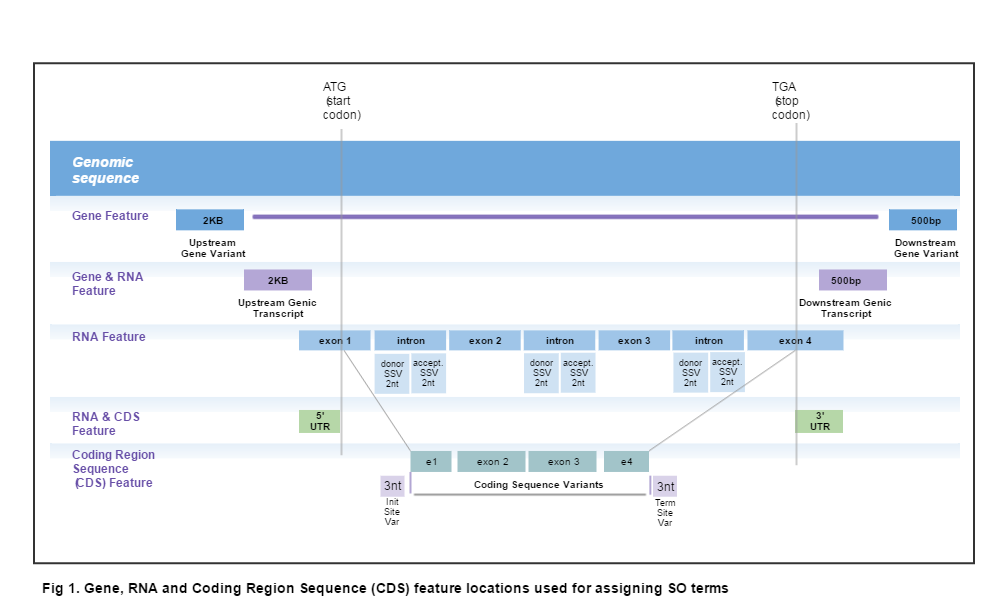
Ein Codon ist ein dreibasiger Nukleotidabschnitt in der DNA oder RNA, der für die genetische Information zur Synthese eines spezifischen Aminosäurerestes in einem Protein kodiert. Es gibt 64 mögliche Codone (inklusive Start- und Stoppcodons), die sich aus den vier Nukleotiden Adenin, Thymin/Uracil, Guanin und Cytosin zusammensetzen. Jedes Codon wird von einem korrespondierenden tRNA-Molekül erkannt und decodiert, um die entsprechende Aminosäure während der Proteinsynthese zu transportieren.
Ein Initiator Codon ist ein genetischer Code in der mRNA (Messenger-RNA), der die Position angibt, an der die Translation eines Proteins beginnt. In den meisten Lebewesen ist das Initiator Codon AUG, was für die Aminosäure Methionin steht. In einigen Fällen kann auch GUG als Initiator Codon fungieren, welches die Aminosäure Valin codiert. Das Initiator Codon ist ein wichtiger Bestandteil des genetischen Codes und spielt eine entscheidende Rolle bei der Regulation der Proteinbiosynthese.
Ein Terminations-Codon, auch bekannt als Stoppcodon, ist ein dreinukleotidisches Muster in der mRNA (Messenger-RNA), das die Proteinsynthese beendet und somit das Ende eines Genabschnitts kennzeichnet. In Eukaryoten sind die drei Terminations-Codons UAG, UAA und UGA, während bei Prokaryoten auch UUA, UUG, CUA, CUC, CUG, GUA, GUG, GUC als Stoppcodons fungieren können. Im Gegensatz zu den anderen Codons, die bestimmte Aminosäuren codieren, besitzen Terminations-Codons keine entsprechenden tRNAs (Transfer-RNAs) und führen stattdessen zur Dissoziation des Ribosoms von der mRNA.
In molecular biology, a base sequence refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), cytosine (C), guanine (G), and thymine (T), while in RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is essential for the synthesis of proteins and the regulation of gene expression. It is determined by the unique combination of these nitrogenous bases along the sugar-phosphate backbone of the nucleic acid molecule.
A 'Base Sequence' in a medical context typically refers to the specific order of these genetic building blocks, which can be analyzed and compared to identify genetic variations, mutations, or polymorphisms that may have implications for an individual's health, disease susceptibility, or response to treatments.
Molekülsequenzdaten beziehen sich auf die Reihenfolge der Bausteine in Biomolekülen wie DNA, RNA oder Proteinen. Jedes Molekül hat eine einzigartige Sequenz, die seine Funktion und Struktur bestimmt.
In Bezug auf DNA und RNA besteht die Sequenz aus vier verschiedenen Nukleotiden (Adenin, Thymin/Uracil, Guanin und Cytosin), während Proteine aus 20 verschiedenen Aminosäuren bestehen. Die Sequenzdaten werden durch Laborverfahren wie DNA-Sequenzierung oder Massenspektrometrie ermittelt und können für Anwendungen in der Genetik, Biochemie und Pharmakologie verwendet werden.
Die Analyse von Molekülsequenzdaten kann zur Identifizierung genetischer Variationen, zur Vorhersage von Proteinstrukturen und -funktionen sowie zur Entwicklung neuer Medikamente beitragen.
Ein Nonsense-Codon ist ein genetischer Code, der während der Proteinsynthese die vorzeitige Beendigung der Translation veranlasst und somit zu einer verkürzten, in der Regel funktionsunfähigen Polypeptidkette führt. Das am häufigsten vorkommende Nonsense-Codon ist UAG (Ambigsus-Code: *), gefolgt von UAA (Ambigsus-Code: * ) und UGA (Ambigsus-Code: *). Diese Codons werden auch als "Stoppcodons" oder "Terminationscodons" bezeichnet. Mutationen, die Nonsense-Codons in normalerweise codierende Sequenzen einführen, können zu schwerwiegenden Erbkrankheiten führen, da sie die Produktion von vollständigen und funktionsfähigen Proteinen verhindern.
Eine Aminosäuresequenz ist die genau festgelegte Reihenfolge der verschiedenen Aminosäuren, aus denen ein Proteinmolekül aufgebaut ist. Sie wird direkt durch die Nukleotidsequenz des entsprechenden Gens bestimmt und spielt eine zentrale Rolle bei der Funktion eines Proteins.
Die Aminosäuren sind über Peptidbindungen miteinander verknüpft, wobei die Carboxylgruppe (-COOH) einer Aminosäure mit der Aminogruppe (-NH2) der nächsten reagiert, wodurch eine neue Peptidbindung entsteht und Wasser abgespalten wird. Diese Reaktion wiederholt sich, bis die gesamte Kette der Proteinsequenz synthetisiert ist.
Die Aminosäuresequenz eines Proteins ist einzigartig und dient als wichtiges Merkmal zur Klassifizierung und Identifizierung von Proteinen. Sie bestimmt auch die räumliche Struktur des Proteins, indem sie hydrophobe und hydrophile Bereiche voneinander trennt und so die Sekundär- und Tertiärstruktur beeinflusst.
Abweichungen in der Aminosäuresequenz können zu Veränderungen in der Proteinstruktur und -funktion führen, was wiederum mit verschiedenen Krankheiten assoziiert sein kann. Daher ist die Bestimmung der Aminosäuresequenz von großer Bedeutung für das Verständnis der Funktion von Proteinen und deren Rolle bei Erkrankungen.
Eine Mutation ist eine dauerhafte, zufällige Veränderung der DNA-Sequenz in den Genen eines Organismus. Diese Veränderungen können spontan während des normalen Wachstums und Entwicklungsprozesses auftreten oder durch äußere Einflüsse wie ionisierende Strahlung, chemische Substanzen oder Viren hervorgerufen werden.
Mutationen können verschiedene Formen annehmen, wie z.B. Punktmutationen (Einzelnukleotidänderungen), Deletionen (Entfernung eines Teilstücks der DNA-Sequenz), Insertionen (Einfügung zusätzlicher Nukleotide) oder Chromosomenaberrationen (größere Veränderungen, die ganze Gene oder Chromosomen betreffen).
Die Auswirkungen von Mutationen auf den Organismus können sehr unterschiedlich sein. Manche Mutationen haben keinen Einfluss auf die Funktion des Gens und werden daher als neutral bezeichnet. Andere Mutationen können dazu führen, dass das Gen nicht mehr oder nur noch eingeschränkt funktioniert, was zu Krankheiten oder Behinderungen führen kann. Es gibt jedoch auch Mutationen, die einen Vorteil für den Organismus darstellen und zu einer verbesserten Anpassungsfähigkeit beitragen können.
Insgesamt spielen Mutationen eine wichtige Rolle bei der Evolution von Arten, da sie zur genetischen Vielfalt beitragen und so die Grundlage für natürliche Selektion bilden.
Escherichia coli (E. coli) ist eine gramnegative, fakultativ anaerobe, sporenlose Bakterienart der Gattung Escherichia, die normalerweise im menschlichen und tierischen Darm vorkommt. Es gibt viele verschiedene Stämme von E. coli, von denen einige harmlos sind und Teil der natürlichen Darmflora bilden, während andere krankheitserregend sein können und Infektionen verursachen, wie Harnwegsinfektionen, Durchfall, Bauchschmerzen und in seltenen Fällen Lebensmittelvergiftungen. Einige Stämme von E. coli sind auch für nosokomiale Infektionen verantwortlich. Die Übertragung von pathogenen E. coli-Stämmen kann durch kontaminierte Nahrungsmittel, Wasser oder direkten Kontakt mit infizierten Personen erfolgen.
Ein Anticodon ist eine Sequenz aus drei Nukleotiden in der RNA, die komplementär zu einer bestimmten Aminosäure-codierenden Sequenz (Kodon) in mRNA ist. Es befindet sich in der tRNA (Transfer-RNA) und spielt eine wichtige Rolle bei der Proteinbiosynthese, indem es die richtige Aminosäure an den Ribosomen zu der entsprechenden codierenden Sequenz in mRNA bringt. Die Basenpaarung zwischen dem Anticodon und dem Kodon ermöglicht die korrekte Decodierung des genetischen Codes während der Translation.
Caspasen sind eine Familie von cystein-abhängigen Proteasen, die eine wichtige Rolle bei der Apoptose, also dem programmierten Zelltod, spielen. Man unterscheidet zwischen Initiator-Caspasen und Exekutor-Caspasen.
Initiator-Caspasen (auch bekannt als Caspase-8, -9 und -10) sind die ersten Caspasen, die während des Apoptoseprozesses aktiviert werden. Sie werden durch sogenannte Apoptosissignale aktiviert, die zum Beispiel durch Stressfaktoren oder Schädigungen der Zelle entstehen.
Sobald die Initiator-Caspasen aktiviert sind, aktivieren sie wiederum die Exekutor-Caspasen (auch bekannt als Caspase-3, -6 und -7), die dann für den eigentlichen Abbau der Zelle verantwortlich sind.
Initiator-Caspasen spielen also eine entscheidende Rolle bei der Aktivierung des Apoptoseprozesses und tragen somit zur Aufrechterhaltung der Homöostase im Körper bei, indem sie die Entstehung von Zellschäden verhindern.
Nucleic acid conformation bezieht sich auf die dreidimensionale Form oder Anordnung von Nukleinsäuren, wie DNA und RNA, auf molekularer Ebene. Die Konformation wird durch die Art und Weise bestimmt, wie sich die Nukleotide, die Bausteine der Nukleinsäure, miteinander verbinden und falten.
Die zwei am besten bekannte Konformationen von DNA sind die A-Form und die B-Form. Die A-Form ist eine rechtsgängige Helix mit 11 Basenpaaren pro Windung und einem Durchmesser von 2,3 Nanometern, während die B-Form eine rechtsgängige Helix mit 10,4 Basenpaaren pro Windung und einem Durchmesser von 2,5 Nanometern ist.
Die Konformation der Nukleinsäure kann sich unter verschiedenen Bedingungen ändern, wie zum Beispiel bei Veränderungen des pH-Werts, der Salzkonzentration oder der Temperatur. Diese Änderungen können die Funktion der Nukleinsäure beeinflussen und sind daher von großem Interesse in der Molekularbiologie.
Der genetische Code bezieht sich auf die spezifische Abfolge von Nukleotiden in der DNA und RNA, die die Reihenfolge der Aminosäuren in Proteinen bestimmt. Dies ist ein grundlegendes Prinzip der Genetik, bei dem die Sequenz von vier verschiedenen Nukleotiden (Adenin, Thymin, Guanin und Cytosin in DNA; Adenin, Uracil, Guanin und Cytosin in RNA) die genetische Information codiert, die für die Synthese eines Proteins erforderlich ist.
Jedes Tripel von Nukleotiden, auch als Codon bezeichnet, repräsentiert eine bestimmte Aminosäure oder ein Stoppsignal für die Proteinsynthese. Da es 64 mögliche Kombinationen von drei Nukleotiden gibt und nur 20 verschiedene Standardaminosäuren in Proteinen vorkommen, ist der genetische Code degeneriert, was bedeutet, dass mehr als ein Codon für die meisten Aminosäuren codieren kann.
Der genetische Code ist universell, d.h. er gilt für fast alle Lebewesen auf der Erde, von Bakterien bis hin zu Menschen. Es gibt jedoch einige Ausnahmen und Variationen im genetischen Code in bestimmten Organismen, wie zum Beispiel Mitochondrien und Mikrosporidien.
DNA-Replikation ist ein biologischer Prozess, bei dem das DNA-Molekül eines Organismus kopiert wird, um zwei identische DNA-Moleküle zu bilden. Es ist eine essenzielle Aufgabe für die Zellteilung und das Wachstum von Lebewesen, da jede neue Zelle eine exakte Kopie des Erbguts benötigt, um die genetische Information korrekt weiterzugeben.
Im Rahmen der DNA-Replikation wird jeder Strang der DNA-Doppelhelix als Matrize verwendet, um einen komplementären Strang zu synthetisieren. Dies geschieht durch das Ablesen der Nukleotidsequenz des ursprünglichen Strangs und die Anlagerung komplementärer Nukleotide, wodurch zwei neue, identische DNA-Moleküle entstehen.
Der Prozess der DNA-Replikation ist hochgradig genau und effizient, mit Fehlerraten von weniger als einem Fehler pro 10 Milliarden Basenpaaren. Dies wird durch die Arbeit mehrerer Enzyme gewährleistet, darunter Helikasen, Primasen, Polymerasen und Ligasen, die zusammenarbeiten, um den Replikationsprozess zu orchestrieren.
Molekulare Klonierung bezieht sich auf ein Laborverfahren in der Molekularbiologie, bei dem ein bestimmtes DNA-Stück (z.B. ein Gen) aus einer Quellorganismus-DNA isoliert und in einen Vektor (wie ein Plasmid oder ein Virus) eingefügt wird, um eine Klonbibliothek zu erstellen. Die Klonierung ermöglicht es, das DNA-Stück zu vervielfältigen, zu sequenzieren, zu exprimieren oder zu modifizieren. Dieses Verfahren ist wichtig für verschiedene Anwendungen in der Grundlagenforschung, Biotechnologie und Medizin, wie beispielsweise die Herstellung rekombinanter Proteine, die Genanalyse und Gentherapie.
DNA-bindende Proteine sind Proteine, die spezifisch und hochaffin mit der DNA interagieren und diese binden können. Diese Proteine spielen eine wichtige Rolle in zellulären Prozessen wie Transkription, Reparatur und Replikation der DNA. Sie erkennen bestimmte Sequenzen oder Strukturen der DNA und binden an sie durch nicht-kovalente Wechselwirkungen wie Wasserstoffbrücken, Van-der-Waals-Kräfte und elektrostatische Anziehung. Einige Beispiele für DNA-bindende Proteine sind Transkriptionsfaktoren, Restriktionsenzyme und Histone.
Hydroxymethyl- und Formyl-Transferasen sind Enzyme, die die Übertragung von Hydroxymethyl- oder Formyl-Gruppen zwischen verschiedenen Molekülen katalysieren. Diese Enzyme spielen eine wichtige Rolle in verschiedenen biochemischen Prozessen, wie beispielsweise der Synthese und Metabolismus von Nukleotiden und Aminosäuren. Ein Beispiel für ein Hydroxymethyl-Transferase ist die DNA-Methyltransferase, die die Übertragung von Methylgruppen auf DNA-Moleküle katalysiert. Formyl-Transferasen sind an Prozessen wie der Bildung von Formylphosphat und der Synthese von Aminosäuren beteiligt. Diese Enzyme sind wichtig für die Aufrechterhaltung der Homöostase im menschlichen Körper und können bei verschiedenen Krankheiten und Störungen eine Rolle spielen, wie zum Beispiel Krebs und neurologischen Erkrankungen.
Bacterial proteins are a type of protein specifically produced by bacteria. They are crucial for various bacterial cellular functions, such as metabolism, DNA replication, transcription, and translation. Bacterial proteins can be categorized based on their roles, including enzymes, structural proteins, regulatory proteins, and toxins. Some of these proteins play a significant role in the pathogenesis of bacterial infections and are potential targets for antibiotic therapy. Examples of bacterial proteins include flagellin (found in the flagella), which enables bacterial motility, and various enzymes involved in bacterial metabolism, such as beta-lactamases that can confer resistance to antibiotics like penicillin.
DNA-Helikasen sind Enzyme, die die Doppelstrangstruktur der DNA durch Aufspaltung der Wasserstoffbrückenbindungen zwischen den Basenpaaren in Einzelstränge trennen. Dieser Prozess ist ein essentieller Schritt bei zahlreichen zellulären Vorgängen, wie beispielsweise der DNA-Replikation, Reparatur und Transkription. Die Helikase bewegt sich dabei entlang des DNA-Strangs und "schraubt" ihn auf, wodurch die beiden Einzelstränge freigelegt werden.
In der Medizin und Biochemie bezieht sich der Begriff "Binding Sites" auf die spezifischen Bereiche auf einer Makromolekül-Oberfläche (wie Proteine, DNA oder RNA), an denen kleinere Moleküle, Ionen oder andere Makromoleküle binden können. Diese Bindungsstellen sind oft konservierte Bereiche mit einer bestimmten dreidimensionalen Struktur, die eine spezifische und hochaffine Bindung ermöglichen.
Die Bindung von Liganden (Molekülen, die an Bindungsstellen binden) an ihre Zielproteine oder Nukleinsäuren spielt eine wichtige Rolle in vielen zellulären Prozessen, wie z.B. Enzymfunktionen, Signaltransduktion, Genregulation und Arzneimittelwirkungen. Die Bindungsstellen können durch verschiedene Methoden wie Röntgenkristallographie, Kernspinresonanzspektroskopie oder computergestützte Modellierung untersucht werden, um mehr über die Wechselwirkungen zwischen Liganden und ihren Zielmolekülen zu erfahren.
DNA, oder Desoxyribonukleinsäure, ist ein Molekül, das die genetische Information in allen Lebewesen und vielen Viren enthält. Es besteht aus zwei langen, sich wiederholenden Ketten von Nukleotiden, die durch Wasserstoffbrückenbindungen miteinander verbunden sind und eine Doppelhelix bilden.
Jeder Nukleotidstrang in der DNA besteht aus einem Zucker (Desoxyribose), einem Phosphatmolekül und einer von vier Nukleobasen: Adenin, Thymin, Guanin oder Cytosin. Die Reihenfolge dieser Basen entlang des Moleküls bildet den genetischen Code, der für die Synthese von Proteinen und anderen wichtigen Molekülen in der Zelle verantwortlich ist.
DNA wird oft als "Blaupause des Lebens" bezeichnet, da sie die Anweisungen enthält, die für das Wachstum, die Entwicklung und die Funktion von Lebewesen erforderlich sind. Die DNA in den Zellen eines Organismus wird in Chromosomen organisiert, die sich im Zellkern befinden.
'Base composition' ist ein Begriff aus der Genetik und bezieht sich auf den Anteil der Nukleobasen in einer DNA- oder RNA-Sequenz. Die vier Nukleobasen, die in DNA vorkommen, sind Adenin (A), Thymin (T), Guanin (G) und Cytosin (C). In RNA wird Thymin durch Uracil (U) ersetzt.
Der Basenanteil wird als Prozentsatz der einzelnen Nukleobasen oder als Verhältnis zweier Basen zueinander ausgedrückt, zum Beispiel GC-Gehalt für den Anteil von Guanin und Cytosin. Der GC-Gehalt ist ein wichtiger Parameter in der Genetik, da Guanin immer mit Cytosin in der DNA gepaart ist und umgekehrt.
Die Basenkomposition kann hilfreich sein, um die Funktion von Genen oder nicht-kodierenden Abschnitten des Genoms zu verstehen, da sie oft mit bestimmten genetischen Merkmalen wie der Chromatinstruktur, der Stabilität der DNA und der Expression von Genen korreliert.
In der Medizin bezieht sich "Genes" auf den Prozess der Wiederherstellung der normalen Funktion und des Wohlbefindens nach einer Krankheit, Verletzung oder Operation. Dieser Begriff beschreibt den Zustand, in dem ein Patient die Symptome seiner Erkrankung überwunden hat und wieder in der Lage ist, seine täglichen Aktivitäten ohne Beeinträchtigung auszuführen.
Es ist wichtig zu beachten, dass "Genes" nicht immer bedeutet, dass eine Person vollständig geheilt ist oder keine Spuren der Erkrankung mehr aufweist. Manchmal kann es sich lediglich um eine Verbesserung des Zustands handeln, bei der die Symptome abgeklungen sind und das Risiko einer erneuten Verschlechterung minimiert wurde.
Die Dauer des Genesungsprozesses hängt von verschiedenen Faktoren ab, wie Art und Schwere der Erkrankung, dem Alter und Gesundheitszustand des Patienten sowie der Qualität der medizinischen Versorgung und Nachsorge. In einigen Fällen kann die Genesung schnell und vollständig sein, während sie in anderen Fällen langwierig und möglicherweise unvollständig sein kann.
"Bacterial Genes" bezieht sich auf die Erbinformation in Bakterien, die als DNA (Desoxyribonukleinsäure) vorliegt und für bestimmte Merkmale oder Funktionen der Bakterien verantwortlich ist. Diese Gene codieren für Proteine und RNA-Moleküle, die eine Vielzahl von Aufgaben im Stoffwechsel und Überleben der Bakterien erfüllen. Bacterial Genes können durch Gentechnik oder durch natürliche Mechanismen wie Mutation oder horizontalen Gentransfer übertragen werden. Die Untersuchung von bakteriellen Genen ist ein wichtiger Bestandteil der Mikrobiologie und Infektionskrankheiten, da sie dazu beitragen kann, das Verhalten von Bakterien zu verstehen, Krankheitsursachen zu identifizieren und neue Behandlungsansätze zu entwickeln.
Exons sind die Abschnitte der DNA, die nach der Transkription und folgenden Prozessen wie Spleißen in das endgültige mature mRNA-Molekül eingebaut werden und somit die codierende Region für Proteine darstellen. Sie entsprechen den Bereichen, die nach dem Entfernen der nichtcodierenden Introns-Abschnitte in der reifen, translationsfähigen mRNA verbleiben. Im Allgemeinen enthalten Exons kodierende Sequenzen, die für Aminosäuren in einem Protein stehen, können aber auch Regulationssequenzen oder nichtcodierende RNA-Abschnitte wie beispielsweise RNA-Elemente mit Funktionen in der RNA-Struktur oder -Funktion enthalten.
Methionin-tRNA-Ligase ist ein Enzym, das die Verbindung von Methionin mit seiner spezifischen transfer-RNA (tRNA) katalysiert, um so die Aminoacyl-tRNA zu bilden. Diese Verbindung ist ein essentieller Schritt bei der Proteinsynthese im menschlichen Körper. Das Enzym hilft dabei, das Methionin an die passende tRNA zu binden, damit es vom Ribosom während des Prozesses der Proteinbiosynthese richtig eingebaut werden kann. Mutationen in diesem Gen können zu verschiedenen Erkrankungen führen, wie beispielsweise Methionin-tRNA-Synthetase-Mangel oder kombinierte Immundefizienz mit B-Zell-Anomalien.
Der Eukaryote Initiationsfaktor-1 (eIF1) ist ein essentielles Protein, das bei der Initiation der Proteinsynthese in eukaryotischen Zellen eine wichtige Rolle spielt. Er ist ein Teil des kleinen eukaryotischen Ribosomen-Initiationskomplexes (eIF2/Met-tRNA/GTP) und hilft bei der richtigen Positionierung der Initiator-tRNA auf dem 40S-Ribosom. Darüber hinaus ist eIF1 an der Überwachung des korrekten Startkodons beteiligt und verhindert die Bindung von falsch positionierten Initiator-tRNAs am Ribosom. Fehlfunktionen oder Mutationen im Zusammenhang mit dem eIF1 können zu Störungen in der Proteinsynthese führen, was wiederum verschiedene Krankheiten und Entwicklungsstörungen verursachen kann.
Methionin ist eine essenzielle Aminosäure, die im menschlichen Körper vorhanden ist und ein wesentlicher Bestandteil der Proteinsynthese ist. Es ist eine sulfurhaltige Aminosäure, die eine methylgruppe (-CH3) enthält und für den Organismus unerlässlich ist, um Proteine zu bilden, Fette abzubauen und Chelatbildung durch Schwermetalle zu verhindern.
Methionin wird über die Nahrung aufgenommen und kommt in Lebensmitteln wie Fleisch, Milchprodukten, Eiern und Sojabohnen vor. Es ist auch als Nahrungsergänzungsmittel erhältlich und wird oft für Lebererkrankungen, zur Entgiftung des Körpers und zur Verbesserung der sportlichen Leistungsfähigkeit eingesetzt.
Eine unzureichende Methioninaufnahme kann zu Erkrankungen wie Lebererkrankungen, Wachstumsstörungen, Erschöpfung und neurologischen Störungen führen.
Caspasen sind eine Familie von Cystein-aspartat-proteasen, die eine wichtige Rolle in der Regulation von Apoptose (programmierter Zelltod) spielen. Sie sind serinähnliche Endopeptidasen, die spezifisch Peptidbindungen an Aspartatsäureresten hydrolysieren. Es gibt zwei Hauptklassen von Caspasen: Initiator-Caspasen und Exekutor-Caspasen. Die Initiator-Caspasen werden aktiviert, wenn sie mit Apoptose-induzierenden Signalproteinen interagieren, während die Exekutor-Caspasen durch Interaktion mit den Initiator-Caspasen aktiviert werden. Aktivierte Caspasen zerlegen dann verschiedene intrazelluläre Proteine und zerstören so die Zelle von innen heraus. Diese proteolytische Kaskade ist ein wichtiger Bestandteil des apoptotischen Signalwegs, der zur Eliminierung von geschädigten oder überflüssigen Zellen führt.
Bakterielle DNA bezieht sich auf die Desoxyribonukleinsäure (DNA) in Bakterienzellen, die das genetische Material darstellt und die Informationen enthält, die für die Replikation, Transkription und Proteinbiosynthese erforderlich sind. Die bakterielle DNA ist ein doppelsträngiges Molekül, das in einem Zirkel organisiert ist und aus vier Nukleotiden besteht: Adenin (A), Thymin (T), Guanin (G) und Cytosin (C). Die beiden Stränge sind an den Basen A-T und G-C komplementär angeordnet. Im Gegensatz zu eukaryotischen Zellen, die ihre DNA im Kern aufbewahren, befindet sich die bakterielle DNA im Zytoplasma der Bakterienzelle.
Die DNA-Mutationsanalyse ist ein Prozess der Genetik, bei dem die Veränderungen in der DNA-Sequenz untersucht werden, um genetisch bedingte Krankheiten oder Veranlagungen zu diagnostizieren, zu bestätigen oder auszuschließen. Eine Mutation ist eine dauerhafte und oft zufällige Veränderung in der DNA-Sequenz, die die Genstruktur und -funktion beeinflussen kann.
Die DNA-Mutationsanalyse umfasst verschiedene Techniken wie PCR (Polymerasekettenreaktion), DNA-Sequenzierung, MLPA (Multiplex-Ligation-dependent Probe Amplification) und Array-CGH (Array Comparative Genomic Hybridization). Diese Techniken ermöglichen es, kleinste Veränderungen in der DNA zu erkennen, wie z.B. Einzelnukleotidpolymorphismen (SNPs), Deletionen, Insertionen oder Chromosomenaberrationen.
Die Ergebnisse der DNA-Mutationsanalyse können wichtige Informationen für die klinische Diagnose und Therapie von genetisch bedingten Krankheiten liefern, wie z.B. Krebs, erbliche Herzkrankheiten, Stoffwechselstörungen oder neuromuskuläre Erkrankungen. Die DNA-Mutationsanalyse wird auch in der Forschung eingesetzt, um die genetischen Grundlagen von Krankheiten besser zu verstehen und neue Therapieansätze zu entwickeln.
Caspase-2 ist ein Mitglied der Caspase-Familie, einem Typ von kastenförmigen Proteasen (Cystein-abhängigen aspartat-spaltenden Proteasen), die eine wichtige Rolle bei der Regulation von programmierten Zelltod oder Apoptose spielen. Caspase-2 ist ein intrazelluläres Enzym, das aus zwei Untereinheiten besteht und als inaktives Prokaspase vorliegt. Es wird aktiviert, wenn es durch andere Caspasen oder durch die Bindung an Apoptose-auslösende Faktoren gespalten wird. Aktivierte Caspase-2 kann dann eine Reihe von Substraten spalten und so den Prozess der Apoptose vorantreiben. Es wird vermutet, dass Caspase-2 an verschiedenen zellulären Signalwegen beteiligt ist, einschließlich des DNA-Schadensantwortpfads und des oxidativen Stresses. Mutationen in dem Gen, das für Caspase-2 kodiert, wurden mit einem erhöhten Risiko für verschiedene Krankheiten wie neurodegenerative Erkrankungen und Krebs in Verbindung gebracht.
N-Formylmethionin ist eine spezielle, modifizierte Aminosäure, die in der Proteinbiosynthese von Prokaryoten (Bakterien) eine Rolle spielt. Es handelt sich um die erste Aminosäure, die während der Proteinsynthese an das startende Codon (Formyl-methionin-tRNA) gebunden wird. Dies geschieht durch die Formyltransferase, ein Enzym, das Methionin mit einer Formylgruppe (einer Gruppe aus einem Kohlenstoffatom und drei Wasserstoffatomen) modifiziert.
Im Gegensatz dazu beginnt die Proteinbiosynthese in Eukaryoten (Organismen, deren Zellen einen echten Zellkern besitzen, wie Tiere, Pflanzen und Pilze) mit der Aminosäure Methionin, das nicht formyliert ist.
N-Formylmethionin spielt auch eine Rolle im angeborenen Immunsystem von Wirbeltieren. Es aktiviert die NOD-like Rezeptorproteine (NLRP), die eine wichtige Rolle bei der Erkennung und Abwehr bakterieller Infektionen spielen.
Genetic models in a medical context refer to theoretical frameworks that describe the inheritance and expression of specific genes or genetic variations associated with certain diseases or traits. These models are used to understand the underlying genetic architecture of a particular condition and can help inform research, diagnosis, and treatment strategies. They may take into account factors such as the mode of inheritance (e.g., autosomal dominant, autosomal recessive, X-linked), penetrance (the likelihood that a person with a particular genetic variant will develop the associated condition), expressivity (the range of severity of the condition among individuals with the same genetic variant), and potential interactions with environmental factors.
Oligoribonucleotide sind kurze Abschnitte aus Ribonukleotiden, die wiederum aus Ribose (Zucker), Phosphat und den vier verschiedenen Nukleinbasen Adenin, Uracil, Guanin und Cytosin bestehen. Sie sind also kurze RNA-Moleküle mit einer Länge von typischerweise 2-20 Nukleotiden. Oligoribonucleotide können sowohl natürlich vorkommen als auch synthetisch hergestellt werden und spielen eine Rolle in verschiedenen biologischen Prozessen, wie beispielsweise der Genregulation oder der Abwehr von Viren durch das Immunsystem.
Ein DNA-Primer ist ein kurzes, einzelsträngiges Stück DNA oder RNA, das spezifisch an die Template-Stränge einer DNA-Sequenz bindet und die Replikation oder Amplifikation der DNA durch Polymerasen ermöglicht. Primers sind notwendig, da Polymerasen nur in 5'-3' Richtung synthetisieren können und deshalb an den Startpunkt der Synthese binden müssen. In der PCR (Polymerase Chain Reaction) sind DNA-Primer entscheidend, um die exakte Amplifikation bestimmter DNA-Sequenzen zu gewährleisten. Sie werden spezifisch an die Sequenz vor und nach der Zielregion designed und erlauben so eine gezielte Vermehrung des gewünschten DNA-Abschnitts.
Benzoylperoxid ist ein topisches Medikament, das häufig in der Dermatologie zur Behandlung von Akne eingesetzt wird. Es ist ein organischer Peroxid-Verbindung, die entzündliche Prozesse in den Hautporen reduziert und Komedonen (Mitesser) auflöst. Benzoylperoxid wirkt durch die Freisetzung von Sauerstoff, was Bakterien abtötet, insbesondere Propionibacterium acnes, die an der Entstehung von Akne beteiligt sind. Es ist in verschiedenen Formulierungen wie Cremes, Gelen und Lösungen erhältlich und wird ein- oder mehrmals täglich auf die betroffene Haut aufgetragen. Potenzielle Nebenwirkungen können Reizungen, Trockenheit und Irritationen sein.
Lokalspezifische Mutagenese bezieht sich auf einen Prozess der Veränderung der DNA in einer spezifischen Region oder Lokalität eines Genoms. Im Gegensatz zur zufälligen Mutagenese, die an beliebigen Stellen des Genoms auftreten kann, ist lokalspezifische Mutagenese gezielt auf eine bestimmte Sequenz oder Region gerichtet.
Diese Art der Mutagenese wird oft in der Molekularbiologie und Gentechnik eingesetzt, um die Funktion eines Gens oder einer Genregion zu untersuchen. Durch die Einführung gezielter Veränderungen in der DNA-Sequenz kann die Wirkung des Gens auf die Organismenfunktion oder -entwicklung studiert werden.
Lokalspezifische Mutagenese kann durch verschiedene Techniken erreicht werden, wie z.B. die Verwendung von Restriktionsendonukleasen, die gezielt bestimmte Sequenzmotive erkennen und schneiden, oder die Verwendung von Oligonukleotid-Primeren für die Polymerasekettenreaktion (PCR), um spezifische Regionen des Genoms zu amplifizieren und zu verändern.
Es ist wichtig zu beachten, dass lokalspezifische Mutagenese auch unbeabsichtigte Folgen haben kann, wie z.B. die Störung der Funktion benachbarter Gene oder Regulationssequenzen. Daher müssen solche Experimente sorgfältig geplant und durchgeführt werden, um unerwünschte Effekte zu minimieren.
Molekulare Evolution bezieht sich auf die Veränderungen der DNA-Sequenzen und Proteinstrukturen von Organismen im Laufe der Zeit. Es ist ein Teilgebiet der Evolutionsbiologie, das sich auf die Untersuchung der genetischen Mechanismen und Prozesse konzentriert, die zur Entstehung von Diversität bei Arten führen.
Dieser Prozess umfasst Mutationen, Rekombination, Genfluss, Drift und Selektion auf molekularer Ebene. Molekulare Uhr-Analysen werden verwendet, um die Zeitskalen der Evolution zu bestimmen und die Beziehungen zwischen verschiedenen Arten und Gruppen von Organismen zu rekonstruieren.
Die Analyse molekularer Daten kann auch dazu beitragen, Informationen über die Funktion von Genen und Proteinen sowie über die Entwicklung neuer Merkmale oder Eigenschaften bei Arten zu gewinnen. Insgesamt ist das Verständnis der molekularen Evolution ein wichtiger Bestandteil der modernen Biologie und hat weitreichende Implikationen für unser Verständnis von Krankheiten, Anpassungen und Biodiversität.
Caspase 9 ist ein Protein, das in der menschlichen Biologie als Initiator-Caspase bei der Aktivierung des programmierten Zelltods oder Apoptose eine wichtige Rolle spielt. Es gehört zur Familie der Caspasen, die cystein-abhängigen aspartat-spezifischen Proteasen sind.
Im apoptotischen Signalweg wird Caspase 9 durch die Bindung an Apaf-1 (Apoptotic Peptidase Activating Factor 1) aktiviert, nachdem dieses durch das proapoptotische Protein cytochrome c gebunden wurde. Die Aktivierung von Caspase 9 führt zur Aktivierung weiterer Effektor-Caspasen wie Caspase 3 und Caspase 7, was letztendlich zum Absterben der Zelle führt.
Eine Fehlfunktion oder Dysregulation von Caspase 9 kann mit verschiedenen Krankheiten assoziiert sein, darunter neurodegenerative Erkrankungen und Krebs.
'Genes, ras' bezieht sich auf ein Gen, das normalerweise an der Regulierung des Zellwachstums und der Differenzierung beteiligt ist. Es gibt drei bekannte Isoformen dieses Gens: H-ras, K-ras und N-ras. Mutationen in diesen onkogenen Genen können dazu führen, dass die Proteine kontinuierlich aktiviert werden und unkontrolliertes Zellwachstum verursachen, was zur Entwicklung von Krebs beitragen kann. Diese Mutationen sind häufig in verschiedenen Arten von Krebs wie Lungenkrebs, Brustkrebs, Dickdarmkrebs und Eierstockkrebs zu finden.
Caspase 8 ist ein Protease-Enzym, das in der Regulation des programmierten Zelltods (Apoptose) eine wichtige Rolle spielt. Es gehört zur Familie der Caspasen, die cystein-abhängigen aspartat-spaltenden Proteasen sind. Caspase 8 wird durch die Aktivierung von sog. Death-Rezeptoren aktiviert, die an der Zellmembran lokalisiert sind und deren Aktivierung zum Beispiel durch extrazelluläre Liganden wie FasL oder TRAIL erfolgen kann. Die Aktivierung von Caspase 8 führt zur Aktivierung weiterer Caspasen und damit letztendlich zum Absterben der Zelle. Eine Fehlregulation von Caspase 8 kann zu verschiedenen Krankheiten führen, darunter Autoimmunerkrankungen und Krebs.
HeLa-Zellen sind eine immortale Zelllinie, die von einem menschlichen Karzinom abstammt. Die Linie wurde erstmals 1951 aus einem bösartigen Tumor isoliert, der bei Henrietta Lacks, einer afro-amerikanischen Frau mit Gebärmutterhalskrebs, entdeckt wurde. HeLa-Zellen sind die am häufigsten verwendeten Zellen in der biologischen und medizinischen Forschung und haben zu zahlreichen wissenschaftlichen Durchbrüchen geführt, wie zum Beispiel in den Bereichen der Virologie, Onkologie und Gentherapie.
Es ist wichtig zu beachten, dass HeLa-Zellen einige einzigartige Eigenschaften haben, die sie von anderen Zelllinien unterscheiden. Dazu gehören ihre Fähigkeit, sich schnell und unbegrenzt zu teilen, sowie ihre hohe Resistenz gegenüber certainen Chemikalien und Strahlung. Diese Eigenschaften machen HeLa-Zellen zu einem wertvollen Werkzeug in der Forschung, können aber auch zu technischen Herausforderungen führen, wenn sie in bestimmten Experimenten eingesetzt werden.
Es ist auch wichtig zu beachten, dass die Verwendung von HeLa-Zellen in der Forschung immer wieder ethische Bedenken aufwirft. Henrietta Lacks wurde nie über die Verwendung ihrer Zellen informiert oder um Erlaubnis gebeten, und ihre Familie hat jahrzehntelang um Anerkennung und Entschädigung gekämpft. Heute gelten strenge Richtlinien für den Umgang mit menschlichen Zelllinien in der Forschung, einschließlich des Erhalts informierter Einwilligung und des Schutzes der Privatsphäre von Spendern.
Der Eukaryote Initiationsfaktor 2 (eIF2) ist ein zentraler Regulator der Proteinbiosynthese in eukaryotischen Zellen. Er spielt eine wichtige Rolle bei der Initialisierung der Translation, dem ersten Schritt der Proteinsynthese, indem er die Bindung des mRNA-Moleküls an das Ribosom vermittelt.
eIF2 ist ein Proteinkomplex, der aus drei Untereinheiten besteht: alpha, beta und gamma. Die gamma-Untereinheit von eIF2 besitzt GTPase-Aktivität und ist für den Austausch von GDP gegen GTP verantwortlich, was ein notwendiger Schritt in der Initiationsphase der Translation ist.
Die Aktivität von eIF2 wird durch Phosphorylierung der alpha-Untereinheit an der Position Ser51 reguliert. Diese Phosphorylierung führt zu einer Hemmung der Austauschaktivität von GDP gegen GTP und damit zu einer Hemmung der Translation. Diese Regulationsmechanismus ist wichtig für die zelluläre Stressantwort, da er bei Überlastung des ER oder bei Virusinfektionen aktiviert wird und so die Proteinsynthese drosselt, um die Zelle zu schützen.
Gene Expression Regulation, Bacterial, bezieht sich auf die Prozesse und Mechanismen, durch die die Aktivität der Gene in Bakterien kontrolliert wird. Dazu gehört die Entscheidung darüber, welche Gene abgelesen und in Proteine übersetzt werden sollen, sowie die Regulierung der Menge an produzierten Proteinen.
Diese Prozesse werden durch verschiedene Faktoren beeinflusst, wie zum Beispiel durch spezifische Signalmoleküle, die als An- oder Aus-Schalter für bestimmte Gene wirken können. Auch die Umweltbedingungen, unter denen sich das Bakterium befindet, spielen eine Rolle bei der Regulation der Genexpression.
Die Regulation der Genexpression ist ein entscheidender Faktor für die Anpassungsfähigkeit von Bakterien an veränderliche Umgebungsbedingungen und ermöglicht es den Bakterien, schnell auf neue Situationen zu reagieren. Sie ist daher ein wichtiges Forschungsgebiet in der Mikrobiologie und hat auch Bedeutung für das Verständnis von Infektionsmechanismen und die Entwicklung neuer Antibiotika.
Introns sind nicht-kodierende Sequenzen in einem DNA-Molekül, die während der Transkription in mRNA (messenger RNA) umgeschrieben werden. Sie werden als "inneres" Segment zwischen zwei kodierenden Abschnitten oder Exons definiert.
Caspase 10 ist ein Protein, das in der menschlichen Biologie als Teil des apoptotischen Signalwegs (programmierter Zelltod) eine Rolle spielt. Es gehört zur Familie der Caspasen, die katalytische Proteasen sind, die andere Proteine durch proteolytische Spaltung abbauen.
Caspase 10 ist aktiviert, wenn es an extrazelluläre Signale bindet, die den programmierten Zelltod einleiten. Sobald aktiviert, katalysiert Caspase 10 die Aktivierung anderer Caspasen (wie Caspase-3 und -7), was letztendlich zum Abbau von Zellstrukturen führt und den programmierten Zelltod verursacht.
Darüber hinaus ist Caspase 10 an der Regulation des Immunsystems beteiligt, indem es die Aktivierung von Entzündungszellen kontrolliert. Mutationen in dem Gen, das für Caspase 10 codiert, können zu Störungen im programmierten Zelltod und möglicherweise zu Krankheiten führen.
'Genes, Viral' bezieht sich auf die Gene, die in viraler DNA oder RNA vorhanden sind und die Funktion haben, die Vermehrung des Virus im Wirt zu ermöglichen. Diese Gene codieren für Proteine, die an der Replikation, Transkription, Translation und Assembly des Virus beteiligt sind. Das Verständnis von viralen Genen ist wichtig für die Entwicklung von antiviralen Therapien und Impfstoffen. Es ist auch nützlich für die Untersuchung der Evolution und Pathogenese von Viren.
Eine "conserved sequence" (konservierte Sequenz) bezieht sich auf eine Abfolge von Nukleotiden in DNA oder Aminosäuren in Proteinen, die in verschiedenen Organismen oder Molekülen über evolutionäre Zeiträume hinweg erhalten geblieben ist. Diese Konservierung deutet darauf hin, dass diese Sequenz eine wichtige biologische Funktion hat, da sie offensichtlich unter Selektionsdruck steht, um unverändert beizubehalten zu werden.
In der DNA können konservierte Sequenzen als Regulärelemente fungieren, die die Genexpression steuern, oder als codierende Sequenzen, die für die Synthese von Proteinen erforderlich sind. In Proteinen können konservierte Sequenzen wichtige Funktionsbereiche wie Bindungsstellen für Liganden, Enzymaktivitätszentren oder Strukturdomänen umfassen.
Die Erforschung konservierter Sequenzen ist ein wichtiges Instrument in der Vergleichenden Biologie und Bioinformatik, da sie dazu beitragen kann, die Funktion unbekannter Gene oder Proteine zu erschließen, evolutionäre Beziehungen zwischen Organismen aufzudecken und mögliche Krankheitsursachen zu identifizieren.
Kokarzinogenese ist ein Begriff aus der Pathologie und Onkologie, der sich auf die gemeinsame Wirkung zweier verschiedener Karzinogene bezieht, die zusammen das Risiko für Krebsentstehung erhöhen oder verkürzte Tumorlatenz verursachen. Dieser Effekt ist stärker als die Summe ihrer Einzeleffekte. Die beiden Karzinogene können gleichzeitig oder nacheinander auftreten und müssen nicht unbedingt in derselben Zelle wirken.
Es gibt verschiedene Arten von Kokarzinogenese, wie synergistische, additive und potentialisierende Effekte. Synergistische Effekte treten auf, wenn zwei Karzinogene zusammen das Krebsrisiko stärker erhöhen als die Summe ihrer Einzeleffekte. Additive Effekte hingegen bedeuten, dass das Gesamtrisiko der Krebsentstehung gleich der Summe der Risiken durch beide Karzinogene ist. Potentialisierende Effekte treten auf, wenn ein Karzinogen das andere Karzinogen unterstützt oder verstärkt, ohne selbst krebserregend zu sein.
Die Mechanismen der Kokarzinogenese sind vielfältig und noch nicht vollständig verstanden. Sie können auf genetischer Ebene durch Veränderungen im Erbgut oder auf epigenetischer Ebene durch Veränderungen in der Genexpression auftreten.
Insgesamt ist die Kokarzinogenese ein wichtiger Aspekt bei der Risikobewertung von Umweltfaktoren und Lebensstilfaktoren, die das Krebsrisiko beeinflussen können.
5'-Nicht-translatierte Regionen (5'-NTRs) beziehen sich auf die Abschnitte der DNA oder RNA, die vor (upstream) der Transkriptionsstartstelle liegen und nicht in das resultierende Protein übersetzt werden. Insbesondere bei mRNA spielen 5'-NTRs eine wichtige Rolle bei der Regulation der Genexpression durch Beteiligung an verschiedenen Prozessen wie Translationseffizienz, RNA-Stabilität und Lokalisation.
Die 5'-NTR enthält häufig verschiedene cis-agierende Elemente, einschließlich Kappenstrukturen, internen Promotoren, IRES (Internal Ribosome Entry Sites) und anderen regulatorischen Sequenzelementen. Diese Strukturen können die Bindung von Proteinfaktoren oder RNA-bindenden Proteinen ermöglichen, was wiederum die Translationseffizienz beeinflusst, indem es die Initiationskomplexe rekrutiert und die richtige Übersetzungsinitiation erleichtert.
Abweichungen in der Länge oder Sequenz von 5'-NTRs können mit verschiedenen Krankheiten assoziiert sein, wie beispielsweise Krebs, neurodegenerativen Erkrankungen und viralen Infektionen. Die Untersuchung dieser Regionen kann somit wichtige Einblicke in die Pathogenese von Krankheiten liefern und möglicherweise neue therapeutische Ziele identifizieren.
In der Pharmakologie und Toxikologie bezieht sich "Kinetik" auf die Studie der Geschwindigkeit und des Mechanismus, mit dem chemische Verbindungen wie Medikamente im Körper aufgenommen, verteilt, metabolisiert und ausgeschieden werden. Es umfasst vier Hauptphasen: Absorption (Aufnahme), Distribution (Transport zum Zielort), Metabolismus (Verstoffwechselung) und Elimination (Ausscheidung). Die Kinetik hilft, die richtige Dosierung eines Medikaments zu bestimmen und seine Wirkungen und Nebenwirkungen vorherzusagen.
Gene Expression Regulation bezieht sich auf die Prozesse, durch die die Aktivität eines Gens kontrolliert und reguliert wird, um die Synthese von Proteinen oder anderen Genprodukten in bestimmten Zellen und Geweben zu einem bestimmten Zeitpunkt und in einer bestimmten Menge zu steuern.
Diese Regulation kann auf verschiedenen Ebenen stattfinden, einschließlich der Transkription (die Synthese von mRNA aus DNA), der Post-Transkriptionsmodifikation (wie RNA-Spleißen und -Stabilisierung) und der Translation (die Synthese von Proteinen aus mRNA).
Die Regulation der Genexpression ist ein komplexer Prozess, der durch verschiedene Faktoren beeinflusst wird, wie z.B. Epigenetik, intrazelluläre Signalwege und Umweltfaktoren. Die Fehlregulation der Genexpression kann zu verschiedenen Krankheiten führen, einschließlich Krebs, Entwicklungsstörungen und neurodegenerativen Erkrankungen.
Oligonucleotide sind kurze Abschnitte oder Sequenzen aus Nukleotiden, die wiederum die Bausteine der Nukleinsäuren DNA und RNA bilden. Ein Oligonukleotid besteht in der Regel aus 2-20 Basenpaaren, wobei ein Nukleotid jeweils eine Base (Desoxyribose oder Ribose), Phosphat und eine organische Base (Adenin, Thymin/Uracil, Guanin oder Cytosin) enthält.
In der biomedizinischen Forschung werden Oligonucleotide häufig als Primer in PCR-Verfahren eingesetzt, um die Amplifikation spezifischer DNA-Sequenzen zu ermöglichen. Darüber hinaus finden sie Anwendung in der Diagnostik von genetischen Erkrankungen und Infektionen sowie in der Entwicklung von antisense-Therapeutika, bei denen die Oligonukleotide an bestimmte mRNA-Moleküle binden, um deren Translation zu blockieren.
Der Origin Recognition Complex (ORC) ist ein Proteinkomplex, der in der Zellteilung und Genexpression eine wichtige Rolle spielt. In der Eukaryotischen Zelle ist er essentiell für die Replikation des Genoms, indem er die Position der DNA-Replikationsursprünge (origins of replication) erkennt und bindet.
Der Komplex besteht aus mehreren Untereinheiten, von denen einige konserviert sind und in allen Eukaryoten vorkommen. Die humane Version des ORC-Komplexes zum Beispiel besteht aus den sechs Untereinheiten ORC1-6.
Die Funktion des ORC ist die Bindung an die Replikationsursprünge und die Initiierung der DNA-Replikation durch das Laden von weiteren Proteinfaktoren wie CDC6 und CDT1, welche wiederum den Mini-Chromosomen-Maintance-Komplex (MCM) rekrutieren. Dieser Komplex ist für die Helicase-Aktivität verantwortlich, die für die Öffnung der DNA-Doppelhelix während der Replikation notwendig ist.
Störungen in der Funktion des ORC können zu verschiedenen Erkrankungen führen, wie zum Beispiel Meier-Gorlin-Syndrom, einer seltenen genetischen Erkrankung, die durch Wachstumsverzögerungen und Anomalien im Skelettsystem gekennzeichnet ist.
Oligodesoxyribonucleotide sind kurze Abschnitte von einzelsträngiger DNA, die aus wenigen Desoxyribonukleotiden bestehen. Sie werden oft in der Molekularbiologie und Gentechnik verwendet, beispielsweise als Primer in der Polymerasekettenreaktion (PCR) oder für die Sequenzierung von DNA. Oligodesoxyribonucleotide können synthetisch hergestellt werden und sind aufgrund ihrer spezifischen Basensequenz in der Lage, an bestimmte Abschnitte der DNA zu binden und so die Reaktion zu katalysieren oder die Expression eines Gens zu regulieren.
DNA-Restriktionsenzyme sind ein Typ von Enzymen, die in Bakterien und Archaeen vorkommen. Sie haben die Fähigkeit, das DNA-Molekül zu schneiden und damit zu zerschneiden. Diese Enzyme erkennen spezifische Sequenzen der DNA-Moleküle, an denen sie binden und dann schneiden. Die Erkennungssequenz ist für jedes Restriktionsenzym einzigartig und kann nur wenige Basenpaare lang sein.
Die Funktion von DNA-Restriktionsenzymen in Bakterien und Archaeen besteht darin, die eigene DNA vor fremden DNA-Molekülen wie Viren oder Plasmiden zu schützen. Wenn ein fremdes DNA-Molekül in die Zelle gelangt, erkennt das Restriktionsenzym seine Erkennungssequenz und zerschneidet das Molekül in mehrere Teile. Auf diese Weise kann die fremde DNA nicht in den Genpool der Wirtszelle integriert werden und ihre Funktion wird unterbrochen.
In der Molekularbiologie werden DNA-Restriktionsenzyme häufig eingesetzt, um DNA-Moleküle zu zerschneiden und dann wieder zusammenzusetzen. Durch die Kombination von verschiedenen Restriktionsenzymen können Forscher DNA-Moleküle in bestimmte Größen und Formen schneiden, was für verschiedene Anwendungen wie Klonierung oder Genetischer Fingerabdruck nützlich ist.
Es gibt keine spezifische medizinische Definition für "Escherichia-coli-Proteine", da Proteine allgemein als Makromoleküle definiert sind, die aus Aminosäuren bestehen und eine wichtige Rolle in der Struktur, Funktion und Regulation von allen lebenden Organismen spielen, einschließlich Bakterien wie Escherichia coli (E. coli).
Allerdings können einige Proteine, die in E. coli gefunden werden, als Virulenzfaktoren bezeichnet werden, da sie dazu beitragen, das Bakterium pathogen für Menschen und Tiere zu machen. Beispiele für solche Proteine sind Hämolysin, Shiga-Toxin und intimin, die an der Entstehung von Durchfall und anderen Krankheitssymptomen beteiligt sind.
Insgesamt bezieht sich der Begriff "Escherichia-coli-Proteine" auf alle Proteine, die in E. coli gefunden werden, einschließlich solcher, die für das Überleben und Wachstum des Bakteriums notwendig sind, sowie solcher, die als Virulenzfaktoren wirken und zur Krankheitserreger-Eigenschaft von E. coli beitragen.
Aminoacyl-tRNA-Ligasen sind ein Enzymtyp, der eine zentrale Rolle in der Proteinbiosynthese spielt. Genauer gesagt katalysieren sie die Verbindung einer bestimmten Aminosäure mit ihrer entsprechenden transfer-RNA (tRNA). Dieser Prozess wird Aminoacylierung genannt und ist ein essentieller Schritt, um sicherzustellen, dass die richtige Aminosäure an die wachsende Polypeptidkette angehängt wird. Jede Art von tRNA bindet eine spezifische Aminoacyl-tRNA-Ligase, die dafür sorgt, dass nur die richtige Aminosäure an die tRNA gebunden wird. Diese enzymatisch katalysierte Reaktion ist ein hohes Präzisionsereignis, da eine Fehlpaarung von Aminosäuren und tRNAs zu einem fehlerhaften Protein führen kann, was möglicherweise funktionsunfähig oder toxisch sein könnte. Daher ist die Funktion der Aminoacyl-tRNA-Ligasen von entscheidender Bedeutung für die Genauigkeit und Effizienz der Proteinbiosynthese.
Alanin-tRNA-Ligase ist ein enzymatisches Molekül, das an der Proteinsynthese beteiligt ist. Genauer gesagt katalysiert es die Verbindung von Alanin mit seiner spezifischen transfer-RNA (tRNA). Diese Reaktion ist ein essenzieller Schritt bei der Übersetzung von genetischer Information in Aminosäurensequenzen während der Proteinbiosynthese. Ohne funktionsfähige Alanin-tRNA-Ligase wäre die korrekte Synthese vieler Proteine nicht möglich, was zu gravierenden Störungen im Organismus führen könnte. Mutationen in diesem Gen können verschiedene Krankheiten verursachen, wie beispielsweise bestimmte Formen der mentalen Retardierung oder Muskeldystrophie.
Apoptosis ist ein programmierter und kontrollierter Zelltod, der Teil eines normalen Gewebewachstums und -abbaus ist. Es handelt sich um einen genetisch festgelegten Prozess, durch den die Zelle in einer geordneten Weise abgebaut wird, ohne dabei entzündliche Reaktionen hervorzurufen.
Im Gegensatz zum nekrotischen Zelltod, der durch äußere Faktoren wie Trauma oder Infektion verursacht wird und oft zu Entzündungen führt, ist Apoptosis ein endogener Prozess, bei dem die Zelle aktiv an ihrer Selbstzerstörung beteiligt ist.
Während des Apoptoseprozesses kommt es zur DNA-Fragmentierung, Verdichtung und Fragmentierung des Zellkerns, Auftrennung der Zellmembran in kleine Vesikel (Apoptosekörperchen) und anschließender Phagocytose durch benachbarte Zellen.
Apoptosis spielt eine wichtige Rolle bei der Embryonalentwicklung, Homöostase von Geweben, Beseitigung von infizierten oder Krebszellen sowie bei der Immunfunktion.
Mutagenesis ist ein Prozess, der zu einer Veränderung des Erbguts (DNA oder RNA) führt und somit zu einer genetischen Mutation führen kann. Diese Veränderungen können spontan auftreten oder durch externe Faktoren wie ionisierende Strahlung, chemische Substanzen oder bestimmte Viren verursacht werden. Die mutagenen Ereignisse können verschiedene Arten von Veränderungen hervorrufen, wie Punktmutationen (Einzelbasensubstitutionen oder Deletionen/Insertionen), Chromosomenaberrationen (strukturelle und numerische Veränderungen) oder Genomrearrangements. Diese Mutationen können zu verschiedenen phänotypischen Veränderungen führen, die von keinen bis hin zu schwerwiegenden Auswirkungen auf das Wachstum, die Entwicklung und die Funktion eines Organismus reichen können. In der Medizin und Biologie ist das Studium von Mutagenese wichtig für das Verständnis der Ursachen und Mechanismen von Krankheiten, insbesondere bei Krebs, genetischen Erkrankungen und altersbedingten Degenerationen.
Carcinogene sind Substanzen oder Agentien, die Krebs auslösen oder fördern können. Dazu gehören chemische Stoffe, ionisierende Strahlung, bestimmte Viren und infektiöse Agens, sowie physikalische Noxen wie Asbest oder nanopartikuläre Stäube. Die Internationale Agentur für Krebsforschung (IARC) stuft diese Substanzen nach ihrem Krebspotenzial ein und teilt sie in Kategorien von 1 (bewiesene krebserregende Wirkung) bis 4 (wahrscheinlich nicht krebserregend für den Menschen) ein. Die Exposition gegenüber Karzinogenen kann das Risiko für die Entwicklung von Krebs erhöhen, wobei das Ausmaß des Risikos von verschiedenen Faktoren abhängt, wie z.B. der Art und Intensität der Exposition, der Dauer der Exposition sowie individuellen Faktoren wie Genetik und Lebensstil.
Caspase Inhibitors are substances that block the activity of caspases, which are a family of enzymes playing essential roles in programmed cell death (apoptosis), inflammation, and other important cellular processes. Caspases are cysteine-aspartic proteases that cleave their substrates at specific aspartic acid residues. Inhibiting caspases can help prevent unwanted or excessive cell death, which may have therapeutic potential in various medical conditions such as neurodegenerative diseases and tissue injuries. There are two main types of caspase inhibitors: synthetic and endogenous (naturally occurring) inhibitors. Synthetic caspase inhibitors include peptide-based and small molecule inhibitors, while endogenous caspase inhibitors include proteins like X-linked inhibitor of apoptosis protein (XIAP), cellular FLICE-inhibitory protein (cFLIP), and survivin.
Ein Papillom ist in der Medizin ein gutartiger (nicht krebsartiger) Tumor, der aus der übermäßigen Vermehrung von Haut- oder Schleimhautzellen entsteht und sich als erhabene, warzenähnliche Wucherung präsentiert. Papillome können an verschiedenen Körperstellen auftreten, wie beispielsweise der Haut oder den Schleimhäuten im Mund, Rachen, Genital- oder Analbereich.
Die humane Papillomviren (HPV) sind die häufigste Ursache für die Entstehung von Papillomen. Es gibt über 200 verschiedene HPV-Typen, einige davon können das Risiko für die Entwicklung von Krebs erhöhen, insbesondere Gebärmutterhalskrebs und andere Genitalkrebserkrankungen. Die meisten Papillome sind jedoch harmlos und können chirurgisch entfernt werden, wenn sie störend oder kosmetisch unangenehm sind.
Ein Operon ist ein Konzept aus der Molekularbiologie, das aus der bakteriellen Genregulation stammt. Es beschreibt eine Organisation mehrerer Gene, die gemeinsam reguliert werden und zusammen ein funktionelles Einheit bilden. In Prokaryoten (Bakterien und Archaeen) sind Operons häufig anzutreffen.
Ein Operon besteht aus einem Promotor, einem Operator und den strukturellen Genen. Der Promotor ist die Region, an der die RNA-Polymerase bindet, um die Transkription einzuleiten. Der Operator ist eine Sequenz, die von Regulatorproteinen besetzt werden kann und so die Transkription reguliert. Die strukturalen Gene codieren für Proteine oder RNAs, die gemeinsam in einem funktionellen Zusammenhang stehen.
Die Transkription des Operons erfolgt als ein einzelnes mRNA-Molekül, welches alle strukturellen Gene des Operons enthält. Somit können diese Gene gemeinsam und koordiniert exprimiert werden. Diese Form der Genregulation ist besonders vorteilhaft für Stoffwechselwege, bei denen mehrere Enzyme gemeinsam benötigt werden, um eine spezifische Reaktionsfolge durchzuführen.
Ein Beispiel für ein Operon ist das lac-Operon von Escherichia coli, welches an der Verwertung verschiedener Zucker wie Lactose beteiligt ist.
Allele sind verschiedene Varianten eines Gens, die an der gleichen Position auf einem Chromosomenpaar zu finden sind und ein bestimmtes Merkmal oder eine Eigenschaft codieren. Jeder Mensch erbt zwei Kopien jedes Gens - eine von jedem Elternteil. Wenn diese beiden Kopien des Gens unterschiedlich sind, werden sie als "Allele" bezeichnet.
Allele können kleine Unterschiede in ihrer DNA-Sequenz aufweisen, die zu verschiedenen Ausprägungen eines Merkmals führen können. Ein Beispiel ist das Gen, das für die Augenfarbe codiert. Es gibt mehrere verschiedene Allele dieses Gens, die jeweils leicht unterschiedliche DNA-Sequenzen aufweisen und zu verschiedenen Augenfarben führen können, wie beispielsweise braune, grüne oder blaue Augen.
Es ist wichtig zu beachten, dass nicht alle Gene mehrere Allele haben - einige Gene haben nur eine einzige Kopie, die bei allen Menschen gleich ist. Andere Gene können hunderte oder sogar tausende verschiedene Allele aufweisen. Die Gesamtheit aller Allele eines Individuums wird als sein Genotyp bezeichnet, während die Ausprägung der Merkmale, die durch diese Allele codiert werden, als Phänotyp bezeichnet wird.
In der Molekularbiologie bezieht sich der Begriff "komplementäre DNA" (cDNA) auf eine DNA-Sequenz, die das komplementäre Gegenstück zu einer RNA-Sequenz darstellt. Diese cDNA wird durch die reverse Transkription von mRNA (messenger RNA) erzeugt, einem Prozess, bei dem die RNA in DNA umgeschrieben wird.
Im Detail: Die komplementäre DNA ist eine einzelsträngige DNA, die synthetisiert wird, indem ein Enzym namens reverse Transkriptase die mRNA als Vorlage verwendet. Die Basenpaarung von RNA und DNA erfolgt nach den üblichen Regeln: Adenin (A) paart sich mit Thymin (T) und Uracil (U) in RNA paart sich mit Guanin (G). Durch diesen Prozess wird die einzelsträngige RNA in eine komplementäre DNA umgeschrieben, die dann weiter verarbeitet werden kann, z.B. durch Klonierung oder Sequenzierungsverfahren.
Die Erzeugung von cDNA ist ein wichtiges Verfahren in der Molekularbiologie und Genetik, insbesondere bei der Untersuchung eukaryotischer Gene, da diese oft durch Introns unterbrochen sind, die in der mRNA nicht vorhanden sind. Die cDNA-Technik ermöglicht es daher, genaue Sequenzinformationen über das exprimierte Gen zu erhalten, ohne dass störende Intron-Sequenzen vorhanden sind.
Es gibt keine medizinische oder wissenschaftliche Bezeichnung namens "DNA-Fu". DNA steht für Desoxyribonukleinsäure und ist die Erbsubstanz, die im Zellkern aller Lebewesen (mit Ausnahme von manchen Viren) gefunden wird. Es enthält die genetische Information, die das Wachstum, die Entwicklung, den Stoffwechsel und die Funktion eines Organismus steuert.
"Fu" ist keine bekannte Abkürzung oder Akronym in der Genetik oder Molekularbiologie. Es ist möglich, dass es sich um einen Tippfehler oder ein Missverständnis handelt und Sie eigentlich "DNA-Fingerabdruck" meinten, was eine Technik zur Analyse eindeutiger DNA-Muster ist, die in jeder Person vorkommen.
Wenn Sie weitere Informationen benötigen oder wenn ich Ihnen bei etwas anderem helfen kann, zögern Sie bitte nicht, mich zu kontaktieren.
Eine "Consensus Sequence" ist ein Begriff aus der Genetik und Molekularbiologie, der sich auf die am häufigsten vorkommende Nukleotidsequenz in einer Gruppe von ähnlichen DNA- oder RNA-Molekülen bezieht. Dabei werden die einzelnen Positionen der Sequenz nach den jeweils meistvertretenen Basen (Adenin, Thymin, Guanin oder Cytosin) benannt. Der Begriff "Consensus" bedeutet hierbei "Übereinstimmung" oder "Einigkeit".
Die Consensus Sequence wird oft verwendet, um die gemeinsamen Merkmale von DNA- oder RNA-Molekülen zu identifizieren und zu beschreiben. Sie kann auch bei der Analyse von Genen und Proteinen hilfreich sein, um die Funktion eines bestimmten Bereichs in der Sequenz vorherzusagen oder um verschiedene Sequenzen miteinander zu vergleichen.
Es ist jedoch wichtig zu beachten, dass eine Consensus Sequence nicht unbedingt die tatsächliche Sequenz jedes einzelnen Moleküls in der Gruppe darstellt. Stattdessen gibt sie nur einen Überblick über die häufigsten Basen an jeder Position und kann daher etwas von den tatsächlichen Sequenzen abweichen.
Molekuläre Modelle sind in der Molekularbiologie, Biochemie und Pharmakologie übliche grafische Darstellungen von molekularen Strukturen, wie Proteinen, Nukleinsäuren (DNA und RNA) und kleineren Molekülen. Sie werden verwendet, um die räumliche Anordnung der Atome in einem Molekül zu veranschaulichen und zu verstehen, wie diese Struktur die Funktion des Moleküls bestimmt.
Es gibt verschiedene Arten von molekularen Modellen, abhängig von dem Grad an Details und der Art der Darstellung. Einige der gebräuchlichsten Arten sind:
1. Strukturformeln: Diese stellen die Bindungen zwischen den Atomen in einer chemischen Verbindung grafisch dar. Es gibt verschiedene Notationssysteme, wie z.B. die Skelettformel oder die Keilstrichformel.
2. Raumfill-Modelle: Hierbei werden die Atome als Kugeln und die Bindungen als Stäbchen dargestellt, wodurch ein dreidimensionales Bild der Molekülstruktur entsteht.
3. Kalottenmodelle: Bei diesen Modellen werden die Atome durch farbige Kugeln repräsentiert, die unterschiedliche Radien haben und so den Van-der-Waals-Radien der Atome entsprechen. Die Bindungen werden durch Stäbe dargestellt.
4. Strukturmodelle: Diese Modelle zeigen eine detailliertere Darstellung der Proteinstruktur, bei der die Seitenketten der Aminosäuren und andere strukturelle Merkmale sichtbar gemacht werden.
Molekulare Modelle können auf verschiedene Weise erstellt werden, z.B. durch Kristallstrukturanalyse, Kernresonanzspektroskopie (NMR) oder durch homologiebasiertes Modellieren. Die Verwendung von molekularen Modellen ist in der modernen Wissenschaft und Technik unverzichtbar geworden, insbesondere in den Bereichen Biochemie, Pharmazie und Materialwissenschaften.
In der Molekularbiologie und Genetik bezieht sich der Begriff "Reportergen" auf ein Gen, das dazu verwendet wird, die Aktivität eines anderen Gens oder einer genetischen Sequenz zu überwachen oder zu bestätigen. Ein Reportergen kodiert für ein Protein, das leicht nachweisbar ist und oft eine enzymatische Funktion besitzt, wie beispielsweise die Fähigkeit, Fluoreszenz oder Chemilumineszenz zu erzeugen.
Wenn ein Reportergen in die Nähe eines Zielgens eingefügt wird, kann die Aktivität des Zielgens durch die Beobachtung der Reportergen-Protein-Expression bestimmt werden. Wenn das Zielgen exprimiert wird, sollte auch das Reportergen exprimiert werden und ein nachweisbares Signal erzeugen. Durch Vergleich der Aktivität des Reportergens in verschiedenen Geweben, Entwicklungsstadien oder unter unterschiedlichen experimentellen Bedingungen kann die räumliche und zeitliche Expression des Zielgens ermittelt werden.
Reportergene sind nützlich für eine Vielzahl von Anwendungen, darunter die Untersuchung der Genregulation, die Identifizierung von regulatorischen Elementen in DNA-Sequenzen und die Überwachung des Gentransfers während gentherapeutischer Behandlungen.
Chromosomenkartierung ist ein Verfahren in der Genetik und Molekularbiologie, bei dem die Position von Genen oder anderen DNA-Sequenzen auf Chromosomen genau bestimmt wird. Dabei werden verschiedene molekularbiologische Techniken eingesetzt, wie beispielsweise die FISH (Fluoreszenz-in-situ-Hybridisierung) oder die Gelelektrophorese nach restrictionemfraktionierter DNA (RFLP).
Durch Chromosomenkartierung können genetische Merkmale und Krankheiten, die mit bestimmten Chromosomenabschnitten assoziiert sind, identifiziert werden. Diese Informationen sind von großer Bedeutung für die Erforschung von Vererbungsmechanismen und der Entwicklung gentherapeutischer Ansätze.
Die Chromosomenkartierung hat in den letzten Jahren durch die Fortschritte in der Genomsequenzierung und Bioinformatik an Präzision gewonnen, was zu einer detaillierteren Darstellung der genetischen Struktur von Organismen geführt hat.
In der Genetik und Molekularbiologie bezieht sich ein "Gen, Regulator" auf ein Gen, das die Expression anderer Gene kontrolliert, indem es deren Transkription oder Translation beeinflusst. Diese Art von Genen codieren normalerweise für Proteine, die als Transkriptionsfaktoren oder Repressoren bekannt sind und an bestimmte DNA-Sequenzen binden, um die Aktivität benachbarter Gene zu modulieren.
Regulatorische Gene spielen eine wichtige Rolle bei der Genregulation und tragen zur Vielfalt und Funktion von Zellen und Geweben bei. Dysfunktionelle regulatorische Gene können mit verschiedenen Krankheiten verbunden sein, einschließlich Krebs, Entwicklungsstörungen und neurologischen Erkrankungen. Daher ist das Verständnis der Funktionsweise regulatorischer Gene ein aktives Forschungsgebiet in der modernen Biomedizin.
Das CRADD-Signal-Adaptor-Protein, auch bekannt als CASP2 and RAIDD adaptor protein oder PRO1764, ist ein Protein, das an der Signaltransduktion von apoptotischen Signalen beteiligt ist. Es handelt sich um ein Adapterprotein, das die Bindung zwischen dem Caspase-2-Protein und dem RAIDD-Protein vermittelt, was zur Aktivierung des apoptotischen Signalwegs führt. Das CRADD-Protein enthält zwei Death-Domänen (DD) und eine Caspase-Recrutierungs-Domäne (CARD), die für die Interaktion mit anderen Proteinen im Zellsignalsystem wichtig sind. Mutationen in diesem Gen wurden mit angeborener Neuropathie und familiärer Glaukomassoziation in Verbindung gebracht.
Es scheint, dass "Edein" kein etablierter Begriff in der Medizin ist. Es gibt keine anerkannte oder allgemein verwendete medizinische Definition dafür. Möglicherweise gibt es Verwechslungen mit dem Begriff "Eosin", das ein rotes Farbstoffpräparat ist, das in der Histopathologie und Hämatologie häufig verwendet wird, um Gewebe oder Zellen zu färben. Wenn Sie nach Informationen über Eosin gesucht haben, bitte korrigieren Sie mich, damit ich Ihre Frage angemessen beantworten kann.
Oligonucleotide Sonden sind kurze, synthetisch hergestellte Einzelstrang-DNA-Moleküle, die aus einer Abfolge von bis zu 25-200 Nukleotiden bestehen. Sie werden in der Molekularbiologie und Genetik eingesetzt, um spezifische DNA- oder RNA-Sequenzen nachzuweisen oder zu sequenzieren. Die Basensequenz der Sonde ist so konzipiert, dass sie komplementär zu einem bestimmten Zielabschnitt auf der DNA oder RNA ist, was eine hohe Affinität und Spezifität ermöglicht. Durch die Verwendung fluoreszenzmarkierter Sonden können auch quantitative oder qualitative Analysen durchgeführt werden, wie beispielsweise bei der Real-Time PCR oder der Fluoreszenz-in-situ-Hybridisierung (FISH).
Erblichkeit bezieht sich in der Genetik auf die Übertragung von genetischen Merkmalen oder Krankheiten von Eltern auf ihre Nachkommen über die Vererbung von Genen. Sie beschreibt das Ausmaß, in dem ein bestimmtes Merkmal oder eine Erkrankung durch Unterschiede in den Genen beeinflusst wird.
Erblichkeit wird in der Regel als ein Wahrscheinlichkeitswert ausgedrückt und gibt an, wie hoch die Chance ist, dass ein Merkmal oder eine Krankheit auftritt, wenn man die Gene einer Person betrachtet. Eine Erblichkeit von 100% würde bedeuten, dass das Merkmal oder die Krankheit sicher vererbt wird, während eine Erblichkeit von 0% bedeutet, dass es nicht vererbt wird. In der Realität liegen die meisten Erblichkeitswerte irgendwo dazwischen.
Es ist wichtig zu beachten, dass Erblichkeit nur einen Teilaspekt der Entstehung von Merkmalen und Krankheiten darstellt. Umweltfaktoren und Wechselwirkungen zwischen Genen und Umwelt spielen oft ebenfalls eine Rolle bei der Entwicklung von Merkmalen und Krankheiten.
Apoptosomen sind Proteinkomplexe, die während des Prozesses der Apoptose, einer Form programmierter Zelltoten, gebildet werden. Die Apoptosomen setzen sich zusammen aus dem Protein Apaf-1 (Apoptotic Peptidase Activating Factor 1), cytoplasmatischem Cytochrom c und Procaspase-9. Wenn diese Komponenten interagieren, wird die Procaspase-9 aktiviert und bildet Caspase-9, welches wiederum andere Caspasen aktiviert, was schließlich zum Absterben der Zelle führt. Dieser Prozess ist ein wichtiger Bestandteil der normalen Entwicklung von Organismen sowie der Immunabwehr und trägt zur Beseitigung von geschädigten oder überflüssigen Zellen bei.
Der Eukaryote Initiationsfaktor 3 (eIF3) ist ein Proteinkomplex, der während des Prozesses der Proteinbiosynthese in Eukaryoten eine wichtige Rolle spielt. Genauer gesagt ist eIF3 an der initialen Phase der Translation beteiligt, bei der die mRNA mit dem 40S-kleinen Ribosom subunit verbunden wird, um einen initiation complex zu bilden. Dieser Komplex ist notwendig, um das richtige Startcodon für die Proteinsynthese zu identifizieren und zu binden.
eIF3 ist aus 13 Untereinheiten aufgebaut, die zusammenwirken, um ihre Funktion zu erfüllen. Diese Untereinheiten haben unterschiedliche Aufgaben und interagieren mit anderen Komponenten des Translationsapparats, wie beispielsweise dem 40S-Ribosomsubunit, anderen eIFs und der mRNA.
Mutationen in den Genen, die für die Untereinheiten von eIF3 codieren, können zu verschiedenen Krankheiten führen, wie beispielsweise Krebs oder neurologischen Erkrankungen. Daher ist es wichtig, die Funktion und Regulation von eIF3 besser zu verstehen, um mögliche Therapien für diese Krankheiten zu entwickeln.
Eukaryotische Zellen sind komplexe und organisierte Zellen, die bei Lebewesen vorkommen, die als Eukaryota zusammengefasst werden. Dazu gehören Tiere, Pflanzen, Pilze und Protisten. Diese Zellen zeichnen sich durch einige gemeinsame Merkmale aus:
1. Abgegrenzter Zellkern: Der eukaryotische Zellkern ist von einer doppelten Membran umgeben, die Nucleoplasma oder Karyoplasma genannt wird. Im Inneren des Kerns befindet sich das Chromatin, das aus DNA und Proteinen besteht.
2. Größere Größe: Im Vergleich zu prokaryotischen Zellen sind eukaryotische Zellen deutlich größer und können komplexere Strukturen aufweisen.
3. Membran-bound Organellen: Eukaryontische Zellen enthalten eine Vielzahl von membranumhüllten Organellen, wie Mitochondrien, Chloroplasten (bei Pflanzen), Endoplasmatisches Retikulum, Golgi-Apparat und Lysosomen. Diese Organellen haben spezifische Funktionen bei Stoffwechselprozessen, Energieproduktion, Proteinsynthese und -verarbeitung sowie Membrantransport.
4. Zellteilung durch Mitose: Eukaryoten vermehren sich durch die Mitose, eine komplexe Form der Zellteilung, bei der Chromosomen verdoppelt und gleichmäßig auf zwei Tochterzellen verteilt werden.
5. DNA im Zellkern: Die DNA in eukaryotischen Zellen ist linear organisiert und befindet sich im Zellkern, wohingegen prokaryotische Zellen eine ringförmige DNA haben, die frei im Cytoplasma vorliegt.
6. Extrachromosomale DNA: Einige eukaryotische Zellen enthalten extrachromosomale DNA in Form von Plasmiden oder Mitochondrien-DNA.
7. Größere Genome: Eukaryoten haben im Vergleich zu Prokaryoten deutlich größere Genome, die mehrere tausend Gene enthalten können.
"Gene Expression" bezieht sich auf den Prozess, durch den die Information in einem Gen in ein fertiges Produkt umgewandelt wird, wie z.B. ein Protein. Dieser Prozess umfasst die Transkription, bei der die DNA in mRNA (messenger RNA) umgeschrieben wird, und die Translation, bei der die mRNA in ein Protein übersetzt wird. Die Genexpression kann durch verschiedene Faktoren beeinflusst werden, wie z.B. Epigenetik, intrazelluläre Signalwege und Umwelteinflüsse, was zu Unterschieden in der Menge und Art der produzierten Proteine führt. Die Genexpression ist ein fundamentaler Aspekt der Genetik und der Biologie überhaupt, da sie darüber entscheidet, welche Gene in einer Zelle aktiv sind und welche Proteine gebildet werden, was wiederum bestimmt, wie die Zelle aussieht und funktioniert.
Aminosäuren sind organische Verbindungen, die sowohl eine Aminogruppe (-NH2) als auch eine Carboxylgruppe (-COOH) in ihrem Molekül enthalten. Es gibt 20 verschiedene proteinogene (aus Proteinen aufgebaute) Aminosäuren, die im menschlichen Körper vorkommen und für den Aufbau von Peptiden und Proteinen unerlässlich sind. Die Aminosäuren unterscheiden sich in ihrer Seitenkette (R-Gruppe), die für ihre jeweiligen Eigenschaften und Funktionen verantwortlich ist. Neun dieser Aminosäuren gelten als essentiell, was bedeutet, dass sie vom Körper nicht selbst hergestellt werden können und daher mit der Nahrung aufgenommen werden müssen.
Guanosintriphosphat (GTP) ist ein Nukleotid, das in biologischen Systemen vorkommt und eine wichtige Rolle als Energiequelle und Signalmolekül spielt. Es besteht aus der Nukleinbase Guanin, dem Zucker Ribose und drei Phosphatgruppen.
In der Zelle wird GTP durch Hydrolyse von Adenosintriphosphat (ATP) synthetisiert. Die Hydrolyse von GTP zu Guanosindiphosphat (GDP) und Phosphat liefert Energie für verschiedene zelluläre Prozesse, wie beispielsweise die Proteinbiosynthese, intrazellulären Transport und Signaltransduktionsprozesse.
Darüber hinaus ist GTP an der Regulation von Enzymaktivitäten beteiligt, indem es als Ligand für G-Proteine dient, die an verschiedenen Signalkaskaden beteiligt sind. Diese Proteine können durch Bindung von GTP aktiviert werden und nach Hydrolyse zu GDP in eine inaktive Form zurückkehren.
Aminosäuresubstitution bezieht sich auf den Prozess, bei dem ein anderes Aminosäurerestmolekül in einen Proteinstrukturstrang eingebaut wird, anstelle des ursprünglichen Aminosäurerests an einer bestimmten Position. Dies tritt auf, wenn es eine genetische Variante oder Mutation gibt, die dazu führt, dass ein anderes Aminosäure codiert wird, was zu einer Veränderung der Aminosäurensequenz im Protein führt. Die Fähigkeit eines Proteins, seine Funktion aufrechtzuerhalten, nachdem eine Aminosäuresubstitution stattgefunden hat, hängt von der Art und Position der substituierten Aminosäure ab. Manche Substitutionen können die Proteinstruktur und -funktion beeinträchtigen oder sogar zerstören, während andere möglicherweise keine Auswirkungen haben.
Es gibt keine medizinische Definition für "Chromosomen, Bakterien-", da Bakterien keine Chromosomen im gleichen Sinne wie eukaryotische Zellen haben. Stattdessen besitzen Bakterien ein einzelnes ringförmiges DNA-Molekül, das als Bakterienchromosom bezeichnet wird und die genetische Information der Bakterienzelle encodiert.
Eine mögliche Definition könnte also lauten:
Bakterienchromosom: Ein einzelnes, ringförmiges DNA-Molekül in Bakterienzellen, das die genetische Information der Zelle encodiert und funktionell einem Chromosom ähnelt, obwohl es sich in Struktur und Replikation von eukaryotischen Chromosomen unterscheidet.
Polyacrylamidgel-Elektrophorese (PAGE) ist ein Laborverfahren in der Molekularbiologie und Biochemie, das zur Trennung von Makromolekülen wie Proteinen oder Nukleinsäuren (DNA, RNA) verwendet wird. Dabei werden die Makromoleküle aufgrund ihrer Ladung und Größe in einem Gel-Elektrophorese-Lauf separiert.
Bei der Polyacrylamidgel-Elektrophorese wird das Gel aus Polyacrylamid hergestellt, ein synthetisches Polymer, das in Lösung viskos ist und sich durch die Zugabe von Chemikalien wie Ammoniumpersulfat und TEMED polymerisieren lässt. Die Konzentration des Polyacrylamids im Gel bestimmt die Porengröße und damit die Trennschärfe der Elektrophorese. Je höher die Konzentration, desto kleiner die Poren und desto besser die Trennung von kleinen Molekülen.
Die Proben werden in eine Gelmatrix eingebracht und einem elektrischen Feld ausgesetzt, wodurch die negativ geladenen Makromoleküle zur Anode migrieren. Die Trennung erfolgt aufgrund der unterschiedlichen Mobilität der Moleküle im Gel, die von ihrer Größe, Form und Ladung abhängt. Proteine können durch den Zusatz von SDS (Sodiumdodecylsulfat), einem Detergent, denaturiert und in eine lineare Konformation gebracht werden, wodurch sie nur noch nach ihrer Molekülmasse getrennt werden.
Die Polyacrylamidgel-Elektrophorese ist ein sensitives und hochauflösendes Verfahren, das in vielen Bereichen der Biowissenschaften eingesetzt wird, wie beispielsweise in der Proteomik oder Genomik. Nach der Elektrophorese können die getrennten Moleküle durch verschiedene Methoden nachgewiesen und identifiziert werden, wie zum Beispiel durch Färbung, Fluoreszenzmarkierung oder Massenspektrometrie.
Methylmethacrylat (MMA) ist ein flüssiger, farbloser und entzündbarer organischer Verbindung, die in der Medizin als Bestandteil von Knochenzement (auch bekannt als Acryl- oder Methylmethacrylat-Zement) verwendet wird. Dieser Zement wird oft bei orthopädischen Eingriffen eingesetzt, wie zum Beispiel bei der Verankerung von Endoprothesen im Hüft- oder Kniegelenk.
MMA-Zement besteht aus einer Mischung aus Pulver und Flüssigkeit, wobei das Pulver hauptsächlich Polymethylmethacrylat (PMMA) ist und die Flüssigkeit Methylmethacrylat-Monomer. Sobald diese beiden Komponenten gemischt werden, beginnt eine Exotherme Reaktion, bei der sich das Pulver polymerisiert und erhärtet, wodurch ein festes Material entsteht, das zur Fixierung von Prothesen oder zum Füllen von Knochendefekten verwendet werden kann.
Es ist jedoch zu beachten, dass MMA-Zement bei der Herstellung und Anwendung die Freisetzung von Dämpfen verursachen kann, die für das medizinische Personal und den Patienten schädlich sein können. Daher sind geeignete Schutzmaßnahmen erforderlich, um die Exposition gegenüber diesen Dämpfen zu minimieren.
Methylmethacrylate (MMA) ist ein flüssiger, farbloser und entzündbarer Kunststoff, der in der Medizin häufig als Bestandteil von Knochenzementen verwendet wird. In dieser Form dient es als Klebstoff zur Befestigung von orthopädischen Implantaten wie Hüft- oder Kniegelenken. Es kann auch in der Zahnmedizin als Füllmaterial für Zahndefekte eingesetzt werden. MMA ist ein Lösungsmittel und wird im Kunststoffbereich häufig verwendet, hat in der Medizin aber nur begrenzte Anwendungsgebiete aufgrund von potenziellen toxischen Wirkungen.
Bovines Papillomavirus 1 (BPV-1) ist ein spezifisches tierisches Papillomavirus, das hauptsächlich Rinder infiziert. Es ist bekannt dafür, verschiedene Arten von gutartigen Haut- und Schleimhautwucherungen oder Warzen zu verursachen, die als Papillome bezeichnet werden. Diese Infektionen treten vor allem in den Genitalien und dem Maul der Tiere auf. Obwohl BPV-1 hauptsächlich bei Rindern vorkommt, kann es unter Laborbedingungen auch andere Spezies infizieren, einschließlich Mäuse und Hamster. Es ist eng mit humanen Papillomaviren (HPV) verwandt, die eine Rolle bei der Entstehung von Krebs beim Menschen spielen, aber BPV-1 selbst gilt nicht als krebsauslösend für den Menschen.
In der Medizin und Biochemie werden Amidine (oder auch Imidamide) als funktionelle Gruppen in Molekülen betrachtet. Strukturell sind Amidine Derivate von Ammoniak, bei denen zwei Wasserstoffatome durch organische oder anorganische Substituenten ersetzt wurden.
Die allgemeine Formel für Amidine lautet R1R2C=N-R3, wobei R1 und R2 organische oder anorganische Substituenten sind (wie Alkyl-, Aryl- oder Heteroarylgruppen), während R3 ein weiterer organischer Rest oder ein Wasserstoffatom sein kann.
Amidine haben beachtliche Bedeutung in der Pharmazie und Medizin, da sie in verschiedenen pharmakologisch aktiven Verbindungen vorkommen. Zum Beispiel sind Amidine Bestandteil von Hydroxylierungsinhibitoren, Proteinkinase-Inhibitoren, sowie Hemmstoffen der Histon-Deacetylasen (HDACs). Diese Enzyme sind an zellulären Prozessen wie Zellwachstum, Differenzierung und Apoptose beteiligt. Da Fehlfunktionen dieser Prozesse mit verschiedenen Krankheiten in Verbindung gebracht werden (wie Krebs, neurodegenerative Erkrankungen und Entzündungen), stellen Amidine vielversprechende Leitstrukturen für die Arzneimittelentwicklung dar.
"Fungal Genes" bezieht sich auf die Gesamtheit der Nukleotidsequenzen in einem Pilzgenom, die für die Herstellung von Proteinen oder funktionellen RNA-Molekülen kodieren. Diese Gene sind Teil der Erbinformation des Pilzes und spielen eine wichtige Rolle bei verschiedenen zellulären Prozessen wie Stoffwechsel, Replikation, Transkription, Übersetzung und Regulation. Fungal Gene können auch für die Produktion von sekundären Metaboliten verantwortlich sein, die als Virulenzfaktoren oder Antibiotika wirken können. Die Untersuchung von Fungal Genen kann zur Entdeckung neuer Enzyme und Stoffwechselwege führen, was für biotechnologische Anwendungen nützlich sein kann.
9,10-Dimethyl-1,2-Benzanthracen ist ein synthetischer aromatischer Kohlenwasserstoff und ein polycyclischer aromatischer Kohlenwasserstoff (PAK), der in der Chemie und Toxikologie für Forschungszwecke verwendet wird. Er besteht aus einem Benzanthracen-Gerüst, das durch Methylierung an den Positionen 9 und 10 modifiziert ist.
In der Medizin und Toxikologie wird 9,10-Dimethyl-1,2-Benzanthracen hauptsächlich als Modellsubstanz für die Erforschung von Karzinogenese (Krebsentstehung) und Mutagenese (Veränderungen der Erbinformation) eingesetzt. Es ist ein starkes Kanzerogen und kann bei Tieren verschiedene Krebsarten hervorrufen, insbesondere Hautkrebs. Aufgrund seiner krebserzeugenden Eigenschaften wird es in der Humanmedizin nicht angewendet.
Nucleotide sind die grundlegenden Bausteine der Nukleinsäuren DNA und RNA. Ein Nukleotid besteht aus einer Phosphatgruppe, einem Zucker (Desoxyribose im DNA-Molekül oder Ribose im RNA-Molekül) und einer Nukleobase. Die Nukleobasen können Purine (Adenin und Guanin) oder Pyrimidine (Thymin, Uracil und Cytosin) sein. In DNA sind die Nukleotide durch Phosphodiesterbindungen miteinander verbunden, wobei sich die Phosphatgruppe des einen Nukleotids mit der Desoxyribose des nächsten verbindet. Diese Kette von Nukleotiden bildet die DNA-Doppelhelix. In RNA ist Uracil anstelle von Thymin vorhanden, und die Desoxyribose wird durch Ribose ersetzt. Nucleotide haben auch andere biologische Funktionen, wie z.B. als Energieträger (Adenosintriphosphat, ATP) oder als Signalmoleküle (z.B. cyclisches Adenosinmonophosphat, cAMP).
Mitochondrien sind komplexe, doppelmembranumschlossene Zellorganellen in eukaryotischen Zellen (außer roten Blutkörperchen), die für die Energiegewinnung der Zelle durch oxidative Phosphorylierung und die Synthese von Adenosintriphosphat (ATP) verantwortlich sind, dem Hauptenergieträger der Zelle. Sie werden oft als "Kraftwerke" der Zelle bezeichnet.
Mitochondrien haben ihre eigene DNA und ribosomale RNA, die sich von der DNA im Zellkern unterscheidet, was darauf hindeutet, dass sie ursprünglich prokaryotische Organismen waren, die in eine symbiotische Beziehung mit frühen eukaryotischen Zellen traten. Diese Beziehung entwickelte sich im Laufe der Evolution zu einem integrierten Bestandteil der Zelle.
Neben ihrer Rolle bei der Energieerzeugung sind Mitochondrien auch an anderen zellulären Prozessen beteiligt, wie z. B. dem Calcium-Haushalt, der Kontrolle des Zellwachstums und -tods (Apoptose), der Synthese von Häm und Steroidhormonen sowie der Abbau bestimmter Aminosäuren und Fettsäuren. Mitochondriale Dysfunktionen wurden mit einer Reihe von Krankheiten in Verbindung gebracht, darunter neurodegenerative Erkrankungen, Diabetes, Krebs und Alterungsprozesse.
Ribosomal Frameshifting ist ein Prozess während der Proteinsynthese, bei dem das Ribosom seine Position auf der mRNA (Messenger-RNA) verschiebt, um ein alternatives Leseraster zu lesen und somit eine andere Aminosäuresequenz in das entstehende Protein zu integrieren.
Es gibt zwei Arten von Ribosomal Frameshifting: +1 Frameshifting und -1 Frameshifting, die sich auf die Verschiebung der Leserasterposition beziehen. Dieser Prozess ermöglicht es den Organismen, genetische Informationen effizient zu komprimieren und erweiterte Genfunktionen ohne Erhöhung des Genomkomplexitätsgrades bereitzustellen.
Ribosomal Frameshifting spielt eine wichtige Rolle bei der Expression bestimmter Gene, insbesondere bei Retroviren wie HIV (Humanes Immunschwächevirus), wo es die Replikation des Virusgenoms unterstützt. Es ist ein hochregulierter und kontrollierter Prozess, der Fehler während der Proteinsynthese verursachen kann, wenn er gestört wird, was zu vorzeitigen Terminierungen oder fehlerhaften Proteinen führen kann.
In der Molekularbiologie bezieht sich "Dimerisierung" auf den Prozess, bei dem zwei identische oder sehr ähnliche Proteine durch nicht-kovalente Wechselwirkungen (wie Wasserstoffbrücken, Van-der-Waals-Kräfte oder elektrostatische Anziehung) oder kovalente Bindungen (wie Disulfidbrücken) miteinander verbunden werden, um ein komplexes Quaternäres Proteinstruktur zu bilden, das als Dimere bezeichnet wird. Diese Interaktion kann spontan auftreten oder durch bestimmte Bedingungen wie pH-Wert, Temperatur oder die Anwesenheit von Kofaktoren gefördert werden. Die Dimerisierung spielt eine wichtige Rolle in der Proteinfunktion, einschließlich Signaltransduktion, Genregulation und Enzymaktivität.
Eine DNA-Virus-Definition wäre:
DNA-Viren sind Viren, die DNA (Desoxyribonukleinsäure) als genetisches Material enthalten. Dieses genetische Material kann entweder als einzelsträngige oder doppelsträngige DNA vorliegen. Die DNA-Viren replizieren sich in der Regel durch Einbau ihrer DNA in das Genom des Wirts, wo sie von der Wirtszellmaschinerie translatiert und transkribiert wird, um neue Virionen zu produzieren.
Beispiele für DNA-Viren sind Herpesviren, Adenoviren, Papillomaviren und Pockenviren. Einige DNA-Viren können auch Krebs verursachen oder zum Auftreten von Krebserkrankungen beitragen. Daher ist es wichtig, sich vor diesen Viren zu schützen und entsprechende Impfstoffe und Behandlungen zu entwickeln.
In Molekularbiologie und Genetik bezieht sich "Base Pairing" auf die spezifische Paarung von komplementären Basen in DNA- (Desoxyribonukleinsäure) und RNA- (Ribonukleinsäure) Molekülen, die für die Synthese dieser Nukleinsäuren verantwortlich ist. Insbesondere bilden sich Wasserstoffbrückenbindungen zwischen den Basen Adenin (A) und Thymin (T)/Uracil (U) sowie zwischen Guanin (G) und Cytosin (C). Diese Paarung ist kritisch für die Replikation, Reparatur und Transkription von Genomsequenzen. Im Doppelstrang der DNA sind Adenin und Thymin bzw. Uracil in der RNA über zwei Wasserstoffbrückenbindungen verbunden, während Guanin und Cytosin über drei Wasserstoffbrückenbindungen miteinander verbunden sind. Diese Basenpaarung ist auch von Bedeutung bei der Proteinsynthese, da die Basensequenz in DNA und RNA die Aminosäuresequenz eines Proteins bestimmt.
Kaliumpermanganat ist ein chemisches Komposit mit der Formel K permit(MnO4). In der Medizin wird es hauptsächlich als Antiseptikum und Adstringens verwendet, um Infektionen und Entzündungen zu behandeln. Es hat stark oxidierende Eigenschaften und kann Mikroorganismen abtöten, die die Ursache für viele Infektionskrankheiten sind.
Kaliumpermanganat wird auch in der Dermatologie zur Behandlung von Hauterkrankungen wie Ekzemen, Psoriasis und Dermatitis eingesetzt. Es kann auch bei der Behandlung von Pilzinfektionen und Insektenstichen hilfreich sein.
In Lösung wird Kaliumpermanganat oft als blaßlila Farbe wahrgenommen, die im Kontakt mit organischem Material (wie Haut oder Schleimhäuten) eine bräunliche Verfärbung annimmt. Es ist wichtig zu beachten, dass Kaliumpermanganat bei unsachgemäßer Anwendung Reizungen der Haut und Schleimhäute verursachen kann. Daher sollte es immer in der richtigen Konzentration und unter Aufsicht eines Arztes oder Apothekers angewendet werden.
Recombinante DNA bezieht sich auf ein Stück genetischen Materials (d.h. DNA), das durch Labortechniken manipuliert wurde, um mindestens zwei verschiedene Quellen zu kombinieren und so eine neue, hybridisierte DNA-Sequenz zu schaffen. Diese Technologie ermöglicht es Wissenschaftlern, gezielt Gene oder Genabschnitte aus verschiedenen Organismen zu isolieren, zu vervielfältigen und in andere Organismen einzuführen, um deren Eigenschaften oder Funktionen zu verändern.
Die Entwicklung von rekombinanter DNA-Technologie hat die Grundlagenforschung und angewandte Biowissenschaften wie Gentechnik, Gentherapie, Impfstoffentwicklung und biotechnologische Produktion revolutioniert. Es ist wichtig zu beachten, dass die Erstellung und Verwendung von rekombinanter DNA streng reguliert wird, um potenzielle Biosicherheits- und Ethikrisiken zu minimieren.
Methacrylate sind eine Gruppe von chemischen Verbindungen, die zu den Esteren der Methacrylsäure gehören. Es handelt sich dabei um wichtige Monomere in der Synthese verschiedener Kunststoffe und Harze. In der Medizin werden Methacrylate vor allem in Zahnersatzmaterialien, Knochenzementen und Hautklebern eingesetzt. Ein bekanntes Beispiel ist Methylmethacrylat (MMA), das als Acrylglas oder Plexiglas gehandelt wird. Es kann allergische Reaktionen hervorrufen und steht im Verdacht, krebserregend zu sein. Deshalb wird es in einigen Anwendungen durch weniger bedenkliche Methacrylate ersetzt.
Northern blotting ist eine Laboruntersuchungsmethode in der Molekularbiologie, die verwendet wird, um spezifische Nukleinsäuren (DNA oder RNA) in einer Probe zu identifizieren und quantifizieren.
Die Methode beinhaltet die Elektrophorese von Nukleinsäureproben in einem Agarose-Gel, um die Nukleinsäuren nach ihrer Größe zu trennen. Die Nukleinsäuren werden dann auf eine Nitrozellulose- oder PVDF-Membran übertragen (d. h. 'geblottert') und mit einer radioaktiv markierten DNA-Sonde inkubiert, die komplementär zur gesuchten Nukleinsäuresequenz ist.
Durch Autoradiographie oder durch Verwendung von Chemilumineszenz-Sonden kann die Lage und Intensität der Bindung zwischen der Sonde und der Ziel-Nukleinsäure auf der Membran bestimmt werden, was Rückschlüsse auf die Größe und Menge der gesuchten Nukleinsäure in der ursprünglichen Probe zulässt.
Northern blotting ist eine empfindliche und spezifische Methode zur Analyse von Nukleinsäuren, insbesondere für die Untersuchung von RNA-Expression und -Regulation in Zellen und Geweben.
p53 ist ein Protein, das im menschlichen Körper als Tumorsuppressor wirkt und eine wichtige Rolle bei der Zellteilungskontrolle spielt. Es hilft dabei, das Wachstum von Zellen mit Schäden an der DNA zu verhindern oder diese Zellen sogar zur Selbstzerstörung (Apoptose) zu bringen. Auf diese Weise verringert p53 das Risiko, dass die geschädigten Zellen sich unkontrolliert teilen und sich zu Tumoren entwickeln.
Die Genexpression von p53 wird durch verschiedene Faktoren reguliert, darunter seine eigene Phosphorylierung, Acetylierung und Ubiquitinierung. Wenn die DNA geschädigt ist, wird p53 aktiviert, indem es durch Kinase-Enzyme phosphoryliert wird, wodurch seine Funktion als Transkriptionsfaktor verstärkt wird. Dadurch kann p53 die Expression von Genen fördern, die das Zellzyklus-Arrest oder die Apoptose induzieren, was letztendlich zur Reparatur der DNA-Schäden führt oder zum Absterben der geschädigten Zellen.
Mutationen im p53-Gen können dazu führen, dass das Protein seine Funktion verliert und somit die Tumorentstehung fördern. Daher wird p53 oft als "Wächter des Genoms" bezeichnet, da es hilft, die Integrität der DNA aufrechtzuerhalten und Krebsentwicklungen vorzubeugen.
Es gibt keine allgemein anerkannte oder offizielle medizinische Definition des Begriffs 'Nanovirus'. Tatsächlich ist dieser Begriff in der Virologie und Medizin nicht etabliert oder anerkannt. Im Allgemeinen bezieht sich 'Nano' auf eine Größenordnung von 10^-9, was einem Billionstel eines Meters entspricht. In der Wissenschaft werden Nanopartikel als Partikel definiert, die kleiner als 100 Nanometer sind.
Es gibt jedoch einige Viren, die sehr klein sind und Größen im Nanobereich aufweisen, wie zum Beispiel das Satellitenvirus G (SV40), das nur etwa 52 Nanometer groß ist. Diese Viren werden jedoch nicht als 'Nanoviren' bezeichnet.
Daher sollten Sie vorsichtig sein, wenn Sie den Begriff 'Nanovirus' in einem medizinischen oder wissenschaftlichen Kontext antreffen, da er möglicherweise nicht offiziell anerkannt ist und Verwirrung stiften kann.
Ein einzelsträngige DNA (ssDNA) ist eine Form der Desoxyribonukleinsäure, die nur aus einer einzigen Polynukleotidkette besteht, die aus Desoxyribonukleotiden aufgebaut ist. Jedes Nukleotid enthält einen Phosphatrest, einen Zucker (Desoxyribose) und eine von vier Nukleobasen: Adenin, Thymin, Guanin oder Cytosin. In der einzelsträngigen DNA sind die Basen durch Wasserstoffbrückenbindungen miteinander verbunden, wobei Adenin mit Thymin und Guanin mit Cytosin paart. Im Gegensatz dazu besteht doppelsträngige DNA (dsDNA) aus zwei komplementären Strängen, die sich in entgegengesetzter Richtung, oder Antiparallelität, zueinander ausrichten und durch Wasserstoffbrückenbindungen zusammengehalten werden.
Einzelsträngige DNA kann während der Replikation, Reparatur und Transkription von Genen auftreten. Während der Replikation wird die doppelsträngige DNA temporär in zwei einzelsträngige DNA-Moleküle aufgetrennt, die dann als Matrizen für die Synthese neuer komplementärer Stränge dienen. Bei der Transkription wird auch ein Teil des doppelsträngigen DNA-Moleküls in eine einzelsträngige RNA transkribiert, die dann aus dem Zellkern exportiert und übersetzt wird, um Proteine zu synthetisieren. Einzelsträngige DNA kann auch während der Reparatur von DNA-Schäden auftreten, wenn beispielsweise ein Strang einer doppelsträngigen DNA beschädigt oder gebrochen ist und entfernt werden muss, um ihn durch einen neuen, intakten Strang zu ersetzen.
Enzyme Activation bezieht sich auf den Prozess, durch den ein Enzym seine katalytische Funktion aktiviert, um eine biochemische Reaktion zu beschleunigen. Dies wird in der Regel durch die Bindung eines spezifischen Moleküls, das als Aktivator oder Coenzym bezeichnet wird, an das Enzym hervorgerufen. Diese Bindung führt zu einer Konformationsänderung des Enzyms, wodurch seine aktive Site zugänglich und in der Lage wird, sein Substrat zu binden und die Reaktion zu katalysieren. Es ist wichtig zu beachten, dass es auch andere Mechanismen der Enzymaktivierung gibt, wie zum Beispiel die proteolytische Spaltung oder die Entfernung von Inhibitoren. Die Aktivierung von Enzymen ist ein essentieller Prozess in lebenden Organismen, da sie die Geschwindigkeit metabolischer Reaktionen regulieren und so das Überleben und Wachstum der Zellen gewährleisten.
Nucleinsäurehybridisierung ist ein Prozess in der Molekularbiologie, bei dem zwei einzelsträngige Nukleinsäuren (entweder DNA oder RNA) miteinander unter Verwendung von Wasserstoffbrückenbindungen paaren, um eine Doppelhelix zu bilden. Dies geschieht üblicherweise unter kontrollierten Bedingungen in Bezug auf Temperatur, pH-Wert und Salzkonzentration. Die beiden Nukleinsäuren können aus demselben Organismus oder aus verschiedenen Quellen stammen.
Die Hybridisierung wird oft verwendet, um die Anwesenheit einer bestimmten Sequenz in einem komplexen Gemisch von Nukleinsäuren nachzuweisen, wie zum Beispiel bei Southern Blotting, Northern Blotting oder In-situ-Hybridisierung. Die Technik kann auch verwendet werden, um die Art und Weise zu bestimmen, in der DNA-Sequenzen organisiert sind, wie zum Beispiel bei Chromosomen-In-situ-Hybridisierung (CISH) oder Genom-weiter Hybridisierung (GWH).
Die Spezifität der Hybridisierung hängt von der Länge und Sequenz der komplementären Bereiche ab. Je länger und spezifischer die komplementäre Sequenz ist, desto stärker ist die Bindung zwischen den beiden Strängen. Die Stabilität der gebildeten Hybride kann durch Messung des Schmelzpunkts (Tm) bestimmt werden, bei dem die Doppelstrangbindung aufgebrochen wird.
Genetic Variation bezieht sich auf die Unterschiede in der DNA-Sequenz oder der Anzahl der Kopien bestimmter Gene zwischen verschiedenen Individuen derselben Art. Diese Variationen entstehen durch Mutationen, Gen-Kreuzungen und Rekombination während der sexuellen Fortpflanzung.
Es gibt drei Hauptarten von genetischen Variationen:
1. Einzelnukleotidische Polymorphismen (SNPs): Dies sind die häufigsten Formen der genetischen Variation, bei denen ein einzelner Nukleotid (DNA-Baustein) in der DNA-Sequenz eines Individuums von dem eines anderen Individuums abweicht.
2. Insertionen/Deletionen (INDELs): Hierbei handelt es sich um kleine Abschnitte der DNA, die bei einigen Individuen vorhanden sind und bei anderen fehlen.
3. Kopienzahlvariationen (CNVs): Bei diesen Variationen liegt eine Abweichung in der Anzahl der Kopien bestimmter Gene oder Segmente der DNA vor.
Genetische Variationen können natürliche Unterschiede zwischen Individuen erklären, wie zum Beispiel die verschiedenen Reaktionen auf Medikamente oder das unterschiedliche Risiko für bestimmte Krankheiten. Einige genetische Variationen sind neutral und haben keinen Einfluss auf die Funktion des Organismus, während andere mit bestimmten Merkmalen oder Erkrankungen assoziiert sein können.
Beta-Galactosidase ist ein Enzym, das die Hydrolyse von Terminalnonreduzierenden Beta-Galactose aus Galactosiden in ihre Bestandteile, Glukose und Galaktose, katalysiert. Es ist in vielen Organismen weit verbreitet, einschließlich Bakterien, Hefen und Tieren. Insbesondere bei E. coli-Bakterien wird Beta-Galactosidase als Marker für die Expression von Klonierungsvektoren verwendet, um das Vorhandensein eines funktionellen Gens zu überprüfen. Mutationen in diesem Gen können mit verschiedenen Stoffwechselstörungen wie Morbus Gaucher und Morbus Fabry assoziiert sein.
Hauttumoren sind Wucherungen oder Geschwülste der Haut, die durch unkontrollierte Zellteilung entstehen. Dabei können bösartige und gutartige Tumoren unterschieden werden. Bösartige Hauttumoren, auch als Hautkrebs bezeichnet, sind in der Lage, sich in umliegendes Gewebe auszubreiten und Metastasen zu bilden. Zu den häufigsten Arten von Hautkrebs zählen das Basalzellkarzinom, das Plattenepithelkarzinom und das malignes Melanom.
Gutartige Hauttumoren hingegen wachsen langsam und sind in der Regel lokal begrenzt. Sie stellen in der Regel keine Gefahr für die Gesundheit dar, können aber kosmetisch störend sein oder zu Beschwerden führen, wenn sie Reibung oder Druck ausgesetzt sind. Beispiele für gutartige Hauttumoren sind Naevus (Muttermal), Fibrome (Weichteilgeschwulst) und Lipome (Fettgewebsgeschwulst).
Es ist wichtig, Veränderungen der Haut ernst zu nehmen und regelmäßige Hautuntersuchungen durchzuführen, um Hauttumoren frühzeitig zu erkennen und behandeln zu können.
Eine Suppressor-Genmutation ist eine Art von Genveränderung, die die Fähigkeit einer Zelle hat, die genetische Information zu lesen und in ein Protein zu übersetzen, beeinträchtigt. Im Gegensatz zu "Loss-of-function"-Mutationen, die die Funktion eines Gens vollständig abschalten, können Suppressor-Mutationen die Funktion eines Gens teilweise wiederherstellen oder modifizieren.
In Bezug auf Krebs kann eine Suppressor-Genmutation dazu führen, dass ein Tumorsuppressorgen, das normalerweise das Wachstum und die Teilung von Zellen kontrolliert, seine Funktion verliert oder verändert. Dies kann dazu führen, dass Zellen unkontrolliert wachsen und sich teilen, was zu Krebs führen kann.
Ein Beispiel für ein Tumorsuppressorgen ist das p53-Gen. Wenn dieses Gen mutiert ist, verliert es seine Fähigkeit, Zellwachstum und -teilung zu kontrollieren, was zu Krebs führen kann. Es gibt jedoch auch Suppressor-Mutationen, die die Funktion von p53 wiederherstellen oder modifizieren können, wodurch das Risiko für Krebs verringert wird.
Insgesamt sind Suppressor-Genmutationen ein komplexes und vielschichtiges Thema in der Genetik und Onkologie, und die Forschung in diesem Bereich ist immer noch im Gange.
Gene Expression Regulation, Viral bezieht sich auf die Prozesse, durch die das Virus die Genexpression in der Wirtszelle kontrolliert und manipuliert. Dies ist ein wesentlicher Bestandteil des viralen Infektionszyklus, bei dem das Virus seine eigenen Gene exprimiert und die Proteine synthetisiert, die für die Vermehrung des Virus erforderlich sind.
Virale Genexpression wird in der Regel durch die Interaktion von viralen Proteinen mit verschiedenen Komponenten des zellulären Transkriptions- und Übersetzungsapparats reguliert. Einige Viren codieren für eigene Enzyme, wie beispielsweise eine reverse Transkriptase oder RNA-Polymerase, um ihre eigenen Gene zu transkribieren und zu replizieren. Andere Viren nutzen die zellulären Maschinerien zur Genexpression und manipulieren diese, um ihre eigenen Gene vorrangig zu exprimieren.
Die Regulation der viralen Genexpression ist ein komplexer Prozess, der durch verschiedene Mechanismen wie epigenetische Modifikationen, alternative Splicing-Muster, Transkriptionsfaktoren und MikroRNAs kontrolliert wird. Die Feinabstimmung der viralen Genexpression ist entscheidend für die erfolgreiche Replikation des Virus und seine Interaktion mit dem Wirt.
Eine gestörte Regulation der viralen Genexpression kann zu verschiedenen Krankheitszuständen führen, wie z.B. Krebs oder Autoimmunerkrankungen. Daher ist das Verständnis der Mechanismen der viralen Genexpression-Regulation ein wichtiger Forschungsbereich in der Virologie und Infektionsbiologie.
Caspase 6 ist ein proteolytisches Enzym, das zur Familie der Caspasen gehört und eine wichtige Rolle bei der Apoptose (programmierter Zelltod) spielt. Es wird als Effektor-Caspase bezeichnet und ist an der Ausführung des apoptotischen Programms beteiligt, indem es essentielle Proteine in der Zelle zerschneidet und so den Prozess der Selbstzerstörung der Zelle einleitet. Caspase 6 wird durch Initiator-Caspasen aktiviert, wie zum Beispiel Caspase 8 oder Caspase 9, die während der Apoptose aktiviert werden. Die Aktivierung von Caspase 6 führt zur Zerstörung von Kernstrukturen und zum Abbau des Zellgerüsts, was schließlich zum Zelltod führt.
Alternatives Spleißen ist ein Prozess in der Genexpression, bei dem verschiedene mRNA-Moleküle aus demselben primary transcript durch die Wahl unterschiedlicher Spleißstellen hergestellt werden können. Dies führt zu einer Erweiterung der Proteinvielfalt, da verschiedene Proteine aus einem einzigen Gens kann exprimiert werden. Es wird geschätzt, dass über 95% der menschlichen Multiexon-Gene alternativ gespleißte Transkripte erzeugen können. Obwohl alternatives Spleißen ein normaler und wichtiger Bestandteil der Genexpression ist, kann es auch mit verschiedenen Krankheiten assoziiert sein, einschließlich Krebs und neurologischen Erkrankungen.
Chloramphenicol-O-Acetyltransferase ist ein Enzym, das durch bestimmte Bakterien und auch in manchen höheren Organismen wie Insekten und Pilzen gefunden wird. Dieses Enzym ist in der Lage, das Antibiotikum Chloramphenicol zu inaktivieren, indem es Acetylgruppen an das Chloramphenicol bindet und so seine Fähigkeit blockiert, an die bakterielle Ribosomal-RNA zu binden und die Proteinsynthese zu hemmen. Die Entstehung von Bakterienstämmen, die dieses Enzym produzieren, kann zu Resistenzen gegen Chloramphenicol führen und ist daher ein klinisch relevantes Problem bei der Behandlung von bakteriellen Infektionen mit diesem Antibiotikum.
Methionyl Aminopeptidases (MAPs) sind Enzyme, die an der posttranslationalen Modifikation von Proteinen beteiligt sind. Genauer gesagt, entfernen sie das initial am N-terminalen Ende des Polypeptids gebundene Methionin-Residuum, sofern dieses nicht Teil der funktionellen Domäne des Proteins ist.
Dieser Prozess wird als Amino-terminale Methionin-Exoprotease-Aktivität bezeichnet und trägt zur korrekten Faltung und Funktionalität der neu synthetisierten Proteine bei. Es sind zwei Isoformen des Enzyms bekannt, MAP-1 und MAP-2, die sich in ihrer Lokalisation und Substratspezifität unterscheiden.
MAP-1 ist membranassoziiert und findet sich hauptsächlich im endoplasmatischen Retikulum (ER), während MAP-2 zytosolisch lokalisiert ist. Beide Enzyme spielen eine wichtige Rolle in der Proteinbiosynthese und sind konserviert von Prokaryoten bis Eukaryoten.
Es gibt keine medizinische Definition für "Kaninchen". Der Begriff Kaninchen bezieht sich auf ein kleines, pflanzenfressendes Säugetier, das zur Familie der Leporidae gehört. Medizinisch gesehen, spielt die Interaktion mit Kaninchen als Haustiere oder Laboratoriumstiere in der Regel eine Rolle in der Veterinärmedizin oder in bestimmten medizinischen Forschungen, aber das Tier selbst ist nicht Gegenstand einer medizinischen Definition.
Mutagenese durch Insertion ist ein Prozess, der zu einer Veränderung im Erbgut führt, indem mindestens eine zusätzliche Nukleotidsequenz in das Genom eingefügt wird. Diese Einfügungen können spontan oder induziert auftreten und können durch verschiedene Faktoren wie Chemikalien, Strahlung oder Viren verursacht werden.
Die Insertion von zusätzlicher Nukleotidsequenz in das Genom kann zu einer Verschiebung der Leserahmenfolge (Frameshift) führen, was wiederum zu einem vorzeitigen Stopp-Codon und zu einer verkürzten, veränderten oder nichtfunktionalen Proteinsynthese führt. Diese Art von Mutationen kann mit genetischen Erkrankungen oder Krebs in Verbindung gebracht werden.
Es ist wichtig zu beachten, dass Insertions-Mutagenese ein wichtiges Instrument in der Molekularbiologie und Gentechnik ist, um die Funktion von Genen zu untersuchen oder gentechnisch veränderte Organismen (GVO) herzustellen. Jedoch müssen solche Eingriffe sorgfältig geplant und durchgeführt werden, um unbeabsichtigte Folgen für die Gesundheit und Umwelt zu minimieren.
DNA-B-Helikasen sind ein Typ von Helikase, die eine zentrale Rolle in der DNA-Replikation vieler Organismen spielen. Sie sind essentiell für den Prozess der DNA-Replikation und wirken als Motorproteine, um die Doppelstrang-DNA in Einzelstränge zu trennen, bevor sie repliziert wird.
Die DNA-B-Helikasen haben eine charakteristische Querstruktur mit zwei Untereinheiten, die sich im Uhrzeigersinn drehen und die Doppelstrang-DNA in Einzelstränge trennen, während sie sich entlang der DNA bewegen. Diese Helikasen sind hochkonserviert und kommen in vielen Organismen vor, von Bakterien bis hin zu Menschen.
In Eukaryoten werden DNA-B-Helikasen als Teil des Replikationsapparats zusammen mit anderen Proteinen wie der Primase und der Single-Strand-Bindungsproteine (SSB) gebunden, um die Replikation von DNA zu erleichtern. Mutationen in diesen Helikasen können zu genetischen Erkrankungen führen und sind auch mit Krebs assoziiert.
Insgesamt sind DNA-B-Helikasen ein wichtiger Bestandteil des Replikationsprozesses und haben eine entscheidende Rolle bei der Aufrechterhaltung der Genomstabilität.
Carrierproteine, auch als Transportproteine bekannt, sind Moleküle, die die Funktion haben, andere Moleküle oder Ionen durch Membranen zu transportieren. Sie spielen eine wichtige Rolle im Stoffwechsel von Zellen und im interzellulären Kommunikationsprozess. Carrierproteine sind in der Lage, Substanzen wie Zucker, Aminosäuren, Ionen und andere Moleküle selektiv zu binden und diese durch die Membran zu transportieren, indem sie einen Konformationswandel durchlaufen.
Es gibt zwei Arten von Carrierproteinen: uniporter und symporter/antiporter. Uniporter transportieren nur eine Art von Substanz in eine Richtung, während Symporter und Antiporter jeweils zwei verschiedene Arten von Substanzen gleichzeitig in die gleiche oder entgegengesetzte Richtung transportieren.
Carrierproteine sind von großer Bedeutung für den Transport von Molekülen durch Zellmembranen, da diese normalerweise nicht-polar und lipophil sind und somit nur unpolare oder lipophile Moleküle passiv durch Diffusion durch die Membran transportieren können. Carrierproteine ermöglichen es so, auch polare und hydrophile Moleküle aktiv zu transportieren.
Bakteriophage Lambda, auch als λ-Phage bekannt, ist ein Virus, das sich ausschließlich an Bakterien der Art Escherichia coli (E. coli) bindet und infiziert. Er gehört zur Familie der Siphoviridae in der Klasse der Caudoviricetes. Mit einer Größe von etwa 48 nm x 20 nm hat er eine unbehüllte, ikosaedrische Kapsidform (Kopf) und einen langen, flexiblen Schwanz (Schwanz).
Die Infektion beginnt, wenn der Bakteriophage an ein spezifisches Rezeptorprotein auf der Oberfläche des Bakteriums andockt. Anschließend injiziert er sein genetisches Material in Form von Einzelstrang-DNA in die Wirtszelle. Das Lambda-Genom enthält etwa 48.500 Basenpaare und kodiert für rund 70 Proteine.
Die Infektion kann auf zwei verschiedene Arten verlaufen: lytisch oder lysogen. Im lytischen Zyklus vermehrt sich der Phage schnell, indem er die bakterielle DNA zerstört und seine eigenen DNA-Kopien in die Wirtszelle einschleust. Sobald eine ausreichende Anzahl an Phagen hergestellt wurde, lysiert (zerstört) der Bakteriophage die Wirtszelle, wodurch neue Phagen freigesetzt werden und weitere Bakterien infizieren können.
Im lysogenen Zyklus integriert sich das Lambda-Genom hingegen in die DNA des Wirtsbakteriums und wird als Prophage bezeichnet. Es vermehrt sich dann gemeinsam mit der bakteriellen DNA, ohne die Bakterienzelle zu zerstören. Unter bestimmten Bedingungen kann der Prophage jedoch wieder aktiviert werden, wodurch er in den lytischen Zyklus übergeht und die Wirtszelle zerstört.
Die Untersuchung von Bakteriophagen wie dem Lambda-Phagen hat zu bedeutenden Erkenntnissen in der Molekularbiologie geführt, insbesondere im Hinblick auf die Funktionsweise und Regulation genetischer Prozesse.
Ein genetischer Komplementaritätstest ist ein molekularbiologisches Verfahren, bei dem die genetische Kompatibilität zwischen zwei potenziellen Spenderschaften (z.B. Knochenmark oder Nierenspende) untersucht wird. Dabei wird die Histokompatibilität der Gewebemerkmale, insbesondere der humanen Leukozytenantigene (HLA), zwischen Spender und Empfänger bestimmt.
Der Test zielt darauf ab, das Risiko einer Abstoßungsreaktion nach der Transplantation zu minimieren, indem die Übereinstimmung der Gewebemerkmale zwischen Spender und Empfänger so hoch wie möglich ist. Das Verfahren umfasst in der Regel die Analyse von HLA-Proteinen oder -DNA-Sequenzen an mehreren Genloci, um eine genaue Beurteilung der Kompatibilität zu ermöglichen.
Ein höheres Maß an Übereinstimmung in den HLA-Merkmalen zwischen Spender und Empfänger kann die Wahrscheinlichkeit einer erfolgreichen Transplantation erhöhen, indem das Risiko von Abstoßungsreaktionen und transplantatassoziierten Komplikationen reduziert wird.
Acylierung ist ein chemischer Prozess, bei dem eine Acylgruppe (eine funktionelle Gruppe, die aus einer Carbonylgruppe mit einem aliphatischen oder aromatischen Rest besteht) auf eine andere Verbindung übertragen wird. In der Biochemie und speziell in der Proteomik bezieht sich Acylierung auf die Modifikation von Proteinen durch die Anbindung einer Acylgruppe, wie zum Beispiel die Anbindung einer Fettsäure an ein Protein durch die Bildung einer Amidbindung. Dieser Prozess spielt eine wichtige Rolle bei der Regulation von Proteinfunktionen und -interaktionen.
Eine Genomlibrary ist in der Genetik und Molekularbiologie eine Sammlung klonierter DNA-Moleküle, die das gesamte Genom eines Organismus oder ein bestimmtes Segment des Genoms, wie beispielsweise alle Gene oder nicht-kodierende DNA-Sequenzen, repräsentieren.
Die DNA wird in kleine Fragmente zerlegt und anschließend in Klonvektoren, wie beispielsweise Plasmide, Phagen oder Bakterienartificial Chromosomen (BACs), eingefügt. Jeder Klonvektor enthält eine einzigartige DNA-Sequenz, die als Marker dient und es ermöglicht, jedes Genomfragment eindeutig zu identifizieren und wiederherzustellen.
Die Genomlibrary wird in einer geeigneten Wirtsorganismuspopulation vermehrt, um eine große Anzahl von Klonen zu erzeugen, die das gesamte Genom oder das interessierende Segment des Genoms abdecken. Die Genomlibrary dient als wertvolles Werkzeug für verschiedene genomische Studien, wie beispielsweise DNA-Sequenzierung, funktionelle Genomanalyse und Genexpressionanalyse.
Western Blotting ist ein etabliertes Laborverfahren in der Molekularbiologie und Biochemie, das zur Detektion und Quantifizierung spezifischer Proteine in komplexen Proteingemischen verwendet wird.
Das Verfahren umfasst mehrere Schritte: Zuerst werden die Proteine aus den Proben (z. B. Zellkulturen, Gewebehomogenaten) extrahiert und mithilfe einer Elektrophorese in Abhängigkeit von ihrer Molekulargewichtsverteilung getrennt. Anschließend werden die Proteine auf eine Membran übertragen (Blotting), wo sie fixiert werden.
Im nächsten Schritt erfolgt die Detektion der Zielproteine mithilfe spezifischer Antikörper, die an das Zielprotein binden. Diese Antikörper sind konjugiert mit einem Enzym, das eine farbige oder lumineszierende Substratreaktion katalysiert, wodurch das Zielprotein sichtbar gemacht wird.
Die Intensität der Farbreaktion oder Lumineszenz ist direkt proportional zur Menge des detektierten Proteins und kann quantifiziert werden, was die Sensitivität und Spezifität des Western Blotting-Verfahrens ausmacht. Es wird oft eingesetzt, um Proteinexpressionsniveaus in verschiedenen Geweben oder Zelllinien zu vergleichen, posttranslationale Modifikationen von Proteinen nachzuweisen oder die Reinheit von proteinreichen Fraktionen zu überprüfen.
Eine Missense-Mutation ist ein spezifischer Typ von Genmutation, bei der ein einzelner Nukleotid (DNA-Basenpaar) ausgetauscht wird, was dazu führt, dass ein anderes Aminosäure-Restmolekül anstelle des ursprünglichen eingebaut wird. Dies kann zu einer Veränderung der Proteinstruktur und -funktion führen, die je nach Art und Ort der Mutation im Genom variieren kann. Manchmal können Missense-Mutationen die Proteinfunktion beeinträchtigen oder sogar vollständig aufheben, was zu verschiedenen Krankheiten oder Fehlbildungen führen kann. Es ist wichtig zu beachten, dass nicht alle Missense-Mutationen pathogen sind und einige von ihnen möglicherweise keine Auswirkungen auf die Proteinfunktion haben.
Biological models sind in der Medizin Veranschaulichungen oder Repräsentationen biologischer Phänomene, Systeme oder Prozesse, die dazu dienen, das Verständnis und die Erforschung von Krankheiten sowie die Entwicklung und Erprobung von medizinischen Therapien und Interventionen zu erleichtern.
Es gibt verschiedene Arten von biologischen Modellen, darunter:
1. Tiermodelle: Hierbei werden Versuchstiere wie Mäuse, Ratten oder Affen eingesetzt, um Krankheitsprozesse und Wirkungen von Medikamenten zu untersuchen.
2. Zellkulturmodelle: In vitro-Modelle, bei denen Zellen in einer Petrischale kultiviert werden, um biologische Prozesse oder die Wirkung von Medikamenten auf Zellen zu untersuchen.
3. Gewebekulturen: Hierbei werden lebende Zellverbände aus einem Organismus isoliert und in einer Nährlösung kultiviert, um das Verhalten von Zellen in ihrem natürlichen Gewebe zu studieren.
4. Mikroorganismen-Modelle: Bakterien oder Viren werden als Modelle eingesetzt, um Infektionskrankheiten und die Wirkung von Antibiotika oder antiviralen Medikamenten zu untersuchen.
5. Computermodelle: Mathematische und simulationsbasierte Modelle, die dazu dienen, komplexe biologische Systeme und Prozesse zu simulieren und vorherzusagen.
Biological models sind ein wichtiges Instrument in der medizinischen Forschung, um Krankheiten besser zu verstehen und neue Behandlungsmethoden zu entwickeln.
Caspase-3 ist ein proteolytisches Enzym, das in der Familie der Caspasen gefunden wird und eine wichtige Rolle bei programmierten Zelltod oder Apoptose spielt. Es ist auch als CPP32 (Cellular Proteinase 32) bekannt.
Caspase-3 wird als "Exekutor-Caspase" bezeichnet, weil es nach Aktivierung eine Vielzahl von Proteinen zerschneidet, die für die Zellfunktion und -struktur wesentlich sind. Diese proteolytische Aktivität führt letztendlich zum charakteristischen morphologischen Umbau der Zelle während des apoptotischen Prozesses, einschließlich DNA-Fragmentierung, Kondensation der Chromosomen und Zellfragmentierung in Apoptosekorparten.
Die Aktivierung von Caspase-3 erfolgt durch die Initiator-Caspasen-8 oder -9, die während der Signaltransduktion der extrinsischen oder intrinsischen Apoptosewege aktiviert werden. Sobald aktiviert, kann Caspase-3 andere Effektor-Caspasen wie Caspase-6 und Caspase-7 weiter aktivieren, was zu einer Kaskade von Ereignissen führt, die den Zelltod verursachen.
Eukaryotic initiation factors (EIFs) sind eine Gruppe von Proteinen, die an der Initiation der Eukaryoten-mRNA-Translation beteiligt sind. Die Initiation ist der erste Schritt des Prozesses der Proteinbiosynthese, bei dem das ribosomale 40S-Unterteil an die richtige Startstelle der mRNA bindet.
Es gibt mindestens zwölf verschiedene EIFs, die in mehreren Komplexen zusammenarbeiten, um den Initiationsprozess zu erleichtern. Einige dieser Faktoren sind beteiligt an:
* Die Bindung des 40S-Unterteils an die mRNA und die Unterscheidung der richtigen Startcodon (meist AUG)
* Die Hydrolyse von GTP, um die Energie für den Initiationsprozess bereitzustellen
* Die Bindung des Met-tRNA an das 40S-Unterteil und die Platzierung an der richtigen Stelle auf der mRNA
* Die Assemblierung des vollständigen 80S-Ribosoms, einschließlich des 60S-Unterteils, um die Elongation zu starten.
Die Eukaryotic initiation factors sind wichtige Regulatoren der Proteinbiosynthese und spielen eine Rolle bei der Kontrolle der Genexpression in eukaryotischen Zellen. Defekte oder Mutationen in diesen Faktoren können zu verschiedenen Krankheiten führen, wie z.B. angeborene Erkrankungen und Krebs.
Ein virales Genom ist die Gesamtheit der Erbinformation, die in einem Virus vorhanden ist. Im Gegensatz zu den meisten Lebewesen, die DNA als genetisches Material verwenden, können Viren entweder DNA oder RNA als genetische Basis haben. Das Genom eines Virus enthält normalerweise nur wenige Gene, die für die Herstellung der viralen Proteine und manchmal auch für die Replikation des Virus kodieren.
Die Größe und Komplexität von viralen Genomen können stark variieren. Einfache Viren wie das Poliovirus haben nur etwa 7.500 Basenpaare und codieren nur wenige Proteine, während komplexe Viren wie das Pockenvirus ein Genom von mehr als 200.000 Basenpaaren haben und mehrere hundert Proteine codieren können.
Das Verständnis des viralen Genoms ist wichtig für die Erforschung der Biologie von Viren, die Entwicklung von Diagnose- und Therapiestrategien gegen Virusinfektionen sowie die Erforschung der Evolution und Diversität von Viren.
'Drosophila' ist ein Gattungsname in der Biologie und beschreibt speziell Fliegenarten, die zur Familie der Drosophilidae gehören. Die bekannteste Art ist Drosophila melanogaster, auch als Taufliege bekannt. Diese Spezies wird häufig in der genetischen Forschung eingesetzt aufgrund ihrer kurzen Generationszeit, hohen Reproduktionsrate und des einfachen Aufbaus ihres Genoms. Die Ergebnisse von Studien an Drosophila melanogaster können oft auf Säugetiere und Menschen übertragen werden, was sie zu einem wertvollen Modellorganismus macht.
In der Medizin und Biowissenschaften bezieht sich die molekulare Masse (auch molare Masse genannt) auf die Massenschaft eines Moleküls, die in Einheiten von Dalton (Da) oder auf Atomare Masseneinheiten (u) ausgedrückt wird. Sie kann berechnet werden, indem man die Summe der durchschnittlichen atomaren Massen aller Atome in einem Molekül addiert. Diese Information ist wichtig in Bereichen wie Proteomik, Genetik und Pharmakologie, wo sie zur Bestimmung von Konzentrationen von Molekülen in Lösungen oder Gasen beiträgt und für die Analyse von Biomolekülen wie DNA, Proteinen und kleineren Molekülen wie Medikamenten und toxischen Substanzen verwendet wird.
Der Eukaryote Initiationsfaktor 5 (eIF5) ist ein Protein, das während des Prozesses der Proteinbiosynthese in Eukaryoten eine wichtige Rolle spielt. Genauer gesagt ist eIF5 an der ersten Phase der Translation beteiligt, bei der die mRNA (Messenger-RNA) mit den Ribosomen assoziiert und in eine positionierbare Konformation gebracht wird.
eIF5 fungiert als ein GTPase-aktivierendes Protein (GAP), das die Hydrolyse von GTP (Guanosintriphosphat) zu GDP (Guanosindiphosphat) katalysiert, was wiederum den Übergang der kleinen Untereinheit des Ribosoms von einer offenen zur geschlossenen Konformation ermöglicht. Diese Änderung der Konformation ist notwendig, damit die tRNA (Transfer-RNA) mit dem Startkodon der mRNA in das A-Site (Aminoacyl-Site) des Ribosoms geladen werden kann.
Insgesamt spielt eIF5 eine entscheidende Rolle bei der Initiation der Proteinbiosynthese und gewährleistet, dass die Translation nur dann beginnt, wenn die richtigen Komponenten an den richtigen Positionen auf dem Ribosom vorhanden sind.
Ich kann Ihnen leider keine allgemeingültige Definition für "Archaea-Proteine" geben, da es sich dabei um einen sehr breiten Begriff handelt, der eine große Vielfalt von Proteinen aus Archaeen einschließt. Archaeen sind Mikroorganismen, die zusammen mit Bakterien und Eukaryoten zu den drei Domänen des Lebens gehören.
Proteine sind in allen Lebewesen, also auch in Archaeen, komplexe Moleküle, die aus Aminosäuren aufgebaut sind und eine Vielzahl von Funktionen im Organismus übernehmen. Dazu zählen beispielsweise Enzyme, Strukturproteine, Transportproteine und Regulatorproteine.
Archaea-Proteine können also je nach Kontext unterschiedliche Bedeutungen haben. Im Allgemeinen bezieht sich der Begriff jedoch auf Proteine, die in Archaeen vorkommen und oft einzigartige Eigenschaften aufweisen, wie zum Beispiel eine erhöhte Thermostabilität oder besondere Reaktivitäten unter extremen Bedingungen.
Um mehr über bestimmte Arten von Archaea-Proteinen zu erfahren, sollten Sie nach spezifischeren Begriffen suchen und sich auf wissenschaftliche Publikationen oder Fachbücher stützen.
Southern Blotting ist eine Labor-Technik in der Molekularbiologie und Genetik, die verwendet wird, um spezifische DNA-Sequenzen in einer DNA-Probe zu erkennen und zu analysieren. Die Methode wurde nach dem Entwickler des Verfahrens, dem britischen Wissenschaftler Edwin Southern, benannt.
Das Southern Blotting-Verfahren umfasst mehrere Schritte:
1. Zuerst wird die DNA-Probe mit Restriktionsenzymen verdaut, die das DNA-Molekül in bestimmten Sequenzen schneiden.
2. Die resultierenden DNA-Fragmente werden dann auf ein Nitrozellulose- oder PVDF-Membran übertragen und an der Membran fixiert.
3. Als Nächstes wird die Membran in eine Lösung mit markierten DNA-Sonden getaucht, die komplementär zu den gesuchten DNA-Sequenzen sind. Die Markierung erfolgt meistens durch radioaktive Isotope (z.B. 32P) oder fluoreszierende Farbstoffe.
4. Die markierten Sonden binden an die entsprechenden DNA-Fragmente auf der Membran, und die ungebundenen Sonden werden weggespült.
5. Schließlich wird die Membran mit einem Film oder durch direkte Fluoreszenzdetektion ausgewertet, um die Lokalisation und Intensität der markierten DNA-Fragmente zu bestimmen.
Southern Blotting ist eine empfindliche und spezifische Methode zur Analyse von DNA-Sequenzen und wird häufig in der Forschung eingesetzt, um Genexpression, Genmutationen, Genomorganisation und andere genetische Phänomene zu untersuchen.
Es gibt keine allgemein anerkannte medizinische Definition des Begriffs „F-Faktor“. Dieser Begriff wird nicht in der Medizin oder Biologie verwendet, um ein bestimmtes Konzept, eine Krankheit oder einen pathologischen Prozess zu beschreiben. Daher ist es unmöglich, eine medizinische Definition dafür bereitzustellen.
'Bacillus subtilis' ist eine gram-positive, sporenbildende Bakterienart, die häufig in der Umwelt vorkommt, insbesondere in Boden und Wasser. Die Bakterien sind bekannt für ihre hohe Beständigkeit gegenüber ungünstigen Umweltbedingungen, wie Hitze, Trockenheit und UV-Strahlung, dank ihrer Fähigkeit, resistente Endosporen zu bilden.
In der medizinischen Forschung wird 'Bacillus subtilis' oft als Modellorganismus eingesetzt, um verschiedene biologische Prozesse wie Sporulation, Zellteilung und Stoffwechsel zu studieren. Darüber hinaus werden einige Stämme von 'Bacillus subtilis' in der Biotechnologie und Industrie verwendet, beispielsweise zur Produktion von Enzymen und als Probiotika in Lebensmitteln.
Obwohl 'Bacillus subtilis' normalerweise nicht als humanpathogen eingestuft wird, können seltene Infektionen auftreten, insbesondere bei immungeschwächten Personen oder nach invasiven medizinischen Eingriffen. Die Symptome solcher Infektionen können Fieber, Schüttelfrost und Entzündungen umfassen.
Es gibt keine direkte medizinische Definition für "Pilz-DNA", da Pilze (Fungi) ein eigenes Reich des Lebens sind und nicht direkt mit menschlicher DNA oder genetischen Erkrankungen bei Menschen in Verbindung stehen. Allerdings kann man die genetische Information von Pilzen, also deren DNA, in der medizinischen Forschung untersuchen, um beispielsweise Krankheiten besser zu verstehen, die durch Pilze verursacht werden, oder Wirkstoffe gegen pilzliche Krankheitserreger zu entwickeln.
In diesem Zusammenhang bezieht sich "Pilz-DNA" auf die Erbinformation von Pilzen, die in Form von Desoxyribonukleinsäure (DNA) vorliegt und die genetische Anlagen der Organismen kodiert. Die DNA von Pilzen ist ähnlich wie bei anderen Lebewesen in Chromosomen organisiert und enthält Gene, die für bestimmte Eigenschaften und Funktionen des Organismus verantwortlich sind.
Im Klartext lautet eine mögliche Definition: "Pilz-DNA bezieht sich auf die Desoxyribonukleinsäure (DNA), welche die Erbinformation von Pilzen enthält und in Chromosomen organisiert ist. Die DNA-Sequenzen kodieren für genetische Merkmale und Eigenschaften der Pilze, die bei medizinischen Fragestellungen, wie z.B. der Untersuchung von Infektionskrankheiten oder der Entwicklung neuer Medikamente, von Interesse sein können."
Es gibt keine direkte medizinische Definition für "Leuchtkäfer". Der Begriff "Leuchtkäfer" bezieht sich auf bestimmte Käferarten, die die Fähigkeit haben, Licht zu erzeugen und zu strahlen. Diese Tiere werden häufig in der Biolumineszenz-Forschung untersucht, aber sie haben keine direkte Verbindung zur Medizin.
Es gibt jedoch ein medizinisches Gerät namens "Leuchtkäfer-Endoskop", das bei der Krebsfrüherkennung eingesetzt wird. Es handelt sich um ein flexibles Endoskop, das mit einer Miniaturkamera und einem Licht ausgestattet ist, um die inneren Organe zu untersuchen. Das Gerät wurde nach dem Leuchtkäfer benannt, weil es wie der Käfer leuchtet, wenn es in den Körper eingeführt wird, um das Innere des Körpers besser sichtbar zu machen.
Hydrolysis ist ein biochemischer Prozess, bei dem Moleküle durch Reaktion mit Wasser in kleinere Bruchstücke zerlegt werden. Dies geschieht, wenn Wassermoleküle sich an die Bindungen von Makromolekülen wie Kohlenhydrate, Fette oder Proteine anlagern und diese aufspalten. Bei diesem Vorgang wird die chemische Bindung zwischen den Teilen der Moleküle durch die Energie des Wasserstoff- und Hydroxidions aufgebrochen.
In der Medizin kann Hydrolyse bei verschiedenen Prozessen eine Rolle spielen, wie zum Beispiel bei der Verdauung von Nahrungsmitteln im Magen-Darm-Trakt oder bei Stoffwechselvorgängen auf Zellebene. Auch in der Diagnostik können hydrolytische Enzyme eingesetzt werden, um bestimmte Biomarker aus Körperflüssigkeiten wie Blut oder Urin zu isolieren und zu identifizieren.
Eine DNA-Nukleotidyl-Exo-Transferase ist ein Enzym, das in der Lage ist, ein oder mehrere Nukleotide an die 3'-OH-Endgruppe einer DNA-Strangspitze zu addieren oder auch abzubauen. Dieses Enzym verfügt über eine exonukleolytische Aktivität, die den Abbau von Nukleotiden an der 3'-Endgruppe eines DNA-Strangs ermöglicht, sowie über eine terminalen Transferase-Aktivität, mit der es neue Nukleotide an die 3'-OH-Endgruppe addieren kann. Diese Art von Enzym ist wichtig für verschiedene zelluläre Prozesse wie DNA-Reparatur und -Replikation.
Biologische Evolution beziehungsweise Biological Evolution ist ein Prozess der Veränderung und Anpassung von Lebewesen über Generationen hinweg. Es handelt sich um einen fundamentalen Aspekt der Biologie, der durch die Veränderungen in der Häufigkeit bestimmter Merkmale in Populationen charakterisiert ist. Diese Veränderungen werden hauptsächlich durch Mechanismen wie Mutation, Genfluss, genetische Drift und natürliche Selektion hervorgerufen.
Evolution erfolgt auf allen Ebenen des biologischen Systems, von Genen über Individuen bis hin zu Arten und Ökosystemen. Die Evolutionsbiologie ist ein interdisziplinäres Fach, das Erkenntnisse aus verschiedenen Bereichen wie Genetik, Populationsgenetik, Paläontologie, Systematik, Vergleichende Anatomie und Verhaltensforschung integriert, um das Phänomen der Evolution zu erklären.
Die moderne Synthese, auch Neodarwinismus genannt, ist ein theoretisches Rahmenwerk, das die Prinzipien der klassischen Mendelschen Genetik mit der darwinistischen Evolutionstheorie verbindet und so ein umfassendes Verständnis der biologischen Evolution ermöglicht.
'Drosophila melanogaster' ist keine medizinische Bezeichnung, sondern die wissenschaftliche Bezeichnung für die Taufliege oder Fruchtfliege. Es handelt sich um ein kleines Insekt, das häufig in der biologischen und genetischen Forschung eingesetzt wird, da es eine kurze Generationszeit hat, leicht zu züchten und zu manipulieren ist, und sein Genom gut erforscht und verstanden ist. Die Entschlüsselung des Genoms von Drosophila melanogaster hat wertvolle Einblicke in die Funktionsweise von Genen bei verschiedenen Tierarten geliefert, einschließlich Menschen.
Apoptotic Protease Activating Factor 1 (APAF-1) ist ein Protein, das eine wichtige Rolle in der Regulierung des programmierten Zelltods oder Apoptose spielt. Es ist ein Schlüsselfaktor in der Aktivierung der Caspasen, einer Gruppe von Cystein-aspartischen Proteasen, die für die Ausführung der Apoptose verantwortlich sind.
APAF-1 wird normalerweise in einer inaktiven Form im Zytoplasma der Zelle gefunden. Im Falle eines apoptotischen Signals, wie beispielsweise DNA-Schäden oder Stress, wird APAF-1 aktiviert und bildet zusammen mit dem proapoptotischen Protein Cytochrom c und dATP das sogenannte Apoptosom. Dieses Multiproteinkomplex initiiert die Aktivierung der Caspasen, insbesondere Caspase-9, was wiederum zur Aktivierung weiterer Effektorcaspasen wie Caspase-3 und -7 führt. Diese Caspasen sind für die Degradation von Proteinen und anderen Zellbestandteilen verantwortlich, was letztendlich zum Zelltod führt.
Da APAF-1 eine zentrale Rolle in der Apoptose spielt, ist es ein wichtiges Protein im Kontext von Krankheiten, bei denen die Regulation des programmierten Zelltods gestört ist, wie beispielsweise Krebs oder neurodegenerative Erkrankungen.
 Genetischer Code
Genetischer Code DeWiki | Genetischer Code
DeWiki | Genetischer Code Allseele to go - Mehr Frieden geht immer - 64 Wege zur (Selbst-) Liebe mit Human Design - Gene Keys - I Ging
Allseele to go - Mehr Frieden geht immer - 64 Wege zur (Selbst-) Liebe mit Human Design - Gene Keys - I Ging Glossar: Tutorium Genetik | Lehrbuch Biologie
Glossar: Tutorium Genetik | Lehrbuch Biologie Glossar cytologischer, biochemischer und mikrobiologischer Fachbegriffe
Glossar cytologischer, biochemischer und mikrobiologischer Fachbegriffe