Cluster Analysis
Multigene Family
Gene Expression Profiling
Oligonucleotide Array Sequence Analysis
Principal Component Analysis
Molecular Sequence Data
Random Amplified Polymorphic DNA Technique
Discriminant Analysis
Space-Time Clustering
DNA Fingerprinting
Sequence Analysis, DNA
Algorithms
Bacterial Typing Techniques
Cluster Headache
Genotype
Phenotype
Base Sequence
Iron-Sulfur Proteins
Reproducibility of Results
Amino Acid Sequence
Geography
Amplified Fragment Length Polymorphism Analysis
Polymerase Chain Reaction
Species Specificity
RNA, Ribosomal, 16S
Software
Data Interpretation, Statistical
Polymorphism, Restriction Fragment Length
Computational Biology
Sequence Alignment
Models, Statistical
Genetic Markers
Classification
Pattern Recognition, Automated
Dental Fissures
Microsatellite Repeats
Factor Analysis, Statistical
Analysis of Variance
Molecular Epidemiology
Spatio-Temporal Analysis
Sequence Homology, Amino Acid
Electrophoresis, Gel, Pulsed-Field
Questionnaires
Evolution, Molecular
Expressed Sequence Tags
DNA Primers
DNA, Ribosomal
Models, Genetic
Electrophoresis, Starch Gel
Ecotype
Genetic Structures
Computer Simulation
Brazil
Polymorphism, Genetic
Statistics as Topic
Cloning, Molecular
Topography, Medical
Minisatellite Repeats
Bacteria
Bayes Theorem
Escherichia coli
Gene Expression Regulation
Geographic Information Systems
Models, Molecular
Transcription, Genetic
Gene Expression Regulation, Neoplastic
Neoplasms, Plasma Cell
Chromosome Mapping
Serotyping
Reverse Transcriptase Polymerase Chain Reaction
Microarray Analysis
Catastrophization
Mutation
Protein Array Analysis
Multivariate Analysis
RNA, Bacterial
Nucleic Acid Hybridization
Soil Microbiology
Gene Expression
Molecular Typing
Gene Library
Cross-Sectional Studies
Demography
Chorda Tympani Nerve
Databases, Factual
Transcriptome
RNA, Messenger
Models, Biological
Artificial Intelligence
Ecosystem
Risk Factors
Phylogeography
Immunohistochemistry
Cohort Studies
Binding Sites
DNA, Ribosomal Spacer
Genetics, Population
Severity of Illness Index
United States
Disease Outbreaks
Alleles
Spectroscopy, Fourier Transform Infrared
Biodiversity
Tumor Markers, Biological
Sequence Homology, Nucleic Acid
Rivers
Gene Expression Regulation, Bacterial
Sensitivity and Specificity
Least-Squares Analysis
Protein Structure, Secondary
Pain Measurement
Conserved Sequence
Pseudomonas
Sequence Analysis, Protein
Italy
Protein Conformation
Enzymes
DNA, Complementary
Cattle
Electron Spin Resonance Spectroscopy
Restriction Mapping
Image Processing, Computer-Assisted
Proteins
Ferredoxins
Socioeconomic Factors
Fibromyalgia
Taste
Ringo, Doty, Demeter and Simard, Cerebral Cortex 1994;4:331-343: a proof of the need for the spatial clustering of interneuronal connections to enhance cortical computation. (1/16506)
It has been argued that an important principle driving the organization of the cerebral cortex towards local processing has been the need to decrease time lost to interneuronal conduction delay. In this paper, I show for a simplified model of the cerebral cortex, using analytical means, that if interneuronal conduction time increases proportional to interneuronal distance, then the only way to increase the numbers of synaptic events occurring in a fixed finite time period is to spatially cluster interneuronal connections. (+info)Cluster survey evaluation of coverage and risk factors for failure to be immunized during the 1995 National Immunization Days in Egypt. (2/16506)
BACKGROUND: In 1995, Egypt continued to experience endemic wild poliovirus transmission despite achieving high routine immunization coverage with at least three doses of oral poliovirus vaccine (OPV3) and implementing National Immunization Days (NIDs) annually for several years. METHODS: Parents of 4188 children in 3216 households throughout Egypt were surveyed after the second round of the 1995 NIDs. RESULTS: Nationwide, 74% of children are estimated to have received both NID doses, 17% one NID dose, and 9% neither NID dose. Previously unimmunized (47%) or partially immunized (64%) children were less likely to receive two NID doses of OPV than were fully immunized children (76%) (P < 0.001). Other risk factors nationwide for failure to receive NID OPV included distance from residence to nearest NID site >10 minute walk (P < 0.001), not being informed about the NID at least one day in advance (P < 0.001), and residing in a household which does not watch television (P < 0.001). Based on these findings, subsequent NIDs in Egypt were modified to improve coverage, which has resulted in a marked decrease in the incidence of paralytic poliomyelitis in Egypt. CONCLUSIONS: In selected situations, surveys can provide important information that is useful for planning future NIDs. (+info)Clusters of Pneumocystis carinii pneumonia: analysis of person-to-person transmission by genotyping. (3/16506)
Genotyping at the internal transcribed spacer (ITS) regions of the nuclear rRNA operon was performed on isolates of P. carinii sp. f. hominis from three clusters of P. carinii pneumonia among eight patients with haematological malignancies and six with HIV infection. Nine different ITS sequence types of P. carinii sp. f. hominis were identified in the samples from the patients with haematological malignancies, suggesting that this cluster of cases of P. carinii pneumonia was unlikely to have resulted from nosocomial transmission. A common ITS sequence type was observed in two of the patients with haematological malignancies who shared a hospital room, and also in two of the patients with HIV infection who had prolonged close contact on the ward. In contrast, different ITS sequence types were detected in samples from an HIV-infected homosexual couple who shared the same household. These data suggest that person-to-person transmission of P. carinii sp. f. hominis may occur from infected to susceptible immunosuppressed patients with close contact within hospital environments. However direct transmission between patients did not account for the majority of cases within the clusters, suggesting that person-to-person transmission of P. carinii sp. f. hominis infection may be a relatively infrequent event and does not constitute the major route of transmission in man. (+info)Influence of sampling on estimates of clustering and recent transmission of Mycobacterium tuberculosis derived from DNA fingerprinting techniques. (4/16506)
The availability of DNA fingerprinting techniques for Mycobacterium tuberculosis has led to attempts to estimate the extent of recent transmission in populations, using the assumption that groups of tuberculosis patients with identical isolates ("clusters") are likely to reflect recently acquired infections. It is never possible to include all cases of tuberculosis in a given population in a study, and the proportion of isolates found to be clustered will depend on the completeness of the sampling. Using stochastic simulation models based on real and hypothetical populations, the authors demonstrate the influence of incomplete sampling on the estimates of clustering obtained. The results show that as the sampling fraction increases, the proportion of isolates identified as clustered also increases and the variance of the estimated proportion clustered decreases. Cluster size is also important: the underestimation of clustering for any given sampling fraction is greater, and the variability in the results obtained is larger, for populations with small clusters than for those with the same number of individuals arranged in large clusters. A considerable amount of caution should be used in interpreting the results of studies on clustering of M. tuberculosis isolates, particularly when sampling fractions are small. (+info)Newly recognized focus of La Crosse encephalitis in Tennessee. (5/16506)
La Crosse virus is a mosquito-borne arbovirus that causes encephalitis in children. Only nine cases were reported in Tennessee during the 33-year period from 1964-1996. We investigated a cluster of La Crosse encephalitis cases in eastern Tennessee in 1997. Medical records of all suspected cases of La Crosse virus infection at a pediatric referral hospital were reviewed, and surveillance was enhanced in the region. Previous unreported cases were identified by surveying 20 hospitals in the surrounding 16 counties. Mosquito eggs were collected from five sites. Ten cases of La Crosse encephalitis were serologically confirmed. None of the patients had been discharged from hospitals in the region with diagnosed La Crosse encephalitis in the preceding 5 years. Aedes triseriatus and Aedes albopictus were collected at the case sites; none of the mosquitos had detectable La Crosse virus. This cluster may represent an extension of a recently identified endemic focus of La Crosse virus infection in West Virginia. (+info)Hierarchical cluster analysis applied to workers' exposures in fiberglass insulation manufacturing. (6/16506)
The objectives of this study were to explore the application of cluster analysis to the characterization of multiple exposures in industrial hygiene practice and to compare exposure groupings based on the result from cluster analysis with that based on non-measurement-based approaches commonly used in epidemiology. Cluster analysis was performed for 37 workers simultaneously exposed to three agents (endotoxin, phenolic compounds and formaldehyde) in fiberglass insulation manufacturing. Different clustering algorithms, including complete-linkage (or farthest-neighbor), single-linkage (or nearest-neighbor), group-average and model-based clustering approaches, were used to construct the tree structures from which clusters can be formed. Differences were observed between the exposure clusters constructed by these different clustering algorithms. When contrasting the exposure classification based on tree structures with that based on non-measurement-based information, the results indicate that the exposure clusters identified from the tree structures had little in common with the classification results from either the traditional exposure zone or the work group classification approach. In terms of the defining homogeneous exposure groups or from the standpoint of health risk, some toxicological normalization in the components of the exposure vector appears to be required in order to form meaningful exposure groupings from cluster analysis. Finally, it remains important to see if the lack of correspondence between exposure groups based on epidemiological classification and measurement data is a peculiarity of the data or a more general problem in multivariate exposure analysis. (+info)A taxonomy of health networks and systems: bringing order out of chaos. (7/16506)
OBJECTIVE: To use existing theory and data for empirical development of a taxonomy that identifies clusters of organizations sharing common strategic/structural features. DATA SOURCES: Data from the 1994 and 1995 American Hospital Association Annual Surveys, which provide extensive data on hospital involvement in hospital-led health networks and systems. STUDY DESIGN: Theories of organization behavior and industrial organization economics were used to identify three strategic/structural dimensions: differentiation, which refers to the number of different products/services along a healthcare continuum; integration, which refers to mechanisms used to achieve unity of effort across organizational components; and centralization, which relates to the extent to which activities take place at centralized versus dispersed locations. These dimensions were applied to three components of the health service/product continuum: hospital services, physician arrangements, and provider-based insurance activities. DATA EXTRACTION METHODS: We identified 295 health systems and 274 health networks across the United States in 1994, and 297 health systems and 306 health networks in 1995 using AHA data. Empirical measures aggregated individual hospital data to the health network and system level. PRINCIPAL FINDINGS: We identified a reliable, internally valid, and stable four-cluster solution for health networks and a five-cluster solution for health systems. We found that differentiation and centralization were particularly important in distinguishing unique clusters of organizations. High differentiation typically occurred with low centralization, which suggests that a broader scope of activity is more difficult to centrally coordinate. Integration was also important, but we found that health networks and systems typically engaged in both ownership-based and contractual-based integration or they were not integrated at all. CONCLUSIONS: Overall, we were able to classify approximately 70 percent of hospital-led health networks and 90 percent of hospital-led health systems into well-defined organizational clusters. Given the widespread perception that organizational change in healthcare has been chaotic, our research suggests that important and meaningful similarities exist across many evolving organizations. The resulting taxonomy provides a new lexicon for researchers, policymakers, and healthcare executives for characterizing key strategic and structural features of evolving organizations. The taxonomy also provides a framework for future inquiry about the relationships between organizational strategy, structure, and performance, and for assessing policy issues, such as Medicare Provider Sponsored Organizations, antitrust, and insurance regulation. (+info)Double blind, cluster randomised trial of low dose supplementation with vitamin A or beta carotene on mortality related to pregnancy in Nepal. The NNIPS-2 Study Group. (8/16506)
OBJECTIVE: To assess the impact on mortality related to pregnancy of supplementing women of reproductive age each week with a recommended dietary allowance of vitamin A, either preformed or as beta carotene. DESIGN: Double blind, cluster randomised, placebo controlled field trial. SETTING: Rural southeast central plains of Nepal (Sarlahi district). SUBJECTS: 44 646 married women, of whom 20 119 became pregnant 22 189 times. INTERVENTION: 270 wards randomised to 3 groups of 90 each for women to receive weekly a single oral supplement of placebo, vitamin A (7000 micrograms retinol equivalents) or beta carotene (42 mg, or 7000 micrograms retinol equivalents) for over 31/2 years. MAIN OUTCOME MEASURES: All cause mortality in women during pregnancy up to 12 weeks post partum (pregnancy related mortality) and mortality during pregnancy to 6 weeks postpartum, excluding deaths apparently related to injury (maternal mortality). RESULTS: Mortality related to pregnancy in the placebo, vitamin A, and beta carotene groups was 704, 426, and 361 deaths per 100 000 pregnancies, yielding relative risks (95% confidence intervals) of 0. 60 (0.37 to 0.97) and 0.51 (0.30 to 0.86). This represented reductions of 40% (P<0.04) and 49% (P<0.01) among those who received vitamin A and beta carotene. Combined, vitamin A or beta carotene lowered mortality by 44% (0.56 (0.37 to 0.84), P<0.005) and reduced the maternal mortality ratio from 645 to 385 deaths per 100 000 live births, or by 40% (P<0.02). Differences in cause of death could not be reliably distinguished between supplemented and placebo groups. CONCLUSION: Supplementation of women with either vitamin A or beta carotene at recommended dietary amounts during childbearing years can lower mortality related to pregnancy in rural, undernourished populations of south Asia. (+info)Cluster analysis is a statistical method used to group similar objects or data points together based on their characteristics or features. In medical and healthcare research, cluster analysis can be used to identify patterns or relationships within complex datasets, such as patient records or genetic information. This technique can help researchers to classify patients into distinct subgroups based on their symptoms, diagnoses, or other variables, which can inform more personalized treatment plans or public health interventions.
Cluster analysis involves several steps, including:
1. Data preparation: The researcher must first collect and clean the data, ensuring that it is complete and free from errors. This may involve removing outlier values or missing data points.
2. Distance measurement: Next, the researcher must determine how to measure the distance between each pair of data points. Common methods include Euclidean distance (the straight-line distance between two points) or Manhattan distance (the distance between two points along a grid).
3. Clustering algorithm: The researcher then applies a clustering algorithm, which groups similar data points together based on their distances from one another. Common algorithms include hierarchical clustering (which creates a tree-like structure of clusters) or k-means clustering (which assigns each data point to the nearest centroid).
4. Validation: Finally, the researcher must validate the results of the cluster analysis by evaluating the stability and robustness of the clusters. This may involve re-running the analysis with different distance measures or clustering algorithms, or comparing the results to external criteria.
Cluster analysis is a powerful tool for identifying patterns and relationships within complex datasets, but it requires careful consideration of the data preparation, distance measurement, and validation steps to ensure accurate and meaningful results.
A multigene family is a group of genetically related genes that share a common ancestry and have similar sequences or structures. These genes are arranged in clusters on a chromosome and often encode proteins with similar functions. They can arise through various mechanisms, including gene duplication, recombination, and transposition. Multigene families play crucial roles in many biological processes, such as development, immunity, and metabolism. Examples of multigene families include the globin genes involved in oxygen transport, the immune system's major histocompatibility complex (MHC) genes, and the cytochrome P450 genes associated with drug metabolism.
Gene expression profiling is a laboratory technique used to measure the activity (expression) of thousands of genes at once. This technique allows researchers and clinicians to identify which genes are turned on or off in a particular cell, tissue, or organism under specific conditions, such as during health, disease, development, or in response to various treatments.
The process typically involves isolating RNA from the cells or tissues of interest, converting it into complementary DNA (cDNA), and then using microarray or high-throughput sequencing technologies to determine which genes are expressed and at what levels. The resulting data can be used to identify patterns of gene expression that are associated with specific biological states or processes, providing valuable insights into the underlying molecular mechanisms of diseases and potential targets for therapeutic intervention.
In recent years, gene expression profiling has become an essential tool in various fields, including cancer research, drug discovery, and personalized medicine, where it is used to identify biomarkers of disease, predict patient outcomes, and guide treatment decisions.
Oligonucleotide Array Sequence Analysis is a type of microarray analysis that allows for the simultaneous measurement of the expression levels of thousands of genes in a single sample. In this technique, oligonucleotides (short DNA sequences) are attached to a solid support, such as a glass slide, in a specific pattern. These oligonucleotides are designed to be complementary to specific target mRNA sequences from the sample being analyzed.
During the analysis, labeled RNA or cDNA from the sample is hybridized to the oligonucleotide array. The level of hybridization is then measured and used to determine the relative abundance of each target sequence in the sample. This information can be used to identify differences in gene expression between samples, which can help researchers understand the underlying biological processes involved in various diseases or developmental stages.
It's important to note that this technique requires specialized equipment and bioinformatics tools for data analysis, as well as careful experimental design and validation to ensure accurate and reproducible results.
Phylogeny is the evolutionary history and relationship among biological entities, such as species or genes, based on their shared characteristics. In other words, it refers to the branching pattern of evolution that shows how various organisms have descended from a common ancestor over time. Phylogenetic analysis involves constructing a tree-like diagram called a phylogenetic tree, which depicts the inferred evolutionary relationships among organisms or genes based on molecular sequence data or other types of characters. This information is crucial for understanding the diversity and distribution of life on Earth, as well as for studying the emergence and spread of diseases.
Principal Component Analysis (PCA) is not a medical term, but a statistical technique that is used in various fields including bioinformatics and medicine. It is a method used to identify patterns in high-dimensional data by reducing the dimensionality of the data while retaining most of the variation in the dataset.
In medical or biological research, PCA may be used to analyze large datasets such as gene expression data or medical imaging data. By applying PCA, researchers can identify the principal components, which are linear combinations of the original variables that explain the maximum amount of variance in the data. These principal components can then be used for further analysis, visualization, and interpretation of the data.
PCA is a widely used technique in data analysis and has applications in various fields such as genomics, proteomics, metabolomics, and medical imaging. It helps researchers to identify patterns and relationships in complex datasets, which can lead to new insights and discoveries in medical research.
Molecular sequence data refers to the specific arrangement of molecules, most commonly nucleotides in DNA or RNA, or amino acids in proteins, that make up a biological macromolecule. This data is generated through laboratory techniques such as sequencing, and provides information about the exact order of the constituent molecules. This data is crucial in various fields of biology, including genetics, evolution, and molecular biology, allowing for comparisons between different organisms, identification of genetic variations, and studies of gene function and regulation.
Random Amplified Polymorphic DNA (RAPD) technique is a type of Polymerase Chain Reaction (PCR)-based method used in molecular biology for DNA fingerprinting and genetic diversity analysis. This technique utilizes random primers of arbitrary nucleotide sequences to amplify random segments of genomic DNA. The amplified products are then separated by electrophoresis, and the resulting banding patterns are analyzed.
In RAPD analysis, the randomly chosen primers bind to multiple sites in the genome, and the intervening regions between the primer binding sites are amplified. Since the primer binding sites can vary among individuals within a species or among different species, the resulting amplicons will also differ. These differences in amplicon size and pattern can be used to distinguish between individuals or populations at the DNA level.
RAPD is a relatively simple and cost-effective technique that does not require prior knowledge of the genome sequence. However, it has some limitations, such as low reproducibility and sensitivity to experimental conditions. Despite these limitations, RAPD remains a useful tool for genetic analysis in various fields, including forensics, plant breeding, and microbial identification.
Discriminant analysis is a statistical method used for classifying observations or individuals into distinct categories or groups based on multiple predictor variables. It is commonly used in medical research to help diagnose or predict the presence or absence of a particular condition or disease.
In discriminant analysis, a linear combination of the predictor variables is created, and the resulting function is used to determine the group membership of each observation. The function is derived from the means and variances of the predictor variables for each group, with the goal of maximizing the separation between the groups while minimizing the overlap.
There are two types of discriminant analysis:
1. Linear Discriminant Analysis (LDA): This method assumes that the predictor variables are normally distributed and have equal variances within each group. LDA is used when there are two or more groups to be distinguished.
2. Quadratic Discriminant Analysis (QDA): This method does not assume equal variances within each group, allowing for more flexibility in modeling the distribution of predictor variables. QDA is used when there are two or more groups to be distinguished.
Discriminant analysis can be useful in medical research for developing diagnostic models that can accurately classify patients based on a set of clinical or laboratory measures. It can also be used to identify which predictor variables are most important in distinguishing between different groups, providing insights into the underlying biological mechanisms of disease.
Genetic variation refers to the differences in DNA sequences among individuals and populations. These variations can result from mutations, genetic recombination, or gene flow between populations. Genetic variation is essential for evolution by providing the raw material upon which natural selection acts. It can occur within a single gene, between different genes, or at larger scales, such as differences in the number of chromosomes or entire sets of chromosomes. The study of genetic variation is crucial in understanding the genetic basis of diseases and traits, as well as the evolutionary history and relationships among species.
Space-time clustering is not a term that has a specific medical definition. However, it is a concept that is used in epidemiology, which is the study of how often diseases occur and what factors may be associated with their occurrence. Space-time clustering refers to the phenomenon where cases of a disease or other health event tend to cluster together in both space and time. This means that the cases are not evenly distributed across a geographic area, but instead are concentrated in certain locations and at certain points in time.
Space-time clustering can be an important tool for identifying potential causes of diseases or other health events. For example, if cases of a particular disease tend to cluster around certain environmental exposures, such as polluted air or water, this may suggest that these exposures are contributing to the development of the disease. Similarly, if cases of a disease tend to cluster in both space and time, this may suggest that there is a common cause, such as an outbreak of a contagious illness.
It's important to note that not all observed clustering is necessarily meaningful or indicative of a causal relationship. It's possible for clusters to occur by chance alone, especially in cases where the number of cases is small. Therefore, statistical methods are often used to determine whether a cluster is statistically significant, taking into account factors such as the number of cases, the size of the population at risk, and the expected distribution of cases based on chance.
DNA fingerprinting, also known as DNA profiling or genetic fingerprinting, is a laboratory technique used to identify and compare the unique genetic makeup of individuals by analyzing specific regions of their DNA. This method is based on the variation in the length of repetitive sequences of DNA called variable number tandem repeats (VNTRs) or short tandem repeats (STRs), which are located at specific locations in the human genome and differ significantly among individuals, except in the case of identical twins.
The process of DNA fingerprinting involves extracting DNA from a sample, amplifying targeted regions using the polymerase chain reaction (PCR), and then separating and visualizing the resulting DNA fragments through electrophoresis. The fragment patterns are then compared to determine the likelihood of a match between two samples.
DNA fingerprinting has numerous applications in forensic science, paternity testing, identity verification, and genealogical research. It is considered an essential tool for providing strong evidence in criminal investigations and resolving disputes related to parentage and inheritance.
DNA Sequence Analysis is the systematic determination of the order of nucleotides in a DNA molecule. It is a critical component of modern molecular biology, genetics, and genetic engineering. The process involves determining the exact order of the four nucleotide bases - adenine (A), guanine (G), cytosine (C), and thymine (T) - in a DNA molecule or fragment. This information is used in various applications such as identifying gene mutations, studying evolutionary relationships, developing molecular markers for breeding, and diagnosing genetic diseases.
The process of DNA Sequence Analysis typically involves several steps, including DNA extraction, PCR amplification (if necessary), purification, sequencing reaction, and electrophoresis. The resulting data is then analyzed using specialized software to determine the exact sequence of nucleotides.
In recent years, high-throughput DNA sequencing technologies have revolutionized the field of genomics, enabling the rapid and cost-effective sequencing of entire genomes. This has led to an explosion of genomic data and new insights into the genetic basis of many diseases and traits.
An algorithm is not a medical term, but rather a concept from computer science and mathematics. In the context of medicine, algorithms are often used to describe step-by-step procedures for diagnosing or managing medical conditions. These procedures typically involve a series of rules or decision points that help healthcare professionals make informed decisions about patient care.
For example, an algorithm for diagnosing a particular type of heart disease might involve taking a patient's medical history, performing a physical exam, ordering certain diagnostic tests, and interpreting the results in a specific way. By following this algorithm, healthcare professionals can ensure that they are using a consistent and evidence-based approach to making a diagnosis.
Algorithms can also be used to guide treatment decisions. For instance, an algorithm for managing diabetes might involve setting target blood sugar levels, recommending certain medications or lifestyle changes based on the patient's individual needs, and monitoring the patient's response to treatment over time.
Overall, algorithms are valuable tools in medicine because they help standardize clinical decision-making and ensure that patients receive high-quality care based on the latest scientific evidence.
Bacterial DNA refers to the genetic material found in bacteria. It is composed of a double-stranded helix containing four nucleotide bases - adenine (A), thymine (T), guanine (G), and cytosine (C) - that are linked together by phosphodiester bonds. The sequence of these bases in the DNA molecule carries the genetic information necessary for the growth, development, and reproduction of bacteria.
Bacterial DNA is circular in most bacterial species, although some have linear chromosomes. In addition to the main chromosome, many bacteria also contain small circular pieces of DNA called plasmids that can carry additional genes and provide resistance to antibiotics or other environmental stressors.
Unlike eukaryotic cells, which have their DNA enclosed within a nucleus, bacterial DNA is present in the cytoplasm of the cell, where it is in direct contact with the cell's metabolic machinery. This allows for rapid gene expression and regulation in response to changing environmental conditions.
Bacterial typing techniques are methods used to identify and differentiate bacterial strains or isolates based on their unique characteristics. These techniques are essential in epidemiological studies, infection control, and research to understand the transmission dynamics, virulence, and antibiotic resistance patterns of bacterial pathogens.
There are various bacterial typing techniques available, including:
1. **Bacteriophage Typing:** This method involves using bacteriophages (viruses that infect bacteria) to identify specific bacterial strains based on their susceptibility or resistance to particular phages.
2. **Serotyping:** It is a technique that differentiates bacterial strains based on the antigenic properties of their cell surface components, such as capsules, flagella, and somatic (O) and flagellar (H) antigens.
3. **Biochemical Testing:** This method uses biochemical reactions to identify specific metabolic pathways or enzymes present in bacterial strains, which can be used for differentiation. Commonly used tests include the catalase test, oxidase test, and various sugar fermentation tests.
4. **Molecular Typing Techniques:** These methods use genetic markers to identify and differentiate bacterial strains at the DNA level. Examples of molecular typing techniques include:
* **Pulsed-Field Gel Electrophoresis (PFGE):** This method uses restriction enzymes to digest bacterial DNA, followed by electrophoresis in an agarose gel under pulsed electrical fields. The resulting banding patterns are analyzed and compared to identify related strains.
* **Multilocus Sequence Typing (MLST):** It involves sequencing specific housekeeping genes to generate unique sequence types that can be used for strain identification and phylogenetic analysis.
* **Whole Genome Sequencing (WGS):** This method sequences the entire genome of a bacterial strain, providing the most detailed information on genetic variation and relatedness between strains. WGS data can be analyzed using various bioinformatics tools to identify single nucleotide polymorphisms (SNPs), gene deletions or insertions, and other genetic changes that can be used for strain differentiation.
These molecular typing techniques provide higher resolution than traditional methods, allowing for more accurate identification and comparison of bacterial strains. They are particularly useful in epidemiological investigations to track the spread of pathogens and identify outbreaks.
A cluster headache is a type of primary headache disorder characterized by severe, one-sided headaches that occur in clusters, meaning they happen several times a day for several weeks or months and then go into remission for a period of time. The pain of a cluster headache is typically intense and often described as a sharp, stabbing, or burning sensation around the eye or temple on one side of the head.
Cluster headaches are relatively rare, affecting fewer than 1 in 1000 people. They tend to affect men more often than women and usually start between the ages of 20 and 50. The exact cause of cluster headaches is not fully understood, but they are thought to be related to abnormalities in the hypothalamus, a part of the brain that regulates various bodily functions, including hormone production and sleep-wake cycles.
Cluster headache attacks can last from 15 minutes to several hours and may be accompanied by other symptoms such as redness or tearing of the eye, runny nose, sweating, or swelling on the affected side of the face. During a cluster period, headaches typically occur at the same time each day, often at night or in the early morning.
Cluster headaches can be treated with various medications, including triptans, oxygen therapy, and local anesthetics. Preventive treatments such as verapamil, lithium, or corticosteroids may also be used to reduce the frequency and severity of cluster headache attacks during a cluster period.
Genotype, in genetics, refers to the complete heritable genetic makeup of an individual organism, including all of its genes. It is the set of instructions contained in an organism's DNA for the development and function of that organism. The genotype is the basis for an individual's inherited traits, and it can be contrasted with an individual's phenotype, which refers to the observable physical or biochemical characteristics of an organism that result from the expression of its genes in combination with environmental influences.
It is important to note that an individual's genotype is not necessarily identical to their genetic sequence. Some genes have multiple forms called alleles, and an individual may inherit different alleles for a given gene from each parent. The combination of alleles that an individual inherits for a particular gene is known as their genotype for that gene.
Understanding an individual's genotype can provide important information about their susceptibility to certain diseases, their response to drugs and other treatments, and their risk of passing on inherited genetic disorders to their offspring.
A phenotype is the physical or biochemical expression of an organism's genes, or the observable traits and characteristics resulting from the interaction of its genetic constitution (genotype) with environmental factors. These characteristics can include appearance, development, behavior, and resistance to disease, among others. Phenotypes can vary widely, even among individuals with identical genotypes, due to differences in environmental influences, gene expression, and genetic interactions.
A base sequence in the context of molecular biology refers to the specific order of nucleotides in a DNA or RNA molecule. In DNA, these nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T). In RNA, uracil (U) takes the place of thymine. The base sequence contains genetic information that is transcribed into RNA and ultimately translated into proteins. It is the exact order of these bases that determines the genetic code and thus the function of the DNA or RNA molecule.
Iron-sulfur proteins are a group of metalloproteins that contain iron and sulfur atoms in their active centers. These clusters of iron and sulfur atoms, also known as iron-sulfur clusters, can exist in various forms, including Fe-S, 2Fe-2S, 3Fe-4S, and 4Fe-4S structures. The iron atoms are coordinated to the protein through cysteine residues, while the sulfur atoms can be in the form of sulfide (S2-) or sulfane (-S-).
These proteins play crucial roles in many biological processes, such as electron transfer, redox reactions, and enzyme catalysis. They are found in various organisms, from bacteria to humans, and are involved in a wide range of cellular functions, including energy metabolism, photosynthesis, nitrogen fixation, and DNA repair.
Iron-sulfur proteins can be classified into several categories based on their structure and function, such as ferredoxins, Rieske proteins, high-potential iron-sulfur proteins (HiPIPs), and radical SAM enzymes. Dysregulation or mutations in iron-sulfur protein genes have been linked to various human diseases, including neurodegenerative disorders, cancer, and mitochondrial disorders.
Reproducibility of results in a medical context refers to the ability to obtain consistent and comparable findings when a particular experiment or study is repeated, either by the same researcher or by different researchers, following the same experimental protocol. It is an essential principle in scientific research that helps to ensure the validity and reliability of research findings.
In medical research, reproducibility of results is crucial for establishing the effectiveness and safety of new treatments, interventions, or diagnostic tools. It involves conducting well-designed studies with adequate sample sizes, appropriate statistical analyses, and transparent reporting of methods and findings to allow other researchers to replicate the study and confirm or refute the results.
The lack of reproducibility in medical research has become a significant concern in recent years, as several high-profile studies have failed to produce consistent findings when replicated by other researchers. This has led to increased scrutiny of research practices and a call for greater transparency, rigor, and standardization in the conduct and reporting of medical research.
An amino acid sequence is the specific order of amino acids in a protein or peptide molecule, formed by the linking of the amino group (-NH2) of one amino acid to the carboxyl group (-COOH) of another amino acid through a peptide bond. The sequence is determined by the genetic code and is unique to each type of protein or peptide. It plays a crucial role in determining the three-dimensional structure and function of proteins.
I'm sorry for any confusion, but "geography" is not a term that has a medical definition. Geography is a field of study that deals with the location and distribution of physical and cultural features on Earth's surface, as well as how humans interact with and affect those features. It is not a concept that is typically used in a medical context. If you have any questions related to medicine or healthcare, I would be happy to try to help answer them for you!
Amplified Fragment Length Polymorphism (AFLP) analysis is a molecular biology technique used for DNA fingerprinting, genetic mapping, and population genetics studies. It is based on the selective amplification of restriction fragments from a total digest of genomic DNA, followed by separation and detection of the resulting fragments using polyacrylamide gel electrophoresis.
In AFLP analysis, genomic DNA is first digested with two different restriction enzymes, one that cuts frequently (e.g., EcoRI) and another that cuts less frequently (e.g., MseI). The resulting fragments are then ligated to adapter sequences that provide recognition sites for PCR amplification.
Selective amplification of the restriction fragments is achieved by using primers that anneal to the adapter sequences and contain additional selective nucleotides at their 3' ends. This allows for the amplification of a subset of the total number of restriction fragments, resulting in a pattern of bands that is specific to the DNA sample being analyzed.
The amplified fragments are then separated by size using polyacrylamide gel electrophoresis and visualized by staining with a fluorescent dye. The resulting banding pattern can be used for various applications, including identification of genetic differences between individuals, detection of genomic alterations in cancer cells, and analysis of population structure and diversity.
Overall, AFLP analysis is a powerful tool for the study of complex genomes and has been widely used in various fields of biology, including plant and animal breeding, forensic science, and medical research.
Polymerase Chain Reaction (PCR) is a laboratory technique used to amplify specific regions of DNA. It enables the production of thousands to millions of copies of a particular DNA sequence in a rapid and efficient manner, making it an essential tool in various fields such as molecular biology, medical diagnostics, forensic science, and research.
The PCR process involves repeated cycles of heating and cooling to separate the DNA strands, allow primers (short sequences of single-stranded DNA) to attach to the target regions, and extend these primers using an enzyme called Taq polymerase, resulting in the exponential amplification of the desired DNA segment.
In a medical context, PCR is often used for detecting and quantifying specific pathogens (viruses, bacteria, fungi, or parasites) in clinical samples, identifying genetic mutations or polymorphisms associated with diseases, monitoring disease progression, and evaluating treatment effectiveness.
A bacterial gene is a segment of DNA (or RNA in some viruses) that contains the genetic information necessary for the synthesis of a functional bacterial protein or RNA molecule. These genes are responsible for encoding various characteristics and functions of bacteria such as metabolism, reproduction, and resistance to antibiotics. They can be transmitted between bacteria through horizontal gene transfer mechanisms like conjugation, transformation, and transduction. Bacterial genes are often organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule.
It's important to note that the term "bacterial gene" is used to describe genetic elements found in bacteria, but not all genetic elements in bacteria are considered genes. For example, some DNA sequences may not encode functional products and are therefore not considered genes. Additionally, some bacterial genes may be plasmid-borne or phage-borne, rather than being located on the bacterial chromosome.
Species specificity is a term used in the field of biology, including medicine, to refer to the characteristic of a biological entity (such as a virus, bacterium, or other microorganism) that allows it to interact exclusively or preferentially with a particular species. This means that the biological entity has a strong affinity for, or is only able to infect, a specific host species.
For example, HIV is specifically adapted to infect human cells and does not typically infect other animal species. Similarly, some bacterial toxins are species-specific and can only affect certain types of animals or humans. This concept is important in understanding the transmission dynamics and host range of various pathogens, as well as in developing targeted therapies and vaccines.
Ribosomal RNA (rRNA) is a type of RNA that combines with proteins to form ribosomes, which are complex structures inside cells where protein synthesis occurs. The "16S" refers to the sedimentation coefficient of the rRNA molecule, which is a measure of its size and shape. In particular, 16S rRNA is a component of the smaller subunit of the prokaryotic ribosome (found in bacteria and archaea), and is often used as a molecular marker for identifying and classifying these organisms due to its relative stability and conservation among species. The sequence of 16S rRNA can be compared across different species to determine their evolutionary relationships and taxonomic positions.
I am not aware of a widely accepted medical definition for the term "software," as it is more commonly used in the context of computer science and technology. Software refers to programs, data, and instructions that are used by computers to perform various tasks. It does not have direct relevance to medical fields such as anatomy, physiology, or clinical practice. If you have any questions related to medicine or healthcare, I would be happy to try to help with those instead!
Statistical data interpretation involves analyzing and interpreting numerical data in order to identify trends, patterns, and relationships. This process often involves the use of statistical methods and tools to organize, summarize, and draw conclusions from the data. The goal is to extract meaningful insights that can inform decision-making, hypothesis testing, or further research.
In medical contexts, statistical data interpretation is used to analyze and make sense of large sets of clinical data, such as patient outcomes, treatment effectiveness, or disease prevalence. This information can help healthcare professionals and researchers better understand the relationships between various factors that impact health outcomes, develop more effective treatments, and identify areas for further study.
Some common statistical methods used in data interpretation include descriptive statistics (e.g., mean, median, mode), inferential statistics (e.g., hypothesis testing, confidence intervals), and regression analysis (e.g., linear, logistic). These methods can help medical professionals identify patterns and trends in the data, assess the significance of their findings, and make evidence-based recommendations for patient care or public health policy.
Bacterial proteins are a type of protein that are produced by bacteria as part of their structural or functional components. These proteins can be involved in various cellular processes, such as metabolism, DNA replication, transcription, and translation. They can also play a role in bacterial pathogenesis, helping the bacteria to evade the host's immune system, acquire nutrients, and multiply within the host.
Bacterial proteins can be classified into different categories based on their function, such as:
1. Enzymes: Proteins that catalyze chemical reactions in the bacterial cell.
2. Structural proteins: Proteins that provide structural support and maintain the shape of the bacterial cell.
3. Signaling proteins: Proteins that help bacteria to communicate with each other and coordinate their behavior.
4. Transport proteins: Proteins that facilitate the movement of molecules across the bacterial cell membrane.
5. Toxins: Proteins that are produced by pathogenic bacteria to damage host cells and promote infection.
6. Surface proteins: Proteins that are located on the surface of the bacterial cell and interact with the environment or host cells.
Understanding the structure and function of bacterial proteins is important for developing new antibiotics, vaccines, and other therapeutic strategies to combat bacterial infections.
Restriction Fragment Length Polymorphism (RFLP) is a term used in molecular biology and genetics. It refers to the presence of variations in DNA sequences among individuals, which can be detected by restriction enzymes. These enzymes cut DNA at specific sites, creating fragments of different lengths.
In RFLP analysis, DNA is isolated from an individual and treated with a specific restriction enzyme that cuts the DNA at particular recognition sites. The resulting fragments are then separated by size using gel electrophoresis, creating a pattern unique to that individual's DNA. If there are variations in the DNA sequence between individuals, the restriction enzyme may cut the DNA at different sites, leading to differences in the length of the fragments and thus, a different pattern on the gel.
These variations can be used for various purposes, such as identifying individuals, diagnosing genetic diseases, or studying evolutionary relationships between species. However, RFLP analysis has largely been replaced by more modern techniques like polymerase chain reaction (PCR)-based methods and DNA sequencing, which offer higher resolution and throughput.
Computational biology is a branch of biology that uses mathematical and computational methods to study biological data, models, and processes. It involves the development and application of algorithms, statistical models, and computational approaches to analyze and interpret large-scale molecular and phenotypic data from genomics, transcriptomics, proteomics, metabolomics, and other high-throughput technologies. The goal is to gain insights into biological systems and processes, develop predictive models, and inform experimental design and hypothesis testing in the life sciences. Computational biology encompasses a wide range of disciplines, including bioinformatics, systems biology, computational genomics, network biology, and mathematical modeling of biological systems.
In genetics, sequence alignment is the process of arranging two or more DNA, RNA, or protein sequences to identify regions of similarity or homology between them. This is often done using computational methods to compare the nucleotide or amino acid sequences and identify matching patterns, which can provide insight into evolutionary relationships, functional domains, or potential genetic disorders. The alignment process typically involves adjusting gaps and mismatches in the sequences to maximize the similarity between them, resulting in an aligned sequence that can be visually represented and analyzed.
Statistical models are mathematical representations that describe the relationship between variables in a given dataset. They are used to analyze and interpret data in order to make predictions or test hypotheses about a population. In the context of medicine, statistical models can be used for various purposes such as:
1. Disease risk prediction: By analyzing demographic, clinical, and genetic data using statistical models, researchers can identify factors that contribute to an individual's risk of developing certain diseases. This information can then be used to develop personalized prevention strategies or early detection methods.
2. Clinical trial design and analysis: Statistical models are essential tools for designing and analyzing clinical trials. They help determine sample size, allocate participants to treatment groups, and assess the effectiveness and safety of interventions.
3. Epidemiological studies: Researchers use statistical models to investigate the distribution and determinants of health-related events in populations. This includes studying patterns of disease transmission, evaluating public health interventions, and estimating the burden of diseases.
4. Health services research: Statistical models are employed to analyze healthcare utilization, costs, and outcomes. This helps inform decisions about resource allocation, policy development, and quality improvement initiatives.
5. Biostatistics and bioinformatics: In these fields, statistical models are used to analyze large-scale molecular data (e.g., genomics, proteomics) to understand biological processes and identify potential therapeutic targets.
In summary, statistical models in medicine provide a framework for understanding complex relationships between variables and making informed decisions based on data-driven insights.
Genetic markers are specific segments of DNA that are used in genetic mapping and genotyping to identify specific genetic locations, diseases, or traits. They can be composed of short tandem repeats (STRs), single nucleotide polymorphisms (SNPs), restriction fragment length polymorphisms (RFLPs), or variable number tandem repeats (VNTRs). These markers are useful in various fields such as genetic research, medical diagnostics, forensic science, and breeding programs. They can help to track inheritance patterns, identify genetic predispositions to diseases, and solve crimes by linking biological evidence to suspects or victims.
In the context of medicine, classification refers to the process of categorizing or organizing diseases, disorders, injuries, or other health conditions based on their characteristics, symptoms, causes, or other factors. This helps healthcare professionals to understand, diagnose, and treat various medical conditions more effectively.
There are several well-known classification systems in medicine, such as:
1. The International Classification of Diseases (ICD) - developed by the World Health Organization (WHO), it is used worldwide for mortality and morbidity statistics, reimbursement systems, and automated decision support in health care. This system includes codes for diseases, signs and symptoms, abnormal findings, social circumstances, and external causes of injury or diseases.
2. The Diagnostic and Statistical Manual of Mental Disorders (DSM) - published by the American Psychiatric Association, it provides a standardized classification system for mental health disorders to improve communication between mental health professionals, facilitate research, and guide treatment.
3. The International Classification of Functioning, Disability and Health (ICF) - developed by the WHO, this system focuses on an individual's functioning and disability rather than solely on their medical condition. It covers body functions and structures, activities, and participation, as well as environmental and personal factors that influence a person's life.
4. The TNM Classification of Malignant Tumors - created by the Union for International Cancer Control (UICC), it is used to describe the anatomical extent of cancer, including the size of the primary tumor (T), involvement of regional lymph nodes (N), and distant metastasis (M).
These classification systems help medical professionals communicate more effectively about patients' conditions, make informed treatment decisions, and track disease trends over time.
Automated Pattern Recognition in a medical context refers to the use of computer algorithms and artificial intelligence techniques to identify, classify, and analyze specific patterns or trends in medical data. This can include recognizing visual patterns in medical images, such as X-rays or MRIs, or identifying patterns in large datasets of physiological measurements or electronic health records.
The goal of automated pattern recognition is to assist healthcare professionals in making more accurate diagnoses, monitoring disease progression, and developing personalized treatment plans. By automating the process of pattern recognition, it can help reduce human error, increase efficiency, and improve patient outcomes.
Examples of automated pattern recognition in medicine include using machine learning algorithms to identify early signs of diabetic retinopathy in eye scans or detecting abnormal heart rhythms in electrocardiograms (ECGs). These techniques can also be used to predict patient risk based on patterns in their medical history, such as identifying patients who are at high risk for readmission to the hospital.
Dental fissures are narrow, deep grooves or depressions on the biting surfaces of posterior teeth, such as premolars and molars. These fissures occur naturally in the tooth structure and can vary in depth and width. They can be a potential site for food debris accumulation and dental plaque, making them more susceptible to tooth decay (dental caries).
There are two main types of dental fissures:
1. Mesiobuccal fissure - This fissure is located between the mesial (toward the front) and buccal (toward the cheek) cusps of a molar tooth.
2. Occclusal fissure - These are the grooves that run across the biting surface of a molar or premolar tooth, often dividing into multiple branches.
To prevent dental caries in these areas, dentists may recommend sealants, which are thin plastic coatings applied to the fissures to seal them off and protect them from bacteria and food particles. Regular dental check-ups and good oral hygiene practices, including brushing twice a day and flossing daily, also help maintain the health of these areas and prevent tooth decay.
Microsatellite repeats, also known as short tandem repeats (STRs), are repetitive DNA sequences made up of units of 1-6 base pairs that are repeated in a head-to-tail manner. These repeats are spread throughout the human genome and are highly polymorphic, meaning they can have different numbers of repeat units in different individuals.
Microsatellites are useful as genetic markers because of their high degree of variability. They are commonly used in forensic science to identify individuals, in genealogy to trace ancestry, and in medical research to study genetic diseases and disorders. Mutations in microsatellite repeats have been associated with various neurological conditions, including Huntington's disease and fragile X syndrome.
Factor analysis is a statistical technique used to identify patterns or structures in a dataset by explaining the correlations between variables. It is a method of simplifying complex data by reducing it to a smaller set of underlying factors that can explain most of the variation in the data. In other words, factor analysis is a way to uncover hidden relationships between multiple variables and group them into meaningful categories or factors.
In factor analysis, each variable is represented as a linear combination of underlying factors, where the factors are unobserved variables that cannot be directly measured but can only be inferred from the observed data. The goal is to identify these underlying factors and determine their relationships with the observed variables. This technique is commonly used in various fields such as psychology, social sciences, marketing, and biomedical research to explore complex datasets and gain insights into the underlying structure of the data.
There are two main types of factor analysis: exploratory factor analysis (EFA) and confirmatory factor analysis (CFA). EFA is used when there is no prior knowledge about the underlying factors, and the goal is to discover the potential structure in the data. CFA, on the other hand, is used when there is a theoretical framework or hypothesis about the underlying factors, and the goal is to test whether the observed data support this framework or hypothesis.
In summary, factor analysis is a statistical method for reducing complex datasets into simpler components called factors, which can help researchers identify patterns, structures, and relationships in the data.
In the field of medicine, "time factors" refer to the duration of symptoms or time elapsed since the onset of a medical condition, which can have significant implications for diagnosis and treatment. Understanding time factors is crucial in determining the progression of a disease, evaluating the effectiveness of treatments, and making critical decisions regarding patient care.
For example, in stroke management, "time is brain," meaning that rapid intervention within a specific time frame (usually within 4.5 hours) is essential to administering tissue plasminogen activator (tPA), a clot-busting drug that can minimize brain damage and improve patient outcomes. Similarly, in trauma care, the "golden hour" concept emphasizes the importance of providing definitive care within the first 60 minutes after injury to increase survival rates and reduce morbidity.
Time factors also play a role in monitoring the progression of chronic conditions like diabetes or heart disease, where regular follow-ups and assessments help determine appropriate treatment adjustments and prevent complications. In infectious diseases, time factors are crucial for initiating antibiotic therapy and identifying potential outbreaks to control their spread.
Overall, "time factors" encompass the significance of recognizing and acting promptly in various medical scenarios to optimize patient outcomes and provide effective care.
Analysis of Variance (ANOVA) is a statistical technique used to compare the means of two or more groups and determine whether there are any significant differences between them. It is a way to analyze the variance in a dataset to determine whether the variability between groups is greater than the variability within groups, which can indicate that the groups are significantly different from one another.
ANOVA is based on the concept of partitioning the total variance in a dataset into two components: variance due to differences between group means (also known as "between-group variance") and variance due to differences within each group (also known as "within-group variance"). By comparing these two sources of variance, ANOVA can help researchers determine whether any observed differences between groups are statistically significant, or whether they could have occurred by chance.
ANOVA is a widely used technique in many areas of research, including biology, psychology, engineering, and business. It is often used to compare the means of two or more experimental groups, such as a treatment group and a control group, to determine whether the treatment had a significant effect. ANOVA can also be used to compare the means of different populations or subgroups within a population, to identify any differences that may exist between them.
Molecular epidemiology is a branch of epidemiology that uses laboratory techniques to identify and analyze the genetic material (DNA, RNA) of pathogens or host cells to understand their distribution, transmission, and disease associations in populations. It combines molecular biology methods with epidemiological approaches to investigate the role of genetic factors in disease occurrence and outcomes. This field has contributed significantly to the identification of infectious disease outbreaks, tracking the spread of antibiotic-resistant bacteria, understanding the transmission dynamics of viruses, and identifying susceptible populations for targeted interventions.
'Spatio-temporal analysis' is not a medical term per se, but rather a term used in various scientific fields including epidemiology and public health research to describe the examination of data that contains both geographical and time-based information. In this context, spatio-temporal analysis involves studying how health outcomes or exposures change over time and across different locations.
The goal of spatio-temporal analysis is to identify patterns, trends, and clusters of health events in space and time, which can help inform public health interventions, monitor disease outbreaks, and evaluate the effectiveness of public health policies. For example, spatio-temporal analysis may be used to examine the spread of a infectious disease over time and across different regions, or to assess the impact of environmental exposures on health outcomes in specific communities.
Spatio-temporal analysis typically involves the use of statistical methods and geographic information systems (GIS) tools to visualize and analyze data in a spatially and temporally explicit manner. These methods can help account for confounding factors, such as population density or demographics, that may affect health outcomes and help identify meaningful patterns in complex datasets.
Sequence homology, amino acid, refers to the similarity in the order of amino acids in a protein or a portion of a protein between two or more species. This similarity can be used to infer evolutionary relationships and functional similarities between proteins. The higher the degree of sequence homology, the more likely it is that the proteins are related and have similar functions. Sequence homology can be determined through various methods such as pairwise alignment or multiple sequence alignment, which compare the sequences and calculate a score based on the number and type of matching amino acids.
DNA, or deoxyribonucleic acid, is the genetic material present in the cells of all living organisms, including plants. In plants, DNA is located in the nucleus of a cell, as well as in chloroplasts and mitochondria. Plant DNA contains the instructions for the development, growth, and function of the plant, and is passed down from one generation to the next through the process of reproduction.
The structure of DNA is a double helix, formed by two strands of nucleotides that are linked together by hydrogen bonds. Each nucleotide contains a sugar molecule (deoxyribose), a phosphate group, and a nitrogenous base. There are four types of nitrogenous bases in DNA: adenine (A), guanine (G), cytosine (C), and thymine (T). Adenine pairs with thymine, and guanine pairs with cytosine, forming the rungs of the ladder that make up the double helix.
The genetic information in DNA is encoded in the sequence of these nitrogenous bases. Large sequences of bases form genes, which provide the instructions for the production of proteins. The process of gene expression involves transcribing the DNA sequence into a complementary RNA molecule, which is then translated into a protein.
Plant DNA is similar to animal DNA in many ways, but there are also some differences. For example, plant DNA contains a higher proportion of repetitive sequences and transposable elements, which are mobile genetic elements that can move around the genome and cause mutations. Additionally, plant cells have cell walls and chloroplasts, which are not present in animal cells, and these structures contain their own DNA.
Pulsed-field gel electrophoresis (PFGE) is a type of electrophoresis technique used in molecular biology to separate DNA molecules based on their size and conformation. In this method, the electric field is applied in varying directions, which allows for the separation of large DNA fragments that are difficult to separate using traditional gel electrophoresis methods.
The DNA sample is prepared by embedding it in a semi-solid matrix, such as agarose or polyacrylamide, and then subjected to an electric field that periodically changes direction. This causes the DNA molecules to reorient themselves in response to the changing electric field, which results in the separation of the DNA fragments based on their size and shape.
PFGE is a powerful tool for molecular biology research and has many applications, including the identification and characterization of bacterial pathogens, the analysis of genomic DNA, and the study of gene organization and regulation. It is also used in forensic science to analyze DNA evidence in criminal investigations.
A questionnaire in the medical context is a standardized, systematic, and structured tool used to gather information from individuals regarding their symptoms, medical history, lifestyle, or other health-related factors. It typically consists of a series of written questions that can be either self-administered or administered by an interviewer. Questionnaires are widely used in various areas of healthcare, including clinical research, epidemiological studies, patient care, and health services evaluation to collect data that can inform diagnosis, treatment planning, and population health management. They provide a consistent and organized method for obtaining information from large groups or individual patients, helping to ensure accurate and comprehensive data collection while minimizing bias and variability in the information gathered.
Molecular evolution is the process of change in the DNA sequence or protein structure over time, driven by mechanisms such as mutation, genetic drift, gene flow, and natural selection. It refers to the evolutionary study of changes in DNA, RNA, and proteins, and how these changes accumulate and lead to new species and diversity of life. Molecular evolution can be used to understand the history and relationships among different organisms, as well as the functional consequences of genetic changes.
Expressed Sequence Tags (ESTs) are short, single-pass DNA sequences that are derived from cDNA libraries. They represent a quick and cost-effective method for large-scale sequencing of gene transcripts and provide an unbiased view of the genes being actively expressed in a particular tissue or developmental stage. ESTs can be used to identify and study new genes, to analyze patterns of gene expression, and to develop molecular markers for genetic mapping and genome analysis.
DNA primers are short single-stranded DNA molecules that serve as a starting point for DNA synthesis. They are typically used in laboratory techniques such as the polymerase chain reaction (PCR) and DNA sequencing. The primer binds to a complementary sequence on the DNA template through base pairing, providing a free 3'-hydroxyl group for the DNA polymerase enzyme to add nucleotides and synthesize a new strand of DNA. This allows for specific and targeted amplification or analysis of a particular region of interest within a larger DNA molecule.
Ribosomal DNA (rDNA) refers to the specific regions of DNA in a cell that contain the genes for ribosomal RNA (rRNA). Ribosomes are complex structures composed of proteins and rRNA, which play a crucial role in protein synthesis by translating messenger RNA (mRNA) into proteins.
In humans, there are four types of rRNA molecules: 18S, 5.8S, 28S, and 5S. These rRNAs are encoded by multiple copies of rDNA genes that are organized in clusters on specific chromosomes. In humans, the majority of rDNA genes are located on the short arms of acrocentric chromosomes 13, 14, 15, 21, and 22.
Each cluster of rDNA genes contains both transcribed and non-transcribed spacer regions. The transcribed regions contain the genes for the four types of rRNA, while the non-transcribed spacers contain regulatory elements that control the transcription of the rRNA genes.
The number of rDNA copies varies between species and even within individuals of the same species. The copy number can also change during development and in response to environmental factors. Variations in rDNA copy number have been associated with various diseases, including cancer and neurological disorders.
Genetic models are theoretical frameworks used in genetics to describe and explain the inheritance patterns and genetic architecture of traits, diseases, or phenomena. These models are based on mathematical equations and statistical methods that incorporate information about gene frequencies, modes of inheritance, and the effects of environmental factors. They can be used to predict the probability of certain genetic outcomes, to understand the genetic basis of complex traits, and to inform medical management and treatment decisions.
There are several types of genetic models, including:
1. Mendelian models: These models describe the inheritance patterns of simple genetic traits that follow Mendel's laws of segregation and independent assortment. Examples include autosomal dominant, autosomal recessive, and X-linked inheritance.
2. Complex trait models: These models describe the inheritance patterns of complex traits that are influenced by multiple genes and environmental factors. Examples include heart disease, diabetes, and cancer.
3. Population genetics models: These models describe the distribution and frequency of genetic variants within populations over time. They can be used to study evolutionary processes, such as natural selection and genetic drift.
4. Quantitative genetics models: These models describe the relationship between genetic variation and phenotypic variation in continuous traits, such as height or IQ. They can be used to estimate heritability and to identify quantitative trait loci (QTLs) that contribute to trait variation.
5. Statistical genetics models: These models use statistical methods to analyze genetic data and infer the presence of genetic associations or linkage. They can be used to identify genetic risk factors for diseases or traits.
Overall, genetic models are essential tools in genetics research and medical genetics, as they allow researchers to make predictions about genetic outcomes, test hypotheses about the genetic basis of traits and diseases, and develop strategies for prevention, diagnosis, and treatment.
Electrophoresis, starch gel is a type of electrophoretic technique used in laboratory settings for the separation and analysis of large biomolecules such as DNA, RNA, and proteins. In this method, a gel made from cooked starch is used as the supporting matrix for the molecules being separated.
The sample containing the mixture of biomolecules is loaded onto the gel and an electric field is applied, causing the negatively charged molecules to migrate towards the positive electrode. The starch gel acts as a molecular sieve, with smaller molecules moving more quickly through the gel than larger ones. This results in the separation of the mixture into individual components based on their size and charge.
Once the separation is complete, the gel can be stained to visualize the separated bands. Different staining techniques are used depending on the type of biomolecule being analyzed. For example, proteins can be stained with dyes such as Coomassie Brilliant Blue or silver nitrate, while nucleic acids can be stained with dyes such as ethidium bromide.
Starch gel electrophoresis is a relatively simple and inexpensive technique that has been widely used in molecular biology research and diagnostic applications. However, it has largely been replaced by other electrophoretic techniques, such as polyacrylamide gel electrophoresis (PAGE), which offer higher resolution and can be automated for high-throughput analysis.
An ecotype is a population of a species that is adapted to specific environmental conditions and exhibits genetic differences from other populations of the same species that live in different environments. These genetic adaptations allow the ecotype to survive and reproduce more successfully in its particular habitat compared to other populations. The term "ecotype" was first introduced by botanist John Gregor Mendel in 1870 to describe the variation within plant species due to environmental factors.
Ecotypes can be found in various organisms, including plants, animals, and microorganisms. They are often studied in ecology and evolutionary biology to understand how genetic differences arise and evolve in response to environmental pressures. Ecotypes can differ from each other in traits such as morphology, physiology, behavior, and life history strategies.
Examples of ecotypes include:
* Desert and coastal ecotypes of the lizard Uta stansburiana, which show differences in body size, limb length, and reproductive strategies due to adaptation to different habitats.
* Arctic and alpine ecotypes of the plant Arabis alpina, which have distinct flowering times and cold tolerance mechanisms that help them survive in their respective environments.
* Freshwater and marine ecotypes of the copepod Eurytemora affinis, which differ in body size, developmental rate, and salinity tolerance due to adaptation to different aquatic habitats.
It is important to note that the concept of ecotype is not always clearly defined or consistently applied in scientific research. Some researchers use it to describe any population that shows genetic differences related to environmental factors, while others reserve it for cases where there is strong evidence of local adaptation and reproductive isolation between populations.
Genetic structures refer to the organization and composition of genetic material, primarily DNA, that contain the information necessary for the development and function of an organism. This includes the chromosomes, genes, and regulatory elements that make up the genome.
Chromosomes are thread-like structures located in the nucleus of a cell that consist of DNA coiled around histone proteins. They come in pairs, with most species having a specific number of chromosomes in each set (diploid).
Genes are segments of DNA that code for specific proteins or RNA molecules, and they are the basic units of heredity. They can be located on chromosomes and can vary in length and complexity.
Regulatory elements are non-coding sequences of DNA that control the expression of genes by regulating when, where, and to what extent a gene is turned on or off. These elements can include promoters, enhancers, silencers, and insulators.
Overall, genetic structures provide the blueprint for an organism's traits and characteristics, and understanding their organization and function is crucial in fields such as genetics, genomics, and molecular biology.
A computer simulation is a process that involves creating a model of a real-world system or phenomenon on a computer and then using that model to run experiments and make predictions about how the system will behave under different conditions. In the medical field, computer simulations are used for a variety of purposes, including:
1. Training and education: Computer simulations can be used to create realistic virtual environments where medical students and professionals can practice their skills and learn new procedures without risk to actual patients. For example, surgeons may use simulation software to practice complex surgical techniques before performing them on real patients.
2. Research and development: Computer simulations can help medical researchers study the behavior of biological systems at a level of detail that would be difficult or impossible to achieve through experimental methods alone. By creating detailed models of cells, tissues, organs, or even entire organisms, researchers can use simulation software to explore how these systems function and how they respond to different stimuli.
3. Drug discovery and development: Computer simulations are an essential tool in modern drug discovery and development. By modeling the behavior of drugs at a molecular level, researchers can predict how they will interact with their targets in the body and identify potential side effects or toxicities. This information can help guide the design of new drugs and reduce the need for expensive and time-consuming clinical trials.
4. Personalized medicine: Computer simulations can be used to create personalized models of individual patients based on their unique genetic, physiological, and environmental characteristics. These models can then be used to predict how a patient will respond to different treatments and identify the most effective therapy for their specific condition.
Overall, computer simulations are a powerful tool in modern medicine, enabling researchers and clinicians to study complex systems and make predictions about how they will behave under a wide range of conditions. By providing insights into the behavior of biological systems at a level of detail that would be difficult or impossible to achieve through experimental methods alone, computer simulations are helping to advance our understanding of human health and disease.
I am not aware of a specific medical definition for the term "China." Generally, it is used to refer to:
1. The People's Republic of China (PRC), which is a country in East Asia. It is the most populous country in the world and the fourth largest by geographical area. Its capital city is Beijing.
2. In a historical context, "China" was used to refer to various dynasties and empires that existed in East Asia over thousands of years. The term "Middle Kingdom" or "Zhongguo" (中国) has been used by the Chinese people to refer to their country for centuries.
3. In a more general sense, "China" can also be used to describe products or goods that originate from or are associated with the People's Republic of China.
If you have a specific context in which you encountered the term "China" related to medicine, please provide it so I can give a more accurate response.
I apologize, but "Brazil" is not a medical term or condition. It is the largest country in both South America and Latin America by land area and population. If you have any questions related to medical terminology or health concerns, please provide more information and I will do my best to help.
Genetic polymorphism refers to the occurrence of multiple forms (called alleles) of a particular gene within a population. These variations in the DNA sequence do not generally affect the function or survival of the organism, but they can contribute to differences in traits among individuals. Genetic polymorphisms can be caused by single nucleotide changes (SNPs), insertions or deletions of DNA segments, or other types of genetic rearrangements. They are important for understanding genetic diversity and evolution, as well as for identifying genetic factors that may contribute to disease susceptibility in humans.
Statistics, as a topic in the context of medicine and healthcare, refers to the scientific discipline that involves the collection, analysis, interpretation, and presentation of numerical data or quantifiable data in a meaningful and organized manner. It employs mathematical theories and models to draw conclusions, make predictions, and support evidence-based decision-making in various areas of medical research and practice.
Some key concepts and methods in medical statistics include:
1. Descriptive Statistics: Summarizing and visualizing data through measures of central tendency (mean, median, mode) and dispersion (range, variance, standard deviation).
2. Inferential Statistics: Drawing conclusions about a population based on a sample using hypothesis testing, confidence intervals, and statistical modeling.
3. Probability Theory: Quantifying the likelihood of events or outcomes in medical scenarios, such as diagnostic tests' sensitivity and specificity.
4. Study Designs: Planning and implementing various research study designs, including randomized controlled trials (RCTs), cohort studies, case-control studies, and cross-sectional surveys.
5. Sampling Methods: Selecting a representative sample from a population to ensure the validity and generalizability of research findings.
6. Multivariate Analysis: Examining the relationships between multiple variables simultaneously using techniques like regression analysis, factor analysis, or cluster analysis.
7. Survival Analysis: Analyzing time-to-event data, such as survival rates in clinical trials or disease progression.
8. Meta-Analysis: Systematically synthesizing and summarizing the results of multiple studies to provide a comprehensive understanding of a research question.
9. Biostatistics: A subfield of statistics that focuses on applying statistical methods to biological data, including medical research.
10. Epidemiology: The study of disease patterns in populations, which often relies on statistical methods for data analysis and interpretation.
Medical statistics is essential for evidence-based medicine, clinical decision-making, public health policy, and healthcare management. It helps researchers and practitioners evaluate the effectiveness and safety of medical interventions, assess risk factors and outcomes associated with diseases or treatments, and monitor trends in population health.
Molecular cloning is a laboratory technique used to create multiple copies of a specific DNA sequence. This process involves several steps:
1. Isolation: The first step in molecular cloning is to isolate the DNA sequence of interest from the rest of the genomic DNA. This can be done using various methods such as PCR (polymerase chain reaction), restriction enzymes, or hybridization.
2. Vector construction: Once the DNA sequence of interest has been isolated, it must be inserted into a vector, which is a small circular DNA molecule that can replicate independently in a host cell. Common vectors used in molecular cloning include plasmids and phages.
3. Transformation: The constructed vector is then introduced into a host cell, usually a bacterial or yeast cell, through a process called transformation. This can be done using various methods such as electroporation or chemical transformation.
4. Selection: After transformation, the host cells are grown in selective media that allow only those cells containing the vector to grow. This ensures that the DNA sequence of interest has been successfully cloned into the vector.
5. Amplification: Once the host cells have been selected, they can be grown in large quantities to amplify the number of copies of the cloned DNA sequence.
Molecular cloning is a powerful tool in molecular biology and has numerous applications, including the production of recombinant proteins, gene therapy, functional analysis of genes, and genetic engineering.
Medical topography refers to the detailed description and mapping of the locations and relative positions of various anatomical structures, abnormalities, or lesions in the body. It is often used in the context of imaging techniques such as X-rays, CT scans, or MRI scans, where it helps to visualize and communicate the spatial relationships between different bodily features. Medical topography may also involve the use of physical examination, surgical exploration, or other diagnostic methods to gather information about the location and extent of medical conditions.
In summary, medical topography is a detailed mapping and description of the location and position of anatomical structures or pathological changes in the body.
Minisatellites, also known as VNTRs (Variable Number Tandem Repeats), are repetitive DNA sequences that consist of a core repeat unit of 10-60 base pairs, arranged in a head-to-tail fashion. They are often found in non-coding regions of the genome and can vary in the number of times the repeat unit is present in an individual's DNA. This variation in repeat number can occur both within and between individuals, making minisatellites useful as genetic markers for identification and forensic applications. They are also associated with certain genetic disorders and play a role in genome instability.
Bacteria are single-celled microorganisms that are among the earliest known life forms on Earth. They are typically characterized as having a cell wall and no membrane-bound organelles. The majority of bacteria have a prokaryotic organization, meaning they lack a nucleus and other membrane-bound organelles.
Bacteria exist in diverse environments and can be found in every habitat on Earth, including soil, water, and the bodies of plants and animals. Some bacteria are beneficial to their hosts, while others can cause disease. Beneficial bacteria play important roles in processes such as digestion, nitrogen fixation, and biogeochemical cycling.
Bacteria reproduce asexually through binary fission or budding, and some species can also exchange genetic material through conjugation. They have a wide range of metabolic capabilities, with many using organic compounds as their source of energy, while others are capable of photosynthesis or chemosynthesis.
Bacteria are highly adaptable and can evolve rapidly in response to environmental changes. This has led to the development of antibiotic resistance in some species, which poses a significant public health challenge. Understanding the biology and behavior of bacteria is essential for developing strategies to prevent and treat bacterial infections and diseases.
Bayes' theorem, also known as Bayes' rule or Bayes' formula, is a fundamental principle in the field of statistics and probability theory. It describes how to update the probability of a hypothesis based on new evidence or data. The theorem is named after Reverend Thomas Bayes, who first formulated it in the 18th century.
In mathematical terms, Bayes' theorem states that the posterior probability of a hypothesis (H) given some observed evidence (E) is proportional to the product of the prior probability of the hypothesis (P(H)) and the likelihood of observing the evidence given the hypothesis (P(E|H)):
Posterior Probability = P(H|E) = [P(E|H) x P(H)] / P(E)
Where:
* P(H|E): The posterior probability of the hypothesis H after observing evidence E. This is the probability we want to calculate.
* P(E|H): The likelihood of observing evidence E given that the hypothesis H is true.
* P(H): The prior probability of the hypothesis H before observing any evidence.
* P(E): The marginal likelihood or probability of observing evidence E, regardless of whether the hypothesis H is true or not. This value can be calculated as the sum of the products of the likelihood and prior probability for all possible hypotheses: P(E) = Σ[P(E|Hi) x P(Hi)]
Bayes' theorem has many applications in various fields, including medicine, where it can be used to update the probability of a disease diagnosis based on test results or other clinical findings. It is also widely used in machine learning and artificial intelligence algorithms for probabilistic reasoning and decision making under uncertainty.
'Escherichia coli' (E. coli) is a type of gram-negative, facultatively anaerobic, rod-shaped bacterium that commonly inhabits the intestinal tract of humans and warm-blooded animals. It is a member of the family Enterobacteriaceae and one of the most well-studied prokaryotic model organisms in molecular biology.
While most E. coli strains are harmless and even beneficial to their hosts, some serotypes can cause various forms of gastrointestinal and extraintestinal illnesses in humans and animals. These pathogenic strains possess virulence factors that enable them to colonize and damage host tissues, leading to diseases such as diarrhea, urinary tract infections, pneumonia, and sepsis.
E. coli is a versatile organism with remarkable genetic diversity, which allows it to adapt to various environmental niches. It can be found in water, soil, food, and various man-made environments, making it an essential indicator of fecal contamination and a common cause of foodborne illnesses. The study of E. coli has contributed significantly to our understanding of fundamental biological processes, including DNA replication, gene regulation, and protein synthesis.
A genetic database is a type of biomedical or health informatics database that stores and organizes genetic data, such as DNA sequences, gene maps, genotypes, haplotypes, and phenotype information. These databases can be used for various purposes, including research, clinical diagnosis, and personalized medicine.
There are different types of genetic databases, including:
1. Genomic databases: These databases store whole genome sequences, gene expression data, and other genomic information. Examples include the National Center for Biotechnology Information's (NCBI) GenBank, the European Nucleotide Archive (ENA), and the DNA Data Bank of Japan (DDBJ).
2. Gene databases: These databases contain information about specific genes, including their location, function, regulation, and evolution. Examples include the Online Mendelian Inheritance in Man (OMIM) database, the Universal Protein Resource (UniProt), and the Gene Ontology (GO) database.
3. Variant databases: These databases store information about genetic variants, such as single nucleotide polymorphisms (SNPs), insertions/deletions (INDELs), and copy number variations (CNVs). Examples include the Database of Single Nucleotide Polymorphisms (dbSNP), the Catalogue of Somatic Mutations in Cancer (COSMIC), and the International HapMap Project.
4. Clinical databases: These databases contain genetic and clinical information about patients, such as their genotype, phenotype, family history, and response to treatments. Examples include the ClinVar database, the Pharmacogenomics Knowledgebase (PharmGKB), and the Genetic Testing Registry (GTR).
5. Population databases: These databases store genetic information about different populations, including their ancestry, demographics, and genetic diversity. Examples include the 1000 Genomes Project, the Human Genome Diversity Project (HGDP), and the Allele Frequency Net Database (AFND).
Genetic databases can be publicly accessible or restricted to authorized users, depending on their purpose and content. They play a crucial role in advancing our understanding of genetics and genomics, as well as improving healthcare and personalized medicine.
'Gene expression regulation' refers to the processes that control whether, when, and where a particular gene is expressed, meaning the production of a specific protein or functional RNA encoded by that gene. This complex mechanism can be influenced by various factors such as transcription factors, chromatin remodeling, DNA methylation, non-coding RNAs, and post-transcriptional modifications, among others. Proper regulation of gene expression is crucial for normal cellular function, development, and maintaining homeostasis in living organisms. Dysregulation of gene expression can lead to various diseases, including cancer and genetic disorders.
I'm sorry for any confusion, but "Geographic Information Systems" (GIS) is not a medical term. GIS is a system designed to capture, store, manipulate, analyze, manage, and present all types of geographical data. It can be used in various fields, including public health and epidemiology, to map and analyze the spread of diseases, identify environmental risk factors, plan health services delivery, and inform evidence-based decision making.
Molecular models are three-dimensional representations of molecular structures that are used in the field of molecular biology and chemistry to visualize and understand the spatial arrangement of atoms and bonds within a molecule. These models can be physical or computer-generated and allow researchers to study the shape, size, and behavior of molecules, which is crucial for understanding their function and interactions with other molecules.
Physical molecular models are often made up of balls (representing atoms) connected by rods or sticks (representing bonds). These models can be constructed manually using materials such as plastic or wooden balls and rods, or they can be created using 3D printing technology.
Computer-generated molecular models, on the other hand, are created using specialized software that allows researchers to visualize and manipulate molecular structures in three dimensions. These models can be used to simulate molecular interactions, predict molecular behavior, and design new drugs or chemicals with specific properties. Overall, molecular models play a critical role in advancing our understanding of molecular structures and their functions.
Genetic transcription is the process by which the information in a strand of DNA is used to create a complementary RNA molecule. This process is the first step in gene expression, where the genetic code in DNA is converted into a form that can be used to produce proteins or functional RNAs.
During transcription, an enzyme called RNA polymerase binds to the DNA template strand and reads the sequence of nucleotide bases. As it moves along the template, it adds complementary RNA nucleotides to the growing RNA chain, creating a single-stranded RNA molecule that is complementary to the DNA template strand. Once transcription is complete, the RNA molecule may undergo further processing before it can be translated into protein or perform its functional role in the cell.
Transcription can be either "constitutive" or "regulated." Constitutive transcription occurs at a relatively constant rate and produces essential proteins that are required for basic cellular functions. Regulated transcription, on the other hand, is subject to control by various intracellular and extracellular signals, allowing cells to respond to changing environmental conditions or developmental cues.
Neoplastic gene expression regulation refers to the processes that control the production of proteins and other molecules from genes in neoplastic cells, or cells that are part of a tumor or cancer. In a normal cell, gene expression is tightly regulated to ensure that the right genes are turned on or off at the right time. However, in cancer cells, this regulation can be disrupted, leading to the overexpression or underexpression of certain genes.
Neoplastic gene expression regulation can be affected by a variety of factors, including genetic mutations, epigenetic changes, and signals from the tumor microenvironment. These changes can lead to the activation of oncogenes (genes that promote cancer growth and development) or the inactivation of tumor suppressor genes (genes that prevent cancer).
Understanding neoplastic gene expression regulation is important for developing new therapies for cancer, as targeting specific genes or pathways involved in this process can help to inhibit cancer growth and progression.
Plasma cell neoplasms are a type of cancer that originates from plasma cells, which are a type of white blood cell found in the bone marrow. These cells are responsible for producing antibodies to help fight off infections. When plasma cells become cancerous and multiply out of control, they can form a tumor called a plasmacytoma.
There are two main types of plasma cell neoplasms: solitary plasmacytoma and multiple myeloma. Solitary plasmacytoma is a localized tumor that typically forms in the bone, while multiple myeloma is a systemic disease that affects multiple bones and can cause a variety of symptoms such as bone pain, fatigue, and anemia.
Plasma cell neoplasms are diagnosed through a combination of tests, including blood tests, imaging studies, and bone marrow biopsy. Treatment options depend on the stage and extent of the disease, but may include radiation therapy, chemotherapy, and stem cell transplantation.
Chromosome mapping, also known as physical mapping, is the process of determining the location and order of specific genes or genetic markers on a chromosome. This is typically done by using various laboratory techniques to identify landmarks along the chromosome, such as restriction enzyme cutting sites or patterns of DNA sequence repeats. The resulting map provides important information about the organization and structure of the genome, and can be used for a variety of purposes, including identifying the location of genes associated with genetic diseases, studying evolutionary relationships between organisms, and developing genetic markers for use in breeding or forensic applications.
Serotyping is a laboratory technique used to classify microorganisms, such as bacteria and viruses, based on the specific antigens or proteins present on their surface. It involves treating the microorganism with different types of antibodies and observing which ones bind to its surface. Each distinct set of antigens corresponds to a specific serotype, allowing for precise identification and characterization of the microorganism. This technique is particularly useful in epidemiology, vaccine development, and infection control.
Reverse Transcriptase Polymerase Chain Reaction (RT-PCR) is a laboratory technique used in molecular biology to amplify and detect specific DNA sequences. This technique is particularly useful for the detection and quantification of RNA viruses, as well as for the analysis of gene expression.
The process involves two main steps: reverse transcription and polymerase chain reaction (PCR). In the first step, reverse transcriptase enzyme is used to convert RNA into complementary DNA (cDNA) by reading the template provided by the RNA molecule. This cDNA then serves as a template for the PCR amplification step.
In the second step, the PCR reaction uses two primers that flank the target DNA sequence and a thermostable polymerase enzyme to repeatedly copy the targeted cDNA sequence. The reaction mixture is heated and cooled in cycles, allowing the primers to anneal to the template, and the polymerase to extend the new strand. This results in exponential amplification of the target DNA sequence, making it possible to detect even small amounts of RNA or cDNA.
RT-PCR is a sensitive and specific technique that has many applications in medical research and diagnostics, including the detection of viruses such as HIV, hepatitis C virus, and SARS-CoV-2 (the virus that causes COVID-19). It can also be used to study gene expression, identify genetic mutations, and diagnose genetic disorders.
Microarray analysis is a laboratory technique used to measure the expression levels of large numbers of genes (or other types of DNA sequences) simultaneously. This technology allows researchers to monitor the expression of thousands of genes in a single experiment, providing valuable information about which genes are turned on or off in response to various stimuli or diseases.
In microarray analysis, samples of RNA from cells or tissues are labeled with fluorescent dyes and then hybridized to a solid surface (such as a glass slide) onto which thousands of known DNA sequences have been spotted in an organized array. The intensity of the fluorescence at each spot on the array is proportional to the amount of RNA that has bound to it, indicating the level of expression of the corresponding gene.
Microarray analysis can be used for a variety of applications, including identifying genes that are differentially expressed between healthy and diseased tissues, studying genetic variations in populations, and monitoring gene expression changes over time or in response to environmental factors. However, it is important to note that microarray data must be analyzed carefully using appropriate statistical methods to ensure the accuracy and reliability of the results.
Catastrophizing is a term used in the medical field, particularly in psychology and psychiatry, to describe a cognitive distortion or a pattern of thinking in which an individual tends to exaggerate the severity or negative consequences of a situation or problem. It involves magnifying or blowing things out of proportion, expecting the worst-case scenario, and having a lack of faith in one's ability to cope with adversity.
Catastrophization can be a symptom of various mental health conditions, such as anxiety disorders, depression, and post-traumatic stress disorder (PTSD). It can also contribute to increased pain perception and disability in individuals with chronic pain conditions.
For example, a person who catastrophizes might think that if they make a small mistake at work, it will lead to them losing their job, which will then cause them to become homeless and destitute. This type of thinking can be debilitating and interfere with an individual's ability to function in daily life.
Cognitive-behavioral therapy (CBT) is often used to help individuals identify and challenge catastrophic thoughts, with the goal of replacing them with more balanced and realistic thinking patterns.
A mutation is a permanent change in the DNA sequence of an organism's genome. Mutations can occur spontaneously or be caused by environmental factors such as exposure to radiation, chemicals, or viruses. They may have various effects on the organism, ranging from benign to harmful, depending on where they occur and whether they alter the function of essential proteins. In some cases, mutations can increase an individual's susceptibility to certain diseases or disorders, while in others, they may confer a survival advantage. Mutations are the driving force behind evolution, as they introduce new genetic variability into populations, which can then be acted upon by natural selection.
Protein array analysis is a high-throughput technology used to detect and measure the presence and activity of specific proteins in biological samples. This technique utilizes arrays or chips containing various capture agents, such as antibodies or aptamers, that are designed to bind to specific target proteins. The sample is then added to the array, allowing the target proteins to bind to their corresponding capture agents. After washing away unbound materials, a detection system is used to identify and quantify the bound proteins. This method can be used for various applications, including protein-protein interaction studies, biomarker discovery, and drug development. The results of protein array analysis provide valuable information about the expression levels, post-translational modifications, and functional states of proteins in complex biological systems.
Multivariate analysis is a statistical method used to examine the relationship between multiple independent variables and a dependent variable. It allows for the simultaneous examination of the effects of two or more independent variables on an outcome, while controlling for the effects of other variables in the model. This technique can be used to identify patterns, associations, and interactions among multiple variables, and is commonly used in medical research to understand complex health outcomes and disease processes. Examples of multivariate analysis methods include multiple regression, factor analysis, cluster analysis, and discriminant analysis.
Proteomics is the large-scale study and analysis of proteins, including their structures, functions, interactions, modifications, and abundance, in a given cell, tissue, or organism. It involves the identification and quantification of all expressed proteins in a biological sample, as well as the characterization of post-translational modifications, protein-protein interactions, and functional pathways. Proteomics can provide valuable insights into various biological processes, diseases, and drug responses, and has applications in basic research, biomedicine, and clinical diagnostics. The field combines various techniques from molecular biology, chemistry, physics, and bioinformatics to study proteins at a systems level.
"Food habits" refer to the established patterns or behaviors that individuals develop in relation to their food choices and eating behaviors. These habits can include preferences for certain types of foods, meal timing, portion sizes, and dining experiences. Food habits are influenced by a variety of factors including cultural background, personal beliefs, taste preferences, social norms, and economic resources. They can have significant impacts on an individual's nutritional status, overall health, and quality of life.
It is important to note that while "food habits" may not be a formal medical term, it is often used in the context of nutrition and public health research and interventions to describe the behaviors related to food choices and eating patterns.
I'm sorry for any confusion, but "fruit" is not a medical term per se. It is a common term used to describe the part of a plant that develops from the ovary after flowering and contains seeds. However, in a nutritional or dietary context, "fruits" are often referred to as foods that are typically sweet and juicy, and come from plants' flowers. They are rich in fiber, vitamins, and minerals, making them an essential part of a healthy diet. But in a strict medical sense, there isn't a specific definition for "fruit."
Bacterial RNA refers to the genetic material present in bacteria that is composed of ribonucleic acid (RNA). Unlike higher organisms, bacteria contain a single circular chromosome made up of DNA, along with smaller circular pieces of DNA called plasmids. These bacterial genetic materials contain the information necessary for the growth and reproduction of the organism.
Bacterial RNA can be divided into three main categories: messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). mRNA carries genetic information copied from DNA, which is then translated into proteins by the rRNA and tRNA molecules. rRNA is a structural component of the ribosome, where protein synthesis occurs, while tRNA acts as an adapter that brings amino acids to the ribosome during protein synthesis.
Bacterial RNA plays a crucial role in various cellular processes, including gene expression, protein synthesis, and regulation of metabolic pathways. Understanding the structure and function of bacterial RNA is essential for developing new antibiotics and other therapeutic strategies to combat bacterial infections.
Nucleic acid hybridization is a process in molecular biology where two single-stranded nucleic acids (DNA, RNA) with complementary sequences pair together to form a double-stranded molecule through hydrogen bonding. The strands can be from the same type of nucleic acid or different types (i.e., DNA-RNA or DNA-cDNA). This process is commonly used in various laboratory techniques, such as Southern blotting, Northern blotting, polymerase chain reaction (PCR), and microarray analysis, to detect, isolate, and analyze specific nucleic acid sequences. The hybridization temperature and conditions are critical to ensure the specificity of the interaction between the two strands.
I apologize, but there seems to be a misunderstanding. "Soil microbiology" is not a medical term; rather, it is a branch of microbiology that deals with the study of microorganisms in soil. It involves understanding the diversity, ecology, and biochemistry of bacteria, fungi, algae, protozoa, and other microscopic life forms found in soil. This field has applications in agriculture, environmental science, and waste management but is not directly related to medical definitions or human health.
Gene expression is the process by which the information encoded in a gene is used to synthesize a functional gene product, such as a protein or RNA molecule. This process involves several steps: transcription, RNA processing, and translation. During transcription, the genetic information in DNA is copied into a complementary RNA molecule, known as messenger RNA (mRNA). The mRNA then undergoes RNA processing, which includes adding a cap and tail to the mRNA and splicing out non-coding regions called introns. The resulting mature mRNA is then translated into a protein on ribosomes in the cytoplasm through the process of translation.
The regulation of gene expression is a complex and highly controlled process that allows cells to respond to changes in their environment, such as growth factors, hormones, and stress signals. This regulation can occur at various stages of gene expression, including transcriptional activation or repression, RNA processing, mRNA stability, and translation. Dysregulation of gene expression has been implicated in many diseases, including cancer, genetic disorders, and neurological conditions.
Molecular typing is a laboratory technique used to identify and characterize specific microorganisms, such as bacteria or viruses, at the molecular level. This method is used to differentiate between strains of the same species based on their genetic or molecular differences. Molecular typing techniques include methods such as pulsed-field gel electrophoresis (PFGE), multiple-locus variable number tandem repeat analysis (MLVA), and whole genome sequencing (WGS). These techniques allow for high-resolution discrimination between strains, enabling epidemiological investigations of outbreaks, tracking the transmission of pathogens, and studying the evolution and population biology of microorganisms.
A "gene library" is not a recognized term in medical genetics or molecular biology. However, the closest concept that might be referred to by this term is a "genomic library," which is a collection of DNA clones that represent the entire genetic material of an organism. These libraries are used for various research purposes, such as identifying and studying specific genes or gene functions.
A cross-sectional study is a type of observational research design that examines the relationship between variables at one point in time. It provides a snapshot or a "cross-section" of the population at a particular moment, allowing researchers to estimate the prevalence of a disease or condition and identify potential risk factors or associations.
In a cross-sectional study, data is collected from a sample of participants at a single time point, and the variables of interest are measured simultaneously. This design can be used to investigate the association between exposure and outcome, but it cannot establish causality because it does not follow changes over time.
Cross-sectional studies can be conducted using various data collection methods, such as surveys, interviews, or medical examinations. They are often used in epidemiology to estimate the prevalence of a disease or condition in a population and to identify potential risk factors that may contribute to its development. However, because cross-sectional studies only provide a snapshot of the population at one point in time, they cannot account for changes over time or determine whether exposure preceded the outcome.
Therefore, while cross-sectional studies can be useful for generating hypotheses and identifying potential associations between variables, further research using other study designs, such as cohort or case-control studies, is necessary to establish causality and confirm any findings.
Demography is the statistical study of populations, particularly in terms of size, distribution, and characteristics such as age, race, gender, and occupation. In medical contexts, demography is often used to analyze health-related data and trends within specific populations. This can include studying the prevalence of certain diseases or conditions, identifying disparities in healthcare access and outcomes, and evaluating the effectiveness of public health interventions. Demographic data can also be used to inform policy decisions and allocate resources to address population health needs.
The chorda tympani nerve is a branch of the facial nerve (cranial nerve VII) that has both sensory and taste functions. It carries taste sensations from the anterior two-thirds of the tongue and sensory information from the oral cavity, including touch, temperature, and pain.
Anatomically, the chorda tympani nerve originates from the facial nerve's intermediate nerve, which is located in the temporal bone of the skull. It then travels through the middle ear, passing near the tympanic membrane (eardrum) before leaving the skull via the petrotympanic fissure. From there, it joins the lingual nerve, a branch of the mandibular division of the trigeminal nerve (cranial nerve V), which carries the taste and sensory information to the brainstem for processing.
Clinically, damage to the chorda tympani nerve can result in loss of taste sensation on the anterior two-thirds of the tongue and altered sensations in the oral cavity. This type of injury can occur during middle ear surgery or as a result of various medical conditions that affect the facial nerve or its branches.
A factual database in the medical context is a collection of organized and structured data that contains verified and accurate information related to medicine, healthcare, or health sciences. These databases serve as reliable resources for various stakeholders, including healthcare professionals, researchers, students, and patients, to access evidence-based information for making informed decisions and enhancing knowledge.
Examples of factual medical databases include:
1. PubMed: A comprehensive database of biomedical literature maintained by the US National Library of Medicine (NLM). It contains citations and abstracts from life sciences journals, books, and conference proceedings.
2. MEDLINE: A subset of PubMed, MEDLINE focuses on high-quality, peer-reviewed articles related to biomedicine and health. It is the primary component of the NLM's database and serves as a critical resource for healthcare professionals and researchers worldwide.
3. Cochrane Library: A collection of systematic reviews and meta-analyses focused on evidence-based medicine. The library aims to provide unbiased, high-quality information to support clinical decision-making and improve patient outcomes.
4. OVID: A platform that offers access to various medical and healthcare databases, including MEDLINE, Embase, and PsycINFO. It facilitates the search and retrieval of relevant literature for researchers, clinicians, and students.
5. ClinicalTrials.gov: A registry and results database of publicly and privately supported clinical studies conducted around the world. The platform aims to increase transparency and accessibility of clinical trial data for healthcare professionals, researchers, and patients.
6. UpToDate: An evidence-based, physician-authored clinical decision support resource that provides information on diagnosis, treatment, and prevention of medical conditions. It serves as a point-of-care tool for healthcare professionals to make informed decisions and improve patient care.
7. TRIP Database: A search engine designed to facilitate evidence-based medicine by providing quick access to high-quality resources, including systematic reviews, clinical guidelines, and practice recommendations.
8. National Guideline Clearinghouse (NGC): A database of evidence-based clinical practice guidelines and related documents developed through a rigorous review process. The NGC aims to provide clinicians, healthcare providers, and policymakers with reliable guidance for patient care.
9. DrugBank: A comprehensive, freely accessible online database containing detailed information about drugs, their mechanisms, interactions, and targets. It serves as a valuable resource for researchers, healthcare professionals, and students in the field of pharmacology and drug discovery.
10. Genetic Testing Registry (GTR): A database that provides centralized information about genetic tests, test developers, laboratories offering tests, and clinical validity and utility of genetic tests. It serves as a resource for healthcare professionals, researchers, and patients to make informed decisions regarding genetic testing.
The transcriptome refers to the complete set of RNA molecules, including messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), and other non-coding RNAs, that are present in a cell or a population of cells at a given point in time. It reflects the genetic activity and provides information about which genes are being actively transcribed and to what extent. The transcriptome can vary under different conditions, such as during development, in response to environmental stimuli, or in various diseases, making it an important area of study in molecular biology and personalized medicine.
Messenger RNA (mRNA) is a type of RNA (ribonucleic acid) that carries genetic information copied from DNA in the form of a series of three-base code "words," each of which specifies a particular amino acid. This information is used by the cell's machinery to construct proteins, a process known as translation. After being transcribed from DNA, mRNA travels out of the nucleus to the ribosomes in the cytoplasm where protein synthesis occurs. Once the protein has been synthesized, the mRNA may be degraded and recycled. Post-transcriptional modifications can also occur to mRNA, such as alternative splicing and addition of a 5' cap and a poly(A) tail, which can affect its stability, localization, and translation efficiency.
Biological models, also known as physiological models or organismal models, are simplified representations of biological systems, processes, or mechanisms that are used to understand and explain the underlying principles and relationships. These models can be theoretical (conceptual or mathematical) or physical (such as anatomical models, cell cultures, or animal models). They are widely used in biomedical research to study various phenomena, including disease pathophysiology, drug action, and therapeutic interventions.
Examples of biological models include:
1. Mathematical models: These use mathematical equations and formulas to describe complex biological systems or processes, such as population dynamics, metabolic pathways, or gene regulation networks. They can help predict the behavior of these systems under different conditions and test hypotheses about their underlying mechanisms.
2. Cell cultures: These are collections of cells grown in a controlled environment, typically in a laboratory dish or flask. They can be used to study cellular processes, such as signal transduction, gene expression, or metabolism, and to test the effects of drugs or other treatments on these processes.
3. Animal models: These are living organisms, usually vertebrates like mice, rats, or non-human primates, that are used to study various aspects of human biology and disease. They can provide valuable insights into the pathophysiology of diseases, the mechanisms of drug action, and the safety and efficacy of new therapies.
4. Anatomical models: These are physical representations of biological structures or systems, such as plastic models of organs or tissues, that can be used for educational purposes or to plan surgical procedures. They can also serve as a basis for developing more sophisticated models, such as computer simulations or 3D-printed replicas.
Overall, biological models play a crucial role in advancing our understanding of biology and medicine, helping to identify new targets for therapeutic intervention, develop novel drugs and treatments, and improve human health.
Artificial Intelligence (AI) in the medical context refers to the simulation of human intelligence processes by machines, particularly computer systems. These processes include learning (the acquisition of information and rules for using the information), reasoning (using the rules to reach approximate or definite conclusions), and self-correction.
In healthcare, AI is increasingly being used to analyze large amounts of data, identify patterns, make decisions, and perform tasks that would normally require human intelligence. This can include tasks such as diagnosing diseases, recommending treatments, personalizing patient care, and improving clinical workflows.
Examples of AI in medicine include machine learning algorithms that analyze medical images to detect signs of disease, natural language processing tools that extract relevant information from electronic health records, and robot-assisted surgery systems that enable more precise and minimally invasive procedures.
An "ecosystem" is not a term that has a specific medical definition, as it is a concept that is more commonly used in the fields of ecology and environmental science. However, I can provide you with the general ecological definition of an ecosystem:
An ecosystem is a community of living organisms interacting with each other and their non-living environment, including both biotic factors (plants, animals, microorganisms) and abiotic factors (climate, soil, water, and air). These interactions create a complex network of relationships that form the foundation of ecological processes, such as energy flow, nutrient cycling, and population dynamics.
While there is no direct medical definition for an ecosystem, understanding the principles of ecosystems can have important implications for human health. For example, healthy ecosystems can provide clean air and water, regulate climate, support food production, and offer opportunities for recreation and relaxation, all of which contribute to overall well-being. Conversely, degraded ecosystems can lead to increased exposure to environmental hazards, reduced access to natural resources, and heightened risks of infectious diseases. Therefore, maintaining the health and integrity of ecosystems is crucial for promoting human health and preventing disease.
A diet, in medical terms, refers to the planned and regular consumption of food and drinks. It is a balanced selection of nutrient-rich foods that an individual eats on a daily or periodic basis to meet their energy needs and maintain good health. A well-balanced diet typically includes a variety of fruits, vegetables, whole grains, lean proteins, and low-fat dairy products.
A diet may also be prescribed for therapeutic purposes, such as in the management of certain medical conditions like diabetes, hypertension, or obesity. In these cases, a healthcare professional may recommend specific restrictions or modifications to an individual's regular diet to help manage their condition and improve their overall health.
It is important to note that a healthy and balanced diet should be tailored to an individual's age, gender, body size, activity level, and any underlying medical conditions. Consulting with a healthcare professional, such as a registered dietitian or nutritionist, can help ensure that an individual's dietary needs are being met in a safe and effective way.
The proteome is the entire set of proteins produced or present in an organism, system, organ, or cell at a certain time under specific conditions. It is a dynamic collection of protein species that changes over time, responding to various internal and external stimuli such as disease, stress, or environmental factors. The study of the proteome, known as proteomics, involves the identification and quantification of these protein components and their post-translational modifications, providing valuable insights into biological processes, functional pathways, and disease mechanisms.
Medical Definition:
"Risk factors" are any attribute, characteristic or exposure of an individual that increases the likelihood of developing a disease or injury. They can be divided into modifiable and non-modifiable risk factors. Modifiable risk factors are those that can be changed through lifestyle choices or medical treatment, while non-modifiable risk factors are inherent traits such as age, gender, or genetic predisposition. Examples of modifiable risk factors include smoking, alcohol consumption, physical inactivity, and unhealthy diet, while non-modifiable risk factors include age, sex, and family history. It is important to note that having a risk factor does not guarantee that a person will develop the disease, but rather indicates an increased susceptibility.
Phylogeography is not a medical term, but rather a subfield of biogeography and phylogenetics that investigates the spatial distribution of genealogical lineages and the historical processes that have shaped them. It uses genetic data to infer the geographic origins, dispersal routes, and demographic history of organisms, including pathogens and vectors that can affect human health.
In medical and public health contexts, phylogeography is often used to study the spread of infectious diseases, such as HIV/AIDS, influenza, or tuberculosis, by analyzing the genetic diversity and geographic distribution of pathogen isolates. This information can help researchers understand how diseases emerge, evolve, and move across populations and landscapes, which can inform disease surveillance, control, and prevention strategies.
Immunohistochemistry (IHC) is a technique used in pathology and laboratory medicine to identify specific proteins or antigens in tissue sections. It combines the principles of immunology and histology to detect the presence and location of these target molecules within cells and tissues. This technique utilizes antibodies that are specific to the protein or antigen of interest, which are then tagged with a detection system such as a chromogen or fluorophore. The stained tissue sections can be examined under a microscope, allowing for the visualization and analysis of the distribution and expression patterns of the target molecule in the context of the tissue architecture. Immunohistochemistry is widely used in diagnostic pathology to help identify various diseases, including cancer, infectious diseases, and immune-mediated disorders.
A cohort study is a type of observational study in which a group of individuals who share a common characteristic or exposure are followed up over time to determine the incidence of a specific outcome or outcomes. The cohort, or group, is defined based on the exposure status (e.g., exposed vs. unexposed) and then monitored prospectively to assess for the development of new health events or conditions.
Cohort studies can be either prospective or retrospective in design. In a prospective cohort study, participants are enrolled and followed forward in time from the beginning of the study. In contrast, in a retrospective cohort study, researchers identify a cohort that has already been assembled through medical records, insurance claims, or other sources and then look back in time to assess exposure status and health outcomes.
Cohort studies are useful for establishing causality between an exposure and an outcome because they allow researchers to observe the temporal relationship between the two. They can also provide information on the incidence of a disease or condition in different populations, which can be used to inform public health policy and interventions. However, cohort studies can be expensive and time-consuming to conduct, and they may be subject to bias if participants are not representative of the population or if there is loss to follow-up.
In the context of medical and biological sciences, a "binding site" refers to a specific location on a protein, molecule, or cell where another molecule can attach or bind. This binding interaction can lead to various functional changes in the original protein or molecule. The other molecule that binds to the binding site is often referred to as a ligand, which can be a small molecule, ion, or even another protein.
The binding between a ligand and its target binding site can be specific and selective, meaning that only certain ligands can bind to particular binding sites with high affinity. This specificity plays a crucial role in various biological processes, such as signal transduction, enzyme catalysis, or drug action.
In the case of drug development, understanding the location and properties of binding sites on target proteins is essential for designing drugs that can selectively bind to these sites and modulate protein function. This knowledge can help create more effective and safer therapeutic options for various diseases.
The ribosomal spacer in DNA refers to the non-coding sequences of DNA that are located between the genes for ribosomal RNA (rRNA). These spacer regions are present in the DNA of organisms that have a nuclear genome, including humans and other animals, plants, and fungi.
In prokaryotic cells, such as bacteria, there are two ribosomal RNA genes, 16S and 23S, separated by a spacer region known as the intergenic spacer (IGS). In eukaryotic cells, there are multiple copies of ribosomal RNA genes arranged in clusters called nucleolar organizer regions (NORs), which are located on the short arms of several acrocentric chromosomes. Each cluster contains hundreds to thousands of copies of the 18S, 5.8S, and 28S rRNA genes, separated by non-transcribed spacer regions known as internal transcribed spacers (ITS) and external transcribed spacers (ETS).
The ribosomal spacer regions in DNA are often used as molecular markers for studying evolutionary relationships among organisms because they evolve more rapidly than the rRNA genes themselves. The sequences of these spacer regions can be compared among different species to infer their phylogenetic relationships and to estimate the time since they diverged from a common ancestor. Additionally, the length and composition of ribosomal spacers can vary between individuals within a species, making them useful for studying genetic diversity and population structure.
Population Genetics is a subfield of genetics that deals with the genetic composition of populations and how this composition changes over time. It involves the study of the frequency and distribution of genes and genetic variations in populations, as well as the evolutionary forces that contribute to these patterns, such as mutation, gene flow, genetic drift, and natural selection.
Population genetics can provide insights into a wide range of topics, including the history and relationships between populations, the genetic basis of diseases and other traits, and the potential impacts of environmental changes on genetic diversity. This field is important for understanding evolutionary processes at the population level and has applications in areas such as conservation biology, medical genetics, and forensic science.
Microdissection is a surgical technique that involves the use of a microscope to allow for precise, minimalistic dissection of tissue. It is often used in research and clinical settings to isolate specific cells, tissues or structures while minimizing damage to surrounding areas. This technique can be performed using various methods such as laser capture microdissection (LCM) or manual microdissection with microsurgical tools. The size and scale of the dissection required will determine the specific method used. In general, microdissection allows for the examination and analysis of very small and delicate structures that would otherwise be difficult to access and study.
A Severity of Illness Index is a measurement tool used in healthcare to assess the severity of a patient's condition and the risk of mortality or other adverse outcomes. These indices typically take into account various physiological and clinical variables, such as vital signs, laboratory values, and co-morbidities, to generate a score that reflects the patient's overall illness severity.
Examples of Severity of Illness Indices include the Acute Physiology and Chronic Health Evaluation (APACHE) system, the Simplified Acute Physiology Score (SAPS), and the Mortality Probability Model (MPM). These indices are often used in critical care settings to guide clinical decision-making, inform prognosis, and compare outcomes across different patient populations.
It is important to note that while these indices can provide valuable information about a patient's condition, they should not be used as the sole basis for clinical decision-making. Rather, they should be considered in conjunction with other factors, such as the patient's overall clinical presentation, treatment preferences, and goals of care.
I'm sorry for any confusion, but "United States" is a geopolitical entity, specifically the name of the country consisting of 50 states, and it is not a medical term or concept. Therefore, I can't provide a medical definition for it. If you have any questions related to health, medicine, or biology, I would be happy to try to help answer those!
A disease outbreak is defined as the occurrence of cases of a disease in excess of what would normally be expected in a given time and place. It may affect a small and localized group or a large number of people spread over a wide area, even internationally. An outbreak may be caused by a new agent, a change in the agent's virulence or host susceptibility, or an increase in the size or density of the host population.
Outbreaks can have significant public health and economic impacts, and require prompt investigation and control measures to prevent further spread of the disease. The investigation typically involves identifying the source of the outbreak, determining the mode of transmission, and implementing measures to interrupt the chain of infection. This may include vaccination, isolation or quarantine, and education of the public about the risks and prevention strategies.
Examples of disease outbreaks include foodborne illnesses linked to contaminated food or water, respiratory infections spread through coughing and sneezing, and mosquito-borne diseases such as Zika virus and West Nile virus. Outbreaks can also occur in healthcare settings, such as hospitals and nursing homes, where vulnerable populations may be at increased risk of infection.
An allele is a variant form of a gene that is located at a specific position on a specific chromosome. Alleles are alternative forms of the same gene that arise by mutation and are found at the same locus or position on homologous chromosomes.
Each person typically inherits two copies of each gene, one from each parent. If the two alleles are identical, a person is said to be homozygous for that trait. If the alleles are different, the person is heterozygous.
For example, the ABO blood group system has three alleles, A, B, and O, which determine a person's blood type. If a person inherits two A alleles, they will have type A blood; if they inherit one A and one B allele, they will have type AB blood; if they inherit two B alleles, they will have type B blood; and if they inherit two O alleles, they will have type O blood.
Alleles can also influence traits such as eye color, hair color, height, and other physical characteristics. Some alleles are dominant, meaning that only one copy of the allele is needed to express the trait, while others are recessive, meaning that two copies of the allele are needed to express the trait.
Fourier Transform Infrared (FTIR) spectroscopy is a type of infrared spectroscopy that uses the Fourier transform mathematical technique to convert the raw data obtained from an interferometer into a more interpretable spectrum. This technique allows for the simultaneous collection of a wide range of wavelengths, resulting in increased sensitivity and speed compared to traditional dispersive infrared spectroscopy.
FTIR spectroscopy measures the absorption or transmission of infrared radiation by a sample as a function of frequency, providing information about the vibrational modes of the molecules present in the sample. This can be used for identification and quantification of chemical compounds, analysis of molecular structure, and investigation of chemical interactions and reactions.
In summary, FTIR spectroscopy is a powerful analytical technique that uses infrared radiation to study the vibrational properties of molecules, with increased sensitivity and speed due to the use of Fourier transform mathematical techniques and an interferometer.
Genomics is the scientific study of genes and their functions. It involves the sequencing and analysis of an organism's genome, which is its complete set of DNA, including all of its genes. Genomics also includes the study of how genes interact with each other and with the environment. This field of study can provide important insights into the genetic basis of diseases and can lead to the development of new diagnostic tools and treatments.
Biodiversity is the variety of different species of plants, animals, and microorganisms that live in an ecosystem. It also includes the variety of genes within a species and the variety of ecosystems (such as forests, grasslands, deserts, and oceans) that exist in a region or on Earth as a whole. Biodiversity is important for maintaining the health and balance of ecosystems, providing resources and services such as food, clean water, and pollination, and contributing to the discovery of new medicines and other useful products. The loss of biodiversity can have negative impacts on the functioning of ecosystems and the services they provide, and can threaten the survival of species and the livelihoods of people who depend on them.
Tumor markers are substances that can be found in the body and their presence can indicate the presence of certain types of cancer or other conditions. Biological tumor markers refer to those substances that are produced by cancer cells or by other cells in response to cancer or certain benign (non-cancerous) conditions. These markers can be found in various bodily fluids such as blood, urine, or tissue samples.
Examples of biological tumor markers include:
1. Proteins: Some tumor markers are proteins that are produced by cancer cells or by other cells in response to the presence of cancer. For example, prostate-specific antigen (PSA) is a protein produced by normal prostate cells and in higher amounts by prostate cancer cells.
2. Genetic material: Tumor markers can also include genetic material such as DNA, RNA, or microRNA that are shed by cancer cells into bodily fluids. For example, circulating tumor DNA (ctDNA) is genetic material from cancer cells that can be found in the bloodstream.
3. Metabolites: Tumor markers can also include metabolic products produced by cancer cells or by other cells in response to cancer. For example, lactate dehydrogenase (LDH) is an enzyme that is released into the bloodstream when cancer cells break down glucose for energy.
It's important to note that tumor markers are not specific to cancer and can be elevated in non-cancerous conditions as well. Therefore, they should not be used alone to diagnose cancer but rather as a tool in conjunction with other diagnostic tests and clinical evaluations.
A gene in plants, like in other organisms, is a hereditary unit that carries genetic information from one generation to the next. It is a segment of DNA (deoxyribonucleic acid) that contains the instructions for the development and function of an organism. Genes in plants determine various traits such as flower color, plant height, resistance to diseases, and many others. They are responsible for encoding proteins and RNA molecules that play crucial roles in the growth, development, and reproduction of plants. Plant genes can be manipulated through traditional breeding methods or genetic engineering techniques to improve crop yield, enhance disease resistance, and increase nutritional value.
Sequence homology in nucleic acids refers to the similarity or identity between the nucleotide sequences of two or more DNA or RNA molecules. It is often used as a measure of biological relationship between genes, organisms, or populations. High sequence homology suggests a recent common ancestry or functional constraint, while low sequence homology may indicate a more distant relationship or different functions.
Nucleic acid sequence homology can be determined by various methods such as pairwise alignment, multiple sequence alignment, and statistical analysis. The degree of homology is typically expressed as a percentage of identical or similar nucleotides in a given window of comparison.
It's important to note that the interpretation of sequence homology depends on the biological context and the evolutionary distance between the sequences compared. Therefore, functional and experimental validation is often necessary to confirm the significance of sequence homology.
I'm sorry for any confusion, but "Rivers" is not a medical term or concept. It is a geographical term referring to large, flowing bodies of water that usually empty into a sea or an ocean. If you have any medical questions or terms you would like defined, I'd be happy to help!
Gene expression regulation in bacteria refers to the complex cellular processes that control the production of proteins from specific genes. This regulation allows bacteria to adapt to changing environmental conditions and ensure the appropriate amount of protein is produced at the right time.
Bacteria have a variety of mechanisms for regulating gene expression, including:
1. Operon structure: Many bacterial genes are organized into operons, which are clusters of genes that are transcribed together as a single mRNA molecule. The expression of these genes can be coordinately regulated by controlling the transcription of the entire operon.
2. Promoter regulation: Transcription is initiated at promoter regions upstream of the gene or operon. Bacteria have regulatory proteins called sigma factors that bind to the promoter and recruit RNA polymerase, the enzyme responsible for transcribing DNA into RNA. The binding of sigma factors can be influenced by environmental signals, allowing for regulation of transcription.
3. Attenuation: Some operons have regulatory regions called attenuators that control transcription termination. These regions contain hairpin structures that can form in the mRNA and cause transcription to stop prematurely. The formation of these hairpins is influenced by the concentration of specific metabolites, allowing for regulation of gene expression based on the availability of those metabolites.
4. Riboswitches: Some bacterial mRNAs contain regulatory elements called riboswitches that bind small molecules directly. When a small molecule binds to the riboswitch, it changes conformation and affects transcription or translation of the associated gene.
5. CRISPR-Cas systems: Bacteria use CRISPR-Cas systems for adaptive immunity against viruses and plasmids. These systems incorporate short sequences from foreign DNA into their own genome, which can then be used to recognize and cleave similar sequences in invading genetic elements.
Overall, gene expression regulation in bacteria is a complex process that allows them to respond quickly and efficiently to changing environmental conditions. Understanding these regulatory mechanisms can provide insights into bacterial physiology and help inform strategies for controlling bacterial growth and behavior.
Sensitivity and specificity are statistical measures used to describe the performance of a diagnostic test or screening tool in identifying true positive and true negative results.
* Sensitivity refers to the proportion of people who have a particular condition (true positives) who are correctly identified by the test. It is also known as the "true positive rate" or "recall." A highly sensitive test will identify most or all of the people with the condition, but may also produce more false positives.
* Specificity refers to the proportion of people who do not have a particular condition (true negatives) who are correctly identified by the test. It is also known as the "true negative rate." A highly specific test will identify most or all of the people without the condition, but may also produce more false negatives.
In medical testing, both sensitivity and specificity are important considerations when evaluating a diagnostic test. High sensitivity is desirable for screening tests that aim to identify as many cases of a condition as possible, while high specificity is desirable for confirmatory tests that aim to rule out the condition in people who do not have it.
It's worth noting that sensitivity and specificity are often influenced by factors such as the prevalence of the condition in the population being tested, the threshold used to define a positive result, and the reliability and validity of the test itself. Therefore, it's important to consider these factors when interpreting the results of a diagnostic test.
Least-Squares Analysis is not a medical term, but rather a statistical method that is used in various fields including medicine. It is a way to find the best fit line or curve for a set of data points by minimizing the sum of the squared distances between the observed data points and the fitted line or curve. This method is often used in medical research to analyze data, such as fitting a regression line to a set of data points to make predictions or identify trends. The goal is to find the line or curve that most closely represents the pattern of the data, which can help researchers understand relationships between variables and make more informed decisions based on their analysis.
Secondary protein structure refers to the local spatial arrangement of amino acid chains in a protein, typically described as regular repeating patterns held together by hydrogen bonds. The two most common types of secondary structures are the alpha-helix (α-helix) and the beta-pleated sheet (β-sheet). In an α-helix, the polypeptide chain twists around itself in a helical shape, with each backbone atom forming a hydrogen bond with the fourth amino acid residue along the chain. This forms a rigid rod-like structure that is resistant to bending or twisting forces. In β-sheets, adjacent segments of the polypeptide chain run parallel or antiparallel to each other and are connected by hydrogen bonds, forming a pleated sheet-like arrangement. These secondary structures provide the foundation for the formation of tertiary and quaternary protein structures, which determine the overall three-dimensional shape and function of the protein.
Pain measurement, in a medical context, refers to the quantification or evaluation of the intensity and/or unpleasantness of a patient's subjective pain experience. This is typically accomplished through the use of standardized self-report measures such as numerical rating scales (NRS), visual analog scales (VAS), or categorical scales (mild, moderate, severe). In some cases, physiological measures like heart rate, blood pressure, and facial expressions may also be used to supplement self-reported pain ratings. The goal of pain measurement is to help healthcare providers better understand the nature and severity of a patient's pain in order to develop an effective treatment plan.
A conserved sequence in the context of molecular biology refers to a pattern of nucleotides (in DNA or RNA) or amino acids (in proteins) that has remained relatively unchanged over evolutionary time. These sequences are often functionally important and are highly conserved across different species, indicating strong selection pressure against changes in these regions.
In the case of protein-coding genes, the corresponding amino acid sequence is deduced from the DNA sequence through the genetic code. Conserved sequences in proteins may indicate structurally or functionally important regions, such as active sites or binding sites, that are critical for the protein's activity. Similarly, conserved non-coding sequences in DNA may represent regulatory elements that control gene expression.
Identifying conserved sequences can be useful for inferring evolutionary relationships between species and for predicting the function of unknown genes or proteins.
Fungal DNA refers to the genetic material present in fungi, which are a group of eukaryotic organisms that include microorganisms such as yeasts and molds, as well as larger organisms like mushrooms. The DNA of fungi, like that of all living organisms, is made up of nucleotides that are arranged in a double helix structure.
Fungal DNA contains the genetic information necessary for the growth, development, and reproduction of fungi. This includes the instructions for making proteins, which are essential for the structure and function of cells, as well as other important molecules such as enzymes and nucleic acids.
Studying fungal DNA can provide valuable insights into the biology and evolution of fungi, as well as their potential uses in medicine, agriculture, and industry. For example, researchers have used genetic engineering techniques to modify the DNA of fungi to produce drugs, biofuels, and other useful products. Additionally, understanding the genetic makeup of pathogenic fungi can help scientists develop new strategies for preventing and treating fungal infections.
"Pseudomonas" is a genus of Gram-negative, rod-shaped bacteria that are widely found in soil, water, and plants. Some species of Pseudomonas can cause disease in animals and humans, with P. aeruginosa being the most clinically relevant as it's an opportunistic pathogen capable of causing various types of infections, particularly in individuals with weakened immune systems.
P. aeruginosa is known for its remarkable ability to resist many antibiotics and disinfectants, making infections caused by this bacterium difficult to treat. It can cause a range of healthcare-associated infections, such as pneumonia, bloodstream infections, urinary tract infections, and surgical site infections. In addition, it can also cause external ear infections and eye infections.
Prompt identification and appropriate antimicrobial therapy are crucial for managing Pseudomonas infections, although the increasing antibiotic resistance poses a significant challenge in treatment.
Protein sequence analysis is the systematic examination and interpretation of the amino acid sequence of a protein to understand its structure, function, evolutionary relationships, and other biological properties. It involves various computational methods and tools to analyze the primary structure of proteins, which is the linear arrangement of amino acids along the polypeptide chain.
Protein sequence analysis can provide insights into several aspects, such as:
1. Identification of functional domains, motifs, or sites within a protein that may be responsible for its specific biochemical activities.
2. Comparison of homologous sequences from different organisms to infer evolutionary relationships and determine the degree of similarity or divergence among them.
3. Prediction of secondary and tertiary structures based on patterns of amino acid composition, hydrophobicity, and charge distribution.
4. Detection of post-translational modifications that may influence protein function, localization, or stability.
5. Identification of protease cleavage sites, signal peptides, or other sequence features that play a role in protein processing and targeting.
Some common techniques used in protein sequence analysis include:
1. Multiple Sequence Alignment (MSA): A method to align multiple protein sequences to identify conserved regions, gaps, and variations.
2. BLAST (Basic Local Alignment Search Tool): A widely-used tool for comparing a query protein sequence against a database of known sequences to find similarities and infer function or evolutionary relationships.
3. Hidden Markov Models (HMMs): Statistical models used to describe the probability distribution of amino acid sequences in protein families, allowing for more sensitive detection of remote homologs.
4. Protein structure prediction: Methods that use various computational approaches to predict the three-dimensional structure of a protein based on its amino acid sequence.
5. Phylogenetic analysis: The construction and interpretation of evolutionary trees (phylogenies) based on aligned protein sequences, which can provide insights into the historical relationships among organisms or proteins.
A plant disease is a disorder that affects the normal growth and development of plants, caused by pathogenic organisms such as bacteria, viruses, fungi, parasites, or nematodes, as well as environmental factors like nutrient deficiencies, extreme temperatures, or physical damage. These diseases can cause various symptoms, including discoloration, wilting, stunted growth, necrosis, and reduced yield or productivity, which can have significant economic and ecological impacts.
I'm sorry for any confusion, but "Italy" is not a medical term or concept. It is a country located in Southern Europe. If you have any questions related to medical terminology or health-related topics, I would be happy to try and help answer those for you.
Protein conformation refers to the specific three-dimensional shape that a protein molecule assumes due to the spatial arrangement of its constituent amino acid residues and their associated chemical groups. This complex structure is determined by several factors, including covalent bonds (disulfide bridges), hydrogen bonds, van der Waals forces, and ionic bonds, which help stabilize the protein's unique conformation.
Protein conformations can be broadly classified into two categories: primary, secondary, tertiary, and quaternary structures. The primary structure represents the linear sequence of amino acids in a polypeptide chain. The secondary structure arises from local interactions between adjacent amino acid residues, leading to the formation of recurring motifs such as α-helices and β-sheets. Tertiary structure refers to the overall three-dimensional folding pattern of a single polypeptide chain, while quaternary structure describes the spatial arrangement of multiple folded polypeptide chains (subunits) that interact to form a functional protein complex.
Understanding protein conformation is crucial for elucidating protein function, as the specific three-dimensional shape of a protein directly influences its ability to interact with other molecules, such as ligands, nucleic acids, or other proteins. Any alterations in protein conformation due to genetic mutations, environmental factors, or chemical modifications can lead to loss of function, misfolding, aggregation, and disease states like neurodegenerative disorders and cancer.
Enzymes are complex proteins that act as catalysts to speed up chemical reactions in the body. They help to lower activation energy required for reactions to occur, thereby enabling the reaction to happen faster and at lower temperatures. Enzymes work by binding to specific molecules, called substrates, and converting them into different molecules, called products. This process is known as catalysis.
Enzymes are highly specific and will only catalyze one particular reaction with a specific substrate. The shape of the enzyme's active site, where the substrate binds, determines this specificity. Enzymes can be regulated by various factors such as temperature, pH, and the presence of inhibitors or activators. They play a crucial role in many biological processes, including digestion, metabolism, and DNA replication.
Complementary DNA (cDNA) is a type of DNA that is synthesized from a single-stranded RNA molecule through the process of reverse transcription. In this process, the enzyme reverse transcriptase uses an RNA molecule as a template to synthesize a complementary DNA strand. The resulting cDNA is therefore complementary to the original RNA molecule and is a copy of its coding sequence, but it does not contain non-coding regions such as introns that are present in genomic DNA.
Complementary DNA is often used in molecular biology research to study gene expression, protein function, and other genetic phenomena. For example, cDNA can be used to create cDNA libraries, which are collections of cloned cDNA fragments that represent the expressed genes in a particular cell type or tissue. These libraries can then be screened for specific genes or gene products of interest. Additionally, cDNA can be used to produce recombinant proteins in heterologous expression systems, allowing researchers to study the structure and function of proteins that may be difficult to express or purify from their native sources.
"Cattle" is a term used in the agricultural and veterinary fields to refer to domesticated animals of the genus *Bos*, primarily *Bos taurus* (European cattle) and *Bos indicus* (Zebu). These animals are often raised for meat, milk, leather, and labor. They are also known as bovines or cows (for females), bulls (intact males), and steers/bullocks (castrated males). However, in a strict medical definition, "cattle" does not apply to humans or other animals.
Electron Spin Resonance (ESR) Spectroscopy, also known as Electron Paramagnetic Resonance (EPR) Spectroscopy, is a technique used to investigate materials with unpaired electrons. It is based on the principle of absorption of energy by the unpaired electrons when they are exposed to an external magnetic field and microwave radiation.
In this technique, a sample is placed in a magnetic field and microwave radiation is applied. The unpaired electrons in the sample absorb energy and change their spin state when the energy of the microwaves matches the energy difference between the spin states. This absorption of energy is recorded as a function of the magnetic field strength, producing an ESR spectrum.
ESR spectroscopy can provide information about the number, type, and behavior of unpaired electrons in a sample, as well as the local environment around the electron. It is widely used in physics, chemistry, and biology to study materials such as free radicals, transition metal ions, and defects in solids.
Restriction mapping is a technique used in molecular biology to identify the location and arrangement of specific restriction endonuclease recognition sites within a DNA molecule. Restriction endonucleases are enzymes that cut double-stranded DNA at specific sequences, producing fragments of various lengths. By digesting the DNA with different combinations of these enzymes and analyzing the resulting fragment sizes through techniques such as agarose gel electrophoresis, researchers can generate a restriction map - a visual representation of the locations and distances between recognition sites on the DNA molecule. This information is crucial for various applications, including cloning, genome analysis, and genetic engineering.
Computer-assisted image processing is a medical term that refers to the use of computer systems and specialized software to improve, analyze, and interpret medical images obtained through various imaging techniques such as X-ray, CT (computed tomography), MRI (magnetic resonance imaging), ultrasound, and others.
The process typically involves several steps, including image acquisition, enhancement, segmentation, restoration, and analysis. Image processing algorithms can be used to enhance the quality of medical images by adjusting contrast, brightness, and sharpness, as well as removing noise and artifacts that may interfere with accurate diagnosis. Segmentation techniques can be used to isolate specific regions or structures of interest within an image, allowing for more detailed analysis.
Computer-assisted image processing has numerous applications in medical imaging, including detection and characterization of lesions, tumors, and other abnormalities; assessment of organ function and morphology; and guidance of interventional procedures such as biopsies and surgeries. By automating and standardizing image analysis tasks, computer-assisted image processing can help to improve diagnostic accuracy, efficiency, and consistency, while reducing the potential for human error.
Proteins are complex, large molecules that play critical roles in the body's functions. They are made up of amino acids, which are organic compounds that are the building blocks of proteins. Proteins are required for the structure, function, and regulation of the body's tissues and organs. They are essential for the growth, repair, and maintenance of body tissues, and they play a crucial role in many biological processes, including metabolism, immune response, and cellular signaling. Proteins can be classified into different types based on their structure and function, such as enzymes, hormones, antibodies, and structural proteins. They are found in various foods, especially animal-derived products like meat, dairy, and eggs, as well as plant-based sources like beans, nuts, and grains.
Ferredoxins are iron-sulfur proteins that play a crucial role in electron transfer reactions in various biological systems, particularly in photosynthesis and nitrogen fixation. They contain one or more clusters of iron and sulfur atoms (known as the iron-sulfur cluster) that facilitate the movement of electrons between different molecules during metabolic processes.
Ferredoxins have a relatively simple structure, consisting of a polypeptide chain that binds to the iron-sulfur cluster. This simple structure allows ferredoxins to participate in a wide range of redox reactions and makes them versatile electron carriers in biological systems. They can accept electrons from various donors and transfer them to different acceptors, depending on the needs of the cell.
In photosynthesis, ferredoxins play a critical role in the light-dependent reactions by accepting electrons from photosystem I and transferring them to NADP+, forming NADPH. This reduced form of nicotinamide adenine dinucleotide phosphate (NADPH) is then used in the Calvin cycle for carbon fixation and the production of glucose.
In nitrogen fixation, ferredoxins help transfer electrons to the nitrogenase enzyme complex, which reduces atmospheric nitrogen gas (N2) into ammonia (NH3), making it available for assimilation by plants and other organisms.
Overall, ferredoxins are essential components of many metabolic pathways, facilitating electron transfer and energy conversion in various biological systems.
Socioeconomic factors are a range of interconnected conditions and influences that affect the opportunities and resources a person or group has to maintain and improve their health and well-being. These factors include:
1. Economic stability: This includes employment status, job security, income level, and poverty status. Lower income and lack of employment are associated with poorer health outcomes.
2. Education: Higher levels of education are generally associated with better health outcomes. Education can affect a person's ability to access and understand health information, as well as their ability to navigate the healthcare system.
3. Social and community context: This includes factors such as social support networks, discrimination, and community safety. Strong social supports and positive community connections are associated with better health outcomes, while discrimination and lack of safety can negatively impact health.
4. Healthcare access and quality: Access to affordable, high-quality healthcare is an important socioeconomic factor that can significantly impact a person's health. Factors such as insurance status, availability of providers, and cultural competency of healthcare systems can all affect healthcare access and quality.
5. Neighborhood and built environment: The physical conditions in which people live, work, and play can also impact their health. Factors such as housing quality, transportation options, availability of healthy foods, and exposure to environmental hazards can all influence health outcomes.
Socioeconomic factors are often interrelated and can have a cumulative effect on health outcomes. For example, someone who lives in a low-income neighborhood with limited access to healthy foods and safe parks may also face challenges related to employment, education, and healthcare access that further impact their health. Addressing socioeconomic factors is an important part of promoting health equity and reducing health disparities.
Fibromyalgia is a chronic disorder characterized by widespread musculoskeletal pain, fatigue, sleep disturbances, and cognitive difficulties. The pain typically occurs in specific tender points or trigger points, which are located on the neck, shoulders, back, hips, arms, and legs. These points are painful when pressure is applied.
The exact cause of fibromyalgia is unknown, but it appears to be related to abnormalities in the way the brain processes pain signals. It may also be associated with certain genetic factors, physical trauma, infection, or emotional stress. Fibromyalgia is more common in women than men and tends to develop between the ages of 20 and 50.
Fibromyalgia can be difficult to diagnose because its symptoms are similar to those of other conditions, such as rheumatoid arthritis, lupus, and chronic fatigue syndrome. However, a diagnosis of fibromyalgia may be made if a person has widespread pain for at least three months and tenderness in at least 11 of 18 specific points on the body when pressure is applied.
There is no cure for fibromyalgia, but medications, therapy, and lifestyle changes can help manage its symptoms. Treatment may include pain relievers, antidepressants, anti-seizure drugs, physical therapy, counseling, stress reduction techniques, and regular exercise.
In a medical context, taste is the sensation produced when a substance in the mouth reacts with taste buds, which are specialized sensory cells found primarily on the tongue. The tongue's surface contains papillae, which house the taste buds. These taste buds can identify five basic tastes: salty, sour, bitter, sweet, and umami (savory). Different areas of the tongue are more sensitive to certain tastes, but all taste buds can detect each of the five tastes, although not necessarily equally.
Taste is a crucial part of our sensory experience, helping us identify and differentiate between various types of food and drinks, and playing an essential role in appetite regulation and enjoyment of meals. Abnormalities in taste sensation can be associated with several medical conditions or side effects of certain medications.
I apologize for any confusion, but "agriculture" is not a term that has a medical definition. Agriculture refers to the cultivation and breeding of animals, plants, and fungi for food, fiber, biofuel, medicinal plants, and other products used to sustain and enhance human life. It is an important industry and practice that has been developed over thousands of years and continues to play a critical role in global food production and security.
 Cluster analysis
Cluster analysis
Clustering high-dimensional data
Single-linkage clustering
Complete-linkage clustering
Cobweb (clustering)
K-medians clustering
Canopy clustering algorithm
Cluster development
Low-energy adaptive clustering hierarchy
Determining the number of clusters in a data set
Cluster-weighted modeling
List of globular clusters
XMM Cluster Survey
Silhouette (clustering)
Business cluster
K-means clustering
Cluster state
Gas cluster ion beam
Quantum clustering
Galaxy groups and clusters
Metabolic gene cluster
Correlation clustering
Elbow method (clustering)
Document clustering
Sequence clustering
Cluster headache
Geographical cluster
Spectral clustering
Automatic clustering algorithms
Chinese whispers (clustering method)
Category:Cluster analysis algorithms - Wikipedia
Cluster analysis - Wikipedia
 10 (Analysis: Hierarchical clustering)
- BASE
10 (Analysis: Hierarchical clustering)
- BASE
Space-Time Cluster Analysis of Invasive Meningococcal Disease - Volume 10, Number 9-September 2004 - Emerging Infectious...
 Analysis of Ribosomal RNA Sequences by Combinatorial Clustering - AAAI
Analysis of Ribosomal RNA Sequences by Combinatorial Clustering - AAAI
 Do Cluster Analysis Using Built-in Sequence Similarity Metrics
Do Cluster Analysis Using Built-in Sequence Similarity Metrics
 Apps with 'Clustering analysis' feature | AlternativeTo
Apps with 'Clustering analysis' feature | AlternativeTo
 The stepped wedge cluster randomised trial: rationale, design, analysis, and reporting | The BMJ
The stepped wedge cluster randomised trial: rationale, design, analysis, and reporting | The BMJ
 Cluster Analysis and Unsupervised Machine Learning in Python | Udemy
Cluster Analysis and Unsupervised Machine Learning in Python | Udemy
 A Modular Cluster Tool for Semiconductor Failure Analysis | SBIR.gov
A Modular Cluster Tool for Semiconductor Failure Analysis | SBIR.gov
 Sustainability | Free Full-Text | Food Waste Behavior among Romanian Consumers: A Cluster Analysis
Sustainability | Free Full-Text | Food Waste Behavior among Romanian Consumers: A Cluster Analysis
 ESA Science & Technology - Four-point Cluster application of magnetic field analysis tools: The Curlometer
ESA Science & Technology - Four-point Cluster application of magnetic field analysis tools: The Curlometer
 Download Convergent Cluster and Ensemble Analysis
Download Convergent Cluster and Ensemble Analysis
 A Comparative Analysis of Biosynthetic Gene Clusters in Lean and Obese Humans
A Comparative Analysis of Biosynthetic Gene Clusters in Lean and Obese Humans
 Morphological analysis of chiral rod clusters from a coarse-grained single-site chiral potential
Morphological analysis of chiral rod clusters from a coarse-grained single-site chiral potential
 Frontiers | Comparison of the Use of Linkage in Cluster Integration With Path Analysis Approach
Frontiers | Comparison of the Use of Linkage in Cluster Integration With Path Analysis Approach
![PRIME PubMed | [Analysis on transmission chain of a cluster epidemic of COVID-19, Nanchang]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAMAAAAoLQ9TAAAAjVBMVEVHcEyABSSMBCaMBCaMBCaeFTaoGDqjAyqAACGaBCqMBCaMBCbCAC+MAyWlASipFzvEAzKOABP9/PySASTAACaCAAObAAKdACDZvMGpAA/AnqTRcX+pV2WoZnGze4TSrrS+ABTSnKXbyMzk1tqYITiIJTi+jZXqvMPx6+2wDzandXyZT1qrK0XIU2fUi5eD4+TyAAAADHRSTlMARNP5/NP6+UjRVlXxulOyAAAAwUlEQVQYlTWPR5bCMBAFG3hgm7GE1MrJORHvf7yxx0ztqv6mGyA/X25fLuccIL8zVn5h7J5D8a9SbqmAbBf5DmGbsi1I+al9GoZ4axoKtGxCF7UL1naI8xqa2WvXdklwhX6xoGfv3kvSlOp2UbWFiDqgoNToulcCR5jwhdEZU/WVGvonB9EjflprH4pP3cgJUDek9FT81dYPRQiBjJUmVpOvRsVXP/2dbgznXJCNIxzo+pwRYnfyA3AoMkp3Ox2v8AuqgBQxU3E0TgAAAABJRU5ErkJggg==) PRIME PubMed | [Analysis on transmission chain of a cluster epidemic of COVID-19, Nanchang]
PRIME PubMed | [Analysis on transmission chain of a cluster epidemic of COVID-19, Nanchang]
 On the Nature and Analysis of Clustered Data | Annals of Family Medicine
On the Nature and Analysis of Clustered Data | Annals of Family Medicine
 Clinical COPD phenotypes identified by cluster analysis: validation with mortality | European Respiratory Society
Clinical COPD phenotypes identified by cluster analysis: validation with mortality | European Respiratory Society
1509.00424] A uvbyCaHbeta CCD Analysis of the Open Cluster Standard, NGC 752
 Gaps and Needs Analysis (GNA) | Logistics Cluster Website
Gaps and Needs Analysis (GNA) | Logistics Cluster Website
 Using cluster analysis to examine dietary patterns: nutrient intakes, gender, and weight status differ across food pattern...
Using cluster analysis to examine dietary patterns: nutrient intakes, gender, and weight status differ across food pattern...
 Iterative transfer learning with neural network for clustering and cell type classification in single-cell RNA-seq analysis |...
Iterative transfer learning with neural network for clustering and cell type classification in single-cell RNA-seq analysis |...
Analysis of a cluster of surgical failures. Application to a series of neonatal arterial switch operations
 Morgan Fouesneau (Obs. de Strasbourg), Accounting for Stochastic Fluctuations in the Analysis of Cluster Properties
Morgan Fouesneau (Obs. de Strasbourg), Accounting for Stochastic Fluctuations in the Analysis of Cluster Properties
 Dienekes' Anthropology Blog: Clusters Galore analysis of East Africans
Dienekes' Anthropology Blog: Clusters Galore analysis of East Africans
 Text Clustering by Selected Latent Semantic Analysis - DAI-Labor
Text Clustering by Selected Latent Semantic Analysis - DAI-Labor
 Bright Cluster Manager Archives - High-Performance Computing News Analysis | insideHPC
Bright Cluster Manager Archives - High-Performance Computing News Analysis | insideHPC
 Chapter 6 Changes in cluster abundance | Multi-Sample Single-Cell Analyses with Bioconductor
Chapter 6 Changes in cluster abundance | Multi-Sample Single-Cell Analyses with Bioconductor
 GMCM: Unsupervised Clustering and Meta-Analysis Using Gaussian Mixture Copula Models
| Journal of Statistical Software
...
GMCM: Unsupervised Clustering and Meta-Analysis Using Gaussian Mixture Copula Models
| Journal of Statistical Software
...
Algorithm9
- Cluster analysis itself is not one specific algorithm, but the general task to be solved. (wikipedia.org)
- The appropriate clustering algorithm and parameter settings (including parameters such as the distance function to use, a density threshold or the number of expected clusters) depend on the individual data set and intended use of the results. (wikipedia.org)
- Centroid models: for example, the k-means algorithm represents each cluster by a single mean vector. (wikipedia.org)
- Distribution models: clusters are modeled using statistical distributions, such as multivariate normal distributions used by the expectation-maximization algorithm. (wikipedia.org)
- Relaxations of the complete connectivity requirement (a fraction of the edges can be missing) are known as quasi-cliques, as in the HCS clustering algorithm. (wikipedia.org)
- with the title "Enhanced path-based Clustering Algorithm" shows the results that path analysis with cluster integration gives results that outperform other cluster algorithms. (frontiersin.org)
- In this paper, we establish the Students' evaluation of teaching (SET) discriminant analysis model and algorithm based on principal component clustering analysis. (ed.gov)
- Finally, the model and algorithm are proved to be effective and objective according to the empirical analysis. (ed.gov)
- hierarchical agglomerative clustering algorithm was performed using Ward's minimum variance method. (uni-koeln.de)
Hierarchical9
- Typical cluster models include: Connectivity models: for example, hierarchical clustering builds models based on distance connectivity. (wikipedia.org)
- Hierarchical clustering, bottom-up. (lu.se)
- Hierarchical clustering is now supported through MeV ( http://www.tm4.org ). (lu.se)
- The main objective was to get Hierarchical clustering working. (lu.se)
- k-means clustering and hierarchical clustering . (udemy.com)
- Clustered data imply a hierarchical nature to the data, and while many levels can be considered, two levels are most commonly specified. (annfammed.org)
- Occasionally, certain aspects of the hierarchical information on clustering displayed by data are partly known (as in the case of clustering by patient service or treatment site, for example). (cam.ac.uk)
- We also study the performance of different estimators - maximum likelihood, weighted least squares and Markov chain Monte Carlo - on factor analytic estimates when hierarchical clustering is ignored. (cam.ac.uk)
- There are five main clustering approaches, but the most common are k-means and hierarchical clustering. (adobe.com)
Simulated clustered data1
- Trained on a variety of simulated clustered data, the neural network can classify millions of points from a typical single-molecule localization microscopy data set, with the potential to include additional classifiers to describe different subtypes of clusters. (nature.com)
Abstract1
- Article: Call detail record-based traffic density analysis using global K-means clustering Journal: International Journal of Intelligent Enterprise (IJIE) 2020 Vol.7 No.1/2/3 pp.176 - 187 Abstract: With the expanding number of vehicles on the road is creating substantial traffic that is hard to control and maintain safety, particularly in extensive urban areas. (inderscience.com)
Globular clusters5
- Nonetheless, the traditional Na-O and Mg-Al (anti-)correlations, typically seen in old globular clusters, are not seen in our data. (aanda.org)
- When turning to low Galactic latitudes, not only the primarily old, globular clusters (GCs) are of interest, but young-to-intermediate-age open clusters (OCs) become the prime tracer of the Galactic disks. (aanda.org)
- The information on Galactic assembly time is imprinted on the chemodynamics of globular clusters. (lu.se)
- The abundance pattern of the globular cluster is compatible with bulge field RR Lyrae stars and in-situ well-studied globular clusters. (lu.se)
- Its relatively low metallicity with respect to old and moderately metal-poor inner Galaxy clusters may suggest a low-metallicity floor for globular clusters that formed in-situ in the early Galactic bulge. (lu.se)
Algorithms8
- It can be achieved by various algorithms that differ significantly in their understanding of what constitutes a cluster and how to efficiently find them. (wikipedia.org)
- The notion of a "cluster" cannot be precisely defined, which is one of the reasons why there are so many clustering algorithms. (wikipedia.org)
- However, different researchers employ different cluster models, and for each of these cluster models again different algorithms can be given. (wikipedia.org)
- The notion of a cluster, as found by different algorithms, varies significantly in its properties. (wikipedia.org)
- Understanding these "cluster models" is key to understanding the differences between the various algorithms. (wikipedia.org)
- This category contains algorithms used for cluster analysis . (wikipedia.org)
- Aside from their utilit in processing large gap-filled multi-alignments, these algorithms can be applied to a broad spectrum of rRNA analysis functions such as subalignment, phylogenetic subtree extraction and construction, and organism tree-placement, and can serve as a framework to organize sequence data in an efficient and easily searchable manner. (aaai.org)
- In our proposed method to discover the density scope of the traffic, we are using two algorithms called k-means clustering and the k nearest neighbour classification algorithms. (inderscience.com)
Logistic regression2
- Second, logistic regression analysis of risk factors was done. (nih.gov)
- We used logistic regression analyses, adjusted for these characteristics, to test whether having previous alcohol, cigarette, or marijuana use was associated with an increased likelihood of subsequently abusing prescription opioids. (who.int)
Methods5
- Statistical methods that can be used to deal with these problems are using cluster integration and path analysis [ 3 ]. (frontiersin.org)
- This study examines the application of integrated clusters in path analysis with three different linkage methods, namely Ward linkage, Complete linkage, and Average linkage. (frontiersin.org)
- Methods: Case investigation was based on the traditional epidemiological survey, combined with analysis based on big data about population movement trajectories. (unboundmedicine.com)
- Methods for clustering in unsupervised learning are an important part of the statistical toolbox in numerous scientific disciplines. (jstatsoft.org)
- Among the different analysis methods, k-means clustering is the most widely used and provides a simple but effective approach to partitioning data into groups. (adobe.com)
Multivariate3
- Brindle RC, Ginty AT, Jones A, Phillips AC, Roseboom TJ, Carroll D, Painter RC & de Rooij SR (2016) Cardiovascular reactivity patterns and pathways to hypertension: a multivariate cluster analysis. (stir.ac.uk)
- For this reason multivariate cluster analysis was carried out to examine the relationship between heart rate and blood pressure reactivity patterns and hypertension in a large prospective cohort (age range 55-60 years). (stir.ac.uk)
- We used multivariate analyses to examine changes on key outcome variables, controlling for major covariates. (cdc.gov)
Fuzzy1
- However, despite their prominence in policy discourse, creative clusters are still a 'fuzzy' concept, defined and treated differently in different strands of research. (lse.ac.uk)
Homogeneous2
- When the clusters are relatively homogeneous (that is, the intra-cluster correlation is small), parallel studies tend to deliver better statistical performance than a stepped wedge trial. (bmj.com)
- According to Solimun [ 4 ], cluster analysis is used to group homogeneous objects into one and the characteristics between groups are heterogeneous. (frontiersin.org)
Approach14
- Here, we develop a supervised machine-learning approach to cluster analysis which is fast and accurate. (nature.com)
- In this study, we want to examine the effect of using linkage on the integrated Cluster path analysis approach. (frontiersin.org)
- From this research, we want to get the best linkage to be used in the integrated Cluster path analysis approach to classify the behavior of compliant to pay for the type of KPR Purchase. (frontiersin.org)
- CONCLUSIONS: The success of cluster analysis in identifying dietary exposure categories with unique demographic and nutritional correlates suggests that the approach may be useful in epidemiologic studies that examine conditions such as obesity, and in the design of nutrition interventions. (lu.se)
- We are developing a Bayesian approach to the study of ages and luminous masses of star clusters that cannot be resolved into stars. (ucsb.edu)
- Li, Brown, Huang, and Bickel (2011) independently discussed a special case of these GMCMs as a novel approach to meta-analysis in highdimensional settings. (jstatsoft.org)
- This multi-method approach allowed us to provide both a meta-analysis of CCR and an exploration of its thematic content. (lse.ac.uk)
- Analysis Plan - Using an intent-to-treat approach, the primary outcome will be analyzed using a patient-level constrained multistate model adjusting for the clustering in CKD programs. (ices.on.ca)
- The clustering approach an organization takes depends on what is being analyzed and why. (adobe.com)
- CDC's approach identifies clusters of rapid transmission, and the most concerning of these are known as "national priority clusters. (cdc.gov)
- Nevertheless, a systematic, integrated approach is needed for responding to reports of clusters. (cdc.gov)
- In addition to having epidemiologic and statistical expertise, health agencies should recognize the social dimensions of a cluster and should develop an approach for investigating clusters that best maintains critical community relationships and that does not excessively deplete resources. (cdc.gov)
- Although a systematic approach is vital, health agencies should be flexible in their method of analysis and tests of statistical significance. (cdc.gov)
- To provide epidemiologic and statistical source material to state and local health agencies to aid in their development of a systematic approach to the evaluation of clusters of health events. (cdc.gov)
Intra-cluster correlation1
- In most situations, the numeric value of the intra-cluster correlation tends to be small and positive. (annfammed.org)
Correlations2
- However, if substantial cluster-level effects are present (that is, larger intra-cluster correlations) or the clusters are large, the stepped wedge design will be more powerful than a parallel design, even one in which the intervention is preceded by a period of baseline control observations. (bmj.com)
- Small intracluster correlations coupled with large cluster size can still affect the validity of conventional statistical analyses. (annfammed.org)
Additionally3
- Additionally, it may specify the relationship of the clusters to each other, for example, a hierarchy of clusters embedded in each other. (wikipedia.org)
- Additionally, we classify the SET by clustering the result of extracting the indexes through the principal component analysis (PCA), then we also test the rationality of the rating using Fisher's discriminant function. (ed.gov)
- Additionally, HIV clusters can be identified by providers, partner services and frontline staff, and community members. (cdc.gov)
Patterns7
- OBJECTIVE: This study explored the usefulness of cluster analysis in identifying food choice patterns of three groups of adults in relation to their energy intake. (lu.se)
- One-way analysis of variance and chi 2 analysis were then performed to compared the weight status, nutrient intakes, and demographics of the food patterns. (lu.se)
- Four clusters emerged with statistically different systolic and diastolic blood pressure and heart rate reactivity patterns. (stir.ac.uk)
- In this work, patterns of technical analysis, like those defined in Lo et al. (witpress.com)
- The main benefit of cluster analysis is that it allows businesses to uncover patterns and relationships within their data, enabling them to make informed decisions and take action based on real-time insights. (adobe.com)
- Stability-based validation of dietary patterns obtained by cluster analysis. (bvsalud.org)
- The objective of this study was to use such a methodology based on stability of clustering solutions to select the most appropriate clustering method and number of clusters for describing dietary patterns in the NESCAV study ( Nutrition , Environment and Cardiovascular Health ), a large population -based cross-sectional study in the Greater Region (N = 2298). (bvsalud.org)
Statistical11
- It is a main task of exploratory data analysis, and a common technique for statistical data analysis, used in many fields, including pattern recognition, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. (wikipedia.org)
- Popular notions of clusters include groups with small distances between cluster members, dense areas of the data space, intervals or particular statistical distributions. (wikipedia.org)
- 2 Failure to take into account the clustered structure of the study design during the planning phase of the study also can lead to underpowered study designs in which the effective sample size and statistical power to detect differences are smaller than planned. (annfammed.org)
- Statistical software to conduct these types of analyses and for computing sample size for clustered data now exist, and we encourage their wider use. (annfammed.org)
- STATISTICAL ANALYSIS PERFORMED: Subjects were clustered according to food energy sources using the FASTCLUS procedure in the Statistical Analysis System. (lu.se)
- Objective - To prespecify the statistical analysis plan for the EnAKT LKD trial. (ices.on.ca)
- This paper addresses the statistical significance of structures in random data: Given a set of vectors and a measure of mutual similarity, how likely does a subset of these vectors form a cluster with enhanced similarity among its elements? (arxiv.org)
- The computation of this cluster p-value for randomly distributed vectors is mapped onto a well-defined problem of statistical mechanics. (arxiv.org)
- In an application to gene expression data, we find a remarkable link between the statistical significance of a cluster and the functional relationships between its genes. (arxiv.org)
- Cluster analysis is a statistical method used to identify and group similar data points together while also highlighting differences between groups. (adobe.com)
- In dealing with cluster reports, the general public is not likely to be satisfied with complex epidemiologic or statistical arguments that deny the existence or importance of a cluster. (cdc.gov)
DBSCAN2
- Density models: for example, DBSCAN and OPTICS defines clusters as connected dense regions in the data space. (wikipedia.org)
- Attendees will learn how to employ two of the most popular clustering techniques (k-means and DBSCAN) to craft new insights from data via hands-on labs. (tdwi.org)
Classify1
- This study aims to compare integrated clusters on various linkages (Ward, Complete, and Average linkage) with path analysis to classify the behavior of subservient to pay for mortgages. (frontiersin.org)
Objective4
- Clustering can therefore be formulated as a multi-objective optimization problem. (wikipedia.org)
- Cluster analysis as such is not an automatic task, but an iterative process of knowledge discovery or interactive multi-objective optimization that involves trial and failure. (wikipedia.org)
- The objective of our study was to explore the phenomenon of meningococcal clustering in a more objective way by using a nearest-neighbor analysis in space and time that compares the actual occurrence of clusters with their background incidence. (cdc.gov)
- Therefore, there is a need of an objective methodology helping researchers in their decisions during cluster analysis . (bvsalud.org)
Procedure6
- We present an analysis of multi-aligned eukaryotic and procaryotic small subunit rRNA sequences using a novel segmentation and clustering procedure capable of extracting subsets of sequences that share common sequence features. (aaai.org)
- 4, 5 In this issue of the Annals , Reed suggests a convenient correction procedure to address clustered data. (annfammed.org)
- DESIGN: Food frequency data were converted to percentage of total energy from 38 food groups and entered into a cluster analysis procedure. (lu.se)
- To find out whether the cluster of failures could have been related to chance alone, to variability of risk factors across time, or to suboptimal performance, we conducted the following analyses: First, identification of trends with the cumulative sum procedure was undertaken and actual mortality compared with the mortality predicted from an equation derived from a multi-institutional study. (nih.gov)
- However, since an analysis session typically includes multiple SUDAAN procedure calls with the same input dataset, it is generally more computationally efficient to sort the dataset once, prior to running any SUDAAN procedures. (cdc.gov)
- When you specify this option, the procedure computes variance estimates by analyzing the non-missing analysis values as a domain (subpopulation), where the entire population includes both non-missing and missing domains. (cdc.gov)
Dataset1
- In my analysis I would like to find different fundamental archtypes in the dataset. (rapidminer.com)
Ward's1
- Clustering solutions were obtained with K-means, K-medians and Ward's method and a number of clusters varying from 2 to 6. (bvsalud.org)
Phenotypes4
- We recently reported the usefulness of applying mathematical models ( i.e. principal component and cluster analyses) to multiple variables for the identification of clinical phenotypes in a cohort of COPD subjects [ 4 ]. (ersjournals.com)
- These original analyses allowed the description of four COPD groups, which we called "clinical COPD phenotypes" [ 4 ]. (ersjournals.com)
- These authors suggested that, before being referred to as clinical phenotypes, clusters of related patients require longitudinal validation to determine how they differ with respect to important clinical outcomes [ 2 ]. (ersjournals.com)
- This cluster analysis identified tinct phenotypes, which differed in clinical presentation, response to therapy, and survival. (uni-koeln.de)
Classification4
- Besides the term clustering, there is a number of terms with similar meanings, including automatic classification, numerical taxonomy, botryology (from Greek βότρυς "grape"), typological analysis, and community detection. (wikipedia.org)
- Cluster analysis was originated in anthropology by Driver and Kroeber in 1932 and introduced to psychology by Joseph Zubin in 1938 and Robert Tryon in 1939 and famously used by Cattell beginning in 1943 for trait theory classification in personality psychology. (wikipedia.org)
- The focus has mainly been on classification, clustering, query by content and relationship finding. (witpress.com)
- Cluster analysis finds useful groups when the groupings are used as inputs into another process (e.g., classification). (tdwi.org)
Servlet1
- parameter is included in the request the servlet will only return clusters that has that configuration option. (lu.se)
Approaches5
- Many existing computational approaches are limited in their ability to process large-scale data sets, to deal effectively with sample heterogeneity, or require subjective user-defined analysis parameters. (nature.com)
- Common among many of these approaches is the selection of analysis parameters, which can lead to a suboptimal interpretation of the data, for example, when points are clustered at a different spatial scale to the one used for assessment or when points are not homogeneously clustered. (nature.com)
- The multi-disciplinary and high-quality data collected from HFTS-2 helped to further understand why completion approaches such as limited entry and tapered perforation design are successful in improving cluster efficiency. (onepetro.org)
- Health departments can also develop their own approaches to time-space analysis. (cdc.gov)
- There are different approaches to analyzing molecular data to identify clusters, and not all focus on identifying rapid transmission. (cdc.gov)
Linkage3
- This takes little RAM, allowing you to cluster a large number of genes, but the clustering results could be inferior to those obtained with e.g. average linkage. (lu.se)
- So, this study uses the cluster integration with path analysis method by comparing the linkage. (frontiersin.org)
- The results showed that cluster integration in the Ward linkage method with path analysis was the best method, by comparing the coefficient of determination. (frontiersin.org)
Identifies4
- HIV cluster detection identifies communities affected by rapid HIV transmission . (cdc.gov)
- Time-space analysis identifies increases in HIV diagnoses in a particular geographic area or population. (cdc.gov)
- Secure HIV-TRACE identifies national priority clusters and other concerning clusters. (cdc.gov)
- Gender analysis identifies, analyses, and informs action to address inequalities that arise from the different roles of women and men, or the unequal power relationships between them, and the consequences of these inequalities on their lives, their health and well-being. (who.int)
Results10
- The weaker "clusterability axiom" (no cycle has exactly one negative edge) yields results with more than two clusters, or subgraphs with only positive edges. (wikipedia.org)
- The results of determining many clusters with different linkages will certainly give different results. (frontiersin.org)
- Results: A total of 27 cases were found in this cluster epidemic, including 25 confirmed cases, 1 suspected case (index case) and 1 asymptomatic carrier. (unboundmedicine.com)
- RESULTS: Six food pattern clusters were identified. (lu.se)
- All Project participants fall in the expected clusters, so there is no need to report any individual clustering results. (blogspot.com)
- We will present first a short review of the main stochastic effects, then results based on the analysis of synthetic star clusters, as well as an application to star clusters in a star forming galaxy. (ucsb.edu)
- The results show that ignoring clustering in the data leads to serious underestimation of the factor loadings and item thresholds in ordinal IRT treatment of rating data. (cam.ac.uk)
- 2002) and between bands suggested by us are used for clustering and the results compared with those obtained with the Euclidean and the lower bound of the dynamic time warping distance defined in Keogh. (witpress.com)
- With visualization techniques such as scatter plots and dendrograms, businesses can effortlessly showcase their cluster analysis results in a clear and understandable way. (adobe.com)
- Introduction: The results of a 2001-2005 polycythemia vera (PV) investigation in Eastern Pennsylvania revealed a disease cluster plus underreporting and false reporting to the Pennsylvania Cancer Registry (PCR). (cdc.gov)
Sequences2
- Find clusters of DNA sequences based on their global similarity to two reference sequences. (wolfram.com)
- Low morbidity jurisdictions (areas that have low numbers of HIV diagnoses) may conduct analyses as needed when new diagnoses or molecular sequences are reported. (cdc.gov)
Data driven2
- Upload an old survey or launch and Akin survey to see your data driven clusters in minutes. (alternativeto.net)
- Cluster analysis is a data-driven method used to create clusters of individuals sharing similar dietary habits . (bvsalud.org)
Differences2
- Any changes we detect between conditions will subsequently represent differences in the proportion of cells in each cluster. (bioconductor.org)
- A gender analysis is an examination of the relationships and role differences between women and men, it is the first step of mainstreaming. (who.int)
Characteristics3
- The purpose of cluster analysis in marketing is to segment consumers into distinct groups with similar characteristics, allowing businesses to understand their target audience better and tailor their marketing strategies accordingly. (adobe.com)
- With customer segmentation at the heart of modern marketing, cluster analysis has become an essential tool for dividing customers into distinct groups based on shared characteristics. (adobe.com)
- Definition, Background, and Characteristics of Clusters As used in these guidelines, the term 'cluster' is an unusual aggregation, real or perceived, of health events that are grouped together in time and space and that are reported to a health agency. (cdc.gov)
Bayesian1
- A solution can be found in model-based cluster analysis, such as Bayesian inference 7 , where cluster analysis outputs are scored against a model of clustering, allowing the best-scoring set of analysis parameters to be selected. (nature.com)
Exploratory1
- We use simulated data to study the consequences of aggregated analysis (i.e., analysis ignoring clustering) on factor analytic estimates (both exploratory factor analysis (EFA) and confirmatory factor analysis (CFA)) and fit indices when the data are clustered. (cam.ac.uk)
Clinical2
- We conducted a cluster-randomized clinical trial to evaluate the effect of the intervention versus usual care on completing key steps toward receiving a kidney transplant. (ices.on.ca)
- Clinical providers or community members may help identify HIV clusters. (cdc.gov)
Respondents1
- In research, data for analysis come principally from two sources: directly from the respondents themselves and from interviewers/raters. (cam.ac.uk)
Conclusions1
- Conclusions: The infection source of this cluster epidemic was a suspected case from Wuhan. (unboundmedicine.com)
Genes1
- Molecular analysis of the fibrinogen gene cluster in 16 patients with congenital afibrinogenemia: novel truncating mutations in the FGA and FGG genes. (medlineplus.gov)
Principal Componen2
- Neural models: the most well known unsupervised neural network is the self-organizing map and these models can usually be characterized as similar to one or more of the above models, and including subspace models when neural networks implement a form of Principal Component Analysis or Independent Component Analysis. (wikipedia.org)
- In this paper, we consider clustering based on principal component analysis (PCA) for high-dimension, low-sample-size (HDLSS) data. (arxiv.org)
Incidence4
- The incidence of such clusters was compared to the incidence that would be expected by chance by using space-time nearest-neighbor analysis of 4,887 confirmed invasive meningococcal cases identified in the 9-year surveillance period 1993-2001 in the Netherlands. (cdc.gov)
- Outbreaks are recognized when place (e.g., an educational institution like a primary school), time (e.g., within 1 month), and conventional phenotypic markers (same serogroup, serotype, and subtype) make a connection likely (field cluster) or when an excess of incidence (e.g., 20x normal) is noticed in a retrospectively specified geographic or population area within a chosen period (community outbreak). (cdc.gov)
- The DAS data combined with downhole high-resolution pressure measurements also helped to quantify the effect of lower cluster efficiency data on the incidence and intensity of FDIs. (onepetro.org)
- The analyses were conducted to determine sensitivity and positive predictive value (PPV) of case reporting to the PCR, estimate cancer incidence rates, and evaluate the presence of cancer clusters. (cdc.gov)
Orbital1
- The orbital parameters suggest that the cluster is currently confined within the bulge volume when we consider a heliocentric distance of 8:54 ± 0:19 kpc and an extinction coefficient of RV = 2:84 ± 0:02. (lu.se)
Priority2
- In such cluster-randomized designs, all patients of a clinician or practice are assigned to the same treatment, and this design is often used when logistics of implementation or the need to avoid contamination of treatment arms is a priority. (annfammed.org)
- Health departments should respond to all national priority clusters. (cdc.gov)
Similarity1
- A major issue in the analysis of clustered data is that observations within a cluster are not independent, and the degree of similarity is typically measured by the intracluster correlation coefficient (ICC). (annfammed.org)
Patients3
- Considering an example of data with patients clustered with physicians, a comprehensive multilevel data analysis aims to assess the direct effect of patient and clinician/practice level variables on the outcome. (annfammed.org)
- Retrospective risk factor analysis suggested an excessive risk for patients with origin of the circumflex or left anterior descending coronary arteries from sinus 2 and a protective effect of phenoxybenzamine. (nih.gov)
- Patients in Cluster 1 had a better response to PAH treatment than patients in the 2 other clusters. (uni-koeln.de)
Depend1
- As the clustering values can depend strongly on the overall density and arrangement of points, it is likely that the appropriate threshold for one image will be unsuitable for the next. (nature.com)
Large cluster1
- Time-space increases need further investigation because they may indicate one large cluster, many small clusters, or an increase in HIV testing that has led to new diagnoses of older infections. (cdc.gov)
Spatial6
- Clusters are recognized when meningococcal cases of the same phenotypic strain (markers: serogroup, serotype, and subtype) occur in spatial and temporal proximity. (cdc.gov)
- A group of unrelated cases that occur in temporal and spatial proximity may be misinterpreted as a cluster or outbreak, but these cases would not justify additional public health measures, except perhaps to reassure the public. (cdc.gov)
- In a real cluster, cases of the same strain occur in temporal and spatial proximity at a higher frequency than by chance. (cdc.gov)
- Quantifying the extent to which points are clustered in single-molecule localization microscopy data is vital to understanding the spatial relationships between molecules in the underlying sample. (nature.com)
- A distribution of points within the imaging field can be interrogated using spatial point pattern analyses to reveal the spatial relationships between the points and higher-scale relationships between clusters of points, or between points from different imaging channels. (nature.com)
- We focus here on the first application of the Curlometer (direct estimation of the electric current density from curl(B), using measured spatial gradients of the magnetic field) analysis technique. (esa.int)
Luminous2
- This is due to the stochastic mass distribution of the finite (small) number of luminous stars in each cluster, stars which may be either particularly blue or particularly red. (ucsb.edu)
- This confirms that Gaia 1 is rather a massive and luminous open cluster than a low-mass globular cluster. (aanda.org)
Photometry2
- Based on Monte-Carlo simulations, we explore the distributions of acceptable properties of star clusters with a given photometry. (ucsb.edu)
- We derived chemical abundances and kinematic and dynamic properties by gathering information from high-resolution spectroscopy with FLAMES-UVES, photometry with the Hubble Space Telescope, and Galactic dynamic calculations applied to the globular cluster NGC 6355. (lu.se)
Detection3
- Analyses should include time-space and molecular cluster detection. (cdc.gov)
- CDC has provided Secure HIV-TRACE, a secure, web-based application for health departments to use for molecular cluster detection. (cdc.gov)
- Numerous related issues--such as the epidemiologic workup of infectious disease outbreaks, the assessment of the health effects of environmental exposures, the prospective detection of clusters, and the investigation of interpersonal networks--are not addressed. (cdc.gov)
Intervals2
- Subsequently, at regular intervals (the "steps") one cluster (or a group of clusters) is randomised to cross from the control to the intervention under evaluation. (bmj.com)
- 1 Ignoring the intracluster correlation in the analysis could lead to incorrect P values, confidence intervals that are too small, and biased estimates and effect sizes, all of which can lead to incorrect interpretation of associations between variables. (annfammed.org)
Calculations1
- Sample size calculations and analysis must make allowance for both the clustered nature of the design and the confounding effect of time. (bmj.com)
Abundances1
- For a DA analysis of cluster abundances, filtering is generally not required as most clusters will not be of low-abundance (otherwise there would not have been enough evidence to define the cluster in the first place). (bioconductor.org)
Compute9
- Also in this issue, the article by Killip et al 7 provides a formula to compute an effective sample size for clustered data. (annfammed.org)
- Companies in Life Sciences have been able to provision additional compute capacity on the fly as needed while keeping their costs much lower than maintaining a cluster in their data center, enabling them to compete effectively with much larger competitors. (insidehpc.com)
- This whitepaper, "Hybrid Cloud with Bright Cluster Manager," from our friends over at Bright Computing discusses how hybrid cloud infrastructures allow organizations to strategically manage their compute requirements from core data center to public cloud and edge, but they are very complex to build and manage. (insidehpc.com)
- Today Amazon CTO Werner Vogels announced on his blog that Amazon EC2 has added what it is calling Cluster Compute instances specifically to support the kinds of closely coupled workloads that traditional HPC users often run. (insidehpc.com)
- Cluster Computer Instances are similar to other Amazon EC2 instances but have been specifically engineered to provide high performance compute and networking. (insidehpc.com)
- Cluster Compute Instances can be grouped as cluster using a "cluster placement group" to indicate that these are instances that require low-latency, high bandwidth communication. (insidehpc.com)
- Next, Cluster Compute Instances are specified down to the processor type so developers can squeeze optimal performance out of them using compiler architecture-specific optimizations. (insidehpc.com)
- Many of our scientific research areas require high-throughput, low-latency, interconnected systems where applications can quickly communicate with each other, so we were happy to collaborate with Amazon Web Services to test drive our HPC applications on Cluster Compute Instances for Amazon EC2," said Keith Jackson, a computer scientist at the Lawrence Berkeley National Lab. (insidehpc.com)
- In our series of comprehensive benchmark tests, we found our HPC applications ran 8.5 times faster on Cluster Compute Instances for Amazon EC2 than the previous EC2 instance types. (insidehpc.com)
Adapt1
- CDC provides software programs that health departments can use or adapt for routine analyses. (cdc.gov)
Conventional1
- This list can be plotted and rasterized for examination with conventional image analysis tools, but an ideal method would operate on the original coordinate data without requiring its transformation. (nature.com)
Density1
- The output can be further refined for the measurement of cluster area, shape, and point-density. (nature.com)
Risks1
- Health agencies should understand the potential legal ramifications of reported clusters, how risks are perceived by the community, and the influence of the media on that perception. (cdc.gov)
Efficiency9
- This whitepaper, "Bright Computing Cluster as a Service for VMware," from Bright Computing discusses how through advanced automation, Bright Cluster Manager eliminates the complexity of building and managing high-performance Linux clusters, enabling greater organizational efficiency and flexibility. (insidehpc.com)
- First, an analysis of different completion designs on cluster efficiency based on near well Distributed Acoustic Sensing (DAS). (onepetro.org)
- Fluid/sand distribution and cluster efficiency analyses were based on near wellbore DAS data collected from two adjacent horizontal wells completed in two different landing zones in the Wolfcamp formation. (onepetro.org)
- Standard deviation from ideal fluid/sand distribution and waterfall plots were used to evaluate cluster efficiency for each design and stage. (onepetro.org)
- Pressure response vs. FDIs trigger factors such distance, cluster efficiency and stage fluid volume were also analyzed. (onepetro.org)
- Extreme limited entry showed the potential of high perforation erosion and reduced cluster efficiency. (onepetro.org)
- The limited entry and tapered perforation design demonstrated potential to improve the cluster efficiency for extended stage lengths. (onepetro.org)
- Some of these stages that produced high intensity FDIs also had high fluid volume per cluster and low cluster efficiency. (onepetro.org)
- Nonparametric efficiency analysis has become a widely applied technique to support industrial benchmarking as well as a variety of incentive- based regulation policies. (repec.org)
Gene cluster1
- Members of the apolipoprotein gene cluster (APOA1/C3/A4/A5) on human chromosome 11q23 play an important role in lipid metabolism. (doe.gov)
Open cluster1
- NGC 6819 is a richly populated, older open cluster situated within the Kepler field. (ku.edu)
Different cluster2
Found2
- We identified several SM-encoding biosynthetic gene clusters (BGCs) from the metagenomic data of lean and obese individuals and found significant association between some BGCs, including those that produce hitherto unknown SM, and obesity. (hindawi.com)
- this mutation, JAK2V617F , is found in more cluster area.3 In 2009, Congress funded ATSDR to continue than 90% of persons with PV and in approximately 50% of this investigation. (cdc.gov)
Study10
- In a stepped wedge design more clusters are exposed to the intervention towards the end of the study than in its early stages. (bmj.com)
- The stepped wedge cluster randomised controlled trial is a relatively new study design that is increasing in popularity. (bmj.com)
- At the end of the study there will be a period when all clusters are exposed. (bmj.com)
- Data collection continues throughout the study, so that each cluster contributes observations under both control and intervention observation periods. (bmj.com)
- The Gambia hepatitis intervention study used a stepped wedge cluster randomised design in the 1980s to investigate the effectiveness of a vaccine for hepatitis B in preventing liver disease. (bmj.com)
- In addition to using cluster analysis, this study also uses path analysis. (frontiersin.org)
- A special case of clustered data is an intervention study where clinicians or practices are randomized into an intervention or control group. (annfammed.org)
- Star clusters in our Milky Way are excellent testbeds in which to study the formation, evolution, and structure of the underlying Galactic components. (aanda.org)
- A cross-sectional study was conducted to identify subgroups of Korean immigrant women based on their Korean as well as American acculturation levels using cluster analysis and to determine whether these subgroups differ on depressive symptoms in 200 Korean immigrant women aged 20-64. (cdc.gov)
- Purpose: The objectives of this study were 1) to assess PV reporting to the PCR in 2006-2009, 2) to determine whether a cancer cluster persisted, and 3) to determine whether other myeloproliferative neoplasms (MPNs), including essential thrombocytopenia (ET), were subject to similar reporting problems. (cdc.gov)
Applicability1
- Cluster analysis has broad applicability across industries and business domains. (tdwi.org)



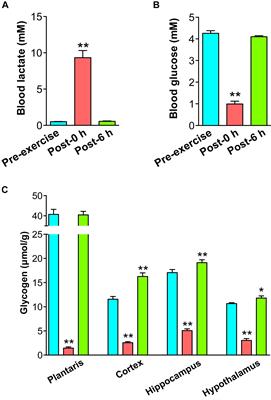





![Data Science and Machine Learning with Python - Hands-On! [Video]](https://cdn.oreillystatic.com/oreilly/images/report-software-architecture-patterns-553x420.jpg)