Clustered Regularly Interspaced Short Palindromic Repeats
Inverted Repeat Sequences
CRISPR-Associated Proteins
CRISPR-Cas Systems
RNA, Archaeal
Streptococcus thermophilus
RNA Cleavage
RNA, Guide
DNA, Intergenic
Sulfolobus solfataricus
DNA Cleavage
Interspersed Repetitive Sequences
Repetitive Sequences, Nucleic Acid
Molecular Sequence Data
Base Sequence
RNA, Bacterial
Archaea
Pyrococcus furiosus
Sequence Analysis, DNA
Evolution, Molecular
Genetic Engineering
Plasmids
Multigene Family
Bacteria
RNA
Escherichia coli
Trinucleotide Repeats
Tandem Repeat Sequences
Gene Transfer, Horizontal
Trinucleotide Repeat Expansion
Minisatellite Repeats
Ankyrin Repeat
Repetitive Sequences, Amino Acid
In defense of phage: viral suppressors of CRISPR-mediated adaptive immunity in bacteria. (1/73)
Viruses that infect bacteria are the most abundant biological agents on the planet and bacteria have evolved diverse defense mechanisms to combat these genetic parasites. One of these bacterial defense systems relies on a repetitive locus, referred to as a CRISPR (clusters of regularly interspaced short palindromic repeats). Bacteria and archaea acquire resistance to invading viruses and plasmids by integrating short fragments of foreign nucleic acids at one end of the CRISPR locus. CRISPR loci are transcribed and the long primary CRISPR transcript is processed into a library of small RNAs that guide the immune system to invading nucleic acids, which are subsequently degraded by dedicated nucleases. However, the development of CRISPR-mediated immune systems has not eradicated phages, suggesting that viruses have evolved mechanisms to subvert CRISPR-mediated protection. Recently, Bondy-Denomy and colleagues discovered several phage-encoded anti-CRISPR proteins that offer new insight into the ongoing molecular arms race between viral parasites and the immune systems of their hosts. (+info)Comparative analysis ofCas6b processing and CRISPR RNA stability. (2/73)
The prokaryotic antiviral defense systems CRISP R (clustered regularly interspaced short palindromic repeats)/Cas (CRISP Rassociated) employs short crRNAs (CRISP R RNAs) to target invading viral nucleic acids. A short spacer sequence of these crRNAs can be derived from a viral genome and recognizes a reoccurring attack of a virus via base complementarity. We analyzed the effect of spacer sequences on the maturation of crRNAs of the subtype I-B Methanococcus maripaludis C5 CRISP R cluster. The responsible endonuclease, termed Cas6b, bound non-hydrolyzable repeat RNA as a dimer and mature crRNA as a monomer. Comparative analysis of Cas6b processing of individual spacer-repeat-spacer RNA substrates and crRNA stability revealed the potential influence of spacer sequence and length on these parameters. Correlation of these observations with the variable abundance of crRNAs visualized by deep-sequencing analyses is discussed. Finally, insertion of spacer and repeat sequences with archaeal poly-T termination signals is suggested to be prevented in archaeal CRISP R/Cas systems. (+info)Protospacer recognition motifs: mixed identities and functional diversity. (3/73)
(+info)Diversity of CRISPR systems in the euryarchaeal Pyrococcales. (4/73)
(+info)Holding a grudge: persisting anti-phage CRISPR immunity in multiple human gut microbiomes. (5/73)
(+info)CRISPR-Cas: evolution of an RNA-based adaptive immunity system in prokaryotes. (6/73)
(+info)Probabilistic models for CRISPR spacer content evolution. (7/73)
(+info)CRISPR-spacer integration reporter plasmids reveal distinct genuine acquisition specificities among CRISPR-Cas I-E variants of Escherichia coli. (8/73)
(+info)Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) is a bacterial defense system that confers resistance to foreign genetic elements such as plasmids and phages, by incorporating short sequences of the invasive genetic material into their own genome. These sequences are then used to recognize and destroy subsequent invasions by identical or similar genetic elements. The CRISPR system consists of two main components: the CRISPR array, which contains the repeats and spacers, and the Cas (CRISPR-associated) proteins, which provide the enzymatic activity for interference.
The CRISPR array is a stretch of DNA in the bacterial genome that contains repetitive sequences interspaced with unique sequences known as "spacers". The repeats are typically palindromic, meaning they read the same backwards as forwards, and are usually 24-48 base pairs long. The spacers are derived from the genetic material of previous invasions by viruses or plasmids, and are used to recognize and target similar sequences in future invaders.
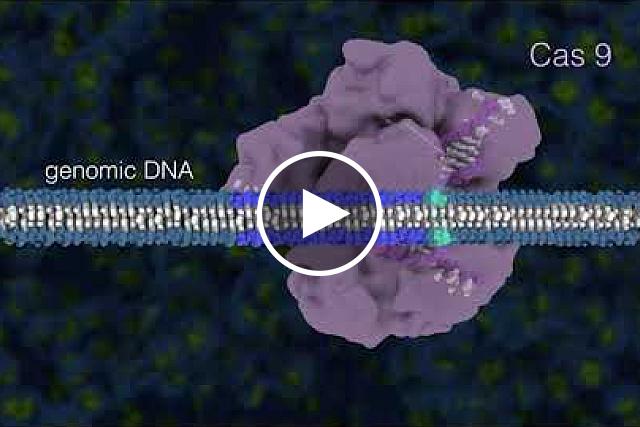
The Cas proteins associated with the CRISPR array provide the enzymatic activity for interference. They can be classified into several different types based on their sequence and domain organization. The most well-studied type is Cas9, which uses a guide RNA derived from the CRISPR array to recognize and cleave specific sequences in the target DNA. This system has been harnessed as a powerful tool for genome editing in various organisms, including humans.
In summary, Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) is a bacterial defense system that confers resistance to foreign genetic elements by incorporating short sequences of the invasive genetic material into their own genome and using them to recognize and destroy subsequent invasions by identical or similar genetic elements. The CRISPR system consists of two main components: the CRISPR array, which contains the repeats and spacers, and the Cas (CRISPR-associated) proteins, which provide the enzymatic activity for interference.
Inverted repeat sequences in a genetic context refer to a pattern of nucleotides (the building blocks of DNA or RNA) where a specific sequence appears in the reverse complementary orientation in the same molecule. This means that if you read the sequence from one end, it will be identical to the sequence read from the other end, but in the opposite direction.
For example, if a DNA segment is 5'-ATGCAT-3', an inverted repeat sequence would be 5'-GTACTC-3' on the same strand or its complementary sequence 3'-CAGTA-5' on the other strand.
These sequences can play significant roles in genetic regulation and expression, as they are often involved in forming hairpin or cruciform structures in single-stranded DNA or RNA molecules. They also have implications in genome rearrangements and stability, including deletions, duplications, and translocations.
CRISPR-associated proteins, often abbreviated as Cas proteins, are a type of enzyme that are involved in the CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) immune system found in bacteria and archaea. The CRISPR-Cas system provides adaptive immunity to these single-celled organisms by providing protection against foreign genetic elements, such as viruses and plasmids.
The Cas proteins play a crucial role in the CRISPR-Cas system by cleaving invading nucleic acids at specific sequences, guided by small RNA molecules known as CRISPR RNAs (crRNAs). These crRNAs are derived from short sequences of DNA that are integrated into the CRISPR array during a previous infection. The Cas proteins use these crRNAs to recognize and cleave complementary sequences in the invading nucleic acids, thereby providing immunity against future infections by the same genetic element.
There are several different types of CRISPR-Cas systems, each with their own distinct set of Cas proteins and mechanisms for target recognition and cleavage. The most well-known and widely used CRISPR-Cas system is Type II, which includes the Cas9 protein. This system has been adapted for use in a variety of genome editing applications, including gene therapy, crop modification, and basic research.
CRISPR-Cas systems are adaptive immune systems found in bacteria and archaea. CRISPR stands for "Clustered Regularly Interspaced Short Palindromic Repeats," which are repeating sequences of DNA found in the genomes of these microorganisms. Cas stands for "CRISPR-associated proteins," which work together with the CRISPR sequences to provide immunity against foreign genetic elements, such as viruses and plasmids.
The CRISPR-Cas system functions by incorporating short segments of DNA from invading genetic elements into the CRISPR array within the microorganism's genome. These incorporated sequences are then transcribed and processed into small RNA molecules called guide RNAs. The Cas proteins, in complex with the guide RNA, recognize and bind to complementary sequences in the invading genetic element, leading to its cleavage and degradation.
The CRISPR-Cas system has been harnessed for use as a powerful tool in genome editing, allowing researchers to precisely modify DNA sequences in various organisms, including humans. This technology holds great promise for treating genetic diseases, improving crops, and developing new therapies for infectious diseases.
Archaeal RNA refers to the Ribonucleic acid (RNA) molecules that are present in archaea, which are a domain of single-celled microorganisms. RNA is a nucleic acid that plays a crucial role in various biological processes, such as protein synthesis, gene expression, and regulation of cellular activities.
Archaeal RNAs can be categorized into different types based on their functions, including:
1. Messenger RNA (mRNA): It carries genetic information from DNA to the ribosome, where it is translated into proteins.
2. Transfer RNA (tRNA): It helps in translating the genetic code present in mRNA into specific amino acids during protein synthesis.
3. Ribosomal RNA (rRNA): It is a structural and functional component of ribosomes, where protein synthesis occurs.
4. Non-coding RNA: These are RNAs that do not code for proteins but have regulatory functions in gene expression and other cellular processes.
Archaeal RNAs share similarities with both bacterial and eukaryotic RNAs, but they also possess unique features that distinguish them from the other two domains of life. For example, archaeal rRNAs contain unique sequence motifs and secondary structures that are not found in bacteria or eukaryotes. These differences suggest that archaeal RNAs have evolved to adapt to the extreme environments where many archaea live.
Overall, understanding the structure, function, and evolution of archaeal RNA is essential for gaining insights into the biology of these unique microorganisms and their roles in various cellular processes.
Streptococcus thermophilus is a gram-positive, facultatively anaerobic, non-motile, non-spore forming bacterium that belongs to the Streptococcaceae family. It is a species of streptococcus that is mesophilic, meaning it grows best at moderate temperatures, typically between 30-45°C. S. thermophilus is commonly found in milk and dairy products and is one of the starter cultures used in the production of yogurt and other fermented dairy products. It is also used as a probiotic due to its potential health benefits, such as improving lactose intolerance and enhancing the immune system. S. thermophilus is not considered pathogenic and does not normally cause infections in humans.
RNA cleavage is a biological process in which RNA molecules are cut or split into smaller fragments by enzymes known as ribonucleases (RNases). This process can occur co-transcriptionally, during splicing, or as a means of regulation of RNA stability and function. Cleavage sites are often defined by specific sequences or structures within the RNA molecule. The cleavage products may have various fates, including degradation, further processing, or serving as functional RNA molecules.
A guide RNA (gRNA) is not a type of RNA itself, but rather a term used to describe various types of RNAs that guide other molecules to specific target sites in the genome or transcriptome. The most well-known example of a guide RNA is the CRISPR RNA (crRNA) used in the CRISPR-Cas system for targeted gene editing.
The crRNA contains a sequence complementary to the target DNA or RNA, and it guides the Cas endonuclease to the correct location in the genome where cleavage and modification can occur. Other types of guide RNAs include small interfering RNAs (siRNAs) and microRNAs (miRNAs), which guide the RNA-induced silencing complex (RISC) to specific mRNA targets for degradation or translational repression.
Overall, guide RNAs play crucial roles in various cellular processes, including gene regulation, genome editing, and defense against foreign genetic elements.
Intergenic DNA refers to the stretches of DNA that are located between genes. These regions do not contain coding sequences for proteins or RNA and thus were once thought to be "junk" DNA with no function. However, recent research has shown that intergenic DNA can play important roles in the regulation of gene expression, chromosome structure and stability, and other cellular processes. Intergenic DNA may contain various types of regulatory elements such as enhancers, silencers, insulators, and promoters that control the transcription of nearby genes. Additionally, intergenic DNA can also include repetitive sequences, transposable elements, and other non-coding RNAs that have diverse functions in the cell.
Archaeal viruses are viruses that infect and replicate within archaea, which are single-celled microorganisms without a nucleus. These viruses have unique characteristics that distinguish them from bacterial and eukaryotic viruses. They often possess distinct morphologies, such as icosahedral or filamentous shapes, and their genomes can be composed of double-stranded DNA (dsDNA), single-stranded DNA (ssDNA), double-stranded RNA (dsRNA), or single-stranded RNA (ssRNA).
Archaeal viruses have evolved various strategies to hijack the host cell's machinery for replication, packaging, and release of new virus particles. Some archaeal viruses even encode their own proteins for transcription and translation, suggesting a more complex relationship with their hosts than previously thought. The study of archaeal viruses provides valuable insights into the evolution of viruses and their hosts and has implications for understanding the origins of life on Earth.
"Sulfolobus solfataricus" is not a medical term, but rather a scientific name used in the field of microbiology. It refers to a species of archaea (single-celled microorganisms) that is thermoacidophilic, meaning it thrives in extremely high temperature and acidic environments. This organism is commonly found in volcanic hot springs and solfataras, which are areas with high sulfur content and acidic pH levels.
While not directly related to medical terminology, the study of extremophiles like "Sulfolobus solfataricus" can provide insights into the limits of life and the potential for the existence of microbial life in extreme environments on Earth and potentially on other planets.
DNA cleavage is the breaking of the phosphodiester bonds in the DNA molecule, resulting in the separation of the two strands of the double helix. This process can occur through chemical or enzymatic reactions and can result in various types of damage to the DNA molecule, including single-strand breaks, double-strand breaks, and base modifications.
Enzymatic DNA cleavage is typically carried out by endonucleases, which are enzymes that cut DNA molecules at specific sequences or structures. There are two main types of endonucleases: restriction endonucleases and repair endonucleases. Restriction endonucleases recognize and cleave specific DNA sequences, often used in molecular biology techniques such as genetic engineering and cloning. Repair endonucleases, on the other hand, are involved in DNA repair processes and recognize and cleave damaged or abnormal DNA structures.
Chemical DNA cleavage can occur through various mechanisms, including oxidation, alkylation, or hydrolysis of the phosphodiester bonds. Chemical agents such as hydrogen peroxide, formaldehyde, or hydrazine can induce chemical DNA cleavage and are often used in laboratory settings for various purposes, such as DNA fragmentation or labeling.
Overall, DNA cleavage is an essential process in many biological functions, including DNA replication, repair, and recombination. However, excessive or improper DNA cleavage can lead to genomic instability, mutations, and cell death.
A bacterial genome is the complete set of genetic material, including both DNA and RNA, found within a single bacterium. It contains all the hereditary information necessary for the bacterium to grow, reproduce, and survive in its environment. The bacterial genome typically includes circular chromosomes, as well as plasmids, which are smaller, circular DNA molecules that can carry additional genes. These genes encode various functional elements such as enzymes, structural proteins, and regulatory sequences that determine the bacterium's characteristics and behavior.
Bacterial genomes vary widely in size, ranging from around 130 kilobases (kb) in Mycoplasma genitalium to over 14 megabases (Mb) in Sorangium cellulosum. The complete sequencing and analysis of bacterial genomes have provided valuable insights into the biology, evolution, and pathogenicity of bacteria, enabling researchers to better understand their roles in various diseases and potential applications in biotechnology.
Interspersed Repeats or Interspersed Repetitive Sequences (IRSs) are repetitive DNA sequences that are dispersed throughout the eukaryotic genome. They include several types of repeats such as SINEs (Short INterspersed Elements), LINEs (Long INterspersed Elements), and LTR retrotransposons (Long Terminal Repeat retrotransposons). These sequences can make up a significant portion of the genome, with varying copy numbers among different species. They are typically non-coding and have been associated with genomic instability, regulation of gene expression, and evolution of genomes.
Repetitive sequences in nucleic acid refer to repeated stretches of DNA or RNA nucleotide bases that are present in a genome. These sequences can vary in length and can be arranged in different patterns such as direct repeats, inverted repeats, or tandem repeats. In some cases, these repetitive sequences do not code for proteins and are often found in non-coding regions of the genome. They can play a role in genetic instability, regulation of gene expression, and evolutionary processes. However, certain types of repeat expansions have been associated with various neurodegenerative disorders and other human diseases.
Bacteriophages, often simply called phages, are viruses that infect and replicate within bacteria. They consist of a protein coat, called the capsid, that encases the genetic material, which can be either DNA or RNA. Bacteriophages are highly specific, meaning they only infect certain types of bacteria, and they reproduce by hijacking the bacterial cell's machinery to produce more viruses.
Once a phage infects a bacterium, it can either replicate its genetic material and create new phages (lytic cycle), or integrate its genetic material into the bacterial chromosome and replicate along with the bacterium (lysogenic cycle). In the lytic cycle, the newly formed phages are released by lysing, or breaking open, the bacterial cell.
Bacteriophages play a crucial role in shaping microbial communities and have been studied as potential alternatives to antibiotics for treating bacterial infections.
An archaeal genome refers to the complete set of genetic material or DNA present in an archaea, a single-celled microorganism that is found in some of the most extreme environments on Earth. The genome of an archaea contains all the information necessary for its survival, including the instructions for building proteins and other essential molecules, as well as the regulatory elements that control gene expression.
Archaeal genomes are typically circular in structure and range in size from about 0.5 to over 5 million base pairs. They contain genes that are similar to those found in bacteria and eukaryotes, as well as unique genes that are specific to archaea. The study of archaeal genomes has provided valuable insights into the evolutionary history of life on Earth and has helped scientists understand the adaptations that allow these organisms to thrive in such harsh environments.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
Bacterial RNA refers to the genetic material present in bacteria that is composed of ribonucleic acid (RNA). Unlike higher organisms, bacteria contain a single circular chromosome made up of DNA, along with smaller circular pieces of DNA called plasmids. These bacterial genetic materials contain the information necessary for the growth and reproduction of the organism.
Bacterial RNA can be divided into three main categories: messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). mRNA carries genetic information copied from DNA, which is then translated into proteins by the rRNA and tRNA molecules. rRNA is a structural component of the ribosome, where protein synthesis occurs, while tRNA acts as an adapter that brings amino acids to the ribosome during protein synthesis.
Bacterial RNA plays a crucial role in various cellular processes, including gene expression, protein synthesis, and regulation of metabolic pathways. Understanding the structure and function of bacterial RNA is essential for developing new antibiotics and other therapeutic strategies to combat bacterial infections.
Archaea are a domain of single-celled microorganisms that lack membrane-bound nuclei and other organelles. They are characterized by the unique structure of their cell walls, membranes, and ribosomes. Archaea were originally classified as bacteria, but they differ from bacteria in several key ways, including their genetic material and metabolic processes.
Archaea can be found in a wide range of environments, including some of the most extreme habitats on Earth, such as hot springs, deep-sea vents, and highly saline lakes. Some species of Archaea are able to survive in the absence of oxygen, while others require oxygen to live.
Archaea play important roles in global nutrient cycles, including the nitrogen cycle and the carbon cycle. They are also being studied for their potential role in industrial processes, such as the production of biofuels and the treatment of wastewater.
"Pyrococcus furiosus" is not a medical term, but a scientific name for an extremophilic archaea species. It's a type of microorganism that thrives in extreme environments, particularly high temperature and acidity. "Pyrococcus furiosus" was first isolated from a marine volcanic vent and has since been studied extensively due to its unique biological properties.
In terms of scientific definition:
"Pyrococcus furiosus" is a species of archaea belonging to the order Thermococcales, family Pyrococcaceae. It's a hyperthermophilic organism, with an optimum growth temperature of around 100°C (212°F), and can survive in temperatures up to 106°C (223°F). The cells are irregularly coccoid, about 0.8-1.5 µm in diameter, and occur singly or in pairs.
The organism obtains energy by fermenting peptides and carbohydrates, producing hydrogen, carbon dioxide, and acetate as end products. "Pyrococcus furiosus" has been used as a model system for studying the biochemistry of archaea and extremophiles, including enzymes that function optimally at high temperatures.
DNA Sequence Analysis is the systematic determination of the order of nucleotides in a DNA molecule. It is a critical component of modern molecular biology, genetics, and genetic engineering. The process involves determining the exact order of the four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - in a DNA molecule or fragment. This information is used in various applications such as identifying gene mutations, studying evolutionary relationships, developing molecular markers for breeding, and diagnosing genetic diseases.
The process of DNA Sequence Analysis typically involves several steps, including DNA extraction, PCR amplification (if necessary), purification, sequencing reaction, and electrophoresis. The resulting data is then analyzed using specialized software to determine the exact sequence of nucleotides.
In recent years, high-throughput DNA sequencing technologies have revolutionized the field of genomics, enabling the rapid and cost-effective sequencing of entire genomes. This has led to an explosion of genomic data and new insights into the genetic basis of many diseases and traits.
Archaeal proteins are proteins that are encoded by the genes found in archaea, a domain of single-celled microorganisms. These proteins are crucial for various cellular functions and structures in archaea, which are adapted to survive in extreme environments such as high temperatures, high salt concentrations, and low pH levels.
Archaeal proteins share similarities with both bacterial and eukaryotic proteins, but they also have unique features that distinguish them from each other. For example, many archaeal proteins contain unusual amino acids or modifications that are not commonly found in other organisms. Additionally, the three-dimensional structures of some archaeal proteins are distinct from their bacterial and eukaryotic counterparts.
Studying archaeal proteins is important for understanding the biology of these unique organisms and for gaining insights into the evolution of life on Earth. Furthermore, because some archaea can survive in extreme environments, their proteins may have properties that make them useful in industrial and medical applications.
Bacterial DNA refers to the genetic material found in bacteria. It is composed of a double-stranded helix containing four nucleotide bases - adenine (A), thymine (T), guanine (G), and cytosine (C) - that are linked together by phosphodiester bonds. The sequence of these bases in the DNA molecule carries the genetic information necessary for the growth, development, and reproduction of bacteria.
Bacterial DNA is circular in most bacterial species, although some have linear chromosomes. In addition to the main chromosome, many bacteria also contain small circular pieces of DNA called plasmids that can carry additional genes and provide resistance to antibiotics or other environmental stressors.
Unlike eukaryotic cells, which have their DNA enclosed within a nucleus, bacterial DNA is present in the cytoplasm of the cell, where it is in direct contact with the cell's metabolic machinery. This allows for rapid gene expression and regulation in response to changing environmental conditions.
Molecular evolution is the process of change in the DNA sequence or protein structure over time, driven by mechanisms such as mutation, genetic drift, gene flow, and natural selection. It refers to the evolutionary study of changes in DNA, RNA, and proteins, and how these changes accumulate and lead to new species and diversity of life. Molecular evolution can be used to understand the history and relationships among different organisms, as well as the functional consequences of genetic changes.
Deoxyribonucleases (DNases) are a group of enzymes that cleave, or cut, the phosphodiester bonds in the backbone of deoxyribonucleic acid (DNA) molecules. DNases are classified based on their mechanism of action into two main categories: double-stranded DNases and single-stranded DNases.
Double-stranded DNases cleave both strands of the DNA duplex, while single-stranded DNases cleave only one strand. These enzymes play important roles in various biological processes, such as DNA replication, repair, recombination, and degradation. They are also used in research and clinical settings for applications such as DNA fragmentation analysis, DNA sequencing, and treatment of cystic fibrosis.
It's worth noting that there are many different types of DNases with varying specificities and activities, and the medical definition may vary depending on the context.
Genetic engineering, also known as genetic modification, is a scientific process where the DNA or genetic material of an organism is manipulated to bring about a change in its characteristics. This is typically done by inserting specific genes into the organism's genome using various molecular biology techniques. These new genes may come from the same species (cisgenesis) or a different species (transgenesis). The goal is to produce a desired trait, such as resistance to pests, improved nutritional content, or increased productivity. It's widely used in research, medicine, and agriculture. However, it's important to note that the use of genetically engineered organisms can raise ethical, environmental, and health concerns.
A plasmid is a small, circular, double-stranded DNA molecule that is separate from the chromosomal DNA of a bacterium or other organism. Plasmids are typically not essential for the survival of the organism, but they can confer beneficial traits such as antibiotic resistance or the ability to degrade certain types of pollutants.
Plasmids are capable of replicating independently of the chromosomal DNA and can be transferred between bacteria through a process called conjugation. They often contain genes that provide resistance to antibiotics, heavy metals, and other environmental stressors. Plasmids have also been engineered for use in molecular biology as cloning vectors, allowing scientists to replicate and manipulate specific DNA sequences.
Plasmids are important tools in genetic engineering and biotechnology because they can be easily manipulated and transferred between organisms. They have been used to produce vaccines, diagnostic tests, and genetically modified organisms (GMOs) for various applications, including agriculture, medicine, and industry.
A multigene family is a group of genetically related genes that share a common ancestry and have similar sequences or structures. These genes are arranged in clusters on a chromosome and often encode proteins with similar functions. They can arise through various mechanisms, including gene duplication, recombination, and transposition. Multigene families play crucial roles in many biological processes, such as development, immunity, and metabolism. Examples of multigene families include the globin genes involved in oxygen transport, the immune system's major histocompatibility complex (MHC) genes, and the cytochrome P450 genes associated with drug metabolism.
Bacteria are single-celled microorganisms that are among the earliest known life forms on Earth. They are typically characterized as having a cell wall and no membrane-bound organelles. The majority of bacteria have a prokaryotic organization, meaning they lack a nucleus and other membrane-bound organelles.
Bacteria exist in diverse environments and can be found in every habitat on Earth, including soil, water, and the bodies of plants and animals. Some bacteria are beneficial to their hosts, while others can cause disease. Beneficial bacteria play important roles in processes such as digestion, nitrogen fixation, and biogeochemical cycling.
Bacteria reproduce asexually through binary fission or budding, and some species can also exchange genetic material through conjugation. They have a wide range of metabolic capabilities, with many using organic compounds as their source of energy, while others are capable of photosynthesis or chemosynthesis.
Bacteria are highly adaptable and can evolve rapidly in response to environmental changes. This has led to the development of antibiotic resistance in some species, which poses a significant public health challenge. Understanding the biology and behavior of bacteria is essential for developing strategies to prevent and treat bacterial infections and diseases.
Bacterial proteins are a type of protein that are produced by bacteria as part of their structural or functional components. These proteins can be involved in various cellular processes, such as metabolism, DNA replication, transcription, and translation. They can also play a role in bacterial pathogenesis, helping the bacteria to evade the host's immune system, acquire nutrients, and multiply within the host.
Bacterial proteins can be classified into different categories based on their function, such as:
1. Enzymes: Proteins that catalyze chemical reactions in the bacterial cell.
2. Structural proteins: Proteins that provide structural support and maintain the shape of the bacterial cell.
3. Signaling proteins: Proteins that help bacteria to communicate with each other and coordinate their behavior.
4. Transport proteins: Proteins that facilitate the movement of molecules across the bacterial cell membrane.
5. Toxins: Proteins that are produced by pathogenic bacteria to damage host cells and promote infection.
6. Surface proteins: Proteins that are located on the surface of the bacterial cell and interact with the environment or host cells.
Understanding the structure and function of bacterial proteins is important for developing new antibiotics, vaccines, and other therapeutic strategies to combat bacterial infections.
Phylogeny is the evolutionary history and relationship among biological entities, such as species or genes, based on their shared characteristics. In other words, it refers to the branching pattern of evolution that shows how various organisms have descended from a common ancestor over time. Phylogenetic analysis involves constructing a tree-like diagram called a phylogenetic tree, which depicts the inferred evolutionary relationships among organisms or genes based on molecular sequence data or other types of characters. This information is crucial for understanding the diversity and distribution of life on Earth, as well as for studying the emergence and spread of diseases.
Genetic variation refers to the differences in DNA sequences among individuals and populations. These variations can result from mutations, genetic recombination, or gene flow between populations. Genetic variation is essential for evolution by providing the raw material upon which natural selection acts. It can occur within a single gene, between different genes, or at larger scales, such as differences in the number of chromosomes or entire sets of chromosomes. The study of genetic variation is crucial in understanding the genetic basis of diseases and traits, as well as the evolutionary history and relationships among species.
RNA (Ribonucleic Acid) is a single-stranded, linear polymer of ribonucleotides. It is a nucleic acid present in the cells of all living organisms and some viruses. RNAs play crucial roles in various biological processes such as protein synthesis, gene regulation, and cellular signaling. There are several types of RNA including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), small nuclear RNA (snRNA), microRNA (miRNA), and long non-coding RNA (lncRNA). These RNAs differ in their structure, function, and location within the cell.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
Trinucleotide repeats refer to a specific type of DNA sequence expansion where a particular trinucleotide (a sequence made up of three nucleotides) is repeated multiple times. In normal genomic DNA, these repeats are usually present in a relatively stable and consistent range. However, when the number of repeats exceeds a certain threshold, it can result in an unstable genetic variant known as a trinucleotide repeat expansion.
These expansions can occur in various genes and are associated with several neurogenetic disorders, such as Huntington's disease, myotonic dystrophy, fragile X syndrome, and Friedreich's ataxia. The length of the trinucleotide repeat tends to expand further in subsequent generations, which can lead to anticipation – an earlier age of onset and increased severity of symptoms in successive generations.
The most common trinucleotide repeats involve CAG (cytosine-adenine-guanine) or CTG (cytosine-thymine-guanine) repeats, although other combinations like CGG, GAA, and GCT can also be involved. These repeat expansions can result in altered gene function, protein misfolding, aggregation, and toxicity, ultimately leading to the development of neurodegenerative diseases and other clinical manifestations.
Tandem Repeat Sequences (TRS) in genetics refer to repeating DNA sequences that are arranged directly after each other, hence the term "tandem." These sequences consist of a core repeat unit that is typically 2-6 base pairs long and is repeated multiple times in a head-to-tail fashion. The number of repetitions can vary between individuals and even between different cells within an individual, leading to genetic heterogeneity.
TRS can be classified into several types based on the number of repeat units and their stability. Short Tandem Repeats (STRs), also known as microsatellites, have fewer than 10 repeats, while Minisatellites have 10-60 repeats. Variations in the number of these repeats can lead to genetic instability and are associated with various genetic disorders and diseases, including neurological disorders, cancer, and forensic identification.
It's worth noting that TRS can also occur in protein-coding regions of genes, leading to the production of repetitive amino acid sequences. These can affect protein structure and function, contributing to disease phenotypes.
Horizontal gene transfer (HGT), also known as lateral gene transfer, is the movement of genetic material between organisms in a manner other than from parent to offspring (vertical gene transfer). In horizontal gene transfer, an organism can take up genetic material directly from its environment and incorporate it into its own genome. This process is common in bacteria and archaea, but has also been observed in eukaryotes including plants and animals.
Horizontal gene transfer can occur through several mechanisms, including:
1. Transformation: the uptake of free DNA from the environment by a cell.
2. Transduction: the transfer of genetic material between cells by a virus (bacteriophage).
3. Conjugation: the direct transfer of genetic material between two cells in physical contact, often facilitated by a conjugative plasmid or other mobile genetic element.
Horizontal gene transfer can play an important role in the evolution and adaptation of organisms, allowing them to acquire new traits and functions rapidly. It is also of concern in the context of genetically modified organisms (GMOs) and antibiotic resistance, as it can facilitate the spread of genes that confer resistance or other undesirable traits.
Trinucleotide Repeat Expansion is a genetic mutation where a sequence of three DNA nucleotides is repeated more frequently than what is typically found in the general population. In this type of mutation, the number of repeats can expand or increase from one generation to the next, leading to an increased risk of developing certain genetic disorders.
These disorders are often neurological and include conditions such as Huntington's disease, myotonic dystrophy, fragile X syndrome, and Friedreich's ataxia. The severity of these diseases can be related to the number of repeats present in the affected gene, with a higher number of repeats leading to more severe symptoms or an earlier age of onset.
It is important to note that not all trinucleotide repeat expansions will result in disease, and some people may carry these mutations without ever developing any symptoms. However, if the number of repeats crosses a certain threshold, it can lead to genetic instability and an increased risk of disease development.
Minisatellites, also known as VNTRs (Variable Number Tandem Repeats), are repetitive DNA sequences that consist of a core repeat unit of 10-60 base pairs, arranged in a head-to-tail fashion. They are often found in non-coding regions of the genome and can vary in the number of times the repeat unit is present in an individual's DNA. This variation in repeat number can occur both within and between individuals, making minisatellites useful as genetic markers for identification and forensic applications. They are also associated with certain genetic disorders and play a role in genome instability.
An ankyrin repeat is a protein structural motif, which is characterized by the repetition of a 33-amino acid long sequence. This motif is responsible for mediating protein-protein interactions and is found in a wide variety of proteins with diverse functions. Ankyrin repeats are known to play a role in various cellular processes such as signal transduction, cell cycle regulation, and ion transport. In particular, ankyrin repeat-containing proteins have been implicated in various human diseases, including cardiovascular disease, neurological disorders, and cancer.
Amino acid repetitive sequences refer to patterns of amino acids that are repeated in a polypeptide chain. These repetitions can vary in length and can be composed of a single type of amino acid or a combination of different types. In some cases, expansions of these repetitive sequences can lead to the production of abnormal proteins that are associated with certain genetic disorders. The expansion of trinucleotide repeats that code for particular amino acids is one example of this phenomenon. These expansions can result in protein misfolding and aggregation, leading to neurodegenerative diseases such as Huntington's disease and spinocerebellar ataxias.
Microsatellite repeats, also known as short tandem repeats (STRs), are repetitive DNA sequences made up of units of 1-6 base pairs that are repeated in a head-to-tail manner. These repeats are spread throughout the human genome and are highly polymorphic, meaning they can have different numbers of repeat units in different individuals.
Microsatellites are useful as genetic markers because of their high degree of variability. They are commonly used in forensic science to identify individuals, in genealogy to trace ancestry, and in medical research to study genetic diseases and disorders. Mutations in microsatellite repeats have been associated with various neurological conditions, including Huntington's disease and fragile X syndrome.
 Restriction enzyme
Restriction enzyme
Samira Kiani
Cancer pharmacogenomics
De-extinction
Philippe Horvath
CRISPR
Cas2
DNA repair
Guide RNA
Non-coding RNA
Cas12a
Joyce Van Eck
Gene knockout
CRISPR-Display
Genome-wide CRISPR-Cas9 knockout screens
No-SCAR genome editing
Shredding (disassembling genomic data)
Francisco Mojica
Genome editing
Trans-activating crRNA
CRISPR interference
Modifications (genetics)
Artificial transcription factor
Gene knockdown
Cas9
Yoshizumi Ishino
Horticulture
Ben Lamm
Designer baby
Pathogen
Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) associated protein 9 | Mad Scientist Laboratory
 The bacterial defense system CRISPR (clustered regularly interspaced short palindromic repeats) - Review of GnRH antagonists
The bacterial defense system CRISPR (clustered regularly interspaced short palindromic repeats) - Review of GnRH antagonists
 Genotyping of Salmonella spp. on the basis of CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) - UMS...
Genotyping of Salmonella spp. on the basis of CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) - UMS...
 Nucleic Acid Amplification Tests (NAATs) | CDC
Nucleic Acid Amplification Tests (NAATs) | CDC
 Transplantation of Clustered Regularly Interspaced Short Palindromic Repeats Modified Hematopoietic Progenitor Stem Cells ...
Transplantation of Clustered Regularly Interspaced Short Palindromic Repeats Modified Hematopoietic Progenitor Stem Cells ...
Clustered regularly interspaced short palindromic repeats (CRISPR) technology and genetic engineering strategies for microalgae...
 NIST Genome Editing Lexicon | NIST
NIST Genome Editing Lexicon | NIST
The clustered regularly interspaced short palindromic repeat (CRISPR)/CRISPR-associated (Cas) system has - DNA Topoisomerase -...
 CRISPRCasFinder, an update of CRISRFinder, includes a portable version, enhanced performance and integrates search for Cas...
CRISPRCasFinder, an update of CRISRFinder, includes a portable version, enhanced performance and integrates search for Cas...
Restriction enzyme - Wikipedia
Biological Informatics 2020 - LLRX
Interactions between the Ig-Superfamily Proteins DIP-α and Dpr6/10 Regulate Assembly of Neural Circuits
 Improving transgene research with split selectable markers
Improving transgene research with split selectable markers
MiR-33a is a therapeutic target in SPG4-related hereditary spastic paraplegia human neurons | Clinical Science | Portland Press
 Orphan crops: their importance and the urgency of improvement | SpringerLink
Orphan crops: their importance and the urgency of improvement | SpringerLink
 SCIplanet - CRISPR and the Age of the Genetically Modified Human
SCIplanet - CRISPR and the Age of the Genetically Modified Human
 Frontiers | Comparative Genomic Analyses Reveal Core-Genome-Wide Genes Under Positive Selection and Major Regulatory Hubs in...
Frontiers | Comparative Genomic Analyses Reveal Core-Genome-Wide Genes Under Positive Selection and Major Regulatory Hubs in...
 DNA interrogation by the CRISPR RNA-guided endonuclease Cas9 | Nature
DNA interrogation by the CRISPR RNA-guided endonuclease Cas9 | Nature
 stories-main | What Really Happened
stories-main | What Really Happened
stories-main | What Really Happened
 The Tree of Life: September 2008
The Tree of Life: September 2008
 Introductory Chapter: Biopharmaceuticals | IntechOpen
Introductory Chapter: Biopharmaceuticals | IntechOpen
 Plus it
Plus it
 Has Lady Gaga's Comeback Album Failed Before It's Even Out?
Has Lady Gaga's Comeback Album Failed Before It's Even Out?
 Alzheimer's: Scientists unveil 2 gene-editing approaches for treatment
Alzheimer's: Scientists unveil 2 gene-editing approaches for treatment
 IJMS | Free Full-Text | Human Brain Organoids in Migraine Research: Pathogenesis and Drug Development
IJMS | Free Full-Text | Human Brain Organoids in Migraine Research: Pathogenesis and Drug Development
 2013's Big Advances in Science | The Scientist Magazine®
2013's Big Advances in Science | The Scientist Magazine®
Jennifer A. Doudna | Molecular and Cell Biology
 Market Trends: CRISPR & CRISPR-associated (Cas) Genes Market
Market Trends: CRISPR & CRISPR-associated (Cas) Genes MarketCRISPR29
- Clustered regularly interspaced short palindromic repeat (CRISPR) elements are a particular family of tandem repeats present in prokaryotic genomes, in almost all archaea and in about half of bacteria, and which participate in a mechanism of acquired resistance against phages. (nih.gov)
- It's a key part of an ancient microbial immune system, called CRISPR-Cas (Clustered Regularly Interspaced Short Palindromic Repeats-Cas), that researchers recently discovered could be put to use as a tool for precisely altering DNA. (nih.gov)
- Clustered regularly interspaced short palindromic repeats (CRISPR) loci are arrays of short repeats separated by equally short "spacer" sequences [1]-[3]. (bioerc-iend.org)
- High prevalence of colonization with livestock-associ- larly interspaced short palindromic repeats (CRISPR) and ated (LA) methicillin-resistant Staphylococcus aureus CRISPR-associated genes ( cas ). (cdc.gov)
- An additional method is called clustered regularly interspaced short palindromic repeats, also known as CRISPR/Cas9. (nih.gov)
- Epigenetic editing strategies typically utilize CRISPR (clustered, regularly interspaced, short, palindromic repeats) or TALE (transcription activator-like effector) systems. (sciencedaily.com)
- The Code Breaker: Jennifer Doudna, CRISPR, and the Future of the Human Race is a big book made up of short chapters headed by attractive color photos - of Doudna, her colleagues and competitors, and of Isaacson himself joyfully doing a gene cutting sequence. (wshu.org)
- Researchers who discovered this pattern named it CRISPR for Clustered Regularly Interspaced Short Palindromic Repeats. (tudelft.nl)
- These patterns, which are widespread in the bacterial world, became known as clustered regularly interspaced short palindromic repeats, or CRISPR . (bostonreview.net)
- The next step came from biologists Jennifer Doudna and Emanuelle Charpentier (Nobel watchers, keep your eye on these two), who found that CRISPR sequences bind to a protein called Cas9, which holds the palindromic DNA stretches in place, making the spacer available for precise cutting. (bostonreview.net)
- CRISPR-menetelmissä (CRISPR = clustered regularly interspaced short palindromic repeats) luodaan kaksijuosteiseen DNA:han katkoksia, eli molekyylejä ikään kuin leikataan saksilla. (novartis.com)
- A well-known one is called CRISPR-Cas9, which is short for clustered regularly interspaced short palindromic repeats and CRISPR-associated protein 9. (medlineplus.gov)
- They create a small piece of RNA with a short "guide" sequence that attaches (binds) to a specific target sequence in a cell's DNA, much like the RNA segments bacteria produce from the CRISPR array. (medlineplus.gov)
- CRISPR-Cas (clustered regularly interspaced short palindromic repeats and CRISPR-associated proteins) adaptive immune systems defend microbes against foreign nucleic acids via RNA-guided endonucleases. (nih.gov)
- They share a common ferredoxin or RNA recognition motif (RRM) fold, and they recognize and excise CRISPR repeat RNAs that vary widely in primary and secondary structures. (nih.gov)
- There are numerous genome editing technologies, such as clustered regularly interspaced short palindromic repeats (CRISPR), site directed nuclease and oligonucleotide-directed mutagenesis. (frontiersin.org)
- There have been many headlines on CRISPR (clustered regularly interspaced short palindromic repeats) technology lately. (bcmj.org)
- Clustered Regularly Interspaced Short Palindromic Repeats» CRISPR )- Cas systemet ble først oppdaget og beskrevet som adaptiv immunitet i prokaryote organismer. (tannlegetidende.no)
- Det er likevel mange uløste oppgaver som krever at verktøyene blir ytterligere forbedret og at de kan leveres på en sikker måte til de celler og vev CRISPR-Cas anvendes til. (tannlegetidende.no)
- Jennifer A. Doudna, Emmanuelle Charpentier og medarbeidere publiserte i 2012 en nøkkelstudie der de beskrev en forbedret utgave av «gensaksen» CRISPR/Cas9 (1). (tannlegetidende.no)
- Denne forskningen er i en tidlig fase der CRISPR-Cas er viktige redskaper. (tannlegetidende.no)
- CRISPR, which stands for "Clustered, Regularly Interspaced, Short Palindromic Repeat," works by making cuts at targeted sites on a genome, altering an organism's DNA. (nih.gov)
- In addition, it offers tools comprising of Clustered, Regularly Interspaced Short Palindromic Repeats/CRISPR associated 9 (CRISPR/Cas9) system. (seekingalpha.com)
- A Chinese scientist stunned the world last month when he revealed he had created the first gene-edited babies using CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats), a powerful new technology that can remove specific genetic traits. (straight.com)
- CRISPR (clustered, regularly interspaced, short, palindromic repeats)/Cas (CRISPR-associated) systems are RNA-based bacterial defense mechanisms designed to recognize and eliminate foreign DNA from invading bacteriophage and plasmids. (jax.org)
- Generation of stable gene-edited plant lines using clustered regularly interspaced short palindromic repeats (CRISPR)-CRISPR-associated protein 9 (Cas9) requires a lengthy process of outcrossing to eliminate CRISPR-Cas9-associated sequences and produce transgene-free lines. (researchgate.net)
- Additionally, mature clustered, regularly interspaced, short palindromic repeats RNA (crRNA) and trans-activating CRISPR RNA (tracrRNA) constitute components of the recently developed CRISPR technology. (biopharminternational.com)
- CRISPR - it stands for clustered regularly interspaced short palindromic repeats - makes it much easier to precisely edit the DNA of living cells. (microsoft.com)
- However, some scientists and food safety advocates question the safety of the gene-editing technology - CRISPR (clustered regularly interspaced short palindromic repeats) - used by the WSU researchers and backed by investors like Bill Gates , and wonder if the products produced by the technology are really safe for human consumption. (blacklistednews.com)
Palindrome1
- The inverted repeat palindrome is also a sequence that reads the same forward and backward, but the forward and backward sequences are found in complementary DNA strands (i.e., of double-stranded DNA), as in GTATAC (GTATAC being complementary to CATATG). (wikipedia.org)
Base Sequence1
- Many of them are palindromic, meaning the base sequence reads the same backwards and forwards. (wikipedia.org)
Spacers2
- They consist in a succession of direct repeats (DR) of 24-47 bp separated by similar sized unique sequences (spacers). (nih.gov)
- In the large majority of cases, the direct repeats are highly conserved, while the number and nature of the spacers are often quite diverse, even among strains of a same species. (nih.gov)
Sequences1
- In theory, there are two types of palindromic sequences that can be possible in DNA. (wikipedia.org)
Proteins1
- In genetic conditions such as amelogenesis imperfecta (AI) in which certain enamel proteins are mutated, the teeth of these children are weak and often require repeated and increasingly progressive restorations to regain partial function. (nih.gov)
Equally1
- The distinctive sequence of repeats in the DNA interspaced with different but equally long fragments stood out in sequenced DNA from some bacteria and archaea . (tudelft.nl)